+# GAN(Generative Adversarial Networks)
+
+The source codes of this tutorial are in book/09.gan . Please refer to the instructions to Book document for first use.
+
+## Backgrounds
+
+GAN \[[1](#References)\] is a kind of unsupervised learning method, which learns through games between two neural networks. This method was proposed by lan·Goodfellow et al in 2014, for whose paper you can refer to [Generative Adversarial Network](https://arxiv.org/abs/1406.2661)。
+
+GAN is constituted by a generative network and a discrimination network. The generative network takes random sampling from latent space as input, while its output results need to imitate the real samples in training set to the greatest extent. The discrimination network takes real samples or the output of the generative network as input, aimed to distinguish the output of the generative network from real samples. And the generative network tries to cheat the discrimination network. These two networks confront each other and adjust parameters constantly in order to tell the samples generated by the generative network and the real samples apart. \[[2](#References)\] ).
+
+GAN is commonly used to generate convincing pictures that can \[[3](#References)\] ). What's more, it can also generate videos and 3D object models etc.
+
+## Effect Display
+
+In this tutorial, MNIST data set are input to the network for training. After training for 19 turns, we can see that the generative pictures are very close to the real pictures. In the figure below, the first eight rows show real pictures and the rest show pictures generated by the network:
+
+
+figure 1. generative handwriting digit effect of GAN
+
+
+
+## Model Overview
+
+### GAN
+
+As its name suggests, GAN means learning generative models of data distribution by adversarial ways. And the word "adversarial" signifies that the Generator and the Discriminator confront each other. Take picture generation for example:
+
+- Generator (G) receives random noise z and generate pictures close to samples to greatest extent, which is dented as G(z)
+- Discriminator (D) receives an input picture x, discriminate whether the picture belongs to real samples or fake samples generated by the network. the output D(x) of Discriminator represents the probability that x is real. D(x)=1 means that Discriminator considers the input a real picture while D(x)=0 means that Discriminator consders it a fake one.
+
+In the process of training, the two networks confront each other to achieve dynamic equilibrium finally. And this can be described as:
+
+$$ \min\limits_{G} \max\limits_{D}V(D,G)=\mathbb{E}_{x\sim P_{data} (x)}\big[logD(x)\big] + \mathbb{E}_{z\sim p_{z}(z)}\big[log(1-D(G(z)))\big] $$
+
+In the optimal situation, G can generate a picture G(z) that is very close to real samples. D has difficulties judging whether the generative picture is real so it guesses randomly about the authenticity randomly, which means D(G(z))=0.5 .
+
+The figure below show the training process of GAN. We have a hypothesis that the black, green and blue lines represent the real sample distribution, the generative sample distribution and the discrimination model in the beginning respectively. When the training starts, it's hard to distinguish between the real samples and the generative samples for the discrimination model. Then when we fix the generative model and optimize the discrimination model, we get optimization results as the second figure shows. It can be seen that the discrimination model has good performance in distinguishing between generative and real data. Third, fix the discrimination model and improve the generative model, trying to make the former unable to distinguishing between generative and real pictures. In this process, we can see that the distribution of pictures generated by model is closer to the real one. Such iteration keeps progressing until convergence. Finally, the generative distribution and the discrimination distribution coincide so that the doscrimination model cannot distinguish between real and generative pictures.
+
+
+
+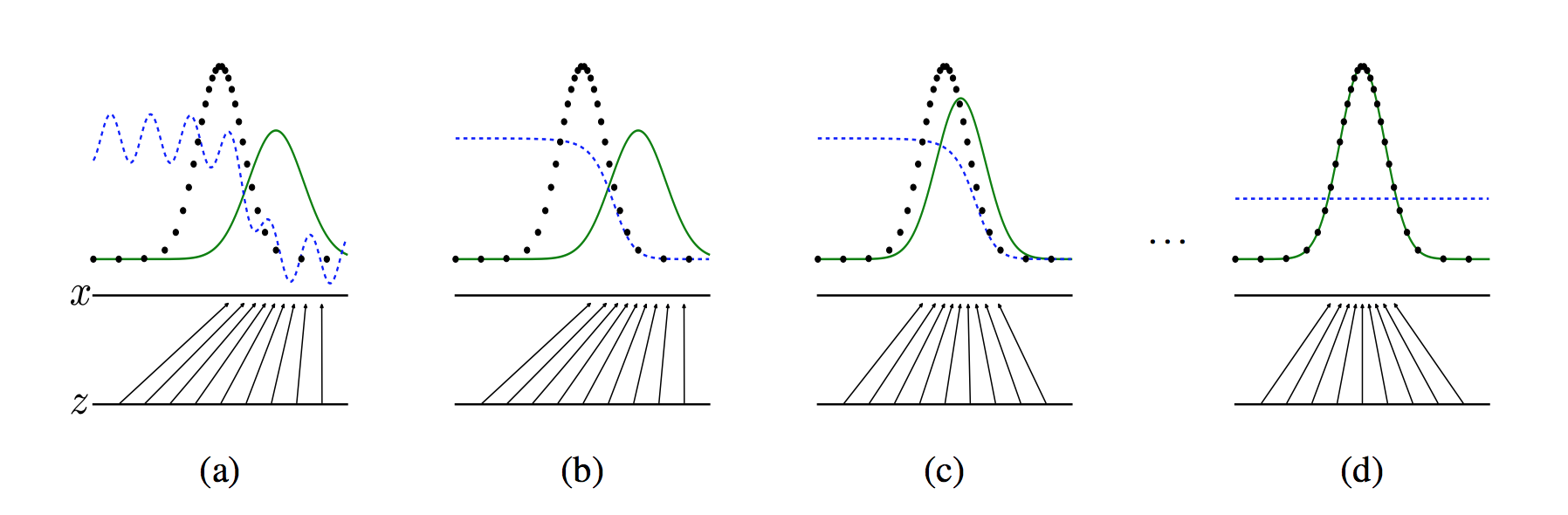
+figure 2. GAN training process
+
+
+However, in real process, it's hard to achieve the perfect balance node. Researches about the convergence theory about GAN is still in the works.
+
+
+### DCGAN
+
+[DCGAN](https://arxiv.org/abs/1511.06434) \[[4](#References)\] is the combination of Deep CNN and GAN, whose rationale is same with GAN except that it replaces Generator and Discriminator with two CNNs. In order to increase the quality of generative samples and the convergence rate of networks, DCGAN in the paper has improved in network structure:
+
+- cancel pooling layer: in the network, all pooling layers replace by strided convolutions (Discriminator) and fractional-strided convolutions (Generator).
+- add batch normalization: add batchnorm in both Generator and Discriminator
+- use FCN: take the FC layer away to achieve deeper network structure
+- the activation function: in Generator(G) ,the last layer adopts Tanh function while the others adopt ReLu function; in Discriminator(D) LeakyReLu function is applied
+
+The structure of Generator(G) in DCGAN(G)is shown in the following figure:
+
+
+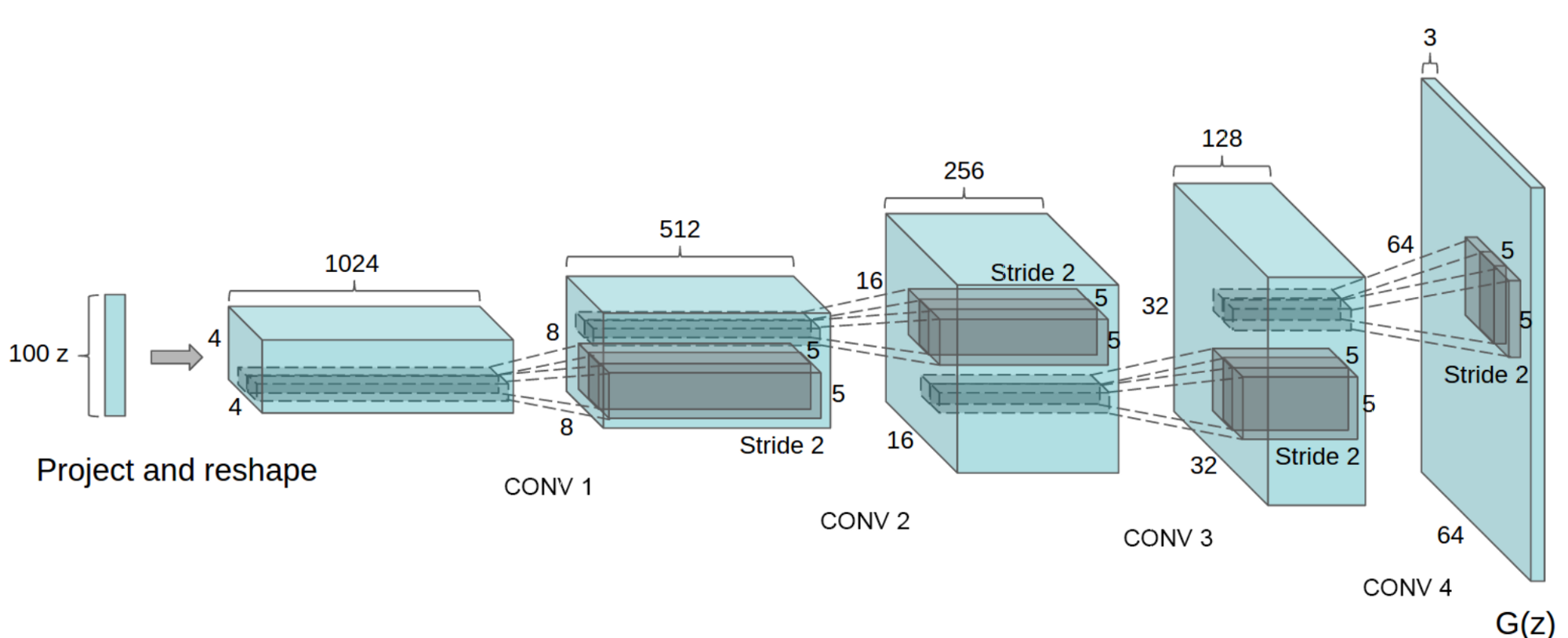
+figure 3. Generator(G) in DCGAN
+
+
+
+## Data Preparation
+
+In this tutorial, MNIST of small data size is used to train Generator ande Discriminator , which can be downloaded to lacal automatically by paddle.dataset module.
+
+Please refer to [Digit Recognition](https://github.com/PaddlePaddle/book/tree/develop/02.recognize_digits) for specific introduction to NMIST.
+
+## Train the Model
+
+ `09.gan/dc_gan.py` demonstrates the whole training process.
+
+### Load the Package
+
+First load the Fluid and other relaterd packages of PaddlePaddle.
+
+```python
+import sys
+import os
+import matplotlib
+import PIL
+import six
+import numpy as np
+import math
+import time
+import paddle
+import paddle.fluid as fluid
+
+matplotlib.use('agg')
+import matplotlib.pyplot as plt
+import matplotlib.gridspec as gridspec
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+```
+### define auxiliary tools
+
+define plot function to visualize the process of generating pictures
+
+```python
+def plot(gen_data):
+ pad_dim = 1
+ paded = pad_dim + img_dim
+ gen_data = gen_data.reshape(gen_data.shape[0], img_dim, img_dim)
+ n = int(math.ceil(math.sqrt(gen_data.shape[0])))
+ gen_data = (np.pad(
+ gen_data, [[0, n * n - gen_data.shape[0]], [pad_dim, 0], [pad_dim, 0]],
+ 'constant').reshape((n, n, paded, paded)).transpose((0, 2, 1, 3))
+ .reshape((n * paded, n * paded)))
+ fig = plt.figure(figsize=(8, 8))
+ plt.axis('off')
+ plt.imshow(gen_data, cmap='Greys_r', vmin=-1, vmax=1)
+ return fig
+```
+### define hyper-papameter
+
+```python
+gf_dim = 64 # the number of basic channels during Discriminator's feature mapping, which is multiples of the number of basic channels
+df_dim = 64 # the number of basic channels during Discriminator's feature mapping, which is multiples of the number of basic channels
+gfc_dim = 1024 * 2 # FCL dimention of Generator
+dfc_dim = 1024 # FCL dimention of Discriminator
+img_dim = 28 # dimention of the input image
+
+NOISE_SIZE = 100 # dimension of the input noise
+LEARNING_RATE = 2e-4 # learning rate of training
+
+epoch = 20 # the number of epochs in training
+output = "./output_dcgan" # storage path of models and test results
+use_cudnn = False # whether cuDNN is used
+use_gpu=False # whether GPU is used to train
+```
+
+### define the network structure
+
+- bn layer
+
+Call `fluid.layers.batch_norm` interface to achieve bn layer, while the activation function is ReLu by default.
+```python
+def bn(x, name=None, act='relu'):
+ return fluid.layers.batch_norm(
+ x,
+ param_attr=name + '1',
+ bias_attr=name + '2',
+ moving_mean_name=name + '3',
+ moving_variance_name=name + '4',
+ name=name,
+ act=act)
+```
+
+- convolution layer
+
+Call `fluid.nets.simple_img_conv_pool` to realize pooling of convolution. The kernel dimension is 3x3, the pooling window dimension is 2x2, the window slide step size is 2, and the activation function is appointed by certain network structure.
+
+```python
+def conv(x, num_filters, name=None, act=None):
+ return fluid.nets.simple_img_conv_pool(
+ input=x,
+ filter_size=5,
+ num_filters=num_filters,
+ pool_size=2,
+ pool_stride=2,
+ param_attr=name + 'w',
+ bias_attr=name + 'b',
+ use_cudnn=use_cudnn,
+ act=act)
+```
+
+- Fully Connected Layer
+
+```python
+def fc(x, num_filters, name=None, act=None):
+ return fluid.layers.fc(input=x,
+ size=num_filters,
+ act=act,
+ param_attr=name + 'w',
+ bias_attr=name + 'b')
+```
+
+- Transpose Convolution Layer
+
+In Generator, we need to generate full-size pictures by random sample value. DCGAN use Transpose Convolution Layer for upsampling. In Fluid, we call `fluid.layers.conv2d_transpose` to realize transpose convolution.
+
+```python
+def deconv(x,
+ num_filters,
+ name=None,
+ filter_size=5,
+ stride=2,
+ dilation=1,
+ padding=2,
+ output_size=None,
+ act=None):
+ return fluid.layers.conv2d_transpose(
+ input=x,
+ param_attr=name + 'w',
+ bias_attr=name + 'b',
+ num_filters=num_filters,
+ output_size=output_size,
+ filter_size=filter_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding,
+ use_cudnn=use_cudnn,
+ act=act)
+```
+
+- Discriminator
+
+Discriminator uses real data set and fake pictures generated by Generator to train at the same time, and try to make the output result 1 in the real data set case and make it 0 in the fake case. In this tutorial, Discriminator realized is constituted by two convolution pooling layers and two fully connected layers, in which the neuron number of the lat FCL is 1, outputting a dichotomy result.
+
+```python
+def D(x):
+ x = fluid.layers.reshape(x=x, shape=[-1, 1, 28, 28])
+ x = conv(x, df_dim, act='leaky_relu',name='conv1')
+ x = bn(conv(x, df_dim * 2,name='conv2'), act='leaky_relu',name='bn1')
+ x = bn(fc(x, dfc_dim,name='fc1'), act='leaky_relu',name='bn2')
+ x = fc(x, 1, act='sigmoid',name='fc2')
+ return x
+```
+
+- Generator
+
+Generator is constituted by two fully connected layers with BN and two transpose convolution layers. The inputs of the network are random noise data, and the kernel number of the last transpose convolution layer is 1, which means the outputs are grayscale images.
+
+```python
+def G(x):
+ x = bn(fc(x, gfc_dim,name='fc3'),name='bn3')
+ x = bn(fc(x, gf_dim * 2 * img_dim // 4 * img_dim // 4,name='fc4'),name='bn4')
+ x = fluid.layers.reshape(x, [-1, gf_dim * 2, img_dim // 4, img_dim // 4])
+ x = deconv(x, gf_dim * 2, act='relu', output_size=[14, 14],name='deconv1')
+ x = deconv(x, num_filters=1, filter_size=5, padding=2, act='tanh', output_size=[28, 28],name='deconv2')
+ x = fluid.layers.reshape(x, shape=[-1, 28 * 28])
+ return x
+```
+### Loss Function
+
+use `sigmoid_cross_entropy_with_logits`
+
+```python
+def loss(x, label):
+ return fluid.layers.mean(
+ fluid.layers.sigmoid_cross_entropy_with_logits(x=x, label=label))
+```
+
+
+### Create Program
+
+```python
+d_program = fluid.Program()
+dg_program = fluid.Program()
+
+# define program to discrinimate real images
+with fluid.program_guard(d_program):
+ # the dimention of the input image is 28*28=784
+ img = fluid.layers.data(name='img', shape=[784], dtype='float32')
+ # label shape=1
+ label = fluid.layers.data(name='label', shape=[1], dtype='float32')
+ d_logit = D(img)
+ d_loss = loss(d_logit, label)
+
+# define program to discrinimate generative images
+with fluid.program_guard(dg_program):
+ noise = fluid.layers.data(
+ name='noise', shape=[NOISE_SIZE], dtype='float32')
+ # get generative images by taking noise data as inputs
+ g_img = G(x=noise)
+
+ g_program = dg_program.clone()
+ g_program_test = dg_program.clone(for_test=True)
+
+ # discriminate the probability that the generative images are real samples
+ dg_logit = D(g_img)
+
+ # compute the loss that the he generative images are judged as real samples
+ dg_loss = loss(
+ dg_logit,
+ fluid.layers.fill_constant_batch_size_like(
+ input=noise, dtype='float32', shape=[-1, 1], value=1.0))
+
+```
+Take adam as optimizer to optimize the loss of judging real images and generative images respectively.
+
+```python
+opt = fluid.optimizer.Adam(learning_rate=LEARNING_RATE)
+opt.minimize(loss=d_loss)
+parameters = [p.name for p in g_program.global_block().all_parameters()]
+opt.minimize(loss=dg_loss, parameter_list=parameters)
+```
+
+### Data Set Feeders Configuration
+
+Next, we start the training process. We take paddle.dataset.mnist.train() as training data set, which returns a reader —— reader in PaddlePaddle is a Python function, which returns a Python yield generator every time it's called.
+
+The shuffle below is reader decorator, which receive a reader A and return another reader B. Reader B writes training data whose quantity is buffer_size into a buffer every time, and then disrupts the order and outputs item by item.
+
+The batch is a special decorator, whose input is a reader and output a batched reader. In PaddlePaddle, a reader yield a piece of training data each time, while a batched reader yield a minibatch each time.
+
+```python
+batch_size = 128 # Minibatch size
+
+train_reader = paddle.batch(
+ paddle.reader.shuffle(
+ paddle.dataset.mnist.train(), buf_size=60000),
+ batch_size=batch_size)
+```
+
+### Create Executor
+
+```python
+if use_gpu:
+ exe = fluid.Executor(fluid.CUDAPlace(0))
+else:
+ exe = fluid.Executor(fluid.CPUPlace())
+
+exe.run(fluid.default_startup_program())
+```
+
+### Start Training
+
+Generator and Discriminator set the iteration times respectively every iteration in the training process. In order to avoid Discriminator converging to 0 very fast, it is a default to train Dscriminator once and Generator twice every iteration in this tutorial.
+```python
+t_time = 0
+losses = [[], []]
+
+# the iteration number of Discriminator
+NUM_TRAIN_TIMES_OF_DG = 2
+
+# noise data of finally generated images
+const_n = np.random.uniform(
+ low=-1.0, high=1.0,
+ size=[batch_size, NOISE_SIZE]).astype('float32')
+
+for pass_id in range(epoch):
+ for batch_id, data in enumerate(train_reader()):
+ if len(data) != batch_size:
+ continue
+
+ # noise data in the generative training process
+ noise_data = np.random.uniform(
+ low=-1.0, high=1.0,
+ size=[batch_size, NOISE_SIZE]).astype('float32')
+
+ # real images
+ real_image = np.array(list(map(lambda x: x[0], data))).reshape(
+ -1, 784).astype('float32')
+ # real labels
+ real_labels = np.ones(
+ shape=[real_image.shape[0], 1], dtype='float32')
+ # fake labels
+ fake_labels = np.zeros(
+ shape=[real_image.shape[0], 1], dtype='float32')
+ total_label = np.concatenate([real_labels, fake_labels])
+ s_time = time.time()
+
+ # fake images
+ generated_image = exe.run(g_program,
+ feed={'noise': noise_data},
+ fetch_list={g_img})[0]
+
+ total_images = np.concatenate([real_image, generated_image])
+
+ # loss that a fake image is judged as False by D
+ d_loss_1 = exe.run(d_program,
+ feed={
+ 'img': generated_image,
+ 'label': fake_labels,
+ },
+ fetch_list={d_loss})[0][0]
+
+ # loss that a real image is judged as True by D
+ d_loss_2 = exe.run(d_program,
+ feed={
+ 'img': real_image,
+ 'label': real_labels,
+ },
+ fetch_list={d_loss})[0][0]
+
+ d_loss_n = d_loss_1 + d_loss_2
+ losses[0].append(d_loss_n)
+
+ # train Generator
+ for _ in six.moves.xrange(NUM_TRAIN_TIMES_OF_DG):
+ noise_data = np.random.uniform(
+ low=-1.0, high=1.0,
+ size=[batch_size, NOISE_SIZE]).astype('float32')
+ dg_loss_n = exe.run(dg_program,
+ feed={'noise': noise_data},
+ fetch_list={dg_loss})[0][0]
+ losses[1].append(dg_loss_n)
+ t_time += (time.time() - s_time)
+ if batch_id % 10 == 0 and not run_ce:
+ if not os.path.exists(output):
+ os.makedirs(output)
+ # generative results each turn
+ generated_images = exe.run(g_program_test,
+ feed={'noise': const_n},
+ fetch_list={g_img})[0]
+ # connect real images with generative images
+ total_images = np.concatenate([real_image, generated_images])
+ fig = plot(total_images)
+ msg = "Epoch ID={0} Batch ID={1} D-Loss={2} DG-Loss={3}\n ".format(
+ pass_id, batch_id,
+ d_loss_n, dg_loss_n)
+ print(msg)
+ plt.title(msg)
+ plt.savefig(
+ '{}/{:04d}_{:04d}.png'.format(output, pass_id,
+ batch_id),
+ bbox_inches='tight')
+ plt.close(fig)
+```
+
+print generative results in a certain turn:
+
+```python
+def display_image(epoch_no,batch_id):
+ return PIL.Image.open('output_dcgan/{:04d}_{:04d}.png'.format(epoch_no,batch_id))
+
+# observe the generative image of the 10th epoch and 460th batch:
+display_image(10,460)
+```
+
+
+## Summary
+
+DCGAN takes a random noise vector as input, which goes through a structure similiar but opposite with CNN and is magnifyed to 2D data. By generative models of such structure and discrimination models of CNN structure, DCGAN can perform very well in image generation. In this example, we generate handwriting digit image by DCGAN. You can try changing data set to generate images satisfied with your personal requirements or changing the network structure to observe different generation effects.
+
+
+## References
+[1] Goodfellow, Ian J.; Pouget-Abadie, Jean; Mirza, Mehdi; Xu, Bing; Warde-Farley, David; Ozair, Sherjil; Courville, Aaron; Bengio, Yoshua. Generative Adversarial Networks. 2014. arXiv:1406.2661 [stat.ML].
+
+[2] Andrej Karpathy, Pieter Abbeel, Greg Brockman, Peter Chen, Vicki Cheung, Rocky Duan, Ian Goodfellow, Durk Kingma, Jonathan Ho, Rein Houthooft, Tim Salimans, John Schulman, Ilya Sutskever, And Wojciech Zaremba, Generative Models, OpenAI, [April 7, 2016]
+
+[3] alimans, Tim; Goodfellow, Ian; Zaremba, Wojciech; Cheung, Vicki; Radford, Alec; Chen, Xi. Improved Techniques for Training GANs. 2016. arXiv:1606.03498 [cs.LG].
+
+[4] Radford A, Metz L, Chintala S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks[J]. Computer Science, 2015.
+
+