# paddle serving 大规模稀疏参数流程化部署
* [ 环境配置](#head0)
* [ 分布式训练](#head1)
* [ 1、集群配置](#head2)
* [1.1 创建集群](#head3)
* [1.2 配置集群环境](#head4)
* [2、 配置开发机环境](#head5)
* [2.1 安装KubeCtl](#head6)
* [2.2 安装Helm](#head7)
* [2.3 配置文件](#head8)
* [2.4 安装Go](#head9)
* [ 3、安装volcano](#head10)
* [ 4、执行训练](#head11)
* [ 5、模型产出](#head12)
* [5.1 模型裁剪](#head13)
* [5.2 稀疏参数产出](#head14)
* [ 大规模稀疏参数服务Cube的部署和使用](#head15)
* [1. 编译](#head16)
* [2. 分片cube server部署](#head17)
* [2.1 配置文件修改](#head18)
* [2.2 拷贝可执行文件和配置文件到物理机](#head19)
* [2.3 启动 cube server](#head20)
* [3. cube-builder部署](#head21)
* [3.1 配置文件修改](#head22)
* [3.2 拷贝可执行文件到物理机](#head23)
* [3.3 启动cube-builder](#head24)
* [4. cube-transfer部署](#head25)
* [4.1 cube-transfer配置修改](#head26)
* [4.2 拷贝cube-transfer到物理机](#head27)
* [4.3 启动cube-transfer](#head28)
* [4.4 验证](#head29)
* [ 预测服务部署](#head30)
* [ 1、Server端](#head31)
* [1.1 Cube服务](#head32)
* [1.2 Serving编译](#head33)
* [1.3 配置修改](#head34)
* [1.3.1 conf/gflags.conf](#head35)
* [1.3.2 conf/model_toolkit.prototxt](#head36)
* [1.3.3 conf/cube.conf](#head37)
* [1.3.4 模型文件](#head38)
* [1.4 启动Serving](#head39)
* [ 2、Client端](#head40)
* [2.1 测试数据](#head41)
* [2.2 Client编译与部署](#head42)
* [2.2.1 配置修改](#head43)
* [2.2.2 运行服务](#head44)
在搜索、推荐、在线广告等业务场景中,embedding参数的规模常常非常庞大,达到数百GB甚至T级别;训练如此规模的模型需要用到多机分布式训练能力,将参数分片更新和保存;另一方面,训练好的模型,要应用于在线业务,也难以单机加载。Paddle Serving提供大规模稀疏参数读写服务,用户可以方便地将超大规模的稀疏参数以kv形式托管到参数服务,在线预测只需将所需要的参数子集从参数服务读取回来,再执行后续的预测流程。
本文以CTR预估任务为例,提供一个完整的基于PaddlePaddle的分布式训练和Serving的流程化部署过程。基于此流程,用户可定制自己的端到端深度学习训练和应用解决方案。
本文演示的基于PaddlePaddle的分布式训练和Serving流程化部署,基于CTR预估任务,原始模型可参见[PaddlePaddle公开模型github repo](https://github.com/PaddlePaddle/models/tree/develop/PaddleRec/ctr)。 整体拓扑架构如下图所示:
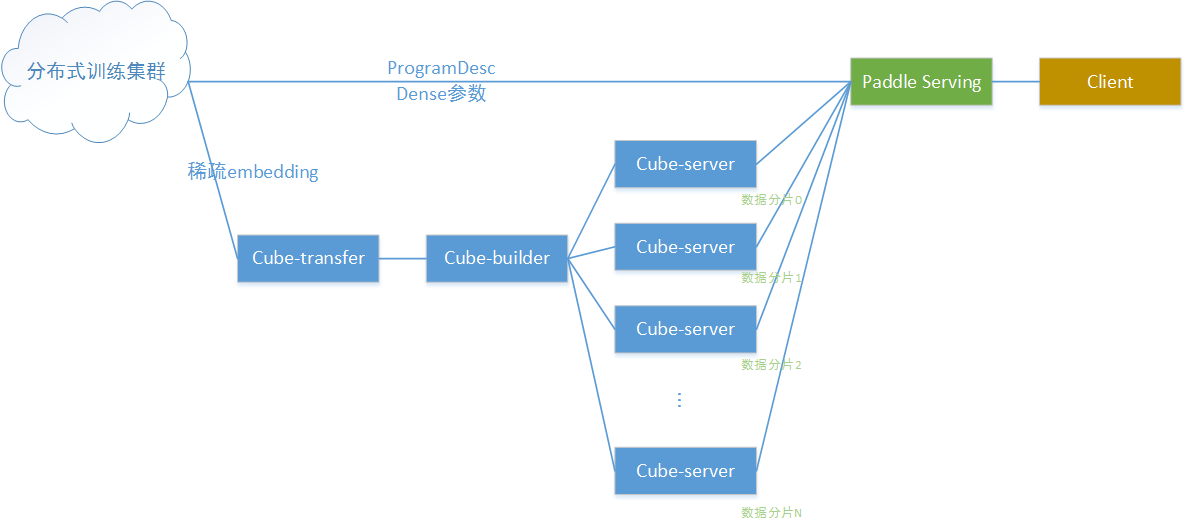
其中:
1) 分布式训练集群在百度云k8s集群上搭建,并通过[volcano](https://volcano.sh/)提交分布式训练任务和资源管理
2) 分布式训练产出dense参数和ProgramDesc,通过http服务直接下载到Serving端,给Serving加载
3) 分布式训练产出sparse embedding,由于体积太大,通过cube稀疏参数服务提供给serving访问
4) 在线预测时,Serving通过访问cube集群获取embedding数据,与dense参数配合完成预测计算过程
以下从3部分分别介绍上图中各个组件:
1) 分布式训练集群和训练任务提交
2) 稀疏参数服务部署与使用
3) Paddle Serving的部署
4) 客户端访问Paddle Serving完成CTR预估任务预测请求
## 环境配置
**环境要求** :helm、kubectl、go
## 分布式训练
分布式训练采用[volcano](https://github.com/volcano-sh/volcano)开源框架以及云平台实现,文档中以[百度智能云](https://cloud.baidu.com/?from=console)以及CTR预估模型为例,演示如何实现大规模稀疏参数模型的分布式训练。
### 1、集群配置
#### 1.1 创建集群
登录百度智能云官网,参考[帮助文档](https://cloud.baidu.com/doc/CCE/s/zjxpoqohb)创建容器引擎。
#### 1.2 配置集群环境
进入“产品服务>容器引擎CCE”,点击“集群管理>集群列表”,可看到用户已创建的集群列表。从集群列表中查看创建的集群信息。

点击左侧的"Helm>Helm实例",点击安装链接为集群一键安装helm。百度智能云为集群安装的helm版本为2.12.3,kubectl版本为1.13.4
为了能够从外部登录集群节点,需要为集群中安装了tiller的节点申请弹性公网。点击"更多操作>控制台"。

点击"命名空间"选择kube-system,点击"容器组",查看tiller开头的节点。

点击"产品服务>网络>弹性公网"
创建弹性公网实例,完成后选择创建的实例,点击"更多操作>绑定到BCC",填写tiller开头的节点信息进行绑定。
### 2、 配置开发机环境
配置过程需要开发机的root权限。
#### 2.1 安装KubeCtl
KubeCtl可以实现在本地开发机上连接百度智能云的Kubernets集群,建议参考百度云操作指南文档中[通过KubeCtl连接集群](https://cloud.baidu.com/doc/CCE/s/6jxpotcn5)部分进行安装。
#### 2.2 安装Helm
建议参考[Helm官方安装文档](https://helm.sh/docs/using_helm/#installing-helm)进行安装。
**注意事项:**
开发机上的kubectl与helm的版本需要与集群上的版本相一致,目前百度智能云为集群安装的helm版本为2.12.3,kubectl版本为1.13.4。
#### 2.3 配置文件
点击"集群列表"界面的"配置文件下载",下载配置文件。

将下载的配置文件移动到~/.kube文件夹下,文件名修改为config。
通过之前创建的弹性公网ip登录运行tiller的节点,账户密码为创建集群时设置的账户和密码,默认账户为root。
将节点上的以下三个文件
> /etc/kubernetes/pki/ca.pem
>
> /etc/kubernetes/pki/admin.pem
>
> /etc/kubernetes/pki/admin-key.pem
下载至开发机并放在相同的路径,添加四个环境变量
```bash
export HELM_TLS_ENABLE=true
export HELM_TLS_CA_CERT=/etc/kubernetes/pki/ca.pem
export HELM_TLS_CERT=/etc/kubernetes/pki/admin.pem
export HELM_TLS_KEY=/etc/kubernetes/pki/admin-key.pem
```
分别执行`kubectl version`与`helm version`,如果返回client端与server端信息,则证明配置成功。
示例:


如果只返回client端信息,server端信息显示"Forbidden",检查开发机是否使用了代理,若有可以尝试关闭代理再次执行命令检查。
#### 2.4 安装Go
推荐安装Go 1.12
下载安装包
```bash
wget https://studygolang.com/dl/golang/go1.12.7.linux-amd64.tar.gz --no-check-certificate
```
解压到 /usr/local/路径下
```bash
tar zxvf go1.12.7.linux-amd64.tar.gz -C /usr/local/
```
设置环境变量
```bash
export GOPATH=/usr/local/go
```
### 3、安装volcano
参考[volcano官方文档](https://github.com/volcano-sh/volcano#quick-start-guide)。
通过yaml文件安装
```bash
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-development.yaml
```
安装完成后执行`kubectl get pods --namespace volcano-system`
若出现以下信息则证明安装成功:

### 4、执行训练
创建cluster role和service account,[defaultserviceaccountclusterrole.yaml](./resource/defaultserviceaccountclusterrole.yaml) 文件示例如下:
```yaml
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: default
namespace: default
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: default
namespace: default
subjects:
- kind: ServiceAccount
name: default
namespace: default
roleRef:
kind: ClusterRole
name: default
apiGroup: rbac.authorization.k8s.io
```
执行
```bash
kubectl create -f defaultserviceaccountclusterrole.yaml
```
CTR模型的训练镜像存放在[dockerhub](https://hub.docker.com/)网站,通过kubectl加载yaml文件启动训练任务,CTR预估模型训练任务的yaml文件为[volcano-ctr-demo-baiduyun.yaml](./resource/volcano-ctr-demo-baiduyun.yaml)。
执行
```bash
kubectl apply -f volcano-ctr-demo-baiduyun.yaml
```
通过`kubectl get pods`命令可以查看训练任务的运行情况

通过`kubectl logs $POD_NAME`可以查看对应的日志,例如`kubectl logs edl-demo-trainer-0`

也可以通过百度云平台提供的web页面观察集群的工作负载

### 5、模型产出
CTR预估模型包含了embedding部分以及dense神经网络两部分,其中embedding部分包含的稀疏参数较多,在某些场景下单机的资源难以加载整个模型,因此需要将这两部分分割开来,稀疏参数部分放在分布式的稀疏参数服务器,dense网络部分加载到serving服务中。
#### 5.1 模型裁剪
产出用于paddle serving预测服务的dense模型需要对保存的原始模型进行裁剪操作,修改模型的输入以及内部结构。具体操作请参考文档[模型裁剪]([https://github.com/PaddlePaddle/Serving/blob/develop/doc/CTR_PREDICTION.md#2-%E6%A8%A1%E5%9E%8B%E8%A3%81%E5%89%AA](https://github.com/PaddlePaddle/Serving/blob/develop/doc/CTR_PREDICTION.md#2-模型裁剪))。
#### 5.2 稀疏参数产出
分布式稀疏参数服务器由paddle serving的cube模块实现。cube服务器中加载的数据格式为seqfile格式,因此需要对paddle保存出的模型文件进行格式转换。
可以通过[格式转换脚本](http://icode.baidu.com/repos/baidu/personal-code/wangguibao/blob/master:ctr-embedding-to-sequencefile/dumper.py)
使用方法:
```bash
python dumper.py --model_path=xxx --output_data_path=xxx
```
**注意事项:**文档中使用的CTR模型训练镜像中已经包含了模型裁剪以及稀疏参数产出的脚本,并且搭建了一个http服务用于从外部获取产出的dense模型以及稀疏参数文件。
## 大规模稀疏参数服务Cube的部署和使用
Cube大规模稀疏参数服务服务组件,用于承载超大规模稀疏参数的查询、更新等各功能。上述分布式训练产出的稀疏参数,在k8s中以http文件服务的形式提供下载;cube则负责将稀疏参数读取、加工,切分成多个分片,灌入稀疏参数服务集群,提供对外访问。
Cube一共拆分成三个组件,共同完成上述工作:
1) cube-transfer 负责监听上游数据产出,当判断到数据更新时,将数据下载到cube-builder建库端
2) cube-builder 负责从上游数据构建cube内部索引格式,并切分成多个分片,配送到由多个物理节点组成的稀疏参数服务集群
3) cube-server 每个单独的cube服务承载一个分片的cube数据
关于Cube的详细说明文档,请参考[Cube设计文档](https://github.com/PaddlePaddle/Serving/tree/develop/cube/doc/DESIGN.md)。本文仅描述从头部署Cube服务的流程。
### 1. 编译
Cube是Paddle Serving内置的组件,只要按常规步骤编译Serving即可。要注意的是,编译Cube需要Go语言编译器。
```bash
$ git clone https://github.com/PaddlePaddle/Serving.git
$ cd Serving
$ makedir build
$ cd build
$ cmake -DWITH_GPU=OFF .. # 不需要GPU
$ make -jN # 这里可修改并发编译线程数
$ make install
$ cd output/
$ ls bin
cube cube-builder cube-transfer pdcodegen
$ ls conf
gflags.conf transfer.conf
```
其中:
1) bin/cube, bin/cube-builder, bin/cube-transfer是上述3个组件的可执行文件。**bin/cube是cube-server的可执行文件**
2) conf/gflags.conf是配合bin/cube使用的配置文件,主要包括端口配置等等
3) conf/transfer.conf是配合bin/cube-transfer使用的配置文件,主要包括要监听的上游数据地址等等
接下来我们按cube server, cube-builder, cube-transfer的顺序,介绍Cube的完整部署流程
### 2. 分片cube server部署
#### 2.1 配置文件修改
首先修改cube server的配置文件,将端口改为我们需要的端口:
```
--port=8000
--dict_split=1
--in_mem=true
```
#### 2.2 拷贝可执行文件和配置文件到物理机
将bin/cube和conf/gflags.conf拷贝到多个物理机上。假设拷贝好的文件结构如下:
```
$ tree
.
|-- bin
| `-- cube
`-- conf
`-- gflags.conf
```
#### 2.3 启动 cube server
```bash
nohup bin/cube &
```
### 3. cube-builder部署
#### 3.1 配置文件修改
cube-builder配置项说明:
TOBE FILLED
修改如下:
```
下游节点地址列表
TOBE FILLED
```
#### 3.2 拷贝可执行文件到物理机
部署完成后目录结构如下:
```
TOBE FILLED
```
#### 3.3 启动cube-builder
```
启动cube-builder命令
```
### 4. cube-transfer部署
#### 4.1 cube-transfer配置修改
cube-transfer配置文件是conf/transfer.conf,配置比较复杂;各个配置项含义如下:
1) TOBE FILLED
2) TOBE FILLED
...
我们要将上游数据地址配置到配置文件中:
```
cube-transfer配置文件修改地方:TOBE FILLED
```
#### 4.2 拷贝cube-transfer到物理机
拷贝完成后,目录结构如下:
```
TOBE FILLED
```
#### 4.3 启动cube-transfer
```
启动cube-transfer命令
```
### 4.4 验证
一旦cube-transfer部署完成,它就不断监听我们配置好的数据位置,发现有数据更新后,即启动数据下载,然后通知cube-builder执行建库和配送流程,将新数据配送给各个分片的cube-server。
在上述过程中,经常遇到如下问题,可自行排查解决:
1) TOBE FILLED
2) TOBE FILLED
3) TOBE FILLED
## 预测服务部署
### 1、Server端
通过wget命令从集群获取dense部分模型用于Server端。
```bash
wget "${公网ip}:/path/to/models"
```
K8s集群上CTR预估任务训练完成后,模型参数分成2部分:一是embedding数据,经过dumper.py已经转成hadoop SequenceFile格式,传输给cube建库流程构建索引和灌cube;二是除embedding之外的参数文件,连同save_program.py裁剪后的program,一起配合传输给Serving加载。save_program.py裁剪原始模型的具体背景和详细步骤请参考文档[Paddle Serving CTR预估模型说明](https://github.com/PaddlePaddle/Serving/blob/develop/doc/CTR_PREDICTION.md)。
本文介绍Serving使用上述模型参数和program加载模型提供预测服务的流程。
#### 1.1 Cube服务
假设Cube服务已经成功部署,用于cube客户端API的配置文件如下所示:
```json
[{
"dict_name": "dict",
"shard": 2,
"dup": 1,
"timeout": 200,
"retry": 3,
"backup_request": 100,
"type": "ipport_list",
"load_balancer": "rr",
"nodes": [{
"ipport_list": "list://192.168.1.1:8000"
},{
"ipport_list": "list://192.168.1.2:8000"
}]
}]
```
上述例子中,cube提供外部访问的表名是`dict`,有2个物理分片,分别在192.168.1.1:8000和192.168.1.2:8000
#### 1.2 Serving编译
截至写本文时,Serving develop分支已经提供了CTR预估服务相关OP,参考[ctr_prediction_op.cpp](https://github.com/PaddlePaddle/Serving/blob/develop/demo-serving/op/ctr_prediction_op.cpp),该OP从client端接收请求后会将每个请求的26个sparse feature id发给cube服务,获得对应的embedding向量,然后填充到模型feed variable对应的LoDTensor,执行预测计算。只要按常规步骤编译Serving即可。
```bash
$ git clone https://github.com/PaddlePaddle/Serving.git
$ cd Serving
$ makedir build
$ cd build
$ cmake -DWITH_GPU=OFF .. # 不需要GPU
$ make -jN # 这里可修改并发编译线程数
$ make install
$ cd output/demo/serving
```
#### 1.3 配置修改
##### 1.3.1 conf/gflags.conf
将--enable_cube改为true:
```json
--enable_cube=true
```
##### 1.3.2 conf/model_toolkit.prototxt
Paddle Serving自带的model_toolkit.prototxt如下所示,如有必要可只保留ctr_prediction一个:
```
engines {
name: "image_classification_resnet"
type: "FLUID_CPU_NATIVE_DIR"
reloadable_meta: "./data/model/paddle/fluid_time_file"
reloadable_type: "timestamp_ne"
model_data_path: "./data/model/paddle/fluid/SE_ResNeXt50_32x4d"
runtime_thread_num: 0
batch_infer_size: 0
enable_batch_align: 0
}
engines {
name: "text_classification_bow"
type: "FLUID_CPU_ANALYSIS_DIR"
reloadable_meta: "./data/model/paddle/fluid_time_file"
reloadable_type: "timestamp_ne"
model_data_path: "./data/model/paddle/fluid/text_classification_lstm"
runtime_thread_num: 0
batch_infer_size: 0
enable_batch_align: 0
}
engines {
name: "ctr_prediction"
type: "FLUID_CPU_ANALYSIS_DIR"
reloadable_meta: "./data/model/paddle/fluid_time_file"
reloadable_type: "timestamp_ne"
model_data_path: "./data/model/paddle/fluid/ctr_prediction"
runtime_thread_num: 0
batch_infer_size: 0
enable_batch_align: 0
sparse_param_service_type: REMOTE
sparse_param_service_table_name: "dict"
}
```
注意ctr_prediction model有如下2行配置:
```json
sparse_param_service_type: REMOTE
sparse_param_service_table_name: "dict"
```
##### 1.3.3 conf/cube.conf
conf/cube.conf是一个完整的cube配置文件模板,其中只要修改nodes列表为真实的物理节点IP:port列表即可。例如 (与第1节cube配置文件内容一致):
```json
[{
"dict_name": "dict",
"shard": 2,
"dup": 1,
"timeout": 200,
"retry": 3,
"backup_request": 100,
"type": "ipport_list",
"load_balancer": "rr",
"nodes": [{
"ipport_list": "list://192.168.1.1:8000"
},{
"ipport_list": "list://192.168.1.2:8000"
}]
}]
```
**注意事项:**如果修改了`dict_name`,需要同步修改1.3.2节中`sparse_param_service_table_name`字段
##### 1.3.4 模型文件
Paddle Serving自带了一个可以工作的CTR预估模型,是从BCE上下载下来的,其制作方法为: 1) 分布式训练CTR预估任务,保存模型program和参数文件 2) 用save_program.py保存一份用于预测的program (文件名为**model**)。save_program.py随trainer docker image发布 3) 第2步中保存的program (**model**) 覆盖到第1)步保存的模型文件夹中**model**文件,打包成.tar.gz上传到BCE
如果只是为了验证demo流程,serving此时已经可以用自带的CTR模型加载模型并提供预测服务能力。
为了应用重新训练的模型,只需要从k8s集群暴露的ftp服务下载新的.tar.gz,解压到data/model/paddle/fluid下,覆盖原来的ctr_prediction目录即可。从K8S集群暴露的ftp服务下载训练模型,请参考文档[PaddlePaddle分布式训练和Serving流程化部署](http://icode.baidu.com/repos/baidu/personal-code/wangguibao/blob/master:ctr-embedding-to-sequencefile/path/to/doc/DISTRIBUTED_TRANING_AND_SERVING.md)
#### 1.4 启动Serving
执行`./bin/serving `启动serving服务,在./log路径下可以查看serving日志。
### 2、Client端
参考[从零开始写一个预测服务:client端]([https://github.com/PaddlePaddle/Serving/blob/develop/doc/CREATING.md#3-client%E7%AB%AF](https://github.com/PaddlePaddle/Serving/blob/develop/doc/CREATING.md#3-client端))文档,实现client端代码。
文档中使用的CTR预估任务client端代码存放在Serving代码库demo-client路径下,链接[ctr_prediction.cpp](https://github.com/PaddlePaddle/Serving/blob/develop/demo-client/src/ctr_prediction.cpp)。
#### 2.1 测试数据
CTR预估任务样例使用的数据来自于[原始模型](https://github.com/PaddlePaddle/models/tree/develop/PaddleRec/ctr)的测试数据,在样例中提供了1000个测试样本,如果需要更多样本可以参照原始模型下载数据的[脚本](https://github.com/PaddlePaddle/models/blob/develop/PaddleRec/ctr/data/download.sh)。
#### 2.2 Client编译与部署
按照[1.2Serving编译](#1.2 Serving编译)部分完成编译后,client端文件在output/demo/client/ctr_prediction路径下。
##### 2.2.1 配置修改
修改conf/predictors.prototxt文件ctr_prediction_service部分
```
predictors {
name: "ctr_prediction_service"
service_name: "baidu.paddle_serving.predictor.ctr_prediction.CTRPredictionService"
endpoint_router: "WeightedRandomRender"
weighted_random_render_conf {
variant_weight_list: "50"
}
variants {
tag: "var1"
naming_conf {
cluster: "list://127.0.0.1:8010"
}
}
}
```
配置Server端ip与端口号,默认为本机ip、8010端口。
##### 2.2.2 运行服务
执行`./bin/ctr_predictoin`启动client端,在./log路径下可以看到client端执行的日志。