fix conflicts
Showing
.DS_Store
0 → 100644
文件已添加
deploy/openvino/CMakeLists.txt
100644 → 100755
deploy/openvino/CMakeSettings.json
100644 → 100755
deploy/openvino/cmake/yaml-cpp.cmake
100644 → 100755
deploy/openvino/demo/detector.cpp
0 → 100644
deploy/openvino/include/paddlex/config_parser.h
100644 → 100755
deploy/openvino/include/paddlex/paddlex.h
100644 → 100755
deploy/openvino/include/paddlex/results.h
100644 → 100755
deploy/openvino/include/paddlex/transforms.h
100644 → 100755
deploy/openvino/python/demo.py
0 → 100644
deploy/openvino/python/deploy.py
0 → 100644
deploy/openvino/scripts/build.sh
100644 → 100755
deploy/openvino/src/paddlex.cpp
100644 → 100755
deploy/openvino/src/transforms.cpp
100644 → 100755
deploy/openvino/src/visualize.cpp
0 → 100644
deploy/raspberry/CMakeLists.txt
0 → 100755
deploy/raspberry/python/demo.py
0 → 100644
deploy/raspberry/scripts/build.sh
0 → 100755
deploy/raspberry/src/paddlex.cpp
0 → 100755
docs/.DS_Store
0 → 100644
文件已添加
docs/apis/analysis.md
0 → 100644
docs/deploy/opencv.md
0 → 100644
docs/deploy/openvino/python.md
0 → 100644
docs/deploy/raspberry/index.rst
0 → 100644
docs/deploy/raspberry/python.md
0 → 100644
docs/gui/.DS_Store
0 → 100644
文件已添加
docs/gui/images/LIME.png
0 → 100644
{kind=link}

49.7 KB
docs/gui/images/QR2.jpg
0 → 100644
{kind=link}

132.0 KB
{kind=link}

237.4 KB
{kind=link}

290.8 KB
{kind=link}
184.2 KB
{kind=link}

245.5 KB
{kind=link}
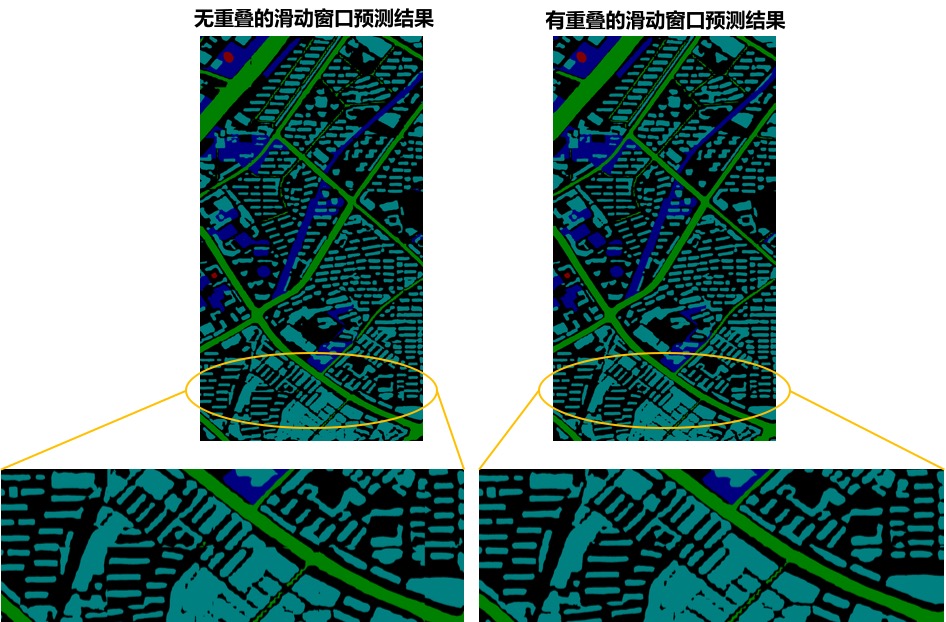
206.2 KB
paddlex/cv/datasets/analysis.py
0 → 100644
| ... | @@ -8,3 +8,4 @@ paddleslim == 1.0.1 | ... | @@ -8,3 +8,4 @@ paddleslim == 1.0.1 |
| shapely | shapely | ||
| x2paddle | x2paddle | ||
| paddlepaddle-gpu | paddlepaddle-gpu | ||
| opencv-python |