diff --git a/.travis.yml b/.travis.yml
index 204c642f96995ec8012601443040ac016474be81..7148edc901b27086a1e8449d50260dc8c7d14c10 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -1,7 +1,6 @@
language: python
python:
- - '2.7'
- '3.5'
- '3.6'
diff --git a/README.md b/README.md
index 23558c5a9e7c099c1599da7bfa1d25ac910fe87a..bdda17a4969ffa0fbfddced80a8a30f4695c443e 100644
--- a/README.md
+++ b/README.md
@@ -1,14 +1,14 @@
-# PaddleSeg 图像分割库
+# PaddleSeg
[](https://travis-ci.org/PaddlePaddle/PaddleSeg)
[](LICENSE)
[](https://github.com/PaddlePaddle/PaddleSeg/releases)
+
+
## 简介
-PaddleSeg是基于[PaddlePaddle](https://www.paddlepaddle.org.cn)开发的语义分割库,覆盖了DeepLabv3+, U-Net, ICNet, PSPNet, HRNet, Fast-SCNN等主流分割模型。通过统一的配置,帮助用户更便捷地完成从训练到部署的全流程图像分割应用。
-
-
+PaddleSeg是基于[PaddlePaddle](https://www.paddlepaddle.org.cn)开发的端到端图像分割开发套件,覆盖了DeepLabv3+, U-Net, ICNet, PSPNet, HRNet, Fast-SCNN等主流分割网络。通过模块化的设计,以配置化方式驱动模型组合,帮助开发者更便捷地完成从训练到部署的全流程图像分割应用。
- [特点](#特点)
- [安装](#安装)
@@ -23,8 +23,6 @@ PaddleSeg是基于[PaddlePaddle](https://www.paddlepaddle.org.cn)开发的语义
- [更新日志](#更新日志)
- [贡献代码](#贡献代码)
-
-
## 特点
- **丰富的数据增强**
@@ -43,13 +41,17 @@ PaddleSeg支持多进程I/O、多卡并行、跨卡Batch Norm同步等训练加
全面提供**服务端**和**移动端**的工业级部署能力,依托飞桨高性能推理引擎和高性能图像处理实现,开发者可以轻松完成高性能的分割模型部署和集成。通过[Paddle-Lite](https://github.com/PaddlePaddle/Paddle-Lite),可以在移动设备或者嵌入式设备上完成轻量级、高性能的人像分割模型部署。
+- **产业实践案例**
+
+PaddleSeg提供丰富地产业实践案例,如[人像分割](./contrib/HumanSeg)、[工业表计检测](https://github.com/PaddlePaddle/PaddleSeg/tree/develop/contrib#%E5%B7%A5%E4%B8%9A%E8%A1%A8%E7%9B%98%E5%88%86%E5%89%B2)、[遥感分割](./contrib/RemoteSensing)、[人体解析](contrib/ACE2P),[工业质检](https://aistudio.baidu.com/aistudio/projectdetail/184392)等产业实践案例,助力开发者更便捷地落地图像分割技术。
+
## 安装
### 1. 安装PaddlePaddle
版本要求
-* PaddlePaddle >= 1.6.1
-* Python 2.7 or 3.5+
+* PaddlePaddle >= 1.7.0
+* Python >= 3.5+
由于图像分割模型计算开销大,推荐在GPU版本的PaddlePaddle下使用PaddleSeg.
```
@@ -70,8 +72,6 @@ cd PaddleSeg
pip install -r requirements.txt
```
-
-
## 使用教程
我们提供了一系列的使用教程,来说明如何使用PaddleSeg完成语义分割模型的训练、评估、部署。
@@ -124,8 +124,6 @@ pip install -r requirements.txt
|人像分割|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/188833)|
|PaddleSeg特色垂类模型|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/226710)|
-
-
## FAQ
#### Q: 安装requirements.txt指定的依赖包时,部分包提示找不到?
@@ -148,26 +146,28 @@ python pdseg/train.py --cfg xxx.yaml TRAIN.RESUME_MODEL_DIR /PATH/TO/MODEL_CKPT/
A: 降低Batch size,使用Group Norm策略;请注意训练过程中当`DEFAULT_NORM_TYPE`选择`bn`时,为了Batch Norm计算稳定性,batch size需要满足>=2
-#### Q: 出现错误 ModuleNotFoundError: No module named 'paddle.fluid.contrib.mixed_precision'
-
-A: 请将PaddlePaddle升级至1.5.2版本或以上。
-
-
-
## 交流与反馈
* 欢迎您通过[Github Issues](https://github.com/PaddlePaddle/PaddleSeg/issues)来提交问题、报告与建议
* 微信公众号:飞桨PaddlePaddle
-* QQ群: 796771754
+* QQ群: 703252161


微信公众号 官方技术交流QQ群
## 更新日志
+* 2020.05.12
+
+ **`v0.5.0`**
+ * 全面升级[HumanSeg人像分割模型](./contrib/HumanSeg),新增超轻量级人像分割模型HumanSeg-lite支持移动端实时人像分割处理,并提供基于光流的视频分割后处理提升分割流畅性。
+ * 新增[气象遥感分割方案](./contrib/RemoteSensing),支持积雪识别、云检测等气象遥感场景。
+ * 新增[Lovasz Loss](docs/lovasz_loss.md),解决数据类别不均衡问题。
+ * 使用VisualDL 2.0作为训练可视化工具
+
* 2020.02.25
**`v0.4.0`**
- * 新增适用于实时场景且不需要预训练模型的分割网络Fast-SCNN,提供基于Cityscapes的[预训练模型](./docs/model_zoo.md)1个。
- * 新增LaneNet车道线检测网络,提供[预训练模型](https://github.com/PaddlePaddle/PaddleSeg/tree/release/v0.4.0/contrib/LaneNet#%E4%B8%83-%E5%8F%AF%E8%A7%86%E5%8C%96)一个。
+ * 新增适用于实时场景且不需要预训练模型的分割网络Fast-SCNN,提供基于Cityscapes的[预训练模型](./docs/model_zoo.md)1个
+ * 新增LaneNet车道线检测网络,提供[预训练模型](https://github.com/PaddlePaddle/PaddleSeg/tree/release/v0.4.0/contrib/LaneNet#%E4%B8%83-%E5%8F%AF%E8%A7%86%E5%8C%96)一个
* 新增基于PaddleSlim的分割库压缩策略([量化](./slim/quantization/README.md), [蒸馏](./slim/distillation/README.md), [剪枝](./slim/prune/README.md), [搜索](./slim/nas/README.md))
@@ -203,4 +203,4 @@ A: 请将PaddlePaddle升级至1.5.2版本或以上。
## 贡献代码
-我们非常欢迎您为PaddleSeg贡献代码或者提供使用建议。如果您可以修复某个issue或者增加一个新功能,欢迎给我们提交pull requests.
+我们非常欢迎您为PaddleSeg贡献代码或者提供使用建议。如果您可以修复某个issue或者增加一个新功能,欢迎给我们提交Pull Requests.
diff --git a/contrib/ACE2P/README.md b/contrib/ACE2P/README.md
index 3b2a4400de02ba08eb9184163cc0f3593d2ec785..3dfdcca521acd58c4d859c8d605560e0a0904608 100644
--- a/contrib/ACE2P/README.md
+++ b/contrib/ACE2P/README.md
@@ -1,8 +1,7 @@
# Augmented Context Embedding with Edge Perceiving(ACE2P)
## 模型概述
-人体解析(Human Parsing)是细粒度的语义分割任务,旨在识别像素级别的人类图像的组成部分(例如,身体部位和服装)。ACE2P通过融合底层特征、全局上下文信息和边缘细节,
-端到端训练学习人体解析任务。以ACE2P单人人体解析网络为基础的解决方案在CVPR2019第三届LIP挑战赛中赢得了全部三个人体解析任务的第一名
+人体解析(Human Parsing)是细粒度的语义分割任务,旨在识别像素级别的人类图像的组成部分(例如,身体部位和服装)。Augmented Context Embedding with Edge Perceiving (ACE2P)通过融合底层特征、全局上下文信息和边缘细节,端到端训练学习人体解析任务。以ACE2P单人人体解析网络为基础的解决方案在CVPR2019第三届Look into Person (LIP)挑战赛中赢得了全部三个人体解析任务的第一名。
## 模型框架图

@@ -38,6 +37,59 @@ ACE2P模型包含三个分支:

+
+
+人体解析(Human Parsing)是细粒度的语义分割任务,旨在识别像素级别的人类图像的组成部分(例如,身体部位和服装)。本章节使用冠军模型Augmented Context Embedding with Edge Perceiving (ACE2P)进行预测分割。
+
+## 代码使用说明
+
+### 1. 模型下载
+
+执行以下命令下载并解压ACE2P预测模型:
+
+```
+python download_ACE2P.py
+```
+
+或点击[链接](https://paddleseg.bj.bcebos.com/models/ACE2P.tgz)进行手动下载, 并在contrib/ACE2P下解压。
+
+### 2. 数据下载
+
+测试图片共10000张,
+点击 [Baidu_Drive](https://pan.baidu.com/s/1nvqmZBN#list/path=%2Fsharelink2787269280-523292635003760%2FLIP%2FLIP&parentPath=%2Fsharelink2787269280-523292635003760)
+下载Testing_images.zip,或前往LIP数据集官网进行下载。
+下载后解压到./data文件夹下
+
+
+### 3. 快速预测
+
+使用GPU预测
+```
+python -u infer.py --example ACE2P --use_gpu
+```
+
+使用CPU预测:
+```
+python -u infer.py --example ACE2P
+```
+
+**NOTE:** 运行该模型需要2G左右显存。由于数据图片较多,预测过程将比较耗时。
+
+#### 4. 预测结果示例:
+
+ 原图:
+
+ 
+
+ 预测结果:
+
+ 
+
+### 备注
+
+1. 数据及模型路径等详细配置见ACE2P/HumanSeg/RoadLine下的config.py文件
+2. ACE2P模型需预留2G显存,若显存超可调小FLAGS_fraction_of_gpu_memory_to_use
+
## 引用
**论文**
diff --git a/contrib/HumanSeg/README.md b/contrib/HumanSeg/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0b51f62e7ed9fe0bd87a6d13e452ccc27b4cf62e
--- /dev/null
+++ b/contrib/HumanSeg/README.md
@@ -0,0 +1,186 @@
+# HumanSeg人像分割模型
+
+本教程基于PaddleSeg核心分割网络,提供针对人像分割场景从预训练模型、Fine-tune、视频分割预测部署的全流程应用指南。最新发布HumanSeg-lite模型超轻量级人像分割模型,支持移动端场景的实时分割。
+
+## 环境依赖
+
+* Python == 3.5/3.6/3.7
+* PaddlePaddle >= 1.7.2
+
+PaddlePaddle的安装可参考[飞桨快速安装](https://www.paddlepaddle.org.cn/install/quick)
+
+通过以下命令安装python包依赖,请确保在该分支上至少执行过一次以下命令
+```shell
+$ pip install -r requirements.txt
+```
+
+## 预训练模型
+HumanSeg开放了在大规模人像数据上训练的三个预训练模型,满足多种使用场景的需求
+
+| 模型类型 | Checkpoint | Inference Model | Quant Inference Model | 备注 |
+| --- | --- | --- | ---| --- |
+| HumanSeg-server | [humanseg_server_ckpt](https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_server_ckpt.zip) | [humanseg_server_inference](https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_server_inference.zip) | -- | 高精度模型,适用于服务端GPU且背景复杂的人像场景, 模型结构为Deeplabv3+/Xcetion65, 输入大小(512, 512) |
+| HumanSeg-mobile | [humanseg_mobile_ckpt](https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_mobile_ckpt.zip) | [humanseg_mobile_inference](https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_mobile_inference.zip) | [humanseg_mobile_quant](https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_mobile_quant.zip) | 轻量级模型, 适用于移动端或服务端CPU的前置摄像头场景,模型结构为HRNet_w18_samll_v1,输入大小(192, 192) |
+| HumanSeg-lite | [humanseg_lite_ckpt](https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_lite_ckpt.zip) | [humanseg_lite_inference](https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_lite_inference.zip) | [humanseg_lite_quant](https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_lite_quant.zip) | 超轻量级模型, 适用于手机自拍人像,且有移动端实时分割场景, 模型结构为优化的ShuffleNetV2,输入大小(192, 192) |
+
+
+模型性能
+
+| 模型 | 模型大小 | 计算耗时 |
+| --- | --- | --- |
+|humanseg_server_inference| 158M | - |
+|humanseg_mobile_inference | 5.8 M | 42.35ms |
+|humanseg_mobile_quant | 1.6M | 24.93ms |
+|humanseg_lite_inference | 541K | 17.26ms |
+|humanseg_lite_quant | 187k | 11.89ms |
+
+计算耗时运行环境: 小米,cpu:骁龙855, 内存:6GB, 图片大小:192*192)
+
+
+**NOTE:**
+其中Checkpoint为模型权重,用于Fine-tuning场景。
+
+* Inference Model和Quant Inference Model为预测部署模型,包含`__model__`计算图结构、`__params__`模型参数和`model.yaml`基础的模型配置信息。
+
+* 其中Inference Model适用于服务端的CPU和GPU预测部署,Qunat Inference Model为量化版本,适用于通过Paddle Lite进行移动端等端侧设备部署。更多Paddle Lite部署说明查看[Paddle Lite文档](https://paddle-lite.readthedocs.io/zh/latest/)
+
+执行以下脚本进行HumanSeg预训练模型的下载
+```bash
+python pretrained_weights/download_pretrained_weights.py
+```
+
+## 下载测试数据
+我们提供了[supervise.ly](https://supervise.ly/)发布人像分割数据集**Supervisely Persons**, 从中随机抽取一小部分并转化成PaddleSeg可直接加载数据格式。通过运行以下代码进行快速下载,其中包含手机前置摄像头的人像测试视频`video_test.mp4`.
+
+```bash
+python data/download_data.py
+```
+
+## 快速体验视频流人像分割
+结合DIS(Dense Inverse Search-basedmethod)光流算法预测结果与分割结果,改善视频流人像分割
+```bash
+# 通过电脑摄像头进行实时分割处理
+python video_infer.py --model_dir pretrained_weights/humanseg_lite_inference
+
+# 对人像视频进行分割处理
+python video_infer.py --model_dir pretrained_weights/humanseg_lite_inference --video_path data/video_test.mp4
+```
+
+视频分割结果如下:
+
+
 +
+**NOTE**:
+
+视频分割处理时间需要几分钟,请耐心等待。
+
+## 训练
+使用下述命令基于与训练模型进行Fine-tuning,请确保选用的模型结构`model_type`与模型参数`pretrained_weights`匹配。
+```bash
+python train.py --model_type HumanSegMobile \
+--save_dir output/ \
+--data_dir data/mini_supervisely \
+--train_list data/mini_supervisely/train.txt \
+--val_list data/mini_supervisely/val.txt \
+--pretrained_weights pretrained_weights/humanseg_mobile_ckpt \
+--batch_size 8 \
+--learning_rate 0.001 \
+--num_epochs 10 \
+--image_shape 192 192
+```
+其中参数含义如下:
+* `--model_type`: 模型类型,可选项为:HumanSegServer、HumanSegMobile和HumanSegLite
+* `--save_dir`: 模型保存路径
+* `--data_dir`: 数据集路径
+* `--train_list`: 训练集列表路径
+* `--val_list`: 验证集列表路径
+* `--pretrained_weights`: 预训练模型路径
+* `--batch_size`: 批大小
+* `--learning_rate`: 初始学习率
+* `--num_epochs`: 训练轮数
+* `--image_shape`: 网络输入图像大小(w, h)
+
+更多命令行帮助可运行下述命令进行查看:
+```bash
+python train.py --help
+```
+**NOTE**
+可通过更换`--model_type`变量与对应的`--pretrained_weights`使用不同的模型快速尝试。
+
+## 评估
+使用下述命令进行评估
+```bash
+python val.py --model_dir output/best_model \
+--data_dir data/mini_supervisely \
+--val_list data/mini_supervisely/val.txt \
+--image_shape 192 192
+```
+其中参数含义如下:
+* `--model_dir`: 模型路径
+* `--data_dir`: 数据集路径
+* `--val_list`: 验证集列表路径
+* `--image_shape`: 网络输入图像大小(w, h)
+
+## 预测
+使用下述命令进行预测
+```bash
+python infer.py --model_dir output/best_model \
+--data_dir data/mini_supervisely \
+--test_list data/mini_supervisely/test.txt \
+--image_shape 192 192
+```
+其中参数含义如下:
+* `--model_dir`: 模型路径
+* `--data_dir`: 数据集路径
+* `--test_list`: 测试集列表路径
+* `--image_shape`: 网络输入图像大小(w, h)
+
+## 模型导出
+```bash
+python export.py --model_dir output/best_model \
+--save_dir output/export
+```
+其中参数含义如下:
+* `--model_dir`: 模型路径
+* `--save_dir`: 导出模型保存路径
+
+## 离线量化
+```bash
+python quant_offline.py --model_dir output/best_model \
+--data_dir data/mini_supervisely \
+--quant_list data/mini_supervisely/val.txt \
+--save_dir output/quant_offline \
+--image_shape 192 192
+```
+其中参数含义如下:
+* `--model_dir`: 待量化模型路径
+* `--data_dir`: 数据集路径
+* `--quant_list`: 量化数据集列表路径,一般直接选择训练集或验证集
+* `--save_dir`: 量化模型保存路径
+* `--image_shape`: 网络输入图像大小(w, h)
+
+## 在线量化
+利用float训练模型进行在线量化。
+```bash
+python quant_online.py --model_type HumanSegMobile \
+--save_dir output/quant_online \
+--data_dir data/mini_supervisely \
+--train_list data/mini_supervisely/train.txt \
+--val_list data/mini_supervisely/val.txt \
+--pretrained_weights output/best_model \
+--batch_size 2 \
+--learning_rate 0.001 \
+--num_epochs 2 \
+--image_shape 192 192
+```
+其中参数含义如下:
+* `--model_type`: 模型类型,可选项为:HumanSegServer、HumanSegMobile和HumanSegLite
+* `--save_dir`: 模型保存路径
+* `--data_dir`: 数据集路径
+* `--train_list`: 训练集列表路径
+* `--val_list`: 验证集列表路径
+* `--pretrained_weights`: 预训练模型路径,
+* `--batch_size`: 批大小
+* `--learning_rate`: 初始学习率
+* `--num_epochs`: 训练轮数
+* `--image_shape`: 网络输入图像大小(w, h)
diff --git a/contrib/HumanSeg/__init__.py b/contrib/HumanSeg/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/contrib/HumanSeg/config.py b/contrib/HumanSeg/config.py
deleted file mode 100644
index 8c661b51c011e958c1c7f88b2b96b25b662213ae..0000000000000000000000000000000000000000
--- a/contrib/HumanSeg/config.py
+++ /dev/null
@@ -1,26 +0,0 @@
-# -*- coding: utf-8 -*-
-from utils.util import AttrDict, get_arguments, merge_cfg_from_args
-import os
-
-args = get_arguments()
-cfg = AttrDict()
-
-# 待预测图像所在路径
-cfg.data_dir = os.path.join(args.example , "data", "test_images")
-# 待预测图像名称列表
-cfg.data_list_file = os.path.join(args.example , "data", "test.txt")
-# 模型加载路径
-cfg.model_path = os.path.join(args.example , "model")
-# 预测结果保存路径
-cfg.vis_dir = os.path.join(args.example , "result")
-
-# 预测类别数
-cfg.class_num = 2
-# 均值, 图像预处理减去的均值
-cfg.MEAN = 104.008, 116.669, 122.675
-# 标准差,图像预处理除以标准差
-cfg.STD = 1.0, 1.0, 1.0
-# 待预测图像输入尺寸
-cfg.input_size = 513, 513
-
-merge_cfg_from_args(args, cfg)
diff --git a/contrib/HumanSeg/data/download_data.py b/contrib/HumanSeg/data/download_data.py
new file mode 100644
index 0000000000000000000000000000000000000000..a788df0f7fe84067e752a37ed1601818cf168557
--- /dev/null
+++ b/contrib/HumanSeg/data/download_data.py
@@ -0,0 +1,40 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+
+LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
+TEST_PATH = os.path.join(LOCAL_PATH, "../../../", "test")
+sys.path.append(TEST_PATH)
+
+from test_utils import download_file_and_uncompress
+
+
+def download_data(savepath, extrapath):
+ url = "https://paddleseg.bj.bcebos.com/humanseg/data/mini_supervisely.zip"
+ download_file_and_uncompress(
+ url=url, savepath=savepath, extrapath=extrapath)
+
+ url = "https://paddleseg.bj.bcebos.com/humanseg/data/video_test.zip"
+ download_file_and_uncompress(
+ url=url,
+ savepath=savepath,
+ extrapath=extrapath,
+ extraname='video_test.mp4')
+
+
+if __name__ == "__main__":
+ download_data(LOCAL_PATH, LOCAL_PATH)
+ print("Data download finish!")
diff --git a/contrib/HumanSeg/datasets/__init__.py b/contrib/HumanSeg/datasets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..81d3255640a0353943cdc9e968f17e3ea765b390
--- /dev/null
+++ b/contrib/HumanSeg/datasets/__init__.py
@@ -0,0 +1,15 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .dataset import Dataset
diff --git a/contrib/HumanSeg/datasets/dataset.py b/contrib/HumanSeg/datasets/dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..263c7af471444c49966c56f72000838a7c55c41e
--- /dev/null
+++ b/contrib/HumanSeg/datasets/dataset.py
@@ -0,0 +1,274 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os.path as osp
+from threading import Thread
+import multiprocessing
+import collections
+import numpy as np
+import six
+import sys
+import copy
+import random
+import platform
+import chardet
+import utils.logging as logging
+
+
+class EndSignal():
+ pass
+
+
+def is_pic(img_name):
+ valid_suffix = ['JPEG', 'jpeg', 'JPG', 'jpg', 'BMP', 'bmp', 'PNG', 'png']
+ suffix = img_name.split('.')[-1]
+ if suffix not in valid_suffix:
+ return False
+ return True
+
+
+def is_valid(sample):
+ if sample is None:
+ return False
+ if isinstance(sample, tuple):
+ for s in sample:
+ if s is None:
+ return False
+ elif isinstance(s, np.ndarray) and s.size == 0:
+ return False
+ elif isinstance(s, collections.Sequence) and len(s) == 0:
+ return False
+ return True
+
+
+def get_encoding(path):
+ f = open(path, 'rb')
+ data = f.read()
+ file_encoding = chardet.detect(data).get('encoding')
+ return file_encoding
+
+
+def multithread_reader(mapper,
+ reader,
+ num_workers=4,
+ buffer_size=1024,
+ batch_size=8,
+ drop_last=True):
+ from queue import Queue
+ end = EndSignal()
+
+ # define a worker to read samples from reader to in_queue
+ def read_worker(reader, in_queue):
+ for i in reader():
+ in_queue.put(i)
+ in_queue.put(end)
+
+ # define a worker to handle samples from in_queue by mapper
+ # and put mapped samples into out_queue
+ def handle_worker(in_queue, out_queue, mapper):
+ sample = in_queue.get()
+ while not isinstance(sample, EndSignal):
+ if len(sample) == 2:
+ r = mapper(sample[0], sample[1])
+ elif len(sample) == 3:
+ r = mapper(sample[0], sample[1], sample[2])
+ else:
+ raise Exception('The sample\'s length must be 2 or 3.')
+ if is_valid(r):
+ out_queue.put(r)
+ sample = in_queue.get()
+ in_queue.put(end)
+ out_queue.put(end)
+
+ def xreader():
+ in_queue = Queue(buffer_size)
+ out_queue = Queue(buffer_size)
+ # start a read worker in a thread
+ target = read_worker
+ t = Thread(target=target, args=(reader, in_queue))
+ t.daemon = True
+ t.start()
+ # start several handle_workers
+ target = handle_worker
+ args = (in_queue, out_queue, mapper)
+ workers = []
+ for i in range(num_workers):
+ worker = Thread(target=target, args=args)
+ worker.daemon = True
+ workers.append(worker)
+ for w in workers:
+ w.start()
+
+ batch_data = []
+ sample = out_queue.get()
+ while not isinstance(sample, EndSignal):
+ batch_data.append(sample)
+ if len(batch_data) == batch_size:
+ yield batch_data
+ batch_data = []
+ sample = out_queue.get()
+ finish = 1
+ while finish < num_workers:
+ sample = out_queue.get()
+ if isinstance(sample, EndSignal):
+ finish += 1
+ else:
+ batch_data.append(sample)
+ if len(batch_data) == batch_size:
+ yield batch_data
+ batch_data = []
+ if not drop_last and len(batch_data) != 0:
+ yield batch_data
+ batch_data = []
+
+ return xreader
+
+
+def multiprocess_reader(mapper,
+ reader,
+ num_workers=4,
+ buffer_size=1024,
+ batch_size=8,
+ drop_last=True):
+ from .shared_queue import SharedQueue as Queue
+
+ def _read_into_queue(samples, mapper, queue):
+ end = EndSignal()
+ try:
+ for sample in samples:
+ if sample is None:
+ raise ValueError("sample has None")
+ if len(sample) == 2:
+ result = mapper(sample[0], sample[1])
+ elif len(sample) == 3:
+ result = mapper(sample[0], sample[1], sample[2])
+ else:
+ raise Exception('The sample\'s length must be 2 or 3.')
+ if is_valid(result):
+ queue.put(result)
+ queue.put(end)
+ except:
+ queue.put("")
+ six.reraise(*sys.exc_info())
+
+ def queue_reader():
+ queue = Queue(buffer_size, memsize=3 * 1024**3)
+ total_samples = [[] for i in range(num_workers)]
+ for i, sample in enumerate(reader()):
+ index = i % num_workers
+ total_samples[index].append(sample)
+ for i in range(num_workers):
+ p = multiprocessing.Process(
+ target=_read_into_queue, args=(total_samples[i], mapper, queue))
+ p.start()
+
+ finish_num = 0
+ batch_data = list()
+ while finish_num < num_workers:
+ sample = queue.get()
+ if isinstance(sample, EndSignal):
+ finish_num += 1
+ elif sample == "":
+ raise ValueError("multiprocess reader raises an exception")
+ else:
+ batch_data.append(sample)
+ if len(batch_data) == batch_size:
+ yield batch_data
+ batch_data = []
+ if len(batch_data) != 0 and not drop_last:
+ yield batch_data
+ batch_data = []
+
+ return queue_reader
+
+
+class Dataset:
+ def __init__(self,
+ data_dir,
+ file_list,
+ label_list=None,
+ transforms=None,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False):
+ if num_workers == 'auto':
+ import multiprocessing as mp
+ num_workers = mp.cpu_count() // 2 if mp.cpu_count() // 2 < 8 else 8
+ if transforms is None:
+ raise Exception("transform should be defined.")
+ self.transforms = transforms
+ self.num_workers = num_workers
+ self.buffer_size = buffer_size
+ self.parallel_method = parallel_method
+ self.shuffle = shuffle
+
+ self.file_list = list()
+ self.labels = list()
+ self._epoch = 0
+
+ if label_list is not None:
+ with open(label_list, encoding=get_encoding(label_list)) as f:
+ for line in f:
+ item = line.strip()
+ self.labels.append(item)
+
+ with open(file_list, encoding=get_encoding(file_list)) as f:
+ for line in f:
+ items = line.strip().split()
+ if not is_pic(items[0]):
+ continue
+ full_path_im = osp.join(data_dir, items[0])
+ full_path_label = osp.join(data_dir, items[1])
+ if not osp.exists(full_path_im):
+ raise IOError(
+ 'The image file {} is not exist!'.format(full_path_im))
+ if not osp.exists(full_path_label):
+ raise IOError('The image file {} is not exist!'.format(
+ full_path_label))
+ self.file_list.append([full_path_im, full_path_label])
+ self.num_samples = len(self.file_list)
+ logging.info("{} samples in file {}".format(
+ len(self.file_list), file_list))
+
+ def iterator(self):
+ self._epoch += 1
+ self._pos = 0
+ files = copy.deepcopy(self.file_list)
+ if self.shuffle:
+ random.shuffle(files)
+ files = files[:self.num_samples]
+ self.num_samples = len(files)
+ for f in files:
+ label_path = f[1]
+ sample = [f[0], None, label_path]
+ yield sample
+
+ def generator(self, batch_size=1, drop_last=True):
+ self.batch_size = batch_size
+ parallel_reader = multithread_reader
+ if self.parallel_method == "process":
+ if platform.platform().startswith("Windows"):
+ logging.debug(
+ "multiprocess_reader is not supported in Windows platform, force to use multithread_reader."
+ )
+ else:
+ parallel_reader = multiprocess_reader
+ return parallel_reader(
+ self.transforms,
+ self.iterator,
+ num_workers=self.num_workers,
+ buffer_size=self.buffer_size,
+ batch_size=batch_size,
+ drop_last=drop_last)
diff --git a/contrib/HumanSeg/datasets/shared_queue/__init__.py b/contrib/HumanSeg/datasets/shared_queue/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4c3990e67d6ade96d20abd1aa34b34b1ff891cb
--- /dev/null
+++ b/contrib/HumanSeg/datasets/shared_queue/__init__.py
@@ -0,0 +1,25 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+
+__all__ = ['SharedBuffer', 'SharedMemoryMgr', 'SharedQueue']
+
+from .sharedmemory import SharedBuffer
+from .sharedmemory import SharedMemoryMgr
+from .sharedmemory import SharedMemoryError
+from .queue import SharedQueue
diff --git a/contrib/HumanSeg/datasets/shared_queue/queue.py b/contrib/HumanSeg/datasets/shared_queue/queue.py
new file mode 100644
index 0000000000000000000000000000000000000000..157df0a51ee3d552c810bafe5e826c1072c75649
--- /dev/null
+++ b/contrib/HumanSeg/datasets/shared_queue/queue.py
@@ -0,0 +1,102 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import sys
+import six
+if six.PY3:
+ import pickle
+ from io import BytesIO as StringIO
+else:
+ import cPickle as pickle
+ from cStringIO import StringIO
+
+import logging
+import traceback
+import multiprocessing as mp
+from multiprocessing.queues import Queue
+from .sharedmemory import SharedMemoryMgr
+
+logger = logging.getLogger(__name__)
+
+
+class SharedQueueError(ValueError):
+ """ SharedQueueError
+ """
+ pass
+
+
+class SharedQueue(Queue):
+ """ a Queue based on shared memory to communicate data between Process,
+ and it's interface is compatible with 'multiprocessing.queues.Queue'
+ """
+
+ def __init__(self, maxsize=0, mem_mgr=None, memsize=None, pagesize=None):
+ """ init
+ """
+ if six.PY3:
+ super(SharedQueue, self).__init__(maxsize, ctx=mp.get_context())
+ else:
+ super(SharedQueue, self).__init__(maxsize)
+
+ if mem_mgr is not None:
+ self._shared_mem = mem_mgr
+ else:
+ self._shared_mem = SharedMemoryMgr(
+ capacity=memsize, pagesize=pagesize)
+
+ def put(self, obj, **kwargs):
+ """ put an object to this queue
+ """
+ obj = pickle.dumps(obj, -1)
+ buff = None
+ try:
+ buff = self._shared_mem.malloc(len(obj))
+ buff.put(obj)
+ super(SharedQueue, self).put(buff, **kwargs)
+ except Exception as e:
+ stack_info = traceback.format_exc()
+ err_msg = 'failed to put a element to SharedQueue '\
+ 'with stack info[%s]' % (stack_info)
+ logger.warn(err_msg)
+
+ if buff is not None:
+ buff.free()
+ raise e
+
+ def get(self, **kwargs):
+ """ get an object from this queue
+ """
+ buff = None
+ try:
+ buff = super(SharedQueue, self).get(**kwargs)
+ data = buff.get()
+ return pickle.load(StringIO(data))
+ except Exception as e:
+ stack_info = traceback.format_exc()
+ err_msg = 'failed to get element from SharedQueue '\
+ 'with stack info[%s]' % (stack_info)
+ logger.warn(err_msg)
+ raise e
+ finally:
+ if buff is not None:
+ buff.free()
+
+ def release(self):
+ self._shared_mem.release()
+ self._shared_mem = None
diff --git a/contrib/HumanSeg/datasets/shared_queue/sharedmemory.py b/contrib/HumanSeg/datasets/shared_queue/sharedmemory.py
new file mode 100644
index 0000000000000000000000000000000000000000..451faa2911185fe279627dfac76b89aa24c5c706
--- /dev/null
+++ b/contrib/HumanSeg/datasets/shared_queue/sharedmemory.py
@@ -0,0 +1,534 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# utils for memory management which is allocated on sharedmemory,
+# note that these structures may not be thread-safe
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import os
+import time
+import math
+import struct
+import sys
+import six
+
+if six.PY3:
+ import pickle
+else:
+ import cPickle as pickle
+
+import json
+import uuid
+import random
+import numpy as np
+import weakref
+import logging
+from multiprocessing import Lock
+from multiprocessing import RawArray
+
+logger = logging.getLogger(__name__)
+
+
+class SharedMemoryError(ValueError):
+ """ SharedMemoryError
+ """
+ pass
+
+
+class SharedBufferError(SharedMemoryError):
+ """ SharedBufferError
+ """
+ pass
+
+
+class MemoryFullError(SharedMemoryError):
+ """ MemoryFullError
+ """
+
+ def __init__(self, errmsg=''):
+ super(MemoryFullError, self).__init__()
+ self.errmsg = errmsg
+
+
+def memcopy(dst, src, offset=0, length=None):
+ """ copy data from 'src' to 'dst' in bytes
+ """
+ length = length if length is not None else len(src)
+ assert type(dst) == np.ndarray, 'invalid type for "dst" in memcopy'
+ if type(src) is not np.ndarray:
+ if type(src) is str and six.PY3:
+ src = src.encode()
+ src = np.frombuffer(src, dtype='uint8', count=len(src))
+
+ dst[:] = src[offset:offset + length]
+
+
+class SharedBuffer(object):
+ """ Buffer allocated from SharedMemoryMgr, and it stores data on shared memory
+
+ note that:
+ every instance of this should be freed explicitely by calling 'self.free'
+ """
+
+ def __init__(self, owner, capacity, pos, size=0, alloc_status=''):
+ """ Init
+
+ Args:
+ owner (str): manager to own this buffer
+ capacity (int): capacity in bytes for this buffer
+ pos (int): page position in shared memory
+ size (int): bytes already used
+ alloc_status (str): debug info about allocator when allocate this
+ """
+ self._owner = owner
+ self._cap = capacity
+ self._pos = pos
+ self._size = size
+ self._alloc_status = alloc_status
+ assert self._pos >= 0 and self._cap > 0, \
+ "invalid params[%d:%d] to construct SharedBuffer" \
+ % (self._pos, self._cap)
+
+ def owner(self):
+ """ get owner
+ """
+ return SharedMemoryMgr.get_mgr(self._owner)
+
+ def put(self, data, override=False):
+ """ put data to this buffer
+
+ Args:
+ data (str): data to be stored in this buffer
+
+ Returns:
+ None
+
+ Raises:
+ SharedMemoryError when not enough space in this buffer
+ """
+ assert type(data) in [str, bytes], \
+ 'invalid type[%s] for SharedBuffer::put' % (str(type(data)))
+ if self._size > 0 and not override:
+ raise SharedBufferError('already has already been setted before')
+
+ if self.capacity() < len(data):
+ raise SharedBufferError('data[%d] is larger than size of buffer[%s]'\
+ % (len(data), str(self)))
+
+ self.owner().put_data(self, data)
+ self._size = len(data)
+
+ def get(self, offset=0, size=None, no_copy=True):
+ """ get the data stored this buffer
+
+ Args:
+ offset (int): position for the start point to 'get'
+ size (int): size to get
+
+ Returns:
+ data (np.ndarray('uint8')): user's data in numpy
+ which is passed in by 'put'
+ None: if no data stored in
+ """
+ offset = offset if offset >= 0 else self._size + offset
+ if self._size <= 0:
+ return None
+
+ size = self._size if size is None else size
+ assert offset + size <= self._cap, 'invalid offset[%d] '\
+ 'or size[%d] for capacity[%d]' % (offset, size, self._cap)
+ return self.owner().get_data(self, offset, size, no_copy=no_copy)
+
+ def size(self):
+ """ bytes of used memory
+ """
+ return self._size
+
+ def resize(self, size):
+ """ resize the used memory to 'size', should not be greater than capacity
+ """
+ assert size >= 0 and size <= self._cap, \
+ "invalid size[%d] for resize" % (size)
+
+ self._size = size
+
+ def capacity(self):
+ """ size of allocated memory
+ """
+ return self._cap
+
+ def __str__(self):
+ """ human readable format
+ """
+ return "SharedBuffer(owner:%s, pos:%d, size:%d, "\
+ "capacity:%d, alloc_status:[%s], pid:%d)" \
+ % (str(self._owner), self._pos, self._size, \
+ self._cap, self._alloc_status, os.getpid())
+
+ def free(self):
+ """ free this buffer to it's owner
+ """
+ if self._owner is not None:
+ self.owner().free(self)
+ self._owner = None
+ self._cap = 0
+ self._pos = -1
+ self._size = 0
+ return True
+ else:
+ return False
+
+
+class PageAllocator(object):
+ """ allocator used to malloc and free shared memory which
+ is split into pages
+ """
+ s_allocator_header = 12
+
+ def __init__(self, base, total_pages, page_size):
+ """ init
+ """
+ self._magic_num = 1234321000 + random.randint(100, 999)
+ self._base = base
+ self._total_pages = total_pages
+ self._page_size = page_size
+
+ header_pages = int(
+ math.ceil((total_pages + self.s_allocator_header) / page_size))
+
+ self._header_pages = header_pages
+ self._free_pages = total_pages - header_pages
+ self._header_size = self._header_pages * page_size
+ self._reset()
+
+ def _dump_alloc_info(self, fname):
+ hpages, tpages, pos, used = self.header()
+
+ start = self.s_allocator_header
+ end = start + self._page_size * hpages
+ alloc_flags = self._base[start:end].tostring()
+ info = {
+ 'magic_num': self._magic_num,
+ 'header_pages': hpages,
+ 'total_pages': tpages,
+ 'pos': pos,
+ 'used': used
+ }
+ info['alloc_flags'] = alloc_flags
+ fname = fname + '.' + str(uuid.uuid4())[:6]
+ with open(fname, 'wb') as f:
+ f.write(pickle.dumps(info, -1))
+ logger.warn('dump alloc info to file[%s]' % (fname))
+
+ def _reset(self):
+ alloc_page_pos = self._header_pages
+ used_pages = self._header_pages
+ header_info = struct.pack(
+ str('III'), self._magic_num, alloc_page_pos, used_pages)
+ assert len(header_info) == self.s_allocator_header, \
+ 'invalid size of header_info'
+
+ memcopy(self._base[0:self.s_allocator_header], header_info)
+ self.set_page_status(0, self._header_pages, '1')
+ self.set_page_status(self._header_pages, self._free_pages, '0')
+
+ def header(self):
+ """ get header info of this allocator
+ """
+ header_str = self._base[0:self.s_allocator_header].tostring()
+ magic, pos, used = struct.unpack(str('III'), header_str)
+
+ assert magic == self._magic_num, \
+ 'invalid header magic[%d] in shared memory' % (magic)
+ return self._header_pages, self._total_pages, pos, used
+
+ def empty(self):
+ """ are all allocatable pages available
+ """
+ header_pages, pages, pos, used = self.header()
+ return header_pages == used
+
+ def full(self):
+ """ are all allocatable pages used
+ """
+ header_pages, pages, pos, used = self.header()
+ return header_pages + used == pages
+
+ def __str__(self):
+ header_pages, pages, pos, used = self.header()
+ desc = '{page_info[magic:%d,total:%d,used:%d,header:%d,alloc_pos:%d,pagesize:%d]}' \
+ % (self._magic_num, pages, used, header_pages, pos, self._page_size)
+ return 'PageAllocator:%s' % (desc)
+
+ def set_alloc_info(self, alloc_pos, used_pages):
+ """ set allocating position to new value
+ """
+ memcopy(self._base[4:12], struct.pack(str('II'), alloc_pos, used_pages))
+
+ def set_page_status(self, start, page_num, status):
+ """ set pages from 'start' to 'end' with new same status 'status'
+ """
+ assert status in ['0', '1'], 'invalid status[%s] for page status '\
+ 'in allocator[%s]' % (status, str(self))
+ start += self.s_allocator_header
+ end = start + page_num
+ assert start >= 0 and end <= self._header_size, 'invalid end[%d] of pages '\
+ 'in allocator[%s]' % (end, str(self))
+ memcopy(self._base[start:end], str(status * page_num))
+
+ def get_page_status(self, start, page_num, ret_flag=False):
+ start += self.s_allocator_header
+ end = start + page_num
+ assert start >= 0 and end <= self._header_size, 'invalid end[%d] of pages '\
+ 'in allocator[%s]' % (end, str(self))
+ status = self._base[start:end].tostring().decode()
+ if ret_flag:
+ return status
+
+ zero_num = status.count('0')
+ if zero_num == 0:
+ return (page_num, 1)
+ else:
+ return (zero_num, 0)
+
+ def malloc_page(self, page_num):
+ header_pages, pages, pos, used = self.header()
+ end = pos + page_num
+ if end > pages:
+ pos = self._header_pages
+ end = pos + page_num
+
+ start_pos = pos
+ flags = ''
+ while True:
+ # maybe flags already has some '0' pages,
+ # so just check 'page_num - len(flags)' pages
+ flags = self.get_page_status(pos, page_num, ret_flag=True)
+
+ if flags.count('0') == page_num:
+ break
+
+ # not found enough pages, so shift to next few pages
+ free_pos = flags.rfind('1') + 1
+ pos += free_pos
+ end = pos + page_num
+ if end > pages:
+ pos = self._header_pages
+ end = pos + page_num
+ flags = ''
+
+ # not found available pages after scan all pages
+ if pos <= start_pos and end >= start_pos:
+ logger.debug('not found available pages after scan all pages')
+ break
+
+ page_status = (flags.count('0'), 0)
+ if page_status != (page_num, 0):
+ free_pages = self._total_pages - used
+ if free_pages == 0:
+ err_msg = 'all pages have been used:%s' % (str(self))
+ else:
+ err_msg = 'not found available pages with page_status[%s] '\
+ 'and %d free pages' % (str(page_status), free_pages)
+ err_msg = 'failed to malloc %d pages at pos[%d] for reason[%s] and allocator status[%s]' \
+ % (page_num, pos, err_msg, str(self))
+ raise MemoryFullError(err_msg)
+
+ self.set_page_status(pos, page_num, '1')
+ used += page_num
+ self.set_alloc_info(end, used)
+ return pos
+
+ def free_page(self, start, page_num):
+ """ free 'page_num' pages start from 'start'
+ """
+ page_status = self.get_page_status(start, page_num)
+ assert page_status == (page_num, 1), \
+ 'invalid status[%s] when free [%d, %d]' \
+ % (str(page_status), start, page_num)
+ self.set_page_status(start, page_num, '0')
+ _, _, pos, used = self.header()
+ used -= page_num
+ self.set_alloc_info(pos, used)
+
+
+DEFAULT_SHARED_MEMORY_SIZE = 1024 * 1024 * 1024
+
+
+class SharedMemoryMgr(object):
+ """ manage a continouse block of memory, provide
+ 'malloc' to allocate new buffer, and 'free' to free buffer
+ """
+ s_memory_mgrs = weakref.WeakValueDictionary()
+ s_mgr_num = 0
+ s_log_statis = False
+
+ @classmethod
+ def get_mgr(cls, id):
+ """ get a SharedMemoryMgr with size of 'capacity'
+ """
+ assert id in cls.s_memory_mgrs, 'invalid id[%s] for memory managers' % (
+ id)
+ return cls.s_memory_mgrs[id]
+
+ def __init__(self, capacity=None, pagesize=None):
+ """ init
+ """
+ logger.debug('create SharedMemoryMgr')
+
+ pagesize = 64 * 1024 if pagesize is None else pagesize
+ assert type(pagesize) is int, "invalid type of pagesize[%s]" \
+ % (str(pagesize))
+
+ capacity = DEFAULT_SHARED_MEMORY_SIZE if capacity is None else capacity
+ assert type(capacity) is int, "invalid type of capacity[%s]" \
+ % (str(capacity))
+
+ assert capacity > 0, '"size of shared memory should be greater than 0'
+ self._released = False
+ self._cap = capacity
+ self._page_size = pagesize
+
+ assert self._cap % self._page_size == 0, \
+ "capacity[%d] and pagesize[%d] are not consistent" \
+ % (self._cap, self._page_size)
+ self._total_pages = self._cap // self._page_size
+
+ self._pid = os.getpid()
+ SharedMemoryMgr.s_mgr_num += 1
+ self._id = self._pid * 100 + SharedMemoryMgr.s_mgr_num
+ SharedMemoryMgr.s_memory_mgrs[self._id] = self
+ self._locker = Lock()
+ self._setup()
+
+ def _setup(self):
+ self._shared_mem = RawArray('c', self._cap)
+ self._base = np.frombuffer(
+ self._shared_mem, dtype='uint8', count=self._cap)
+ self._locker.acquire()
+ try:
+ self._allocator = PageAllocator(self._base, self._total_pages,
+ self._page_size)
+ finally:
+ self._locker.release()
+
+ def malloc(self, size, wait=True):
+ """ malloc a new SharedBuffer
+
+ Args:
+ size (int): buffer size to be malloc
+ wait (bool): whether to wait when no enough memory
+
+ Returns:
+ SharedBuffer
+
+ Raises:
+ SharedMemoryError when not found available memory
+ """
+ page_num = int(math.ceil(size / self._page_size))
+ size = page_num * self._page_size
+
+ start = None
+ ct = 0
+ errmsg = ''
+ while True:
+ self._locker.acquire()
+ try:
+ start = self._allocator.malloc_page(page_num)
+ alloc_status = str(self._allocator)
+ except MemoryFullError as e:
+ start = None
+ errmsg = e.errmsg
+ if not wait:
+ raise e
+ finally:
+ self._locker.release()
+
+ if start is None:
+ time.sleep(0.1)
+ if ct % 100 == 0:
+ logger.warn('not enough space for reason[%s]' % (errmsg))
+
+ ct += 1
+ else:
+ break
+
+ return SharedBuffer(self._id, size, start, alloc_status=alloc_status)
+
+ def free(self, shared_buf):
+ """ free a SharedBuffer
+
+ Args:
+ shared_buf (SharedBuffer): buffer to be freed
+
+ Returns:
+ None
+
+ Raises:
+ SharedMemoryError when failed to release this buffer
+ """
+ assert shared_buf._owner == self._id, "invalid shared_buf[%s] "\
+ "for it's not allocated from me[%s]" % (str(shared_buf), str(self))
+ cap = shared_buf.capacity()
+ start_page = shared_buf._pos
+ page_num = cap // self._page_size
+
+ #maybe we don't need this lock here
+ self._locker.acquire()
+ try:
+ self._allocator.free_page(start_page, page_num)
+ finally:
+ self._locker.release()
+
+ def put_data(self, shared_buf, data):
+ """ fill 'data' into 'shared_buf'
+ """
+ assert len(data) <= shared_buf.capacity(), 'too large data[%d] '\
+ 'for this buffer[%s]' % (len(data), str(shared_buf))
+ start = shared_buf._pos * self._page_size
+ end = start + len(data)
+ assert start >= 0 and end <= self._cap, "invalid start "\
+ "position[%d] when put data to buff:%s" % (start, str(shared_buf))
+ self._base[start:end] = np.frombuffer(data, 'uint8', len(data))
+
+ def get_data(self, shared_buf, offset, size, no_copy=True):
+ """ extract 'data' from 'shared_buf' in range [offset, offset + size)
+ """
+ start = shared_buf._pos * self._page_size
+ start += offset
+ if no_copy:
+ return self._base[start:start + size]
+ else:
+ return self._base[start:start + size].tostring()
+
+ def __str__(self):
+ return 'SharedMemoryMgr:{id:%d, %s}' % (self._id, str(self._allocator))
+
+ def __del__(self):
+ if SharedMemoryMgr.s_log_statis:
+ logger.info('destroy [%s]' % (self))
+
+ if not self._released and not self._allocator.empty():
+ logger.debug(
+ 'not empty when delete this SharedMemoryMgr[%s]' % (self))
+ else:
+ self._released = True
+
+ if self._id in SharedMemoryMgr.s_memory_mgrs:
+ del SharedMemoryMgr.s_memory_mgrs[self._id]
+ SharedMemoryMgr.s_mgr_num -= 1
diff --git a/contrib/HumanSeg/export.py b/contrib/HumanSeg/export.py
new file mode 100644
index 0000000000000000000000000000000000000000..6fcae141398a6718db5710d595d95842b1596753
--- /dev/null
+++ b/contrib/HumanSeg/export.py
@@ -0,0 +1,28 @@
+import models
+import argparse
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Export model')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for exporting',
+ type=str)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the export model',
+ type=str,
+ default='./output/export')
+ return parser.parse_args()
+
+
+def export(args):
+ model = models.load_model(args.model_dir)
+ model.export_inference_model(args.save_dir)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ export(args)
diff --git a/contrib/HumanSeg/imgs/Human.jpg b/contrib/HumanSeg/imgs/Human.jpg
deleted file mode 100644
index 77b9a93e69db37e825c6e0c092636f9e4b3b5c33..0000000000000000000000000000000000000000
Binary files a/contrib/HumanSeg/imgs/Human.jpg and /dev/null differ
diff --git a/contrib/HumanSeg/imgs/HumanSeg.jpg b/contrib/HumanSeg/imgs/HumanSeg.jpg
deleted file mode 100644
index 6935ba2482a5f7359fb4b430cc730b026e517723..0000000000000000000000000000000000000000
Binary files a/contrib/HumanSeg/imgs/HumanSeg.jpg and /dev/null differ
diff --git a/contrib/HumanSeg/infer.py b/contrib/HumanSeg/infer.py
index 971476933c431977ce80c73e1d939fe079e1af19..96aabac6c44c164504f6626accfadd36983219e5 100644
--- a/contrib/HumanSeg/infer.py
+++ b/contrib/HumanSeg/infer.py
@@ -1,130 +1,96 @@
-# -*- coding: utf-8 -*-
+import argparse
import os
+import os.path as osp
import cv2
import numpy as np
-from utils.util import get_arguments
-from utils.palette import get_palette
-from PIL import Image as PILImage
-import importlib
-
-args = get_arguments()
-config = importlib.import_module('config')
-cfg = getattr(config, 'cfg')
-
-# paddle垃圾回收策略FLAG,ACE2P模型较大,当显存不够时建议开启
-os.environ['FLAGS_eager_delete_tensor_gb']='0.0'
-
-import paddle.fluid as fluid
-
-# 预测数据集类
-class TestDataSet():
- def __init__(self):
- self.data_dir = cfg.data_dir
- self.data_list_file = cfg.data_list_file
- self.data_list = self.get_data_list()
- self.data_num = len(self.data_list)
-
- def get_data_list(self):
- # 获取预测图像路径列表
- data_list = []
- data_file_handler = open(self.data_list_file, 'r')
- for line in data_file_handler:
- img_name = line.strip()
- name_prefix = img_name.split('.')[0]
- if len(img_name.split('.')) == 1:
- img_name = img_name + '.jpg'
- img_path = os.path.join(self.data_dir, img_name)
- data_list.append(img_path)
- return data_list
-
- def preprocess(self, img):
- # 图像预处理
- if cfg.example == 'ACE2P':
- reader = importlib.import_module(args.example+'.reader')
- ACE2P_preprocess = getattr(reader, 'preprocess')
- img = ACE2P_preprocess(img)
- else:
- img = cv2.resize(img, cfg.input_size).astype(np.float32)
- img -= np.array(cfg.MEAN)
- img /= np.array(cfg.STD)
- img = img.transpose((2, 0, 1))
- img = np.expand_dims(img, axis=0)
- return img
-
- def get_data(self, index):
- # 获取图像信息
- img_path = self.data_list[index]
- img = cv2.imread(img_path, cv2.IMREAD_COLOR)
- if img is None:
- return img, img,img_path, None
-
- img_name = img_path.split(os.sep)[-1]
- name_prefix = img_name.replace('.'+img_name.split('.')[-1],'')
- img_shape = img.shape[:2]
- img_process = self.preprocess(img)
-
- return img, img_process, name_prefix, img_shape
-
-
-def infer():
- if not os.path.exists(cfg.vis_dir):
- os.makedirs(cfg.vis_dir)
- palette = get_palette(cfg.class_num)
- # 人像分割结果显示阈值
- thresh = 120
-
- place = fluid.CUDAPlace(0) if cfg.use_gpu else fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- # 加载预测模型
- test_prog, feed_name, fetch_list = fluid.io.load_inference_model(
- dirname=cfg.model_path, executor=exe, params_filename='__params__')
-
- #加载预测数据集
- test_dataset = TestDataSet()
- data_num = test_dataset.data_num
-
- for idx in range(data_num):
- # 数据获取
- ori_img, image, im_name, im_shape = test_dataset.get_data(idx)
- if image is None:
- print(im_name, 'is None')
- continue
-
- # 预测
- if cfg.example == 'ACE2P':
- # ACE2P模型使用多尺度预测
- reader = importlib.import_module(args.example+'.reader')
- multi_scale_test = getattr(reader, 'multi_scale_test')
- parsing, logits = multi_scale_test(exe, test_prog, feed_name, fetch_list, image, im_shape)
- else:
- # HumanSeg,RoadLine模型单尺度预测
- result = exe.run(program=test_prog, feed={feed_name[0]: image}, fetch_list=fetch_list)
- parsing = np.argmax(result[0][0], axis=0)
- parsing = cv2.resize(parsing.astype(np.uint8), im_shape[::-1])
-
- # 预测结果保存
- result_path = os.path.join(cfg.vis_dir, im_name + '.png')
- if cfg.example == 'HumanSeg':
- logits = result[0][0][1]*255
- logits = cv2.resize(logits, im_shape[::-1])
- ret, logits = cv2.threshold(logits, thresh, 0, cv2.THRESH_TOZERO)
- logits = 255 *(logits - thresh)/(255 - thresh)
- # 将分割结果添加到alpha通道
- rgba = np.concatenate((ori_img, np.expand_dims(logits, axis=2)), axis=2)
- cv2.imwrite(result_path, rgba)
- else:
- output_im = PILImage.fromarray(np.asarray(parsing, dtype=np.uint8))
- output_im.putpalette(palette)
- output_im.save(result_path)
-
- if (idx + 1) % 100 == 0:
- print('%d processd' % (idx + 1))
-
- print('%d processd done' % (idx + 1))
-
- return 0
-
-
-if __name__ == "__main__":
- infer()
+import tqdm
+
+import utils
+import models
+import transforms
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='HumanSeg inference and visualization')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for inference',
+ type=str)
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='The root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--test_list',
+ dest='test_list',
+ help='Test list file of dataset',
+ type=str)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the inference results',
+ type=str,
+ default='./output/result')
+ parser.add_argument(
+ "--image_shape",
+ dest="image_shape",
+ help="The image shape for net inputs.",
+ nargs=2,
+ default=[192, 192],
+ type=int)
+ return parser.parse_args()
+
+
+def mkdir(path):
+ sub_dir = osp.dirname(path)
+ if not osp.exists(sub_dir):
+ os.makedirs(sub_dir)
+
+
+def infer(args):
+ test_transforms = transforms.Compose(
+ [transforms.Resize(args.image_shape),
+ transforms.Normalize()])
+ model = models.load_model(args.model_dir)
+ added_saveed_path = osp.join(args.save_dir, 'added')
+ mat_saved_path = osp.join(args.save_dir, 'mat')
+ scoremap_saved_path = osp.join(args.save_dir, 'scoremap')
+
+ with open(args.test_list, 'r') as f:
+ files = f.readlines()
+
+ for file in tqdm.tqdm(files):
+ file = file.strip()
+ im_file = osp.join(args.data_dir, file)
+ im = cv2.imread(im_file)
+ result = model.predict(im, transforms=test_transforms)
+
+ # save added image
+ added_image = utils.visualize(im_file, result, weight=0.6)
+ added_image_file = osp.join(added_saveed_path, file)
+ mkdir(added_image_file)
+ cv2.imwrite(added_image_file, added_image)
+
+ # save score map
+ score_map = result['score_map'][:, :, 1]
+ score_map = (score_map * 255).astype(np.uint8)
+ score_map_file = osp.join(scoremap_saved_path, file)
+ mkdir(score_map_file)
+ cv2.imwrite(score_map_file, score_map)
+
+ # save mat image
+ score_map = np.expand_dims(score_map, axis=-1)
+ mat_image = np.concatenate([im, score_map], axis=2)
+ mat_file = osp.join(mat_saved_path, file)
+ ext = osp.splitext(mat_file)[-1]
+ mat_file = mat_file.replace(ext, '.png')
+ mkdir(mat_file)
+ cv2.imwrite(mat_file, mat_image)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ infer(args)
diff --git a/contrib/HumanSeg/models/__init__.py b/contrib/HumanSeg/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..02704a07cc4a476253f80a8defbc42929f4175ad
--- /dev/null
+++ b/contrib/HumanSeg/models/__init__.py
@@ -0,0 +1,4 @@
+from .humanseg import HumanSegMobile
+from .humanseg import HumanSegServer
+from .humanseg import HumanSegLite
+from .load_model import load_model
diff --git a/contrib/HumanSeg/models/humanseg.py b/contrib/HumanSeg/models/humanseg.py
new file mode 100644
index 0000000000000000000000000000000000000000..5873c992ab8405d397806593fd690d3b668c38f2
--- /dev/null
+++ b/contrib/HumanSeg/models/humanseg.py
@@ -0,0 +1,898 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+import paddle.fluid as fluid
+import os
+from os import path as osp
+import numpy as np
+from collections import OrderedDict
+import copy
+import math
+import time
+import tqdm
+import cv2
+import yaml
+import paddleslim as slim
+
+import utils
+import utils.logging as logging
+from utils import seconds_to_hms
+from utils import ConfusionMatrix
+from utils import get_environ_info
+from nets import DeepLabv3p, ShuffleSeg, HRNet
+import transforms as T
+
+
+def dict2str(dict_input):
+ out = ''
+ for k, v in dict_input.items():
+ try:
+ v = round(float(v), 6)
+ except:
+ pass
+ out = out + '{}={}, '.format(k, v)
+ return out.strip(', ')
+
+
+class SegModel(object):
+ # DeepLab mobilenet
+ def __init__(self,
+ num_classes=2,
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255,
+ sync_bn=True):
+ self.init_params = locals()
+ if num_classes > 2 and (use_bce_loss or use_dice_loss):
+ raise ValueError(
+ "dice loss and bce loss is only applicable to binary classfication"
+ )
+
+ if class_weight is not None:
+ if isinstance(class_weight, list):
+ if len(class_weight) != num_classes:
+ raise ValueError(
+ "Length of class_weight should be equal to number of classes"
+ )
+ elif isinstance(class_weight, str):
+ if class_weight.lower() != 'dynamic':
+ raise ValueError(
+ "if class_weight is string, must be dynamic!")
+ else:
+ raise TypeError(
+ 'Expect class_weight is a list or string but receive {}'.
+ format(type(class_weight)))
+
+ self.num_classes = num_classes
+ self.use_bce_loss = use_bce_loss
+ self.use_dice_loss = use_dice_loss
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+ self.sync_bn = sync_bn
+
+ self.labels = None
+ self.env_info = get_environ_info()
+ if self.env_info['place'] == 'cpu':
+ self.places = fluid.cpu_places()
+ else:
+ self.places = fluid.cuda_places()
+ self.exe = fluid.Executor(self.places[0])
+ self.train_prog = None
+ self.test_prog = None
+ self.parallel_train_prog = None
+ self.train_inputs = None
+ self.test_inputs = None
+ self.train_outputs = None
+ self.test_outputs = None
+ self.train_data_loader = None
+ self.eval_metrics = None
+ # 当前模型状态
+ self.status = 'Normal'
+
+ def _get_single_car_bs(self, batch_size):
+ if batch_size % len(self.places) == 0:
+ return int(batch_size // len(self.places))
+ else:
+ raise Exception("Please support correct batch_size, \
+ which can be divided by available cards({}) in {}".
+ format(self.env_info['num'],
+ self.env_info['place']))
+
+ def build_net(self, mode='train'):
+ """应根据不同的情况进行构建"""
+ pass
+
+ def build_program(self):
+ # build training network
+ self.train_inputs, self.train_outputs = self.build_net(mode='train')
+ self.train_prog = fluid.default_main_program()
+ startup_prog = fluid.default_startup_program()
+
+ # build prediction network
+ self.test_prog = fluid.Program()
+ with fluid.program_guard(self.test_prog, startup_prog):
+ with fluid.unique_name.guard():
+ self.test_inputs, self.test_outputs = self.build_net(
+ mode='test')
+ self.test_prog = self.test_prog.clone(for_test=True)
+
+ def arrange_transform(self, transforms, mode='train'):
+ arrange_transform = T.ArrangeSegmenter
+ if type(transforms.transforms[-1]).__name__.startswith('Arrange'):
+ transforms.transforms[-1] = arrange_transform(mode=mode)
+ else:
+ transforms.transforms.append(arrange_transform(mode=mode))
+
+ def build_train_data_loader(self, dataset, batch_size):
+ # init data_loader
+ if self.train_data_loader is None:
+ self.train_data_loader = fluid.io.DataLoader.from_generator(
+ feed_list=list(self.train_inputs.values()),
+ capacity=64,
+ use_double_buffer=True,
+ iterable=True)
+ batch_size_each_gpu = self._get_single_car_bs(batch_size)
+ self.train_data_loader.set_sample_list_generator(
+ dataset.generator(batch_size=batch_size_each_gpu),
+ places=self.places)
+
+ def net_initialize(self,
+ startup_prog=None,
+ pretrained_weights=None,
+ resume_weights=None):
+ if startup_prog is None:
+ startup_prog = fluid.default_startup_program()
+ self.exe.run(startup_prog)
+ if resume_weights is not None:
+ logging.info("Resume weights from {}".format(resume_weights))
+ if not osp.exists(resume_weights):
+ raise Exception("Path {} not exists.".format(resume_weights))
+ fluid.load(self.train_prog, osp.join(resume_weights, 'model'),
+ self.exe)
+ # Check is path ended by path spearator
+ if resume_weights[-1] == os.sep:
+ resume_weights = resume_weights[0:-1]
+ epoch_name = osp.basename(resume_weights)
+ # If resume weights is end of digit, restore epoch status
+ epoch = epoch_name.split('_')[-1]
+ if epoch.isdigit():
+ self.begin_epoch = int(epoch)
+ else:
+ raise ValueError("Resume model path is not valid!")
+ logging.info("Model checkpoint loaded successfully!")
+
+ elif pretrained_weights is not None:
+ logging.info(
+ "Load pretrain weights from {}.".format(pretrained_weights))
+ utils.load_pretrained_weights(self.exe, self.train_prog,
+ pretrained_weights)
+
+ def get_model_info(self):
+ # 存储相应的信息到yml文件
+ info = dict()
+ info['Model'] = self.__class__.__name__
+ if 'self' in self.init_params:
+ del self.init_params['self']
+ if '__class__' in self.init_params:
+ del self.init_params['__class__']
+ info['_init_params'] = self.init_params
+
+ info['_Attributes'] = dict()
+ info['_Attributes']['num_classes'] = self.num_classes
+ info['_Attributes']['labels'] = self.labels
+ try:
+ info['_Attributes']['eval_metric'] = dict()
+ for k, v in self.eval_metrics.items():
+ if isinstance(v, np.ndarray):
+ if v.size > 1:
+ v = [float(i) for i in v]
+ else:
+ v = float(v)
+ info['_Attributes']['eval_metric'][k] = v
+ except:
+ pass
+
+ if hasattr(self, 'test_transforms'):
+ if self.test_transforms is not None:
+ info['test_transforms'] = list()
+ for op in self.test_transforms.transforms:
+ name = op.__class__.__name__
+ attr = op.__dict__
+ info['test_transforms'].append({name: attr})
+
+ if hasattr(self, 'train_transforms'):
+ if self.train_transforms is not None:
+ info['train_transforms'] = list()
+ for op in self.train_transforms.transforms:
+ name = op.__class__.__name__
+ attr = op.__dict__
+ info['train_transforms'].append({name: attr})
+
+ if hasattr(self, 'train_init'):
+ if 'self' in self.train_init:
+ del self.train_init['self']
+ if 'train_dataset' in self.train_init:
+ del self.train_init['train_dataset']
+ if 'eval_dataset' in self.train_init:
+ del self.train_init['eval_dataset']
+ if 'optimizer' in self.train_init:
+ del self.train_init['optimizer']
+ info['train_init'] = self.train_init
+ return info
+
+ def save_model(self, save_dir):
+ if not osp.isdir(save_dir):
+ if osp.exists(save_dir):
+ os.remove(save_dir)
+ os.makedirs(save_dir)
+ model_info = self.get_model_info()
+
+ if self.status == 'Normal':
+ fluid.save(self.train_prog, osp.join(save_dir, 'model'))
+ elif self.status == 'Quant':
+ float_prog, _ = slim.quant.convert(
+ self.test_prog, self.exe.place, save_int8=True)
+ test_input_names = [
+ var.name for var in list(self.test_inputs.values())
+ ]
+ test_outputs = list(self.test_outputs.values())
+ fluid.io.save_inference_model(
+ dirname=save_dir,
+ executor=self.exe,
+ params_filename='__params__',
+ feeded_var_names=test_input_names,
+ target_vars=test_outputs,
+ main_program=float_prog)
+
+ model_info['_ModelInputsOutputs'] = dict()
+ model_info['_ModelInputsOutputs']['test_inputs'] = [
+ [k, v.name] for k, v in self.test_inputs.items()
+ ]
+ model_info['_ModelInputsOutputs']['test_outputs'] = [
+ [k, v.name] for k, v in self.test_outputs.items()
+ ]
+
+ model_info['status'] = self.status
+ with open(
+ osp.join(save_dir, 'model.yml'), encoding='utf-8',
+ mode='w') as f:
+ yaml.dump(model_info, f)
+
+ # The flag of model for saving successfully
+ open(osp.join(save_dir, '.success'), 'w').close()
+ logging.info("Model saved in {}.".format(save_dir))
+
+ def export_inference_model(self, save_dir):
+ test_input_names = [var.name for var in list(self.test_inputs.values())]
+ test_outputs = list(self.test_outputs.values())
+ fluid.io.save_inference_model(
+ dirname=save_dir,
+ executor=self.exe,
+ params_filename='__params__',
+ feeded_var_names=test_input_names,
+ target_vars=test_outputs,
+ main_program=self.test_prog)
+ model_info = self.get_model_info()
+ model_info['status'] = 'Infer'
+
+ # Save input and output descrition of model
+ model_info['_ModelInputsOutputs'] = dict()
+ model_info['_ModelInputsOutputs']['test_inputs'] = [
+ [k, v.name] for k, v in self.test_inputs.items()
+ ]
+ model_info['_ModelInputsOutputs']['test_outputs'] = [
+ [k, v.name] for k, v in self.test_outputs.items()
+ ]
+
+ with open(
+ osp.join(save_dir, 'model.yml'), encoding='utf-8',
+ mode='w') as f:
+ yaml.dump(model_info, f)
+
+ # The flag of model for saving successfully
+ open(osp.join(save_dir, '.success'), 'w').close()
+ logging.info("Model for inference deploy saved in {}.".format(save_dir))
+
+ def export_quant_model(self,
+ dataset,
+ save_dir,
+ batch_size=1,
+ batch_nums=10,
+ cache_dir="./.temp"):
+ self.arrange_transform(transforms=dataset.transforms, mode='quant')
+ dataset.num_samples = batch_size * batch_nums
+ try:
+ from utils import HumanSegPostTrainingQuantization
+ except:
+ raise Exception(
+ "Model Quantization is not available, try to upgrade your paddlepaddle>=1.7.0"
+ )
+ is_use_cache_file = True
+ if cache_dir is None:
+ is_use_cache_file = False
+ post_training_quantization = HumanSegPostTrainingQuantization(
+ executor=self.exe,
+ dataset=dataset,
+ program=self.test_prog,
+ inputs=self.test_inputs,
+ outputs=self.test_outputs,
+ batch_size=batch_size,
+ batch_nums=batch_nums,
+ scope=None,
+ algo='KL',
+ quantizable_op_type=["conv2d", "depthwise_conv2d", "mul"],
+ is_full_quantize=False,
+ is_use_cache_file=is_use_cache_file,
+ cache_dir=cache_dir)
+ post_training_quantization.quantize()
+ post_training_quantization.save_quantized_model(save_dir)
+ if cache_dir is not None:
+ os.system('rm -r' + cache_dir)
+ model_info = self.get_model_info()
+ model_info['status'] = 'Quant'
+
+ # Save input and output descrition of model
+ model_info['_ModelInputsOutputs'] = dict()
+ model_info['_ModelInputsOutputs']['test_inputs'] = [
+ [k, v.name] for k, v in self.test_inputs.items()
+ ]
+ model_info['_ModelInputsOutputs']['test_outputs'] = [
+ [k, v.name] for k, v in self.test_outputs.items()
+ ]
+
+ with open(
+ osp.join(save_dir, 'model.yml'), encoding='utf-8',
+ mode='w') as f:
+ yaml.dump(model_info, f)
+
+ # The flag of model for saving successfully
+ open(osp.join(save_dir, '.success'), 'w').close()
+ logging.info("Model for quant saved in {}.".format(save_dir))
+
+ def default_optimizer(self,
+ learning_rate,
+ num_epochs,
+ num_steps_each_epoch,
+ lr_decay_power=0.9,
+ regularization_coeff=4e-5):
+ decay_step = num_epochs * num_steps_each_epoch
+ lr_decay = fluid.layers.polynomial_decay(
+ learning_rate,
+ decay_step,
+ end_learning_rate=0,
+ power=lr_decay_power)
+ optimizer = fluid.optimizer.Momentum(
+ lr_decay,
+ momentum=0.9,
+ regularization=fluid.regularizer.L2Decay(
+ regularization_coeff=regularization_coeff))
+ return optimizer
+
+ def train(self,
+ num_epochs,
+ train_dataset,
+ train_batch_size=2,
+ eval_dataset=None,
+ save_interval_epochs=1,
+ log_interval_steps=2,
+ save_dir='output',
+ pretrained_weights=None,
+ resume_weights=None,
+ optimizer=None,
+ learning_rate=0.01,
+ lr_decay_power=0.9,
+ regularization_coeff=4e-5,
+ use_vdl=False,
+ quant=False):
+ self.labels = train_dataset.labels
+ self.train_transforms = train_dataset.transforms
+ self.train_init = locals()
+ self.begin_epoch = 0
+
+ if optimizer is None:
+ num_steps_each_epoch = train_dataset.num_samples // train_batch_size
+ optimizer = self.default_optimizer(
+ learning_rate=learning_rate,
+ num_epochs=num_epochs,
+ num_steps_each_epoch=num_steps_each_epoch,
+ lr_decay_power=lr_decay_power,
+ regularization_coeff=regularization_coeff)
+ self.optimizer = optimizer
+ self.build_program()
+ self.net_initialize(
+ startup_prog=fluid.default_startup_program(),
+ pretrained_weights=pretrained_weights,
+ resume_weights=resume_weights)
+
+ # 进行量化
+ if quant:
+ # 当 for_test=False ,返回类型为 fluid.CompiledProgram
+ # 当 for_test=True ,返回类型为 fluid.Program
+ self.train_prog = slim.quant.quant_aware(
+ self.train_prog, self.exe.place, for_test=False)
+ self.test_prog = slim.quant.quant_aware(
+ self.test_prog, self.exe.place, for_test=True)
+ # self.parallel_train_prog = self.train_prog.with_data_parallel(
+ # loss_name=self.train_outputs['loss'].name)
+ self.status = 'Quant'
+
+ if self.begin_epoch >= num_epochs:
+ raise ValueError(
+ ("begin epoch[{}] is larger than num_epochs[{}]").format(
+ self.begin_epoch, num_epochs))
+
+ if not osp.isdir(save_dir):
+ if osp.exists(save_dir):
+ os.remove(save_dir)
+ os.makedirs(save_dir)
+
+ # add arrange op tor transforms
+ self.arrange_transform(
+ transforms=train_dataset.transforms, mode='train')
+ self.build_train_data_loader(
+ dataset=train_dataset, batch_size=train_batch_size)
+
+ if eval_dataset is not None:
+ self.eval_transforms = eval_dataset.transforms
+ self.test_transforms = copy.deepcopy(eval_dataset.transforms)
+
+ lr = self.optimizer._learning_rate
+ lr.persistable = True
+ if isinstance(lr, fluid.framework.Variable):
+ self.train_outputs['lr'] = lr
+
+ # 多卡训练
+ if self.parallel_train_prog is None:
+ build_strategy = fluid.compiler.BuildStrategy()
+ if self.env_info['place'] != 'cpu' and len(self.places) > 1:
+ build_strategy.sync_batch_norm = self.sync_bn
+ exec_strategy = fluid.ExecutionStrategy()
+ exec_strategy.num_iteration_per_drop_scope = 1
+ if quant:
+ build_strategy.fuse_all_reduce_ops = False
+ build_strategy.sync_batch_norm = False
+ self.parallel_train_prog = self.train_prog.with_data_parallel(
+ loss_name=self.train_outputs['loss'].name,
+ build_strategy=build_strategy,
+ exec_strategy=exec_strategy)
+ else:
+ self.parallel_train_prog = fluid.CompiledProgram(
+ self.train_prog).with_data_parallel(
+ loss_name=self.train_outputs['loss'].name,
+ build_strategy=build_strategy,
+ exec_strategy=exec_strategy)
+
+ total_num_steps = math.floor(
+ train_dataset.num_samples / train_batch_size)
+ num_steps = 0
+ time_stat = list()
+ time_train_one_epoch = None
+ time_eval_one_epoch = None
+
+ total_num_steps_eval = 0
+ # eval times
+ total_eval_times = math.ceil(num_epochs / save_interval_epochs)
+ eval_batch_size = train_batch_size
+ if eval_dataset is not None:
+ total_num_steps_eval = math.ceil(
+ eval_dataset.num_samples / eval_batch_size)
+
+ if use_vdl:
+ from visualdl import LogWriter
+ vdl_logdir = osp.join(save_dir, 'vdl_log')
+ log_writer = LogWriter(vdl_logdir)
+ best_miou = -1.0
+ best_model_epoch = 1
+ for i in range(self.begin_epoch, num_epochs):
+ records = list()
+ step_start_time = time.time()
+ epoch_start_time = time.time()
+ for step, data in enumerate(self.train_data_loader()):
+ outputs = self.exe.run(
+ self.parallel_train_prog,
+ feed=data,
+ fetch_list=list(self.train_outputs.values()))
+ outputs_avg = np.mean(np.array(outputs), axis=1)
+ records.append(outputs_avg)
+
+ # time estimated to complete the training
+ currend_time = time.time()
+ step_cost_time = currend_time - step_start_time
+ step_start_time = currend_time
+ if len(time_stat) < 20:
+ time_stat.append(step_cost_time)
+ else:
+ time_stat[num_steps % 20] = step_cost_time
+
+ num_steps += 1
+ if num_steps % log_interval_steps == 0:
+ step_metrics = OrderedDict(
+ zip(list(self.train_outputs.keys()), outputs_avg))
+
+ if use_vdl:
+ for k, v in step_metrics.items():
+ log_writer.add_scalar(
+ step=num_steps,
+ tag='train/{}'.format(k),
+ value=v)
+
+ # 计算剩余时间
+ avg_step_time = np.mean(time_stat)
+ if time_train_one_epoch is not None:
+ eta = (num_epochs - i - 1) * time_train_one_epoch + (
+ total_num_steps - step - 1) * avg_step_time
+ else:
+ eta = ((num_epochs - i) * total_num_steps - step -
+ 1) * avg_step_time
+ if time_eval_one_epoch is not None:
+ eval_eta = (total_eval_times - i // save_interval_epochs
+ ) * time_eval_one_epoch
+ else:
+ eval_eta = (total_eval_times - i // save_interval_epochs
+ ) * total_num_steps_eval * avg_step_time
+ eta_str = seconds_to_hms(eta + eval_eta)
+
+ logging.info(
+ "[TRAIN] Epoch={}/{}, Step={}/{}, {}, time_each_step={}s, eta={}"
+ .format(i + 1, num_epochs, step + 1, total_num_steps,
+ dict2str(step_metrics), round(avg_step_time, 2),
+ eta_str))
+
+ train_metrics = OrderedDict(
+ zip(list(self.train_outputs.keys()), np.mean(records, axis=0)))
+ logging.info('[TRAIN] Epoch {} finished, {} .'.format(
+ i + 1, dict2str(train_metrics)))
+ time_train_one_epoch = time.time() - epoch_start_time
+
+ eval_epoch_start_time = time.time()
+ if (i + 1) % save_interval_epochs == 0 or i == num_epochs - 1:
+ current_save_dir = osp.join(save_dir, "epoch_{}".format(i + 1))
+ if not osp.isdir(current_save_dir):
+ os.makedirs(current_save_dir)
+ if eval_dataset is not None:
+ self.eval_metrics = self.evaluate(
+ eval_dataset=eval_dataset,
+ batch_size=eval_batch_size,
+ epoch_id=i + 1)
+ # 保存最优模型
+ current_miou = self.eval_metrics['miou']
+ if current_miou > best_miou:
+ best_miou = current_miou
+ best_model_epoch = i + 1
+ best_model_dir = osp.join(save_dir, "best_model")
+ self.save_model(save_dir=best_model_dir)
+ if use_vdl:
+ for k, v in self.eval_metrics.items():
+ if isinstance(v, list):
+ continue
+ if isinstance(v, np.ndarray):
+ if v.size > 1:
+ continue
+ log_writer.add_scalar(
+ step=num_steps,
+ tag='evaluate/{}'.format(k),
+ value=v)
+ self.save_model(save_dir=current_save_dir)
+ time_eval_one_epoch = time.time() - eval_epoch_start_time
+ if eval_dataset is not None:
+ logging.info(
+ 'Current evaluated best model in eval_dataset is epoch_{}, miou={}'
+ .format(best_model_epoch, best_miou))
+
+ def evaluate(self, eval_dataset, batch_size=1, epoch_id=None):
+ """评估。
+
+ Args:
+ eval_dataset (paddlex.datasets): 评估数据读取器。
+ batch_size (int): 评估时的batch大小。默认1。
+ epoch_id (int): 当前评估模型所在的训练轮数。
+ return_details (bool): 是否返回详细信息。默认False。
+
+ Returns:
+ dict: 当return_details为False时,返回dict。包含关键字:'miou'、'category_iou'、'macc'、
+ 'category_acc'和'kappa',分别表示平均iou、各类别iou、平均准确率、各类别准确率和kappa系数。
+ tuple (metrics, eval_details):当return_details为True时,增加返回dict (eval_details),
+ 包含关键字:'confusion_matrix',表示评估的混淆矩阵。
+ """
+ self.arrange_transform(transforms=eval_dataset.transforms, mode='train')
+ total_steps = math.ceil(eval_dataset.num_samples * 1.0 / batch_size)
+ conf_mat = ConfusionMatrix(self.num_classes, streaming=True)
+ data_generator = eval_dataset.generator(
+ batch_size=batch_size, drop_last=False)
+ if not hasattr(self, 'parallel_test_prog'):
+ self.parallel_test_prog = fluid.CompiledProgram(
+ self.test_prog).with_data_parallel(
+ share_vars_from=self.parallel_train_prog)
+ logging.info(
+ "Start to evaluating(total_samples={}, total_steps={})...".format(
+ eval_dataset.num_samples, total_steps))
+ for step, data in tqdm.tqdm(
+ enumerate(data_generator()), total=total_steps):
+ images = np.array([d[0] for d in data])
+ labels = np.array([d[1] for d in data])
+ num_samples = images.shape[0]
+ if num_samples < batch_size:
+ num_pad_samples = batch_size - num_samples
+ pad_images = np.tile(images[0:1], (num_pad_samples, 1, 1, 1))
+ images = np.concatenate([images, pad_images])
+ feed_data = {'image': images}
+ outputs = self.exe.run(
+ self.parallel_test_prog,
+ feed=feed_data,
+ fetch_list=list(self.test_outputs.values()),
+ return_numpy=True)
+ pred = outputs[0]
+ if num_samples < batch_size:
+ pred = pred[0:num_samples]
+
+ mask = labels != self.ignore_index
+ conf_mat.calculate(pred=pred, label=labels, ignore=mask)
+ _, iou = conf_mat.mean_iou()
+
+ logging.debug("[EVAL] Epoch={}, Step={}/{}, iou={}".format(
+ epoch_id, step + 1, total_steps, iou))
+
+ category_iou, miou = conf_mat.mean_iou()
+ category_acc, macc = conf_mat.accuracy()
+
+ metrics = OrderedDict(
+ zip(['miou', 'category_iou', 'macc', 'category_acc', 'kappa'],
+ [miou, category_iou, macc, category_acc,
+ conf_mat.kappa()]))
+
+ logging.info('[EVAL] Finished, Epoch={}, {} .'.format(
+ epoch_id, dict2str(metrics)))
+ return metrics
+
+ def predict(self, im_file, transforms=None):
+ """预测。
+ Args:
+ img_file(str|np.ndarray): 预测图像。
+ transforms(paddlex.cv.transforms): 数据预处理操作。
+
+ Returns:
+ dict: 包含关键字'label_map'和'score_map', 'label_map'存储预测结果灰度图,
+ 像素值表示对应的类别,'score_map'存储各类别的概率,shape=(h, w, num_classes)
+ """
+ if isinstance(im_file, str):
+ if not osp.exists(im_file):
+ raise ValueError(
+ 'The Image file does not exist: {}'.format(im_file))
+
+ if transforms is None and not hasattr(self, 'test_transforms'):
+ raise Exception("transforms need to be defined, now is None.")
+ if transforms is not None:
+ self.arrange_transform(transforms=transforms, mode='test')
+ im, im_info = transforms(im_file)
+ else:
+ self.arrange_transform(transforms=self.test_transforms, mode='test')
+ im, im_info = self.test_transforms(im_file)
+ im = np.expand_dims(im, axis=0)
+ result = self.exe.run(
+ self.test_prog,
+ feed={'image': im},
+ fetch_list=list(self.test_outputs.values()))
+ pred = result[0]
+ logit = result[1]
+ logit = np.squeeze(logit)
+ logit = np.transpose(logit, (1, 2, 0))
+ pred = np.squeeze(pred).astype('uint8')
+ keys = list(im_info.keys())
+ for k in keys[::-1]:
+ if k == 'shape_before_resize':
+ h, w = im_info[k][0], im_info[k][1]
+ pred = cv2.resize(pred, (w, h), cv2.INTER_NEAREST)
+ logit = cv2.resize(logit, (w, h), cv2.INTER_LINEAR)
+ elif k == 'shape_before_padding':
+ h, w = im_info[k][0], im_info[k][1]
+ pred = pred[0:h, 0:w]
+ logit = logit[0:h, 0:w, :]
+
+ return {'label_map': pred, 'score_map': logit}
+
+
+class HumanSegLite(SegModel):
+ # DeepLab ShuffleNet
+ def build_net(self, mode='train'):
+ """应根据不同的情况进行构建"""
+ model = ShuffleSeg(
+ self.num_classes,
+ mode=mode,
+ use_bce_loss=self.use_bce_loss,
+ use_dice_loss=self.use_dice_loss,
+ class_weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ inputs = model.generate_inputs()
+ model_out = model.build_net(inputs)
+ outputs = OrderedDict()
+ if mode == 'train':
+ self.optimizer.minimize(model_out)
+ outputs['loss'] = model_out
+ else:
+ outputs['pred'] = model_out[0]
+ outputs['logit'] = model_out[1]
+ return inputs, outputs
+
+
+class HumanSegServer(SegModel):
+ # DeepLab Xception
+ def __init__(self,
+ num_classes=2,
+ backbone='Xception65',
+ output_stride=16,
+ aspp_with_sep_conv=True,
+ decoder_use_sep_conv=True,
+ encoder_with_aspp=True,
+ enable_decoder=True,
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255,
+ sync_bn=True):
+ super().__init__(
+ num_classes=num_classes,
+ use_bce_loss=use_bce_loss,
+ use_dice_loss=use_dice_loss,
+ class_weight=class_weight,
+ ignore_index=ignore_index,
+ sync_bn=sync_bn)
+ self.init_params = locals()
+
+ self.output_stride = output_stride
+
+ if backbone not in ['Xception65', 'Xception41']:
+ raise ValueError("backbone: {} is set wrong. it should be one of "
+ "('Xception65', 'Xception41')".format(backbone))
+
+ self.backbone = backbone
+ self.aspp_with_sep_conv = aspp_with_sep_conv
+ self.decoder_use_sep_conv = decoder_use_sep_conv
+ self.encoder_with_aspp = encoder_with_aspp
+ self.enable_decoder = enable_decoder
+ self.sync_bn = sync_bn
+
+ def build_net(self, mode='train'):
+ model = DeepLabv3p(
+ self.num_classes,
+ mode=mode,
+ backbone=self.backbone,
+ output_stride=self.output_stride,
+ aspp_with_sep_conv=self.aspp_with_sep_conv,
+ decoder_use_sep_conv=self.decoder_use_sep_conv,
+ encoder_with_aspp=self.encoder_with_aspp,
+ enable_decoder=self.enable_decoder,
+ use_bce_loss=self.use_bce_loss,
+ use_dice_loss=self.use_dice_loss,
+ class_weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ inputs = model.generate_inputs()
+ model_out = model.build_net(inputs)
+ outputs = OrderedDict()
+ if mode == 'train':
+ self.optimizer.minimize(model_out)
+ outputs['loss'] = model_out
+ else:
+ outputs['pred'] = model_out[0]
+ outputs['logit'] = model_out[1]
+ return inputs, outputs
+
+
+class HumanSegMobile(SegModel):
+ def __init__(self,
+ num_classes=2,
+ stage1_num_modules=1,
+ stage1_num_blocks=[1],
+ stage1_num_channels=[32],
+ stage2_num_modules=1,
+ stage2_num_blocks=[2, 2],
+ stage2_num_channels=[16, 32],
+ stage3_num_modules=1,
+ stage3_num_blocks=[2, 2, 2],
+ stage3_num_channels=[16, 32, 64],
+ stage4_num_modules=1,
+ stage4_num_blocks=[2, 2, 2, 2],
+ stage4_num_channels=[16, 32, 64, 128],
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255,
+ sync_bn=True):
+ super().__init__(
+ num_classes=num_classes,
+ use_bce_loss=use_bce_loss,
+ use_dice_loss=use_dice_loss,
+ class_weight=class_weight,
+ ignore_index=ignore_index,
+ sync_bn=sync_bn)
+ self.init_params = locals()
+
+ self.stage1_num_modules = stage1_num_modules
+ self.stage1_num_blocks = stage1_num_blocks
+ self.stage1_num_channels = stage1_num_channels
+ self.stage2_num_modules = stage2_num_modules
+ self.stage2_num_blocks = stage2_num_blocks
+ self.stage2_num_channels = stage2_num_channels
+ self.stage3_num_modules = stage3_num_modules
+ self.stage3_num_blocks = stage3_num_blocks
+ self.stage3_num_channels = stage3_num_channels
+ self.stage4_num_modules = stage4_num_modules
+ self.stage4_num_blocks = stage4_num_blocks
+ self.stage4_num_channels = stage4_num_channels
+
+ def build_net(self, mode='train'):
+ """应根据不同的情况进行构建"""
+ model = HRNet(
+ self.num_classes,
+ mode=mode,
+ stage1_num_modules=self.stage1_num_modules,
+ stage1_num_blocks=self.stage1_num_blocks,
+ stage1_num_channels=self.stage1_num_channels,
+ stage2_num_modules=self.stage2_num_modules,
+ stage2_num_blocks=self.stage2_num_blocks,
+ stage2_num_channels=self.stage2_num_channels,
+ stage3_num_modules=self.stage3_num_modules,
+ stage3_num_blocks=self.stage3_num_blocks,
+ stage3_num_channels=self.stage3_num_channels,
+ stage4_num_modules=self.stage4_num_modules,
+ stage4_num_blocks=self.stage4_num_blocks,
+ stage4_num_channels=self.stage4_num_channels,
+ use_bce_loss=self.use_bce_loss,
+ use_dice_loss=self.use_dice_loss,
+ class_weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ inputs = model.generate_inputs()
+ model_out = model.build_net(inputs)
+ outputs = OrderedDict()
+ if mode == 'train':
+ self.optimizer.minimize(model_out)
+ outputs['loss'] = model_out
+ else:
+ outputs['pred'] = model_out[0]
+ outputs['logit'] = model_out[1]
+ return inputs, outputs
+
+ def train(self,
+ num_epochs,
+ train_dataset,
+ train_batch_size=2,
+ eval_dataset=None,
+ save_interval_epochs=1,
+ log_interval_steps=2,
+ save_dir='output',
+ pretrained_weights=None,
+ resume_weights=None,
+ optimizer=None,
+ learning_rate=0.01,
+ lr_decay_power=0.9,
+ regularization_coeff=5e-4,
+ use_vdl=False,
+ quant=False):
+ super().train(
+ num_epochs=num_epochs,
+ train_dataset=train_dataset,
+ train_batch_size=train_batch_size,
+ eval_dataset=eval_dataset,
+ save_interval_epochs=save_interval_epochs,
+ log_interval_steps=log_interval_steps,
+ save_dir=save_dir,
+ pretrained_weights=pretrained_weights,
+ resume_weights=resume_weights,
+ optimizer=optimizer,
+ learning_rate=learning_rate,
+ lr_decay_power=lr_decay_power,
+ regularization_coeff=regularization_coeff,
+ use_vdl=use_vdl,
+ quant=quant)
diff --git a/contrib/HumanSeg/models/load_model.py b/contrib/HumanSeg/models/load_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc6e3db7a7f1b51a7522cbe6b65c7cde0b01940b
--- /dev/null
+++ b/contrib/HumanSeg/models/load_model.py
@@ -0,0 +1,86 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import yaml
+import os.path as osp
+import six
+import copy
+from collections import OrderedDict
+import paddle.fluid as fluid
+import utils.logging as logging
+import models
+
+
+def load_model(model_dir):
+ if not osp.exists(osp.join(model_dir, "model.yml")):
+ raise Exception("There's not model.yml in {}".format(model_dir))
+ with open(osp.join(model_dir, "model.yml")) as f:
+ info = yaml.load(f.read(), Loader=yaml.Loader)
+ status = info['status']
+
+ if not hasattr(models, info['Model']):
+ raise Exception("There's no attribute {} in models".format(
+ info['Model']))
+ model = getattr(models, info['Model'])(**info['_init_params'])
+ if status == "Normal":
+ startup_prog = fluid.Program()
+ model.test_prog = fluid.Program()
+ with fluid.program_guard(model.test_prog, startup_prog):
+ with fluid.unique_name.guard():
+ model.test_inputs, model.test_outputs = model.build_net(
+ mode='test')
+ model.test_prog = model.test_prog.clone(for_test=True)
+ model.exe.run(startup_prog)
+ import pickle
+ with open(osp.join(model_dir, 'model.pdparams'), 'rb') as f:
+ load_dict = pickle.load(f)
+ fluid.io.set_program_state(model.test_prog, load_dict)
+
+ elif status in ['Infer', 'Quant']:
+ [prog, input_names, outputs] = fluid.io.load_inference_model(
+ model_dir, model.exe, params_filename='__params__')
+ model.test_prog = prog
+ test_outputs_info = info['_ModelInputsOutputs']['test_outputs']
+ model.test_inputs = OrderedDict()
+ model.test_outputs = OrderedDict()
+ for name in input_names:
+ model.test_inputs[name] = model.test_prog.global_block().var(name)
+ for i, out in enumerate(outputs):
+ var_desc = test_outputs_info[i]
+ model.test_outputs[var_desc[0]] = out
+ if 'test_transforms' in info:
+ model.test_transforms = build_transforms(info['test_transforms'])
+ model.eval_transforms = copy.deepcopy(model.test_transforms)
+
+ if '_Attributes' in info:
+ for k, v in info['_Attributes'].items():
+ if k in model.__dict__:
+ model.__dict__[k] = v
+
+ logging.info("Model[{}] loaded.".format(info['Model']))
+ return model
+
+
+def build_transforms(transforms_info):
+ import transforms as T
+ transforms = list()
+ for op_info in transforms_info:
+ op_name = list(op_info.keys())[0]
+ op_attr = op_info[op_name]
+ if not hasattr(T, op_name):
+ raise Exception(
+ "There's no operator named '{}' in transforms".format(op_name))
+ transforms.append(getattr(T, op_name)(**op_attr))
+ eval_transforms = T.Compose(transforms)
+ return eval_transforms
diff --git a/contrib/HumanSeg/nets/__init__.py b/contrib/HumanSeg/nets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..cab1682745084e736992e4aa5e555db6bc1d5c53
--- /dev/null
+++ b/contrib/HumanSeg/nets/__init__.py
@@ -0,0 +1,5 @@
+from .backbone import mobilenet_v2
+from .backbone import xception
+from .deeplabv3p import DeepLabv3p
+from .shufflenet_slim import ShuffleSeg
+from .hrnet import HRNet
diff --git a/contrib/HumanSeg/nets/backbone/__init__.py b/contrib/HumanSeg/nets/backbone/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..18f39d40802011843007ae7c6ca9cf4fb64aa789
--- /dev/null
+++ b/contrib/HumanSeg/nets/backbone/__init__.py
@@ -0,0 +1,2 @@
+from .mobilenet_v2 import MobileNetV2
+from .xception import Xception
diff --git a/contrib/HumanSeg/nets/backbone/mobilenet_v2.py b/contrib/HumanSeg/nets/backbone/mobilenet_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..845d5a3f6b997e2c323e577275670bdfc5193530
--- /dev/null
+++ b/contrib/HumanSeg/nets/backbone/mobilenet_v2.py
@@ -0,0 +1,242 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+import paddle.fluid as fluid
+from paddle.fluid.param_attr import ParamAttr
+
+
+class MobileNetV2:
+ def __init__(self,
+ num_classes=None,
+ scale=1.0,
+ output_stride=None,
+ end_points=None,
+ decode_points=None):
+ self.scale = scale
+ self.num_classes = num_classes
+ self.output_stride = output_stride
+ self.end_points = end_points
+ self.decode_points = decode_points
+ self.bottleneck_params_list = [(1, 16, 1, 1), (6, 24, 2, 2),
+ (6, 32, 3, 2), (6, 64, 4, 2),
+ (6, 96, 3, 1), (6, 160, 3, 2),
+ (6, 320, 1, 1)]
+ self.modify_bottle_params(output_stride)
+
+ def __call__(self, input):
+ scale = self.scale
+ decode_ends = dict()
+
+ def check_points(count, points):
+ if points is None:
+ return False
+ else:
+ if isinstance(points, list):
+ return (True if count in points else False)
+ else:
+ return (True if count == points else False)
+
+ # conv1
+ input = self.conv_bn_layer(
+ input,
+ num_filters=int(32 * scale),
+ filter_size=3,
+ stride=2,
+ padding=1,
+ if_act=True,
+ name='conv1_1')
+
+ layer_count = 1
+
+ if check_points(layer_count, self.decode_points):
+ decode_ends[layer_count] = input
+
+ if check_points(layer_count, self.end_points):
+ return input, decode_ends
+
+ # bottleneck sequences
+ i = 1
+ in_c = int(32 * scale)
+ for layer_setting in self.bottleneck_params_list:
+ t, c, n, s = layer_setting
+ i += 1
+ input, depthwise_output = self.invresi_blocks(
+ input=input,
+ in_c=in_c,
+ t=t,
+ c=int(c * scale),
+ n=n,
+ s=s,
+ name='conv' + str(i))
+ in_c = int(c * scale)
+ layer_count += n
+
+ if check_points(layer_count, self.decode_points):
+ decode_ends[layer_count] = depthwise_output
+
+ if check_points(layer_count, self.end_points):
+ return input, decode_ends
+
+ # last_conv
+ output = self.conv_bn_layer(
+ input=input,
+ num_filters=int(1280 * scale) if scale > 1.0 else 1280,
+ filter_size=1,
+ stride=1,
+ padding=0,
+ if_act=True,
+ name='conv9')
+
+ if self.num_classes is not None:
+ output = fluid.layers.pool2d(
+ input=output, pool_type='avg', global_pooling=True)
+
+ output = fluid.layers.fc(
+ input=output,
+ size=self.num_classes,
+ param_attr=ParamAttr(name='fc10_weights'),
+ bias_attr=ParamAttr(name='fc10_offset'))
+ return output
+
+ def modify_bottle_params(self, output_stride=None):
+ if output_stride is not None and output_stride % 2 != 0:
+ raise Exception("output stride must to be even number")
+ if output_stride is None:
+ return
+ else:
+ stride = 2
+ for i, layer_setting in enumerate(self.bottleneck_params_list):
+ t, c, n, s = layer_setting
+ stride = stride * s
+ if stride > output_stride:
+ s = 1
+ self.bottleneck_params_list[i] = (t, c, n, s)
+
+ def conv_bn_layer(self,
+ input,
+ filter_size,
+ num_filters,
+ stride,
+ padding,
+ channels=None,
+ num_groups=1,
+ if_act=True,
+ name=None,
+ use_cudnn=True):
+ conv = fluid.layers.conv2d(
+ input=input,
+ num_filters=num_filters,
+ filter_size=filter_size,
+ stride=stride,
+ padding=padding,
+ groups=num_groups,
+ act=None,
+ use_cudnn=use_cudnn,
+ param_attr=ParamAttr(name=name + '_weights'),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ bn = fluid.layers.batch_norm(
+ input=conv,
+ param_attr=ParamAttr(name=bn_name + "_scale"),
+ bias_attr=ParamAttr(name=bn_name + "_offset"),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+ if if_act:
+ return fluid.layers.relu6(bn)
+ else:
+ return bn
+
+ def shortcut(self, input, data_residual):
+ return fluid.layers.elementwise_add(input, data_residual)
+
+ def inverted_residual_unit(self,
+ input,
+ num_in_filter,
+ num_filters,
+ ifshortcut,
+ stride,
+ filter_size,
+ padding,
+ expansion_factor,
+ name=None):
+ num_expfilter = int(round(num_in_filter * expansion_factor))
+
+ channel_expand = self.conv_bn_layer(
+ input=input,
+ num_filters=num_expfilter,
+ filter_size=1,
+ stride=1,
+ padding=0,
+ num_groups=1,
+ if_act=True,
+ name=name + '_expand')
+
+ bottleneck_conv = self.conv_bn_layer(
+ input=channel_expand,
+ num_filters=num_expfilter,
+ filter_size=filter_size,
+ stride=stride,
+ padding=padding,
+ num_groups=num_expfilter,
+ if_act=True,
+ name=name + '_dwise',
+ use_cudnn=False)
+
+ depthwise_output = bottleneck_conv
+
+ linear_out = self.conv_bn_layer(
+ input=bottleneck_conv,
+ num_filters=num_filters,
+ filter_size=1,
+ stride=1,
+ padding=0,
+ num_groups=1,
+ if_act=False,
+ name=name + '_linear')
+
+ if ifshortcut:
+ out = self.shortcut(input=input, data_residual=linear_out)
+ return out, depthwise_output
+ else:
+ return linear_out, depthwise_output
+
+ def invresi_blocks(self, input, in_c, t, c, n, s, name=None):
+ first_block, depthwise_output = self.inverted_residual_unit(
+ input=input,
+ num_in_filter=in_c,
+ num_filters=c,
+ ifshortcut=False,
+ stride=s,
+ filter_size=3,
+ padding=1,
+ expansion_factor=t,
+ name=name + '_1')
+
+ last_residual_block = first_block
+ last_c = c
+
+ for i in range(1, n):
+ last_residual_block, depthwise_output = self.inverted_residual_unit(
+ input=last_residual_block,
+ num_in_filter=last_c,
+ num_filters=c,
+ ifshortcut=True,
+ stride=1,
+ filter_size=3,
+ padding=1,
+ expansion_factor=t,
+ name=name + '_' + str(i + 1))
+ return last_residual_block, depthwise_output
diff --git a/contrib/HumanSeg/nets/backbone/xception.py b/contrib/HumanSeg/nets/backbone/xception.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad5c3821933e6ed10d7e5bbce810cc14b579a7b2
--- /dev/null
+++ b/contrib/HumanSeg/nets/backbone/xception.py
@@ -0,0 +1,321 @@
+# coding: utf8
+# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+import math
+import paddle.fluid as fluid
+from nets.libs import scope, name_scope
+from nets.libs import bn, bn_relu, relu
+from nets.libs import conv
+from nets.libs import separate_conv
+
+__all__ = ['xception_65', 'xception_41', 'xception_71']
+
+
+def check_data(data, number):
+ if type(data) == int:
+ return [data] * number
+ assert len(data) == number
+ return data
+
+
+def check_stride(s, os):
+ if s <= os:
+ return True
+ else:
+ return False
+
+
+def check_points(count, points):
+ if points is None:
+ return False
+ else:
+ if isinstance(points, list):
+ return (True if count in points else False)
+ else:
+ return (True if count == points else False)
+
+
+class Xception():
+ def __init__(self,
+ num_classes=None,
+ layers=65,
+ output_stride=32,
+ end_points=None,
+ decode_points=None):
+ self.backbone = 'xception_' + str(layers)
+ self.num_classes = num_classes
+ self.output_stride = output_stride
+ self.end_points = end_points
+ self.decode_points = decode_points
+ self.bottleneck_params = self.gen_bottleneck_params(self.backbone)
+
+ def __call__(
+ self,
+ input,
+ ):
+ self.stride = 2
+ self.block_point = 0
+ self.short_cuts = dict()
+ with scope(self.backbone):
+ # Entry flow
+ data = self.entry_flow(input)
+ if check_points(self.block_point, self.end_points):
+ return data, self.short_cuts
+
+ # Middle flow
+ data = self.middle_flow(data)
+ if check_points(self.block_point, self.end_points):
+ return data, self.short_cuts
+
+ # Exit flow
+ data = self.exit_flow(data)
+ if check_points(self.block_point, self.end_points):
+ return data, self.short_cuts
+
+ if self.num_classes is not None:
+ data = fluid.layers.reduce_mean(data, [2, 3], keep_dim=True)
+ data = fluid.layers.dropout(data, 0.5)
+ stdv = 1.0 / math.sqrt(data.shape[1] * 1.0)
+ with scope("logit"):
+ out = fluid.layers.fc(
+ input=data,
+ size=self.num_classes,
+ act='softmax',
+ param_attr=fluid.param_attr.ParamAttr(
+ name='weights',
+ initializer=fluid.initializer.Uniform(-stdv, stdv)),
+ bias_attr=fluid.param_attr.ParamAttr(name='bias'))
+
+ return out
+ else:
+ return data
+
+ def gen_bottleneck_params(self, backbone='xception_65'):
+ if backbone == 'xception_65':
+ bottleneck_params = {
+ "entry_flow": (3, [2, 2, 2], [128, 256, 728]),
+ "middle_flow": (16, 1, 728),
+ "exit_flow": (2, [2, 1], [[728, 1024, 1024], [1536, 1536,
+ 2048]])
+ }
+ elif backbone == 'xception_41':
+ bottleneck_params = {
+ "entry_flow": (3, [2, 2, 2], [128, 256, 728]),
+ "middle_flow": (8, 1, 728),
+ "exit_flow": (2, [2, 1], [[728, 1024, 1024], [1536, 1536,
+ 2048]])
+ }
+ elif backbone == 'xception_71':
+ bottleneck_params = {
+ "entry_flow": (5, [2, 1, 2, 1, 2], [128, 256, 256, 728, 728]),
+ "middle_flow": (16, 1, 728),
+ "exit_flow": (2, [2, 1], [[728, 1024, 1024], [1536, 1536,
+ 2048]])
+ }
+ else:
+ raise Exception(
+ "xception backbont only support xception_41/xception_65/xception_71"
+ )
+ return bottleneck_params
+
+ def entry_flow(self, data):
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=None,
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.09))
+ with scope("entry_flow"):
+ with scope("conv1"):
+ data = bn_relu(
+ conv(
+ data, 32, 3, stride=2, padding=1,
+ param_attr=param_attr),
+ eps=1e-3)
+ with scope("conv2"):
+ data = bn_relu(
+ conv(
+ data, 64, 3, stride=1, padding=1,
+ param_attr=param_attr),
+ eps=1e-3)
+
+ # get entry flow params
+ block_num = self.bottleneck_params["entry_flow"][0]
+ strides = self.bottleneck_params["entry_flow"][1]
+ chns = self.bottleneck_params["entry_flow"][2]
+ strides = check_data(strides, block_num)
+ chns = check_data(chns, block_num)
+
+ # params to control your flow
+ s = self.stride
+ block_point = self.block_point
+ output_stride = self.output_stride
+ with scope("entry_flow"):
+ for i in range(block_num):
+ block_point = block_point + 1
+ with scope("block" + str(i + 1)):
+ stride = strides[i] if check_stride(s * strides[i],
+ output_stride) else 1
+ data, short_cuts = self.xception_block(
+ data, chns[i], [1, 1, stride])
+ s = s * stride
+ if check_points(block_point, self.decode_points):
+ self.short_cuts[block_point] = short_cuts[1]
+
+ self.stride = s
+ self.block_point = block_point
+ return data
+
+ def middle_flow(self, data):
+ block_num = self.bottleneck_params["middle_flow"][0]
+ strides = self.bottleneck_params["middle_flow"][1]
+ chns = self.bottleneck_params["middle_flow"][2]
+ strides = check_data(strides, block_num)
+ chns = check_data(chns, block_num)
+
+ # params to control your flow
+ s = self.stride
+ block_point = self.block_point
+ output_stride = self.output_stride
+ with scope("middle_flow"):
+ for i in range(block_num):
+ block_point = block_point + 1
+ with scope("block" + str(i + 1)):
+ stride = strides[i] if check_stride(s * strides[i],
+ output_stride) else 1
+ data, short_cuts = self.xception_block(
+ data, chns[i], [1, 1, strides[i]], skip_conv=False)
+ s = s * stride
+ if check_points(block_point, self.decode_points):
+ self.short_cuts[block_point] = short_cuts[1]
+
+ self.stride = s
+ self.block_point = block_point
+ return data
+
+ def exit_flow(self, data):
+ block_num = self.bottleneck_params["exit_flow"][0]
+ strides = self.bottleneck_params["exit_flow"][1]
+ chns = self.bottleneck_params["exit_flow"][2]
+ strides = check_data(strides, block_num)
+ chns = check_data(chns, block_num)
+
+ assert (block_num == 2)
+ # params to control your flow
+ s = self.stride
+ block_point = self.block_point
+ output_stride = self.output_stride
+ with scope("exit_flow"):
+ with scope('block1'):
+ block_point += 1
+ stride = strides[0] if check_stride(s * strides[0],
+ output_stride) else 1
+ data, short_cuts = self.xception_block(data, chns[0],
+ [1, 1, stride])
+ s = s * stride
+ if check_points(block_point, self.decode_points):
+ self.short_cuts[block_point] = short_cuts[1]
+ with scope('block2'):
+ block_point += 1
+ stride = strides[1] if check_stride(s * strides[1],
+ output_stride) else 1
+ data, short_cuts = self.xception_block(
+ data,
+ chns[1], [1, 1, stride],
+ dilation=2,
+ has_skip=False,
+ activation_fn_in_separable_conv=True)
+ s = s * stride
+ if check_points(block_point, self.decode_points):
+ self.short_cuts[block_point] = short_cuts[1]
+
+ self.stride = s
+ self.block_point = block_point
+ return data
+
+ def xception_block(self,
+ input,
+ channels,
+ strides=1,
+ filters=3,
+ dilation=1,
+ skip_conv=True,
+ has_skip=True,
+ activation_fn_in_separable_conv=False):
+ repeat_number = 3
+ channels = check_data(channels, repeat_number)
+ filters = check_data(filters, repeat_number)
+ strides = check_data(strides, repeat_number)
+ data = input
+ results = []
+ for i in range(repeat_number):
+ with scope('separable_conv' + str(i + 1)):
+ if not activation_fn_in_separable_conv:
+ data = relu(data)
+ data = separate_conv(
+ data,
+ channels[i],
+ strides[i],
+ filters[i],
+ dilation=dilation,
+ eps=1e-3)
+ else:
+ data = separate_conv(
+ data,
+ channels[i],
+ strides[i],
+ filters[i],
+ dilation=dilation,
+ act=relu,
+ eps=1e-3)
+ results.append(data)
+ if not has_skip:
+ return data, results
+ if skip_conv:
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=None,
+ initializer=fluid.initializer.TruncatedNormal(
+ loc=0.0, scale=0.09))
+ with scope('shortcut'):
+ skip = bn(
+ conv(
+ input,
+ channels[-1],
+ 1,
+ strides[-1],
+ groups=1,
+ padding=0,
+ param_attr=param_attr),
+ eps=1e-3)
+ else:
+ skip = input
+ return data + skip, results
+
+
+def xception_65(num_classes=None):
+ model = Xception(num_classes, 65)
+ return model
+
+
+def xception_41(num_classes=None):
+ model = Xception(num_classes, 41)
+ return model
+
+
+def xception_71(num_classes=None):
+ model = Xception(num_classes, 71)
+ return model
diff --git a/contrib/HumanSeg/nets/deeplabv3p.py b/contrib/HumanSeg/nets/deeplabv3p.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb363c8ca1934c5276556b51f9a3d3a3e537b781
--- /dev/null
+++ b/contrib/HumanSeg/nets/deeplabv3p.py
@@ -0,0 +1,415 @@
+# coding: utf8
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from collections import OrderedDict
+
+import paddle.fluid as fluid
+from .libs import scope, name_scope
+from .libs import bn_relu, relu
+from .libs import conv
+from .libs import separate_conv
+from .libs import sigmoid_to_softmax
+from .seg_modules import softmax_with_loss
+from .seg_modules import dice_loss
+from .seg_modules import bce_loss
+from .backbone import MobileNetV2
+from .backbone import Xception
+
+
+class DeepLabv3p(object):
+ """实现DeepLabv3+模型
+ `"Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation"
+ `
+
+ Args:
+ num_classes (int): 类别数。
+ backbone (str): DeepLabv3+的backbone网络,实现特征图的计算,取值范围为['Xception65', 'Xception41',
+ 'MobileNetV2_x0.25', 'MobileNetV2_x0.5', 'MobileNetV2_x1.0', 'MobileNetV2_x1.5',
+ 'MobileNetV2_x2.0']。默认'MobileNetV2_x1.0'。
+ mode (str): 网络运行模式,根据mode构建网络的输入和返回。
+ 当mode为'train'时,输入为image(-1, 3, -1, -1)和label (-1, 1, -1, -1) 返回loss。
+ 当mode为'train'时,输入为image (-1, 3, -1, -1)和label (-1, 1, -1, -1),返回loss,
+ pred (与网络输入label 相同大小的预测结果,值代表相应的类别),label,mask(非忽略值的mask,
+ 与label相同大小,bool类型)。
+ 当mode为'test'时,输入为image(-1, 3, -1, -1)返回pred (-1, 1, -1, -1)和
+ logit (-1, num_classes, -1, -1) 通道维上代表每一类的概率值。
+ output_stride (int): backbone 输出特征图相对于输入的下采样倍数,一般取值为8或16。
+ aspp_with_sep_conv (bool): 在asspp模块是否采用separable convolutions。
+ decoder_use_sep_conv (bool): decoder模块是否采用separable convolutions。
+ encoder_with_aspp (bool): 是否在encoder阶段采用aspp模块。
+ enable_decoder (bool): 是否使用decoder模块。
+ use_bce_loss (bool): 是否使用bce loss作为网络的损失函数,只能用于两类分割。可与dice loss同时使用。
+ use_dice_loss (bool): 是否使用dice loss作为网络的损失函数,只能用于两类分割,可与bce loss同时使用。
+ 当use_bce_loss和use_dice_loss都为False时,使用交叉熵损失函数。
+ class_weight (list/str): 交叉熵损失函数各类损失的权重。当class_weight为list的时候,长度应为
+ num_classes。当class_weight为str时, weight.lower()应为'dynamic',这时会根据每一轮各类像素的比重
+ 自行计算相应的权重,每一类的权重为:每类的比例 * num_classes。class_weight取默认值None是,各类的权重1,
+ 即平时使用的交叉熵损失函数。
+ ignore_index (int): label上忽略的值,label为ignore_index的像素不参与损失函数的计算。
+
+ Raises:
+ ValueError: use_bce_loss或use_dice_loss为真且num_calsses > 2。
+ ValueError: class_weight为list, 但长度不等于num_class。
+ class_weight为str, 但class_weight.low()不等于dynamic。
+ TypeError: class_weight不为None时,其类型不是list或str。
+ """
+
+ def __init__(self,
+ num_classes,
+ backbone='MobileNetV2_x1.0',
+ mode='train',
+ output_stride=16,
+ aspp_with_sep_conv=True,
+ decoder_use_sep_conv=True,
+ encoder_with_aspp=True,
+ enable_decoder=True,
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255):
+ # dice_loss或bce_loss只适用两类分割中
+ if num_classes > 2 and (use_bce_loss or use_dice_loss):
+ raise ValueError(
+ "dice loss and bce loss is only applicable to binary classfication"
+ )
+
+ if class_weight is not None:
+ if isinstance(class_weight, list):
+ if len(class_weight) != num_classes:
+ raise ValueError(
+ "Length of class_weight should be equal to number of classes"
+ )
+ elif isinstance(class_weight, str):
+ if class_weight.lower() != 'dynamic':
+ raise ValueError(
+ "if class_weight is string, must be dynamic!")
+ else:
+ raise TypeError(
+ 'Expect class_weight is a list or string but receive {}'.
+ format(type(class_weight)))
+
+ self.num_classes = num_classes
+ self.backbone = backbone
+ self.mode = mode
+ self.use_bce_loss = use_bce_loss
+ self.use_dice_loss = use_dice_loss
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+ self.output_stride = output_stride
+ self.aspp_with_sep_conv = aspp_with_sep_conv
+ self.decoder_use_sep_conv = decoder_use_sep_conv
+ self.encoder_with_aspp = encoder_with_aspp
+ self.enable_decoder = enable_decoder
+
+ def _get_backbone(self, backbone):
+ def mobilenetv2(backbone):
+ # backbone: xception结构配置
+ # output_stride:下采样倍数
+ # end_points: mobilenetv2的block数
+ # decode_point: 从mobilenetv2中引出分支所在block数, 作为decoder输入
+ if '0.25' in backbone:
+ scale = 0.25
+ elif '0.5' in backbone:
+ scale = 0.5
+ elif '1.0' in backbone:
+ scale = 1.0
+ elif '1.5' in backbone:
+ scale = 1.5
+ elif '2.0' in backbone:
+ scale = 2.0
+ end_points = 18
+ decode_points = 4
+ return MobileNetV2(
+ scale=scale,
+ output_stride=self.output_stride,
+ end_points=end_points,
+ decode_points=decode_points)
+
+ def xception(backbone):
+ # decode_point: 从Xception中引出分支所在block数,作为decoder输入
+ # end_point:Xception的block数
+ if '65' in backbone:
+ decode_points = 2
+ end_points = 21
+ layers = 65
+ if '41' in backbone:
+ decode_points = 2
+ end_points = 13
+ layers = 41
+ if '71' in backbone:
+ decode_points = 3
+ end_points = 23
+ layers = 71
+ return Xception(
+ layers=layers,
+ output_stride=self.output_stride,
+ end_points=end_points,
+ decode_points=decode_points)
+
+ if 'Xception' in backbone:
+ return xception(backbone)
+ elif 'MobileNetV2' in backbone:
+ return mobilenetv2(backbone)
+
+ def _encoder(self, input):
+ # 编码器配置,采用ASPP架构,pooling + 1x1_conv + 三个不同尺度的空洞卷积并行, concat后1x1conv
+ # ASPP_WITH_SEP_CONV:默认为真,使用depthwise可分离卷积,否则使用普通卷积
+ # OUTPUT_STRIDE: 下采样倍数,8或16,决定aspp_ratios大小
+ # aspp_ratios:ASPP模块空洞卷积的采样率
+
+ if self.output_stride == 16:
+ aspp_ratios = [6, 12, 18]
+ elif self.output_stride == 8:
+ aspp_ratios = [12, 24, 36]
+ else:
+ raise Exception("DeepLabv3p only support stride 8 or 16")
+
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=None,
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.06))
+ with scope('encoder'):
+ channel = 256
+ with scope("image_pool"):
+ image_avg = fluid.layers.reduce_mean(
+ input, [2, 3], keep_dim=True)
+ image_avg = bn_relu(
+ conv(
+ image_avg,
+ channel,
+ 1,
+ 1,
+ groups=1,
+ padding=0,
+ param_attr=param_attr))
+ input_shape = fluid.layers.shape(input)
+ image_avg = fluid.layers.resize_bilinear(
+ image_avg, input_shape[2:])
+
+ with scope("aspp0"):
+ aspp0 = bn_relu(
+ conv(
+ input,
+ channel,
+ 1,
+ 1,
+ groups=1,
+ padding=0,
+ param_attr=param_attr))
+ with scope("aspp1"):
+ if self.aspp_with_sep_conv:
+ aspp1 = separate_conv(
+ input, channel, 1, 3, dilation=aspp_ratios[0], act=relu)
+ else:
+ aspp1 = bn_relu(
+ conv(
+ input,
+ channel,
+ stride=1,
+ filter_size=3,
+ dilation=aspp_ratios[0],
+ padding=aspp_ratios[0],
+ param_attr=param_attr))
+ with scope("aspp2"):
+ if self.aspp_with_sep_conv:
+ aspp2 = separate_conv(
+ input, channel, 1, 3, dilation=aspp_ratios[1], act=relu)
+ else:
+ aspp2 = bn_relu(
+ conv(
+ input,
+ channel,
+ stride=1,
+ filter_size=3,
+ dilation=aspp_ratios[1],
+ padding=aspp_ratios[1],
+ param_attr=param_attr))
+ with scope("aspp3"):
+ if self.aspp_with_sep_conv:
+ aspp3 = separate_conv(
+ input, channel, 1, 3, dilation=aspp_ratios[2], act=relu)
+ else:
+ aspp3 = bn_relu(
+ conv(
+ input,
+ channel,
+ stride=1,
+ filter_size=3,
+ dilation=aspp_ratios[2],
+ padding=aspp_ratios[2],
+ param_attr=param_attr))
+ with scope("concat"):
+ data = fluid.layers.concat(
+ [image_avg, aspp0, aspp1, aspp2, aspp3], axis=1)
+ data = bn_relu(
+ conv(
+ data,
+ channel,
+ 1,
+ 1,
+ groups=1,
+ padding=0,
+ param_attr=param_attr))
+ data = fluid.layers.dropout(data, 0.9)
+ return data
+
+ def _decoder(self, encode_data, decode_shortcut):
+ # 解码器配置
+ # encode_data:编码器输出
+ # decode_shortcut: 从backbone引出的分支, resize后与encode_data concat
+ # decoder_use_sep_conv: 默认为真,则concat后连接两个可分离卷积,否则为普通卷积
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=None,
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.06))
+ with scope('decoder'):
+ with scope('concat'):
+ decode_shortcut = bn_relu(
+ conv(
+ decode_shortcut,
+ 48,
+ 1,
+ 1,
+ groups=1,
+ padding=0,
+ param_attr=param_attr))
+
+ decode_shortcut_shape = fluid.layers.shape(decode_shortcut)
+ encode_data = fluid.layers.resize_bilinear(
+ encode_data, decode_shortcut_shape[2:])
+ encode_data = fluid.layers.concat(
+ [encode_data, decode_shortcut], axis=1)
+ if self.decoder_use_sep_conv:
+ with scope("separable_conv1"):
+ encode_data = separate_conv(
+ encode_data, 256, 1, 3, dilation=1, act=relu)
+ with scope("separable_conv2"):
+ encode_data = separate_conv(
+ encode_data, 256, 1, 3, dilation=1, act=relu)
+ else:
+ with scope("decoder_conv1"):
+ encode_data = bn_relu(
+ conv(
+ encode_data,
+ 256,
+ stride=1,
+ filter_size=3,
+ dilation=1,
+ padding=1,
+ param_attr=param_attr))
+ with scope("decoder_conv2"):
+ encode_data = bn_relu(
+ conv(
+ encode_data,
+ 256,
+ stride=1,
+ filter_size=3,
+ dilation=1,
+ padding=1,
+ param_attr=param_attr))
+ return encode_data
+
+ def _get_loss(self, logit, label, mask):
+ avg_loss = 0
+ if not (self.use_dice_loss or self.use_bce_loss):
+ avg_loss += softmax_with_loss(
+ logit,
+ label,
+ mask,
+ num_classes=self.num_classes,
+ weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ else:
+ if self.use_dice_loss:
+ avg_loss += dice_loss(logit, label, mask)
+ if self.use_bce_loss:
+ avg_loss += bce_loss(
+ logit, label, mask, ignore_index=self.ignore_index)
+
+ return avg_loss
+
+ def generate_inputs(self):
+ inputs = OrderedDict()
+ inputs['image'] = fluid.data(
+ dtype='float32', shape=[None, 3, None, None], name='image')
+ if self.mode == 'train':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ elif self.mode == 'eval':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ return inputs
+
+ def build_net(self, inputs):
+ # 在两类分割情况下,当loss函数选择dice_loss或bce_loss的时候,最后logit输出通道数设置为1
+ if self.use_dice_loss or self.use_bce_loss:
+ self.num_classes = 1
+ image = inputs['image']
+
+ backbone_net = self._get_backbone(self.backbone)
+ data, decode_shortcuts = backbone_net(image)
+ decode_shortcut = decode_shortcuts[backbone_net.decode_points]
+
+ # 编码器解码器设置
+ if self.encoder_with_aspp:
+ data = self._encoder(data)
+ if self.enable_decoder:
+ data = self._decoder(data, decode_shortcut)
+
+ # 根据类别数设置最后一个卷积层输出,并resize到图片原始尺寸
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.0),
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.01))
+ with scope('logit'):
+ with fluid.name_scope('last_conv'):
+ logit = conv(
+ data,
+ self.num_classes,
+ 1,
+ stride=1,
+ padding=0,
+ bias_attr=True,
+ param_attr=param_attr)
+ image_shape = fluid.layers.shape(image)
+ logit = fluid.layers.resize_bilinear(logit, image_shape[2:])
+
+ if self.num_classes == 1:
+ out = sigmoid_to_softmax(logit)
+ out = fluid.layers.transpose(out, [0, 2, 3, 1])
+ else:
+ out = fluid.layers.transpose(logit, [0, 2, 3, 1])
+
+ pred = fluid.layers.argmax(out, axis=3)
+ pred = fluid.layers.unsqueeze(pred, axes=[3])
+
+ if self.mode == 'train':
+ label = inputs['label']
+ mask = label != self.ignore_index
+ return self._get_loss(logit, label, mask)
+
+ else:
+ if self.num_classes == 1:
+ logit = sigmoid_to_softmax(logit)
+ else:
+ logit = fluid.layers.softmax(logit, axis=1)
+ return pred, logit
+
+ return logit
diff --git a/contrib/HumanSeg/nets/hrnet.py b/contrib/HumanSeg/nets/hrnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..47f100c19f934c9f829b6069913cf19abbdfca3c
--- /dev/null
+++ b/contrib/HumanSeg/nets/hrnet.py
@@ -0,0 +1,449 @@
+# coding: utf8
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from collections import OrderedDict
+
+import paddle.fluid as fluid
+from paddle.fluid.initializer import MSRA
+from paddle.fluid.param_attr import ParamAttr
+from .seg_modules import softmax_with_loss
+from .seg_modules import dice_loss
+from .seg_modules import bce_loss
+from .libs import sigmoid_to_softmax
+
+
+class HRNet(object):
+ def __init__(self,
+ num_classes,
+ mode='train',
+ stage1_num_modules=1,
+ stage1_num_blocks=[4],
+ stage1_num_channels=[64],
+ stage2_num_modules=1,
+ stage2_num_blocks=[4, 4],
+ stage2_num_channels=[18, 36],
+ stage3_num_modules=4,
+ stage3_num_blocks=[4, 4, 4],
+ stage3_num_channels=[18, 36, 72],
+ stage4_num_modules=3,
+ stage4_num_blocks=[4, 4, 4, 4],
+ stage4_num_channels=[18, 36, 72, 144],
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255):
+ # dice_loss或bce_loss只适用两类分割中
+ if num_classes > 2 and (use_bce_loss or use_dice_loss):
+ raise ValueError(
+ "dice loss and bce loss is only applicable to binary classfication"
+ )
+
+ if class_weight is not None:
+ if isinstance(class_weight, list):
+ if len(class_weight) != num_classes:
+ raise ValueError(
+ "Length of class_weight should be equal to number of classes"
+ )
+ elif isinstance(class_weight, str):
+ if class_weight.lower() != 'dynamic':
+ raise ValueError(
+ "if class_weight is string, must be dynamic!")
+ else:
+ raise TypeError(
+ 'Expect class_weight is a list or string but receive {}'.
+ format(type(class_weight)))
+
+ self.num_classes = num_classes
+ self.mode = mode
+ self.use_bce_loss = use_bce_loss
+ self.use_dice_loss = use_dice_loss
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+ self.stage1_num_modules = stage1_num_modules
+ self.stage1_num_blocks = stage1_num_blocks
+ self.stage1_num_channels = stage1_num_channels
+ self.stage2_num_modules = stage2_num_modules
+ self.stage2_num_blocks = stage2_num_blocks
+ self.stage2_num_channels = stage2_num_channels
+ self.stage3_num_modules = stage3_num_modules
+ self.stage3_num_blocks = stage3_num_blocks
+ self.stage3_num_channels = stage3_num_channels
+ self.stage4_num_modules = stage4_num_modules
+ self.stage4_num_blocks = stage4_num_blocks
+ self.stage4_num_channels = stage4_num_channels
+
+ def build_net(self, inputs):
+ image = inputs['image']
+ logit = self._high_resolution_net(image, self.num_classes)
+ if self.num_classes == 1:
+ out = sigmoid_to_softmax(logit)
+ out = fluid.layers.transpose(out, [0, 2, 3, 1])
+ else:
+ out = fluid.layers.transpose(logit, [0, 2, 3, 1])
+
+ pred = fluid.layers.argmax(out, axis=3)
+ pred = fluid.layers.unsqueeze(pred, axes=[3])
+
+ if self.mode == 'train':
+ label = inputs['label']
+ mask = label != self.ignore_index
+ return self._get_loss(logit, label, mask)
+
+ else:
+ if self.num_classes == 1:
+ logit = sigmoid_to_softmax(logit)
+ else:
+ logit = fluid.layers.softmax(logit, axis=1)
+ return pred, logit
+
+ return logit
+
+ def generate_inputs(self):
+ inputs = OrderedDict()
+ inputs['image'] = fluid.data(
+ dtype='float32', shape=[None, 3, None, None], name='image')
+ if self.mode == 'train':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ elif self.mode == 'eval':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ return inputs
+
+ def _get_loss(self, logit, label, mask):
+ avg_loss = 0
+ if not (self.use_dice_loss or self.use_bce_loss):
+ avg_loss += softmax_with_loss(
+ logit,
+ label,
+ mask,
+ num_classes=self.num_classes,
+ weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ else:
+ if self.use_dice_loss:
+ avg_loss += dice_loss(logit, label, mask)
+ if self.use_bce_loss:
+ avg_loss += bce_loss(
+ logit, label, mask, ignore_index=self.ignore_index)
+
+ return avg_loss
+
+ def _conv_bn_layer(self,
+ input,
+ filter_size,
+ num_filters,
+ stride=1,
+ padding=1,
+ num_groups=1,
+ if_act=True,
+ name=None):
+ conv = fluid.layers.conv2d(
+ input=input,
+ num_filters=num_filters,
+ filter_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) // 2,
+ groups=num_groups,
+ act=None,
+ param_attr=ParamAttr(initializer=MSRA(), name=name + '_weights'),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ bn = fluid.layers.batch_norm(
+ input=conv,
+ param_attr=ParamAttr(
+ name=bn_name + "_scale",
+ initializer=fluid.initializer.Constant(1.0)),
+ bias_attr=ParamAttr(
+ name=bn_name + "_offset",
+ initializer=fluid.initializer.Constant(0.0)),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+ if if_act:
+ bn = fluid.layers.relu(bn)
+ return bn
+
+ def _basic_block(self,
+ input,
+ num_filters,
+ stride=1,
+ downsample=False,
+ name=None):
+ residual = input
+ conv = self._conv_bn_layer(
+ input=input,
+ filter_size=3,
+ num_filters=num_filters,
+ stride=stride,
+ name=name + '_conv1')
+ conv = self._conv_bn_layer(
+ input=conv,
+ filter_size=3,
+ num_filters=num_filters,
+ if_act=False,
+ name=name + '_conv2')
+ if downsample:
+ residual = self._conv_bn_layer(
+ input=input,
+ filter_size=1,
+ num_filters=num_filters,
+ if_act=False,
+ name=name + '_downsample')
+ return fluid.layers.elementwise_add(x=residual, y=conv, act='relu')
+
+ def _bottleneck_block(self,
+ input,
+ num_filters,
+ stride=1,
+ downsample=False,
+ name=None):
+ residual = input
+ conv = self._conv_bn_layer(
+ input=input,
+ filter_size=1,
+ num_filters=num_filters,
+ name=name + '_conv1')
+ conv = self._conv_bn_layer(
+ input=conv,
+ filter_size=3,
+ num_filters=num_filters,
+ stride=stride,
+ name=name + '_conv2')
+ conv = self._conv_bn_layer(
+ input=conv,
+ filter_size=1,
+ num_filters=num_filters * 4,
+ if_act=False,
+ name=name + '_conv3')
+ if downsample:
+ residual = self._conv_bn_layer(
+ input=input,
+ filter_size=1,
+ num_filters=num_filters * 4,
+ if_act=False,
+ name=name + '_downsample')
+ return fluid.layers.elementwise_add(x=residual, y=conv, act='relu')
+
+ def _fuse_layers(self, x, channels, multi_scale_output=True, name=None):
+ out = []
+ for i in range(len(channels) if multi_scale_output else 1):
+ residual = x[i]
+ shape = fluid.layers.shape(residual)[-2:]
+ for j in range(len(channels)):
+ if j > i:
+ y = self._conv_bn_layer(
+ x[j],
+ filter_size=1,
+ num_filters=channels[i],
+ if_act=False,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1))
+ y = fluid.layers.resize_bilinear(input=y, out_shape=shape)
+ residual = fluid.layers.elementwise_add(
+ x=residual, y=y, act=None)
+ elif j < i:
+ y = x[j]
+ for k in range(i - j):
+ if k == i - j - 1:
+ y = self._conv_bn_layer(
+ y,
+ filter_size=3,
+ num_filters=channels[i],
+ stride=2,
+ if_act=False,
+ name=name + '_layer_' + str(i + 1) + '_' +
+ str(j + 1) + '_' + str(k + 1))
+ else:
+ y = self._conv_bn_layer(
+ y,
+ filter_size=3,
+ num_filters=channels[j],
+ stride=2,
+ name=name + '_layer_' + str(i + 1) + '_' +
+ str(j + 1) + '_' + str(k + 1))
+ residual = fluid.layers.elementwise_add(
+ x=residual, y=y, act=None)
+
+ residual = fluid.layers.relu(residual)
+ out.append(residual)
+ return out
+
+ def _branches(self, x, block_num, channels, name=None):
+ out = []
+ for i in range(len(channels)):
+ residual = x[i]
+ for j in range(block_num[i]):
+ residual = self._basic_block(
+ residual,
+ channels[i],
+ name=name + '_branch_layer_' + str(i + 1) + '_' +
+ str(j + 1))
+ out.append(residual)
+ return out
+
+ def _high_resolution_module(self,
+ x,
+ blocks,
+ channels,
+ multi_scale_output=True,
+ name=None):
+ residual = self._branches(x, blocks, channels, name=name)
+ out = self._fuse_layers(
+ residual,
+ channels,
+ multi_scale_output=multi_scale_output,
+ name=name)
+ return out
+
+ def _transition_layer(self, x, in_channels, out_channels, name=None):
+ num_in = len(in_channels)
+ num_out = len(out_channels)
+ out = []
+ for i in range(num_out):
+ if i < num_in:
+ if in_channels[i] != out_channels[i]:
+ residual = self._conv_bn_layer(
+ x[i],
+ filter_size=3,
+ num_filters=out_channels[i],
+ name=name + '_layer_' + str(i + 1))
+ out.append(residual)
+ else:
+ out.append(x[i])
+ else:
+ residual = self._conv_bn_layer(
+ x[-1],
+ filter_size=3,
+ num_filters=out_channels[i],
+ stride=2,
+ name=name + '_layer_' + str(i + 1))
+ out.append(residual)
+ return out
+
+ def _stage(self,
+ x,
+ num_modules,
+ num_blocks,
+ num_channels,
+ multi_scale_output=True,
+ name=None):
+ out = x
+ for i in range(num_modules):
+ if i == num_modules - 1 and multi_scale_output == False:
+ out = self._high_resolution_module(
+ out,
+ num_blocks,
+ num_channels,
+ multi_scale_output=False,
+ name=name + '_' + str(i + 1))
+ else:
+ out = self._high_resolution_module(
+ out, num_blocks, num_channels, name=name + '_' + str(i + 1))
+
+ return out
+
+ def _layer1(self, input, num_modules, num_blocks, num_channels, name=None):
+ # num_modules 默认为1,是否增加处理,官网实现为[1],是否对齐。
+ conv = input
+ for i in range(num_blocks[0]):
+ conv = self._bottleneck_block(
+ conv,
+ num_filters=num_channels[0],
+ downsample=True if i == 0 else False,
+ name=name + '_' + str(i + 1))
+ return conv
+
+ def _high_resolution_net(self, input, num_classes):
+ x = self._conv_bn_layer(
+ input=input,
+ filter_size=3,
+ num_filters=self.stage1_num_channels[0],
+ stride=2,
+ if_act=True,
+ name='layer1_1')
+ x = self._conv_bn_layer(
+ input=x,
+ filter_size=3,
+ num_filters=self.stage1_num_channels[0],
+ stride=2,
+ if_act=True,
+ name='layer1_2')
+
+ la1 = self._layer1(
+ x,
+ self.stage1_num_modules,
+ self.stage1_num_blocks,
+ self.stage1_num_channels,
+ name='layer2')
+ tr1 = self._transition_layer([la1],
+ self.stage1_num_channels,
+ self.stage2_num_channels,
+ name='tr1')
+ st2 = self._stage(
+ tr1,
+ self.stage2_num_modules,
+ self.stage2_num_blocks,
+ self.stage2_num_channels,
+ name='st2')
+ tr2 = self._transition_layer(
+ st2, self.stage2_num_channels, self.stage3_num_channels, name='tr2')
+ st3 = self._stage(
+ tr2,
+ self.stage3_num_modules,
+ self.stage3_num_blocks,
+ self.stage3_num_channels,
+ name='st3')
+ tr3 = self._transition_layer(
+ st3, self.stage3_num_channels, self.stage4_num_channels, name='tr3')
+ st4 = self._stage(
+ tr3,
+ self.stage4_num_modules,
+ self.stage4_num_blocks,
+ self.stage4_num_channels,
+ name='st4')
+
+ # upsample
+ shape = fluid.layers.shape(st4[0])[-2:]
+ st4[1] = fluid.layers.resize_bilinear(st4[1], out_shape=shape)
+ st4[2] = fluid.layers.resize_bilinear(st4[2], out_shape=shape)
+ st4[3] = fluid.layers.resize_bilinear(st4[3], out_shape=shape)
+
+ out = fluid.layers.concat(st4, axis=1)
+ last_channels = sum(self.stage4_num_channels)
+
+ out = self._conv_bn_layer(
+ input=out,
+ filter_size=1,
+ num_filters=last_channels,
+ stride=1,
+ if_act=True,
+ name='conv-2')
+ out = fluid.layers.conv2d(
+ input=out,
+ num_filters=num_classes,
+ filter_size=1,
+ stride=1,
+ padding=0,
+ act=None,
+ param_attr=ParamAttr(initializer=MSRA(), name='conv-1_weights'),
+ bias_attr=False)
+
+ input_shape = fluid.layers.shape(input)[-2:]
+ out = fluid.layers.resize_bilinear(out, input_shape)
+
+ return out
diff --git a/contrib/HumanSeg/nets/libs.py b/contrib/HumanSeg/nets/libs.py
new file mode 100644
index 0000000000000000000000000000000000000000..01fdad2cec6ce4b13cea2b7c957fb648edb4aeb2
--- /dev/null
+++ b/contrib/HumanSeg/nets/libs.py
@@ -0,0 +1,219 @@
+# coding: utf8
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+import paddle
+import paddle.fluid as fluid
+import contextlib
+
+bn_regularizer = fluid.regularizer.L2DecayRegularizer(regularization_coeff=0.0)
+name_scope = ""
+
+
+@contextlib.contextmanager
+def scope(name):
+ global name_scope
+ bk = name_scope
+ name_scope = name_scope + name + '/'
+ yield
+ name_scope = bk
+
+
+def max_pool(input, kernel, stride, padding):
+ data = fluid.layers.pool2d(
+ input,
+ pool_size=kernel,
+ pool_type='max',
+ pool_stride=stride,
+ pool_padding=padding)
+ return data
+
+
+def avg_pool(input, kernel, stride, padding=0):
+ data = fluid.layers.pool2d(
+ input,
+ pool_size=kernel,
+ pool_type='avg',
+ pool_stride=stride,
+ pool_padding=padding)
+ return data
+
+
+def group_norm(input, G, eps=1e-5, param_attr=None, bias_attr=None):
+ N, C, H, W = input.shape
+ if C % G != 0:
+ for d in range(10):
+ for t in [d, -d]:
+ if G + t <= 0: continue
+ if C % (G + t) == 0:
+ G = G + t
+ break
+ if C % G == 0:
+ break
+ assert C % G == 0, "group can not divide channle"
+ x = fluid.layers.group_norm(
+ input,
+ groups=G,
+ param_attr=param_attr,
+ bias_attr=bias_attr,
+ name=name_scope + 'group_norm')
+ return x
+
+
+def bn(*args,
+ norm_type='bn',
+ eps=1e-5,
+ bn_momentum=0.99,
+ group_norm=32,
+ **kargs):
+
+ if norm_type == 'bn':
+ with scope('BatchNorm'):
+ return fluid.layers.batch_norm(
+ *args,
+ epsilon=eps,
+ momentum=bn_momentum,
+ param_attr=fluid.ParamAttr(
+ name=name_scope + 'gamma', regularizer=bn_regularizer),
+ bias_attr=fluid.ParamAttr(
+ name=name_scope + 'beta', regularizer=bn_regularizer),
+ moving_mean_name=name_scope + 'moving_mean',
+ moving_variance_name=name_scope + 'moving_variance',
+ **kargs)
+ elif norm_type == 'gn':
+ with scope('GroupNorm'):
+ return group_norm(
+ args[0],
+ group_norm,
+ eps=eps,
+ param_attr=fluid.ParamAttr(
+ name=name_scope + 'gamma', regularizer=bn_regularizer),
+ bias_attr=fluid.ParamAttr(
+ name=name_scope + 'beta', regularizer=bn_regularizer))
+ else:
+ raise Exception("Unsupport norm type:" + norm_type)
+
+
+def bn_relu(data, norm_type='bn', eps=1e-5):
+ return fluid.layers.relu(bn(data, norm_type=norm_type, eps=eps))
+
+
+def relu(data):
+ return fluid.layers.relu(data)
+
+
+def conv(*args, **kargs):
+ kargs['param_attr'] = name_scope + 'weights'
+ if 'bias_attr' in kargs and kargs['bias_attr']:
+ kargs['bias_attr'] = fluid.ParamAttr(
+ name=name_scope + 'biases',
+ regularizer=None,
+ initializer=fluid.initializer.ConstantInitializer(value=0.0))
+ else:
+ kargs['bias_attr'] = False
+ return fluid.layers.conv2d(*args, **kargs)
+
+
+def deconv(*args, **kargs):
+ kargs['param_attr'] = name_scope + 'weights'
+ if 'bias_attr' in kargs and kargs['bias_attr']:
+ kargs['bias_attr'] = name_scope + 'biases'
+ else:
+ kargs['bias_attr'] = False
+ return fluid.layers.conv2d_transpose(*args, **kargs)
+
+
+def separate_conv(input,
+ channel,
+ stride,
+ filter,
+ dilation=1,
+ act=None,
+ eps=1e-5):
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.0),
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.33))
+ with scope('depthwise'):
+ input = conv(
+ input,
+ input.shape[1],
+ filter,
+ stride,
+ groups=input.shape[1],
+ padding=(filter // 2) * dilation,
+ dilation=dilation,
+ use_cudnn=False,
+ param_attr=param_attr)
+ input = bn(input, eps=eps)
+ if act: input = act(input)
+
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=None,
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.06))
+ with scope('pointwise'):
+ input = conv(
+ input, channel, 1, 1, groups=1, padding=0, param_attr=param_attr)
+ input = bn(input, eps=eps)
+ if act: input = act(input)
+ return input
+
+
+def conv_bn_layer(input,
+ filter_size,
+ num_filters,
+ stride,
+ padding,
+ channels=None,
+ num_groups=1,
+ if_act=True,
+ name=None,
+ use_cudnn=True):
+ conv = fluid.layers.conv2d(
+ input=input,
+ num_filters=num_filters,
+ filter_size=filter_size,
+ stride=stride,
+ padding=padding,
+ groups=num_groups,
+ act=None,
+ use_cudnn=use_cudnn,
+ param_attr=fluid.ParamAttr(name=name + '_weights'),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ bn = fluid.layers.batch_norm(
+ input=conv,
+ param_attr=fluid.ParamAttr(name=bn_name + "_scale"),
+ bias_attr=fluid.ParamAttr(name=bn_name + "_offset"),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+ if if_act:
+ return fluid.layers.relu6(bn)
+ else:
+ return bn
+
+
+def sigmoid_to_softmax(input):
+ """
+ one channel to two channel
+ """
+ logit = fluid.layers.sigmoid(input)
+ logit_back = 1 - logit
+ logit = fluid.layers.concat([logit_back, logit], axis=1)
+ return logit
diff --git a/contrib/HumanSeg/nets/seg_modules.py b/contrib/HumanSeg/nets/seg_modules.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb59dce486420585edd47559c6fdd3cf88e59350
--- /dev/null
+++ b/contrib/HumanSeg/nets/seg_modules.py
@@ -0,0 +1,115 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import paddle.fluid as fluid
+import numpy as np
+
+
+def softmax_with_loss(logit,
+ label,
+ ignore_mask=None,
+ num_classes=2,
+ weight=None,
+ ignore_index=255):
+ ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
+ label = fluid.layers.elementwise_min(
+ label, fluid.layers.assign(np.array([num_classes - 1], dtype=np.int32)))
+ logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
+ logit = fluid.layers.reshape(logit, [-1, num_classes])
+ label = fluid.layers.reshape(label, [-1, 1])
+ label = fluid.layers.cast(label, 'int64')
+ ignore_mask = fluid.layers.reshape(ignore_mask, [-1, 1])
+ if weight is None:
+ loss, probs = fluid.layers.softmax_with_cross_entropy(
+ logit, label, ignore_index=ignore_index, return_softmax=True)
+ else:
+ label_one_hot = fluid.one_hot(input=label, depth=num_classes)
+ if isinstance(weight, list):
+ assert len(
+ weight
+ ) == num_classes, "weight length must equal num of classes"
+ weight = fluid.layers.assign(np.array([weight], dtype='float32'))
+ elif isinstance(weight, str):
+ assert weight.lower(
+ ) == 'dynamic', 'if weight is string, must be dynamic!'
+ tmp = []
+ total_num = fluid.layers.cast(
+ fluid.layers.shape(label)[0], 'float32')
+ for i in range(num_classes):
+ cls_pixel_num = fluid.layers.reduce_sum(label_one_hot[:, i])
+ ratio = total_num / (cls_pixel_num + 1)
+ tmp.append(ratio)
+ weight = fluid.layers.concat(tmp)
+ weight = weight / fluid.layers.reduce_sum(weight) * num_classes
+ elif isinstance(weight, fluid.layers.Variable):
+ pass
+ else:
+ raise ValueError(
+ 'Expect weight is a list, string or Variable, but receive {}'.
+ format(type(weight)))
+ weight = fluid.layers.reshape(weight, [1, num_classes])
+ weighted_label_one_hot = fluid.layers.elementwise_mul(
+ label_one_hot, weight)
+ probs = fluid.layers.softmax(logit)
+ loss = fluid.layers.cross_entropy(
+ probs,
+ weighted_label_one_hot,
+ soft_label=True,
+ ignore_index=ignore_index)
+ weighted_label_one_hot.stop_gradient = True
+
+ loss = loss * ignore_mask
+ avg_loss = fluid.layers.mean(loss) / (
+ fluid.layers.mean(ignore_mask) + 0.00001)
+
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return avg_loss
+
+
+# to change, how to appicate ignore index and ignore mask
+def dice_loss(logit, label, ignore_mask=None, epsilon=0.00001):
+ if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
+ raise Exception(
+ "dice loss is only applicable to one channel classfication")
+ ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
+ logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
+ label = fluid.layers.transpose(label, [0, 2, 3, 1])
+ label = fluid.layers.cast(label, 'int64')
+ ignore_mask = fluid.layers.transpose(ignore_mask, [0, 2, 3, 1])
+ logit = fluid.layers.sigmoid(logit)
+ logit = logit * ignore_mask
+ label = label * ignore_mask
+ reduce_dim = list(range(1, len(logit.shape)))
+ inse = fluid.layers.reduce_sum(logit * label, dim=reduce_dim)
+ dice_denominator = fluid.layers.reduce_sum(
+ logit, dim=reduce_dim) + fluid.layers.reduce_sum(
+ label, dim=reduce_dim)
+ dice_score = 1 - inse * 2 / (dice_denominator + epsilon)
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return fluid.layers.reduce_mean(dice_score)
+
+
+def bce_loss(logit, label, ignore_mask=None, ignore_index=255):
+ if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
+ raise Exception("bce loss is only applicable to binary classfication")
+ label = fluid.layers.cast(label, 'float32')
+ loss = fluid.layers.sigmoid_cross_entropy_with_logits(
+ x=logit, label=label, ignore_index=ignore_index,
+ normalize=True) # or False
+ loss = fluid.layers.reduce_sum(loss)
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return loss
diff --git a/contrib/HumanSeg/nets/shufflenet_slim.py b/contrib/HumanSeg/nets/shufflenet_slim.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ca76b9c4eedca6814e545324c2b330b952431b1
--- /dev/null
+++ b/contrib/HumanSeg/nets/shufflenet_slim.py
@@ -0,0 +1,247 @@
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from collections import OrderedDict
+import paddle.fluid as fluid
+from paddle.fluid.initializer import MSRA
+from paddle.fluid.param_attr import ParamAttr
+from .libs import sigmoid_to_softmax
+from .seg_modules import softmax_with_loss
+from .seg_modules import dice_loss
+from .seg_modules import bce_loss
+
+
+class ShuffleSeg(object):
+ # def __init__(self):
+ # self.params = train_parameters
+ def __init__(self,
+ num_classes,
+ mode='train',
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255):
+ # dice_loss或bce_loss只适用两类分割中
+ if num_classes > 2 and (use_bce_loss or use_dice_loss):
+ raise ValueError(
+ "dice loss and bce loss is only applicable to binary classfication"
+ )
+
+ if class_weight is not None:
+ if isinstance(class_weight, list):
+ if len(class_weight) != num_classes:
+ raise ValueError(
+ "Length of class_weight should be equal to number of classes"
+ )
+ elif isinstance(class_weight, str):
+ if class_weight.lower() != 'dynamic':
+ raise ValueError(
+ "if class_weight is string, must be dynamic!")
+ else:
+ raise TypeError(
+ 'Expect class_weight is a list or string but receive {}'.
+ format(type(class_weight)))
+
+ self.num_classes = num_classes
+ self.mode = mode
+ self.use_bce_loss = use_bce_loss
+ self.use_dice_loss = use_dice_loss
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+
+ def _get_loss(self, logit, label, mask):
+ avg_loss = 0
+ if not (self.use_dice_loss or self.use_bce_loss):
+ avg_loss += softmax_with_loss(
+ logit,
+ label,
+ mask,
+ num_classes=self.num_classes,
+ weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ else:
+ if self.use_dice_loss:
+ avg_loss += dice_loss(logit, label, mask)
+ if self.use_bce_loss:
+ avg_loss += bce_loss(
+ logit, label, mask, ignore_index=self.ignore_index)
+
+ return avg_loss
+
+ def generate_inputs(self):
+ inputs = OrderedDict()
+ inputs['image'] = fluid.data(
+ dtype='float32', shape=[None, 3, None, None], name='image')
+ if self.mode == 'train':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ elif self.mode == 'eval':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ return inputs
+
+ def build_net(self, inputs, class_dim=2):
+ if self.use_dice_loss or self.use_bce_loss:
+ self.num_classes = 1
+ image = inputs['image']
+ ## Encoder
+ conv1 = self.conv_bn(image, 3, 36, 2, 1)
+ print('encoder 1', conv1.shape)
+ shortcut = self.conv_bn(
+ input=conv1, filter_size=1, num_filters=18, stride=1, padding=0)
+ print('shortcut 1', shortcut.shape)
+
+ pool = fluid.layers.pool2d(
+ input=conv1,
+ pool_size=3,
+ pool_type='max',
+ pool_stride=2,
+ pool_padding=1)
+ print('encoder 2', pool.shape)
+
+ # Block 1
+ conv = self.sfnetv2module(pool, stride=2, num_filters=72)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ print('encoder 3', conv.shape)
+
+ # Block 2
+ conv = self.sfnetv2module(conv, stride=2)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ print('encoder 4', conv.shape)
+
+ ### decoder
+ conv = self.depthwise_separable(conv, 3, 64, 1)
+ shortcut_shape = fluid.layers.shape(shortcut)[2:]
+ conv_b = fluid.layers.resize_bilinear(conv, shortcut_shape)
+ concat = fluid.layers.concat([shortcut, conv_b], axis=1)
+ decode_conv = self.depthwise_separable(concat, 3, 64, 1)
+ logit = self.output_layer(decode_conv, class_dim)
+
+ if self.num_classes == 1:
+ out = sigmoid_to_softmax(logit)
+ out = fluid.layers.transpose(out, [0, 2, 3, 1])
+ else:
+ out = fluid.layers.transpose(logit, [0, 2, 3, 1])
+
+ pred = fluid.layers.argmax(out, axis=3)
+ pred = fluid.layers.unsqueeze(pred, axes=[3])
+
+ if self.mode == 'train':
+ label = inputs['label']
+ mask = label != self.ignore_index
+ return self._get_loss(logit, label, mask)
+
+ else:
+ if self.num_classes == 1:
+ logit = sigmoid_to_softmax(logit)
+ else:
+ logit = fluid.layers.softmax(logit, axis=1)
+ return pred, logit
+
+ return logit
+
+ def conv_bn(self,
+ input,
+ filter_size,
+ num_filters,
+ stride,
+ padding,
+ channels=None,
+ num_groups=1,
+ act='relu',
+ use_cudnn=True):
+ parameter_attr = ParamAttr(learning_rate=1, initializer=MSRA())
+ conv = fluid.layers.conv2d(
+ input=input,
+ num_filters=num_filters,
+ filter_size=filter_size,
+ stride=stride,
+ padding=padding,
+ groups=num_groups,
+ act=None,
+ use_cudnn=use_cudnn,
+ param_attr=parameter_attr,
+ bias_attr=False)
+ return fluid.layers.batch_norm(input=conv, act=act)
+
+ def depthwise_separable(self, input, filter_size, num_filters, stride):
+ num_filters1 = int(input.shape[1])
+ num_groups = num_filters1
+ depthwise_conv = self.conv_bn(
+ input=input,
+ filter_size=filter_size,
+ num_filters=int(num_filters1),
+ stride=stride,
+ padding=int(filter_size / 2),
+ num_groups=num_groups,
+ use_cudnn=False,
+ act=None)
+
+ pointwise_conv = self.conv_bn(
+ input=depthwise_conv,
+ filter_size=1,
+ num_filters=num_filters,
+ stride=1,
+ padding=0)
+ return pointwise_conv
+
+ def sfnetv2module(self, input, stride, num_filters=None):
+ if stride == 1:
+ shortcut, branch = fluid.layers.split(
+ input, num_or_sections=2, dim=1)
+ if num_filters is None:
+ in_channels = int(branch.shape[1])
+ else:
+ in_channels = int(num_filters / 2)
+ else:
+ branch = input
+ if num_filters is None:
+ in_channels = int(branch.shape[1])
+ else:
+ in_channels = int(num_filters / 2)
+ shortcut = self.depthwise_separable(input, 3, in_channels, stride)
+ branch_1x1 = self.conv_bn(
+ input=branch,
+ filter_size=1,
+ num_filters=int(in_channels),
+ stride=1,
+ padding=0)
+ branch_dw1x1 = self.depthwise_separable(branch_1x1, 3, in_channels,
+ stride)
+ output = fluid.layers.concat(input=[shortcut, branch_dw1x1], axis=1)
+
+ # channel shuffle
+ # b, c, h, w = output.shape
+ shape = fluid.layers.shape(output)
+ c = output.shape[1]
+ b, h, w = shape[0], shape[2], shape[3]
+ output = fluid.layers.reshape(x=output, shape=[b, 2, in_channels, h, w])
+ output = fluid.layers.transpose(x=output, perm=[0, 2, 1, 3, 4])
+ output = fluid.layers.reshape(x=output, shape=[b, c, h, w])
+ return output
+
+ def output_layer(self, input, out_dim):
+ param_attr = fluid.param_attr.ParamAttr(
+ learning_rate=1.,
+ regularizer=fluid.regularizer.L2Decay(0.),
+ initializer=fluid.initializer.Xavier())
+ # deconv
+ output = fluid.layers.conv2d_transpose(
+ input=input,
+ num_filters=out_dim,
+ filter_size=2,
+ padding=0,
+ stride=2,
+ bias_attr=True,
+ param_attr=param_attr,
+ act=None)
+ return output
diff --git a/contrib/HumanSeg/pretrained_weights/download_pretrained_weights.py b/contrib/HumanSeg/pretrained_weights/download_pretrained_weights.py
new file mode 100644
index 0000000000000000000000000000000000000000..e573df05f94f5a612ef6c2f5a2eb2c9cd55cc2f1
--- /dev/null
+++ b/contrib/HumanSeg/pretrained_weights/download_pretrained_weights.py
@@ -0,0 +1,51 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+
+LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
+TEST_PATH = os.path.join(LOCAL_PATH, "../../../", "test")
+sys.path.append(TEST_PATH)
+
+from test_utils import download_file_and_uncompress
+
+model_urls = {
+ "humanseg_server_ckpt":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_server_ckpt.zip",
+ "humanseg_server_inference":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_server_inference.zip",
+ "humanseg_mobile_ckpt":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_mobile_ckpt.zip",
+ "humanseg_mobile_inference":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_mobile_inference.zip",
+ "humanseg_mobile_quant":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_mobile_quant.zip",
+ "humanseg_lite_ckpt":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_lite_ckpt.zip",
+ "humanseg_lite_inference":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_lite_inference.zip",
+ "humanseg_lite_quant":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_lite_quant.zip",
+}
+
+if __name__ == "__main__":
+ for model_name, url in model_urls.items():
+ download_file_and_uncompress(
+ url=url,
+ savepath=LOCAL_PATH,
+ extrapath=LOCAL_PATH,
+ extraname=model_name)
+
+ print("Pretrained Model download success!")
diff --git a/contrib/HumanSeg/quant_offline.py b/contrib/HumanSeg/quant_offline.py
new file mode 100644
index 0000000000000000000000000000000000000000..92a393f07bd2b70fc7df658290abf440f3069752
--- /dev/null
+++ b/contrib/HumanSeg/quant_offline.py
@@ -0,0 +1,80 @@
+import argparse
+from datasets.dataset import Dataset
+import transforms
+import models
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg training')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for quant',
+ type=str,
+ default='output/best_model')
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size',
+ type=int,
+ default=1)
+ parser.add_argument(
+ '--batch_nums',
+ dest='batch_nums',
+ help='Batch number for quant',
+ type=int,
+ default=10)
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='the root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--quant_list',
+ dest='quant_list',
+ help=
+ 'Image file list for model quantization, it can be vat.txt or train.txt',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the quant model',
+ type=str,
+ default='./output/quant_offline')
+ parser.add_argument(
+ "--image_shape",
+ dest="image_shape",
+ help="The image shape for net inputs.",
+ nargs=2,
+ default=[192, 192],
+ type=int)
+ return parser.parse_args()
+
+
+def evaluate(args):
+ eval_transforms = transforms.Compose(
+ [transforms.Resize(args.image_shape),
+ transforms.Normalize()])
+
+ eval_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.quant_list,
+ transforms=eval_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False)
+
+ model = models.load_model(args.model_dir)
+ model.export_quant_model(
+ dataset=eval_dataset,
+ save_dir=args.save_dir,
+ batch_size=args.batch_size,
+ batch_nums=args.batch_nums)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ evaluate(args)
diff --git a/contrib/HumanSeg/quant_online.py b/contrib/HumanSeg/quant_online.py
new file mode 100644
index 0000000000000000000000000000000000000000..04eea4d3d9f357897e300da87297a8f6c9515e06
--- /dev/null
+++ b/contrib/HumanSeg/quant_online.py
@@ -0,0 +1,142 @@
+import argparse
+from datasets.dataset import Dataset
+from models import HumanSegMobile, HumanSegLite, HumanSegServer
+import transforms
+
+MODEL_TYPE = ['HumanSegMobile', 'HumanSegLite', 'HumanSegServer']
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg training')
+ parser.add_argument(
+ '--model_type',
+ dest='model_type',
+ help=
+ "Model type for traing, which is one of ('HumanSegMobile', 'HumanSegLite', 'HumanSegServer')",
+ type=str,
+ default='HumanSegMobile')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='The root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--train_list',
+ dest='train_list',
+ help='Train list file of dataset',
+ type=str)
+ parser.add_argument(
+ '--val_list',
+ dest='val_list',
+ help='Val list file of dataset',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the model snapshot',
+ type=str,
+ default='./output/quant_train')
+ parser.add_argument(
+ '--num_classes',
+ dest='num_classes',
+ help='Number of classes',
+ type=int,
+ default=2)
+ parser.add_argument(
+ '--num_epochs',
+ dest='num_epochs',
+ help='Number epochs for training',
+ type=int,
+ default=2)
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size',
+ type=int,
+ default=128)
+ parser.add_argument(
+ '--learning_rate',
+ dest='learning_rate',
+ help='Learning rate',
+ type=float,
+ default=0.001)
+ parser.add_argument(
+ '--pretrained_weights',
+ dest='pretrained_weights',
+ help='The model path for quant',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_interval_epochs',
+ dest='save_interval_epochs',
+ help='The interval epochs for save a model snapshot',
+ type=int,
+ default=1)
+ parser.add_argument(
+ "--image_shape",
+ dest="image_shape",
+ help="The image shape for net inputs.",
+ nargs=2,
+ default=[192, 192],
+ type=int)
+
+ return parser.parse_args()
+
+
+def train(args):
+ train_transforms = transforms.Compose([
+ transforms.RandomHorizontalFlip(),
+ transforms.Resize(args.image_shape),
+ transforms.Normalize()
+ ])
+
+ eval_transforms = transforms.Compose(
+ [transforms.Resize(args.image_shape),
+ transforms.Normalize()])
+
+ train_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.train_list,
+ transforms=train_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=True)
+
+ eval_dataset = None
+ if args.val_list is not None:
+ eval_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.val_list,
+ transforms=eval_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False)
+
+ if args.model_type == 'HumanSegMobile':
+ model = HumanSegMobile(num_classes=2)
+ elif args.model_type == 'HumanSegLite':
+ model = HumanSegLite(num_classes=2)
+ elif args.model_type == 'HumanSegServer':
+ model = HumanSegServer(num_classes=2)
+ else:
+ raise ValueError(
+ "--model_type: {} is set wrong, it shold be one of ('HumanSegMobile', "
+ "'HumanSegLite', 'HumanSegServer')".format(args.model_type))
+ model.train(
+ num_epochs=args.num_epochs,
+ train_dataset=train_dataset,
+ train_batch_size=args.batch_size,
+ eval_dataset=eval_dataset,
+ save_interval_epochs=args.save_interval_epochs,
+ save_dir=args.save_dir,
+ pretrained_weights=args.pretrained_weights,
+ learning_rate=args.learning_rate,
+ quant=True)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ train(args)
diff --git a/contrib/HumanSeg/requirements.txt b/contrib/HumanSeg/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1c8a597b0c937f0a8560d4f1bbf46de5f752178a
--- /dev/null
+++ b/contrib/HumanSeg/requirements.txt
@@ -0,0 +1,2 @@
+visualdl == 2.0.0-alpha.1
+paddleslim
diff --git a/contrib/HumanSeg/train.py b/contrib/HumanSeg/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..65e66ae1dcd07f65b062744216ed6cbfc85cad40
--- /dev/null
+++ b/contrib/HumanSeg/train.py
@@ -0,0 +1,155 @@
+import argparse
+from datasets.dataset import Dataset
+from models import HumanSegMobile, HumanSegLite, HumanSegServer
+import transforms
+
+MODEL_TYPE = ['HumanSegMobile', 'HumanSegLite', 'HumanSegServer']
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg training')
+ parser.add_argument(
+ '--model_type',
+ dest='model_type',
+ help=
+ "Model type for traing, which is one of ('HumanSegMobile', 'HumanSegLite', 'HumanSegServer')",
+ type=str,
+ default='HumanSegMobile')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='The root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--train_list',
+ dest='train_list',
+ help='Train list file of dataset',
+ type=str)
+ parser.add_argument(
+ '--val_list',
+ dest='val_list',
+ help='Val list file of dataset',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the model snapshot',
+ type=str,
+ default='./output')
+ parser.add_argument(
+ '--num_classes',
+ dest='num_classes',
+ help='Number of classes',
+ type=int,
+ default=2)
+ parser.add_argument(
+ "--image_shape",
+ dest="image_shape",
+ help="The image shape for net inputs.",
+ nargs=2,
+ default=[192, 192],
+ type=int)
+ parser.add_argument(
+ '--num_epochs',
+ dest='num_epochs',
+ help='Number epochs for training',
+ type=int,
+ default=100)
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size',
+ type=int,
+ default=128)
+ parser.add_argument(
+ '--learning_rate',
+ dest='learning_rate',
+ help='Learning rate',
+ type=float,
+ default=0.01)
+ parser.add_argument(
+ '--pretrained_weights',
+ dest='pretrained_weights',
+ help='The path of pretrianed weight',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--resume_weights',
+ dest='resume_weights',
+ help='The path of resume weight',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--use_vdl',
+ dest='use_vdl',
+ help='Whether to use visualdl',
+ type=bool,
+ default=True)
+ parser.add_argument(
+ '--save_interval_epochs',
+ dest='save_interval_epochs',
+ help='The interval epochs for save a model snapshot',
+ type=int,
+ default=5)
+
+ return parser.parse_args()
+
+
+def train(args):
+ train_transforms = transforms.Compose([
+ transforms.Resize(args.image_shape),
+ transforms.RandomHorizontalFlip(),
+ transforms.Normalize()
+ ])
+
+ eval_transforms = transforms.Compose(
+ [transforms.Resize(args.image_shape),
+ transforms.Normalize()])
+
+ train_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.train_list,
+ transforms=train_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=True)
+
+ eval_dataset = None
+ if args.val_list is not None:
+ eval_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.val_list,
+ transforms=eval_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False)
+
+ if args.model_type == 'HumanSegMobile':
+ model = HumanSegMobile(num_classes=2)
+ elif args.model_type == 'HumanSegLite':
+ model = HumanSegLite(num_classes=2)
+ elif args.model_type == 'HumanSegServer':
+ model = HumanSegServer(num_classes=2)
+ else:
+ raise ValueError(
+ "--model_type: {} is set wrong, it shold be one of ('HumanSegMobile', "
+ "'HumanSegLite', 'HumanSegServer')".format(args.model_type))
+ model.train(
+ num_epochs=args.num_epochs,
+ train_dataset=train_dataset,
+ train_batch_size=args.batch_size,
+ eval_dataset=eval_dataset,
+ save_interval_epochs=args.save_interval_epochs,
+ save_dir=args.save_dir,
+ pretrained_weights=args.pretrained_weights,
+ resume_weights=args.resume_weights,
+ learning_rate=args.learning_rate,
+ use_vdl=args.use_vdl)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ train(args)
diff --git a/contrib/HumanSeg/transforms/__init__.py b/contrib/HumanSeg/transforms/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..db17cedcac20183456e79121565b35ddaae82e1c
--- /dev/null
+++ b/contrib/HumanSeg/transforms/__init__.py
@@ -0,0 +1,16 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .transforms import *
+from . import functional
diff --git a/contrib/HumanSeg/transforms/functional.py b/contrib/HumanSeg/transforms/functional.py
new file mode 100644
index 0000000000000000000000000000000000000000..a446f9097043b9447a4b6eeda0906bea6ebeb625
--- /dev/null
+++ b/contrib/HumanSeg/transforms/functional.py
@@ -0,0 +1,99 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import cv2
+import numpy as np
+from PIL import Image, ImageEnhance
+
+
+def normalize(im, mean, std):
+ im = im.astype(np.float32, copy=False) / 255.0
+ im -= mean
+ im /= std
+ return im
+
+
+def permute(im):
+ im = np.transpose(im, (2, 0, 1))
+ return im
+
+
+def resize(im, target_size=608, interp=cv2.INTER_LINEAR):
+ if isinstance(target_size, list) or isinstance(target_size, tuple):
+ w = target_size[0]
+ h = target_size[1]
+ else:
+ w = target_size
+ h = target_size
+ im = cv2.resize(im, (w, h), interpolation=interp)
+ return im
+
+
+def resize_long(im, long_size=224, interpolation=cv2.INTER_LINEAR):
+ value = max(im.shape[0], im.shape[1])
+ scale = float(long_size) / float(value)
+ resized_width = int(round(im.shape[1] * scale))
+ resized_height = int(round(im.shape[0] * scale))
+
+ im = cv2.resize(
+ im, (resized_width, resized_height), interpolation=interpolation)
+ return im
+
+
+def horizontal_flip(im):
+ if len(im.shape) == 3:
+ im = im[:, ::-1, :]
+ elif len(im.shape) == 2:
+ im = im[:, ::-1]
+ return im
+
+
+def vertical_flip(im):
+ if len(im.shape) == 3:
+ im = im[::-1, :, :]
+ elif len(im.shape) == 2:
+ im = im[::-1, :]
+ return im
+
+
+def brightness(im, brightness_lower, brightness_upper):
+ brightness_delta = np.random.uniform(brightness_lower, brightness_upper)
+ im = ImageEnhance.Brightness(im).enhance(brightness_delta)
+ return im
+
+
+def contrast(im, contrast_lower, contrast_upper):
+ contrast_delta = np.random.uniform(contrast_lower, contrast_upper)
+ im = ImageEnhance.Contrast(im).enhance(contrast_delta)
+ return im
+
+
+def saturation(im, saturation_lower, saturation_upper):
+ saturation_delta = np.random.uniform(saturation_lower, saturation_upper)
+ im = ImageEnhance.Color(im).enhance(saturation_delta)
+ return im
+
+
+def hue(im, hue_lower, hue_upper):
+ hue_delta = np.random.uniform(hue_lower, hue_upper)
+ im = np.array(im.convert('HSV'))
+ im[:, :, 0] = im[:, :, 0] + hue_delta
+ im = Image.fromarray(im, mode='HSV').convert('RGB')
+ return im
+
+
+def rotate(im, rotate_lower, rotate_upper):
+ rotate_delta = np.random.uniform(rotate_lower, rotate_upper)
+ im = im.rotate(int(rotate_delta))
+ return im
diff --git a/contrib/HumanSeg/transforms/transforms.py b/contrib/HumanSeg/transforms/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..f19359b24819ef7a91b78bc1058a308a7f48735e
--- /dev/null
+++ b/contrib/HumanSeg/transforms/transforms.py
@@ -0,0 +1,914 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .functional import *
+import random
+import numpy as np
+from PIL import Image
+import cv2
+from collections import OrderedDict
+
+
+class Compose:
+ """根据数据预处理/增强算子对输入数据进行操作。
+ 所有操作的输入图像流形状均是[H, W, C],其中H为图像高,W为图像宽,C为图像通道数。
+
+ Args:
+ transforms (list): 数据预处理/增强算子。
+ to_rgb (bool): 是否转化为rgb通道格式
+
+ Raises:
+ TypeError: transforms不是list对象
+ ValueError: transforms元素个数小于1。
+
+ """
+
+ def __init__(self, transforms, to_rgb=False):
+ if not isinstance(transforms, list):
+ raise TypeError('The transforms must be a list!')
+ if len(transforms) < 1:
+ raise ValueError('The length of transforms ' + \
+ 'must be equal or larger than 1!')
+ self.transforms = transforms
+ self.to_rgb = to_rgb
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (str/np.ndarray): 图像路径/图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息,dict中的字段如下:
+ - shape_before_resize (tuple): 图像resize之前的大小(h, w)。
+ - shape_before_padding (tuple): 图像padding之前的大小(h, w)。
+ label (str/np.ndarray): 标注图像路径/标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 根据网络所需字段所组成的tuple;字段由transforms中的最后一个数据预处理操作决定。
+ """
+
+ if im_info is None:
+ im_info = dict()
+ if isinstance(im, str):
+ im = cv2.imread(im).astype('float32')
+ if isinstance(label, str):
+ label = np.asarray(Image.open(label))
+ if im is None:
+ raise ValueError('Can\'t read The image file {}!'.format(im))
+ if self.to_rgb:
+ im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
+
+ for op in self.transforms:
+ outputs = op(im, im_info, label)
+ im = outputs[0]
+ if len(outputs) >= 2:
+ im_info = outputs[1]
+ if len(outputs) == 3:
+ label = outputs[2]
+ return outputs
+
+
+class RandomHorizontalFlip:
+ """以一定的概率对图像进行水平翻转。当存在标注图像时,则同步进行翻转。
+
+ Args:
+ prob (float): 随机水平翻转的概率。默认值为0.5。
+
+ """
+
+ def __init__(self, prob=0.5):
+ self.prob = prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if random.random() < self.prob:
+ im = horizontal_flip(im)
+ if label is not None:
+ label = horizontal_flip(label)
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomVerticalFlip:
+ """以一定的概率对图像进行垂直翻转。当存在标注图像时,则同步进行翻转。
+
+ Args:
+ prob (float): 随机垂直翻转的概率。默认值为0.1。
+ """
+
+ def __init__(self, prob=0.1):
+ self.prob = prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if random.random() < self.prob:
+ im = vertical_flip(im)
+ if label is not None:
+ label = vertical_flip(label)
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Resize:
+ """调整图像大小(resize)。
+
+ - 当目标大小(target_size)类型为int时,根据插值方式,
+ 将图像resize为[target_size, target_size]。
+ - 当目标大小(target_size)类型为list或tuple时,根据插值方式,
+ 将图像resize为target_size。
+ 注意:当插值方式为“RANDOM”时,则随机选取一种插值方式进行resize。
+
+ Args:
+ target_size (int/list/tuple): 短边目标长度。默认为608。
+ interp (str): resize的插值方式,与opencv的插值方式对应,取值范围为
+ ['NEAREST', 'LINEAR', 'CUBIC', 'AREA', 'LANCZOS4', 'RANDOM']。默认为"LINEAR"。
+
+ Raises:
+ TypeError: 形参数据类型不满足需求。
+ ValueError: 插值方式不在['NEAREST', 'LINEAR', 'CUBIC',
+ 'AREA', 'LANCZOS4', 'RANDOM']中。
+ """
+
+ # The interpolation mode
+ interp_dict = {
+ 'NEAREST': cv2.INTER_NEAREST,
+ 'LINEAR': cv2.INTER_LINEAR,
+ 'CUBIC': cv2.INTER_CUBIC,
+ 'AREA': cv2.INTER_AREA,
+ 'LANCZOS4': cv2.INTER_LANCZOS4
+ }
+
+ def __init__(self, target_size=512, interp='LINEAR'):
+ self.interp = interp
+ if not (interp == "RANDOM" or interp in self.interp_dict):
+ raise ValueError("interp should be one of {}".format(
+ self.interp_dict.keys()))
+ if isinstance(target_size, list) or isinstance(target_size, tuple):
+ if len(target_size) != 2:
+ raise TypeError(
+ 'when target is list or tuple, it should include 2 elements, but it is {}'
+ .format(target_size))
+ elif not isinstance(target_size, int):
+ raise TypeError(
+ "Type of target_size is invalid. Must be Integer or List or tuple, now is {}"
+ .format(type(target_size)))
+
+ self.target_size = target_size
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict, 可选): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ 其中,im_info跟新字段为:
+ -shape_before_resize (tuple): 保存resize之前图像的形状(h, w)。
+
+ Raises:
+ TypeError: 形参数据类型不满足需求。
+ ValueError: 数据长度不匹配。
+ """
+ if im_info is None:
+ im_info = OrderedDict()
+ im_info['shape_before_resize'] = im.shape[:2]
+ if not isinstance(im, np.ndarray):
+ raise TypeError("Resize: image type is not numpy.")
+ if len(im.shape) != 3:
+ raise ValueError('Resize: image is not 3-dimensional.')
+ if self.interp == "RANDOM":
+ interp = random.choice(list(self.interp_dict.keys()))
+ else:
+ interp = self.interp
+ im = resize(im, self.target_size, self.interp_dict[interp])
+ if label is not None:
+ label = resize(label, self.target_size, cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ResizeByLong:
+ """对图像长边resize到固定值,短边按比例进行缩放。当存在标注图像时,则同步进行处理。
+
+ Args:
+ long_size (int): resize后图像的长边大小。
+ """
+
+ def __init__(self, long_size):
+ self.long_size = long_size
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ 其中,im_info新增字段为:
+ -shape_before_resize (tuple): 保存resize之前图像的形状(h, w)。
+ """
+ if im_info is None:
+ im_info = OrderedDict()
+
+ im_info['shape_before_resize'] = im.shape[:2]
+ im = resize_long(im, self.long_size)
+ if label is not None:
+ label = resize_long(label, self.long_size, cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ResizeRangeScaling:
+ """对图像长边随机resize到指定范围内,短边按比例进行缩放。当存在标注图像时,则同步进行处理。
+
+ Args:
+ min_value (int): 图像长边resize后的最小值。默认值400。
+ max_value (int): 图像长边resize后的最大值。默认值600。
+
+ Raises:
+ ValueError: min_value大于max_value
+ """
+
+ def __init__(self, min_value=400, max_value=600):
+ if min_value > max_value:
+ raise ValueError('min_value must be less than max_value, '
+ 'but they are {} and {}.'.format(
+ min_value, max_value))
+ self.min_value = min_value
+ self.max_value = max_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.min_value == self.max_value:
+ random_size = self.max_value
+ else:
+ random_size = int(
+ np.random.uniform(self.min_value, self.max_value) + 0.5)
+ im = resize_long(im, random_size, cv2.INTER_LINEAR)
+ if label is not None:
+ label = resize_long(label, random_size, cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ResizeStepScaling:
+ """对图像按照某一个比例resize,这个比例以scale_step_size为步长
+ 在[min_scale_factor, max_scale_factor]随机变动。当存在标注图像时,则同步进行处理。
+
+ Args:
+ min_scale_factor(float), resize最小尺度。默认值0.75。
+ max_scale_factor (float), resize最大尺度。默认值1.25。
+ scale_step_size (float), resize尺度范围间隔。默认值0.25。
+
+ Raises:
+ ValueError: min_scale_factor大于max_scale_factor
+ """
+
+ def __init__(self,
+ min_scale_factor=0.75,
+ max_scale_factor=1.25,
+ scale_step_size=0.25):
+ if min_scale_factor > max_scale_factor:
+ raise ValueError(
+ 'min_scale_factor must be less than max_scale_factor, '
+ 'but they are {} and {}.'.format(min_scale_factor,
+ max_scale_factor))
+ self.min_scale_factor = min_scale_factor
+ self.max_scale_factor = max_scale_factor
+ self.scale_step_size = scale_step_size
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.min_scale_factor == self.max_scale_factor:
+ scale_factor = self.min_scale_factor
+
+ elif self.scale_step_size == 0:
+ scale_factor = np.random.uniform(self.min_scale_factor,
+ self.max_scale_factor)
+
+ else:
+ num_steps = int((self.max_scale_factor - self.min_scale_factor) /
+ self.scale_step_size + 1)
+ scale_factors = np.linspace(self.min_scale_factor,
+ self.max_scale_factor,
+ num_steps).tolist()
+ np.random.shuffle(scale_factors)
+ scale_factor = scale_factors[0]
+ w = int(round(scale_factor * im.shape[1]))
+ h = int(round(scale_factor * im.shape[0]))
+
+ im = resize(im, (w, h), cv2.INTER_LINEAR)
+ if label is not None:
+ label = resize(label, (w, h), cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Normalize:
+ """对图像进行标准化。
+ 1.尺度缩放到 [0,1]。
+ 2.对图像进行减均值除以标准差操作。
+
+ Args:
+ mean (list): 图像数据集的均值。默认值[0.5, 0.5, 0.5]。
+ std (list): 图像数据集的标准差。默认值[0.5, 0.5, 0.5]。
+
+ Raises:
+ ValueError: mean或std不是list对象。std包含0。
+ """
+
+ def __init__(self, mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]):
+ self.mean = mean
+ self.std = std
+ if not (isinstance(self.mean, list) and isinstance(self.std, list)):
+ raise ValueError("{}: input type is invalid.".format(self))
+ from functools import reduce
+ if reduce(lambda x, y: x * y, self.std) == 0:
+ raise ValueError('{}: std is invalid!'.format(self))
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+
+ mean = np.array(self.mean)[np.newaxis, np.newaxis, :]
+ std = np.array(self.std)[np.newaxis, np.newaxis, :]
+ im = normalize(im, mean, std)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Padding:
+ """对图像或标注图像进行padding,padding方向为右和下。
+ 根据提供的值对图像或标注图像进行padding操作。
+
+ Args:
+ target_size (int|list|tuple): padding后图像的大小。
+ im_padding_value (list): 图像padding的值。默认为[127.5, 127.5, 127.5]。
+ label_padding_value (int): 标注图像padding的值。默认值为255。
+
+ Raises:
+ TypeError: target_size不是int|list|tuple。
+ ValueError: target_size为list|tuple时元素个数不等于2。
+ """
+
+ def __init__(self,
+ target_size,
+ im_padding_value=[127.5, 127.5, 127.5],
+ label_padding_value=255):
+ if isinstance(target_size, list) or isinstance(target_size, tuple):
+ if len(target_size) != 2:
+ raise ValueError(
+ 'when target is list or tuple, it should include 2 elements, but it is {}'
+ .format(target_size))
+ elif not isinstance(target_size, int):
+ raise TypeError(
+ "Type of target_size is invalid. Must be Integer or List or tuple, now is {}"
+ .format(type(target_size)))
+ self.target_size = target_size
+ self.im_padding_value = im_padding_value
+ self.label_padding_value = label_padding_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ 其中,im_info新增字段为:
+ -shape_before_padding (tuple): 保存padding之前图像的形状(h, w)。
+
+ Raises:
+ ValueError: 输入图像im或label的形状大于目标值
+ """
+ if im_info is None:
+ im_info = OrderedDict()
+ im_info['shape_before_padding'] = im.shape[:2]
+
+ im_height, im_width = im.shape[0], im.shape[1]
+ if isinstance(self.target_size, int):
+ target_height = self.target_size
+ target_width = self.target_size
+ else:
+ target_height = self.target_size[1]
+ target_width = self.target_size[0]
+ pad_height = target_height - im_height
+ pad_width = target_width - im_width
+ if pad_height < 0 or pad_width < 0:
+ raise ValueError(
+ 'the size of image should be less than target_size, but the size of image ({}, {}), is larger than target_size ({}, {})'
+ .format(im_width, im_height, target_width, target_height))
+ else:
+ im = cv2.copyMakeBorder(
+ im,
+ 0,
+ pad_height,
+ 0,
+ pad_width,
+ cv2.BORDER_CONSTANT,
+ value=self.im_padding_value)
+ if label is not None:
+ label = cv2.copyMakeBorder(
+ label,
+ 0,
+ pad_height,
+ 0,
+ pad_width,
+ cv2.BORDER_CONSTANT,
+ value=self.label_padding_value)
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomPaddingCrop:
+ """对图像和标注图进行随机裁剪,当所需要的裁剪尺寸大于原图时,则进行padding操作。
+
+ Args:
+ crop_size (int|list|tuple): 裁剪图像大小。默认为512。
+ im_padding_value (list): 图像padding的值。默认为[127.5, 127.5, 127.5]。
+ label_padding_value (int): 标注图像padding的值。默认值为255。
+
+ Raises:
+ TypeError: crop_size不是int/list/tuple。
+ ValueError: target_size为list/tuple时元素个数不等于2。
+ """
+
+ def __init__(self,
+ crop_size=512,
+ im_padding_value=[127.5, 127.5, 127.5],
+ label_padding_value=255):
+ if isinstance(crop_size, list) or isinstance(crop_size, tuple):
+ if len(crop_size) != 2:
+ raise ValueError(
+ 'when crop_size is list or tuple, it should include 2 elements, but it is {}'
+ .format(crop_size))
+ elif not isinstance(crop_size, int):
+ raise TypeError(
+ "Type of crop_size is invalid. Must be Integer or List or tuple, now is {}"
+ .format(type(crop_size)))
+ self.crop_size = crop_size
+ self.im_padding_value = im_padding_value
+ self.label_padding_value = label_padding_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if isinstance(self.crop_size, int):
+ crop_width = self.crop_size
+ crop_height = self.crop_size
+ else:
+ crop_width = self.crop_size[0]
+ crop_height = self.crop_size[1]
+
+ img_height = im.shape[0]
+ img_width = im.shape[1]
+
+ if img_height == crop_height and img_width == crop_width:
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+ else:
+ pad_height = max(crop_height - img_height, 0)
+ pad_width = max(crop_width - img_width, 0)
+ if (pad_height > 0 or pad_width > 0):
+ im = cv2.copyMakeBorder(
+ im,
+ 0,
+ pad_height,
+ 0,
+ pad_width,
+ cv2.BORDER_CONSTANT,
+ value=self.im_padding_value)
+ if label is not None:
+ label = cv2.copyMakeBorder(
+ label,
+ 0,
+ pad_height,
+ 0,
+ pad_width,
+ cv2.BORDER_CONSTANT,
+ value=self.label_padding_value)
+ img_height = im.shape[0]
+ img_width = im.shape[1]
+
+ if crop_height > 0 and crop_width > 0:
+ h_off = np.random.randint(img_height - crop_height + 1)
+ w_off = np.random.randint(img_width - crop_width + 1)
+
+ im = im[h_off:(crop_height + h_off), w_off:(
+ w_off + crop_width), :]
+ if label is not None:
+ label = label[h_off:(crop_height + h_off), w_off:(
+ w_off + crop_width)]
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomBlur:
+ """以一定的概率对图像进行高斯模糊。
+
+ Args:
+ prob (float): 图像模糊概率。默认为0.1。
+ """
+
+ def __init__(self, prob=0.1):
+ self.prob = prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.prob <= 0:
+ n = 0
+ elif self.prob >= 1:
+ n = 1
+ else:
+ n = int(1.0 / self.prob)
+ if n > 0:
+ if np.random.randint(0, n) == 0:
+ radius = np.random.randint(3, 10)
+ if radius % 2 != 1:
+ radius = radius + 1
+ if radius > 9:
+ radius = 9
+ im = cv2.GaussianBlur(im, (radius, radius), 0, 0)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomRotation:
+ """对图像进行随机旋转。
+ 在不超过最大旋转角度的情况下,图像进行随机旋转,当存在标注图像时,同步进行,
+ 并对旋转后的图像和标注图像进行相应的padding。
+
+ Args:
+ max_rotation (float): 最大旋转角度。默认为15度。
+ im_padding_value (list): 图像padding的值。默认为[127.5, 127.5, 127.5]。
+ label_padding_value (int): 标注图像padding的值。默认为255。
+
+ """
+
+ def __init__(self,
+ max_rotation=15,
+ im_padding_value=[127.5, 127.5, 127.5],
+ label_padding_value=255):
+ self.max_rotation = max_rotation
+ self.im_padding_value = im_padding_value
+ self.label_padding_value = label_padding_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.max_rotation > 0:
+ (h, w) = im.shape[:2]
+ do_rotation = np.random.uniform(-self.max_rotation,
+ self.max_rotation)
+ pc = (w // 2, h // 2)
+ r = cv2.getRotationMatrix2D(pc, do_rotation, 1.0)
+ cos = np.abs(r[0, 0])
+ sin = np.abs(r[0, 1])
+
+ nw = int((h * sin) + (w * cos))
+ nh = int((h * cos) + (w * sin))
+
+ (cx, cy) = pc
+ r[0, 2] += (nw / 2) - cx
+ r[1, 2] += (nh / 2) - cy
+ dsize = (nw, nh)
+ im = cv2.warpAffine(
+ im,
+ r,
+ dsize=dsize,
+ flags=cv2.INTER_LINEAR,
+ borderMode=cv2.BORDER_CONSTANT,
+ borderValue=self.im_padding_value)
+ label = cv2.warpAffine(
+ label,
+ r,
+ dsize=dsize,
+ flags=cv2.INTER_NEAREST,
+ borderMode=cv2.BORDER_CONSTANT,
+ borderValue=self.label_padding_value)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomScaleAspect:
+ """裁剪并resize回原始尺寸的图像和标注图像。
+ 按照一定的面积比和宽高比对图像进行裁剪,并reszie回原始图像的图像,当存在标注图时,同步进行。
+
+ Args:
+ min_scale (float):裁取图像占原始图像的面积比,取值[0,1],为0时则返回原图。默认为0.5。
+ aspect_ratio (float): 裁取图像的宽高比范围,非负值,为0时返回原图。默认为0.33。
+ """
+
+ def __init__(self, min_scale=0.5, aspect_ratio=0.33):
+ self.min_scale = min_scale
+ self.aspect_ratio = aspect_ratio
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.min_scale != 0 and self.aspect_ratio != 0:
+ img_height = im.shape[0]
+ img_width = im.shape[1]
+ for i in range(0, 10):
+ area = img_height * img_width
+ target_area = area * np.random.uniform(self.min_scale, 1.0)
+ aspectRatio = np.random.uniform(self.aspect_ratio,
+ 1.0 / self.aspect_ratio)
+
+ dw = int(np.sqrt(target_area * 1.0 * aspectRatio))
+ dh = int(np.sqrt(target_area * 1.0 / aspectRatio))
+ if (np.random.randint(10) < 5):
+ tmp = dw
+ dw = dh
+ dh = tmp
+
+ if (dh < img_height and dw < img_width):
+ h1 = np.random.randint(0, img_height - dh)
+ w1 = np.random.randint(0, img_width - dw)
+
+ im = im[h1:(h1 + dh), w1:(w1 + dw), :]
+ label = label[h1:(h1 + dh), w1:(w1 + dw)]
+ im = cv2.resize(
+ im, (img_width, img_height),
+ interpolation=cv2.INTER_LINEAR)
+ label = cv2.resize(
+ label, (img_width, img_height),
+ interpolation=cv2.INTER_NEAREST)
+ break
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomDistort:
+ """对图像进行随机失真。
+
+ 1. 对变换的操作顺序进行随机化操作。
+ 2. 按照1中的顺序以一定的概率对图像进行随机像素内容变换。
+
+ Args:
+ brightness_range (float): 明亮度因子的范围。默认为0.5。
+ brightness_prob (float): 随机调整明亮度的概率。默认为0.5。
+ contrast_range (float): 对比度因子的范围。默认为0.5。
+ contrast_prob (float): 随机调整对比度的概率。默认为0.5。
+ saturation_range (float): 饱和度因子的范围。默认为0.5。
+ saturation_prob (float): 随机调整饱和度的概率。默认为0.5。
+ hue_range (int): 色调因子的范围。默认为18。
+ hue_prob (float): 随机调整色调的概率。默认为0.5。
+ """
+
+ def __init__(self,
+ brightness_range=0.5,
+ brightness_prob=0.5,
+ contrast_range=0.5,
+ contrast_prob=0.5,
+ saturation_range=0.5,
+ saturation_prob=0.5,
+ hue_range=18,
+ hue_prob=0.5):
+ self.brightness_range = brightness_range
+ self.brightness_prob = brightness_prob
+ self.contrast_range = contrast_range
+ self.contrast_prob = contrast_prob
+ self.saturation_range = saturation_range
+ self.saturation_prob = saturation_prob
+ self.hue_range = hue_range
+ self.hue_prob = hue_prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ brightness_lower = 1 - self.brightness_range
+ brightness_upper = 1 + self.brightness_range
+ contrast_lower = 1 - self.contrast_range
+ contrast_upper = 1 + self.contrast_range
+ saturation_lower = 1 - self.saturation_range
+ saturation_upper = 1 + self.saturation_range
+ hue_lower = -self.hue_range
+ hue_upper = self.hue_range
+ ops = [brightness, contrast, saturation, hue]
+ random.shuffle(ops)
+ params_dict = {
+ 'brightness': {
+ 'brightness_lower': brightness_lower,
+ 'brightness_upper': brightness_upper
+ },
+ 'contrast': {
+ 'contrast_lower': contrast_lower,
+ 'contrast_upper': contrast_upper
+ },
+ 'saturation': {
+ 'saturation_lower': saturation_lower,
+ 'saturation_upper': saturation_upper
+ },
+ 'hue': {
+ 'hue_lower': hue_lower,
+ 'hue_upper': hue_upper
+ }
+ }
+ prob_dict = {
+ 'brightness': self.brightness_prob,
+ 'contrast': self.contrast_prob,
+ 'saturation': self.saturation_prob,
+ 'hue': self.hue_prob
+ }
+ im = im.astype('uint8')
+ im = Image.fromarray(im)
+ for id in range(4):
+ params = params_dict[ops[id].__name__]
+ prob = prob_dict[ops[id].__name__]
+ params['im'] = im
+ if np.random.uniform(0, 1) < prob:
+ im = ops[id](**params)
+ im = np.asarray(im).astype('float32')
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ArrangeSegmenter:
+ """获取训练/验证/预测所需的信息。
+
+ Args:
+ mode (str): 指定数据用于何种用途,取值范围为['train', 'eval', 'test', 'quant']。
+
+ Raises:
+ ValueError: mode的取值不在['train', 'eval', 'test', 'quant']之内
+ """
+
+ def __init__(self, mode):
+ if mode not in ['train', 'eval', 'test', 'quant']:
+ raise ValueError(
+ "mode should be defined as one of ['train', 'eval', 'test', 'quant']!"
+ )
+ self.mode = mode
+
+ def __call__(self, im, im_info, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当mode为'train'或'eval'时,返回的tuple为(im, label),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当mode为'test'时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;当mode为
+ 'quant'时,返回的tuple为(im,),为图像np.ndarray数据。
+ """
+ im = permute(im)
+ if self.mode == 'train' or self.mode == 'eval':
+ label = label[np.newaxis, :, :]
+ return (im, label)
+ elif self.mode == 'test':
+ return (im, im_info)
+ else:
+ return (im, )
diff --git a/contrib/HumanSeg/utils/__init__.py b/contrib/HumanSeg/utils/__init__.py
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..a7760ee48accc71122d07a35f6287117313ac51e 100644
--- a/contrib/HumanSeg/utils/__init__.py
+++ b/contrib/HumanSeg/utils/__init__.py
@@ -0,0 +1,19 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from . import logging
+from . import humanseg_postprocess
+from .metrics import ConfusionMatrix
+from .utils import *
+from .post_quantization import HumanSegPostTrainingQuantization
diff --git a/contrib/HumanSeg/utils/humanseg_postprocess.py b/contrib/HumanSeg/utils/humanseg_postprocess.py
new file mode 100644
index 0000000000000000000000000000000000000000..44376726703c4f533f7fa3888c4dd694b19ff031
--- /dev/null
+++ b/contrib/HumanSeg/utils/humanseg_postprocess.py
@@ -0,0 +1,122 @@
+import numpy as np
+import cv2
+import os
+
+
+def get_round(data):
+ round = 0.5 if data >= 0 else -0.5
+ return (int)(data + round)
+
+
+def human_seg_tracking(pre_gray, cur_gray, prev_cfd, dl_weights, disflow):
+ """计算光流跟踪匹配点和光流图
+ 输入参数:
+ pre_gray: 上一帧灰度图
+ cur_gray: 当前帧灰度图
+ prev_cfd: 上一帧光流图
+ dl_weights: 融合权重图
+ disflow: 光流数据结构
+ 返回值:
+ is_track: 光流点跟踪二值图,即是否具有光流点匹配
+ track_cfd: 光流跟踪图
+ """
+ check_thres = 8
+ h, w = pre_gray.shape[:2]
+ track_cfd = np.zeros_like(prev_cfd)
+ is_track = np.zeros_like(pre_gray)
+ flow_fw = disflow.calc(pre_gray, cur_gray, None)
+ flow_bw = disflow.calc(cur_gray, pre_gray, None)
+ for r in range(h):
+ for c in range(w):
+ fxy_fw = flow_fw[r, c]
+ dx_fw = get_round(fxy_fw[0])
+ cur_x = dx_fw + c
+ dy_fw = get_round(fxy_fw[1])
+ cur_y = dy_fw + r
+ if cur_x < 0 or cur_x >= w or cur_y < 0 or cur_y >= h:
+ continue
+ fxy_bw = flow_bw[cur_y, cur_x]
+ dx_bw = get_round(fxy_bw[0])
+ dy_bw = get_round(fxy_bw[1])
+ if ((dy_fw + dy_bw) * (dy_fw + dy_bw) +
+ (dx_fw + dx_bw) * (dx_fw + dx_bw)) >= check_thres:
+ continue
+ if abs(dy_fw) <= 0 and abs(dx_fw) <= 0 and abs(dy_bw) <= 0 and abs(
+ dx_bw) <= 0:
+ dl_weights[cur_y, cur_x] = 0.05
+ is_track[cur_y, cur_x] = 1
+ track_cfd[cur_y, cur_x] = prev_cfd[r, c]
+ return track_cfd, is_track, dl_weights
+
+
+def human_seg_track_fuse(track_cfd, dl_cfd, dl_weights, is_track):
+ """光流追踪图和人像分割结构融合
+ 输入参数:
+ track_cfd: 光流追踪图
+ dl_cfd: 当前帧分割结果
+ dl_weights: 融合权重图
+ is_track: 光流点匹配二值图
+ 返回
+ cur_cfd: 光流跟踪图和人像分割结果融合图
+ """
+ fusion_cfd = dl_cfd.copy()
+ idxs = np.where(is_track > 0)
+ for i in range(len(idxs[0])):
+ x, y = idxs[0][i], idxs[1][i]
+ dl_score = dl_cfd[x, y]
+ track_score = track_cfd[x, y]
+ fusion_cfd[x, y] = dl_weights[x, y] * dl_score + (
+ 1 - dl_weights[x, y]) * track_score
+ if dl_score > 0.9 or dl_score < 0.1:
+ if dl_weights[x, y] < 0.1:
+ fusion_cfd[x, y] = 0.3 * dl_score + 0.7 * track_score
+ else:
+ fusion_cfd[x, y] = 0.4 * dl_score + 0.6 * track_score
+ else:
+ fusion_cfd[x, y] = dl_weights[x, y] * dl_score + (
+ 1 - dl_weights[x, y]) * track_score
+ return fusion_cfd
+
+
+def postprocess(cur_gray, scoremap, prev_gray, pre_cfd, disflow, is_init):
+ """光流优化
+ Args:
+ cur_gray : 当前帧灰度图
+ pre_gray : 前一帧灰度图
+ pre_cfd :前一帧融合结果
+ scoremap : 当前帧分割结果
+ difflow : 光流
+ is_init : 是否第一帧
+ Returns:
+ fusion_cfd : 光流追踪图和预测结果融合图
+ """
+ height, width = scoremap.shape[0], scoremap.shape[1]
+ disflow = cv2.DISOpticalFlow_create(cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
+ h, w = scoremap.shape
+ cur_cfd = scoremap.copy()
+
+ if is_init:
+ is_init = False
+ if h <= 64 or w <= 64:
+ disflow.setFinestScale(1)
+ elif h <= 160 or w <= 160:
+ disflow.setFinestScale(2)
+ else:
+ disflow.setFinestScale(3)
+ fusion_cfd = cur_cfd
+ else:
+ weights = np.ones((w, h), np.float32) * 0.3
+ track_cfd, is_track, weights = human_seg_tracking(
+ prev_gray, cur_gray, pre_cfd, weights, disflow)
+ fusion_cfd = human_seg_track_fuse(track_cfd, cur_cfd, weights, is_track)
+
+ fusion_cfd = cv2.GaussianBlur(fusion_cfd, (3, 3), 0)
+
+ return fusion_cfd
+
+
+def threshold_mask(img, thresh_bg, thresh_fg):
+ dst = (img / 255.0 - thresh_bg) / (thresh_fg - thresh_bg)
+ dst[np.where(dst > 1)] = 1
+ dst[np.where(dst < 0)] = 0
+ return dst.astype(np.float32)
diff --git a/contrib/HumanSeg/utils/logging.py b/contrib/HumanSeg/utils/logging.py
new file mode 100644
index 0000000000000000000000000000000000000000..1669466f839b6953aa368dedc80e32a9a68725f7
--- /dev/null
+++ b/contrib/HumanSeg/utils/logging.py
@@ -0,0 +1,46 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import time
+import os
+import sys
+
+levels = {0: 'ERROR', 1: 'WARNING', 2: 'INFO', 3: 'DEBUG'}
+log_level = 2
+
+
+def log(level=2, message=""):
+ current_time = time.time()
+ time_array = time.localtime(current_time)
+ current_time = time.strftime("%Y-%m-%d %H:%M:%S", time_array)
+ if log_level >= level:
+ print("{} [{}]\t{}".format(current_time, levels[level],
+ message).encode("utf-8").decode("latin1"))
+ sys.stdout.flush()
+
+
+def debug(message=""):
+ log(level=3, message=message)
+
+
+def info(message=""):
+ log(level=2, message=message)
+
+
+def warning(message=""):
+ log(level=1, message=message)
+
+
+def error(message=""):
+ log(level=0, message=message)
diff --git a/contrib/HumanSeg/utils/metrics.py b/contrib/HumanSeg/utils/metrics.py
new file mode 100644
index 0000000000000000000000000000000000000000..2898be028f3dfa03ad9892310da89f7695829542
--- /dev/null
+++ b/contrib/HumanSeg/utils/metrics.py
@@ -0,0 +1,145 @@
+# coding: utf8
+# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import sys
+import numpy as np
+from scipy.sparse import csr_matrix
+
+
+class ConfusionMatrix(object):
+ """
+ Confusion Matrix for segmentation evaluation
+ """
+
+ def __init__(self, num_classes=2, streaming=False):
+ self.confusion_matrix = np.zeros([num_classes, num_classes],
+ dtype='int64')
+ self.num_classes = num_classes
+ self.streaming = streaming
+
+ def calculate(self, pred, label, ignore=None):
+ # If not in streaming mode, clear matrix everytime when call `calculate`
+ if not self.streaming:
+ self.zero_matrix()
+
+ label = np.transpose(label, (0, 2, 3, 1))
+ ignore = np.transpose(ignore, (0, 2, 3, 1))
+ mask = np.array(ignore) == 1
+
+ label = np.asarray(label)[mask]
+ pred = np.asarray(pred)[mask]
+ one = np.ones_like(pred)
+ # Accumuate ([row=label, col=pred], 1) into sparse matrix
+ spm = csr_matrix((one, (label, pred)),
+ shape=(self.num_classes, self.num_classes))
+ spm = spm.todense()
+ self.confusion_matrix += spm
+
+ def zero_matrix(self):
+ """ Clear confusion matrix """
+ self.confusion_matrix = np.zeros([self.num_classes, self.num_classes],
+ dtype='int64')
+
+ def mean_iou(self):
+ iou_list = []
+ avg_iou = 0
+ # TODO: use numpy sum axis api to simpliy
+ vji = np.zeros(self.num_classes, dtype=int)
+ vij = np.zeros(self.num_classes, dtype=int)
+ for j in range(self.num_classes):
+ v_j = 0
+ for i in range(self.num_classes):
+ v_j += self.confusion_matrix[j][i]
+ vji[j] = v_j
+
+ for i in range(self.num_classes):
+ v_i = 0
+ for j in range(self.num_classes):
+ v_i += self.confusion_matrix[j][i]
+ vij[i] = v_i
+
+ for c in range(self.num_classes):
+ total = vji[c] + vij[c] - self.confusion_matrix[c][c]
+ if total == 0:
+ iou = 0
+ else:
+ iou = float(self.confusion_matrix[c][c]) / total
+ avg_iou += iou
+ iou_list.append(iou)
+ avg_iou = float(avg_iou) / float(self.num_classes)
+ return np.array(iou_list), avg_iou
+
+ def accuracy(self):
+ total = self.confusion_matrix.sum()
+ total_right = 0
+ for c in range(self.num_classes):
+ total_right += self.confusion_matrix[c][c]
+ if total == 0:
+ avg_acc = 0
+ else:
+ avg_acc = float(total_right) / total
+
+ vij = np.zeros(self.num_classes, dtype=int)
+ for i in range(self.num_classes):
+ v_i = 0
+ for j in range(self.num_classes):
+ v_i += self.confusion_matrix[j][i]
+ vij[i] = v_i
+
+ acc_list = []
+ for c in range(self.num_classes):
+ if vij[c] == 0:
+ acc = 0
+ else:
+ acc = self.confusion_matrix[c][c] / float(vij[c])
+ acc_list.append(acc)
+ return np.array(acc_list), avg_acc
+
+ def kappa(self):
+ vji = np.zeros(self.num_classes)
+ vij = np.zeros(self.num_classes)
+ for j in range(self.num_classes):
+ v_j = 0
+ for i in range(self.num_classes):
+ v_j += self.confusion_matrix[j][i]
+ vji[j] = v_j
+
+ for i in range(self.num_classes):
+ v_i = 0
+ for j in range(self.num_classes):
+ v_i += self.confusion_matrix[j][i]
+ vij[i] = v_i
+
+ total = self.confusion_matrix.sum()
+
+ # avoid spillovers
+ # TODO: is it reasonable to hard code 10000.0?
+ total = float(total) / 10000.0
+ vji = vji / 10000.0
+ vij = vij / 10000.0
+
+ tp = 0
+ tc = 0
+ for c in range(self.num_classes):
+ tp += vji[c] * vij[c]
+ tc += self.confusion_matrix[c][c]
+
+ tc = tc / 10000.0
+ pe = tp / (total * total)
+ po = tc / total
+
+ kappa = (po - pe) / (1 - pe)
+ return kappa
diff --git a/contrib/HumanSeg/utils/palette.py b/contrib/HumanSeg/utils/palette.py
deleted file mode 100644
index 2186203cbc2789f6eff70dfd92f724b4fe16cdb7..0000000000000000000000000000000000000000
--- a/contrib/HumanSeg/utils/palette.py
+++ /dev/null
@@ -1,38 +0,0 @@
-##+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
-## Created by: RainbowSecret
-## Microsoft Research
-## yuyua@microsoft.com
-## Copyright (c) 2018
-##
-## This source code is licensed under the MIT-style license found in the
-## LICENSE file in the root directory of this source tree
-##+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-import numpy as np
-import cv2
-
-
-def get_palette(num_cls):
- """ Returns the color map for visualizing the segmentation mask.
- Args:
- num_cls: Number of classes
- Returns:
- The color map
- """
- n = num_cls
- palette = [0] * (n * 3)
- for j in range(0, n):
- lab = j
- palette[j * 3 + 0] = 0
- palette[j * 3 + 1] = 0
- palette[j * 3 + 2] = 0
- i = 0
- while lab:
- palette[j * 3 + 0] |= (((lab >> 0) & 1) << (7 - i))
- palette[j * 3 + 1] |= (((lab >> 1) & 1) << (7 - i))
- palette[j * 3 + 2] |= (((lab >> 2) & 1) << (7 - i))
- i += 1
- lab >>= 3
- return palette
diff --git a/contrib/HumanSeg/utils/post_quantization.py b/contrib/HumanSeg/utils/post_quantization.py
new file mode 100644
index 0000000000000000000000000000000000000000..00d61c8034ad8b332f2270d937a85812e6a63c0a
--- /dev/null
+++ b/contrib/HumanSeg/utils/post_quantization.py
@@ -0,0 +1,224 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from paddle.fluid.contrib.slim.quantization.quantization_pass import QuantizationTransformPass
+from paddle.fluid.contrib.slim.quantization.quantization_pass import AddQuantDequantPass
+from paddle.fluid.contrib.slim.quantization.quantization_pass import _op_real_in_out_name
+from paddle.fluid.contrib.slim.quantization import PostTrainingQuantization
+import paddle.fluid as fluid
+import os
+
+import utils.logging as logging
+
+
+class HumanSegPostTrainingQuantization(PostTrainingQuantization):
+ def __init__(self,
+ executor,
+ dataset,
+ program,
+ inputs,
+ outputs,
+ batch_size=10,
+ batch_nums=None,
+ scope=None,
+ algo="KL",
+ quantizable_op_type=["conv2d", "depthwise_conv2d", "mul"],
+ is_full_quantize=False,
+ is_use_cache_file=False,
+ cache_dir="./temp_post_training"):
+ '''
+ The class utilizes post training quantization methon to quantize the
+ fp32 model. It uses calibrate data to calculate the scale factor of
+ quantized variables, and inserts fake quant/dequant op to obtain the
+ quantized model.
+
+ Args:
+ executor(fluid.Executor): The executor to load, run and save the
+ quantized model.
+ dataset(Python Iterator): The data Reader.
+ program(fluid.Program): The paddle program, save the parameters for model.
+ inputs(dict): The input of prigram.
+ outputs(dict): The output of program.
+ batch_size(int, optional): The batch size of DataLoader. Default is 10.
+ batch_nums(int, optional): If batch_nums is not None, the number of
+ calibrate data is batch_size*batch_nums. If batch_nums is None, use
+ all data provided by sample_generator as calibrate data.
+ scope(fluid.Scope, optional): The scope of the program, use it to load
+ and save variables. If scope=None, get scope by global_scope().
+ algo(str, optional): If algo=KL, use KL-divergenc method to
+ get the more precise scale factor. If algo='direct', use
+ abs_max methon to get the scale factor. Default is KL.
+ quantizable_op_type(list[str], optional): List the type of ops
+ that will be quantized. Default is ["conv2d", "depthwise_conv2d",
+ "mul"].
+ is_full_quantized(bool, optional): If set is_full_quantized as True,
+ apply quantization to all supported quantizable op type. If set
+ is_full_quantized as False, only apply quantization to the op type
+ according to the input quantizable_op_type.
+ is_use_cache_file(bool, optional): If set is_use_cache_file as False,
+ all temp data will be saved in memory. If set is_use_cache_file as True,
+ it will save temp data to disk. When the fp32 model is complex or
+ the number of calibrate data is large, we should set is_use_cache_file
+ as True. Defalut is False.
+ cache_dir(str, optional): When is_use_cache_file is True, set cache_dir as
+ the directory for saving temp data. Default is ./temp_post_training.
+ Returns:
+ None
+ '''
+ self._executor = executor
+ self._dataset = dataset
+ self._batch_size = batch_size
+ self._batch_nums = batch_nums
+ self._scope = fluid.global_scope() if scope == None else scope
+ self._algo = algo
+ self._is_use_cache_file = is_use_cache_file
+ self._cache_dir = cache_dir
+ if self._is_use_cache_file and not os.path.exists(self._cache_dir):
+ os.mkdir(self._cache_dir)
+
+ supported_quantizable_op_type = \
+ QuantizationTransformPass._supported_quantizable_op_type + \
+ AddQuantDequantPass._supported_quantizable_op_type
+ if is_full_quantize:
+ self._quantizable_op_type = supported_quantizable_op_type
+ else:
+ self._quantizable_op_type = quantizable_op_type
+ for op_type in self._quantizable_op_type:
+ assert op_type in supported_quantizable_op_type + \
+ AddQuantDequantPass._activation_type, \
+ op_type + " is not supported for quantization."
+
+ self._place = self._executor.place
+ self._program = program
+ self._feed_list = list(inputs.values())
+ self._fetch_list = list(outputs.values())
+ self._data_loader = None
+
+ self._op_real_in_out_name = _op_real_in_out_name
+ self._bit_length = 8
+ self._quantized_weight_var_name = set()
+ self._quantized_act_var_name = set()
+ self._sampling_data = {}
+ self._quantized_var_scale_factor = {}
+
+ def quantize(self):
+ '''
+ Quantize the fp32 model. Use calibrate data to calculate the scale factor of
+ quantized variables, and inserts fake quant/dequant op to obtain the
+ quantized model.
+
+ Args:
+ None
+ Returns:
+ the program of quantized model.
+ '''
+ self._preprocess()
+
+ batch_id = 0
+ for data in self._data_loader():
+ self._executor.run(
+ program=self._program,
+ feed=data,
+ fetch_list=self._fetch_list,
+ return_numpy=False)
+ self._sample_data(batch_id)
+
+ if batch_id % 5 == 0:
+ logging.info("run batch: {}".format(batch_id))
+ batch_id += 1
+ if self._batch_nums and batch_id >= self._batch_nums:
+ break
+ logging.info("all run batch: ".format(batch_id))
+ logging.info("calculate scale factor ...")
+ self._calculate_scale_factor()
+ logging.info("update the program ...")
+ self._update_program()
+
+ self._save_output_scale()
+ return self._program
+
+ def save_quantized_model(self, save_model_path):
+ '''
+ Save the quantized model to the disk.
+
+ Args:
+ save_model_path(str): The path to save the quantized model
+ Returns:
+ None
+ '''
+ feed_vars_names = [var.name for var in self._feed_list]
+ fluid.io.save_inference_model(
+ dirname=save_model_path,
+ feeded_var_names=feed_vars_names,
+ target_vars=self._fetch_list,
+ executor=self._executor,
+ params_filename='__params__',
+ main_program=self._program)
+
+ def _preprocess(self):
+ '''
+ Load model and set data loader, collect the variable names for sampling,
+ and set activation variables to be persistable.
+ '''
+ feed_vars = [fluid.framework._get_var(var.name, self._program) \
+ for var in self._feed_list]
+
+ self._data_loader = fluid.io.DataLoader.from_generator(
+ feed_list=feed_vars, capacity=3 * self._batch_size, iterable=True)
+ self._data_loader.set_sample_list_generator(
+ self._dataset.generator(self._batch_size, drop_last=True),
+ places=self._place)
+
+ # collect the variable names for sampling
+ persistable_var_names = []
+ for var in self._program.list_vars():
+ if var.persistable:
+ persistable_var_names.append(var.name)
+
+ for op in self._program.global_block().ops:
+ op_type = op.type
+ if op_type in self._quantizable_op_type:
+ if op_type in ("conv2d", "depthwise_conv2d"):
+ self._quantized_act_var_name.add(op.input("Input")[0])
+ self._quantized_weight_var_name.add(op.input("Filter")[0])
+ self._quantized_act_var_name.add(op.output("Output")[0])
+ elif op_type == "mul":
+ if self._is_input_all_not_persistable(
+ op, persistable_var_names):
+ op._set_attr("skip_quant", True)
+ logging.warning(
+ "Skip quant a mul op for two input variables are not persistable"
+ )
+ else:
+ self._quantized_act_var_name.add(op.input("X")[0])
+ self._quantized_weight_var_name.add(op.input("Y")[0])
+ self._quantized_act_var_name.add(op.output("Out")[0])
+ else:
+ # process other quantizable op type, the input must all not persistable
+ if self._is_input_all_not_persistable(
+ op, persistable_var_names):
+ input_output_name_list = self._op_real_in_out_name[
+ op_type]
+ for input_name in input_output_name_list[0]:
+ for var_name in op.input(input_name):
+ self._quantized_act_var_name.add(var_name)
+ for output_name in input_output_name_list[1]:
+ for var_name in op.output(output_name):
+ self._quantized_act_var_name.add(var_name)
+
+ # set activation variables to be persistable, so can obtain
+ # the tensor data in sample_data
+ for var in self._program.list_vars():
+ if var.name in self._quantized_act_var_name:
+ var.persistable = True
diff --git a/contrib/HumanSeg/utils/util.py b/contrib/HumanSeg/utils/util.py
deleted file mode 100644
index 7394870e7c94c1fb16169e314696b931eecdc3b2..0000000000000000000000000000000000000000
--- a/contrib/HumanSeg/utils/util.py
+++ /dev/null
@@ -1,47 +0,0 @@
-from __future__ import division
-from __future__ import print_function
-from __future__ import unicode_literals
-import argparse
-import os
-
-def get_arguments():
- parser = argparse.ArgumentParser()
- parser.add_argument("--use_gpu",
- action="store_true",
- help="Use gpu or cpu to test.")
- parser.add_argument('--example',
- type=str,
- help='RoadLine, HumanSeg or ACE2P')
-
- return parser.parse_args()
-
-
-class AttrDict(dict):
- def __init__(self, *args, **kwargs):
- super(AttrDict, self).__init__(*args, **kwargs)
-
- def __getattr__(self, name):
- if name in self.__dict__:
- return self.__dict__[name]
- elif name in self:
- return self[name]
- else:
- raise AttributeError(name)
-
- def __setattr__(self, name, value):
- if name in self.__dict__:
- self.__dict__[name] = value
- else:
- self[name] = value
-
-def merge_cfg_from_args(args, cfg):
- """Merge config keys, values in args into the global config."""
- for k, v in vars(args).items():
- d = cfg
- try:
- value = eval(v)
- except:
- value = v
- if value is not None:
- cfg[k] = value
-
diff --git a/contrib/HumanSeg/utils/utils.py b/contrib/HumanSeg/utils/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e09e8b232bfc1d7436ab94a391175446c8e12be
--- /dev/null
+++ b/contrib/HumanSeg/utils/utils.py
@@ -0,0 +1,276 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import time
+import os
+import os.path as osp
+import numpy as np
+import six
+import yaml
+import math
+import cv2
+from . import logging
+
+
+def seconds_to_hms(seconds):
+ h = math.floor(seconds / 3600)
+ m = math.floor((seconds - h * 3600) / 60)
+ s = int(seconds - h * 3600 - m * 60)
+ hms_str = "{}:{}:{}".format(h, m, s)
+ return hms_str
+
+
+def setting_environ_flags():
+ if 'FLAGS_eager_delete_tensor_gb' not in os.environ:
+ os.environ['FLAGS_eager_delete_tensor_gb'] = '0.0'
+ if 'FLAGS_allocator_strategy' not in os.environ:
+ os.environ['FLAGS_allocator_strategy'] = 'auto_growth'
+ if "CUDA_VISIBLE_DEVICES" in os.environ:
+ if os.environ["CUDA_VISIBLE_DEVICES"].count("-1") > 0:
+ os.environ["CUDA_VISIBLE_DEVICES"] = ""
+
+
+def get_environ_info():
+ setting_environ_flags()
+ import paddle.fluid as fluid
+ info = dict()
+ info['place'] = 'cpu'
+ info['num'] = int(os.environ.get('CPU_NUM', 1))
+ if os.environ.get('CUDA_VISIBLE_DEVICES', None) != "":
+ if hasattr(fluid.core, 'get_cuda_device_count'):
+ gpu_num = 0
+ try:
+ gpu_num = fluid.core.get_cuda_device_count()
+ except:
+ os.environ['CUDA_VISIBLE_DEVICES'] = ''
+ pass
+ if gpu_num > 0:
+ info['place'] = 'cuda'
+ info['num'] = fluid.core.get_cuda_device_count()
+ return info
+
+
+def parse_param_file(param_file, return_shape=True):
+ from paddle.fluid.proto.framework_pb2 import VarType
+ f = open(param_file, 'rb')
+ version = np.fromstring(f.read(4), dtype='int32')
+ lod_level = np.fromstring(f.read(8), dtype='int64')
+ for i in range(int(lod_level)):
+ _size = np.fromstring(f.read(8), dtype='int64')
+ _ = f.read(_size)
+ version = np.fromstring(f.read(4), dtype='int32')
+ tensor_desc = VarType.TensorDesc()
+ tensor_desc_size = np.fromstring(f.read(4), dtype='int32')
+ tensor_desc.ParseFromString(f.read(int(tensor_desc_size)))
+ tensor_shape = tuple(tensor_desc.dims)
+ if return_shape:
+ f.close()
+ return tuple(tensor_desc.dims)
+ if tensor_desc.data_type != 5:
+ raise Exception(
+ "Unexpected data type while parse {}".format(param_file))
+ data_size = 4
+ for i in range(len(tensor_shape)):
+ data_size *= tensor_shape[i]
+ weight = np.fromstring(f.read(data_size), dtype='float32')
+ f.close()
+ return np.reshape(weight, tensor_shape)
+
+
+def fuse_bn_weights(exe, main_prog, weights_dir):
+ import paddle.fluid as fluid
+ logging.info("Try to fuse weights of batch_norm...")
+ bn_vars = list()
+ for block in main_prog.blocks:
+ ops = list(block.ops)
+ for op in ops:
+ if op.type == 'affine_channel':
+ scale_name = op.input('Scale')[0]
+ bias_name = op.input('Bias')[0]
+ prefix = scale_name[:-5]
+ mean_name = prefix + 'mean'
+ variance_name = prefix + 'variance'
+ if not osp.exists(osp.join(
+ weights_dir, mean_name)) or not osp.exists(
+ osp.join(weights_dir, variance_name)):
+ logging.info(
+ "There's no batch_norm weight found to fuse, skip fuse_bn."
+ )
+ return
+
+ bias = block.var(bias_name)
+ pretrained_shape = parse_param_file(
+ osp.join(weights_dir, bias_name))
+ actual_shape = tuple(bias.shape)
+ if pretrained_shape != actual_shape:
+ continue
+ bn_vars.append(
+ [scale_name, bias_name, mean_name, variance_name])
+ eps = 1e-5
+ for names in bn_vars:
+ scale_name, bias_name, mean_name, variance_name = names
+ scale = parse_param_file(
+ osp.join(weights_dir, scale_name), return_shape=False)
+ bias = parse_param_file(
+ osp.join(weights_dir, bias_name), return_shape=False)
+ mean = parse_param_file(
+ osp.join(weights_dir, mean_name), return_shape=False)
+ variance = parse_param_file(
+ osp.join(weights_dir, variance_name), return_shape=False)
+ bn_std = np.sqrt(np.add(variance, eps))
+ new_scale = np.float32(np.divide(scale, bn_std))
+ new_bias = bias - mean * new_scale
+ scale_tensor = fluid.global_scope().find_var(scale_name).get_tensor()
+ bias_tensor = fluid.global_scope().find_var(bias_name).get_tensor()
+ scale_tensor.set(new_scale, exe.place)
+ bias_tensor.set(new_bias, exe.place)
+ if len(bn_vars) == 0:
+ logging.info(
+ "There's no batch_norm weight found to fuse, skip fuse_bn.")
+ else:
+ logging.info("There's {} batch_norm ops been fused.".format(
+ len(bn_vars)))
+
+
+def load_pdparams(exe, main_prog, model_dir):
+ import paddle.fluid as fluid
+ from paddle.fluid.proto.framework_pb2 import VarType
+ from paddle.fluid.framework import Program
+
+ vars_to_load = list()
+ import pickle
+ with open(osp.join(model_dir, 'model.pdparams'), 'rb') as f:
+ params_dict = pickle.load(f) if six.PY2 else pickle.load(
+ f, encoding='latin1')
+ unused_vars = list()
+ for var in main_prog.list_vars():
+ if not isinstance(var, fluid.framework.Parameter):
+ continue
+ if var.name not in params_dict:
+ raise Exception("{} is not in saved model".format(var.name))
+ if var.shape != params_dict[var.name].shape:
+ unused_vars.append(var.name)
+ logging.warning(
+ "[SKIP] Shape of pretrained weight {} doesn't match.(Pretrained: {}, Actual: {})"
+ .format(var.name, params_dict[var.name].shape, var.shape))
+ continue
+ vars_to_load.append(var)
+ logging.debug("Weight {} will be load".format(var.name))
+ for var_name in unused_vars:
+ del params_dict[var_name]
+ fluid.io.set_program_state(main_prog, params_dict)
+
+ if len(vars_to_load) == 0:
+ logging.warning(
+ "There is no pretrain weights loaded, maybe you should check you pretrain model!"
+ )
+ else:
+ logging.info("There are {} varaibles in {} are loaded.".format(
+ len(vars_to_load), model_dir))
+
+
+def load_pretrained_weights(exe, main_prog, weights_dir, fuse_bn=False):
+ if not osp.exists(weights_dir):
+ raise Exception("Path {} not exists.".format(weights_dir))
+ if osp.exists(osp.join(weights_dir, "model.pdparams")):
+ return load_pdparams(exe, main_prog, weights_dir)
+ import paddle.fluid as fluid
+ vars_to_load = list()
+ for var in main_prog.list_vars():
+ if not isinstance(var, fluid.framework.Parameter):
+ continue
+ if not osp.exists(osp.join(weights_dir, var.name)):
+ logging.debug("[SKIP] Pretrained weight {}/{} doesn't exist".format(
+ weights_dir, var.name))
+ continue
+ pretrained_shape = parse_param_file(osp.join(weights_dir, var.name))
+ actual_shape = tuple(var.shape)
+ if pretrained_shape != actual_shape:
+ logging.warning(
+ "[SKIP] Shape of pretrained weight {}/{} doesn't match.(Pretrained: {}, Actual: {})"
+ .format(weights_dir, var.name, pretrained_shape, actual_shape))
+ continue
+ vars_to_load.append(var)
+ logging.debug("Weight {} will be load".format(var.name))
+
+ fluid.io.load_vars(
+ executor=exe,
+ dirname=weights_dir,
+ main_program=main_prog,
+ vars=vars_to_load)
+ if len(vars_to_load) == 0:
+ logging.warning(
+ "There is no pretrain weights loaded, maybe you should check you pretrain model!"
+ )
+ else:
+ logging.info("There are {} varaibles in {} are loaded.".format(
+ len(vars_to_load), weights_dir))
+ if fuse_bn:
+ fuse_bn_weights(exe, main_prog, weights_dir)
+
+
+def visualize(image, result, save_dir=None, weight=0.6):
+ """
+ Convert segment result to color image, and save added image.
+ Args:
+ image: the path of origin image
+ result: the predict result of image
+ save_dir: the directory for saving visual image
+ weight: the image weight of visual image, and the result weight is (1 - weight)
+ """
+ label_map = result['label_map']
+ color_map = get_color_map_list(256)
+ color_map = np.array(color_map).astype("uint8")
+ # Use OpenCV LUT for color mapping
+ c1 = cv2.LUT(label_map, color_map[:, 0])
+ c2 = cv2.LUT(label_map, color_map[:, 1])
+ c3 = cv2.LUT(label_map, color_map[:, 2])
+ pseudo_img = np.dstack((c1, c2, c3))
+
+ im = cv2.imread(image)
+ vis_result = cv2.addWeighted(im, weight, pseudo_img, 1 - weight, 0)
+
+ if save_dir is not None:
+ if not os.path.exists(save_dir):
+ os.makedirs(save_dir)
+ image_name = os.path.split(image)[-1]
+ out_path = os.path.join(save_dir, image_name)
+ cv2.imwrite(out_path, vis_result)
+ else:
+ return vis_result
+
+
+def get_color_map_list(num_classes):
+ """ Returns the color map for visualizing the segmentation mask,
+ which can support arbitrary number of classes.
+ Args:
+ num_classes: Number of classes
+ Returns:
+ The color map
+ """
+ num_classes += 1
+ color_map = num_classes * [0, 0, 0]
+ for i in range(0, num_classes):
+ j = 0
+ lab = i
+ while lab:
+ color_map[i * 3] |= (((lab >> 0) & 1) << (7 - j))
+ color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j))
+ color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j))
+ j += 1
+ lab >>= 3
+ color_map = [color_map[i:i + 3] for i in range(0, len(color_map), 3)]
+ color_map = color_map[1:]
+ return color_map
diff --git a/contrib/HumanSeg/val.py b/contrib/HumanSeg/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..cecdb5d5c579b22688a092d700863737ec35a13d
--- /dev/null
+++ b/contrib/HumanSeg/val.py
@@ -0,0 +1,63 @@
+import argparse
+from datasets.dataset import Dataset
+import transforms
+import models
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg training')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for evaluating',
+ type=str,
+ default='output/best_model')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='The root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--val_list',
+ dest='val_list',
+ help='Val list file of dataset',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size',
+ type=int,
+ default=128)
+ parser.add_argument(
+ "--image_shape",
+ dest="image_shape",
+ help="The image shape for net inputs.",
+ nargs=2,
+ default=[192, 192],
+ type=int)
+ return parser.parse_args()
+
+
+def evaluate(args):
+ eval_transforms = transforms.Compose(
+ [transforms.Resize(args.image_shape),
+ transforms.Normalize()])
+
+ eval_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.val_list,
+ transforms=eval_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False)
+
+ model = models.load_model(args.model_dir)
+ model.evaluate(eval_dataset, args.batch_size)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ evaluate(args)
diff --git a/contrib/HumanSeg/video_infer.py b/contrib/HumanSeg/video_infer.py
new file mode 100644
index 0000000000000000000000000000000000000000..b248669cf9455e908d2c8dfb98f8edae273f73a9
--- /dev/null
+++ b/contrib/HumanSeg/video_infer.py
@@ -0,0 +1,163 @@
+import argparse
+import os
+import os.path as osp
+import cv2
+import numpy as np
+
+from utils.humanseg_postprocess import postprocess, threshold_mask
+import models
+import transforms
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg inference for video')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for inference',
+ type=str)
+ parser.add_argument(
+ '--video_path',
+ dest='video_path',
+ help=
+ 'Video path for inference, camera will be used if the path not existing',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the inference results',
+ type=str,
+ default='./output')
+ parser.add_argument(
+ "--image_shape",
+ dest="image_shape",
+ help="The image shape for net inputs.",
+ nargs=2,
+ default=[192, 192],
+ type=int)
+
+ return parser.parse_args()
+
+
+def predict(img, model, test_transforms):
+ model.arrange_transform(transforms=test_transforms, mode='test')
+ img, im_info = test_transforms(img)
+ img = np.expand_dims(img, axis=0)
+ result = model.exe.run(
+ model.test_prog,
+ feed={'image': img},
+ fetch_list=list(model.test_outputs.values()))
+ score_map = result[1]
+ score_map = np.squeeze(score_map, axis=0)
+ score_map = np.transpose(score_map, (1, 2, 0))
+ return score_map, im_info
+
+
+def recover(img, im_info):
+ keys = list(im_info.keys())
+ for k in keys[::-1]:
+ if k == 'shape_before_resize':
+ h, w = im_info[k][0], im_info[k][1]
+ img = cv2.resize(img, (w, h), cv2.INTER_LINEAR)
+ elif k == 'shape_before_padding':
+ h, w = im_info[k][0], im_info[k][1]
+ img = img[0:h, 0:w]
+ return img
+
+
+def video_infer(args):
+ resize_h = args.image_shape[1]
+ resize_w = args.image_shape[0]
+
+ test_transforms = transforms.Compose(
+ [transforms.Resize((resize_w, resize_h)),
+ transforms.Normalize()])
+ model = models.load_model(args.model_dir)
+ if not args.video_path:
+ cap = cv2.VideoCapture(0)
+ else:
+ cap = cv2.VideoCapture(args.video_path)
+ if not cap.isOpened():
+ raise IOError("Error opening video stream or file, "
+ "--video_path whether existing: {}"
+ " or camera whether working".format(args.video_path))
+ return
+
+ width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
+ height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
+
+ disflow = cv2.DISOpticalFlow_create(cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
+ prev_gray = np.zeros((resize_h, resize_w), np.uint8)
+ prev_cfd = np.zeros((resize_h, resize_w), np.float32)
+ is_init = True
+
+ fps = cap.get(cv2.CAP_PROP_FPS)
+ if args.video_path:
+
+ # 用于保存预测结果视频
+ if not osp.exists(args.save_dir):
+ os.makedirs(args.save_dir)
+ out = cv2.VideoWriter(
+ osp.join(args.save_dir, 'result.avi'),
+ cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps, (width, height))
+ # 开始获取视频帧
+ while cap.isOpened():
+ ret, frame = cap.read()
+ if ret:
+ score_map, im_info = predict(frame, model, test_transforms)
+ cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
+ cur_gray = cv2.resize(cur_gray, (resize_w, resize_h))
+ scoremap = 255 * score_map[:, :, 1]
+ optflow_map = postprocess(cur_gray, scoremap, prev_gray, prev_cfd, \
+ disflow, is_init)
+ prev_gray = cur_gray.copy()
+ prev_cfd = optflow_map.copy()
+ is_init = False
+ optflow_map = cv2.GaussianBlur(optflow_map, (3, 3), 0)
+ optflow_map = threshold_mask(
+ optflow_map, thresh_bg=0.2, thresh_fg=0.8)
+ img_mat = np.repeat(optflow_map[:, :, np.newaxis], 3, axis=2)
+ img_mat = recover(img_mat, im_info)
+ bg_im = np.ones_like(img_mat) * 255
+ comb = (img_mat * frame + (1 - img_mat) * bg_im).astype(
+ np.uint8)
+ out.write(comb)
+ else:
+ break
+ cap.release()
+ out.release()
+
+ else:
+ while cap.isOpened():
+ ret, frame = cap.read()
+ if ret:
+ score_map, im_info = predict(frame, model, test_transforms)
+ cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
+ cur_gray = cv2.resize(cur_gray, (resize_w, resize_h))
+ scoremap = 255 * score_map[:, :, 1]
+ optflow_map = postprocess(cur_gray, scoremap, prev_gray, prev_cfd, \
+ disflow, is_init)
+ prev_gray = cur_gray.copy()
+ prev_cfd = optflow_map.copy()
+ is_init = False
+ # optflow_map = optflow_map/255.0
+ optflow_map = cv2.GaussianBlur(optflow_map, (3, 3), 0)
+ optflow_map = threshold_mask(
+ optflow_map, thresh_bg=0.2, thresh_fg=0.8)
+ img_mat = np.repeat(optflow_map[:, :, np.newaxis], 3, axis=2)
+ img_mat = recover(img_mat, im_info)
+ bg_im = np.ones_like(img_mat) * 255
+ comb = (img_mat * frame + (1 - img_mat) * bg_im).astype(
+ np.uint8)
+ cv2.imshow('HumanSegmentation', comb)
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+ else:
+ break
+ cap.release()
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ video_infer(args)
diff --git a/contrib/LaneNet/requirements.txt b/contrib/LaneNet/requirements.txt
index 2b5eb8643803e1177297d2a766227e274dcdc29d..b084ca5748e061d31190b9e29bdb932f0a2c9ec8 100644
--- a/contrib/LaneNet/requirements.txt
+++ b/contrib/LaneNet/requirements.txt
@@ -2,8 +2,6 @@ pre-commit
yapf == 0.26.0
flake8
pyyaml >= 5.1
-tb-paddle
-tensorboard >= 1.15.0
Pillow
numpy
six
@@ -11,3 +9,4 @@ opencv-python
tqdm
requests
sklearn
+visualdl == 2.0.0-alpha.2
diff --git a/contrib/LaneNet/train.py b/contrib/LaneNet/train.py
index c2f5bee7547eabe9ef5c998b197fbaf59130d679..d9d22ba999cbbc3a9252f258e973612c68fe4ee4 100644
--- a/contrib/LaneNet/train.py
+++ b/contrib/LaneNet/train.py
@@ -78,14 +78,14 @@ def parse_args():
help='debug mode, display detail information of training',
action='store_true')
parser.add_argument(
- '--use_tb',
- dest='use_tb',
- help='whether to record the data during training to Tensorboard',
+ '--use_vdl',
+ dest='use_vdl',
+ help='whether to record the data during training to VisualDL',
action='store_true')
parser.add_argument(
- '--tb_log_dir',
- dest='tb_log_dir',
- help='Tensorboard logging directory',
+ '--vdl_log_dir',
+ dest='vdl_log_dir',
+ help='VisualDL logging directory',
default=None,
type=str)
parser.add_argument(
@@ -327,17 +327,17 @@ def train(cfg):
fetch_list.extend([pred.name, grts.name, masks.name])
# cm = ConfusionMatrix(cfg.DATASET.NUM_CLASSES, streaming=True)
- if args.use_tb:
- if not args.tb_log_dir:
- print_info("Please specify the log directory by --tb_log_dir.")
+ if args.use_vdl:
+ if not args.vdl_log_dir:
+ print_info("Please specify the log directory by --vdl_log_dir.")
exit(1)
- from tb_paddle import SummaryWriter
- log_writer = SummaryWriter(args.tb_log_dir)
+ from visualdl import LogWriter
+ log_writer = LogWriter(args.vdl_log_dir)
# trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
# num_trainers = int(os.environ.get('PADDLE_TRAINERS_NUM', 1))
- global_step = 0
+ step = 0
all_step = cfg.DATASET.TRAIN_TOTAL_IMAGES // cfg.BATCH_SIZE
if cfg.DATASET.TRAIN_TOTAL_IMAGES % cfg.BATCH_SIZE and drop_last != True:
all_step += 1
@@ -377,9 +377,9 @@ def train(cfg):
avg_acc += np.mean(out_acc)
avg_fp += np.mean(out_fp)
avg_fn += np.mean(out_fn)
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
+ if step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
avg_loss /= args.log_steps
avg_seg_loss /= args.log_steps
avg_emb_loss /= args.log_steps
@@ -389,14 +389,14 @@ def train(cfg):
speed = args.log_steps / timer.elapsed_time()
print((
"epoch={} step={} lr={:.5f} loss={:.4f} seg_loss={:.4f} emb_loss={:.4f} accuracy={:.4} fp={:.4} fn={:.4} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss, avg_seg_loss,
+ ).format(epoch, step, lr[0], avg_loss, avg_seg_loss,
avg_emb_loss, avg_acc, avg_fp, avg_fn, speed,
- calculate_eta(all_step - global_step, speed)))
- if args.use_tb:
+ calculate_eta(all_step - step, speed)))
+ if args.use_vdl:
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
- log_writer.add_scalar('Train/lr', lr[0], global_step)
- log_writer.add_scalar('Train/speed', speed, global_step)
+ step)
+ log_writer.add_scalar('Train/lr', lr[0], step)
+ log_writer.add_scalar('Train/speed', speed, step)
sys.stdout.flush()
avg_loss = 0.0
avg_seg_loss = 0.0
@@ -422,14 +422,14 @@ def train(cfg):
ckpt_dir=ckpt_dir,
use_gpu=args.use_gpu,
use_mpio=args.use_mpio)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Evaluate/accuracy', accuracy,
- global_step)
- log_writer.add_scalar('Evaluate/fp', fp, global_step)
- log_writer.add_scalar('Evaluate/fn', fn, global_step)
+ step)
+ log_writer.add_scalar('Evaluate/fp', fp, step)
+ log_writer.add_scalar('Evaluate/fn', fn, step)
- # Use Tensorboard to visualize results
- if args.use_tb and cfg.DATASET.VIS_FILE_LIST is not None:
+ # Use VisualDL to visualize results
+ if args.use_vdl and cfg.DATASET.VIS_FILE_LIST is not None:
visualize(
cfg=cfg,
use_gpu=args.use_gpu,
diff --git a/contrib/LaneNet/utils/config.py b/contrib/LaneNet/utils/config.py
index d1186636c7d2b8004756bdfbaaca74aa47d32b7f..7c2019d44a100b033520138632fc0e7b56d65676 100644
--- a/contrib/LaneNet/utils/config.py
+++ b/contrib/LaneNet/utils/config.py
@@ -68,7 +68,7 @@ cfg.DATASET.VAL_TOTAL_IMAGES = 500
cfg.DATASET.TEST_FILE_LIST = './dataset/cityscapes/test.list'
# 测试数据数量
cfg.DATASET.TEST_TOTAL_IMAGES = 500
-# Tensorboard 可视化的数据集
+# VisualDL 可视化的数据集
cfg.DATASET.VIS_FILE_LIST = None
# 类别数(需包括背景类)
cfg.DATASET.NUM_CLASSES = 19
diff --git a/contrib/README.md b/contrib/README.md
index 7b6a9b8b865f7c573c5e34bb0047ea28a57c52a4..6d70394c00b2e133a1c011f66bbca334b038e81a 100644
--- a/contrib/README.md
+++ b/contrib/README.md
@@ -1,194 +1,43 @@
-# PaddleSeg 特色垂类分割模型
+# PaddleSeg 产业实践
-提供基于PaddlePaddle最新的分割特色模型:
+提供基于PaddlSeg最新的分割特色模型:
-- [人像分割](#人像分割)
-- [人体解析](#人体解析)
-- [车道线分割](#车道线分割)
-- [工业用表分割](#工业用表分割)
-- [在线体验](#在线体验)
+- [人像分割](./HumanSeg)
+- [人体解析](./ACE2P)
+- [车道线分割](./LaneNet)
+- [工业表盘分割](#工业表盘分割)
+- [AIStudio在线教程](#AIStudio在线教程)
-## 人像分割
+## 人像分割 HumanSeg
-**Note:** 本章节所有命令均在`contrib/HumanSeg`目录下执行。
+HumanSeg系列全新升级,提供三个适用于不同场景,包含适用于移动端实时分割场景的模型`HumanSeg-lite`,提供了包含光流的后处理的优化,使人像分割在视频场景中更加顺畅,更多详情请参考[HumanSeg](./HumanSeg)
-```
-cd contrib/HumanSeg
-```
-
-### 1. 模型结构
-
-DeepLabv3+ backbone为Xception65
-
-### 2. 下载模型和数据
-
-执行以下命令下载并解压模型和数据集:
-
-```
-python download_HumanSeg.py
-```
-
-或点击[链接](https://paddleseg.bj.bcebos.com/models/HumanSeg.tgz)进行手动下载,并解压到contrib/HumanSeg文件夹下
-
-
-### 3. 运行
-
-使用GPU预测:
-```
-python -u infer.py --example HumanSeg --use_gpu
-```
-
-
-使用CPU预测:
-```
-python -u infer.py --example HumanSeg
-```
-
-
-预测结果存放在contrib/HumanSeg/HumanSeg/result目录下。
-
-### 4. 预测结果示例:
-
- 原图:
-
- 
-
- 预测结果:
-
- 
-
-
-
-## 人体解析
-
-
-
-人体解析(Human Parsing)是细粒度的语义分割任务,旨在识别像素级别的人类图像的组成部分(例如,身体部位和服装)。本章节使用冠军模型Augmented Context Embedding with Edge Perceiving (ACE2P)进行预测分割。
-
-
-**Note:** 本章节所有命令均在`contrib/ACE2P`目录下执行。
-
-```
-cd contrib/ACE2P
-```
-
-### 1. 模型概述
-
-Augmented Context Embedding with Edge Perceiving (ACE2P)通过融合底层特征、全局上下文信息和边缘细节,端到端训练学习人体解析任务。以ACE2P单人人体解析网络为基础的解决方案在CVPR2019第三届Look into Person (LIP)挑战赛中赢得了全部三个人体解析任务的第一名。详情请参见[ACE2P](./ACE2P)
-
-### 2. 模型下载
-
-执行以下命令下载并解压ACE2P预测模型:
-
-```
-python download_ACE2P.py
-```
-
-或点击[链接](https://paddleseg.bj.bcebos.com/models/ACE2P.tgz)进行手动下载, 并在contrib/ACE2P下解压。
-
-### 3. 数据下载
-
-测试图片共10000张,
-点击 [Baidu_Drive](https://pan.baidu.com/s/1nvqmZBN#list/path=%2Fsharelink2787269280-523292635003760%2FLIP%2FLIP&parentPath=%2Fsharelink2787269280-523292635003760)
-下载Testing_images.zip,或前往LIP数据集官网进行下载。
-下载后解压到contrib/ACE2P/data文件夹下
-
-
-### 4. 运行
+## 人体解析 Human Parsing
-使用GPU预测
-```
-python -u infer.py --example ACE2P --use_gpu
-```
-
-使用CPU预测:
-```
-python -u infer.py --example ACE2P
-```
-
-**NOTE:** 运行该模型需要2G左右显存。由于数据图片较多,预测过程将比较耗时。
-
-#### 5. 预测结果示例:
-
- 原图:
-
- 
-
- 预测结果:
-
- 
-
-### 备注
-
-1. 数据及模型路径等详细配置见ACE2P/HumanSeg/RoadLine下的config.py文件
-2. ACE2P模型需预留2G显存,若显存超可调小FLAGS_fraction_of_gpu_memory_to_use
+人体解析(Human Parsing)是细粒度的语义分割任务,旨在识别像素级别的人类图像的组成部分(例如,身体部位和服装)。ACE2P通过融合底层特征、全局上下文信息和边缘细节,端到端训练学习人体解析任务。以ACE2P单人人体解析网络为基础的解决方案在CVPR2019第三届LIP挑战赛中赢得了全部三个人体解析任务的第一名
+#### ACE2P模型框架图
+
+PaddleSeg提供了ACE2P获得比赛冠军的预训练模型,更多详情请点击[ACE2P](./ACE2P)
-## 车道线分割
+## 车道线分割 LaneNet
-**Note:** 本章节所有命令均在`contrib/RoadLine`目录下执行。
-
-```
-cd contrib/RoadLine
-```
-
-### 1. 模型结构
+PaddleSeg提供了基于LaneNet的车道线分割模型,更多详情请点击[LaneNet](./LaneNet)
-Deeplabv3+ backbone为MobileNetv2
+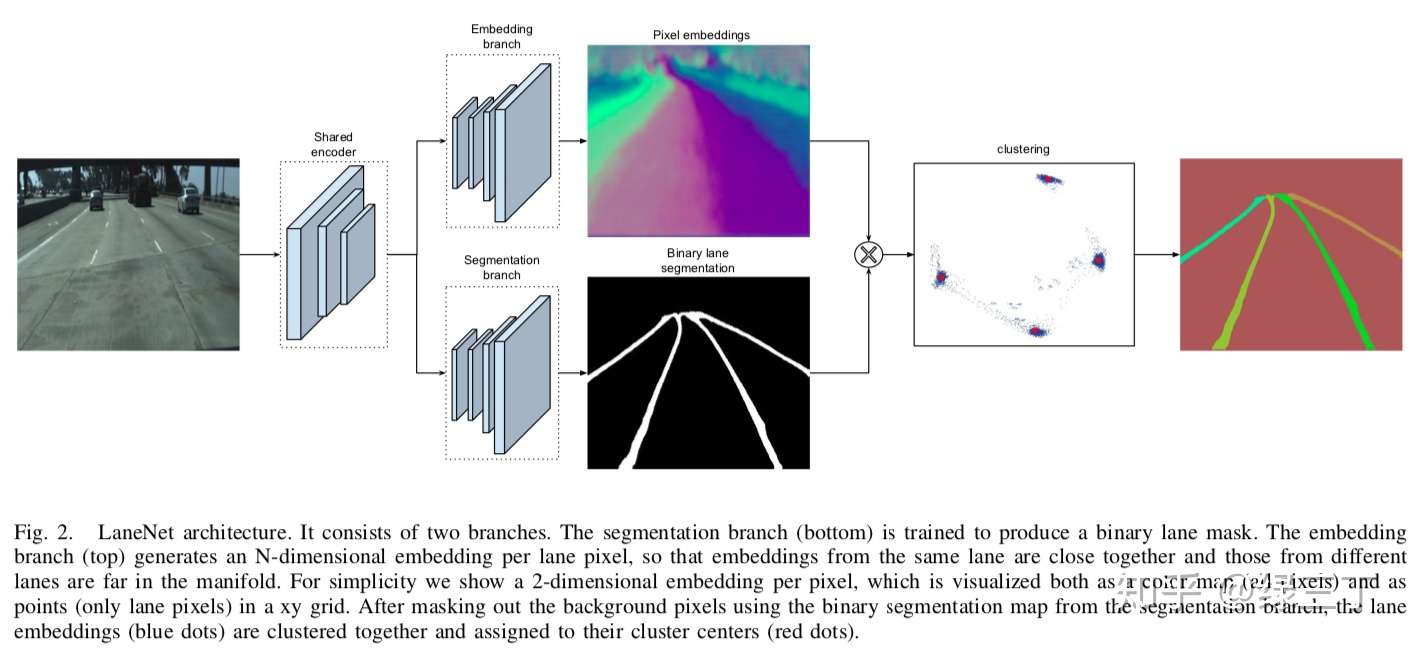
-### 2. 下载模型和数据
-
-
-执行以下命令下载并解压模型和数据集:
-
-```
-python download_RoadLine.py
-```
-
-或点击[链接](https://paddleseg.bj.bcebos.com/inference_model/RoadLine.tgz)进行手动下载,并解压到contrib/RoadLine文件夹下
-
-
-### 3. 运行
-
-使用GPU预测:
-
-```
-python -u infer.py --example RoadLine --use_gpu
-```
-
-
-使用CPU预测:
-
-```
-python -u infer.py --example RoadLine
-```
-
-预测结果存放在contrib/RoadLine/RoadLine/result目录下。
-
-#### 4. 预测结果示例:
-
- 原图:
-
- 
-
- 预测结果:
-
- 
-
-
-
-## 工业用表分割
+## 工业表盘分割
**Note:** 本章节所有命令均在`PaddleSeg`目录下执行。
### 1. 模型结构
-unet
+U-Net
### 2. 数据准备
@@ -198,7 +47,6 @@ unet
python ./contrib/MechanicalIndustryMeter/download_mini_mechanical_industry_meter.py
```
-
### 3. 下载预训练模型
```
@@ -237,7 +85,7 @@ TEST.TEST_MODEL "./contrib/MechanicalIndustryMeter/unet_mechanical_industry_mete

-## 在线体验
+## AIStudio在线教程
PaddleSeg在AI Studio平台上提供了在线体验的教程,欢迎体验:
@@ -246,5 +94,3 @@ PaddleSeg在AI Studio平台上提供了在线体验的教程,欢迎体验:
|工业质检|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/184392)|
|人像分割|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/188833)|
|特色垂类模型|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/226710)|
-
-
diff --git a/contrib/RealTimeHumanSeg/README.md b/contrib/RealTimeHumanSeg/README.md
deleted file mode 100644
index e8693e11e4d66b9a2ee04bf1e03a5704a95fb426..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/README.md
+++ /dev/null
@@ -1,28 +0,0 @@
-# 实时人像分割预测部署
-
-本模型基于飞浆开源的人像分割模型,并做了大量的针对视频的光流追踪优化,提供了完整的支持视频流的实时人像分割解决方案,并提供了高性能的`Python`和`C++`集成部署方案,以满足不同场景的需求。
-
-
-## 模型下载
-
-支持的模型文件如下,请根据应用场景选择合适的模型:
-|模型文件 | 说明 |
-|---|---|
-|[shv75_deeplab_0303_quant](https://paddleseg.bj.bcebos.com/deploy/models/shv75_0303_quant.zip) | 小模型, 适合轻量级计算环境 |
-|[shv75_deeplab_0303](https://paddleseg.bj.bcebos.com/deploy/models/shv75_deeplab_0303.zip)| 小模型,适合轻量级计算环境 |
-|[deeplabv3_xception_humanseg](https://paddleseg.bj.bcebos.com/deploy/models/deeplabv3_xception_humanseg.zip) | 服务端GPU环境 |
-
-**注意:下载后解压到合适的路径,后续该路径将做为预测参数用于加载模型。**
-
-
-## 预测部署
-- [Python预测部署](./python)
-- [C++预测部署](./cpp)
-
-## 效果预览
-
-
-
+
+**NOTE**:
+
+视频分割处理时间需要几分钟,请耐心等待。
+
+## 训练
+使用下述命令基于与训练模型进行Fine-tuning,请确保选用的模型结构`model_type`与模型参数`pretrained_weights`匹配。
+```bash
+python train.py --model_type HumanSegMobile \
+--save_dir output/ \
+--data_dir data/mini_supervisely \
+--train_list data/mini_supervisely/train.txt \
+--val_list data/mini_supervisely/val.txt \
+--pretrained_weights pretrained_weights/humanseg_mobile_ckpt \
+--batch_size 8 \
+--learning_rate 0.001 \
+--num_epochs 10 \
+--image_shape 192 192
+```
+其中参数含义如下:
+* `--model_type`: 模型类型,可选项为:HumanSegServer、HumanSegMobile和HumanSegLite
+* `--save_dir`: 模型保存路径
+* `--data_dir`: 数据集路径
+* `--train_list`: 训练集列表路径
+* `--val_list`: 验证集列表路径
+* `--pretrained_weights`: 预训练模型路径
+* `--batch_size`: 批大小
+* `--learning_rate`: 初始学习率
+* `--num_epochs`: 训练轮数
+* `--image_shape`: 网络输入图像大小(w, h)
+
+更多命令行帮助可运行下述命令进行查看:
+```bash
+python train.py --help
+```
+**NOTE**
+可通过更换`--model_type`变量与对应的`--pretrained_weights`使用不同的模型快速尝试。
+
+## 评估
+使用下述命令进行评估
+```bash
+python val.py --model_dir output/best_model \
+--data_dir data/mini_supervisely \
+--val_list data/mini_supervisely/val.txt \
+--image_shape 192 192
+```
+其中参数含义如下:
+* `--model_dir`: 模型路径
+* `--data_dir`: 数据集路径
+* `--val_list`: 验证集列表路径
+* `--image_shape`: 网络输入图像大小(w, h)
+
+## 预测
+使用下述命令进行预测
+```bash
+python infer.py --model_dir output/best_model \
+--data_dir data/mini_supervisely \
+--test_list data/mini_supervisely/test.txt \
+--image_shape 192 192
+```
+其中参数含义如下:
+* `--model_dir`: 模型路径
+* `--data_dir`: 数据集路径
+* `--test_list`: 测试集列表路径
+* `--image_shape`: 网络输入图像大小(w, h)
+
+## 模型导出
+```bash
+python export.py --model_dir output/best_model \
+--save_dir output/export
+```
+其中参数含义如下:
+* `--model_dir`: 模型路径
+* `--save_dir`: 导出模型保存路径
+
+## 离线量化
+```bash
+python quant_offline.py --model_dir output/best_model \
+--data_dir data/mini_supervisely \
+--quant_list data/mini_supervisely/val.txt \
+--save_dir output/quant_offline \
+--image_shape 192 192
+```
+其中参数含义如下:
+* `--model_dir`: 待量化模型路径
+* `--data_dir`: 数据集路径
+* `--quant_list`: 量化数据集列表路径,一般直接选择训练集或验证集
+* `--save_dir`: 量化模型保存路径
+* `--image_shape`: 网络输入图像大小(w, h)
+
+## 在线量化
+利用float训练模型进行在线量化。
+```bash
+python quant_online.py --model_type HumanSegMobile \
+--save_dir output/quant_online \
+--data_dir data/mini_supervisely \
+--train_list data/mini_supervisely/train.txt \
+--val_list data/mini_supervisely/val.txt \
+--pretrained_weights output/best_model \
+--batch_size 2 \
+--learning_rate 0.001 \
+--num_epochs 2 \
+--image_shape 192 192
+```
+其中参数含义如下:
+* `--model_type`: 模型类型,可选项为:HumanSegServer、HumanSegMobile和HumanSegLite
+* `--save_dir`: 模型保存路径
+* `--data_dir`: 数据集路径
+* `--train_list`: 训练集列表路径
+* `--val_list`: 验证集列表路径
+* `--pretrained_weights`: 预训练模型路径,
+* `--batch_size`: 批大小
+* `--learning_rate`: 初始学习率
+* `--num_epochs`: 训练轮数
+* `--image_shape`: 网络输入图像大小(w, h)
diff --git a/contrib/HumanSeg/__init__.py b/contrib/HumanSeg/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/contrib/HumanSeg/config.py b/contrib/HumanSeg/config.py
deleted file mode 100644
index 8c661b51c011e958c1c7f88b2b96b25b662213ae..0000000000000000000000000000000000000000
--- a/contrib/HumanSeg/config.py
+++ /dev/null
@@ -1,26 +0,0 @@
-# -*- coding: utf-8 -*-
-from utils.util import AttrDict, get_arguments, merge_cfg_from_args
-import os
-
-args = get_arguments()
-cfg = AttrDict()
-
-# 待预测图像所在路径
-cfg.data_dir = os.path.join(args.example , "data", "test_images")
-# 待预测图像名称列表
-cfg.data_list_file = os.path.join(args.example , "data", "test.txt")
-# 模型加载路径
-cfg.model_path = os.path.join(args.example , "model")
-# 预测结果保存路径
-cfg.vis_dir = os.path.join(args.example , "result")
-
-# 预测类别数
-cfg.class_num = 2
-# 均值, 图像预处理减去的均值
-cfg.MEAN = 104.008, 116.669, 122.675
-# 标准差,图像预处理除以标准差
-cfg.STD = 1.0, 1.0, 1.0
-# 待预测图像输入尺寸
-cfg.input_size = 513, 513
-
-merge_cfg_from_args(args, cfg)
diff --git a/contrib/HumanSeg/data/download_data.py b/contrib/HumanSeg/data/download_data.py
new file mode 100644
index 0000000000000000000000000000000000000000..a788df0f7fe84067e752a37ed1601818cf168557
--- /dev/null
+++ b/contrib/HumanSeg/data/download_data.py
@@ -0,0 +1,40 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+
+LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
+TEST_PATH = os.path.join(LOCAL_PATH, "../../../", "test")
+sys.path.append(TEST_PATH)
+
+from test_utils import download_file_and_uncompress
+
+
+def download_data(savepath, extrapath):
+ url = "https://paddleseg.bj.bcebos.com/humanseg/data/mini_supervisely.zip"
+ download_file_and_uncompress(
+ url=url, savepath=savepath, extrapath=extrapath)
+
+ url = "https://paddleseg.bj.bcebos.com/humanseg/data/video_test.zip"
+ download_file_and_uncompress(
+ url=url,
+ savepath=savepath,
+ extrapath=extrapath,
+ extraname='video_test.mp4')
+
+
+if __name__ == "__main__":
+ download_data(LOCAL_PATH, LOCAL_PATH)
+ print("Data download finish!")
diff --git a/contrib/HumanSeg/datasets/__init__.py b/contrib/HumanSeg/datasets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..81d3255640a0353943cdc9e968f17e3ea765b390
--- /dev/null
+++ b/contrib/HumanSeg/datasets/__init__.py
@@ -0,0 +1,15 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .dataset import Dataset
diff --git a/contrib/HumanSeg/datasets/dataset.py b/contrib/HumanSeg/datasets/dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..263c7af471444c49966c56f72000838a7c55c41e
--- /dev/null
+++ b/contrib/HumanSeg/datasets/dataset.py
@@ -0,0 +1,274 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os.path as osp
+from threading import Thread
+import multiprocessing
+import collections
+import numpy as np
+import six
+import sys
+import copy
+import random
+import platform
+import chardet
+import utils.logging as logging
+
+
+class EndSignal():
+ pass
+
+
+def is_pic(img_name):
+ valid_suffix = ['JPEG', 'jpeg', 'JPG', 'jpg', 'BMP', 'bmp', 'PNG', 'png']
+ suffix = img_name.split('.')[-1]
+ if suffix not in valid_suffix:
+ return False
+ return True
+
+
+def is_valid(sample):
+ if sample is None:
+ return False
+ if isinstance(sample, tuple):
+ for s in sample:
+ if s is None:
+ return False
+ elif isinstance(s, np.ndarray) and s.size == 0:
+ return False
+ elif isinstance(s, collections.Sequence) and len(s) == 0:
+ return False
+ return True
+
+
+def get_encoding(path):
+ f = open(path, 'rb')
+ data = f.read()
+ file_encoding = chardet.detect(data).get('encoding')
+ return file_encoding
+
+
+def multithread_reader(mapper,
+ reader,
+ num_workers=4,
+ buffer_size=1024,
+ batch_size=8,
+ drop_last=True):
+ from queue import Queue
+ end = EndSignal()
+
+ # define a worker to read samples from reader to in_queue
+ def read_worker(reader, in_queue):
+ for i in reader():
+ in_queue.put(i)
+ in_queue.put(end)
+
+ # define a worker to handle samples from in_queue by mapper
+ # and put mapped samples into out_queue
+ def handle_worker(in_queue, out_queue, mapper):
+ sample = in_queue.get()
+ while not isinstance(sample, EndSignal):
+ if len(sample) == 2:
+ r = mapper(sample[0], sample[1])
+ elif len(sample) == 3:
+ r = mapper(sample[0], sample[1], sample[2])
+ else:
+ raise Exception('The sample\'s length must be 2 or 3.')
+ if is_valid(r):
+ out_queue.put(r)
+ sample = in_queue.get()
+ in_queue.put(end)
+ out_queue.put(end)
+
+ def xreader():
+ in_queue = Queue(buffer_size)
+ out_queue = Queue(buffer_size)
+ # start a read worker in a thread
+ target = read_worker
+ t = Thread(target=target, args=(reader, in_queue))
+ t.daemon = True
+ t.start()
+ # start several handle_workers
+ target = handle_worker
+ args = (in_queue, out_queue, mapper)
+ workers = []
+ for i in range(num_workers):
+ worker = Thread(target=target, args=args)
+ worker.daemon = True
+ workers.append(worker)
+ for w in workers:
+ w.start()
+
+ batch_data = []
+ sample = out_queue.get()
+ while not isinstance(sample, EndSignal):
+ batch_data.append(sample)
+ if len(batch_data) == batch_size:
+ yield batch_data
+ batch_data = []
+ sample = out_queue.get()
+ finish = 1
+ while finish < num_workers:
+ sample = out_queue.get()
+ if isinstance(sample, EndSignal):
+ finish += 1
+ else:
+ batch_data.append(sample)
+ if len(batch_data) == batch_size:
+ yield batch_data
+ batch_data = []
+ if not drop_last and len(batch_data) != 0:
+ yield batch_data
+ batch_data = []
+
+ return xreader
+
+
+def multiprocess_reader(mapper,
+ reader,
+ num_workers=4,
+ buffer_size=1024,
+ batch_size=8,
+ drop_last=True):
+ from .shared_queue import SharedQueue as Queue
+
+ def _read_into_queue(samples, mapper, queue):
+ end = EndSignal()
+ try:
+ for sample in samples:
+ if sample is None:
+ raise ValueError("sample has None")
+ if len(sample) == 2:
+ result = mapper(sample[0], sample[1])
+ elif len(sample) == 3:
+ result = mapper(sample[0], sample[1], sample[2])
+ else:
+ raise Exception('The sample\'s length must be 2 or 3.')
+ if is_valid(result):
+ queue.put(result)
+ queue.put(end)
+ except:
+ queue.put("")
+ six.reraise(*sys.exc_info())
+
+ def queue_reader():
+ queue = Queue(buffer_size, memsize=3 * 1024**3)
+ total_samples = [[] for i in range(num_workers)]
+ for i, sample in enumerate(reader()):
+ index = i % num_workers
+ total_samples[index].append(sample)
+ for i in range(num_workers):
+ p = multiprocessing.Process(
+ target=_read_into_queue, args=(total_samples[i], mapper, queue))
+ p.start()
+
+ finish_num = 0
+ batch_data = list()
+ while finish_num < num_workers:
+ sample = queue.get()
+ if isinstance(sample, EndSignal):
+ finish_num += 1
+ elif sample == "":
+ raise ValueError("multiprocess reader raises an exception")
+ else:
+ batch_data.append(sample)
+ if len(batch_data) == batch_size:
+ yield batch_data
+ batch_data = []
+ if len(batch_data) != 0 and not drop_last:
+ yield batch_data
+ batch_data = []
+
+ return queue_reader
+
+
+class Dataset:
+ def __init__(self,
+ data_dir,
+ file_list,
+ label_list=None,
+ transforms=None,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False):
+ if num_workers == 'auto':
+ import multiprocessing as mp
+ num_workers = mp.cpu_count() // 2 if mp.cpu_count() // 2 < 8 else 8
+ if transforms is None:
+ raise Exception("transform should be defined.")
+ self.transforms = transforms
+ self.num_workers = num_workers
+ self.buffer_size = buffer_size
+ self.parallel_method = parallel_method
+ self.shuffle = shuffle
+
+ self.file_list = list()
+ self.labels = list()
+ self._epoch = 0
+
+ if label_list is not None:
+ with open(label_list, encoding=get_encoding(label_list)) as f:
+ for line in f:
+ item = line.strip()
+ self.labels.append(item)
+
+ with open(file_list, encoding=get_encoding(file_list)) as f:
+ for line in f:
+ items = line.strip().split()
+ if not is_pic(items[0]):
+ continue
+ full_path_im = osp.join(data_dir, items[0])
+ full_path_label = osp.join(data_dir, items[1])
+ if not osp.exists(full_path_im):
+ raise IOError(
+ 'The image file {} is not exist!'.format(full_path_im))
+ if not osp.exists(full_path_label):
+ raise IOError('The image file {} is not exist!'.format(
+ full_path_label))
+ self.file_list.append([full_path_im, full_path_label])
+ self.num_samples = len(self.file_list)
+ logging.info("{} samples in file {}".format(
+ len(self.file_list), file_list))
+
+ def iterator(self):
+ self._epoch += 1
+ self._pos = 0
+ files = copy.deepcopy(self.file_list)
+ if self.shuffle:
+ random.shuffle(files)
+ files = files[:self.num_samples]
+ self.num_samples = len(files)
+ for f in files:
+ label_path = f[1]
+ sample = [f[0], None, label_path]
+ yield sample
+
+ def generator(self, batch_size=1, drop_last=True):
+ self.batch_size = batch_size
+ parallel_reader = multithread_reader
+ if self.parallel_method == "process":
+ if platform.platform().startswith("Windows"):
+ logging.debug(
+ "multiprocess_reader is not supported in Windows platform, force to use multithread_reader."
+ )
+ else:
+ parallel_reader = multiprocess_reader
+ return parallel_reader(
+ self.transforms,
+ self.iterator,
+ num_workers=self.num_workers,
+ buffer_size=self.buffer_size,
+ batch_size=batch_size,
+ drop_last=drop_last)
diff --git a/contrib/HumanSeg/datasets/shared_queue/__init__.py b/contrib/HumanSeg/datasets/shared_queue/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4c3990e67d6ade96d20abd1aa34b34b1ff891cb
--- /dev/null
+++ b/contrib/HumanSeg/datasets/shared_queue/__init__.py
@@ -0,0 +1,25 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+
+__all__ = ['SharedBuffer', 'SharedMemoryMgr', 'SharedQueue']
+
+from .sharedmemory import SharedBuffer
+from .sharedmemory import SharedMemoryMgr
+from .sharedmemory import SharedMemoryError
+from .queue import SharedQueue
diff --git a/contrib/HumanSeg/datasets/shared_queue/queue.py b/contrib/HumanSeg/datasets/shared_queue/queue.py
new file mode 100644
index 0000000000000000000000000000000000000000..157df0a51ee3d552c810bafe5e826c1072c75649
--- /dev/null
+++ b/contrib/HumanSeg/datasets/shared_queue/queue.py
@@ -0,0 +1,102 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import sys
+import six
+if six.PY3:
+ import pickle
+ from io import BytesIO as StringIO
+else:
+ import cPickle as pickle
+ from cStringIO import StringIO
+
+import logging
+import traceback
+import multiprocessing as mp
+from multiprocessing.queues import Queue
+from .sharedmemory import SharedMemoryMgr
+
+logger = logging.getLogger(__name__)
+
+
+class SharedQueueError(ValueError):
+ """ SharedQueueError
+ """
+ pass
+
+
+class SharedQueue(Queue):
+ """ a Queue based on shared memory to communicate data between Process,
+ and it's interface is compatible with 'multiprocessing.queues.Queue'
+ """
+
+ def __init__(self, maxsize=0, mem_mgr=None, memsize=None, pagesize=None):
+ """ init
+ """
+ if six.PY3:
+ super(SharedQueue, self).__init__(maxsize, ctx=mp.get_context())
+ else:
+ super(SharedQueue, self).__init__(maxsize)
+
+ if mem_mgr is not None:
+ self._shared_mem = mem_mgr
+ else:
+ self._shared_mem = SharedMemoryMgr(
+ capacity=memsize, pagesize=pagesize)
+
+ def put(self, obj, **kwargs):
+ """ put an object to this queue
+ """
+ obj = pickle.dumps(obj, -1)
+ buff = None
+ try:
+ buff = self._shared_mem.malloc(len(obj))
+ buff.put(obj)
+ super(SharedQueue, self).put(buff, **kwargs)
+ except Exception as e:
+ stack_info = traceback.format_exc()
+ err_msg = 'failed to put a element to SharedQueue '\
+ 'with stack info[%s]' % (stack_info)
+ logger.warn(err_msg)
+
+ if buff is not None:
+ buff.free()
+ raise e
+
+ def get(self, **kwargs):
+ """ get an object from this queue
+ """
+ buff = None
+ try:
+ buff = super(SharedQueue, self).get(**kwargs)
+ data = buff.get()
+ return pickle.load(StringIO(data))
+ except Exception as e:
+ stack_info = traceback.format_exc()
+ err_msg = 'failed to get element from SharedQueue '\
+ 'with stack info[%s]' % (stack_info)
+ logger.warn(err_msg)
+ raise e
+ finally:
+ if buff is not None:
+ buff.free()
+
+ def release(self):
+ self._shared_mem.release()
+ self._shared_mem = None
diff --git a/contrib/HumanSeg/datasets/shared_queue/sharedmemory.py b/contrib/HumanSeg/datasets/shared_queue/sharedmemory.py
new file mode 100644
index 0000000000000000000000000000000000000000..451faa2911185fe279627dfac76b89aa24c5c706
--- /dev/null
+++ b/contrib/HumanSeg/datasets/shared_queue/sharedmemory.py
@@ -0,0 +1,534 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# utils for memory management which is allocated on sharedmemory,
+# note that these structures may not be thread-safe
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import os
+import time
+import math
+import struct
+import sys
+import six
+
+if six.PY3:
+ import pickle
+else:
+ import cPickle as pickle
+
+import json
+import uuid
+import random
+import numpy as np
+import weakref
+import logging
+from multiprocessing import Lock
+from multiprocessing import RawArray
+
+logger = logging.getLogger(__name__)
+
+
+class SharedMemoryError(ValueError):
+ """ SharedMemoryError
+ """
+ pass
+
+
+class SharedBufferError(SharedMemoryError):
+ """ SharedBufferError
+ """
+ pass
+
+
+class MemoryFullError(SharedMemoryError):
+ """ MemoryFullError
+ """
+
+ def __init__(self, errmsg=''):
+ super(MemoryFullError, self).__init__()
+ self.errmsg = errmsg
+
+
+def memcopy(dst, src, offset=0, length=None):
+ """ copy data from 'src' to 'dst' in bytes
+ """
+ length = length if length is not None else len(src)
+ assert type(dst) == np.ndarray, 'invalid type for "dst" in memcopy'
+ if type(src) is not np.ndarray:
+ if type(src) is str and six.PY3:
+ src = src.encode()
+ src = np.frombuffer(src, dtype='uint8', count=len(src))
+
+ dst[:] = src[offset:offset + length]
+
+
+class SharedBuffer(object):
+ """ Buffer allocated from SharedMemoryMgr, and it stores data on shared memory
+
+ note that:
+ every instance of this should be freed explicitely by calling 'self.free'
+ """
+
+ def __init__(self, owner, capacity, pos, size=0, alloc_status=''):
+ """ Init
+
+ Args:
+ owner (str): manager to own this buffer
+ capacity (int): capacity in bytes for this buffer
+ pos (int): page position in shared memory
+ size (int): bytes already used
+ alloc_status (str): debug info about allocator when allocate this
+ """
+ self._owner = owner
+ self._cap = capacity
+ self._pos = pos
+ self._size = size
+ self._alloc_status = alloc_status
+ assert self._pos >= 0 and self._cap > 0, \
+ "invalid params[%d:%d] to construct SharedBuffer" \
+ % (self._pos, self._cap)
+
+ def owner(self):
+ """ get owner
+ """
+ return SharedMemoryMgr.get_mgr(self._owner)
+
+ def put(self, data, override=False):
+ """ put data to this buffer
+
+ Args:
+ data (str): data to be stored in this buffer
+
+ Returns:
+ None
+
+ Raises:
+ SharedMemoryError when not enough space in this buffer
+ """
+ assert type(data) in [str, bytes], \
+ 'invalid type[%s] for SharedBuffer::put' % (str(type(data)))
+ if self._size > 0 and not override:
+ raise SharedBufferError('already has already been setted before')
+
+ if self.capacity() < len(data):
+ raise SharedBufferError('data[%d] is larger than size of buffer[%s]'\
+ % (len(data), str(self)))
+
+ self.owner().put_data(self, data)
+ self._size = len(data)
+
+ def get(self, offset=0, size=None, no_copy=True):
+ """ get the data stored this buffer
+
+ Args:
+ offset (int): position for the start point to 'get'
+ size (int): size to get
+
+ Returns:
+ data (np.ndarray('uint8')): user's data in numpy
+ which is passed in by 'put'
+ None: if no data stored in
+ """
+ offset = offset if offset >= 0 else self._size + offset
+ if self._size <= 0:
+ return None
+
+ size = self._size if size is None else size
+ assert offset + size <= self._cap, 'invalid offset[%d] '\
+ 'or size[%d] for capacity[%d]' % (offset, size, self._cap)
+ return self.owner().get_data(self, offset, size, no_copy=no_copy)
+
+ def size(self):
+ """ bytes of used memory
+ """
+ return self._size
+
+ def resize(self, size):
+ """ resize the used memory to 'size', should not be greater than capacity
+ """
+ assert size >= 0 and size <= self._cap, \
+ "invalid size[%d] for resize" % (size)
+
+ self._size = size
+
+ def capacity(self):
+ """ size of allocated memory
+ """
+ return self._cap
+
+ def __str__(self):
+ """ human readable format
+ """
+ return "SharedBuffer(owner:%s, pos:%d, size:%d, "\
+ "capacity:%d, alloc_status:[%s], pid:%d)" \
+ % (str(self._owner), self._pos, self._size, \
+ self._cap, self._alloc_status, os.getpid())
+
+ def free(self):
+ """ free this buffer to it's owner
+ """
+ if self._owner is not None:
+ self.owner().free(self)
+ self._owner = None
+ self._cap = 0
+ self._pos = -1
+ self._size = 0
+ return True
+ else:
+ return False
+
+
+class PageAllocator(object):
+ """ allocator used to malloc and free shared memory which
+ is split into pages
+ """
+ s_allocator_header = 12
+
+ def __init__(self, base, total_pages, page_size):
+ """ init
+ """
+ self._magic_num = 1234321000 + random.randint(100, 999)
+ self._base = base
+ self._total_pages = total_pages
+ self._page_size = page_size
+
+ header_pages = int(
+ math.ceil((total_pages + self.s_allocator_header) / page_size))
+
+ self._header_pages = header_pages
+ self._free_pages = total_pages - header_pages
+ self._header_size = self._header_pages * page_size
+ self._reset()
+
+ def _dump_alloc_info(self, fname):
+ hpages, tpages, pos, used = self.header()
+
+ start = self.s_allocator_header
+ end = start + self._page_size * hpages
+ alloc_flags = self._base[start:end].tostring()
+ info = {
+ 'magic_num': self._magic_num,
+ 'header_pages': hpages,
+ 'total_pages': tpages,
+ 'pos': pos,
+ 'used': used
+ }
+ info['alloc_flags'] = alloc_flags
+ fname = fname + '.' + str(uuid.uuid4())[:6]
+ with open(fname, 'wb') as f:
+ f.write(pickle.dumps(info, -1))
+ logger.warn('dump alloc info to file[%s]' % (fname))
+
+ def _reset(self):
+ alloc_page_pos = self._header_pages
+ used_pages = self._header_pages
+ header_info = struct.pack(
+ str('III'), self._magic_num, alloc_page_pos, used_pages)
+ assert len(header_info) == self.s_allocator_header, \
+ 'invalid size of header_info'
+
+ memcopy(self._base[0:self.s_allocator_header], header_info)
+ self.set_page_status(0, self._header_pages, '1')
+ self.set_page_status(self._header_pages, self._free_pages, '0')
+
+ def header(self):
+ """ get header info of this allocator
+ """
+ header_str = self._base[0:self.s_allocator_header].tostring()
+ magic, pos, used = struct.unpack(str('III'), header_str)
+
+ assert magic == self._magic_num, \
+ 'invalid header magic[%d] in shared memory' % (magic)
+ return self._header_pages, self._total_pages, pos, used
+
+ def empty(self):
+ """ are all allocatable pages available
+ """
+ header_pages, pages, pos, used = self.header()
+ return header_pages == used
+
+ def full(self):
+ """ are all allocatable pages used
+ """
+ header_pages, pages, pos, used = self.header()
+ return header_pages + used == pages
+
+ def __str__(self):
+ header_pages, pages, pos, used = self.header()
+ desc = '{page_info[magic:%d,total:%d,used:%d,header:%d,alloc_pos:%d,pagesize:%d]}' \
+ % (self._magic_num, pages, used, header_pages, pos, self._page_size)
+ return 'PageAllocator:%s' % (desc)
+
+ def set_alloc_info(self, alloc_pos, used_pages):
+ """ set allocating position to new value
+ """
+ memcopy(self._base[4:12], struct.pack(str('II'), alloc_pos, used_pages))
+
+ def set_page_status(self, start, page_num, status):
+ """ set pages from 'start' to 'end' with new same status 'status'
+ """
+ assert status in ['0', '1'], 'invalid status[%s] for page status '\
+ 'in allocator[%s]' % (status, str(self))
+ start += self.s_allocator_header
+ end = start + page_num
+ assert start >= 0 and end <= self._header_size, 'invalid end[%d] of pages '\
+ 'in allocator[%s]' % (end, str(self))
+ memcopy(self._base[start:end], str(status * page_num))
+
+ def get_page_status(self, start, page_num, ret_flag=False):
+ start += self.s_allocator_header
+ end = start + page_num
+ assert start >= 0 and end <= self._header_size, 'invalid end[%d] of pages '\
+ 'in allocator[%s]' % (end, str(self))
+ status = self._base[start:end].tostring().decode()
+ if ret_flag:
+ return status
+
+ zero_num = status.count('0')
+ if zero_num == 0:
+ return (page_num, 1)
+ else:
+ return (zero_num, 0)
+
+ def malloc_page(self, page_num):
+ header_pages, pages, pos, used = self.header()
+ end = pos + page_num
+ if end > pages:
+ pos = self._header_pages
+ end = pos + page_num
+
+ start_pos = pos
+ flags = ''
+ while True:
+ # maybe flags already has some '0' pages,
+ # so just check 'page_num - len(flags)' pages
+ flags = self.get_page_status(pos, page_num, ret_flag=True)
+
+ if flags.count('0') == page_num:
+ break
+
+ # not found enough pages, so shift to next few pages
+ free_pos = flags.rfind('1') + 1
+ pos += free_pos
+ end = pos + page_num
+ if end > pages:
+ pos = self._header_pages
+ end = pos + page_num
+ flags = ''
+
+ # not found available pages after scan all pages
+ if pos <= start_pos and end >= start_pos:
+ logger.debug('not found available pages after scan all pages')
+ break
+
+ page_status = (flags.count('0'), 0)
+ if page_status != (page_num, 0):
+ free_pages = self._total_pages - used
+ if free_pages == 0:
+ err_msg = 'all pages have been used:%s' % (str(self))
+ else:
+ err_msg = 'not found available pages with page_status[%s] '\
+ 'and %d free pages' % (str(page_status), free_pages)
+ err_msg = 'failed to malloc %d pages at pos[%d] for reason[%s] and allocator status[%s]' \
+ % (page_num, pos, err_msg, str(self))
+ raise MemoryFullError(err_msg)
+
+ self.set_page_status(pos, page_num, '1')
+ used += page_num
+ self.set_alloc_info(end, used)
+ return pos
+
+ def free_page(self, start, page_num):
+ """ free 'page_num' pages start from 'start'
+ """
+ page_status = self.get_page_status(start, page_num)
+ assert page_status == (page_num, 1), \
+ 'invalid status[%s] when free [%d, %d]' \
+ % (str(page_status), start, page_num)
+ self.set_page_status(start, page_num, '0')
+ _, _, pos, used = self.header()
+ used -= page_num
+ self.set_alloc_info(pos, used)
+
+
+DEFAULT_SHARED_MEMORY_SIZE = 1024 * 1024 * 1024
+
+
+class SharedMemoryMgr(object):
+ """ manage a continouse block of memory, provide
+ 'malloc' to allocate new buffer, and 'free' to free buffer
+ """
+ s_memory_mgrs = weakref.WeakValueDictionary()
+ s_mgr_num = 0
+ s_log_statis = False
+
+ @classmethod
+ def get_mgr(cls, id):
+ """ get a SharedMemoryMgr with size of 'capacity'
+ """
+ assert id in cls.s_memory_mgrs, 'invalid id[%s] for memory managers' % (
+ id)
+ return cls.s_memory_mgrs[id]
+
+ def __init__(self, capacity=None, pagesize=None):
+ """ init
+ """
+ logger.debug('create SharedMemoryMgr')
+
+ pagesize = 64 * 1024 if pagesize is None else pagesize
+ assert type(pagesize) is int, "invalid type of pagesize[%s]" \
+ % (str(pagesize))
+
+ capacity = DEFAULT_SHARED_MEMORY_SIZE if capacity is None else capacity
+ assert type(capacity) is int, "invalid type of capacity[%s]" \
+ % (str(capacity))
+
+ assert capacity > 0, '"size of shared memory should be greater than 0'
+ self._released = False
+ self._cap = capacity
+ self._page_size = pagesize
+
+ assert self._cap % self._page_size == 0, \
+ "capacity[%d] and pagesize[%d] are not consistent" \
+ % (self._cap, self._page_size)
+ self._total_pages = self._cap // self._page_size
+
+ self._pid = os.getpid()
+ SharedMemoryMgr.s_mgr_num += 1
+ self._id = self._pid * 100 + SharedMemoryMgr.s_mgr_num
+ SharedMemoryMgr.s_memory_mgrs[self._id] = self
+ self._locker = Lock()
+ self._setup()
+
+ def _setup(self):
+ self._shared_mem = RawArray('c', self._cap)
+ self._base = np.frombuffer(
+ self._shared_mem, dtype='uint8', count=self._cap)
+ self._locker.acquire()
+ try:
+ self._allocator = PageAllocator(self._base, self._total_pages,
+ self._page_size)
+ finally:
+ self._locker.release()
+
+ def malloc(self, size, wait=True):
+ """ malloc a new SharedBuffer
+
+ Args:
+ size (int): buffer size to be malloc
+ wait (bool): whether to wait when no enough memory
+
+ Returns:
+ SharedBuffer
+
+ Raises:
+ SharedMemoryError when not found available memory
+ """
+ page_num = int(math.ceil(size / self._page_size))
+ size = page_num * self._page_size
+
+ start = None
+ ct = 0
+ errmsg = ''
+ while True:
+ self._locker.acquire()
+ try:
+ start = self._allocator.malloc_page(page_num)
+ alloc_status = str(self._allocator)
+ except MemoryFullError as e:
+ start = None
+ errmsg = e.errmsg
+ if not wait:
+ raise e
+ finally:
+ self._locker.release()
+
+ if start is None:
+ time.sleep(0.1)
+ if ct % 100 == 0:
+ logger.warn('not enough space for reason[%s]' % (errmsg))
+
+ ct += 1
+ else:
+ break
+
+ return SharedBuffer(self._id, size, start, alloc_status=alloc_status)
+
+ def free(self, shared_buf):
+ """ free a SharedBuffer
+
+ Args:
+ shared_buf (SharedBuffer): buffer to be freed
+
+ Returns:
+ None
+
+ Raises:
+ SharedMemoryError when failed to release this buffer
+ """
+ assert shared_buf._owner == self._id, "invalid shared_buf[%s] "\
+ "for it's not allocated from me[%s]" % (str(shared_buf), str(self))
+ cap = shared_buf.capacity()
+ start_page = shared_buf._pos
+ page_num = cap // self._page_size
+
+ #maybe we don't need this lock here
+ self._locker.acquire()
+ try:
+ self._allocator.free_page(start_page, page_num)
+ finally:
+ self._locker.release()
+
+ def put_data(self, shared_buf, data):
+ """ fill 'data' into 'shared_buf'
+ """
+ assert len(data) <= shared_buf.capacity(), 'too large data[%d] '\
+ 'for this buffer[%s]' % (len(data), str(shared_buf))
+ start = shared_buf._pos * self._page_size
+ end = start + len(data)
+ assert start >= 0 and end <= self._cap, "invalid start "\
+ "position[%d] when put data to buff:%s" % (start, str(shared_buf))
+ self._base[start:end] = np.frombuffer(data, 'uint8', len(data))
+
+ def get_data(self, shared_buf, offset, size, no_copy=True):
+ """ extract 'data' from 'shared_buf' in range [offset, offset + size)
+ """
+ start = shared_buf._pos * self._page_size
+ start += offset
+ if no_copy:
+ return self._base[start:start + size]
+ else:
+ return self._base[start:start + size].tostring()
+
+ def __str__(self):
+ return 'SharedMemoryMgr:{id:%d, %s}' % (self._id, str(self._allocator))
+
+ def __del__(self):
+ if SharedMemoryMgr.s_log_statis:
+ logger.info('destroy [%s]' % (self))
+
+ if not self._released and not self._allocator.empty():
+ logger.debug(
+ 'not empty when delete this SharedMemoryMgr[%s]' % (self))
+ else:
+ self._released = True
+
+ if self._id in SharedMemoryMgr.s_memory_mgrs:
+ del SharedMemoryMgr.s_memory_mgrs[self._id]
+ SharedMemoryMgr.s_mgr_num -= 1
diff --git a/contrib/HumanSeg/export.py b/contrib/HumanSeg/export.py
new file mode 100644
index 0000000000000000000000000000000000000000..6fcae141398a6718db5710d595d95842b1596753
--- /dev/null
+++ b/contrib/HumanSeg/export.py
@@ -0,0 +1,28 @@
+import models
+import argparse
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Export model')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for exporting',
+ type=str)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the export model',
+ type=str,
+ default='./output/export')
+ return parser.parse_args()
+
+
+def export(args):
+ model = models.load_model(args.model_dir)
+ model.export_inference_model(args.save_dir)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ export(args)
diff --git a/contrib/HumanSeg/imgs/Human.jpg b/contrib/HumanSeg/imgs/Human.jpg
deleted file mode 100644
index 77b9a93e69db37e825c6e0c092636f9e4b3b5c33..0000000000000000000000000000000000000000
Binary files a/contrib/HumanSeg/imgs/Human.jpg and /dev/null differ
diff --git a/contrib/HumanSeg/imgs/HumanSeg.jpg b/contrib/HumanSeg/imgs/HumanSeg.jpg
deleted file mode 100644
index 6935ba2482a5f7359fb4b430cc730b026e517723..0000000000000000000000000000000000000000
Binary files a/contrib/HumanSeg/imgs/HumanSeg.jpg and /dev/null differ
diff --git a/contrib/HumanSeg/infer.py b/contrib/HumanSeg/infer.py
index 971476933c431977ce80c73e1d939fe079e1af19..96aabac6c44c164504f6626accfadd36983219e5 100644
--- a/contrib/HumanSeg/infer.py
+++ b/contrib/HumanSeg/infer.py
@@ -1,130 +1,96 @@
-# -*- coding: utf-8 -*-
+import argparse
import os
+import os.path as osp
import cv2
import numpy as np
-from utils.util import get_arguments
-from utils.palette import get_palette
-from PIL import Image as PILImage
-import importlib
-
-args = get_arguments()
-config = importlib.import_module('config')
-cfg = getattr(config, 'cfg')
-
-# paddle垃圾回收策略FLAG,ACE2P模型较大,当显存不够时建议开启
-os.environ['FLAGS_eager_delete_tensor_gb']='0.0'
-
-import paddle.fluid as fluid
-
-# 预测数据集类
-class TestDataSet():
- def __init__(self):
- self.data_dir = cfg.data_dir
- self.data_list_file = cfg.data_list_file
- self.data_list = self.get_data_list()
- self.data_num = len(self.data_list)
-
- def get_data_list(self):
- # 获取预测图像路径列表
- data_list = []
- data_file_handler = open(self.data_list_file, 'r')
- for line in data_file_handler:
- img_name = line.strip()
- name_prefix = img_name.split('.')[0]
- if len(img_name.split('.')) == 1:
- img_name = img_name + '.jpg'
- img_path = os.path.join(self.data_dir, img_name)
- data_list.append(img_path)
- return data_list
-
- def preprocess(self, img):
- # 图像预处理
- if cfg.example == 'ACE2P':
- reader = importlib.import_module(args.example+'.reader')
- ACE2P_preprocess = getattr(reader, 'preprocess')
- img = ACE2P_preprocess(img)
- else:
- img = cv2.resize(img, cfg.input_size).astype(np.float32)
- img -= np.array(cfg.MEAN)
- img /= np.array(cfg.STD)
- img = img.transpose((2, 0, 1))
- img = np.expand_dims(img, axis=0)
- return img
-
- def get_data(self, index):
- # 获取图像信息
- img_path = self.data_list[index]
- img = cv2.imread(img_path, cv2.IMREAD_COLOR)
- if img is None:
- return img, img,img_path, None
-
- img_name = img_path.split(os.sep)[-1]
- name_prefix = img_name.replace('.'+img_name.split('.')[-1],'')
- img_shape = img.shape[:2]
- img_process = self.preprocess(img)
-
- return img, img_process, name_prefix, img_shape
-
-
-def infer():
- if not os.path.exists(cfg.vis_dir):
- os.makedirs(cfg.vis_dir)
- palette = get_palette(cfg.class_num)
- # 人像分割结果显示阈值
- thresh = 120
-
- place = fluid.CUDAPlace(0) if cfg.use_gpu else fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- # 加载预测模型
- test_prog, feed_name, fetch_list = fluid.io.load_inference_model(
- dirname=cfg.model_path, executor=exe, params_filename='__params__')
-
- #加载预测数据集
- test_dataset = TestDataSet()
- data_num = test_dataset.data_num
-
- for idx in range(data_num):
- # 数据获取
- ori_img, image, im_name, im_shape = test_dataset.get_data(idx)
- if image is None:
- print(im_name, 'is None')
- continue
-
- # 预测
- if cfg.example == 'ACE2P':
- # ACE2P模型使用多尺度预测
- reader = importlib.import_module(args.example+'.reader')
- multi_scale_test = getattr(reader, 'multi_scale_test')
- parsing, logits = multi_scale_test(exe, test_prog, feed_name, fetch_list, image, im_shape)
- else:
- # HumanSeg,RoadLine模型单尺度预测
- result = exe.run(program=test_prog, feed={feed_name[0]: image}, fetch_list=fetch_list)
- parsing = np.argmax(result[0][0], axis=0)
- parsing = cv2.resize(parsing.astype(np.uint8), im_shape[::-1])
-
- # 预测结果保存
- result_path = os.path.join(cfg.vis_dir, im_name + '.png')
- if cfg.example == 'HumanSeg':
- logits = result[0][0][1]*255
- logits = cv2.resize(logits, im_shape[::-1])
- ret, logits = cv2.threshold(logits, thresh, 0, cv2.THRESH_TOZERO)
- logits = 255 *(logits - thresh)/(255 - thresh)
- # 将分割结果添加到alpha通道
- rgba = np.concatenate((ori_img, np.expand_dims(logits, axis=2)), axis=2)
- cv2.imwrite(result_path, rgba)
- else:
- output_im = PILImage.fromarray(np.asarray(parsing, dtype=np.uint8))
- output_im.putpalette(palette)
- output_im.save(result_path)
-
- if (idx + 1) % 100 == 0:
- print('%d processd' % (idx + 1))
-
- print('%d processd done' % (idx + 1))
-
- return 0
-
-
-if __name__ == "__main__":
- infer()
+import tqdm
+
+import utils
+import models
+import transforms
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='HumanSeg inference and visualization')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for inference',
+ type=str)
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='The root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--test_list',
+ dest='test_list',
+ help='Test list file of dataset',
+ type=str)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the inference results',
+ type=str,
+ default='./output/result')
+ parser.add_argument(
+ "--image_shape",
+ dest="image_shape",
+ help="The image shape for net inputs.",
+ nargs=2,
+ default=[192, 192],
+ type=int)
+ return parser.parse_args()
+
+
+def mkdir(path):
+ sub_dir = osp.dirname(path)
+ if not osp.exists(sub_dir):
+ os.makedirs(sub_dir)
+
+
+def infer(args):
+ test_transforms = transforms.Compose(
+ [transforms.Resize(args.image_shape),
+ transforms.Normalize()])
+ model = models.load_model(args.model_dir)
+ added_saveed_path = osp.join(args.save_dir, 'added')
+ mat_saved_path = osp.join(args.save_dir, 'mat')
+ scoremap_saved_path = osp.join(args.save_dir, 'scoremap')
+
+ with open(args.test_list, 'r') as f:
+ files = f.readlines()
+
+ for file in tqdm.tqdm(files):
+ file = file.strip()
+ im_file = osp.join(args.data_dir, file)
+ im = cv2.imread(im_file)
+ result = model.predict(im, transforms=test_transforms)
+
+ # save added image
+ added_image = utils.visualize(im_file, result, weight=0.6)
+ added_image_file = osp.join(added_saveed_path, file)
+ mkdir(added_image_file)
+ cv2.imwrite(added_image_file, added_image)
+
+ # save score map
+ score_map = result['score_map'][:, :, 1]
+ score_map = (score_map * 255).astype(np.uint8)
+ score_map_file = osp.join(scoremap_saved_path, file)
+ mkdir(score_map_file)
+ cv2.imwrite(score_map_file, score_map)
+
+ # save mat image
+ score_map = np.expand_dims(score_map, axis=-1)
+ mat_image = np.concatenate([im, score_map], axis=2)
+ mat_file = osp.join(mat_saved_path, file)
+ ext = osp.splitext(mat_file)[-1]
+ mat_file = mat_file.replace(ext, '.png')
+ mkdir(mat_file)
+ cv2.imwrite(mat_file, mat_image)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ infer(args)
diff --git a/contrib/HumanSeg/models/__init__.py b/contrib/HumanSeg/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..02704a07cc4a476253f80a8defbc42929f4175ad
--- /dev/null
+++ b/contrib/HumanSeg/models/__init__.py
@@ -0,0 +1,4 @@
+from .humanseg import HumanSegMobile
+from .humanseg import HumanSegServer
+from .humanseg import HumanSegLite
+from .load_model import load_model
diff --git a/contrib/HumanSeg/models/humanseg.py b/contrib/HumanSeg/models/humanseg.py
new file mode 100644
index 0000000000000000000000000000000000000000..5873c992ab8405d397806593fd690d3b668c38f2
--- /dev/null
+++ b/contrib/HumanSeg/models/humanseg.py
@@ -0,0 +1,898 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+import paddle.fluid as fluid
+import os
+from os import path as osp
+import numpy as np
+from collections import OrderedDict
+import copy
+import math
+import time
+import tqdm
+import cv2
+import yaml
+import paddleslim as slim
+
+import utils
+import utils.logging as logging
+from utils import seconds_to_hms
+from utils import ConfusionMatrix
+from utils import get_environ_info
+from nets import DeepLabv3p, ShuffleSeg, HRNet
+import transforms as T
+
+
+def dict2str(dict_input):
+ out = ''
+ for k, v in dict_input.items():
+ try:
+ v = round(float(v), 6)
+ except:
+ pass
+ out = out + '{}={}, '.format(k, v)
+ return out.strip(', ')
+
+
+class SegModel(object):
+ # DeepLab mobilenet
+ def __init__(self,
+ num_classes=2,
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255,
+ sync_bn=True):
+ self.init_params = locals()
+ if num_classes > 2 and (use_bce_loss or use_dice_loss):
+ raise ValueError(
+ "dice loss and bce loss is only applicable to binary classfication"
+ )
+
+ if class_weight is not None:
+ if isinstance(class_weight, list):
+ if len(class_weight) != num_classes:
+ raise ValueError(
+ "Length of class_weight should be equal to number of classes"
+ )
+ elif isinstance(class_weight, str):
+ if class_weight.lower() != 'dynamic':
+ raise ValueError(
+ "if class_weight is string, must be dynamic!")
+ else:
+ raise TypeError(
+ 'Expect class_weight is a list or string but receive {}'.
+ format(type(class_weight)))
+
+ self.num_classes = num_classes
+ self.use_bce_loss = use_bce_loss
+ self.use_dice_loss = use_dice_loss
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+ self.sync_bn = sync_bn
+
+ self.labels = None
+ self.env_info = get_environ_info()
+ if self.env_info['place'] == 'cpu':
+ self.places = fluid.cpu_places()
+ else:
+ self.places = fluid.cuda_places()
+ self.exe = fluid.Executor(self.places[0])
+ self.train_prog = None
+ self.test_prog = None
+ self.parallel_train_prog = None
+ self.train_inputs = None
+ self.test_inputs = None
+ self.train_outputs = None
+ self.test_outputs = None
+ self.train_data_loader = None
+ self.eval_metrics = None
+ # 当前模型状态
+ self.status = 'Normal'
+
+ def _get_single_car_bs(self, batch_size):
+ if batch_size % len(self.places) == 0:
+ return int(batch_size // len(self.places))
+ else:
+ raise Exception("Please support correct batch_size, \
+ which can be divided by available cards({}) in {}".
+ format(self.env_info['num'],
+ self.env_info['place']))
+
+ def build_net(self, mode='train'):
+ """应根据不同的情况进行构建"""
+ pass
+
+ def build_program(self):
+ # build training network
+ self.train_inputs, self.train_outputs = self.build_net(mode='train')
+ self.train_prog = fluid.default_main_program()
+ startup_prog = fluid.default_startup_program()
+
+ # build prediction network
+ self.test_prog = fluid.Program()
+ with fluid.program_guard(self.test_prog, startup_prog):
+ with fluid.unique_name.guard():
+ self.test_inputs, self.test_outputs = self.build_net(
+ mode='test')
+ self.test_prog = self.test_prog.clone(for_test=True)
+
+ def arrange_transform(self, transforms, mode='train'):
+ arrange_transform = T.ArrangeSegmenter
+ if type(transforms.transforms[-1]).__name__.startswith('Arrange'):
+ transforms.transforms[-1] = arrange_transform(mode=mode)
+ else:
+ transforms.transforms.append(arrange_transform(mode=mode))
+
+ def build_train_data_loader(self, dataset, batch_size):
+ # init data_loader
+ if self.train_data_loader is None:
+ self.train_data_loader = fluid.io.DataLoader.from_generator(
+ feed_list=list(self.train_inputs.values()),
+ capacity=64,
+ use_double_buffer=True,
+ iterable=True)
+ batch_size_each_gpu = self._get_single_car_bs(batch_size)
+ self.train_data_loader.set_sample_list_generator(
+ dataset.generator(batch_size=batch_size_each_gpu),
+ places=self.places)
+
+ def net_initialize(self,
+ startup_prog=None,
+ pretrained_weights=None,
+ resume_weights=None):
+ if startup_prog is None:
+ startup_prog = fluid.default_startup_program()
+ self.exe.run(startup_prog)
+ if resume_weights is not None:
+ logging.info("Resume weights from {}".format(resume_weights))
+ if not osp.exists(resume_weights):
+ raise Exception("Path {} not exists.".format(resume_weights))
+ fluid.load(self.train_prog, osp.join(resume_weights, 'model'),
+ self.exe)
+ # Check is path ended by path spearator
+ if resume_weights[-1] == os.sep:
+ resume_weights = resume_weights[0:-1]
+ epoch_name = osp.basename(resume_weights)
+ # If resume weights is end of digit, restore epoch status
+ epoch = epoch_name.split('_')[-1]
+ if epoch.isdigit():
+ self.begin_epoch = int(epoch)
+ else:
+ raise ValueError("Resume model path is not valid!")
+ logging.info("Model checkpoint loaded successfully!")
+
+ elif pretrained_weights is not None:
+ logging.info(
+ "Load pretrain weights from {}.".format(pretrained_weights))
+ utils.load_pretrained_weights(self.exe, self.train_prog,
+ pretrained_weights)
+
+ def get_model_info(self):
+ # 存储相应的信息到yml文件
+ info = dict()
+ info['Model'] = self.__class__.__name__
+ if 'self' in self.init_params:
+ del self.init_params['self']
+ if '__class__' in self.init_params:
+ del self.init_params['__class__']
+ info['_init_params'] = self.init_params
+
+ info['_Attributes'] = dict()
+ info['_Attributes']['num_classes'] = self.num_classes
+ info['_Attributes']['labels'] = self.labels
+ try:
+ info['_Attributes']['eval_metric'] = dict()
+ for k, v in self.eval_metrics.items():
+ if isinstance(v, np.ndarray):
+ if v.size > 1:
+ v = [float(i) for i in v]
+ else:
+ v = float(v)
+ info['_Attributes']['eval_metric'][k] = v
+ except:
+ pass
+
+ if hasattr(self, 'test_transforms'):
+ if self.test_transforms is not None:
+ info['test_transforms'] = list()
+ for op in self.test_transforms.transforms:
+ name = op.__class__.__name__
+ attr = op.__dict__
+ info['test_transforms'].append({name: attr})
+
+ if hasattr(self, 'train_transforms'):
+ if self.train_transforms is not None:
+ info['train_transforms'] = list()
+ for op in self.train_transforms.transforms:
+ name = op.__class__.__name__
+ attr = op.__dict__
+ info['train_transforms'].append({name: attr})
+
+ if hasattr(self, 'train_init'):
+ if 'self' in self.train_init:
+ del self.train_init['self']
+ if 'train_dataset' in self.train_init:
+ del self.train_init['train_dataset']
+ if 'eval_dataset' in self.train_init:
+ del self.train_init['eval_dataset']
+ if 'optimizer' in self.train_init:
+ del self.train_init['optimizer']
+ info['train_init'] = self.train_init
+ return info
+
+ def save_model(self, save_dir):
+ if not osp.isdir(save_dir):
+ if osp.exists(save_dir):
+ os.remove(save_dir)
+ os.makedirs(save_dir)
+ model_info = self.get_model_info()
+
+ if self.status == 'Normal':
+ fluid.save(self.train_prog, osp.join(save_dir, 'model'))
+ elif self.status == 'Quant':
+ float_prog, _ = slim.quant.convert(
+ self.test_prog, self.exe.place, save_int8=True)
+ test_input_names = [
+ var.name for var in list(self.test_inputs.values())
+ ]
+ test_outputs = list(self.test_outputs.values())
+ fluid.io.save_inference_model(
+ dirname=save_dir,
+ executor=self.exe,
+ params_filename='__params__',
+ feeded_var_names=test_input_names,
+ target_vars=test_outputs,
+ main_program=float_prog)
+
+ model_info['_ModelInputsOutputs'] = dict()
+ model_info['_ModelInputsOutputs']['test_inputs'] = [
+ [k, v.name] for k, v in self.test_inputs.items()
+ ]
+ model_info['_ModelInputsOutputs']['test_outputs'] = [
+ [k, v.name] for k, v in self.test_outputs.items()
+ ]
+
+ model_info['status'] = self.status
+ with open(
+ osp.join(save_dir, 'model.yml'), encoding='utf-8',
+ mode='w') as f:
+ yaml.dump(model_info, f)
+
+ # The flag of model for saving successfully
+ open(osp.join(save_dir, '.success'), 'w').close()
+ logging.info("Model saved in {}.".format(save_dir))
+
+ def export_inference_model(self, save_dir):
+ test_input_names = [var.name for var in list(self.test_inputs.values())]
+ test_outputs = list(self.test_outputs.values())
+ fluid.io.save_inference_model(
+ dirname=save_dir,
+ executor=self.exe,
+ params_filename='__params__',
+ feeded_var_names=test_input_names,
+ target_vars=test_outputs,
+ main_program=self.test_prog)
+ model_info = self.get_model_info()
+ model_info['status'] = 'Infer'
+
+ # Save input and output descrition of model
+ model_info['_ModelInputsOutputs'] = dict()
+ model_info['_ModelInputsOutputs']['test_inputs'] = [
+ [k, v.name] for k, v in self.test_inputs.items()
+ ]
+ model_info['_ModelInputsOutputs']['test_outputs'] = [
+ [k, v.name] for k, v in self.test_outputs.items()
+ ]
+
+ with open(
+ osp.join(save_dir, 'model.yml'), encoding='utf-8',
+ mode='w') as f:
+ yaml.dump(model_info, f)
+
+ # The flag of model for saving successfully
+ open(osp.join(save_dir, '.success'), 'w').close()
+ logging.info("Model for inference deploy saved in {}.".format(save_dir))
+
+ def export_quant_model(self,
+ dataset,
+ save_dir,
+ batch_size=1,
+ batch_nums=10,
+ cache_dir="./.temp"):
+ self.arrange_transform(transforms=dataset.transforms, mode='quant')
+ dataset.num_samples = batch_size * batch_nums
+ try:
+ from utils import HumanSegPostTrainingQuantization
+ except:
+ raise Exception(
+ "Model Quantization is not available, try to upgrade your paddlepaddle>=1.7.0"
+ )
+ is_use_cache_file = True
+ if cache_dir is None:
+ is_use_cache_file = False
+ post_training_quantization = HumanSegPostTrainingQuantization(
+ executor=self.exe,
+ dataset=dataset,
+ program=self.test_prog,
+ inputs=self.test_inputs,
+ outputs=self.test_outputs,
+ batch_size=batch_size,
+ batch_nums=batch_nums,
+ scope=None,
+ algo='KL',
+ quantizable_op_type=["conv2d", "depthwise_conv2d", "mul"],
+ is_full_quantize=False,
+ is_use_cache_file=is_use_cache_file,
+ cache_dir=cache_dir)
+ post_training_quantization.quantize()
+ post_training_quantization.save_quantized_model(save_dir)
+ if cache_dir is not None:
+ os.system('rm -r' + cache_dir)
+ model_info = self.get_model_info()
+ model_info['status'] = 'Quant'
+
+ # Save input and output descrition of model
+ model_info['_ModelInputsOutputs'] = dict()
+ model_info['_ModelInputsOutputs']['test_inputs'] = [
+ [k, v.name] for k, v in self.test_inputs.items()
+ ]
+ model_info['_ModelInputsOutputs']['test_outputs'] = [
+ [k, v.name] for k, v in self.test_outputs.items()
+ ]
+
+ with open(
+ osp.join(save_dir, 'model.yml'), encoding='utf-8',
+ mode='w') as f:
+ yaml.dump(model_info, f)
+
+ # The flag of model for saving successfully
+ open(osp.join(save_dir, '.success'), 'w').close()
+ logging.info("Model for quant saved in {}.".format(save_dir))
+
+ def default_optimizer(self,
+ learning_rate,
+ num_epochs,
+ num_steps_each_epoch,
+ lr_decay_power=0.9,
+ regularization_coeff=4e-5):
+ decay_step = num_epochs * num_steps_each_epoch
+ lr_decay = fluid.layers.polynomial_decay(
+ learning_rate,
+ decay_step,
+ end_learning_rate=0,
+ power=lr_decay_power)
+ optimizer = fluid.optimizer.Momentum(
+ lr_decay,
+ momentum=0.9,
+ regularization=fluid.regularizer.L2Decay(
+ regularization_coeff=regularization_coeff))
+ return optimizer
+
+ def train(self,
+ num_epochs,
+ train_dataset,
+ train_batch_size=2,
+ eval_dataset=None,
+ save_interval_epochs=1,
+ log_interval_steps=2,
+ save_dir='output',
+ pretrained_weights=None,
+ resume_weights=None,
+ optimizer=None,
+ learning_rate=0.01,
+ lr_decay_power=0.9,
+ regularization_coeff=4e-5,
+ use_vdl=False,
+ quant=False):
+ self.labels = train_dataset.labels
+ self.train_transforms = train_dataset.transforms
+ self.train_init = locals()
+ self.begin_epoch = 0
+
+ if optimizer is None:
+ num_steps_each_epoch = train_dataset.num_samples // train_batch_size
+ optimizer = self.default_optimizer(
+ learning_rate=learning_rate,
+ num_epochs=num_epochs,
+ num_steps_each_epoch=num_steps_each_epoch,
+ lr_decay_power=lr_decay_power,
+ regularization_coeff=regularization_coeff)
+ self.optimizer = optimizer
+ self.build_program()
+ self.net_initialize(
+ startup_prog=fluid.default_startup_program(),
+ pretrained_weights=pretrained_weights,
+ resume_weights=resume_weights)
+
+ # 进行量化
+ if quant:
+ # 当 for_test=False ,返回类型为 fluid.CompiledProgram
+ # 当 for_test=True ,返回类型为 fluid.Program
+ self.train_prog = slim.quant.quant_aware(
+ self.train_prog, self.exe.place, for_test=False)
+ self.test_prog = slim.quant.quant_aware(
+ self.test_prog, self.exe.place, for_test=True)
+ # self.parallel_train_prog = self.train_prog.with_data_parallel(
+ # loss_name=self.train_outputs['loss'].name)
+ self.status = 'Quant'
+
+ if self.begin_epoch >= num_epochs:
+ raise ValueError(
+ ("begin epoch[{}] is larger than num_epochs[{}]").format(
+ self.begin_epoch, num_epochs))
+
+ if not osp.isdir(save_dir):
+ if osp.exists(save_dir):
+ os.remove(save_dir)
+ os.makedirs(save_dir)
+
+ # add arrange op tor transforms
+ self.arrange_transform(
+ transforms=train_dataset.transforms, mode='train')
+ self.build_train_data_loader(
+ dataset=train_dataset, batch_size=train_batch_size)
+
+ if eval_dataset is not None:
+ self.eval_transforms = eval_dataset.transforms
+ self.test_transforms = copy.deepcopy(eval_dataset.transforms)
+
+ lr = self.optimizer._learning_rate
+ lr.persistable = True
+ if isinstance(lr, fluid.framework.Variable):
+ self.train_outputs['lr'] = lr
+
+ # 多卡训练
+ if self.parallel_train_prog is None:
+ build_strategy = fluid.compiler.BuildStrategy()
+ if self.env_info['place'] != 'cpu' and len(self.places) > 1:
+ build_strategy.sync_batch_norm = self.sync_bn
+ exec_strategy = fluid.ExecutionStrategy()
+ exec_strategy.num_iteration_per_drop_scope = 1
+ if quant:
+ build_strategy.fuse_all_reduce_ops = False
+ build_strategy.sync_batch_norm = False
+ self.parallel_train_prog = self.train_prog.with_data_parallel(
+ loss_name=self.train_outputs['loss'].name,
+ build_strategy=build_strategy,
+ exec_strategy=exec_strategy)
+ else:
+ self.parallel_train_prog = fluid.CompiledProgram(
+ self.train_prog).with_data_parallel(
+ loss_name=self.train_outputs['loss'].name,
+ build_strategy=build_strategy,
+ exec_strategy=exec_strategy)
+
+ total_num_steps = math.floor(
+ train_dataset.num_samples / train_batch_size)
+ num_steps = 0
+ time_stat = list()
+ time_train_one_epoch = None
+ time_eval_one_epoch = None
+
+ total_num_steps_eval = 0
+ # eval times
+ total_eval_times = math.ceil(num_epochs / save_interval_epochs)
+ eval_batch_size = train_batch_size
+ if eval_dataset is not None:
+ total_num_steps_eval = math.ceil(
+ eval_dataset.num_samples / eval_batch_size)
+
+ if use_vdl:
+ from visualdl import LogWriter
+ vdl_logdir = osp.join(save_dir, 'vdl_log')
+ log_writer = LogWriter(vdl_logdir)
+ best_miou = -1.0
+ best_model_epoch = 1
+ for i in range(self.begin_epoch, num_epochs):
+ records = list()
+ step_start_time = time.time()
+ epoch_start_time = time.time()
+ for step, data in enumerate(self.train_data_loader()):
+ outputs = self.exe.run(
+ self.parallel_train_prog,
+ feed=data,
+ fetch_list=list(self.train_outputs.values()))
+ outputs_avg = np.mean(np.array(outputs), axis=1)
+ records.append(outputs_avg)
+
+ # time estimated to complete the training
+ currend_time = time.time()
+ step_cost_time = currend_time - step_start_time
+ step_start_time = currend_time
+ if len(time_stat) < 20:
+ time_stat.append(step_cost_time)
+ else:
+ time_stat[num_steps % 20] = step_cost_time
+
+ num_steps += 1
+ if num_steps % log_interval_steps == 0:
+ step_metrics = OrderedDict(
+ zip(list(self.train_outputs.keys()), outputs_avg))
+
+ if use_vdl:
+ for k, v in step_metrics.items():
+ log_writer.add_scalar(
+ step=num_steps,
+ tag='train/{}'.format(k),
+ value=v)
+
+ # 计算剩余时间
+ avg_step_time = np.mean(time_stat)
+ if time_train_one_epoch is not None:
+ eta = (num_epochs - i - 1) * time_train_one_epoch + (
+ total_num_steps - step - 1) * avg_step_time
+ else:
+ eta = ((num_epochs - i) * total_num_steps - step -
+ 1) * avg_step_time
+ if time_eval_one_epoch is not None:
+ eval_eta = (total_eval_times - i // save_interval_epochs
+ ) * time_eval_one_epoch
+ else:
+ eval_eta = (total_eval_times - i // save_interval_epochs
+ ) * total_num_steps_eval * avg_step_time
+ eta_str = seconds_to_hms(eta + eval_eta)
+
+ logging.info(
+ "[TRAIN] Epoch={}/{}, Step={}/{}, {}, time_each_step={}s, eta={}"
+ .format(i + 1, num_epochs, step + 1, total_num_steps,
+ dict2str(step_metrics), round(avg_step_time, 2),
+ eta_str))
+
+ train_metrics = OrderedDict(
+ zip(list(self.train_outputs.keys()), np.mean(records, axis=0)))
+ logging.info('[TRAIN] Epoch {} finished, {} .'.format(
+ i + 1, dict2str(train_metrics)))
+ time_train_one_epoch = time.time() - epoch_start_time
+
+ eval_epoch_start_time = time.time()
+ if (i + 1) % save_interval_epochs == 0 or i == num_epochs - 1:
+ current_save_dir = osp.join(save_dir, "epoch_{}".format(i + 1))
+ if not osp.isdir(current_save_dir):
+ os.makedirs(current_save_dir)
+ if eval_dataset is not None:
+ self.eval_metrics = self.evaluate(
+ eval_dataset=eval_dataset,
+ batch_size=eval_batch_size,
+ epoch_id=i + 1)
+ # 保存最优模型
+ current_miou = self.eval_metrics['miou']
+ if current_miou > best_miou:
+ best_miou = current_miou
+ best_model_epoch = i + 1
+ best_model_dir = osp.join(save_dir, "best_model")
+ self.save_model(save_dir=best_model_dir)
+ if use_vdl:
+ for k, v in self.eval_metrics.items():
+ if isinstance(v, list):
+ continue
+ if isinstance(v, np.ndarray):
+ if v.size > 1:
+ continue
+ log_writer.add_scalar(
+ step=num_steps,
+ tag='evaluate/{}'.format(k),
+ value=v)
+ self.save_model(save_dir=current_save_dir)
+ time_eval_one_epoch = time.time() - eval_epoch_start_time
+ if eval_dataset is not None:
+ logging.info(
+ 'Current evaluated best model in eval_dataset is epoch_{}, miou={}'
+ .format(best_model_epoch, best_miou))
+
+ def evaluate(self, eval_dataset, batch_size=1, epoch_id=None):
+ """评估。
+
+ Args:
+ eval_dataset (paddlex.datasets): 评估数据读取器。
+ batch_size (int): 评估时的batch大小。默认1。
+ epoch_id (int): 当前评估模型所在的训练轮数。
+ return_details (bool): 是否返回详细信息。默认False。
+
+ Returns:
+ dict: 当return_details为False时,返回dict。包含关键字:'miou'、'category_iou'、'macc'、
+ 'category_acc'和'kappa',分别表示平均iou、各类别iou、平均准确率、各类别准确率和kappa系数。
+ tuple (metrics, eval_details):当return_details为True时,增加返回dict (eval_details),
+ 包含关键字:'confusion_matrix',表示评估的混淆矩阵。
+ """
+ self.arrange_transform(transforms=eval_dataset.transforms, mode='train')
+ total_steps = math.ceil(eval_dataset.num_samples * 1.0 / batch_size)
+ conf_mat = ConfusionMatrix(self.num_classes, streaming=True)
+ data_generator = eval_dataset.generator(
+ batch_size=batch_size, drop_last=False)
+ if not hasattr(self, 'parallel_test_prog'):
+ self.parallel_test_prog = fluid.CompiledProgram(
+ self.test_prog).with_data_parallel(
+ share_vars_from=self.parallel_train_prog)
+ logging.info(
+ "Start to evaluating(total_samples={}, total_steps={})...".format(
+ eval_dataset.num_samples, total_steps))
+ for step, data in tqdm.tqdm(
+ enumerate(data_generator()), total=total_steps):
+ images = np.array([d[0] for d in data])
+ labels = np.array([d[1] for d in data])
+ num_samples = images.shape[0]
+ if num_samples < batch_size:
+ num_pad_samples = batch_size - num_samples
+ pad_images = np.tile(images[0:1], (num_pad_samples, 1, 1, 1))
+ images = np.concatenate([images, pad_images])
+ feed_data = {'image': images}
+ outputs = self.exe.run(
+ self.parallel_test_prog,
+ feed=feed_data,
+ fetch_list=list(self.test_outputs.values()),
+ return_numpy=True)
+ pred = outputs[0]
+ if num_samples < batch_size:
+ pred = pred[0:num_samples]
+
+ mask = labels != self.ignore_index
+ conf_mat.calculate(pred=pred, label=labels, ignore=mask)
+ _, iou = conf_mat.mean_iou()
+
+ logging.debug("[EVAL] Epoch={}, Step={}/{}, iou={}".format(
+ epoch_id, step + 1, total_steps, iou))
+
+ category_iou, miou = conf_mat.mean_iou()
+ category_acc, macc = conf_mat.accuracy()
+
+ metrics = OrderedDict(
+ zip(['miou', 'category_iou', 'macc', 'category_acc', 'kappa'],
+ [miou, category_iou, macc, category_acc,
+ conf_mat.kappa()]))
+
+ logging.info('[EVAL] Finished, Epoch={}, {} .'.format(
+ epoch_id, dict2str(metrics)))
+ return metrics
+
+ def predict(self, im_file, transforms=None):
+ """预测。
+ Args:
+ img_file(str|np.ndarray): 预测图像。
+ transforms(paddlex.cv.transforms): 数据预处理操作。
+
+ Returns:
+ dict: 包含关键字'label_map'和'score_map', 'label_map'存储预测结果灰度图,
+ 像素值表示对应的类别,'score_map'存储各类别的概率,shape=(h, w, num_classes)
+ """
+ if isinstance(im_file, str):
+ if not osp.exists(im_file):
+ raise ValueError(
+ 'The Image file does not exist: {}'.format(im_file))
+
+ if transforms is None and not hasattr(self, 'test_transforms'):
+ raise Exception("transforms need to be defined, now is None.")
+ if transforms is not None:
+ self.arrange_transform(transforms=transforms, mode='test')
+ im, im_info = transforms(im_file)
+ else:
+ self.arrange_transform(transforms=self.test_transforms, mode='test')
+ im, im_info = self.test_transforms(im_file)
+ im = np.expand_dims(im, axis=0)
+ result = self.exe.run(
+ self.test_prog,
+ feed={'image': im},
+ fetch_list=list(self.test_outputs.values()))
+ pred = result[0]
+ logit = result[1]
+ logit = np.squeeze(logit)
+ logit = np.transpose(logit, (1, 2, 0))
+ pred = np.squeeze(pred).astype('uint8')
+ keys = list(im_info.keys())
+ for k in keys[::-1]:
+ if k == 'shape_before_resize':
+ h, w = im_info[k][0], im_info[k][1]
+ pred = cv2.resize(pred, (w, h), cv2.INTER_NEAREST)
+ logit = cv2.resize(logit, (w, h), cv2.INTER_LINEAR)
+ elif k == 'shape_before_padding':
+ h, w = im_info[k][0], im_info[k][1]
+ pred = pred[0:h, 0:w]
+ logit = logit[0:h, 0:w, :]
+
+ return {'label_map': pred, 'score_map': logit}
+
+
+class HumanSegLite(SegModel):
+ # DeepLab ShuffleNet
+ def build_net(self, mode='train'):
+ """应根据不同的情况进行构建"""
+ model = ShuffleSeg(
+ self.num_classes,
+ mode=mode,
+ use_bce_loss=self.use_bce_loss,
+ use_dice_loss=self.use_dice_loss,
+ class_weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ inputs = model.generate_inputs()
+ model_out = model.build_net(inputs)
+ outputs = OrderedDict()
+ if mode == 'train':
+ self.optimizer.minimize(model_out)
+ outputs['loss'] = model_out
+ else:
+ outputs['pred'] = model_out[0]
+ outputs['logit'] = model_out[1]
+ return inputs, outputs
+
+
+class HumanSegServer(SegModel):
+ # DeepLab Xception
+ def __init__(self,
+ num_classes=2,
+ backbone='Xception65',
+ output_stride=16,
+ aspp_with_sep_conv=True,
+ decoder_use_sep_conv=True,
+ encoder_with_aspp=True,
+ enable_decoder=True,
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255,
+ sync_bn=True):
+ super().__init__(
+ num_classes=num_classes,
+ use_bce_loss=use_bce_loss,
+ use_dice_loss=use_dice_loss,
+ class_weight=class_weight,
+ ignore_index=ignore_index,
+ sync_bn=sync_bn)
+ self.init_params = locals()
+
+ self.output_stride = output_stride
+
+ if backbone not in ['Xception65', 'Xception41']:
+ raise ValueError("backbone: {} is set wrong. it should be one of "
+ "('Xception65', 'Xception41')".format(backbone))
+
+ self.backbone = backbone
+ self.aspp_with_sep_conv = aspp_with_sep_conv
+ self.decoder_use_sep_conv = decoder_use_sep_conv
+ self.encoder_with_aspp = encoder_with_aspp
+ self.enable_decoder = enable_decoder
+ self.sync_bn = sync_bn
+
+ def build_net(self, mode='train'):
+ model = DeepLabv3p(
+ self.num_classes,
+ mode=mode,
+ backbone=self.backbone,
+ output_stride=self.output_stride,
+ aspp_with_sep_conv=self.aspp_with_sep_conv,
+ decoder_use_sep_conv=self.decoder_use_sep_conv,
+ encoder_with_aspp=self.encoder_with_aspp,
+ enable_decoder=self.enable_decoder,
+ use_bce_loss=self.use_bce_loss,
+ use_dice_loss=self.use_dice_loss,
+ class_weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ inputs = model.generate_inputs()
+ model_out = model.build_net(inputs)
+ outputs = OrderedDict()
+ if mode == 'train':
+ self.optimizer.minimize(model_out)
+ outputs['loss'] = model_out
+ else:
+ outputs['pred'] = model_out[0]
+ outputs['logit'] = model_out[1]
+ return inputs, outputs
+
+
+class HumanSegMobile(SegModel):
+ def __init__(self,
+ num_classes=2,
+ stage1_num_modules=1,
+ stage1_num_blocks=[1],
+ stage1_num_channels=[32],
+ stage2_num_modules=1,
+ stage2_num_blocks=[2, 2],
+ stage2_num_channels=[16, 32],
+ stage3_num_modules=1,
+ stage3_num_blocks=[2, 2, 2],
+ stage3_num_channels=[16, 32, 64],
+ stage4_num_modules=1,
+ stage4_num_blocks=[2, 2, 2, 2],
+ stage4_num_channels=[16, 32, 64, 128],
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255,
+ sync_bn=True):
+ super().__init__(
+ num_classes=num_classes,
+ use_bce_loss=use_bce_loss,
+ use_dice_loss=use_dice_loss,
+ class_weight=class_weight,
+ ignore_index=ignore_index,
+ sync_bn=sync_bn)
+ self.init_params = locals()
+
+ self.stage1_num_modules = stage1_num_modules
+ self.stage1_num_blocks = stage1_num_blocks
+ self.stage1_num_channels = stage1_num_channels
+ self.stage2_num_modules = stage2_num_modules
+ self.stage2_num_blocks = stage2_num_blocks
+ self.stage2_num_channels = stage2_num_channels
+ self.stage3_num_modules = stage3_num_modules
+ self.stage3_num_blocks = stage3_num_blocks
+ self.stage3_num_channels = stage3_num_channels
+ self.stage4_num_modules = stage4_num_modules
+ self.stage4_num_blocks = stage4_num_blocks
+ self.stage4_num_channels = stage4_num_channels
+
+ def build_net(self, mode='train'):
+ """应根据不同的情况进行构建"""
+ model = HRNet(
+ self.num_classes,
+ mode=mode,
+ stage1_num_modules=self.stage1_num_modules,
+ stage1_num_blocks=self.stage1_num_blocks,
+ stage1_num_channels=self.stage1_num_channels,
+ stage2_num_modules=self.stage2_num_modules,
+ stage2_num_blocks=self.stage2_num_blocks,
+ stage2_num_channels=self.stage2_num_channels,
+ stage3_num_modules=self.stage3_num_modules,
+ stage3_num_blocks=self.stage3_num_blocks,
+ stage3_num_channels=self.stage3_num_channels,
+ stage4_num_modules=self.stage4_num_modules,
+ stage4_num_blocks=self.stage4_num_blocks,
+ stage4_num_channels=self.stage4_num_channels,
+ use_bce_loss=self.use_bce_loss,
+ use_dice_loss=self.use_dice_loss,
+ class_weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ inputs = model.generate_inputs()
+ model_out = model.build_net(inputs)
+ outputs = OrderedDict()
+ if mode == 'train':
+ self.optimizer.minimize(model_out)
+ outputs['loss'] = model_out
+ else:
+ outputs['pred'] = model_out[0]
+ outputs['logit'] = model_out[1]
+ return inputs, outputs
+
+ def train(self,
+ num_epochs,
+ train_dataset,
+ train_batch_size=2,
+ eval_dataset=None,
+ save_interval_epochs=1,
+ log_interval_steps=2,
+ save_dir='output',
+ pretrained_weights=None,
+ resume_weights=None,
+ optimizer=None,
+ learning_rate=0.01,
+ lr_decay_power=0.9,
+ regularization_coeff=5e-4,
+ use_vdl=False,
+ quant=False):
+ super().train(
+ num_epochs=num_epochs,
+ train_dataset=train_dataset,
+ train_batch_size=train_batch_size,
+ eval_dataset=eval_dataset,
+ save_interval_epochs=save_interval_epochs,
+ log_interval_steps=log_interval_steps,
+ save_dir=save_dir,
+ pretrained_weights=pretrained_weights,
+ resume_weights=resume_weights,
+ optimizer=optimizer,
+ learning_rate=learning_rate,
+ lr_decay_power=lr_decay_power,
+ regularization_coeff=regularization_coeff,
+ use_vdl=use_vdl,
+ quant=quant)
diff --git a/contrib/HumanSeg/models/load_model.py b/contrib/HumanSeg/models/load_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc6e3db7a7f1b51a7522cbe6b65c7cde0b01940b
--- /dev/null
+++ b/contrib/HumanSeg/models/load_model.py
@@ -0,0 +1,86 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import yaml
+import os.path as osp
+import six
+import copy
+from collections import OrderedDict
+import paddle.fluid as fluid
+import utils.logging as logging
+import models
+
+
+def load_model(model_dir):
+ if not osp.exists(osp.join(model_dir, "model.yml")):
+ raise Exception("There's not model.yml in {}".format(model_dir))
+ with open(osp.join(model_dir, "model.yml")) as f:
+ info = yaml.load(f.read(), Loader=yaml.Loader)
+ status = info['status']
+
+ if not hasattr(models, info['Model']):
+ raise Exception("There's no attribute {} in models".format(
+ info['Model']))
+ model = getattr(models, info['Model'])(**info['_init_params'])
+ if status == "Normal":
+ startup_prog = fluid.Program()
+ model.test_prog = fluid.Program()
+ with fluid.program_guard(model.test_prog, startup_prog):
+ with fluid.unique_name.guard():
+ model.test_inputs, model.test_outputs = model.build_net(
+ mode='test')
+ model.test_prog = model.test_prog.clone(for_test=True)
+ model.exe.run(startup_prog)
+ import pickle
+ with open(osp.join(model_dir, 'model.pdparams'), 'rb') as f:
+ load_dict = pickle.load(f)
+ fluid.io.set_program_state(model.test_prog, load_dict)
+
+ elif status in ['Infer', 'Quant']:
+ [prog, input_names, outputs] = fluid.io.load_inference_model(
+ model_dir, model.exe, params_filename='__params__')
+ model.test_prog = prog
+ test_outputs_info = info['_ModelInputsOutputs']['test_outputs']
+ model.test_inputs = OrderedDict()
+ model.test_outputs = OrderedDict()
+ for name in input_names:
+ model.test_inputs[name] = model.test_prog.global_block().var(name)
+ for i, out in enumerate(outputs):
+ var_desc = test_outputs_info[i]
+ model.test_outputs[var_desc[0]] = out
+ if 'test_transforms' in info:
+ model.test_transforms = build_transforms(info['test_transforms'])
+ model.eval_transforms = copy.deepcopy(model.test_transforms)
+
+ if '_Attributes' in info:
+ for k, v in info['_Attributes'].items():
+ if k in model.__dict__:
+ model.__dict__[k] = v
+
+ logging.info("Model[{}] loaded.".format(info['Model']))
+ return model
+
+
+def build_transforms(transforms_info):
+ import transforms as T
+ transforms = list()
+ for op_info in transforms_info:
+ op_name = list(op_info.keys())[0]
+ op_attr = op_info[op_name]
+ if not hasattr(T, op_name):
+ raise Exception(
+ "There's no operator named '{}' in transforms".format(op_name))
+ transforms.append(getattr(T, op_name)(**op_attr))
+ eval_transforms = T.Compose(transforms)
+ return eval_transforms
diff --git a/contrib/HumanSeg/nets/__init__.py b/contrib/HumanSeg/nets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..cab1682745084e736992e4aa5e555db6bc1d5c53
--- /dev/null
+++ b/contrib/HumanSeg/nets/__init__.py
@@ -0,0 +1,5 @@
+from .backbone import mobilenet_v2
+from .backbone import xception
+from .deeplabv3p import DeepLabv3p
+from .shufflenet_slim import ShuffleSeg
+from .hrnet import HRNet
diff --git a/contrib/HumanSeg/nets/backbone/__init__.py b/contrib/HumanSeg/nets/backbone/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..18f39d40802011843007ae7c6ca9cf4fb64aa789
--- /dev/null
+++ b/contrib/HumanSeg/nets/backbone/__init__.py
@@ -0,0 +1,2 @@
+from .mobilenet_v2 import MobileNetV2
+from .xception import Xception
diff --git a/contrib/HumanSeg/nets/backbone/mobilenet_v2.py b/contrib/HumanSeg/nets/backbone/mobilenet_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..845d5a3f6b997e2c323e577275670bdfc5193530
--- /dev/null
+++ b/contrib/HumanSeg/nets/backbone/mobilenet_v2.py
@@ -0,0 +1,242 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+import paddle.fluid as fluid
+from paddle.fluid.param_attr import ParamAttr
+
+
+class MobileNetV2:
+ def __init__(self,
+ num_classes=None,
+ scale=1.0,
+ output_stride=None,
+ end_points=None,
+ decode_points=None):
+ self.scale = scale
+ self.num_classes = num_classes
+ self.output_stride = output_stride
+ self.end_points = end_points
+ self.decode_points = decode_points
+ self.bottleneck_params_list = [(1, 16, 1, 1), (6, 24, 2, 2),
+ (6, 32, 3, 2), (6, 64, 4, 2),
+ (6, 96, 3, 1), (6, 160, 3, 2),
+ (6, 320, 1, 1)]
+ self.modify_bottle_params(output_stride)
+
+ def __call__(self, input):
+ scale = self.scale
+ decode_ends = dict()
+
+ def check_points(count, points):
+ if points is None:
+ return False
+ else:
+ if isinstance(points, list):
+ return (True if count in points else False)
+ else:
+ return (True if count == points else False)
+
+ # conv1
+ input = self.conv_bn_layer(
+ input,
+ num_filters=int(32 * scale),
+ filter_size=3,
+ stride=2,
+ padding=1,
+ if_act=True,
+ name='conv1_1')
+
+ layer_count = 1
+
+ if check_points(layer_count, self.decode_points):
+ decode_ends[layer_count] = input
+
+ if check_points(layer_count, self.end_points):
+ return input, decode_ends
+
+ # bottleneck sequences
+ i = 1
+ in_c = int(32 * scale)
+ for layer_setting in self.bottleneck_params_list:
+ t, c, n, s = layer_setting
+ i += 1
+ input, depthwise_output = self.invresi_blocks(
+ input=input,
+ in_c=in_c,
+ t=t,
+ c=int(c * scale),
+ n=n,
+ s=s,
+ name='conv' + str(i))
+ in_c = int(c * scale)
+ layer_count += n
+
+ if check_points(layer_count, self.decode_points):
+ decode_ends[layer_count] = depthwise_output
+
+ if check_points(layer_count, self.end_points):
+ return input, decode_ends
+
+ # last_conv
+ output = self.conv_bn_layer(
+ input=input,
+ num_filters=int(1280 * scale) if scale > 1.0 else 1280,
+ filter_size=1,
+ stride=1,
+ padding=0,
+ if_act=True,
+ name='conv9')
+
+ if self.num_classes is not None:
+ output = fluid.layers.pool2d(
+ input=output, pool_type='avg', global_pooling=True)
+
+ output = fluid.layers.fc(
+ input=output,
+ size=self.num_classes,
+ param_attr=ParamAttr(name='fc10_weights'),
+ bias_attr=ParamAttr(name='fc10_offset'))
+ return output
+
+ def modify_bottle_params(self, output_stride=None):
+ if output_stride is not None and output_stride % 2 != 0:
+ raise Exception("output stride must to be even number")
+ if output_stride is None:
+ return
+ else:
+ stride = 2
+ for i, layer_setting in enumerate(self.bottleneck_params_list):
+ t, c, n, s = layer_setting
+ stride = stride * s
+ if stride > output_stride:
+ s = 1
+ self.bottleneck_params_list[i] = (t, c, n, s)
+
+ def conv_bn_layer(self,
+ input,
+ filter_size,
+ num_filters,
+ stride,
+ padding,
+ channels=None,
+ num_groups=1,
+ if_act=True,
+ name=None,
+ use_cudnn=True):
+ conv = fluid.layers.conv2d(
+ input=input,
+ num_filters=num_filters,
+ filter_size=filter_size,
+ stride=stride,
+ padding=padding,
+ groups=num_groups,
+ act=None,
+ use_cudnn=use_cudnn,
+ param_attr=ParamAttr(name=name + '_weights'),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ bn = fluid.layers.batch_norm(
+ input=conv,
+ param_attr=ParamAttr(name=bn_name + "_scale"),
+ bias_attr=ParamAttr(name=bn_name + "_offset"),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+ if if_act:
+ return fluid.layers.relu6(bn)
+ else:
+ return bn
+
+ def shortcut(self, input, data_residual):
+ return fluid.layers.elementwise_add(input, data_residual)
+
+ def inverted_residual_unit(self,
+ input,
+ num_in_filter,
+ num_filters,
+ ifshortcut,
+ stride,
+ filter_size,
+ padding,
+ expansion_factor,
+ name=None):
+ num_expfilter = int(round(num_in_filter * expansion_factor))
+
+ channel_expand = self.conv_bn_layer(
+ input=input,
+ num_filters=num_expfilter,
+ filter_size=1,
+ stride=1,
+ padding=0,
+ num_groups=1,
+ if_act=True,
+ name=name + '_expand')
+
+ bottleneck_conv = self.conv_bn_layer(
+ input=channel_expand,
+ num_filters=num_expfilter,
+ filter_size=filter_size,
+ stride=stride,
+ padding=padding,
+ num_groups=num_expfilter,
+ if_act=True,
+ name=name + '_dwise',
+ use_cudnn=False)
+
+ depthwise_output = bottleneck_conv
+
+ linear_out = self.conv_bn_layer(
+ input=bottleneck_conv,
+ num_filters=num_filters,
+ filter_size=1,
+ stride=1,
+ padding=0,
+ num_groups=1,
+ if_act=False,
+ name=name + '_linear')
+
+ if ifshortcut:
+ out = self.shortcut(input=input, data_residual=linear_out)
+ return out, depthwise_output
+ else:
+ return linear_out, depthwise_output
+
+ def invresi_blocks(self, input, in_c, t, c, n, s, name=None):
+ first_block, depthwise_output = self.inverted_residual_unit(
+ input=input,
+ num_in_filter=in_c,
+ num_filters=c,
+ ifshortcut=False,
+ stride=s,
+ filter_size=3,
+ padding=1,
+ expansion_factor=t,
+ name=name + '_1')
+
+ last_residual_block = first_block
+ last_c = c
+
+ for i in range(1, n):
+ last_residual_block, depthwise_output = self.inverted_residual_unit(
+ input=last_residual_block,
+ num_in_filter=last_c,
+ num_filters=c,
+ ifshortcut=True,
+ stride=1,
+ filter_size=3,
+ padding=1,
+ expansion_factor=t,
+ name=name + '_' + str(i + 1))
+ return last_residual_block, depthwise_output
diff --git a/contrib/HumanSeg/nets/backbone/xception.py b/contrib/HumanSeg/nets/backbone/xception.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad5c3821933e6ed10d7e5bbce810cc14b579a7b2
--- /dev/null
+++ b/contrib/HumanSeg/nets/backbone/xception.py
@@ -0,0 +1,321 @@
+# coding: utf8
+# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+import math
+import paddle.fluid as fluid
+from nets.libs import scope, name_scope
+from nets.libs import bn, bn_relu, relu
+from nets.libs import conv
+from nets.libs import separate_conv
+
+__all__ = ['xception_65', 'xception_41', 'xception_71']
+
+
+def check_data(data, number):
+ if type(data) == int:
+ return [data] * number
+ assert len(data) == number
+ return data
+
+
+def check_stride(s, os):
+ if s <= os:
+ return True
+ else:
+ return False
+
+
+def check_points(count, points):
+ if points is None:
+ return False
+ else:
+ if isinstance(points, list):
+ return (True if count in points else False)
+ else:
+ return (True if count == points else False)
+
+
+class Xception():
+ def __init__(self,
+ num_classes=None,
+ layers=65,
+ output_stride=32,
+ end_points=None,
+ decode_points=None):
+ self.backbone = 'xception_' + str(layers)
+ self.num_classes = num_classes
+ self.output_stride = output_stride
+ self.end_points = end_points
+ self.decode_points = decode_points
+ self.bottleneck_params = self.gen_bottleneck_params(self.backbone)
+
+ def __call__(
+ self,
+ input,
+ ):
+ self.stride = 2
+ self.block_point = 0
+ self.short_cuts = dict()
+ with scope(self.backbone):
+ # Entry flow
+ data = self.entry_flow(input)
+ if check_points(self.block_point, self.end_points):
+ return data, self.short_cuts
+
+ # Middle flow
+ data = self.middle_flow(data)
+ if check_points(self.block_point, self.end_points):
+ return data, self.short_cuts
+
+ # Exit flow
+ data = self.exit_flow(data)
+ if check_points(self.block_point, self.end_points):
+ return data, self.short_cuts
+
+ if self.num_classes is not None:
+ data = fluid.layers.reduce_mean(data, [2, 3], keep_dim=True)
+ data = fluid.layers.dropout(data, 0.5)
+ stdv = 1.0 / math.sqrt(data.shape[1] * 1.0)
+ with scope("logit"):
+ out = fluid.layers.fc(
+ input=data,
+ size=self.num_classes,
+ act='softmax',
+ param_attr=fluid.param_attr.ParamAttr(
+ name='weights',
+ initializer=fluid.initializer.Uniform(-stdv, stdv)),
+ bias_attr=fluid.param_attr.ParamAttr(name='bias'))
+
+ return out
+ else:
+ return data
+
+ def gen_bottleneck_params(self, backbone='xception_65'):
+ if backbone == 'xception_65':
+ bottleneck_params = {
+ "entry_flow": (3, [2, 2, 2], [128, 256, 728]),
+ "middle_flow": (16, 1, 728),
+ "exit_flow": (2, [2, 1], [[728, 1024, 1024], [1536, 1536,
+ 2048]])
+ }
+ elif backbone == 'xception_41':
+ bottleneck_params = {
+ "entry_flow": (3, [2, 2, 2], [128, 256, 728]),
+ "middle_flow": (8, 1, 728),
+ "exit_flow": (2, [2, 1], [[728, 1024, 1024], [1536, 1536,
+ 2048]])
+ }
+ elif backbone == 'xception_71':
+ bottleneck_params = {
+ "entry_flow": (5, [2, 1, 2, 1, 2], [128, 256, 256, 728, 728]),
+ "middle_flow": (16, 1, 728),
+ "exit_flow": (2, [2, 1], [[728, 1024, 1024], [1536, 1536,
+ 2048]])
+ }
+ else:
+ raise Exception(
+ "xception backbont only support xception_41/xception_65/xception_71"
+ )
+ return bottleneck_params
+
+ def entry_flow(self, data):
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=None,
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.09))
+ with scope("entry_flow"):
+ with scope("conv1"):
+ data = bn_relu(
+ conv(
+ data, 32, 3, stride=2, padding=1,
+ param_attr=param_attr),
+ eps=1e-3)
+ with scope("conv2"):
+ data = bn_relu(
+ conv(
+ data, 64, 3, stride=1, padding=1,
+ param_attr=param_attr),
+ eps=1e-3)
+
+ # get entry flow params
+ block_num = self.bottleneck_params["entry_flow"][0]
+ strides = self.bottleneck_params["entry_flow"][1]
+ chns = self.bottleneck_params["entry_flow"][2]
+ strides = check_data(strides, block_num)
+ chns = check_data(chns, block_num)
+
+ # params to control your flow
+ s = self.stride
+ block_point = self.block_point
+ output_stride = self.output_stride
+ with scope("entry_flow"):
+ for i in range(block_num):
+ block_point = block_point + 1
+ with scope("block" + str(i + 1)):
+ stride = strides[i] if check_stride(s * strides[i],
+ output_stride) else 1
+ data, short_cuts = self.xception_block(
+ data, chns[i], [1, 1, stride])
+ s = s * stride
+ if check_points(block_point, self.decode_points):
+ self.short_cuts[block_point] = short_cuts[1]
+
+ self.stride = s
+ self.block_point = block_point
+ return data
+
+ def middle_flow(self, data):
+ block_num = self.bottleneck_params["middle_flow"][0]
+ strides = self.bottleneck_params["middle_flow"][1]
+ chns = self.bottleneck_params["middle_flow"][2]
+ strides = check_data(strides, block_num)
+ chns = check_data(chns, block_num)
+
+ # params to control your flow
+ s = self.stride
+ block_point = self.block_point
+ output_stride = self.output_stride
+ with scope("middle_flow"):
+ for i in range(block_num):
+ block_point = block_point + 1
+ with scope("block" + str(i + 1)):
+ stride = strides[i] if check_stride(s * strides[i],
+ output_stride) else 1
+ data, short_cuts = self.xception_block(
+ data, chns[i], [1, 1, strides[i]], skip_conv=False)
+ s = s * stride
+ if check_points(block_point, self.decode_points):
+ self.short_cuts[block_point] = short_cuts[1]
+
+ self.stride = s
+ self.block_point = block_point
+ return data
+
+ def exit_flow(self, data):
+ block_num = self.bottleneck_params["exit_flow"][0]
+ strides = self.bottleneck_params["exit_flow"][1]
+ chns = self.bottleneck_params["exit_flow"][2]
+ strides = check_data(strides, block_num)
+ chns = check_data(chns, block_num)
+
+ assert (block_num == 2)
+ # params to control your flow
+ s = self.stride
+ block_point = self.block_point
+ output_stride = self.output_stride
+ with scope("exit_flow"):
+ with scope('block1'):
+ block_point += 1
+ stride = strides[0] if check_stride(s * strides[0],
+ output_stride) else 1
+ data, short_cuts = self.xception_block(data, chns[0],
+ [1, 1, stride])
+ s = s * stride
+ if check_points(block_point, self.decode_points):
+ self.short_cuts[block_point] = short_cuts[1]
+ with scope('block2'):
+ block_point += 1
+ stride = strides[1] if check_stride(s * strides[1],
+ output_stride) else 1
+ data, short_cuts = self.xception_block(
+ data,
+ chns[1], [1, 1, stride],
+ dilation=2,
+ has_skip=False,
+ activation_fn_in_separable_conv=True)
+ s = s * stride
+ if check_points(block_point, self.decode_points):
+ self.short_cuts[block_point] = short_cuts[1]
+
+ self.stride = s
+ self.block_point = block_point
+ return data
+
+ def xception_block(self,
+ input,
+ channels,
+ strides=1,
+ filters=3,
+ dilation=1,
+ skip_conv=True,
+ has_skip=True,
+ activation_fn_in_separable_conv=False):
+ repeat_number = 3
+ channels = check_data(channels, repeat_number)
+ filters = check_data(filters, repeat_number)
+ strides = check_data(strides, repeat_number)
+ data = input
+ results = []
+ for i in range(repeat_number):
+ with scope('separable_conv' + str(i + 1)):
+ if not activation_fn_in_separable_conv:
+ data = relu(data)
+ data = separate_conv(
+ data,
+ channels[i],
+ strides[i],
+ filters[i],
+ dilation=dilation,
+ eps=1e-3)
+ else:
+ data = separate_conv(
+ data,
+ channels[i],
+ strides[i],
+ filters[i],
+ dilation=dilation,
+ act=relu,
+ eps=1e-3)
+ results.append(data)
+ if not has_skip:
+ return data, results
+ if skip_conv:
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=None,
+ initializer=fluid.initializer.TruncatedNormal(
+ loc=0.0, scale=0.09))
+ with scope('shortcut'):
+ skip = bn(
+ conv(
+ input,
+ channels[-1],
+ 1,
+ strides[-1],
+ groups=1,
+ padding=0,
+ param_attr=param_attr),
+ eps=1e-3)
+ else:
+ skip = input
+ return data + skip, results
+
+
+def xception_65(num_classes=None):
+ model = Xception(num_classes, 65)
+ return model
+
+
+def xception_41(num_classes=None):
+ model = Xception(num_classes, 41)
+ return model
+
+
+def xception_71(num_classes=None):
+ model = Xception(num_classes, 71)
+ return model
diff --git a/contrib/HumanSeg/nets/deeplabv3p.py b/contrib/HumanSeg/nets/deeplabv3p.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb363c8ca1934c5276556b51f9a3d3a3e537b781
--- /dev/null
+++ b/contrib/HumanSeg/nets/deeplabv3p.py
@@ -0,0 +1,415 @@
+# coding: utf8
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from collections import OrderedDict
+
+import paddle.fluid as fluid
+from .libs import scope, name_scope
+from .libs import bn_relu, relu
+from .libs import conv
+from .libs import separate_conv
+from .libs import sigmoid_to_softmax
+from .seg_modules import softmax_with_loss
+from .seg_modules import dice_loss
+from .seg_modules import bce_loss
+from .backbone import MobileNetV2
+from .backbone import Xception
+
+
+class DeepLabv3p(object):
+ """实现DeepLabv3+模型
+ `"Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation"
+ `
+
+ Args:
+ num_classes (int): 类别数。
+ backbone (str): DeepLabv3+的backbone网络,实现特征图的计算,取值范围为['Xception65', 'Xception41',
+ 'MobileNetV2_x0.25', 'MobileNetV2_x0.5', 'MobileNetV2_x1.0', 'MobileNetV2_x1.5',
+ 'MobileNetV2_x2.0']。默认'MobileNetV2_x1.0'。
+ mode (str): 网络运行模式,根据mode构建网络的输入和返回。
+ 当mode为'train'时,输入为image(-1, 3, -1, -1)和label (-1, 1, -1, -1) 返回loss。
+ 当mode为'train'时,输入为image (-1, 3, -1, -1)和label (-1, 1, -1, -1),返回loss,
+ pred (与网络输入label 相同大小的预测结果,值代表相应的类别),label,mask(非忽略值的mask,
+ 与label相同大小,bool类型)。
+ 当mode为'test'时,输入为image(-1, 3, -1, -1)返回pred (-1, 1, -1, -1)和
+ logit (-1, num_classes, -1, -1) 通道维上代表每一类的概率值。
+ output_stride (int): backbone 输出特征图相对于输入的下采样倍数,一般取值为8或16。
+ aspp_with_sep_conv (bool): 在asspp模块是否采用separable convolutions。
+ decoder_use_sep_conv (bool): decoder模块是否采用separable convolutions。
+ encoder_with_aspp (bool): 是否在encoder阶段采用aspp模块。
+ enable_decoder (bool): 是否使用decoder模块。
+ use_bce_loss (bool): 是否使用bce loss作为网络的损失函数,只能用于两类分割。可与dice loss同时使用。
+ use_dice_loss (bool): 是否使用dice loss作为网络的损失函数,只能用于两类分割,可与bce loss同时使用。
+ 当use_bce_loss和use_dice_loss都为False时,使用交叉熵损失函数。
+ class_weight (list/str): 交叉熵损失函数各类损失的权重。当class_weight为list的时候,长度应为
+ num_classes。当class_weight为str时, weight.lower()应为'dynamic',这时会根据每一轮各类像素的比重
+ 自行计算相应的权重,每一类的权重为:每类的比例 * num_classes。class_weight取默认值None是,各类的权重1,
+ 即平时使用的交叉熵损失函数。
+ ignore_index (int): label上忽略的值,label为ignore_index的像素不参与损失函数的计算。
+
+ Raises:
+ ValueError: use_bce_loss或use_dice_loss为真且num_calsses > 2。
+ ValueError: class_weight为list, 但长度不等于num_class。
+ class_weight为str, 但class_weight.low()不等于dynamic。
+ TypeError: class_weight不为None时,其类型不是list或str。
+ """
+
+ def __init__(self,
+ num_classes,
+ backbone='MobileNetV2_x1.0',
+ mode='train',
+ output_stride=16,
+ aspp_with_sep_conv=True,
+ decoder_use_sep_conv=True,
+ encoder_with_aspp=True,
+ enable_decoder=True,
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255):
+ # dice_loss或bce_loss只适用两类分割中
+ if num_classes > 2 and (use_bce_loss or use_dice_loss):
+ raise ValueError(
+ "dice loss and bce loss is only applicable to binary classfication"
+ )
+
+ if class_weight is not None:
+ if isinstance(class_weight, list):
+ if len(class_weight) != num_classes:
+ raise ValueError(
+ "Length of class_weight should be equal to number of classes"
+ )
+ elif isinstance(class_weight, str):
+ if class_weight.lower() != 'dynamic':
+ raise ValueError(
+ "if class_weight is string, must be dynamic!")
+ else:
+ raise TypeError(
+ 'Expect class_weight is a list or string but receive {}'.
+ format(type(class_weight)))
+
+ self.num_classes = num_classes
+ self.backbone = backbone
+ self.mode = mode
+ self.use_bce_loss = use_bce_loss
+ self.use_dice_loss = use_dice_loss
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+ self.output_stride = output_stride
+ self.aspp_with_sep_conv = aspp_with_sep_conv
+ self.decoder_use_sep_conv = decoder_use_sep_conv
+ self.encoder_with_aspp = encoder_with_aspp
+ self.enable_decoder = enable_decoder
+
+ def _get_backbone(self, backbone):
+ def mobilenetv2(backbone):
+ # backbone: xception结构配置
+ # output_stride:下采样倍数
+ # end_points: mobilenetv2的block数
+ # decode_point: 从mobilenetv2中引出分支所在block数, 作为decoder输入
+ if '0.25' in backbone:
+ scale = 0.25
+ elif '0.5' in backbone:
+ scale = 0.5
+ elif '1.0' in backbone:
+ scale = 1.0
+ elif '1.5' in backbone:
+ scale = 1.5
+ elif '2.0' in backbone:
+ scale = 2.0
+ end_points = 18
+ decode_points = 4
+ return MobileNetV2(
+ scale=scale,
+ output_stride=self.output_stride,
+ end_points=end_points,
+ decode_points=decode_points)
+
+ def xception(backbone):
+ # decode_point: 从Xception中引出分支所在block数,作为decoder输入
+ # end_point:Xception的block数
+ if '65' in backbone:
+ decode_points = 2
+ end_points = 21
+ layers = 65
+ if '41' in backbone:
+ decode_points = 2
+ end_points = 13
+ layers = 41
+ if '71' in backbone:
+ decode_points = 3
+ end_points = 23
+ layers = 71
+ return Xception(
+ layers=layers,
+ output_stride=self.output_stride,
+ end_points=end_points,
+ decode_points=decode_points)
+
+ if 'Xception' in backbone:
+ return xception(backbone)
+ elif 'MobileNetV2' in backbone:
+ return mobilenetv2(backbone)
+
+ def _encoder(self, input):
+ # 编码器配置,采用ASPP架构,pooling + 1x1_conv + 三个不同尺度的空洞卷积并行, concat后1x1conv
+ # ASPP_WITH_SEP_CONV:默认为真,使用depthwise可分离卷积,否则使用普通卷积
+ # OUTPUT_STRIDE: 下采样倍数,8或16,决定aspp_ratios大小
+ # aspp_ratios:ASPP模块空洞卷积的采样率
+
+ if self.output_stride == 16:
+ aspp_ratios = [6, 12, 18]
+ elif self.output_stride == 8:
+ aspp_ratios = [12, 24, 36]
+ else:
+ raise Exception("DeepLabv3p only support stride 8 or 16")
+
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=None,
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.06))
+ with scope('encoder'):
+ channel = 256
+ with scope("image_pool"):
+ image_avg = fluid.layers.reduce_mean(
+ input, [2, 3], keep_dim=True)
+ image_avg = bn_relu(
+ conv(
+ image_avg,
+ channel,
+ 1,
+ 1,
+ groups=1,
+ padding=0,
+ param_attr=param_attr))
+ input_shape = fluid.layers.shape(input)
+ image_avg = fluid.layers.resize_bilinear(
+ image_avg, input_shape[2:])
+
+ with scope("aspp0"):
+ aspp0 = bn_relu(
+ conv(
+ input,
+ channel,
+ 1,
+ 1,
+ groups=1,
+ padding=0,
+ param_attr=param_attr))
+ with scope("aspp1"):
+ if self.aspp_with_sep_conv:
+ aspp1 = separate_conv(
+ input, channel, 1, 3, dilation=aspp_ratios[0], act=relu)
+ else:
+ aspp1 = bn_relu(
+ conv(
+ input,
+ channel,
+ stride=1,
+ filter_size=3,
+ dilation=aspp_ratios[0],
+ padding=aspp_ratios[0],
+ param_attr=param_attr))
+ with scope("aspp2"):
+ if self.aspp_with_sep_conv:
+ aspp2 = separate_conv(
+ input, channel, 1, 3, dilation=aspp_ratios[1], act=relu)
+ else:
+ aspp2 = bn_relu(
+ conv(
+ input,
+ channel,
+ stride=1,
+ filter_size=3,
+ dilation=aspp_ratios[1],
+ padding=aspp_ratios[1],
+ param_attr=param_attr))
+ with scope("aspp3"):
+ if self.aspp_with_sep_conv:
+ aspp3 = separate_conv(
+ input, channel, 1, 3, dilation=aspp_ratios[2], act=relu)
+ else:
+ aspp3 = bn_relu(
+ conv(
+ input,
+ channel,
+ stride=1,
+ filter_size=3,
+ dilation=aspp_ratios[2],
+ padding=aspp_ratios[2],
+ param_attr=param_attr))
+ with scope("concat"):
+ data = fluid.layers.concat(
+ [image_avg, aspp0, aspp1, aspp2, aspp3], axis=1)
+ data = bn_relu(
+ conv(
+ data,
+ channel,
+ 1,
+ 1,
+ groups=1,
+ padding=0,
+ param_attr=param_attr))
+ data = fluid.layers.dropout(data, 0.9)
+ return data
+
+ def _decoder(self, encode_data, decode_shortcut):
+ # 解码器配置
+ # encode_data:编码器输出
+ # decode_shortcut: 从backbone引出的分支, resize后与encode_data concat
+ # decoder_use_sep_conv: 默认为真,则concat后连接两个可分离卷积,否则为普通卷积
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=None,
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.06))
+ with scope('decoder'):
+ with scope('concat'):
+ decode_shortcut = bn_relu(
+ conv(
+ decode_shortcut,
+ 48,
+ 1,
+ 1,
+ groups=1,
+ padding=0,
+ param_attr=param_attr))
+
+ decode_shortcut_shape = fluid.layers.shape(decode_shortcut)
+ encode_data = fluid.layers.resize_bilinear(
+ encode_data, decode_shortcut_shape[2:])
+ encode_data = fluid.layers.concat(
+ [encode_data, decode_shortcut], axis=1)
+ if self.decoder_use_sep_conv:
+ with scope("separable_conv1"):
+ encode_data = separate_conv(
+ encode_data, 256, 1, 3, dilation=1, act=relu)
+ with scope("separable_conv2"):
+ encode_data = separate_conv(
+ encode_data, 256, 1, 3, dilation=1, act=relu)
+ else:
+ with scope("decoder_conv1"):
+ encode_data = bn_relu(
+ conv(
+ encode_data,
+ 256,
+ stride=1,
+ filter_size=3,
+ dilation=1,
+ padding=1,
+ param_attr=param_attr))
+ with scope("decoder_conv2"):
+ encode_data = bn_relu(
+ conv(
+ encode_data,
+ 256,
+ stride=1,
+ filter_size=3,
+ dilation=1,
+ padding=1,
+ param_attr=param_attr))
+ return encode_data
+
+ def _get_loss(self, logit, label, mask):
+ avg_loss = 0
+ if not (self.use_dice_loss or self.use_bce_loss):
+ avg_loss += softmax_with_loss(
+ logit,
+ label,
+ mask,
+ num_classes=self.num_classes,
+ weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ else:
+ if self.use_dice_loss:
+ avg_loss += dice_loss(logit, label, mask)
+ if self.use_bce_loss:
+ avg_loss += bce_loss(
+ logit, label, mask, ignore_index=self.ignore_index)
+
+ return avg_loss
+
+ def generate_inputs(self):
+ inputs = OrderedDict()
+ inputs['image'] = fluid.data(
+ dtype='float32', shape=[None, 3, None, None], name='image')
+ if self.mode == 'train':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ elif self.mode == 'eval':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ return inputs
+
+ def build_net(self, inputs):
+ # 在两类分割情况下,当loss函数选择dice_loss或bce_loss的时候,最后logit输出通道数设置为1
+ if self.use_dice_loss or self.use_bce_loss:
+ self.num_classes = 1
+ image = inputs['image']
+
+ backbone_net = self._get_backbone(self.backbone)
+ data, decode_shortcuts = backbone_net(image)
+ decode_shortcut = decode_shortcuts[backbone_net.decode_points]
+
+ # 编码器解码器设置
+ if self.encoder_with_aspp:
+ data = self._encoder(data)
+ if self.enable_decoder:
+ data = self._decoder(data, decode_shortcut)
+
+ # 根据类别数设置最后一个卷积层输出,并resize到图片原始尺寸
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.0),
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.01))
+ with scope('logit'):
+ with fluid.name_scope('last_conv'):
+ logit = conv(
+ data,
+ self.num_classes,
+ 1,
+ stride=1,
+ padding=0,
+ bias_attr=True,
+ param_attr=param_attr)
+ image_shape = fluid.layers.shape(image)
+ logit = fluid.layers.resize_bilinear(logit, image_shape[2:])
+
+ if self.num_classes == 1:
+ out = sigmoid_to_softmax(logit)
+ out = fluid.layers.transpose(out, [0, 2, 3, 1])
+ else:
+ out = fluid.layers.transpose(logit, [0, 2, 3, 1])
+
+ pred = fluid.layers.argmax(out, axis=3)
+ pred = fluid.layers.unsqueeze(pred, axes=[3])
+
+ if self.mode == 'train':
+ label = inputs['label']
+ mask = label != self.ignore_index
+ return self._get_loss(logit, label, mask)
+
+ else:
+ if self.num_classes == 1:
+ logit = sigmoid_to_softmax(logit)
+ else:
+ logit = fluid.layers.softmax(logit, axis=1)
+ return pred, logit
+
+ return logit
diff --git a/contrib/HumanSeg/nets/hrnet.py b/contrib/HumanSeg/nets/hrnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..47f100c19f934c9f829b6069913cf19abbdfca3c
--- /dev/null
+++ b/contrib/HumanSeg/nets/hrnet.py
@@ -0,0 +1,449 @@
+# coding: utf8
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from collections import OrderedDict
+
+import paddle.fluid as fluid
+from paddle.fluid.initializer import MSRA
+from paddle.fluid.param_attr import ParamAttr
+from .seg_modules import softmax_with_loss
+from .seg_modules import dice_loss
+from .seg_modules import bce_loss
+from .libs import sigmoid_to_softmax
+
+
+class HRNet(object):
+ def __init__(self,
+ num_classes,
+ mode='train',
+ stage1_num_modules=1,
+ stage1_num_blocks=[4],
+ stage1_num_channels=[64],
+ stage2_num_modules=1,
+ stage2_num_blocks=[4, 4],
+ stage2_num_channels=[18, 36],
+ stage3_num_modules=4,
+ stage3_num_blocks=[4, 4, 4],
+ stage3_num_channels=[18, 36, 72],
+ stage4_num_modules=3,
+ stage4_num_blocks=[4, 4, 4, 4],
+ stage4_num_channels=[18, 36, 72, 144],
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255):
+ # dice_loss或bce_loss只适用两类分割中
+ if num_classes > 2 and (use_bce_loss or use_dice_loss):
+ raise ValueError(
+ "dice loss and bce loss is only applicable to binary classfication"
+ )
+
+ if class_weight is not None:
+ if isinstance(class_weight, list):
+ if len(class_weight) != num_classes:
+ raise ValueError(
+ "Length of class_weight should be equal to number of classes"
+ )
+ elif isinstance(class_weight, str):
+ if class_weight.lower() != 'dynamic':
+ raise ValueError(
+ "if class_weight is string, must be dynamic!")
+ else:
+ raise TypeError(
+ 'Expect class_weight is a list or string but receive {}'.
+ format(type(class_weight)))
+
+ self.num_classes = num_classes
+ self.mode = mode
+ self.use_bce_loss = use_bce_loss
+ self.use_dice_loss = use_dice_loss
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+ self.stage1_num_modules = stage1_num_modules
+ self.stage1_num_blocks = stage1_num_blocks
+ self.stage1_num_channels = stage1_num_channels
+ self.stage2_num_modules = stage2_num_modules
+ self.stage2_num_blocks = stage2_num_blocks
+ self.stage2_num_channels = stage2_num_channels
+ self.stage3_num_modules = stage3_num_modules
+ self.stage3_num_blocks = stage3_num_blocks
+ self.stage3_num_channels = stage3_num_channels
+ self.stage4_num_modules = stage4_num_modules
+ self.stage4_num_blocks = stage4_num_blocks
+ self.stage4_num_channels = stage4_num_channels
+
+ def build_net(self, inputs):
+ image = inputs['image']
+ logit = self._high_resolution_net(image, self.num_classes)
+ if self.num_classes == 1:
+ out = sigmoid_to_softmax(logit)
+ out = fluid.layers.transpose(out, [0, 2, 3, 1])
+ else:
+ out = fluid.layers.transpose(logit, [0, 2, 3, 1])
+
+ pred = fluid.layers.argmax(out, axis=3)
+ pred = fluid.layers.unsqueeze(pred, axes=[3])
+
+ if self.mode == 'train':
+ label = inputs['label']
+ mask = label != self.ignore_index
+ return self._get_loss(logit, label, mask)
+
+ else:
+ if self.num_classes == 1:
+ logit = sigmoid_to_softmax(logit)
+ else:
+ logit = fluid.layers.softmax(logit, axis=1)
+ return pred, logit
+
+ return logit
+
+ def generate_inputs(self):
+ inputs = OrderedDict()
+ inputs['image'] = fluid.data(
+ dtype='float32', shape=[None, 3, None, None], name='image')
+ if self.mode == 'train':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ elif self.mode == 'eval':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ return inputs
+
+ def _get_loss(self, logit, label, mask):
+ avg_loss = 0
+ if not (self.use_dice_loss or self.use_bce_loss):
+ avg_loss += softmax_with_loss(
+ logit,
+ label,
+ mask,
+ num_classes=self.num_classes,
+ weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ else:
+ if self.use_dice_loss:
+ avg_loss += dice_loss(logit, label, mask)
+ if self.use_bce_loss:
+ avg_loss += bce_loss(
+ logit, label, mask, ignore_index=self.ignore_index)
+
+ return avg_loss
+
+ def _conv_bn_layer(self,
+ input,
+ filter_size,
+ num_filters,
+ stride=1,
+ padding=1,
+ num_groups=1,
+ if_act=True,
+ name=None):
+ conv = fluid.layers.conv2d(
+ input=input,
+ num_filters=num_filters,
+ filter_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) // 2,
+ groups=num_groups,
+ act=None,
+ param_attr=ParamAttr(initializer=MSRA(), name=name + '_weights'),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ bn = fluid.layers.batch_norm(
+ input=conv,
+ param_attr=ParamAttr(
+ name=bn_name + "_scale",
+ initializer=fluid.initializer.Constant(1.0)),
+ bias_attr=ParamAttr(
+ name=bn_name + "_offset",
+ initializer=fluid.initializer.Constant(0.0)),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+ if if_act:
+ bn = fluid.layers.relu(bn)
+ return bn
+
+ def _basic_block(self,
+ input,
+ num_filters,
+ stride=1,
+ downsample=False,
+ name=None):
+ residual = input
+ conv = self._conv_bn_layer(
+ input=input,
+ filter_size=3,
+ num_filters=num_filters,
+ stride=stride,
+ name=name + '_conv1')
+ conv = self._conv_bn_layer(
+ input=conv,
+ filter_size=3,
+ num_filters=num_filters,
+ if_act=False,
+ name=name + '_conv2')
+ if downsample:
+ residual = self._conv_bn_layer(
+ input=input,
+ filter_size=1,
+ num_filters=num_filters,
+ if_act=False,
+ name=name + '_downsample')
+ return fluid.layers.elementwise_add(x=residual, y=conv, act='relu')
+
+ def _bottleneck_block(self,
+ input,
+ num_filters,
+ stride=1,
+ downsample=False,
+ name=None):
+ residual = input
+ conv = self._conv_bn_layer(
+ input=input,
+ filter_size=1,
+ num_filters=num_filters,
+ name=name + '_conv1')
+ conv = self._conv_bn_layer(
+ input=conv,
+ filter_size=3,
+ num_filters=num_filters,
+ stride=stride,
+ name=name + '_conv2')
+ conv = self._conv_bn_layer(
+ input=conv,
+ filter_size=1,
+ num_filters=num_filters * 4,
+ if_act=False,
+ name=name + '_conv3')
+ if downsample:
+ residual = self._conv_bn_layer(
+ input=input,
+ filter_size=1,
+ num_filters=num_filters * 4,
+ if_act=False,
+ name=name + '_downsample')
+ return fluid.layers.elementwise_add(x=residual, y=conv, act='relu')
+
+ def _fuse_layers(self, x, channels, multi_scale_output=True, name=None):
+ out = []
+ for i in range(len(channels) if multi_scale_output else 1):
+ residual = x[i]
+ shape = fluid.layers.shape(residual)[-2:]
+ for j in range(len(channels)):
+ if j > i:
+ y = self._conv_bn_layer(
+ x[j],
+ filter_size=1,
+ num_filters=channels[i],
+ if_act=False,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1))
+ y = fluid.layers.resize_bilinear(input=y, out_shape=shape)
+ residual = fluid.layers.elementwise_add(
+ x=residual, y=y, act=None)
+ elif j < i:
+ y = x[j]
+ for k in range(i - j):
+ if k == i - j - 1:
+ y = self._conv_bn_layer(
+ y,
+ filter_size=3,
+ num_filters=channels[i],
+ stride=2,
+ if_act=False,
+ name=name + '_layer_' + str(i + 1) + '_' +
+ str(j + 1) + '_' + str(k + 1))
+ else:
+ y = self._conv_bn_layer(
+ y,
+ filter_size=3,
+ num_filters=channels[j],
+ stride=2,
+ name=name + '_layer_' + str(i + 1) + '_' +
+ str(j + 1) + '_' + str(k + 1))
+ residual = fluid.layers.elementwise_add(
+ x=residual, y=y, act=None)
+
+ residual = fluid.layers.relu(residual)
+ out.append(residual)
+ return out
+
+ def _branches(self, x, block_num, channels, name=None):
+ out = []
+ for i in range(len(channels)):
+ residual = x[i]
+ for j in range(block_num[i]):
+ residual = self._basic_block(
+ residual,
+ channels[i],
+ name=name + '_branch_layer_' + str(i + 1) + '_' +
+ str(j + 1))
+ out.append(residual)
+ return out
+
+ def _high_resolution_module(self,
+ x,
+ blocks,
+ channels,
+ multi_scale_output=True,
+ name=None):
+ residual = self._branches(x, blocks, channels, name=name)
+ out = self._fuse_layers(
+ residual,
+ channels,
+ multi_scale_output=multi_scale_output,
+ name=name)
+ return out
+
+ def _transition_layer(self, x, in_channels, out_channels, name=None):
+ num_in = len(in_channels)
+ num_out = len(out_channels)
+ out = []
+ for i in range(num_out):
+ if i < num_in:
+ if in_channels[i] != out_channels[i]:
+ residual = self._conv_bn_layer(
+ x[i],
+ filter_size=3,
+ num_filters=out_channels[i],
+ name=name + '_layer_' + str(i + 1))
+ out.append(residual)
+ else:
+ out.append(x[i])
+ else:
+ residual = self._conv_bn_layer(
+ x[-1],
+ filter_size=3,
+ num_filters=out_channels[i],
+ stride=2,
+ name=name + '_layer_' + str(i + 1))
+ out.append(residual)
+ return out
+
+ def _stage(self,
+ x,
+ num_modules,
+ num_blocks,
+ num_channels,
+ multi_scale_output=True,
+ name=None):
+ out = x
+ for i in range(num_modules):
+ if i == num_modules - 1 and multi_scale_output == False:
+ out = self._high_resolution_module(
+ out,
+ num_blocks,
+ num_channels,
+ multi_scale_output=False,
+ name=name + '_' + str(i + 1))
+ else:
+ out = self._high_resolution_module(
+ out, num_blocks, num_channels, name=name + '_' + str(i + 1))
+
+ return out
+
+ def _layer1(self, input, num_modules, num_blocks, num_channels, name=None):
+ # num_modules 默认为1,是否增加处理,官网实现为[1],是否对齐。
+ conv = input
+ for i in range(num_blocks[0]):
+ conv = self._bottleneck_block(
+ conv,
+ num_filters=num_channels[0],
+ downsample=True if i == 0 else False,
+ name=name + '_' + str(i + 1))
+ return conv
+
+ def _high_resolution_net(self, input, num_classes):
+ x = self._conv_bn_layer(
+ input=input,
+ filter_size=3,
+ num_filters=self.stage1_num_channels[0],
+ stride=2,
+ if_act=True,
+ name='layer1_1')
+ x = self._conv_bn_layer(
+ input=x,
+ filter_size=3,
+ num_filters=self.stage1_num_channels[0],
+ stride=2,
+ if_act=True,
+ name='layer1_2')
+
+ la1 = self._layer1(
+ x,
+ self.stage1_num_modules,
+ self.stage1_num_blocks,
+ self.stage1_num_channels,
+ name='layer2')
+ tr1 = self._transition_layer([la1],
+ self.stage1_num_channels,
+ self.stage2_num_channels,
+ name='tr1')
+ st2 = self._stage(
+ tr1,
+ self.stage2_num_modules,
+ self.stage2_num_blocks,
+ self.stage2_num_channels,
+ name='st2')
+ tr2 = self._transition_layer(
+ st2, self.stage2_num_channels, self.stage3_num_channels, name='tr2')
+ st3 = self._stage(
+ tr2,
+ self.stage3_num_modules,
+ self.stage3_num_blocks,
+ self.stage3_num_channels,
+ name='st3')
+ tr3 = self._transition_layer(
+ st3, self.stage3_num_channels, self.stage4_num_channels, name='tr3')
+ st4 = self._stage(
+ tr3,
+ self.stage4_num_modules,
+ self.stage4_num_blocks,
+ self.stage4_num_channels,
+ name='st4')
+
+ # upsample
+ shape = fluid.layers.shape(st4[0])[-2:]
+ st4[1] = fluid.layers.resize_bilinear(st4[1], out_shape=shape)
+ st4[2] = fluid.layers.resize_bilinear(st4[2], out_shape=shape)
+ st4[3] = fluid.layers.resize_bilinear(st4[3], out_shape=shape)
+
+ out = fluid.layers.concat(st4, axis=1)
+ last_channels = sum(self.stage4_num_channels)
+
+ out = self._conv_bn_layer(
+ input=out,
+ filter_size=1,
+ num_filters=last_channels,
+ stride=1,
+ if_act=True,
+ name='conv-2')
+ out = fluid.layers.conv2d(
+ input=out,
+ num_filters=num_classes,
+ filter_size=1,
+ stride=1,
+ padding=0,
+ act=None,
+ param_attr=ParamAttr(initializer=MSRA(), name='conv-1_weights'),
+ bias_attr=False)
+
+ input_shape = fluid.layers.shape(input)[-2:]
+ out = fluid.layers.resize_bilinear(out, input_shape)
+
+ return out
diff --git a/contrib/HumanSeg/nets/libs.py b/contrib/HumanSeg/nets/libs.py
new file mode 100644
index 0000000000000000000000000000000000000000..01fdad2cec6ce4b13cea2b7c957fb648edb4aeb2
--- /dev/null
+++ b/contrib/HumanSeg/nets/libs.py
@@ -0,0 +1,219 @@
+# coding: utf8
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+import paddle
+import paddle.fluid as fluid
+import contextlib
+
+bn_regularizer = fluid.regularizer.L2DecayRegularizer(regularization_coeff=0.0)
+name_scope = ""
+
+
+@contextlib.contextmanager
+def scope(name):
+ global name_scope
+ bk = name_scope
+ name_scope = name_scope + name + '/'
+ yield
+ name_scope = bk
+
+
+def max_pool(input, kernel, stride, padding):
+ data = fluid.layers.pool2d(
+ input,
+ pool_size=kernel,
+ pool_type='max',
+ pool_stride=stride,
+ pool_padding=padding)
+ return data
+
+
+def avg_pool(input, kernel, stride, padding=0):
+ data = fluid.layers.pool2d(
+ input,
+ pool_size=kernel,
+ pool_type='avg',
+ pool_stride=stride,
+ pool_padding=padding)
+ return data
+
+
+def group_norm(input, G, eps=1e-5, param_attr=None, bias_attr=None):
+ N, C, H, W = input.shape
+ if C % G != 0:
+ for d in range(10):
+ for t in [d, -d]:
+ if G + t <= 0: continue
+ if C % (G + t) == 0:
+ G = G + t
+ break
+ if C % G == 0:
+ break
+ assert C % G == 0, "group can not divide channle"
+ x = fluid.layers.group_norm(
+ input,
+ groups=G,
+ param_attr=param_attr,
+ bias_attr=bias_attr,
+ name=name_scope + 'group_norm')
+ return x
+
+
+def bn(*args,
+ norm_type='bn',
+ eps=1e-5,
+ bn_momentum=0.99,
+ group_norm=32,
+ **kargs):
+
+ if norm_type == 'bn':
+ with scope('BatchNorm'):
+ return fluid.layers.batch_norm(
+ *args,
+ epsilon=eps,
+ momentum=bn_momentum,
+ param_attr=fluid.ParamAttr(
+ name=name_scope + 'gamma', regularizer=bn_regularizer),
+ bias_attr=fluid.ParamAttr(
+ name=name_scope + 'beta', regularizer=bn_regularizer),
+ moving_mean_name=name_scope + 'moving_mean',
+ moving_variance_name=name_scope + 'moving_variance',
+ **kargs)
+ elif norm_type == 'gn':
+ with scope('GroupNorm'):
+ return group_norm(
+ args[0],
+ group_norm,
+ eps=eps,
+ param_attr=fluid.ParamAttr(
+ name=name_scope + 'gamma', regularizer=bn_regularizer),
+ bias_attr=fluid.ParamAttr(
+ name=name_scope + 'beta', regularizer=bn_regularizer))
+ else:
+ raise Exception("Unsupport norm type:" + norm_type)
+
+
+def bn_relu(data, norm_type='bn', eps=1e-5):
+ return fluid.layers.relu(bn(data, norm_type=norm_type, eps=eps))
+
+
+def relu(data):
+ return fluid.layers.relu(data)
+
+
+def conv(*args, **kargs):
+ kargs['param_attr'] = name_scope + 'weights'
+ if 'bias_attr' in kargs and kargs['bias_attr']:
+ kargs['bias_attr'] = fluid.ParamAttr(
+ name=name_scope + 'biases',
+ regularizer=None,
+ initializer=fluid.initializer.ConstantInitializer(value=0.0))
+ else:
+ kargs['bias_attr'] = False
+ return fluid.layers.conv2d(*args, **kargs)
+
+
+def deconv(*args, **kargs):
+ kargs['param_attr'] = name_scope + 'weights'
+ if 'bias_attr' in kargs and kargs['bias_attr']:
+ kargs['bias_attr'] = name_scope + 'biases'
+ else:
+ kargs['bias_attr'] = False
+ return fluid.layers.conv2d_transpose(*args, **kargs)
+
+
+def separate_conv(input,
+ channel,
+ stride,
+ filter,
+ dilation=1,
+ act=None,
+ eps=1e-5):
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.0),
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.33))
+ with scope('depthwise'):
+ input = conv(
+ input,
+ input.shape[1],
+ filter,
+ stride,
+ groups=input.shape[1],
+ padding=(filter // 2) * dilation,
+ dilation=dilation,
+ use_cudnn=False,
+ param_attr=param_attr)
+ input = bn(input, eps=eps)
+ if act: input = act(input)
+
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=None,
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.06))
+ with scope('pointwise'):
+ input = conv(
+ input, channel, 1, 1, groups=1, padding=0, param_attr=param_attr)
+ input = bn(input, eps=eps)
+ if act: input = act(input)
+ return input
+
+
+def conv_bn_layer(input,
+ filter_size,
+ num_filters,
+ stride,
+ padding,
+ channels=None,
+ num_groups=1,
+ if_act=True,
+ name=None,
+ use_cudnn=True):
+ conv = fluid.layers.conv2d(
+ input=input,
+ num_filters=num_filters,
+ filter_size=filter_size,
+ stride=stride,
+ padding=padding,
+ groups=num_groups,
+ act=None,
+ use_cudnn=use_cudnn,
+ param_attr=fluid.ParamAttr(name=name + '_weights'),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ bn = fluid.layers.batch_norm(
+ input=conv,
+ param_attr=fluid.ParamAttr(name=bn_name + "_scale"),
+ bias_attr=fluid.ParamAttr(name=bn_name + "_offset"),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+ if if_act:
+ return fluid.layers.relu6(bn)
+ else:
+ return bn
+
+
+def sigmoid_to_softmax(input):
+ """
+ one channel to two channel
+ """
+ logit = fluid.layers.sigmoid(input)
+ logit_back = 1 - logit
+ logit = fluid.layers.concat([logit_back, logit], axis=1)
+ return logit
diff --git a/contrib/HumanSeg/nets/seg_modules.py b/contrib/HumanSeg/nets/seg_modules.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb59dce486420585edd47559c6fdd3cf88e59350
--- /dev/null
+++ b/contrib/HumanSeg/nets/seg_modules.py
@@ -0,0 +1,115 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import paddle.fluid as fluid
+import numpy as np
+
+
+def softmax_with_loss(logit,
+ label,
+ ignore_mask=None,
+ num_classes=2,
+ weight=None,
+ ignore_index=255):
+ ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
+ label = fluid.layers.elementwise_min(
+ label, fluid.layers.assign(np.array([num_classes - 1], dtype=np.int32)))
+ logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
+ logit = fluid.layers.reshape(logit, [-1, num_classes])
+ label = fluid.layers.reshape(label, [-1, 1])
+ label = fluid.layers.cast(label, 'int64')
+ ignore_mask = fluid.layers.reshape(ignore_mask, [-1, 1])
+ if weight is None:
+ loss, probs = fluid.layers.softmax_with_cross_entropy(
+ logit, label, ignore_index=ignore_index, return_softmax=True)
+ else:
+ label_one_hot = fluid.one_hot(input=label, depth=num_classes)
+ if isinstance(weight, list):
+ assert len(
+ weight
+ ) == num_classes, "weight length must equal num of classes"
+ weight = fluid.layers.assign(np.array([weight], dtype='float32'))
+ elif isinstance(weight, str):
+ assert weight.lower(
+ ) == 'dynamic', 'if weight is string, must be dynamic!'
+ tmp = []
+ total_num = fluid.layers.cast(
+ fluid.layers.shape(label)[0], 'float32')
+ for i in range(num_classes):
+ cls_pixel_num = fluid.layers.reduce_sum(label_one_hot[:, i])
+ ratio = total_num / (cls_pixel_num + 1)
+ tmp.append(ratio)
+ weight = fluid.layers.concat(tmp)
+ weight = weight / fluid.layers.reduce_sum(weight) * num_classes
+ elif isinstance(weight, fluid.layers.Variable):
+ pass
+ else:
+ raise ValueError(
+ 'Expect weight is a list, string or Variable, but receive {}'.
+ format(type(weight)))
+ weight = fluid.layers.reshape(weight, [1, num_classes])
+ weighted_label_one_hot = fluid.layers.elementwise_mul(
+ label_one_hot, weight)
+ probs = fluid.layers.softmax(logit)
+ loss = fluid.layers.cross_entropy(
+ probs,
+ weighted_label_one_hot,
+ soft_label=True,
+ ignore_index=ignore_index)
+ weighted_label_one_hot.stop_gradient = True
+
+ loss = loss * ignore_mask
+ avg_loss = fluid.layers.mean(loss) / (
+ fluid.layers.mean(ignore_mask) + 0.00001)
+
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return avg_loss
+
+
+# to change, how to appicate ignore index and ignore mask
+def dice_loss(logit, label, ignore_mask=None, epsilon=0.00001):
+ if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
+ raise Exception(
+ "dice loss is only applicable to one channel classfication")
+ ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
+ logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
+ label = fluid.layers.transpose(label, [0, 2, 3, 1])
+ label = fluid.layers.cast(label, 'int64')
+ ignore_mask = fluid.layers.transpose(ignore_mask, [0, 2, 3, 1])
+ logit = fluid.layers.sigmoid(logit)
+ logit = logit * ignore_mask
+ label = label * ignore_mask
+ reduce_dim = list(range(1, len(logit.shape)))
+ inse = fluid.layers.reduce_sum(logit * label, dim=reduce_dim)
+ dice_denominator = fluid.layers.reduce_sum(
+ logit, dim=reduce_dim) + fluid.layers.reduce_sum(
+ label, dim=reduce_dim)
+ dice_score = 1 - inse * 2 / (dice_denominator + epsilon)
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return fluid.layers.reduce_mean(dice_score)
+
+
+def bce_loss(logit, label, ignore_mask=None, ignore_index=255):
+ if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
+ raise Exception("bce loss is only applicable to binary classfication")
+ label = fluid.layers.cast(label, 'float32')
+ loss = fluid.layers.sigmoid_cross_entropy_with_logits(
+ x=logit, label=label, ignore_index=ignore_index,
+ normalize=True) # or False
+ loss = fluid.layers.reduce_sum(loss)
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return loss
diff --git a/contrib/HumanSeg/nets/shufflenet_slim.py b/contrib/HumanSeg/nets/shufflenet_slim.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ca76b9c4eedca6814e545324c2b330b952431b1
--- /dev/null
+++ b/contrib/HumanSeg/nets/shufflenet_slim.py
@@ -0,0 +1,247 @@
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from collections import OrderedDict
+import paddle.fluid as fluid
+from paddle.fluid.initializer import MSRA
+from paddle.fluid.param_attr import ParamAttr
+from .libs import sigmoid_to_softmax
+from .seg_modules import softmax_with_loss
+from .seg_modules import dice_loss
+from .seg_modules import bce_loss
+
+
+class ShuffleSeg(object):
+ # def __init__(self):
+ # self.params = train_parameters
+ def __init__(self,
+ num_classes,
+ mode='train',
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255):
+ # dice_loss或bce_loss只适用两类分割中
+ if num_classes > 2 and (use_bce_loss or use_dice_loss):
+ raise ValueError(
+ "dice loss and bce loss is only applicable to binary classfication"
+ )
+
+ if class_weight is not None:
+ if isinstance(class_weight, list):
+ if len(class_weight) != num_classes:
+ raise ValueError(
+ "Length of class_weight should be equal to number of classes"
+ )
+ elif isinstance(class_weight, str):
+ if class_weight.lower() != 'dynamic':
+ raise ValueError(
+ "if class_weight is string, must be dynamic!")
+ else:
+ raise TypeError(
+ 'Expect class_weight is a list or string but receive {}'.
+ format(type(class_weight)))
+
+ self.num_classes = num_classes
+ self.mode = mode
+ self.use_bce_loss = use_bce_loss
+ self.use_dice_loss = use_dice_loss
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+
+ def _get_loss(self, logit, label, mask):
+ avg_loss = 0
+ if not (self.use_dice_loss or self.use_bce_loss):
+ avg_loss += softmax_with_loss(
+ logit,
+ label,
+ mask,
+ num_classes=self.num_classes,
+ weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ else:
+ if self.use_dice_loss:
+ avg_loss += dice_loss(logit, label, mask)
+ if self.use_bce_loss:
+ avg_loss += bce_loss(
+ logit, label, mask, ignore_index=self.ignore_index)
+
+ return avg_loss
+
+ def generate_inputs(self):
+ inputs = OrderedDict()
+ inputs['image'] = fluid.data(
+ dtype='float32', shape=[None, 3, None, None], name='image')
+ if self.mode == 'train':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ elif self.mode == 'eval':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ return inputs
+
+ def build_net(self, inputs, class_dim=2):
+ if self.use_dice_loss or self.use_bce_loss:
+ self.num_classes = 1
+ image = inputs['image']
+ ## Encoder
+ conv1 = self.conv_bn(image, 3, 36, 2, 1)
+ print('encoder 1', conv1.shape)
+ shortcut = self.conv_bn(
+ input=conv1, filter_size=1, num_filters=18, stride=1, padding=0)
+ print('shortcut 1', shortcut.shape)
+
+ pool = fluid.layers.pool2d(
+ input=conv1,
+ pool_size=3,
+ pool_type='max',
+ pool_stride=2,
+ pool_padding=1)
+ print('encoder 2', pool.shape)
+
+ # Block 1
+ conv = self.sfnetv2module(pool, stride=2, num_filters=72)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ print('encoder 3', conv.shape)
+
+ # Block 2
+ conv = self.sfnetv2module(conv, stride=2)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ conv = self.sfnetv2module(conv, stride=1)
+ print('encoder 4', conv.shape)
+
+ ### decoder
+ conv = self.depthwise_separable(conv, 3, 64, 1)
+ shortcut_shape = fluid.layers.shape(shortcut)[2:]
+ conv_b = fluid.layers.resize_bilinear(conv, shortcut_shape)
+ concat = fluid.layers.concat([shortcut, conv_b], axis=1)
+ decode_conv = self.depthwise_separable(concat, 3, 64, 1)
+ logit = self.output_layer(decode_conv, class_dim)
+
+ if self.num_classes == 1:
+ out = sigmoid_to_softmax(logit)
+ out = fluid.layers.transpose(out, [0, 2, 3, 1])
+ else:
+ out = fluid.layers.transpose(logit, [0, 2, 3, 1])
+
+ pred = fluid.layers.argmax(out, axis=3)
+ pred = fluid.layers.unsqueeze(pred, axes=[3])
+
+ if self.mode == 'train':
+ label = inputs['label']
+ mask = label != self.ignore_index
+ return self._get_loss(logit, label, mask)
+
+ else:
+ if self.num_classes == 1:
+ logit = sigmoid_to_softmax(logit)
+ else:
+ logit = fluid.layers.softmax(logit, axis=1)
+ return pred, logit
+
+ return logit
+
+ def conv_bn(self,
+ input,
+ filter_size,
+ num_filters,
+ stride,
+ padding,
+ channels=None,
+ num_groups=1,
+ act='relu',
+ use_cudnn=True):
+ parameter_attr = ParamAttr(learning_rate=1, initializer=MSRA())
+ conv = fluid.layers.conv2d(
+ input=input,
+ num_filters=num_filters,
+ filter_size=filter_size,
+ stride=stride,
+ padding=padding,
+ groups=num_groups,
+ act=None,
+ use_cudnn=use_cudnn,
+ param_attr=parameter_attr,
+ bias_attr=False)
+ return fluid.layers.batch_norm(input=conv, act=act)
+
+ def depthwise_separable(self, input, filter_size, num_filters, stride):
+ num_filters1 = int(input.shape[1])
+ num_groups = num_filters1
+ depthwise_conv = self.conv_bn(
+ input=input,
+ filter_size=filter_size,
+ num_filters=int(num_filters1),
+ stride=stride,
+ padding=int(filter_size / 2),
+ num_groups=num_groups,
+ use_cudnn=False,
+ act=None)
+
+ pointwise_conv = self.conv_bn(
+ input=depthwise_conv,
+ filter_size=1,
+ num_filters=num_filters,
+ stride=1,
+ padding=0)
+ return pointwise_conv
+
+ def sfnetv2module(self, input, stride, num_filters=None):
+ if stride == 1:
+ shortcut, branch = fluid.layers.split(
+ input, num_or_sections=2, dim=1)
+ if num_filters is None:
+ in_channels = int(branch.shape[1])
+ else:
+ in_channels = int(num_filters / 2)
+ else:
+ branch = input
+ if num_filters is None:
+ in_channels = int(branch.shape[1])
+ else:
+ in_channels = int(num_filters / 2)
+ shortcut = self.depthwise_separable(input, 3, in_channels, stride)
+ branch_1x1 = self.conv_bn(
+ input=branch,
+ filter_size=1,
+ num_filters=int(in_channels),
+ stride=1,
+ padding=0)
+ branch_dw1x1 = self.depthwise_separable(branch_1x1, 3, in_channels,
+ stride)
+ output = fluid.layers.concat(input=[shortcut, branch_dw1x1], axis=1)
+
+ # channel shuffle
+ # b, c, h, w = output.shape
+ shape = fluid.layers.shape(output)
+ c = output.shape[1]
+ b, h, w = shape[0], shape[2], shape[3]
+ output = fluid.layers.reshape(x=output, shape=[b, 2, in_channels, h, w])
+ output = fluid.layers.transpose(x=output, perm=[0, 2, 1, 3, 4])
+ output = fluid.layers.reshape(x=output, shape=[b, c, h, w])
+ return output
+
+ def output_layer(self, input, out_dim):
+ param_attr = fluid.param_attr.ParamAttr(
+ learning_rate=1.,
+ regularizer=fluid.regularizer.L2Decay(0.),
+ initializer=fluid.initializer.Xavier())
+ # deconv
+ output = fluid.layers.conv2d_transpose(
+ input=input,
+ num_filters=out_dim,
+ filter_size=2,
+ padding=0,
+ stride=2,
+ bias_attr=True,
+ param_attr=param_attr,
+ act=None)
+ return output
diff --git a/contrib/HumanSeg/pretrained_weights/download_pretrained_weights.py b/contrib/HumanSeg/pretrained_weights/download_pretrained_weights.py
new file mode 100644
index 0000000000000000000000000000000000000000..e573df05f94f5a612ef6c2f5a2eb2c9cd55cc2f1
--- /dev/null
+++ b/contrib/HumanSeg/pretrained_weights/download_pretrained_weights.py
@@ -0,0 +1,51 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+
+LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
+TEST_PATH = os.path.join(LOCAL_PATH, "../../../", "test")
+sys.path.append(TEST_PATH)
+
+from test_utils import download_file_and_uncompress
+
+model_urls = {
+ "humanseg_server_ckpt":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_server_ckpt.zip",
+ "humanseg_server_inference":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_server_inference.zip",
+ "humanseg_mobile_ckpt":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_mobile_ckpt.zip",
+ "humanseg_mobile_inference":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_mobile_inference.zip",
+ "humanseg_mobile_quant":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_mobile_quant.zip",
+ "humanseg_lite_ckpt":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_lite_ckpt.zip",
+ "humanseg_lite_inference":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_lite_inference.zip",
+ "humanseg_lite_quant":
+ "https://paddleseg.bj.bcebos.com/humanseg/models/humanseg_lite_quant.zip",
+}
+
+if __name__ == "__main__":
+ for model_name, url in model_urls.items():
+ download_file_and_uncompress(
+ url=url,
+ savepath=LOCAL_PATH,
+ extrapath=LOCAL_PATH,
+ extraname=model_name)
+
+ print("Pretrained Model download success!")
diff --git a/contrib/HumanSeg/quant_offline.py b/contrib/HumanSeg/quant_offline.py
new file mode 100644
index 0000000000000000000000000000000000000000..92a393f07bd2b70fc7df658290abf440f3069752
--- /dev/null
+++ b/contrib/HumanSeg/quant_offline.py
@@ -0,0 +1,80 @@
+import argparse
+from datasets.dataset import Dataset
+import transforms
+import models
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg training')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for quant',
+ type=str,
+ default='output/best_model')
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size',
+ type=int,
+ default=1)
+ parser.add_argument(
+ '--batch_nums',
+ dest='batch_nums',
+ help='Batch number for quant',
+ type=int,
+ default=10)
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='the root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--quant_list',
+ dest='quant_list',
+ help=
+ 'Image file list for model quantization, it can be vat.txt or train.txt',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the quant model',
+ type=str,
+ default='./output/quant_offline')
+ parser.add_argument(
+ "--image_shape",
+ dest="image_shape",
+ help="The image shape for net inputs.",
+ nargs=2,
+ default=[192, 192],
+ type=int)
+ return parser.parse_args()
+
+
+def evaluate(args):
+ eval_transforms = transforms.Compose(
+ [transforms.Resize(args.image_shape),
+ transforms.Normalize()])
+
+ eval_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.quant_list,
+ transforms=eval_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False)
+
+ model = models.load_model(args.model_dir)
+ model.export_quant_model(
+ dataset=eval_dataset,
+ save_dir=args.save_dir,
+ batch_size=args.batch_size,
+ batch_nums=args.batch_nums)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ evaluate(args)
diff --git a/contrib/HumanSeg/quant_online.py b/contrib/HumanSeg/quant_online.py
new file mode 100644
index 0000000000000000000000000000000000000000..04eea4d3d9f357897e300da87297a8f6c9515e06
--- /dev/null
+++ b/contrib/HumanSeg/quant_online.py
@@ -0,0 +1,142 @@
+import argparse
+from datasets.dataset import Dataset
+from models import HumanSegMobile, HumanSegLite, HumanSegServer
+import transforms
+
+MODEL_TYPE = ['HumanSegMobile', 'HumanSegLite', 'HumanSegServer']
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg training')
+ parser.add_argument(
+ '--model_type',
+ dest='model_type',
+ help=
+ "Model type for traing, which is one of ('HumanSegMobile', 'HumanSegLite', 'HumanSegServer')",
+ type=str,
+ default='HumanSegMobile')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='The root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--train_list',
+ dest='train_list',
+ help='Train list file of dataset',
+ type=str)
+ parser.add_argument(
+ '--val_list',
+ dest='val_list',
+ help='Val list file of dataset',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the model snapshot',
+ type=str,
+ default='./output/quant_train')
+ parser.add_argument(
+ '--num_classes',
+ dest='num_classes',
+ help='Number of classes',
+ type=int,
+ default=2)
+ parser.add_argument(
+ '--num_epochs',
+ dest='num_epochs',
+ help='Number epochs for training',
+ type=int,
+ default=2)
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size',
+ type=int,
+ default=128)
+ parser.add_argument(
+ '--learning_rate',
+ dest='learning_rate',
+ help='Learning rate',
+ type=float,
+ default=0.001)
+ parser.add_argument(
+ '--pretrained_weights',
+ dest='pretrained_weights',
+ help='The model path for quant',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_interval_epochs',
+ dest='save_interval_epochs',
+ help='The interval epochs for save a model snapshot',
+ type=int,
+ default=1)
+ parser.add_argument(
+ "--image_shape",
+ dest="image_shape",
+ help="The image shape for net inputs.",
+ nargs=2,
+ default=[192, 192],
+ type=int)
+
+ return parser.parse_args()
+
+
+def train(args):
+ train_transforms = transforms.Compose([
+ transforms.RandomHorizontalFlip(),
+ transforms.Resize(args.image_shape),
+ transforms.Normalize()
+ ])
+
+ eval_transforms = transforms.Compose(
+ [transforms.Resize(args.image_shape),
+ transforms.Normalize()])
+
+ train_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.train_list,
+ transforms=train_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=True)
+
+ eval_dataset = None
+ if args.val_list is not None:
+ eval_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.val_list,
+ transforms=eval_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False)
+
+ if args.model_type == 'HumanSegMobile':
+ model = HumanSegMobile(num_classes=2)
+ elif args.model_type == 'HumanSegLite':
+ model = HumanSegLite(num_classes=2)
+ elif args.model_type == 'HumanSegServer':
+ model = HumanSegServer(num_classes=2)
+ else:
+ raise ValueError(
+ "--model_type: {} is set wrong, it shold be one of ('HumanSegMobile', "
+ "'HumanSegLite', 'HumanSegServer')".format(args.model_type))
+ model.train(
+ num_epochs=args.num_epochs,
+ train_dataset=train_dataset,
+ train_batch_size=args.batch_size,
+ eval_dataset=eval_dataset,
+ save_interval_epochs=args.save_interval_epochs,
+ save_dir=args.save_dir,
+ pretrained_weights=args.pretrained_weights,
+ learning_rate=args.learning_rate,
+ quant=True)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ train(args)
diff --git a/contrib/HumanSeg/requirements.txt b/contrib/HumanSeg/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1c8a597b0c937f0a8560d4f1bbf46de5f752178a
--- /dev/null
+++ b/contrib/HumanSeg/requirements.txt
@@ -0,0 +1,2 @@
+visualdl == 2.0.0-alpha.1
+paddleslim
diff --git a/contrib/HumanSeg/train.py b/contrib/HumanSeg/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..65e66ae1dcd07f65b062744216ed6cbfc85cad40
--- /dev/null
+++ b/contrib/HumanSeg/train.py
@@ -0,0 +1,155 @@
+import argparse
+from datasets.dataset import Dataset
+from models import HumanSegMobile, HumanSegLite, HumanSegServer
+import transforms
+
+MODEL_TYPE = ['HumanSegMobile', 'HumanSegLite', 'HumanSegServer']
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg training')
+ parser.add_argument(
+ '--model_type',
+ dest='model_type',
+ help=
+ "Model type for traing, which is one of ('HumanSegMobile', 'HumanSegLite', 'HumanSegServer')",
+ type=str,
+ default='HumanSegMobile')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='The root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--train_list',
+ dest='train_list',
+ help='Train list file of dataset',
+ type=str)
+ parser.add_argument(
+ '--val_list',
+ dest='val_list',
+ help='Val list file of dataset',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the model snapshot',
+ type=str,
+ default='./output')
+ parser.add_argument(
+ '--num_classes',
+ dest='num_classes',
+ help='Number of classes',
+ type=int,
+ default=2)
+ parser.add_argument(
+ "--image_shape",
+ dest="image_shape",
+ help="The image shape for net inputs.",
+ nargs=2,
+ default=[192, 192],
+ type=int)
+ parser.add_argument(
+ '--num_epochs',
+ dest='num_epochs',
+ help='Number epochs for training',
+ type=int,
+ default=100)
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size',
+ type=int,
+ default=128)
+ parser.add_argument(
+ '--learning_rate',
+ dest='learning_rate',
+ help='Learning rate',
+ type=float,
+ default=0.01)
+ parser.add_argument(
+ '--pretrained_weights',
+ dest='pretrained_weights',
+ help='The path of pretrianed weight',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--resume_weights',
+ dest='resume_weights',
+ help='The path of resume weight',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--use_vdl',
+ dest='use_vdl',
+ help='Whether to use visualdl',
+ type=bool,
+ default=True)
+ parser.add_argument(
+ '--save_interval_epochs',
+ dest='save_interval_epochs',
+ help='The interval epochs for save a model snapshot',
+ type=int,
+ default=5)
+
+ return parser.parse_args()
+
+
+def train(args):
+ train_transforms = transforms.Compose([
+ transforms.Resize(args.image_shape),
+ transforms.RandomHorizontalFlip(),
+ transforms.Normalize()
+ ])
+
+ eval_transforms = transforms.Compose(
+ [transforms.Resize(args.image_shape),
+ transforms.Normalize()])
+
+ train_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.train_list,
+ transforms=train_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=True)
+
+ eval_dataset = None
+ if args.val_list is not None:
+ eval_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.val_list,
+ transforms=eval_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False)
+
+ if args.model_type == 'HumanSegMobile':
+ model = HumanSegMobile(num_classes=2)
+ elif args.model_type == 'HumanSegLite':
+ model = HumanSegLite(num_classes=2)
+ elif args.model_type == 'HumanSegServer':
+ model = HumanSegServer(num_classes=2)
+ else:
+ raise ValueError(
+ "--model_type: {} is set wrong, it shold be one of ('HumanSegMobile', "
+ "'HumanSegLite', 'HumanSegServer')".format(args.model_type))
+ model.train(
+ num_epochs=args.num_epochs,
+ train_dataset=train_dataset,
+ train_batch_size=args.batch_size,
+ eval_dataset=eval_dataset,
+ save_interval_epochs=args.save_interval_epochs,
+ save_dir=args.save_dir,
+ pretrained_weights=args.pretrained_weights,
+ resume_weights=args.resume_weights,
+ learning_rate=args.learning_rate,
+ use_vdl=args.use_vdl)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ train(args)
diff --git a/contrib/HumanSeg/transforms/__init__.py b/contrib/HumanSeg/transforms/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..db17cedcac20183456e79121565b35ddaae82e1c
--- /dev/null
+++ b/contrib/HumanSeg/transforms/__init__.py
@@ -0,0 +1,16 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .transforms import *
+from . import functional
diff --git a/contrib/HumanSeg/transforms/functional.py b/contrib/HumanSeg/transforms/functional.py
new file mode 100644
index 0000000000000000000000000000000000000000..a446f9097043b9447a4b6eeda0906bea6ebeb625
--- /dev/null
+++ b/contrib/HumanSeg/transforms/functional.py
@@ -0,0 +1,99 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import cv2
+import numpy as np
+from PIL import Image, ImageEnhance
+
+
+def normalize(im, mean, std):
+ im = im.astype(np.float32, copy=False) / 255.0
+ im -= mean
+ im /= std
+ return im
+
+
+def permute(im):
+ im = np.transpose(im, (2, 0, 1))
+ return im
+
+
+def resize(im, target_size=608, interp=cv2.INTER_LINEAR):
+ if isinstance(target_size, list) or isinstance(target_size, tuple):
+ w = target_size[0]
+ h = target_size[1]
+ else:
+ w = target_size
+ h = target_size
+ im = cv2.resize(im, (w, h), interpolation=interp)
+ return im
+
+
+def resize_long(im, long_size=224, interpolation=cv2.INTER_LINEAR):
+ value = max(im.shape[0], im.shape[1])
+ scale = float(long_size) / float(value)
+ resized_width = int(round(im.shape[1] * scale))
+ resized_height = int(round(im.shape[0] * scale))
+
+ im = cv2.resize(
+ im, (resized_width, resized_height), interpolation=interpolation)
+ return im
+
+
+def horizontal_flip(im):
+ if len(im.shape) == 3:
+ im = im[:, ::-1, :]
+ elif len(im.shape) == 2:
+ im = im[:, ::-1]
+ return im
+
+
+def vertical_flip(im):
+ if len(im.shape) == 3:
+ im = im[::-1, :, :]
+ elif len(im.shape) == 2:
+ im = im[::-1, :]
+ return im
+
+
+def brightness(im, brightness_lower, brightness_upper):
+ brightness_delta = np.random.uniform(brightness_lower, brightness_upper)
+ im = ImageEnhance.Brightness(im).enhance(brightness_delta)
+ return im
+
+
+def contrast(im, contrast_lower, contrast_upper):
+ contrast_delta = np.random.uniform(contrast_lower, contrast_upper)
+ im = ImageEnhance.Contrast(im).enhance(contrast_delta)
+ return im
+
+
+def saturation(im, saturation_lower, saturation_upper):
+ saturation_delta = np.random.uniform(saturation_lower, saturation_upper)
+ im = ImageEnhance.Color(im).enhance(saturation_delta)
+ return im
+
+
+def hue(im, hue_lower, hue_upper):
+ hue_delta = np.random.uniform(hue_lower, hue_upper)
+ im = np.array(im.convert('HSV'))
+ im[:, :, 0] = im[:, :, 0] + hue_delta
+ im = Image.fromarray(im, mode='HSV').convert('RGB')
+ return im
+
+
+def rotate(im, rotate_lower, rotate_upper):
+ rotate_delta = np.random.uniform(rotate_lower, rotate_upper)
+ im = im.rotate(int(rotate_delta))
+ return im
diff --git a/contrib/HumanSeg/transforms/transforms.py b/contrib/HumanSeg/transforms/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..f19359b24819ef7a91b78bc1058a308a7f48735e
--- /dev/null
+++ b/contrib/HumanSeg/transforms/transforms.py
@@ -0,0 +1,914 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .functional import *
+import random
+import numpy as np
+from PIL import Image
+import cv2
+from collections import OrderedDict
+
+
+class Compose:
+ """根据数据预处理/增强算子对输入数据进行操作。
+ 所有操作的输入图像流形状均是[H, W, C],其中H为图像高,W为图像宽,C为图像通道数。
+
+ Args:
+ transforms (list): 数据预处理/增强算子。
+ to_rgb (bool): 是否转化为rgb通道格式
+
+ Raises:
+ TypeError: transforms不是list对象
+ ValueError: transforms元素个数小于1。
+
+ """
+
+ def __init__(self, transforms, to_rgb=False):
+ if not isinstance(transforms, list):
+ raise TypeError('The transforms must be a list!')
+ if len(transforms) < 1:
+ raise ValueError('The length of transforms ' + \
+ 'must be equal or larger than 1!')
+ self.transforms = transforms
+ self.to_rgb = to_rgb
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (str/np.ndarray): 图像路径/图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息,dict中的字段如下:
+ - shape_before_resize (tuple): 图像resize之前的大小(h, w)。
+ - shape_before_padding (tuple): 图像padding之前的大小(h, w)。
+ label (str/np.ndarray): 标注图像路径/标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 根据网络所需字段所组成的tuple;字段由transforms中的最后一个数据预处理操作决定。
+ """
+
+ if im_info is None:
+ im_info = dict()
+ if isinstance(im, str):
+ im = cv2.imread(im).astype('float32')
+ if isinstance(label, str):
+ label = np.asarray(Image.open(label))
+ if im is None:
+ raise ValueError('Can\'t read The image file {}!'.format(im))
+ if self.to_rgb:
+ im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
+
+ for op in self.transforms:
+ outputs = op(im, im_info, label)
+ im = outputs[0]
+ if len(outputs) >= 2:
+ im_info = outputs[1]
+ if len(outputs) == 3:
+ label = outputs[2]
+ return outputs
+
+
+class RandomHorizontalFlip:
+ """以一定的概率对图像进行水平翻转。当存在标注图像时,则同步进行翻转。
+
+ Args:
+ prob (float): 随机水平翻转的概率。默认值为0.5。
+
+ """
+
+ def __init__(self, prob=0.5):
+ self.prob = prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if random.random() < self.prob:
+ im = horizontal_flip(im)
+ if label is not None:
+ label = horizontal_flip(label)
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomVerticalFlip:
+ """以一定的概率对图像进行垂直翻转。当存在标注图像时,则同步进行翻转。
+
+ Args:
+ prob (float): 随机垂直翻转的概率。默认值为0.1。
+ """
+
+ def __init__(self, prob=0.1):
+ self.prob = prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if random.random() < self.prob:
+ im = vertical_flip(im)
+ if label is not None:
+ label = vertical_flip(label)
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Resize:
+ """调整图像大小(resize)。
+
+ - 当目标大小(target_size)类型为int时,根据插值方式,
+ 将图像resize为[target_size, target_size]。
+ - 当目标大小(target_size)类型为list或tuple时,根据插值方式,
+ 将图像resize为target_size。
+ 注意:当插值方式为“RANDOM”时,则随机选取一种插值方式进行resize。
+
+ Args:
+ target_size (int/list/tuple): 短边目标长度。默认为608。
+ interp (str): resize的插值方式,与opencv的插值方式对应,取值范围为
+ ['NEAREST', 'LINEAR', 'CUBIC', 'AREA', 'LANCZOS4', 'RANDOM']。默认为"LINEAR"。
+
+ Raises:
+ TypeError: 形参数据类型不满足需求。
+ ValueError: 插值方式不在['NEAREST', 'LINEAR', 'CUBIC',
+ 'AREA', 'LANCZOS4', 'RANDOM']中。
+ """
+
+ # The interpolation mode
+ interp_dict = {
+ 'NEAREST': cv2.INTER_NEAREST,
+ 'LINEAR': cv2.INTER_LINEAR,
+ 'CUBIC': cv2.INTER_CUBIC,
+ 'AREA': cv2.INTER_AREA,
+ 'LANCZOS4': cv2.INTER_LANCZOS4
+ }
+
+ def __init__(self, target_size=512, interp='LINEAR'):
+ self.interp = interp
+ if not (interp == "RANDOM" or interp in self.interp_dict):
+ raise ValueError("interp should be one of {}".format(
+ self.interp_dict.keys()))
+ if isinstance(target_size, list) or isinstance(target_size, tuple):
+ if len(target_size) != 2:
+ raise TypeError(
+ 'when target is list or tuple, it should include 2 elements, but it is {}'
+ .format(target_size))
+ elif not isinstance(target_size, int):
+ raise TypeError(
+ "Type of target_size is invalid. Must be Integer or List or tuple, now is {}"
+ .format(type(target_size)))
+
+ self.target_size = target_size
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict, 可选): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ 其中,im_info跟新字段为:
+ -shape_before_resize (tuple): 保存resize之前图像的形状(h, w)。
+
+ Raises:
+ TypeError: 形参数据类型不满足需求。
+ ValueError: 数据长度不匹配。
+ """
+ if im_info is None:
+ im_info = OrderedDict()
+ im_info['shape_before_resize'] = im.shape[:2]
+ if not isinstance(im, np.ndarray):
+ raise TypeError("Resize: image type is not numpy.")
+ if len(im.shape) != 3:
+ raise ValueError('Resize: image is not 3-dimensional.')
+ if self.interp == "RANDOM":
+ interp = random.choice(list(self.interp_dict.keys()))
+ else:
+ interp = self.interp
+ im = resize(im, self.target_size, self.interp_dict[interp])
+ if label is not None:
+ label = resize(label, self.target_size, cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ResizeByLong:
+ """对图像长边resize到固定值,短边按比例进行缩放。当存在标注图像时,则同步进行处理。
+
+ Args:
+ long_size (int): resize后图像的长边大小。
+ """
+
+ def __init__(self, long_size):
+ self.long_size = long_size
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ 其中,im_info新增字段为:
+ -shape_before_resize (tuple): 保存resize之前图像的形状(h, w)。
+ """
+ if im_info is None:
+ im_info = OrderedDict()
+
+ im_info['shape_before_resize'] = im.shape[:2]
+ im = resize_long(im, self.long_size)
+ if label is not None:
+ label = resize_long(label, self.long_size, cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ResizeRangeScaling:
+ """对图像长边随机resize到指定范围内,短边按比例进行缩放。当存在标注图像时,则同步进行处理。
+
+ Args:
+ min_value (int): 图像长边resize后的最小值。默认值400。
+ max_value (int): 图像长边resize后的最大值。默认值600。
+
+ Raises:
+ ValueError: min_value大于max_value
+ """
+
+ def __init__(self, min_value=400, max_value=600):
+ if min_value > max_value:
+ raise ValueError('min_value must be less than max_value, '
+ 'but they are {} and {}.'.format(
+ min_value, max_value))
+ self.min_value = min_value
+ self.max_value = max_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.min_value == self.max_value:
+ random_size = self.max_value
+ else:
+ random_size = int(
+ np.random.uniform(self.min_value, self.max_value) + 0.5)
+ im = resize_long(im, random_size, cv2.INTER_LINEAR)
+ if label is not None:
+ label = resize_long(label, random_size, cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ResizeStepScaling:
+ """对图像按照某一个比例resize,这个比例以scale_step_size为步长
+ 在[min_scale_factor, max_scale_factor]随机变动。当存在标注图像时,则同步进行处理。
+
+ Args:
+ min_scale_factor(float), resize最小尺度。默认值0.75。
+ max_scale_factor (float), resize最大尺度。默认值1.25。
+ scale_step_size (float), resize尺度范围间隔。默认值0.25。
+
+ Raises:
+ ValueError: min_scale_factor大于max_scale_factor
+ """
+
+ def __init__(self,
+ min_scale_factor=0.75,
+ max_scale_factor=1.25,
+ scale_step_size=0.25):
+ if min_scale_factor > max_scale_factor:
+ raise ValueError(
+ 'min_scale_factor must be less than max_scale_factor, '
+ 'but they are {} and {}.'.format(min_scale_factor,
+ max_scale_factor))
+ self.min_scale_factor = min_scale_factor
+ self.max_scale_factor = max_scale_factor
+ self.scale_step_size = scale_step_size
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.min_scale_factor == self.max_scale_factor:
+ scale_factor = self.min_scale_factor
+
+ elif self.scale_step_size == 0:
+ scale_factor = np.random.uniform(self.min_scale_factor,
+ self.max_scale_factor)
+
+ else:
+ num_steps = int((self.max_scale_factor - self.min_scale_factor) /
+ self.scale_step_size + 1)
+ scale_factors = np.linspace(self.min_scale_factor,
+ self.max_scale_factor,
+ num_steps).tolist()
+ np.random.shuffle(scale_factors)
+ scale_factor = scale_factors[0]
+ w = int(round(scale_factor * im.shape[1]))
+ h = int(round(scale_factor * im.shape[0]))
+
+ im = resize(im, (w, h), cv2.INTER_LINEAR)
+ if label is not None:
+ label = resize(label, (w, h), cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Normalize:
+ """对图像进行标准化。
+ 1.尺度缩放到 [0,1]。
+ 2.对图像进行减均值除以标准差操作。
+
+ Args:
+ mean (list): 图像数据集的均值。默认值[0.5, 0.5, 0.5]。
+ std (list): 图像数据集的标准差。默认值[0.5, 0.5, 0.5]。
+
+ Raises:
+ ValueError: mean或std不是list对象。std包含0。
+ """
+
+ def __init__(self, mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]):
+ self.mean = mean
+ self.std = std
+ if not (isinstance(self.mean, list) and isinstance(self.std, list)):
+ raise ValueError("{}: input type is invalid.".format(self))
+ from functools import reduce
+ if reduce(lambda x, y: x * y, self.std) == 0:
+ raise ValueError('{}: std is invalid!'.format(self))
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+
+ mean = np.array(self.mean)[np.newaxis, np.newaxis, :]
+ std = np.array(self.std)[np.newaxis, np.newaxis, :]
+ im = normalize(im, mean, std)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Padding:
+ """对图像或标注图像进行padding,padding方向为右和下。
+ 根据提供的值对图像或标注图像进行padding操作。
+
+ Args:
+ target_size (int|list|tuple): padding后图像的大小。
+ im_padding_value (list): 图像padding的值。默认为[127.5, 127.5, 127.5]。
+ label_padding_value (int): 标注图像padding的值。默认值为255。
+
+ Raises:
+ TypeError: target_size不是int|list|tuple。
+ ValueError: target_size为list|tuple时元素个数不等于2。
+ """
+
+ def __init__(self,
+ target_size,
+ im_padding_value=[127.5, 127.5, 127.5],
+ label_padding_value=255):
+ if isinstance(target_size, list) or isinstance(target_size, tuple):
+ if len(target_size) != 2:
+ raise ValueError(
+ 'when target is list or tuple, it should include 2 elements, but it is {}'
+ .format(target_size))
+ elif not isinstance(target_size, int):
+ raise TypeError(
+ "Type of target_size is invalid. Must be Integer or List or tuple, now is {}"
+ .format(type(target_size)))
+ self.target_size = target_size
+ self.im_padding_value = im_padding_value
+ self.label_padding_value = label_padding_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ 其中,im_info新增字段为:
+ -shape_before_padding (tuple): 保存padding之前图像的形状(h, w)。
+
+ Raises:
+ ValueError: 输入图像im或label的形状大于目标值
+ """
+ if im_info is None:
+ im_info = OrderedDict()
+ im_info['shape_before_padding'] = im.shape[:2]
+
+ im_height, im_width = im.shape[0], im.shape[1]
+ if isinstance(self.target_size, int):
+ target_height = self.target_size
+ target_width = self.target_size
+ else:
+ target_height = self.target_size[1]
+ target_width = self.target_size[0]
+ pad_height = target_height - im_height
+ pad_width = target_width - im_width
+ if pad_height < 0 or pad_width < 0:
+ raise ValueError(
+ 'the size of image should be less than target_size, but the size of image ({}, {}), is larger than target_size ({}, {})'
+ .format(im_width, im_height, target_width, target_height))
+ else:
+ im = cv2.copyMakeBorder(
+ im,
+ 0,
+ pad_height,
+ 0,
+ pad_width,
+ cv2.BORDER_CONSTANT,
+ value=self.im_padding_value)
+ if label is not None:
+ label = cv2.copyMakeBorder(
+ label,
+ 0,
+ pad_height,
+ 0,
+ pad_width,
+ cv2.BORDER_CONSTANT,
+ value=self.label_padding_value)
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomPaddingCrop:
+ """对图像和标注图进行随机裁剪,当所需要的裁剪尺寸大于原图时,则进行padding操作。
+
+ Args:
+ crop_size (int|list|tuple): 裁剪图像大小。默认为512。
+ im_padding_value (list): 图像padding的值。默认为[127.5, 127.5, 127.5]。
+ label_padding_value (int): 标注图像padding的值。默认值为255。
+
+ Raises:
+ TypeError: crop_size不是int/list/tuple。
+ ValueError: target_size为list/tuple时元素个数不等于2。
+ """
+
+ def __init__(self,
+ crop_size=512,
+ im_padding_value=[127.5, 127.5, 127.5],
+ label_padding_value=255):
+ if isinstance(crop_size, list) or isinstance(crop_size, tuple):
+ if len(crop_size) != 2:
+ raise ValueError(
+ 'when crop_size is list or tuple, it should include 2 elements, but it is {}'
+ .format(crop_size))
+ elif not isinstance(crop_size, int):
+ raise TypeError(
+ "Type of crop_size is invalid. Must be Integer or List or tuple, now is {}"
+ .format(type(crop_size)))
+ self.crop_size = crop_size
+ self.im_padding_value = im_padding_value
+ self.label_padding_value = label_padding_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if isinstance(self.crop_size, int):
+ crop_width = self.crop_size
+ crop_height = self.crop_size
+ else:
+ crop_width = self.crop_size[0]
+ crop_height = self.crop_size[1]
+
+ img_height = im.shape[0]
+ img_width = im.shape[1]
+
+ if img_height == crop_height and img_width == crop_width:
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+ else:
+ pad_height = max(crop_height - img_height, 0)
+ pad_width = max(crop_width - img_width, 0)
+ if (pad_height > 0 or pad_width > 0):
+ im = cv2.copyMakeBorder(
+ im,
+ 0,
+ pad_height,
+ 0,
+ pad_width,
+ cv2.BORDER_CONSTANT,
+ value=self.im_padding_value)
+ if label is not None:
+ label = cv2.copyMakeBorder(
+ label,
+ 0,
+ pad_height,
+ 0,
+ pad_width,
+ cv2.BORDER_CONSTANT,
+ value=self.label_padding_value)
+ img_height = im.shape[0]
+ img_width = im.shape[1]
+
+ if crop_height > 0 and crop_width > 0:
+ h_off = np.random.randint(img_height - crop_height + 1)
+ w_off = np.random.randint(img_width - crop_width + 1)
+
+ im = im[h_off:(crop_height + h_off), w_off:(
+ w_off + crop_width), :]
+ if label is not None:
+ label = label[h_off:(crop_height + h_off), w_off:(
+ w_off + crop_width)]
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomBlur:
+ """以一定的概率对图像进行高斯模糊。
+
+ Args:
+ prob (float): 图像模糊概率。默认为0.1。
+ """
+
+ def __init__(self, prob=0.1):
+ self.prob = prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.prob <= 0:
+ n = 0
+ elif self.prob >= 1:
+ n = 1
+ else:
+ n = int(1.0 / self.prob)
+ if n > 0:
+ if np.random.randint(0, n) == 0:
+ radius = np.random.randint(3, 10)
+ if radius % 2 != 1:
+ radius = radius + 1
+ if radius > 9:
+ radius = 9
+ im = cv2.GaussianBlur(im, (radius, radius), 0, 0)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomRotation:
+ """对图像进行随机旋转。
+ 在不超过最大旋转角度的情况下,图像进行随机旋转,当存在标注图像时,同步进行,
+ 并对旋转后的图像和标注图像进行相应的padding。
+
+ Args:
+ max_rotation (float): 最大旋转角度。默认为15度。
+ im_padding_value (list): 图像padding的值。默认为[127.5, 127.5, 127.5]。
+ label_padding_value (int): 标注图像padding的值。默认为255。
+
+ """
+
+ def __init__(self,
+ max_rotation=15,
+ im_padding_value=[127.5, 127.5, 127.5],
+ label_padding_value=255):
+ self.max_rotation = max_rotation
+ self.im_padding_value = im_padding_value
+ self.label_padding_value = label_padding_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.max_rotation > 0:
+ (h, w) = im.shape[:2]
+ do_rotation = np.random.uniform(-self.max_rotation,
+ self.max_rotation)
+ pc = (w // 2, h // 2)
+ r = cv2.getRotationMatrix2D(pc, do_rotation, 1.0)
+ cos = np.abs(r[0, 0])
+ sin = np.abs(r[0, 1])
+
+ nw = int((h * sin) + (w * cos))
+ nh = int((h * cos) + (w * sin))
+
+ (cx, cy) = pc
+ r[0, 2] += (nw / 2) - cx
+ r[1, 2] += (nh / 2) - cy
+ dsize = (nw, nh)
+ im = cv2.warpAffine(
+ im,
+ r,
+ dsize=dsize,
+ flags=cv2.INTER_LINEAR,
+ borderMode=cv2.BORDER_CONSTANT,
+ borderValue=self.im_padding_value)
+ label = cv2.warpAffine(
+ label,
+ r,
+ dsize=dsize,
+ flags=cv2.INTER_NEAREST,
+ borderMode=cv2.BORDER_CONSTANT,
+ borderValue=self.label_padding_value)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomScaleAspect:
+ """裁剪并resize回原始尺寸的图像和标注图像。
+ 按照一定的面积比和宽高比对图像进行裁剪,并reszie回原始图像的图像,当存在标注图时,同步进行。
+
+ Args:
+ min_scale (float):裁取图像占原始图像的面积比,取值[0,1],为0时则返回原图。默认为0.5。
+ aspect_ratio (float): 裁取图像的宽高比范围,非负值,为0时返回原图。默认为0.33。
+ """
+
+ def __init__(self, min_scale=0.5, aspect_ratio=0.33):
+ self.min_scale = min_scale
+ self.aspect_ratio = aspect_ratio
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.min_scale != 0 and self.aspect_ratio != 0:
+ img_height = im.shape[0]
+ img_width = im.shape[1]
+ for i in range(0, 10):
+ area = img_height * img_width
+ target_area = area * np.random.uniform(self.min_scale, 1.0)
+ aspectRatio = np.random.uniform(self.aspect_ratio,
+ 1.0 / self.aspect_ratio)
+
+ dw = int(np.sqrt(target_area * 1.0 * aspectRatio))
+ dh = int(np.sqrt(target_area * 1.0 / aspectRatio))
+ if (np.random.randint(10) < 5):
+ tmp = dw
+ dw = dh
+ dh = tmp
+
+ if (dh < img_height and dw < img_width):
+ h1 = np.random.randint(0, img_height - dh)
+ w1 = np.random.randint(0, img_width - dw)
+
+ im = im[h1:(h1 + dh), w1:(w1 + dw), :]
+ label = label[h1:(h1 + dh), w1:(w1 + dw)]
+ im = cv2.resize(
+ im, (img_width, img_height),
+ interpolation=cv2.INTER_LINEAR)
+ label = cv2.resize(
+ label, (img_width, img_height),
+ interpolation=cv2.INTER_NEAREST)
+ break
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomDistort:
+ """对图像进行随机失真。
+
+ 1. 对变换的操作顺序进行随机化操作。
+ 2. 按照1中的顺序以一定的概率对图像进行随机像素内容变换。
+
+ Args:
+ brightness_range (float): 明亮度因子的范围。默认为0.5。
+ brightness_prob (float): 随机调整明亮度的概率。默认为0.5。
+ contrast_range (float): 对比度因子的范围。默认为0.5。
+ contrast_prob (float): 随机调整对比度的概率。默认为0.5。
+ saturation_range (float): 饱和度因子的范围。默认为0.5。
+ saturation_prob (float): 随机调整饱和度的概率。默认为0.5。
+ hue_range (int): 色调因子的范围。默认为18。
+ hue_prob (float): 随机调整色调的概率。默认为0.5。
+ """
+
+ def __init__(self,
+ brightness_range=0.5,
+ brightness_prob=0.5,
+ contrast_range=0.5,
+ contrast_prob=0.5,
+ saturation_range=0.5,
+ saturation_prob=0.5,
+ hue_range=18,
+ hue_prob=0.5):
+ self.brightness_range = brightness_range
+ self.brightness_prob = brightness_prob
+ self.contrast_range = contrast_range
+ self.contrast_prob = contrast_prob
+ self.saturation_range = saturation_range
+ self.saturation_prob = saturation_prob
+ self.hue_range = hue_range
+ self.hue_prob = hue_prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ brightness_lower = 1 - self.brightness_range
+ brightness_upper = 1 + self.brightness_range
+ contrast_lower = 1 - self.contrast_range
+ contrast_upper = 1 + self.contrast_range
+ saturation_lower = 1 - self.saturation_range
+ saturation_upper = 1 + self.saturation_range
+ hue_lower = -self.hue_range
+ hue_upper = self.hue_range
+ ops = [brightness, contrast, saturation, hue]
+ random.shuffle(ops)
+ params_dict = {
+ 'brightness': {
+ 'brightness_lower': brightness_lower,
+ 'brightness_upper': brightness_upper
+ },
+ 'contrast': {
+ 'contrast_lower': contrast_lower,
+ 'contrast_upper': contrast_upper
+ },
+ 'saturation': {
+ 'saturation_lower': saturation_lower,
+ 'saturation_upper': saturation_upper
+ },
+ 'hue': {
+ 'hue_lower': hue_lower,
+ 'hue_upper': hue_upper
+ }
+ }
+ prob_dict = {
+ 'brightness': self.brightness_prob,
+ 'contrast': self.contrast_prob,
+ 'saturation': self.saturation_prob,
+ 'hue': self.hue_prob
+ }
+ im = im.astype('uint8')
+ im = Image.fromarray(im)
+ for id in range(4):
+ params = params_dict[ops[id].__name__]
+ prob = prob_dict[ops[id].__name__]
+ params['im'] = im
+ if np.random.uniform(0, 1) < prob:
+ im = ops[id](**params)
+ im = np.asarray(im).astype('float32')
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ArrangeSegmenter:
+ """获取训练/验证/预测所需的信息。
+
+ Args:
+ mode (str): 指定数据用于何种用途,取值范围为['train', 'eval', 'test', 'quant']。
+
+ Raises:
+ ValueError: mode的取值不在['train', 'eval', 'test', 'quant']之内
+ """
+
+ def __init__(self, mode):
+ if mode not in ['train', 'eval', 'test', 'quant']:
+ raise ValueError(
+ "mode should be defined as one of ['train', 'eval', 'test', 'quant']!"
+ )
+ self.mode = mode
+
+ def __call__(self, im, im_info, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当mode为'train'或'eval'时,返回的tuple为(im, label),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当mode为'test'时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;当mode为
+ 'quant'时,返回的tuple为(im,),为图像np.ndarray数据。
+ """
+ im = permute(im)
+ if self.mode == 'train' or self.mode == 'eval':
+ label = label[np.newaxis, :, :]
+ return (im, label)
+ elif self.mode == 'test':
+ return (im, im_info)
+ else:
+ return (im, )
diff --git a/contrib/HumanSeg/utils/__init__.py b/contrib/HumanSeg/utils/__init__.py
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..a7760ee48accc71122d07a35f6287117313ac51e 100644
--- a/contrib/HumanSeg/utils/__init__.py
+++ b/contrib/HumanSeg/utils/__init__.py
@@ -0,0 +1,19 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from . import logging
+from . import humanseg_postprocess
+from .metrics import ConfusionMatrix
+from .utils import *
+from .post_quantization import HumanSegPostTrainingQuantization
diff --git a/contrib/HumanSeg/utils/humanseg_postprocess.py b/contrib/HumanSeg/utils/humanseg_postprocess.py
new file mode 100644
index 0000000000000000000000000000000000000000..44376726703c4f533f7fa3888c4dd694b19ff031
--- /dev/null
+++ b/contrib/HumanSeg/utils/humanseg_postprocess.py
@@ -0,0 +1,122 @@
+import numpy as np
+import cv2
+import os
+
+
+def get_round(data):
+ round = 0.5 if data >= 0 else -0.5
+ return (int)(data + round)
+
+
+def human_seg_tracking(pre_gray, cur_gray, prev_cfd, dl_weights, disflow):
+ """计算光流跟踪匹配点和光流图
+ 输入参数:
+ pre_gray: 上一帧灰度图
+ cur_gray: 当前帧灰度图
+ prev_cfd: 上一帧光流图
+ dl_weights: 融合权重图
+ disflow: 光流数据结构
+ 返回值:
+ is_track: 光流点跟踪二值图,即是否具有光流点匹配
+ track_cfd: 光流跟踪图
+ """
+ check_thres = 8
+ h, w = pre_gray.shape[:2]
+ track_cfd = np.zeros_like(prev_cfd)
+ is_track = np.zeros_like(pre_gray)
+ flow_fw = disflow.calc(pre_gray, cur_gray, None)
+ flow_bw = disflow.calc(cur_gray, pre_gray, None)
+ for r in range(h):
+ for c in range(w):
+ fxy_fw = flow_fw[r, c]
+ dx_fw = get_round(fxy_fw[0])
+ cur_x = dx_fw + c
+ dy_fw = get_round(fxy_fw[1])
+ cur_y = dy_fw + r
+ if cur_x < 0 or cur_x >= w or cur_y < 0 or cur_y >= h:
+ continue
+ fxy_bw = flow_bw[cur_y, cur_x]
+ dx_bw = get_round(fxy_bw[0])
+ dy_bw = get_round(fxy_bw[1])
+ if ((dy_fw + dy_bw) * (dy_fw + dy_bw) +
+ (dx_fw + dx_bw) * (dx_fw + dx_bw)) >= check_thres:
+ continue
+ if abs(dy_fw) <= 0 and abs(dx_fw) <= 0 and abs(dy_bw) <= 0 and abs(
+ dx_bw) <= 0:
+ dl_weights[cur_y, cur_x] = 0.05
+ is_track[cur_y, cur_x] = 1
+ track_cfd[cur_y, cur_x] = prev_cfd[r, c]
+ return track_cfd, is_track, dl_weights
+
+
+def human_seg_track_fuse(track_cfd, dl_cfd, dl_weights, is_track):
+ """光流追踪图和人像分割结构融合
+ 输入参数:
+ track_cfd: 光流追踪图
+ dl_cfd: 当前帧分割结果
+ dl_weights: 融合权重图
+ is_track: 光流点匹配二值图
+ 返回
+ cur_cfd: 光流跟踪图和人像分割结果融合图
+ """
+ fusion_cfd = dl_cfd.copy()
+ idxs = np.where(is_track > 0)
+ for i in range(len(idxs[0])):
+ x, y = idxs[0][i], idxs[1][i]
+ dl_score = dl_cfd[x, y]
+ track_score = track_cfd[x, y]
+ fusion_cfd[x, y] = dl_weights[x, y] * dl_score + (
+ 1 - dl_weights[x, y]) * track_score
+ if dl_score > 0.9 or dl_score < 0.1:
+ if dl_weights[x, y] < 0.1:
+ fusion_cfd[x, y] = 0.3 * dl_score + 0.7 * track_score
+ else:
+ fusion_cfd[x, y] = 0.4 * dl_score + 0.6 * track_score
+ else:
+ fusion_cfd[x, y] = dl_weights[x, y] * dl_score + (
+ 1 - dl_weights[x, y]) * track_score
+ return fusion_cfd
+
+
+def postprocess(cur_gray, scoremap, prev_gray, pre_cfd, disflow, is_init):
+ """光流优化
+ Args:
+ cur_gray : 当前帧灰度图
+ pre_gray : 前一帧灰度图
+ pre_cfd :前一帧融合结果
+ scoremap : 当前帧分割结果
+ difflow : 光流
+ is_init : 是否第一帧
+ Returns:
+ fusion_cfd : 光流追踪图和预测结果融合图
+ """
+ height, width = scoremap.shape[0], scoremap.shape[1]
+ disflow = cv2.DISOpticalFlow_create(cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
+ h, w = scoremap.shape
+ cur_cfd = scoremap.copy()
+
+ if is_init:
+ is_init = False
+ if h <= 64 or w <= 64:
+ disflow.setFinestScale(1)
+ elif h <= 160 or w <= 160:
+ disflow.setFinestScale(2)
+ else:
+ disflow.setFinestScale(3)
+ fusion_cfd = cur_cfd
+ else:
+ weights = np.ones((w, h), np.float32) * 0.3
+ track_cfd, is_track, weights = human_seg_tracking(
+ prev_gray, cur_gray, pre_cfd, weights, disflow)
+ fusion_cfd = human_seg_track_fuse(track_cfd, cur_cfd, weights, is_track)
+
+ fusion_cfd = cv2.GaussianBlur(fusion_cfd, (3, 3), 0)
+
+ return fusion_cfd
+
+
+def threshold_mask(img, thresh_bg, thresh_fg):
+ dst = (img / 255.0 - thresh_bg) / (thresh_fg - thresh_bg)
+ dst[np.where(dst > 1)] = 1
+ dst[np.where(dst < 0)] = 0
+ return dst.astype(np.float32)
diff --git a/contrib/HumanSeg/utils/logging.py b/contrib/HumanSeg/utils/logging.py
new file mode 100644
index 0000000000000000000000000000000000000000..1669466f839b6953aa368dedc80e32a9a68725f7
--- /dev/null
+++ b/contrib/HumanSeg/utils/logging.py
@@ -0,0 +1,46 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import time
+import os
+import sys
+
+levels = {0: 'ERROR', 1: 'WARNING', 2: 'INFO', 3: 'DEBUG'}
+log_level = 2
+
+
+def log(level=2, message=""):
+ current_time = time.time()
+ time_array = time.localtime(current_time)
+ current_time = time.strftime("%Y-%m-%d %H:%M:%S", time_array)
+ if log_level >= level:
+ print("{} [{}]\t{}".format(current_time, levels[level],
+ message).encode("utf-8").decode("latin1"))
+ sys.stdout.flush()
+
+
+def debug(message=""):
+ log(level=3, message=message)
+
+
+def info(message=""):
+ log(level=2, message=message)
+
+
+def warning(message=""):
+ log(level=1, message=message)
+
+
+def error(message=""):
+ log(level=0, message=message)
diff --git a/contrib/HumanSeg/utils/metrics.py b/contrib/HumanSeg/utils/metrics.py
new file mode 100644
index 0000000000000000000000000000000000000000..2898be028f3dfa03ad9892310da89f7695829542
--- /dev/null
+++ b/contrib/HumanSeg/utils/metrics.py
@@ -0,0 +1,145 @@
+# coding: utf8
+# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import sys
+import numpy as np
+from scipy.sparse import csr_matrix
+
+
+class ConfusionMatrix(object):
+ """
+ Confusion Matrix for segmentation evaluation
+ """
+
+ def __init__(self, num_classes=2, streaming=False):
+ self.confusion_matrix = np.zeros([num_classes, num_classes],
+ dtype='int64')
+ self.num_classes = num_classes
+ self.streaming = streaming
+
+ def calculate(self, pred, label, ignore=None):
+ # If not in streaming mode, clear matrix everytime when call `calculate`
+ if not self.streaming:
+ self.zero_matrix()
+
+ label = np.transpose(label, (0, 2, 3, 1))
+ ignore = np.transpose(ignore, (0, 2, 3, 1))
+ mask = np.array(ignore) == 1
+
+ label = np.asarray(label)[mask]
+ pred = np.asarray(pred)[mask]
+ one = np.ones_like(pred)
+ # Accumuate ([row=label, col=pred], 1) into sparse matrix
+ spm = csr_matrix((one, (label, pred)),
+ shape=(self.num_classes, self.num_classes))
+ spm = spm.todense()
+ self.confusion_matrix += spm
+
+ def zero_matrix(self):
+ """ Clear confusion matrix """
+ self.confusion_matrix = np.zeros([self.num_classes, self.num_classes],
+ dtype='int64')
+
+ def mean_iou(self):
+ iou_list = []
+ avg_iou = 0
+ # TODO: use numpy sum axis api to simpliy
+ vji = np.zeros(self.num_classes, dtype=int)
+ vij = np.zeros(self.num_classes, dtype=int)
+ for j in range(self.num_classes):
+ v_j = 0
+ for i in range(self.num_classes):
+ v_j += self.confusion_matrix[j][i]
+ vji[j] = v_j
+
+ for i in range(self.num_classes):
+ v_i = 0
+ for j in range(self.num_classes):
+ v_i += self.confusion_matrix[j][i]
+ vij[i] = v_i
+
+ for c in range(self.num_classes):
+ total = vji[c] + vij[c] - self.confusion_matrix[c][c]
+ if total == 0:
+ iou = 0
+ else:
+ iou = float(self.confusion_matrix[c][c]) / total
+ avg_iou += iou
+ iou_list.append(iou)
+ avg_iou = float(avg_iou) / float(self.num_classes)
+ return np.array(iou_list), avg_iou
+
+ def accuracy(self):
+ total = self.confusion_matrix.sum()
+ total_right = 0
+ for c in range(self.num_classes):
+ total_right += self.confusion_matrix[c][c]
+ if total == 0:
+ avg_acc = 0
+ else:
+ avg_acc = float(total_right) / total
+
+ vij = np.zeros(self.num_classes, dtype=int)
+ for i in range(self.num_classes):
+ v_i = 0
+ for j in range(self.num_classes):
+ v_i += self.confusion_matrix[j][i]
+ vij[i] = v_i
+
+ acc_list = []
+ for c in range(self.num_classes):
+ if vij[c] == 0:
+ acc = 0
+ else:
+ acc = self.confusion_matrix[c][c] / float(vij[c])
+ acc_list.append(acc)
+ return np.array(acc_list), avg_acc
+
+ def kappa(self):
+ vji = np.zeros(self.num_classes)
+ vij = np.zeros(self.num_classes)
+ for j in range(self.num_classes):
+ v_j = 0
+ for i in range(self.num_classes):
+ v_j += self.confusion_matrix[j][i]
+ vji[j] = v_j
+
+ for i in range(self.num_classes):
+ v_i = 0
+ for j in range(self.num_classes):
+ v_i += self.confusion_matrix[j][i]
+ vij[i] = v_i
+
+ total = self.confusion_matrix.sum()
+
+ # avoid spillovers
+ # TODO: is it reasonable to hard code 10000.0?
+ total = float(total) / 10000.0
+ vji = vji / 10000.0
+ vij = vij / 10000.0
+
+ tp = 0
+ tc = 0
+ for c in range(self.num_classes):
+ tp += vji[c] * vij[c]
+ tc += self.confusion_matrix[c][c]
+
+ tc = tc / 10000.0
+ pe = tp / (total * total)
+ po = tc / total
+
+ kappa = (po - pe) / (1 - pe)
+ return kappa
diff --git a/contrib/HumanSeg/utils/palette.py b/contrib/HumanSeg/utils/palette.py
deleted file mode 100644
index 2186203cbc2789f6eff70dfd92f724b4fe16cdb7..0000000000000000000000000000000000000000
--- a/contrib/HumanSeg/utils/palette.py
+++ /dev/null
@@ -1,38 +0,0 @@
-##+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
-## Created by: RainbowSecret
-## Microsoft Research
-## yuyua@microsoft.com
-## Copyright (c) 2018
-##
-## This source code is licensed under the MIT-style license found in the
-## LICENSE file in the root directory of this source tree
-##+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-import numpy as np
-import cv2
-
-
-def get_palette(num_cls):
- """ Returns the color map for visualizing the segmentation mask.
- Args:
- num_cls: Number of classes
- Returns:
- The color map
- """
- n = num_cls
- palette = [0] * (n * 3)
- for j in range(0, n):
- lab = j
- palette[j * 3 + 0] = 0
- palette[j * 3 + 1] = 0
- palette[j * 3 + 2] = 0
- i = 0
- while lab:
- palette[j * 3 + 0] |= (((lab >> 0) & 1) << (7 - i))
- palette[j * 3 + 1] |= (((lab >> 1) & 1) << (7 - i))
- palette[j * 3 + 2] |= (((lab >> 2) & 1) << (7 - i))
- i += 1
- lab >>= 3
- return palette
diff --git a/contrib/HumanSeg/utils/post_quantization.py b/contrib/HumanSeg/utils/post_quantization.py
new file mode 100644
index 0000000000000000000000000000000000000000..00d61c8034ad8b332f2270d937a85812e6a63c0a
--- /dev/null
+++ b/contrib/HumanSeg/utils/post_quantization.py
@@ -0,0 +1,224 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from paddle.fluid.contrib.slim.quantization.quantization_pass import QuantizationTransformPass
+from paddle.fluid.contrib.slim.quantization.quantization_pass import AddQuantDequantPass
+from paddle.fluid.contrib.slim.quantization.quantization_pass import _op_real_in_out_name
+from paddle.fluid.contrib.slim.quantization import PostTrainingQuantization
+import paddle.fluid as fluid
+import os
+
+import utils.logging as logging
+
+
+class HumanSegPostTrainingQuantization(PostTrainingQuantization):
+ def __init__(self,
+ executor,
+ dataset,
+ program,
+ inputs,
+ outputs,
+ batch_size=10,
+ batch_nums=None,
+ scope=None,
+ algo="KL",
+ quantizable_op_type=["conv2d", "depthwise_conv2d", "mul"],
+ is_full_quantize=False,
+ is_use_cache_file=False,
+ cache_dir="./temp_post_training"):
+ '''
+ The class utilizes post training quantization methon to quantize the
+ fp32 model. It uses calibrate data to calculate the scale factor of
+ quantized variables, and inserts fake quant/dequant op to obtain the
+ quantized model.
+
+ Args:
+ executor(fluid.Executor): The executor to load, run and save the
+ quantized model.
+ dataset(Python Iterator): The data Reader.
+ program(fluid.Program): The paddle program, save the parameters for model.
+ inputs(dict): The input of prigram.
+ outputs(dict): The output of program.
+ batch_size(int, optional): The batch size of DataLoader. Default is 10.
+ batch_nums(int, optional): If batch_nums is not None, the number of
+ calibrate data is batch_size*batch_nums. If batch_nums is None, use
+ all data provided by sample_generator as calibrate data.
+ scope(fluid.Scope, optional): The scope of the program, use it to load
+ and save variables. If scope=None, get scope by global_scope().
+ algo(str, optional): If algo=KL, use KL-divergenc method to
+ get the more precise scale factor. If algo='direct', use
+ abs_max methon to get the scale factor. Default is KL.
+ quantizable_op_type(list[str], optional): List the type of ops
+ that will be quantized. Default is ["conv2d", "depthwise_conv2d",
+ "mul"].
+ is_full_quantized(bool, optional): If set is_full_quantized as True,
+ apply quantization to all supported quantizable op type. If set
+ is_full_quantized as False, only apply quantization to the op type
+ according to the input quantizable_op_type.
+ is_use_cache_file(bool, optional): If set is_use_cache_file as False,
+ all temp data will be saved in memory. If set is_use_cache_file as True,
+ it will save temp data to disk. When the fp32 model is complex or
+ the number of calibrate data is large, we should set is_use_cache_file
+ as True. Defalut is False.
+ cache_dir(str, optional): When is_use_cache_file is True, set cache_dir as
+ the directory for saving temp data. Default is ./temp_post_training.
+ Returns:
+ None
+ '''
+ self._executor = executor
+ self._dataset = dataset
+ self._batch_size = batch_size
+ self._batch_nums = batch_nums
+ self._scope = fluid.global_scope() if scope == None else scope
+ self._algo = algo
+ self._is_use_cache_file = is_use_cache_file
+ self._cache_dir = cache_dir
+ if self._is_use_cache_file and not os.path.exists(self._cache_dir):
+ os.mkdir(self._cache_dir)
+
+ supported_quantizable_op_type = \
+ QuantizationTransformPass._supported_quantizable_op_type + \
+ AddQuantDequantPass._supported_quantizable_op_type
+ if is_full_quantize:
+ self._quantizable_op_type = supported_quantizable_op_type
+ else:
+ self._quantizable_op_type = quantizable_op_type
+ for op_type in self._quantizable_op_type:
+ assert op_type in supported_quantizable_op_type + \
+ AddQuantDequantPass._activation_type, \
+ op_type + " is not supported for quantization."
+
+ self._place = self._executor.place
+ self._program = program
+ self._feed_list = list(inputs.values())
+ self._fetch_list = list(outputs.values())
+ self._data_loader = None
+
+ self._op_real_in_out_name = _op_real_in_out_name
+ self._bit_length = 8
+ self._quantized_weight_var_name = set()
+ self._quantized_act_var_name = set()
+ self._sampling_data = {}
+ self._quantized_var_scale_factor = {}
+
+ def quantize(self):
+ '''
+ Quantize the fp32 model. Use calibrate data to calculate the scale factor of
+ quantized variables, and inserts fake quant/dequant op to obtain the
+ quantized model.
+
+ Args:
+ None
+ Returns:
+ the program of quantized model.
+ '''
+ self._preprocess()
+
+ batch_id = 0
+ for data in self._data_loader():
+ self._executor.run(
+ program=self._program,
+ feed=data,
+ fetch_list=self._fetch_list,
+ return_numpy=False)
+ self._sample_data(batch_id)
+
+ if batch_id % 5 == 0:
+ logging.info("run batch: {}".format(batch_id))
+ batch_id += 1
+ if self._batch_nums and batch_id >= self._batch_nums:
+ break
+ logging.info("all run batch: ".format(batch_id))
+ logging.info("calculate scale factor ...")
+ self._calculate_scale_factor()
+ logging.info("update the program ...")
+ self._update_program()
+
+ self._save_output_scale()
+ return self._program
+
+ def save_quantized_model(self, save_model_path):
+ '''
+ Save the quantized model to the disk.
+
+ Args:
+ save_model_path(str): The path to save the quantized model
+ Returns:
+ None
+ '''
+ feed_vars_names = [var.name for var in self._feed_list]
+ fluid.io.save_inference_model(
+ dirname=save_model_path,
+ feeded_var_names=feed_vars_names,
+ target_vars=self._fetch_list,
+ executor=self._executor,
+ params_filename='__params__',
+ main_program=self._program)
+
+ def _preprocess(self):
+ '''
+ Load model and set data loader, collect the variable names for sampling,
+ and set activation variables to be persistable.
+ '''
+ feed_vars = [fluid.framework._get_var(var.name, self._program) \
+ for var in self._feed_list]
+
+ self._data_loader = fluid.io.DataLoader.from_generator(
+ feed_list=feed_vars, capacity=3 * self._batch_size, iterable=True)
+ self._data_loader.set_sample_list_generator(
+ self._dataset.generator(self._batch_size, drop_last=True),
+ places=self._place)
+
+ # collect the variable names for sampling
+ persistable_var_names = []
+ for var in self._program.list_vars():
+ if var.persistable:
+ persistable_var_names.append(var.name)
+
+ for op in self._program.global_block().ops:
+ op_type = op.type
+ if op_type in self._quantizable_op_type:
+ if op_type in ("conv2d", "depthwise_conv2d"):
+ self._quantized_act_var_name.add(op.input("Input")[0])
+ self._quantized_weight_var_name.add(op.input("Filter")[0])
+ self._quantized_act_var_name.add(op.output("Output")[0])
+ elif op_type == "mul":
+ if self._is_input_all_not_persistable(
+ op, persistable_var_names):
+ op._set_attr("skip_quant", True)
+ logging.warning(
+ "Skip quant a mul op for two input variables are not persistable"
+ )
+ else:
+ self._quantized_act_var_name.add(op.input("X")[0])
+ self._quantized_weight_var_name.add(op.input("Y")[0])
+ self._quantized_act_var_name.add(op.output("Out")[0])
+ else:
+ # process other quantizable op type, the input must all not persistable
+ if self._is_input_all_not_persistable(
+ op, persistable_var_names):
+ input_output_name_list = self._op_real_in_out_name[
+ op_type]
+ for input_name in input_output_name_list[0]:
+ for var_name in op.input(input_name):
+ self._quantized_act_var_name.add(var_name)
+ for output_name in input_output_name_list[1]:
+ for var_name in op.output(output_name):
+ self._quantized_act_var_name.add(var_name)
+
+ # set activation variables to be persistable, so can obtain
+ # the tensor data in sample_data
+ for var in self._program.list_vars():
+ if var.name in self._quantized_act_var_name:
+ var.persistable = True
diff --git a/contrib/HumanSeg/utils/util.py b/contrib/HumanSeg/utils/util.py
deleted file mode 100644
index 7394870e7c94c1fb16169e314696b931eecdc3b2..0000000000000000000000000000000000000000
--- a/contrib/HumanSeg/utils/util.py
+++ /dev/null
@@ -1,47 +0,0 @@
-from __future__ import division
-from __future__ import print_function
-from __future__ import unicode_literals
-import argparse
-import os
-
-def get_arguments():
- parser = argparse.ArgumentParser()
- parser.add_argument("--use_gpu",
- action="store_true",
- help="Use gpu or cpu to test.")
- parser.add_argument('--example',
- type=str,
- help='RoadLine, HumanSeg or ACE2P')
-
- return parser.parse_args()
-
-
-class AttrDict(dict):
- def __init__(self, *args, **kwargs):
- super(AttrDict, self).__init__(*args, **kwargs)
-
- def __getattr__(self, name):
- if name in self.__dict__:
- return self.__dict__[name]
- elif name in self:
- return self[name]
- else:
- raise AttributeError(name)
-
- def __setattr__(self, name, value):
- if name in self.__dict__:
- self.__dict__[name] = value
- else:
- self[name] = value
-
-def merge_cfg_from_args(args, cfg):
- """Merge config keys, values in args into the global config."""
- for k, v in vars(args).items():
- d = cfg
- try:
- value = eval(v)
- except:
- value = v
- if value is not None:
- cfg[k] = value
-
diff --git a/contrib/HumanSeg/utils/utils.py b/contrib/HumanSeg/utils/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e09e8b232bfc1d7436ab94a391175446c8e12be
--- /dev/null
+++ b/contrib/HumanSeg/utils/utils.py
@@ -0,0 +1,276 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import time
+import os
+import os.path as osp
+import numpy as np
+import six
+import yaml
+import math
+import cv2
+from . import logging
+
+
+def seconds_to_hms(seconds):
+ h = math.floor(seconds / 3600)
+ m = math.floor((seconds - h * 3600) / 60)
+ s = int(seconds - h * 3600 - m * 60)
+ hms_str = "{}:{}:{}".format(h, m, s)
+ return hms_str
+
+
+def setting_environ_flags():
+ if 'FLAGS_eager_delete_tensor_gb' not in os.environ:
+ os.environ['FLAGS_eager_delete_tensor_gb'] = '0.0'
+ if 'FLAGS_allocator_strategy' not in os.environ:
+ os.environ['FLAGS_allocator_strategy'] = 'auto_growth'
+ if "CUDA_VISIBLE_DEVICES" in os.environ:
+ if os.environ["CUDA_VISIBLE_DEVICES"].count("-1") > 0:
+ os.environ["CUDA_VISIBLE_DEVICES"] = ""
+
+
+def get_environ_info():
+ setting_environ_flags()
+ import paddle.fluid as fluid
+ info = dict()
+ info['place'] = 'cpu'
+ info['num'] = int(os.environ.get('CPU_NUM', 1))
+ if os.environ.get('CUDA_VISIBLE_DEVICES', None) != "":
+ if hasattr(fluid.core, 'get_cuda_device_count'):
+ gpu_num = 0
+ try:
+ gpu_num = fluid.core.get_cuda_device_count()
+ except:
+ os.environ['CUDA_VISIBLE_DEVICES'] = ''
+ pass
+ if gpu_num > 0:
+ info['place'] = 'cuda'
+ info['num'] = fluid.core.get_cuda_device_count()
+ return info
+
+
+def parse_param_file(param_file, return_shape=True):
+ from paddle.fluid.proto.framework_pb2 import VarType
+ f = open(param_file, 'rb')
+ version = np.fromstring(f.read(4), dtype='int32')
+ lod_level = np.fromstring(f.read(8), dtype='int64')
+ for i in range(int(lod_level)):
+ _size = np.fromstring(f.read(8), dtype='int64')
+ _ = f.read(_size)
+ version = np.fromstring(f.read(4), dtype='int32')
+ tensor_desc = VarType.TensorDesc()
+ tensor_desc_size = np.fromstring(f.read(4), dtype='int32')
+ tensor_desc.ParseFromString(f.read(int(tensor_desc_size)))
+ tensor_shape = tuple(tensor_desc.dims)
+ if return_shape:
+ f.close()
+ return tuple(tensor_desc.dims)
+ if tensor_desc.data_type != 5:
+ raise Exception(
+ "Unexpected data type while parse {}".format(param_file))
+ data_size = 4
+ for i in range(len(tensor_shape)):
+ data_size *= tensor_shape[i]
+ weight = np.fromstring(f.read(data_size), dtype='float32')
+ f.close()
+ return np.reshape(weight, tensor_shape)
+
+
+def fuse_bn_weights(exe, main_prog, weights_dir):
+ import paddle.fluid as fluid
+ logging.info("Try to fuse weights of batch_norm...")
+ bn_vars = list()
+ for block in main_prog.blocks:
+ ops = list(block.ops)
+ for op in ops:
+ if op.type == 'affine_channel':
+ scale_name = op.input('Scale')[0]
+ bias_name = op.input('Bias')[0]
+ prefix = scale_name[:-5]
+ mean_name = prefix + 'mean'
+ variance_name = prefix + 'variance'
+ if not osp.exists(osp.join(
+ weights_dir, mean_name)) or not osp.exists(
+ osp.join(weights_dir, variance_name)):
+ logging.info(
+ "There's no batch_norm weight found to fuse, skip fuse_bn."
+ )
+ return
+
+ bias = block.var(bias_name)
+ pretrained_shape = parse_param_file(
+ osp.join(weights_dir, bias_name))
+ actual_shape = tuple(bias.shape)
+ if pretrained_shape != actual_shape:
+ continue
+ bn_vars.append(
+ [scale_name, bias_name, mean_name, variance_name])
+ eps = 1e-5
+ for names in bn_vars:
+ scale_name, bias_name, mean_name, variance_name = names
+ scale = parse_param_file(
+ osp.join(weights_dir, scale_name), return_shape=False)
+ bias = parse_param_file(
+ osp.join(weights_dir, bias_name), return_shape=False)
+ mean = parse_param_file(
+ osp.join(weights_dir, mean_name), return_shape=False)
+ variance = parse_param_file(
+ osp.join(weights_dir, variance_name), return_shape=False)
+ bn_std = np.sqrt(np.add(variance, eps))
+ new_scale = np.float32(np.divide(scale, bn_std))
+ new_bias = bias - mean * new_scale
+ scale_tensor = fluid.global_scope().find_var(scale_name).get_tensor()
+ bias_tensor = fluid.global_scope().find_var(bias_name).get_tensor()
+ scale_tensor.set(new_scale, exe.place)
+ bias_tensor.set(new_bias, exe.place)
+ if len(bn_vars) == 0:
+ logging.info(
+ "There's no batch_norm weight found to fuse, skip fuse_bn.")
+ else:
+ logging.info("There's {} batch_norm ops been fused.".format(
+ len(bn_vars)))
+
+
+def load_pdparams(exe, main_prog, model_dir):
+ import paddle.fluid as fluid
+ from paddle.fluid.proto.framework_pb2 import VarType
+ from paddle.fluid.framework import Program
+
+ vars_to_load = list()
+ import pickle
+ with open(osp.join(model_dir, 'model.pdparams'), 'rb') as f:
+ params_dict = pickle.load(f) if six.PY2 else pickle.load(
+ f, encoding='latin1')
+ unused_vars = list()
+ for var in main_prog.list_vars():
+ if not isinstance(var, fluid.framework.Parameter):
+ continue
+ if var.name not in params_dict:
+ raise Exception("{} is not in saved model".format(var.name))
+ if var.shape != params_dict[var.name].shape:
+ unused_vars.append(var.name)
+ logging.warning(
+ "[SKIP] Shape of pretrained weight {} doesn't match.(Pretrained: {}, Actual: {})"
+ .format(var.name, params_dict[var.name].shape, var.shape))
+ continue
+ vars_to_load.append(var)
+ logging.debug("Weight {} will be load".format(var.name))
+ for var_name in unused_vars:
+ del params_dict[var_name]
+ fluid.io.set_program_state(main_prog, params_dict)
+
+ if len(vars_to_load) == 0:
+ logging.warning(
+ "There is no pretrain weights loaded, maybe you should check you pretrain model!"
+ )
+ else:
+ logging.info("There are {} varaibles in {} are loaded.".format(
+ len(vars_to_load), model_dir))
+
+
+def load_pretrained_weights(exe, main_prog, weights_dir, fuse_bn=False):
+ if not osp.exists(weights_dir):
+ raise Exception("Path {} not exists.".format(weights_dir))
+ if osp.exists(osp.join(weights_dir, "model.pdparams")):
+ return load_pdparams(exe, main_prog, weights_dir)
+ import paddle.fluid as fluid
+ vars_to_load = list()
+ for var in main_prog.list_vars():
+ if not isinstance(var, fluid.framework.Parameter):
+ continue
+ if not osp.exists(osp.join(weights_dir, var.name)):
+ logging.debug("[SKIP] Pretrained weight {}/{} doesn't exist".format(
+ weights_dir, var.name))
+ continue
+ pretrained_shape = parse_param_file(osp.join(weights_dir, var.name))
+ actual_shape = tuple(var.shape)
+ if pretrained_shape != actual_shape:
+ logging.warning(
+ "[SKIP] Shape of pretrained weight {}/{} doesn't match.(Pretrained: {}, Actual: {})"
+ .format(weights_dir, var.name, pretrained_shape, actual_shape))
+ continue
+ vars_to_load.append(var)
+ logging.debug("Weight {} will be load".format(var.name))
+
+ fluid.io.load_vars(
+ executor=exe,
+ dirname=weights_dir,
+ main_program=main_prog,
+ vars=vars_to_load)
+ if len(vars_to_load) == 0:
+ logging.warning(
+ "There is no pretrain weights loaded, maybe you should check you pretrain model!"
+ )
+ else:
+ logging.info("There are {} varaibles in {} are loaded.".format(
+ len(vars_to_load), weights_dir))
+ if fuse_bn:
+ fuse_bn_weights(exe, main_prog, weights_dir)
+
+
+def visualize(image, result, save_dir=None, weight=0.6):
+ """
+ Convert segment result to color image, and save added image.
+ Args:
+ image: the path of origin image
+ result: the predict result of image
+ save_dir: the directory for saving visual image
+ weight: the image weight of visual image, and the result weight is (1 - weight)
+ """
+ label_map = result['label_map']
+ color_map = get_color_map_list(256)
+ color_map = np.array(color_map).astype("uint8")
+ # Use OpenCV LUT for color mapping
+ c1 = cv2.LUT(label_map, color_map[:, 0])
+ c2 = cv2.LUT(label_map, color_map[:, 1])
+ c3 = cv2.LUT(label_map, color_map[:, 2])
+ pseudo_img = np.dstack((c1, c2, c3))
+
+ im = cv2.imread(image)
+ vis_result = cv2.addWeighted(im, weight, pseudo_img, 1 - weight, 0)
+
+ if save_dir is not None:
+ if not os.path.exists(save_dir):
+ os.makedirs(save_dir)
+ image_name = os.path.split(image)[-1]
+ out_path = os.path.join(save_dir, image_name)
+ cv2.imwrite(out_path, vis_result)
+ else:
+ return vis_result
+
+
+def get_color_map_list(num_classes):
+ """ Returns the color map for visualizing the segmentation mask,
+ which can support arbitrary number of classes.
+ Args:
+ num_classes: Number of classes
+ Returns:
+ The color map
+ """
+ num_classes += 1
+ color_map = num_classes * [0, 0, 0]
+ for i in range(0, num_classes):
+ j = 0
+ lab = i
+ while lab:
+ color_map[i * 3] |= (((lab >> 0) & 1) << (7 - j))
+ color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j))
+ color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j))
+ j += 1
+ lab >>= 3
+ color_map = [color_map[i:i + 3] for i in range(0, len(color_map), 3)]
+ color_map = color_map[1:]
+ return color_map
diff --git a/contrib/HumanSeg/val.py b/contrib/HumanSeg/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..cecdb5d5c579b22688a092d700863737ec35a13d
--- /dev/null
+++ b/contrib/HumanSeg/val.py
@@ -0,0 +1,63 @@
+import argparse
+from datasets.dataset import Dataset
+import transforms
+import models
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg training')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for evaluating',
+ type=str,
+ default='output/best_model')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='The root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--val_list',
+ dest='val_list',
+ help='Val list file of dataset',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size',
+ type=int,
+ default=128)
+ parser.add_argument(
+ "--image_shape",
+ dest="image_shape",
+ help="The image shape for net inputs.",
+ nargs=2,
+ default=[192, 192],
+ type=int)
+ return parser.parse_args()
+
+
+def evaluate(args):
+ eval_transforms = transforms.Compose(
+ [transforms.Resize(args.image_shape),
+ transforms.Normalize()])
+
+ eval_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.val_list,
+ transforms=eval_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False)
+
+ model = models.load_model(args.model_dir)
+ model.evaluate(eval_dataset, args.batch_size)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ evaluate(args)
diff --git a/contrib/HumanSeg/video_infer.py b/contrib/HumanSeg/video_infer.py
new file mode 100644
index 0000000000000000000000000000000000000000..b248669cf9455e908d2c8dfb98f8edae273f73a9
--- /dev/null
+++ b/contrib/HumanSeg/video_infer.py
@@ -0,0 +1,163 @@
+import argparse
+import os
+import os.path as osp
+import cv2
+import numpy as np
+
+from utils.humanseg_postprocess import postprocess, threshold_mask
+import models
+import transforms
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg inference for video')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for inference',
+ type=str)
+ parser.add_argument(
+ '--video_path',
+ dest='video_path',
+ help=
+ 'Video path for inference, camera will be used if the path not existing',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the inference results',
+ type=str,
+ default='./output')
+ parser.add_argument(
+ "--image_shape",
+ dest="image_shape",
+ help="The image shape for net inputs.",
+ nargs=2,
+ default=[192, 192],
+ type=int)
+
+ return parser.parse_args()
+
+
+def predict(img, model, test_transforms):
+ model.arrange_transform(transforms=test_transforms, mode='test')
+ img, im_info = test_transforms(img)
+ img = np.expand_dims(img, axis=0)
+ result = model.exe.run(
+ model.test_prog,
+ feed={'image': img},
+ fetch_list=list(model.test_outputs.values()))
+ score_map = result[1]
+ score_map = np.squeeze(score_map, axis=0)
+ score_map = np.transpose(score_map, (1, 2, 0))
+ return score_map, im_info
+
+
+def recover(img, im_info):
+ keys = list(im_info.keys())
+ for k in keys[::-1]:
+ if k == 'shape_before_resize':
+ h, w = im_info[k][0], im_info[k][1]
+ img = cv2.resize(img, (w, h), cv2.INTER_LINEAR)
+ elif k == 'shape_before_padding':
+ h, w = im_info[k][0], im_info[k][1]
+ img = img[0:h, 0:w]
+ return img
+
+
+def video_infer(args):
+ resize_h = args.image_shape[1]
+ resize_w = args.image_shape[0]
+
+ test_transforms = transforms.Compose(
+ [transforms.Resize((resize_w, resize_h)),
+ transforms.Normalize()])
+ model = models.load_model(args.model_dir)
+ if not args.video_path:
+ cap = cv2.VideoCapture(0)
+ else:
+ cap = cv2.VideoCapture(args.video_path)
+ if not cap.isOpened():
+ raise IOError("Error opening video stream or file, "
+ "--video_path whether existing: {}"
+ " or camera whether working".format(args.video_path))
+ return
+
+ width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
+ height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
+
+ disflow = cv2.DISOpticalFlow_create(cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
+ prev_gray = np.zeros((resize_h, resize_w), np.uint8)
+ prev_cfd = np.zeros((resize_h, resize_w), np.float32)
+ is_init = True
+
+ fps = cap.get(cv2.CAP_PROP_FPS)
+ if args.video_path:
+
+ # 用于保存预测结果视频
+ if not osp.exists(args.save_dir):
+ os.makedirs(args.save_dir)
+ out = cv2.VideoWriter(
+ osp.join(args.save_dir, 'result.avi'),
+ cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps, (width, height))
+ # 开始获取视频帧
+ while cap.isOpened():
+ ret, frame = cap.read()
+ if ret:
+ score_map, im_info = predict(frame, model, test_transforms)
+ cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
+ cur_gray = cv2.resize(cur_gray, (resize_w, resize_h))
+ scoremap = 255 * score_map[:, :, 1]
+ optflow_map = postprocess(cur_gray, scoremap, prev_gray, prev_cfd, \
+ disflow, is_init)
+ prev_gray = cur_gray.copy()
+ prev_cfd = optflow_map.copy()
+ is_init = False
+ optflow_map = cv2.GaussianBlur(optflow_map, (3, 3), 0)
+ optflow_map = threshold_mask(
+ optflow_map, thresh_bg=0.2, thresh_fg=0.8)
+ img_mat = np.repeat(optflow_map[:, :, np.newaxis], 3, axis=2)
+ img_mat = recover(img_mat, im_info)
+ bg_im = np.ones_like(img_mat) * 255
+ comb = (img_mat * frame + (1 - img_mat) * bg_im).astype(
+ np.uint8)
+ out.write(comb)
+ else:
+ break
+ cap.release()
+ out.release()
+
+ else:
+ while cap.isOpened():
+ ret, frame = cap.read()
+ if ret:
+ score_map, im_info = predict(frame, model, test_transforms)
+ cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
+ cur_gray = cv2.resize(cur_gray, (resize_w, resize_h))
+ scoremap = 255 * score_map[:, :, 1]
+ optflow_map = postprocess(cur_gray, scoremap, prev_gray, prev_cfd, \
+ disflow, is_init)
+ prev_gray = cur_gray.copy()
+ prev_cfd = optflow_map.copy()
+ is_init = False
+ # optflow_map = optflow_map/255.0
+ optflow_map = cv2.GaussianBlur(optflow_map, (3, 3), 0)
+ optflow_map = threshold_mask(
+ optflow_map, thresh_bg=0.2, thresh_fg=0.8)
+ img_mat = np.repeat(optflow_map[:, :, np.newaxis], 3, axis=2)
+ img_mat = recover(img_mat, im_info)
+ bg_im = np.ones_like(img_mat) * 255
+ comb = (img_mat * frame + (1 - img_mat) * bg_im).astype(
+ np.uint8)
+ cv2.imshow('HumanSegmentation', comb)
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+ else:
+ break
+ cap.release()
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ video_infer(args)
diff --git a/contrib/LaneNet/requirements.txt b/contrib/LaneNet/requirements.txt
index 2b5eb8643803e1177297d2a766227e274dcdc29d..b084ca5748e061d31190b9e29bdb932f0a2c9ec8 100644
--- a/contrib/LaneNet/requirements.txt
+++ b/contrib/LaneNet/requirements.txt
@@ -2,8 +2,6 @@ pre-commit
yapf == 0.26.0
flake8
pyyaml >= 5.1
-tb-paddle
-tensorboard >= 1.15.0
Pillow
numpy
six
@@ -11,3 +9,4 @@ opencv-python
tqdm
requests
sklearn
+visualdl == 2.0.0-alpha.2
diff --git a/contrib/LaneNet/train.py b/contrib/LaneNet/train.py
index c2f5bee7547eabe9ef5c998b197fbaf59130d679..d9d22ba999cbbc3a9252f258e973612c68fe4ee4 100644
--- a/contrib/LaneNet/train.py
+++ b/contrib/LaneNet/train.py
@@ -78,14 +78,14 @@ def parse_args():
help='debug mode, display detail information of training',
action='store_true')
parser.add_argument(
- '--use_tb',
- dest='use_tb',
- help='whether to record the data during training to Tensorboard',
+ '--use_vdl',
+ dest='use_vdl',
+ help='whether to record the data during training to VisualDL',
action='store_true')
parser.add_argument(
- '--tb_log_dir',
- dest='tb_log_dir',
- help='Tensorboard logging directory',
+ '--vdl_log_dir',
+ dest='vdl_log_dir',
+ help='VisualDL logging directory',
default=None,
type=str)
parser.add_argument(
@@ -327,17 +327,17 @@ def train(cfg):
fetch_list.extend([pred.name, grts.name, masks.name])
# cm = ConfusionMatrix(cfg.DATASET.NUM_CLASSES, streaming=True)
- if args.use_tb:
- if not args.tb_log_dir:
- print_info("Please specify the log directory by --tb_log_dir.")
+ if args.use_vdl:
+ if not args.vdl_log_dir:
+ print_info("Please specify the log directory by --vdl_log_dir.")
exit(1)
- from tb_paddle import SummaryWriter
- log_writer = SummaryWriter(args.tb_log_dir)
+ from visualdl import LogWriter
+ log_writer = LogWriter(args.vdl_log_dir)
# trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
# num_trainers = int(os.environ.get('PADDLE_TRAINERS_NUM', 1))
- global_step = 0
+ step = 0
all_step = cfg.DATASET.TRAIN_TOTAL_IMAGES // cfg.BATCH_SIZE
if cfg.DATASET.TRAIN_TOTAL_IMAGES % cfg.BATCH_SIZE and drop_last != True:
all_step += 1
@@ -377,9 +377,9 @@ def train(cfg):
avg_acc += np.mean(out_acc)
avg_fp += np.mean(out_fp)
avg_fn += np.mean(out_fn)
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
+ if step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
avg_loss /= args.log_steps
avg_seg_loss /= args.log_steps
avg_emb_loss /= args.log_steps
@@ -389,14 +389,14 @@ def train(cfg):
speed = args.log_steps / timer.elapsed_time()
print((
"epoch={} step={} lr={:.5f} loss={:.4f} seg_loss={:.4f} emb_loss={:.4f} accuracy={:.4} fp={:.4} fn={:.4} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss, avg_seg_loss,
+ ).format(epoch, step, lr[0], avg_loss, avg_seg_loss,
avg_emb_loss, avg_acc, avg_fp, avg_fn, speed,
- calculate_eta(all_step - global_step, speed)))
- if args.use_tb:
+ calculate_eta(all_step - step, speed)))
+ if args.use_vdl:
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
- log_writer.add_scalar('Train/lr', lr[0], global_step)
- log_writer.add_scalar('Train/speed', speed, global_step)
+ step)
+ log_writer.add_scalar('Train/lr', lr[0], step)
+ log_writer.add_scalar('Train/speed', speed, step)
sys.stdout.flush()
avg_loss = 0.0
avg_seg_loss = 0.0
@@ -422,14 +422,14 @@ def train(cfg):
ckpt_dir=ckpt_dir,
use_gpu=args.use_gpu,
use_mpio=args.use_mpio)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Evaluate/accuracy', accuracy,
- global_step)
- log_writer.add_scalar('Evaluate/fp', fp, global_step)
- log_writer.add_scalar('Evaluate/fn', fn, global_step)
+ step)
+ log_writer.add_scalar('Evaluate/fp', fp, step)
+ log_writer.add_scalar('Evaluate/fn', fn, step)
- # Use Tensorboard to visualize results
- if args.use_tb and cfg.DATASET.VIS_FILE_LIST is not None:
+ # Use VisualDL to visualize results
+ if args.use_vdl and cfg.DATASET.VIS_FILE_LIST is not None:
visualize(
cfg=cfg,
use_gpu=args.use_gpu,
diff --git a/contrib/LaneNet/utils/config.py b/contrib/LaneNet/utils/config.py
index d1186636c7d2b8004756bdfbaaca74aa47d32b7f..7c2019d44a100b033520138632fc0e7b56d65676 100644
--- a/contrib/LaneNet/utils/config.py
+++ b/contrib/LaneNet/utils/config.py
@@ -68,7 +68,7 @@ cfg.DATASET.VAL_TOTAL_IMAGES = 500
cfg.DATASET.TEST_FILE_LIST = './dataset/cityscapes/test.list'
# 测试数据数量
cfg.DATASET.TEST_TOTAL_IMAGES = 500
-# Tensorboard 可视化的数据集
+# VisualDL 可视化的数据集
cfg.DATASET.VIS_FILE_LIST = None
# 类别数(需包括背景类)
cfg.DATASET.NUM_CLASSES = 19
diff --git a/contrib/README.md b/contrib/README.md
index 7b6a9b8b865f7c573c5e34bb0047ea28a57c52a4..6d70394c00b2e133a1c011f66bbca334b038e81a 100644
--- a/contrib/README.md
+++ b/contrib/README.md
@@ -1,194 +1,43 @@
-# PaddleSeg 特色垂类分割模型
+# PaddleSeg 产业实践
-提供基于PaddlePaddle最新的分割特色模型:
+提供基于PaddlSeg最新的分割特色模型:
-- [人像分割](#人像分割)
-- [人体解析](#人体解析)
-- [车道线分割](#车道线分割)
-- [工业用表分割](#工业用表分割)
-- [在线体验](#在线体验)
+- [人像分割](./HumanSeg)
+- [人体解析](./ACE2P)
+- [车道线分割](./LaneNet)
+- [工业表盘分割](#工业表盘分割)
+- [AIStudio在线教程](#AIStudio在线教程)
-## 人像分割
+## 人像分割 HumanSeg
-**Note:** 本章节所有命令均在`contrib/HumanSeg`目录下执行。
+HumanSeg系列全新升级,提供三个适用于不同场景,包含适用于移动端实时分割场景的模型`HumanSeg-lite`,提供了包含光流的后处理的优化,使人像分割在视频场景中更加顺畅,更多详情请参考[HumanSeg](./HumanSeg)
-```
-cd contrib/HumanSeg
-```
-
-### 1. 模型结构
-
-DeepLabv3+ backbone为Xception65
-
-### 2. 下载模型和数据
-
-执行以下命令下载并解压模型和数据集:
-
-```
-python download_HumanSeg.py
-```
-
-或点击[链接](https://paddleseg.bj.bcebos.com/models/HumanSeg.tgz)进行手动下载,并解压到contrib/HumanSeg文件夹下
-
-
-### 3. 运行
-
-使用GPU预测:
-```
-python -u infer.py --example HumanSeg --use_gpu
-```
-
-
-使用CPU预测:
-```
-python -u infer.py --example HumanSeg
-```
-
-
-预测结果存放在contrib/HumanSeg/HumanSeg/result目录下。
-
-### 4. 预测结果示例:
-
- 原图:
-
- 
-
- 预测结果:
-
- 
-
-
-
-## 人体解析
-
-
-
-人体解析(Human Parsing)是细粒度的语义分割任务,旨在识别像素级别的人类图像的组成部分(例如,身体部位和服装)。本章节使用冠军模型Augmented Context Embedding with Edge Perceiving (ACE2P)进行预测分割。
-
-
-**Note:** 本章节所有命令均在`contrib/ACE2P`目录下执行。
-
-```
-cd contrib/ACE2P
-```
-
-### 1. 模型概述
-
-Augmented Context Embedding with Edge Perceiving (ACE2P)通过融合底层特征、全局上下文信息和边缘细节,端到端训练学习人体解析任务。以ACE2P单人人体解析网络为基础的解决方案在CVPR2019第三届Look into Person (LIP)挑战赛中赢得了全部三个人体解析任务的第一名。详情请参见[ACE2P](./ACE2P)
-
-### 2. 模型下载
-
-执行以下命令下载并解压ACE2P预测模型:
-
-```
-python download_ACE2P.py
-```
-
-或点击[链接](https://paddleseg.bj.bcebos.com/models/ACE2P.tgz)进行手动下载, 并在contrib/ACE2P下解压。
-
-### 3. 数据下载
-
-测试图片共10000张,
-点击 [Baidu_Drive](https://pan.baidu.com/s/1nvqmZBN#list/path=%2Fsharelink2787269280-523292635003760%2FLIP%2FLIP&parentPath=%2Fsharelink2787269280-523292635003760)
-下载Testing_images.zip,或前往LIP数据集官网进行下载。
-下载后解压到contrib/ACE2P/data文件夹下
-
-
-### 4. 运行
+## 人体解析 Human Parsing
-使用GPU预测
-```
-python -u infer.py --example ACE2P --use_gpu
-```
-
-使用CPU预测:
-```
-python -u infer.py --example ACE2P
-```
-
-**NOTE:** 运行该模型需要2G左右显存。由于数据图片较多,预测过程将比较耗时。
-
-#### 5. 预测结果示例:
-
- 原图:
-
- 
-
- 预测结果:
-
- 
-
-### 备注
-
-1. 数据及模型路径等详细配置见ACE2P/HumanSeg/RoadLine下的config.py文件
-2. ACE2P模型需预留2G显存,若显存超可调小FLAGS_fraction_of_gpu_memory_to_use
+人体解析(Human Parsing)是细粒度的语义分割任务,旨在识别像素级别的人类图像的组成部分(例如,身体部位和服装)。ACE2P通过融合底层特征、全局上下文信息和边缘细节,端到端训练学习人体解析任务。以ACE2P单人人体解析网络为基础的解决方案在CVPR2019第三届LIP挑战赛中赢得了全部三个人体解析任务的第一名
+#### ACE2P模型框架图
+
+PaddleSeg提供了ACE2P获得比赛冠军的预训练模型,更多详情请点击[ACE2P](./ACE2P)
-## 车道线分割
+## 车道线分割 LaneNet
-**Note:** 本章节所有命令均在`contrib/RoadLine`目录下执行。
-
-```
-cd contrib/RoadLine
-```
-
-### 1. 模型结构
+PaddleSeg提供了基于LaneNet的车道线分割模型,更多详情请点击[LaneNet](./LaneNet)
-Deeplabv3+ backbone为MobileNetv2
+
-### 2. 下载模型和数据
-
-
-执行以下命令下载并解压模型和数据集:
-
-```
-python download_RoadLine.py
-```
-
-或点击[链接](https://paddleseg.bj.bcebos.com/inference_model/RoadLine.tgz)进行手动下载,并解压到contrib/RoadLine文件夹下
-
-
-### 3. 运行
-
-使用GPU预测:
-
-```
-python -u infer.py --example RoadLine --use_gpu
-```
-
-
-使用CPU预测:
-
-```
-python -u infer.py --example RoadLine
-```
-
-预测结果存放在contrib/RoadLine/RoadLine/result目录下。
-
-#### 4. 预测结果示例:
-
- 原图:
-
- 
-
- 预测结果:
-
- 
-
-
-
-## 工业用表分割
+## 工业表盘分割
**Note:** 本章节所有命令均在`PaddleSeg`目录下执行。
### 1. 模型结构
-unet
+U-Net
### 2. 数据准备
@@ -198,7 +47,6 @@ unet
python ./contrib/MechanicalIndustryMeter/download_mini_mechanical_industry_meter.py
```
-
### 3. 下载预训练模型
```
@@ -237,7 +85,7 @@ TEST.TEST_MODEL "./contrib/MechanicalIndustryMeter/unet_mechanical_industry_mete

-## 在线体验
+## AIStudio在线教程
PaddleSeg在AI Studio平台上提供了在线体验的教程,欢迎体验:
@@ -246,5 +94,3 @@ PaddleSeg在AI Studio平台上提供了在线体验的教程,欢迎体验:
|工业质检|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/184392)|
|人像分割|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/188833)|
|特色垂类模型|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/226710)|
-
-
diff --git a/contrib/RealTimeHumanSeg/README.md b/contrib/RealTimeHumanSeg/README.md
deleted file mode 100644
index e8693e11e4d66b9a2ee04bf1e03a5704a95fb426..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/README.md
+++ /dev/null
@@ -1,28 +0,0 @@
-# 实时人像分割预测部署
-
-本模型基于飞浆开源的人像分割模型,并做了大量的针对视频的光流追踪优化,提供了完整的支持视频流的实时人像分割解决方案,并提供了高性能的`Python`和`C++`集成部署方案,以满足不同场景的需求。
-
-
-## 模型下载
-
-支持的模型文件如下,请根据应用场景选择合适的模型:
-|模型文件 | 说明 |
-|---|---|
-|[shv75_deeplab_0303_quant](https://paddleseg.bj.bcebos.com/deploy/models/shv75_0303_quant.zip) | 小模型, 适合轻量级计算环境 |
-|[shv75_deeplab_0303](https://paddleseg.bj.bcebos.com/deploy/models/shv75_deeplab_0303.zip)| 小模型,适合轻量级计算环境 |
-|[deeplabv3_xception_humanseg](https://paddleseg.bj.bcebos.com/deploy/models/deeplabv3_xception_humanseg.zip) | 服务端GPU环境 |
-
-**注意:下载后解压到合适的路径,后续该路径将做为预测参数用于加载模型。**
-
-
-## 预测部署
-- [Python预测部署](./python)
-- [C++预测部署](./cpp)
-
-## 效果预览
-
-
-  -
-  -
-
diff --git a/contrib/RealTimeHumanSeg/cpp/CMakeLists.txt b/contrib/RealTimeHumanSeg/cpp/CMakeLists.txt
deleted file mode 100644
index 5a7b89acc41da5576a0f0ead7205385feabf5dab..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/CMakeLists.txt
+++ /dev/null
@@ -1,221 +0,0 @@
-cmake_minimum_required(VERSION 3.0)
-project(PaddleMaskDetector CXX C)
-
-option(WITH_MKL "Compile demo with MKL/OpenBlas support,defaultuseMKL." ON)
-option(WITH_GPU "Compile demo with GPU/CPU, default use CPU." ON)
-option(WITH_STATIC_LIB "Compile demo with static/shared library, default use static." ON)
-option(USE_TENSORRT "Compile demo with TensorRT." OFF)
-
-SET(PADDLE_DIR "" CACHE PATH "Location of libraries")
-SET(OPENCV_DIR "" CACHE PATH "Location of libraries")
-SET(CUDA_LIB "" CACHE PATH "Location of libraries")
-
-macro(safe_set_static_flag)
- foreach(flag_var
- CMAKE_CXX_FLAGS CMAKE_CXX_FLAGS_DEBUG CMAKE_CXX_FLAGS_RELEASE
- CMAKE_CXX_FLAGS_MINSIZEREL CMAKE_CXX_FLAGS_RELWITHDEBINFO)
- if(${flag_var} MATCHES "/MD")
- string(REGEX REPLACE "/MD" "/MT" ${flag_var} "${${flag_var}}")
- endif(${flag_var} MATCHES "/MD")
- endforeach(flag_var)
-endmacro()
-
-if (WITH_MKL)
- ADD_DEFINITIONS(-DUSE_MKL)
-endif()
-
-if (NOT DEFINED PADDLE_DIR OR ${PADDLE_DIR} STREQUAL "")
- message(FATAL_ERROR "please set PADDLE_DIR with -DPADDLE_DIR=/path/paddle_influence_dir")
-endif()
-
-if (NOT DEFINED OPENCV_DIR OR ${OPENCV_DIR} STREQUAL "")
- message(FATAL_ERROR "please set OPENCV_DIR with -DOPENCV_DIR=/path/opencv")
-endif()
-
-include_directories("${CMAKE_SOURCE_DIR}/")
-include_directories("${PADDLE_DIR}/")
-include_directories("${PADDLE_DIR}/third_party/install/protobuf/include")
-include_directories("${PADDLE_DIR}/third_party/install/glog/include")
-include_directories("${PADDLE_DIR}/third_party/install/gflags/include")
-include_directories("${PADDLE_DIR}/third_party/install/xxhash/include")
-if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/include")
- include_directories("${PADDLE_DIR}/third_party/install/snappy/include")
-endif()
-if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/include")
- include_directories("${PADDLE_DIR}/third_party/install/snappystream/include")
-endif()
-include_directories("${PADDLE_DIR}/third_party/install/zlib/include")
-include_directories("${PADDLE_DIR}/third_party/boost")
-include_directories("${PADDLE_DIR}/third_party/eigen3")
-
-if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
- link_directories("${PADDLE_DIR}/third_party/install/snappy/lib")
-endif()
-if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
- link_directories("${PADDLE_DIR}/third_party/install/snappystream/lib")
-endif()
-
-link_directories("${PADDLE_DIR}/third_party/install/zlib/lib")
-link_directories("${PADDLE_DIR}/third_party/install/protobuf/lib")
-link_directories("${PADDLE_DIR}/third_party/install/glog/lib")
-link_directories("${PADDLE_DIR}/third_party/install/gflags/lib")
-link_directories("${PADDLE_DIR}/third_party/install/xxhash/lib")
-link_directories("${PADDLE_DIR}/paddle/lib/")
-link_directories("${CMAKE_CURRENT_BINARY_DIR}")
-if (WIN32)
- include_directories("${PADDLE_DIR}/paddle/fluid/inference")
- include_directories("${PADDLE_DIR}/paddle/include")
- link_directories("${PADDLE_DIR}/paddle/fluid/inference")
- include_directories("${OPENCV_DIR}/build/include")
- include_directories("${OPENCV_DIR}/opencv/build/include")
- link_directories("${OPENCV_DIR}/build/x64/vc14/lib")
-else ()
- find_package(OpenCV REQUIRED PATHS ${OPENCV_DIR}/share/OpenCV NO_DEFAULT_PATH)
- include_directories("${PADDLE_DIR}/paddle/include")
- link_directories("${PADDLE_DIR}/paddle/lib")
- include_directories(${OpenCV_INCLUDE_DIRS})
-endif ()
-
-if (WIN32)
- add_definitions("/DGOOGLE_GLOG_DLL_DECL=")
- set(CMAKE_C_FLAGS_DEBUG "${CMAKE_C_FLAGS_DEBUG} /bigobj /MTd")
- set(CMAKE_C_FLAGS_RELEASE "${CMAKE_C_FLAGS_RELEASE} /bigobj /MT")
- set(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} /bigobj /MTd")
- set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} /bigobj /MT")
- if (WITH_STATIC_LIB)
- safe_set_static_flag()
- add_definitions(-DSTATIC_LIB)
- endif()
-else()
- set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -g -o2 -fopenmp -std=c++11")
- set(CMAKE_STATIC_LIBRARY_PREFIX "")
-endif()
-
-# TODO let users define cuda lib path
-if (WITH_GPU)
- if (NOT DEFINED CUDA_LIB OR ${CUDA_LIB} STREQUAL "")
- message(FATAL_ERROR "please set CUDA_LIB with -DCUDA_LIB=/path/cuda-8.0/lib64")
- endif()
- if (NOT WIN32)
- if (NOT DEFINED CUDNN_LIB)
- message(FATAL_ERROR "please set CUDNN_LIB with -DCUDNN_LIB=/path/cudnn_v7.4/cuda/lib64")
- endif()
- endif(NOT WIN32)
-endif()
-
-
-if (NOT WIN32)
- if (USE_TENSORRT AND WITH_GPU)
- include_directories("${PADDLE_DIR}/third_party/install/tensorrt/include")
- link_directories("${PADDLE_DIR}/third_party/install/tensorrt/lib")
- endif()
-endif(NOT WIN32)
-
-if (NOT WIN32)
- set(NGRAPH_PATH "${PADDLE_DIR}/third_party/install/ngraph")
- if(EXISTS ${NGRAPH_PATH})
- include(GNUInstallDirs)
- include_directories("${NGRAPH_PATH}/include")
- link_directories("${NGRAPH_PATH}/${CMAKE_INSTALL_LIBDIR}")
- set(NGRAPH_LIB ${NGRAPH_PATH}/${CMAKE_INSTALL_LIBDIR}/libngraph${CMAKE_SHARED_LIBRARY_SUFFIX})
- endif()
-endif()
-
-if(WITH_MKL)
- include_directories("${PADDLE_DIR}/third_party/install/mklml/include")
- if (WIN32)
- set(MATH_LIB ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.lib
- ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.lib)
- else ()
- set(MATH_LIB ${PADDLE_DIR}/third_party/install/mklml/lib/libmklml_intel${CMAKE_SHARED_LIBRARY_SUFFIX}
- ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5${CMAKE_SHARED_LIBRARY_SUFFIX})
- execute_process(COMMAND cp -r ${PADDLE_DIR}/third_party/install/mklml/lib/libmklml_intel${CMAKE_SHARED_LIBRARY_SUFFIX} /usr/lib)
- endif ()
- set(MKLDNN_PATH "${PADDLE_DIR}/third_party/install/mkldnn")
- if(EXISTS ${MKLDNN_PATH})
- include_directories("${MKLDNN_PATH}/include")
- if (WIN32)
- set(MKLDNN_LIB ${MKLDNN_PATH}/lib/mkldnn.lib)
- else ()
- set(MKLDNN_LIB ${MKLDNN_PATH}/lib/libmkldnn.so.0)
- endif ()
- endif()
-else()
- set(MATH_LIB ${PADDLE_DIR}/third_party/install/openblas/lib/libopenblas${CMAKE_STATIC_LIBRARY_SUFFIX})
-endif()
-
-if (WIN32)
- if(EXISTS "${PADDLE_DIR}/paddle/fluid/inference/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX}")
- set(DEPS
- ${PADDLE_DIR}/paddle/fluid/inference/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX})
- else()
- set(DEPS
- ${PADDLE_DIR}/paddle/lib/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX})
- endif()
-endif()
-
-if(WITH_STATIC_LIB)
- set(DEPS
- ${PADDLE_DIR}/paddle/lib/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX})
-else()
- set(DEPS
- ${PADDLE_DIR}/paddle/lib/libpaddle_fluid${CMAKE_SHARED_LIBRARY_SUFFIX})
-endif()
-
-if (NOT WIN32)
- set(DEPS ${DEPS}
- ${MATH_LIB} ${MKLDNN_LIB}
- glog gflags protobuf z xxhash
- )
- if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
- set(DEPS ${DEPS} snappystream)
- endif()
- if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
- set(DEPS ${DEPS} snappy)
- endif()
-else()
- set(DEPS ${DEPS}
- ${MATH_LIB} ${MKLDNN_LIB}
- opencv_world346 glog gflags_static libprotobuf zlibstatic xxhash)
- set(DEPS ${DEPS} libcmt shlwapi)
- if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
- set(DEPS ${DEPS} snappy)
- endif()
- if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
- set(DEPS ${DEPS} snappystream)
- endif()
-endif(NOT WIN32)
-
-if(WITH_GPU)
- if(NOT WIN32)
- if (USE_TENSORRT)
- set(DEPS ${DEPS} ${PADDLE_DIR}/third_party/install/tensorrt/lib/libnvinfer${CMAKE_STATIC_LIBRARY_SUFFIX})
- set(DEPS ${DEPS} ${PADDLE_DIR}/third_party/install/tensorrt/lib/libnvinfer_plugin${CMAKE_STATIC_LIBRARY_SUFFIX})
- endif()
- set(DEPS ${DEPS} ${CUDA_LIB}/libcudart${CMAKE_SHARED_LIBRARY_SUFFIX})
- set(DEPS ${DEPS} ${CUDNN_LIB}/libcudnn${CMAKE_SHARED_LIBRARY_SUFFIX})
- else()
- set(DEPS ${DEPS} ${CUDA_LIB}/cudart${CMAKE_STATIC_LIBRARY_SUFFIX} )
- set(DEPS ${DEPS} ${CUDA_LIB}/cublas${CMAKE_STATIC_LIBRARY_SUFFIX} )
- set(DEPS ${DEPS} ${CUDA_LIB}/cudnn${CMAKE_STATIC_LIBRARY_SUFFIX})
- endif()
-endif()
-
-if (NOT WIN32)
- set(EXTERNAL_LIB "-ldl -lrt -lgomp -lz -lm -lpthread")
- set(DEPS ${DEPS} ${EXTERNAL_LIB} ${OpenCV_LIBS})
-endif()
-
-add_executable(main main.cc humanseg.cc humanseg_postprocess.cc)
-target_link_libraries(main ${DEPS})
-
-if (WIN32)
- add_custom_command(TARGET main POST_BUILD
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.dll ./mklml.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.dll ./libiomp5md.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mkldnn/lib/mkldnn.dll ./mkldnn.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.dll ./release/mklml.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.dll ./release/libiomp5md.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mkldnn/lib/mkldnn.dll ./release/mkldnn.dll
- )
-endif()
diff --git a/contrib/RealTimeHumanSeg/cpp/CMakeSettings.json b/contrib/RealTimeHumanSeg/cpp/CMakeSettings.json
deleted file mode 100644
index 87cbe721d98dc9a12079d2eb79c77e50d0e0408a..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/CMakeSettings.json
+++ /dev/null
@@ -1,42 +0,0 @@
-{
- "configurations": [
- {
- "name": "x64-Release",
- "generator": "Ninja",
- "configurationType": "RelWithDebInfo",
- "inheritEnvironments": [ "msvc_x64_x64" ],
- "buildRoot": "${projectDir}\\out\\build\\${name}",
- "installRoot": "${projectDir}\\out\\install\\${name}",
- "cmakeCommandArgs": "",
- "buildCommandArgs": "-v",
- "ctestCommandArgs": "",
- "variables": [
- {
- "name": "CUDA_LIB",
- "value": "D:/projects/packages/cuda10_0/lib64",
- "type": "PATH"
- },
- {
- "name": "CUDNN_LIB",
- "value": "D:/projects/packages/cuda10_0/lib64",
- "type": "PATH"
- },
- {
- "name": "OPENCV_DIR",
- "value": "D:/projects/packages/opencv3_4_6",
- "type": "PATH"
- },
- {
- "name": "PADDLE_DIR",
- "value": "D:/projects/packages/fluid_inference1_6_1",
- "type": "PATH"
- },
- {
- "name": "CMAKE_BUILD_TYPE",
- "value": "Release",
- "type": "STRING"
- }
- ]
- }
- ]
-}
\ No newline at end of file
diff --git a/contrib/RealTimeHumanSeg/cpp/README.md b/contrib/RealTimeHumanSeg/cpp/README.md
deleted file mode 100644
index 5f1184130cb4ebf18fd10f30378caa8c98bb8083..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/README.md
+++ /dev/null
@@ -1,15 +0,0 @@
-# 视频实时图像分割模型C++预测部署
-
-本文档主要介绍实时图像分割模型如何在`Windows`和`Linux`上完成基于`C++`的预测部署。
-
-## C++预测部署编译
-
-### 1. 下载模型
-点击右边下载:[模型下载地址](https://paddleseg.bj.bcebos.com/deploy/models/humanseg_paddleseg_int8.zip)
-
-模型文件路径将做为预测时的输入参数,请解压到合适的目录位置。
-
-### 2. 编译
-本项目支持在Windows和Linux上编译并部署C++项目,不同平台的编译请参考:
-- [Linux 编译](./docs/linux_build.md)
-- [Windows 使用 Visual Studio 2019编译](./docs/windows_build.md)
diff --git a/contrib/RealTimeHumanSeg/cpp/docs/linux_build.md b/contrib/RealTimeHumanSeg/cpp/docs/linux_build.md
deleted file mode 100644
index 823ff3ae7cc6b16d9f5696924ae5def746bc8892..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/docs/linux_build.md
+++ /dev/null
@@ -1,86 +0,0 @@
-# 视频实时人像分割模型Linux平台C++预测部署
-
-
-## 1. 系统和软件依赖
-
-### 1.1 操作系统及硬件要求
-
-- Ubuntu 14.04 或者 16.04 (其它平台未测试)
-- GCC版本4.8.5 ~ 4.9.2
-- 支持Intel MKL-DNN的CPU
-- NOTE: 如需在Nvidia GPU运行,请自行安装CUDA 9.0 / 10.0 + CUDNN 7.3+ (不支持9.1/10.1版本的CUDA)
-
-### 1.2 下载PaddlePaddle C++预测库
-
-PaddlePaddle C++ 预测库主要分为CPU版本和GPU版本。
-
-其中,GPU 版本支持`CUDA 10.0` 和 `CUDA 9.0`:
-
-以下为各版本C++预测库的下载链接:
-
-| 版本 | 链接 |
-| ---- | ---- |
-| CPU+MKL版 | [fluid_inference.tgz](https://paddle-inference-lib.bj.bcebos.com/1.6.3-cpu-avx-mkl/fluid_inference.tgz) |
-| CUDA9.0+MKL 版 | [fluid_inference.tgz](https://paddle-inference-lib.bj.bcebos.com/1.6.3-gpu-cuda9-cudnn7-avx-mkl/fluid_inference.tgz) |
-| CUDA10.0+MKL 版 | [fluid_inference.tgz](https://paddle-inference-lib.bj.bcebos.com/1.6.3-gpu-cuda10-cudnn7-avx-mkl/fluid_inference.tgz) |
-
-更多可用预测库版本,请点击以下链接下载:[C++预测库下载列表](https://paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/deploy/inference/build_and_install_lib_cn.html)
-
-
-下载并解压, 解压后的 `fluid_inference`目录包含的内容:
-```
-fluid_inference
-├── paddle # paddle核心库和头文件
-|
-├── third_party # 第三方依赖库和头文件
-|
-└── version.txt # 版本和编译信息
-```
-
-**注意:** 请把解压后的目录放到合适的路径,**该目录路径后续会作为编译依赖**使用。
-
-## 2. 编译与运行
-
-### 2.1 配置编译脚本
-
-打开文件`linux_build.sh`, 看到以下内容:
-```shell
-# 是否使用GPU
-WITH_GPU=OFF
-# Paddle 预测库路径
-PADDLE_DIR=/PATH/TO/fluid_inference/
-# CUDA库路径, 仅 WITH_GPU=ON 时设置
-CUDA_LIB=/PATH/TO/CUDA_LIB64/
-# CUDNN库路径,仅 WITH_GPU=ON 且 CUDA_LIB有效时设置
-CUDNN_LIB=/PATH/TO/CUDNN_LIB64/
-# OpenCV 库路径, 无须设置
-OPENCV_DIR=/PATH/TO/opencv3gcc4.8/
-
-cd build
-cmake .. \
- -DWITH_GPU=${WITH_GPU} \
- -DPADDLE_DIR=${PADDLE_DIR} \
- -DCUDA_LIB=${CUDA_LIB} \
- -DCUDNN_LIB=${CUDNN_LIB} \
- -DOPENCV_DIR=${OPENCV_DIR} \
- -DWITH_STATIC_LIB=OFF
-make -j4
-```
-
-把上述参数根据实际情况做修改后,运行脚本编译程序:
-```shell
-sh linux_build.sh
-```
-
-### 2.2. 运行和可视化
-
-可执行文件有 **2** 个参数,第一个是前面导出的`inference_model`路径,第二个是需要预测的视频路径。
-
-示例:
-```shell
-./build/main ./models /PATH/TO/TEST_VIDEO
-```
-
-点击下载[测试视频](https://paddleseg.bj.bcebos.com/deploy/data/test.avi)
-
-预测的结果保存在视频文件`result.avi`中。
diff --git a/contrib/RealTimeHumanSeg/cpp/docs/windows_build.md b/contrib/RealTimeHumanSeg/cpp/docs/windows_build.md
deleted file mode 100644
index 6937dbcff4f55c5a085aa9d0bd2674c04f3ac8e5..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/docs/windows_build.md
+++ /dev/null
@@ -1,83 +0,0 @@
-# 视频实时人像分割模型Windows平台C++预测部署
-
-## 1. 系统和软件依赖
-
-### 1.1 基础依赖
-
-- Windows 10 / Windows Server 2016+ (其它平台未测试)
-- Visual Studio 2019 (社区版或专业版均可)
-- CUDA 9.0 / 10.0 + CUDNN 7.3+ (不支持9.1/10.1版本的CUDA)
-
-### 1.2 下载OpenCV并设置环境变量
-
-- 在OpenCV官网下载适用于Windows平台的3.4.6版本: [点击下载](https://sourceforge.net/projects/opencvlibrary/files/3.4.6/opencv-3.4.6-vc14_vc15.exe/download)
-- 运行下载的可执行文件,将OpenCV解压至合适目录,这里以解压到`D:\projects\opencv`为例
-- 把OpenCV动态库加入到系统环境变量
- - 此电脑(我的电脑)->属性->高级系统设置->环境变量
- - 在系统变量中找到Path(如没有,自行创建),并双击编辑
- - 新建,将opencv路径填入并保存,如D:\projects\opencv\build\x64\vc14\bin
-
-**注意:** `OpenCV`的解压目录后续将做为编译配置项使用,所以请放置合适的目录中。
-
-### 1.3 下载PaddlePaddle C++ 预测库
-
-`PaddlePaddle` **C++ 预测库** 主要分为`CPU`和`GPU`版本, 其中`GPU版本`提供`CUDA 9.0` 和 `CUDA 10.0` 支持。
-
-常用的版本如下:
-
-| 版本 | 链接 |
-| ---- | ---- |
-| CPU+MKL版 | [fluid_inference_install_dir.zip](https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/cpu/fluid_inference_install_dir.zip) |
-| CUDA9.0+MKL 版 | [fluid_inference_install_dir.zip](https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/post97/fluid_inference_install_dir.zip) |
-| CUDA10.0+MKL 版 | [fluid_inference_install_dir.zip](https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/post107/fluid_inference_install_dir.zip) |
-
-更多不同平台的可用预测库版本,请[点击查看](https://paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/deploy/inference/windows_cpp_inference.html) 选择适合你的版本。
-
-
-下载并解压, 解压后的 `fluid_inference`目录包含的内容:
-```
-fluid_inference_install_dir
-├── paddle # paddle核心库和头文件
-|
-├── third_party # 第三方依赖库和头文件
-|
-└── version.txt # 版本和编译信息
-```
-
-**注意:** 这里的`fluid_inference_install_dir` 目录所在路径,将用于后面的编译参数设置,请放置在合适的位置。
-
-## 2. Visual Studio 2019 编译
-
-- 2.1 打开Visual Studio 2019 Community,点击`继续但无需代码`, 如下图:
-
-
-- 2.2 点击 `文件`->`打开`->`CMake`, 如下图:
-
-
-- 2.3 选择本项目根目录`CMakeList.txt`文件打开, 如下图:
-
-
-- 2.4 点击:`项目`->`PaddleMaskDetector的CMake设置`
-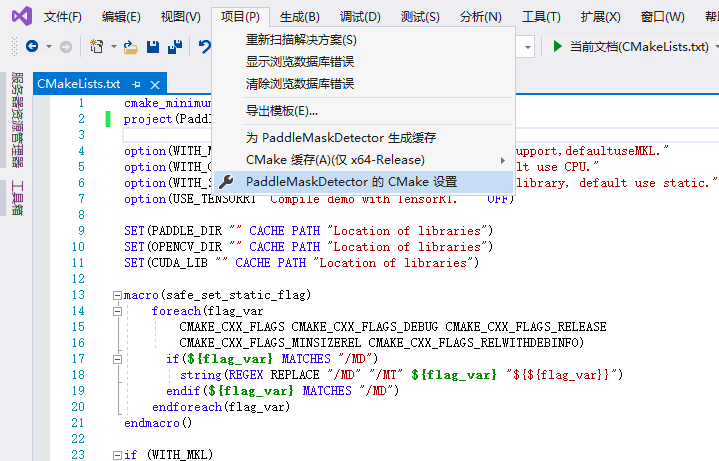
-
-- 2.5 点击浏览设置`OPENCV_DIR`, `CUDA_LIB` 和 `PADDLE_DIR` 3个编译依赖库的位置, 设置完成后点击`保存并生成CMake缓存并加载变量`
-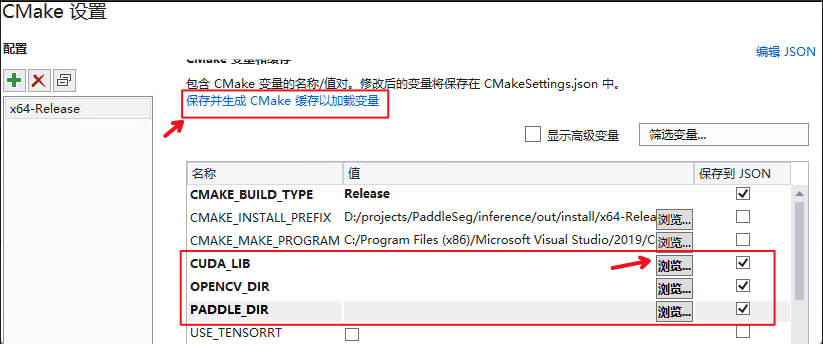
-
-- 2.6 点击`生成`->`全部生成` 编译项目
-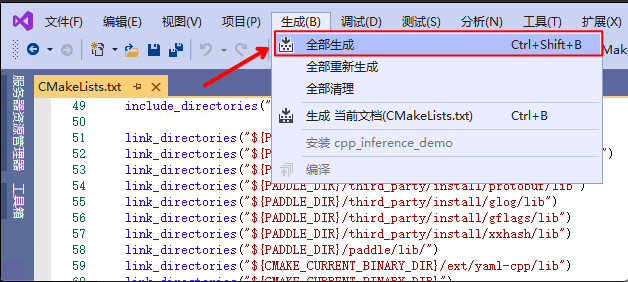
-
-## 3. 运行程序
-
-成功编译后, 产出的可执行文件在项目子目录`out\build\x64-Release`目录, 按以下步骤运行代码:
-
-- 打开`cmd`切换至该目录
-- 运行以下命令传入模型路径与测试视频
-
-```shell
-main.exe ./models/ ./data/test.avi
-```
-第一个参数即人像分割预测模型的路径,第二个参数即要预测的视频。
-
-点击下载[测试视频](https://paddleseg.bj.bcebos.com/deploy/data/test.avi)
-
-运行后,预测结果保存在文件`result.avi`中。
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg.cc b/contrib/RealTimeHumanSeg/cpp/humanseg.cc
deleted file mode 100644
index b81c81200064f6191e18cdb39fc8d6414aa5fe9d..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg.cc
+++ /dev/null
@@ -1,132 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-# include "humanseg.h"
-# include "humanseg_postprocess.h"
-
-// Normalize the image by (pix - mean) * scale
-void NormalizeImage(
- const std::vector &mean,
- const std::vector &scale,
- cv::Mat& im, // NOLINT
- float* input_buffer) {
- int height = im.rows;
- int width = im.cols;
- int stride = width * height;
- for (int h = 0; h < height; h++) {
- for (int w = 0; w < width; w++) {
- int base = h * width + w;
- input_buffer[base + 0 * stride] =
- (im.at(h, w)[0] - mean[0]) * scale[0];
- input_buffer[base + 1 * stride] =
- (im.at(h, w)[1] - mean[1]) * scale[1];
- input_buffer[base + 2 * stride] =
- (im.at(h, w)[2] - mean[2]) * scale[2];
- }
- }
-}
-
-// Load Model and return model predictor
-void LoadModel(
- const std::string& model_dir,
- bool use_gpu,
- std::unique_ptr* predictor) {
- // Config the model info
- paddle::AnalysisConfig config;
- auto prog_file = model_dir + "/__model__";
- auto params_file = model_dir + "/__params__";
- config.SetModel(prog_file, params_file);
- if (use_gpu) {
- config.EnableUseGpu(100, 0);
- } else {
- config.DisableGpu();
- }
- config.SwitchUseFeedFetchOps(false);
- config.SwitchSpecifyInputNames(true);
- // Memory optimization
- config.EnableMemoryOptim();
- *predictor = std::move(CreatePaddlePredictor(config));
-}
-
-void HumanSeg::Preprocess(const cv::Mat& image_mat) {
- // Clone the image : keep the original mat for postprocess
- cv::Mat im = image_mat.clone();
- auto eval_wh = cv::Size(eval_size_[0], eval_size_[1]);
- cv::resize(im, im, eval_wh, 0.f, 0.f, cv::INTER_LINEAR);
-
- im.convertTo(im, CV_32FC3, 1.0);
- int rc = im.channels();
- int rh = im.rows;
- int rw = im.cols;
- input_shape_ = {1, rc, rh, rw};
- input_data_.resize(1 * rc * rh * rw);
- float* buffer = input_data_.data();
- NormalizeImage(mean_, scale_, im, input_data_.data());
-}
-
-cv::Mat HumanSeg::Postprocess(const cv::Mat& im) {
- int h = input_shape_[2];
- int w = input_shape_[3];
- scoremap_data_.resize(3 * h * w * sizeof(float));
- float* base = output_data_.data() + h * w;
- for (int i = 0; i < h * w; ++i) {
- scoremap_data_[i] = uchar(base[i] * 255);
- }
-
- cv::Mat im_scoremap = cv::Mat(h, w, CV_8UC1);
- im_scoremap.data = scoremap_data_.data();
- cv::resize(im_scoremap, im_scoremap, cv::Size(im.cols, im.rows));
- im_scoremap.convertTo(im_scoremap, CV_32FC1, 1 / 255.0);
-
- float* pblob = reinterpret_cast(im_scoremap.data);
- int out_buff_capacity = 10 * im.cols * im.rows * sizeof(float);
- segout_data_.resize(out_buff_capacity);
- unsigned char* seg_result = segout_data_.data();
- MergeProcess(im.data, pblob, im.rows, im.cols, seg_result);
- cv::Mat seg_mat(im.rows, im.cols, CV_8UC1, seg_result);
- cv::resize(seg_mat, seg_mat, cv::Size(im.cols, im.rows));
- cv::GaussianBlur(seg_mat, seg_mat, cv::Size(5, 5), 0, 0);
- float fg_threshold = 0.8;
- float bg_threshold = 0.4;
- cv::Mat show_seg_mat;
- seg_mat.convertTo(seg_mat, CV_32FC1, 1 / 255.0);
- ThresholdMask(seg_mat, fg_threshold, bg_threshold, show_seg_mat);
- auto out_im = MergeSegMat(show_seg_mat, im);
- return out_im;
-}
-
-cv::Mat HumanSeg::Predict(const cv::Mat& im) {
- // Preprocess image
- Preprocess(im);
- // Prepare input tensor
- auto input_names = predictor_->GetInputNames();
- auto in_tensor = predictor_->GetInputTensor(input_names[0]);
- in_tensor->Reshape(input_shape_);
- in_tensor->copy_from_cpu(input_data_.data());
- // Run predictor
- predictor_->ZeroCopyRun();
- // Get output tensor
- auto output_names = predictor_->GetOutputNames();
- auto out_tensor = predictor_->GetOutputTensor(output_names[0]);
- auto output_shape = out_tensor->shape();
- // Calculate output length
- int output_size = 1;
- for (int j = 0; j < output_shape.size(); ++j) {
- output_size *= output_shape[j];
- }
- output_data_.resize(output_size);
- out_tensor->copy_to_cpu(output_data_.data());
- // Postprocessing result
- return Postprocess(im);
-}
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg.h b/contrib/RealTimeHumanSeg/cpp/humanseg.h
deleted file mode 100644
index edaf825f713847a3b2c8bf5bae3a36de6ec03395..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg.h
+++ /dev/null
@@ -1,66 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#pragma once
-
-#include
-#include
-#include
-#include
-
-#include
-#include
-#include
-#include
-
-#include "paddle_inference_api.h" // NOLINT
-
-// Load Paddle Inference Model
-void LoadModel(
- const std::string& model_dir,
- bool use_gpu,
- std::unique_ptr* predictor);
-
-class HumanSeg {
- public:
- explicit HumanSeg(const std::string& model_dir,
- const std::vector& mean,
- const std::vector& scale,
- const std::vector& eval_size,
- bool use_gpu = false) :
- mean_(mean),
- scale_(scale),
- eval_size_(eval_size) {
- LoadModel(model_dir, use_gpu, &predictor_);
- }
-
- // Run predictor
- cv::Mat Predict(const cv::Mat& im);
-
- private:
- // Preprocess image and copy data to input buffer
- void Preprocess(const cv::Mat& im);
- // Postprocess result
- cv::Mat Postprocess(const cv::Mat& im);
-
- std::unique_ptr predictor_;
- std::vector input_data_;
- std::vector input_shape_;
- std::vector output_data_;
- std::vector scoremap_data_;
- std::vector segout_data_;
- std::vector mean_;
- std::vector scale_;
- std::vector eval_size_;
-};
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc b/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc
deleted file mode 100644
index a373df3985b5bd72d05145d2c6d106043b5303ff..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc
+++ /dev/null
@@ -1,282 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-#include
-
-#include
-#include
-#include
-#include
-
-#include "humanseg_postprocess.h" // NOLINT
-
-int HumanSegTrackFuse(const cv::Mat &track_fg_cfd,
- const cv::Mat &dl_fg_cfd,
- const cv::Mat &dl_weights,
- const cv::Mat &is_track,
- const float cfd_diff_thres,
- const int patch_size,
- cv::Mat cur_fg_cfd) {
- float *cur_fg_cfd_ptr = reinterpret_cast(cur_fg_cfd.data);
- float *dl_fg_cfd_ptr = reinterpret_cast(dl_fg_cfd.data);
- float *track_fg_cfd_ptr = reinterpret_cast(track_fg_cfd.data);
- float *dl_weights_ptr = reinterpret_cast(dl_weights.data);
- uchar *is_track_ptr = reinterpret_cast(is_track.data);
- int y_offset = 0;
- int ptr_offset = 0;
- int h = track_fg_cfd.rows;
- int w = track_fg_cfd.cols;
- float dl_fg_score = 0.0;
- float track_fg_score = 0.0;
- for (int y = 0; y < h; ++y) {
- for (int x = 0; x < w; ++x) {
- dl_fg_score = dl_fg_cfd_ptr[ptr_offset];
- if (is_track_ptr[ptr_offset] > 0) {
- track_fg_score = track_fg_cfd_ptr[ptr_offset];
- if (dl_fg_score > 0.9 || dl_fg_score < 0.1) {
- if (dl_weights_ptr[ptr_offset] <= 0.10) {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score * 0.3
- + track_fg_score * 0.7;
- } else {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score * 0.4
- + track_fg_score * 0.6;
- }
- } else {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score * dl_weights_ptr[ptr_offset]
- + track_fg_score * (1 - dl_weights_ptr[ptr_offset]);
- }
- } else {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score;
- }
- ++ptr_offset;
- }
- y_offset += w;
- ptr_offset = y_offset;
- }
- return 0;
-}
-
-int HumanSegTracking(const cv::Mat &prev_gray,
- const cv::Mat &cur_gray,
- const cv::Mat &prev_fg_cfd,
- int patch_size,
- cv::Mat track_fg_cfd,
- cv::Mat is_track,
- cv::Mat dl_weights,
- cv::Ptr disflow) {
- cv::Mat flow_fw;
- disflow->calc(prev_gray, cur_gray, flow_fw);
-
- cv::Mat flow_bw;
- disflow->calc(cur_gray, prev_gray, flow_bw);
-
- float double_check_thres = 8;
-
- cv::Point2f fxy_fw;
- int dy_fw = 0;
- int dx_fw = 0;
- cv::Point2f fxy_bw;
- int dy_bw = 0;
- int dx_bw = 0;
-
- float *prev_fg_cfd_ptr = reinterpret_cast(prev_fg_cfd.data);
- float *track_fg_cfd_ptr = reinterpret_cast(track_fg_cfd.data);
- float *dl_weights_ptr = reinterpret_cast(dl_weights.data);
- uchar *is_track_ptr = reinterpret_cast(is_track.data);
-
- int prev_y_offset = 0;
- int prev_ptr_offset = 0;
- int cur_ptr_offset = 0;
- float *flow_fw_ptr = reinterpret_cast(flow_fw.data);
-
- float roundy_fw = 0.0;
- float roundx_fw = 0.0;
- float roundy_bw = 0.0;
- float roundx_bw = 0.0;
-
- int h = prev_fg_cfd.rows;
- int w = prev_fg_cfd.cols;
- for (int r = 0; r < h; ++r) {
- for (int c = 0; c < w; ++c) {
- ++prev_ptr_offset;
-
- fxy_fw = flow_fw.ptr(r)[c];
- roundy_fw = fxy_fw.y >= 0 ? 0.5 : -0.5;
- roundx_fw = fxy_fw.x >= 0 ? 0.5 : -0.5;
- dy_fw = static_cast(fxy_fw.y + roundy_fw);
- dx_fw = static_cast(fxy_fw.x + roundx_fw);
-
- int cur_x = c + dx_fw;
- int cur_y = r + dy_fw;
-
- if (cur_x < 0
- || cur_x >= h
- || cur_y < 0
- || cur_y >= w) {
- continue;
- }
- fxy_bw = flow_bw.ptr(cur_y)[cur_x];
- roundy_bw = fxy_bw.y >= 0 ? 0.5 : -0.5;
- roundx_bw = fxy_bw.x >= 0 ? 0.5 : -0.5;
- dy_bw = static_cast(fxy_bw.y + roundy_bw);
- dx_bw = static_cast(fxy_bw.x + roundx_bw);
-
- auto total = (dy_fw + dy_bw) * (dy_fw + dy_bw)
- + (dx_fw + dx_bw) * (dx_fw + dx_bw);
- if (total >= double_check_thres) {
- continue;
- }
-
- cur_ptr_offset = cur_y * w + cur_x;
- if (abs(dy_fw) <= 0
- && abs(dx_fw) <= 0
- && abs(dy_bw) <= 0
- && abs(dx_bw) <= 0) {
- dl_weights_ptr[cur_ptr_offset] = 0.05;
- }
- is_track_ptr[cur_ptr_offset] = 1;
- track_fg_cfd_ptr[cur_ptr_offset] = prev_fg_cfd_ptr[prev_ptr_offset];
- }
- prev_y_offset += w;
- prev_ptr_offset = prev_y_offset - 1;
- }
- return 0;
-}
-
-int MergeProcess(const uchar *im_buff,
- const float *scoremap_buff,
- const int height,
- const int width,
- uchar *result_buff) {
- cv::Mat prev_fg_cfd;
- cv::Mat cur_fg_cfd;
- cv::Mat cur_fg_mask;
- cv::Mat track_fg_cfd;
- cv::Mat prev_gray;
- cv::Mat cur_gray;
- cv::Mat bgr_temp;
- cv::Mat is_track;
- cv::Mat static_roi;
- cv::Mat weights;
- cv::Ptr disflow =
- cv::optflow::createOptFlow_DIS(
- cv::optflow::DISOpticalFlow::PRESET_ULTRAFAST);
-
- bool is_init = false;
- const float *cfd_ptr = scoremap_buff;
- if (!is_init) {
- is_init = true;
- cur_fg_cfd = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0));
- memcpy(cur_fg_cfd.data, cfd_ptr, height * width * sizeof(float));
- cur_fg_mask = cv::Mat(height, width, CV_8UC1, cv::Scalar::all(0));
-
- if (height <= 64 || width <= 64) {
- disflow->setFinestScale(1);
- } else if (height <= 160 || width <= 160) {
- disflow->setFinestScale(2);
- } else {
- disflow->setFinestScale(3);
- }
- is_track = cv::Mat(height, width, CV_8UC1, cv::Scalar::all(0));
- static_roi = cv::Mat(height, width, CV_8UC1, cv::Scalar::all(0));
- track_fg_cfd = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0));
-
- bgr_temp = cv::Mat(height, width, CV_8UC3);
- memcpy(bgr_temp.data, im_buff, height * width * 3 * sizeof(uchar));
- cv::cvtColor(bgr_temp, cur_gray, cv::COLOR_BGR2GRAY);
- weights = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0.30));
- } else {
- memcpy(cur_fg_cfd.data, cfd_ptr, height * width * sizeof(float));
- memcpy(bgr_temp.data, im_buff, height * width * 3 * sizeof(uchar));
- cv::cvtColor(bgr_temp, cur_gray, cv::COLOR_BGR2GRAY);
- memset(is_track.data, 0, height * width * sizeof(uchar));
- memset(static_roi.data, 0, height * width * sizeof(uchar));
- weights = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0.30));
- HumanSegTracking(prev_gray,
- cur_gray,
- prev_fg_cfd,
- 0,
- track_fg_cfd,
- is_track,
- weights,
- disflow);
- HumanSegTrackFuse(track_fg_cfd,
- cur_fg_cfd,
- weights,
- is_track,
- 1.1,
- 0,
- cur_fg_cfd);
- }
- int ksize = 3;
- cv::GaussianBlur(cur_fg_cfd, cur_fg_cfd, cv::Size(ksize, ksize), 0, 0);
- prev_fg_cfd = cur_fg_cfd.clone();
- prev_gray = cur_gray.clone();
- cur_fg_cfd.convertTo(cur_fg_mask, CV_8UC1, 255);
- memcpy(result_buff, cur_fg_mask.data, height * width);
- return 0;
-}
-
-cv::Mat MergeSegMat(const cv::Mat& seg_mat,
- const cv::Mat& ori_frame) {
- cv::Mat return_frame;
- cv::resize(ori_frame, return_frame, cv::Size(ori_frame.cols, ori_frame.rows));
- for (int i = 0; i < ori_frame.rows; i++) {
- for (int j = 0; j < ori_frame.cols; j++) {
- float score = seg_mat.at(i, j) / 255.0;
- if (score > 0.1) {
- return_frame.at(i, j)[2] = static_cast((1 - score) * 255
- + score*return_frame.at(i, j)[2]);
- return_frame.at(i, j)[1] = static_cast((1 - score) * 255
- + score*return_frame.at(i, j)[1]);
- return_frame.at(i, j)[0] = static_cast((1 - score) * 255
- + score*return_frame.at(i, j)[0]);
- } else {
- return_frame.at(i, j) = {255, 255, 255};
- }
- }
- }
- return return_frame;
-}
-
-int ThresholdMask(const cv::Mat &fg_cfd,
- const float fg_thres,
- const float bg_thres,
- cv::Mat& fg_mask) {
- if (fg_cfd.type() != CV_32FC1) {
- printf("ThresholdMask: type is not CV_32FC1.\n");
- return -1;
- }
- if (!(fg_mask.type() == CV_8UC1
- && fg_mask.rows == fg_cfd.rows
- && fg_mask.cols == fg_cfd.cols)) {
- fg_mask = cv::Mat(fg_cfd.rows, fg_cfd.cols, CV_8UC1, cv::Scalar::all(0));
- }
-
- for (int r = 0; r < fg_cfd.rows; ++r) {
- for (int c = 0; c < fg_cfd.cols; ++c) {
- float score = fg_cfd.at(r, c);
- if (score < bg_thres) {
- fg_mask.at(r, c) = 0;
- } else if (score > fg_thres) {
- fg_mask.at(r, c) = 255;
- } else {
- fg_mask.at(r, c) = static_cast(
- (score-bg_thres) / (fg_thres - bg_thres) * 255);
- }
- }
- }
- return 0;
-}
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h b/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h
deleted file mode 100644
index f5059857c0108c600a6bd98bcaa355647fdc21e2..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h
+++ /dev/null
@@ -1,34 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#pragma once
-
-#include
-#include
-#include
-#include
-
-int ThresholdMask(const cv::Mat &fg_cfd,
- const float fg_thres,
- const float bg_thres,
- cv::Mat& fg_mask);
-
-cv::Mat MergeSegMat(const cv::Mat& seg_mat,
- const cv::Mat& ori_frame);
-
-int MergeProcess(const uchar *im_buff,
- const float *im_scoremap_buff,
- const int height,
- const int width,
- uchar *result_buff);
diff --git a/contrib/RealTimeHumanSeg/cpp/linux_build.sh b/contrib/RealTimeHumanSeg/cpp/linux_build.sh
deleted file mode 100644
index ff0b11bcf60f1b4ec4d7a9f63f7490ffb70ad6e0..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/linux_build.sh
+++ /dev/null
@@ -1,30 +0,0 @@
-OPENCV_URL=https://paddleseg.bj.bcebos.com/deploy/deps/opencv346.tar.bz2
-if [ ! -d "./deps/opencv346" ]; then
- mkdir -p deps
- cd deps
- wget -c ${OPENCV_URL}
- tar xvfj opencv346.tar.bz2
- rm -rf opencv346.tar.bz2
- cd ..
-fi
-
-WITH_GPU=OFF
-PADDLE_DIR=/root/projects/deps/fluid_inference/
-CUDA_LIB=/usr/local/cuda-10.0/lib64/
-CUDNN_LIB=/usr/local/cuda-10.0/lib64/
-OPENCV_DIR=$(pwd)/deps/opencv346/
-echo ${OPENCV_DIR}
-
-rm -rf build
-mkdir -p build
-cd build
-
-cmake .. \
- -DWITH_GPU=${WITH_GPU} \
- -DPADDLE_DIR=${PADDLE_DIR} \
- -DCUDA_LIB=${CUDA_LIB} \
- -DCUDNN_LIB=${CUDNN_LIB} \
- -DOPENCV_DIR=${OPENCV_DIR} \
- -DWITH_STATIC_LIB=OFF
-make clean
-make -j12
diff --git a/contrib/RealTimeHumanSeg/cpp/main.cc b/contrib/RealTimeHumanSeg/cpp/main.cc
deleted file mode 100644
index 303051f051b885a83b0ef608fe2ab1319f97294e..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/main.cc
+++ /dev/null
@@ -1,92 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-#include
-
-#include "humanseg.h" // NOLINT
-#include "humanseg_postprocess.h" // NOLINT
-
-// Do predicting on a video file
-int VideoPredict(const std::string& video_path, HumanSeg& seg)
-{
- cv::VideoCapture capture;
- capture.open(video_path.c_str());
- if (!capture.isOpened()) {
- printf("can not open video : %s\n", video_path.c_str());
- return -1;
- }
-
- int video_width = static_cast(capture.get(CV_CAP_PROP_FRAME_WIDTH));
- int video_height = static_cast(capture.get(CV_CAP_PROP_FRAME_HEIGHT));
- cv::VideoWriter video_out;
- std::string video_out_path = "result.avi";
- video_out.open(video_out_path.c_str(),
- CV_FOURCC('M', 'J', 'P', 'G'),
- 30.0,
- cv::Size(video_width, video_height),
- true);
- if (!video_out.isOpened()) {
- printf("create video writer failed!\n");
- return -1;
- }
- cv::Mat frame;
- while (capture.read(frame)) {
- if (frame.empty()) {
- break;
- }
- cv::Mat out_im = seg.Predict(frame);
- video_out.write(out_im);
- }
- capture.release();
- video_out.release();
- return 0;
-}
-
-// Do predicting on a image file
-int ImagePredict(const std::string& image_path, HumanSeg& seg)
-{
- cv::Mat img = imread(image_path, cv::IMREAD_COLOR);
- cv::Mat out_im = seg.Predict(img);
- imwrite("result.jpeg", out_im);
- return 0;
-}
-
-int main(int argc, char* argv[]) {
- if (argc < 3 || argc > 4) {
- std::cout << "Usage:"
- << "./humanseg ./models/ ./data/test.avi"
- << std::endl;
- return -1;
- }
-
- bool use_gpu = (argc == 4 ? std::stoi(argv[3]) : false);
- auto model_dir = std::string(argv[1]);
- auto input_path = std::string(argv[2]);
-
- // Init Model
- std::vector means = {104.008, 116.669, 122.675};
- std::vector scale = {1.000, 1.000, 1.000};
- std::vector eval_sz = {192, 192};
- HumanSeg seg(model_dir, means, scale, eval_sz, use_gpu);
-
- // Call ImagePredict while input_path is a image file path
- // The output will be saved as result.jpeg
- // ImagePredict(input_path, seg);
-
- // Call VideoPredict while input_path is a video file path
- // The output will be saved as result.avi
- VideoPredict(input_path, seg);
- return 0;
-}
diff --git a/contrib/RealTimeHumanSeg/python/README.md b/contrib/RealTimeHumanSeg/python/README.md
deleted file mode 100644
index 1e089c9f5226e2482cd6e8957406c00095706b1b..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/python/README.md
+++ /dev/null
@@ -1,61 +0,0 @@
-# 实时人像分割Python预测部署方案
-
-本方案基于Python实现,最小化依赖并把所有模型加载、数据预处理、预测、光流处理等后处理都封装在文件`infer.py`中,用户可以直接使用或集成到自己项目中。
-
-
-## 前置依赖
-- Windows(7,8,10) / Linux (Ubuntu 16.04) or MacOS 10.1+
-- Paddle 1.6.1+
-- Python 3.0+
-
-注意:
-1. 仅测试过Paddle1.6 和 1.7, 其它版本不支持
-2. MacOS上不支持GPU预测
-3. Python2上未测试
-
-其它未涉及情形,能正常安装`Paddle` 和`OpenCV`通常都能正常使用。
-
-
-## 安装依赖
-### 1. 安装paddle
-
-PaddlePaddle的安装, 请按照[官网指引](https://paddlepaddle.org.cn/install/quick)安装合适自己的版本。
-
-### 2. 安装其它依赖
-
-执行如下命令
-
-```shell
-pip install -r requirements.txt
-```
-
-## 运行
-
-
-1. 输入图片进行分割
-```
-python infer.py --model_dir /PATH/TO/INFERENCE/MODEL --img_path /PATH/TO/INPUT/IMAGE
-```
-
-预测结果会保存为`result.jpeg`。
-2. 输入视频进行分割
-```shell
-python infer.py --model_dir /PATH/TO/INFERENCE/MODEL --video_path /PATH/TO/INPUT/VIDEO
-```
-
-预测结果会保存在`result.avi`。
-
-3. 使用摄像头视频流
-```shell
-python infer.py --model_dir /PATH/TO/INFERENCE/MODEL --use_camera 1
-```
-预测结果会通过可视化窗口实时显示。
-
-**注意:**
-
-
-`GPU`默认关闭, 如果要使用`GPU`进行加速,则先运行
-```
-export CUDA_VISIBLE_DEVICES=0
-```
-然后在前面的预测命令中增加参数`--use_gpu 1`即可。
diff --git a/contrib/RealTimeHumanSeg/python/infer.py b/contrib/RealTimeHumanSeg/python/infer.py
deleted file mode 100644
index 73df081e4cbda06e20b471b2eae60a2ba037e49a..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/python/infer.py
+++ /dev/null
@@ -1,345 +0,0 @@
-# coding: utf8
-# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""实时人像分割Python预测部署"""
-
-import os
-import argparse
-import numpy as np
-import cv2
-
-import paddle.fluid as fluid
-
-
-def human_seg_tracking(pre_gray, cur_gray, prev_cfd, dl_weights, disflow):
- """计算光流跟踪匹配点和光流图
- 输入参数:
- pre_gray: 上一帧灰度图
- cur_gray: 当前帧灰度图
- prev_cfd: 上一帧光流图
- dl_weights: 融合权重图
- disflow: 光流数据结构
- 返回值:
- is_track: 光流点跟踪二值图,即是否具有光流点匹配
- track_cfd: 光流跟踪图
- """
- check_thres = 8
- hgt, wdh = pre_gray.shape[:2]
- track_cfd = np.zeros_like(prev_cfd)
- is_track = np.zeros_like(pre_gray)
- # 计算前向光流
- flow_fw = disflow.calc(pre_gray, cur_gray, None)
- # 计算后向光流
- flow_bw = disflow.calc(cur_gray, pre_gray, None)
- get_round = lambda data: (int)(data + 0.5) if data >= 0 else (int)(data -0.5)
- for row in range(hgt):
- for col in range(wdh):
- # 计算光流处理后对应点坐标
- # (row, col) -> (cur_x, cur_y)
- fxy_fw = flow_fw[row, col]
- dx_fw = get_round(fxy_fw[0])
- cur_x = dx_fw + col
- dy_fw = get_round(fxy_fw[1])
- cur_y = dy_fw + row
- if cur_x < 0 or cur_x >= wdh or cur_y < 0 or cur_y >= hgt:
- continue
- fxy_bw = flow_bw[cur_y, cur_x]
- dx_bw = get_round(fxy_bw[0])
- dy_bw = get_round(fxy_bw[1])
- # 光流移动小于阈值
- lmt = ((dy_fw + dy_bw) * (dy_fw + dy_bw) + (dx_fw + dx_bw) * (dx_fw + dx_bw))
- if lmt >= check_thres:
- continue
- # 静止点降权
- if abs(dy_fw) <= 0 and abs(dx_fw) <= 0 and abs(dy_bw) <= 0 and abs(dx_bw) <= 0:
- dl_weights[cur_y, cur_x] = 0.05
- is_track[cur_y, cur_x] = 1
- track_cfd[cur_y, cur_x] = prev_cfd[row, col]
- return track_cfd, is_track, dl_weights
-
-
-def human_seg_track_fuse(track_cfd, dl_cfd, dl_weights, is_track):
- """光流追踪图和人像分割结构融合
- 输入参数:
- track_cfd: 光流追踪图
- dl_cfd: 当前帧分割结果
- dl_weights: 融合权重图
- is_track: 光流点匹配二值图
- 返回值:
- cur_cfd: 光流跟踪图和人像分割结果融合图
- """
- cur_cfd = dl_cfd.copy()
- idxs = np.where(is_track > 0)
- for i in range(len(idxs)):
- x, y = idxs[0][i], idxs[1][i]
- dl_score = dl_cfd[y, x]
- track_score = track_cfd[y, x]
- if dl_score > 0.9 or dl_score < 0.1:
- if dl_weights[x, y] < 0.1:
- cur_cfd[x, y] = 0.3 * dl_score + 0.7 * track_score
- else:
- cur_cfd[x, y] = 0.4 * dl_score + 0.6 * track_score
- else:
- cur_cfd[x, y] = dl_weights[x, y] * dl_score + (1 - dl_weights[x, y]) * track_score
- return cur_cfd
-
-
-def threshold_mask(img, thresh_bg, thresh_fg):
- """设置背景和前景阈值mask
- 输入参数:
- img : 原始图像, np.uint8 类型.
- thresh_bg : 背景阈值百分比,低于该值置为0.
- thresh_fg : 前景阈值百分比,超过该值置为1.
- 返回值:
- dst : 原始图像设置完前景背景阈值mask结果, np.float32 类型.
- """
- dst = (img / 255.0 - thresh_bg) / (thresh_fg - thresh_bg)
- dst[np.where(dst > 1)] = 1
- dst[np.where(dst < 0)] = 0
- return dst.astype(np.float32)
-
-
-def optflow_handle(cur_gray, scoremap, is_init):
- """光流优化
- Args:
- cur_gray : 当前帧灰度图
- scoremap : 当前帧分割结果
- is_init : 是否第一帧
- Returns:
- dst : 光流追踪图和预测结果融合图, 类型为 np.float32
- """
- width, height = scoremap.shape[0], scoremap.shape[1]
- disflow = cv2.DISOpticalFlow_create(
- cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
- prev_gray = np.zeros((height, width), np.uint8)
- prev_cfd = np.zeros((height, width), np.float32)
- cur_cfd = scoremap.copy()
- if is_init:
- is_init = False
- if height <= 64 or width <= 64:
- disflow.setFinestScale(1)
- elif height <= 160 or width <= 160:
- disflow.setFinestScale(2)
- else:
- disflow.setFinestScale(3)
- fusion_cfd = cur_cfd
- else:
- weights = np.ones((width, height), np.float32) * 0.3
- track_cfd, is_track, weights = human_seg_tracking(
- prev_gray, cur_gray, prev_cfd, weights, disflow)
- fusion_cfd = human_seg_track_fuse(track_cfd, cur_cfd, weights, is_track)
- fusion_cfd = cv2.GaussianBlur(fusion_cfd, (3, 3), 0)
- return fusion_cfd
-
-
-class HumanSeg:
- """人像分割类
- 封装了人像分割模型的加载,数据预处理,预测,后处理等
- """
- def __init__(self, model_dir, mean, scale, eval_size, use_gpu=False):
-
- self.mean = np.array(mean).reshape((3, 1, 1))
- self.scale = np.array(scale).reshape((3, 1, 1))
- self.eval_size = eval_size
- self.load_model(model_dir, use_gpu)
-
- def load_model(self, model_dir, use_gpu):
- """加载模型并创建predictor
- Args:
- model_dir: 预测模型路径, 包含 `__model__` 和 `__params__`
- use_gpu: 是否使用GPU加速
- """
- prog_file = os.path.join(model_dir, '__model__')
- params_file = os.path.join(model_dir, '__params__')
- config = fluid.core.AnalysisConfig(prog_file, params_file)
- if use_gpu:
- config.enable_use_gpu(100, 0)
- config.switch_ir_optim(True)
- else:
- config.disable_gpu()
- config.disable_glog_info()
- config.switch_specify_input_names(True)
- config.enable_memory_optim()
- self.predictor = fluid.core.create_paddle_predictor(config)
-
- def preprocess(self, image):
- """图像预处理
- hwc_rgb 转换为 chw_bgr,并进行归一化
- 输入参数:
- image: 原始图像
- 返回值:
- 经过预处理后的图片结果
- """
- img_mat = cv2.resize(
- image, self.eval_size, interpolation=cv2.INTER_LINEAR)
- # HWC -> CHW
- img_mat = img_mat.swapaxes(1, 2)
- img_mat = img_mat.swapaxes(0, 1)
- # Convert to float
- img_mat = img_mat[:, :, :].astype('float32')
- # img_mat = (img_mat - mean) * scale
- img_mat = img_mat - self.mean
- img_mat = img_mat * self.scale
- img_mat = img_mat[np.newaxis, :, :, :]
- return img_mat
-
- def postprocess(self, image, output_data):
- """对预测结果进行后处理
- Args:
- image: 原始图,opencv 图片对象
- output_data: Paddle预测结果原始数据
- Returns:
- 原图和预测结果融合并做了光流优化的结果图
- """
- scoremap = output_data[0, 1, :, :]
- scoremap = (scoremap * 255).astype(np.uint8)
- ori_h, ori_w = image.shape[0], image.shape[1]
- evl_h, evl_w = self.eval_size[0], self.eval_size[1]
- # 光流处理
- cur_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
- cur_gray = cv2.resize(cur_gray, (evl_w, evl_h))
- optflow_map = optflow_handle(cur_gray, scoremap, False)
- optflow_map = cv2.GaussianBlur(optflow_map, (3, 3), 0)
- optflow_map = threshold_mask(optflow_map, thresh_bg=0.2, thresh_fg=0.8)
- optflow_map = cv2.resize(optflow_map, (ori_w, ori_h))
- optflow_map = np.repeat(optflow_map[:, :, np.newaxis], 3, axis=2)
- bg_im = np.ones_like(optflow_map) * 255
- comb = (optflow_map * image + (1 - optflow_map) * bg_im).astype(np.uint8)
- return comb
-
- def run_predict(self, image):
- """运行预测并返回可视化结果图
- 输入参数:
- image: 需要预测的原始图, opencv图片对象
- 返回值:
- 可视化的预测结果图
- """
- im_mat = self.preprocess(image)
- im_tensor = fluid.core.PaddleTensor(im_mat.copy().astype('float32'))
- output_data = self.predictor.run([im_tensor])[0]
- output_data = output_data.as_ndarray()
- return self.postprocess(image, output_data)
-
-
-def predict_image(seg, image_path):
- """对图片文件进行分割
- 结果保存到`result.jpeg`文件中
- """
- img_mat = cv2.imread(image_path)
- img_mat = seg.run_predict(img_mat)
- cv2.imwrite('result.jpeg', img_mat)
-
-
-def predict_video(seg, video_path):
- """对视频文件进行分割
- 结果保存到`result.avi`文件中
- """
- cap = cv2.VideoCapture(video_path)
- if not cap.isOpened():
- print("Error opening video stream or file")
- return
- width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
- height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
- fps = cap.get(cv2.CAP_PROP_FPS)
- # 用于保存预测结果视频
- out = cv2.VideoWriter('result.avi',
- cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps,
- (width, height))
- # 开始获取视频帧
- while cap.isOpened():
- ret, frame = cap.read()
- if ret:
- img_mat = seg.run_predict(frame)
- out.write(img_mat)
- else:
- break
- cap.release()
- out.release()
-
-
-def predict_camera(seg):
- """从摄像头获取视频流进行预测
- 视频分割结果实时显示到可视化窗口中
- """
- cap = cv2.VideoCapture(0)
- if not cap.isOpened():
- print("Error opening video stream or file")
- return
- # Start capturing from video
- while cap.isOpened():
- ret, frame = cap.read()
- if ret:
- img_mat = seg.run_predict(frame)
- cv2.imshow('HumanSegmentation', img_mat)
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
- else:
- break
- cap.release()
-
-
-def main(args):
- """预测程序入口
- 完成模型加载, 对视频、摄像头、图片文件等预测过程
- """
- model_dir = args.model_dir
- use_gpu = args.use_gpu
-
- # 加载模型
- mean = [104.008, 116.669, 122.675]
- scale = [1.0, 1.0, 1.0]
- eval_size = (192, 192)
- seg = HumanSeg(model_dir, mean, scale, eval_size, use_gpu)
- if args.use_camera:
- # 开启摄像头
- predict_camera(seg)
- elif args.video_path:
- # 使用视频文件作为输入
- predict_video(seg, args.video_path)
- elif args.img_path:
- # 使用图片文件作为输入
- predict_image(seg, args.img_path)
-
-
-def parse_args():
- """解析命令行参数
- """
- parser = argparse.ArgumentParser('Realtime Human Segmentation')
- parser.add_argument('--model_dir',
- type=str,
- default='',
- help='path of human segmentation model')
- parser.add_argument('--img_path',
- type=str,
- default='',
- help='path of input image')
- parser.add_argument('--video_path',
- type=str,
- default='',
- help='path of input video')
- parser.add_argument('--use_camera',
- type=bool,
- default=False,
- help='input video stream from camera')
- parser.add_argument('--use_gpu',
- type=bool,
- default=False,
- help='enable gpu')
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- main(args)
diff --git a/contrib/RealTimeHumanSeg/python/requirements.txt b/contrib/RealTimeHumanSeg/python/requirements.txt
deleted file mode 100644
index 953dae0cf5e2036ad093907b30ac9a3a10858d27..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/python/requirements.txt
+++ /dev/null
@@ -1,2 +0,0 @@
-opencv-python==4.1.2.30
-opencv-contrib-python==4.2.0.32
diff --git a/contrib/RemoteSensing/README.md b/contrib/RemoteSensing/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4f96cccf8e542e7185f9cd66d29e4f2899fbcb94
--- /dev/null
+++ b/contrib/RemoteSensing/README.md
@@ -0,0 +1,246 @@
+# 遥感分割(RemoteSensing)
+遥感影像分割是图像分割领域中的重要应用场景,广泛应用于土地测绘、环境监测、城市建设等领域。遥感影像分割的目标多种多样,有诸如积雪、农作物、道路、建筑、水源等地物目标,也有例如云层的空中目标。
+
+PaddleSeg提供了针对遥感专题的语义分割库RemoteSensing,涵盖图像预处理、数据增强、模型训练、预测流程,帮助用户利用深度学习技术解决遥感影像分割问题。
+
+## 特点
+针对遥感数据多通道、分布范围大、分布不均的特点,我们支持多通道训练预测,内置一系列多通道预处理和数据增强的策略,可结合实际业务场景进行定制组合,提升模型泛化能力和鲁棒性。
+
+**Note:** 所有命令需要在`PaddleSeg/contrib/RemoteSensing/`目录下执行。
+
+## 前置依赖
+- Paddle 1.7.1+
+由于图像分割模型计算开销大,推荐在GPU版本的PaddlePaddle下使用。
+PaddlePaddle的安装, 请按照[官网指引](https://paddlepaddle.org.cn/install/quick)安装合适自己的版本。
+
+- Python 3.5+
+
+- 其他依赖安装
+通过以下命令安装python包依赖,请确保至少执行过一次以下命令:
+```
+cd RemoteSensing
+pip install -r requirements.txt
+```
+
+## 目录结构说明
+ ```
+RemoteSensing # 根目录
+ |-- dataset # 数据集
+ |-- docs # 文档
+ |-- models # 模型类定义模块
+ |-- nets # 组网模块
+ |-- readers # 数据读取模块
+ |-- tools # 工具集
+ |-- transforms # 数据增强模块
+ |-- utils # 公用模块
+ |-- train_demo.py # 训练demo脚本
+ |-- predict_demo.py # 预测demo脚本
+ |-- README.md # 使用手册
+
+ ```
+## 数据协议
+数据集包含原图、标注图及相应的文件列表文件。
+
+参考数据文件结构如下:
+```
+./dataset/ # 数据集根目录
+|--images # 原图目录
+| |--xxx1.npy
+| |--...
+| └--...
+|
+|--annotations # 标注图目录
+| |--xxx1.png
+| |--...
+| └--...
+|
+|--train_list.txt # 训练文件列表文件
+|
+|--val_list.txt # 验证文件列表文件
+|
+└--labels.txt # 标签列表
+
+```
+其中,相应的文件名可根据需要自行定义。
+
+遥感领域图像格式多种多样,不同传感器产生的数据格式可能不同。为方便数据加载,本分割库统一采用numpy存储格式`npy`作为原图格式,采用`png`无损压缩格式作为标注图片格式。
+原图的前两维是图像的尺寸,第3维是图像的通道数。
+标注图像为单通道图像,像素值即为对应的类别,像素标注类别需要从0开始递增,
+例如0,1,2,3表示有4种类别,标注类别最多为256类。其中可以指定特定的像素值用于表示该值的像素不参与训练和评估(默认为255)。
+
+`train_list.txt`和`val_list.txt`文本以空格为分割符分为两列,第一列为图像文件相对于dataset的相对路径,第二列为标注图像文件相对于dataset的相对路径。如下所示:
+```
+images/xxx1.npy annotations/xxx1.png
+images/xxx2.npy annotations/xxx2.png
+...
+```
+
+具体要求和如何生成文件列表可参考[文件列表规范](../../docs/data_prepare.md#文件列表)。
+
+`labels.txt`: 每一行为一个单独的类别,相应的行号即为类别对应的id(行号从0开始),如下所示:
+```
+labelA
+labelB
+...
+```
+
+
+
+## 快速上手
+
+本章节在一个小数据集上展示了如何通过RemoteSensing进行训练预测。
+
+### 1. 准备数据集
+为了快速体验,我们准备了一个小型demo数据集,已位于`RemoteSensing/dataset/demo/`目录下.
+
+对于您自己的数据集,您需要按照上述的数据协议进行格式转换,可分别使用numpy和pil库保存遥感数据和标注图片。其中numpy api示例如下:
+```python
+import numpy as np
+
+# 保存遥感数据
+# img类型:numpy.ndarray
+np.save(save_path, img)
+```
+
+### 2. 训练代码开发
+通过如下`train_demo.py`代码进行训练。
+
+> 导入RemoteSensing api
+```python
+import transforms.transforms as T
+from readers.reader import Reader
+from models import UNet
+```
+
+> 定义训练和验证时的数据处理和增强流程, 在`train_transforms`中加入了`RandomVerticalFlip`,`RandomHorizontalFlip`等数据增强方式。
+```python
+train_transforms = T.Compose([
+ T.RandomVerticalFlip(0.5),
+ T.RandomHorizontalFlip(0.5),
+ T.ResizeStepScaling(0.5, 2.0, 0.25),
+ T.RandomPaddingCrop(256),
+ T.Normalize(mean=[0.5] * channel, std=[0.5] * channel),
+])
+
+eval_transforms = T.Compose([
+ T.Normalize(mean=[0.5] * channel, std=[0.5] * channel),
+])
+```
+
+> 定义数据读取器
+```python
+import os
+import os.path as osp
+
+train_list = osp.join(data_dir, 'train.txt')
+val_list = osp.join(data_dir, 'val.txt')
+label_list = osp.join(data_dir, 'labels.txt')
+
+train_reader = Reader(
+ data_dir=data_dir,
+ file_list=train_list,
+ label_list=label_list,
+ transforms=train_transforms,
+ num_workers=8,
+ buffer_size=16,
+ shuffle=True,
+ parallel_method='thread')
+
+eval_reader = Reader(
+ data_dir=data_dir,
+ file_list=val_list,
+ label_list=label_list,
+ transforms=eval_transforms,
+ num_workers=8,
+ buffer_size=16,
+ shuffle=False,
+ parallel_method='thread')
+```
+> 模型构建
+```python
+model = UNet(
+ num_classes=2, input_channel=channel, use_bce_loss=True, use_dice_loss=True)
+```
+> 模型训练,并开启边训边评估
+```python
+model.train(
+ num_epochs=num_epochs,
+ train_reader=train_reader,
+ train_batch_size=train_batch_size,
+ eval_reader=eval_reader,
+ save_interval_epochs=5,
+ log_interval_steps=10,
+ save_dir=save_dir,
+ pretrain_weights=None,
+ optimizer=None,
+ learning_rate=lr,
+ use_vdl=True
+)
+```
+
+
+### 3. 模型训练
+> 设置GPU卡号
+```shell script
+export CUDA_VISIBLE_DEVICES=0
+```
+> 在RemoteSensing目录下运行`train_demo.py`即可开始训练。
+```shell script
+python train_demo.py --data_dir dataset/demo/ --save_dir saved_model/unet/ --channel 3 --num_epochs 20
+```
+### 4. 模型预测代码开发
+通过如下`predict_demo.py`代码进行预测。
+
+> 导入RemoteSensing api
+```python
+from models import load_model
+```
+> 加载训练过程中最好的模型,设置预测结果保存路径。
+```python
+import os
+import os.path as osp
+model = load_model(osp.join(save_dir, 'best_model'))
+pred_dir = osp.join(save_dir, 'pred')
+if not osp.exists(pred_dir):
+ os.mkdir(pred_dir)
+```
+
+> 使用模型对验证集进行测试,并保存预测结果。
+```python
+import numpy as np
+from PIL import Image as Image
+val_list = osp.join(data_dir, 'val.txt')
+color_map = [0, 0, 0, 255, 255, 255]
+with open(val_list) as f:
+ lines = f.readlines()
+ for line in lines:
+ img_path = line.split(' ')[0]
+ print('Predicting {}'.format(img_path))
+ img_path_ = osp.join(data_dir, img_path)
+
+ pred = model.predict(img_path_)
+
+ # 以伪彩色png图片保存预测结果
+ pred_name = osp.basename(img_path).rstrip('npy') + 'png'
+ pred_path = osp.join(pred_dir, pred_name)
+ pred_mask = Image.fromarray(pred.astype(np.uint8), mode='P')
+ pred_mask.putpalette(color_map)
+ pred_mask.save(pred_path)
+```
+
+### 5. 模型预测
+> 设置GPU卡号
+```shell script
+export CUDA_VISIBLE_DEVICES=0
+```
+> 在RemoteSensing目录下运行`predict_demo.py`即可开始训练。
+```shell script
+python predict_demo.py --data_dir dataset/demo/ --load_model_dir saved_model/unet/best_model/
+```
+
+
+## Api说明
+
+您可以使用`RemoteSensing`目录下提供的api构建自己的分割代码。
+
+- [数据处理-transforms](docs/transforms.md)
diff --git a/contrib/RemoteSensing/__init__.py b/contrib/RemoteSensing/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea9751219a9eda9e50a80e9dff2a8b3d7cba0066
--- /dev/null
+++ b/contrib/RemoteSensing/__init__.py
@@ -0,0 +1,24 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import utils
+import nets
+import models
+import transforms
+import readers
+from utils.utils import get_environ_info
+
+env_info = get_environ_info()
+
+log_level = 2
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/0.png b/contrib/RemoteSensing/dataset/demo/annotations/0.png
new file mode 100644
index 0000000000000000000000000000000000000000..cf1b91544aac136d78f25c6818ae3aaf8aca23bb
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/0.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1.png b/contrib/RemoteSensing/dataset/demo/annotations/1.png
new file mode 100644
index 0000000000000000000000000000000000000000..b9f0d5df904ff9cd9df1bffdf456d48e3fae38f9
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/10.png b/contrib/RemoteSensing/dataset/demo/annotations/10.png
new file mode 100644
index 0000000000000000000000000000000000000000..59950c118bd981bcfaa805e27a3d4929daa7b213
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/10.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/100.png b/contrib/RemoteSensing/dataset/demo/annotations/100.png
new file mode 100644
index 0000000000000000000000000000000000000000..6fef4400ce8e4e0f13937bca398ba50a4aab729a
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/100.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1000.png b/contrib/RemoteSensing/dataset/demo/annotations/1000.png
new file mode 100644
index 0000000000000000000000000000000000000000..891dfdcaa591640a9dab4b046bdf34f8606d282b
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1000.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1001.png b/contrib/RemoteSensing/dataset/demo/annotations/1001.png
new file mode 100644
index 0000000000000000000000000000000000000000..891dfdcaa591640a9dab4b046bdf34f8606d282b
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1001.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1002.png b/contrib/RemoteSensing/dataset/demo/annotations/1002.png
new file mode 100644
index 0000000000000000000000000000000000000000..e247cb90c9044a8044e0e595a9917e14d69d42de
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1002.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1003.png b/contrib/RemoteSensing/dataset/demo/annotations/1003.png
new file mode 100644
index 0000000000000000000000000000000000000000..f98df538a2c1c027deeb3e6530d04e8900ef6e07
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1003.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1004.png b/contrib/RemoteSensing/dataset/demo/annotations/1004.png
new file mode 100644
index 0000000000000000000000000000000000000000..1da4b7b5bcdb9ff3f3b70438409753e0e4e28fe4
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1004.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1005.png b/contrib/RemoteSensing/dataset/demo/annotations/1005.png
new file mode 100644
index 0000000000000000000000000000000000000000..09173b87cbc02dbe92fcfd92b0ea376fb8d8a91d
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1005.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/0.npy b/contrib/RemoteSensing/dataset/demo/images/0.npy
new file mode 100644
index 0000000000000000000000000000000000000000..4cbb1c56d8d902629585fb20e026f35773a5f7a4
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/0.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1.npy b/contrib/RemoteSensing/dataset/demo/images/1.npy
new file mode 100644
index 0000000000000000000000000000000000000000..11b6433300481381a2877da6453e04a7f116c4aa
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/10.npy b/contrib/RemoteSensing/dataset/demo/images/10.npy
new file mode 100644
index 0000000000000000000000000000000000000000..cfbf1ab896203d4962ccb254ad046487648af8ce
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/10.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/100.npy b/contrib/RemoteSensing/dataset/demo/images/100.npy
new file mode 100644
index 0000000000000000000000000000000000000000..7162a79fc2ce958e86b1f728f97a4266b5b4f6cd
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/100.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1000.npy b/contrib/RemoteSensing/dataset/demo/images/1000.npy
new file mode 100644
index 0000000000000000000000000000000000000000..7ddf3cb11b906a0776a0e407090a0ddefe5980f9
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1000.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1001.npy b/contrib/RemoteSensing/dataset/demo/images/1001.npy
new file mode 100644
index 0000000000000000000000000000000000000000..cbf6b692692cb57f0d66f6f6908361e1315e0b89
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1001.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1002.npy b/contrib/RemoteSensing/dataset/demo/images/1002.npy
new file mode 100644
index 0000000000000000000000000000000000000000..d5d4a4775248299347f430575c4716511f24a808
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1002.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1003.npy b/contrib/RemoteSensing/dataset/demo/images/1003.npy
new file mode 100644
index 0000000000000000000000000000000000000000..9b4c94db3368ded7f615f20e2943dbd8b9a75372
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1003.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1004.npy b/contrib/RemoteSensing/dataset/demo/images/1004.npy
new file mode 100644
index 0000000000000000000000000000000000000000..6b2f51dfc0893da79208cb6602baa403bd1a35ea
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1004.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1005.npy b/contrib/RemoteSensing/dataset/demo/images/1005.npy
new file mode 100644
index 0000000000000000000000000000000000000000..21198e2cbe958e96d4fbeab81f1c88026b9d2fab
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1005.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/labels.txt b/contrib/RemoteSensing/dataset/demo/labels.txt
new file mode 100644
index 0000000000000000000000000000000000000000..69548aabb6c89d4535c6567b7e1160c3ba2874ca
--- /dev/null
+++ b/contrib/RemoteSensing/dataset/demo/labels.txt
@@ -0,0 +1,2 @@
+__background__
+cloud
\ No newline at end of file
diff --git a/contrib/RemoteSensing/dataset/demo/train.txt b/contrib/RemoteSensing/dataset/demo/train.txt
new file mode 100644
index 0000000000000000000000000000000000000000..babb17608b22ecda5c38db00e11e6c4579722784
--- /dev/null
+++ b/contrib/RemoteSensing/dataset/demo/train.txt
@@ -0,0 +1,7 @@
+images/1001.npy annotations/1001.png
+images/1002.npy annotations/1002.png
+images/1005.npy annotations/1005.png
+images/0.npy annotations/0.png
+images/1003.npy annotations/1003.png
+images/1000.npy annotations/1000.png
+images/1004.npy annotations/1004.png
diff --git a/contrib/RemoteSensing/dataset/demo/val.txt b/contrib/RemoteSensing/dataset/demo/val.txt
new file mode 100644
index 0000000000000000000000000000000000000000..073dbf76d4309dfeea0b242e6eace3bc6024ba61
--- /dev/null
+++ b/contrib/RemoteSensing/dataset/demo/val.txt
@@ -0,0 +1,3 @@
+images/100.npy annotations/100.png
+images/1.npy annotations/1.png
+images/10.npy annotations/10.png
diff --git a/contrib/RemoteSensing/docs/transforms.md b/contrib/RemoteSensing/docs/transforms.md
new file mode 100644
index 0000000000000000000000000000000000000000..a35e6cd1bdcf03dc84687a6bb7a4e13c274dc572
--- /dev/null
+++ b/contrib/RemoteSensing/docs/transforms.md
@@ -0,0 +1,145 @@
+# transforms.transforms
+
+对用于分割任务的数据进行操作。可以利用[Compose](#compose)类将图像预处理/增强操作进行组合。
+
+
+## Compose类
+```python
+transforms.transforms.Compose(transforms)
+```
+根据数据预处理/数据增强列表对输入数据进行操作。
+### 参数
+* **transforms** (list): 数据预处理/数据增强列表。
+
+
+## RandomHorizontalFlip类
+```python
+transforms.transforms.RandomHorizontalFlip(prob=0.5)
+```
+以一定的概率对图像进行水平翻转,模型训练时的数据增强操作。
+### 参数
+* **prob** (float): 随机水平翻转的概率。默认值为0.5。
+
+
+## RandomVerticalFlip类
+```python
+transforms.transforms.RandomVerticalFlip(prob=0.1)
+```
+以一定的概率对图像进行垂直翻转,模型训练时的数据增强操作。
+### 参数
+* **prob** (float): 随机垂直翻转的概率。默认值为0.1。
+
+
+## Resize类
+```python
+transforms.transforms.Resize(target_size, interp='LINEAR')
+```
+调整图像大小(resize)。
+
+- 当目标大小(target_size)类型为int时,根据插值方式,
+ 将图像resize为[target_size, target_size]。
+- 当目标大小(target_size)类型为list或tuple时,根据插值方式,
+ 将图像resize为target_size, target_size的输入应为[w, h]或(w, h)。
+### 参数
+* **target_size** (int|list|tuple): 目标大小
+* **interp** (str): resize的插值方式,与opencv的插值方式对应,
+可选的值为['NEAREST', 'LINEAR', 'CUBIC', 'AREA', 'LANCZOS4'],默认为"LINEAR"。
+
+
+## ResizeByLong类
+```python
+transforms.transforms.ResizeByLong(long_size)
+```
+对图像长边resize到固定值,短边按比例进行缩放。
+### 参数
+* **long_size** (int): resize后图像的长边大小。
+
+
+## ResizeRangeScaling类
+```python
+transforms.transforms.ResizeRangeScaling(min_value=400, max_value=600)
+```
+对图像长边随机resize到指定范围内,短边按比例进行缩放,模型训练时的数据增强操作。
+### 参数
+* **min_value** (int): 图像长边resize后的最小值。默认值400。
+* **max_value** (int): 图像长边resize后的最大值。默认值600。
+
+
+## ResizeStepScaling类
+```python
+transforms.transforms.ResizeStepScaling(min_scale_factor=0.75, max_scale_factor=1.25, scale_step_size=0.25)
+```
+对图像按照某一个比例resize,这个比例以scale_step_size为步长,在[min_scale_factor, max_scale_factor]随机变动,模型训练时的数据增强操作。
+### 参数
+* **min_scale_factor**(float), resize最小尺度。默认值0.75。
+* **max_scale_factor** (float), resize最大尺度。默认值1.25。
+* **scale_step_size** (float), resize尺度范围间隔。默认值0.25。
+
+
+## Clip类
+```python
+transforms.transforms.Clip(min_val=[0, 0, 0], max_val=[255.0, 255.0, 255.0])
+```
+对图像上超出一定范围的数据进行裁剪。
+
+### 参数
+* **min_var** (list): 裁剪的下限,小于min_val的数值均设为min_val. 默认值[0, 0, 0].
+* **max_var** (list): 裁剪的上限,大于max_val的数值均设为max_val. 默认值[255.0, 255.0, 255.0]
+
+
+## Normalize类
+```python
+transforms.transforms.Normalize(min_val=[0, 0, 0], max_val=[255.0, 255.0, 255.0], mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
+```
+对图像进行标准化。
+
+1.图像像素归一化到区间 [0.0, 1.0]。
+2.对图像进行减均值除以标准差操作。
+### 参数
+* **min_val** (list): 图像数据集的最小值。默认值[0, 0, 0].
+* **max_val** (list): 图像数据集的最大值。默认值[255.0, 255.0, 255.0]
+* **mean** (list): 图像数据集的均值。默认值[0.5, 0.5, 0.5]。
+* **std** (list): 图像数据集的标准差。默认值[0.5, 0.5, 0.5]。
+
+
+## Padding类
+```python
+transforms.transforms.Padding(target_size, im_padding_value=127.5, label_padding_value=255)
+```
+对图像或标注图像进行padding,padding方向为右和下。根据提供的值对图像或标注图像进行padding操作。
+### 参数
+* **target_size** (int|list|tuple): padding后图像的大小。
+* **im_padding_value** (list): 图像padding的值。默认为127.5
+* **label_padding_value** (int): 标注图像padding的值。默认值为255(仅在训练时需要设定该参数)。
+
+
+## RandomPaddingCrop类
+```python
+transforms.transforms.RandomPaddingCrop(crop_size=512, im_padding_value=127.5, label_padding_value=255)
+```
+对图像和标注图进行随机裁剪,当所需要的裁剪尺寸大于原图时,则进行padding操作,模型训练时的数据增强操作。
+### 参数
+* **crop_size**(int|list|tuple): 裁剪图像大小。默认为512。
+* **im_padding_value** (list): 图像padding的值。默认为127.5。
+* **label_padding_value** (int): 标注图像padding的值。默认值为255。
+
+
+## RandomBlur类
+```python
+transforms.transforms.RandomBlur(prob=0.1)
+```
+以一定的概率对图像进行高斯模糊,模型训练时的数据增强操作。
+### 参数
+* **prob** (float): 图像模糊概率。默认为0.1。
+
+
+## RandomScaleAspect类
+```python
+transforms.transforms.RandomScaleAspect(min_scale=0.5, aspect_ratio=0.33)
+```
+裁剪并resize回原始尺寸的图像和标注图像,模型训练时的数据增强操作。
+
+按照一定的面积比和宽高比对图像进行裁剪,并reszie回原始图像的图像,当存在标注图时,同步进行。
+### 参数
+* **min_scale** (float):裁取图像占原始图像的面积比,取值[0,1],为0时则返回原图。默认为0.5。
+* **aspect_ratio** (float): 裁取图像的宽高比范围,非负值,为0时返回原图。默认为0.33。
diff --git a/contrib/RemoteSensing/models/__init__.py b/contrib/RemoteSensing/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..49098e44c699162e728cedff915f60d66e37a229
--- /dev/null
+++ b/contrib/RemoteSensing/models/__init__.py
@@ -0,0 +1,2 @@
+from .load_model import *
+from .unet import *
diff --git a/contrib/RemoteSensing/models/base.py b/contrib/RemoteSensing/models/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..849947306392cdc2a04427168d2355ae019864bc
--- /dev/null
+++ b/contrib/RemoteSensing/models/base.py
@@ -0,0 +1,353 @@
+#copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+#Licensed under the Apache License, Version 2.0 (the "License");
+#you may not use this file except in compliance with the License.
+#You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+#Unless required by applicable law or agreed to in writing, software
+#distributed under the License is distributed on an "AS IS" BASIS,
+#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+#See the License for the specific language governing permissions and
+#limitations under the License.
+
+from __future__ import absolute_import
+import paddle.fluid as fluid
+import os
+import numpy as np
+import time
+import math
+import yaml
+import copy
+import json
+import utils.logging as logging
+from collections import OrderedDict
+from os import path as osp
+from utils.pretrain_weights import get_pretrain_weights
+import transforms.transforms as T
+import utils
+import __init__
+
+
+def dict2str(dict_input):
+ out = ''
+ for k, v in dict_input.items():
+ try:
+ v = round(float(v), 6)
+ except:
+ pass
+ out = out + '{}={}, '.format(k, v)
+ return out.strip(', ')
+
+
+class BaseAPI:
+ def __init__(self):
+ # 现有的CV模型都有这个属性,而这个属且也需要在eval时用到
+ self.num_classes = None
+ self.labels = None
+ if __init__.env_info['place'] == 'cpu':
+ self.places = fluid.cpu_places()
+ else:
+ self.places = fluid.cuda_places()
+ self.exe = fluid.Executor(self.places[0])
+ self.train_prog = None
+ self.test_prog = None
+ self.parallel_train_prog = None
+ self.train_inputs = None
+ self.test_inputs = None
+ self.train_outputs = None
+ self.test_outputs = None
+ self.train_data_loader = None
+ self.eval_metrics = None
+ # 若模型是从inference model加载进来的,无法调用训练接口进行训练
+ self.trainable = True
+ # 是否使用多卡间同步BatchNorm均值和方差
+ self.sync_bn = False
+ # 当前模型状态
+ self.status = 'Normal'
+
+ def _get_single_card_bs(self, batch_size):
+ if batch_size % len(self.places) == 0:
+ return int(batch_size // len(self.places))
+ else:
+ raise Exception("Please support correct batch_size, \
+ which can be divided by available cards({}) in {}".
+ format(__init__.env_info['num'],
+ __init__.env_info['place']))
+
+ def build_program(self):
+ # 构建训练网络
+ self.train_inputs, self.train_outputs = self.build_net(mode='train')
+ self.train_prog = fluid.default_main_program()
+ startup_prog = fluid.default_startup_program()
+
+ # 构建预测网络
+ self.test_prog = fluid.Program()
+ with fluid.program_guard(self.test_prog, startup_prog):
+ with fluid.unique_name.guard():
+ self.test_inputs, self.test_outputs = self.build_net(
+ mode='test')
+ self.test_prog = self.test_prog.clone(for_test=True)
+
+ def arrange_transforms(self, transforms, mode='train'):
+ # 给transforms添加arrange操作
+ if transforms.transforms[-1].__class__.__name__.startswith('Arrange'):
+ transforms.transforms[-1] = T.ArrangeSegmenter(mode=mode)
+ else:
+ transforms.transforms.append(T.ArrangeSegmenter(mode=mode))
+
+ def build_train_data_loader(self, reader, batch_size):
+ # 初始化data_loader
+ if self.train_data_loader is None:
+ self.train_data_loader = fluid.io.DataLoader.from_generator(
+ feed_list=list(self.train_inputs.values()),
+ capacity=64,
+ use_double_buffer=True,
+ iterable=True)
+ batch_size_each_gpu = self._get_single_card_bs(batch_size)
+ generator = reader.generator(
+ batch_size=batch_size_each_gpu, drop_last=True)
+ self.train_data_loader.set_sample_list_generator(
+ reader.generator(batch_size=batch_size_each_gpu),
+ places=self.places)
+
+ def net_initialize(self,
+ startup_prog=None,
+ pretrain_weights=None,
+ fuse_bn=False,
+ save_dir='.',
+ sensitivities_file=None,
+ eval_metric_loss=0.05):
+ if hasattr(self, 'backbone'):
+ backbone = self.backbone
+ else:
+ backbone = self.__class__.__name__
+ pretrain_weights = get_pretrain_weights(pretrain_weights, backbone,
+ save_dir)
+ if startup_prog is None:
+ startup_prog = fluid.default_startup_program()
+ self.exe.run(startup_prog)
+ if pretrain_weights is not None:
+ logging.info(
+ "Load pretrain weights from {}.".format(pretrain_weights))
+ utils.utils.load_pretrain_weights(self.exe, self.train_prog,
+ pretrain_weights, fuse_bn)
+ # 进行裁剪
+ if sensitivities_file is not None:
+ from .slim.prune_config import get_sensitivities
+ sensitivities_file = get_sensitivities(sensitivities_file, self,
+ save_dir)
+ from .slim.prune import get_params_ratios, prune_program
+ prune_params_ratios = get_params_ratios(
+ sensitivities_file, eval_metric_loss=eval_metric_loss)
+ prune_program(self, prune_params_ratios)
+ self.status = 'Prune'
+
+ def get_model_info(self):
+ info = dict()
+ info['Model'] = self.__class__.__name__
+ info['_Attributes'] = {}
+ if 'self' in self.init_params:
+ del self.init_params['self']
+ if '__class__' in self.init_params:
+ del self.init_params['__class__']
+ info['_init_params'] = self.init_params
+
+ info['_Attributes']['num_classes'] = self.num_classes
+ info['_Attributes']['labels'] = self.labels
+ try:
+ primary_metric_key = list(self.eval_metrics.keys())[0]
+ primary_metric_value = float(self.eval_metrics[primary_metric_key])
+ info['_Attributes']['eval_metrics'] = {
+ primary_metric_key: primary_metric_value
+ }
+ except:
+ pass
+
+ if hasattr(self, 'test_transforms'):
+ if self.test_transforms is not None:
+ info['Transforms'] = list()
+ for op in self.test_transforms.transforms:
+ name = op.__class__.__name__
+ attr = op.__dict__
+ info['Transforms'].append({name: attr})
+ return info
+
+ def save_model(self, save_dir):
+ if not osp.isdir(save_dir):
+ if osp.exists(save_dir):
+ os.remove(save_dir)
+ os.makedirs(save_dir)
+ fluid.save(self.train_prog, osp.join(save_dir, 'model'))
+ model_info = self.get_model_info()
+ model_info['status'] = self.status
+ with open(
+ osp.join(save_dir, 'model.yml'), encoding='utf-8',
+ mode='w') as f:
+ yaml.dump(model_info, f)
+ # 评估结果保存
+ if hasattr(self, 'eval_details'):
+ with open(osp.join(save_dir, 'eval_details.json'), 'w') as f:
+ json.dump(self.eval_details, f)
+
+ if self.status == 'Prune':
+ # 保存裁剪的shape
+ shapes = {}
+ for block in self.train_prog.blocks:
+ for param in block.all_parameters():
+ pd_var = fluid.global_scope().find_var(param.name)
+ pd_param = pd_var.get_tensor()
+ shapes[param.name] = np.array(pd_param).shape
+ with open(
+ osp.join(save_dir, 'prune.yml'), encoding='utf-8',
+ mode='w') as f:
+ yaml.dump(shapes, f)
+
+ # 模型保存成功的标志
+ open(osp.join(save_dir, '.success'), 'w').close()
+ logging.info("Model saved in {}.".format(save_dir))
+
+ def train_loop(self,
+ num_epochs,
+ train_reader,
+ train_batch_size,
+ eval_reader=None,
+ eval_best_metric=None,
+ save_interval_epochs=1,
+ log_interval_steps=10,
+ save_dir='output',
+ use_vdl=False):
+ if not osp.isdir(save_dir):
+ if osp.exists(save_dir):
+ os.remove(save_dir)
+ os.makedirs(save_dir)
+ if use_vdl:
+ from visualdl import LogWriter
+ vdl_logdir = osp.join(save_dir, 'vdl_log')
+ # 给transform添加arrange操作
+ self.arrange_transforms(
+ transforms=train_reader.transforms, mode='train')
+ # 构建train_data_loader
+ self.build_train_data_loader(
+ reader=train_reader, batch_size=train_batch_size)
+
+ if eval_reader is not None:
+ self.eval_transforms = eval_reader.transforms
+ self.test_transforms = copy.deepcopy(eval_reader.transforms)
+
+ # 获取实时变化的learning rate
+ lr = self.optimizer._learning_rate
+ if isinstance(lr, fluid.framework.Variable):
+ self.train_outputs['lr'] = lr
+
+ # 在多卡上跑训练
+ if self.parallel_train_prog is None:
+ build_strategy = fluid.compiler.BuildStrategy()
+ build_strategy.fuse_all_optimizer_ops = False
+ if __init__.env_info['place'] != 'cpu' and len(self.places) > 1:
+ build_strategy.sync_batch_norm = self.sync_bn
+ exec_strategy = fluid.ExecutionStrategy()
+ exec_strategy.num_iteration_per_drop_scope = 1
+ self.parallel_train_prog = fluid.CompiledProgram(
+ self.train_prog).with_data_parallel(
+ loss_name=self.train_outputs['loss'].name,
+ build_strategy=build_strategy,
+ exec_strategy=exec_strategy)
+
+ total_num_steps = math.floor(
+ train_reader.num_samples / train_batch_size)
+ num_steps = 0
+ time_stat = list()
+
+ if use_vdl:
+ # VisualDL component
+ log_writer = LogWriter(vdl_logdir)
+
+ best_accuracy = -1.0
+ best_model_epoch = 1
+ for i in range(num_epochs):
+ records = list()
+ step_start_time = time.time()
+ for step, data in enumerate(self.train_data_loader()):
+ outputs = self.exe.run(
+ self.parallel_train_prog,
+ feed=data,
+ fetch_list=list(self.train_outputs.values()))
+ outputs_avg = np.mean(np.array(outputs), axis=1)
+ records.append(outputs_avg)
+
+ # 训练完成剩余时间预估
+ current_time = time.time()
+ step_cost_time = current_time - step_start_time
+ step_start_time = current_time
+ if len(time_stat) < 20:
+ time_stat.append(step_cost_time)
+ else:
+ time_stat[num_steps % 20] = step_cost_time
+ eta = ((num_epochs - i) * total_num_steps - step -
+ 1) * np.mean(time_stat)
+ eta_h = math.floor(eta / 3600)
+ eta_m = math.floor((eta - eta_h * 3600) / 60)
+ eta_s = int(eta - eta_h * 3600 - eta_m * 60)
+ eta_str = "{}:{}:{}".format(eta_h, eta_m, eta_s)
+
+ # 每间隔log_interval_steps,输出loss信息
+ num_steps += 1
+ if num_steps % log_interval_steps == 0:
+ step_metrics = OrderedDict(
+ zip(list(self.train_outputs.keys()), outputs_avg))
+
+ if use_vdl:
+ for k, v in step_metrics.items():
+ log_writer.add_scalar(
+ tag="Training: {}".format(k),
+ value=v,
+ step=num_steps)
+ logging.info(
+ "[TRAIN] Epoch={}/{}, Step={}/{}, {}, eta={}".format(
+ i + 1, num_epochs, step + 1, total_num_steps,
+ dict2str(step_metrics), eta_str))
+ train_metrics = OrderedDict(
+ zip(list(self.train_outputs.keys()), np.mean(records, axis=0)))
+ logging.info('[TRAIN] Epoch {} finished, {} .'.format(
+ i + 1, dict2str(train_metrics)))
+
+ # 每间隔save_interval_epochs, 在验证集上评估和对模型进行保存
+ if (i + 1) % save_interval_epochs == 0 or i == num_epochs - 1:
+ current_save_dir = osp.join(save_dir, "epoch_{}".format(i + 1))
+ if not osp.isdir(current_save_dir):
+ os.makedirs(current_save_dir)
+ if eval_reader is not None:
+ # 检测目前仅支持单卡评估,训练数据batch大小与显卡数量之商为验证数据batch大小。
+ eval_batch_size = train_batch_size
+ self.eval_metrics, self.eval_details = self.evaluate(
+ eval_reader=eval_reader,
+ batch_size=eval_batch_size,
+ verbose=True,
+ epoch_id=i + 1,
+ return_details=True)
+ logging.info('[EVAL] Finished, Epoch={}, {} .'.format(
+ i + 1, dict2str(self.eval_metrics)))
+ # 保存最优模型
+ current_metric = self.eval_metrics[eval_best_metric]
+ if current_metric > best_accuracy:
+ best_accuracy = current_metric
+ best_model_epoch = i + 1
+ best_model_dir = osp.join(save_dir, "best_model")
+ self.save_model(save_dir=best_model_dir)
+ if use_vdl:
+ for k, v in self.eval_metrics.items():
+ if isinstance(v, list):
+ continue
+ if isinstance(v, np.ndarray):
+ if v.size > 1:
+ continue
+ log_writer.add_scalar(
+ tag="Evaluation: {}".format(k),
+ step=i + 1,
+ value=v)
+ self.save_model(save_dir=current_save_dir)
+ logging.info(
+ 'Current evaluated best model in eval_reader is epoch_{}, {}={}'
+ .format(best_model_epoch, eval_best_metric, best_accuracy))
diff --git a/contrib/RemoteSensing/models/load_model.py b/contrib/RemoteSensing/models/load_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb55c13125c7ad194196082be00fb5df7c037dd8
--- /dev/null
+++ b/contrib/RemoteSensing/models/load_model.py
@@ -0,0 +1,94 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import yaml
+import os.path as osp
+import six
+import copy
+from collections import OrderedDict
+import paddle.fluid as fluid
+from paddle.fluid.framework import Parameter
+from utils import logging
+import models
+
+
+def load_model(model_dir):
+ if not osp.exists(osp.join(model_dir, "model.yml")):
+ raise Exception("There's not model.yml in {}".format(model_dir))
+ with open(osp.join(model_dir, "model.yml")) as f:
+ info = yaml.load(f.read(), Loader=yaml.Loader)
+ status = info['status']
+
+ if not hasattr(models, info['Model']):
+ raise Exception("There's no attribute {} in models".format(
+ info['Model']))
+
+ model = getattr(models, info['Model'])(**info['_init_params'])
+ if status == "Normal" or \
+ status == "Prune":
+ startup_prog = fluid.Program()
+ model.test_prog = fluid.Program()
+ with fluid.program_guard(model.test_prog, startup_prog):
+ with fluid.unique_name.guard():
+ model.test_inputs, model.test_outputs = model.build_net(
+ mode='test')
+ model.test_prog = model.test_prog.clone(for_test=True)
+ model.exe.run(startup_prog)
+ if status == "Prune":
+ from .slim.prune import update_program
+ model.test_prog = update_program(model.test_prog, model_dir,
+ model.places[0])
+ import pickle
+ with open(osp.join(model_dir, 'model.pdparams'), 'rb') as f:
+ load_dict = pickle.load(f)
+ fluid.io.set_program_state(model.test_prog, load_dict)
+
+ elif status == "Infer" or \
+ status == "Quant":
+ [prog, input_names, outputs] = fluid.io.load_inference_model(
+ model_dir, model.exe, params_filename='__params__')
+ model.test_prog = prog
+ test_outputs_info = info['_ModelInputsOutputs']['test_outputs']
+ model.test_inputs = OrderedDict()
+ model.test_outputs = OrderedDict()
+ for name in input_names:
+ model.test_inputs[name] = model.test_prog.global_block().var(name)
+ for i, out in enumerate(outputs):
+ var_desc = test_outputs_info[i]
+ model.test_outputs[var_desc[0]] = out
+ if 'Transforms' in info:
+ model.test_transforms = build_transforms(info['Transforms'])
+ model.eval_transforms = copy.deepcopy(model.test_transforms)
+
+ if '_Attributes' in info:
+ for k, v in info['_Attributes'].items():
+ if k in model.__dict__:
+ model.__dict__[k] = v
+
+ logging.info("Model[{}] loaded.".format(info['Model']))
+ return model
+
+
+def build_transforms(transforms_info):
+ from transforms import transforms as T
+ transforms = list()
+ for op_info in transforms_info:
+ op_name = list(op_info.keys())[0]
+ op_attr = op_info[op_name]
+ if not hasattr(T, op_name):
+ raise Exception(
+ "There's no operator named '{}' in transforms".format(op_name))
+ transforms.append(getattr(T, op_name)(**op_attr))
+ eval_transforms = T.Compose(transforms)
+ return eval_transforms
diff --git a/contrib/RemoteSensing/models/unet.py b/contrib/RemoteSensing/models/unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..bd56a929aa8e0253ce04a899454cadf956d28fbe
--- /dev/null
+++ b/contrib/RemoteSensing/models/unet.py
@@ -0,0 +1,322 @@
+#copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+#Licensed under the Apache License, Version 2.0 (the "License");
+#you may not use this file except in compliance with the License.
+#You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+#Unless required by applicable law or agreed to in writing, software
+#distributed under the License is distributed on an "AS IS" BASIS,
+#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+#See the License for the specific language governing permissions and
+#limitations under the License.
+
+from __future__ import absolute_import
+import os.path as osp
+import numpy as np
+import math
+import cv2
+import paddle.fluid as fluid
+import utils.logging as logging
+from collections import OrderedDict
+from .base import BaseAPI
+from utils.metrics import ConfusionMatrix
+import nets
+
+
+class UNet(BaseAPI):
+ """实现UNet网络的构建并进行训练、评估、预测和模型导出。
+
+ Args:
+ num_classes (int): 类别数。
+ upsample_mode (str): UNet decode时采用的上采样方式,取值为'bilinear'时利用双线行差值进行上菜样,
+ 当输入其他选项时则利用反卷积进行上菜样,默认为'bilinear'。
+ use_bce_loss (bool): 是否使用bce loss作为网络的损失函数,只能用于两类分割。可与dice loss同时使用。默认False。
+ use_dice_loss (bool): 是否使用dice loss作为网络的损失函数,只能用于两类分割,可与bce loss同时使用。
+ 当use_bce_loss和use_dice_loss都为False时,使用交叉熵损失函数。默认False。
+ class_weight (list/str): 交叉熵损失函数各类损失的权重。当class_weight为list的时候,长度应为
+ num_classes。当class_weight为str时, weight.lower()应为'dynamic',这时会根据每一轮各类像素的比重
+ 自行计算相应的权重,每一类的权重为:每类的比例 * num_classes。class_weight取默认值None是,各类的权重1,
+ 即平时使用的交叉熵损失函数。
+ ignore_index (int): label上忽略的值,label为ignore_index的像素不参与损失函数的计算。默认255。
+
+ Raises:
+ ValueError: use_bce_loss或use_dice_loss为真且num_calsses > 2。
+ ValueError: class_weight为list, 但长度不等于num_class。
+ class_weight为str, 但class_weight.low()不等于dynamic。
+ TypeError: class_weight不为None时,其类型不是list或str。
+ """
+
+ def __init__(self,
+ num_classes=2,
+ upsample_mode='bilinear',
+ input_channel=3,
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255):
+ self.init_params = locals()
+ super(UNet, self).__init__()
+ # dice_loss或bce_loss只适用两类分割中
+ if num_classes > 2 and (use_bce_loss or use_dice_loss):
+ raise ValueError(
+ "dice loss and bce loss is only applicable to binary classfication"
+ )
+
+ if class_weight is not None:
+ if isinstance(class_weight, list):
+ if len(class_weight) != num_classes:
+ raise ValueError(
+ "Length of class_weight should be equal to number of classes"
+ )
+ elif isinstance(class_weight, str):
+ if class_weight.lower() != 'dynamic':
+ raise ValueError(
+ "if class_weight is string, must be dynamic!")
+ else:
+ raise TypeError(
+ 'Expect class_weight is a list or string but receive {}'.
+ format(type(class_weight)))
+ self.num_classes = num_classes
+ self.upsample_mode = upsample_mode
+ self.input_channel = input_channel
+ self.use_bce_loss = use_bce_loss
+ self.use_dice_loss = use_dice_loss
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+ self.labels = None
+ # 若模型是从inference model加载进来的,无法调用训练接口进行训练
+ self.trainable = True
+
+ def build_net(self, mode='train'):
+ model = nets.UNet(
+ self.num_classes,
+ mode=mode,
+ upsample_mode=self.upsample_mode,
+ input_channel=self.input_channel,
+ use_bce_loss=self.use_bce_loss,
+ use_dice_loss=self.use_dice_loss,
+ class_weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ inputs = model.generate_inputs()
+ model_out = model.build_net(inputs)
+ outputs = OrderedDict()
+ if mode == 'train':
+ self.optimizer.minimize(model_out)
+ outputs['loss'] = model_out
+ elif mode == 'eval':
+ outputs['loss'] = model_out[0]
+ outputs['pred'] = model_out[1]
+ outputs['label'] = model_out[2]
+ outputs['mask'] = model_out[3]
+ else:
+ outputs['pred'] = model_out[0]
+ outputs['logit'] = model_out[1]
+ return inputs, outputs
+
+ def default_optimizer(self,
+ learning_rate,
+ num_epochs,
+ num_steps_each_epoch,
+ lr_decay_power=0.9):
+ decay_step = num_epochs * num_steps_each_epoch
+ lr_decay = fluid.layers.polynomial_decay(
+ learning_rate,
+ decay_step,
+ end_learning_rate=0,
+ power=lr_decay_power)
+ optimizer = fluid.optimizer.Momentum(
+ lr_decay,
+ momentum=0.9,
+ regularization=fluid.regularizer.L2Decay(
+ regularization_coeff=4e-05))
+ return optimizer
+
+ def train(self,
+ num_epochs,
+ train_reader,
+ train_batch_size=2,
+ eval_reader=None,
+ eval_best_metric='kappa',
+ save_interval_epochs=1,
+ log_interval_steps=2,
+ save_dir='output',
+ pretrain_weights='COCO',
+ optimizer=None,
+ learning_rate=0.01,
+ lr_decay_power=0.9,
+ use_vdl=False,
+ sensitivities_file=None,
+ eval_metric_loss=0.05):
+ """训练。
+
+ Args:
+ num_epochs (int): 训练迭代轮数。
+ train_reader (readers): 训练数据读取器。
+ train_batch_size (int): 训练数据batch大小。同时作为验证数据batch大小。默认2。
+ eval_reader (readers): 边训边评估的评估数据读取器。
+ eval_best_metric (str): 边训边评估保存最好模型的指标。默认为'kappa'。
+ save_interval_epochs (int): 模型保存间隔(单位:迭代轮数)。默认为1。
+ log_interval_steps (int): 训练日志输出间隔(单位:迭代次数)。默认为2。
+ save_dir (str): 模型保存路径。默认'output'。
+ pretrain_weights (str): 若指定为路径时,则加载路径下预训练模型;若为字符串'COCO',
+ 则自动下载在COCO图片数据上预训练的模型权重;若为None,则不使用预训练模型。默认为'COCO'。
+ optimizer (paddle.fluid.optimizer): 优化器。当改参数为None时,使用默认的优化器:使用
+ fluid.optimizer.Momentum优化方法,polynomial的学习率衰减策略。
+ learning_rate (float): 默认优化器的初始学习率。默认0.01。
+ lr_decay_power (float): 默认优化器学习率多项式衰减系数。默认0.9。
+ use_vdl (bool): 是否使用VisualDL进行可视化。默认False。
+ sensitivities_file (str): 若指定为路径时,则加载路径下敏感度信息进行裁剪;若为字符串'DEFAULT',
+ 则自动下载在ImageNet图片数据上获得的敏感度信息进行裁剪;若为None,则不进行裁剪。默认为None。
+ eval_metric_loss (float): 可容忍的精度损失。默认为0.05。
+
+ Raises:
+ ValueError: 模型从inference model进行加载。
+ """
+ if not self.trainable:
+ raise ValueError(
+ "Model is not trainable since it was loaded from a inference model."
+ )
+
+ self.labels = train_reader.labels
+
+ if optimizer is None:
+ num_steps_each_epoch = train_reader.num_samples // train_batch_size
+ optimizer = self.default_optimizer(
+ learning_rate=learning_rate,
+ num_epochs=num_epochs,
+ num_steps_each_epoch=num_steps_each_epoch,
+ lr_decay_power=lr_decay_power)
+ self.optimizer = optimizer
+ # 构建训练、验证、预测网络
+ self.build_program()
+ # 初始化网络权重
+ self.net_initialize(
+ startup_prog=fluid.default_startup_program(),
+ pretrain_weights=pretrain_weights,
+ save_dir=save_dir,
+ sensitivities_file=sensitivities_file,
+ eval_metric_loss=eval_metric_loss)
+ # 训练
+ self.train_loop(
+ num_epochs=num_epochs,
+ train_reader=train_reader,
+ train_batch_size=train_batch_size,
+ eval_reader=eval_reader,
+ eval_best_metric=eval_best_metric,
+ save_interval_epochs=save_interval_epochs,
+ log_interval_steps=log_interval_steps,
+ save_dir=save_dir,
+ use_vdl=use_vdl)
+
+ def evaluate(self,
+ eval_reader,
+ batch_size=1,
+ verbose=True,
+ epoch_id=None,
+ return_details=False):
+ """评估。
+
+ Args:
+ eval_reader (readers): 评估数据读取器。
+ batch_size (int): 评估时的batch大小。默认1。
+ verbose (bool): 是否打印日志。默认True。
+ epoch_id (int): 当前评估模型所在的训练轮数。
+ return_details (bool): 是否返回详细信息。默认False。
+
+ Returns:
+ dict: 当return_details为False时,返回dict。包含关键字:'miou'、'category_iou'、'macc'、
+ 'category_acc'和'kappa',分别表示平均iou、各类别iou、平均准确率、各类别准确率和kappa系数。
+ tuple (metrics, eval_details):当return_details为True时,增加返回dict (eval_details),
+ 包含关键字:'confusion_matrix',表示评估的混淆矩阵。
+ """
+ self.arrange_transforms(transforms=eval_reader.transforms, mode='eval')
+ total_steps = math.ceil(eval_reader.num_samples * 1.0 / batch_size)
+ conf_mat = ConfusionMatrix(self.num_classes, streaming=True)
+ data_generator = eval_reader.generator(
+ batch_size=batch_size, drop_last=False)
+ if not hasattr(self, 'parallel_test_prog'):
+ self.parallel_test_prog = fluid.CompiledProgram(
+ self.test_prog).with_data_parallel(
+ share_vars_from=self.parallel_train_prog)
+ batch_size_each_gpu = self._get_single_card_bs(batch_size)
+
+ for step, data in enumerate(data_generator()):
+ images = np.array([d[0] for d in data])
+ images = images.astype(np.float32)
+
+ labels = np.array([d[1] for d in data])
+ num_samples = images.shape[0]
+ if num_samples < batch_size:
+ num_pad_samples = batch_size - num_samples
+ pad_images = np.tile(images[0:1], (num_pad_samples, 1, 1, 1))
+ images = np.concatenate([images, pad_images])
+ feed_data = {'image': images}
+ outputs = self.exe.run(
+ self.parallel_test_prog,
+ feed=feed_data,
+ fetch_list=list(self.test_outputs.values()),
+ return_numpy=True)
+ pred = outputs[0]
+ if num_samples < batch_size:
+ pred = pred[0:num_samples]
+
+ mask = labels != self.ignore_index
+ conf_mat.calculate(pred=pred, label=labels, ignore=mask)
+ _, iou = conf_mat.mean_iou()
+
+ if verbose:
+ logging.info("[EVAL] Epoch={}, Step={}/{}, iou={}".format(
+ epoch_id, step + 1, total_steps, iou))
+
+ category_iou, miou = conf_mat.mean_iou()
+ category_acc, macc = conf_mat.accuracy()
+
+ metrics = OrderedDict(
+ zip(['miou', 'category_iou', 'macc', 'category_acc', 'kappa'],
+ [miou, category_iou, macc, category_acc,
+ conf_mat.kappa()]))
+ if return_details:
+ eval_details = {
+ 'confusion_matrix': conf_mat.confusion_matrix.tolist()
+ }
+ return metrics, eval_details
+ return metrics
+
+ def predict(self, im_file, transforms=None):
+ """预测。
+ Args:
+ img_file(str): 预测图像路径。
+ transforms(transforms): 数据预处理操作。
+
+ Returns:
+ np.ndarray: 预测结果灰度图。
+ """
+ if transforms is None and not hasattr(self, 'test_transforms'):
+ raise Exception("transforms need to be defined, now is None.")
+ if transforms is not None:
+ self.arrange_transforms(transforms=transforms, mode='test')
+ im, im_info = transforms(im_file)
+ else:
+ self.arrange_transforms(
+ transforms=self.test_transforms, mode='test')
+ im, im_info = self.test_transforms(im_file)
+ im = im.astype(np.float32)
+ im = np.expand_dims(im, axis=0)
+ result = self.exe.run(
+ self.test_prog,
+ feed={'image': im},
+ fetch_list=list(self.test_outputs.values()))
+ pred = result[0]
+ pred = np.squeeze(pred).astype(np.uint8)
+ keys = list(im_info.keys())
+ for k in keys[::-1]:
+ if k == 'shape_before_resize':
+ h, w = im_info[k][0], im_info[k][1]
+ pred = cv2.resize(pred, (w, h), cv2.INTER_NEAREST)
+ elif k == 'shape_before_padding':
+ h, w = im_info[k][0], im_info[k][1]
+ pred = pred[0:h, 0:w]
+
+ return pred
diff --git a/contrib/RemoteSensing/nets/__init__.py b/contrib/RemoteSensing/nets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..67cafc4f4222e392c2552e71f5ab1df194d860c8
--- /dev/null
+++ b/contrib/RemoteSensing/nets/__init__.py
@@ -0,0 +1 @@
+from .unet import UNet
diff --git a/contrib/RemoteSensing/nets/libs.py b/contrib/RemoteSensing/nets/libs.py
new file mode 100644
index 0000000000000000000000000000000000000000..01fdad2cec6ce4b13cea2b7c957fb648edb4aeb2
--- /dev/null
+++ b/contrib/RemoteSensing/nets/libs.py
@@ -0,0 +1,219 @@
+# coding: utf8
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+import paddle
+import paddle.fluid as fluid
+import contextlib
+
+bn_regularizer = fluid.regularizer.L2DecayRegularizer(regularization_coeff=0.0)
+name_scope = ""
+
+
+@contextlib.contextmanager
+def scope(name):
+ global name_scope
+ bk = name_scope
+ name_scope = name_scope + name + '/'
+ yield
+ name_scope = bk
+
+
+def max_pool(input, kernel, stride, padding):
+ data = fluid.layers.pool2d(
+ input,
+ pool_size=kernel,
+ pool_type='max',
+ pool_stride=stride,
+ pool_padding=padding)
+ return data
+
+
+def avg_pool(input, kernel, stride, padding=0):
+ data = fluid.layers.pool2d(
+ input,
+ pool_size=kernel,
+ pool_type='avg',
+ pool_stride=stride,
+ pool_padding=padding)
+ return data
+
+
+def group_norm(input, G, eps=1e-5, param_attr=None, bias_attr=None):
+ N, C, H, W = input.shape
+ if C % G != 0:
+ for d in range(10):
+ for t in [d, -d]:
+ if G + t <= 0: continue
+ if C % (G + t) == 0:
+ G = G + t
+ break
+ if C % G == 0:
+ break
+ assert C % G == 0, "group can not divide channle"
+ x = fluid.layers.group_norm(
+ input,
+ groups=G,
+ param_attr=param_attr,
+ bias_attr=bias_attr,
+ name=name_scope + 'group_norm')
+ return x
+
+
+def bn(*args,
+ norm_type='bn',
+ eps=1e-5,
+ bn_momentum=0.99,
+ group_norm=32,
+ **kargs):
+
+ if norm_type == 'bn':
+ with scope('BatchNorm'):
+ return fluid.layers.batch_norm(
+ *args,
+ epsilon=eps,
+ momentum=bn_momentum,
+ param_attr=fluid.ParamAttr(
+ name=name_scope + 'gamma', regularizer=bn_regularizer),
+ bias_attr=fluid.ParamAttr(
+ name=name_scope + 'beta', regularizer=bn_regularizer),
+ moving_mean_name=name_scope + 'moving_mean',
+ moving_variance_name=name_scope + 'moving_variance',
+ **kargs)
+ elif norm_type == 'gn':
+ with scope('GroupNorm'):
+ return group_norm(
+ args[0],
+ group_norm,
+ eps=eps,
+ param_attr=fluid.ParamAttr(
+ name=name_scope + 'gamma', regularizer=bn_regularizer),
+ bias_attr=fluid.ParamAttr(
+ name=name_scope + 'beta', regularizer=bn_regularizer))
+ else:
+ raise Exception("Unsupport norm type:" + norm_type)
+
+
+def bn_relu(data, norm_type='bn', eps=1e-5):
+ return fluid.layers.relu(bn(data, norm_type=norm_type, eps=eps))
+
+
+def relu(data):
+ return fluid.layers.relu(data)
+
+
+def conv(*args, **kargs):
+ kargs['param_attr'] = name_scope + 'weights'
+ if 'bias_attr' in kargs and kargs['bias_attr']:
+ kargs['bias_attr'] = fluid.ParamAttr(
+ name=name_scope + 'biases',
+ regularizer=None,
+ initializer=fluid.initializer.ConstantInitializer(value=0.0))
+ else:
+ kargs['bias_attr'] = False
+ return fluid.layers.conv2d(*args, **kargs)
+
+
+def deconv(*args, **kargs):
+ kargs['param_attr'] = name_scope + 'weights'
+ if 'bias_attr' in kargs and kargs['bias_attr']:
+ kargs['bias_attr'] = name_scope + 'biases'
+ else:
+ kargs['bias_attr'] = False
+ return fluid.layers.conv2d_transpose(*args, **kargs)
+
+
+def separate_conv(input,
+ channel,
+ stride,
+ filter,
+ dilation=1,
+ act=None,
+ eps=1e-5):
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.0),
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.33))
+ with scope('depthwise'):
+ input = conv(
+ input,
+ input.shape[1],
+ filter,
+ stride,
+ groups=input.shape[1],
+ padding=(filter // 2) * dilation,
+ dilation=dilation,
+ use_cudnn=False,
+ param_attr=param_attr)
+ input = bn(input, eps=eps)
+ if act: input = act(input)
+
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=None,
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.06))
+ with scope('pointwise'):
+ input = conv(
+ input, channel, 1, 1, groups=1, padding=0, param_attr=param_attr)
+ input = bn(input, eps=eps)
+ if act: input = act(input)
+ return input
+
+
+def conv_bn_layer(input,
+ filter_size,
+ num_filters,
+ stride,
+ padding,
+ channels=None,
+ num_groups=1,
+ if_act=True,
+ name=None,
+ use_cudnn=True):
+ conv = fluid.layers.conv2d(
+ input=input,
+ num_filters=num_filters,
+ filter_size=filter_size,
+ stride=stride,
+ padding=padding,
+ groups=num_groups,
+ act=None,
+ use_cudnn=use_cudnn,
+ param_attr=fluid.ParamAttr(name=name + '_weights'),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ bn = fluid.layers.batch_norm(
+ input=conv,
+ param_attr=fluid.ParamAttr(name=bn_name + "_scale"),
+ bias_attr=fluid.ParamAttr(name=bn_name + "_offset"),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+ if if_act:
+ return fluid.layers.relu6(bn)
+ else:
+ return bn
+
+
+def sigmoid_to_softmax(input):
+ """
+ one channel to two channel
+ """
+ logit = fluid.layers.sigmoid(input)
+ logit_back = 1 - logit
+ logit = fluid.layers.concat([logit_back, logit], axis=1)
+ return logit
diff --git a/contrib/RemoteSensing/nets/loss.py b/contrib/RemoteSensing/nets/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb59dce486420585edd47559c6fdd3cf88e59350
--- /dev/null
+++ b/contrib/RemoteSensing/nets/loss.py
@@ -0,0 +1,115 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import paddle.fluid as fluid
+import numpy as np
+
+
+def softmax_with_loss(logit,
+ label,
+ ignore_mask=None,
+ num_classes=2,
+ weight=None,
+ ignore_index=255):
+ ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
+ label = fluid.layers.elementwise_min(
+ label, fluid.layers.assign(np.array([num_classes - 1], dtype=np.int32)))
+ logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
+ logit = fluid.layers.reshape(logit, [-1, num_classes])
+ label = fluid.layers.reshape(label, [-1, 1])
+ label = fluid.layers.cast(label, 'int64')
+ ignore_mask = fluid.layers.reshape(ignore_mask, [-1, 1])
+ if weight is None:
+ loss, probs = fluid.layers.softmax_with_cross_entropy(
+ logit, label, ignore_index=ignore_index, return_softmax=True)
+ else:
+ label_one_hot = fluid.one_hot(input=label, depth=num_classes)
+ if isinstance(weight, list):
+ assert len(
+ weight
+ ) == num_classes, "weight length must equal num of classes"
+ weight = fluid.layers.assign(np.array([weight], dtype='float32'))
+ elif isinstance(weight, str):
+ assert weight.lower(
+ ) == 'dynamic', 'if weight is string, must be dynamic!'
+ tmp = []
+ total_num = fluid.layers.cast(
+ fluid.layers.shape(label)[0], 'float32')
+ for i in range(num_classes):
+ cls_pixel_num = fluid.layers.reduce_sum(label_one_hot[:, i])
+ ratio = total_num / (cls_pixel_num + 1)
+ tmp.append(ratio)
+ weight = fluid.layers.concat(tmp)
+ weight = weight / fluid.layers.reduce_sum(weight) * num_classes
+ elif isinstance(weight, fluid.layers.Variable):
+ pass
+ else:
+ raise ValueError(
+ 'Expect weight is a list, string or Variable, but receive {}'.
+ format(type(weight)))
+ weight = fluid.layers.reshape(weight, [1, num_classes])
+ weighted_label_one_hot = fluid.layers.elementwise_mul(
+ label_one_hot, weight)
+ probs = fluid.layers.softmax(logit)
+ loss = fluid.layers.cross_entropy(
+ probs,
+ weighted_label_one_hot,
+ soft_label=True,
+ ignore_index=ignore_index)
+ weighted_label_one_hot.stop_gradient = True
+
+ loss = loss * ignore_mask
+ avg_loss = fluid.layers.mean(loss) / (
+ fluid.layers.mean(ignore_mask) + 0.00001)
+
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return avg_loss
+
+
+# to change, how to appicate ignore index and ignore mask
+def dice_loss(logit, label, ignore_mask=None, epsilon=0.00001):
+ if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
+ raise Exception(
+ "dice loss is only applicable to one channel classfication")
+ ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
+ logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
+ label = fluid.layers.transpose(label, [0, 2, 3, 1])
+ label = fluid.layers.cast(label, 'int64')
+ ignore_mask = fluid.layers.transpose(ignore_mask, [0, 2, 3, 1])
+ logit = fluid.layers.sigmoid(logit)
+ logit = logit * ignore_mask
+ label = label * ignore_mask
+ reduce_dim = list(range(1, len(logit.shape)))
+ inse = fluid.layers.reduce_sum(logit * label, dim=reduce_dim)
+ dice_denominator = fluid.layers.reduce_sum(
+ logit, dim=reduce_dim) + fluid.layers.reduce_sum(
+ label, dim=reduce_dim)
+ dice_score = 1 - inse * 2 / (dice_denominator + epsilon)
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return fluid.layers.reduce_mean(dice_score)
+
+
+def bce_loss(logit, label, ignore_mask=None, ignore_index=255):
+ if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
+ raise Exception("bce loss is only applicable to binary classfication")
+ label = fluid.layers.cast(label, 'float32')
+ loss = fluid.layers.sigmoid_cross_entropy_with_logits(
+ x=logit, label=label, ignore_index=ignore_index,
+ normalize=True) # or False
+ loss = fluid.layers.reduce_sum(loss)
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return loss
diff --git a/contrib/RemoteSensing/nets/unet.py b/contrib/RemoteSensing/nets/unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..fef193ec72190ef5c08a54b8444e21ac6a901e6f
--- /dev/null
+++ b/contrib/RemoteSensing/nets/unet.py
@@ -0,0 +1,268 @@
+# coding: utf8
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from collections import OrderedDict
+
+import paddle.fluid as fluid
+from .libs import scope, name_scope
+from .libs import bn, bn_relu, relu
+from .libs import conv, max_pool, deconv
+from .libs import sigmoid_to_softmax
+from .loss import softmax_with_loss
+from .loss import dice_loss
+from .loss import bce_loss
+
+
+class UNet(object):
+ """实现Unet模型
+ `"U-Net: Convolutional Networks for Biomedical Image Segmentation"
+ `
+
+ Args:
+ num_classes (int): 类别数
+ mode (str): 网络运行模式,根据mode构建网络的输入和返回。
+ 当mode为'train'时,输入为image(-1, 3, -1, -1)和label (-1, 1, -1, -1) 返回loss。
+ 当mode为'train'时,输入为image (-1, 3, -1, -1)和label (-1, 1, -1, -1),返回loss,
+ pred (与网络输入label 相同大小的预测结果,值代表相应的类别),label,mask(非忽略值的mask,
+ 与label相同大小,bool类型)。
+ 当mode为'test'时,输入为image(-1, 3, -1, -1)返回pred (-1, 1, -1, -1)和
+ logit (-1, num_classes, -1, -1) 通道维上代表每一类的概率值。
+ upsample_mode (str): UNet decode时采用的上采样方式,取值为'bilinear'时利用双线行差值进行上菜样,
+ 当输入其他选项时则利用反卷积进行上菜样,默认为'bilinear'。
+ use_bce_loss (bool): 是否使用bce loss作为网络的损失函数,只能用于两类分割。可与dice loss同时使用。
+ use_dice_loss (bool): 是否使用dice loss作为网络的损失函数,只能用于两类分割,可与bce loss同时使用。
+ 当use_bce_loss和use_dice_loss都为False时,使用交叉熵损失函数。
+ class_weight (list/str): 交叉熵损失函数各类损失的权重。当class_weight为list的时候,长度应为
+ num_classes。当class_weight为str时, weight.lower()应为'dynamic',这时会根据每一轮各类像素的比重
+ 自行计算相应的权重,每一类的权重为:每类的比例 * num_classes。class_weight取默认值None是,各类的权重1,
+ 即平时使用的交叉熵损失函数。
+ ignore_index (int): label上忽略的值,label为ignore_index的像素不参与损失函数的计算。
+
+ Raises:
+ ValueError: use_bce_loss或use_dice_loss为真且num_calsses > 2。
+ ValueError: class_weight为list, 但长度不等于num_class。
+ class_weight为str, 但class_weight.low()不等于dynamic。
+ TypeError: class_weight不为None时,其类型不是list或str。
+ """
+
+ def __init__(self,
+ num_classes,
+ mode='train',
+ upsample_mode='bilinear',
+ input_channel=3,
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255):
+ # dice_loss或bce_loss只适用两类分割中
+ if num_classes > 2 and (use_bce_loss or use_dice_loss):
+ raise Exception(
+ "dice loss and bce loss is only applicable to binary classfication"
+ )
+
+ if class_weight is not None:
+ if isinstance(class_weight, list):
+ if len(class_weight) != num_classes:
+ raise ValueError(
+ "Length of class_weight should be equal to number of classes"
+ )
+ elif isinstance(class_weight, str):
+ if class_weight.lower() != 'dynamic':
+ raise ValueError(
+ "if class_weight is string, must be dynamic!")
+ else:
+ raise TypeError(
+ 'Expect class_weight is a list or string but receive {}'.
+ format(type(class_weight)))
+ self.num_classes = num_classes
+ self.mode = mode
+ self.upsample_mode = upsample_mode
+ self.input_channel = input_channel
+ self.use_bce_loss = use_bce_loss
+ self.use_dice_loss = use_dice_loss
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+
+ def _double_conv(self, data, out_ch):
+ param_attr = fluid.ParamAttr(
+ name='weights',
+ regularizer=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.0),
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.33))
+ with scope("conv0"):
+ data = bn_relu(
+ conv(
+ data, out_ch, 3, stride=1, padding=1,
+ param_attr=param_attr))
+ with scope("conv1"):
+ data = bn_relu(
+ conv(
+ data, out_ch, 3, stride=1, padding=1,
+ param_attr=param_attr))
+ return data
+
+ def _down(self, data, out_ch):
+ # 下采样:max_pool + 2个卷积
+ with scope("down"):
+ data = max_pool(data, 2, 2, 0)
+ data = self._double_conv(data, out_ch)
+ return data
+
+ def _up(self, data, short_cut, out_ch):
+ # 上采样:data上采样(resize或deconv), 并与short_cut concat
+ param_attr = fluid.ParamAttr(
+ name='weights',
+ regularizer=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.0),
+ initializer=fluid.initializer.XavierInitializer(),
+ )
+ with scope("up"):
+ if self.upsample_mode == 'bilinear':
+ short_cut_shape = fluid.layers.shape(short_cut)
+ data = fluid.layers.resize_bilinear(data, short_cut_shape[2:])
+ else:
+ data = deconv(
+ data,
+ out_ch // 2,
+ filter_size=2,
+ stride=2,
+ padding=0,
+ param_attr=param_attr)
+ data = fluid.layers.concat([data, short_cut], axis=1)
+ data = self._double_conv(data, out_ch)
+ return data
+
+ def _encode(self, data):
+ # 编码器设置
+ short_cuts = []
+ with scope("encode"):
+ with scope("block1"):
+ data = self._double_conv(data, 64)
+ short_cuts.append(data)
+ with scope("block2"):
+ data = self._down(data, 128)
+ short_cuts.append(data)
+ with scope("block3"):
+ data = self._down(data, 256)
+ short_cuts.append(data)
+ with scope("block4"):
+ data = self._down(data, 512)
+ short_cuts.append(data)
+ with scope("block5"):
+ data = self._down(data, 512)
+ return data, short_cuts
+
+ def _decode(self, data, short_cuts):
+ # 解码器设置,与编码器对称
+ with scope("decode"):
+ with scope("decode1"):
+ data = self._up(data, short_cuts[3], 256)
+ with scope("decode2"):
+ data = self._up(data, short_cuts[2], 128)
+ with scope("decode3"):
+ data = self._up(data, short_cuts[1], 64)
+ with scope("decode4"):
+ data = self._up(data, short_cuts[0], 64)
+ return data
+
+ def _get_logit(self, data, num_classes):
+ # 根据类别数设置最后一个卷积层输出
+ param_attr = fluid.ParamAttr(
+ name='weights',
+ regularizer=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.0),
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.01))
+ with scope("logit"):
+ data = conv(
+ data,
+ num_classes,
+ 3,
+ stride=1,
+ padding=1,
+ param_attr=param_attr)
+ return data
+
+ def _get_loss(self, logit, label, mask):
+ avg_loss = 0
+ if not (self.use_dice_loss or self.use_bce_loss):
+ avg_loss += softmax_with_loss(
+ logit,
+ label,
+ mask,
+ num_classes=self.num_classes,
+ weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ else:
+ if self.use_dice_loss:
+ avg_loss += dice_loss(logit, label, mask)
+ if self.use_bce_loss:
+ avg_loss += bce_loss(
+ logit, label, mask, ignore_index=self.ignore_index)
+
+ return avg_loss
+
+ def generate_inputs(self):
+ inputs = OrderedDict()
+ inputs['image'] = fluid.data(
+ dtype='float32',
+ shape=[None, self.input_channel, None, None],
+ name='image')
+ if self.mode == 'train':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ elif self.mode == 'eval':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ return inputs
+
+ def build_net(self, inputs):
+ # 在两类分割情况下,当loss函数选择dice_loss或bce_loss的时候,最后logit输出通道数设置为1
+ if self.use_dice_loss or self.use_bce_loss:
+ self.num_classes = 1
+
+ image = inputs['image']
+ encode_data, short_cuts = self._encode(image)
+ decode_data = self._decode(encode_data, short_cuts)
+ logit = self._get_logit(decode_data, self.num_classes)
+
+ if self.num_classes == 1:
+ out = sigmoid_to_softmax(logit)
+ out = fluid.layers.transpose(out, [0, 2, 3, 1])
+ else:
+ out = fluid.layers.transpose(logit, [0, 2, 3, 1])
+
+ pred = fluid.layers.argmax(out, axis=3)
+ pred = fluid.layers.unsqueeze(pred, axes=[3])
+
+ if self.mode == 'train':
+ label = inputs['label']
+ mask = label != self.ignore_index
+ return self._get_loss(logit, label, mask)
+
+ elif self.mode == 'eval':
+ label = inputs['label']
+ mask = label != self.ignore_index
+ loss = self._get_loss(logit, label, mask)
+ return loss, pred, label, mask
+ else:
+ if self.num_classes == 1:
+ logit = sigmoid_to_softmax(logit)
+ else:
+ logit = fluid.layers.softmax(logit, axis=1)
+ return pred, logit
diff --git a/contrib/RemoteSensing/predict_demo.py b/contrib/RemoteSensing/predict_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d7b8c2940882783f69685286cc5d7970e768cb0
--- /dev/null
+++ b/contrib/RemoteSensing/predict_demo.py
@@ -0,0 +1,53 @@
+import os
+import os.path as osp
+import numpy as np
+from PIL import Image as Image
+import argparse
+from models import load_model
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='RemoteSensing predict')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='dataset directory',
+ default=None,
+ type=str)
+ parser.add_argument(
+ '--load_model_dir',
+ dest='load_model_dir',
+ help='model load directory',
+ default=None,
+ type=str)
+ return parser.parse_args()
+
+
+args = parse_args()
+
+data_dir = args.data_dir
+load_model_dir = args.load_model_dir
+
+# predict
+model = load_model(load_model_dir)
+pred_dir = osp.join(load_model_dir, 'predict')
+if not osp.exists(pred_dir):
+ os.mkdir(pred_dir)
+
+val_list = osp.join(data_dir, 'val.txt')
+color_map = [0, 0, 0, 255, 255, 255]
+with open(val_list) as f:
+ lines = f.readlines()
+ for line in lines:
+ img_path = line.split(' ')[0]
+ print('Predicting {}'.format(img_path))
+ img_path_ = osp.join(data_dir, img_path)
+
+ pred = model.predict(img_path_)
+
+ # 以伪彩色png图片保存预测结果
+ pred_name = osp.basename(img_path).rstrip('npy') + 'png'
+ pred_path = osp.join(pred_dir, pred_name)
+ pred_mask = Image.fromarray(pred.astype(np.uint8), mode='P')
+ pred_mask.putpalette(color_map)
+ pred_mask.save(pred_path)
diff --git a/contrib/RemoteSensing/readers/__init__.py b/contrib/RemoteSensing/readers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..babbe0866c625fc81f810a2cff82b8d138b9aa94
--- /dev/null
+++ b/contrib/RemoteSensing/readers/__init__.py
@@ -0,0 +1,15 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .reader import Reader
diff --git a/contrib/RemoteSensing/readers/base.py b/contrib/RemoteSensing/readers/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..1427bd60ad4637a3f13c8a08f59291f15fe5ac82
--- /dev/null
+++ b/contrib/RemoteSensing/readers/base.py
@@ -0,0 +1,249 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from threading import Thread
+import multiprocessing
+import collections
+import numpy as np
+import six
+import sys
+import copy
+import random
+import platform
+import chardet
+from utils import logging
+
+
+class EndSignal():
+ pass
+
+
+def is_pic(img_name):
+ valid_suffix = ['JPEG', 'jpeg', 'JPG', 'jpg', 'BMP', 'bmp', 'PNG', 'png']
+ suffix = img_name.split('.')[-1]
+ if suffix not in valid_suffix:
+ return False
+ return True
+
+
+def is_valid(sample):
+ if sample is None:
+ return False
+ if isinstance(sample, tuple):
+ for s in sample:
+ if s is None:
+ return False
+ elif isinstance(s, np.ndarray) and s.size == 0:
+ return False
+ elif isinstance(s, collections.Sequence) and len(s) == 0:
+ return False
+ return True
+
+
+def get_encoding(path):
+ f = open(path, 'rb')
+ data = f.read()
+ file_encoding = chardet.detect(data).get('encoding')
+ return file_encoding
+
+
+def multithread_reader(mapper,
+ reader,
+ num_workers=4,
+ buffer_size=1024,
+ batch_size=8,
+ drop_last=True):
+ from queue import Queue
+ end = EndSignal()
+
+ # define a worker to read samples from reader to in_queue
+ def read_worker(reader, in_queue):
+ for i in reader():
+ in_queue.put(i)
+ in_queue.put(end)
+
+ # define a worker to handle samples from in_queue by mapper
+ # and put mapped samples into out_queue
+ def handle_worker(in_queue, out_queue, mapper):
+ sample = in_queue.get()
+ while not isinstance(sample, EndSignal):
+ if len(sample) == 2:
+ r = mapper(sample[0], sample[1])
+ elif len(sample) == 3:
+ r = mapper(sample[0], sample[1], sample[2])
+ else:
+ raise Exception('The sample\'s length must be 2 or 3.')
+ if is_valid(r):
+ out_queue.put(r)
+ sample = in_queue.get()
+ in_queue.put(end)
+ out_queue.put(end)
+
+ def xreader():
+ in_queue = Queue(buffer_size)
+ out_queue = Queue(buffer_size)
+ # start a read worker in a thread
+ target = read_worker
+ t = Thread(target=target, args=(reader, in_queue))
+ t.daemon = True
+ t.start()
+ # start several handle_workers
+ target = handle_worker
+ args = (in_queue, out_queue, mapper)
+ workers = []
+ for i in range(num_workers):
+ worker = Thread(target=target, args=args)
+ worker.daemon = True
+ workers.append(worker)
+ for w in workers:
+ w.start()
+
+ batch_data = []
+ sample = out_queue.get()
+ while not isinstance(sample, EndSignal):
+ batch_data.append(sample)
+ if len(batch_data) == batch_size:
+ batch_data = GenerateMiniBatch(batch_data)
+ yield batch_data
+ batch_data = []
+ sample = out_queue.get()
+ finish = 1
+ while finish < num_workers:
+ sample = out_queue.get()
+ if isinstance(sample, EndSignal):
+ finish += 1
+ else:
+ batch_data.append(sample)
+ if len(batch_data) == batch_size:
+ batch_data = GenerateMiniBatch(batch_data)
+ yield batch_data
+ batch_data = []
+ if not drop_last and len(batch_data) != 0:
+ batch_data = GenerateMiniBatch(batch_data)
+ yield batch_data
+ batch_data = []
+
+ return xreader
+
+
+def multiprocess_reader(mapper,
+ reader,
+ num_workers=4,
+ buffer_size=1024,
+ batch_size=8,
+ drop_last=True):
+ from .shared_queue import SharedQueue as Queue
+
+ def _read_into_queue(samples, mapper, queue):
+ end = EndSignal()
+ try:
+ for sample in samples:
+ if sample is None:
+ raise ValueError("sample has None")
+ if len(sample) == 2:
+ result = mapper(sample[0], sample[1])
+ elif len(sample) == 3:
+ result = mapper(sample[0], sample[1], sample[2])
+ else:
+ raise Exception('The sample\'s length must be 2 or 3.')
+ if is_valid(result):
+ queue.put(result)
+ queue.put(end)
+ except:
+ queue.put("")
+ six.reraise(*sys.exc_info())
+
+ def queue_reader():
+ queue = Queue(buffer_size, memsize=3 * 1024**3)
+ total_samples = [[] for i in range(num_workers)]
+ for i, sample in enumerate(reader()):
+ index = i % num_workers
+ total_samples[index].append(sample)
+ for i in range(num_workers):
+ p = multiprocessing.Process(
+ target=_read_into_queue, args=(total_samples[i], mapper, queue))
+ p.start()
+
+ finish_num = 0
+ batch_data = list()
+ while finish_num < num_workers:
+ sample = queue.get()
+ if isinstance(sample, EndSignal):
+ finish_num += 1
+ elif sample == "":
+ raise ValueError("multiprocess reader raises an exception")
+ else:
+ batch_data.append(sample)
+ if len(batch_data) == batch_size:
+ batch_data = GenerateMiniBatch(batch_data)
+ yield batch_data
+ batch_data = []
+ if len(batch_data) != 0 and not drop_last:
+ batch_data = GenerateMiniBatch(batch_data)
+ yield batch_data
+ batch_data = []
+
+ return queue_reader
+
+
+def GenerateMiniBatch(batch_data):
+ if len(batch_data) == 1:
+ return batch_data
+ width = [data[0].shape[2] for data in batch_data]
+ height = [data[0].shape[1] for data in batch_data]
+ if len(set(width)) == 1 and len(set(height)) == 1:
+ return batch_data
+ max_shape = np.array([data[0].shape for data in batch_data]).max(axis=0)
+ padding_batch = []
+ for data in batch_data:
+ im_c, im_h, im_w = data[0].shape[:]
+ padding_im = np.zeros((im_c, max_shape[1], max_shape[2]),
+ dtype=np.float32)
+ padding_im[:, :im_h, :im_w] = data[0]
+ padding_batch.append((padding_im, ) + data[1:])
+ return padding_batch
+
+
+class BaseReader:
+ def __init__(self,
+ transforms=None,
+ num_workers=4,
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False):
+ if transforms is None:
+ raise Exception("transform should be defined.")
+ self.transforms = transforms
+ self.num_workers = num_workers
+ self.buffer_size = buffer_size
+ self.parallel_method = parallel_method
+ self.shuffle = shuffle
+
+ def generator(self, batch_size=1, drop_last=True):
+ self.batch_size = batch_size
+ parallel_reader = multithread_reader
+ if self.parallel_method == "process":
+ if platform.platform().startswith("Windows"):
+ logging.debug(
+ "multiprocess_reader is not supported in Windows platform, force to use multithread_reader."
+ )
+ else:
+ parallel_reader = multiprocess_reader
+ return parallel_reader(
+ self.transforms,
+ self.iterator,
+ num_workers=self.num_workers,
+ buffer_size=self.buffer_size,
+ batch_size=batch_size,
+ drop_last=drop_last)
diff --git a/contrib/RemoteSensing/readers/reader.py b/contrib/RemoteSensing/readers/reader.py
new file mode 100644
index 0000000000000000000000000000000000000000..343d25b15034e1905a1e55ae926fbdfa62916cf1
--- /dev/null
+++ b/contrib/RemoteSensing/readers/reader.py
@@ -0,0 +1,90 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import absolute_import
+import os.path as osp
+import random
+from utils import logging
+from .base import BaseReader
+from .base import get_encoding
+from collections import OrderedDict
+from .base import is_pic
+
+
+class Reader(BaseReader):
+ """读取语分分割任务数据集,并对样本进行相应的处理。
+
+ Args:
+ data_dir (str): 数据集所在的目录路径。
+ file_list (str): 描述数据集图片文件和对应标注文件的文件路径(文本内每行路径为相对data_dir的相对路)。
+ label_list (str): 描述数据集包含的类别信息文件路径。
+ transforms (list): 数据集中每个样本的预处理/增强算子。
+ num_workers (int): 数据集中样本在预处理过程中的线程或进程数。默认为4。
+ buffer_size (int): 数据集中样本在预处理过程中队列的缓存长度,以样本数为单位。默认为100。
+ parallel_method (str): 数据集中样本在预处理过程中并行处理的方式,支持'thread'
+ 线程和'process'进程两种方式。默认为'thread'。
+ shuffle (bool): 是否需要对数据集中样本打乱顺序。默认为False。
+ """
+
+ def __init__(self,
+ data_dir,
+ file_list,
+ label_list,
+ transforms=None,
+ num_workers=4,
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False):
+ super(Reader, self).__init__(
+ transforms=transforms,
+ num_workers=num_workers,
+ buffer_size=buffer_size,
+ parallel_method=parallel_method,
+ shuffle=shuffle)
+ self.file_list = OrderedDict()
+ self.labels = list()
+ self._epoch = 0
+
+ with open(label_list, encoding=get_encoding(label_list)) as f:
+ for line in f:
+ item = line.strip()
+ self.labels.append(item)
+
+ with open(file_list, encoding=get_encoding(file_list)) as f:
+ for line in f:
+ items = line.strip().split()
+ full_path_im = osp.join(data_dir, items[0])
+ full_path_label = osp.join(data_dir, items[1])
+ if not osp.exists(full_path_im):
+ raise IOError(
+ 'The image file {} is not exist!'.format(full_path_im))
+ if not osp.exists(full_path_label):
+ raise IOError('The image file {} is not exist!'.format(
+ full_path_label))
+ self.file_list[full_path_im] = full_path_label
+ self.num_samples = len(self.file_list)
+ logging.info("{} samples in file {}".format(
+ len(self.file_list), file_list))
+
+ def iterator(self):
+ self._epoch += 1
+ self._pos = 0
+ files = list(self.file_list.keys())
+ if self.shuffle:
+ random.shuffle(files)
+ files = files[:self.num_samples]
+ self.num_samples = len(files)
+ for f in files:
+ label_path = self.file_list[f]
+ sample = [f, None, label_path]
+ yield sample
diff --git a/contrib/RemoteSensing/requirements.txt b/contrib/RemoteSensing/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..339faddb107efd8de7f36fdd298b3008437ba23c
--- /dev/null
+++ b/contrib/RemoteSensing/requirements.txt
@@ -0,0 +1 @@
+visualdl >= 2.0.0-alpha.2
diff --git a/contrib/RemoteSensing/tools/create_dataset_list.py b/contrib/RemoteSensing/tools/create_dataset_list.py
new file mode 100644
index 0000000000000000000000000000000000000000..430eea5e75f4dc8e1ed4babff6baa6d2fbdeb7f7
--- /dev/null
+++ b/contrib/RemoteSensing/tools/create_dataset_list.py
@@ -0,0 +1,145 @@
+# coding: utf8
+# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import glob
+import os.path
+import argparse
+import warnings
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description=
+ 'A tool for dividing dataset and generating file lists by file directory structure.'
+ )
+ parser.add_argument('dataset_root', help='dataset root directory', type=str)
+ parser.add_argument(
+ '--separator',
+ dest='separator',
+ help='file list separator',
+ default=" ",
+ type=str)
+ parser.add_argument(
+ '--folder',
+ help='the folder names of images and labels',
+ type=str,
+ nargs=2,
+ default=['images', 'annotations'])
+ parser.add_argument(
+ '--second_folder',
+ help=
+ 'the second-level folder names of train set, validation set, test set',
+ type=str,
+ nargs='*',
+ default=['train', 'val', 'test'])
+ parser.add_argument(
+ '--format',
+ help='data format of images and labels, default npy, png.',
+ type=str,
+ nargs=2,
+ default=['npy', 'png'])
+ parser.add_argument(
+ '--label_class',
+ help='label class names',
+ type=str,
+ nargs='*',
+ default=['__background__', '__foreground__'])
+ parser.add_argument(
+ '--postfix',
+ help='postfix of images or labels',
+ type=str,
+ nargs=2,
+ default=['', ''])
+
+ return parser.parse_args()
+
+
+def get_files(image_or_label, dataset_split, args):
+ dataset_root = args.dataset_root
+ postfix = args.postfix
+ format = args.format
+ folder = args.folder
+
+ pattern = '*%s.%s' % (postfix[image_or_label], format[image_or_label])
+
+ search_files = os.path.join(dataset_root, folder[image_or_label],
+ dataset_split, pattern)
+ search_files2 = os.path.join(dataset_root, folder[image_or_label],
+ dataset_split, "*", pattern) # 包含子目录
+ search_files3 = os.path.join(dataset_root, folder[image_or_label],
+ dataset_split, "*", "*", pattern) # 包含三级目录
+
+ filenames = glob.glob(search_files)
+ filenames2 = glob.glob(search_files2)
+ filenames3 = glob.glob(search_files3)
+
+ filenames = filenames + filenames2 + filenames3
+
+ return sorted(filenames)
+
+
+def generate_list(args):
+ dataset_root = args.dataset_root
+ separator = args.separator
+
+ file_list = os.path.join(dataset_root, 'labels.txt')
+ with open(file_list, "w") as f:
+ for label_class in args.label_class:
+ f.write(label_class + '\n')
+
+ for dataset_split in args.second_folder:
+ print("Creating {}.txt...".format(dataset_split))
+ image_files = get_files(0, dataset_split, args)
+ label_files = get_files(1, dataset_split, args)
+ if not image_files:
+ img_dir = os.path.join(dataset_root, args.folder[0], dataset_split)
+ warnings.warn("No images in {} !!!".format(img_dir))
+ num_images = len(image_files)
+
+ if not label_files:
+ label_dir = os.path.join(dataset_root, args.folder[1],
+ dataset_split)
+ warnings.warn("No labels in {} !!!".format(label_dir))
+ num_label = len(label_files)
+
+ if num_images != num_label and num_label > 0:
+ raise Exception(
+ "Number of images = {} number of labels = {} \n"
+ "Either number of images is equal to number of labels, "
+ "or number of labels is equal to 0.\n"
+ "Please check your dataset!".format(num_images, num_label))
+
+ file_list = os.path.join(dataset_root, dataset_split + '.txt')
+ with open(file_list, "w") as f:
+ for item in range(num_images):
+ left = image_files[item].replace(dataset_root, '')
+ if left[0] == os.path.sep:
+ left = left.lstrip(os.path.sep)
+
+ try:
+ right = label_files[item].replace(dataset_root, '')
+ if right[0] == os.path.sep:
+ right = right.lstrip(os.path.sep)
+ line = left + separator + right + '\n'
+ except:
+ line = left + '\n'
+
+ f.write(line)
+ print(line)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ generate_list(args)
diff --git a/contrib/RemoteSensing/tools/split_dataset_list.py b/contrib/RemoteSensing/tools/split_dataset_list.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff15987aee2b6a30c961cbad28ebc4e7cb8f6f1d
--- /dev/null
+++ b/contrib/RemoteSensing/tools/split_dataset_list.py
@@ -0,0 +1,149 @@
+# coding: utf8
+# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import glob
+import os.path
+import argparse
+import warnings
+import numpy as np
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description=
+ 'A tool for proportionally randomizing dataset to produce file lists.')
+ parser.add_argument('dataset_root', help='the dataset root path', type=str)
+ parser.add_argument('images', help='the directory name of images', type=str)
+ parser.add_argument('labels', help='the directory name of labels', type=str)
+ parser.add_argument(
+ '--split', help='', nargs=3, type=float, default=[0.7, 0.3, 0])
+ parser.add_argument(
+ '--label_class',
+ help='label class names',
+ type=str,
+ nargs='*',
+ default=['__background__', '__foreground__'])
+ parser.add_argument(
+ '--separator',
+ dest='separator',
+ help='file list separator',
+ default=" ",
+ type=str)
+ parser.add_argument(
+ '--format',
+ help='data format of images and labels, e.g. jpg, npy or png.',
+ type=str,
+ nargs=2,
+ default=['npy', 'png'])
+ parser.add_argument(
+ '--postfix',
+ help='postfix of images or labels',
+ type=str,
+ nargs=2,
+ default=['', ''])
+
+ return parser.parse_args()
+
+
+def get_files(path, format, postfix):
+ pattern = '*%s.%s' % (postfix, format)
+
+ search_files = os.path.join(path, pattern)
+ search_files2 = os.path.join(path, "*", pattern) # 包含子目录
+ search_files3 = os.path.join(path, "*", "*", pattern) # 包含三级目录
+
+ filenames = glob.glob(search_files)
+ filenames2 = glob.glob(search_files2)
+ filenames3 = glob.glob(search_files3)
+
+ filenames = filenames + filenames2 + filenames3
+
+ return sorted(filenames)
+
+
+def generate_list(args):
+ separator = args.separator
+ dataset_root = args.dataset_root
+ if sum(args.split) != 1.0:
+ raise ValueError("划分比例之和必须为1")
+
+ file_list = os.path.join(dataset_root, 'labels.txt')
+ with open(file_list, "w") as f:
+ for label_class in args.label_class:
+ f.write(label_class + '\n')
+
+ image_dir = os.path.join(dataset_root, args.images)
+ label_dir = os.path.join(dataset_root, args.labels)
+ image_files = get_files(image_dir, args.format[0], args.postfix[0])
+ label_files = get_files(label_dir, args.format[1], args.postfix[1])
+ if not image_files:
+ warnings.warn("No files in {}".format(image_dir))
+ num_images = len(image_files)
+
+ if not label_files:
+ warnings.warn("No files in {}".format(label_dir))
+ num_label = len(label_files)
+
+ if num_images != num_label and num_label > 0:
+ raise Exception("Number of images = {} number of labels = {} \n"
+ "Either number of images is equal to number of labels, "
+ "or number of labels is equal to 0.\n"
+ "Please check your dataset!".format(
+ num_images, num_label))
+
+ image_files = np.array(image_files)
+ label_files = np.array(label_files)
+ state = np.random.get_state()
+ np.random.shuffle(image_files)
+ np.random.set_state(state)
+ np.random.shuffle(label_files)
+
+ start = 0
+ num_split = len(args.split)
+ dataset_name = ['train', 'val', 'test']
+ for i in range(num_split):
+ dataset_split = dataset_name[i]
+ print("Creating {}.txt...".format(dataset_split))
+ if args.split[i] > 1.0 or args.split[i] < 0:
+ raise ValueError(
+ "{} dataset percentage should be 0~1.".format(dataset_split))
+
+ file_list = os.path.join(dataset_root, dataset_split + '.txt')
+ with open(file_list, "w") as f:
+ num = round(args.split[i] * num_images)
+ end = start + num
+ if i == num_split - 1:
+ end = num_images
+ for item in range(start, end):
+ left = image_files[item].replace(dataset_root, '')
+ if left[0] == os.path.sep:
+ left = left.lstrip(os.path.sep)
+
+ try:
+ right = label_files[item].replace(dataset_root, '')
+ if right[0] == os.path.sep:
+ right = right.lstrip(os.path.sep)
+ line = left + separator + right + '\n'
+ except:
+ line = left + '\n'
+
+ f.write(line)
+ print(line)
+ start = end
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ generate_list(args)
diff --git a/contrib/RemoteSensing/train_demo.py b/contrib/RemoteSensing/train_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..afd3e8523a4e8007d5d0847cfd5f2460d19dc269
--- /dev/null
+++ b/contrib/RemoteSensing/train_demo.py
@@ -0,0 +1,106 @@
+import os.path as osp
+import argparse
+import transforms.transforms as T
+from readers.reader import Reader
+from models import UNet
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='RemoteSensing training')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='dataset directory',
+ default=None,
+ type=str)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='model save directory',
+ default=None,
+ type=str)
+ parser.add_argument(
+ '--channel',
+ dest='channel',
+ help='number of data channel',
+ default=3,
+ type=int)
+ parser.add_argument(
+ '--num_epochs',
+ dest='num_epochs',
+ help='number of traing epochs',
+ default=100,
+ type=int)
+ parser.add_argument(
+ '--train_batch_size',
+ dest='train_batch_size',
+ help='training batch size',
+ default=4,
+ type=int)
+ parser.add_argument(
+ '--lr', dest='lr', help='learning rate', default=0.01, type=float)
+ return parser.parse_args()
+
+
+args = parse_args()
+
+data_dir = args.data_dir
+save_dir = args.save_dir
+channel = args.channel
+num_epochs = args.num_epochs
+train_batch_size = args.train_batch_size
+lr = args.lr
+
+# 定义训练和验证时的transforms
+train_transforms = T.Compose([
+ T.RandomVerticalFlip(0.5),
+ T.RandomHorizontalFlip(0.5),
+ T.ResizeStepScaling(0.5, 2.0, 0.25),
+ T.RandomPaddingCrop(256),
+ T.Normalize(mean=[0.5] * channel, std=[0.5] * channel),
+])
+
+eval_transforms = T.Compose([
+ T.Normalize(mean=[0.5] * channel, std=[0.5] * channel),
+])
+
+train_list = osp.join(data_dir, 'train.txt')
+val_list = osp.join(data_dir, 'val.txt')
+label_list = osp.join(data_dir, 'labels.txt')
+
+# 定义数据读取器
+train_reader = Reader(
+ data_dir=data_dir,
+ file_list=train_list,
+ label_list=label_list,
+ transforms=train_transforms,
+ num_workers=8,
+ buffer_size=16,
+ shuffle=True,
+ parallel_method='thread')
+
+eval_reader = Reader(
+ data_dir=data_dir,
+ file_list=val_list,
+ label_list=label_list,
+ transforms=eval_transforms,
+ num_workers=8,
+ buffer_size=16,
+ shuffle=False,
+ parallel_method='thread')
+
+model = UNet(
+ num_classes=2, input_channel=channel, use_bce_loss=True, use_dice_loss=True)
+
+model.train(
+ num_epochs=num_epochs,
+ train_reader=train_reader,
+ train_batch_size=train_batch_size,
+ eval_reader=eval_reader,
+ save_interval_epochs=5,
+ log_interval_steps=10,
+ save_dir=save_dir,
+ pretrain_weights=None,
+ optimizer=None,
+ learning_rate=lr,
+ use_vdl=True)
diff --git a/contrib/RemoteSensing/transforms/__init__.py b/contrib/RemoteSensing/transforms/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8eba87ecc700db36f930be3a39c2ece981e00572
--- /dev/null
+++ b/contrib/RemoteSensing/transforms/__init__.py
@@ -0,0 +1,16 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from . import transforms
+from . import ops
diff --git a/contrib/RemoteSensing/transforms/ops.py b/contrib/RemoteSensing/transforms/ops.py
new file mode 100644
index 0000000000000000000000000000000000000000..e04e695410e5f1e089de838526889c02cadd7da1
--- /dev/null
+++ b/contrib/RemoteSensing/transforms/ops.py
@@ -0,0 +1,178 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import cv2
+import math
+import numpy as np
+from PIL import Image, ImageEnhance
+
+
+def normalize(im, min_value, max_value, mean, std):
+ # Rescaling (min-max normalization)
+ range_value = [max_value[i] - min_value[i] for i in range(len(max_value))]
+ im = (im.astype(np.float32, copy=False) - min_value) / range_value
+
+ # Standardization (Z-score Normalization)
+ im -= mean
+ im /= std
+ return im
+
+
+def permute(im, to_bgr=False):
+ im = np.swapaxes(im, 1, 2)
+ im = np.swapaxes(im, 1, 0)
+ if to_bgr:
+ im = im[[2, 1, 0], :, :]
+ return im
+
+
+def _resize(im, shape):
+ return cv2.resize(im, shape)
+
+
+def resize_short(im, short_size=224):
+ percent = float(short_size) / min(im.shape[0], im.shape[1])
+ resized_width = int(round(im.shape[1] * percent))
+ resized_height = int(round(im.shape[0] * percent))
+ im = _resize(im, shape=(resized_width, resized_height))
+ return im
+
+
+def resize_long(im, long_size=224, interpolation=cv2.INTER_LINEAR):
+ value = max(im.shape[0], im.shape[1])
+ scale = float(long_size) / float(value)
+ im = cv2.resize(im, (0, 0), fx=scale, fy=scale, interpolation=interpolation)
+ return im
+
+
+def random_crop(im,
+ crop_size=224,
+ lower_scale=0.08,
+ lower_ratio=3. / 4,
+ upper_ratio=4. / 3):
+ scale = [lower_scale, 1.0]
+ ratio = [lower_ratio, upper_ratio]
+ aspect_ratio = math.sqrt(np.random.uniform(*ratio))
+ w = 1. * aspect_ratio
+ h = 1. / aspect_ratio
+ bound = min((float(im.shape[0]) / im.shape[1]) / (h**2),
+ (float(im.shape[1]) / im.shape[0]) / (w**2))
+ scale_max = min(scale[1], bound)
+ scale_min = min(scale[0], bound)
+ target_area = im.shape[0] * im.shape[1] * np.random.uniform(
+ scale_min, scale_max)
+ target_size = math.sqrt(target_area)
+ w = int(target_size * w)
+ h = int(target_size * h)
+ i = np.random.randint(0, im.shape[0] - h + 1)
+ j = np.random.randint(0, im.shape[1] - w + 1)
+ im = im[i:i + h, j:j + w, :]
+ im = _resize(im, shape=(crop_size, crop_size))
+ return im
+
+
+def center_crop(im, crop_size=224):
+ height, width = im.shape[:2]
+ w_start = (width - crop_size) // 2
+ h_start = (height - crop_size) // 2
+ w_end = w_start + crop_size
+ h_end = h_start + crop_size
+ im = im[h_start:h_end, w_start:w_end, :]
+ return im
+
+
+def horizontal_flip(im):
+ if len(im.shape) == 3:
+ im = im[:, ::-1, :]
+ elif len(im.shape) == 2:
+ im = im[:, ::-1]
+ return im
+
+
+def vertical_flip(im):
+ if len(im.shape) == 3:
+ im = im[::-1, :, :]
+ elif len(im.shape) == 2:
+ im = im[::-1, :]
+ return im
+
+
+def bgr2rgb(im):
+ return im[:, :, ::-1]
+
+
+def brightness(im, brightness_lower, brightness_upper):
+ brightness_delta = np.random.uniform(brightness_lower, brightness_upper)
+ im = ImageEnhance.Brightness(im).enhance(brightness_delta)
+ return im
+
+
+def contrast(im, contrast_lower, contrast_upper):
+ contrast_delta = np.random.uniform(contrast_lower, contrast_upper)
+ im = ImageEnhance.Contrast(im).enhance(contrast_delta)
+ return im
+
+
+def saturation(im, saturation_lower, saturation_upper):
+ saturation_delta = np.random.uniform(saturation_lower, saturation_upper)
+ im = ImageEnhance.Color(im).enhance(saturation_delta)
+ return im
+
+
+def hue(im, hue_lower, hue_upper):
+ hue_delta = np.random.uniform(hue_lower, hue_upper)
+ im = np.array(im.convert('HSV'))
+ im[:, :, 0] = im[:, :, 0] + hue_delta
+ im = Image.fromarray(im, mode='HSV').convert('RGB')
+ return im
+
+
+def rotate(im, rotate_lower, rotate_upper):
+ rotate_delta = np.random.uniform(rotate_lower, rotate_upper)
+ im = im.rotate(int(rotate_delta))
+ return im
+
+
+def resize_padding(im, max_side_len=2400):
+ '''
+ resize image to a size multiple of 32 which is required by the network
+ :param im: the resized image
+ :param max_side_len: limit of max image size to avoid out of memory in gpu
+ :return: the resized image and the resize ratio
+ '''
+ h, w, _ = im.shape
+
+ resize_w = w
+ resize_h = h
+
+ # limit the max side
+ if max(resize_h, resize_w) > max_side_len:
+ ratio = float(
+ max_side_len) / resize_h if resize_h > resize_w else float(
+ max_side_len) / resize_w
+ else:
+ ratio = 1.
+ resize_h = int(resize_h * ratio)
+ resize_w = int(resize_w * ratio)
+
+ resize_h = resize_h if resize_h % 32 == 0 else (resize_h // 32 - 1) * 32
+ resize_w = resize_w if resize_w % 32 == 0 else (resize_w // 32 - 1) * 32
+ resize_h = max(32, resize_h)
+ resize_w = max(32, resize_w)
+ im = cv2.resize(im, (int(resize_w), int(resize_h)))
+ #im = cv2.resize(im, (512, 512))
+ ratio_h = resize_h / float(h)
+ ratio_w = resize_w / float(w)
+ _ratio = np.array([ratio_h, ratio_w]).reshape(-1, 2)
+ return im, _ratio
diff --git a/contrib/RemoteSensing/transforms/transforms.py b/contrib/RemoteSensing/transforms/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..abac1746e09e8e95d4149e8243d6ea4258f347ef
--- /dev/null
+++ b/contrib/RemoteSensing/transforms/transforms.py
@@ -0,0 +1,811 @@
+# coding: utf8
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .ops import *
+import random
+import os.path as osp
+import numpy as np
+from PIL import Image
+import cv2
+from collections import OrderedDict
+
+
+class Compose:
+ """根据数据预处理/增强算子对输入数据进行操作。
+ 所有操作的输入图像流形状均是[H, W, C],其中H为图像高,W为图像宽,C为图像通道数。
+
+ Args:
+ transforms (list): 数据预处理/增强算子。
+
+ Raises:
+ TypeError: transforms不是list对象
+ ValueError: transforms元素个数小于1。
+
+ """
+
+ def __init__(self, transforms):
+ if not isinstance(transforms, list):
+ raise TypeError('The transforms must be a list!')
+ if len(transforms) < 1:
+ raise ValueError('The length of transforms ' + \
+ 'must be equal or larger than 1!')
+ self.transforms = transforms
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (str/np.ndarray): 图像路径/图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息,dict中的字段如下:
+ - shape_before_resize (tuple): 图像resize之前的大小(h, w)。
+ - shape_before_padding (tuple): 图像padding之前的大小(h, w)。
+ label (str/np.ndarray): 标注图像路径/标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 根据网络所需字段所组成的tuple;字段由transforms中的最后一个数据预处理操作决定。
+ """
+
+ if im_info is None:
+ im_info = dict()
+ im = np.load(im)
+ if im is None:
+ raise ValueError('Can\'t read The image file {}!'.format(im))
+ if label is not None:
+ label = np.asarray(Image.open(label))
+
+ for op in self.transforms:
+ outputs = op(im, im_info, label)
+ im = outputs[0]
+ if len(outputs) >= 2:
+ im_info = outputs[1]
+ if len(outputs) == 3:
+ label = outputs[2]
+ return outputs
+
+
+class RandomHorizontalFlip:
+ """以一定的概率对图像进行水平翻转。当存在标注图像时,则同步进行翻转。
+
+ Args:
+ prob (float): 随机水平翻转的概率。默认值为0.5。
+
+ """
+
+ def __init__(self, prob=0.5):
+ self.prob = prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if random.random() < self.prob:
+ im = horizontal_flip(im)
+ if label is not None:
+ label = horizontal_flip(label)
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomVerticalFlip:
+ """以一定的概率对图像进行垂直翻转。当存在标注图像时,则同步进行翻转。
+
+ Args:
+ prob (float): 随机垂直翻转的概率。默认值为0.1。
+ """
+
+ def __init__(self, prob=0.1):
+ self.prob = prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if random.random() < self.prob:
+ im = vertical_flip(im)
+ if label is not None:
+ label = vertical_flip(label)
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Resize:
+ """调整图像大小(resize),当存在标注图像时,则同步进行处理。
+
+ - 当目标大小(target_size)类型为int时,根据插值方式,
+ 将图像resize为[target_size, target_size]。
+ - 当目标大小(target_size)类型为list或tuple时,根据插值方式,
+ 将图像resize为target_size, target_size的输入应为[w, h]或(w, h)。
+
+ Args:
+ target_size (int/list/tuple): 目标大小
+ interp (str): resize的插值方式,与opencv的插值方式对应,
+ 可选的值为['NEAREST', 'LINEAR', 'CUBIC', 'AREA', 'LANCZOS4'],默认为"LINEAR"。
+
+ Raises:
+ TypeError: target_size不是int/list/tuple。
+ ValueError: target_size为list/tuple时元素个数不等于2。
+ AssertionError: interp的取值不在['NEAREST', 'LINEAR', 'CUBIC', 'AREA', 'LANCZOS4']之内
+ """
+
+ # The interpolation mode
+ interp_dict = {
+ 'NEAREST': cv2.INTER_NEAREST,
+ 'LINEAR': cv2.INTER_LINEAR,
+ 'CUBIC': cv2.INTER_CUBIC,
+ 'AREA': cv2.INTER_AREA,
+ 'LANCZOS4': cv2.INTER_LANCZOS4
+ }
+
+ def __init__(self, target_size, interp='LINEAR'):
+ self.interp = interp
+ assert interp in self.interp_dict, "interp should be one of {}".format(
+ self.interp_dict.keys())
+ if isinstance(target_size, list) or isinstance(target_size, tuple):
+ if len(target_size) != 2:
+ raise ValueError(
+ 'when target is list or tuple, it should include 2 elements, but it is {}'
+ .format(target_size))
+ elif not isinstance(target_size, int):
+ raise TypeError(
+ "Type of target_size is invalid. Must be Integer or List or tuple, now is {}"
+ .format(type(target_size)))
+
+ self.target_size = target_size
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ 其中,im_info跟新字段为:
+ -shape_before_resize (tuple): 保存resize之前图像的形状(h, w)。
+
+ Raises:
+ ZeroDivisionError: im的短边为0。
+ TypeError: im不是np.ndarray数据。
+ ValueError: im不是3维nd.ndarray。
+ """
+ if im_info is None:
+ im_info = OrderedDict()
+ im_info['shape_before_resize'] = im.shape[:2]
+
+ if not isinstance(im, np.ndarray):
+ raise TypeError("ResizeImage: image type is not np.ndarray.")
+ if len(im.shape) != 3:
+ raise ValueError('ResizeImage: image is not 3-dimensional.')
+ im_shape = im.shape
+ im_size_min = np.min(im_shape[0:2])
+ im_size_max = np.max(im_shape[0:2])
+ if float(im_size_min) == 0:
+ raise ZeroDivisionError('ResizeImage: min size of image is 0')
+
+ if isinstance(self.target_size, int):
+ resize_w = self.target_size
+ resize_h = self.target_size
+ else:
+ resize_w = self.target_size[0]
+ resize_h = self.target_size[1]
+ im_scale_x = float(resize_w) / float(im_shape[1])
+ im_scale_y = float(resize_h) / float(im_shape[0])
+
+ im = cv2.resize(
+ im,
+ None,
+ None,
+ fx=im_scale_x,
+ fy=im_scale_y,
+ interpolation=self.interp_dict[self.interp])
+ if label is not None:
+ label = cv2.resize(
+ label,
+ None,
+ None,
+ fx=im_scale_x,
+ fy=im_scale_y,
+ interpolation=self.interp_dict['NEAREST'])
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ResizeByLong:
+ """对图像长边resize到固定值,短边按比例进行缩放。当存在标注图像时,则同步进行处理。
+
+ Args:
+ long_size (int): resize后图像的长边大小。
+ """
+
+ def __init__(self, long_size):
+ self.long_size = long_size
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ 其中,im_info新增字段为:
+ -shape_before_resize (tuple): 保存resize之前图像的形状(h, w)。
+ """
+ if im_info is None:
+ im_info = OrderedDict()
+
+ im_info['shape_before_resize'] = im.shape[:2]
+ im = resize_long(im, self.long_size)
+ if label is not None:
+ label = resize_long(label, self.long_size, cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ResizeRangeScaling:
+ """对图像长边随机resize到指定范围内,短边按比例进行缩放。当存在标注图像时,则同步进行处理。
+
+ Args:
+ min_value (int): 图像长边resize后的最小值。默认值400。
+ max_value (int): 图像长边resize后的最大值。默认值600。
+
+ Raises:
+ ValueError: min_value大于max_value
+ """
+
+ def __init__(self, min_value=400, max_value=600):
+ if min_value > max_value:
+ raise ValueError('min_value must be less than max_value, '
+ 'but they are {} and {}.'.format(
+ min_value, max_value))
+ self.min_value = min_value
+ self.max_value = max_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.min_value == self.max_value:
+ random_size = self.max_value
+ else:
+ random_size = int(
+ np.random.uniform(self.min_value, self.max_value) + 0.5)
+ value = max(im.shape[0], im.shape[1])
+ scale = float(random_size) / float(value)
+ im = cv2.resize(
+ im, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR)
+ if label is not None:
+ label = cv2.resize(
+ label, (0, 0),
+ fx=scale,
+ fy=scale,
+ interpolation=cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ResizeStepScaling:
+ """对图像按照某一个比例resize,这个比例以scale_step_size为步长
+ 在[min_scale_factor, max_scale_factor]随机变动。当存在标注图像时,则同步进行处理。
+
+ Args:
+ min_scale_factor(float), resize最小尺度。默认值0.75。
+ max_scale_factor (float), resize最大尺度。默认值1.25。
+ scale_step_size (float), resize尺度范围间隔。默认值0.25。
+
+ Raises:
+ ValueError: min_scale_factor大于max_scale_factor
+ """
+
+ def __init__(self,
+ min_scale_factor=0.75,
+ max_scale_factor=1.25,
+ scale_step_size=0.25):
+ if min_scale_factor > max_scale_factor:
+ raise ValueError(
+ 'min_scale_factor must be less than max_scale_factor, '
+ 'but they are {} and {}.'.format(min_scale_factor,
+ max_scale_factor))
+ self.min_scale_factor = min_scale_factor
+ self.max_scale_factor = max_scale_factor
+ self.scale_step_size = scale_step_size
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.min_scale_factor == self.max_scale_factor:
+ scale_factor = self.min_scale_factor
+
+ elif self.scale_step_size == 0:
+ scale_factor = np.random.uniform(self.min_scale_factor,
+ self.max_scale_factor)
+
+ else:
+ num_steps = int((self.max_scale_factor - self.min_scale_factor) /
+ self.scale_step_size + 1)
+ scale_factors = np.linspace(self.min_scale_factor,
+ self.max_scale_factor,
+ num_steps).tolist()
+ np.random.shuffle(scale_factors)
+ scale_factor = scale_factors[0]
+
+ im = cv2.resize(
+ im, (0, 0),
+ fx=scale_factor,
+ fy=scale_factor,
+ interpolation=cv2.INTER_LINEAR)
+ if label is not None:
+ label = cv2.resize(
+ label, (0, 0),
+ fx=scale_factor,
+ fy=scale_factor,
+ interpolation=cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Clip:
+ """
+ 对图像上超出一定范围的数据进行裁剪。
+
+ Args:
+ min_val (list): 裁剪的下限,小于min_val的数值均设为min_val. 默认值[0, 0, 0].
+ max_val (list): 裁剪的上限,大于max_val的数值均设为max_val. 默认值[255.0, 255.0, 255.0]
+ """
+
+ def __init__(self, min_val=[0, 0, 0], max_val=[255.0, 255.0, 255.0]):
+ self.min_val = min_val
+ self.max_val = max_val
+
+ def __call__(self, im, im_info=None, label=None):
+ if isinstance(self.min_val, list) and isinstance(self.max_val, list):
+ for k in range(im.shape[2]):
+ np.clip(
+ im[:, :, k],
+ self.min_val[k],
+ self.max_val[k],
+ out=im[:, :, k])
+ else:
+ raise TypeError('min_val and max_val must be list')
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Normalize:
+ """对图像进行标准化。
+ 1.图像像素归一化到区间 [0.0, 1.0]。
+ 2.对图像进行减均值除以标准差操作。
+
+ Args:
+ min_val (list): 图像数据集的最小值。默认值[0, 0, 0].
+ max_val (list): 图像数据集的最大值。默认值[255.0, 255.0, 255.0]
+ mean (list): 图像数据集的均值。默认值[0.5, 0.5, 0.5].
+ std (list): 图像数据集的标准差。默认值[0.5, 0.5, 0.5].
+
+ Raises:
+ ValueError: mean或std不是list对象。std包含0。
+ """
+
+ def __init__(self,
+ min_val=[0, 0, 0],
+ max_val=[255.0, 255.0, 255.0],
+ mean=[0.5, 0.5, 0.5],
+ std=[0.5, 0.5, 0.5]):
+ self.min_val = min_val
+ self.max_val = max_val
+ self.mean = mean
+ self.std = std
+ if not (isinstance(self.mean, list) and isinstance(self.std, list)):
+ raise ValueError("{}: input type is invalid.".format(self))
+ from functools import reduce
+ if reduce(lambda x, y: x * y, self.std) == 0:
+ raise ValueError('{}: std is invalid!'.format(self))
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+
+ mean = np.array(self.mean)[np.newaxis, np.newaxis, :]
+ std = np.array(self.std)[np.newaxis, np.newaxis, :]
+
+ im = normalize(im, self.min_val, self.max_val, mean, std)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Padding:
+ """对图像或标注图像进行padding,padding方向为右和下。
+ 根据提供的值对图像或标注图像进行padding操作。
+
+ Args:
+ target_size (int/list/tuple): padding后图像的大小。
+ im_padding_value (list): 图像padding的值。默认为127.5。
+ label_padding_value (int): 标注图像padding的值。默认值为255。
+
+ Raises:
+ TypeError: target_size不是int/list/tuple。
+ ValueError: target_size为list/tuple时元素个数不等于2。
+ """
+
+ def __init__(self,
+ target_size,
+ im_padding_value=127.5,
+ label_padding_value=255):
+ if isinstance(target_size, list) or isinstance(target_size, tuple):
+ if len(target_size) != 2:
+ raise ValueError(
+ 'when target is list or tuple, it should include 2 elements, but it is {}'
+ .format(target_size))
+ elif not isinstance(target_size, int):
+ raise TypeError(
+ "Type of target_size is invalid. Must be Integer or List or tuple, now is {}"
+ .format(type(target_size)))
+ self.target_size = target_size
+ self.im_padding_value = im_padding_value
+ self.label_padding_value = label_padding_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ 其中,im_info新增字段为:
+ -shape_before_padding (tuple): 保存padding之前图像的形状(h, w)。
+
+ Raises:
+ ValueError: 输入图像im或label的形状大于目标值
+ """
+ if im_info is None:
+ im_info = OrderedDict()
+ im_info['shape_before_padding'] = im.shape[:2]
+
+ im_height, im_width = im.shape[0], im.shape[1]
+ if isinstance(self.target_size, int):
+ target_height = self.target_size
+ target_width = self.target_size
+ else:
+ target_height = self.target_size[1]
+ target_width = self.target_size[0]
+ pad_height = target_height - im_height
+ pad_width = target_width - im_width
+ if pad_height < 0 or pad_width < 0:
+ raise ValueError(
+ 'the size of image should be less than target_size, but the size of image ({}, {}), is larger than target_size ({}, {})'
+ .format(im_width, im_height, target_width, target_height))
+ else:
+ im = np.pad(
+ im,
+ pad_width=((0, pad_height), (0, pad_width), (0, 0)),
+ mode='constant',
+ constant_values=(self.im_padding_value, self.im_padding_value))
+ if label is not None:
+ label = np.pad(
+ label,
+ pad_width=((0, pad_height), (0, pad_width)),
+ mode='constant',
+ constant_values=(self.label_padding_value,
+ self.label_padding_value))
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomPaddingCrop:
+ """对图像和标注图进行随机裁剪,当所需要的裁剪尺寸大于原图时,则进行padding操作。
+
+ Args:
+ crop_size(int or list or tuple): 裁剪图像大小。默认为512。
+ im_padding_value (list): 图像padding的值。默认为127.5
+ label_padding_value (int): 标注图像padding的值。默认值为255。
+
+ Raises:
+ TypeError: crop_size不是int/list/tuple。
+ ValueError: target_size为list/tuple时元素个数不等于2。
+ """
+
+ def __init__(self,
+ crop_size=512,
+ im_padding_value=127.5,
+ label_padding_value=255):
+ if isinstance(crop_size, list) or isinstance(crop_size, tuple):
+ if len(crop_size) != 2:
+ raise ValueError(
+ 'when crop_size is list or tuple, it should include 2 elements, but it is {}'
+ .format(crop_size))
+ elif not isinstance(crop_size, int):
+ raise TypeError(
+ "Type of crop_size is invalid. Must be Integer or List or tuple, now is {}"
+ .format(type(crop_size)))
+ self.crop_size = crop_size
+ self.im_padding_value = im_padding_value
+ self.label_padding_value = label_padding_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if isinstance(self.crop_size, int):
+ crop_width = self.crop_size
+ crop_height = self.crop_size
+ else:
+ crop_width = self.crop_size[0]
+ crop_height = self.crop_size[1]
+
+ img_height = im.shape[0]
+ img_width = im.shape[1]
+
+ if img_height == crop_height and img_width == crop_width:
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+ else:
+ pad_height = max(crop_height - img_height, 0)
+ pad_width = max(crop_width - img_width, 0)
+ if (pad_height > 0 or pad_width > 0):
+ im = np.pad(
+ im,
+ pad_width=((0, pad_height), (0, pad_width), (0, 0)),
+ mode='constant',
+ constant_values=(self.im_padding_value,
+ self.im_padding_value))
+ if label is not None:
+ label = np.pad(
+ label,
+ pad_width=((0, pad_height), (0, pad_width)),
+ mode='constant',
+ constant_values=(self.label_padding_value,
+ self.label_padding_value))
+ img_height = im.shape[0]
+ img_width = im.shape[1]
+
+ if crop_height > 0 and crop_width > 0:
+ h_off = np.random.randint(img_height - crop_height + 1)
+ w_off = np.random.randint(img_width - crop_width + 1)
+
+ im = im[h_off:(crop_height + h_off), w_off:(
+ w_off + crop_width), :]
+ if label is not None:
+ label = label[h_off:(crop_height + h_off), w_off:(
+ w_off + crop_width)]
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomBlur:
+ """以一定的概率对图像进行高斯模糊。
+
+ Args:
+ prob (float): 图像模糊概率。默认为0.1。
+ """
+
+ def __init__(self, prob=0.1):
+ self.prob = prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.prob <= 0:
+ n = 0
+ elif self.prob >= 1:
+ n = 1
+ else:
+ n = int(1.0 / self.prob)
+ if n > 0:
+ if np.random.randint(0, n) == 0:
+ radius = np.random.randint(3, 10)
+ if radius % 2 != 1:
+ radius = radius + 1
+ if radius > 9:
+ radius = 9
+ im = cv2.GaussianBlur(im, (radius, radius), 0, 0)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomScaleAspect:
+ """裁剪并resize回原始尺寸的图像和标注图像。
+ 按照一定的面积比和宽高比对图像进行裁剪,并reszie回原始图像的图像,当存在标注图时,同步进行。
+
+ Args:
+ min_scale (float):裁取图像占原始图像的面积比,0-1,默认0返回原图。默认为0.5。
+ aspect_ratio (float): 裁取图像的宽高比范围,非负,默认0返回原图。默认为0.33。
+ """
+
+ def __init__(self, min_scale=0.5, aspect_ratio=0.33):
+ self.min_scale = min_scale
+ self.aspect_ratio = aspect_ratio
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.min_scale != 0 and self.aspect_ratio != 0:
+ img_height = im.shape[0]
+ img_width = im.shape[1]
+ for i in range(0, 10):
+ area = img_height * img_width
+ target_area = area * np.random.uniform(self.min_scale, 1.0)
+ aspectRatio = np.random.uniform(self.aspect_ratio,
+ 1.0 / self.aspect_ratio)
+
+ dw = int(np.sqrt(target_area * 1.0 * aspectRatio))
+ dh = int(np.sqrt(target_area * 1.0 / aspectRatio))
+ if (np.random.randint(10) < 5):
+ tmp = dw
+ dw = dh
+ dh = tmp
+
+ if (dh < img_height and dw < img_width):
+ h1 = np.random.randint(0, img_height - dh)
+ w1 = np.random.randint(0, img_width - dw)
+
+ im = im[h1:(h1 + dh), w1:(w1 + dw), :]
+ label = label[h1:(h1 + dh), w1:(w1 + dw)]
+ im = cv2.resize(
+ im, (img_width, img_height),
+ interpolation=cv2.INTER_LINEAR)
+ label = cv2.resize(
+ label, (img_width, img_height),
+ interpolation=cv2.INTER_NEAREST)
+ break
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ArrangeSegmenter:
+ """获取训练/验证/预测所需的信息。
+
+ Args:
+ mode (str): 指定数据用于何种用途,取值范围为['train', 'eval', 'test', 'quant']。
+
+ Raises:
+ ValueError: mode的取值不在['train', 'eval', 'test', 'quant']之内
+ """
+
+ def __init__(self, mode):
+ if mode not in ['train', 'eval', 'test', 'quant']:
+ raise ValueError(
+ "mode should be defined as one of ['train', 'eval', 'test', 'quant']!"
+ )
+ self.mode = mode
+
+ def __call__(self, im, im_info, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当mode为'train'或'eval'时,返回的tuple为(im, label),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当mode为'test'时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;当mode为
+ 'quant'时,返回的tuple为(im,),为图像np.ndarray数据。
+ """
+ im = permute(im, False)
+ if self.mode == 'train' or self.mode == 'eval':
+ label = label[np.newaxis, :, :]
+ return (im, label)
+ elif self.mode == 'test':
+ return (im, im_info)
+ else:
+ return (im, )
diff --git a/contrib/RemoteSensing/utils/__init__.py b/contrib/RemoteSensing/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f27f5ea79417cdfd65da5744527cc6f7869dcc02
--- /dev/null
+++ b/contrib/RemoteSensing/utils/__init__.py
@@ -0,0 +1,18 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from . import logging
+from . import utils
+from .metrics import ConfusionMatrix
+from .utils import *
diff --git a/contrib/RemoteSensing/utils/logging.py b/contrib/RemoteSensing/utils/logging.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d14b1a5df23827c2ddea2a0959801fab6e70552
--- /dev/null
+++ b/contrib/RemoteSensing/utils/logging.py
@@ -0,0 +1,46 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import time
+import os
+import sys
+import __init__
+
+levels = {0: 'ERROR', 1: 'WARNING', 2: 'INFO', 3: 'DEBUG'}
+
+
+def log(level=2, message=""):
+ current_time = time.time()
+ time_array = time.localtime(current_time)
+ current_time = time.strftime("%Y-%m-%d %H:%M:%S", time_array)
+ if __init__.log_level >= level:
+ print("{} [{}]\t{}".format(current_time, levels[level],
+ message).encode("utf-8").decode("latin1"))
+ sys.stdout.flush()
+
+
+def debug(message=""):
+ log(level=3, message=message)
+
+
+def info(message=""):
+ log(level=2, message=message)
+
+
+def warning(message=""):
+ log(level=1, message=message)
+
+
+def error(message=""):
+ log(level=0, message=message)
diff --git a/contrib/RemoteSensing/utils/metrics.py b/contrib/RemoteSensing/utils/metrics.py
new file mode 100644
index 0000000000000000000000000000000000000000..2898be028f3dfa03ad9892310da89f7695829542
--- /dev/null
+++ b/contrib/RemoteSensing/utils/metrics.py
@@ -0,0 +1,145 @@
+# coding: utf8
+# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import sys
+import numpy as np
+from scipy.sparse import csr_matrix
+
+
+class ConfusionMatrix(object):
+ """
+ Confusion Matrix for segmentation evaluation
+ """
+
+ def __init__(self, num_classes=2, streaming=False):
+ self.confusion_matrix = np.zeros([num_classes, num_classes],
+ dtype='int64')
+ self.num_classes = num_classes
+ self.streaming = streaming
+
+ def calculate(self, pred, label, ignore=None):
+ # If not in streaming mode, clear matrix everytime when call `calculate`
+ if not self.streaming:
+ self.zero_matrix()
+
+ label = np.transpose(label, (0, 2, 3, 1))
+ ignore = np.transpose(ignore, (0, 2, 3, 1))
+ mask = np.array(ignore) == 1
+
+ label = np.asarray(label)[mask]
+ pred = np.asarray(pred)[mask]
+ one = np.ones_like(pred)
+ # Accumuate ([row=label, col=pred], 1) into sparse matrix
+ spm = csr_matrix((one, (label, pred)),
+ shape=(self.num_classes, self.num_classes))
+ spm = spm.todense()
+ self.confusion_matrix += spm
+
+ def zero_matrix(self):
+ """ Clear confusion matrix """
+ self.confusion_matrix = np.zeros([self.num_classes, self.num_classes],
+ dtype='int64')
+
+ def mean_iou(self):
+ iou_list = []
+ avg_iou = 0
+ # TODO: use numpy sum axis api to simpliy
+ vji = np.zeros(self.num_classes, dtype=int)
+ vij = np.zeros(self.num_classes, dtype=int)
+ for j in range(self.num_classes):
+ v_j = 0
+ for i in range(self.num_classes):
+ v_j += self.confusion_matrix[j][i]
+ vji[j] = v_j
+
+ for i in range(self.num_classes):
+ v_i = 0
+ for j in range(self.num_classes):
+ v_i += self.confusion_matrix[j][i]
+ vij[i] = v_i
+
+ for c in range(self.num_classes):
+ total = vji[c] + vij[c] - self.confusion_matrix[c][c]
+ if total == 0:
+ iou = 0
+ else:
+ iou = float(self.confusion_matrix[c][c]) / total
+ avg_iou += iou
+ iou_list.append(iou)
+ avg_iou = float(avg_iou) / float(self.num_classes)
+ return np.array(iou_list), avg_iou
+
+ def accuracy(self):
+ total = self.confusion_matrix.sum()
+ total_right = 0
+ for c in range(self.num_classes):
+ total_right += self.confusion_matrix[c][c]
+ if total == 0:
+ avg_acc = 0
+ else:
+ avg_acc = float(total_right) / total
+
+ vij = np.zeros(self.num_classes, dtype=int)
+ for i in range(self.num_classes):
+ v_i = 0
+ for j in range(self.num_classes):
+ v_i += self.confusion_matrix[j][i]
+ vij[i] = v_i
+
+ acc_list = []
+ for c in range(self.num_classes):
+ if vij[c] == 0:
+ acc = 0
+ else:
+ acc = self.confusion_matrix[c][c] / float(vij[c])
+ acc_list.append(acc)
+ return np.array(acc_list), avg_acc
+
+ def kappa(self):
+ vji = np.zeros(self.num_classes)
+ vij = np.zeros(self.num_classes)
+ for j in range(self.num_classes):
+ v_j = 0
+ for i in range(self.num_classes):
+ v_j += self.confusion_matrix[j][i]
+ vji[j] = v_j
+
+ for i in range(self.num_classes):
+ v_i = 0
+ for j in range(self.num_classes):
+ v_i += self.confusion_matrix[j][i]
+ vij[i] = v_i
+
+ total = self.confusion_matrix.sum()
+
+ # avoid spillovers
+ # TODO: is it reasonable to hard code 10000.0?
+ total = float(total) / 10000.0
+ vji = vji / 10000.0
+ vij = vij / 10000.0
+
+ tp = 0
+ tc = 0
+ for c in range(self.num_classes):
+ tp += vji[c] * vij[c]
+ tc += self.confusion_matrix[c][c]
+
+ tc = tc / 10000.0
+ pe = tp / (total * total)
+ po = tc / total
+
+ kappa = (po - pe) / (1 - pe)
+ return kappa
diff --git a/contrib/RemoteSensing/utils/pretrain_weights.py b/contrib/RemoteSensing/utils/pretrain_weights.py
new file mode 100644
index 0000000000000000000000000000000000000000..e23686406897bc84e705640640bd7ee17d9d95ec
--- /dev/null
+++ b/contrib/RemoteSensing/utils/pretrain_weights.py
@@ -0,0 +1,11 @@
+import os.path as osp
+
+
+def get_pretrain_weights(flag, backbone, save_dir):
+ if flag is None:
+ return None
+ elif osp.isdir(flag):
+ return flag
+ else:
+ raise Exception(
+ "pretrain_weights need to be defined as directory path.")
diff --git a/contrib/RemoteSensing/utils/utils.py b/contrib/RemoteSensing/utils/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..ecce788190e594eef8c259db84e47e0959cae184
--- /dev/null
+++ b/contrib/RemoteSensing/utils/utils.py
@@ -0,0 +1,220 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import time
+import os
+import os.path as osp
+import numpy as np
+import six
+import yaml
+import math
+from . import logging
+
+
+def seconds_to_hms(seconds):
+ h = math.floor(seconds / 3600)
+ m = math.floor((seconds - h * 3600) / 60)
+ s = int(seconds - h * 3600 - m * 60)
+ hms_str = "{}:{}:{}".format(h, m, s)
+ return hms_str
+
+
+def setting_environ_flags():
+ if 'FLAGS_eager_delete_tensor_gb' not in os.environ:
+ os.environ['FLAGS_eager_delete_tensor_gb'] = '0.0'
+ if 'FLAGS_allocator_strategy' not in os.environ:
+ os.environ['FLAGS_allocator_strategy'] = 'auto_growth'
+ if "CUDA_VISIBLE_DEVICES" in os.environ:
+ if os.environ["CUDA_VISIBLE_DEVICES"].count("-1") > 0:
+ os.environ["CUDA_VISIBLE_DEVICES"] = ""
+
+
+def get_environ_info():
+ setting_environ_flags()
+ import paddle.fluid as fluid
+ info = dict()
+ info['place'] = 'cpu'
+ info['num'] = int(os.environ.get('CPU_NUM', 1))
+ if os.environ.get('CUDA_VISIBLE_DEVICES', None) != "":
+ if hasattr(fluid.core, 'get_cuda_device_count'):
+ gpu_num = 0
+ try:
+ gpu_num = fluid.core.get_cuda_device_count()
+ except:
+ os.environ['CUDA_VISIBLE_DEVICES'] = ''
+ pass
+ if gpu_num > 0:
+ info['place'] = 'cuda'
+ info['num'] = fluid.core.get_cuda_device_count()
+ return info
+
+
+def parse_param_file(param_file, return_shape=True):
+ from paddle.fluid.proto.framework_pb2 import VarType
+ f = open(param_file, 'rb')
+ version = np.fromstring(f.read(4), dtype='int32')
+ lod_level = np.fromstring(f.read(8), dtype='int64')
+ for i in range(int(lod_level)):
+ _size = np.fromstring(f.read(8), dtype='int64')
+ _ = f.read(_size)
+ version = np.fromstring(f.read(4), dtype='int32')
+ tensor_desc = VarType.TensorDesc()
+ tensor_desc_size = np.fromstring(f.read(4), dtype='int32')
+ tensor_desc.ParseFromString(f.read(int(tensor_desc_size)))
+ tensor_shape = tuple(tensor_desc.dims)
+ if return_shape:
+ f.close()
+ return tuple(tensor_desc.dims)
+ if tensor_desc.data_type != 5:
+ raise Exception(
+ "Unexpected data type while parse {}".format(param_file))
+ data_size = 4
+ for i in range(len(tensor_shape)):
+ data_size *= tensor_shape[i]
+ weight = np.fromstring(f.read(data_size), dtype='float32')
+ f.close()
+ return np.reshape(weight, tensor_shape)
+
+
+def fuse_bn_weights(exe, main_prog, weights_dir):
+ import paddle.fluid as fluid
+ logging.info("Try to fuse weights of batch_norm...")
+ bn_vars = list()
+ for block in main_prog.blocks:
+ ops = list(block.ops)
+ for op in ops:
+ if op.type == 'affine_channel':
+ scale_name = op.input('Scale')[0]
+ bias_name = op.input('Bias')[0]
+ prefix = scale_name[:-5]
+ mean_name = prefix + 'mean'
+ variance_name = prefix + 'variance'
+ if not osp.exists(osp.join(
+ weights_dir, mean_name)) or not osp.exists(
+ osp.join(weights_dir, variance_name)):
+ logging.info(
+ "There's no batch_norm weight found to fuse, skip fuse_bn."
+ )
+ return
+
+ bias = block.var(bias_name)
+ pretrained_shape = parse_param_file(
+ osp.join(weights_dir, bias_name))
+ actual_shape = tuple(bias.shape)
+ if pretrained_shape != actual_shape:
+ continue
+ bn_vars.append(
+ [scale_name, bias_name, mean_name, variance_name])
+ eps = 1e-5
+ for names in bn_vars:
+ scale_name, bias_name, mean_name, variance_name = names
+ scale = parse_param_file(
+ osp.join(weights_dir, scale_name), return_shape=False)
+ bias = parse_param_file(
+ osp.join(weights_dir, bias_name), return_shape=False)
+ mean = parse_param_file(
+ osp.join(weights_dir, mean_name), return_shape=False)
+ variance = parse_param_file(
+ osp.join(weights_dir, variance_name), return_shape=False)
+ bn_std = np.sqrt(np.add(variance, eps))
+ new_scale = np.float32(np.divide(scale, bn_std))
+ new_bias = bias - mean * new_scale
+ scale_tensor = fluid.global_scope().find_var(scale_name).get_tensor()
+ bias_tensor = fluid.global_scope().find_var(bias_name).get_tensor()
+ scale_tensor.set(new_scale, exe.place)
+ bias_tensor.set(new_bias, exe.place)
+ if len(bn_vars) == 0:
+ logging.info(
+ "There's no batch_norm weight found to fuse, skip fuse_bn.")
+ else:
+ logging.info("There's {} batch_norm ops been fused.".format(
+ len(bn_vars)))
+
+
+def load_pdparams(exe, main_prog, model_dir):
+ import paddle.fluid as fluid
+ from paddle.fluid.proto.framework_pb2 import VarType
+ from paddle.fluid.framework import Program
+
+ vars_to_load = list()
+ import pickle
+ with open(osp.join(model_dir, 'model.pdparams'), 'rb') as f:
+ params_dict = pickle.load(f) if six.PY2 else pickle.load(
+ f, encoding='latin1')
+ unused_vars = list()
+ for var in main_prog.list_vars():
+ if not isinstance(var, fluid.framework.Parameter):
+ continue
+ if var.name not in params_dict:
+ raise Exception("{} is not in saved model".format(var.name))
+ if var.shape != params_dict[var.name].shape:
+ unused_vars.append(var.name)
+ logging.warning(
+ "[SKIP] Shape of pretrained weight {} doesn't match.(Pretrained: {}, Actual: {})"
+ .format(var.name, params_dict[var.name].shape, var.shape))
+ continue
+ vars_to_load.append(var)
+ logging.debug("Weight {} will be load".format(var.name))
+ for var_name in unused_vars:
+ del params_dict[var_name]
+ fluid.io.set_program_state(main_prog, params_dict)
+
+ if len(vars_to_load) == 0:
+ logging.warning(
+ "There is no pretrain weights loaded, maybe you should check you pretrain model!"
+ )
+ else:
+ logging.info("There are {} varaibles in {} are loaded.".format(
+ len(vars_to_load), model_dir))
+
+
+def load_pretrain_weights(exe, main_prog, weights_dir, fuse_bn=False):
+ if not osp.exists(weights_dir):
+ raise Exception("Path {} not exists.".format(weights_dir))
+ if osp.exists(osp.join(weights_dir, "model.pdparams")):
+ return load_pdparams(exe, main_prog, weights_dir)
+ import paddle.fluid as fluid
+ vars_to_load = list()
+ for var in main_prog.list_vars():
+ if not isinstance(var, fluid.framework.Parameter):
+ continue
+ if not osp.exists(osp.join(weights_dir, var.name)):
+ logging.debug("[SKIP] Pretrained weight {}/{} doesn't exist".format(
+ weights_dir, var.name))
+ continue
+ pretrained_shape = parse_param_file(osp.join(weights_dir, var.name))
+ actual_shape = tuple(var.shape)
+ if pretrained_shape != actual_shape:
+ logging.warning(
+ "[SKIP] Shape of pretrained weight {}/{} doesn't match.(Pretrained: {}, Actual: {})"
+ .format(weights_dir, var.name, pretrained_shape, actual_shape))
+ continue
+ vars_to_load.append(var)
+ logging.debug("Weight {} will be load".format(var.name))
+
+ fluid.io.load_vars(
+ executor=exe,
+ dirname=weights_dir,
+ main_program=main_prog,
+ vars=vars_to_load)
+ if len(vars_to_load) == 0:
+ logging.warning(
+ "There is no pretrain weights loaded, maybe you should check you pretrain model!"
+ )
+ else:
+ logging.info("There are {} varaibles in {} are loaded.".format(
+ len(vars_to_load), weights_dir))
+ if fuse_bn:
+ fuse_bn_weights(exe, main_prog, weights_dir)
diff --git a/docs/config.md b/docs/config.md
index 67e1353a7d88994b584d5bd3da4dd36d81430a59..24d11bd4ced6d53a961ffb5d8bbd379e821def01 100644
--- a/docs/config.md
+++ b/docs/config.md
@@ -27,10 +27,10 @@ python pdseg/train.py BATCH_SIZE 1 --cfg configs/unet_optic.yaml
|--cfg|配置文件路径|ALL|None||
|--use_gpu|是否使用GPU进行训练|train/eval/vis|False||
|--use_mpio|是否使用多进程进行IO处理|train/eval|False|打开该开关会占用一定量的CPU内存,但是可以提高训练速度。 **NOTE:** windows平台下不支持该功能, 建议使用自定义数据初次训练时不打开,打开会导致数据读取异常不可见。 |
-|--use_tb|是否使用TensorBoard记录训练数据|train|False||
+|--use_vdl|是否使用VisualDL记录训练数据|train|False||
|--log_steps|训练日志的打印周期(单位为step)|train|10||
|--debug|是否打印debug信息|train|False|IOU等指标涉及到混淆矩阵的计算,会降低训练速度|
-|--tb_log_dir |TensorBoard的日志路径|train|None||
+|--vdl_log_dir |VisualDL的日志路径|train|None||
|--do_eval|是否在保存模型时进行效果评估 |train|False||
|--vis_dir|保存可视化图片的路径|vis|"visual"||
@@ -80,7 +80,7 @@ DATASET:
VAL_FILE_LIST: './dataset/cityscapes/val.list'
# 测试数据列表
TEST_FILE_LIST: './dataset/cityscapes/test.list'
- # Tensorboard 可视化的数据集
+ # VisualDL 可视化的数据集
VIS_FILE_LIST: None
# 类别数(需包括背景类)
NUM_CLASSES: 19
diff --git a/docs/configs/dataset_group.md b/docs/configs/dataset_group.md
index 917f01ade91598916a9399417a6c7ee62337dff5..7623c4f199db49571e15b7efef997d144c36301b 100644
--- a/docs/configs/dataset_group.md
+++ b/docs/configs/dataset_group.md
@@ -62,7 +62,7 @@ DATASET Group存放所有与数据集相关的配置
## `VIS_FILE_LIST`
-可视化列表,调用`pdseg/train.py`进行训练时,如果打开了--use_tb开关,则在每次模型保存的时候,会读取该列表中的图片进行可视化
+可视化列表,调用`pdseg/train.py`进行训练时,如果打开了--use_vdl开关,则在每次模型保存的时候,会读取该列表中的图片进行可视化
文件列表由多行组成,每一行的格式为
```
diff --git a/docs/imgs/tensorboard_image.JPG b/docs/imgs/tensorboard_image.JPG
deleted file mode 100644
index 140aa2a0ed6a9b1a2d0a98477685b9e6d434a113..0000000000000000000000000000000000000000
Binary files a/docs/imgs/tensorboard_image.JPG and /dev/null differ
diff --git a/docs/imgs/tensorboard_scalar.JPG b/docs/imgs/tensorboard_scalar.JPG
deleted file mode 100644
index 322c98dc8ba7e5ca96477f3dbe193a70a8cf4609..0000000000000000000000000000000000000000
Binary files a/docs/imgs/tensorboard_scalar.JPG and /dev/null differ
diff --git a/docs/imgs/visualdl_image.png b/docs/imgs/visualdl_image.png
new file mode 100644
index 0000000000000000000000000000000000000000..49ecc661739139e896413611f8daa1a7875b8dd2
Binary files /dev/null and b/docs/imgs/visualdl_image.png differ
diff --git a/docs/imgs/visualdl_scalar.png b/docs/imgs/visualdl_scalar.png
new file mode 100644
index 0000000000000000000000000000000000000000..196d0ab728f859b2d32960ba8f50df4eb6361556
Binary files /dev/null and b/docs/imgs/visualdl_scalar.png differ
diff --git a/docs/usage.md b/docs/usage.md
index 6da85a2de7b8be220e955a9e20a351c2d306b489..b07a01ebcb3a9a2527ae60a4105f6fd8410f17f7 100644
--- a/docs/usage.md
+++ b/docs/usage.md
@@ -49,8 +49,8 @@ export CUDA_VISIBLE_DEVICES=0
python pdseg/train.py --cfg configs/unet_optic.yaml \
--use_gpu \
--do_eval \
- --use_tb \
- --tb_log_dir train_log \
+ --use_vdl \
+ --vdl_log_dir train_log \
BATCH_SIZE 4 \
SOLVER.LR 0.001
@@ -70,22 +70,22 @@ export CUDA_VISIBLE_DEVICES=0,1,2
## 5.训练过程可视化
-当打开do_eval和use_tb两个开关后,我们可以通过TensorBoard查看边训练边评估的效果。
+训练过程可视化需要在启动训练脚本`train.py`时,打开`--do_eval`和`--use_vdl`两个开关,并设置日志保存目录`--vdl_log_dir`,然后便可以通过VisualDL查看边训练边评估的效果。
```shell
-tensorboard --logdir train_log --host {$HOST_IP} --port {$PORT}
+visualdl --logdir train_log --host {$HOST_IP} --port {$PORT}
```
NOTE:
1. 上述示例中,$HOST\_IP为机器IP地址,请替换为实际IP,$PORT请替换为可访问的端口。
2. 数据量较大时,前端加载速度会比较慢,请耐心等待。
-启动TensorBoard命令后,我们可以在浏览器中查看对应的训练数据。
+启动VisualDL命令后,我们可以在浏览器中查看对应的训练数据。
在`SCALAR`这个tab中,查看训练loss、iou、acc的变化趋势。
-
+
在`IMAGE`这个tab中,查看样本图片。
-
+
## 6.模型评估
训练完成后,我们可以通过eval.py来评估模型效果。由于我们设置的训练EPOCH数量为10,保存间隔为5,因此一共会产生2个定期保存的模型,加上最终保存的final模型,一共有3个模型。我们选择最后保存的模型进行效果的评估:
diff --git a/pdseg/loss.py b/pdseg/loss.py
index 14f1b3794b6c8a15f4da5cf2a838ab7339eeffc4..92638a9caaa15d749a8dfd3abc7cc8dec550b7fe 100644
--- a/pdseg/loss.py
+++ b/pdseg/loss.py
@@ -20,7 +20,11 @@ import importlib
from utils.config import cfg
-def softmax_with_loss(logit, label, ignore_mask=None, num_classes=2, weight=None):
+def softmax_with_loss(logit,
+ label,
+ ignore_mask=None,
+ num_classes=2,
+ weight=None):
ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
label = fluid.layers.elementwise_min(
label, fluid.layers.assign(np.array([num_classes - 1], dtype=np.int32)))
@@ -36,14 +40,18 @@ def softmax_with_loss(logit, label, ignore_mask=None, num_classes=2, weight=None
ignore_index=cfg.DATASET.IGNORE_INDEX,
return_softmax=True)
else:
- label_one_hot = fluid.layers.one_hot(input=label, depth=num_classes)
+ label_one_hot = fluid.one_hot(input=label, depth=num_classes)
if isinstance(weight, list):
- assert len(weight) == num_classes, "weight length must equal num of classes"
+ assert len(
+ weight
+ ) == num_classes, "weight length must equal num of classes"
weight = fluid.layers.assign(np.array([weight], dtype='float32'))
elif isinstance(weight, str):
- assert weight.lower() == 'dynamic', 'if weight is string, must be dynamic!'
+ assert weight.lower(
+ ) == 'dynamic', 'if weight is string, must be dynamic!'
tmp = []
- total_num = fluid.layers.cast(fluid.layers.shape(label)[0], 'float32')
+ total_num = fluid.layers.cast(
+ fluid.layers.shape(label)[0], 'float32')
for i in range(num_classes):
cls_pixel_num = fluid.layers.reduce_sum(label_one_hot[:, i])
ratio = total_num / (cls_pixel_num + 1)
@@ -53,9 +61,12 @@ def softmax_with_loss(logit, label, ignore_mask=None, num_classes=2, weight=None
elif isinstance(weight, fluid.layers.Variable):
pass
else:
- raise ValueError('Expect weight is a list, string or Variable, but receive {}'.format(type(weight)))
+ raise ValueError(
+ 'Expect weight is a list, string or Variable, but receive {}'.
+ format(type(weight)))
weight = fluid.layers.reshape(weight, [1, num_classes])
- weighted_label_one_hot = fluid.layers.elementwise_mul(label_one_hot, weight)
+ weighted_label_one_hot = fluid.layers.elementwise_mul(
+ label_one_hot, weight)
probs = fluid.layers.softmax(logit)
loss = fluid.layers.cross_entropy(
probs,
@@ -75,10 +86,11 @@ def softmax_with_loss(logit, label, ignore_mask=None, num_classes=2, weight=None
# to change, how to appicate ignore index and ignore mask
def dice_loss(logit, label, ignore_mask=None, epsilon=0.00001):
if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
- raise Exception("dice loss is only applicable to one channel classfication")
+ raise Exception(
+ "dice loss is only applicable to one channel classfication")
ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
- label = fluid.layers.transpose(label, [0, 2, 3, 1])
+ label = fluid.layers.transpose(label, [0, 2, 3, 1])
label = fluid.layers.cast(label, 'int64')
ignore_mask = fluid.layers.transpose(ignore_mask, [0, 2, 3, 1])
logit = fluid.layers.sigmoid(logit)
@@ -88,7 +100,7 @@ def dice_loss(logit, label, ignore_mask=None, epsilon=0.00001):
inse = fluid.layers.reduce_sum(logit * label, dim=reduce_dim)
dice_denominator = fluid.layers.reduce_sum(
logit, dim=reduce_dim) + fluid.layers.reduce_sum(
- label, dim=reduce_dim)
+ label, dim=reduce_dim)
dice_score = 1 - inse * 2 / (dice_denominator + epsilon)
label.stop_gradient = True
ignore_mask.stop_gradient = True
@@ -103,26 +115,31 @@ def bce_loss(logit, label, ignore_mask=None):
x=logit,
label=label,
ignore_index=cfg.DATASET.IGNORE_INDEX,
- normalize=True) # or False
+ normalize=True) # or False
loss = fluid.layers.reduce_sum(loss)
label.stop_gradient = True
ignore_mask.stop_gradient = True
return loss
-def multi_softmax_with_loss(logits, label, ignore_mask=None, num_classes=2, weight=None):
+def multi_softmax_with_loss(logits,
+ label,
+ ignore_mask=None,
+ num_classes=2,
+ weight=None):
if isinstance(logits, tuple):
avg_loss = 0
for i, logit in enumerate(logits):
- if label.shape[2] != logit.shape[2] or label.shape[3] != logit.shape[3]:
+ if label.shape[2] != logit.shape[2] or label.shape[
+ 3] != logit.shape[3]:
label = fluid.layers.resize_nearest(label, logit.shape[2:])
logit_mask = (label.astype('int32') !=
cfg.DATASET.IGNORE_INDEX).astype('int32')
- loss = softmax_with_loss(logit, label, logit_mask,
- num_classes)
+ loss = softmax_with_loss(logit, label, logit_mask, num_classes)
avg_loss += cfg.MODEL.MULTI_LOSS_WEIGHT[i] * loss
else:
- avg_loss = softmax_with_loss(logits, label, ignore_mask, num_classes, weight=weight)
+ avg_loss = softmax_with_loss(
+ logits, label, ignore_mask, num_classes, weight=weight)
return avg_loss
diff --git a/pdseg/tools/jingling2seg.py b/pdseg/tools/jingling2seg.py
index 28bce3b0436242f5174087c0852dde99a7878684..5f031823a14894bdf5244b4d42b4a7dd216b0619 100644
--- a/pdseg/tools/jingling2seg.py
+++ b/pdseg/tools/jingling2seg.py
@@ -17,10 +17,8 @@ from gray2pseudo_color import get_color_map_list
def parse_args():
parser = argparse.ArgumentParser(
- formatter_class=argparse.ArgumentDefaultsHelpFormatter
- )
- parser.add_argument('input_dir',
- help='input annotated directory')
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('input_dir', help='input annotated directory')
return parser.parse_args()
@@ -62,8 +60,7 @@ def main(args):
print('Generating dataset from:', label_file)
with open(label_file) as f:
base = osp.splitext(osp.basename(label_file))[0]
- out_png_file = osp.join(
- output_dir, base + '.png')
+ out_png_file = osp.join(output_dir, base + '.png')
data = json.load(f)
@@ -77,14 +74,20 @@ def main(args):
# convert jingling format to labelme format
points = []
for i in range(1, int(len(polygon) / 2) + 1):
- points.append([polygon['x' + str(i)], polygon['y' + str(i)]])
- shape = {'label': name, 'points': points, 'shape_type': 'polygon'}
+ points.append(
+ [polygon['x' + str(i)], polygon['y' + str(i)]])
+ shape = {
+ 'label': name,
+ 'points': points,
+ 'shape_type': 'polygon'
+ }
data_shapes.append(shape)
if 'size' not in data:
continue
data_size = data['size']
- img_shape = (data_size['height'], data_size['width'], data_size['depth'])
+ img_shape = (data_size['height'], data_size['width'],
+ data_size['depth'])
lbl = labelme.utils.shapes_to_label(
img_shape=img_shape,
@@ -102,8 +105,7 @@ def main(args):
else:
raise ValueError(
'[%s] Cannot save the pixel-wise class label as PNG. '
- 'Please consider using the .npy format.' % out_png_file
- )
+ 'Please consider using the .npy format.' % out_png_file)
if __name__ == '__main__':
diff --git a/pdseg/tools/labelme2seg.py b/pdseg/tools/labelme2seg.py
index 6ae3ad3a50a6df750ce321d94b7235ef57dcf80b..3f06e977e9a91418c4eeb060d50f4bd021a6f8ab 100755
--- a/pdseg/tools/labelme2seg.py
+++ b/pdseg/tools/labelme2seg.py
@@ -17,10 +17,8 @@ from gray2pseudo_color import get_color_map_list
def parse_args():
parser = argparse.ArgumentParser(
- formatter_class=argparse.ArgumentDefaultsHelpFormatter
- )
- parser.add_argument('input_dir',
- help='input annotated directory')
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('input_dir', help='input annotated directory')
return parser.parse_args()
@@ -61,8 +59,7 @@ def main(args):
print('Generating dataset from:', label_file)
with open(label_file) as f:
base = osp.splitext(osp.basename(label_file))[0]
- out_png_file = osp.join(
- output_dir, base + '.png')
+ out_png_file = osp.join(output_dir, base + '.png')
data = json.load(f)
@@ -85,8 +82,7 @@ def main(args):
else:
raise ValueError(
'[%s] Cannot save the pixel-wise class label as PNG. '
- 'Please consider using the .npy format.' % out_png_file
- )
+ 'Please consider using the .npy format.' % out_png_file)
if __name__ == '__main__':
diff --git a/pdseg/train.py b/pdseg/train.py
index 9e30c0f2050bd4987d84675985a86922e1c993c3..e1c498a4355950af155efc79e69a6788ad86e0ba 100644
--- a/pdseg/train.py
+++ b/pdseg/train.py
@@ -77,14 +77,14 @@ def parse_args():
help='debug mode, display detail information of training',
action='store_true')
parser.add_argument(
- '--use_tb',
- dest='use_tb',
- help='whether to record the data during training to Tensorboard',
+ '--use_vdl',
+ dest='use_vdl',
+ help='whether to record the data during training to VisualDL',
action='store_true')
parser.add_argument(
- '--tb_log_dir',
- dest='tb_log_dir',
- help='Tensorboard logging directory',
+ '--vdl_log_dir',
+ dest='vdl_log_dir',
+ help='VisualDL logging directory',
default=None,
type=str)
parser.add_argument(
@@ -354,17 +354,17 @@ def train(cfg):
fetch_list.extend([pred.name, grts.name, masks.name])
cm = ConfusionMatrix(cfg.DATASET.NUM_CLASSES, streaming=True)
- if args.use_tb:
- if not args.tb_log_dir:
- print_info("Please specify the log directory by --tb_log_dir.")
+ if args.use_vdl:
+ if not args.vdl_log_dir:
+ print_info("Please specify the log directory by --vdl_log_dir.")
exit(1)
- from tb_paddle import SummaryWriter
- log_writer = SummaryWriter(args.tb_log_dir)
+ from visualdl import LogWriter
+ log_writer = LogWriter(args.vdl_log_dir)
# trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
# num_trainers = int(os.environ.get('PADDLE_TRAINERS_NUM', 1))
- global_step = 0
+ step = 0
all_step = cfg.DATASET.TRAIN_TOTAL_IMAGES // cfg.BATCH_SIZE
if cfg.DATASET.TRAIN_TOTAL_IMAGES % cfg.BATCH_SIZE and drop_last != True:
all_step += 1
@@ -398,9 +398,9 @@ def train(cfg):
return_numpy=True)
cm.calculate(pred, grts, masks)
avg_loss += np.mean(np.array(loss))
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0:
+ if step % args.log_steps == 0:
speed = args.log_steps / timer.elapsed_time()
avg_loss /= args.log_steps
category_acc, mean_acc = cm.accuracy()
@@ -408,22 +408,22 @@ def train(cfg):
print_info((
"epoch={} step={} lr={:.5f} loss={:.4f} acc={:.5f} mIoU={:.5f} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss, mean_acc,
+ ).format(epoch, step, lr[0], avg_loss, mean_acc,
mean_iou, speed,
- calculate_eta(all_step - global_step, speed)))
+ calculate_eta(all_step - step, speed)))
print_info("Category IoU: ", category_iou)
print_info("Category Acc: ", category_acc)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Train/mean_iou', mean_iou,
- global_step)
+ step)
log_writer.add_scalar('Train/mean_acc', mean_acc,
- global_step)
+ step)
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
+ step)
log_writer.add_scalar('Train/lr', lr[0],
- global_step)
+ step)
log_writer.add_scalar('Train/step/sec', speed,
- global_step)
+ step)
sys.stdout.flush()
avg_loss = 0.0
cm.zero_matrix()
@@ -435,30 +435,30 @@ def train(cfg):
fetch_list=fetch_list,
return_numpy=True)
avg_loss += np.mean(np.array(loss))
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
+ if step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
avg_loss /= args.log_steps
speed = args.log_steps / timer.elapsed_time()
print((
"epoch={} step={} lr={:.5f} loss={:.4f} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss, speed,
- calculate_eta(all_step - global_step, speed)))
- if args.use_tb:
+ ).format(epoch, step, lr[0], avg_loss, speed,
+ calculate_eta(all_step - step, speed)))
+ if args.use_vdl:
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
+ step)
log_writer.add_scalar('Train/lr', lr[0],
- global_step)
+ step)
log_writer.add_scalar('Train/speed', speed,
- global_step)
+ step)
sys.stdout.flush()
avg_loss = 0.0
timer.restart()
# NOTE : used for benchmark, profiler tools
- if args.is_profiler and epoch == 1 and global_step == args.log_steps:
+ if args.is_profiler and epoch == 1 and step == args.log_steps:
profiler.start_profiler("All")
- elif args.is_profiler and epoch == 1 and global_step == args.log_steps + 5:
+ elif args.is_profiler and epoch == 1 and step == args.log_steps + 5:
profiler.stop_profiler("total", args.profiler_path)
return
@@ -479,11 +479,11 @@ def train(cfg):
ckpt_dir=ckpt_dir,
use_gpu=args.use_gpu,
use_mpio=args.use_mpio)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Evaluate/mean_iou', mean_iou,
- global_step)
+ step)
log_writer.add_scalar('Evaluate/mean_acc', mean_acc,
- global_step)
+ step)
if mean_iou > best_mIoU:
best_mIoU = mean_iou
@@ -493,8 +493,8 @@ def train(cfg):
os.path.join(cfg.TRAIN.MODEL_SAVE_DIR, 'best_model'),
mean_iou))
- # Use Tensorboard to visualize results
- if args.use_tb and cfg.DATASET.VIS_FILE_LIST is not None:
+ # Use VisualDL to visualize results
+ if args.use_vdl and cfg.DATASET.VIS_FILE_LIST is not None:
visualize(
cfg=cfg,
use_gpu=args.use_gpu,
diff --git a/pdseg/utils/config.py b/pdseg/utils/config.py
index 141b17ce24df1f78310975ef236290011ebffb56..e58bc39695f62c733c39dde9270d1d7fdd96a677 100644
--- a/pdseg/utils/config.py
+++ b/pdseg/utils/config.py
@@ -56,7 +56,7 @@ cfg.DATASET.VAL_TOTAL_IMAGES = 500
cfg.DATASET.TEST_FILE_LIST = './dataset/cityscapes/test.list'
# 测试数据数量
cfg.DATASET.TEST_TOTAL_IMAGES = 500
-# Tensorboard 可视化的数据集
+# VisualDL 可视化的数据集
cfg.DATASET.VIS_FILE_LIST = None
# 类别数(需包括背景类)
cfg.DATASET.NUM_CLASSES = 19
diff --git a/pdseg/vis.py b/pdseg/vis.py
index d94221c0be1a0b4abe241e75966215863d8fd35d..0dc30273b8bf8e7c61ffeb09336959e09949ac8d 100644
--- a/pdseg/vis.py
+++ b/pdseg/vis.py
@@ -162,18 +162,17 @@ def visualize(cfg,
img_cnt += 1
print("#{} visualize image path: {}".format(img_cnt, vis_fn))
- # Use Tensorboard to visualize image
+ # Use VisualDL to visualize image
if log_writer is not None:
# Calulate epoch from ckpt_dir folder name
epoch = int(os.path.split(ckpt_dir)[-1])
- print("Tensorboard visualization epoch", epoch)
+ print("VisualDL visualization epoch", epoch)
pred_mask_np = np.array(pred_mask.convert("RGB"))
log_writer.add_image(
"Predict/{}".format(img_name),
pred_mask_np,
- epoch,
- dataformats='HWC')
+ epoch)
# Original image
# BGR->RGB
img = cv2.imread(
@@ -181,8 +180,7 @@ def visualize(cfg,
log_writer.add_image(
"Images/{}".format(img_name),
img,
- epoch,
- dataformats='HWC')
+ epoch)
# add ground truth (label) images
grt = grts[i]
if grt is not None:
@@ -194,8 +192,7 @@ def visualize(cfg,
log_writer.add_image(
"Label/{}".format(img_name),
grt,
- epoch,
- dataformats='HWC')
+ epoch)
# If in local_test mode, only visualize 5 images just for testing
# procedure
diff --git a/requirements.txt b/requirements.txt
index 5a04fa523ced707663c197b6a51467552692ede5..f52068232f228c14e74ac7274902dcf0c296e687 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -2,11 +2,4 @@ pre-commit
yapf == 0.26.0
flake8
pyyaml >= 5.1
-tb-paddle
-tensorboard >= 1.15.0
-Pillow
-numpy
-six
-opencv-python
-tqdm
-requests
+visualdl == 2.0.0-alpha.2
diff --git a/slim/distillation/train_distill.py b/slim/distillation/train_distill.py
index e354107f173eea203d9df3f01f93fae62f41eabc..995cab1f11a8f6d88d19a7b10f9f768f4d6ccbf1 100644
--- a/slim/distillation/train_distill.py
+++ b/slim/distillation/train_distill.py
@@ -87,14 +87,14 @@ def parse_args():
help='debug mode, display detail information of training',
action='store_true')
parser.add_argument(
- '--use_tb',
- dest='use_tb',
- help='whether to record the data during training to Tensorboard',
+ '--use_vdl',
+ dest='use_vdl',
+ help='whether to record the data during training to VisualDL',
action='store_true')
parser.add_argument(
- '--tb_log_dir',
- dest='tb_log_dir',
- help='Tensorboard logging directory',
+ '--vdl_log_dir',
+ dest='vd;_log_dir',
+ help='VisualDL logging directory',
default=None,
type=str)
parser.add_argument(
@@ -409,17 +409,17 @@ def train(cfg):
fetch_list.extend([pred.name, grts.name, masks.name])
cm = ConfusionMatrix(cfg.DATASET.NUM_CLASSES, streaming=True)
- if args.use_tb:
- if not args.tb_log_dir:
- print_info("Please specify the log directory by --tb_log_dir.")
+ if args.use_vdl:
+ if not args.vdl_log_dir:
+ print_info("Please specify the log directory by --vdl_log_dir.")
exit(1)
- from tb_paddle import SummaryWriter
- log_writer = SummaryWriter(args.tb_log_dir)
+ from visualdl import LogWriter
+ log_writer = LogWriter(args.vdl_log_dir)
# trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
# num_trainers = int(os.environ.get('PADDLE_TRAINERS_NUM', 1))
- global_step = 0
+ step = 0
all_step = cfg.DATASET.TRAIN_TOTAL_IMAGES // cfg.BATCH_SIZE
if cfg.DATASET.TRAIN_TOTAL_IMAGES % cfg.BATCH_SIZE and drop_last != True:
all_step += 1
@@ -455,9 +455,9 @@ def train(cfg):
return_numpy=True)
cm.calculate(pred, grts, masks)
avg_loss += np.mean(np.array(loss))
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0:
+ if step % args.log_steps == 0:
speed = args.log_steps / timer.elapsed_time()
avg_loss /= args.log_steps
category_acc, mean_acc = cm.accuracy()
@@ -465,22 +465,22 @@ def train(cfg):
print_info((
"epoch={} step={} lr={:.5f} loss={:.4f} acc={:.5f} mIoU={:.5f} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss, mean_acc,
+ ).format(epoch, step, lr[0], avg_loss, mean_acc,
mean_iou, speed,
- calculate_eta(all_step - global_step, speed)))
+ calculate_eta(all_step - step, speed)))
print_info("Category IoU: ", category_iou)
print_info("Category Acc: ", category_acc)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Train/mean_iou', mean_iou,
- global_step)
+ step)
log_writer.add_scalar('Train/mean_acc', mean_acc,
- global_step)
+ step)
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
+ step)
log_writer.add_scalar('Train/lr', lr[0],
- global_step)
+ step)
log_writer.add_scalar('Train/step/sec', speed,
- global_step)
+ step)
sys.stdout.flush()
avg_loss = 0.0
cm.zero_matrix()
@@ -494,25 +494,25 @@ def train(cfg):
avg_loss += np.mean(np.array(loss))
avg_t_loss += np.mean(np.array(t_loss))
avg_d_loss += np.mean(np.array(d_loss))
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
+ if step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
avg_loss /= args.log_steps
avg_t_loss /= args.log_steps
avg_d_loss /= args.log_steps
speed = args.log_steps / timer.elapsed_time()
print((
"epoch={} step={} lr={:.5f} loss={:.4f} teacher loss={:.4f} distill loss={:.4f} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss,
+ ).format(epoch, step, lr[0], avg_loss,
avg_t_loss, avg_d_loss, speed,
- calculate_eta(all_step - global_step, speed)))
- if args.use_tb:
+ calculate_eta(all_step - step, speed)))
+ if args.use_vdl:
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
+ step)
log_writer.add_scalar('Train/lr', lr[0],
- global_step)
+ step)
log_writer.add_scalar('Train/speed', speed,
- global_step)
+ step)
sys.stdout.flush()
avg_loss = 0.0
avg_t_loss = 0.0
@@ -536,11 +536,11 @@ def train(cfg):
ckpt_dir=ckpt_dir,
use_gpu=args.use_gpu,
use_mpio=args.use_mpio)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Evaluate/mean_iou', mean_iou,
- global_step)
+ step)
log_writer.add_scalar('Evaluate/mean_acc', mean_acc,
- global_step)
+ step)
if mean_iou > best_mIoU:
best_mIoU = mean_iou
@@ -550,8 +550,8 @@ def train(cfg):
os.path.join(cfg.TRAIN.MODEL_SAVE_DIR, 'best_model'),
mean_iou))
- # Use Tensorboard to visualize results
- if args.use_tb and cfg.DATASET.VIS_FILE_LIST is not None:
+ # Use VisualDL to visualize results
+ if args.use_vdl and cfg.DATASET.VIS_FILE_LIST is not None:
visualize(
cfg=cfg,
use_gpu=args.use_gpu,
diff --git a/slim/nas/train_nas.py b/slim/nas/train_nas.py
index 6ab4d899dc2406275daf3fecd3738fb4b3b82c49..f4cd8f81b1f73b7d30ce948be700beba9932c314 100644
--- a/slim/nas/train_nas.py
+++ b/slim/nas/train_nas.py
@@ -87,14 +87,14 @@ def parse_args():
help='debug mode, display detail information of training',
action='store_true')
parser.add_argument(
- '--use_tb',
- dest='use_tb',
- help='whether to record the data during training to Tensorboard',
+ '--use_vdl',
+ dest='use_vdl',
+ help='whether to record the data during training to VisualDL',
action='store_true')
parser.add_argument(
- '--tb_log_dir',
- dest='tb_log_dir',
- help='Tensorboard logging directory',
+ '--vdl_log_dir',
+ dest='vdl_log_dir',
+ help='VisualDL logging directory',
default=None,
type=str)
parser.add_argument(
diff --git a/slim/prune/train_prune.py b/slim/prune/train_prune.py
index 05c599e3327728ee1ef5e3f2dea359ab9dab5834..6c41e74beb62423354445b45d250bb0f2f75b2d3 100644
--- a/slim/prune/train_prune.py
+++ b/slim/prune/train_prune.py
@@ -83,14 +83,14 @@ def parse_args():
help='debug mode, display detail information of training',
action='store_true')
parser.add_argument(
- '--use_tb',
- dest='use_tb',
- help='whether to record the data during training to Tensorboard',
+ '--use_vdl',
+ dest='use_vdl',
+ help='whether to record the data during training to VisualDL',
action='store_true')
parser.add_argument(
- '--tb_log_dir',
- dest='tb_log_dir',
- help='Tensorboard logging directory',
+ '--vdl_log_dir',
+ dest='vdl_log_dir',
+ help='VisualDL logging directory',
default=None,
type=str)
parser.add_argument(
@@ -335,13 +335,13 @@ def train(cfg):
fetch_list.extend([pred.name, grts.name, masks.name])
cm = ConfusionMatrix(cfg.DATASET.NUM_CLASSES, streaming=True)
- if args.use_tb:
- if not args.tb_log_dir:
- print_info("Please specify the log directory by --tb_log_dir.")
+ if args.use_vdl:
+ if not args.vdl_log_dir:
+ print_info("Please specify the log directory by --vdl_log_dir.")
exit(1)
- from tb_paddle import SummaryWriter
- log_writer = SummaryWriter(args.tb_log_dir)
+ from visualdl import LogWriter
+ log_writer = LogWriter(args.vdl_log_dir)
pruner = Pruner()
train_prog = pruner.prune(
@@ -357,7 +357,7 @@ def train(cfg):
exec_strategy=exec_strategy,
build_strategy=build_strategy)
- global_step = 0
+ step = 0
all_step = cfg.DATASET.TRAIN_TOTAL_IMAGES // cfg.BATCH_SIZE
if cfg.DATASET.TRAIN_TOTAL_IMAGES % cfg.BATCH_SIZE and drop_last != True:
all_step += 1
@@ -389,9 +389,9 @@ def train(cfg):
return_numpy=True)
cm.calculate(pred, grts, masks)
avg_loss += np.mean(np.array(loss))
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0:
+ if step % args.log_steps == 0:
speed = args.log_steps / timer.elapsed_time()
avg_loss /= args.log_steps
category_acc, mean_acc = cm.accuracy()
@@ -399,22 +399,22 @@ def train(cfg):
print_info((
"epoch={} step={} lr={:.5f} loss={:.4f} acc={:.5f} mIoU={:.5f} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss, mean_acc,
+ ).format(epoch, step, lr[0], avg_loss, mean_acc,
mean_iou, speed,
- calculate_eta(all_step - global_step, speed)))
+ calculate_eta(all_step - step, speed)))
print_info("Category IoU: ", category_iou)
print_info("Category Acc: ", category_acc)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Train/mean_iou', mean_iou,
- global_step)
+ step)
log_writer.add_scalar('Train/mean_acc', mean_acc,
- global_step)
+ step)
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
+ step)
log_writer.add_scalar('Train/lr', lr[0],
- global_step)
+ step)
log_writer.add_scalar('Train/step/sec', speed,
- global_step)
+ step)
sys.stdout.flush()
avg_loss = 0.0
cm.zero_matrix()
@@ -426,22 +426,22 @@ def train(cfg):
fetch_list=fetch_list,
return_numpy=True)
avg_loss += np.mean(np.array(loss))
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
+ if step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
avg_loss /= args.log_steps
speed = args.log_steps / timer.elapsed_time()
print((
"epoch={} step={} lr={:.5f} loss={:.4f} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss, speed,
- calculate_eta(all_step - global_step, speed)))
- if args.use_tb:
+ ).format(epoch, step, lr[0], avg_loss, speed,
+ calculate_eta(all_step - step, speed)))
+ if args.use_vdl:
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
+ step)
log_writer.add_scalar('Train/lr', lr[0],
- global_step)
+ step)
log_writer.add_scalar('Train/speed', speed,
- global_step)
+ step)
sys.stdout.flush()
avg_loss = 0.0
timer.restart()
@@ -463,14 +463,14 @@ def train(cfg):
ckpt_dir=ckpt_dir,
use_gpu=args.use_gpu,
use_mpio=args.use_mpio)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Evaluate/mean_iou', mean_iou,
- global_step)
+ step)
log_writer.add_scalar('Evaluate/mean_acc', mean_acc,
- global_step)
+ step)
- # Use Tensorboard to visualize results
- if args.use_tb and cfg.DATASET.VIS_FILE_LIST is not None:
+ # Use VisualDL to visualize results
+ if args.use_vdl and cfg.DATASET.VIS_FILE_LIST is not None:
visualize(
cfg=cfg,
use_gpu=args.use_gpu,
-
-
diff --git a/contrib/RealTimeHumanSeg/cpp/CMakeLists.txt b/contrib/RealTimeHumanSeg/cpp/CMakeLists.txt
deleted file mode 100644
index 5a7b89acc41da5576a0f0ead7205385feabf5dab..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/CMakeLists.txt
+++ /dev/null
@@ -1,221 +0,0 @@
-cmake_minimum_required(VERSION 3.0)
-project(PaddleMaskDetector CXX C)
-
-option(WITH_MKL "Compile demo with MKL/OpenBlas support,defaultuseMKL." ON)
-option(WITH_GPU "Compile demo with GPU/CPU, default use CPU." ON)
-option(WITH_STATIC_LIB "Compile demo with static/shared library, default use static." ON)
-option(USE_TENSORRT "Compile demo with TensorRT." OFF)
-
-SET(PADDLE_DIR "" CACHE PATH "Location of libraries")
-SET(OPENCV_DIR "" CACHE PATH "Location of libraries")
-SET(CUDA_LIB "" CACHE PATH "Location of libraries")
-
-macro(safe_set_static_flag)
- foreach(flag_var
- CMAKE_CXX_FLAGS CMAKE_CXX_FLAGS_DEBUG CMAKE_CXX_FLAGS_RELEASE
- CMAKE_CXX_FLAGS_MINSIZEREL CMAKE_CXX_FLAGS_RELWITHDEBINFO)
- if(${flag_var} MATCHES "/MD")
- string(REGEX REPLACE "/MD" "/MT" ${flag_var} "${${flag_var}}")
- endif(${flag_var} MATCHES "/MD")
- endforeach(flag_var)
-endmacro()
-
-if (WITH_MKL)
- ADD_DEFINITIONS(-DUSE_MKL)
-endif()
-
-if (NOT DEFINED PADDLE_DIR OR ${PADDLE_DIR} STREQUAL "")
- message(FATAL_ERROR "please set PADDLE_DIR with -DPADDLE_DIR=/path/paddle_influence_dir")
-endif()
-
-if (NOT DEFINED OPENCV_DIR OR ${OPENCV_DIR} STREQUAL "")
- message(FATAL_ERROR "please set OPENCV_DIR with -DOPENCV_DIR=/path/opencv")
-endif()
-
-include_directories("${CMAKE_SOURCE_DIR}/")
-include_directories("${PADDLE_DIR}/")
-include_directories("${PADDLE_DIR}/third_party/install/protobuf/include")
-include_directories("${PADDLE_DIR}/third_party/install/glog/include")
-include_directories("${PADDLE_DIR}/third_party/install/gflags/include")
-include_directories("${PADDLE_DIR}/third_party/install/xxhash/include")
-if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/include")
- include_directories("${PADDLE_DIR}/third_party/install/snappy/include")
-endif()
-if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/include")
- include_directories("${PADDLE_DIR}/third_party/install/snappystream/include")
-endif()
-include_directories("${PADDLE_DIR}/third_party/install/zlib/include")
-include_directories("${PADDLE_DIR}/third_party/boost")
-include_directories("${PADDLE_DIR}/third_party/eigen3")
-
-if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
- link_directories("${PADDLE_DIR}/third_party/install/snappy/lib")
-endif()
-if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
- link_directories("${PADDLE_DIR}/third_party/install/snappystream/lib")
-endif()
-
-link_directories("${PADDLE_DIR}/third_party/install/zlib/lib")
-link_directories("${PADDLE_DIR}/third_party/install/protobuf/lib")
-link_directories("${PADDLE_DIR}/third_party/install/glog/lib")
-link_directories("${PADDLE_DIR}/third_party/install/gflags/lib")
-link_directories("${PADDLE_DIR}/third_party/install/xxhash/lib")
-link_directories("${PADDLE_DIR}/paddle/lib/")
-link_directories("${CMAKE_CURRENT_BINARY_DIR}")
-if (WIN32)
- include_directories("${PADDLE_DIR}/paddle/fluid/inference")
- include_directories("${PADDLE_DIR}/paddle/include")
- link_directories("${PADDLE_DIR}/paddle/fluid/inference")
- include_directories("${OPENCV_DIR}/build/include")
- include_directories("${OPENCV_DIR}/opencv/build/include")
- link_directories("${OPENCV_DIR}/build/x64/vc14/lib")
-else ()
- find_package(OpenCV REQUIRED PATHS ${OPENCV_DIR}/share/OpenCV NO_DEFAULT_PATH)
- include_directories("${PADDLE_DIR}/paddle/include")
- link_directories("${PADDLE_DIR}/paddle/lib")
- include_directories(${OpenCV_INCLUDE_DIRS})
-endif ()
-
-if (WIN32)
- add_definitions("/DGOOGLE_GLOG_DLL_DECL=")
- set(CMAKE_C_FLAGS_DEBUG "${CMAKE_C_FLAGS_DEBUG} /bigobj /MTd")
- set(CMAKE_C_FLAGS_RELEASE "${CMAKE_C_FLAGS_RELEASE} /bigobj /MT")
- set(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} /bigobj /MTd")
- set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} /bigobj /MT")
- if (WITH_STATIC_LIB)
- safe_set_static_flag()
- add_definitions(-DSTATIC_LIB)
- endif()
-else()
- set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -g -o2 -fopenmp -std=c++11")
- set(CMAKE_STATIC_LIBRARY_PREFIX "")
-endif()
-
-# TODO let users define cuda lib path
-if (WITH_GPU)
- if (NOT DEFINED CUDA_LIB OR ${CUDA_LIB} STREQUAL "")
- message(FATAL_ERROR "please set CUDA_LIB with -DCUDA_LIB=/path/cuda-8.0/lib64")
- endif()
- if (NOT WIN32)
- if (NOT DEFINED CUDNN_LIB)
- message(FATAL_ERROR "please set CUDNN_LIB with -DCUDNN_LIB=/path/cudnn_v7.4/cuda/lib64")
- endif()
- endif(NOT WIN32)
-endif()
-
-
-if (NOT WIN32)
- if (USE_TENSORRT AND WITH_GPU)
- include_directories("${PADDLE_DIR}/third_party/install/tensorrt/include")
- link_directories("${PADDLE_DIR}/third_party/install/tensorrt/lib")
- endif()
-endif(NOT WIN32)
-
-if (NOT WIN32)
- set(NGRAPH_PATH "${PADDLE_DIR}/third_party/install/ngraph")
- if(EXISTS ${NGRAPH_PATH})
- include(GNUInstallDirs)
- include_directories("${NGRAPH_PATH}/include")
- link_directories("${NGRAPH_PATH}/${CMAKE_INSTALL_LIBDIR}")
- set(NGRAPH_LIB ${NGRAPH_PATH}/${CMAKE_INSTALL_LIBDIR}/libngraph${CMAKE_SHARED_LIBRARY_SUFFIX})
- endif()
-endif()
-
-if(WITH_MKL)
- include_directories("${PADDLE_DIR}/third_party/install/mklml/include")
- if (WIN32)
- set(MATH_LIB ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.lib
- ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.lib)
- else ()
- set(MATH_LIB ${PADDLE_DIR}/third_party/install/mklml/lib/libmklml_intel${CMAKE_SHARED_LIBRARY_SUFFIX}
- ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5${CMAKE_SHARED_LIBRARY_SUFFIX})
- execute_process(COMMAND cp -r ${PADDLE_DIR}/third_party/install/mklml/lib/libmklml_intel${CMAKE_SHARED_LIBRARY_SUFFIX} /usr/lib)
- endif ()
- set(MKLDNN_PATH "${PADDLE_DIR}/third_party/install/mkldnn")
- if(EXISTS ${MKLDNN_PATH})
- include_directories("${MKLDNN_PATH}/include")
- if (WIN32)
- set(MKLDNN_LIB ${MKLDNN_PATH}/lib/mkldnn.lib)
- else ()
- set(MKLDNN_LIB ${MKLDNN_PATH}/lib/libmkldnn.so.0)
- endif ()
- endif()
-else()
- set(MATH_LIB ${PADDLE_DIR}/third_party/install/openblas/lib/libopenblas${CMAKE_STATIC_LIBRARY_SUFFIX})
-endif()
-
-if (WIN32)
- if(EXISTS "${PADDLE_DIR}/paddle/fluid/inference/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX}")
- set(DEPS
- ${PADDLE_DIR}/paddle/fluid/inference/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX})
- else()
- set(DEPS
- ${PADDLE_DIR}/paddle/lib/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX})
- endif()
-endif()
-
-if(WITH_STATIC_LIB)
- set(DEPS
- ${PADDLE_DIR}/paddle/lib/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX})
-else()
- set(DEPS
- ${PADDLE_DIR}/paddle/lib/libpaddle_fluid${CMAKE_SHARED_LIBRARY_SUFFIX})
-endif()
-
-if (NOT WIN32)
- set(DEPS ${DEPS}
- ${MATH_LIB} ${MKLDNN_LIB}
- glog gflags protobuf z xxhash
- )
- if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
- set(DEPS ${DEPS} snappystream)
- endif()
- if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
- set(DEPS ${DEPS} snappy)
- endif()
-else()
- set(DEPS ${DEPS}
- ${MATH_LIB} ${MKLDNN_LIB}
- opencv_world346 glog gflags_static libprotobuf zlibstatic xxhash)
- set(DEPS ${DEPS} libcmt shlwapi)
- if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
- set(DEPS ${DEPS} snappy)
- endif()
- if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
- set(DEPS ${DEPS} snappystream)
- endif()
-endif(NOT WIN32)
-
-if(WITH_GPU)
- if(NOT WIN32)
- if (USE_TENSORRT)
- set(DEPS ${DEPS} ${PADDLE_DIR}/third_party/install/tensorrt/lib/libnvinfer${CMAKE_STATIC_LIBRARY_SUFFIX})
- set(DEPS ${DEPS} ${PADDLE_DIR}/third_party/install/tensorrt/lib/libnvinfer_plugin${CMAKE_STATIC_LIBRARY_SUFFIX})
- endif()
- set(DEPS ${DEPS} ${CUDA_LIB}/libcudart${CMAKE_SHARED_LIBRARY_SUFFIX})
- set(DEPS ${DEPS} ${CUDNN_LIB}/libcudnn${CMAKE_SHARED_LIBRARY_SUFFIX})
- else()
- set(DEPS ${DEPS} ${CUDA_LIB}/cudart${CMAKE_STATIC_LIBRARY_SUFFIX} )
- set(DEPS ${DEPS} ${CUDA_LIB}/cublas${CMAKE_STATIC_LIBRARY_SUFFIX} )
- set(DEPS ${DEPS} ${CUDA_LIB}/cudnn${CMAKE_STATIC_LIBRARY_SUFFIX})
- endif()
-endif()
-
-if (NOT WIN32)
- set(EXTERNAL_LIB "-ldl -lrt -lgomp -lz -lm -lpthread")
- set(DEPS ${DEPS} ${EXTERNAL_LIB} ${OpenCV_LIBS})
-endif()
-
-add_executable(main main.cc humanseg.cc humanseg_postprocess.cc)
-target_link_libraries(main ${DEPS})
-
-if (WIN32)
- add_custom_command(TARGET main POST_BUILD
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.dll ./mklml.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.dll ./libiomp5md.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mkldnn/lib/mkldnn.dll ./mkldnn.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.dll ./release/mklml.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.dll ./release/libiomp5md.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mkldnn/lib/mkldnn.dll ./release/mkldnn.dll
- )
-endif()
diff --git a/contrib/RealTimeHumanSeg/cpp/CMakeSettings.json b/contrib/RealTimeHumanSeg/cpp/CMakeSettings.json
deleted file mode 100644
index 87cbe721d98dc9a12079d2eb79c77e50d0e0408a..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/CMakeSettings.json
+++ /dev/null
@@ -1,42 +0,0 @@
-{
- "configurations": [
- {
- "name": "x64-Release",
- "generator": "Ninja",
- "configurationType": "RelWithDebInfo",
- "inheritEnvironments": [ "msvc_x64_x64" ],
- "buildRoot": "${projectDir}\\out\\build\\${name}",
- "installRoot": "${projectDir}\\out\\install\\${name}",
- "cmakeCommandArgs": "",
- "buildCommandArgs": "-v",
- "ctestCommandArgs": "",
- "variables": [
- {
- "name": "CUDA_LIB",
- "value": "D:/projects/packages/cuda10_0/lib64",
- "type": "PATH"
- },
- {
- "name": "CUDNN_LIB",
- "value": "D:/projects/packages/cuda10_0/lib64",
- "type": "PATH"
- },
- {
- "name": "OPENCV_DIR",
- "value": "D:/projects/packages/opencv3_4_6",
- "type": "PATH"
- },
- {
- "name": "PADDLE_DIR",
- "value": "D:/projects/packages/fluid_inference1_6_1",
- "type": "PATH"
- },
- {
- "name": "CMAKE_BUILD_TYPE",
- "value": "Release",
- "type": "STRING"
- }
- ]
- }
- ]
-}
\ No newline at end of file
diff --git a/contrib/RealTimeHumanSeg/cpp/README.md b/contrib/RealTimeHumanSeg/cpp/README.md
deleted file mode 100644
index 5f1184130cb4ebf18fd10f30378caa8c98bb8083..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/README.md
+++ /dev/null
@@ -1,15 +0,0 @@
-# 视频实时图像分割模型C++预测部署
-
-本文档主要介绍实时图像分割模型如何在`Windows`和`Linux`上完成基于`C++`的预测部署。
-
-## C++预测部署编译
-
-### 1. 下载模型
-点击右边下载:[模型下载地址](https://paddleseg.bj.bcebos.com/deploy/models/humanseg_paddleseg_int8.zip)
-
-模型文件路径将做为预测时的输入参数,请解压到合适的目录位置。
-
-### 2. 编译
-本项目支持在Windows和Linux上编译并部署C++项目,不同平台的编译请参考:
-- [Linux 编译](./docs/linux_build.md)
-- [Windows 使用 Visual Studio 2019编译](./docs/windows_build.md)
diff --git a/contrib/RealTimeHumanSeg/cpp/docs/linux_build.md b/contrib/RealTimeHumanSeg/cpp/docs/linux_build.md
deleted file mode 100644
index 823ff3ae7cc6b16d9f5696924ae5def746bc8892..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/docs/linux_build.md
+++ /dev/null
@@ -1,86 +0,0 @@
-# 视频实时人像分割模型Linux平台C++预测部署
-
-
-## 1. 系统和软件依赖
-
-### 1.1 操作系统及硬件要求
-
-- Ubuntu 14.04 或者 16.04 (其它平台未测试)
-- GCC版本4.8.5 ~ 4.9.2
-- 支持Intel MKL-DNN的CPU
-- NOTE: 如需在Nvidia GPU运行,请自行安装CUDA 9.0 / 10.0 + CUDNN 7.3+ (不支持9.1/10.1版本的CUDA)
-
-### 1.2 下载PaddlePaddle C++预测库
-
-PaddlePaddle C++ 预测库主要分为CPU版本和GPU版本。
-
-其中,GPU 版本支持`CUDA 10.0` 和 `CUDA 9.0`:
-
-以下为各版本C++预测库的下载链接:
-
-| 版本 | 链接 |
-| ---- | ---- |
-| CPU+MKL版 | [fluid_inference.tgz](https://paddle-inference-lib.bj.bcebos.com/1.6.3-cpu-avx-mkl/fluid_inference.tgz) |
-| CUDA9.0+MKL 版 | [fluid_inference.tgz](https://paddle-inference-lib.bj.bcebos.com/1.6.3-gpu-cuda9-cudnn7-avx-mkl/fluid_inference.tgz) |
-| CUDA10.0+MKL 版 | [fluid_inference.tgz](https://paddle-inference-lib.bj.bcebos.com/1.6.3-gpu-cuda10-cudnn7-avx-mkl/fluid_inference.tgz) |
-
-更多可用预测库版本,请点击以下链接下载:[C++预测库下载列表](https://paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/deploy/inference/build_and_install_lib_cn.html)
-
-
-下载并解压, 解压后的 `fluid_inference`目录包含的内容:
-```
-fluid_inference
-├── paddle # paddle核心库和头文件
-|
-├── third_party # 第三方依赖库和头文件
-|
-└── version.txt # 版本和编译信息
-```
-
-**注意:** 请把解压后的目录放到合适的路径,**该目录路径后续会作为编译依赖**使用。
-
-## 2. 编译与运行
-
-### 2.1 配置编译脚本
-
-打开文件`linux_build.sh`, 看到以下内容:
-```shell
-# 是否使用GPU
-WITH_GPU=OFF
-# Paddle 预测库路径
-PADDLE_DIR=/PATH/TO/fluid_inference/
-# CUDA库路径, 仅 WITH_GPU=ON 时设置
-CUDA_LIB=/PATH/TO/CUDA_LIB64/
-# CUDNN库路径,仅 WITH_GPU=ON 且 CUDA_LIB有效时设置
-CUDNN_LIB=/PATH/TO/CUDNN_LIB64/
-# OpenCV 库路径, 无须设置
-OPENCV_DIR=/PATH/TO/opencv3gcc4.8/
-
-cd build
-cmake .. \
- -DWITH_GPU=${WITH_GPU} \
- -DPADDLE_DIR=${PADDLE_DIR} \
- -DCUDA_LIB=${CUDA_LIB} \
- -DCUDNN_LIB=${CUDNN_LIB} \
- -DOPENCV_DIR=${OPENCV_DIR} \
- -DWITH_STATIC_LIB=OFF
-make -j4
-```
-
-把上述参数根据实际情况做修改后,运行脚本编译程序:
-```shell
-sh linux_build.sh
-```
-
-### 2.2. 运行和可视化
-
-可执行文件有 **2** 个参数,第一个是前面导出的`inference_model`路径,第二个是需要预测的视频路径。
-
-示例:
-```shell
-./build/main ./models /PATH/TO/TEST_VIDEO
-```
-
-点击下载[测试视频](https://paddleseg.bj.bcebos.com/deploy/data/test.avi)
-
-预测的结果保存在视频文件`result.avi`中。
diff --git a/contrib/RealTimeHumanSeg/cpp/docs/windows_build.md b/contrib/RealTimeHumanSeg/cpp/docs/windows_build.md
deleted file mode 100644
index 6937dbcff4f55c5a085aa9d0bd2674c04f3ac8e5..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/docs/windows_build.md
+++ /dev/null
@@ -1,83 +0,0 @@
-# 视频实时人像分割模型Windows平台C++预测部署
-
-## 1. 系统和软件依赖
-
-### 1.1 基础依赖
-
-- Windows 10 / Windows Server 2016+ (其它平台未测试)
-- Visual Studio 2019 (社区版或专业版均可)
-- CUDA 9.0 / 10.0 + CUDNN 7.3+ (不支持9.1/10.1版本的CUDA)
-
-### 1.2 下载OpenCV并设置环境变量
-
-- 在OpenCV官网下载适用于Windows平台的3.4.6版本: [点击下载](https://sourceforge.net/projects/opencvlibrary/files/3.4.6/opencv-3.4.6-vc14_vc15.exe/download)
-- 运行下载的可执行文件,将OpenCV解压至合适目录,这里以解压到`D:\projects\opencv`为例
-- 把OpenCV动态库加入到系统环境变量
- - 此电脑(我的电脑)->属性->高级系统设置->环境变量
- - 在系统变量中找到Path(如没有,自行创建),并双击编辑
- - 新建,将opencv路径填入并保存,如D:\projects\opencv\build\x64\vc14\bin
-
-**注意:** `OpenCV`的解压目录后续将做为编译配置项使用,所以请放置合适的目录中。
-
-### 1.3 下载PaddlePaddle C++ 预测库
-
-`PaddlePaddle` **C++ 预测库** 主要分为`CPU`和`GPU`版本, 其中`GPU版本`提供`CUDA 9.0` 和 `CUDA 10.0` 支持。
-
-常用的版本如下:
-
-| 版本 | 链接 |
-| ---- | ---- |
-| CPU+MKL版 | [fluid_inference_install_dir.zip](https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/cpu/fluid_inference_install_dir.zip) |
-| CUDA9.0+MKL 版 | [fluid_inference_install_dir.zip](https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/post97/fluid_inference_install_dir.zip) |
-| CUDA10.0+MKL 版 | [fluid_inference_install_dir.zip](https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/post107/fluid_inference_install_dir.zip) |
-
-更多不同平台的可用预测库版本,请[点击查看](https://paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/deploy/inference/windows_cpp_inference.html) 选择适合你的版本。
-
-
-下载并解压, 解压后的 `fluid_inference`目录包含的内容:
-```
-fluid_inference_install_dir
-├── paddle # paddle核心库和头文件
-|
-├── third_party # 第三方依赖库和头文件
-|
-└── version.txt # 版本和编译信息
-```
-
-**注意:** 这里的`fluid_inference_install_dir` 目录所在路径,将用于后面的编译参数设置,请放置在合适的位置。
-
-## 2. Visual Studio 2019 编译
-
-- 2.1 打开Visual Studio 2019 Community,点击`继续但无需代码`, 如下图:
-
-
-- 2.2 点击 `文件`->`打开`->`CMake`, 如下图:
-
-
-- 2.3 选择本项目根目录`CMakeList.txt`文件打开, 如下图:
-
-
-- 2.4 点击:`项目`->`PaddleMaskDetector的CMake设置`
-
-
-- 2.5 点击浏览设置`OPENCV_DIR`, `CUDA_LIB` 和 `PADDLE_DIR` 3个编译依赖库的位置, 设置完成后点击`保存并生成CMake缓存并加载变量`
-
-
-- 2.6 点击`生成`->`全部生成` 编译项目
-
-
-## 3. 运行程序
-
-成功编译后, 产出的可执行文件在项目子目录`out\build\x64-Release`目录, 按以下步骤运行代码:
-
-- 打开`cmd`切换至该目录
-- 运行以下命令传入模型路径与测试视频
-
-```shell
-main.exe ./models/ ./data/test.avi
-```
-第一个参数即人像分割预测模型的路径,第二个参数即要预测的视频。
-
-点击下载[测试视频](https://paddleseg.bj.bcebos.com/deploy/data/test.avi)
-
-运行后,预测结果保存在文件`result.avi`中。
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg.cc b/contrib/RealTimeHumanSeg/cpp/humanseg.cc
deleted file mode 100644
index b81c81200064f6191e18cdb39fc8d6414aa5fe9d..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg.cc
+++ /dev/null
@@ -1,132 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-# include "humanseg.h"
-# include "humanseg_postprocess.h"
-
-// Normalize the image by (pix - mean) * scale
-void NormalizeImage(
- const std::vector &mean,
- const std::vector &scale,
- cv::Mat& im, // NOLINT
- float* input_buffer) {
- int height = im.rows;
- int width = im.cols;
- int stride = width * height;
- for (int h = 0; h < height; h++) {
- for (int w = 0; w < width; w++) {
- int base = h * width + w;
- input_buffer[base + 0 * stride] =
- (im.at(h, w)[0] - mean[0]) * scale[0];
- input_buffer[base + 1 * stride] =
- (im.at(h, w)[1] - mean[1]) * scale[1];
- input_buffer[base + 2 * stride] =
- (im.at(h, w)[2] - mean[2]) * scale[2];
- }
- }
-}
-
-// Load Model and return model predictor
-void LoadModel(
- const std::string& model_dir,
- bool use_gpu,
- std::unique_ptr* predictor) {
- // Config the model info
- paddle::AnalysisConfig config;
- auto prog_file = model_dir + "/__model__";
- auto params_file = model_dir + "/__params__";
- config.SetModel(prog_file, params_file);
- if (use_gpu) {
- config.EnableUseGpu(100, 0);
- } else {
- config.DisableGpu();
- }
- config.SwitchUseFeedFetchOps(false);
- config.SwitchSpecifyInputNames(true);
- // Memory optimization
- config.EnableMemoryOptim();
- *predictor = std::move(CreatePaddlePredictor(config));
-}
-
-void HumanSeg::Preprocess(const cv::Mat& image_mat) {
- // Clone the image : keep the original mat for postprocess
- cv::Mat im = image_mat.clone();
- auto eval_wh = cv::Size(eval_size_[0], eval_size_[1]);
- cv::resize(im, im, eval_wh, 0.f, 0.f, cv::INTER_LINEAR);
-
- im.convertTo(im, CV_32FC3, 1.0);
- int rc = im.channels();
- int rh = im.rows;
- int rw = im.cols;
- input_shape_ = {1, rc, rh, rw};
- input_data_.resize(1 * rc * rh * rw);
- float* buffer = input_data_.data();
- NormalizeImage(mean_, scale_, im, input_data_.data());
-}
-
-cv::Mat HumanSeg::Postprocess(const cv::Mat& im) {
- int h = input_shape_[2];
- int w = input_shape_[3];
- scoremap_data_.resize(3 * h * w * sizeof(float));
- float* base = output_data_.data() + h * w;
- for (int i = 0; i < h * w; ++i) {
- scoremap_data_[i] = uchar(base[i] * 255);
- }
-
- cv::Mat im_scoremap = cv::Mat(h, w, CV_8UC1);
- im_scoremap.data = scoremap_data_.data();
- cv::resize(im_scoremap, im_scoremap, cv::Size(im.cols, im.rows));
- im_scoremap.convertTo(im_scoremap, CV_32FC1, 1 / 255.0);
-
- float* pblob = reinterpret_cast(im_scoremap.data);
- int out_buff_capacity = 10 * im.cols * im.rows * sizeof(float);
- segout_data_.resize(out_buff_capacity);
- unsigned char* seg_result = segout_data_.data();
- MergeProcess(im.data, pblob, im.rows, im.cols, seg_result);
- cv::Mat seg_mat(im.rows, im.cols, CV_8UC1, seg_result);
- cv::resize(seg_mat, seg_mat, cv::Size(im.cols, im.rows));
- cv::GaussianBlur(seg_mat, seg_mat, cv::Size(5, 5), 0, 0);
- float fg_threshold = 0.8;
- float bg_threshold = 0.4;
- cv::Mat show_seg_mat;
- seg_mat.convertTo(seg_mat, CV_32FC1, 1 / 255.0);
- ThresholdMask(seg_mat, fg_threshold, bg_threshold, show_seg_mat);
- auto out_im = MergeSegMat(show_seg_mat, im);
- return out_im;
-}
-
-cv::Mat HumanSeg::Predict(const cv::Mat& im) {
- // Preprocess image
- Preprocess(im);
- // Prepare input tensor
- auto input_names = predictor_->GetInputNames();
- auto in_tensor = predictor_->GetInputTensor(input_names[0]);
- in_tensor->Reshape(input_shape_);
- in_tensor->copy_from_cpu(input_data_.data());
- // Run predictor
- predictor_->ZeroCopyRun();
- // Get output tensor
- auto output_names = predictor_->GetOutputNames();
- auto out_tensor = predictor_->GetOutputTensor(output_names[0]);
- auto output_shape = out_tensor->shape();
- // Calculate output length
- int output_size = 1;
- for (int j = 0; j < output_shape.size(); ++j) {
- output_size *= output_shape[j];
- }
- output_data_.resize(output_size);
- out_tensor->copy_to_cpu(output_data_.data());
- // Postprocessing result
- return Postprocess(im);
-}
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg.h b/contrib/RealTimeHumanSeg/cpp/humanseg.h
deleted file mode 100644
index edaf825f713847a3b2c8bf5bae3a36de6ec03395..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg.h
+++ /dev/null
@@ -1,66 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#pragma once
-
-#include
-#include
-#include
-#include
-
-#include
-#include
-#include
-#include
-
-#include "paddle_inference_api.h" // NOLINT
-
-// Load Paddle Inference Model
-void LoadModel(
- const std::string& model_dir,
- bool use_gpu,
- std::unique_ptr* predictor);
-
-class HumanSeg {
- public:
- explicit HumanSeg(const std::string& model_dir,
- const std::vector& mean,
- const std::vector& scale,
- const std::vector& eval_size,
- bool use_gpu = false) :
- mean_(mean),
- scale_(scale),
- eval_size_(eval_size) {
- LoadModel(model_dir, use_gpu, &predictor_);
- }
-
- // Run predictor
- cv::Mat Predict(const cv::Mat& im);
-
- private:
- // Preprocess image and copy data to input buffer
- void Preprocess(const cv::Mat& im);
- // Postprocess result
- cv::Mat Postprocess(const cv::Mat& im);
-
- std::unique_ptr predictor_;
- std::vector input_data_;
- std::vector input_shape_;
- std::vector output_data_;
- std::vector scoremap_data_;
- std::vector segout_data_;
- std::vector mean_;
- std::vector scale_;
- std::vector eval_size_;
-};
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc b/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc
deleted file mode 100644
index a373df3985b5bd72d05145d2c6d106043b5303ff..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc
+++ /dev/null
@@ -1,282 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-#include
-
-#include
-#include
-#include
-#include
-
-#include "humanseg_postprocess.h" // NOLINT
-
-int HumanSegTrackFuse(const cv::Mat &track_fg_cfd,
- const cv::Mat &dl_fg_cfd,
- const cv::Mat &dl_weights,
- const cv::Mat &is_track,
- const float cfd_diff_thres,
- const int patch_size,
- cv::Mat cur_fg_cfd) {
- float *cur_fg_cfd_ptr = reinterpret_cast(cur_fg_cfd.data);
- float *dl_fg_cfd_ptr = reinterpret_cast(dl_fg_cfd.data);
- float *track_fg_cfd_ptr = reinterpret_cast(track_fg_cfd.data);
- float *dl_weights_ptr = reinterpret_cast(dl_weights.data);
- uchar *is_track_ptr = reinterpret_cast(is_track.data);
- int y_offset = 0;
- int ptr_offset = 0;
- int h = track_fg_cfd.rows;
- int w = track_fg_cfd.cols;
- float dl_fg_score = 0.0;
- float track_fg_score = 0.0;
- for (int y = 0; y < h; ++y) {
- for (int x = 0; x < w; ++x) {
- dl_fg_score = dl_fg_cfd_ptr[ptr_offset];
- if (is_track_ptr[ptr_offset] > 0) {
- track_fg_score = track_fg_cfd_ptr[ptr_offset];
- if (dl_fg_score > 0.9 || dl_fg_score < 0.1) {
- if (dl_weights_ptr[ptr_offset] <= 0.10) {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score * 0.3
- + track_fg_score * 0.7;
- } else {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score * 0.4
- + track_fg_score * 0.6;
- }
- } else {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score * dl_weights_ptr[ptr_offset]
- + track_fg_score * (1 - dl_weights_ptr[ptr_offset]);
- }
- } else {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score;
- }
- ++ptr_offset;
- }
- y_offset += w;
- ptr_offset = y_offset;
- }
- return 0;
-}
-
-int HumanSegTracking(const cv::Mat &prev_gray,
- const cv::Mat &cur_gray,
- const cv::Mat &prev_fg_cfd,
- int patch_size,
- cv::Mat track_fg_cfd,
- cv::Mat is_track,
- cv::Mat dl_weights,
- cv::Ptr disflow) {
- cv::Mat flow_fw;
- disflow->calc(prev_gray, cur_gray, flow_fw);
-
- cv::Mat flow_bw;
- disflow->calc(cur_gray, prev_gray, flow_bw);
-
- float double_check_thres = 8;
-
- cv::Point2f fxy_fw;
- int dy_fw = 0;
- int dx_fw = 0;
- cv::Point2f fxy_bw;
- int dy_bw = 0;
- int dx_bw = 0;
-
- float *prev_fg_cfd_ptr = reinterpret_cast(prev_fg_cfd.data);
- float *track_fg_cfd_ptr = reinterpret_cast(track_fg_cfd.data);
- float *dl_weights_ptr = reinterpret_cast(dl_weights.data);
- uchar *is_track_ptr = reinterpret_cast(is_track.data);
-
- int prev_y_offset = 0;
- int prev_ptr_offset = 0;
- int cur_ptr_offset = 0;
- float *flow_fw_ptr = reinterpret_cast(flow_fw.data);
-
- float roundy_fw = 0.0;
- float roundx_fw = 0.0;
- float roundy_bw = 0.0;
- float roundx_bw = 0.0;
-
- int h = prev_fg_cfd.rows;
- int w = prev_fg_cfd.cols;
- for (int r = 0; r < h; ++r) {
- for (int c = 0; c < w; ++c) {
- ++prev_ptr_offset;
-
- fxy_fw = flow_fw.ptr(r)[c];
- roundy_fw = fxy_fw.y >= 0 ? 0.5 : -0.5;
- roundx_fw = fxy_fw.x >= 0 ? 0.5 : -0.5;
- dy_fw = static_cast(fxy_fw.y + roundy_fw);
- dx_fw = static_cast(fxy_fw.x + roundx_fw);
-
- int cur_x = c + dx_fw;
- int cur_y = r + dy_fw;
-
- if (cur_x < 0
- || cur_x >= h
- || cur_y < 0
- || cur_y >= w) {
- continue;
- }
- fxy_bw = flow_bw.ptr(cur_y)[cur_x];
- roundy_bw = fxy_bw.y >= 0 ? 0.5 : -0.5;
- roundx_bw = fxy_bw.x >= 0 ? 0.5 : -0.5;
- dy_bw = static_cast(fxy_bw.y + roundy_bw);
- dx_bw = static_cast(fxy_bw.x + roundx_bw);
-
- auto total = (dy_fw + dy_bw) * (dy_fw + dy_bw)
- + (dx_fw + dx_bw) * (dx_fw + dx_bw);
- if (total >= double_check_thres) {
- continue;
- }
-
- cur_ptr_offset = cur_y * w + cur_x;
- if (abs(dy_fw) <= 0
- && abs(dx_fw) <= 0
- && abs(dy_bw) <= 0
- && abs(dx_bw) <= 0) {
- dl_weights_ptr[cur_ptr_offset] = 0.05;
- }
- is_track_ptr[cur_ptr_offset] = 1;
- track_fg_cfd_ptr[cur_ptr_offset] = prev_fg_cfd_ptr[prev_ptr_offset];
- }
- prev_y_offset += w;
- prev_ptr_offset = prev_y_offset - 1;
- }
- return 0;
-}
-
-int MergeProcess(const uchar *im_buff,
- const float *scoremap_buff,
- const int height,
- const int width,
- uchar *result_buff) {
- cv::Mat prev_fg_cfd;
- cv::Mat cur_fg_cfd;
- cv::Mat cur_fg_mask;
- cv::Mat track_fg_cfd;
- cv::Mat prev_gray;
- cv::Mat cur_gray;
- cv::Mat bgr_temp;
- cv::Mat is_track;
- cv::Mat static_roi;
- cv::Mat weights;
- cv::Ptr disflow =
- cv::optflow::createOptFlow_DIS(
- cv::optflow::DISOpticalFlow::PRESET_ULTRAFAST);
-
- bool is_init = false;
- const float *cfd_ptr = scoremap_buff;
- if (!is_init) {
- is_init = true;
- cur_fg_cfd = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0));
- memcpy(cur_fg_cfd.data, cfd_ptr, height * width * sizeof(float));
- cur_fg_mask = cv::Mat(height, width, CV_8UC1, cv::Scalar::all(0));
-
- if (height <= 64 || width <= 64) {
- disflow->setFinestScale(1);
- } else if (height <= 160 || width <= 160) {
- disflow->setFinestScale(2);
- } else {
- disflow->setFinestScale(3);
- }
- is_track = cv::Mat(height, width, CV_8UC1, cv::Scalar::all(0));
- static_roi = cv::Mat(height, width, CV_8UC1, cv::Scalar::all(0));
- track_fg_cfd = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0));
-
- bgr_temp = cv::Mat(height, width, CV_8UC3);
- memcpy(bgr_temp.data, im_buff, height * width * 3 * sizeof(uchar));
- cv::cvtColor(bgr_temp, cur_gray, cv::COLOR_BGR2GRAY);
- weights = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0.30));
- } else {
- memcpy(cur_fg_cfd.data, cfd_ptr, height * width * sizeof(float));
- memcpy(bgr_temp.data, im_buff, height * width * 3 * sizeof(uchar));
- cv::cvtColor(bgr_temp, cur_gray, cv::COLOR_BGR2GRAY);
- memset(is_track.data, 0, height * width * sizeof(uchar));
- memset(static_roi.data, 0, height * width * sizeof(uchar));
- weights = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0.30));
- HumanSegTracking(prev_gray,
- cur_gray,
- prev_fg_cfd,
- 0,
- track_fg_cfd,
- is_track,
- weights,
- disflow);
- HumanSegTrackFuse(track_fg_cfd,
- cur_fg_cfd,
- weights,
- is_track,
- 1.1,
- 0,
- cur_fg_cfd);
- }
- int ksize = 3;
- cv::GaussianBlur(cur_fg_cfd, cur_fg_cfd, cv::Size(ksize, ksize), 0, 0);
- prev_fg_cfd = cur_fg_cfd.clone();
- prev_gray = cur_gray.clone();
- cur_fg_cfd.convertTo(cur_fg_mask, CV_8UC1, 255);
- memcpy(result_buff, cur_fg_mask.data, height * width);
- return 0;
-}
-
-cv::Mat MergeSegMat(const cv::Mat& seg_mat,
- const cv::Mat& ori_frame) {
- cv::Mat return_frame;
- cv::resize(ori_frame, return_frame, cv::Size(ori_frame.cols, ori_frame.rows));
- for (int i = 0; i < ori_frame.rows; i++) {
- for (int j = 0; j < ori_frame.cols; j++) {
- float score = seg_mat.at(i, j) / 255.0;
- if (score > 0.1) {
- return_frame.at(i, j)[2] = static_cast((1 - score) * 255
- + score*return_frame.at(i, j)[2]);
- return_frame.at(i, j)[1] = static_cast((1 - score) * 255
- + score*return_frame.at(i, j)[1]);
- return_frame.at(i, j)[0] = static_cast((1 - score) * 255
- + score*return_frame.at(i, j)[0]);
- } else {
- return_frame.at(i, j) = {255, 255, 255};
- }
- }
- }
- return return_frame;
-}
-
-int ThresholdMask(const cv::Mat &fg_cfd,
- const float fg_thres,
- const float bg_thres,
- cv::Mat& fg_mask) {
- if (fg_cfd.type() != CV_32FC1) {
- printf("ThresholdMask: type is not CV_32FC1.\n");
- return -1;
- }
- if (!(fg_mask.type() == CV_8UC1
- && fg_mask.rows == fg_cfd.rows
- && fg_mask.cols == fg_cfd.cols)) {
- fg_mask = cv::Mat(fg_cfd.rows, fg_cfd.cols, CV_8UC1, cv::Scalar::all(0));
- }
-
- for (int r = 0; r < fg_cfd.rows; ++r) {
- for (int c = 0; c < fg_cfd.cols; ++c) {
- float score = fg_cfd.at(r, c);
- if (score < bg_thres) {
- fg_mask.at(r, c) = 0;
- } else if (score > fg_thres) {
- fg_mask.at(r, c) = 255;
- } else {
- fg_mask.at(r, c) = static_cast(
- (score-bg_thres) / (fg_thres - bg_thres) * 255);
- }
- }
- }
- return 0;
-}
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h b/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h
deleted file mode 100644
index f5059857c0108c600a6bd98bcaa355647fdc21e2..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h
+++ /dev/null
@@ -1,34 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#pragma once
-
-#include
-#include
-#include
-#include
-
-int ThresholdMask(const cv::Mat &fg_cfd,
- const float fg_thres,
- const float bg_thres,
- cv::Mat& fg_mask);
-
-cv::Mat MergeSegMat(const cv::Mat& seg_mat,
- const cv::Mat& ori_frame);
-
-int MergeProcess(const uchar *im_buff,
- const float *im_scoremap_buff,
- const int height,
- const int width,
- uchar *result_buff);
diff --git a/contrib/RealTimeHumanSeg/cpp/linux_build.sh b/contrib/RealTimeHumanSeg/cpp/linux_build.sh
deleted file mode 100644
index ff0b11bcf60f1b4ec4d7a9f63f7490ffb70ad6e0..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/linux_build.sh
+++ /dev/null
@@ -1,30 +0,0 @@
-OPENCV_URL=https://paddleseg.bj.bcebos.com/deploy/deps/opencv346.tar.bz2
-if [ ! -d "./deps/opencv346" ]; then
- mkdir -p deps
- cd deps
- wget -c ${OPENCV_URL}
- tar xvfj opencv346.tar.bz2
- rm -rf opencv346.tar.bz2
- cd ..
-fi
-
-WITH_GPU=OFF
-PADDLE_DIR=/root/projects/deps/fluid_inference/
-CUDA_LIB=/usr/local/cuda-10.0/lib64/
-CUDNN_LIB=/usr/local/cuda-10.0/lib64/
-OPENCV_DIR=$(pwd)/deps/opencv346/
-echo ${OPENCV_DIR}
-
-rm -rf build
-mkdir -p build
-cd build
-
-cmake .. \
- -DWITH_GPU=${WITH_GPU} \
- -DPADDLE_DIR=${PADDLE_DIR} \
- -DCUDA_LIB=${CUDA_LIB} \
- -DCUDNN_LIB=${CUDNN_LIB} \
- -DOPENCV_DIR=${OPENCV_DIR} \
- -DWITH_STATIC_LIB=OFF
-make clean
-make -j12
diff --git a/contrib/RealTimeHumanSeg/cpp/main.cc b/contrib/RealTimeHumanSeg/cpp/main.cc
deleted file mode 100644
index 303051f051b885a83b0ef608fe2ab1319f97294e..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/cpp/main.cc
+++ /dev/null
@@ -1,92 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-#include
-
-#include "humanseg.h" // NOLINT
-#include "humanseg_postprocess.h" // NOLINT
-
-// Do predicting on a video file
-int VideoPredict(const std::string& video_path, HumanSeg& seg)
-{
- cv::VideoCapture capture;
- capture.open(video_path.c_str());
- if (!capture.isOpened()) {
- printf("can not open video : %s\n", video_path.c_str());
- return -1;
- }
-
- int video_width = static_cast(capture.get(CV_CAP_PROP_FRAME_WIDTH));
- int video_height = static_cast(capture.get(CV_CAP_PROP_FRAME_HEIGHT));
- cv::VideoWriter video_out;
- std::string video_out_path = "result.avi";
- video_out.open(video_out_path.c_str(),
- CV_FOURCC('M', 'J', 'P', 'G'),
- 30.0,
- cv::Size(video_width, video_height),
- true);
- if (!video_out.isOpened()) {
- printf("create video writer failed!\n");
- return -1;
- }
- cv::Mat frame;
- while (capture.read(frame)) {
- if (frame.empty()) {
- break;
- }
- cv::Mat out_im = seg.Predict(frame);
- video_out.write(out_im);
- }
- capture.release();
- video_out.release();
- return 0;
-}
-
-// Do predicting on a image file
-int ImagePredict(const std::string& image_path, HumanSeg& seg)
-{
- cv::Mat img = imread(image_path, cv::IMREAD_COLOR);
- cv::Mat out_im = seg.Predict(img);
- imwrite("result.jpeg", out_im);
- return 0;
-}
-
-int main(int argc, char* argv[]) {
- if (argc < 3 || argc > 4) {
- std::cout << "Usage:"
- << "./humanseg ./models/ ./data/test.avi"
- << std::endl;
- return -1;
- }
-
- bool use_gpu = (argc == 4 ? std::stoi(argv[3]) : false);
- auto model_dir = std::string(argv[1]);
- auto input_path = std::string(argv[2]);
-
- // Init Model
- std::vector means = {104.008, 116.669, 122.675};
- std::vector scale = {1.000, 1.000, 1.000};
- std::vector eval_sz = {192, 192};
- HumanSeg seg(model_dir, means, scale, eval_sz, use_gpu);
-
- // Call ImagePredict while input_path is a image file path
- // The output will be saved as result.jpeg
- // ImagePredict(input_path, seg);
-
- // Call VideoPredict while input_path is a video file path
- // The output will be saved as result.avi
- VideoPredict(input_path, seg);
- return 0;
-}
diff --git a/contrib/RealTimeHumanSeg/python/README.md b/contrib/RealTimeHumanSeg/python/README.md
deleted file mode 100644
index 1e089c9f5226e2482cd6e8957406c00095706b1b..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/python/README.md
+++ /dev/null
@@ -1,61 +0,0 @@
-# 实时人像分割Python预测部署方案
-
-本方案基于Python实现,最小化依赖并把所有模型加载、数据预处理、预测、光流处理等后处理都封装在文件`infer.py`中,用户可以直接使用或集成到自己项目中。
-
-
-## 前置依赖
-- Windows(7,8,10) / Linux (Ubuntu 16.04) or MacOS 10.1+
-- Paddle 1.6.1+
-- Python 3.0+
-
-注意:
-1. 仅测试过Paddle1.6 和 1.7, 其它版本不支持
-2. MacOS上不支持GPU预测
-3. Python2上未测试
-
-其它未涉及情形,能正常安装`Paddle` 和`OpenCV`通常都能正常使用。
-
-
-## 安装依赖
-### 1. 安装paddle
-
-PaddlePaddle的安装, 请按照[官网指引](https://paddlepaddle.org.cn/install/quick)安装合适自己的版本。
-
-### 2. 安装其它依赖
-
-执行如下命令
-
-```shell
-pip install -r requirements.txt
-```
-
-## 运行
-
-
-1. 输入图片进行分割
-```
-python infer.py --model_dir /PATH/TO/INFERENCE/MODEL --img_path /PATH/TO/INPUT/IMAGE
-```
-
-预测结果会保存为`result.jpeg`。
-2. 输入视频进行分割
-```shell
-python infer.py --model_dir /PATH/TO/INFERENCE/MODEL --video_path /PATH/TO/INPUT/VIDEO
-```
-
-预测结果会保存在`result.avi`。
-
-3. 使用摄像头视频流
-```shell
-python infer.py --model_dir /PATH/TO/INFERENCE/MODEL --use_camera 1
-```
-预测结果会通过可视化窗口实时显示。
-
-**注意:**
-
-
-`GPU`默认关闭, 如果要使用`GPU`进行加速,则先运行
-```
-export CUDA_VISIBLE_DEVICES=0
-```
-然后在前面的预测命令中增加参数`--use_gpu 1`即可。
diff --git a/contrib/RealTimeHumanSeg/python/infer.py b/contrib/RealTimeHumanSeg/python/infer.py
deleted file mode 100644
index 73df081e4cbda06e20b471b2eae60a2ba037e49a..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/python/infer.py
+++ /dev/null
@@ -1,345 +0,0 @@
-# coding: utf8
-# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""实时人像分割Python预测部署"""
-
-import os
-import argparse
-import numpy as np
-import cv2
-
-import paddle.fluid as fluid
-
-
-def human_seg_tracking(pre_gray, cur_gray, prev_cfd, dl_weights, disflow):
- """计算光流跟踪匹配点和光流图
- 输入参数:
- pre_gray: 上一帧灰度图
- cur_gray: 当前帧灰度图
- prev_cfd: 上一帧光流图
- dl_weights: 融合权重图
- disflow: 光流数据结构
- 返回值:
- is_track: 光流点跟踪二值图,即是否具有光流点匹配
- track_cfd: 光流跟踪图
- """
- check_thres = 8
- hgt, wdh = pre_gray.shape[:2]
- track_cfd = np.zeros_like(prev_cfd)
- is_track = np.zeros_like(pre_gray)
- # 计算前向光流
- flow_fw = disflow.calc(pre_gray, cur_gray, None)
- # 计算后向光流
- flow_bw = disflow.calc(cur_gray, pre_gray, None)
- get_round = lambda data: (int)(data + 0.5) if data >= 0 else (int)(data -0.5)
- for row in range(hgt):
- for col in range(wdh):
- # 计算光流处理后对应点坐标
- # (row, col) -> (cur_x, cur_y)
- fxy_fw = flow_fw[row, col]
- dx_fw = get_round(fxy_fw[0])
- cur_x = dx_fw + col
- dy_fw = get_round(fxy_fw[1])
- cur_y = dy_fw + row
- if cur_x < 0 or cur_x >= wdh or cur_y < 0 or cur_y >= hgt:
- continue
- fxy_bw = flow_bw[cur_y, cur_x]
- dx_bw = get_round(fxy_bw[0])
- dy_bw = get_round(fxy_bw[1])
- # 光流移动小于阈值
- lmt = ((dy_fw + dy_bw) * (dy_fw + dy_bw) + (dx_fw + dx_bw) * (dx_fw + dx_bw))
- if lmt >= check_thres:
- continue
- # 静止点降权
- if abs(dy_fw) <= 0 and abs(dx_fw) <= 0 and abs(dy_bw) <= 0 and abs(dx_bw) <= 0:
- dl_weights[cur_y, cur_x] = 0.05
- is_track[cur_y, cur_x] = 1
- track_cfd[cur_y, cur_x] = prev_cfd[row, col]
- return track_cfd, is_track, dl_weights
-
-
-def human_seg_track_fuse(track_cfd, dl_cfd, dl_weights, is_track):
- """光流追踪图和人像分割结构融合
- 输入参数:
- track_cfd: 光流追踪图
- dl_cfd: 当前帧分割结果
- dl_weights: 融合权重图
- is_track: 光流点匹配二值图
- 返回值:
- cur_cfd: 光流跟踪图和人像分割结果融合图
- """
- cur_cfd = dl_cfd.copy()
- idxs = np.where(is_track > 0)
- for i in range(len(idxs)):
- x, y = idxs[0][i], idxs[1][i]
- dl_score = dl_cfd[y, x]
- track_score = track_cfd[y, x]
- if dl_score > 0.9 or dl_score < 0.1:
- if dl_weights[x, y] < 0.1:
- cur_cfd[x, y] = 0.3 * dl_score + 0.7 * track_score
- else:
- cur_cfd[x, y] = 0.4 * dl_score + 0.6 * track_score
- else:
- cur_cfd[x, y] = dl_weights[x, y] * dl_score + (1 - dl_weights[x, y]) * track_score
- return cur_cfd
-
-
-def threshold_mask(img, thresh_bg, thresh_fg):
- """设置背景和前景阈值mask
- 输入参数:
- img : 原始图像, np.uint8 类型.
- thresh_bg : 背景阈值百分比,低于该值置为0.
- thresh_fg : 前景阈值百分比,超过该值置为1.
- 返回值:
- dst : 原始图像设置完前景背景阈值mask结果, np.float32 类型.
- """
- dst = (img / 255.0 - thresh_bg) / (thresh_fg - thresh_bg)
- dst[np.where(dst > 1)] = 1
- dst[np.where(dst < 0)] = 0
- return dst.astype(np.float32)
-
-
-def optflow_handle(cur_gray, scoremap, is_init):
- """光流优化
- Args:
- cur_gray : 当前帧灰度图
- scoremap : 当前帧分割结果
- is_init : 是否第一帧
- Returns:
- dst : 光流追踪图和预测结果融合图, 类型为 np.float32
- """
- width, height = scoremap.shape[0], scoremap.shape[1]
- disflow = cv2.DISOpticalFlow_create(
- cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
- prev_gray = np.zeros((height, width), np.uint8)
- prev_cfd = np.zeros((height, width), np.float32)
- cur_cfd = scoremap.copy()
- if is_init:
- is_init = False
- if height <= 64 or width <= 64:
- disflow.setFinestScale(1)
- elif height <= 160 or width <= 160:
- disflow.setFinestScale(2)
- else:
- disflow.setFinestScale(3)
- fusion_cfd = cur_cfd
- else:
- weights = np.ones((width, height), np.float32) * 0.3
- track_cfd, is_track, weights = human_seg_tracking(
- prev_gray, cur_gray, prev_cfd, weights, disflow)
- fusion_cfd = human_seg_track_fuse(track_cfd, cur_cfd, weights, is_track)
- fusion_cfd = cv2.GaussianBlur(fusion_cfd, (3, 3), 0)
- return fusion_cfd
-
-
-class HumanSeg:
- """人像分割类
- 封装了人像分割模型的加载,数据预处理,预测,后处理等
- """
- def __init__(self, model_dir, mean, scale, eval_size, use_gpu=False):
-
- self.mean = np.array(mean).reshape((3, 1, 1))
- self.scale = np.array(scale).reshape((3, 1, 1))
- self.eval_size = eval_size
- self.load_model(model_dir, use_gpu)
-
- def load_model(self, model_dir, use_gpu):
- """加载模型并创建predictor
- Args:
- model_dir: 预测模型路径, 包含 `__model__` 和 `__params__`
- use_gpu: 是否使用GPU加速
- """
- prog_file = os.path.join(model_dir, '__model__')
- params_file = os.path.join(model_dir, '__params__')
- config = fluid.core.AnalysisConfig(prog_file, params_file)
- if use_gpu:
- config.enable_use_gpu(100, 0)
- config.switch_ir_optim(True)
- else:
- config.disable_gpu()
- config.disable_glog_info()
- config.switch_specify_input_names(True)
- config.enable_memory_optim()
- self.predictor = fluid.core.create_paddle_predictor(config)
-
- def preprocess(self, image):
- """图像预处理
- hwc_rgb 转换为 chw_bgr,并进行归一化
- 输入参数:
- image: 原始图像
- 返回值:
- 经过预处理后的图片结果
- """
- img_mat = cv2.resize(
- image, self.eval_size, interpolation=cv2.INTER_LINEAR)
- # HWC -> CHW
- img_mat = img_mat.swapaxes(1, 2)
- img_mat = img_mat.swapaxes(0, 1)
- # Convert to float
- img_mat = img_mat[:, :, :].astype('float32')
- # img_mat = (img_mat - mean) * scale
- img_mat = img_mat - self.mean
- img_mat = img_mat * self.scale
- img_mat = img_mat[np.newaxis, :, :, :]
- return img_mat
-
- def postprocess(self, image, output_data):
- """对预测结果进行后处理
- Args:
- image: 原始图,opencv 图片对象
- output_data: Paddle预测结果原始数据
- Returns:
- 原图和预测结果融合并做了光流优化的结果图
- """
- scoremap = output_data[0, 1, :, :]
- scoremap = (scoremap * 255).astype(np.uint8)
- ori_h, ori_w = image.shape[0], image.shape[1]
- evl_h, evl_w = self.eval_size[0], self.eval_size[1]
- # 光流处理
- cur_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
- cur_gray = cv2.resize(cur_gray, (evl_w, evl_h))
- optflow_map = optflow_handle(cur_gray, scoremap, False)
- optflow_map = cv2.GaussianBlur(optflow_map, (3, 3), 0)
- optflow_map = threshold_mask(optflow_map, thresh_bg=0.2, thresh_fg=0.8)
- optflow_map = cv2.resize(optflow_map, (ori_w, ori_h))
- optflow_map = np.repeat(optflow_map[:, :, np.newaxis], 3, axis=2)
- bg_im = np.ones_like(optflow_map) * 255
- comb = (optflow_map * image + (1 - optflow_map) * bg_im).astype(np.uint8)
- return comb
-
- def run_predict(self, image):
- """运行预测并返回可视化结果图
- 输入参数:
- image: 需要预测的原始图, opencv图片对象
- 返回值:
- 可视化的预测结果图
- """
- im_mat = self.preprocess(image)
- im_tensor = fluid.core.PaddleTensor(im_mat.copy().astype('float32'))
- output_data = self.predictor.run([im_tensor])[0]
- output_data = output_data.as_ndarray()
- return self.postprocess(image, output_data)
-
-
-def predict_image(seg, image_path):
- """对图片文件进行分割
- 结果保存到`result.jpeg`文件中
- """
- img_mat = cv2.imread(image_path)
- img_mat = seg.run_predict(img_mat)
- cv2.imwrite('result.jpeg', img_mat)
-
-
-def predict_video(seg, video_path):
- """对视频文件进行分割
- 结果保存到`result.avi`文件中
- """
- cap = cv2.VideoCapture(video_path)
- if not cap.isOpened():
- print("Error opening video stream or file")
- return
- width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
- height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
- fps = cap.get(cv2.CAP_PROP_FPS)
- # 用于保存预测结果视频
- out = cv2.VideoWriter('result.avi',
- cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps,
- (width, height))
- # 开始获取视频帧
- while cap.isOpened():
- ret, frame = cap.read()
- if ret:
- img_mat = seg.run_predict(frame)
- out.write(img_mat)
- else:
- break
- cap.release()
- out.release()
-
-
-def predict_camera(seg):
- """从摄像头获取视频流进行预测
- 视频分割结果实时显示到可视化窗口中
- """
- cap = cv2.VideoCapture(0)
- if not cap.isOpened():
- print("Error opening video stream or file")
- return
- # Start capturing from video
- while cap.isOpened():
- ret, frame = cap.read()
- if ret:
- img_mat = seg.run_predict(frame)
- cv2.imshow('HumanSegmentation', img_mat)
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
- else:
- break
- cap.release()
-
-
-def main(args):
- """预测程序入口
- 完成模型加载, 对视频、摄像头、图片文件等预测过程
- """
- model_dir = args.model_dir
- use_gpu = args.use_gpu
-
- # 加载模型
- mean = [104.008, 116.669, 122.675]
- scale = [1.0, 1.0, 1.0]
- eval_size = (192, 192)
- seg = HumanSeg(model_dir, mean, scale, eval_size, use_gpu)
- if args.use_camera:
- # 开启摄像头
- predict_camera(seg)
- elif args.video_path:
- # 使用视频文件作为输入
- predict_video(seg, args.video_path)
- elif args.img_path:
- # 使用图片文件作为输入
- predict_image(seg, args.img_path)
-
-
-def parse_args():
- """解析命令行参数
- """
- parser = argparse.ArgumentParser('Realtime Human Segmentation')
- parser.add_argument('--model_dir',
- type=str,
- default='',
- help='path of human segmentation model')
- parser.add_argument('--img_path',
- type=str,
- default='',
- help='path of input image')
- parser.add_argument('--video_path',
- type=str,
- default='',
- help='path of input video')
- parser.add_argument('--use_camera',
- type=bool,
- default=False,
- help='input video stream from camera')
- parser.add_argument('--use_gpu',
- type=bool,
- default=False,
- help='enable gpu')
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- main(args)
diff --git a/contrib/RealTimeHumanSeg/python/requirements.txt b/contrib/RealTimeHumanSeg/python/requirements.txt
deleted file mode 100644
index 953dae0cf5e2036ad093907b30ac9a3a10858d27..0000000000000000000000000000000000000000
--- a/contrib/RealTimeHumanSeg/python/requirements.txt
+++ /dev/null
@@ -1,2 +0,0 @@
-opencv-python==4.1.2.30
-opencv-contrib-python==4.2.0.32
diff --git a/contrib/RemoteSensing/README.md b/contrib/RemoteSensing/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4f96cccf8e542e7185f9cd66d29e4f2899fbcb94
--- /dev/null
+++ b/contrib/RemoteSensing/README.md
@@ -0,0 +1,246 @@
+# 遥感分割(RemoteSensing)
+遥感影像分割是图像分割领域中的重要应用场景,广泛应用于土地测绘、环境监测、城市建设等领域。遥感影像分割的目标多种多样,有诸如积雪、农作物、道路、建筑、水源等地物目标,也有例如云层的空中目标。
+
+PaddleSeg提供了针对遥感专题的语义分割库RemoteSensing,涵盖图像预处理、数据增强、模型训练、预测流程,帮助用户利用深度学习技术解决遥感影像分割问题。
+
+## 特点
+针对遥感数据多通道、分布范围大、分布不均的特点,我们支持多通道训练预测,内置一系列多通道预处理和数据增强的策略,可结合实际业务场景进行定制组合,提升模型泛化能力和鲁棒性。
+
+**Note:** 所有命令需要在`PaddleSeg/contrib/RemoteSensing/`目录下执行。
+
+## 前置依赖
+- Paddle 1.7.1+
+由于图像分割模型计算开销大,推荐在GPU版本的PaddlePaddle下使用。
+PaddlePaddle的安装, 请按照[官网指引](https://paddlepaddle.org.cn/install/quick)安装合适自己的版本。
+
+- Python 3.5+
+
+- 其他依赖安装
+通过以下命令安装python包依赖,请确保至少执行过一次以下命令:
+```
+cd RemoteSensing
+pip install -r requirements.txt
+```
+
+## 目录结构说明
+ ```
+RemoteSensing # 根目录
+ |-- dataset # 数据集
+ |-- docs # 文档
+ |-- models # 模型类定义模块
+ |-- nets # 组网模块
+ |-- readers # 数据读取模块
+ |-- tools # 工具集
+ |-- transforms # 数据增强模块
+ |-- utils # 公用模块
+ |-- train_demo.py # 训练demo脚本
+ |-- predict_demo.py # 预测demo脚本
+ |-- README.md # 使用手册
+
+ ```
+## 数据协议
+数据集包含原图、标注图及相应的文件列表文件。
+
+参考数据文件结构如下:
+```
+./dataset/ # 数据集根目录
+|--images # 原图目录
+| |--xxx1.npy
+| |--...
+| └--...
+|
+|--annotations # 标注图目录
+| |--xxx1.png
+| |--...
+| └--...
+|
+|--train_list.txt # 训练文件列表文件
+|
+|--val_list.txt # 验证文件列表文件
+|
+└--labels.txt # 标签列表
+
+```
+其中,相应的文件名可根据需要自行定义。
+
+遥感领域图像格式多种多样,不同传感器产生的数据格式可能不同。为方便数据加载,本分割库统一采用numpy存储格式`npy`作为原图格式,采用`png`无损压缩格式作为标注图片格式。
+原图的前两维是图像的尺寸,第3维是图像的通道数。
+标注图像为单通道图像,像素值即为对应的类别,像素标注类别需要从0开始递增,
+例如0,1,2,3表示有4种类别,标注类别最多为256类。其中可以指定特定的像素值用于表示该值的像素不参与训练和评估(默认为255)。
+
+`train_list.txt`和`val_list.txt`文本以空格为分割符分为两列,第一列为图像文件相对于dataset的相对路径,第二列为标注图像文件相对于dataset的相对路径。如下所示:
+```
+images/xxx1.npy annotations/xxx1.png
+images/xxx2.npy annotations/xxx2.png
+...
+```
+
+具体要求和如何生成文件列表可参考[文件列表规范](../../docs/data_prepare.md#文件列表)。
+
+`labels.txt`: 每一行为一个单独的类别,相应的行号即为类别对应的id(行号从0开始),如下所示:
+```
+labelA
+labelB
+...
+```
+
+
+
+## 快速上手
+
+本章节在一个小数据集上展示了如何通过RemoteSensing进行训练预测。
+
+### 1. 准备数据集
+为了快速体验,我们准备了一个小型demo数据集,已位于`RemoteSensing/dataset/demo/`目录下.
+
+对于您自己的数据集,您需要按照上述的数据协议进行格式转换,可分别使用numpy和pil库保存遥感数据和标注图片。其中numpy api示例如下:
+```python
+import numpy as np
+
+# 保存遥感数据
+# img类型:numpy.ndarray
+np.save(save_path, img)
+```
+
+### 2. 训练代码开发
+通过如下`train_demo.py`代码进行训练。
+
+> 导入RemoteSensing api
+```python
+import transforms.transforms as T
+from readers.reader import Reader
+from models import UNet
+```
+
+> 定义训练和验证时的数据处理和增强流程, 在`train_transforms`中加入了`RandomVerticalFlip`,`RandomHorizontalFlip`等数据增强方式。
+```python
+train_transforms = T.Compose([
+ T.RandomVerticalFlip(0.5),
+ T.RandomHorizontalFlip(0.5),
+ T.ResizeStepScaling(0.5, 2.0, 0.25),
+ T.RandomPaddingCrop(256),
+ T.Normalize(mean=[0.5] * channel, std=[0.5] * channel),
+])
+
+eval_transforms = T.Compose([
+ T.Normalize(mean=[0.5] * channel, std=[0.5] * channel),
+])
+```
+
+> 定义数据读取器
+```python
+import os
+import os.path as osp
+
+train_list = osp.join(data_dir, 'train.txt')
+val_list = osp.join(data_dir, 'val.txt')
+label_list = osp.join(data_dir, 'labels.txt')
+
+train_reader = Reader(
+ data_dir=data_dir,
+ file_list=train_list,
+ label_list=label_list,
+ transforms=train_transforms,
+ num_workers=8,
+ buffer_size=16,
+ shuffle=True,
+ parallel_method='thread')
+
+eval_reader = Reader(
+ data_dir=data_dir,
+ file_list=val_list,
+ label_list=label_list,
+ transforms=eval_transforms,
+ num_workers=8,
+ buffer_size=16,
+ shuffle=False,
+ parallel_method='thread')
+```
+> 模型构建
+```python
+model = UNet(
+ num_classes=2, input_channel=channel, use_bce_loss=True, use_dice_loss=True)
+```
+> 模型训练,并开启边训边评估
+```python
+model.train(
+ num_epochs=num_epochs,
+ train_reader=train_reader,
+ train_batch_size=train_batch_size,
+ eval_reader=eval_reader,
+ save_interval_epochs=5,
+ log_interval_steps=10,
+ save_dir=save_dir,
+ pretrain_weights=None,
+ optimizer=None,
+ learning_rate=lr,
+ use_vdl=True
+)
+```
+
+
+### 3. 模型训练
+> 设置GPU卡号
+```shell script
+export CUDA_VISIBLE_DEVICES=0
+```
+> 在RemoteSensing目录下运行`train_demo.py`即可开始训练。
+```shell script
+python train_demo.py --data_dir dataset/demo/ --save_dir saved_model/unet/ --channel 3 --num_epochs 20
+```
+### 4. 模型预测代码开发
+通过如下`predict_demo.py`代码进行预测。
+
+> 导入RemoteSensing api
+```python
+from models import load_model
+```
+> 加载训练过程中最好的模型,设置预测结果保存路径。
+```python
+import os
+import os.path as osp
+model = load_model(osp.join(save_dir, 'best_model'))
+pred_dir = osp.join(save_dir, 'pred')
+if not osp.exists(pred_dir):
+ os.mkdir(pred_dir)
+```
+
+> 使用模型对验证集进行测试,并保存预测结果。
+```python
+import numpy as np
+from PIL import Image as Image
+val_list = osp.join(data_dir, 'val.txt')
+color_map = [0, 0, 0, 255, 255, 255]
+with open(val_list) as f:
+ lines = f.readlines()
+ for line in lines:
+ img_path = line.split(' ')[0]
+ print('Predicting {}'.format(img_path))
+ img_path_ = osp.join(data_dir, img_path)
+
+ pred = model.predict(img_path_)
+
+ # 以伪彩色png图片保存预测结果
+ pred_name = osp.basename(img_path).rstrip('npy') + 'png'
+ pred_path = osp.join(pred_dir, pred_name)
+ pred_mask = Image.fromarray(pred.astype(np.uint8), mode='P')
+ pred_mask.putpalette(color_map)
+ pred_mask.save(pred_path)
+```
+
+### 5. 模型预测
+> 设置GPU卡号
+```shell script
+export CUDA_VISIBLE_DEVICES=0
+```
+> 在RemoteSensing目录下运行`predict_demo.py`即可开始训练。
+```shell script
+python predict_demo.py --data_dir dataset/demo/ --load_model_dir saved_model/unet/best_model/
+```
+
+
+## Api说明
+
+您可以使用`RemoteSensing`目录下提供的api构建自己的分割代码。
+
+- [数据处理-transforms](docs/transforms.md)
diff --git a/contrib/RemoteSensing/__init__.py b/contrib/RemoteSensing/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea9751219a9eda9e50a80e9dff2a8b3d7cba0066
--- /dev/null
+++ b/contrib/RemoteSensing/__init__.py
@@ -0,0 +1,24 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import utils
+import nets
+import models
+import transforms
+import readers
+from utils.utils import get_environ_info
+
+env_info = get_environ_info()
+
+log_level = 2
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/0.png b/contrib/RemoteSensing/dataset/demo/annotations/0.png
new file mode 100644
index 0000000000000000000000000000000000000000..cf1b91544aac136d78f25c6818ae3aaf8aca23bb
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/0.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1.png b/contrib/RemoteSensing/dataset/demo/annotations/1.png
new file mode 100644
index 0000000000000000000000000000000000000000..b9f0d5df904ff9cd9df1bffdf456d48e3fae38f9
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/10.png b/contrib/RemoteSensing/dataset/demo/annotations/10.png
new file mode 100644
index 0000000000000000000000000000000000000000..59950c118bd981bcfaa805e27a3d4929daa7b213
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/10.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/100.png b/contrib/RemoteSensing/dataset/demo/annotations/100.png
new file mode 100644
index 0000000000000000000000000000000000000000..6fef4400ce8e4e0f13937bca398ba50a4aab729a
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/100.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1000.png b/contrib/RemoteSensing/dataset/demo/annotations/1000.png
new file mode 100644
index 0000000000000000000000000000000000000000..891dfdcaa591640a9dab4b046bdf34f8606d282b
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1000.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1001.png b/contrib/RemoteSensing/dataset/demo/annotations/1001.png
new file mode 100644
index 0000000000000000000000000000000000000000..891dfdcaa591640a9dab4b046bdf34f8606d282b
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1001.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1002.png b/contrib/RemoteSensing/dataset/demo/annotations/1002.png
new file mode 100644
index 0000000000000000000000000000000000000000..e247cb90c9044a8044e0e595a9917e14d69d42de
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1002.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1003.png b/contrib/RemoteSensing/dataset/demo/annotations/1003.png
new file mode 100644
index 0000000000000000000000000000000000000000..f98df538a2c1c027deeb3e6530d04e8900ef6e07
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1003.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1004.png b/contrib/RemoteSensing/dataset/demo/annotations/1004.png
new file mode 100644
index 0000000000000000000000000000000000000000..1da4b7b5bcdb9ff3f3b70438409753e0e4e28fe4
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1004.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/annotations/1005.png b/contrib/RemoteSensing/dataset/demo/annotations/1005.png
new file mode 100644
index 0000000000000000000000000000000000000000..09173b87cbc02dbe92fcfd92b0ea376fb8d8a91d
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/annotations/1005.png differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/0.npy b/contrib/RemoteSensing/dataset/demo/images/0.npy
new file mode 100644
index 0000000000000000000000000000000000000000..4cbb1c56d8d902629585fb20e026f35773a5f7a4
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/0.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1.npy b/contrib/RemoteSensing/dataset/demo/images/1.npy
new file mode 100644
index 0000000000000000000000000000000000000000..11b6433300481381a2877da6453e04a7f116c4aa
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/10.npy b/contrib/RemoteSensing/dataset/demo/images/10.npy
new file mode 100644
index 0000000000000000000000000000000000000000..cfbf1ab896203d4962ccb254ad046487648af8ce
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/10.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/100.npy b/contrib/RemoteSensing/dataset/demo/images/100.npy
new file mode 100644
index 0000000000000000000000000000000000000000..7162a79fc2ce958e86b1f728f97a4266b5b4f6cd
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/100.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1000.npy b/contrib/RemoteSensing/dataset/demo/images/1000.npy
new file mode 100644
index 0000000000000000000000000000000000000000..7ddf3cb11b906a0776a0e407090a0ddefe5980f9
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1000.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1001.npy b/contrib/RemoteSensing/dataset/demo/images/1001.npy
new file mode 100644
index 0000000000000000000000000000000000000000..cbf6b692692cb57f0d66f6f6908361e1315e0b89
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1001.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1002.npy b/contrib/RemoteSensing/dataset/demo/images/1002.npy
new file mode 100644
index 0000000000000000000000000000000000000000..d5d4a4775248299347f430575c4716511f24a808
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1002.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1003.npy b/contrib/RemoteSensing/dataset/demo/images/1003.npy
new file mode 100644
index 0000000000000000000000000000000000000000..9b4c94db3368ded7f615f20e2943dbd8b9a75372
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1003.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1004.npy b/contrib/RemoteSensing/dataset/demo/images/1004.npy
new file mode 100644
index 0000000000000000000000000000000000000000..6b2f51dfc0893da79208cb6602baa403bd1a35ea
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1004.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/images/1005.npy b/contrib/RemoteSensing/dataset/demo/images/1005.npy
new file mode 100644
index 0000000000000000000000000000000000000000..21198e2cbe958e96d4fbeab81f1c88026b9d2fab
Binary files /dev/null and b/contrib/RemoteSensing/dataset/demo/images/1005.npy differ
diff --git a/contrib/RemoteSensing/dataset/demo/labels.txt b/contrib/RemoteSensing/dataset/demo/labels.txt
new file mode 100644
index 0000000000000000000000000000000000000000..69548aabb6c89d4535c6567b7e1160c3ba2874ca
--- /dev/null
+++ b/contrib/RemoteSensing/dataset/demo/labels.txt
@@ -0,0 +1,2 @@
+__background__
+cloud
\ No newline at end of file
diff --git a/contrib/RemoteSensing/dataset/demo/train.txt b/contrib/RemoteSensing/dataset/demo/train.txt
new file mode 100644
index 0000000000000000000000000000000000000000..babb17608b22ecda5c38db00e11e6c4579722784
--- /dev/null
+++ b/contrib/RemoteSensing/dataset/demo/train.txt
@@ -0,0 +1,7 @@
+images/1001.npy annotations/1001.png
+images/1002.npy annotations/1002.png
+images/1005.npy annotations/1005.png
+images/0.npy annotations/0.png
+images/1003.npy annotations/1003.png
+images/1000.npy annotations/1000.png
+images/1004.npy annotations/1004.png
diff --git a/contrib/RemoteSensing/dataset/demo/val.txt b/contrib/RemoteSensing/dataset/demo/val.txt
new file mode 100644
index 0000000000000000000000000000000000000000..073dbf76d4309dfeea0b242e6eace3bc6024ba61
--- /dev/null
+++ b/contrib/RemoteSensing/dataset/demo/val.txt
@@ -0,0 +1,3 @@
+images/100.npy annotations/100.png
+images/1.npy annotations/1.png
+images/10.npy annotations/10.png
diff --git a/contrib/RemoteSensing/docs/transforms.md b/contrib/RemoteSensing/docs/transforms.md
new file mode 100644
index 0000000000000000000000000000000000000000..a35e6cd1bdcf03dc84687a6bb7a4e13c274dc572
--- /dev/null
+++ b/contrib/RemoteSensing/docs/transforms.md
@@ -0,0 +1,145 @@
+# transforms.transforms
+
+对用于分割任务的数据进行操作。可以利用[Compose](#compose)类将图像预处理/增强操作进行组合。
+
+
+## Compose类
+```python
+transforms.transforms.Compose(transforms)
+```
+根据数据预处理/数据增强列表对输入数据进行操作。
+### 参数
+* **transforms** (list): 数据预处理/数据增强列表。
+
+
+## RandomHorizontalFlip类
+```python
+transforms.transforms.RandomHorizontalFlip(prob=0.5)
+```
+以一定的概率对图像进行水平翻转,模型训练时的数据增强操作。
+### 参数
+* **prob** (float): 随机水平翻转的概率。默认值为0.5。
+
+
+## RandomVerticalFlip类
+```python
+transforms.transforms.RandomVerticalFlip(prob=0.1)
+```
+以一定的概率对图像进行垂直翻转,模型训练时的数据增强操作。
+### 参数
+* **prob** (float): 随机垂直翻转的概率。默认值为0.1。
+
+
+## Resize类
+```python
+transforms.transforms.Resize(target_size, interp='LINEAR')
+```
+调整图像大小(resize)。
+
+- 当目标大小(target_size)类型为int时,根据插值方式,
+ 将图像resize为[target_size, target_size]。
+- 当目标大小(target_size)类型为list或tuple时,根据插值方式,
+ 将图像resize为target_size, target_size的输入应为[w, h]或(w, h)。
+### 参数
+* **target_size** (int|list|tuple): 目标大小
+* **interp** (str): resize的插值方式,与opencv的插值方式对应,
+可选的值为['NEAREST', 'LINEAR', 'CUBIC', 'AREA', 'LANCZOS4'],默认为"LINEAR"。
+
+
+## ResizeByLong类
+```python
+transforms.transforms.ResizeByLong(long_size)
+```
+对图像长边resize到固定值,短边按比例进行缩放。
+### 参数
+* **long_size** (int): resize后图像的长边大小。
+
+
+## ResizeRangeScaling类
+```python
+transforms.transforms.ResizeRangeScaling(min_value=400, max_value=600)
+```
+对图像长边随机resize到指定范围内,短边按比例进行缩放,模型训练时的数据增强操作。
+### 参数
+* **min_value** (int): 图像长边resize后的最小值。默认值400。
+* **max_value** (int): 图像长边resize后的最大值。默认值600。
+
+
+## ResizeStepScaling类
+```python
+transforms.transforms.ResizeStepScaling(min_scale_factor=0.75, max_scale_factor=1.25, scale_step_size=0.25)
+```
+对图像按照某一个比例resize,这个比例以scale_step_size为步长,在[min_scale_factor, max_scale_factor]随机变动,模型训练时的数据增强操作。
+### 参数
+* **min_scale_factor**(float), resize最小尺度。默认值0.75。
+* **max_scale_factor** (float), resize最大尺度。默认值1.25。
+* **scale_step_size** (float), resize尺度范围间隔。默认值0.25。
+
+
+## Clip类
+```python
+transforms.transforms.Clip(min_val=[0, 0, 0], max_val=[255.0, 255.0, 255.0])
+```
+对图像上超出一定范围的数据进行裁剪。
+
+### 参数
+* **min_var** (list): 裁剪的下限,小于min_val的数值均设为min_val. 默认值[0, 0, 0].
+* **max_var** (list): 裁剪的上限,大于max_val的数值均设为max_val. 默认值[255.0, 255.0, 255.0]
+
+
+## Normalize类
+```python
+transforms.transforms.Normalize(min_val=[0, 0, 0], max_val=[255.0, 255.0, 255.0], mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
+```
+对图像进行标准化。
+
+1.图像像素归一化到区间 [0.0, 1.0]。
+2.对图像进行减均值除以标准差操作。
+### 参数
+* **min_val** (list): 图像数据集的最小值。默认值[0, 0, 0].
+* **max_val** (list): 图像数据集的最大值。默认值[255.0, 255.0, 255.0]
+* **mean** (list): 图像数据集的均值。默认值[0.5, 0.5, 0.5]。
+* **std** (list): 图像数据集的标准差。默认值[0.5, 0.5, 0.5]。
+
+
+## Padding类
+```python
+transforms.transforms.Padding(target_size, im_padding_value=127.5, label_padding_value=255)
+```
+对图像或标注图像进行padding,padding方向为右和下。根据提供的值对图像或标注图像进行padding操作。
+### 参数
+* **target_size** (int|list|tuple): padding后图像的大小。
+* **im_padding_value** (list): 图像padding的值。默认为127.5
+* **label_padding_value** (int): 标注图像padding的值。默认值为255(仅在训练时需要设定该参数)。
+
+
+## RandomPaddingCrop类
+```python
+transforms.transforms.RandomPaddingCrop(crop_size=512, im_padding_value=127.5, label_padding_value=255)
+```
+对图像和标注图进行随机裁剪,当所需要的裁剪尺寸大于原图时,则进行padding操作,模型训练时的数据增强操作。
+### 参数
+* **crop_size**(int|list|tuple): 裁剪图像大小。默认为512。
+* **im_padding_value** (list): 图像padding的值。默认为127.5。
+* **label_padding_value** (int): 标注图像padding的值。默认值为255。
+
+
+## RandomBlur类
+```python
+transforms.transforms.RandomBlur(prob=0.1)
+```
+以一定的概率对图像进行高斯模糊,模型训练时的数据增强操作。
+### 参数
+* **prob** (float): 图像模糊概率。默认为0.1。
+
+
+## RandomScaleAspect类
+```python
+transforms.transforms.RandomScaleAspect(min_scale=0.5, aspect_ratio=0.33)
+```
+裁剪并resize回原始尺寸的图像和标注图像,模型训练时的数据增强操作。
+
+按照一定的面积比和宽高比对图像进行裁剪,并reszie回原始图像的图像,当存在标注图时,同步进行。
+### 参数
+* **min_scale** (float):裁取图像占原始图像的面积比,取值[0,1],为0时则返回原图。默认为0.5。
+* **aspect_ratio** (float): 裁取图像的宽高比范围,非负值,为0时返回原图。默认为0.33。
diff --git a/contrib/RemoteSensing/models/__init__.py b/contrib/RemoteSensing/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..49098e44c699162e728cedff915f60d66e37a229
--- /dev/null
+++ b/contrib/RemoteSensing/models/__init__.py
@@ -0,0 +1,2 @@
+from .load_model import *
+from .unet import *
diff --git a/contrib/RemoteSensing/models/base.py b/contrib/RemoteSensing/models/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..849947306392cdc2a04427168d2355ae019864bc
--- /dev/null
+++ b/contrib/RemoteSensing/models/base.py
@@ -0,0 +1,353 @@
+#copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+#Licensed under the Apache License, Version 2.0 (the "License");
+#you may not use this file except in compliance with the License.
+#You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+#Unless required by applicable law or agreed to in writing, software
+#distributed under the License is distributed on an "AS IS" BASIS,
+#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+#See the License for the specific language governing permissions and
+#limitations under the License.
+
+from __future__ import absolute_import
+import paddle.fluid as fluid
+import os
+import numpy as np
+import time
+import math
+import yaml
+import copy
+import json
+import utils.logging as logging
+from collections import OrderedDict
+from os import path as osp
+from utils.pretrain_weights import get_pretrain_weights
+import transforms.transforms as T
+import utils
+import __init__
+
+
+def dict2str(dict_input):
+ out = ''
+ for k, v in dict_input.items():
+ try:
+ v = round(float(v), 6)
+ except:
+ pass
+ out = out + '{}={}, '.format(k, v)
+ return out.strip(', ')
+
+
+class BaseAPI:
+ def __init__(self):
+ # 现有的CV模型都有这个属性,而这个属且也需要在eval时用到
+ self.num_classes = None
+ self.labels = None
+ if __init__.env_info['place'] == 'cpu':
+ self.places = fluid.cpu_places()
+ else:
+ self.places = fluid.cuda_places()
+ self.exe = fluid.Executor(self.places[0])
+ self.train_prog = None
+ self.test_prog = None
+ self.parallel_train_prog = None
+ self.train_inputs = None
+ self.test_inputs = None
+ self.train_outputs = None
+ self.test_outputs = None
+ self.train_data_loader = None
+ self.eval_metrics = None
+ # 若模型是从inference model加载进来的,无法调用训练接口进行训练
+ self.trainable = True
+ # 是否使用多卡间同步BatchNorm均值和方差
+ self.sync_bn = False
+ # 当前模型状态
+ self.status = 'Normal'
+
+ def _get_single_card_bs(self, batch_size):
+ if batch_size % len(self.places) == 0:
+ return int(batch_size // len(self.places))
+ else:
+ raise Exception("Please support correct batch_size, \
+ which can be divided by available cards({}) in {}".
+ format(__init__.env_info['num'],
+ __init__.env_info['place']))
+
+ def build_program(self):
+ # 构建训练网络
+ self.train_inputs, self.train_outputs = self.build_net(mode='train')
+ self.train_prog = fluid.default_main_program()
+ startup_prog = fluid.default_startup_program()
+
+ # 构建预测网络
+ self.test_prog = fluid.Program()
+ with fluid.program_guard(self.test_prog, startup_prog):
+ with fluid.unique_name.guard():
+ self.test_inputs, self.test_outputs = self.build_net(
+ mode='test')
+ self.test_prog = self.test_prog.clone(for_test=True)
+
+ def arrange_transforms(self, transforms, mode='train'):
+ # 给transforms添加arrange操作
+ if transforms.transforms[-1].__class__.__name__.startswith('Arrange'):
+ transforms.transforms[-1] = T.ArrangeSegmenter(mode=mode)
+ else:
+ transforms.transforms.append(T.ArrangeSegmenter(mode=mode))
+
+ def build_train_data_loader(self, reader, batch_size):
+ # 初始化data_loader
+ if self.train_data_loader is None:
+ self.train_data_loader = fluid.io.DataLoader.from_generator(
+ feed_list=list(self.train_inputs.values()),
+ capacity=64,
+ use_double_buffer=True,
+ iterable=True)
+ batch_size_each_gpu = self._get_single_card_bs(batch_size)
+ generator = reader.generator(
+ batch_size=batch_size_each_gpu, drop_last=True)
+ self.train_data_loader.set_sample_list_generator(
+ reader.generator(batch_size=batch_size_each_gpu),
+ places=self.places)
+
+ def net_initialize(self,
+ startup_prog=None,
+ pretrain_weights=None,
+ fuse_bn=False,
+ save_dir='.',
+ sensitivities_file=None,
+ eval_metric_loss=0.05):
+ if hasattr(self, 'backbone'):
+ backbone = self.backbone
+ else:
+ backbone = self.__class__.__name__
+ pretrain_weights = get_pretrain_weights(pretrain_weights, backbone,
+ save_dir)
+ if startup_prog is None:
+ startup_prog = fluid.default_startup_program()
+ self.exe.run(startup_prog)
+ if pretrain_weights is not None:
+ logging.info(
+ "Load pretrain weights from {}.".format(pretrain_weights))
+ utils.utils.load_pretrain_weights(self.exe, self.train_prog,
+ pretrain_weights, fuse_bn)
+ # 进行裁剪
+ if sensitivities_file is not None:
+ from .slim.prune_config import get_sensitivities
+ sensitivities_file = get_sensitivities(sensitivities_file, self,
+ save_dir)
+ from .slim.prune import get_params_ratios, prune_program
+ prune_params_ratios = get_params_ratios(
+ sensitivities_file, eval_metric_loss=eval_metric_loss)
+ prune_program(self, prune_params_ratios)
+ self.status = 'Prune'
+
+ def get_model_info(self):
+ info = dict()
+ info['Model'] = self.__class__.__name__
+ info['_Attributes'] = {}
+ if 'self' in self.init_params:
+ del self.init_params['self']
+ if '__class__' in self.init_params:
+ del self.init_params['__class__']
+ info['_init_params'] = self.init_params
+
+ info['_Attributes']['num_classes'] = self.num_classes
+ info['_Attributes']['labels'] = self.labels
+ try:
+ primary_metric_key = list(self.eval_metrics.keys())[0]
+ primary_metric_value = float(self.eval_metrics[primary_metric_key])
+ info['_Attributes']['eval_metrics'] = {
+ primary_metric_key: primary_metric_value
+ }
+ except:
+ pass
+
+ if hasattr(self, 'test_transforms'):
+ if self.test_transforms is not None:
+ info['Transforms'] = list()
+ for op in self.test_transforms.transforms:
+ name = op.__class__.__name__
+ attr = op.__dict__
+ info['Transforms'].append({name: attr})
+ return info
+
+ def save_model(self, save_dir):
+ if not osp.isdir(save_dir):
+ if osp.exists(save_dir):
+ os.remove(save_dir)
+ os.makedirs(save_dir)
+ fluid.save(self.train_prog, osp.join(save_dir, 'model'))
+ model_info = self.get_model_info()
+ model_info['status'] = self.status
+ with open(
+ osp.join(save_dir, 'model.yml'), encoding='utf-8',
+ mode='w') as f:
+ yaml.dump(model_info, f)
+ # 评估结果保存
+ if hasattr(self, 'eval_details'):
+ with open(osp.join(save_dir, 'eval_details.json'), 'w') as f:
+ json.dump(self.eval_details, f)
+
+ if self.status == 'Prune':
+ # 保存裁剪的shape
+ shapes = {}
+ for block in self.train_prog.blocks:
+ for param in block.all_parameters():
+ pd_var = fluid.global_scope().find_var(param.name)
+ pd_param = pd_var.get_tensor()
+ shapes[param.name] = np.array(pd_param).shape
+ with open(
+ osp.join(save_dir, 'prune.yml'), encoding='utf-8',
+ mode='w') as f:
+ yaml.dump(shapes, f)
+
+ # 模型保存成功的标志
+ open(osp.join(save_dir, '.success'), 'w').close()
+ logging.info("Model saved in {}.".format(save_dir))
+
+ def train_loop(self,
+ num_epochs,
+ train_reader,
+ train_batch_size,
+ eval_reader=None,
+ eval_best_metric=None,
+ save_interval_epochs=1,
+ log_interval_steps=10,
+ save_dir='output',
+ use_vdl=False):
+ if not osp.isdir(save_dir):
+ if osp.exists(save_dir):
+ os.remove(save_dir)
+ os.makedirs(save_dir)
+ if use_vdl:
+ from visualdl import LogWriter
+ vdl_logdir = osp.join(save_dir, 'vdl_log')
+ # 给transform添加arrange操作
+ self.arrange_transforms(
+ transforms=train_reader.transforms, mode='train')
+ # 构建train_data_loader
+ self.build_train_data_loader(
+ reader=train_reader, batch_size=train_batch_size)
+
+ if eval_reader is not None:
+ self.eval_transforms = eval_reader.transforms
+ self.test_transforms = copy.deepcopy(eval_reader.transforms)
+
+ # 获取实时变化的learning rate
+ lr = self.optimizer._learning_rate
+ if isinstance(lr, fluid.framework.Variable):
+ self.train_outputs['lr'] = lr
+
+ # 在多卡上跑训练
+ if self.parallel_train_prog is None:
+ build_strategy = fluid.compiler.BuildStrategy()
+ build_strategy.fuse_all_optimizer_ops = False
+ if __init__.env_info['place'] != 'cpu' and len(self.places) > 1:
+ build_strategy.sync_batch_norm = self.sync_bn
+ exec_strategy = fluid.ExecutionStrategy()
+ exec_strategy.num_iteration_per_drop_scope = 1
+ self.parallel_train_prog = fluid.CompiledProgram(
+ self.train_prog).with_data_parallel(
+ loss_name=self.train_outputs['loss'].name,
+ build_strategy=build_strategy,
+ exec_strategy=exec_strategy)
+
+ total_num_steps = math.floor(
+ train_reader.num_samples / train_batch_size)
+ num_steps = 0
+ time_stat = list()
+
+ if use_vdl:
+ # VisualDL component
+ log_writer = LogWriter(vdl_logdir)
+
+ best_accuracy = -1.0
+ best_model_epoch = 1
+ for i in range(num_epochs):
+ records = list()
+ step_start_time = time.time()
+ for step, data in enumerate(self.train_data_loader()):
+ outputs = self.exe.run(
+ self.parallel_train_prog,
+ feed=data,
+ fetch_list=list(self.train_outputs.values()))
+ outputs_avg = np.mean(np.array(outputs), axis=1)
+ records.append(outputs_avg)
+
+ # 训练完成剩余时间预估
+ current_time = time.time()
+ step_cost_time = current_time - step_start_time
+ step_start_time = current_time
+ if len(time_stat) < 20:
+ time_stat.append(step_cost_time)
+ else:
+ time_stat[num_steps % 20] = step_cost_time
+ eta = ((num_epochs - i) * total_num_steps - step -
+ 1) * np.mean(time_stat)
+ eta_h = math.floor(eta / 3600)
+ eta_m = math.floor((eta - eta_h * 3600) / 60)
+ eta_s = int(eta - eta_h * 3600 - eta_m * 60)
+ eta_str = "{}:{}:{}".format(eta_h, eta_m, eta_s)
+
+ # 每间隔log_interval_steps,输出loss信息
+ num_steps += 1
+ if num_steps % log_interval_steps == 0:
+ step_metrics = OrderedDict(
+ zip(list(self.train_outputs.keys()), outputs_avg))
+
+ if use_vdl:
+ for k, v in step_metrics.items():
+ log_writer.add_scalar(
+ tag="Training: {}".format(k),
+ value=v,
+ step=num_steps)
+ logging.info(
+ "[TRAIN] Epoch={}/{}, Step={}/{}, {}, eta={}".format(
+ i + 1, num_epochs, step + 1, total_num_steps,
+ dict2str(step_metrics), eta_str))
+ train_metrics = OrderedDict(
+ zip(list(self.train_outputs.keys()), np.mean(records, axis=0)))
+ logging.info('[TRAIN] Epoch {} finished, {} .'.format(
+ i + 1, dict2str(train_metrics)))
+
+ # 每间隔save_interval_epochs, 在验证集上评估和对模型进行保存
+ if (i + 1) % save_interval_epochs == 0 or i == num_epochs - 1:
+ current_save_dir = osp.join(save_dir, "epoch_{}".format(i + 1))
+ if not osp.isdir(current_save_dir):
+ os.makedirs(current_save_dir)
+ if eval_reader is not None:
+ # 检测目前仅支持单卡评估,训练数据batch大小与显卡数量之商为验证数据batch大小。
+ eval_batch_size = train_batch_size
+ self.eval_metrics, self.eval_details = self.evaluate(
+ eval_reader=eval_reader,
+ batch_size=eval_batch_size,
+ verbose=True,
+ epoch_id=i + 1,
+ return_details=True)
+ logging.info('[EVAL] Finished, Epoch={}, {} .'.format(
+ i + 1, dict2str(self.eval_metrics)))
+ # 保存最优模型
+ current_metric = self.eval_metrics[eval_best_metric]
+ if current_metric > best_accuracy:
+ best_accuracy = current_metric
+ best_model_epoch = i + 1
+ best_model_dir = osp.join(save_dir, "best_model")
+ self.save_model(save_dir=best_model_dir)
+ if use_vdl:
+ for k, v in self.eval_metrics.items():
+ if isinstance(v, list):
+ continue
+ if isinstance(v, np.ndarray):
+ if v.size > 1:
+ continue
+ log_writer.add_scalar(
+ tag="Evaluation: {}".format(k),
+ step=i + 1,
+ value=v)
+ self.save_model(save_dir=current_save_dir)
+ logging.info(
+ 'Current evaluated best model in eval_reader is epoch_{}, {}={}'
+ .format(best_model_epoch, eval_best_metric, best_accuracy))
diff --git a/contrib/RemoteSensing/models/load_model.py b/contrib/RemoteSensing/models/load_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb55c13125c7ad194196082be00fb5df7c037dd8
--- /dev/null
+++ b/contrib/RemoteSensing/models/load_model.py
@@ -0,0 +1,94 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import yaml
+import os.path as osp
+import six
+import copy
+from collections import OrderedDict
+import paddle.fluid as fluid
+from paddle.fluid.framework import Parameter
+from utils import logging
+import models
+
+
+def load_model(model_dir):
+ if not osp.exists(osp.join(model_dir, "model.yml")):
+ raise Exception("There's not model.yml in {}".format(model_dir))
+ with open(osp.join(model_dir, "model.yml")) as f:
+ info = yaml.load(f.read(), Loader=yaml.Loader)
+ status = info['status']
+
+ if not hasattr(models, info['Model']):
+ raise Exception("There's no attribute {} in models".format(
+ info['Model']))
+
+ model = getattr(models, info['Model'])(**info['_init_params'])
+ if status == "Normal" or \
+ status == "Prune":
+ startup_prog = fluid.Program()
+ model.test_prog = fluid.Program()
+ with fluid.program_guard(model.test_prog, startup_prog):
+ with fluid.unique_name.guard():
+ model.test_inputs, model.test_outputs = model.build_net(
+ mode='test')
+ model.test_prog = model.test_prog.clone(for_test=True)
+ model.exe.run(startup_prog)
+ if status == "Prune":
+ from .slim.prune import update_program
+ model.test_prog = update_program(model.test_prog, model_dir,
+ model.places[0])
+ import pickle
+ with open(osp.join(model_dir, 'model.pdparams'), 'rb') as f:
+ load_dict = pickle.load(f)
+ fluid.io.set_program_state(model.test_prog, load_dict)
+
+ elif status == "Infer" or \
+ status == "Quant":
+ [prog, input_names, outputs] = fluid.io.load_inference_model(
+ model_dir, model.exe, params_filename='__params__')
+ model.test_prog = prog
+ test_outputs_info = info['_ModelInputsOutputs']['test_outputs']
+ model.test_inputs = OrderedDict()
+ model.test_outputs = OrderedDict()
+ for name in input_names:
+ model.test_inputs[name] = model.test_prog.global_block().var(name)
+ for i, out in enumerate(outputs):
+ var_desc = test_outputs_info[i]
+ model.test_outputs[var_desc[0]] = out
+ if 'Transforms' in info:
+ model.test_transforms = build_transforms(info['Transforms'])
+ model.eval_transforms = copy.deepcopy(model.test_transforms)
+
+ if '_Attributes' in info:
+ for k, v in info['_Attributes'].items():
+ if k in model.__dict__:
+ model.__dict__[k] = v
+
+ logging.info("Model[{}] loaded.".format(info['Model']))
+ return model
+
+
+def build_transforms(transforms_info):
+ from transforms import transforms as T
+ transforms = list()
+ for op_info in transforms_info:
+ op_name = list(op_info.keys())[0]
+ op_attr = op_info[op_name]
+ if not hasattr(T, op_name):
+ raise Exception(
+ "There's no operator named '{}' in transforms".format(op_name))
+ transforms.append(getattr(T, op_name)(**op_attr))
+ eval_transforms = T.Compose(transforms)
+ return eval_transforms
diff --git a/contrib/RemoteSensing/models/unet.py b/contrib/RemoteSensing/models/unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..bd56a929aa8e0253ce04a899454cadf956d28fbe
--- /dev/null
+++ b/contrib/RemoteSensing/models/unet.py
@@ -0,0 +1,322 @@
+#copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+#Licensed under the Apache License, Version 2.0 (the "License");
+#you may not use this file except in compliance with the License.
+#You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+#Unless required by applicable law or agreed to in writing, software
+#distributed under the License is distributed on an "AS IS" BASIS,
+#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+#See the License for the specific language governing permissions and
+#limitations under the License.
+
+from __future__ import absolute_import
+import os.path as osp
+import numpy as np
+import math
+import cv2
+import paddle.fluid as fluid
+import utils.logging as logging
+from collections import OrderedDict
+from .base import BaseAPI
+from utils.metrics import ConfusionMatrix
+import nets
+
+
+class UNet(BaseAPI):
+ """实现UNet网络的构建并进行训练、评估、预测和模型导出。
+
+ Args:
+ num_classes (int): 类别数。
+ upsample_mode (str): UNet decode时采用的上采样方式,取值为'bilinear'时利用双线行差值进行上菜样,
+ 当输入其他选项时则利用反卷积进行上菜样,默认为'bilinear'。
+ use_bce_loss (bool): 是否使用bce loss作为网络的损失函数,只能用于两类分割。可与dice loss同时使用。默认False。
+ use_dice_loss (bool): 是否使用dice loss作为网络的损失函数,只能用于两类分割,可与bce loss同时使用。
+ 当use_bce_loss和use_dice_loss都为False时,使用交叉熵损失函数。默认False。
+ class_weight (list/str): 交叉熵损失函数各类损失的权重。当class_weight为list的时候,长度应为
+ num_classes。当class_weight为str时, weight.lower()应为'dynamic',这时会根据每一轮各类像素的比重
+ 自行计算相应的权重,每一类的权重为:每类的比例 * num_classes。class_weight取默认值None是,各类的权重1,
+ 即平时使用的交叉熵损失函数。
+ ignore_index (int): label上忽略的值,label为ignore_index的像素不参与损失函数的计算。默认255。
+
+ Raises:
+ ValueError: use_bce_loss或use_dice_loss为真且num_calsses > 2。
+ ValueError: class_weight为list, 但长度不等于num_class。
+ class_weight为str, 但class_weight.low()不等于dynamic。
+ TypeError: class_weight不为None时,其类型不是list或str。
+ """
+
+ def __init__(self,
+ num_classes=2,
+ upsample_mode='bilinear',
+ input_channel=3,
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255):
+ self.init_params = locals()
+ super(UNet, self).__init__()
+ # dice_loss或bce_loss只适用两类分割中
+ if num_classes > 2 and (use_bce_loss or use_dice_loss):
+ raise ValueError(
+ "dice loss and bce loss is only applicable to binary classfication"
+ )
+
+ if class_weight is not None:
+ if isinstance(class_weight, list):
+ if len(class_weight) != num_classes:
+ raise ValueError(
+ "Length of class_weight should be equal to number of classes"
+ )
+ elif isinstance(class_weight, str):
+ if class_weight.lower() != 'dynamic':
+ raise ValueError(
+ "if class_weight is string, must be dynamic!")
+ else:
+ raise TypeError(
+ 'Expect class_weight is a list or string but receive {}'.
+ format(type(class_weight)))
+ self.num_classes = num_classes
+ self.upsample_mode = upsample_mode
+ self.input_channel = input_channel
+ self.use_bce_loss = use_bce_loss
+ self.use_dice_loss = use_dice_loss
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+ self.labels = None
+ # 若模型是从inference model加载进来的,无法调用训练接口进行训练
+ self.trainable = True
+
+ def build_net(self, mode='train'):
+ model = nets.UNet(
+ self.num_classes,
+ mode=mode,
+ upsample_mode=self.upsample_mode,
+ input_channel=self.input_channel,
+ use_bce_loss=self.use_bce_loss,
+ use_dice_loss=self.use_dice_loss,
+ class_weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ inputs = model.generate_inputs()
+ model_out = model.build_net(inputs)
+ outputs = OrderedDict()
+ if mode == 'train':
+ self.optimizer.minimize(model_out)
+ outputs['loss'] = model_out
+ elif mode == 'eval':
+ outputs['loss'] = model_out[0]
+ outputs['pred'] = model_out[1]
+ outputs['label'] = model_out[2]
+ outputs['mask'] = model_out[3]
+ else:
+ outputs['pred'] = model_out[0]
+ outputs['logit'] = model_out[1]
+ return inputs, outputs
+
+ def default_optimizer(self,
+ learning_rate,
+ num_epochs,
+ num_steps_each_epoch,
+ lr_decay_power=0.9):
+ decay_step = num_epochs * num_steps_each_epoch
+ lr_decay = fluid.layers.polynomial_decay(
+ learning_rate,
+ decay_step,
+ end_learning_rate=0,
+ power=lr_decay_power)
+ optimizer = fluid.optimizer.Momentum(
+ lr_decay,
+ momentum=0.9,
+ regularization=fluid.regularizer.L2Decay(
+ regularization_coeff=4e-05))
+ return optimizer
+
+ def train(self,
+ num_epochs,
+ train_reader,
+ train_batch_size=2,
+ eval_reader=None,
+ eval_best_metric='kappa',
+ save_interval_epochs=1,
+ log_interval_steps=2,
+ save_dir='output',
+ pretrain_weights='COCO',
+ optimizer=None,
+ learning_rate=0.01,
+ lr_decay_power=0.9,
+ use_vdl=False,
+ sensitivities_file=None,
+ eval_metric_loss=0.05):
+ """训练。
+
+ Args:
+ num_epochs (int): 训练迭代轮数。
+ train_reader (readers): 训练数据读取器。
+ train_batch_size (int): 训练数据batch大小。同时作为验证数据batch大小。默认2。
+ eval_reader (readers): 边训边评估的评估数据读取器。
+ eval_best_metric (str): 边训边评估保存最好模型的指标。默认为'kappa'。
+ save_interval_epochs (int): 模型保存间隔(单位:迭代轮数)。默认为1。
+ log_interval_steps (int): 训练日志输出间隔(单位:迭代次数)。默认为2。
+ save_dir (str): 模型保存路径。默认'output'。
+ pretrain_weights (str): 若指定为路径时,则加载路径下预训练模型;若为字符串'COCO',
+ 则自动下载在COCO图片数据上预训练的模型权重;若为None,则不使用预训练模型。默认为'COCO'。
+ optimizer (paddle.fluid.optimizer): 优化器。当改参数为None时,使用默认的优化器:使用
+ fluid.optimizer.Momentum优化方法,polynomial的学习率衰减策略。
+ learning_rate (float): 默认优化器的初始学习率。默认0.01。
+ lr_decay_power (float): 默认优化器学习率多项式衰减系数。默认0.9。
+ use_vdl (bool): 是否使用VisualDL进行可视化。默认False。
+ sensitivities_file (str): 若指定为路径时,则加载路径下敏感度信息进行裁剪;若为字符串'DEFAULT',
+ 则自动下载在ImageNet图片数据上获得的敏感度信息进行裁剪;若为None,则不进行裁剪。默认为None。
+ eval_metric_loss (float): 可容忍的精度损失。默认为0.05。
+
+ Raises:
+ ValueError: 模型从inference model进行加载。
+ """
+ if not self.trainable:
+ raise ValueError(
+ "Model is not trainable since it was loaded from a inference model."
+ )
+
+ self.labels = train_reader.labels
+
+ if optimizer is None:
+ num_steps_each_epoch = train_reader.num_samples // train_batch_size
+ optimizer = self.default_optimizer(
+ learning_rate=learning_rate,
+ num_epochs=num_epochs,
+ num_steps_each_epoch=num_steps_each_epoch,
+ lr_decay_power=lr_decay_power)
+ self.optimizer = optimizer
+ # 构建训练、验证、预测网络
+ self.build_program()
+ # 初始化网络权重
+ self.net_initialize(
+ startup_prog=fluid.default_startup_program(),
+ pretrain_weights=pretrain_weights,
+ save_dir=save_dir,
+ sensitivities_file=sensitivities_file,
+ eval_metric_loss=eval_metric_loss)
+ # 训练
+ self.train_loop(
+ num_epochs=num_epochs,
+ train_reader=train_reader,
+ train_batch_size=train_batch_size,
+ eval_reader=eval_reader,
+ eval_best_metric=eval_best_metric,
+ save_interval_epochs=save_interval_epochs,
+ log_interval_steps=log_interval_steps,
+ save_dir=save_dir,
+ use_vdl=use_vdl)
+
+ def evaluate(self,
+ eval_reader,
+ batch_size=1,
+ verbose=True,
+ epoch_id=None,
+ return_details=False):
+ """评估。
+
+ Args:
+ eval_reader (readers): 评估数据读取器。
+ batch_size (int): 评估时的batch大小。默认1。
+ verbose (bool): 是否打印日志。默认True。
+ epoch_id (int): 当前评估模型所在的训练轮数。
+ return_details (bool): 是否返回详细信息。默认False。
+
+ Returns:
+ dict: 当return_details为False时,返回dict。包含关键字:'miou'、'category_iou'、'macc'、
+ 'category_acc'和'kappa',分别表示平均iou、各类别iou、平均准确率、各类别准确率和kappa系数。
+ tuple (metrics, eval_details):当return_details为True时,增加返回dict (eval_details),
+ 包含关键字:'confusion_matrix',表示评估的混淆矩阵。
+ """
+ self.arrange_transforms(transforms=eval_reader.transforms, mode='eval')
+ total_steps = math.ceil(eval_reader.num_samples * 1.0 / batch_size)
+ conf_mat = ConfusionMatrix(self.num_classes, streaming=True)
+ data_generator = eval_reader.generator(
+ batch_size=batch_size, drop_last=False)
+ if not hasattr(self, 'parallel_test_prog'):
+ self.parallel_test_prog = fluid.CompiledProgram(
+ self.test_prog).with_data_parallel(
+ share_vars_from=self.parallel_train_prog)
+ batch_size_each_gpu = self._get_single_card_bs(batch_size)
+
+ for step, data in enumerate(data_generator()):
+ images = np.array([d[0] for d in data])
+ images = images.astype(np.float32)
+
+ labels = np.array([d[1] for d in data])
+ num_samples = images.shape[0]
+ if num_samples < batch_size:
+ num_pad_samples = batch_size - num_samples
+ pad_images = np.tile(images[0:1], (num_pad_samples, 1, 1, 1))
+ images = np.concatenate([images, pad_images])
+ feed_data = {'image': images}
+ outputs = self.exe.run(
+ self.parallel_test_prog,
+ feed=feed_data,
+ fetch_list=list(self.test_outputs.values()),
+ return_numpy=True)
+ pred = outputs[0]
+ if num_samples < batch_size:
+ pred = pred[0:num_samples]
+
+ mask = labels != self.ignore_index
+ conf_mat.calculate(pred=pred, label=labels, ignore=mask)
+ _, iou = conf_mat.mean_iou()
+
+ if verbose:
+ logging.info("[EVAL] Epoch={}, Step={}/{}, iou={}".format(
+ epoch_id, step + 1, total_steps, iou))
+
+ category_iou, miou = conf_mat.mean_iou()
+ category_acc, macc = conf_mat.accuracy()
+
+ metrics = OrderedDict(
+ zip(['miou', 'category_iou', 'macc', 'category_acc', 'kappa'],
+ [miou, category_iou, macc, category_acc,
+ conf_mat.kappa()]))
+ if return_details:
+ eval_details = {
+ 'confusion_matrix': conf_mat.confusion_matrix.tolist()
+ }
+ return metrics, eval_details
+ return metrics
+
+ def predict(self, im_file, transforms=None):
+ """预测。
+ Args:
+ img_file(str): 预测图像路径。
+ transforms(transforms): 数据预处理操作。
+
+ Returns:
+ np.ndarray: 预测结果灰度图。
+ """
+ if transforms is None and not hasattr(self, 'test_transforms'):
+ raise Exception("transforms need to be defined, now is None.")
+ if transforms is not None:
+ self.arrange_transforms(transforms=transforms, mode='test')
+ im, im_info = transforms(im_file)
+ else:
+ self.arrange_transforms(
+ transforms=self.test_transforms, mode='test')
+ im, im_info = self.test_transforms(im_file)
+ im = im.astype(np.float32)
+ im = np.expand_dims(im, axis=0)
+ result = self.exe.run(
+ self.test_prog,
+ feed={'image': im},
+ fetch_list=list(self.test_outputs.values()))
+ pred = result[0]
+ pred = np.squeeze(pred).astype(np.uint8)
+ keys = list(im_info.keys())
+ for k in keys[::-1]:
+ if k == 'shape_before_resize':
+ h, w = im_info[k][0], im_info[k][1]
+ pred = cv2.resize(pred, (w, h), cv2.INTER_NEAREST)
+ elif k == 'shape_before_padding':
+ h, w = im_info[k][0], im_info[k][1]
+ pred = pred[0:h, 0:w]
+
+ return pred
diff --git a/contrib/RemoteSensing/nets/__init__.py b/contrib/RemoteSensing/nets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..67cafc4f4222e392c2552e71f5ab1df194d860c8
--- /dev/null
+++ b/contrib/RemoteSensing/nets/__init__.py
@@ -0,0 +1 @@
+from .unet import UNet
diff --git a/contrib/RemoteSensing/nets/libs.py b/contrib/RemoteSensing/nets/libs.py
new file mode 100644
index 0000000000000000000000000000000000000000..01fdad2cec6ce4b13cea2b7c957fb648edb4aeb2
--- /dev/null
+++ b/contrib/RemoteSensing/nets/libs.py
@@ -0,0 +1,219 @@
+# coding: utf8
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+import paddle
+import paddle.fluid as fluid
+import contextlib
+
+bn_regularizer = fluid.regularizer.L2DecayRegularizer(regularization_coeff=0.0)
+name_scope = ""
+
+
+@contextlib.contextmanager
+def scope(name):
+ global name_scope
+ bk = name_scope
+ name_scope = name_scope + name + '/'
+ yield
+ name_scope = bk
+
+
+def max_pool(input, kernel, stride, padding):
+ data = fluid.layers.pool2d(
+ input,
+ pool_size=kernel,
+ pool_type='max',
+ pool_stride=stride,
+ pool_padding=padding)
+ return data
+
+
+def avg_pool(input, kernel, stride, padding=0):
+ data = fluid.layers.pool2d(
+ input,
+ pool_size=kernel,
+ pool_type='avg',
+ pool_stride=stride,
+ pool_padding=padding)
+ return data
+
+
+def group_norm(input, G, eps=1e-5, param_attr=None, bias_attr=None):
+ N, C, H, W = input.shape
+ if C % G != 0:
+ for d in range(10):
+ for t in [d, -d]:
+ if G + t <= 0: continue
+ if C % (G + t) == 0:
+ G = G + t
+ break
+ if C % G == 0:
+ break
+ assert C % G == 0, "group can not divide channle"
+ x = fluid.layers.group_norm(
+ input,
+ groups=G,
+ param_attr=param_attr,
+ bias_attr=bias_attr,
+ name=name_scope + 'group_norm')
+ return x
+
+
+def bn(*args,
+ norm_type='bn',
+ eps=1e-5,
+ bn_momentum=0.99,
+ group_norm=32,
+ **kargs):
+
+ if norm_type == 'bn':
+ with scope('BatchNorm'):
+ return fluid.layers.batch_norm(
+ *args,
+ epsilon=eps,
+ momentum=bn_momentum,
+ param_attr=fluid.ParamAttr(
+ name=name_scope + 'gamma', regularizer=bn_regularizer),
+ bias_attr=fluid.ParamAttr(
+ name=name_scope + 'beta', regularizer=bn_regularizer),
+ moving_mean_name=name_scope + 'moving_mean',
+ moving_variance_name=name_scope + 'moving_variance',
+ **kargs)
+ elif norm_type == 'gn':
+ with scope('GroupNorm'):
+ return group_norm(
+ args[0],
+ group_norm,
+ eps=eps,
+ param_attr=fluid.ParamAttr(
+ name=name_scope + 'gamma', regularizer=bn_regularizer),
+ bias_attr=fluid.ParamAttr(
+ name=name_scope + 'beta', regularizer=bn_regularizer))
+ else:
+ raise Exception("Unsupport norm type:" + norm_type)
+
+
+def bn_relu(data, norm_type='bn', eps=1e-5):
+ return fluid.layers.relu(bn(data, norm_type=norm_type, eps=eps))
+
+
+def relu(data):
+ return fluid.layers.relu(data)
+
+
+def conv(*args, **kargs):
+ kargs['param_attr'] = name_scope + 'weights'
+ if 'bias_attr' in kargs and kargs['bias_attr']:
+ kargs['bias_attr'] = fluid.ParamAttr(
+ name=name_scope + 'biases',
+ regularizer=None,
+ initializer=fluid.initializer.ConstantInitializer(value=0.0))
+ else:
+ kargs['bias_attr'] = False
+ return fluid.layers.conv2d(*args, **kargs)
+
+
+def deconv(*args, **kargs):
+ kargs['param_attr'] = name_scope + 'weights'
+ if 'bias_attr' in kargs and kargs['bias_attr']:
+ kargs['bias_attr'] = name_scope + 'biases'
+ else:
+ kargs['bias_attr'] = False
+ return fluid.layers.conv2d_transpose(*args, **kargs)
+
+
+def separate_conv(input,
+ channel,
+ stride,
+ filter,
+ dilation=1,
+ act=None,
+ eps=1e-5):
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.0),
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.33))
+ with scope('depthwise'):
+ input = conv(
+ input,
+ input.shape[1],
+ filter,
+ stride,
+ groups=input.shape[1],
+ padding=(filter // 2) * dilation,
+ dilation=dilation,
+ use_cudnn=False,
+ param_attr=param_attr)
+ input = bn(input, eps=eps)
+ if act: input = act(input)
+
+ param_attr = fluid.ParamAttr(
+ name=name_scope + 'weights',
+ regularizer=None,
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.06))
+ with scope('pointwise'):
+ input = conv(
+ input, channel, 1, 1, groups=1, padding=0, param_attr=param_attr)
+ input = bn(input, eps=eps)
+ if act: input = act(input)
+ return input
+
+
+def conv_bn_layer(input,
+ filter_size,
+ num_filters,
+ stride,
+ padding,
+ channels=None,
+ num_groups=1,
+ if_act=True,
+ name=None,
+ use_cudnn=True):
+ conv = fluid.layers.conv2d(
+ input=input,
+ num_filters=num_filters,
+ filter_size=filter_size,
+ stride=stride,
+ padding=padding,
+ groups=num_groups,
+ act=None,
+ use_cudnn=use_cudnn,
+ param_attr=fluid.ParamAttr(name=name + '_weights'),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ bn = fluid.layers.batch_norm(
+ input=conv,
+ param_attr=fluid.ParamAttr(name=bn_name + "_scale"),
+ bias_attr=fluid.ParamAttr(name=bn_name + "_offset"),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+ if if_act:
+ return fluid.layers.relu6(bn)
+ else:
+ return bn
+
+
+def sigmoid_to_softmax(input):
+ """
+ one channel to two channel
+ """
+ logit = fluid.layers.sigmoid(input)
+ logit_back = 1 - logit
+ logit = fluid.layers.concat([logit_back, logit], axis=1)
+ return logit
diff --git a/contrib/RemoteSensing/nets/loss.py b/contrib/RemoteSensing/nets/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb59dce486420585edd47559c6fdd3cf88e59350
--- /dev/null
+++ b/contrib/RemoteSensing/nets/loss.py
@@ -0,0 +1,115 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import paddle.fluid as fluid
+import numpy as np
+
+
+def softmax_with_loss(logit,
+ label,
+ ignore_mask=None,
+ num_classes=2,
+ weight=None,
+ ignore_index=255):
+ ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
+ label = fluid.layers.elementwise_min(
+ label, fluid.layers.assign(np.array([num_classes - 1], dtype=np.int32)))
+ logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
+ logit = fluid.layers.reshape(logit, [-1, num_classes])
+ label = fluid.layers.reshape(label, [-1, 1])
+ label = fluid.layers.cast(label, 'int64')
+ ignore_mask = fluid.layers.reshape(ignore_mask, [-1, 1])
+ if weight is None:
+ loss, probs = fluid.layers.softmax_with_cross_entropy(
+ logit, label, ignore_index=ignore_index, return_softmax=True)
+ else:
+ label_one_hot = fluid.one_hot(input=label, depth=num_classes)
+ if isinstance(weight, list):
+ assert len(
+ weight
+ ) == num_classes, "weight length must equal num of classes"
+ weight = fluid.layers.assign(np.array([weight], dtype='float32'))
+ elif isinstance(weight, str):
+ assert weight.lower(
+ ) == 'dynamic', 'if weight is string, must be dynamic!'
+ tmp = []
+ total_num = fluid.layers.cast(
+ fluid.layers.shape(label)[0], 'float32')
+ for i in range(num_classes):
+ cls_pixel_num = fluid.layers.reduce_sum(label_one_hot[:, i])
+ ratio = total_num / (cls_pixel_num + 1)
+ tmp.append(ratio)
+ weight = fluid.layers.concat(tmp)
+ weight = weight / fluid.layers.reduce_sum(weight) * num_classes
+ elif isinstance(weight, fluid.layers.Variable):
+ pass
+ else:
+ raise ValueError(
+ 'Expect weight is a list, string or Variable, but receive {}'.
+ format(type(weight)))
+ weight = fluid.layers.reshape(weight, [1, num_classes])
+ weighted_label_one_hot = fluid.layers.elementwise_mul(
+ label_one_hot, weight)
+ probs = fluid.layers.softmax(logit)
+ loss = fluid.layers.cross_entropy(
+ probs,
+ weighted_label_one_hot,
+ soft_label=True,
+ ignore_index=ignore_index)
+ weighted_label_one_hot.stop_gradient = True
+
+ loss = loss * ignore_mask
+ avg_loss = fluid.layers.mean(loss) / (
+ fluid.layers.mean(ignore_mask) + 0.00001)
+
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return avg_loss
+
+
+# to change, how to appicate ignore index and ignore mask
+def dice_loss(logit, label, ignore_mask=None, epsilon=0.00001):
+ if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
+ raise Exception(
+ "dice loss is only applicable to one channel classfication")
+ ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
+ logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
+ label = fluid.layers.transpose(label, [0, 2, 3, 1])
+ label = fluid.layers.cast(label, 'int64')
+ ignore_mask = fluid.layers.transpose(ignore_mask, [0, 2, 3, 1])
+ logit = fluid.layers.sigmoid(logit)
+ logit = logit * ignore_mask
+ label = label * ignore_mask
+ reduce_dim = list(range(1, len(logit.shape)))
+ inse = fluid.layers.reduce_sum(logit * label, dim=reduce_dim)
+ dice_denominator = fluid.layers.reduce_sum(
+ logit, dim=reduce_dim) + fluid.layers.reduce_sum(
+ label, dim=reduce_dim)
+ dice_score = 1 - inse * 2 / (dice_denominator + epsilon)
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return fluid.layers.reduce_mean(dice_score)
+
+
+def bce_loss(logit, label, ignore_mask=None, ignore_index=255):
+ if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
+ raise Exception("bce loss is only applicable to binary classfication")
+ label = fluid.layers.cast(label, 'float32')
+ loss = fluid.layers.sigmoid_cross_entropy_with_logits(
+ x=logit, label=label, ignore_index=ignore_index,
+ normalize=True) # or False
+ loss = fluid.layers.reduce_sum(loss)
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return loss
diff --git a/contrib/RemoteSensing/nets/unet.py b/contrib/RemoteSensing/nets/unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..fef193ec72190ef5c08a54b8444e21ac6a901e6f
--- /dev/null
+++ b/contrib/RemoteSensing/nets/unet.py
@@ -0,0 +1,268 @@
+# coding: utf8
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from collections import OrderedDict
+
+import paddle.fluid as fluid
+from .libs import scope, name_scope
+from .libs import bn, bn_relu, relu
+from .libs import conv, max_pool, deconv
+from .libs import sigmoid_to_softmax
+from .loss import softmax_with_loss
+from .loss import dice_loss
+from .loss import bce_loss
+
+
+class UNet(object):
+ """实现Unet模型
+ `"U-Net: Convolutional Networks for Biomedical Image Segmentation"
+ `
+
+ Args:
+ num_classes (int): 类别数
+ mode (str): 网络运行模式,根据mode构建网络的输入和返回。
+ 当mode为'train'时,输入为image(-1, 3, -1, -1)和label (-1, 1, -1, -1) 返回loss。
+ 当mode为'train'时,输入为image (-1, 3, -1, -1)和label (-1, 1, -1, -1),返回loss,
+ pred (与网络输入label 相同大小的预测结果,值代表相应的类别),label,mask(非忽略值的mask,
+ 与label相同大小,bool类型)。
+ 当mode为'test'时,输入为image(-1, 3, -1, -1)返回pred (-1, 1, -1, -1)和
+ logit (-1, num_classes, -1, -1) 通道维上代表每一类的概率值。
+ upsample_mode (str): UNet decode时采用的上采样方式,取值为'bilinear'时利用双线行差值进行上菜样,
+ 当输入其他选项时则利用反卷积进行上菜样,默认为'bilinear'。
+ use_bce_loss (bool): 是否使用bce loss作为网络的损失函数,只能用于两类分割。可与dice loss同时使用。
+ use_dice_loss (bool): 是否使用dice loss作为网络的损失函数,只能用于两类分割,可与bce loss同时使用。
+ 当use_bce_loss和use_dice_loss都为False时,使用交叉熵损失函数。
+ class_weight (list/str): 交叉熵损失函数各类损失的权重。当class_weight为list的时候,长度应为
+ num_classes。当class_weight为str时, weight.lower()应为'dynamic',这时会根据每一轮各类像素的比重
+ 自行计算相应的权重,每一类的权重为:每类的比例 * num_classes。class_weight取默认值None是,各类的权重1,
+ 即平时使用的交叉熵损失函数。
+ ignore_index (int): label上忽略的值,label为ignore_index的像素不参与损失函数的计算。
+
+ Raises:
+ ValueError: use_bce_loss或use_dice_loss为真且num_calsses > 2。
+ ValueError: class_weight为list, 但长度不等于num_class。
+ class_weight为str, 但class_weight.low()不等于dynamic。
+ TypeError: class_weight不为None时,其类型不是list或str。
+ """
+
+ def __init__(self,
+ num_classes,
+ mode='train',
+ upsample_mode='bilinear',
+ input_channel=3,
+ use_bce_loss=False,
+ use_dice_loss=False,
+ class_weight=None,
+ ignore_index=255):
+ # dice_loss或bce_loss只适用两类分割中
+ if num_classes > 2 and (use_bce_loss or use_dice_loss):
+ raise Exception(
+ "dice loss and bce loss is only applicable to binary classfication"
+ )
+
+ if class_weight is not None:
+ if isinstance(class_weight, list):
+ if len(class_weight) != num_classes:
+ raise ValueError(
+ "Length of class_weight should be equal to number of classes"
+ )
+ elif isinstance(class_weight, str):
+ if class_weight.lower() != 'dynamic':
+ raise ValueError(
+ "if class_weight is string, must be dynamic!")
+ else:
+ raise TypeError(
+ 'Expect class_weight is a list or string but receive {}'.
+ format(type(class_weight)))
+ self.num_classes = num_classes
+ self.mode = mode
+ self.upsample_mode = upsample_mode
+ self.input_channel = input_channel
+ self.use_bce_loss = use_bce_loss
+ self.use_dice_loss = use_dice_loss
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+
+ def _double_conv(self, data, out_ch):
+ param_attr = fluid.ParamAttr(
+ name='weights',
+ regularizer=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.0),
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.33))
+ with scope("conv0"):
+ data = bn_relu(
+ conv(
+ data, out_ch, 3, stride=1, padding=1,
+ param_attr=param_attr))
+ with scope("conv1"):
+ data = bn_relu(
+ conv(
+ data, out_ch, 3, stride=1, padding=1,
+ param_attr=param_attr))
+ return data
+
+ def _down(self, data, out_ch):
+ # 下采样:max_pool + 2个卷积
+ with scope("down"):
+ data = max_pool(data, 2, 2, 0)
+ data = self._double_conv(data, out_ch)
+ return data
+
+ def _up(self, data, short_cut, out_ch):
+ # 上采样:data上采样(resize或deconv), 并与short_cut concat
+ param_attr = fluid.ParamAttr(
+ name='weights',
+ regularizer=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.0),
+ initializer=fluid.initializer.XavierInitializer(),
+ )
+ with scope("up"):
+ if self.upsample_mode == 'bilinear':
+ short_cut_shape = fluid.layers.shape(short_cut)
+ data = fluid.layers.resize_bilinear(data, short_cut_shape[2:])
+ else:
+ data = deconv(
+ data,
+ out_ch // 2,
+ filter_size=2,
+ stride=2,
+ padding=0,
+ param_attr=param_attr)
+ data = fluid.layers.concat([data, short_cut], axis=1)
+ data = self._double_conv(data, out_ch)
+ return data
+
+ def _encode(self, data):
+ # 编码器设置
+ short_cuts = []
+ with scope("encode"):
+ with scope("block1"):
+ data = self._double_conv(data, 64)
+ short_cuts.append(data)
+ with scope("block2"):
+ data = self._down(data, 128)
+ short_cuts.append(data)
+ with scope("block3"):
+ data = self._down(data, 256)
+ short_cuts.append(data)
+ with scope("block4"):
+ data = self._down(data, 512)
+ short_cuts.append(data)
+ with scope("block5"):
+ data = self._down(data, 512)
+ return data, short_cuts
+
+ def _decode(self, data, short_cuts):
+ # 解码器设置,与编码器对称
+ with scope("decode"):
+ with scope("decode1"):
+ data = self._up(data, short_cuts[3], 256)
+ with scope("decode2"):
+ data = self._up(data, short_cuts[2], 128)
+ with scope("decode3"):
+ data = self._up(data, short_cuts[1], 64)
+ with scope("decode4"):
+ data = self._up(data, short_cuts[0], 64)
+ return data
+
+ def _get_logit(self, data, num_classes):
+ # 根据类别数设置最后一个卷积层输出
+ param_attr = fluid.ParamAttr(
+ name='weights',
+ regularizer=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.0),
+ initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.01))
+ with scope("logit"):
+ data = conv(
+ data,
+ num_classes,
+ 3,
+ stride=1,
+ padding=1,
+ param_attr=param_attr)
+ return data
+
+ def _get_loss(self, logit, label, mask):
+ avg_loss = 0
+ if not (self.use_dice_loss or self.use_bce_loss):
+ avg_loss += softmax_with_loss(
+ logit,
+ label,
+ mask,
+ num_classes=self.num_classes,
+ weight=self.class_weight,
+ ignore_index=self.ignore_index)
+ else:
+ if self.use_dice_loss:
+ avg_loss += dice_loss(logit, label, mask)
+ if self.use_bce_loss:
+ avg_loss += bce_loss(
+ logit, label, mask, ignore_index=self.ignore_index)
+
+ return avg_loss
+
+ def generate_inputs(self):
+ inputs = OrderedDict()
+ inputs['image'] = fluid.data(
+ dtype='float32',
+ shape=[None, self.input_channel, None, None],
+ name='image')
+ if self.mode == 'train':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ elif self.mode == 'eval':
+ inputs['label'] = fluid.data(
+ dtype='int32', shape=[None, 1, None, None], name='label')
+ return inputs
+
+ def build_net(self, inputs):
+ # 在两类分割情况下,当loss函数选择dice_loss或bce_loss的时候,最后logit输出通道数设置为1
+ if self.use_dice_loss or self.use_bce_loss:
+ self.num_classes = 1
+
+ image = inputs['image']
+ encode_data, short_cuts = self._encode(image)
+ decode_data = self._decode(encode_data, short_cuts)
+ logit = self._get_logit(decode_data, self.num_classes)
+
+ if self.num_classes == 1:
+ out = sigmoid_to_softmax(logit)
+ out = fluid.layers.transpose(out, [0, 2, 3, 1])
+ else:
+ out = fluid.layers.transpose(logit, [0, 2, 3, 1])
+
+ pred = fluid.layers.argmax(out, axis=3)
+ pred = fluid.layers.unsqueeze(pred, axes=[3])
+
+ if self.mode == 'train':
+ label = inputs['label']
+ mask = label != self.ignore_index
+ return self._get_loss(logit, label, mask)
+
+ elif self.mode == 'eval':
+ label = inputs['label']
+ mask = label != self.ignore_index
+ loss = self._get_loss(logit, label, mask)
+ return loss, pred, label, mask
+ else:
+ if self.num_classes == 1:
+ logit = sigmoid_to_softmax(logit)
+ else:
+ logit = fluid.layers.softmax(logit, axis=1)
+ return pred, logit
diff --git a/contrib/RemoteSensing/predict_demo.py b/contrib/RemoteSensing/predict_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d7b8c2940882783f69685286cc5d7970e768cb0
--- /dev/null
+++ b/contrib/RemoteSensing/predict_demo.py
@@ -0,0 +1,53 @@
+import os
+import os.path as osp
+import numpy as np
+from PIL import Image as Image
+import argparse
+from models import load_model
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='RemoteSensing predict')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='dataset directory',
+ default=None,
+ type=str)
+ parser.add_argument(
+ '--load_model_dir',
+ dest='load_model_dir',
+ help='model load directory',
+ default=None,
+ type=str)
+ return parser.parse_args()
+
+
+args = parse_args()
+
+data_dir = args.data_dir
+load_model_dir = args.load_model_dir
+
+# predict
+model = load_model(load_model_dir)
+pred_dir = osp.join(load_model_dir, 'predict')
+if not osp.exists(pred_dir):
+ os.mkdir(pred_dir)
+
+val_list = osp.join(data_dir, 'val.txt')
+color_map = [0, 0, 0, 255, 255, 255]
+with open(val_list) as f:
+ lines = f.readlines()
+ for line in lines:
+ img_path = line.split(' ')[0]
+ print('Predicting {}'.format(img_path))
+ img_path_ = osp.join(data_dir, img_path)
+
+ pred = model.predict(img_path_)
+
+ # 以伪彩色png图片保存预测结果
+ pred_name = osp.basename(img_path).rstrip('npy') + 'png'
+ pred_path = osp.join(pred_dir, pred_name)
+ pred_mask = Image.fromarray(pred.astype(np.uint8), mode='P')
+ pred_mask.putpalette(color_map)
+ pred_mask.save(pred_path)
diff --git a/contrib/RemoteSensing/readers/__init__.py b/contrib/RemoteSensing/readers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..babbe0866c625fc81f810a2cff82b8d138b9aa94
--- /dev/null
+++ b/contrib/RemoteSensing/readers/__init__.py
@@ -0,0 +1,15 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .reader import Reader
diff --git a/contrib/RemoteSensing/readers/base.py b/contrib/RemoteSensing/readers/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..1427bd60ad4637a3f13c8a08f59291f15fe5ac82
--- /dev/null
+++ b/contrib/RemoteSensing/readers/base.py
@@ -0,0 +1,249 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from threading import Thread
+import multiprocessing
+import collections
+import numpy as np
+import six
+import sys
+import copy
+import random
+import platform
+import chardet
+from utils import logging
+
+
+class EndSignal():
+ pass
+
+
+def is_pic(img_name):
+ valid_suffix = ['JPEG', 'jpeg', 'JPG', 'jpg', 'BMP', 'bmp', 'PNG', 'png']
+ suffix = img_name.split('.')[-1]
+ if suffix not in valid_suffix:
+ return False
+ return True
+
+
+def is_valid(sample):
+ if sample is None:
+ return False
+ if isinstance(sample, tuple):
+ for s in sample:
+ if s is None:
+ return False
+ elif isinstance(s, np.ndarray) and s.size == 0:
+ return False
+ elif isinstance(s, collections.Sequence) and len(s) == 0:
+ return False
+ return True
+
+
+def get_encoding(path):
+ f = open(path, 'rb')
+ data = f.read()
+ file_encoding = chardet.detect(data).get('encoding')
+ return file_encoding
+
+
+def multithread_reader(mapper,
+ reader,
+ num_workers=4,
+ buffer_size=1024,
+ batch_size=8,
+ drop_last=True):
+ from queue import Queue
+ end = EndSignal()
+
+ # define a worker to read samples from reader to in_queue
+ def read_worker(reader, in_queue):
+ for i in reader():
+ in_queue.put(i)
+ in_queue.put(end)
+
+ # define a worker to handle samples from in_queue by mapper
+ # and put mapped samples into out_queue
+ def handle_worker(in_queue, out_queue, mapper):
+ sample = in_queue.get()
+ while not isinstance(sample, EndSignal):
+ if len(sample) == 2:
+ r = mapper(sample[0], sample[1])
+ elif len(sample) == 3:
+ r = mapper(sample[0], sample[1], sample[2])
+ else:
+ raise Exception('The sample\'s length must be 2 or 3.')
+ if is_valid(r):
+ out_queue.put(r)
+ sample = in_queue.get()
+ in_queue.put(end)
+ out_queue.put(end)
+
+ def xreader():
+ in_queue = Queue(buffer_size)
+ out_queue = Queue(buffer_size)
+ # start a read worker in a thread
+ target = read_worker
+ t = Thread(target=target, args=(reader, in_queue))
+ t.daemon = True
+ t.start()
+ # start several handle_workers
+ target = handle_worker
+ args = (in_queue, out_queue, mapper)
+ workers = []
+ for i in range(num_workers):
+ worker = Thread(target=target, args=args)
+ worker.daemon = True
+ workers.append(worker)
+ for w in workers:
+ w.start()
+
+ batch_data = []
+ sample = out_queue.get()
+ while not isinstance(sample, EndSignal):
+ batch_data.append(sample)
+ if len(batch_data) == batch_size:
+ batch_data = GenerateMiniBatch(batch_data)
+ yield batch_data
+ batch_data = []
+ sample = out_queue.get()
+ finish = 1
+ while finish < num_workers:
+ sample = out_queue.get()
+ if isinstance(sample, EndSignal):
+ finish += 1
+ else:
+ batch_data.append(sample)
+ if len(batch_data) == batch_size:
+ batch_data = GenerateMiniBatch(batch_data)
+ yield batch_data
+ batch_data = []
+ if not drop_last and len(batch_data) != 0:
+ batch_data = GenerateMiniBatch(batch_data)
+ yield batch_data
+ batch_data = []
+
+ return xreader
+
+
+def multiprocess_reader(mapper,
+ reader,
+ num_workers=4,
+ buffer_size=1024,
+ batch_size=8,
+ drop_last=True):
+ from .shared_queue import SharedQueue as Queue
+
+ def _read_into_queue(samples, mapper, queue):
+ end = EndSignal()
+ try:
+ for sample in samples:
+ if sample is None:
+ raise ValueError("sample has None")
+ if len(sample) == 2:
+ result = mapper(sample[0], sample[1])
+ elif len(sample) == 3:
+ result = mapper(sample[0], sample[1], sample[2])
+ else:
+ raise Exception('The sample\'s length must be 2 or 3.')
+ if is_valid(result):
+ queue.put(result)
+ queue.put(end)
+ except:
+ queue.put("")
+ six.reraise(*sys.exc_info())
+
+ def queue_reader():
+ queue = Queue(buffer_size, memsize=3 * 1024**3)
+ total_samples = [[] for i in range(num_workers)]
+ for i, sample in enumerate(reader()):
+ index = i % num_workers
+ total_samples[index].append(sample)
+ for i in range(num_workers):
+ p = multiprocessing.Process(
+ target=_read_into_queue, args=(total_samples[i], mapper, queue))
+ p.start()
+
+ finish_num = 0
+ batch_data = list()
+ while finish_num < num_workers:
+ sample = queue.get()
+ if isinstance(sample, EndSignal):
+ finish_num += 1
+ elif sample == "":
+ raise ValueError("multiprocess reader raises an exception")
+ else:
+ batch_data.append(sample)
+ if len(batch_data) == batch_size:
+ batch_data = GenerateMiniBatch(batch_data)
+ yield batch_data
+ batch_data = []
+ if len(batch_data) != 0 and not drop_last:
+ batch_data = GenerateMiniBatch(batch_data)
+ yield batch_data
+ batch_data = []
+
+ return queue_reader
+
+
+def GenerateMiniBatch(batch_data):
+ if len(batch_data) == 1:
+ return batch_data
+ width = [data[0].shape[2] for data in batch_data]
+ height = [data[0].shape[1] for data in batch_data]
+ if len(set(width)) == 1 and len(set(height)) == 1:
+ return batch_data
+ max_shape = np.array([data[0].shape for data in batch_data]).max(axis=0)
+ padding_batch = []
+ for data in batch_data:
+ im_c, im_h, im_w = data[0].shape[:]
+ padding_im = np.zeros((im_c, max_shape[1], max_shape[2]),
+ dtype=np.float32)
+ padding_im[:, :im_h, :im_w] = data[0]
+ padding_batch.append((padding_im, ) + data[1:])
+ return padding_batch
+
+
+class BaseReader:
+ def __init__(self,
+ transforms=None,
+ num_workers=4,
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False):
+ if transforms is None:
+ raise Exception("transform should be defined.")
+ self.transforms = transforms
+ self.num_workers = num_workers
+ self.buffer_size = buffer_size
+ self.parallel_method = parallel_method
+ self.shuffle = shuffle
+
+ def generator(self, batch_size=1, drop_last=True):
+ self.batch_size = batch_size
+ parallel_reader = multithread_reader
+ if self.parallel_method == "process":
+ if platform.platform().startswith("Windows"):
+ logging.debug(
+ "multiprocess_reader is not supported in Windows platform, force to use multithread_reader."
+ )
+ else:
+ parallel_reader = multiprocess_reader
+ return parallel_reader(
+ self.transforms,
+ self.iterator,
+ num_workers=self.num_workers,
+ buffer_size=self.buffer_size,
+ batch_size=batch_size,
+ drop_last=drop_last)
diff --git a/contrib/RemoteSensing/readers/reader.py b/contrib/RemoteSensing/readers/reader.py
new file mode 100644
index 0000000000000000000000000000000000000000..343d25b15034e1905a1e55ae926fbdfa62916cf1
--- /dev/null
+++ b/contrib/RemoteSensing/readers/reader.py
@@ -0,0 +1,90 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import absolute_import
+import os.path as osp
+import random
+from utils import logging
+from .base import BaseReader
+from .base import get_encoding
+from collections import OrderedDict
+from .base import is_pic
+
+
+class Reader(BaseReader):
+ """读取语分分割任务数据集,并对样本进行相应的处理。
+
+ Args:
+ data_dir (str): 数据集所在的目录路径。
+ file_list (str): 描述数据集图片文件和对应标注文件的文件路径(文本内每行路径为相对data_dir的相对路)。
+ label_list (str): 描述数据集包含的类别信息文件路径。
+ transforms (list): 数据集中每个样本的预处理/增强算子。
+ num_workers (int): 数据集中样本在预处理过程中的线程或进程数。默认为4。
+ buffer_size (int): 数据集中样本在预处理过程中队列的缓存长度,以样本数为单位。默认为100。
+ parallel_method (str): 数据集中样本在预处理过程中并行处理的方式,支持'thread'
+ 线程和'process'进程两种方式。默认为'thread'。
+ shuffle (bool): 是否需要对数据集中样本打乱顺序。默认为False。
+ """
+
+ def __init__(self,
+ data_dir,
+ file_list,
+ label_list,
+ transforms=None,
+ num_workers=4,
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False):
+ super(Reader, self).__init__(
+ transforms=transforms,
+ num_workers=num_workers,
+ buffer_size=buffer_size,
+ parallel_method=parallel_method,
+ shuffle=shuffle)
+ self.file_list = OrderedDict()
+ self.labels = list()
+ self._epoch = 0
+
+ with open(label_list, encoding=get_encoding(label_list)) as f:
+ for line in f:
+ item = line.strip()
+ self.labels.append(item)
+
+ with open(file_list, encoding=get_encoding(file_list)) as f:
+ for line in f:
+ items = line.strip().split()
+ full_path_im = osp.join(data_dir, items[0])
+ full_path_label = osp.join(data_dir, items[1])
+ if not osp.exists(full_path_im):
+ raise IOError(
+ 'The image file {} is not exist!'.format(full_path_im))
+ if not osp.exists(full_path_label):
+ raise IOError('The image file {} is not exist!'.format(
+ full_path_label))
+ self.file_list[full_path_im] = full_path_label
+ self.num_samples = len(self.file_list)
+ logging.info("{} samples in file {}".format(
+ len(self.file_list), file_list))
+
+ def iterator(self):
+ self._epoch += 1
+ self._pos = 0
+ files = list(self.file_list.keys())
+ if self.shuffle:
+ random.shuffle(files)
+ files = files[:self.num_samples]
+ self.num_samples = len(files)
+ for f in files:
+ label_path = self.file_list[f]
+ sample = [f, None, label_path]
+ yield sample
diff --git a/contrib/RemoteSensing/requirements.txt b/contrib/RemoteSensing/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..339faddb107efd8de7f36fdd298b3008437ba23c
--- /dev/null
+++ b/contrib/RemoteSensing/requirements.txt
@@ -0,0 +1 @@
+visualdl >= 2.0.0-alpha.2
diff --git a/contrib/RemoteSensing/tools/create_dataset_list.py b/contrib/RemoteSensing/tools/create_dataset_list.py
new file mode 100644
index 0000000000000000000000000000000000000000..430eea5e75f4dc8e1ed4babff6baa6d2fbdeb7f7
--- /dev/null
+++ b/contrib/RemoteSensing/tools/create_dataset_list.py
@@ -0,0 +1,145 @@
+# coding: utf8
+# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import glob
+import os.path
+import argparse
+import warnings
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description=
+ 'A tool for dividing dataset and generating file lists by file directory structure.'
+ )
+ parser.add_argument('dataset_root', help='dataset root directory', type=str)
+ parser.add_argument(
+ '--separator',
+ dest='separator',
+ help='file list separator',
+ default=" ",
+ type=str)
+ parser.add_argument(
+ '--folder',
+ help='the folder names of images and labels',
+ type=str,
+ nargs=2,
+ default=['images', 'annotations'])
+ parser.add_argument(
+ '--second_folder',
+ help=
+ 'the second-level folder names of train set, validation set, test set',
+ type=str,
+ nargs='*',
+ default=['train', 'val', 'test'])
+ parser.add_argument(
+ '--format',
+ help='data format of images and labels, default npy, png.',
+ type=str,
+ nargs=2,
+ default=['npy', 'png'])
+ parser.add_argument(
+ '--label_class',
+ help='label class names',
+ type=str,
+ nargs='*',
+ default=['__background__', '__foreground__'])
+ parser.add_argument(
+ '--postfix',
+ help='postfix of images or labels',
+ type=str,
+ nargs=2,
+ default=['', ''])
+
+ return parser.parse_args()
+
+
+def get_files(image_or_label, dataset_split, args):
+ dataset_root = args.dataset_root
+ postfix = args.postfix
+ format = args.format
+ folder = args.folder
+
+ pattern = '*%s.%s' % (postfix[image_or_label], format[image_or_label])
+
+ search_files = os.path.join(dataset_root, folder[image_or_label],
+ dataset_split, pattern)
+ search_files2 = os.path.join(dataset_root, folder[image_or_label],
+ dataset_split, "*", pattern) # 包含子目录
+ search_files3 = os.path.join(dataset_root, folder[image_or_label],
+ dataset_split, "*", "*", pattern) # 包含三级目录
+
+ filenames = glob.glob(search_files)
+ filenames2 = glob.glob(search_files2)
+ filenames3 = glob.glob(search_files3)
+
+ filenames = filenames + filenames2 + filenames3
+
+ return sorted(filenames)
+
+
+def generate_list(args):
+ dataset_root = args.dataset_root
+ separator = args.separator
+
+ file_list = os.path.join(dataset_root, 'labels.txt')
+ with open(file_list, "w") as f:
+ for label_class in args.label_class:
+ f.write(label_class + '\n')
+
+ for dataset_split in args.second_folder:
+ print("Creating {}.txt...".format(dataset_split))
+ image_files = get_files(0, dataset_split, args)
+ label_files = get_files(1, dataset_split, args)
+ if not image_files:
+ img_dir = os.path.join(dataset_root, args.folder[0], dataset_split)
+ warnings.warn("No images in {} !!!".format(img_dir))
+ num_images = len(image_files)
+
+ if not label_files:
+ label_dir = os.path.join(dataset_root, args.folder[1],
+ dataset_split)
+ warnings.warn("No labels in {} !!!".format(label_dir))
+ num_label = len(label_files)
+
+ if num_images != num_label and num_label > 0:
+ raise Exception(
+ "Number of images = {} number of labels = {} \n"
+ "Either number of images is equal to number of labels, "
+ "or number of labels is equal to 0.\n"
+ "Please check your dataset!".format(num_images, num_label))
+
+ file_list = os.path.join(dataset_root, dataset_split + '.txt')
+ with open(file_list, "w") as f:
+ for item in range(num_images):
+ left = image_files[item].replace(dataset_root, '')
+ if left[0] == os.path.sep:
+ left = left.lstrip(os.path.sep)
+
+ try:
+ right = label_files[item].replace(dataset_root, '')
+ if right[0] == os.path.sep:
+ right = right.lstrip(os.path.sep)
+ line = left + separator + right + '\n'
+ except:
+ line = left + '\n'
+
+ f.write(line)
+ print(line)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ generate_list(args)
diff --git a/contrib/RemoteSensing/tools/split_dataset_list.py b/contrib/RemoteSensing/tools/split_dataset_list.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff15987aee2b6a30c961cbad28ebc4e7cb8f6f1d
--- /dev/null
+++ b/contrib/RemoteSensing/tools/split_dataset_list.py
@@ -0,0 +1,149 @@
+# coding: utf8
+# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import glob
+import os.path
+import argparse
+import warnings
+import numpy as np
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description=
+ 'A tool for proportionally randomizing dataset to produce file lists.')
+ parser.add_argument('dataset_root', help='the dataset root path', type=str)
+ parser.add_argument('images', help='the directory name of images', type=str)
+ parser.add_argument('labels', help='the directory name of labels', type=str)
+ parser.add_argument(
+ '--split', help='', nargs=3, type=float, default=[0.7, 0.3, 0])
+ parser.add_argument(
+ '--label_class',
+ help='label class names',
+ type=str,
+ nargs='*',
+ default=['__background__', '__foreground__'])
+ parser.add_argument(
+ '--separator',
+ dest='separator',
+ help='file list separator',
+ default=" ",
+ type=str)
+ parser.add_argument(
+ '--format',
+ help='data format of images and labels, e.g. jpg, npy or png.',
+ type=str,
+ nargs=2,
+ default=['npy', 'png'])
+ parser.add_argument(
+ '--postfix',
+ help='postfix of images or labels',
+ type=str,
+ nargs=2,
+ default=['', ''])
+
+ return parser.parse_args()
+
+
+def get_files(path, format, postfix):
+ pattern = '*%s.%s' % (postfix, format)
+
+ search_files = os.path.join(path, pattern)
+ search_files2 = os.path.join(path, "*", pattern) # 包含子目录
+ search_files3 = os.path.join(path, "*", "*", pattern) # 包含三级目录
+
+ filenames = glob.glob(search_files)
+ filenames2 = glob.glob(search_files2)
+ filenames3 = glob.glob(search_files3)
+
+ filenames = filenames + filenames2 + filenames3
+
+ return sorted(filenames)
+
+
+def generate_list(args):
+ separator = args.separator
+ dataset_root = args.dataset_root
+ if sum(args.split) != 1.0:
+ raise ValueError("划分比例之和必须为1")
+
+ file_list = os.path.join(dataset_root, 'labels.txt')
+ with open(file_list, "w") as f:
+ for label_class in args.label_class:
+ f.write(label_class + '\n')
+
+ image_dir = os.path.join(dataset_root, args.images)
+ label_dir = os.path.join(dataset_root, args.labels)
+ image_files = get_files(image_dir, args.format[0], args.postfix[0])
+ label_files = get_files(label_dir, args.format[1], args.postfix[1])
+ if not image_files:
+ warnings.warn("No files in {}".format(image_dir))
+ num_images = len(image_files)
+
+ if not label_files:
+ warnings.warn("No files in {}".format(label_dir))
+ num_label = len(label_files)
+
+ if num_images != num_label and num_label > 0:
+ raise Exception("Number of images = {} number of labels = {} \n"
+ "Either number of images is equal to number of labels, "
+ "or number of labels is equal to 0.\n"
+ "Please check your dataset!".format(
+ num_images, num_label))
+
+ image_files = np.array(image_files)
+ label_files = np.array(label_files)
+ state = np.random.get_state()
+ np.random.shuffle(image_files)
+ np.random.set_state(state)
+ np.random.shuffle(label_files)
+
+ start = 0
+ num_split = len(args.split)
+ dataset_name = ['train', 'val', 'test']
+ for i in range(num_split):
+ dataset_split = dataset_name[i]
+ print("Creating {}.txt...".format(dataset_split))
+ if args.split[i] > 1.0 or args.split[i] < 0:
+ raise ValueError(
+ "{} dataset percentage should be 0~1.".format(dataset_split))
+
+ file_list = os.path.join(dataset_root, dataset_split + '.txt')
+ with open(file_list, "w") as f:
+ num = round(args.split[i] * num_images)
+ end = start + num
+ if i == num_split - 1:
+ end = num_images
+ for item in range(start, end):
+ left = image_files[item].replace(dataset_root, '')
+ if left[0] == os.path.sep:
+ left = left.lstrip(os.path.sep)
+
+ try:
+ right = label_files[item].replace(dataset_root, '')
+ if right[0] == os.path.sep:
+ right = right.lstrip(os.path.sep)
+ line = left + separator + right + '\n'
+ except:
+ line = left + '\n'
+
+ f.write(line)
+ print(line)
+ start = end
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ generate_list(args)
diff --git a/contrib/RemoteSensing/train_demo.py b/contrib/RemoteSensing/train_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..afd3e8523a4e8007d5d0847cfd5f2460d19dc269
--- /dev/null
+++ b/contrib/RemoteSensing/train_demo.py
@@ -0,0 +1,106 @@
+import os.path as osp
+import argparse
+import transforms.transforms as T
+from readers.reader import Reader
+from models import UNet
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='RemoteSensing training')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='dataset directory',
+ default=None,
+ type=str)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='model save directory',
+ default=None,
+ type=str)
+ parser.add_argument(
+ '--channel',
+ dest='channel',
+ help='number of data channel',
+ default=3,
+ type=int)
+ parser.add_argument(
+ '--num_epochs',
+ dest='num_epochs',
+ help='number of traing epochs',
+ default=100,
+ type=int)
+ parser.add_argument(
+ '--train_batch_size',
+ dest='train_batch_size',
+ help='training batch size',
+ default=4,
+ type=int)
+ parser.add_argument(
+ '--lr', dest='lr', help='learning rate', default=0.01, type=float)
+ return parser.parse_args()
+
+
+args = parse_args()
+
+data_dir = args.data_dir
+save_dir = args.save_dir
+channel = args.channel
+num_epochs = args.num_epochs
+train_batch_size = args.train_batch_size
+lr = args.lr
+
+# 定义训练和验证时的transforms
+train_transforms = T.Compose([
+ T.RandomVerticalFlip(0.5),
+ T.RandomHorizontalFlip(0.5),
+ T.ResizeStepScaling(0.5, 2.0, 0.25),
+ T.RandomPaddingCrop(256),
+ T.Normalize(mean=[0.5] * channel, std=[0.5] * channel),
+])
+
+eval_transforms = T.Compose([
+ T.Normalize(mean=[0.5] * channel, std=[0.5] * channel),
+])
+
+train_list = osp.join(data_dir, 'train.txt')
+val_list = osp.join(data_dir, 'val.txt')
+label_list = osp.join(data_dir, 'labels.txt')
+
+# 定义数据读取器
+train_reader = Reader(
+ data_dir=data_dir,
+ file_list=train_list,
+ label_list=label_list,
+ transforms=train_transforms,
+ num_workers=8,
+ buffer_size=16,
+ shuffle=True,
+ parallel_method='thread')
+
+eval_reader = Reader(
+ data_dir=data_dir,
+ file_list=val_list,
+ label_list=label_list,
+ transforms=eval_transforms,
+ num_workers=8,
+ buffer_size=16,
+ shuffle=False,
+ parallel_method='thread')
+
+model = UNet(
+ num_classes=2, input_channel=channel, use_bce_loss=True, use_dice_loss=True)
+
+model.train(
+ num_epochs=num_epochs,
+ train_reader=train_reader,
+ train_batch_size=train_batch_size,
+ eval_reader=eval_reader,
+ save_interval_epochs=5,
+ log_interval_steps=10,
+ save_dir=save_dir,
+ pretrain_weights=None,
+ optimizer=None,
+ learning_rate=lr,
+ use_vdl=True)
diff --git a/contrib/RemoteSensing/transforms/__init__.py b/contrib/RemoteSensing/transforms/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8eba87ecc700db36f930be3a39c2ece981e00572
--- /dev/null
+++ b/contrib/RemoteSensing/transforms/__init__.py
@@ -0,0 +1,16 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from . import transforms
+from . import ops
diff --git a/contrib/RemoteSensing/transforms/ops.py b/contrib/RemoteSensing/transforms/ops.py
new file mode 100644
index 0000000000000000000000000000000000000000..e04e695410e5f1e089de838526889c02cadd7da1
--- /dev/null
+++ b/contrib/RemoteSensing/transforms/ops.py
@@ -0,0 +1,178 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import cv2
+import math
+import numpy as np
+from PIL import Image, ImageEnhance
+
+
+def normalize(im, min_value, max_value, mean, std):
+ # Rescaling (min-max normalization)
+ range_value = [max_value[i] - min_value[i] for i in range(len(max_value))]
+ im = (im.astype(np.float32, copy=False) - min_value) / range_value
+
+ # Standardization (Z-score Normalization)
+ im -= mean
+ im /= std
+ return im
+
+
+def permute(im, to_bgr=False):
+ im = np.swapaxes(im, 1, 2)
+ im = np.swapaxes(im, 1, 0)
+ if to_bgr:
+ im = im[[2, 1, 0], :, :]
+ return im
+
+
+def _resize(im, shape):
+ return cv2.resize(im, shape)
+
+
+def resize_short(im, short_size=224):
+ percent = float(short_size) / min(im.shape[0], im.shape[1])
+ resized_width = int(round(im.shape[1] * percent))
+ resized_height = int(round(im.shape[0] * percent))
+ im = _resize(im, shape=(resized_width, resized_height))
+ return im
+
+
+def resize_long(im, long_size=224, interpolation=cv2.INTER_LINEAR):
+ value = max(im.shape[0], im.shape[1])
+ scale = float(long_size) / float(value)
+ im = cv2.resize(im, (0, 0), fx=scale, fy=scale, interpolation=interpolation)
+ return im
+
+
+def random_crop(im,
+ crop_size=224,
+ lower_scale=0.08,
+ lower_ratio=3. / 4,
+ upper_ratio=4. / 3):
+ scale = [lower_scale, 1.0]
+ ratio = [lower_ratio, upper_ratio]
+ aspect_ratio = math.sqrt(np.random.uniform(*ratio))
+ w = 1. * aspect_ratio
+ h = 1. / aspect_ratio
+ bound = min((float(im.shape[0]) / im.shape[1]) / (h**2),
+ (float(im.shape[1]) / im.shape[0]) / (w**2))
+ scale_max = min(scale[1], bound)
+ scale_min = min(scale[0], bound)
+ target_area = im.shape[0] * im.shape[1] * np.random.uniform(
+ scale_min, scale_max)
+ target_size = math.sqrt(target_area)
+ w = int(target_size * w)
+ h = int(target_size * h)
+ i = np.random.randint(0, im.shape[0] - h + 1)
+ j = np.random.randint(0, im.shape[1] - w + 1)
+ im = im[i:i + h, j:j + w, :]
+ im = _resize(im, shape=(crop_size, crop_size))
+ return im
+
+
+def center_crop(im, crop_size=224):
+ height, width = im.shape[:2]
+ w_start = (width - crop_size) // 2
+ h_start = (height - crop_size) // 2
+ w_end = w_start + crop_size
+ h_end = h_start + crop_size
+ im = im[h_start:h_end, w_start:w_end, :]
+ return im
+
+
+def horizontal_flip(im):
+ if len(im.shape) == 3:
+ im = im[:, ::-1, :]
+ elif len(im.shape) == 2:
+ im = im[:, ::-1]
+ return im
+
+
+def vertical_flip(im):
+ if len(im.shape) == 3:
+ im = im[::-1, :, :]
+ elif len(im.shape) == 2:
+ im = im[::-1, :]
+ return im
+
+
+def bgr2rgb(im):
+ return im[:, :, ::-1]
+
+
+def brightness(im, brightness_lower, brightness_upper):
+ brightness_delta = np.random.uniform(brightness_lower, brightness_upper)
+ im = ImageEnhance.Brightness(im).enhance(brightness_delta)
+ return im
+
+
+def contrast(im, contrast_lower, contrast_upper):
+ contrast_delta = np.random.uniform(contrast_lower, contrast_upper)
+ im = ImageEnhance.Contrast(im).enhance(contrast_delta)
+ return im
+
+
+def saturation(im, saturation_lower, saturation_upper):
+ saturation_delta = np.random.uniform(saturation_lower, saturation_upper)
+ im = ImageEnhance.Color(im).enhance(saturation_delta)
+ return im
+
+
+def hue(im, hue_lower, hue_upper):
+ hue_delta = np.random.uniform(hue_lower, hue_upper)
+ im = np.array(im.convert('HSV'))
+ im[:, :, 0] = im[:, :, 0] + hue_delta
+ im = Image.fromarray(im, mode='HSV').convert('RGB')
+ return im
+
+
+def rotate(im, rotate_lower, rotate_upper):
+ rotate_delta = np.random.uniform(rotate_lower, rotate_upper)
+ im = im.rotate(int(rotate_delta))
+ return im
+
+
+def resize_padding(im, max_side_len=2400):
+ '''
+ resize image to a size multiple of 32 which is required by the network
+ :param im: the resized image
+ :param max_side_len: limit of max image size to avoid out of memory in gpu
+ :return: the resized image and the resize ratio
+ '''
+ h, w, _ = im.shape
+
+ resize_w = w
+ resize_h = h
+
+ # limit the max side
+ if max(resize_h, resize_w) > max_side_len:
+ ratio = float(
+ max_side_len) / resize_h if resize_h > resize_w else float(
+ max_side_len) / resize_w
+ else:
+ ratio = 1.
+ resize_h = int(resize_h * ratio)
+ resize_w = int(resize_w * ratio)
+
+ resize_h = resize_h if resize_h % 32 == 0 else (resize_h // 32 - 1) * 32
+ resize_w = resize_w if resize_w % 32 == 0 else (resize_w // 32 - 1) * 32
+ resize_h = max(32, resize_h)
+ resize_w = max(32, resize_w)
+ im = cv2.resize(im, (int(resize_w), int(resize_h)))
+ #im = cv2.resize(im, (512, 512))
+ ratio_h = resize_h / float(h)
+ ratio_w = resize_w / float(w)
+ _ratio = np.array([ratio_h, ratio_w]).reshape(-1, 2)
+ return im, _ratio
diff --git a/contrib/RemoteSensing/transforms/transforms.py b/contrib/RemoteSensing/transforms/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..abac1746e09e8e95d4149e8243d6ea4258f347ef
--- /dev/null
+++ b/contrib/RemoteSensing/transforms/transforms.py
@@ -0,0 +1,811 @@
+# coding: utf8
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .ops import *
+import random
+import os.path as osp
+import numpy as np
+from PIL import Image
+import cv2
+from collections import OrderedDict
+
+
+class Compose:
+ """根据数据预处理/增强算子对输入数据进行操作。
+ 所有操作的输入图像流形状均是[H, W, C],其中H为图像高,W为图像宽,C为图像通道数。
+
+ Args:
+ transforms (list): 数据预处理/增强算子。
+
+ Raises:
+ TypeError: transforms不是list对象
+ ValueError: transforms元素个数小于1。
+
+ """
+
+ def __init__(self, transforms):
+ if not isinstance(transforms, list):
+ raise TypeError('The transforms must be a list!')
+ if len(transforms) < 1:
+ raise ValueError('The length of transforms ' + \
+ 'must be equal or larger than 1!')
+ self.transforms = transforms
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (str/np.ndarray): 图像路径/图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息,dict中的字段如下:
+ - shape_before_resize (tuple): 图像resize之前的大小(h, w)。
+ - shape_before_padding (tuple): 图像padding之前的大小(h, w)。
+ label (str/np.ndarray): 标注图像路径/标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 根据网络所需字段所组成的tuple;字段由transforms中的最后一个数据预处理操作决定。
+ """
+
+ if im_info is None:
+ im_info = dict()
+ im = np.load(im)
+ if im is None:
+ raise ValueError('Can\'t read The image file {}!'.format(im))
+ if label is not None:
+ label = np.asarray(Image.open(label))
+
+ for op in self.transforms:
+ outputs = op(im, im_info, label)
+ im = outputs[0]
+ if len(outputs) >= 2:
+ im_info = outputs[1]
+ if len(outputs) == 3:
+ label = outputs[2]
+ return outputs
+
+
+class RandomHorizontalFlip:
+ """以一定的概率对图像进行水平翻转。当存在标注图像时,则同步进行翻转。
+
+ Args:
+ prob (float): 随机水平翻转的概率。默认值为0.5。
+
+ """
+
+ def __init__(self, prob=0.5):
+ self.prob = prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if random.random() < self.prob:
+ im = horizontal_flip(im)
+ if label is not None:
+ label = horizontal_flip(label)
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomVerticalFlip:
+ """以一定的概率对图像进行垂直翻转。当存在标注图像时,则同步进行翻转。
+
+ Args:
+ prob (float): 随机垂直翻转的概率。默认值为0.1。
+ """
+
+ def __init__(self, prob=0.1):
+ self.prob = prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if random.random() < self.prob:
+ im = vertical_flip(im)
+ if label is not None:
+ label = vertical_flip(label)
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Resize:
+ """调整图像大小(resize),当存在标注图像时,则同步进行处理。
+
+ - 当目标大小(target_size)类型为int时,根据插值方式,
+ 将图像resize为[target_size, target_size]。
+ - 当目标大小(target_size)类型为list或tuple时,根据插值方式,
+ 将图像resize为target_size, target_size的输入应为[w, h]或(w, h)。
+
+ Args:
+ target_size (int/list/tuple): 目标大小
+ interp (str): resize的插值方式,与opencv的插值方式对应,
+ 可选的值为['NEAREST', 'LINEAR', 'CUBIC', 'AREA', 'LANCZOS4'],默认为"LINEAR"。
+
+ Raises:
+ TypeError: target_size不是int/list/tuple。
+ ValueError: target_size为list/tuple时元素个数不等于2。
+ AssertionError: interp的取值不在['NEAREST', 'LINEAR', 'CUBIC', 'AREA', 'LANCZOS4']之内
+ """
+
+ # The interpolation mode
+ interp_dict = {
+ 'NEAREST': cv2.INTER_NEAREST,
+ 'LINEAR': cv2.INTER_LINEAR,
+ 'CUBIC': cv2.INTER_CUBIC,
+ 'AREA': cv2.INTER_AREA,
+ 'LANCZOS4': cv2.INTER_LANCZOS4
+ }
+
+ def __init__(self, target_size, interp='LINEAR'):
+ self.interp = interp
+ assert interp in self.interp_dict, "interp should be one of {}".format(
+ self.interp_dict.keys())
+ if isinstance(target_size, list) or isinstance(target_size, tuple):
+ if len(target_size) != 2:
+ raise ValueError(
+ 'when target is list or tuple, it should include 2 elements, but it is {}'
+ .format(target_size))
+ elif not isinstance(target_size, int):
+ raise TypeError(
+ "Type of target_size is invalid. Must be Integer or List or tuple, now is {}"
+ .format(type(target_size)))
+
+ self.target_size = target_size
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ 其中,im_info跟新字段为:
+ -shape_before_resize (tuple): 保存resize之前图像的形状(h, w)。
+
+ Raises:
+ ZeroDivisionError: im的短边为0。
+ TypeError: im不是np.ndarray数据。
+ ValueError: im不是3维nd.ndarray。
+ """
+ if im_info is None:
+ im_info = OrderedDict()
+ im_info['shape_before_resize'] = im.shape[:2]
+
+ if not isinstance(im, np.ndarray):
+ raise TypeError("ResizeImage: image type is not np.ndarray.")
+ if len(im.shape) != 3:
+ raise ValueError('ResizeImage: image is not 3-dimensional.')
+ im_shape = im.shape
+ im_size_min = np.min(im_shape[0:2])
+ im_size_max = np.max(im_shape[0:2])
+ if float(im_size_min) == 0:
+ raise ZeroDivisionError('ResizeImage: min size of image is 0')
+
+ if isinstance(self.target_size, int):
+ resize_w = self.target_size
+ resize_h = self.target_size
+ else:
+ resize_w = self.target_size[0]
+ resize_h = self.target_size[1]
+ im_scale_x = float(resize_w) / float(im_shape[1])
+ im_scale_y = float(resize_h) / float(im_shape[0])
+
+ im = cv2.resize(
+ im,
+ None,
+ None,
+ fx=im_scale_x,
+ fy=im_scale_y,
+ interpolation=self.interp_dict[self.interp])
+ if label is not None:
+ label = cv2.resize(
+ label,
+ None,
+ None,
+ fx=im_scale_x,
+ fy=im_scale_y,
+ interpolation=self.interp_dict['NEAREST'])
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ResizeByLong:
+ """对图像长边resize到固定值,短边按比例进行缩放。当存在标注图像时,则同步进行处理。
+
+ Args:
+ long_size (int): resize后图像的长边大小。
+ """
+
+ def __init__(self, long_size):
+ self.long_size = long_size
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ 其中,im_info新增字段为:
+ -shape_before_resize (tuple): 保存resize之前图像的形状(h, w)。
+ """
+ if im_info is None:
+ im_info = OrderedDict()
+
+ im_info['shape_before_resize'] = im.shape[:2]
+ im = resize_long(im, self.long_size)
+ if label is not None:
+ label = resize_long(label, self.long_size, cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ResizeRangeScaling:
+ """对图像长边随机resize到指定范围内,短边按比例进行缩放。当存在标注图像时,则同步进行处理。
+
+ Args:
+ min_value (int): 图像长边resize后的最小值。默认值400。
+ max_value (int): 图像长边resize后的最大值。默认值600。
+
+ Raises:
+ ValueError: min_value大于max_value
+ """
+
+ def __init__(self, min_value=400, max_value=600):
+ if min_value > max_value:
+ raise ValueError('min_value must be less than max_value, '
+ 'but they are {} and {}.'.format(
+ min_value, max_value))
+ self.min_value = min_value
+ self.max_value = max_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.min_value == self.max_value:
+ random_size = self.max_value
+ else:
+ random_size = int(
+ np.random.uniform(self.min_value, self.max_value) + 0.5)
+ value = max(im.shape[0], im.shape[1])
+ scale = float(random_size) / float(value)
+ im = cv2.resize(
+ im, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR)
+ if label is not None:
+ label = cv2.resize(
+ label, (0, 0),
+ fx=scale,
+ fy=scale,
+ interpolation=cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ResizeStepScaling:
+ """对图像按照某一个比例resize,这个比例以scale_step_size为步长
+ 在[min_scale_factor, max_scale_factor]随机变动。当存在标注图像时,则同步进行处理。
+
+ Args:
+ min_scale_factor(float), resize最小尺度。默认值0.75。
+ max_scale_factor (float), resize最大尺度。默认值1.25。
+ scale_step_size (float), resize尺度范围间隔。默认值0.25。
+
+ Raises:
+ ValueError: min_scale_factor大于max_scale_factor
+ """
+
+ def __init__(self,
+ min_scale_factor=0.75,
+ max_scale_factor=1.25,
+ scale_step_size=0.25):
+ if min_scale_factor > max_scale_factor:
+ raise ValueError(
+ 'min_scale_factor must be less than max_scale_factor, '
+ 'but they are {} and {}.'.format(min_scale_factor,
+ max_scale_factor))
+ self.min_scale_factor = min_scale_factor
+ self.max_scale_factor = max_scale_factor
+ self.scale_step_size = scale_step_size
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.min_scale_factor == self.max_scale_factor:
+ scale_factor = self.min_scale_factor
+
+ elif self.scale_step_size == 0:
+ scale_factor = np.random.uniform(self.min_scale_factor,
+ self.max_scale_factor)
+
+ else:
+ num_steps = int((self.max_scale_factor - self.min_scale_factor) /
+ self.scale_step_size + 1)
+ scale_factors = np.linspace(self.min_scale_factor,
+ self.max_scale_factor,
+ num_steps).tolist()
+ np.random.shuffle(scale_factors)
+ scale_factor = scale_factors[0]
+
+ im = cv2.resize(
+ im, (0, 0),
+ fx=scale_factor,
+ fy=scale_factor,
+ interpolation=cv2.INTER_LINEAR)
+ if label is not None:
+ label = cv2.resize(
+ label, (0, 0),
+ fx=scale_factor,
+ fy=scale_factor,
+ interpolation=cv2.INTER_NEAREST)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Clip:
+ """
+ 对图像上超出一定范围的数据进行裁剪。
+
+ Args:
+ min_val (list): 裁剪的下限,小于min_val的数值均设为min_val. 默认值[0, 0, 0].
+ max_val (list): 裁剪的上限,大于max_val的数值均设为max_val. 默认值[255.0, 255.0, 255.0]
+ """
+
+ def __init__(self, min_val=[0, 0, 0], max_val=[255.0, 255.0, 255.0]):
+ self.min_val = min_val
+ self.max_val = max_val
+
+ def __call__(self, im, im_info=None, label=None):
+ if isinstance(self.min_val, list) and isinstance(self.max_val, list):
+ for k in range(im.shape[2]):
+ np.clip(
+ im[:, :, k],
+ self.min_val[k],
+ self.max_val[k],
+ out=im[:, :, k])
+ else:
+ raise TypeError('min_val and max_val must be list')
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Normalize:
+ """对图像进行标准化。
+ 1.图像像素归一化到区间 [0.0, 1.0]。
+ 2.对图像进行减均值除以标准差操作。
+
+ Args:
+ min_val (list): 图像数据集的最小值。默认值[0, 0, 0].
+ max_val (list): 图像数据集的最大值。默认值[255.0, 255.0, 255.0]
+ mean (list): 图像数据集的均值。默认值[0.5, 0.5, 0.5].
+ std (list): 图像数据集的标准差。默认值[0.5, 0.5, 0.5].
+
+ Raises:
+ ValueError: mean或std不是list对象。std包含0。
+ """
+
+ def __init__(self,
+ min_val=[0, 0, 0],
+ max_val=[255.0, 255.0, 255.0],
+ mean=[0.5, 0.5, 0.5],
+ std=[0.5, 0.5, 0.5]):
+ self.min_val = min_val
+ self.max_val = max_val
+ self.mean = mean
+ self.std = std
+ if not (isinstance(self.mean, list) and isinstance(self.std, list)):
+ raise ValueError("{}: input type is invalid.".format(self))
+ from functools import reduce
+ if reduce(lambda x, y: x * y, self.std) == 0:
+ raise ValueError('{}: std is invalid!'.format(self))
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+
+ mean = np.array(self.mean)[np.newaxis, np.newaxis, :]
+ std = np.array(self.std)[np.newaxis, np.newaxis, :]
+
+ im = normalize(im, self.min_val, self.max_val, mean, std)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class Padding:
+ """对图像或标注图像进行padding,padding方向为右和下。
+ 根据提供的值对图像或标注图像进行padding操作。
+
+ Args:
+ target_size (int/list/tuple): padding后图像的大小。
+ im_padding_value (list): 图像padding的值。默认为127.5。
+ label_padding_value (int): 标注图像padding的值。默认值为255。
+
+ Raises:
+ TypeError: target_size不是int/list/tuple。
+ ValueError: target_size为list/tuple时元素个数不等于2。
+ """
+
+ def __init__(self,
+ target_size,
+ im_padding_value=127.5,
+ label_padding_value=255):
+ if isinstance(target_size, list) or isinstance(target_size, tuple):
+ if len(target_size) != 2:
+ raise ValueError(
+ 'when target is list or tuple, it should include 2 elements, but it is {}'
+ .format(target_size))
+ elif not isinstance(target_size, int):
+ raise TypeError(
+ "Type of target_size is invalid. Must be Integer or List or tuple, now is {}"
+ .format(type(target_size)))
+ self.target_size = target_size
+ self.im_padding_value = im_padding_value
+ self.label_padding_value = label_padding_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ 其中,im_info新增字段为:
+ -shape_before_padding (tuple): 保存padding之前图像的形状(h, w)。
+
+ Raises:
+ ValueError: 输入图像im或label的形状大于目标值
+ """
+ if im_info is None:
+ im_info = OrderedDict()
+ im_info['shape_before_padding'] = im.shape[:2]
+
+ im_height, im_width = im.shape[0], im.shape[1]
+ if isinstance(self.target_size, int):
+ target_height = self.target_size
+ target_width = self.target_size
+ else:
+ target_height = self.target_size[1]
+ target_width = self.target_size[0]
+ pad_height = target_height - im_height
+ pad_width = target_width - im_width
+ if pad_height < 0 or pad_width < 0:
+ raise ValueError(
+ 'the size of image should be less than target_size, but the size of image ({}, {}), is larger than target_size ({}, {})'
+ .format(im_width, im_height, target_width, target_height))
+ else:
+ im = np.pad(
+ im,
+ pad_width=((0, pad_height), (0, pad_width), (0, 0)),
+ mode='constant',
+ constant_values=(self.im_padding_value, self.im_padding_value))
+ if label is not None:
+ label = np.pad(
+ label,
+ pad_width=((0, pad_height), (0, pad_width)),
+ mode='constant',
+ constant_values=(self.label_padding_value,
+ self.label_padding_value))
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomPaddingCrop:
+ """对图像和标注图进行随机裁剪,当所需要的裁剪尺寸大于原图时,则进行padding操作。
+
+ Args:
+ crop_size(int or list or tuple): 裁剪图像大小。默认为512。
+ im_padding_value (list): 图像padding的值。默认为127.5
+ label_padding_value (int): 标注图像padding的值。默认值为255。
+
+ Raises:
+ TypeError: crop_size不是int/list/tuple。
+ ValueError: target_size为list/tuple时元素个数不等于2。
+ """
+
+ def __init__(self,
+ crop_size=512,
+ im_padding_value=127.5,
+ label_padding_value=255):
+ if isinstance(crop_size, list) or isinstance(crop_size, tuple):
+ if len(crop_size) != 2:
+ raise ValueError(
+ 'when crop_size is list or tuple, it should include 2 elements, but it is {}'
+ .format(crop_size))
+ elif not isinstance(crop_size, int):
+ raise TypeError(
+ "Type of crop_size is invalid. Must be Integer or List or tuple, now is {}"
+ .format(type(crop_size)))
+ self.crop_size = crop_size
+ self.im_padding_value = im_padding_value
+ self.label_padding_value = label_padding_value
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if isinstance(self.crop_size, int):
+ crop_width = self.crop_size
+ crop_height = self.crop_size
+ else:
+ crop_width = self.crop_size[0]
+ crop_height = self.crop_size[1]
+
+ img_height = im.shape[0]
+ img_width = im.shape[1]
+
+ if img_height == crop_height and img_width == crop_width:
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+ else:
+ pad_height = max(crop_height - img_height, 0)
+ pad_width = max(crop_width - img_width, 0)
+ if (pad_height > 0 or pad_width > 0):
+ im = np.pad(
+ im,
+ pad_width=((0, pad_height), (0, pad_width), (0, 0)),
+ mode='constant',
+ constant_values=(self.im_padding_value,
+ self.im_padding_value))
+ if label is not None:
+ label = np.pad(
+ label,
+ pad_width=((0, pad_height), (0, pad_width)),
+ mode='constant',
+ constant_values=(self.label_padding_value,
+ self.label_padding_value))
+ img_height = im.shape[0]
+ img_width = im.shape[1]
+
+ if crop_height > 0 and crop_width > 0:
+ h_off = np.random.randint(img_height - crop_height + 1)
+ w_off = np.random.randint(img_width - crop_width + 1)
+
+ im = im[h_off:(crop_height + h_off), w_off:(
+ w_off + crop_width), :]
+ if label is not None:
+ label = label[h_off:(crop_height + h_off), w_off:(
+ w_off + crop_width)]
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomBlur:
+ """以一定的概率对图像进行高斯模糊。
+
+ Args:
+ prob (float): 图像模糊概率。默认为0.1。
+ """
+
+ def __init__(self, prob=0.1):
+ self.prob = prob
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.prob <= 0:
+ n = 0
+ elif self.prob >= 1:
+ n = 1
+ else:
+ n = int(1.0 / self.prob)
+ if n > 0:
+ if np.random.randint(0, n) == 0:
+ radius = np.random.randint(3, 10)
+ if radius % 2 != 1:
+ radius = radius + 1
+ if radius > 9:
+ radius = 9
+ im = cv2.GaussianBlur(im, (radius, radius), 0, 0)
+
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class RandomScaleAspect:
+ """裁剪并resize回原始尺寸的图像和标注图像。
+ 按照一定的面积比和宽高比对图像进行裁剪,并reszie回原始图像的图像,当存在标注图时,同步进行。
+
+ Args:
+ min_scale (float):裁取图像占原始图像的面积比,0-1,默认0返回原图。默认为0.5。
+ aspect_ratio (float): 裁取图像的宽高比范围,非负,默认0返回原图。默认为0.33。
+ """
+
+ def __init__(self, min_scale=0.5, aspect_ratio=0.33):
+ self.min_scale = min_scale
+ self.aspect_ratio = aspect_ratio
+
+ def __call__(self, im, im_info=None, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当label为空时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当label不为空时,返回的tuple为(im, im_info, label),分别对应图像np.ndarray数据、
+ 存储与图像相关信息的字典和标注图像np.ndarray数据。
+ """
+ if self.min_scale != 0 and self.aspect_ratio != 0:
+ img_height = im.shape[0]
+ img_width = im.shape[1]
+ for i in range(0, 10):
+ area = img_height * img_width
+ target_area = area * np.random.uniform(self.min_scale, 1.0)
+ aspectRatio = np.random.uniform(self.aspect_ratio,
+ 1.0 / self.aspect_ratio)
+
+ dw = int(np.sqrt(target_area * 1.0 * aspectRatio))
+ dh = int(np.sqrt(target_area * 1.0 / aspectRatio))
+ if (np.random.randint(10) < 5):
+ tmp = dw
+ dw = dh
+ dh = tmp
+
+ if (dh < img_height and dw < img_width):
+ h1 = np.random.randint(0, img_height - dh)
+ w1 = np.random.randint(0, img_width - dw)
+
+ im = im[h1:(h1 + dh), w1:(w1 + dw), :]
+ label = label[h1:(h1 + dh), w1:(w1 + dw)]
+ im = cv2.resize(
+ im, (img_width, img_height),
+ interpolation=cv2.INTER_LINEAR)
+ label = cv2.resize(
+ label, (img_width, img_height),
+ interpolation=cv2.INTER_NEAREST)
+ break
+ if label is None:
+ return (im, im_info)
+ else:
+ return (im, im_info, label)
+
+
+class ArrangeSegmenter:
+ """获取训练/验证/预测所需的信息。
+
+ Args:
+ mode (str): 指定数据用于何种用途,取值范围为['train', 'eval', 'test', 'quant']。
+
+ Raises:
+ ValueError: mode的取值不在['train', 'eval', 'test', 'quant']之内
+ """
+
+ def __init__(self, mode):
+ if mode not in ['train', 'eval', 'test', 'quant']:
+ raise ValueError(
+ "mode should be defined as one of ['train', 'eval', 'test', 'quant']!"
+ )
+ self.mode = mode
+
+ def __call__(self, im, im_info, label=None):
+ """
+ Args:
+ im (np.ndarray): 图像np.ndarray数据。
+ im_info (dict): 存储与图像相关的信息。
+ label (np.ndarray): 标注图像np.ndarray数据。
+
+ Returns:
+ tuple: 当mode为'train'或'eval'时,返回的tuple为(im, label),分别对应图像np.ndarray数据、存储与图像相关信息的字典;
+ 当mode为'test'时,返回的tuple为(im, im_info),分别对应图像np.ndarray数据、存储与图像相关信息的字典;当mode为
+ 'quant'时,返回的tuple为(im,),为图像np.ndarray数据。
+ """
+ im = permute(im, False)
+ if self.mode == 'train' or self.mode == 'eval':
+ label = label[np.newaxis, :, :]
+ return (im, label)
+ elif self.mode == 'test':
+ return (im, im_info)
+ else:
+ return (im, )
diff --git a/contrib/RemoteSensing/utils/__init__.py b/contrib/RemoteSensing/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f27f5ea79417cdfd65da5744527cc6f7869dcc02
--- /dev/null
+++ b/contrib/RemoteSensing/utils/__init__.py
@@ -0,0 +1,18 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from . import logging
+from . import utils
+from .metrics import ConfusionMatrix
+from .utils import *
diff --git a/contrib/RemoteSensing/utils/logging.py b/contrib/RemoteSensing/utils/logging.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d14b1a5df23827c2ddea2a0959801fab6e70552
--- /dev/null
+++ b/contrib/RemoteSensing/utils/logging.py
@@ -0,0 +1,46 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import time
+import os
+import sys
+import __init__
+
+levels = {0: 'ERROR', 1: 'WARNING', 2: 'INFO', 3: 'DEBUG'}
+
+
+def log(level=2, message=""):
+ current_time = time.time()
+ time_array = time.localtime(current_time)
+ current_time = time.strftime("%Y-%m-%d %H:%M:%S", time_array)
+ if __init__.log_level >= level:
+ print("{} [{}]\t{}".format(current_time, levels[level],
+ message).encode("utf-8").decode("latin1"))
+ sys.stdout.flush()
+
+
+def debug(message=""):
+ log(level=3, message=message)
+
+
+def info(message=""):
+ log(level=2, message=message)
+
+
+def warning(message=""):
+ log(level=1, message=message)
+
+
+def error(message=""):
+ log(level=0, message=message)
diff --git a/contrib/RemoteSensing/utils/metrics.py b/contrib/RemoteSensing/utils/metrics.py
new file mode 100644
index 0000000000000000000000000000000000000000..2898be028f3dfa03ad9892310da89f7695829542
--- /dev/null
+++ b/contrib/RemoteSensing/utils/metrics.py
@@ -0,0 +1,145 @@
+# coding: utf8
+# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import sys
+import numpy as np
+from scipy.sparse import csr_matrix
+
+
+class ConfusionMatrix(object):
+ """
+ Confusion Matrix for segmentation evaluation
+ """
+
+ def __init__(self, num_classes=2, streaming=False):
+ self.confusion_matrix = np.zeros([num_classes, num_classes],
+ dtype='int64')
+ self.num_classes = num_classes
+ self.streaming = streaming
+
+ def calculate(self, pred, label, ignore=None):
+ # If not in streaming mode, clear matrix everytime when call `calculate`
+ if not self.streaming:
+ self.zero_matrix()
+
+ label = np.transpose(label, (0, 2, 3, 1))
+ ignore = np.transpose(ignore, (0, 2, 3, 1))
+ mask = np.array(ignore) == 1
+
+ label = np.asarray(label)[mask]
+ pred = np.asarray(pred)[mask]
+ one = np.ones_like(pred)
+ # Accumuate ([row=label, col=pred], 1) into sparse matrix
+ spm = csr_matrix((one, (label, pred)),
+ shape=(self.num_classes, self.num_classes))
+ spm = spm.todense()
+ self.confusion_matrix += spm
+
+ def zero_matrix(self):
+ """ Clear confusion matrix """
+ self.confusion_matrix = np.zeros([self.num_classes, self.num_classes],
+ dtype='int64')
+
+ def mean_iou(self):
+ iou_list = []
+ avg_iou = 0
+ # TODO: use numpy sum axis api to simpliy
+ vji = np.zeros(self.num_classes, dtype=int)
+ vij = np.zeros(self.num_classes, dtype=int)
+ for j in range(self.num_classes):
+ v_j = 0
+ for i in range(self.num_classes):
+ v_j += self.confusion_matrix[j][i]
+ vji[j] = v_j
+
+ for i in range(self.num_classes):
+ v_i = 0
+ for j in range(self.num_classes):
+ v_i += self.confusion_matrix[j][i]
+ vij[i] = v_i
+
+ for c in range(self.num_classes):
+ total = vji[c] + vij[c] - self.confusion_matrix[c][c]
+ if total == 0:
+ iou = 0
+ else:
+ iou = float(self.confusion_matrix[c][c]) / total
+ avg_iou += iou
+ iou_list.append(iou)
+ avg_iou = float(avg_iou) / float(self.num_classes)
+ return np.array(iou_list), avg_iou
+
+ def accuracy(self):
+ total = self.confusion_matrix.sum()
+ total_right = 0
+ for c in range(self.num_classes):
+ total_right += self.confusion_matrix[c][c]
+ if total == 0:
+ avg_acc = 0
+ else:
+ avg_acc = float(total_right) / total
+
+ vij = np.zeros(self.num_classes, dtype=int)
+ for i in range(self.num_classes):
+ v_i = 0
+ for j in range(self.num_classes):
+ v_i += self.confusion_matrix[j][i]
+ vij[i] = v_i
+
+ acc_list = []
+ for c in range(self.num_classes):
+ if vij[c] == 0:
+ acc = 0
+ else:
+ acc = self.confusion_matrix[c][c] / float(vij[c])
+ acc_list.append(acc)
+ return np.array(acc_list), avg_acc
+
+ def kappa(self):
+ vji = np.zeros(self.num_classes)
+ vij = np.zeros(self.num_classes)
+ for j in range(self.num_classes):
+ v_j = 0
+ for i in range(self.num_classes):
+ v_j += self.confusion_matrix[j][i]
+ vji[j] = v_j
+
+ for i in range(self.num_classes):
+ v_i = 0
+ for j in range(self.num_classes):
+ v_i += self.confusion_matrix[j][i]
+ vij[i] = v_i
+
+ total = self.confusion_matrix.sum()
+
+ # avoid spillovers
+ # TODO: is it reasonable to hard code 10000.0?
+ total = float(total) / 10000.0
+ vji = vji / 10000.0
+ vij = vij / 10000.0
+
+ tp = 0
+ tc = 0
+ for c in range(self.num_classes):
+ tp += vji[c] * vij[c]
+ tc += self.confusion_matrix[c][c]
+
+ tc = tc / 10000.0
+ pe = tp / (total * total)
+ po = tc / total
+
+ kappa = (po - pe) / (1 - pe)
+ return kappa
diff --git a/contrib/RemoteSensing/utils/pretrain_weights.py b/contrib/RemoteSensing/utils/pretrain_weights.py
new file mode 100644
index 0000000000000000000000000000000000000000..e23686406897bc84e705640640bd7ee17d9d95ec
--- /dev/null
+++ b/contrib/RemoteSensing/utils/pretrain_weights.py
@@ -0,0 +1,11 @@
+import os.path as osp
+
+
+def get_pretrain_weights(flag, backbone, save_dir):
+ if flag is None:
+ return None
+ elif osp.isdir(flag):
+ return flag
+ else:
+ raise Exception(
+ "pretrain_weights need to be defined as directory path.")
diff --git a/contrib/RemoteSensing/utils/utils.py b/contrib/RemoteSensing/utils/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..ecce788190e594eef8c259db84e47e0959cae184
--- /dev/null
+++ b/contrib/RemoteSensing/utils/utils.py
@@ -0,0 +1,220 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import time
+import os
+import os.path as osp
+import numpy as np
+import six
+import yaml
+import math
+from . import logging
+
+
+def seconds_to_hms(seconds):
+ h = math.floor(seconds / 3600)
+ m = math.floor((seconds - h * 3600) / 60)
+ s = int(seconds - h * 3600 - m * 60)
+ hms_str = "{}:{}:{}".format(h, m, s)
+ return hms_str
+
+
+def setting_environ_flags():
+ if 'FLAGS_eager_delete_tensor_gb' not in os.environ:
+ os.environ['FLAGS_eager_delete_tensor_gb'] = '0.0'
+ if 'FLAGS_allocator_strategy' not in os.environ:
+ os.environ['FLAGS_allocator_strategy'] = 'auto_growth'
+ if "CUDA_VISIBLE_DEVICES" in os.environ:
+ if os.environ["CUDA_VISIBLE_DEVICES"].count("-1") > 0:
+ os.environ["CUDA_VISIBLE_DEVICES"] = ""
+
+
+def get_environ_info():
+ setting_environ_flags()
+ import paddle.fluid as fluid
+ info = dict()
+ info['place'] = 'cpu'
+ info['num'] = int(os.environ.get('CPU_NUM', 1))
+ if os.environ.get('CUDA_VISIBLE_DEVICES', None) != "":
+ if hasattr(fluid.core, 'get_cuda_device_count'):
+ gpu_num = 0
+ try:
+ gpu_num = fluid.core.get_cuda_device_count()
+ except:
+ os.environ['CUDA_VISIBLE_DEVICES'] = ''
+ pass
+ if gpu_num > 0:
+ info['place'] = 'cuda'
+ info['num'] = fluid.core.get_cuda_device_count()
+ return info
+
+
+def parse_param_file(param_file, return_shape=True):
+ from paddle.fluid.proto.framework_pb2 import VarType
+ f = open(param_file, 'rb')
+ version = np.fromstring(f.read(4), dtype='int32')
+ lod_level = np.fromstring(f.read(8), dtype='int64')
+ for i in range(int(lod_level)):
+ _size = np.fromstring(f.read(8), dtype='int64')
+ _ = f.read(_size)
+ version = np.fromstring(f.read(4), dtype='int32')
+ tensor_desc = VarType.TensorDesc()
+ tensor_desc_size = np.fromstring(f.read(4), dtype='int32')
+ tensor_desc.ParseFromString(f.read(int(tensor_desc_size)))
+ tensor_shape = tuple(tensor_desc.dims)
+ if return_shape:
+ f.close()
+ return tuple(tensor_desc.dims)
+ if tensor_desc.data_type != 5:
+ raise Exception(
+ "Unexpected data type while parse {}".format(param_file))
+ data_size = 4
+ for i in range(len(tensor_shape)):
+ data_size *= tensor_shape[i]
+ weight = np.fromstring(f.read(data_size), dtype='float32')
+ f.close()
+ return np.reshape(weight, tensor_shape)
+
+
+def fuse_bn_weights(exe, main_prog, weights_dir):
+ import paddle.fluid as fluid
+ logging.info("Try to fuse weights of batch_norm...")
+ bn_vars = list()
+ for block in main_prog.blocks:
+ ops = list(block.ops)
+ for op in ops:
+ if op.type == 'affine_channel':
+ scale_name = op.input('Scale')[0]
+ bias_name = op.input('Bias')[0]
+ prefix = scale_name[:-5]
+ mean_name = prefix + 'mean'
+ variance_name = prefix + 'variance'
+ if not osp.exists(osp.join(
+ weights_dir, mean_name)) or not osp.exists(
+ osp.join(weights_dir, variance_name)):
+ logging.info(
+ "There's no batch_norm weight found to fuse, skip fuse_bn."
+ )
+ return
+
+ bias = block.var(bias_name)
+ pretrained_shape = parse_param_file(
+ osp.join(weights_dir, bias_name))
+ actual_shape = tuple(bias.shape)
+ if pretrained_shape != actual_shape:
+ continue
+ bn_vars.append(
+ [scale_name, bias_name, mean_name, variance_name])
+ eps = 1e-5
+ for names in bn_vars:
+ scale_name, bias_name, mean_name, variance_name = names
+ scale = parse_param_file(
+ osp.join(weights_dir, scale_name), return_shape=False)
+ bias = parse_param_file(
+ osp.join(weights_dir, bias_name), return_shape=False)
+ mean = parse_param_file(
+ osp.join(weights_dir, mean_name), return_shape=False)
+ variance = parse_param_file(
+ osp.join(weights_dir, variance_name), return_shape=False)
+ bn_std = np.sqrt(np.add(variance, eps))
+ new_scale = np.float32(np.divide(scale, bn_std))
+ new_bias = bias - mean * new_scale
+ scale_tensor = fluid.global_scope().find_var(scale_name).get_tensor()
+ bias_tensor = fluid.global_scope().find_var(bias_name).get_tensor()
+ scale_tensor.set(new_scale, exe.place)
+ bias_tensor.set(new_bias, exe.place)
+ if len(bn_vars) == 0:
+ logging.info(
+ "There's no batch_norm weight found to fuse, skip fuse_bn.")
+ else:
+ logging.info("There's {} batch_norm ops been fused.".format(
+ len(bn_vars)))
+
+
+def load_pdparams(exe, main_prog, model_dir):
+ import paddle.fluid as fluid
+ from paddle.fluid.proto.framework_pb2 import VarType
+ from paddle.fluid.framework import Program
+
+ vars_to_load = list()
+ import pickle
+ with open(osp.join(model_dir, 'model.pdparams'), 'rb') as f:
+ params_dict = pickle.load(f) if six.PY2 else pickle.load(
+ f, encoding='latin1')
+ unused_vars = list()
+ for var in main_prog.list_vars():
+ if not isinstance(var, fluid.framework.Parameter):
+ continue
+ if var.name not in params_dict:
+ raise Exception("{} is not in saved model".format(var.name))
+ if var.shape != params_dict[var.name].shape:
+ unused_vars.append(var.name)
+ logging.warning(
+ "[SKIP] Shape of pretrained weight {} doesn't match.(Pretrained: {}, Actual: {})"
+ .format(var.name, params_dict[var.name].shape, var.shape))
+ continue
+ vars_to_load.append(var)
+ logging.debug("Weight {} will be load".format(var.name))
+ for var_name in unused_vars:
+ del params_dict[var_name]
+ fluid.io.set_program_state(main_prog, params_dict)
+
+ if len(vars_to_load) == 0:
+ logging.warning(
+ "There is no pretrain weights loaded, maybe you should check you pretrain model!"
+ )
+ else:
+ logging.info("There are {} varaibles in {} are loaded.".format(
+ len(vars_to_load), model_dir))
+
+
+def load_pretrain_weights(exe, main_prog, weights_dir, fuse_bn=False):
+ if not osp.exists(weights_dir):
+ raise Exception("Path {} not exists.".format(weights_dir))
+ if osp.exists(osp.join(weights_dir, "model.pdparams")):
+ return load_pdparams(exe, main_prog, weights_dir)
+ import paddle.fluid as fluid
+ vars_to_load = list()
+ for var in main_prog.list_vars():
+ if not isinstance(var, fluid.framework.Parameter):
+ continue
+ if not osp.exists(osp.join(weights_dir, var.name)):
+ logging.debug("[SKIP] Pretrained weight {}/{} doesn't exist".format(
+ weights_dir, var.name))
+ continue
+ pretrained_shape = parse_param_file(osp.join(weights_dir, var.name))
+ actual_shape = tuple(var.shape)
+ if pretrained_shape != actual_shape:
+ logging.warning(
+ "[SKIP] Shape of pretrained weight {}/{} doesn't match.(Pretrained: {}, Actual: {})"
+ .format(weights_dir, var.name, pretrained_shape, actual_shape))
+ continue
+ vars_to_load.append(var)
+ logging.debug("Weight {} will be load".format(var.name))
+
+ fluid.io.load_vars(
+ executor=exe,
+ dirname=weights_dir,
+ main_program=main_prog,
+ vars=vars_to_load)
+ if len(vars_to_load) == 0:
+ logging.warning(
+ "There is no pretrain weights loaded, maybe you should check you pretrain model!"
+ )
+ else:
+ logging.info("There are {} varaibles in {} are loaded.".format(
+ len(vars_to_load), weights_dir))
+ if fuse_bn:
+ fuse_bn_weights(exe, main_prog, weights_dir)
diff --git a/docs/config.md b/docs/config.md
index 67e1353a7d88994b584d5bd3da4dd36d81430a59..24d11bd4ced6d53a961ffb5d8bbd379e821def01 100644
--- a/docs/config.md
+++ b/docs/config.md
@@ -27,10 +27,10 @@ python pdseg/train.py BATCH_SIZE 1 --cfg configs/unet_optic.yaml
|--cfg|配置文件路径|ALL|None||
|--use_gpu|是否使用GPU进行训练|train/eval/vis|False||
|--use_mpio|是否使用多进程进行IO处理|train/eval|False|打开该开关会占用一定量的CPU内存,但是可以提高训练速度。 **NOTE:** windows平台下不支持该功能, 建议使用自定义数据初次训练时不打开,打开会导致数据读取异常不可见。 |
-|--use_tb|是否使用TensorBoard记录训练数据|train|False||
+|--use_vdl|是否使用VisualDL记录训练数据|train|False||
|--log_steps|训练日志的打印周期(单位为step)|train|10||
|--debug|是否打印debug信息|train|False|IOU等指标涉及到混淆矩阵的计算,会降低训练速度|
-|--tb_log_dir |TensorBoard的日志路径|train|None||
+|--vdl_log_dir |VisualDL的日志路径|train|None||
|--do_eval|是否在保存模型时进行效果评估 |train|False||
|--vis_dir|保存可视化图片的路径|vis|"visual"||
@@ -80,7 +80,7 @@ DATASET:
VAL_FILE_LIST: './dataset/cityscapes/val.list'
# 测试数据列表
TEST_FILE_LIST: './dataset/cityscapes/test.list'
- # Tensorboard 可视化的数据集
+ # VisualDL 可视化的数据集
VIS_FILE_LIST: None
# 类别数(需包括背景类)
NUM_CLASSES: 19
diff --git a/docs/configs/dataset_group.md b/docs/configs/dataset_group.md
index 917f01ade91598916a9399417a6c7ee62337dff5..7623c4f199db49571e15b7efef997d144c36301b 100644
--- a/docs/configs/dataset_group.md
+++ b/docs/configs/dataset_group.md
@@ -62,7 +62,7 @@ DATASET Group存放所有与数据集相关的配置
## `VIS_FILE_LIST`
-可视化列表,调用`pdseg/train.py`进行训练时,如果打开了--use_tb开关,则在每次模型保存的时候,会读取该列表中的图片进行可视化
+可视化列表,调用`pdseg/train.py`进行训练时,如果打开了--use_vdl开关,则在每次模型保存的时候,会读取该列表中的图片进行可视化
文件列表由多行组成,每一行的格式为
```
diff --git a/docs/imgs/tensorboard_image.JPG b/docs/imgs/tensorboard_image.JPG
deleted file mode 100644
index 140aa2a0ed6a9b1a2d0a98477685b9e6d434a113..0000000000000000000000000000000000000000
Binary files a/docs/imgs/tensorboard_image.JPG and /dev/null differ
diff --git a/docs/imgs/tensorboard_scalar.JPG b/docs/imgs/tensorboard_scalar.JPG
deleted file mode 100644
index 322c98dc8ba7e5ca96477f3dbe193a70a8cf4609..0000000000000000000000000000000000000000
Binary files a/docs/imgs/tensorboard_scalar.JPG and /dev/null differ
diff --git a/docs/imgs/visualdl_image.png b/docs/imgs/visualdl_image.png
new file mode 100644
index 0000000000000000000000000000000000000000..49ecc661739139e896413611f8daa1a7875b8dd2
Binary files /dev/null and b/docs/imgs/visualdl_image.png differ
diff --git a/docs/imgs/visualdl_scalar.png b/docs/imgs/visualdl_scalar.png
new file mode 100644
index 0000000000000000000000000000000000000000..196d0ab728f859b2d32960ba8f50df4eb6361556
Binary files /dev/null and b/docs/imgs/visualdl_scalar.png differ
diff --git a/docs/usage.md b/docs/usage.md
index 6da85a2de7b8be220e955a9e20a351c2d306b489..b07a01ebcb3a9a2527ae60a4105f6fd8410f17f7 100644
--- a/docs/usage.md
+++ b/docs/usage.md
@@ -49,8 +49,8 @@ export CUDA_VISIBLE_DEVICES=0
python pdseg/train.py --cfg configs/unet_optic.yaml \
--use_gpu \
--do_eval \
- --use_tb \
- --tb_log_dir train_log \
+ --use_vdl \
+ --vdl_log_dir train_log \
BATCH_SIZE 4 \
SOLVER.LR 0.001
@@ -70,22 +70,22 @@ export CUDA_VISIBLE_DEVICES=0,1,2
## 5.训练过程可视化
-当打开do_eval和use_tb两个开关后,我们可以通过TensorBoard查看边训练边评估的效果。
+训练过程可视化需要在启动训练脚本`train.py`时,打开`--do_eval`和`--use_vdl`两个开关,并设置日志保存目录`--vdl_log_dir`,然后便可以通过VisualDL查看边训练边评估的效果。
```shell
-tensorboard --logdir train_log --host {$HOST_IP} --port {$PORT}
+visualdl --logdir train_log --host {$HOST_IP} --port {$PORT}
```
NOTE:
1. 上述示例中,$HOST\_IP为机器IP地址,请替换为实际IP,$PORT请替换为可访问的端口。
2. 数据量较大时,前端加载速度会比较慢,请耐心等待。
-启动TensorBoard命令后,我们可以在浏览器中查看对应的训练数据。
+启动VisualDL命令后,我们可以在浏览器中查看对应的训练数据。
在`SCALAR`这个tab中,查看训练loss、iou、acc的变化趋势。
-
+
在`IMAGE`这个tab中,查看样本图片。
-
+
## 6.模型评估
训练完成后,我们可以通过eval.py来评估模型效果。由于我们设置的训练EPOCH数量为10,保存间隔为5,因此一共会产生2个定期保存的模型,加上最终保存的final模型,一共有3个模型。我们选择最后保存的模型进行效果的评估:
diff --git a/pdseg/loss.py b/pdseg/loss.py
index 14f1b3794b6c8a15f4da5cf2a838ab7339eeffc4..92638a9caaa15d749a8dfd3abc7cc8dec550b7fe 100644
--- a/pdseg/loss.py
+++ b/pdseg/loss.py
@@ -20,7 +20,11 @@ import importlib
from utils.config import cfg
-def softmax_with_loss(logit, label, ignore_mask=None, num_classes=2, weight=None):
+def softmax_with_loss(logit,
+ label,
+ ignore_mask=None,
+ num_classes=2,
+ weight=None):
ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
label = fluid.layers.elementwise_min(
label, fluid.layers.assign(np.array([num_classes - 1], dtype=np.int32)))
@@ -36,14 +40,18 @@ def softmax_with_loss(logit, label, ignore_mask=None, num_classes=2, weight=None
ignore_index=cfg.DATASET.IGNORE_INDEX,
return_softmax=True)
else:
- label_one_hot = fluid.layers.one_hot(input=label, depth=num_classes)
+ label_one_hot = fluid.one_hot(input=label, depth=num_classes)
if isinstance(weight, list):
- assert len(weight) == num_classes, "weight length must equal num of classes"
+ assert len(
+ weight
+ ) == num_classes, "weight length must equal num of classes"
weight = fluid.layers.assign(np.array([weight], dtype='float32'))
elif isinstance(weight, str):
- assert weight.lower() == 'dynamic', 'if weight is string, must be dynamic!'
+ assert weight.lower(
+ ) == 'dynamic', 'if weight is string, must be dynamic!'
tmp = []
- total_num = fluid.layers.cast(fluid.layers.shape(label)[0], 'float32')
+ total_num = fluid.layers.cast(
+ fluid.layers.shape(label)[0], 'float32')
for i in range(num_classes):
cls_pixel_num = fluid.layers.reduce_sum(label_one_hot[:, i])
ratio = total_num / (cls_pixel_num + 1)
@@ -53,9 +61,12 @@ def softmax_with_loss(logit, label, ignore_mask=None, num_classes=2, weight=None
elif isinstance(weight, fluid.layers.Variable):
pass
else:
- raise ValueError('Expect weight is a list, string or Variable, but receive {}'.format(type(weight)))
+ raise ValueError(
+ 'Expect weight is a list, string or Variable, but receive {}'.
+ format(type(weight)))
weight = fluid.layers.reshape(weight, [1, num_classes])
- weighted_label_one_hot = fluid.layers.elementwise_mul(label_one_hot, weight)
+ weighted_label_one_hot = fluid.layers.elementwise_mul(
+ label_one_hot, weight)
probs = fluid.layers.softmax(logit)
loss = fluid.layers.cross_entropy(
probs,
@@ -75,10 +86,11 @@ def softmax_with_loss(logit, label, ignore_mask=None, num_classes=2, weight=None
# to change, how to appicate ignore index and ignore mask
def dice_loss(logit, label, ignore_mask=None, epsilon=0.00001):
if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
- raise Exception("dice loss is only applicable to one channel classfication")
+ raise Exception(
+ "dice loss is only applicable to one channel classfication")
ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
- label = fluid.layers.transpose(label, [0, 2, 3, 1])
+ label = fluid.layers.transpose(label, [0, 2, 3, 1])
label = fluid.layers.cast(label, 'int64')
ignore_mask = fluid.layers.transpose(ignore_mask, [0, 2, 3, 1])
logit = fluid.layers.sigmoid(logit)
@@ -88,7 +100,7 @@ def dice_loss(logit, label, ignore_mask=None, epsilon=0.00001):
inse = fluid.layers.reduce_sum(logit * label, dim=reduce_dim)
dice_denominator = fluid.layers.reduce_sum(
logit, dim=reduce_dim) + fluid.layers.reduce_sum(
- label, dim=reduce_dim)
+ label, dim=reduce_dim)
dice_score = 1 - inse * 2 / (dice_denominator + epsilon)
label.stop_gradient = True
ignore_mask.stop_gradient = True
@@ -103,26 +115,31 @@ def bce_loss(logit, label, ignore_mask=None):
x=logit,
label=label,
ignore_index=cfg.DATASET.IGNORE_INDEX,
- normalize=True) # or False
+ normalize=True) # or False
loss = fluid.layers.reduce_sum(loss)
label.stop_gradient = True
ignore_mask.stop_gradient = True
return loss
-def multi_softmax_with_loss(logits, label, ignore_mask=None, num_classes=2, weight=None):
+def multi_softmax_with_loss(logits,
+ label,
+ ignore_mask=None,
+ num_classes=2,
+ weight=None):
if isinstance(logits, tuple):
avg_loss = 0
for i, logit in enumerate(logits):
- if label.shape[2] != logit.shape[2] or label.shape[3] != logit.shape[3]:
+ if label.shape[2] != logit.shape[2] or label.shape[
+ 3] != logit.shape[3]:
label = fluid.layers.resize_nearest(label, logit.shape[2:])
logit_mask = (label.astype('int32') !=
cfg.DATASET.IGNORE_INDEX).astype('int32')
- loss = softmax_with_loss(logit, label, logit_mask,
- num_classes)
+ loss = softmax_with_loss(logit, label, logit_mask, num_classes)
avg_loss += cfg.MODEL.MULTI_LOSS_WEIGHT[i] * loss
else:
- avg_loss = softmax_with_loss(logits, label, ignore_mask, num_classes, weight=weight)
+ avg_loss = softmax_with_loss(
+ logits, label, ignore_mask, num_classes, weight=weight)
return avg_loss
diff --git a/pdseg/tools/jingling2seg.py b/pdseg/tools/jingling2seg.py
index 28bce3b0436242f5174087c0852dde99a7878684..5f031823a14894bdf5244b4d42b4a7dd216b0619 100644
--- a/pdseg/tools/jingling2seg.py
+++ b/pdseg/tools/jingling2seg.py
@@ -17,10 +17,8 @@ from gray2pseudo_color import get_color_map_list
def parse_args():
parser = argparse.ArgumentParser(
- formatter_class=argparse.ArgumentDefaultsHelpFormatter
- )
- parser.add_argument('input_dir',
- help='input annotated directory')
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('input_dir', help='input annotated directory')
return parser.parse_args()
@@ -62,8 +60,7 @@ def main(args):
print('Generating dataset from:', label_file)
with open(label_file) as f:
base = osp.splitext(osp.basename(label_file))[0]
- out_png_file = osp.join(
- output_dir, base + '.png')
+ out_png_file = osp.join(output_dir, base + '.png')
data = json.load(f)
@@ -77,14 +74,20 @@ def main(args):
# convert jingling format to labelme format
points = []
for i in range(1, int(len(polygon) / 2) + 1):
- points.append([polygon['x' + str(i)], polygon['y' + str(i)]])
- shape = {'label': name, 'points': points, 'shape_type': 'polygon'}
+ points.append(
+ [polygon['x' + str(i)], polygon['y' + str(i)]])
+ shape = {
+ 'label': name,
+ 'points': points,
+ 'shape_type': 'polygon'
+ }
data_shapes.append(shape)
if 'size' not in data:
continue
data_size = data['size']
- img_shape = (data_size['height'], data_size['width'], data_size['depth'])
+ img_shape = (data_size['height'], data_size['width'],
+ data_size['depth'])
lbl = labelme.utils.shapes_to_label(
img_shape=img_shape,
@@ -102,8 +105,7 @@ def main(args):
else:
raise ValueError(
'[%s] Cannot save the pixel-wise class label as PNG. '
- 'Please consider using the .npy format.' % out_png_file
- )
+ 'Please consider using the .npy format.' % out_png_file)
if __name__ == '__main__':
diff --git a/pdseg/tools/labelme2seg.py b/pdseg/tools/labelme2seg.py
index 6ae3ad3a50a6df750ce321d94b7235ef57dcf80b..3f06e977e9a91418c4eeb060d50f4bd021a6f8ab 100755
--- a/pdseg/tools/labelme2seg.py
+++ b/pdseg/tools/labelme2seg.py
@@ -17,10 +17,8 @@ from gray2pseudo_color import get_color_map_list
def parse_args():
parser = argparse.ArgumentParser(
- formatter_class=argparse.ArgumentDefaultsHelpFormatter
- )
- parser.add_argument('input_dir',
- help='input annotated directory')
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('input_dir', help='input annotated directory')
return parser.parse_args()
@@ -61,8 +59,7 @@ def main(args):
print('Generating dataset from:', label_file)
with open(label_file) as f:
base = osp.splitext(osp.basename(label_file))[0]
- out_png_file = osp.join(
- output_dir, base + '.png')
+ out_png_file = osp.join(output_dir, base + '.png')
data = json.load(f)
@@ -85,8 +82,7 @@ def main(args):
else:
raise ValueError(
'[%s] Cannot save the pixel-wise class label as PNG. '
- 'Please consider using the .npy format.' % out_png_file
- )
+ 'Please consider using the .npy format.' % out_png_file)
if __name__ == '__main__':
diff --git a/pdseg/train.py b/pdseg/train.py
index 9e30c0f2050bd4987d84675985a86922e1c993c3..e1c498a4355950af155efc79e69a6788ad86e0ba 100644
--- a/pdseg/train.py
+++ b/pdseg/train.py
@@ -77,14 +77,14 @@ def parse_args():
help='debug mode, display detail information of training',
action='store_true')
parser.add_argument(
- '--use_tb',
- dest='use_tb',
- help='whether to record the data during training to Tensorboard',
+ '--use_vdl',
+ dest='use_vdl',
+ help='whether to record the data during training to VisualDL',
action='store_true')
parser.add_argument(
- '--tb_log_dir',
- dest='tb_log_dir',
- help='Tensorboard logging directory',
+ '--vdl_log_dir',
+ dest='vdl_log_dir',
+ help='VisualDL logging directory',
default=None,
type=str)
parser.add_argument(
@@ -354,17 +354,17 @@ def train(cfg):
fetch_list.extend([pred.name, grts.name, masks.name])
cm = ConfusionMatrix(cfg.DATASET.NUM_CLASSES, streaming=True)
- if args.use_tb:
- if not args.tb_log_dir:
- print_info("Please specify the log directory by --tb_log_dir.")
+ if args.use_vdl:
+ if not args.vdl_log_dir:
+ print_info("Please specify the log directory by --vdl_log_dir.")
exit(1)
- from tb_paddle import SummaryWriter
- log_writer = SummaryWriter(args.tb_log_dir)
+ from visualdl import LogWriter
+ log_writer = LogWriter(args.vdl_log_dir)
# trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
# num_trainers = int(os.environ.get('PADDLE_TRAINERS_NUM', 1))
- global_step = 0
+ step = 0
all_step = cfg.DATASET.TRAIN_TOTAL_IMAGES // cfg.BATCH_SIZE
if cfg.DATASET.TRAIN_TOTAL_IMAGES % cfg.BATCH_SIZE and drop_last != True:
all_step += 1
@@ -398,9 +398,9 @@ def train(cfg):
return_numpy=True)
cm.calculate(pred, grts, masks)
avg_loss += np.mean(np.array(loss))
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0:
+ if step % args.log_steps == 0:
speed = args.log_steps / timer.elapsed_time()
avg_loss /= args.log_steps
category_acc, mean_acc = cm.accuracy()
@@ -408,22 +408,22 @@ def train(cfg):
print_info((
"epoch={} step={} lr={:.5f} loss={:.4f} acc={:.5f} mIoU={:.5f} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss, mean_acc,
+ ).format(epoch, step, lr[0], avg_loss, mean_acc,
mean_iou, speed,
- calculate_eta(all_step - global_step, speed)))
+ calculate_eta(all_step - step, speed)))
print_info("Category IoU: ", category_iou)
print_info("Category Acc: ", category_acc)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Train/mean_iou', mean_iou,
- global_step)
+ step)
log_writer.add_scalar('Train/mean_acc', mean_acc,
- global_step)
+ step)
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
+ step)
log_writer.add_scalar('Train/lr', lr[0],
- global_step)
+ step)
log_writer.add_scalar('Train/step/sec', speed,
- global_step)
+ step)
sys.stdout.flush()
avg_loss = 0.0
cm.zero_matrix()
@@ -435,30 +435,30 @@ def train(cfg):
fetch_list=fetch_list,
return_numpy=True)
avg_loss += np.mean(np.array(loss))
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
+ if step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
avg_loss /= args.log_steps
speed = args.log_steps / timer.elapsed_time()
print((
"epoch={} step={} lr={:.5f} loss={:.4f} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss, speed,
- calculate_eta(all_step - global_step, speed)))
- if args.use_tb:
+ ).format(epoch, step, lr[0], avg_loss, speed,
+ calculate_eta(all_step - step, speed)))
+ if args.use_vdl:
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
+ step)
log_writer.add_scalar('Train/lr', lr[0],
- global_step)
+ step)
log_writer.add_scalar('Train/speed', speed,
- global_step)
+ step)
sys.stdout.flush()
avg_loss = 0.0
timer.restart()
# NOTE : used for benchmark, profiler tools
- if args.is_profiler and epoch == 1 and global_step == args.log_steps:
+ if args.is_profiler and epoch == 1 and step == args.log_steps:
profiler.start_profiler("All")
- elif args.is_profiler and epoch == 1 and global_step == args.log_steps + 5:
+ elif args.is_profiler and epoch == 1 and step == args.log_steps + 5:
profiler.stop_profiler("total", args.profiler_path)
return
@@ -479,11 +479,11 @@ def train(cfg):
ckpt_dir=ckpt_dir,
use_gpu=args.use_gpu,
use_mpio=args.use_mpio)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Evaluate/mean_iou', mean_iou,
- global_step)
+ step)
log_writer.add_scalar('Evaluate/mean_acc', mean_acc,
- global_step)
+ step)
if mean_iou > best_mIoU:
best_mIoU = mean_iou
@@ -493,8 +493,8 @@ def train(cfg):
os.path.join(cfg.TRAIN.MODEL_SAVE_DIR, 'best_model'),
mean_iou))
- # Use Tensorboard to visualize results
- if args.use_tb and cfg.DATASET.VIS_FILE_LIST is not None:
+ # Use VisualDL to visualize results
+ if args.use_vdl and cfg.DATASET.VIS_FILE_LIST is not None:
visualize(
cfg=cfg,
use_gpu=args.use_gpu,
diff --git a/pdseg/utils/config.py b/pdseg/utils/config.py
index 141b17ce24df1f78310975ef236290011ebffb56..e58bc39695f62c733c39dde9270d1d7fdd96a677 100644
--- a/pdseg/utils/config.py
+++ b/pdseg/utils/config.py
@@ -56,7 +56,7 @@ cfg.DATASET.VAL_TOTAL_IMAGES = 500
cfg.DATASET.TEST_FILE_LIST = './dataset/cityscapes/test.list'
# 测试数据数量
cfg.DATASET.TEST_TOTAL_IMAGES = 500
-# Tensorboard 可视化的数据集
+# VisualDL 可视化的数据集
cfg.DATASET.VIS_FILE_LIST = None
# 类别数(需包括背景类)
cfg.DATASET.NUM_CLASSES = 19
diff --git a/pdseg/vis.py b/pdseg/vis.py
index d94221c0be1a0b4abe241e75966215863d8fd35d..0dc30273b8bf8e7c61ffeb09336959e09949ac8d 100644
--- a/pdseg/vis.py
+++ b/pdseg/vis.py
@@ -162,18 +162,17 @@ def visualize(cfg,
img_cnt += 1
print("#{} visualize image path: {}".format(img_cnt, vis_fn))
- # Use Tensorboard to visualize image
+ # Use VisualDL to visualize image
if log_writer is not None:
# Calulate epoch from ckpt_dir folder name
epoch = int(os.path.split(ckpt_dir)[-1])
- print("Tensorboard visualization epoch", epoch)
+ print("VisualDL visualization epoch", epoch)
pred_mask_np = np.array(pred_mask.convert("RGB"))
log_writer.add_image(
"Predict/{}".format(img_name),
pred_mask_np,
- epoch,
- dataformats='HWC')
+ epoch)
# Original image
# BGR->RGB
img = cv2.imread(
@@ -181,8 +180,7 @@ def visualize(cfg,
log_writer.add_image(
"Images/{}".format(img_name),
img,
- epoch,
- dataformats='HWC')
+ epoch)
# add ground truth (label) images
grt = grts[i]
if grt is not None:
@@ -194,8 +192,7 @@ def visualize(cfg,
log_writer.add_image(
"Label/{}".format(img_name),
grt,
- epoch,
- dataformats='HWC')
+ epoch)
# If in local_test mode, only visualize 5 images just for testing
# procedure
diff --git a/requirements.txt b/requirements.txt
index 5a04fa523ced707663c197b6a51467552692ede5..f52068232f228c14e74ac7274902dcf0c296e687 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -2,11 +2,4 @@ pre-commit
yapf == 0.26.0
flake8
pyyaml >= 5.1
-tb-paddle
-tensorboard >= 1.15.0
-Pillow
-numpy
-six
-opencv-python
-tqdm
-requests
+visualdl == 2.0.0-alpha.2
diff --git a/slim/distillation/train_distill.py b/slim/distillation/train_distill.py
index e354107f173eea203d9df3f01f93fae62f41eabc..995cab1f11a8f6d88d19a7b10f9f768f4d6ccbf1 100644
--- a/slim/distillation/train_distill.py
+++ b/slim/distillation/train_distill.py
@@ -87,14 +87,14 @@ def parse_args():
help='debug mode, display detail information of training',
action='store_true')
parser.add_argument(
- '--use_tb',
- dest='use_tb',
- help='whether to record the data during training to Tensorboard',
+ '--use_vdl',
+ dest='use_vdl',
+ help='whether to record the data during training to VisualDL',
action='store_true')
parser.add_argument(
- '--tb_log_dir',
- dest='tb_log_dir',
- help='Tensorboard logging directory',
+ '--vdl_log_dir',
+ dest='vd;_log_dir',
+ help='VisualDL logging directory',
default=None,
type=str)
parser.add_argument(
@@ -409,17 +409,17 @@ def train(cfg):
fetch_list.extend([pred.name, grts.name, masks.name])
cm = ConfusionMatrix(cfg.DATASET.NUM_CLASSES, streaming=True)
- if args.use_tb:
- if not args.tb_log_dir:
- print_info("Please specify the log directory by --tb_log_dir.")
+ if args.use_vdl:
+ if not args.vdl_log_dir:
+ print_info("Please specify the log directory by --vdl_log_dir.")
exit(1)
- from tb_paddle import SummaryWriter
- log_writer = SummaryWriter(args.tb_log_dir)
+ from visualdl import LogWriter
+ log_writer = LogWriter(args.vdl_log_dir)
# trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
# num_trainers = int(os.environ.get('PADDLE_TRAINERS_NUM', 1))
- global_step = 0
+ step = 0
all_step = cfg.DATASET.TRAIN_TOTAL_IMAGES // cfg.BATCH_SIZE
if cfg.DATASET.TRAIN_TOTAL_IMAGES % cfg.BATCH_SIZE and drop_last != True:
all_step += 1
@@ -455,9 +455,9 @@ def train(cfg):
return_numpy=True)
cm.calculate(pred, grts, masks)
avg_loss += np.mean(np.array(loss))
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0:
+ if step % args.log_steps == 0:
speed = args.log_steps / timer.elapsed_time()
avg_loss /= args.log_steps
category_acc, mean_acc = cm.accuracy()
@@ -465,22 +465,22 @@ def train(cfg):
print_info((
"epoch={} step={} lr={:.5f} loss={:.4f} acc={:.5f} mIoU={:.5f} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss, mean_acc,
+ ).format(epoch, step, lr[0], avg_loss, mean_acc,
mean_iou, speed,
- calculate_eta(all_step - global_step, speed)))
+ calculate_eta(all_step - step, speed)))
print_info("Category IoU: ", category_iou)
print_info("Category Acc: ", category_acc)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Train/mean_iou', mean_iou,
- global_step)
+ step)
log_writer.add_scalar('Train/mean_acc', mean_acc,
- global_step)
+ step)
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
+ step)
log_writer.add_scalar('Train/lr', lr[0],
- global_step)
+ step)
log_writer.add_scalar('Train/step/sec', speed,
- global_step)
+ step)
sys.stdout.flush()
avg_loss = 0.0
cm.zero_matrix()
@@ -494,25 +494,25 @@ def train(cfg):
avg_loss += np.mean(np.array(loss))
avg_t_loss += np.mean(np.array(t_loss))
avg_d_loss += np.mean(np.array(d_loss))
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
+ if step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
avg_loss /= args.log_steps
avg_t_loss /= args.log_steps
avg_d_loss /= args.log_steps
speed = args.log_steps / timer.elapsed_time()
print((
"epoch={} step={} lr={:.5f} loss={:.4f} teacher loss={:.4f} distill loss={:.4f} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss,
+ ).format(epoch, step, lr[0], avg_loss,
avg_t_loss, avg_d_loss, speed,
- calculate_eta(all_step - global_step, speed)))
- if args.use_tb:
+ calculate_eta(all_step - step, speed)))
+ if args.use_vdl:
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
+ step)
log_writer.add_scalar('Train/lr', lr[0],
- global_step)
+ step)
log_writer.add_scalar('Train/speed', speed,
- global_step)
+ step)
sys.stdout.flush()
avg_loss = 0.0
avg_t_loss = 0.0
@@ -536,11 +536,11 @@ def train(cfg):
ckpt_dir=ckpt_dir,
use_gpu=args.use_gpu,
use_mpio=args.use_mpio)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Evaluate/mean_iou', mean_iou,
- global_step)
+ step)
log_writer.add_scalar('Evaluate/mean_acc', mean_acc,
- global_step)
+ step)
if mean_iou > best_mIoU:
best_mIoU = mean_iou
@@ -550,8 +550,8 @@ def train(cfg):
os.path.join(cfg.TRAIN.MODEL_SAVE_DIR, 'best_model'),
mean_iou))
- # Use Tensorboard to visualize results
- if args.use_tb and cfg.DATASET.VIS_FILE_LIST is not None:
+ # Use VisualDL to visualize results
+ if args.use_vdl and cfg.DATASET.VIS_FILE_LIST is not None:
visualize(
cfg=cfg,
use_gpu=args.use_gpu,
diff --git a/slim/nas/train_nas.py b/slim/nas/train_nas.py
index 6ab4d899dc2406275daf3fecd3738fb4b3b82c49..f4cd8f81b1f73b7d30ce948be700beba9932c314 100644
--- a/slim/nas/train_nas.py
+++ b/slim/nas/train_nas.py
@@ -87,14 +87,14 @@ def parse_args():
help='debug mode, display detail information of training',
action='store_true')
parser.add_argument(
- '--use_tb',
- dest='use_tb',
- help='whether to record the data during training to Tensorboard',
+ '--use_vdl',
+ dest='use_vdl',
+ help='whether to record the data during training to VisualDL',
action='store_true')
parser.add_argument(
- '--tb_log_dir',
- dest='tb_log_dir',
- help='Tensorboard logging directory',
+ '--vdl_log_dir',
+ dest='vdl_log_dir',
+ help='VisualDL logging directory',
default=None,
type=str)
parser.add_argument(
diff --git a/slim/prune/train_prune.py b/slim/prune/train_prune.py
index 05c599e3327728ee1ef5e3f2dea359ab9dab5834..6c41e74beb62423354445b45d250bb0f2f75b2d3 100644
--- a/slim/prune/train_prune.py
+++ b/slim/prune/train_prune.py
@@ -83,14 +83,14 @@ def parse_args():
help='debug mode, display detail information of training',
action='store_true')
parser.add_argument(
- '--use_tb',
- dest='use_tb',
- help='whether to record the data during training to Tensorboard',
+ '--use_vdl',
+ dest='use_vdl',
+ help='whether to record the data during training to VisualDL',
action='store_true')
parser.add_argument(
- '--tb_log_dir',
- dest='tb_log_dir',
- help='Tensorboard logging directory',
+ '--vdl_log_dir',
+ dest='vdl_log_dir',
+ help='VisualDL logging directory',
default=None,
type=str)
parser.add_argument(
@@ -335,13 +335,13 @@ def train(cfg):
fetch_list.extend([pred.name, grts.name, masks.name])
cm = ConfusionMatrix(cfg.DATASET.NUM_CLASSES, streaming=True)
- if args.use_tb:
- if not args.tb_log_dir:
- print_info("Please specify the log directory by --tb_log_dir.")
+ if args.use_vdl:
+ if not args.vdl_log_dir:
+ print_info("Please specify the log directory by --vdl_log_dir.")
exit(1)
- from tb_paddle import SummaryWriter
- log_writer = SummaryWriter(args.tb_log_dir)
+ from visualdl import LogWriter
+ log_writer = LogWriter(args.vdl_log_dir)
pruner = Pruner()
train_prog = pruner.prune(
@@ -357,7 +357,7 @@ def train(cfg):
exec_strategy=exec_strategy,
build_strategy=build_strategy)
- global_step = 0
+ step = 0
all_step = cfg.DATASET.TRAIN_TOTAL_IMAGES // cfg.BATCH_SIZE
if cfg.DATASET.TRAIN_TOTAL_IMAGES % cfg.BATCH_SIZE and drop_last != True:
all_step += 1
@@ -389,9 +389,9 @@ def train(cfg):
return_numpy=True)
cm.calculate(pred, grts, masks)
avg_loss += np.mean(np.array(loss))
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0:
+ if step % args.log_steps == 0:
speed = args.log_steps / timer.elapsed_time()
avg_loss /= args.log_steps
category_acc, mean_acc = cm.accuracy()
@@ -399,22 +399,22 @@ def train(cfg):
print_info((
"epoch={} step={} lr={:.5f} loss={:.4f} acc={:.5f} mIoU={:.5f} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss, mean_acc,
+ ).format(epoch, step, lr[0], avg_loss, mean_acc,
mean_iou, speed,
- calculate_eta(all_step - global_step, speed)))
+ calculate_eta(all_step - step, speed)))
print_info("Category IoU: ", category_iou)
print_info("Category Acc: ", category_acc)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Train/mean_iou', mean_iou,
- global_step)
+ step)
log_writer.add_scalar('Train/mean_acc', mean_acc,
- global_step)
+ step)
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
+ step)
log_writer.add_scalar('Train/lr', lr[0],
- global_step)
+ step)
log_writer.add_scalar('Train/step/sec', speed,
- global_step)
+ step)
sys.stdout.flush()
avg_loss = 0.0
cm.zero_matrix()
@@ -426,22 +426,22 @@ def train(cfg):
fetch_list=fetch_list,
return_numpy=True)
avg_loss += np.mean(np.array(loss))
- global_step += 1
+ step += 1
- if global_step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
+ if step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
avg_loss /= args.log_steps
speed = args.log_steps / timer.elapsed_time()
print((
"epoch={} step={} lr={:.5f} loss={:.4f} step/sec={:.3f} | ETA {}"
- ).format(epoch, global_step, lr[0], avg_loss, speed,
- calculate_eta(all_step - global_step, speed)))
- if args.use_tb:
+ ).format(epoch, step, lr[0], avg_loss, speed,
+ calculate_eta(all_step - step, speed)))
+ if args.use_vdl:
log_writer.add_scalar('Train/loss', avg_loss,
- global_step)
+ step)
log_writer.add_scalar('Train/lr', lr[0],
- global_step)
+ step)
log_writer.add_scalar('Train/speed', speed,
- global_step)
+ step)
sys.stdout.flush()
avg_loss = 0.0
timer.restart()
@@ -463,14 +463,14 @@ def train(cfg):
ckpt_dir=ckpt_dir,
use_gpu=args.use_gpu,
use_mpio=args.use_mpio)
- if args.use_tb:
+ if args.use_vdl:
log_writer.add_scalar('Evaluate/mean_iou', mean_iou,
- global_step)
+ step)
log_writer.add_scalar('Evaluate/mean_acc', mean_acc,
- global_step)
+ step)
- # Use Tensorboard to visualize results
- if args.use_tb and cfg.DATASET.VIS_FILE_LIST is not None:
+ # Use VisualDL to visualize results
+ if args.use_vdl and cfg.DATASET.VIS_FILE_LIST is not None:
visualize(
cfg=cfg,
use_gpu=args.use_gpu,