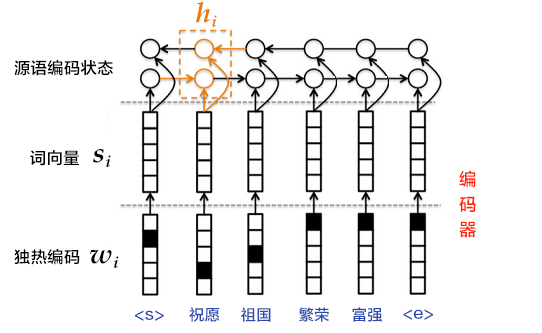
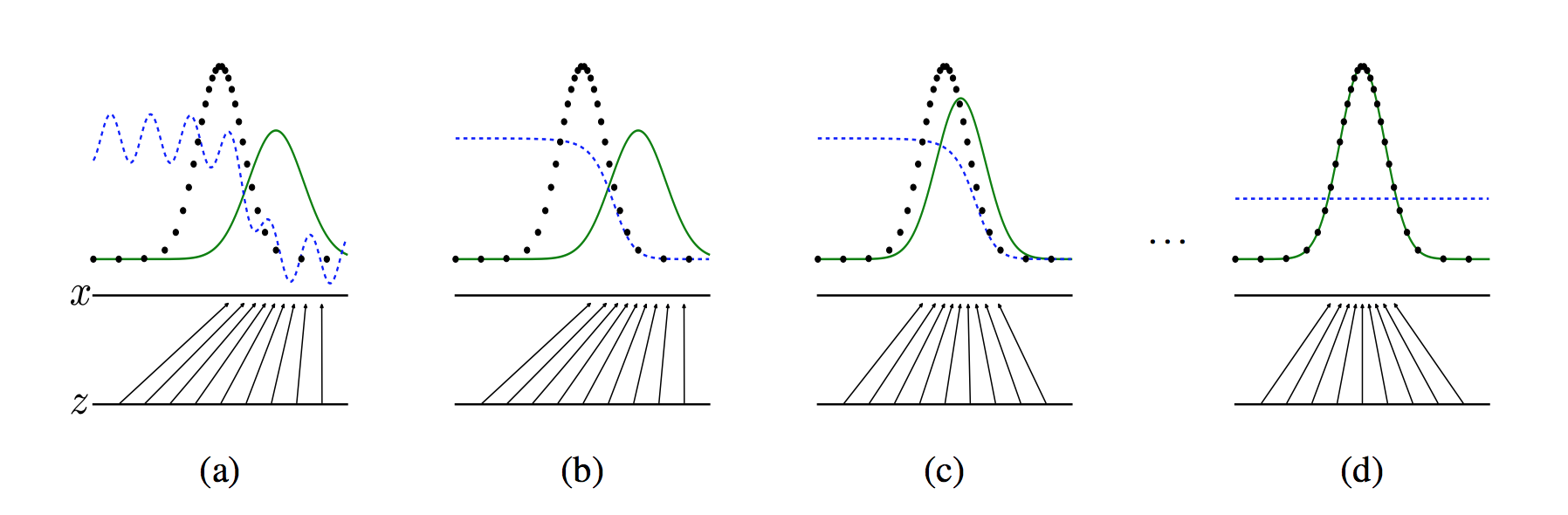
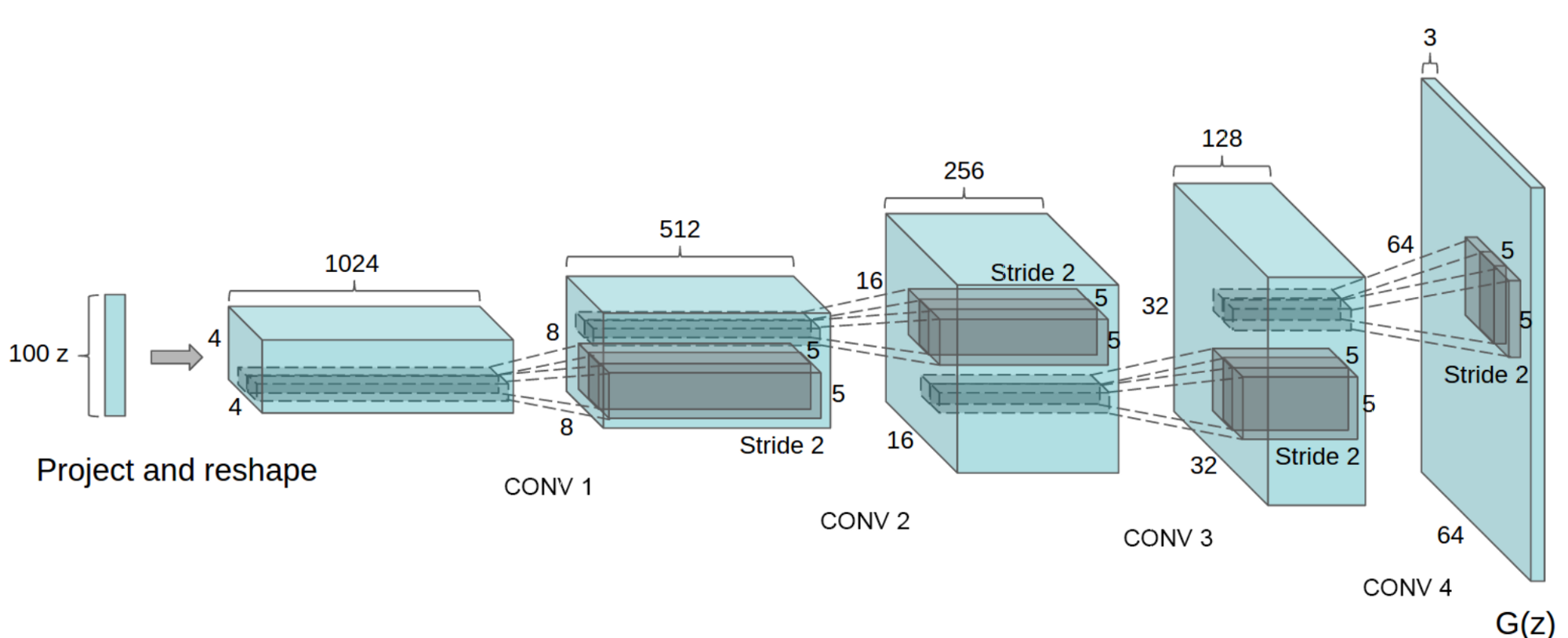
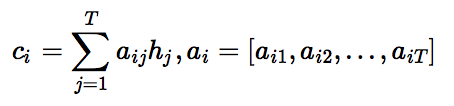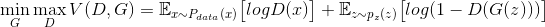+
+
+
+ 
+
+ 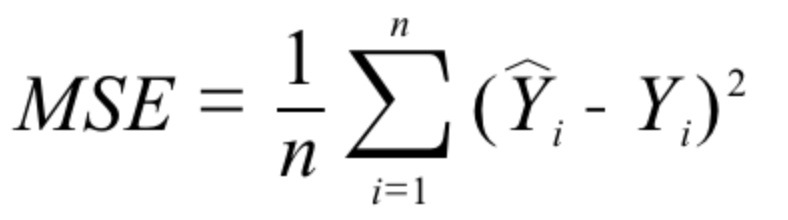
+
+ 
+


- 
- Figure 1. Predicted Value V.S. Actual Value
+ 
+ Figure One. Predict value V.S Ground-truth value
- 
- Figure 2. The value ranges of the features
+ 
+ Figure 2. Value range of attributes for all dimensions
+
+
+
+
+
+
+
+
-
-图1. MNIST图片示例
-
-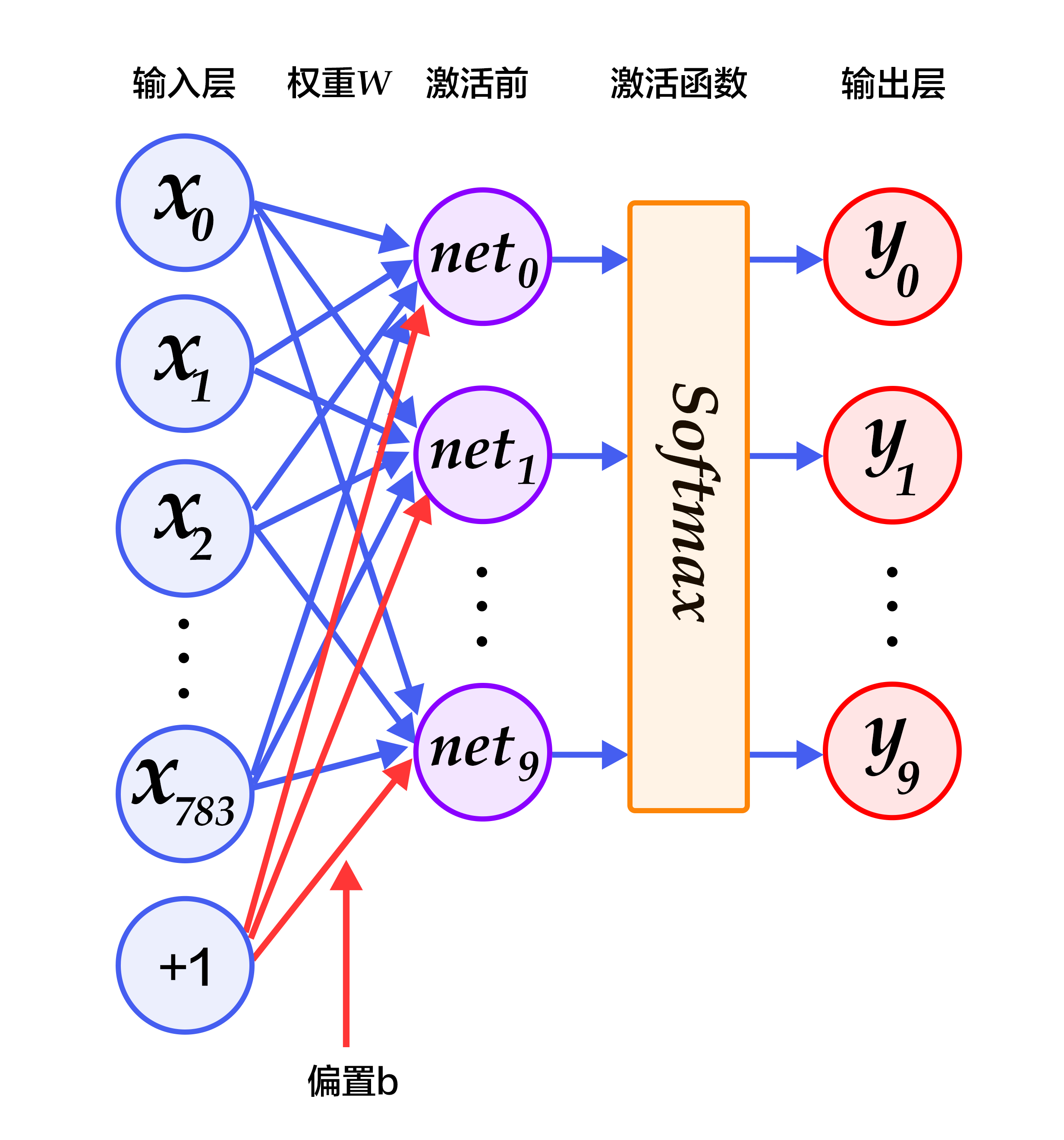
-图2. softmax回归网络结构图
-
-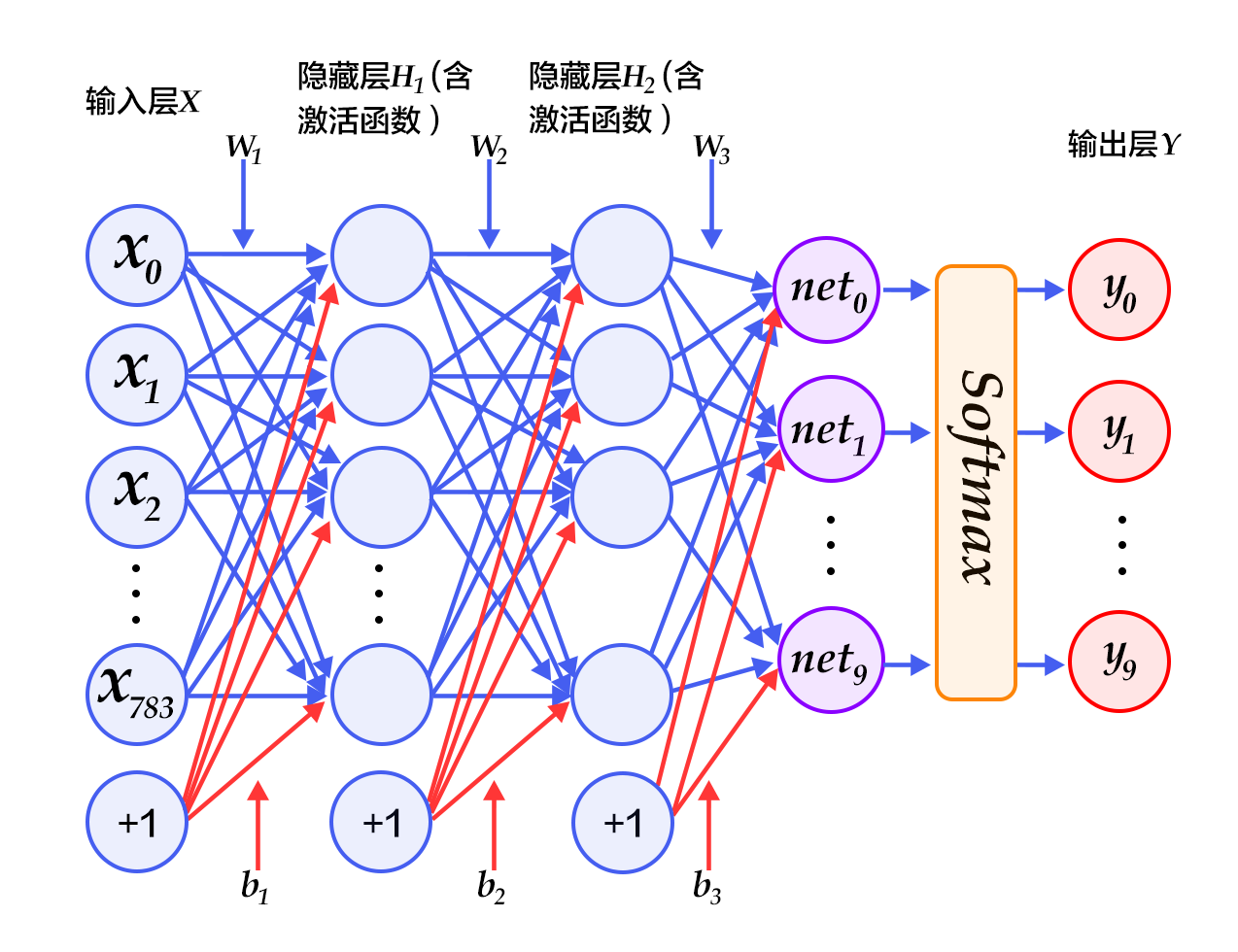
-图3. 多层感知器网络结构图
-
-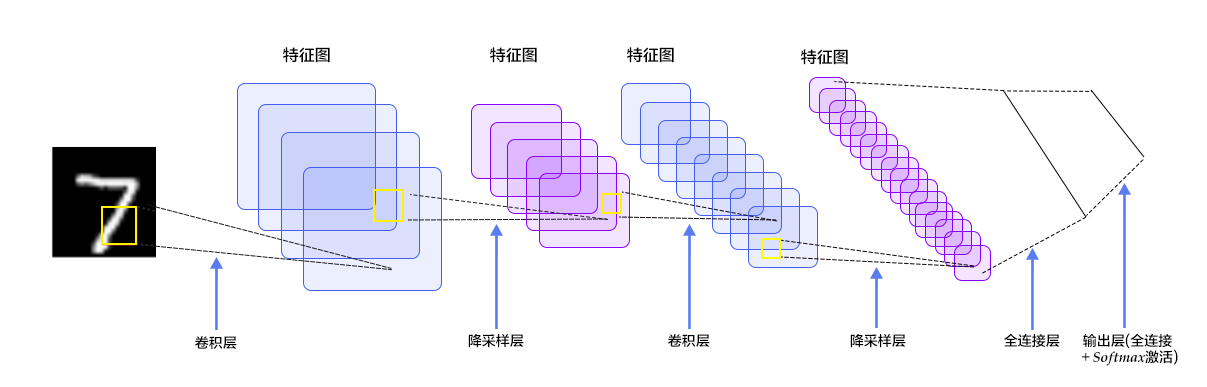
-图4. LeNet-5卷积神经网络结构
-
-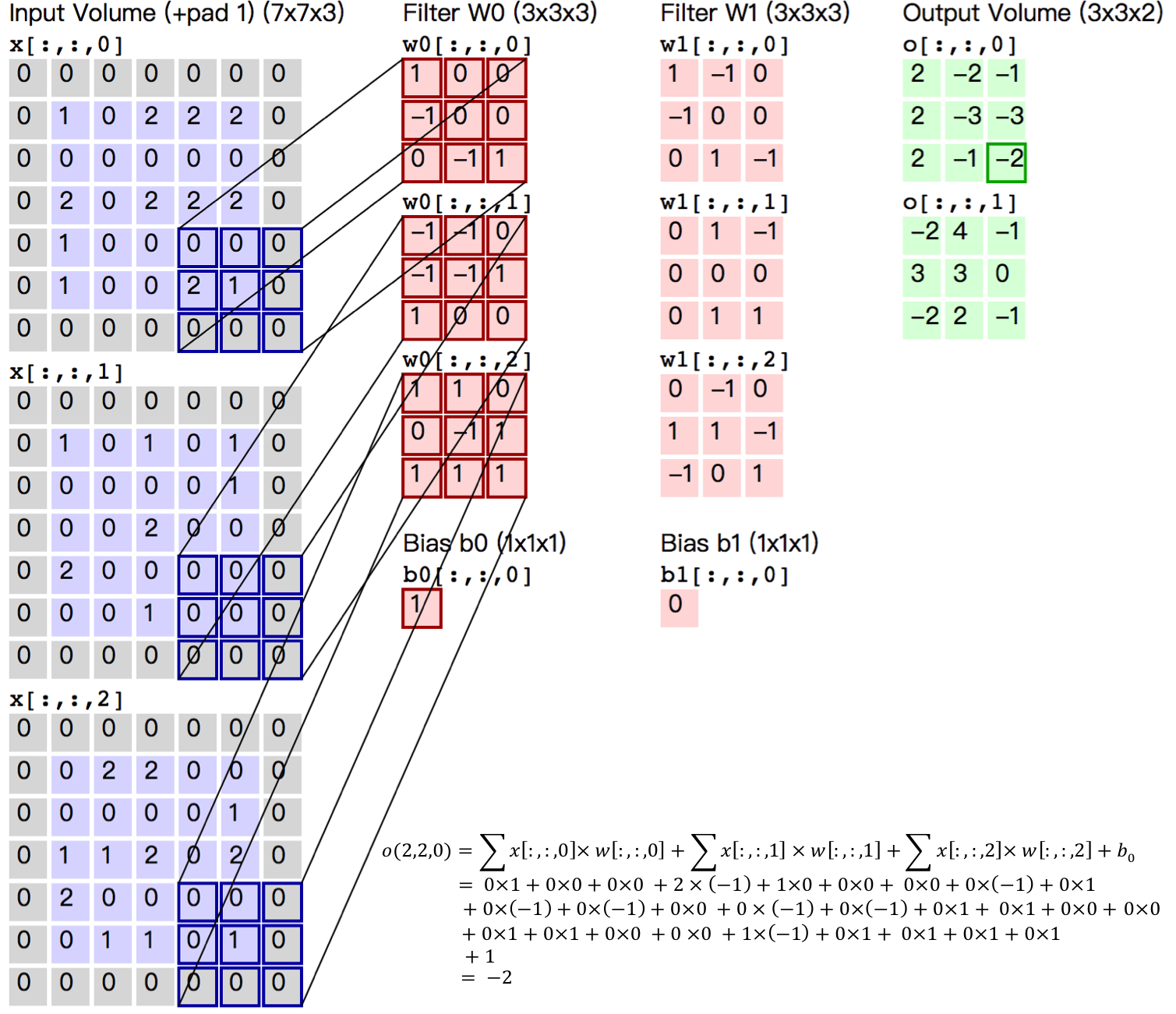
-图5. 卷积层图片
-
-
-图6. 池化层图片
-
+
+图1. MNIST图片示例
+
+
+
+
+
+
+图2. softmax回归网络结构图
+
+
+
+
+图3. 多层感知器网络结构图
+
+
+图4. LeNet-5卷积神经网络结构
+
+
+图5. 卷积层图片
+
+
+图6. 池化层图片
+
+
+
+
+
-
-Fig. 1. Examples of MNIST images
+
+Figure 1. Example of a MNIST picture
+
+Figure 2. Softmax regression network structure
+
-
-Fig. 2. Softmax regression network architecture
-
-
-Fig. 3. Multilayer Perceptron network architecture
+Figure 3 is a network structure of a multi-layer perceptron, in which weights are represented by blue lines, bias are represented by red lines, and +1 indicates that the bias is $1$.
+
+
+Figure 3. Multilayer perceptron network structure
-
-Fig. 4. Convolutional layer
+
+Figure 4. LeNet-5 convolutional neural network structure
-
-Fig. 5 Pooling layer using max-pooling
+
+Figure 5. Convolutional Layer Picture
-
-Fig. 6. LeNet-5 Convolutional Neural Network architecture
+
+Figure 6. Picture in pooling layer
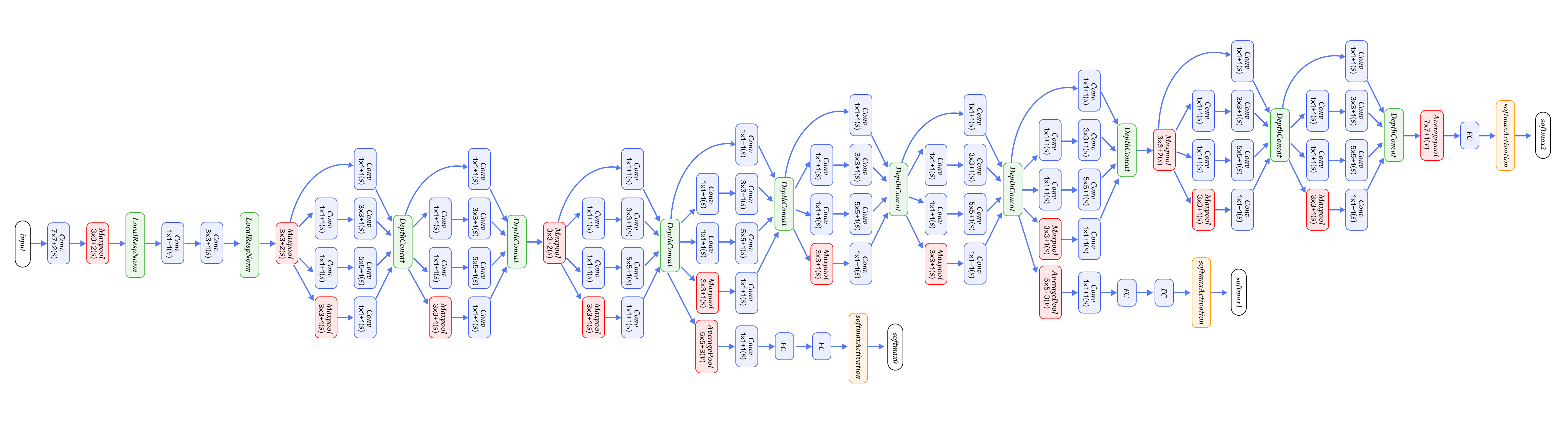
-图8. GoogleNet[12]
+图8. GoogLeNet[12]
-
+
Figure 1. General image classification
-
+
Figure 2. Fine-grained image classification
-
-Figure 3. Disturbed images [22]
+
+Figure 3. Disturbed images [22]
-
+
+
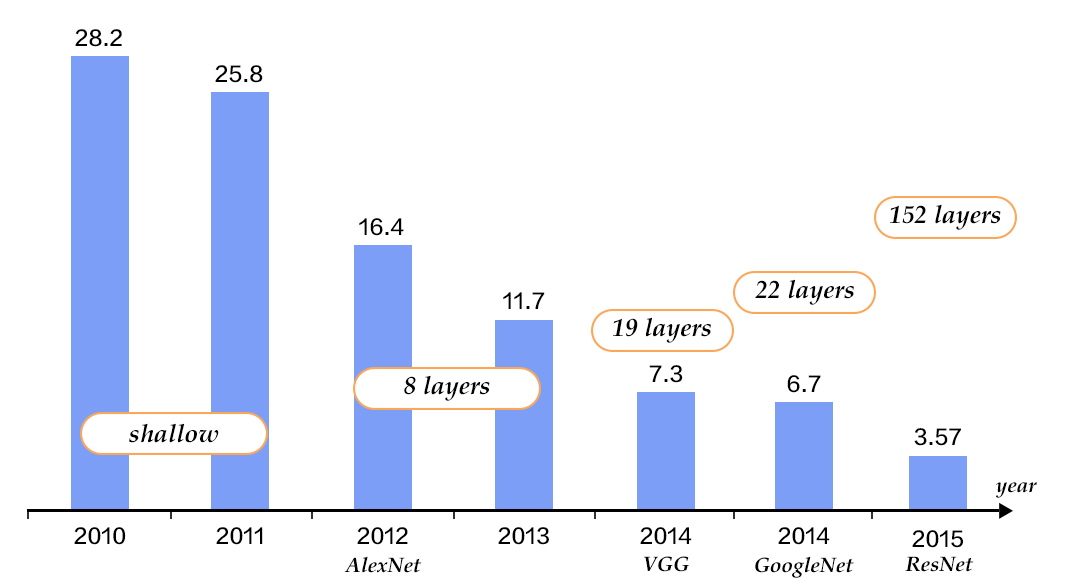
Figure 4. Top-5 error rates on ILSVRC image classification
-
-Figure 5. A CNN example [20]
+
+Figure 5. A CNN example [20]
-
+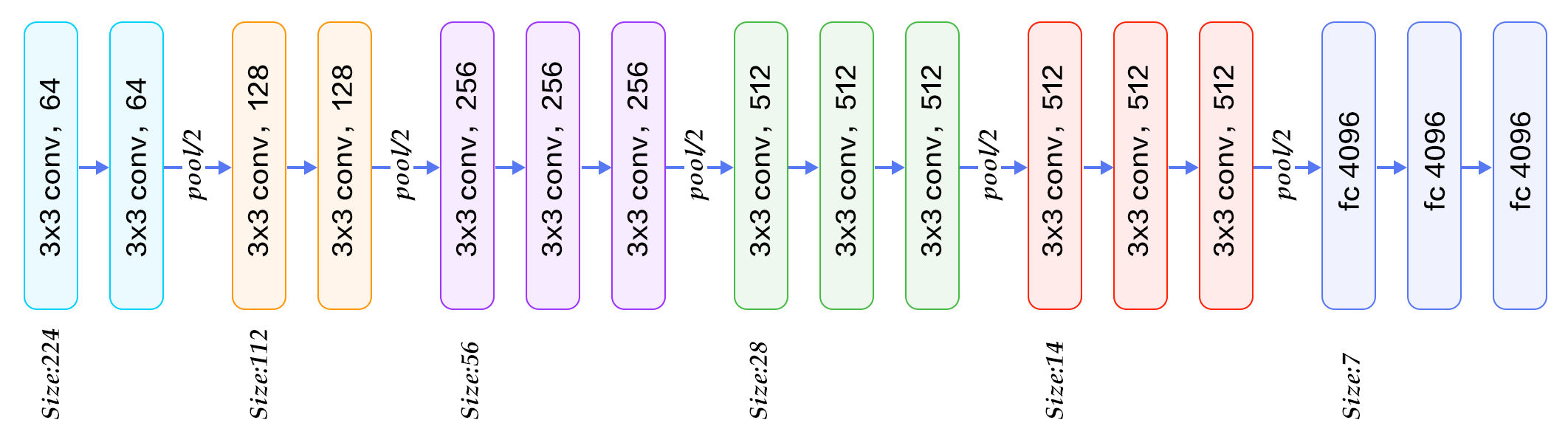
Figure 6. VGG16 model for ImageNet
-
+
Figure 7. Inception block
-
-Figure 8. GoogleNet[12]
+
+Figure 8. GoogLeNet [12]
-
+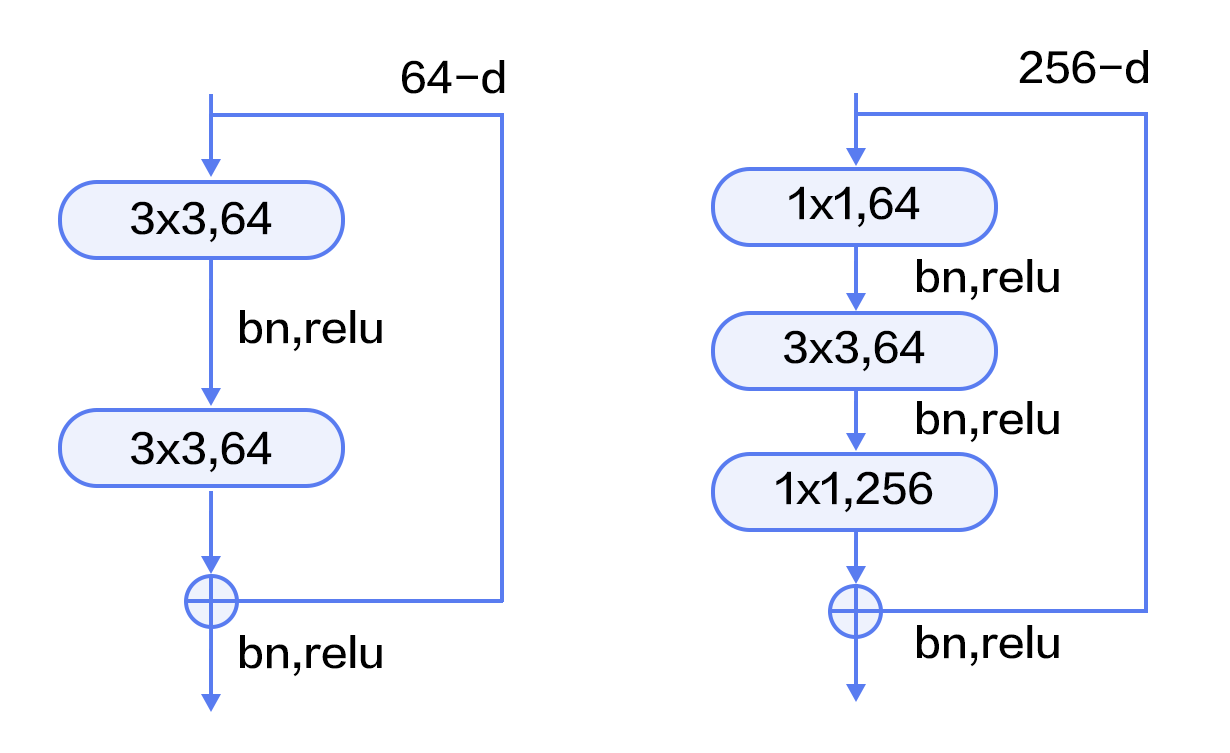
Figure 9. Residual block
-
+
Figure 10. ResNet model for ImageNet
-
-Figure 11. CIFAR10 dataset[21]
+
+Figure 11. CIFAR10 dataset [21]
-
-Figure 12. The error rate of VGG model on CIFAR10
+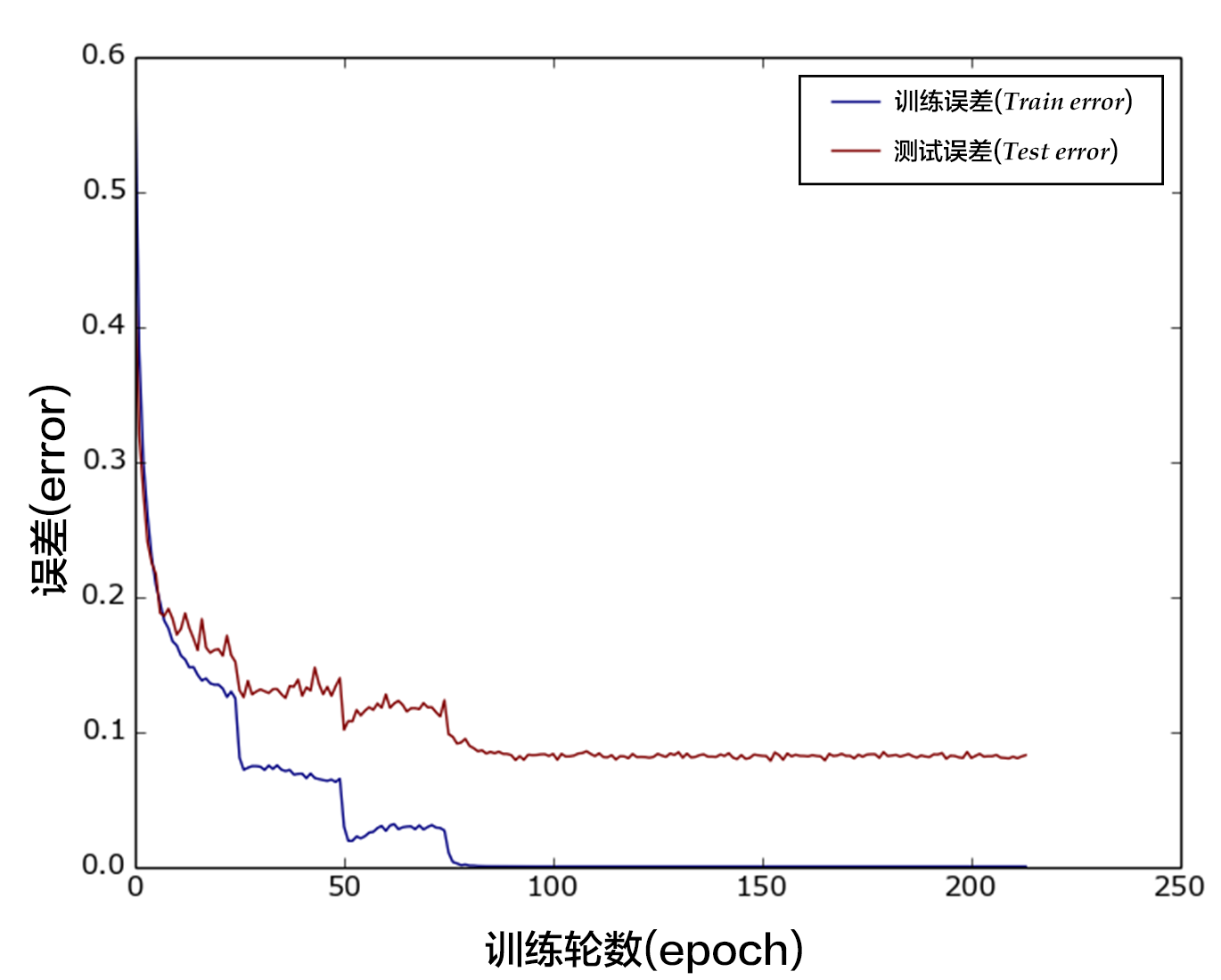
+Figure 13. Classification error rate of VGG model on the CIFAR10 data set
-图8. GoogleNet[12]
+图8. GoogLeNet[12]
+ 
+
+ 
+
+ 
+
+ 
+
+ 
+
+ 
+
+ 
+
+ 
+
+ 
+
- 
- Figure 1. Two dimension projection of word embeddings
+ 
+ Figure 1. Two-dimensional projection of a word vector
- 
- Figure 2. N-gram neural network model
+ 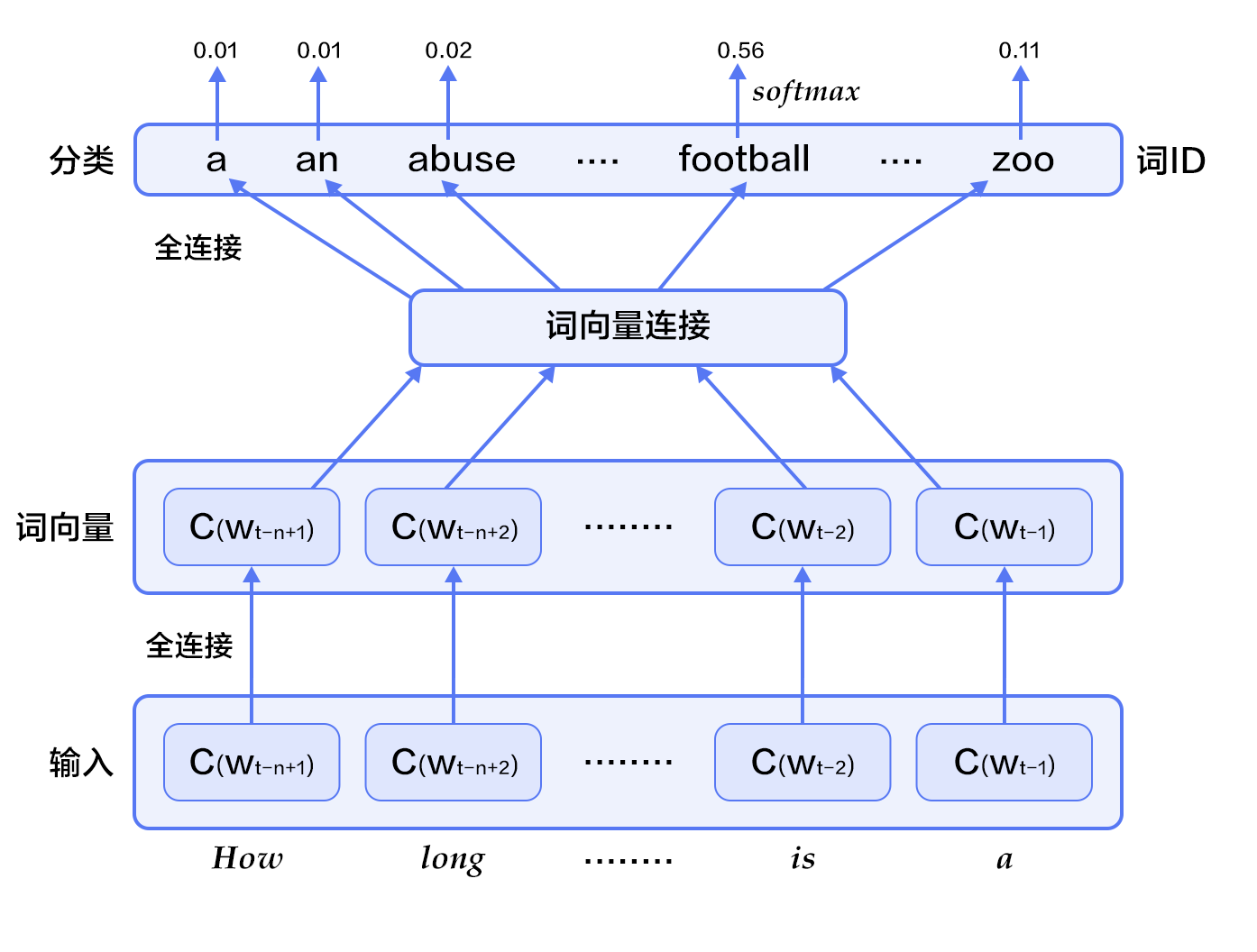
+ Figure 2. N-gram neural network model
- 
- Figure 3. CBOW model
+ 
+ Figure 3. CBOW model
- 
- Figure 4. Skip-gram model
+ 
+ Figure 4. Skip-gram model
| training set | -validation set | -test set | -
| ptb.train.txt | -ptb.valid.txt | -ptb.test.txt | -
| 42068 lines | -3370 lines | -3761 lines | -
| Training data | +Verify data | +Test data | +
| ptb.train.txt | +ptb.valid.txt | +ptb.test.txt | +
| 42068 sentences | +3370 sentences | +3761 sentence | +
- 
- Figure 5. N-gram neural network model in model configuration
+ 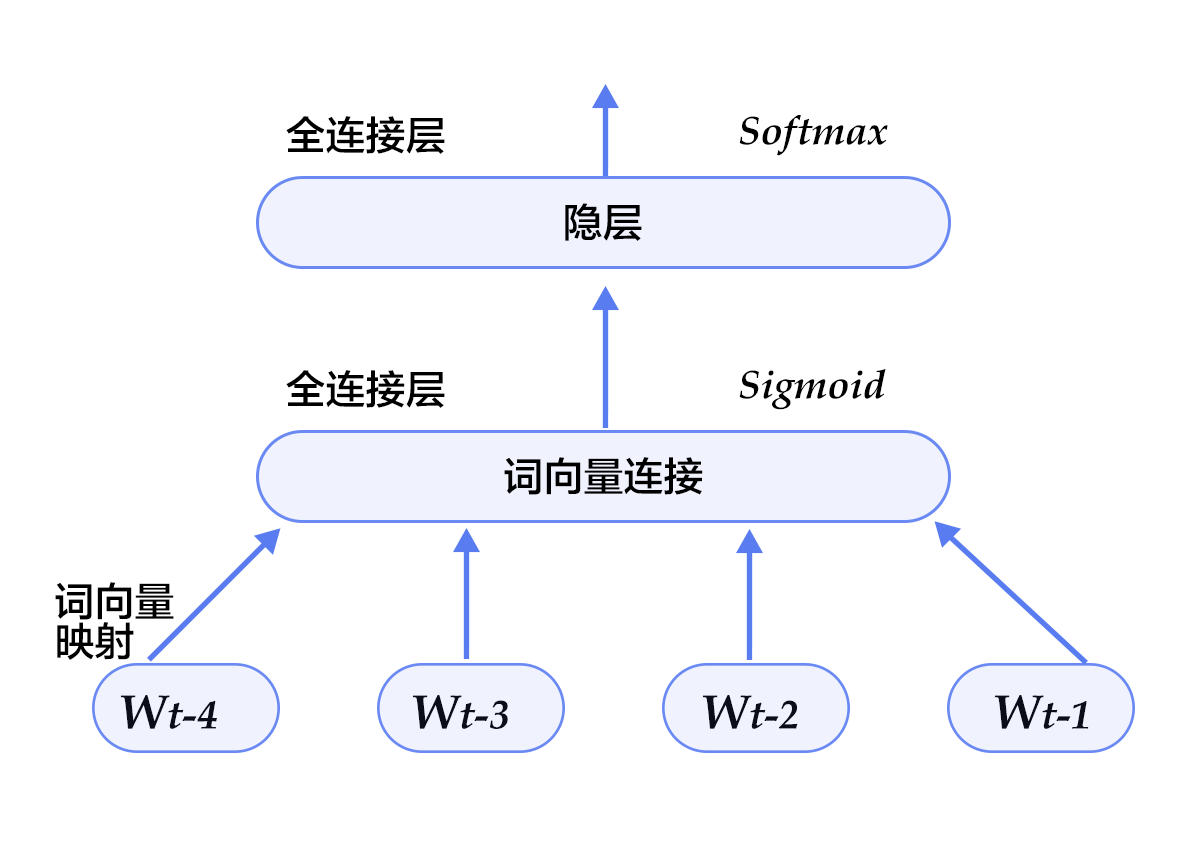
+ Figure 5. N-gram neural network model in model configuration
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+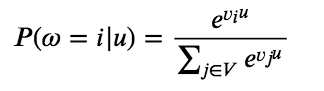
+
+
+
+
+
-
-Figure 1. YouTube recommender system overview.
+
+Figure 1. YouTube personalized recommendation system structure
-
-Figure 2. Deep candidate generation model.
+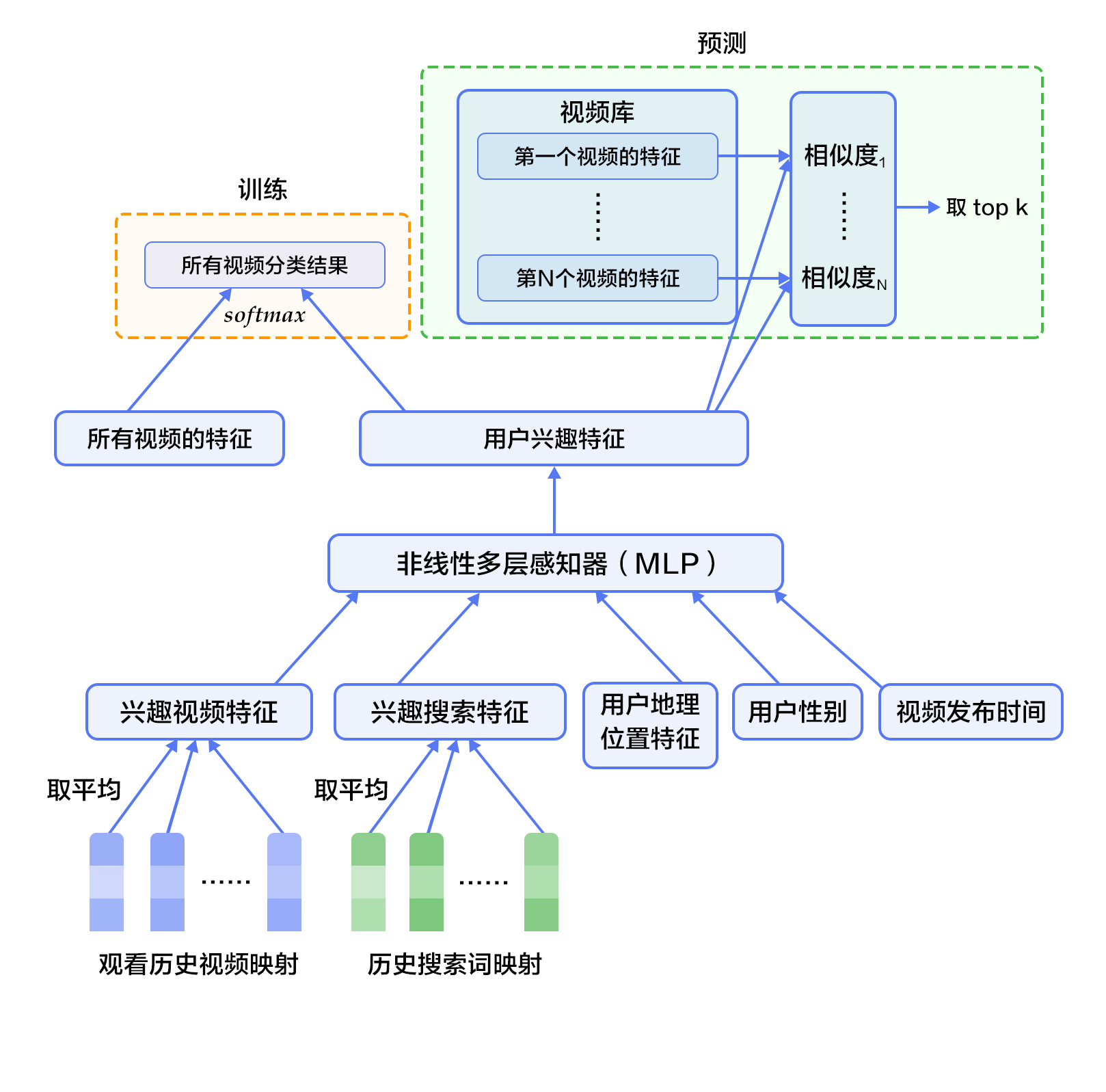
+Figure 2. Candidate generation network structure
-
-Figure 3. CNN for text modeling.
+
+Figure 3. Convolutional neural network text classification model
-
-Figure 4. A hybrid recommendation model.
+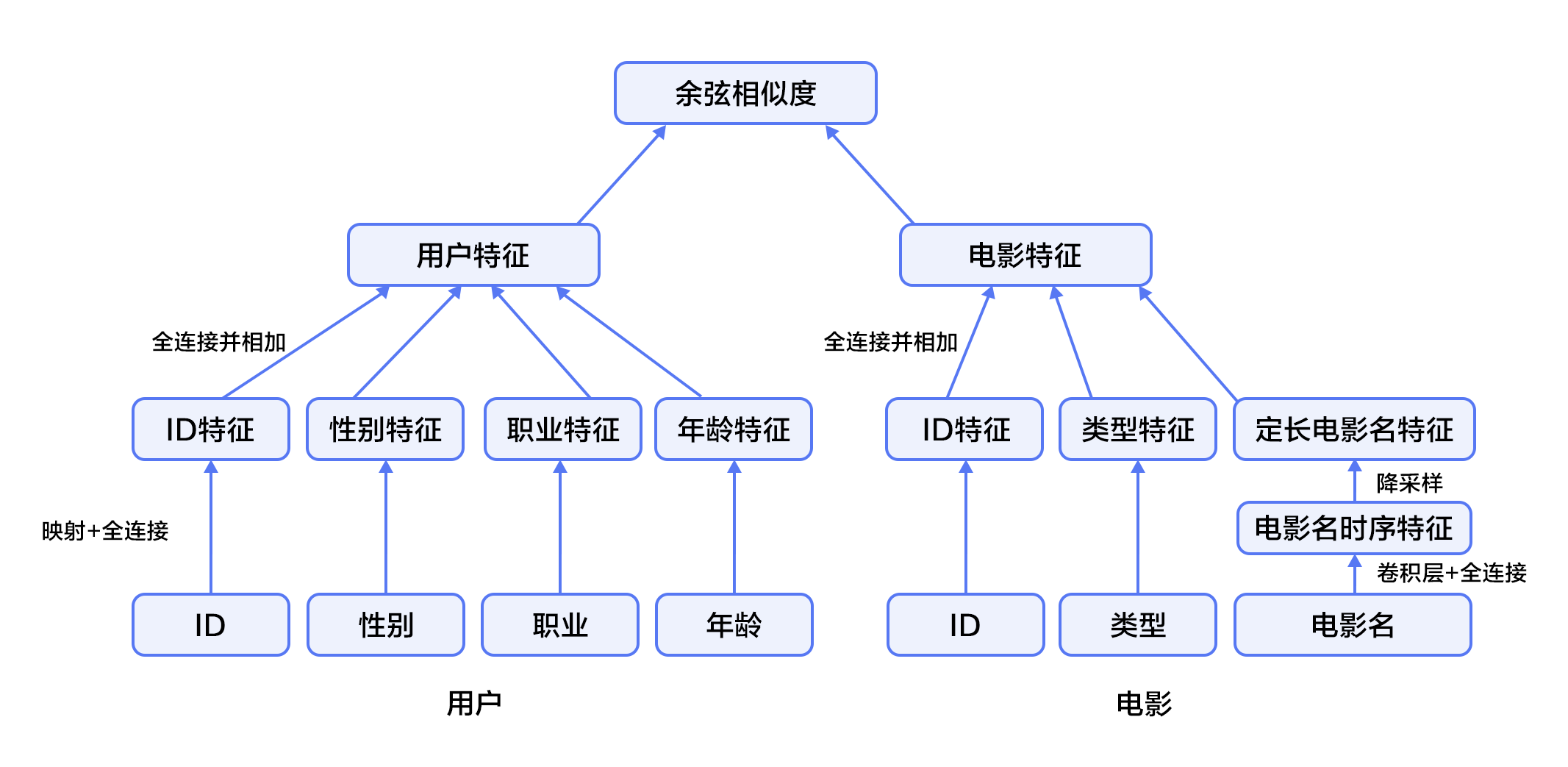
+Figure 4. Fusion recommendation model
+
+
+
+
+
+
+
+
+
+
+
+
@@ -77,9 +91,11 @@ $$ h_t = o_t\odot tanh(c_t) $$ LSTM通过给简单的循环神经网络增加记忆及控制门的方式,增强了其处理远距离依赖问题的能力。类似原理的改进还有Gated Recurrent Unit (GRU)\[[8](#参考文献)\],其设计更为简洁一些。**这些改进虽然各有不同,但是它们的宏观描述却与简单的循环神经网络一样(如图2所示),即隐状态依据当前输入及前一时刻的隐状态来改变,不断地循环这一过程直至输入处理完毕:** -$$ h_t=Recrurent(x_t,h_{t-1})$$ +
+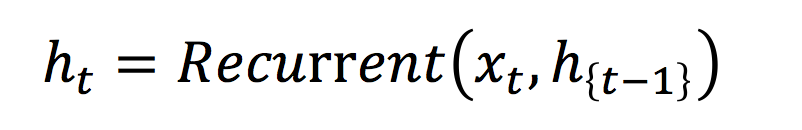
+
Table 1 Sentiment Analysis in Movie Reviews
+Form 1 Sentiment analysis of movie comments
-In natural language processing, sentiment analysis can be categorized as a **Text Classification problem**, i.e., to categorize a piece of text to a specific class. It involves two related tasks: text representation and classification. Before the emergence of deep learning techniques, the mainstream methods for text representation include BOW (*bag of words*) and topic modeling, while the latter contains SVM (*support vector machine*) and LR (*logistic regression*). +In natural language processing, sentiment is a typical problem of **text categorization**, which divides the text that needs to be sentiment analysis into its category. Text categorization involves two issues: text representation and classification methods. Before the emergence of the deep learning, the mainstream text representation methods are BOW (bag of words), topic models, etc.; the classification methods are SVM (support vector machine), LR (logistic regression) and so on. -The BOW model does not capture all the information in a piece of text, as it ignores syntax and grammar and just treats the text as a set of words. For example, “this movie is extremely bad“ and “boring, dull, and empty work” describe very similar semantic meaning, yet their BOW representations have very little similarity. Furthermore, “the movie is bad“ and “the movie is not bad“ have high similarity with BOW features, but they express completely opposite semantics. +For a piece of text, BOW means that its word order, grammar and syntax are ignored, and this text is only treated as a collection of words, so the BOW method does not adequately represent the semantic information of the text. For example, the sentence "This movie is awful" and "a boring, empty, non-connotative work" have a high semantic similarity in sentiment analysis, but their BOW representation has a similarity of zero. Another example is that the BOW is very similar to the sentence "an empty, work without connotations" and "a work that is not empty and has connotations", but in fact they mean differently. -This chapter introduces a deep learning model that handles these issues in BOW. Our model embeds texts into a low-dimensional space and takes word order into consideration. It is an end-to-end framework and it has large performance improvement over traditional methods \[[1](#references)\]. +The deep learning we are going to introduce in this chapter overcomes the above shortcomings of BOW representation. It maps text to low-dimensional semantic space based on word order, and performs text representation and classification in end-to-end mode. Its performance is significantly improved compared to the traditional method \[[1](#References)\]. ## Model Overview +The text representation models used in this chapter are Convolutional Neural Networks and Recurrent Neural Networks and their extensions. These models are described below. -The model we used in this chapter uses **Convolutional Neural Networks** (**CNNs**) and **Recurrent Neural Networks** (**RNNs**) with some specific extensions. - +### Introduction of Text Convolutional Neural Networks (CNN) -### Revisit to the Convolutional Neural Networks for Texts (CNN) +We introduced the calculation process of the CNN model applied to text data in the [Recommended System](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system) section. Here is a simple review. -The convolutional neural network for texts is introduced in chapter [recommender_system](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system), here is a brief overview. +For a CNN, first convolute input word vector sequence to generate a feature map, and then obtain the features of the whole sentence corresponding to the kernel by using a max pooling over time on the feature map. Finally, the splicing of all the features obtained is the fixed-length vector representation of the text. For the text classification problem, connecting it via softmax to construct a complete model. In actual applications, we use multiple convolution kernels to process sentences, and convolution kernels with the same window size are stacked to form a matrix, which can complete the operation more efficiently. In addition, we can also use the convolution kernel with different window sizes to process the sentence. Figure 3 in the [Recommend System](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system) section shows four convolution kernels, namely Figure 1 below, with different colors representing convolution kernel operations of different sizes. -CNN mainly contains convolution and pooling operation, with versatile combinations in various applications. We firstly apply the convolution operation: we apply the kernel in each window, extracting features. Convolving by the kernel at every window produces a feature map. Next, we apply *max pooling* over time to represent the whole sentence, which is the maximum element across the feature map. In real applications, we will apply multiple CNN kernels on the sentences. It can be implemented efficiently by concatenating the kernels together as a matrix. Also, we can use CNN kernels with different kernel size. Finally, concatenating the resulting features produces a fixed-length representation, which can be combined with a softmax to form the model for the sentiment analysis problem. +
+
+Figure 1. CNN text classification model
+
-
-Figure 1. An illustration of an unfolded RNN in time.
+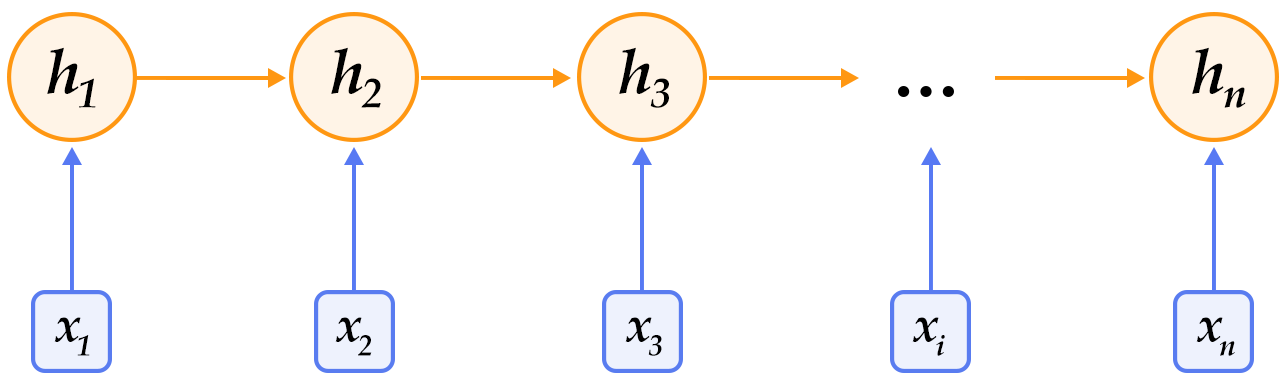
+Figure 2. Schematic diagram of the RNN expanded by time
-
-Figure 2. LSTM at time step $t$ [7].
+
+Figure 3. LSTM for time $t$ [7]
-
-Figure 3. Stacked Bidirectional LSTM for NLP modeling.
+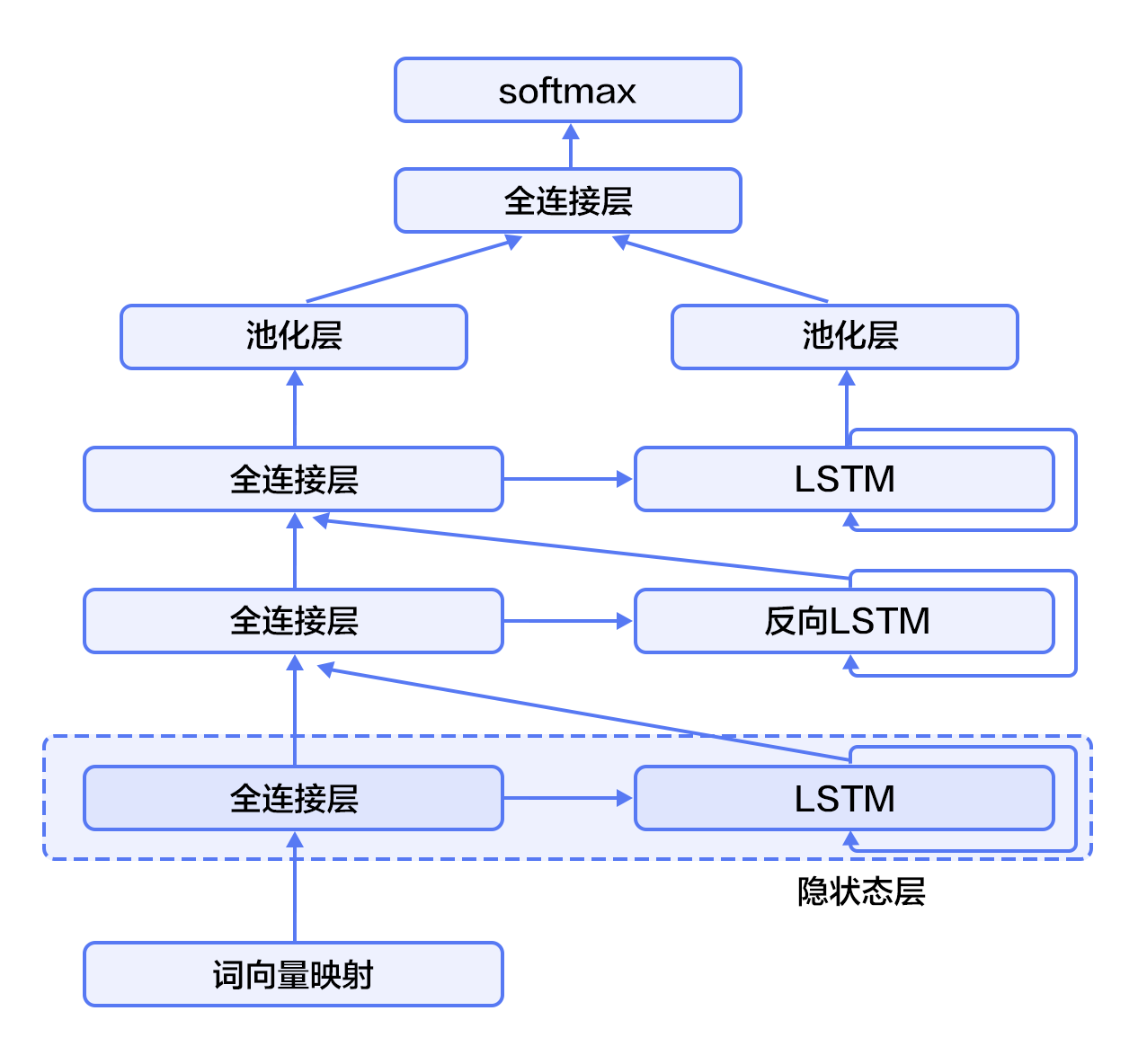
+Figure 4. Stacked bidirectional LSTM for text categorization
+
+
+
+
+
+
@@ -119,9 +133,11 @@ $$ h_t = o_t\odot tanh(c_t) $$ LSTM通过给简单的循环神经网络增加记忆及控制门的方式,增强了其处理远距离依赖问题的能力。类似原理的改进还有Gated Recurrent Unit (GRU)\[[8](#参考文献)\],其设计更为简洁一些。**这些改进虽然各有不同,但是它们的宏观描述却与简单的循环神经网络一样(如图2所示),即隐状态依据当前输入及前一时刻的隐状态来改变,不断地循环这一过程直至输入处理完毕:** -$$ h_t=Recrurent(x_t,h_{t-1})$$ +
+
+
+ 
+
+ 
+
+ 
+
+ 
+




-
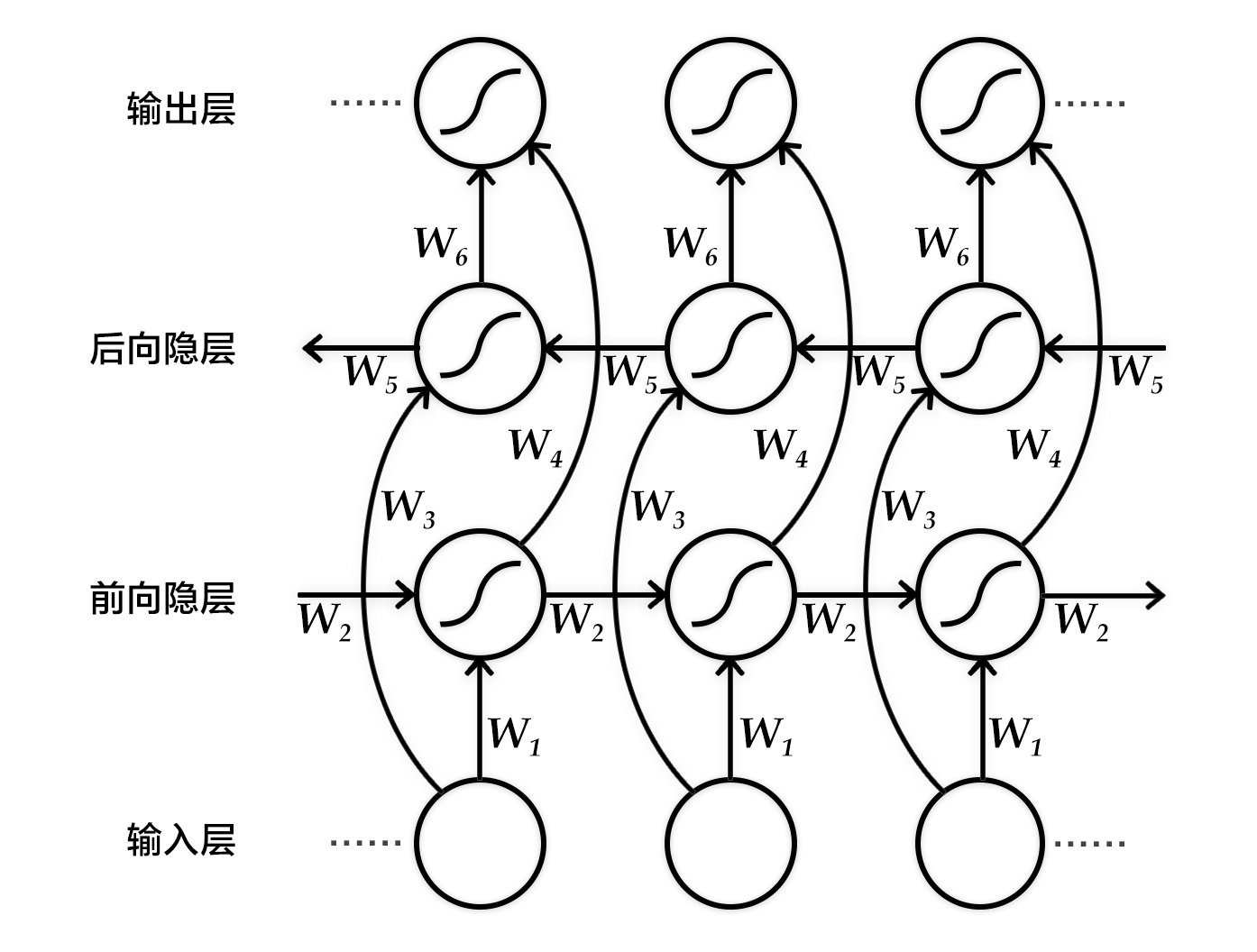
-Fig 3. Stacked Recurrent Neural Networks
+
+Figure 3. Schematic diagram of stack-based recurrent neural network based on LSTM
-
-Fig 4. Bidirectional LSTMs
+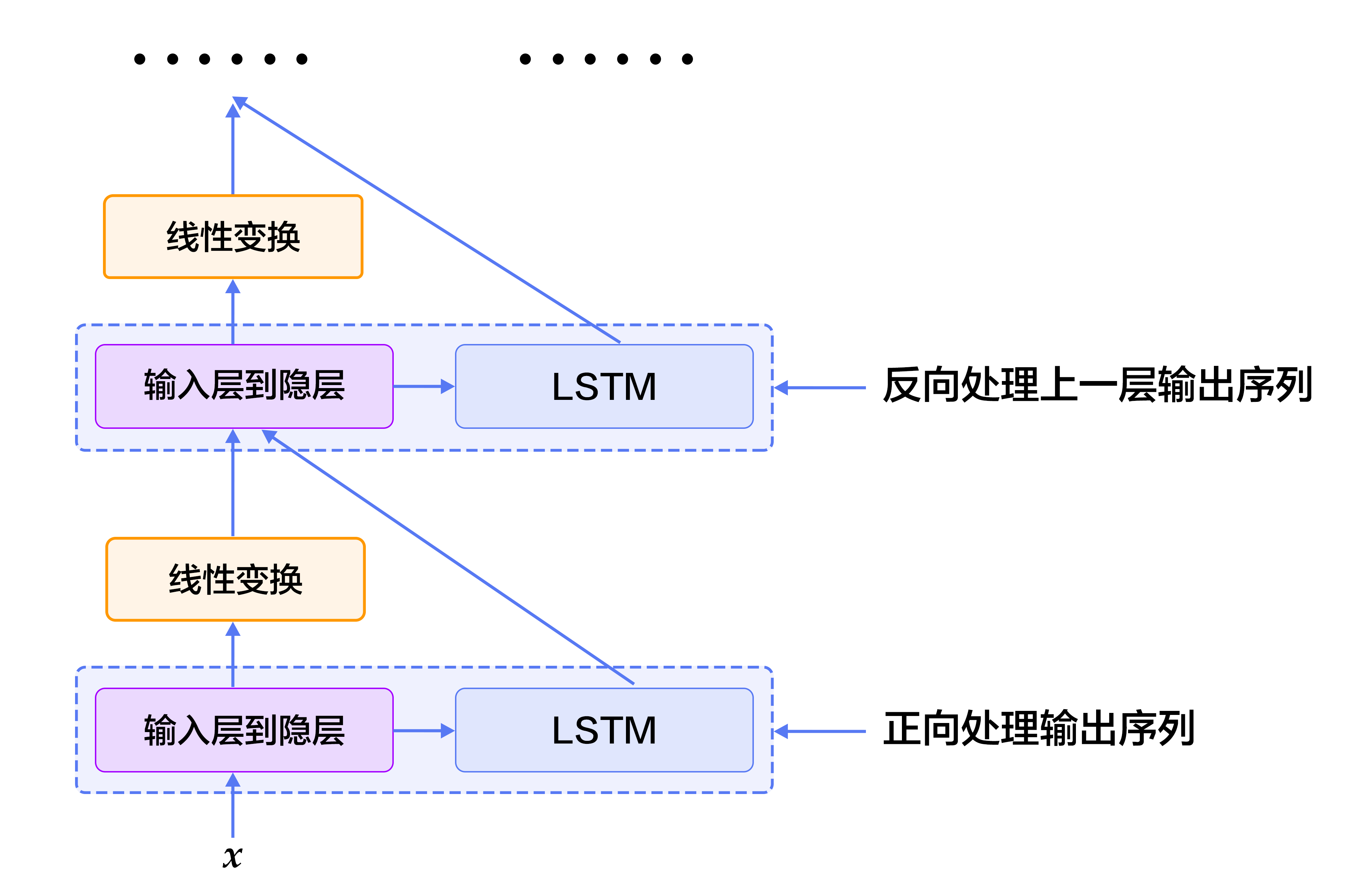
+Figure 4. Schematic diagram of a bidirectional recurrent neural network based on LSTM
-
-Fig 5. Linear Chain Conditional Random Field used in SRL tasks
+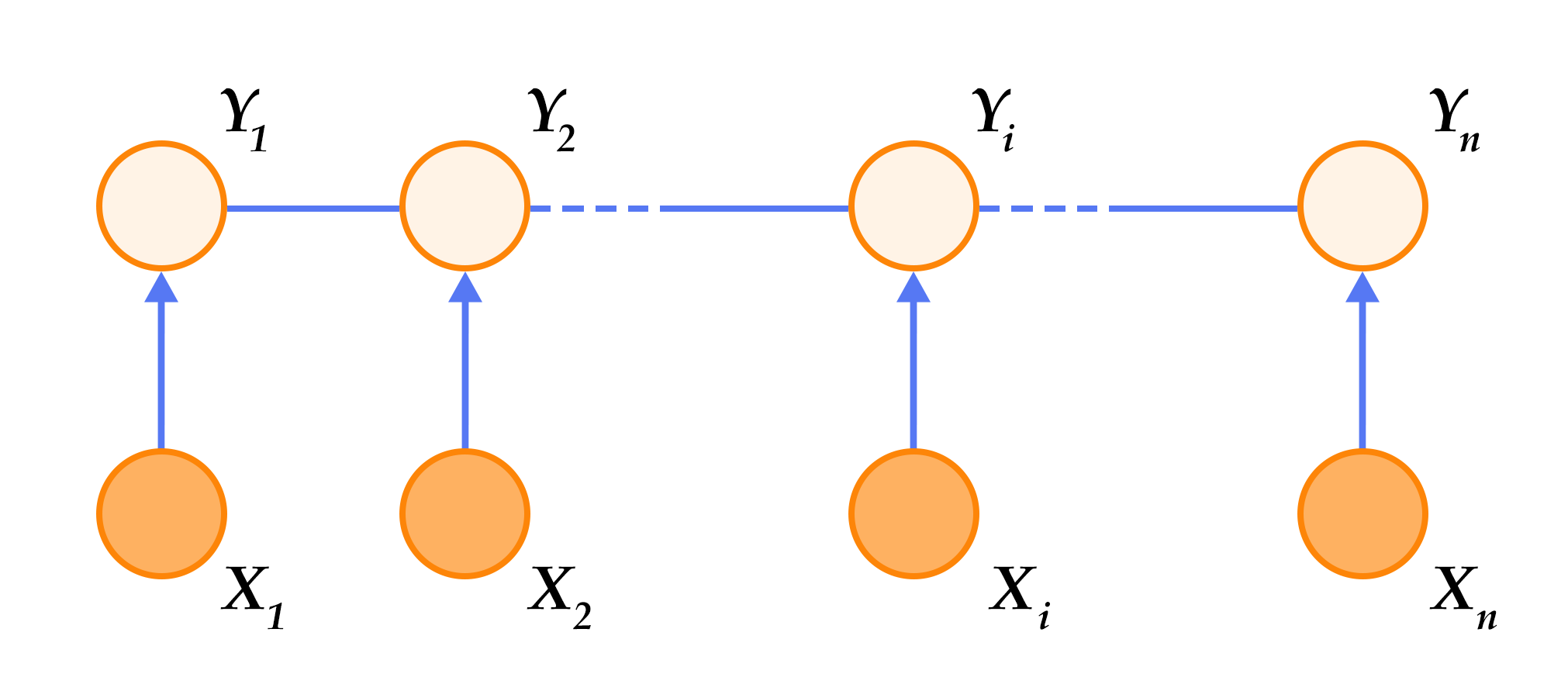
+Figure 5. Linear chain conditional random field used in sequence labeling tasks


+
+
+
+
+
+
+
+