|
模型 |
原始模型 (单位 ms/image) |
OP 优化模型 (单位 ms/image) |
||||
|
Fluid |
Fluid-TRT FP32 |
Fluid-TRT FP16 |
Fluid |
Fluid-TRT FP32 |
Fluid-TRT FP16 |
|
|
deeplabv3p_mobilenetv2-1-0_bn_192x192 |
4.717 |
3.085 |
2.607 |
3.705 |
2.09 |
1.775 |
|
deeplabv3p_mobilenetv2-1-0_bn_512x512 |
15.848 |
14.243 |
13.699 |
8.284 |
6.972 |
6.013 |
|
deeplabv3p_mobilenetv2-1-0_bn_768x768 |
63.148 |
61.133 |
59.262 |
16.242 |
13.624 |
12.018 |
|
deeplabv3p_xception65_bn_192x192 |
9.703 |
9.393 |
6.46 |
8.555 |
8.202 |
5.15 |
|
deeplabv3p_xception65_bn_512x512 |
30.944 |
30.031 |
20.716 |
23.571 |
22.601 |
13.327 |
|
deeplabv3p_xception65_bn_768x768 |
92.109 |
89.338 |
43.342 |
44.341 |
41.945 |
25.486 |
|
icnet_bn_192x192 |
5.706 |
5.057 |
4.515 |
4.694 |
4.066 |
3.369 |
|
icnet_bn_512x512 |
18.326 |
16.971 |
16.663 |
10.576 |
9.779 |
9.389 |
|
icnet_bn_768x768 |
67.542 |
65.436 |
64.197 |
18.464 |
17.881 |
16.958 |
|
pspnet101_bn_192x192 |
20.978 |
18.089 |
11.946 |
20.102 |
17.128 |
11.011 |
|
pspnet101_bn_512x512 |
72.085 |
71.114 |
43.009 |
64.584 |
63.715 |
35.806 |
|
pspnet101_bn_768x768 |
160.552 |
157.791 |
110.544 |
111.996 |
111.22 |
69.646 |
|
pspnet50_bn_192x192 |
13.854 |
12.491 |
9.357 |
12.889 |
11.479 |
8.516 |
|
pspnet50_bn_512x512 |
55.868 |
55.205 |
39.659 |
48.647 |
48.076 |
32.403 |
|
pspnet50_bn_768x768 |
135.268 |
131.268 |
109.732 |
85.167 |
84.615 |
65.483 |
|
unet_bn_coco_192x192 |
7.557 |
7.979 |
8.049 |
4.933 |
4.952 |
4.959 |
|
unet_bn_coco_512x512 |
37.131 |
36.668 |
36.706 |
26.857 |
26.917 |
26.928 |
|
unet_bn_coco_768x768 |
110.578 |
110.031 |
109.979 |
59.118 |
59.173 |
59.124 |
## 数据分析 ### 1. 新版OP优化模型的加速效果 下图是`PaddleSeg 0.3.0`进行OP优化的模型和原模型的性能数据对比(以512x512 为例):  `分析`: - 优化模型的加速效果在各模型上都很明显,最高优化效果可达100% - 模型的 `eval_crop_size`越大,加速效果越明显 ### 2. 使用 TensorRT 开启 FP16 和 FP32 优化效果分析 在原始模型上的加速效果: 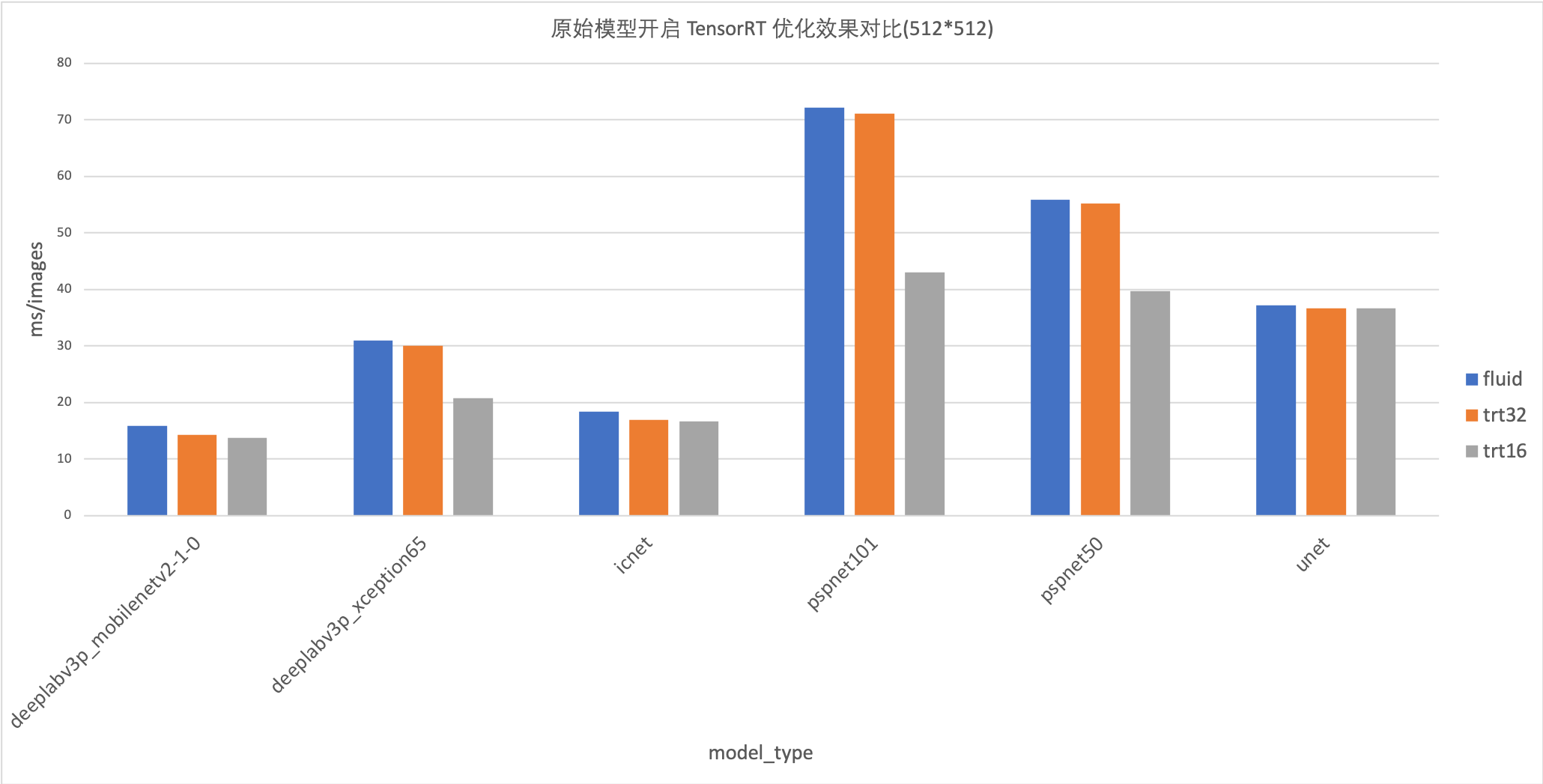 在优化模型上的加速效果: 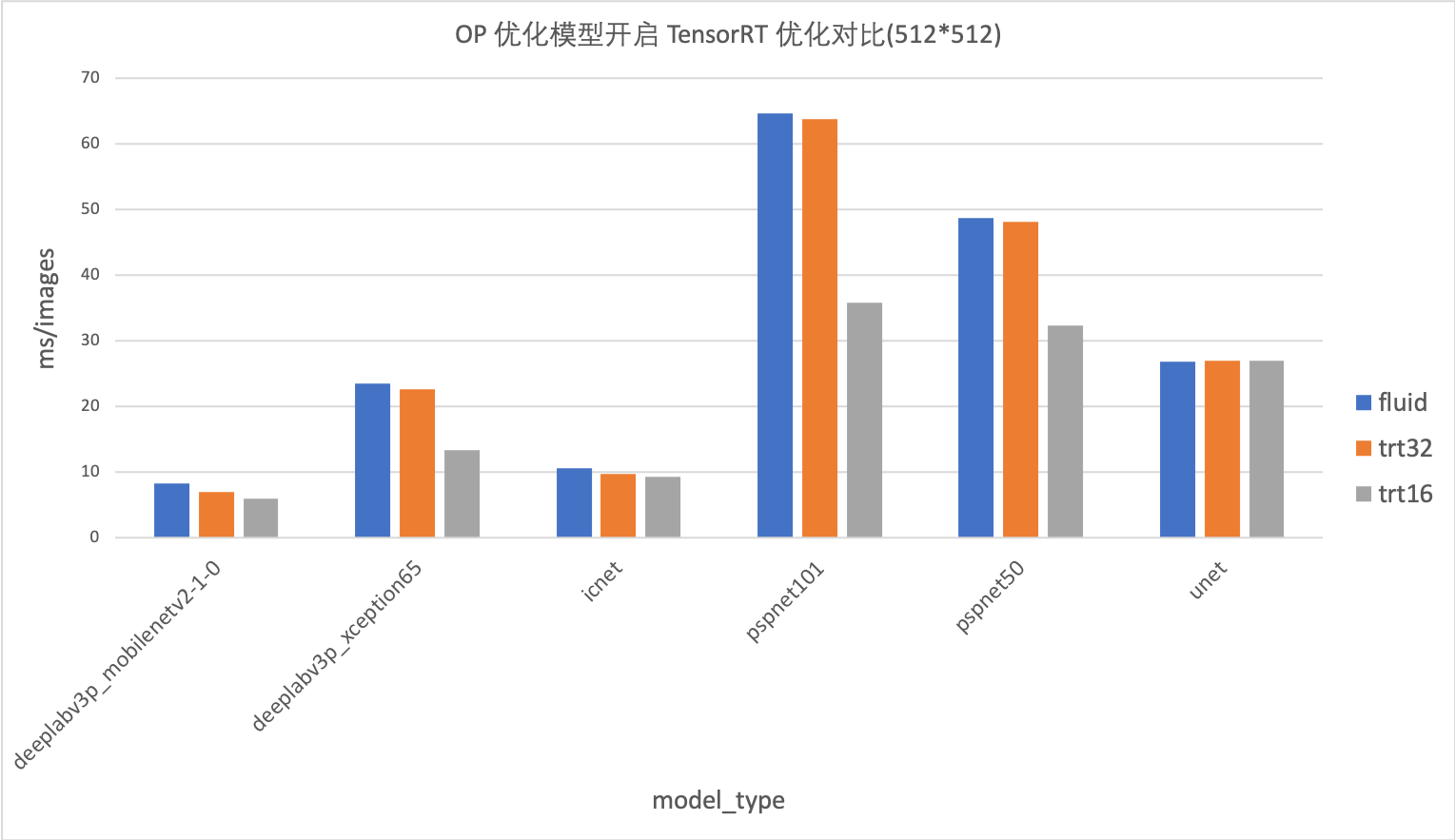 `分析`: - unet和icnet模型,使用Fluid-TensorRT的加速效果不明显,甚至没有加速。 - deeplabv3p_mobilenetv2模型,Fluid-TensorRT在原生模型的加速效果不明显,仅3%-5%的加速效果。在优化模型的加速效果可以达到20%。 - `deeplabv3_xception`、`pspnet50` 和 `pspnet101`模型,`fp16`加速效果很明显,在`768x768` 的size下加速效果最高可达110%。 ### 3. 不同的EVAL_CROP_SIZE对图片性能的影响 在 `deeplabv3p_xception`上的数据对比图:  在`deeplabv3p_mobilenet`上的数据对比图:  在`unet`上的测试数据对比图:  在`icnet`上的测试数据对比图:  在`pspnet101`上的测试数据对比图:  在`pspnet50`上的测试数据对比图:  `分析`: - 对于同一模型,`eval_crop_size`越大,推理速度越慢 - 同一模型,不管是 TensorRT 优化还是 OP 优化,`eval_crop_size`越大效果越明显