From 2a6a637dc9e70d8683536fa2ef4a6d1d74fca8e0 Mon Sep 17 00:00:00 2001
From: Hao Wang <31058429+haowang101779990@users.noreply.github.com>
Date: Sat, 9 Mar 2019 09:38:31 +0800
Subject: [PATCH] book translation all (#690)
---
01.fit_a_line/README.md | 432 +++++++++-------
01.fit_a_line/index.html | 432 +++++++++-------
02.recognize_digits/README.md | 563 ++++++++++++--------
02.recognize_digits/index.html | 563 ++++++++++++--------
03.image_classification/README.md | 371 ++++++++------
03.image_classification/index.html | 371 ++++++++------
04.word2vec/README.md | 535 +++++++++----------
04.word2vec/index.html | 535 +++++++++----------
05.recommender_system/README.md | 487 ++++++++++--------
05.recommender_system/index.html | 485 ++++++++++--------
06.understand_sentiment/README.md | 364 +++++++------
06.understand_sentiment/index.html | 364 +++++++------
07.label_semantic_roles/README.md | 792 ++++++++++++++---------------
07.label_semantic_roles/index.html | 792 ++++++++++++++---------------
08.machine_translation/README.md | 321 ++++++------
08.machine_translation/index.html | 321 ++++++------
16 files changed, 4279 insertions(+), 3449 deletions(-)
diff --git a/01.fit_a_line/README.md b/01.fit_a_line/README.md
index ecb4cde..23a9762 100644
--- a/01.fit_a_line/README.md
+++ b/01.fit_a_line/README.md
@@ -1,139 +1,146 @@
# Linear Regression
-Let us begin the tutorial with a classical problem called Linear Regression \[[1](#References)\]. In this chapter, we will train a model from a realistic dataset to predict home prices. Some important concepts in Machine Learning will be covered through this example.
+Let's start this tutorial from the classic Linear Regression ([[1](#References)]) model.
-The source code for this tutorial lives on [book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/01.fit_a_line). For instructions on getting started with this book,see [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book).
+In this chapter, you will build a model to predict house price with real datasets and learn about several important concepts about machine learning.
-## Problem Setup
+The source code of this tutorial is in [book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/01.fit_a_line). For the new users, please refer to [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book) .
-Suppose we have a dataset of $n$ real estate properties. Each real estate property will be referred to as **homes** in this chapter for clarity.
-Each home is associated with $d$ attributes. The attributes describe characteristics such as the number of rooms in the home, the number of schools or hospitals in the neighborhood, and the traffic condition nearby.
-In our problem setup, the attribute $x_{i,j}$ denotes the $j$th characteristic of the $i$th home. In addition, $y_i$ denotes the price of the $i$th home. Our task is to predict $y_i$ given a set of attributes $\{x_{i,1}, ..., x_{i,d}\}$. We assume that the price of a home is a linear combination of all of its attributes, namely,
+## Background
+Given a $n$ dataset ${\{y_{i}, x_{i1}, ..., x_{id}\}}_{i=1}^{n}$, of which $ x_{i1}, \ldots, x_{id}$ are the values of the $d$th attribute of $i$ sample, and $y_i$ is the target to be predicted for this sample.
-$$y_i = \omega_1x_{i,1} + \omega_2x_{i,2} + \ldots + \omega_dx_{i,d} + b, i=1,\ldots,n$$
+ The linear regression model assumes that the target $y_i$ can be described by a linear combination among attributes, i.e.
-where $\vec{\omega}$ and $b$ are the model parameters we want to estimate. Once they are learned, we will be able to predict the price of a home, given the attributes associated with it. We call this model **Linear Regression**. In other words, we want to regress a value against several values linearly. In practice, a linear model is often too simplistic to capture the real relationships between the variables. Yet, because Linear Regression is easy to train and analyze, it has been applied to a large number of real problems. As a result, it is an important topic in many classic Statistical Learning and Machine Learning textbooks \[[2,3,4](#References)\].
+$$y_i = \omega_1x_{i1} + \omega_2x_{i2} + \ldots + \omega_dx_{id} + b, i=1,\ldots,n$$
-## Results Demonstration
-We first show the result of our model. The dataset [UCI Housing Data Set](http://paddlemodels.bj.bcebos.com/uci_housing/housing.data) is used to train a linear model to predict the home prices in Boston. The figure below shows the predictions the model makes for some home prices. The $X$-axis represents the median value of the prices of similar homes within a bin, while the $Y$-axis represents the home value our linear model predicts. The dotted line represents points where $X=Y$. When reading the diagram, the closer the point is to the dotted line, better the model's prediction.
+For example, in the problem of prediction of house price we are going to explore, $x_{ij}$ is a description of the various attributes of the house $i$ (such as the number of rooms, the number of schools and hospitals around, traffic conditions, etc.). $y_i$ is the price of the house.
+
+
+
+At first glance, this assumption is too simple, and the true relationship among variables is unlikely to be linear. However, because the linear regression model has the advantages of simple form and easy to be modeled and analyzed, it has been widely applied in practical problems. Many classic statistical learning and machine learning books \[[2,3,4](#references)\] also focus on linear model in a chapter.
+
+## Result Demo
+We used the Boston house price dataset obtained from [UCI Housing dataset](http://paddlemodels.bj.bcebos.com/uci_housing/housing.data) to train and predict the model. The scatter plot below shows the result of price prediction for parts of house with model. Each point on x-axis represents the median of the real price of the same type of house, and the y-axis represents the result of the linear regression model based on the feature prediction. When the two values are completely equal, they will fall on the dotted line. So the more accurate the model is predicted, the closer the point is to the dotted line.
- 
- Figure 1. Predicted Value V.S. Actual Value
+ 
+ Figure One. Predict value V.S Ground-truth value
## Model Overview
### Model Definition
-In the UCI Housing Data Set, there are 13 home attributes $\{x_{i,j}\}$ that are related to the median home price $y_i$, which we aim to predict. Thus, our model can be written as:
+In the dataset of Boston house price, there are 14 values associated with the home: the first 13 are used to describe various information of house, that is $x_i$ in the model; the last value is the medium price of the house we want to predict, which is $y_i$ in the model.
+
+Therefore, our model can be expressed as:
$$\hat{Y} = \omega_1X_{1} + \omega_2X_{2} + \ldots + \omega_{13}X_{13} + b$$
-where $\hat{Y}$ is the predicted value used to differentiate from actual value $Y$. The model learns parameters $\omega_1, \ldots, \omega_{13}, b$, where the entries of $\vec{\omega}$ are **weights** and $b$ is **bias**.
+$\hat{Y}$ represents the predicted result of the model and is used to distinguish it from the real value $Y$. The parameters to be learned by the model are: $\omega_1, \ldots, \omega_{13}, b$.
-Now we need an objective to optimize, so that the learned parameters can make $\hat{Y}$ as close to $Y$ as possible. Let's refer to the concept of [Loss Function (Cost Function)](https://en.wikipedia.org/wiki/Loss_function). A loss function must output a non-negative value, given any pair of the actual value $y_i$ and the predicted value $\hat{y_i}$. This value reflects the magnitutude of the model error.
+After building the model, we need to give the model an optimization goal so that the learned parameters can make the predicted value $\hat{Y}$ get as close to the true value $Y$. Here we introduce the concept of loss function ([Loss Function](https://en.wikipedia.org/wiki/Loss_function), or Cost Function. Input the target value $y_{i}$ of any data sample and the predicted value $\hat{y_{i}}$ given by a model. Then the loss function outputs a non-negative real number, which is usually used to represent model error.
-For Linear Regression, the most common loss function is [Mean Square Error (MSE)](https://en.wikipedia.org/wiki/Mean_squared_error) which has the following form:
+For linear regression models, the most common loss function is the Mean Squared Error ([MSE](https://en.wikipedia.org/wiki/Mean_squared_error)), which is:
$$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
-That is, for a dataset of size $n$, MSE is the average value of the the prediction sqaure errors.
+That is, for a test set in size of $n$, $MSE$ is the mean of the squared error of the $n$ data prediction results.
+
+The method used to optimize the loss function is generally the gradient descent method. The gradient descent method is a first-order optimization algorithm. If $f(x)$ is defined and divisible at point $x_n$, then $f(x)$ is considered to be the fastest in the negative direction of the gradient $-▽f(x_n)$ at point of $x_n$. Adjust $x$ repeatedly to make $f(x)$ close to the local or global minimum value. The adjustment is as follows:
+
+$$x_n+1=x_n-λ▽f(x), n≧0$$
+
+Where λ represents the learning rate. This method of adjustment is called the gradient descent method.
### Training Process
-After setting up our model, there are several major steps to go through to train it:
-1. Initialize the parameters including the weights $\vec{\omega}$ and the bias $b$. For example, we can set their mean values as $0$s, and their standard deviations as $1$s.
-2. Feedforward. Evaluate the network output and compute the corresponding loss.
-3. [Backpropagate](https://en.wikipedia.org/wiki/Backpropagation) the errors. The errors will be propagated from the output layer back to the input layer, during which the model parameters will be updated with the corresponding errors.
-4. Repeat steps 2~3, until the loss is below a predefined threshold or the maximum number of epochs is reached.
+After defining the model structure, we will train the model through the following steps.
+
+ 1. Initialize parameters, including weights $\omega_i$ and bias $b$, to initialize them (eg. 0 as mean, 1 as variance).
+ 2. Forward propagation of network calculates network output and loss functions.
+ 3. Reverse error propagation according to the loss function ( [backpropagation](https://en.wikipedia.org/wiki/Backpropagation) ), passing forward the network error from the output layer and updating the parameters in the network.
+ 4. Repeat steps 2~3 until the network training error reaches the specified level or the training round reaches the set value.
-## Dataset
-### An Introduction of the Dataset
+## Dataset
-The UCI housing dataset has 506 instances. Each instance describes the attributes of a house in surburban Boston. The attributes are explained below:
+### Dataset Introduction
+The dataset consists of 506 lines, each containing information about a type of houses in a suburb of Boston and the median price of that type of house. The meaning of each dimensional attribute is as follows:
-| Attribute Name | Characteristic | Data Type |
+| Property Name | Explanation | Type |
| ------| ------ | ------ |
-| CRIM | per capita crime rate by town | Continuous|
-| ZN | proportion of residential land zoned for lots over 25,000 sq.ft. | Continuous |
-| INDUS | proportion of non-retail business acres per town | Continuous |
-| CHAS | Charles River dummy variable | Discrete, 1 if tract bounds river; 0 otherwise|
-| NOX | nitric oxides concentration (parts per 10 million) | Continuous |
-| RM | average number of rooms per dwelling | Continuous |
-| AGE | proportion of owner-occupied units built prior to 1940 | Continuous |
-| DIS | weighted distances to five Boston employment centres | Continuous |
-| RAD | index of accessibility to radial highways | Continuous |
-| TAX | full-value property-tax rate per \$10,000 | Continuous |
-| PTRATIO | pupil-teacher ratio by town | Continuous |
-| B | 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town | Continuous |
-| LSTAT | % lower status of the population | Continuous |
-| MEDV | Median value of owner-occupied homes in $1000's | Continuous |
+CRIM | Per capita crime rate in the town | Continuous value |
+| ZN | Proportion of residential land with an area of over 25,000 square feet | Continuous value |
+| INDUS | Proportion of non-retail commercial land | Continuous value |
+CHAS | Whether it is adjacent to Charles River | Discrete value, 1=proximity; 0=not adjacent |
+NOX | Nitric Oxide Concentration | Continuous value |
+| RM | Average number of rooms per house | Continuous value |
+| AGE | Proportion of self-use units built before 1940 | Continuous value |
+| DIS | Weighted Distance to 5 Job Centers in Boston | Continuous value |
+| RAD | Accessibility Index to Radial Highway | Continuous value |
+| TAX | Tax Rate of Full-value Property | Continuous value |
+| PTRATIO | Proportion of Student and Teacher | Continuous value |
+| B | 1000(BK - 0.63)^2, where BK is black ratio | Continuous value |
+LSTAT | Low-income population ratio | Continuous value |
+| MEDV | Median price of a similar home | Continuous value |
+
+### Data Pre-processing
-The last entry is the median home price.
+#### Continuous value and discrete value
+Analyzing the data, first we find that all 13-dimensional attributes exist 12-dimensional continuous value and 1-dimensional discrete values (CHAS). Discrete value is often represented by numbers like 0, 1, and 2, but its meaning is different from continuous value's because the difference of discrete value here has no meaning. For example, if we use 0, 1, and 2 to represent red, green, and blue, we cannot infer that the distance between blue and red is longer than that between green and red. So usually for a discrete property with $d$ possible values, we will convert them to $d$ binary properties with a value of 0 or 1 or map each possible value to a multidimensional vector. However, there is no this problem for CHAS, since CHAS itself is a binary attribute .
-### Preprocessing
+#### Normalization of attributes
+Another fact that can be easily found is that the range of values of each dimensional attribute is largely different (as shown in Figure 2). For example, the value range of attribute B is [0.32, 396.90], and the value range of attribute NOX is [0.3850, 0.8170]. Here is a common operation - normalization. The goal of normalization is to scale the value of each attribute to a similar range, such as [-0.5, 0.5]. Here we use a very common operation method: subtract the mean and divide by the range of values.
-#### Continuous and Discrete Data
+There are at least three reasons for implementing normalization (or [Feature scaling](https://en.wikipedia.org/wiki/Feature_scaling)):
-We define a feature vector of length 13 for each home, where each entry corresponds to an attribute. Our first observation is that, among the 13 dimensions, there are 12 continuous dimensions and 1 discrete dimension.
+- A range of values that are too large or too small can cause floating value overflow or underflow during calculation.
-Note that although a discrete value is also written as numeric values such as 0, 1, or 2, its meaning differs from a continuous value drastically. The linear difference between two discrete values has no meaning. For example, suppose $0$, $1$, and $2$ are used to represent colors *Red*, *Green*, and *Blue* respectively. Judging from the numeric representation of these colors, *Red* differs more from *Blue* than it does from *Green*. Yet in actuality, it is not true that extent to which the color *Blue* is different from *Red* is greater than the extent to which *Green* is different from *Red*. Therefore, when handling a discrete feature that has $d$ possible values, we usually convert it to $d$ new features where each feature takes a binary value, $0$ or $1$, indicating whether the original value is absent or present. Alternatively, the discrete features can be mapped onto a continuous multi-dimensional vector through an embedding table. For our problem here, because CHAS itself is a binary discrete value, we do not need to do any preprocessing.
+- Different ranges of number result in different attributes being different for the model (at least in the initial period of training), and this implicit assumption is often unreasonable. This can make the optimization process difficult and the training time greatly longer.
-#### Feature Normalization
+- Many machine learning techniques/models (such as L1, L2 regular items, Vector Space Model) are based on the assumption that all attribute values are almost zero and their ranges of value are similar.
-We also observe a huge difference among the value ranges of the 13 features (Figure 2). For instance, the values of feature *B* fall in $[0.32, 396.90]$, whereas those of feature *NOX* has a range of $[0.3850, 0.8170]$. An effective optimization would require data normalization. The goal of data normalization is to scale the values of each feature into roughly the same range, perhaps $[-0.5, 0.5]$. Here, we adopt a popular normalization technique where we subtract the mean value from the feature value and divide the result by the width of the original range.
-There are at least three reasons for [Feature Normalization](https://en.wikipedia.org/wiki/Feature_scaling) (Feature Scaling):
-- A value range that is too large or too small might cause floating number overflow or underflow during computation.
-- Different value ranges might result in varying *importances* of different features to the model (at least in the beginning of the training process). This assumption about the data is often unreasonable, making the optimization difficult, which in turn results in increased training time.
-- Many machine learning techniques or models (e.g., *L1/L2 regularization* and *Vector Space Model*) assumes that all the features have roughly zero means and their value ranges are similar.
- 
- Figure 2. The value ranges of the features
+ 
+ Figure 2. Value range of attributes for all dimensions
-#### Prepare Training and Test Sets
+#### Organizing training set and testing set
+
+We split the dataset into two parts: one is used to adjust the parameters of the model, that is, to train the model, the error of the model on this dataset is called ** training error **; the other is used to test.The error of the model on this dataset is called the ** test error**. The goal of our training model is to predict unknown new data by finding the regulation from the training data, so the test error is an better indicator for the performance of the model. When it comes to the ratio of the segmentation data, we should take into account two factors: more training data will reduce the square error of estimated parameters, resulting in a more reliable model; and more test data will reduce the square error of the test error, resulting in more credible test error. The split ratio set in our example is $8:2$
-We split the dataset in two, one for adjusting the model parameters, namely, for training the model, and the other for testing. The model error on the former is called the **training error**, and the error on the latter is called the **test error**. Our goal in training a model is to find the statistical dependency between the outputs and the inputs, so that we can predict outputs given new inputs. As a result, the test error reflects the performance of the model better than the training error does. We consider two things when deciding the ratio of the training set to the test set: 1) More training data will decrease the variance of the parameter estimation, yielding more reliable models; 2) More test data will decrease the variance of the test error, yielding more reliable test errors. One standard split ratio is $8:2$.
-When training complex models, we usually have one more split: the validation set. Complex models usually have [Hyperparameters](https://en.wikipedia.org/wiki/Hyperparameter_optimization) that need to be set before the training process, such as the number of layers in the network. Because hyperparameters are not part of the model parameters, they cannot be trained using the same loss function. Thus we will try several sets of hyperparameters to train several models and cross-validate them on the validation set to pick the best one; finally, the selected trained model is tested on the test set. Because our model is relatively simple, we will omit this validation process.
+In a more complex model training process, we often need more than one dataset: the validation set. Because complex models often have some hyperparameters ([Hyperparameter](https://en.wikipedia.org/wiki/Hyperparameter_optimization)) that need to be adjusted, we will try a combination of multiple hyperparameters to train multiple models separately and then compare their performance on the validation set to select the relatively best set of hyperparameters, and finally use the model with this set of parameters to evaluate the test error on the test set. Since the model trained in this chapter is relatively simple, we won't talk about this process at present.
## Training
-`fit_a_line/trainer.py` demonstrates the training using [PaddlePaddle](http://paddlepaddle.org).
+`fit_a_line/trainer.py` demonstrates the overall process of training.
-### Datafeeder Configuration
+### Configuring the Data feeder
-Our program starts with importing necessary packages:
+First we import the libraries:
```python
import paddle
import paddle.fluid as fluid
import numpy
+import math
+import sys
from __future__ import print_function
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
-
```
-We encapsulated the [UCI Housing Data Set](http://paddlemodels.bj.bcebos.com/uci_housing/housing.data) in our Python module `uci_housing`. This module can
+We introduced the dataset [UCI Housing dataset](http://paddlemodels.bj.bcebos.com/uci_housing/housing.data) via the uci_housing module
-1. download the dataset to `~/.cache/paddle/dataset/uci_housing/housing.data`, if you haven't yet, and
-2. [preprocess](#preprocessing) the dataset.
+It is encapsulated in the uci_housing module:
+1. The process of data download. The download data is saved in ~/.cache/paddle/dataset/uci_housing/housing.data.
+2. The process of [data preprocessing](#data preprocessing).
-We define data feeders for test and train. The feeder reads a `BATCH_SIZE` of data each time and feed them to the training/testing process. If the user wants some randomness on the data order, she can define both a `BATCH_SIZE` and a `buf_size`. That way the datafeeder will yield the first `BATCH_SIZE` data out of a shuffle of the first `buf_size` data.
+Next we define the data feeder for training. The data feeder reads a batch of data in the size of `BATCH_SIZE` each time. If the user wants the data to be random, it can define data in size of a batch and a cache. In this case, each time the data feeder randomly reads as same data as the batch size from the cache.
```python
BATCH_SIZE = 20
@@ -141,177 +148,244 @@ BATCH_SIZE = 20
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.uci_housing.train(), buf_size=500),
- batch_size=BATCH_SIZE)
+ batch_size=BATCH_SIZE)
test_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.uci_housing.test(), buf_size=500),
- batch_size=BATCH_SIZE)
+ batch_size=BATCH_SIZE)
```
-### Train Program Configuration
+If you want to read data directly from \*.txt file, you can refer to the method as follows.
-`train_program` sets up the network structure of this current training model. For linear regression, it is simply a fully connected layer from the input to the output. More complex structures like CNN and RNN will be introduced in later chapters. The `train_program` must return an avg_loss as its first returned parameter because it is needed in backpropagation.
+feature_names = [
+ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
+ 'PTRATIO', 'B', 'LSTAT', 'convert'
+]
-```python
-def train_program():
- y = fluid.layers.data(name='y', shape=[1], dtype='float32')
+feature_num = len(feature_names)
- # feature vector of length 13
- x = fluid.layers.data(name='x', shape=[13], dtype='float32')
- y_predict = fluid.layers.fc(input=x, size=1, act=None)
+data = numpy.fromfile(filename, sep=' ') # Read primary data from file
- loss = fluid.layers.square_error_cost(input=y_predict, label=y)
- avg_loss = fluid.layers.mean(loss)
+data = data.reshape(data.shape[0] // feature_num, feature_num)
- return avg_loss
-```
+maximums, minimums, avgs = data.max(axis=0), data.min(axis=0), data.sum(axis=0)/data.shape[0]
-### Optimizer Function Configuration
+for i in six.moves.range(feature_num-1):
+ data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i]) # six.moves is compatible to python2 and python3
-In the following `SGD` optimizer, `learning_rate` specifies the learning rate in the optimization procedure.
+ratio = 0.8 # distribution ratio of train dataset and verification dataset
-```python
-def optimizer_program():
- return fluid.optimizer.SGD(learning_rate=0.001)
-```
+offset = int(data.shape[0]\*ratio)
-### Specify Place
+train_data = data[:offset]
-Specify your training environment, you should specify if the training is on CPU or GPU.
+test_data = data[offset:]
-```python
-use_cuda = False
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-```
+train_reader = paddle.batch(
+ paddle.reader.shuffle(
+ train_data, buf_size=500),
+ batch_size=BATCH_SIZE)
-### Create Trainer
+test_reader = paddle.batch(
+ paddle.reader.shuffle(
+ test_data, buf_size=500),
+ batch_size=BATCH_SIZE)
-The trainer will take the `train_program` as input.
+### Configure Program for Training
+The aim of the program for training is to define a network structure of a training model. For linear regression, it is a simple fully connected layer from input to output. More complex result, such as Convolutional Neural Network and Recurrent Neural Network, will be introduced in later chapters. It must return `mean error` as the first return value in program for training, for that `mean error` will be used for BackPropagation.
```python
-trainer = Trainer(
- train_func=train_program,
- place=place,
- optimizer_func=optimizer_program)
+x = fluid.layers.data(name='x', shape=[13], dtype='float32') # define shape and data type of input
+y = fluid.layers.data(name='y', shape=[1], dtype='float32') # define shape and data type of output
+y_predict = fluid.layers.fc(input=x, size=1, act=None) # fully connected layer connecting input and output
+
+main_program = fluid.default_main_program() # get default/global main function
+startup_program = fluid.default_startup_program() # get default/global launch program
+
+cost = fluid.layers.square_error_cost(input=y_predict, label=y) # use label and output predicted data to estimate square error
+avg_loss = fluid.layers.mean(cost) # compute mean value for square error and get mean loss
```
+For details, please refer to:
+[fluid.default_main_program](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#default-main-program)
+[fluid.default_startup_program](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#default-startup-program)
-### Feeding Data
+### Optimizer Function Configuration
-PaddlePaddle provides the
-[reader mechanism](https://github.com/PaddlePaddle/Paddle/tree/develop/doc/design/reader)
-for loading the training data. A reader may return multiple columns, and we need a Python dictionary to specify the mapping from column index to data layers.
+`SGD optimizer`, `learning_rate` below are learning rate, which is related to rate of convergence for train of network.
```python
-feed_order=['x', 'y']
+sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001)
+sgd_optimizer.minimize(avg_loss)
+
+#Clone main_program to get test_program
+# operations of some operators are different between train and test. For example, batch_norm use parameter for_test to determine whether the program is for training or for testing.
+#The api will not delete any operator, please apply it before backward and optimization.
+test_program = main_program.clone(for_test=True)
```
-Moreover, an event handler is provided to print the training progress:
+### Define Training Place
-```python
-# Specify the directory to save the parameters
-params_dirname = "fit_a_line.inference.model"
+We can define whether an operation runs on the CPU or on the GPU.
+```python
+use_cuda = False
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace() # define the execution space of executor
-train_title = "Train cost"
-test_title = "Test cost"
+###executor can accept input program and add data input operator and result fetch operator based on feed map and fetch list. Use close() to close executor and call run(...) to run the program.
+exe = fluid.Executor(place)
-step = 0
+```
+For details, please refer to:
+[fluid.executor](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#permalink-15-executor)
-# event_handler prints training and testing info
-def event_handler(event):
- global step
- if isinstance(event, EndStepEvent):
- if step % 10 == 0: # record a train cost every 10 batches
- print("%s, Step %d, Cost %f" % (train_title, step, event.metrics[0]))
-
- if step % 100 == 0: # record a test cost every 100 batches
- test_metrics = trainer.test(
- reader=test_reader, feed_order=feed_order)
- print("%s, Step %d, Cost %f" % (test_title, step, test_metrics[0]))
- if test_metrics[0] < 10.0:
- # If the accuracy is good enough, we can stop the training.
- print('loss is less than 10.0, stop')
- trainer.stop()
- step += 1
+### Create Training Process
+To train, it needs a train program and some parameters and creates a function to get test error in the process of train necessary parameters contain executor, program, reader, feeder, fetch_list, executor represents executor created before. Program created before represents program executed by executor. If the parameter is undefined, then it is defined default_main_program by default. Reader represents data read. Feeder represents forward input variable and fetch_list represents variable user wants to get or name.
- if isinstance(event, EndEpochEvent):
- if event.epoch % 10 == 0:
- # We can save the trained parameters for the inferences later
- if params_dirname is not None:
- trainer.save_params(params_dirname)
+```python
+num_epochs = 100
+
+def train_test(executor, program, reader, feeder, fetch_list):
+ accumulated = 1 * [0]
+ count = 0
+ for data_test in reader():
+ outs = executor.run(program=program,
+ feed=feeder.feed(data_test),
+ fetch_list=fetch_list)
+ accumulated = [x_c[0] + x_c[1][0] for x_c in zip(accumulated, outs)] # accumulate loss value in the process of test
+ count += 1 # accumulate samples in test dataset
+ return [x_d / count for x_d in accumulated] # compute mean loss
```
-### Start Training
+### Train Main Loop
-We now can start training by calling `trainer.train()`.
+give name of directory to be stored and initialize an executor
```python
%matplotlib inline
+params_dirname = "fit_a_line.inference.model"
+feeder = fluid.DataFeeder(place=place, feed_list=[x, y])
+exe.run(startup_program)
+train_prompt = "train cost"
+test_prompt = "test cost"
+from paddle.utils.plot import Ploter
+plot_prompt = Ploter(train_prompt, test_prompt)
+step = 0
-# The training could take up to a few minutes.
-trainer.train(
- reader=train_reader,
- num_epochs=100,
- event_handler=event_handler,
- feed_order=feed_order)
-
+exe_test = fluid.Executor(place)
```
+Paddlepaddle provides reader mechanism to read training data. Reader provide multiple columns of data at one time. Therefore, we need a python list to read sequence. We create a loop to train until the result of train is good enough or time of loop is enough.
+If the number of iterations for train is equal to the number of iterations for saving parameters, you can save train parameter into `params_dirname`.
+Set main loop for training.
+```python
+for pass_id in range(num_epochs):
+ for data_train in train_reader():
+ avg_loss_value, = exe.run(main_program,
+ feed=feeder.feed(data_train),
+ fetch_list=[avg_loss])
+ if step % 10 == 0: # record and output train loss for every 10 batches.
+ plot_prompt.append(train_prompt, step, avg_loss_value[0])
+ plot_prompt.plot()
+ print("%s, Step %d, Cost %f" %
+ (train_prompt, step, avg_loss_value[0]))
+ if step % 100 == 0: # record and output test loss for every 100 batches.
+ test_metics = train_test(executor=exe_test,
+ program=test_program,
+ reader=test_reader,
+ fetch_list=[avg_loss.name],
+ feeder=feeder)
+ plot_prompt.append(test_prompt, step, test_metics[0])
+ plot_prompt.plot()
+ print("%s, Step %d, Cost %f" %
+ (test_prompt, step, test_metics[0]))
+ if test_metics[0] < 10.0: # If the accuracy is up to the requirement, the train can be stopped.
+ break
-
+ step += 1
-## Inference
+ if math.isnan(float(avg_loss_value[0])):
+ sys.exit("got NaN loss, training failed.")
-Initialize the Inferencer with the inference_program and the params_dirname, which is where we saved our params
+ #save train parameters into the path given before
+ if params_dirname is not None:
+ fluid.io.save_inference_model(params_dirname, ['x'], [y_predict], exe)
+```
-### Setup the Inference Program
+## Predict
+It needs to create trained parameters to run program for prediction. The trained parameters is in `params_dirname`.
-Similar to the trainer.train, the Inferencer needs to take an inference_program to do inference.
-Prune the train_program to only have the y_predict.
+### Prepare Environment for Prediction
+Similar to the process of training, predictor needs a program for prediction. We can slightly modify our training program to include the prediction value.
```python
-def inference_program():
- x = fluid.layers.data(name='x', shape=[13], dtype='float32')
- y_predict = fluid.layers.fc(input=x, size=1, act=None)
- return y_predict
+infer_exe = fluid.Executor(place)
+inference_scope = fluid.core.Scope()
```
-### Infer
-
-Inferencer will load the trained model from `params_dirname` and use it to infer the unseen data.
+### Predict
+Save pictures
```python
-inferencer = Inferencer(
- infer_func=inference_program, param_path=params_dirname, place=place)
+def save_result(points1, points2):
+ import matplotlib
+ matplotlib.use('Agg')
+ import matplotlib.pyplot as plt
+ x1 = [idx for idx in range(len(points1))]
+ y1 = points1
+ y2 = points2
+ l1 = plt.plot(x1, y1, 'r--', label='predictions')
+ l2 = plt.plot(x1, y2, 'g--', label='GT')
+ plt.plot(x1, y1, 'ro-', x1, y2, 'g+-')
+ plt.title('predictions VS GT')
+ plt.legend()
+ plt.savefig('./image/prediction_gt.png')
+```
-batch_size = 10
-test_reader = paddle.batch(paddle.dataset.uci_housing.test(),batch_size=batch_size)
-test_data = next(test_reader())
-test_x = numpy.array([data[0] for data in test_data]).astype("float32")
-test_y = numpy.array([data[1] for data in test_data]).astype("float32")
+Via fluid.io.load_inference_model, predictor will read well-trained model from `params_dirname` to predict unknown data.
-results = inferencer.infer({'x': test_x})
+```python
+with fluid.scope_guard(inference_scope):
+ [inference_program, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(params_dirname, infer_exe) # load pre-predict model
+ batch_size = 10
+
+ infer_reader = paddle.batch(
+ paddle.dataset.uci_housing.test(), batch_size=batch_size) # prepare test dataset
+
+ infer_data = next(infer_reader())
+ infer_feat = numpy.array(
+ [data[0] for data in infer_data]).astype("float32") # extract data in test dataset
+ infer_label = numpy.array(
+ [data[1] for data in infer_data]).astype("float32") # extract label in test dataset
+
+ assert feed_target_names[0] == 'x'
+ results = infer_exe.run(inference_program,
+ feed={feed_target_names[0]: numpy.array(infer_feat)},
+ fetch_list=fetch_targets) # predict
+ #print predict result and label and visualize the result
+ print("infer results: (House Price)")
+ for idx, val in enumerate(results[0]):
+ print("%d: %.2f" % (idx, val)) # print predict result
+
+ print("\nground truth:")
+ for idx, val in enumerate(infer_label):
+ print("%d: %.2f" % (idx, val)) # print label
+
+ save_result(results[0], infer_label) # save picture
+```
-print("infer results: (House Price)")
-for idx, val in enumerate(results[0]):
- print("%d: %.2f" % (idx, val))
-print("\nground truth:")
-for idx, val in enumerate(test_y):
- print("%d: %.2f" % (idx, val))
-```
## Summary
+In this chapter, we analyzed dataset of Boston House Price to introduce the basic concepts of linear regression model and how to use PaddlePaddle to implement training and testing. A number of models and theories are derived from linear regression model. Therefore, it is not unnecessary to figure out the principle and limitation of linear regression model.
-This chapter introduces *Linear Regression* and how to train and test this model with PaddlePaddle, using the UCI Housing Data Set. Because a large number of more complex models and techniques are derived from linear regression, it is important to understand its underlying theory and limitation.
-
+
## References
-
1. https://en.wikipedia.org/wiki/Linear_regression
2. Friedman J, Hastie T, Tibshirani R. The elements of statistical learning[M]. Springer, Berlin: Springer series in statistics, 2001.
3. Murphy K P. Machine learning: a probabilistic perspective[M]. MIT press, 2012.
4. Bishop C M. Pattern recognition[J]. Machine Learning, 2006, 128.
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/01.fit_a_line/index.html b/01.fit_a_line/index.html
index 8613f6c..56876f2 100644
--- a/01.fit_a_line/index.html
+++ b/01.fit_a_line/index.html
@@ -42,140 +42,147 @@
# Linear Regression
-Let us begin the tutorial with a classical problem called Linear Regression \[[1](#References)\]. In this chapter, we will train a model from a realistic dataset to predict home prices. Some important concepts in Machine Learning will be covered through this example.
+Let's start this tutorial from the classic Linear Regression ([[1](#References)]) model.
-The source code for this tutorial lives on [book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/01.fit_a_line). For instructions on getting started with this book,see [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book).
+In this chapter, you will build a model to predict house price with real datasets and learn about several important concepts about machine learning.
-## Problem Setup
+The source code of this tutorial is in [book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/01.fit_a_line). For the new users, please refer to [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book) .
-Suppose we have a dataset of $n$ real estate properties. Each real estate property will be referred to as **homes** in this chapter for clarity.
-Each home is associated with $d$ attributes. The attributes describe characteristics such as the number of rooms in the home, the number of schools or hospitals in the neighborhood, and the traffic condition nearby.
-In our problem setup, the attribute $x_{i,j}$ denotes the $j$th characteristic of the $i$th home. In addition, $y_i$ denotes the price of the $i$th home. Our task is to predict $y_i$ given a set of attributes $\{x_{i,1}, ..., x_{i,d}\}$. We assume that the price of a home is a linear combination of all of its attributes, namely,
+## Background
+Given a $n$ dataset ${\{y_{i}, x_{i1}, ..., x_{id}\}}_{i=1}^{n}$, of which $ x_{i1}, \ldots, x_{id}$ are the values of the $d$th attribute of $i$ sample, and $y_i$ is the target to be predicted for this sample.
-$$y_i = \omega_1x_{i,1} + \omega_2x_{i,2} + \ldots + \omega_dx_{i,d} + b, i=1,\ldots,n$$
+ The linear regression model assumes that the target $y_i$ can be described by a linear combination among attributes, i.e.
-where $\vec{\omega}$ and $b$ are the model parameters we want to estimate. Once they are learned, we will be able to predict the price of a home, given the attributes associated with it. We call this model **Linear Regression**. In other words, we want to regress a value against several values linearly. In practice, a linear model is often too simplistic to capture the real relationships between the variables. Yet, because Linear Regression is easy to train and analyze, it has been applied to a large number of real problems. As a result, it is an important topic in many classic Statistical Learning and Machine Learning textbooks \[[2,3,4](#References)\].
+$$y_i = \omega_1x_{i1} + \omega_2x_{i2} + \ldots + \omega_dx_{id} + b, i=1,\ldots,n$$
-## Results Demonstration
-We first show the result of our model. The dataset [UCI Housing Data Set](http://paddlemodels.bj.bcebos.com/uci_housing/housing.data) is used to train a linear model to predict the home prices in Boston. The figure below shows the predictions the model makes for some home prices. The $X$-axis represents the median value of the prices of similar homes within a bin, while the $Y$-axis represents the home value our linear model predicts. The dotted line represents points where $X=Y$. When reading the diagram, the closer the point is to the dotted line, better the model's prediction.
+For example, in the problem of prediction of house price we are going to explore, $x_{ij}$ is a description of the various attributes of the house $i$ (such as the number of rooms, the number of schools and hospitals around, traffic conditions, etc.). $y_i$ is the price of the house.
+
+
+
+At first glance, this assumption is too simple, and the true relationship among variables is unlikely to be linear. However, because the linear regression model has the advantages of simple form and easy to be modeled and analyzed, it has been widely applied in practical problems. Many classic statistical learning and machine learning books \[[2,3,4](#references)\] also focus on linear model in a chapter.
+
+## Result Demo
+We used the Boston house price dataset obtained from [UCI Housing dataset](http://paddlemodels.bj.bcebos.com/uci_housing/housing.data) to train and predict the model. The scatter plot below shows the result of price prediction for parts of house with model. Each point on x-axis represents the median of the real price of the same type of house, and the y-axis represents the result of the linear regression model based on the feature prediction. When the two values are completely equal, they will fall on the dotted line. So the more accurate the model is predicted, the closer the point is to the dotted line.
-
- Figure 1. Predicted Value V.S. Actual Value
+
+ Figure One. Predict value V.S Ground-truth value
## Model Overview
### Model Definition
-In the UCI Housing Data Set, there are 13 home attributes $\{x_{i,j}\}$ that are related to the median home price $y_i$, which we aim to predict. Thus, our model can be written as:
+In the dataset of Boston house price, there are 14 values associated with the home: the first 13 are used to describe various information of house, that is $x_i$ in the model; the last value is the medium price of the house we want to predict, which is $y_i$ in the model.
+
+Therefore, our model can be expressed as:
$$\hat{Y} = \omega_1X_{1} + \omega_2X_{2} + \ldots + \omega_{13}X_{13} + b$$
-where $\hat{Y}$ is the predicted value used to differentiate from actual value $Y$. The model learns parameters $\omega_1, \ldots, \omega_{13}, b$, where the entries of $\vec{\omega}$ are **weights** and $b$ is **bias**.
+$\hat{Y}$ represents the predicted result of the model and is used to distinguish it from the real value $Y$. The parameters to be learned by the model are: $\omega_1, \ldots, \omega_{13}, b$.
-Now we need an objective to optimize, so that the learned parameters can make $\hat{Y}$ as close to $Y$ as possible. Let's refer to the concept of [Loss Function (Cost Function)](https://en.wikipedia.org/wiki/Loss_function). A loss function must output a non-negative value, given any pair of the actual value $y_i$ and the predicted value $\hat{y_i}$. This value reflects the magnitutude of the model error.
+After building the model, we need to give the model an optimization goal so that the learned parameters can make the predicted value $\hat{Y}$ get as close to the true value $Y$. Here we introduce the concept of loss function ([Loss Function](https://en.wikipedia.org/wiki/Loss_function), or Cost Function. Input the target value $y_{i}$ of any data sample and the predicted value $\hat{y_{i}}$ given by a model. Then the loss function outputs a non-negative real number, which is usually used to represent model error.
-For Linear Regression, the most common loss function is [Mean Square Error (MSE)](https://en.wikipedia.org/wiki/Mean_squared_error) which has the following form:
+For linear regression models, the most common loss function is the Mean Squared Error ([MSE](https://en.wikipedia.org/wiki/Mean_squared_error)), which is:
$$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
-That is, for a dataset of size $n$, MSE is the average value of the the prediction sqaure errors.
+That is, for a test set in size of $n$, $MSE$ is the mean of the squared error of the $n$ data prediction results.
+
+The method used to optimize the loss function is generally the gradient descent method. The gradient descent method is a first-order optimization algorithm. If $f(x)$ is defined and divisible at point $x_n$, then $f(x)$ is considered to be the fastest in the negative direction of the gradient $-▽f(x_n)$ at point of $x_n$. Adjust $x$ repeatedly to make $f(x)$ close to the local or global minimum value. The adjustment is as follows:
+
+$$x_n+1=x_n-λ▽f(x), n≧0$$
+
+Where λ represents the learning rate. This method of adjustment is called the gradient descent method.
### Training Process
-After setting up our model, there are several major steps to go through to train it:
-1. Initialize the parameters including the weights $\vec{\omega}$ and the bias $b$. For example, we can set their mean values as $0$s, and their standard deviations as $1$s.
-2. Feedforward. Evaluate the network output and compute the corresponding loss.
-3. [Backpropagate](https://en.wikipedia.org/wiki/Backpropagation) the errors. The errors will be propagated from the output layer back to the input layer, during which the model parameters will be updated with the corresponding errors.
-4. Repeat steps 2~3, until the loss is below a predefined threshold or the maximum number of epochs is reached.
+After defining the model structure, we will train the model through the following steps.
+
+ 1. Initialize parameters, including weights $\omega_i$ and bias $b$, to initialize them (eg. 0 as mean, 1 as variance).
+ 2. Forward propagation of network calculates network output and loss functions.
+ 3. Reverse error propagation according to the loss function ( [backpropagation](https://en.wikipedia.org/wiki/Backpropagation) ), passing forward the network error from the output layer and updating the parameters in the network.
+ 4. Repeat steps 2~3 until the network training error reaches the specified level or the training round reaches the set value.
-## Dataset
-### An Introduction of the Dataset
+## Dataset
-The UCI housing dataset has 506 instances. Each instance describes the attributes of a house in surburban Boston. The attributes are explained below:
+### Dataset Introduction
+The dataset consists of 506 lines, each containing information about a type of houses in a suburb of Boston and the median price of that type of house. The meaning of each dimensional attribute is as follows:
-| Attribute Name | Characteristic | Data Type |
+| Property Name | Explanation | Type |
| ------| ------ | ------ |
-| CRIM | per capita crime rate by town | Continuous|
-| ZN | proportion of residential land zoned for lots over 25,000 sq.ft. | Continuous |
-| INDUS | proportion of non-retail business acres per town | Continuous |
-| CHAS | Charles River dummy variable | Discrete, 1 if tract bounds river; 0 otherwise|
-| NOX | nitric oxides concentration (parts per 10 million) | Continuous |
-| RM | average number of rooms per dwelling | Continuous |
-| AGE | proportion of owner-occupied units built prior to 1940 | Continuous |
-| DIS | weighted distances to five Boston employment centres | Continuous |
-| RAD | index of accessibility to radial highways | Continuous |
-| TAX | full-value property-tax rate per \$10,000 | Continuous |
-| PTRATIO | pupil-teacher ratio by town | Continuous |
-| B | 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town | Continuous |
-| LSTAT | % lower status of the population | Continuous |
-| MEDV | Median value of owner-occupied homes in $1000's | Continuous |
+CRIM | Per capita crime rate in the town | Continuous value |
+| ZN | Proportion of residential land with an area of over 25,000 square feet | Continuous value |
+| INDUS | Proportion of non-retail commercial land | Continuous value |
+CHAS | Whether it is adjacent to Charles River | Discrete value, 1=proximity; 0=not adjacent |
+NOX | Nitric Oxide Concentration | Continuous value |
+| RM | Average number of rooms per house | Continuous value |
+| AGE | Proportion of self-use units built before 1940 | Continuous value |
+| DIS | Weighted Distance to 5 Job Centers in Boston | Continuous value |
+| RAD | Accessibility Index to Radial Highway | Continuous value |
+| TAX | Tax Rate of Full-value Property | Continuous value |
+| PTRATIO | Proportion of Student and Teacher | Continuous value |
+| B | 1000(BK - 0.63)^2, where BK is black ratio | Continuous value |
+LSTAT | Low-income population ratio | Continuous value |
+| MEDV | Median price of a similar home | Continuous value |
+
+### Data Pre-processing
-The last entry is the median home price.
+#### Continuous value and discrete value
+Analyzing the data, first we find that all 13-dimensional attributes exist 12-dimensional continuous value and 1-dimensional discrete values (CHAS). Discrete value is often represented by numbers like 0, 1, and 2, but its meaning is different from continuous value's because the difference of discrete value here has no meaning. For example, if we use 0, 1, and 2 to represent red, green, and blue, we cannot infer that the distance between blue and red is longer than that between green and red. So usually for a discrete property with $d$ possible values, we will convert them to $d$ binary properties with a value of 0 or 1 or map each possible value to a multidimensional vector. However, there is no this problem for CHAS, since CHAS itself is a binary attribute .
-### Preprocessing
+#### Normalization of attributes
+Another fact that can be easily found is that the range of values of each dimensional attribute is largely different (as shown in Figure 2). For example, the value range of attribute B is [0.32, 396.90], and the value range of attribute NOX is [0.3850, 0.8170]. Here is a common operation - normalization. The goal of normalization is to scale the value of each attribute to a similar range, such as [-0.5, 0.5]. Here we use a very common operation method: subtract the mean and divide by the range of values.
-#### Continuous and Discrete Data
+There are at least three reasons for implementing normalization (or [Feature scaling](https://en.wikipedia.org/wiki/Feature_scaling)):
-We define a feature vector of length 13 for each home, where each entry corresponds to an attribute. Our first observation is that, among the 13 dimensions, there are 12 continuous dimensions and 1 discrete dimension.
+- A range of values that are too large or too small can cause floating value overflow or underflow during calculation.
-Note that although a discrete value is also written as numeric values such as 0, 1, or 2, its meaning differs from a continuous value drastically. The linear difference between two discrete values has no meaning. For example, suppose $0$, $1$, and $2$ are used to represent colors *Red*, *Green*, and *Blue* respectively. Judging from the numeric representation of these colors, *Red* differs more from *Blue* than it does from *Green*. Yet in actuality, it is not true that extent to which the color *Blue* is different from *Red* is greater than the extent to which *Green* is different from *Red*. Therefore, when handling a discrete feature that has $d$ possible values, we usually convert it to $d$ new features where each feature takes a binary value, $0$ or $1$, indicating whether the original value is absent or present. Alternatively, the discrete features can be mapped onto a continuous multi-dimensional vector through an embedding table. For our problem here, because CHAS itself is a binary discrete value, we do not need to do any preprocessing.
+- Different ranges of number result in different attributes being different for the model (at least in the initial period of training), and this implicit assumption is often unreasonable. This can make the optimization process difficult and the training time greatly longer.
-#### Feature Normalization
+- Many machine learning techniques/models (such as L1, L2 regular items, Vector Space Model) are based on the assumption that all attribute values are almost zero and their ranges of value are similar.
-We also observe a huge difference among the value ranges of the 13 features (Figure 2). For instance, the values of feature *B* fall in $[0.32, 396.90]$, whereas those of feature *NOX* has a range of $[0.3850, 0.8170]$. An effective optimization would require data normalization. The goal of data normalization is to scale the values of each feature into roughly the same range, perhaps $[-0.5, 0.5]$. Here, we adopt a popular normalization technique where we subtract the mean value from the feature value and divide the result by the width of the original range.
-There are at least three reasons for [Feature Normalization](https://en.wikipedia.org/wiki/Feature_scaling) (Feature Scaling):
-- A value range that is too large or too small might cause floating number overflow or underflow during computation.
-- Different value ranges might result in varying *importances* of different features to the model (at least in the beginning of the training process). This assumption about the data is often unreasonable, making the optimization difficult, which in turn results in increased training time.
-- Many machine learning techniques or models (e.g., *L1/L2 regularization* and *Vector Space Model*) assumes that all the features have roughly zero means and their value ranges are similar.
-
- Figure 2. The value ranges of the features
+
+ Figure 2. Value range of attributes for all dimensions
-#### Prepare Training and Test Sets
+#### Organizing training set and testing set
+
+We split the dataset into two parts: one is used to adjust the parameters of the model, that is, to train the model, the error of the model on this dataset is called ** training error **; the other is used to test.The error of the model on this dataset is called the ** test error**. The goal of our training model is to predict unknown new data by finding the regulation from the training data, so the test error is an better indicator for the performance of the model. When it comes to the ratio of the segmentation data, we should take into account two factors: more training data will reduce the square error of estimated parameters, resulting in a more reliable model; and more test data will reduce the square error of the test error, resulting in more credible test error. The split ratio set in our example is $8:2$
-We split the dataset in two, one for adjusting the model parameters, namely, for training the model, and the other for testing. The model error on the former is called the **training error**, and the error on the latter is called the **test error**. Our goal in training a model is to find the statistical dependency between the outputs and the inputs, so that we can predict outputs given new inputs. As a result, the test error reflects the performance of the model better than the training error does. We consider two things when deciding the ratio of the training set to the test set: 1) More training data will decrease the variance of the parameter estimation, yielding more reliable models; 2) More test data will decrease the variance of the test error, yielding more reliable test errors. One standard split ratio is $8:2$.
-When training complex models, we usually have one more split: the validation set. Complex models usually have [Hyperparameters](https://en.wikipedia.org/wiki/Hyperparameter_optimization) that need to be set before the training process, such as the number of layers in the network. Because hyperparameters are not part of the model parameters, they cannot be trained using the same loss function. Thus we will try several sets of hyperparameters to train several models and cross-validate them on the validation set to pick the best one; finally, the selected trained model is tested on the test set. Because our model is relatively simple, we will omit this validation process.
+In a more complex model training process, we often need more than one dataset: the validation set. Because complex models often have some hyperparameters ([Hyperparameter](https://en.wikipedia.org/wiki/Hyperparameter_optimization)) that need to be adjusted, we will try a combination of multiple hyperparameters to train multiple models separately and then compare their performance on the validation set to select the relatively best set of hyperparameters, and finally use the model with this set of parameters to evaluate the test error on the test set. Since the model trained in this chapter is relatively simple, we won't talk about this process at present.
## Training
-`fit_a_line/trainer.py` demonstrates the training using [PaddlePaddle](http://paddlepaddle.org).
+`fit_a_line/trainer.py` demonstrates the overall process of training.
-### Datafeeder Configuration
+### Configuring the Data feeder
-Our program starts with importing necessary packages:
+First we import the libraries:
```python
import paddle
import paddle.fluid as fluid
import numpy
+import math
+import sys
from __future__ import print_function
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
-
```
-We encapsulated the [UCI Housing Data Set](http://paddlemodels.bj.bcebos.com/uci_housing/housing.data) in our Python module `uci_housing`. This module can
+We introduced the dataset [UCI Housing dataset](http://paddlemodels.bj.bcebos.com/uci_housing/housing.data) via the uci_housing module
-1. download the dataset to `~/.cache/paddle/dataset/uci_housing/housing.data`, if you haven't yet, and
-2. [preprocess](#preprocessing) the dataset.
+It is encapsulated in the uci_housing module:
+1. The process of data download. The download data is saved in ~/.cache/paddle/dataset/uci_housing/housing.data.
+2. The process of [data preprocessing](#data preprocessing).
-We define data feeders for test and train. The feeder reads a `BATCH_SIZE` of data each time and feed them to the training/testing process. If the user wants some randomness on the data order, she can define both a `BATCH_SIZE` and a `buf_size`. That way the datafeeder will yield the first `BATCH_SIZE` data out of a shuffle of the first `buf_size` data.
+Next we define the data feeder for training. The data feeder reads a batch of data in the size of `BATCH_SIZE` each time. If the user wants the data to be random, it can define data in size of a batch and a cache. In this case, each time the data feeder randomly reads as same data as the batch size from the cache.
```python
BATCH_SIZE = 20
@@ -183,180 +190,247 @@ BATCH_SIZE = 20
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.uci_housing.train(), buf_size=500),
- batch_size=BATCH_SIZE)
+ batch_size=BATCH_SIZE)
test_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.uci_housing.test(), buf_size=500),
- batch_size=BATCH_SIZE)
+ batch_size=BATCH_SIZE)
```
-### Train Program Configuration
+If you want to read data directly from \*.txt file, you can refer to the method as follows.
-`train_program` sets up the network structure of this current training model. For linear regression, it is simply a fully connected layer from the input to the output. More complex structures like CNN and RNN will be introduced in later chapters. The `train_program` must return an avg_loss as its first returned parameter because it is needed in backpropagation.
+feature_names = [
+ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
+ 'PTRATIO', 'B', 'LSTAT', 'convert'
+]
-```python
-def train_program():
- y = fluid.layers.data(name='y', shape=[1], dtype='float32')
+feature_num = len(feature_names)
- # feature vector of length 13
- x = fluid.layers.data(name='x', shape=[13], dtype='float32')
- y_predict = fluid.layers.fc(input=x, size=1, act=None)
+data = numpy.fromfile(filename, sep=' ') # Read primary data from file
- loss = fluid.layers.square_error_cost(input=y_predict, label=y)
- avg_loss = fluid.layers.mean(loss)
+data = data.reshape(data.shape[0] // feature_num, feature_num)
- return avg_loss
-```
+maximums, minimums, avgs = data.max(axis=0), data.min(axis=0), data.sum(axis=0)/data.shape[0]
-### Optimizer Function Configuration
+for i in six.moves.range(feature_num-1):
+ data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i]) # six.moves is compatible to python2 and python3
-In the following `SGD` optimizer, `learning_rate` specifies the learning rate in the optimization procedure.
+ratio = 0.8 # distribution ratio of train dataset and verification dataset
-```python
-def optimizer_program():
- return fluid.optimizer.SGD(learning_rate=0.001)
-```
+offset = int(data.shape[0]\*ratio)
-### Specify Place
+train_data = data[:offset]
-Specify your training environment, you should specify if the training is on CPU or GPU.
+test_data = data[offset:]
-```python
-use_cuda = False
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-```
+train_reader = paddle.batch(
+ paddle.reader.shuffle(
+ train_data, buf_size=500),
+ batch_size=BATCH_SIZE)
-### Create Trainer
+test_reader = paddle.batch(
+ paddle.reader.shuffle(
+ test_data, buf_size=500),
+ batch_size=BATCH_SIZE)
-The trainer will take the `train_program` as input.
+### Configure Program for Training
+The aim of the program for training is to define a network structure of a training model. For linear regression, it is a simple fully connected layer from input to output. More complex result, such as Convolutional Neural Network and Recurrent Neural Network, will be introduced in later chapters. It must return `mean error` as the first return value in program for training, for that `mean error` will be used for BackPropagation.
```python
-trainer = Trainer(
- train_func=train_program,
- place=place,
- optimizer_func=optimizer_program)
+x = fluid.layers.data(name='x', shape=[13], dtype='float32') # define shape and data type of input
+y = fluid.layers.data(name='y', shape=[1], dtype='float32') # define shape and data type of output
+y_predict = fluid.layers.fc(input=x, size=1, act=None) # fully connected layer connecting input and output
+
+main_program = fluid.default_main_program() # get default/global main function
+startup_program = fluid.default_startup_program() # get default/global launch program
+
+cost = fluid.layers.square_error_cost(input=y_predict, label=y) # use label and output predicted data to estimate square error
+avg_loss = fluid.layers.mean(cost) # compute mean value for square error and get mean loss
```
+For details, please refer to:
+[fluid.default_main_program](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#default-main-program)
+[fluid.default_startup_program](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#default-startup-program)
-### Feeding Data
+### Optimizer Function Configuration
-PaddlePaddle provides the
-[reader mechanism](https://github.com/PaddlePaddle/Paddle/tree/develop/doc/design/reader)
-for loading the training data. A reader may return multiple columns, and we need a Python dictionary to specify the mapping from column index to data layers.
+`SGD optimizer`, `learning_rate` below are learning rate, which is related to rate of convergence for train of network.
```python
-feed_order=['x', 'y']
+sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001)
+sgd_optimizer.minimize(avg_loss)
+
+#Clone main_program to get test_program
+# operations of some operators are different between train and test. For example, batch_norm use parameter for_test to determine whether the program is for training or for testing.
+#The api will not delete any operator, please apply it before backward and optimization.
+test_program = main_program.clone(for_test=True)
```
-Moreover, an event handler is provided to print the training progress:
+### Define Training Place
-```python
-# Specify the directory to save the parameters
-params_dirname = "fit_a_line.inference.model"
+We can define whether an operation runs on the CPU or on the GPU.
+```python
+use_cuda = False
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace() # define the execution space of executor
-train_title = "Train cost"
-test_title = "Test cost"
+###executor can accept input program and add data input operator and result fetch operator based on feed map and fetch list. Use close() to close executor and call run(...) to run the program.
+exe = fluid.Executor(place)
-step = 0
+```
+For details, please refer to:
+[fluid.executor](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#permalink-15-executor)
-# event_handler prints training and testing info
-def event_handler(event):
- global step
- if isinstance(event, EndStepEvent):
- if step % 10 == 0: # record a train cost every 10 batches
- print("%s, Step %d, Cost %f" % (train_title, step, event.metrics[0]))
-
- if step % 100 == 0: # record a test cost every 100 batches
- test_metrics = trainer.test(
- reader=test_reader, feed_order=feed_order)
- print("%s, Step %d, Cost %f" % (test_title, step, test_metrics[0]))
- if test_metrics[0] < 10.0:
- # If the accuracy is good enough, we can stop the training.
- print('loss is less than 10.0, stop')
- trainer.stop()
- step += 1
+### Create Training Process
+To train, it needs a train program and some parameters and creates a function to get test error in the process of train necessary parameters contain executor, program, reader, feeder, fetch_list, executor represents executor created before. Program created before represents program executed by executor. If the parameter is undefined, then it is defined default_main_program by default. Reader represents data read. Feeder represents forward input variable and fetch_list represents variable user wants to get or name.
- if isinstance(event, EndEpochEvent):
- if event.epoch % 10 == 0:
- # We can save the trained parameters for the inferences later
- if params_dirname is not None:
- trainer.save_params(params_dirname)
+```python
+num_epochs = 100
+
+def train_test(executor, program, reader, feeder, fetch_list):
+ accumulated = 1 * [0]
+ count = 0
+ for data_test in reader():
+ outs = executor.run(program=program,
+ feed=feeder.feed(data_test),
+ fetch_list=fetch_list)
+ accumulated = [x_c[0] + x_c[1][0] for x_c in zip(accumulated, outs)] # accumulate loss value in the process of test
+ count += 1 # accumulate samples in test dataset
+ return [x_d / count for x_d in accumulated] # compute mean loss
```
-### Start Training
+### Train Main Loop
-We now can start training by calling `trainer.train()`.
+give name of directory to be stored and initialize an executor
```python
%matplotlib inline
+params_dirname = "fit_a_line.inference.model"
+feeder = fluid.DataFeeder(place=place, feed_list=[x, y])
+exe.run(startup_program)
+train_prompt = "train cost"
+test_prompt = "test cost"
+from paddle.utils.plot import Ploter
+plot_prompt = Ploter(train_prompt, test_prompt)
+step = 0
-# The training could take up to a few minutes.
-trainer.train(
- reader=train_reader,
- num_epochs=100,
- event_handler=event_handler,
- feed_order=feed_order)
-
+exe_test = fluid.Executor(place)
```
+Paddlepaddle provides reader mechanism to read training data. Reader provide multiple columns of data at one time. Therefore, we need a python list to read sequence. We create a loop to train until the result of train is good enough or time of loop is enough.
+If the number of iterations for train is equal to the number of iterations for saving parameters, you can save train parameter into `params_dirname`.
+Set main loop for training.
+```python
+for pass_id in range(num_epochs):
+ for data_train in train_reader():
+ avg_loss_value, = exe.run(main_program,
+ feed=feeder.feed(data_train),
+ fetch_list=[avg_loss])
+ if step % 10 == 0: # record and output train loss for every 10 batches.
+ plot_prompt.append(train_prompt, step, avg_loss_value[0])
+ plot_prompt.plot()
+ print("%s, Step %d, Cost %f" %
+ (train_prompt, step, avg_loss_value[0]))
+ if step % 100 == 0: # record and output test loss for every 100 batches.
+ test_metics = train_test(executor=exe_test,
+ program=test_program,
+ reader=test_reader,
+ fetch_list=[avg_loss.name],
+ feeder=feeder)
+ plot_prompt.append(test_prompt, step, test_metics[0])
+ plot_prompt.plot()
+ print("%s, Step %d, Cost %f" %
+ (test_prompt, step, test_metics[0]))
+ if test_metics[0] < 10.0: # If the accuracy is up to the requirement, the train can be stopped.
+ break
-
+ step += 1
-## Inference
+ if math.isnan(float(avg_loss_value[0])):
+ sys.exit("got NaN loss, training failed.")
-Initialize the Inferencer with the inference_program and the params_dirname, which is where we saved our params
+ #save train parameters into the path given before
+ if params_dirname is not None:
+ fluid.io.save_inference_model(params_dirname, ['x'], [y_predict], exe)
+```
-### Setup the Inference Program
+## Predict
+It needs to create trained parameters to run program for prediction. The trained parameters is in `params_dirname`.
-Similar to the trainer.train, the Inferencer needs to take an inference_program to do inference.
-Prune the train_program to only have the y_predict.
+### Prepare Environment for Prediction
+Similar to the process of training, predictor needs a program for prediction. We can slightly modify our training program to include the prediction value.
```python
-def inference_program():
- x = fluid.layers.data(name='x', shape=[13], dtype='float32')
- y_predict = fluid.layers.fc(input=x, size=1, act=None)
- return y_predict
+infer_exe = fluid.Executor(place)
+inference_scope = fluid.core.Scope()
```
-### Infer
-
-Inferencer will load the trained model from `params_dirname` and use it to infer the unseen data.
+### Predict
+Save pictures
```python
-inferencer = Inferencer(
- infer_func=inference_program, param_path=params_dirname, place=place)
+def save_result(points1, points2):
+ import matplotlib
+ matplotlib.use('Agg')
+ import matplotlib.pyplot as plt
+ x1 = [idx for idx in range(len(points1))]
+ y1 = points1
+ y2 = points2
+ l1 = plt.plot(x1, y1, 'r--', label='predictions')
+ l2 = plt.plot(x1, y2, 'g--', label='GT')
+ plt.plot(x1, y1, 'ro-', x1, y2, 'g+-')
+ plt.title('predictions VS GT')
+ plt.legend()
+ plt.savefig('./image/prediction_gt.png')
+```
-batch_size = 10
-test_reader = paddle.batch(paddle.dataset.uci_housing.test(),batch_size=batch_size)
-test_data = next(test_reader())
-test_x = numpy.array([data[0] for data in test_data]).astype("float32")
-test_y = numpy.array([data[1] for data in test_data]).astype("float32")
+Via fluid.io.load_inference_model, predictor will read well-trained model from `params_dirname` to predict unknown data.
-results = inferencer.infer({'x': test_x})
+```python
+with fluid.scope_guard(inference_scope):
+ [inference_program, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(params_dirname, infer_exe) # load pre-predict model
+ batch_size = 10
+
+ infer_reader = paddle.batch(
+ paddle.dataset.uci_housing.test(), batch_size=batch_size) # prepare test dataset
+
+ infer_data = next(infer_reader())
+ infer_feat = numpy.array(
+ [data[0] for data in infer_data]).astype("float32") # extract data in test dataset
+ infer_label = numpy.array(
+ [data[1] for data in infer_data]).astype("float32") # extract label in test dataset
+
+ assert feed_target_names[0] == 'x'
+ results = infer_exe.run(inference_program,
+ feed={feed_target_names[0]: numpy.array(infer_feat)},
+ fetch_list=fetch_targets) # predict
+ #print predict result and label and visualize the result
+ print("infer results: (House Price)")
+ for idx, val in enumerate(results[0]):
+ print("%d: %.2f" % (idx, val)) # print predict result
+
+ print("\nground truth:")
+ for idx, val in enumerate(infer_label):
+ print("%d: %.2f" % (idx, val)) # print label
+
+ save_result(results[0], infer_label) # save picture
+```
-print("infer results: (House Price)")
-for idx, val in enumerate(results[0]):
- print("%d: %.2f" % (idx, val))
-print("\nground truth:")
-for idx, val in enumerate(test_y):
- print("%d: %.2f" % (idx, val))
-```
## Summary
+In this chapter, we analyzed dataset of Boston House Price to introduce the basic concepts of linear regression model and how to use PaddlePaddle to implement training and testing. A number of models and theories are derived from linear regression model. Therefore, it is not unnecessary to figure out the principle and limitation of linear regression model.
-This chapter introduces *Linear Regression* and how to train and test this model with PaddlePaddle, using the UCI Housing Data Set. Because a large number of more complex models and techniques are derived from linear regression, it is important to understand its underlying theory and limitation.
-
+
## References
-
1. https://en.wikipedia.org/wiki/Linear_regression
2. Friedman J, Hastie T, Tibshirani R. The elements of statistical learning[M]. Springer, Berlin: Springer series in statistics, 2001.
3. Murphy K P. Machine learning: a probabilistic perspective[M]. MIT press, 2012.
4. Bishop C M. Pattern recognition[J]. Machine Learning, 2006, 128.
-This tutorial is contributed by
PaddlePaddle, and licensed under a
Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by
PaddlePaddle, and licensed under a
Creative Commons Attribution-ShareAlike 4.0 International License.
-
-Fig. 1. Examples of MNIST images
+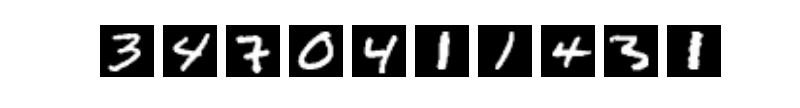
+Figure 1. Example of a MNIST picture
-The MNIST dataset is from the [NIST](https://www.nist.gov/srd/nist-special-database-19) Special Database 3 (SD-3) and the Special Database 1 (SD-1).
-The SD-3 is labeled by the staff of the U.S. Census Bureau, while SD-1 is labeled by high school students. Therefore the SD-3 is cleaner and easier to recognize than the SD-1 dataset.
-Yann LeCun et al. used half of the samples from each of SD-1 and SD-3 to create the MNIST training set of 60,000 samples and test set of 10,000 samples.
-250 annotators labeled the training set, thus guaranteed that there wasn't a complete overlap of annotators of training set and test set.
+MNIST dataset is created from [NIST](https://www.nist.gov/srd/nist-special-database-19) Special Database 3(SD-3) and Special Database 1(SD-1). Because SD-3 is labeled by stuff of US Census Bureau and SD-1 is labeled by US high school students, so SD-3 is clearer and easier to be recognized than SD-1. Yann LeCun et al. pick half of SD-1 and half of SD-3 as train dataset (60000 data) and test dataset (10000 data).250 annotators labeled the training set, thus guaranteed that there wasn't a complete overlap of annotators of training set and test set.
-The MNIST dataset has been used for evaluating many image recognition algorithms such as a single layer linear classifier,
-Multilayer Perceptron (MLP) and Multilayer CNN LeNet\[[1](#references)\], K-Nearest Neighbors (k-NN) \[[2](#references)\], Support Vector Machine (SVM) \[[3](#references)\],
-Neural Networks \[[4-7](#references)\], Boosting \[[8](#references)\] and preprocessing methods like distortion removal, noise removal, and blurring.
-Among these algorithms, the *Convolutional Neural Network* (CNN) has achieved a series of impressive results in Image Classification tasks, including VGGNet, GoogLeNet,
-and ResNet (See [Image Classification](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification) tutorial).
+MNIST attracts scholars to train model based on the dataset. In 1998, LeCun conducted experiments respectively using Single layer classifier, Multilayer Perceptron and Multilayer convolutional neural network LeNet, constantly decreasing the error on test dataset ( from 12% to 0.7%)\[[1](#References)\]。 In the process of research, LeCun, the pioneer in the field of deep learning, came up with Convolutional Neural Network, largely improving the performance of handwriting recognition. After that, researchers take a large number of experiments based on K-Nearest Neighbors algorithm\[[2](#References)\], SVM\[[3](#References)\], Neural Network\[[4-7](#References)\] and Boosting method\[[8](#References)\] and so on, with multiple pre-processing methods(like distortion removal, noise removal, and blurring) to upgrade accuracy of recognition.
-In this tutorial, we start with a simple **softmax** regression model and go on with MLP and CNN. Readers will see how these methods improve the recognition accuracy step-by-step.
+Convolutional Neural Network plays an important role in the field of deep learning now. From simple LeNet proposed by Yann LeCun in early days to model VGGNet, GoogleNet, ResNet and so on in the ImageNet competition (please refer to [Image Classification](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification) tutorial ), we have gain a serious of great achievements with convolutional neural network in the field of image classification.
-## Model Overview
-Before introducing classification algorithms and training procedure, we define the following symbols:
-- $X$ is the input: Input is a $28\times 28$ MNIST image. It is flattened to a $784$ dimensional vector. $X=\left (x_0, x_1, \dots, x_{783} \right )$.
-- $Y$ is the output: Output of the classifier is 1 of the 10 classes (digits from 0 to 9). $Y=\left (y_0, y_1, \dots, y_9 \right )$. Each dimension $y_i$ represents the probability that the input image belongs to class $i$.
-- $L$ is the ground truth label: $L=\left ( l_0, l_1, \dots, l_9 \right )$. It is also 10 dimensional, but only one entry is $1$ and all others are $0$s.
+In this tutorial, starting from simple Softmax regression model, we help you learn about handwriting recognition and introduce you how to upgrade model and how to use MLP and CNN to optimize recognition result.
+
+
+## Exploration of Models
+
+To train a classifier based on MNIST dataset, before the introduction of three basic image classification networks used in this tutorial, we first give some definitions:
+
+- $X$ is the input: the MNIST image is a two-dimensional image of $28\times28$. For the calculation, we transform it into a $784$ dimensional vector, ie $X=\left ( x_0, x_1, \dots, x_{783} \right )$.
+
+- $Y$ is the output: the output of the classifier is number (0-9), ie $Y=\left ( y_0, y_1, \dots, y_9 \right )$, and each dimension $y_i$ represents the probability of image classification as $i$th number.
+
+- $Label$ is the actual label of the picture: $Label=\left ( l_0, l_1, \dots, l_9 \right ) $ is also 10 dimensions, but only one dimension represents 1, and the rest is 0. For example, if the number on an image is 2, its label is $(0,0,1,0, \dot, 0)$
### Softmax Regression
-In a simple softmax regression model, the input is first fed to fully connected layers. Then, a softmax function is applied to output probabilities of multiple output classes\[[9](#references)\].
+The simplest Softmax regression model is to get features with input layer passing through a fully connected layer and then compute and ouput probabilities of multiple classifications directly via Softmax function \[[9](#references)\].
-The input $X$ is multiplied by weights $W$ and then added to the bias $b$ to generate activations.
+The data of the input layer $X$ is passed to the output layer. The input $X$ is multiplied by weights $W$ and then added to the bias $b$ to generate activations:
$$ y_i = \text{softmax}(\sum_j W_{i,j}x_j + b_i) $$
where $ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $
-For an $N$-class classification problem with $N$ output nodes, Softmax normalizes the resulting $N$ dimensional vector so that each of its entries falls in the range $[0,1]\in {R}$, representing the probability that the sample belongs to a certain class. Here $y_i$ denotes the predicted probability that an image is of digit $i$.
+Figure 2 is a network of softmax regression, in which weights are represented by blue lines, bias are represented by red lines, and +1 indicates that the bias is $1$.
-In such a classification problem, we usually use the cross entropy loss function:
+
+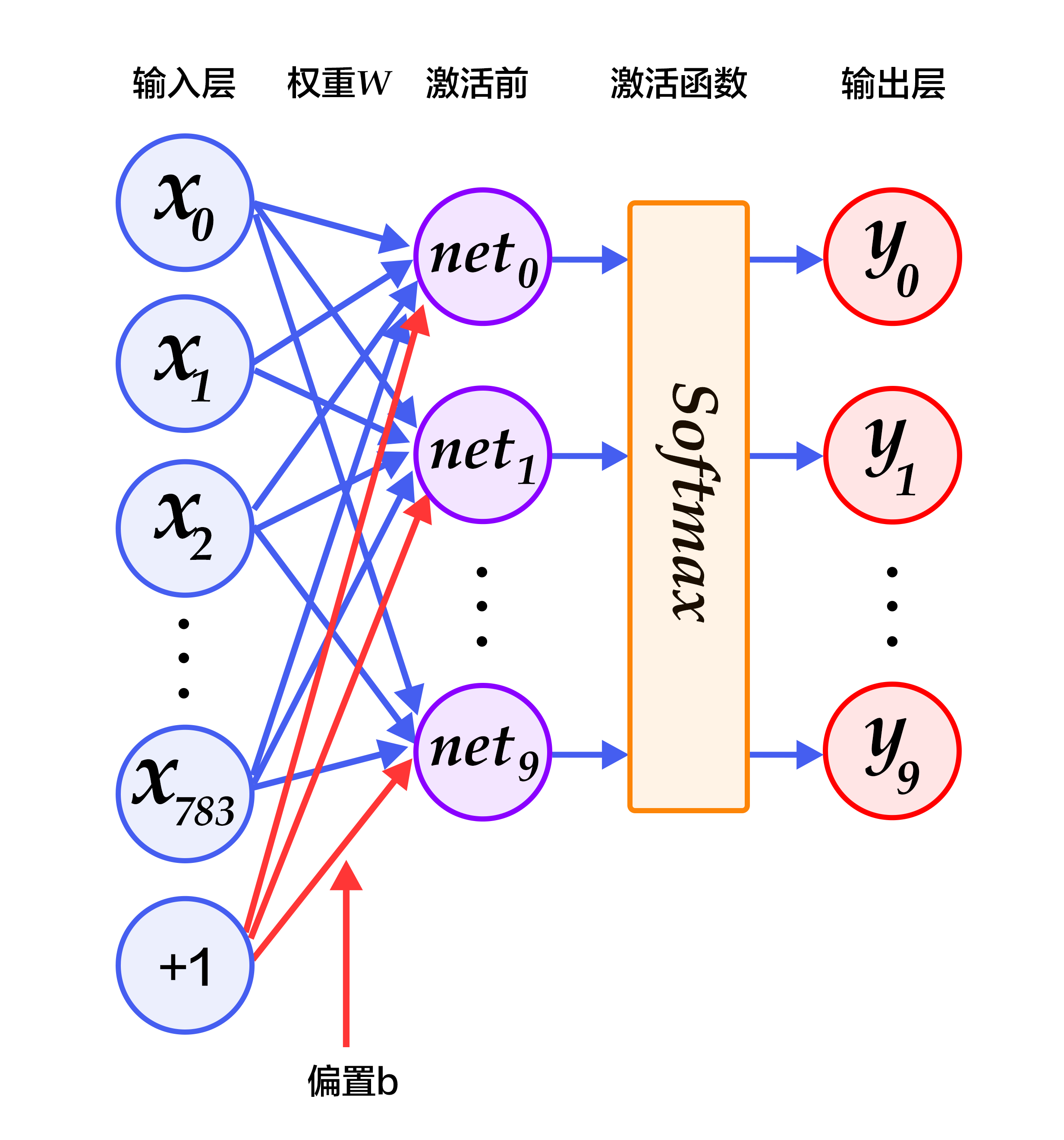
+Figure 2. Softmax regression network structure
+
-$$ \text{_L_cross-entropy}(label, y) = -\sum_i label_ilog(y_i) $$
+For an $N$-class classification problem with $N$ output nodes, Softmax normalizes the resulting $N$ dimensional vector so that each of its entries falls in the range $[0,1]\in {R}$, representing the probability that the sample belongs to a certain category. Here $y_i$ denotes the predicted probability that an image is of number $i$.
+
+In the classification problem, we usually use cross-entropy loss, the formula is as follows:
+
+$$ L_{cross-entropy}(label, y) = -\sum_i label_ilog(y_i) $$
-Fig. 2 illustrates a softmax regression network, with the weights in blue, and the bias in red. `+1` indicates that the bias is $1$.
-
-
-Fig. 2. Softmax regression network architecture
-
### Multilayer Perceptron
-The softmax regression model described above uses the simplest two-layer neural network. That is, it only contains an input layer and an output layer, with limited regression capability. To achieve better recognition results, consider adding several hidden layers\[[10](#references)\] between the input layer and the output layer.
+The Softmax regression model uses the simplest two-layer neural network, which contains only the input layer and the output layer, so its performance is limited. In order to achieve better recognition, we consider adding several hidden layers \[[10](#references)\] between the input and output layer.
-1. After the first hidden layer, we get $ H_1 = \phi(W_1X + b_1) $, where $\phi$ denotes the activation function. Some [common ones](###list-of-common-activation-functions) are sigmoid, tanh and ReLU.
-2. After the second hidden layer, we get $ H_2 = \phi(W_2H_1 + b_2) $.
-3. Finally, the output layer outputs $Y=\text{softmax}(W_3H_2 + b_3)$, the vector denoting our classification result.
+1.In the first hidden layer, you can get $ H_1 = \phi(W_1X + b_1) $, where $\phi$ represents the activation function. And common functions are [sigmoid, tanh or ReLU](#common activation functions).
+2.In the second hidden layer, you can get $ H_2 = \phi(W_2H_1 + b_2) $.
+3.Finally, in the output layer, you can get $Y=\text{softmax}(W_3H_2 + b_3)$, that is the final classification result vector.
-Fig. 3. shows a Multilayer Perceptron network, with the weights in blue, and the bias in red. +1 indicates that the bias is $1$.
-
-
-Fig. 3. Multilayer Perceptron network architecture
+Figure 3 is a network structure of a multi-layer perceptron, in which weights are represented by blue lines, bias are represented by red lines, and +1 indicates that the bias is $1$.
+
+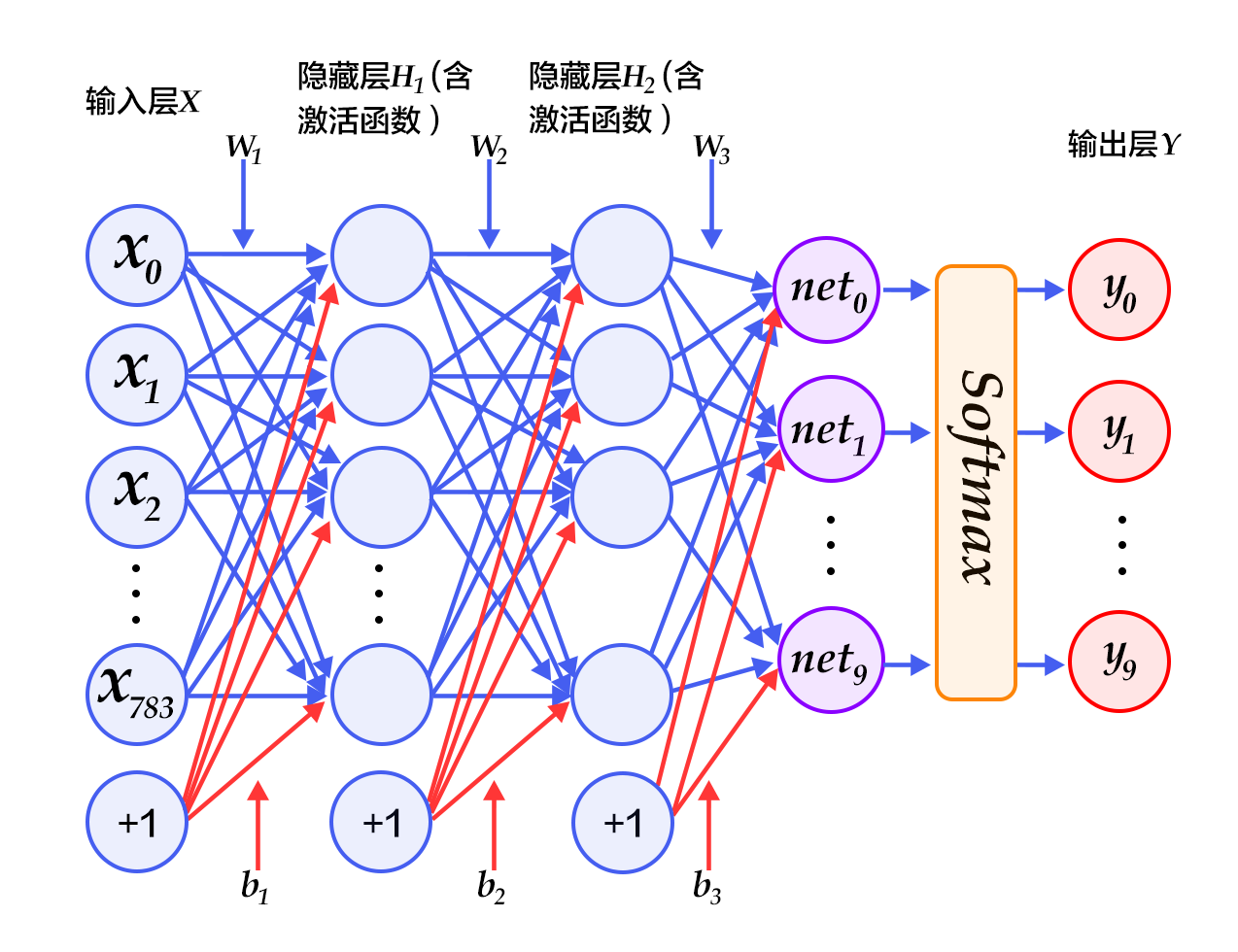
+Figure 3. Multilayer perceptron network structure
### Convolutional Neural Network
-#### Convolutional Layer
+In the multi-layer perceptron model, an image is expanded into a one-dimensional vector and input into the network, ignoring its position and structure information. And the convolutional neural network can better utilize the structure information of the image. [LeNet-5](http://yann.lecun.com/exdb/lenet/) is a relatively simple convolutional neural network. Figure 4 shows the structure: the input two-dimensional image, first through the two convolutional layers to the pooling layer, then through the fully connected layer, and finally using the softmax as the output layer. Below we mainly introduce the convolutional layer and the pooling layer.
-
-Fig. 4. Convolutional layer
+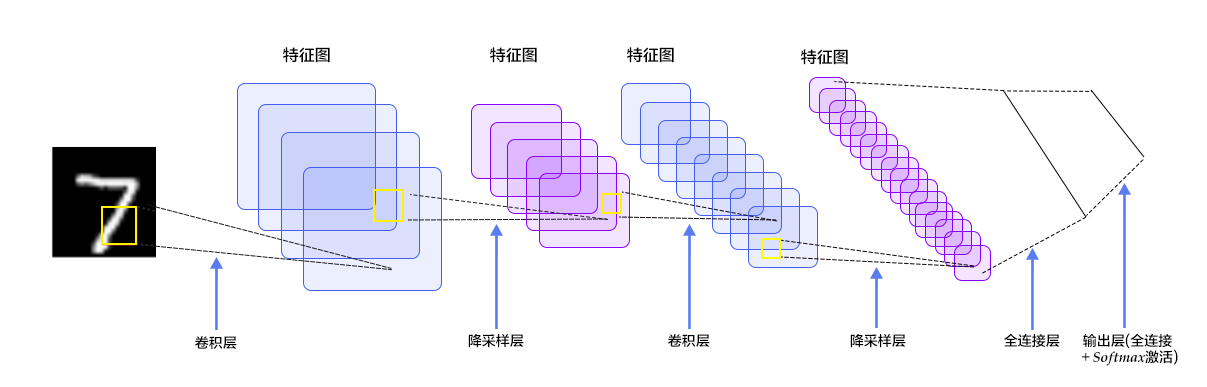
+Figure 4. LeNet-5 convolutional neural network structure
-The **convolutional layer** is the core of a Convolutional Neural Network. The parameters in this layer are composed of a set of filters, also called kernels. We could visualize the convolution step in the following fashion: Each kernel slides horizontally and vertically till it covers the whole image. At every window, we compute the dot product of the kernel and the input. Then, we add the bias and apply an activation function. The result is a two-dimensional activation map. For example, some kernel may recognize corners, and some may recognize circles. These convolution kernels may respond strongly to the corresponding features.
-
-Fig. 4 illustrates the dynamic programming of a convolutional layer, where depths are flattened for simplicity. The input is $W_1=5$, $H_1=5$, $D_1=3$. In fact, this is a common representation for colored images. $W_1$ and $H_1$ correspond to the width and height in a colored image. $D_1$ corresponds to the three color channels for RGB. The parameters of the convolutional layer are $K=2$, $F=3$, $S=2$, $P=1$. $K$ denotes the number of kernels; specifically, $Filter$ $W_0$ and $Filter$ $W_1$ are the kernels. $F$ is kernel size while $W0$ and $W1$ are both $F\timesF = 3\times3$ matrices in all depths. $S$ is the stride, which is the width of the sliding window; here, kernels move leftwards or downwards by two units each time. $P$ is the width of the padding, which denotes an extension of the input; here, the gray area shows zero padding with size 1.
+#### Convolutional Layer
-#### Pooling Layer
+Convolutional Layer is the core of convolutional neural network. The convolution we mentioned in image recognition is a two-dimensional convolution, that is, a discrete two-dimensional filter (also called a convolutional kernel) and a two-dimensional image for convoluting. In short, the two-dimensional filter slides to all positions on two-dimensional images and dot product is taken for this pixel and its domain pixel at each position. Convolution operations are widely used in the field of image processing. Different convolutional kernels can extract different features, such as edges, lines, and angles. In deep convolutional neural networks, low-level to complex image features can be extracted by convolution operation.
-
-Fig. 5 Pooling layer using max-pooling
+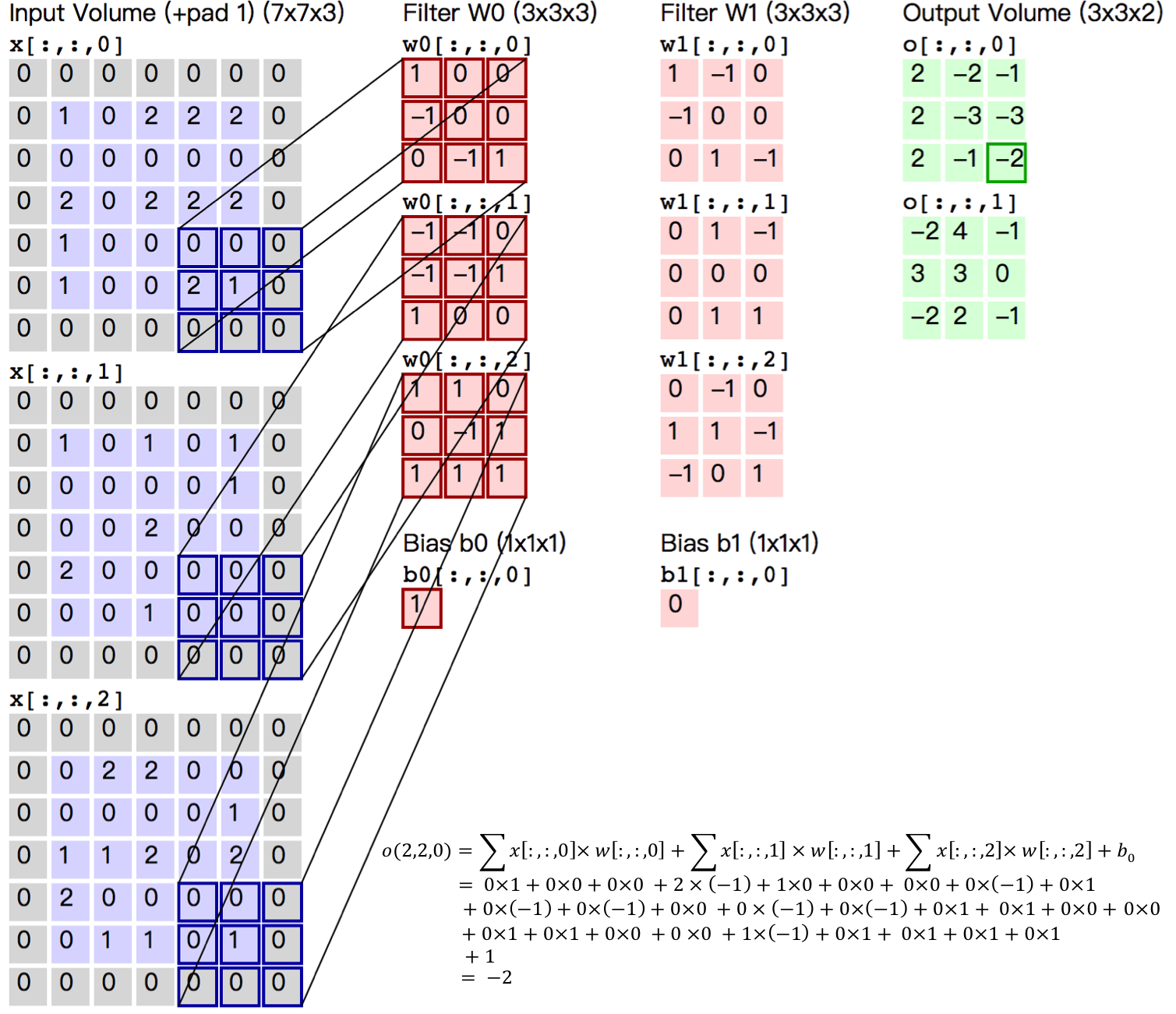
+Figure 5. Convolutional Layer Picture
-A **pooling layer** performs downsampling. The main functionality of this layer is to reduce computation by reducing the network parameters. It also prevents over-fitting to some extent. Usually, a pooling layer is added after a convolutional layer. Pooling layer can use various techniques, such as max pooling and average pooling. As shown in Fig.5, max pooling uses rectangles to segment the input layer into several parts and computes the maximum value in each part as the output.
+Figure 5 shows an example of the process of computing convolution with input image in size of $H=5, W=5, D=3$, ie $5 \times 5$ size of 3 channel (RGB, also known as depth) color image.
+
+This example contains two (denoted by $K$) groups of convolutional kernels, i.e. $Filter W_0$ and $Filter W_1$ in the figure. In convolution calculation, different convolutional kernels are usually used for different input channels. In the example, each set of convolutional kernels contains ($D=3$) $3\times 3$ (indicated by $F \times F$) convolutional kernel. In addition, the stride of convolutional kernel in horizontal and vertical direction of image is 2 (indicated by $S$); Pad 1 (represented by $P$) 0 in the four directions of input image, that is, the input layer raw data in the figure is the blue part, and the gray part is expanded with 0 in the size of 1. The convolution operation yields a feature map of the size of $3 \times 3 \times 2$ (represented by $H_{o} \times W_{o} \times K$), which is a 2-channel feature map in size of $3 \times 3$, where $H_o$ is calculated as: $H_o = (H - F + 2 \times P)/S + 1$, so is $W_o$. And each pixel in the output feature map is the summation of the inner product of each set of filters and each feature of the input image, plus the bias $b_o$, the bias is usually shared by each output feature map. The last $-2$ in the output feature map $o[:,:,0]$ is calculated as shown in the lower right corner of Figure 5.
+
+The convolutional kernel is a learnable parameter in the convolution operation. As shown in the example above, the parameter of each layer of convolution is $D \times F \times F \times K$. In the multi-layer perceptron model, neurons are usually fully connected therefore with a large number of parameters. There are fewer parameters in the convolutional layer, which is also determined by main features of the convolutional layer, namely local connections and shared weights.
+
+- Local connection: Each neuron is connected to only one region of the input neuron, which is called Receptive Field. In the image convolution operation, that is, the neurons are locally connected in the spatial dimension (the plane in which the above examples H and W are located), but are fully connected in depth. For the two-dimensional image itself, the local pixels are strongly related. This local connection ensures that the learned filter makes the strongest response to local input features. The idea of local connection is also inspired by the structure of visual system in biology. The neurons in the visual cortex receive information locally.
+
+- Weight sharing: The filters used to calculate neurons in the same deep slice are shared. For example, in Figure 4, the filter for each neuron calculated by $o[:,:,0]$ is the same, both are $W_0$, which can greatly reduce the parameters. The sharing weight is meaningful to a certain extent, for example, the bottom edge feature of the image is independent of the specific location of the feature in the graph. However, it is unintentional in some cases. For example, the input picture is a face, eyes and hair are in different positions. And to learn different features in different positions, please (refer to [Stanford University Open Class](http://cs231n.Github.io/convolutional-networks/)). Note that the weights are only shared for the neurons of the same depth slice. In the convolutional layer, multiple sets of convolutional kernels are usually used to extract different features, that is, the weights of neurons with different depth slices are not shared by the features with different depth slices. In addition, bias are shared by all neurons with the same depth.
-#### LeNet-5 Network
+By introducing the calculation process of convolution and its features, convolution could be seen as a linear operation with shift-invariant, which is the same operation performed at each position of the image. The local connection and weight sharing of the convolutional layer greatly reduce the parameters that need to be learned, which helps with training larger convolutional neural networks.
+
+For more information about convolution, please refer to [Reference Reading](http://ufldl.stanford.edu/wiki/index.php/Feature_extraction_using_convolution#Convolutions)。
+
+### Pooling Layer
-
-Fig. 6. LeNet-5 Convolutional Neural Network architecture
+
+Figure 6. Picture in pooling layer
-[**LeNet-5**](http://yann.lecun.com/exdb/lenet/) is one of the simplest Convolutional Neural Networks. Fig. 6. shows its architecture: A 2-dimensional input image is fed into two sets of convolutional layers and pooling layers. This output is then fed to a fully connected layer and a softmax classifier. Compared to multilayer, fully connected perceptrons, the LeNet-5 can recognize images better. This is due to the following three properties of the convolution:
+Pooling is a form of nonlinear downsampling. The main functionality of this layer is to reduce computation by reducing the network parameters and to control the overfitting to some extent. Normally a pooling layer is added after the convolutional layer. Pooling includes maximum pooling, average pooling and so on. The largest pooling is to divide the input layer into different areas by non-overlapping rectangular boxes, and the maximum value of each rectangular box is taken as the output layer, as shown in Figure. 6.
-- The 3D nature of the neurons: a convolutional layer is organized by width, height, and depth. Neurons in each layer are connected to only a small region in the previous layer. This region is called the receptive field.
-- Local connectivity: A CNN utilizes the local space correlation by connecting local neurons. This design guarantees that the learned filter has a strong response to local input features. Stacking many such layers generates a non-linear filter that is more global. This enables the network to first obtain good representation for small parts of input and then combine them to represent a larger region.
-- Weight sharing: In a CNN, computation is iterated on shared parameters (weights and bias) to form a feature map. This means that all the neurons in the same depth of the output response to the same feature. This allows the network to detect a feature regardless of its position in the input.
+For details about convolutional neural network, please refer to the tutorial of [Standford Online Course]( http://cs231n.github.io/convolutional-networks/ ), [Ufldl](http://ufldl.stanford.edu/wiki/index.php/Pooling) and [Image Classification]( https://github.com/PaddlePaddle/book/tree/develop/03.image_classification ).
-For more details on Convolutional Neural Networks, please refer to the tutorial on [Image Classification](https://github.com/PaddlePaddle/book/blob/develop/image_classification/README.md) and the [relevant lecture](http://cs231n.github.io/convolutional-networks/) from a Stanford course.
+
+### Common activation functions
-### List of Common Activation Functions
- Sigmoid activation function: $ f(x) = sigmoid(x) = \frac{1}{1+e^{-x}} $
- Tanh activation function: $ f(x) = tanh(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}} $
- In fact, tanh function is just a rescaled version of the sigmoid function. It is obtained by magnifying the value of the sigmoid function and moving it downwards by 1.
+In fact, the tanh function is only a sigmoid function with change of scale. The value of the sigmoid function is doubled and then shifted down by 1 unit: tanh(x) = 2sigmoid(2x) - 1 .
- ReLU activation function: $ f(x) = max(0, x) $
-For more information, please refer to [Activation functions on Wikipedia](https://en.wikipedia.org/wiki/Activation_function).
-
-## Data Preparation
+For details, please refer to [activation function in Wikipedia](https://en.wikipedia.org/wiki/Activation_function).
-PaddlePaddle provides a Python module, `paddle.dataset.mnist`, which downloads and caches the [MNIST dataset](http://yann.lecun.com/exdb/mnist/). The cache is under `/home/username/.cache/paddle/dataset/mnist`:
+## Dataset Preparation
+PaddlePaddle provides a module `paddle.dataset.mnist` that automatically loads [MNIST] (http://yann.lecun.com/exdb/mnist/) data in the API. The loaded data is located under `/home/username/.cache/paddle/dataset/mnist`:
-| File name | Description | Size |
-|----------------------|--------------|-----------|
-|train-images-idx3-ubyte| Training images | 60,000 |
-|train-labels-idx1-ubyte| Training labels | 60,000 |
-|t10k-images-idx3-ubyte | Evaluation images | 10,000 |
-|t10k-labels-idx1-ubyte | Evaluation labels | 10,000 |
+| filename | note |
+|----------------------|-------------------------|
+|train-images-idx3-ubyte| train data picture, 60,000 data |
+|train-labels-idx1-ubyte| train data label, 60,000 data |
+|t10k-images-idx3-ubyte | test data picture, 10,000 data |
+|t10k-labels-idx1-ubyte | test data label, 10,000 data |
## Fluid API Overview
-The demo will be using the latest paddle fluid API. Fluid API is the latest Paddle API. It simplifies the model configurations without sacrifice the performance.
-We recommend using Fluid API as it is much easier to pick up.
-Here are the quick overview on the major fluid API complements.
+The demo will use the latest [Fluid API](http://paddlepaddle.org/documentation/docs/en/1.2/api_cn/index_cn.html). Fluid API is the latest PaddlePaddle API. It simplifies model configuration without sacrificing performance.
+We recommend using the Fluid API, which is easy to learn and use to help you complete your machine learning tasks quickly.
+
+Here is an overview of several important concepts in the Fluid API:
+
+1. `inference_program`: specifies how to get the inference function from the data input.
+This is where the network flow is defined.
+
+2. `train_program`: specifies how to get the `loss` function from `inference_program` and `tag value`.
+This is where the loss calculation is specified.
-1. `inference_program`: A function that specify how to get the prediction from the data input.
-This is where you specify the network flow.
-1. `train_program`: A function that specify how to get avg_cost from `inference_program` and labels.
-This is where you specify the loss calculations.
-1. `optimizer_func`:"A function that specifies the configuration of the the optimizer. The optimizer is responsible for minimizing the loss and driving the training. Paddle supports many different optimizers."
-1. `Trainer`: Fluid trainer manages the training process specified by the `train_program` and `optimizer`. Users can monitor the training
-progress through the `event_handler` callback function.
-1. `Inferencer`: Fluid inferencer loads the `inference_program` and the parameters trained by the Trainer.
-It then can infer the data and return prediction
+3. `optimizer_func`: Specifies the function of the optimizer configuration. The optimizer is responsible for reducing losses and driving training. Paddle supports a number of different optimizers.
-We will go though all of them and dig more on the configurations in this demo.
+In the code examples below, we'll take a closer look at them.
-## Model Configuration
+## Configuration Instructions
-A PaddlePaddle program starts from importing the API package:
+Load the Fluid API package for PaddlePaddle.
```python
-import paddle
+import os
+from PIL import Image # load module of image processing
+import matplotlib.pyplot as plt
+import numpy
+import paddle # load paddle module
import paddle.fluid as fluid
-from __future__ import print_function
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
+from __future__ import print_function #load print of python3 into current version
```
### Program Functions Configuration
-First, We need to setup the `inference_program` function. We want to use this program to demonstrate three different classifiers, each defined as a Python function.
-We need to feed image data to the classifier. PaddlePaddle provides a special layer `layer.data` for reading data.
-Let us create a data layer for reading images and connect it to the classification network.
+We need to configure `inference_program` function. We want to use this program to show three different classifiers, each of which is defined as a Python function.
+We need to input the image data into the classifier. Paddle provides a special layer `layer.data` for reading data.
+Let's create a data layer to read the image and connect it to the network of classification.
-- Softmax regression: the network has a fully-connection layer with softmax activation:
+-Softmax regression: The results of the classification can be obtained only through a simple layer of simple fully connected layer with softmax as the activation function.
```python
def softmax_regression():
+ """
+ Define softmax classifier:
+ A fully connected layer with activation function softmax
+ Return:
+ predict_image -- result of classification
+ """
+ # input original image data in size of 28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
+ # With softmax as the fully connected layer of the activation function, the size of the output layer must be 10
predict = fluid.layers.fc(
- input=img, size=10, act='softmax')
+ input=img, size=10, act='softmax')
return predict
```
-- Multi-Layer Perceptron: this network has two hidden fully-connected layers, both are using ReLU as activation function. The output layer is using softmax activation:
+-Multilayer Perceptron: The following code implements a multilayer perceptron with two hidden layers (that is, fully connected layers). The activation functions of the two hidden layers are all ReLU, and the activation function of the output layer is Softmax.
```python
def multilayer_perceptron():
+ """
+ Define multilayer perceptron classifier:
+ Multilayer perceptron with two hidden layers (fully connected layers)
+ The activation function of the first two hidden layers uses ReLU, and the activation function of the output layer uses Softmax.
+
+ Return:
+ predict_image -- result of classification
+ """
+ # input raw image data in size of 28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
- # first fully-connected layer, using ReLu as its activation function
+ # the first fully connected layer, whose activation function is ReLU
hidden = fluid.layers.fc(input=img, size=200, act='relu')
- # second fully-connected layer, using ReLu as its activation function
+ # the second fully connected layer, whose activation function is ReLU
hidden = fluid.layers.fc(input=hidden, size=200, act='relu')
+ # With softmax as the fully connected output layer of the activation function, the size of the output layer must be 10
prediction = fluid.layers.fc(input=hidden, size=10, act='softmax')
return prediction
```
-- Convolution network LeNet-5: the input image is fed through two convolution-pooling layers, a fully-connected layer, and the softmax output layer:
+-Convolutional neural network LeNet-5: The input two-dimensional image first passes through two convolutional layers to the pooling layer, then passes through the fully connected layer, and finally fully connection layer with softmax as activation function is used as output layer.
```python
def convolutional_neural_network():
+ """
+ Define convolutional neural network classifier:
+ The input 2D image passes through two convolution-pooling layers, using the fully connected layer with softmax as the output layer
+
+ Return:
+ predict -- result of classification
+ """
+ # input raw image data in size of 28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
- # first conv pool
+ # the first convolution-pooling layer
+ # Use 20 5*5 filters, the pooling size is 2, the pooling step is 2, and the activation function is Relu.
conv_pool_1 = fluid.nets.simple_img_conv_pool(
input=img,
filter_size=5,
@@ -215,7 +241,8 @@ def convolutional_neural_network():
pool_stride=2,
act="relu")
conv_pool_1 = fluid.layers.batch_norm(conv_pool_1)
- # second conv pool
+ # the second convolution-pooling layer
+ # Use 20 5*5 filters, the pooling size is 2, the pooling step is 2, and the activation function is Relu.
conv_pool_2 = fluid.nets.simple_img_conv_pool(
input=conv_pool_1,
filter_size=5,
@@ -223,121 +250,240 @@ def convolutional_neural_network():
pool_size=2,
pool_stride=2,
act="relu")
- # output layer with softmax activation function. size = 10 since there are only 10 possible digits.
+ # With softmax as the fully connected output layer of the activation function, the size of the output layer must be 10
prediction = fluid.layers.fc(input=conv_pool_2, size=10, act='softmax')
return prediction
```
#### Train Program Configuration
-Then we need to setup the the `train_program`. It takes the prediction from the classifier first.
-During the training, it will calculate the `avg_loss` from the prediction.
+Then we need to set train program `train_program` It firstly infers from classifier.
+During the training, it will compute `avg_cost`.
-**NOTE:** A train program should return an array and the first return argument has to be `avg_cost`.
-The trainer always implicitly use it to calculate the gradient.
+** Note:** train program should return an array. The first parameter returned must be `avg_cost`. The trainer uses it to compute gradient.
-Please feel free to modify the code to test different results between `softmax regression`, `mlp`, and `convolutional neural network` classifier.
+Please write your code and then test results of different classifiers of `softmax_regression`, `MLP` and `convolutional neural network`.
```python
def train_program():
+ """
+ Configure train_program
+
+ Return:
+ predict -- result of classification
+ avg_cost -- mean loss
+ acc -- accuracy of classification
+
+ """
+ # label layer, called label, correspondent with label category of input picture
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
- # predict = softmax_regression() # uncomment for Softmax
- # predict = multilayer_perceptron() # uncomment for MLP
- predict = convolutional_neural_network() # uncomment for LeNet5
+ # predict = softmax_regression() # cancel note and run Softmax regression
+ # predict = multilayer_perceptron() # cancel note and run multiple perceptron
+ predict = convolutional_neural_network() # cancel note and run LeNet5 convolutional neural network
- # Calculate the cost from the prediction and label.
+ # use class cross-entropy function to compute loss function between predict and label
cost = fluid.layers.cross_entropy(input=predict, label=label)
+ # compute mean loss
avg_cost = fluid.layers.mean(cost)
+ # compute accuracy of classification
acc = fluid.layers.accuracy(input=predict, label=label)
+ return predict, [avg_cost, acc]
- # The first item needs to be avg_cost.
- return [avg_cost, acc]
```
#### Optimizer Function Configuration
-In the following `Adam` optimizer, `learning_rate` specifies the learning rate in the optimization procedure.
+`Adam optimizer`,`learning_rate` below are learning rate. Their size is associated with speed of network train convergence.
```python
def optimizer_program():
return fluid.optimizer.Adam(learning_rate=0.001)
```
-### Data Feeders Configuration
+### Data Feeders for dataset Configuration
-Then we specify the training data `paddle.dataset.mnist.train()` and testing data `paddle.dataset.mnist.test()`. These two methods are *reader creators*. Once called, a reader creator returns a *reader*. A reader is a Python method, which, once called, returns a Python generator, which yields instances of data.
+Next We start the training process. `Paddle.dataset.mnist.train()` and `paddle.dataset.mnist.test()` are respectively as train dataset and test dataset. These two functions respectively return a reader-- reader in PaddlePaddle is a Python function, which returns a Python yield generator when calling the reader.
-`shuffle` is a reader decorator. It takes a reader A as input and returns a new reader B. Under the hood, B calls A to read data in the following fashion: it copies in `buffer_size` instances at a time into a buffer, shuffles the data, and yields the shuffled instances one at a time. A large buffer size would yield very shuffled data.
+`Shuffle` below is a reader decorator, which receives a reader A and returns another reader B. Reader B read `buffer_size` train data into a buffer and then the data is disordered randomly and is output one by one.
-`batch` is a special decorator, which takes a reader and outputs a *batch reader*, which doesn't yield an instance, but a minibatch at a time.
+`Batch` is a special decorator. Its input is a reader and output is a batched reader. In PaddlePaddle, a reader yield a piece of data every time while batched reader yield a minibatch every time.
```python
+# there are 64 data in a minibatch
+BATCH_SIZE = 64
+
+# read 500 data in train dataset, randomly disorder them and then transfer it into batched reader which yield 64 data each time.
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.mnist.train(), buf_size=500),
- batch_size=64)
-
+ batch_size=BATCH_SIZE)
+# read data in test dataset and yield 64 data every time
test_reader = paddle.batch(
- paddle.dataset.mnist.test(), batch_size=64)
+ paddle.dataset.mnist.test(), batch_size=BATCH_SIZE)
+```
+
+### create training process
+
+Now we need to create a training process. We will use `train_program`, `place` and `optimizer` defined before, conclude test loss in the period of training iteration and training verification and save parameters of model for prediction.
+
+
+#### Event Handler Configuration
+
+We can call a handler function to supervise training process during training.
+We display two `event_handler` programs here. Please freely update Jupyter Notebook and find the changes.
+
+`Event_handler` is used to output training result during the train
+
+```python
+def event_handler(pass_id, batch_id, cost):
+ # print the intermediate results of training, like
+ # training iterations, number of batch, and loss function
+ print("Pass %d, Batch %d, Cost %f" % (pass_id,batch_id, cost))
+```
+
+```python
+from paddle.utils.plot import Ploter
+
+train_prompt = "Train cost"
+test_prompt = "Test cost"
+cost_ploter = Ploter(train_prompt, test_prompt)
+
+# visualize training process
+def event_handler_plot(ploter_title, step, cost):
+ cost_ploter.append(ploter_title, step, cost)
+ cost_ploter.plot()
```
-### Trainer Configuration
+`event_handler_plot` can be visualized as follows:
+
+
+
-Now, we need to setup the trainer. The trainer need to take in `train_program`, `place`, and `optimizer`.
+### Start training
+
+Aftering adding `event_handler` and `data reader` we configured, we can start to train the model.
+Set parameters for operation to configure data description.
+`Feed_order` is used to map data directory to `train_program`
+Create a `train_test` reflecting the loss during our training.
+
+Define network structure:
```python
-use_cuda = False # set to True if training with GPU
+# the model is run on single CPU
+use_cuda = False # If you want to use GPU, please set it True
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-trainer = Trainer(
- train_func=train_program, place=place, optimizer_func=optimizer_program)
- ```
+# call train_program to get prediction value and loss value,
+prediction, [avg_loss, acc] = train_program()
-#### Event Handler
+# input original image data in size of 28*28*1
+img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
+# label layer, called label, correspondent with label category of input picture.
+label = fluid.layers.data(name='label', shape=[1], dtype='int64')
+# It is informed that data in network consists of two parts. One is img value, the other is label value.
+feeder = fluid.DataFeeder(feed_list=[img, label], place=place)
-Fluid API provides a hook to the callback function during training. Users are able to monitor training progress through mechanism.
-We will demonstrate two event handlers here. Please feel free to modify on the Jupyter notebook to see the differences.
+# choose Adam optimizer
+optimizer = fluid.optimizer.Adam(learning_rate=0.001)
+optimizer.minimize(avg_loss)
+```
-`event_handler` is used to plot some text data when training.
+Configure hyper parameter during the training:
```python
-# Save the parameter into a directory. The Inferencer can load the parameters from it to do infer
-params_dirname = "recognize_digits_network.inference.model"
-lists = []
-def event_handler(event):
- if isinstance(event, EndStepEvent):
- if event.step % 100 == 0:
- # event.metrics maps with train program return arguments.
- # event.metrics[0] will yeild avg_cost and event.metrics[1] will yeild acc in this example.
- print("Pass %d, Batch %d, Cost %f" % (
- event.step, event.epoch, event.metrics[0]))
-
- if isinstance(event, EndEpochEvent):
- avg_cost, acc = trainer.test(
- reader=test_reader, feed_order=['img', 'label'])
-
- print("Test with Epoch %d, avg_cost: %s, acc: %s" % (event.epoch, avg_cost, acc))
-
- # save parameters
- trainer.save_params(params_dirname)
- lists.append((event.epoch, avg_cost, acc))
+
+PASS_NUM = 5 #train 5 iterations
+epochs = [epoch_id for epoch_id in range(PASS_NUM)]
+
+# save parameters of model into save_dirname file
+save_dirname = "recognize_digits.inference.model"
+```
+
+
+```python
+def train_test(train_test_program,
+ train_test_feed, train_test_reader):
+
+ # save classification accuracy into acc_set
+ acc_set = []
+ # save mean loss in avg_loss_set
+ avg_loss_set = []
+ # transfer each data which is the output of testing reader_yield into network to train
+ for test_data in train_test_reader():
+ acc_np, avg_loss_np = exe.run(
+ program=train_test_program,
+ feed=train_test_feed.feed(test_data),
+ fetch_list=[acc, avg_loss])
+ acc_set.append(float(acc_np))
+ avg_loss_set.append(float(avg_loss_np))
+ # get accuracy and loss value on the test data
+ acc_val_mean = numpy.array(acc_set).mean()
+ avg_loss_val_mean = numpy.array(avg_loss_set).mean()
+ # return mean loss value and mean accuracy
+ return avg_loss_val_mean, acc_val_mean
+```
+
+Create executor
+
+```python
+exe = fluid.Executor(place)
+exe.run(fluid.default_startup_program())
+```
+
+Set up main_program and test_program:
+
+```python
+main_program = fluid.default_main_program()
+test_program = fluid.default_main_program().clone(for_test=True)
```
+Start training:
+
-#### Start training
-Now that we setup the event_handler and the reader, we can start training the model. `feed_order` is used to map the data dict to the train_program
```python
-# Train the model now
-trainer.train(
- num_epochs=5,
- event_handler=event_handler,
- reader=train_reader,
- feed_order=['img', 'label'])
+lists = []
+step = 0
+for epoch_id in epochs:
+ for step_id, data in enumerate(train_reader()):
+ metrics = exe.run(main_program,
+ feed=feeder.feed(data),
+ fetch_list=[avg_loss, acc])
+ if step % 100 == 0: # print a log for every 100 times of training
+ print("Pass %d, Batch %d, Cost %f" % (step, epoch_id, metrics[0]))
+ event_handler_plot(train_prompt, step, metrics[0])
+ step += 1
+
+ # test classification result of each epoch
+ avg_loss_val, acc_val = train_test(train_test_program=test_program,
+ train_test_reader=test_reader,
+ train_test_feed=feeder)
+
+ print("Test with Epoch %d, avg_cost: %s, acc: %s" %(epoch_id, avg_loss_val, acc_val))
+ event_handler_plot(test_prompt, step, metrics[0])
+
+ lists.append((epoch_id, avg_loss_val, acc_val))
+
+ # save parameters of trained model for prediction
+ if save_dirname is not None:
+ fluid.io.save_inference_model(save_dirname,
+ ["img"], [prediction], exe,
+ model_filename=None,
+ params_filename=None)
+
+# Choose the best pass
+best = sorted(lists, key=lambda list: float(list[1]))[0]
+print('Best pass is %s, testing Avgcost is %s' % (best[0], best[1]))
+print('The classification accuracy is %.2f%%' % (float(best[2]) * 100))
```
-During training, `trainer.train` invokes `event_handler` for certain events. This gives us a chance to print the training progress.
+
+The training process is completely automatic. The log printed in event_handler is like as follows.
+
+Pass represents iterations of train. Batch represents times to train all data. cost represents loss value of current pass.
+
+Compute the mean loss and accuracy of classification after an epoch.
```
Pass 0, Batch 0, Cost 0.125650
@@ -353,79 +499,76 @@ Pass 900, Batch 0, Cost 0.239809
Test with Epoch 0, avg_cost: 0.053097883707459624, acc: 0.9822850318471338
```
-After the training, we can check the model's prediction accuracy.
+Check prediction accuracy of the model after training. In the train with MNIST, generally classification accuracy of softmax regression model is about 92.34%, while that of multilayer perceptron is 97.66% and that of convolutional neural network is 99.20%.
-```python
-# find the best pass
-best = sorted(lists, key=lambda list: float(list[1]))[0]
-print 'Best pass is %s, testing Avgcost is %s' % (best[0], best[1])
-print 'The classification accuracy is %.2f%%' % (float(best[2]) * 100)
-```
-
-Usually, with MNIST data, the softmax regression model achieves an accuracy around 92.34%, the MLP 97.66%, and the convolution network around 99.20%. Convolution layers have been widely considered a great invention for image processing.
-
-## Application
-After training, users can use the trained model to classify images. The following code shows how to inference MNIST images through `fluid.contrib.inferencer.Inferencer`.
+## Deploy the Model
-### Create Inferencer
+You can use trained model to classify handwriting pictures of digits. The program below shows how to use well-trained model to predict.
-The `Inferencer` takes an `infer_func` and `param_path` to setup the network and the trained parameters.
-We can simply plug-in the classifier defined earlier here.
-
-```python
-inferencer = Inferencer(
- # infer_func=softmax_regression, # uncomment for softmax regression
- # infer_func=multilayer_perceptron, # uncomment for MLP
- infer_func=convolutional_neural_network, # uncomment for LeNet5
- param_path=params_dirname,
- place=place)
-```
+### Generate input data to be inferred
-#### Generate input data for inferring
+`infer_3.png` is an example picture of number 3. Transform it into a numpy to match feed data format
-`infer_3.png` is an example image of the digit `3`. Turn it into an numpy array to match the data feeder format.
```python
-# Prepare the test image
-import os
-import numpy as np
-from PIL import Image
def load_image(file):
im = Image.open(file).convert('L')
im = im.resize((28, 28), Image.ANTIALIAS)
- im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32)
+ im = numpy.array(im).reshape(1, 1, 28, 28).astype(numpy.float32)
im = im / 255.0 * 2.0 - 1.0
return im
cur_dir = os.getcwd()
-img = load_image(cur_dir + '/image/infer_3.png')
+tensor_img = load_image(cur_dir + '/image/infer_3.png')
```
### Inference
-Now we are ready to do inference.
+By configuring network and training parameters via `load_inference_model`, We can simply insert classifier defined before.
+
+
```python
-results = inferencer.infer({'img': img})
-lab = np.argsort(results) # probs and lab are the results of one batch data
-print("Inference result of image/infer_3.png is: %d" % lab[0][0][-1])
+inference_scope = fluid.core.Scope()
+with fluid.scope_guard(inference_scope):
+ # use fluid.io.load_inference_model to get inference program desc,
+ # feed_target_names is used to define variable name needed to be passed into network
+ # fetch_targets define variable name to be fetched from network
+ [inference_program, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(
+ save_dirname, exe, None, None)
+
+ # Make feed a dictionary {feed_target_name: feed_target_data}
+ # The result will contain a data list corresponding to fetch_targets
+ results = exe.run(inference_program,
+ feed={feed_target_names[0]: tensor_img},
+ fetch_list=fetch_targets)
+ lab = numpy.argsort(results)
+
+ # Print prediction result of infer_3.png
+ img=Image.open('image/infer_3.png')
+ plt.imshow(img)
+ print("Inference result of image/infer_3.png is: %d" % lab[0][0][-1])
```
-## Conclusion
-This tutorial describes a few common deep learning models using **Softmax regression**, **Multilayer Perceptron Network**, and **Convolutional Neural Network**. Understanding these models is crucial for future learning; the subsequent tutorials derive more sophisticated networks by building on top of them.
-When our model evolves from a simple softmax regression to a slightly complex Convolutional Neural Network, the recognition accuracy on the MNIST dataset achieves a large improvement. This is due to the Convolutional layers' local connections and parameter sharing. While learning new models in the future, we encourage the readers to understand the key ideas that lead a new model to improve the results of an old one.
+### Result
+
+If successful, the inference result input is as follows:
+`Inference result of image/infer_3.png is: 3` , which indicates that out network successfully recognize the picture!
-Moreover, this tutorial introduces the basic flow of PaddlePaddle model design, which starts with a *data provider*, a model layer construction, and finally training and prediction. Motivated readers can leverage the flow used in this MNIST handwritten digit classification example and experiment with different data and network architectures to train models for classification tasks of their choice.
+## Summary
+Softmax regression, multilayer perceptron and convolutional neural network are the most basic deep learning model, from which complex neural networks are all derivative, so these models are helpful for later learning. At the same time, we found that from simple softmax regression transform to slightly complex convolutional neural network, the accuracy of recognition on MNIST dataset largely increased, resulting from that convolution layer is featured with local connection and sharing weight. When study of new models later, hope you make a deep understand of the key upgrade of new model compared with original model. In addition, this tutorial also talks about the basic steps to build PaddlePadle model, from the code of dataprovider, build of network to training and prediction. Familiar with the work flow, you can use your own data, define your own network model and finish your training and prediction tasks.
+
## References
1. LeCun, Yann, Léon Bottou, Yoshua Bengio, and Patrick Haffner. ["Gradient-based learning applied to document recognition."](http://ieeexplore.ieee.org/abstract/document/726791/) Proceedings of the IEEE 86, no. 11 (1998): 2278-2324.
-2. Wejéus, Samuel. ["A Neural Network Approach to Arbitrary SymbolRecognition on Modern Smartphones."](http://www.diva-portal.org/smash/record.jsf?pid=diva2:753279&dswid=-434) (2014).
+2. Wejéus, Samuel. ["A Neural Network Approach to Arbitrary SymbolRecognition on Modern Smartphones."](http://www.diva-portal.org/smash/record.jsf?pid=diva2%3A753279&dswid=-434) (2014).
3. Decoste, Dennis, and Bernhard Schölkopf. ["Training invariant support vector machines."](http://link.springer.com/article/10.1023/A:1012454411458) Machine learning 46, no. 1-3 (2002): 161-190.
4. Simard, Patrice Y., David Steinkraus, and John C. Platt. ["Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis."](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.160.8494&rep=rep1&type=pdf) In ICDAR, vol. 3, pp. 958-962. 2003.
5. Salakhutdinov, Ruslan, and Geoffrey E. Hinton. ["Learning a Nonlinear Embedding by Preserving Class Neighbourhood Structure."](http://www.jmlr.org/proceedings/papers/v2/salakhutdinov07a/salakhutdinov07a.pdf) In AISTATS, vol. 11. 2007.
@@ -436,4 +579,4 @@ Moreover, this tutorial introduces the basic flow of PaddlePaddle model design,
10. Bishop, Christopher M. ["Pattern recognition."](http://users.isr.ist.utl.pt/~wurmd/Livros/school/Bishop%20-%20Pattern%20Recognition%20And%20Machine%20Learning%20-%20Springer%20%202006.pdf) Machine Learning 128 (2006): 1-58.
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/02.recognize_digits/index.html b/02.recognize_digits/index.html
index 2e86cb8..2001fc2 100644
--- a/02.recognize_digits/index.html
+++ b/02.recognize_digits/index.html
@@ -42,213 +42,239 @@
# Recognize Digits
-The source code for this tutorial is here: [book/recognize_digits](https://github.com/PaddlePaddle/book/tree/develop/02.recognize_digits). For instructions on getting started with this book,see [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book).
+The source code of this tutorial is in [book/recognize_digits](https://github.com/PaddlePaddle/book/tree/develop/02.recognize_digits). For new users, please refer to [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book) .
-## Introduction
-When one learns to program, the first task is usually to write a program that prints "Hello World!".
-In Machine Learning or Deep Learning, an equivalent task is to train a model to recognize hand-written digits using the [MNIST](http://yann.lecun.com/exdb/mnist/) dataset.
-Handwriting recognition is a classic image classification problem. The problem is relatively easy and MNIST is a complete dataset.
-As a simple Computer Vision dataset, MNIST contains images of handwritten digits and their corresponding labels (Fig. 1).
-The input image is a $28\times28$ matrix, and the label is one of the digits from $0$ to $9$. All images are normalized, meaning that they are both rescaled and centered.
+## Background
+When we learning programming, the first program we write is generally to implement printing “Hello World”. But the tutorial of machine learning or deep learning for the beginner is usually handwriting recognition on the [MNIST](http://yann.lecun.com/exdb/mnist/) database. Because handwriting recognition is a typical classification problem, relatively simple and the MNIST dataset is complete. MNIST dataset as a simple computer vision dataset contains a series of pictures and corresponding labels of handwriting digits. The picture is a 28x28 pixel matrix, and the label corresponds to 10 numbers from 0 to 9. Each picture has been normalized in size and centered in the position.
-
-Fig. 1. Examples of MNIST images
+
+Figure 1. Example of a MNIST picture
-The MNIST dataset is from the [NIST](https://www.nist.gov/srd/nist-special-database-19) Special Database 3 (SD-3) and the Special Database 1 (SD-1).
-The SD-3 is labeled by the staff of the U.S. Census Bureau, while SD-1 is labeled by high school students. Therefore the SD-3 is cleaner and easier to recognize than the SD-1 dataset.
-Yann LeCun et al. used half of the samples from each of SD-1 and SD-3 to create the MNIST training set of 60,000 samples and test set of 10,000 samples.
-250 annotators labeled the training set, thus guaranteed that there wasn't a complete overlap of annotators of training set and test set.
+MNIST dataset is created from [NIST](https://www.nist.gov/srd/nist-special-database-19) Special Database 3(SD-3) and Special Database 1(SD-1). Because SD-3 is labeled by stuff of US Census Bureau and SD-1 is labeled by US high school students, so SD-3 is clearer and easier to be recognized than SD-1. Yann LeCun et al. pick half of SD-1 and half of SD-3 as train dataset (60000 data) and test dataset (10000 data).250 annotators labeled the training set, thus guaranteed that there wasn't a complete overlap of annotators of training set and test set.
-The MNIST dataset has been used for evaluating many image recognition algorithms such as a single layer linear classifier,
-Multilayer Perceptron (MLP) and Multilayer CNN LeNet\[[1](#references)\], K-Nearest Neighbors (k-NN) \[[2](#references)\], Support Vector Machine (SVM) \[[3](#references)\],
-Neural Networks \[[4-7](#references)\], Boosting \[[8](#references)\] and preprocessing methods like distortion removal, noise removal, and blurring.
-Among these algorithms, the *Convolutional Neural Network* (CNN) has achieved a series of impressive results in Image Classification tasks, including VGGNet, GoogLeNet,
-and ResNet (See [Image Classification](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification) tutorial).
+MNIST attracts scholars to train model based on the dataset. In 1998, LeCun conducted experiments respectively using Single layer classifier, Multilayer Perceptron and Multilayer convolutional neural network LeNet, constantly decreasing the error on test dataset ( from 12% to 0.7%)\[[1](#References)\]。 In the process of research, LeCun, the pioneer in the field of deep learning, came up with Convolutional Neural Network, largely improving the performance of handwriting recognition. After that, researchers take a large number of experiments based on K-Nearest Neighbors algorithm\[[2](#References)\], SVM\[[3](#References)\], Neural Network\[[4-7](#References)\] and Boosting method\[[8](#References)\] and so on, with multiple pre-processing methods(like distortion removal, noise removal, and blurring) to upgrade accuracy of recognition.
-In this tutorial, we start with a simple **softmax** regression model and go on with MLP and CNN. Readers will see how these methods improve the recognition accuracy step-by-step.
+Convolutional Neural Network plays an important role in the field of deep learning now. From simple LeNet proposed by Yann LeCun in early days to model VGGNet, GoogleNet, ResNet and so on in the ImageNet competition (please refer to [Image Classification](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification) tutorial ), we have gain a serious of great achievements with convolutional neural network in the field of image classification.
-## Model Overview
-Before introducing classification algorithms and training procedure, we define the following symbols:
-- $X$ is the input: Input is a $28\times 28$ MNIST image. It is flattened to a $784$ dimensional vector. $X=\left (x_0, x_1, \dots, x_{783} \right )$.
-- $Y$ is the output: Output of the classifier is 1 of the 10 classes (digits from 0 to 9). $Y=\left (y_0, y_1, \dots, y_9 \right )$. Each dimension $y_i$ represents the probability that the input image belongs to class $i$.
-- $L$ is the ground truth label: $L=\left ( l_0, l_1, \dots, l_9 \right )$. It is also 10 dimensional, but only one entry is $1$ and all others are $0$s.
+In this tutorial, starting from simple Softmax regression model, we help you learn about handwriting recognition and introduce you how to upgrade model and how to use MLP and CNN to optimize recognition result.
+
+
+## Exploration of Models
+
+To train a classifier based on MNIST dataset, before the introduction of three basic image classification networks used in this tutorial, we first give some definitions:
+
+- $X$ is the input: the MNIST image is a two-dimensional image of $28\times28$. For the calculation, we transform it into a $784$ dimensional vector, ie $X=\left ( x_0, x_1, \dots, x_{783} \right )$.
+
+- $Y$ is the output: the output of the classifier is number (0-9), ie $Y=\left ( y_0, y_1, \dots, y_9 \right )$, and each dimension $y_i$ represents the probability of image classification as $i$th number.
+
+- $Label$ is the actual label of the picture: $Label=\left ( l_0, l_1, \dots, l_9 \right ) $ is also 10 dimensions, but only one dimension represents 1, and the rest is 0. For example, if the number on an image is 2, its label is $(0,0,1,0, \dot, 0)$
### Softmax Regression
-In a simple softmax regression model, the input is first fed to fully connected layers. Then, a softmax function is applied to output probabilities of multiple output classes\[[9](#references)\].
+The simplest Softmax regression model is to get features with input layer passing through a fully connected layer and then compute and ouput probabilities of multiple classifications directly via Softmax function \[[9](#references)\].
-The input $X$ is multiplied by weights $W$ and then added to the bias $b$ to generate activations.
+The data of the input layer $X$ is passed to the output layer. The input $X$ is multiplied by weights $W$ and then added to the bias $b$ to generate activations:
$$ y_i = \text{softmax}(\sum_j W_{i,j}x_j + b_i) $$
where $ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $
-For an $N$-class classification problem with $N$ output nodes, Softmax normalizes the resulting $N$ dimensional vector so that each of its entries falls in the range $[0,1]\in {R}$, representing the probability that the sample belongs to a certain class. Here $y_i$ denotes the predicted probability that an image is of digit $i$.
+Figure 2 is a network of softmax regression, in which weights are represented by blue lines, bias are represented by red lines, and +1 indicates that the bias is $1$.
-In such a classification problem, we usually use the cross entropy loss function:
+
+
+Figure 2. Softmax regression network structure
+
-$$ \text{_L_
cross-entropy}(label, y) = -\sum_i label_ilog(y_i) $$
+For an $N$-class classification problem with $N$ output nodes, Softmax normalizes the resulting $N$ dimensional vector so that each of its entries falls in the range $[0,1]\in {R}$, representing the probability that the sample belongs to a certain category. Here $y_i$ denotes the predicted probability that an image is of number $i$.
+
+In the classification problem, we usually use cross-entropy loss, the formula is as follows:
+
+$$ L_{cross-entropy}(label, y) = -\sum_i label_ilog(y_i) $$
-Fig. 2 illustrates a softmax regression network, with the weights in blue, and the bias in red. `+1` indicates that the bias is $1$.
-
-
-Fig. 2. Softmax regression network architecture
-
### Multilayer Perceptron
-The softmax regression model described above uses the simplest two-layer neural network. That is, it only contains an input layer and an output layer, with limited regression capability. To achieve better recognition results, consider adding several hidden layers\[[10](#references)\] between the input layer and the output layer.
+The Softmax regression model uses the simplest two-layer neural network, which contains only the input layer and the output layer, so its performance is limited. In order to achieve better recognition, we consider adding several hidden layers \[[10](#references)\] between the input and output layer.
-1. After the first hidden layer, we get $ H_1 = \phi(W_1X + b_1) $, where $\phi$ denotes the activation function. Some [common ones](###list-of-common-activation-functions) are sigmoid, tanh and ReLU.
-2. After the second hidden layer, we get $ H_2 = \phi(W_2H_1 + b_2) $.
-3. Finally, the output layer outputs $Y=\text{softmax}(W_3H_2 + b_3)$, the vector denoting our classification result.
+1.In the first hidden layer, you can get $ H_1 = \phi(W_1X + b_1) $, where $\phi$ represents the activation function. And common functions are [sigmoid, tanh or ReLU](#common activation functions).
+2.In the second hidden layer, you can get $ H_2 = \phi(W_2H_1 + b_2) $.
+3.Finally, in the output layer, you can get $Y=\text{softmax}(W_3H_2 + b_3)$, that is the final classification result vector.
-Fig. 3. shows a Multilayer Perceptron network, with the weights in blue, and the bias in red. +1 indicates that the bias is $1$.
-
-
-Fig. 3. Multilayer Perceptron network architecture
+Figure 3 is a network structure of a multi-layer perceptron, in which weights are represented by blue lines, bias are represented by red lines, and +1 indicates that the bias is $1$.
+
+
+Figure 3. Multilayer perceptron network structure
### Convolutional Neural Network
-#### Convolutional Layer
+In the multi-layer perceptron model, an image is expanded into a one-dimensional vector and input into the network, ignoring its position and structure information. And the convolutional neural network can better utilize the structure information of the image. [LeNet-5](http://yann.lecun.com/exdb/lenet/) is a relatively simple convolutional neural network. Figure 4 shows the structure: the input two-dimensional image, first through the two convolutional layers to the pooling layer, then through the fully connected layer, and finally using the softmax as the output layer. Below we mainly introduce the convolutional layer and the pooling layer.
-
-Fig. 4. Convolutional layer
+
+Figure 4. LeNet-5 convolutional neural network structure
-The **convolutional layer** is the core of a Convolutional Neural Network. The parameters in this layer are composed of a set of filters, also called kernels. We could visualize the convolution step in the following fashion: Each kernel slides horizontally and vertically till it covers the whole image. At every window, we compute the dot product of the kernel and the input. Then, we add the bias and apply an activation function. The result is a two-dimensional activation map. For example, some kernel may recognize corners, and some may recognize circles. These convolution kernels may respond strongly to the corresponding features.
-
-Fig. 4 illustrates the dynamic programming of a convolutional layer, where depths are flattened for simplicity. The input is $W_1=5$, $H_1=5$, $D_1=3$. In fact, this is a common representation for colored images. $W_1$ and $H_1$ correspond to the width and height in a colored image. $D_1$ corresponds to the three color channels for RGB. The parameters of the convolutional layer are $K=2$, $F=3$, $S=2$, $P=1$. $K$ denotes the number of kernels; specifically, $Filter$ $W_0$ and $Filter$ $W_1$ are the kernels. $F$ is kernel size while $W0$ and $W1$ are both $F\timesF = 3\times3$ matrices in all depths. $S$ is the stride, which is the width of the sliding window; here, kernels move leftwards or downwards by two units each time. $P$ is the width of the padding, which denotes an extension of the input; here, the gray area shows zero padding with size 1.
+#### Convolutional Layer
-#### Pooling Layer
+Convolutional Layer is the core of convolutional neural network. The convolution we mentioned in image recognition is a two-dimensional convolution, that is, a discrete two-dimensional filter (also called a convolutional kernel) and a two-dimensional image for convoluting. In short, the two-dimensional filter slides to all positions on two-dimensional images and dot product is taken for this pixel and its domain pixel at each position. Convolution operations are widely used in the field of image processing. Different convolutional kernels can extract different features, such as edges, lines, and angles. In deep convolutional neural networks, low-level to complex image features can be extracted by convolution operation.
-
-Fig. 5 Pooling layer using max-pooling
+
+Figure 5. Convolutional Layer Picture
-A **pooling layer** performs downsampling. The main functionality of this layer is to reduce computation by reducing the network parameters. It also prevents over-fitting to some extent. Usually, a pooling layer is added after a convolutional layer. Pooling layer can use various techniques, such as max pooling and average pooling. As shown in Fig.5, max pooling uses rectangles to segment the input layer into several parts and computes the maximum value in each part as the output.
+Figure 5 shows an example of the process of computing convolution with input image in size of $H=5, W=5, D=3$, ie $5 \times 5$ size of 3 channel (RGB, also known as depth) color image.
+
+This example contains two (denoted by $K$) groups of convolutional kernels, i.e. $Filter W_0$ and $Filter W_1$ in the figure. In convolution calculation, different convolutional kernels are usually used for different input channels. In the example, each set of convolutional kernels contains ($D=3$) $3\times 3$ (indicated by $F \times F$) convolutional kernel. In addition, the stride of convolutional kernel in horizontal and vertical direction of image is 2 (indicated by $S$); Pad 1 (represented by $P$) 0 in the four directions of input image, that is, the input layer raw data in the figure is the blue part, and the gray part is expanded with 0 in the size of 1. The convolution operation yields a feature map of the size of $3 \times 3 \times 2$ (represented by $H_{o} \times W_{o} \times K$), which is a 2-channel feature map in size of $3 \times 3$, where $H_o$ is calculated as: $H_o = (H - F + 2 \times P)/S + 1$, so is $W_o$. And each pixel in the output feature map is the summation of the inner product of each set of filters and each feature of the input image, plus the bias $b_o$, the bias is usually shared by each output feature map. The last $-2$ in the output feature map $o[:,:,0]$ is calculated as shown in the lower right corner of Figure 5.
+
+The convolutional kernel is a learnable parameter in the convolution operation. As shown in the example above, the parameter of each layer of convolution is $D \times F \times F \times K$. In the multi-layer perceptron model, neurons are usually fully connected therefore with a large number of parameters. There are fewer parameters in the convolutional layer, which is also determined by main features of the convolutional layer, namely local connections and shared weights.
+
+- Local connection: Each neuron is connected to only one region of the input neuron, which is called Receptive Field. In the image convolution operation, that is, the neurons are locally connected in the spatial dimension (the plane in which the above examples H and W are located), but are fully connected in depth. For the two-dimensional image itself, the local pixels are strongly related. This local connection ensures that the learned filter makes the strongest response to local input features. The idea of local connection is also inspired by the structure of visual system in biology. The neurons in the visual cortex receive information locally.
+
+- Weight sharing: The filters used to calculate neurons in the same deep slice are shared. For example, in Figure 4, the filter for each neuron calculated by $o[:,:,0]$ is the same, both are $W_0$, which can greatly reduce the parameters. The sharing weight is meaningful to a certain extent, for example, the bottom edge feature of the image is independent of the specific location of the feature in the graph. However, it is unintentional in some cases. For example, the input picture is a face, eyes and hair are in different positions. And to learn different features in different positions, please (refer to [Stanford University Open Class](http://cs231n.Github.io/convolutional-networks/)). Note that the weights are only shared for the neurons of the same depth slice. In the convolutional layer, multiple sets of convolutional kernels are usually used to extract different features, that is, the weights of neurons with different depth slices are not shared by the features with different depth slices. In addition, bias are shared by all neurons with the same depth.
-#### LeNet-5 Network
+By introducing the calculation process of convolution and its features, convolution could be seen as a linear operation with shift-invariant, which is the same operation performed at each position of the image. The local connection and weight sharing of the convolutional layer greatly reduce the parameters that need to be learned, which helps with training larger convolutional neural networks.
+
+For more information about convolution, please refer to [Reference Reading](http://ufldl.stanford.edu/wiki/index.php/Feature_extraction_using_convolution#Convolutions)。
+
+### Pooling Layer
-
-Fig. 6. LeNet-5 Convolutional Neural Network architecture
+
+Figure 6. Picture in pooling layer
-[**LeNet-5**](http://yann.lecun.com/exdb/lenet/) is one of the simplest Convolutional Neural Networks. Fig. 6. shows its architecture: A 2-dimensional input image is fed into two sets of convolutional layers and pooling layers. This output is then fed to a fully connected layer and a softmax classifier. Compared to multilayer, fully connected perceptrons, the LeNet-5 can recognize images better. This is due to the following three properties of the convolution:
+Pooling is a form of nonlinear downsampling. The main functionality of this layer is to reduce computation by reducing the network parameters and to control the overfitting to some extent. Normally a pooling layer is added after the convolutional layer. Pooling includes maximum pooling, average pooling and so on. The largest pooling is to divide the input layer into different areas by non-overlapping rectangular boxes, and the maximum value of each rectangular box is taken as the output layer, as shown in Figure. 6.
-- The 3D nature of the neurons: a convolutional layer is organized by width, height, and depth. Neurons in each layer are connected to only a small region in the previous layer. This region is called the receptive field.
-- Local connectivity: A CNN utilizes the local space correlation by connecting local neurons. This design guarantees that the learned filter has a strong response to local input features. Stacking many such layers generates a non-linear filter that is more global. This enables the network to first obtain good representation for small parts of input and then combine them to represent a larger region.
-- Weight sharing: In a CNN, computation is iterated on shared parameters (weights and bias) to form a feature map. This means that all the neurons in the same depth of the output response to the same feature. This allows the network to detect a feature regardless of its position in the input.
+For details about convolutional neural network, please refer to the tutorial of [Standford Online Course]( http://cs231n.github.io/convolutional-networks/ ), [Ufldl](http://ufldl.stanford.edu/wiki/index.php/Pooling) and [Image Classification]( https://github.com/PaddlePaddle/book/tree/develop/03.image_classification ).
-For more details on Convolutional Neural Networks, please refer to the tutorial on [Image Classification](https://github.com/PaddlePaddle/book/blob/develop/image_classification/README.md) and the [relevant lecture](http://cs231n.github.io/convolutional-networks/) from a Stanford course.
+
+### Common activation functions
-### List of Common Activation Functions
- Sigmoid activation function: $ f(x) = sigmoid(x) = \frac{1}{1+e^{-x}} $
- Tanh activation function: $ f(x) = tanh(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}} $
- In fact, tanh function is just a rescaled version of the sigmoid function. It is obtained by magnifying the value of the sigmoid function and moving it downwards by 1.
+In fact, the tanh function is only a sigmoid function with change of scale. The value of the sigmoid function is doubled and then shifted down by 1 unit: tanh(x) = 2sigmoid(2x) - 1 .
- ReLU activation function: $ f(x) = max(0, x) $
-For more information, please refer to [Activation functions on Wikipedia](https://en.wikipedia.org/wiki/Activation_function).
-
-## Data Preparation
+For details, please refer to [activation function in Wikipedia](https://en.wikipedia.org/wiki/Activation_function).
-PaddlePaddle provides a Python module, `paddle.dataset.mnist`, which downloads and caches the [MNIST dataset](http://yann.lecun.com/exdb/mnist/). The cache is under `/home/username/.cache/paddle/dataset/mnist`:
+## Dataset Preparation
+PaddlePaddle provides a module `paddle.dataset.mnist` that automatically loads [MNIST] (http://yann.lecun.com/exdb/mnist/) data in the API. The loaded data is located under `/home/username/.cache/paddle/dataset/mnist`:
-| File name | Description | Size |
-|----------------------|--------------|-----------|
-|train-images-idx3-ubyte| Training images | 60,000 |
-|train-labels-idx1-ubyte| Training labels | 60,000 |
-|t10k-images-idx3-ubyte | Evaluation images | 10,000 |
-|t10k-labels-idx1-ubyte | Evaluation labels | 10,000 |
+| filename | note |
+|----------------------|-------------------------|
+|train-images-idx3-ubyte| train data picture, 60,000 data |
+|train-labels-idx1-ubyte| train data label, 60,000 data |
+|t10k-images-idx3-ubyte | test data picture, 10,000 data |
+|t10k-labels-idx1-ubyte | test data label, 10,000 data |
## Fluid API Overview
-The demo will be using the latest paddle fluid API. Fluid API is the latest Paddle API. It simplifies the model configurations without sacrifice the performance.
-We recommend using Fluid API as it is much easier to pick up.
-Here are the quick overview on the major fluid API complements.
+The demo will use the latest [Fluid API](http://paddlepaddle.org/documentation/docs/en/1.2/api_cn/index_cn.html). Fluid API is the latest PaddlePaddle API. It simplifies model configuration without sacrificing performance.
+We recommend using the Fluid API, which is easy to learn and use to help you complete your machine learning tasks quickly.
+
+Here is an overview of several important concepts in the Fluid API:
+
+1. `inference_program`: specifies how to get the inference function from the data input.
+This is where the network flow is defined.
+
+2. `train_program`: specifies how to get the `loss` function from `inference_program` and `tag value`.
+This is where the loss calculation is specified.
-1. `inference_program`: A function that specify how to get the prediction from the data input.
-This is where you specify the network flow.
-1. `train_program`: A function that specify how to get avg_cost from `inference_program` and labels.
-This is where you specify the loss calculations.
-1. `optimizer_func`:"A function that specifies the configuration of the the optimizer. The optimizer is responsible for minimizing the loss and driving the training. Paddle supports many different optimizers."
-1. `Trainer`: Fluid trainer manages the training process specified by the `train_program` and `optimizer`. Users can monitor the training
-progress through the `event_handler` callback function.
-1. `Inferencer`: Fluid inferencer loads the `inference_program` and the parameters trained by the Trainer.
-It then can infer the data and return prediction
+3. `optimizer_func`: Specifies the function of the optimizer configuration. The optimizer is responsible for reducing losses and driving training. Paddle supports a number of different optimizers.
-We will go though all of them and dig more on the configurations in this demo.
+In the code examples below, we'll take a closer look at them.
-## Model Configuration
+## Configuration Instructions
-A PaddlePaddle program starts from importing the API package:
+Load the Fluid API package for PaddlePaddle.
```python
-import paddle
+import os
+from PIL import Image # load module of image processing
+import matplotlib.pyplot as plt
+import numpy
+import paddle # load paddle module
import paddle.fluid as fluid
-from __future__ import print_function
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
+from __future__ import print_function #load print of python3 into current version
```
### Program Functions Configuration
-First, We need to setup the `inference_program` function. We want to use this program to demonstrate three different classifiers, each defined as a Python function.
-We need to feed image data to the classifier. PaddlePaddle provides a special layer `layer.data` for reading data.
-Let us create a data layer for reading images and connect it to the classification network.
+We need to configure `inference_program` function. We want to use this program to show three different classifiers, each of which is defined as a Python function.
+We need to input the image data into the classifier. Paddle provides a special layer `layer.data` for reading data.
+Let's create a data layer to read the image and connect it to the network of classification.
-- Softmax regression: the network has a fully-connection layer with softmax activation:
+-Softmax regression: The results of the classification can be obtained only through a simple layer of simple fully connected layer with softmax as the activation function.
```python
def softmax_regression():
+ """
+ Define softmax classifier:
+ A fully connected layer with activation function softmax
+ Return:
+ predict_image -- result of classification
+ """
+ # input original image data in size of 28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
+ # With softmax as the fully connected layer of the activation function, the size of the output layer must be 10
predict = fluid.layers.fc(
- input=img, size=10, act='softmax')
+ input=img, size=10, act='softmax')
return predict
```
-- Multi-Layer Perceptron: this network has two hidden fully-connected layers, both are using ReLU as activation function. The output layer is using softmax activation:
+-Multilayer Perceptron: The following code implements a multilayer perceptron with two hidden layers (that is, fully connected layers). The activation functions of the two hidden layers are all ReLU, and the activation function of the output layer is Softmax.
```python
def multilayer_perceptron():
+ """
+ Define multilayer perceptron classifier:
+ Multilayer perceptron with two hidden layers (fully connected layers)
+ The activation function of the first two hidden layers uses ReLU, and the activation function of the output layer uses Softmax.
+
+ Return:
+ predict_image -- result of classification
+ """
+ # input raw image data in size of 28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
- # first fully-connected layer, using ReLu as its activation function
+ # the first fully connected layer, whose activation function is ReLU
hidden = fluid.layers.fc(input=img, size=200, act='relu')
- # second fully-connected layer, using ReLu as its activation function
+ # the second fully connected layer, whose activation function is ReLU
hidden = fluid.layers.fc(input=hidden, size=200, act='relu')
+ # With softmax as the fully connected output layer of the activation function, the size of the output layer must be 10
prediction = fluid.layers.fc(input=hidden, size=10, act='softmax')
return prediction
```
-- Convolution network LeNet-5: the input image is fed through two convolution-pooling layers, a fully-connected layer, and the softmax output layer:
+-Convolutional neural network LeNet-5: The input two-dimensional image first passes through two convolutional layers to the pooling layer, then passes through the fully connected layer, and finally fully connection layer with softmax as activation function is used as output layer.
```python
def convolutional_neural_network():
+ """
+ Define convolutional neural network classifier:
+ The input 2D image passes through two convolution-pooling layers, using the fully connected layer with softmax as the output layer
+
+ Return:
+ predict -- result of classification
+ """
+ # input raw image data in size of 28*28*1
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
- # first conv pool
+ # the first convolution-pooling layer
+ # Use 20 5*5 filters, the pooling size is 2, the pooling step is 2, and the activation function is Relu.
conv_pool_1 = fluid.nets.simple_img_conv_pool(
input=img,
filter_size=5,
@@ -257,7 +283,8 @@ def convolutional_neural_network():
pool_stride=2,
act="relu")
conv_pool_1 = fluid.layers.batch_norm(conv_pool_1)
- # second conv pool
+ # the second convolution-pooling layer
+ # Use 20 5*5 filters, the pooling size is 2, the pooling step is 2, and the activation function is Relu.
conv_pool_2 = fluid.nets.simple_img_conv_pool(
input=conv_pool_1,
filter_size=5,
@@ -265,121 +292,240 @@ def convolutional_neural_network():
pool_size=2,
pool_stride=2,
act="relu")
- # output layer with softmax activation function. size = 10 since there are only 10 possible digits.
+ # With softmax as the fully connected output layer of the activation function, the size of the output layer must be 10
prediction = fluid.layers.fc(input=conv_pool_2, size=10, act='softmax')
return prediction
```
#### Train Program Configuration
-Then we need to setup the the `train_program`. It takes the prediction from the classifier first.
-During the training, it will calculate the `avg_loss` from the prediction.
+Then we need to set train program `train_program` It firstly infers from classifier.
+During the training, it will compute `avg_cost`.
-**NOTE:** A train program should return an array and the first return argument has to be `avg_cost`.
-The trainer always implicitly use it to calculate the gradient.
+** Note:** train program should return an array. The first parameter returned must be `avg_cost`. The trainer uses it to compute gradient.
-Please feel free to modify the code to test different results between `softmax regression`, `mlp`, and `convolutional neural network` classifier.
+Please write your code and then test results of different classifiers of `softmax_regression`, `MLP` and `convolutional neural network`.
```python
def train_program():
+ """
+ Configure train_program
+
+ Return:
+ predict -- result of classification
+ avg_cost -- mean loss
+ acc -- accuracy of classification
+
+ """
+ # label layer, called label, correspondent with label category of input picture
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
- # predict = softmax_regression() # uncomment for Softmax
- # predict = multilayer_perceptron() # uncomment for MLP
- predict = convolutional_neural_network() # uncomment for LeNet5
+ # predict = softmax_regression() # cancel note and run Softmax regression
+ # predict = multilayer_perceptron() # cancel note and run multiple perceptron
+ predict = convolutional_neural_network() # cancel note and run LeNet5 convolutional neural network
- # Calculate the cost from the prediction and label.
+ # use class cross-entropy function to compute loss function between predict and label
cost = fluid.layers.cross_entropy(input=predict, label=label)
+ # compute mean loss
avg_cost = fluid.layers.mean(cost)
+ # compute accuracy of classification
acc = fluid.layers.accuracy(input=predict, label=label)
+ return predict, [avg_cost, acc]
- # The first item needs to be avg_cost.
- return [avg_cost, acc]
```
#### Optimizer Function Configuration
-In the following `Adam` optimizer, `learning_rate` specifies the learning rate in the optimization procedure.
+`Adam optimizer`,`learning_rate` below are learning rate. Their size is associated with speed of network train convergence.
```python
def optimizer_program():
return fluid.optimizer.Adam(learning_rate=0.001)
```
-### Data Feeders Configuration
+### Data Feeders for dataset Configuration
-Then we specify the training data `paddle.dataset.mnist.train()` and testing data `paddle.dataset.mnist.test()`. These two methods are *reader creators*. Once called, a reader creator returns a *reader*. A reader is a Python method, which, once called, returns a Python generator, which yields instances of data.
+Next We start the training process. `Paddle.dataset.mnist.train()` and `paddle.dataset.mnist.test()` are respectively as train dataset and test dataset. These two functions respectively return a reader-- reader in PaddlePaddle is a Python function, which returns a Python yield generator when calling the reader.
-`shuffle` is a reader decorator. It takes a reader A as input and returns a new reader B. Under the hood, B calls A to read data in the following fashion: it copies in `buffer_size` instances at a time into a buffer, shuffles the data, and yields the shuffled instances one at a time. A large buffer size would yield very shuffled data.
+`Shuffle` below is a reader decorator, which receives a reader A and returns another reader B. Reader B read `buffer_size` train data into a buffer and then the data is disordered randomly and is output one by one.
-`batch` is a special decorator, which takes a reader and outputs a *batch reader*, which doesn't yield an instance, but a minibatch at a time.
+`Batch` is a special decorator. Its input is a reader and output is a batched reader. In PaddlePaddle, a reader yield a piece of data every time while batched reader yield a minibatch every time.
```python
+# there are 64 data in a minibatch
+BATCH_SIZE = 64
+
+# read 500 data in train dataset, randomly disorder them and then transfer it into batched reader which yield 64 data each time.
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.mnist.train(), buf_size=500),
- batch_size=64)
-
+ batch_size=BATCH_SIZE)
+# read data in test dataset and yield 64 data every time
test_reader = paddle.batch(
- paddle.dataset.mnist.test(), batch_size=64)
+ paddle.dataset.mnist.test(), batch_size=BATCH_SIZE)
+```
+
+### create training process
+
+Now we need to create a training process. We will use `train_program`, `place` and `optimizer` defined before, conclude test loss in the period of training iteration and training verification and save parameters of model for prediction.
+
+
+#### Event Handler Configuration
+
+We can call a handler function to supervise training process during training.
+We display two `event_handler` programs here. Please freely update Jupyter Notebook and find the changes.
+
+`Event_handler` is used to output training result during the train
+
+```python
+def event_handler(pass_id, batch_id, cost):
+ # print the intermediate results of training, like
+ # training iterations, number of batch, and loss function
+ print("Pass %d, Batch %d, Cost %f" % (pass_id,batch_id, cost))
+```
+
+```python
+from paddle.utils.plot import Ploter
+
+train_prompt = "Train cost"
+test_prompt = "Test cost"
+cost_ploter = Ploter(train_prompt, test_prompt)
+
+# visualize training process
+def event_handler_plot(ploter_title, step, cost):
+ cost_ploter.append(ploter_title, step, cost)
+ cost_ploter.plot()
```
-### Trainer Configuration
+`event_handler_plot` can be visualized as follows:
+
+
+
-Now, we need to setup the trainer. The trainer need to take in `train_program`, `place`, and `optimizer`.
+### Start training
+
+Aftering adding `event_handler` and `data reader` we configured, we can start to train the model.
+Set parameters for operation to configure data description.
+`Feed_order` is used to map data directory to `train_program`
+Create a `train_test` reflecting the loss during our training.
+
+Define network structure:
```python
-use_cuda = False # set to True if training with GPU
+# the model is run on single CPU
+use_cuda = False # If you want to use GPU, please set it True
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-trainer = Trainer(
- train_func=train_program, place=place, optimizer_func=optimizer_program)
- ```
+# call train_program to get prediction value and loss value,
+prediction, [avg_loss, acc] = train_program()
-#### Event Handler
+# input original image data in size of 28*28*1
+img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
+# label layer, called label, correspondent with label category of input picture.
+label = fluid.layers.data(name='label', shape=[1], dtype='int64')
+# It is informed that data in network consists of two parts. One is img value, the other is label value.
+feeder = fluid.DataFeeder(feed_list=[img, label], place=place)
-Fluid API provides a hook to the callback function during training. Users are able to monitor training progress through mechanism.
-We will demonstrate two event handlers here. Please feel free to modify on the Jupyter notebook to see the differences.
+# choose Adam optimizer
+optimizer = fluid.optimizer.Adam(learning_rate=0.001)
+optimizer.minimize(avg_loss)
+```
-`event_handler` is used to plot some text data when training.
+Configure hyper parameter during the training:
```python
-# Save the parameter into a directory. The Inferencer can load the parameters from it to do infer
-params_dirname = "recognize_digits_network.inference.model"
-lists = []
-def event_handler(event):
- if isinstance(event, EndStepEvent):
- if event.step % 100 == 0:
- # event.metrics maps with train program return arguments.
- # event.metrics[0] will yeild avg_cost and event.metrics[1] will yeild acc in this example.
- print("Pass %d, Batch %d, Cost %f" % (
- event.step, event.epoch, event.metrics[0]))
-
- if isinstance(event, EndEpochEvent):
- avg_cost, acc = trainer.test(
- reader=test_reader, feed_order=['img', 'label'])
-
- print("Test with Epoch %d, avg_cost: %s, acc: %s" % (event.epoch, avg_cost, acc))
-
- # save parameters
- trainer.save_params(params_dirname)
- lists.append((event.epoch, avg_cost, acc))
+
+PASS_NUM = 5 #train 5 iterations
+epochs = [epoch_id for epoch_id in range(PASS_NUM)]
+
+# save parameters of model into save_dirname file
+save_dirname = "recognize_digits.inference.model"
+```
+
+
+```python
+def train_test(train_test_program,
+ train_test_feed, train_test_reader):
+
+ # save classification accuracy into acc_set
+ acc_set = []
+ # save mean loss in avg_loss_set
+ avg_loss_set = []
+ # transfer each data which is the output of testing reader_yield into network to train
+ for test_data in train_test_reader():
+ acc_np, avg_loss_np = exe.run(
+ program=train_test_program,
+ feed=train_test_feed.feed(test_data),
+ fetch_list=[acc, avg_loss])
+ acc_set.append(float(acc_np))
+ avg_loss_set.append(float(avg_loss_np))
+ # get accuracy and loss value on the test data
+ acc_val_mean = numpy.array(acc_set).mean()
+ avg_loss_val_mean = numpy.array(avg_loss_set).mean()
+ # return mean loss value and mean accuracy
+ return avg_loss_val_mean, acc_val_mean
+```
+
+Create executor
+
+```python
+exe = fluid.Executor(place)
+exe.run(fluid.default_startup_program())
+```
+
+Set up main_program and test_program:
+
+```python
+main_program = fluid.default_main_program()
+test_program = fluid.default_main_program().clone(for_test=True)
```
+Start training:
+
-#### Start training
-Now that we setup the event_handler and the reader, we can start training the model. `feed_order` is used to map the data dict to the train_program
```python
-# Train the model now
-trainer.train(
- num_epochs=5,
- event_handler=event_handler,
- reader=train_reader,
- feed_order=['img', 'label'])
+lists = []
+step = 0
+for epoch_id in epochs:
+ for step_id, data in enumerate(train_reader()):
+ metrics = exe.run(main_program,
+ feed=feeder.feed(data),
+ fetch_list=[avg_loss, acc])
+ if step % 100 == 0: # print a log for every 100 times of training
+ print("Pass %d, Batch %d, Cost %f" % (step, epoch_id, metrics[0]))
+ event_handler_plot(train_prompt, step, metrics[0])
+ step += 1
+
+ # test classification result of each epoch
+ avg_loss_val, acc_val = train_test(train_test_program=test_program,
+ train_test_reader=test_reader,
+ train_test_feed=feeder)
+
+ print("Test with Epoch %d, avg_cost: %s, acc: %s" %(epoch_id, avg_loss_val, acc_val))
+ event_handler_plot(test_prompt, step, metrics[0])
+
+ lists.append((epoch_id, avg_loss_val, acc_val))
+
+ # save parameters of trained model for prediction
+ if save_dirname is not None:
+ fluid.io.save_inference_model(save_dirname,
+ ["img"], [prediction], exe,
+ model_filename=None,
+ params_filename=None)
+
+# Choose the best pass
+best = sorted(lists, key=lambda list: float(list[1]))[0]
+print('Best pass is %s, testing Avgcost is %s' % (best[0], best[1]))
+print('The classification accuracy is %.2f%%' % (float(best[2]) * 100))
```
-During training, `trainer.train` invokes `event_handler` for certain events. This gives us a chance to print the training progress.
+
+The training process is completely automatic. The log printed in event_handler is like as follows.
+
+Pass represents iterations of train. Batch represents times to train all data. cost represents loss value of current pass.
+
+Compute the mean loss and accuracy of classification after an epoch.
```
Pass 0, Batch 0, Cost 0.125650
@@ -395,79 +541,76 @@ Pass 900, Batch 0, Cost 0.239809
Test with Epoch 0, avg_cost: 0.053097883707459624, acc: 0.9822850318471338
```
-After the training, we can check the model's prediction accuracy.
+Check prediction accuracy of the model after training. In the train with MNIST, generally classification accuracy of softmax regression model is about 92.34%, while that of multilayer perceptron is 97.66% and that of convolutional neural network is 99.20%.
-```python
-# find the best pass
-best = sorted(lists, key=lambda list: float(list[1]))[0]
-print 'Best pass is %s, testing Avgcost is %s' % (best[0], best[1])
-print 'The classification accuracy is %.2f%%' % (float(best[2]) * 100)
-```
-
-Usually, with MNIST data, the softmax regression model achieves an accuracy around 92.34%, the MLP 97.66%, and the convolution network around 99.20%. Convolution layers have been widely considered a great invention for image processing.
-
-## Application
-After training, users can use the trained model to classify images. The following code shows how to inference MNIST images through `fluid.contrib.inferencer.Inferencer`.
+## Deploy the Model
-### Create Inferencer
+You can use trained model to classify handwriting pictures of digits. The program below shows how to use well-trained model to predict.
-The `Inferencer` takes an `infer_func` and `param_path` to setup the network and the trained parameters.
-We can simply plug-in the classifier defined earlier here.
-
-```python
-inferencer = Inferencer(
- # infer_func=softmax_regression, # uncomment for softmax regression
- # infer_func=multilayer_perceptron, # uncomment for MLP
- infer_func=convolutional_neural_network, # uncomment for LeNet5
- param_path=params_dirname,
- place=place)
-```
+### Generate input data to be inferred
-#### Generate input data for inferring
+`infer_3.png` is an example picture of number 3. Transform it into a numpy to match feed data format
-`infer_3.png` is an example image of the digit `3`. Turn it into an numpy array to match the data feeder format.
```python
-# Prepare the test image
-import os
-import numpy as np
-from PIL import Image
def load_image(file):
im = Image.open(file).convert('L')
im = im.resize((28, 28), Image.ANTIALIAS)
- im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32)
+ im = numpy.array(im).reshape(1, 1, 28, 28).astype(numpy.float32)
im = im / 255.0 * 2.0 - 1.0
return im
cur_dir = os.getcwd()
-img = load_image(cur_dir + '/image/infer_3.png')
+tensor_img = load_image(cur_dir + '/image/infer_3.png')
```
### Inference
-Now we are ready to do inference.
+By configuring network and training parameters via `load_inference_model`, We can simply insert classifier defined before.
+
+
```python
-results = inferencer.infer({'img': img})
-lab = np.argsort(results) # probs and lab are the results of one batch data
-print("Inference result of image/infer_3.png is: %d" % lab[0][0][-1])
+inference_scope = fluid.core.Scope()
+with fluid.scope_guard(inference_scope):
+ # use fluid.io.load_inference_model to get inference program desc,
+ # feed_target_names is used to define variable name needed to be passed into network
+ # fetch_targets define variable name to be fetched from network
+ [inference_program, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(
+ save_dirname, exe, None, None)
+
+ # Make feed a dictionary {feed_target_name: feed_target_data}
+ # The result will contain a data list corresponding to fetch_targets
+ results = exe.run(inference_program,
+ feed={feed_target_names[0]: tensor_img},
+ fetch_list=fetch_targets)
+ lab = numpy.argsort(results)
+
+ # Print prediction result of infer_3.png
+ img=Image.open('image/infer_3.png')
+ plt.imshow(img)
+ print("Inference result of image/infer_3.png is: %d" % lab[0][0][-1])
```
-## Conclusion
-This tutorial describes a few common deep learning models using **Softmax regression**, **Multilayer Perceptron Network**, and **Convolutional Neural Network**. Understanding these models is crucial for future learning; the subsequent tutorials derive more sophisticated networks by building on top of them.
-When our model evolves from a simple softmax regression to a slightly complex Convolutional Neural Network, the recognition accuracy on the MNIST dataset achieves a large improvement. This is due to the Convolutional layers' local connections and parameter sharing. While learning new models in the future, we encourage the readers to understand the key ideas that lead a new model to improve the results of an old one.
+### Result
+
+If successful, the inference result input is as follows:
+`Inference result of image/infer_3.png is: 3` , which indicates that out network successfully recognize the picture!
-Moreover, this tutorial introduces the basic flow of PaddlePaddle model design, which starts with a *data provider*, a model layer construction, and finally training and prediction. Motivated readers can leverage the flow used in this MNIST handwritten digit classification example and experiment with different data and network architectures to train models for classification tasks of their choice.
+## Summary
+Softmax regression, multilayer perceptron and convolutional neural network are the most basic deep learning model, from which complex neural networks are all derivative, so these models are helpful for later learning. At the same time, we found that from simple softmax regression transform to slightly complex convolutional neural network, the accuracy of recognition on MNIST dataset largely increased, resulting from that convolution layer is featured with local connection and sharing weight. When study of new models later, hope you make a deep understand of the key upgrade of new model compared with original model. In addition, this tutorial also talks about the basic steps to build PaddlePadle model, from the code of dataprovider, build of network to training and prediction. Familiar with the work flow, you can use your own data, define your own network model and finish your training and prediction tasks.
+
## References
1. LeCun, Yann, Léon Bottou, Yoshua Bengio, and Patrick Haffner. ["Gradient-based learning applied to document recognition."](http://ieeexplore.ieee.org/abstract/document/726791/) Proceedings of the IEEE 86, no. 11 (1998): 2278-2324.
-2. Wejéus, Samuel. ["A Neural Network Approach to Arbitrary SymbolRecognition on Modern Smartphones."](http://www.diva-portal.org/smash/record.jsf?pid=diva2:753279&dswid=-434) (2014).
+2. Wejéus, Samuel. ["A Neural Network Approach to Arbitrary SymbolRecognition on Modern Smartphones."](http://www.diva-portal.org/smash/record.jsf?pid=diva2%3A753279&dswid=-434) (2014).
3. Decoste, Dennis, and Bernhard Schölkopf. ["Training invariant support vector machines."](http://link.springer.com/article/10.1023/A:1012454411458) Machine learning 46, no. 1-3 (2002): 161-190.
4. Simard, Patrice Y., David Steinkraus, and John C. Platt. ["Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis."](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.160.8494&rep=rep1&type=pdf) In ICDAR, vol. 3, pp. 958-962. 2003.
5. Salakhutdinov, Ruslan, and Geoffrey E. Hinton. ["Learning a Nonlinear Embedding by Preserving Class Neighbourhood Structure."](http://www.jmlr.org/proceedings/papers/v2/salakhutdinov07a/salakhutdinov07a.pdf) In AISTATS, vol. 11. 2007.
@@ -478,7 +621,7 @@ Moreover, this tutorial introduces the basic flow of PaddlePaddle model design,
10. Bishop, Christopher M. ["Pattern recognition."](http://users.isr.ist.utl.pt/~wurmd/Livros/school/Bishop%20-%20Pattern%20Recognition%20And%20Machine%20Learning%20-%20Springer%20%202006.pdf) Machine Learning 128 (2006): 1-58.
-This tutorial is contributed by
PaddlePaddle, and licensed under a
Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by
PaddlePaddle, and licensed under a
Creative Commons Attribution-ShareAlike 4.0 International License.
-
+
Figure 1. General image classification
-Figure 2 shows the results of a fine-grained image classifier. This task of flower recognition requires correctly recognizing of the flower's categories.
+Figure 2 shows the results of a fine-grained image classifier. This task of flower recognition ought to correctly recognize of the flower's breed.
-
+
Figure 2. Fine-grained image classification
-A good model should recognize objects of different categories correctly. The results of such a model should not vary due to viewpoint variation, illumination conditions, object distortion or occlusion.
+A qualified model should recognize objects of different categories correctly. The results of such a model should remain accurate in different perspectives, illumination conditions, object distortion or occlusion (we refer to these conditions as Image Disturbance).
Figure 3 shows some images with various disturbances. A good model should classify these images correctly like humans.
-
-Figure 3. Disturbed images [22]
+
+Figure 3. Disturbed images [22]
-## Model Overview
+## Exploration of Models
+
+A large amount of researches in image classification are built upon benchmark datasets such as [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/), [ImageNet](http://image-net.org/) etc. Many image classification algorithms are usually evaluated and compared based on these datasets. PASCAL VOC is a computer vision competition started in 2005, and ImageNet is a dataset holding Large Scale Visual Recognition Challenge (ILSVRC) started in 2010. In this chapter, we introduce some image classification models from the submissions to these competitions.
-A large amount of research in image classification is built upon public datasets such as [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/), [ImageNet](http://image-net.org/) etc. Many image classification algorithms are usually evaluated and compared on top of these datasets. PASCAL VOC is a computer vision competition started in 2005, and ImageNet is a dataset for Large Scale Visual Recognition Challenge (ILSVRC) started in 2010. In this chapter, we introduce some image classification models from the submissions to these competitions.
Before 2012, traditional image classification was accomplished with the three steps described in the background section. A complete model construction usually involves the following stages: low-level feature extraction, feature encoding, spatial constraint or feature clustering, classifier design, model ensemble.
- 1). **Low-level feature extraction**: This step extracts large amounts of local features according to fixed strides and scales. Popular local features include Scale-Invariant Feature Transform (SIFT)[1], Histogram of Oriented Gradient(HOG)[2], Local Binary Pattern(LBP)[3], etc. A common practice is to employ multiple feature descriptors in order to avoid missing a lot of information.
+ 1). **Low-level feature extraction**: This step extracts large amounts of local features according to fixed strides and scales. Popular local features include Scale-Invariant Feature Transform (SIFT) \[[1](#References)\], Histogram of Oriented Gradient(HOG) \[[2](#References)\], Local Binary Pattern(LBP) \[[3](#References)\], etc. A common practice is to employ multiple feature descriptors in order to avoid missing a lot of information.
- 2). **Feature encoding**: Low-level features contain a large amount of redundancy and noise. In order to improve the robustness of features, it is necessary to employ a feature transformation to encode low-level features. This is called feature encoding. Common feature encoding methods include vector quantization [4], sparse coding [5], locality-constrained linear coding [6], Fisher vector encoding [7], etc.
+ 2). **Feature encoding**: Low-level features contain a large amount of redundancy and noise. In order to improve the robustness of features, it is necessary to employ a feature transformation to encode low-level features. This is called feature encoding. Common feature encoding methods include vector quantization \[[4](#References)\], sparse coding \[[5](#References)\], locality-constrained linear coding \[[6](#References)\], Fisher vector encoding \[[7](#References)\], etc.
3). **Spatial constraint**: Spatial constraint or feature clustering is usually adopted after feature encoding for extracting the maximum or average of each dimension in the spatial domain. Pyramid feature matching--a popular feature clustering method--divides an image uniformly into patches and performs feature clustering in each patch.
4). **Classification**: In the above steps an image can be described by a vector of fixed dimension. Then a classifier can be used to classify the image into categories. Common classifiers include Support Vector Machine(SVM), random forest etc. Kernel SVM is the most popular classifier and has achieved very good performance in traditional image classification tasks.
-This method has been used widely as image classification algorithm in PASCAL VOC [18]. NEC Labs(http://www.nec-labs.com/) won the championship by employing SIFT and LBP features, two non-linear encoders and SVM in ILSVRC 2010 [8].
+This classic method has been used widely as image classification algorithm in PASCAL VOC \[[18](#References)\]. [NEC Labs](http://www.nec-labs.com/) won the championship by employing SIFT and LBP features, two non-linear encoders and SVM in ILSVRC 2010 \[[8](#References)\].
-The CNN model--AlexNet proposed by Alex Krizhevsky et al.[9], made a breakthrough in ILSVRC 2012. It dramatically outperformed traditional methods and won the ILSVRC championship in 2012. This was also the first time that a deep learning method was used for large-scale image classification. Since AlexNet, a series of CNN models have been proposed that have advanced the state of the art steadily on Imagenet as shown in Figure 4. With deeper and more sophisticated architectures, Top-5 error rate is getting lower and lower (to around 3.5%). The error rate of human raters on the same Imagenet dataset is 5.1%, which means that the image classification capability of a deep learning model has surpassed human raters.
+The CNN model--AlexNet proposed by Alex Krizhevsky et al. \[[9](#References)\], made a breakthrough in ILSVRC 2012. It dramatically outperformed classical methods and won the ILSVRC championship in 2012. This was also the first time that a deep learning method was adopted for large-scale image classification. Since AlexNet, a series of CNN models have been proposed that have advanced the state of the art steadily on Imagenet as shown in Figure 4. With deeper and more sophisticated architectures, Top-5 error rate is getting lower and lower (to around 3.5%). The error rate of human raters on the same Imagenet dataset is 5.1%, which means that the image classification capability of a deep learning model has surpassed human raters.
-
+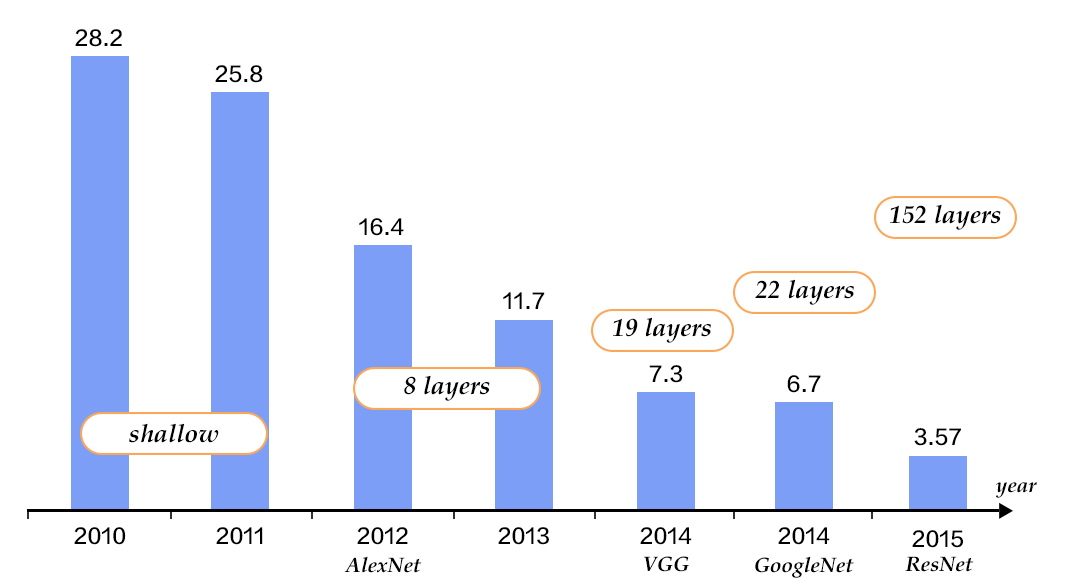
+
Figure 4. Top-5 error rates on ILSVRC image classification
### CNN
-Traditional CNNs consist of convolutional and fully-connected layers and use the softmax multi-category classifier with the cross-entropy loss function. Figure 5 shows a typical CNN. We first introduce the common components of a CNN.
+Traditional CNNs consist of convolution and fully-connected layers and use the softmax multi-category classifier with the cross-entropy loss function. Figure 5 shows a typical CNN. We first take look at the common components of a CNN.
-
-Figure 5. A CNN example [20]
+
+Figure 5. A CNN example [20]
- convolutional layer: this layer uses the convolution operation to extract (low-level and high-level) features and to discover local correlation and spatial invariance.
-- pooling layer: this layer down samples feature maps by extracting local max (max-pooling) or average (avg-pooling) value of each patch in the feature map. Down-sampling is a common operation in image processing and is used to filter out high-frequency information.
+- pooling layer: this layer down-samples feature maps by extracting local max (max-pooling) or average (avg-pooling) value of each patch in the feature map. Down-sampling is a common operation in image processing and is used to filter out trivial high-frequency information.
- fully-connected layer: this layer fully connects neurons between two adjacent layers.
- non-linear activation: Convolutional and fully-connected layers are usually followed by some non-linear activation layers. Non-linearities enhance the expression capability of the network. Some examples of non-linear activation functions are Sigmoid, Tanh and ReLU. ReLU is the most commonly used activation function in CNN.
-- Dropout [10]: At each training stage, individual nodes are dropped out of the network with a certain probability. This improves the network's ability to generalize and avoids overfitting.
+- Dropout \[[10](#References)\]: At each training stage, individual nodes are dropped out of the network with a certain random probability. This improves the network's ability to generalize and avoids overfitting.
-Parameter updates at each layer during training causes input layer distributions to change and in turn requires hyper-parameters to be carefully tuned. In 2015, Sergey Ioffe and Christian Szegedy proposed a Batch Normalization (BN) algorithm [14], which normalizes the features of each batch in a layer, and enables relatively stable distribution in each layer. Not only does BN algorithm act as a regularizer, but also reduces the need for careful hyper-parameter design. Experiments demonstrate that BN algorithm accelerates the training convergence and has been widely used in later deeper models.
+Parameter updates at each layer during training causes input layer distributions to change and in turn requires hyper-parameters to be carefully tuned. In 2015, Sergey Ioffe and Christian Szegedy proposed a Batch Normalization (BN) algorithm \[[14](#References)\], which normalizes the features of each batch in a layer, and enables relatively stable distribution in each layer. Not only does BN algorithm act as a regularizer, but also eliminates the need for meticulous hyper-parameter design. Experiments demonstrate that BN algorithm accelerates the training convergence and has been widely used in further deeper models.
-In the following sections, we will introduce the following network architectures - VGG, GoogleNet and ResNets.
+In the following sections, we will take a tour through the following network architectures - VGG, GoogleNet and ResNets.
### VGG
-The Oxford Visual Geometry Group (VGG) proposed the VGG network in ILSVRC 2014 [11]. This model is deeper and wider than previous neural architectures. It consists of five main groups of convolution operations. Adjacent convolution groups are connected via max-pooling layers. Each group contains a series of 3x3 convolutional layers (i.e. kernels). The number of convolution kernels stays the same within the group and increases from 64 in the first group to 512 in the last one. The total number of learnable layers could be 11, 13, 16, or 19 depending on the number of convolutional layers in each group. Figure 6 illustrates a 16-layer VGG. The neural architecture of VGG is relatively simple and has been adopted by many papers such as the first one that surpassed human-level performance on ImageNet [19].
+The Oxford Visual Geometry Group (VGG) proposed the VGG network in ILSVRC 2014 \[[11](#References)\]. This model is deeper and wider than previous neural architectures. Its major part is the five main groups of convolution operations. Adjacent convolution groups are connected via max-pooling layers to perform dimensionality reduction. Each group contains a series of 3x3 convolutional layers (i.e. kernels). The number of convolution kernels stays the same within the single group and increases from 64 in the first group to 512 in the last one. Double FC layers and a classifier layer will follow afterwards. The total number of learnable layers could be 11, 13, 16, or 19 depending on the number of convolutional layers in each group. Figure 6 illustrates a 16-layer VGG. The architecture of VGG is relatively simple and has been adopted by many papers such as the first one that surpassed human-level performance on ImageNet \[[19](#References)\].
-
+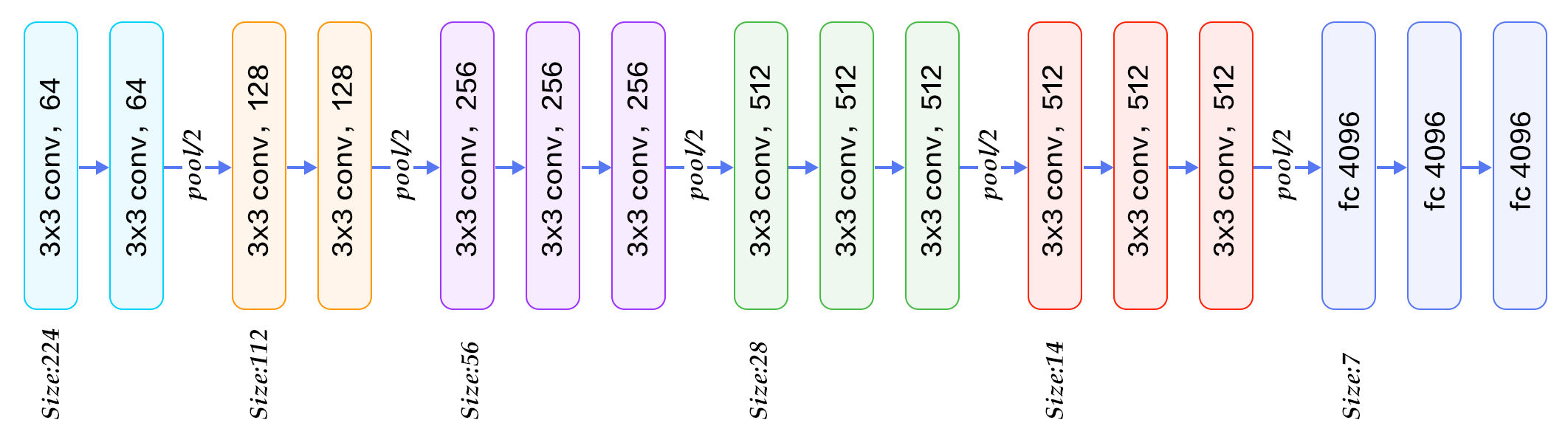
Figure 6. VGG16 model for ImageNet
### GoogleNet
-GoogleNet [12] won the ILSVRC championship in 2014. GoogleNet borrowed some ideas from the Network in Network(NIN) model [13] and is built on the Inception blocks. Let us first familiarize ourselves with these first.
+GoogleNet \[[12](#References)\] won the ILSVRC championship in 2014. GoogleNet borrowed some ideas from the Network in Network(NIN) model \[[13](#References)\] and is built on the Inception blocks. Let us first familiarize ourselves with these concepts first.
The two main characteristics of the NIN model are:
1) A single-layer convolutional network is replaced with a Multi-Layer Perceptron Convolution (MLPconv). MLPconv is a tiny multi-layer convolutional network. It enhances non-linearity by adding several 1x1 convolutional layers after linear ones.
-2) In traditional CNNs, the last fewer layers are usually fully-connected with a large number of parameters. In contrast, NIN replaces all fully-connected layers with convolutional layers with feature maps of the same size as the category dimension and a global average pooling. This replacement of fully-connected layers significantly reduces the number of parameters.
+2) In traditional CNNs, the last fewer layers are usually fully-connected with a large number of parameters. In contrast, the last convolution layer of NIN contains feature maps of the same size as the category dimension, and NIN replaces fully-connected layers with global average pooling to fetch a vector of the same size as category dimension and classify them. This replacement of fully-connected layers significantly reduces the number of parameters.
-Figure 7 depicts two Inception blocks. Figure 7(a) is the simplest design. The output is a concatenation of features from three convolutional layers and one pooling layer. The disadvantage of this design is that the pooling layer does not change the number of filters and leads to an increase in the number of outputs. After several of such blocks, the number of outputs and parameters become larger and larger and lead to higher computation complexity. To overcome this drawback, the Inception block in Figure 7(b) employs three 1x1 convolutional layers. These reduce dimensions or the number of channels but improve the non-linearity of the network.
+Figure 7 depicts two Inception blocks. Figure 7(a) is the simplest design. The output is a concatenation of features from three convolutional layers and one pooling layer. The disadvantage of this design is that the pooling layer does not change the number of channels and leads to an increased channel number of features after concatenation. After several such blocks, the number of channels and parameters become larger and larger and lead to higher computation complexity. To overcome this drawback, the Inception block in Figure 7(b) employs three 1x1 convolutional layers to perform dimensionality reduction, which, to put it simply, is to reduce the number of channels and simultaneously improve the non-linearity of the network.
-
+
Figure 7. Inception block
-GoogleNet consists of multiple stacked Inception blocks followed by an avg-pooling layer as in NIN instead of traditional fully connected layers. The difference between GoogleNet and NIN is that GoogleNet adds a fully connected layer after avg-pooling layer to output a vector of category size. Besides these two characteristics, the features from middle layers of a GoogleNet are also very discriminative. Therefore, GoogeleNet inserts two auxiliary classifiers in the model for enhancing gradient and regularization when doing backpropagation. The loss function of the whole network is the weighted sum of these three classifiers.
+GoogleNet comprises multiple stacked Inception blocks followed by an avg-pooling layer as in NIN instead of traditional fully connected layers. The difference between GoogleNet and NIN is that GoogleNet adds a fully connected layer after avg-pooling layer to output a vector of category size. Besides these two characteristics, the features from middle layers of a GoogleNet are also very discriminative. Therefore, GoogeleNet inserts two auxiliary classifiers in the model for enhancing gradient and regularization when doing back-propagation. The loss function of the whole network is the weighted sum of these three classifiers.
-Figure 8 illustrates the neural architecture of a GoogleNet which consists of 22 layers: it starts with three regular convolutional layers followed by three groups of sub-networks -- the first group contains two Inception blocks, the second group has five, and the third group has two. It ends with an average pooling and a fully-connected layer.
+Figure 8 illustrates the neural architecture of a GoogleNet which consists of 22 layers: it starts with three regular convolutional layers followed by three groups of sub-networks -- the first group contains two Inception blocks, the second group has five, and the third group has two again. Finally, It ends with an average pooling and a fully-connected layer.
-
-Figure 8. GoogleNet[12]
+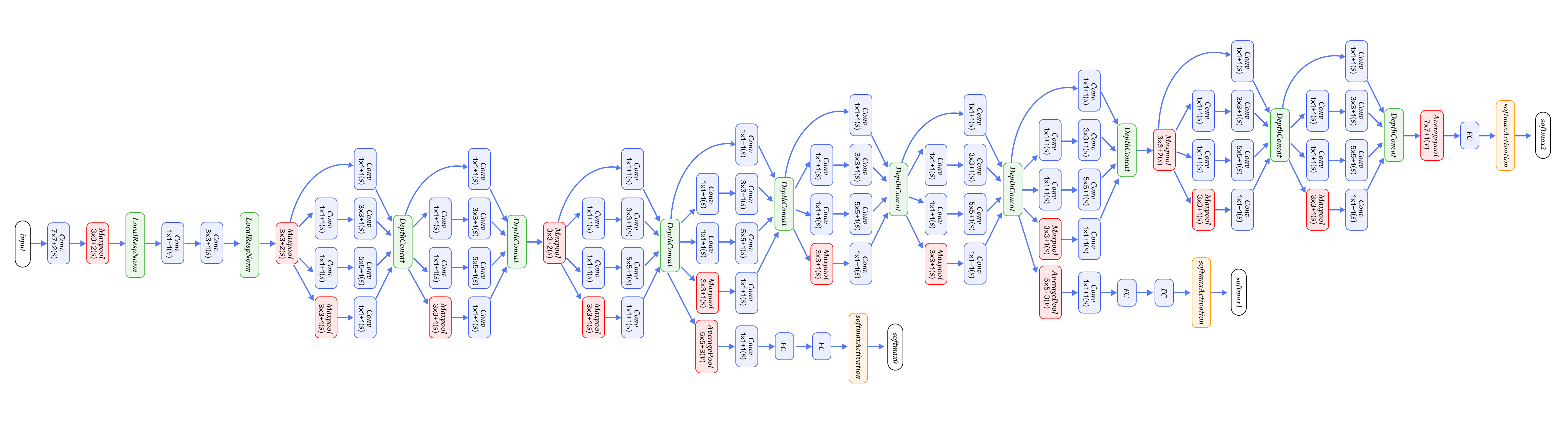
+Figure 8. GoogleNet [12]
-The above model is the first version of GoogleNet or GoogelNet-v1. GoogleNet-v2 [14] introduced BN layer; GoogleNet-v3 [16] further split some convolutional layers, which increases non-linearity and network depth; GoogelNet-v4 [17] leads to the design idea of ResNet which will be introduced in the next section. The evolution from v1 to v4 improved the accuracy rate consistently. We will not go into details of the neural architectures of v2 to v4.
+The model above is the first version of GoogleNet or the so-called GoogelNet-v1. GoogleNet-v2 \[[14](#References)\] introduced BN layer; GoogleNet-v3 \[[16](#References)\] further split some convolutional layers, which increases non-linearity and network depth; GoogelNet-v4 \[[17](#References)\] is inspired by the design idea of ResNet which will be introduced in the next section. The evolution from v1 to v4 improved the accuracy rate consistently. The length of this article being limited, we will not scrutinize the neural architectures of v2 to v4.
### ResNet
-Residual Network(ResNet)[15] won the 2015 championship on three ImageNet competitions -- image classification, object localization, and object detection. The main challenge in training deeper networks is that accuracy degrades with network depth. The authors of ResNet proposed a residual learning approach to ease the difficulty of training deeper networks. Based on the design ideas of BN, small convolutional kernels, full convolutional network, ResNets reformulate the layers as residual blocks, with each block containing two branches, one directly connecting input to the output, the other performing two to three convolutions and calculating the residual function with reference to the layer's inputs. The outputs of these two branches are then added up.
+Residual Network(ResNet) \[[15](#References)\] won the 2015 championship on three ImageNet competitions -- image classification, object localization, and object detection. The main challenge in training deeper networks is that accuracy degrades with network depth. The authors of ResNet proposed a residual learning approach to ease the training of deeper networks. Based on the design ideas of BN, small convolutional kernels, full convolutional network, ResNets reformulate the layers as residual blocks, with each block containing two branches, one directly connecting input to the output, the other performing two to three convolutions and calculating the residual function with reference to the layer's inputs. The output features of these two branches are then added up.
-Figure 9 illustrates the ResNet architecture. To the left is the basic building block, it consists of two 3x3 convolutional layers of the same channels. To the right is a Bottleneck block. The bottleneck is a 1x1 convolutional layer used to reduce dimension from 256 to 64. The other 1x1 convolutional layer is used to increase dimension from 64 to 256. Thus, the number of input and output channels of the middle 3x3 convolutional layer is 64, which is relatively small.
+Figure 9 illustrates the ResNet architecture. To the left is the basic building block, it consists of two 3x3 convolutional layers with the same size of output channels. To the right is a Bottleneck block. The bottleneck is a 1x1 convolutional layer used to reduce dimension (from 256 to 64 here). The following 1x1 convolutional layer is used to increase dimension from 64 to 256. Thus, the number of input and output channels of the middle 3x3 convolutional layer is relatively small (64->64 in this example).
-
+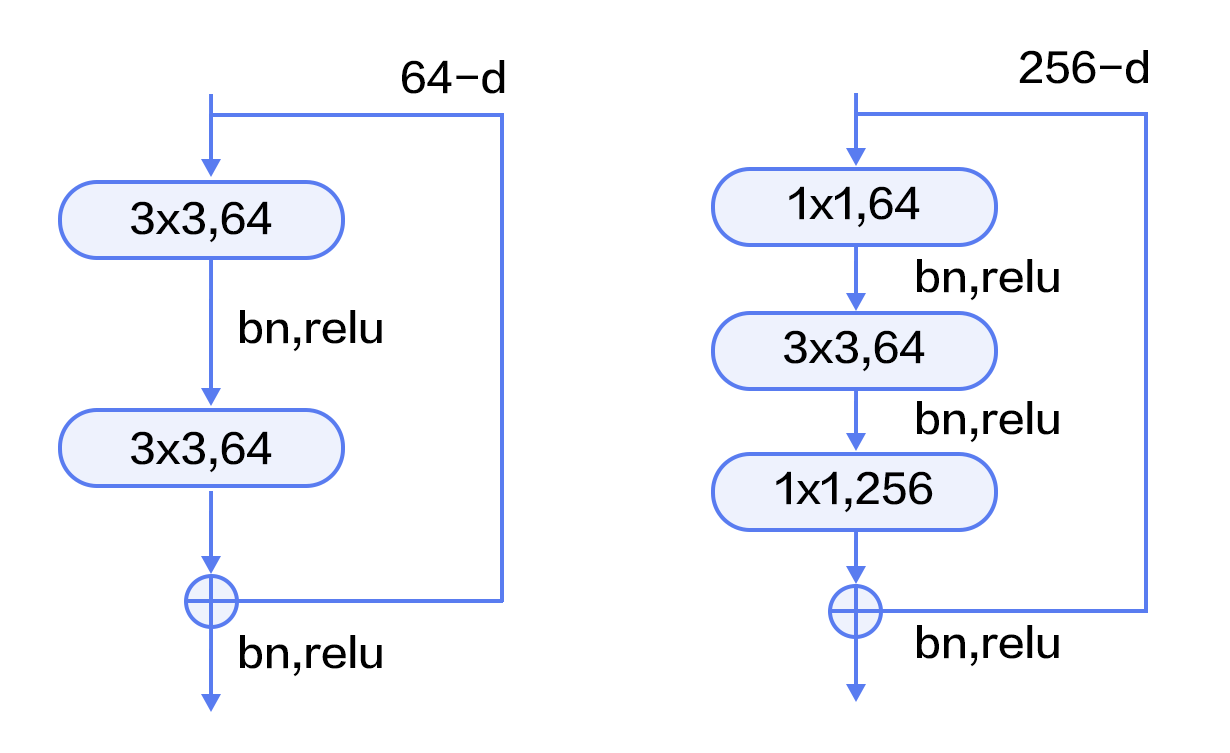
Figure 9. Residual block
-Figure 10 illustrates ResNets with 50, 101, 152 layers, respectively. All three networks use bottleneck blocks of different numbers of repetitions. ResNet converges very fast and can be trained with hundreds or thousands of layers.
+Figure 10 illustrates ResNets with 50, 101, 152 layers, respectively. All three networks use bottleneck blocks and their difference lies in the repetition time of residual blocks. ResNet converges very fast and can be trained with hundreds or thousands of layers.
-
+
Figure 10. ResNet model for ImageNet
-## Dataset
+## Get Data Ready
-Commonly used public datasets for image classification are [CIFAR](https://www.cs.toronto.edu/~kriz/cifar.html), [ImageNet](http://image-net.org/), [COCO](http://mscoco.org/), etc. Those used for fine-grained image classification are [CUB-200-2011](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html), [Stanford Dog](http://vision.stanford.edu/aditya86/ImageNetDogs/), [Oxford-flowers](http://www.robots.ox.ac.uk/~vgg/data/flowers/), etc. Among these, the ImageNet dataset is the largest. Most research results are reported on ImageNet as mentioned in the Model Overview section. Since 2010, the ImageNet dataset has gone through some changes. The commonly used ImageNet-2012 dataset contains 1000 categories. There are 1,281,167 training images, ranging from 732 to 1200 images per category, and 50,000 validation images with 50 images per category in average.
+Common public benchmark datasets for image classification are [CIFAR](https://www.cs.toronto.edu/~kriz/cifar.html), [ImageNet](http://image-net.org/), [COCO](http://mscoco.org/), etc. Those used for fine-grained image classification are [CUB-200-2011](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html), [Stanford Dog](http://vision.stanford.edu/aditya86/ImageNetDogs/), [Oxford-flowers](http://www.robots.ox.ac.uk/~vgg/data/flowers/), etc. Among these, the ImageNet dataset is the largest. Most research results are reported on ImageNet as mentioned in the "Exploration of Models" section. Since 2010, the ImageNet dataset has gone through some changes. The commonly used ImageNet-2012 dataset contains 1000 categories. There are 1,281,167 training images, ranging from 732 to 1200 images per category, and 50,000 validation images with 50 images per category in average.
Since ImageNet is too large to be downloaded and trained efficiently, we use [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) in this tutorial. The CIFAR-10 dataset consists of 60000 32x32 color images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images. Figure 11 shows all the classes in CIFAR-10 as well as 10 images randomly sampled from each category.
-
-Figure 11. CIFAR10 dataset[21]
+
+Figure 11. CIFAR10 dataset [21]
- `paddle.datasets` package encapsulates multiple public datasets, including `cifar`, `imdb`, `mnist`, `moivelens` and `wmt14`, etc. There's no need to manually download and preprocess CIFAR-10.
+The Paddle API invents 'Paddle.dataset.cifar' to automatically load the Cifar DataSet module.
-After running the command `python train.py`, training will start immediately. The following sections will describe in details.
+After running the command `python train.py`, training will start immediately. The following sections will explain `train.py` inside and out.
## Model Configuration
+#### Initialize Paddle
+
Let's start with importing the Paddle Fluid API package and the helper modules.
```python
@@ -172,24 +175,16 @@ import paddle.fluid as fluid
import numpy
import sys
from __future__ import print_function
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
+
```
Now we are going to walk you through the implementations of the VGG and ResNet.
### VGG
-Let's start with the VGG model. Since the image size and amount of CIFAR10 are relatively small comparing to ImageNet, we use a small version of VGG network for CIFAR10. Convolution groups incorporate BN and dropout operations.
+Let's start with the VGG model. Since the image size and amount of CIFAR10 are smaller than ImageNet, we tailor our model to fit CIFAR10 dataset. Convolution groups incorporate BN and dropout operations.
-The input to VGG main module is from the data layer. `vgg_bn_drop` defines a 16-layer VGG network, with each convolutional layer followed by BN and dropout layers. Here is the definition in detail:
+The input to VGG core module is the data layer. `vgg_bn_drop` defines a 16-layer VGG network, with each convolutional layer followed by BN and dropout layers. Here is the definition in detail:
```python
def vgg_bn_drop(input):
@@ -220,24 +215,26 @@ def vgg_bn_drop(input):
return predict
```
- 1. Firstly, it defines a convolution block or conv_block. The default convolution kernel is 3x3, and the default pooling size is 2x2 with stride 2. Dropout specifies the probability in dropout operation. Function `img_conv_group` is defined in `paddle.networks` consisting of a series of `Conv->BN->ReLu->Dropout` and a `Pooling`.
- 2. Five groups of convolutions. The first two groups perform two convolutions, while the last three groups perform three convolutions. The dropout rate of the last convolution in each group is set to 0, which means there is no dropout for this layer.
+ 1. Firstly, it defines a convolution block or conv_block. The default convolution kernel is 3x3, and the default pooling size is 2x2 with stride 2. Groups decide the number of consecutive convolution operations in each VGG block. Dropout specifies the probability to perform dropout operation. Function `img_conv_group` is predefined in `paddle.networks` consisting of a series of `Conv->BN->ReLu->Dropout` and a group of `Pooling` .
+
+ 2. Five groups of convolutions. The first two groups perform two consecutive convolutions, while the last three groups perform three convolutions in sequence. The dropout rate of the last convolution in each group is set to 0, which means there is no dropout for this layer.
- 3. The last two layers are fully-connected layers of dimension 512.
+ 3. The last two layers are fully-connected layers of 512 dimensions.
- 4. The above VGG network extracts high-level features and maps them to a vector of the same size as the categories. Softmax function or classifier is then used for calculating the probability of the image belonging to each category.
+ 4. The VGG network begins with extracting high-level features and then maps them to a vector of the same size as the category dimension. Finally, Softmax function is used for calculating the probability of classifying the image to each category.
### ResNet
-Here are some basic functions used in `resnet_cifar10`:
+The 1st, 3rd, and 4th step is identical to the counterparts in VGG, which are skipped hereby.
+We will explain the 2nd step at lengths, namely the core module of ResNet on CIFAR10.
- - `conv_bn_layer` : convolutional layer followed by BN.
- - `shortcut` : the shortcut branch in a residual block. There are two kinds of shortcuts: 1x1 convolution used when the number of channels between input and output is different; direct connection used otherwise.
+To start with, here are some basic functions used in `resnet_cifar10` ,and the network connection procedure is illustrated afterwards:
+ - `conv_bn_layer` : convolutional layer with BN.
+ - `shortcut` : the shortcut connection in a residual block. There are two kinds of shortcuts: 1x1 convolutions are used to increase dimensionality when in the residual block the number of channels in input feature and that in output feature are different; direct connection used otherwise.
- `basicblock` : a basic residual module as shown in the left of Figure 9, it consists of two sequential 3x3 convolutions and one "shortcut" branch.
- - `bottleneck` : a bottleneck module as shown in the right of Figure 9, it consists of two 1x1 convolutions with one 3x3 convolution in between branch and a "shortcut" branch.
- - `layer_warp` : a group of residual modules consisting of several stacking blocks. In each group, the sliding window size of the first residual block could be different from the rest of blocks, in order to reduce the size of feature maps along horizontal and vertical directions.
+ - `layer_warp` : a group of residual modules consisting of several stacked blocks. In each group, the sliding window size of the first residual block could be different from the rest, in order to reduce the size of feature maps along horizontal and vertical directions.
```python
def conv_bn_layer(input,
@@ -279,13 +276,14 @@ def layer_warp(block_func, input, ch_in, ch_out, count, stride):
return tmp
```
+
The following are the components of `resnet_cifar10`:
-1. The lowest level is `conv_bn_layer`.
-2. The middle level consists of three `layer_warp`, each of which uses the left residual block in Figure 9.
+1. The lowest level is `conv_bn_layer` , e.t. the convolution layer with BN.
+2. The next level is composed of three residual blocks, namely three `layer_warp`, each of which uses the left residual block in Figure 10.
3. The last level is average pooling layer.
-Note: besides the first convolutional layer and the last fully-connected layer, the total number of layers in three `layer_warp` should be dividable by 6, that is the depth of `resnet_cifar10` should satisfy $(depth - 2) % 6 == 0$.
+Note: Except the first convolutional layer and the last fully-connected layer, the total number of layers with parameters in three `layer_warp` should be dividable by 6. In other words, the depth of `resnet_cifar10` should satisfy $(depth - 2) % 6 == 0$.
```python
def resnet_cifar10(ipt, depth=32):
@@ -303,9 +301,10 @@ def resnet_cifar10(ipt, depth=32):
return predict
```
-## Infererence Program Configuration
-The input to the network is defined as `fluid.layers.data`, or image pixels in the context of image classification. The images in CIFAR10 are 32x32 color images of three channels. Therefore, the size of the input data is 3072 (3x32x32).
+## Inference Program Configuration
+
+The input to the network is defined as `fluid.layers.data` , corresponding to image pixels in the context of image classification. The images in CIFAR10 are 32x32 coloured images with three channels. Therefore, the size of the input data is 3072 (3x32x32).
```python
def inference_program():
@@ -318,14 +317,14 @@ def inference_program():
return predict
```
-## Train Program Configuration
-Then we need to setup the the `train_program`. It takes the prediction from the inference_program first.
+## Training Program Configuration
+Then we need to set up the the `train_program`. It takes the prediction from the inference_program first.
During the training, it will calculate the `avg_loss` from the prediction.
-In the context of supervised learning, labels of training images are defined in `fluid.layers.data` as well. During training, the cross-entropy loss function is used and the loss is the output of the network. During testing, the outputs are the probabilities calculated in the classifier.
+In the context of supervised learning, labels of training images are defined in `fluid.layers.data` as well. During training, the multi-class cross-entropy is used as the loss function and becomes the output of the network. During testing, the outputs are the probabilities calculated in the classifier.
-**NOTE:** A train program should return an array and the first returned argument has to be `avg_cost`.
-The trainer always implicitly use it to calculate the gradient.
+**NOTE:** A training program should return an array and the first returned argument has to be `avg_cost` .
+The trainer always uses it to calculate the gradients.
```python
def train_program():
@@ -340,7 +339,7 @@ def train_program():
## Optimizer Function Configuration
-In the following `Adam` optimizer, `learning_rate` specifies the learning rate in the optimization procedure.
+In the following `Adam` optimizer, `learning_rate` specifies the learning rate in the optimization procedure. It influences the convergence speed.
```python
def optimizer_program():
@@ -349,23 +348,10 @@ def optimizer_program():
## Model Training
-### Create Trainer
-
-Before creating a training module, it is necessary to set the algorithm.
-Here we specify `Adam` optimization algorithm via `fluid.optimizer`.
-
-```python
-use_cuda = False
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-trainer = Trainer(
- train_func=train_program,
- optimizer_func=optimizer_program,
- place=place)
-```
### Data Feeders Configuration
-`cifar.train10()` will yield records during each pass, after shuffling, a batch input is generated for training.
+`cifar.train10()` generates one sample at a time as the input for training after completing shuffle and batch.
```python
# Each batch will yield 128 images
@@ -381,54 +367,109 @@ test_reader = paddle.batch(
paddle.dataset.cifar.test10(), batch_size=BATCH_SIZE)
```
-### Event Handler
-Callback function `event_handler` will be called during training when a pre-defined event happens.
+### Implementation of the trainer program
+We need to develop a main_program for the training process. Similarly, we need to configure a test_program for the test program. It's also necessary to define the `place` of the training and use the optimizer `optimizer_func` previously defined .
+
-`event_handler` is used to plot some text data when training.
```python
-params_dirname = "image_classification_resnet.inference.model"
+use_cuda = False
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+
+feed_order = ['pixel', 'label']
+
+main_program = fluid.default_main_program()
+star_program = fluid.default_startup_program()
+
+avg_cost, acc = train_program()
-# event handler to track training and testing process
-def event_handler(event):
- if isinstance(event, EndStepEvent):
- if event.step % 100 == 0:
- print("\nPass %d, Batch %d, Cost %f, Acc %f" %
- (event.step, event.epoch, event.metrics[0],
- event.metrics[1]))
- else:
- sys.stdout.write('.')
- sys.stdout.flush()
+# Test program
+test_program = main_program.clone(for_test=True)
- if isinstance(event, EndEpochEvent):
- # Test against with the test dataset to get accuracy.
- avg_cost, accuracy = trainer.test(
- reader=test_reader, feed_order=['pixel', 'label'])
+optimizer = optimizer_program()
+optimizer.minimize(avg_cost)
- print('\nTest with Pass {0}, Loss {1:2.2}, Acc {2:2.2}'.format(event.epoch, avg_cost, accuracy))
+exe = fluid.Executor(place)
+
+EPOCH_NUM = 2
+
+# For training test cost
+def train_test(program, reader):
+ count = 0
+ feed_var_list = [
+ program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder_test = fluid.DataFeeder(
+ feed_list=feed_var_list, place=place)
+ test_exe = fluid.Executor(place)
+ accumulated = len([avg_cost, acc]) * [0]
+ for tid, test_data in enumerate(reader()):
+ avg_cost_np = test_exe.run(program=program,
+ feed=feeder_test.feed(test_data),
+ fetch_list=[avg_cost, acc])
+ accumulated = [x[0] + x[1][0] for x in zip(accumulated, avg_cost_np)]
+ count += 1
+ return [x / count for x in accumulated]
+```
+
+### The main loop of training and the outputs along the process
+
+In the next main training cycle, we will observe the training process or run test in good use of the outputs.
+
+You can also use `plot` to plot the process by calling back data:
+
+
+```python
+params_dirname = "image_classification_resnet.inference.model"
+
+from paddle.utils.plot import Ploter
+
+train_prompt = "Train cost"
+test_prompt = "Test cost"
+plot_cost = Ploter(test_prompt,train_prompt)
+
+# main train loop.
+def train_loop():
+ feed_var_list_loop = [
+ main_program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder = fluid.DataFeeder(
+ feed_list=feed_var_list_loop, place=place)
+ exe.run(star_program)
+
+ step = 0
+ for pass_id in range(EPOCH_NUM):
+ for step_id, data_train in enumerate(train_reader()):
+ avg_loss_value = exe.run(main_program,
+ feed=feeder.feed(data_train),
+ fetch_list=[avg_cost, acc])
+ if step % 1 == 0:
+ plot_cost.append(train_prompt, step, avg_loss_value[0])
+ plot_cost.plot()
+ step += 1
+
+ avg_cost_test, accuracy_test = train_test(test_program,
+ reader=test_reader)
+ plot_cost.append(test_prompt, step, avg_cost_test)
# save parameters
if params_dirname is not None:
- trainer.save_params(params_dirname)
+ fluid.io.save_inference_model(params_dirname, ["pixel"],
+ [predict], exe)
```
### Training
-Finally, we can invoke `trainer.train` to start training.
-
-**Note:** On CPU, each epoch will take about 15~20 minutes. This part may take a while. Please feel free to modify the code to run the test on GPU to increase the training speed.
+Training via `trainer_loop` function, here we only have 2 Epoch iterations. Generally we need to execute above a hundred Epoch in practice.
+**Note:** On CPU, each Epoch will take approximately 15 to 20 minutes. It may cost some time in this part. Please freely update the code and run test on GPU to accelerate training
```python
-trainer.train(
- reader=train_reader,
- num_epochs=2,
- event_handler=event_handler,
- feed_order=['pixel', 'label'])
+train_loop()
```
-Here is an example log after training for one pass. The accuracy rates are 0.59 on the training set and 0.6 on the validation set.
+An example of an epoch of training log is shown below. After 1 pass, the average Accuracy on the training set is 0.59 and the average Accuracy on the testing set is 0.6.
```text
Pass 0, Batch 0, Cost 3.869598, Acc 0.164062
@@ -442,32 +483,31 @@ Pass 300, Batch 0, Cost 1.223424, Acc 0.593750
Test with Pass 0, Loss 1.1, Acc 0.6
```
-Figure 12 shows the curve of training error rate, which indicates it converges at Pass 200 with error rate 8.54%.
+Figure 13 is a curve graph of the classification error rate of the training. After pass of 200 times, it almost converges, and finally the classification error rate on the test set is 8.54%.
+
-
-Figure 12. The error rate of VGG model on CIFAR10
+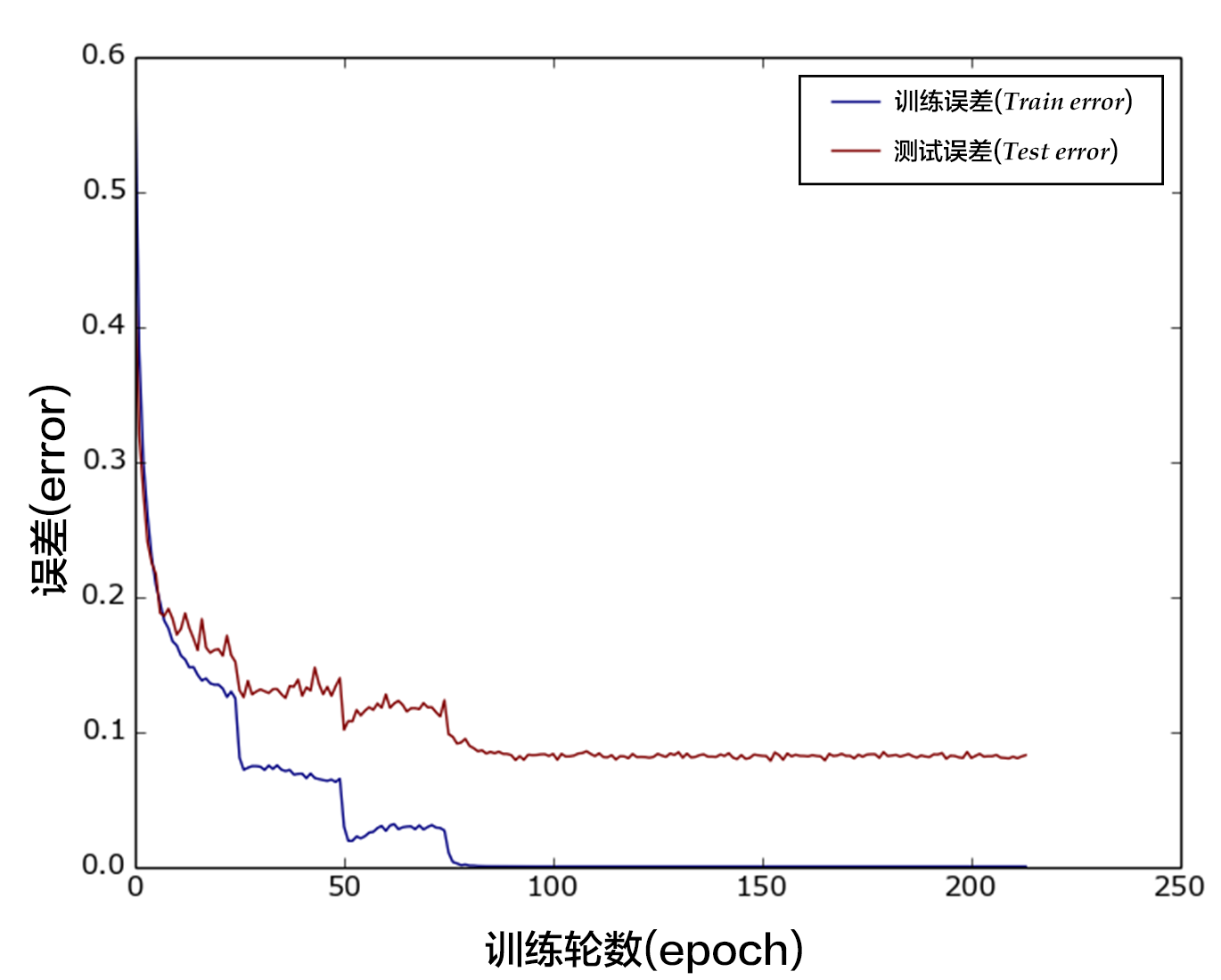
+Figure 13. Classification error rate of VGG model on the CIFAR10 data set
+## Model Application
-## Application
+You can use a trained model to classify your images. The following program shows how to load a trained network and optimized parameters for inference.
-After training is completed, users can use the trained model to classify images. The following code shows how to infer through `fluid.contrib.inferencer.Inferencer` interface. You can uncomment some lines from below to change the model name.
+### Generate Input Data to infer
-### Generate input data for inferring
-
-`dog.png` is an example image of a dog. Turn it into a numpy array to match the data feeder format.
+`dog.png` is a picture of a puppy. We convert it to a `numpy` array to meet the `feeder` format.
```python
# Prepare testing data.
from PIL import Image
-import numpy as np
import os
def load_image(file):
im = Image.open(file)
im = im.resize((32, 32), Image.ANTIALIAS)
- im = np.array(im).astype(np.float32)
+ im = numpy.array(im).astype(numpy.float32)
# The storage order of the loaded image is W(width),
# H(height), C(channel). PaddlePaddle requires
# the CHW order, so transpose them.
@@ -484,26 +524,59 @@ img = load_image(cur_dir + '/image/dog.png')
### Inferencer Configuration and Inference
-The `Inferencer` takes an `infer_func` and `param_path` to setup the network and the trained parameters.
-We can simply plug-in the inference_program defined earlier here.
-Now we are ready to do inference.
+Similar to the training process, a inferencer needs to build the corresponding process. We load the trained network and parameters from `params_dirname` .
+We can just insert the inference program defined previously.
+Now let's make our inference.
-```python
-inferencer = Inferencer(
- infer_func=inference_program, param_path=params_dirname, place=place)
-label_list = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
-# inference
-results = inferencer.infer({'pixel': img})
-print("infer results: %s" % label_list[np.argmax(results[0])])
+
+```python
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+exe = fluid.Executor(place)
+inference_scope = fluid.core.Scope()
+
+with fluid.scope_guard(inference_scope):
+
+ [inference_program, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(params_dirname, exe)
+
+ # The input's dimension of conv should be 4-D or 5-D.
+ # Use inference_transpiler to speedup
+ inference_transpiler_program = inference_program.clone()
+ t = fluid.transpiler.InferenceTranspiler()
+ t.transpile(inference_transpiler_program, place)
+
+ # Construct feed as a dictionary of {feed_target_name: feed_target_data}
+ # and results will contain a list of data corresponding to fetch_targets.
+ results = exe.run(inference_program,
+ feed={feed_target_names[0]: img},
+ fetch_list=fetch_targets)
+
+ transpiler_results = exe.run(inference_transpiler_program,
+ feed={feed_target_names[0]: img},
+ fetch_list=fetch_targets)
+
+ assert len(results[0]) == len(transpiler_results[0])
+ for i in range(len(results[0])):
+ numpy.testing.assert_almost_equal(
+ results[0][i], transpiler_results[0][i], decimal=5)
+
+ # infer label
+ label_list = [
+ "airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse",
+ "ship", "truck"
+ ]
+
+ print("infer results: %s" % label_list[numpy.argmax(results[0])])
```
-## Conclusion
-Traditional image classification methods involve multiple stages of processing, which has to utilize complex frameworks. Contrarily, CNN models can be trained end-to-end with a significant increase in classification accuracy. In this chapter, we introduced three models -- VGG, GoogleNet, ResNet and provided PaddlePaddle config files for training VGG and ResNet on CIFAR10. We also explained how to perform prediction and feature extraction using the PaddlePaddle API. For other datasets such as ImageNet, the procedure for config and training are the same and you are welcome to give it a try.
+## Summary
+The traditional image classification method consists of multiple stages. The framework is a little complex. In contrast, the end-to-end CNN model can be implemented in one step, and the accuracy of classification is greatly improved. In this article, we first introduced three classic models, VGG, GoogleNet and ResNet. Then we have introduced how to use PaddlePaddle to configure and train CNN models based on CIFAR10 dataset, especially VGG and ResNet models. Finally, we have guided you how to use PaddlePaddle's API interfaces to predict images and extract features. For other datasets such as ImageNet, the configuration and training process is the same, so you can embark on your adventure on your own.
+
## References
[1] D. G. Lowe, [Distinctive image features from scale-invariant keypoints](http://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf). IJCV, 60(2):91-110, 2004.
@@ -550,5 +623,7 @@ Traditional image classification methods involve multiple stages of processing,
[22] http://cs231n.github.io/classification/
+
+
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/03.image_classification/index.html b/03.image_classification/index.html
index 4da0476..506f348 100644
--- a/03.image_classification/index.html
+++ b/03.image_classification/index.html
@@ -40,172 +40,175 @@
-
Image Classification
=======================
-The source code for this chapter is at [book/image_classification](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification). For instructions on getting started with this book,see [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book).
+The source code for this chapter is in [book/image_classification](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification). For users new to book, check [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book) .
## Background
-Compared to words, images provide much more vivid and easier to understand information with an artistic sense. They are an important source for people to express and exchange ideas. In this chapter, we focus on one of the essential problems in image recognition -- image classification.
+Compared with words, images provide information in a much more vivid, artistic, easy-to-understand manner. They are an important source for people to express and exchange ideas. In this chapter, we focus on one of the essential problems in image recognition -- image classification.
-Image classification is the task of distinguishing images in different categories based on their semantic meaning. It is a core problem in computer vision and is also the foundation of other higher level computer vision tasks such as object detection, image segmentation, object tracking, action recognition, etc. Image classification has applications in many areas such as face recognition, intelligent video analysis in security systems, traffic scene recognition in transportation systems, content-based image retrieval and automatic photo indexing in web services, image classification in medicine, etc.
+Image classification is the task of distinguishing images in different categories based on their semantic meaning. It is a core problem in computer vision and is also the foundation of other higher level computer vision tasks such as object detection, image segmentation, object tracking, action recognition. Image classification has applications in many areas such as face recognition, intelligent video analysis in security systems, traffic scene recognition in transportation systems, content-based image retrieval and automatic photo indexing in Internet services, image classification in medicine industry.
-To classify an image we firstly encode the entire image using handcrafted or learned features and then determine the category using a classifier. Thus, feature extraction plays an important role in image classification. Prior to deep learning the BoW(Bag of Words) model was the most widely used method for classifying an image as well as an object. The BoW technique was introduced in Natural Language Processing where a training sentence is represented as a bag of words. In the context of image classification, the BoW model requires constructing a dictionary. The simplest BoW framework can be designed with three steps: **feature extraction**, **feature encoding** and **classifier design**.
+To classify an image we firstly encode the entire image using manual or learned features and then determine the category using a classifier. Thus, feature extraction plays an important role in image classification. Prior to deep learning the BoW(Bag of Words) model was the most widely used method for classifying an image. The BoW technique was introduced in Natural Language Processing where a training sentence is represented as a bag of words. In the context of image classification, the BoW model requires constructing a dictionary. The simplest BoW framework can be designed in three steps: **feature extraction**, **feature encoding** and **classifier design**.
-Using Deep learning, image classification can be framed as a supervised or unsupervised learning problem that uses hierarchical features automatically without any need for manually crafted features from the image. In recent years, Convolutional Neural Networks (CNNs) have made significant progress in image classification. CNNs use raw image pixels as input, extract low-level and high-level abstract features through convolution operations, and directly output the classification results from the model. This style of end-to-end learning has lead to not only increased performance but also wider adoption various applications.
+With Deep learning, image classification can be framed as a supervised or unsupervised learning problem that uses hierarchical features automatically without any need for manually crafted features from the image. In recent years, Convolution Neural Networks (CNNs) have made significant progress in image classification. CNNs use raw image pixels as input, extract low-level and high-level abstract features through convolution operations, and directly output the classification results from the model. This style of end-to-end learning has led to not only higher performance but also wider adoption in various applications.
In this chapter, we introduce deep-learning-based image classification methods and explain how to train a CNN model using PaddlePaddle.
-## Demonstration
+## Result Demo
-An image can be classified by a general as well as fine-grained image classifier.
+Image Classification can be divided into general image classification and fine-grained image classification.
-Figure 1 shows the results of a general image classifier -- the trained model can correctly recognize the main objects in the images.
+Figure 1 shows the results of general image classification -- the trained model can correctly recognize the main objects in the images.
-
+
Figure 1. General image classification
-Figure 2 shows the results of a fine-grained image classifier. This task of flower recognition requires correctly recognizing of the flower's categories.
+Figure 2 shows the results of a fine-grained image classifier. This task of flower recognition ought to correctly recognize of the flower's breed.
-
+
Figure 2. Fine-grained image classification
-A good model should recognize objects of different categories correctly. The results of such a model should not vary due to viewpoint variation, illumination conditions, object distortion or occlusion.
+A qualified model should recognize objects of different categories correctly. The results of such a model should remain accurate in different perspectives, illumination conditions, object distortion or occlusion (we refer to these conditions as Image Disturbance).
Figure 3 shows some images with various disturbances. A good model should classify these images correctly like humans.
-
-Figure 3. Disturbed images [22]
+
+Figure 3. Disturbed images [22]
-## Model Overview
+## Exploration of Models
+
+A large amount of researches in image classification are built upon benchmark datasets such as [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/), [ImageNet](http://image-net.org/) etc. Many image classification algorithms are usually evaluated and compared based on these datasets. PASCAL VOC is a computer vision competition started in 2005, and ImageNet is a dataset holding Large Scale Visual Recognition Challenge (ILSVRC) started in 2010. In this chapter, we introduce some image classification models from the submissions to these competitions.
-A large amount of research in image classification is built upon public datasets such as [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/), [ImageNet](http://image-net.org/) etc. Many image classification algorithms are usually evaluated and compared on top of these datasets. PASCAL VOC is a computer vision competition started in 2005, and ImageNet is a dataset for Large Scale Visual Recognition Challenge (ILSVRC) started in 2010. In this chapter, we introduce some image classification models from the submissions to these competitions.
Before 2012, traditional image classification was accomplished with the three steps described in the background section. A complete model construction usually involves the following stages: low-level feature extraction, feature encoding, spatial constraint or feature clustering, classifier design, model ensemble.
- 1). **Low-level feature extraction**: This step extracts large amounts of local features according to fixed strides and scales. Popular local features include Scale-Invariant Feature Transform (SIFT)[1], Histogram of Oriented Gradient(HOG)[2], Local Binary Pattern(LBP)[3], etc. A common practice is to employ multiple feature descriptors in order to avoid missing a lot of information.
+ 1). **Low-level feature extraction**: This step extracts large amounts of local features according to fixed strides and scales. Popular local features include Scale-Invariant Feature Transform (SIFT) \[[1](#References)\], Histogram of Oriented Gradient(HOG) \[[2](#References)\], Local Binary Pattern(LBP) \[[3](#References)\], etc. A common practice is to employ multiple feature descriptors in order to avoid missing a lot of information.
- 2). **Feature encoding**: Low-level features contain a large amount of redundancy and noise. In order to improve the robustness of features, it is necessary to employ a feature transformation to encode low-level features. This is called feature encoding. Common feature encoding methods include vector quantization [4], sparse coding [5], locality-constrained linear coding [6], Fisher vector encoding [7], etc.
+ 2). **Feature encoding**: Low-level features contain a large amount of redundancy and noise. In order to improve the robustness of features, it is necessary to employ a feature transformation to encode low-level features. This is called feature encoding. Common feature encoding methods include vector quantization \[[4](#References)\], sparse coding \[[5](#References)\], locality-constrained linear coding \[[6](#References)\], Fisher vector encoding \[[7](#References)\], etc.
3). **Spatial constraint**: Spatial constraint or feature clustering is usually adopted after feature encoding for extracting the maximum or average of each dimension in the spatial domain. Pyramid feature matching--a popular feature clustering method--divides an image uniformly into patches and performs feature clustering in each patch.
4). **Classification**: In the above steps an image can be described by a vector of fixed dimension. Then a classifier can be used to classify the image into categories. Common classifiers include Support Vector Machine(SVM), random forest etc. Kernel SVM is the most popular classifier and has achieved very good performance in traditional image classification tasks.
-This method has been used widely as image classification algorithm in PASCAL VOC [18]. NEC Labs(http://www.nec-labs.com/) won the championship by employing SIFT and LBP features, two non-linear encoders and SVM in ILSVRC 2010 [8].
+This classic method has been used widely as image classification algorithm in PASCAL VOC \[[18](#References)\]. [NEC Labs](http://www.nec-labs.com/) won the championship by employing SIFT and LBP features, two non-linear encoders and SVM in ILSVRC 2010 \[[8](#References)\].
-The CNN model--AlexNet proposed by Alex Krizhevsky et al.[9], made a breakthrough in ILSVRC 2012. It dramatically outperformed traditional methods and won the ILSVRC championship in 2012. This was also the first time that a deep learning method was used for large-scale image classification. Since AlexNet, a series of CNN models have been proposed that have advanced the state of the art steadily on Imagenet as shown in Figure 4. With deeper and more sophisticated architectures, Top-5 error rate is getting lower and lower (to around 3.5%). The error rate of human raters on the same Imagenet dataset is 5.1%, which means that the image classification capability of a deep learning model has surpassed human raters.
+The CNN model--AlexNet proposed by Alex Krizhevsky et al. \[[9](#References)\], made a breakthrough in ILSVRC 2012. It dramatically outperformed classical methods and won the ILSVRC championship in 2012. This was also the first time that a deep learning method was adopted for large-scale image classification. Since AlexNet, a series of CNN models have been proposed that have advanced the state of the art steadily on Imagenet as shown in Figure 4. With deeper and more sophisticated architectures, Top-5 error rate is getting lower and lower (to around 3.5%). The error rate of human raters on the same Imagenet dataset is 5.1%, which means that the image classification capability of a deep learning model has surpassed human raters.
-
+
+
Figure 4. Top-5 error rates on ILSVRC image classification
### CNN
-Traditional CNNs consist of convolutional and fully-connected layers and use the softmax multi-category classifier with the cross-entropy loss function. Figure 5 shows a typical CNN. We first introduce the common components of a CNN.
+Traditional CNNs consist of convolution and fully-connected layers and use the softmax multi-category classifier with the cross-entropy loss function. Figure 5 shows a typical CNN. We first take look at the common components of a CNN.
-
-Figure 5. A CNN example [20]
+
+Figure 5. A CNN example [20]
- convolutional layer: this layer uses the convolution operation to extract (low-level and high-level) features and to discover local correlation and spatial invariance.
-- pooling layer: this layer down samples feature maps by extracting local max (max-pooling) or average (avg-pooling) value of each patch in the feature map. Down-sampling is a common operation in image processing and is used to filter out high-frequency information.
+- pooling layer: this layer down-samples feature maps by extracting local max (max-pooling) or average (avg-pooling) value of each patch in the feature map. Down-sampling is a common operation in image processing and is used to filter out trivial high-frequency information.
- fully-connected layer: this layer fully connects neurons between two adjacent layers.
- non-linear activation: Convolutional and fully-connected layers are usually followed by some non-linear activation layers. Non-linearities enhance the expression capability of the network. Some examples of non-linear activation functions are Sigmoid, Tanh and ReLU. ReLU is the most commonly used activation function in CNN.
-- Dropout [10]: At each training stage, individual nodes are dropped out of the network with a certain probability. This improves the network's ability to generalize and avoids overfitting.
+- Dropout \[[10](#References)\]: At each training stage, individual nodes are dropped out of the network with a certain random probability. This improves the network's ability to generalize and avoids overfitting.
-Parameter updates at each layer during training causes input layer distributions to change and in turn requires hyper-parameters to be carefully tuned. In 2015, Sergey Ioffe and Christian Szegedy proposed a Batch Normalization (BN) algorithm [14], which normalizes the features of each batch in a layer, and enables relatively stable distribution in each layer. Not only does BN algorithm act as a regularizer, but also reduces the need for careful hyper-parameter design. Experiments demonstrate that BN algorithm accelerates the training convergence and has been widely used in later deeper models.
+Parameter updates at each layer during training causes input layer distributions to change and in turn requires hyper-parameters to be carefully tuned. In 2015, Sergey Ioffe and Christian Szegedy proposed a Batch Normalization (BN) algorithm \[[14](#References)\], which normalizes the features of each batch in a layer, and enables relatively stable distribution in each layer. Not only does BN algorithm act as a regularizer, but also eliminates the need for meticulous hyper-parameter design. Experiments demonstrate that BN algorithm accelerates the training convergence and has been widely used in further deeper models.
-In the following sections, we will introduce the following network architectures - VGG, GoogleNet and ResNets.
+In the following sections, we will take a tour through the following network architectures - VGG, GoogleNet and ResNets.
### VGG
-The Oxford Visual Geometry Group (VGG) proposed the VGG network in ILSVRC 2014 [11]. This model is deeper and wider than previous neural architectures. It consists of five main groups of convolution operations. Adjacent convolution groups are connected via max-pooling layers. Each group contains a series of 3x3 convolutional layers (i.e. kernels). The number of convolution kernels stays the same within the group and increases from 64 in the first group to 512 in the last one. The total number of learnable layers could be 11, 13, 16, or 19 depending on the number of convolutional layers in each group. Figure 6 illustrates a 16-layer VGG. The neural architecture of VGG is relatively simple and has been adopted by many papers such as the first one that surpassed human-level performance on ImageNet [19].
+The Oxford Visual Geometry Group (VGG) proposed the VGG network in ILSVRC 2014 \[[11](#References)\]. This model is deeper and wider than previous neural architectures. Its major part is the five main groups of convolution operations. Adjacent convolution groups are connected via max-pooling layers to perform dimensionality reduction. Each group contains a series of 3x3 convolutional layers (i.e. kernels). The number of convolution kernels stays the same within the single group and increases from 64 in the first group to 512 in the last one. Double FC layers and a classifier layer will follow afterwards. The total number of learnable layers could be 11, 13, 16, or 19 depending on the number of convolutional layers in each group. Figure 6 illustrates a 16-layer VGG. The architecture of VGG is relatively simple and has been adopted by many papers such as the first one that surpassed human-level performance on ImageNet \[[19](#References)\].
-
+
Figure 6. VGG16 model for ImageNet
### GoogleNet
-GoogleNet [12] won the ILSVRC championship in 2014. GoogleNet borrowed some ideas from the Network in Network(NIN) model [13] and is built on the Inception blocks. Let us first familiarize ourselves with these first.
+GoogleNet \[[12](#References)\] won the ILSVRC championship in 2014. GoogleNet borrowed some ideas from the Network in Network(NIN) model \[[13](#References)\] and is built on the Inception blocks. Let us first familiarize ourselves with these concepts first.
The two main characteristics of the NIN model are:
1) A single-layer convolutional network is replaced with a Multi-Layer Perceptron Convolution (MLPconv). MLPconv is a tiny multi-layer convolutional network. It enhances non-linearity by adding several 1x1 convolutional layers after linear ones.
-2) In traditional CNNs, the last fewer layers are usually fully-connected with a large number of parameters. In contrast, NIN replaces all fully-connected layers with convolutional layers with feature maps of the same size as the category dimension and a global average pooling. This replacement of fully-connected layers significantly reduces the number of parameters.
+2) In traditional CNNs, the last fewer layers are usually fully-connected with a large number of parameters. In contrast, the last convolution layer of NIN contains feature maps of the same size as the category dimension, and NIN replaces fully-connected layers with global average pooling to fetch a vector of the same size as category dimension and classify them. This replacement of fully-connected layers significantly reduces the number of parameters.
-Figure 7 depicts two Inception blocks. Figure 7(a) is the simplest design. The output is a concatenation of features from three convolutional layers and one pooling layer. The disadvantage of this design is that the pooling layer does not change the number of filters and leads to an increase in the number of outputs. After several of such blocks, the number of outputs and parameters become larger and larger and lead to higher computation complexity. To overcome this drawback, the Inception block in Figure 7(b) employs three 1x1 convolutional layers. These reduce dimensions or the number of channels but improve the non-linearity of the network.
+Figure 7 depicts two Inception blocks. Figure 7(a) is the simplest design. The output is a concatenation of features from three convolutional layers and one pooling layer. The disadvantage of this design is that the pooling layer does not change the number of channels and leads to an increased channel number of features after concatenation. After several such blocks, the number of channels and parameters become larger and larger and lead to higher computation complexity. To overcome this drawback, the Inception block in Figure 7(b) employs three 1x1 convolutional layers to perform dimensionality reduction, which, to put it simply, is to reduce the number of channels and simultaneously improve the non-linearity of the network.
-
+
Figure 7. Inception block
-GoogleNet consists of multiple stacked Inception blocks followed by an avg-pooling layer as in NIN instead of traditional fully connected layers. The difference between GoogleNet and NIN is that GoogleNet adds a fully connected layer after avg-pooling layer to output a vector of category size. Besides these two characteristics, the features from middle layers of a GoogleNet are also very discriminative. Therefore, GoogeleNet inserts two auxiliary classifiers in the model for enhancing gradient and regularization when doing backpropagation. The loss function of the whole network is the weighted sum of these three classifiers.
+GoogleNet comprises multiple stacked Inception blocks followed by an avg-pooling layer as in NIN instead of traditional fully connected layers. The difference between GoogleNet and NIN is that GoogleNet adds a fully connected layer after avg-pooling layer to output a vector of category size. Besides these two characteristics, the features from middle layers of a GoogleNet are also very discriminative. Therefore, GoogeleNet inserts two auxiliary classifiers in the model for enhancing gradient and regularization when doing back-propagation. The loss function of the whole network is the weighted sum of these three classifiers.
-Figure 8 illustrates the neural architecture of a GoogleNet which consists of 22 layers: it starts with three regular convolutional layers followed by three groups of sub-networks -- the first group contains two Inception blocks, the second group has five, and the third group has two. It ends with an average pooling and a fully-connected layer.
+Figure 8 illustrates the neural architecture of a GoogleNet which consists of 22 layers: it starts with three regular convolutional layers followed by three groups of sub-networks -- the first group contains two Inception blocks, the second group has five, and the third group has two again. Finally, It ends with an average pooling and a fully-connected layer.
-
-Figure 8. GoogleNet[12]
+
+Figure 8. GoogleNet [12]
-The above model is the first version of GoogleNet or GoogelNet-v1. GoogleNet-v2 [14] introduced BN layer; GoogleNet-v3 [16] further split some convolutional layers, which increases non-linearity and network depth; GoogelNet-v4 [17] leads to the design idea of ResNet which will be introduced in the next section. The evolution from v1 to v4 improved the accuracy rate consistently. We will not go into details of the neural architectures of v2 to v4.
+The model above is the first version of GoogleNet or the so-called GoogelNet-v1. GoogleNet-v2 \[[14](#References)\] introduced BN layer; GoogleNet-v3 \[[16](#References)\] further split some convolutional layers, which increases non-linearity and network depth; GoogelNet-v4 \[[17](#References)\] is inspired by the design idea of ResNet which will be introduced in the next section. The evolution from v1 to v4 improved the accuracy rate consistently. The length of this article being limited, we will not scrutinize the neural architectures of v2 to v4.
### ResNet
-Residual Network(ResNet)[15] won the 2015 championship on three ImageNet competitions -- image classification, object localization, and object detection. The main challenge in training deeper networks is that accuracy degrades with network depth. The authors of ResNet proposed a residual learning approach to ease the difficulty of training deeper networks. Based on the design ideas of BN, small convolutional kernels, full convolutional network, ResNets reformulate the layers as residual blocks, with each block containing two branches, one directly connecting input to the output, the other performing two to three convolutions and calculating the residual function with reference to the layer's inputs. The outputs of these two branches are then added up.
+Residual Network(ResNet) \[[15](#References)\] won the 2015 championship on three ImageNet competitions -- image classification, object localization, and object detection. The main challenge in training deeper networks is that accuracy degrades with network depth. The authors of ResNet proposed a residual learning approach to ease the training of deeper networks. Based on the design ideas of BN, small convolutional kernels, full convolutional network, ResNets reformulate the layers as residual blocks, with each block containing two branches, one directly connecting input to the output, the other performing two to three convolutions and calculating the residual function with reference to the layer's inputs. The output features of these two branches are then added up.
-Figure 9 illustrates the ResNet architecture. To the left is the basic building block, it consists of two 3x3 convolutional layers of the same channels. To the right is a Bottleneck block. The bottleneck is a 1x1 convolutional layer used to reduce dimension from 256 to 64. The other 1x1 convolutional layer is used to increase dimension from 64 to 256. Thus, the number of input and output channels of the middle 3x3 convolutional layer is 64, which is relatively small.
+Figure 9 illustrates the ResNet architecture. To the left is the basic building block, it consists of two 3x3 convolutional layers with the same size of output channels. To the right is a Bottleneck block. The bottleneck is a 1x1 convolutional layer used to reduce dimension (from 256 to 64 here). The following 1x1 convolutional layer is used to increase dimension from 64 to 256. Thus, the number of input and output channels of the middle 3x3 convolutional layer is relatively small (64->64 in this example).
-
+
Figure 9. Residual block
-Figure 10 illustrates ResNets with 50, 101, 152 layers, respectively. All three networks use bottleneck blocks of different numbers of repetitions. ResNet converges very fast and can be trained with hundreds or thousands of layers.
+Figure 10 illustrates ResNets with 50, 101, 152 layers, respectively. All three networks use bottleneck blocks and their difference lies in the repetition time of residual blocks. ResNet converges very fast and can be trained with hundreds or thousands of layers.
-
+
Figure 10. ResNet model for ImageNet
-## Dataset
+## Get Data Ready
-Commonly used public datasets for image classification are [CIFAR](https://www.cs.toronto.edu/~kriz/cifar.html), [ImageNet](http://image-net.org/), [COCO](http://mscoco.org/), etc. Those used for fine-grained image classification are [CUB-200-2011](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html), [Stanford Dog](http://vision.stanford.edu/aditya86/ImageNetDogs/), [Oxford-flowers](http://www.robots.ox.ac.uk/~vgg/data/flowers/), etc. Among these, the ImageNet dataset is the largest. Most research results are reported on ImageNet as mentioned in the Model Overview section. Since 2010, the ImageNet dataset has gone through some changes. The commonly used ImageNet-2012 dataset contains 1000 categories. There are 1,281,167 training images, ranging from 732 to 1200 images per category, and 50,000 validation images with 50 images per category in average.
+Common public benchmark datasets for image classification are [CIFAR](https://www.cs.toronto.edu/~kriz/cifar.html), [ImageNet](http://image-net.org/), [COCO](http://mscoco.org/), etc. Those used for fine-grained image classification are [CUB-200-2011](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html), [Stanford Dog](http://vision.stanford.edu/aditya86/ImageNetDogs/), [Oxford-flowers](http://www.robots.ox.ac.uk/~vgg/data/flowers/), etc. Among these, the ImageNet dataset is the largest. Most research results are reported on ImageNet as mentioned in the "Exploration of Models" section. Since 2010, the ImageNet dataset has gone through some changes. The commonly used ImageNet-2012 dataset contains 1000 categories. There are 1,281,167 training images, ranging from 732 to 1200 images per category, and 50,000 validation images with 50 images per category in average.
Since ImageNet is too large to be downloaded and trained efficiently, we use [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) in this tutorial. The CIFAR-10 dataset consists of 60000 32x32 color images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images. Figure 11 shows all the classes in CIFAR-10 as well as 10 images randomly sampled from each category.
-
-Figure 11. CIFAR10 dataset[21]
+
+Figure 11. CIFAR10 dataset [21]
- `paddle.datasets` package encapsulates multiple public datasets, including `cifar`, `imdb`, `mnist`, `moivelens` and `wmt14`, etc. There's no need to manually download and preprocess CIFAR-10.
+The Paddle API invents 'Paddle.dataset.cifar' to automatically load the Cifar DataSet module.
-After running the command `python train.py`, training will start immediately. The following sections will describe in details.
+After running the command `python train.py`, training will start immediately. The following sections will explain `train.py` inside and out.
## Model Configuration
+#### Initialize Paddle
+
Let's start with importing the Paddle Fluid API package and the helper modules.
```python
@@ -214,24 +217,16 @@ import paddle.fluid as fluid
import numpy
import sys
from __future__ import print_function
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
+
```
Now we are going to walk you through the implementations of the VGG and ResNet.
### VGG
-Let's start with the VGG model. Since the image size and amount of CIFAR10 are relatively small comparing to ImageNet, we use a small version of VGG network for CIFAR10. Convolution groups incorporate BN and dropout operations.
+Let's start with the VGG model. Since the image size and amount of CIFAR10 are smaller than ImageNet, we tailor our model to fit CIFAR10 dataset. Convolution groups incorporate BN and dropout operations.
-The input to VGG main module is from the data layer. `vgg_bn_drop` defines a 16-layer VGG network, with each convolutional layer followed by BN and dropout layers. Here is the definition in detail:
+The input to VGG core module is the data layer. `vgg_bn_drop` defines a 16-layer VGG network, with each convolutional layer followed by BN and dropout layers. Here is the definition in detail:
```python
def vgg_bn_drop(input):
@@ -262,24 +257,26 @@ def vgg_bn_drop(input):
return predict
```
- 1. Firstly, it defines a convolution block or conv_block. The default convolution kernel is 3x3, and the default pooling size is 2x2 with stride 2. Dropout specifies the probability in dropout operation. Function `img_conv_group` is defined in `paddle.networks` consisting of a series of `Conv->BN->ReLu->Dropout` and a `Pooling`.
- 2. Five groups of convolutions. The first two groups perform two convolutions, while the last three groups perform three convolutions. The dropout rate of the last convolution in each group is set to 0, which means there is no dropout for this layer.
+ 1. Firstly, it defines a convolution block or conv_block. The default convolution kernel is 3x3, and the default pooling size is 2x2 with stride 2. Groups decide the number of consecutive convolution operations in each VGG block. Dropout specifies the probability to perform dropout operation. Function `img_conv_group` is predefined in `paddle.networks` consisting of a series of `Conv->BN->ReLu->Dropout` and a group of `Pooling` .
+
+ 2. Five groups of convolutions. The first two groups perform two consecutive convolutions, while the last three groups perform three convolutions in sequence. The dropout rate of the last convolution in each group is set to 0, which means there is no dropout for this layer.
- 3. The last two layers are fully-connected layers of dimension 512.
+ 3. The last two layers are fully-connected layers of 512 dimensions.
- 4. The above VGG network extracts high-level features and maps them to a vector of the same size as the categories. Softmax function or classifier is then used for calculating the probability of the image belonging to each category.
+ 4. The VGG network begins with extracting high-level features and then maps them to a vector of the same size as the category dimension. Finally, Softmax function is used for calculating the probability of classifying the image to each category.
### ResNet
-Here are some basic functions used in `resnet_cifar10`:
+The 1st, 3rd, and 4th step is identical to the counterparts in VGG, which are skipped hereby.
+We will explain the 2nd step at lengths, namely the core module of ResNet on CIFAR10.
- - `conv_bn_layer` : convolutional layer followed by BN.
- - `shortcut` : the shortcut branch in a residual block. There are two kinds of shortcuts: 1x1 convolution used when the number of channels between input and output is different; direct connection used otherwise.
+To start with, here are some basic functions used in `resnet_cifar10` ,and the network connection procedure is illustrated afterwards:
+ - `conv_bn_layer` : convolutional layer with BN.
+ - `shortcut` : the shortcut connection in a residual block. There are two kinds of shortcuts: 1x1 convolutions are used to increase dimensionality when in the residual block the number of channels in input feature and that in output feature are different; direct connection used otherwise.
- `basicblock` : a basic residual module as shown in the left of Figure 9, it consists of two sequential 3x3 convolutions and one "shortcut" branch.
- - `bottleneck` : a bottleneck module as shown in the right of Figure 9, it consists of two 1x1 convolutions with one 3x3 convolution in between branch and a "shortcut" branch.
- - `layer_warp` : a group of residual modules consisting of several stacking blocks. In each group, the sliding window size of the first residual block could be different from the rest of blocks, in order to reduce the size of feature maps along horizontal and vertical directions.
+ - `layer_warp` : a group of residual modules consisting of several stacked blocks. In each group, the sliding window size of the first residual block could be different from the rest, in order to reduce the size of feature maps along horizontal and vertical directions.
```python
def conv_bn_layer(input,
@@ -321,13 +318,14 @@ def layer_warp(block_func, input, ch_in, ch_out, count, stride):
return tmp
```
+
The following are the components of `resnet_cifar10`:
-1. The lowest level is `conv_bn_layer`.
-2. The middle level consists of three `layer_warp`, each of which uses the left residual block in Figure 9.
+1. The lowest level is `conv_bn_layer` , e.t. the convolution layer with BN.
+2. The next level is composed of three residual blocks, namely three `layer_warp`, each of which uses the left residual block in Figure 10.
3. The last level is average pooling layer.
-Note: besides the first convolutional layer and the last fully-connected layer, the total number of layers in three `layer_warp` should be dividable by 6, that is the depth of `resnet_cifar10` should satisfy $(depth - 2) % 6 == 0$.
+Note: Except the first convolutional layer and the last fully-connected layer, the total number of layers with parameters in three `layer_warp` should be dividable by 6. In other words, the depth of `resnet_cifar10` should satisfy $(depth - 2) % 6 == 0$.
```python
def resnet_cifar10(ipt, depth=32):
@@ -345,9 +343,10 @@ def resnet_cifar10(ipt, depth=32):
return predict
```
-## Infererence Program Configuration
-The input to the network is defined as `fluid.layers.data`, or image pixels in the context of image classification. The images in CIFAR10 are 32x32 color images of three channels. Therefore, the size of the input data is 3072 (3x32x32).
+## Inference Program Configuration
+
+The input to the network is defined as `fluid.layers.data` , corresponding to image pixels in the context of image classification. The images in CIFAR10 are 32x32 coloured images with three channels. Therefore, the size of the input data is 3072 (3x32x32).
```python
def inference_program():
@@ -360,14 +359,14 @@ def inference_program():
return predict
```
-## Train Program Configuration
-Then we need to setup the the `train_program`. It takes the prediction from the inference_program first.
+## Training Program Configuration
+Then we need to set up the the `train_program`. It takes the prediction from the inference_program first.
During the training, it will calculate the `avg_loss` from the prediction.
-In the context of supervised learning, labels of training images are defined in `fluid.layers.data` as well. During training, the cross-entropy loss function is used and the loss is the output of the network. During testing, the outputs are the probabilities calculated in the classifier.
+In the context of supervised learning, labels of training images are defined in `fluid.layers.data` as well. During training, the multi-class cross-entropy is used as the loss function and becomes the output of the network. During testing, the outputs are the probabilities calculated in the classifier.
-**NOTE:** A train program should return an array and the first returned argument has to be `avg_cost`.
-The trainer always implicitly use it to calculate the gradient.
+**NOTE:** A training program should return an array and the first returned argument has to be `avg_cost` .
+The trainer always uses it to calculate the gradients.
```python
def train_program():
@@ -382,7 +381,7 @@ def train_program():
## Optimizer Function Configuration
-In the following `Adam` optimizer, `learning_rate` specifies the learning rate in the optimization procedure.
+In the following `Adam` optimizer, `learning_rate` specifies the learning rate in the optimization procedure. It influences the convergence speed.
```python
def optimizer_program():
@@ -391,23 +390,10 @@ def optimizer_program():
## Model Training
-### Create Trainer
-
-Before creating a training module, it is necessary to set the algorithm.
-Here we specify `Adam` optimization algorithm via `fluid.optimizer`.
-
-```python
-use_cuda = False
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-trainer = Trainer(
- train_func=train_program,
- optimizer_func=optimizer_program,
- place=place)
-```
### Data Feeders Configuration
-`cifar.train10()` will yield records during each pass, after shuffling, a batch input is generated for training.
+`cifar.train10()` generates one sample at a time as the input for training after completing shuffle and batch.
```python
# Each batch will yield 128 images
@@ -423,54 +409,109 @@ test_reader = paddle.batch(
paddle.dataset.cifar.test10(), batch_size=BATCH_SIZE)
```
-### Event Handler
-Callback function `event_handler` will be called during training when a pre-defined event happens.
+### Implementation of the trainer program
+We need to develop a main_program for the training process. Similarly, we need to configure a test_program for the test program. It's also necessary to define the `place` of the training and use the optimizer `optimizer_func` previously defined .
+
-`event_handler` is used to plot some text data when training.
```python
-params_dirname = "image_classification_resnet.inference.model"
+use_cuda = False
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+
+feed_order = ['pixel', 'label']
+
+main_program = fluid.default_main_program()
+star_program = fluid.default_startup_program()
+
+avg_cost, acc = train_program()
-# event handler to track training and testing process
-def event_handler(event):
- if isinstance(event, EndStepEvent):
- if event.step % 100 == 0:
- print("\nPass %d, Batch %d, Cost %f, Acc %f" %
- (event.step, event.epoch, event.metrics[0],
- event.metrics[1]))
- else:
- sys.stdout.write('.')
- sys.stdout.flush()
+# Test program
+test_program = main_program.clone(for_test=True)
- if isinstance(event, EndEpochEvent):
- # Test against with the test dataset to get accuracy.
- avg_cost, accuracy = trainer.test(
- reader=test_reader, feed_order=['pixel', 'label'])
+optimizer = optimizer_program()
+optimizer.minimize(avg_cost)
- print('\nTest with Pass {0}, Loss {1:2.2}, Acc {2:2.2}'.format(event.epoch, avg_cost, accuracy))
+exe = fluid.Executor(place)
+
+EPOCH_NUM = 2
+
+# For training test cost
+def train_test(program, reader):
+ count = 0
+ feed_var_list = [
+ program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder_test = fluid.DataFeeder(
+ feed_list=feed_var_list, place=place)
+ test_exe = fluid.Executor(place)
+ accumulated = len([avg_cost, acc]) * [0]
+ for tid, test_data in enumerate(reader()):
+ avg_cost_np = test_exe.run(program=program,
+ feed=feeder_test.feed(test_data),
+ fetch_list=[avg_cost, acc])
+ accumulated = [x[0] + x[1][0] for x in zip(accumulated, avg_cost_np)]
+ count += 1
+ return [x / count for x in accumulated]
+```
+
+### The main loop of training and the outputs along the process
+
+In the next main training cycle, we will observe the training process or run test in good use of the outputs.
+
+You can also use `plot` to plot the process by calling back data:
+
+
+```python
+params_dirname = "image_classification_resnet.inference.model"
+
+from paddle.utils.plot import Ploter
+
+train_prompt = "Train cost"
+test_prompt = "Test cost"
+plot_cost = Ploter(test_prompt,train_prompt)
+
+# main train loop.
+def train_loop():
+ feed_var_list_loop = [
+ main_program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder = fluid.DataFeeder(
+ feed_list=feed_var_list_loop, place=place)
+ exe.run(star_program)
+
+ step = 0
+ for pass_id in range(EPOCH_NUM):
+ for step_id, data_train in enumerate(train_reader()):
+ avg_loss_value = exe.run(main_program,
+ feed=feeder.feed(data_train),
+ fetch_list=[avg_cost, acc])
+ if step % 1 == 0:
+ plot_cost.append(train_prompt, step, avg_loss_value[0])
+ plot_cost.plot()
+ step += 1
+
+ avg_cost_test, accuracy_test = train_test(test_program,
+ reader=test_reader)
+ plot_cost.append(test_prompt, step, avg_cost_test)
# save parameters
if params_dirname is not None:
- trainer.save_params(params_dirname)
+ fluid.io.save_inference_model(params_dirname, ["pixel"],
+ [predict], exe)
```
### Training
-Finally, we can invoke `trainer.train` to start training.
-
-**Note:** On CPU, each epoch will take about 15~20 minutes. This part may take a while. Please feel free to modify the code to run the test on GPU to increase the training speed.
+Training via `trainer_loop` function, here we only have 2 Epoch iterations. Generally we need to execute above a hundred Epoch in practice.
+**Note:** On CPU, each Epoch will take approximately 15 to 20 minutes. It may cost some time in this part. Please freely update the code and run test on GPU to accelerate training
```python
-trainer.train(
- reader=train_reader,
- num_epochs=2,
- event_handler=event_handler,
- feed_order=['pixel', 'label'])
+train_loop()
```
-Here is an example log after training for one pass. The accuracy rates are 0.59 on the training set and 0.6 on the validation set.
+An example of an epoch of training log is shown below. After 1 pass, the average Accuracy on the training set is 0.59 and the average Accuracy on the testing set is 0.6.
```text
Pass 0, Batch 0, Cost 3.869598, Acc 0.164062
@@ -484,32 +525,31 @@ Pass 300, Batch 0, Cost 1.223424, Acc 0.593750
Test with Pass 0, Loss 1.1, Acc 0.6
```
-Figure 12 shows the curve of training error rate, which indicates it converges at Pass 200 with error rate 8.54%.
+Figure 13 is a curve graph of the classification error rate of the training. After pass of 200 times, it almost converges, and finally the classification error rate on the test set is 8.54%.
+
-
-Figure 12. The error rate of VGG model on CIFAR10
+
+Figure 13. Classification error rate of VGG model on the CIFAR10 data set
+## Model Application
-## Application
+You can use a trained model to classify your images. The following program shows how to load a trained network and optimized parameters for inference.
-After training is completed, users can use the trained model to classify images. The following code shows how to infer through `fluid.contrib.inferencer.Inferencer` interface. You can uncomment some lines from below to change the model name.
+### Generate Input Data to infer
-### Generate input data for inferring
-
-`dog.png` is an example image of a dog. Turn it into a numpy array to match the data feeder format.
+`dog.png` is a picture of a puppy. We convert it to a `numpy` array to meet the `feeder` format.
```python
# Prepare testing data.
from PIL import Image
-import numpy as np
import os
def load_image(file):
im = Image.open(file)
im = im.resize((32, 32), Image.ANTIALIAS)
- im = np.array(im).astype(np.float32)
+ im = numpy.array(im).astype(numpy.float32)
# The storage order of the loaded image is W(width),
# H(height), C(channel). PaddlePaddle requires
# the CHW order, so transpose them.
@@ -526,26 +566,59 @@ img = load_image(cur_dir + '/image/dog.png')
### Inferencer Configuration and Inference
-The `Inferencer` takes an `infer_func` and `param_path` to setup the network and the trained parameters.
-We can simply plug-in the inference_program defined earlier here.
-Now we are ready to do inference.
+Similar to the training process, a inferencer needs to build the corresponding process. We load the trained network and parameters from `params_dirname` .
+We can just insert the inference program defined previously.
+Now let's make our inference.
-```python
-inferencer = Inferencer(
- infer_func=inference_program, param_path=params_dirname, place=place)
-label_list = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
-# inference
-results = inferencer.infer({'pixel': img})
-print("infer results: %s" % label_list[np.argmax(results[0])])
+
+```python
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+exe = fluid.Executor(place)
+inference_scope = fluid.core.Scope()
+
+with fluid.scope_guard(inference_scope):
+
+ [inference_program, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(params_dirname, exe)
+
+ # The input's dimension of conv should be 4-D or 5-D.
+ # Use inference_transpiler to speedup
+ inference_transpiler_program = inference_program.clone()
+ t = fluid.transpiler.InferenceTranspiler()
+ t.transpile(inference_transpiler_program, place)
+
+ # Construct feed as a dictionary of {feed_target_name: feed_target_data}
+ # and results will contain a list of data corresponding to fetch_targets.
+ results = exe.run(inference_program,
+ feed={feed_target_names[0]: img},
+ fetch_list=fetch_targets)
+
+ transpiler_results = exe.run(inference_transpiler_program,
+ feed={feed_target_names[0]: img},
+ fetch_list=fetch_targets)
+
+ assert len(results[0]) == len(transpiler_results[0])
+ for i in range(len(results[0])):
+ numpy.testing.assert_almost_equal(
+ results[0][i], transpiler_results[0][i], decimal=5)
+
+ # infer label
+ label_list = [
+ "airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse",
+ "ship", "truck"
+ ]
+
+ print("infer results: %s" % label_list[numpy.argmax(results[0])])
```
-## Conclusion
-Traditional image classification methods involve multiple stages of processing, which has to utilize complex frameworks. Contrarily, CNN models can be trained end-to-end with a significant increase in classification accuracy. In this chapter, we introduced three models -- VGG, GoogleNet, ResNet and provided PaddlePaddle config files for training VGG and ResNet on CIFAR10. We also explained how to perform prediction and feature extraction using the PaddlePaddle API. For other datasets such as ImageNet, the procedure for config and training are the same and you are welcome to give it a try.
+## Summary
+The traditional image classification method consists of multiple stages. The framework is a little complex. In contrast, the end-to-end CNN model can be implemented in one step, and the accuracy of classification is greatly improved. In this article, we first introduced three classic models, VGG, GoogleNet and ResNet. Then we have introduced how to use PaddlePaddle to configure and train CNN models based on CIFAR10 dataset, especially VGG and ResNet models. Finally, we have guided you how to use PaddlePaddle's API interfaces to predict images and extract features. For other datasets such as ImageNet, the configuration and training process is the same, so you can embark on your adventure on your own.
+
## References
[1] D. G. Lowe, [Distinctive image features from scale-invariant keypoints](http://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf). IJCV, 60(2):91-110, 2004.
@@ -592,8 +665,10 @@ Traditional image classification methods involve multiple stages of processing,
[22] http://cs231n.github.io/classification/
+
+
-This tutorial is contributed by
PaddlePaddle, and licensed under a
Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by
PaddlePaddle, and licensed under a
Creative Commons Attribution-ShareAlike 4.0 International License.
- 
- Figure 1. Two dimension projection of word embeddings
+ 
+ Figure 1. Two-dimensional projection of a word vector
-### Cosine Similarity
-
-On the other hand, we know that the cosine similarity between two vectors falls between $[-1,1]$. Specifically, the cosine similarity is 1 when the vectors are identical, 0 when the vectors are perpendicular, -1 when the are of opposite directions. That is, the cosine similarity between two vectors scales with their relevance. So we can calculate the cosine similarity of two word embedding vectors to represent their relevance:
+On the other hand, we know that the cosine of two vectors is in the interval of $[-1,1]$: two identical vector cosines are 1, and the cosine value between two mutually perpendicular vectors is 0, The vector cosine of the opposite direction is -1, which the correlation is proportional to the magnitude of the cosine. So we can also calculate the cosine similarity of two word vectors:
```
+
please input two words: big huge
-similarity: 0.899180685161
+Similarity: 0.899180685161
please input two words: from company
-similarity: -0.0997506977351
-```
-
-The above results could be obtained by running `calculate_dis.py`, which loads the words in the dictionary and their corresponding trained word embeddings. For detailed instruction, see section [Model Application](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec#model-application).
+Similarity: -0.0997506977351
+```
-## Model Overview
+The results above can be obtained by running `calculate_dis.py`, loading the words in the dictionary and the corresponding training feature results. We will describe the usage for details in [model application](#model application).
-In this section, we will introduce three word embedding models: N-gram model, CBOW, and Skip-gram, which all output the frequency of each word given its immediate context.
-For N-gram model, we will first introduce the concept of language model, and implement it using PaddlePaddle in section [Training](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec#model-application).
+## Overview of Models
-The latter two models, which became popular recently, are neural word embedding model developed by Tomas Mikolov at Google \[[3](#references)\]. Despite their apparent simplicity, these models train very well.
+Here we introduce three models of training word vectors: N-gram model, CBOW model and Skip-gram model. Their central idea is to get the probability of a word appearing through the context. For the N-gram model, we will first introduce the concept of the language model. In the section [training model](#training model), we'll tutor you to implement it with PaddlePaddle. The latter two models are the most famous neuron word vector models in recent years, developed by Tomas Mikolov in Google \[[3](#references)\], although they are very simple, but the training effect is very good.
### Language Model
-Before diving into word embedding models, we will first introduce the concept of **language model**. Language models build the joint probability function $P(w_1, ..., w_T)$ of a sentence, where $w_i$ is the i-th word in the sentence. The goal is to give higher probabilities to meaningful sentences, and lower probabilities to meaningless constructions.
+Before introducing the word embedding model, let us introduce a concept: the language model.
+The language model is intended to model the joint probability function $P(w_1, ..., w_T)$ of a sentence, where $w_i$ represents the ith word in the sentence. The goal of the language model isn that the model gives a high probability to meaningful sentences and a small probability to meaningless sentences.Such models can be applied to many fields, such as machine translation, speech recognition, information retrieval, part-of-speech tagging, handwriting recognition, etc., All of which hope to obtain the probability of a continuous sequence. Take information retrieval as an example, when you search for "how long is a football bame" (bame is a medical term), the search engine will prompt you if you want to search for "how long is a football game", because the probability of calculating "how long is a football bame" is very low, and the word is similar to bame, which may cause errors, the game will maximize the probability of generating the sentence.
-In general, models that generate the probability of a sequence can be applied to many fields, like machine translation, speech recognition, information retrieval, part-of-speech tagging, and handwriting recognition. Take information retrieval, for example. If you were to search for "how long is a football bame" (where bame is a medical noun), the search engine would have asked if you had meant "how long is a football game" instead. This is because the probability of "how long is a football bame" is very low according to the language model; in addition, among all of the words easily confused with "bame", "game" would build the most probable sentence.
-
-#### Target Probability
-For language model's target probability $P(w_1, ..., w_T)$, if the words in the sentence were to be independent, the joint probability of the whole sentence would be the product of each word's probability:
+For the target probability of the language model $P(w_1, ..., w_T)$, if it is assumed that each word in the text is independent, the joint probability of the whole sentence can be expressed as the product of the conditional probabilities of all the words. which is:
$$P(w_1, ..., w_T) = \prod_{t=1}^TP(w_t)$$
-However, the frequency of words in a sentence typically relates to the words before them, so canonical language models are constructed using conditional probability in its target probability:
+However, we know that the probability of each word in the statement is closely related to the word in front of it, so in fact, the language model is usually represented by conditional probability:
$$P(w_1, ..., w_T) = \prod_{t=1}^TP(w_t | w_1, ... , w_{t-1})$$
+
### N-gram neural model
-In computational linguistics, n-gram is an important method to represent text. An n-gram represents a contiguous sequence of n consecutive items given a text. Based on the desired application scenario, each item could be a letter, a syllable or a word. The N-gram model is also an important method in statistical language modeling. When training language models with n-grams, the first (n-1) words of an n-gram are used to predict the *n*th word.
+In computational linguistics, n-gram is an important text representation method that represents a continuous n items in a text. Each item can be a letter, word or syllable based on the specific application scenario. The n-gram model is also an important method in the statistical language model. When n-gram is used to train the language model, the nth word is generally predicted by the content of the n-1 words of each n-gram.
-Yoshua Bengio and other scientists describe how to train a word embedding model using neural network in the famous paper of Neural Probabilistic Language Models \[[1](#references)\] published in 2003. The Neural Network Language Model (NNLM) described in the paper learns the language model and word embedding simultaneously through a linear transformation and a non-linear hidden connection. That is, after training on large amounts of corpus, the model learns the word embedding; then, it computes the probability of the whole sentence, using the embedding. This type of language model can overcome the **curse of dimensionality** i.e. model inaccuracy caused by the difference in dimensionality between training and testing data. Note that the term *neural network language model* is ill-defined, so we will not use the name NNLM but only refer to it as *N-gram neural model* in this section.
+Scientists such as Yoshua Bengio introduced how to learn a word vector model of a neural network representation in the famous paper Neural Probabilistic Language Models \[[1](#references)\ in 2003. The Neural Network Language Model (NNLM) in this paper connects the linear model and a nonlinear hidden layer. It learns the language model and the word vector simultaneously, that is, by learning a large number of corpora to obtain the vector expression of the words, and the probability of the entire sentence is obtained by using these vectors. Since all words are represented by a low-dimensional vector, learning the language model in this way can overcome the curse of dimensionality.
+Note: Because the "Neural Network Language Model" is more general, we do not use the real name of NNLM here, considering its specific practice, this model here is called N-gram neural model.
-We have previously described language model using conditional probability, where the probability of the *t*-th word in a sentence depends on all $t-1$ words before it. Furthermore, since words further prior have less impact on a word, and every word within an n-gram is only effected by its previous n-1 words, we have:
+We have already mentioned above using the conditional probability language model, that is, the probability of the $t$ word in a sentence is related to the first $t-1$ words of the sentence. The farther the word actually has the smaller effect on the word, then if you consider an n-gram, each word is only affected by the preceding `n-1` words, then:
-$$P(w_1, ..., w_T) = \prod_{t=n}^TP(w_t|w_{t-1}, w_{t-2}, ..., w_{t-n+1})$$
+$$P(w_1, ..., w_T) = \prod_{t=n}^TP(w_t|w_{t-1}, w_{t-2}, ..., w_{t-n+1 })$$
-Given some real corpus in which all sentences are meaningful, the n-gram model should maximize the following objective function:
+Given some real corpora, these corpora are meaningful sentences, and the optimization goal of the N-gram model is to maximize the objective function:
$$\frac{1}{T}\sum_t f(w_t, w_{t-1}, ..., w_{t-n+1};\theta) + R(\theta)$$
-where $f(w_t, w_{t-1}, ..., w_{t-n+1})$ represents the conditional logarithmic probability of the current word $w_t$ given its previous $n-1$ words, and $R(\theta)$ represents parameter regularization term.
+Where $f(w_t, w_{t-1}, ..., w_{t-n+1})$ represents the conditional probability of getting the current word $w_t$ based on historical n-1 words, $R(\theta )$ represents a parameter regularization item.
- 
- Figure 2. N-gram neural network model
+ 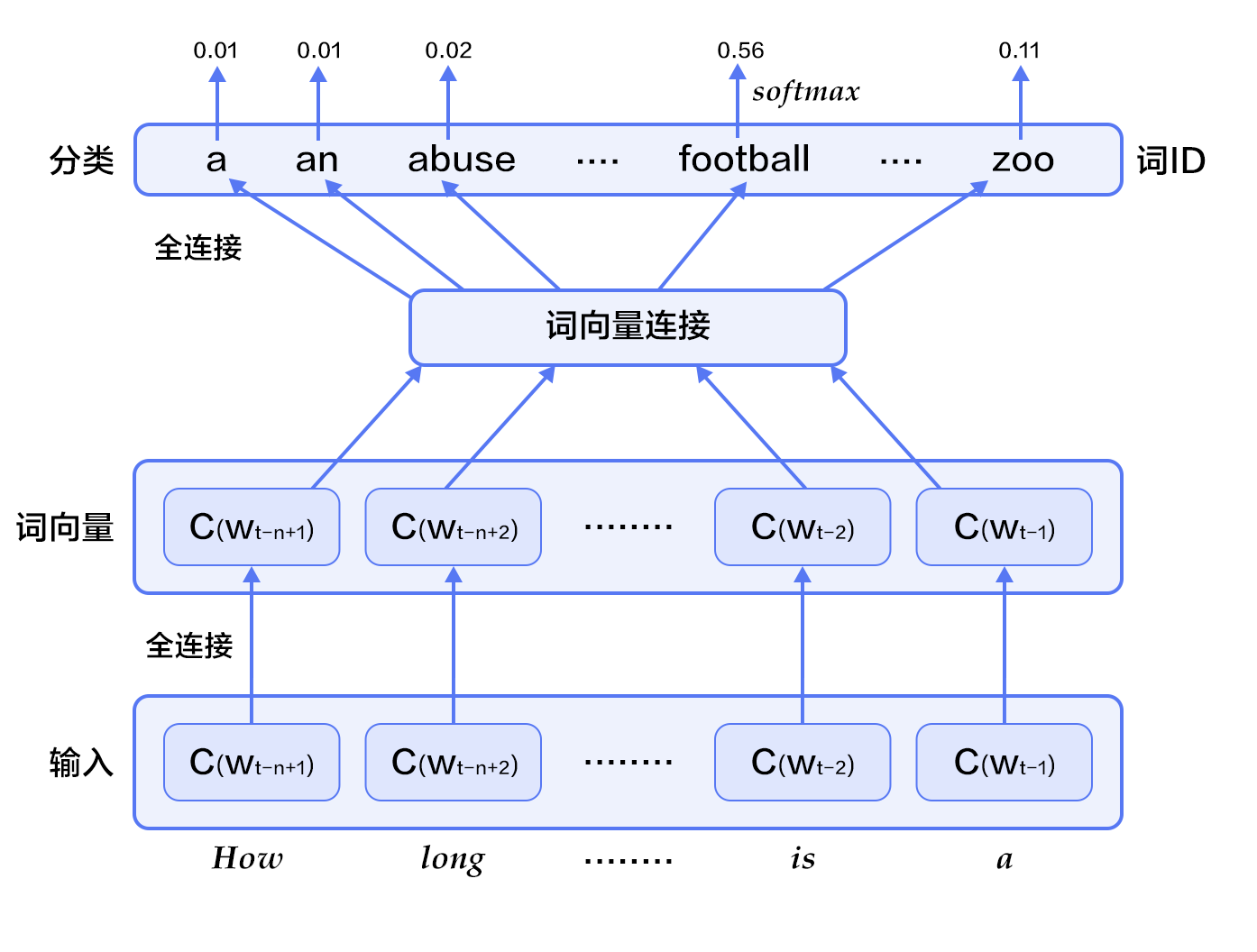
+ Figure 2. N-gram neural network model
+Figure 2 shows the N-gram neural network model. From the bottom up, the model is divided into the following parts:
+ - For each sample, the model enters $w_{t-n+1},...w_{t-1}$, and outputs the probability distribution of the t-th word in the dictionary on the `|V|` words.
-Figure 2 shows the N-gram neural network model. From the bottom up, the model has the following components:
-
- - For each sample, the model gets input $w_{t-n+1},...w_{t-1}$, and outputs the probability that the t-th word is one of `|V|` in the dictionary.
+ Each input word $w_{t-n+1},...w_{t-1}$ first maps to the word vector $C(w_{t-n+1}),...W_{t-1})$ by the mapping matrix.
- Every input word $w_{t-n+1},...w_{t-1}$ first gets transformed into word embedding $C(w_{t-n+1}),...C(w_{t-1})$ through a transformation matrix.
-
- - All the word embeddings concatenate into a single vector, which is mapped (nonlinearly) into the $t$-th word hidden representation:
+ - Then the word vectors of all words are spliced into a large vector, and a hidden layer representation of the historical words is obtained through a non-linear mapping:
$$g=Utanh(\theta^Tx + b_1) + Wx + b_2$$
- where $x$ is the large vector concatenated from all the word embeddings representing the context; $\theta$, $U$, $b_1$, $b_2$ and $W$ are parameters connecting word embedding layers to the hidden layers. $g$ represents the unnormalized probability of the output word, $g_i$ represents the unnormalized probability of the output word being the i-th word in the dictionary.
+Among them, $x$ is a large vector of all words, representing text history features; $\theta$, $U$, $b_1$, $b_2$, and $W$ are respectively parameters for the word vector layer to the hidden layer connection. $g$ represents the probability of all output words that are not normalized, and $g_i$ represents the output probability of the $i$ word in the unnormalized dictionary.
- - Based on the definition of softmax, using normalized $g_i$, the probability that the output word is $w_t$ is represented as:
+ - According to the definition of softmax, by normalizing $g_i$, the probability of generating the target word $w_t$ is:
$$P(w_t | w_1, ..., w_{t-n+1}) = \frac{e^{g_{w_t}}}{\sum_i^{|V|} e^{g_i}}$$
- - The cost of the entire network is a multi-class cross-entropy and can be described by the following loss function
+ - The loss value of the entire network is the multi-class classification cross entropy, which is expressed as
+
+ $$J(\theta) = -\sum_{i=1}^N\sum_{k=1}^{|V|}y_k^{i}log(softmax(g_k^i))$$
+
+ where $y_k^i$ represents the real label (0 or 1) of the $i$ sample of the $k$ class, and $softmax(g_k^i)$ represents the probability of the kth softmax output of the i-th sample.
- $$J(\theta) = -\sum_{i=1}^N\sum_{c=1}^{|V|}y_k^{i}log(softmax(g_k^i))$$
- where $y_k^i$ represents the true label for the $k$-th class in the $i$-th sample ($0$ or $1$), $softmax(g_k^i)$ represents the softmax probability for the $k$-th class in the $i$-th sample.
### Continuous Bag-of-Words model(CBOW)
-CBOW model predicts the current word based on the N words both before and after it. When $N=2$, the model is as the figure below:
+The CBOW model predicts the current word through the context of a word (each N words). When N=2, the model is shown below:
- 
- Figure 3. CBOW model
+ 
+ Figure 3. CBOW model
-Specifically, by ignoring the order of words in the sequence, CBOW uses the average value of the word embedding of the context to predict the current word:
+Specifically, regardless of the contextual word input order, CBOW uses the mean of the word vectors of the context words to predict the current word. which is:
-$$\text{context} = \frac{x_{t-1} + x_{t-2} + x_{t+1} + x_{t+2}}{4}$$
+$$context = \frac{x_{t-1} + x_{t-2} + x_{t+1} + x_{t+2}}{4}$$
-where $x_t$ is the word embedding of the t-th word, classification score vector is $z=U*\text{context}$, the final classification $y$ uses softmax and the loss function uses multi-class cross-entropy.
+Where $x_t$ is the word vector of the $t$th word, the score vector (score) $z=U\*context$, the final classification $y$ uses softmax, and the loss function uses multi-class classification cross entropy.
### Skip-gram model
-The advantages of CBOW is that it smooths over the word embeddings of the context and reduces noise, so it is very effective on small dataset. Skip-gram uses a word to predict its context and get multiple context for the given word, so it can be used in larger datasets.
+The benefit of CBOW is that the distribution of contextual words is smoothed over the word vector, removing noise. Therefore it is very effective on small data sets. In the Skip-gram method, a word is used to predict its context, and many samples of the current word context are obtained, so it can be used for a larger data set.
- 
- Figure 4. Skip-gram model
+ 
+ Figure 4. Skip-gram model
-As illustrated in the figure above, skip-gram model maps the word embedding of the given word onto $2n$ word embeddings (including $n$ words before and $n$ words after the given word), and then combine the classification loss of all those $2n$ words by softmax.
+As shown in the figure above, the specific method of the Skip-gram model is to map the word vector of a word to the word vector of $2n$ words ($2n$ represents the $n$ words before and after the input word), and then obtained the sum of the classification loss values of the $2n$ words by softmax.
-## Dataset
-We will use Penn Treebank (PTB) (Tomas Mikolov's pre-processed version) dataset. PTB is a small dataset, used in Recurrent Neural Network Language Modeling Toolkit\[[2](#references)\]. Its statistics are as follows:
+## Data Preparation
+
+### Data Introduction
+
+This tutorial uses the Penn Treebank (PTB) (pre-processed version of Tomas Mikolov) dataset. The PTB data set is small and the training speed is fast. It is applied to Mikolov's open language model training tool \[[2](#references)\]. Its statistics are as follows:
-
- | training set |
- validation set |
- test set |
-
-
- | ptb.train.txt |
- ptb.valid.txt |
- ptb.test.txt |
-
-
- | 42068 lines |
- 3370 lines |
- 3761 lines |
-
+
+ | Training data |
+ Verify data |
+ Test data |
+
+
+ | ptb.train.txt |
+ ptb.valid.txt |
+ ptb.test.txt |
+
+
+ | 42068 sentences |
+ 3370 sentences |
+ 3761 sentence |
+
-### Python Dataset Module
-
-We encapsulated the PTB Data Set in our Python module `paddle.dataset.imikolov`. This module can
-
-1. download the dataset to `~/.cache/paddle/dataset/imikolov`, if not yet, and
-2. [preprocesses](#preprocessing) the dataset.
-### Preprocessing
+### Data Preprocessing
-We will be training a 5-gram model. Given five words in a window, we will predict the fifth word given the first four words.
+This chapter trains the 5-gram model, which means that the first 4 words of each piece of data are used to predict the 5th word during PaddlePaddle training. PaddlePaddle provides the python package `paddle.dataset.imikolov` corresponding to the PTB dataset, which automatically downloads and preprocesses the data for your convenience.
-Beginning and end of a sentence have a special meaning, so we will add begin token `` in the front of the sentence. And end token `` in the end of the sentence. By moving the five word window in the sentence, data instances are generated.
+Preprocessing adds the start symbol `` and the end symbol `` to each sentence in the data set. Then, depending on the window size (5 in this tutorial), slide the window to the right each time from start to end and generate a piece of data.
-For example, the sentence "I have a dream that one day" generates five data instances:
+For example, "I have a dream that one day" provides 5 pieces of data:
```text
I have a dream
I have a dream that
-have a dream that one
+Have a dream that one
a dream that one day
-dream that one day
+Dream that one day
```
-At last, each data instance will be converted into an integer sequence according it's words' index inside the dictionary.
+Finally, based on the position of its word in the dictionary, each input is converted to an index sequence of integers as the input to PaddlePaddle.
-## Training
+
+## Program the Model
-The neural network that we will be using is illustrated in the graph below:
+The model structure of this configuration is shown below:
- 
- Figure 5. N-gram neural network model in model configuration
+ 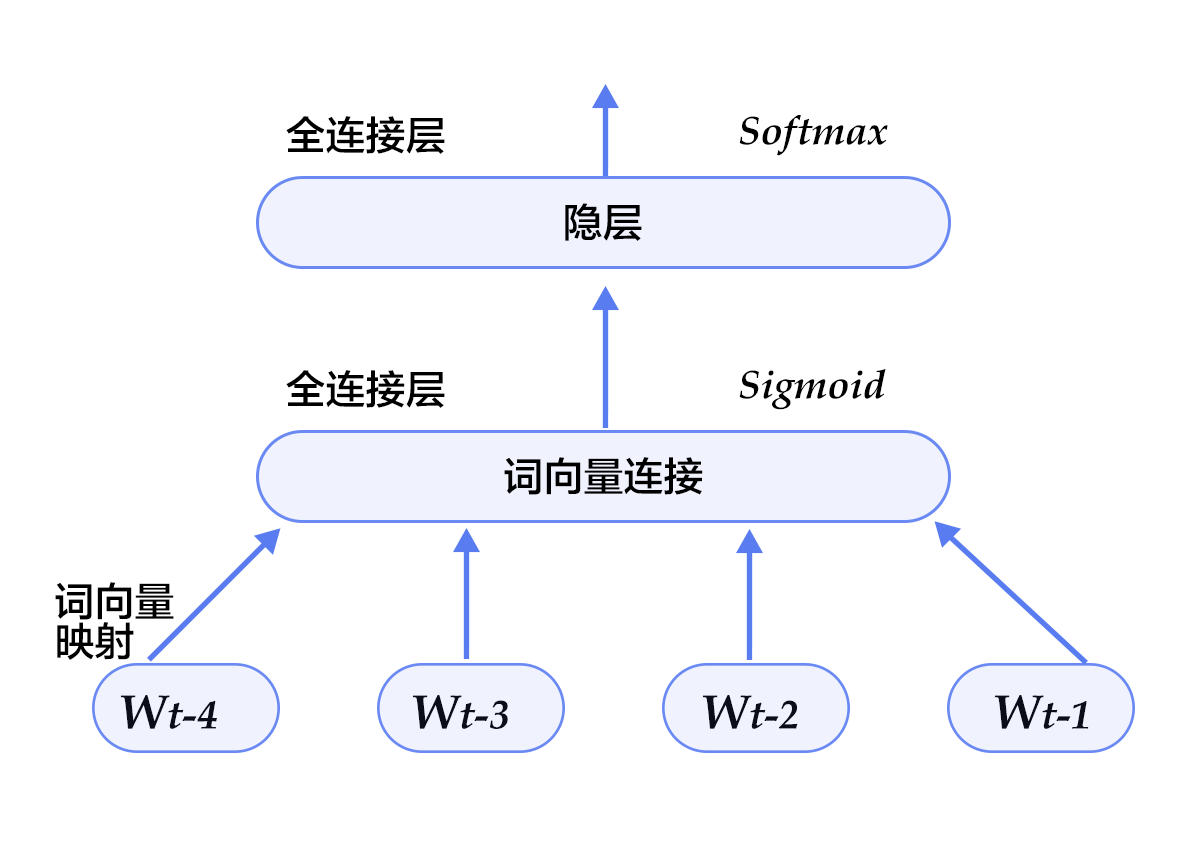
+ Figure 5. N-gram neural network model in model configuration
-`word2vec/train.py` demonstrates training word2vec using PaddlePaddle:
-
-### Datafeeder Configuration
-Our program starts with importing necessary packages:
-
-- Import packages.
+First, load packages:
```python
-import paddle
+
+import paddle as paddle
import paddle.fluid as fluid
+import six
import numpy
-from functools import partial
import math
-import os
-import six
-import sys
+
from __future__ import print_function
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
+
```
-- Configure parameters and build word dictionary.
+Then, define the parameters:
```python
-EMBED_SIZE = 32 # word vector dimension
-HIDDEN_SIZE = 256 # hidden layer dimension
-N = 5 # train 5-gram
-BATCH_SIZE = 32 # batch size
+EMBED_SIZE = 32 # embedding dimensions
+HIDDEN_SIZE = 256 # hidden layer size
+N = 5 # ngram size, here fixed 5
+BATCH_SIZE = 100 # batch size
+PASS_NUM = 100 # Training rounds
-# can use CPU or GPU
-use_cuda = os.getenv('WITH_GPU', '0') != '0'
+use_cuda = False # Set to True if trained with GPU
word_dict = paddle.dataset.imikolov.build_dict()
dict_size = len(word_dict)
```
-Unlike from the previous PaddlePaddle v2, in the new API (Fluid), we do not need to calculate word embedding ourselves. PaddlePaddle provides a built-in method `fluid.layers.embedding` and we can use it directly to build our N-gram neural network model.
+A larger `BATCH_SIZE` will make the training converge faster, but it will also consume more memory. Since the word vector calculation is large, if the environment allows, please turn on the GPU for training, and get results faster.
+Unlike the previous PaddlePaddle v2 version, in the new Fluid version, we don't have to manually calculate the word vector. PaddlePaddle provides a built-in method `fluid.layers.embedding`, which we can use directly to construct an N-gram neural network.
-- We define our N-gram neural network structure as below. This structure will be used both in `train` and in `infer`. We can specify `is_sparse = True` to accelerate sparse matrix update for word embedding.
+- Let's define our N-gram neural network structure. This structure is used in both training and predicting. Because the word vector is sparse, we pass the parameter `is_sparse == True` to speed up the update of the sparse matrix.
```python
-def inference_program(is_sparse):
- first_word = fluid.layers.data(name='firstw', shape=[1], dtype='int64')
- second_word = fluid.layers.data(name='secondw', shape=[1], dtype='int64')
- third_word = fluid.layers.data(name='thirdw', shape=[1], dtype='int64')
- fourth_word = fluid.layers.data(name='fourthw', shape=[1], dtype='int64')
+def inference_program(words, is_sparse):
embed_first = fluid.layers.embedding(
- input=first_word,
+ input=words[0],
size=[dict_size, EMBED_SIZE],
dtype='float32',
is_sparse=is_sparse,
param_attr='shared_w')
embed_second = fluid.layers.embedding(
- input=second_word,
+ input=words[1],
size=[dict_size, EMBED_SIZE],
dtype='float32',
is_sparse=is_sparse,
param_attr='shared_w')
embed_third = fluid.layers.embedding(
- input=third_word,
+ input=words[2],
size=[dict_size, EMBED_SIZE],
dtype='float32',
is_sparse=is_sparse,
param_attr='shared_w')
embed_fourth = fluid.layers.embedding(
- input=fourth_word,
+ input=words[3],
size=[dict_size, EMBED_SIZE],
dtype='float32',
is_sparse=is_sparse,
@@ -295,79 +268,116 @@ def inference_program(is_sparse):
return predict_word
```
-- As we already defined the N-gram neural network structure in the above, we can use it in our `train` method.
+- Based on the neural network structure above, we can define our training method as follows:
```python
-def train_program(is_sparse):
- # The declaration of 'next_word' must be after the invoking of inference_program,
- # or the data input order of train program would be [next_word, firstw, secondw,
- # thirdw, fourthw], which is not correct.
- predict_word = inference_program(is_sparse)
+def train_program(predict_word):
+ # The definition of'next_word' must be after the declaration of inference_program.
+ # Otherwise the sequence of the train program input data becomes [next_word, firstw, secondw,
+ #thirdw, fourthw], This is not true.
next_word = fluid.layers.data(name='nextw', shape=[1], dtype='int64')
cost = fluid.layers.cross_entropy(input=predict_word, label=next_word)
avg_cost = fluid.layers.mean(cost)
return avg_cost
-```
-
-- Now we will begin the training process. It is relatively simple compared to the previous version. `paddle.dataset.imikolov.train()` and `paddle.dataset.imikolov.test()` are our training and test set. Both of the functions will return a **reader**: In PaddlePaddle, reader is a python function which returns a Python iterator which output a single data instance at a time.
-
-`paddle.batch` takes reader as input, outputs a **batched reader**: In PaddlePaddle, a reader outputs a single data instance at a time but batched reader outputs a minibatch of data instances.
-`event_handler` can be passed into `trainer.train` so that we can do some tasks after each step or epoch. These tasks include recording current metrics or terminate current training process.
-
-```python
def optimizer_func():
return fluid.optimizer.AdagradOptimizer(
learning_rate=3e-3,
regularization=fluid.regularizer.L2DecayRegularizer(8e-4))
+```
+
+- Now we can start training. This version is much simpler than before. We have ready-made training and test sets: `paddle.dataset.imikolov.train()` and `paddle.dataset.imikolov.test()`. Both will return a reader. In PaddlePaddle, the reader is a Python function that reads the next piece of data when called each time . It is a Python generator.
+
+`paddle.batch` will read in a reader and output a batched reader. We can also output the training of each step and batch during the training process.
+
+```python
+def train(if_use_cuda, params_dirname, is_sparse=True):
+ place = fluid.CUDAPlace(0) if if_use_cuda else fluid.CPUPlace()
-def train(use_cuda, train_program, params_dirname):
train_reader = paddle.batch(
paddle.dataset.imikolov.train(word_dict, N), BATCH_SIZE)
test_reader = paddle.batch(
paddle.dataset.imikolov.test(word_dict, N), BATCH_SIZE)
- place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+ first_word = fluid.layers.data(name='firstw', shape=[1], dtype='int64')
+ second_word = fluid.layers.data(name='secondw', shape=[1], dtype='int64')
+ third_word = fluid.layers.data(name='thirdw', shape=[1], dtype='int64')
+ forth_word = fluid.layers.data(name='fourthw', shape=[1], dtype='int64')
+ next_word = fluid.layers.data(name='nextw', shape=[1], dtype='int64')
- def event_handler(event):
- if isinstance(event, EndStepEvent):
- outs = trainer.test(
- reader=test_reader,
- feed_order=['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw'])
- avg_cost = outs[0]
-
- # We output cost every 10 steps.
- if event.step % 10 == 0:
- print("Step %d: Average Cost %f" % (event.step, avg_cost))
-
- # If average cost is lower than 5.8, we consider the model good enough to stop.
- # Note 5.8 is a relatively high value. In order to get a better model, one should
- # aim for avg_cost lower than 3.5. But the training could take longer time.
- if avg_cost < 5.8:
- trainer.save_params(params_dirname)
- trainer.stop()
-
- if math.isnan(avg_cost):
- sys.exit("got NaN loss, training failed.")
-
- trainer = Trainer(
- train_func=train_program,
- # Note here we need to chse more sophisticated optimizer
- # such as AdaGrad with a decay rate. The normal SGD converges
- # very slowly.
- # optimizer=fluid.optimizer.SGD(learning_rate=0.001),
- optimizer_func=optimizer_func,
- place=place)
-
- trainer.train(
- reader=train_reader,
- num_epochs=1,
- event_handler=event_handler,
- feed_order=['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw'])
+ word_list = [first_word, second_word, third_word, forth_word, next_word]
+ feed_order = ['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw']
+
+ main_program = fluid.default_main_program()
+ star_program = fluid.default_startup_program()
+
+ predict_word = inference_program(word_list, is_sparse)
+ avg_cost = train_program(predict_word)
+ test_program = main_program.clone(for_test=True)
+
+ sgd_optimizer = optimizer_func()
+ sgd_optimizer.minimize(avg_cost)
+
+ exe = fluid.Executor(place)
+
+ def train_test(program, reader):
+ count = 0
+ feed_var_list = [
+ program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder_test = fluid.DataFeeder(feed_list=feed_var_list, place=place)
+ test_exe = fluid.Executor(place)
+ accumulated = len([avg_cost]) * [0]
+ for test_data in reader():
+ avg_cost_np = test_exe.run(
+ program=program,
+ feed=feeder_test.feed(test_data),
+ fetch_list=[avg_cost])
+ accumulated = [
+ x[0] + x[1][0] for x in zip(accumulated, avg_cost_np)
+ ]
+ count += 1
+ return [x / count for x in accumulated]
+
+ def train_loop():
+ step = 0
+ feed_var_list_loop = [
+ main_program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder = fluid.DataFeeder(feed_list=feed_var_list_loop, place=place)
+ exe.run(star_program)
+ for pass_id in range(PASS_NUM):
+ for data in train_reader():
+ avg_cost_np = exe.run(
+ main_program, feed=feeder.feed(data), fetch_list=[avg_cost])
+
+ if step % 10 == 0:
+ outs = train_test(test_program, test_reader)
+
+ print("Step %d: Average Cost %f" % (step, outs[0]))
+
+ # The entire training process takes several hours if the average loss is less than 5.8,
+ # We think that the model has achieved good results and can stop training.
+ # Note 5.8 is a relatively high value, in order to get a better model, you can
+ # set the threshold here to be 3.5, but the training time will be longer.
+ if outs[0] < 5.8:
+ if params_dirname is not None:
+ fluid.io.save_inference_model(params_dirname, [
+ 'firstw', 'secondw', 'thirdw', 'fourthw'
+ ], [predict_word], exe)
+ return
+ step += 1
+ if math.isnan(float(avg_cost_np[0])):
+ sys.exit("got NaN loss, training failed.")
+
+ raise AssertionError("Cost is too large {0:2.2}".format(avg_cost_np[0]))
+
+ train_loop()
```
-`trainer.train` will start training, the output of `event_handler` will be similar to following:
+- `train_loop` will start training. The log of the training process during the period is as follows:
+
```text
Step 0: Average Cost 7.337213
Step 10: Average Cost 6.136128
@@ -375,67 +385,78 @@ Step 20: Average Cost 5.766995
...
```
-
+
## Model Application
+After the model is trained, we can use it to make some predictions.
-After the model is trained, we can load the saved model parameters and do some inference.
-
-### Predicting the next word
-
-We can use our trained model to predict the next word given its previous N-gram. For example
-
+### Predict the next word
+We can use our trained model to predict the next word after learning the previous N-gram.
```python
-def infer(use_cuda, inference_program, params_dirname=None):
+def infer(use_cuda, params_dirname=None):
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
- inferencer = Inferencer(
- infer_func=inference_program, param_path=params_dirname, place=place)
-
- # Setup inputs by creating 4 LoDTensors representing 4 words. Here each word
- # is simply an index to look up for the corresponding word vector and hence
- # the shape of word (base_shape) should be [1]. The length-based level of
- # detail (lod) info of each LoDtensor should be [[1]] meaning there is only
- # one lod_level and there is only one sequence of one word on this level.
- # Note that lod info should be a list of lists.
-
- data1 = [[211]] # 'among'
- data2 = [[6]] # 'a'
- data3 = [[96]] # 'group'
- data4 = [[4]] # 'of'
- lod = [[1]]
-
- first_word = fluid.create_lod_tensor(data1, lod, place)
- second_word = fluid.create_lod_tensor(data2, lod, place)
- third_word = fluid.create_lod_tensor(data3, lod, place)
- fourth_word = fluid.create_lod_tensor(data4, lod, place)
-
- result = inferencer.infer(
- {
- 'firstw': first_word,
- 'secondw': second_word,
- 'thirdw': third_word,
- 'fourthw': fourth_word
- },
- return_numpy=False)
-
- print(numpy.array(result[0]))
- most_possible_word_index = numpy.argmax(result[0])
- print(most_possible_word_index)
- print([
- key for key, value in six.iteritems(word_dict)
- if value == most_possible_word_index
- ][0])
+
+ exe = fluid.Executor(place)
+
+ inference_scope = fluid.core.Scope()
+ with fluid.scope_guard(inference_scope):
+ #Get the inference program using fluid.io.load_inference_model,
+ #feed variable name by feed_target_names and fetch fetch_targets from scope
+ [inferencer, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(params_dirname, exe)
+
+ # Set the input and use 4 LoDTensor to represent 4 words. Each word here is an id,
+ # Used to query the embedding table to get the corresponding word vector, so its shape size is [1].
+ # recursive_sequence_lengths sets the length based on LoD, so it should all be set to [[1]]
+ # Note that recursive_sequence_lengths is a list of lists
+ data1 = [[211]] # 'among'
+ data2 = [[6]] # 'a'
+ data3 = [[96]] # 'group'
+ data4 = [[4]] # 'of'
+ lod = [[1]]
+
+ first_word = fluid.create_lod_tensor(data1, lod, place)
+ second_word = fluid.create_lod_tensor(data2, lod, place)
+ third_word = fluid.create_lod_tensor(data3, lod, place)
+ fourth_word = fluid.create_lod_tensor(data4, lod, place)
+
+ assert feed_target_names[0] == 'firstw'
+ assert feed_target_names[1] == 'secondw'
+ assert feed_target_names[2] == 'thirdw'
+ assert feed_target_names[3] == 'fourthw'
+
+ # Construct the feed dictionary {feed_target_name: feed_target_data}
+ # Prediction results are included in results
+ results = exe.run(
+ inferencer,
+ feed={
+ feed_target_names[0]: first_word,
+ feed_target_names[1]: second_word,
+ feed_target_names[2]: third_word,
+ feed_target_names[3]: fourth_word
+ },
+ fetch_list=fetch_targets,
+ return_numpy=False)
+
+ print(numpy.array(results[0]))
+ most_possible_word_index = numpy.argmax(results[0])
+ print(most_possible_word_index)
+ print([
+ key for key, value in six.iteritems(word_dict)
+ if value == most_possible_word_index
+ ][0])
```
-When we spent 3 mins in training, the output is like below, which means the next word for `among a group of` is `a`. If we train the model with a longer time, it will give a meaningful prediction as `workers`.
+Since the word vector matrix itself is relatively sparse, the training process takes a long time to reach a certain precision. In order to see the effect simply, the tutorial only sets up with a few rounds of training and ends with the following result. Our model predicts that the next word for `among a group of` is `the`. This is in line with the law of grammar. If we train for longer time, such as several hours, then the next predicted word we will get is `workers`. The format of the predicted output is as follows:
```text
-[[0.00106646 0.0007907 0.00072041 ... 0.00049024 0.00041355 0.00084464]]
-6
-a
+[[0.03768077 0.03463154 0.00018074 ... 0.00022283 0.00029888 0.02967956]]
+0
+the
```
+The first line represents the probability distribution of the predicted word in the dictionary, the second line represents the id corresponding to the word with the highest probability, and the third line represents the word with the highest probability.
-The main entrance of the program is fairly simple:
+The entrance to the entire program is simple:
```python
def main(use_cuda, is_sparse):
@@ -445,32 +466,26 @@ def main(use_cuda, is_sparse):
params_dirname = "word2vec.inference.model"
train(
- use_cuda=use_cuda,
- train_program=partial(train_program, is_sparse),
- params_dirname=params_dirname)
+ if_use_cuda=use_cuda,
+ params_dirname=params_dirname,
+ is_sparse=is_sparse)
- infer(
- use_cuda=use_cuda,
- inference_program=partial(inference_program, is_sparse),
- params_dirname=params_dirname)
+ infer(use_cuda=use_cuda, params_dirname=params_dirname)
main(use_cuda=use_cuda, is_sparse=True)
```
## Conclusion
+In this chapter, we introduced word vectors, the relationship between language models and word vectors and how to obtain word vectors by training neural network models. In information retrieval, we can judge the correlation between query and document keywords based on the cosine value between vectors. In syntactic analysis and semantic analysis, trained word vectors can be used to initialize the model for better results. In the document classification, after the word vector, you can cluster to group synonyms in a document, or you can use N-gram to predict the next word. We hope that everyone can easily use the word vector to conduct research in related fields after reading this chapter.
-This chapter introduces word embeddings, the relationship between language model and word embedding, and how to train neural networks to learn word embedding.
-
-In grammar analysis and semantic analysis, a previously trained word embedding can initialize models for better performance. We hope that readers can use word embedding models in their work after reading this chapter.
-
-
+
## References
-1. Bengio Y, Ducharme R, Vincent P, et al. [A neural probabilistic language model](http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)[J]. journal of machine learning research, 2003, 3(Feb): 1137-1155.
-2. Mikolov T, Kombrink S, Deoras A, et al. [Rnnlm-recurrent neural network language modeling toolkit](http://www.fit.vutbr.cz/~imikolov/rnnlm/rnnlm-demo.pdf)[C]//Proc. of the 2011 ASRU Workshop. 2011: 196-201.
-3. Mikolov T, Chen K, Corrado G, et al. [Efficient estimation of word representations in vector space](https://arxiv.org/pdf/1301.3781.pdf)[J]. arXiv preprint arXiv:1301.3781, 2013.
-4. Maaten L, Hinton G. [Visualizing data using t-SNE](https://lvdmaaten.github.io/publications/papers/JMLR_2008.pdf)[J]. Journal of Machine Learning Research, 2008, 9(Nov): 2579-2605.
+1. Bengio Y, Ducharme R, Vincent P, et al. [A neural probabilistic language model](http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)[J]. journal of machine learning Research, 2003, 3(Feb): 1137-1155.
+2. Mikolov T, Kombrink S, Deoras A, et al. [Rnnlm-recurrent neural network language modeling toolkit](http://www.fit.vutbr.cz/~imikolov/rnnlm/rnnlm-demo.pdf)[C ]//Proc. of the 2011 ASRU Workshop. 2011: 196-201.
+3. Mikolov T, Chen K, Corrado G, et al. [Efficient estimation of word representations in vector space](https://arxiv.org/pdf/1301.3781.pdf)[J]. arXiv preprint arXiv:1301.3781, 2013 .
+4. Maaten L, Hinton G. [Visualizing data using t-SNE](https://lvdmaaten.github.io/publications/papers/JMLR_2008.pdf)[J]. Journal of Machine Learning Research, 2008, 9(Nov ): 2579-2605.
5. https://en.wikipedia.org/wiki/Singular_value_decomposition
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/04.word2vec/index.html b/04.word2vec/index.html
index 6cfc0cd..f67aeba 100644
--- a/04.word2vec/index.html
+++ b/04.word2vec/index.html
@@ -40,289 +40,262 @@
-# Word2Vec
+# Word Vector
-This is intended as a reference tutorial. The source code of this tutorial is located at [book/word2vec](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec).
+The source code of this tutorial is in [book/word2vec](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec). For new users, please refer to [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book) .
-For instructions on getting started with this book,see [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book).
+## Background
-## Background Introduction
+In this chapter, we'll introduce the vector representation of words, also known as word embedding. Word vector is a common operation in natural language processing. It is a common technology underlying Internet services such as search engines, advertising systems, and recommendation systems.
-This section introduces the concept of **word embeddings**, which are vector representations of words. Word embeddings is a popular technique used in natural language processing to support applications such as search engines, advertising systems, and recommendation systems.
+In these Internet services, we often compare the correlation between two words or two paragraphs of text. In order to make such comparisons, we often have to express words in a way that is suitable for computer processing. The most natural way is probably the vector space model.In this way, each word is represented as a one-hot vector whose length is the dictionary size, and each dimension corresponds to each word in a dictionary, except that the value in the corresponding dimension of the word is 1, other elements are 0.
-### One-Hot Vectors
+The One-hot vector is natural but has limitation. For example, in the internet advertising system, if the query entered by the user is "Mother's Day", the keyword of an advertisement is "Carnation". Although according to common sense, we know that there is a connection between these two words - Mother's Day should usually give the mother a bunch of carnations; but the distance between the two words corresponds to the one-hot vectors, whether it is Euclidean distance or cosine similarity, the two words are considered to be irrelevant due to their vector orthogonality. The root cause of this conclusion contradicting us is that the amount of information in each word itself is too small. Therefore, just giving two words is not enough for us to accurately determine whether they are relevant. To accurately calculate correlations, we need more information—knowledge from a large amount of data through machine learning methods.
-Building these applications requires us to quantify the similarity between two words or paragraphs. This calls for a new representation of all the words to make them more suitable for computation. An obvious way to achieve this is through the vector space model, where every word is represented as an **one-hot vector**.
+In the field of machine learning, all kinds of "knowledge" are represented by various models, and the word embedding model is one of them. A one-hot vector can be mapped to a lower-dimensional embedding vector by the word embedding model, such as $embedding (Mother's day) = [0.3, 4.2, -1.5, ...], embedding (carnation) = [0.2, 5.6, -2.3, ...]$. In this representation of the embedding vector to which it is mapped, it is desirable that the word vectors corresponding to the similar words on the two semantics (or usages) are "more like", such that the cosine similarity of the corresponding word vectors of "Mother's Day" and "Carnation" is no longer zero.
-For each word, its vector representation has the corresponding entry in the vector as 1, and all other entries as 0. The lengths of one-hot vectors match the size of the dictionary. Each entry of a vector corresponds to the presence (or absence) of a word in the dictionary.
+The word embedding model can be a probability model, a co-occurrence matrix model, or a neural network model. Before implementing neural networks to calculate the embedding vector, the traditional method is to count the co-occurrence matrix $X$ of a word. $X$ is a matrix of $|V| \times |V|$ size, $X_{ij}$ means that in all corpora, The number of words appearing simultaneously with the i-th word and the j-th word in the vocabulary $V$(vocabulary), $|V|$ is the size of the vocabulary. Do matrix decomposition for $X$ (such as singular value decomposition, Singular Value Decomposition \[[5](#references)\]), and the result $U$ is treated as the embedding vector for all words:
-One-hot vectors are intuitive, yet they have limited usefulness. Take the example of an Internet advertising system: Suppose a customer enters the query "Mother's Day", while an ad bids for the keyword "carnations". Because the one-hot vectors of these two words are perpendicular, the metric distance (either Euclidean or cosine similarity) between them would indicate little relevance. However, *we* know that these two queries are connected semantically, since people often gift their mothers bundles of carnation flowers on Mother's Day. This discrepancy is due to the low information capacity in each vector. That is, comparing the vector representations of two words does not assess their relevance sufficiently. To calculate their similarity accurately, we need more information, which could be learned from large amounts of data through machine learning methods.
+$$X = USV^T$$
-Like many machine learning models, word embeddings can represent knowledge in various ways. Another model may project an one-hot vector to an embedding vector of lower dimension e.g. $embedding(mother's day) = [0.3, 4.2, -1.5, ...], embedding(carnations) = [0.2, 5.6, -2.3, ...]$. Mapping one-hot vectors onto an embedded vector space has the potential to bring the embedding vectors of similar words (either semantically or usage-wise) closer to each other, so that the cosine similarity between the corresponding vectors for words like "Mother's Day" and "carnations" are no longer zero.
+But such traditional method has many problems:
-A word embedding model could be a probabilistic model, a co-occurrence matrix model, or a neural network. Before people started using neural networks to generate word embedding, the traditional method was to calculate a co-occurrence matrix $X$ of words. Here, $X$ is a $|V| \times |V|$ matrix, where $X_{ij}$ represents the co-occurrence times of the $i$th and $j$th words in the vocabulary `V` within all corpus, and $|V|$ is the size of the vocabulary. By performing matrix decomposition on $X$ e.g. Singular Value Decomposition \[[5](#references)\]
+1) Since many words do not appear, the matrix is extremely sparse, so additional processing of the word frequency is needed to achieve a good matrix decomposition effect;
-$$X = USV^T$$
+2) The matrix is very large and the dimensions are too high (usually up to $10^6 \times 10^6$);
-the resulting $U$ can be seen as the word embedding of all the words.
+3) You need to manually remove the stop words (such as although, a, ...), otherwise these frequently occurring words will also affect the effect of matrix decomposition.
-However, this method suffers from many drawbacks:
-1) Since many pairs of words don't co-occur, the co-occurrence matrix is sparse. To achieve good performance of matrix factorization, further treatment on word frequency is needed;
-2) The matrix is large, frequently on the order of $10^6*10^6$;
-3) We need to manually filter out stop words (like "although", "a", ...), otherwise these frequent words will affect the performance of matrix factorization.
+The neural-network-based model does not need to calculate and store a large table that is statistically generated on the whole corpus, but obtains the word vector by learning the semantic information, so the problem above can be well solved. In this chapter, we will show the details of training word vectors based on neural networks and how to train a word embedding model with PaddlePaddle.
-The neural network based model does not require storing huge hash tables of statistics on all of the corpus. It obtains the word embedding by learning from semantic information, hence could avoid the aforementioned problems in the traditional method. In this chapter, we will introduce the details of neural network word embedding model and how to train such model in PaddlePaddle.
-## Results Demonstration
+## Result Demo
-In this section, we use the $t-$SNE\[[4](#references)\] data visualization algorithm to draw the word embedding vectors after projecting them onto a two-dimensional space (see figure below). From the figure we can see that the semantically relevant words -- *a*, *the*, and *these* or *big* and *huge* -- are close to each other in the projected space, while irrelevant words -- *say* and *business* or *decision* and *japan* -- are far from each other.
+In this chapter, after the embedding vector is trained, we can use the data visualization algorithm t-SNE\[[4](#references)\] to draw the projection of the word features in two dimensions (as shown below). As can be seen from the figure, semantically related words (such as a, the, these; big, huge) are very close in projection, and semantic unrelated words (such as say, business; decision, japan) are far away from the projection.
-
- Figure 1. Two dimension projection of word embeddings
+
+ Figure 1. Two-dimensional projection of a word vector
-### Cosine Similarity
-
-On the other hand, we know that the cosine similarity between two vectors falls between $[-1,1]$. Specifically, the cosine similarity is 1 when the vectors are identical, 0 when the vectors are perpendicular, -1 when the are of opposite directions. That is, the cosine similarity between two vectors scales with their relevance. So we can calculate the cosine similarity of two word embedding vectors to represent their relevance:
+On the other hand, we know that the cosine of two vectors is in the interval of $[-1,1]$: two identical vector cosines are 1, and the cosine value between two mutually perpendicular vectors is 0, The vector cosine of the opposite direction is -1, which the correlation is proportional to the magnitude of the cosine. So we can also calculate the cosine similarity of two word vectors:
```
+
please input two words: big huge
-similarity: 0.899180685161
+Similarity: 0.899180685161
please input two words: from company
-similarity: -0.0997506977351
-```
-
-The above results could be obtained by running `calculate_dis.py`, which loads the words in the dictionary and their corresponding trained word embeddings. For detailed instruction, see section [Model Application](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec#model-application).
+Similarity: -0.0997506977351
+```
-## Model Overview
+The results above can be obtained by running `calculate_dis.py`, loading the words in the dictionary and the corresponding training feature results. We will describe the usage for details in [model application](#model application).
-In this section, we will introduce three word embedding models: N-gram model, CBOW, and Skip-gram, which all output the frequency of each word given its immediate context.
-For N-gram model, we will first introduce the concept of language model, and implement it using PaddlePaddle in section [Training](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec#model-application).
+## Overview of Models
-The latter two models, which became popular recently, are neural word embedding model developed by Tomas Mikolov at Google \[[3](#references)\]. Despite their apparent simplicity, these models train very well.
+Here we introduce three models of training word vectors: N-gram model, CBOW model and Skip-gram model. Their central idea is to get the probability of a word appearing through the context. For the N-gram model, we will first introduce the concept of the language model. In the section [training model](#training model), we'll tutor you to implement it with PaddlePaddle. The latter two models are the most famous neuron word vector models in recent years, developed by Tomas Mikolov in Google \[[3](#references)\], although they are very simple, but the training effect is very good.
### Language Model
-Before diving into word embedding models, we will first introduce the concept of **language model**. Language models build the joint probability function $P(w_1, ..., w_T)$ of a sentence, where $w_i$ is the i-th word in the sentence. The goal is to give higher probabilities to meaningful sentences, and lower probabilities to meaningless constructions.
+Before introducing the word embedding model, let us introduce a concept: the language model.
+The language model is intended to model the joint probability function $P(w_1, ..., w_T)$ of a sentence, where $w_i$ represents the ith word in the sentence. The goal of the language model isn that the model gives a high probability to meaningful sentences and a small probability to meaningless sentences.Such models can be applied to many fields, such as machine translation, speech recognition, information retrieval, part-of-speech tagging, handwriting recognition, etc., All of which hope to obtain the probability of a continuous sequence. Take information retrieval as an example, when you search for "how long is a football bame" (bame is a medical term), the search engine will prompt you if you want to search for "how long is a football game", because the probability of calculating "how long is a football bame" is very low, and the word is similar to bame, which may cause errors, the game will maximize the probability of generating the sentence.
-In general, models that generate the probability of a sequence can be applied to many fields, like machine translation, speech recognition, information retrieval, part-of-speech tagging, and handwriting recognition. Take information retrieval, for example. If you were to search for "how long is a football bame" (where bame is a medical noun), the search engine would have asked if you had meant "how long is a football game" instead. This is because the probability of "how long is a football bame" is very low according to the language model; in addition, among all of the words easily confused with "bame", "game" would build the most probable sentence.
-
-#### Target Probability
-For language model's target probability $P(w_1, ..., w_T)$, if the words in the sentence were to be independent, the joint probability of the whole sentence would be the product of each word's probability:
+For the target probability of the language model $P(w_1, ..., w_T)$, if it is assumed that each word in the text is independent, the joint probability of the whole sentence can be expressed as the product of the conditional probabilities of all the words. which is:
$$P(w_1, ..., w_T) = \prod_{t=1}^TP(w_t)$$
-However, the frequency of words in a sentence typically relates to the words before them, so canonical language models are constructed using conditional probability in its target probability:
+However, we know that the probability of each word in the statement is closely related to the word in front of it, so in fact, the language model is usually represented by conditional probability:
$$P(w_1, ..., w_T) = \prod_{t=1}^TP(w_t | w_1, ... , w_{t-1})$$
+
### N-gram neural model
-In computational linguistics, n-gram is an important method to represent text. An n-gram represents a contiguous sequence of n consecutive items given a text. Based on the desired application scenario, each item could be a letter, a syllable or a word. The N-gram model is also an important method in statistical language modeling. When training language models with n-grams, the first (n-1) words of an n-gram are used to predict the *n*th word.
+In computational linguistics, n-gram is an important text representation method that represents a continuous n items in a text. Each item can be a letter, word or syllable based on the specific application scenario. The n-gram model is also an important method in the statistical language model. When n-gram is used to train the language model, the nth word is generally predicted by the content of the n-1 words of each n-gram.
-Yoshua Bengio and other scientists describe how to train a word embedding model using neural network in the famous paper of Neural Probabilistic Language Models \[[1](#references)\] published in 2003. The Neural Network Language Model (NNLM) described in the paper learns the language model and word embedding simultaneously through a linear transformation and a non-linear hidden connection. That is, after training on large amounts of corpus, the model learns the word embedding; then, it computes the probability of the whole sentence, using the embedding. This type of language model can overcome the **curse of dimensionality** i.e. model inaccuracy caused by the difference in dimensionality between training and testing data. Note that the term *neural network language model* is ill-defined, so we will not use the name NNLM but only refer to it as *N-gram neural model* in this section.
+Scientists such as Yoshua Bengio introduced how to learn a word vector model of a neural network representation in the famous paper Neural Probabilistic Language Models \[[1](#references)\ in 2003. The Neural Network Language Model (NNLM) in this paper connects the linear model and a nonlinear hidden layer. It learns the language model and the word vector simultaneously, that is, by learning a large number of corpora to obtain the vector expression of the words, and the probability of the entire sentence is obtained by using these vectors. Since all words are represented by a low-dimensional vector, learning the language model in this way can overcome the curse of dimensionality.
+Note: Because the "Neural Network Language Model" is more general, we do not use the real name of NNLM here, considering its specific practice, this model here is called N-gram neural model.
-We have previously described language model using conditional probability, where the probability of the *t*-th word in a sentence depends on all $t-1$ words before it. Furthermore, since words further prior have less impact on a word, and every word within an n-gram is only effected by its previous n-1 words, we have:
+We have already mentioned above using the conditional probability language model, that is, the probability of the $t$ word in a sentence is related to the first $t-1$ words of the sentence. The farther the word actually has the smaller effect on the word, then if you consider an n-gram, each word is only affected by the preceding `n-1` words, then:
-$$P(w_1, ..., w_T) = \prod_{t=n}^TP(w_t|w_{t-1}, w_{t-2}, ..., w_{t-n+1})$$
+$$P(w_1, ..., w_T) = \prod_{t=n}^TP(w_t|w_{t-1}, w_{t-2}, ..., w_{t-n+1 })$$
-Given some real corpus in which all sentences are meaningful, the n-gram model should maximize the following objective function:
+Given some real corpora, these corpora are meaningful sentences, and the optimization goal of the N-gram model is to maximize the objective function:
$$\frac{1}{T}\sum_t f(w_t, w_{t-1}, ..., w_{t-n+1};\theta) + R(\theta)$$
-where $f(w_t, w_{t-1}, ..., w_{t-n+1})$ represents the conditional logarithmic probability of the current word $w_t$ given its previous $n-1$ words, and $R(\theta)$ represents parameter regularization term.
+Where $f(w_t, w_{t-1}, ..., w_{t-n+1})$ represents the conditional probability of getting the current word $w_t$ based on historical n-1 words, $R(\theta )$ represents a parameter regularization item.
-
- Figure 2. N-gram neural network model
+
+ Figure 2. N-gram neural network model
+Figure 2 shows the N-gram neural network model. From the bottom up, the model is divided into the following parts:
+ - For each sample, the model enters $w_{t-n+1},...w_{t-1}$, and outputs the probability distribution of the t-th word in the dictionary on the `|V|` words.
-Figure 2 shows the N-gram neural network model. From the bottom up, the model has the following components:
-
- - For each sample, the model gets input $w_{t-n+1},...w_{t-1}$, and outputs the probability that the t-th word is one of `|V|` in the dictionary.
+ Each input word $w_{t-n+1},...w_{t-1}$ first maps to the word vector $C(w_{t-n+1}),...W_{t-1})$ by the mapping matrix.
- Every input word $w_{t-n+1},...w_{t-1}$ first gets transformed into word embedding $C(w_{t-n+1}),...C(w_{t-1})$ through a transformation matrix.
-
- - All the word embeddings concatenate into a single vector, which is mapped (nonlinearly) into the $t$-th word hidden representation:
+ - Then the word vectors of all words are spliced into a large vector, and a hidden layer representation of the historical words is obtained through a non-linear mapping:
$$g=Utanh(\theta^Tx + b_1) + Wx + b_2$$
- where $x$ is the large vector concatenated from all the word embeddings representing the context; $\theta$, $U$, $b_1$, $b_2$ and $W$ are parameters connecting word embedding layers to the hidden layers. $g$ represents the unnormalized probability of the output word, $g_i$ represents the unnormalized probability of the output word being the i-th word in the dictionary.
+Among them, $x$ is a large vector of all words, representing text history features; $\theta$, $U$, $b_1$, $b_2$, and $W$ are respectively parameters for the word vector layer to the hidden layer connection. $g$ represents the probability of all output words that are not normalized, and $g_i$ represents the output probability of the $i$ word in the unnormalized dictionary.
- - Based on the definition of softmax, using normalized $g_i$, the probability that the output word is $w_t$ is represented as:
+ - According to the definition of softmax, by normalizing $g_i$, the probability of generating the target word $w_t$ is:
$$P(w_t | w_1, ..., w_{t-n+1}) = \frac{e^{g_{w_t}}}{\sum_i^{|V|} e^{g_i}}$$
- - The cost of the entire network is a multi-class cross-entropy and can be described by the following loss function
+ - The loss value of the entire network is the multi-class classification cross entropy, which is expressed as
+
+ $$J(\theta) = -\sum_{i=1}^N\sum_{k=1}^{|V|}y_k^{i}log(softmax(g_k^i))$$
+
+ where $y_k^i$ represents the real label (0 or 1) of the $i$ sample of the $k$ class, and $softmax(g_k^i)$ represents the probability of the kth softmax output of the i-th sample.
- $$J(\theta) = -\sum_{i=1}^N\sum_{c=1}^{|V|}y_k^{i}log(softmax(g_k^i))$$
- where $y_k^i$ represents the true label for the $k$-th class in the $i$-th sample ($0$ or $1$), $softmax(g_k^i)$ represents the softmax probability for the $k$-th class in the $i$-th sample.
### Continuous Bag-of-Words model(CBOW)
-CBOW model predicts the current word based on the N words both before and after it. When $N=2$, the model is as the figure below:
+The CBOW model predicts the current word through the context of a word (each N words). When N=2, the model is shown below:
-
- Figure 3. CBOW model
+
+ Figure 3. CBOW model
-Specifically, by ignoring the order of words in the sequence, CBOW uses the average value of the word embedding of the context to predict the current word:
+Specifically, regardless of the contextual word input order, CBOW uses the mean of the word vectors of the context words to predict the current word. which is:
-$$\text{context} = \frac{x_{t-1} + x_{t-2} + x_{t+1} + x_{t+2}}{4}$$
+$$context = \frac{x_{t-1} + x_{t-2} + x_{t+1} + x_{t+2}}{4}$$
-where $x_t$ is the word embedding of the t-th word, classification score vector is $z=U*\text{context}$, the final classification $y$ uses softmax and the loss function uses multi-class cross-entropy.
+Where $x_t$ is the word vector of the $t$th word, the score vector (score) $z=U\*context$, the final classification $y$ uses softmax, and the loss function uses multi-class classification cross entropy.
### Skip-gram model
-The advantages of CBOW is that it smooths over the word embeddings of the context and reduces noise, so it is very effective on small dataset. Skip-gram uses a word to predict its context and get multiple context for the given word, so it can be used in larger datasets.
+The benefit of CBOW is that the distribution of contextual words is smoothed over the word vector, removing noise. Therefore it is very effective on small data sets. In the Skip-gram method, a word is used to predict its context, and many samples of the current word context are obtained, so it can be used for a larger data set.
-
- Figure 4. Skip-gram model
+
+ Figure 4. Skip-gram model
-As illustrated in the figure above, skip-gram model maps the word embedding of the given word onto $2n$ word embeddings (including $n$ words before and $n$ words after the given word), and then combine the classification loss of all those $2n$ words by softmax.
+As shown in the figure above, the specific method of the Skip-gram model is to map the word vector of a word to the word vector of $2n$ words ($2n$ represents the $n$ words before and after the input word), and then obtained the sum of the classification loss values of the $2n$ words by softmax.
-## Dataset
-We will use Penn Treebank (PTB) (Tomas Mikolov's pre-processed version) dataset. PTB is a small dataset, used in Recurrent Neural Network Language Modeling Toolkit\[[2](#references)\]. Its statistics are as follows:
+## Data Preparation
+
+### Data Introduction
+
+This tutorial uses the Penn Treebank (PTB) (pre-processed version of Tomas Mikolov) dataset. The PTB data set is small and the training speed is fast. It is applied to Mikolov's open language model training tool \[[2](#references)\]. Its statistics are as follows:
-
- | training set |
- validation set |
- test set |
-
-
- | ptb.train.txt |
- ptb.valid.txt |
- ptb.test.txt |
-
-
- | 42068 lines |
- 3370 lines |
- 3761 lines |
-
+
+ | Training data |
+ Verify data |
+ Test data |
+
+
+ | ptb.train.txt |
+ ptb.valid.txt |
+ ptb.test.txt |
+
+
+ | 42068 sentences |
+ 3370 sentences |
+ 3761 sentence |
+
-### Python Dataset Module
-
-We encapsulated the PTB Data Set in our Python module `paddle.dataset.imikolov`. This module can
-
-1. download the dataset to `~/.cache/paddle/dataset/imikolov`, if not yet, and
-2. [preprocesses](#preprocessing) the dataset.
-### Preprocessing
+### Data Preprocessing
-We will be training a 5-gram model. Given five words in a window, we will predict the fifth word given the first four words.
+This chapter trains the 5-gram model, which means that the first 4 words of each piece of data are used to predict the 5th word during PaddlePaddle training. PaddlePaddle provides the python package `paddle.dataset.imikolov` corresponding to the PTB dataset, which automatically downloads and preprocesses the data for your convenience.
-Beginning and end of a sentence have a special meaning, so we will add begin token `
` in the front of the sentence. And end token `` in the end of the sentence. By moving the five word window in the sentence, data instances are generated.
+Preprocessing adds the start symbol `` and the end symbol `` to each sentence in the data set. Then, depending on the window size (5 in this tutorial), slide the window to the right each time from start to end and generate a piece of data.
-For example, the sentence "I have a dream that one day" generates five data instances:
+For example, "I have a dream that one day" provides 5 pieces of data:
```text
I have a dream
I have a dream that
-have a dream that one
+Have a dream that one
a dream that one day
-dream that one day
+Dream that one day
```
-At last, each data instance will be converted into an integer sequence according it's words' index inside the dictionary.
+Finally, based on the position of its word in the dictionary, each input is converted to an index sequence of integers as the input to PaddlePaddle.
-## Training
+
+## Program the Model
-The neural network that we will be using is illustrated in the graph below:
+The model structure of this configuration is shown below:
-
- Figure 5. N-gram neural network model in model configuration
+
+ Figure 5. N-gram neural network model in model configuration
-`word2vec/train.py` demonstrates training word2vec using PaddlePaddle:
-
-### Datafeeder Configuration
-Our program starts with importing necessary packages:
-
-- Import packages.
+First, load packages:
```python
-import paddle
+
+import paddle as paddle
import paddle.fluid as fluid
+import six
import numpy
-from functools import partial
import math
-import os
-import six
-import sys
+
from __future__ import print_function
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
+
```
-- Configure parameters and build word dictionary.
+Then, define the parameters:
```python
-EMBED_SIZE = 32 # word vector dimension
-HIDDEN_SIZE = 256 # hidden layer dimension
-N = 5 # train 5-gram
-BATCH_SIZE = 32 # batch size
+EMBED_SIZE = 32 # embedding dimensions
+HIDDEN_SIZE = 256 # hidden layer size
+N = 5 # ngram size, here fixed 5
+BATCH_SIZE = 100 # batch size
+PASS_NUM = 100 # Training rounds
-# can use CPU or GPU
-use_cuda = os.getenv('WITH_GPU', '0') != '0'
+use_cuda = False # Set to True if trained with GPU
word_dict = paddle.dataset.imikolov.build_dict()
dict_size = len(word_dict)
```
-Unlike from the previous PaddlePaddle v2, in the new API (Fluid), we do not need to calculate word embedding ourselves. PaddlePaddle provides a built-in method `fluid.layers.embedding` and we can use it directly to build our N-gram neural network model.
+A larger `BATCH_SIZE` will make the training converge faster, but it will also consume more memory. Since the word vector calculation is large, if the environment allows, please turn on the GPU for training, and get results faster.
+Unlike the previous PaddlePaddle v2 version, in the new Fluid version, we don't have to manually calculate the word vector. PaddlePaddle provides a built-in method `fluid.layers.embedding`, which we can use directly to construct an N-gram neural network.
-- We define our N-gram neural network structure as below. This structure will be used both in `train` and in `infer`. We can specify `is_sparse = True` to accelerate sparse matrix update for word embedding.
+- Let's define our N-gram neural network structure. This structure is used in both training and predicting. Because the word vector is sparse, we pass the parameter `is_sparse == True` to speed up the update of the sparse matrix.
```python
-def inference_program(is_sparse):
- first_word = fluid.layers.data(name='firstw', shape=[1], dtype='int64')
- second_word = fluid.layers.data(name='secondw', shape=[1], dtype='int64')
- third_word = fluid.layers.data(name='thirdw', shape=[1], dtype='int64')
- fourth_word = fluid.layers.data(name='fourthw', shape=[1], dtype='int64')
+def inference_program(words, is_sparse):
embed_first = fluid.layers.embedding(
- input=first_word,
+ input=words[0],
size=[dict_size, EMBED_SIZE],
dtype='float32',
is_sparse=is_sparse,
param_attr='shared_w')
embed_second = fluid.layers.embedding(
- input=second_word,
+ input=words[1],
size=[dict_size, EMBED_SIZE],
dtype='float32',
is_sparse=is_sparse,
param_attr='shared_w')
embed_third = fluid.layers.embedding(
- input=third_word,
+ input=words[2],
size=[dict_size, EMBED_SIZE],
dtype='float32',
is_sparse=is_sparse,
param_attr='shared_w')
embed_fourth = fluid.layers.embedding(
- input=fourth_word,
+ input=words[3],
size=[dict_size, EMBED_SIZE],
dtype='float32',
is_sparse=is_sparse,
@@ -337,79 +310,116 @@ def inference_program(is_sparse):
return predict_word
```
-- As we already defined the N-gram neural network structure in the above, we can use it in our `train` method.
+- Based on the neural network structure above, we can define our training method as follows:
```python
-def train_program(is_sparse):
- # The declaration of 'next_word' must be after the invoking of inference_program,
- # or the data input order of train program would be [next_word, firstw, secondw,
- # thirdw, fourthw], which is not correct.
- predict_word = inference_program(is_sparse)
+def train_program(predict_word):
+ # The definition of'next_word' must be after the declaration of inference_program.
+ # Otherwise the sequence of the train program input data becomes [next_word, firstw, secondw,
+ #thirdw, fourthw], This is not true.
next_word = fluid.layers.data(name='nextw', shape=[1], dtype='int64')
cost = fluid.layers.cross_entropy(input=predict_word, label=next_word)
avg_cost = fluid.layers.mean(cost)
return avg_cost
-```
-
-- Now we will begin the training process. It is relatively simple compared to the previous version. `paddle.dataset.imikolov.train()` and `paddle.dataset.imikolov.test()` are our training and test set. Both of the functions will return a **reader**: In PaddlePaddle, reader is a python function which returns a Python iterator which output a single data instance at a time.
-
-`paddle.batch` takes reader as input, outputs a **batched reader**: In PaddlePaddle, a reader outputs a single data instance at a time but batched reader outputs a minibatch of data instances.
-`event_handler` can be passed into `trainer.train` so that we can do some tasks after each step or epoch. These tasks include recording current metrics or terminate current training process.
-
-```python
def optimizer_func():
return fluid.optimizer.AdagradOptimizer(
learning_rate=3e-3,
regularization=fluid.regularizer.L2DecayRegularizer(8e-4))
+```
+
+- Now we can start training. This version is much simpler than before. We have ready-made training and test sets: `paddle.dataset.imikolov.train()` and `paddle.dataset.imikolov.test()`. Both will return a reader. In PaddlePaddle, the reader is a Python function that reads the next piece of data when called each time . It is a Python generator.
+
+`paddle.batch` will read in a reader and output a batched reader. We can also output the training of each step and batch during the training process.
+
+```python
+def train(if_use_cuda, params_dirname, is_sparse=True):
+ place = fluid.CUDAPlace(0) if if_use_cuda else fluid.CPUPlace()
-def train(use_cuda, train_program, params_dirname):
train_reader = paddle.batch(
paddle.dataset.imikolov.train(word_dict, N), BATCH_SIZE)
test_reader = paddle.batch(
paddle.dataset.imikolov.test(word_dict, N), BATCH_SIZE)
- place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+ first_word = fluid.layers.data(name='firstw', shape=[1], dtype='int64')
+ second_word = fluid.layers.data(name='secondw', shape=[1], dtype='int64')
+ third_word = fluid.layers.data(name='thirdw', shape=[1], dtype='int64')
+ forth_word = fluid.layers.data(name='fourthw', shape=[1], dtype='int64')
+ next_word = fluid.layers.data(name='nextw', shape=[1], dtype='int64')
- def event_handler(event):
- if isinstance(event, EndStepEvent):
- outs = trainer.test(
- reader=test_reader,
- feed_order=['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw'])
- avg_cost = outs[0]
-
- # We output cost every 10 steps.
- if event.step % 10 == 0:
- print("Step %d: Average Cost %f" % (event.step, avg_cost))
-
- # If average cost is lower than 5.8, we consider the model good enough to stop.
- # Note 5.8 is a relatively high value. In order to get a better model, one should
- # aim for avg_cost lower than 3.5. But the training could take longer time.
- if avg_cost < 5.8:
- trainer.save_params(params_dirname)
- trainer.stop()
-
- if math.isnan(avg_cost):
- sys.exit("got NaN loss, training failed.")
-
- trainer = Trainer(
- train_func=train_program,
- # Note here we need to chse more sophisticated optimizer
- # such as AdaGrad with a decay rate. The normal SGD converges
- # very slowly.
- # optimizer=fluid.optimizer.SGD(learning_rate=0.001),
- optimizer_func=optimizer_func,
- place=place)
-
- trainer.train(
- reader=train_reader,
- num_epochs=1,
- event_handler=event_handler,
- feed_order=['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw'])
+ word_list = [first_word, second_word, third_word, forth_word, next_word]
+ feed_order = ['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw']
+
+ main_program = fluid.default_main_program()
+ star_program = fluid.default_startup_program()
+
+ predict_word = inference_program(word_list, is_sparse)
+ avg_cost = train_program(predict_word)
+ test_program = main_program.clone(for_test=True)
+
+ sgd_optimizer = optimizer_func()
+ sgd_optimizer.minimize(avg_cost)
+
+ exe = fluid.Executor(place)
+
+ def train_test(program, reader):
+ count = 0
+ feed_var_list = [
+ program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder_test = fluid.DataFeeder(feed_list=feed_var_list, place=place)
+ test_exe = fluid.Executor(place)
+ accumulated = len([avg_cost]) * [0]
+ for test_data in reader():
+ avg_cost_np = test_exe.run(
+ program=program,
+ feed=feeder_test.feed(test_data),
+ fetch_list=[avg_cost])
+ accumulated = [
+ x[0] + x[1][0] for x in zip(accumulated, avg_cost_np)
+ ]
+ count += 1
+ return [x / count for x in accumulated]
+
+ def train_loop():
+ step = 0
+ feed_var_list_loop = [
+ main_program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder = fluid.DataFeeder(feed_list=feed_var_list_loop, place=place)
+ exe.run(star_program)
+ for pass_id in range(PASS_NUM):
+ for data in train_reader():
+ avg_cost_np = exe.run(
+ main_program, feed=feeder.feed(data), fetch_list=[avg_cost])
+
+ if step % 10 == 0:
+ outs = train_test(test_program, test_reader)
+
+ print("Step %d: Average Cost %f" % (step, outs[0]))
+
+ # The entire training process takes several hours if the average loss is less than 5.8,
+ # We think that the model has achieved good results and can stop training.
+ # Note 5.8 is a relatively high value, in order to get a better model, you can
+ # set the threshold here to be 3.5, but the training time will be longer.
+ if outs[0] < 5.8:
+ if params_dirname is not None:
+ fluid.io.save_inference_model(params_dirname, [
+ 'firstw', 'secondw', 'thirdw', 'fourthw'
+ ], [predict_word], exe)
+ return
+ step += 1
+ if math.isnan(float(avg_cost_np[0])):
+ sys.exit("got NaN loss, training failed.")
+
+ raise AssertionError("Cost is too large {0:2.2}".format(avg_cost_np[0]))
+
+ train_loop()
```
-`trainer.train` will start training, the output of `event_handler` will be similar to following:
+- `train_loop` will start training. The log of the training process during the period is as follows:
+
```text
Step 0: Average Cost 7.337213
Step 10: Average Cost 6.136128
@@ -417,67 +427,78 @@ Step 20: Average Cost 5.766995
...
```
-
+
## Model Application
+After the model is trained, we can use it to make some predictions.
-After the model is trained, we can load the saved model parameters and do some inference.
-
-### Predicting the next word
-
-We can use our trained model to predict the next word given its previous N-gram. For example
-
+### Predict the next word
+We can use our trained model to predict the next word after learning the previous N-gram.
```python
-def infer(use_cuda, inference_program, params_dirname=None):
+def infer(use_cuda, params_dirname=None):
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
- inferencer = Inferencer(
- infer_func=inference_program, param_path=params_dirname, place=place)
-
- # Setup inputs by creating 4 LoDTensors representing 4 words. Here each word
- # is simply an index to look up for the corresponding word vector and hence
- # the shape of word (base_shape) should be [1]. The length-based level of
- # detail (lod) info of each LoDtensor should be [[1]] meaning there is only
- # one lod_level and there is only one sequence of one word on this level.
- # Note that lod info should be a list of lists.
-
- data1 = [[211]] # 'among'
- data2 = [[6]] # 'a'
- data3 = [[96]] # 'group'
- data4 = [[4]] # 'of'
- lod = [[1]]
-
- first_word = fluid.create_lod_tensor(data1, lod, place)
- second_word = fluid.create_lod_tensor(data2, lod, place)
- third_word = fluid.create_lod_tensor(data3, lod, place)
- fourth_word = fluid.create_lod_tensor(data4, lod, place)
-
- result = inferencer.infer(
- {
- 'firstw': first_word,
- 'secondw': second_word,
- 'thirdw': third_word,
- 'fourthw': fourth_word
- },
- return_numpy=False)
-
- print(numpy.array(result[0]))
- most_possible_word_index = numpy.argmax(result[0])
- print(most_possible_word_index)
- print([
- key for key, value in six.iteritems(word_dict)
- if value == most_possible_word_index
- ][0])
+
+ exe = fluid.Executor(place)
+
+ inference_scope = fluid.core.Scope()
+ with fluid.scope_guard(inference_scope):
+ #Get the inference program using fluid.io.load_inference_model,
+ #feed variable name by feed_target_names and fetch fetch_targets from scope
+ [inferencer, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(params_dirname, exe)
+
+ # Set the input and use 4 LoDTensor to represent 4 words. Each word here is an id,
+ # Used to query the embedding table to get the corresponding word vector, so its shape size is [1].
+ # recursive_sequence_lengths sets the length based on LoD, so it should all be set to [[1]]
+ # Note that recursive_sequence_lengths is a list of lists
+ data1 = [[211]] # 'among'
+ data2 = [[6]] # 'a'
+ data3 = [[96]] # 'group'
+ data4 = [[4]] # 'of'
+ lod = [[1]]
+
+ first_word = fluid.create_lod_tensor(data1, lod, place)
+ second_word = fluid.create_lod_tensor(data2, lod, place)
+ third_word = fluid.create_lod_tensor(data3, lod, place)
+ fourth_word = fluid.create_lod_tensor(data4, lod, place)
+
+ assert feed_target_names[0] == 'firstw'
+ assert feed_target_names[1] == 'secondw'
+ assert feed_target_names[2] == 'thirdw'
+ assert feed_target_names[3] == 'fourthw'
+
+ # Construct the feed dictionary {feed_target_name: feed_target_data}
+ # Prediction results are included in results
+ results = exe.run(
+ inferencer,
+ feed={
+ feed_target_names[0]: first_word,
+ feed_target_names[1]: second_word,
+ feed_target_names[2]: third_word,
+ feed_target_names[3]: fourth_word
+ },
+ fetch_list=fetch_targets,
+ return_numpy=False)
+
+ print(numpy.array(results[0]))
+ most_possible_word_index = numpy.argmax(results[0])
+ print(most_possible_word_index)
+ print([
+ key for key, value in six.iteritems(word_dict)
+ if value == most_possible_word_index
+ ][0])
```
-When we spent 3 mins in training, the output is like below, which means the next word for `among a group of` is `a`. If we train the model with a longer time, it will give a meaningful prediction as `workers`.
+Since the word vector matrix itself is relatively sparse, the training process takes a long time to reach a certain precision. In order to see the effect simply, the tutorial only sets up with a few rounds of training and ends with the following result. Our model predicts that the next word for `among a group of` is `the`. This is in line with the law of grammar. If we train for longer time, such as several hours, then the next predicted word we will get is `workers`. The format of the predicted output is as follows:
```text
-[[0.00106646 0.0007907 0.00072041 ... 0.00049024 0.00041355 0.00084464]]
-6
-a
+[[0.03768077 0.03463154 0.00018074 ... 0.00022283 0.00029888 0.02967956]]
+0
+the
```
+The first line represents the probability distribution of the predicted word in the dictionary, the second line represents the id corresponding to the word with the highest probability, and the third line represents the word with the highest probability.
-The main entrance of the program is fairly simple:
+The entrance to the entire program is simple:
```python
def main(use_cuda, is_sparse):
@@ -487,35 +508,29 @@ def main(use_cuda, is_sparse):
params_dirname = "word2vec.inference.model"
train(
- use_cuda=use_cuda,
- train_program=partial(train_program, is_sparse),
- params_dirname=params_dirname)
+ if_use_cuda=use_cuda,
+ params_dirname=params_dirname,
+ is_sparse=is_sparse)
- infer(
- use_cuda=use_cuda,
- inference_program=partial(inference_program, is_sparse),
- params_dirname=params_dirname)
+ infer(use_cuda=use_cuda, params_dirname=params_dirname)
main(use_cuda=use_cuda, is_sparse=True)
```
## Conclusion
+In this chapter, we introduced word vectors, the relationship between language models and word vectors and how to obtain word vectors by training neural network models. In information retrieval, we can judge the correlation between query and document keywords based on the cosine value between vectors. In syntactic analysis and semantic analysis, trained word vectors can be used to initialize the model for better results. In the document classification, after the word vector, you can cluster to group synonyms in a document, or you can use N-gram to predict the next word. We hope that everyone can easily use the word vector to conduct research in related fields after reading this chapter.
-This chapter introduces word embeddings, the relationship between language model and word embedding, and how to train neural networks to learn word embedding.
-
-In grammar analysis and semantic analysis, a previously trained word embedding can initialize models for better performance. We hope that readers can use word embedding models in their work after reading this chapter.
-
-
+
## References
-1. Bengio Y, Ducharme R, Vincent P, et al. [A neural probabilistic language model](http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)[J]. journal of machine learning research, 2003, 3(Feb): 1137-1155.
-2. Mikolov T, Kombrink S, Deoras A, et al. [Rnnlm-recurrent neural network language modeling toolkit](http://www.fit.vutbr.cz/~imikolov/rnnlm/rnnlm-demo.pdf)[C]//Proc. of the 2011 ASRU Workshop. 2011: 196-201.
-3. Mikolov T, Chen K, Corrado G, et al. [Efficient estimation of word representations in vector space](https://arxiv.org/pdf/1301.3781.pdf)[J]. arXiv preprint arXiv:1301.3781, 2013.
-4. Maaten L, Hinton G. [Visualizing data using t-SNE](https://lvdmaaten.github.io/publications/papers/JMLR_2008.pdf)[J]. Journal of Machine Learning Research, 2008, 9(Nov): 2579-2605.
+1. Bengio Y, Ducharme R, Vincent P, et al. [A neural probabilistic language model](http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)[J]. journal of machine learning Research, 2003, 3(Feb): 1137-1155.
+2. Mikolov T, Kombrink S, Deoras A, et al. [Rnnlm-recurrent neural network language modeling toolkit](http://www.fit.vutbr.cz/~imikolov/rnnlm/rnnlm-demo.pdf)[C ]//Proc. of the 2011 ASRU Workshop. 2011: 196-201.
+3. Mikolov T, Chen K, Corrado G, et al. [Efficient estimation of word representations in vector space](https://arxiv.org/pdf/1301.3781.pdf)[J]. arXiv preprint arXiv:1301.3781, 2013 .
+4. Maaten L, Hinton G. [Visualizing data using t-SNE](https://lvdmaaten.github.io/publications/papers/JMLR_2008.pdf)[J]. Journal of Machine Learning Research, 2008, 9(Nov ): 2579-2605.
5. https://en.wikipedia.org/wiki/Singular_value_decomposition
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
-
-Figure 1. YouTube recommender system overview.
+
+Figure 1. YouTube personalized recommendation system structure
#### Candidate Generation Network
-YouTube models candidate generation as a multi-class classification problem with a huge number of classes equal to the number of videos. The architecture of the model is as follows:
+The candidate generation network models the recommendation problem as a multi-class classification problem with a large number of categories. For a Youtube user, using its watching history (video ID), search tokens, demographic information (such as geographic location, user login device), binary features (such as gender, whether to log in), and continuous features (such as user age), etc., multi-classify all videos in the video library to obtain the classification result of each category (ie, the recommendation probability of each video), eventually outputting hundreds of videos with high probability.
+
+First, the historical information such as watching history and search token records are mapped to vectors and averaged to obtain a fixed length representation. At the same time, demographic characteristics are input to optimize the recommendation effect of new users, and the binary features and continuous features are normalized to the range [0, 1]. Next, put all the feature representations into a vector and input them to the non-linear multilayer perceptron (MLP, see [Identification Figures](https://github.com/PaddlePaddle/book/blob/develop/02.recognize_digits/README.md) tutorial). Finally, during training, the output of the MLP is classified by softmax. When predicting, the similarity of the user's comprehensive features (MLP output) to all videos' features is calculated, and the highest score of $k$ is obtained as the result of the candidate generation network. Figure 2 shows the candidate generation network structure.
-
-Figure 2. Deep candidate generation model.
+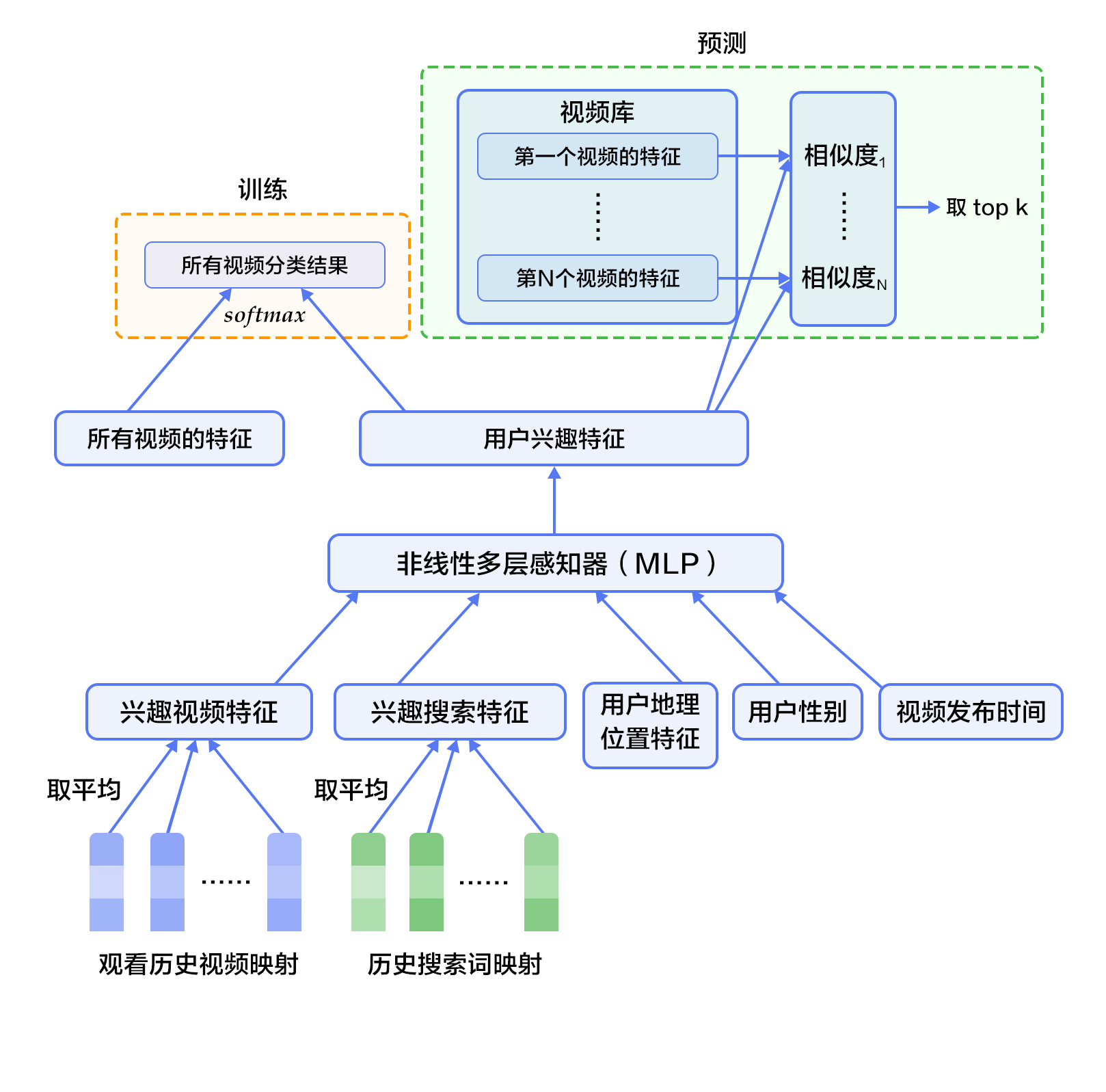
+Figure 2. Candidate generation network structure
-The first stage of this model maps watching history and search queries into fixed-length representative features. Then, an MLP (multi-layer Perceptron, as described in the [Recognize Digits](https://github.com/PaddlePaddle/book/blob/develop/recognize_digits/README.md) tutorial) takes the concatenation of all representative vectors. The output of the MLP represents the user' *intrinsic interests*. At training time, it is used together with a softmax output layer for minimizing the classification error. At serving time, it is used to compute the relevance of the user with all movies.
-
-For a user $U$, the predicted watching probability of video $i$ is
+For a user $U$, the formula for predicting whether the video $\omega$ that the user wants to watch at the moment is video $i$ is:
$$P(\omega=i|u)=\frac{e^{v_{i}u}}{\sum_{j \in V}e^{v_{j}u}}$$
-where $u$ is the representative vector of user $U$, $V$ is the corpus of all videos, $v_i$ is the representative vector of the $i$-th video. $u$ and $v_i$ are vectors of the same length, so we can compute their dot product using a fully connected layer.
+Where $u$ is the feature representation of the user $U$, $V$ is the video library collection, and $v_i$ is the feature representation of the $i$ video in the video library. $u$ and $v_i$ are vectors of equal length, and the dot product can be implemented by a fully connected layer.
-This model could have a performance issue as the softmax output covers millions of classification labels. To optimize performance, at the training time, the authors down-sample negative samples, so the actual number of classes is reduced to thousands. At serving time, the authors ignore the normalization of the softmax outputs, because the results are just for ranking.
+Considering that the number of categories in the softmax classification is very large, in order to ensure a certain computational efficiency: 1) in the training phase, use negative sample category sampling to reduce the number of actually calculated categories to thousands; 2) in the recommendation (prediction) phase, ignore the normalized calculation of softmax (does not affect the result), and simplifies the category scoring problem into the nearest neighbor search problem in the dot product space, then takes the nearest $k$ video of $u$ as a candidate for generation.
#### Ranking Network
+The structure of the ranking network is similar to the candidate generation network, but its goal is to perform finer ranking of the candidates. Similar to the feature extraction method in traditional advertisement ranking, a large number of related features (such as video ID, last watching time, etc.) for video sorting are also constructed here. These features are treated similarly to the candidate generation network, except that at the top of the ranking network is a weighted logistic regression that scores all candidate videos and sorts them from high to low. Then, return to the user.
-The architecture of the ranking network is similar to that of the candidate generation network. Similar to ranking models widely used in online advertising, it uses rich features like video ID, last watching time, etc. The output layer of the ranking network is a weighted logistic regression, which rates all candidate videos.
-
-### Hybrid Model
-
-In the section, let us introduce our movie recommendation system. Especially, we feed moives titles into a text convolution network to get a fixed-length representative feature vector. Accordingly we will introduce the convolutional neural network for texts and the hybrid recommendation model respectively.
+### Fusion recommendation model
+This section uses Convolutional Neural Networks to learn the representation of movie titles. The convolutional neural network for text and the fusion recommendation model are introduced in turn.
-#### Convolutional Neural Networks for Texts (CNN)
+#### Convolutional Neural Network (CNN) for text
-**Convolutional Neural Networks** are frequently applied to data with grid-like topology such as two-dimensional images and one-dimensional texts. A CNN can extract multiple local features, combine them, and produce high-level abstractions, which correspond to semantic understanding. Empirically, CNN is shown to be efficient for image and text modeling.
-
-CNN mainly contains convolution and pooling operation, with versatile combinations in various applications. Here, we briefly describe a CNN as shown in Figure 3.
+Convolutional neural networks are often used to deal with data of a grid-like topology. For example, an image can be viewed as a pixel of a two-dimensional grid, and a natural language can be viewed as a one-dimensional sequence of words. Convolutional neural networks can extract a variety of local features and combine them to obtain more advanced feature representations. Experiments show that convolutional neural networks can efficiently model image and text problems.
+The convolutional neural network is mainly composed of convolution and pooling operations, and its application and combination methods are flexible and varied. In this section we will explain the network as shown in Figure 3:
-
-Figure 3. CNN for text modeling.
+
+Figure 3. Convolutional neural network text classification model
-Let $n$ be the length of the sentence to process, and the $i$-th word has embedding as $x_i\in\mathbb{R}^k$,where $k$ is the embedding dimensionality.
+Suppose the length of the sentence to be processed is $n$, where the word vector of the $i$ word is $x_i\in\mathbb{R}^k$, and $k$ is the dimension size.
-First, we concatenate the words by piecing together every $h$ words, each as a window of length $h$. This window is denoted as $x_{i:i+h-1}$, consisting of $x_{i},x_{i+1},\ldots,x_{i+h-1}$, where $x_i$ is the first word in the window and $i$ takes value ranging from $1$ to $n-h+1$: $x_{i:i+h-1}\in\mathbb{R}^{hk}$.
+First, splicing the word vector: splicing each $h$ word to form a word window of size $h$, denoted as $x_{i:i+h-1}$, which represents the word sequence splicing of $x_{i}, x_{i+1}, \ldots, x_{i+h-1}$, where $i$ represents the position of the first word in the word window throughout the sentence, ranging from $1$ to $n-h+1$, $x_{i:i+h-1}\in\mathbb{R}^{hk}$.
-Next, we apply the convolution operation: we apply the kernel $w\in\mathbb{R}^{hk}$ in each window, extracting features $c_i=f(w\cdot x_{i:i+h-1}+b)$, where $b\in\mathbb{R}$ is the bias and $f$ is a non-linear activation function such as $sigmoid$. Convolving by the kernel at every window ${x_{1:h},x_{2:h+1},\ldots,x_{n-h+1:n}}$ produces a feature map in the following form:
+Second, perform a convolution operation: apply the convolution kernel $w\in\mathbb{R}^{hk}$ to the window $x_{i:i+h-1}$ containing $h$ words. , get the feature $c_i=f(w\cdot x_{i:i+h-1}+b)$, where $b\in\mathbb{R}$ is the bias and $f$ is the non Linear activation function, such as $sigmoid$. Apply the convolution kernel to all word windows ${x_{1:h}, x_{2:h+1},\ldots,x_{n-h+1:n}}$ in the sentence, producing a feature map:
$$c=[c_1,c_2,\ldots,c_{n-h+1}], c \in \mathbb{R}^{n-h+1}$$
-Next, we apply *max pooling* over time to represent the whole sentence $\hat c$, which is the maximum element across the feature map:
+Next, using the max pooling over time for feature maps to obtain the feature $\hat c$, of the whole sentence corresponding to this convolution kernel, which is the maximum value of all elements in the feature map:
$$\hat c=max(c)$$
-#### Model Structure Of The Hybrid Model
+#### Fusion recommendation model overview
+
+In the film personalized recommendation system that incorporates the recommendation model:
+
+1. First, take user features and movie features as input to the neural network, where:
+
+ - The user features incorporate four attribute information: user ID, gender, occupation, and age.
-In our network, the input includes features of users and movies. The user feature includes four properties: user ID, gender, occupation, and age. Movie features include their IDs, genres, and titles.
+ - The movie feature incorporate three attribute information: movie ID, movie type ID, and movie name.
-We use fully-connected layers to map user features into representative feature vectors and concatenate them. The process of movie features is similar, except that for movie titles -- we feed titles into a text convolution network as described in the above section to get a fixed-length representative feature vector.
+2. For the user feature, map the user ID to a vector representation with a dimension size of 256, enter the fully connected layer, and do similar processing for the other three attributes. Then the feature representations of the four attributes are fully connected and added separately.
-Given the feature vectors of users and movies, we compute the relevance using cosine similarity. We minimize the squared error at training time.
+3. For movie features, the movie ID is processed in a manner similar to the user ID. The movie type ID is directly input into the fully connected layer in the form of a vector, and the movie name is represented by a fixed-length vector using a text convolutional neural network. The feature representations of the three attributes are then fully connected and added separately.
+
+4. After obtaining the vector representation of the user and the movie, calculate the cosine similarity of them as the score of the personalized recommendation system. Finally, the square of the difference between the similarity score and the user's true score is used as the loss function of the regression model.
-
-Figure 4. A hybrid recommendation model.
+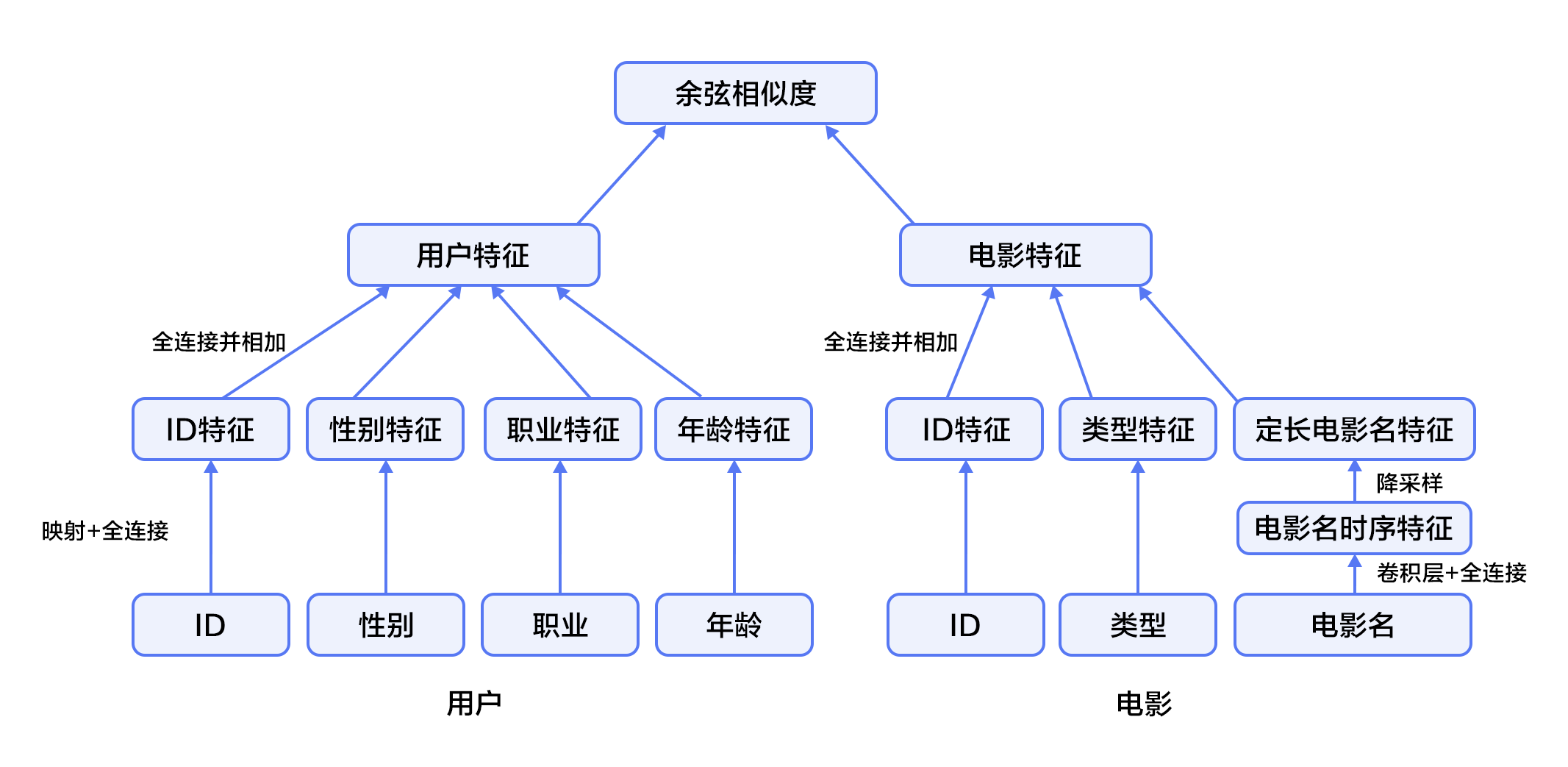
+Figure 4. Fusion recommendation model
-## Dataset
+## Data Preparation
+
+### Data Introduction and Download
-We use the [MovieLens ml-1m](http://files.grouplens.org/datasets/movielens/ml-1m.zip) to train our model. This dataset includes 10,000 ratings of 4,000 movies from 6,000 users to 4,000 movies. Each rate is in the range of 1~5. Thanks to GroupLens Research for collecting, processing and publishing the dataset.
+We take [MovieLens Million Dataset (ml-1m)](http://files.grouplens.org/datasets/movielens/ml-1m.zip) as an example. The ml-1m dataset contains 1,000,000 reviews of 4,000 movies by 6,000 users (scores ranging from 1 to 5, all integer), collected by the GroupLens Research lab.
-`paddle.datasets` package encapsulates multiple public datasets, including `cifar`, `imdb`, `mnist`, `movielens` and `wmt14`, etc. There's no need for us to manually download and preprocess `MovieLens` dataset.
+Paddle provides modules for automatically loading data in the API. The data module is `paddle.dataset.movielens`
-The raw `MoiveLens` contains movie ratings, relevant features from both movies and users.
-For instance, one movie's feature could be:
```python
import paddle
@@ -109,61 +125,77 @@ movie_info = paddle.dataset.movielens.movie_info()
print movie_info.values()[0]
```
-```text
-
+
+```python
+# Run this block to show dataset's documentation
+# help(paddle.dataset.movielens)
+```
+
+The original data includes feature data of the movie, user's feature data, and the user's rating of the movie.
+
+For example, one of the movie features is:
+
+
+```python
+movie_info = paddle.dataset.movielens.movie_info()
+print movie_info.values()[0]
```
-One user's feature could be:
+
+
+
+This means that the movie id is 1, and the title is 《Toy Story》, which is divided into three categories. These three categories are animation, children, and comedy.
+
```python
user_info = paddle.dataset.movielens.user_info()
print user_info.values()[0]
```
-```text
-
-```
+
-In this dateset, the distribution of age is shown as follows:
-```text
-1: "Under 18"
-18: "18-24"
-25: "25-34"
-35: "35-44"
-45: "45-49"
-50: "50-55"
-56: "56+"
-```
+This means that the user ID is 1, female, and younger than 18 years old. The occupation ID is 10.
-User's occupation is selected from the following options:
-
-```text
-0: "other" or not specified
-1: "academic/educator"
-2: "artist"
-3: "clerical/admin"
-4: "college/grad student"
-5: "customer service"
-6: "doctor/health care"
-7: "executive/managerial"
-8: "farmer"
-9: "homemaker"
-10: "K-12 student"
-11: "lawyer"
-12: "programmer"
-13: "retired"
-14: "sales/marketing"
-15: "scientist"
-16: "self-employed"
-17: "technician/engineer"
-18: "tradesman/craftsman"
-19: "unemployed"
-20: "writer"
-```
-Each record consists of three main components: user features, movie features and movie ratings.
-Likewise, as a simple example, consider the following:
+Among them, the age uses the following distribution
+
+* 1: "Under 18"
+* 18: "18-24"
+* 25: "25-34"
+* 35: "35-44"
+* 45: "45-49"
+* 50: "50-55"
+* 56: "56+"
+
+The occupation is selected from the following options:
+
+* 0: "other" or not specified
+* 1: "academic/educator"
+* 2: "artist"
+* 3: "clerical/admin"
+* 4: "college/grad student"
+* 5: "customer service"
+* 6: "doctor/health care"
+* 7: "executive/managerial"
+* 8: "farmer"
+* 9: "homemaker"
+* 10: "K-12 student"
+* 11: "lawyer"
+* 12: "programmer"
+* 13: "retired"
+* 14: "sales/marketing"
+* 15: "scientist"
+* 16: "self-employed"
+* 17: "technician/engineer"
+* 18: "tradesman/craftsman"
+* 19: "unemployed"
+* 20: "writer"
+
+For each training or test data, it is + + rating.
+
+For example, we get the first training data:
+
```python
train_set_creator = paddle.dataset.movielens.train()
@@ -173,17 +205,20 @@ mov_id = train_sample[len(user_info[uid].value())]
print "User %s rates Movie %s with Score %s"%(user_info[uid], movie_info[mov_id], train_sample[-1])
```
-```text
-User rates Movie with Score [5.0]
+```python
+User rates Movie with Score [5.0]
```
-The output shows that user 1 gave movie `1193` a rating of 5.
+That is, the user 1 evaluates the movie 1193 as 5 points.
+
+## Configuration Instruction
-After issuing a command `python train.py`, training will start immediately. The details will be unpacked by the following sessions to see how it works.
+Below we begin to configure the model based on the form of the input data. First import the required library functions and define global variables.
+
+- IS_SPARSE: whether to use sparse update in embedding
+- PASS_NUM: number of epoch
-## Model Configuration
-Our program starts with importing necessary packages and initializing some global variables:
```python
from __future__ import print_function
import math
@@ -193,26 +228,17 @@ import paddle
import paddle.fluid as fluid
import paddle.fluid.layers as layers
import paddle.fluid.nets as nets
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
IS_SPARSE = True
-USE_GPU = False
BATCH_SIZE = 256
+PASS_NUM = 20
```
-
-Then we define the model configuration for user combined features:
+Then define the model configuration for our user feature synthesis model
```python
def get_usr_combined_features():
+ """network definition for user part"""
USR_DICT_SIZE = paddle.dataset.movielens.max_user_id() + 1
@@ -269,14 +295,16 @@ def get_usr_combined_features():
return usr_combined_features
```
-As shown in the above code, the input is four dimension integers for each user, that is `user_id`,`gender_id`, `age_id` and `job_id`. In order to deal with these features conveniently, we use the language model in NLP to transform these discrete values into embedding vaules `usr_emb`, `usr_gender_emb`, `usr_age_emb` and `usr_job_emb`.
+As shown in the code above, for each user, we enter a 4-dimensional feature. This includes user_id, gender_id, age_id, job_id. These dimensional features are simple integer values. In order to facilitate the subsequent neural network processing of these features, we use the language model in NLP to transform these discrete integer values into embedding. And form them into usr_emb, usr_gender_emb, usr_age_emb, usr_job_emb, respectively.
-Then we can use user features as input, directly connecting to a fully-connected layer, which is used to reduce dimension to 200.
+Then, we enter all the user features into a fully connected layer(fc). Combine all features into one 200-dimension feature.
+
+Furthermore, we make a similar transformation for each movie feature, the network configuration is:
-Furthermore, we do a similar transformation for each movie feature. The model configuration is:
```python
def get_mov_combined_features():
+ """network definition for item(movie) part"""
MOV_DICT_SIZE = paddle.dataset.movielens.max_movie_id() + 1
@@ -325,13 +353,15 @@ def get_mov_combined_features():
return mov_combined_features
```
-Movie title, which is a sequence of words represented by an integer word index sequence, will be fed into a `sequence_conv_pool` layer, which will apply convolution and pooling on time dimension. Because pooling is done on time dimension, the output will be a fixed-length vector regardless the length of the input sequence.
+The title of a movie is a sequence of integers, and the integer represents the subscript of the word in the index sequence. This sequence is sent to the `sequence_conv_pool` layer, which uses convolution and pooling on the time dimension. Because of this, the output will be fixed length, although the length of the input sequence will vary.
-Finally, we can define a `inference_program` that uses cosine similarity to calculate the similarity between user characteristics and movie features.
+Finally, we define an `inference_program` to calculate the similarity between user features and movie features using cosine similarity.
```python
def inference_program():
+ """the combined network"""
+
usr_combined_features = get_usr_combined_features()
mov_combined_features = get_mov_combined_features()
@@ -341,11 +371,11 @@ def inference_program():
return scale_infer
```
-Then we define a `training_program` that uses the result from `inference_program` to compute the cost with label data.
-Also define `optimizer_func` to specify the optimizer.
+Furthermore, we define a `train_program` to use the result computed by `inference_program`, and calculate the error with the help of the tag data. We also define an `optimizer_func` to define the optimizer.
```python
def train_program():
+ """define the cost function"""
scale_infer = inference_program()
@@ -360,21 +390,19 @@ def optimizer_func():
return fluid.optimizer.SGD(learning_rate=0.2)
```
-## Model Training
-### Specify training environment
+## Training Model
-Specify your training environment, you should specify if the training is on CPU or GPU.
+### Defining the training environment
+Define your training environment and specify whether the training takes place on CPU or GPU.
```python
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
```
-### Datafeeder Configuration
-
-Next we define data feeders for test and train. The feeder reads a `buf_size` of data each time and feed them to the training/testing process.
-`paddle.dataset.movielens.train` will yield records during each pass, after shuffling, a batch input of `BATCH_SIZE` is generated for training.
+### Defining the data provider
+The next step is to define a data provider for training and testing. The provider reads in a data of size `BATCH_SIZE`. `paddle.dataset.movielens.train` will provide a data of size `BATCH_SIZE` after each scribbling, and the size of the out-of-order is the cache size `buf_size`.
```python
train_reader = paddle.batch(
@@ -386,87 +414,111 @@ test_reader = paddle.batch(
paddle.dataset.movielens.test(), batch_size=BATCH_SIZE)
```
-### Create Trainer
+### Constructing a training process (trainer)
+We have constructed a training process here, including training optimization functions.
+
+### Provide data
-Create a trainer that takes `train_program` as input and specify optimizer function.
+`feed_order` is used to define the mapping between each generated data and `paddle.layer.data`. For example, the data in the first column generated by `movielens.train` corresponds to the feature `user_id`.
```python
-trainer = Trainer(
- train_func=train_program, place=place, optimizer_func=optimizer_func)
+feed_order = [
+ 'user_id', 'gender_id', 'age_id', 'job_id', 'movie_id', 'category_id',
+ 'movie_title', 'score'
+]
```
-### Feeding Data
-
-`feed_order` is devoted to specifying the correspondence between each yield record and `paddle.layer.data`. For instance, the first column of data generated by `movielens.train` corresponds to `user_id` feature.
+### Building training programs and testing programs
+The training program and the test program are separately constructed, and the training optimizer is imported.
```python
-feed_order = [
- 'user_id', 'gender_id', 'age_id', 'job_id', 'movie_id', 'category_id',
- 'movie_title', 'score'
+main_program = fluid.default_main_program()
+star_program = fluid.default_startup_program()
+[avg_cost, scale_infer] = train_program()
+
+test_program = main_program.clone(for_test=True)
+sgd_optimizer = optimizer_func()
+sgd_optimizer.minimize(avg_cost)
+exe = fluid.Executor(place)
+
+def train_test(program, reader):
+ count = 0
+ feed_var_list = [
+ program.global_block().var(var_name) for var_name in feed_order
]
+ feeder_test = fluid.DataFeeder(
+ feed_list=feed_var_list, place=place)
+ test_exe = fluid.Executor(place)
+ accumulated = 0
+ for test_data in reader():
+ avg_cost_np = test_exe.run(program=program,
+ feed=feeder_test.feed(test_data),
+ fetch_list=[avg_cost])
+ accumulated += avg_cost_np[0]
+ count += 1
+ return accumulated / count
```
-### Event Handler
-
-Callback function `event_handler` will be called during training when a pre-defined event happens.
-For example, we can check the cost by `trainer.test` when `EndStepEvent` occurs
+### Build a training main loop and start training
+We perform the training cycle according to the training cycle number (`PASS_NUM`) defined above and some other parameters, and perform a test every time. When the test result is good enough, we exit the training and save the trained parameters.
```python
# Specify the directory path to save the parameters
params_dirname = "recommender_system.inference.model"
-def event_handler(event):
- if isinstance(event, EndStepEvent):
- test_reader = paddle.batch(
- paddle.dataset.movielens.test(), batch_size=BATCH_SIZE)
- avg_cost_set = trainer.test(
- reader=test_reader, feed_order=feed_order)
-
- # get avg cost
- avg_cost = np.array(avg_cost_set).mean()
-
- print("avg_cost: %s" % avg_cost)
-
- if float(avg_cost) < 4: # Change this number to adjust accuracy
- trainer.save_params(params_dirname)
- trainer.stop()
- else:
- print('BatchID {0}, Test Loss {1:0.2}'.format(event.epoch + 1,
- float(avg_cost)))
- if math.isnan(float(avg_cost)):
- sys.exit("got NaN loss, training failed.")
-```
-
-### Training
+from paddle.utils.plot import Ploter
+train_prompt = "Train cost"
+test_prompt = "Test cost"
-Finally, we invoke `trainer.train` to start training with `num_epochs` and other parameters.
+plot_cost = Ploter(train_prompt, test_prompt)
-```python
-trainer.train(
- num_epochs=1,
- event_handler=event_handler,
- reader=train_reader,
- feed_order=feed_order)
+def train_loop():
+ feed_list = [
+ main_program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder = fluid.DataFeeder(feed_list, place)
+ exe.run(star_program)
+
+ for pass_id in range(PASS_NUM):
+ for batch_id, data in enumerate(train_reader()):
+ # train a mini-batch
+ outs = exe.run(program=main_program,
+ feed=feeder.feed(data),
+ fetch_list=[avg_cost])
+ out = np.array(outs[0])
+
+ # get test avg_cost
+ test_avg_cost = train_test(test_program, test_reader)
+
+ plot_cost.append(train_prompt, batch_id, outs[0])
+ plot_cost.append(test_prompt, batch_id, test_avg_cost)
+ plot_cost.plot()
+
+ if batch_id == 20:
+ if params_dirname is not None:
+ fluid.io.save_inference_model(params_dirname, [
+ "user_id", "gender_id", "age_id", "job_id",
+ "movie_id", "category_id", "movie_title"
+ ], [scale_infer], exe)
+ return
+ print('EpochID {0}, BatchID {1}, Test Loss {2:0.2}'.format(
+ pass_id + 1, batch_id + 1, float(test_avg_cost)))
+
+ if math.isnan(float(out[0])):
+ sys.exit("got NaN loss, training failed.")
```
-
-## Inference
-
-### Create Inferencer
-
-Initialize Inferencer with `inference_program` and `params_dirname` which is where we save params from training.
-
+Start training
```python
-inferencer = Inferencer(
- inference_program, param_path=params_dirname, place=place)
+train_loop()
```
-### Generate input data for testing
+## Model Application
+
+### Generate test data
+Use the API of create_lod_tensor(data, lod, place) to generate the tensor of the detail level. `data` is a sequence, and each element is a sequence of index numbers. `lod` is the detail level's information, corresponding to `data`. For example, data = [[10, 2, 3], [2, 3]] means that it contains two sequences of lengths 3 and 2. Correspondingly lod = [[3, 2]], which indicates that it contains a layer of detail information, meaning that `data` has two sequences, lengths of 3 and 2.
-Use create_lod_tensor(data, lod, place) API to generate LoD Tensor, where `data` is a list of sequences of index numbers, `lod` is the level of detail (lod) info associated with `data`.
-For example, data = [[10, 2, 3], [2, 3]] means that it contains two sequences of indices, of length 3 and 2, respectively.
-Correspondingly, lod = [[3, 2]] contains one level of detail info, indicating that `data` consists of two sequences of length 3 and 2.
+In this prediction example, we try to predict the score given by user with ID1 for the movie 'Hunchback of Notre Dame'.
-In this infer example, we try to predict rating of movie 'Hunchback of Notre Dame' from the info of user id 1.
```python
infer_movie_id = 783
infer_movie_name = paddle.dataset.movielens.movie_info()[infer_movie_id].title
@@ -480,42 +532,59 @@ movie_title = fluid.create_lod_tensor([[1069, 4140, 2923, 710, 988]], [[5]],
place) # 'hunchback','of','notre','dame','the'
```
-### Infer
-
-Now we can infer with inputs that we provide in `feed_order` during training.
+### Building the prediction process and testing
+Similar to the training process, we need to build a prediction process, where `params_dirname` is the address used to store the various parameters in the training process.
```python
-results = inferencer.infer(
- {
- 'user_id': user_id,
- 'gender_id': gender_id,
- 'age_id': age_id,
- 'job_id': job_id,
- 'movie_id': movie_id,
- 'category_id': category_id,
- 'movie_title': movie_title
- },
- return_numpy=False)
-
-predict_rating = np.array(results[0])
-print("Predict Rating of user id 1 on movie \"" + infer_movie_name + "\" is " + str(predict_rating[0][0]))
-print("Actual Rating of user id 1 on movie \"" + infer_movie_name + "\" is 4.")
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+exe = fluid.Executor(place)
+
+inference_scope = fluid.core.Scope()
+```
+### Testing
+Now we can make predictions. The `feed_order` we provide should be consistent with the training process.
+
+
+```python
+with fluid.scope_guard(inference_scope):
+ [inferencer, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(params_dirname, exe)
+
+ results = exe.run(inferencer,
+ feed={
+ 'user_id': user_id,
+ 'gender_id': gender_id,
+ 'age_id': age_id,
+ 'job_id': job_id,
+ 'movie_id': movie_id,
+ 'category_id': category_id,
+ 'movie_title': movie_title
+ },
+ fetch_list=fetch_targets,
+ return_numpy=False)
+ predict_rating = np.array(results[0])
+ print("Predict Rating of user id 1 on movie \"" + infer_movie_name +
+ "\" is " + str(predict_rating[0][0]))
+ print("Actual Rating of user id 1 on movie \"" + infer_movie_name +
+ "\" is 4.")
```
-## Conclusion
+## Summary
-This tutorial goes over traditional approaches in recommender system and a deep learning based approach. We also show that how to train and use the model with PaddlePaddle. Deep learning has been well used in computer vision and NLP, we look forward to its new successes in recommender systems.
+This chapter introduced the traditional personalized recommendation system method and YouTube's deep neural network personalized recommendation system. It further took movie recommendation as an example, and used PaddlePaddle to train a personalized recommendation neural network model. The personalized recommendation system covers almost all aspects of e-commerce systems, social networks, advertising recommendations, search engines, etc. Deep learning technologies have played an important role in image processing, natural language processing, etc., and will also prevail in personalized recommendation systems.
+
## References
-1. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
-2. Robin Burke , [Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
-3. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
-4. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th International Conference on World Wide Web*. ACM, 2001.
-5. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: Combining Social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
-6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf) *arXiv preprint arXiv:1611.05480* (2016).
-7. Covington P, Adams J, Sargin E. [Deep neural networks for youtube recommendations](https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf)[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 191-198.
+1. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
+2. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th international conference on World Wide Web*. ACM, 2001.
+3. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: combining social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
+4. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
+5. Robin Burke , [Hybrid Web recommendation systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
+6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf) *arXiv preprint arXiv:1611.05480* (2016).
+7. Covington P, Adams J, Sargin E. [Deep neural networks for youtube recommendations](https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf)[C]//Proceedings of the 10th ACM Conference on recommendation systems. ACM, 2016: 191-198.
+
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/05.recommender_system/index.html b/05.recommender_system/index.html
index 8601885..20665be 100644
--- a/05.recommender_system/index.html
+++ b/05.recommender_system/index.html
@@ -40,110 +40,126 @@
-# Personalized Recommendation
+# Recommender System
-The source code from this tutorial is at [here](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system). For instructions on getting started with this book,see [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book).
+The source code of this tutorial is in [book/recommender_system](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system). For new users, please refer to [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book) .
+## Background Introduction
-## Background
+With the continuous development of network technology and the ever-expanding scale of e-commerce, the number and variety of goods grow rapidly and users need to spend a lot of time to find the goods they want to buy. This is information overload. In order to solve this problem, recommendation system came into being.
-The recommender system is a component of e-commerce, online videos, and online reading services. There are several different approaches for recommender systems to learn from user behavior and product properties and to understand users' interests.
+The recommendation system is a subset of the Information Filtering System, which can be used in a range of areas such as movies, music, e-commerce, and Feed stream recommendations. The recommendation system discovers the user's personalized needs and interests by analyzing and mining user behaviors, and recommends information or products that may be of interest to the user. Unlike search engines, recommendation system do not require users to accurately describe their needs, but model their historical behavior to proactively provide information that meets user interests and needs.
-- User behavior-based approach. A well-known method of this approach is collaborative filtering, which assumes that if two users made similar purchases, they share common interests and would likely go on making the same decision. Some variants of collaborative filtering are user-based[[3](#references)], item-based [[4](#references)], social network based[[5](#references)], and model-based.
+The GroupLens system \[[1](#references)\] introduced by the University of Minnesota in 1994 is generally considered to be a relatively independent research direction for the recommendation system. The system first proposed the idea of completing recommendation task based on collaborative filtering. After that, the collaborative filtering recommendation based on the model led the development of recommendation system for more than ten years.
-- Content-based approach[[1](#references)]. This approach represents product properties and user interests as feature vectors of the same space so that it could measure how much a user is interested in a product by the distance between two feature vectors.
+The traditional personalized recommendation system methods mainly include:
-- Hybrid approach[[2](#references)]: This one combines above two to help with each other about the data sparsity problem[[6](#references)].
+- Collaborative Filtering Recommendation: This method is one of the most widely used technologies which requires the collection and analysis of users' historical behaviors, activities and preferences. It can usually be divided into two sub-categories: User-Based Recommendation \[[1](#references)\] and Item-Based Recommendation \[[2](#references)\]. A key advantage of this method is that it does not rely on the machine to analyze the content characteristics of the item, so it does not need to understand the item itself to accurately recommend complex items such as movies. However, the disadvantage is that there is a cold start problem for new users without any behavior. At the same time, there is also a sparsity problem caused by insufficient interaction data between users and commodities. It is worth mentioning that social network \[[3](#references)\] or geographic location and other context information can be integrated into collaborative filtering.
+- Content-Based Filtering Recommendation \[[4](#references)\] : This method uses the content description of the product to abstract meaningful features by calculating the similarity between the user's interest and the product description to make recommendations to users. The advantage is that it is simple and straightforward. It does not need to evaluate products based on the comments of users. Instead, it compares the product similarity by product attributes to recommend similar products to the users of interest. The disadvantage is that there is also a cold start problem for new users without any behavior.
+- Hybrid Recommendation \[[5](#references)\]: Use different inputs and techniques to jointly recommend items to complement each single recommendation technique.
-This tutorial explains a deep learning based hybrid approach and its implement in PaddlePaddle. We are going to train a model using a dataset that includes user information, movie information, and ratings. Once we train the model, we will be able to get a predicted rating given a pair of user and movie IDs.
+In recent years, deep learning has achieved great success in many fields. Both academia and industry are trying to apply deep learning to the field of recommendation systems. Deep learning has excellent ability to automatically extract features, can learn multi-level abstract feature representations, and learn heterogeneous or cross-domain content information, which can deal with the cold start problem \[[6](#references)\] of recommendation system to some extent. This tutorial focuses on the deep learning model of recommendation system and how to implement the model with PaddlePaddle.
+## Result Demo
-## Model Overview
+We use a dataset containing user information, movie information, and movie ratings as a recommendation system. When we train the model, we only need to input the corresponding user ID and movie ID, we can get a matching score (range [0, 5], the higher the score is regarded as the greater interest), and then according to the recommendation of all movies sort the scores and recommend them to movies that may be of interest to the user.
-To know more about deep learning based recommendation, let us start from going over the Youtube recommender system[[7](#references)] before introducing our hybrid model.
+```
+Input movie_id: 1962
+Input user_id: 1
+Prediction Score is 4.25
+```
+
+## Model Overview
+In this chapter, we first introduce YouTube's video personalization recommendation system \[[7](#references)\], and then introduce the fusion recommendation model we implemented.
-### YouTube's Deep Learning Recommendation Model
+### YouTube's Deep Neural Network Personalized Recommendation System
-YouTube is a video-sharing Web site with one of the largest user base in the world. Its recommender system serves more than a billion users. This system is composed of two major parts: candidate generation and ranking. The former selects few hundreds of candidates from millions of videos, and the latter ranks and outputs the top 10.
+YouTube is the world's largest video uploading, sharing and discovery site, and the YouTube Personalized Recommendation System recommends personalized content from a growing library to more than 1 billion users. The entire system consists of two neural networks: a candidate generation network and a ranking network. The candidate generation network generates hundreds of candidates from a million-level video library, and the ranking network sorts the candidates and outputs the highest ranked tens of results. The system structure is shown in Figure 1:
-
-Figure 1. YouTube recommender system overview.
+
+Figure 1. YouTube personalized recommendation system structure
#### Candidate Generation Network
-YouTube models candidate generation as a multi-class classification problem with a huge number of classes equal to the number of videos. The architecture of the model is as follows:
+The candidate generation network models the recommendation problem as a multi-class classification problem with a large number of categories. For a Youtube user, using its watching history (video ID), search tokens, demographic information (such as geographic location, user login device), binary features (such as gender, whether to log in), and continuous features (such as user age), etc., multi-classify all videos in the video library to obtain the classification result of each category (ie, the recommendation probability of each video), eventually outputting hundreds of videos with high probability.
+
+First, the historical information such as watching history and search token records are mapped to vectors and averaged to obtain a fixed length representation. At the same time, demographic characteristics are input to optimize the recommendation effect of new users, and the binary features and continuous features are normalized to the range [0, 1]. Next, put all the feature representations into a vector and input them to the non-linear multilayer perceptron (MLP, see [Identification Figures](https://github.com/PaddlePaddle/book/blob/develop/02.recognize_digits/README.md) tutorial). Finally, during training, the output of the MLP is classified by softmax. When predicting, the similarity of the user's comprehensive features (MLP output) to all videos' features is calculated, and the highest score of $k$ is obtained as the result of the candidate generation network. Figure 2 shows the candidate generation network structure.
-
-Figure 2. Deep candidate generation model.
+
+Figure 2. Candidate generation network structure
-The first stage of this model maps watching history and search queries into fixed-length representative features. Then, an MLP (multi-layer Perceptron, as described in the [Recognize Digits](https://github.com/PaddlePaddle/book/blob/develop/recognize_digits/README.md) tutorial) takes the concatenation of all representative vectors. The output of the MLP represents the user' *intrinsic interests*. At training time, it is used together with a softmax output layer for minimizing the classification error. At serving time, it is used to compute the relevance of the user with all movies.
-
-For a user $U$, the predicted watching probability of video $i$ is
+For a user $U$, the formula for predicting whether the video $\omega$ that the user wants to watch at the moment is video $i$ is:
$$P(\omega=i|u)=\frac{e^{v_{i}u}}{\sum_{j \in V}e^{v_{j}u}}$$
-where $u$ is the representative vector of user $U$, $V$ is the corpus of all videos, $v_i$ is the representative vector of the $i$-th video. $u$ and $v_i$ are vectors of the same length, so we can compute their dot product using a fully connected layer.
+Where $u$ is the feature representation of the user $U$, $V$ is the video library collection, and $v_i$ is the feature representation of the $i$ video in the video library. $u$ and $v_i$ are vectors of equal length, and the dot product can be implemented by a fully connected layer.
-This model could have a performance issue as the softmax output covers millions of classification labels. To optimize performance, at the training time, the authors down-sample negative samples, so the actual number of classes is reduced to thousands. At serving time, the authors ignore the normalization of the softmax outputs, because the results are just for ranking.
+Considering that the number of categories in the softmax classification is very large, in order to ensure a certain computational efficiency: 1) in the training phase, use negative sample category sampling to reduce the number of actually calculated categories to thousands; 2) in the recommendation (prediction) phase, ignore the normalized calculation of softmax (does not affect the result), and simplifies the category scoring problem into the nearest neighbor search problem in the dot product space, then takes the nearest $k$ video of $u$ as a candidate for generation.
#### Ranking Network
+The structure of the ranking network is similar to the candidate generation network, but its goal is to perform finer ranking of the candidates. Similar to the feature extraction method in traditional advertisement ranking, a large number of related features (such as video ID, last watching time, etc.) for video sorting are also constructed here. These features are treated similarly to the candidate generation network, except that at the top of the ranking network is a weighted logistic regression that scores all candidate videos and sorts them from high to low. Then, return to the user.
-The architecture of the ranking network is similar to that of the candidate generation network. Similar to ranking models widely used in online advertising, it uses rich features like video ID, last watching time, etc. The output layer of the ranking network is a weighted logistic regression, which rates all candidate videos.
-
-### Hybrid Model
-
-In the section, let us introduce our movie recommendation system. Especially, we feed moives titles into a text convolution network to get a fixed-length representative feature vector. Accordingly we will introduce the convolutional neural network for texts and the hybrid recommendation model respectively.
+### Fusion recommendation model
+This section uses Convolutional Neural Networks to learn the representation of movie titles. The convolutional neural network for text and the fusion recommendation model are introduced in turn.
-#### Convolutional Neural Networks for Texts (CNN)
+#### Convolutional Neural Network (CNN) for text
-**Convolutional Neural Networks** are frequently applied to data with grid-like topology such as two-dimensional images and one-dimensional texts. A CNN can extract multiple local features, combine them, and produce high-level abstractions, which correspond to semantic understanding. Empirically, CNN is shown to be efficient for image and text modeling.
-
-CNN mainly contains convolution and pooling operation, with versatile combinations in various applications. Here, we briefly describe a CNN as shown in Figure 3.
+Convolutional neural networks are often used to deal with data of a grid-like topology. For example, an image can be viewed as a pixel of a two-dimensional grid, and a natural language can be viewed as a one-dimensional sequence of words. Convolutional neural networks can extract a variety of local features and combine them to obtain more advanced feature representations. Experiments show that convolutional neural networks can efficiently model image and text problems.
+The convolutional neural network is mainly composed of convolution and pooling operations, and its application and combination methods are flexible and varied. In this section we will explain the network as shown in Figure 3:
-
-Figure 3. CNN for text modeling.
+
+Figure 3. Convolutional neural network text classification model
-Let $n$ be the length of the sentence to process, and the $i$-th word has embedding as $x_i\in\mathbb{R}^k$,where $k$ is the embedding dimensionality.
+Suppose the length of the sentence to be processed is $n$, where the word vector of the $i$ word is $x_i\in\mathbb{R}^k$, and $k$ is the dimension size.
-First, we concatenate the words by piecing together every $h$ words, each as a window of length $h$. This window is denoted as $x_{i:i+h-1}$, consisting of $x_{i},x_{i+1},\ldots,x_{i+h-1}$, where $x_i$ is the first word in the window and $i$ takes value ranging from $1$ to $n-h+1$: $x_{i:i+h-1}\in\mathbb{R}^{hk}$.
+First, splicing the word vector: splicing each $h$ word to form a word window of size $h$, denoted as $x_{i:i+h-1}$, which represents the word sequence splicing of $x_{i}, x_{i+1}, \ldots, x_{i+h-1}$, where $i$ represents the position of the first word in the word window throughout the sentence, ranging from $1$ to $n-h+1$, $x_{i:i+h-1}\in\mathbb{R}^{hk}$.
-Next, we apply the convolution operation: we apply the kernel $w\in\mathbb{R}^{hk}$ in each window, extracting features $c_i=f(w\cdot x_{i:i+h-1}+b)$, where $b\in\mathbb{R}$ is the bias and $f$ is a non-linear activation function such as $sigmoid$. Convolving by the kernel at every window ${x_{1:h},x_{2:h+1},\ldots,x_{n-h+1:n}}$ produces a feature map in the following form:
+Second, perform a convolution operation: apply the convolution kernel $w\in\mathbb{R}^{hk}$ to the window $x_{i:i+h-1}$ containing $h$ words. , get the feature $c_i=f(w\cdot x_{i:i+h-1}+b)$, where $b\in\mathbb{R}$ is the bias and $f$ is the non Linear activation function, such as $sigmoid$. Apply the convolution kernel to all word windows ${x_{1:h}, x_{2:h+1},\ldots,x_{n-h+1:n}}$ in the sentence, producing a feature map:
$$c=[c_1,c_2,\ldots,c_{n-h+1}], c \in \mathbb{R}^{n-h+1}$$
-Next, we apply *max pooling* over time to represent the whole sentence $\hat c$, which is the maximum element across the feature map:
+Next, using the max pooling over time for feature maps to obtain the feature $\hat c$, of the whole sentence corresponding to this convolution kernel, which is the maximum value of all elements in the feature map:
$$\hat c=max(c)$$
-#### Model Structure Of The Hybrid Model
+#### Fusion recommendation model overview
+
+In the film personalized recommendation system that incorporates the recommendation model:
+
+1. First, take user features and movie features as input to the neural network, where:
+
+ - The user features incorporate four attribute information: user ID, gender, occupation, and age.
-In our network, the input includes features of users and movies. The user feature includes four properties: user ID, gender, occupation, and age. Movie features include their IDs, genres, and titles.
+ - The movie feature incorporate three attribute information: movie ID, movie type ID, and movie name.
-We use fully-connected layers to map user features into representative feature vectors and concatenate them. The process of movie features is similar, except that for movie titles -- we feed titles into a text convolution network as described in the above section to get a fixed-length representative feature vector.
+2. For the user feature, map the user ID to a vector representation with a dimension size of 256, enter the fully connected layer, and do similar processing for the other three attributes. Then the feature representations of the four attributes are fully connected and added separately.
-Given the feature vectors of users and movies, we compute the relevance using cosine similarity. We minimize the squared error at training time.
+3. For movie features, the movie ID is processed in a manner similar to the user ID. The movie type ID is directly input into the fully connected layer in the form of a vector, and the movie name is represented by a fixed-length vector using a text convolutional neural network. The feature representations of the three attributes are then fully connected and added separately.
+
+4. After obtaining the vector representation of the user and the movie, calculate the cosine similarity of them as the score of the personalized recommendation system. Finally, the square of the difference between the similarity score and the user's true score is used as the loss function of the regression model.
-
-Figure 4. A hybrid recommendation model.
+
+Figure 4. Fusion recommendation model
-## Dataset
+## Data Preparation
+
+### Data Introduction and Download
-We use the [MovieLens ml-1m](http://files.grouplens.org/datasets/movielens/ml-1m.zip) to train our model. This dataset includes 10,000 ratings of 4,000 movies from 6,000 users to 4,000 movies. Each rate is in the range of 1~5. Thanks to GroupLens Research for collecting, processing and publishing the dataset.
+We take [MovieLens Million Dataset (ml-1m)](http://files.grouplens.org/datasets/movielens/ml-1m.zip) as an example. The ml-1m dataset contains 1,000,000 reviews of 4,000 movies by 6,000 users (scores ranging from 1 to 5, all integer), collected by the GroupLens Research lab.
-`paddle.datasets` package encapsulates multiple public datasets, including `cifar`, `imdb`, `mnist`, `movielens` and `wmt14`, etc. There's no need for us to manually download and preprocess `MovieLens` dataset.
+Paddle provides modules for automatically loading data in the API. The data module is `paddle.dataset.movielens`
-The raw `MoiveLens` contains movie ratings, relevant features from both movies and users.
-For instance, one movie's feature could be:
```python
import paddle
@@ -151,61 +167,77 @@ movie_info = paddle.dataset.movielens.movie_info()
print movie_info.values()[0]
```
-```text
-
+
+```python
+# Run this block to show dataset's documentation
+# help(paddle.dataset.movielens)
+```
+
+The original data includes feature data of the movie, user's feature data, and the user's rating of the movie.
+
+For example, one of the movie features is:
+
+
+```python
+movie_info = paddle.dataset.movielens.movie_info()
+print movie_info.values()[0]
```
-One user's feature could be:
+
+
+
+This means that the movie id is 1, and the title is 《Toy Story》, which is divided into three categories. These three categories are animation, children, and comedy.
+
```python
user_info = paddle.dataset.movielens.user_info()
print user_info.values()[0]
```
-```text
-
-```
+
-In this dateset, the distribution of age is shown as follows:
-```text
-1: "Under 18"
-18: "18-24"
-25: "25-34"
-35: "35-44"
-45: "45-49"
-50: "50-55"
-56: "56+"
-```
+This means that the user ID is 1, female, and younger than 18 years old. The occupation ID is 10.
-User's occupation is selected from the following options:
-
-```text
-0: "other" or not specified
-1: "academic/educator"
-2: "artist"
-3: "clerical/admin"
-4: "college/grad student"
-5: "customer service"
-6: "doctor/health care"
-7: "executive/managerial"
-8: "farmer"
-9: "homemaker"
-10: "K-12 student"
-11: "lawyer"
-12: "programmer"
-13: "retired"
-14: "sales/marketing"
-15: "scientist"
-16: "self-employed"
-17: "technician/engineer"
-18: "tradesman/craftsman"
-19: "unemployed"
-20: "writer"
-```
-Each record consists of three main components: user features, movie features and movie ratings.
-Likewise, as a simple example, consider the following:
+Among them, the age uses the following distribution
+
+* 1: "Under 18"
+* 18: "18-24"
+* 25: "25-34"
+* 35: "35-44"
+* 45: "45-49"
+* 50: "50-55"
+* 56: "56+"
+
+The occupation is selected from the following options:
+
+* 0: "other" or not specified
+* 1: "academic/educator"
+* 2: "artist"
+* 3: "clerical/admin"
+* 4: "college/grad student"
+* 5: "customer service"
+* 6: "doctor/health care"
+* 7: "executive/managerial"
+* 8: "farmer"
+* 9: "homemaker"
+* 10: "K-12 student"
+* 11: "lawyer"
+* 12: "programmer"
+* 13: "retired"
+* 14: "sales/marketing"
+* 15: "scientist"
+* 16: "self-employed"
+* 17: "technician/engineer"
+* 18: "tradesman/craftsman"
+* 19: "unemployed"
+* 20: "writer"
+
+For each training or test data, it is + + rating.
+
+For example, we get the first training data:
+
```python
train_set_creator = paddle.dataset.movielens.train()
@@ -215,17 +247,20 @@ mov_id = train_sample[len(user_info[uid].value())]
print "User %s rates Movie %s with Score %s"%(user_info[uid], movie_info[mov_id], train_sample[-1])
```
-```text
-User rates Movie with Score [5.0]
+```python
+User rates Movie with Score [5.0]
```
-The output shows that user 1 gave movie `1193` a rating of 5.
+That is, the user 1 evaluates the movie 1193 as 5 points.
+
+## Configuration Instruction
-After issuing a command `python train.py`, training will start immediately. The details will be unpacked by the following sessions to see how it works.
+Below we begin to configure the model based on the form of the input data. First import the required library functions and define global variables.
+
+- IS_SPARSE: whether to use sparse update in embedding
+- PASS_NUM: number of epoch
-## Model Configuration
-Our program starts with importing necessary packages and initializing some global variables:
```python
from __future__ import print_function
import math
@@ -235,26 +270,17 @@ import paddle
import paddle.fluid as fluid
import paddle.fluid.layers as layers
import paddle.fluid.nets as nets
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
IS_SPARSE = True
-USE_GPU = False
BATCH_SIZE = 256
+PASS_NUM = 20
```
-
-Then we define the model configuration for user combined features:
+Then define the model configuration for our user feature synthesis model
```python
def get_usr_combined_features():
+ """network definition for user part"""
USR_DICT_SIZE = paddle.dataset.movielens.max_user_id() + 1
@@ -311,14 +337,16 @@ def get_usr_combined_features():
return usr_combined_features
```
-As shown in the above code, the input is four dimension integers for each user, that is `user_id`,`gender_id`, `age_id` and `job_id`. In order to deal with these features conveniently, we use the language model in NLP to transform these discrete values into embedding vaules `usr_emb`, `usr_gender_emb`, `usr_age_emb` and `usr_job_emb`.
+As shown in the code above, for each user, we enter a 4-dimensional feature. This includes user_id, gender_id, age_id, job_id. These dimensional features are simple integer values. In order to facilitate the subsequent neural network processing of these features, we use the language model in NLP to transform these discrete integer values into embedding. And form them into usr_emb, usr_gender_emb, usr_age_emb, usr_job_emb, respectively.
-Then we can use user features as input, directly connecting to a fully-connected layer, which is used to reduce dimension to 200.
+Then, we enter all the user features into a fully connected layer(fc). Combine all features into one 200-dimension feature.
+
+Furthermore, we make a similar transformation for each movie feature, the network configuration is:
-Furthermore, we do a similar transformation for each movie feature. The model configuration is:
```python
def get_mov_combined_features():
+ """network definition for item(movie) part"""
MOV_DICT_SIZE = paddle.dataset.movielens.max_movie_id() + 1
@@ -367,13 +395,15 @@ def get_mov_combined_features():
return mov_combined_features
```
-Movie title, which is a sequence of words represented by an integer word index sequence, will be fed into a `sequence_conv_pool` layer, which will apply convolution and pooling on time dimension. Because pooling is done on time dimension, the output will be a fixed-length vector regardless the length of the input sequence.
+The title of a movie is a sequence of integers, and the integer represents the subscript of the word in the index sequence. This sequence is sent to the `sequence_conv_pool` layer, which uses convolution and pooling on the time dimension. Because of this, the output will be fixed length, although the length of the input sequence will vary.
-Finally, we can define a `inference_program` that uses cosine similarity to calculate the similarity between user characteristics and movie features.
+Finally, we define an `inference_program` to calculate the similarity between user features and movie features using cosine similarity.
```python
def inference_program():
+ """the combined network"""
+
usr_combined_features = get_usr_combined_features()
mov_combined_features = get_mov_combined_features()
@@ -383,11 +413,11 @@ def inference_program():
return scale_infer
```
-Then we define a `training_program` that uses the result from `inference_program` to compute the cost with label data.
-Also define `optimizer_func` to specify the optimizer.
+Furthermore, we define a `train_program` to use the result computed by `inference_program`, and calculate the error with the help of the tag data. We also define an `optimizer_func` to define the optimizer.
```python
def train_program():
+ """define the cost function"""
scale_infer = inference_program()
@@ -402,21 +432,19 @@ def optimizer_func():
return fluid.optimizer.SGD(learning_rate=0.2)
```
-## Model Training
-### Specify training environment
+## Training Model
-Specify your training environment, you should specify if the training is on CPU or GPU.
+### Defining the training environment
+Define your training environment and specify whether the training takes place on CPU or GPU.
```python
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
```
-### Datafeeder Configuration
-
-Next we define data feeders for test and train. The feeder reads a `buf_size` of data each time and feed them to the training/testing process.
-`paddle.dataset.movielens.train` will yield records during each pass, after shuffling, a batch input of `BATCH_SIZE` is generated for training.
+### Defining the data provider
+The next step is to define a data provider for training and testing. The provider reads in a data of size `BATCH_SIZE`. `paddle.dataset.movielens.train` will provide a data of size `BATCH_SIZE` after each scribbling, and the size of the out-of-order is the cache size `buf_size`.
```python
train_reader = paddle.batch(
@@ -428,87 +456,111 @@ test_reader = paddle.batch(
paddle.dataset.movielens.test(), batch_size=BATCH_SIZE)
```
-### Create Trainer
+### Constructing a training process (trainer)
+We have constructed a training process here, including training optimization functions.
+
+### Provide data
-Create a trainer that takes `train_program` as input and specify optimizer function.
+`feed_order` is used to define the mapping between each generated data and `paddle.layer.data`. For example, the data in the first column generated by `movielens.train` corresponds to the feature `user_id`.
```python
-trainer = Trainer(
- train_func=train_program, place=place, optimizer_func=optimizer_func)
+feed_order = [
+ 'user_id', 'gender_id', 'age_id', 'job_id', 'movie_id', 'category_id',
+ 'movie_title', 'score'
+]
```
-### Feeding Data
-
-`feed_order` is devoted to specifying the correspondence between each yield record and `paddle.layer.data`. For instance, the first column of data generated by `movielens.train` corresponds to `user_id` feature.
+### Building training programs and testing programs
+The training program and the test program are separately constructed, and the training optimizer is imported.
```python
-feed_order = [
- 'user_id', 'gender_id', 'age_id', 'job_id', 'movie_id', 'category_id',
- 'movie_title', 'score'
+main_program = fluid.default_main_program()
+star_program = fluid.default_startup_program()
+[avg_cost, scale_infer] = train_program()
+
+test_program = main_program.clone(for_test=True)
+sgd_optimizer = optimizer_func()
+sgd_optimizer.minimize(avg_cost)
+exe = fluid.Executor(place)
+
+def train_test(program, reader):
+ count = 0
+ feed_var_list = [
+ program.global_block().var(var_name) for var_name in feed_order
]
+ feeder_test = fluid.DataFeeder(
+ feed_list=feed_var_list, place=place)
+ test_exe = fluid.Executor(place)
+ accumulated = 0
+ for test_data in reader():
+ avg_cost_np = test_exe.run(program=program,
+ feed=feeder_test.feed(test_data),
+ fetch_list=[avg_cost])
+ accumulated += avg_cost_np[0]
+ count += 1
+ return accumulated / count
```
-### Event Handler
-
-Callback function `event_handler` will be called during training when a pre-defined event happens.
-For example, we can check the cost by `trainer.test` when `EndStepEvent` occurs
+### Build a training main loop and start training
+We perform the training cycle according to the training cycle number (`PASS_NUM`) defined above and some other parameters, and perform a test every time. When the test result is good enough, we exit the training and save the trained parameters.
```python
# Specify the directory path to save the parameters
params_dirname = "recommender_system.inference.model"
-def event_handler(event):
- if isinstance(event, EndStepEvent):
- test_reader = paddle.batch(
- paddle.dataset.movielens.test(), batch_size=BATCH_SIZE)
- avg_cost_set = trainer.test(
- reader=test_reader, feed_order=feed_order)
-
- # get avg cost
- avg_cost = np.array(avg_cost_set).mean()
-
- print("avg_cost: %s" % avg_cost)
-
- if float(avg_cost) < 4: # Change this number to adjust accuracy
- trainer.save_params(params_dirname)
- trainer.stop()
- else:
- print('BatchID {0}, Test Loss {1:0.2}'.format(event.epoch + 1,
- float(avg_cost)))
- if math.isnan(float(avg_cost)):
- sys.exit("got NaN loss, training failed.")
-```
-
-### Training
+from paddle.utils.plot import Ploter
+train_prompt = "Train cost"
+test_prompt = "Test cost"
-Finally, we invoke `trainer.train` to start training with `num_epochs` and other parameters.
+plot_cost = Ploter(train_prompt, test_prompt)
-```python
-trainer.train(
- num_epochs=1,
- event_handler=event_handler,
- reader=train_reader,
- feed_order=feed_order)
+def train_loop():
+ feed_list = [
+ main_program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder = fluid.DataFeeder(feed_list, place)
+ exe.run(star_program)
+
+ for pass_id in range(PASS_NUM):
+ for batch_id, data in enumerate(train_reader()):
+ # train a mini-batch
+ outs = exe.run(program=main_program,
+ feed=feeder.feed(data),
+ fetch_list=[avg_cost])
+ out = np.array(outs[0])
+
+ # get test avg_cost
+ test_avg_cost = train_test(test_program, test_reader)
+
+ plot_cost.append(train_prompt, batch_id, outs[0])
+ plot_cost.append(test_prompt, batch_id, test_avg_cost)
+ plot_cost.plot()
+
+ if batch_id == 20:
+ if params_dirname is not None:
+ fluid.io.save_inference_model(params_dirname, [
+ "user_id", "gender_id", "age_id", "job_id",
+ "movie_id", "category_id", "movie_title"
+ ], [scale_infer], exe)
+ return
+ print('EpochID {0}, BatchID {1}, Test Loss {2:0.2}'.format(
+ pass_id + 1, batch_id + 1, float(test_avg_cost)))
+
+ if math.isnan(float(out[0])):
+ sys.exit("got NaN loss, training failed.")
```
-
-## Inference
-
-### Create Inferencer
-
-Initialize Inferencer with `inference_program` and `params_dirname` which is where we save params from training.
-
+Start training
```python
-inferencer = Inferencer(
- inference_program, param_path=params_dirname, place=place)
+train_loop()
```
-### Generate input data for testing
+## Model Application
+
+### Generate test data
+Use the API of create_lod_tensor(data, lod, place) to generate the tensor of the detail level. `data` is a sequence, and each element is a sequence of index numbers. `lod` is the detail level's information, corresponding to `data`. For example, data = [[10, 2, 3], [2, 3]] means that it contains two sequences of lengths 3 and 2. Correspondingly lod = [[3, 2]], which indicates that it contains a layer of detail information, meaning that `data` has two sequences, lengths of 3 and 2.
-Use create_lod_tensor(data, lod, place) API to generate LoD Tensor, where `data` is a list of sequences of index numbers, `lod` is the level of detail (lod) info associated with `data`.
-For example, data = [[10, 2, 3], [2, 3]] means that it contains two sequences of indices, of length 3 and 2, respectively.
-Correspondingly, lod = [[3, 2]] contains one level of detail info, indicating that `data` consists of two sequences of length 3 and 2.
+In this prediction example, we try to predict the score given by user with ID1 for the movie 'Hunchback of Notre Dame'.
-In this infer example, we try to predict rating of movie 'Hunchback of Notre Dame' from the info of user id 1.
```python
infer_movie_id = 783
infer_movie_name = paddle.dataset.movielens.movie_info()[infer_movie_id].title
@@ -522,45 +574,62 @@ movie_title = fluid.create_lod_tensor([[1069, 4140, 2923, 710, 988]], [[5]],
place) # 'hunchback','of','notre','dame','the'
```
-### Infer
-
-Now we can infer with inputs that we provide in `feed_order` during training.
+### Building the prediction process and testing
+Similar to the training process, we need to build a prediction process, where `params_dirname` is the address used to store the various parameters in the training process.
```python
-results = inferencer.infer(
- {
- 'user_id': user_id,
- 'gender_id': gender_id,
- 'age_id': age_id,
- 'job_id': job_id,
- 'movie_id': movie_id,
- 'category_id': category_id,
- 'movie_title': movie_title
- },
- return_numpy=False)
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+exe = fluid.Executor(place)
+
+inference_scope = fluid.core.Scope()
+```
+
+### Testing
+Now we can make predictions. The `feed_order` we provide should be consistent with the training process.
-predict_rating = np.array(results[0])
-print("Predict Rating of user id 1 on movie \"" + infer_movie_name + "\" is " + str(predict_rating[0][0]))
-print("Actual Rating of user id 1 on movie \"" + infer_movie_name + "\" is 4.")
+```python
+with fluid.scope_guard(inference_scope):
+ [inferencer, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(params_dirname, exe)
+
+ results = exe.run(inferencer,
+ feed={
+ 'user_id': user_id,
+ 'gender_id': gender_id,
+ 'age_id': age_id,
+ 'job_id': job_id,
+ 'movie_id': movie_id,
+ 'category_id': category_id,
+ 'movie_title': movie_title
+ },
+ fetch_list=fetch_targets,
+ return_numpy=False)
+ predict_rating = np.array(results[0])
+ print("Predict Rating of user id 1 on movie \"" + infer_movie_name +
+ "\" is " + str(predict_rating[0][0]))
+ print("Actual Rating of user id 1 on movie \"" + infer_movie_name +
+ "\" is 4.")
```
-## Conclusion
+## Summary
-This tutorial goes over traditional approaches in recommender system and a deep learning based approach. We also show that how to train and use the model with PaddlePaddle. Deep learning has been well used in computer vision and NLP, we look forward to its new successes in recommender systems.
+This chapter introduced the traditional personalized recommendation system method and YouTube's deep neural network personalized recommendation system. It further took movie recommendation as an example, and used PaddlePaddle to train a personalized recommendation neural network model. The personalized recommendation system covers almost all aspects of e-commerce systems, social networks, advertising recommendations, search engines, etc. Deep learning technologies have played an important role in image processing, natural language processing, etc., and will also prevail in personalized recommendation systems.
+
## References
-1. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
-2. Robin Burke , [Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
-3. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
-4. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th International Conference on World Wide Web*. ACM, 2001.
-5. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: Combining Social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
-6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf) *arXiv preprint arXiv:1611.05480* (2016).
-7. Covington P, Adams J, Sargin E. [Deep neural networks for youtube recommendations](https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf)[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 191-198.
+1. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
+2. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th international conference on World Wide Web*. ACM, 2001.
+3. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: combining social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
+4. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
+5. Robin Burke , [Hybrid Web recommendation systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
+6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf) *arXiv preprint arXiv:1611.05480* (2016).
+7. Covington P, Adams J, Sargin E. [Deep neural networks for youtube recommendations](https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf)[C]//Proceedings of the 10th ACM Conference on recommendation systems. ACM, 2016: 191-198.
+
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Table 1 Sentiment Analysis in Movie Reviews
+Form 1 Sentiment analysis of movie comments
-In natural language processing, sentiment analysis can be categorized as a **Text Classification problem**, i.e., to categorize a piece of text to a specific class. It involves two related tasks: text representation and classification. Before the emergence of deep learning techniques, the mainstream methods for text representation include BOW (*bag of words*) and topic modeling, while the latter contains SVM (*support vector machine*) and LR (*logistic regression*).
+In natural language processing, sentiment is a typical problem of **text categorization**, which divides the text that needs to be sentiment analysis into its category. Text categorization involves two issues: text representation and classification methods. Before the emergence of the deep learning, the mainstream text representation methods are BOW (bag of words), topic models, etc.; the classification methods are SVM (support vector machine), LR (logistic regression) and so on.
-The BOW model does not capture all the information in a piece of text, as it ignores syntax and grammar and just treats the text as a set of words. For example, “this movie is extremely bad“ and “boring, dull, and empty work” describe very similar semantic meaning, yet their BOW representations have very little similarity. Furthermore, “the movie is bad“ and “the movie is not bad“ have high similarity with BOW features, but they express completely opposite semantics.
+For a piece of text, BOW means that its word order, grammar and syntax are ignored, and this text is only treated as a collection of words, so the BOW method does not adequately represent the semantic information of the text. For example, the sentence "This movie is awful" and "a boring, empty, non-connotative work" have a high semantic similarity in sentiment analysis, but their BOW representation has a similarity of zero. Another example is that the BOW is very similar to the sentence "an empty, work without connotations" and "a work that is not empty and has connotations", but in fact they mean differently.
-This chapter introduces a deep learning model that handles these issues in BOW. Our model embeds texts into a low-dimensional space and takes word order into consideration. It is an end-to-end framework and it has large performance improvement over traditional methods \[[1](#references)\].
+The deep learning we are going to introduce in this chapter overcomes the above shortcomings of BOW representation. It maps text to low-dimensional semantic space based on word order, and performs text representation and classification in end-to-end mode. Its performance is significantly improved compared to the traditional method \[[1](#References)\].
## Model Overview
+The text representation models used in this chapter are Convolutional Neural Networks and Recurrent Neural Networks and their extensions. These models are described below.
-The model we used in this chapter uses **Convolutional Neural Networks** (**CNNs**) and **Recurrent Neural Networks** (**RNNs**) with some specific extensions.
-
+### Introduction of Text Convolutional Neural Networks (CNN)
-### Revisit to the Convolutional Neural Networks for Texts (CNN)
+We introduced the calculation process of the CNN model applied to text data in the [Recommended System](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system) section. Here is a simple review.
-The convolutional neural network for texts is introduced in chapter [recommender_system](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system), here is a brief overview.
+For a CNN, first convolute input word vector sequence to generate a feature map, and then obtain the features of the whole sentence corresponding to the kernel by using a max pooling over time on the feature map. Finally, the splicing of all the features obtained is the fixed-length vector representation of the text. For the text classification problem, connecting it via softmax to construct a complete model. In actual applications, we use multiple convolution kernels to process sentences, and convolution kernels with the same window size are stacked to form a matrix, which can complete the operation more efficiently. In addition, we can also use the convolution kernel with different window sizes to process the sentence. Figure 3 in the [Recommend System](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system) section shows four convolution kernels, namely Figure 1 below, with different colors representing convolution kernel operations of different sizes.
-CNN mainly contains convolution and pooling operation, with versatile combinations in various applications. We firstly apply the convolution operation: we apply the kernel in each window, extracting features. Convolving by the kernel at every window produces a feature map. Next, we apply *max pooling* over time to represent the whole sentence, which is the maximum element across the feature map. In real applications, we will apply multiple CNN kernels on the sentences. It can be implemented efficiently by concatenating the kernels together as a matrix. Also, we can use CNN kernels with different kernel size. Finally, concatenating the resulting features produces a fixed-length representation, which can be combined with a softmax to form the model for the sentiment analysis problem.
+
+
+Figure 1. CNN text classification model
+
-For short texts, the aforementioned CNN model can achieve very high accuracy \[[1](#references)\]. If we want to extract more abstract representations, we may apply a deeper CNN model \[[2](#references),[3](#references)\].
+For the general short text classification problem, the simple text convolution network described above can achieve a high accuracy rate \[[1](#References)\]. If you want a more abstract and advanced text feature representation, you can construct a deep text convolutional neural network\[[2](#References), [3](#References)\].
### Recurrent Neural Network (RNN)
-RNN is an effective model for sequential data. In terms of computability, the RNN is Turing-complete \[[4](#references)\]. Since NLP is a classical problem of sequential data, the RNN, especially its variant LSTM\[[5](#references)\]), achieves state-of-the-art performance on various NLP tasks, such as language modeling, syntax parsing, POS-tagging, image captioning, dialog, machine translation, and so forth.
+RNN is a powerful tool for accurately modeling sequence data. In fact, the theoretical computational power of the RNN is perfected by Turing' \[[4](#References)\]. Natural language is a typical sequence data (word sequence). In recent years, RNN and its derivation (such as long short term memory\[[5](#References)\]) have been applied in many natural language fields, such as in language models, syntactic parsing, semantic role labeling (or general sequence labeling), semantic representation, graphic generation, dialogue, machine translation, etc., all perform well and even become the best at present.
-
-Figure 1. An illustration of an unfolded RNN in time.
+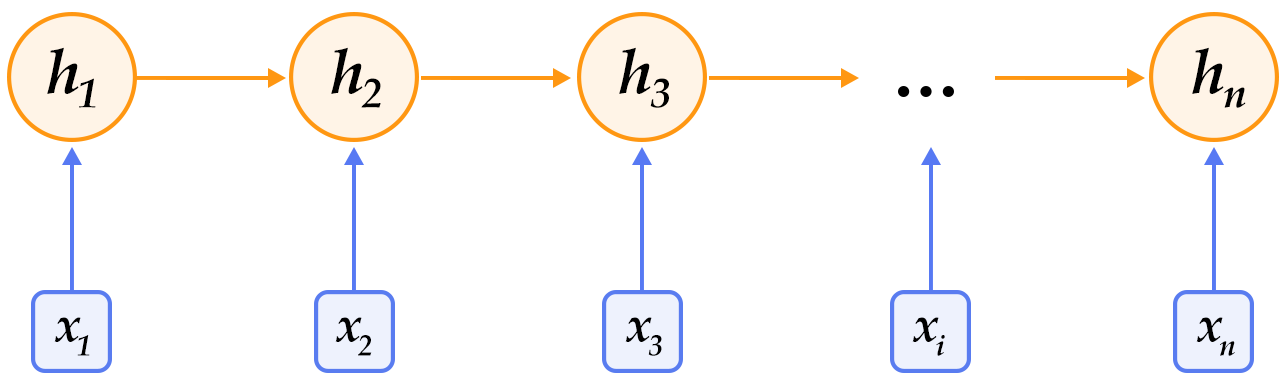
+Figure 2. Schematic diagram of the RNN expanded by time
-As shown in Figure 1, we unfold an RNN: at the $t$-th time step, the network takes two inputs: the $t$-th input vector $\vec{x_t}$ and the latent state from the last time-step $\vec{h_{t-1}}$. From those, it computes the latent state of the current step $\vec{h_t}$. This process is repeated until all inputs are consumed. Denoting the RNN as function $f$, it can be formulated as follows:
+The RNN expands as time is shown in Figure 2: at the time of $t$, the network reads the $t$th input $x_t$ (vector representation) and the state value of the hidden layer at the previous moment $h_{t- 1}$ (vector representation, $h_0$ is normally initialized to $0$ vector), and calculate the state value $h_t$ of the hidden layer at this moment. Repeat this step until all the inputs have been read. If the function is recorded as $f$, its formula can be expressed as:
-$$\vec{h_t}=f(\vec{x_t},\vec{h_{t-1}})=\sigma(W_{xh}\vec{x_t}+W_{hh}\vec{h_{t-1}}+\vec{b_h})$$
+$$h_t=f(x_t,h_{t-1})=\sigma(W_{xh}x_t+W_{hh}h_{t-1}+b_h)$$
-where $W_{xh}$ is the weight matrix to feed into the latent layer; $W_{hh}$ is the latent-to-latent matrix; $b_h$ is the latent bias and $\sigma$ refers to the $sigmoid$ function.
+Where $W_{xh}$ is the matrix parameter of the input to the hidden layer, $W_{hh}$ is the matrix parameter of the hidden layer to the hidden layer, and $b_h$ is the bias vector parameter of the hidden layer, $\sigma $ is the $sigmoid$ function.
-In NLP, words are often represented as one-hot vectors and then mapped to an embedding. The embedded feature goes through an RNN as input $x_t$ at every time step. Moreover, we can add other layers on top of RNN, such as a deep or stacked RNN. Finally, the last latent state may be used as a feature for sentence classification.
+When dealing with natural language, the word (one-hot representation) is usually mapped to its word vector representation, and then used as the input $x_t$ for each moment of the recurrent neural network. In addition, other layers may be connected to the hidden layer of the RNN depending on actual needs. For example, you can connect the hidden layer output of a RNN to the input of the next RNN to build a deep or stacked RNN, or extract the hidden layer state at the last moment as a sentence representation and then implement a classification model, etc.
-### Long-Short Term Memory (LSTM)
+### Long and Short Term Memory Network (LSTM)
-Training an RNN on long sequential data sometimes leads to the gradient vanishing or exploding\[[6](#references)\]. To solve this problem Hochreiter S, Schmidhuber J. (1997) proposed **Long Short Term Memory** (LSTM)\[[5](#references)\]).
+For longer sequence data, the gradient disappearance or explosion phenomenon is likely to occur during training RNN\[[6](#References)\]. To solve this problem, Hochreiter S, Schmidhuber J. (1997) proposed LSTM (long short term memory\[[5](#References)\]).
-Compared to the structure of a simple RNN, an LSTM includes memory cell $c$, input gate $i$, forget gate $f$ and output gate $o$. These gates and memory cells dramatically improve the ability for the network to handle long sequences. We can formulate the **LSTM-RNN**, denoted as a function $F$, as follows:
+Compared to a simple RNN, LSTM adds memory unit $c$, input gate $i$, forget gate $f$, and output gate $o$. The combination of these gates and memory units greatly enhances the ability of the recurrent neural network to process long sequence data. If the function \is denoted as $F$, the formula is:
$$ h_t=F(x_t,h_{t-1})$$
-$F$ contains following formulations\[[7](#references)\]:
+$F$ It is a combination of the following formulas\[[7](#References)\]:
$$ i_t = \sigma{(W_{xi}x_t+W_{hi}h_{t-1}+W_{ci}c_{t-1}+b_i)} $$
$$ f_t = \sigma(W_{xf}x_t+W_{hf}h_{t-1}+W_{cf}c_{t-1}+b_f) $$
$$ c_t = f_t\odot c_{t-1}+i_t\odot tanh(W_{xc}x_t+W_{hc}h_{t-1}+b_c) $$
$$ o_t = \sigma(W_{xo}x_t+W_{ho}h_{t-1}+W_{co}c_{t}+b_o) $$
$$ h_t = o_t\odot tanh(c_t) $$
-
-In the equation,$i_t, f_t, c_t, o_t$ stand for input gate, forget gate, memory cell and output gate, respectively. $W$ and $b$ are model parameters, $\tanh$ is a hyperbolic tangent, and $\odot$ denotes an element-wise product operation. The input gate controls the magnitude of the new input into the memory cell $c$; the forget gate controls the memory propagated from the last time step; the output gate controls the magnitutde of the output. The three gates are computed similarly with different parameters, and they influence memory cell $c$ separately, as shown in Figure 2:
+Where $i_t, f_t, c_t, o_t$ respectively represent the vector representation of the input gate, the forget gate, the memory unit and the output gate, the $W$ and $b$ with the angular label are the model parameters, and the $tanh$ is the hyperbolic tangent function. , $\odot$ represents an elementwise multiplication operation. The input gate controls the intensity of the new input into the memory unit $c$, the forget gate controls the intensity of the memory unit to maintain the previous time value, and the output gate controls the intensity of the output memory unit. The three gates are calculated in a similar way, but with completely different parameters.They controll the memory unit $c$ in different ways, as shown in Figure 3:
-
-Figure 2. LSTM at time step $t$ [7].
+
+Figure 3. LSTM for time $t$ [7]
-LSTM enhances the ability of considering long-term reliance, with the help of memory cell and gate. Similar structures are also proposed in Gated Recurrent Unit (GRU)\[[8](Reference)\] with a simpler design. **The structures are still similar to RNN, though with some modifications (As shown in Figure 2), i.e., latent status depends on input as well as the latent status of the last time step, and the process goes on recurrently until all inputs are consumed:**
+LSTM enhances its ability to handle long-range dependencies by adding memory and control gates to RNN. A similar principle improvement is Gated Recurrent Unit (GRU)\[[8](#References)\], which is more concise in design. **These improvements are different, but their macro descriptions are the same as simple recurrent neural networks (as shown in Figure 2). That is, the hidden state changes according to the current input and the hidden state of the previous moment, and this process is continuous until the input is processed:**
$$ h_t=Recrurent(x_t,h_{t-1})$$
-where $Recrurent$ is a simple RNN, GRU or LSTM.
+Among them, $Recrurent$ can represent a RNN, GRU or LSTM.
+
+
+
+
### Stacked Bidirectional LSTM
-For vanilla LSTM, $h_t$ contains input information from previous time-step $1..t-1$ context. We can also apply an RNN with reverse-direction to take successive context $t+1…n$ into consideration. Combining constructing deep RNN (deeper RNN can contain more abstract and higher level semantic), we can design structures with deep stacked bidirectional LSTM to model sequential data\[[9](#references)\].
+For a normal directional RNN, $h_t$ contains the input information before the $t$ time, which is the above context information. Similarly, in order to get the following context information, we can use a RNN in the opposite direction (which will be processed in reverse order). Combined with the method of constructing deep-loop neural networks (deep neural networks often get more abstract and advanced feature representations), we can build a more powerful LSTM-based stack bidirectional recurrent neural network\[[9](#References )\] to model time series data.
-As shown in Figure 3 (3-layer RNN), odd/even layers are forward/reverse LSTM. Higher layers of LSTM take lower-layers LSTM as input, and the top-layer LSTM produces a fixed length vector by max-pooling (this representation considers contexts from previous and successive words for higher-level abstractions). Finally, we concatenate the output to a softmax layer for classification.
+As shown in Figure 4 (taking three layers as an example), the odd-numbered LSTM is forward and the even-numbered LSTM is inverted. The higher-level LSTM uses the lower LSTM and all previous layers of information as input. The maximum pooling of the highest-level LSTM sequence in the time dimension can be used to obtain a fixed-length vector representation of the text (this representation fully fuses the contextual information and deeply abstracts of the text), and finally we connect the text representation to the softmax to build the classification model.
-
-Figure 3. Stacked Bidirectional LSTM for NLP modeling.
+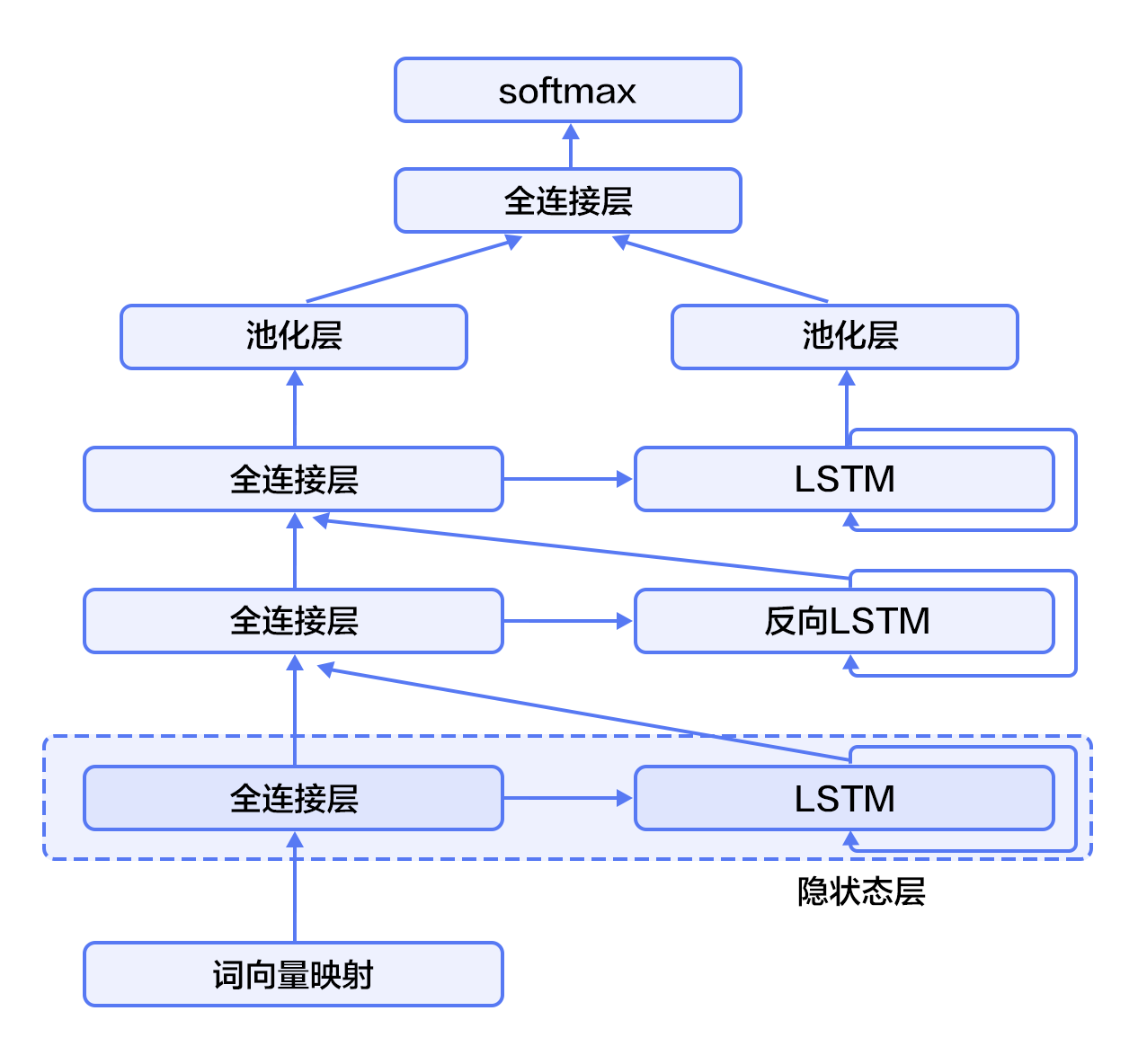
+Figure 4. Stacked bidirectional LSTM for text categorization
-## Dataset
-We use [IMDB](http://ai.stanford.edu/%7Eamaas/data/sentiment/) dataset for sentiment analysis in this tutorial, which consists of 50,000 movie reviews split evenly into a 25k train set and a 25k test set. In the labeled train/test sets, a negative review has a score <= 4 out of 10, and a positive review has a score >= 7 out of 10.
-
-`paddle.datasets` package encapsulates multiple public datasets, including `cifar`, `imdb`, `mnist`, `moivelens`, and `wmt14`, etc. There's no need for us to manually download and preprocess IMDB.
-
-After issuing a command `python train.py`, training will start immediately. The details will be unpacked by the following sessions to see how it works.
+## Dataset Introduction
+We use the [IMDB sentiment analysis data set](http://ai.stanford.edu/%7Eamaas/data/sentiment/) as an example. The training and testing IMDB dataset contain 25,000 labeled movie reviews respectively. Among them, the score of the negative comment is less than or equal to 4, and the score of the positive comment is greater than or equal to 7, full score is 10.
+```text
+aclImdb
+|- test
+ |-- neg
+ |-- pos
+|- train
+ |-- neg
+ |-- pos
+```
+Paddle implements the automatic download and read the imdb dataset in `dataset/imdb.py`, and provides API for reading dictionary, training data, testing data, and so on.
## Model Configuration
-Our program starts with importing necessary packages and initializing some global variables:
+In this example, we implement two text categorization algorithms based on the text convolutional neural network described in the [Recommender System](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system) section and [Stacked Bidirectional LSTM](#Stacked Bidirectional LSTM). We first import the packages we need to use and define global variables:
```python
from __future__ import print_function
import paddle
import paddle.fluid as fluid
-from functools import partial
import numpy as np
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
-
-CLASS_DIM = 2
-EMB_DIM = 128
-HID_DIM = 512
-STACKED_NUM = 3
-BATCH_SIZE = 128
-USE_GPU = False
-```
+import sys
+import math
-As alluded to in section [Model Overview](#model-overview), here we provide the implementations of both Text CNN and Stacked-bidirectional LSTM models.
+CLASS_DIM = 2 #Number of categories for sentiment analysis
+EMB_DIM = 128 #Dimensions of the word vector
+HID_DIM = 512 #Dimensions of hide layer
+STACKED_NUM = 3 #LSTM Layers of the bidirectional stack
+BATCH_SIZE = 128 #batch size
-### Text Convolution Neural Network (Text CNN)
+```
-We create a neural network `convolution_net` as the following snippet code.
-Note: `fluid.nets.sequence_conv_pool` includes both convolution and pooling layer operations.
+### Text Convolutional Neural Network
+We build the neural network `convolution_net`, the sample code is as follows.
+Note that `fluid.nets.sequence_conv_pool` contains both convolution and pooling layers.
```python
+#Textconvolution neural network
def convolution_net(data, input_dim, class_dim, emb_dim, hid_dim):
emb = fluid.layers.embedding(
input=data, size=[input_dim, emb_dim], is_sparse=True)
@@ -153,48 +157,53 @@ def convolution_net(data, input_dim, class_dim, emb_dim, hid_dim):
prediction = fluid.layers.fc(
input=[conv_3, conv_4], size=class_dim, act="softmax")
return prediction
-
```
-Parameter `input_dim` denotes the dictionary size, and `class_dim` is the number of categories.
-The above Text CNN network extracts high-level features and maps them to a vector of the same size as the categories. `paddle.activation.Softmax` function or classifier is then used for calculating the probability of the sentence belonging to each category.
+The network input `input_dim` indicates the size of the dictionary, and `class_dim` indicates the number of categories. Here, we implement the convolution and pooling operations using the [`sequence_conv_pool`](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/trainer_config_helpers/networks.py) API.
+
### Stacked bidirectional LSTM
-We create a neural network `stacked_lstm_net` as below.
+The code of the stack bidirectional LSTM `stacked_lstm_net` is as follows:
```python
+#Stack Bidirectional LSTM
def stacked_lstm_net(data, input_dim, class_dim, emb_dim, hid_dim, stacked_num):
+ # Calculate word vectorvector
emb = fluid.layers.embedding(
- input=data, size=[input_dim, emb_dim], is_sparse=True)
+ input=data, size=[input_dim, emb_dim], is_sparse=True)=True)
+ #First stack
+ #Fully connected layer
fc1 = fluid.layers.fc(input=emb, size=hid_dim)
+ #lstm layer
lstm1, cell1 = fluid.layers.dynamic_lstm(input=fc1, size=hid_dim)
inputs = [fc1, lstm1]
+ #All remaining stack structures
for i in range(2, stacked_num + 1):
fc = fluid.layers.fc(input=inputs, size=hid_dim)
lstm, cell = fluid.layers.dynamic_lstm(
input=fc, size=hid_dim, is_reverse=(i % 2) == 0)
inputs = [fc, lstm]
- fc_last = fluid.layers.sequence_pool(input=inputs[0], pool_type='max')
+ #pooling layer
+ pc_last = fluid.layers.sequence_pool(input=inputs[0], pool_type='max')
lstm_last = fluid.layers.sequence_pool(input=inputs[1], pool_type='max')
- prediction = fluid.layers.fc(input=[fc_last, lstm_last],
- size=class_dim,
- act='softmax')
+ #Fully connected layer, softmax prediction
+ prediction = fluid.layers.fc(
+ input=[fc_last, lstm_last], size=class_dim, act='softmax')
return prediction
-
```
-The above stacked bidirectional LSTM network extracts high-level features and maps them to a vector of the same size as the categories. `paddle.activation.Softmax` function or classifier is then used for calculating the probability of the sentence belonging to each category.
+The above stacked bidirectional LSTM abstracts the advanced features and maps them to vectors of the same size as the number of classification. The 'softmax' activation function of the last fully connected layer is used to calculate the probability of a certain category.
-To reiterate, we can either invoke `convolution_net` or `stacked_lstm_net`. In below steps, we will go with `convolution_net`.
+Again, here we can call any network structure of `convolution_net` or `stacked_lstm_net` for training and learning. Let's take `convolution_net` as an example.
-Next we define an `inference_program` that simply uses `convolution_net` to predict output with the input from `fluid.layer.data`.
+Next we define the prediction program (`inference_program`). We use `convolution_net` to predict the input of `fluid.layer.data`.
```python
def inference_program(word_dict):
@@ -207,47 +216,44 @@ def inference_program(word_dict):
return net
```
-Then we define a `training_program` that uses the result from `inference_program` to compute the cost with label data.
-Also define `optimizer_func` to specify the optimizer.
+We define `training_program` here, which uses the result returned from `inference_program` to calculate the error. We also define the optimization function `optimizer_func`.
+Because it is supervised learning, the training set tags are also defined in `fluid.layers.data`. During training, cross-entropy is used as a loss function in `fluid.layer.cross_entropy`.
-In the context of supervised learning, labels of the training set are defined in `paddle.layer.data` too. During training, cross-entropy is used as loss function in `paddle.layer.classification_cost` and as the output of the network; During testing, the outputs are the probabilities calculated in the classifier.
-First result that returns from the list must be cost.
+During the testing, the classifier calculates the probability of each output. The first returned value is specified as cost.
```python
-def train_program(word_dict):
- prediction = inference_program(word_dict)
+def train_program(prediction):
label = fluid.layers.data(name="label", shape=[1], dtype="int64")
cost = fluid.layers.cross_entropy(input=prediction, label=label)
avg_cost = fluid.layers.mean(cost)
accuracy = fluid.layers.accuracy(input=prediction, label=label)
- return [avg_cost, accuracy]
-
+ return [avg_cost, accuracy] #return average cost and accuracy acc
+#Optimization function
def optimizer_func():
return fluid.optimizer.Adagrad(learning_rate=0.002)
```
-## Model Training
+## Training Model
+
+### Defining the training environment
-### Specify training environment
+Define whether your training is on the CPU or GPU:
-Specify your training environment, you should specify if the training is on CPU or GPU.
```python
-use_cuda = False
+use_cuda = False #train on cpu
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
```
-### Datafeeder Configuration
+### Defining the data creator
-Next we define data feeders for test and train. The feeder reads a `buf_size` of data each time and feed them to the training/testing process.
-`paddle.dataset.imdb.train` will yield records during each pass, after shuffling, a batch input of `BATCH_SIZE` is generated for training.
+The next step is to define a data creator for training and testing. The creator reads in a data of size BATCH_SIZE. Paddle.dataset.imdb.word_dict will provide a size of BATCH_SIZE after each time shuffling, which is the cache size: buf_size.
-Notice for loading and reading IMDB data, it could take up to 1 minute. Please be patient.
+Note: It may take a few minutes to read the IMDB data, please be patient.
```python
-
print("Loading IMDB word dict....")
word_dict = paddle.dataset.imdb.word_dict()
@@ -256,77 +262,125 @@ train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.imdb.train(word_dict), buf_size=25000),
batch_size=BATCH_SIZE)
+print("Reading testing data....")
+test_reader = paddle.batch(
+ paddle.dataset.imdb.test(word_dict), batch_size=BATCH_SIZE)
```
-
-
-### Create Trainer
-
-Create a trainer that takes `train_program` as input and specify optimizer function.
-
+Word_dict is a dictionary sequence, which is the correspondence between words and labels. You can see it specifically by running the next code:
```python
-trainer = Trainer(
- train_func=partial(train_program, word_dict),
- place=place,
- optimizer_func=optimizer_func)
+word_dict
```
+Each line is a correspondence such as ('limited': 1726), which indicates that the label corresponding to the word limited is 1726.
-### Feeding Data
+### Construction Trainer
+The trainer requires a training program and a training optimization function.
-`feed_order` is devoted to specifying the correspondence between each yield record and `paddle.layer.data`. For instance, the first column of data generated by `imdb.train` corresponds to `words`.
+```python
+exe = fluid.Executor(place)
+prediction = inference_program(word_dict)
+[avg_cost, accuracy] = train_program(prediction)#training program
+sgd_optimizer = optimizer_func()# training optimization function
+sgd_optimizer.minimize(avg_cost)
+```
+This function is used to calculate the result of the model on the test dataset.
```python
-feed_order = ['words', 'label']
+def train_test(program, reader):
+ count = 0
+ feed_var_list = [
+ program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder_test = fluid.DataFeeder(feed_list=feed_var_list, place=place)
+ test_exe = fluid.Executor(place)
+ accumulated = len([avg_cost, accuracy]) * [0]
+ for test_data in reader():
+ avg_cost_np = test_exe.run(
+ program=program,
+ feed=feeder_test.feed(test_data),
+ fetch_list=[avg_cost, accuracy])
+ accumulated = [
+ x[0] + x[1][0] for x in zip(accumulated, avg_cost_np)
+ ]
+ count += 1
+ return [x / count for x in accumulated]
```
-### Event Handler
+### Providing data and building a main training loop
-Callback function `event_handler` will be called during training when a pre-defined event happens.
-For example, we can check the cost by `trainer.test` when `EndStepEvent` occurs
+`feed_order` is used to define the mapping relationship between each generated data and `fluid.layers.data`. For example, the data in the first column generated by `imdb.train` corresponds to the `words` feature.
```python
# Specify the directory path to save the parameters
params_dirname = "understand_sentiment_conv.inference.model"
-def event_handler(event):
- if isinstance(event, EndStepEvent):
- print("Step {0}, Epoch {1} Metrics {2}".format(
- event.step, event.epoch, list(map(np.array, event.metrics))))
-
- if event.step == 10:
- trainer.save_params(params_dirname)
- trainer.stop()
+feed_order = ['words', 'label']
+pass_num = 1 #Number rounds of the training loop
+
+# Main loop part of the program
+def train_loop(main_program):
+ # Start the trainer built above
+ exe.run(fluid.default_startup_program())
+
+ feed_var_list_loop = [
+ main_program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder = fluid.DataFeeder(
+ feed_list=feed_var_list_loop, place=place)
+
+ test_program = fluid.default_main_program().clone(for_test=True)
+
+ # Training loop
+ for epoch_id in range(pass_num):
+ for step_id, data in enumerate(train_reader()):
+ # Running trainer
+ metrics = exe.run(main_program,
+ feed=feeder.feed(data),
+ fetch_list=[avg_cost, accuracy])
+
+ # Testing Results
+ avg_cost_test, acc_test = train_test(test_program, test_reader)
+ print('Step {0}, Test Loss {1:0.2}, Acc {2:0.2}'.format(
+ step_id, avg_cost_test, acc_test))
+
+ print("Step {0}, Epoch {1} Metrics {2}".format(
+ step_id, epoch_id, list(map(np.array,
+ metrics))))
+
+ if step_id == 30:
+ if params_dirname is not None:
+ fluid.io.save_inference_model(params_dirname, ["words"],
+ prediction, exe)# Save model
+ return
```
-### Training
+### Training process
+
+We print the output of each step in the main loop of the training, and we can observe the training situation.
-Finally, we invoke `trainer.train` to start training with `num_epochs` and other parameters.
+### Start training
+
+Finally, we start the training main loop to start training. The training time is longer. If you want to get the result faster, you can shorten the training time by adjusting the loss value range or the number of training steps at the cost of reducing the accuracy.
```python
-trainer.train(
- num_epochs=1,
- event_handler=event_handler,
- reader=train_reader,
- feed_order=feed_order)
+train_loop(fluid.default_main_program())
```
-## Inference
+## Application Model
-### Create Inferencer
+### Building a predictor
-Initialize Inferencer with `inference_program` and `params_dirname` which is where we save params from training.
+As the training process, we need to create a prediction process and use the trained models and parameters to make predictions. `params_dirname` is used to store the various parameters in the training process.
```python
-inferencer = Inferencer(
- infer_func=partial(inference_program, word_dict),
- param_path=params_dirname,
- place=place)
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+exe = fluid.Executor(place)
+inference_scope = fluid.core.Scope()
```
-### Create Lod Tensor with test data
+### Generating test input data
-To do inference, we pick 3 potential reviews out of our mind as testing data. Feel free to modify any of them.
-We map each word in the reviews to id from `word_dict`, replaced by 'unknown' if the word is not in `word_dict`.
-Then we create lod data with the id list and use `create_lod_tensor` to create lod tensor.
+In order to make predictions, we randomly select 3 comments. We correspond each word in the comment to the id in `word_dict`. If the word is not in the dictionary, set it to `unknown`.
+Then we use `create_lod_tensor` to create the tensor of the detail level. For a detailed explanation of this function, please refer to [API documentation](http://paddlepaddle.org/documentation/docs/en/1.2/user_guides/howto/basic_concept/lod_tensor.html).
```python
reviews_str = [
@@ -344,27 +398,39 @@ base_shape = [[len(c) for c in lod]]
tensor_words = fluid.create_lod_tensor(lod, base_shape, place)
```
-### Infer
+## Applying models and making predictions
-Now we can infer and predict probability of positive or negative from each review above.
+Now we can make positive or negative predictions for each comment.
```python
-results = inferencer.infer({'words': tensor_words})
+with fluid.scope_guard(inference_scope):
-for i, r in enumerate(results[0]):
- print("Predict probability of ", r[0], " to be positive and ", r[1], " to be negative for review \'", reviews_str[i], "\'")
+ [inferencer, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(params_dirname, exe)
+ assert feed_target_names[0] == "words"
+ results = exe.run(inferencer,
+ feed={feed_target_names[0]: tensor_words},
+ fetch_list=fetch_targets,
+ return_numpy=False)
+ np_data = np.array(results[0])
+ for i, r in enumerate(np_data):
+ print("Predict probability of ", r[0], " to be positive and ", r[1],
+ " to be negative for review \'", reviews_str[i], "\'")
```
+
## Conclusion
-In this chapter, we use sentiment analysis as an example to introduce applying deep learning models on end-to-end short text classification, as well as how to use PaddlePaddle to implement the model. Meanwhile, we briefly introduce two models for text processing: CNN and RNN. In following chapters, we will see how these models can be applied in other tasks.
+In this chapter, we take sentiment analysis as an example to introduce end-to-end short text classification using deep learning, and complete all relevant experiments using PaddlePaddle. At the same time, we briefly introduce two text processing models: convolutional neural networks and recurrent neural networks. In the following chapters, we will see the application of these two basic deep learning models on other tasks.
+
+
## References
1. Kim Y. [Convolutional neural networks for sentence classification](http://arxiv.org/pdf/1408.5882)[J]. arXiv preprint arXiv:1408.5882, 2014.
-2. Kalchbrenner N, Grefenstette E, Blunsom P. [A convolutional neural network for modeling sentences](http://arxiv.org/pdf/1404.2188.pdf?utm_medium=App.net&utm_source=PourOver)[J]. arXiv preprint arXiv:1404.2188, 2014.
+2. Kalchbrenner N, Grefenstette E, Blunsom P. [A convolutional neural network for modelling sentences](http://arxiv.org/pdf/1404.2188.pdf?utm_medium=App.net&utm_source=PourOver)[J]. arXiv preprint arXiv:1404.2188, 2014.
3. Yann N. Dauphin, et al. [Language Modeling with Gated Convolutional Networks](https://arxiv.org/pdf/1612.08083v1.pdf)[J] arXiv preprint arXiv:1612.08083, 2016.
4. Siegelmann H T, Sontag E D. [On the computational power of neural nets](http://research.cs.queensu.ca/home/akl/cisc879/papers/SELECTED_PAPERS_FROM_VARIOUS_SOURCES/05070215382317071.pdf)[C]//Proceedings of the fifth annual workshop on Computational learning theory. ACM, 1992: 440-449.
5. Hochreiter S, Schmidhuber J. [Long short-term memory](http://web.eecs.utk.edu/~itamar/courses/ECE-692/Bobby_paper1.pdf)[J]. Neural computation, 1997, 9(8): 1735-1780.
@@ -374,4 +440,4 @@ In this chapter, we use sentiment analysis as an example to introduce applying d
9. Zhou J, Xu W. [End-to-end learning of semantic role labeling using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/06.understand_sentiment/index.html b/06.understand_sentiment/index.html
index be17664..e809088 100644
--- a/06.understand_sentiment/index.html
+++ b/06.understand_sentiment/index.html
@@ -40,143 +40,147 @@
+
+
# Sentiment Analysis
-The source codes of this section is located at [book/understand_sentiment](https://github.com/PaddlePaddle/book/tree/develop/06.understand_sentiment). For instructions on getting started with this book,see [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book).
+The source code of this tutorial is in [book/understand_sentiment](https://github.com/PaddlePaddle/book/tree/develop/06.understand_sentiment). For new users, please refer to [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book) .
-## Background
+## Background Introduction
-In natural language processing, sentiment analysis refers to determining the emotion expressed in a piece of text. The text can be a sentence, a paragraph, or a document. Emotion categorization can be binary -- positive/negative or happy/sad -- or in three classes -- positive/neutral/negative. Sentiment analysis is applicable in a wide range of services, such as e-commerce sites like Amazon and Taobao, hospitality services like Airbnb and hotels.com, and movie rating sites like Rotten Tomatoes and IMDB. It can be used to gauge from the reviews how the customers feel about the product. Table 1 illustrates an example of sentiment analysis in movie reviews:
+In natural language processing, sentiment analysis generally refers to judging the emotion expressed by a piece of text. Among them, a piece of text can be a sentence, a paragraph or a document. Emotional state can be two categories, such as (positive, negative), (happy, sad); or three categories, such as (positive, negative, neutral) and so on.The application scenarios of understanding sentiment are very broad, such as dividing the comments posted by users on shopping websites (Amazon, Tmall, Taobao, etc.), travel websites, and movie review websites into positive comments and negative comments; or in order to analyze the user's overall experience with a product, grab user reviews of the product, and perform sentiment analysis. Table 1 shows an example of understanding sentiment of movie reviews:
-| Movie Review | Category |
-| -------- | ----- |
-| Best movie of Xiaogang Feng in recent years!| Positive |
-| Pretty bad. Feels like a tv-series from a local TV-channel | Negative |
-| Politically correct version of Taken ... and boring as Heck| Negative|
-|delightful, mesmerizing, and completely unexpected. The plot is nicely designed.|Positive|
+| Movie Comments | Category |
+| -------- | ----- |
+|In Feng Xiaogang’s movies of the past few years, it is the best one | Positive |
+|Very bad feat, like a local TV series | Negative |
+|The round-lens lens is full of brilliance, and the tonal background is beautiful, but the plot is procrastinating, the accent is not good, and even though taking an effort but it is hard to focus on the show | Negative |
+|The plot could be scored 4 stars. In addition, the angle of the round lens plusing the scenery of Wuyuan is very much like the feeling of Chinese landscape painting. It satisfied me. | Positive |
-
Table 1 Sentiment Analysis in Movie Reviews
+
Form 1 Sentiment analysis of movie comments
-In natural language processing, sentiment analysis can be categorized as a **Text Classification problem**, i.e., to categorize a piece of text to a specific class. It involves two related tasks: text representation and classification. Before the emergence of deep learning techniques, the mainstream methods for text representation include BOW (*bag of words*) and topic modeling, while the latter contains SVM (*support vector machine*) and LR (*logistic regression*).
+In natural language processing, sentiment is a typical problem of **text categorization**, which divides the text that needs to be sentiment analysis into its category. Text categorization involves two issues: text representation and classification methods. Before the emergence of the deep learning, the mainstream text representation methods are BOW (bag of words), topic models, etc.; the classification methods are SVM (support vector machine), LR (logistic regression) and so on.
-The BOW model does not capture all the information in a piece of text, as it ignores syntax and grammar and just treats the text as a set of words. For example, “this movie is extremely bad“ and “boring, dull, and empty work” describe very similar semantic meaning, yet their BOW representations have very little similarity. Furthermore, “the movie is bad“ and “the movie is not bad“ have high similarity with BOW features, but they express completely opposite semantics.
+For a piece of text, BOW means that its word order, grammar and syntax are ignored, and this text is only treated as a collection of words, so the BOW method does not adequately represent the semantic information of the text. For example, the sentence "This movie is awful" and "a boring, empty, non-connotative work" have a high semantic similarity in sentiment analysis, but their BOW representation has a similarity of zero. Another example is that the BOW is very similar to the sentence "an empty, work without connotations" and "a work that is not empty and has connotations", but in fact they mean differently.
-This chapter introduces a deep learning model that handles these issues in BOW. Our model embeds texts into a low-dimensional space and takes word order into consideration. It is an end-to-end framework and it has large performance improvement over traditional methods \[[1](#references)\].
+The deep learning we are going to introduce in this chapter overcomes the above shortcomings of BOW representation. It maps text to low-dimensional semantic space based on word order, and performs text representation and classification in end-to-end mode. Its performance is significantly improved compared to the traditional method \[[1](#References)\].
## Model Overview
+The text representation models used in this chapter are Convolutional Neural Networks and Recurrent Neural Networks and their extensions. These models are described below.
-The model we used in this chapter uses **Convolutional Neural Networks** (**CNNs**) and **Recurrent Neural Networks** (**RNNs**) with some specific extensions.
-
+### Introduction of Text Convolutional Neural Networks (CNN)
-### Revisit to the Convolutional Neural Networks for Texts (CNN)
+We introduced the calculation process of the CNN model applied to text data in the [Recommended System](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system) section. Here is a simple review.
-The convolutional neural network for texts is introduced in chapter [recommender_system](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system), here is a brief overview.
+For a CNN, first convolute input word vector sequence to generate a feature map, and then obtain the features of the whole sentence corresponding to the kernel by using a max pooling over time on the feature map. Finally, the splicing of all the features obtained is the fixed-length vector representation of the text. For the text classification problem, connecting it via softmax to construct a complete model. In actual applications, we use multiple convolution kernels to process sentences, and convolution kernels with the same window size are stacked to form a matrix, which can complete the operation more efficiently. In addition, we can also use the convolution kernel with different window sizes to process the sentence. Figure 3 in the [Recommend System](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system) section shows four convolution kernels, namely Figure 1 below, with different colors representing convolution kernel operations of different sizes.
-CNN mainly contains convolution and pooling operation, with versatile combinations in various applications. We firstly apply the convolution operation: we apply the kernel in each window, extracting features. Convolving by the kernel at every window produces a feature map. Next, we apply *max pooling* over time to represent the whole sentence, which is the maximum element across the feature map. In real applications, we will apply multiple CNN kernels on the sentences. It can be implemented efficiently by concatenating the kernels together as a matrix. Also, we can use CNN kernels with different kernel size. Finally, concatenating the resulting features produces a fixed-length representation, which can be combined with a softmax to form the model for the sentiment analysis problem.
+
+
+Figure 1. CNN text classification model
+
-For short texts, the aforementioned CNN model can achieve very high accuracy \[[1](#references)\]. If we want to extract more abstract representations, we may apply a deeper CNN model \[[2](#references),[3](#references)\].
+For the general short text classification problem, the simple text convolution network described above can achieve a high accuracy rate \[[1](#References)\]. If you want a more abstract and advanced text feature representation, you can construct a deep text convolutional neural network\[[2](#References), [3](#References)\].
### Recurrent Neural Network (RNN)
-RNN is an effective model for sequential data. In terms of computability, the RNN is Turing-complete \[[4](#references)\]. Since NLP is a classical problem of sequential data, the RNN, especially its variant LSTM\[[5](#references)\]), achieves state-of-the-art performance on various NLP tasks, such as language modeling, syntax parsing, POS-tagging, image captioning, dialog, machine translation, and so forth.
+RNN is a powerful tool for accurately modeling sequence data. In fact, the theoretical computational power of the RNN is perfected by Turing' \[[4](#References)\]. Natural language is a typical sequence data (word sequence). In recent years, RNN and its derivation (such as long short term memory\[[5](#References)\]) have been applied in many natural language fields, such as in language models, syntactic parsing, semantic role labeling (or general sequence labeling), semantic representation, graphic generation, dialogue, machine translation, etc., all perform well and even become the best at present.
-
-Figure 1. An illustration of an unfolded RNN in time.
+
+Figure 2. Schematic diagram of the RNN expanded by time
-As shown in Figure 1, we unfold an RNN: at the $t$-th time step, the network takes two inputs: the $t$-th input vector $\vec{x_t}$ and the latent state from the last time-step $\vec{h_{t-1}}$. From those, it computes the latent state of the current step $\vec{h_t}$. This process is repeated until all inputs are consumed. Denoting the RNN as function $f$, it can be formulated as follows:
+The RNN expands as time is shown in Figure 2: at the time of $t$, the network reads the $t$th input $x_t$ (vector representation) and the state value of the hidden layer at the previous moment $h_{t- 1}$ (vector representation, $h_0$ is normally initialized to $0$ vector), and calculate the state value $h_t$ of the hidden layer at this moment. Repeat this step until all the inputs have been read. If the function is recorded as $f$, its formula can be expressed as:
-$$\vec{h_t}=f(\vec{x_t},\vec{h_{t-1}})=\sigma(W_{xh}\vec{x_t}+W_{hh}\vec{h_{t-1}}+\vec{b_h})$$
+$$h_t=f(x_t,h_{t-1})=\sigma(W_{xh}x_t+W_{hh}h_{t-1}+b_h)$$
-where $W_{xh}$ is the weight matrix to feed into the latent layer; $W_{hh}$ is the latent-to-latent matrix; $b_h$ is the latent bias and $\sigma$ refers to the $sigmoid$ function.
+Where $W_{xh}$ is the matrix parameter of the input to the hidden layer, $W_{hh}$ is the matrix parameter of the hidden layer to the hidden layer, and $b_h$ is the bias vector parameter of the hidden layer, $\sigma $ is the $sigmoid$ function.
-In NLP, words are often represented as one-hot vectors and then mapped to an embedding. The embedded feature goes through an RNN as input $x_t$ at every time step. Moreover, we can add other layers on top of RNN, such as a deep or stacked RNN. Finally, the last latent state may be used as a feature for sentence classification.
+When dealing with natural language, the word (one-hot representation) is usually mapped to its word vector representation, and then used as the input $x_t$ for each moment of the recurrent neural network. In addition, other layers may be connected to the hidden layer of the RNN depending on actual needs. For example, you can connect the hidden layer output of a RNN to the input of the next RNN to build a deep or stacked RNN, or extract the hidden layer state at the last moment as a sentence representation and then implement a classification model, etc.
-### Long-Short Term Memory (LSTM)
+### Long and Short Term Memory Network (LSTM)
-Training an RNN on long sequential data sometimes leads to the gradient vanishing or exploding\[[6](#references)\]. To solve this problem Hochreiter S, Schmidhuber J. (1997) proposed **Long Short Term Memory** (LSTM)\[[5](#references)\]).
+For longer sequence data, the gradient disappearance or explosion phenomenon is likely to occur during training RNN\[[6](#References)\]. To solve this problem, Hochreiter S, Schmidhuber J. (1997) proposed LSTM (long short term memory\[[5](#References)\]).
-Compared to the structure of a simple RNN, an LSTM includes memory cell $c$, input gate $i$, forget gate $f$ and output gate $o$. These gates and memory cells dramatically improve the ability for the network to handle long sequences. We can formulate the **LSTM-RNN**, denoted as a function $F$, as follows:
+Compared to a simple RNN, LSTM adds memory unit $c$, input gate $i$, forget gate $f$, and output gate $o$. The combination of these gates and memory units greatly enhances the ability of the recurrent neural network to process long sequence data. If the function \is denoted as $F$, the formula is:
$$ h_t=F(x_t,h_{t-1})$$
-$F$ contains following formulations\[[7](#references)\]:
+$F$ It is a combination of the following formulas\[[7](#References)\]:
$$ i_t = \sigma{(W_{xi}x_t+W_{hi}h_{t-1}+W_{ci}c_{t-1}+b_i)} $$
$$ f_t = \sigma(W_{xf}x_t+W_{hf}h_{t-1}+W_{cf}c_{t-1}+b_f) $$
$$ c_t = f_t\odot c_{t-1}+i_t\odot tanh(W_{xc}x_t+W_{hc}h_{t-1}+b_c) $$
$$ o_t = \sigma(W_{xo}x_t+W_{ho}h_{t-1}+W_{co}c_{t}+b_o) $$
$$ h_t = o_t\odot tanh(c_t) $$
-
-In the equation,$i_t, f_t, c_t, o_t$ stand for input gate, forget gate, memory cell and output gate, respectively. $W$ and $b$ are model parameters, $\tanh$ is a hyperbolic tangent, and $\odot$ denotes an element-wise product operation. The input gate controls the magnitude of the new input into the memory cell $c$; the forget gate controls the memory propagated from the last time step; the output gate controls the magnitutde of the output. The three gates are computed similarly with different parameters, and they influence memory cell $c$ separately, as shown in Figure 2:
+Where $i_t, f_t, c_t, o_t$ respectively represent the vector representation of the input gate, the forget gate, the memory unit and the output gate, the $W$ and $b$ with the angular label are the model parameters, and the $tanh$ is the hyperbolic tangent function. , $\odot$ represents an elementwise multiplication operation. The input gate controls the intensity of the new input into the memory unit $c$, the forget gate controls the intensity of the memory unit to maintain the previous time value, and the output gate controls the intensity of the output memory unit. The three gates are calculated in a similar way, but with completely different parameters.They controll the memory unit $c$ in different ways, as shown in Figure 3:
-
-Figure 2. LSTM at time step $t$ [7].
+
+Figure 3. LSTM for time $t$ [7]
-LSTM enhances the ability of considering long-term reliance, with the help of memory cell and gate. Similar structures are also proposed in Gated Recurrent Unit (GRU)\[[8](Reference)\] with a simpler design. **The structures are still similar to RNN, though with some modifications (As shown in Figure 2), i.e., latent status depends on input as well as the latent status of the last time step, and the process goes on recurrently until all inputs are consumed:**
+LSTM enhances its ability to handle long-range dependencies by adding memory and control gates to RNN. A similar principle improvement is Gated Recurrent Unit (GRU)\[[8](#References)\], which is more concise in design. **These improvements are different, but their macro descriptions are the same as simple recurrent neural networks (as shown in Figure 2). That is, the hidden state changes according to the current input and the hidden state of the previous moment, and this process is continuous until the input is processed:**
$$ h_t=Recrurent(x_t,h_{t-1})$$
-where $Recrurent$ is a simple RNN, GRU or LSTM.
+Among them, $Recrurent$ can represent a RNN, GRU or LSTM.
+
+
+
+
### Stacked Bidirectional LSTM
-For vanilla LSTM, $h_t$ contains input information from previous time-step $1..t-1$ context. We can also apply an RNN with reverse-direction to take successive context $t+1…n$ into consideration. Combining constructing deep RNN (deeper RNN can contain more abstract and higher level semantic), we can design structures with deep stacked bidirectional LSTM to model sequential data\[[9](#references)\].
+For a normal directional RNN, $h_t$ contains the input information before the $t$ time, which is the above context information. Similarly, in order to get the following context information, we can use a RNN in the opposite direction (which will be processed in reverse order). Combined with the method of constructing deep-loop neural networks (deep neural networks often get more abstract and advanced feature representations), we can build a more powerful LSTM-based stack bidirectional recurrent neural network\[[9](#References )\] to model time series data.
-As shown in Figure 3 (3-layer RNN), odd/even layers are forward/reverse LSTM. Higher layers of LSTM take lower-layers LSTM as input, and the top-layer LSTM produces a fixed length vector by max-pooling (this representation considers contexts from previous and successive words for higher-level abstractions). Finally, we concatenate the output to a softmax layer for classification.
+As shown in Figure 4 (taking three layers as an example), the odd-numbered LSTM is forward and the even-numbered LSTM is inverted. The higher-level LSTM uses the lower LSTM and all previous layers of information as input. The maximum pooling of the highest-level LSTM sequence in the time dimension can be used to obtain a fixed-length vector representation of the text (this representation fully fuses the contextual information and deeply abstracts of the text), and finally we connect the text representation to the softmax to build the classification model.
-
-Figure 3. Stacked Bidirectional LSTM for NLP modeling.
+
+Figure 4. Stacked bidirectional LSTM for text categorization
-## Dataset
-We use [IMDB](http://ai.stanford.edu/%7Eamaas/data/sentiment/) dataset for sentiment analysis in this tutorial, which consists of 50,000 movie reviews split evenly into a 25k train set and a 25k test set. In the labeled train/test sets, a negative review has a score <= 4 out of 10, and a positive review has a score >= 7 out of 10.
-
-`paddle.datasets` package encapsulates multiple public datasets, including `cifar`, `imdb`, `mnist`, `moivelens`, and `wmt14`, etc. There's no need for us to manually download and preprocess IMDB.
-
-After issuing a command `python train.py`, training will start immediately. The details will be unpacked by the following sessions to see how it works.
+## Dataset Introduction
+We use the [IMDB sentiment analysis data set](http://ai.stanford.edu/%7Eamaas/data/sentiment/) as an example. The training and testing IMDB dataset contain 25,000 labeled movie reviews respectively. Among them, the score of the negative comment is less than or equal to 4, and the score of the positive comment is greater than or equal to 7, full score is 10.
+```text
+aclImdb
+|- test
+ |-- neg
+ |-- pos
+|- train
+ |-- neg
+ |-- pos
+```
+Paddle implements the automatic download and read the imdb dataset in `dataset/imdb.py`, and provides API for reading dictionary, training data, testing data, and so on.
## Model Configuration
-Our program starts with importing necessary packages and initializing some global variables:
+In this example, we implement two text categorization algorithms based on the text convolutional neural network described in the [Recommender System](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system) section and [Stacked Bidirectional LSTM](#Stacked Bidirectional LSTM). We first import the packages we need to use and define global variables:
```python
from __future__ import print_function
import paddle
import paddle.fluid as fluid
-from functools import partial
import numpy as np
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
-
-CLASS_DIM = 2
-EMB_DIM = 128
-HID_DIM = 512
-STACKED_NUM = 3
-BATCH_SIZE = 128
-USE_GPU = False
-```
+import sys
+import math
-As alluded to in section [Model Overview](#model-overview), here we provide the implementations of both Text CNN and Stacked-bidirectional LSTM models.
+CLASS_DIM = 2 #Number of categories for sentiment analysis
+EMB_DIM = 128 #Dimensions of the word vector
+HID_DIM = 512 #Dimensions of hide layer
+STACKED_NUM = 3 #LSTM Layers of the bidirectional stack
+BATCH_SIZE = 128 #batch size
-### Text Convolution Neural Network (Text CNN)
+```
-We create a neural network `convolution_net` as the following snippet code.
-Note: `fluid.nets.sequence_conv_pool` includes both convolution and pooling layer operations.
+### Text Convolutional Neural Network
+We build the neural network `convolution_net`, the sample code is as follows.
+Note that `fluid.nets.sequence_conv_pool` contains both convolution and pooling layers.
```python
+#Textconvolution neural network
def convolution_net(data, input_dim, class_dim, emb_dim, hid_dim):
emb = fluid.layers.embedding(
input=data, size=[input_dim, emb_dim], is_sparse=True)
@@ -195,48 +199,53 @@ def convolution_net(data, input_dim, class_dim, emb_dim, hid_dim):
prediction = fluid.layers.fc(
input=[conv_3, conv_4], size=class_dim, act="softmax")
return prediction
-
```
-Parameter `input_dim` denotes the dictionary size, and `class_dim` is the number of categories.
-The above Text CNN network extracts high-level features and maps them to a vector of the same size as the categories. `paddle.activation.Softmax` function or classifier is then used for calculating the probability of the sentence belonging to each category.
+The network input `input_dim` indicates the size of the dictionary, and `class_dim` indicates the number of categories. Here, we implement the convolution and pooling operations using the [`sequence_conv_pool`](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/trainer_config_helpers/networks.py) API.
+
### Stacked bidirectional LSTM
-We create a neural network `stacked_lstm_net` as below.
+The code of the stack bidirectional LSTM `stacked_lstm_net` is as follows:
```python
+#Stack Bidirectional LSTM
def stacked_lstm_net(data, input_dim, class_dim, emb_dim, hid_dim, stacked_num):
+ # Calculate word vectorvector
emb = fluid.layers.embedding(
- input=data, size=[input_dim, emb_dim], is_sparse=True)
+ input=data, size=[input_dim, emb_dim], is_sparse=True)=True)
+ #First stack
+ #Fully connected layer
fc1 = fluid.layers.fc(input=emb, size=hid_dim)
+ #lstm layer
lstm1, cell1 = fluid.layers.dynamic_lstm(input=fc1, size=hid_dim)
inputs = [fc1, lstm1]
+ #All remaining stack structures
for i in range(2, stacked_num + 1):
fc = fluid.layers.fc(input=inputs, size=hid_dim)
lstm, cell = fluid.layers.dynamic_lstm(
input=fc, size=hid_dim, is_reverse=(i % 2) == 0)
inputs = [fc, lstm]
- fc_last = fluid.layers.sequence_pool(input=inputs[0], pool_type='max')
+ #pooling layer
+ pc_last = fluid.layers.sequence_pool(input=inputs[0], pool_type='max')
lstm_last = fluid.layers.sequence_pool(input=inputs[1], pool_type='max')
- prediction = fluid.layers.fc(input=[fc_last, lstm_last],
- size=class_dim,
- act='softmax')
+ #Fully connected layer, softmax prediction
+ prediction = fluid.layers.fc(
+ input=[fc_last, lstm_last], size=class_dim, act='softmax')
return prediction
-
```
-The above stacked bidirectional LSTM network extracts high-level features and maps them to a vector of the same size as the categories. `paddle.activation.Softmax` function or classifier is then used for calculating the probability of the sentence belonging to each category.
+The above stacked bidirectional LSTM abstracts the advanced features and maps them to vectors of the same size as the number of classification. The 'softmax' activation function of the last fully connected layer is used to calculate the probability of a certain category.
-To reiterate, we can either invoke `convolution_net` or `stacked_lstm_net`. In below steps, we will go with `convolution_net`.
+Again, here we can call any network structure of `convolution_net` or `stacked_lstm_net` for training and learning. Let's take `convolution_net` as an example.
-Next we define an `inference_program` that simply uses `convolution_net` to predict output with the input from `fluid.layer.data`.
+Next we define the prediction program (`inference_program`). We use `convolution_net` to predict the input of `fluid.layer.data`.
```python
def inference_program(word_dict):
@@ -249,47 +258,44 @@ def inference_program(word_dict):
return net
```
-Then we define a `training_program` that uses the result from `inference_program` to compute the cost with label data.
-Also define `optimizer_func` to specify the optimizer.
+We define `training_program` here, which uses the result returned from `inference_program` to calculate the error. We also define the optimization function `optimizer_func`.
+Because it is supervised learning, the training set tags are also defined in `fluid.layers.data`. During training, cross-entropy is used as a loss function in `fluid.layer.cross_entropy`.
-In the context of supervised learning, labels of the training set are defined in `paddle.layer.data` too. During training, cross-entropy is used as loss function in `paddle.layer.classification_cost` and as the output of the network; During testing, the outputs are the probabilities calculated in the classifier.
-First result that returns from the list must be cost.
+During the testing, the classifier calculates the probability of each output. The first returned value is specified as cost.
```python
-def train_program(word_dict):
- prediction = inference_program(word_dict)
+def train_program(prediction):
label = fluid.layers.data(name="label", shape=[1], dtype="int64")
cost = fluid.layers.cross_entropy(input=prediction, label=label)
avg_cost = fluid.layers.mean(cost)
accuracy = fluid.layers.accuracy(input=prediction, label=label)
- return [avg_cost, accuracy]
-
+ return [avg_cost, accuracy] #return average cost and accuracy acc
+#Optimization function
def optimizer_func():
return fluid.optimizer.Adagrad(learning_rate=0.002)
```
-## Model Training
+## Training Model
+
+### Defining the training environment
-### Specify training environment
+Define whether your training is on the CPU or GPU:
-Specify your training environment, you should specify if the training is on CPU or GPU.
```python
-use_cuda = False
+use_cuda = False #train on cpu
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
```
-### Datafeeder Configuration
+### Defining the data creator
-Next we define data feeders for test and train. The feeder reads a `buf_size` of data each time and feed them to the training/testing process.
-`paddle.dataset.imdb.train` will yield records during each pass, after shuffling, a batch input of `BATCH_SIZE` is generated for training.
+The next step is to define a data creator for training and testing. The creator reads in a data of size BATCH_SIZE. Paddle.dataset.imdb.word_dict will provide a size of BATCH_SIZE after each time shuffling, which is the cache size: buf_size.
-Notice for loading and reading IMDB data, it could take up to 1 minute. Please be patient.
+Note: It may take a few minutes to read the IMDB data, please be patient.
```python
-
print("Loading IMDB word dict....")
word_dict = paddle.dataset.imdb.word_dict()
@@ -298,77 +304,125 @@ train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.imdb.train(word_dict), buf_size=25000),
batch_size=BATCH_SIZE)
+print("Reading testing data....")
+test_reader = paddle.batch(
+ paddle.dataset.imdb.test(word_dict), batch_size=BATCH_SIZE)
```
-
-
-### Create Trainer
-
-Create a trainer that takes `train_program` as input and specify optimizer function.
-
+Word_dict is a dictionary sequence, which is the correspondence between words and labels. You can see it specifically by running the next code:
```python
-trainer = Trainer(
- train_func=partial(train_program, word_dict),
- place=place,
- optimizer_func=optimizer_func)
+word_dict
```
+Each line is a correspondence such as ('limited': 1726), which indicates that the label corresponding to the word limited is 1726.
-### Feeding Data
+### Construction Trainer
+The trainer requires a training program and a training optimization function.
-`feed_order` is devoted to specifying the correspondence between each yield record and `paddle.layer.data`. For instance, the first column of data generated by `imdb.train` corresponds to `words`.
+```python
+exe = fluid.Executor(place)
+prediction = inference_program(word_dict)
+[avg_cost, accuracy] = train_program(prediction)#training program
+sgd_optimizer = optimizer_func()# training optimization function
+sgd_optimizer.minimize(avg_cost)
+```
+This function is used to calculate the result of the model on the test dataset.
```python
-feed_order = ['words', 'label']
+def train_test(program, reader):
+ count = 0
+ feed_var_list = [
+ program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder_test = fluid.DataFeeder(feed_list=feed_var_list, place=place)
+ test_exe = fluid.Executor(place)
+ accumulated = len([avg_cost, accuracy]) * [0]
+ for test_data in reader():
+ avg_cost_np = test_exe.run(
+ program=program,
+ feed=feeder_test.feed(test_data),
+ fetch_list=[avg_cost, accuracy])
+ accumulated = [
+ x[0] + x[1][0] for x in zip(accumulated, avg_cost_np)
+ ]
+ count += 1
+ return [x / count for x in accumulated]
```
-### Event Handler
+### Providing data and building a main training loop
-Callback function `event_handler` will be called during training when a pre-defined event happens.
-For example, we can check the cost by `trainer.test` when `EndStepEvent` occurs
+`feed_order` is used to define the mapping relationship between each generated data and `fluid.layers.data`. For example, the data in the first column generated by `imdb.train` corresponds to the `words` feature.
```python
# Specify the directory path to save the parameters
params_dirname = "understand_sentiment_conv.inference.model"
-def event_handler(event):
- if isinstance(event, EndStepEvent):
- print("Step {0}, Epoch {1} Metrics {2}".format(
- event.step, event.epoch, list(map(np.array, event.metrics))))
-
- if event.step == 10:
- trainer.save_params(params_dirname)
- trainer.stop()
+feed_order = ['words', 'label']
+pass_num = 1 #Number rounds of the training loop
+
+# Main loop part of the program
+def train_loop(main_program):
+ # Start the trainer built above
+ exe.run(fluid.default_startup_program())
+
+ feed_var_list_loop = [
+ main_program.global_block().var(var_name) for var_name in feed_order
+ ]
+ feeder = fluid.DataFeeder(
+ feed_list=feed_var_list_loop, place=place)
+
+ test_program = fluid.default_main_program().clone(for_test=True)
+
+ # Training loop
+ for epoch_id in range(pass_num):
+ for step_id, data in enumerate(train_reader()):
+ # Running trainer
+ metrics = exe.run(main_program,
+ feed=feeder.feed(data),
+ fetch_list=[avg_cost, accuracy])
+
+ # Testing Results
+ avg_cost_test, acc_test = train_test(test_program, test_reader)
+ print('Step {0}, Test Loss {1:0.2}, Acc {2:0.2}'.format(
+ step_id, avg_cost_test, acc_test))
+
+ print("Step {0}, Epoch {1} Metrics {2}".format(
+ step_id, epoch_id, list(map(np.array,
+ metrics))))
+
+ if step_id == 30:
+ if params_dirname is not None:
+ fluid.io.save_inference_model(params_dirname, ["words"],
+ prediction, exe)# Save model
+ return
```
-### Training
+### Training process
+
+We print the output of each step in the main loop of the training, and we can observe the training situation.
-Finally, we invoke `trainer.train` to start training with `num_epochs` and other parameters.
+### Start training
+
+Finally, we start the training main loop to start training. The training time is longer. If you want to get the result faster, you can shorten the training time by adjusting the loss value range or the number of training steps at the cost of reducing the accuracy.
```python
-trainer.train(
- num_epochs=1,
- event_handler=event_handler,
- reader=train_reader,
- feed_order=feed_order)
+train_loop(fluid.default_main_program())
```
-## Inference
+## Application Model
-### Create Inferencer
+### Building a predictor
-Initialize Inferencer with `inference_program` and `params_dirname` which is where we save params from training.
+As the training process, we need to create a prediction process and use the trained models and parameters to make predictions. `params_dirname` is used to store the various parameters in the training process.
```python
-inferencer = Inferencer(
- infer_func=partial(inference_program, word_dict),
- param_path=params_dirname,
- place=place)
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+exe = fluid.Executor(place)
+inference_scope = fluid.core.Scope()
```
-### Create Lod Tensor with test data
+### Generating test input data
-To do inference, we pick 3 potential reviews out of our mind as testing data. Feel free to modify any of them.
-We map each word in the reviews to id from `word_dict`, replaced by 'unknown' if the word is not in `word_dict`.
-Then we create lod data with the id list and use `create_lod_tensor` to create lod tensor.
+In order to make predictions, we randomly select 3 comments. We correspond each word in the comment to the id in `word_dict`. If the word is not in the dictionary, set it to `unknown`.
+Then we use `create_lod_tensor` to create the tensor of the detail level. For a detailed explanation of this function, please refer to [API documentation](http://paddlepaddle.org/documentation/docs/en/1.2/user_guides/howto/basic_concept/lod_tensor.html).
```python
reviews_str = [
@@ -386,27 +440,39 @@ base_shape = [[len(c) for c in lod]]
tensor_words = fluid.create_lod_tensor(lod, base_shape, place)
```
-### Infer
+## Applying models and making predictions
-Now we can infer and predict probability of positive or negative from each review above.
+Now we can make positive or negative predictions for each comment.
```python
-results = inferencer.infer({'words': tensor_words})
+with fluid.scope_guard(inference_scope):
-for i, r in enumerate(results[0]):
- print("Predict probability of ", r[0], " to be positive and ", r[1], " to be negative for review \'", reviews_str[i], "\'")
+ [inferencer, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(params_dirname, exe)
+ assert feed_target_names[0] == "words"
+ results = exe.run(inferencer,
+ feed={feed_target_names[0]: tensor_words},
+ fetch_list=fetch_targets,
+ return_numpy=False)
+ np_data = np.array(results[0])
+ for i, r in enumerate(np_data):
+ print("Predict probability of ", r[0], " to be positive and ", r[1],
+ " to be negative for review \'", reviews_str[i], "\'")
```
+
## Conclusion
-In this chapter, we use sentiment analysis as an example to introduce applying deep learning models on end-to-end short text classification, as well as how to use PaddlePaddle to implement the model. Meanwhile, we briefly introduce two models for text processing: CNN and RNN. In following chapters, we will see how these models can be applied in other tasks.
+In this chapter, we take sentiment analysis as an example to introduce end-to-end short text classification using deep learning, and complete all relevant experiments using PaddlePaddle. At the same time, we briefly introduce two text processing models: convolutional neural networks and recurrent neural networks. In the following chapters, we will see the application of these two basic deep learning models on other tasks.
+
+
## References
1. Kim Y. [Convolutional neural networks for sentence classification](http://arxiv.org/pdf/1408.5882)[J]. arXiv preprint arXiv:1408.5882, 2014.
-2. Kalchbrenner N, Grefenstette E, Blunsom P. [A convolutional neural network for modeling sentences](http://arxiv.org/pdf/1404.2188.pdf?utm_medium=App.net&utm_source=PourOver)[J]. arXiv preprint arXiv:1404.2188, 2014.
+2. Kalchbrenner N, Grefenstette E, Blunsom P. [A convolutional neural network for modelling sentences](http://arxiv.org/pdf/1404.2188.pdf?utm_medium=App.net&utm_source=PourOver)[J]. arXiv preprint arXiv:1404.2188, 2014.
3. Yann N. Dauphin, et al. [Language Modeling with Gated Convolutional Networks](https://arxiv.org/pdf/1612.08083v1.pdf)[J] arXiv preprint arXiv:1612.08083, 2016.
4. Siegelmann H T, Sontag E D. [On the computational power of neural nets](http://research.cs.queensu.ca/home/akl/cisc879/papers/SELECTED_PAPERS_FROM_VARIOUS_SOURCES/05070215382317071.pdf)[C]//Proceedings of the fifth annual workshop on Computational learning theory. ACM, 1992: 440-449.
5. Hochreiter S, Schmidhuber J. [Long short-term memory](http://web.eecs.utk.edu/~itamar/courses/ECE-692/Bobby_paper1.pdf)[J]. Neural computation, 1997, 9(8): 1735-1780.
@@ -416,7 +482,7 @@ In this chapter, we use sentiment analysis as an example to introduce applying d
9. Zhou J, Xu W. [End-to-end learning of semantic role labeling using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
-This tutorial is contributed by
PaddlePaddle, and licensed under a
Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by
PaddlePaddle, and licensed under a
Creative Commons Attribution-ShareAlike 4.0 International License.
-

-Fig 1. Syntax tree
+
+

+Figure 1. Example of dependency syntax analysis tree
+However, complete syntactic analysis needs to determine all the syntactic information contained in a sentence and the relationship between the components of the sentence. It is a very difficult task. The accuracy of syntactic analysis in current technology is not good, and the little errors in syntactic analysis will caused the SRL error. In order to reduce the complexity of the problem and obtain certain syntactic structure information, the idea of "shallow syntactic analysis" came into being. Shallow syntactic analysis is also called partial parsing or chunking. Different from full syntactic analysis which obtains a complete syntactic tree, shallow syntactic analysis only needs to identify some relatively simple independent components of the sentence, such as verb phrases, these identified structures are called chunks. In order to avoid the difficulties caused by the failure to obtain a syntactic tree with high accuracy, some studies \[[1](#References)\] also proposed a chunk-based SRL method. The block-based SRL method solves the SRL as a sequence labeling problem. Sequence labeling tasks generally use the BIO representation to define the set of labels for sequence annotations. Firstly, Let's introduce this representation. In the BIO notation, B stands for the beginning of the block, I stands for the middle of the block, and O stands for the end of the block. Different blocks are assigned different labels by B, I, and O. For example, for a block group extended by role A, the first block it contains is assigned to tag B-A, the other blocks it contains are assigned to tag I-A, and the block not belonging to any argument is assigned tag O.
-However, a complete syntactic analysis requires identifying the relationship among all constituents. Thus, the accuracy of SRL is sensitive to the preciseness of the syntactic analysis, making SRL challenging. To reduce its complexity and obtain some information on the syntactic structures, we often use *shallow syntactic analysis* a.k.a. partial parsing or chunking. Unlike complete syntactic analysis, which requires the construction of the complete parsing tree, *Shallow Syntactic Analysis* only requires identifying some independent constituents with relatively simple structures, such as verb phrases (chunk). To avoid difficulties in constructing a syntax tree with high accuracy, some work\[[1](#reference)\] proposed semantic chunking-based SRL methods, which reduces SRL into a sequence tagging problem. Sequence tagging tasks classify syntactic chunks using **BIO representation**. For syntactic chunks forming role A, its first chunk receives the B-A tag (Begin) and the remaining ones receive the tag I-A (Inside); in the end, the chunks left out will receive the tag O.
+Let's continue to take the above sentence as an example. Figure 1 shows the BIO representation method.
-The BIO representation of above example is shown in Fig.1.
-
-
-

-Fig 2. BIO representation
+
+

+Figure 2. Example of BIO labeling method
-This example illustrates the simplicity of sequence tagging, since
-
-1. It only relies on shallow syntactic analysis, reduces the precision requirement of syntactic analysis;
-2. Pruning the candidate arguments is no longer necessary;
-3. Arguments are identified and tagged at the same time. Simplifying the workflow reduces the risk of accumulating errors; oftentimes, methods that unify multiple steps boost performance.
+As can be seen from the above example, it is a relatively simple process to directly get the semantic roles labeling result of the argument according to the sequence labeling result. This simplicity is reflected in: (1) relying on shallow syntactic analysis, reducing the requirements and difficulty of syntactic analysis; (2) there is no candidate argument to pruning in this step; (3) the identification and labeling of arguments are realized at the same time. This integrated approach to arguments identification and labeling simplifies the process, reduces the risk of error accumulation, and often achieves better results.
-In this tutorial, our SRL system is built as an end-to-end system via a neural network. The system takes only text sequences as input, without using any syntactic parsing results or complex hand-designed features. The public dataset [CoNLL-2004 and CoNLL-2005 Shared Tasks](http://www.cs.upc.edu/~srlconll/) is used for the following task: given a sentence with predicates marked, identify the corresponding arguments and their semantic roles through sequence tagging.
+Similar to the block-based SRL method, in this tutorial we also regard the SRL as a sequence labeling problem. The difference is that we only rely on input text sequences, without relying on any additional syntax analysis results or complex artificial features. And constructing an end-to-end learning SRL system by using deep neural networks. Let's take the public data set of the SRL task in the [CoNLL-2004 and CoNLL-2005 Shared Tasks](http://www.cs.upc.edu/~srlconll/) task as an example to practice the following tasks. Giving a sentence and a predicate in this sentence, through the way of sequence labeling, find the arguments corresponding to the predicate from the sentence, and mark their semantic roles.
-## Model
+## Model Overview
-**Recurrent Neural Networks** (*RNN*) are important tools for sequence modeling and have been successfully used in some natural language processing tasks. Unlike feed-forward neural networks, RNNs can model the dependencies between elements of sequences. As a variant of RNNs', LSTMs aim modeling long-term dependency in long sequences. We have introduced this in [understand_sentiment](https://github.com/PaddlePaddle/book/tree/develop/05.understand_sentiment). In this chapter, we continue to use LSTMs to solve SRL problems.
+Recurrent Neural Network is an important model for modeling sequences. It is widely used in natural language processing tasks. Unlike the feed-forward neural network, the RNN is able to handle the contextual correlation between inputs. LSTM is an important variant of RNN that is commonly used to learn the long-range dependencies contained in long sequences. We have already introduced in [Sentiment Analysis](https://github.com/PaddlePaddle/book/tree/develop/06.understand_sentiment), in this article we still use LSTM to solve the SRL problem.
### Stacked Recurrent Neural Network
-*Deep Neural Networks* can extract hierarchical representations. The higher layers can form relatively abstract/complex representations, based on primitive features discovered through the lower layers. Unfolding LSTMs through time results in a deep feed-forward neural network. This is because any computational path between the input at time $k < t$ to the output at time $t$ crosses several nonlinear layers. On the other hand, due to parameter sharing over time, LSTMs are also *shallow*; that is, the computation carried out at each time-step is just a linear transformation. Deep LSTM networks are typically constructed by stacking multiple LSTM layers on top of each other and taking the output from lower LSTM layer at time $t$ as the input of upper LSTM layer at time $t$. Deep, hierarchical neural networks can be efficient at representing some functions and modeling varying-length dependencies\[[2](#reference)\].
-
-
-However, in a deep LSTM network, any gradient propagated back in depth needs to traverse a large number of nonlinear steps. As a result, while LSTMs of 4 layers can be trained properly, those with 4-8 have much worse performance. Conventional LSTMs prevent back-propagated errors from vanishing or exploding by introducing shortcut connections to skip the intermediate nonlinear layers. Therefore, deep LSTMs can consider shortcut connections in depth as well.
-
-
-A single LSTM cell has three operations:
+The deep network helps to form hierarchical features, and the upper layers of the network form more complex advanced features based on the primary features that have been learned in the lower layers. Although the LSTM is expanded along the time axis and is equivalent to a very "deep" feedforward network. However, since the LSTM time step parameters are shared, the mapping of the $t-1$ time state to the time of $t$ always passes only one non-linear mapping. It means that the modeling of state transitions by single-layer LSTM is “shallow”. Stacking multiple LSTM units, making the output of the previous LSTM$t$ time as the input of the next LSTM unit $t$ time, helps us build a deep network. We call it the first version of the stack ecurrent neural networks. Deep networks improve the ability of models to fit complex patterns and better model patterns across different time steps\[[2](#References)\].
-1. input-to-hidden: map input $x$ to the input of the forget gates, input gates, memory cells and output gates by linear transformation (i.e., matrix mapping);
-2. hidden-to-hidden: calculate forget gates, input gates, output gates and update memory cell, this is the main part of LSTMs;
-3. hidden-to-output: this part typically involves an activation operation on hidden states.
+However, training a deep LSTM network is not an easy task. Stacking multiple LSTM cells in portrait orientation may encounter problems with the propagation of gradients in the longitudinal depth. Generally, stacking 4 layers of LSTM units can be trained normally. When the number of layers reaches 4~8 layers, performance degradation will occur. At this time, some new structures must be considered to ensure the gradient is transmitted vertically and smoothly. This is a problem that must be solved in training a deep LSTM networks. We can learn from LSTM to solve one of the tips of the "gradient disappearance and gradient explosion" problem: there is no nonlinear mapping on the information propagation route of Memory Cell, and neither gradient decay nor explosion when the gradient propagates back. Therefore, the deep LSTM model can also add a path that ensures smooth gradient propagation in the vertical direction.
-Based on the stacked LSTMs, we add shortcut connections: take the input-to-hidden from the previous layer as a new input and learn another linear transformation.
+The operation performed by an LSTM unit can be divided into three parts: (1) Input-to-hidden: Each time step input information $x$ will first pass through a matrix map and then as a forgetting gate, input gate, memory unit, output gate's input. Note that this mapping does not introduce nonlinear activation; (2) Hidden-to-hidden: this step is the main body of LSTM calculation, including forgotten gate, input gate, memory unit update, output gate calculation; (3) hidden-to-output: usually simple to activate the hidden layer vector. On the basis of the first version of the stack network, we add a new path: in addition to the previous LSTM output, the mapping of the input of the previous LSTM to the hidden layer is used as a new input. and a new input is added. At the same time, add a linear map to learn a new transform.
-Fig.3 illustrates the final stacked recurrent neural networks.
+Figure 3 is a schematic structural diagram of a finally obtained stack recurrent neural network.
-
-Fig 3. Stacked Recurrent Neural Networks
+
+Figure 3. Schematic diagram of stack-based recurrent neural network based on LSTM
### Bidirectional Recurrent Neural Network
-While LSTMs can summarize the history, they can not see the future. Because most NLP (natural language processing) tasks provide the entirety of sentences, sequential learning can benefit from having the future encoded as well as the history.
-
-To address this, we can design a bidirectional recurrent neural network by making a minor modification. A higher LSTM layer can process the sequence in reversed direction with regards to its immediate lower LSTM layer, i.e., deep LSTM layers take turns to train on input sequences from left-to-right and right-to-left. Therefore, LSTM layers at time-step $t$ can see both histories and the future, starting from the second layer. Fig. 4 illustrates the bidirectional recurrent neural networks.
+In LSTM, the hidden layer vector at the time of $t$ encodes all input information until the time of $t$. The LSTM at $t$ can see the history, but cannot see the future. In most natural language processing tasks, we almost always get the whole sentence. In this case, if you can get future information like the historical information, it will be of great help to the sequence learning task.
+In order to overcome this shortcoming, we can design a bidirectional recurrent network unit, which is simple and straightforward: make a small modification to the stack recurrent neural network of the previous section, stack multiple LSTM units, and let each layer of LSTM units learn the output sequence of the previous layer in the order of forward, reverse, forward …… So, starting from layer 2, our LSTM unit will always see historical and future information at $t$. Figure 4 is a schematic diagram showing the structure of a bidirectional recurrent neural network based on LSTM.
-
-Fig 4. Bidirectional LSTMs
+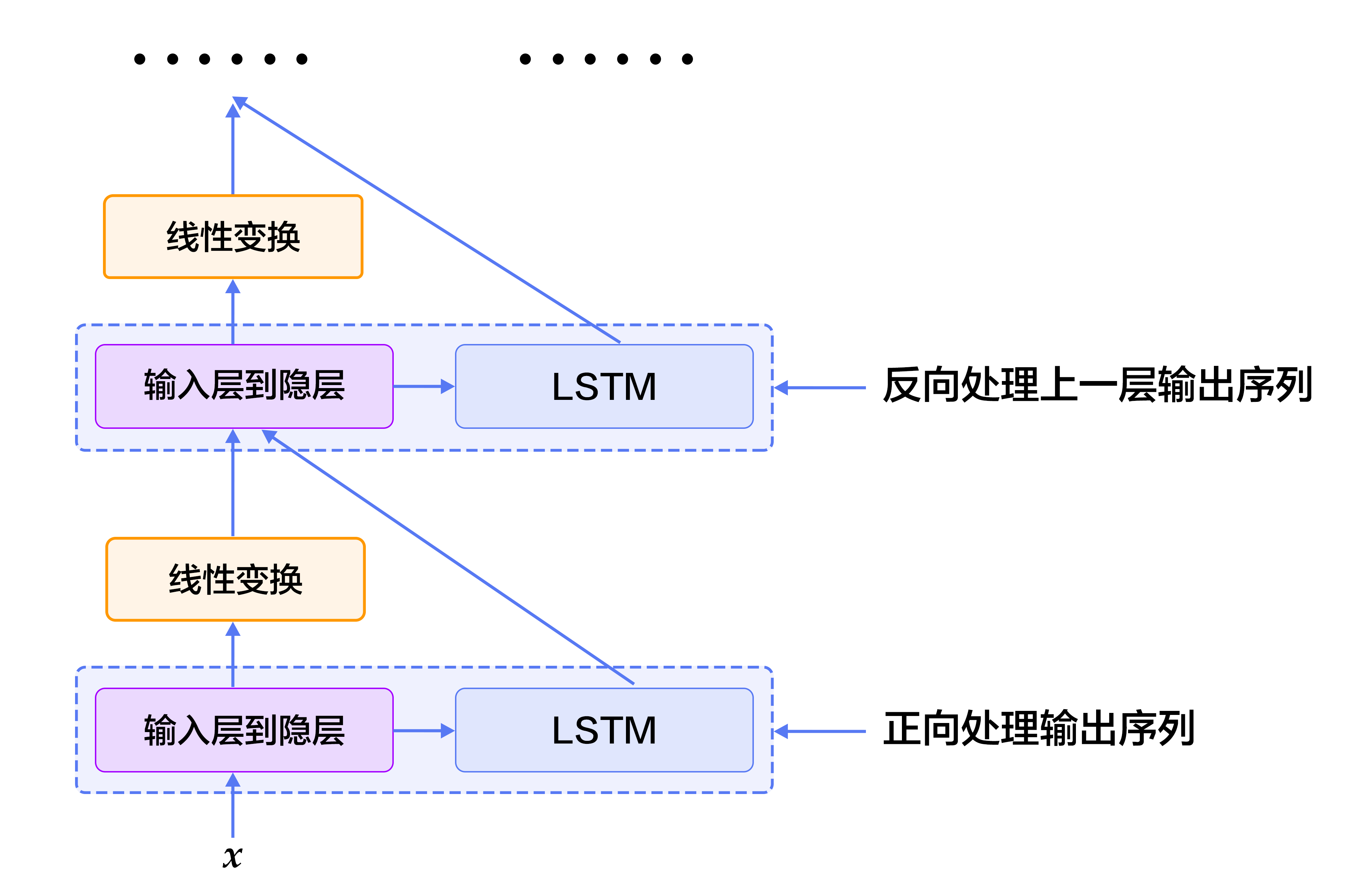
+Figure 4. Schematic diagram of a bidirectional recurrent neural network based on LSTM
-Note that, this bidirectional RNNs is different from the one proposed by Bengio et al. in machine translation tasks \[[3](#reference), [4](#reference)\]. We will introduce another bidirectional RNNs in the following chapter [machine translation](https://github.com/PaddlePaddle/book/blob/develop/08.machine_translation/README.md)
-
-### Conditional Random Field (CRF)
+It should be noted that this bidirectional RNN structure is not the same as the bidirectional RNN structure used by Bengio etc in machine translation tasks\[[3](#References), [4](#References)\] Another bidirectional recurrent neural network will be introduced in the following [Machine Translation](https://github.com/PaddlePaddle/book/blob/develop/08.machine_translation) task.
-Typically, a neural network's lower layers learn representations while its very top layer accomplishes the final task. These principles can guide our problem-solving approaches. In SRL tasks, a **Conditional Random Field** (*CRF*) is built on top of the network in order to perform the final prediction to tag sequences. It takes representations provided by the last LSTM layer as input.
+### Conditional Random Field
+The idea of using a neural network model to solve a problem usually is: the front-layer network learns the feature representation of the input, and the last layer of the network completes the final task based on the feature. In the SRL task, the feature representation of the deep LSTM network learns input. Conditional Random Filed (CRF) completes the sequence labeling on th basis of features at the end of the entire network.
-The CRF is an undirected probabilistic graph with nodes denoting random variables and edges denoting dependencies between these variables. In essence, CRFs learn the conditional probability $P(Y|X)$, where $X = (x_1, x_2, ... , x_n)$ are sequences of input and $Y = (y_1, y_2, ... , y_n)$ are label sequences; to decode, simply search through $Y$ for a sequence that maximizes the conditional probability $P(Y|X)$, i.e., $Y^* = \mbox{arg max}_{Y} P(Y | X)$。
+CRF is a probabilistic structural model, which can be regarded as a probabilistic undirected graph model. Nodes represent random variables and edges represent probability dependencies between random variables. In simple terms, CRF learns the conditional probability $P(X|Y)$, where $X = (x_1, x_2, ... , x_n)$ is the input sequence, $Y = (y_1, y_2, ..., y_n $ is a sequence of tokens; the decoding process is given the $X$ sequence to solve the $Y$ sequence with the largest $P(Y|X)$, that is $Y^* = \mbox{arg max}_{Y} P( Y | X)$.
-Sequence tagging tasks do not assume a lot of conditional independence, because they only concern about the input and the output being linear sequences. Thus, the graph model of sequence tagging tasks is usually a simple chain or line, which results in a **Linear-Chain Conditional Random Field**, shown in Fig.5.
+The sequence labeling task only needs to consider that both the input and the output are a linear sequence. And since we only use the input sequence as a condition and do not make any conditional independent assumptions, there is no graph structure between the elements of the input sequence. In summary, the CRF defined on the chain diagram shown in Figure 5 is used in the sequence labeling task, which is called Linear Chain Conditional Random Field.
-
-Fig 5. Linear Chain Conditional Random Field used in SRL tasks
+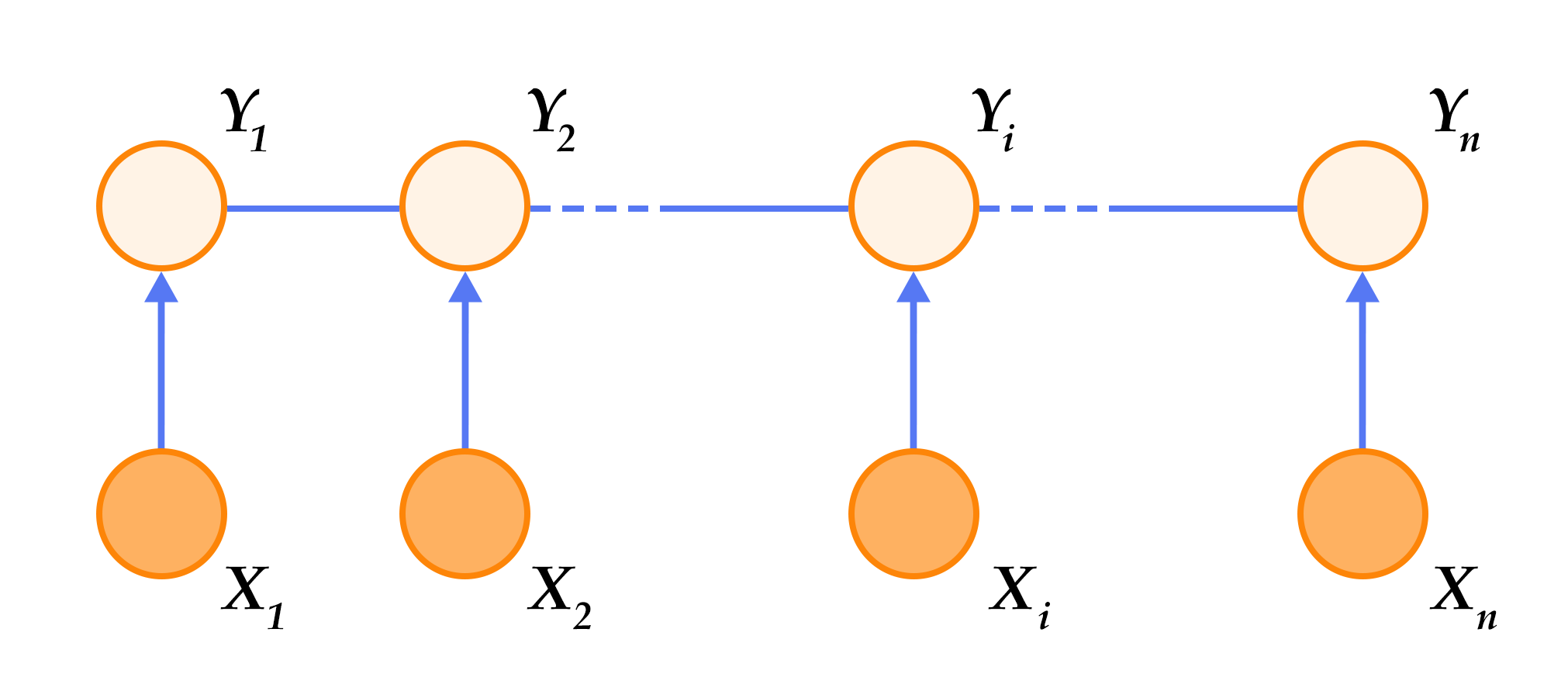
+Figure 5. Linear chain conditional random field used in sequence labeling tasks
-By the fundamental theorem of random fields \[[5](#reference)\], the joint distribution over the label sequence $Y$ given $X$ has the form:
+According to the factorization theorem on the linear chain condition random field \[[5](#References)\], the probability of a particular tag sequence $Y$ can be defined as given in the observation sequence $X$:
-$$p(Y | X) = \frac{1}{Z(X)} \text{exp}\left(\sum_{i=1}^{n}\left(\sum_{j}\lambda_{j}t_{j} (y_{i - 1}, y_{i}, X, i) + \sum_{k} \mu_k s_k (y_i, X, i)\right)\right)$$
+$$p(Y | X) = \frac{1}{Z(X)} \text{exp}\left(\sum_{i=1}^{n}\left(\sum_{j}\lambda_{ j}t_{j} (y_{i - 1}, y_{i}, X, i) + \sum_{k} \mu_k s_k (y_i, X, i)\right)\right)$$
-
-where, $Z(X)$ is normalization constant, ${t_j}$ represents the feature functions defined on edges called the *transition feature*, which denotes the transition probabilities from $y_{i-1}$ to $y_i$ given input sequence $X$. ${s_k}$ represents the feature function defined on nodes, called the state feature, denoting the probability of $y_i$ given input sequence $X$. In addition, $\lambda_j$ and $\mu_k$ are weights corresponding to $t_j$ and $s_k$. Alternatively, $t$ and $s$ can be written in the same form that depends on $y_{i - 1}$, $y_i$, $X$, and $i$. Taking its summation over all nodes $i$, we have: $f_{k}(Y, X) = \sum_{i=1}^{n}f_k({y_{i - 1}, y_i, X, i})$, which defines the *feature function* $f$. Thus, $P(Y|X)$ can be written as:
+Where $Z(X)$ is the normalization factor, and $t_j$ is the feature function defined on the edge, depending on the current and previous position, which called the transition feature. It represents the transition probability of the input sequence $X$ and its labeling sequence marked at the $i$ and $i - 1$ positions. $s_k$ is a feature function defined on the node, called a state feature, which depends on the current position. It represents the probability of marking for the observation sequence $X$ and its $i$ position. $\lambda_j$ and $\mu_k$ are the weights corresponding to the transfer feature function and the state feature function respectively. In fact, $t$ and $s$ can be represented in the same mathematical form, and the transfer feature and state are summed at each position $i$: $f_{k}(Y, X) = \sum_{i =1}^{n}f_k({y_{i - 1}, y_i, X, i})$. Calling $f$ collectively as a feature function, so $P(Y|X)$ can be expressed as:
$$p(Y|X, W) = \frac{1}{Z(X)}\text{exp}\sum_{k}\omega_{k}f_{k}(Y, X)$$
-where $\omega$ are the weights to the feature function that the CRF learns. While training, given input sequences and label sequences $D = \left[(X_1, Y_1), (X_2 , Y_2) , ... , (X_N, Y_N)\right]$, by maximum likelihood estimation (**MLE**), we construct the following objective function:
-
+$\omega$ is the weight corresponding to the feature function and is the parameter to be learned by the CRF model. During training, for a given input sequence and the corresponding set of markup sequences $D = \left[(X_1, Y_1), (X_2 , Y_2) , ... , (X_N, Y_N)\right]$ , by regularizing the maximum likelihood estimation to solve the following optimization objectives:
-$$\DeclareMathOperator*{\argmax}{arg\,max} L(\lambda, D) = - \text{log}\left(\prod_{m=1}^{N}p(Y_m|X_m, W)\right) + C \frac{1}{2}\lVert W\rVert^{2}$$
+$$\DeclareMathOperator*{\argmax}{arg\,max} L(\lambda, D) = - \text{log}\left(\prod_{m=1}^{N}p(Y_m|X_m, W )\right) + C \frac{1}{2}\lVert W\rVert^{2}$$
+This optimization objectives can be solved by the back propagation algorithm together with the entire neural network. When decoding, for a given input sequence $X$, the output sequence $\bar{Y}$ of maximizing the conditional probability $\bar{P}(Y|X)$ by the decoding algorithm (such as: Viterbi algorithm, Beam Search).
-This objective function can be solved via back-propagation in an end-to-end manner. While decoding, given input sequences $X$, search for sequence $\bar{Y}$ to maximize the conditional probability $\bar{P}(Y|X)$ via decoding methods (such as *Viterbi*, or [Beam Search Algorithm](https://github.com/PaddlePaddle/book/blob/develop/08.machine_translation/README.md#beam-search-algorithm)).
+### Deep bidirectional LSTM (DB-LSTM) SRL model
-### Deep Bidirectional LSTM (DB-LSTM) SRL model
+In the SRL task, the input is “predicate” and “a sentence”. The goal is to find the argument of the predicate from this sentence and mark the semantic role of the argument. If a sentence contains $n$ predicates, the sentence will be processed for $n$ times. One of the most straightforward models is the following:
-Given predicates and a sentence, SRL tasks aim to identify arguments of the given predicate and their semantic roles. If a sequence has $n$ predicates, we will process this sequence $n$ times. Here is the breakdown of a straight-forward model:
+1. Construct the input;
+ - Input 1 is the predicate and 2 is the sentence
+ - Extend input 1 to a sequence as long as input 2, expressed by one-hot mode;
+2. The predicate sequence and sentence sequence of the one-hot format are converted into a sequence of word vectors represented by real vectors through a vocabulary;
+3. The two word vector sequences in step 2 are used as input of the bidirectional LSTM to learn the feature representation of the input sequence;
+4. The CRF takes the features learned in the model in step 3 as input, and uses the tag sequence as the supervised signal to implement sequence labeling;
-1. Construct inputs;
- - input 1: predicate, input 2: sentence
- - expand input 1 into a sequence of the same length with input 2's sentence, using one-hot representation;
-2. Convert the one-hot sequences from step 1 to vector sequences via a word embedding's lookup table;
-3. Learn the representation of input sequences by taking vector sequences from step 2 as inputs;
-4. Take the representation from step 3 as input, label sequence as a supervisory signal, and realize sequence tagging tasks.
+You can try this method. Here, we propose some improvements that introduce two simple features that are very effective in improving system performance:
-Here, we propose some improvements by introducing two simple but effective features:
+- Predicate's context: In the above method, only the word vector of the predicate is used to express all the information related to the predicate. This method is always very weak, especially if the predicate appears multiple times in the sentence, it may cause certain ambiguity. From experience, a small segment of several words before and after the predicate can provide more information to help resolve ambiguity. So, we add this kind of experience to the model, and extract a "predicate context" fragment for each predicate, that is, a window fragment composed of $n$ words before and after the predicate;
+- Predicate context area's tag: Introduces a 0-1 binary variable for each word in the sentence, which indicats whether they are in the "predicate context" fragment;
-- predicate context (**ctx-p**): A single predicate word may not describe all the predicate information, especially when the same words appear multiple times in a sentence. With the expanded context, the ambiguity can be largely eliminated. Thus, we extract $n$ words before and after predicate to construct a window chunk.
+The modified model is as follows (Figure 6 is a schematic diagram of the model structure with a depth of 4):
-- region mark ($m_r$): The binary marker on a word, $m_r$, takes the value of $1$ when the word is in the predicate context region, and $0$ if not.
+1. Construct input
+ - Input 1 is a sentence sequence, input 2 is a predicate sequence, input 3 is a predicate context, and $n$ words before and after the predicate are extracted from the sentence to form a predicate context, which represented by one-hot. Input 4 is a predicate context area which marks whether each word in the sentence is in the context of the predicate;
+ - Extend the input 2~3 to a sequence as long as the input 1;
+2. Input 1~4 are converted into a sequence of word vectors represented by real vectors in vocabulary; where inputs 1 and 3 share the same vocabulary, and inputs 2 and 4 each have their own vocabulary;
+3. The four word vector sequences in step 2 are used as input to the bidirectional LSTM model; the LSTM model learns the feature representation of the input sequence to obtain a new feature representation sequence;
+4. The CRF takes the features learned in step 3 of the LSTM as input, and uses the marked sequence as the supervised signal to complete the sequence labeling;
-After these modifications, the model is as follows, as illustrated in Figure 6:
-
-1. Construct inputs
- - Input 1: word sequence. Input 2: predicate. Input 3: predicate context, extract $n$ words before and after predicate. Input 4: region mark sequence, where an entry is 1 if the word is located in the predicate context region, 0 otherwise.
- - expand input 2~3 into sequences with the same length with input 1
-2. Convert input 1~4 to vector sequences via word embedding lookup tables; While input 1 and 3 shares the same lookup table, input 2 and 4 have separate lookup tables.
-3. Take the four vector sequences from step 2 as inputs to bidirectional LSTMs; Train the LSTMs to update representations.
-4. Take the representation from step 3 as input to CRF, label sequence as a supervisory signal, and complete sequence tagging tasks.
-
-
-
-

-Fig 6. DB-LSTM for SRL tasks
+
+

+Figure 6. Deep bidirectional LSTM model on the SRL task
-## Data Preparation
-In the tutorial, we use [CoNLL 2005](http://www.cs.upc.edu/~srlconll/) SRL task open dataset as an example. Note that the training set and development set of the CoNLL 2005 SRL task are not free to download after the competition. Currently, only the test set can be obtained, including 23 sections of the Wall Street Journal and three sections of the Brown corpus. In this tutorial, we use the WSJ corpus as the training dataset to explain the model. However, since the training set is small, for a usable neural network SRL system, please consider paying for the full corpus.
+## Data Introduction
+
+In this tutorial, We use the data set opened by the [CoNLL 2005](http://www.cs.upc.edu/~srlconll/) SRL task as an example. It is important to note that the training set and development set of the CoNLL 2005 SRL task are not free for public after the competition. Currently, only the test set is available, including 23 in the Wall Street Journal and 3 in the Brown corpus. In this tutorial, we use the WSJ data in the test set to solve the model for the training set. However, since the number of samples in the test set is far from enough, if you want to train an available neural network SRL system, consider paying for the full amount of data.
-The original data includes a variety of information such as POS tagging, naming entity recognition, syntax tree, etc. In this tutorial, we only use the data under `test.wsj/words/` (text sequence) and `test.wsj/props/` (label results). The data directory used in this tutorial is as follows:
+The original data also includes a variety of information such as part-of-speech tagging, named entity recognition, and syntax parse tree. In this tutorial, we use the data in the test.wsj folder for training and testing, and only use the data under the words folder (text sequence) and the props folder (labeled results). The data directories used in this tutorial are as follows:
```text
conll05st-release/
└── test.wsj
- ├── props # label results
- └── words # text sequence
+ ├── props # Label result
+ └── words # Input text sequence
```
-The annotation information is derived from the results of Penn TreeBank\[[7](#references)\] and PropBank \[[8](#references)\]. The labeling of the PropBank is different from the labeling methods mentioned before, but shares with it the same underlying principle. For descriptions of the labeling, please refer to the paper \[[9](#references)\].
+The labeling information is derived from the labeling results of Penn TreeBank\[[7](#References)\] and PropBank\[[8](#References)\]. The label of the PropBank labeling result is different from the labeling result label we used in the first example of the article, but the principle is the same. For the description of the meaning of the labeling result label, please refer to the paper \[[9](#References)\].
-The raw data needs to be preprocessed into formats that PaddlePaddle can handle. The preprocessing consists of the following steps:
+The raw data needs to be preprocessed in order to be processed by PaddlePaddle. The preprocessing includes the following steps:
-1. Merge the text sequence and the tag sequence into the same record;
-2. If a sentence contains $n$ predicates, the sentence will be processed $n$ times into $n$ separate training samples, each sample with a different predicate;
-3. Extract the predicate context and construct the predicate context region marker;
-4. Construct the markings in BIO format;
-5. Obtain the integer index corresponding to the word according to the dictionary.
+1. Combine text sequences and tag sequences into one record;
+2. If a sentence contains $n$ predicates, the sentence will be processed for $n$ times, becoming a $n$ independent training sample, each sample with a different predicate;
+3. Extract the predicate context and construct the predicate context area tag;
+4. Construct a tag represented by the BIO method;
+5. Get the integer index corresponding to the word according to the dictionary.
-After preprocessing, a training sample contains nine features, namely: word sequence, predicate, predicate context (5 columns), region mark sequence, label sequence. The following table is an example of a training sample.
+After the pre-processing is completed, a training sample data contains 9 fields, namely: sentence sequence, predicate, predicate context (accounting for 5 columns), predicate context area tag, and labeling sequence. The following table is an example of a training sample.
-| word sequence | predicate | predicate context(5 columns) | region mark sequence | label sequence|
+| Sentence Sequence | Predicate | Predicate Context (Window = 5) | Predicate Context Area Tag | Label Sequence |
|---|---|---|---|---|
| A | set | n't been set . × | 0 | B-A1 |
| record | set | n't been set . × | 0 | I-A1 |
@@ -188,18 +165,19 @@ After preprocessing, a training sample contains nine features, namely: word sequ
| set | set | n't been set . × | 1 | B-V |
| . | set | n't been set . × | 1 | O |
-In addition to the data, we provide following resources:
-| filename | explanation |
+In addition to the data, we also provide the following resources:
+
+| File Name | Description |
|---|---|
-| word_dict | dictionary of input sentences, total 44068 words |
-| label_dict | dictionary of labels, total 106 labels |
-| predicate_dict | predicate dictionary, total 3162 predicates |
-| emb | a pre-trained word vector lookup table, 32-dimensional |
+| word_dict | Input a dictionary of sentences for a total of 44068 words |
+| label_dict | Tag dictionary, total 106 tags |
+| predicate_dict | Dictionary of predicates, totaling 3162 words |
+| emb | A trained vocabulary, 32-dimensional |
-We trained a language model on the English Wikipedia to get a word vector lookup table used to initialize the SRL model. While training the SRL model, the word vector lookup table is no longer updated. To learn more about the language model and the word vector lookup table, please refer to the tutorial [word vector](https://github.com/PaddlePaddle/book/blob/develop/04.word2vec/README.md). There are 995,000,000 tokens in the training corpus, and the dictionary size is 4900,000 words. In the CoNLL 2005 training corpus, 5% of the words are not in the 4900,000 words, and we see them all as unknown words, represented by `
`.
+We trained a language model on English Wikipedia to get a word vector to initialize the SRL model. During the training of the SRL model, the word vector is no longer updated. For the language model and word vector, refer to [Word Vector](https://github.com/PaddlePaddle/book/blob/develop/04.word2vec) for this tutorial. The corpus of our training language model has a total of 995,000,000 tokens, and the dictionary size is controlled to 4,900,000 words. CoNLL 2005 training corpus 5% of this word is not in 4900,000 words, we have seen them all unknown words, with `` representation.
-Here we fetch the dictionary, and print its size:
+Get the dictionary and print the dictionary size:
```python
from __future__ import print_function
@@ -229,346 +207,350 @@ print('pred_dict_len: ', pred_dict_len)
- Define input data dimensions and model hyperparameters.
```python
-mark_dict_len = 2
-word_dim = 32
-mark_dim = 5
-hidden_dim = 512
-depth = 8
-mix_hidden_lr = 1e-3
-
-IS_SPARSE = True
-PASS_NUM = 10
-BATCH_SIZE = 10
-
-embedding_name = 'emb'
+mark_dict_len = 2 # The dimension of the context area flag, which is a 0-1 2 value feature, so the dimension is 2
+Word_dim = 32 # Word vector dimension
+Mark_dim = 5 # The predicate context area is mapped to a real vector by the vocabulary, which is the adjacent dimension
+Hidden_dim = 512 # LSTM Hidden Layer Vector Dimensions : 512 / 4
+Depth = 8 # depth of stack LSTM
+Mix_hidden_lr = 1e-3 # Basic learning rate of fundamental_chain_crf layer
+
+IS_SPARSE = True # Whether to update embedding in sparse way
+PASS_NUM = 10 # Training epoches
+BATCH_SIZE = 10 # Batch size
+
+Embeddding_name = 'emb'
```
-Note that `hidden_dim = 512` means a LSTM hidden vector of 128 dimension (512/4). Please refer to PaddlePaddle's official documentation for detail: [lstmemory](http://www.paddlepaddle.org/doc/ui/api/trainer_config_helpers/layers.html#lstmemory)。
+It should be specially noted that the parameter `hidden_dim = 512` actually specifies the dimension of the LSTM hidden layer's vector is 128. For this, please refer to the description of `dynamic_lstm` in the official PaddlePaddle API documentation.
-- Define a parameter loader method to load the pre-trained word lookup tables from word embeddings trained on the English language Wikipedia.
+- As is mentioned above, we use the trained word vector based on English Wikipedia to initialize the embedding layer parameters of the total six features of the sequence input and predicate context, which are not updated during training.
```python
+#Here load the binary parameters saved by PaddlePaddle
def load_parameter(file_name, h, w):
with open(file_name, 'rb') as f:
f.read(16) # skip header.
return np.fromfile(f, dtype=np.float32).reshape(h, w)
```
-- Transform the word sequence itself, the predicate, the predicate context, and the region mark sequence into embedded vector sequences.
-- 8 LSTM units are trained through alternating left-to-right / right-to-left order denoted by the variable `reverse`.
+
+## Training Model
+
+- We train according to the network topology and model parameters. We also need to specify the optimization method when constructing. Here we use the most basic SGD method (momentum is set to 0), and set the learning rate, regularition, and so on.
+
+Define hyperparameters for the training process
+
+```python
+use_cuda = False #Execute training on cpu
+save_dirname = "label_semantic_roles.inference.model" #The model parameters obtained by training are saved in the file.
+is_local = True
+```
+
+### Data input layer definition
+Defines the format of the model input features, including the sentence sequence, the predicate, the five features of the predicate context, and the predicate context area flags.
+
+```python
+# Sentence sequences
+word = fluid.layers.data(
+ name='word_data', shape=[1], dtype='int64', lod_level=1)
+
+# predicate
+predicate = fluid.layers.data(
+ name='verb_data', shape=[1], dtype='int64', lod_level=1)
+
+# predicate context's 5 features
+ctx_n2 = fluid.layers.data(
+ name='ctx_n2_data', shape=[1], dtype='int64', lod_level=1)
+ctx_n1 = fluid.layers.data(
+ name='ctx_n1_data', shape=[1], dtype='int64', lod_level=1)
+ctx_0 = fluid.layers.data(
+ name='ctx_0_data', shape=[1], dtype='int64', lod_level=1)
+ctx_p1 = fluid.layers.data(
+ name='ctx_p1_data', shape=[1], dtype='int64', lod_level=1)
+ctx_p2 = fluid.layers.data(
+ name='ctx_p2_data', shape=[1], dtype='int64', lod_level=1)
+
+# Predicate conotext area flag
+mark = fluid.layers.data(
+ name='mark_data', shape=[1], dtype='int64', lod_level=1)
+```
+### Defining the network structure
+First pre-train and define the model input layer
+
+```python
+#pre-training predicate and predicate context area flags
+predicate_embedding = fluid.layers.embedding(
+ input=predicate,
+ size=[pred_dict_len, word_dim],
+ dtype='float32',
+ is_sparse=IS_SPARSE,
+ param_attr='vemb')
+
+mark_embedding = fluid.layers.embedding(
+ input=mark,
+ size=[mark_dict_len, mark_dim],
+ dtype='float32',
+ is_sparse=IS_SPARSE)
+
+#Sentence sequences and predicate context 5 features then pre-trained
+word_input = [word, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2]
+#Because word vector is pre-trained, no longer training embedding table,
+# The trainable's parameter attribute set to False prevents the embedding table from being updated during training
+emb_layers = [
+ fluid.layers.embedding(
+ size=[word_dict_len, word_dim],
+ input=x,
+ param_attr=fluid.ParamAttr(
+ name=embedding_name, trainable=False)) for x in word_input
+]
+# Pre-training results for adding predicate and predicate context area tags
+emb_layers.append(predicate_embedding)
+emb_layers.append(mark_embedding)
+```
+Define eight LSTM units to learn all input sequences in "forward/reverse" order.
```python
-def db_lstm(word, predicate, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2, mark,
- **ignored):
- # 8 features
- predicate_embedding = fluid.layers.embedding(
- input=predicate,
- size=[pred_dict_len, word_dim],
- dtype='float32',
- is_sparse=IS_SPARSE,
- param_attr='vemb')
-
- mark_embedding = fluid.layers.embedding(
- input=mark,
- size=[mark_dict_len, mark_dim],
- dtype='float32',
- is_sparse=IS_SPARSE)
-
- word_input = [word, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2]
- # Since word vector lookup table is pre-trained, we won't update it this time.
- # trainable being False prevents updating the lookup table during training.
- emb_layers = [
- fluid.layers.embedding(
- size=[word_dict_len, word_dim],
- input=x,
- param_attr=fluid.ParamAttr(
- name=embedding_name, trainable=False)) for x in word_input
- ]
- emb_layers.append(predicate_embedding)
- emb_layers.append(mark_embedding)
-
- # 8 LSTM units are trained through alternating left-to-right / right-to-left order
- # denoted by the variable `reverse`.
- hidden_0_layers = [
- fluid.layers.fc(input=emb, size=hidden_dim, act='tanh')
- for emb in emb_layers
- ]
-
- hidden_0 = fluid.layers.sums(input=hidden_0_layers)
-
- lstm_0 = fluid.layers.dynamic_lstm(
- input=hidden_0,
+# A total of 8 LSTM units are trained, each unit is oriented from left to right or right to left.
+# Determined by the parameter `is_reverse`
+# First stack structure
+hidden_0_layers = [
+ fluid.layers.fc(input=emb, size=hidden_dim, act='tanh')
+ for emb in emb_layers
+]
+
+hidden_0 = fluid.layers.sums(input=hidden_0_layers)
+
+lstm_0 = fluid.layers.dynamic_lstm(
+ input=hidden_0,
+ size=hidden_dim,
+ candidate_activation='relu',
+ gate_activation='sigmoid',
+ cell_activation='sigmoid')
+
+# Stack L-LSTM and R-LSTM with directly connected sides
+input_tmp = [hidden_0, lstm_0]
+
+# remaining stack structure
+for i in range(1, depth):
+ mix_hidden = fluid.layers.sums(input=[
+ fluid.layers.fc(input=input_tmp[0], size=hidden_dim, act='tanh'),
+ fluid.layers.fc(input=input_tmp[1], size=hidden_dim, act='tanh')
+ ])
+
+ lstm = fluid.layers.dynamic_lstm(
+ input=mix_hidden,
size=hidden_dim,
candidate_activation='relu',
gate_activation='sigmoid',
- cell_activation='sigmoid')
-
- # stack L-LSTM and R-LSTM with direct edges
- input_tmp = [hidden_0, lstm_0]
-
- # In PaddlePaddle, state features and transition features of a CRF are implemented
- # by a fully connected layer and a CRF layer seperately. The fully connected layer
- # with linear activation learns the state features, here we use fluid.layers.sums
- # (fluid.layers.fc can be uesed as well), and the CRF layer in PaddlePaddle:
- # fluid.layers.linear_chain_crf only
- # learns the transition features, which is a cost layer and is the last layer of the network.
- # fluid.layers.linear_chain_crf outputs the log probability of true tag sequence
- # as the cost by given the input sequence and it requires the true tag sequence
- # as target in the learning process.
-
- for i in range(1, depth):
- mix_hidden = fluid.layers.sums(input=[
- fluid.layers.fc(input=input_tmp[0], size=hidden_dim, act='tanh'),
- fluid.layers.fc(input=input_tmp[1], size=hidden_dim, act='tanh')
- ])
-
- lstm = fluid.layers.dynamic_lstm(
- input=mix_hidden,
- size=hidden_dim,
- candidate_activation='relu',
- gate_activation='sigmoid',
- cell_activation='sigmoid',
- is_reverse=((i % 2) == 1))
-
- input_tmp = [mix_hidden, lstm]
-
- feature_out = fluid.layers.sums(input=[
- fluid.layers.fc(input=input_tmp[0], size=label_dict_len, act='tanh'),
- fluid.layers.fc(input=input_tmp[1], size=label_dict_len, act='tanh')
- ])
+ cell_activation='sigmoid',
+ is_reverse=((i % 2) == 1))
+
+ input_tmp = [mix_hidden, lstm]
+
+# Fetch the output of the last stack LSTM and the input of this LSTM unit to the hidden layer mapping,
+# Learn the state feature of CRF after a fully connected layer maps to the dimensions of the tags dictionary
+feature_out = fluid.layers.sums(input=[
+ fluid.layers.fc(input=input_tmp[0], size=label_dict_len, act='tanh'),
+ fluid.layers.fc(input=input_tmp[1], size=label_dict_len, act='tanh')
+])
+
+# tag/label sequence
+target = fluid.layers.data(
+ name='target', shape=[1], dtype='int64', lod_level=1)
+
+# Learning CRF transfer features
+crf_cost = fluid.layers.linear_chain_crf(
+ input=feature_out,
+ label=target,
+ param_attr=fluid.ParamAttr(
+ name='crfw', learning_rate=mix_hidden_lr))
+
+
+avg_cost = fluid.layers.mean(crf_cost)
+
+# Use the most basic SGD optimization method (momentum is set to 0)
+sgd_optimizer = fluid.optimizer.SGD(
+ learning_rate=fluid.layers.exponential_decay(
+ learning_rate=0.01,
+ decay_steps=100000,
+ decay_rate=0.5,
+ staircase=True))
+
+sgd_optimizer.minimize(avg_cost)
+
- return feature_out
```
-## Train model
+The data introduction section mentions the payment of the CoNLL 2005 training set. Here we use the test set training for everyone to learn. Conll05.test() produces one sample every time, containing 9 features, then shuffle and after batching as the input for training.
+
+```python
+crf_decode = fluid.layers.crf_decoding(
+ input=feature_out, param_attr=fluid.ParamAttr(name='crfw'))
-- In the `train` method, we will create trainer given model topology, parameters, and optimization method. We will use the most basic **SGD** method, which is a momentum optimizer with 0 momentum. Meanwhile, we will set learning rate and decay.
+train_data = paddle.batch(
+ paddle.reader.shuffle(
+ paddle.dataset.conll05.test(), buf_size=8192),
+ batch_size=BATCH_SIZE)
-- As mentioned in data preparation section, we will use CoNLL 2005 test corpus as the training data set. `conll05.test()` outputs one training instance at a time. It is shuffled and batched into mini batches, and used as input.
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-- `feeding` is used to specify the correspondence between data instance and data layer. For example, according to the `feeding`, the 0th column of data instance produced by`conll05.test()` is matched to the data layer named `word_data`.
+```
-- `event_handler` can be used as callback for training events, it will be used as an argument for the `train` method. Following `event_handler` prints cost during training.
+The corresponding relationship between each data and data_layer is specified by the feeder. The following feeder indicates that the data_layer corresponding to the 0th column of the data generated by conll05.test() is `word`.
-- `trainer.train` will train the model.
```python
-def train(use_cuda, save_dirname=None, is_local=True):
- # define network topology
- word = fluid.layers.data(
- name='word_data', shape=[1], dtype='int64', lod_level=1)
- predicate = fluid.layers.data(
- name='verb_data', shape=[1], dtype='int64', lod_level=1)
- ctx_n2 = fluid.layers.data(
- name='ctx_n2_data', shape=[1], dtype='int64', lod_level=1)
- ctx_n1 = fluid.layers.data(
- name='ctx_n1_data', shape=[1], dtype='int64', lod_level=1)
- ctx_0 = fluid.layers.data(
- name='ctx_0_data', shape=[1], dtype='int64', lod_level=1)
- ctx_p1 = fluid.layers.data(
- name='ctx_p1_data', shape=[1], dtype='int64', lod_level=1)
- ctx_p2 = fluid.layers.data(
- name='ctx_p2_data', shape=[1], dtype='int64', lod_level=1)
- mark = fluid.layers.data(
- name='mark_data', shape=[1], dtype='int64', lod_level=1)
-
- # define network topology
- feature_out = db_lstm(**locals())
- target = fluid.layers.data(
- name='target', shape=[1], dtype='int64', lod_level=1)
- crf_cost = fluid.layers.linear_chain_crf(
- input=feature_out,
- label=target,
- param_attr=fluid.ParamAttr(
- name='crfw', learning_rate=mix_hidden_lr))
-
- avg_cost = fluid.layers.mean(crf_cost)
-
- sgd_optimizer = fluid.optimizer.SGD(
- learning_rate=fluid.layers.exponential_decay(
- learning_rate=0.01,
- decay_steps=100000,
- decay_rate=0.5,
- staircase=True))
-
- sgd_optimizer.minimize(avg_cost)
-
- # The CRF decoding layer is used for evaluation and inference.
- # It shares weights with CRF layer. The sharing of parameters among multiple layers
- # is specified by using the same parameter name in these layers. If true tag sequence
- # is provided in training process, `fluid.layers.crf_decoding` calculates labelling error
- # for each input token and sums the error over the entire sequence.
- # Otherwise, `fluid.layers.crf_decoding` generates the labelling tags.
- crf_decode = fluid.layers.crf_decoding(
- input=feature_out, param_attr=fluid.ParamAttr(name='crfw'))
-
- train_data = paddle.batch(
- paddle.reader.shuffle(
- paddle.dataset.conll05.test(), buf_size=8192),
- batch_size=BATCH_SIZE)
-
- place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-
-
- feeder = fluid.DataFeeder(
- feed_list=[
- word, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2, predicate, mark, target
- ],
- place=place)
- exe = fluid.Executor(place)
-
- def train_loop(main_program):
- exe.run(fluid.default_startup_program())
- embedding_param = fluid.global_scope().find_var(
- embedding_name).get_tensor()
- embedding_param.set(
- load_parameter(conll05.get_embedding(), word_dict_len, word_dim),
- place)
-
- start_time = time.time()
- batch_id = 0
- for pass_id in six.moves.xrange(PASS_NUM):
- for data in train_data():
- cost = exe.run(main_program,
- feed=feeder.feed(data),
- fetch_list=[avg_cost])
- cost = cost[0]
-
- if batch_id % 10 == 0:
- print("avg_cost: " + str(cost))
- if batch_id != 0:
- print("second per batch: " + str((time.time(
- ) - start_time) / batch_id))
- # Set the threshold low to speed up the CI test
- if float(cost) < 60.0:
- if save_dirname is not None:
- fluid.io.save_inference_model(save_dirname, [
- 'word_data', 'verb_data', 'ctx_n2_data',
- 'ctx_n1_data', 'ctx_0_data', 'ctx_p1_data',
- 'ctx_p2_data', 'mark_data'
- ], [feature_out], exe)
- return
-
- batch_id = batch_id + 1
-
- train_loop(fluid.default_main_program())
+feeder = fluid.DataFeeder(
+ feed_list=[
+ word, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2, predicate, mark, target
+ ],
+ place=place)
+exe = fluid.Executor(place)
+```
+
+Start training
+
+```python
+main_program = fluid.default_main_program()
+
+exe.run(fluid.default_startup_program())
+embedding_param = fluid.global_scope().find_var(
+ embedding_name).get_tensor()
+embedding_param.set(
+ load_parameter(conll05.get_embedding(), word_dict_len, word_dim),
+ place)
+
+start_time = time.time()
+batch_id = 0
+for pass_id in six.moves.xrange(PASS_NUM):
+ for data in train_data():
+ cost = exe.run(main_program,
+ feed=feeder.feed(data),
+ fetch_list=[avg_cost])
+ cost = cost[0]
+
+ if batch_id % 10 == 0:
+ print("avg_cost: " + str(cost))
+ if batch_id != 0:
+ print("second per batch: " + str((time.time(
+ ) - start_time) / batch_id))
+ # Set the threshold low to speed up the CI test
+ if float(cost) < 60.0:
+ if save_dirname is not None:
+ fluid.io.save_inference_model(save_dirname, [
+ 'word_data', 'verb_data', 'ctx_n2_data',
+ 'ctx_n1_data', 'ctx_0_data', 'ctx_p1_data',
+ 'ctx_p2_data', 'mark_data'
+ ], [feature_out], exe)
+ break
+
+ batch_id = batch_id + 1
```
-## Application
+## Model Application
+
+After completing the training, the optimal model needs to be selected according to a performance indicator we care about. You can simply select the model with the least markup error on the test set. We give an example of using a trained model for prediction as follows.
-- When training is completed, we need to select an optimal model based one performance index to do inference. In this task, one can simply select the model with the least number of marks on the test set. We demonstrate doing an inference using the trained model.
+First set the parameters of the prediction process
```python
-def infer(use_cuda, save_dirname=None):
- if save_dirname is None:
- return
-
- place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- inference_scope = fluid.core.Scope()
- with fluid.scope_guard(inference_scope):
- # Use fluid.io.load_inference_model to obtain the inference program desc,
- # the feed_target_names (the names of variables that will be fed
- # data using feed operators), and the fetch_targets (variables that
- # we want to obtain data from using fetch operators).
- [inference_program, feed_target_names,
- fetch_targets] = fluid.io.load_inference_model(save_dirname, exe)
-
- # Setup inputs by creating LoDTensors to represent sequences of words.
- # Here each word is the basic element of these LoDTensors and the shape of
- # each word (base_shape) should be [1] since it is simply an index to
- # look up for the corresponding word vector.
- # Suppose the length_based level of detail (lod) info is set to [[3, 4, 2]],
- # which has only one lod level. Then the created LoDTensors will have only
- # one higher level structure (sequence of words, or sentence) than the basic
- # element (word). Hence the LoDTensor will hold data for three sentences of
- # length 3, 4 and 2, respectively.
- # Note that lod info should be a list of lists.
- lod = [[3, 4, 2]]
- base_shape = [1]
- # The range of random integers is [low, high]
- word = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=word_dict_len - 1)
- pred = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=pred_dict_len - 1)
- ctx_n2 = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=word_dict_len - 1)
- ctx_n1 = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=word_dict_len - 1)
- ctx_0 = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=word_dict_len - 1)
- ctx_p1 = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=word_dict_len - 1)
- ctx_p2 = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=word_dict_len - 1)
- mark = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=mark_dict_len - 1)
-
- # Construct feed as a dictionary of {feed_target_name: feed_target_data}
- # and results will contain a list of data corresponding to fetch_targets.
- assert feed_target_names[0] == 'word_data'
- assert feed_target_names[1] == 'verb_data'
- assert feed_target_names[2] == 'ctx_n2_data'
- assert feed_target_names[3] == 'ctx_n1_data'
- assert feed_target_names[4] == 'ctx_0_data'
- assert feed_target_names[5] == 'ctx_p1_data'
- assert feed_target_names[6] == 'ctx_p2_data'
- assert feed_target_names[7] == 'mark_data'
-
- results = exe.run(inference_program,
- feed={
- feed_target_names[0]: word,
- feed_target_names[1]: pred,
- feed_target_names[2]: ctx_n2,
- feed_target_names[3]: ctx_n1,
- feed_target_names[4]: ctx_0,
- feed_target_names[5]: ctx_p1,
- feed_target_names[6]: ctx_p2,
- feed_target_names[7]: mark
- },
- fetch_list=fetch_targets,
- return_numpy=False)
- print(results[0].lod())
- np_data = np.array(results[0])
- print("Inference Shape: ", np_data.shape)
+use_cuda = False #predict on cpu
+save_dirname = "label_semantic_roles.inference.model" #call trained model for prediction
+
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+exe = fluid.Executor(place)
```
+Set the input, use LoDTensor to represent the input word sequence, where the shape of each word's base_shape is [1], because each word is represented by an id. If the length-based LoD is [[3, 4, 2]], which is a single-layer LoD, then the constructed LoDTensor contains three sequences which their length are 3, 4, and 2.
+
+Note that LoD is a list of lists.
-- The main entrance of the whole program is as below:
+```python
+lod = [[3, 4, 2]]
+base_shape = [1]
+
+# Construct fake data as input, the range of random integer numbers is [low, high]
+word = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=word_dict_len - 1)
+pred = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=pred_dict_len - 1)
+ctx_n2 = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=word_dict_len - 1)
+ctx_n1 = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=word_dict_len - 1)
+ctx_0 = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=word_dict_len - 1)
+ctx_p1 = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=word_dict_len - 1)
+ctx_p2 = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=word_dict_len - 1)
+mark = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=mark_dict_len - 1)
+```
+
+Using fluid.io.load_inference_model to load inference_program, feed_target_names is the name of the model's input variable, and fetch_targets is the predicted object.
```python
-def main(use_cuda, is_local=True):
- if use_cuda and not fluid.core.is_compiled_with_cuda():
- return
+[inference_program, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(save_dirname, exe)
+```
+Construct the feed dictionary {feed_target_name: feed_target_data}, where the results are a list of predicted targets
- # Directory for saving the trained model
- save_dirname = "label_semantic_roles.inference.model"
+```python
+assert feed_target_names[0] == 'word_data'
+assert feed_target_names[1] == 'verb_data'
+assert feed_target_names[2] == 'ctx_n2_data'
+assert feed_target_names[3] == 'ctx_n1_data'
+assert feed_target_names[4] == 'ctx_0_data'
+assert feed_target_names[5] == 'ctx_p1_data'
+assert feed_target_names[6] == 'ctx_p2_data'
+assert feed_target_names[7] == 'mark_data'
+```
+Execute prediction
- train(use_cuda, save_dirname, is_local)
- infer(use_cuda, save_dirname)
+```python
+results = exe.run(inference_program,
+ feed={
+ feed_target_names[0]: word,
+ feed_target_names[1]: pred,
+ feed_target_names[2]: ctx_n2,
+ feed_target_names[3]: ctx_n1,
+ feed_target_names[4]: ctx_0,
+ feed_target_names[5]: ctx_p1,
+ feed_target_names[6]: ctx_p2,
+ feed_target_names[7]: mark
+ },
+ fetch_list=fetch_targets,
+ return_numpy=False)
+```
+Output result
-main(use_cuda=False)
+```python
+print(results[0].lod())
+np_data = np.array(results[0])
+print("Inference Shape: ", np_data.shape)
```
+
## Conclusion
-Semantic Role Labeling is an important intermediate step in a wide range of natural language processing tasks. In this tutorial, we use SRL as an example to illustrate using PaddlePaddle to do sequence tagging tasks. The models proposed are from our published paper\[[10](#Reference)\]. We only use test data for illustration since the training data on the CoNLL 2005 dataset is not completely public. This aims to propose an end-to-end neural network model with fewer dependencies on natural language processing tools but is comparable, or even better than traditional models in terms of performance. Please check out our paper for more information and discussions.
+Labeling semantic roles is an important intermediate step in many natural language understanding tasks. In this tutorial, we take the label semantic roles task as an example to introduce how to use PaddlePaddle for sequence labeling tasks. The model presented in the tutorial comes from our published paper \[[10](#References)\]. Since the training data for the CoNLL 2005 SRL task is not currently fully open, only the test data is used as an example in the tutorial. In this process, we hope to reduce our reliance on other natural language processing tools. We can use neural network data-driven, end-to-end learning capabilities to get a model that is comparable or even better than traditional methods. In the paper, we confirmed this possibility. More information and discussion about the model can be found in the paper.
+
## References
-1. Sun W, Sui Z, Wang M, et al. [Chinese semantic role labeling with shallow parsing](http://www.aclweb.org/anthology/D09-1#page=1513)[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 3-Volume 3. Association for Computational Linguistics, 2009: 1475-1483.
+1. Sun W, Sui Z, Wang M, et al. [Chinese label semantic roles with shallow parsing](http://www.aclweb.org/anthology/D09-1#page=1513)[C]//Proceedings Of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 3-Volume 3. Association for Computational Linguistics, 2009: 1475-1483.
2. Pascanu R, Gulcehre C, Cho K, et al. [How to construct deep recurrent neural networks](https://arxiv.org/abs/1312.6026)[J]. arXiv preprint arXiv:1312.6026, 2013.
-3. Cho K, Van Merriënboer B, Gulcehre C, et al. [Learning phrase representations using RNN encoder-decoder for statistical machine translation](https://arxiv.org/abs/1406.1078)[J]. arXiv preprint arXiv:1406.1078, 2014.
+3. Cho K, Van Merriënboer B, Gulcehre C, et al. [Learning phrase representations using RNN encoder-decoder for statistical machine translation](https://arxiv.org/abs/1406.1078)[J]. arXiv preprint arXiv: 1406.1078, 2014.
4. Bahdanau D, Cho K, Bengio Y. [Neural machine translation by jointly learning to align and translate](https://arxiv.org/abs/1409.0473)[J]. arXiv preprint arXiv:1409.0473, 2014.
-5. Lafferty J, McCallum A, Pereira F. [Conditional random fields: Probabilistic models for segmenting and labeling sequence data](http://www.jmlr.org/papers/volume15/doppa14a/source/biblio.bib.old)[C]//Proceedings of the eighteenth international conference on machine learning, ICML. 2001, 1: 282-289.
-6. 李航. 统计学习方法[J]. 清华大学出版社, 北京, 2012.
-7. Marcus M P, Marcinkiewicz M A, Santorini B. [Building a large annotated corpus of English: The Penn Treebank](http://repository.upenn.edu/cgi/viewcontent.cgi?article=1246&context=cis_reports)[J]. Computational linguistics, 1993, 19(2): 313-330.
-8. Palmer M, Gildea D, Kingsbury P. [The proposition bank: An annotated corpus of semantic roles](http://www.mitpressjournals.org/doi/pdfplus/10.1162/0891201053630264)[J]. Computational linguistics, 2005, 31(1): 71-106.
-9. Carreras X, Màrquez L. [Introduction to the CoNLL-2005 shared task: Semantic role labeling](http://www.cs.upc.edu/~srlconll/st05/papers/intro.pdf)[C]//Proceedings of the Ninth Conference on Computational Natural Language Learning. Association for Computational Linguistics, 2005: 152-164.
-10. Zhou J, Xu W. [End-to-end learning of semantic role labeling using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
+5. Lafferty J, McCallum A, Pereira F. [Conditional random fields: Probabilistic models for segmenting and labeling sequence data](http://www.jmlr.org/papers/volume15/doppa14a/source/biblio.bib.old) [C]//Proceedings of the eighteenth international conference on machine learning, ICML. 2001, 1: 282-289.
+6. Li Hang. Statistical Learning Method[J]. Tsinghua University Press, Beijing, 2012.
+7. Marcus MP, Marcinkiewicz MA, Santorini B. [Building a large annotated corpus of English: The Penn Treebank](http://repository.upenn.edu/cgi/viewcontent.cgi?article=1246&context=cis_reports)[J] Computational linguistics, 1993, 19(2): 313-330.
+8. Palmer M, Gildea D, Kingsbury P. [The proposition bank: An annotated corpus of semantic roles](http://www.mitpressjournals.org/doi/pdfplus/10.1162/0891201053630264) [J]. Computational linguistics, 2005 , 31(1): 71-106.
+9. Carreras X, Màrquez L. [Introduction to the CoNLL-2005 shared task: label semantic roles](http://www.cs.upc.edu/~srlconll/st05/papers/intro.pdf)[C]/ /Proceedings of the Ninth Conference on Computational Natural Language Learning. Association for Computational Linguistics, 2005: 152-164.
+10. Zhou J, Xu W. [End-to-end learning of label semantic roles using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C] //Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/07.label_semantic_roles/index.html b/07.label_semantic_roles/index.html
index b23e079..3d42f7f 100644
--- a/07.label_semantic_roles/index.html
+++ b/07.label_semantic_roles/index.html
@@ -40,186 +40,163 @@
-# Semantic Role Labeling
-The source code of this chapter locates at [book/label_semantic_roles](https://github.com/PaddlePaddle/book/tree/develop/07.label_semantic_roles).
+# Label Semantic Roles
-For instructions on getting started with this book,see [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book).
+The source code of this tutorial is in [book/label_semantic_roles](https://github.com/PaddlePaddle/book/tree/develop/07.label_semantic_roles). For the new users to Paddle book, please refer to [Book Documentation Instructions](https://github.com/PaddlePaddle/book#running-the-book) .
## Background
-Natural language analysis techniques consist of lexical, syntactic, and semantic analysis. **Semantic Role Labeling (SRL)** is an instance of **Shallow Semantic Analysis**.
+Natural language analysis techniques are roughly divided into three levels: lexical analysis, syntactic analysis, and semantic analysis. Labeling semantic roles is a way to implement shallow semantic analysis. In a sentence, the predicate is a statement or explanation of the subject, pointing out "what to do", "what is it" or "how is it", which represents the majority of an event. The noun with a predicate is called argument. The semantic role is the role of argument in the events. It mainly includes: Agent, Patient, Theme, Experiencer, Beneficiary, Instrument , Location, Goal, Source and so on.
-In a sentence, a **predicate** states a property or a characterization of a *subject*, such as what it does and what it is like. The predicate represents the core of an event, whereas the words accompanying the predicate are **arguments**. A **semantic role** refers to the abstract role an argument of a predicate take on in the event, including *agent*, *patient*, *theme*, *experiencer*, *beneficiary*, *instrument*, *location*, *goal*, and *source*.
+Please look at the following example. "Encounter" is a predicate (Predicate, usually abbreviated as "Pred"), "Xiaoming" is an agent, "Xiaohong" is a patient, "Yesterday" is the time when the event occurred, the "park" is the location where the event occurred.
-In the following example of a Chinese sentence, "to encounter" is the predicate (*pred*); "Ming" is the *agent*; "Hong" is the *patient*; "yesterday" and "evening" are the *time*; finally, "the park" is the *location*.
+$$\mbox{[Xiaoming]}_{\mbox{Agent}}\mbox{[yesterday]}_{\mbox{Time}}\mbox{[evening]}_\mbox{Time}\mbox{in[Park]}_{\mbox{Location}}\mbox{[encounter]}_{\mbox{Predicate}}\mbox{[Xiaohong]}_{\mbox{Patient}}\mbox{. }$$
-$$\mbox{[小明 Ming]}_{\mbox{Agent}}\mbox{[昨天 yesterday]}_{\mbox{Time}}\mbox{[晚上 evening]}_\mbox{Time}\mbox{在[公园 a park]}_{\mbox{Location}}\mbox{[遇到 to encounter]}_{\mbox{Predicate}}\mbox{了[小红 Hong]}_{\mbox{Patient}}\mbox{。}$$
+Semantic role labeling (SRL) is centered on the predicate of the sentence. It does not analyze the semantic information contained in the sentence. It only analyzes the relationship between the components and the predicate in the sentence, that is, the predicate of the sentence--the Argument structure. And using semantic roles to describe these structural relationships is an important intermediate step in many natural language understanding tasks (such as information extraction, text analysis, deep question and answer, etc.). It is generally assumed in the research that the predicate is given, and all that has to be done is to find the individual arguments of the given predicate and their semantic roles.
-Instead of analyzing the semantic information, **Semantic Role Labeling** (**SRL**) identifies the relationship between the predicate and the other constituents surrounding it. The predicate-argument structures are labeled as specific semantic roles. A wide range of natural language understanding tasks, including *information extraction*, *discourse analysis*, and *deepQA*. Research usually assumes a predicate of a sentence to be specified; the only task is to identify its arguments and their semantic roles.
+Traditional SRL systems are mostly based on syntactic analysis and usually consist of five processes:
-Conventional SRL systems mostly build on top of syntactic analysis, usually consisting of five steps:
+1. Construct a parse tree. For example, Figure 1 is a syntactic tree for the dependency syntax analysis of the above example.
+2. Identify candidate arguments for a given predicate from the syntax tree.
+3. Prune the candidate arguments; there may be many candidate arguments in a sentence, and pruning candidate arguments is pruned out of a large number of candidates that are the most unlikely candidates arguments.
+4. Argument recognition: This process is to judge which is the real argument from the candidates after the previous pruning, usually as a two-classification problem.
+5. For the result of step 4, get the semantic role label of the argument by multi-classification. It can be seen that syntactic analysis is the basis, and some artificial features are often constructed in subsequent steps, and these features are often also derived from syntactic analysis.
-1. Construct a syntax tree, as shown in Fig. 1
-2. Identity the candidate arguments of the given predicate on the tree.
-3. Prune the most unlikely candidate arguments.
-4. Identify the real arguments, often by a binary classifier.
-5. Multi-classify on results from step 4 to label the semantic roles. Steps 2 and 3 usually introduce hand-designed features based on syntactic analysis (step 1).
-
-
-
-
-Fig 1. Syntax tree
+
+
+Figure 1. Example of dependency syntax analysis tree
+However, complete syntactic analysis needs to determine all the syntactic information contained in a sentence and the relationship between the components of the sentence. It is a very difficult task. The accuracy of syntactic analysis in current technology is not good, and the little errors in syntactic analysis will caused the SRL error. In order to reduce the complexity of the problem and obtain certain syntactic structure information, the idea of "shallow syntactic analysis" came into being. Shallow syntactic analysis is also called partial parsing or chunking. Different from full syntactic analysis which obtains a complete syntactic tree, shallow syntactic analysis only needs to identify some relatively simple independent components of the sentence, such as verb phrases, these identified structures are called chunks. In order to avoid the difficulties caused by the failure to obtain a syntactic tree with high accuracy, some studies \[[1](#References)\] also proposed a chunk-based SRL method. The block-based SRL method solves the SRL as a sequence labeling problem. Sequence labeling tasks generally use the BIO representation to define the set of labels for sequence annotations. Firstly, Let's introduce this representation. In the BIO notation, B stands for the beginning of the block, I stands for the middle of the block, and O stands for the end of the block. Different blocks are assigned different labels by B, I, and O. For example, for a block group extended by role A, the first block it contains is assigned to tag B-A, the other blocks it contains are assigned to tag I-A, and the block not belonging to any argument is assigned tag O.
-However, a complete syntactic analysis requires identifying the relationship among all constituents. Thus, the accuracy of SRL is sensitive to the preciseness of the syntactic analysis, making SRL challenging. To reduce its complexity and obtain some information on the syntactic structures, we often use *shallow syntactic analysis* a.k.a. partial parsing or chunking. Unlike complete syntactic analysis, which requires the construction of the complete parsing tree, *Shallow Syntactic Analysis* only requires identifying some independent constituents with relatively simple structures, such as verb phrases (chunk). To avoid difficulties in constructing a syntax tree with high accuracy, some work\[[1](#reference)\] proposed semantic chunking-based SRL methods, which reduces SRL into a sequence tagging problem. Sequence tagging tasks classify syntactic chunks using **BIO representation**. For syntactic chunks forming role A, its first chunk receives the B-A tag (Begin) and the remaining ones receive the tag I-A (Inside); in the end, the chunks left out will receive the tag O.
+Let's continue to take the above sentence as an example. Figure 1 shows the BIO representation method.
-The BIO representation of above example is shown in Fig.1.
-
-
-
-Fig 2. BIO representation
+
+
+Figure 2. Example of BIO labeling method
-This example illustrates the simplicity of sequence tagging, since
-
-1. It only relies on shallow syntactic analysis, reduces the precision requirement of syntactic analysis;
-2. Pruning the candidate arguments is no longer necessary;
-3. Arguments are identified and tagged at the same time. Simplifying the workflow reduces the risk of accumulating errors; oftentimes, methods that unify multiple steps boost performance.
+As can be seen from the above example, it is a relatively simple process to directly get the semantic roles labeling result of the argument according to the sequence labeling result. This simplicity is reflected in: (1) relying on shallow syntactic analysis, reducing the requirements and difficulty of syntactic analysis; (2) there is no candidate argument to pruning in this step; (3) the identification and labeling of arguments are realized at the same time. This integrated approach to arguments identification and labeling simplifies the process, reduces the risk of error accumulation, and often achieves better results.
-In this tutorial, our SRL system is built as an end-to-end system via a neural network. The system takes only text sequences as input, without using any syntactic parsing results or complex hand-designed features. The public dataset [CoNLL-2004 and CoNLL-2005 Shared Tasks](http://www.cs.upc.edu/~srlconll/) is used for the following task: given a sentence with predicates marked, identify the corresponding arguments and their semantic roles through sequence tagging.
+Similar to the block-based SRL method, in this tutorial we also regard the SRL as a sequence labeling problem. The difference is that we only rely on input text sequences, without relying on any additional syntax analysis results or complex artificial features. And constructing an end-to-end learning SRL system by using deep neural networks. Let's take the public data set of the SRL task in the [CoNLL-2004 and CoNLL-2005 Shared Tasks](http://www.cs.upc.edu/~srlconll/) task as an example to practice the following tasks. Giving a sentence and a predicate in this sentence, through the way of sequence labeling, find the arguments corresponding to the predicate from the sentence, and mark their semantic roles.
-## Model
+## Model Overview
-**Recurrent Neural Networks** (*RNN*) are important tools for sequence modeling and have been successfully used in some natural language processing tasks. Unlike feed-forward neural networks, RNNs can model the dependencies between elements of sequences. As a variant of RNNs', LSTMs aim modeling long-term dependency in long sequences. We have introduced this in [understand_sentiment](https://github.com/PaddlePaddle/book/tree/develop/05.understand_sentiment). In this chapter, we continue to use LSTMs to solve SRL problems.
+Recurrent Neural Network is an important model for modeling sequences. It is widely used in natural language processing tasks. Unlike the feed-forward neural network, the RNN is able to handle the contextual correlation between inputs. LSTM is an important variant of RNN that is commonly used to learn the long-range dependencies contained in long sequences. We have already introduced in [Sentiment Analysis](https://github.com/PaddlePaddle/book/tree/develop/06.understand_sentiment), in this article we still use LSTM to solve the SRL problem.
### Stacked Recurrent Neural Network
-*Deep Neural Networks* can extract hierarchical representations. The higher layers can form relatively abstract/complex representations, based on primitive features discovered through the lower layers. Unfolding LSTMs through time results in a deep feed-forward neural network. This is because any computational path between the input at time $k < t$ to the output at time $t$ crosses several nonlinear layers. On the other hand, due to parameter sharing over time, LSTMs are also *shallow*; that is, the computation carried out at each time-step is just a linear transformation. Deep LSTM networks are typically constructed by stacking multiple LSTM layers on top of each other and taking the output from lower LSTM layer at time $t$ as the input of upper LSTM layer at time $t$. Deep, hierarchical neural networks can be efficient at representing some functions and modeling varying-length dependencies\[[2](#reference)\].
-
-
-However, in a deep LSTM network, any gradient propagated back in depth needs to traverse a large number of nonlinear steps. As a result, while LSTMs of 4 layers can be trained properly, those with 4-8 have much worse performance. Conventional LSTMs prevent back-propagated errors from vanishing or exploding by introducing shortcut connections to skip the intermediate nonlinear layers. Therefore, deep LSTMs can consider shortcut connections in depth as well.
-
-
-A single LSTM cell has three operations:
+The deep network helps to form hierarchical features, and the upper layers of the network form more complex advanced features based on the primary features that have been learned in the lower layers. Although the LSTM is expanded along the time axis and is equivalent to a very "deep" feedforward network. However, since the LSTM time step parameters are shared, the mapping of the $t-1$ time state to the time of $t$ always passes only one non-linear mapping. It means that the modeling of state transitions by single-layer LSTM is “shallow”. Stacking multiple LSTM units, making the output of the previous LSTM$t$ time as the input of the next LSTM unit $t$ time, helps us build a deep network. We call it the first version of the stack ecurrent neural networks. Deep networks improve the ability of models to fit complex patterns and better model patterns across different time steps\[[2](#References)\].
-1. input-to-hidden: map input $x$ to the input of the forget gates, input gates, memory cells and output gates by linear transformation (i.e., matrix mapping);
-2. hidden-to-hidden: calculate forget gates, input gates, output gates and update memory cell, this is the main part of LSTMs;
-3. hidden-to-output: this part typically involves an activation operation on hidden states.
+However, training a deep LSTM network is not an easy task. Stacking multiple LSTM cells in portrait orientation may encounter problems with the propagation of gradients in the longitudinal depth. Generally, stacking 4 layers of LSTM units can be trained normally. When the number of layers reaches 4~8 layers, performance degradation will occur. At this time, some new structures must be considered to ensure the gradient is transmitted vertically and smoothly. This is a problem that must be solved in training a deep LSTM networks. We can learn from LSTM to solve one of the tips of the "gradient disappearance and gradient explosion" problem: there is no nonlinear mapping on the information propagation route of Memory Cell, and neither gradient decay nor explosion when the gradient propagates back. Therefore, the deep LSTM model can also add a path that ensures smooth gradient propagation in the vertical direction.
-Based on the stacked LSTMs, we add shortcut connections: take the input-to-hidden from the previous layer as a new input and learn another linear transformation.
+The operation performed by an LSTM unit can be divided into three parts: (1) Input-to-hidden: Each time step input information $x$ will first pass through a matrix map and then as a forgetting gate, input gate, memory unit, output gate's input. Note that this mapping does not introduce nonlinear activation; (2) Hidden-to-hidden: this step is the main body of LSTM calculation, including forgotten gate, input gate, memory unit update, output gate calculation; (3) hidden-to-output: usually simple to activate the hidden layer vector. On the basis of the first version of the stack network, we add a new path: in addition to the previous LSTM output, the mapping of the input of the previous LSTM to the hidden layer is used as a new input. and a new input is added. At the same time, add a linear map to learn a new transform.
-Fig.3 illustrates the final stacked recurrent neural networks.
+Figure 3 is a schematic structural diagram of a finally obtained stack recurrent neural network.
-
-Fig 3. Stacked Recurrent Neural Networks
+
+Figure 3. Schematic diagram of stack-based recurrent neural network based on LSTM
### Bidirectional Recurrent Neural Network
-While LSTMs can summarize the history, they can not see the future. Because most NLP (natural language processing) tasks provide the entirety of sentences, sequential learning can benefit from having the future encoded as well as the history.
-
-To address this, we can design a bidirectional recurrent neural network by making a minor modification. A higher LSTM layer can process the sequence in reversed direction with regards to its immediate lower LSTM layer, i.e., deep LSTM layers take turns to train on input sequences from left-to-right and right-to-left. Therefore, LSTM layers at time-step $t$ can see both histories and the future, starting from the second layer. Fig. 4 illustrates the bidirectional recurrent neural networks.
+In LSTM, the hidden layer vector at the time of $t$ encodes all input information until the time of $t$. The LSTM at $t$ can see the history, but cannot see the future. In most natural language processing tasks, we almost always get the whole sentence. In this case, if you can get future information like the historical information, it will be of great help to the sequence learning task.
+In order to overcome this shortcoming, we can design a bidirectional recurrent network unit, which is simple and straightforward: make a small modification to the stack recurrent neural network of the previous section, stack multiple LSTM units, and let each layer of LSTM units learn the output sequence of the previous layer in the order of forward, reverse, forward …… So, starting from layer 2, our LSTM unit will always see historical and future information at $t$. Figure 4 is a schematic diagram showing the structure of a bidirectional recurrent neural network based on LSTM.
-
-Fig 4. Bidirectional LSTMs
+
+Figure 4. Schematic diagram of a bidirectional recurrent neural network based on LSTM
-Note that, this bidirectional RNNs is different from the one proposed by Bengio et al. in machine translation tasks \[[3](#reference), [4](#reference)\]. We will introduce another bidirectional RNNs in the following chapter [machine translation](https://github.com/PaddlePaddle/book/blob/develop/08.machine_translation/README.md)
-
-### Conditional Random Field (CRF)
+It should be noted that this bidirectional RNN structure is not the same as the bidirectional RNN structure used by Bengio etc in machine translation tasks\[[3](#References), [4](#References)\] Another bidirectional recurrent neural network will be introduced in the following [Machine Translation](https://github.com/PaddlePaddle/book/blob/develop/08.machine_translation) task.
-Typically, a neural network's lower layers learn representations while its very top layer accomplishes the final task. These principles can guide our problem-solving approaches. In SRL tasks, a **Conditional Random Field** (*CRF*) is built on top of the network in order to perform the final prediction to tag sequences. It takes representations provided by the last LSTM layer as input.
+### Conditional Random Field
+The idea of using a neural network model to solve a problem usually is: the front-layer network learns the feature representation of the input, and the last layer of the network completes the final task based on the feature. In the SRL task, the feature representation of the deep LSTM network learns input. Conditional Random Filed (CRF) completes the sequence labeling on th basis of features at the end of the entire network.
-The CRF is an undirected probabilistic graph with nodes denoting random variables and edges denoting dependencies between these variables. In essence, CRFs learn the conditional probability $P(Y|X)$, where $X = (x_1, x_2, ... , x_n)$ are sequences of input and $Y = (y_1, y_2, ... , y_n)$ are label sequences; to decode, simply search through $Y$ for a sequence that maximizes the conditional probability $P(Y|X)$, i.e., $Y^* = \mbox{arg max}_{Y} P(Y | X)$。
+CRF is a probabilistic structural model, which can be regarded as a probabilistic undirected graph model. Nodes represent random variables and edges represent probability dependencies between random variables. In simple terms, CRF learns the conditional probability $P(X|Y)$, where $X = (x_1, x_2, ... , x_n)$ is the input sequence, $Y = (y_1, y_2, ..., y_n $ is a sequence of tokens; the decoding process is given the $X$ sequence to solve the $Y$ sequence with the largest $P(Y|X)$, that is $Y^* = \mbox{arg max}_{Y} P( Y | X)$.
-Sequence tagging tasks do not assume a lot of conditional independence, because they only concern about the input and the output being linear sequences. Thus, the graph model of sequence tagging tasks is usually a simple chain or line, which results in a **Linear-Chain Conditional Random Field**, shown in Fig.5.
+The sequence labeling task only needs to consider that both the input and the output are a linear sequence. And since we only use the input sequence as a condition and do not make any conditional independent assumptions, there is no graph structure between the elements of the input sequence. In summary, the CRF defined on the chain diagram shown in Figure 5 is used in the sequence labeling task, which is called Linear Chain Conditional Random Field.
-
-Fig 5. Linear Chain Conditional Random Field used in SRL tasks
+
+Figure 5. Linear chain conditional random field used in sequence labeling tasks
-By the fundamental theorem of random fields \[[5](#reference)\], the joint distribution over the label sequence $Y$ given $X$ has the form:
+According to the factorization theorem on the linear chain condition random field \[[5](#References)\], the probability of a particular tag sequence $Y$ can be defined as given in the observation sequence $X$:
-$$p(Y | X) = \frac{1}{Z(X)} \text{exp}\left(\sum_{i=1}^{n}\left(\sum_{j}\lambda_{j}t_{j} (y_{i - 1}, y_{i}, X, i) + \sum_{k} \mu_k s_k (y_i, X, i)\right)\right)$$
+$$p(Y | X) = \frac{1}{Z(X)} \text{exp}\left(\sum_{i=1}^{n}\left(\sum_{j}\lambda_{ j}t_{j} (y_{i - 1}, y_{i}, X, i) + \sum_{k} \mu_k s_k (y_i, X, i)\right)\right)$$
-
-where, $Z(X)$ is normalization constant, ${t_j}$ represents the feature functions defined on edges called the *transition feature*, which denotes the transition probabilities from $y_{i-1}$ to $y_i$ given input sequence $X$. ${s_k}$ represents the feature function defined on nodes, called the state feature, denoting the probability of $y_i$ given input sequence $X$. In addition, $\lambda_j$ and $\mu_k$ are weights corresponding to $t_j$ and $s_k$. Alternatively, $t$ and $s$ can be written in the same form that depends on $y_{i - 1}$, $y_i$, $X$, and $i$. Taking its summation over all nodes $i$, we have: $f_{k}(Y, X) = \sum_{i=1}^{n}f_k({y_{i - 1}, y_i, X, i})$, which defines the *feature function* $f$. Thus, $P(Y|X)$ can be written as:
+Where $Z(X)$ is the normalization factor, and $t_j$ is the feature function defined on the edge, depending on the current and previous position, which called the transition feature. It represents the transition probability of the input sequence $X$ and its labeling sequence marked at the $i$ and $i - 1$ positions. $s_k$ is a feature function defined on the node, called a state feature, which depends on the current position. It represents the probability of marking for the observation sequence $X$ and its $i$ position. $\lambda_j$ and $\mu_k$ are the weights corresponding to the transfer feature function and the state feature function respectively. In fact, $t$ and $s$ can be represented in the same mathematical form, and the transfer feature and state are summed at each position $i$: $f_{k}(Y, X) = \sum_{i =1}^{n}f_k({y_{i - 1}, y_i, X, i})$. Calling $f$ collectively as a feature function, so $P(Y|X)$ can be expressed as:
$$p(Y|X, W) = \frac{1}{Z(X)}\text{exp}\sum_{k}\omega_{k}f_{k}(Y, X)$$
-where $\omega$ are the weights to the feature function that the CRF learns. While training, given input sequences and label sequences $D = \left[(X_1, Y_1), (X_2 , Y_2) , ... , (X_N, Y_N)\right]$, by maximum likelihood estimation (**MLE**), we construct the following objective function:
-
+$\omega$ is the weight corresponding to the feature function and is the parameter to be learned by the CRF model. During training, for a given input sequence and the corresponding set of markup sequences $D = \left[(X_1, Y_1), (X_2 , Y_2) , ... , (X_N, Y_N)\right]$ , by regularizing the maximum likelihood estimation to solve the following optimization objectives:
-$$\DeclareMathOperator*{\argmax}{arg\,max} L(\lambda, D) = - \text{log}\left(\prod_{m=1}^{N}p(Y_m|X_m, W)\right) + C \frac{1}{2}\lVert W\rVert^{2}$$
+$$\DeclareMathOperator*{\argmax}{arg\,max} L(\lambda, D) = - \text{log}\left(\prod_{m=1}^{N}p(Y_m|X_m, W )\right) + C \frac{1}{2}\lVert W\rVert^{2}$$
+This optimization objectives can be solved by the back propagation algorithm together with the entire neural network. When decoding, for a given input sequence $X$, the output sequence $\bar{Y}$ of maximizing the conditional probability $\bar{P}(Y|X)$ by the decoding algorithm (such as: Viterbi algorithm, Beam Search).
-This objective function can be solved via back-propagation in an end-to-end manner. While decoding, given input sequences $X$, search for sequence $\bar{Y}$ to maximize the conditional probability $\bar{P}(Y|X)$ via decoding methods (such as *Viterbi*, or [Beam Search Algorithm](https://github.com/PaddlePaddle/book/blob/develop/08.machine_translation/README.md#beam-search-algorithm)).
+### Deep bidirectional LSTM (DB-LSTM) SRL model
-### Deep Bidirectional LSTM (DB-LSTM) SRL model
+In the SRL task, the input is “predicate” and “a sentence”. The goal is to find the argument of the predicate from this sentence and mark the semantic role of the argument. If a sentence contains $n$ predicates, the sentence will be processed for $n$ times. One of the most straightforward models is the following:
-Given predicates and a sentence, SRL tasks aim to identify arguments of the given predicate and their semantic roles. If a sequence has $n$ predicates, we will process this sequence $n$ times. Here is the breakdown of a straight-forward model:
+1. Construct the input;
+ - Input 1 is the predicate and 2 is the sentence
+ - Extend input 1 to a sequence as long as input 2, expressed by one-hot mode;
+2. The predicate sequence and sentence sequence of the one-hot format are converted into a sequence of word vectors represented by real vectors through a vocabulary;
+3. The two word vector sequences in step 2 are used as input of the bidirectional LSTM to learn the feature representation of the input sequence;
+4. The CRF takes the features learned in the model in step 3 as input, and uses the tag sequence as the supervised signal to implement sequence labeling;
-1. Construct inputs;
- - input 1: predicate, input 2: sentence
- - expand input 1 into a sequence of the same length with input 2's sentence, using one-hot representation;
-2. Convert the one-hot sequences from step 1 to vector sequences via a word embedding's lookup table;
-3. Learn the representation of input sequences by taking vector sequences from step 2 as inputs;
-4. Take the representation from step 3 as input, label sequence as a supervisory signal, and realize sequence tagging tasks.
+You can try this method. Here, we propose some improvements that introduce two simple features that are very effective in improving system performance:
-Here, we propose some improvements by introducing two simple but effective features:
+- Predicate's context: In the above method, only the word vector of the predicate is used to express all the information related to the predicate. This method is always very weak, especially if the predicate appears multiple times in the sentence, it may cause certain ambiguity. From experience, a small segment of several words before and after the predicate can provide more information to help resolve ambiguity. So, we add this kind of experience to the model, and extract a "predicate context" fragment for each predicate, that is, a window fragment composed of $n$ words before and after the predicate;
+- Predicate context area's tag: Introduces a 0-1 binary variable for each word in the sentence, which indicats whether they are in the "predicate context" fragment;
-- predicate context (**ctx-p**): A single predicate word may not describe all the predicate information, especially when the same words appear multiple times in a sentence. With the expanded context, the ambiguity can be largely eliminated. Thus, we extract $n$ words before and after predicate to construct a window chunk.
+The modified model is as follows (Figure 6 is a schematic diagram of the model structure with a depth of 4):
-- region mark ($m_r$): The binary marker on a word, $m_r$, takes the value of $1$ when the word is in the predicate context region, and $0$ if not.
+1. Construct input
+ - Input 1 is a sentence sequence, input 2 is a predicate sequence, input 3 is a predicate context, and $n$ words before and after the predicate are extracted from the sentence to form a predicate context, which represented by one-hot. Input 4 is a predicate context area which marks whether each word in the sentence is in the context of the predicate;
+ - Extend the input 2~3 to a sequence as long as the input 1;
+2. Input 1~4 are converted into a sequence of word vectors represented by real vectors in vocabulary; where inputs 1 and 3 share the same vocabulary, and inputs 2 and 4 each have their own vocabulary;
+3. The four word vector sequences in step 2 are used as input to the bidirectional LSTM model; the LSTM model learns the feature representation of the input sequence to obtain a new feature representation sequence;
+4. The CRF takes the features learned in step 3 of the LSTM as input, and uses the marked sequence as the supervised signal to complete the sequence labeling;
-After these modifications, the model is as follows, as illustrated in Figure 6:
-
-1. Construct inputs
- - Input 1: word sequence. Input 2: predicate. Input 3: predicate context, extract $n$ words before and after predicate. Input 4: region mark sequence, where an entry is 1 if the word is located in the predicate context region, 0 otherwise.
- - expand input 2~3 into sequences with the same length with input 1
-2. Convert input 1~4 to vector sequences via word embedding lookup tables; While input 1 and 3 shares the same lookup table, input 2 and 4 have separate lookup tables.
-3. Take the four vector sequences from step 2 as inputs to bidirectional LSTMs; Train the LSTMs to update representations.
-4. Take the representation from step 3 as input to CRF, label sequence as a supervisory signal, and complete sequence tagging tasks.
-
-
-
-
-Fig 6. DB-LSTM for SRL tasks
+
+
+Figure 6. Deep bidirectional LSTM model on the SRL task
-## Data Preparation
-In the tutorial, we use [CoNLL 2005](http://www.cs.upc.edu/~srlconll/) SRL task open dataset as an example. Note that the training set and development set of the CoNLL 2005 SRL task are not free to download after the competition. Currently, only the test set can be obtained, including 23 sections of the Wall Street Journal and three sections of the Brown corpus. In this tutorial, we use the WSJ corpus as the training dataset to explain the model. However, since the training set is small, for a usable neural network SRL system, please consider paying for the full corpus.
+## Data Introduction
+
+In this tutorial, We use the data set opened by the [CoNLL 2005](http://www.cs.upc.edu/~srlconll/) SRL task as an example. It is important to note that the training set and development set of the CoNLL 2005 SRL task are not free for public after the competition. Currently, only the test set is available, including 23 in the Wall Street Journal and 3 in the Brown corpus. In this tutorial, we use the WSJ data in the test set to solve the model for the training set. However, since the number of samples in the test set is far from enough, if you want to train an available neural network SRL system, consider paying for the full amount of data.
-The original data includes a variety of information such as POS tagging, naming entity recognition, syntax tree, etc. In this tutorial, we only use the data under `test.wsj/words/` (text sequence) and `test.wsj/props/` (label results). The data directory used in this tutorial is as follows:
+The original data also includes a variety of information such as part-of-speech tagging, named entity recognition, and syntax parse tree. In this tutorial, we use the data in the test.wsj folder for training and testing, and only use the data under the words folder (text sequence) and the props folder (labeled results). The data directories used in this tutorial are as follows:
```text
conll05st-release/
└── test.wsj
- ├── props # label results
- └── words # text sequence
+ ├── props # Label result
+ └── words # Input text sequence
```
-The annotation information is derived from the results of Penn TreeBank\[[7](#references)\] and PropBank \[[8](#references)\]. The labeling of the PropBank is different from the labeling methods mentioned before, but shares with it the same underlying principle. For descriptions of the labeling, please refer to the paper \[[9](#references)\].
+The labeling information is derived from the labeling results of Penn TreeBank\[[7](#References)\] and PropBank\[[8](#References)\]. The label of the PropBank labeling result is different from the labeling result label we used in the first example of the article, but the principle is the same. For the description of the meaning of the labeling result label, please refer to the paper \[[9](#References)\].
-The raw data needs to be preprocessed into formats that PaddlePaddle can handle. The preprocessing consists of the following steps:
+The raw data needs to be preprocessed in order to be processed by PaddlePaddle. The preprocessing includes the following steps:
-1. Merge the text sequence and the tag sequence into the same record;
-2. If a sentence contains $n$ predicates, the sentence will be processed $n$ times into $n$ separate training samples, each sample with a different predicate;
-3. Extract the predicate context and construct the predicate context region marker;
-4. Construct the markings in BIO format;
-5. Obtain the integer index corresponding to the word according to the dictionary.
+1. Combine text sequences and tag sequences into one record;
+2. If a sentence contains $n$ predicates, the sentence will be processed for $n$ times, becoming a $n$ independent training sample, each sample with a different predicate;
+3. Extract the predicate context and construct the predicate context area tag;
+4. Construct a tag represented by the BIO method;
+5. Get the integer index corresponding to the word according to the dictionary.
-After preprocessing, a training sample contains nine features, namely: word sequence, predicate, predicate context (5 columns), region mark sequence, label sequence. The following table is an example of a training sample.
+After the pre-processing is completed, a training sample data contains 9 fields, namely: sentence sequence, predicate, predicate context (accounting for 5 columns), predicate context area tag, and labeling sequence. The following table is an example of a training sample.
-| word sequence | predicate | predicate context(5 columns) | region mark sequence | label sequence|
+| Sentence Sequence | Predicate | Predicate Context (Window = 5) | Predicate Context Area Tag | Label Sequence |
|---|---|---|---|---|
| A | set | n't been set . × | 0 | B-A1 |
| record | set | n't been set . × | 0 | I-A1 |
@@ -230,18 +207,19 @@ After preprocessing, a training sample contains nine features, namely: word sequ
| set | set | n't been set . × | 1 | B-V |
| . | set | n't been set . × | 1 | O |
-In addition to the data, we provide following resources:
-| filename | explanation |
+In addition to the data, we also provide the following resources:
+
+| File Name | Description |
|---|---|
-| word_dict | dictionary of input sentences, total 44068 words |
-| label_dict | dictionary of labels, total 106 labels |
-| predicate_dict | predicate dictionary, total 3162 predicates |
-| emb | a pre-trained word vector lookup table, 32-dimensional |
+| word_dict | Input a dictionary of sentences for a total of 44068 words |
+| label_dict | Tag dictionary, total 106 tags |
+| predicate_dict | Dictionary of predicates, totaling 3162 words |
+| emb | A trained vocabulary, 32-dimensional |
-We trained a language model on the English Wikipedia to get a word vector lookup table used to initialize the SRL model. While training the SRL model, the word vector lookup table is no longer updated. To learn more about the language model and the word vector lookup table, please refer to the tutorial [word vector](https://github.com/PaddlePaddle/book/blob/develop/04.word2vec/README.md). There are 995,000,000 tokens in the training corpus, and the dictionary size is 4900,000 words. In the CoNLL 2005 training corpus, 5% of the words are not in the 4900,000 words, and we see them all as unknown words, represented by `
`.
+We trained a language model on English Wikipedia to get a word vector to initialize the SRL model. During the training of the SRL model, the word vector is no longer updated. For the language model and word vector, refer to [Word Vector](https://github.com/PaddlePaddle/book/blob/develop/04.word2vec) for this tutorial. The corpus of our training language model has a total of 995,000,000 tokens, and the dictionary size is controlled to 4,900,000 words. CoNLL 2005 training corpus 5% of this word is not in 4900,000 words, we have seen them all unknown words, with `` representation.
-Here we fetch the dictionary, and print its size:
+Get the dictionary and print the dictionary size:
```python
from __future__ import print_function
@@ -271,349 +249,353 @@ print('pred_dict_len: ', pred_dict_len)
- Define input data dimensions and model hyperparameters.
```python
-mark_dict_len = 2
-word_dim = 32
-mark_dim = 5
-hidden_dim = 512
-depth = 8
-mix_hidden_lr = 1e-3
-
-IS_SPARSE = True
-PASS_NUM = 10
-BATCH_SIZE = 10
-
-embedding_name = 'emb'
+mark_dict_len = 2 # The dimension of the context area flag, which is a 0-1 2 value feature, so the dimension is 2
+Word_dim = 32 # Word vector dimension
+Mark_dim = 5 # The predicate context area is mapped to a real vector by the vocabulary, which is the adjacent dimension
+Hidden_dim = 512 # LSTM Hidden Layer Vector Dimensions : 512 / 4
+Depth = 8 # depth of stack LSTM
+Mix_hidden_lr = 1e-3 # Basic learning rate of fundamental_chain_crf layer
+
+IS_SPARSE = True # Whether to update embedding in sparse way
+PASS_NUM = 10 # Training epoches
+BATCH_SIZE = 10 # Batch size
+
+Embeddding_name = 'emb'
```
-Note that `hidden_dim = 512` means a LSTM hidden vector of 128 dimension (512/4). Please refer to PaddlePaddle's official documentation for detail: [lstmemory](http://www.paddlepaddle.org/doc/ui/api/trainer_config_helpers/layers.html#lstmemory)。
+It should be specially noted that the parameter `hidden_dim = 512` actually specifies the dimension of the LSTM hidden layer's vector is 128. For this, please refer to the description of `dynamic_lstm` in the official PaddlePaddle API documentation.
-- Define a parameter loader method to load the pre-trained word lookup tables from word embeddings trained on the English language Wikipedia.
+- As is mentioned above, we use the trained word vector based on English Wikipedia to initialize the embedding layer parameters of the total six features of the sequence input and predicate context, which are not updated during training.
```python
+#Here load the binary parameters saved by PaddlePaddle
def load_parameter(file_name, h, w):
with open(file_name, 'rb') as f:
f.read(16) # skip header.
return np.fromfile(f, dtype=np.float32).reshape(h, w)
```
-- Transform the word sequence itself, the predicate, the predicate context, and the region mark sequence into embedded vector sequences.
-- 8 LSTM units are trained through alternating left-to-right / right-to-left order denoted by the variable `reverse`.
+
+## Training Model
+
+- We train according to the network topology and model parameters. We also need to specify the optimization method when constructing. Here we use the most basic SGD method (momentum is set to 0), and set the learning rate, regularition, and so on.
+
+Define hyperparameters for the training process
+
+```python
+use_cuda = False #Execute training on cpu
+save_dirname = "label_semantic_roles.inference.model" #The model parameters obtained by training are saved in the file.
+is_local = True
+```
+
+### Data input layer definition
+Defines the format of the model input features, including the sentence sequence, the predicate, the five features of the predicate context, and the predicate context area flags.
+
+```python
+# Sentence sequences
+word = fluid.layers.data(
+ name='word_data', shape=[1], dtype='int64', lod_level=1)
+
+# predicate
+predicate = fluid.layers.data(
+ name='verb_data', shape=[1], dtype='int64', lod_level=1)
+
+# predicate context's 5 features
+ctx_n2 = fluid.layers.data(
+ name='ctx_n2_data', shape=[1], dtype='int64', lod_level=1)
+ctx_n1 = fluid.layers.data(
+ name='ctx_n1_data', shape=[1], dtype='int64', lod_level=1)
+ctx_0 = fluid.layers.data(
+ name='ctx_0_data', shape=[1], dtype='int64', lod_level=1)
+ctx_p1 = fluid.layers.data(
+ name='ctx_p1_data', shape=[1], dtype='int64', lod_level=1)
+ctx_p2 = fluid.layers.data(
+ name='ctx_p2_data', shape=[1], dtype='int64', lod_level=1)
+
+# Predicate conotext area flag
+mark = fluid.layers.data(
+ name='mark_data', shape=[1], dtype='int64', lod_level=1)
+```
+### Defining the network structure
+First pre-train and define the model input layer
+
+```python
+#pre-training predicate and predicate context area flags
+predicate_embedding = fluid.layers.embedding(
+ input=predicate,
+ size=[pred_dict_len, word_dim],
+ dtype='float32',
+ is_sparse=IS_SPARSE,
+ param_attr='vemb')
+
+mark_embedding = fluid.layers.embedding(
+ input=mark,
+ size=[mark_dict_len, mark_dim],
+ dtype='float32',
+ is_sparse=IS_SPARSE)
+
+#Sentence sequences and predicate context 5 features then pre-trained
+word_input = [word, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2]
+#Because word vector is pre-trained, no longer training embedding table,
+# The trainable's parameter attribute set to False prevents the embedding table from being updated during training
+emb_layers = [
+ fluid.layers.embedding(
+ size=[word_dict_len, word_dim],
+ input=x,
+ param_attr=fluid.ParamAttr(
+ name=embedding_name, trainable=False)) for x in word_input
+]
+# Pre-training results for adding predicate and predicate context area tags
+emb_layers.append(predicate_embedding)
+emb_layers.append(mark_embedding)
+```
+Define eight LSTM units to learn all input sequences in "forward/reverse" order.
```python
-def db_lstm(word, predicate, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2, mark,
- **ignored):
- # 8 features
- predicate_embedding = fluid.layers.embedding(
- input=predicate,
- size=[pred_dict_len, word_dim],
- dtype='float32',
- is_sparse=IS_SPARSE,
- param_attr='vemb')
-
- mark_embedding = fluid.layers.embedding(
- input=mark,
- size=[mark_dict_len, mark_dim],
- dtype='float32',
- is_sparse=IS_SPARSE)
-
- word_input = [word, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2]
- # Since word vector lookup table is pre-trained, we won't update it this time.
- # trainable being False prevents updating the lookup table during training.
- emb_layers = [
- fluid.layers.embedding(
- size=[word_dict_len, word_dim],
- input=x,
- param_attr=fluid.ParamAttr(
- name=embedding_name, trainable=False)) for x in word_input
- ]
- emb_layers.append(predicate_embedding)
- emb_layers.append(mark_embedding)
-
- # 8 LSTM units are trained through alternating left-to-right / right-to-left order
- # denoted by the variable `reverse`.
- hidden_0_layers = [
- fluid.layers.fc(input=emb, size=hidden_dim, act='tanh')
- for emb in emb_layers
- ]
-
- hidden_0 = fluid.layers.sums(input=hidden_0_layers)
-
- lstm_0 = fluid.layers.dynamic_lstm(
- input=hidden_0,
+# A total of 8 LSTM units are trained, each unit is oriented from left to right or right to left.
+# Determined by the parameter `is_reverse`
+# First stack structure
+hidden_0_layers = [
+ fluid.layers.fc(input=emb, size=hidden_dim, act='tanh')
+ for emb in emb_layers
+]
+
+hidden_0 = fluid.layers.sums(input=hidden_0_layers)
+
+lstm_0 = fluid.layers.dynamic_lstm(
+ input=hidden_0,
+ size=hidden_dim,
+ candidate_activation='relu',
+ gate_activation='sigmoid',
+ cell_activation='sigmoid')
+
+# Stack L-LSTM and R-LSTM with directly connected sides
+input_tmp = [hidden_0, lstm_0]
+
+# remaining stack structure
+for i in range(1, depth):
+ mix_hidden = fluid.layers.sums(input=[
+ fluid.layers.fc(input=input_tmp[0], size=hidden_dim, act='tanh'),
+ fluid.layers.fc(input=input_tmp[1], size=hidden_dim, act='tanh')
+ ])
+
+ lstm = fluid.layers.dynamic_lstm(
+ input=mix_hidden,
size=hidden_dim,
candidate_activation='relu',
gate_activation='sigmoid',
- cell_activation='sigmoid')
-
- # stack L-LSTM and R-LSTM with direct edges
- input_tmp = [hidden_0, lstm_0]
-
- # In PaddlePaddle, state features and transition features of a CRF are implemented
- # by a fully connected layer and a CRF layer seperately. The fully connected layer
- # with linear activation learns the state features, here we use fluid.layers.sums
- # (fluid.layers.fc can be uesed as well), and the CRF layer in PaddlePaddle:
- # fluid.layers.linear_chain_crf only
- # learns the transition features, which is a cost layer and is the last layer of the network.
- # fluid.layers.linear_chain_crf outputs the log probability of true tag sequence
- # as the cost by given the input sequence and it requires the true tag sequence
- # as target in the learning process.
-
- for i in range(1, depth):
- mix_hidden = fluid.layers.sums(input=[
- fluid.layers.fc(input=input_tmp[0], size=hidden_dim, act='tanh'),
- fluid.layers.fc(input=input_tmp[1], size=hidden_dim, act='tanh')
- ])
-
- lstm = fluid.layers.dynamic_lstm(
- input=mix_hidden,
- size=hidden_dim,
- candidate_activation='relu',
- gate_activation='sigmoid',
- cell_activation='sigmoid',
- is_reverse=((i % 2) == 1))
-
- input_tmp = [mix_hidden, lstm]
-
- feature_out = fluid.layers.sums(input=[
- fluid.layers.fc(input=input_tmp[0], size=label_dict_len, act='tanh'),
- fluid.layers.fc(input=input_tmp[1], size=label_dict_len, act='tanh')
- ])
+ cell_activation='sigmoid',
+ is_reverse=((i % 2) == 1))
+
+ input_tmp = [mix_hidden, lstm]
+
+# Fetch the output of the last stack LSTM and the input of this LSTM unit to the hidden layer mapping,
+# Learn the state feature of CRF after a fully connected layer maps to the dimensions of the tags dictionary
+feature_out = fluid.layers.sums(input=[
+ fluid.layers.fc(input=input_tmp[0], size=label_dict_len, act='tanh'),
+ fluid.layers.fc(input=input_tmp[1], size=label_dict_len, act='tanh')
+])
+
+# tag/label sequence
+target = fluid.layers.data(
+ name='target', shape=[1], dtype='int64', lod_level=1)
+
+# Learning CRF transfer features
+crf_cost = fluid.layers.linear_chain_crf(
+ input=feature_out,
+ label=target,
+ param_attr=fluid.ParamAttr(
+ name='crfw', learning_rate=mix_hidden_lr))
+
+
+avg_cost = fluid.layers.mean(crf_cost)
+
+# Use the most basic SGD optimization method (momentum is set to 0)
+sgd_optimizer = fluid.optimizer.SGD(
+ learning_rate=fluid.layers.exponential_decay(
+ learning_rate=0.01,
+ decay_steps=100000,
+ decay_rate=0.5,
+ staircase=True))
+
+sgd_optimizer.minimize(avg_cost)
+
- return feature_out
```
-## Train model
+The data introduction section mentions the payment of the CoNLL 2005 training set. Here we use the test set training for everyone to learn. Conll05.test() produces one sample every time, containing 9 features, then shuffle and after batching as the input for training.
+
+```python
+crf_decode = fluid.layers.crf_decoding(
+ input=feature_out, param_attr=fluid.ParamAttr(name='crfw'))
-- In the `train` method, we will create trainer given model topology, parameters, and optimization method. We will use the most basic **SGD** method, which is a momentum optimizer with 0 momentum. Meanwhile, we will set learning rate and decay.
+train_data = paddle.batch(
+ paddle.reader.shuffle(
+ paddle.dataset.conll05.test(), buf_size=8192),
+ batch_size=BATCH_SIZE)
-- As mentioned in data preparation section, we will use CoNLL 2005 test corpus as the training data set. `conll05.test()` outputs one training instance at a time. It is shuffled and batched into mini batches, and used as input.
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-- `feeding` is used to specify the correspondence between data instance and data layer. For example, according to the `feeding`, the 0th column of data instance produced by`conll05.test()` is matched to the data layer named `word_data`.
+```
-- `event_handler` can be used as callback for training events, it will be used as an argument for the `train` method. Following `event_handler` prints cost during training.
+The corresponding relationship between each data and data_layer is specified by the feeder. The following feeder indicates that the data_layer corresponding to the 0th column of the data generated by conll05.test() is `word`.
-- `trainer.train` will train the model.
```python
-def train(use_cuda, save_dirname=None, is_local=True):
- # define network topology
- word = fluid.layers.data(
- name='word_data', shape=[1], dtype='int64', lod_level=1)
- predicate = fluid.layers.data(
- name='verb_data', shape=[1], dtype='int64', lod_level=1)
- ctx_n2 = fluid.layers.data(
- name='ctx_n2_data', shape=[1], dtype='int64', lod_level=1)
- ctx_n1 = fluid.layers.data(
- name='ctx_n1_data', shape=[1], dtype='int64', lod_level=1)
- ctx_0 = fluid.layers.data(
- name='ctx_0_data', shape=[1], dtype='int64', lod_level=1)
- ctx_p1 = fluid.layers.data(
- name='ctx_p1_data', shape=[1], dtype='int64', lod_level=1)
- ctx_p2 = fluid.layers.data(
- name='ctx_p2_data', shape=[1], dtype='int64', lod_level=1)
- mark = fluid.layers.data(
- name='mark_data', shape=[1], dtype='int64', lod_level=1)
-
- # define network topology
- feature_out = db_lstm(**locals())
- target = fluid.layers.data(
- name='target', shape=[1], dtype='int64', lod_level=1)
- crf_cost = fluid.layers.linear_chain_crf(
- input=feature_out,
- label=target,
- param_attr=fluid.ParamAttr(
- name='crfw', learning_rate=mix_hidden_lr))
-
- avg_cost = fluid.layers.mean(crf_cost)
-
- sgd_optimizer = fluid.optimizer.SGD(
- learning_rate=fluid.layers.exponential_decay(
- learning_rate=0.01,
- decay_steps=100000,
- decay_rate=0.5,
- staircase=True))
-
- sgd_optimizer.minimize(avg_cost)
-
- # The CRF decoding layer is used for evaluation and inference.
- # It shares weights with CRF layer. The sharing of parameters among multiple layers
- # is specified by using the same parameter name in these layers. If true tag sequence
- # is provided in training process, `fluid.layers.crf_decoding` calculates labelling error
- # for each input token and sums the error over the entire sequence.
- # Otherwise, `fluid.layers.crf_decoding` generates the labelling tags.
- crf_decode = fluid.layers.crf_decoding(
- input=feature_out, param_attr=fluid.ParamAttr(name='crfw'))
-
- train_data = paddle.batch(
- paddle.reader.shuffle(
- paddle.dataset.conll05.test(), buf_size=8192),
- batch_size=BATCH_SIZE)
-
- place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-
-
- feeder = fluid.DataFeeder(
- feed_list=[
- word, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2, predicate, mark, target
- ],
- place=place)
- exe = fluid.Executor(place)
-
- def train_loop(main_program):
- exe.run(fluid.default_startup_program())
- embedding_param = fluid.global_scope().find_var(
- embedding_name).get_tensor()
- embedding_param.set(
- load_parameter(conll05.get_embedding(), word_dict_len, word_dim),
- place)
-
- start_time = time.time()
- batch_id = 0
- for pass_id in six.moves.xrange(PASS_NUM):
- for data in train_data():
- cost = exe.run(main_program,
- feed=feeder.feed(data),
- fetch_list=[avg_cost])
- cost = cost[0]
-
- if batch_id % 10 == 0:
- print("avg_cost: " + str(cost))
- if batch_id != 0:
- print("second per batch: " + str((time.time(
- ) - start_time) / batch_id))
- # Set the threshold low to speed up the CI test
- if float(cost) < 60.0:
- if save_dirname is not None:
- fluid.io.save_inference_model(save_dirname, [
- 'word_data', 'verb_data', 'ctx_n2_data',
- 'ctx_n1_data', 'ctx_0_data', 'ctx_p1_data',
- 'ctx_p2_data', 'mark_data'
- ], [feature_out], exe)
- return
-
- batch_id = batch_id + 1
-
- train_loop(fluid.default_main_program())
+feeder = fluid.DataFeeder(
+ feed_list=[
+ word, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2, predicate, mark, target
+ ],
+ place=place)
+exe = fluid.Executor(place)
+```
+
+Start training
+
+```python
+main_program = fluid.default_main_program()
+
+exe.run(fluid.default_startup_program())
+embedding_param = fluid.global_scope().find_var(
+ embedding_name).get_tensor()
+embedding_param.set(
+ load_parameter(conll05.get_embedding(), word_dict_len, word_dim),
+ place)
+
+start_time = time.time()
+batch_id = 0
+for pass_id in six.moves.xrange(PASS_NUM):
+ for data in train_data():
+ cost = exe.run(main_program,
+ feed=feeder.feed(data),
+ fetch_list=[avg_cost])
+ cost = cost[0]
+
+ if batch_id % 10 == 0:
+ print("avg_cost: " + str(cost))
+ if batch_id != 0:
+ print("second per batch: " + str((time.time(
+ ) - start_time) / batch_id))
+ # Set the threshold low to speed up the CI test
+ if float(cost) < 60.0:
+ if save_dirname is not None:
+ fluid.io.save_inference_model(save_dirname, [
+ 'word_data', 'verb_data', 'ctx_n2_data',
+ 'ctx_n1_data', 'ctx_0_data', 'ctx_p1_data',
+ 'ctx_p2_data', 'mark_data'
+ ], [feature_out], exe)
+ break
+
+ batch_id = batch_id + 1
```
-## Application
+## Model Application
+
+After completing the training, the optimal model needs to be selected according to a performance indicator we care about. You can simply select the model with the least markup error on the test set. We give an example of using a trained model for prediction as follows.
-- When training is completed, we need to select an optimal model based one performance index to do inference. In this task, one can simply select the model with the least number of marks on the test set. We demonstrate doing an inference using the trained model.
+First set the parameters of the prediction process
```python
-def infer(use_cuda, save_dirname=None):
- if save_dirname is None:
- return
-
- place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- inference_scope = fluid.core.Scope()
- with fluid.scope_guard(inference_scope):
- # Use fluid.io.load_inference_model to obtain the inference program desc,
- # the feed_target_names (the names of variables that will be fed
- # data using feed operators), and the fetch_targets (variables that
- # we want to obtain data from using fetch operators).
- [inference_program, feed_target_names,
- fetch_targets] = fluid.io.load_inference_model(save_dirname, exe)
-
- # Setup inputs by creating LoDTensors to represent sequences of words.
- # Here each word is the basic element of these LoDTensors and the shape of
- # each word (base_shape) should be [1] since it is simply an index to
- # look up for the corresponding word vector.
- # Suppose the length_based level of detail (lod) info is set to [[3, 4, 2]],
- # which has only one lod level. Then the created LoDTensors will have only
- # one higher level structure (sequence of words, or sentence) than the basic
- # element (word). Hence the LoDTensor will hold data for three sentences of
- # length 3, 4 and 2, respectively.
- # Note that lod info should be a list of lists.
- lod = [[3, 4, 2]]
- base_shape = [1]
- # The range of random integers is [low, high]
- word = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=word_dict_len - 1)
- pred = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=pred_dict_len - 1)
- ctx_n2 = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=word_dict_len - 1)
- ctx_n1 = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=word_dict_len - 1)
- ctx_0 = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=word_dict_len - 1)
- ctx_p1 = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=word_dict_len - 1)
- ctx_p2 = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=word_dict_len - 1)
- mark = fluid.create_random_int_lodtensor(
- lod, base_shape, place, low=0, high=mark_dict_len - 1)
-
- # Construct feed as a dictionary of {feed_target_name: feed_target_data}
- # and results will contain a list of data corresponding to fetch_targets.
- assert feed_target_names[0] == 'word_data'
- assert feed_target_names[1] == 'verb_data'
- assert feed_target_names[2] == 'ctx_n2_data'
- assert feed_target_names[3] == 'ctx_n1_data'
- assert feed_target_names[4] == 'ctx_0_data'
- assert feed_target_names[5] == 'ctx_p1_data'
- assert feed_target_names[6] == 'ctx_p2_data'
- assert feed_target_names[7] == 'mark_data'
-
- results = exe.run(inference_program,
- feed={
- feed_target_names[0]: word,
- feed_target_names[1]: pred,
- feed_target_names[2]: ctx_n2,
- feed_target_names[3]: ctx_n1,
- feed_target_names[4]: ctx_0,
- feed_target_names[5]: ctx_p1,
- feed_target_names[6]: ctx_p2,
- feed_target_names[7]: mark
- },
- fetch_list=fetch_targets,
- return_numpy=False)
- print(results[0].lod())
- np_data = np.array(results[0])
- print("Inference Shape: ", np_data.shape)
+use_cuda = False #predict on cpu
+save_dirname = "label_semantic_roles.inference.model" #call trained model for prediction
+
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+exe = fluid.Executor(place)
```
+Set the input, use LoDTensor to represent the input word sequence, where the shape of each word's base_shape is [1], because each word is represented by an id. If the length-based LoD is [[3, 4, 2]], which is a single-layer LoD, then the constructed LoDTensor contains three sequences which their length are 3, 4, and 2.
+
+Note that LoD is a list of lists.
-- The main entrance of the whole program is as below:
+```python
+lod = [[3, 4, 2]]
+base_shape = [1]
+
+# Construct fake data as input, the range of random integer numbers is [low, high]
+word = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=word_dict_len - 1)
+pred = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=pred_dict_len - 1)
+ctx_n2 = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=word_dict_len - 1)
+ctx_n1 = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=word_dict_len - 1)
+ctx_0 = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=word_dict_len - 1)
+ctx_p1 = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=word_dict_len - 1)
+ctx_p2 = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=word_dict_len - 1)
+mark = fluid.create_random_int_lodtensor(
+ lod, base_shape, place, low=0, high=mark_dict_len - 1)
+```
+
+Using fluid.io.load_inference_model to load inference_program, feed_target_names is the name of the model's input variable, and fetch_targets is the predicted object.
```python
-def main(use_cuda, is_local=True):
- if use_cuda and not fluid.core.is_compiled_with_cuda():
- return
+[inference_program, feed_target_names,
+ fetch_targets] = fluid.io.load_inference_model(save_dirname, exe)
+```
+Construct the feed dictionary {feed_target_name: feed_target_data}, where the results are a list of predicted targets
- # Directory for saving the trained model
- save_dirname = "label_semantic_roles.inference.model"
+```python
+assert feed_target_names[0] == 'word_data'
+assert feed_target_names[1] == 'verb_data'
+assert feed_target_names[2] == 'ctx_n2_data'
+assert feed_target_names[3] == 'ctx_n1_data'
+assert feed_target_names[4] == 'ctx_0_data'
+assert feed_target_names[5] == 'ctx_p1_data'
+assert feed_target_names[6] == 'ctx_p2_data'
+assert feed_target_names[7] == 'mark_data'
+```
+Execute prediction
- train(use_cuda, save_dirname, is_local)
- infer(use_cuda, save_dirname)
+```python
+results = exe.run(inference_program,
+ feed={
+ feed_target_names[0]: word,
+ feed_target_names[1]: pred,
+ feed_target_names[2]: ctx_n2,
+ feed_target_names[3]: ctx_n1,
+ feed_target_names[4]: ctx_0,
+ feed_target_names[5]: ctx_p1,
+ feed_target_names[6]: ctx_p2,
+ feed_target_names[7]: mark
+ },
+ fetch_list=fetch_targets,
+ return_numpy=False)
+```
+Output result
-main(use_cuda=False)
+```python
+print(results[0].lod())
+np_data = np.array(results[0])
+print("Inference Shape: ", np_data.shape)
```
+
## Conclusion
-Semantic Role Labeling is an important intermediate step in a wide range of natural language processing tasks. In this tutorial, we use SRL as an example to illustrate using PaddlePaddle to do sequence tagging tasks. The models proposed are from our published paper\[[10](#Reference)\]. We only use test data for illustration since the training data on the CoNLL 2005 dataset is not completely public. This aims to propose an end-to-end neural network model with fewer dependencies on natural language processing tools but is comparable, or even better than traditional models in terms of performance. Please check out our paper for more information and discussions.
+Labeling semantic roles is an important intermediate step in many natural language understanding tasks. In this tutorial, we take the label semantic roles task as an example to introduce how to use PaddlePaddle for sequence labeling tasks. The model presented in the tutorial comes from our published paper \[[10](#References)\]. Since the training data for the CoNLL 2005 SRL task is not currently fully open, only the test data is used as an example in the tutorial. In this process, we hope to reduce our reliance on other natural language processing tools. We can use neural network data-driven, end-to-end learning capabilities to get a model that is comparable or even better than traditional methods. In the paper, we confirmed this possibility. More information and discussion about the model can be found in the paper.
+
## References
-1. Sun W, Sui Z, Wang M, et al. [Chinese semantic role labeling with shallow parsing](http://www.aclweb.org/anthology/D09-1#page=1513)[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 3-Volume 3. Association for Computational Linguistics, 2009: 1475-1483.
+1. Sun W, Sui Z, Wang M, et al. [Chinese label semantic roles with shallow parsing](http://www.aclweb.org/anthology/D09-1#page=1513)[C]//Proceedings Of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 3-Volume 3. Association for Computational Linguistics, 2009: 1475-1483.
2. Pascanu R, Gulcehre C, Cho K, et al. [How to construct deep recurrent neural networks](https://arxiv.org/abs/1312.6026)[J]. arXiv preprint arXiv:1312.6026, 2013.
-3. Cho K, Van Merriënboer B, Gulcehre C, et al. [Learning phrase representations using RNN encoder-decoder for statistical machine translation](https://arxiv.org/abs/1406.1078)[J]. arXiv preprint arXiv:1406.1078, 2014.
+3. Cho K, Van Merriënboer B, Gulcehre C, et al. [Learning phrase representations using RNN encoder-decoder for statistical machine translation](https://arxiv.org/abs/1406.1078)[J]. arXiv preprint arXiv: 1406.1078, 2014.
4. Bahdanau D, Cho K, Bengio Y. [Neural machine translation by jointly learning to align and translate](https://arxiv.org/abs/1409.0473)[J]. arXiv preprint arXiv:1409.0473, 2014.
-5. Lafferty J, McCallum A, Pereira F. [Conditional random fields: Probabilistic models for segmenting and labeling sequence data](http://www.jmlr.org/papers/volume15/doppa14a/source/biblio.bib.old)[C]//Proceedings of the eighteenth international conference on machine learning, ICML. 2001, 1: 282-289.
-6. 李航. 统计学习方法[J]. 清华大学出版社, 北京, 2012.
-7. Marcus M P, Marcinkiewicz M A, Santorini B. [Building a large annotated corpus of English: The Penn Treebank](http://repository.upenn.edu/cgi/viewcontent.cgi?article=1246&context=cis_reports)[J]. Computational linguistics, 1993, 19(2): 313-330.
-8. Palmer M, Gildea D, Kingsbury P. [The proposition bank: An annotated corpus of semantic roles](http://www.mitpressjournals.org/doi/pdfplus/10.1162/0891201053630264)[J]. Computational linguistics, 2005, 31(1): 71-106.
-9. Carreras X, Màrquez L. [Introduction to the CoNLL-2005 shared task: Semantic role labeling](http://www.cs.upc.edu/~srlconll/st05/papers/intro.pdf)[C]//Proceedings of the Ninth Conference on Computational Natural Language Learning. Association for Computational Linguistics, 2005: 152-164.
-10. Zhou J, Xu W. [End-to-end learning of semantic role labeling using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
+5. Lafferty J, McCallum A, Pereira F. [Conditional random fields: Probabilistic models for segmenting and labeling sequence data](http://www.jmlr.org/papers/volume15/doppa14a/source/biblio.bib.old) [C]//Proceedings of the eighteenth international conference on machine learning, ICML. 2001, 1: 282-289.
+6. Li Hang. Statistical Learning Method[J]. Tsinghua University Press, Beijing, 2012.
+7. Marcus MP, Marcinkiewicz MA, Santorini B. [Building a large annotated corpus of English: The Penn Treebank](http://repository.upenn.edu/cgi/viewcontent.cgi?article=1246&context=cis_reports)[J] Computational linguistics, 1993, 19(2): 313-330.
+8. Palmer M, Gildea D, Kingsbury P. [The proposition bank: An annotated corpus of semantic roles](http://www.mitpressjournals.org/doi/pdfplus/10.1162/0891201053630264) [J]. Computational linguistics, 2005 , 31(1): 71-106.
+9. Carreras X, Màrquez L. [Introduction to the CoNLL-2005 shared task: label semantic roles](http://www.cs.upc.edu/~srlconll/st05/papers/intro.pdf)[C]/ /Proceedings of the Ninth Conference on Computational Natural Language Learning. Association for Computational Linguistics, 2005: 152-164.
+10. Zhou J, Xu W. [End-to-end learning of label semantic roles using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C] //Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+
This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/08.machine_translation/README.md b/08.machine_translation/README.md
index febd0cd..eb279ba 100644
--- a/08.machine_translation/README.md
+++ b/08.machine_translation/README.md
@@ -1,172 +1,147 @@
# Machine Translation
-The source code of this tutorial is live at [book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/08.machine_translation). For instructions on getting started with this book,see [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book).
+Source code of this tutorial is in [book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/08.machine_translation). For users new to Paddle book, please refer to [the user guide of Book Documentation](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#run_the_book).
-## Background
+## Background
-Machine translation (MT) leverages computers to translate from one language to another. The language to be translated is referred to as the source language, while the language to be translated into is referred to as the target language. Thus, Machine translation is the process of translating from the source language to the target language. It is one of the most important research topics in the field of natural language processing.
+Machine translation is to translate different languages with computer. The language to be translated is usually called source language, and the language representing the result of translation is called target language. Machine translation is the process of transformation from source language to target language, which is an important research assignment of Natural Language Processing.
+Machine translation systems at early age were mostly rule-based translation system, which needs linguists make transformation rule between two languages and then input these rules into computer. This method requires proficient professional linguistic background, but it is hard to cover all rules of a language, let it alone two or more languages. Therefore, the major challenge of traditional machine translation method is the impossibility of a completest set of rules\[[1](#References)\].
-Early machine translation systems are mainly rule-based i.e. they rely on a language expert to specify the translation rules between the two languages. It is quite difficult to cover all the rules used in one language. So it is quite a challenge for language experts to specify all possible rules in two or more different languages. Hence, a major challenge in conventional machine translation has been the difficulty in obtaining a complete rule set \[[1](#references)\].
+To solve the problem mentioned above, Statistical Machine Translation technology emerged afterwards. For Statistical Machine Translation, transformation rules are automatically learned from a large scale corpus instead of handcrafted rule. So it tackles with the limit of obtaining knowledge in rule-based machine translation systems. However, it still faces certain challenges: 1. man-made feature can never cover all language phenomena. 2. it is hard to use global feature. 3. it depends on many pre-processing parts, such as Word Alignment, Tokenization, Rule Extraction, Parsing. Errors accumulated by those parts will have a great influence on translation.
+In recent years, Deep Learning technology proposes new solutions to overcome the bottleneck. Two methods for machine translation are realized with the aid of deep learning. 1. Based on the framework of statistical machine translation system, the neural network is in place to improve core parts, such as language model, reordering model and so on (See the left part in figure One). 2. Abandoning the framework of statistical machine translation system, it directly uses neural network to transform source language to target language, which is End-to-End Neural Machine Translation (See right part in figure One), NMT model in short.
+
+

+Figure One. Neural Network Machine Translation System
+
-To address the aforementioned problems, statistical machine translation techniques have been developed. These techniques learn the translation rules from a large corpus, instead of being designed by a language expert. While these techniques overcome the bottleneck of knowledge acquisition, there are still quite a lot of challenges, for example:
+In the following parts, we'll guide you through NMT model and its hands-on implementation in PaddlePaddle
-1. Human designed features cannot cover all possible linguistic variations;
+## Result Demo
-2. It is difficult to use global features;
+Take Chinese to English translation model as an example. For a trained model, if input the following tokenized Chinese sentence :
-3. The techniques heavily rely on pre-processing techniques like word alignment, word segmentation and tokenization, rule-extraction and syntactic parsing etc. The error introduced in any of these steps could accumulate and impact translation quality.
-
-
-
-The recent development of deep learning provides new solutions to these challenges. The two main categories for deep learning based machine translation techniques are:
-
-1. Techniques based on the statistical machine translation system but with some key components improved with neural networks, e.g., language model, reordering model (please refer to the left part of Figure 1);
-
-2. Techniques mapping from source language to target language directly using a neural network, or end-to-end neural machine translation (NMT).
-
-
-
-Figure 1. Neural Network based Machine Translation
-
-
-
-This tutorial will mainly introduce an NMT model and how to use PaddlePaddle to train it.
-
-## Illustrative Results
-
-Let's consider an example of Chinese-to-English translation. The model is given the following segmented sentence in Chinese
```text
这些 是 希望 的 曙光 和 解脱 的 迹象 .
```
-After training and with a beam-search size of 3, the generated translations are as follows:
+
+If it sets the entries of translation result ( e.t. the width of [beam search algorithm](#beam search algorithm)) as 3, the generated English sentence is as follows:
+
```text
0 -5.36816 These are signs of hope and relief .
1 -6.23177 These are the light of hope and relief .
2 -7.7914 These are the light of hope and the relief of hope .
```
-- The first column corresponds to the id of the generated sentence; the second column corresponds to the score of the generated sentence (in descending order), where a larger value indicates better quality; the last column corresponds to the generated sentence.
-- There are two special tokens: `` denotes the end of a sentence while `` denotes unknown word, i.e., a word not in the training dictionary.
-## Overview of the Model
-
-This section will introduce Bi-directional Recurrent Neural Network, the Encoder-Decoder framework used in NMT, as well as the beam search algorithm.
-
-### Bi-directional Recurrent Neural Network
+- The first column to the left is the serial numbers of generated sentences. The second column from left is scores of the sentences in descending order, in which higher score is better. The third column contains the generated English sentences.
-We already introduced an instance of bi-directional RNN in the [Semantic Role Labeling](https://github.com/PaddlePaddle/book/blob/develop/label_semantic_roles/README.md) chapter. Here we present another bi-directional RNN model with a different architecture proposed by Bengio et al. in \[[2](#references),[4](#references)\]. This model takes a sequence as input and outputs a fixed dimensional feature vector at each step, encoding the context information at the corresponding time step.
+- In addition, there are two special marks. One is ``, indicating the end of a sentence and another one is ``, representing unknown word, which have never appeared in dictionary.
-Specifically, this bi-directional RNN processes the input sequence in the original and reverse order respectively, and then concatenates the output feature vectors at each time step as the final output. Thus the output node at each time step contains information from the past and future as context. The figure below shows an unrolled bi-directional RNN. This network contains a forward RNN and backward RNN with six weight matrices: weight matrices from input to forward hidden layer and backward hidden ($W_1, W_3$), weight matrices from hidden to itself ($W_2, W_5$), matrices from forward hidden and backward hidden to output layer ($W_4, W_6$). Note that there are no connections between forward hidden and backward hidden layers.
+## Exploration of Models
-
-
-Figure 3. Temporally unrolled bi-directional RNN
-
+In this section, let's scrutinize Bi-directional Recurrent Neural Network, typical Encoder-Decoder structure in NMT model and beam search algorithm.
-### Encoder-Decoder Framework
-
-The Encoder-Decoder\[[2](#references)\] framework aims to solve the mapping of a sequence to another sequence, for sequences with arbitrary lengths. The source sequence is encoded into a vector via an encoder, which is then decoded to a target sequence via a decoder by maximizing the predictive probability. Both the encoder and the decoder are typically implemented via RNN.
+### Bi-directional Recurrent Neural Network
-
-
-Figure 4. Encoder-Decoder Framework
-
+We have introduced a bi-directional recurrent neural network in the chapter [label_semantic_roles](https://github.com/PaddlePaddle/book/blob/develop/07.label_semantic_roles/README.md). Here we introduce another network proposed by Bengio team in thesis \[[2](#References),[4](#References)\] The aim of this network is to input a sequence and get its features at each time step. Specifically, fixed-length vector is incorporated to represent contextual semantic information for each time step in the output.
-#### Encoder
+To be concrete, the Bi-directional recurrent neural network sequentially processes the input sequences in time dimension in sequential order or in reverse order, i.e., forward and backward. And the output of RNN at each time step are concatenated to be the final output layer. Hereby the output node of each time step contains complete past and future context information of current time step of input sequence. The figure below shows a bi-directional recurrent neural network expanded by time step. The network consists of a forward and a backward RNN with six weight matrices: a weight matrix ($W_1, W_3$) from input layer to the forward and backward hidden layers, and a weight matrix ($W_2, W_5$) from a hidden layer to itself (self-loop), the weight matrix from the forward hidden layer and the backward hidden layer to the output layer ($W_4, W_6$). Note that there is no connection between the forward hidden layer and the backward hidden layer.
-There are three steps for encoding a sentence:
-1. One-hot vector representation of a word: Each word $x_i$ in the source sentence $x=\left \{ x_1,x_2,...,x_T \right \}$ is represented as a vector $w_i\epsilon \left \{ 0,1 \right \}^{\left | V \right |},i=1,2,...,T$ where $w_i$ has the same dimensionality as the size of the dictionary, i.e., $\left | V \right |$, and has an element of one at the location corresponding to the location of the word in the dictionary and zero elsewhere.
+
+
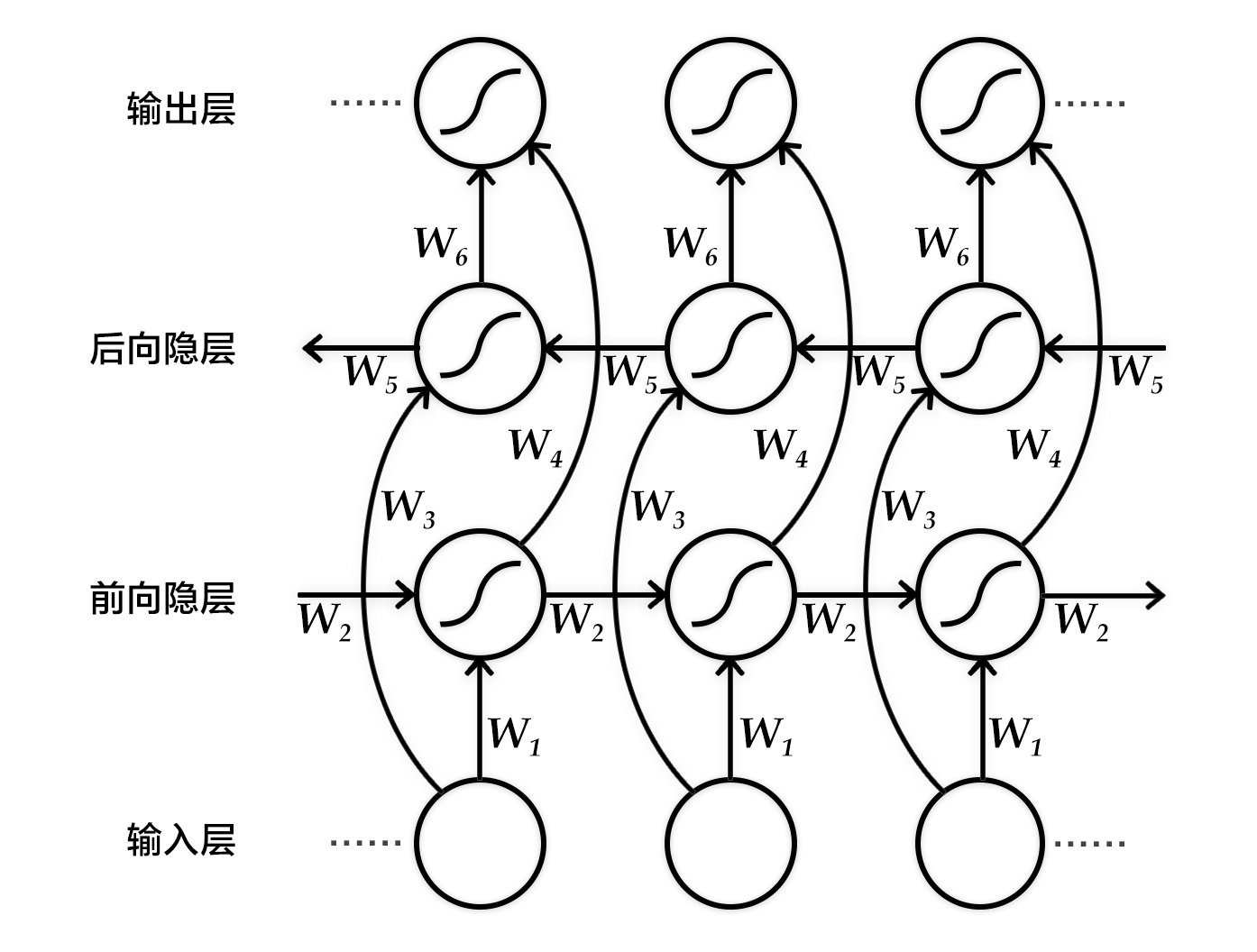
+Figure 2. Bi-directional Recurrent Neural Network expanded by time step.
+
+

+Figure 3. Encoder-Decoder Frame
+
-
-Figure 5. Encoder using bi-directional GRU
-
+Step 3 can also use bi-directional recurrent neural network to implement more complex sentence-coded representation, which can be implemented with bi-directional GRU. The forward GRU sequentially encodes the source language word in the order of the word sequence $(x_1, x_2,..., x_T)$, and obtains a series of hidden layer states $(\overrightarrow{h_1},\overrightarrow{h_2},. ..,\overrightarrow{h_T})$. Similarly, the backward GRU encodes the source language word in the order of $(x_T,x_{T-1},...,x_1)$, resulting in $(\overleftarrow{h_1},\overleftarrow{h_2},. ..,\overleftarrow{h_T})$. Finally, for the word $x_i$, the hidden layer state is obtained by jointing the two GRUs, namely $h_i=\left [ \overrightarrow{h_i^T},\overleftarrow{h_i^T} \right ]^{T} $.
+
+
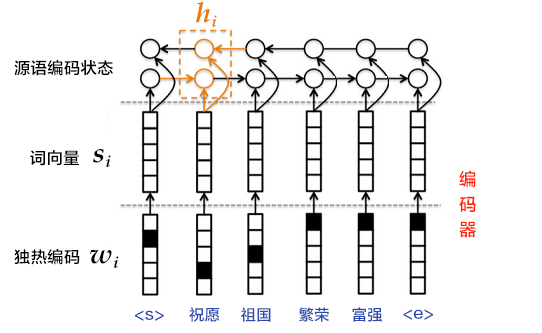
+Figure 4. Use bi-directional GRU encoder
+
` of the target language sequence, indicating the start of decoding; $z_i$ is the hidden layer state of the RNN at $i$th time, and $z_0$ is an all-zero vector.
-1. At each time step $i$, given the encoding vector (or context vector) $c$ of the source sentence, the $i$-th word $u_i$ from the ground-truth target language and the RNN hidden state $z_i$, the next hidden state $z_{i+1}$ is computed as:
+2.Normalize $z_{i+1}$ by `softmax` to get the probability distribution $p_{i+1}$ of the $i+1$th word of the target language sequence. The probability distribution formula is as follows:
+$$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
+Where $W_sz_{i+1}+b_z$ scores each possible output word and normalizes with softmax to get the probability $p_{i+1}$ of $i+1$th word.
- $$z_{i+1}=\phi _{\theta '}\left ( c,u_i,z_i \right )$$
- where $\phi _{\theta '}$ is a non-linear activation function and $c=q\mathbf{h}$ is the context vector of the source sentence. Without using [attention](#Attention Mechanism), if the output of the [encoder](#Encoder) is the encoding vector at the last time step of the source sentence, then $c$ can be defined as $c=h_T$. $u_i$ denotes the $i$-th word from the target language sentence and $u_0$ denotes the beginning of the target language sentence (i.e., ``), indicating the beginning of decoding. $z_i$ is the RNN hidden state at time step $i$ and $z_0$ is an all zero vector.
+3.Calculate the cost according to $p_{i+1}$ and $u_{i+1}$.
-2. Calculate the probability $p_{i+1}$ for the $i+1$-th word in the target language sequence by normalizing $z_{i+1}$ using `softmax` as follows
+4.Repeat steps 1~3 until all words in the target language sequence have been processed.
- $$p\left ( u_{i+1}|u_{
+### Beam Search Algorithm
-3. Compute the cost accoding to $p_{i+1}$ and $u_{i+1}$.
-4. Repeat Steps 1-3, until all the words in the target language sentence have been processed.
+Beam Search ([beam search](http://en.wikipedia.org/wiki/Beam_search)) is a heuristic graph search algorithm for searching the graph or tree for the optimal extended nodes in a finite set, usually used in systems with very large solution space (such as machine translation, speech recognition), for that the memory can't fit all the unfolded solutions in the graph or tree. If you want to translate "`Hello`" in the machine translation task, even if there are only 3 words (``, ``, `hello`) in the target language dictionary, it is possible generate infinite sentences (the number of occurrences of `hello` is uncertain). In order to find better translation results, we can use beam search algorithm.
-The generation process of machine translation is to translate the source sentence into a sentence in the target language according to a pre-trained model. There are some differences between the decoding step in generation and training. Please refer to [Beam Search Algorithm](#Beam Search Algorithm) for details.
+The beam search algorithm uses a breadth-first strategy to build a search tree. At each level of the tree, the nodes are sorted according to the heuristic cost (in this tutorial, the sum of the log probabilities of the generated words), and then only the predetermined number of nodes (commonly referred to in the literature as beam width, beam size, 柱宽度, etc.). Only these nodes will continue to expand in the next layer, and other nodes will be cut off, that is, the nodes with higher quality are retained, and the nodes with poor quality are pruned. Therefore, the space and time occupied by the search are greatly reduced, but the disadvantage is that there is no guarantee that an optimal solution will be obtained.
-### Beam Search Algorithm
+In the decode period of using beam search algorithm, the goal is to maximize the probability of generated sequence. The idea is:
+1.At each time, the next hidden layer state $z_{i+1}$ is calculated according to the encoding information $c$ of the source language sentence, the generated $i$th target language sequence words $u_i$, and the hidden layer state $z_i$ of RNN at $i$th time.
-[Beam Search](http://en.wikipedia.org/wiki/Beam_search) is a heuristic search algorithm that explores a graph by expanding the most promising node in a limited set. It is typically used when the solution space is huge (e.g., for machine translation, speech recognition), and there is not enough memory for all the possible solutions. For example, if we want to translate “`你好`” into English, even if there are only three words in the dictionary (``, ``, `hello`), it is still possible to generate an infinite number of sentences, where the word `hello` can appear different number of times. Beam search could be used to find a good translation among them.
+2.Normalize $z_{i+1}$ by `softmax` to get the probability distribution $p_{i+1}$ of the $i+1$th words of the target language sequence.
-Beam search builds a search tree using breadth first search and sorts the nodes according to a heuristic cost (sum of the log probability of the generated words) at each level of the tree. Only a fixed number of nodes according to the pre-specified beam size (or beam width) are considered. Thus, only nodes with highest scores are expanded in the next level. This reduces the space and time requirements significantly. However, a globally optimal solution is not guaranteed.
+3.The word $u_{i+1}$ is sampled according to $p_{i+1}$.
-The goal is to maximize the probability of the generated sequence when using beam search in decoding, The procedure is as follows:
+4.Repeat steps 1~3 until you get the sentence end tag `` or exceed the maximum generation length of the sentence.
-1. At each time step $i$, compute the hidden state $z_{i+1}$ of the next time step according to the context vector $c$ of the source sentence, the $i$-th word $u_i$ generated for the target language sentence and the RNN hidden state $z_i$.
-2. Normalize $z_{i+1}$ using `softmax` to get the probability $p_{i+1}$ for the $i+1$-th word for the target language sentence.
-3. Sample the word $u_{i+1}$ according to $p_{i+1}$.
-4. Repeat Steps 1-3, until end-of-sentence token `` is generated or the maximum length of the sentence is reached.
+Note: The formula for $z_{i+1}$ and $p_{i+1}$ is the same as in [Decoder](#Decoder). And since each step of the generation is implemented by the greedy method, it is not guaranteed to obtain the global optimal solution.
-Note: $z_{i+1}$ and $p_{i+1}$ are computed the same way as in [Decoder](#Decoder). In generation mode, each step is greedy in so there is no guarantee of a global optimum.
+## Data Preparation
-## BLEU Score
+This tutorial uses [bitexts(after selection)] in the [WMT-14](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/) dataset (http://www-lium.univ- Lemans.fr/~schwenk/cslm_joint_paper/data/bitexts.tgz) as a training set, [dev+test data](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/dev+test.tgz) as a test set and generated set.
-Bilingual Evaluation understudy (BLEU) is a metric widely used for automatic machine translation proposed by IBM Watson Research Center in 2002\[[5](#References)\]. The closer the translation produced by a machine is to the translation produced by a human expert, the better the performance of the translation system.
+### Data Pre-processing
-To measure the closeness between machine translation and human translation, sentence precision is used. It compares the number of matched n-grams. More matches will lead to higher BLEU scores.
+It contains two steps in pre-processing:
-## Data Preparation
+-Merge parallel corpora files from source language to target language into one file:
-This tutorial uses a dataset from [WMT-14](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/), where [bitexts (after selection)](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/bitexts.tgz) is used as the training set, and [dev+test data](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/dev+test.tgz) is used as test and generation set.
+-Merge every `XXX.src` and `XXX.trg` into one file as `XXX`.
+-Content in $i$th row of `XXX` is the connection of $i$th row of `XXX.src` with $i$th row of `XXX.trg`, which is divided by '\t'.
-### Data Preprocessing
+-Create source language dictionary and target language dictionary of train data. There are **DICTSIZE** words in each dictionary, including: (DICTSIZE - 3) words with highest frequency in the corpus, and 3 special symbols `` (the beginning of the sequence), `` ( the end of the sequence) and `` (unknown word).
-There are two steps for pre-processing:
-- Merge the source and target parallel corpus files into one file
- - Merge `XXX.src` and `XXX.trg` file pair as `XXX`
- - The $i$-th row in `XXX` is the concatenation of the $i$-th row from `XXX.src` with the $i$-th row from `XXX.trg`, separated with '\t'.
+### Sample Data
-- Create source dictionary and target dictionary, each containing **DICTSIZE** number of words, including the most frequent (DICTSIZE - 3) fo word from the corpus and 3 special token `` (begin of sequence), `` (end of sequence) and `` (unknown words that are not in the vocabulary).
+Because the data volume of the complete data set is large, in order to verify the training process, the PaddlePaddle interface paddle.data set.wmt14 provides a pre-processed [smaller scale dataset](http://paddlepaddle.bj.bcebos.com/demo/wmt_shrinked_data/wmt14.tgz) by default .
-### A Subset of Dataset
+In the data set, there are 193,319 training data, 6003 test data, and a dictionary with length of 30,000. Due to the limit of data size, the effects of models trained with this dataset are not guaranteed.
-Because the full dataset is very big, to reduce the time for downloading the full dataset. PadddlePaddle package `paddle.dataset.wmt14` provides a preprocessed `subset of dataset`(http://paddlepaddle.bj.bcebos.com/demo/wmt_shrinked_data/wmt14.tgz).
+## Model Configuration
-This subset has 193319 instances of training data and 6003 instances of test data. Dictionary size is 30000. Because of the limitation of size of the subset, the effectiveness of trained model from this subset is not guaranteed.
+Next we start configuring model according to input data. First we import necessary library functions and define global variables.
-## Model Configuration
-Our program starts with importing necessary packages and initializing some global variables:
```python
from __future__ import print_function
@@ -190,41 +165,51 @@ except ImportError:
from paddle.fluid.trainer import *
from paddle.fluid.inferencer import *
-dict_size = 30000
-source_dict_dim = target_dict_dim = dict_size
-hidden_dim = 32
-word_dim = 16
-batch_size = 2
-max_length = 8
-topk_size = 50
-beam_size = 2
+dict_size = 30000 # dictionary dimension
+source_dict_dim = target_dict_dim = dict_size # source/target language dictionary dimension
+hidden_dim = 32 # size of hidden layer in encoder
+word_dim = 16 # dimension of word vector
+batch_size = 2 # the number of samples in batch
+max_length = 8 # the maximum length of generated sentence
+beam_size = 2 # width of beam
-decoder_size = hidden_dim
+decoder_size = hidden_dim # size of hidden layer in decoder
```
-Then we implement encoder as follows:
- ```python
+
+
+Then the frame of encoder is implemented as follows:
+
+
+```python
def encoder(is_sparse):
+ # define input data id of source language
src_word_id = pd.data(
name="src_word_id", shape=[1], dtype='int64', lod_level=1)
+ # reflect encode above on the word vector of low-dimension language space.
src_embedding = pd.embedding(
input=src_word_id,
size=[dict_size, word_dim],
dtype='float32',
is_sparse=is_sparse,
param_attr=fluid.ParamAttr(name='vemb'))
-
+ # LSTM layer:fc + dynamic_lstm
fc1 = pd.fc(input=src_embedding, size=hidden_dim * 4, act='tanh')
lstm_hidden0, lstm_0 = pd.dynamic_lstm(input=fc1, size=hidden_dim * 4)
+ # Fetch the final state after the sequence encode of source language
encoder_out = pd.sequence_last_step(input=lstm_hidden0)
return encoder_out
- ```
+```
+
+
+
+Then implement decoder in training mode:
-Implement the decoder for training as follows:
```python
def train_decoder(context, is_sparse):
+ # Define input data of sequence id of target language and reflect it on word vector of low-dimension language space
trg_language_word = pd.data(
name="target_language_word", shape=[1], dtype='int64', lod_level=1)
trg_embedding = pd.embedding(
@@ -235,35 +220,44 @@ Implement the decoder for training as follows:
param_attr=fluid.ParamAttr(name='vemb'))
rnn = pd.DynamicRNN()
- with rnn.block():
+ with rnn.block(): # use DynamicRNN to define computation at each step
+ # Fetch input word vector of target language at present step
current_word = rnn.step_input(trg_embedding)
+ # obtain state of hidden layer
pre_state = rnn.memory(init=context)
+ # computing unit of decoder: single-layer forward network
current_state = pd.fc(input=[current_word, pre_state],
size=decoder_size,
act='tanh')
-
+ # compute predicting probability of nomarlized word
current_score = pd.fc(input=current_state,
size=target_dict_dim,
act='softmax')
+ # update hidden layer of RNN
rnn.update_memory(pre_state, current_state)
+ # output predicted probability
rnn.output(current_score)
return rnn()
```
-Implement the decoder for prediction as follows:
+
+
+implement decoder in inference mode
+
+
```python
def decode(context, is_sparse):
init_state = context
+ # define counter variable in the decoding
array_len = pd.fill_constant(shape=[1], dtype='int64', value=max_length)
counter = pd.zeros(shape=[1], dtype='int64', force_cpu=True)
- # fill the first element with init_state
+ # define tensor array to save content at each time step, and write initial id, score and state
state_array = pd.create_array('float32')
pd.array_write(init_state, array=state_array, i=counter)
- # ids, scores as memory
ids_array = pd.create_array('int64')
scores_array = pd.create_array('float32')
@@ -274,34 +268,35 @@ def decode(context, is_sparse):
pd.array_write(init_ids, array=ids_array, i=counter)
pd.array_write(init_scores, array=scores_array, i=counter)
+ # define conditional variable to stop loop
cond = pd.less_than(x=counter, y=array_len)
-
+ # define while_op
while_op = pd.While(cond=cond)
- with while_op.block():
+ with while_op.block(): # define the computing of each step
+ # obtain input at present step of decoder, including id chosen at previous step, corresponding score and state at previous step.
pre_ids = pd.array_read(array=ids_array, i=counter)
pre_state = pd.array_read(array=state_array, i=counter)
pre_score = pd.array_read(array=scores_array, i=counter)
- # expand the lod of pre_state to be the same with pre_score
+ # update input state as state correspondent with id chosen at previous step
pre_state_expanded = pd.sequence_expand(pre_state, pre_score)
-
+ # computing logic of decoder under the same train mode, including input vector and computing unit of decoder
+ # compute predicting probability of normalized word
pre_ids_emb = pd.embedding(
input=pre_ids,
size=[dict_size, word_dim],
dtype='float32',
is_sparse=is_sparse)
-
- # use rnn unit to update rnn
current_state = pd.fc(input=[pre_state_expanded, pre_ids_emb],
size=decoder_size,
act='tanh')
current_state_with_lod = pd.lod_reset(x=current_state, y=pre_score)
- # use score to do beam search
current_score = pd.fc(input=current_state_with_lod,
size=target_dict_dim,
act='softmax')
topk_scores, topk_indices = pd.topk(current_score, k=beam_size)
- # calculate accumulated scores after topk to reduce computation cost
+
+ # compute accumulated score and perform beam search
accu_scores = pd.elementwise_add(
x=pd.log(topk_scores), y=pd.reshape(pre_score, shape=[-1]), axis=0)
selected_ids, selected_scores = pd.beam_search(
@@ -314,14 +309,12 @@ def decode(context, is_sparse):
level=0)
pd.increment(x=counter, value=1, in_place=True)
-
- # update the memories
+ # write search result and corresponding hidden layer into tensor array
pd.array_write(current_state, array=state_array, i=counter)
pd.array_write(selected_ids, array=ids_array, i=counter)
pd.array_write(selected_scores, array=scores_array, i=counter)
- # update the break condition: up to the max length or all candidates of
- # source sentences have ended.
+ # update condition to stop loop
length_cond = pd.less_than(x=counter, y=array_len)
finish_cond = pd.logical_not(pd.is_empty(x=selected_ids))
pd.logical_and(x=length_cond, y=finish_cond, out=cond)
@@ -333,8 +326,9 @@ def decode(context, is_sparse):
```
-Then we define a `training_program` that uses the result from `encoder` and `train_decoder` to compute the cost with label data.
-Also define `optimizer_func` to specify the optimizer.
+
+
+Furthermore, we define a `train_program` to use result computed by `inference_program` and compute error with the help of marked data. We also define an `optimizer_func` to define optimizer.
```python
def train_program(is_sparse):
@@ -354,21 +348,18 @@ def optimizer_func():
regularization_coeff=0.1))
```
-## Model Training
+## Train Model
-### Specify training environment
-
-Specify your training environment, you should specify if the training is on CPU or GPU.
+### Define Training Environment
+Define your training environment and define the train executed on CPU or on GPU.
```python
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
```
-### Datafeeder Configuration
-
-Next we define data feeders for test and train. The feeder reads a `buf_size` of data each time and feed them to the training/testing process.
-`paddle.dataset.wmt14.train` will yield records during each pass, after shuffling, a batch input of `BATCH_SIZE` is generated for training.
+### Define Data Provider
+The next step is to define data provider for train and test. Data Provider read data with size of `BATCH_SIZE` `paddle.dataset.wmt.train` will provide data with size of `BATCH_SIZE` after reordering every time. The size of reordering is `buf_size`.
```python
train_reader = paddle.batch(
@@ -378,8 +369,7 @@ train_reader = paddle.batch(
```
### Create Trainer
-
-Create a trainer that takes `train_program` as input and specify optimizer function.
+Trainer needs a train program and a train optimizer.
```python
is_sparse = False
@@ -389,20 +379,17 @@ trainer = Trainer(
optimizer_func=optimizer_func)
```
-### Feeding Data
+### Provide Data
-`feed_order` is devoted to specifying the correspondence between each yield record and `paddle.layer.data`. For instance, the first column of data generated by `wmt14.train` corresponds to `src_word_id`.
+`feed_order` is used to define every generated data and reflecting relationship between `paddle.layer.data`. For example, the first column data generated by `wmt14.train` is correspondent with the feature `src_word_id`.
```python
-feed_order = [
- 'src_word_id', 'target_language_word', 'target_language_next_word'
- ]
+feed_order = ['src_word_id', 'target_language_word', 'target_language_next_word'
+]
```
### Event Handler
-
-Callback function `event_handler` will be called during training when a pre-defined event happens.
-For example, we can check the cost by `trainer.test` when `EndStepEvent` occurs
+Call function `event_handler` will be called after the touch of an event defined before. For example, we can examine the loss after the training at each step.
```python
def event_handler(event):
@@ -414,10 +401,8 @@ def event_handler(event):
trainer.stop()
```
-
-### Training
-
-Finally, we invoke `trainer.train` to start training with `num_epochs` and other parameters.
+### Start Training
+Finally, we feed in `num_epoch` and other parameters and call `trainer.train` to start training.
```python
EPOCH_NUM = 1
@@ -429,20 +414,20 @@ trainer.train(
feed_order=feed_order)
```
-## Inference
+## Model Application
-### Define the decode part
+### Define Decoder Part
-Use the `encoder` and `decoder` function we defined above to predict translation ids and scores.
+Use `encoder` and `decoder` function defined above to infer corresponding id and score after the translation.
```python
context = encoder(is_sparse)
translation_ids, translation_scores = decode(context, is_sparse)
```
-### Define DataSet
+### Define Data
-We initialize ids and scores and create tensors for input. In this test we are using first record data from `wmt14.test` for inference. At the end we get src dict and target dict for printing out results later.
+First we initialize id and score to generate tensor as input data. In this prediction, we use the first record in `wmt14.test` to infer and finally use "source language dictionary" and "target language dictionary" to output corresponding sentence.
```python
init_ids_data = np.array([1 for _ in range(batch_size)], dtype='int64')
@@ -471,9 +456,9 @@ feeder = fluid.DataFeeder(feed_list, place)
src_dict, trg_dict = paddle.dataset.wmt14.get_dict(dict_size)
```
-### Infer
+### Test
+Now we can start predicting. We need provide corresponding parameters in `feed_order` and run it on `executor` to obtain id and score.
-We create `feed_dict` with all the inputs we need and run with `executor` to get predicted results id and corresponding scores.
```python
exe = Executor(place)
@@ -507,6 +492,11 @@ for data in test_data():
break
```
+## Summary
+
+End-to-End neural network translation is an recently acclaimed machine translation method. In this section, we introduced the typical Encoder-Decoder of NMT. Because NMT is a typical Seq2Seq (Sequence to Sequence) learning task, tasks of Seq2Seq, such as query rewriting, abstraction, single round dialogue, can be tackled by this model.
+
+
## References
1. Koehn P. [Statistical machine translation](https://books.google.com.hk/books?id=4v_Cx1wIMLkC&printsec=frontcover&hl=zh-CN&source=gbs_ge_summary_r&cad=0#v=onepage&q&f=false)[M]. Cambridge University Press, 2009.
@@ -516,4 +506,5 @@ for data in test_data():
5. Papineni K, Roukos S, Ward T, et al. [BLEU: a method for automatic evaluation of machine translation](http://dl.acm.org/citation.cfm?id=1073135)[C]//Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, 2002: 311-318.
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+
+
This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/08.machine_translation/index.html b/08.machine_translation/index.html
index cef1466..d5d85ab 100644
--- a/08.machine_translation/index.html
+++ b/08.machine_translation/index.html
@@ -42,173 +42,148 @@
# Machine Translation
-The source code of this tutorial is live at [book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/08.machine_translation). For instructions on getting started with this book,see [Running This Book](https://github.com/PaddlePaddle/book/blob/develop/README.md#running-the-book).
+Source code of this tutorial is in [book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/08.machine_translation). For users new to Paddle book, please refer to [the user guide of Book Documentation](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#run_the_book).
-## Background
+## Background
-Machine translation (MT) leverages computers to translate from one language to another. The language to be translated is referred to as the source language, while the language to be translated into is referred to as the target language. Thus, Machine translation is the process of translating from the source language to the target language. It is one of the most important research topics in the field of natural language processing.
+Machine translation is to translate different languages with computer. The language to be translated is usually called source language, and the language representing the result of translation is called target language. Machine translation is the process of transformation from source language to target language, which is an important research assignment of Natural Language Processing.
+Machine translation systems at early age were mostly rule-based translation system, which needs linguists make transformation rule between two languages and then input these rules into computer. This method requires proficient professional linguistic background, but it is hard to cover all rules of a language, let it alone two or more languages. Therefore, the major challenge of traditional machine translation method is the impossibility of a completest set of rules\[[1](#References)\].
-Early machine translation systems are mainly rule-based i.e. they rely on a language expert to specify the translation rules between the two languages. It is quite difficult to cover all the rules used in one language. So it is quite a challenge for language experts to specify all possible rules in two or more different languages. Hence, a major challenge in conventional machine translation has been the difficulty in obtaining a complete rule set \[[1](#references)\].
+To solve the problem mentioned above, Statistical Machine Translation technology emerged afterwards. For Statistical Machine Translation, transformation rules are automatically learned from a large scale corpus instead of handcrafted rule. So it tackles with the limit of obtaining knowledge in rule-based machine translation systems. However, it still faces certain challenges: 1. man-made feature can never cover all language phenomena. 2. it is hard to use global feature. 3. it depends on many pre-processing parts, such as Word Alignment, Tokenization, Rule Extraction, Parsing. Errors accumulated by those parts will have a great influence on translation.
+In recent years, Deep Learning technology proposes new solutions to overcome the bottleneck. Two methods for machine translation are realized with the aid of deep learning. 1. Based on the framework of statistical machine translation system, the neural network is in place to improve core parts, such as language model, reordering model and so on (See the left part in figure One). 2. Abandoning the framework of statistical machine translation system, it directly uses neural network to transform source language to target language, which is End-to-End Neural Machine Translation (See right part in figure One), NMT model in short.
+
+
+Figure One. Neural Network Machine Translation System
+
-To address the aforementioned problems, statistical machine translation techniques have been developed. These techniques learn the translation rules from a large corpus, instead of being designed by a language expert. While these techniques overcome the bottleneck of knowledge acquisition, there are still quite a lot of challenges, for example:
-
-1. Human designed features cannot cover all possible linguistic variations;
-
-2. It is difficult to use global features;
-
-3. The techniques heavily rely on pre-processing techniques like word alignment, word segmentation and tokenization, rule-extraction and syntactic parsing etc. The error introduced in any of these steps could accumulate and impact translation quality.
-
-
-
-The recent development of deep learning provides new solutions to these challenges. The two main categories for deep learning based machine translation techniques are:
-
-1. Techniques based on the statistical machine translation system but with some key components improved with neural networks, e.g., language model, reordering model (please refer to the left part of Figure 1);
-
-2. Techniques mapping from source language to target language directly using a neural network, or end-to-end neural machine translation (NMT).
-
-
-
-Figure 1. Neural Network based Machine Translation
-
-
+In the following parts, we'll guide you through NMT model and its hands-on implementation in PaddlePaddle
-This tutorial will mainly introduce an NMT model and how to use PaddlePaddle to train it.
+## Result Demo
-## Illustrative Results
+Take Chinese to English translation model as an example. For a trained model, if input the following tokenized Chinese sentence :
-Let's consider an example of Chinese-to-English translation. The model is given the following segmented sentence in Chinese
```text
这些 是 希望 的 曙光 和 解脱 的 迹象 .
```
-After training and with a beam-search size of 3, the generated translations are as follows:
+
+If it sets the entries of translation result ( e.t. the width of [beam search algorithm](#beam search algorithm)) as 3, the generated English sentence is as follows:
+
```text
0 -5.36816 These are signs of hope and relief .
1 -6.23177 These are the light of hope and relief .
2 -7.7914 These are the light of hope and the relief of hope .
```
-- The first column corresponds to the id of the generated sentence; the second column corresponds to the score of the generated sentence (in descending order), where a larger value indicates better quality; the last column corresponds to the generated sentence.
-- There are two special tokens: `` denotes the end of a sentence while `` denotes unknown word, i.e., a word not in the training dictionary.
-
-## Overview of the Model
-This section will introduce Bi-directional Recurrent Neural Network, the Encoder-Decoder framework used in NMT, as well as the beam search algorithm.
-
-### Bi-directional Recurrent Neural Network
+- The first column to the left is the serial numbers of generated sentences. The second column from left is scores of the sentences in descending order, in which higher score is better. The third column contains the generated English sentences.
-We already introduced an instance of bi-directional RNN in the [Semantic Role Labeling](https://github.com/PaddlePaddle/book/blob/develop/label_semantic_roles/README.md) chapter. Here we present another bi-directional RNN model with a different architecture proposed by Bengio et al. in \[[2](#references),[4](#references)\]. This model takes a sequence as input and outputs a fixed dimensional feature vector at each step, encoding the context information at the corresponding time step.
+- In addition, there are two special marks. One is ``, indicating the end of a sentence and another one is ``, representing unknown word, which have never appeared in dictionary.
-Specifically, this bi-directional RNN processes the input sequence in the original and reverse order respectively, and then concatenates the output feature vectors at each time step as the final output. Thus the output node at each time step contains information from the past and future as context. The figure below shows an unrolled bi-directional RNN. This network contains a forward RNN and backward RNN with six weight matrices: weight matrices from input to forward hidden layer and backward hidden ($W_1, W_3$), weight matrices from hidden to itself ($W_2, W_5$), matrices from forward hidden and backward hidden to output layer ($W_4, W_6$). Note that there are no connections between forward hidden and backward hidden layers.
+## Exploration of Models
-
-
-Figure 3. Temporally unrolled bi-directional RNN
-
+In this section, let's scrutinize Bi-directional Recurrent Neural Network, typical Encoder-Decoder structure in NMT model and beam search algorithm.
-### Encoder-Decoder Framework
-
-The Encoder-Decoder\[[2](#references)\] framework aims to solve the mapping of a sequence to another sequence, for sequences with arbitrary lengths. The source sequence is encoded into a vector via an encoder, which is then decoded to a target sequence via a decoder by maximizing the predictive probability. Both the encoder and the decoder are typically implemented via RNN.
+### Bi-directional Recurrent Neural Network
-
-
-Figure 4. Encoder-Decoder Framework
-
+We have introduced a bi-directional recurrent neural network in the chapter [label_semantic_roles](https://github.com/PaddlePaddle/book/blob/develop/07.label_semantic_roles/README.md). Here we introduce another network proposed by Bengio team in thesis \[[2](#References),[4](#References)\] The aim of this network is to input a sequence and get its features at each time step. Specifically, fixed-length vector is incorporated to represent contextual semantic information for each time step in the output.
-#### Encoder
+To be concrete, the Bi-directional recurrent neural network sequentially processes the input sequences in time dimension in sequential order or in reverse order, i.e., forward and backward. And the output of RNN at each time step are concatenated to be the final output layer. Hereby the output node of each time step contains complete past and future context information of current time step of input sequence. The figure below shows a bi-directional recurrent neural network expanded by time step. The network consists of a forward and a backward RNN with six weight matrices: a weight matrix ($W_1, W_3$) from input layer to the forward and backward hidden layers, and a weight matrix ($W_2, W_5$) from a hidden layer to itself (self-loop), the weight matrix from the forward hidden layer and the backward hidden layer to the output layer ($W_4, W_6$). Note that there is no connection between the forward hidden layer and the backward hidden layer.
-There are three steps for encoding a sentence:
-1. One-hot vector representation of a word: Each word $x_i$ in the source sentence $x=\left \{ x_1,x_2,...,x_T \right \}$ is represented as a vector $w_i\epsilon \left \{ 0,1 \right \}^{\left | V \right |},i=1,2,...,T$ where $w_i$ has the same dimensionality as the size of the dictionary, i.e., $\left | V \right |$, and has an element of one at the location corresponding to the location of the word in the dictionary and zero elsewhere.
+
+
+Figure 2. Bi-directional Recurrent Neural Network expanded by time step.
+
+
+Figure 3. Encoder-Decoder Frame
+
-
-Figure 5. Encoder using bi-directional GRU
-
+Step 3 can also use bi-directional recurrent neural network to implement more complex sentence-coded representation, which can be implemented with bi-directional GRU. The forward GRU sequentially encodes the source language word in the order of the word sequence $(x_1, x_2,..., x_T)$, and obtains a series of hidden layer states $(\overrightarrow{h_1},\overrightarrow{h_2},. ..,\overrightarrow{h_T})$. Similarly, the backward GRU encodes the source language word in the order of $(x_T,x_{T-1},...,x_1)$, resulting in $(\overleftarrow{h_1},\overleftarrow{h_2},. ..,\overleftarrow{h_T})$. Finally, for the word $x_i$, the hidden layer state is obtained by jointing the two GRUs, namely $h_i=\left [ \overrightarrow{h_i^T},\overleftarrow{h_i^T} \right ]^{T} $.
+
+
+Figure 4. Use bi-directional GRU encoder
+
` of the target language sequence, indicating the start of decoding; $z_i$ is the hidden layer state of the RNN at $i$th time, and $z_0$ is an all-zero vector.
-1. At each time step $i$, given the encoding vector (or context vector) $c$ of the source sentence, the $i$-th word $u_i$ from the ground-truth target language and the RNN hidden state $z_i$, the next hidden state $z_{i+1}$ is computed as:
+2.Normalize $z_{i+1}$ by `softmax` to get the probability distribution $p_{i+1}$ of the $i+1$th word of the target language sequence. The probability distribution formula is as follows:
+$$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
+Where $W_sz_{i+1}+b_z$ scores each possible output word and normalizes with softmax to get the probability $p_{i+1}$ of $i+1$th word.
- $$z_{i+1}=\phi _{\theta '}\left ( c,u_i,z_i \right )$$
- where $\phi _{\theta '}$ is a non-linear activation function and $c=q\mathbf{h}$ is the context vector of the source sentence. Without using [attention](#Attention Mechanism), if the output of the [encoder](#Encoder) is the encoding vector at the last time step of the source sentence, then $c$ can be defined as $c=h_T$. $u_i$ denotes the $i$-th word from the target language sentence and $u_0$ denotes the beginning of the target language sentence (i.e., ``), indicating the beginning of decoding. $z_i$ is the RNN hidden state at time step $i$ and $z_0$ is an all zero vector.
+3.Calculate the cost according to $p_{i+1}$ and $u_{i+1}$.
-2. Calculate the probability $p_{i+1}$ for the $i+1$-th word in the target language sequence by normalizing $z_{i+1}$ using `softmax` as follows
+4.Repeat steps 1~3 until all words in the target language sequence have been processed.
- $$p\left ( u_{i+1}|u_{
+### Beam Search Algorithm
-3. Compute the cost accoding to $p_{i+1}$ and $u_{i+1}$.
-4. Repeat Steps 1-3, until all the words in the target language sentence have been processed.
+Beam Search ([beam search](http://en.wikipedia.org/wiki/Beam_search)) is a heuristic graph search algorithm for searching the graph or tree for the optimal extended nodes in a finite set, usually used in systems with very large solution space (such as machine translation, speech recognition), for that the memory can't fit all the unfolded solutions in the graph or tree. If you want to translate "`Hello`" in the machine translation task, even if there are only 3 words (``, ``, `hello`) in the target language dictionary, it is possible generate infinite sentences (the number of occurrences of `hello` is uncertain). In order to find better translation results, we can use beam search algorithm.
-The generation process of machine translation is to translate the source sentence into a sentence in the target language according to a pre-trained model. There are some differences between the decoding step in generation and training. Please refer to [Beam Search Algorithm](#Beam Search Algorithm) for details.
+The beam search algorithm uses a breadth-first strategy to build a search tree. At each level of the tree, the nodes are sorted according to the heuristic cost (in this tutorial, the sum of the log probabilities of the generated words), and then only the predetermined number of nodes (commonly referred to in the literature as beam width, beam size, 柱宽度, etc.). Only these nodes will continue to expand in the next layer, and other nodes will be cut off, that is, the nodes with higher quality are retained, and the nodes with poor quality are pruned. Therefore, the space and time occupied by the search are greatly reduced, but the disadvantage is that there is no guarantee that an optimal solution will be obtained.
-### Beam Search Algorithm
+In the decode period of using beam search algorithm, the goal is to maximize the probability of generated sequence. The idea is:
+1.At each time, the next hidden layer state $z_{i+1}$ is calculated according to the encoding information $c$ of the source language sentence, the generated $i$th target language sequence words $u_i$, and the hidden layer state $z_i$ of RNN at $i$th time.
-[Beam Search](http://en.wikipedia.org/wiki/Beam_search) is a heuristic search algorithm that explores a graph by expanding the most promising node in a limited set. It is typically used when the solution space is huge (e.g., for machine translation, speech recognition), and there is not enough memory for all the possible solutions. For example, if we want to translate “`你好`” into English, even if there are only three words in the dictionary (``, ``, `hello`), it is still possible to generate an infinite number of sentences, where the word `hello` can appear different number of times. Beam search could be used to find a good translation among them.
+2.Normalize $z_{i+1}$ by `softmax` to get the probability distribution $p_{i+1}$ of the $i+1$th words of the target language sequence.
-Beam search builds a search tree using breadth first search and sorts the nodes according to a heuristic cost (sum of the log probability of the generated words) at each level of the tree. Only a fixed number of nodes according to the pre-specified beam size (or beam width) are considered. Thus, only nodes with highest scores are expanded in the next level. This reduces the space and time requirements significantly. However, a globally optimal solution is not guaranteed.
+3.The word $u_{i+1}$ is sampled according to $p_{i+1}$.
-The goal is to maximize the probability of the generated sequence when using beam search in decoding, The procedure is as follows:
+4.Repeat steps 1~3 until you get the sentence end tag `` or exceed the maximum generation length of the sentence.
-1. At each time step $i$, compute the hidden state $z_{i+1}$ of the next time step according to the context vector $c$ of the source sentence, the $i$-th word $u_i$ generated for the target language sentence and the RNN hidden state $z_i$.
-2. Normalize $z_{i+1}$ using `softmax` to get the probability $p_{i+1}$ for the $i+1$-th word for the target language sentence.
-3. Sample the word $u_{i+1}$ according to $p_{i+1}$.
-4. Repeat Steps 1-3, until end-of-sentence token `` is generated or the maximum length of the sentence is reached.
+Note: The formula for $z_{i+1}$ and $p_{i+1}$ is the same as in [Decoder](#Decoder). And since each step of the generation is implemented by the greedy method, it is not guaranteed to obtain the global optimal solution.
-Note: $z_{i+1}$ and $p_{i+1}$ are computed the same way as in [Decoder](#Decoder). In generation mode, each step is greedy in so there is no guarantee of a global optimum.
+## Data Preparation
-## BLEU Score
+This tutorial uses [bitexts(after selection)] in the [WMT-14](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/) dataset (http://www-lium.univ- Lemans.fr/~schwenk/cslm_joint_paper/data/bitexts.tgz) as a training set, [dev+test data](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/dev+test.tgz) as a test set and generated set.
-Bilingual Evaluation understudy (BLEU) is a metric widely used for automatic machine translation proposed by IBM Watson Research Center in 2002\[[5](#References)\]. The closer the translation produced by a machine is to the translation produced by a human expert, the better the performance of the translation system.
+### Data Pre-processing
-To measure the closeness between machine translation and human translation, sentence precision is used. It compares the number of matched n-grams. More matches will lead to higher BLEU scores.
+It contains two steps in pre-processing:
-## Data Preparation
+-Merge parallel corpora files from source language to target language into one file:
-This tutorial uses a dataset from [WMT-14](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/), where [bitexts (after selection)](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/bitexts.tgz) is used as the training set, and [dev+test data](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/dev+test.tgz) is used as test and generation set.
+-Merge every `XXX.src` and `XXX.trg` into one file as `XXX`.
+-Content in $i$th row of `XXX` is the connection of $i$th row of `XXX.src` with $i$th row of `XXX.trg`, which is divided by '\t'.
-### Data Preprocessing
+-Create source language dictionary and target language dictionary of train data. There are **DICTSIZE** words in each dictionary, including: (DICTSIZE - 3) words with highest frequency in the corpus, and 3 special symbols `` (the beginning of the sequence), `` ( the end of the sequence) and `` (unknown word).
-There are two steps for pre-processing:
-- Merge the source and target parallel corpus files into one file
- - Merge `XXX.src` and `XXX.trg` file pair as `XXX`
- - The $i$-th row in `XXX` is the concatenation of the $i$-th row from `XXX.src` with the $i$-th row from `XXX.trg`, separated with '\t'.
+### Sample Data
-- Create source dictionary and target dictionary, each containing **DICTSIZE** number of words, including the most frequent (DICTSIZE - 3) fo word from the corpus and 3 special token `` (begin of sequence), `` (end of sequence) and `` (unknown words that are not in the vocabulary).
+Because the data volume of the complete data set is large, in order to verify the training process, the PaddlePaddle interface paddle.data set.wmt14 provides a pre-processed [smaller scale dataset](http://paddlepaddle.bj.bcebos.com/demo/wmt_shrinked_data/wmt14.tgz) by default .
-### A Subset of Dataset
+In the data set, there are 193,319 training data, 6003 test data, and a dictionary with length of 30,000. Due to the limit of data size, the effects of models trained with this dataset are not guaranteed.
-Because the full dataset is very big, to reduce the time for downloading the full dataset. PadddlePaddle package `paddle.dataset.wmt14` provides a preprocessed `subset of dataset`(http://paddlepaddle.bj.bcebos.com/demo/wmt_shrinked_data/wmt14.tgz).
+## Model Configuration
-This subset has 193319 instances of training data and 6003 instances of test data. Dictionary size is 30000. Because of the limitation of size of the subset, the effectiveness of trained model from this subset is not guaranteed.
+Next we start configuring model according to input data. First we import necessary library functions and define global variables.
-## Model Configuration
-Our program starts with importing necessary packages and initializing some global variables:
```python
from __future__ import print_function
@@ -232,41 +207,51 @@ except ImportError:
from paddle.fluid.trainer import *
from paddle.fluid.inferencer import *
-dict_size = 30000
-source_dict_dim = target_dict_dim = dict_size
-hidden_dim = 32
-word_dim = 16
-batch_size = 2
-max_length = 8
-topk_size = 50
-beam_size = 2
+dict_size = 30000 # dictionary dimension
+source_dict_dim = target_dict_dim = dict_size # source/target language dictionary dimension
+hidden_dim = 32 # size of hidden layer in encoder
+word_dim = 16 # dimension of word vector
+batch_size = 2 # the number of samples in batch
+max_length = 8 # the maximum length of generated sentence
+beam_size = 2 # width of beam
-decoder_size = hidden_dim
+decoder_size = hidden_dim # size of hidden layer in decoder
```
-Then we implement encoder as follows:
- ```python
+
+
+Then the frame of encoder is implemented as follows:
+
+
+```python
def encoder(is_sparse):
+ # define input data id of source language
src_word_id = pd.data(
name="src_word_id", shape=[1], dtype='int64', lod_level=1)
+ # reflect encode above on the word vector of low-dimension language space.
src_embedding = pd.embedding(
input=src_word_id,
size=[dict_size, word_dim],
dtype='float32',
is_sparse=is_sparse,
param_attr=fluid.ParamAttr(name='vemb'))
-
+ # LSTM layer:fc + dynamic_lstm
fc1 = pd.fc(input=src_embedding, size=hidden_dim * 4, act='tanh')
lstm_hidden0, lstm_0 = pd.dynamic_lstm(input=fc1, size=hidden_dim * 4)
+ # Fetch the final state after the sequence encode of source language
encoder_out = pd.sequence_last_step(input=lstm_hidden0)
return encoder_out
- ```
+```
+
+
+
+Then implement decoder in training mode:
-Implement the decoder for training as follows:
```python
def train_decoder(context, is_sparse):
+ # Define input data of sequence id of target language and reflect it on word vector of low-dimension language space
trg_language_word = pd.data(
name="target_language_word", shape=[1], dtype='int64', lod_level=1)
trg_embedding = pd.embedding(
@@ -277,35 +262,44 @@ Implement the decoder for training as follows:
param_attr=fluid.ParamAttr(name='vemb'))
rnn = pd.DynamicRNN()
- with rnn.block():
+ with rnn.block(): # use DynamicRNN to define computation at each step
+ # Fetch input word vector of target language at present step
current_word = rnn.step_input(trg_embedding)
+ # obtain state of hidden layer
pre_state = rnn.memory(init=context)
+ # computing unit of decoder: single-layer forward network
current_state = pd.fc(input=[current_word, pre_state],
size=decoder_size,
act='tanh')
-
+ # compute predicting probability of nomarlized word
current_score = pd.fc(input=current_state,
size=target_dict_dim,
act='softmax')
+ # update hidden layer of RNN
rnn.update_memory(pre_state, current_state)
+ # output predicted probability
rnn.output(current_score)
return rnn()
```
-Implement the decoder for prediction as follows:
+
+
+implement decoder in inference mode
+
+
```python
def decode(context, is_sparse):
init_state = context
+ # define counter variable in the decoding
array_len = pd.fill_constant(shape=[1], dtype='int64', value=max_length)
counter = pd.zeros(shape=[1], dtype='int64', force_cpu=True)
- # fill the first element with init_state
+ # define tensor array to save content at each time step, and write initial id, score and state
state_array = pd.create_array('float32')
pd.array_write(init_state, array=state_array, i=counter)
- # ids, scores as memory
ids_array = pd.create_array('int64')
scores_array = pd.create_array('float32')
@@ -316,34 +310,35 @@ def decode(context, is_sparse):
pd.array_write(init_ids, array=ids_array, i=counter)
pd.array_write(init_scores, array=scores_array, i=counter)
+ # define conditional variable to stop loop
cond = pd.less_than(x=counter, y=array_len)
-
+ # define while_op
while_op = pd.While(cond=cond)
- with while_op.block():
+ with while_op.block(): # define the computing of each step
+ # obtain input at present step of decoder, including id chosen at previous step, corresponding score and state at previous step.
pre_ids = pd.array_read(array=ids_array, i=counter)
pre_state = pd.array_read(array=state_array, i=counter)
pre_score = pd.array_read(array=scores_array, i=counter)
- # expand the lod of pre_state to be the same with pre_score
+ # update input state as state correspondent with id chosen at previous step
pre_state_expanded = pd.sequence_expand(pre_state, pre_score)
-
+ # computing logic of decoder under the same train mode, including input vector and computing unit of decoder
+ # compute predicting probability of normalized word
pre_ids_emb = pd.embedding(
input=pre_ids,
size=[dict_size, word_dim],
dtype='float32',
is_sparse=is_sparse)
-
- # use rnn unit to update rnn
current_state = pd.fc(input=[pre_state_expanded, pre_ids_emb],
size=decoder_size,
act='tanh')
current_state_with_lod = pd.lod_reset(x=current_state, y=pre_score)
- # use score to do beam search
current_score = pd.fc(input=current_state_with_lod,
size=target_dict_dim,
act='softmax')
topk_scores, topk_indices = pd.topk(current_score, k=beam_size)
- # calculate accumulated scores after topk to reduce computation cost
+
+ # compute accumulated score and perform beam search
accu_scores = pd.elementwise_add(
x=pd.log(topk_scores), y=pd.reshape(pre_score, shape=[-1]), axis=0)
selected_ids, selected_scores = pd.beam_search(
@@ -356,14 +351,12 @@ def decode(context, is_sparse):
level=0)
pd.increment(x=counter, value=1, in_place=True)
-
- # update the memories
+ # write search result and corresponding hidden layer into tensor array
pd.array_write(current_state, array=state_array, i=counter)
pd.array_write(selected_ids, array=ids_array, i=counter)
pd.array_write(selected_scores, array=scores_array, i=counter)
- # update the break condition: up to the max length or all candidates of
- # source sentences have ended.
+ # update condition to stop loop
length_cond = pd.less_than(x=counter, y=array_len)
finish_cond = pd.logical_not(pd.is_empty(x=selected_ids))
pd.logical_and(x=length_cond, y=finish_cond, out=cond)
@@ -375,8 +368,9 @@ def decode(context, is_sparse):
```
-Then we define a `training_program` that uses the result from `encoder` and `train_decoder` to compute the cost with label data.
-Also define `optimizer_func` to specify the optimizer.
+
+
+Furthermore, we define a `train_program` to use result computed by `inference_program` and compute error with the help of marked data. We also define an `optimizer_func` to define optimizer.
```python
def train_program(is_sparse):
@@ -396,21 +390,18 @@ def optimizer_func():
regularization_coeff=0.1))
```
-## Model Training
-
-### Specify training environment
+## Train Model
-Specify your training environment, you should specify if the training is on CPU or GPU.
+### Define Training Environment
+Define your training environment and define the train executed on CPU or on GPU.
```python
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
```
-### Datafeeder Configuration
-
-Next we define data feeders for test and train. The feeder reads a `buf_size` of data each time and feed them to the training/testing process.
-`paddle.dataset.wmt14.train` will yield records during each pass, after shuffling, a batch input of `BATCH_SIZE` is generated for training.
+### Define Data Provider
+The next step is to define data provider for train and test. Data Provider read data with size of `BATCH_SIZE` `paddle.dataset.wmt.train` will provide data with size of `BATCH_SIZE` after reordering every time. The size of reordering is `buf_size`.
```python
train_reader = paddle.batch(
@@ -420,8 +411,7 @@ train_reader = paddle.batch(
```
### Create Trainer
-
-Create a trainer that takes `train_program` as input and specify optimizer function.
+Trainer needs a train program and a train optimizer.
```python
is_sparse = False
@@ -431,20 +421,17 @@ trainer = Trainer(
optimizer_func=optimizer_func)
```
-### Feeding Data
+### Provide Data
-`feed_order` is devoted to specifying the correspondence between each yield record and `paddle.layer.data`. For instance, the first column of data generated by `wmt14.train` corresponds to `src_word_id`.
+`feed_order` is used to define every generated data and reflecting relationship between `paddle.layer.data`. For example, the first column data generated by `wmt14.train` is correspondent with the feature `src_word_id`.
```python
-feed_order = [
- 'src_word_id', 'target_language_word', 'target_language_next_word'
- ]
+feed_order = ['src_word_id', 'target_language_word', 'target_language_next_word'
+]
```
### Event Handler
-
-Callback function `event_handler` will be called during training when a pre-defined event happens.
-For example, we can check the cost by `trainer.test` when `EndStepEvent` occurs
+Call function `event_handler` will be called after the touch of an event defined before. For example, we can examine the loss after the training at each step.
```python
def event_handler(event):
@@ -456,10 +443,8 @@ def event_handler(event):
trainer.stop()
```
-
-### Training
-
-Finally, we invoke `trainer.train` to start training with `num_epochs` and other parameters.
+### Start Training
+Finally, we feed in `num_epoch` and other parameters and call `trainer.train` to start training.
```python
EPOCH_NUM = 1
@@ -471,20 +456,20 @@ trainer.train(
feed_order=feed_order)
```
-## Inference
+## Model Application
-### Define the decode part
+### Define Decoder Part
-Use the `encoder` and `decoder` function we defined above to predict translation ids and scores.
+Use `encoder` and `decoder` function defined above to infer corresponding id and score after the translation.
```python
context = encoder(is_sparse)
translation_ids, translation_scores = decode(context, is_sparse)
```
-### Define DataSet
+### Define Data
-We initialize ids and scores and create tensors for input. In this test we are using first record data from `wmt14.test` for inference. At the end we get src dict and target dict for printing out results later.
+First we initialize id and score to generate tensor as input data. In this prediction, we use the first record in `wmt14.test` to infer and finally use "source language dictionary" and "target language dictionary" to output corresponding sentence.
```python
init_ids_data = np.array([1 for _ in range(batch_size)], dtype='int64')
@@ -513,9 +498,9 @@ feeder = fluid.DataFeeder(feed_list, place)
src_dict, trg_dict = paddle.dataset.wmt14.get_dict(dict_size)
```
-### Infer
+### Test
+Now we can start predicting. We need provide corresponding parameters in `feed_order` and run it on `executor` to obtain id and score.
-We create `feed_dict` with all the inputs we need and run with `executor` to get predicted results id and corresponding scores.
```python
exe = Executor(place)
@@ -549,6 +534,11 @@ for data in test_data():
break
```
+## Summary
+
+End-to-End neural network translation is an recently acclaimed machine translation method. In this section, we introduced the typical Encoder-Decoder of NMT. Because NMT is a typical Seq2Seq (Sequence to Sequence) learning task, tasks of Seq2Seq, such as query rewriting, abstraction, single round dialogue, can be tackled by this model.
+
+
## References
1. Koehn P. [Statistical machine translation](https://books.google.com.hk/books?id=4v_Cx1wIMLkC&printsec=frontcover&hl=zh-CN&source=gbs_ge_summary_r&cad=0#v=onepage&q&f=false)[M]. Cambridge University Press, 2009.
@@ -558,7 +548,8 @@ for data in test_data():
5. Papineni K, Roukos S, Ward T, et al. [BLEU: a method for automatic evaluation of machine translation](http://dl.acm.org/citation.cfm?id=1073135)[C]//Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, 2002: 311-318.
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+
+
This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.