一般来说,图像分类通过手工特征或特征学习方法对整个图像进行全部描述,然后使用分类器判别物体类别,因此如何提取图像的特征至关重要。在深度学习算法之前使用较多的是基于词袋(Bag of Words)模型的物体分类方法,词袋方法从自然语言处理中引入,即一句话可以用一个装了词的袋子表示其特征,袋子中的词为句子中的单词、短语或字。对于图像而言,词袋方法需要构建字典。最简单的词袋模型框架可以设计为**底层特征抽取**、**特征编码**、**分类器设计**三个过程。
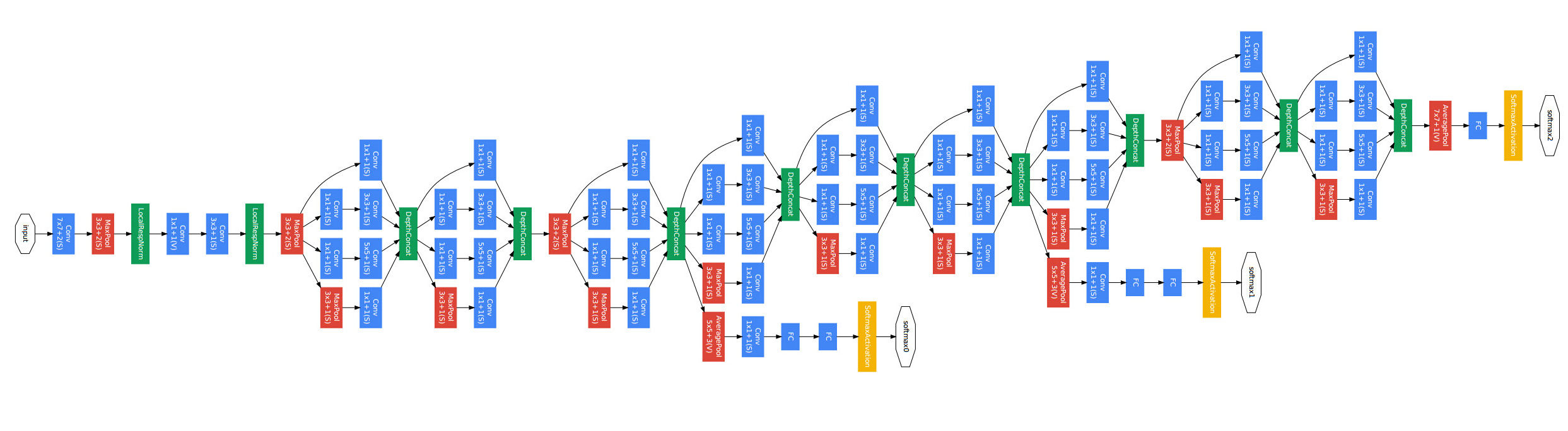
Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC 2012冠军,该模型被称作AlexNet,这也是首次将深度学习用于大规模图像分类中,并使用GPU加速模型训练。从此,涌现了一系列CNN模型,不断的在ImageNet上刷新成绩,如图4展示。随着模型变得越来越深以及精妙的结构设计,Top-5的错误率也越来越低,目前降到了3.5%附近,而在同样的ImageNet数据集上,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC2012冠军,该模型被称作AlexNet。这也是首次将深度学习用于大规模图像分类中。从AlexNet之后,涌现了一系列CNN模型,不断的在ImageNet上刷新成绩,如图 4 展示。随着模型变得越来越深以及精妙的结构设计,Top-5的错误率也越来越低,降到了3.5%附近。而在同样的ImageNet数据集上,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
[1] D. G. Lowe, Distinctive image features from scale-invariant keypoints. IJCV, 60(2):91-110, 2004.
[1] D. G. Lowe, [Distinctive image features from scale-invariant keypoints](http://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf). IJCV, 60(2):91-110, 2004.
[2] N. Dalal, B. Triggs, [Histograms of Oriented Gradients for Human Detection](http://vision.stanford.edu/teaching/cs231b_spring1213/papers/CVPR05_DalalTriggs.pdf), Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2005.
[3] Ahonen, T., Hadid, A., and Pietikinen, M. (2006). [Face description with local binary patterns: Application to face recognition](http://ieeexplore.ieee.org/document/1717463/). PAMI, 28.
[2] N. Dalal, B. Triggs, Histograms of Oriented Gradients for Human Detection, Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2005.
[4] J. Sivic, A. Zisserman, [Video Google: A Text Retrieval Approach to Object Matching in Videos](http://www.robots.ox.ac.uk/~vgg/publications/papers/sivic03.pdf), Proc. Ninth Int'l Conf. Computer Vision, pp. 1470-1478, 2003.
[3] Ahonen, T., Hadid, A., and Pietikinen, M. (2006). Face description with local binary patterns: Application to face recognition. PAMI, 28.
[5] B. Olshausen, D. Field, [Sparse Coding with an Overcomplete Basis Set: A Strategy Employed by V1?](http://redwood.psych.cornell.edu/papers/olshausen_field_1997.pdf), Vision Research, vol. 37, pp. 3311-3325, 1997.
[4] J. Sivic, A. Zisserman, "Video Google: A Text Retrieval Approach to Object Matching in Videos", Proc. Ninth Int'l Conf. Computer Vision, pp. 1470-1478, 2003.
[6] Wang, J., Yang, J., Yu, K., Lv, F., Huang, T., and Gong, Y. (2010). [Locality-constrained Linear Coding for image classification](http://ieeexplore.ieee.org/abstract/document/5540018/). In CVPR.
[5] B. Olshausen, D. Field, "Sparse Coding with an Overcomplete Basis Set: A Strategy Employed by V1?", Vision Research, vol. 37, pp. 3311-3325, 1997.
[7] Perronnin, F., Sánchez, J., & Mensink, T. (2010). [Improving the fisher kernel for large-scale image classification](http://dl.acm.org/citation.cfm?id=1888101). In ECCV (4).
[6] Wang, J., Yang, J., Yu, K., Lv, F., Huang, T., and Gong, Y. (2010). Locality-constrained Linear Coding for image classification. In CVPR.
[8] Lin, Y., Lv, F., Cao, L., Zhu, S., Yang, M., Cour, T., Yu, K., and Huang, T. (2011). [Large-scale image clas- sification: Fast feature extraction and SVM training](http://ieeexplore.ieee.org/document/5995477/). In CVPR.
[7] Perronnin, F., Sánchez, J., & Mensink, T. (2010). Improving the fisher kernel for large-scale image classification. In ECCV (4).
[9] Krizhevsky, A., Sutskever, I., and Hinton, G. (2012). [ImageNet classification with deep convolutional neu- ral networks](http://www.cs.toronto.edu/~kriz/imagenet_classification_with_deep_convolutional.pdf). In NIPS.
[8] Lin, Y., Lv, F., Cao, L., Zhu, S., Yang, M., Cour, T., Yu, K., and Huang, T. (2011). Large-scale image clas- sification: Fast feature extraction and SVM training. In CVPR.
[10] G.E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R.R. Salakhutdinov. [Improving neural networks by preventing co-adaptation of feature detectors](https://arxiv.org/abs/1207.0580). arXiv preprint arXiv:1207.0580, 2012.
[9] Krizhevsky, A., Sutskever, I., and Hinton, G. (2012). ImageNet classification with deep convolutional neu- ral networks. In NIPS.
[11] K. Chatfield, K. Simonyan, A. Vedaldi, A. Zisserman. [Return of the Devil in the Details: Delving Deep into Convolutional Nets](https://arxiv.org/abs/1405.3531). BMVC, 2014。
[10] G.E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R.R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012.
[12] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A., [Going deeper with convolutions](https://arxiv.org/abs/1409.4842). In: CVPR. (2015)
[11] K. Chatfield, K. Simonyan, A. Vedaldi, A. Zisserman. Return of the Devil in the Details: Delving Deep into Convolutional Nets. BMVC, 2014。
[13] Lin, M., Chen, Q., and Yan, S. [Network in network](https://arxiv.org/abs/1312.4400). In Proc. ICLR, 2014.
[12] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: CVPR. (2015)
[14] S. Ioffe and C. Szegedy. [Batch normalization: Accelerating deep network training by reducing internal covariate shift](https://arxiv.org/abs/1502.03167). In ICML, 2015.
[13] Lin, M., Chen, Q., and Yan, S. Network in network. In Proc. ICLR, 2014.
[15] K. He, X. Zhang, S. Ren, J. Sun. [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385). CVPR 2016.
[14] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
[16] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z. [Rethinking the incep-tion architecture for computer vision](https://arxiv.org/abs/1512.00567). In: CVPR. (2016).
[15] K. He, X. Zhang, S. Ren, J. Sun. Deep Residual Learning for Image Recognition. CVPR 2016.
[17] Szegedy, C., Ioffe, S., Vanhoucke, V. [Inception-v4, inception-resnet and the impact of residual connections on learning](https://arxiv.org/abs/1602.07261). arXiv:1602.07261 (2016).
[18] Everingham, M., Eslami, S. M. A., Van Gool, L., Williams, C. K. I., Winn, J. and Zisserman, A. [The Pascal Visual Object Classes Challenge: A Retrospective]((http://link.springer.com/article/10.1007/s11263-014-0733-5)). International Journal of Computer Vision, 111(1), 98-136, 2015.
[17] Szegedy, C., Ioffe, S., Vanhoucke, V.: Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv:1602.07261 (2016).
[19] He, K., Zhang, X., Ren, S., and Sun, J. [Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification](https://arxiv.org/abs/1502.01852). ArXiv e-prints, February 2015.
{kind=link}