Merge pull request #1478 from TeslaZhao/v0.7.0
cherry-pick
Showing
doc/HTTP_SERVICE_CN.md
100755 → 100644
文件模式从 100755 更改为 100644
doc/Makefile
已删除
100644 → 0
doc/UWSGI_DEPLOY.md
已删除
100644 → 0
doc/UWSGI_DEPLOY_CN.md
已删除
100644 → 0
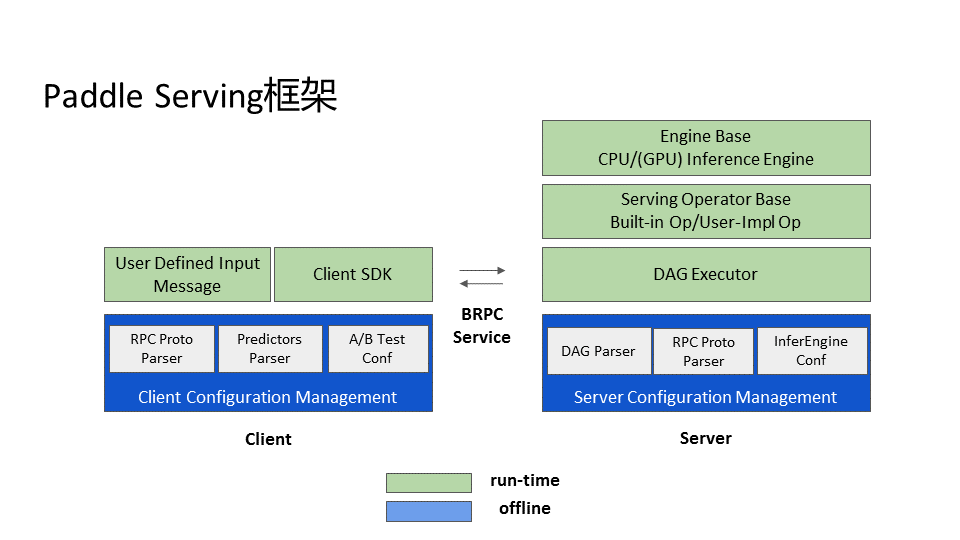
doc/architecture.png
已删除
100644 → 0
{kind=link}
21.9 KB
{kind=link}

24.2 KB
doc/blank.png
已删除
100644 → 0
{kind=link}

18.2 KB
doc/coding_mode.png
已删除
100644 → 0
{kind=link}

126.6 KB
文件已移动
文件已移动
此差异已折叠。
doc/doc_test_list
已删除
100644 → 0
{kind=link}

25.6 KB
{kind=link}
30.4 KB
{kind=link}

129.0 KB
{kind=link}

126.2 KB
{kind=link}
39.0 KB
{kind=link}
44.2 KB
{kind=link}

68.1 KB
{kind=link}

60.4 KB
{kind=link}

17.0 KB
{kind=link}
18.4 KB
{kind=link}
36.6 KB
{kind=link}
51.6 KB
{kind=link}

23.2 KB
{kind=link}
14.3 KB
{kind=link}

62.3 KB
{kind=link}
51.4 KB
{kind=link}
文件已移动
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
文件已移动
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

24.3 KB
doc/imdb_loss.png
已删除
100644 → 0
{kind=link}

81.2 KB
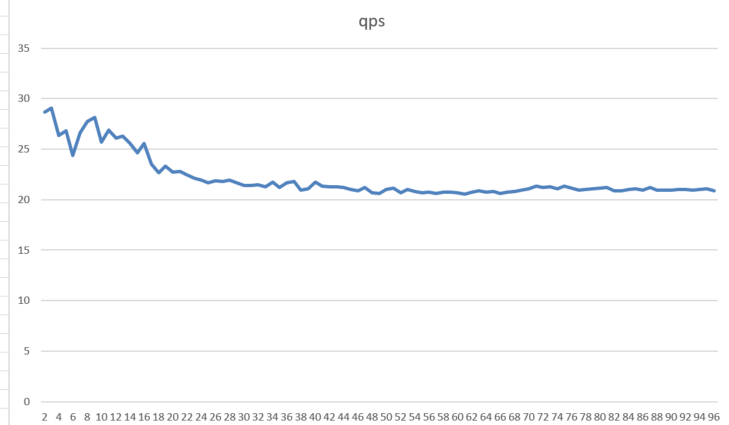
doc/qps-threads-bow.png
已删除
100644 → 0
{kind=link}

237.2 KB
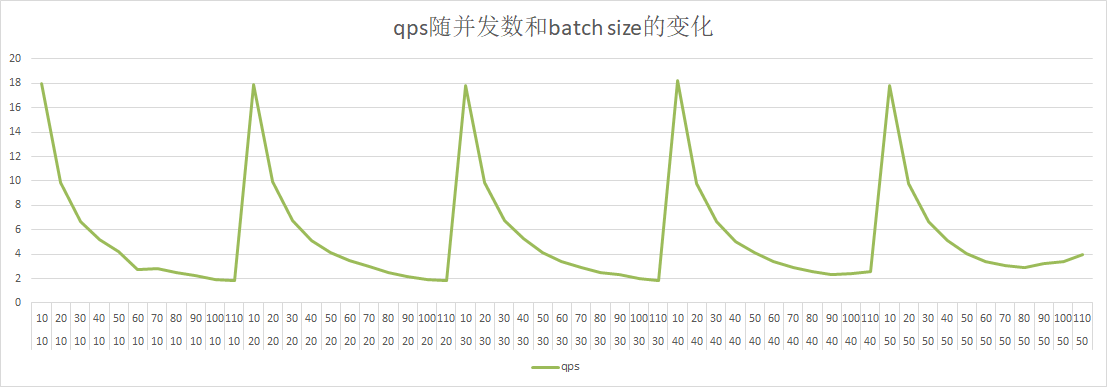
doc/qps-threads-cnn.png
已删除
100644 → 0
{kind=link}

174.9 KB
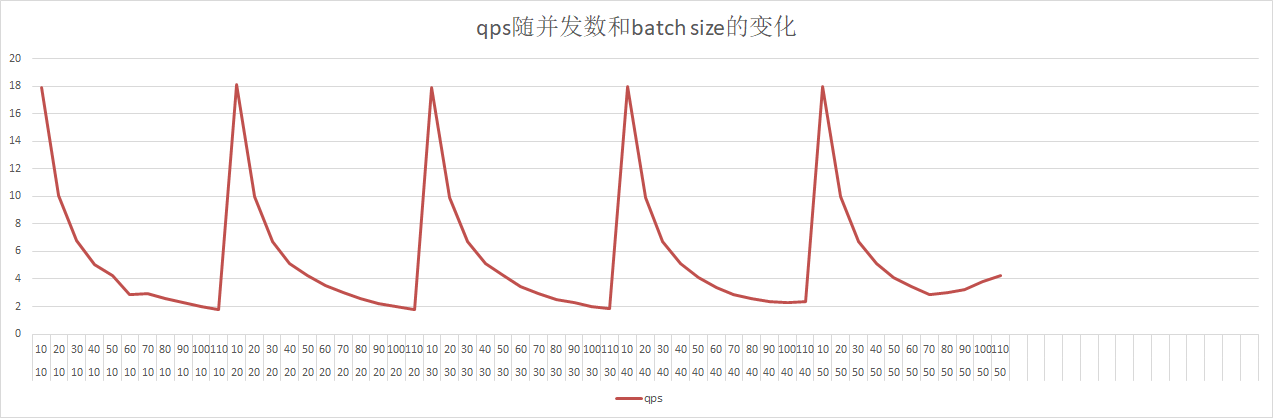
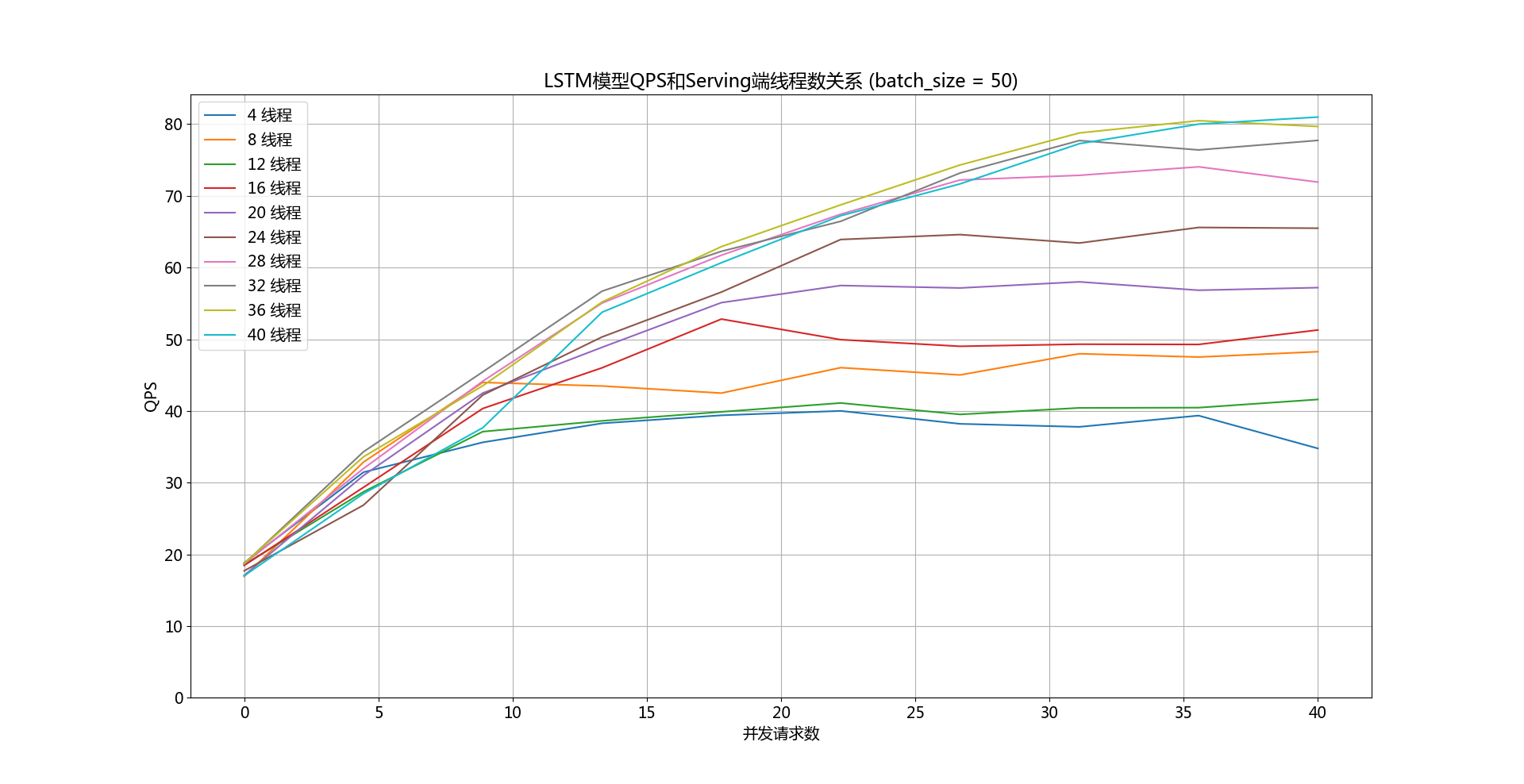
doc/qps-threads-lstm.png
已删除
100644 → 0
{kind=link}
176.9 KB
doc/qq.jpeg
已删除
100644 → 0
{kind=link}
53.3 KB
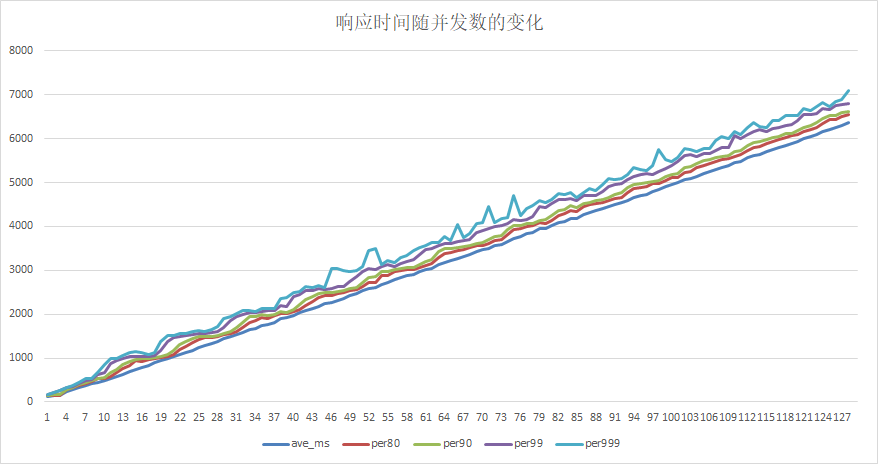
doc/serving-timings.png
已删除
100644 → 0
{kind=link}

36.9 KB
doc/wechat.jpeg
已删除
100644 → 0
{kind=link}
此差异已折叠。