Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
book
提交
39e86cf7
B
book
项目概览
PaddlePaddle
/
book
通知
17
Star
4
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
40
列表
看板
标记
里程碑
合并请求
37
Wiki
5
Wiki
分析
仓库
DevOps
项目成员
Pages
B
book
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
40
Issue
40
列表
看板
标记
里程碑
合并请求
37
合并请求
37
Pages
分析
分析
仓库分析
DevOps
Wiki
5
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
39e86cf7
编写于
3月 08, 2017
作者:
D
dangqingqing
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update figure
上级
fe3bc159
变更
6
隐藏空白更改
内联
并排
Showing
6 changed file
with
14 addition
and
26 deletion
+14
-26
recognize_digits/README.en.md
recognize_digits/README.en.md
+1
-1
recognize_digits/README.md
recognize_digits/README.md
+6
-12
recognize_digits/image/conv_layer.png
recognize_digits/image/conv_layer.png
+0
-0
recognize_digits/image/conv_layer_en.png
recognize_digits/image/conv_layer_en.png
+0
-0
recognize_digits/index.en.html
recognize_digits/index.en.html
+1
-1
recognize_digits/index.html
recognize_digits/index.html
+6
-12
未找到文件。
recognize_digits/README.en.md
浏览文件 @
39e86cf7
...
...
@@ -70,7 +70,7 @@ Fig. 3. Multilayer Perceptron network architecture<br/>
#### Convolutional Layer
<p
align=
"center"
>
<img
src=
"image/conv_layer
_en
.png"
width=
500
><br/>
<img
src=
"image/conv_layer.png"
width=
500
><br/>
Fig. 4. Convolutional layer
<br/>
</p>
...
...
recognize_digits/README.md
浏览文件 @
39e86cf7
...
...
@@ -67,11 +67,11 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
### 卷积神经网络(Convolutional Neural Network, CNN)
在多层感知器模型中,将图像展开成一维向量输入到网络中,忽略了图像的位置和结构信息,而卷积神经网络能够更好的利用图像的结构信息。
[
LeNet-5
](
http://yann.lecun.com/exdb/lenet/
)
是一个较简单的卷积神经网络。图
6
显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。下面我们主要介绍卷积层和池化层。
在多层感知器模型中,将图像展开成一维向量输入到网络中,忽略了图像的位置和结构信息,而卷积神经网络能够更好的利用图像的结构信息。
[
LeNet-5
](
http://yann.lecun.com/exdb/lenet/
)
是一个较简单的卷积神经网络。图
4
显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。下面我们主要介绍卷积层和池化层。
<p
align=
"center"
>
<img
src=
"image/cnn.png"
><br/>
图
6
. LeNet-5卷积神经网络结构
<br/>
图
4
. LeNet-5卷积神经网络结构
<br/>
</p>
#### 卷积层
...
...
@@ -80,16 +80,10 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
<p
align=
"center"
>
<img
src=
"image/conv_layer.png"
><br/>
图
4
. 卷积层图片
<br/>
图
5
. 卷积层图片
<br/>
</p>
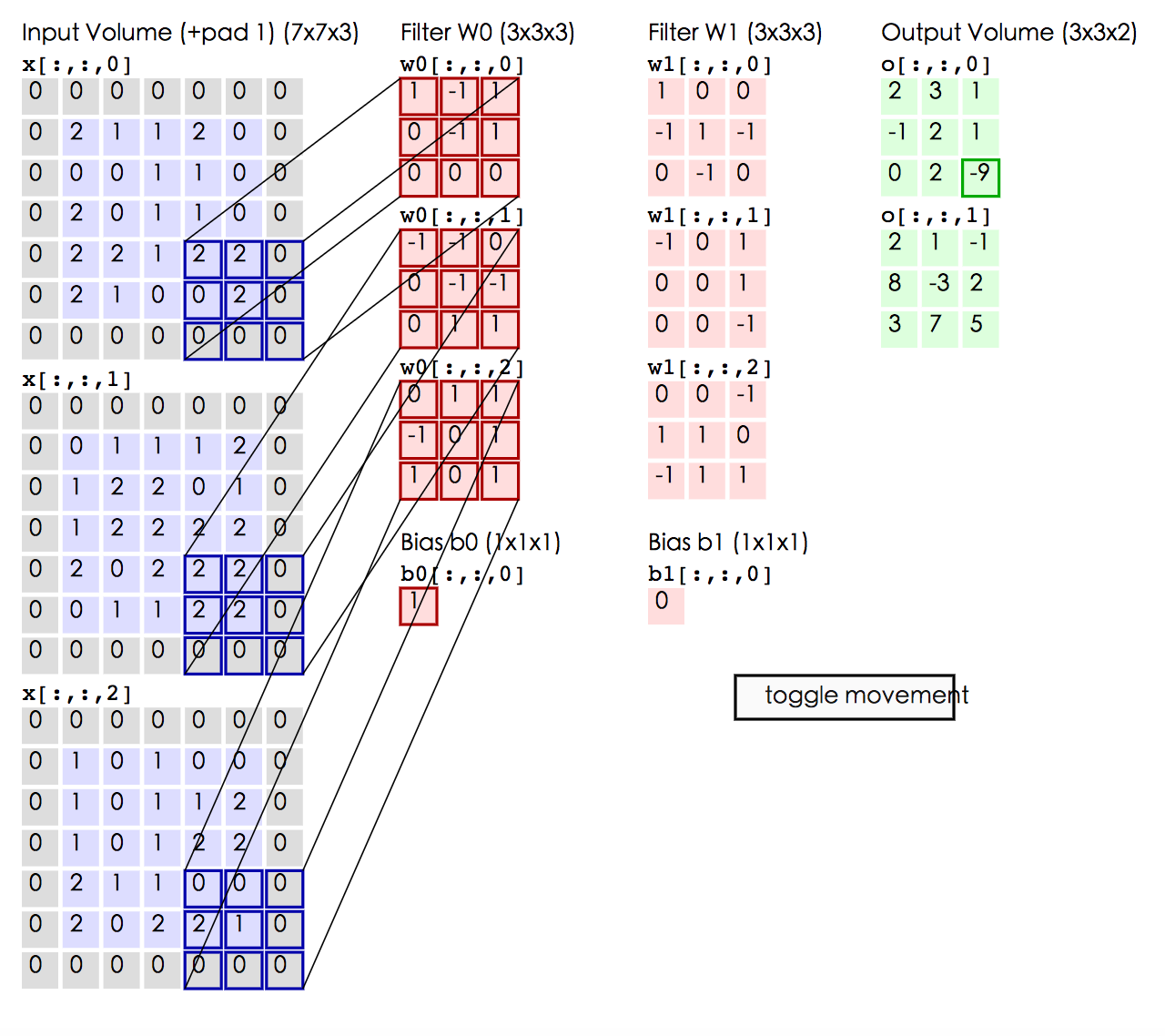
图4给出一个卷积计算过程的示例图,输入图像大小为$H=5,W=5,D=3$,即$5
\t
imes 5$大小的3通道(RGB,也称作深度)彩色图像。这个示例图中包含两(用$K$表示)组卷积核,即图中滤波器$W_0$和$W_1$。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含($D=3)$个$3
\t
imes 3$(用$F
\t
imes F$表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向($W$方向)和垂直方向($H$方向)的滑动步长为2(用$S$表示);对输入图像周围各填充1(用$P$表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为$3
\t
imes 3
\t
imes 2$(用$H_{o}
\t
imes W_{o}
\t
imes K$表示)大小的特征图,即$3
\t
imes 3$大小的2通道特征图,其中$H_o$计算公式为:$H_o = (H - F + 2
\t
imes P)/S + 1$,$W_o$同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置$b_o$,偏置通常对于每个输出特征图是共享的。例如图中输出特征图$o[:,:,0]$中的第一个$2$计算如下:
$$ o[0,0,0] =
\s
um x[0:3,0:3,0]
* w_{0}[:,:,0]] + \sum x[0:3,0:3,1] *
w_{0}[:,:,1]] +
\s
um x[0:3,0:3,2]
*
w_{0}[:,:,2]] + b_0 = 2 $$
$$
\s
um x[0:3,0:3,0]
* w_{0}[:,:,0]] = 0*
1 + 0
*1 + 0*
1 + 0
*1 + 1*
1 + 2
*(-1) + 0*
(-1) + 0
*1 + 0*
(-1) = -1 $$
$$
\s
um x[0:3,0:3,1]
* w_{0}[:,:,1]] = 0*
0 + 0
*1 + 0*
1 + 0
*(-1) + 0*
0 + 1
*1 + 0*
1 + 2
*0 + 1*
1 = 2 $$
$$
\s
um x[0:3,0:3,2]
* w_{0}[:,:,2]] = 0*
(-1) + 0
*1 + 0*
(-1) + 0
*0 + 1*
1 + 1
*0 + 0*
(-1) + 1
*0 + 1*
(-1) = 0 $$
$$ b_0 = 1 $$
图5给出一个卷积计算过程的示例图,输入图像大小为$H=5,W=5,D=3$,即$5
\t
imes 5$大小的3通道(RGB,也称作深度)彩色图像。这个示例图中包含两(用$K$表示)组卷积核,即图中滤波器$W_0$和$W_1$。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含($D=3)$个$3
\t
imes 3$(用$F
\t
imes F$表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向($W$方向)和垂直方向($H$方向)的滑动步长为2(用$S$表示);对输入图像周围各填充1(用$P$表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为$3
\t
imes 3
\t
imes 2$(用$H_{o}
\t
imes W_{o}
\t
imes K$表示)大小的特征图,即$3
\t
imes 3$大小的2通道特征图,其中$H_o$计算公式为:$H_o = (H - F + 2
\t
imes P)/S + 1$,$W_o$同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置$b_o$,偏置通常对于每个输出特征图是共享的。输出特征图$o[:,:,0]$中的最后一个$-2$计算如图5右下角公式所示。
在卷积操作中卷积核是可学习的参数,经过上面示例介绍,每层卷积的参数大小为$D
\t
imes F
\t
imes F
\t
imes K$。在多层感知器模型中,神经元通常是全部连接,参数较多。而卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
...
...
@@ -103,10 +97,10 @@ $$ b_0 = 1 $$
<p
align=
"center"
>
<img
src=
"image/max_pooling.png"
width=
"400px"
><br/>
图
5
. 池化层图片
<br/>
图
6
. 池化层图片
<br/>
</p>
池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,如图
5
所示。
池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,如图
6
所示。
更详细的关于卷积神经网络的具体知识可以参考
[
斯坦福大学公开课
](
http://cs231n.github.io/convolutional-networks/
)
和
[
图像分类
](
https://github.com/PaddlePaddle/book/blob/develop/image_classification/README.md
)
教程。
...
...
recognize_digits/image/conv_layer.png
查看替换文件 @
fe3bc159
浏览文件 @
39e86cf7
248.3 KB
|
W:
|
H:
571.8 KB
|
W:
|
H:
2-up
Swipe
Onion skin
recognize_digits/image/conv_layer_en.png
已删除
100755 → 0
浏览文件 @
fe3bc159
248.5 KB
recognize_digits/index.en.html
浏览文件 @
39e86cf7
...
...
@@ -112,7 +112,7 @@ Fig. 3. Multilayer Perceptron network architecture<br/>
#### Convolutional Layer
<p
align=
"center"
>
<img
src=
"image/conv_layer
_en
.png"
width=
500
><br/>
<img
src=
"image/conv_layer.png"
width=
500
><br/>
Fig. 4. Convolutional layer
<br/>
</p>
...
...
recognize_digits/index.html
浏览文件 @
39e86cf7
...
...
@@ -109,11 +109,11 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
### 卷积神经网络(Convolutional Neural Network, CNN)
在多层感知器模型中,将图像展开成一维向量输入到网络中,忽略了图像的位置和结构信息,而卷积神经网络能够更好的利用图像的结构信息。[LeNet-5](http://yann.lecun.com/exdb/lenet/)是一个较简单的卷积神经网络。图
6
显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。下面我们主要介绍卷积层和池化层。
在多层感知器模型中,将图像展开成一维向量输入到网络中,忽略了图像的位置和结构信息,而卷积神经网络能够更好的利用图像的结构信息。[LeNet-5](http://yann.lecun.com/exdb/lenet/)是一个较简单的卷积神经网络。图
4
显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。下面我们主要介绍卷积层和池化层。
<p
align=
"center"
>
<img
src=
"image/cnn.png"
><br/>
图
6
. LeNet-5卷积神经网络结构
<br/>
图
4
. LeNet-5卷积神经网络结构
<br/>
</p>
#### 卷积层
...
...
@@ -122,16 +122,10 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
<p
align=
"center"
>
<img
src=
"image/conv_layer.png"
><br/>
图
4
. 卷积层图片
<br/>
图
5
. 卷积层图片
<br/>
</p>
图4给出一个卷积计算过程的示例图,输入图像大小为$H=5,W=5,D=3$,即$5 \times 5$大小的3通道(RGB,也称作深度)彩色图像。这个示例图中包含两(用$K$表示)组卷积核,即图中滤波器$W_0$和$W_1$。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含($D=3)$个$3 \times 3$(用$F \times F$表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向($W$方向)和垂直方向($H$方向)的滑动步长为2(用$S$表示);对输入图像周围各填充1(用$P$表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为$3 \times 3 \times 2$(用$H_{o} \times W_{o} \times K$表示)大小的特征图,即$3 \times 3$大小的2通道特征图,其中$H_o$计算公式为:$H_o = (H - F + 2 \times P)/S + 1$,$W_o$同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置$b_o$,偏置通常对于每个输出特征图是共享的。例如图中输出特征图$o[:,:,0]$中的第一个$2$计算如下:
$$ o[0,0,0] = \sum x[0:3,0:3,0] * w_{0}[:,:,0]] + \sum x[0:3,0:3,1] * w_{0}[:,:,1]] + \sum x[0:3,0:3,2] * w_{0}[:,:,2]] + b_0 = 2 $$
$$ \sum x[0:3,0:3,0] * w_{0}[:,:,0]] = 0*1 + 0*1 + 0*1 + 0*1 + 1*1 + 2*(-1) + 0*(-1) + 0*1 + 0*(-1) = -1 $$
$$ \sum x[0:3,0:3,1] * w_{0}[:,:,1]] = 0*0 + 0*1 + 0*1 + 0*(-1) + 0*0 + 1*1 + 0*1 + 2*0 + 1*1 = 2 $$
$$ \sum x[0:3,0:3,2] * w_{0}[:,:,2]] = 0*(-1) + 0*1 + 0*(-1) + 0*0 + 1*1 + 1*0 + 0*(-1) + 1*0 + 1*(-1) = 0 $$
$$ b_0 = 1 $$
图5给出一个卷积计算过程的示例图,输入图像大小为$H=5,W=5,D=3$,即$5 \times 5$大小的3通道(RGB,也称作深度)彩色图像。这个示例图中包含两(用$K$表示)组卷积核,即图中滤波器$W_0$和$W_1$。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含($D=3)$个$3 \times 3$(用$F \times F$表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向($W$方向)和垂直方向($H$方向)的滑动步长为2(用$S$表示);对输入图像周围各填充1(用$P$表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为$3 \times 3 \times 2$(用$H_{o} \times W_{o} \times K$表示)大小的特征图,即$3 \times 3$大小的2通道特征图,其中$H_o$计算公式为:$H_o = (H - F + 2 \times P)/S + 1$,$W_o$同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置$b_o$,偏置通常对于每个输出特征图是共享的。输出特征图$o[:,:,0]$中的最后一个$-2$计算如图5右下角公式所示。
在卷积操作中卷积核是可学习的参数,经过上面示例介绍,每层卷积的参数大小为$D \times F \times F \times K$。在多层感知器模型中,神经元通常是全部连接,参数较多。而卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
...
...
@@ -145,10 +139,10 @@ $$ b_0 = 1 $$
<p
align=
"center"
>
<img
src=
"image/max_pooling.png"
width=
"400px"
><br/>
图
5
. 池化层图片
<br/>
图
6
. 池化层图片
<br/>
</p>
池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,如图
5
所示。
池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,如图
6
所示。
更详细的关于卷积神经网络的具体知识可以参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/ )和[图像分类](https://github.com/PaddlePaddle/book/blob/develop/image_classification/README.md)教程。
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}

{kind=link}
