code modification
Showing
gan/image/.DS_Store
0 → 100644
文件已添加
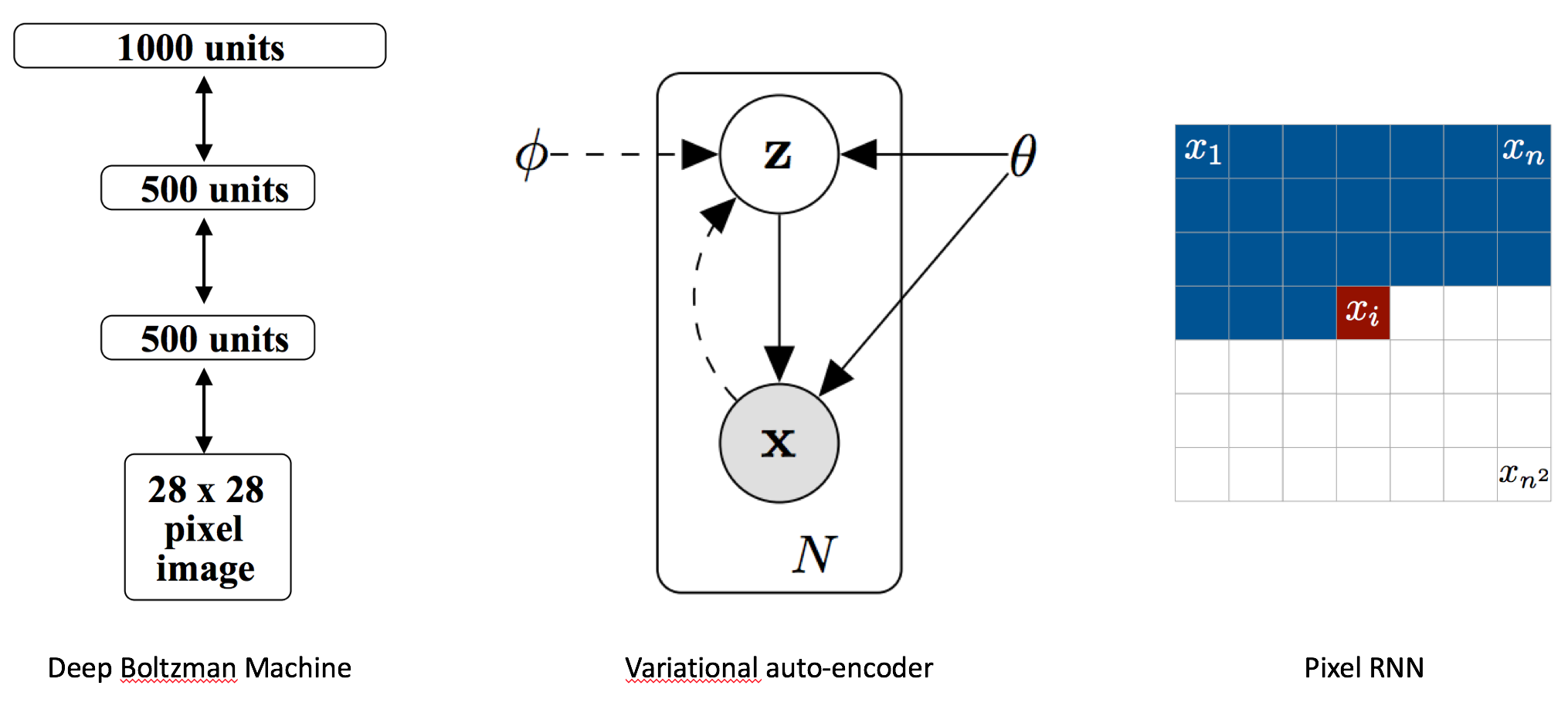
gan/image/background_intro.png
0 → 100644
{kind=link}
207.9 KB
{kind=link}

456.9 KB
gan/image/cifar_gan.png
0 → 100644
{kind=link}

140.8 KB
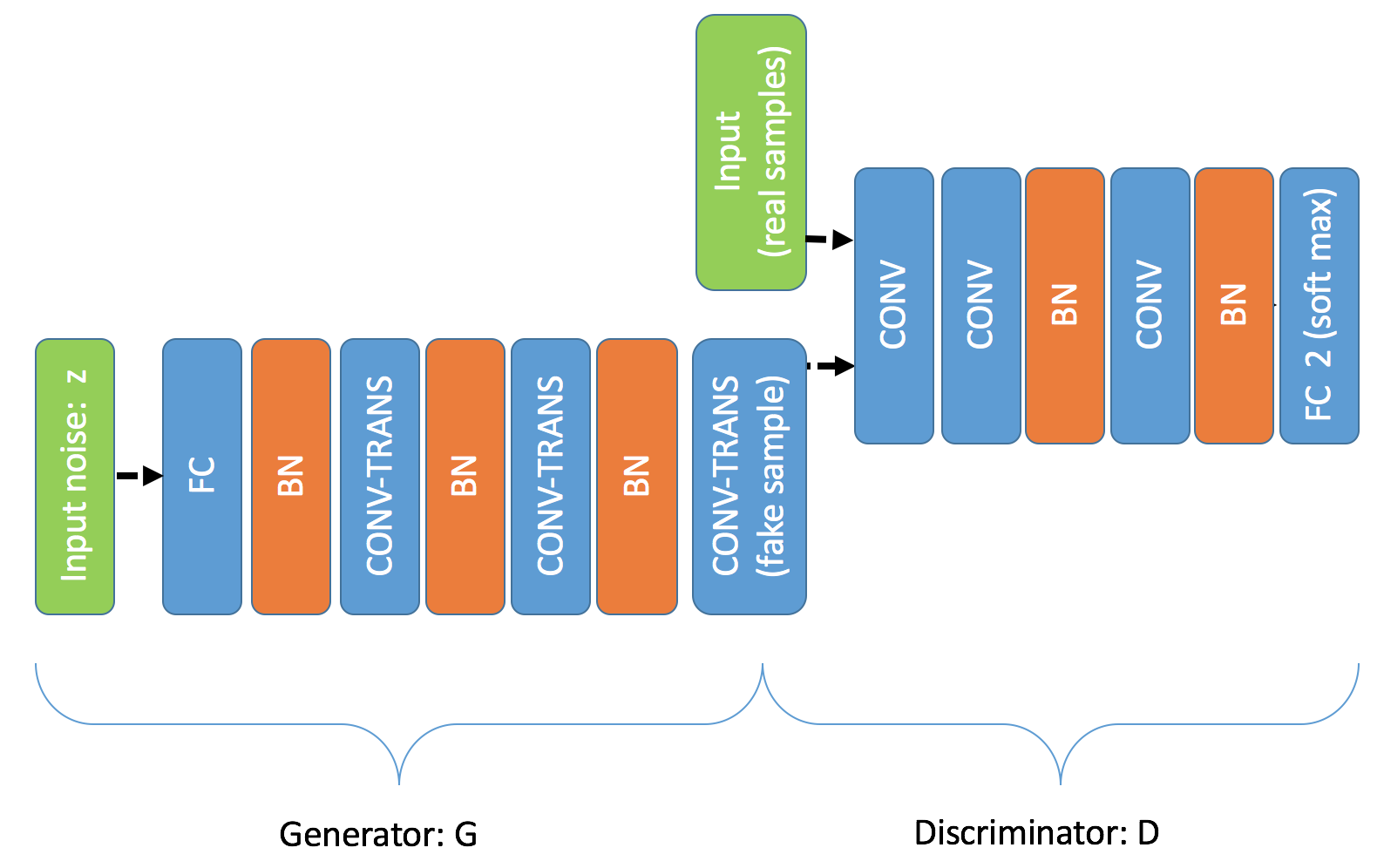
gan/image/dcgan_conf_graph.png
0 → 100644
{kind=link}
137.3 KB
{kind=link}
{kind=link}
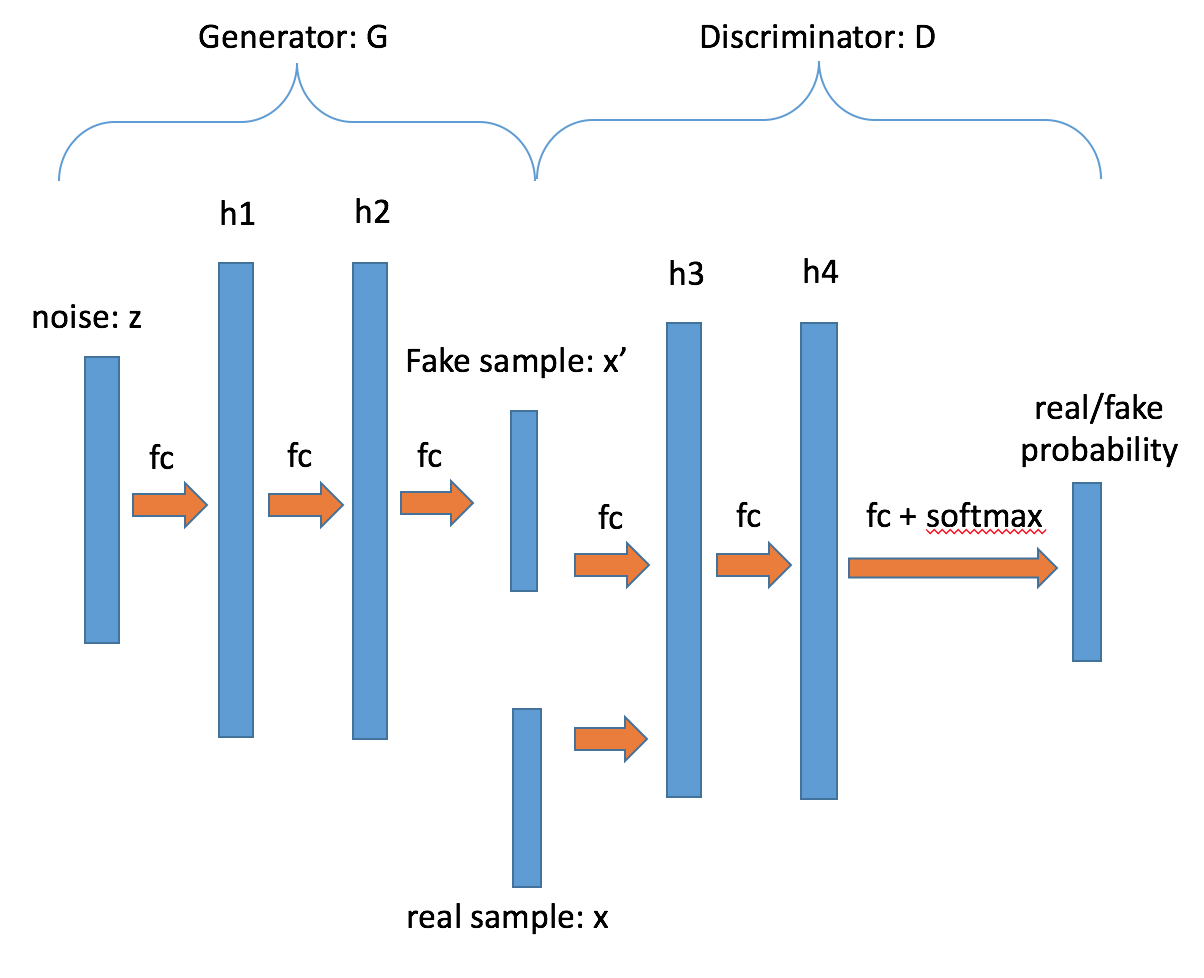
| W: | H:
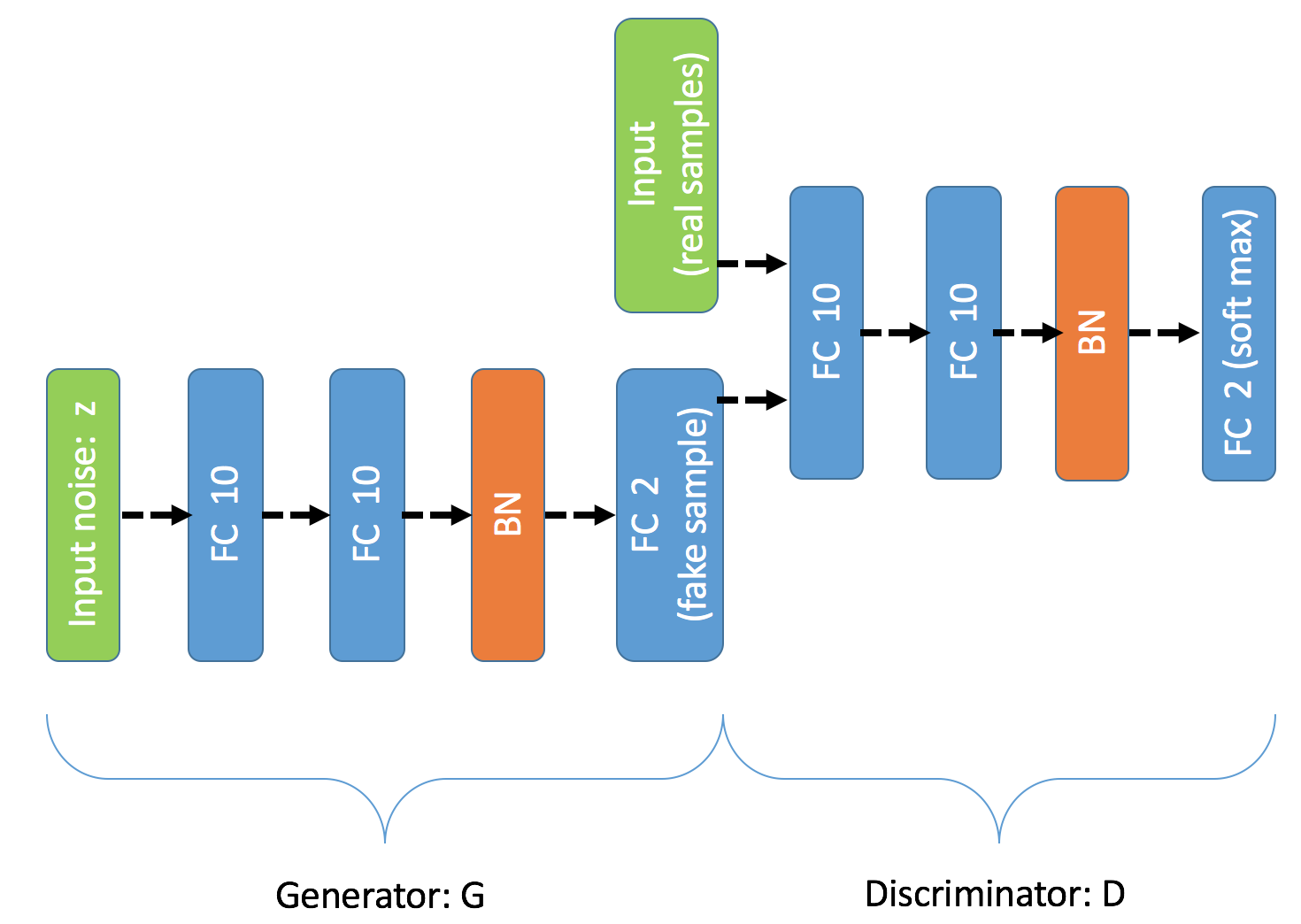
| W: | H:
gan/image/gan_openai.png
已删除
100644 → 0
{kind=link}
65.9 KB
gan/image/gan_samples.jpg
0 → 100644
{kind=link}

320.8 KB