飞桨全流程开发客户端,集成飞桨核心框架、模型库、工具及组件等核心模块,打通深度学习开发全流程。不仅提供一键安装的客户端,开源开放的技术内核更方便您根据实际生产需求进行直接调用或二次开发,为开发者提供飞桨全流程开发的最佳实践。
PaddleX由PaddleX Client可视化前端和PaddleX Core后端技术内核两个部分组成。
PaddleX Client是提升项目开发效率、有效降低深度学习应用中繁杂的配置成本的前端模块,帮助开发者快速完成深度学习模型全流程开发。开源开放的后端技术内核--PaddleX Core,为开发者提供了基于飞桨核心框架的全流程应用API,在集成飞桨模型库、工具组件的基础上,提供更高层、简洁的开发方式。开发者可以根据实际业务需求,选择使用可视化前端,或直接调用PaddleX Core后端技术内核进行任务开发或软件集成。
PaddleX不仅打通了深度学习开发的全流程、提供可视化开发界面, 还保证开发者可以直接灵活地使用底层技术模块。
我们诚挚地邀请您前往 [官网](https://www.paddlepaddle.org.cn/paddle/paddlex)下载试用PaddleX可视化前端,并获得您宝贵的意见或开源项目贡献。
## 目录
* **产品特性**
* **PaddleX Client可视化前端**
1. 下载客户端
2. 准备数据
3. 导入我的数据集
4. 创建项目
5. 项目开发
* **PaddleX Core后端技术内核**
* **FAQ**
## 产品特性
1. **全流程打通**
将深度学习开发从数据接入、模型训练、参数调优、模型评估、预测部署全流程打通,并提供可视化的使用界面,省去了对各环节间串连的代码开发与脚本调用,极大地提升了开发效率。
2. **开源技术内核**
集成PaddleCV领先的视觉算法和面向任务的开发套件、预训练模型应用工具PaddleHub、训练可视化工具VisualDL、模型压缩工具库PaddleSlim等技术能力于一身,并提供简明易懂的Python API,完全开源开放,易于集成和二次开发,为您的业务实践全程助力。
3. **本地一键安装**
提供兼容Windows、Mac、Linux多平台的客户端,同时支持NVIDIA GPU加速深度学习训练。无需繁琐的前置依赖,一键安装,开箱即用。本地开发、保证数据安全,高度符合产业应用的实际需求。
4. **教程与服务**
从数据集准备到上线部署,为您提供业务开发全流程的文档说明及技术服务。开发者可以通过QQ群、微信群、GitHub社区等多种形式与飞桨团队及同业合作伙伴交流沟通。
## PaddleX Client可视化前端
**第一步:下载客户端**
您需要前往 [官网](https://www.paddlepaddle.org.cn/paddle/paddlex)填写基本信息后下载试用PaddleX可视化前端
**第二步:准备数据**
在开始模型训练前,您需要根据不同的任务类型,将数据标注为相应的格式。目前PaddleX支持【图像分类】、【目标检测】、【语义分割】、【实例分割】四种任务类型。不同类型任务的数据处理方式可查看[数据标注方式](https://github.com/PaddlePaddle/PaddleX/tree/master/DataAnnotation/AnnotationNote)。
**第三步:导入我的数据集**
①数据标注完成后,您需要根据不同的任务,将数据和标注文件,按照客户端提示更名并保存到正确的文件中。
②在客户端新建数据集,选择与数据集匹配的任务类型,并选择数据集对应的路径,将数据集导入。
 ③选定导入数据集后,客户端会自动校验数据及标注文件是否合规,校验成功后,您可根据实际需求,将数据集按比例划分为训练集、验证集、测试集。
④您可在「数据分析」模块按规则预览您标注的数据集,双击单张图片可放大查看。
③选定导入数据集后,客户端会自动校验数据及标注文件是否合规,校验成功后,您可根据实际需求,将数据集按比例划分为训练集、验证集、测试集。
④您可在「数据分析」模块按规则预览您标注的数据集,双击单张图片可放大查看。
 **第四步:创建项目**
① 在完成数据导入后,您可以点击「新建项目」创建一个项目。
② 您可根据实际任务需求选择项目的任务类型,需要注意项目所采用的数据集也带有任务类型属性,两者需要进行匹配。
**第四步:创建项目**
① 在完成数据导入后,您可以点击「新建项目」创建一个项目。
② 您可根据实际任务需求选择项目的任务类型,需要注意项目所采用的数据集也带有任务类型属性,两者需要进行匹配。
 **第五步:项目开发**
① **数据选择**:项目创建完成后,您需要选择已载入客户端并校验后的数据集,并点击下一步,进入参数配置页面。
**第五步:项目开发**
① **数据选择**:项目创建完成后,您需要选择已载入客户端并校验后的数据集,并点击下一步,进入参数配置页面。
 ② **参数配置**:主要分为**模型参数**、**训练参数**、**优化策略**三部分。您可根据实际需求选择模型结构及对应的训练参数、优化策略,使得任务效果最佳。
② **参数配置**:主要分为**模型参数**、**训练参数**、**优化策略**三部分。您可根据实际需求选择模型结构及对应的训练参数、优化策略,使得任务效果最佳。
 参数配置完成后,点击启动训练,模型开始训练并进行效果评估。
③ **训练可视化**:
在训练过程中,您可通过VisualDL查看模型训练过程时的参数变化、日志详情,及当前最优的训练集和验证集训练指标。模型在训练过程中通过点击"终止训练"随时终止训练过程。
参数配置完成后,点击启动训练,模型开始训练并进行效果评估。
③ **训练可视化**:
在训练过程中,您可通过VisualDL查看模型训练过程时的参数变化、日志详情,及当前最优的训练集和验证集训练指标。模型在训练过程中通过点击"终止训练"随时终止训练过程。

 模型训练结束后,点击”下一步“,进入模型评估页面。
④ **模型评估**
在模型评估页面,您可将训练后的模型应用在切分时留出的「验证数据集」以测试模型在验证集上的效果。评估方法包括混淆矩阵、精度、召回率等。在这个页面,您也可以直接查看模型在测试数据集上的预测效果。
根据评估结果,您可决定进入模型发布页面,或返回先前步骤调整参数配置重新进行训练。
模型训练结束后,点击”下一步“,进入模型评估页面。
④ **模型评估**
在模型评估页面,您可将训练后的模型应用在切分时留出的「验证数据集」以测试模型在验证集上的效果。评估方法包括混淆矩阵、精度、召回率等。在这个页面,您也可以直接查看模型在测试数据集上的预测效果。
根据评估结果,您可决定进入模型发布页面,或返回先前步骤调整参数配置重新进行训练。
 ⑤**模型发布**
当模型效果满意后,您可根据实际的生产环境需求,选择将模型发布为需要的版本。
⑤**模型发布**
当模型效果满意后,您可根据实际的生产环境需求,选择将模型发布为需要的版本。
 ## PaddleX Core后端技术内核
## FAQ
1. **为什么我的数据集没办法切分?**
如果您的数据集已经被一个或多个项目引用,数据集将无法切分,您可以额外新建一个数据集,并引用同一批数据,再选择不同的切分比例。
2. **任务和项目的区别是什么?**
一个项目可以包含多条任务,一个项目拥有唯一的数据集,但采用不同的参数配置启动训练会创建多条任务,方便您对比采用不同参数配置的训练效果,并管理多个任务。
3. **为什么训练速度这么慢?**
PaddleX完全采用您本地的硬件进行计算,深度学习任务确实对算力的要求比较高,为了使您能快速体验应用PaddleX进行开发,我们适配了CPU硬件,但强烈建议您使用GPU以提升训练速度和开发体验。
4. **我可以在服务器或云平台上部署PaddleX么?**
PaddleX Client是一个适配本地单机安装的客户端,无法在服务器上直接进行部署,您可以直接使用PaddleX Core后端技术内核,或采用飞桨核心框架进行服务器上的部署。如果您希望使用公有算力,强烈建议您尝试飞桨产品系列中的 [EasyDL](https://ai.baidu.com/easydl/) 或 [AI Studio](https://aistudio.baidu.com/aistudio/index)进行开发。
5. **为什么我的安装总是报错?**
PaddleX的安装包中打包了PaddlePaddle全流程开发所需的所有依赖,理论上不需要您额外安装CUDA等ToolKit (如使用NVIDIA GPU), 但对操作系统版本、处理器架构、驱动版本等有一定要求,如安装发生错误,建议您先检查开发环境是否与PaddleX推荐环境匹配。
**这里我们推荐您在以下环境中安装使用PaddleX:**
* **操作系统:** Windows7/8/10(推荐),64位操作系统;Mac OS 10.13+
注:处理器需为x86_64架构,支持 MKL。
* **训练硬件:**
* **GPU**(Windows及Linux系统):
推荐使用支持CUDA的NVIDIA显卡(驱动版本>=411.31,显存8G以上)
例如:GTX 1070+以上性能的显卡
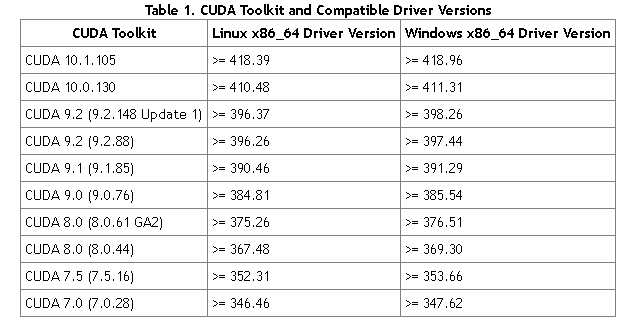
***Windows及Linux系统CUDA版本及驱动版本对应表:***
## PaddleX Core后端技术内核
## FAQ
1. **为什么我的数据集没办法切分?**
如果您的数据集已经被一个或多个项目引用,数据集将无法切分,您可以额外新建一个数据集,并引用同一批数据,再选择不同的切分比例。
2. **任务和项目的区别是什么?**
一个项目可以包含多条任务,一个项目拥有唯一的数据集,但采用不同的参数配置启动训练会创建多条任务,方便您对比采用不同参数配置的训练效果,并管理多个任务。
3. **为什么训练速度这么慢?**
PaddleX完全采用您本地的硬件进行计算,深度学习任务确实对算力的要求比较高,为了使您能快速体验应用PaddleX进行开发,我们适配了CPU硬件,但强烈建议您使用GPU以提升训练速度和开发体验。
4. **我可以在服务器或云平台上部署PaddleX么?**
PaddleX Client是一个适配本地单机安装的客户端,无法在服务器上直接进行部署,您可以直接使用PaddleX Core后端技术内核,或采用飞桨核心框架进行服务器上的部署。如果您希望使用公有算力,强烈建议您尝试飞桨产品系列中的 [EasyDL](https://ai.baidu.com/easydl/) 或 [AI Studio](https://aistudio.baidu.com/aistudio/index)进行开发。
5. **为什么我的安装总是报错?**
PaddleX的安装包中打包了PaddlePaddle全流程开发所需的所有依赖,理论上不需要您额外安装CUDA等ToolKit (如使用NVIDIA GPU), 但对操作系统版本、处理器架构、驱动版本等有一定要求,如安装发生错误,建议您先检查开发环境是否与PaddleX推荐环境匹配。
**这里我们推荐您在以下环境中安装使用PaddleX:**
* **操作系统:** Windows7/8/10(推荐),64位操作系统;Mac OS 10.13+
注:处理器需为x86_64架构,支持 MKL。
* **训练硬件:**
* **GPU**(Windows及Linux系统):
推荐使用支持CUDA的NVIDIA显卡(驱动版本>=411.31,显存8G以上)
例如:GTX 1070+以上性能的显卡
***Windows及Linux系统CUDA版本及驱动版本对应表:***
 * **CPU**:
PaddleX 当前支持您用本地CPU进行训练,但推荐使用GPU以获得更好的开发体验。
* **内存:**建议8G以上
* **硬盘空间:**建议SSD剩余空间1T以上(非必须)
***注:PaddleX 在 Windows及Mac系统只支持单卡模式。Windows暂时不支持NCCL。***
**如果您有更多问题或建议,欢迎以issue的形式,或加入PaddleX官方QQ群(1045148026)直接反馈您的意见及建议**
* **CPU**:
PaddleX 当前支持您用本地CPU进行训练,但推荐使用GPU以获得更好的开发体验。
* **内存:**建议8G以上
* **硬盘空间:**建议SSD剩余空间1T以上(非必须)
***注:PaddleX 在 Windows及Mac系统只支持单卡模式。Windows暂时不支持NCCL。***
**如果您有更多问题或建议,欢迎以issue的形式,或加入PaddleX官方QQ群(1045148026)直接反馈您的意见及建议**

