Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
book
提交
3aacf881
B
book
项目概览
PaddlePaddle
/
book
通知
16
Star
4
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
40
列表
看板
标记
里程碑
合并请求
37
Wiki
5
Wiki
分析
仓库
DevOps
项目成员
Pages
B
book
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
40
Issue
40
列表
看板
标记
里程碑
合并请求
37
合并请求
37
Pages
分析
分析
仓库分析
DevOps
Wiki
5
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
3aacf881
编写于
3月 06, 2017
作者:
T
Tao Luo
提交者:
GitHub
3月 06, 2017
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #47 from qingqing01/mnist
Refine conv in recognize digits
上级
c727bca7
5a380f55
变更
2
显示空白变更内容
内联
并排
Showing
2 changed file
with
32 addition
and
25 deletion
+32
-25
recognize_digits/README.md
recognize_digits/README.md
+32
-25
recognize_digits/image/conv_layer.png
recognize_digits/image/conv_layer.png
+0
-0
未找到文件。
recognize_digits/README.md
浏览文件 @
3aacf881
...
@@ -67,16 +67,36 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
...
@@ -67,16 +67,36 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
### 卷积神经网络(Convolutional Neural Network, CNN)
### 卷积神经网络(Convolutional Neural Network, CNN)
在多层感知器模型中,将图像展开成一维向量输入到网络中,忽略了图像的位置和结构信息,而卷积神经网络能够更好的利用图像的结构信息。
[
LeNet-5
](
http://yann.lecun.com/exdb/lenet/
)
是一个较简单的卷积神经网络。图6显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。下面我们主要介绍卷积层和池化层。
<p
align=
"center"
>
<img
src=
"image/cnn.png"
><br/>
图6. LeNet-5卷积神经网络结构
<br/>
</p>
#### 卷积层
#### 卷积层
卷积层是卷积神经网络的核心基石。在图像识别里我们提到的卷积是二维卷积,即离散二维滤波器(也称作卷积核)与二维图像做卷积操作,简单的讲是二维滤波器滑动到二维图像上所有位置,并在每个位置上与该像素点及其领域像素点做内积。卷积操作被广泛应用与图像处理领域,不同卷积核可以提取不同的特征,例如边沿、线性、角等特征。在深层卷积神经网络中,通过卷积操作可以提取出图像低级到复杂的特征。
<p
align=
"center"
>
<p
align=
"center"
>
<img
src=
"image/conv_layer.png"
width=
500
><br/>
<img
src=
"image/conv_layer.png"
><br/>
图4. 卷积层图片
<br/>
图4. 卷积层图片
<br/>
</p>
</p>
卷积层是卷积神经网络的核心基石。该层的参数由一组可学习的过滤器(也叫作卷积核)组成。在前向过程中,每个卷积核在输入层进行横向和纵向的扫描,与输入层对应扫描位置进行卷积,得到的结果加上偏置并用相应的激活函数进行激活,结果能够得到一个二维的激活图(activation map)。每个特定的卷积核都能得到特定的激活图(activation map),如有的卷积核可能对识别边角,有的可能识别圆圈,那这些卷积核可能对于对应的特征响应要强。
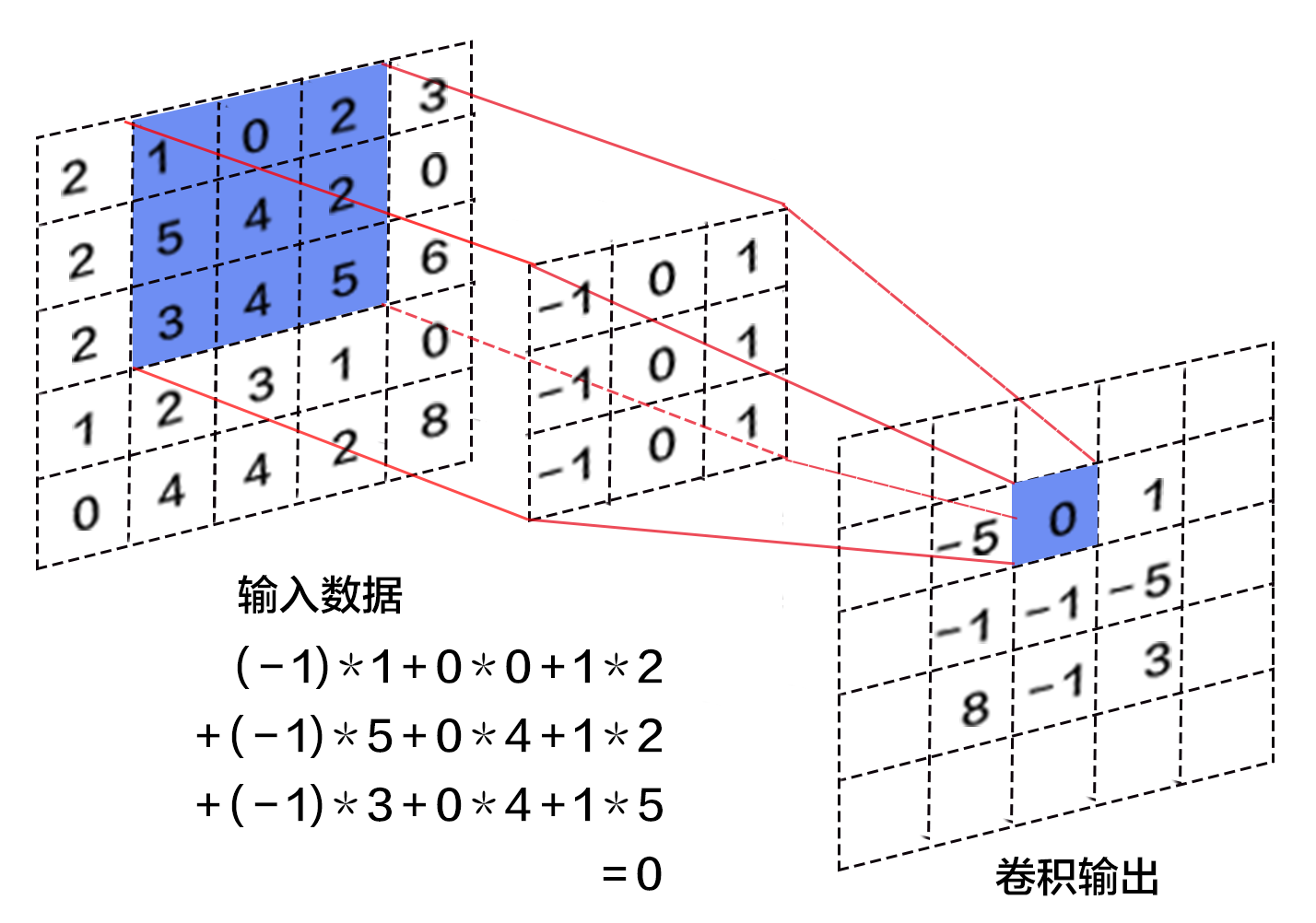
图4给出一个卷积计算过程的示例图,输入图像大小为$H=5,W=5,D=3$,即$5x5$大小的3通道(RGB,也称作深度)彩色图像。这个示例图中包含两(用$K$表示)组卷积核,即图中$Filter W_0$和$Filter W_1$,在卷积计算中,通常对不同的输入通道采用不同的卷积核,在图示例中每组卷积核又包含3($D$)个$3x3$(用$FXF$表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向($W$方向)和垂直方向($H$方向)的滑动步长为2(用$S$表示);对输入图像周围各填充1(用$P$表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为$3x3x2$(用$H_{o}xW_{o}xK$表示)大小的特征图,即$3x3$大小的2通道特征图,其中$H_o$计算公式为:$H_o = (H - F + 2
*
P)/S + 1$,$W_o$同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置($b_o$),偏置通常对于每个输出特征图是共享的。例如图中输出特征图
`o[:,:,0]`
中的$-9$计算如下:
$$-9 =
\s
um x[4:6,4:6,0]
* W[:,:,0]] + \sum x[4:6,4:6,1] *
W[:,:,1]] +
\s
um x[4:6,4:6,2]
*
W[:,:,2]] + b_0
\\
\s
um x[4:6,4:6,0]
* W[:,:,0]] = 2*
1 + 2
*(-1) + 0*
1 + 0
*0 + 2*
(-1) + 0
*1 + 0*
0 + 0
*0 + 0*
0 = -2
\\
\s
um x[4:6,4:6,1]
* W[:,:,1]] = 2*
(-1) + 2
*(-1) + 0*
0 + 2
*0 + 2*
(-1) + 0
*(-1) + 0*
0 + 0
*1 + 0*
1 = -6
\\
\s
um x[4:6,4:6,2]
* W[:,:,2]] = 0*
0 + 0
*1 + 0*
1 + 2
*(-1) + 1*
0 + 0
*1 + 0*
1 + 0
*0 + 0*
1 = -2$$
在卷积操作中卷积核是可学习的参数,经过上面示例介绍,每层卷积的参数大小为$DxFxFxK$。在多层感知器模型中,神经元通常是全部连接,参数较多。而卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
-
局部连接:每个神经元仅与输入神经元的一块区域连接,这块局部区域称作感受野(receptive field)。在图像卷积操作中,即神经元在空间维度(spatial dimension,即上图示例H和W所在的平面)是局部连接,但在深度上是全部连接。对于二维图像本身而言,也是局部像素关联较强。这种局部连接保证了学习后的过滤器能够对于局部的输入特征有最强的响应。局部连接的思想,也是受启发于生物学里面的视觉系统结构,视觉皮层的神经元就是局部接受信息的。
图4是卷积层的一个动态图。由于3D量难以表示,所有的3D量(输入的3D量(蓝色),权重3D量(红色),输出3D量(绿色))通过将深度在行上堆叠来表示。如图4,输入层是$W_1=5,H_1=5,D_1=3$,我们常见的彩色图片其实就是类似这样的输入层,彩色图片的宽和高对应这里的$W_1$和$H_1$,而彩色图片有RGB三个颜色通道,对应这里的$D_1$;卷积层的参数为$K=2,F=3,S=2,P=1$,这里的$K$是卷积核的数量,如图4中有$Filter W_0$和$Filter W_1$两个卷积核,$F$对应卷积核的大小,图中$W0$和$W1$在每一层深度上都是$3
\t
imes3$的矩阵,$S$对应卷积核扫描的步长,从动态图中可以看到,方框每次左移或下移2个单位,$P$对应Padding扩展,是对输入层的扩展,图中输入层,原始数据为蓝色部分,可以看到灰色部分是进行了大小为1的扩展,用0来进行扩展;图4的动态可视化对输出层结果(绿色)进行迭代,显示每个输出元素是通过将突出显示的输入(蓝色)与滤波器(红色)进行元素相乘,将其相加,然后通过偏置抵消结果来计算的。
-
权重共享:计算同一个深度切片的神经元时采用的滤波器是共享的。例如图4中计算$o
[
:,:,0]$的每个每个神经元的滤波器均相同,都为$W_0$,这样可以很大程度上减少参数。共享权重在一定程度上讲是有意义的,例如图片的底层边缘特征与特征在图中的具体位置无关。但是在一些场景中是无意的,比如输入的图片是人脸,眼睛和头发位于不同的位置,希望在不同的位置学到不同的特征 (参考[斯坦福大学公开课
](
http://cs231n.github.io/convolutional-networks/
)
)。请注意权重只是对于同一深度切片的神经元是共享的,在卷积层,通常采用多组卷积核提取不同特征,即对应不同深度切片的特征,不同深度切片的神经元权重是不共享。另外,偏重对同一深度切片的所有神经元都是共享的。
通过介绍卷积计算过程及其特性,可以看出卷积是线性操作,并具有平移不变性(shift-invariant),平移不变性即在图像每个位置执行相同的操作。卷积层的局部连接和权重共享使得需要学习的参数大大减小,这样也有利于训练较大卷积神经网络。
#### 池化层
#### 池化层
...
@@ -87,19 +107,6 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
...
@@ -87,19 +107,6 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,如图5所示。
池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,如图5所示。
#### LeNet-5网络
<p
align=
"center"
>
<img
src=
"image/cnn.png"
><br/>
图6. LeNet-5卷积神经网络结构
<br/>
</p>
[
LeNet-5
](
http://yann.lecun.com/exdb/lenet/
)
是一个最简单的卷积神经网络。图6显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。卷积的如下三个特性,决定了LeNet-5能比同样使用全连接层的多层感知器更好地识别图像:
-
神经元的三维特性: 卷积层的神经元在宽度、高度和深度上进行了组织排列。每一层的神经元仅仅与前一层的一块小区域连接,这块小区域被称为感受野(receptive field)。
-
局部连接:CNN通过在相邻层的神经元之间实施局部连接模式来利用空间局部相关性。这样的结构保证了学习后的过滤器能够对于局部的输入特征有最强的响应。堆叠许多这样的层导致非线性“过滤器”变得越来越“全局”。这允许网络首先创建输入的小部分的良好表示,然后从它们组合较大区域的表示。
-
共享权重:在CNN中,每个滤波器在整个视野中重复扫描。 这些复制单元共享相同的参数化(权重向量和偏差)并形成特征图。 这意味着给定卷积层中的所有神经元检测完全相同的特征。 以这种方式的复制单元允许不管它们在视野中的位置都能检测到特征,从而构成平移不变性的性质。
更详细的关于卷积神经网络的具体知识可以参考
[
斯坦福大学公开课
](
http://cs231n.github.io/convolutional-networks/
)
和
[
图像分类
](
https://github.com/PaddlePaddle/book/blob/develop/image_classification/README.md
)
教程。
更详细的关于卷积神经网络的具体知识可以参考
[
斯坦福大学公开课
](
http://cs231n.github.io/convolutional-networks/
)
和
[
图像分类
](
https://github.com/PaddlePaddle/book/blob/develop/image_classification/README.md
)
教程。
### 常见激活函数介绍
### 常见激活函数介绍
...
...
recognize_digits/image/conv_layer.png
查看替换文件 @
c727bca7
浏览文件 @
3aacf881
249.7 KB
|
W:
|
H:
248.3 KB
|
W:
|
H:
2-up
Swipe
Onion skin
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}