Add GPU Benchmarking Documentation (#9)
* Add documentation for GPU Benchmarking * Fix documentation
Showing
doc/GPU_BENCHMARKING.md
0 → 100755
此差异已折叠。
doc/gpu-local-qps-batchsize.png
0 → 100755
{kind=link}
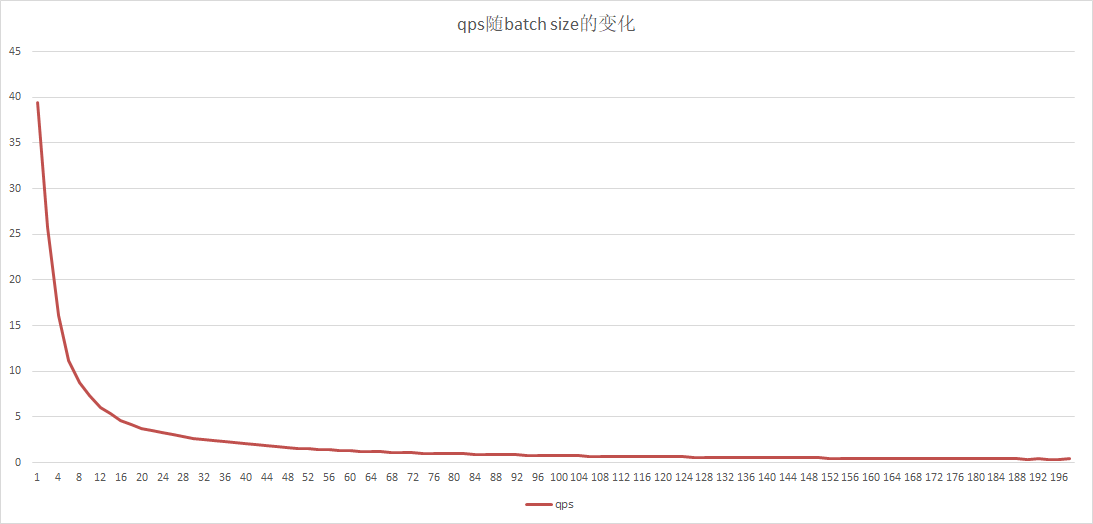
25.6 KB
doc/gpu-local-qps-concurrency.png
0 → 100755
{kind=link}
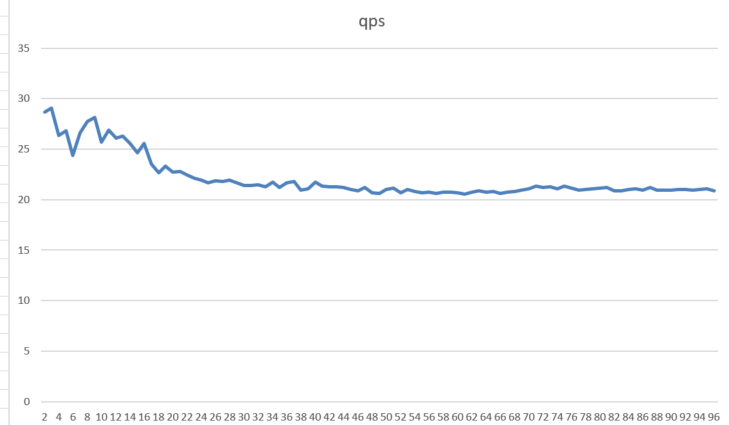
30.4 KB
doc/gpu-local-time-batchsize.png
0 → 100755
{kind=link}
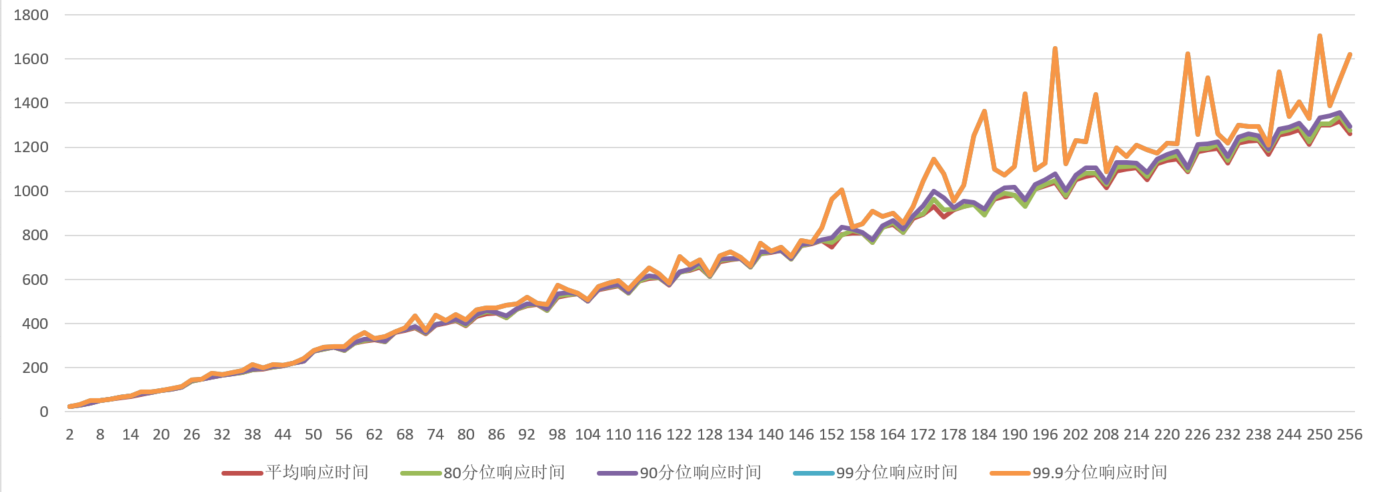
129.0 KB
{kind=link}
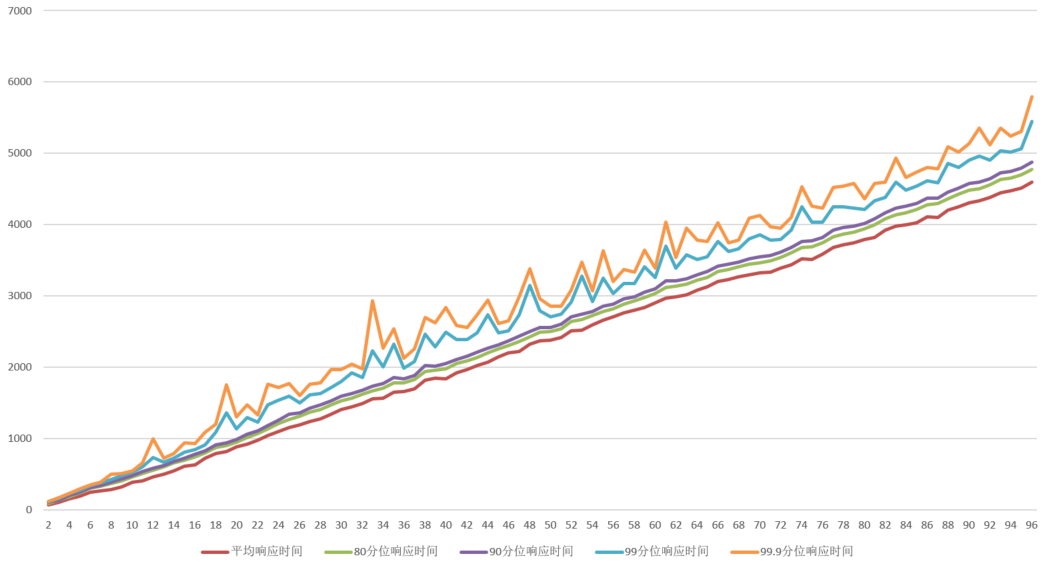
126.2 KB
{kind=link}
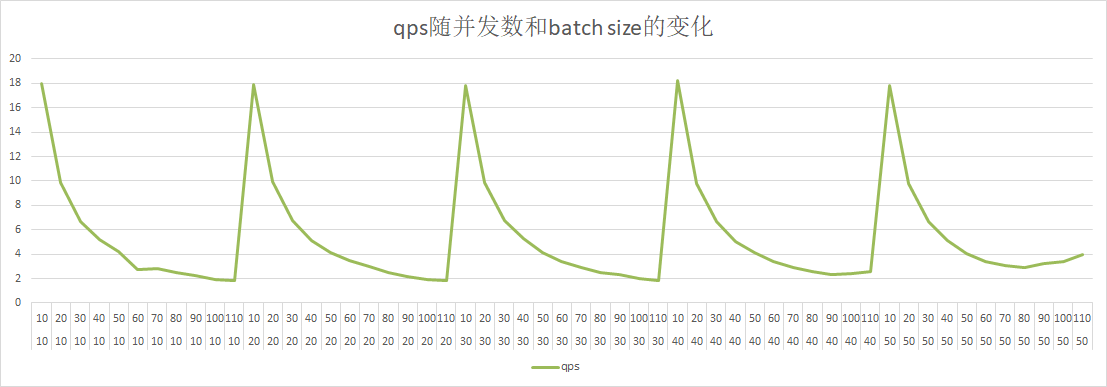
39.0 KB
{kind=link}
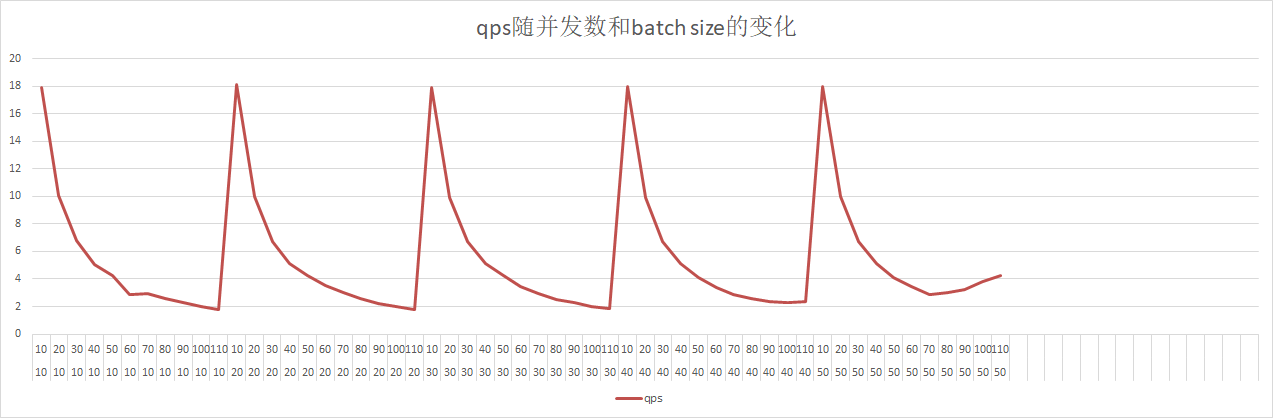
44.2 KB
{kind=link}
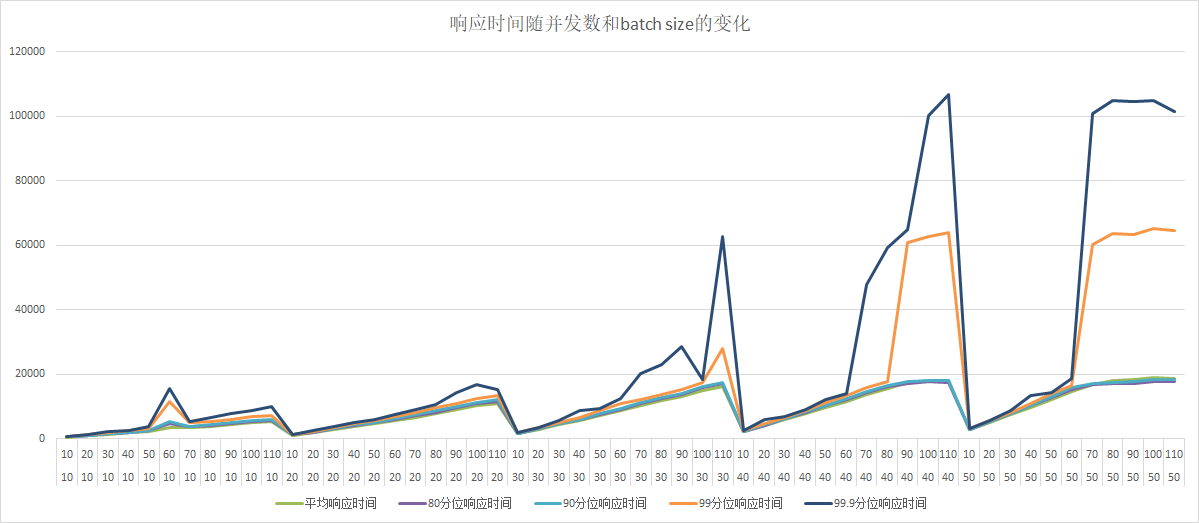
68.1 KB
{kind=link}
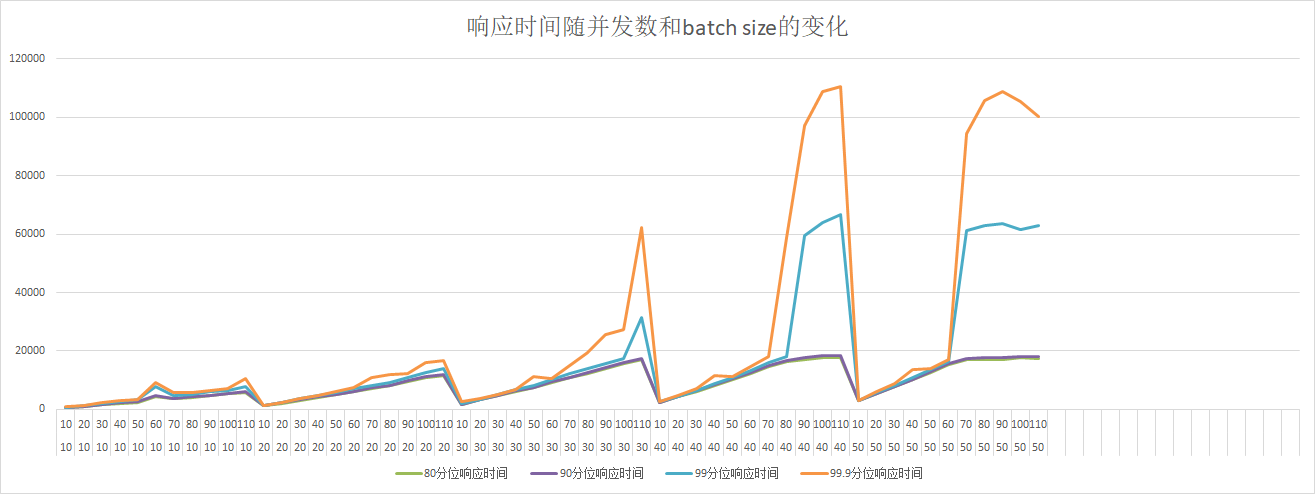
60.4 KB
{kind=link}
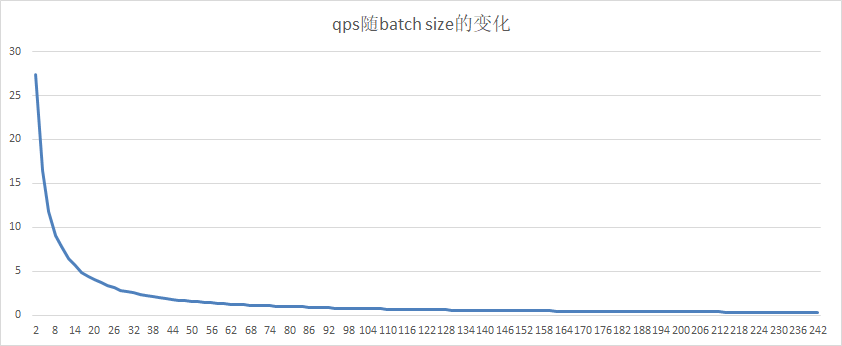
17.0 KB
{kind=link}
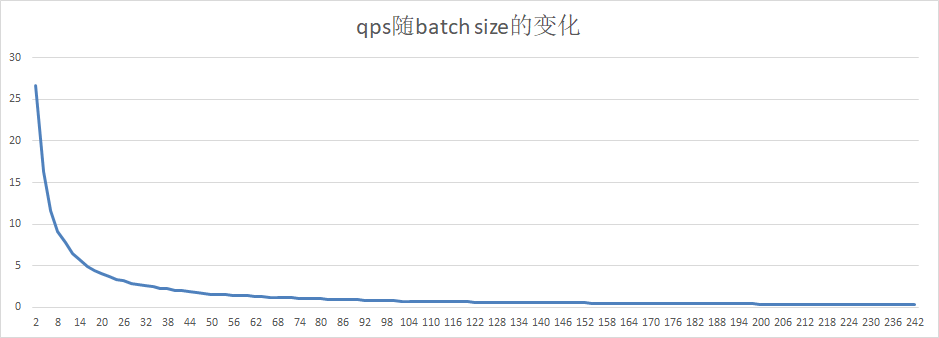
18.4 KB
{kind=link}
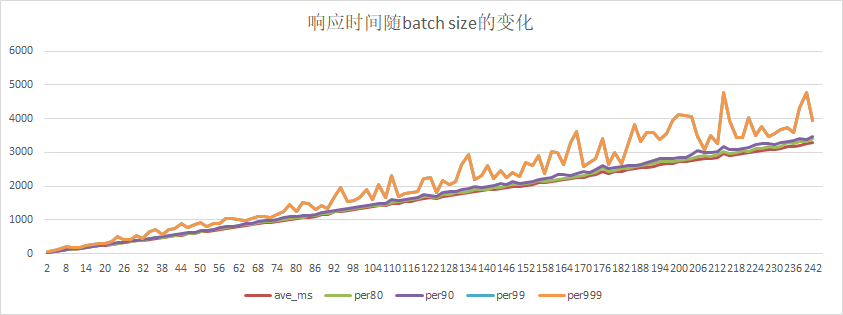
36.6 KB
{kind=link}
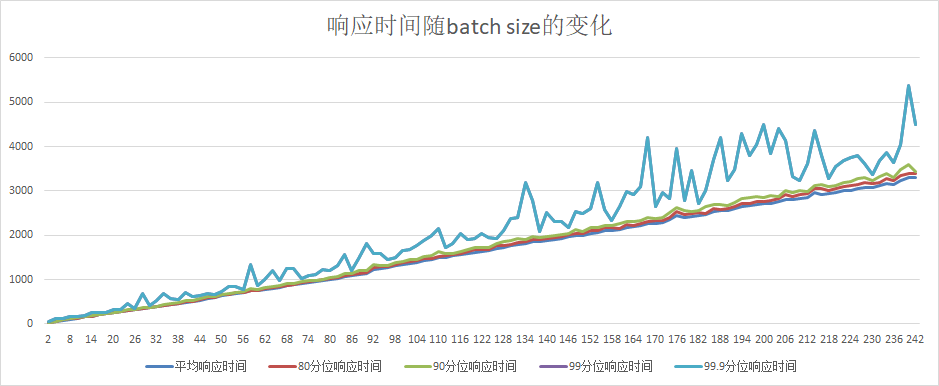
51.6 KB
{kind=link}
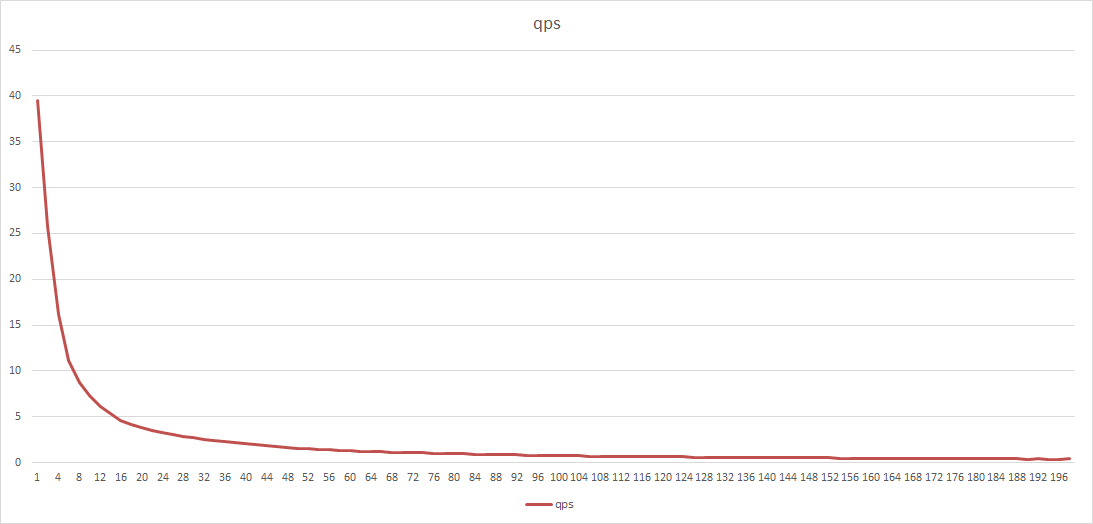
23.2 KB
{kind=link}
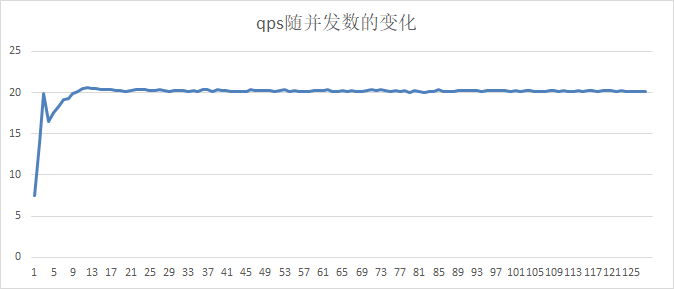
14.3 KB
{kind=link}
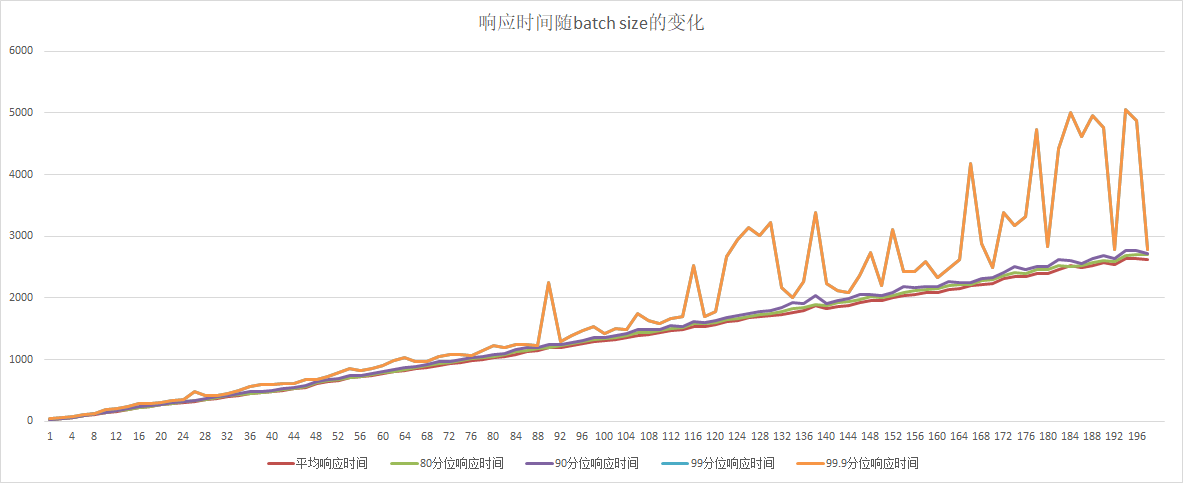
62.3 KB
{kind=link}
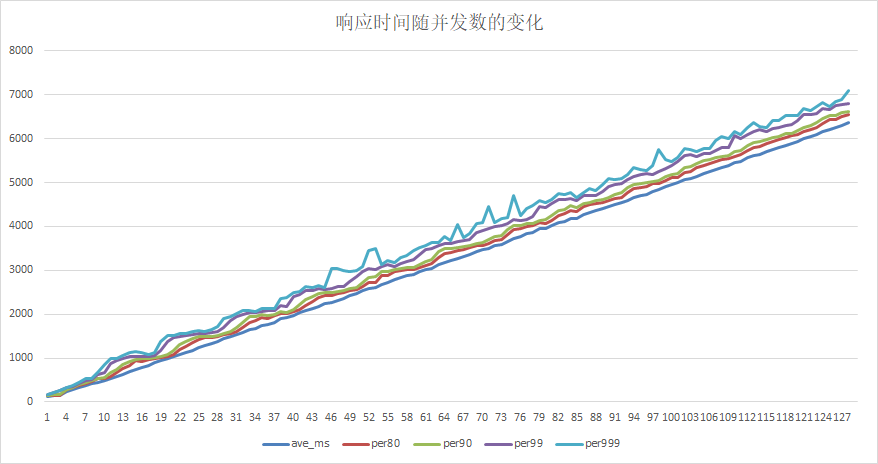
51.4 KB
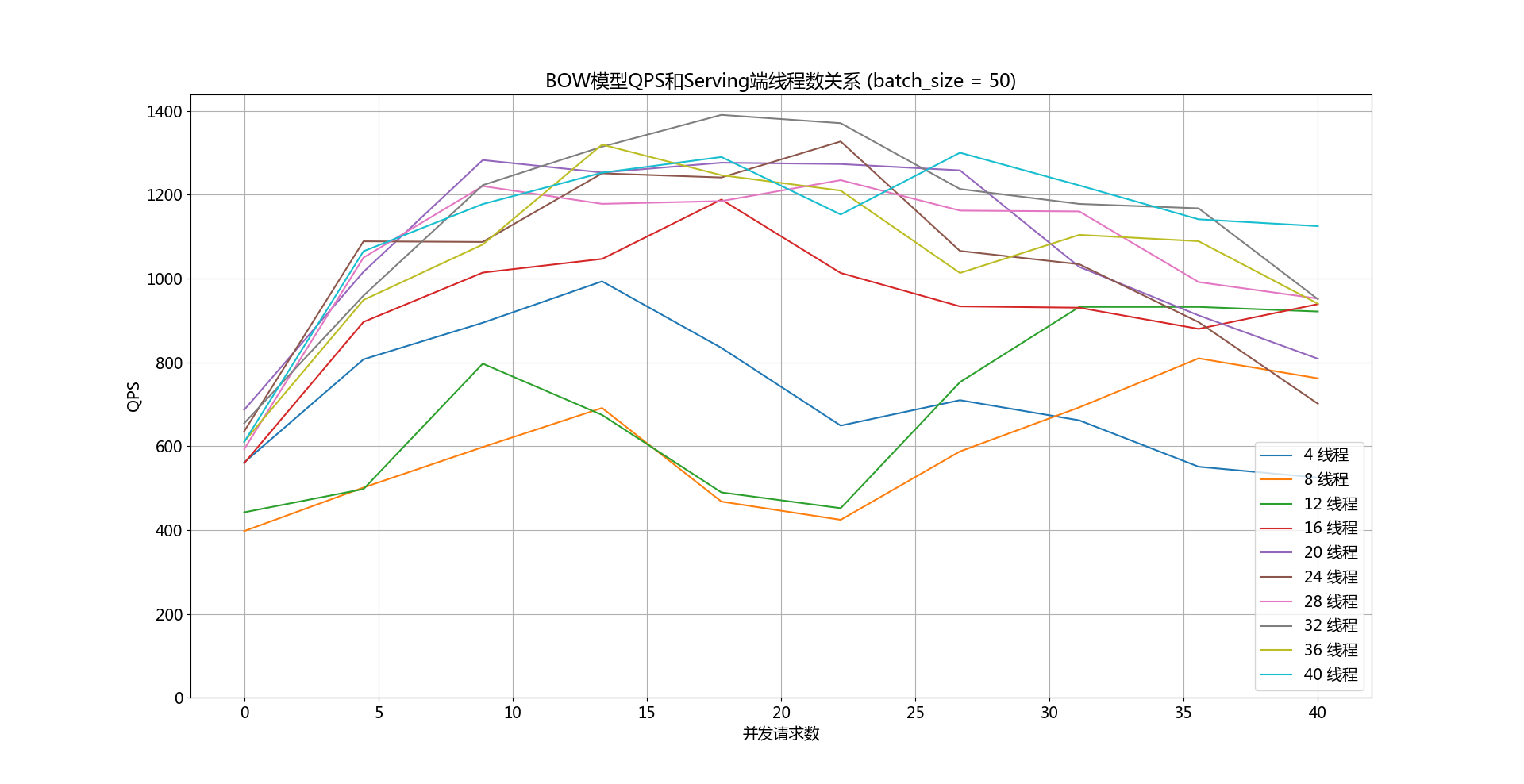
doc/qps-threads-bow.png
0 → 100755
{kind=link}
237.2 KB
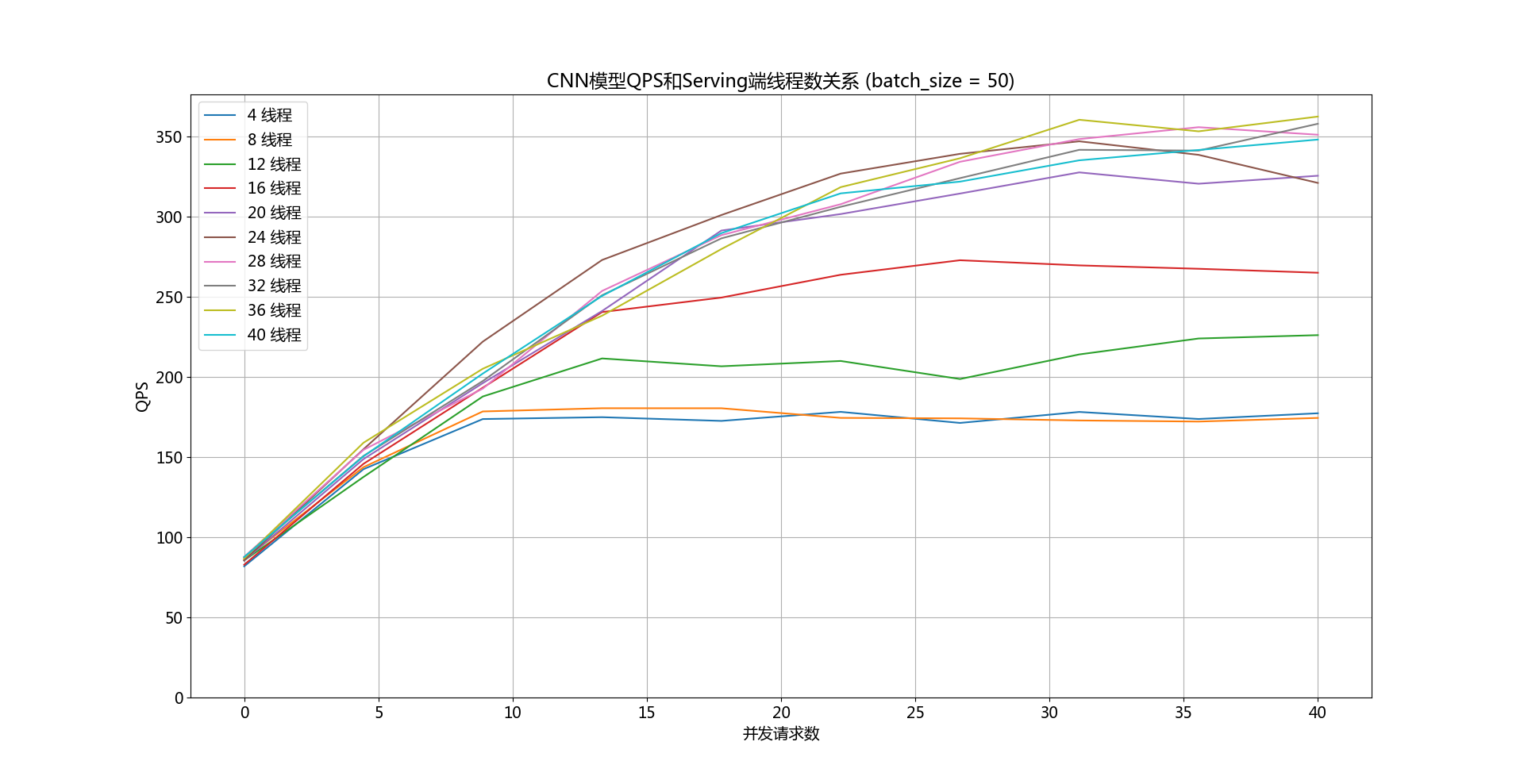
doc/qps-threads-cnn.png
0 → 100755
{kind=link}
174.9 KB
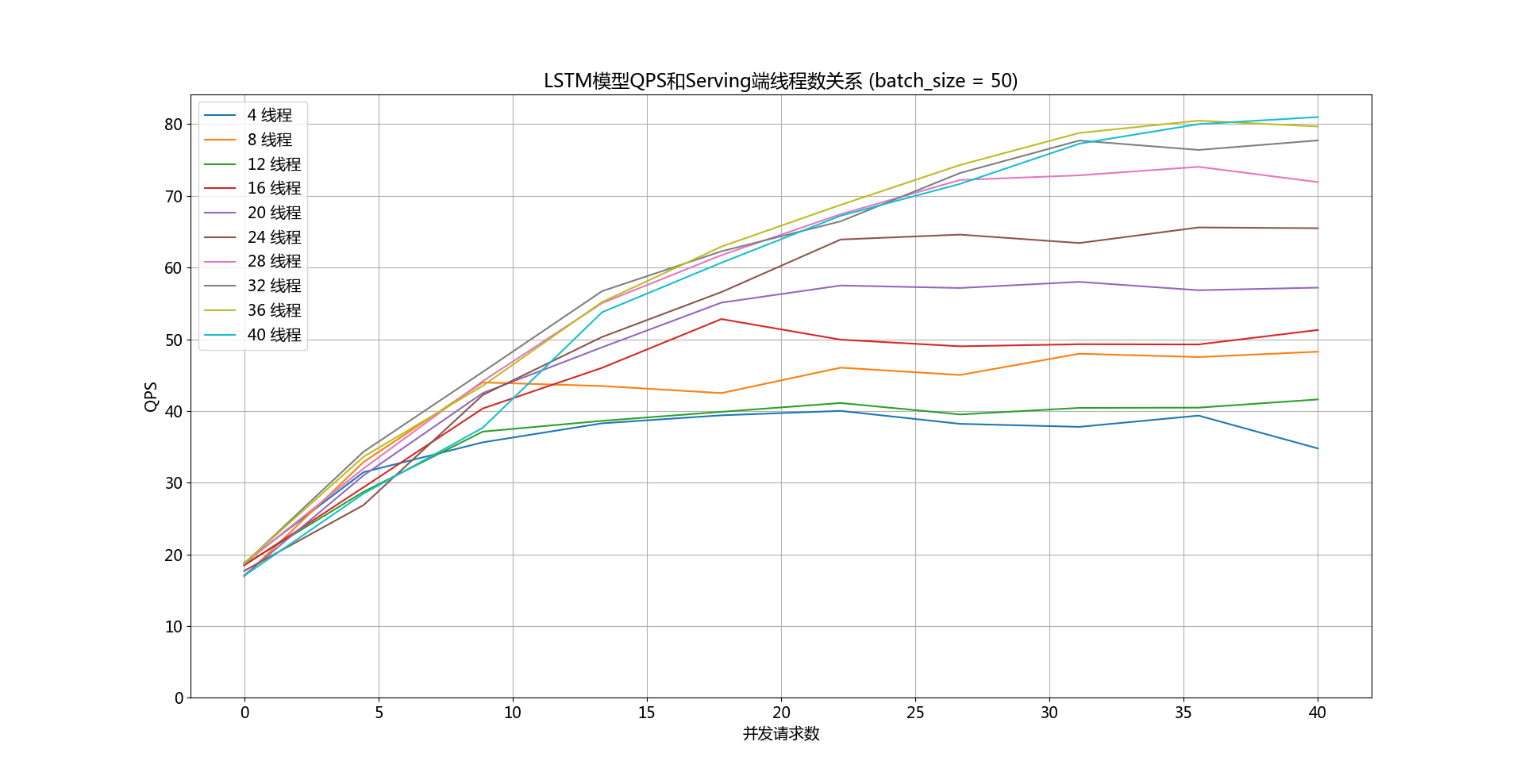
doc/qps-threads-lstm.png
0 → 100755
{kind=link}
176.9 KB
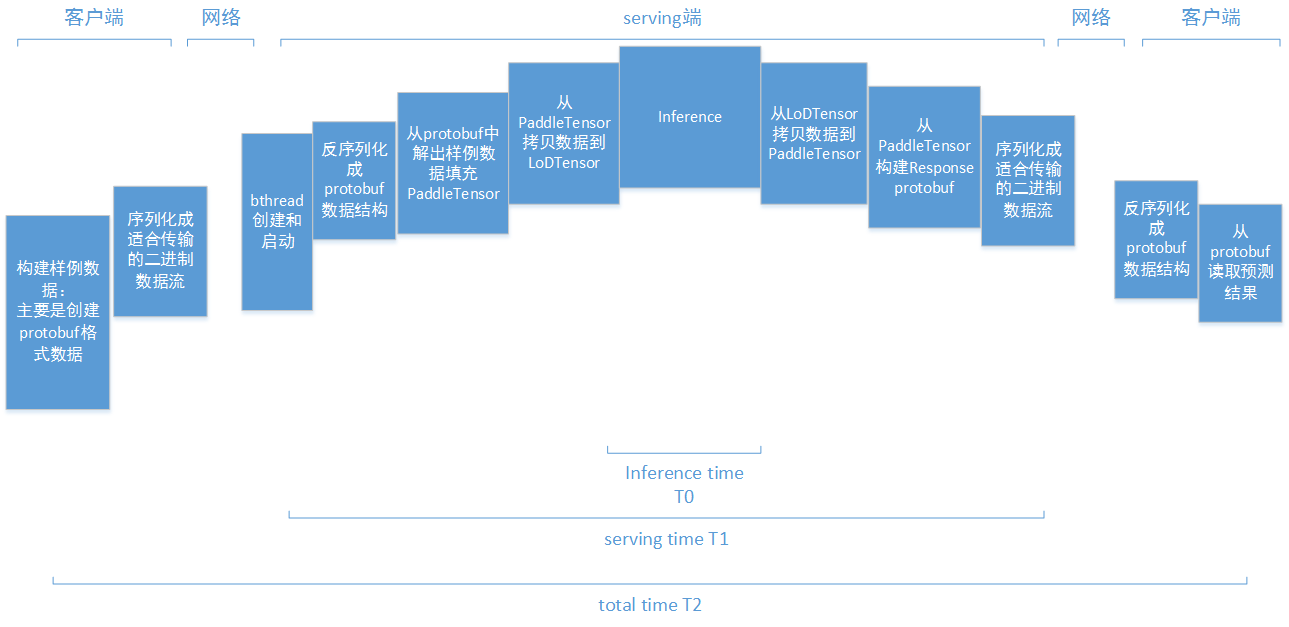
doc/serving-timings.png
0 → 100755
{kind=link}
36.9 KB