# Embedding量化示例
本示例介绍如何使用Embedding量化的接口 [paddleslim.quant.quant_embedding]() 。``quant_embedding``接口将网络中的Embedding参数从``float32``类型量化到 ``8-bit``整数类型,在几乎不损失模型精度的情况下减少模型的存储空间和显存占用。
接口介绍请参考 量化API文档。
该接口对program的修改:
量化前:

图1:量化前的模型结构
量化后:
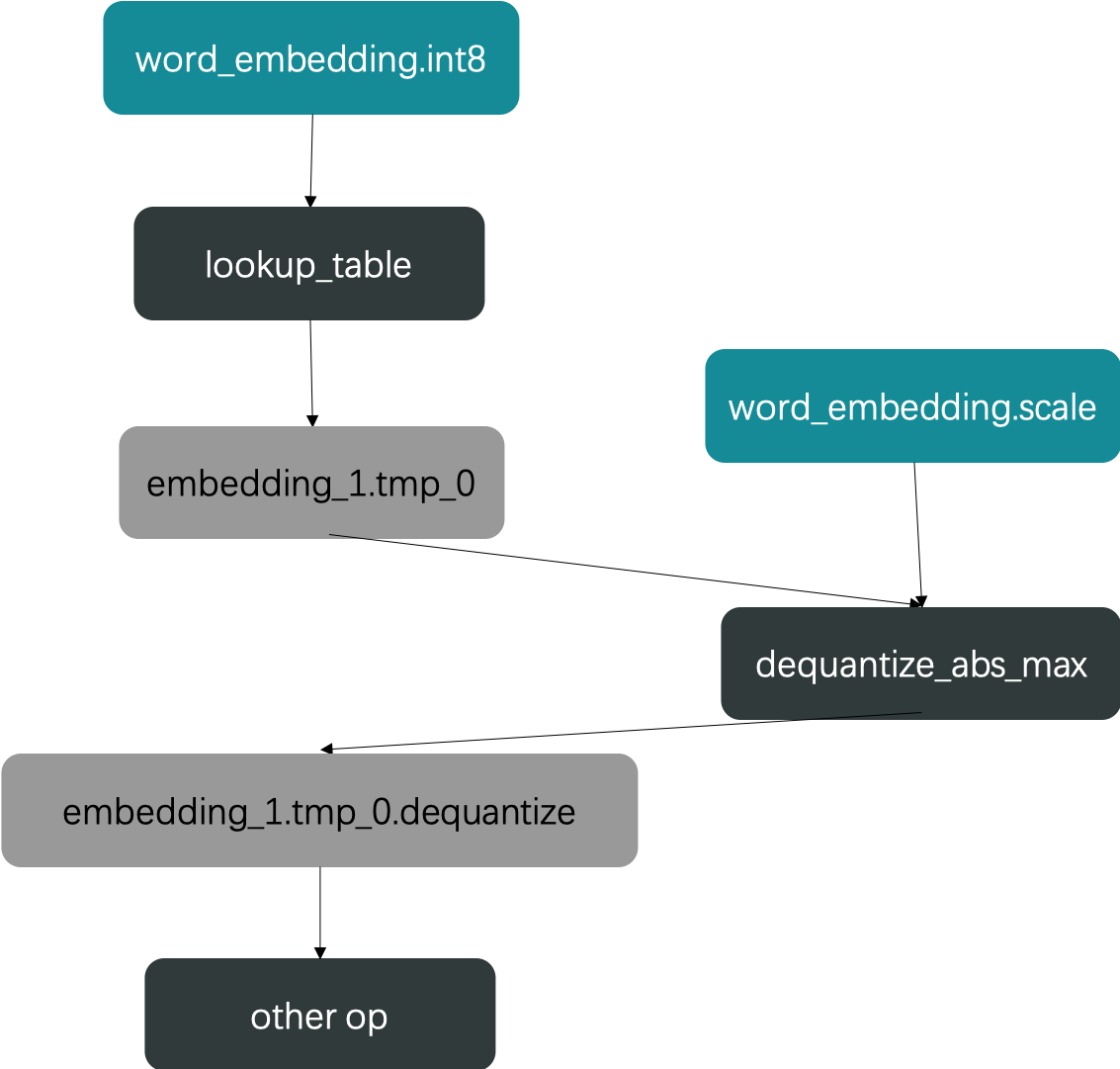
图2: 量化后的模型结构
以下将以 ``基于skip-gram的word2vector模型`` 为例来说明如何使用``quant_embedding``接口。首先介绍 ``基于skip-gram的word2vector模型`` 的正常训练和测试流程。
## 基于skip-gram的word2vector模型
以下是本例的简要目录结构及说明:
```text
.
├── cluster_train.py # 分布式训练函数
├── cluster_train.sh # 本地模拟多机脚本
├── train.py # 训练函数
├── infer.py # 预测脚本
├── net.py # 网络结构
├── preprocess.py # 预处理脚本,包括构建词典和预处理文本
├── reader.py # 训练阶段的文本读写
├── train.py # 训练函数
└── utils.py # 通用函数
```
### 介绍
本例实现了skip-gram模式的word2vector模型。
同时推荐用户参考[ IPython Notebook demo](https://aistudio.baidu.com/aistudio/projectDetail/124377)
### 数据下载
全量数据集使用的是来自1 Billion Word Language Model Benchmark的(http://www.statmt.org/lm-benchmark) 的数据集.
```bash
mkdir data
wget http://www.statmt.org/lm-benchmark/1-billion-word-language-modeling-benchmark-r13output.tar.gz
tar xzvf 1-billion-word-language-modeling-benchmark-r13output.tar.gz
mv 1-billion-word-language-modeling-benchmark-r13output/training-monolingual.tokenized.shuffled/ data/
```
备用数据地址下载命令如下
```bash
mkdir data
wget https://paddlerec.bj.bcebos.com/word2vec/1-billion-word-language-modeling-benchmark-r13output.tar
tar xvf 1-billion-word-language-modeling-benchmark-r13output.tar
mv 1-billion-word-language-modeling-benchmark-r13output/training-monolingual.tokenized.shuffled/ data/
```
为了方便快速验证,我们也提供了经典的text8样例数据集,包含1700w个词。 下载命令如下
```bash
mkdir data
wget https://paddlerec.bj.bcebos.com/word2vec/text.tar
tar xvf text.tar
mv text data/
```
### 数据预处理
以样例数据集为例进行预处理。全量数据集注意解压后以training-monolingual.tokenized.shuffled 目录为预处理目录,和样例数据集的text目录并列。
词典格式: 词<空格>词频。注意低频词用'UNK'表示
可以按格式自建词典,如果自建词典跳过第一步。
```
the 1061396
of 593677
and 416629
one 411764
in 372201
a 325873
324608
to 316376
zero 264975
nine 250430
```
第一步根据英文语料生成词典,中文语料可以通过修改text_strip方法自定义处理方法。
```bash
python preprocess.py --build_dict --build_dict_corpus_dir data/text/ --dict_path data/test_build_dict
```
第二步根据词典将文本转成id, 同时进行downsample,按照概率过滤常见词, 同时生成word和id映射的文件,文件名为词典+"_word_to_id_"。
```bash
python preprocess.py --filter_corpus --dict_path data/test_build_dict --input_corpus_dir data/text --output_corpus_dir data/convert_text8 --min_count 5 --downsample 0.001
```
### 训练
具体的参数配置可运行
```bash
python train.py -h
```
单机多线程训练
```bash
OPENBLAS_NUM_THREADS=1 CPU_NUM=5 python train.py --train_data_dir data/convert_text8 --dict_path data/test_build_dict --num_passes 10 --batch_size 100 --model_output_dir v1_cpu5_b100_lr1dir --base_lr 1.0 --print_batch 1000 --with_speed --is_sparse
```
本地单机模拟多机训练
```bash
sh cluster_train.sh
```
本示例中按照单机多线程训练的命令进行训练,训练完毕后,可看到在当前文件夹下保存模型的路径为: ``v1_cpu5_b100_lr1dir``, 运行 ``ls v1_cpu5_b100_lr1dir``可看到该文件夹下保存了训练的10个epoch的模型文件。
```
pass-0 pass-1 pass-2 pass-3 pass-4 pass-5 pass-6 pass-7 pass-8 pass-9
```
### 预测
测试集下载命令如下
```bash
#全量数据集测试集
wget https://paddlerec.bj.bcebos.com/word2vec/test_dir.tar
#样本数据集测试集
wget https://paddlerec.bj.bcebos.com/word2vec/test_mid_dir.tar
```
预测命令,注意词典名称需要加后缀"_word_to_id_", 此文件是预处理阶段生成的。
```bash
python infer.py --infer_epoch --test_dir data/test_mid_dir --dict_path data/test_build_dict_word_to_id_ --batch_size 20000 --model_dir v1_cpu5_b100_lr1dir/ --start_index 0 --last_index 9
```
运行该预测命令, 可看到如下输出
```
('start index: ', 0, ' last_index:', 9)
('vocab_size:', 63642)
step:1 249
epoch:0 acc:0.014
step:1 590
epoch:1 acc:0.033
step:1 982
epoch:2 acc:0.055
step:1 1338
epoch:3 acc:0.075
step:1 1653
epoch:4 acc:0.093
step:1 1914
epoch:5 acc:0.107
step:1 2204
epoch:6 acc:0.124
step:1 2416
epoch:7 acc:0.136
step:1 2606
epoch:8 acc:0.146
step:1 2722
epoch:9 acc:0.153
```
## 量化``基于skip-gram的word2vector模型``
量化配置为:
```
config = {
'params_name': 'emb',
'quantize_type': 'abs_max'
}
```
运行命令为:
```bash
python infer.py --infer_epoch --test_dir data/test_mid_dir --dict_path data/test_build_dict_word_to_id_ --batch_size 20000 --model_dir v1_cpu5_b100_lr1dir/ --start_index 0 --last_index 9 --emb_quant True
```
运行输出为:
```
('start index: ', 0, ' last_index:', 9)
('vocab_size:', 63642)
quant_embedding config {'quantize_type': 'abs_max', 'params_name': 'emb', 'quantize_bits': 8, 'dtype': 'int8'}
step:1 253
epoch:0 acc:0.014
quant_embedding config {'quantize_type': 'abs_max', 'params_name': 'emb', 'quantize_bits': 8, 'dtype': 'int8'}
step:1 586
epoch:1 acc:0.033
quant_embedding config {'quantize_type': 'abs_max', 'params_name': 'emb', 'quantize_bits': 8, 'dtype': 'int8'}
step:1 970
epoch:2 acc:0.054
quant_embedding config {'quantize_type': 'abs_max', 'params_name': 'emb', 'quantize_bits': 8, 'dtype': 'int8'}
step:1 1364
epoch:3 acc:0.077
quant_embedding config {'quantize_type': 'abs_max', 'params_name': 'emb', 'quantize_bits': 8, 'dtype': 'int8'}
step:1 1642
epoch:4 acc:0.092
quant_embedding config {'quantize_type': 'abs_max', 'params_name': 'emb', 'quantize_bits': 8, 'dtype': 'int8'}
step:1 1936
epoch:5 acc:0.109
quant_embedding config {'quantize_type': 'abs_max', 'params_name': 'emb', 'quantize_bits': 8, 'dtype': 'int8'}
step:1 2216
epoch:6 acc:0.124
quant_embedding config {'quantize_type': 'abs_max', 'params_name': 'emb', 'quantize_bits': 8, 'dtype': 'int8'}
step:1 2419
epoch:7 acc:0.136
quant_embedding config {'quantize_type': 'abs_max', 'params_name': 'emb', 'quantize_bits': 8, 'dtype': 'int8'}
step:1 2603
epoch:8 acc:0.146
quant_embedding config {'quantize_type': 'abs_max', 'params_name': 'emb', 'quantize_bits': 8, 'dtype': 'int8'}
step:1 2719
epoch:9 acc:0.153
```
量化后的模型保存在``./output_quant``中,可看到量化后的参数``'emb.int8'``的大小为3.9M, 在``./v1_cpu5_b100_lr1dir``中可看到量化前的参数``'emb'``的大小为16M。