diff --git a/02.recognize_digits/README.cn.md b/02.recognize_digits/README.cn.md
index bf435a62a06682c81f9e2d6a5c84bd62678d8ee4..5731b48efa3dfc37bdc1ad4ad9bffb1d2aa36ff7 100644
--- a/02.recognize_digits/README.cn.md
+++ b/02.recognize_digits/README.cn.md
@@ -1,4 +1,4 @@
-# 识别数字
+# 数字识别
本教程源代码目录在[book/recognize_digits](https://github.com/PaddlePaddle/book/tree/develop/02.recognize_digits),初次使用请您参考[Book文档使用说明](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
@@ -12,26 +12,28 @@
MNIST数据集是从 [NIST](https://www.nist.gov/srd/nist-special-database-19) 的Special Database 3(SD-3)和Special Database 1(SD-1)构建而来。由于SD-3是由美国人口调查局的员工进行标注,SD-1是由美国高中生进行标注,因此SD-3比SD-1更干净也更容易识别。Yann LeCun等人从SD-1和SD-3中各取一半作为MNIST的训练集(60000条数据)和测试集(10000条数据),其中训练集来自250位不同的标注员,此外还保证了训练集和测试集的标注员是不完全相同的。
-Yann LeCun早先在手写字符识别上做了很多研究,并在研究过程中提出了卷积神经网络(Convolutional Neural Network),大幅度地提高了手写字符的识别能力,也因此成为了深度学习领域的奠基人之一。如今的深度学习领域,卷积神经网络占据了至关重要的地位,从最早Yann LeCun提出的简单LeNet,到如今ImageNet大赛上的优胜模型VGGNet、GoogLeNet、ResNet等(请参见[图像分类](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification) 教程),人们在图像分类领域,利用卷积神经网络得到了一系列惊人的结果。
+MNIST吸引了大量的科学家基于此数据集训练模型,1998年,LeCun分别用单层线性分类器、多层感知器(Multilayer Perceptron, MLP)和多层卷积神经网络LeNet进行实验,使得测试集上的误差不断下降(从12%下降到0.7%)\[[1](#参考文献)\]。在研究过程中,LeCun提出了卷积神经网络(Convolutional Neural Network),大幅度地提高了手写字符的识别能力,也因此成为了深度学习领域的奠基人之一。此后,科学家们又基于K近邻(K-Nearest Neighbors)算法\[[2](#参考文献)\]、支持向量机(SVM)\[[3](#参考文献)\]、神经网络\[[4-7](#参考文献)\]和Boosting方法\[[8](#参考文献)\]等做了大量实验,并采用多种预处理方法(如去除歪曲、去噪、模糊等)来提高识别的准确率。
-有很多算法在MNIST上进行实验。1998年,LeCun分别用单层线性分类器、多层感知器(Multilayer Perceptron, MLP)和多层卷积神经网络LeNet进行实验,使得测试集上的误差不断下降(从12%下降到0.7%)\[[1](#参考文献)\]。此后,科学家们又基于K近邻(K-Nearest Neighbors)算法\[[2](#参考文献)\]、支持向量机(SVM)\[[3](#参考文献)\]、神经网络\[[4-7](#参考文献)\]和Boosting方法\[[8](#参考文献)\]等做了大量实验,并采用多种预处理方法(如去除歪曲、去噪、模糊等)来提高识别的准确率。
+如今的深度学习领域,卷积神经网络占据了至关重要的地位,从最早Yann LeCun提出的简单LeNet,到如今ImageNet大赛上的优胜模型VGGNet、GoogLeNet、ResNet等(请参见[图像分类](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification) 教程),人们在图像分类领域,利用卷积神经网络得到了一系列惊人的结果。
-本教程中,我们从简单的模型Softmax回归开始,带大家入门手写字符识别,并逐步进行模型优化。
+
+
+本教程中,我们从简单的Softmax回归模型开始,带大家了解手写字符识别,并向大家介绍如何改进模型,利用多层感知机(MLP)和卷积神经网络(CNN)优化识别效果。
## 模型概览
-基于MNIST数据训练一个分类器,在介绍本教程使用的三个基本图像分类网络前,我们先给出一些定义:
+基于MNIST数据集训练一个分类器,在介绍本教程使用的三个基本图像分类网络前,我们先给出一些定义:
- $X$是输入:MNIST图片是$28\times28$ 的二维图像,为了进行计算,我们将其转化为$784$维向量,即$X=\left ( x_0, x_1, \dots, x_{783} \right )$。
- $Y$是输出:分类器的输出是10类数字(0-9),即$Y=\left ( y_0, y_1, \dots, y_9 \right )$,每一维$y_i$代表图片分类为第$i$类数字的概率。
-- $L$是图片的真实标签:$L=\left ( l_0, l_1, \dots, l_9 \right )$也是10维,但只有一维为1,其他都为0。
+- $Label$是图片的真实标签:$Label=\left ( l_0, l_1, \dots, l_9 \right )$也是10维,但只有一维为1,其他都为0。例如某张图片上的数字为2,则它的标签为$(0,0,1,0, \dot, 0)$
### Softmax回归(Softmax Regression)
-最简单的Softmax回归模型是先将输入层经过一个全连接层得到的特征,然后直接通过softmax 函数进行多分类\[[9](#参考文献)\]。
+最简单的Softmax回归模型是先将输入层经过一个全连接层得到特征,然后直接通过 softmax 函数计算多个类别的概率并输出\[[9](#参考文献)\]。
输入层的数据$X$传到输出层,在激活操作之前,会乘以相应的权重 $W$ ,并加上偏置变量 $b$ ,具体如下:
@@ -39,24 +41,26 @@ $$ y_i = \text{softmax}(\sum_j W_{i,j}x_j + b_i) $$
其中 $ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $
+图2为softmax回归的网络图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
+
+
+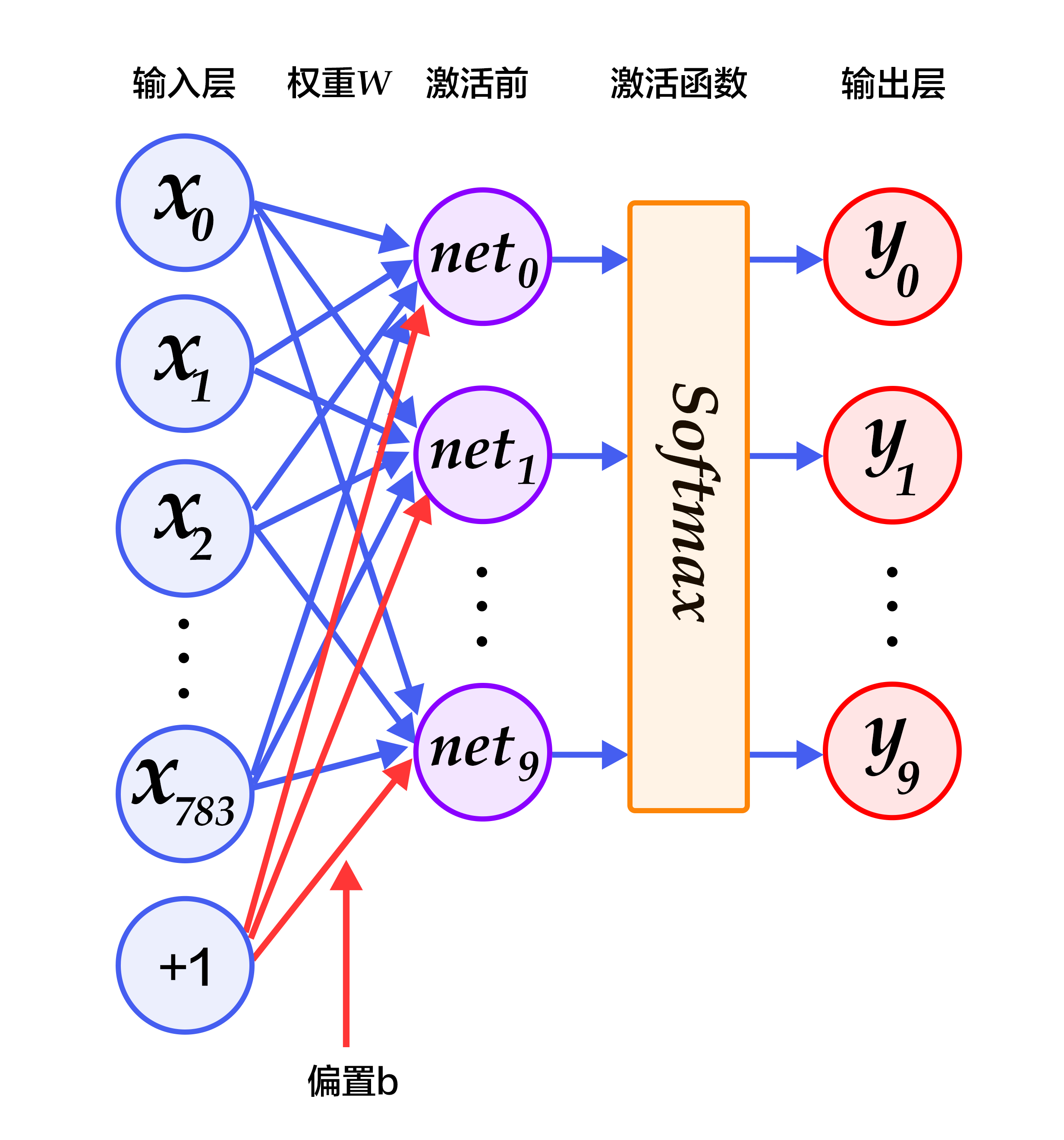
+图2. softmax回归网络结构图
+
+
对于有 $N$ 个类别的多分类问题,指定 $N$ 个输出节点,$N$ 维结果向量经过softmax将归一化为 $N$ 个[0,1]范围内的实数值,分别表示该样本属于这 $N$ 个类别的概率。此处的 $y_i$ 即对应该图片为数字 $i$ 的预测概率。
在分类问题中,我们一般采用交叉熵代价损失函数(cross entropy loss),公式如下:
$$ L_{cross-entropy}(label, y) = -\sum_i label_ilog(y_i) $$
-图2为softmax回归的网络图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
-
-
-图2. softmax回归网络结构图
-
-### 多层感知器(Multilayer Perceptron, MLP)
+### 多层感知机(Multilayer Perceptron, MLP)
Softmax回归模型采用了最简单的两层神经网络,即只有输入层和输出层,因此其拟合能力有限。为了达到更好的识别效果,我们考虑在输入层和输出层中间加上若干个隐藏层\[[10](#参考文献)\]。
-1. 经过第一个隐藏层,可以得到 $ H_1 = \phi(W_1X + b_1) $,其中$\phi$代表激活函数,常见的有sigmoid、tanh或ReLU等函数。
+1. 经过第一个隐藏层,可以得到 $ H_1 = \phi(W_1X + b_1) $,其中$\phi$代表激活函数,常见的有[sigmoid、tanh或ReLU](#常见激活函数介绍)等函数。
2. 经过第二个隐藏层,可以得到 $ H_2 = \phi(W_2H_1 + b_2) $。
3. 最后,再经过输出层,得到的$Y=\text{softmax}(W_3H_2 + b_3)$,即为最后的分类结果向量。
@@ -73,7 +77,7 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
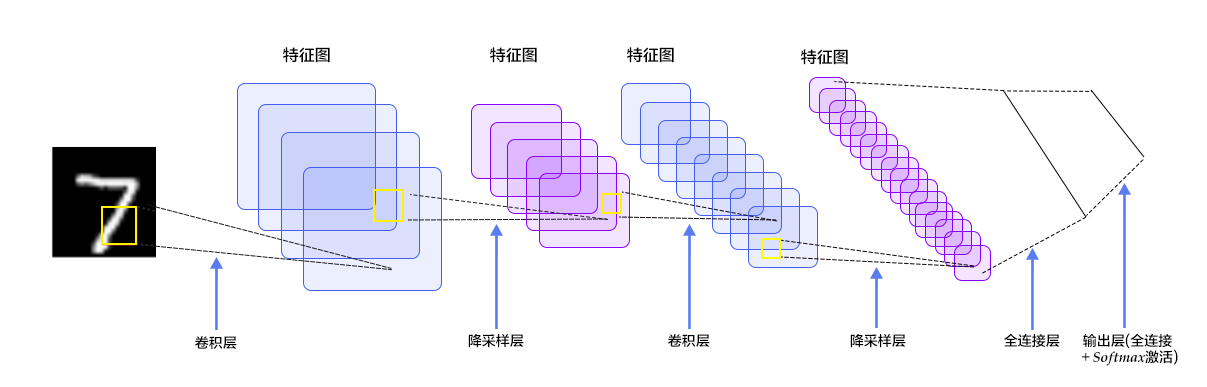
在多层感知器模型中,将图像展开成一维向量输入到网络中,忽略了图像的位置和结构信息,而卷积神经网络能够更好的利用图像的结构信息。[LeNet-5](http://yann.lecun.com/exdb/lenet/)是一个较简单的卷积神经网络。图4显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。下面我们主要介绍卷积层和池化层。
-
+
图4. LeNet-5卷积神经网络结构
@@ -86,7 +90,9 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
图5. 卷积层图片
-图5给出一个卷积计算过程的示例图,输入图像大小为$H=5,W=5,D=3$,即$5 \times 5$大小的3通道(RGB,也称作深度)彩色图像。这个示例图中包含两(用$K$表示)组卷积核,即图中滤波器$W_0$和$W_1$。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含($D=3)$个$3 \times 3$(用$F \times F$表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向($W$方向)和垂直方向($H$方向)的滑动步长为2(用$S$表示);对输入图像周围各填充1(用$P$表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为$3 \times 3 \times 2$(用$H_{o} \times W_{o} \times K$表示)大小的特征图,即$3 \times 3$大小的2通道特征图,其中$H_o$计算公式为:$H_o = (H - F + 2 \times P)/S + 1$,$W_o$同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置$b_o$,偏置通常对于每个输出特征图是共享的。输出特征图$o[:,:,0]$中的最后一个$-2$计算如图5右下角公式所示。
+图5给出一个卷积计算过程的示例图,输入图像大小为$H=5,W=5,D=3$,即$5 \times 5$大小的3通道(RGB,也称作深度)彩色图像。
+
+这个示例图中包含两(用$K$表示)组卷积核,即图中$Filter W_0$ 和 $Filter W_1$。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含($D=3)$个$3 \times 3$(用$F \times F$表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向($W$方向)和垂直方向($H$方向)的滑动步长为2(用$S$表示);对输入图像周围各填充1(用$P$表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为$3 \times 3 \times 2$(用$H_{o} \times W_{o} \times K$表示)大小的特征图,即$3 \times 3$大小的2通道特征图,其中$H_o$计算公式为:$H_o = (H - F + 2 \times P)/S + 1$,$W_o$同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置$b_o$,偏置通常对于每个输出特征图是共享的。输出特征图$o[:,:,0]$中的最后一个$-2$计算如图5右下角公式所示。
在卷积操作中卷积核是可学习的参数,经过上面示例介绍,每层卷积的参数大小为$D \times F \times F \times K$。在多层感知器模型中,神经元通常是全部连接,参数较多。而卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
@@ -96,6 +102,8 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
通过介绍卷积计算过程及其特性,可以看出卷积是线性操作,并具有平移不变性(shift-invariant),平移不变性即在图像每个位置执行相同的操作。卷积层的局部连接和权重共享使得需要学习的参数大大减小,这样也有利于训练较大卷积神经网络。
+关于卷积的更多内容可[参考阅读](http://ufldl.stanford.edu/wiki/index.php/Feature_extraction_using_convolution#Convolutions)。
+
#### 池化层
@@ -105,8 +113,9 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,如图6所示。
-更详细的关于卷积神经网络的具体知识可以参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/ )和[图像分类]( https://github.com/PaddlePaddle/book/tree/develop/03.image_classification )教程。
+更详细的关于卷积神经网络的具体知识可以参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/ )、[Ufldl](http://ufldl.stanford.edu/wiki/index.php/Pooling) 和 [图像分类]( https://github.com/PaddlePaddle/book/tree/develop/03.image_classification )教程。
+
### 常见激活函数介绍
- sigmoid激活函数: $ f(x) = sigmoid(x) = \frac{1}{1+e^{-x}} $
@@ -132,50 +141,53 @@ PaddlePaddle在API中提供了自动加载[MNIST](http://yann.lecun.com/exdb/mni
## Fluid API 概述
-演示将使用最新的 `Fluid API`。Fluid API是最新的 PaddlePaddle API。它在不牺牲性能的情况下简化了模型配置。
-我们建议使用 Fluid API,因为它更容易学起来。
+演示将使用最新的 [Fluid API](http://paddlepaddle.org/documentation/docs/zh/1.2/api_cn/index_cn.html)。Fluid API是最新的 PaddlePaddle API。它在不牺牲性能的情况下简化了模型配置。
+我们建议使用 Fluid API,它易学易用的特性将帮助您快速完成机器学习任务。。
-下面是快速的 Fluid API 概述。
+下面是 Fluid API 中几个重要概念的概述:
-1. `inference_program`:指定如何从数据输入中获得预测的函数。
+1. `inference_program`:指定如何从数据输入中获得预测的函数,
这是指定网络流的地方。
-2. `train_program`:指定如何从 `inference_program` 和`标签值`中获取 `loss` 的函数。
+2. `train_program`:指定如何从 `inference_program` 和`标签值`中获取 `loss` 的函数,
这是指定损失计算的地方。
-3. `optimizer_func`: “指定优化器配置的函数。优化器负责减少损失并驱动培训。Paddle 支持多种不同的优化器。
-
-4. `Trainer`:PaddlePaddle Trainer 管理由 `train_program` 和 `optimizer` 指定的训练过程。
-通过 `event_handler` 回调函数,用户可以监控培训的进展。
-
-5. `Inferencer`:Fluid inferencer 加载 `inference_program` 和由 Trainer 训练的参数。
-然后,它可以推断数据和返回预测。
+3. `optimizer_func`: 指定优化器配置的函数,优化器负责减少损失并驱动训练,Paddle 支持多种不同的优化器。
-在这个演示中,我们将深入了解它们。
+在下面的代码示例中,我们将深入了解它们。
## 配置说明
加载 PaddlePaddle 的 Fluid API 包。
```python
import os
-from PIL import Image
+from PIL import Image # 导入图像处理模块
+import matplotlib.pyplot as plt
import numpy
-import paddle
+import paddle # 导入paddle模块
import paddle.fluid as fluid
-from __future__ import print_function
+from __future__ import print_function # 将python3中的print特性导入当前版本
```
### Program Functions 配置
-我们需要设置“推理程序”函数。我们想用这个程序来演示三个不同的分类器,每个分类器都定义为 Python 函数。
-我们需要将图像数据馈送到分类器。Paddle 为读取数据提供了一个特殊的层 `layer.data` 层。
+我们需要设置 `inference_program` 函数。我们想用这个程序来演示三个不同的分类器,每个分类器都定义为 Python 函数。
+我们需要将图像数据输入到分类器中。Paddle 为读取数据提供了一个特殊的层 `layer.data` 层。
让我们创建一个数据层来读取图像并将其连接到分类网络。
- Softmax回归:只通过一层简单的以softmax为激活函数的全连接层,就可以得到分类的结果。
```python
def softmax_regression():
+ """
+ 定义softmax分类器:
+ 一个以softmax为激活函数的全连接层
+ Return:
+ predict_image -- 分类的结果
+ """
+ # 输入的原始图像数据,大小为28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
+ # 以softmax为激活函数的全连接层,输出层的大小必须为数字的个数10
predict = fluid.layers.fc(
input=img, size=10, act='softmax')
return predict
@@ -185,6 +197,15 @@ def softmax_regression():
```python
def multilayer_perceptron():
+ """
+ 定义多层感知机分类器:
+ 含有两个隐藏层(全连接层)的多层感知器
+ 其中前两个隐藏层的激活函数采用 ReLU,输出层的激活函数用 Softmax
+
+ Return:
+ predict_image -- 分类的结果
+ """
+ # 输入的原始图像数据,大小为28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
# 第一个全连接层,激活函数为ReLU
hidden = fluid.layers.fc(input=img, size=200, act='relu')
@@ -199,8 +220,17 @@ def multilayer_perceptron():
```python
def convolutional_neural_network():
+ """
+ 定义卷积神经网络分类器:
+ 输入的二维图像,经过两个卷积-池化层,使用以softmax为激活函数的全连接层作为输出层
+
+ Return:
+ predict -- 分类的结果
+ """
+ # 输入的原始图像数据,大小为28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
# 第一个卷积-池化层
+ # 使用20个5*5的滤波器,池化大小为2,池化步长为2,激活函数为Relu
conv_pool_1 = fluid.nets.simple_img_conv_pool(
input=img,
filter_size=5,
@@ -210,6 +240,7 @@ def convolutional_neural_network():
act="relu")
conv_pool_1 = fluid.layers.batch_norm(conv_pool_1)
# 第二个卷积-池化层
+ # 使用20个5*5的滤波器,池化大小为2,池化步长为2,激活函数为Relu
conv_pool_2 = fluid.nets.simple_img_conv_pool(
input=conv_pool_1,
filter_size=5,
@@ -232,13 +263,27 @@ def convolutional_neural_network():
```python
def train_program():
+ """
+ 配置train_program
+
+ Return:
+ predict -- 分类的结果
+ avg_cost -- 平均损失
+ acc -- 分类的准确率
+
+ """
+ # 标签层,名称为label,对应输入图片的类别标签
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
- # predict = softmax_regression() # uncomment for Softmax回归
- # predict = multilayer_perceptron() # uncomment for 多层感知器
- predict = convolutional_neural_network() # uncomment for LeNet5卷积神经网络
+ # predict = softmax_regression() # 取消注释将使用 Softmax回归
+ # predict = multilayer_perceptron() # 取消注释将使用 多层感知器
+ predict = convolutional_neural_network() # 取消注释将使用 LeNet5卷积神经网络
+
+ # 使用类交叉熵函数计算predict和label之间的损失函数
cost = fluid.layers.cross_entropy(input=predict, label=label)
+ # 计算平均损失
avg_cost = fluid.layers.mean(cost)
+ # 计算分类准确率
acc = fluid.layers.accuracy(input=predict, label=label)
return predict, [avg_cost, acc]
@@ -246,7 +291,7 @@ def train_program():
#### Optimizer Function 配置
-在下面的 `Adam optimizer`,`learning_rate` 是训练的速度,与网络的训练收敛速度有关系。
+在下面的 `Adam optimizer`,`learning_rate` 是学习率,它的大小与网络的训练收敛速度有关系。
```python
def optimizer_program():
@@ -262,43 +307,45 @@ def optimizer_program():
`batch`是一个特殊的decorator,它的输入是一个reader,输出是一个batched reader。在PaddlePaddle里,一个reader每次yield一条训练数据,而一个batched reader每次yield一个minibatch。
```python
-
+# 一个minibatch中有64个数据
BATCH_SIZE = 64
+# 每次读取训练集中的500个数据并随机打乱,传入batched reader中,batched reader 每次 yield 64个数据
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.mnist.train(), buf_size=500),
batch_size=BATCH_SIZE)
-
+# 读取测试集的数据,每次 yield 64个数据
test_reader = paddle.batch(
paddle.dataset.mnist.test(), batch_size=BATCH_SIZE)
```
-### Trainer 训练过程
+### 构建训练过程
-现在,我们需要构建一个训练过程。将使用到前面定义的训练程序 `train_program`, `place` 和优化器 `optimizer`,并包含训练迭代、检查训练期间测试误差以及保存所需要用来预测的模型参数。
+现在,我们需要构建一个训练过程。将使用到前面定义的训练程序 `train_program`, `place` 和优化器 `optimizer`,并包含训练迭代、检查训练期间测试误差以及保存所需要用来预测的模型参数。
#### Event Handler 配置
-我们可以在训练期间通过调用一个handler函数来监控培训进度。
-我们将在这里演示两个 `event_handler` 程序。请随意修改 Jupyter 笔记本 ,看看有什么不同。
+我们可以在训练期间通过调用一个handler函数来监控训练进度。
+我们将在这里演示两个 `event_handler` 程序。请随意修改 Jupyter Notebook ,看看有什么不同。
`event_handler` 用来在训练过程中输出训练结果
```python
def event_handler(pass_id, batch_id, cost):
+ # 打印训练的中间结果,训练轮次,batch数,损失函数
print("Pass %d, Batch %d, Cost %f" % (pass_id,batch_id, cost))
```
```python
-from paddle.v2.plot import Ploter
+from paddle.utils.plot import Ploter
train_prompt = "Train cost"
test_prompt = "Test cost"
cost_ploter = Ploter(train_prompt, test_prompt)
-# event_handler to plot a figure
+# 将训练过程绘图表示
def event_handler_plot(ploter_title, step, cost):
cost_ploter.append(ploter_title, step, cost)
cost_ploter.plot()
@@ -316,31 +363,49 @@ def event_handler_plot(ploter_title, step, cost):
`feed_order` 用于将数据目录映射到 `train_program`
创建一个反馈训练过程中误差的`train_test`
-训练完成后,模型参数存入`save_dirname`中
+定义网络结构:
```python
# 该模型运行在单个CPU上
-use_cuda = False # set to True if training with GPU
+use_cuda = False # 如想使用GPU,请设置为 True
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+# 调用train_program 获取预测值,损失值,
prediction, [avg_loss, acc] = train_program()
+# 输入的原始图像数据,大小为28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
+# 标签层,名称为label,对应输入图片的类别标签
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
+# 告知网络传入的数据分为两部分,第一部分是img值,第二部分是label值
feeder = fluid.DataFeeder(feed_list=[img, label], place=place)
+# 选择Adam优化器
optimizer = fluid.optimizer.Adam(learning_rate=0.001)
optimizer.minimize(avg_loss)
+```
+
+设置训练过程的超参:
+
+```python
-PASS_NUM = 5
+PASS_NUM = 5 #训练5轮
epochs = [epoch_id for epoch_id in range(PASS_NUM)]
+# 将模型参数存储在名为 save_dirname 的文件中
save_dirname = "recognize_digits.inference.model"
+```
+
+```python
def train_test(train_test_program,
train_test_feed, train_test_reader):
+
+ # 将分类准确率存储在acc_set中
acc_set = []
+ # 将平均损失存储在avg_loss_set中
avg_loss_set = []
+ # 将测试 reader yield 出的每一个数据传入网络中进行训练
for test_data in train_test_reader():
acc_np, avg_loss_np = exe.run(
program=train_test_program,
@@ -348,17 +413,30 @@ def train_test(train_test_program,
fetch_list=[acc, avg_loss])
acc_set.append(float(acc_np))
avg_loss_set.append(float(avg_loss_np))
- # get test acc and loss
+ # 获得测试数据上的准确率和损失值
acc_val_mean = numpy.array(acc_set).mean()
avg_loss_val_mean = numpy.array(avg_loss_set).mean()
+ # 返回平均损失值,平均准确率
return avg_loss_val_mean, acc_val_mean
+```
+创建执行器:
+
+```python
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
+```
+
+设置 main_program 和 test_program :
+```python
main_program = fluid.default_main_program()
test_program = fluid.default_main_program().clone(for_test=True)
+```
+
+开始训练:
+```python
lists = []
step = 0
for epoch_id in epochs:
@@ -366,12 +444,12 @@ for epoch_id in epochs:
metrics = exe.run(main_program,
feed=feeder.feed(data),
fetch_list=[avg_loss, acc])
- if step % 100 == 0:
+ if step % 100 == 0: #每训练100次 打印一次log
print("Pass %d, Batch %d, Cost %f" % (step, epoch_id, metrics[0]))
event_handler_plot(train_prompt, step, metrics[0])
step += 1
- # test for epoch
+ # 测试每个epoch的分类效果
avg_loss_val, acc_val = train_test(train_test_program=test_program,
train_test_reader=test_reader,
train_test_feed=feeder)
@@ -380,19 +458,25 @@ for epoch_id in epochs:
event_handler_plot(test_prompt, step, metrics[0])
lists.append((epoch_id, avg_loss_val, acc_val))
+
+ # 保存训练好的模型参数用于预测
if save_dirname is not None:
fluid.io.save_inference_model(save_dirname,
["img"], [prediction], exe,
model_filename=None,
params_filename=None)
- # find the best pass
+# 选择效果最好的pass
best = sorted(lists, key=lambda list: float(list[1]))[0]
print('Best pass is %s, testing Avgcost is %s' % (best[0], best[1]))
print('The classification accuracy is %.2f%%' % (float(best[2]) * 100))
```
-训练过程是完全自动的,event_handler里打印的日志类似如下所示:
+训练过程是完全自动的,event_handler里打印的日志类似如下所示。
+
+Pass表示训练轮次,Batch表示训练全量数据的次数,cost表示当前pass的损失值。
+
+每训练完一个Epoch后,计算一次平均损失和分类准确率。
```
Pass 0, Batch 0, Cost 0.125650
@@ -417,7 +501,7 @@ Test with Epoch 0, avg_cost: 0.053097883707459624, acc: 0.9822850318471338
### 生成预测输入数据
-`infer_3.png` 是数字 3 的一个示例图像。把它变成一个 numpy 数组以匹配数据馈送格式。
+`infer_3.png` 是数字 3 的一个示例图像。把它变成一个 numpy 数组以匹配数据feed格式。
```python
def load_image(file):
@@ -427,7 +511,7 @@ def load_image(file):
im = im / 255.0 * 2.0 - 1.0
return im
-cur_dir = cur_dir = os.getcwd()
+cur_dir = os.getcwd()
tensor_img = load_image(cur_dir + '/image/infer_3.png')
```
@@ -436,20 +520,23 @@ tensor_img = load_image(cur_dir + '/image/infer_3.png')
```python
inference_scope = fluid.core.Scope()
with fluid.scope_guard(inference_scope):
- # Use fluid.io.load_inference_model to obtain the inference program desc,
- # the feed_target_names (the names of variables that will be feeded
- # data using feed operators), and the fetch_targets (variables that
- # we want to obtain data from using fetch operators).
+ # 使用 fluid.io.load_inference_model 获取 inference program desc,
+ # feed_target_names 用于指定需要传入网络的变量名
+ # fetch_targets 指定希望从网络中fetch出的变量名
[inference_program, feed_target_names,
fetch_targets] = fluid.io.load_inference_model(
save_dirname, exe, None, None)
- # Construct feed as a dictionary of {feed_target_name: feed_target_data}
- # and results will contain a list of data corresponding to fetch_targets.
+ # 将feed构建成字典 {feed_target_name: feed_target_data}
+ # 结果将包含一个与fetch_targets对应的数据列表
results = exe.run(inference_program,
feed={feed_target_names[0]: tensor_img},
fetch_list=fetch_targets)
lab = numpy.argsort(results)
+
+ # 打印 infer_3.png 这张图片的预测结果
+ img=Image.open('image/infer_3.png')
+ plt.imshow(img)
print("Inference result of image/infer_3.png is: %d" % lab[0][0][-1])
```
@@ -457,11 +544,11 @@ with fluid.scope_guard(inference_scope):
### 预测结果
如果顺利,预测结果输入如下:
-`Inference result of image/infer_3.png is: 3`
+`Inference result of image/infer_3.png is: 3` , 说明我们的网络成功的识别出了这张图片!
## 总结
-本教程的softmax回归、多层感知器和卷积神经网络是最基础的深度学习模型,后续章节中复杂的神经网络都是从它们衍生出来的,因此这几个模型对之后的学习大有裨益。同时,我们也观察到从最简单的softmax回归变换到稍复杂的卷积神经网络的时候,MNIST数据集上的识别准确率有了大幅度的提升,原因是卷积层具有局部连接和共享权重的特性。在之后学习新模型的时候,希望大家也要深入到新模型相比原模型带来效果提升的关键之处。此外,本教程还介绍了PaddlePaddle模型搭建的基本流程,从dataprovider的编写、网络层的构建,到最后的训练和预测。对这个流程熟悉以后,大家就可以用自己的数据,定义自己的网络模型,并完成自己的训练和预测任务了。
+本教程的softmax回归、多层感知机和卷积神经网络是最基础的深度学习模型,后续章节中复杂的神经网络都是从它们衍生出来的,因此这几个模型对之后的学习大有裨益。同时,我们也观察到从最简单的softmax回归变换到稍复杂的卷积神经网络的时候,MNIST数据集上的识别准确率有了大幅度的提升,原因是卷积层具有局部连接和共享权重的特性。在之后学习新模型的时候,希望大家也要深入到新模型相比原模型带来效果提升的关键之处。此外,本教程还介绍了PaddlePaddle模型搭建的基本流程,从dataprovider的编写、网络层的构建,到最后的训练和预测。对这个流程熟悉以后,大家就可以用自己的数据,定义自己的网络模型,并完成自己的训练和预测任务了。
## 参考文献
@@ -479,3 +566,4 @@ with fluid.scope_guard(inference_scope):

本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
+
diff --git a/02.recognize_digits/index.cn.html b/02.recognize_digits/index.cn.html
index 5267aa7532440d6f0f51370e1809bc91c3304d7a..974b95735d4981fc8c267e7a4a1cf9dad8989c48 100644
--- a/02.recognize_digits/index.cn.html
+++ b/02.recognize_digits/index.cn.html
@@ -40,7 +40,7 @@
-# 识别数字
+# 数字识别
本教程源代码目录在[book/recognize_digits](https://github.com/PaddlePaddle/book/tree/develop/02.recognize_digits),初次使用请您参考[Book文档使用说明](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
@@ -54,26 +54,28 @@
MNIST数据集是从 [NIST](https://www.nist.gov/srd/nist-special-database-19) 的Special Database 3(SD-3)和Special Database 1(SD-1)构建而来。由于SD-3是由美国人口调查局的员工进行标注,SD-1是由美国高中生进行标注,因此SD-3比SD-1更干净也更容易识别。Yann LeCun等人从SD-1和SD-3中各取一半作为MNIST的训练集(60000条数据)和测试集(10000条数据),其中训练集来自250位不同的标注员,此外还保证了训练集和测试集的标注员是不完全相同的。
-Yann LeCun早先在手写字符识别上做了很多研究,并在研究过程中提出了卷积神经网络(Convolutional Neural Network),大幅度地提高了手写字符的识别能力,也因此成为了深度学习领域的奠基人之一。如今的深度学习领域,卷积神经网络占据了至关重要的地位,从最早Yann LeCun提出的简单LeNet,到如今ImageNet大赛上的优胜模型VGGNet、GoogLeNet、ResNet等(请参见[图像分类](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification) 教程),人们在图像分类领域,利用卷积神经网络得到了一系列惊人的结果。
+MNIST吸引了大量的科学家基于此数据集训练模型,1998年,LeCun分别用单层线性分类器、多层感知器(Multilayer Perceptron, MLP)和多层卷积神经网络LeNet进行实验,使得测试集上的误差不断下降(从12%下降到0.7%)\[[1](#参考文献)\]。在研究过程中,LeCun提出了卷积神经网络(Convolutional Neural Network),大幅度地提高了手写字符的识别能力,也因此成为了深度学习领域的奠基人之一。此后,科学家们又基于K近邻(K-Nearest Neighbors)算法\[[2](#参考文献)\]、支持向量机(SVM)\[[3](#参考文献)\]、神经网络\[[4-7](#参考文献)\]和Boosting方法\[[8](#参考文献)\]等做了大量实验,并采用多种预处理方法(如去除歪曲、去噪、模糊等)来提高识别的准确率。
-有很多算法在MNIST上进行实验。1998年,LeCun分别用单层线性分类器、多层感知器(Multilayer Perceptron, MLP)和多层卷积神经网络LeNet进行实验,使得测试集上的误差不断下降(从12%下降到0.7%)\[[1](#参考文献)\]。此后,科学家们又基于K近邻(K-Nearest Neighbors)算法\[[2](#参考文献)\]、支持向量机(SVM)\[[3](#参考文献)\]、神经网络\[[4-7](#参考文献)\]和Boosting方法\[[8](#参考文献)\]等做了大量实验,并采用多种预处理方法(如去除歪曲、去噪、模糊等)来提高识别的准确率。
+如今的深度学习领域,卷积神经网络占据了至关重要的地位,从最早Yann LeCun提出的简单LeNet,到如今ImageNet大赛上的优胜模型VGGNet、GoogLeNet、ResNet等(请参见[图像分类](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification) 教程),人们在图像分类领域,利用卷积神经网络得到了一系列惊人的结果。
-本教程中,我们从简单的模型Softmax回归开始,带大家入门手写字符识别,并逐步进行模型优化。
+
+
+本教程中,我们从简单的Softmax回归模型开始,带大家了解手写字符识别,并向大家介绍如何改进模型,利用多层感知机(MLP)和卷积神经网络(CNN)优化识别效果。
## 模型概览
-基于MNIST数据训练一个分类器,在介绍本教程使用的三个基本图像分类网络前,我们先给出一些定义:
+基于MNIST数据集训练一个分类器,在介绍本教程使用的三个基本图像分类网络前,我们先给出一些定义:
- $X$是输入:MNIST图片是$28\times28$ 的二维图像,为了进行计算,我们将其转化为$784$维向量,即$X=\left ( x_0, x_1, \dots, x_{783} \right )$。
- $Y$是输出:分类器的输出是10类数字(0-9),即$Y=\left ( y_0, y_1, \dots, y_9 \right )$,每一维$y_i$代表图片分类为第$i$类数字的概率。
-- $L$是图片的真实标签:$L=\left ( l_0, l_1, \dots, l_9 \right )$也是10维,但只有一维为1,其他都为0。
+- $Label$是图片的真实标签:$Label=\left ( l_0, l_1, \dots, l_9 \right )$也是10维,但只有一维为1,其他都为0。例如某张图片上的数字为2,则它的标签为$(0,0,1,0, \dot, 0)$
### Softmax回归(Softmax Regression)
-最简单的Softmax回归模型是先将输入层经过一个全连接层得到的特征,然后直接通过softmax 函数进行多分类\[[9](#参考文献)\]。
+最简单的Softmax回归模型是先将输入层经过一个全连接层得到特征,然后直接通过 softmax 函数计算多个类别的概率并输出\[[9](#参考文献)\]。
输入层的数据$X$传到输出层,在激活操作之前,会乘以相应的权重 $W$ ,并加上偏置变量 $b$ ,具体如下:
@@ -81,24 +83,26 @@ $$ y_i = \text{softmax}(\sum_j W_{i,j}x_j + b_i) $$
其中 $ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $
+图2为softmax回归的网络图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
+
+
+
+图2. softmax回归网络结构图
+
+
对于有 $N$ 个类别的多分类问题,指定 $N$ 个输出节点,$N$ 维结果向量经过softmax将归一化为 $N$ 个[0,1]范围内的实数值,分别表示该样本属于这 $N$ 个类别的概率。此处的 $y_i$ 即对应该图片为数字 $i$ 的预测概率。
在分类问题中,我们一般采用交叉熵代价损失函数(cross entropy loss),公式如下:
$$ L_{cross-entropy}(label, y) = -\sum_i label_ilog(y_i) $$
-图2为softmax回归的网络图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
-
-
-图2. softmax回归网络结构图
-
-### 多层感知器(Multilayer Perceptron, MLP)
+### 多层感知机(Multilayer Perceptron, MLP)
Softmax回归模型采用了最简单的两层神经网络,即只有输入层和输出层,因此其拟合能力有限。为了达到更好的识别效果,我们考虑在输入层和输出层中间加上若干个隐藏层\[[10](#参考文献)\]。
-1. 经过第一个隐藏层,可以得到 $ H_1 = \phi(W_1X + b_1) $,其中$\phi$代表激活函数,常见的有sigmoid、tanh或ReLU等函数。
+1. 经过第一个隐藏层,可以得到 $ H_1 = \phi(W_1X + b_1) $,其中$\phi$代表激活函数,常见的有[sigmoid、tanh或ReLU](#常见激活函数介绍)等函数。
2. 经过第二个隐藏层,可以得到 $ H_2 = \phi(W_2H_1 + b_2) $。
3. 最后,再经过输出层,得到的$Y=\text{softmax}(W_3H_2 + b_3)$,即为最后的分类结果向量。
@@ -115,7 +119,7 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
在多层感知器模型中,将图像展开成一维向量输入到网络中,忽略了图像的位置和结构信息,而卷积神经网络能够更好的利用图像的结构信息。[LeNet-5](http://yann.lecun.com/exdb/lenet/)是一个较简单的卷积神经网络。图4显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。下面我们主要介绍卷积层和池化层。
-
+
图4. LeNet-5卷积神经网络结构
@@ -128,7 +132,9 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
图5. 卷积层图片
-图5给出一个卷积计算过程的示例图,输入图像大小为$H=5,W=5,D=3$,即$5 \times 5$大小的3通道(RGB,也称作深度)彩色图像。这个示例图中包含两(用$K$表示)组卷积核,即图中滤波器$W_0$和$W_1$。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含($D=3)$个$3 \times 3$(用$F \times F$表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向($W$方向)和垂直方向($H$方向)的滑动步长为2(用$S$表示);对输入图像周围各填充1(用$P$表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为$3 \times 3 \times 2$(用$H_{o} \times W_{o} \times K$表示)大小的特征图,即$3 \times 3$大小的2通道特征图,其中$H_o$计算公式为:$H_o = (H - F + 2 \times P)/S + 1$,$W_o$同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置$b_o$,偏置通常对于每个输出特征图是共享的。输出特征图$o[:,:,0]$中的最后一个$-2$计算如图5右下角公式所示。
+图5给出一个卷积计算过程的示例图,输入图像大小为$H=5,W=5,D=3$,即$5 \times 5$大小的3通道(RGB,也称作深度)彩色图像。
+
+这个示例图中包含两(用$K$表示)组卷积核,即图中$Filter W_0$ 和 $Filter W_1$。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含($D=3)$个$3 \times 3$(用$F \times F$表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向($W$方向)和垂直方向($H$方向)的滑动步长为2(用$S$表示);对输入图像周围各填充1(用$P$表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为$3 \times 3 \times 2$(用$H_{o} \times W_{o} \times K$表示)大小的特征图,即$3 \times 3$大小的2通道特征图,其中$H_o$计算公式为:$H_o = (H - F + 2 \times P)/S + 1$,$W_o$同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置$b_o$,偏置通常对于每个输出特征图是共享的。输出特征图$o[:,:,0]$中的最后一个$-2$计算如图5右下角公式所示。
在卷积操作中卷积核是可学习的参数,经过上面示例介绍,每层卷积的参数大小为$D \times F \times F \times K$。在多层感知器模型中,神经元通常是全部连接,参数较多。而卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
@@ -138,6 +144,8 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
通过介绍卷积计算过程及其特性,可以看出卷积是线性操作,并具有平移不变性(shift-invariant),平移不变性即在图像每个位置执行相同的操作。卷积层的局部连接和权重共享使得需要学习的参数大大减小,这样也有利于训练较大卷积神经网络。
+关于卷积的更多内容可[参考阅读](http://ufldl.stanford.edu/wiki/index.php/Feature_extraction_using_convolution#Convolutions)。
+
#### 池化层
@@ -147,8 +155,9 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,如图6所示。
-更详细的关于卷积神经网络的具体知识可以参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/ )和[图像分类]( https://github.com/PaddlePaddle/book/tree/develop/03.image_classification )教程。
+更详细的关于卷积神经网络的具体知识可以参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/ )、[Ufldl](http://ufldl.stanford.edu/wiki/index.php/Pooling) 和 [图像分类]( https://github.com/PaddlePaddle/book/tree/develop/03.image_classification )教程。
+
### 常见激活函数介绍
- sigmoid激活函数: $ f(x) = sigmoid(x) = \frac{1}{1+e^{-x}} $
@@ -174,50 +183,53 @@ PaddlePaddle在API中提供了自动加载[MNIST](http://yann.lecun.com/exdb/mni
## Fluid API 概述
-演示将使用最新的 `Fluid API`。Fluid API是最新的 PaddlePaddle API。它在不牺牲性能的情况下简化了模型配置。
-我们建议使用 Fluid API,因为它更容易学起来。
+演示将使用最新的 [Fluid API](http://paddlepaddle.org/documentation/docs/zh/1.2/api_cn/index_cn.html)。Fluid API是最新的 PaddlePaddle API。它在不牺牲性能的情况下简化了模型配置。
+我们建议使用 Fluid API,它易学易用的特性将帮助您快速完成机器学习任务。。
-下面是快速的 Fluid API 概述。
+下面是 Fluid API 中几个重要概念的概述:
-1. `inference_program`:指定如何从数据输入中获得预测的函数。
+1. `inference_program`:指定如何从数据输入中获得预测的函数,
这是指定网络流的地方。
-2. `train_program`:指定如何从 `inference_program` 和`标签值`中获取 `loss` 的函数。
+2. `train_program`:指定如何从 `inference_program` 和`标签值`中获取 `loss` 的函数,
这是指定损失计算的地方。
-3. `optimizer_func`: “指定优化器配置的函数。优化器负责减少损失并驱动培训。Paddle 支持多种不同的优化器。
-
-4. `Trainer`:PaddlePaddle Trainer 管理由 `train_program` 和 `optimizer` 指定的训练过程。
-通过 `event_handler` 回调函数,用户可以监控培训的进展。
-
-5. `Inferencer`:Fluid inferencer 加载 `inference_program` 和由 Trainer 训练的参数。
-然后,它可以推断数据和返回预测。
+3. `optimizer_func`: 指定优化器配置的函数,优化器负责减少损失并驱动训练,Paddle 支持多种不同的优化器。
-在这个演示中,我们将深入了解它们。
+在下面的代码示例中,我们将深入了解它们。
## 配置说明
加载 PaddlePaddle 的 Fluid API 包。
```python
import os
-from PIL import Image
+from PIL import Image # 导入图像处理模块
+import matplotlib.pyplot as plt
import numpy
-import paddle
+import paddle # 导入paddle模块
import paddle.fluid as fluid
-from __future__ import print_function
+from __future__ import print_function # 将python3中的print特性导入当前版本
```
### Program Functions 配置
-我们需要设置“推理程序”函数。我们想用这个程序来演示三个不同的分类器,每个分类器都定义为 Python 函数。
-我们需要将图像数据馈送到分类器。Paddle 为读取数据提供了一个特殊的层 `layer.data` 层。
+我们需要设置 `inference_program` 函数。我们想用这个程序来演示三个不同的分类器,每个分类器都定义为 Python 函数。
+我们需要将图像数据输入到分类器中。Paddle 为读取数据提供了一个特殊的层 `layer.data` 层。
让我们创建一个数据层来读取图像并将其连接到分类网络。
- Softmax回归:只通过一层简单的以softmax为激活函数的全连接层,就可以得到分类的结果。
```python
def softmax_regression():
+ """
+ 定义softmax分类器:
+ 一个以softmax为激活函数的全连接层
+ Return:
+ predict_image -- 分类的结果
+ """
+ # 输入的原始图像数据,大小为28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
+ # 以softmax为激活函数的全连接层,输出层的大小必须为数字的个数10
predict = fluid.layers.fc(
input=img, size=10, act='softmax')
return predict
@@ -227,6 +239,15 @@ def softmax_regression():
```python
def multilayer_perceptron():
+ """
+ 定义多层感知机分类器:
+ 含有两个隐藏层(全连接层)的多层感知器
+ 其中前两个隐藏层的激活函数采用 ReLU,输出层的激活函数用 Softmax
+
+ Return:
+ predict_image -- 分类的结果
+ """
+ # 输入的原始图像数据,大小为28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
# 第一个全连接层,激活函数为ReLU
hidden = fluid.layers.fc(input=img, size=200, act='relu')
@@ -241,8 +262,17 @@ def multilayer_perceptron():
```python
def convolutional_neural_network():
+ """
+ 定义卷积神经网络分类器:
+ 输入的二维图像,经过两个卷积-池化层,使用以softmax为激活函数的全连接层作为输出层
+
+ Return:
+ predict -- 分类的结果
+ """
+ # 输入的原始图像数据,大小为28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
# 第一个卷积-池化层
+ # 使用20个5*5的滤波器,池化大小为2,池化步长为2,激活函数为Relu
conv_pool_1 = fluid.nets.simple_img_conv_pool(
input=img,
filter_size=5,
@@ -252,6 +282,7 @@ def convolutional_neural_network():
act="relu")
conv_pool_1 = fluid.layers.batch_norm(conv_pool_1)
# 第二个卷积-池化层
+ # 使用20个5*5的滤波器,池化大小为2,池化步长为2,激活函数为Relu
conv_pool_2 = fluid.nets.simple_img_conv_pool(
input=conv_pool_1,
filter_size=5,
@@ -274,13 +305,27 @@ def convolutional_neural_network():
```python
def train_program():
+ """
+ 配置train_program
+
+ Return:
+ predict -- 分类的结果
+ avg_cost -- 平均损失
+ acc -- 分类的准确率
+
+ """
+ # 标签层,名称为label,对应输入图片的类别标签
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
- # predict = softmax_regression() # uncomment for Softmax回归
- # predict = multilayer_perceptron() # uncomment for 多层感知器
- predict = convolutional_neural_network() # uncomment for LeNet5卷积神经网络
+ # predict = softmax_regression() # 取消注释将使用 Softmax回归
+ # predict = multilayer_perceptron() # 取消注释将使用 多层感知器
+ predict = convolutional_neural_network() # 取消注释将使用 LeNet5卷积神经网络
+
+ # 使用类交叉熵函数计算predict和label之间的损失函数
cost = fluid.layers.cross_entropy(input=predict, label=label)
+ # 计算平均损失
avg_cost = fluid.layers.mean(cost)
+ # 计算分类准确率
acc = fluid.layers.accuracy(input=predict, label=label)
return predict, [avg_cost, acc]
@@ -288,7 +333,7 @@ def train_program():
#### Optimizer Function 配置
-在下面的 `Adam optimizer`,`learning_rate` 是训练的速度,与网络的训练收敛速度有关系。
+在下面的 `Adam optimizer`,`learning_rate` 是学习率,它的大小与网络的训练收敛速度有关系。
```python
def optimizer_program():
@@ -304,43 +349,45 @@ def optimizer_program():
`batch`是一个特殊的decorator,它的输入是一个reader,输出是一个batched reader。在PaddlePaddle里,一个reader每次yield一条训练数据,而一个batched reader每次yield一个minibatch。
```python
-
+# 一个minibatch中有64个数据
BATCH_SIZE = 64
+# 每次读取训练集中的500个数据并随机打乱,传入batched reader中,batched reader 每次 yield 64个数据
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.mnist.train(), buf_size=500),
batch_size=BATCH_SIZE)
-
+# 读取测试集的数据,每次 yield 64个数据
test_reader = paddle.batch(
paddle.dataset.mnist.test(), batch_size=BATCH_SIZE)
```
-### Trainer 训练过程
+### 构建训练过程
-现在,我们需要构建一个训练过程。将使用到前面定义的训练程序 `train_program`, `place` 和优化器 `optimizer`,并包含训练迭代、检查训练期间测试误差以及保存所需要用来预测的模型参数。
+现在,我们需要构建一个训练过程。将使用到前面定义的训练程序 `train_program`, `place` 和优化器 `optimizer`,并包含训练迭代、检查训练期间测试误差以及保存所需要用来预测的模型参数。
#### Event Handler 配置
-我们可以在训练期间通过调用一个handler函数来监控培训进度。
-我们将在这里演示两个 `event_handler` 程序。请随意修改 Jupyter 笔记本 ,看看有什么不同。
+我们可以在训练期间通过调用一个handler函数来监控训练进度。
+我们将在这里演示两个 `event_handler` 程序。请随意修改 Jupyter Notebook ,看看有什么不同。
`event_handler` 用来在训练过程中输出训练结果
```python
def event_handler(pass_id, batch_id, cost):
+ # 打印训练的中间结果,训练轮次,batch数,损失函数
print("Pass %d, Batch %d, Cost %f" % (pass_id,batch_id, cost))
```
```python
-from paddle.v2.plot import Ploter
+from paddle.utils.plot import Ploter
train_prompt = "Train cost"
test_prompt = "Test cost"
cost_ploter = Ploter(train_prompt, test_prompt)
-# event_handler to plot a figure
+# 将训练过程绘图表示
def event_handler_plot(ploter_title, step, cost):
cost_ploter.append(ploter_title, step, cost)
cost_ploter.plot()
@@ -358,31 +405,49 @@ def event_handler_plot(ploter_title, step, cost):
`feed_order` 用于将数据目录映射到 `train_program`
创建一个反馈训练过程中误差的`train_test`
-训练完成后,模型参数存入`save_dirname`中
+定义网络结构:
```python
# 该模型运行在单个CPU上
-use_cuda = False # set to True if training with GPU
+use_cuda = False # 如想使用GPU,请设置为 True
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+# 调用train_program 获取预测值,损失值,
prediction, [avg_loss, acc] = train_program()
+# 输入的原始图像数据,大小为28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
+# 标签层,名称为label,对应输入图片的类别标签
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
+# 告知网络传入的数据分为两部分,第一部分是img值,第二部分是label值
feeder = fluid.DataFeeder(feed_list=[img, label], place=place)
+# 选择Adam优化器
optimizer = fluid.optimizer.Adam(learning_rate=0.001)
optimizer.minimize(avg_loss)
+```
+
+设置训练过程的超参:
+
+```python
-PASS_NUM = 5
+PASS_NUM = 5 #训练5轮
epochs = [epoch_id for epoch_id in range(PASS_NUM)]
+# 将模型参数存储在名为 save_dirname 的文件中
save_dirname = "recognize_digits.inference.model"
+```
+
+```python
def train_test(train_test_program,
train_test_feed, train_test_reader):
+
+ # 将分类准确率存储在acc_set中
acc_set = []
+ # 将平均损失存储在avg_loss_set中
avg_loss_set = []
+ # 将测试 reader yield 出的每一个数据传入网络中进行训练
for test_data in train_test_reader():
acc_np, avg_loss_np = exe.run(
program=train_test_program,
@@ -390,17 +455,30 @@ def train_test(train_test_program,
fetch_list=[acc, avg_loss])
acc_set.append(float(acc_np))
avg_loss_set.append(float(avg_loss_np))
- # get test acc and loss
+ # 获得测试数据上的准确率和损失值
acc_val_mean = numpy.array(acc_set).mean()
avg_loss_val_mean = numpy.array(avg_loss_set).mean()
+ # 返回平均损失值,平均准确率
return avg_loss_val_mean, acc_val_mean
+```
+创建执行器:
+
+```python
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
+```
+
+设置 main_program 和 test_program :
+```python
main_program = fluid.default_main_program()
test_program = fluid.default_main_program().clone(for_test=True)
+```
+
+开始训练:
+```python
lists = []
step = 0
for epoch_id in epochs:
@@ -408,12 +486,12 @@ for epoch_id in epochs:
metrics = exe.run(main_program,
feed=feeder.feed(data),
fetch_list=[avg_loss, acc])
- if step % 100 == 0:
+ if step % 100 == 0: #每训练100次 打印一次log
print("Pass %d, Batch %d, Cost %f" % (step, epoch_id, metrics[0]))
event_handler_plot(train_prompt, step, metrics[0])
step += 1
- # test for epoch
+ # 测试每个epoch的分类效果
avg_loss_val, acc_val = train_test(train_test_program=test_program,
train_test_reader=test_reader,
train_test_feed=feeder)
@@ -422,19 +500,25 @@ for epoch_id in epochs:
event_handler_plot(test_prompt, step, metrics[0])
lists.append((epoch_id, avg_loss_val, acc_val))
+
+ # 保存训练好的模型参数用于预测
if save_dirname is not None:
fluid.io.save_inference_model(save_dirname,
["img"], [prediction], exe,
model_filename=None,
params_filename=None)
- # find the best pass
+# 选择效果最好的pass
best = sorted(lists, key=lambda list: float(list[1]))[0]
print('Best pass is %s, testing Avgcost is %s' % (best[0], best[1]))
print('The classification accuracy is %.2f%%' % (float(best[2]) * 100))
```
-训练过程是完全自动的,event_handler里打印的日志类似如下所示:
+训练过程是完全自动的,event_handler里打印的日志类似如下所示。
+
+Pass表示训练轮次,Batch表示训练全量数据的次数,cost表示当前pass的损失值。
+
+每训练完一个Epoch后,计算一次平均损失和分类准确率。
```
Pass 0, Batch 0, Cost 0.125650
@@ -459,7 +543,7 @@ Test with Epoch 0, avg_cost: 0.053097883707459624, acc: 0.9822850318471338
### 生成预测输入数据
-`infer_3.png` 是数字 3 的一个示例图像。把它变成一个 numpy 数组以匹配数据馈送格式。
+`infer_3.png` 是数字 3 的一个示例图像。把它变成一个 numpy 数组以匹配数据feed格式。
```python
def load_image(file):
@@ -469,7 +553,7 @@ def load_image(file):
im = im / 255.0 * 2.0 - 1.0
return im
-cur_dir = cur_dir = os.getcwd()
+cur_dir = os.getcwd()
tensor_img = load_image(cur_dir + '/image/infer_3.png')
```
@@ -478,20 +562,23 @@ tensor_img = load_image(cur_dir + '/image/infer_3.png')
```python
inference_scope = fluid.core.Scope()
with fluid.scope_guard(inference_scope):
- # Use fluid.io.load_inference_model to obtain the inference program desc,
- # the feed_target_names (the names of variables that will be feeded
- # data using feed operators), and the fetch_targets (variables that
- # we want to obtain data from using fetch operators).
+ # 使用 fluid.io.load_inference_model 获取 inference program desc,
+ # feed_target_names 用于指定需要传入网络的变量名
+ # fetch_targets 指定希望从网络中fetch出的变量名
[inference_program, feed_target_names,
fetch_targets] = fluid.io.load_inference_model(
save_dirname, exe, None, None)
- # Construct feed as a dictionary of {feed_target_name: feed_target_data}
- # and results will contain a list of data corresponding to fetch_targets.
+ # 将feed构建成字典 {feed_target_name: feed_target_data}
+ # 结果将包含一个与fetch_targets对应的数据列表
results = exe.run(inference_program,
feed={feed_target_names[0]: tensor_img},
fetch_list=fetch_targets)
lab = numpy.argsort(results)
+
+ # 打印 infer_3.png 这张图片的预测结果
+ img=Image.open('image/infer_3.png')
+ plt.imshow(img)
print("Inference result of image/infer_3.png is: %d" % lab[0][0][-1])
```
@@ -499,11 +586,11 @@ with fluid.scope_guard(inference_scope):
### 预测结果
如果顺利,预测结果输入如下:
-`Inference result of image/infer_3.png is: 3`
+`Inference result of image/infer_3.png is: 3` , 说明我们的网络成功的识别出了这张图片!
## 总结
-本教程的softmax回归、多层感知器和卷积神经网络是最基础的深度学习模型,后续章节中复杂的神经网络都是从它们衍生出来的,因此这几个模型对之后的学习大有裨益。同时,我们也观察到从最简单的softmax回归变换到稍复杂的卷积神经网络的时候,MNIST数据集上的识别准确率有了大幅度的提升,原因是卷积层具有局部连接和共享权重的特性。在之后学习新模型的时候,希望大家也要深入到新模型相比原模型带来效果提升的关键之处。此外,本教程还介绍了PaddlePaddle模型搭建的基本流程,从dataprovider的编写、网络层的构建,到最后的训练和预测。对这个流程熟悉以后,大家就可以用自己的数据,定义自己的网络模型,并完成自己的训练和预测任务了。
+本教程的softmax回归、多层感知机和卷积神经网络是最基础的深度学习模型,后续章节中复杂的神经网络都是从它们衍生出来的,因此这几个模型对之后的学习大有裨益。同时,我们也观察到从最简单的softmax回归变换到稍复杂的卷积神经网络的时候,MNIST数据集上的识别准确率有了大幅度的提升,原因是卷积层具有局部连接和共享权重的特性。在之后学习新模型的时候,希望大家也要深入到新模型相比原模型带来效果提升的关键之处。此外,本教程还介绍了PaddlePaddle模型搭建的基本流程,从dataprovider的编写、网络层的构建,到最后的训练和预测。对这个流程熟悉以后,大家就可以用自己的数据,定义自己的网络模型,并完成自己的训练和预测任务了。
## 参考文献
@@ -521,6 +608,7 @@ with fluid.scope_guard(inference_scope):
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
+

-图1. YouTube 推荐系统结构
+图1. YouTube 个性化推荐系统结构
#### 候选生成网络(Candidate Generation Network)
@@ -64,7 +64,7 @@ $$P(\omega=i|u)=\frac{e^{v_{i}u}}{\sum_{j \in V}e^{v_{j}u}}$$
排序网络的结构类似于候选生成网络,但是它的目标是对候选进行更细致的打分排序。和传统广告排序中的特征抽取方法类似,这里也构造了大量的用于视频排序的相关特征(如视频 ID、上次观看时间等)。这些特征的处理方式和候选生成网络类似,不同之处是排序网络的顶部是一个加权逻辑回归(weighted logistic regression),它对所有候选视频进行打分,从高到底排序后将分数较高的一些视频返回给用户。
### 融合推荐模型
-本节会使卷积神经网络(Convolutional Neural Networks)来学习电影名称的表示。下面会依次介绍文本卷积神经网络以及融合推荐模型。
+本节会使用卷积神经网络(Convolutional Neural Networks)来学习电影名称的表示。下面会依次介绍文本卷积神经网络以及融合推荐模型。
#### 文本卷积神经网络(CNN)
@@ -77,7 +77,7 @@ $$P(\omega=i|u)=\frac{e^{v_{i}u}}{\sum_{j \in V}e^{v_{j}u}}$$
图3. 卷积神经网络文本分类模型
-假设待处理句子的长度为$n$,其中第$i$个词的词向量(word embedding)为$x_i\in\mathbb{R}^k$,$k$为维度大小。
+假设待处理句子的长度为$n$,其中第$i$个词的词向量为$x_i\in\mathbb{R}^k$,$k$为维度大小。
首先,进行词向量的拼接操作:将每$h$个词拼接起来形成一个大小为$h$的词窗口,记为$x_{i:i+h-1}$,它表示词序列$x_{i},x_{i+1},\ldots,x_{i+h-1}$的拼接,其中,$i$表示词窗口中第一个词在整个句子中的位置,取值范围从$1$到$n-h+1$,$x_{i:i+h-1}\in\mathbb{R}^{hk}$。
@@ -89,9 +89,9 @@ $$c=[c_1,c_2,\ldots,c_{n-h+1}], c \in \mathbb{R}^{n-h+1}$$
$$\hat c=max(c)$$
-#### 模型概览
+#### 融合推荐模型概览
-在融合推荐模型的电影推荐系统中:
+在融合推荐模型的电影个性化推荐系统中:
1. 首先,使用用户特征和电影特征作为神经网络的输入,其中:
@@ -103,10 +103,9 @@ $$\hat c=max(c)$$
3. 对电影特征,将电影ID以类似用户ID的方式进行处理,电影类型ID以向量的形式直接输入全连接层,电影名称用文本卷积神经网络得到其定长向量表示。然后将三个属性的特征表示分别全连接并相加。
-4. 得到用户和电影的向量表示后,计算二者的余弦相似度作为推荐系统的打分。最后,用该相似度打分和用户真实打分的差异的平方作为该回归模型的损失函数。
+4. 得到用户和电影的向量表示后,计算二者的余弦相似度作为个性化推荐系统的打分。最后,用该相似度打分和用户真实打分的差异的平方作为该回归模型的损失函数。
-
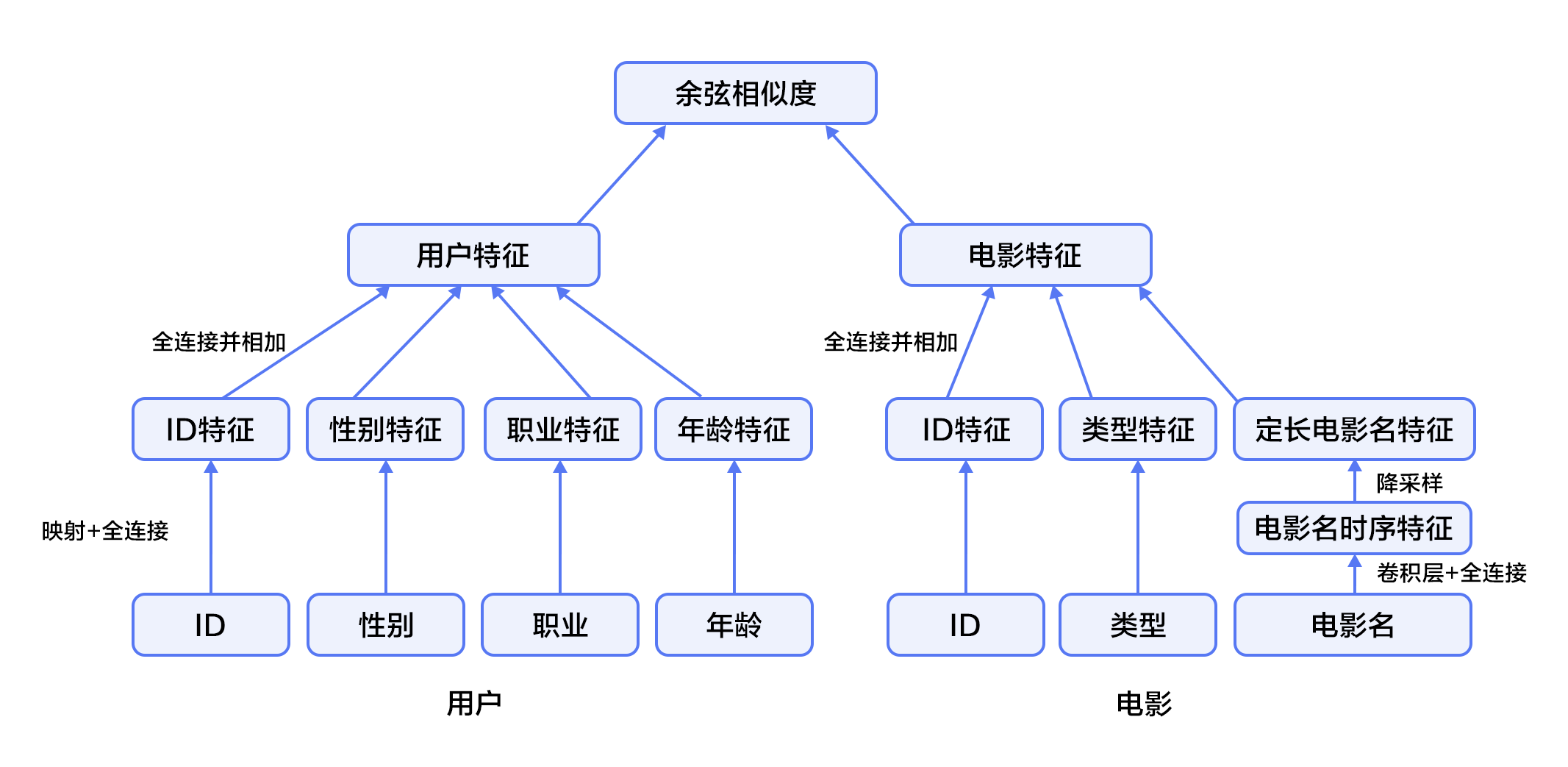
图4. 融合推荐模型
@@ -214,6 +213,8 @@ print "User %s rates Movie %s with Score %s"%(user_info[uid], movie_info[mov_id]
## 模型配置说明
下面我们开始根据输入数据的形式配置模型。首先引入所需的库函数以及定义全局变量。
+- IS_SPARSE: embedding中是否使用稀疏更新
+- PASS_NUM: epoch数量
```python
@@ -227,14 +228,15 @@ import paddle.fluid.layers as layers
import paddle.fluid.nets as nets
IS_SPARSE = True
-USE_GPU = False
BATCH_SIZE = 256
+PASS_NUM = 20
```
然后为我们的用户特征综合模型定义模型配置
```python
def get_usr_combined_features():
+ """network definition for user part"""
USR_DICT_SIZE = paddle.dataset.movielens.max_user_id() + 1
@@ -300,6 +302,7 @@ def get_usr_combined_features():
```python
def get_mov_combined_features():
+ """network definition for item(movie) part"""
MOV_DICT_SIZE = paddle.dataset.movielens.max_movie_id() + 1
@@ -354,6 +357,8 @@ def get_mov_combined_features():
```python
def inference_program():
+ """the combined network"""
+
usr_combined_features = get_usr_combined_features()
mov_combined_features = get_mov_combined_features()
@@ -367,6 +372,7 @@ def inference_program():
```python
def train_program():
+ """define the cost function"""
scale_infer = inference_program()
@@ -440,14 +446,14 @@ def train_test(program, reader):
feeder_test = fluid.DataFeeder(
feed_list=feed_var_list, place=place)
test_exe = fluid.Executor(place)
- accumulated = len([avg_cost, scale_infer]) * [0]
+ accumulated = 0
for test_data in reader():
avg_cost_np = test_exe.run(program=program,
feed=feeder_test.feed(test_data),
- fetch_list=[avg_cost, scale_infer])
- accumulated = [x[0] + x[1][0] for x in zip(accumulated, avg_cost_np)]
+ fetch_list=[avg_cost])
+ accumulated += avg_cost_np[0]
count += 1
- return [x / count for x in accumulated]
+ return accumulated / count
```
### 构建训练主循环并开始训练
@@ -458,8 +464,10 @@ def train_test(program, reader):
params_dirname = "recommender_system.inference.model"
from paddle.utils.plot import Ploter
+train_prompt = "Train cost"
test_prompt = "Test cost"
-plot_cost = Ploter(test_prompt)
+
+plot_cost = Ploter(train_prompt, test_prompt)
def train_loop():
feed_list = [
@@ -476,13 +484,12 @@ def train_loop():
fetch_list=[avg_cost])
out = np.array(outs[0])
- avg_cost_set = train_test(test_program, test_reader)
-
# get test avg_cost
- test_avg_cost = np.array(avg_cost_set).mean()
- plot_cost.append(test_prompt, batch_id, outs[0])
+ test_avg_cost = train_test(test_program, test_reader)
+
+ plot_cost.append(train_prompt, batch_id, outs[0])
+ plot_cost.append(test_prompt, batch_id, test_avg_cost)
plot_cost.plot()
- print("avg_cost: %s" % test_avg_cost)
if batch_id == 20:
if params_dirname is not None:
@@ -491,13 +498,13 @@ def train_loop():
"movie_id", "category_id", "movie_title"
], [scale_infer], exe)
return
- else:
- print('BatchID {0}, Test Loss {1:0.2}'.format(pass_id + 1,
- float(test_avg_cost)))
+ print('EpochID {0}, BatchID {1}, Test Loss {2:0.2}'.format(
+ pass_id + 1, batch_id + 1, float(test_avg_cost)))
if math.isnan(float(out[0])):
sys.exit("got NaN loss, training failed.")
```
+开始训练
```python
train_loop()
```
@@ -562,16 +569,16 @@ with fluid.scope_guard(inference_scope):
## 总结
-本章介绍了传统的推荐系统方法和YouTube的深度神经网络推荐系统,并以电影推荐为例,使用PaddlePaddle训练了一个个性化推荐神经网络模型。推荐系统几乎涵盖了电商系统、社交网络、广告推荐、搜索引擎等领域的方方面面,而在图像处理、自然语言处理等领域已经发挥重要作用的深度学习技术,也将会在推荐系统领域大放异彩。
+本章介绍了传统的个性化推荐系统方法和YouTube的深度神经网络个性化推荐系统,并以电影推荐为例,使用PaddlePaddle训练了一个个性化推荐神经网络模型。个性化推荐系统几乎涵盖了电商系统、社交网络、广告推荐、搜索引擎等领域的方方面面,而在图像处理、自然语言处理等领域已经发挥重要作用的深度学习技术,也将会在个性化推荐系统领域大放异彩。
## 参考文献
-1. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
-2. Robin Burke , [Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
-3. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
-4. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th international conference on World Wide Web*. ACM, 2001.
-5. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: combining social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
+1. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
+2. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th international conference on World Wide Web*. ACM, 2001.
+3. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: combining social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
+4. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
+5. Robin Burke , [Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf) *arXiv preprint arXiv:1611.05480* (2016).
7. Covington P, Adams J, Sargin E. [Deep neural networks for youtube recommendations](https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf)[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 191-198.
diff --git a/05.recommender_system/index.cn.html b/05.recommender_system/index.cn.html
index e8d6ff0bc6504341f903c17aff12eff1a3ae1415..ea41aaa17231153901391b3116cc3987e986a8ab 100644
--- a/05.recommender_system/index.cn.html
+++ b/05.recommender_system/index.cn.html
@@ -46,19 +46,19 @@
## 背景介绍
-在网络技术不断发展和电子商务规模不断扩大的背景下,商品数量和种类快速增长,用户需要花费大量时间才能找到自己想买的商品,这就是信息超载问题。为了解决这个难题,推荐系统(Recommender System)应运而生。
+在网络技术不断发展和电子商务规模不断扩大的背景下,商品数量和种类快速增长,用户需要花费大量时间才能找到自己想买的商品,这就是信息超载问题。为了解决这个难题,个性化推荐系统(Recommender System)应运而生。
-个性化推荐系统是信息过滤系统(Information Filtering System)的子集,它可以用在很多领域,如电影、音乐、电商和 Feed 流推荐等。推荐系统通过分析、挖掘用户行为,发现用户的个性化需求与兴趣特点,将用户可能感兴趣的信息或商品推荐给用户。与搜索引擎不同,推荐系统不需要用户准确地描述出自己的需求,而是根据分析历史行为建模,主动提供满足用户兴趣和需求的信息。
+个性化推荐系统是信息过滤系统(Information Filtering System)的子集,它可以用在很多领域,如电影、音乐、电商和 Feed 流推荐等。个性化推荐系统通过分析、挖掘用户行为,发现用户的个性化需求与兴趣特点,将用户可能感兴趣的信息或商品推荐给用户。与搜索引擎不同,个性化推荐系统不需要用户准确地描述出自己的需求,而是根据用户的历史行为进行建模,主动提供满足用户兴趣和需求的信息。
-传统的推荐系统方法主要有:
+1994年明尼苏达大学推出的GroupLens系统[[1](#参考文献)]一般被认为是个性化推荐系统成为一个相对独立的研究方向的标志。该系统首次提出了基于协同过滤来完成推荐任务的思想,此后,基于该模型的协同过滤推荐引领了个性化推荐系统十几年的发展方向。
-- 协同过滤推荐(Collaborative Filtering Recommendation):该方法收集分析用户历史行为、活动、偏好,计算一个用户与其他用户的相似度,利用目标用户的相似用户对商品评价的加权评价值,来预测目标用户对特定商品的喜好程度。优点是可以给用户推荐未浏览过的新产品;缺点是对于没有任何行为的新用户存在冷启动的问题,同时也存在用户与商品之间的交互数据不够多造成的稀疏问题,会导致模型难以找到相近用户。
-- 基于内容过滤推荐[[1](#参考文献)](Content-based Filtering Recommendation):该方法利用商品的内容描述,抽象出有意义的特征,通过计算用户的兴趣和商品描述之间的相似度,来给用户做推荐。优点是简单直接,不需要依据其他用户对商品的评价,而是通过商品属性进行商品相似度度量,从而推荐给用户所感兴趣商品的相似商品;缺点是对于没有任何行为的新用户同样存在冷启动的问题。
-- 组合推荐[[2](#参考文献)](Hybrid Recommendation):运用不同的输入和技术共同进行推荐,以弥补各自推荐技术的缺点。
+传统的个性化推荐系统方法主要有:
-其中协同过滤是应用最广泛的技术之一,它又可以分为多个子类:基于用户 (User-Based)的推荐[[3](#参考文献)] 、基于物品(Item-Based)的推荐[[4](#参考文献)]、基于社交网络关系(Social-Based)的推荐[[5](#参考文献)]、基于模型(Model-based)的推荐等。1994年明尼苏达大学推出的GroupLens系统[[3](#参考文献)]一般被认为是推荐系统成为一个相对独立的研究方向的标志。该系统首次提出了基于协同过滤来完成推荐任务的思想,此后,基于该模型的协同过滤推荐引领了推荐系统十几年的发展方向。
+- 协同过滤推荐(Collaborative Filtering Recommendation):该方法是应用最广泛的技术之一,需要收集和分析用户的历史行为、活动和偏好。它通常可以分为两个子类:基于用户 (User-Based)的推荐[[1](#参考文献)] 和基于物品(Item-Based)的推荐[[2](#参考文献)]。该方法的一个关键优势是它不依赖于机器去分析物品的内容特征,因此它无需理解物品本身也能够准确地推荐诸如电影之类的复杂物品;缺点是对于没有任何行为的新用户存在冷启动的问题,同时也存在用户与商品之间的交互数据不够多造成的稀疏问题。值得一提的是,社交网络[[3](#参考文献)]或地理位置等上下文信息都可以结合到协同过滤中去。
+- 基于内容过滤推荐[[4](#参考文献)](Content-based Filtering Recommendation):该方法利用商品的内容描述,抽象出有意义的特征,通过计算用户的兴趣和商品描述之间的相似度,来给用户做推荐。优点是简单直接,不需要依据其他用户对商品的评价,而是通过商品属性进行商品相似度度量,从而推荐给用户所感兴趣商品的相似商品;缺点是对于没有任何行为的新用户同样存在冷启动的问题。
+- 组合推荐[[5](#参考文献)](Hybrid Recommendation):运用不同的输入和技术共同进行推荐,以弥补各自推荐技术的缺点。
-深度学习具有优秀的自动提取特征的能力,能够学习多层次的抽象特征表示,并对异质或跨域的内容信息进行学习,可以一定程度上处理推荐系统冷启动问题[[6](#参考文献)]。本教程主要介绍个性化推荐的深度学习模型,以及如何使用PaddlePaddle实现模型。
+近些年来,深度学习在很多领域都取得了巨大的成功。学术界和工业界都在尝试将深度学习应用于个性化推荐系统领域中。深度学习具有优秀的自动提取特征的能力,能够学习多层次的抽象特征表示,并对异质或跨域的内容信息进行学习,可以一定程度上处理个性化推荐系统冷启动问题[[6](#参考文献)]。本教程主要介绍个性化推荐的深度学习模型,以及如何使用PaddlePaddle实现模型。
## 效果展示
@@ -72,15 +72,15 @@ Prediction Score is 4.25
## 模型概览
-本章中,我们首先介绍YouTube的视频推荐系统[[7](#参考文献)],然后介绍我们实现的融合推荐模型。
+本章中,我们首先介绍YouTube的视频个性化推荐系统[[7](#参考文献)],然后介绍我们实现的融合推荐模型。
-### YouTube的深度神经网络推荐系统
+### YouTube的深度神经网络个性化推荐系统
-YouTube是世界上最大的视频上传、分享和发现网站,YouTube推荐系统为超过10亿用户从不断增长的视频库中推荐个性化的内容。整个系统由两个神经网络组成:候选生成网络和排序网络。候选生成网络从百万量级的视频库中生成上百个候选,排序网络对候选进行打分排序,输出排名最高的数十个结果。系统结构如图1所示:
+YouTube是世界上最大的视频上传、分享和发现网站,YouTube个性化推荐系统为超过10亿用户从不断增长的视频库中推荐个性化的内容。整个系统由两个神经网络组成:候选生成网络和排序网络。候选生成网络从百万量级的视频库中生成上百个候选,排序网络对候选进行打分排序,输出排名最高的数十个结果。系统结构如图1所示:
-图1. YouTube 推荐系统结构
+图1. YouTube 个性化推荐系统结构
#### 候选生成网络(Candidate Generation Network)
@@ -106,7 +106,7 @@ $$P(\omega=i|u)=\frac{e^{v_{i}u}}{\sum_{j \in V}e^{v_{j}u}}$$
排序网络的结构类似于候选生成网络,但是它的目标是对候选进行更细致的打分排序。和传统广告排序中的特征抽取方法类似,这里也构造了大量的用于视频排序的相关特征(如视频 ID、上次观看时间等)。这些特征的处理方式和候选生成网络类似,不同之处是排序网络的顶部是一个加权逻辑回归(weighted logistic regression),它对所有候选视频进行打分,从高到底排序后将分数较高的一些视频返回给用户。
### 融合推荐模型
-本节会使卷积神经网络(Convolutional Neural Networks)来学习电影名称的表示。下面会依次介绍文本卷积神经网络以及融合推荐模型。
+本节会使用卷积神经网络(Convolutional Neural Networks)来学习电影名称的表示。下面会依次介绍文本卷积神经网络以及融合推荐模型。
#### 文本卷积神经网络(CNN)
@@ -119,7 +119,7 @@ $$P(\omega=i|u)=\frac{e^{v_{i}u}}{\sum_{j \in V}e^{v_{j}u}}$$
图3. 卷积神经网络文本分类模型
-假设待处理句子的长度为$n$,其中第$i$个词的词向量(word embedding)为$x_i\in\mathbb{R}^k$,$k$为维度大小。
+假设待处理句子的长度为$n$,其中第$i$个词的词向量为$x_i\in\mathbb{R}^k$,$k$为维度大小。
首先,进行词向量的拼接操作:将每$h$个词拼接起来形成一个大小为$h$的词窗口,记为$x_{i:i+h-1}$,它表示词序列$x_{i},x_{i+1},\ldots,x_{i+h-1}$的拼接,其中,$i$表示词窗口中第一个词在整个句子中的位置,取值范围从$1$到$n-h+1$,$x_{i:i+h-1}\in\mathbb{R}^{hk}$。
@@ -131,9 +131,9 @@ $$c=[c_1,c_2,\ldots,c_{n-h+1}], c \in \mathbb{R}^{n-h+1}$$
$$\hat c=max(c)$$
-#### 模型概览
+#### 融合推荐模型概览
-在融合推荐模型的电影推荐系统中:
+在融合推荐模型的电影个性化推荐系统中:
1. 首先,使用用户特征和电影特征作为神经网络的输入,其中:
@@ -145,10 +145,9 @@ $$\hat c=max(c)$$
3. 对电影特征,将电影ID以类似用户ID的方式进行处理,电影类型ID以向量的形式直接输入全连接层,电影名称用文本卷积神经网络得到其定长向量表示。然后将三个属性的特征表示分别全连接并相加。
-4. 得到用户和电影的向量表示后,计算二者的余弦相似度作为推荐系统的打分。最后,用该相似度打分和用户真实打分的差异的平方作为该回归模型的损失函数。
+4. 得到用户和电影的向量表示后,计算二者的余弦相似度作为个性化推荐系统的打分。最后,用该相似度打分和用户真实打分的差异的平方作为该回归模型的损失函数。
-
图4. 融合推荐模型
@@ -256,6 +255,8 @@ print "User %s rates Movie %s with Score %s"%(user_info[uid], movie_info[mov_id]
## 模型配置说明
下面我们开始根据输入数据的形式配置模型。首先引入所需的库函数以及定义全局变量。
+- IS_SPARSE: embedding中是否使用稀疏更新
+- PASS_NUM: epoch数量
```python
@@ -269,14 +270,15 @@ import paddle.fluid.layers as layers
import paddle.fluid.nets as nets
IS_SPARSE = True
-USE_GPU = False
BATCH_SIZE = 256
+PASS_NUM = 20
```
然后为我们的用户特征综合模型定义模型配置
```python
def get_usr_combined_features():
+ """network definition for user part"""
USR_DICT_SIZE = paddle.dataset.movielens.max_user_id() + 1
@@ -342,6 +344,7 @@ def get_usr_combined_features():
```python
def get_mov_combined_features():
+ """network definition for item(movie) part"""
MOV_DICT_SIZE = paddle.dataset.movielens.max_movie_id() + 1
@@ -396,6 +399,8 @@ def get_mov_combined_features():
```python
def inference_program():
+ """the combined network"""
+
usr_combined_features = get_usr_combined_features()
mov_combined_features = get_mov_combined_features()
@@ -409,6 +414,7 @@ def inference_program():
```python
def train_program():
+ """define the cost function"""
scale_infer = inference_program()
@@ -482,14 +488,14 @@ def train_test(program, reader):
feeder_test = fluid.DataFeeder(
feed_list=feed_var_list, place=place)
test_exe = fluid.Executor(place)
- accumulated = len([avg_cost, scale_infer]) * [0]
+ accumulated = 0
for test_data in reader():
avg_cost_np = test_exe.run(program=program,
feed=feeder_test.feed(test_data),
- fetch_list=[avg_cost, scale_infer])
- accumulated = [x[0] + x[1][0] for x in zip(accumulated, avg_cost_np)]
+ fetch_list=[avg_cost])
+ accumulated += avg_cost_np[0]
count += 1
- return [x / count for x in accumulated]
+ return accumulated / count
```
### 构建训练主循环并开始训练
@@ -500,8 +506,10 @@ def train_test(program, reader):
params_dirname = "recommender_system.inference.model"
from paddle.utils.plot import Ploter
+train_prompt = "Train cost"
test_prompt = "Test cost"
-plot_cost = Ploter(test_prompt)
+
+plot_cost = Ploter(train_prompt, test_prompt)
def train_loop():
feed_list = [
@@ -518,13 +526,12 @@ def train_loop():
fetch_list=[avg_cost])
out = np.array(outs[0])
- avg_cost_set = train_test(test_program, test_reader)
-
# get test avg_cost
- test_avg_cost = np.array(avg_cost_set).mean()
- plot_cost.append(test_prompt, batch_id, outs[0])
+ test_avg_cost = train_test(test_program, test_reader)
+
+ plot_cost.append(train_prompt, batch_id, outs[0])
+ plot_cost.append(test_prompt, batch_id, test_avg_cost)
plot_cost.plot()
- print("avg_cost: %s" % test_avg_cost)
if batch_id == 20:
if params_dirname is not None:
@@ -533,13 +540,13 @@ def train_loop():
"movie_id", "category_id", "movie_title"
], [scale_infer], exe)
return
- else:
- print('BatchID {0}, Test Loss {1:0.2}'.format(pass_id + 1,
- float(test_avg_cost)))
+ print('EpochID {0}, BatchID {1}, Test Loss {2:0.2}'.format(
+ pass_id + 1, batch_id + 1, float(test_avg_cost)))
if math.isnan(float(out[0])):
sys.exit("got NaN loss, training failed.")
```
+开始训练
```python
train_loop()
```
@@ -604,16 +611,16 @@ with fluid.scope_guard(inference_scope):
## 总结
-本章介绍了传统的推荐系统方法和YouTube的深度神经网络推荐系统,并以电影推荐为例,使用PaddlePaddle训练了一个个性化推荐神经网络模型。推荐系统几乎涵盖了电商系统、社交网络、广告推荐、搜索引擎等领域的方方面面,而在图像处理、自然语言处理等领域已经发挥重要作用的深度学习技术,也将会在推荐系统领域大放异彩。
+本章介绍了传统的个性化推荐系统方法和YouTube的深度神经网络个性化推荐系统,并以电影推荐为例,使用PaddlePaddle训练了一个个性化推荐神经网络模型。个性化推荐系统几乎涵盖了电商系统、社交网络、广告推荐、搜索引擎等领域的方方面面,而在图像处理、自然语言处理等领域已经发挥重要作用的深度学习技术,也将会在个性化推荐系统领域大放异彩。
## 参考文献
-1. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
-2. Robin Burke , [Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
-3. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
-4. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th international conference on World Wide Web*. ACM, 2001.
-5. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: combining social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
+1. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
+2. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th international conference on World Wide Web*. ACM, 2001.
+3. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: combining social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
+4. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
+5. Robin Burke , [Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf) *arXiv preprint arXiv:1611.05480* (2016).
7. Covington P, Adams J, Sargin E. [Deep neural networks for youtube recommendations](https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf)[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 191-198.
diff --git a/05.recommender_system/train.py b/05.recommender_system/train.py
index 569cb0eccd42d3170d329cf01bfdb06611190f50..a4eafdb4d0588c522ae04236d0921cd770e36765 100644
--- a/05.recommender_system/train.py
+++ b/05.recommender_system/train.py
@@ -181,17 +181,15 @@ def train(use_cuda, params_dirname):
]
feeder_test = fluid.DataFeeder(feed_list=feed_var_list, place=place)
test_exe = fluid.Executor(place)
- accumulated = len([avg_cost, scale_infer]) * [0]
+ accumulated = 0
for test_data in reader():
avg_cost_np = test_exe.run(
program=program,
feed=feeder_test.feed(test_data),
- fetch_list=[avg_cost, scale_infer])
- accumulated = [
- x[0] + x[1][0] for x in zip(accumulated, avg_cost_np)
- ]
+ fetch_list=[avg_cost])
+ accumulated += avg_cost_np[0]
count += 1
- return [x / count for x in accumulated]
+ return accumulated / count
def train_loop():
feed_list = [
@@ -209,11 +207,8 @@ def train(use_cuda, params_dirname):
fetch_list=[avg_cost])
out = np.array(outs[0])
- avg_cost_set = train_test(test_program, test_reader)
-
# get test avg_cost
- test_avg_cost = np.array(avg_cost_set).mean()
- print("avg_cost: %s" % test_avg_cost)
+ test_avg_cost = train_test(test_program, test_reader)
# if test_avg_cost < 4.0: # Change this number to adjust accuracy
if batch_id == 20:
@@ -223,9 +218,8 @@ def train(use_cuda, params_dirname):
"movie_id", "category_id", "movie_title"
], [scale_infer], exe)
return
- else:
- print('BatchID {0}, Test Loss {1:0.2}'.format(
- pass_id + 1, float(test_avg_cost)))
+ print('EpochID {0}, BatchID {1}, Test Loss {2:0.2}'.format(
+ pass_id + 1, batch_id + 1, float(test_avg_cost)))
if math.isnan(float(out[0])):
sys.exit("got NaN loss, training failed.")
diff --git a/README.cn.md b/README.cn.md
index 91698eb06d8f825e3ce862ad6ce0c52c2c76a2ba..75af7d95df4f819496d1789faafefedf16f9dbc5 100644
--- a/README.cn.md
+++ b/README.cn.md
@@ -1,8 +1,8 @@
# 深度学习入门
[](https://travis-ci.org/PaddlePaddle/book)
-[](http://www.paddlepaddle.org/docs/develop/book/01.fit_a_line/index.html)
-[](http://www.paddlepaddle.org/docs/develop/book/01.fit_a_line/index.cn.html)
+[](https://github.com/PaddlePaddle/book/blob/develop/README.md)
+[](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md)
1. [线性回归](http://www.paddlepaddle.org/documentation/book/zh/develop/01.fit_a_line/index.cn.html)
1. [识别数字](http://www.paddlepaddle.org/documentation/book/zh/develop/02.recognize_digits/index.cn.html)
@@ -69,4 +69,4 @@ use_cuda = True
**Note:** We also provide [English Readme](https://github.com/PaddlePaddle/book/blob/develop/README.md) for PaddlePaddle book.
-
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
+
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
diff --git a/README.md b/README.md
index 27deade2317c70e8d67335e567dbcf18f03a0081..d70e23143c4d8730f561fed5671e0891e5ce0bcf 100644
--- a/README.md
+++ b/README.md
@@ -1,8 +1,8 @@
# Deep Learning with PaddlePaddle
[](https://travis-ci.org/PaddlePaddle/book)
-[](http://www.paddlepaddle.org/docs/develop/book/01.fit_a_line/index.html)
-[](http://www.paddlepaddle.org/docs/develop/book/01.fit_a_line/index.cn.html)
+[](https://github.com/PaddlePaddle/book/blob/develop/README.md)
+[](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md)
1. [Fit a Line](http://www.paddlepaddle.org/documentation/book/en/develop/01.fit_a_line/index.html)
1. [Recognize Digits](http://www.paddlepaddle.org/documentation/book/en/develop/02.recognize_digits/index.html)
@@ -69,4 +69,4 @@ use_cuda = True
Your contribution is welcome! Please feel free to file Pull Requests to add your chapter as a directory under `/pending`. Once it is going stable, the community would like to move it to `/`.
To write, run, and debug your chapters, you will need Python 2.x, Go >1.5. You can build the Docker image using [this script](https://github.com/PaddlePaddle/book/blob/develop/.tools/convert-markdown-into-ipynb-and-test.sh).
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.