Merge remote-tracking branch 'PaddlePaddle/develop' into llxxxll
Showing
.tmpl/build.sh
已删除
100644 → 0
build.sh
100644 → 100755
fit_a_line/README.en.md
0 → 100644
fit_a_line/image/predictions_en.png
100755 → 100644
{kind=link}
文件模式从 100755 更改为 100644
{kind=link}
文件已移动
fit_a_line/index.en.html
0 → 100644
image_classification/README.en.md
0 → 100644
label_semantic_roles/README.en.md
0 → 100644
label_semantic_roles/api_train.py
0 → 100644
machine_translation/README.en.md
0 → 100644
machine_translation/index.en.html
0 → 100644
recognize_digits/README.en.md
0 → 100644
recognize_digits/index.en.html
0 → 100644
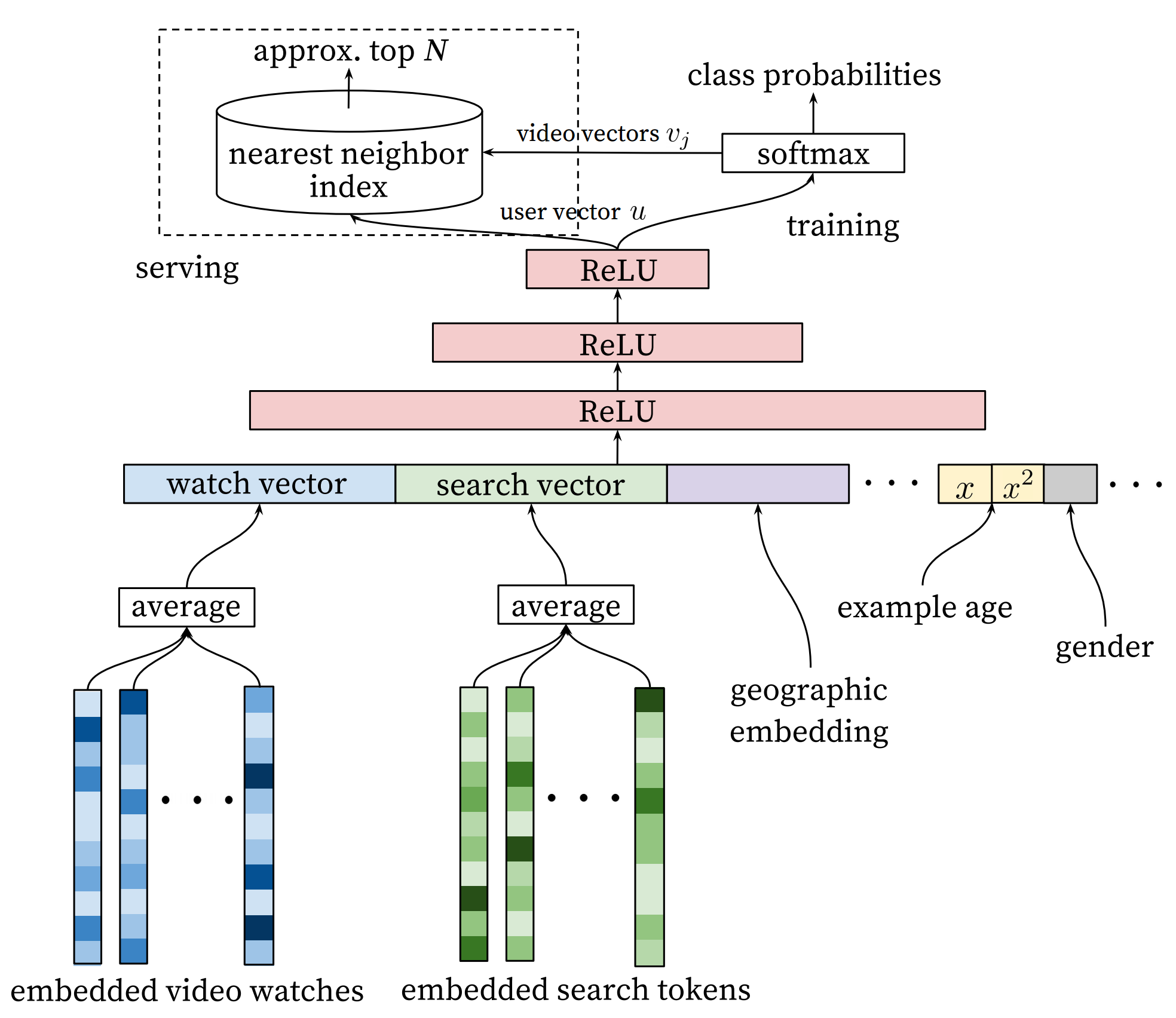
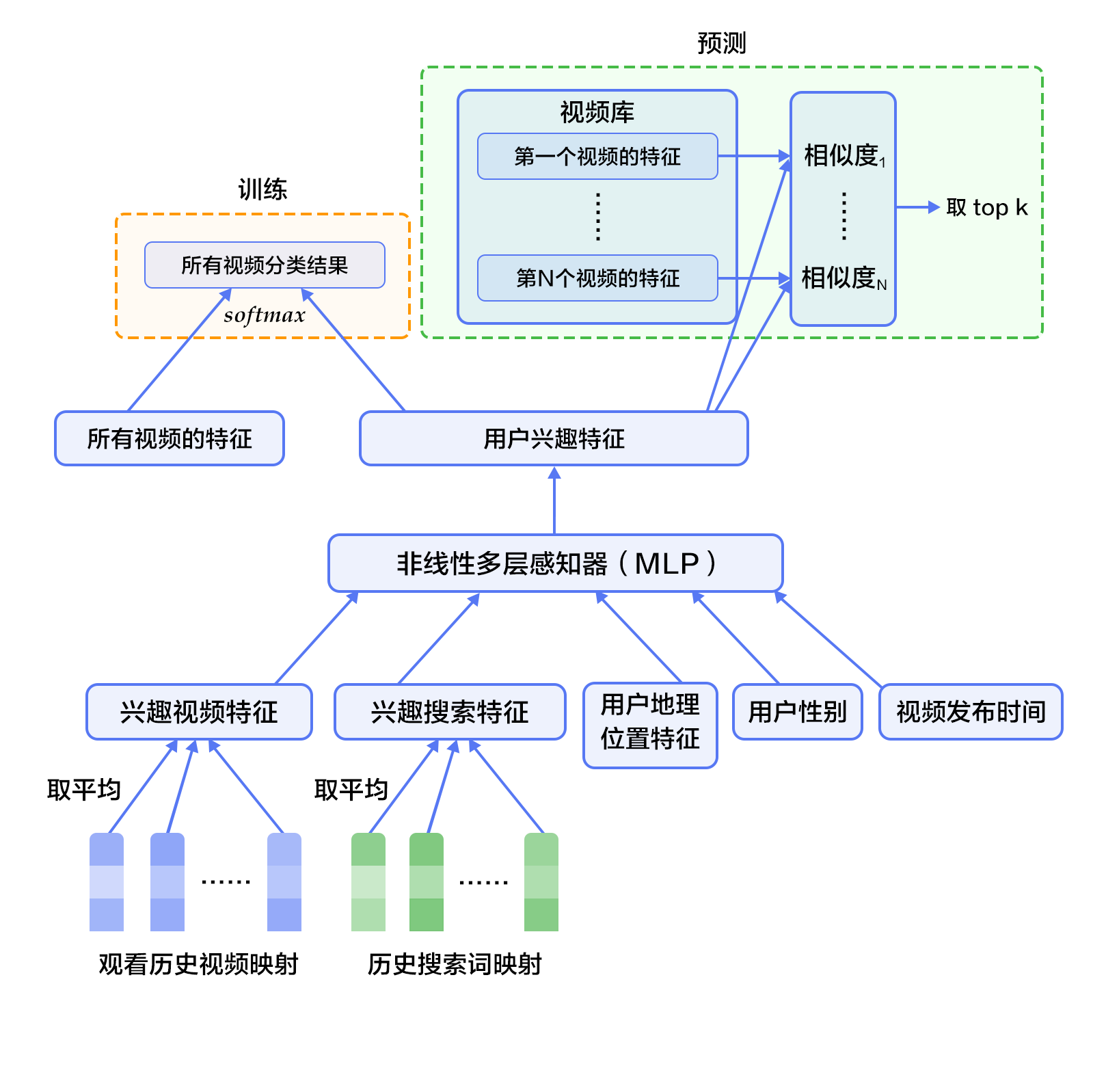
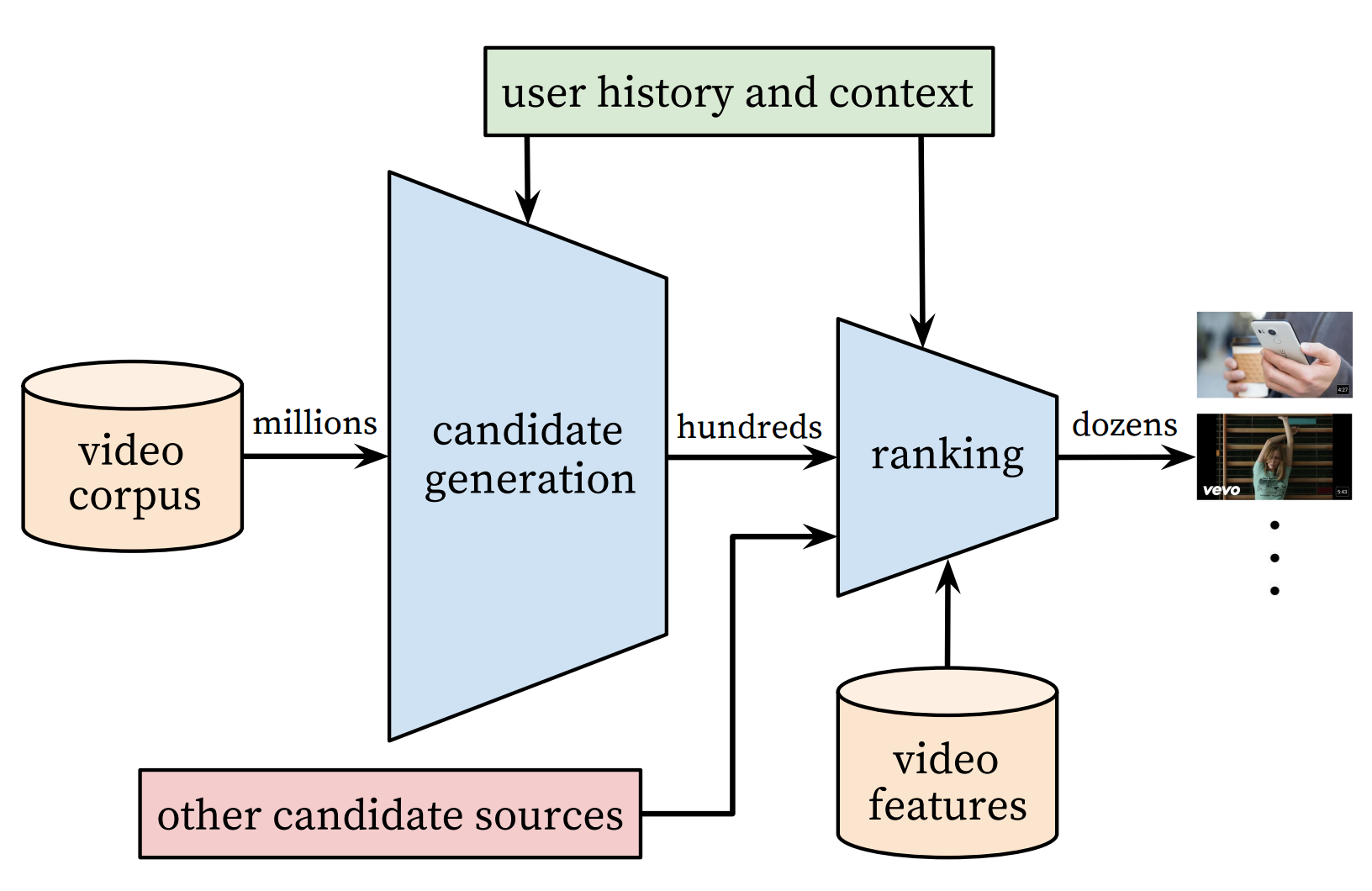
recommender_system/README.en.md
0 → 100644
{kind=link}
322.8 KB
{kind=link}
{kind=link}

| W: | H:
| W: | H:
{kind=link}
264.7 KB
recommender_system/index.en.html
0 → 100644
understand_sentiment/README.en.md
0 → 100644
word2vec/README.en.md
0 → 100644
{kind=link}
word2vec/index.en.html
0 → 100644