Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
X2Paddle
提交
54ca1dbb
X
X2Paddle
项目概览
PaddlePaddle
/
X2Paddle
大约 2 年 前同步成功
通知
329
Star
698
Fork
167
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
26
列表
看板
标记
里程碑
合并请求
4
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
X
X2Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
26
Issue
26
列表
看板
标记
里程碑
合并请求
4
合并请求
4
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
54ca1dbb
编写于
4月 22, 2021
作者:
J
Jason
提交者:
GitHub
4月 22, 2021
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #548 from SunAhong1993/dev
add pytorch mapper and update readme
上级
f079c8a7
8868239e
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
224 addition
and
193 deletion
+224
-193
README.md
README.md
+67
-62
docs/images/frame.png
docs/images/frame.png
+0
-0
docs/user_guides/pd_folder_introduction.md
docs/user_guides/pd_folder_introduction.md
+10
-0
x2paddle/op_mapper/dygraph/pytorch2paddle/aten.py
x2paddle/op_mapper/dygraph/pytorch2paddle/aten.py
+147
-131
未找到文件。
README.md
浏览文件 @
54ca1dbb
# X2Paddle
# X2Paddle
[

](LICENSE)
[

](LICENSE)
[

](https://github.com/PaddlePaddle/X2Paddle/releases)
[

](https://github.com/PaddlePaddle/X2Paddle/releases)
X2Paddle支持将其余深度学习框架训练得到的模型,转换至PaddlePaddle模型。

X2Paddle is a toolkit for converting trained model to PaddlePaddle from other deep learning frameworks.
## 简介
X2Paddle用于不同框架模型或项目到PaddlePaddle框架模型或项目的迁移,旨在为飞桨开发者提升框架间迁移的效率。
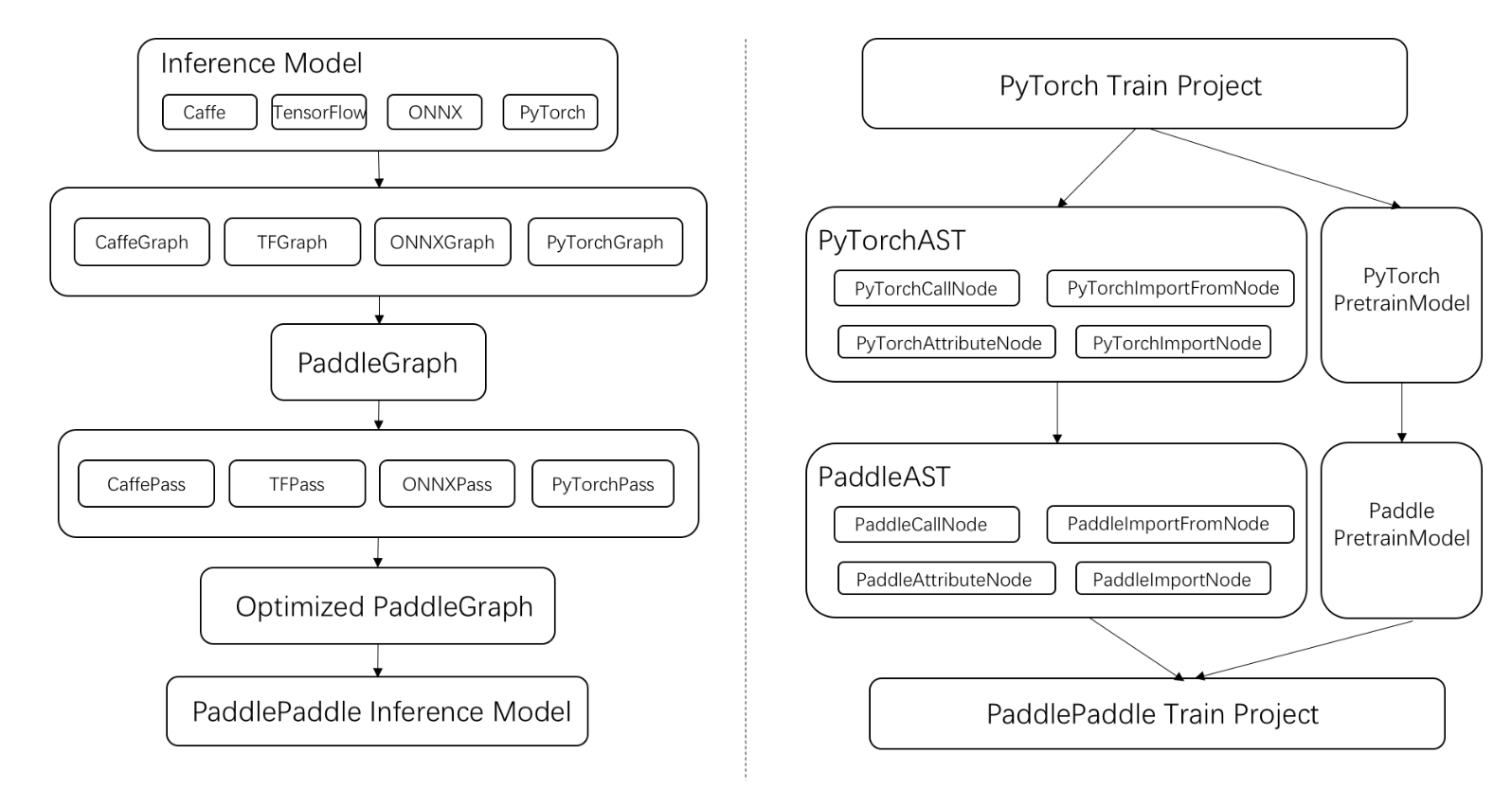
X2Paddle支持Caffe/TensorFlow/ONNX/PyTorch的预测模型,一步转换至PaddlePaddle预测模型;同时,支持PyTorch训练项目,转换至PaddlePaddle项目,助力用户在PaddlePaddlePaddle上进行模型训练。
### 架构设计
X2Paddle的架构设计着重考虑了对多深度学习框架的的支持以及代码的易读性、易扩展性,并且在多个层面的对转换后OP进行优化处理。

### 特性
-
***支持框架丰富**
*
:目前已经支持Caffe/TensorFlow/ONNX/PyTorch四大框架的迁移,涵盖目前市面主流深度学习框架。
-
***转换模型丰富**
*
:在主流的CV和NLP模型上均支持转换,涵盖了19+个Caffe模型转换、27+个TensorFlow模型转换、32+个ONNX模型转换、27+个PyTorch模型转换、2+个PyTorch项目转换。
-
***简洁易用**
*
:一条命令行或者一个API即可完成迁移。
## 转换模型库
X2Paddle在多个主流的CV模型上,测试过TensorFlow/Caffe/ONNX/PyTorch模型的转换,可以在
[
X2Paddle-Model-Zoo
](
./docs/introduction/x2paddle_model_zoo.md
)
查看我们的模型测试列表,可以在
[
OP-LIST
](
./docs/introduction/op_list.md
)
中查看目前X2Paddle支持的OP列表。如果你在新的模型上进行了测试转换,也欢迎继续补充该列表;如若无法转换,可通过ISSUE反馈给我们,我们会尽快跟进。
## 环境依赖
## 环境依赖
-
python >= 3.5
python >= 3.5
-
paddlepaddle >= 2.0.0
paddlepaddle 2.0.0-rc1 或者 develop
**按需安装以下依赖**
**按需安装以下依赖**
tensorflow : tensorflow == 1.14.0
-
tensorflow : tensorflow == 1.14.0
caffe : 无
-
caffe : 无
onnx : onnx >= 1.6.0
-
onnx : onnx >= 1.6.0
pytorch:torch >=1.5.0 (script方式暂不支持1.7.0)
-
pytorch:torch >=1.5.0 (script方式暂不支持1.7.0)
## 安装
## 安装
###
安装方式一
(推荐)
###
方式一:源码安装
(推荐)
```
```
git clone https://github.com/PaddlePaddle/X2Paddle.git
git clone https://github.com/PaddlePaddle/X2Paddle.git
cd X2Paddle
cd X2Paddle
...
@@ -28,83 +39,77 @@ git checkout develop
...
@@ -28,83 +39,77 @@ git checkout develop
python setup.py install
python setup.py install
```
```
###
安装方式二
###
方式二:pip安装
我们会定期更新pip源上的x2paddle版本
我们会定期更新pip源上的x2paddle版本
```
```
pip install x2paddle
==1.0.0rc0
--index https://pypi.Python.org/simple/
pip install x2paddle --index https://pypi.Python.org/simple/
```
```
## 使用方法
## 快速开始
### TensorFlow
### 预测模型转换
| 参数 | 作用 |
| -------------------- | ------------------------------------------------------------ |
| --framework | 源模型类型 (tensorflow、caffe、onnx) |
| --prototxt | 当framework为caffe时,该参数指定caffe模型的proto文件路径 |
| --weight | 当framework为caffe时,该参数指定caffe模型的参数文件路径 |
| --save_dir | 指定转换后的模型保存目录路径 |
| --model | 当framework为tensorflow/onnx时,该参数指定tensorflow的pb模型文件或onnx模型路径 |
| --caffe_proto |
**[可选]**
由caffe.proto编译成caffe_pb2.py文件的存放路径,当存在自定义Layer时使用,默认为None |
| --define_input_shape |
**[可选]**
For TensorFlow, 当指定该参数时,强制用户输入每个Placeholder的shape,见
[
文档Q2
](
./docs/user_guides/FAQ.md
)
|
| --paddle_type |
**[可选]**
该参数指定转换为动态图代码(dygraph)或者静态图代码(static),默认为dygraph |
#### TensorFlow
```
```
x2paddle --framework=tensorflow --model=tf_model.pb --save_dir=pd_model --paddle_type dygraph
x2paddle --framework=tensorflow --model=tf_model.pb --save_dir=pd_model --paddle_type dygraph
```
```
### Caffe
###
#
Caffe
```
```
x2paddle --framework=caffe --prototxt=deploy.prototxt --weight=deploy.caffemodel --save_dir=pd_model --paddle_type dygraph
x2paddle --framework=caffe --prototxt=deploy.prototxt --weight=deploy.caffemodel --save_dir=pd_model --paddle_type dygraph
```
```
### ONNX
###
#
ONNX
```
```
x2paddle --framework=onnx --model=onnx_model.onnx --save_dir=pd_model --paddle_type dygraph
x2paddle --framework=onnx --model=onnx_model.onnx --save_dir=pd_model --paddle_type dygraph
```
```
### PyTorch
#### PyTorch
> PyTorch不支持命令行使用方式,详见[PyTorch2Paddle](./docs/user_guides/pytorch2paddle.md)
PyTorch仅支持API使用方式,详见
[
PyTorch预测模型转换文档
](
./docs/user_guides/pytorch2paddle.md
)
。
### Paddle2ONNX
> Paddle2ONNX功能已迁移至新的github: https://github.com/PaddlePaddle/paddle2onnx, 欢迎大家去新的代码仓库查看详细介绍以及新功能。
### 训练项目转换
#### PyTorch
【待更新】可安装
[
分支
](
https://github.com/PaddlePaddle/X2Paddle/tree/pytorch_project_convertor
)
源码进行使用。
详见
[
PyTorch训练项目转换文档
](
https://github.com/SunAhong1993/X2Paddle/blob/code_convert_last/docs/pytorch_project_convertor/README.md
)
。
### 参数选项
| 参数 | |
|----------|--------------|
|--framework | 源模型类型 (tensorflow、caffe、onnx) |
|--prototxt | 当framework为caffe时,该参数指定caffe模型的proto文件路径 |
|--weight | 当framework为caffe时,该参数指定caffe模型的参数文件路径 |
|--save_dir | 指定转换后的模型保存目录路径 |
|--model | 当framework为tensorflow/onnx时,该参数指定tensorflow的pb模型文件或onnx模型路径 |
|--caffe_proto |
**[可选]**
由caffe.proto编译成caffe_pb2.py文件的存放路径,当存在自定义Layer时使用,默认为None |
|--define_input_shape |
**[可选]**
For TensorFlow, 当指定该参数时,强制用户输入每个Placeholder的shape,见
[
文档Q2
](
./docs/user_guides/FAQ.md
)
|
|--paddle_type |
**[可选]**
该参数指定转换为动态图代码(dygraph)或者静态图代码(static),默认为dygraph|
## 使用转换后的模型
-
静态图:
转换后的模型包括
`model_with_code`
和
`inference_model`
两个目录。
`model_with_code`
中保存了模型参数,和转换后的python模型静态图代码。
`inference_model`
中保存了序列化的模型结构和参数,可直接使用paddle的接口进行加载,见
[
paddle.static.load_inference_model
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/static/load_inference_model_cn.html#load-inference-model
)
。
-
动态图:
转换后的模型包括
`model.pdparams`
和
`x2paddle_code.py`
两个文件,以及
`inference_model`
一个目录。
`model.pdparams`
中保存了模型参数。
`x2paddle_code.py`
是转换后的python模型动态图代码。
`inference_model`
中保存了序列化的模型结构和参数,可直接使用paddle的接口进行加载,见
[
paddle.static.load_inference_model
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/static/load_inference_model_cn.html#load-inference-model
)
。
## 小工具
## 小工具
X2Paddle提供了工具解决如下问题,详见
[
tools/README.md
](
tools/README.md
)
X2Paddle提供了工具解决如下问题,详见
[
tools/README.md
](
tools/README.md
)
1.
检测模型是否在PaddleLite中支持
1.
检测模型是否在PaddleLite中支持
2.
合并模型参数文件
2.
合并模型参数文件
## 相关文档
## 使用相关文档
1.
[
X2Paddle使用过程中常见问题
](
./docs/user_guides/FAQ.md
)
1.
[
X2Paddle使用过程中常见问题
](
./docs/user_guides/FAQ.md
)
2.
[
如何导出TensorFlow的pb模型
](
./docs/user_guides/export_tf_model.md
)
2.
[
如何导出TensorFlow的Frozen Model
](
./docs/user_guides/export_tf_model.md
)
3.
[
X2Paddle测试模型库
](
./docs/introduction/x2paddle_model_zoo.md
)
3.
[
PyTorch模型导出为ONNX模型
](
./docs/user_guides/pytorch2onnx.md
)
4.
[
X2Paddle支持的op列表
](
./docs/introduction/op_list.md
)
4.
[
X2Paddle添加内置的Caffe自定义层
](
./docs/user_guides/add_caffe_custom_layer.md
)
5.
[
PyTorch模型导出为ONNX模型
](
./docs/user_guides/pytorch2onnx.md
)
5.
[
转换后PaddlePaddle预测模型简介
](
./docs/user_guides/pd_folder_introduction.py
)
6.
[
X2Paddle添加内置的Caffe自定义层
](
./docs/user_guides/add_caffe_custom_layer.md
)
7.
[
TensorFlow转换教程
](
./docs/demo/tensorflow2paddle.ipynb
)
## 支持列表文档
8.
[
PyTorch转换教程
](
./docs/demo/pytorch2paddle.ipynb
)
1.
[
X2Paddle测试模型库
](
./docs/introduction/x2paddle_model_zoo.md
)
2.
[
X2Paddle支持的op列表
](
./docs/introduction/op_list.md
)
## 转换教程
1.
[
TensorFlow预测模型转换教程
](
./docs/demo/tensorflow2paddle.ipynb
)
2.
[
PyTorch预测模型转换教程
](
./docs/demo/pytorch2paddle.ipynb
)
## 更新历史
## 更新历史
2020.
12.09
2020.
12.09
1.
新增PyTorch2Paddle转换方式,转换得到Paddle动态图代码,并动转静获得inference_model。
1.
新增PyTorch2Paddle转换方式,转换得到Paddle动态图代码,并动转静获得inference_model。
方式一:trace方式,转换后的代码有模块划分,每个模块的功能与PyTorch相同。
方式一:trace方式,转换后的代码有模块划分,每个模块的功能与PyTorch相同。
方式二:script方式,转换后的代码按执行顺序逐行出现。
方式二:script方式,转换后的代码按执行顺序逐行出现。
2.
新增Caffe/ONNX/Tensorflow到Paddle动态图的转换。
2.
新增Caffe/ONNX/Tensorflow到Paddle动态图的转换。
3.
新增TensorFlow op(14个):Neg、Greater、FloorMod、LogicalAdd、Prd、Equal、Conv3D、Ceil、AddN、DivNoNan、Where、MirrorPad、Size、TopKv2
3.
新增TensorFlow op(14个):Neg、Greater、FloorMod、LogicalAdd、Prd、Equal、Conv3D、Ceil、AddN、DivNoNan、Where、MirrorPad、Size、TopKv2
4.
新增Optimizer模块,主要包括op融合、op消除功能,转换后的代码可读性更强,进行预测时耗时更短。
4.
新增Optimizer模块,主要包括op融合、op消除功能,转换后的代码可读性更强,进行预测时耗时更短。
##
Acknowledgements
##
贡献代码
X2Paddle refers to the following projects:
我们非常欢迎您为X2Paddle贡献代码或者提供使用建议。如果您可以修复某个issue或者增加一个新功能,欢迎给我们提交Pull Requests。
-
[
MMdnn
](
https://github.com/microsoft/MMdnn
)
docs/images/frame.png
0 → 100644
浏览文件 @
54ca1dbb
187.7 KB
docs/user_guides/pd_folder_introduction.md
0 → 100644
浏览文件 @
54ca1dbb
# 转换后PaddlePaddle预测模型简介
-
静态图:
转换后的模型包括
`model_with_code`
和
`inference_model`
两个目录。
`model_with_code`
中保存了模型参数,和转换后的python模型静态图代码。
`inference_model`
中保存了序列化的模型结构和参数,可直接使用paddle的接口进行加载,见
[
paddle.static.load_inference_model
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/static/load_inference_model_cn.html#load-inference-model
)
。
-
动态图:
转换后的模型包括
`model.pdparams`
和
`x2paddle_code.py`
两个文件,以及
`inference_model`
一个目录。
`model.pdparams`
中保存了模型参数。
`x2paddle_code.py`
是转换后的python模型动态图代码。
`inference_model`
中保存了序列化的模型结构和参数,可直接使用paddle的接口进行加载,见
[
paddle.static.load_inference_model
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/static/load_inference_model_cn.html#load-inference-model
)
。
x2paddle/op_mapper/dygraph/pytorch2paddle/aten.py
浏览文件 @
54ca1dbb
...
@@ -33,7 +33,6 @@ dtype_dict = {
...
@@ -33,7 +33,6 @@ dtype_dict = {
def
aten_abs
(
mapper
,
graph
,
node
):
def
aten_abs
(
mapper
,
graph
,
node
):
""" 构造获取绝对值的PaddleLayer。
""" 构造获取绝对值的PaddleLayer。
TorchScript示例:
TorchScript示例:
%n0.3 : Tensor = aten::abs(%n.3)
%n0.3 : Tensor = aten::abs(%n.3)
参数含义:
参数含义:
...
@@ -62,9 +61,61 @@ def aten_abs(mapper, graph, node):
...
@@ -62,9 +61,61 @@ def aten_abs(mapper, graph, node):
return
current_inputs
,
current_outputs
return
current_inputs
,
current_outputs
def
aten_adaptive_avg_pool1d
(
mapper
,
graph
,
node
):
""" 构造average adaptive pool1d的PaddleLayer。
TorchScript示例:
%x.5 : Tensor = aten::adaptive_avg_pool1d(%x.3, %_output_size.1)
参数含义:
%x.5 (Tensor): 池化后结果Tensor。
%x.3 (Tensor): 输入Tensor。
%_output_size.1 (list): 自适应池化后的Tensor的长度大小。
"""
scope_name
=
mapper
.
normalize_scope_name
(
node
)
op_name
=
name_generator
(
"pool1d"
,
mapper
.
nn_name2id
)
output_name
=
mapper
.
_get_outputs_name
(
node
)[
0
]
layer_outputs
=
[
op_name
,
output_name
]
layer_inputs
=
{}
layer_attrs
=
{}
inputs_name
,
inputs_node
=
mapper
.
_get_inputs_name
(
node
)
# 获取当前节点输出的list
current_outputs
=
[
output_name
]
# 处理输入0,即%x.3
mapper
.
_check_input
(
graph
,
inputs_node
[
0
],
inputs_name
[
0
],
current_outputs
,
scope_name
)
layer_inputs
[
"x"
]
=
inputs_name
[
0
]
# 获取当前节点输入的list
current_inputs
=
list
(
layer_inputs
.
values
())
# 处理输入1,即%_output_size.1
if
inputs_name
[
1
]
in
mapper
.
attrs
:
layer_attrs
[
"output_size"
]
=
mapper
.
attrs
[
inputs_name
[
1
]][
0
]
graph
.
add_layer
(
"paddle.nn.AdaptiveAvgPool1D"
,
inputs
=
layer_inputs
,
outputs
=
layer_outputs
,
scope_name
=
scope_name
,
**
layer_attrs
)
else
:
mapper
.
_check_input
(
graph
,
inputs_node
[
1
],
inputs_name
[
1
],
current_outputs
,
scope_name
)
layer_inputs
[
"output_size"
]
=
inputs_name
[
1
]
current_inputs
.
append
(
inputs_name
[
1
])
graph
.
add_layer
(
"prim.getitem"
,
inputs
=
{
"list"
:
layer_inputs
[
"output_size"
]},
outputs
=
[
layer_inputs
[
"output_size"
]],
scope_name
=
scope_name
,
index
=
0
)
graph
.
add_layer
(
"paddle.nn.functional.adaptive_avg_pool1d"
,
inputs
=
layer_inputs
,
outputs
=
layer_outputs
[
1
:],
scope_name
=
scope_name
,
**
layer_attrs
)
return
current_inputs
,
current_outputs
def
aten_adaptive_avg_pool2d
(
mapper
,
graph
,
node
):
def
aten_adaptive_avg_pool2d
(
mapper
,
graph
,
node
):
""" 构造average adaptive pool2d的PaddleLayer。
""" 构造average adaptive pool2d的PaddleLayer。
TorchScript示例:
TorchScript示例:
%x.5 : Tensor = aten::adaptive_avg_pool2d(%x.3, %_output_size.1)
%x.5 : Tensor = aten::adaptive_avg_pool2d(%x.3, %_output_size.1)
参数含义:
参数含义:
...
@@ -112,7 +163,6 @@ def aten_adaptive_avg_pool2d(mapper, graph, node):
...
@@ -112,7 +163,6 @@ def aten_adaptive_avg_pool2d(mapper, graph, node):
def
aten_addmm
(
mapper
,
graph
,
node
):
def
aten_addmm
(
mapper
,
graph
,
node
):
""" 构造addmm的PaddleLayer,该节点实现out = alpha ∗ x ∗ y + beta ∗ input。
""" 构造addmm的PaddleLayer,该节点实现out = alpha ∗ x ∗ y + beta ∗ input。
TorchScript示例:
TorchScript示例:
%ret.2 : Tensor = aten::addmm(%150, %input.3, %156, %151, %152)
%ret.2 : Tensor = aten::addmm(%150, %input.3, %156, %151, %152)
参数含义:
参数含义:
...
@@ -178,7 +228,6 @@ def aten_addmm(mapper, graph, node):
...
@@ -178,7 +228,6 @@ def aten_addmm(mapper, graph, node):
def
aten_add
(
mapper
,
graph
,
node
):
def
aten_add
(
mapper
,
graph
,
node
):
""" 构造数值相加的PaddleLayer,该节点实现out = x + y。
""" 构造数值相加的PaddleLayer,该节点实现out = x + y。
TorchScript示例:
TorchScript示例:
%296 : int = aten::add(%i.12, %288)
%296 : int = aten::add(%i.12, %288)
参数含义:
参数含义:
...
@@ -219,7 +268,6 @@ def aten_add(mapper, graph, node):
...
@@ -219,7 +268,6 @@ def aten_add(mapper, graph, node):
def
aten_add_
(
mapper
,
graph
,
node
):
def
aten_add_
(
mapper
,
graph
,
node
):
""" 构造数值相加的PaddleLayer,该节点实现out = x + alpha * y。
""" 构造数值相加的PaddleLayer,该节点实现out = x + alpha * y。
TorchScript示例:
TorchScript示例:
%137 : Tensor = aten::add(%136, %130, %130)
%137 : Tensor = aten::add(%136, %130, %130)
参数含义:
参数含义:
...
@@ -271,7 +319,6 @@ def aten_add_(mapper, graph, node):
...
@@ -271,7 +319,6 @@ def aten_add_(mapper, graph, node):
def
aten___and__
(
mapper
,
graph
,
node
):
def
aten___and__
(
mapper
,
graph
,
node
):
""" 构造与计算的PaddleLayer。
""" 构造与计算的PaddleLayer。
TorchScript示例:
TorchScript示例:
%361 : bool = aten::__and__(%360, %358)
%361 : bool = aten::__and__(%360, %358)
参数含义:
参数含义:
...
@@ -307,7 +354,6 @@ def aten___and__(mapper, graph, node):
...
@@ -307,7 +354,6 @@ def aten___and__(mapper, graph, node):
def
aten_append
(
mapper
,
graph
,
node
):
def
aten_append
(
mapper
,
graph
,
node
):
""" 构造对list进行append的PaddleLayer。
""" 构造对list进行append的PaddleLayer。
TorchScript示例:
TorchScript示例:
%90 : int[] = aten::append(%_output_size.1, %v.1)
%90 : int[] = aten::append(%_output_size.1, %v.1)
参数含义:
参数含义:
...
@@ -342,7 +388,6 @@ def aten_append(mapper, graph, node):
...
@@ -342,7 +388,6 @@ def aten_append(mapper, graph, node):
def
aten_arange
(
mapper
,
graph
,
node
):
def
aten_arange
(
mapper
,
graph
,
node
):
""" 构造以步长均匀分隔给定数值区间的PaddleLayer。
""" 构造以步长均匀分隔给定数值区间的PaddleLayer。
TorchScript示例:
TorchScript示例:
有三种情况,分别处理。
有三种情况,分别处理。
"""
"""
...
@@ -442,7 +487,6 @@ def aten_arange(mapper, graph, node):
...
@@ -442,7 +487,6 @@ def aten_arange(mapper, graph, node):
def
aten_avg_pool2d
(
mapper
,
graph
,
node
):
def
aten_avg_pool2d
(
mapper
,
graph
,
node
):
""" 构造最大池化的PaddleLayer。
""" 构造最大池化的PaddleLayer。
TorchScript示例:
TorchScript示例:
%branch_pool.2 : Tensor = aten::avg_pool2d(%x.43, %538, %539, %540, %273, %272, %271)
%branch_pool.2 : Tensor = aten::avg_pool2d(%x.43, %538, %539, %540, %273, %272, %271)
参数含义:
参数含义:
...
@@ -502,7 +546,6 @@ def aten_avg_pool2d(mapper, graph, node):
...
@@ -502,7 +546,6 @@ def aten_avg_pool2d(mapper, graph, node):
def
aten_avg_pool3d
(
mapper
,
graph
,
node
):
def
aten_avg_pool3d
(
mapper
,
graph
,
node
):
""" 构造最大池化的PaddleLayer。
""" 构造最大池化的PaddleLayer。
TorchScript示例:
TorchScript示例:
%branch_pool.2 : Tensor = aten::avg_pool2d(%x.43, %538, %539, %540, %273, %272, %271)
%branch_pool.2 : Tensor = aten::avg_pool2d(%x.43, %538, %539, %540, %273, %272, %271)
参数含义:
参数含义:
...
@@ -561,7 +604,6 @@ def aten_avg_pool3d(mapper, graph, node):
...
@@ -561,7 +604,6 @@ def aten_avg_pool3d(mapper, graph, node):
def
aten_avg_pool1d
(
mapper
,
graph
,
node
):
def
aten_avg_pool1d
(
mapper
,
graph
,
node
):
""" 构造最大池化的PaddleLayer。
""" 构造最大池化的PaddleLayer。
TorchScript示例:
TorchScript示例:
%branch_pool.2 : Tensor = aten::avg_pool1d(%x.43, %538, %539, %540, %273, %272, %271)
%branch_pool.2 : Tensor = aten::avg_pool1d(%x.43, %538, %539, %540, %273, %272, %271)
参数含义:
参数含义:
...
@@ -620,7 +662,6 @@ def aten_avg_pool1d(mapper, graph, node):
...
@@ -620,7 +662,6 @@ def aten_avg_pool1d(mapper, graph, node):
def
aten_batch_norm
(
mapper
,
graph
,
node
):
def
aten_batch_norm
(
mapper
,
graph
,
node
):
""" 构造BatchNorm的PaddleLayer。
""" 构造BatchNorm的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input.81 : Tensor = aten::batch_norm(%input.80, %778, %779, %776, %777, %780,
%input.81 : Tensor = aten::batch_norm(%input.80, %778, %779, %776, %777, %780,
%exponential_average_factor.23, %766, %781)
%exponential_average_factor.23, %766, %781)
...
@@ -685,7 +726,6 @@ def aten_batch_norm(mapper, graph, node):
...
@@ -685,7 +726,6 @@ def aten_batch_norm(mapper, graph, node):
def
aten_bmm
(
mapper
,
graph
,
node
):
def
aten_bmm
(
mapper
,
graph
,
node
):
""" 构造矩阵相乘的PaddleLayer。
""" 构造矩阵相乘的PaddleLayer。
TorchScript示例:
TorchScript示例:
%x.222 : Tensor = aten::bmm(%32, %7)
%x.222 : Tensor = aten::bmm(%32, %7)
参数含义:
参数含义:
...
@@ -726,7 +766,6 @@ def aten_bmm(mapper, graph, node):
...
@@ -726,7 +766,6 @@ def aten_bmm(mapper, graph, node):
def
aten_cat
(
mapper
,
graph
,
node
):
def
aten_cat
(
mapper
,
graph
,
node
):
""" 构造连接Tensor的PaddleLayer。
""" 构造连接Tensor的PaddleLayer。
TorchScript示例:
TorchScript示例:
%x.222 : Tensor = aten::cat(%32, %7)
%x.222 : Tensor = aten::cat(%32, %7)
参数含义:
参数含义:
...
@@ -767,7 +806,6 @@ def aten_cat(mapper, graph, node):
...
@@ -767,7 +806,6 @@ def aten_cat(mapper, graph, node):
def
aten_chunk
(
mapper
,
graph
,
node
):
def
aten_chunk
(
mapper
,
graph
,
node
):
"""构造分割Tensor的PaddleLayer。
"""构造分割Tensor的PaddleLayer。
TorchScript示例:
TorchScript示例:
%724 : Tensor[] = aten::chunk(%input.170, %720, %719)
%724 : Tensor[] = aten::chunk(%input.170, %720, %719)
参数含义:
参数含义:
...
@@ -817,7 +855,6 @@ def aten_chunk(mapper, graph, node):
...
@@ -817,7 +855,6 @@ def aten_chunk(mapper, graph, node):
def
aten_clamp
(
mapper
,
graph
,
node
):
def
aten_clamp
(
mapper
,
graph
,
node
):
""" 构造元素剪裁的PaddleLayer。
""" 构造元素剪裁的PaddleLayer。
TorchScript示例:
TorchScript示例:
%56 : Tensor = aten::clamp(%input.1, %46, %48, %49)
%56 : Tensor = aten::clamp(%input.1, %46, %48, %49)
参数含义:
参数含义:
...
@@ -868,7 +905,6 @@ def aten_clamp(mapper, graph, node):
...
@@ -868,7 +905,6 @@ def aten_clamp(mapper, graph, node):
def
aten_clamp_min
(
mapper
,
graph
,
node
):
def
aten_clamp_min
(
mapper
,
graph
,
node
):
""" 构造元素剪裁的PaddleLayer。
""" 构造元素剪裁的PaddleLayer。
TorchScript示例:
TorchScript示例:
%56 : Tensor = aten::clamp_min(%input.1, %46)
%56 : Tensor = aten::clamp_min(%input.1, %46)
参数含义:
参数含义:
...
@@ -910,7 +946,6 @@ def aten_clamp_min(mapper, graph, node):
...
@@ -910,7 +946,6 @@ def aten_clamp_min(mapper, graph, node):
def
aten___contains__
(
mapper
,
graph
,
node
):
def
aten___contains__
(
mapper
,
graph
,
node
):
""" 构造in的PaddleLayer。
""" 构造in的PaddleLayer。
TorchScript示例:
TorchScript示例:
%51 : bool = aten::__contains__(%50, %name.1)
%51 : bool = aten::__contains__(%50, %name.1)
参数含义:
参数含义:
...
@@ -946,7 +981,6 @@ def aten___contains__(mapper, graph, node):
...
@@ -946,7 +981,6 @@ def aten___contains__(mapper, graph, node):
def
aten_constant_pad_nd
(
mapper
,
graph
,
node
):
def
aten_constant_pad_nd
(
mapper
,
graph
,
node
):
""" 构造填充固定值的PaddleLayer。
""" 构造填充固定值的PaddleLayer。
TorchScript示例:
TorchScript示例:
%58 : Tensor = aten::constant_pad_nd(%input1.24, %4876, %42)
%58 : Tensor = aten::constant_pad_nd(%input1.24, %4876, %42)
参数含义:
参数含义:
...
@@ -1059,14 +1093,12 @@ def aten_constant_pad_nd(mapper, graph, node):
...
@@ -1059,14 +1093,12 @@ def aten_constant_pad_nd(mapper, graph, node):
def
aten_contiguous
(
mapper
,
graph
,
node
):
def
aten_contiguous
(
mapper
,
graph
,
node
):
""" 构造在内存中连续存储的PaddleLayer。
""" 构造在内存中连续存储的PaddleLayer。
TorchScript示例:
TorchScript示例:
%x.7 : Tensor = aten::contiguous(%4058, %4046)
%x.7 : Tensor = aten::contiguous(%4058, %4046)
参数含义:
参数含义:
%x.7 (Tensor): 输出,在内存中连续存储的Tensor。
%x.7 (Tensor): 输出,在内存中连续存储的Tensor。
%4058 (Tensor): 原始Tensor。
%4058 (Tensor): 原始Tensor。
%4046 (int): 存储的形式。
%4046 (int): 存储的形式。
【注意】Paddle中无此用法,所以此处翻译成赋值。
【注意】Paddle中无此用法,所以此处翻译成赋值。
"""
"""
scope_name
=
mapper
.
normalize_scope_name
(
node
)
scope_name
=
mapper
.
normalize_scope_name
(
node
)
...
@@ -1094,7 +1126,6 @@ def aten_contiguous(mapper, graph, node):
...
@@ -1094,7 +1126,6 @@ def aten_contiguous(mapper, graph, node):
def
aten_conv2d
(
mapper
,
graph
,
node
):
def
aten_conv2d
(
mapper
,
graph
,
node
):
""" 构造conv2d的PaddleLayer。
""" 构造conv2d的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input.10 : Tensor = aten::conv2d(%input.8, %25, %27, %28, %29, %30, %26)
%input.10 : Tensor = aten::conv2d(%input.8, %25, %27, %28, %29, %30, %26)
参数含义:
参数含义:
...
@@ -1157,7 +1188,6 @@ def aten_conv2d(mapper, graph, node):
...
@@ -1157,7 +1188,6 @@ def aten_conv2d(mapper, graph, node):
def
aten__convolution
(
mapper
,
graph
,
node
):
def
aten__convolution
(
mapper
,
graph
,
node
):
""" 构造conv2d的PaddleLayer。
""" 构造conv2d的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input.10 : Tensor = aten::_convolution(%input.1, %18, %10, %19, %20, %21, %13, %22, %12, %13, %13, %15)
%input.10 : Tensor = aten::_convolution(%input.1, %18, %10, %19, %20, %21, %13, %22, %12, %13, %13, %15)
参数含义:
参数含义:
...
@@ -1242,7 +1272,6 @@ def aten__convolution(mapper, graph, node):
...
@@ -1242,7 +1272,6 @@ def aten__convolution(mapper, graph, node):
def
aten_conv_transpose2d
(
mapper
,
graph
,
node
):
def
aten_conv_transpose2d
(
mapper
,
graph
,
node
):
""" 构造conv_transpose2d的PaddleLayer。
""" 构造conv_transpose2d的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input.10 : Tensor = aten::conv_transpose2d(%input.1, %18, %10, %19, %20, %21, %13, %22)
%input.10 : Tensor = aten::conv_transpose2d(%input.1, %18, %10, %19, %20, %21, %13, %22)
参数含义:
参数含义:
...
@@ -1307,7 +1336,6 @@ def aten_conv_transpose2d(mapper, graph, node):
...
@@ -1307,7 +1336,6 @@ def aten_conv_transpose2d(mapper, graph, node):
def
aten_cos
(
mapper
,
graph
,
node
):
def
aten_cos
(
mapper
,
graph
,
node
):
""" 构造数学计算cos的PaddleLayer。
""" 构造数学计算cos的PaddleLayer。
TorchScript示例:
TorchScript示例:
%94 : Tensor = aten::cos(%sinusoid_inp.1)
%94 : Tensor = aten::cos(%sinusoid_inp.1)
参数含义:
参数含义:
...
@@ -1338,7 +1366,6 @@ def aten_cos(mapper, graph, node):
...
@@ -1338,7 +1366,6 @@ def aten_cos(mapper, graph, node):
def
aten_cumsum
(
mapper
,
graph
,
node
):
def
aten_cumsum
(
mapper
,
graph
,
node
):
""" 构造与前一个元素累加的PaddleLayer。
""" 构造与前一个元素累加的PaddleLayer。
TorchScript示例:
TorchScript示例:
%56 : Tensor = aten::cumsum(%mask.1, %46, %48)
%56 : Tensor = aten::cumsum(%mask.1, %46, %48)
参数含义:
参数含义:
...
@@ -1386,13 +1413,11 @@ def aten_cumsum(mapper, graph, node):
...
@@ -1386,13 +1413,11 @@ def aten_cumsum(mapper, graph, node):
def
aten_detach
(
mapper
,
graph
,
node
):
def
aten_detach
(
mapper
,
graph
,
node
):
""" 构造返回一个新的Tensor,从当前计算图中分离下来的,但是仍指向原变量的存放位置的PaddleLayer。
""" 构造返回一个新的Tensor,从当前计算图中分离下来的,但是仍指向原变量的存放位置的PaddleLayer。
TorchScript示例:
TorchScript示例:
%107 : Tensor = aten::detach(%new_mem.1)
%107 : Tensor = aten::detach(%new_mem.1)
参数含义:
参数含义:
%107 (Tensor): 输出,得到的Scalar。
%107 (Tensor): 输出,得到的Scalar。
%new_mem.1 (Tensor): 输入。
%new_mem.1 (Tensor): 输入。
【注意】由于Paddle无此操作,所以此处制转换为赋值。
【注意】由于Paddle无此操作,所以此处制转换为赋值。
"""
"""
scope_name
=
mapper
.
normalize_scope_name
(
node
)
scope_name
=
mapper
.
normalize_scope_name
(
node
)
...
@@ -1420,7 +1445,6 @@ def aten_detach(mapper, graph, node):
...
@@ -1420,7 +1445,6 @@ def aten_detach(mapper, graph, node):
def
aten_dict
(
mapper
,
graph
,
node
):
def
aten_dict
(
mapper
,
graph
,
node
):
""" 构造初始化dict的PaddleLayer。
""" 构造初始化dict的PaddleLayer。
TorchScript示例:
TorchScript示例:
%features.1 : Dict(str, Tensor) = aten::dict()
%features.1 : Dict(str, Tensor) = aten::dict()
参数含义:
参数含义:
...
@@ -1444,7 +1468,6 @@ def aten_dict(mapper, graph, node):
...
@@ -1444,7 +1468,6 @@ def aten_dict(mapper, graph, node):
def
aten_dim
(
mapper
,
graph
,
node
):
def
aten_dim
(
mapper
,
graph
,
node
):
""" 构造获取维度的PaddleLayer。
""" 构造获取维度的PaddleLayer。
TorchScript示例:
TorchScript示例:
%106 : int = aten::dim(%101)
%106 : int = aten::dim(%101)
参数含义:
参数含义:
...
@@ -1479,7 +1502,6 @@ def aten_dim(mapper, graph, node):
...
@@ -1479,7 +1502,6 @@ def aten_dim(mapper, graph, node):
def
aten_div_
(
mapper
,
graph
,
node
):
def
aten_div_
(
mapper
,
graph
,
node
):
""" 构造除法的PaddleLayer。
""" 构造除法的PaddleLayer。
TorchScript示例:
TorchScript示例:
%bx_bw0.3 : Tensor = aten::div_(%bx_bw.3, %2678)
%bx_bw0.3 : Tensor = aten::div_(%bx_bw.3, %2678)
参数含义:
参数含义:
...
@@ -1514,7 +1536,6 @@ def aten_div_(mapper, graph, node):
...
@@ -1514,7 +1536,6 @@ def aten_div_(mapper, graph, node):
def
aten_div
(
mapper
,
graph
,
node
):
def
aten_div
(
mapper
,
graph
,
node
):
""" 构造除法的PaddleLayer。
""" 构造除法的PaddleLayer。
TorchScript示例:
TorchScript示例:
%bx_bw0.3 : Tensor = aten::div_(%bx_bw.3, %2678)
%bx_bw0.3 : Tensor = aten::div_(%bx_bw.3, %2678)
参数含义:
参数含义:
...
@@ -1550,7 +1571,6 @@ def aten_div(mapper, graph, node):
...
@@ -1550,7 +1571,6 @@ def aten_div(mapper, graph, node):
def
aten_dropout
(
mapper
,
graph
,
node
):
def
aten_dropout
(
mapper
,
graph
,
node
):
""" 构造Dropout的PaddleLayer。
""" 构造Dropout的PaddleLayer。
TorchScript示例:
TorchScript示例:
%119 : Tensor = aten::dropout(%result.3, %117, %118)
%119 : Tensor = aten::dropout(%result.3, %117, %118)
参数含义:
参数含义:
...
@@ -1584,7 +1604,6 @@ def aten_dropout(mapper, graph, node):
...
@@ -1584,7 +1604,6 @@ def aten_dropout(mapper, graph, node):
def
aten_dropout_
(
mapper
,
graph
,
node
):
def
aten_dropout_
(
mapper
,
graph
,
node
):
""" 构造Dropout的PaddleLayer。
""" 构造Dropout的PaddleLayer。
TorchScript示例:
TorchScript示例:
%119 : Tensor = aten::dropout_(%result.3, %117, %118)
%119 : Tensor = aten::dropout_(%result.3, %117, %118)
参数含义:
参数含义:
...
@@ -1618,7 +1637,6 @@ def aten_dropout_(mapper, graph, node):
...
@@ -1618,7 +1637,6 @@ def aten_dropout_(mapper, graph, node):
def
aten_embedding
(
mapper
,
graph
,
node
):
def
aten_embedding
(
mapper
,
graph
,
node
):
""" 构造embedding的PaddleLayer。
""" 构造embedding的PaddleLayer。
TorchScript示例:
TorchScript示例:
%inputs_embeds.1 : Tensor = aten::embedding(%57, %input_ids.1, %45, %46, %46)
%inputs_embeds.1 : Tensor = aten::embedding(%57, %input_ids.1, %45, %46, %46)
参数含义:
参数含义:
...
@@ -1668,7 +1686,6 @@ def aten_embedding(mapper, graph, node):
...
@@ -1668,7 +1686,6 @@ def aten_embedding(mapper, graph, node):
def
aten_eq
(
mapper
,
graph
,
node
):
def
aten_eq
(
mapper
,
graph
,
node
):
""" 构造判断数值是否相等的PaddleLayer。
""" 构造判断数值是否相等的PaddleLayer。
TorchScript示例:
TorchScript示例:
%125 : bool = aten::eq(%124, %123)
%125 : bool = aten::eq(%124, %123)
参数含义:
参数含义:
...
@@ -1707,7 +1724,6 @@ def aten_eq(mapper, graph, node):
...
@@ -1707,7 +1724,6 @@ def aten_eq(mapper, graph, node):
def
aten_erf
(
mapper
,
graph
,
node
):
def
aten_erf
(
mapper
,
graph
,
node
):
""" 构造逐元素计算 Erf 激活函数的PaddleLayer。
""" 构造逐元素计算 Erf 激活函数的PaddleLayer。
TorchScript示例:
TorchScript示例:
%94 : Tensor = aten::erf(%sinusoid_inp.1)
%94 : Tensor = aten::erf(%sinusoid_inp.1)
参数含义:
参数含义:
...
@@ -1738,7 +1754,6 @@ def aten_erf(mapper, graph, node):
...
@@ -1738,7 +1754,6 @@ def aten_erf(mapper, graph, node):
def
aten_exp
(
mapper
,
graph
,
node
):
def
aten_exp
(
mapper
,
graph
,
node
):
""" 构造以自然数e为底指数运算的PaddleLayer。
""" 构造以自然数e为底指数运算的PaddleLayer。
TorchScript示例:
TorchScript示例:
%55 : Tensor = aten::tanh(%54)
%55 : Tensor = aten::tanh(%54)
参数含义:
参数含义:
...
@@ -1769,7 +1784,6 @@ def aten_exp(mapper, graph, node):
...
@@ -1769,7 +1784,6 @@ def aten_exp(mapper, graph, node):
def
aten_expand
(
mapper
,
graph
,
node
):
def
aten_expand
(
mapper
,
graph
,
node
):
""" 构造对某维度进行广播的PaddleLayer。
""" 构造对某维度进行广播的PaddleLayer。
TorchScript示例:
TorchScript示例:
%1889 : Tensor = aten::expand(%1875, %1888, %1567)
%1889 : Tensor = aten::expand(%1875, %1888, %1567)
参数含义:
参数含义:
...
@@ -1810,7 +1824,6 @@ def aten_expand(mapper, graph, node):
...
@@ -1810,7 +1824,6 @@ def aten_expand(mapper, graph, node):
def
aten_expand_as
(
mapper
,
graph
,
node
):
def
aten_expand_as
(
mapper
,
graph
,
node
):
""" 构造广播的PaddleLayer。
""" 构造广播的PaddleLayer。
TorchScript示例:
TorchScript示例:
%1889 : Tensor = aten::expand_as(%1875, %1888)
%1889 : Tensor = aten::expand_as(%1875, %1888)
参数含义:
参数含义:
...
@@ -1915,7 +1928,6 @@ def aten_expand_as(mapper, graph, node):
...
@@ -1915,7 +1928,6 @@ def aten_expand_as(mapper, graph, node):
def
aten_eye
(
mapper
,
graph
,
node
):
def
aten_eye
(
mapper
,
graph
,
node
):
""" 构造批次二维矩阵的PaddleLayer。
""" 构造批次二维矩阵的PaddleLayer。
TorchScript示例:
TorchScript示例:
%68 : Tensor = aten::eye(%49, %_50, %_51, %15, %9, %67, %7)
%68 : Tensor = aten::eye(%49, %_50, %_51, %15, %9, %67, %7)
参数含义:
参数含义:
...
@@ -1960,7 +1972,6 @@ def aten_eye(mapper, graph, node):
...
@@ -1960,7 +1972,6 @@ def aten_eye(mapper, graph, node):
def
aten_feature_dropout
(
mapper
,
graph
,
node
):
def
aten_feature_dropout
(
mapper
,
graph
,
node
):
""" 构造Dropout的PaddleLayer。
""" 构造Dropout的PaddleLayer。
TorchScript示例:
TorchScript示例:
%119 : Tensor = aten::feature_dropout(%result.3, %117, %118)
%119 : Tensor = aten::feature_dropout(%result.3, %117, %118)
参数含义:
参数含义:
...
@@ -1994,7 +2005,6 @@ def aten_feature_dropout(mapper, graph, node):
...
@@ -1994,7 +2005,6 @@ def aten_feature_dropout(mapper, graph, node):
def
aten_flatten
(
mapper
,
graph
,
node
):
def
aten_flatten
(
mapper
,
graph
,
node
):
""" 构造flatten的PaddleLayer。
""" 构造flatten的PaddleLayer。
TorchScript示例:
TorchScript示例:
%x.8 : Tensor = aten::flatten(%x, %4, %2)
%x.8 : Tensor = aten::flatten(%x, %4, %2)
参数含义:
参数含义:
...
@@ -2002,7 +2012,6 @@ def aten_flatten(mapper, graph, node):
...
@@ -2002,7 +2012,6 @@ def aten_flatten(mapper, graph, node):
%x (Tensor): 输入Tensor。
%x (Tensor): 输入Tensor。
%4 (int): flatten的开始维度。
%4 (int): flatten的开始维度。
%2 (int): flatten的结束维度。
%2 (int): flatten的结束维度。
"""
"""
scope_name
=
mapper
.
normalize_scope_name
(
node
)
scope_name
=
mapper
.
normalize_scope_name
(
node
)
output_name
=
mapper
.
_get_outputs_name
(
node
)[
0
]
output_name
=
mapper
.
_get_outputs_name
(
node
)[
0
]
...
@@ -2034,7 +2043,6 @@ def aten_flatten(mapper, graph, node):
...
@@ -2034,7 +2043,6 @@ def aten_flatten(mapper, graph, node):
def
aten_Float
(
mapper
,
graph
,
node
):
def
aten_Float
(
mapper
,
graph
,
node
):
""" 构造取浮点型的PaddleLayer。
""" 构造取浮点型的PaddleLayer。
TorchScript示例:
TorchScript示例:
%3992 : float = aten::Float(%3991)
%3992 : float = aten::Float(%3991)
参数含义:
参数含义:
...
@@ -2065,7 +2073,6 @@ def aten_Float(mapper, graph, node):
...
@@ -2065,7 +2073,6 @@ def aten_Float(mapper, graph, node):
def
aten_floor
(
mapper
,
graph
,
node
):
def
aten_floor
(
mapper
,
graph
,
node
):
""" 构造向上取整的PaddleLayer。
""" 构造向上取整的PaddleLayer。
TorchScript示例:
TorchScript示例:
%3978 : int = aten::floor(%scale.18)
%3978 : int = aten::floor(%scale.18)
参数含义:
参数含义:
...
@@ -2126,7 +2133,6 @@ def aten_floor(mapper, graph, node):
...
@@ -2126,7 +2133,6 @@ def aten_floor(mapper, graph, node):
def
aten_floordiv
(
mapper
,
graph
,
node
):
def
aten_floordiv
(
mapper
,
graph
,
node
):
""" 构造向上取整除法的PaddleLayer。
""" 构造向上取整除法的PaddleLayer。
TorchScript示例:
TorchScript示例:
%channels_per_group.2 : int = aten::floordiv(%num_channels.2, %3690)
%channels_per_group.2 : int = aten::floordiv(%num_channels.2, %3690)
参数含义:
参数含义:
...
@@ -2162,7 +2168,6 @@ def aten_floordiv(mapper, graph, node):
...
@@ -2162,7 +2168,6 @@ def aten_floordiv(mapper, graph, node):
def
aten_floor_divide
(
mapper
,
graph
,
node
):
def
aten_floor_divide
(
mapper
,
graph
,
node
):
""" 构造向上取整除法的PaddleLayer。
""" 构造向上取整除法的PaddleLayer。
TorchScript示例:
TorchScript示例:
%channels_per_group.2 : int = aten::floor_divide(%num_channels.2, %3690)
%channels_per_group.2 : int = aten::floor_divide(%num_channels.2, %3690)
参数含义:
参数含义:
...
@@ -2198,7 +2203,6 @@ def aten_floor_divide(mapper, graph, node):
...
@@ -2198,7 +2203,6 @@ def aten_floor_divide(mapper, graph, node):
def
aten_full_like
(
mapper
,
graph
,
node
):
def
aten_full_like
(
mapper
,
graph
,
node
):
""" 构造创建一个与输入具有相同的形状并且数据类型固定的Tensor的PaddleLayer。
""" 构造创建一个与输入具有相同的形状并且数据类型固定的Tensor的PaddleLayer。
TorchScript示例:
TorchScript示例:
%159 : Tensor = aten::full_like(%val_if_large.3, %51, %50, %62, %53, %65, %66)
%159 : Tensor = aten::full_like(%val_if_large.3, %51, %50, %62, %53, %65, %66)
参数含义:
参数含义:
...
@@ -2247,7 +2251,6 @@ def aten_full_like(mapper, graph, node):
...
@@ -2247,7 +2251,6 @@ def aten_full_like(mapper, graph, node):
def
aten_gather
(
mapper
,
graph
,
node
):
def
aten_gather
(
mapper
,
graph
,
node
):
""" 构造gather激活的PaddleLayer。
""" 构造gather激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%result.3 : Tensor = aten::gather(%input.5, %18, %19, %20, %21)
%result.3 : Tensor = aten::gather(%input.5, %18, %19, %20, %21)
参数含义:
参数含义:
...
@@ -2289,13 +2292,11 @@ def aten_gather(mapper, graph, node):
...
@@ -2289,13 +2292,11 @@ def aten_gather(mapper, graph, node):
def
aten_gelu
(
mapper
,
graph
,
node
):
def
aten_gelu
(
mapper
,
graph
,
node
):
""" 构造GeLU激活的PaddleLayer。
""" 构造GeLU激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%result.3 : Tensor = aten::gelu(%input.5)
%result.3 : Tensor = aten::gelu(%input.5)
参数含义:
参数含义:
%result.3 (Tensor): 输出,GELU后的结果。
%result.3 (Tensor): 输出,GELU后的结果。
%result.5 (Tensor): 需要GELU的Tensor。
%result.5 (Tensor): 需要GELU的Tensor。
注意: inplace这个参数在paddle中未实现
注意: inplace这个参数在paddle中未实现
"""
"""
scope_name
=
mapper
.
normalize_scope_name
(
node
)
scope_name
=
mapper
.
normalize_scope_name
(
node
)
...
@@ -2323,7 +2324,6 @@ def aten_gelu(mapper, graph, node):
...
@@ -2323,7 +2324,6 @@ def aten_gelu(mapper, graph, node):
def
aten___getitem__
(
mapper
,
graph
,
node
):
def
aten___getitem__
(
mapper
,
graph
,
node
):
""" 构造获取list中元素的PaddleLayer。
""" 构造获取list中元素的PaddleLayer。
TorchScript示例:
TorchScript示例:
%v.1 : int = aten::__getitem__(%72, %88)
%v.1 : int = aten::__getitem__(%72, %88)
参数含义:
参数含义:
...
@@ -2359,7 +2359,6 @@ def aten___getitem__(mapper, graph, node):
...
@@ -2359,7 +2359,6 @@ def aten___getitem__(mapper, graph, node):
def
aten_gt
(
mapper
,
graph
,
node
):
def
aten_gt
(
mapper
,
graph
,
node
):
""" 构造对比大小的PaddleLayer。
""" 构造对比大小的PaddleLayer。
TorchScript示例:
TorchScript示例:
%83 : bool = aten::gt(%82, %78)
%83 : bool = aten::gt(%82, %78)
参数含义:
参数含义:
...
@@ -2395,7 +2394,6 @@ def aten_gt(mapper, graph, node):
...
@@ -2395,7 +2394,6 @@ def aten_gt(mapper, graph, node):
def
aten_gru
(
mapper
,
graph
,
node
):
def
aten_gru
(
mapper
,
graph
,
node
):
""" 构造门控循环单元网络(GRU)的PaddleLayer。
""" 构造门控循环单元网络(GRU)的PaddleLayer。
TorchScript示例:
TorchScript示例:
%21, %22 = aten::gru(%input, %hx, %20, %11, %10, %9, %11, %8, %11)
%21, %22 = aten::gru(%input, %hx, %20, %11, %10, %9, %11, %8, %11)
参数含义:
参数含义:
...
@@ -2486,7 +2484,6 @@ def aten_gru(mapper, graph, node):
...
@@ -2486,7 +2484,6 @@ def aten_gru(mapper, graph, node):
def
aten_hardtanh_
(
mapper
,
graph
,
node
):
def
aten_hardtanh_
(
mapper
,
graph
,
node
):
""" 构造hardtanh激活的PaddleLayer。
""" 构造hardtanh激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%result.9 : Tensor = aten::hardtanh_(%input.20, %67, %66)
%result.9 : Tensor = aten::hardtanh_(%input.20, %67, %66)
参数含义:
参数含义:
...
@@ -2531,9 +2528,51 @@ def aten_hardtanh_(mapper, graph, node):
...
@@ -2531,9 +2528,51 @@ def aten_hardtanh_(mapper, graph, node):
return
current_inputs
,
current_outputs
return
current_inputs
,
current_outputs
def
aten_index_select
(
mapper
,
graph
,
node
):
def
aten_index
(
mapper
,
graph
,
node
):
""" 构造对dict加入元素的PaddleLayer。
""" 构造选择元素的PaddleLayer。
TorchScript示例:
%1681 : Float = aten::index(%1653, %1680)
参数含义:
%1681 (Tensor): 输出,选择后的Tensor。
%1653 (Tensor): 需要选择的Tensor。
%1680 (int): 选择的索引。
"""
scope_name
=
mapper
.
normalize_scope_name
(
node
)
output_name
=
mapper
.
_get_outputs_name
(
node
)[
0
]
layer_outputs
=
[
output_name
]
layer_inputs
=
{}
layer_attrs
=
{}
inputs_name
,
inputs_node
=
mapper
.
_get_inputs_name
(
node
)
# 获取当前节点输出的list
current_outputs
=
[
output_name
]
# 处理输入0,即%1653
mapper
.
_check_input
(
graph
,
inputs_node
[
0
],
inputs_name
[
0
],
current_outputs
,
scope_name
)
layer_inputs
[
"x"
]
=
inputs_name
[
0
]
# 处理输入1,即%1680
mapper
.
_check_input
(
graph
,
inputs_node
[
1
],
inputs_name
[
1
],
current_outputs
,
scope_name
)
layer_inputs
[
"index"
]
=
inputs_name
[
1
]
# 获取当前节点输入的list
current_inputs
=
list
(
layer_inputs
.
values
())
graph
.
add_layer
(
"prim.getitem"
,
inputs
=
{
"list"
:
layer_inputs
[
"index"
]},
outputs
=
[
layer_inputs
[
"index"
]],
scope_name
=
scope_name
,
index
=
0
)
graph
.
add_layer
(
"paddle.index_select"
,
inputs
=
layer_inputs
,
outputs
=
layer_outputs
,
scope_name
=
scope_name
,
**
layer_attrs
)
return
current_inputs
,
current_outputs
def
aten_index_select
(
mapper
,
graph
,
node
):
""" 构造选择元素的PaddleLayer。
TorchScript示例:
TorchScript示例:
%bd.3 : Tensor = aten::index_select(%x2.3, %320, %371)
%bd.3 : Tensor = aten::index_select(%x2.3, %320, %371)
参数含义:
参数含义:
...
@@ -2580,7 +2619,6 @@ def aten_index_select(mapper, graph, node):
...
@@ -2580,7 +2619,6 @@ def aten_index_select(mapper, graph, node):
def
aten_instance_norm
(
mapper
,
graph
,
node
):
def
aten_instance_norm
(
mapper
,
graph
,
node
):
"""构造InstanceNorm的PaddleLayer
"""构造InstanceNorm的PaddleLayer
TorchScript示例:
TorchScript示例:
%res.7 : Tensor = aten::instance_norm(%res.5, %88, %85, %84, %83, %87, %91, %92, %87)
%res.7 : Tensor = aten::instance_norm(%res.5, %88, %85, %84, %83, %87, %91, %92, %87)
参数含义:
参数含义:
...
@@ -2643,7 +2681,6 @@ def aten_instance_norm(mapper, graph, node):
...
@@ -2643,7 +2681,6 @@ def aten_instance_norm(mapper, graph, node):
def
aten_Int
(
mapper
,
graph
,
node
):
def
aten_Int
(
mapper
,
graph
,
node
):
""" 构造强转为int的PaddleLayer。
""" 构造强转为int的PaddleLayer。
TorchScript示例:
TorchScript示例:
%1739 : int = aten::Int(%1738)
%1739 : int = aten::Int(%1738)
参数含义:
参数含义:
...
@@ -2674,7 +2711,6 @@ def aten_Int(mapper, graph, node):
...
@@ -2674,7 +2711,6 @@ def aten_Int(mapper, graph, node):
def
aten___is__
(
mapper
,
graph
,
node
):
def
aten___is__
(
mapper
,
graph
,
node
):
""" 构造is not的PaddleLayer。
""" 构造is not的PaddleLayer。
TorchScript示例:
TorchScript示例:
%3949 : bool = aten::__isnot__(%size.122, %3931)
%3949 : bool = aten::__isnot__(%size.122, %3931)
参数含义:
参数含义:
...
@@ -2710,7 +2746,6 @@ def aten___is__(mapper, graph, node):
...
@@ -2710,7 +2746,6 @@ def aten___is__(mapper, graph, node):
def
aten___isnot__
(
mapper
,
graph
,
node
):
def
aten___isnot__
(
mapper
,
graph
,
node
):
""" 构造is not的PaddleLayer。
""" 构造is not的PaddleLayer。
TorchScript示例:
TorchScript示例:
%3949 : bool = aten::__isnot__(%size.122, %3931)
%3949 : bool = aten::__isnot__(%size.122, %3931)
参数含义:
参数含义:
...
@@ -2746,7 +2781,6 @@ def aten___isnot__(mapper, graph, node):
...
@@ -2746,7 +2781,6 @@ def aten___isnot__(mapper, graph, node):
def
aten_layer_norm
(
mapper
,
graph
,
node
):
def
aten_layer_norm
(
mapper
,
graph
,
node
):
""" 构造层归一化的PaddleLayer。
""" 构造层归一化的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input0.4 : Tensor = aten::layer_norm(%input.6, %1181, %174, %173, %70, %71)
%input0.4 : Tensor = aten::layer_norm(%input.6, %1181, %174, %173, %70, %71)
参数含义:
参数含义:
...
@@ -2799,7 +2833,6 @@ def aten_layer_norm(mapper, graph, node):
...
@@ -2799,7 +2833,6 @@ def aten_layer_norm(mapper, graph, node):
def
aten_le
(
mapper
,
graph
,
node
):
def
aten_le
(
mapper
,
graph
,
node
):
""" 构造对比大小的PaddleLayer。
""" 构造对比大小的PaddleLayer。
TorchScript示例:
TorchScript示例:
%80 : bool = aten::le(%78, %79)
%80 : bool = aten::le(%78, %79)
参数含义:
参数含义:
...
@@ -2835,7 +2868,6 @@ def aten_le(mapper, graph, node):
...
@@ -2835,7 +2868,6 @@ def aten_le(mapper, graph, node):
def
aten_leaky_relu_
(
mapper
,
graph
,
node
):
def
aten_leaky_relu_
(
mapper
,
graph
,
node
):
""" 构造leaky relu激活的PaddleLayer。
""" 构造leaky relu激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input.117 : Tensor = aten::leaky_relu_(%input.114, %1570)
%input.117 : Tensor = aten::leaky_relu_(%input.114, %1570)
参数含义:
参数含义:
...
@@ -2872,7 +2904,6 @@ def aten_leaky_relu_(mapper, graph, node):
...
@@ -2872,7 +2904,6 @@ def aten_leaky_relu_(mapper, graph, node):
def
aten_len
(
mapper
,
graph
,
node
):
def
aten_len
(
mapper
,
graph
,
node
):
""" 构造获取list长度的PaddleLayer。
""" 构造获取list长度的PaddleLayer。
TorchScript示例:
TorchScript示例:
%85 : int = aten::len(%83)
%85 : int = aten::len(%83)
参数含义:
参数含义:
...
@@ -2903,7 +2934,6 @@ def aten_len(mapper, graph, node):
...
@@ -2903,7 +2934,6 @@ def aten_len(mapper, graph, node):
def
aten_log
(
mapper
,
graph
,
node
):
def
aten_log
(
mapper
,
graph
,
node
):
""" 构构造log的PaddleLayer。
""" 构构造log的PaddleLayer。
TorchScript示例:
TorchScript示例:
%787 : Tensor = aten::log(%786)
%787 : Tensor = aten::log(%786)
参数含义:
参数含义:
...
@@ -2934,7 +2964,6 @@ def aten_log(mapper, graph, node):
...
@@ -2934,7 +2964,6 @@ def aten_log(mapper, graph, node):
def
aten_lstm
(
mapper
,
graph
,
node
):
def
aten_lstm
(
mapper
,
graph
,
node
):
""" 构造长短期记忆网络(LSTM)的PaddleLayer。
""" 构造长短期记忆网络(LSTM)的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input.96, %551, %552 = aten::lstm(%input.95, %734, %549, %526, %525, %524, %526, %526, %526)
%input.96, %551, %552 = aten::lstm(%input.95, %734, %549, %526, %525, %524, %526, %526, %526)
参数含义:
参数含义:
...
@@ -3026,7 +3055,6 @@ def aten_lstm(mapper, graph, node):
...
@@ -3026,7 +3055,6 @@ def aten_lstm(mapper, graph, node):
def
aten_lt
(
mapper
,
graph
,
node
):
def
aten_lt
(
mapper
,
graph
,
node
):
""" 构造对比大小的PaddleLayer。
""" 构造对比大小的PaddleLayer。
TorchScript示例:
TorchScript示例:
%80 : bool = aten::lt(%78, %79)
%80 : bool = aten::lt(%78, %79)
参数含义:
参数含义:
...
@@ -3062,7 +3090,6 @@ def aten_lt(mapper, graph, node):
...
@@ -3062,7 +3090,6 @@ def aten_lt(mapper, graph, node):
def
aten_masked_fill_
(
mapper
,
graph
,
node
):
def
aten_masked_fill_
(
mapper
,
graph
,
node
):
""" 构造填充mask的PaddleLayer。
""" 构造填充mask的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input.4 : Tensor = aten::masked_fill_(%scores.2, %mask.2, %46)
%input.4 : Tensor = aten::masked_fill_(%scores.2, %mask.2, %46)
参数含义:
参数含义:
...
@@ -3175,7 +3202,6 @@ def aten_masked_fill_(mapper, graph, node):
...
@@ -3175,7 +3202,6 @@ def aten_masked_fill_(mapper, graph, node):
def
aten_masked_fill
(
mapper
,
graph
,
node
):
def
aten_masked_fill
(
mapper
,
graph
,
node
):
""" 构造填充mask的PaddleLayer。
""" 构造填充mask的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input.4 : Tensor = aten::masked_fill(%scores.2, %mask.2, %46)
%input.4 : Tensor = aten::masked_fill(%scores.2, %mask.2, %46)
参数含义:
参数含义:
...
@@ -3288,7 +3314,6 @@ def aten_masked_fill(mapper, graph, node):
...
@@ -3288,7 +3314,6 @@ def aten_masked_fill(mapper, graph, node):
def
aten_max
(
mapper
,
graph
,
node
):
def
aten_max
(
mapper
,
graph
,
node
):
""" 构造获取最大值的PaddleLayer。
""" 构造获取最大值的PaddleLayer。
TorchScript示例:
TorchScript示例:
%val_if_large0.3 : Tensor = aten::max(%val_if_large.3, %159)
%val_if_large0.3 : Tensor = aten::max(%val_if_large.3, %159)
参数含义:
参数含义:
...
@@ -3327,7 +3352,6 @@ def aten_max(mapper, graph, node):
...
@@ -3327,7 +3352,6 @@ def aten_max(mapper, graph, node):
def
aten_max_pool2d
(
mapper
,
graph
,
node
):
def
aten_max_pool2d
(
mapper
,
graph
,
node
):
""" 构造最大池化的PaddleLayer。
""" 构造最大池化的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input.8 : Tensor = aten::max_pool2d(%result.11, %20, %23, %21, %22, %19)
%input.8 : Tensor = aten::max_pool2d(%result.11, %20, %23, %21, %22, %19)
参数含义:
参数含义:
...
@@ -3388,7 +3412,6 @@ def aten_max_pool2d(mapper, graph, node):
...
@@ -3388,7 +3412,6 @@ def aten_max_pool2d(mapper, graph, node):
def
aten_matmul
(
mapper
,
graph
,
node
):
def
aten_matmul
(
mapper
,
graph
,
node
):
""" 构造矩阵相乘的PaddleLayer。
""" 构造矩阵相乘的PaddleLayer。
TorchScript示例:
TorchScript示例:
%output.2 : Tensor = aten::matmul(%101, %111)
%output.2 : Tensor = aten::matmul(%101, %111)
参数含义:
参数含义:
...
@@ -3424,7 +3447,6 @@ def aten_matmul(mapper, graph, node):
...
@@ -3424,7 +3447,6 @@ def aten_matmul(mapper, graph, node):
def
aten_min
(
mapper
,
graph
,
node
):
def
aten_min
(
mapper
,
graph
,
node
):
""" 构造获取最小值的PaddleLayer。
""" 构造获取最小值的PaddleLayer。
TorchScript示例:
TorchScript示例:
%val_if_large0.3 : Tensor = aten::min(%val_if_large.3, %159)
%val_if_large0.3 : Tensor = aten::min(%val_if_large.3, %159)
参数含义:
参数含义:
...
@@ -3463,7 +3485,6 @@ def aten_min(mapper, graph, node):
...
@@ -3463,7 +3485,6 @@ def aten_min(mapper, graph, node):
def
aten_mean
(
mapper
,
graph
,
node
):
def
aten_mean
(
mapper
,
graph
,
node
):
""" 构造求均值的PaddleLayer。
""" 构造求均值的PaddleLayer。
TorchScript示例:
TorchScript示例:
%x.28 : Tensor = aten::mean(%result.1, %4967, %3, %2)
%x.28 : Tensor = aten::mean(%result.1, %4967, %3, %2)
参数含义:
参数含义:
...
@@ -3514,7 +3535,6 @@ def aten_mean(mapper, graph, node):
...
@@ -3514,7 +3535,6 @@ def aten_mean(mapper, graph, node):
def
aten_meshgrid
(
mapper
,
graph
,
node
):
def
aten_meshgrid
(
mapper
,
graph
,
node
):
""" 构造对每个张量做扩充操作的PaddleLayer。
""" 构造对每个张量做扩充操作的PaddleLayer。
TorchScript示例:
TorchScript示例:
%out.39 : int = aten::mshgrid(%input.1)
%out.39 : int = aten::mshgrid(%input.1)
参数含义:
参数含义:
...
@@ -3546,7 +3566,6 @@ def aten_meshgrid(mapper, graph, node):
...
@@ -3546,7 +3566,6 @@ def aten_meshgrid(mapper, graph, node):
def
aten_mul
(
mapper
,
graph
,
node
):
def
aten_mul
(
mapper
,
graph
,
node
):
""" 构造数值相乘的PaddleLayer。
""" 构造数值相乘的PaddleLayer。
TorchScript示例:
TorchScript示例:
%size_prods.39 : int = aten::mul(%size_prods.38, %114)
%size_prods.39 : int = aten::mul(%size_prods.38, %114)
参数含义:
参数含义:
...
@@ -3583,7 +3602,6 @@ def aten_mul(mapper, graph, node):
...
@@ -3583,7 +3602,6 @@ def aten_mul(mapper, graph, node):
def
aten_mul_
(
mapper
,
graph
,
node
):
def
aten_mul_
(
mapper
,
graph
,
node
):
""" 构造数值相乘的PaddleLayer。
""" 构造数值相乘的PaddleLayer。
TorchScript示例:
TorchScript示例:
%size_prods.39 : int = aten::mul_(%size_prods.38, %114)
%size_prods.39 : int = aten::mul_(%size_prods.38, %114)
参数含义:
参数含义:
...
@@ -3620,7 +3638,6 @@ def aten_mul_(mapper, graph, node):
...
@@ -3620,7 +3638,6 @@ def aten_mul_(mapper, graph, node):
def
aten_ne
(
mapper
,
graph
,
node
):
def
aten_ne
(
mapper
,
graph
,
node
):
""" 构造判断数值是否不相等的PaddleLayer。
""" 构造判断数值是否不相等的PaddleLayer。
TorchScript示例:
TorchScript示例:
%134 : bool = aten::ne(%133, %132)
%134 : bool = aten::ne(%133, %132)
参数含义:
参数含义:
...
@@ -3656,7 +3673,6 @@ def aten_ne(mapper, graph, node):
...
@@ -3656,7 +3673,6 @@ def aten_ne(mapper, graph, node):
def
aten_neg
(
mapper
,
graph
,
node
):
def
aten_neg
(
mapper
,
graph
,
node
):
""" 构造对数值取负的PaddleLayer。
""" 构造对数值取负的PaddleLayer。
TorchScript示例:
TorchScript示例:
%909 : int = aten::neg(%908)
%909 : int = aten::neg(%908)
参数含义:
参数含义:
...
@@ -3687,7 +3703,6 @@ def aten_neg(mapper, graph, node):
...
@@ -3687,7 +3703,6 @@ def aten_neg(mapper, graph, node):
def
aten_norm
(
mapper
,
graph
,
node
):
def
aten_norm
(
mapper
,
graph
,
node
):
""" 构造计算范数的PaddleLayer。
""" 构造计算范数的PaddleLayer。
TorchScript示例:
TorchScript示例:
%25 = aten::norm(%input, %21, %58, %24)
%25 = aten::norm(%input, %21, %58, %24)
参数含义:
参数含义:
...
@@ -3746,7 +3761,6 @@ def aten_norm(mapper, graph, node):
...
@@ -3746,7 +3761,6 @@ def aten_norm(mapper, graph, node):
def
aten___not__
(
mapper
,
graph
,
node
):
def
aten___not__
(
mapper
,
graph
,
node
):
""" 构造对bool型取负的PaddleLayer。
""" 构造对bool型取负的PaddleLayer。
TorchScript示例:
TorchScript示例:
%4498 : bool = aten::__not__(%aux_defined.2)
%4498 : bool = aten::__not__(%aux_defined.2)
参数含义:
参数含义:
...
@@ -3777,7 +3791,6 @@ def aten___not__(mapper, graph, node):
...
@@ -3777,7 +3791,6 @@ def aten___not__(mapper, graph, node):
def
aten_ones
(
mapper
,
graph
,
node
):
def
aten_ones
(
mapper
,
graph
,
node
):
""" 构造创建固定形状、数据类型且值全为0的Tensor的PaddleLayer。
""" 构造创建固定形状、数据类型且值全为0的Tensor的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input.49 : Tensor = aten::ones(%23, %8, %6, %24, %5)
%input.49 : Tensor = aten::ones(%23, %8, %6, %24, %5)
参数含义:
参数含义:
...
@@ -3819,7 +3832,6 @@ def aten_ones(mapper, graph, node):
...
@@ -3819,7 +3832,6 @@ def aten_ones(mapper, graph, node):
def
aten_permute
(
mapper
,
graph
,
node
):
def
aten_permute
(
mapper
,
graph
,
node
):
""" 构造对bool型取负的PaddleLayer。
""" 构造对bool型取负的PaddleLayer。
TorchScript示例:
TorchScript示例:
%2385 : Tensor = aten::permute(%cls_confs0.2, %2384)
%2385 : Tensor = aten::permute(%cls_confs0.2, %2384)
参数含义:
参数含义:
...
@@ -3861,7 +3873,6 @@ def aten_permute(mapper, graph, node):
...
@@ -3861,7 +3873,6 @@ def aten_permute(mapper, graph, node):
def
aten_pixel_shuffle
(
mapper
,
graph
,
node
):
def
aten_pixel_shuffle
(
mapper
,
graph
,
node
):
""" 构造以像素的方式重排的PaddleLayer。
""" 构造以像素的方式重排的PaddleLayer。
TorchScript示例:
TorchScript示例:
%x.6 : aten::pixel_shuffle(%input.101, %726)
%x.6 : aten::pixel_shuffle(%input.101, %726)
参数含义:
参数含义:
...
@@ -3896,7 +3907,6 @@ def aten_pixel_shuffle(mapper, graph, node):
...
@@ -3896,7 +3907,6 @@ def aten_pixel_shuffle(mapper, graph, node):
def
aten_pow
(
mapper
,
graph
,
node
):
def
aten_pow
(
mapper
,
graph
,
node
):
""" 构造指数激活的PaddleLayer。
""" 构造指数激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%x.6 : Tensor = aten::pow(%4700, %4703)
%x.6 : Tensor = aten::pow(%4700, %4703)
参数含义:
参数含义:
...
@@ -3937,7 +3947,6 @@ def aten_pow(mapper, graph, node):
...
@@ -3937,7 +3947,6 @@ def aten_pow(mapper, graph, node):
def
aten_prelu
(
mapper
,
graph
,
node
):
def
aten_prelu
(
mapper
,
graph
,
node
):
""" 构造prelu激活的PaddleLayer。
""" 构造prelu激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%result.3 : aten::prelu(%input.150, %999)
%result.3 : aten::prelu(%input.150, %999)
参数含义:
参数含义:
...
@@ -3974,7 +3983,6 @@ def aten_prelu(mapper, graph, node):
...
@@ -3974,7 +3983,6 @@ def aten_prelu(mapper, graph, node):
def
aten_reflection_pad1d
(
mapper
,
graph
,
node
):
def
aten_reflection_pad1d
(
mapper
,
graph
,
node
):
""" 构造1维映射填充的PaddleLayer。
""" 构造1维映射填充的PaddleLayer。
TorchScript示例:
TorchScript示例:
%6 = aten::reflection_pad1d(%input, %7)
%6 = aten::reflection_pad1d(%input, %7)
参数含义:
参数含义:
...
@@ -4021,7 +4029,6 @@ def aten_reflection_pad1d(mapper, graph, node):
...
@@ -4021,7 +4029,6 @@ def aten_reflection_pad1d(mapper, graph, node):
def
aten_reflection_pad2d
(
mapper
,
graph
,
node
):
def
aten_reflection_pad2d
(
mapper
,
graph
,
node
):
""" 构造2维映射填充的PaddleLayer。
""" 构造2维映射填充的PaddleLayer。
TorchScript示例:
TorchScript示例:
%6 = aten::reflection_pad2d(%input, %7)
%6 = aten::reflection_pad2d(%input, %7)
参数含义:
参数含义:
...
@@ -4068,13 +4075,11 @@ def aten_reflection_pad2d(mapper, graph, node):
...
@@ -4068,13 +4075,11 @@ def aten_reflection_pad2d(mapper, graph, node):
def
aten_relu
(
mapper
,
graph
,
node
):
def
aten_relu
(
mapper
,
graph
,
node
):
""" 构造ReLU激活的PaddleLayer。
""" 构造ReLU激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%result.3 : Tensor = aten::relu(%input.5)
%result.3 : Tensor = aten::relu(%input.5)
参数含义:
参数含义:
%result.3 (Tensor): 输出,ReLU后的结果。
%result.3 (Tensor): 输出,ReLU后的结果。
%result.5 (Tensor): 需要ReLU的Tensor。
%result.5 (Tensor): 需要ReLU的Tensor。
注意: inplace这个参数在paddle中未实现
注意: inplace这个参数在paddle中未实现
"""
"""
scope_name
=
mapper
.
normalize_scope_name
(
node
)
scope_name
=
mapper
.
normalize_scope_name
(
node
)
...
@@ -4102,13 +4107,11 @@ def aten_relu(mapper, graph, node):
...
@@ -4102,13 +4107,11 @@ def aten_relu(mapper, graph, node):
def
aten_relu_
(
mapper
,
graph
,
node
):
def
aten_relu_
(
mapper
,
graph
,
node
):
""" 构造ReLU激活的PaddleLayer。
""" 构造ReLU激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%result.3 : Tensor = aten::relu_(%input.5)
%result.3 : Tensor = aten::relu_(%input.5)
参数含义:
参数含义:
%result.3 (Tensor): 输出,ReLU后的结果。
%result.3 (Tensor): 输出,ReLU后的结果。
%result.5 (Tensor): 需要ReLU的Tensor。
%result.5 (Tensor): 需要ReLU的Tensor。
注意: inplace这个参数在paddle中未实现
注意: inplace这个参数在paddle中未实现
"""
"""
scope_name
=
mapper
.
normalize_scope_name
(
node
)
scope_name
=
mapper
.
normalize_scope_name
(
node
)
...
@@ -4136,13 +4139,11 @@ def aten_relu_(mapper, graph, node):
...
@@ -4136,13 +4139,11 @@ def aten_relu_(mapper, graph, node):
def
aten_relu6
(
mapper
,
graph
,
node
):
def
aten_relu6
(
mapper
,
graph
,
node
):
""" 构造ReLU6激活的PaddleLayer。
""" 构造ReLU6激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%result.3 : Tensor = aten::relu6(%input.5)
%result.3 : Tensor = aten::relu6(%input.5)
参数含义:
参数含义:
%result.3 (Tensor): 输出,ReLU6后的结果。
%result.3 (Tensor): 输出,ReLU6后的结果。
%result.5 (Tensor): 需要ReLU6的Tensor。
%result.5 (Tensor): 需要ReLU6的Tensor。
注意: inplace这个参数在paddle中未实现
注意: inplace这个参数在paddle中未实现
"""
"""
scope_name
=
mapper
.
normalize_scope_name
(
node
)
scope_name
=
mapper
.
normalize_scope_name
(
node
)
...
@@ -4170,7 +4171,6 @@ def aten_relu6(mapper, graph, node):
...
@@ -4170,7 +4171,6 @@ def aten_relu6(mapper, graph, node):
def
aten_repeat
(
mapper
,
graph
,
node
):
def
aten_repeat
(
mapper
,
graph
,
node
):
""" 构造根据参数对输入各维度进行复制的PaddleLayer。
""" 构造根据参数对输入各维度进行复制的PaddleLayer。
TorchScript示例:
TorchScript示例:
701 : Tensor = aten::repeat(%699, %700)
701 : Tensor = aten::repeat(%699, %700)
参数含义:
参数含义:
...
@@ -4212,7 +4212,6 @@ def aten_repeat(mapper, graph, node):
...
@@ -4212,7 +4212,6 @@ def aten_repeat(mapper, graph, node):
def
aten_reshape
(
mapper
,
graph
,
node
):
def
aten_reshape
(
mapper
,
graph
,
node
):
""" 构造调整大小的PaddleLayer。
""" 构造调整大小的PaddleLayer。
TorchScript示例:
TorchScript示例:
%x.6 : Tensor = aten::reshape(%4700, %4703)
%x.6 : Tensor = aten::reshape(%4700, %4703)
参数含义:
参数含义:
...
@@ -4252,9 +4251,58 @@ def aten_reshape(mapper, graph, node):
...
@@ -4252,9 +4251,58 @@ def aten_reshape(mapper, graph, node):
return
current_inputs
,
current_outputs
return
current_inputs
,
current_outputs
def
aten_roll
(
mapper
,
graph
,
node
):
""" 构造循环滚动的PaddleLayer。
TorchScript示例:
%x.87 : Float = aten::roll(%x.86, %1862, %1863)
参数含义:
%x.87 (Tensor): 输出Tensor。
%x.86 (Tensor): 输入Tensor。
%1862 (int/list/tuple): 滚动位移。
%1863 (int/list/tuple): 滚动轴。
"""
scope_name
=
mapper
.
normalize_scope_name
(
node
)
output_name
=
mapper
.
_get_outputs_name
(
node
)[
0
]
layer_outputs
=
[
output_name
]
layer_inputs
=
{}
layer_attrs
=
{}
inputs_name
,
inputs_node
=
mapper
.
_get_inputs_name
(
node
)
# 获取当前节点输出的list
current_outputs
=
[
output_name
]
# 处理输入0,即%x.86
mapper
.
_check_input
(
graph
,
inputs_node
[
0
],
inputs_name
[
0
],
current_outputs
,
scope_name
)
layer_inputs
[
"x"
]
=
inputs_name
[
0
]
# 获取当前节点输入、输出的list
current_inputs
=
list
(
layer_inputs
.
values
())
# 处理输入1,即%1862
if
inputs_name
[
1
]
in
mapper
.
attrs
:
layer_attrs
[
"shifts"
]
=
mapper
.
attrs
[
inputs_name
[
1
]]
else
:
mapper
.
_check_input
(
graph
,
inputs_node
[
1
],
inputs_name
[
1
],
current_outputs
,
scope_name
)
layer_inputs
[
"shifts"
]
=
inputs_name
[
1
]
current_inputs
.
append
(
inputs_name
[
1
])
# 处理输入2,即%1863
if
inputs_name
[
1
]
in
mapper
.
attrs
:
layer_attrs
[
"axis"
]
=
mapper
.
attrs
[
inputs_name
[
2
]]
else
:
mapper
.
_check_input
(
graph
,
inputs_node
[
2
],
inputs_name
[
2
],
current_outputs
,
scope_name
)
layer_inputs
[
"axis"
]
=
inputs_name
[
2
]
current_inputs
.
append
(
inputs_name
[
2
])
graph
.
add_layer
(
"paddle.roll"
,
inputs
=
layer_inputs
,
outputs
=
layer_outputs
,
scope_name
=
scope_name
,
**
layer_attrs
)
return
current_inputs
,
current_outputs
def
aten_rsub
(
mapper
,
graph
,
node
):
def
aten_rsub
(
mapper
,
graph
,
node
):
""" 构造数值相减的PaddleLayer,计算公式为:out = y - alpha * x。
""" 构造数值相减的PaddleLayer,计算公式为:out = y - alpha * x。
TorchScript示例:
TorchScript示例:
%31 : Tensor = aten::rsub(%30, %13, %7)
%31 : Tensor = aten::rsub(%30, %13, %7)
参数含义:
参数含义:
...
@@ -4296,13 +4344,11 @@ def aten_rsub(mapper, graph, node):
...
@@ -4296,13 +4344,11 @@ def aten_rsub(mapper, graph, node):
def
aten_ScalarImplicit
(
mapper
,
graph
,
node
):
def
aten_ScalarImplicit
(
mapper
,
graph
,
node
):
""" 构造获取scalar的PaddleLayer。
""" 构造获取scalar的PaddleLayer。
TorchScript示例:
TorchScript示例:
%89 : Scalar = aten::ScalarImplicit(%end.1)
%89 : Scalar = aten::ScalarImplicit(%end.1)
参数含义:
参数含义:
%89 (Scalar): 输出,得到的Scalar。
%89 (Scalar): 输出,得到的Scalar。
%end.1 (-): 组要转换的数据。
%end.1 (-): 组要转换的数据。
【注意】由于Paddle无Scalar,所以最后转换为Tensor。
【注意】由于Paddle无Scalar,所以最后转换为Tensor。
"""
"""
scope_name
=
mapper
.
normalize_scope_name
(
node
)
scope_name
=
mapper
.
normalize_scope_name
(
node
)
...
@@ -4335,7 +4381,6 @@ def aten_ScalarImplicit(mapper, graph, node):
...
@@ -4335,7 +4381,6 @@ def aten_ScalarImplicit(mapper, graph, node):
def
aten_select
(
mapper
,
graph
,
node
):
def
aten_select
(
mapper
,
graph
,
node
):
""" 构造选取特定维度Variable的PaddleLayer。
""" 构造选取特定维度Variable的PaddleLayer。
TorchScript示例:
TorchScript示例:
%19 : Tensor = aten::select(%18, %8, %7)
%19 : Tensor = aten::select(%18, %8, %7)
参数含义:
参数含义:
...
@@ -4376,7 +4421,6 @@ def aten_select(mapper, graph, node):
...
@@ -4376,7 +4421,6 @@ def aten_select(mapper, graph, node):
def
aten__set_item
(
mapper
,
graph
,
node
):
def
aten__set_item
(
mapper
,
graph
,
node
):
""" 构造对dict加入元素的PaddleLayer。
""" 构造对dict加入元素的PaddleLayer。
TorchScript示例:
TorchScript示例:
= aten::_set_item(%features.1, %out_name.1, %x.3)
= aten::_set_item(%features.1, %out_name.1, %x.3)
参数含义:
参数含义:
...
@@ -4411,7 +4455,6 @@ def aten__set_item(mapper, graph, node):
...
@@ -4411,7 +4455,6 @@ def aten__set_item(mapper, graph, node):
def
aten_sigmoid
(
mapper
,
graph
,
node
):
def
aten_sigmoid
(
mapper
,
graph
,
node
):
""" 构造sigmoid激活的PaddleLayer。
""" 构造sigmoid激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%55 : Tensor = aten::sigmoid(%54)
%55 : Tensor = aten::sigmoid(%54)
参数含义:
参数含义:
...
@@ -4443,7 +4486,6 @@ def aten_sigmoid(mapper, graph, node):
...
@@ -4443,7 +4486,6 @@ def aten_sigmoid(mapper, graph, node):
def
aten_sin
(
mapper
,
graph
,
node
):
def
aten_sin
(
mapper
,
graph
,
node
):
""" 构造数学计算sin的PaddleLayer。
""" 构造数学计算sin的PaddleLayer。
TorchScript示例:
TorchScript示例:
%94 : Tensor = aten::sin(%sinusoid_inp.1)
%94 : Tensor = aten::sin(%sinusoid_inp.1)
参数含义:
参数含义:
...
@@ -4474,7 +4516,6 @@ def aten_sin(mapper, graph, node):
...
@@ -4474,7 +4516,6 @@ def aten_sin(mapper, graph, node):
def
aten_size
(
mapper
,
graph
,
node
):
def
aten_size
(
mapper
,
graph
,
node
):
""" 构造获取shape的PaddleLayer。
""" 构造获取shape的PaddleLayer。
TorchScript示例:
TorchScript示例:
%73 : int[] = aten::size(%x.12, %10)
%73 : int[] = aten::size(%x.12, %10)
参数含义:
参数含义:
...
@@ -4523,7 +4564,6 @@ def aten_size(mapper, graph, node):
...
@@ -4523,7 +4564,6 @@ def aten_size(mapper, graph, node):
def
aten_slice
(
mapper
,
graph
,
node
):
def
aten_slice
(
mapper
,
graph
,
node
):
""" 构造切分list或Variable的PaddleLayer。
""" 构造切分list或Variable的PaddleLayer。
TorchScript示例:
TorchScript示例:
%83 : int[] = aten::slice(%73, %_81, %82, %75, %77)
%83 : int[] = aten::slice(%73, %_81, %82, %75, %77)
参数含义:
参数含义:
...
@@ -4665,7 +4705,6 @@ def aten_slice(mapper, graph, node):
...
@@ -4665,7 +4705,6 @@ def aten_slice(mapper, graph, node):
def
aten_softmax
(
mapper
,
graph
,
node
):
def
aten_softmax
(
mapper
,
graph
,
node
):
""" 构造softmax激活的PaddleLayer。
""" 构造softmax激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input2.1 : Tensor = aten::softmax(%input.5, %80, %72)
%input2.1 : Tensor = aten::softmax(%input.5, %80, %72)
参数含义:
参数含义:
...
@@ -4702,7 +4741,6 @@ def aten_softmax(mapper, graph, node):
...
@@ -4702,7 +4741,6 @@ def aten_softmax(mapper, graph, node):
def
aten_softplus
(
mapper
,
graph
,
node
):
def
aten_softplus
(
mapper
,
graph
,
node
):
""" 构造softplus激活的PaddleLayer。
""" 构造softplus激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%54 : Tensor = aten::softplus(%x.31, %30, %29)
%54 : Tensor = aten::softplus(%x.31, %30, %29)
参数含义:
参数含义:
...
@@ -4740,7 +4778,6 @@ def aten_softplus(mapper, graph, node):
...
@@ -4740,7 +4778,6 @@ def aten_softplus(mapper, graph, node):
def
aten_split_with_sizes
(
mapper
,
graph
,
node
):
def
aten_split_with_sizes
(
mapper
,
graph
,
node
):
""" 构构造split的PaddleLayer。
""" 构构造split的PaddleLayer。
TorchScript示例:
TorchScript示例:
%1450 : Tensor[] = aten::split_with_sizes(%1446, %1750, %41)
%1450 : Tensor[] = aten::split_with_sizes(%1446, %1750, %41)
参数含义:
参数含义:
...
@@ -4791,7 +4828,6 @@ def aten_split_with_sizes(mapper, graph, node):
...
@@ -4791,7 +4828,6 @@ def aten_split_with_sizes(mapper, graph, node):
def
aten_sqrt
(
mapper
,
graph
,
node
):
def
aten_sqrt
(
mapper
,
graph
,
node
):
""" 构构造sqrt的PaddleLayer。
""" 构构造sqrt的PaddleLayer。
TorchScript示例:
TorchScript示例:
%787 : Tensor = aten::sqrt(%786)
%787 : Tensor = aten::sqrt(%786)
参数含义:
参数含义:
...
@@ -4822,7 +4858,6 @@ def aten_sqrt(mapper, graph, node):
...
@@ -4822,7 +4858,6 @@ def aten_sqrt(mapper, graph, node):
def
aten_squeeze
(
mapper
,
graph
,
node
):
def
aten_squeeze
(
mapper
,
graph
,
node
):
""" 构造删除位数为1的维度的PaddleLayer。
""" 构造删除位数为1的维度的PaddleLayer。
TorchScript示例:
TorchScript示例:
%12 : Tensor = aten::squeeze(%start_logits.1, %4)
%12 : Tensor = aten::squeeze(%start_logits.1, %4)
参数含义:
参数含义:
...
@@ -4863,7 +4898,6 @@ def aten_squeeze(mapper, graph, node):
...
@@ -4863,7 +4898,6 @@ def aten_squeeze(mapper, graph, node):
def
aten_stack
(
mapper
,
graph
,
node
):
def
aten_stack
(
mapper
,
graph
,
node
):
""" 构造堆叠Tensor的PaddleLayer。
""" 构造堆叠Tensor的PaddleLayer。
TorchScript示例:
TorchScript示例:
%x.222 : Tensor = aten::stack(%32, %7)
%x.222 : Tensor = aten::stack(%32, %7)
参数含义:
参数含义:
...
@@ -4904,7 +4938,6 @@ def aten_stack(mapper, graph, node):
...
@@ -4904,7 +4938,6 @@ def aten_stack(mapper, graph, node):
def
aten_sub
(
mapper
,
graph
,
node
):
def
aten_sub
(
mapper
,
graph
,
node
):
""" 构造数值相减的PaddleLayer。
""" 构造数值相减的PaddleLayer。
TorchScript示例:
TorchScript示例:
%840 : int = aten::sub(%839, %836, %3)
%840 : int = aten::sub(%839, %836, %3)
参数含义:
参数含义:
...
@@ -4959,7 +4992,6 @@ def aten_sub(mapper, graph, node):
...
@@ -4959,7 +4992,6 @@ def aten_sub(mapper, graph, node):
def
aten_sub_
(
mapper
,
graph
,
node
):
def
aten_sub_
(
mapper
,
graph
,
node
):
""" 构造数值相减的PaddleLayer。
""" 构造数值相减的PaddleLayer。
TorchScript示例:
TorchScript示例:
%840 : int = aten::sub_(%839, %836, %3)
%840 : int = aten::sub_(%839, %836, %3)
参数含义:
参数含义:
...
@@ -4973,7 +5005,6 @@ def aten_sub_(mapper, graph, node):
...
@@ -4973,7 +5005,6 @@ def aten_sub_(mapper, graph, node):
def
aten_t
(
mapper
,
graph
,
node
):
def
aten_t
(
mapper
,
graph
,
node
):
""" 构造矩阵转置的PaddleLayer。
""" 构造矩阵转置的PaddleLayer。
TorchScript示例:
TorchScript示例:
%840 : int = aten::sub(%839, %836)
%840 : int = aten::sub(%839, %836)
参数含义:
参数含义:
...
@@ -5005,7 +5036,6 @@ def aten_t(mapper, graph, node):
...
@@ -5005,7 +5036,6 @@ def aten_t(mapper, graph, node):
def
aten_tanh
(
mapper
,
graph
,
node
):
def
aten_tanh
(
mapper
,
graph
,
node
):
""" 构造tanh激活的PaddleLayer。
""" 构造tanh激活的PaddleLayer。
TorchScript示例:
TorchScript示例:
%55 : Tensor = aten::tanh(%54)
%55 : Tensor = aten::tanh(%54)
参数含义:
参数含义:
...
@@ -5037,7 +5067,6 @@ def aten_tanh(mapper, graph, node):
...
@@ -5037,7 +5067,6 @@ def aten_tanh(mapper, graph, node):
def
aten_split
(
mapper
,
graph
,
node
):
def
aten_split
(
mapper
,
graph
,
node
):
""" 构造分割Tensor的PaddleLayer。
""" 构造分割Tensor的PaddleLayer。
TorchScript示例:
TorchScript示例:
%160 : Tensor[] = aten::split(%159, %135, %123)
%160 : Tensor[] = aten::split(%159, %135, %123)
参数含义:
参数含义:
...
@@ -5084,7 +5113,6 @@ def aten_split(mapper, graph, node):
...
@@ -5084,7 +5113,6 @@ def aten_split(mapper, graph, node):
def
aten_transpose
(
mapper
,
graph
,
node
):
def
aten_transpose
(
mapper
,
graph
,
node
):
""" 构造矩阵转置的PaddleLayer。
""" 构造矩阵转置的PaddleLayer。
TorchScript示例:
TorchScript示例:
%715 : Tensor = aten::transpose(%x.21, %704, %705)
%715 : Tensor = aten::transpose(%x.21, %704, %705)
参数含义:
参数含义:
...
@@ -5176,7 +5204,6 @@ def aten_transpose(mapper, graph, node):
...
@@ -5176,7 +5204,6 @@ def aten_transpose(mapper, graph, node):
def
aten_to
(
mapper
,
graph
,
node
):
def
aten_to
(
mapper
,
graph
,
node
):
""" 构造类型转换的PaddleLayer。
""" 构造类型转换的PaddleLayer。
TorchScript示例:
TorchScript示例:
%30 : Tensor = aten::to(%extended_attention_mask.1, %12, %5, %5, %4)
%30 : Tensor = aten::to(%extended_attention_mask.1, %12, %5, %5, %4)
参数含义:
参数含义:
...
@@ -5215,7 +5242,6 @@ def aten_to(mapper, graph, node):
...
@@ -5215,7 +5242,6 @@ def aten_to(mapper, graph, node):
def
aten_type_as
(
mapper
,
graph
,
node
):
def
aten_type_as
(
mapper
,
graph
,
node
):
""" 构造转换Tensor类型的PaddleLayer。
""" 构造转换Tensor类型的PaddleLayer。
TorchScript示例:
TorchScript示例:
%57 : Tensor = aten::type_as(%56, %mask.1)
%57 : Tensor = aten::type_as(%56, %mask.1)
参数含义:
参数含义:
...
@@ -5257,7 +5283,6 @@ def aten_type_as(mapper, graph, node):
...
@@ -5257,7 +5283,6 @@ def aten_type_as(mapper, graph, node):
def
aten_unsqueeze
(
mapper
,
graph
,
node
):
def
aten_unsqueeze
(
mapper
,
graph
,
node
):
""" 构造插入维度的PaddleLayer。
""" 构造插入维度的PaddleLayer。
TorchScript示例:
TorchScript示例:
%13 : Tensor = aten::unsqueeze(%12, %7)
%13 : Tensor = aten::unsqueeze(%12, %7)
参数含义:
参数含义:
...
@@ -5298,7 +5323,6 @@ def aten_unsqueeze(mapper, graph, node):
...
@@ -5298,7 +5323,6 @@ def aten_unsqueeze(mapper, graph, node):
def
aten_upsample_bilinear2d
(
mapper
,
graph
,
node
):
def
aten_upsample_bilinear2d
(
mapper
,
graph
,
node
):
""" 构造使用bilinear上采样的PaddleLayer。
""" 构造使用bilinear上采样的PaddleLayer。
TorchScript示例:
TorchScript示例:
%4997 : Tensor = aten::upsample_bilinear2d(%x.13, %4963, %5421, %4995, %4996)
%4997 : Tensor = aten::upsample_bilinear2d(%x.13, %4963, %5421, %4995, %4996)
参数含义:
参数含义:
...
@@ -5380,7 +5404,6 @@ def aten_upsample_bilinear2d(mapper, graph, node):
...
@@ -5380,7 +5404,6 @@ def aten_upsample_bilinear2d(mapper, graph, node):
def
aten_upsample_nearest2d
(
mapper
,
graph
,
node
):
def
aten_upsample_nearest2d
(
mapper
,
graph
,
node
):
""" 构造使用nearest上采样的PaddleLayer。
""" 构造使用nearest上采样的PaddleLayer。
TorchScript示例:
TorchScript示例:
%4997 : Tensor = aten::upsample_nearest2d(%x.13, %4963, %5421, %4995)
%4997 : Tensor = aten::upsample_nearest2d(%x.13, %4963, %5421, %4995)
参数含义:
参数含义:
...
@@ -5453,7 +5476,6 @@ def aten_upsample_nearest2d(mapper, graph, node):
...
@@ -5453,7 +5476,6 @@ def aten_upsample_nearest2d(mapper, graph, node):
def
aten_values
(
mapper
,
graph
,
node
):
def
aten_values
(
mapper
,
graph
,
node
):
""" 构造对比大小的PaddleLayer。
""" 构造对比大小的PaddleLayer。
TorchScript示例:
TorchScript示例:
%5 : Float(1, *, 1024, 2048)[] = aten::values(%1)
%5 : Float(1, *, 1024, 2048)[] = aten::values(%1)
参数含义:
参数含义:
...
@@ -5484,14 +5506,12 @@ def aten_values(mapper, graph, node):
...
@@ -5484,14 +5506,12 @@ def aten_values(mapper, graph, node):
def
aten_view
(
mapper
,
graph
,
node
):
def
aten_view
(
mapper
,
graph
,
node
):
""" 构造调整大小的PaddleLayer。
""" 构造调整大小的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input.152 : Tensor = aten::view(%x.20, %430)
%input.152 : Tensor = aten::view(%x.20, %430)
参数含义:
参数含义:
%input.152 (Tensor): 输出,view后的Tensor。
%input.152 (Tensor): 输出,view后的Tensor。
%x.20 (Tensor): 需要view的Tensor。
%x.20 (Tensor): 需要view的Tensor。
%430 (list): 形状大小组成的list。
%430 (list): 形状大小组成的list。
【注意】view 函数只能用于contiguous后的Tensor上,
【注意】view 函数只能用于contiguous后的Tensor上,
也就是只能用于内存中连续存储的Tensor。
也就是只能用于内存中连续存储的Tensor。
如果对Tensor调用过transpose,permute等操作的话会使该Tensor在内存中变得不再连续,
如果对Tensor调用过transpose,permute等操作的话会使该Tensor在内存中变得不再连续,
...
@@ -5531,7 +5551,6 @@ def aten_view(mapper, graph, node):
...
@@ -5531,7 +5551,6 @@ def aten_view(mapper, graph, node):
def
aten_warn
(
mapper
,
graph
,
node
):
def
aten_warn
(
mapper
,
graph
,
node
):
""" 构造warning的PaddleLayer。
""" 构造warning的PaddleLayer。
TorchScript示例:
TorchScript示例:
= aten::warn(%3, %2)
= aten::warn(%3, %2)
参数含义:
参数含义:
...
@@ -5572,7 +5591,6 @@ def aten_warn(mapper, graph, node):
...
@@ -5572,7 +5591,6 @@ def aten_warn(mapper, graph, node):
def
aten_where
(
mapper
,
graph
,
node
):
def
aten_where
(
mapper
,
graph
,
node
):
""" 构造返回一个根据输入condition, 选择x或y的元素组成的多维Tensor的PaddleLayer,该节点实现out = x + y。
""" 构造返回一个根据输入condition, 选择x或y的元素组成的多维Tensor的PaddleLayer,该节点实现out = x + y。
TorchScript示例:
TorchScript示例:
%input.4 : Tensor = aten::where(%209, %w0.2, %210)
%input.4 : Tensor = aten::where(%209, %w0.2, %210)
参数含义:
参数含义:
...
@@ -5613,7 +5631,6 @@ def aten_where(mapper, graph, node):
...
@@ -5613,7 +5631,6 @@ def aten_where(mapper, graph, node):
def
aten_zeros
(
mapper
,
graph
,
node
):
def
aten_zeros
(
mapper
,
graph
,
node
):
""" 构造创建固定形状、数据类型且值全为0的Tensor的PaddleLayer。
""" 构造创建固定形状、数据类型且值全为0的Tensor的PaddleLayer。
TorchScript示例:
TorchScript示例:
%input.49 : Tensor = aten::zeros(%23, %8, %6, %24, %5)
%input.49 : Tensor = aten::zeros(%23, %8, %6, %24, %5)
参数含义:
参数含义:
...
@@ -5655,7 +5672,6 @@ def aten_zeros(mapper, graph, node):
...
@@ -5655,7 +5672,6 @@ def aten_zeros(mapper, graph, node):
def
aten_zeros_like
(
mapper
,
graph
,
node
):
def
aten_zeros_like
(
mapper
,
graph
,
node
):
""" 构造创建与输入Tensor形状一致的、数据类型且值全为0的Tensor的PaddleLayer。
""" 构造创建与输入Tensor形状一致的、数据类型且值全为0的Tensor的PaddleLayer。
TorchScript示例:
TorchScript示例:
%782 : Tensor = aten::zeros_like(%n.2, %655, %670, %662, %671, %672)
%782 : Tensor = aten::zeros_like(%n.2, %655, %670, %662, %671, %672)
参数含义:
参数含义:
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}