| Teacher |
Student |
Supported Graph |
Mode |
remarks |
| static |
dynamic |
online |
offline |
__init__(
out_path=None,
out_port=None) |
__init__(
merge_strategy=None) |
✅ |
✅ |
✅ |
✅ |
[1] |
|
register_teacher(
in_path=None,
in_address=None)
|
✅ |
✅ |
✅ |
✅ |
[2] |
| start() |
start() |
✅ |
✅ |
✅ |
✅ |
[3] |
| send(data) |
recv(teacher_id) |
✅ |
✅ |
✅ |
|
[4] |
| recv() |
send(data,
teacher_ids=None)
|
✅ |
✅ |
✅ |
|
[5] |
| dump(knowledge) |
|
✅ |
✅ |
|
✅ |
[6] |
start_knowledge_service(
feed_list,
schema,
program,
reader_config,
exe,
buf_size=10,
use_fp16=False,
times=1) |
get_knowledge_desc() |
✅ |
|
✅ |
✅ |
[7] |
| get_knowledge_qsize() |
✅ |
|
✅ |
✅ |
get_knowledge_generator(
batch_size,
drop_last=False) |
✅ |
|
✅ |
✅ |
**Remarks:**
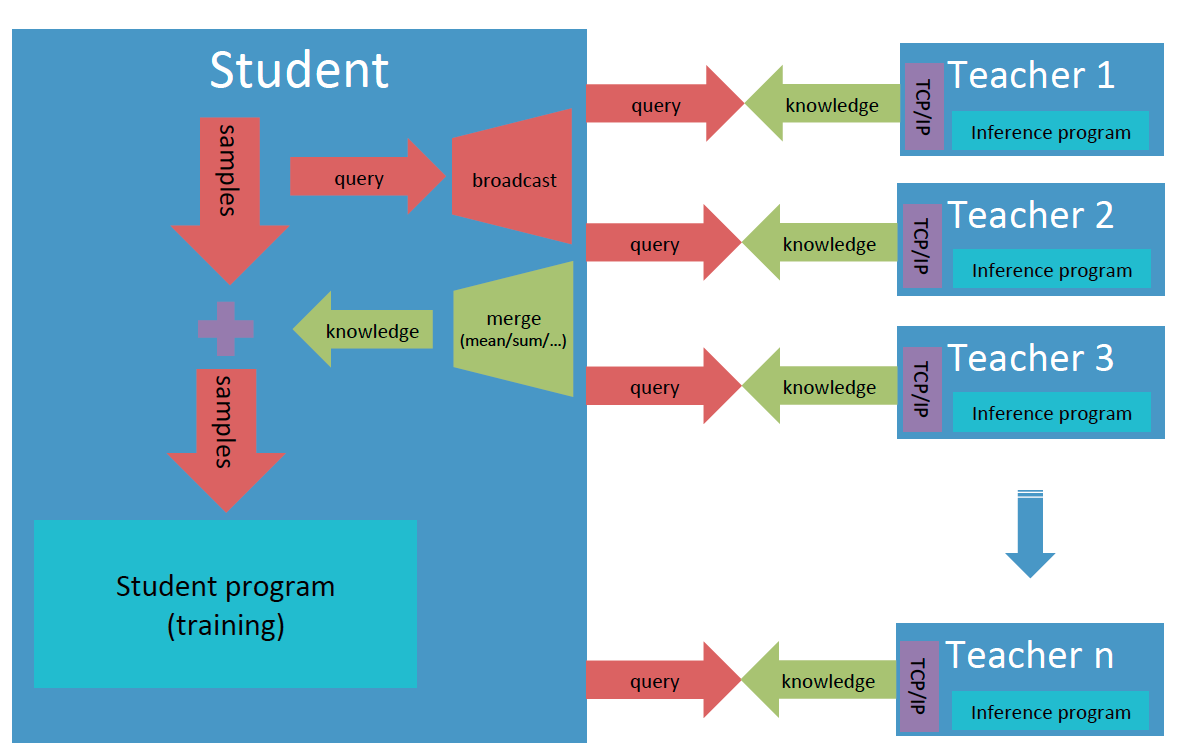
- [1] Decalre the teacher object for teacher model with **out\_path** or **out\_port**, and the student for student model with **merge\_strategy** for knowledge from different teachers.
- [2] Register a teacher, and allocate an id for it which starts from zero in the order of registration. **register\_teacher()** can be called many times for multiple-teacher mode.
- [3] Estabish TCP/IP link between teachers and the student, and synchronize all of them.
- [4] Send one data from teacher to student.
- [5] Send one data from student to teacher.
- [6] Dump one batch knowledge data into the output file.
- [7] Highly optimized high-level interfaces to build service for knowledge transfer:
- **start\_knowledge\_service()** can perform large-scale prediction of teacher model on multiple devices;
- Support auto merging of knowledge from different teachers;
- Support auto reconnection of student and teachers.
### About the data format
- **Knowledge**: A dictionary with the keys specified by users and the values that are numpy ndarray tensors predicted by teacher models. The first dimension of tensors should be batch size and LoDTensor is not supported yet. One can call **get\_knowledge\_desc()** to get the description of knowledge, which is also a dictionary, including the shape, data type and LoD level about knowledge data.
- **Offline knowledge file**: The first line is knowledge description, and the following lines are knowledge data, one line for one batch samples, all dumped by cPickle.
### Usage
If separately runnable teacher models and the student model
have been ready, basically one can build the trainable system with knowledge
distillation by following two simple steps.
1) Instantiate a **Teacher** object for the teacher model, and launch knowledge serving
```python
from paddleslim.pantheon import Teacher
...
teacher = Teacher(out_path=args.out_path, out_port=args.out_port)
teacher.start()
teacher.start_knowledge_service(
feed_list=[inp_x.name],
schema={"x": inp_x,
"y": y},
program=program,
reader_config={"batch_generator": batch_generator},
exe=exe,
buf_size=100,
times=1)
```
2) Instantiate a **Student** object, specify the way to merge knowledge, register teachers,
and get knowledge description and data generator for the student model
```python
from paddleslim.pantheon import Student
...
student = Student(merge_strategy={"result": "sum"})
student.register_teacher(
in_address=args.in_address0, in_path=args.in_path0)
student.register_teacher(
in_address=args.in_address1, in_path=args.in_path1)
student.start()
knowledge_desc = student.get_knowledge_desc()
data_generator = student.get_knowledge_generator(
batch_size=32, drop_last=False)
```
## Examples
### Toy Example
A toy example is provied to show how the knowledge data is transferred from teachers to the student model and merged, including offline, online modes and their hybrid. See [demo/pantheon/toy](../../demo/pantheon/toy).