| Teacher |
Student |
Supported Graph |
Mode |
remarks |
| static |
dynamic |
online |
offline |
__init__(
out_path=None,
out_port=None) |
__init__(
merge_strategy=None) |
✅ |
✅ |
✅ |
✅ |
[1] |
|
register_teacher(
in_path=None,
in_address=None)
|
✅ |
✅ |
✅ |
✅ |
[2] |
| start() |
start() |
✅ |
✅ |
✅ |
✅ |
[3] |
| send(data) |
recv(teacher_id) |
✅ |
✅ |
✅ |
|
[4] |
| recv() |
send(data,
teacher_ids=None)
|
✅ |
✅ |
✅ |
|
[5] |
| dump(knowledge) |
|
✅ |
✅ |
|
✅ |
[6] |
start_knowledge_service(
feed_list,
schema,
program,
reader_config,
exe,
buf_size=10,
times=1) |
get_knowledge_desc() |
✅ |
|
✅ |
✅ |
[7] |
| get_knowledge_qsize() |
✅ |
|
✅ |
✅ |
get_knowledge_generator(
batch_size,
drop_last=False) |
✅ |
|
✅ |
✅ |
**Remarks:**
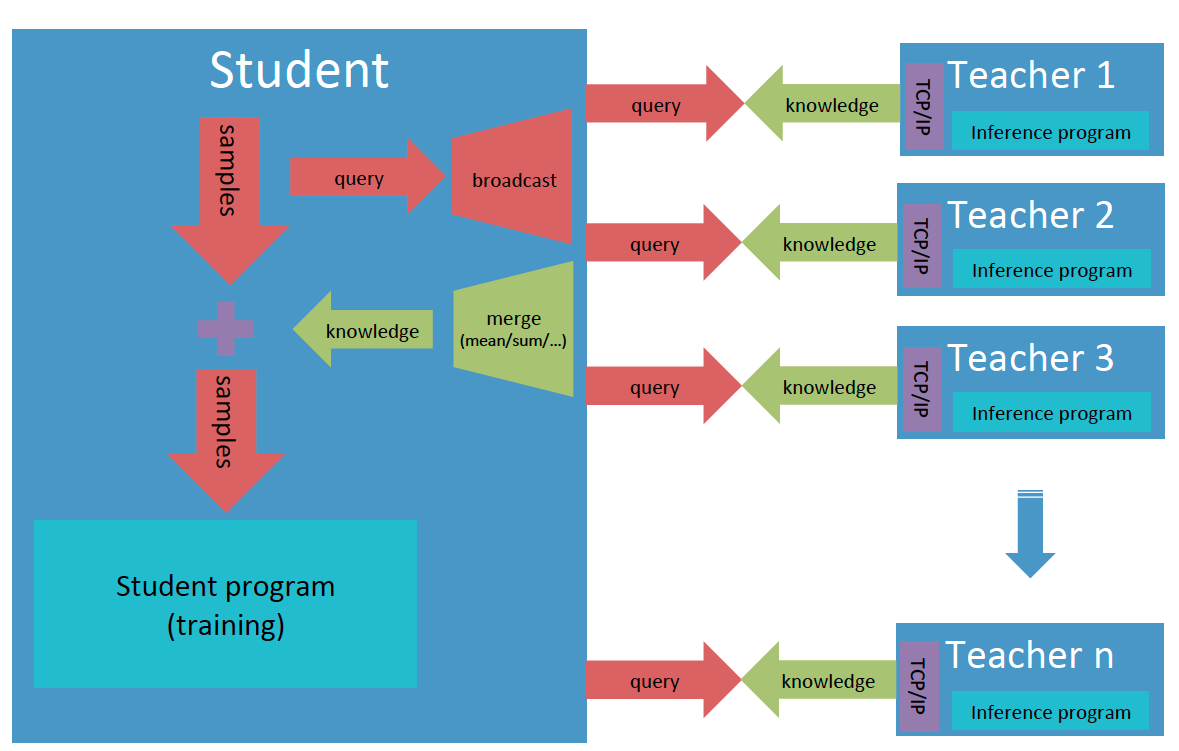
- [1] Decalre the teacher object for teacher model with **out\_path** or **out\_port**, and the student for student model with **merge\_strategy** for knowledge from different teachers.
- [2] Register a teacher, and allocate an id for it which starts from zero in the order of registration. **register\_teacher()** can be called many times for multiple-teacher mode.
- [3] Estabish TCP/IP link between teachers and the student, and synchronize all of them.
- [4] Send one data from teacher to student.
- [5] Send one data from student to teacher.
- [6] Dump one batch knowledge data into the output file.
- [7] Highly optimized high-level interfaces to build service for knowledge transfer:
- **start\_knowledge\_service()** can perform large-scale prediction of teacher model on multiple devices;
- Support auto merging of knowledge from different teachers;
- Support auto reconnection of student and teachers.
### About the data format
- **Knowledge**: A dictionary with the keys specified by users and the values that are numpy ndarray tensors predicted by teacher models. The first dimension of tensors should be batch size and LoDTensor is not supported yet. One can call **get\_knowledge\_desc()** to get the description of knowledge, which is also a dictionary, including the shape, data type and LoD level about knowledge data.
- **Offline knowledge file**: The first line is knowledge description, and the following lines are knowledge data, one line for one batch samples, all dumped by cPickle.
### Usage
If separately runnable teacher models and the student model
have been ready, basically one can build the trainable system with knowledge
distillation by following two simple steps.
1) Instantiate a **Teacher** object for the teacher model, and launch knowledge serving
```python
from paddleslim.pantheon import Teacher
...
teacher = Teacher(out_path=args.out_path, out_port=args.out_port)
teacher.start()
teacher.start_knowledge_service(
feed_list=[inp_x.name],
schema={"x": inp_x,
"y": y},
program=program,
reader_config={"batch_generator": batch_generator},
exe=exe,
buf_size=100,
times=1)
```
2) Instantiate a **Student** object, specify the way to merge knowledge, register teachers,
and get knowledge description and data generator for the student model
```python
from paddleslim.pantheon import Student
...
student = Student(merge_strategy={"result": "sum"})
student.register_teacher(
in_address=args.in_address0, in_path=args.in_path0)
student.register_teacher(
in_address=args.in_address1, in_path=args.in_path1)
student.start()
knowledge_desc = student.get_knowledge_desc()
data_generator = student.get_knowledge_generator(
batch_size=32, drop_last=False)
```
### Example
Here provide a toy example to show how the knowledge data is transferred from teachers to the student model and merged.
In the directory [demo/pantheon/](../../demo/pantheon/), there implement two teacher models (not trainable, just for demo): teacher1 takes an integer **x** as input and predicts value **2x-1**, see in [run_teacher1.py](../../demo/pantheon/run_teacher1.py); teacher2 also takes **x** as input and predicts **2x+1**, see in [run_teacher2.py](../../demo/pantheon/run_teacher2.py). They two share a data reader to read a sequence of increasing natural numbers from zero to some positive inter **max_n** as input and generate different knowledge. And the schema keys for knowledge in teacher1 is [**"x", "2x-1", "result"**], and [**"2x+1", "result"**] for knowledge in teacher2, in which **"result"** is the common schema and the copy of two predictions respectively. On instantiating the **Student** object, the merging strategy for the common schema **"result"** should be specified, and the schema keys for the merged knowledge will be [**"x", "2x-1", "2x+1", "result"**], with the merged **"result"** equal to **"2x"** when the merging strategy is **"mean"** and **"4x"** when merging strategy is **"sum"**. The student model gets merged knowledge from teachers and prints them out, see in [run_student.py](../../demo/pantheon/run_student.py).
The toy "knowledge distillation" system can be launched in three different modes, i.e., offline, online and their hybrid. All three modes should have the same outputs, and the correctness of results can be verified by checking the order and values of outputs.
1) **Offline**
The two teachers work in offline mode, and start them with given local file paths.
```shell
export PYTHONPATH=../../:$PYTHONPATH
export CUDA_VISIBLE_DEVICES=0,1
nohup python -u run_teacher1.py --use_cuda true --out_path teacher1_offline.dat > teacher1_offline.log 2>&1&
export CUDA_VISIBLE_DEVICES=2
nohup python -u run_teacher2.py --use_cuda true --out_path teacher2_offline.dat > teacher2_offline.log 2>&1&
```
After the two executions both finished, start the student model with the two generated knowledge files.
```shell
export PYTHONPATH=../../:$PYTHONPATH
python -u run_student.py \
--in_path0 teacher1_offline.dat \
--in_path1 teacher2_offline.dat
```
2) **Online**
The two teachers work in online mode, and start them with given TCP/IP ports. Please make sure that the ICP/IP ports are available.
```shell
export PYTHONPATH=../../:$PYTHONPATH
export CUDA_VISIBLE_DEVICES=0
nohup python -u run_teacher1.py --use_cuda true --out_port 8080 > teacher1_online.log 2>&1&
export CUDA_VISIBLE_DEVICES=1,2
nohup python -u run_teacher2.py --use_cuda true --out_port 8081 > teacher2_online.log 2>&1&
```
Start the student model with the IP addresses that can reach the ports of the two teacher models, e.g., in the same node
```shell
export PYTHONPATH=../../:$PYTHONPATH
python -u run_student.py \
--in_address0 127.0.0.1:8080 \
--in_address1 127.0.0.1:8081 \
```
**Note:** in online mode, the starting order of teachers and the sudent doesn't matter, and they will wait for each other to establish connection.
3) **Hybrid of offline and online**
One teacher works in offline mode and another one works in online mode. This time, start the offline teacher first. After the offline knowledge file gets well prepared, start the online teacher and the student at the same time.