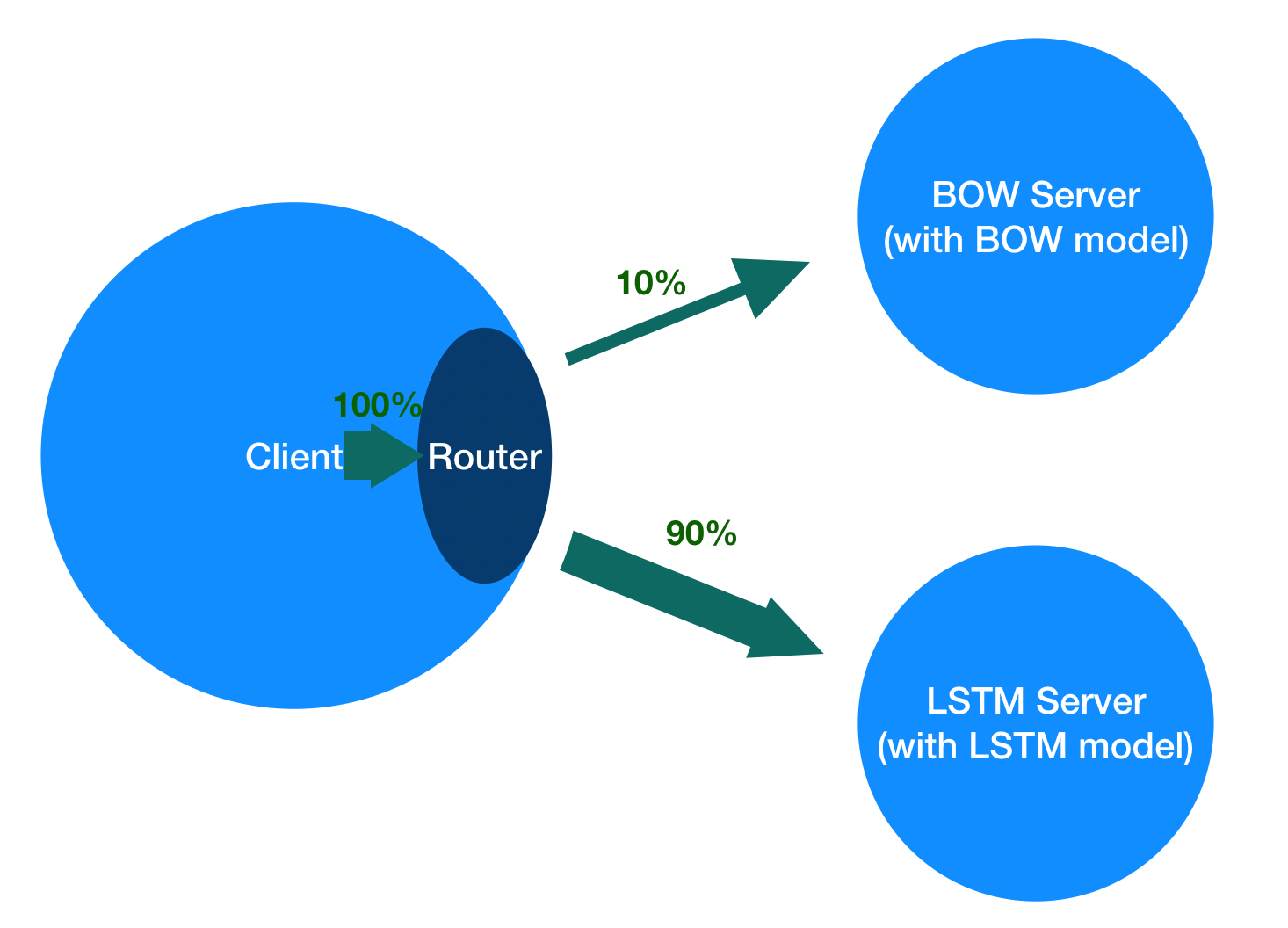
This document will use an example of text classification task based on IMDB dataset to show how to build a A/B Test framework using Paddle Serving. The structure relationship between the client and servers in the example is shown in the figure below.
<imgsrc="/abtest.png"style="zoom:33%;"/>
Note that: A/B Test is only applicable to RPC mode, not web mode.
### Download Data and Models
```shell
cd Serving/python/examples/imdb
sh get_data.sh
```
### Processing Data
The following Python code will process the data `test_data/part-0` and write to the `processed.data` file.
Here, we [use docker](https://github.com/PaddlePaddle/Serving/blob/develop/doc/RUN_IN_DOCKER.md) to start the server-side service.
First, start the BOW server, which enables the `8000` port:
``` shell
docker run -dit-v$PWD/imdb_bow_model:/model -p 8000:8000 --name bow-server hub.baidubce.com/ctr/paddleserving:0.1.3
docker exec-it bow-server bash
pip install paddle-serving-server
python -m paddle_serving_server.serve --model model --port 8000 >std.log 2>err.log &
exit
```
Similarly, start the LSTM server, which enables the `9000` port:
```bash
docker run -dit-v$PWD/imdb_lstm_model:/model -p 9000:9000 --name lstm-server hub.baidubce.com/ctr/paddleserving:0.1.3
docker exec-it lstm-server bash
pip install paddle-serving-server
python -m paddle_serving_server.serve --model model --port 9000 >std.log 2>err.log &
exit
```
### Start Client
Run the following Python code on the host computer to start client. Make sure that the host computer is installed with the `paddle-serving-client` package.
In the code, the function `client.add_variant(tag, clusters, variant_weight)` is to add a variant with label `tag` and flow weight `variant_weight`. In this example, a BOW variant with label of `bow` and flow weight of `10`, and an LSTM variant with label of `lstm` and a flow weight of `90` are added. The flow on the client side will be distributed to two variants according to the ratio of `10:90`.
When making prediction on the client side, if the parameter `need_variant_tag=True` is specified, the response will contains the variant tag corresponding to the distribution flow.
{kind=link}