This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
Let us begin the tutorial with a classical problem called Linear Regression \[[1](#References)\]. In this chapter, we will train a model from a realistic dataset to predict home prices. Some important concepts in Machine Learning will be covered through this example.
The source code for this tutorial lives on [book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/fit_a_line). For instructions on getting started with PaddlePaddle, see [PaddlePaddle installation guide](http://www.paddlepaddle.org/doc_cn/build_and_install/index.html).
The source code for this tutorial lives on [book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/fit_a_line). For instructions on getting started with PaddlePaddle, see [PaddlePaddle installation guide](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
## Problem Setup
Suppose we have a dataset of $n$ real estate properties. These real estate properties will be referred to as *homes* in this chapter for clarity.
...
...
@@ -202,4 +202,4 @@ This chapter introduces *Linear Regression* and how to train and test this model
4. Bishop C M. Pattern recognition[J]. Machine Learning, 2006, 128.
<br/>
<arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><imgalt="Common Creative License"style="border-width:0"src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png"/></a> This tutorial was created and published with [Creative Common License 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/).
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
Let us begin the tutorial with a classical problem called Linear Regression \[[1](#References)\]. In this chapter, we will train a model from a realistic dataset to predict home prices. Some important concepts in Machine Learning will be covered through this example.
The source code for this tutorial lives on [book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/fit_a_line). For instructions on getting started with PaddlePaddle, see [PaddlePaddle installation guide](http://www.paddlepaddle.org/doc_cn/build_and_install/index.html).
The source code for this tutorial lives on [book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/fit_a_line). For instructions on getting started with PaddlePaddle, see [PaddlePaddle installation guide](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
## Problem Setup
Suppose we have a dataset of $n$ real estate properties. These real estate properties will be referred to as *homes* in this chapter for clarity.
...
...
@@ -244,7 +244,7 @@ This chapter introduces *Linear Regression* and how to train and test this model
4. Bishop C M. Pattern recognition[J]. Machine Learning, 2006, 128.
<br/>
<arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><imgalt="Common Creative License"style="border-width:0"src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png"/></a> This tutorial was created and published with [Creative Common License 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/).
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
The source code of this chapter is in [book/image_classification](https://github.com/PaddlePaddle/book/tree/develop/image_classification). For the first-time users, please refer to PaddlePaddle[Installation Tutorial](http://www.paddlepaddle.org/doc_cn/build_and_install/index.html) for installation instructions.
The source code of this chapter is in [book/image_classification](https://github.com/PaddlePaddle/book/tree/develop/image_classification). For the first-time users, please refer to PaddlePaddle[Installation Tutorial](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst) for installation instructions.
## Background
...
...
@@ -135,146 +135,73 @@ Figure 10. ResNet model for ImageNet
</p>
## Data Preparation
### Data description and downloading
## Dataset
Commonly used public datasets for image classification are CIFAR(https://www.cs.toronto.edu/~kriz/cifar.html), ImageNet(http://image-net.org/), COCO(http://mscoco.org/), etc. Those used for fine-grained image classification are CUB-200-2011(http://www.vision.caltech.edu/visipedia/CUB-200-2011.html), Stanford Dog(http://vision.stanford.edu/aditya86/ImageNetDogs/), Oxford-flowers(http://www.robots.ox.ac.uk/~vgg/data/flowers/), etc. Among them, ImageNet are the largest and most research results are reported on ImageNet as mentioned in Model Overview section. Since 2010, the data of Imagenet has gone through some changes. The commonly used ImageNet-2012 dataset contains 1000 categories. There are 1,281,167 training images, ranging from 732 to 1200 images per category, and 50,000 validation images with 50 images per category in average.
Since ImageNet is too large to be downloaded and trained efficiently, we use CIFAR10 (https://www.cs.toronto.edu/~kriz/cifar.html) in this tutorial. The CIFAR-10 dataset consists of 60000 32x32 color images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images. Figure 11 shows all the classes in CIFAR10 as well as 10 images randomly sampled from each category.
Since ImageNet is too large to be downloaded and trained efficiently, we use CIFAR-10 (https://www.cs.toronto.edu/~kriz/cifar.html) in this tutorial. The CIFAR-10 dataset consists of 60000 32x32 color images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images. Figure 11 shows all the classes in CIFAR-10 as well as 10 images randomly sampled from each category.
<palign="center">
<imgsrc="image/cifar.png"width="350"><br/>
Figure 11. CIFAR10 dataset[21]
</p>
The following command is used for downloading data and calculating the mean image used for data preprocessing.
```bash
./data/get_data.sh
```
`paddle.datasets` package encapsulates multiple public datasets, including `cifar`, `imdb`, `mnist`, `moivelens` and `wmt14`, etc. There's no need for us to manually download and preprocess CIFAR-10.
### Data provider for PaddlePaddle
After issuing a command `python train.py`, training will starting immediately. The details will be unpacked by the following sessions to see how it works.
We use Python interface for providing data to PaddlePaddle. The following file dataprovider.py is a complete example for CIFAR10.
## Model Structure
- 'initializer' function performs initialization of dataprovider: loading the mean image, defining two input types -- image and label.
### Initialize PaddlePaddle
- 'process' function sends preprocessed data to PaddlePaddle. Data preprocessing performed in this function includes data perturbation, random horizontal flipping, deducting mean image from the raw image.
We must import and initialize PaddlePaddle (enable/disable GPU, set the number of trainers, etc).
In model config file, function `define_py_data_sources2` sets argument 'module' to dataprovider file for loading data, 'args' to mean image file. If the config file is used for prediction, then there is no need to set argument 'train_list'.
In model config file, function 'settings' specifies optimization algorithm, batch size, learning rate, momentum and L2 regularization.
```python
settings(
batch_size=128,
learning_rate=0.1/128.0,
learning_rate_decay_a=0.1,
learning_rate_decay_b=50000*100,
learning_rate_schedule='discexp',
learning_method=MomentumOptimizer(0.9),
regularization=L2Regularization(0.0005*128),)
# PaddlePaddle init
paddle.init(use_gpu=False,trainer_count=1)
```
The learning rate adjustment policy can be defined with variables `learning_rate_decay_a`($a$), `learning_rate_decay_b`($b$) and `learning_rate_schedule`. In this example, discrete exponential method is used for adjusting learning rate. The formula is as follows,
$$ lr = lr_{0} * a^ {\lfloor \frac{n}{ b}\rfloor} $$
where $n$ is the number of processed samples, $lr_{0}$ is the learning_rate set in 'settings'.
### Model Architecture
Here we provide the cofig files for VGG and ResNet models.
As alluded to in section [Model Overview](#model-overview), here we provide the implementations of both VGG and ResNet models.
#### VGG
### VGG
First we define VGG network. Since the image size and amount of CIFAR10 are relatively small comparing to ImageNet, we uses a small version of VGG network for CIFAR10. Convolution groups incorporate BN and dropout operations.
First, we use a VGG network. Since the image size and amount of CIFAR10 are relatively small comparing to ImageNet, we uses a small version of VGG network for CIFAR10. Convolution groups incorporate BN and dropout operations.
1. Define input data and its dimension
The input to the network is defined as `data_layer`, or image pixels in the context of image classification. The images in CIFAR10 are 32x32 color images of three channels. Therefore, the size of the input data is 3072 (3x32x32), and the number of categories is 10.
The input to the network is defined as `paddle.layer.data`, or image pixels in the context of image classification. The images in CIFAR10 are 32x32 color images of three channels. Therefore, the size of the input data is 3072 (3x32x32), and the number of categories is 10.
The input to VGG main module is from data layer. `vgg_bn_drop` defines a 16-layer VGG network, with each convolutional layer followed by BN and dropout layers. Here is the definition in detail:
The input to VGG main module is from the data layer. `vgg_bn_drop` defines a 16-layer VGG network, with each convolutional layer followed by BN and dropout layers. Here is the definition in detail:
2.1. First defines a convolution block or conv_block. The default convolution kernel is 3x3, and the default pooling size is 2x2 with stride 2. Dropout specifies the probability in dropout operation. Function `img_conv_group` is defined in `paddle.trainer_config_helpers` consisting of a series of `Conv->BN->ReLu->Dropout` and a `Pooling`.
2.1. First defines a convolution block or conv_block. The default convolution kernel is 3x3, and the default pooling size is 2x2 with stride 2. Dropout specifies the probability in dropout operation. Function `img_conv_group` is defined in `paddle.networks` consisting of a series of `Conv->BN->ReLu->Dropout` and a `Pooling`.
2.2. Five groups of convolutions. The first two groups perform two convolutions, while the last three groups perform three convolutions. The dropout rate of the last convolution in each group is set to 0, which means there is no dropout for this layer.
...
...
@@ -309,15 +237,12 @@ First we define VGG network. Since the image size and amount of CIFAR10 are rela
4. Define Loss Function and Outputs
In the context of supervised learning, labels of training images are defined in `data_layer`, too. During training, cross-entropy is used as loss function and as the output of the network; During testing, the outputs are the probabilities calculated in the classifier.
In the context of supervised learning, labels of training images are defined in `paddle.layer.data`, too. During training, cross-entropy is used as loss function and as the output of the network; During testing, the outputs are the probabilities calculated in the classifier.
@@ -325,13 +250,13 @@ First we define VGG network. Since the image size and amount of CIFAR10 are rela
The first, third and forth steps of a ResNet are the same as a VGG. The second one is the main module.
```python
net=resnet_cifar10(data,depth=56)
net=resnet_cifar10(data,depth=32)
```
Here are some basic functions used in `resnet_cifar10`:
-`conv_bn_layer` : convolutional layer followed by BN.
-`shortcut` : the shortcut branch in a residual block. There are two kinds of shortcuts: 1x1 convolution used when the number of channels between input and output are different; direct connection used otherwise.
-`shortcut` : the shortcut branch in a residual block. There are two kinds of shortcuts: 1x1 convolution used when the number of channels between input and output is different; direct connection used otherwise.
-`basicblock` : a basic residual module as shown in the left of Figure 9, consisting of two sequential 3x3 convolutions and one "shortcut" branch.
-`bottleneck` : a bottleneck module as shown in the right of Figure 9, consisting of a two 1x1 convolutions with one 3x3 convolution in between branch and a "shortcut" branch.
The following are the components of `resnet_cifar10`:
...
...
@@ -395,106 +311,131 @@ The following are the components of `resnet_cifar10`:
Note: besides the first convolutional layer and the last fully-connected layer, the total number of layers in three `layer_warp` should be dividable by 6, that is the depth of `resnet_cifar10` should satisfy $(depth - 2) % 6 == 0$.
```python
defresnet_cifar10(ipt,depth=56):
defresnet_cifar10(ipt,depth=32):
# depth should be one of 20, 32, 44, 56, 110, 1202
We can train the model by running the script train.sh, which specifies config file, device type, number of threads, number of passes, path to the trained models, etc,
### Define Parameters
``` bash
sh train.sh
```
First, we create the model parameters according to the previous model configuration `cost`.
Here is an example script `train.sh`:
```bash
#cfg=models/resnet.py
cfg=models/vgg.py
output=output
log=train.log
paddle train \
--config=$cfg\
--use_gpu=true\
--trainer_count=1 \
--log_period=100 \
--num_passes=300 \
--save_dir=$output\
2>&1 | tee$log
```python
# Create parameters
parameters=paddle.parameters.create(cost)
```
-`--config=$cfg` : specifies config file. The default is `models/vgg.py`.
-`--use_gpu=true` : uses GPU for training. If use CPU,set it to be false.
-`--trainer_count=1` : specifies the number of threads or GPUs.
-`--log_period=100` : specifies the number of batches between two logs.
-`--save_dir=$output` : specifies the path for saving trained models.
### Create Trainer
Here is an example log after training for one pass. The average error rates are 0.79958 on training set and 0.7858 on validation set.
Before jumping into creating a training module, algorithm setting is also necessary.
Here we specified `Momentum` optimization algorithm via `paddle.optimizer`.
Figure 12 shows the curve of training error rate, which indicates it converges at Pass 200 with error rate 8.54%.
The learning rate adjustment policy can be defined with variables `learning_rate_decay_a`($a$), `learning_rate_decay_b`($b$) and `learning_rate_schedule`. In this example, discrete exponential method is used for adjusting learning rate. The formula is as follows,
$$ lr = lr_{0} * a^ {\lfloor \frac{n}{ b}\rfloor} $$
where $n$ is the number of processed samples, $lr_{0}$ is the learning_rate.
<palign="center">
<imgsrc="image/plot_en.png"width="400"><br/>
Figure 12. The error rate of VGG model on CIFAR10
</p>
### Training
`cifar.train10()` will yield records during each pass, after shuffling, a batch input is generated for training.
## Model Application
```python
reader=paddle.batch(
paddle.reader.shuffle(
paddle.dataset.cifar.train10(),buf_size=50000),
batch_size=128)
```
After training is done, the model from each pass is saved in `output/pass-%05d`. For example, the model of Pass 300 is saved in `output/pass-00299`. The script `classify.py` can be used to extract features and to classify an image. The default config file of this script is `models/vgg.py`.
`feeding` is devoted to specifying the correspondence between each yield record and `paddle.layer.data`. For instance,
the first column of data generated by `cifar.train10()` corresponds to image layer's feature.
```python
feeding={'image':0,
'label':1}
```
### Prediction
Callback function `event_handler` will be called during training when a pre-defined event happens.
We can run the following script to predict the category of an image. The default device is GPU. If to use CPU, set `-c`.
print"\nTest with Pass %d, %s"%(event.pass_id,result.metrics)
```
Here is the result:
Finally, we can invoke `trainer.train` to start training:
```text
Label of image/dog.png is: 5
```python
trainer.train(
reader=reader,
num_passes=200,
event_handler=event_handler,
feeding=feeding)
```
### Feature Extraction
Here is an example log after training for one pass. The average error rates are 0.6875 on the training set and 0.8852 on the validation set.
We can run the following command to extract features from an image. Here `job` should be `extract` and the default layer is the first convolutional layer. Figure 13 shows the 64 feature maps output from the first convolutional layer of the VGG model.
Test with Pass 0, {'classification_error_evaluator': 0.885200023651123}
```
Figure 12 shows the curve of training error rate, which indicates it converges at Pass 200 with error rate 8.54%.
<palign="center">
<imgsrc="image/fea_conv0.png"width="500"><br/>
Figre 13. Visualization of convolution layer feature maps
<imgsrc="image/plot_en.png"width="400"><br/>
Figure 12. The error rate of VGG model on CIFAR10
</p>
After training is done, the model from each pass is saved in `output/pass-%05d`. For example, the model of Pass 300 is saved in `output/pass-00299`.
## Conclusion
Traditional image classification methods involve multiple stages of processing and the framework is very complicated. In contrast, CNN models can be trained end-to-end with significant increase of classification accuracy. In this chapter, we introduce three models -- VGG, GoogleNet, ResNet, provide PaddlePaddle config files for training VGG and ResNet on CIFAR10, and explain how to perform prediction and feature extraction using PaddlePaddle API. For other datasets such as ImageNet, the procedure for config and training are the same and you are welcome to give it a try.
...
...
@@ -547,4 +488,4 @@ Traditional image classification methods involve multiple stages of processing a
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
The source code of this chapter is in [book/image_classification](https://github.com/PaddlePaddle/book/tree/develop/image_classification). For the first-time users, please refer to PaddlePaddle[Installation Tutorial](http://www.paddlepaddle.org/doc_cn/build_and_install/index.html) for installation instructions.
The source code of this chapter is in [book/image_classification](https://github.com/PaddlePaddle/book/tree/develop/image_classification). For the first-time users, please refer to PaddlePaddle [Installation Tutorial](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst) for installation instructions.
## Background
...
...
@@ -177,146 +177,73 @@ Figure 10. ResNet model for ImageNet
</p>
## Data Preparation
### Data description and downloading
## Dataset
Commonly used public datasets for image classification are CIFAR(https://www.cs.toronto.edu/~kriz/cifar.html), ImageNet(http://image-net.org/), COCO(http://mscoco.org/), etc. Those used for fine-grained image classification are CUB-200-2011(http://www.vision.caltech.edu/visipedia/CUB-200-2011.html), Stanford Dog(http://vision.stanford.edu/aditya86/ImageNetDogs/), Oxford-flowers(http://www.robots.ox.ac.uk/~vgg/data/flowers/), etc. Among them, ImageNet are the largest and most research results are reported on ImageNet as mentioned in Model Overview section. Since 2010, the data of Imagenet has gone through some changes. The commonly used ImageNet-2012 dataset contains 1000 categories. There are 1,281,167 training images, ranging from 732 to 1200 images per category, and 50,000 validation images with 50 images per category in average.
Since ImageNet is too large to be downloaded and trained efficiently, we use CIFAR10 (https://www.cs.toronto.edu/~kriz/cifar.html) in this tutorial. The CIFAR-10 dataset consists of 60000 32x32 color images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images. Figure 11 shows all the classes in CIFAR10 as well as 10 images randomly sampled from each category.
Since ImageNet is too large to be downloaded and trained efficiently, we use CIFAR-10 (https://www.cs.toronto.edu/~kriz/cifar.html) in this tutorial. The CIFAR-10 dataset consists of 60000 32x32 color images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images. Figure 11 shows all the classes in CIFAR-10 as well as 10 images randomly sampled from each category.
<palign="center">
<imgsrc="image/cifar.png"width="350"><br/>
Figure 11. CIFAR10 dataset[21]
</p>
The following command is used for downloading data and calculating the mean image used for data preprocessing.
```bash
./data/get_data.sh
```
### Data provider for PaddlePaddle
We use Python interface for providing data to PaddlePaddle. The following file dataprovider.py is a complete example for CIFAR10.
- 'initializer' function performs initialization of dataprovider: loading the mean image, defining two input types -- image and label.
- 'process' function sends preprocessed data to PaddlePaddle. Data preprocessing performed in this function includes data perturbation, random horizontal flipping, deducting mean image from the raw image.
`paddle.datasets` package encapsulates multiple public datasets, including `cifar`, `imdb`, `mnist`, `moivelens` and `wmt14`, etc. There's no need for us to manually download and preprocess CIFAR-10.
After issuing a command `python train.py`, training will starting immediately. The details will be unpacked by the following sessions to see how it works.
@provider(init_hook=initializer, pool_size=50000)
def process(settings, file_list):
with open(file_list, 'r') as fdata:
for fname in fdata:
fo = open(fname.strip(), 'rb')
batch = cPickle.load(fo)
fo.close()
images = batch['data']
labels = batch['labels']
for im, lab in zip(images, labels):
if settings.is_train and np.random.randint(2):
im = im.reshape(3, 32, 32)
im = im[:,:,::-1]
im = im.flatten()
im = im - settings.mean
yield {
'image': im.astype('float32'),
'label': int(lab)
}
```
## Model Config
## Model Structure
### Data Definition
### Initialize PaddlePaddle
In model config file, function `define_py_data_sources2` sets argument 'module' to dataprovider file for loading data, 'args' to mean image file. If the config file is used for prediction, then there is no need to set argument 'train_list'.
We must import and initialize PaddlePaddle (enable/disable GPU, set the number of trainers, etc).
In model config file, function 'settings' specifies optimization algorithm, batch size, learning rate, momentum and L2 regularization.
import sys
import paddle.v2 as paddle
```python
settings(
batch_size=128,
learning_rate=0.1 / 128.0,
learning_rate_decay_a=0.1,
learning_rate_decay_b=50000 * 100,
learning_rate_schedule='discexp',
learning_method=MomentumOptimizer(0.9),
regularization=L2Regularization(0.0005 * 128),)
# PaddlePaddle init
paddle.init(use_gpu=False, trainer_count=1)
```
The learning rate adjustment policy can be defined with variables `learning_rate_decay_a`($a$), `learning_rate_decay_b`($b$) and `learning_rate_schedule`. In this example, discrete exponential method is used for adjusting learning rate. The formula is as follows,
$$ lr = lr_{0} * a^ {\lfloor \frac{n}{ b}\rfloor} $$
where $n$ is the number of processed samples, $lr_{0}$ is the learning_rate set in 'settings'.
### Model Architecture
As alluded to in section [Model Overview](#model-overview), here we provide the implementations of both VGG and ResNet models.
Here we provide the cofig files for VGG and ResNet models.
#### VGG
### VGG
First we define VGG network. Since the image size and amount of CIFAR10 are relatively small comparing to ImageNet, we uses a small version of VGG network for CIFAR10. Convolution groups incorporate BN and dropout operations.
First, we use a VGG network. Since the image size and amount of CIFAR10 are relatively small comparing to ImageNet, we uses a small version of VGG network for CIFAR10. Convolution groups incorporate BN and dropout operations.
1. Define input data and its dimension
The input to the network is defined as `data_layer`, or image pixels in the context of image classification. The images in CIFAR10 are 32x32 color images of three channels. Therefore, the size of the input data is 3072 (3x32x32), and the number of categories is 10.
The input to the network is defined as `paddle.layer.data`, or image pixels in the context of image classification. The images in CIFAR10 are 32x32 color images of three channels. Therefore, the size of the input data is 3072 (3x32x32), and the number of categories is 10.
The input to VGG main module is from data layer. `vgg_bn_drop` defines a 16-layer VGG network, with each convolutional layer followed by BN and dropout layers. Here is the definition in detail:
The input to VGG main module is from the data layer. `vgg_bn_drop` defines a 16-layer VGG network, with each convolutional layer followed by BN and dropout layers. Here is the definition in detail:
2.1. First defines a convolution block or conv_block. The default convolution kernel is 3x3, and the default pooling size is 2x2 with stride 2. Dropout specifies the probability in dropout operation. Function `img_conv_group` is defined in `paddle.trainer_config_helpers` consisting of a series of `Conv->BN->ReLu->Dropout` and a `Pooling`.
2.1. First defines a convolution block or conv_block. The default convolution kernel is 3x3, and the default pooling size is 2x2 with stride 2. Dropout specifies the probability in dropout operation. Function `img_conv_group` is defined in `paddle.networks` consisting of a series of `Conv->BN->ReLu->Dropout` and a `Pooling`.
2.2. Five groups of convolutions. The first two groups perform two convolutions, while the last three groups perform three convolutions. The dropout rate of the last convolution in each group is set to 0, which means there is no dropout for this layer.
...
...
@@ -351,15 +279,12 @@ First we define VGG network. Since the image size and amount of CIFAR10 are rela
4. Define Loss Function and Outputs
In the context of supervised learning, labels of training images are defined in `data_layer`, too. During training, cross-entropy is used as loss function and as the output of the network; During testing, the outputs are the probabilities calculated in the classifier.
In the context of supervised learning, labels of training images are defined in `paddle.layer.data`, too. During training, cross-entropy is used as loss function and as the output of the network; During testing, the outputs are the probabilities calculated in the classifier.
@@ -367,13 +292,13 @@ First we define VGG network. Since the image size and amount of CIFAR10 are rela
The first, third and forth steps of a ResNet are the same as a VGG. The second one is the main module.
```python
net = resnet_cifar10(data, depth=56)
net = resnet_cifar10(data, depth=32)
```
Here are some basic functions used in `resnet_cifar10`:
- `conv_bn_layer` : convolutional layer followed by BN.
- `shortcut` : the shortcut branch in a residual block. There are two kinds of shortcuts: 1x1 convolution used when the number of channels between input and output are different; direct connection used otherwise.
- `shortcut` : the shortcut branch in a residual block. There are two kinds of shortcuts: 1x1 convolution used when the number of channels between input and output is different; direct connection used otherwise.
- `basicblock` : a basic residual module as shown in the left of Figure 9, consisting of two sequential 3x3 convolutions and one "shortcut" branch.
- `bottleneck` : a bottleneck module as shown in the right of Figure 9, consisting of a two 1x1 convolutions with one 3x3 convolution in between branch and a "shortcut" branch.
The following are the components of `resnet_cifar10`:
...
...
@@ -437,106 +353,131 @@ The following are the components of `resnet_cifar10`:
Note: besides the first convolutional layer and the last fully-connected layer, the total number of layers in three `layer_warp` should be dividable by 6, that is the depth of `resnet_cifar10` should satisfy $(depth - 2) % 6 == 0$.
```python
def resnet_cifar10(ipt, depth=56):
def resnet_cifar10(ipt, depth=32):
# depth should be one of 20, 32, 44, 56, 110, 1202
We can train the model by running the script train.sh, which specifies config file, device type, number of threads, number of passes, path to the trained models, etc,
### Define Parameters
``` bash
sh train.sh
```
First, we create the model parameters according to the previous model configuration `cost`.
Here is an example script `train.sh`:
```bash
#cfg=models/resnet.py
cfg=models/vgg.py
output=output
log=train.log
paddle train \
--config=$cfg \
--use_gpu=true \
--trainer_count=1 \
--log_period=100 \
--num_passes=300 \
--save_dir=$output \
2>&1 | tee $log
```python
# Create parameters
parameters = paddle.parameters.create(cost)
```
- `--config=$cfg` : specifies config file. The default is `models/vgg.py`.
- `--use_gpu=true` : uses GPU for training. If use CPU,set it to be false.
- `--trainer_count=1` : specifies the number of threads or GPUs.
- `--log_period=100` : specifies the number of batches between two logs.
- `--save_dir=$output` : specifies the path for saving trained models.
### Create Trainer
Here is an example log after training for one pass. The average error rates are 0.79958 on training set and 0.7858 on validation set.
Before jumping into creating a training module, algorithm setting is also necessary.
Here we specified `Momentum` optimization algorithm via `paddle.optimizer`.
Figure 12 shows the curve of training error rate, which indicates it converges at Pass 200 with error rate 8.54%.
The learning rate adjustment policy can be defined with variables `learning_rate_decay_a`($a$), `learning_rate_decay_b`($b$) and `learning_rate_schedule`. In this example, discrete exponential method is used for adjusting learning rate. The formula is as follows,
$$ lr = lr_{0} * a^ {\lfloor \frac{n}{ b}\rfloor} $$
where $n$ is the number of processed samples, $lr_{0}$ is the learning_rate.
<palign="center">
<imgsrc="image/plot_en.png"width="400"><br/>
Figure 12. The error rate of VGG model on CIFAR10
</p>
### Training
## Model Application
`cifar.train10()` will yield records during each pass, after shuffling, a batch input is generated for training.
After training is done, the model from each pass is saved in `output/pass-%05d`. For example, the model of Pass 300 is saved in `output/pass-00299`. The script `classify.py` can be used to extract features and to classify an image. The default config file of this script is `models/vgg.py`.
```python
reader=paddle.batch(
paddle.reader.shuffle(
paddle.dataset.cifar.train10(), buf_size=50000),
batch_size=128)
```
`feeding` is devoted to specifying the correspondence between each yield record and `paddle.layer.data`. For instance,
the first column of data generated by `cifar.train10()` corresponds to image layer's feature.
```python
feeding={'image': 0,
'label': 1}
```
### Prediction
Callback function `event_handler` will be called during training when a pre-defined event happens.
We can run the following script to predict the category of an image. The default device is GPU. If to use CPU, set `-c`.
print "\nTest with Pass %d, %s" % (event.pass_id, result.metrics)
```
Here is the result:
Finally, we can invoke `trainer.train` to start training:
```text
Label of image/dog.png is: 5
```python
trainer.train(
reader=reader,
num_passes=200,
event_handler=event_handler,
feeding=feeding)
```
### Feature Extraction
We can run the following command to extract features from an image. Here `job` should be `extract` and the default layer is the first convolutional layer. Figure 13 shows the 64 feature maps output from the first convolutional layer of the VGG model.
Here is an example log after training for one pass. The average error rates are 0.6875 on the training set and 0.8852 on the validation set.
Test with Pass 0, {'classification_error_evaluator': 0.885200023651123}
```
Figure 12 shows the curve of training error rate, which indicates it converges at Pass 200 with error rate 8.54%.
<palign="center">
<imgsrc="image/fea_conv0.png"width="500"><br/>
Figre 13. Visualization of convolution layer feature maps
<imgsrc="image/plot_en.png"width="400"><br/>
Figure 12. The error rate of VGG model on CIFAR10
</p>
After training is done, the model from each pass is saved in `output/pass-%05d`. For example, the model of Pass 300 is saved in `output/pass-00299`.
## Conclusion
Traditional image classification methods involve multiple stages of processing and the framework is very complicated. In contrast, CNN models can be trained end-to-end with significant increase of classification accuracy. In this chapter, we introduce three models -- VGG, GoogleNet, ResNet, provide PaddlePaddle config files for training VGG and ResNet on CIFAR10, and explain how to perform prediction and feature extraction using PaddlePaddle API. For other datasets such as ImageNet, the procedure for config and training are the same and you are welcome to give it a try.
...
...
@@ -589,7 +530,7 @@ Traditional image classification methods involve multiple stages of processing a
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
Source code of this chapter is in [book/label_semantic_roles](https://github.com/PaddlePaddle/book/tree/develop/label_semantic_roles).
For instructions on getting started with PaddlePaddle, see [PaddlePaddle installation guide](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
## Background
Natural Language Analysis contains three components: Lexical Analysis, Syntactic Analysis, and Semantic Analysis. Semantic Role Labelling (SRL) is one way for Shallow Semantic Analysis. A predicate of a sentence is a property that a subject possesses or is characterized, such as what it does, what it is or how it is, which mostly corresponds to the core of an event. The noun associated with a predicate is called Argument. Semantic roles express the abstract roles that arguments of a predicate can take in the event, such as Agent, Patient, Theme, Experiencer, Beneficiary, Instrument, Location, Goal and Source, etc.
...
...
@@ -134,7 +136,7 @@ After modification, the model is as follows:
-3. 8 LSTM units will be trained in "forward / backward" order.
- 8 LSTM units will be trained in "forward / backward" order.
```python
hidden_0=paddle.layer.mixed(
...
...
@@ -326,7 +330,7 @@ for i in range(1, depth):
input_tmp=[mix_hidden,lstm]
```
-4. We will concatenate the output of top LSTM unit with it's input, and project into a hidden layer. Then put a fully connected layer on top of it to get the final vector representation.
- We will concatenate the output of top LSTM unit with it's input, and project into a hidden layer. Then put a fully connected layer on top of it to get the final vector representation.
```python
feature_out=paddle.layer.mixed(
...
...
@@ -340,7 +344,7 @@ for i in range(1, depth):
],)
```
-5. We use CRF as cost function, the parameter of CRF cost will be named `crfw`.
- We use CRF as cost function, the parameter of CRF cost will be named `crfw`.
```python
crf_cost=paddle.layer.crf(
...
...
@@ -353,7 +357,7 @@ crf_cost = paddle.layer.crf(
learning_rate=mix_hidden_lr))
```
-6. CRF decoding layer is used for evaluation and inference. It shares parameter with CRF layer. The sharing of parameters among multiple layers is specified by the same parameter name in these layers.
- CRF decoding layer is used for evaluation and inference. It shares parameter with CRF layer. The sharing of parameters among multiple layers is specified by the same parameter name in these layers.
```python
crf_dec=paddle.layer.crf_decoding(
...
...
@@ -470,4 +474,4 @@ Semantic Role Labeling is an important intermediate step in a wide range of natu
10. Zhou J, Xu W. [End-to-end learning of semantic role labeling using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
Source code of this chapter is in [book/label_semantic_roles](https://github.com/PaddlePaddle/book/tree/develop/label_semantic_roles).
For instructions on getting started with PaddlePaddle, see [PaddlePaddle installation guide](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
## Background
Natural Language Analysis contains three components: Lexical Analysis, Syntactic Analysis, and Semantic Analysis. Semantic Role Labelling (SRL) is one way for Shallow Semantic Analysis. A predicate of a sentence is a property that a subject possesses or is characterized, such as what it does, what it is or how it is, which mostly corresponds to the core of an event. The noun associated with a predicate is called Argument. Semantic roles express the abstract roles that arguments of a predicate can take in the event, such as Agent, Patient, Theme, Experiencer, Beneficiary, Instrument, Location, Goal and Source, etc.
...
...
@@ -176,7 +178,7 @@ After modification, the model is as follows:
- 3. 8 LSTM units will be trained in "forward / backward" order.
- 8 LSTM units will be trained in "forward / backward" order.
```python
hidden_0 = paddle.layer.mixed(
...
...
@@ -368,7 +372,7 @@ for i in range(1, depth):
input_tmp = [mix_hidden, lstm]
```
- 4. We will concatenate the output of top LSTM unit with it's input, and project into a hidden layer. Then put a fully connected layer on top of it to get the final vector representation.
- We will concatenate the output of top LSTM unit with it's input, and project into a hidden layer. Then put a fully connected layer on top of it to get the final vector representation.
```python
feature_out = paddle.layer.mixed(
...
...
@@ -382,7 +386,7 @@ for i in range(1, depth):
], )
```
- 5. We use CRF as cost function, the parameter of CRF cost will be named `crfw`.
- We use CRF as cost function, the parameter of CRF cost will be named `crfw`.
```python
crf_cost = paddle.layer.crf(
...
...
@@ -395,7 +399,7 @@ crf_cost = paddle.layer.crf(
learning_rate=mix_hidden_lr))
```
- 6. CRF decoding layer is used for evaluation and inference. It shares parameter with CRF layer. The sharing of parameters among multiple layers is specified by the same parameter name in these layers.
- CRF decoding layer is used for evaluation and inference. It shares parameter with CRF layer. The sharing of parameters among multiple layers is specified by the same parameter name in these layers.
```python
crf_dec = paddle.layer.crf_decoding(
...
...
@@ -512,7 +516,7 @@ Semantic Role Labeling is an important intermediate step in a wide range of natu
10. Zhou J, Xu W. [End-to-end learning of semantic role labeling using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
The source codes is located at [book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/machine_translation). Please refer to the PaddlePaddle [installation tutorial](http://www.paddlepaddle.org/doc_cn/build_and_install/index.html) if you are a first time user.
The source codes is located at [book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/machine_translation). Please refer to the PaddlePaddle [installation tutorial](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst) if you are a first time user.
## Background
...
...
@@ -185,77 +185,10 @@ Note: $z_{i+1}$ and $p_{i+1}$ are computed the same way as in [Decoder](#Decoder
## Data Preparation
### Download and Uncompression
This tutorial uses a dataset from [WMT-14](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/), where [bitexts (after selection)](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/bitexts.tgz) is used as the training set, and [dev+test data](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/dev+test.tgz) is used as test and generation set.
Run the following command in Linux to obtain the data:
```bash
cd data
./wmt14_data.sh
```
There are three folders in the downloaded dataset `data/wmt14`:
<palign = "center">
<table>
<tr>
<td>Folder Name</td>
<td>French-English Parallel Corpus</td>
<td>Number of Files</td>
<td>Size of Files</td>
</tr>
<tr>
<td>train</td>
<td>ccb2_pc30.src, ccb2_pc30.trg, etc</td>
<td>12</td>
<td>3.55G</td>
</tr>
<tr>
<td>test</td>
<td>ntst1213.src, ntst1213.trg</td>
<td>2</td>
<td>1636k</td>
</tr>
</tr>
<tr>
<td>gen</td>
<td>ntst14.src, ntst14.trg</td>
<td>2</td>
<td>864k</td>
</tr>
</table>
</p>
-`XXX.src` is the source file in French and `XXX.trg`is the target file in English. Each row of the file contains one sentence.
-`XXX.src` and `XXX.trg` has the same number of rows and there is a one-to-one correspondance between the sentences at any row from the two files.
### User Defined Dataset (Optional)
To use your own dataset, just put it under the `data` folder and organize it as follows
```text
user_dataset
├── train
│ ├── train_file1.src
│ ├── train_file1.trg
│ └── ...
├── test
│ ├── test_file1.src
│ ├── test_file1.trg
│ └── ...
├── gen
│ ├── gen_file1.src
│ ├── gen_file1.trg
│ └── ...
```
Explanation of the directories:
- First level: `user_dataset`: the name of the user defined dataset.
- Second level: `train`、`test` and `gen`: these names should not be changed.
- Third level: Parallel corpus in source language and target language, each with a postfix of `.src` and `.trg`.
### Data Pre-processing
### Data Preprocessing
There are two steps for pre-processing:
- Merge the source and target parallel corpus files into one file
...
...
@@ -264,245 +197,104 @@ There are two steps for pre-processing:
- Create source dictionary and target dictionary, each containing **DICTSIZE** number of words, including the most frequent (DICTSIZE - 3) fo word from the corpus and 3 special token `<s>` (begin of sequence), `<e>` (end of sequence) and `<unk>` (unknown words that are not in the vocabulary).
`preprocess.py` is used for pre-processing:
```python
pythonpreprocess.py-iINPUT[-dDICTSIZE][-m]
```
-`-i INPUT`: path to the original dataset.
-`-d DICTSIZE`: number of words in the dictionary. If unspecified, the dictionary will contain all the words appeared in the input dataset.
-`-m --mergeDict`: merge the source dictionary with target dictionary, making the two dictionaries have the same content.
### A Subset of Dataset
The specific command to run the script is as follows:
```python
pythonpreprocess.py-idata/wmt14-d30000
```
You will see the following messages after a few minutes:
```text
concat parallel corpora for dataset
build source dictionary for train data
build target dictionary for train data
dictionary size is 30000
```
The pre-processed data is located at `data/pre-wmt14`:
```text
pre-wmt14
├── train
│ └── train
├── test
│ └── test
├── gen
│ └── gen
├── train.list
├── test.list
├── gen.list
├── src.dict
└── trg.dict
```
-`train`, `test` and `gen`: contains French-English parallel corpus for training, testing and generation. Each row from each file is separated into two columns with a "\t", where the first column is the sequence in French and the second one is in English.
-`train.list`, `test.list` and `gen.list`: record respectively the path to `train`, `test` and `gen` folders.
-`src.dict` and `trg.dict`: source (French) and target (English) dictionary. Each dictionary contains 30000 words (29997 most frequent words and 3 special tokens).
Because the full dataset is very big, to reduce the time for downloading the full dataset. PadddlePaddle package `paddle.dataset.wmt14` provides a preprocessed `subset of dataset`(http://paddlepaddle.bj.bcebos.com/demo/wmt_shrinked_data/wmt14.tgz).
### Providing Data to PaddlePaddle
This subset has 193319 instances of training data and 6003 instances of test data. Dictionary size is 30000. Because of the limitation of size of the subset, the effectiveness of trained model from this subset is not guaranteed.
We use `dataprovider.py` to provide data to PaddlePaddle as follows:
## Training Instructions
1. Import PyDataProvider2 package from PaddlePaddle and define three special tokens:
### Initialize PaddlePaddle
```python
frompaddle.trainer.PyDataProvider2import*
UNK_IDX=2#out of vocabulary word
START="<s>"#begin of sequence
END="<e>"#end of sequence
```
2. Use initialization function `hook` to define the input data types (`input_types`) for training and generation:
- Training: there are three input sequences, where "source language sequence" and "target language sequence" are input and the "target language next word sequence" is the label.
- Generation: there are two input sequences, where the "source language sequence" is the input and “source language sequence id” are the ids for the input data (optional).
`src_dict_path` in the `hook` function is the path to the source language dictionary, while `trg_dict_path` the path to target language dictionary. `is_generating` is passed from model config file. For more details on the usage of the `hook` function please refer to [Model Config](#Model Config).
3. Use `process` function to open the file `file_name`, read each row of the file, convert the data to be compatible with `input_types`, and then use `yield` to return to PaddlePaddle process. More specifically
- add `<s>` to the beginning of each source language sequence and add `<e>` to the end, producing "source_language_word".
- add `<s>` to the beginning of each target language senquence, producing "target_language_word".
- add `<e>` to the end of each target language senquence, producing "target_language_next_word".
```python
def_get_ids(s,dictionary):# get the location of each word from the source language sequence in the dictionary
Note: The size of the training data is 3.55G. For machines with limited memories, it is recommended to use `pool_size` to set the number of data samples stored in memory.
## Model Config
### Data Definition
1. Specify the path to data and source/target dictionaries. `is_generating` accepts argument passed from command lines and is used to denote whether the current configuration is for training (default) or generation. See [Usage and Resutls](#Usage and Results).
```python
importos
frompaddle.trainer_config_helpersimport*
```python
importsys
importpaddle.v2aspaddle
data_dir="./data/pre-wmt14"# data path
src_lang_dict=os.path.join(data_dir,'src.dict')# path to the source language dictionary
trg_lang_dict=os.path.join(data_dir,'trg.dict')# path to the target language dictionary
2. Use `define_py_data_sources2` to get data from `dataprovider.py`, and use `args` variable to input the source/target language dicitonary path and config mode.
# train with a single CPU
paddle.init(use_gpu=False,trainer_count=1)
```
```python
ifnotis_generating:
train_list=os.path.join(data_dir,'train.list')
test_list=os.path.join(data_dir,'test.list')
else:
train_list=None
test_list=os.path.join(data_dir,'gen.list')
define_py_data_sources2(
train_list,
test_list,
module="dataprovider",
obj="process",
args={
"src_dict_path":src_lang_dict,# source language dictionary path
"trg_dict_path":trg_lang_dict,# target language dictionary path
"is_generating":is_generating# config mode
})
```
### Define DataSet
### Algorithm Configuration
We will define dictionary size, and create [**data reader**](https://github.com/PaddlePaddle/Paddle/tree/develop/doc/design/reader#python-data-reader-design-doc) for WMT-14 dataset.
This tutorial will use the default SGD and Adam learning algorithm, with a learning rate of 5e-4. Note that the `batch_size = 50` denotes generating 50 sequence each time.
### Model Structure
### Model Configuration
1. Define some global variables
```python
source_dict_dim=len(open(src_lang_dict,"r").readlines())# size of the source language dictionary
target_dict_dim=len(open(trg_lang_dict,"r").readlines())# size of target language dictionary
word_vector_dim=512# dimensionality of word vector
encoder_size=512# dimensionality of the hidden state of encoder GRU
decoder_size=512# dimentionality of the hidden state of decoder GRU
ifis_generating:
beam_size=3# beam size for the beam search algorithm
max_length=250# maximum length for the generated sentence
3.2 Use a non-linear transformation of the last hidden state of the backward GRU on the source language sentence as the initial state of the decoder RNN $c_0=h_T$
1. Use a non-linear transformation of the last hidden state of the backward GRU on the source language sentence as the initial state of the decoder RNN $c_0=h_T$
3.3 Define the computation in each time step for the decoder RNN, i.e., according to the current context vector $c_i$, hidden state for the decoder $z_i$ and the $i$-th word $u_i$ in the target language to predict the probability $p_{i+1}$ for the $i+1$-th word.
1. Define the computation in each time step for the decoder RNN, i.e., according to the current context vector $c_i$, hidden state for the decoder $z_i$ and the $i$-th word $u_i$ in the target language to predict the probability $p_{i+1}$ for the $i+1$-th word.
- decoder_mem records the hidden state $z_i$ from the previous time step, with an initial state as decoder_boot.
- context is computed via `simple_attention` as $c_i=\sum {j=1}^{T}a_{ij}h_j$, where enc_vec is the projection of $h_j$ and enc_proj is the projection of $h_j$ (c.f. 3.1). $a_{ij}$ is calculated within `simple_attention`.
...
...
@@ -512,180 +304,147 @@ This tutorial will use the default SGD and Adam learning algorithm, with a learn
out += paddle.layer.full_matrix_projection(input=gru_step)
return out
```
4. Decoder differences between the training and generation
4.1 Define the name for the decoder and the first two input for `gru_decoder_with_attention`. Note that `StaticInput` is used for the two inputs. Please refer to [StaticInput Document](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/howto/deep_model/rnn/recurrent_group_cn.md#输入) for more details.
1. Define the name for the decoder and the first two input for `gru_decoder_with_attention`. Note that `StaticInput` is used for the two inputs. Please refer to [StaticInput Document](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/howto/deep_model/rnn/recurrent_group_cn.md#输入) for more details.
- during generation, as the decoder RNN will take the word vector generated from the previous time step as input, `GeneratedInput` is used to implement this automatically. Please refer to [GeneratedInput Document](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/howto/deep_model/rnn/recurrent_group_cn.md#输入) for details.
- `beam_search` will call `gru_decoder_with_attention` to generate id
- `seqtext_printer_evaluator` outputs the generated sentence to `gen_trans_file` according to `trg_lang_dict`
Note: Our configuration is based on Bahdanau et al. \[[4](#Reference)\] but with a few simplifications. Please refer to [issue #1133](https://github.com/PaddlePaddle/Paddle/issues/1133) for more details.
```python
else:
trg_embedding=GeneratedInput(
size=target_dict_dim,
embedding_name='_target_language_embedding',
embedding_size=word_vector_dim)
group_inputs.append(trg_embedding)
### Create Parameters
beam_gen=beam_search(
name=decoder_group_name,
step=gru_decoder_with_attention,
input=group_inputs,
bos_id=0,
eos_id=1,
beam_size=beam_size,
max_length=max_length)
seqtext_printer_evaluator(
input=beam_gen,
id_input=data_layer(
name="sent_id",size=1),
dict_file=trg_lang_dict,
result_file=gen_trans_file)
outputs(beam_gen)
```
Note: Our configuration is based on Bahdanau et al. \[[4](#Reference)\] but with a few simplifications. Please refer to [issue #1133](https://github.com/PaddlePaddle/Paddle/issues/1133) for more details.
Create every parameter that `cost` layer needs.
```python
parameters=paddle.parameters.create(cost)
```
We can get parameter names. If the parameter name is not specified during model configuration, it will be generated.
```python
forparaminparameters.keys():
printparam
```
## Model Training
Training can be started with the following command:
1. Create trainer
```bash
./train.sh
```
where `train.sh` contains
We need to tell trainer what to optimize, and how to optimize. Here trainer will optimize `cost` layer using stochastic gradient descent (SDG).
```bash
paddle train \
--config='seqToseq_net.py'\
--save_dir='model'\
--use_gpu=false\
--num_passes=16 \
--show_parameter_stats_period=100 \
--trainer_count=4 \
--log_period=10 \
--dot_period=5 \
2>&1 | tee'train.log'
```
- config: configuration file for the network
- save_dir: path to save the trained model
- use_gpu: whether to use GPU for training; CPU is used here
- num_passes: number of passes for training. In PaddlePaddle, one pass meansing one pass of complete training pass using all the data in the training set
- show_parameter_stats_period: here we show the statistics of parameters every 100 batches
- trainer_count: the number of CPU processes or GPU devices
- log_period: here we print log every 10 batches
- dot_period: we print one "." every 5 batches
The training loss will the printed every 10 batches, and you will see messages like those below:
As the training of an NMT model is very time consuming, we provide a pre-trained model (pass-00012, ~205M). The model is trained with a cluster of 50 physical nodes (each node has two 6-core CPU). We trained 16 passes (taking about 5 days) with each pass taking about 7 hours. The provided model (pass-00012) has the highest [BLEU Score](#BLEU Score) of 26.92. Run the following command to down load the model:
Run the following command to perform translation from French to English:
The model training is successful when the `classification_error_evaluator` is lower than 0.35.
```bash
./gen.sh
```
where `gen.sh` contains:
## Model Usage
### Download Pre-trained Model
As the training of an NMT model is very time consuming, we provide a pre-trained model (pass-00012, ~205M). The model is trained with a cluster of 50 physical nodes (each node has two 6-core CPU). We trained 16 passes (taking about 5 days) with each pass taking about 7 hours. The provided model (pass-00012) has the highest [BLEU Score](#BLEU Score) of 26.92. Run the following command to download the model:
Parameters different training are listed as follows:
- job: set the mode as testing.
- save_dir: path to the pre-trained model.
- num_passes and test_pass: load the model parameters from pass $i\epsilon \left [ test\\_pass,num\\_passes-1 \right ]$. Here we only load `data/wmt14_model/pass-00012`.
- config_args: pass the self-defined command line parameters to model configuration. `is_generating=1` indicates generation mode and `gen_trans_file="gen_result"` represents the file generated.
For translation results please refer to [Illustrative Results](#Illustrative Results).
### BLEU Evaluation
...
...
@@ -711,7 +470,7 @@ BLEU = 26.92
## Summary
End-to-end neural machine translation is a recently developed way to perform machine translations. In this chapter, we introduced the typical "Encoder-Decoder" framework and "attention" mechanism. Since NMT is a typical Sequence-to-Sequence (Seq2Seq) learning problem, tasks such as query rewriting, abstraction generation and single-turn dialogues can all be solved with the model presented in this chapter.
End-to-end neural machine translation is a recently developed way to perform machine translations. In this chapter, we introduced the typical "Encoder-Decoder" framework and "attention" mechanism. Since NMT is a typical Sequence-to-Sequence (Seq2Seq) learning problem, tasks such as query rewriting, abstraction generation, and single-turn dialogues can all be solved with the model presented in this chapter.
## References
...
...
@@ -722,4 +481,4 @@ End-to-end neural machine translation is a recently developed way to perform mac
5. Papineni K, Roukos S, Ward T, et al. [BLEU: a method for automatic evaluation of machine translation](http://dl.acm.org/citation.cfm?id=1073135)[C]//Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, 2002: 311-318.
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
The source codes is located at [book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/machine_translation). Please refer to the PaddlePaddle [installation tutorial](http://www.paddlepaddle.org/doc_cn/build_and_install/index.html) if you are a first time user.
The source codes is located at [book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/machine_translation). Please refer to the PaddlePaddle [installation tutorial](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst) if you are a first time user.
## Background
...
...
@@ -227,77 +227,10 @@ Note: $z_{i+1}$ and $p_{i+1}$ are computed the same way as in [Decoder](#Decoder
## Data Preparation
### Download and Uncompression
This tutorial uses a dataset from [WMT-14](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/), where [bitexts (after selection)](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/bitexts.tgz) is used as the training set, and [dev+test data](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/dev+test.tgz) is used as test and generation set.
Run the following command in Linux to obtain the data:
```bash
cd data
./wmt14_data.sh
```
There are three folders in the downloaded dataset `data/wmt14`:
<palign = "center">
<table>
<tr>
<td>Folder Name</td>
<td>French-English Parallel Corpus</td>
<td>Number of Files</td>
<td>Size of Files</td>
</tr>
<tr>
<td>train</td>
<td>ccb2_pc30.src, ccb2_pc30.trg, etc</td>
<td>12</td>
<td>3.55G</td>
</tr>
<tr>
<td>test</td>
<td>ntst1213.src, ntst1213.trg</td>
<td>2</td>
<td>1636k</td>
</tr>
</tr>
<tr>
<td>gen</td>
<td>ntst14.src, ntst14.trg</td>
<td>2</td>
<td>864k</td>
</tr>
</table>
</p>
- `XXX.src` is the source file in French and `XXX.trg`is the target file in English. Each row of the file contains one sentence.
- `XXX.src` and `XXX.trg` has the same number of rows and there is a one-to-one correspondance between the sentences at any row from the two files.
### User Defined Dataset (Optional)
To use your own dataset, just put it under the `data` folder and organize it as follows
```text
user_dataset
├── train
│ ├── train_file1.src
│ ├── train_file1.trg
│ └── ...
├── test
│ ├── test_file1.src
│ ├── test_file1.trg
│ └── ...
├── gen
│ ├── gen_file1.src
│ ├── gen_file1.trg
│ └── ...
```
Explanation of the directories:
- First level: `user_dataset`: the name of the user defined dataset.
- Second level: `train`、`test` and `gen`: these names should not be changed.
- Third level: Parallel corpus in source language and target language, each with a postfix of `.src` and `.trg`.
### Data Pre-processing
### Data Preprocessing
There are two steps for pre-processing:
- Merge the source and target parallel corpus files into one file
...
...
@@ -306,245 +239,104 @@ There are two steps for pre-processing:
- Create source dictionary and target dictionary, each containing **DICTSIZE** number of words, including the most frequent (DICTSIZE - 3) fo word from the corpus and 3 special token `<s>` (begin of sequence), `<e>` (end of sequence) and `<unk>` (unknown words that are not in the vocabulary).
`preprocess.py` is used for pre-processing:
```python
python preprocess.py -i INPUT [-d DICTSIZE] [-m]
```
- `-i INPUT`: path to the original dataset.
- `-d DICTSIZE`: number of words in the dictionary. If unspecified, the dictionary will contain all the words appeared in the input dataset.
- `-m --mergeDict`: merge the source dictionary with target dictionary, making the two dictionaries have the same content.
The specific command to run the script is as follows:
```python
python preprocess.py -i data/wmt14 -d 30000
```
You will see the following messages after a few minutes:
```text
concat parallel corpora for dataset
build source dictionary for train data
build target dictionary for train data
dictionary size is 30000
```
The pre-processed data is located at `data/pre-wmt14`:
```text
pre-wmt14
├── train
│ └── train
├── test
│ └── test
├── gen
│ └── gen
├── train.list
├── test.list
├── gen.list
├── src.dict
└── trg.dict
```
- `train`, `test` and `gen`: contains French-English parallel corpus for training, testing and generation. Each row from each file is separated into two columns with a "\t", where the first column is the sequence in French and the second one is in English.
- `train.list`, `test.list` and `gen.list`: record respectively the path to `train`, `test` and `gen` folders.
- `src.dict` and `trg.dict`: source (French) and target (English) dictionary. Each dictionary contains 30000 words (29997 most frequent words and 3 special tokens).
### Providing Data to PaddlePaddle
We use `dataprovider.py` to provide data to PaddlePaddle as follows:
1. Import PyDataProvider2 package from PaddlePaddle and define three special tokens:
```python
from paddle.trainer.PyDataProvider2 import *
UNK_IDX = 2 #out of vocabulary word
START = "<s>" #begin of sequence
END = "<e>" #end of sequence
```
2. Use initialization function `hook` to define the input data types (`input_types`) for training and generation:
- Training: there are three input sequences, where "source language sequence" and "target language sequence" are input and the "target language next word sequence" is the label.
- Generation: there are two input sequences, where the "source language sequence" is the input and “source language sequence id” are the ids for the input data (optional).
`src_dict_path` in the `hook` function is the path to the source language dictionary, while `trg_dict_path` the path to target language dictionary. `is_generating` is passed from model config file. For more details on the usage of the `hook` function please refer to [Model Config](#Model Config).
3. Use `process` function to open the file `file_name`, read each row of the file, convert the data to be compatible with `input_types`, and then use `yield` to return to PaddlePaddle process. More specifically
- add `<s>` to the beginning of each source language sequence and add `<e>` to the end, producing "source_language_word".
- add `<s>` to the beginning of each target language senquence, producing "target_language_word".
- add `<e>` to the end of each target language senquence, producing "target_language_next_word".
### A Subset of Dataset
```python
def _get_ids(s, dictionary): # get the location of each word from the source language sequence in the dictionary
words = s.strip().split()
return [dictionary[START]] + \
[dictionary.get(w, UNK_IDX) for w in words] + \
[dictionary[END]]
@provider(init_hook=hook, pool_size=50000)
def process(settings, file_name):
with open(file_name, 'r') as f:
for line_count, line in enumerate(f):
line_split = line.strip().split('\t')
if settings.job_mode and len(line_split) != 2:
continue
src_seq = line_split[0]
src_ids = _get_ids(src_seq, settings.src_dict)
if settings.job_mode:
trg_seq = line_split[1]
trg_words = trg_seq.split()
trg_ids = [settings.trg_dict.get(w, UNK_IDX) for w in trg_words]
# sequence with length longer than 80 with be removed during training to avoid an overly deep RNN.
Note: The size of the training data is 3.55G. For machines with limited memories, it is recommended to use `pool_size` to set the number of data samples stored in memory.
Because the full dataset is very big, to reduce the time for downloading the full dataset. PadddlePaddle package `paddle.dataset.wmt14` provides a preprocessed `subset of dataset`(http://paddlepaddle.bj.bcebos.com/demo/wmt_shrinked_data/wmt14.tgz).
## Model Config
This subset has 193319 instances of training data and 6003 instances of test data. Dictionary size is 30000. Because of the limitation of size of the subset, the effectiveness of trained model from this subset is not guaranteed.
### Data Definition
## Training Instructions
1. Specify the path to data and source/target dictionaries. `is_generating` accepts argument passed from command lines and is used to denote whether the current configuration is for training (default) or generation. See [Usage and Resutls](#Usage and Results).
### Initialize PaddlePaddle
```python
import os
from paddle.trainer_config_helpers import *
```python
import sys
import paddle.v2 as paddle
data_dir = "./data/pre-wmt14" # data path
src_lang_dict = os.path.join(data_dir, 'src.dict') # path to the source language dictionary
trg_lang_dict = os.path.join(data_dir, 'trg.dict') # path to the target language dictionary
2. Use `define_py_data_sources2` to get data from `dataprovider.py`, and use `args` variable to input the source/target language dicitonary path and config mode.
# train with a single CPU
paddle.init(use_gpu=False, trainer_count=1)
```
```python
if not is_generating:
train_list = os.path.join(data_dir, 'train.list')
test_list = os.path.join(data_dir, 'test.list')
else:
train_list = None
test_list = os.path.join(data_dir, 'gen.list')
define_py_data_sources2(
train_list,
test_list,
module="dataprovider",
obj="process",
args={
"src_dict_path": src_lang_dict, # source language dictionary path
"trg_dict_path": trg_lang_dict, # target language dictionary path
"is_generating": is_generating # config mode
})
```
### Define DataSet
### Algorithm Configuration
We will define dictionary size, and create [**data reader**](https://github.com/PaddlePaddle/Paddle/tree/develop/doc/design/reader#python-data-reader-design-doc) for WMT-14 dataset.
This tutorial will use the default SGD and Adam learning algorithm, with a learning rate of 5e-4. Note that the `batch_size = 50` denotes generating 50 sequence each time.
### Model Structure
### Model Configuration
1. Define some global variables
```python
source_dict_dim = len(open(src_lang_dict, "r").readlines()) # size of the source language dictionary
target_dict_dim = len(open(trg_lang_dict, "r").readlines()) # size of target language dictionary
word_vector_dim = 512 # dimensionality of word vector
encoder_size = 512 # dimensionality of the hidden state of encoder GRU
decoder_size = 512 # dimentionality of the hidden state of decoder GRU
if is_generating:
beam_size=3 # beam size for the beam search algorithm
max_length=250 # maximum length for the generated sentence
source_dict_dim = dict_size # source language dictionary size
target_dict_dim = dict_size # destination language dictionary size
word_vector_dim = 512 # word embedding dimension
encoder_size = 512 # hidden layer size of GRU in encoder
decoder_size = 512 # hidden layer size of GRU in decoder
```
2. Implement Encoder as follows:
2.1 Input one-hot vector representations $\mathbf{w}$ converted with `dataprovider.py` from the source language sentence
1. Implement Encoder as follows:
1. Input is a sequence of words represented by an integer word index sequence. So we define data layer of data type `integer_value_sequence`. The value range of each element in the sequence is `[0, source_dict_dim)`
3.2 Use a non-linear transformation of the last hidden state of the backward GRU on the source language sentence as the initial state of the decoder RNN $c_0=h_T$
1. Use a non-linear transformation of the last hidden state of the backward GRU on the source language sentence as the initial state of the decoder RNN $c_0=h_T$
3.3 Define the computation in each time step for the decoder RNN, i.e., according to the current context vector $c_i$, hidden state for the decoder $z_i$ and the $i$-th word $u_i$ in the target language to predict the probability $p_{i+1}$ for the $i+1$-th word.
1. Define the computation in each time step for the decoder RNN, i.e., according to the current context vector $c_i$, hidden state for the decoder $z_i$ and the $i$-th word $u_i$ in the target language to predict the probability $p_{i+1}$ for the $i+1$-th word.
- decoder_mem records the hidden state $z_i$ from the previous time step, with an initial state as decoder_boot.
- context is computed via `simple_attention` as $c_i=\sum {j=1}^{T}a_{ij}h_j$, where enc_vec is the projection of $h_j$ and enc_proj is the projection of $h_j$ (c.f. 3.1). $a_{ij}$ is calculated within `simple_attention`.
...
...
@@ -554,180 +346,147 @@ This tutorial will use the default SGD and Adam learning algorithm, with a learn
out += paddle.layer.full_matrix_projection(input=gru_step)
return out
```
4. Decoder differences between the training and generation
4.1 Define the name for the decoder and the first two input for `gru_decoder_with_attention`. Note that `StaticInput` is used for the two inputs. Please refer to [StaticInput Document](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/howto/deep_model/rnn/recurrent_group_cn.md#输入) for more details.
1. Define the name for the decoder and the first two input for `gru_decoder_with_attention`. Note that `StaticInput` is used for the two inputs. Please refer to [StaticInput Document](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/howto/deep_model/rnn/recurrent_group_cn.md#输入) for more details.
- during generation, as the decoder RNN will take the word vector generated from the previous time step as input, `GeneratedInput` is used to implement this automatically. Please refer to [GeneratedInput Document](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/howto/deep_model/rnn/recurrent_group_cn.md#输入) for details.
- `beam_search` will call `gru_decoder_with_attention` to generate id
- `seqtext_printer_evaluator` outputs the generated sentence to `gen_trans_file` according to `trg_lang_dict`
Note: Our configuration is based on Bahdanau et al. \[[4](#Reference)\] but with a few simplifications. Please refer to [issue #1133](https://github.com/PaddlePaddle/Paddle/issues/1133) for more details.
```python
else:
trg_embedding = GeneratedInput(
size=target_dict_dim,
embedding_name='_target_language_embedding',
embedding_size=word_vector_dim)
group_inputs.append(trg_embedding)
### Create Parameters
beam_gen = beam_search(
name=decoder_group_name,
step=gru_decoder_with_attention,
input=group_inputs,
bos_id=0,
eos_id=1,
beam_size=beam_size,
max_length=max_length)
seqtext_printer_evaluator(
input=beam_gen,
id_input=data_layer(
name="sent_id", size=1),
dict_file=trg_lang_dict,
result_file=gen_trans_file)
outputs(beam_gen)
```
Note: Our configuration is based on Bahdanau et al. \[[4](#Reference)\] but with a few simplifications. Please refer to [issue #1133](https://github.com/PaddlePaddle/Paddle/issues/1133) for more details.
Create every parameter that `cost` layer needs.
```python
parameters = paddle.parameters.create(cost)
```
We can get parameter names. If the parameter name is not specified during model configuration, it will be generated.
```python
for param in parameters.keys():
print param
```
## Model Training
Training can be started with the following command:
1. Create trainer
```bash
./train.sh
```
where `train.sh` contains
We need to tell trainer what to optimize, and how to optimize. Here trainer will optimize `cost` layer using stochastic gradient descent (SDG).
```bash
paddle train \
--config='seqToseq_net.py' \
--save_dir='model' \
--use_gpu=false \
--num_passes=16 \
--show_parameter_stats_period=100 \
--trainer_count=4 \
--log_period=10 \
--dot_period=5 \
2>&1 | tee 'train.log'
```
- config: configuration file for the network
- save_dir: path to save the trained model
- use_gpu: whether to use GPU for training; CPU is used here
- num_passes: number of passes for training. In PaddlePaddle, one pass meansing one pass of complete training pass using all the data in the training set
- show_parameter_stats_period: here we show the statistics of parameters every 100 batches
- trainer_count: the number of CPU processes or GPU devices
- log_period: here we print log every 10 batches
- dot_period: we print one "." every 5 batches
The training loss will the printed every 10 batches, and you will see messages like those below:
As the training of an NMT model is very time consuming, we provide a pre-trained model (pass-00012, ~205M). The model is trained with a cluster of 50 physical nodes (each node has two 6-core CPU). We trained 16 passes (taking about 5 days) with each pass taking about 7 hours. The provided model (pass-00012) has the highest [BLEU Score](#BLEU Score) of 26.92. Run the following command to down load the model:
Run the following command to perform translation from French to English:
The model training is successful when the `classification_error_evaluator` is lower than 0.35.
```bash
./gen.sh
```
where `gen.sh` contains:
## Model Usage
### Download Pre-trained Model
As the training of an NMT model is very time consuming, we provide a pre-trained model (pass-00012, ~205M). The model is trained with a cluster of 50 physical nodes (each node has two 6-core CPU). We trained 16 passes (taking about 5 days) with each pass taking about 7 hours. The provided model (pass-00012) has the highest [BLEU Score](#BLEU Score) of 26.92. Run the following command to download the model:
Parameters different training are listed as follows:
- job: set the mode as testing.
- save_dir: path to the pre-trained model.
- num_passes and test_pass: load the model parameters from pass $i\epsilon \left [ test\\_pass,num\\_passes-1 \right ]$. Here we only load `data/wmt14_model/pass-00012`.
- config_args: pass the self-defined command line parameters to model configuration. `is_generating=1` indicates generation mode and `gen_trans_file="gen_result"` represents the file generated.
For translation results please refer to [Illustrative Results](#Illustrative Results).
### BLEU Evaluation
...
...
@@ -753,7 +512,7 @@ BLEU = 26.92
## Summary
End-to-end neural machine translation is a recently developed way to perform machine translations. In this chapter, we introduced the typical "Encoder-Decoder" framework and "attention" mechanism. Since NMT is a typical Sequence-to-Sequence (Seq2Seq) learning problem, tasks such as query rewriting, abstraction generation and single-turn dialogues can all be solved with the model presented in this chapter.
End-to-end neural machine translation is a recently developed way to perform machine translations. In this chapter, we introduced the typical "Encoder-Decoder" framework and "attention" mechanism. Since NMT is a typical Sequence-to-Sequence (Seq2Seq) learning problem, tasks such as query rewriting, abstraction generation, and single-turn dialogues can all be solved with the model presented in this chapter.
## References
...
...
@@ -764,7 +523,7 @@ End-to-end neural machine translation is a recently developed way to perform mac
5. Papineni K, Roukos S, Ward T, et al. [BLEU: a method for automatic evaluation of machine translation](http://dl.acm.org/citation.cfm?id=1073135)[C]//Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, 2002: 311-318.
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
The source code for this tutorial is under [book/recognize_digits](https://github.com/PaddlePaddle/book/tree/develop/recognize_digits). First-time readers, please refer to PaddlePaddle [installation instructions](http://www.paddlepaddle.org/doc_cn/build_and_install/index.html).
The source code for this tutorial is under [book/recognize_digits](https://github.com/PaddlePaddle/book/tree/develop/recognize_digits). First-time readers, please refer to PaddlePaddle [installation instructions](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
## Introduction
When we learn a new programming language, the first task is usually to write a program that prints "Hello World." In Machine Learning or Deep Learning, the equivalent task is to train a model to perform handwritten digit recognition with [MNIST](http://yann.lecun.com/exdb/mnist/) dataset. Handwriting recognition is a typical image classification problem. The problem is relatively easy, and MNIST is a complete dataset. As a simple Computer Vision dataset, MNIST contains images of handwritten digits and their corresponding labels (Fig. 1). The input image is a 28x28 matrix, and the label is one of the digits from 0 to 9. Each image is normalized in size and centered.
...
...
@@ -32,15 +32,15 @@ In a simple softmax regression model, the input is fed to fully connected layers
Input $X$ is multiplied with weights $W$, and bias $b$ is added to generate activations.
where $ softmax(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $
where $ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $
For an $N$ class classification problem with $N$ output nodes, an $N$ dimensional vector is normalized to $N$ real values in the range [0, 1], each representing the probability of the sample to belong to the class. Here $y_i$ is the prediction probability that an image is digit $i$.
In such a classification problem, we usually use the cross entropy loss function:
Fig. 2 shows a softmax regression network, with weights in blue, and bias in red. +1 indicates bias is 1.
...
...
@@ -55,7 +55,7 @@ The Softmax regression model described above uses the simplest two-layer neural
1. After the first hidden layer, we get $ H_1 = \phi(W_1X + b_1) $, where $\phi$ is the activation function. Some common ones are sigmoid, tanh and ReLU.
2. After the second hidden layer, we get $ H_2 = \phi(W_2H_1 + b_2) $.
3. Finally, after output layer, we get $Y=softmax(W_3H_2 + b_3)$, the final classification result vector.
3. Finally, after output layer, we get $Y=\text{softmax}(W_3H_2 + b_3)$, the final classification result vector.
Fig. 3. is Multilayer Perceptron network, with weights in blue, and bias in red. +1 indicates bias is 1.
@@ -293,7 +293,7 @@ This tutorial describes a few basic Deep Learning models viz. Softmax regression
7. Deng, Li, Michael L. Seltzer, Dong Yu, Alex Acero, Abdel-rahman Mohamed, and Geoffrey E. Hinton. ["Binary coding of speech spectrograms using a deep auto-encoder."](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.185.1908&rep=rep1&type=pdf) In Interspeech, pp. 1692-1695. 2010.
8. Kégl, Balázs, and Róbert Busa-Fekete. ["Boosting products of base classifiers."](http://dl.acm.org/citation.cfm?id=1553439) In Proceedings of the 26th Annual International Conference on Machine Learning, pp. 497-504. ACM, 2009.
9. Rosenblatt, Frank. ["The perceptron: A probabilistic model for information storage and organization in the brain."](http://psycnet.apa.org/journals/rev/65/6/386/) Psychological review 65, no. 6 (1958): 386.
10. Bishop, Christopher M. ["Pattern recognition."](http://s3.amazonaws.com/academia.edu.documents/30428242/bg0137.pdf?AWSAccessKeyId=AKIAJ56TQJRTWSMTNPEA&Expires=1484816640&Signature=85Ad6%2Fca8T82pmHzxaSXermovIA%3D&response-content-disposition=inline%3B%20filename%3DPattern_recognition_and_machine_learning.pdf) Machine Learning 128 (2006): 1-58.
10. Bishop, Christopher M. ["Pattern recognition."](http://users.isr.ist.utl.pt/~wurmd/Livros/school/Bishop%20-%20Pattern%20Recognition%20And%20Machine%20Learning%20-%20Springer%20%202006.pdf) Machine Learning 128 (2006): 1-58.
<br/>
<arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><imgalt="知识共享许可协议"style="border-width:0"src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png"/></a><br/><spanxmlns:dct="http://purl.org/dc/terms/"href="http://purl.org/dc/dcmitype/Text"property="dct:title"rel="dct:type">This book</span> is created by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and uses <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Shared knowledge signature - non commercial use-Sharing 4.0 International Licensing Protocal</a>.
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
7. Deng, Li, Michael L. Seltzer, Dong Yu, Alex Acero, Abdel-rahman Mohamed, and Geoffrey E. Hinton. ["Binary coding of speech spectrograms using a deep auto-encoder."](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.185.1908&rep=rep1&type=pdf) In Interspeech, pp. 1692-1695. 2010.
8. Kégl, Balázs, and Róbert Busa-Fekete. ["Boosting products of base classifiers."](http://dl.acm.org/citation.cfm?id=1553439) In Proceedings of the 26th Annual International Conference on Machine Learning, pp. 497-504. ACM, 2009.
9. Rosenblatt, Frank. ["The perceptron: A probabilistic model for information storage and organization in the brain."](http://psycnet.apa.org/journals/rev/65/6/386/) Psychological review 65, no. 6 (1958): 386.
10. Bishop, Christopher M. ["Pattern recognition."](http://s3.amazonaws.com/academia.edu.documents/30428242/bg0137.pdf?AWSAccessKeyId=AKIAJ56TQJRTWSMTNPEA&Expires=1484816640&Signature=85Ad6%2Fca8T82pmHzxaSXermovIA%3D&response-content-disposition=inline%3B%20filename%3DPattern_recognition_and_machine_learning.pdf) Machine Learning 128 (2006): 1-58.
10. Bishop, Christopher M. ["Pattern recognition."](http://users.isr.ist.utl.pt/~wurmd/Livros/school/Bishop%20-%20Pattern%20Recognition%20And%20Machine%20Learning%20-%20Springer%20%202006.pdf) Machine Learning 128 (2006): 1-58.
The source code for this tutorial is under [book/recognize_digits](https://github.com/PaddlePaddle/book/tree/develop/recognize_digits). First-time readers, please refer to PaddlePaddle [installation instructions](http://www.paddlepaddle.org/doc_cn/build_and_install/index.html).
The source code for this tutorial is under [book/recognize_digits](https://github.com/PaddlePaddle/book/tree/develop/recognize_digits). First-time readers, please refer to PaddlePaddle [installation instructions](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
## Introduction
When we learn a new programming language, the first task is usually to write a program that prints "Hello World." In Machine Learning or Deep Learning, the equivalent task is to train a model to perform handwritten digit recognition with [MNIST](http://yann.lecun.com/exdb/mnist/) dataset. Handwriting recognition is a typical image classification problem. The problem is relatively easy, and MNIST is a complete dataset. As a simple Computer Vision dataset, MNIST contains images of handwritten digits and their corresponding labels (Fig. 1). The input image is a 28x28 matrix, and the label is one of the digits from 0 to 9. Each image is normalized in size and centered.
...
...
@@ -74,15 +74,15 @@ In a simple softmax regression model, the input is fed to fully connected layers
Input $X$ is multiplied with weights $W$, and bias $b$ is added to generate activations.
where $ softmax(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $
where $ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $
For an $N$ class classification problem with $N$ output nodes, an $N$ dimensional vector is normalized to $N$ real values in the range [0, 1], each representing the probability of the sample to belong to the class. Here $y_i$ is the prediction probability that an image is digit $i$.
In such a classification problem, we usually use the cross entropy loss function:
Fig. 2 shows a softmax regression network, with weights in blue, and bias in red. +1 indicates bias is 1.
...
...
@@ -97,7 +97,7 @@ The Softmax regression model described above uses the simplest two-layer neural
1. After the first hidden layer, we get $ H_1 = \phi(W_1X + b_1) $, where $\phi$ is the activation function. Some common ones are sigmoid, tanh and ReLU.
2. After the second hidden layer, we get $ H_2 = \phi(W_2H_1 + b_2) $.
3. Finally, after output layer, we get $Y=softmax(W_3H_2 + b_3)$, the final classification result vector.
3. Finally, after output layer, we get $Y=\text{softmax}(W_3H_2 + b_3)$, the final classification result vector.
Fig. 3. is Multilayer Perceptron network, with weights in blue, and bias in red. +1 indicates bias is 1.
@@ -335,10 +335,10 @@ This tutorial describes a few basic Deep Learning models viz. Softmax regression
7. Deng, Li, Michael L. Seltzer, Dong Yu, Alex Acero, Abdel-rahman Mohamed, and Geoffrey E. Hinton. ["Binary coding of speech spectrograms using a deep auto-encoder."](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.185.1908&rep=rep1&type=pdf) In Interspeech, pp. 1692-1695. 2010.
8. Kégl, Balázs, and Róbert Busa-Fekete. ["Boosting products of base classifiers."](http://dl.acm.org/citation.cfm?id=1553439) In Proceedings of the 26th Annual International Conference on Machine Learning, pp. 497-504. ACM, 2009.
9. Rosenblatt, Frank. ["The perceptron: A probabilistic model for information storage and organization in the brain."](http://psycnet.apa.org/journals/rev/65/6/386/) Psychological review 65, no. 6 (1958): 386.
10. Bishop, Christopher M. ["Pattern recognition."](http://s3.amazonaws.com/academia.edu.documents/30428242/bg0137.pdf?AWSAccessKeyId=AKIAJ56TQJRTWSMTNPEA&Expires=1484816640&Signature=85Ad6%2Fca8T82pmHzxaSXermovIA%3D&response-content-disposition=inline%3B%20filename%3DPattern_recognition_and_machine_learning.pdf) Machine Learning 128 (2006): 1-58.
10. Bishop, Christopher M. ["Pattern recognition."](http://users.isr.ist.utl.pt/~wurmd/Livros/school/Bishop%20-%20Pattern%20Recognition%20And%20Machine%20Learning%20-%20Springer%20%202006.pdf) Machine Learning 128 (2006): 1-58.
<br/>
<arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><imgalt="知识共享许可协议"style="border-width:0"src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png"/></a><br/><spanxmlns:dct="http://purl.org/dc/terms/"href="http://purl.org/dc/dcmitype/Text"property="dct:title"rel="dct:type">This book</span> is created by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and uses <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Shared knowledge signature - non commercial use-Sharing 4.0 International Licensing Protocal</a>.
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
7. Deng, Li, Michael L. Seltzer, Dong Yu, Alex Acero, Abdel-rahman Mohamed, and Geoffrey E. Hinton. ["Binary coding of speech spectrograms using a deep auto-encoder."](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.185.1908&rep=rep1&type=pdf) In Interspeech, pp. 1692-1695. 2010.
8. Kégl, Balázs, and Róbert Busa-Fekete. ["Boosting products of base classifiers."](http://dl.acm.org/citation.cfm?id=1553439) In Proceedings of the 26th Annual International Conference on Machine Learning, pp. 497-504. ACM, 2009.
9. Rosenblatt, Frank. ["The perceptron: A probabilistic model for information storage and organization in the brain."](http://psycnet.apa.org/journals/rev/65/6/386/) Psychological review 65, no. 6 (1958): 386.
10. Bishop, Christopher M. ["Pattern recognition."](http://s3.amazonaws.com/academia.edu.documents/30428242/bg0137.pdf?AWSAccessKeyId=AKIAJ56TQJRTWSMTNPEA&Expires=1484816640&Signature=85Ad6%2Fca8T82pmHzxaSXermovIA%3D&response-content-disposition=inline%3B%20filename%3DPattern_recognition_and_machine_learning.pdf) Machine Learning 128 (2006): 1-58.
10. Bishop, Christopher M. ["Pattern recognition."](http://users.isr.ist.utl.pt/~wurmd/Livros/school/Bishop%20-%20Pattern%20Recognition%20And%20Machine%20Learning%20-%20Springer%20%202006.pdf) Machine Learning 128 (2006): 1-58.
The source code of this tutorial is in [book/recommender_system](https://github.com/PaddlePaddle/book/tree/develop/recommender_system).
For instructions on getting started with PaddlePaddle, see [PaddlePaddle installation guide](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
## Background
With the fast growth of e-commerce, online videos, and online reading business, users have to rely on recommender systems to avoid manually browsing tremendous volume of choices. Recommender systems understand users' interest by mining user behavior and other properties of users and products.
...
...
@@ -78,20 +81,285 @@ Figure 3. A hybrid recommendation model.
We use the [MovieLens ml-1m](http://files.grouplens.org/datasets/movielens/ml-1m.zip) to train our model. This dataset includes 10,000 ratings of 4,000 movies from 6,000 users to 4,000 movies. Each rate is in the range of 1~5. Thanks to GroupLens Research for collecting, processing and publishing the dataset.
We don't have to download and preprocess the data. Instead, we can use PaddlePaddle's dataset module `paddle.v2.dataset.movielens`.
## Model Specification
## Training
## Inference
`paddle.v2.datasets` package encapsulates multiple public datasets, including `cifar`, `imdb`, `mnist`, `moivelens` and `wmt14`, etc. There's no need for us to manually download and preprocess `MovieLens` dataset.
```python
# Run this block to show dataset's documentation
help(paddle.v2.dataset.movielens)
```
The raw `MoiveLens` contains movie ratings, relevant features from both movies and users.
print"User %s rates Movie %s with Score %s"%(user_info[uid],movie_info[mov_id],train_sample[-1])
```
```text
User <UserInfo id(1), gender(F), age(1), job(10)> rates Movie <MovieInfo id(1193), title(One Flew Over the Cuckoo's Nest), categories(['Drama'])> with Score [5.0]
```
The output shows that user 1 gave movie `1193` a rating of 5.
After issuing a command `python train.py`, training will start immediately. The details will be unpacked by the following sessions to see how it works.
## Model Architecture
### Initialize PaddlePaddle
First, we must import and initialize PaddlePaddle (enable/disable GPU, set the number of trainers, etc).
As shown in the above code, the input is four dimension integers for each user, that is, `user_id`,`gender_id`, `age_id` and `job_id`. In order to deal with these features conveniently, we use the language model in NLP to transform these discrete values into embedding vaules `usr_emb`, `usr_gender_emb`, `usr_age_emb` and `usr_job_emb`.
Movie title, a sequence of words represented by an integer word index sequence, will be feed into a `sequence_conv_pool` layer, which will apply convolution and pooling on time dimension. Because pooling is done on time dimension, the output will be a fixed-length vector regardless the length of the input sequence.
Finally, we can use cosine similarity to calculate the similarity between user characteristics and movie features.
First, we define the model parameters according to the previous model configuration `cost`.
```python
# Create parameters
parameters=paddle.parameters.create(cost)
```
### Create Trainer
Before jumping into creating a training module, algorithm setting is also necessary. Here we specified Adam optimization algorithm via `paddle.optimizer`.
[INFO 2017-03-06 17:12:13,378 networks.py:1472] The input order is [user_id, gender_id, age_id, job_id, movie_id, category_id, movie_title, score]
[INFO 2017-03-06 17:12:13,379 networks.py:1478] The output order is [__regression_cost_0__]
```
### Training
`paddle.dataset.movielens.train` will yield records during each pass, after shuffling, a batch input is generated for training.
```python
reader=paddle.reader.batch(
paddle.reader.shuffle(
paddle.dataset.movielens.trai(),buf_size=8192),
batch_size=256)
```
`feeding` is devoted to specifying the correspondence between each yield record and `paddle.layer.data`. For instance, the first column of data generated by `movielens.train` corresponds to `user_id` feature.
```python
feeding={
'user_id':0,
'gender_id':1,
'age_id':2,
'job_id':3,
'movie_id':4,
'category_id':5,
'movie_title':6,
'score':7
}
```
Callback function `event_handler` will be called during training when a pre-defined event happens.
```python
step=0
train_costs=[],[]
test_costs=[],[]
defevent_handler(event):
globalstep
globaltrain_costs
globaltest_costs
ifisinstance(event,paddle.event.EndIteration):
need_plot=False
ifstep%10==0:# every 10 batches, record a train cost
train_costs[0].append(step)
train_costs[1].append(event.cost)
ifstep%1000==0:# every 1000 batches, record a test cost
result=trainer.test(reader=paddle.batch(
paddle.dataset.movielens.test(),batch_size=256))
test_costs[0].append(step)
test_costs[1].append(result.cost)
ifstep%100==0:# every 100 batches, update cost plot
Finally, we can invoke `trainer.train` to start training:
```python
trainer.train(
reader=reader,
event_handler=event_handler,
feeding=feeding,
num_passes=200)
```
## Conclusion
...
...
@@ -99,13 +367,13 @@ This tutorial goes over traditional approaches in recommender system and a deep
## Reference
1.[Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
2. Robin Burke ,[Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
1.[Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky)(2007). *The Adaptive Web*. p. 325.
2. Robin Burke ,[Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
3. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
4. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)"*Proceedings of the 10th International Conference on World Wide Web*. ACM, 2001.
4. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)"*Proceedings of the 10th International Conference on World Wide Web*. ACM, 2001.
5. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: Combining Social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf)*arXiv preprint arXiv:1611.05480*(2016).
6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf)*arXiv preprint arXiv:1611.05480*(2016).
7. Covington P, Adams J, Sargin E. [Deep neural networks for youtube recommendations](https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf)[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 191-198.
<br/>
<arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><imgalt="Creative Commons"style="border-width:0"src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png"/></a><br/><spanxmlns:dct="http://purl.org/dc/terms/"href="http://purl.org/dc/dcmitype/Text"property="dct:title"rel="dct:type">This tutorial</span> was created by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">the PaddlePaddle community</a> and published under <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Common Creative 4.0 License</a>。
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
The source code of this tutorial is in [book/recommender_system](https://github.com/PaddlePaddle/book/tree/develop/recommender_system).
For instructions on getting started with PaddlePaddle, see [PaddlePaddle installation guide](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
## Background
With the fast growth of e-commerce, online videos, and online reading business, users have to rely on recommender systems to avoid manually browsing tremendous volume of choices. Recommender systems understand users' interest by mining user behavior and other properties of users and products.
...
...
@@ -120,20 +123,285 @@ Figure 3. A hybrid recommendation model.
We use the [MovieLens ml-1m](http://files.grouplens.org/datasets/movielens/ml-1m.zip) to train our model. This dataset includes 10,000 ratings of 4,000 movies from 6,000 users to 4,000 movies. Each rate is in the range of 1~5. Thanks to GroupLens Research for collecting, processing and publishing the dataset.
We don't have to download and preprocess the data. Instead, we can use PaddlePaddle's dataset module `paddle.v2.dataset.movielens`.
`paddle.v2.datasets` package encapsulates multiple public datasets, including `cifar`, `imdb`, `mnist`, `moivelens` and `wmt14`, etc. There's no need for us to manually download and preprocess `MovieLens` dataset.
```python
# Run this block to show dataset's documentation
help(paddle.v2.dataset.movielens)
```
The raw `MoiveLens` contains movie ratings, relevant features from both movies and users.
print "User %s rates Movie %s with Score %s"%(user_info[uid], movie_info[mov_id], train_sample[-1])
```
```text
User <UserInfoid(1),gender(F),age(1),job(10)> rates Movie <MovieInfoid(1193),title(OneFlewOvertheCuckoo'sNest),categories(['Drama'])> with Score [5.0]
```
The output shows that user 1 gave movie `1193` a rating of 5.
After issuing a command `python train.py`, training will start immediately. The details will be unpacked by the following sessions to see how it works.
## Model Architecture
### Initialize PaddlePaddle
First, we must import and initialize PaddlePaddle (enable/disable GPU, set the number of trainers, etc).
As shown in the above code, the input is four dimension integers for each user, that is, `user_id`,`gender_id`, `age_id` and `job_id`. In order to deal with these features conveniently, we use the language model in NLP to transform these discrete values into embedding vaules `usr_emb`, `usr_gender_emb`, `usr_age_emb` and `usr_job_emb`.
Movie title, a sequence of words represented by an integer word index sequence, will be feed into a `sequence_conv_pool` layer, which will apply convolution and pooling on time dimension. Because pooling is done on time dimension, the output will be a fixed-length vector regardless the length of the input sequence.
Finally, we can use cosine similarity to calculate the similarity between user characteristics and movie features.
First, we define the model parameters according to the previous model configuration `cost`.
## Inference
```python
# Create parameters
parameters = paddle.parameters.create(cost)
```
### Create Trainer
Before jumping into creating a training module, algorithm setting is also necessary. Here we specified Adam optimization algorithm via `paddle.optimizer`.
[INFO 2017-03-06 17:12:13,378 networks.py:1472] The input order is [user_id, gender_id, age_id, job_id, movie_id, category_id, movie_title, score]
[INFO 2017-03-06 17:12:13,379 networks.py:1478] The output order is [__regression_cost_0__]
```
### Training
`paddle.dataset.movielens.train` will yield records during each pass, after shuffling, a batch input is generated for training.
```python
reader=paddle.reader.batch(
paddle.reader.shuffle(
paddle.dataset.movielens.trai(), buf_size=8192),
batch_size=256)
```
`feeding` is devoted to specifying the correspondence between each yield record and `paddle.layer.data`. For instance, the first column of data generated by `movielens.train` corresponds to `user_id` feature.
```python
feeding = {
'user_id': 0,
'gender_id': 1,
'age_id': 2,
'job_id': 3,
'movie_id': 4,
'category_id': 5,
'movie_title': 6,
'score': 7
}
```
Callback function `event_handler` will be called during training when a pre-defined event happens.
```python
step=0
train_costs=[],[]
test_costs=[],[]
def event_handler(event):
global step
global train_costs
global test_costs
if isinstance(event, paddle.event.EndIteration):
need_plot = False
if step % 10 == 0: # every 10 batches, record a train cost
train_costs[0].append(step)
train_costs[1].append(event.cost)
if step % 1000 == 0: # every 1000 batches, record a test cost
result = trainer.test(reader=paddle.batch(
paddle.dataset.movielens.test(), batch_size=256))
test_costs[0].append(step)
test_costs[1].append(result.cost)
if step % 100 == 0: # every 100 batches, update cost plot
Finally, we can invoke `trainer.train` to start training:
```python
trainer.train(
reader=reader,
event_handler=event_handler,
feeding=feeding,
num_passes=200)
```
## Conclusion
...
...
@@ -141,16 +409,16 @@ This tutorial goes over traditional approaches in recommender system and a deep
## Reference
1. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
2. Robin Burke ,[Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
1. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
2. Robin Burke ,[Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
3. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
4. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)"*Proceedings of the 10th International Conference on World Wide Web*. ACM, 2001.
4. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)"*Proceedings of the 10th International Conference on World Wide Web*. ACM, 2001.
5. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: Combining Social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf) *arXiv preprint arXiv:1611.05480* (2016).
6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf) *arXiv preprint arXiv:1611.05480* (2016).
7. Covington P, Adams J, Sargin E. [Deep neural networks for youtube recommendations](https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf)[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 191-198.
<br/>
<arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><imgalt="Creative Commons"style="border-width:0"src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png"/></a><br/><spanxmlns:dct="http://purl.org/dc/terms/"href="http://purl.org/dc/dcmitype/Text"property="dct:title"rel="dct:type">This tutorial</span> was created by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">the PaddlePaddle community</a> and published under <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Common Creative 4.0 License</a>。
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
The source codes of this section can be located at [book/understand_sentiment](https://github.com/PaddlePaddle/book/tree/develop/understand_sentiment). First-time users may refer to PaddlePaddle for [Installation guide](http://www.paddlepaddle.org/doc_cn/build_and_install/index.html).
The source codes of this section can be located at [book/understand_sentiment](https://github.com/PaddlePaddle/book/tree/develop/understand_sentiment). First-time users may refer to PaddlePaddle for [Installation guide](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
## Background
## Background Introduction
In natural language processing, sentiment analysis refers to describing emotion status in texts. The texts may refer to a sentence, a paragraph or a document. Emotion status can be a binary classification problem (positive/negative or happy/sad), or a three-class problem (positive/neutral/negative). Sentiment analysis can be applied widely in various situations, such as online shopping (Amazon, Taobao), travel and movie websites. It can be used to grasp from the reviews how the customers feel about the product. Table 1 is an example of sentiment analysis in movie reviews:
| Movie Review | Category |
...
...
@@ -22,10 +23,12 @@ For a piece of text, BOW model ignores its word order, grammar and syntax, and r
In this chapter, we introduce our deep learning model which handles these issues in BOW. Our model embeds texts into a low-dimensional space and takes word order into consideration. It is an end-to-end framework, and has large performance improvement over traditional methods \[[1](#Reference)\].
## Model Overview
The model we used in this chapter is the CNN (Convolutional Neural Networks) and RNN (Recurrent Neural Networks) with some specific extension.
### Convolutional Neural Networks for Texts (CNN)
Convolutional Neural Networks are always applied in data with grid-like topology, such as 2-d images and 1-d texts. CNN can combine extracted multiple local features to produce higher-level abstract semantics. Experimentally, CNN is very efficient for image and text modeling.
CNN mainly contains convolution and pooling operation, with various extensions. We briefly describe CNN here with an example \[[1](#Refernce)\]. As shown in Figure 1:
...
...
@@ -55,7 +58,8 @@ Finally, the CNN features are concatenated together to produce a fixed-length re
For short texts, above CNN model can achieve high accuracy \[[1](#Reference)\]. If we want to extract more abstract representation, we may apply a deeper CNN model \[[2](#Reference),[3](#Reference)\].
### Recurrent Neural Network(RNN)
### Recurrent Neural Network (RNN)
RNN is an effective model for sequential data. Theoretical, the computational ability of RNN is Turing-complete \[[4](#Reference)\]. NLP is a classical sequential data, and RNN (especially its variant LSTM\[[5](#Reference)\]) achieves State-of-the-Art performance on various tasks in NLP, such as language modeling, syntax parsing, POS-tagging, image captioning, dialog, machine translation and so forth.
<palign="center">
...
...
@@ -70,8 +74,9 @@ where $W_{xh}$ is the weight matrix from input to latent; $W_{hh}$ is the latent
In NLP, words are first represented as a one-hot vector and then mapped to an embedding. The embedded feature goes through an RNN as input $x_t$ at every time step. Moreover, we can add other layers on top of RNN. e.g., a deep or stacked RNN. Also, the last latent state can be used as a feature for sentence classification.
### Long-Short Term Memory
For data of long sequence, training RNN sometimes has gradient vanishing and explosion problem \[[6](#)\]. To solve this problem Hochreiter S, Schmidhuber J. (1997) proposed the LSTM(long short term memory\[[5](#Refernce)\]).
### Long-Short Term Memory (LSTM)
For data of long sequence, training RNN sometimes has gradient vanishing and explosion problem \[[6](#)\]. To solve this problem Hochreiter S, Schmidhuber J. (1997) proposed the LSTM(long short term memory\[[5](#Reference)\]).
Compared with simple RNN, the structrue of LSTM has included memory cell $c$, input gate $i$, forget gate $f$ and output gate $o$. These gates and memory cells largely improves the ability of handling long sequences. We can formulate LSTM-RNN as a function $F$ as:
For vanilla LSTM, $h_t$ contains input information from previous time-step $1..t-1$ context. We can also apply an RNN with reverse-direction to take successive context $t+1…n$ into consideration. Combining constructing deep RNN (deeper RNN can contain more abstract and higher level semantic), we can design structures with deep stacked bidirectional LSTM to model sequential data\[[9](#Reference)\].
As shown in Figure 4 (3-layer RNN), odd/even layers are forward/reverse LSTM. Higher layers of LSTM take lower-layers LSTM as input, and the top-layer LSTM produces a fixed length vector by max-pooling (this representation considers contexts from previous and successive words for higher-level abstractions). Finally, we concatenate the output to a softmax layer for classification.
...
...
@@ -108,377 +114,247 @@ As shown in Figure 4 (3-layer RNN), odd/even layers are forward/reverse LSTM. Hi
Figure 4. Stacked Bidirectional LSTM for NLP modeling.
</p>
## Data Preparation
### Data introduction and Download
We taks the [IMDB sentiment analysis dataset](http://ai.stanford.edu/%7Eamaas/data/sentiment/) as an example. IMDB dataset contains training and testing set, with 25000 movie reviews. With a 1-10 score, negative reviews are those with score<=4,whilepositivesarethosewithscore>=7. You may use following scripts to download the IMDB dataset and [Moses](http://www.statmt.org/moses/) toolbox:
## Dataset
We use [IMDB](http://ai.stanford.edu/%7Eamaas/data/sentiment/) dataset for sentiment analysis in this tutorial, which consists of 50,000 movie reviews split evenly into 25k train and 25k test sets. In the labeled train/test sets, a negative review has a score <=4outof10,andapositivereviewhasascore>= 7 out of 10.
```bash
./data/get_imdb.sh
```
If successful, you should see the directory ```data``` with following files:
`paddle.datasets` package encapsulates multiple public datasets, including `cifar`, `imdb`, `mnist`, `moivelens`, and `wmt14`, etc. There's no need for us to manually download and preprocess IMDB.
```
aclImdb get_imdb.sh imdb mosesdecoder-master
```
After issuing a command `python train.py`, training will start immediately. The details will be unpacked by the following sessions to see how it works.
* aclImdb: original data downloaded from the website;
* imdb: containing only training and testing data
* mosesdecoder-master: Moses tool
### Data Preprocessing
We use the script `preprocess.py` to preprocess the data. It will call `tokenizer.perl` in the Moses toolbox to split words and punctuations, randomly shuffle training set and construct the dictionary. Notice: we only use labeled training and testing set. Executing following commands will preprocess the data:
## Model Structure
```
data_dir="./data/imdb"
python preprocess.py -i $data_dir
```
### Initialize PaddlePaddle
If it runs successfully, `./data/pre-imdb` will contain:
We must import and initialize PaddlePaddle (enable/disable GPU, set the number of trainers, etc).
* test\_part\_000 和 train\_part\_000: all labeled training and testing set, and the training set is shuffled.
* train.list and test.list: training and testing file-list (containing list of file names).
* dict.txt: dictionary generated from training set.
* labels.list: class label, 0 stands for negative while 1 for positive.
As alluded to in section [Model Overview](#model-overview), here we provide the implementations of both Text CNN and Stacked-bidirectional LSTM models.
### Data Provider for PaddlePaddle
PaddlePaddle can read Python-style script for configuration. The following `dataprovider.py` provides a detailed example, consisting of two parts:
### Text Convolution Neural Network (Text CNN)
* hook: define text information and class Id. Texts are defined as `integer_value_sequence` while class Ids are defined as `integer_value`.
* process: read line by line for ID and text information split by `’\t\t’`, and yield the data as a generator.
We create a neural network `convolution_net` as the following snippet code.
Parameter `input_dim` denotes the dictionary size, and `class_dim` is the number of categories. In `convolution_net`, the input to the network is defined in `paddle.layer.data`.
* Batch size set as 128;
* Set global learning rate;
* Apply ADAM algorithm for optimization;
* Set up L2 regularization;
* Set up gradient clipping threshold;
1. Define Classifier
### Model Structure
We use PaddlePaddle to implement two classification algorithms, based on above mentioned model [Text-CNN](#Text-CNN(CNN))和[Stacked-bidirectional LSTM](#Stacked-bidirectional LSTM(Stacked Bidirectional LSTM))。
#### Implementation of Text CNN
```python
defconvolution_net(input_dim,
class_dim=2,
emb_dim=128,
hid_dim=128,
is_predict=False):
# network input: id denotes word order, dictionary size as input_dim
data=data_layer("word",input_dim)
# Embed one-hot id to embedding subspace
emb=embedding_layer(input=data,size=emb_dim)
# Convolution and max-pooling operation, convolution kernel size set as 3
The above Text CNN network extracts high-level features and maps them to a vector of the same size as the categories. `paddle.activation.Softmax` function or classifier is then used for calculating the probability of the sentence belonging to each category.
1. Define Loss Function
In the context of supervised learning, labels of the training set are defined in `paddle.layer.data`, too. During training, cross-entropy is used as loss function in `paddle.layer.classification_cost` and as the output of the network; During testing, the outputs are the probabilities calculated in the classifier.
In our implementation, we can use just a single layer [`sequence_conv_pool`](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/trainer_config_helpers/networks.py) to do convolution and pooling operation, convolution kernel size set as hidden_size parameters.
#### Stacked bidirectional LSTM
#### Implementation of Stacked bidirectional LSTM
We create a neural network `stacked_lstm_net` as below.
```python
defstacked_lstm_net(input_dim,
class_dim=2,
emb_dim=128,
hid_dim=512,
stacked_num=3,
is_predict=False):
# layer number of LSTM “stacked_num” is an odd number to confirm the top-layer LSTM is forward
Our model defined in `trainer_config.py` uses the `stacked_lstm_net` structure as default. If you want to use `convolution_net`, you can comment related lines.
1. Define input data and its dimension
Parameter `input_dim` denotes the dictionary size, and `class_dim` is the number of categories. In `stacked_lstm_net`, the input to the network is defined in `paddle.layer.data`.
1. Define Classifier
The above stacked bidirectional LSTM network extracts high-level features and maps them to a vector of the same size as the categories. `paddle.activation.Softmax` function or classifier is then used for calculating the probability of the sentence belonging to each category.
1. Define Loss Function
In the context of supervised learning, labels of the training set are defined in `paddle.layer.data`, too. During training, cross-entropy is used as loss function in `paddle.layer.classification_cost` and as the output of the network; During testing, the outputs are the probabilities calculated in the classifier.
To reiterate, we can either invoke `convolution_net` or `stacked_lstm_net`.
First, we create the model parameters according to the previous model configuration `cost`.
```python
# create parameters
parameters=paddle.parameters.create(cost)
```
*\--config=trainer_config.py: set up model configuration.
*\--save\_dir=./model_output: set up output folder to save model parameters.
*\--job=train: set job mode as training.
*\--use\_gpu=false: Use CPU for training. If you have installed GPU-version PaddlePaddle and want to try GPU training, you may set this term as true.
*\--trainer\_count=4: setup thread number (or GPU numer).
*\--num\_passes=15: Setup pass. In PaddlePaddle, a pass means a training epoch over all samples.
*\--log\_period=20: print log every 20 batches.
*\--show\_parameter\_stats\_period=100: Print statistics to screen every 100 batch.
*\--test\_all_data\_in\_one\_period=1: Predict all testing data every time.
### Create Trainer
If it is running sussefully, the output log will be saved at `train.log`, model parameters will be saved at the directory `model_output/`. Output log will be as following:
Before jumping into creating a training module, algorithm setting is also necessary.
Here we specified `Adam` optimization algorithm via `paddle.optimizer`.
`feeding` is devoted to specifying the correspondence between each yield record and `paddle.layer.data`. For instance, the first column of data generated by `paddle.dataset.imdb.train()` corresponds to `word` feature.
```python
feeding={'word':0,'label':1}
```
Different from training, testing requires denoting `--job = test` and model path `--model_list = $model_list`. If successful, log will be saved at `test.log`. In our test, the best model is `model_output/pass-00002`, with classification error rate as 0.115645:
Callback function `event_handler` will be invoked to track training progress when a pre-defined event happens.
*`--label=$label` : set up the label dictionary, mapping integer IDs to string labels.
*`--dict=data/pre-imdb/dict.txt` : set up the dictionary file.
*`--batch_size=1` : batch size during prediction.
Prediction result of our example:
## Conclusion
```
Loading parameters from model_output/pass-00002/
predicting label is pos
```
In this chapter, we use sentiment analysis as an example to introduce applying deep learning models on end-to-end short text classification, as well as how to use PaddlePaddle to implement the model. Meanwhile, we briefly introduce two models for text processing: CNN and RNN. In following chapters, we will see how these models can be applied in other tasks.
`10007_10.txt` in folder`./data/aclImdb/test/pos`, the predicted label is also pos,so the prediction is correct.
## Summary
In this chapter, we use sentiment analysis as an example to introduce applying deep learning models on end-to-end short text classification, as well as how to use PaddlePaddle to implement the model. Meanwhile, we briefly introduce two models for text processing: CNN and RNN. In following chapters we will see how these models can be applied in other tasks.
## Reference
1. Kim Y. [Convolutional neural networks for sentence classification](http://arxiv.org/pdf/1408.5882)[J]. arXiv preprint arXiv:1408.5882, 2014.
2. Kalchbrenner N, Grefenstette E, Blunsom P. [A convolutional neural network for modelling sentences](http://arxiv.org/pdf/1404.2188.pdf?utm_medium=App.net&utm_source=PourOver)[J]. arXiv preprint arXiv:1404.2188, 2014.
3. Yann N. Dauphin, et al. [Language Modeling with Gated Convolutional Networks](https://arxiv.org/pdf/1612.08083v1.pdf)[J] arXiv preprint arXiv:1612.08083, 2016.
...
...
@@ -490,4 +366,4 @@ In this chapter, we use sentiment analysis as an example to introduce applying d
9. Zhou J, Xu W. [End-to-end learning of semantic role labeling using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
The source codes of this section can be located at [book/understand_sentiment](https://github.com/PaddlePaddle/book/tree/develop/understand_sentiment). First-time users may refer to PaddlePaddle for [Installation guide](http://www.paddlepaddle.org/doc_cn/build_and_install/index.html).
The source codes of this section can be located at [book/understand_sentiment](https://github.com/PaddlePaddle/book/tree/develop/understand_sentiment). First-time users may refer to PaddlePaddle for [Installation guide](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
## Background
## Background Introduction
In natural language processing, sentiment analysis refers to describing emotion status in texts. The texts may refer to a sentence, a paragraph or a document. Emotion status can be a binary classification problem (positive/negative or happy/sad), or a three-class problem (positive/neutral/negative). Sentiment analysis can be applied widely in various situations, such as online shopping (Amazon, Taobao), travel and movie websites. It can be used to grasp from the reviews how the customers feel about the product. Table 1 is an example of sentiment analysis in movie reviews:
| Movie Review | Category |
...
...
@@ -64,10 +65,12 @@ For a piece of text, BOW model ignores its word order, grammar and syntax, and r
In this chapter, we introduce our deep learning model which handles these issues in BOW. Our model embeds texts into a low-dimensional space and takes word order into consideration. It is an end-to-end framework, and has large performance improvement over traditional methods \[[1](#Reference)\].
## Model Overview
The model we used in this chapter is the CNN (Convolutional Neural Networks) and RNN (Recurrent Neural Networks) with some specific extension.
### Convolutional Neural Networks for Texts (CNN)
Convolutional Neural Networks are always applied in data with grid-like topology, such as 2-d images and 1-d texts. CNN can combine extracted multiple local features to produce higher-level abstract semantics. Experimentally, CNN is very efficient for image and text modeling.
CNN mainly contains convolution and pooling operation, with various extensions. We briefly describe CNN here with an example \[[1](#Refernce)\]. As shown in Figure 1:
...
...
@@ -97,7 +100,8 @@ Finally, the CNN features are concatenated together to produce a fixed-length re
For short texts, above CNN model can achieve high accuracy \[[1](#Reference)\]. If we want to extract more abstract representation, we may apply a deeper CNN model \[[2](#Reference),[3](#Reference)\].
### Recurrent Neural Network(RNN)
### Recurrent Neural Network (RNN)
RNN is an effective model for sequential data. Theoretical, the computational ability of RNN is Turing-complete \[[4](#Reference)\]. NLP is a classical sequential data, and RNN (especially its variant LSTM\[[5](#Reference)\]) achieves State-of-the-Art performance on various tasks in NLP, such as language modeling, syntax parsing, POS-tagging, image captioning, dialog, machine translation and so forth.
<palign="center">
...
...
@@ -112,8 +116,9 @@ where $W_{xh}$ is the weight matrix from input to latent; $W_{hh}$ is the latent
In NLP, words are first represented as a one-hot vector and then mapped to an embedding. The embedded feature goes through an RNN as input $x_t$ at every time step. Moreover, we can add other layers on top of RNN. e.g., a deep or stacked RNN. Also, the last latent state can be used as a feature for sentence classification.
### Long-Short Term Memory
For data of long sequence, training RNN sometimes has gradient vanishing and explosion problem \[[6](#)\]. To solve this problem Hochreiter S, Schmidhuber J. (1997) proposed the LSTM(long short term memory\[[5](#Refernce)\]).
### Long-Short Term Memory (LSTM)
For data of long sequence, training RNN sometimes has gradient vanishing and explosion problem \[[6](#)\]. To solve this problem Hochreiter S, Schmidhuber J. (1997) proposed the LSTM(long short term memory\[[5](#Reference)\]).
Compared with simple RNN, the structrue of LSTM has included memory cell $c$, input gate $i$, forget gate $f$ and output gate $o$. These gates and memory cells largely improves the ability of handling long sequences. We can formulate LSTM-RNN as a function $F$ as:
For vanilla LSTM, $h_t$ contains input information from previous time-step $1..t-1$ context. We can also apply an RNN with reverse-direction to take successive context $t+1…n$ into consideration. Combining constructing deep RNN (deeper RNN can contain more abstract and higher level semantic), we can design structures with deep stacked bidirectional LSTM to model sequential data\[[9](#Reference)\].
As shown in Figure 4 (3-layer RNN), odd/even layers are forward/reverse LSTM. Higher layers of LSTM take lower-layers LSTM as input, and the top-layer LSTM produces a fixed length vector by max-pooling (this representation considers contexts from previous and successive words for higher-level abstractions). Finally, we concatenate the output to a softmax layer for classification.
...
...
@@ -150,377 +156,247 @@ As shown in Figure 4 (3-layer RNN), odd/even layers are forward/reverse LSTM. Hi
Figure 4. Stacked Bidirectional LSTM for NLP modeling.
</p>
## Data Preparation
### Data introduction and Download
We taks the [IMDB sentiment analysis dataset](http://ai.stanford.edu/%7Eamaas/data/sentiment/) as an example. IMDB dataset contains training and testing set, with 25000 movie reviews. With a 1-10 score, negative reviews are those with score<=4,whilepositivesarethosewithscore>=7. You may use following scripts to download the IMDB dataset and [Moses](http://www.statmt.org/moses/) toolbox:
## Dataset
We use [IMDB](http://ai.stanford.edu/%7Eamaas/data/sentiment/) dataset for sentiment analysis in this tutorial, which consists of 50,000 movie reviews split evenly into 25k train and 25k test sets. In the labeled train/test sets, a negative review has a score <=4outof10,andapositivereviewhasascore>= 7 out of 10.
```bash
./data/get_imdb.sh
```
If successful, you should see the directory ```data``` with following files:
`paddle.datasets` package encapsulates multiple public datasets, including `cifar`, `imdb`, `mnist`, `moivelens`, and `wmt14`, etc. There's no need for us to manually download and preprocess IMDB.
```
aclImdb get_imdb.sh imdb mosesdecoder-master
```
After issuing a command `python train.py`, training will start immediately. The details will be unpacked by the following sessions to see how it works.
* aclImdb: original data downloaded from the website;
* imdb: containing only training and testing data
* mosesdecoder-master: Moses tool
### Data Preprocessing
We use the script `preprocess.py` to preprocess the data. It will call `tokenizer.perl` in the Moses toolbox to split words and punctuations, randomly shuffle training set and construct the dictionary. Notice: we only use labeled training and testing set. Executing following commands will preprocess the data:
## Model Structure
```
data_dir="./data/imdb"
python preprocess.py -i $data_dir
```
### Initialize PaddlePaddle
If it runs successfully, `./data/pre-imdb` will contain:
We must import and initialize PaddlePaddle (enable/disable GPU, set the number of trainers, etc).
* test\_part\_000 和 train\_part\_000: all labeled training and testing set, and the training set is shuffled.
* train.list and test.list: training and testing file-list (containing list of file names).
* dict.txt: dictionary generated from training set.
* labels.list: class label, 0 stands for negative while 1 for positive.
# PaddlePaddle init
paddle.init(use_gpu=False, trainer_count=1)
```
### Data Provider for PaddlePaddle
PaddlePaddle can read Python-style script for configuration. The following `dataprovider.py` provides a detailed example, consisting of two parts:
As alluded to in section [Model Overview](#model-overview), here we provide the implementations of both Text CNN and Stacked-bidirectional LSTM models.
* hook: define text information and class Id. Texts are defined as `integer_value_sequence` while class Ids are defined as `integer_value`.
* process: read line by line for ID and text information split by `’\t\t’`, and yield the data as a generator.
### Text Convolution Neural Network (Text CNN)
```python
from paddle.trainer.PyDataProvider2 import *
We create a neural network `convolution_net` as the following snippet code.
Parameter `input_dim` denotes the dictionary size, and `class_dim` is the number of categories. In `convolution_net`, the input to the network is defined in `paddle.layer.data`.
* Batch size set as 128;
* Set global learning rate;
* Apply ADAM algorithm for optimization;
* Set up L2 regularization;
* Set up gradient clipping threshold;
1. Define Classifier
### Model Structure
We use PaddlePaddle to implement two classification algorithms, based on above mentioned model [Text-CNN](#Text-CNN(CNN))和[Stacked-bidirectional LSTM](#Stacked-bidirectional LSTM(Stacked Bidirectional LSTM))。
#### Implementation of Text CNN
```python
def convolution_net(input_dim,
class_dim=2,
emb_dim=128,
hid_dim=128,
is_predict=False):
# network input: id denotes word order, dictionary size as input_dim
data = data_layer("word", input_dim)
# Embed one-hot id to embedding subspace
emb = embedding_layer(input=data, size=emb_dim)
# Convolution and max-pooling operation, convolution kernel size set as 3
The above Text CNN network extracts high-level features and maps them to a vector of the same size as the categories. `paddle.activation.Softmax` function or classifier is then used for calculating the probability of the sentence belonging to each category.
1. Define Loss Function
In our implementation, we can use just a single layer [`sequence_conv_pool`](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/trainer_config_helpers/networks.py) to do convolution and pooling operation, convolution kernel size set as hidden_size parameters.
In the context of supervised learning, labels of the training set are defined in `paddle.layer.data`, too. During training, cross-entropy is used as loss function in `paddle.layer.classification_cost` and as the output of the network; During testing, the outputs are the probabilities calculated in the classifier.
#### Implementation of Stacked bidirectional LSTM
#### Stacked bidirectional LSTM
We create a neural network `stacked_lstm_net` as below.
```python
def stacked_lstm_net(input_dim,
class_dim=2,
emb_dim=128,
hid_dim=512,
stacked_num=3,
is_predict=False):
# layer number of LSTM “stacked_num” is an odd number to confirm the top-layer LSTM is forward
Our model defined in `trainer_config.py` uses the `stacked_lstm_net` structure as default. If you want to use `convolution_net`, you can comment related lines.
1. Define input data and its dimension
Parameter `input_dim` denotes the dictionary size, and `class_dim` is the number of categories. In `stacked_lstm_net`, the input to the network is defined in `paddle.layer.data`.
1. Define Classifier
The above stacked bidirectional LSTM network extracts high-level features and maps them to a vector of the same size as the categories. `paddle.activation.Softmax` function or classifier is then used for calculating the probability of the sentence belonging to each category.
1. Define Loss Function
In the context of supervised learning, labels of the training set are defined in `paddle.layer.data`, too. During training, cross-entropy is used as loss function in `paddle.layer.classification_cost` and as the output of the network; During testing, the outputs are the probabilities calculated in the classifier.
To reiterate, we can either invoke `convolution_net` or `stacked_lstm_net`.
First, we create the model parameters according to the previous model configuration `cost`.
```python
# create parameters
parameters = paddle.parameters.create(cost)
```
* \--config=trainer_config.py: set up model configuration.
* \--save\_dir=./model_output: set up output folder to save model parameters.
* \--job=train: set job mode as training.
* \--use\_gpu=false: Use CPU for training. If you have installed GPU-version PaddlePaddle and want to try GPU training, you may set this term as true.
* \--trainer\_count=4: setup thread number (or GPU numer).
* \--num\_passes=15: Setup pass. In PaddlePaddle, a pass means a training epoch over all samples.
* \--log\_period=20: print log every 20 batches.
* \--show\_parameter\_stats\_period=100: Print statistics to screen every 100 batch.
* \--test\_all_data\_in\_one\_period=1: Predict all testing data every time.
### Create Trainer
If it is running sussefully, the output log will be saved at `train.log`, model parameters will be saved at the directory `model_output/`. Output log will be as following:
Before jumping into creating a training module, algorithm setting is also necessary.
Here we specified `Adam` optimization algorithm via `paddle.optimizer`.
Scripts for testing `test.sh` is as following, where the function `get_best_pass` ranks classification accuracy to obtain the best model:
```bash
function get_best_pass() {
cat $1 | grep -Pzo 'Test .*\n.*pass-.*' | \
sed -r 'N;s/Test.* error=([0-9]+\.[0-9]+).*\n.*pass-([0-9]+)/\1 \2/g' | \
sort | head -n 1
}
`feeding` is devoted to specifying the correspondence between each yield record and `paddle.layer.data`. For instance, the first column of data generated by `paddle.dataset.imdb.train()` corresponds to `word` feature.
Different from training, testing requires denoting `--job = test` and model path `--model_list = $model_list`. If successful, log will be saved at `test.log`. In our test, the best model is `model_output/pass-00002`, with classification error rate as 0.115645:
Callback function `event_handler` will be invoked to track training progress when a pre-defined event happens.
* `--label=$label` : set up the label dictionary, mapping integer IDs to string labels.
* `--dict=data/pre-imdb/dict.txt` : set up the dictionary file.
* `--batch_size=1` : batch size during prediction.
Prediction result of our example:
## Conclusion
```
Loading parameters from model_output/pass-00002/
predicting label is pos
```
In this chapter, we use sentiment analysis as an example to introduce applying deep learning models on end-to-end short text classification, as well as how to use PaddlePaddle to implement the model. Meanwhile, we briefly introduce two models for text processing: CNN and RNN. In following chapters, we will see how these models can be applied in other tasks.
`10007_10.txt` in folder`./data/aclImdb/test/pos`, the predicted label is also pos,so the prediction is correct.
## Summary
In this chapter, we use sentiment analysis as an example to introduce applying deep learning models on end-to-end short text classification, as well as how to use PaddlePaddle to implement the model. Meanwhile, we briefly introduce two models for text processing: CNN and RNN. In following chapters we will see how these models can be applied in other tasks.
## Reference
1. Kim Y. [Convolutional neural networks for sentence classification](http://arxiv.org/pdf/1408.5882)[J]. arXiv preprint arXiv:1408.5882, 2014.
2. Kalchbrenner N, Grefenstette E, Blunsom P. [A convolutional neural network for modelling sentences](http://arxiv.org/pdf/1404.2188.pdf?utm_medium=App.net&utm_source=PourOver)[J]. arXiv preprint arXiv:1404.2188, 2014.
3. Yann N. Dauphin, et al. [Language Modeling with Gated Convolutional Networks](https://arxiv.org/pdf/1612.08083v1.pdf)[J] arXiv preprint arXiv:1612.08083, 2016.
...
...
@@ -532,7 +408,7 @@ In this chapter, we use sentiment analysis as an example to introduce applying d
9. Zhou J, Xu W. [End-to-end learning of semantic role labeling using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
This is intended as a reference tutorial. The source code of this tutorial lives on [book/word2vec](https://github.com/PaddlePaddle/book/tree/develop/word2vec).
For instructions on getting started with PaddlePaddle, see [PaddlePaddle installation guide](http://www.paddlepaddle.org/doc_cn/build_and_install/index.html).
For instructions on getting started with PaddlePaddle, see [PaddlePaddle installation guide](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
## Background Introduction
...
...
@@ -149,19 +149,257 @@ The advantages of CBOW is that it smooths over the word embeddings of the contex
As illustrated in the figure above, skip-gram model maps the word embedding of the given word onto $2n$ word embeddings (including $n$ words before and $n$ words after the given word), and then combine the classification loss of all those $2n$ words by softmax.
## Data Preparation
## Dataset
We will use Peen Treebank (PTB) (Tomas Mikolov's pre-processed version) dataset. PTB is a small dataset, used in Recurrent Neural Network Language Modeling Toolkit\[[2](#reference)\]. Its statistics are as follows:
<palign="center">
<table>
<tr>
<td>training set</td>
<td>validation set</td>
<td>test set</td>
</tr>
<tr>
<td>ptb.train.txt</td>
<td>ptb.valid.txt</td>
<td>ptb.test.txt</td>
</tr>
<tr>
<td>42068 lines</td>
<td>3370 lines</td>
<td>3761 lines</td>
</tr>
</table>
</p>
### Python Dataset Module
We encapsulated the PTB Data Set in our Python module `paddle.dataset.imikolov`. This module can
1. download the dataset to `~/.cache/paddle/dataset/imikolov`, if not yet, and
2.[preprocesses](#preprocessing) the dataset.
### Preprocessing
We will be training a 5-gram model. Given five words in a window, we will predict the fifth word given the first four words.
Beginning and end of a sentence have a special meaning, so we will add begin token `<s>` in the front of the sentence. And end token `<e>` in the end of the sentence. By moving the five word window in the sentence, data instances are generated.
For example, the sentence "I have a dream that one day" generates five data instances:
```text
<s> I have a dream
I have a dream that
have a dream that one
a dream that one day
dream that one day <e>
```
At last, each data instance will be converted into an integer sequence according it's words' index inside the dictionary.
## Training
The neural network that we will be using is illustrated in the graph below:
## Model Configuration
<palign="center">
<imgsrc="image/ngram.en.png"width=400><br/>
Figure 5. N-gram neural network model in model configuration
</p>
`word2vec/train.py` demonstrates training word2vec using PaddlePaddle:
- Import packages.
```python
importmath
importpaddle.v2aspaddle
```
- Configure parameter.
```python
embsize=32# word vector dimension
hiddensize=256# hidden layer dimension
N=5# train 5-gram
```
- Map the $n-1$ words $w_{t-n+1},...w_{t-1}$ before $w_t$ to a D-dimensional vector though matrix of dimention $|V|\times D$ (D=32 in this example).
```python
defwordemb(inlayer):
wordemb=paddle.layer.table_projection(
input=inlayer,
size=embsize,
param_attr=paddle.attr.Param(
name="_proj",
initial_std=0.001,
learning_rate=1,
l2_rate=0,))
returnwordemb
```
- Define name and type for input to data layer.
```python
paddle.init(use_gpu=False,trainer_count=3)
word_dict=paddle.dataset.imikolov.build_dict()
dict_size=len(word_dict)
# Every layer takes integer value of range [0, dict_size)
- Feature vector will go through a fully connected layer which outputs a hidden feature vector.
```python
hidden1=paddle.layer.fc(input=contextemb,
size=hiddensize,
act=paddle.activation.Sigmoid(),
layer_attr=paddle.attr.Extra(drop_rate=0.5),
bias_attr=paddle.attr.Param(learning_rate=2),
param_attr=paddle.attr.Param(
initial_std=1./math.sqrt(embsize*8),
learning_rate=1))
```
- Hidden feature vector will go through another fully conected layer, turn into a $|V|$ dimensional vector. At the same time softmax will be applied to get the probability of each word being generated.
Next, we will begin the training process. `paddle.dataset.imikolov.train()` and `paddle.dataset.imikolov.test()` is our training set and test set. Both of the function will return a **reader**: In PaddlePaddle, reader is a python function which returns a Python iterator which output a single data instance at a time.
`paddle.batch` takes reader as input, outputs a **batched reader**: In PaddlePaddle, a reader outputs a single data instance at a time but batched reader outputs a minibatch of data instances.
Word vectors (`embeddings`) that we get is a numpy array. We can modify this array and set it back to `parameters`.
```python
defmodify_embedding(emb):
# Add your modification here.
pass
modify_embedding(embeddings)
parameters.set("_proj",embeddings)
```
### Calculating Cosine Similarity
Cosine similarity is one way of quantifying the similarity between two vectors. The range of result is $[-1, 1]$. The bigger the value, the similar two vectors are:
```python
fromscipyimportspatial
emb_1=embeddings[word_dict['world']]
emb_2=embeddings[word_dict['would']]
printspatial.distance.cosine(emb_1,emb_2)
```
```text
0.99375076448
```
## Conclusion
This chapter introduces word embedding, the relationship between language model and word embedding, and how to train neural networks to learn word embedding.
...
...
@@ -177,4 +415,4 @@ In information retrieval, the relevance between the query and document keyword c
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
This is intended as a reference tutorial. The source code of this tutorial lives on [book/word2vec](https://github.com/PaddlePaddle/book/tree/develop/word2vec).
For instructions on getting started with PaddlePaddle, see [PaddlePaddle installation guide](http://www.paddlepaddle.org/doc_cn/build_and_install/index.html).
For instructions on getting started with PaddlePaddle, see [PaddlePaddle installation guide](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
## Background Introduction
...
...
@@ -191,19 +191,257 @@ The advantages of CBOW is that it smooths over the word embeddings of the contex
As illustrated in the figure above, skip-gram model maps the word embedding of the given word onto $2n$ word embeddings (including $n$ words before and $n$ words after the given word), and then combine the classification loss of all those $2n$ words by softmax.
## Data Preparation
## Dataset
We will use Peen Treebank (PTB) (Tomas Mikolov's pre-processed version) dataset. PTB is a small dataset, used in Recurrent Neural Network Language Modeling Toolkit\[[2](#reference)\]. Its statistics are as follows:
<palign="center">
<table>
<tr>
<td>training set</td>
<td>validation set</td>
<td>test set</td>
</tr>
<tr>
<td>ptb.train.txt</td>
<td>ptb.valid.txt</td>
<td>ptb.test.txt</td>
</tr>
<tr>
<td>42068 lines</td>
<td>3370 lines</td>
<td>3761 lines</td>
</tr>
</table>
</p>
### Python Dataset Module
We encapsulated the PTB Data Set in our Python module `paddle.dataset.imikolov`. This module can
1. download the dataset to `~/.cache/paddle/dataset/imikolov`, if not yet, and
2. [preprocesses](#preprocessing) the dataset.
### Preprocessing
We will be training a 5-gram model. Given five words in a window, we will predict the fifth word given the first four words.
Beginning and end of a sentence have a special meaning, so we will add begin token `<s>` in the front of the sentence. And end token `<e>` in the end of the sentence. By moving the five word window in the sentence, data instances are generated.
For example, the sentence "I have a dream that one day" generates five data instances:
```text
<s> I have a dream
I have a dream that
have a dream that one
a dream that one day
dream that one day <e>
```
At last, each data instance will be converted into an integer sequence according it's words' index inside the dictionary.
## Training
The neural network that we will be using is illustrated in the graph below:
## Model Configuration
<palign="center">
<imgsrc="image/ngram.en.png"width=400><br/>
Figure 5. N-gram neural network model in model configuration
</p>
`word2vec/train.py` demonstrates training word2vec using PaddlePaddle:
- Import packages.
```python
import math
import paddle.v2 as paddle
```
- Configure parameter.
```python
embsize = 32 # word vector dimension
hiddensize = 256 # hidden layer dimension
N = 5 # train 5-gram
```
- Map the $n-1$ words $w_{t-n+1},...w_{t-1}$ before $w_t$ to a D-dimensional vector though matrix of dimention $|V|\times D$ (D=32 in this example).
```python
def wordemb(inlayer):
wordemb = paddle.layer.table_projection(
input=inlayer,
size=embsize,
param_attr=paddle.attr.Param(
name="_proj",
initial_std=0.001,
learning_rate=1,
l2_rate=0, ))
return wordemb
```
- Define name and type for input to data layer.
```python
paddle.init(use_gpu=False, trainer_count=3)
word_dict = paddle.dataset.imikolov.build_dict()
dict_size = len(word_dict)
# Every layer takes integer value of range [0, dict_size)
- Feature vector will go through a fully connected layer which outputs a hidden feature vector.
```python
hidden1 = paddle.layer.fc(input=contextemb,
size=hiddensize,
act=paddle.activation.Sigmoid(),
layer_attr=paddle.attr.Extra(drop_rate=0.5),
bias_attr=paddle.attr.Param(learning_rate=2),
param_attr=paddle.attr.Param(
initial_std=1. / math.sqrt(embsize * 8),
learning_rate=1))
```
- Hidden feature vector will go through another fully conected layer, turn into a $|V|$ dimensional vector. At the same time softmax will be applied to get the probability of each word being generated.
Next, we will begin the training process. `paddle.dataset.imikolov.train()` and `paddle.dataset.imikolov.test()` is our training set and test set. Both of the function will return a **reader**: In PaddlePaddle, reader is a python function which returns a Python iterator which output a single data instance at a time.
`paddle.batch` takes reader as input, outputs a **batched reader**: In PaddlePaddle, a reader outputs a single data instance at a time but batched reader outputs a minibatch of data instances.
Word vectors (`embeddings`) that we get is a numpy array. We can modify this array and set it back to `parameters`.
```python
def modify_embedding(emb):
# Add your modification here.
pass
modify_embedding(embeddings)
parameters.set("_proj", embeddings)
```
### Calculating Cosine Similarity
Cosine similarity is one way of quantifying the similarity between two vectors. The range of result is $[-1, 1]$. The bigger the value, the similar two vectors are:
```python
from scipy import spatial
emb_1 = embeddings[word_dict['world']]
emb_2 = embeddings[word_dict['would']]
print spatial.distance.cosine(emb_1, emb_2)
```
```text
0.99375076448
```
## Conclusion
This chapter introduces word embedding, the relationship between language model and word embedding, and how to train neural networks to learn word embedding.
...
...
@@ -219,7 +457,7 @@ In information retrieval, the relevance between the query and document keyword c
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.
{kind=link}
{kind=link}
{kind=link}
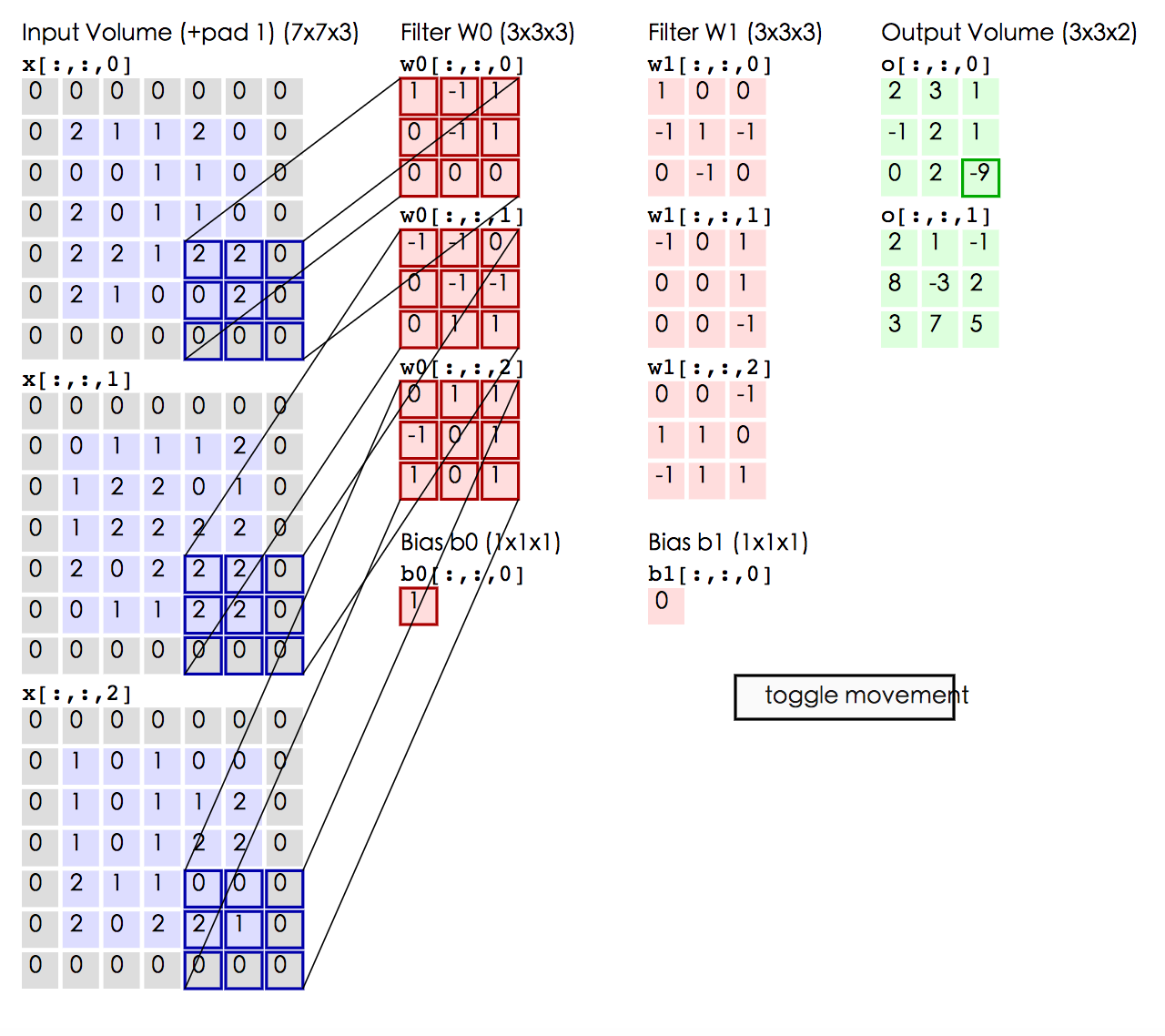
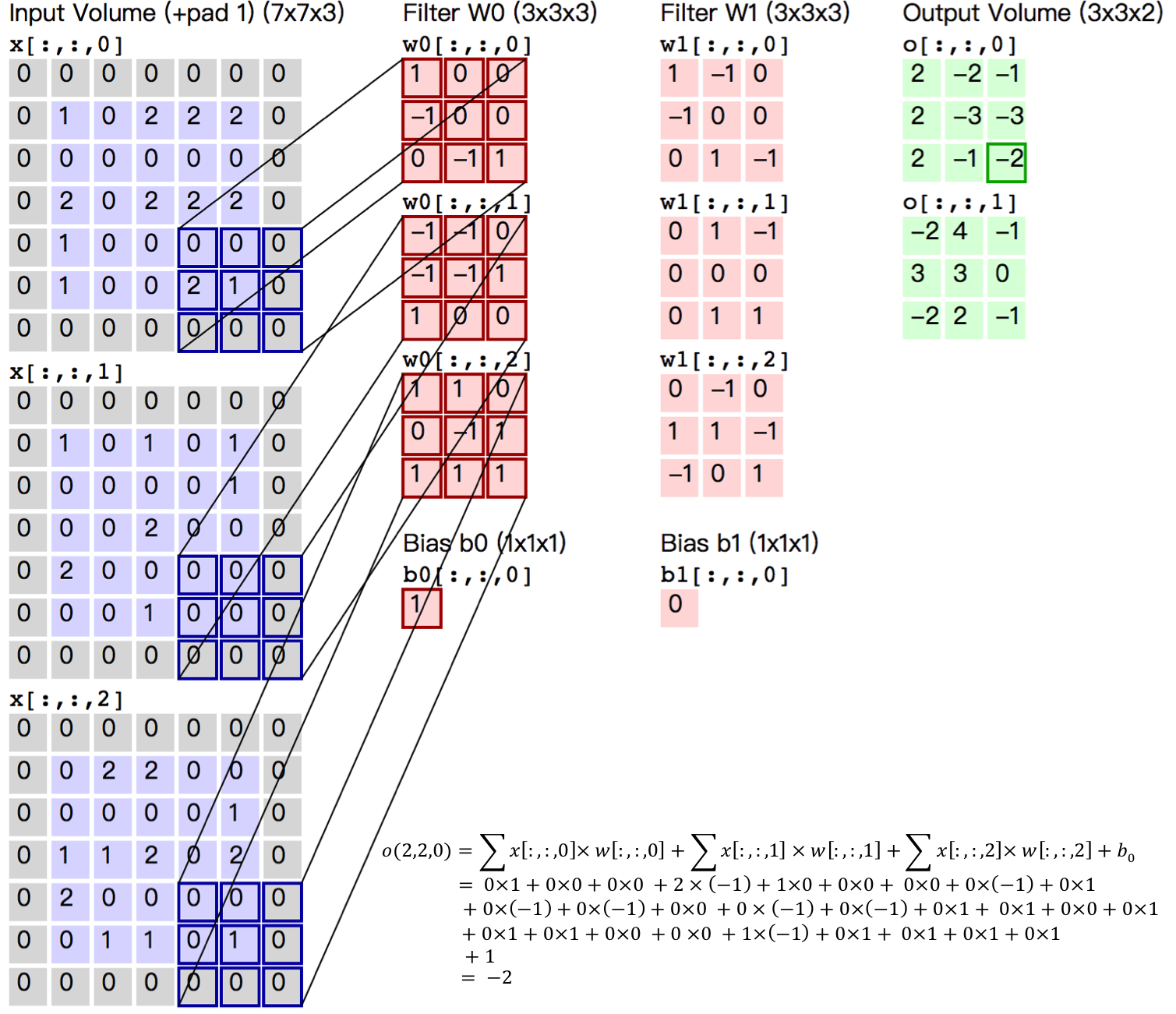
{kind=link}