Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Serving
提交
162bd4a2
S
Serving
项目概览
PaddlePaddle
/
Serving
大约 1 年 前同步成功
通知
186
Star
833
Fork
253
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
105
列表
看板
标记
里程碑
合并请求
10
Wiki
2
Wiki
分析
仓库
DevOps
项目成员
Pages
S
Serving
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
105
Issue
105
列表
看板
标记
里程碑
合并请求
10
合并请求
10
Pages
分析
分析
仓库分析
DevOps
Wiki
2
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
162bd4a2
编写于
8月 08, 2019
作者:
X
xulongteng
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add cube doc
上级
8b661cc3
变更
2
显示空白变更内容
内联
并排
Showing
2 changed file
with
207 addition
and
31 deletion
+207
-31
doc/DEPLOY.md
doc/DEPLOY.md
+207
-31
doc/deploy/ctr-prediction-end-to-end-deployment.png
doc/deploy/ctr-prediction-end-to-end-deployment.png
+0
-0
未找到文件。
doc/DEPLOY.md
浏览文件 @
162bd4a2
...
...
@@ -15,22 +15,56 @@
*
[
5、模型产出
](
#head12
)
*
[
5.1 模型裁剪
](
#head13
)
*
[
5.2 稀疏参数产出
](
#head14
)
*
[
预测服务部署
](
#head15
)
*
[
1、Server端
](
#head16
)
*
[
1.1 Cube服务
](
#head17
)
*
[
1.2 Serving编译
](
#head18
)
*
[
1.3 配置修改
](
#head19
)
*
[
1.3.1 conf/gflags.conf
](
#head20
)
*
[
1.3.2 conf/model_toolkit.prototxt
](
#head21
)
*
[
1.3.3 conf/cube.conf
](
#head22
)
*
[
1.3.4 模型文件
](
#head23
)
*
[
1.4 启动Serving
](
#head24
)
*
[
2、Client端
](
#head25
)
*
[
2.1 测试数据
](
#head26
)
*
[
2.2 Client编译与部署
](
#head27
)
*
[
2.2.1 配置修改
](
#head28
)
*
[
2.2.2 运行服务
](
#head29
)
*
[
大规模稀疏参数服务Cube的部署和使用
](
#head15
)
*
[
1. 编译
](
#head16
)
*
[
2. 分片cube server部署
](
#head17
)
*
[
2.1 配置文件修改
](
#head18
)
*
[
2.2 拷贝可执行文件和配置文件到物理机
](
#head19
)
*
[
2.3 启动 cube server
](
#head20
)
*
[
3. cube-builder部署
](
#head21
)
*
[
3.1 配置文件修改
](
#head22
)
*
[
3.2 拷贝可执行文件到物理机
](
#head23
)
*
[
3.3 启动cube-builder
](
#head24
)
*
[
4. cube-transfer部署
](
#head25
)
*
[
4.1 cube-transfer配置修改
](
#head26
)
*
[
4.2 拷贝cube-transfer到物理机
](
#head27
)
*
[
4.3 启动cube-transfer
](
#head28
)
*
[
4.4 验证
](
#head29
)
*
[
预测服务部署
](
#head30
)
*
[
1、Server端
](
#head31
)
*
[
1.1 Cube服务
](
#head32
)
*
[
1.2 Serving编译
](
#head33
)
*
[
1.3 配置修改
](
#head34
)
*
[
1.3.1 conf/gflags.conf
](
#head35
)
*
[
1.3.2 conf/model_toolkit.prototxt
](
#head36
)
*
[
1.3.3 conf/cube.conf
](
#head37
)
*
[
1.3.4 模型文件
](
#head38
)
*
[
1.4 启动Serving
](
#head39
)
*
[
2、Client端
](
#head40
)
*
[
2.1 测试数据
](
#head41
)
*
[
2.2 Client编译与部署
](
#head42
)
*
[
2.2.1 配置修改
](
#head43
)
*
[
2.2.2 运行服务
](
#head44
)
在搜索、推荐、在线广告等业务场景中,embedding参数的规模常常非常庞大,达到数百GB甚至T级别;训练如此规模的模型需要用到多机分布式训练能力,将参数分片更新和保存;另一方面,训练好的模型,要应用于在线业务,也难以单机加载。Paddle Serving提供大规模稀疏参数读写服务,用户可以方便地将超大规模的稀疏参数以kv形式托管到参数服务,在线预测只需将所需要的参数子集从参数服务读取回来,再执行后续的预测流程。
本文以CTR预估任务为例,提供一个完整的基于PaddlePaddle的分布式训练和Serving的流程化部署过程。基于此流程,用户可定制自己的端到端深度学习训练和应用解决方案。
本文演示的基于PaddlePaddle的分布式训练和Serving流程化部署,基于CTR预估任务,原始模型可参见
[
PaddlePaddle公开模型github repo
](
https://github.com/PaddlePaddle/models/tree/develop/PaddleRec/ctr
)
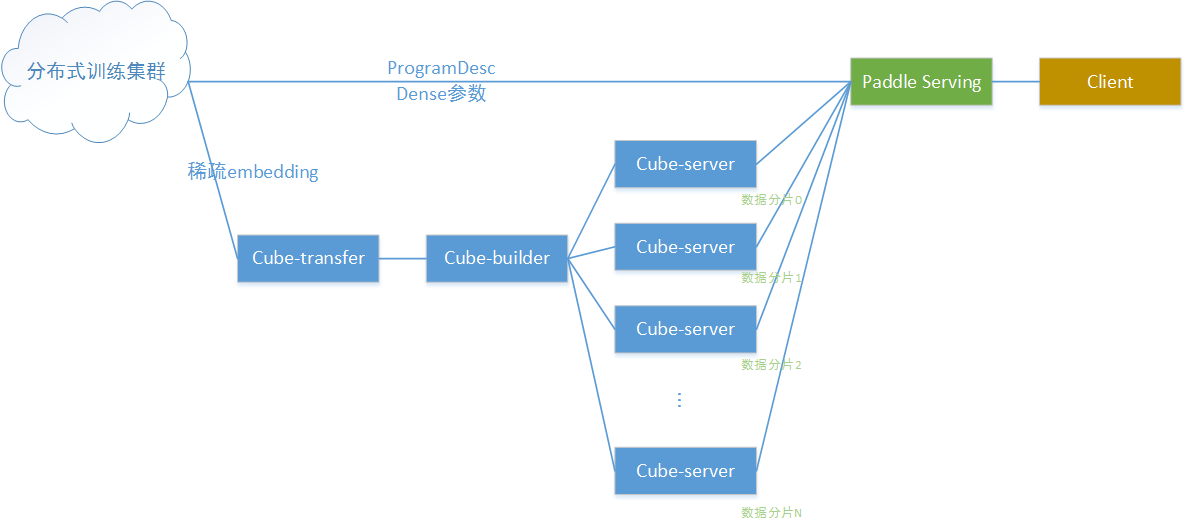
。 整体拓扑架构如下图所示:

其中:
1) 分布式训练集群在百度云k8s集群上搭建,并通过
[
volcano
](
https://volcano.sh/
)
提交分布式训练任务和资源管理
2) 分布式训练产出dense参数和ProgramDesc,通过http服务直接下载到Serving端,给Serving加载
3) 分布式训练产出sparse embedding,由于体积太大,通过cube稀疏参数服务提供给serving访问
4) 在线预测时,Serving通过访问cube集群获取embedding数据,与dense参数配合完成预测计算过程
以下从3部分分别介绍上图中各个组件:
1) 分布式训练集群和训练任务提交
2) 稀疏参数服务部署与使用
3) Paddle Serving的部署
4) 客户端访问Paddle Serving完成CTR预估任务预测请求
## <span id="head0"> 环境配置</span>
**环境要求**
:helm、kubectl、go
...
...
@@ -240,9 +274,151 @@ python dumper.py --model_path=xxx --output_data_path=xxx
**注意事项:**
文档中使用的CTR模型训练镜像中已经包含了模型裁剪以及稀疏参数产出的脚本,并且搭建了一个http服务用于从外部获取产出的dense模型以及稀疏参数文件。
## <span id="head15"> 预测服务部署</span>
### <span id="head16"> 1、Server端</span>
## <span id="head15"> 大规模稀疏参数服务Cube的部署和使用</span>
Cube大规模稀疏参数服务服务组件,用于承载超大规模稀疏参数的查询、更新等各功能。上述分布式训练产出的稀疏参数,在k8s中以http文件服务的形式提供下载;cube则负责将稀疏参数读取、加工,切分成多个分片,灌入稀疏参数服务集群,提供对外访问。
Cube一共拆分成三个组件,共同完成上述工作:
1) cube-transfer 负责监听上游数据产出,当判断到数据更新时,将数据下载到cube-builder建库端
2) cube-builder 负责从上游数据构建cube内部索引格式,并切分成多个分片,配送到由多个物理节点组成的稀疏参数服务集群
3) cube-server 每个单独的cube服务承载一个分片的cube数据
关于Cube的详细说明文档,请参考
[
Cube设计文档
](
https://github.com/PaddlePaddle/Serving/tree/develop/cube/doc/DESIGN.md
)
。本文仅描述从头部署Cube服务的流程。
### <span id="head16">1. 编译</span>
Cube是Paddle Serving内置的组件,只要按常规步骤编译Serving即可。要注意的是,编译Cube需要Go语言编译器。
```
bash
$
git clone https://github.com/PaddlePaddle/Serving.git
$
cd
Serving
$
makedir build
$
cd
build
$
cmake
-DWITH_GPU
=
OFF ..
# 不需要GPU
$
make
-jN
# 这里可修改并发编译线程数
$
make
install
$
cd
output/
$
ls
bin
cube cube-builder cube-transfer pdcodegen
$
ls
conf
gflags.conf transfer.conf
```
其中:
1) bin/cube, bin/cube-builder, bin/cube-transfer是上述3个组件的可执行文件。
**bin/cube是cube-server的可执行文件**
2) conf/gflags.conf是配合bin/cube使用的配置文件,主要包括端口配置等等
3) conf/transfer.conf是配合bin/cube-transfer使用的配置文件,主要包括要监听的上游数据地址等等
接下来我们按cube server, cube-builder, cube-transfer的顺序,介绍Cube的完整部署流程
### <span id="head17">2. 分片cube server部署</span>
#### <span id="head18">2.1 配置文件修改</span>
首先修改cube server的配置文件,将端口改为我们需要的端口:
```
--port=8000
--dict_split=1
--in_mem=true
```
#### <span id="head19">2.2 拷贝可执行文件和配置文件到物理机</span>
将bin/cube和conf/gflags.conf拷贝到多个物理机上。假设拷贝好的文件结构如下:
```
$ tree
.
|-- bin
| `-- cube
`-- conf
`-- gflags.conf
```
#### <span id="head20">2.3 启动 cube server</span>
```
bash
nohup
bin/cube &
```
### <span id="head21">3. cube-builder部署</span>
#### <span id="head22">3.1 配置文件修改</span>
cube-builder配置项说明:
TOBE FILLED
修改如下:
```
下游节点地址列表
TOBE FILLED
```
#### <span id="head23">3.2 拷贝可执行文件到物理机</span>
部署完成后目录结构如下:
```
TOBE FILLED
```
#### <span id="head24">3.3 启动cube-builder</span>
```
启动cube-builder命令
```
### <span id="head25">4. cube-transfer部署</span>
#### <span id="head26">4.1 cube-transfer配置修改</span>
cube-transfer配置文件是conf/transfer.conf,配置比较复杂;各个配置项含义如下:
1) TOBE FILLED
2) TOBE FILLED
...
我们要将上游数据地址配置到配置文件中:
```
cube-transfer配置文件修改地方:TOBE FILLED
```
#### <span id="head27">4.2 拷贝cube-transfer到物理机</span>
拷贝完成后,目录结构如下:
```
TOBE FILLED
```
#### <span id="head28">4.3 启动cube-transfer</span>
```
启动cube-transfer命令
```
### <span id="head29">4.4 验证</span>
一旦cube-transfer部署完成,它就不断监听我们配置好的数据位置,发现有数据更新后,即启动数据下载,然后通知cube-builder执行建库和配送流程,将新数据配送给各个分片的cube-server。
在上述过程中,经常遇到如下问题,可自行排查解决:
1) TOBE FILLED
2) TOBE FILLED
3) TOBE FILLED
## <span id="head30"> 预测服务部署</span>
### <span id="head31"> 1、Server端</span>
通过wget命令从集群获取dense部分模型用于Server端。
...
...
@@ -254,7 +430,7 @@ K8s集群上CTR预估任务训练完成后,模型参数分成2部分:一是e
本文介绍Serving使用上述模型参数和program加载模型提供预测服务的流程。
#### <span id="head
17
">1.1 Cube服务</span>
#### <span id="head
32
">1.1 Cube服务</span>
假设Cube服务已经成功部署,用于cube客户端API的配置文件如下所示:
...
...
@@ -278,7 +454,7 @@ K8s集群上CTR预估任务训练完成后,模型参数分成2部分:一是e
上述例子中,cube提供外部访问的表名是
`dict`
,有2个物理分片,分别在192.168.1.1:8000和192.168.1.2:8000
#### <span id="head
18
">1.2 Serving编译</span>
#### <span id="head
33
">1.2 Serving编译</span>
截至写本文时,Serving develop分支已经提供了CTR预估服务相关OP,参考
[
ctr_prediction_op.cpp
](
https://github.com/PaddlePaddle/Serving/blob/develop/demo-serving/op/ctr_prediction_op.cpp
)
,该OP从client端接收请求后会将每个请求的26个sparse feature id发给cube服务,获得对应的embedding向量,然后填充到模型feed variable对应的LoDTensor,执行预测计算。只要按常规步骤编译Serving即可。
...
...
@@ -293,9 +469,9 @@ $ make install
$
cd
output/demo/serving
```
#### <span id="head
19
">1.3 配置修改</span>
#### <span id="head
34
">1.3 配置修改</span>
##### <span id="head
20
">1.3.1 conf/gflags.conf</span>
##### <span id="head
35
">1.3.1 conf/gflags.conf</span>
将--enable_cube改为true:
...
...
@@ -303,7 +479,7 @@ $ cd output/demo/serving
--enable_cube=
true
```
##### <span id="head
21
">1.3.2 conf/model_toolkit.prototxt</span>
##### <span id="head
36
">1.3.2 conf/model_toolkit.prototxt</span>
Paddle Serving自带的model_toolkit.prototxt如下所示,如有必要可只保留ctr_prediction一个:
...
...
@@ -350,7 +526,7 @@ sparse_param_service_type: REMOTE
sparse_param_service_table_name:
"dict"
```
##### <span id="head
22
">1.3.3 conf/cube.conf</span>
##### <span id="head
37
">1.3.3 conf/cube.conf</span>
conf/cube.conf是一个完整的cube配置文件模板,其中只要修改nodes列表为真实的物理节点IP:port列表即可。例如 (与第1节cube配置文件内容一致):
...
...
@@ -374,7 +550,7 @@ conf/cube.conf是一个完整的cube配置文件模板,其中只要修改nodes
**注意事项:**
如果修改了
`dict_name`
,需要同步修改1.3.2节中
`sparse_param_service_table_name`
字段
##### <span id="head
23
">1.3.4 模型文件</span>
##### <span id="head
38
">1.3.4 模型文件</span>
Paddle Serving自带了一个可以工作的CTR预估模型,是从BCE上下载下来的,其制作方法为: 1) 分布式训练CTR预估任务,保存模型program和参数文件 2) 用save_program.py保存一份用于预测的program (文件名为
**model**
)。save_program.py随trainer docker image发布 3) 第2步中保存的program (
**model**
) 覆盖到第1)步保存的模型文件夹中
**model**
文件,打包成.tar.gz上传到BCE
...
...
@@ -382,25 +558,25 @@ Paddle Serving自带了一个可以工作的CTR预估模型,是从BCE上下载
为了应用重新训练的模型,只需要从k8s集群暴露的ftp服务下载新的.tar.gz,解压到data/model/paddle/fluid下,覆盖原来的ctr_prediction目录即可。从K8S集群暴露的ftp服务下载训练模型,请参考文档
[
PaddlePaddle分布式训练和Serving流程化部署
](
http://icode.baidu.com/repos/baidu/personal-code/wangguibao/blob/master:ctr-embedding-to-sequencefile/path/to/doc/DISTRIBUTED_TRANING_AND_SERVING.md
)
#### <span id="head
24
">1.4 启动Serving</span>
#### <span id="head
39
">1.4 启动Serving</span>
执行
`./bin/serving `
启动serving服务,在./log路径下可以查看serving日志。
### <span id="head
25
"> 2、Client端</span>
### <span id="head
40
"> 2、Client端</span>
参考
[
从零开始写一个预测服务:client端
](
[https://github.com/PaddlePaddle/Serving/blob/develop/doc/CREATING.md#3-client%E7%AB%AF](https://github.com/PaddlePaddle/Serving/blob/develop/doc/CREATING.md#3-client端
)
)文档,实现client端代码。
文档中使用的CTR预估任务client端代码存放在Serving代码库demo-client路径下,链接
[
ctr_prediction.cpp
](
https://github.com/PaddlePaddle/Serving/blob/develop/demo-client/src/ctr_prediction.cpp
)
。
#### <span id="head
26
">2.1 测试数据</span>
#### <span id="head
41
">2.1 测试数据</span>
CTR预估任务样例使用的数据来自于
[
原始模型
](
https://github.com/PaddlePaddle/models/tree/develop/PaddleRec/ctr
)
的测试数据,在样例中提供了1000个测试样本,如果需要更多样本可以参照原始模型下载数据的
[
脚本
](
https://github.com/PaddlePaddle/models/blob/develop/PaddleRec/ctr/data/download.sh
)
。
#### <span id="head
27
">2.2 Client编译与部署</span>
#### <span id="head
42
">2.2 Client编译与部署</span>
按照
[
1.2Serving编译
](
#1.2
Serving编译)部分完成编译后,client端文件在output/demo/client/ctr_prediction路径下。
##### <span id="head
28
">2.2.1 配置修改</span>
##### <span id="head
43
">2.2.1 配置修改</span>
修改conf/predictors.prototxt文件ctr_prediction_service部分
...
...
@@ -423,6 +599,6 @@ cluster: "list://127.0.0.1:8010"
配置Server端ip与端口号,默认为本机ip、8010端口。
##### <span id="head
29
">2.2.2 运行服务</span>
##### <span id="head
44
">2.2.2 运行服务</span>
执行
`./bin/ctr_predictoin`
启动client端,在./log路径下可以看到client端执行的日志。
doc/deploy/ctr-prediction-end-to-end-deployment.png
0 → 100755
浏览文件 @
162bd4a2
34.5 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}