From fca76c3a3ed2075d3aca9f18f59a305378c8c438 Mon Sep 17 00:00:00 2001
From: wuyefeilin <30919197+wuyefeilin@users.noreply.github.com>
Date: Sat, 12 Oct 2019 10:10:56 +0800
Subject: [PATCH] add dice loss and bce loss (#52)
* update solver_group.md
---
docs/configs/solver_group.md | 39 +++++++++++++++++-
pdseg/loss.py | 75 ++++++++++++++++++++++++++++-------
pdseg/models/model_builder.py | 59 +++++++++++++++++++++++----
pdseg/utils/config.py | 2 +
4 files changed, 152 insertions(+), 23 deletions(-)
diff --git a/docs/configs/solver_group.md b/docs/configs/solver_group.md
index 8db49fce..f38d9574 100644
--- a/docs/configs/solver_group.md
+++ b/docs/configs/solver_group.md
@@ -121,4 +121,41 @@ L2正则化系数
10(意味着每训练10个EPOCH保存一次模型)
-
\ No newline at end of file
+
+
+## `loss`
+
+训练时选择的损失函数, 支持`softmax_loss(sotfmax with cross entroy loss)`,
+`dice_loss(dice coefficient loss)`, `bce_loss(binary cross entroy loss)`三种损失函数。
+其中`dice_loss`和`bce_loss`仅在两类分割问题中适用,`softmax_loss`不能与`dice_loss`
+或`bce_loss`组合,`dice_loss`可以和`bce_loss`组合使用。使用示例如下:
+
+`['softmax_loss']`或`['dice_loss','bce_loss']`
+
+* softmax_loss
+
+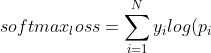})
+
+
+
+* dice_loss
+
+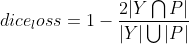
+
+[dice系数](https://zh.wikipedia.org/wiki/Dice%E7%B3%BB%E6%95%B0)
+
+
+
+* bce_loss
+
+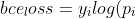}+(1-y_i)log(1-p_i))
+
+其中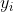和*Y*为标签,
+ 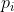和*P*为预测结果
+
+### 默认值
+
+['softmax_loss']
+
+
+
diff --git a/pdseg/loss.py b/pdseg/loss.py
index b2f7d4c9..626ea3a9 100644
--- a/pdseg/loss.py
+++ b/pdseg/loss.py
@@ -48,6 +48,42 @@ def softmax_with_loss(logit, label, ignore_mask=None, num_classes=2):
ignore_mask.stop_gradient = True
return avg_loss
+# to change, how to appicate ignore index and ignore mask
+def dice_loss(logit, label, ignore_mask=None, epsilon=0.00001):
+ if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
+ raise Exception("dice loss is only applicable to one channel classfication")
+ ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
+ logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
+ label = fluid.layers.transpose(label, [0, 2, 3, 1])
+ label = fluid.layers.cast(label, 'int64')
+ ignore_mask = fluid.layers.transpose(ignore_mask, [0, 2, 3, 1])
+ logit = fluid.layers.sigmoid(logit)
+ logit = logit * ignore_mask
+ label = label * ignore_mask
+ reduce_dim = list(range(1, len(logit.shape)))
+ inse = fluid.layers.reduce_sum(logit * label, dim=reduce_dim)
+ dice_denominator = fluid.layers.reduce_sum(
+ logit, dim=reduce_dim) + fluid.layers.reduce_sum(
+ label, dim=reduce_dim)
+ dice_score = 1 - inse * 2 / (dice_denominator + epsilon)
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return fluid.layers.reduce_mean(dice_score)
+
+def bce_loss(logit, label, ignore_mask=None):
+ if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
+ raise Exception("bce loss is only applicable to binary classfication")
+ label = fluid.layers.cast(label, 'float32')
+ loss = fluid.layers.sigmoid_cross_entropy_with_logits(
+ x=logit,
+ label=label,
+ ignore_index=cfg.DATASET.IGNORE_INDEX,
+ normalize=True) # or False
+ loss = fluid.layers.reduce_sum(loss)
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return loss
+
def multi_softmax_with_loss(logits, label, ignore_mask=None, num_classes=2):
if isinstance(logits, tuple):
@@ -63,19 +99,28 @@ def multi_softmax_with_loss(logits, label, ignore_mask=None, num_classes=2):
avg_loss = softmax_with_loss(logits, label, ignore_mask, num_classes)
return avg_loss
+def multi_dice_loss(logits, label, ignore_mask=None):
+ if isinstance(logits, tuple):
+ avg_loss = 0
+ for i, logit in enumerate(logits):
+ logit_label = fluid.layers.resize_nearest(label, logit.shape[2:])
+ logit_mask = (logit_label.astype('int32') !=
+ cfg.DATASET.IGNORE_INDEX).astype('int32')
+ loss = dice_loss(logit, logit_label, logit_mask)
+ avg_loss += cfg.MODEL.MULTI_LOSS_WEIGHT[i] * loss
+ else:
+ avg_loss = dice_loss(logits, label, ignore_mask)
+ return avg_loss
-# to change, how to appicate ignore index and ignore mask
-def dice_loss(logit, label, ignore_mask=None, num_classes=2):
- if num_classes != 2:
- raise Exception("dice loss is only applicable to binary classfication")
- ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
- label = fluid.layers.elementwise_min(
- label, fluid.layers.assign(np.array([num_classes - 1], dtype=np.int32)))
- logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
- logit = fluid.layers.reshape(logit, [-1, num_classes])
- logit = fluid.layers.softmax(logit)
- label = fluid.layers.reshape(label, [-1, 1])
- label = fluid.layers.cast(label, 'int64')
- ignore_mask = fluid.layers.reshape(ignore_mask, [-1, 1])
- loss = fluid.layers.dice_loss(logit, label)
- return loss
+def multi_bce_loss(logits, label, ignore_mask=None):
+ if isinstance(logits, tuple):
+ avg_loss = 0
+ for i, logit in enumerate(logits):
+ logit_label = fluid.layers.resize_nearest(label, logit.shape[2:])
+ logit_mask = (logit_label.astype('int32') !=
+ cfg.DATASET.IGNORE_INDEX).astype('int32')
+ loss = bce_loss(logit, logit_label, logit_mask)
+ avg_loss += cfg.MODEL.MULTI_LOSS_WEIGHT[i] * loss
+ else:
+ avg_loss = bce_loss(logits, label, ignore_mask)
+ return avg_loss
diff --git a/pdseg/models/model_builder.py b/pdseg/models/model_builder.py
index f2ba513a..e1e37bd6 100644
--- a/pdseg/models/model_builder.py
+++ b/pdseg/models/model_builder.py
@@ -24,6 +24,8 @@ from paddle.fluid.proto.framework_pb2 import VarType
import solver
from utils.config import cfg
from loss import multi_softmax_with_loss
+from loss import multi_dice_loss
+from loss import multi_bce_loss
class ModelPhase(object):
@@ -109,6 +111,17 @@ def softmax(logit):
logit = fluid.layers.transpose(logit, [0, 3, 1, 2])
return logit
+def sigmoid_to_softmax(logit):
+ """
+ one channel to two channel
+ """
+ logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
+ logit = fluid.layers.sigmoid(logit)
+ logit_back = 1 - logit
+ logit = fluid.layers.concat([logit_back, logit], axis=-1)
+ logit = fluid.layers.transpose(logit, [0, 3, 1, 2])
+ return logit
+
def build_model(main_prog, start_prog, phase=ModelPhase.TRAIN):
if not ModelPhase.is_valid_phase(phase):
@@ -144,11 +157,35 @@ def build_model(main_prog, start_prog, phase=ModelPhase.TRAIN):
image = fluid.layers.cast(image, "float16")
model_name = map_model_name(cfg.MODEL.MODEL_NAME)
model_func = get_func("modeling." + model_name)
+
+ loss_type = cfg.SOLVER.LOSS
+ if ("dice_loss" in loss_type) or ("bce_loss" in loss_type):
+ class_num = 1
+ if "softmax_loss" in loss_type:
+ raise Exception("softmax loss can not combine with dice loss or bce loss")
+
logits = model_func(image, class_num)
if ModelPhase.is_train(phase) or ModelPhase.is_eval(phase):
- avg_loss = multi_softmax_with_loss(logits, label, mask,
- class_num)
+ loss_valid = False
+ avg_loss_list = []
+ if "softmax_loss" in loss_type:
+ avg_loss_list.append(multi_softmax_with_loss(logits,
+ label, mask,class_num))
+ loss_valid = True
+ if "dice_loss" in loss_type:
+ avg_loss_list.append(multi_dice_loss(logits, label, mask))
+ loss_valid = True
+ if "bce_loss" in loss_type:
+ avg_loss_list.append(multi_bce_loss(logits, label, mask))
+ loss_valid = True
+ if not loss_valid:
+ raise Exception("SOLVER.LOSS: {} is set wrong. it should "
+ "include one of (softmax_loss, bce_loss, dice_loss) at least"
+ " example: ['softmax_loss'], ['dice_loss'], ['bce_loss', 'dice_loss']".format(cfg.SOLVER.LOSS))
+ avg_loss = 0
+ for i in range(0, len(avg_loss_list)):
+ avg_loss += avg_loss_list[i]
#get pred result in original size
if isinstance(logits, tuple):
@@ -161,17 +198,25 @@ def build_model(main_prog, start_prog, phase=ModelPhase.TRAIN):
# return image input and logit output for inference graph prune
if ModelPhase.is_predict(phase):
- logit = softmax(logit)
+ if class_num == 1:
+ logit = sigmoid_to_softmax(logit)
+ else:
+ logit = softmax(logit)
return image, logit
-
- out = fluid.layers.transpose(x=logit, perm=[0, 2, 3, 1])
+ if class_num == 1:
+ out = sigmoid_to_softmax(logit)
+ out = fluid.layers.transpose(out, [0, 2, 3, 1])
+ else:
+ out = fluid.layers.transpose(logit, [0, 2, 3, 1])
if cfg.MODEL.FP16:
out = fluid.layers.cast(out, 'float32')
pred = fluid.layers.argmax(out, axis=3)
pred = fluid.layers.unsqueeze(pred, axes=[3])
-
if ModelPhase.is_visual(phase):
- logit = softmax(logit)
+ if class_num == 1:
+ logit = sigmoid_to_softmax(logit)
+ else:
+ logit = softmax(logit)
return pred, logit
if ModelPhase.is_eval(phase):
diff --git a/pdseg/utils/config.py b/pdseg/utils/config.py
index 12a3e1ba..abaaa53d 100644
--- a/pdseg/utils/config.py
+++ b/pdseg/utils/config.py
@@ -149,6 +149,8 @@ cfg.SOLVER.WEIGHT_DECAY = 0.00004
cfg.SOLVER.BEGIN_EPOCH = 1
# 训练epoch数,正整数
cfg.SOLVER.NUM_EPOCHS = 30
+# loss的选择,支持softmax_loss, bce_loss, dice_loss
+cfg.SOLVER.LOSS = ["softmax_loss"]
########################## 测试配置 ###########################################
# 测试模型路径
--
GitLab