# Paddle Serving设计文档
## 1. 整体设计目标
- 长期使命:Paddle Serving是一个PaddlePaddle开源的在线服务框架,长期目标就是围绕着人工智能落地的最后一公里提供越来越专业、可靠、易用的服务。
- 工业级:为了达到工业级深度学习模型在线部署的要求,
Paddle Serving提供很多大规模场景需要的部署功能:1)分布式稀疏参数索引功能;2)高并发底层通信能力;3)模型管理、在线A/B流量测试、模型热加载。
- 简单易用:为了让使用Paddle的用户能够以极低的成本部署模型,PaddleServing设计了一套与Paddle训练框架无缝打通的预测部署API,普通模型可以使用一行命令进行服务部署。
- 功能扩展:当前,Paddle Serving支持C++、Python、Golang的客户端,未来也会面向不同类型的客户新增多种语言的客户端。在Paddle Serving的框架设计方面,尽管当前Paddle Serving以支持Paddle模型的部署为核心功能,
用户可以很容易嵌入其他的机器学习库部署在线预测。
## 2. 模块设计与实现
### 2.1 Python API接口设计
#### 2.1.1 训练模型的保存
Paddle的模型预测需要重点关注的内容:1)模型的输入变量;2)模型的输出变量;3)模型结构和模型参数。Paddle Serving Python API提供用户可以在训练过程中保存模型的接口,并将Paddle Serving在部署阶段需要保存的配置打包保存,一个示例如下:
``` python
import paddle_serving_client.io as serving_io
serving_io.save_model("serving_model", "client_conf",
{"words": data}, {"prediction": prediction},
fluid.default_main_program())
```
代码示例中,`{"words": data}`和`{"prediction": prediction}`分别指定了模型的输入和输出,`"words"`和`"prediction"`是输出和输出变量的别名,设计别名的目的是为了使开发者能够记忆自己训练模型的输入输出对应的字段。`data`和`prediction`则是Paddle训练过程中的`[Variable](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/fluid_cn/Variable_cn.html#variable)`,通常代表张量([Tensor](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/fluid_cn/Tensor_cn.html#tensor))或变长张量([LodTensor](https://www.paddlepaddle.org.cn/documentation/docs/zh/beginners_guide/basic_concept/lod_tensor.html#lodtensor))。调用保存命令后,会按照用户指定的`"serving_model"`和`"client_conf"`生成两个目录,内容如下:
``` shell
.
├── client_conf
│ ├── serving_client_conf.prototxt
│ └── serving_client_conf.stream.prototxt
└── serving_model
├── embedding_0.w_0
├── fc_0.b_0
├── fc_0.w_0
├── fc_1.b_0
├── fc_1.w_0
├── fc_2.b_0
├── fc_2.w_0
├── lstm_0.b_0
├── lstm_0.w_0
├── __model__
├── serving_server_conf.prototxt
└── serving_server_conf.stream.prototxt
```
其中,`"serving_client_conf.prototxt"`和`"serving_server_conf.prototxt"`是Paddle Serving的Client和Server端需要加载的配置,`"serving_client_conf.stream.prototxt"`和`"serving_server_conf.stream.prototxt"`是配置文件的二进制形式。`"serving_model"`下保存的其他内容和Paddle保存的模型文件是一致的。我们会考虑未来在Paddle框架中直接保存可服务的配置,实现配置保存对用户无感。
#### 2.1.2 服务端模型加载
当前Paddle Serving中的预估引擎支持在CPU/GPU上进行预测,对应的预测服务安装包以及镜像也有两个。但无论是CPU上进行模型预估还是GPU上进行模型预估,普通模型的预测都可用一行命令进行启动。
``` shell
python -m paddle_serving_server.serve --model your_servable_model --thread 10 --port 9292
```
``` shell
python -m paddle_serving_server_gpu.serve --model your_servable_model --thread 10 --port 9292
```
服务端的预测逻辑也可以通过Paddle Serving Server端的API进行人工定义,一个例子:
``` python
``` python
import paddle_serving_server as serving
op_maker = serving.OpMaker()
read_op = op_maker.create('general_reader')
dist_kv_op = op_maker.create('general_dist_kv')
general_infer_op = op_maker.create('general_infer')
general_response_op = op_maker.create('general_response')
op_seq_maker = serving.OpSeqMaker()
op_seq_maker.add_op(read_op)
op_seq_maker.add_op(dist_kv_op)
op_seq_maker.add_op(general_infer_op)
op_seq_maker.add_op(general_response_op)
```
当前Paddle Serving在Server端支持的主要Op请参考如下列表:
| Op 名称 | 描述 |
|--------------|------|
| `general_reader` | 通用数据格式的读取Op |
| `genreal_infer` | 通用数据格式的Paddle预测Op |
| `general_response` | 通用数据格式的响应Op |
| `general_dist_kv` | 分布式索引Op |
#### 2.1.3 客户端访问API
Paddle Serving支持远程服务访问的协议一种是基于RPC,另一种是HTTP。用户通过RPC访问,可以使用Paddle Serving提供的Python Client API,通过定制输入数据的格式来实现服务访问。下面的例子解释Paddle Serving Client如何定义输入数据。保存可部署模型时需要指定每个输入的别名,例如`sparse`和`dense`,对应的数据可以是离散的ID序列`[1, 1001, 100001]`,也可以是稠密的向量`[0.2, 0.5, 0.1, 0.4, 0.11, 0.22]`。当前Client的设计,对于离散的ID序列,支持Paddle中的`lod_level=0`和`lod_level=1`的情况,即张量以及一维变长张量。对于稠密的向量,支持`N-D Tensor`。用户不想要显式指定输入数据的形状,Paddle Serving的Client API会通过保存配置时记录的输入形状进行对应的检查。
``` python
feed_dict["sparse"] = [1, 1001, 100001]
feed_dict["dense"] = [0.2, 0.5, 0.1, 0.4, 0.11, 0.22]
fetch_map = client.predict(feed=feed_dict, fetch=["prob"])
```
Client链接Server的代码,通常只需要加载保存模型时保存的Client端配置,以及指定要去访问的服务端点即可。为了保持内部访问进行数据并行的扩展能力,Paddle Serving Client允许定义多个服务端点。
``` python
client = Client()
client.load_client_config('servable_client_configs')
client.connect(["127.0.0.1:9292"])
```
### 2.2 底层通信机制
Paddle Serving采用[baidu-rpc](https://github.com/apache/incubator-brpc)进行底层的通信。baidu-rpc是百度开源的一款PRC通信库,具有高并发、低延时等特点,已经支持了包括百度在内上百万在线预估实例、上千个在线预估服务,稳定可靠。Paddle Serving底层采用baidu-rpc的另一个原因是深度学习模型的远程调用服务通常对延时比较敏感,需要采用一款延时较低的rpc。
### 2.3 核心执行引擎
Paddle Serving的核心执行引擎是一个有向无环图,图中的每个节点代表预估服务的一个环节,例如计算模型预测打分就是其中一个环节。有向无环图有利于可并发节点充分利用部署实例内的计算资源,缩短延时。一个例子,当同一份输入需要送入两个不同的模型进行预估,并将两个模型预估的打分进行加权求和时,两个模型的打分过程即可以通过有向无环图的拓扑关系并发。
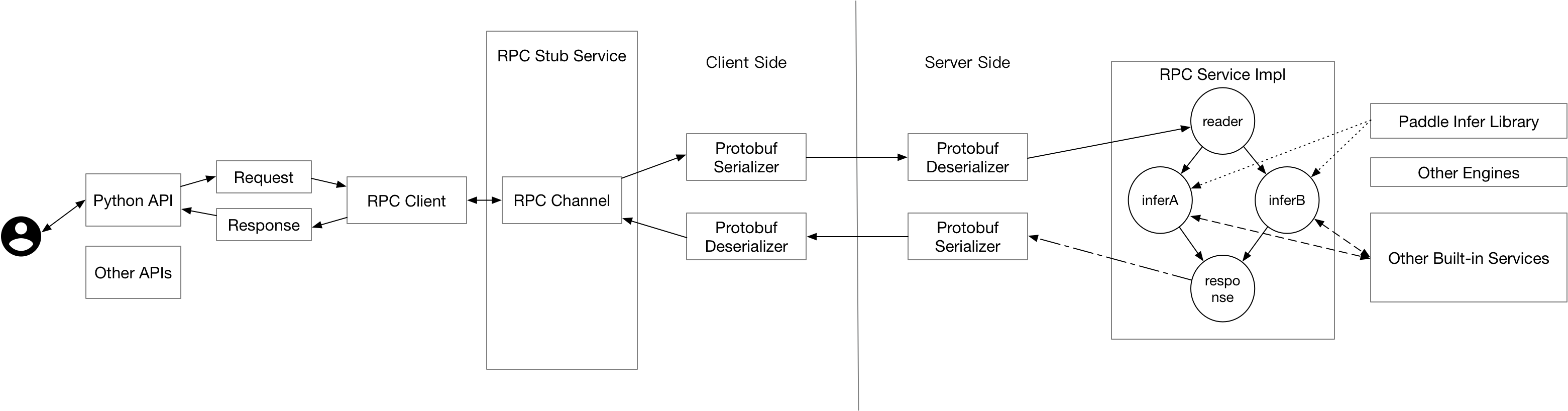
### 2.4 微服务插件模式
由于Paddle Serving底层采用基于C++的通信组件,并且核心框架也是基于C/C++编写,当用户想要在服务端定义复杂的前处理与后处理逻辑时,一种办法是修改Paddle Serving底层框架,重新编译源码。另一种方式可以通过在服务端嵌入轻量级的Web服务,通过在Web服务中实现更复杂的预处理逻辑,从而搭建一套逻辑完整的服务。当访问量超过了Web服务能够接受的范围,开发者有足够的理由开发一些高性能的C++预处理逻辑,并嵌入到Serving的原生服务库中。Web服务和RPC服务的关系以及他们的组合方式可以参考下文`用户类型`中的说明。
## 3. 工业级特性
### 3.1 分布式稀疏参数索引
分布式稀疏参数索引通常在广告推荐中出现,并与分布式训练配合形成完整的离线-在线一体化部署。下图解释了其中的流程,产品的在线服务接受用户请求后将请求发送给预估服务,同时系统会记录用户的请求以进行相应的训练日志处理和拼接。离线分布式训练系统会针对流式产出的训练日志进行模型增量训练,而增量产生的模型会配送至分布式稀疏参数索引服务,同时对应的稠密的模型参数也会配送至在线的预估服务。在线服务由两部分组成,一部分是针对用户的请求提取特征后,将需要进行模型的稀疏参数索引的特征发送请求给分布式稀疏参数索引服务,针对分布式稀疏参数索引服务返回的稀疏参数再进行后续深度学习模型的计算流程,从而完成预估。

为什么要使用Paddle Serving提供的分布式稀疏参数索引服务?1)在一些推荐场景中,模型的输入特征规模通常可以达到上千亿,单台机器无法支撑T级别模型在内存的保存,因此需要进行分布式存储。2)Paddle Serving提供的分布式稀疏参数索引服务,具有并发请求多个节点的能力,从而以较低的延时完成预估服务。
### 3.2 模型管理、在线A/B流量测试、模型热加载
## 4. 用户类型

## 5. 未来计划
### 5.1 有向无环图结构定义开放
当前版本开放的python API仅支持用户定义Sequential类型的执行流,如果想要进行Server进程内复杂的计算,需要增加对应的用户API。
### 5.2 云端自动部署能力
为了方便用户更容易将Paddle的预测模型部署到线上,Paddle Serving在接下来的版本会提供Kubernetes生态下任务编排的工具。
### 5.3 向量检索、树结构检索
在推荐与广告场景的召回系统中,通常需要采用基于向量的快速检索或者基于树结构的快速检索,Paddle Serving会对这方面的检索引擎进行集成或扩展。