diff --git a/02.recognize_digits/README.cn.md b/02.recognize_digits/README.cn.md
index ab11f7cf9108ff6df8a92008e36ac36d403196e2..70b7abfd291d562f5c805095c58124c82ea88d9f 100644
--- a/02.recognize_digits/README.cn.md
+++ b/02.recognize_digits/README.cn.md
@@ -46,12 +46,12 @@ MNIST吸引了大量的科学家基于此数据集训练模型,1998年,LeCun
输入层的数据$X$传到输出层,在激活操作之前,会乘以相应的权重 $W$ ,并加上偏置变量 $b$ ,具体如下:
-
+
其中
-
+
图2为softmax回归的网络图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
@@ -66,7 +66,7 @@ MNIST吸引了大量的科学家基于此数据集训练模型,1998年,LeCun
在分类问题中,我们一般采用交叉熵代价损失函数(cross entropy loss),公式如下:
-
+
@@ -135,13 +135,13 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
- sigmoid激活函数:
-
+
- tanh激活函数:
-
+
实际上,tanh函数只是规模变化的sigmoid函数,将sigmoid函数值放大2倍之后再向下平移1个单位:tanh(x) = 2sigmoid(2x) - 1 。
diff --git a/02.recognize_digits/image/01.gif b/02.recognize_digits/image/01.gif
new file mode 100644
index 0000000000000000000000000000000000000000..90c8349b08bebc35122766fc6c67f5f9c0a53db2
Binary files /dev/null and b/02.recognize_digits/image/01.gif differ
diff --git a/02.recognize_digits/image/01.png b/02.recognize_digits/image/01.png
deleted file mode 100644
index cb7e70cb5ddf77a870c95f0409f209ebaeff59d3..0000000000000000000000000000000000000000
Binary files a/02.recognize_digits/image/01.png and /dev/null differ
diff --git a/02.recognize_digits/image/02.gif b/02.recognize_digits/image/02.gif
new file mode 100644
index 0000000000000000000000000000000000000000..4a023509e8b6862cddc674ce6682c5b8549feb4f
Binary files /dev/null and b/02.recognize_digits/image/02.gif differ
diff --git a/02.recognize_digits/image/02.png b/02.recognize_digits/image/02.png
deleted file mode 100644
index 623fb3a8dbf9638a4771b2259c4e18089ff1787d..0000000000000000000000000000000000000000
Binary files a/02.recognize_digits/image/02.png and /dev/null differ
diff --git a/02.recognize_digits/image/03.gif b/02.recognize_digits/image/03.gif
new file mode 100644
index 0000000000000000000000000000000000000000..521bc209d5a496f28e42f72b51bf45ea6bb4c2f1
Binary files /dev/null and b/02.recognize_digits/image/03.gif differ
diff --git a/02.recognize_digits/image/03.png b/02.recognize_digits/image/03.png
deleted file mode 100644
index 6ddfa6ca692a0f7029f77ac46fba819b1c305a88..0000000000000000000000000000000000000000
Binary files a/02.recognize_digits/image/03.png and /dev/null differ
diff --git a/02.recognize_digits/image/04.gif b/02.recognize_digits/image/04.gif
new file mode 100644
index 0000000000000000000000000000000000000000..c201c5f480a63b03a58c9d02f5e059cb4a39634f
Binary files /dev/null and b/02.recognize_digits/image/04.gif differ
diff --git a/02.recognize_digits/image/04.png b/02.recognize_digits/image/04.png
deleted file mode 100644
index 4aba1801294c97a930ea193449a2bf610c61b160..0000000000000000000000000000000000000000
Binary files a/02.recognize_digits/image/04.png and /dev/null differ
diff --git a/02.recognize_digits/image/05.gif b/02.recognize_digits/image/05.gif
new file mode 100644
index 0000000000000000000000000000000000000000..fde225756e3a9696ef4d8f08c92c71e47460589d
Binary files /dev/null and b/02.recognize_digits/image/05.gif differ
diff --git a/02.recognize_digits/image/05.png b/02.recognize_digits/image/05.png
deleted file mode 100644
index ae8d505da283d78261d15039807e3797733b91c4..0000000000000000000000000000000000000000
Binary files a/02.recognize_digits/image/05.png and /dev/null differ
diff --git a/02.recognize_digits/index.cn.html b/02.recognize_digits/index.cn.html
index b1d752fe114a9d6587b169111b1e41796152feb7..2a3df1f19a22ee626c9291381c90348887ddaf30 100644
--- a/02.recognize_digits/index.cn.html
+++ b/02.recognize_digits/index.cn.html
@@ -88,12 +88,12 @@ MNIST吸引了大量的科学家基于此数据集训练模型,1998年,LeCun
输入层的数据$X$传到输出层,在激活操作之前,会乘以相应的权重 $W$ ,并加上偏置变量 $b$ ,具体如下:
-
+
其中
-
+
图2为softmax回归的网络图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
@@ -108,7 +108,7 @@ MNIST吸引了大量的科学家基于此数据集训练模型,1998年,LeCun
在分类问题中,我们一般采用交叉熵代价损失函数(cross entropy loss),公式如下:
-
+
@@ -177,13 +177,13 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
- sigmoid激活函数:
-
+
- tanh激活函数:
-
+
实际上,tanh函数只是规模变化的sigmoid函数,将sigmoid函数值放大2倍之后再向下平移1个单位:tanh(x) = 2sigmoid(2x) - 1 。
diff --git a/09.gan/README.cn.md b/09.gan/README.cn.md
index 23789a22db175dc9be8934b7c5aa2b3d17975922..0180960598f6e94ff6541795b0fd9c8f05ec63db 100644
--- a/09.gan/README.cn.md
+++ b/09.gan/README.cn.md
@@ -2,6 +2,14 @@
本教程源代码目录在book/09.gan,初次使用请您参考Book文档使用说明。
+### 说明: ###
+1. 硬件环境要求:
+本文可支持在CPU、GPU下运行
+2. Docker镜像支持的CUDA/cuDNN版本:
+如果使用了Docker运行Book,请注意:这里所提供的默认镜像的GPU环境为 CUDA 8/cuDNN 5,对于NVIDIA Tesla V100等要求CUDA 9的 GPU,使用该镜像可能会运行失败。
+3. 文档和脚本中代码的一致性问题:
+请注意:为使本文更加易读易用,我们拆分、调整了train.py的代码并放入本文。本文中代码与train.py的运行结果一致,可直接运行[train.py](https://github.com/PaddlePaddle/book/blob/develop/09.gan/dc_gan.py)进行验证。
+
## 背景介绍
生成对抗网络(Generative Adversarial Network \[[1](#参考文献)\],简称GAN)是非监督式学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。该方法最初由 lan·Goodfellow 等人于2014年提出,原论文见 [Generative Adversarial Network](https://arxiv.org/abs/1406.2661)。
@@ -30,7 +38,9 @@ GAN 网络顾名思义,是一种通过对抗的方式,去学习数据分布
在训练的过程中,两个网络互相对抗,最终形成了一个动态的平衡,上述过程用公式可以被描述为:
-$$ \min\limits_{G} \max\limits_{D}V(D,G)=\mathbb{E}_{x\sim P_{data} (x)}\big[logD(x)\big] + \mathbb{E}_{z\sim p_{z}(z)}\big[log(1-D(G(z)))\big] $$
+
+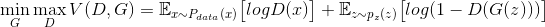
+
在最理想的情况下,G 可以生成与真实样本极其相似的图片G(z),而 D 很难判断这张生成的图片是否为真,对图片的真假进行随机猜测,即 D(G(z))=0.5。
diff --git a/09.gan/image/01.gif b/09.gan/image/01.gif
new file mode 100644
index 0000000000000000000000000000000000000000..9f952ae8d77ff2a5c07d4fcef90743393d9dcb59
Binary files /dev/null and b/09.gan/image/01.gif differ
diff --git a/09.gan/index.cn.html b/09.gan/index.cn.html
index 60b0ce9df3e2efe7061f4a6e7bfb746ea0638db4..3990a93ca9e6c547c5f93ce3d5a624ce054e8049 100644
--- a/09.gan/index.cn.html
+++ b/09.gan/index.cn.html
@@ -44,6 +44,14 @@
本教程源代码目录在book/09.gan,初次使用请您参考Book文档使用说明。
+### 说明: ###
+1. 硬件环境要求:
+本文可支持在CPU、GPU下运行
+2. Docker镜像支持的CUDA/cuDNN版本:
+如果使用了Docker运行Book,请注意:这里所提供的默认镜像的GPU环境为 CUDA 8/cuDNN 5,对于NVIDIA Tesla V100等要求CUDA 9的 GPU,使用该镜像可能会运行失败。
+3. 文档和脚本中代码的一致性问题:
+请注意:为使本文更加易读易用,我们拆分、调整了train.py的代码并放入本文。本文中代码与train.py的运行结果一致,可直接运行[train.py](https://github.com/PaddlePaddle/book/blob/develop/09.gan/dc_gan.py)进行验证。
+
## 背景介绍
生成对抗网络(Generative Adversarial Network \[[1](#参考文献)\],简称GAN)是非监督式学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。该方法最初由 lan·Goodfellow 等人于2014年提出,原论文见 [Generative Adversarial Network](https://arxiv.org/abs/1406.2661)。
@@ -72,7 +80,9 @@ GAN 网络顾名思义,是一种通过对抗的方式,去学习数据分布
在训练的过程中,两个网络互相对抗,最终形成了一个动态的平衡,上述过程用公式可以被描述为:
-$$ \min\limits_{G} \max\limits_{D}V(D,G)=\mathbb{E}_{x\sim P_{data} (x)}\big[logD(x)\big] + \mathbb{E}_{z\sim p_{z}(z)}\big[log(1-D(G(z)))\big] $$
+
+
+
在最理想的情况下,G 可以生成与真实样本极其相似的图片G(z),而 D 很难判断这张生成的图片是否为真,对图片的真假进行随机猜测,即 D(G(z))=0.5。