# An End-to-end Tutorial from Training to Inference Service Deployment
([简体中文](./TRAIN_TO_SERVICE_CN.md)|English)
Paddle Serving is Paddle's high-performance online inference service framework, which can flexibly support the deployment of most models. In this article, the IMDB review sentiment analysis task is used as an example to show the entire process from model training to deployment of inference service through 9 steps.
## Step1:Prepare for Running Environment
Paddle Serving can be deployed on Linux environments.Currently the server supports deployment on Centos7. [Docker deployment is recommended](RUN_IN_DOCKER.md). The rpc client supports deploymen on Centos7 and Ubuntu 18.On other systems or in environments where you do not want to install the serving module, you can still access the server-side prediction service through the http service.
You can choose to install the cpu or gpu version of the server module according to the requirements and machine environment, and install the client module on the client machine. When you want to access the server with http, there is not need to install client module.
```shell
pip install paddle_serving_server #cpu version server side
pip install paddle_serving_server_gpu #gpu version server side
pip install paddle_serving_client #client version
```
After simple preparation, we will take the IMDB review sentiment analysis task as an example to show the process from model training to deployment of prediction services. All the code in the example can be found in the [IMDB example](https://github.com/PaddlePaddle/Serving/tree/develop/python/examples/imdb) of the Paddle Serving code base, the data and dictionary used in the example The file can be obtained by executing the get_data.sh script in the IMDB sample code.
## Step2:Determine Tasks and Raw Data Format
IMDB review sentiment analysis task is to classify the content of movie reviews to determine whether the review is a positive review or a negative review.
First let's take a look at the raw data:
```
saw a trailer for this on another video, and decided to rent when it came out. boy, was i disappointed! the story is extremely boring, the acting (aside from christopher walken) is bad, and i couldn't care less about the characters, aside from really wanting to see nora's husband get thrashed. christopher walken's role is such a throw-away, what a tease! | 0
```
This is a sample of English comments. The sample uses | as the separator. The content of the comment is before the separator. The label is the sample after the separator. 0 is the negative while 1 is the positive.
## Step3:Define Reader, divide training set and test set
For the original text we need to convert it to a numeric id that the neural network can use. The imdb_reader.py script defines the method of text idization, and the words are mapped to integers through the dictionary file imdb.vocab.
imdb_reader.py
```python
import sys
import os
import paddle
import re
import paddle.fluid.incubate.data_generator as dg
class IMDBDataset(dg.MultiSlotDataGenerator):
def load_resource(self, dictfile):
self._vocab = {}
wid = 0
with open(dictfile) as f:
for line in f:
self._vocab[line.strip()] = wid
wid += 1
self._unk_id = len(self._vocab)
self._pattern = re.compile(r'(;|,|\.|\?|!|\s|\(|\))')
self.return_value = ("words", [1, 2, 3, 4, 5, 6]), ("label", [0])
def get_words_only(self, line):
sent = line.lower().replace("
", " ").strip()
words = [x for x in self._pattern.split(sent) if x and x != " "]
feas = [
self._vocab[x] if x in self._vocab else self._unk_id for x in words
]
return feas
def get_words_and_label(self, line):
send = '|'.join(line.split('|')[:-1]).lower().replace("
",
" ").strip()
label = [int(line.split('|')[-1])]
words = [x for x in self._pattern.split(send) if x and x != " "]
feas = [
self._vocab[x] if x in self._vocab else self._unk_id for x in words
]
return feas, label
def infer_reader(self, infer_filelist, batch, buf_size):
def local_iter():
for fname in infer_filelist:
with open(fname, "r") as fin:
for line in fin:
feas, label = self.get_words_and_label(line)
yield feas, label
import paddle
batch_iter = paddle.batch(
paddle.reader.shuffle(
local_iter, buf_size=buf_size),
batch_size=batch)
return batch_iter
def generate_sample(self, line):
def memory_iter():
for i in range(1000):
yield self.return_value
def data_iter():
feas, label = self.get_words_and_label(line)
yield ("words", feas), ("label", label)
return data_iter
```
The sample after mapping is similar to the following format:
```
257 142 52 898 7 0 12899 1083 824 122 89527 134 6 65 47 48 904 89527 13 0 87 170 8 248 9 15 4 25 1365 4360 89527 702 89527 1 89527 240 3 28 89527 19 7 0 216 219 614 89527 0 84 89527 225 3 0 15 67 2356 89527 0 498 117 2 314 282 7 38 1097 89527 1 0 174 181 38 11 71 198 44 1 3110 89527 454 89527 34 37 89527 0 15 5912 80 2 9856 7748 89527 8 421 80 9 15 14 55 2218 12 4 45 6 58 25 89527 154 119 224 41 0 151 89527 871 89527 505 89527 501 89527 29 2 773 211 89527 54 307 90 0 893 89527 9 407 4 25 2 614 15 46 89527 89527 71 8 1356 35 89527 12 0 89527 89527 89 527 577 374 3 39091 22950 1 3771 48900 95 371 156 313 89527 37 154 296 4 25 2 217 169 3 2759 7 0 15 89527 0 714 580 11 2094 559 34 0 84 539 89527 1 0 330 355 3 0 15 15607 935 80 0 5369 3 0 622 89527 2 15 36 9 2291 2 7599 6968 2449 89527 1 454 37 256 2 211 113 0 480 218 1152 700 4 1684 1253 352 10 2449 89527 39 4 1819 129 1 316 462 29 0 12957 3 6 28 89527 13 0 457 8952 7 225 89527 8 2389 0 1514 89527 1
```
In this way, the neural network can train the transformed text information as feature values.
## Step4:Define CNN network for training and saving
Net we use [CNN Model](https://www.paddlepaddle.org.cn/documentation/docs/zh/user_guides/nlp_case/understand_sentiment/README.cn.html#cnn) for training, in nets.py we define the network structure.
nets.py
```python
import sys
import time
import numpy as np
import paddle
import paddle.fluid as fluid
def cnn_net(data,
label,
dict_dim,
emb_dim=128,
hid_dim=128,
hid_dim2=96,
class_dim=2,
win_size=3):
""" conv net. """
emb = fluid.layers.embedding(
input=data, size=[dict_dim, emb_dim], is_sparse=True)
conv_3 = fluid.nets.sequence_conv_pool(
input=emb,
num_filters=hid_dim,
filter_size=win_size,
act="tanh",
pool_type="max")
fc_1 = fluid.layers.fc(input=[conv_3], size=hid_dim2)
prediction = fluid.layers.fc(input=[fc_1], size=class_dim, act="softmax")
cost = fluid.layers.cross_entropy(input=prediction, label=label)
avg_cost = fluid.layers.mean(x=cost)
acc = fluid.layers.accuracy(input=prediction, label=label)
return avg_cost, acc, prediction
```
Use training dataset for training. The training script is local_train.py. After training, use the paddle_serving_client.io.save_model function to save the model files and configuration files used by the servingdeployment.
local_train.py
```python
import os
import sys
import paddle
import logging
import paddle.fluid as fluid
logging.basicConfig(format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger("fluid")
logger.setLevel(logging.INFO)
# load dict file
def load_vocab(filename):
vocab = {}
with open(filename) as f:
wid = 0
for line in f:
vocab[line.strip()] = wid
wid += 1
vocab[""] = len(vocab)
return vocab
if __name__ == "__main__":
from nets import cnn_net
model_name = "imdb_cnn"
vocab = load_vocab('imdb.vocab')
dict_dim = len(vocab)
#define model input
data = fluid.layers.data(
name="words", shape=[1], dtype="int64", lod_level=1)
label = fluid.layers.data(name="label", shape=[1], dtype="int64")
#define dataset,train_data is the dataset directory
dataset = fluid.DatasetFactory().create_dataset()
filelist = ["train_data/%s" % x for x in os.listdir("train_data")]
dataset.set_use_var([data, label])
pipe_command = "python imdb_reader.py"
dataset.set_pipe_command(pipe_command)
dataset.set_batch_size(4)
dataset.set_filelist(filelist)
dataset.set_thread(10)
#define model
avg_cost, acc, prediction = cnn_net(data, label, dict_dim)
optimizer = fluid.optimizer.SGD(learning_rate=0.001)
optimizer.minimize(avg_cost)
#execute training
exe = fluid.Executor(fluid.CPUPlace())
exe.run(fluid.default_startup_program())
epochs = 100
import paddle_serving_client.io as serving_io
for i in range(epochs):
exe.train_from_dataset(
program=fluid.default_main_program(), dataset=dataset, debug=False)
logger.info("TRAIN --> pass: {}".format(i))
if i == 64:
#At the end of training, use the model save interface in PaddleServing to save the models and configuration files required by Serving
serving_io.save_model("{}_model".format(model_name),
"{}_client_conf".format(model_name),
{"words": data}, {"prediction": prediction},
fluid.default_main_program())
```
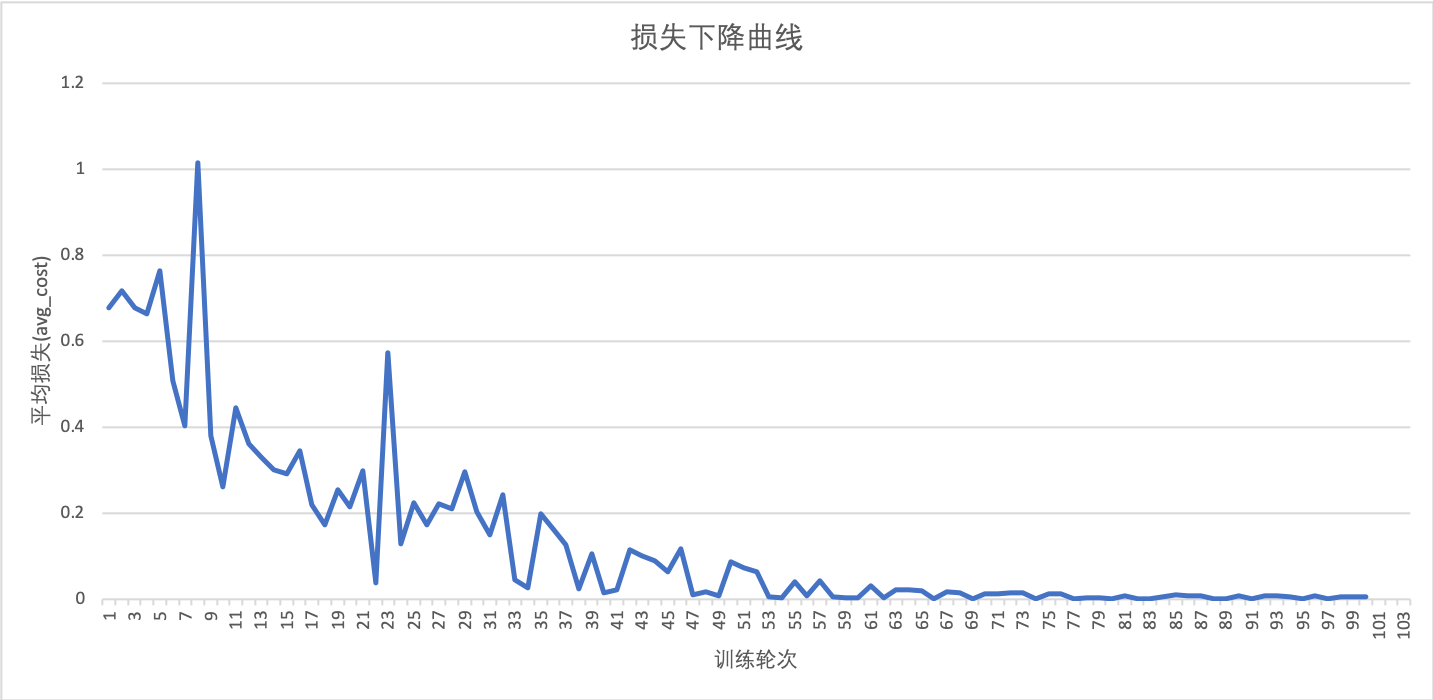 As can be seen from the above figure, the loss of the model starts to converge after the 65th round. We save the model and configuration file after the 65th round of training is completed. The saved files are divided into imdb_cnn_client_conf and imdb_cnn_model folders. The former contains client-side configuration files, and the latter contains server-side configuration files and saved model files.
The parameter list of the save_model function is as follows:
| Parameter | Meaning |
| -------------------- | ------------------------------------------------------------ |
| server_model_folder | Directory for server-side configuration files and model files |
| client_config_folder | Directory for saving client configuration files |
| feed_var_dict | The input of the inference model. The dict type and key can be customized. The value is the input variable in the model. Each key corresponds to a variable. When using the prediction service, the input data uses the key as the input name. |
| fetch_var_dict | The output of the model used for prediction, dict type, key can be customized, value is the input variable in the model, and each key corresponds to a variable. When using the prediction service, use the key to get the returned data |
| main_program | Model's program |
## Step5: Deploy RPC Prediction Service
The Paddle Serving framework supports two types of prediction service methods. One is to communicate through RPC and the other is to communicate through HTTP. The deployment and use of RPC prediction service will be introduced first. The deployment and use of HTTP prediction service will be introduced at Step 8. .
```shell
python -m paddle_serving_server.serve --model imdb_cnn_model / --port 9292 #cpu prediction service
python -m paddle_serving_server_gpu.serve --model imdb_cnn_model / --port 9292 --gpu_ids 0 #gpu prediction service
```
The parameter --model in the command specifies the server-side model and configuration file directory previously saved, --port specifies the port of the prediction service. When deploying the gpu prediction service using the gpu version, you can use --gpu_ids to specify the gpu used.
After executing one of the above commands, the RPC prediction service deployment of the IMDB sentiment analysis task is completed.
## Step6: Reuse Reader, define remote RPC client
Below we access the RPC prediction service through Python code, the script is test_client.py
test_client.py
```python
from paddle_serving_client import Client
from imdb_reader import IMDBDataset
import sys
client = Client()
client.load_client_config(sys.argv[1])
client.connect(["127.0.0.1:9292"])
#The code of the data preprocessing part is reused here to convert the original text into a numeric id
imdb_dataset = IMDBDataset()
imdb_dataset.load_resource(sys.argv[2])
for line in sys.stdin:
word_ids, label = imdb_dataset.get_words_and_label(line)
feed = {"words": word_ids}
fetch = ["acc", "cost", "prediction"]
fetch_map = client.predict(feed=feed, fetch=fetch)
print("{} {}".format(fetch_map["prediction"][1], label[0]))
```
The script receives data from standard input and prints out the probability that the sample whose infer result is 1 and its real label.
## Step7: Call the RPC service to test the model effect
The client implemented in the previous step runs the prediction service as an example. The usage method is as follows:
```shell
cat test_data/part-0 | python test_client.py imdb_lstm_client_conf / serving_client_conf.prototxt imdb.vocab
```
Using 2084 samples in the test_data/part-0 file for test testing, the model prediction accuracy is 88.19%.
**Note**: The effect of each model training may be slightly different, and the accuracy of predictions using the trained model will be close to the examples but may not be exactly the same.
## Step8: Deploy HTTP Prediction Service
When using the HTTP prediction service, the client does not need to install any modules of Paddle Serving, it only needs to be able to send HTTP requests. Of course, the HTTP method consumes more time in the communication phase than the RPC method.
For the IMDB sentiment analysis task, the original text needs to be preprocessed before prediction. In the RPC prediction service, we put the preprocessing in the client's script, and in the HTTP prediction service, we put the preprocessing on the server. Paddle Serving's HTTP prediction service framework prepares data pre-processing and post-processing interfaces for this situation. We just need to rewrite it according to the needs of the task.
Serving provides sample code, which is obtained by executing the imdb_web_service_demo.sh script in [IMDB Example](https://github.com/PaddlePaddle/Serving/tree/develop/python/examples/imdb).
Let's take a look at the script text_classify_service.py that starts the HTTP prediction service.
text_clssify_service.py
```python
from paddle_serving_server.web_service import WebService
from imdb_reader import IMDBDataset
import sys
#extend class WebService
class IMDBService(WebService):
def prepare_dict(self, args={}):
if len(args) == 0:
exit(-1)
self.dataset = IMDBDataset()
self.dataset.load_resource(args["dict_file_path"])
#rewrite preprocess() to implement data preprocessing, here we reuse reader script for training
def preprocess(self, feed={}, fetch=[]):
if "words" not in feed:
exit(-1)
res_feed = {}
res_feed["words"] = self.dataset.get_words_only(feed["words"])[0]
return res_feed, fetch
#Here you need to use the name parameter to specify the name of the prediction service.
imdb_service = IMDBService(name="imdb")
imdb_service.load_model_config(sys.argv[1])
imdb_service.prepare_server(
workdir=sys.argv[2], port=int(sys.argv[3]), device="cpu")
imdb_service.prepare_dict({"dict_file_path": sys.argv[4]})
imdb_service.run_server()
```
run
```shell
python text_classify_service.py imdb_cnn_model/ workdir/ 9292 imdb.vocab
```
In the above command, the first parameter is the saved server-side model and configuration file. The second parameter is the working directory, which will save some configuration files for the prediction service. The directory may not exist but needs to be specified. The prediction service will be created by itself. the third parameter is Port number, the fourth parameter is the dictionary file.
## Step9: Call the prediction service with plaintext data
After starting the HTTP prediction service, you can make prediction with a single command:
```
curl -H "Content-Type: application / json" -X POST -d '{"words": "i am very sad | 0", "fetch": ["prediction"]}' http://127.0.0.1:9292/imdb/prediction
```
When the inference process is normal, the prediction probability is returned, as shown below.
```
{"prediction": [0.5592559576034546,0.44074398279190063]}
```
**Note**: The effect of each model training may be slightly different, and the inferred probability value using the trained model may not be consistent with the example.