Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Serving
提交
e1013d75
S
Serving
项目概览
PaddlePaddle
/
Serving
1 年多 前同步成功
通知
186
Star
833
Fork
253
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
105
列表
看板
标记
里程碑
合并请求
10
Wiki
2
Wiki
分析
仓库
DevOps
项目成员
Pages
S
Serving
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
105
Issue
105
列表
看板
标记
里程碑
合并请求
10
合并请求
10
Pages
分析
分析
仓库分析
DevOps
Wiki
2
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
e1013d75
编写于
6月 26, 2020
作者:
B
barriery
提交者:
GitHub
6月 26, 2020
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' into ce
上级
cb387a91
e0b8b21d
变更
40
显示空白变更内容
内联
并排
Showing
40 changed file
with
1722 addition
and
209 deletion
+1722
-209
core/configure/proto/multi_lang_general_model_service.proto
core/configure/proto/multi_lang_general_model_service.proto
+15
-3
core/predictor/tools/seq_generator.cpp
core/predictor/tools/seq_generator.cpp
+1
-1
doc/GRPC_IMPL_CN.md
doc/GRPC_IMPL_CN.md
+52
-0
doc/grpc_impl.png
doc/grpc_impl.png
+0
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/README_CN.md
...mples/grpc_impl_example/criteo_ctr_with_cube/README_CN.md
+40
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/args.py
...n/examples/grpc_impl_example/criteo_ctr_with_cube/args.py
+105
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/clean.sh
.../examples/grpc_impl_example/criteo_ctr_with_cube/clean.sh
+4
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/criteo.py
...examples/grpc_impl_example/criteo_ctr_with_cube/criteo.py
+81
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/criteo_reader.py
...s/grpc_impl_example/criteo_ctr_with_cube/criteo_reader.py
+83
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/cube/conf/cube.conf
...rpc_impl_example/criteo_ctr_with_cube/cube/conf/cube.conf
+13
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/cube/conf/gflags.conf
...c_impl_example/criteo_ctr_with_cube/cube/conf/gflags.conf
+4
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/cube/keys
...examples/grpc_impl_example/criteo_ctr_with_cube/cube/keys
+10
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/cube_prepare.sh
...es/grpc_impl_example/criteo_ctr_with_cube/cube_prepare.sh
+22
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/cube_quant_prepare.sh
...c_impl_example/criteo_ctr_with_cube/cube_quant_prepare.sh
+22
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/get_data.sh
...amples/grpc_impl_example/criteo_ctr_with_cube/get_data.sh
+2
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/local_train.py
...les/grpc_impl_example/criteo_ctr_with_cube/local_train.py
+100
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/network_conf.py
...es/grpc_impl_example/criteo_ctr_with_cube/network_conf.py
+77
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/test_client.py
...les/grpc_impl_example/criteo_ctr_with_cube/test_client.py
+49
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/test_server.py
...les/grpc_impl_example/criteo_ctr_with_cube/test_server.py
+37
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/test_server_gpu.py
...grpc_impl_example/criteo_ctr_with_cube/test_server_gpu.py
+37
-0
python/examples/grpc_impl_example/criteo_ctr_with_cube/test_server_quant.py
...pc_impl_example/criteo_ctr_with_cube/test_server_quant.py
+37
-0
python/examples/grpc_impl_example/fit_a_line/README_CN.md
python/examples/grpc_impl_example/fit_a_line/README_CN.md
+57
-0
python/examples/grpc_impl_example/fit_a_line/get_data.sh
python/examples/grpc_impl_example/fit_a_line/get_data.sh
+2
-0
python/examples/grpc_impl_example/fit_a_line/test_asyn_client.py
...examples/grpc_impl_example/fit_a_line/test_asyn_client.py
+19
-18
python/examples/grpc_impl_example/fit_a_line/test_batch_client.py
...xamples/grpc_impl_example/fit_a_line/test_batch_client.py
+32
-0
python/examples/grpc_impl_example/fit_a_line/test_general_pb_client.py
...es/grpc_impl_example/fit_a_line/test_general_pb_client.py
+30
-0
python/examples/grpc_impl_example/fit_a_line/test_numpy_input_client.py
...s/grpc_impl_example/fit_a_line/test_numpy_input_client.py
+31
-0
python/examples/grpc_impl_example/fit_a_line/test_server.py
python/examples/grpc_impl_example/fit_a_line/test_server.py
+2
-2
python/examples/grpc_impl_example/fit_a_line/test_server_gpu.py
.../examples/grpc_impl_example/fit_a_line/test_server_gpu.py
+37
-0
python/examples/grpc_impl_example/fit_a_line/test_sync_client.py
...examples/grpc_impl_example/fit_a_line/test_sync_client.py
+30
-0
python/examples/grpc_impl_example/fit_a_line/test_timeout_client.py
...mples/grpc_impl_example/fit_a_line/test_timeout_client.py
+34
-0
python/examples/imdb/test_ensemble_client.py
python/examples/imdb/test_ensemble_client.py
+3
-7
python/examples/imdb/test_multilang_ensemble_client.py
python/examples/imdb/test_multilang_ensemble_client.py
+37
-0
python/examples/imdb/test_multilang_ensemble_server.py
python/examples/imdb/test_multilang_ensemble_server.py
+40
-0
python/paddle_serving_client/__init__.py
python/paddle_serving_client/__init__.py
+124
-70
python/paddle_serving_server/__init__.py
python/paddle_serving_server/__init__.py
+146
-54
python/paddle_serving_server/serve.py
python/paddle_serving_server/serve.py
+11
-1
python/paddle_serving_server_gpu/__init__.py
python/paddle_serving_server_gpu/__init__.py
+146
-52
python/paddle_serving_server_gpu/serve.py
python/paddle_serving_server_gpu/serve.py
+5
-1
tools/serving_build.sh
tools/serving_build.sh
+145
-0
未找到文件。
core/configure/proto/multi_lang_general_model_service.proto
浏览文件 @
e1013d75
...
@@ -28,16 +28,17 @@ message FeedInst { repeated Tensor tensor_array = 1; };
...
@@ -28,16 +28,17 @@ message FeedInst { repeated Tensor tensor_array = 1; };
message
FetchInst
{
repeated
Tensor
tensor_array
=
1
;
};
message
FetchInst
{
repeated
Tensor
tensor_array
=
1
;
};
message
Request
{
message
Inference
Request
{
repeated
FeedInst
insts
=
1
;
repeated
FeedInst
insts
=
1
;
repeated
string
feed_var_names
=
2
;
repeated
string
feed_var_names
=
2
;
repeated
string
fetch_var_names
=
3
;
repeated
string
fetch_var_names
=
3
;
required
bool
is_python
=
4
[
default
=
false
];
required
bool
is_python
=
4
[
default
=
false
];
};
};
message
Response
{
message
Inference
Response
{
repeated
ModelOutput
outputs
=
1
;
repeated
ModelOutput
outputs
=
1
;
optional
string
tag
=
2
;
optional
string
tag
=
2
;
required
int32
err_code
=
3
;
};
};
message
ModelOutput
{
message
ModelOutput
{
...
@@ -45,6 +46,17 @@ message ModelOutput {
...
@@ -45,6 +46,17 @@ message ModelOutput {
optional
string
engine_name
=
2
;
optional
string
engine_name
=
2
;
}
}
message
SetTimeoutRequest
{
required
int32
timeout_ms
=
1
;
}
message
SimpleResponse
{
required
int32
err_code
=
1
;
}
message
GetClientConfigRequest
{}
message
GetClientConfigResponse
{
required
string
client_config_str
=
1
;
}
service
MultiLangGeneralModelService
{
service
MultiLangGeneralModelService
{
rpc
inference
(
Request
)
returns
(
Response
)
{}
rpc
Inference
(
InferenceRequest
)
returns
(
InferenceResponse
)
{}
rpc
SetTimeout
(
SetTimeoutRequest
)
returns
(
SimpleResponse
)
{}
rpc
GetClientConfig
(
GetClientConfigRequest
)
returns
(
GetClientConfigResponse
)
{}
};
};
core/predictor/tools/seq_generator.cpp
浏览文件 @
e1013d75
...
@@ -233,7 +233,7 @@ int compress_parameter_parallel(const char *file1,
...
@@ -233,7 +233,7 @@ int compress_parameter_parallel(const char *file1,
greedy_search
(
greedy_search
(
emb_table
+
k
*
emb_size
,
xmin
,
xmax
,
loss
,
emb_size
,
bits
);
emb_table
+
k
*
emb_size
,
xmin
,
xmax
,
loss
,
emb_size
,
bits
);
// 得出 loss 最小的时候的 scale
// 得出 loss 最小的时候的 scale
float
scale
=
(
xmax
-
xmin
)
*
(
pow2bits
-
1
);
float
scale
=
(
xmax
-
xmin
)
/
(
pow2bits
-
1
);
char
*
min_ptr
=
tensor_temp
;
char
*
min_ptr
=
tensor_temp
;
char
*
max_ptr
=
tensor_temp
+
sizeof
(
float
);
char
*
max_ptr
=
tensor_temp
+
sizeof
(
float
);
memcpy
(
min_ptr
,
&
xmin
,
sizeof
(
float
));
memcpy
(
min_ptr
,
&
xmin
,
sizeof
(
float
));
...
...
doc/GRPC_IMPL_CN.md
0 → 100644
浏览文件 @
e1013d75
# gRPC接口
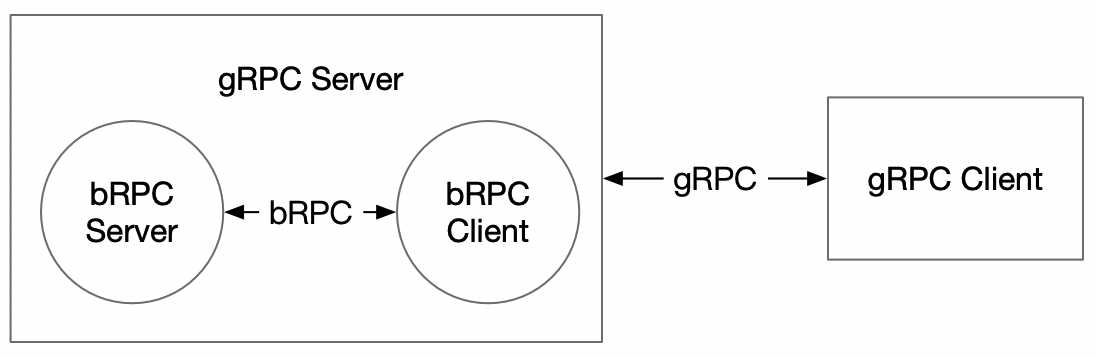
gRPC 接口实现形式类似 Web Service:

## 与bRPC接口对比
1.
gRPC Server 端
`load_model_config`
函数添加
`client_config_path`
参数:
```
python
def
load_model_config
(
self
,
server_config_paths
,
client_config_path
=
None
)
```
在一些例子中 bRPC Server 端与 bRPC Client 端的配置文件可能是不同的(如 cube local 例子中,Client 端的数据先交给 cube,经过 cube 处理后再交给预测库),所以 gRPC Server 端需要获取 gRPC Client 端的配置;同时为了取消 gRPC Client 端手动加载配置文件的过程,所以设计 gRPC Server 端同时加载两个配置文件。
`client_config_path`
默认为
`<server_config_path>/serving_server_conf.prototxt`
。
2.
gRPC Client 端取消
`load_client_config`
步骤:
在
`connect`
步骤通过 RPC 获取相应的 prototxt(从任意一个 endpoint 获取即可)。
3.
gRPC Client 需要通过 RPC 方式设置 timeout 时间(调用形式与 bRPC Client保持一致)
因为 bRPC Client 在
`connect`
后无法更改 timeout 时间,所以当 gRPC Server 收到变更 timeout 的调用请求时会重新创建 bRPC Client 实例以变更 bRPC Client timeout时间,同时 gRPC Client 会设置 gRPC 的 deadline 时间。
**注意,设置 timeout 接口和 Inference 接口不能同时调用(非线程安全),出于性能考虑暂时不加锁。**
4.
gRPC Client 端
`predict`
函数添加
`asyn`
和
`is_python`
参数:
```
python
def
predict
(
self
,
feed
,
fetch
,
need_variant_tag
=
False
,
asyn
=
False
,
is_python
=
True
)
```
其中,
`asyn`
为异步调用选项。当
`asyn=True`
时为异步调用,返回
`MultiLangPredictFuture`
对象,通过
`MultiLangPredictFuture.result()`
阻塞获取预测值;当
`asyn=Fasle`
为同步调用。
`is_python`
为 proto 格式选项。当
`is_python=True`
时,基于 numpy bytes 格式进行数据传输,目前只适用于 Python;当
`is_python=False`
时,以普通数据格式传输,更加通用。使用 numpy bytes 格式传输耗时比普通数据格式小很多(详见
[
#654
](
https://github.com/PaddlePaddle/Serving/pull/654
)
)。
5.
异常处理:当 gRPC Server 端的 bRPC Client 预测失败(返回
`None`
)时,gRPC Client 端同样返回None。其他 gRPC 异常会在 Client 内部捕获,并在返回的 fetch_map 中添加一个 "status_code" 字段来区分是否预测正常(参考 timeout 样例)。
6.
由于 gRPC 只支持 pick_first 和 round_robin 负载均衡策略,ABTEST 特性还未打齐。
7.
经测试,gRPC 版本可以在 Windows、macOS 平台使用。
8.
计划支持的客户端语言:
-
[x] Python
-
[ ] Java
-
[ ] Go
-
[ ] JavaScript
## Python 端的一些例子
详见
`python/examples/grpc_impl_example`
下的示例文件。
doc/grpc_impl.png
0 → 100644
浏览文件 @
e1013d75
113.8 KB
python/examples/grpc_impl_example/criteo_ctr_with_cube/README_CN.md
0 → 100644
浏览文件 @
e1013d75
## 带稀疏参数索引服务的CTR预测服务
该样例是为了展示gRPC Server 端
`load_model_config`
函数,在这个例子中,bRPC Server 端与 bRPC Client 端的配置文件是不同的(bPRC Client 端的数据先交给 cube,经过 cube 处理后再交给预测库)
### 获取样例数据
```
sh get_data.sh
```
### 下载模型和稀疏参数序列文件
```
wget https://paddle-serving.bj.bcebos.com/unittest/ctr_cube_unittest.tar.gz
tar xf ctr_cube_unittest.tar.gz
mv models/ctr_client_conf ./
mv models/ctr_serving_model_kv ./
mv models/data ./cube/
```
执行脚本后会在当前目录有ctr_server_model_kv和ctr_client_config文件夹。
### 启动稀疏参数索引服务
```
wget https://paddle-serving.bj.bcebos.com/others/cube_app.tar.gz
tar xf cube_app.tar.gz
mv cube_app/cube* ./cube/
sh cube_prepare.sh &
```
此处,模型当中的稀疏参数会被存放在稀疏参数索引服务Cube当中,关于稀疏参数索引服务Cube的介绍,请阅读
[
稀疏参数索引服务Cube单机版使用指南
](
../../../doc/CUBE_LOCAL_CN.md
)
### 启动RPC预测服务,服务端线程数为4(可在test_server.py配置)
```
python test_server.py ctr_serving_model_kv ctr_client_conf/serving_client_conf.prototxt
```
### 执行预测
```
python test_client.py ./raw_data
```
python/examples/grpc_impl_example/criteo_ctr_with_cube/args.py
0 → 100755
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
import
argparse
def
parse_args
():
parser
=
argparse
.
ArgumentParser
(
description
=
"PaddlePaddle CTR example"
)
parser
.
add_argument
(
'--train_data_path'
,
type
=
str
,
default
=
'./data/raw/train.txt'
,
help
=
"The path of training dataset"
)
parser
.
add_argument
(
'--sparse_only'
,
type
=
bool
,
default
=
False
,
help
=
"Whether we use sparse features only"
)
parser
.
add_argument
(
'--test_data_path'
,
type
=
str
,
default
=
'./data/raw/valid.txt'
,
help
=
"The path of testing dataset"
)
parser
.
add_argument
(
'--batch_size'
,
type
=
int
,
default
=
1000
,
help
=
"The size of mini-batch (default:1000)"
)
parser
.
add_argument
(
'--embedding_size'
,
type
=
int
,
default
=
10
,
help
=
"The size for embedding layer (default:10)"
)
parser
.
add_argument
(
'--num_passes'
,
type
=
int
,
default
=
10
,
help
=
"The number of passes to train (default: 10)"
)
parser
.
add_argument
(
'--model_output_dir'
,
type
=
str
,
default
=
'models'
,
help
=
'The path for model to store (default: models)'
)
parser
.
add_argument
(
'--sparse_feature_dim'
,
type
=
int
,
default
=
1000001
,
help
=
'sparse feature hashing space for index processing'
)
parser
.
add_argument
(
'--is_local'
,
type
=
int
,
default
=
1
,
help
=
'Local train or distributed train (default: 1)'
)
parser
.
add_argument
(
'--cloud_train'
,
type
=
int
,
default
=
0
,
help
=
'Local train or distributed train on paddlecloud (default: 0)'
)
parser
.
add_argument
(
'--async_mode'
,
action
=
'store_true'
,
default
=
False
,
help
=
'Whether start pserver in async mode to support ASGD'
)
parser
.
add_argument
(
'--no_split_var'
,
action
=
'store_true'
,
default
=
False
,
help
=
'Whether split variables into blocks when update_method is pserver'
)
parser
.
add_argument
(
'--role'
,
type
=
str
,
default
=
'pserver'
,
# trainer or pserver
help
=
'The path for model to store (default: models)'
)
parser
.
add_argument
(
'--endpoints'
,
type
=
str
,
default
=
'127.0.0.1:6000'
,
help
=
'The pserver endpoints, like: 127.0.0.1:6000,127.0.0.1:6001'
)
parser
.
add_argument
(
'--current_endpoint'
,
type
=
str
,
default
=
'127.0.0.1:6000'
,
help
=
'The path for model to store (default: 127.0.0.1:6000)'
)
parser
.
add_argument
(
'--trainer_id'
,
type
=
int
,
default
=
0
,
help
=
'The path for model to store (default: models)'
)
parser
.
add_argument
(
'--trainers'
,
type
=
int
,
default
=
1
,
help
=
'The num of trianers, (default: 1)'
)
return
parser
.
parse_args
()
python/examples/grpc_impl_example/criteo_ctr_with_cube/clean.sh
0 → 100755
浏览文件 @
e1013d75
ps
-ef
|
grep
cube |
awk
{
'print $2'
}
| xargs
kill
-9
rm
-rf
cube/cube_data cube/data cube/log
*
cube/nohup
*
cube/output/ cube/donefile cube/input cube/monitor cube/cube-builder.INFO
ps
-ef
|
grep test
|
awk
{
'print $2'
}
| xargs
kill
-9
ps
-ef
|
grep
serving |
awk
{
'print $2'
}
| xargs
kill
-9
python/examples/grpc_impl_example/criteo_ctr_with_cube/criteo.py
0 → 100755
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
sys
class
CriteoDataset
(
object
):
def
setup
(
self
,
sparse_feature_dim
):
self
.
cont_min_
=
[
0
,
-
3
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
]
self
.
cont_max_
=
[
20
,
600
,
100
,
50
,
64000
,
500
,
100
,
50
,
500
,
10
,
10
,
10
,
50
]
self
.
cont_diff_
=
[
20
,
603
,
100
,
50
,
64000
,
500
,
100
,
50
,
500
,
10
,
10
,
10
,
50
]
self
.
hash_dim_
=
sparse_feature_dim
# here, training data are lines with line_index < train_idx_
self
.
train_idx_
=
41256555
self
.
continuous_range_
=
range
(
1
,
14
)
self
.
categorical_range_
=
range
(
14
,
40
)
def
_process_line
(
self
,
line
):
features
=
line
.
rstrip
(
'
\n
'
).
split
(
'
\t
'
)
dense_feature
=
[]
sparse_feature
=
[]
for
idx
in
self
.
continuous_range_
:
if
features
[
idx
]
==
''
:
dense_feature
.
append
(
0.0
)
else
:
dense_feature
.
append
((
float
(
features
[
idx
])
-
self
.
cont_min_
[
idx
-
1
])
/
\
self
.
cont_diff_
[
idx
-
1
])
for
idx
in
self
.
categorical_range_
:
sparse_feature
.
append
(
[
hash
(
str
(
idx
)
+
features
[
idx
])
%
self
.
hash_dim_
])
return
dense_feature
,
sparse_feature
,
[
int
(
features
[
0
])]
def
infer_reader
(
self
,
filelist
,
batch
,
buf_size
):
def
local_iter
():
for
fname
in
filelist
:
with
open
(
fname
.
strip
(),
"r"
)
as
fin
:
for
line
in
fin
:
dense_feature
,
sparse_feature
,
label
=
self
.
_process_line
(
line
)
#yield dense_feature, sparse_feature, label
yield
[
dense_feature
]
+
sparse_feature
+
[
label
]
import
paddle
batch_iter
=
paddle
.
batch
(
paddle
.
reader
.
shuffle
(
local_iter
,
buf_size
=
buf_size
),
batch_size
=
batch
)
return
batch_iter
def
generate_sample
(
self
,
line
):
def
data_iter
():
dense_feature
,
sparse_feature
,
label
=
self
.
_process_line
(
line
)
feature_name
=
[
"dense_input"
]
for
idx
in
self
.
categorical_range_
:
feature_name
.
append
(
"C"
+
str
(
idx
-
13
))
feature_name
.
append
(
"label"
)
yield
zip
(
feature_name
,
[
dense_feature
]
+
sparse_feature
+
[
label
])
return
data_iter
if
__name__
==
"__main__"
:
criteo_dataset
=
CriteoDataset
()
criteo_dataset
.
setup
(
int
(
sys
.
argv
[
1
]))
criteo_dataset
.
run_from_stdin
()
python/examples/grpc_impl_example/criteo_ctr_with_cube/criteo_reader.py
0 → 100755
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
import
sys
import
paddle.fluid.incubate.data_generator
as
dg
class
CriteoDataset
(
dg
.
MultiSlotDataGenerator
):
def
setup
(
self
,
sparse_feature_dim
):
self
.
cont_min_
=
[
0
,
-
3
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
]
self
.
cont_max_
=
[
20
,
600
,
100
,
50
,
64000
,
500
,
100
,
50
,
500
,
10
,
10
,
10
,
50
]
self
.
cont_diff_
=
[
20
,
603
,
100
,
50
,
64000
,
500
,
100
,
50
,
500
,
10
,
10
,
10
,
50
]
self
.
hash_dim_
=
sparse_feature_dim
# here, training data are lines with line_index < train_idx_
self
.
train_idx_
=
41256555
self
.
continuous_range_
=
range
(
1
,
14
)
self
.
categorical_range_
=
range
(
14
,
40
)
def
_process_line
(
self
,
line
):
features
=
line
.
rstrip
(
'
\n
'
).
split
(
'
\t
'
)
dense_feature
=
[]
sparse_feature
=
[]
for
idx
in
self
.
continuous_range_
:
if
features
[
idx
]
==
''
:
dense_feature
.
append
(
0.0
)
else
:
dense_feature
.
append
((
float
(
features
[
idx
])
-
self
.
cont_min_
[
idx
-
1
])
/
\
self
.
cont_diff_
[
idx
-
1
])
for
idx
in
self
.
categorical_range_
:
sparse_feature
.
append
(
[
hash
(
str
(
idx
)
+
features
[
idx
])
%
self
.
hash_dim_
])
return
dense_feature
,
sparse_feature
,
[
int
(
features
[
0
])]
def
infer_reader
(
self
,
filelist
,
batch
,
buf_size
):
def
local_iter
():
for
fname
in
filelist
:
with
open
(
fname
.
strip
(),
"r"
)
as
fin
:
for
line
in
fin
:
dense_feature
,
sparse_feature
,
label
=
self
.
_process_line
(
line
)
#yield dense_feature, sparse_feature, label
yield
[
dense_feature
]
+
sparse_feature
+
[
label
]
import
paddle
batch_iter
=
paddle
.
batch
(
paddle
.
reader
.
shuffle
(
local_iter
,
buf_size
=
buf_size
),
batch_size
=
batch
)
return
batch_iter
def
generate_sample
(
self
,
line
):
def
data_iter
():
dense_feature
,
sparse_feature
,
label
=
self
.
_process_line
(
line
)
feature_name
=
[
"dense_input"
]
for
idx
in
self
.
categorical_range_
:
feature_name
.
append
(
"C"
+
str
(
idx
-
13
))
feature_name
.
append
(
"label"
)
yield
zip
(
feature_name
,
[
dense_feature
]
+
sparse_feature
+
[
label
])
return
data_iter
if
__name__
==
"__main__"
:
criteo_dataset
=
CriteoDataset
()
criteo_dataset
.
setup
(
int
(
sys
.
argv
[
1
]))
criteo_dataset
.
run_from_stdin
()
python/examples/grpc_impl_example/criteo_ctr_with_cube/cube/conf/cube.conf
0 → 100755
浏览文件 @
e1013d75
[{
"dict_name"
:
"test_dict"
,
"shard"
:
1
,
"dup"
:
1
,
"timeout"
:
200
,
"retry"
:
3
,
"backup_request"
:
100
,
"type"
:
"ipport_list"
,
"load_balancer"
:
"rr"
,
"nodes"
: [{
"ipport_list"
:
"list://127.0.0.1:8027"
}]
}]
python/examples/grpc_impl_example/criteo_ctr_with_cube/cube/conf/gflags.conf
0 → 100755
浏览文件 @
e1013d75
--
port
=
8027
--
dict_split
=
1
--
in_mem
=
true
--
log_dir
=./
log
/
python/examples/grpc_impl_example/criteo_ctr_with_cube/cube/keys
0 → 100755
浏览文件 @
e1013d75
1
2
3
4
5
6
7
8
9
10
python/examples/grpc_impl_example/criteo_ctr_with_cube/cube_prepare.sh
0 → 100755
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
#! /bin/bash
mkdir
-p
cube_model
mkdir
-p
cube/data
./seq_generator ctr_serving_model/SparseFeatFactors ./cube_model/feature
./cube/cube-builder
-dict_name
=
test_dict
-job_mode
=
base
-last_version
=
0
-cur_version
=
0
-depend_version
=
0
-input_path
=
./cube_model
-output_path
=
${
PWD
}
/cube/data
-shard_num
=
1
-only_build
=
false
mv
./cube/data/0_0/test_dict_part0/
*
./cube/data/
cd
cube
&&
./cube
python/examples/grpc_impl_example/criteo_ctr_with_cube/cube_quant_prepare.sh
0 → 100755
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
#! /bin/bash
mkdir
-p
cube_model
mkdir
-p
cube/data
./seq_generator ctr_serving_model/SparseFeatFactors ./cube_model/feature 8
./cube/cube-builder
-dict_name
=
test_dict
-job_mode
=
base
-last_version
=
0
-cur_version
=
0
-depend_version
=
0
-input_path
=
./cube_model
-output_path
=
${
PWD
}
/cube/data
-shard_num
=
1
-only_build
=
false
mv
./cube/data/0_0/test_dict_part0/
*
./cube/data/
cd
cube
&&
./cube
python/examples/grpc_impl_example/criteo_ctr_with_cube/get_data.sh
0 → 100755
浏览文件 @
e1013d75
wget
--no-check-certificate
https://paddle-serving.bj.bcebos.com/data/ctr_prediction/ctr_data.tar.gz
tar
-zxvf
ctr_data.tar.gz
python/examples/grpc_impl_example/criteo_ctr_with_cube/local_train.py
0 → 100755
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
__future__
import
print_function
from
args
import
parse_args
import
os
import
paddle.fluid
as
fluid
import
sys
from
network_conf
import
dnn_model
dense_feature_dim
=
13
def
train
():
args
=
parse_args
()
sparse_only
=
args
.
sparse_only
if
not
os
.
path
.
isdir
(
args
.
model_output_dir
):
os
.
mkdir
(
args
.
model_output_dir
)
dense_input
=
fluid
.
layers
.
data
(
name
=
"dense_input"
,
shape
=
[
dense_feature_dim
],
dtype
=
'float32'
)
sparse_input_ids
=
[
fluid
.
layers
.
data
(
name
=
"C"
+
str
(
i
),
shape
=
[
1
],
lod_level
=
1
,
dtype
=
"int64"
)
for
i
in
range
(
1
,
27
)
]
label
=
fluid
.
layers
.
data
(
name
=
'label'
,
shape
=
[
1
],
dtype
=
'int64'
)
#nn_input = None if sparse_only else dense_input
nn_input
=
dense_input
predict_y
,
loss
,
auc_var
,
batch_auc_var
,
infer_vars
=
dnn_model
(
nn_input
,
sparse_input_ids
,
label
,
args
.
embedding_size
,
args
.
sparse_feature_dim
)
optimizer
=
fluid
.
optimizer
.
SGD
(
learning_rate
=
1e-4
)
optimizer
.
minimize
(
loss
)
exe
=
fluid
.
Executor
(
fluid
.
CPUPlace
())
exe
.
run
(
fluid
.
default_startup_program
())
dataset
=
fluid
.
DatasetFactory
().
create_dataset
(
"InMemoryDataset"
)
dataset
.
set_use_var
([
dense_input
]
+
sparse_input_ids
+
[
label
])
python_executable
=
"python"
pipe_command
=
"{} criteo_reader.py {}"
.
format
(
python_executable
,
args
.
sparse_feature_dim
)
dataset
.
set_pipe_command
(
pipe_command
)
dataset
.
set_batch_size
(
128
)
thread_num
=
10
dataset
.
set_thread
(
thread_num
)
whole_filelist
=
[
"raw_data/part-%d"
%
x
for
x
in
range
(
len
(
os
.
listdir
(
"raw_data"
)))
]
print
(
whole_filelist
)
dataset
.
set_filelist
(
whole_filelist
[:
100
])
dataset
.
load_into_memory
()
fluid
.
layers
.
Print
(
auc_var
)
epochs
=
1
for
i
in
range
(
epochs
):
exe
.
train_from_dataset
(
program
=
fluid
.
default_main_program
(),
dataset
=
dataset
,
debug
=
True
)
print
(
"epoch {} finished"
.
format
(
i
))
import
paddle_serving_client.io
as
server_io
feed_var_dict
=
{}
feed_var_dict
[
'dense_input'
]
=
dense_input
for
i
,
sparse
in
enumerate
(
sparse_input_ids
):
feed_var_dict
[
"embedding_{}.tmp_0"
.
format
(
i
)]
=
sparse
fetch_var_dict
=
{
"prob"
:
predict_y
}
feed_kv_dict
=
{}
feed_kv_dict
[
'dense_input'
]
=
dense_input
for
i
,
emb
in
enumerate
(
infer_vars
):
feed_kv_dict
[
"embedding_{}.tmp_0"
.
format
(
i
)]
=
emb
fetch_var_dict
=
{
"prob"
:
predict_y
}
server_io
.
save_model
(
"ctr_serving_model"
,
"ctr_client_conf"
,
feed_var_dict
,
fetch_var_dict
,
fluid
.
default_main_program
())
server_io
.
save_model
(
"ctr_serving_model_kv"
,
"ctr_client_conf_kv"
,
feed_kv_dict
,
fetch_var_dict
,
fluid
.
default_main_program
())
if
__name__
==
'__main__'
:
train
()
python/examples/grpc_impl_example/criteo_ctr_with_cube/network_conf.py
0 → 100755
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
import
paddle.fluid
as
fluid
import
math
def
dnn_model
(
dense_input
,
sparse_inputs
,
label
,
embedding_size
,
sparse_feature_dim
):
def
embedding_layer
(
input
):
emb
=
fluid
.
layers
.
embedding
(
input
=
input
,
is_sparse
=
True
,
is_distributed
=
False
,
size
=
[
sparse_feature_dim
,
embedding_size
],
param_attr
=
fluid
.
ParamAttr
(
name
=
"SparseFeatFactors"
,
initializer
=
fluid
.
initializer
.
Uniform
()))
x
=
fluid
.
layers
.
sequence_pool
(
input
=
emb
,
pool_type
=
'sum'
)
return
emb
,
x
def
mlp_input_tensor
(
emb_sums
,
dense_tensor
):
#if isinstance(dense_tensor, fluid.Variable):
# return fluid.layers.concat(emb_sums, axis=1)
#else:
return
fluid
.
layers
.
concat
(
emb_sums
+
[
dense_tensor
],
axis
=
1
)
def
mlp
(
mlp_input
):
fc1
=
fluid
.
layers
.
fc
(
input
=
mlp_input
,
size
=
400
,
act
=
'relu'
,
param_attr
=
fluid
.
ParamAttr
(
initializer
=
fluid
.
initializer
.
Normal
(
scale
=
1
/
math
.
sqrt
(
mlp_input
.
shape
[
1
]))))
fc2
=
fluid
.
layers
.
fc
(
input
=
fc1
,
size
=
400
,
act
=
'relu'
,
param_attr
=
fluid
.
ParamAttr
(
initializer
=
fluid
.
initializer
.
Normal
(
scale
=
1
/
math
.
sqrt
(
fc1
.
shape
[
1
]))))
fc3
=
fluid
.
layers
.
fc
(
input
=
fc2
,
size
=
400
,
act
=
'relu'
,
param_attr
=
fluid
.
ParamAttr
(
initializer
=
fluid
.
initializer
.
Normal
(
scale
=
1
/
math
.
sqrt
(
fc2
.
shape
[
1
]))))
pre
=
fluid
.
layers
.
fc
(
input
=
fc3
,
size
=
2
,
act
=
'softmax'
,
param_attr
=
fluid
.
ParamAttr
(
initializer
=
fluid
.
initializer
.
Normal
(
scale
=
1
/
math
.
sqrt
(
fc3
.
shape
[
1
]))))
return
pre
emb_pair_sums
=
list
(
map
(
embedding_layer
,
sparse_inputs
))
emb_sums
=
[
x
[
1
]
for
x
in
emb_pair_sums
]
infer_vars
=
[
x
[
0
]
for
x
in
emb_pair_sums
]
mlp_in
=
mlp_input_tensor
(
emb_sums
,
dense_input
)
predict
=
mlp
(
mlp_in
)
cost
=
fluid
.
layers
.
cross_entropy
(
input
=
predict
,
label
=
label
)
avg_cost
=
fluid
.
layers
.
reduce_sum
(
cost
)
accuracy
=
fluid
.
layers
.
accuracy
(
input
=
predict
,
label
=
label
)
auc_var
,
batch_auc_var
,
auc_states
=
\
fluid
.
layers
.
auc
(
input
=
predict
,
label
=
label
,
num_thresholds
=
2
**
12
,
slide_steps
=
20
)
return
predict
,
avg_cost
,
auc_var
,
batch_auc_var
,
infer_vars
python/examples/grpc_impl_example/criteo_ctr_with_cube/test_client.py
0 → 100755
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
paddle_serving_client
import
MultiLangClient
as
Client
import
sys
import
os
import
criteo
as
criteo
import
time
from
paddle_serving_client.metric
import
auc
import
grpc
client
=
Client
()
client
.
connect
([
"127.0.0.1:9292"
])
batch
=
1
buf_size
=
100
dataset
=
criteo
.
CriteoDataset
()
dataset
.
setup
(
1000001
)
test_filelists
=
[
"{}/part-0"
.
format
(
sys
.
argv
[
1
])]
reader
=
dataset
.
infer_reader
(
test_filelists
,
batch
,
buf_size
)
label_list
=
[]
prob_list
=
[]
start
=
time
.
time
()
for
ei
in
range
(
10000
):
data
=
reader
().
next
()
feed_dict
=
{}
feed_dict
[
'dense_input'
]
=
data
[
0
][
0
]
for
i
in
range
(
1
,
27
):
feed_dict
[
"embedding_{}.tmp_0"
.
format
(
i
-
1
)]
=
data
[
0
][
i
]
fetch_map
=
client
.
predict
(
feed
=
feed_dict
,
fetch
=
[
"prob"
])
if
fetch_map
[
"serving_status_code"
]
==
0
:
prob_list
.
append
(
fetch_map
[
'prob'
][
0
][
1
])
label_list
.
append
(
data
[
0
][
-
1
][
0
])
print
(
auc
(
label_list
,
prob_list
))
end
=
time
.
time
()
print
(
end
-
start
)
python/examples/grpc_impl_example/criteo_ctr_with_cube/test_server.py
0 → 100755
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
import
os
import
sys
from
paddle_serving_server
import
OpMaker
from
paddle_serving_server
import
OpSeqMaker
from
paddle_serving_server
import
MultiLangServer
as
Server
op_maker
=
OpMaker
()
read_op
=
op_maker
.
create
(
'general_reader'
)
general_dist_kv_infer_op
=
op_maker
.
create
(
'general_dist_kv_infer'
)
response_op
=
op_maker
.
create
(
'general_response'
)
op_seq_maker
=
OpSeqMaker
()
op_seq_maker
.
add_op
(
read_op
)
op_seq_maker
.
add_op
(
general_dist_kv_infer_op
)
op_seq_maker
.
add_op
(
response_op
)
server
=
Server
()
server
.
set_op_sequence
(
op_seq_maker
.
get_op_sequence
())
server
.
set_num_threads
(
4
)
server
.
load_model_config
(
sys
.
argv
[
1
],
sys
.
argv
[
2
])
server
.
prepare_server
(
workdir
=
"work_dir1"
,
port
=
9292
,
device
=
"cpu"
)
server
.
run_server
()
python/examples/grpc_impl_example/criteo_ctr_with_cube/test_server_gpu.py
0 → 100755
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
import
os
import
sys
from
paddle_serving_server_gpu
import
OpMaker
from
paddle_serving_server_gpu
import
OpSeqMaker
from
paddle_serving_server_gpu
import
MultiLangServer
as
Server
op_maker
=
OpMaker
()
read_op
=
op_maker
.
create
(
'general_reader'
)
general_dist_kv_infer_op
=
op_maker
.
create
(
'general_dist_kv_infer'
)
response_op
=
op_maker
.
create
(
'general_response'
)
op_seq_maker
=
OpSeqMaker
()
op_seq_maker
.
add_op
(
read_op
)
op_seq_maker
.
add_op
(
general_dist_kv_infer_op
)
op_seq_maker
.
add_op
(
response_op
)
server
=
Server
()
server
.
set_op_sequence
(
op_seq_maker
.
get_op_sequence
())
server
.
set_num_threads
(
4
)
server
.
load_model_config
(
sys
.
argv
[
1
],
sys
.
argv
[
2
])
server
.
prepare_server
(
workdir
=
"work_dir1"
,
port
=
9292
,
device
=
"cpu"
)
server
.
run_server
()
python/examples/grpc_impl_example/criteo_ctr_with_cube/test_server_quant.py
0 → 100755
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
import
os
import
sys
from
paddle_serving_server
import
OpMaker
from
paddle_serving_server
import
OpSeqMaker
from
paddle_serving_server
import
MultiLangServer
as
Server
op_maker
=
OpMaker
()
read_op
=
op_maker
.
create
(
'general_reader'
)
general_dist_kv_infer_op
=
op_maker
.
create
(
'general_dist_kv_quant_infer'
)
response_op
=
op_maker
.
create
(
'general_response'
)
op_seq_maker
=
OpSeqMaker
()
op_seq_maker
.
add_op
(
read_op
)
op_seq_maker
.
add_op
(
general_dist_kv_infer_op
)
op_seq_maker
.
add_op
(
response_op
)
server
=
Server
()
server
.
set_op_sequence
(
op_seq_maker
.
get_op_sequence
())
server
.
set_num_threads
(
4
)
server
.
load_model_config
(
sys
.
argv
[
1
],
sys
.
argv
[
2
])
server
.
prepare_server
(
workdir
=
"work_dir1"
,
port
=
9292
,
device
=
"cpu"
)
server
.
run_server
()
python/examples/grpc_impl_example/fit_a_line/README_CN.md
0 → 100644
浏览文件 @
e1013d75
# 线性回归预测服务示例
## 获取数据
```
shell
sh get_data.sh
```
## 开启 gRPC 服务端
```
shell
python test_server.py uci_housing_model/
```
也可以通过下面的一行代码开启默认 gRPC 服务:
```
shell
python
-m
paddle_serving_server.serve
--model
uci_housing_model
--thread
10
--port
9393
--use_multilang
```
## 客户端预测
### 同步预测
```
shell
python test_sync_client.py
```
### 异步预测
```
shell
python test_asyn_client.py
```
### Batch 预测
```
shell
python test_batch_client.py
```
### 通用 pb 预测
```
shell
python test_general_pb_client.py
```
### 预测超时
```
shell
python test_timeout_client.py
```
### List 输入
```
shell
python test_list_input_client.py
```
python/examples/grpc_impl_example/fit_a_line/get_data.sh
0 → 100644
浏览文件 @
e1013d75
wget
--no-check-certificate
https://paddle-serving.bj.bcebos.com/uci_housing.tar.gz
tar
-xzf
uci_housing.tar.gz
python/examples/
fit_a_line/test_multilang
_client.py
→
python/examples/
grpc_impl_example/fit_a_line/test_asyn
_client.py
浏览文件 @
e1013d75
...
@@ -13,38 +13,39 @@
...
@@ -13,38 +13,39 @@
# limitations under the License.
# limitations under the License.
# pylint: disable=doc-string-missing
# pylint: disable=doc-string-missing
from
paddle_serving_client
import
MultiLangClient
from
paddle_serving_client
import
MultiLangClient
as
Client
import
functools
import
functools
import
sys
import
time
import
time
import
threading
import
threading
import
grpc
client
=
MultiLangClient
()
client
=
Client
()
client
.
load_client_config
(
sys
.
argv
[
1
])
client
.
connect
([
"127.0.0.1:9393"
])
client
.
connect
([
"127.0.0.1:9393"
])
import
paddle
test_reader
=
paddle
.
batch
(
paddle
.
reader
.
shuffle
(
paddle
.
dataset
.
uci_housing
.
test
(),
buf_size
=
500
),
batch_size
=
1
)
complete_task_count
=
[
0
]
complete_task_count
=
[
0
]
lock
=
threading
.
Lock
()
lock
=
threading
.
Lock
()
def
call_back
(
call_future
,
data
):
def
call_back
(
call_future
):
try
:
fetch_map
=
call_future
.
result
()
fetch_map
=
call_future
.
result
()
print
(
"{} {}"
.
format
(
fetch_map
[
"price"
][
0
],
data
[
0
][
1
][
0
]))
print
(
fetch_map
)
except
grpc
.
RpcError
as
e
:
print
(
e
.
code
())
finally
:
with
lock
:
with
lock
:
complete_task_count
[
0
]
+=
1
complete_task_count
[
0
]
+=
1
x
=
[
0.0137
,
-
0.1136
,
0.2553
,
-
0.0692
,
0.0582
,
-
0.0727
,
-
0.1583
,
-
0.0584
,
0.6283
,
0.4919
,
0.1856
,
0.0795
,
-
0.0332
]
task_count
=
0
task_count
=
0
for
data
in
test_reader
(
):
for
i
in
range
(
3
):
future
=
client
.
predict
(
feed
=
{
"x"
:
data
[
0
][
0
]
},
fetch
=
[
"price"
],
asyn
=
True
)
future
=
client
.
predict
(
feed
=
{
"x"
:
x
},
fetch
=
[
"price"
],
asyn
=
True
)
task_count
+=
1
task_count
+=
1
future
.
add_done_callback
(
functools
.
partial
(
call_back
,
data
=
data
))
future
.
add_done_callback
(
functools
.
partial
(
call_back
))
while
complete_task_count
[
0
]
!=
task_count
:
while
complete_task_count
[
0
]
!=
task_count
:
time
.
sleep
(
0.1
)
time
.
sleep
(
0.1
)
python/examples/grpc_impl_example/fit_a_line/test_batch_client.py
0 → 100644
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
paddle_serving_client
import
MultiLangClient
as
Client
client
=
Client
()
client
.
connect
([
"127.0.0.1:9393"
])
batch_size
=
2
x
=
[
0.0137
,
-
0.1136
,
0.2553
,
-
0.0692
,
0.0582
,
-
0.0727
,
-
0.1583
,
-
0.0584
,
0.6283
,
0.4919
,
0.1856
,
0.0795
,
-
0.0332
]
for
i
in
range
(
3
):
batch_feed
=
[{
"x"
:
x
}
for
j
in
range
(
batch_size
)]
fetch_map
=
client
.
predict
(
feed
=
batch_feed
,
fetch
=
[
"price"
])
if
fetch_map
[
"serving_status_code"
]
==
0
:
print
(
fetch_map
)
else
:
print
(
fetch_map
[
"serving_status_code"
])
python/examples/grpc_impl_example/fit_a_line/test_general_pb_client.py
0 → 100644
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
paddle_serving_client
import
MultiLangClient
as
Client
client
=
Client
()
client
.
connect
([
"127.0.0.1:9393"
])
x
=
[
0.0137
,
-
0.1136
,
0.2553
,
-
0.0692
,
0.0582
,
-
0.0727
,
-
0.1583
,
-
0.0584
,
0.6283
,
0.4919
,
0.1856
,
0.0795
,
-
0.0332
]
for
i
in
range
(
3
):
fetch_map
=
client
.
predict
(
feed
=
{
"x"
:
x
},
fetch
=
[
"price"
],
is_python
=
False
)
if
fetch_map
[
"serving_status_code"
]
==
0
:
print
(
fetch_map
)
else
:
print
(
fetch_map
[
"serving_status_code"
])
python/examples/grpc_impl_example/fit_a_line/test_numpy_input_client.py
0 → 100644
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
paddle_serving_client
import
MultiLangClient
as
Client
import
numpy
as
np
client
=
Client
()
client
.
connect
([
"127.0.0.1:9393"
])
x
=
[
0.0137
,
-
0.1136
,
0.2553
,
-
0.0692
,
0.0582
,
-
0.0727
,
-
0.1583
,
-
0.0584
,
0.6283
,
0.4919
,
0.1856
,
0.0795
,
-
0.0332
]
for
i
in
range
(
3
):
fetch_map
=
client
.
predict
(
feed
=
{
"x"
:
np
.
array
(
x
)},
fetch
=
[
"price"
])
if
fetch_map
[
"serving_status_code"
]
==
0
:
print
(
fetch_map
)
else
:
print
(
fetch_map
[
"serving_status_code"
])
python/examples/
fit_a_line/test_multilang
_server.py
→
python/examples/
grpc_impl_example/fit_a_line/test
_server.py
浏览文件 @
e1013d75
...
@@ -17,7 +17,7 @@ import os
...
@@ -17,7 +17,7 @@ import os
import
sys
import
sys
from
paddle_serving_server
import
OpMaker
from
paddle_serving_server
import
OpMaker
from
paddle_serving_server
import
OpSeqMaker
from
paddle_serving_server
import
OpSeqMaker
from
paddle_serving_server
import
MultiLangServer
from
paddle_serving_server
import
MultiLangServer
as
Server
op_maker
=
OpMaker
()
op_maker
=
OpMaker
()
read_op
=
op_maker
.
create
(
'general_reader'
)
read_op
=
op_maker
.
create
(
'general_reader'
)
...
@@ -29,7 +29,7 @@ op_seq_maker.add_op(read_op)
...
@@ -29,7 +29,7 @@ op_seq_maker.add_op(read_op)
op_seq_maker
.
add_op
(
general_infer_op
)
op_seq_maker
.
add_op
(
general_infer_op
)
op_seq_maker
.
add_op
(
response_op
)
op_seq_maker
.
add_op
(
response_op
)
server
=
MultiLang
Server
()
server
=
Server
()
server
.
set_op_sequence
(
op_seq_maker
.
get_op_sequence
())
server
.
set_op_sequence
(
op_seq_maker
.
get_op_sequence
())
server
.
load_model_config
(
sys
.
argv
[
1
])
server
.
load_model_config
(
sys
.
argv
[
1
])
server
.
prepare_server
(
workdir
=
"work_dir1"
,
port
=
9393
,
device
=
"cpu"
)
server
.
prepare_server
(
workdir
=
"work_dir1"
,
port
=
9393
,
device
=
"cpu"
)
...
...
python/examples/grpc_impl_example/fit_a_line/test_server_gpu.py
0 → 100644
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
import
os
import
sys
from
paddle_serving_server_gpu
import
OpMaker
from
paddle_serving_server_gpu
import
OpSeqMaker
from
paddle_serving_server_gpu
import
MultiLangServer
as
Server
op_maker
=
OpMaker
()
read_op
=
op_maker
.
create
(
'general_reader'
)
general_infer_op
=
op_maker
.
create
(
'general_infer'
)
response_op
=
op_maker
.
create
(
'general_response'
)
op_seq_maker
=
OpSeqMaker
()
op_seq_maker
.
add_op
(
read_op
)
op_seq_maker
.
add_op
(
general_infer_op
)
op_seq_maker
.
add_op
(
response_op
)
server
=
Server
()
server
.
set_op_sequence
(
op_seq_maker
.
get_op_sequence
())
server
.
load_model_config
(
sys
.
argv
[
1
])
server
.
set_gpuid
(
0
)
server
.
prepare_server
(
workdir
=
"work_dir1"
,
port
=
9393
,
device
=
"cpu"
)
server
.
run_server
()
python/examples/grpc_impl_example/fit_a_line/test_sync_client.py
0 → 100644
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
paddle_serving_client
import
MultiLangClient
as
Client
client
=
Client
()
client
.
connect
([
"127.0.0.1:9393"
])
x
=
[
0.0137
,
-
0.1136
,
0.2553
,
-
0.0692
,
0.0582
,
-
0.0727
,
-
0.1583
,
-
0.0584
,
0.6283
,
0.4919
,
0.1856
,
0.0795
,
-
0.0332
]
for
i
in
range
(
3
):
fetch_map
=
client
.
predict
(
feed
=
{
"x"
:
x
},
fetch
=
[
"price"
])
if
fetch_map
[
"serving_status_code"
]
==
0
:
print
(
fetch_map
)
else
:
print
(
fetch_map
[
"serving_status_code"
])
python/examples/grpc_impl_example/fit_a_line/test_timeout_client.py
0 → 100644
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
paddle_serving_client
import
MultiLangClient
as
Client
import
grpc
client
=
Client
()
client
.
connect
([
"127.0.0.1:9393"
])
client
.
set_rpc_timeout_ms
(
1
)
x
=
[
0.0137
,
-
0.1136
,
0.2553
,
-
0.0692
,
0.0582
,
-
0.0727
,
-
0.1583
,
-
0.0584
,
0.6283
,
0.4919
,
0.1856
,
0.0795
,
-
0.0332
]
for
i
in
range
(
3
):
fetch_map
=
client
.
predict
(
feed
=
{
"x"
:
x
},
fetch
=
[
"price"
])
if
fetch_map
[
"serving_status_code"
]
==
0
:
print
(
fetch_map
)
elif
fetch_map
[
"serving_status_code"
]
==
grpc
.
StatusCode
.
DEADLINE_EXCEEDED
:
print
(
'timeout'
)
else
:
print
(
fetch_map
[
"serving_status_code"
])
python/examples/imdb/test_ensemble_client.py
浏览文件 @
e1013d75
...
@@ -32,11 +32,7 @@ for i in range(3):
...
@@ -32,11 +32,7 @@ for i in range(3):
line
=
'i am very sad | 0'
line
=
'i am very sad | 0'
word_ids
,
label
=
imdb_dataset
.
get_words_and_label
(
line
)
word_ids
,
label
=
imdb_dataset
.
get_words_and_label
(
line
)
feed
=
{
"words"
:
word_ids
}
feed
=
{
"words"
:
word_ids
}
fetch
=
[
"
acc"
,
"cost"
,
"
prediction"
]
fetch
=
[
"prediction"
]
fetch_maps
=
client
.
predict
(
feed
=
feed
,
fetch
=
fetch
)
fetch_maps
=
client
.
predict
(
feed
=
feed
,
fetch
=
fetch
)
if
len
(
fetch_maps
)
==
1
:
print
(
"step: {}, res: {}"
.
format
(
i
,
fetch_maps
[
'prediction'
][
0
][
1
]))
else
:
for
model
,
fetch_map
in
fetch_maps
.
items
():
for
model
,
fetch_map
in
fetch_maps
.
items
():
print
(
"step: {}, model: {}, res: {}"
.
format
(
i
,
model
,
fetch_map
[
print
(
"step: {}, model: {}, res: {}"
.
format
(
i
,
model
,
fetch_map
))
'prediction'
][
0
][
1
]))
python/examples/imdb/test_multilang_ensemble_client.py
0 → 100644
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
paddle_serving_client
import
MultiLangClient
from
imdb_reader
import
IMDBDataset
client
=
MultiLangClient
()
# If you have more than one model, make sure that the input
# and output of more than one model are the same.
client
.
connect
([
"127.0.0.1:9393"
])
# you can define any english sentence or dataset here
# This example reuses imdb reader in training, you
# can define your own data preprocessing easily.
imdb_dataset
=
IMDBDataset
()
imdb_dataset
.
load_resource
(
'imdb.vocab'
)
for
i
in
range
(
3
):
line
=
'i am very sad | 0'
word_ids
,
label
=
imdb_dataset
.
get_words_and_label
(
line
)
feed
=
{
"words"
:
word_ids
}
fetch
=
[
"prediction"
]
fetch_maps
=
client
.
predict
(
feed
=
feed
,
fetch
=
fetch
)
for
model
,
fetch_map
in
fetch_maps
.
items
():
print
(
"step: {}, model: {}, res: {}"
.
format
(
i
,
model
,
fetch_map
))
python/examples/imdb/test_multilang_ensemble_server.py
0 → 100644
浏览文件 @
e1013d75
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
paddle_serving_server
import
OpMaker
from
paddle_serving_server
import
OpGraphMaker
from
paddle_serving_server
import
MultiLangServer
op_maker
=
OpMaker
()
read_op
=
op_maker
.
create
(
'general_reader'
)
cnn_infer_op
=
op_maker
.
create
(
'general_infer'
,
engine_name
=
'cnn'
,
inputs
=
[
read_op
])
bow_infer_op
=
op_maker
.
create
(
'general_infer'
,
engine_name
=
'bow'
,
inputs
=
[
read_op
])
response_op
=
op_maker
.
create
(
'general_response'
,
inputs
=
[
cnn_infer_op
,
bow_infer_op
])
op_graph_maker
=
OpGraphMaker
()
op_graph_maker
.
add_op
(
read_op
)
op_graph_maker
.
add_op
(
cnn_infer_op
)
op_graph_maker
.
add_op
(
bow_infer_op
)
op_graph_maker
.
add_op
(
response_op
)
server
=
MultiLangServer
()
server
.
set_op_graph
(
op_graph_maker
.
get_op_graph
())
model_config
=
{
cnn_infer_op
:
'imdb_cnn_model'
,
bow_infer_op
:
'imdb_bow_model'
}
server
.
load_model_config
(
model_config
)
server
.
prepare_server
(
workdir
=
"work_dir1"
,
port
=
9393
,
device
=
"cpu"
)
server
.
run_server
()
python/paddle_serving_client/__init__.py
浏览文件 @
e1013d75
...
@@ -397,22 +397,41 @@ class Client(object):
...
@@ -397,22 +397,41 @@ class Client(object):
class
MultiLangClient
(
object
):
class
MultiLangClient
(
object
):
def
__init__
(
self
):
def
__init__
(
self
):
self
.
channel_
=
None
self
.
channel_
=
None
self
.
stub_
=
None
self
.
rpc_timeout_s_
=
2
def
load_client_config
(
self
,
path
):
def
add_variant
(
self
,
tag
,
cluster
,
variant_weight
):
if
not
isinstance
(
path
,
str
):
# TODO
raise
Exception
(
"GClient only supports multi-model temporarily"
)
raise
Exception
(
"cannot support ABtest yet"
)
self
.
_parse_model_config
(
path
)
def
connect
(
self
,
endpoint
):
def
set_rpc_timeout_ms
(
self
,
rpc_timeout
):
if
self
.
stub_
is
None
:
raise
Exception
(
"set timeout must be set after connect."
)
if
not
isinstance
(
rpc_timeout
,
int
):
# for bclient
raise
ValueError
(
"rpc_timeout must be int type."
)
self
.
rpc_timeout_s_
=
rpc_timeout
/
1000.0
timeout_req
=
multi_lang_general_model_service_pb2
.
SetTimeoutRequest
()
timeout_req
.
timeout_ms
=
rpc_timeout
resp
=
self
.
stub_
.
SetTimeout
(
timeout_req
)
return
resp
.
err_code
==
0
def
connect
(
self
,
endpoints
):
# https://github.com/tensorflow/serving/issues/1382
# https://github.com/tensorflow/serving/issues/1382
options
=
[(
'grpc.max_receive_message_length'
,
512
*
1024
*
1024
),
options
=
[(
'grpc.max_receive_message_length'
,
512
*
1024
*
1024
),
(
'grpc.max_send_message_length'
,
512
*
1024
*
1024
),
(
'grpc.max_send_message_length'
,
512
*
1024
*
1024
),
(
'grpc.
max_receive_message_length'
,
512
*
1024
*
1024
)]
(
'grpc.
lb_policy_name'
,
'round_robin'
)]
# TODO: weight round robin
self
.
channel_
=
grpc
.
insecure_channel
(
g_endpoint
=
'ipv4:{}'
.
format
(
','
.
join
(
endpoints
))
endpoint
[
0
],
options
=
options
)
#TODO
self
.
channel_
=
grpc
.
insecure_channel
(
g_endpoint
,
options
=
options
)
self
.
stub_
=
multi_lang_general_model_service_pb2_grpc
.
MultiLangGeneralModelServiceStub
(
self
.
stub_
=
multi_lang_general_model_service_pb2_grpc
.
MultiLangGeneralModelServiceStub
(
self
.
channel_
)
self
.
channel_
)
# get client model config
get_client_config_req
=
multi_lang_general_model_service_pb2
.
GetClientConfigRequest
(
)
resp
=
self
.
stub_
.
GetClientConfig
(
get_client_config_req
)
model_config_str
=
resp
.
client_config_str
self
.
_parse_model_config
(
model_config_str
)
def
_flatten_list
(
self
,
nested_list
):
def
_flatten_list
(
self
,
nested_list
):
for
item
in
nested_list
:
for
item
in
nested_list
:
...
@@ -422,11 +441,10 @@ class MultiLangClient(object):
...
@@ -422,11 +441,10 @@ class MultiLangClient(object):
else
:
else
:
yield
item
yield
item
def
_parse_model_config
(
self
,
model_config_
path
):
def
_parse_model_config
(
self
,
model_config_
str
):
model_conf
=
m_config
.
GeneralModelConfig
()
model_conf
=
m_config
.
GeneralModelConfig
()
f
=
open
(
model_config_path
,
'r'
)
model_conf
=
google
.
protobuf
.
text_format
.
Merge
(
model_config_str
,
model_conf
=
google
.
protobuf
.
text_format
.
Merge
(
model_conf
)
str
(
f
.
read
()),
model_conf
)
self
.
feed_names_
=
[
var
.
alias_name
for
var
in
model_conf
.
feed_var
]
self
.
feed_names_
=
[
var
.
alias_name
for
var
in
model_conf
.
feed_var
]
self
.
feed_types_
=
{}
self
.
feed_types_
=
{}
self
.
feed_shapes_
=
{}
self
.
feed_shapes_
=
{}
...
@@ -447,8 +465,8 @@ class MultiLangClient(object):
...
@@ -447,8 +465,8 @@ class MultiLangClient(object):
if
var
.
is_lod_tensor
:
if
var
.
is_lod_tensor
:
self
.
lod_tensor_set_
.
add
(
var
.
alias_name
)
self
.
lod_tensor_set_
.
add
(
var
.
alias_name
)
def
_pack_
feed_data
(
self
,
feed
,
fetch
,
is_python
):
def
_pack_
inference_request
(
self
,
feed
,
fetch
,
is_python
):
req
=
multi_lang_general_model_service_pb2
.
Request
()
req
=
multi_lang_general_model_service_pb2
.
Inference
Request
()
req
.
fetch_var_names
.
extend
(
fetch
)
req
.
fetch_var_names
.
extend
(
fetch
)
req
.
is_python
=
is_python
req
.
is_python
=
is_python
feed_batch
=
None
feed_batch
=
None
...
@@ -473,33 +491,50 @@ class MultiLangClient(object):
...
@@ -473,33 +491,50 @@ class MultiLangClient(object):
data
=
np
.
array
(
var
,
dtype
=
"int64"
)
data
=
np
.
array
(
var
,
dtype
=
"int64"
)
elif
v_type
==
1
:
# float32
elif
v_type
==
1
:
# float32
data
=
np
.
array
(
var
,
dtype
=
"float32"
)
data
=
np
.
array
(
var
,
dtype
=
"float32"
)
elif
v_type
==
2
:
#int32
elif
v_type
==
2
:
#
int32
data
=
np
.
array
(
var
,
dtype
=
"int32"
)
data
=
np
.
array
(
var
,
dtype
=
"int32"
)
else
:
else
:
raise
Exception
(
"error type."
)
raise
Exception
(
"error t
ensor value t
ype."
)
el
se
:
el
if
isinstance
(
var
,
np
.
ndarray
)
:
data
=
var
data
=
var
if
var
.
dtype
==
"float64"
:
if
v_type
==
0
:
if
data
.
dtype
!=
'int64'
:
data
=
data
.
astype
(
"int64"
)
elif
v_type
==
1
:
if
data
.
dtype
!=
'float32'
:
data
=
data
.
astype
(
"float32"
)
data
=
data
.
astype
(
"float32"
)
elif
v_type
==
2
:
if
data
.
dtype
!=
'int32'
:
data
=
data
.
astype
(
"int32"
)
else
:
raise
Exception
(
"error tensor value type."
)
else
:
raise
Exception
(
"var must be list or ndarray."
)
tensor
.
data
=
data
.
tobytes
()
tensor
.
data
=
data
.
tobytes
()
else
:
else
:
if
v_type
==
0
:
# int64
if
isinstance
(
var
,
np
.
ndarray
):
if
isinstance
(
var
,
np
.
ndarray
):
tensor
.
int64_data
.
extend
(
var
.
reshape
(
-
1
).
tolist
())
if
v_type
==
0
:
# int64
tensor
.
int64_data
.
extend
(
var
.
reshape
(
-
1
).
astype
(
"int64"
).
tolist
())
elif
v_type
==
1
:
tensor
.
float_data
.
extend
(
var
.
reshape
(
-
1
).
astype
(
'float32'
).
tolist
())
elif
v_type
==
2
:
tensor
.
int32_data
.
extend
(
var
.
reshape
(
-
1
).
astype
(
'int32'
).
tolist
())
else
:
else
:
raise
Exception
(
"error tensor value type."
)
elif
isinstance
(
var
,
list
):
if
v_type
==
0
:
tensor
.
int64_data
.
extend
(
self
.
_flatten_list
(
var
))
tensor
.
int64_data
.
extend
(
self
.
_flatten_list
(
var
))
elif
v_type
==
1
:
# float32
elif
v_type
==
1
:
if
isinstance
(
var
,
np
.
ndarray
):
tensor
.
float_data
.
extend
(
var
.
reshape
(
-
1
).
tolist
())
else
:
tensor
.
float_data
.
extend
(
self
.
_flatten_list
(
var
))
tensor
.
float_data
.
extend
(
self
.
_flatten_list
(
var
))
elif
v_type
==
2
:
#int32
elif
v_type
==
2
:
if
isinstance
(
car
,
np
.
array
):
tensor
.
int32_data
.
extend
(
self
.
_flatten_list
(
var
))
tensor
.
int_data
.
extend
(
var
.
reshape
(
-
1
).
tolist
())
else
:
else
:
tensor
.
int_data
.
extend
(
self
.
_flatten_list
(
var
)
)
raise
Exception
(
"error tensor value type."
)
else
:
else
:
raise
Exception
(
"
error type
."
)
raise
Exception
(
"
var must be list or ndarray
."
)
if
isinstance
(
var
,
np
.
ndarray
):
if
isinstance
(
var
,
np
.
ndarray
):
tensor
.
shape
.
extend
(
list
(
var
.
shape
))
tensor
.
shape
.
extend
(
list
(
var
.
shape
))
else
:
else
:
...
@@ -508,18 +543,25 @@ class MultiLangClient(object):
...
@@ -508,18 +543,25 @@ class MultiLangClient(object):
req
.
insts
.
append
(
inst
)
req
.
insts
.
append
(
inst
)
return
req
return
req
def
_unpack_resp
(
self
,
resp
,
fetch
,
is_python
,
need_variant_tag
):
def
_unpack_inference_response
(
self
,
resp
,
fetch
,
is_python
,
result_map
=
{}
need_variant_tag
):
inst
=
resp
.
outputs
[
0
].
insts
[
0
]
if
resp
.
err_code
!=
0
:
return
None
tag
=
resp
.
tag
tag
=
resp
.
tag
multi_result_map
=
{}
for
model_result
in
resp
.
outputs
:
inst
=
model_result
.
insts
[
0
]
result_map
=
{}
for
i
,
name
in
enumerate
(
fetch
):
for
i
,
name
in
enumerate
(
fetch
):
var
=
inst
.
tensor_array
[
i
]
var
=
inst
.
tensor_array
[
i
]
v_type
=
self
.
fetch_types_
[
name
]
v_type
=
self
.
fetch_types_
[
name
]
if
is_python
:
if
is_python
:
if
v_type
==
0
:
# int64
if
v_type
==
0
:
# int64
result_map
[
name
]
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"int64"
)
result_map
[
name
]
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"int64"
)
elif
v_type
==
1
:
# float32
elif
v_type
==
1
:
# float32
result_map
[
name
]
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"float32"
)
result_map
[
name
]
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"float32"
)
else
:
else
:
raise
Exception
(
"error type."
)
raise
Exception
(
"error type."
)
else
:
else
:
...
@@ -529,19 +571,24 @@ class MultiLangClient(object):
...
@@ -529,19 +571,24 @@ class MultiLangClient(object):
elif
v_type
==
1
:
# float32
elif
v_type
==
1
:
# float32
result_map
[
name
]
=
np
.
array
(
result_map
[
name
]
=
np
.
array
(
list
(
var
.
float_data
),
dtype
=
"float32"
)
list
(
var
.
float_data
),
dtype
=
"float32"
)
elif
v_type
==
2
:
# int32
result_map
[
name
]
=
np
.
array
(
list
(
var
.
int_data
),
dtype
=
"int32"
)
else
:
else
:
raise
Exception
(
"error type."
)
raise
Exception
(
"error type."
)
result_map
[
name
].
shape
=
list
(
var
.
shape
)
result_map
[
name
].
shape
=
list
(
var
.
shape
)
if
name
in
self
.
lod_tensor_set_
:
if
name
in
self
.
lod_tensor_set_
:
result_map
[
"{}.lod"
.
format
(
name
)]
=
np
.
array
(
list
(
var
.
lod
))
result_map
[
"{}.lod"
.
format
(
name
)]
=
np
.
array
(
list
(
var
.
lod
))
return
result_map
if
not
need_variant_tag
else
[
result_map
,
tag
]
multi_result_map
[
model_result
.
engine_name
]
=
result_map
ret
=
None
if
len
(
resp
.
outputs
)
==
1
:
ret
=
list
(
multi_result_map
.
values
())[
0
]
else
:
ret
=
multi_result_map
ret
[
"serving_status_code"
]
=
0
return
ret
if
not
need_variant_tag
else
[
ret
,
tag
]
def
_done_callback_func
(
self
,
fetch
,
is_python
,
need_variant_tag
):
def
_done_callback_func
(
self
,
fetch
,
is_python
,
need_variant_tag
):
def
unpack_resp
(
resp
):
def
unpack_resp
(
resp
):
return
self
.
_unpack_resp
(
resp
,
fetch
,
is_python
,
need_variant_tag
)
return
self
.
_unpack_inference_response
(
resp
,
fetch
,
is_python
,
need_variant_tag
)
return
unpack_resp
return
unpack_resp
...
@@ -554,16 +601,20 @@ class MultiLangClient(object):
...
@@ -554,16 +601,20 @@ class MultiLangClient(object):
need_variant_tag
=
False
,
need_variant_tag
=
False
,
asyn
=
False
,
asyn
=
False
,
is_python
=
True
):
is_python
=
True
):
req
=
self
.
_pack_
feed_data
(
feed
,
fetch
,
is_python
=
is_python
)
req
=
self
.
_pack_
inference_request
(
feed
,
fetch
,
is_python
=
is_python
)
if
not
asyn
:
if
not
asyn
:
resp
=
self
.
stub_
.
inference
(
req
)
try
:
return
self
.
_unpack_resp
(
resp
=
self
.
stub_
.
Inference
(
req
,
timeout
=
self
.
rpc_timeout_s_
)
return
self
.
_unpack_inference_response
(
resp
,
resp
,
fetch
,
fetch
,
is_python
=
is_python
,
is_python
=
is_python
,
need_variant_tag
=
need_variant_tag
)
need_variant_tag
=
need_variant_tag
)
except
grpc
.
RpcError
as
e
:
return
{
"serving_status_code"
:
e
.
code
()}
else
:
else
:
call_future
=
self
.
stub_
.
inference
.
future
(
req
)
call_future
=
self
.
stub_
.
Inference
.
future
(
req
,
timeout
=
self
.
rpc_timeout_s_
)
return
MultiLangPredictFuture
(
return
MultiLangPredictFuture
(
call_future
,
call_future
,
self
.
_done_callback_func
(
self
.
_done_callback_func
(
...
@@ -578,7 +629,10 @@ class MultiLangPredictFuture(object):
...
@@ -578,7 +629,10 @@ class MultiLangPredictFuture(object):
self
.
callback_func_
=
callback_func
self
.
callback_func_
=
callback_func
def
result
(
self
):
def
result
(
self
):
try
:
resp
=
self
.
call_future_
.
result
()
resp
=
self
.
call_future_
.
result
()
except
grpc
.
RpcError
as
e
:
return
{
"serving_status_code"
:
e
.
code
()}
return
self
.
callback_func_
(
resp
)
return
self
.
callback_func_
(
resp
)
def
add_done_callback
(
self
,
fn
):
def
add_done_callback
(
self
,
fn
):
...
...
python/paddle_serving_server/__init__.py
浏览文件 @
e1013d75
...
@@ -440,22 +440,29 @@ class Server(object):
...
@@ -440,22 +440,29 @@ class Server(object):
os
.
system
(
command
)
os
.
system
(
command
)
class
MultiLangServerService
(
class
MultiLangServerServiceServicer
(
multi_lang_general_model_service_pb2_grpc
.
multi_lang_general_model_service_pb2_grpc
.
MultiLangGeneralModelService
):
MultiLangGeneralModelServiceServicer
):
def
__init__
(
self
,
model_config_path
,
endpoints
):
def
__init__
(
self
,
model_config_path
,
is_multi_model
,
endpoints
):
self
.
is_multi_model_
=
is_multi_model
self
.
model_config_path_
=
model_config_path
self
.
endpoints_
=
endpoints
with
open
(
self
.
model_config_path_
)
as
f
:
self
.
model_config_str_
=
str
(
f
.
read
())
self
.
_parse_model_config
(
self
.
model_config_str_
)
self
.
_init_bclient
(
self
.
model_config_path_
,
self
.
endpoints_
)
def
_init_bclient
(
self
,
model_config_path
,
endpoints
,
timeout_ms
=
None
):
from
paddle_serving_client
import
Client
from
paddle_serving_client
import
Client
self
.
_parse_model_config
(
model_config_path
)
self
.
bclient_
=
Client
()
self
.
bclient_
=
Client
()
self
.
bclient_
.
load_client_config
(
if
timeout_ms
is
not
None
:
"{}/serving_server_conf.prototxt"
.
format
(
model_config_path
))
self
.
bclient_
.
set_rpc_timeout_ms
(
timeout_ms
)
self
.
bclient_
.
load_client_config
(
model_config_path
)
self
.
bclient_
.
connect
(
endpoints
)
self
.
bclient_
.
connect
(
endpoints
)
def
_parse_model_config
(
self
,
model_config_
path
):
def
_parse_model_config
(
self
,
model_config_
str
):
model_conf
=
m_config
.
GeneralModelConfig
()
model_conf
=
m_config
.
GeneralModelConfig
()
f
=
open
(
"{}/serving_server_conf.prototxt"
.
format
(
model_config_path
),
model_conf
=
google
.
protobuf
.
text_format
.
Merge
(
model_config_str
,
'r'
)
model_conf
)
model_conf
=
google
.
protobuf
.
text_format
.
Merge
(
str
(
f
.
read
()),
model_conf
)
self
.
feed_names_
=
[
var
.
alias_name
for
var
in
model_conf
.
feed_var
]
self
.
feed_names_
=
[
var
.
alias_name
for
var
in
model_conf
.
feed_var
]
self
.
feed_types_
=
{}
self
.
feed_types_
=
{}
self
.
feed_shapes_
=
{}
self
.
feed_shapes_
=
{}
...
@@ -480,7 +487,7 @@ class MultiLangServerService(
...
@@ -480,7 +487,7 @@ class MultiLangServerService(
else
:
else
:
yield
item
yield
item
def
_unpack_request
(
self
,
request
):
def
_unpack_
inference_
request
(
self
,
request
):
feed_names
=
list
(
request
.
feed_var_names
)
feed_names
=
list
(
request
.
feed_var_names
)
fetch_names
=
list
(
request
.
fetch_var_names
)
fetch_names
=
list
(
request
.
fetch_var_names
)
is_python
=
request
.
is_python
is_python
=
request
.
is_python
...
@@ -492,10 +499,12 @@ class MultiLangServerService(
...
@@ -492,10 +499,12 @@ class MultiLangServerService(
v_type
=
self
.
feed_types_
[
name
]
v_type
=
self
.
feed_types_
[
name
]
data
=
None
data
=
None
if
is_python
:
if
is_python
:
if
v_type
==
0
:
if
v_type
==
0
:
# int64
data
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"int64"
)
data
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"int64"
)
elif
v_type
==
1
:
elif
v_type
==
1
:
# float32
data
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"float32"
)
data
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"float32"
)
elif
v_type
==
2
:
# int32
data
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"int32"
)
else
:
else
:
raise
Exception
(
"error type."
)
raise
Exception
(
"error type."
)
else
:
else
:
...
@@ -503,6 +512,8 @@ class MultiLangServerService(
...
@@ -503,6 +512,8 @@ class MultiLangServerService(
data
=
np
.
array
(
list
(
var
.
int64_data
),
dtype
=
"int64"
)
data
=
np
.
array
(
list
(
var
.
int64_data
),
dtype
=
"int64"
)
elif
v_type
==
1
:
# float32
elif
v_type
==
1
:
# float32
data
=
np
.
array
(
list
(
var
.
float_data
),
dtype
=
"float32"
)
data
=
np
.
array
(
list
(
var
.
float_data
),
dtype
=
"float32"
)
elif
v_type
==
2
:
# int32
data
=
np
.
array
(
list
(
var
.
int32_data
),
dtype
=
"int32"
)
else
:
else
:
raise
Exception
(
"error type."
)
raise
Exception
(
"error type."
)
data
.
shape
=
list
(
feed_inst
.
tensor_array
[
idx
].
shape
)
data
.
shape
=
list
(
feed_inst
.
tensor_array
[
idx
].
shape
)
...
@@ -510,55 +521,132 @@ class MultiLangServerService(
...
@@ -510,55 +521,132 @@ class MultiLangServerService(
feed_batch
.
append
(
feed_dict
)
feed_batch
.
append
(
feed_dict
)
return
feed_batch
,
fetch_names
,
is_python
return
feed_batch
,
fetch_names
,
is_python
def
_pack_resp_package
(
self
,
result
,
fetch_names
,
is_python
,
tag
):
def
_pack_inference_response
(
self
,
ret
,
fetch_names
,
is_python
):
resp
=
multi_lang_general_model_service_pb2
.
Response
()
resp
=
multi_lang_general_model_service_pb2
.
InferenceResponse
()
# Only one model is supported temporarily
if
ret
is
None
:
resp
.
err_code
=
1
return
resp
results
,
tag
=
ret
resp
.
tag
=
tag
resp
.
err_code
=
0
if
not
self
.
is_multi_model_
:
results
=
{
'general_infer_0'
:
results
}
for
model_name
,
model_result
in
results
.
items
():
model_output
=
multi_lang_general_model_service_pb2
.
ModelOutput
()
model_output
=
multi_lang_general_model_service_pb2
.
ModelOutput
()
inst
=
multi_lang_general_model_service_pb2
.
FetchInst
()
inst
=
multi_lang_general_model_service_pb2
.
FetchInst
()
for
idx
,
name
in
enumerate
(
fetch_names
):
for
idx
,
name
in
enumerate
(
fetch_names
):
tensor
=
multi_lang_general_model_service_pb2
.
Tensor
()
tensor
=
multi_lang_general_model_service_pb2
.
Tensor
()
v_type
=
self
.
fetch_types_
[
name
]
v_type
=
self
.
fetch_types_
[
name
]
if
is_python
:
if
is_python
:
tensor
.
data
=
result
[
name
].
tobytes
()
tensor
.
data
=
model_
result
[
name
].
tobytes
()
else
:
else
:
if
v_type
==
0
:
# int64
if
v_type
==
0
:
# int64
tensor
.
int64_data
.
extend
(
result
[
name
].
reshape
(
-
1
).
tolist
())
tensor
.
int64_data
.
extend
(
model_result
[
name
].
reshape
(
-
1
)
.
tolist
())
elif
v_type
==
1
:
# float32
elif
v_type
==
1
:
# float32
tensor
.
float_data
.
extend
(
result
[
name
].
reshape
(
-
1
).
tolist
())
tensor
.
float_data
.
extend
(
model_result
[
name
].
reshape
(
-
1
)
.
tolist
())
elif
v_type
==
2
:
# int32
tensor
.
int32_data
.
extend
(
model_result
[
name
].
reshape
(
-
1
)
.
tolist
())
else
:
else
:
raise
Exception
(
"error type."
)
raise
Exception
(
"error type."
)
tensor
.
shape
.
extend
(
list
(
result
[
name
].
shape
))
tensor
.
shape
.
extend
(
list
(
model_
result
[
name
].
shape
))
if
name
in
self
.
lod_tensor_set_
:
if
name
in
self
.
lod_tensor_set_
:
tensor
.
lod
.
extend
(
result
[
"{}.lod"
.
format
(
name
)].
tolist
())
tensor
.
lod
.
extend
(
model_result
[
"{}.lod"
.
format
(
name
)]
.
tolist
())
inst
.
tensor_array
.
append
(
tensor
)
inst
.
tensor_array
.
append
(
tensor
)
model_output
.
insts
.
append
(
inst
)
model_output
.
insts
.
append
(
inst
)
model_output
.
engine_name
=
model_name
resp
.
outputs
.
append
(
model_output
)
resp
.
outputs
.
append
(
model_output
)
resp
.
tag
=
tag
return
resp
return
resp
def
inference
(
self
,
request
,
context
):
def
SetTimeout
(
self
,
request
,
context
):
feed_dict
,
fetch_names
,
is_python
=
self
.
_unpack_request
(
request
)
# This porcess and Inference process cannot be operate at the same time.
data
,
tag
=
self
.
bclient_
.
predict
(
# For performance reasons, do not add thread lock temporarily.
timeout_ms
=
request
.
timeout_ms
self
.
_init_bclient
(
self
.
model_config_path_
,
self
.
endpoints_
,
timeout_ms
)
resp
=
multi_lang_general_model_service_pb2
.
SimpleResponse
()
resp
.
err_code
=
0
return
resp
def
Inference
(
self
,
request
,
context
):
feed_dict
,
fetch_names
,
is_python
=
self
.
_unpack_inference_request
(
request
)
ret
=
self
.
bclient_
.
predict
(
feed
=
feed_dict
,
fetch
=
fetch_names
,
need_variant_tag
=
True
)
feed
=
feed_dict
,
fetch
=
fetch_names
,
need_variant_tag
=
True
)
return
self
.
_pack_resp_package
(
data
,
fetch_names
,
is_python
,
tag
)
return
self
.
_pack_inference_response
(
ret
,
fetch_names
,
is_python
)
def
GetClientConfig
(
self
,
request
,
context
):
resp
=
multi_lang_general_model_service_pb2
.
GetClientConfigResponse
()
resp
.
client_config_str
=
self
.
model_config_str_
return
resp
class
MultiLangServer
(
object
):
class
MultiLangServer
(
object
):
def
__init__
(
self
,
worker_num
=
2
):
def
__init__
(
self
):
self
.
bserver_
=
Server
()
self
.
bserver_
=
Server
()
self
.
worker_num_
=
worker_num
self
.
worker_num_
=
4
self
.
body_size_
=
64
*
1024
*
1024
self
.
concurrency_
=
100000
self
.
is_multi_model_
=
False
# for model ensemble
def
set_max_concurrency
(
self
,
concurrency
):
self
.
concurrency_
=
concurrency
self
.
bserver_
.
set_max_concurrency
(
concurrency
)
def
set_num_threads
(
self
,
threads
):
self
.
worker_num_
=
threads
self
.
bserver_
.
set_num_threads
(
threads
)
def
set_max_body_size
(
self
,
body_size
):
self
.
bserver_
.
set_max_body_size
(
body_size
)
if
body_size
>=
self
.
body_size_
:
self
.
body_size_
=
body_size
else
:
print
(
"max_body_size is less than default value, will use default value in service."
)
def
set_port
(
self
,
port
):
self
.
gport_
=
port
def
set_reload_interval
(
self
,
interval
):
self
.
bserver_
.
set_reload_interval
(
interval
)
def
set_op_sequence
(
self
,
op_seq
):
def
set_op_sequence
(
self
,
op_seq
):
self
.
bserver_
.
set_op_sequence
(
op_seq
)
self
.
bserver_
.
set_op_sequence
(
op_seq
)
def
load_model_config
(
self
,
model_config_path
):
def
set_op_graph
(
self
,
op_graph
):
if
not
isinstance
(
model_config_path
,
str
):
self
.
bserver_
.
set_op_graph
(
op_graph
)
raise
Exception
(
"MultiLangServer only supports multi-model temporarily"
)
def
set_memory_optimize
(
self
,
flag
=
False
):
self
.
bserver_
.
load_model_config
(
model_config_path
)
self
.
bserver_
.
set_memory_optimize
(
flag
)
self
.
model_config_path_
=
model_config_path
def
set_ir_optimize
(
self
,
flag
=
False
):
self
.
bserver_
.
set_ir_optimize
(
flag
)
def
set_op_sequence
(
self
,
op_seq
):
self
.
bserver_
.
set_op_sequence
(
op_seq
)
def
use_mkl
(
self
,
flag
):
self
.
bserver_
.
use_mkl
(
flag
)
def
load_model_config
(
self
,
server_config_paths
,
client_config_path
=
None
):
self
.
bserver_
.
load_model_config
(
server_config_paths
)
if
client_config_path
is
None
:
if
isinstance
(
server_config_paths
,
dict
):
self
.
is_multi_model_
=
True
client_config_path
=
'{}/serving_server_conf.prototxt'
.
format
(
list
(
server_config_paths
.
items
())[
0
][
1
])
else
:
client_config_path
=
'{}/serving_server_conf.prototxt'
.
format
(
server_config_paths
)
self
.
bclient_config_path_
=
client_config_path
def
prepare_server
(
self
,
workdir
=
None
,
port
=
9292
,
device
=
"cpu"
):
def
prepare_server
(
self
,
workdir
=
None
,
port
=
9292
,
device
=
"cpu"
):
if
not
self
.
_port_is_available
(
port
):
raise
SystemExit
(
"Prot {} is already used"
.
format
(
port
))
default_port
=
12000
default_port
=
12000
self
.
port_list_
=
[]
self
.
port_list_
=
[]
for
i
in
range
(
1000
):
for
i
in
range
(
1000
):
...
@@ -568,7 +656,7 @@ class MultiLangServer(object):
...
@@ -568,7 +656,7 @@ class MultiLangServer(object):
break
break
self
.
bserver_
.
prepare_server
(
self
.
bserver_
.
prepare_server
(
workdir
=
workdir
,
port
=
self
.
port_list_
[
0
],
device
=
device
)
workdir
=
workdir
,
port
=
self
.
port_list_
[
0
],
device
=
device
)
self
.
gport_
=
port
self
.
set_port
(
port
)
def
_launch_brpc_service
(
self
,
bserver
):
def
_launch_brpc_service
(
self
,
bserver
):
bserver
.
run_server
()
bserver
.
run_server
()
...
@@ -583,12 +671,16 @@ class MultiLangServer(object):
...
@@ -583,12 +671,16 @@ class MultiLangServer(object):
p_bserver
=
Process
(
p_bserver
=
Process
(
target
=
self
.
_launch_brpc_service
,
args
=
(
self
.
bserver_
,
))
target
=
self
.
_launch_brpc_service
,
args
=
(
self
.
bserver_
,
))
p_bserver
.
start
()
p_bserver
.
start
()
options
=
[(
'grpc.max_send_message_length'
,
self
.
body_size_
),
(
'grpc.max_receive_message_length'
,
self
.
body_size_
)]
server
=
grpc
.
server
(
server
=
grpc
.
server
(
futures
.
ThreadPoolExecutor
(
max_workers
=
self
.
worker_num_
))
futures
.
ThreadPoolExecutor
(
max_workers
=
self
.
worker_num_
),
options
=
options
,
maximum_concurrent_rpcs
=
self
.
concurrency_
)
multi_lang_general_model_service_pb2_grpc
.
add_MultiLangGeneralModelServiceServicer_to_server
(
multi_lang_general_model_service_pb2_grpc
.
add_MultiLangGeneralModelServiceServicer_to_server
(
MultiLangServerService
(
self
.
model_config_path_
,
MultiLangServerService
Servicer
(
[
"0.0.0.0:{}"
.
format
(
self
.
port_list_
[
0
])])
,
self
.
bclient_config_path_
,
self
.
is_multi_model_
,
server
)
[
"0.0.0.0:{}"
.
format
(
self
.
port_list_
[
0
])]),
server
)
server
.
add_insecure_port
(
'[::]:{}'
.
format
(
self
.
gport_
))
server
.
add_insecure_port
(
'[::]:{}'
.
format
(
self
.
gport_
))
server
.
start
()
server
.
start
()
p_bserver
.
join
()
p_bserver
.
join
()
...
...
python/paddle_serving_server/serve.py
浏览文件 @
e1013d75
...
@@ -53,6 +53,11 @@ def parse_args(): # pylint: disable=doc-string-missing
...
@@ -53,6 +53,11 @@ def parse_args(): # pylint: disable=doc-string-missing
type
=
int
,
type
=
int
,
default
=
512
*
1024
*
1024
,
default
=
512
*
1024
*
1024
,
help
=
"Limit sizes of messages"
)
help
=
"Limit sizes of messages"
)
parser
.
add_argument
(
"--use_multilang"
,
default
=
False
,
action
=
"store_true"
,
help
=
"Use Multi-language-service"
)
return
parser
.
parse_args
()
return
parser
.
parse_args
()
...
@@ -67,6 +72,7 @@ def start_standard_model(): # pylint: disable=doc-string-missing
...
@@ -67,6 +72,7 @@ def start_standard_model(): # pylint: disable=doc-string-missing
ir_optim
=
args
.
ir_optim
ir_optim
=
args
.
ir_optim
max_body_size
=
args
.
max_body_size
max_body_size
=
args
.
max_body_size
use_mkl
=
args
.
use_mkl
use_mkl
=
args
.
use_mkl
use_multilang
=
args
.
use_multilang
if
model
==
""
:
if
model
==
""
:
print
(
"You must specify your serving model"
)
print
(
"You must specify your serving model"
)
...
@@ -83,6 +89,10 @@ def start_standard_model(): # pylint: disable=doc-string-missing
...
@@ -83,6 +89,10 @@ def start_standard_model(): # pylint: disable=doc-string-missing
op_seq_maker
.
add_op
(
general_infer_op
)
op_seq_maker
.
add_op
(
general_infer_op
)
op_seq_maker
.
add_op
(
general_response_op
)
op_seq_maker
.
add_op
(
general_response_op
)
server
=
None
if
use_multilang
:
server
=
serving
.
MultiLangServer
()
else
:
server
=
serving
.
Server
()
server
=
serving
.
Server
()
server
.
set_op_sequence
(
op_seq_maker
.
get_op_sequence
())
server
.
set_op_sequence
(
op_seq_maker
.
get_op_sequence
())
server
.
set_num_threads
(
thread_num
)
server
.
set_num_threads
(
thread_num
)
...
...
python/paddle_serving_server_gpu/__init__.py
浏览文件 @
e1013d75
...
@@ -68,6 +68,11 @@ def serve_args():
...
@@ -68,6 +68,11 @@ def serve_args():
type
=
int
,
type
=
int
,
default
=
512
*
1024
*
1024
,
default
=
512
*
1024
*
1024
,
help
=
"Limit sizes of messages"
)
help
=
"Limit sizes of messages"
)
parser
.
add_argument
(
"--use_multilang"
,
default
=
False
,
action
=
"store_true"
,
help
=
"Use Multi-language-service"
)
return
parser
.
parse_args
()
return
parser
.
parse_args
()
...
@@ -484,22 +489,29 @@ class Server(object):
...
@@ -484,22 +489,29 @@ class Server(object):
os
.
system
(
command
)
os
.
system
(
command
)
class
MultiLangServerService
(
class
MultiLangServerServiceServicer
(
multi_lang_general_model_service_pb2_grpc
.
multi_lang_general_model_service_pb2_grpc
.
MultiLangGeneralModelService
):
MultiLangGeneralModelServiceServicer
):
def
__init__
(
self
,
model_config_path
,
endpoints
):
def
__init__
(
self
,
model_config_path
,
is_multi_model
,
endpoints
):
self
.
is_multi_model_
=
is_multi_model
self
.
model_config_path_
=
model_config_path
self
.
endpoints_
=
endpoints
with
open
(
self
.
model_config_path_
)
as
f
:
self
.
model_config_str_
=
str
(
f
.
read
())
self
.
_parse_model_config
(
self
.
model_config_str_
)
self
.
_init_bclient
(
self
.
model_config_path_
,
self
.
endpoints_
)
def
_init_bclient
(
self
,
model_config_path
,
endpoints
,
timeout_ms
=
None
):
from
paddle_serving_client
import
Client
from
paddle_serving_client
import
Client
self
.
_parse_model_config
(
model_config_path
)
self
.
bclient_
=
Client
()
self
.
bclient_
=
Client
()
self
.
bclient_
.
load_client_config
(
if
timeout_ms
is
not
None
:
"{}/serving_server_conf.prototxt"
.
format
(
model_config_path
))
self
.
bclient_
.
set_rpc_timeout_ms
(
timeout_ms
)
self
.
bclient_
.
load_client_config
(
model_config_path
)
self
.
bclient_
.
connect
(
endpoints
)
self
.
bclient_
.
connect
(
endpoints
)
def
_parse_model_config
(
self
,
model_config_
path
):
def
_parse_model_config
(
self
,
model_config_
str
):
model_conf
=
m_config
.
GeneralModelConfig
()
model_conf
=
m_config
.
GeneralModelConfig
()
f
=
open
(
"{}/serving_server_conf.prototxt"
.
format
(
model_config_path
),
model_conf
=
google
.
protobuf
.
text_format
.
Merge
(
model_config_str
,
'r'
)
model_conf
)
model_conf
=
google
.
protobuf
.
text_format
.
Merge
(
str
(
f
.
read
()),
model_conf
)
self
.
feed_names_
=
[
var
.
alias_name
for
var
in
model_conf
.
feed_var
]
self
.
feed_names_
=
[
var
.
alias_name
for
var
in
model_conf
.
feed_var
]
self
.
feed_types_
=
{}
self
.
feed_types_
=
{}
self
.
feed_shapes_
=
{}
self
.
feed_shapes_
=
{}
...
@@ -524,7 +536,7 @@ class MultiLangServerService(
...
@@ -524,7 +536,7 @@ class MultiLangServerService(
else
:
else
:
yield
item
yield
item
def
_unpack_request
(
self
,
request
):
def
_unpack_
inference_
request
(
self
,
request
):
feed_names
=
list
(
request
.
feed_var_names
)
feed_names
=
list
(
request
.
feed_var_names
)
fetch_names
=
list
(
request
.
fetch_var_names
)
fetch_names
=
list
(
request
.
fetch_var_names
)
is_python
=
request
.
is_python
is_python
=
request
.
is_python
...
@@ -540,6 +552,8 @@ class MultiLangServerService(
...
@@ -540,6 +552,8 @@ class MultiLangServerService(
data
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"int64"
)
data
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"int64"
)
elif
v_type
==
1
:
elif
v_type
==
1
:
data
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"float32"
)
data
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"float32"
)
elif
v_type
==
2
:
data
=
np
.
frombuffer
(
var
.
data
,
dtype
=
"int32"
)
else
:
else
:
raise
Exception
(
"error type."
)
raise
Exception
(
"error type."
)
else
:
else
:
...
@@ -547,6 +561,8 @@ class MultiLangServerService(
...
@@ -547,6 +561,8 @@ class MultiLangServerService(
data
=
np
.
array
(
list
(
var
.
int64_data
),
dtype
=
"int64"
)
data
=
np
.
array
(
list
(
var
.
int64_data
),
dtype
=
"int64"
)
elif
v_type
==
1
:
# float32
elif
v_type
==
1
:
# float32
data
=
np
.
array
(
list
(
var
.
float_data
),
dtype
=
"float32"
)
data
=
np
.
array
(
list
(
var
.
float_data
),
dtype
=
"float32"
)
elif
v_type
==
2
:
data
=
np
.
array
(
list
(
var
.
int32_data
),
dtype
=
"int32"
)
else
:
else
:
raise
Exception
(
"error type."
)
raise
Exception
(
"error type."
)
data
.
shape
=
list
(
feed_inst
.
tensor_array
[
idx
].
shape
)
data
.
shape
=
list
(
feed_inst
.
tensor_array
[
idx
].
shape
)
...
@@ -554,55 +570,129 @@ class MultiLangServerService(
...
@@ -554,55 +570,129 @@ class MultiLangServerService(
feed_batch
.
append
(
feed_dict
)
feed_batch
.
append
(
feed_dict
)
return
feed_batch
,
fetch_names
,
is_python
return
feed_batch
,
fetch_names
,
is_python
def
_pack_resp_package
(
self
,
result
,
fetch_names
,
is_python
,
tag
):
def
_pack_inference_response
(
self
,
ret
,
fetch_names
,
is_python
):
resp
=
multi_lang_general_model_service_pb2
.
Response
()
resp
=
multi_lang_general_model_service_pb2
.
InferenceResponse
()
# Only one model is supported temporarily
if
ret
is
None
:
resp
.
err_code
=
1
return
resp
results
,
tag
=
ret
resp
.
tag
=
tag
resp
.
err_code
=
0
if
not
self
.
is_multi_model_
:
results
=
{
'general_infer_0'
:
results
}
for
model_name
,
model_result
in
results
.
items
():
model_output
=
multi_lang_general_model_service_pb2
.
ModelOutput
()
model_output
=
multi_lang_general_model_service_pb2
.
ModelOutput
()
inst
=
multi_lang_general_model_service_pb2
.
FetchInst
()
inst
=
multi_lang_general_model_service_pb2
.
FetchInst
()
for
idx
,
name
in
enumerate
(
fetch_names
):
for
idx
,
name
in
enumerate
(
fetch_names
):
tensor
=
multi_lang_general_model_service_pb2
.
Tensor
()
tensor
=
multi_lang_general_model_service_pb2
.
Tensor
()
v_type
=
self
.
fetch_types_
[
name
]
v_type
=
self
.
fetch_types_
[
name
]
if
is_python
:
if
is_python
:
tensor
.
data
=
result
[
name
].
tobytes
()
tensor
.
data
=
model_
result
[
name
].
tobytes
()
else
:
else
:
if
v_type
==
0
:
# int64
if
v_type
==
0
:
# int64
tensor
.
int64_data
.
extend
(
result
[
name
].
reshape
(
-
1
).
tolist
())
tensor
.
int64_data
.
extend
(
model_result
[
name
].
reshape
(
-
1
)
.
tolist
())
elif
v_type
==
1
:
# float32
elif
v_type
==
1
:
# float32
tensor
.
float_data
.
extend
(
result
[
name
].
reshape
(
-
1
).
tolist
())
tensor
.
float_data
.
extend
(
model_result
[
name
].
reshape
(
-
1
)
.
tolist
())
elif
v_type
==
2
:
# int32
tensor
.
int32_data
.
extend
(
model_result
[
name
].
reshape
(
-
1
)
.
tolist
())
else
:
else
:
raise
Exception
(
"error type."
)
raise
Exception
(
"error type."
)
tensor
.
shape
.
extend
(
list
(
result
[
name
].
shape
))
tensor
.
shape
.
extend
(
list
(
model_
result
[
name
].
shape
))
if
name
in
self
.
lod_tensor_set_
:
if
name
in
self
.
lod_tensor_set_
:
tensor
.
lod
.
extend
(
result
[
"{}.lod"
.
format
(
name
)].
tolist
())
tensor
.
lod
.
extend
(
model_result
[
"{}.lod"
.
format
(
name
)]
.
tolist
())
inst
.
tensor_array
.
append
(
tensor
)
inst
.
tensor_array
.
append
(
tensor
)
model_output
.
insts
.
append
(
inst
)
model_output
.
insts
.
append
(
inst
)
model_output
.
engine_name
=
model_name
resp
.
outputs
.
append
(
model_output
)
resp
.
outputs
.
append
(
model_output
)
resp
.
tag
=
tag
return
resp
return
resp
def
inference
(
self
,
request
,
context
):
def
SetTimeout
(
self
,
request
,
context
):
feed_dict
,
fetch_names
,
is_python
=
self
.
_unpack_request
(
request
)
# This porcess and Inference process cannot be operate at the same time.
data
,
tag
=
self
.
bclient_
.
predict
(
# For performance reasons, do not add thread lock temporarily.
timeout_ms
=
request
.
timeout_ms
self
.
_init_bclient
(
self
.
model_config_path_
,
self
.
endpoints_
,
timeout_ms
)
resp
=
multi_lang_general_model_service_pb2
.
SimpleResponse
()
resp
.
err_code
=
0
return
resp
def
Inference
(
self
,
request
,
context
):
feed_dict
,
fetch_names
,
is_python
=
self
.
_unpack_inference_request
(
request
)
ret
=
self
.
bclient_
.
predict
(
feed
=
feed_dict
,
fetch
=
fetch_names
,
need_variant_tag
=
True
)
feed
=
feed_dict
,
fetch
=
fetch_names
,
need_variant_tag
=
True
)
return
self
.
_pack_resp_package
(
data
,
fetch_names
,
is_python
,
tag
)
return
self
.
_pack_inference_response
(
ret
,
fetch_names
,
is_python
)
def
GetClientConfig
(
self
,
request
,
context
):
resp
=
multi_lang_general_model_service_pb2
.
GetClientConfigResponse
()
resp
.
client_config_str
=
self
.
model_config_str_
return
resp
class
MultiLangServer
(
object
):
class
MultiLangServer
(
object
):
def
__init__
(
self
,
worker_num
=
2
):
def
__init__
(
self
):
self
.
bserver_
=
Server
()
self
.
bserver_
=
Server
()
self
.
worker_num_
=
worker_num
self
.
worker_num_
=
4
self
.
body_size_
=
64
*
1024
*
1024
self
.
concurrency_
=
100000
self
.
is_multi_model_
=
False
# for model ensemble
def
set_max_concurrency
(
self
,
concurrency
):
self
.
concurrency_
=
concurrency
self
.
bserver_
.
set_max_concurrency
(
concurrency
)
def
set_num_threads
(
self
,
threads
):
self
.
worker_num_
=
threads
self
.
bserver_
.
set_num_threads
(
threads
)
def
set_max_body_size
(
self
,
body_size
):
self
.
bserver_
.
set_max_body_size
(
body_size
)
if
body_size
>=
self
.
body_size_
:
self
.
body_size_
=
body_size
else
:
print
(
"max_body_size is less than default value, will use default value in service."
)
def
set_port
(
self
,
port
):
self
.
gport_
=
port
def
set_reload_interval
(
self
,
interval
):
self
.
bserver_
.
set_reload_interval
(
interval
)
def
set_op_sequence
(
self
,
op_seq
):
def
set_op_sequence
(
self
,
op_seq
):
self
.
bserver_
.
set_op_sequence
(
op_seq
)
self
.
bserver_
.
set_op_sequence
(
op_seq
)
def
load_model_config
(
self
,
model_config_path
):
def
set_op_graph
(
self
,
op_graph
):
if
not
isinstance
(
model_config_path
,
str
):
self
.
bserver_
.
set_op_graph
(
op_graph
)
raise
Exception
(
"MultiLangServer only supports multi-model temporarily"
)
def
set_memory_optimize
(
self
,
flag
=
False
):
self
.
bserver_
.
load_model_config
(
model_config_path
)
self
.
bserver_
.
set_memory_optimize
(
flag
)
self
.
model_config_path_
=
model_config_path
def
set_ir_optimize
(
self
,
flag
=
False
):
self
.
bserver_
.
set_ir_optimize
(
flag
)
def
set_gpuid
(
self
,
gpuid
=
0
):
self
.
bserver_
.
set_gpuid
(
gpuid
)
def
load_model_config
(
self
,
server_config_paths
,
client_config_path
=
None
):
self
.
bserver_
.
load_model_config
(
server_config_paths
)
if
client_config_path
is
None
:
if
isinstance
(
server_config_paths
,
dict
):
self
.
is_multi_model_
=
True
client_config_path
=
'{}/serving_server_conf.prototxt'
.
format
(
list
(
server_config_paths
.
items
())[
0
][
1
])
else
:
client_config_path
=
'{}/serving_server_conf.prototxt'
.
format
(
server_config_paths
)
self
.
bclient_config_path_
=
client_config_path
def
prepare_server
(
self
,
workdir
=
None
,
port
=
9292
,
device
=
"cpu"
):
def
prepare_server
(
self
,
workdir
=
None
,
port
=
9292
,
device
=
"cpu"
):
if
not
self
.
_port_is_available
(
port
):
raise
SystemExit
(
"Prot {} is already used"
.
format
(
port
))
default_port
=
12000
default_port
=
12000
self
.
port_list_
=
[]
self
.
port_list_
=
[]
for
i
in
range
(
1000
):
for
i
in
range
(
1000
):
...
@@ -612,7 +702,7 @@ class MultiLangServer(object):
...
@@ -612,7 +702,7 @@ class MultiLangServer(object):
break
break
self
.
bserver_
.
prepare_server
(
self
.
bserver_
.
prepare_server
(
workdir
=
workdir
,
port
=
self
.
port_list_
[
0
],
device
=
device
)
workdir
=
workdir
,
port
=
self
.
port_list_
[
0
],
device
=
device
)
self
.
gport_
=
port
self
.
set_port
(
port
)
def
_launch_brpc_service
(
self
,
bserver
):
def
_launch_brpc_service
(
self
,
bserver
):
bserver
.
run_server
()
bserver
.
run_server
()
...
@@ -627,12 +717,16 @@ class MultiLangServer(object):
...
@@ -627,12 +717,16 @@ class MultiLangServer(object):
p_bserver
=
Process
(
p_bserver
=
Process
(
target
=
self
.
_launch_brpc_service
,
args
=
(
self
.
bserver_
,
))
target
=
self
.
_launch_brpc_service
,
args
=
(
self
.
bserver_
,
))
p_bserver
.
start
()
p_bserver
.
start
()
options
=
[(
'grpc.max_send_message_length'
,
self
.
body_size_
),
(
'grpc.max_receive_message_length'
,
self
.
body_size_
)]
server
=
grpc
.
server
(
server
=
grpc
.
server
(
futures
.
ThreadPoolExecutor
(
max_workers
=
self
.
worker_num_
))
futures
.
ThreadPoolExecutor
(
max_workers
=
self
.
worker_num_
),
options
=
options
,
maximum_concurrent_rpcs
=
self
.
concurrency_
)
multi_lang_general_model_service_pb2_grpc
.
add_MultiLangGeneralModelServiceServicer_to_server
(
multi_lang_general_model_service_pb2_grpc
.
add_MultiLangGeneralModelServiceServicer_to_server
(
MultiLangServerService
(
self
.
model_config_path_
,
MultiLangServerService
Servicer
(
[
"0.0.0.0:{}"
.
format
(
self
.
port_list_
[
0
])])
,
self
.
bclient_config_path_
,
self
.
is_multi_model_
,
server
)
[
"0.0.0.0:{}"
.
format
(
self
.
port_list_
[
0
])]),
server
)
server
.
add_insecure_port
(
'[::]:{}'
.
format
(
self
.
gport_
))
server
.
add_insecure_port
(
'[::]:{}'
.
format
(
self
.
gport_
))
server
.
start
()
server
.
start
()
p_bserver
.
join
()
p_bserver
.
join
()
...
...
python/paddle_serving_server_gpu/serve.py
浏览文件 @
e1013d75
...
@@ -37,6 +37,7 @@ def start_gpu_card_model(index, gpuid, args): # pylint: disable=doc-string-miss
...
@@ -37,6 +37,7 @@ def start_gpu_card_model(index, gpuid, args): # pylint: disable=doc-string-miss
mem_optim
=
args
.
mem_optim
mem_optim
=
args
.
mem_optim
ir_optim
=
args
.
ir_optim
ir_optim
=
args
.
ir_optim
max_body_size
=
args
.
max_body_size
max_body_size
=
args
.
max_body_size
use_multilang
=
args
.
use_multilang
workdir
=
"{}_{}"
.
format
(
args
.
workdir
,
gpuid
)
workdir
=
"{}_{}"
.
format
(
args
.
workdir
,
gpuid
)
if
model
==
""
:
if
model
==
""
:
...
@@ -54,6 +55,9 @@ def start_gpu_card_model(index, gpuid, args): # pylint: disable=doc-string-miss
...
@@ -54,6 +55,9 @@ def start_gpu_card_model(index, gpuid, args): # pylint: disable=doc-string-miss
op_seq_maker
.
add_op
(
general_infer_op
)
op_seq_maker
.
add_op
(
general_infer_op
)
op_seq_maker
.
add_op
(
general_response_op
)
op_seq_maker
.
add_op
(
general_response_op
)
if
use_multilang
:
server
=
serving
.
MultiLangServer
()
else
:
server
=
serving
.
Server
()
server
=
serving
.
Server
()
server
.
set_op_sequence
(
op_seq_maker
.
get_op_sequence
())
server
.
set_op_sequence
(
op_seq_maker
.
get_op_sequence
())
server
.
set_num_threads
(
thread_num
)
server
.
set_num_threads
(
thread_num
)
...
...
tools/serving_build.sh
浏览文件 @
e1013d75
...
@@ -134,6 +134,7 @@ function build_server() {
...
@@ -134,6 +134,7 @@ function build_server() {
function
kill_server_process
()
{
function
kill_server_process
()
{
ps
-ef
|
grep
"serving"
|
grep
-v
serving_build |
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
ps
-ef
|
grep
"serving"
|
grep
-v
serving_build |
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
sleep
1
}
}
function
python_test_fit_a_line
()
{
function
python_test_fit_a_line
()
{
...
@@ -246,6 +247,7 @@ function python_run_criteo_ctr_with_cube() {
...
@@ -246,6 +247,7 @@ function python_run_criteo_ctr_with_cube() {
echo
"criteo_ctr_with_cube inference auc test success"
echo
"criteo_ctr_with_cube inference auc test success"
kill_server_process
kill_server_process
ps
-ef
|
grep
"cube"
|
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
ps
-ef
|
grep
"cube"
|
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
sleep
1
;;
;;
GPU
)
GPU
)
check_cmd
"wget https://paddle-serving.bj.bcebos.com/unittest/ctr_cube_unittest.tar.gz"
check_cmd
"wget https://paddle-serving.bj.bcebos.com/unittest/ctr_cube_unittest.tar.gz"
...
@@ -261,6 +263,8 @@ function python_run_criteo_ctr_with_cube() {
...
@@ -261,6 +263,8 @@ function python_run_criteo_ctr_with_cube() {
check_cmd
"mkdir work_dir1 && cp cube/conf/cube.conf ./work_dir1/"
check_cmd
"mkdir work_dir1 && cp cube/conf/cube.conf ./work_dir1/"
python test_server_gpu.py ctr_serving_model_kv &
python test_server_gpu.py ctr_serving_model_kv &
sleep
5
sleep
5
# for warm up
python test_client.py ctr_client_conf/serving_client_conf.prototxt ./ut_data
>
/dev/null
||
true
check_cmd
"python test_client.py ctr_client_conf/serving_client_conf.prototxt ./ut_data >score"
check_cmd
"python test_client.py ctr_client_conf/serving_client_conf.prototxt ./ut_data >score"
tail
-n
2 score |
awk
'NR==1'
tail
-n
2 score |
awk
'NR==1'
AUC
=
$(
tail
-n
2 score |
awk
'NR==1'
)
AUC
=
$(
tail
-n
2 score |
awk
'NR==1'
)
...
@@ -273,6 +277,7 @@ function python_run_criteo_ctr_with_cube() {
...
@@ -273,6 +277,7 @@ function python_run_criteo_ctr_with_cube() {
echo
"criteo_ctr_with_cube inference auc test success"
echo
"criteo_ctr_with_cube inference auc test success"
kill_server_process
kill_server_process
ps
-ef
|
grep
"cube"
|
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
ps
-ef
|
grep
"cube"
|
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
sleep
1
;;
;;
*
)
*
)
echo
"error type"
echo
"error type"
...
@@ -484,6 +489,7 @@ function python_test_lac() {
...
@@ -484,6 +489,7 @@ function python_test_lac() {
setproxy
# recover proxy state
setproxy
# recover proxy state
kill_server_process
kill_server_process
ps
-ef
|
grep
"lac_web_service"
|
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
ps
-ef
|
grep
"lac_web_service"
|
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
sleep
1
echo
"lac CPU HTTP inference pass"
echo
"lac CPU HTTP inference pass"
;;
;;
GPU
)
GPU
)
...
@@ -499,6 +505,143 @@ function python_test_lac() {
...
@@ -499,6 +505,143 @@ function python_test_lac() {
cd
..
cd
..
}
}
function
python_test_grpc_impl
()
{
# pwd: /Serving/python/examples
cd
grpc_impl_example
# pwd: /Serving/python/examples/grpc_impl_example
local
TYPE
=
$1
export
SERVING_BIN
=
${
SERVING_WORKDIR
}
/build-server-
${
TYPE
}
/core/general-server/serving
unsetproxy
case
$TYPE
in
CPU
)
# test general case
cd
fit_a_line
# pwd: /Serving/python/examples/grpc_impl_example/fit_a_line
sh get_data.sh
# one line command start
check_cmd
"python -m paddle_serving_server.serve --model uci_housing_model --port 9393 --thread 4 --use_multilang > /dev/null &"
sleep
5
# wait for the server to start
check_cmd
"python test_sync_client.py > /dev/null"
check_cmd
"python test_asyn_client.py > /dev/null"
check_cmd
"python test_general_pb_client.py > /dev/null"
check_cmd
"python test_numpy_input_client.py > /dev/null"
check_cmd
"python test_batch_client.py > /dev/null"
check_cmd
"python test_timeout_client.py > /dev/null"
kill_server_process
check_cmd
"python test_server.py uci_housing_model > /dev/null &"
sleep
5
# wait for the server to start
check_cmd
"python test_sync_client.py > /dev/null"
check_cmd
"python test_asyn_client.py > /dev/null"
check_cmd
"python test_general_pb_client.py > /dev/null"
check_cmd
"python test_numpy_input_client.py > /dev/null"
check_cmd
"python test_batch_client.py > /dev/null"
check_cmd
"python test_timeout_client.py > /dev/null"
kill_server_process
cd
..
# pwd: /Serving/python/examples/grpc_impl_example
# test load server config and client config in Server side
cd
criteo_ctr_with_cube
# pwd: /Serving/python/examples/grpc_impl_example/criteo_ctr_with_cube
check_cmd
"wget https://paddle-serving.bj.bcebos.com/unittest/ctr_cube_unittest.tar.gz"
check_cmd
"tar xf ctr_cube_unittest.tar.gz"
check_cmd
"mv models/ctr_client_conf ./"
check_cmd
"mv models/ctr_serving_model_kv ./"
check_cmd
"mv models/data ./cube/"
check_cmd
"mv models/ut_data ./"
cp
../../../../build-server-
$TYPE
/output/bin/cube
*
./cube/
sh cube_prepare.sh &
check_cmd
"mkdir work_dir1 && cp cube/conf/cube.conf ./work_dir1/"
python test_server.py ctr_serving_model_kv ctr_client_conf/serving_client_conf.prototxt &
sleep
5
check_cmd
"python test_client.py ./ut_data >score"
tail
-n
2 score |
awk
'NR==1'
AUC
=
$(
tail
-n
2 score |
awk
'NR==1'
)
VAR2
=
"0.67"
#TODO: temporarily relax the threshold to 0.67
RES
=
$(
echo
"
$AUC
>
$VAR2
"
| bc
)
if
[[
$RES
-eq
0
]]
;
then
echo
"error with criteo_ctr_with_cube inference auc test, auc should > 0.67"
exit
1
fi
echo
"grpc impl test success"
kill_server_process
ps
-ef
|
grep
"cube"
|
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
cd
..
# pwd: /Serving/python/examples/grpc_impl_example
;;
GPU
)
export
CUDA_VISIBLE_DEVICES
=
0
# test general case
cd
fit_a_line
# pwd: /Serving/python/examples/grpc_impl_example/fit_a_line
sh get_data.sh
# one line command start
check_cmd
"python -m paddle_serving_server_gpu.serve --model uci_housing_model --port 9393 --thread 4 --gpu_ids 0 --use_multilang > /dev/null &"
sleep
5
# wait for the server to start
check_cmd
"python test_sync_client.py > /dev/null"
check_cmd
"python test_asyn_client.py > /dev/null"
check_cmd
"python test_general_pb_client.py > /dev/null"
check_cmd
"python test_numpy_input_client.py > /dev/null"
check_cmd
"python test_batch_client.py > /dev/null"
check_cmd
"python test_timeout_client.py > /dev/null"
kill_server_process
check_cmd
"python test_server_gpu.py uci_housing_model > /dev/null &"
sleep
5
# wait for the server to start
check_cmd
"python test_sync_client.py > /dev/null"
check_cmd
"python test_asyn_client.py > /dev/null"
check_cmd
"python test_general_pb_client.py > /dev/null"
check_cmd
"python test_numpy_input_client.py > /dev/null"
check_cmd
"python test_batch_client.py > /dev/null"
check_cmd
"python test_timeout_client.py > /dev/null"
kill_server_process
ps
-ef
|
grep
"test_server_gpu"
|
grep
-v
serving_build |
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
cd
..
# pwd: /Serving/python/examples/grpc_impl_example
# test load server config and client config in Server side
cd
criteo_ctr_with_cube
# pwd: /Serving/python/examples/grpc_impl_example/criteo_ctr_with_cube
check_cmd
"wget https://paddle-serving.bj.bcebos.com/unittest/ctr_cube_unittest.tar.gz"
check_cmd
"tar xf ctr_cube_unittest.tar.gz"
check_cmd
"mv models/ctr_client_conf ./"
check_cmd
"mv models/ctr_serving_model_kv ./"
check_cmd
"mv models/data ./cube/"
check_cmd
"mv models/ut_data ./"
cp
../../../../build-server-
$TYPE
/output/bin/cube
*
./cube/
sh cube_prepare.sh &
check_cmd
"mkdir work_dir1 && cp cube/conf/cube.conf ./work_dir1/"
python test_server_gpu.py ctr_serving_model_kv ctr_client_conf/serving_client_conf.prototxt &
sleep
5
# for warm up
python test_client.py ./ut_data &> /dev/null
||
true
check_cmd
"python test_client.py ./ut_data >score"
tail
-n
2 score |
awk
'NR==1'
AUC
=
$(
tail
-n
2 score |
awk
'NR==1'
)
VAR2
=
"0.67"
#TODO: temporarily relax the threshold to 0.67
RES
=
$(
echo
"
$AUC
>
$VAR2
"
| bc
)
if
[[
$RES
-eq
0
]]
;
then
echo
"error with criteo_ctr_with_cube inference auc test, auc should > 0.67"
exit
1
fi
echo
"grpc impl test success"
kill_server_process
ps
-ef
|
grep
"test_server_gpu"
|
grep
-v
serving_build |
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
ps
-ef
|
grep
"cube"
|
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
cd
..
# pwd: /Serving/python/examples/grpc_impl_example
;;
*
)
echo
"error type"
exit
1
;;
esac
echo
"test grpc impl
$TYPE
part finished as expected."
setproxy
unset
SERVING_BIN
cd
..
# pwd: /Serving/python/examples
}
function
python_test_yolov4
(){
function
python_test_yolov4
(){
#pwd:/ Serving/python/examples
#pwd:/ Serving/python/examples
local
TYPE
=
$1
local
TYPE
=
$1
...
@@ -546,6 +689,7 @@ function python_run_test() {
...
@@ -546,6 +689,7 @@ function python_run_test() {
python_test_multi_process
$TYPE
# pwd: /Serving/python/examples
python_test_multi_process
$TYPE
# pwd: /Serving/python/examples
python_test_multi_fetch
$TYPE
# pwd: /Serving/python/examples
python_test_multi_fetch
$TYPE
# pwd: /Serving/python/examples
python_test_yolov4
$TYPE
# pwd: /Serving/python/examples
python_test_yolov4
$TYPE
# pwd: /Serving/python/examples
python_test_grpc_impl
$TYPE
# pwd: /Serving/python/examples
echo
"test python
$TYPE
part finished as expected."
echo
"test python
$TYPE
part finished as expected."
cd
../..
# pwd: /Serving
cd
../..
# pwd: /Serving
}
}
...
@@ -804,3 +948,4 @@ function main() {
...
@@ -804,3 +948,4 @@ function main() {
}
}
main
$@
main
$@
exit
0
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}