diff --git a/06.understand_sentiment/README.cn.md b/06.understand_sentiment/README.cn.md
index 5a60edd6695569c091fb5c06db25cd7fa8423b08..d7b80d80264828aa43e5333d6976504f8716e9ca 100644
--- a/06.understand_sentiment/README.cn.md
+++ b/06.understand_sentiment/README.cn.md
@@ -28,7 +28,12 @@
我们在[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节介绍过应用于文本数据的卷积神经网络模型的计算过程,这里进行一个简单的回顾。
-对卷积神经网络来说,首先使用卷积处理输入的词向量序列,产生一个特征图(feature map),对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征,最后,将所有卷积核得到的特征拼接起来即为文本的定长向量表示,对于文本分类问题,将其连接至softmax即构建出完整的模型。在实际应用中,我们会使用多个卷积核来处理句子,窗口大小相同的卷积核堆叠起来形成一个矩阵,这样可以更高效的完成运算。另外,我们也可使用窗口大小不同的卷积核来处理句子,[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节的图3作为示意画了四个卷积核,不同颜色表示不同大小的卷积核操作。
+对卷积神经网络来说,首先使用卷积处理输入的词向量序列,产生一个特征图(feature map),对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征,最后,将所有卷积核得到的特征拼接起来即为文本的定长向量表示,对于文本分类问题,将其连接至softmax即构建出完整的模型。在实际应用中,我们会使用多个卷积核来处理句子,窗口大小相同的卷积核堆叠起来形成一个矩阵,这样可以更高效的完成运算。另外,我们也可使用窗口大小不同的卷积核来处理句子,[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节的图3作为示意画了四个卷积核,既文本图1,不同颜色表示不同大小的卷积核操作。
+
+
+
+图1. 卷积神经网络文本分类模型
+
对于一般的短文本分类问题,上文所述的简单的文本卷积网络即可达到很高的正确率\[[1](#参考文献)\]。若想得到更抽象更高级的文本特征表示,可以构建深层文本卷积神经网络\[[2](#参考文献),[3](#参考文献)\]。
@@ -38,16 +43,16 @@
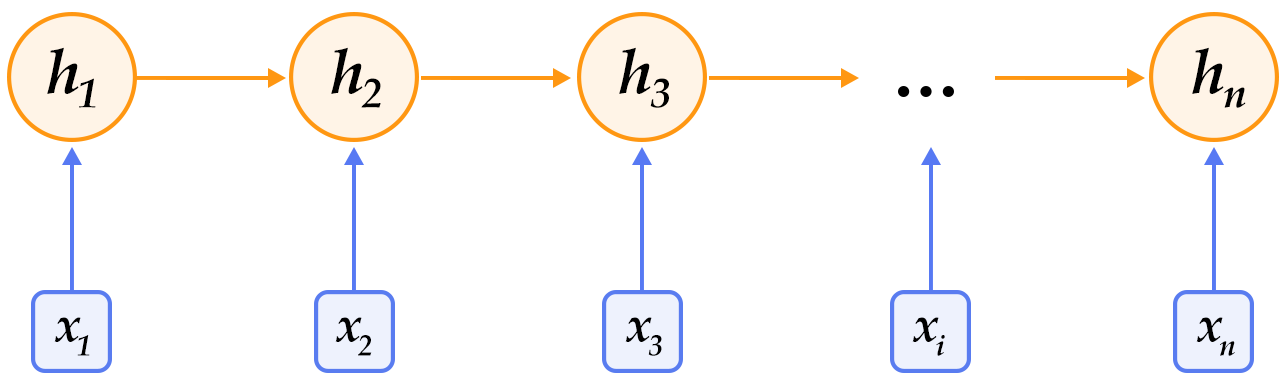
-图1. 循环神经网络按时间展开的示意图
+图2. 循环神经网络按时间展开的示意图
-循环神经网络按时间展开后如图1所示:在第$t$时刻,网络读入第$t$个输入$x_t$(向量表示)及前一时刻隐层的状态值$h_{t-1}$(向量表示,$h_0$一般初始化为$0$向量),计算得出本时刻隐层的状态值$h_t$,重复这一步骤直至读完所有输入。如果将循环神经网络所表示的函数记为$f$,则其公式可表示为:
+循环神经网络按时间展开后如图2所示:在第$t$时刻,网络读入第$t$个输入$x_t$(向量表示)及前一时刻隐层的状态值$h_{t-1}$(向量表示,$h_0$一般初始化为$0$向量),计算得出本时刻隐层的状态值$h_t$,重复这一步骤直至读完所有输入。如果将循环神经网络所表示的函数记为$f$,则其公式可表示为:
$$h_t=f(x_t,h_{t-1})=\sigma(W_{xh}x_t+W_{hh}h_{t-1}+b_h)$$
其中$W_{xh}$是输入到隐层的矩阵参数,$W_{hh}$是隐层到隐层的矩阵参数,$b_h$为隐层的偏置向量(bias)参数,$\sigma$为$sigmoid$函数。
-在处理自然语言时,一般会先将词(one-hot表示)映射为其词向量(word embedding)表示,然后再作为循环神经网络每一时刻的输入$x_t$。此外,可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
+在处理自然语言时,一般会先将词(one-hot表示)映射为其词向量表示,然后再作为循环神经网络每一时刻的输入$x_t$。此外,可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
### 长短期记忆网络(LSTM)
@@ -63,11 +68,11 @@ $$ f_t = \sigma(W_{xf}x_t+W_{hf}h_{t-1}+W_{cf}c_{t-1}+b_f) $$
$$ c_t = f_t\odot c_{t-1}+i_t\odot tanh(W_{xc}x_t+W_{hc}h_{t-1}+b_c) $$
$$ o_t = \sigma(W_{xo}x_t+W_{ho}h_{t-1}+W_{co}c_{t}+b_o) $$
$$ h_t = o_t\odot tanh(c_t) $$
-其中,$i_t, f_t, c_t, o_t$分别表示输入门,遗忘门,记忆单元及输出门的向量值,带角标的$W$及$b$为模型参数,$tanh$为双曲正切函数,$\odot$表示逐元素(elementwise)的乘法操作。输入门控制着新输入进入记忆单元$c$的强度,遗忘门控制着记忆单元维持上一时刻值的强度,输出门控制着输出记忆单元的强度。三种门的计算方式类似,但有着完全不同的参数,它们各自以不同的方式控制着记忆单元$c$,如图2所示:
+其中,$i_t, f_t, c_t, o_t$分别表示输入门,遗忘门,记忆单元及输出门的向量值,带角标的$W$及$b$为模型参数,$tanh$为双曲正切函数,$\odot$表示逐元素(elementwise)的乘法操作。输入门控制着新输入进入记忆单元$c$的强度,遗忘门控制着记忆单元维持上一时刻值的强度,输出门控制着输出记忆单元的强度。三种门的计算方式类似,但有着完全不同的参数,它们各自以不同的方式控制着记忆单元$c$,如图3所示:

-图2. 时刻$t$的LSTM [7]
+图3. 时刻$t$的LSTM [7]
LSTM通过给简单的循环神经网络增加记忆及控制门的方式,增强了其处理远距离依赖问题的能力。类似原理的改进还有Gated Recurrent Unit (GRU)\[[8](#参考文献)\],其设计更为简洁一些。**这些改进虽然各有不同,但是它们的宏观描述却与简单的循环神经网络一样(如图2所示),即隐状态依据当前输入及前一时刻的隐状态来改变,不断地循环这一过程直至输入处理完毕:**
@@ -80,11 +85,11 @@ $$ h_t=Recrurent(x_t,h_{t-1})$$
对于正常顺序的循环神经网络,$h_t$包含了$t$时刻之前的输入信息,也就是上文信息。同样,为了得到下文信息,我们可以使用反方向(将输入逆序处理)的循环神经网络。结合构建深层循环神经网络的方法(深层神经网络往往能得到更抽象和高级的特征表示),我们可以通过构建更加强有力的基于LSTM的栈式双向循环神经网络\[[9](#参考文献)\],来对时序数据进行建模。
-如图3所示(以三层为例),奇数层LSTM正向,偶数层LSTM反向,高一层的LSTM使用低一层LSTM及之前所有层的信息作为输入,对最高层LSTM序列使用时间维度上的最大池化即可得到文本的定长向量表示(这一表示充分融合了文本的上下文信息,并且对文本进行了深层次抽象),最后我们将文本表示连接至softmax构建分类模型。
+如图4所示(以三层为例),奇数层LSTM正向,偶数层LSTM反向,高一层的LSTM使用低一层LSTM及之前所有层的信息作为输入,对最高层LSTM序列使用时间维度上的最大池化即可得到文本的定长向量表示(这一表示充分融合了文本的上下文信息,并且对文本进行了深层次抽象),最后我们将文本表示连接至softmax构建分类模型。
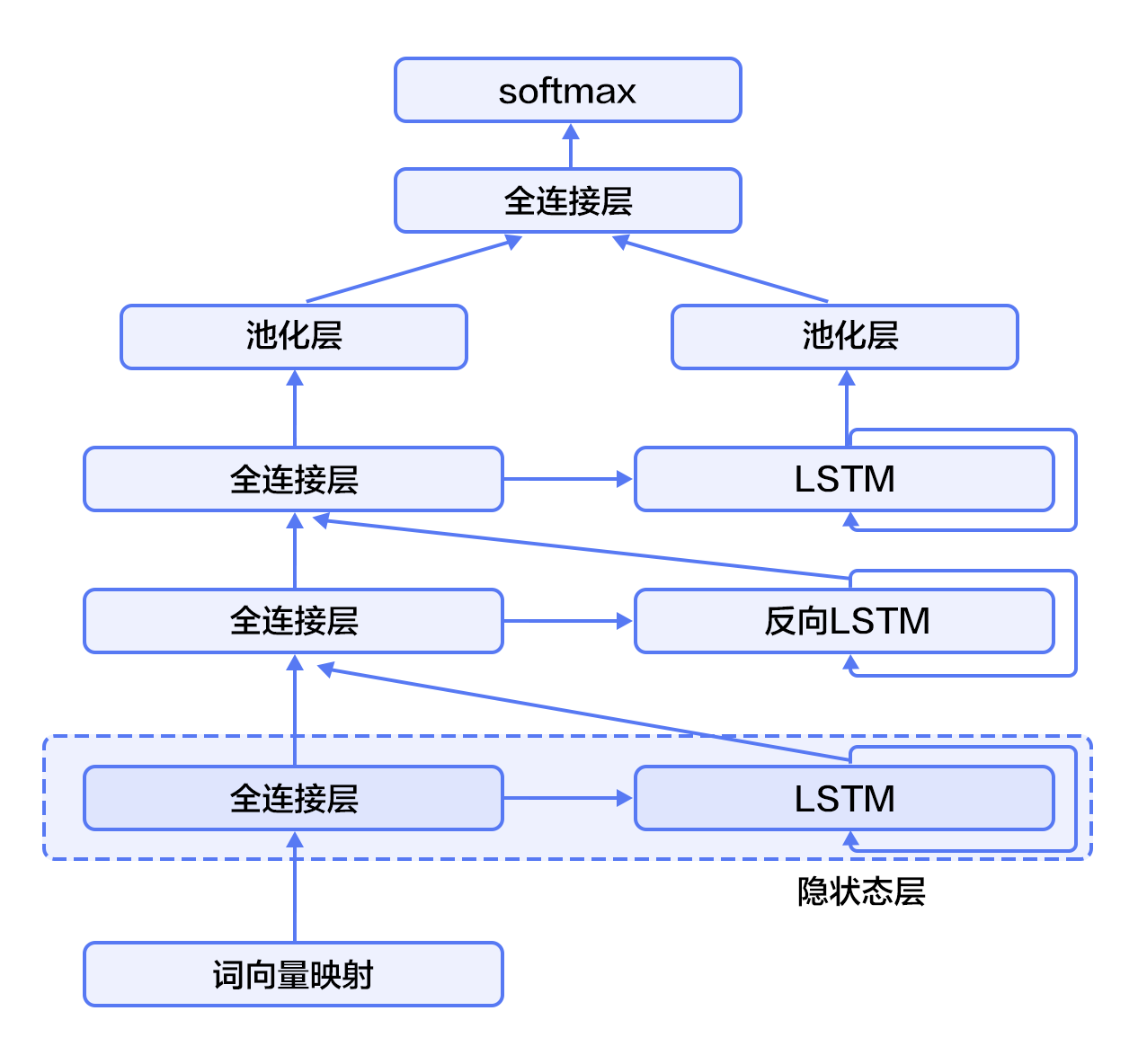
-图3. 栈式双向LSTM用于文本分类
+图4. 栈式双向LSTM用于文本分类
@@ -114,11 +119,11 @@ import numpy as np
import sys
import math
-CLASS_DIM = 2
-EMB_DIM = 128
-HID_DIM = 512
-STACKED_NUM = 3
-BATCH_SIZE = 128
+CLASS_DIM = 2 #情感分类的类别数
+EMB_DIM = 128 #词向量的维度
+HID_DIM = 512 #隐藏层的维度
+STACKED_NUM = 3 #LSTM双向栈的层数
+BATCH_SIZE = 128 #batch的大小
```
@@ -128,6 +133,7 @@ BATCH_SIZE = 128
需要注意的是:`fluid.nets.sequence_conv_pool` 包含卷积和池化层两个操作。
```python
+#文本卷积神经网络
def convolution_net(data, input_dim, class_dim, emb_dim, hid_dim):
emb = fluid.layers.embedding(
input=data, size=[input_dim, emb_dim], is_sparse=True)
@@ -157,32 +163,40 @@ def convolution_net(data, input_dim, class_dim, emb_dim, hid_dim):
栈式双向神经网络`stacked_lstm_net`的代码片段如下:
```python
+#栈式双向LSTM
def stacked_lstm_net(data, input_dim, class_dim, emb_dim, hid_dim, stacked_num):
+ #计算词向量
emb = fluid.layers.embedding(
input=data, size=[input_dim, emb_dim], is_sparse=True)
+ #第一层栈
+ #全连接层
fc1 = fluid.layers.fc(input=emb, size=hid_dim)
+ #lstm层
lstm1, cell1 = fluid.layers.dynamic_lstm(input=fc1, size=hid_dim)
inputs = [fc1, lstm1]
+ #其余的所有栈结构
for i in range(2, stacked_num + 1):
fc = fluid.layers.fc(input=inputs, size=hid_dim)
lstm, cell = fluid.layers.dynamic_lstm(
input=fc, size=hid_dim, is_reverse=(i % 2) == 0)
inputs = [fc, lstm]
+ #池化层
fc_last = fluid.layers.sequence_pool(input=inputs[0], pool_type='max')
lstm_last = fluid.layers.sequence_pool(input=inputs[1], pool_type='max')
+ #全连接层,softmax预测
prediction = fluid.layers.fc(
input=[fc_last, lstm_last], size=class_dim, act='softmax')
return prediction
```
-以上的栈式双向LSTM抽象出了高级特征并把其映射到和分类类别数同样大小的向量上。`paddle.activation.Softmax`函数用来计算分类属于某个类别的概率。
+以上的栈式双向LSTM抽象出了高级特征并把其映射到和分类类别数同样大小的向量上。最后一个全连接层的'softmax'激活函数用来计算分类属于某个类别的概率。
-重申一下,此处我们可以调用`convolution_net`或`stacked_lstm_net`的任何一个。我们以`convolution_net`为例。
+重申一下,此处我们可以调用`convolution_net`或`stacked_lstm_net`的任何一个网络结构进行训练学习。我们以`convolution_net`为例。
接下来我们定义预测程序(`inference_program`)。预测程序使用`convolution_net`来对`fluid.layer.data`的输入进行预测。
@@ -199,9 +213,9 @@ def inference_program(word_dict):
我们这里定义了`training_program`。它使用了从`inference_program`返回的结果来计算误差。我们同时定义了优化函数`optimizer_func`。
-因为是有监督的学习,训练集的标签也在`paddle.layer.data`中定义了。在训练过程中,交叉熵用来在`paddle.layer.classification_cost`中作为损失函数。
+因为是有监督的学习,训练集的标签也在`fluid.layers.data`中定义了。在训练过程中,交叉熵用来在`fluid.layer.cross_entropy`中作为损失函数。
-在测试过程中,分类器会计算各个输出的概率。第一个返回的数值规定为 损耗(cost)。
+在测试过程中,分类器会计算各个输出的概率。第一个返回的数值规定为cost。
```python
def train_program(prediction):
@@ -209,9 +223,9 @@ def train_program(prediction):
cost = fluid.layers.cross_entropy(input=prediction, label=label)
avg_cost = fluid.layers.mean(cost)
accuracy = fluid.layers.accuracy(input=prediction, label=label)
- return [avg_cost, accuracy]
-
+ return [avg_cost, accuracy] #返回平均cost和准确率acc
+#优化函数
def optimizer_func():
return fluid.optimizer.Adagrad(learning_rate=0.002)
```
@@ -224,13 +238,13 @@ def optimizer_func():
```python
-use_cuda = False
+use_cuda = False #在cpu上进行训练
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
```
### 定义数据提供器
-下一步是为训练和测试定义数据提供器。提供器读入一个大小为 BATCH_SIZE的数据。paddle.dataset.imdb.train 每次会在乱序化后提供一个大小为BATCH_SIZE的数据,乱序化的大小为缓存大小buf_size。
+下一步是为训练和测试定义数据提供器。提供器读入一个大小为 BATCH_SIZE的数据。paddle.dataset.imdb.word_dict 每次会在乱序化后提供一个大小为BATCH_SIZE的数据,乱序化的大小为缓存大小buf_size。
注意:读取IMDB的数据可能会花费几分钟的时间,请耐心等待。
@@ -244,31 +258,39 @@ train_reader = paddle.batch(
paddle.dataset.imdb.train(word_dict), buf_size=25000),
batch_size=BATCH_SIZE)
```
+word_dict是一个字典序列,是词和label的对应关系,运行下一行可以看到具体内容:
+```python
+word_dict
+```
+每行是如('limited': 1726)的对应关系,该行表示单词limited所对应的label是1726。
-### 构造训练器(trainer)
+### 构造训练器
训练器需要一个训练程序和一个训练优化函数。
```python
exe = fluid.Executor(place)
prediction = inference_program(word_dict)
-[avg_cost, accuracy] = train_program(prediction)
-sgd_optimizer = optimizer_func()
+[avg_cost, accuracy] = train_program(prediction)#训练程序
+sgd_optimizer = optimizer_func()#训练优化函数
sgd_optimizer.minimize(avg_cost)
```
### 提供数据并构建主训练循环
-`feed_order`用来定义每条产生的数据和`paddle.layer.data`之间的映射关系。比如,`imdb.train`产生的第一列的数据对应的是`words`这个特征。
+`feed_order`用来定义每条产生的数据和`fluid.layers.data`之间的映射关系。比如,`imdb.train`产生的第一列的数据对应的是`words`这个特征。
```python
# Specify the directory path to save the parameters
params_dirname = "understand_sentiment_conv.inference.model"
feed_order = ['words', 'label']
-pass_num = 1
+pass_num = 1 #训练循环的轮数
+#程序主循环部分
def train_loop(main_program):
+ #启动上文构建的训练器
exe.run(fluid.default_startup_program())
+
feed_var_list_loop = [
main_program.global_block().var(var_name) for var_name in feed_order
]
@@ -277,12 +299,15 @@ def train_loop(main_program):
test_program = fluid.default_main_program().clone(for_test=True)
+ #训练循环
for epoch_id in range(pass_num):
for step_id, data in enumerate(train_reader()):
+ #运行训练器
metrics = exe.run(main_program,
feed=feeder.feed(data),
fetch_list=[avg_cost, accuracy])
+ #测试结果
avg_cost_test, acc_test = train_test(test_program, test_reader)
print('Step {0}, Test Loss {1:0.2}, Acc {2:0.2}'.format(
step_id, avg_cost_test, acc_test))
@@ -294,7 +319,7 @@ def train_loop(main_program):
if step_id == 30:
if params_dirname is not None:
fluid.io.save_inference_model(params_dirname, ["words"],
- prediction, exe)
+ prediction, exe)#保存模型
return
```
@@ -325,7 +350,7 @@ inference_scope = fluid.core.Scope()
### 生成测试用输入数据
为了进行预测,我们任意选取3个评论。请随意选取您看好的3个。我们把评论中的每个词对应到`word_dict`中的id。如果词典中没有这个词,则设为`unknown`。
-然后我们用`create_lod_tensor`来创建细节层次的张量。
+然后我们用`create_lod_tensor`来创建细节层次的张量,关于该函数的详细解释请参照[API文档](http://paddlepaddle.org/documentation/docs/zh/1.2/user_guides/howto/basic_concept/lod_tensor.html)。
```python
reviews_str = [
diff --git a/06.understand_sentiment/index.cn.html b/06.understand_sentiment/index.cn.html
index b9de3f8b74218e9870aa7889a81624c0453a2b06..f1817c137359047d628e4f1cbe0fe0c6e84096e1 100644
--- a/06.understand_sentiment/index.cn.html
+++ b/06.understand_sentiment/index.cn.html
@@ -70,7 +70,12 @@
我们在[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节介绍过应用于文本数据的卷积神经网络模型的计算过程,这里进行一个简单的回顾。
-对卷积神经网络来说,首先使用卷积处理输入的词向量序列,产生一个特征图(feature map),对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征,最后,将所有卷积核得到的特征拼接起来即为文本的定长向量表示,对于文本分类问题,将其连接至softmax即构建出完整的模型。在实际应用中,我们会使用多个卷积核来处理句子,窗口大小相同的卷积核堆叠起来形成一个矩阵,这样可以更高效的完成运算。另外,我们也可使用窗口大小不同的卷积核来处理句子,[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节的图3作为示意画了四个卷积核,不同颜色表示不同大小的卷积核操作。
+对卷积神经网络来说,首先使用卷积处理输入的词向量序列,产生一个特征图(feature map),对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征,最后,将所有卷积核得到的特征拼接起来即为文本的定长向量表示,对于文本分类问题,将其连接至softmax即构建出完整的模型。在实际应用中,我们会使用多个卷积核来处理句子,窗口大小相同的卷积核堆叠起来形成一个矩阵,这样可以更高效的完成运算。另外,我们也可使用窗口大小不同的卷积核来处理句子,[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节的图3作为示意画了四个卷积核,既文本图1,不同颜色表示不同大小的卷积核操作。
+
+
+
+图1. 卷积神经网络文本分类模型
+
对于一般的短文本分类问题,上文所述的简单的文本卷积网络即可达到很高的正确率\[[1](#参考文献)\]。若想得到更抽象更高级的文本特征表示,可以构建深层文本卷积神经网络\[[2](#参考文献),[3](#参考文献)\]。
@@ -80,16 +85,16 @@
-图1. 循环神经网络按时间展开的示意图
+图2. 循环神经网络按时间展开的示意图
-循环神经网络按时间展开后如图1所示:在第$t$时刻,网络读入第$t$个输入$x_t$(向量表示)及前一时刻隐层的状态值$h_{t-1}$(向量表示,$h_0$一般初始化为$0$向量),计算得出本时刻隐层的状态值$h_t$,重复这一步骤直至读完所有输入。如果将循环神经网络所表示的函数记为$f$,则其公式可表示为:
+循环神经网络按时间展开后如图2所示:在第$t$时刻,网络读入第$t$个输入$x_t$(向量表示)及前一时刻隐层的状态值$h_{t-1}$(向量表示,$h_0$一般初始化为$0$向量),计算得出本时刻隐层的状态值$h_t$,重复这一步骤直至读完所有输入。如果将循环神经网络所表示的函数记为$f$,则其公式可表示为:
$$h_t=f(x_t,h_{t-1})=\sigma(W_{xh}x_t+W_{hh}h_{t-1}+b_h)$$
其中$W_{xh}$是输入到隐层的矩阵参数,$W_{hh}$是隐层到隐层的矩阵参数,$b_h$为隐层的偏置向量(bias)参数,$\sigma$为$sigmoid$函数。
-在处理自然语言时,一般会先将词(one-hot表示)映射为其词向量(word embedding)表示,然后再作为循环神经网络每一时刻的输入$x_t$。此外,可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
+在处理自然语言时,一般会先将词(one-hot表示)映射为其词向量表示,然后再作为循环神经网络每一时刻的输入$x_t$。此外,可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
### 长短期记忆网络(LSTM)
@@ -105,11 +110,11 @@ $$ f_t = \sigma(W_{xf}x_t+W_{hf}h_{t-1}+W_{cf}c_{t-1}+b_f) $$
$$ c_t = f_t\odot c_{t-1}+i_t\odot tanh(W_{xc}x_t+W_{hc}h_{t-1}+b_c) $$
$$ o_t = \sigma(W_{xo}x_t+W_{ho}h_{t-1}+W_{co}c_{t}+b_o) $$
$$ h_t = o_t\odot tanh(c_t) $$
-其中,$i_t, f_t, c_t, o_t$分别表示输入门,遗忘门,记忆单元及输出门的向量值,带角标的$W$及$b$为模型参数,$tanh$为双曲正切函数,$\odot$表示逐元素(elementwise)的乘法操作。输入门控制着新输入进入记忆单元$c$的强度,遗忘门控制着记忆单元维持上一时刻值的强度,输出门控制着输出记忆单元的强度。三种门的计算方式类似,但有着完全不同的参数,它们各自以不同的方式控制着记忆单元$c$,如图2所示:
+其中,$i_t, f_t, c_t, o_t$分别表示输入门,遗忘门,记忆单元及输出门的向量值,带角标的$W$及$b$为模型参数,$tanh$为双曲正切函数,$\odot$表示逐元素(elementwise)的乘法操作。输入门控制着新输入进入记忆单元$c$的强度,遗忘门控制着记忆单元维持上一时刻值的强度,输出门控制着输出记忆单元的强度。三种门的计算方式类似,但有着完全不同的参数,它们各自以不同的方式控制着记忆单元$c$,如图3所示:
-图2. 时刻$t$的LSTM [7]
+图3. 时刻$t$的LSTM [7]
LSTM通过给简单的循环神经网络增加记忆及控制门的方式,增强了其处理远距离依赖问题的能力。类似原理的改进还有Gated Recurrent Unit (GRU)\[[8](#参考文献)\],其设计更为简洁一些。**这些改进虽然各有不同,但是它们的宏观描述却与简单的循环神经网络一样(如图2所示),即隐状态依据当前输入及前一时刻的隐状态来改变,不断地循环这一过程直至输入处理完毕:**
@@ -122,11 +127,11 @@ $$ h_t=Recrurent(x_t,h_{t-1})$$
对于正常顺序的循环神经网络,$h_t$包含了$t$时刻之前的输入信息,也就是上文信息。同样,为了得到下文信息,我们可以使用反方向(将输入逆序处理)的循环神经网络。结合构建深层循环神经网络的方法(深层神经网络往往能得到更抽象和高级的特征表示),我们可以通过构建更加强有力的基于LSTM的栈式双向循环神经网络\[[9](#参考文献)\],来对时序数据进行建模。
-如图3所示(以三层为例),奇数层LSTM正向,偶数层LSTM反向,高一层的LSTM使用低一层LSTM及之前所有层的信息作为输入,对最高层LSTM序列使用时间维度上的最大池化即可得到文本的定长向量表示(这一表示充分融合了文本的上下文信息,并且对文本进行了深层次抽象),最后我们将文本表示连接至softmax构建分类模型。
+如图4所示(以三层为例),奇数层LSTM正向,偶数层LSTM反向,高一层的LSTM使用低一层LSTM及之前所有层的信息作为输入,对最高层LSTM序列使用时间维度上的最大池化即可得到文本的定长向量表示(这一表示充分融合了文本的上下文信息,并且对文本进行了深层次抽象),最后我们将文本表示连接至softmax构建分类模型。
-图3. 栈式双向LSTM用于文本分类
+图4. 栈式双向LSTM用于文本分类
@@ -156,11 +161,11 @@ import numpy as np
import sys
import math
-CLASS_DIM = 2
-EMB_DIM = 128
-HID_DIM = 512
-STACKED_NUM = 3
-BATCH_SIZE = 128
+CLASS_DIM = 2 #情感分类的类别数
+EMB_DIM = 128 #词向量的维度
+HID_DIM = 512 #隐藏层的维度
+STACKED_NUM = 3 #LSTM双向栈的层数
+BATCH_SIZE = 128 #batch的大小
```
@@ -170,6 +175,7 @@ BATCH_SIZE = 128
需要注意的是:`fluid.nets.sequence_conv_pool` 包含卷积和池化层两个操作。
```python
+#文本卷积神经网络
def convolution_net(data, input_dim, class_dim, emb_dim, hid_dim):
emb = fluid.layers.embedding(
input=data, size=[input_dim, emb_dim], is_sparse=True)
@@ -199,32 +205,40 @@ def convolution_net(data, input_dim, class_dim, emb_dim, hid_dim):
栈式双向神经网络`stacked_lstm_net`的代码片段如下:
```python
+#栈式双向LSTM
def stacked_lstm_net(data, input_dim, class_dim, emb_dim, hid_dim, stacked_num):
+ #计算词向量
emb = fluid.layers.embedding(
input=data, size=[input_dim, emb_dim], is_sparse=True)
+ #第一层栈
+ #全连接层
fc1 = fluid.layers.fc(input=emb, size=hid_dim)
+ #lstm层
lstm1, cell1 = fluid.layers.dynamic_lstm(input=fc1, size=hid_dim)
inputs = [fc1, lstm1]
+ #其余的所有栈结构
for i in range(2, stacked_num + 1):
fc = fluid.layers.fc(input=inputs, size=hid_dim)
lstm, cell = fluid.layers.dynamic_lstm(
input=fc, size=hid_dim, is_reverse=(i % 2) == 0)
inputs = [fc, lstm]
+ #池化层
fc_last = fluid.layers.sequence_pool(input=inputs[0], pool_type='max')
lstm_last = fluid.layers.sequence_pool(input=inputs[1], pool_type='max')
+ #全连接层,softmax预测
prediction = fluid.layers.fc(
input=[fc_last, lstm_last], size=class_dim, act='softmax')
return prediction
```
-以上的栈式双向LSTM抽象出了高级特征并把其映射到和分类类别数同样大小的向量上。`paddle.activation.Softmax`函数用来计算分类属于某个类别的概率。
+以上的栈式双向LSTM抽象出了高级特征并把其映射到和分类类别数同样大小的向量上。最后一个全连接层的'softmax'激活函数用来计算分类属于某个类别的概率。
-重申一下,此处我们可以调用`convolution_net`或`stacked_lstm_net`的任何一个。我们以`convolution_net`为例。
+重申一下,此处我们可以调用`convolution_net`或`stacked_lstm_net`的任何一个网络结构进行训练学习。我们以`convolution_net`为例。
接下来我们定义预测程序(`inference_program`)。预测程序使用`convolution_net`来对`fluid.layer.data`的输入进行预测。
@@ -241,9 +255,9 @@ def inference_program(word_dict):
我们这里定义了`training_program`。它使用了从`inference_program`返回的结果来计算误差。我们同时定义了优化函数`optimizer_func`。
-因为是有监督的学习,训练集的标签也在`paddle.layer.data`中定义了。在训练过程中,交叉熵用来在`paddle.layer.classification_cost`中作为损失函数。
+因为是有监督的学习,训练集的标签也在`fluid.layers.data`中定义了。在训练过程中,交叉熵用来在`fluid.layer.cross_entropy`中作为损失函数。
-在测试过程中,分类器会计算各个输出的概率。第一个返回的数值规定为 损耗(cost)。
+在测试过程中,分类器会计算各个输出的概率。第一个返回的数值规定为cost。
```python
def train_program(prediction):
@@ -251,9 +265,9 @@ def train_program(prediction):
cost = fluid.layers.cross_entropy(input=prediction, label=label)
avg_cost = fluid.layers.mean(cost)
accuracy = fluid.layers.accuracy(input=prediction, label=label)
- return [avg_cost, accuracy]
-
+ return [avg_cost, accuracy] #返回平均cost和准确率acc
+#优化函数
def optimizer_func():
return fluid.optimizer.Adagrad(learning_rate=0.002)
```
@@ -266,13 +280,13 @@ def optimizer_func():
```python
-use_cuda = False
+use_cuda = False #在cpu上进行训练
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
```
### 定义数据提供器
-下一步是为训练和测试定义数据提供器。提供器读入一个大小为 BATCH_SIZE的数据。paddle.dataset.imdb.train 每次会在乱序化后提供一个大小为BATCH_SIZE的数据,乱序化的大小为缓存大小buf_size。
+下一步是为训练和测试定义数据提供器。提供器读入一个大小为 BATCH_SIZE的数据。paddle.dataset.imdb.word_dict 每次会在乱序化后提供一个大小为BATCH_SIZE的数据,乱序化的大小为缓存大小buf_size。
注意:读取IMDB的数据可能会花费几分钟的时间,请耐心等待。
@@ -286,31 +300,39 @@ train_reader = paddle.batch(
paddle.dataset.imdb.train(word_dict), buf_size=25000),
batch_size=BATCH_SIZE)
```
+word_dict是一个字典序列,是词和label的对应关系,运行下一行可以看到具体内容:
+```python
+word_dict
+```
+每行是如('limited': 1726)的对应关系,该行表示单词limited所对应的label是1726。
-### 构造训练器(trainer)
+### 构造训练器
训练器需要一个训练程序和一个训练优化函数。
```python
exe = fluid.Executor(place)
prediction = inference_program(word_dict)
-[avg_cost, accuracy] = train_program(prediction)
-sgd_optimizer = optimizer_func()
+[avg_cost, accuracy] = train_program(prediction)#训练程序
+sgd_optimizer = optimizer_func()#训练优化函数
sgd_optimizer.minimize(avg_cost)
```
### 提供数据并构建主训练循环
-`feed_order`用来定义每条产生的数据和`paddle.layer.data`之间的映射关系。比如,`imdb.train`产生的第一列的数据对应的是`words`这个特征。
+`feed_order`用来定义每条产生的数据和`fluid.layers.data`之间的映射关系。比如,`imdb.train`产生的第一列的数据对应的是`words`这个特征。
```python
# Specify the directory path to save the parameters
params_dirname = "understand_sentiment_conv.inference.model"
feed_order = ['words', 'label']
-pass_num = 1
+pass_num = 1 #训练循环的轮数
+#程序主循环部分
def train_loop(main_program):
+ #启动上文构建的训练器
exe.run(fluid.default_startup_program())
+
feed_var_list_loop = [
main_program.global_block().var(var_name) for var_name in feed_order
]
@@ -319,12 +341,15 @@ def train_loop(main_program):
test_program = fluid.default_main_program().clone(for_test=True)
+ #训练循环
for epoch_id in range(pass_num):
for step_id, data in enumerate(train_reader()):
+ #运行训练器
metrics = exe.run(main_program,
feed=feeder.feed(data),
fetch_list=[avg_cost, accuracy])
+ #测试结果
avg_cost_test, acc_test = train_test(test_program, test_reader)
print('Step {0}, Test Loss {1:0.2}, Acc {2:0.2}'.format(
step_id, avg_cost_test, acc_test))
@@ -336,7 +361,7 @@ def train_loop(main_program):
if step_id == 30:
if params_dirname is not None:
fluid.io.save_inference_model(params_dirname, ["words"],
- prediction, exe)
+ prediction, exe)#保存模型
return
```
@@ -367,7 +392,7 @@ inference_scope = fluid.core.Scope()
### 生成测试用输入数据
为了进行预测,我们任意选取3个评论。请随意选取您看好的3个。我们把评论中的每个词对应到`word_dict`中的id。如果词典中没有这个词,则设为`unknown`。
-然后我们用`create_lod_tensor`来创建细节层次的张量。
+然后我们用`create_lod_tensor`来创建细节层次的张量,关于该函数的详细解释请参照[API文档](http://paddlepaddle.org/documentation/docs/zh/1.2/user_guides/howto/basic_concept/lod_tensor.html)。
```python
reviews_str = [