From da0650ec2131d5047acc63b708df2ba97fc1d3d3 Mon Sep 17 00:00:00 2001
From: wuyefeilin <30919197+wuyefeilin@users.noreply.github.com>
Date: Mon, 11 May 2020 23:22:50 +0800
Subject: [PATCH] reorganize HumanSeg contrib folder (#237)
---
contrib/HumanSeg/README.md | 147 ++++++-
contrib/HumanSeg/__init__.py | 25 --
contrib/HumanSeg/data/download_data.py | 33 ++
contrib/HumanSeg/datasets/dataset.py | 2 +-
contrib/HumanSeg/deploy/README.md | 13 +-
contrib/HumanSeg/deploy/python/README.md | 2 +-
.../deploy/python/infer_resizebylong.py | 365 ------------------
contrib/HumanSeg/export.py | 28 ++
contrib/HumanSeg/{human_infer.py => infer.py} | 36 +-
contrib/HumanSeg/main.py | 57 ---
contrib/HumanSeg/models/__init__.py | 1 -
contrib/HumanSeg/models/humanseg.py | 176 ++++-----
contrib/HumanSeg/models/load_model.py | 12 +-
contrib/HumanSeg/nets/backbone/xception.py | 8 +-
.../download_pretrained_weights.py | 38 ++
contrib/HumanSeg/quant_offline.py | 73 ++++
contrib/HumanSeg/quant_online.py | 135 +++++++
contrib/HumanSeg/requirements.txt | 10 +
contrib/HumanSeg/setup.py | 28 --
contrib/HumanSeg/train.py | 148 +++++++
contrib/HumanSeg/tutorial/export_demo.py | 3 -
contrib/HumanSeg/tutorial/infer_demo.py | 7 -
contrib/HumanSeg/tutorial/train_demo.py | 51 ---
contrib/HumanSeg/tutorial/val_demo.py | 22 --
contrib/HumanSeg/utils/__init__.py | 2 +-
.../HumanSeg/utils/humanseg_postprocess.py | 163 ++++++++
contrib/HumanSeg/utils/logging.py | 4 +-
contrib/HumanSeg/utils/post_quantization.py | 2 +-
contrib/HumanSeg/utils/utils.py | 4 +-
contrib/HumanSeg/val.py | 56 +++
contrib/HumanSeg/video_infer.py | 87 +++++
contrib/RealTimeHumanSeg/README.md | 28 --
contrib/RealTimeHumanSeg/cpp/CMakeLists.txt | 221 -----------
.../RealTimeHumanSeg/cpp/CMakeSettings.json | 42 --
contrib/RealTimeHumanSeg/cpp/README.md | 15 -
.../RealTimeHumanSeg/cpp/docs/linux_build.md | 86 -----
.../cpp/docs/windows_build.md | 83 ----
contrib/RealTimeHumanSeg/cpp/humanseg.cc | 132 -------
contrib/RealTimeHumanSeg/cpp/humanseg.h | 66 ----
.../cpp/humanseg_postprocess.cc | 282 --------------
.../cpp/humanseg_postprocess.h | 34 --
contrib/RealTimeHumanSeg/cpp/linux_build.sh | 31 --
contrib/RealTimeHumanSeg/cpp/main.cc | 92 -----
contrib/RealTimeHumanSeg/python/README.md | 61 ---
contrib/RealTimeHumanSeg/python/infer.py | 345 -----------------
.../RealTimeHumanSeg/python/requirements.txt | 2 -
46 files changed, 1036 insertions(+), 2222 deletions(-)
delete mode 100644 contrib/HumanSeg/__init__.py
create mode 100644 contrib/HumanSeg/data/download_data.py
delete mode 100644 contrib/HumanSeg/deploy/python/infer_resizebylong.py
create mode 100644 contrib/HumanSeg/export.py
rename contrib/HumanSeg/{human_infer.py => infer.py} (70%)
delete mode 100644 contrib/HumanSeg/main.py
create mode 100644 contrib/HumanSeg/pretrained_weights/download_pretrained_weights.py
create mode 100644 contrib/HumanSeg/quant_offline.py
create mode 100644 contrib/HumanSeg/quant_online.py
create mode 100644 contrib/HumanSeg/requirements.txt
delete mode 100644 contrib/HumanSeg/setup.py
create mode 100644 contrib/HumanSeg/train.py
delete mode 100644 contrib/HumanSeg/tutorial/export_demo.py
delete mode 100644 contrib/HumanSeg/tutorial/infer_demo.py
delete mode 100644 contrib/HumanSeg/tutorial/train_demo.py
delete mode 100644 contrib/HumanSeg/tutorial/val_demo.py
create mode 100644 contrib/HumanSeg/utils/humanseg_postprocess.py
create mode 100644 contrib/HumanSeg/val.py
create mode 100644 contrib/HumanSeg/video_infer.py
delete mode 100644 contrib/RealTimeHumanSeg/README.md
delete mode 100644 contrib/RealTimeHumanSeg/cpp/CMakeLists.txt
delete mode 100644 contrib/RealTimeHumanSeg/cpp/CMakeSettings.json
delete mode 100644 contrib/RealTimeHumanSeg/cpp/README.md
delete mode 100644 contrib/RealTimeHumanSeg/cpp/docs/linux_build.md
delete mode 100644 contrib/RealTimeHumanSeg/cpp/docs/windows_build.md
delete mode 100644 contrib/RealTimeHumanSeg/cpp/humanseg.cc
delete mode 100644 contrib/RealTimeHumanSeg/cpp/humanseg.h
delete mode 100644 contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc
delete mode 100644 contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h
delete mode 100644 contrib/RealTimeHumanSeg/cpp/linux_build.sh
delete mode 100644 contrib/RealTimeHumanSeg/cpp/main.cc
delete mode 100644 contrib/RealTimeHumanSeg/python/README.md
delete mode 100644 contrib/RealTimeHumanSeg/python/infer.py
delete mode 100644 contrib/RealTimeHumanSeg/python/requirements.txt
diff --git a/contrib/HumanSeg/README.md b/contrib/HumanSeg/README.md
index 0e1fd3b1..6539b9f9 100644
--- a/contrib/HumanSeg/README.md
+++ b/contrib/HumanSeg/README.md
@@ -1,6 +1,147 @@
# HumanSeg
-## 环境
-将contrib目录加入环境变量PYTHONPATH
+本教程旨在通过paddlepaddle框架实现人像分割从训练到部署的流程。
-## 训练、验证、预测、模型导出参见[turtorial](./turtorial)
+HumanSeg从复杂到简单提供三种人像分割模型:HumanSegServer、HumanSegMobile、HumanSegLite,
+HumanSegServer适用于服务端,HumanSegMobile和HumanSegLite适用于移动端。
+
+## 环境依赖
+
+* PaddlePaddle >= 1.7.0 或develop版本
+* Python 3.5+
+
+通过以下命令安装python包依赖,请确保在该分支上至少执行过一次以下命令
+```shell
+$ pip install -r requirements.txt
+```
+
+## 模型
+| 模型类型 | 预训练模型 | 导出模型 | 量化模型 | 说明 |
+| --- | --- | --- | --- | --- |
+| HumanSegServer | [humanseg_server]() | [humanseg_server_export]() | [humanseg_server_quant]() | 服务端GPU环境 |
+| HumanSegMobile | [humanseg_mobile]() | [humanseg_mobile_export]() | [humanseg_mobile_quant]() | 小模型, 适合轻量级计算环境 |
+| HumanSegLite | [humanseg_lite]() | [humanseg_lite_export]() | [humanseg_lite_quant]() | 小模型, 适合轻量级计算环境 |
+
+## 视频流分割
+```bash
+python video_infer.py --model_dir path/to/model_dir
+```
+
+## 准备训练数据
+我们提供了一份demo数据集,通过运行以下代码进行下载,该数据集是从supervise.ly抽取的一个小数据集。
+
+```bash
+python data/download_data.py
+```
+
+## 下载预训练模型
+运行以下代码进行预训练模型的下载
+```bash
+python pretrained_weights/download_pretrained_weights.py
+```
+
+## 训练
+使用下述命令进行训练
+```bash
+CUDA_VISIBLE_DEVICES=0 && python train.py --model_type HumanSegMobile \
+--save_dir output/ \
+--data_dir data/mini_supervisely \
+--train_list data/mini_supervisely/train.txt \
+--val_list data/mini_supervisely/val.txt \
+--pretrained_weights pretrained_weights/humanseg_Mobile \
+--batch_size 8 \
+--learning_rate 0.001 \
+--num_epochs 10 \
+--save_interval_epochs 2
+```
+其中参数含义如下:
+* `--model_type`: 模型类型,可选项为:HumanSegServer、HumanSegMobile和HumanSegLite
+* `--save_dir`: 模型保存路径
+* `--data_dir`: 数据集路径
+* `--train_list`: 训练集列表路径
+* `--val_list`: 验证集列表路径
+* `--pretrained_weights`: 预训练模型路径
+* `--batch_size`: 批大小
+* `--learning_rate`: 初始学习率
+* `--num_epochs`: 训练轮数
+* `--save_interval_epochs`: 模型保存间隔
+
+更多参数请运行下述命令进行参看:
+```bash
+python train.py --help
+```
+
+## 评估
+使用下述命令进行评估
+```bash
+python val.py --model_dir output/best_model \
+--data_dir data/mini_supervisely \
+--val_list data/mini_supervisely/val.txt \
+--batch_size 2
+```
+其中参数含义如下:
+* `--model_dir`: 模型路径
+* `--data_dir`: 数据集路径
+* `--val_list`: 验证集列表路径
+* `--batch_size`: 批大小
+
+## 预测
+使用下述命令进行预测
+```bash
+python infer.py --model_dir output/best_model \
+--data_dir data/mini_supervisely \
+--test_list data/mini_supervisely/test.txt
+```
+其中参数含义如下:
+* `--model_dir`: 模型路径
+* `--data_dir`: 数据集路径
+* `--test_list`: 测试集列表路径
+
+## 模型导出
+```bash
+python export.py --model_dir output/best_model \
+--save_dir output/export
+```
+其中参数含义如下:
+* `--model_dir`: 模型路径
+* `--data_dir`: 数据集路径
+* `--save_dir`: 导出模型保存路径
+
+## 离线量化
+```bash
+python quant_offline.py --model_dir output/best_model \
+--data_dir data/mini_supervisely \
+--quant_list data/mini_supervisely/val.txt \
+--save_dir output/quant_offline
+```
+其中参数含义如下:
+* `--model_dir`: 待量化模型路径
+* `--data_dir`: 数据集路径
+* `--quant_list`: 量化数据集列表路径,一般直接选择训练集或验证集
+* `--save_dir`: 量化模型保存路径
+
+## 在线量化
+利用float训练模型进行在线量化。
+```bash
+python quant_online.py --model_type HumanSegMobile \
+--save_dir output/quant_online \
+--data_dir data/mini_supervisely \
+--train_list data/mini_supervisely/train.txt \
+--val_list data/mini_supervisely/val.txt \
+--pretrained_weights output/best_model \
+--batch_size 2 \
+--learning_rate 0.001 \
+--num_epochs 2 \
+--save_interval_epochs 1
+```
+其中参数含义如下:
+* `--model_type`: 模型类型,可选项为:HumanSegServer、HumanSegMobile和HumanSegLite
+* `--save_dir`: 模型保存路径
+* `--data_dir`: 数据集路径
+* `--train_list`: 训练集列表路径
+* `--val_list`: 验证集列表路径
+* `--pretrained_weights`: 预训练模型路径,
+* `--batch_size`: 批大小
+* `--learning_rate`: 初始学习率
+* `--num_epochs`: 训练轮数
+* `--save_interval_epochs`: 模型保存间隔
diff --git a/contrib/HumanSeg/__init__.py b/contrib/HumanSeg/__init__.py
deleted file mode 100644
index c50c9945..00000000
--- a/contrib/HumanSeg/__init__.py
+++ /dev/null
@@ -1,25 +0,0 @@
-# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License"
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from . import utils
-from . import nets
-from . import models
-from . import datasets
-from . import transforms
-from .utils import get_environ_info
-
-env_info = get_environ_info()
-
-log_level = 2
-__version__ = '1.0.0.github'
diff --git a/contrib/HumanSeg/data/download_data.py b/contrib/HumanSeg/data/download_data.py
new file mode 100644
index 00000000..cce0e540
--- /dev/null
+++ b/contrib/HumanSeg/data/download_data.py
@@ -0,0 +1,33 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+
+LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
+TEST_PATH = os.path.join(LOCAL_PATH, "../../../", "test")
+sys.path.append(TEST_PATH)
+
+from test_utils import download_file_and_uncompress
+
+
+def download_pet_dataset(savepath, extrapath):
+ url = "https://paddleseg.bj.bcebos.com/dataset/mini_supervisely.zip"
+ download_file_and_uncompress(
+ url=url, savepath=savepath, extrapath=extrapath)
+
+
+if __name__ == "__main__":
+ download_pet_dataset(LOCAL_PATH, LOCAL_PATH)
+ print("Dataset download finish!")
diff --git a/contrib/HumanSeg/datasets/dataset.py b/contrib/HumanSeg/datasets/dataset.py
index 2c707a31..263c7af4 100644
--- a/contrib/HumanSeg/datasets/dataset.py
+++ b/contrib/HumanSeg/datasets/dataset.py
@@ -23,7 +23,7 @@ import copy
import random
import platform
import chardet
-import HumanSeg.utils.logging as logging
+import utils.logging as logging
class EndSignal():
diff --git a/contrib/HumanSeg/deploy/README.md b/contrib/HumanSeg/deploy/README.md
index a36188e2..b5baf00a 100644
--- a/contrib/HumanSeg/deploy/README.md
+++ b/contrib/HumanSeg/deploy/README.md
@@ -1,6 +1,6 @@
-# 实时人像分割预测部署
+# 人像分割预测部署
-本模型基于飞浆开源的人像分割模型,并做了大量的针对视频的光流追踪优化,提供了完整的支持视频流的实时人像分割解决方案,并提供了高性能的`Python`集成部署方案。
+本模型基于飞浆开源的人像分割模型,并做了大量的针对视频的光流追踪优化,提供了完整的支持视频流的人像分割解决方案,并提供了高性能的`Python`集成部署方案。
## 模型下载
@@ -9,9 +9,12 @@
|模型文件 | 说明 |
| --- | --- |
-|[shv75_deeplab_0303_quant](https://paddleseg.bj.bcebos.com/deploy/models/shv75_0303_quant.zip) | 小模型, 适合轻量级计算环境 |
-|[shv75_deeplab_0303](https://paddleseg.bj.bcebos.com/deploy/models/shv75_deeplab_0303.zip)| 小模型,适合轻量级计算环境 |
-|[deeplabv3_xception_humanseg](https://paddleseg.bj.bcebos.com/deploy/models/deeplabv3_xception_humanseg.zip) | 服务端GPU环境 |
+|[humanseg_lite_quant]() | 小模型, 适合轻量级计算环境 |
+|[humanseg_lite]()| 小模型,适合轻量级计算环境 |
+|[humanseg_mobile_quant]() | 小模型, 适合轻量级计算环境 |
+|[humanseg_mobile]()| 小模型,适合轻量级计算环境 |
+|[humanseg_server_quant]() | 服务端GPU环境 |
+|[humanseg_server]() | 服务端GPU环境 |
**注意:下载后解压到合适的路径,后续该路径将做为预测参数用于加载模型。**
diff --git a/contrib/HumanSeg/deploy/python/README.md b/contrib/HumanSeg/deploy/python/README.md
index 5a12ed12..e5aa6f2f 100644
--- a/contrib/HumanSeg/deploy/python/README.md
+++ b/contrib/HumanSeg/deploy/python/README.md
@@ -1,4 +1,4 @@
-# 实时人像分割Python预测部署方案
+# 人像分割Python预测部署方案
本方案基于Python实现,最小化依赖并把所有模型加载、数据预处理、预测、光流处理等后处理都封装在文件`infer.py`中,用户可以直接使用或集成到自己项目中。
diff --git a/contrib/HumanSeg/deploy/python/infer_resizebylong.py b/contrib/HumanSeg/deploy/python/infer_resizebylong.py
deleted file mode 100644
index d4c3a4e8..00000000
--- a/contrib/HumanSeg/deploy/python/infer_resizebylong.py
+++ /dev/null
@@ -1,365 +0,0 @@
-# coding: utf8
-# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""实时人像分割Python预测部署"""
-
-import os
-import argparse
-import numpy as np
-import cv2
-
-import paddle.fluid as fluid
-
-
-def humanseg_tracking(pre_gray, cur_gray, prev_cfd, dl_weights, disflow):
- """计算光流跟踪匹配点和光流图
- 输入参数:
- pre_gray: 上一帧灰度图
- cur_gray: 当前帧灰度图
- prev_cfd: 上一帧光流图
- dl_weights: 融合权重图
- disflow: 光流数据结构
- 返回值:
- is_track: 光流点跟踪二值图,即是否具有光流点匹配
- track_cfd: 光流跟踪图
- """
- check_thres = 8
- hgt, wdh = pre_gray.shape[:2]
- track_cfd = np.zeros_like(prev_cfd)
- is_track = np.zeros_like(pre_gray)
- # 计算前向光流
- flow_fw = disflow.calc(pre_gray, cur_gray, None)
- # 计算后向光流
- flow_bw = disflow.calc(cur_gray, pre_gray, None)
- get_round = lambda data: (int)(data + 0.5) if data >= 0 else (int)(data -
- 0.5)
- for row in range(hgt):
- for col in range(wdh):
- # 计算光流处理后对应点坐标
- # (row, col) -> (cur_x, cur_y)
- fxy_fw = flow_fw[row, col]
- dx_fw = get_round(fxy_fw[0])
- cur_x = dx_fw + col
- dy_fw = get_round(fxy_fw[1])
- cur_y = dy_fw + row
- if cur_x < 0 or cur_x >= wdh or cur_y < 0 or cur_y >= hgt:
- continue
- fxy_bw = flow_bw[cur_y, cur_x]
- dx_bw = get_round(fxy_bw[0])
- dy_bw = get_round(fxy_bw[1])
- # 光流移动小于阈值
- lmt = ((dy_fw + dy_bw) * (dy_fw + dy_bw) +
- (dx_fw + dx_bw) * (dx_fw + dx_bw))
- if lmt >= check_thres:
- continue
- # 静止点降权
- if abs(dy_fw) <= 0 and abs(dx_fw) <= 0 and abs(dy_bw) <= 0 and abs(
- dx_bw) <= 0:
- dl_weights[cur_y, cur_x] = 0.05
- is_track[cur_y, cur_x] = 1
- track_cfd[cur_y, cur_x] = prev_cfd[row, col]
- return track_cfd, is_track, dl_weights
-
-
-def humanseg_track_fuse(track_cfd, dl_cfd, dl_weights, is_track):
- """光流追踪图和人像分割结构融合
- 输入参数:
- track_cfd: 光流追踪图
- dl_cfd: 当前帧分割结果
- dl_weights: 融合权重图
- is_track: 光流点匹配二值图
- 返回值:
- cur_cfd: 光流跟踪图和人像分割结果融合图
- """
- cur_cfd = dl_cfd.copy()
- idxs = np.where(is_track > 0)
- for i in range(len(idxs)):
- x, y = idxs[0][i], idxs[1][i]
- dl_score = dl_cfd[y, x]
- track_score = track_cfd[y, x]
- if dl_score > 0.9 or dl_score < 0.1:
- if dl_weights[x, y] < 0.1:
- cur_cfd[x, y] = 0.3 * dl_score + 0.7 * track_score
- else:
- cur_cfd[x, y] = 0.4 * dl_score + 0.6 * track_score
- else:
- cur_cfd[x, y] = dl_weights[x, y] * dl_score + (
- 1 - dl_weights[x, y]) * track_score
- return cur_cfd
-
-
-def threshold_mask(img, thresh_bg, thresh_fg):
- """设置背景和前景阈值mask
- 输入参数:
- img : 原始图像, np.uint8 类型.
- thresh_bg : 背景阈值百分比,低于该值置为0.
- thresh_fg : 前景阈值百分比,超过该值置为1.
- 返回值:
- dst : 原始图像设置完前景背景阈值mask结果, np.float32 类型.
- """
- dst = (img / 255.0 - thresh_bg) / (thresh_fg - thresh_bg)
- dst[np.where(dst > 1)] = 1
- dst[np.where(dst < 0)] = 0
- return dst.astype(np.float32)
-
-
-def optflow_handle(cur_gray, scoremap, is_init):
- """光流优化
- Args:
- cur_gray : 当前帧灰度图
- scoremap : 当前帧分割结果
- is_init : 是否第一帧
- Returns:
- dst : 光流追踪图和预测结果融合图, 类型为 np.float32
- """
- width, height = scoremap.shape[0], scoremap.shape[1]
- disflow = cv2.DISOpticalFlow_create(cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
- prev_gray = np.zeros((height, width), np.uint8)
- prev_cfd = np.zeros((height, width), np.float32)
- cur_cfd = scoremap.copy()
- if is_init:
- is_init = False
- if height <= 64 or width <= 64:
- disflow.setFinestScale(1)
- elif height <= 160 or width <= 160:
- disflow.setFinestScale(2)
- else:
- disflow.setFinestScale(3)
- fusion_cfd = cur_cfd
- else:
- weights = np.ones((width, height), np.float32) * 0.3
- track_cfd, is_track, weights = humanseg_tracking(
- prev_gray, cur_gray, prev_cfd, weights, disflow)
- fusion_cfd = humanseg_track_fuse(track_cfd, cur_cfd, weights, is_track)
- fusion_cfd = cv2.GaussianBlur(fusion_cfd, (3, 3), 0)
- return fusion_cfd
-
-
-class HumanSeg:
- """人像分割类
- 封装了人像分割模型的加载,数据预处理,预测,后处理等
- """
-
- def __init__(self, model_dir, mean, scale, long_size, use_gpu=False):
-
- self.mean = np.array(mean).reshape((3, 1, 1))
- self.scale = np.array(scale).reshape((3, 1, 1))
- self.long_size = long_size
- self.load_model(model_dir, use_gpu)
-
- def load_model(self, model_dir, use_gpu):
- """加载模型并创建predictor
- Args:
- model_dir: 预测模型路径, 包含 `__model__` 和 `__params__`
- use_gpu: 是否使用GPU加速
- """
- prog_file = os.path.join(model_dir, '__model__')
- params_file = os.path.join(model_dir, '__params__')
- config = fluid.core.AnalysisConfig(prog_file, params_file)
- if use_gpu:
- config.enable_use_gpu(100, 0)
- config.switch_ir_optim(True)
- else:
- config.disable_gpu()
- config.disable_glog_info()
- config.switch_specify_input_names(True)
- config.enable_memory_optim()
- self.predictor = fluid.core.create_paddle_predictor(config)
-
- def preprocess(self, image):
- """图像预处理
- hwc_rgb 转换为 chw_bgr,并进行归一化
- 输入参数:
- image: 原始图像
- 返回值:
- 经过预处理后的图片结果
- """
- origin_h, origin_w = image.shape[0], image.shape[1]
- scale = float(self.long_size) / max(origin_w, origin_h)
- resize_w = int(round(origin_w * scale))
- resize_h = int(round(origin_h * scale))
- img_mat = cv2.resize(
- image, (resize_w, resize_h), interpolation=cv2.INTER_LINEAR)
- pad_h = self.long_size - resize_h
- pad_w = self.long_size - resize_w
- img_mat = cv2.copyMakeBorder(
- img_mat,
- 0,
- pad_h,
- 0,
- pad_w,
- cv2.BORDER_CONSTANT,
- value=[127.5, 127.5, 127.5])
-
- # HWC -> CHW
- img_mat = img_mat.swapaxes(1, 2)
- img_mat = img_mat.swapaxes(0, 1)
- # Convert to float
- img_mat = img_mat[:, :, :].astype('float32')
- img_mat = (img_mat / 255. - self.mean) / self.scale
- img_mat = img_mat[np.newaxis, :, :, :]
- return img_mat
-
- def postprocess(self, image, output_data):
- """对预测结果进行后处理
- Args:
- image: 原始图,opencv 图片对象
- output_data: Paddle预测结果原始数据
- Returns:
- 原图和预测结果融合并做了光流优化的结果图
- """
- scoremap = output_data[0, 1, :, :]
- scoremap = (scoremap * 255).astype(np.uint8)
- # 光流处理
- cur_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
- origin_h, origin_w = image.shape[0], image.shape[1]
- scale = float(self.long_size) / max(origin_w, origin_h)
- resize_w = int(round(origin_w * scale))
- resize_h = int(round(origin_h * scale))
- cur_gray = cv2.resize(
- cur_gray, (resize_w, resize_h), interpolation=cv2.INTER_LINEAR)
- pad_h = self.long_size - resize_h
- pad_w = self.long_size - resize_w
- cur_gray = cv2.copyMakeBorder(
- cur_gray, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=127.5)
- optflow_map = optflow_handle(cur_gray, scoremap, False)
- optflow_map = cv2.GaussianBlur(optflow_map, (3, 3), 0)
- optflow_map = threshold_mask(optflow_map, thresh_bg=0.2, thresh_fg=0.8)
- optflow_map = optflow_map[0:resize_h, 0:resize_w]
- optflow_map = cv2.resize(optflow_map, (origin_w, origin_h))
- optflow_map = np.repeat(optflow_map[:, :, np.newaxis], 3, axis=2)
- bg_im = np.ones_like(optflow_map) * 255
- comb = (optflow_map * image + (1 - optflow_map) * bg_im).astype(
- np.uint8)
- return comb
-
- def run_predict(self, image):
- """运行预测并返回可视化结果图
- 输入参数:
- image: 需要预测的原始图, opencv图片对象
- 返回值:
- 可视化的预测结果图
- """
- im_mat = self.preprocess(image)
- im_tensor = fluid.core.PaddleTensor(im_mat.copy().astype('float32'))
- output_data = self.predictor.run([im_tensor])[1]
- output_data = output_data.as_ndarray()
- return self.postprocess(image, output_data)
-
- def image_segment(self, path):
- """对图片文件进行分割
- 结果保存到`result.jpeg`文件中
- """
- img_mat = cv2.imread(path)
- img_mat = self.run_predict(img_mat)
- cv2.imwrite('result.jpeg', img_mat)
-
- def video_segment(self, path=None):
- """
- 对视屏流进行分割,
- path为None时默认打开摄像头。
- """
- if path is None:
- cap = cv2.VideoCapture(0)
- else:
- cap = cv2.VideoCapture(path)
- if not cap.isOpened():
- raise IOError("Error opening video stream or file")
- return
-
- if path is not None:
- width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
- height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
- fps = cap.get(cv2.CAP_PROP_FPS)
- # 用于保存预测结果视频
- out = cv2.VideoWriter('result.avi',
- cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'),
- fps, (width, height))
- # 开始获取视频帧
- while cap.isOpened():
- ret, frame = cap.read()
- if ret:
- img_mat = self.run_predict(frame)
- out.write(img_mat)
- else:
- break
- cap.release()
- out.release()
-
- else:
- while cap.isOpened():
- ret, frame = cap.read()
- if ret:
- img_mat = self.run_predict(frame)
- cv2.imshow('HumanSegmentation', img_mat)
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
- else:
- break
- cap.release()
-
-
-def main(args):
- """预测程序入口
- 完成模型加载, 对视频、摄像头、图片文件等预测过程
- """
- model_dir = args.model_dir
- use_gpu = args.use_gpu
-
- # 加载模型
- mean = [0.5, 0.5, 0.5]
- scale = [0.5, 0.5, 0.5]
- long_size = 192
- model = HumanSeg(model_dir, mean, scale, long_size, use_gpu)
- if args.use_camera:
- # 开启摄像头
- model.video_segment()
- elif args.video_path:
- # 使用视频文件作为输入
- model.video_segment(args.video_path)
- elif args.img_path:
- # 使用图片文件作为输入
- model.image_segment(args.img_path)
- else:
- raise ValueError(
- 'One of (--model_dir, --video_path, --use_camera) should be given.')
-
-
-def parse_args():
- """解析命令行参数
- """
- parser = argparse.ArgumentParser('Realtime Human Segmentation')
- parser.add_argument(
- '--model_dir',
- type=str,
- default='',
- help='path of human segmentation model')
- parser.add_argument(
- '--img_path', type=str, default='', help='path of input image')
- parser.add_argument(
- '--video_path', type=str, default='', help='path of input video')
- parser.add_argument(
- '--use_camera',
- type=bool,
- default=False,
- help='input video stream from camera')
- parser.add_argument(
- '--use_gpu', type=bool, default=False, help='enable gpu')
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- main(args)
diff --git a/contrib/HumanSeg/export.py b/contrib/HumanSeg/export.py
new file mode 100644
index 00000000..6fcae141
--- /dev/null
+++ b/contrib/HumanSeg/export.py
@@ -0,0 +1,28 @@
+import models
+import argparse
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Export model')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for exporting',
+ type=str)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the export model',
+ type=str,
+ default='./output/export')
+ return parser.parse_args()
+
+
+def export(args):
+ model = models.load_model(args.model_dir)
+ model.export_inference_model(args.save_dir)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ export(args)
diff --git a/contrib/HumanSeg/human_infer.py b/contrib/HumanSeg/infer.py
similarity index 70%
rename from contrib/HumanSeg/human_infer.py
rename to contrib/HumanSeg/infer.py
index 0764aabb..3e5ac836 100644
--- a/contrib/HumanSeg/human_infer.py
+++ b/contrib/HumanSeg/infer.py
@@ -5,30 +5,35 @@ import cv2
import numpy as np
import tqdm
-import HumanSeg
+import utils
+import models
+import transforms
def parse_args():
parser = argparse.ArgumentParser(
description='HumanSeg inference and visualization')
parser.add_argument(
- '--test_model',
- dest='test_model',
- help='model path for inference',
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for inference',
type=str)
parser.add_argument(
'--data_dir',
dest='data_dir',
- help='the root directory of dataset',
+ help='The root directory of dataset',
type=str)
parser.add_argument(
- '--file_list', dest='file_list', help='file list for test', type=str)
+ '--test_list',
+ dest='test_list',
+ help='Test list file of dataset',
+ type=str)
parser.add_argument(
'--save_dir',
dest='save_dir',
- help='the directory for saveing the inferenc results',
+ help='The directory for saving the inference results',
type=str,
- default='./result')
+ default='./output/result')
return parser.parse_args()
@@ -38,23 +43,26 @@ def mkdir(path):
os.makedirs(sub_dir)
-def process(args):
- model = HumanSeg.models.load_model(args.test_model)
+def infer(args):
+ test_transforms = transforms.Compose(
+ [transforms.Resize((192, 192)),
+ transforms.Normalize()])
+ model = models.load_model(args.model_dir)
added_saveed_path = osp.join(args.save_dir, 'added')
mat_saved_path = osp.join(args.save_dir, 'mat')
scoremap_saved_path = osp.join(args.save_dir, 'scoremap')
- with open(args.file_list, 'r') as f:
+ with open(args.test_list, 'r') as f:
files = f.readlines()
for file in tqdm.tqdm(files):
file = file.strip()
im_file = osp.join(args.data_dir, file)
im = cv2.imread(im_file)
- result = model.predict(im)
+ result = model.predict(im, transforms=test_transforms)
# save added image
- added_image = HumanSeg.utils.visualize(im_file, result, weight=0.6)
+ added_image = utils.visualize(im_file, result, weight=0.6)
added_image_file = osp.join(added_saveed_path, file)
mkdir(added_image_file)
cv2.imwrite(added_image_file, added_image)
@@ -78,4 +86,4 @@ def process(args):
if __name__ == '__main__':
args = parse_args()
- process(args)
+ infer(args)
diff --git a/contrib/HumanSeg/main.py b/contrib/HumanSeg/main.py
deleted file mode 100644
index 53cbe0b7..00000000
--- a/contrib/HumanSeg/main.py
+++ /dev/null
@@ -1,57 +0,0 @@
-import os
-import numpy as np
-from HumanSeg.datasets.dataset import Dataset
-from HumanSeg.models import HumanSegMobile
-from HumanSeg.transforms import transforms
-
-train_transforms = transforms.Compose([
- transforms.RandomHorizontalFlip(),
- transforms.Resize((192, 192)),
- transforms.Normalize()
-])
-
-eval_transforms = transforms.Compose(
- [transforms.Resize((192, 192)),
- transforms.Normalize()])
-
-data_dir = '/ssd1/chenguowei01/dataset/humanseg/supervise.ly'
-train_list = '/ssd1/chenguowei01/dataset/humanseg/supervise.ly/train.txt'
-val_list = '/ssd1/chenguowei01/dataset/humanseg/supervise.ly/val.txt'
-
-train_dataset = Dataset(
- data_dir=data_dir,
- file_list=train_list,
- transforms=train_transforms,
- num_workers='auto',
- buffer_size=100,
- parallel_method='thread',
- shuffle=True)
-
-eval_dataset = Dataset(
- data_dir=data_dir,
- file_list=val_list,
- transforms=eval_transforms,
- num_workers='auto',
- buffer_size=100,
- parallel_method='thread',
- shuffle=False)
-
-model = HumanSegMobile(num_classes=2)
-
-model.train(
- num_epochs=100,
- train_dataset=train_dataset,
- eval_dataset=eval_dataset,
- save_interval_epochs=5,
- train_batch_size=256,
- # resume_weights='/Users/chenguowei01/PycharmProjects/github/PaddleSeg/contrib/HumanSeg/output/epoch_20',
- log_interval_steps=2,
- save_dir='output',
- use_vdl=True,
-)
-
-model.evaluate(eval_dataset, batch_size=10)
-im_file = '/ssd1/chenguowei01/dataset/humanseg/supervise.ly/images/8d308c9cc0326a3bdfc90f7f6e1813df89786122.jpg'
-result = model.predict(im_file)
-import cv2
-cv2.imwrite('pred.png', result['label_map'] * 200)
diff --git a/contrib/HumanSeg/models/__init__.py b/contrib/HumanSeg/models/__init__.py
index cbd15db2..02704a07 100644
--- a/contrib/HumanSeg/models/__init__.py
+++ b/contrib/HumanSeg/models/__init__.py
@@ -1,5 +1,4 @@
from .humanseg import HumanSegMobile
from .humanseg import HumanSegServer
from .humanseg import HumanSegLite
-from .humanseg import HRNet
from .load_model import load_model
diff --git a/contrib/HumanSeg/models/humanseg.py b/contrib/HumanSeg/models/humanseg.py
index 93e0064c..cca23954 100644
--- a/contrib/HumanSeg/models/humanseg.py
+++ b/contrib/HumanSeg/models/humanseg.py
@@ -26,10 +26,13 @@ import cv2
import yaml
import paddleslim as slim
-import HumanSeg
-import HumanSeg.utils.logging as logging
-from HumanSeg.utils import seconds_to_hms
-from HumanSeg.utils import ConfusionMatrix
+import utils
+import utils.logging as logging
+from utils import seconds_to_hms
+from utils import ConfusionMatrix
+from utils import get_environ_info
+from nets import DeepLabv3p, ShuffleSeg, HRNet
+import transforms as T
def dict2str(dict_input):
@@ -81,8 +84,8 @@ class SegModel(object):
self.sync_bn = sync_bn
self.labels = None
- self.version = HumanSeg.__version__
- if HumanSeg.env_info['place'] == 'cpu':
+ self.env_info = get_environ_info()
+ if self.env_info['place'] == 'cpu':
self.places = fluid.cpu_places()
else:
self.places = fluid.cuda_places()
@@ -105,8 +108,8 @@ class SegModel(object):
else:
raise Exception("Please support correct batch_size, \
which can be divided by available cards({}) in {}".
- format(HumanSeg.env_info['num'],
- HumanSeg.env_info['place']))
+ format(self.env_info['num'],
+ self.env_info['place']))
def build_net(self, mode='train'):
"""应根据不同的情况进行构建"""
@@ -127,7 +130,7 @@ class SegModel(object):
self.test_prog = self.test_prog.clone(for_test=True)
def arrange_transform(self, transforms, mode='train'):
- arrange_transform = HumanSeg.transforms.transforms.ArrangeSegmenter
+ arrange_transform = T.ArrangeSegmenter
if type(transforms.transforms[-1]).__name__.startswith('Arrange'):
transforms.transforms[-1] = arrange_transform(mode=mode)
else:
@@ -148,7 +151,7 @@ class SegModel(object):
def net_initialize(self,
startup_prog=None,
- pretrain_weights=None,
+ pretrained_weights=None,
resume_weights=None):
if startup_prog is None:
startup_prog = fluid.default_startup_program()
@@ -171,16 +174,15 @@ class SegModel(object):
raise ValueError("Resume model path is not valid!")
logging.info("Model checkpoint loaded successfully!")
- elif pretrain_weights is not None:
+ elif pretrained_weights is not None:
logging.info(
- "Load pretrain weights from {}.".format(pretrain_weights))
- HumanSeg.utils.utils.load_pretrain_weights(
- self.exe, self.train_prog, pretrain_weights)
+ "Load pretrain weights from {}.".format(pretrained_weights))
+ utils.load_pretrained_weights(self.exe, self.train_prog,
+ pretrained_weights)
def get_model_info(self):
# 存储相应的信息到yml文件
info = dict()
- info['version'] = HumanSeg.__version__
info['Model'] = self.__class__.__name__
if 'self' in self.init_params:
del self.init_params['self']
@@ -226,6 +228,8 @@ class SegModel(object):
del self.train_init['train_dataset']
if 'eval_dataset' in self.train_init:
del self.train_init['eval_dataset']
+ if 'optimizer' in self.train_init:
+ del self.train_init['optimizer']
info['train_init'] = self.train_init
return info
@@ -307,11 +311,11 @@ class SegModel(object):
save_dir,
batch_size=1,
batch_nums=10,
- cache_dir="./temp"):
+ cache_dir="./.temp"):
self.arrange_transform(transforms=dataset.transforms, mode='quant')
dataset.num_samples = batch_size * batch_nums
try:
- from HumanSeg.utils import HumanSegPostTrainingQuantization
+ from utils import HumanSegPostTrainingQuantization
except:
raise Exception(
"Model Quantization is not available, try to upgrade your paddlepaddle>=1.7.0"
@@ -335,6 +339,8 @@ class SegModel(object):
cache_dir=cache_dir)
post_training_quantization.quantize()
post_training_quantization.save_quantized_model(save_dir)
+ if cache_dir is not None:
+ os.system('rm -r' + cache_dir)
model_info = self.get_model_info()
model_info['status'] = 'Quant'
@@ -383,7 +389,7 @@ class SegModel(object):
save_interval_epochs=1,
log_interval_steps=2,
save_dir='output',
- pretrain_weights=None,
+ pretrained_weights=None,
resume_weights=None,
optimizer=None,
learning_rate=0.01,
@@ -408,7 +414,7 @@ class SegModel(object):
self.build_program()
self.net_initialize(
startup_prog=fluid.default_startup_program(),
- pretrain_weights=pretrain_weights,
+ pretrained_weights=pretrained_weights,
resume_weights=resume_weights)
# 进行量化
@@ -451,7 +457,7 @@ class SegModel(object):
# 多卡训练
if self.parallel_train_prog is None:
build_strategy = fluid.compiler.BuildStrategy()
- if HumanSeg.env_info['place'] != 'cpu' and len(self.places) > 1:
+ if self.env_info['place'] != 'cpu' and len(self.places) > 1:
build_strategy.sync_batch_norm = self.sync_bn
exec_strategy = fluid.ExecutionStrategy()
exec_strategy.num_iteration_per_drop_scope = 1
@@ -706,80 +712,11 @@ class SegModel(object):
return {'label_map': pred, 'score_map': logit}
-class HumanSegMobile(SegModel):
- # DeepLab mobilenet
- def __init__(self,
- num_classes=2,
- backbone='MobileNetV2_x1.0',
- output_stride=16,
- aspp_with_sep_conv=True,
- decoder_use_sep_conv=True,
- encoder_with_aspp=False,
- enable_decoder=False,
- use_bce_loss=False,
- use_dice_loss=False,
- class_weight=None,
- ignore_index=255,
- sync_bn=True):
- super().__init__(
- num_classes=num_classes,
- use_bce_loss=use_bce_loss,
- use_dice_loss=use_dice_loss,
- class_weight=class_weight,
- ignore_index=ignore_index,
- sync_bn=sync_bn)
- self.init_params = locals()
-
- self.output_stride = output_stride
-
- if backbone not in [
- 'MobileNetV2_x0.25', 'MobileNetV2_x0.5', 'MobileNetV2_x1.0',
- 'MobileNetV2_x1.5', 'MobileNetV2_x2.0'
- ]:
- raise ValueError(
- "backbone: {} is set wrong. it should be one of "
- "('MobileNetV2_x0.25', 'MobileNetV2_x0.5',"
- " 'MobileNetV2_x1.0', 'MobileNetV2_x1.5', 'MobileNetV2_x2.0')".
- format(backbone))
-
- self.backbone = backbone
- self.aspp_with_sep_conv = aspp_with_sep_conv
- self.decoder_use_sep_conv = decoder_use_sep_conv
- self.encoder_with_aspp = encoder_with_aspp
- self.enable_decoder = enable_decoder
- self.sync_bn = sync_bn
-
- def build_net(self, mode='train'):
- model = HumanSeg.nets.DeepLabv3p(
- self.num_classes,
- mode=mode,
- backbone=self.backbone,
- output_stride=self.output_stride,
- aspp_with_sep_conv=self.aspp_with_sep_conv,
- decoder_use_sep_conv=self.decoder_use_sep_conv,
- encoder_with_aspp=self.encoder_with_aspp,
- enable_decoder=self.enable_decoder,
- use_bce_loss=self.use_bce_loss,
- use_dice_loss=self.use_dice_loss,
- class_weight=self.class_weight,
- ignore_index=self.ignore_index)
- inputs = model.generate_inputs()
- model_out = model.build_net(inputs)
- outputs = OrderedDict()
- if mode == 'train':
- self.optimizer.minimize(model_out)
- outputs['loss'] = model_out
- else:
- outputs['pred'] = model_out[0]
- outputs['logit'] = model_out[1]
- return inputs, outputs
-
-
class HumanSegLite(SegModel):
# DeepLab ShuffleNet
def build_net(self, mode='train'):
"""应根据不同的情况进行构建"""
- model = HumanSeg.nets.ShuffleSeg(
+ model = ShuffleSeg(
self.num_classes,
mode=mode,
use_bce_loss=self.use_bce_loss,
@@ -836,7 +773,7 @@ class HumanSegServer(SegModel):
self.sync_bn = sync_bn
def build_net(self, mode='train'):
- model = HumanSeg.nets.DeepLabv3p(
+ model = DeepLabv3p(
self.num_classes,
mode=mode,
backbone=self.backbone,
@@ -861,21 +798,21 @@ class HumanSegServer(SegModel):
return inputs, outputs
-class HRNet(SegModel):
+class HumanSegMobile(SegModel):
def __init__(self,
num_classes=2,
stage1_num_modules=1,
- stage1_num_blocks=[4],
- stage1_num_channels=[64],
+ stage1_num_blocks=[1],
+ stage1_num_channels=[32],
stage2_num_modules=1,
- stage2_num_blocks=[4, 4],
- stage2_num_channels=[18, 36],
- stage3_num_modules=4,
- stage3_num_blocks=[4, 4, 4],
- stage3_num_channels=[18, 36, 72],
- stage4_num_modules=3,
- stage4_num_blocks=[4, 4, 4, 4],
- stage4_num_channels=[18, 36, 72, 144],
+ stage2_num_blocks=[2, 2],
+ stage2_num_channels=[16, 32],
+ stage3_num_modules=1,
+ stage3_num_blocks=[2, 2, 2],
+ stage3_num_channels=[16, 32, 64],
+ stage4_num_modules=1,
+ stage4_num_blocks=[2, 2, 2, 2],
+ stage4_num_channels=[16, 32, 64, 128],
use_bce_loss=False,
use_dice_loss=False,
class_weight=None,
@@ -905,7 +842,7 @@ class HRNet(SegModel):
def build_net(self, mode='train'):
"""应根据不同的情况进行构建"""
- model = HumanSeg.nets.HRNet(
+ model = HRNet(
self.num_classes,
mode=mode,
stage1_num_modules=self.stage1_num_modules,
@@ -934,3 +871,36 @@ class HRNet(SegModel):
outputs['pred'] = model_out[0]
outputs['logit'] = model_out[1]
return inputs, outputs
+
+ def train(self,
+ num_epochs,
+ train_dataset,
+ train_batch_size=2,
+ eval_dataset=None,
+ save_interval_epochs=1,
+ log_interval_steps=2,
+ save_dir='output',
+ pretrained_weights=None,
+ resume_weights=None,
+ optimizer=None,
+ learning_rate=0.01,
+ lr_decay_power=0.9,
+ regularization_coeff=5e-4,
+ use_vdl=False,
+ quant=False):
+ super().train(
+ num_epochs=num_epochs,
+ train_dataset=train_dataset,
+ train_batch_size=train_batch_size,
+ eval_dataset=eval_dataset,
+ save_interval_epochs=save_interval_epochs,
+ log_interval_steps=log_interval_steps,
+ save_dir=save_dir,
+ pretrained_weights=pretrained_weights,
+ resume_weights=resume_weights,
+ optimizer=optimizer,
+ learning_rate=learning_rate,
+ lr_decay_power=lr_decay_power,
+ regularization_coeff=regularization_coeff,
+ use_vdl=use_vdl,
+ quant=quant)
diff --git a/contrib/HumanSeg/models/load_model.py b/contrib/HumanSeg/models/load_model.py
index a7c4de3b..fc6e3db7 100644
--- a/contrib/HumanSeg/models/load_model.py
+++ b/contrib/HumanSeg/models/load_model.py
@@ -18,8 +18,8 @@ import six
import copy
from collections import OrderedDict
import paddle.fluid as fluid
-import HumanSeg
-import HumanSeg.utils.logging as logging
+import utils.logging as logging
+import models
def load_model(model_dir):
@@ -29,10 +29,10 @@ def load_model(model_dir):
info = yaml.load(f.read(), Loader=yaml.Loader)
status = info['status']
- if not hasattr(HumanSeg.models, info['Model']):
- raise Exception("There's no attribute {} in HumanSeg.models".format(
+ if not hasattr(models, info['Model']):
+ raise Exception("There's no attribute {} in models".format(
info['Model']))
- model = getattr(HumanSeg.models, info['Model'])(**info['_init_params'])
+ model = getattr(models, info['Model'])(**info['_init_params'])
if status == "Normal":
startup_prog = fluid.Program()
model.test_prog = fluid.Program()
@@ -73,7 +73,7 @@ def load_model(model_dir):
def build_transforms(transforms_info):
- import HumanSeg.transforms as T
+ import transforms as T
transforms = list()
for op_info in transforms_info:
op_name = list(op_info.keys())[0]
diff --git a/contrib/HumanSeg/nets/backbone/xception.py b/contrib/HumanSeg/nets/backbone/xception.py
index b0ae9641..ad5c3821 100644
--- a/contrib/HumanSeg/nets/backbone/xception.py
+++ b/contrib/HumanSeg/nets/backbone/xception.py
@@ -18,10 +18,10 @@ from __future__ import division
from __future__ import print_function
import math
import paddle.fluid as fluid
-from HumanSeg.nets.libs import scope, name_scope
-from HumanSeg.nets.libs import bn, bn_relu, relu
-from HumanSeg.nets.libs import conv
-from HumanSeg.nets.libs import separate_conv
+from nets.libs import scope, name_scope
+from nets.libs import bn, bn_relu, relu
+from nets.libs import conv
+from nets.libs import separate_conv
__all__ = ['xception_65', 'xception_41', 'xception_71']
diff --git a/contrib/HumanSeg/pretrained_weights/download_pretrained_weights.py b/contrib/HumanSeg/pretrained_weights/download_pretrained_weights.py
new file mode 100644
index 00000000..7ac4000c
--- /dev/null
+++ b/contrib/HumanSeg/pretrained_weights/download_pretrained_weights.py
@@ -0,0 +1,38 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+
+LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
+TEST_PATH = os.path.join(LOCAL_PATH, "../../../", "test")
+sys.path.append(TEST_PATH)
+
+from test_utils import download_file_and_uncompress
+
+model_urls = {
+ "humanseg_server": "",
+ "humanseg_mobile": "",
+ "humanseg_lite": "",
+}
+
+if __name__ == "__main__":
+ for model_name, url in model_urls.items():
+ download_file_and_uncompress(
+ url=url,
+ savepath=LOCAL_PATH,
+ extrapath=LOCAL_PATH,
+ extraname=model_name)
+
+ print("Pretrained Model download success!")
diff --git a/contrib/HumanSeg/quant_offline.py b/contrib/HumanSeg/quant_offline.py
new file mode 100644
index 00000000..c2d51e0c
--- /dev/null
+++ b/contrib/HumanSeg/quant_offline.py
@@ -0,0 +1,73 @@
+import argparse
+from datasets.dataset import Dataset
+import transforms
+import models
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg training')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for quant',
+ type=str,
+ default='output/best_model')
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size',
+ type=int,
+ default=1)
+ parser.add_argument(
+ '--batch_nums',
+ dest='batch_nums',
+ help='Batch number for quant',
+ type=int,
+ default=10)
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='the root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--quant_list',
+ dest='quant_list',
+ help=
+ 'Image file list for model quantization, it can be vat.txt or train.txt',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the quant model',
+ type=str,
+ default='./output/quant_offline')
+ return parser.parse_args()
+
+
+def evaluate(args):
+ eval_transforms = transforms.Compose(
+ [transforms.Resize((192, 192)),
+ transforms.Normalize()])
+
+ eval_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.quant_list,
+ transforms=eval_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False)
+
+ model = models.load_model(args.model_dir)
+ model.export_quant_model(
+ dataset=eval_dataset,
+ save_dir=args.save_dir,
+ batch_size=args.batch_size,
+ batch_nums=args.batch_nums)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ evaluate(args)
diff --git a/contrib/HumanSeg/quant_online.py b/contrib/HumanSeg/quant_online.py
new file mode 100644
index 00000000..fbc1d026
--- /dev/null
+++ b/contrib/HumanSeg/quant_online.py
@@ -0,0 +1,135 @@
+import argparse
+from datasets.dataset import Dataset
+from models import HumanSegMobile, HumanSegLite, HumanSegServer
+import transforms
+
+MODEL_TYPE = ['HumanSegMobile', 'HumanSegLite', 'HumanSegServer']
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg training')
+ parser.add_argument(
+ '--model_type',
+ dest='model_type',
+ help=
+ "Model type for traing, which is one of ('HumanSegMobile', 'HumanSegLite', 'HumanSegServer')",
+ type=str,
+ default='HumanSegMobile')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='The root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--train_list',
+ dest='train_list',
+ help='Train list file of dataset',
+ type=str)
+ parser.add_argument(
+ '--val_list',
+ dest='val_list',
+ help='Val list file of dataset',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the model snapshot',
+ type=str,
+ default='./output/quant_train')
+ parser.add_argument(
+ '--num_classes',
+ dest='num_classes',
+ help='Number of classes',
+ type=int,
+ default=2)
+ parser.add_argument(
+ '--num_epochs',
+ dest='num_epochs',
+ help='Number epochs for training',
+ type=int,
+ default=2)
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size',
+ type=int,
+ default=128)
+ parser.add_argument(
+ '--learning_rate',
+ dest='learning_rate',
+ help='Learning rate',
+ type=float,
+ default=0.001)
+ parser.add_argument(
+ '--pretrained_weights',
+ dest='pretrained_weights',
+ help='The model path for quant',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_interval_epochs',
+ dest='save_interval_epochs',
+ help='The interval epochs for save a model snapshot',
+ type=int,
+ default=1)
+
+ return parser.parse_args()
+
+
+def train(args):
+ train_transforms = transforms.Compose([
+ transforms.RandomHorizontalFlip(),
+ transforms.Resize((192, 192)),
+ transforms.Normalize()
+ ])
+
+ eval_transforms = transforms.Compose(
+ [transforms.Resize((192, 192)),
+ transforms.Normalize()])
+
+ train_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.train_list,
+ transforms=train_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=True)
+
+ eval_dataset = None
+ if args.val_list is not None:
+ eval_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.val_list,
+ transforms=eval_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False)
+
+ if args.model_type == 'HumanSegMobile':
+ model = HumanSegMobile(num_classes=2)
+ elif args.model_type == 'HumanSegLite':
+ model = HumanSegLite(num_classes=2)
+ elif args.model_type == 'HumanSegServer':
+ model = HumanSegServer(num_classes=2)
+ else:
+ raise ValueError(
+ "--model_type: {} is set wrong, it shold be one of ('HumanSegMobile', "
+ "'HumanSegLite', 'HumanSegServer')".format(args.model_type))
+ model.train(
+ num_epochs=args.num_epochs,
+ train_dataset=train_dataset,
+ train_batch_size=args.batch_size,
+ eval_dataset=eval_dataset,
+ save_interval_epochs=args.save_interval_epochs,
+ save_dir=args.save_dir,
+ pretrained_weights=args.pretrained_weights,
+ learning_rate=args.learning_rate,
+ quant=True)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ train(args)
diff --git a/contrib/HumanSeg/requirements.txt b/contrib/HumanSeg/requirements.txt
new file mode 100644
index 00000000..2f4dd30f
--- /dev/null
+++ b/contrib/HumanSeg/requirements.txt
@@ -0,0 +1,10 @@
+pre-commit
+yapf == 0.26.0
+flake8
+pyyaml >= 5.1
+visual >= 1.3.0
+Pillow
+numpy
+six
+opencv-python
+tqdm
diff --git a/contrib/HumanSeg/setup.py b/contrib/HumanSeg/setup.py
deleted file mode 100644
index e87e1ecd..00000000
--- a/contrib/HumanSeg/setup.py
+++ /dev/null
@@ -1,28 +0,0 @@
-# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import setuptools
-
-long_descrition = 'HumanSeg'
-
-setuptools.setup(
- name='HumanSeg',
- version='1.0.0',
- author='paddleseg',
- description=long_descrition,
- long_descrition=long_descrition,
- packages='./',
- setup_requires=['cython', 'numpy'],
- install_requires=['pyyaml', 'tqdm', 'visualdl==1.3.0', 'paddleslim==1.0.1'],
- license='Apache 2.0')
diff --git a/contrib/HumanSeg/train.py b/contrib/HumanSeg/train.py
new file mode 100644
index 00000000..c7463962
--- /dev/null
+++ b/contrib/HumanSeg/train.py
@@ -0,0 +1,148 @@
+import argparse
+from datasets.dataset import Dataset
+from models import HumanSegMobile, HumanSegLite, HumanSegServer
+import transforms
+
+MODEL_TYPE = ['HumanSegMobile', 'HumanSegLite', 'HumanSegServer']
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg training')
+ parser.add_argument(
+ '--model_type',
+ dest='model_type',
+ help=
+ "Model type for traing, which is one of ('HumanSegMobile', 'HumanSegLite', 'HumanSegServer')",
+ type=str,
+ default='HumanSegMobile')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='The root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--train_list',
+ dest='train_list',
+ help='Train list file of dataset',
+ type=str)
+ parser.add_argument(
+ '--val_list',
+ dest='val_list',
+ help='Val list file of dataset',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the model snapshot',
+ type=str,
+ default='./output')
+ parser.add_argument(
+ '--num_classes',
+ dest='num_classes',
+ help='Number of classes',
+ type=int,
+ default=2)
+ parser.add_argument(
+ '--num_epochs',
+ dest='num_epochs',
+ help='Number epochs for training',
+ type=int,
+ default=100)
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size',
+ type=int,
+ default=128)
+ parser.add_argument(
+ '--learning_rate',
+ dest='learning_rate',
+ help='Learning rate',
+ type=float,
+ default=0.01)
+ parser.add_argument(
+ '--pretrained_weights',
+ dest='pretrained_weights',
+ help='The path of pretrianed weight',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--resume_weights',
+ dest='resume_weights',
+ help='The path of resume weight',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--use_vdl',
+ dest='use_vdl',
+ help='Whether to use visualdl',
+ type=bool,
+ default=True)
+ parser.add_argument(
+ '--save_interval_epochs',
+ dest='save_interval_epochs',
+ help='The interval epochs for save a model snapshot',
+ type=int,
+ default=5)
+
+ return parser.parse_args()
+
+
+def train(args):
+ train_transforms = transforms.Compose([
+ transforms.RandomHorizontalFlip(),
+ transforms.Resize((192, 192)),
+ transforms.Normalize()
+ ])
+
+ eval_transforms = transforms.Compose(
+ [transforms.Resize((192, 192)),
+ transforms.Normalize()])
+
+ train_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.train_list,
+ transforms=train_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=True)
+
+ eval_dataset = None
+ if args.val_list is not None:
+ eval_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.val_list,
+ transforms=eval_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False)
+
+ if args.model_type == 'HumanSegMobile':
+ model = HumanSegMobile(num_classes=2)
+ elif args.model_type == 'HumanSegLite':
+ model = HumanSegLite(num_classes=2)
+ elif args.model_type == 'HumanSegServer':
+ model = HumanSegServer(num_classes=2)
+ else:
+ raise ValueError(
+ "--model_type: {} is set wrong, it shold be one of ('HumanSegMobile', "
+ "'HumanSegLite', 'HumanSegServer')".format(args.model_type))
+ model.train(
+ num_epochs=args.num_epochs,
+ train_dataset=train_dataset,
+ train_batch_size=args.batch_size,
+ eval_dataset=eval_dataset,
+ save_interval_epochs=args.save_interval_epochs,
+ save_dir=args.save_dir,
+ pretrained_weights=args.pretrained_weights,
+ resume_weights=args.resume_weights,
+ learning_rate=args.learning_rate,
+ use_vdl=args.use_vdl)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ train(args)
diff --git a/contrib/HumanSeg/tutorial/export_demo.py b/contrib/HumanSeg/tutorial/export_demo.py
deleted file mode 100644
index 449cf89b..00000000
--- a/contrib/HumanSeg/tutorial/export_demo.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import HumanSeg
-model = HumanSeg.models.load_model('output/best_model')
-model.export_inference_model('output/export')
diff --git a/contrib/HumanSeg/tutorial/infer_demo.py b/contrib/HumanSeg/tutorial/infer_demo.py
deleted file mode 100644
index 89957e71..00000000
--- a/contrib/HumanSeg/tutorial/infer_demo.py
+++ /dev/null
@@ -1,7 +0,0 @@
-import HumanSeg
-from HumanSeg.utils import visualize
-
-im_file = '/ssd1/chenguowei01/dataset/humanseg/supervise.ly/pexel/img/person_detection__ds6/img/pexels-photo-704264.jpg'
-model = HumanSeg.models.load_model('output/best_model')
-result = model.predict(im_file)
-visualize(im_file, result, save_dir='output/')
diff --git a/contrib/HumanSeg/tutorial/train_demo.py b/contrib/HumanSeg/tutorial/train_demo.py
deleted file mode 100644
index 3ebccbbb..00000000
--- a/contrib/HumanSeg/tutorial/train_demo.py
+++ /dev/null
@@ -1,51 +0,0 @@
-import os
-import numpy as np
-from HumanSeg.datasets.dataset import Dataset
-from HumanSeg.models import HumanSegMobile
-from HumanSeg.transforms import transforms
-
-train_transforms = transforms.Compose([
- transforms.RandomHorizontalFlip(),
- transforms.Resize((192, 192)),
- transforms.Normalize()
-])
-
-eval_transforms = transforms.Compose(
- [transforms.Resize((192, 192)),
- transforms.Normalize()])
-
-data_dir = '/ssd1/chenguowei01/dataset/humanseg/supervise.ly'
-train_list = '/ssd1/chenguowei01/dataset/humanseg/supervise.ly/train.txt'
-val_list = '/ssd1/chenguowei01/dataset/humanseg/supervise.ly/val.txt'
-
-train_dataset = Dataset(
- data_dir=data_dir,
- file_list=train_list,
- transforms=train_transforms,
- num_workers='auto',
- buffer_size=100,
- parallel_method='thread',
- shuffle=True)
-
-eval_dataset = Dataset(
- data_dir=data_dir,
- file_list=val_list,
- transforms=eval_transforms,
- num_workers='auto',
- buffer_size=100,
- parallel_method='thread',
- shuffle=False)
-
-model = HumanSegMobile(num_classes=2)
-
-model.train(
- num_epochs=100,
- train_dataset=train_dataset,
- eval_dataset=eval_dataset,
- save_interval_epochs=5,
- train_batch_size=256,
- # resume_weights='/Users/chenguowei01/PycharmProjects/github/PaddleSeg/contrib/HumanSeg/output/epoch_20',
- log_interval_steps=2,
- save_dir='output',
- use_vdl=True,
-)
diff --git a/contrib/HumanSeg/tutorial/val_demo.py b/contrib/HumanSeg/tutorial/val_demo.py
deleted file mode 100644
index f75453dc..00000000
--- a/contrib/HumanSeg/tutorial/val_demo.py
+++ /dev/null
@@ -1,22 +0,0 @@
-import HumanSeg
-from HumanSeg.datasets.dataset import Dataset
-from HumanSeg.transforms import transforms
-
-eval_transforms = transforms.Compose(
- [transforms.Resize((192, 192)),
- transforms.Normalize()])
-
-data_dir = '/ssd1/chenguowei01/dataset/humanseg/supervise.ly'
-val_list = '/ssd1/chenguowei01/dataset/humanseg/supervise.ly/val.txt'
-
-eval_dataset = Dataset(
- data_dir=data_dir,
- file_list=val_list,
- transforms=eval_transforms,
- num_workers='auto',
- buffer_size=100,
- parallel_method='thread',
- shuffle=False)
-
-model = HumanSeg.models.load_model('output/best_model')
-model.evaluate(eval_dataset, 2)
diff --git a/contrib/HumanSeg/utils/__init__.py b/contrib/HumanSeg/utils/__init__.py
index a26f4459..a7760ee4 100644
--- a/contrib/HumanSeg/utils/__init__.py
+++ b/contrib/HumanSeg/utils/__init__.py
@@ -13,7 +13,7 @@
# limitations under the License.
from . import logging
-from . import utils
+from . import humanseg_postprocess
from .metrics import ConfusionMatrix
from .utils import *
from .post_quantization import HumanSegPostTrainingQuantization
diff --git a/contrib/HumanSeg/utils/humanseg_postprocess.py b/contrib/HumanSeg/utils/humanseg_postprocess.py
new file mode 100644
index 00000000..1e5466f6
--- /dev/null
+++ b/contrib/HumanSeg/utils/humanseg_postprocess.py
@@ -0,0 +1,163 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+import os
+import numpy as np
+import cv2
+
+
+def humanseg_tracking(pre_gray, cur_gray, prev_cfd, dl_weights, disflow):
+ """计算光流跟踪匹配点和光流图
+ 输入参数:
+ pre_gray: 上一帧灰度图
+ cur_gray: 当前帧灰度图
+ prev_cfd: 上一帧光流图
+ dl_weights: 融合权重图
+ disflow: 光流数据结构
+ 返回值:
+ is_track: 光流点跟踪二值图,即是否具有光流点匹配
+ track_cfd: 光流跟踪图
+ """
+ check_thres = 8
+ hgt, wdh = pre_gray.shape[:2]
+ track_cfd = np.zeros_like(prev_cfd)
+ is_track = np.zeros_like(pre_gray)
+ # 计算前向光流
+ flow_fw = disflow.calc(pre_gray, cur_gray, None)
+ # 计算后向光流
+ flow_bw = disflow.calc(cur_gray, pre_gray, None)
+ get_round = lambda data: (int)(data + 0.5) if data >= 0 else (int)(data -
+ 0.5)
+ for row in range(hgt):
+ for col in range(wdh):
+ # 计算光流处理后对应点坐标
+ # (row, col) -> (cur_x, cur_y)
+ fxy_fw = flow_fw[row, col]
+ dx_fw = get_round(fxy_fw[0])
+ cur_x = dx_fw + col
+ dy_fw = get_round(fxy_fw[1])
+ cur_y = dy_fw + row
+ if cur_x < 0 or cur_x >= wdh or cur_y < 0 or cur_y >= hgt:
+ continue
+ fxy_bw = flow_bw[cur_y, cur_x]
+ dx_bw = get_round(fxy_bw[0])
+ dy_bw = get_round(fxy_bw[1])
+ # 光流移动小于阈值
+ lmt = ((dy_fw + dy_bw) * (dy_fw + dy_bw) +
+ (dx_fw + dx_bw) * (dx_fw + dx_bw))
+ if lmt >= check_thres:
+ continue
+ # 静止点降权
+ if abs(dy_fw) <= 0 and abs(dx_fw) <= 0 and abs(dy_bw) <= 0 and abs(
+ dx_bw) <= 0:
+ dl_weights[cur_y, cur_x] = 0.05
+ is_track[cur_y, cur_x] = 1
+ track_cfd[cur_y, cur_x] = prev_cfd[row, col]
+ return track_cfd, is_track, dl_weights
+
+
+def humanseg_track_fuse(track_cfd, dl_cfd, dl_weights, is_track):
+ """光流追踪图和人像分割结构融合
+ 输入参数:
+ track_cfd: 光流追踪图
+ dl_cfd: 当前帧分割结果
+ dl_weights: 融合权重图
+ is_track: 光流点匹配二值图
+ 返回值:
+ cur_cfd: 光流跟踪图和人像分割结果融合图
+ """
+ cur_cfd = dl_cfd.copy()
+ idxs = np.where(is_track > 0)
+ for i in range(len(idxs)):
+ x, y = idxs[0][i], idxs[1][i]
+ dl_score = dl_cfd[x, y]
+ track_score = track_cfd[x, y]
+ if dl_score > 0.9 or dl_score < 0.1:
+ if dl_weights[x, y] < 0.1:
+ cur_cfd[x, y] = 0.3 * dl_score + 0.7 * track_score
+ else:
+ cur_cfd[x, y] = 0.4 * dl_score + 0.6 * track_score
+ else:
+ cur_cfd[x, y] = dl_weights[x, y] * dl_score + (
+ 1 - dl_weights[x, y]) * track_score
+ return cur_cfd
+
+
+def threshold_mask(img, thresh_bg, thresh_fg):
+ """设置背景和前景阈值mask
+ 输入参数:
+ img : 原始图像, np.uint8 类型.
+ thresh_bg : 背景阈值百分比,低于该值置为0.
+ thresh_fg : 前景阈值百分比,超过该值置为1.
+ 返回值:
+ dst : 原始图像设置完前景背景阈值mask结果, np.float32 类型.
+ """
+ dst = (img / 255.0 - thresh_bg) / (thresh_fg - thresh_bg)
+ dst[np.where(dst > 1)] = 1
+ dst[np.where(dst < 0)] = 0
+ return dst.astype(np.float32)
+
+
+def optflow_handle(cur_gray, scoremap, is_init):
+ """光流优化
+ Args:
+ cur_gray : 当前帧灰度图
+ scoremap : 当前帧分割结果
+ is_init : 是否第一帧
+ Returns:
+ dst : 光流追踪图和预测结果融合图, 类型为 np.float32
+ """
+ height, width = scoremap.shape[0], scoremap.shape[1]
+ disflow = cv2.DISOpticalFlow_create(cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
+ prev_gray = np.zeros((height, width), np.uint8)
+ prev_cfd = np.zeros((height, width), np.float32)
+ cur_cfd = scoremap.copy()
+ if is_init:
+ is_init = False
+ if height <= 64 or width <= 64:
+ disflow.setFinestScale(1)
+ elif height <= 160 or width <= 160:
+ disflow.setFinestScale(2)
+ else:
+ disflow.setFinestScale(3)
+ fusion_cfd = cur_cfd
+ else:
+ weights = np.ones((height, width), np.float32) * 0.3
+ track_cfd, is_track, weights = humanseg_tracking(
+ prev_gray, cur_gray, prev_cfd, weights, disflow)
+ fusion_cfd = humanseg_track_fuse(track_cfd, cur_cfd, weights, is_track)
+ fusion_cfd = cv2.GaussianBlur(fusion_cfd, (3, 3), 0)
+ return fusion_cfd
+
+
+def postprocess(image, output_data):
+ """对预测结果进行后处理
+ Args:
+ image: 原始图,opencv 图片对象
+ output_data: Paddle预测结果原始数据
+ Returns:
+ 原图和预测结果融合并做了光流优化的结果图
+ """
+ scoremap = output_data[:, :, 1]
+ scoremap = (scoremap * 255).astype(np.uint8)
+ # 光流处理
+ cur_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
+ optflow_map = optflow_handle(cur_gray, scoremap, False)
+ optflow_map = cv2.GaussianBlur(optflow_map, (3, 3), 0)
+ optflow_map = threshold_mask(optflow_map, thresh_bg=0.2, thresh_fg=0.8)
+ optflow_map = np.repeat(optflow_map[:, :, np.newaxis], 3, axis=2)
+ bg_im = np.ones_like(optflow_map) * 255
+ comb = (optflow_map * image + (1 - optflow_map) * bg_im).astype(np.uint8)
+ return comb
diff --git a/contrib/HumanSeg/utils/logging.py b/contrib/HumanSeg/utils/logging.py
index d0a97deb..1669466f 100644
--- a/contrib/HumanSeg/utils/logging.py
+++ b/contrib/HumanSeg/utils/logging.py
@@ -15,16 +15,16 @@
import time
import os
import sys
-import HumanSeg
levels = {0: 'ERROR', 1: 'WARNING', 2: 'INFO', 3: 'DEBUG'}
+log_level = 2
def log(level=2, message=""):
current_time = time.time()
time_array = time.localtime(current_time)
current_time = time.strftime("%Y-%m-%d %H:%M:%S", time_array)
- if HumanSeg.log_level >= level:
+ if log_level >= level:
print("{} [{}]\t{}".format(current_time, levels[level],
message).encode("utf-8").decode("latin1"))
sys.stdout.flush()
diff --git a/contrib/HumanSeg/utils/post_quantization.py b/contrib/HumanSeg/utils/post_quantization.py
index 84153c52..00d61c80 100644
--- a/contrib/HumanSeg/utils/post_quantization.py
+++ b/contrib/HumanSeg/utils/post_quantization.py
@@ -19,7 +19,7 @@ from paddle.fluid.contrib.slim.quantization import PostTrainingQuantization
import paddle.fluid as fluid
import os
-import HumanSeg.utils.logging as logging
+import utils.logging as logging
class HumanSegPostTrainingQuantization(PostTrainingQuantization):
diff --git a/contrib/HumanSeg/utils/utils.py b/contrib/HumanSeg/utils/utils.py
index 87382542..0e09e8b2 100644
--- a/contrib/HumanSeg/utils/utils.py
+++ b/contrib/HumanSeg/utils/utils.py
@@ -159,7 +159,7 @@ def load_pdparams(exe, main_prog, model_dir):
if not isinstance(var, fluid.framework.Parameter):
continue
if var.name not in params_dict:
- raise Exception("{} is not in saved paddlex model".format(var.name))
+ raise Exception("{} is not in saved model".format(var.name))
if var.shape != params_dict[var.name].shape:
unused_vars.append(var.name)
logging.warning(
@@ -181,7 +181,7 @@ def load_pdparams(exe, main_prog, model_dir):
len(vars_to_load), model_dir))
-def load_pretrain_weights(exe, main_prog, weights_dir, fuse_bn=False):
+def load_pretrained_weights(exe, main_prog, weights_dir, fuse_bn=False):
if not osp.exists(weights_dir):
raise Exception("Path {} not exists.".format(weights_dir))
if osp.exists(osp.join(weights_dir, "model.pdparams")):
diff --git a/contrib/HumanSeg/val.py b/contrib/HumanSeg/val.py
new file mode 100644
index 00000000..ffceecdc
--- /dev/null
+++ b/contrib/HumanSeg/val.py
@@ -0,0 +1,56 @@
+import argparse
+from datasets.dataset import Dataset
+import transforms
+import models
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg training')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for evaluating',
+ type=str,
+ default='output/best_model')
+ parser.add_argument(
+ '--data_dir',
+ dest='data_dir',
+ help='The root directory of dataset',
+ type=str)
+ parser.add_argument(
+ '--val_list',
+ dest='val_list',
+ help='Val list file of dataset',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size',
+ type=int,
+ default=128)
+ return parser.parse_args()
+
+
+def evaluate(args):
+ eval_transforms = transforms.Compose(
+ [transforms.Resize((192, 192)),
+ transforms.Normalize()])
+
+ eval_dataset = Dataset(
+ data_dir=args.data_dir,
+ file_list=args.val_list,
+ transforms=eval_transforms,
+ num_workers='auto',
+ buffer_size=100,
+ parallel_method='thread',
+ shuffle=False)
+
+ model = models.load_model(args.model_dir)
+ model.evaluate(eval_dataset, args.batch_size)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ evaluate(args)
diff --git a/contrib/HumanSeg/video_infer.py b/contrib/HumanSeg/video_infer.py
new file mode 100644
index 00000000..b4fa79ad
--- /dev/null
+++ b/contrib/HumanSeg/video_infer.py
@@ -0,0 +1,87 @@
+import argparse
+import os
+import os.path as osp
+import cv2
+import numpy as np
+
+from utils.humanseg_postprocess import postprocess
+import models
+import transforms
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='HumanSeg inference for video')
+ parser.add_argument(
+ '--model_dir',
+ dest='model_dir',
+ help='Model path for inference',
+ type=str)
+ parser.add_argument(
+ '--video_path',
+ dest='video_path',
+ help=
+ 'Video path for inference, camera will be used if the path not existing',
+ type=str,
+ default=None)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the inference results',
+ type=str,
+ default='./output')
+
+ return parser.parse_args()
+
+
+def video_infer(args):
+ test_transforms = transforms.Compose(
+ [transforms.Resize((192, 192)),
+ transforms.Normalize()])
+ model = models.load_model(args.model_dir)
+ if not args.video_path:
+ cap = cv2.VideoCapture(0)
+ else:
+ cap = cv2.VideoCapture(args.video_path)
+ if not cap.isOpened():
+ raise IOError("Error opening video stream or file, "
+ "--video_path whether existing: {}"
+ " or camera whether working".format(args.video_path))
+ return
+ if args.video_path:
+ width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
+ height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ fps = cap.get(cv2.CAP_PROP_FPS)
+ # 用于保存预测结果视频
+ out = cv2.VideoWriter(
+ osp.join(args.save_dir, 'result.avi'),
+ cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps, (width, height))
+ # 开始获取视频帧
+ while cap.isOpened():
+ ret, frame = cap.read()
+ if ret:
+ results = model.predict(frame, test_transforms)
+ img_mat = postprocess(frame, results['score_map'])
+ out.write(img_mat)
+ else:
+ break
+ cap.release()
+ out.release()
+
+ else:
+ while cap.isOpened():
+ ret, frame = cap.read()
+ if ret:
+ results = model.predict(frame, test_transforms)
+ print(frame.shape, results['score_map'].shape)
+ img_mat = postprocess(frame, results['score_map'])
+ cv2.imshow('HumanSegmentation', img_mat)
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+ else:
+ break
+ cap.release()
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ video_infer(args)
diff --git a/contrib/RealTimeHumanSeg/README.md b/contrib/RealTimeHumanSeg/README.md
deleted file mode 100644
index e8693e11..00000000
--- a/contrib/RealTimeHumanSeg/README.md
+++ /dev/null
@@ -1,28 +0,0 @@
-# 实时人像分割预测部署
-
-本模型基于飞浆开源的人像分割模型,并做了大量的针对视频的光流追踪优化,提供了完整的支持视频流的实时人像分割解决方案,并提供了高性能的`Python`和`C++`集成部署方案,以满足不同场景的需求。
-
-
-## 模型下载
-
-支持的模型文件如下,请根据应用场景选择合适的模型:
-|模型文件 | 说明 |
-|---|---|
-|[shv75_deeplab_0303_quant](https://paddleseg.bj.bcebos.com/deploy/models/shv75_0303_quant.zip) | 小模型, 适合轻量级计算环境 |
-|[shv75_deeplab_0303](https://paddleseg.bj.bcebos.com/deploy/models/shv75_deeplab_0303.zip)| 小模型,适合轻量级计算环境 |
-|[deeplabv3_xception_humanseg](https://paddleseg.bj.bcebos.com/deploy/models/deeplabv3_xception_humanseg.zip) | 服务端GPU环境 |
-
-**注意:下载后解压到合适的路径,后续该路径将做为预测参数用于加载模型。**
-
-
-## 预测部署
-- [Python预测部署](./python)
-- [C++预测部署](./cpp)
-
-## 效果预览
-
-
-  -
-  -
-
diff --git a/contrib/RealTimeHumanSeg/cpp/CMakeLists.txt b/contrib/RealTimeHumanSeg/cpp/CMakeLists.txt
deleted file mode 100644
index 5a7b89ac..00000000
--- a/contrib/RealTimeHumanSeg/cpp/CMakeLists.txt
+++ /dev/null
@@ -1,221 +0,0 @@
-cmake_minimum_required(VERSION 3.0)
-project(PaddleMaskDetector CXX C)
-
-option(WITH_MKL "Compile demo with MKL/OpenBlas support,defaultuseMKL." ON)
-option(WITH_GPU "Compile demo with GPU/CPU, default use CPU." ON)
-option(WITH_STATIC_LIB "Compile demo with static/shared library, default use static." ON)
-option(USE_TENSORRT "Compile demo with TensorRT." OFF)
-
-SET(PADDLE_DIR "" CACHE PATH "Location of libraries")
-SET(OPENCV_DIR "" CACHE PATH "Location of libraries")
-SET(CUDA_LIB "" CACHE PATH "Location of libraries")
-
-macro(safe_set_static_flag)
- foreach(flag_var
- CMAKE_CXX_FLAGS CMAKE_CXX_FLAGS_DEBUG CMAKE_CXX_FLAGS_RELEASE
- CMAKE_CXX_FLAGS_MINSIZEREL CMAKE_CXX_FLAGS_RELWITHDEBINFO)
- if(${flag_var} MATCHES "/MD")
- string(REGEX REPLACE "/MD" "/MT" ${flag_var} "${${flag_var}}")
- endif(${flag_var} MATCHES "/MD")
- endforeach(flag_var)
-endmacro()
-
-if (WITH_MKL)
- ADD_DEFINITIONS(-DUSE_MKL)
-endif()
-
-if (NOT DEFINED PADDLE_DIR OR ${PADDLE_DIR} STREQUAL "")
- message(FATAL_ERROR "please set PADDLE_DIR with -DPADDLE_DIR=/path/paddle_influence_dir")
-endif()
-
-if (NOT DEFINED OPENCV_DIR OR ${OPENCV_DIR} STREQUAL "")
- message(FATAL_ERROR "please set OPENCV_DIR with -DOPENCV_DIR=/path/opencv")
-endif()
-
-include_directories("${CMAKE_SOURCE_DIR}/")
-include_directories("${PADDLE_DIR}/")
-include_directories("${PADDLE_DIR}/third_party/install/protobuf/include")
-include_directories("${PADDLE_DIR}/third_party/install/glog/include")
-include_directories("${PADDLE_DIR}/third_party/install/gflags/include")
-include_directories("${PADDLE_DIR}/third_party/install/xxhash/include")
-if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/include")
- include_directories("${PADDLE_DIR}/third_party/install/snappy/include")
-endif()
-if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/include")
- include_directories("${PADDLE_DIR}/third_party/install/snappystream/include")
-endif()
-include_directories("${PADDLE_DIR}/third_party/install/zlib/include")
-include_directories("${PADDLE_DIR}/third_party/boost")
-include_directories("${PADDLE_DIR}/third_party/eigen3")
-
-if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
- link_directories("${PADDLE_DIR}/third_party/install/snappy/lib")
-endif()
-if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
- link_directories("${PADDLE_DIR}/third_party/install/snappystream/lib")
-endif()
-
-link_directories("${PADDLE_DIR}/third_party/install/zlib/lib")
-link_directories("${PADDLE_DIR}/third_party/install/protobuf/lib")
-link_directories("${PADDLE_DIR}/third_party/install/glog/lib")
-link_directories("${PADDLE_DIR}/third_party/install/gflags/lib")
-link_directories("${PADDLE_DIR}/third_party/install/xxhash/lib")
-link_directories("${PADDLE_DIR}/paddle/lib/")
-link_directories("${CMAKE_CURRENT_BINARY_DIR}")
-if (WIN32)
- include_directories("${PADDLE_DIR}/paddle/fluid/inference")
- include_directories("${PADDLE_DIR}/paddle/include")
- link_directories("${PADDLE_DIR}/paddle/fluid/inference")
- include_directories("${OPENCV_DIR}/build/include")
- include_directories("${OPENCV_DIR}/opencv/build/include")
- link_directories("${OPENCV_DIR}/build/x64/vc14/lib")
-else ()
- find_package(OpenCV REQUIRED PATHS ${OPENCV_DIR}/share/OpenCV NO_DEFAULT_PATH)
- include_directories("${PADDLE_DIR}/paddle/include")
- link_directories("${PADDLE_DIR}/paddle/lib")
- include_directories(${OpenCV_INCLUDE_DIRS})
-endif ()
-
-if (WIN32)
- add_definitions("/DGOOGLE_GLOG_DLL_DECL=")
- set(CMAKE_C_FLAGS_DEBUG "${CMAKE_C_FLAGS_DEBUG} /bigobj /MTd")
- set(CMAKE_C_FLAGS_RELEASE "${CMAKE_C_FLAGS_RELEASE} /bigobj /MT")
- set(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} /bigobj /MTd")
- set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} /bigobj /MT")
- if (WITH_STATIC_LIB)
- safe_set_static_flag()
- add_definitions(-DSTATIC_LIB)
- endif()
-else()
- set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -g -o2 -fopenmp -std=c++11")
- set(CMAKE_STATIC_LIBRARY_PREFIX "")
-endif()
-
-# TODO let users define cuda lib path
-if (WITH_GPU)
- if (NOT DEFINED CUDA_LIB OR ${CUDA_LIB} STREQUAL "")
- message(FATAL_ERROR "please set CUDA_LIB with -DCUDA_LIB=/path/cuda-8.0/lib64")
- endif()
- if (NOT WIN32)
- if (NOT DEFINED CUDNN_LIB)
- message(FATAL_ERROR "please set CUDNN_LIB with -DCUDNN_LIB=/path/cudnn_v7.4/cuda/lib64")
- endif()
- endif(NOT WIN32)
-endif()
-
-
-if (NOT WIN32)
- if (USE_TENSORRT AND WITH_GPU)
- include_directories("${PADDLE_DIR}/third_party/install/tensorrt/include")
- link_directories("${PADDLE_DIR}/third_party/install/tensorrt/lib")
- endif()
-endif(NOT WIN32)
-
-if (NOT WIN32)
- set(NGRAPH_PATH "${PADDLE_DIR}/third_party/install/ngraph")
- if(EXISTS ${NGRAPH_PATH})
- include(GNUInstallDirs)
- include_directories("${NGRAPH_PATH}/include")
- link_directories("${NGRAPH_PATH}/${CMAKE_INSTALL_LIBDIR}")
- set(NGRAPH_LIB ${NGRAPH_PATH}/${CMAKE_INSTALL_LIBDIR}/libngraph${CMAKE_SHARED_LIBRARY_SUFFIX})
- endif()
-endif()
-
-if(WITH_MKL)
- include_directories("${PADDLE_DIR}/third_party/install/mklml/include")
- if (WIN32)
- set(MATH_LIB ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.lib
- ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.lib)
- else ()
- set(MATH_LIB ${PADDLE_DIR}/third_party/install/mklml/lib/libmklml_intel${CMAKE_SHARED_LIBRARY_SUFFIX}
- ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5${CMAKE_SHARED_LIBRARY_SUFFIX})
- execute_process(COMMAND cp -r ${PADDLE_DIR}/third_party/install/mklml/lib/libmklml_intel${CMAKE_SHARED_LIBRARY_SUFFIX} /usr/lib)
- endif ()
- set(MKLDNN_PATH "${PADDLE_DIR}/third_party/install/mkldnn")
- if(EXISTS ${MKLDNN_PATH})
- include_directories("${MKLDNN_PATH}/include")
- if (WIN32)
- set(MKLDNN_LIB ${MKLDNN_PATH}/lib/mkldnn.lib)
- else ()
- set(MKLDNN_LIB ${MKLDNN_PATH}/lib/libmkldnn.so.0)
- endif ()
- endif()
-else()
- set(MATH_LIB ${PADDLE_DIR}/third_party/install/openblas/lib/libopenblas${CMAKE_STATIC_LIBRARY_SUFFIX})
-endif()
-
-if (WIN32)
- if(EXISTS "${PADDLE_DIR}/paddle/fluid/inference/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX}")
- set(DEPS
- ${PADDLE_DIR}/paddle/fluid/inference/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX})
- else()
- set(DEPS
- ${PADDLE_DIR}/paddle/lib/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX})
- endif()
-endif()
-
-if(WITH_STATIC_LIB)
- set(DEPS
- ${PADDLE_DIR}/paddle/lib/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX})
-else()
- set(DEPS
- ${PADDLE_DIR}/paddle/lib/libpaddle_fluid${CMAKE_SHARED_LIBRARY_SUFFIX})
-endif()
-
-if (NOT WIN32)
- set(DEPS ${DEPS}
- ${MATH_LIB} ${MKLDNN_LIB}
- glog gflags protobuf z xxhash
- )
- if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
- set(DEPS ${DEPS} snappystream)
- endif()
- if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
- set(DEPS ${DEPS} snappy)
- endif()
-else()
- set(DEPS ${DEPS}
- ${MATH_LIB} ${MKLDNN_LIB}
- opencv_world346 glog gflags_static libprotobuf zlibstatic xxhash)
- set(DEPS ${DEPS} libcmt shlwapi)
- if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
- set(DEPS ${DEPS} snappy)
- endif()
- if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
- set(DEPS ${DEPS} snappystream)
- endif()
-endif(NOT WIN32)
-
-if(WITH_GPU)
- if(NOT WIN32)
- if (USE_TENSORRT)
- set(DEPS ${DEPS} ${PADDLE_DIR}/third_party/install/tensorrt/lib/libnvinfer${CMAKE_STATIC_LIBRARY_SUFFIX})
- set(DEPS ${DEPS} ${PADDLE_DIR}/third_party/install/tensorrt/lib/libnvinfer_plugin${CMAKE_STATIC_LIBRARY_SUFFIX})
- endif()
- set(DEPS ${DEPS} ${CUDA_LIB}/libcudart${CMAKE_SHARED_LIBRARY_SUFFIX})
- set(DEPS ${DEPS} ${CUDNN_LIB}/libcudnn${CMAKE_SHARED_LIBRARY_SUFFIX})
- else()
- set(DEPS ${DEPS} ${CUDA_LIB}/cudart${CMAKE_STATIC_LIBRARY_SUFFIX} )
- set(DEPS ${DEPS} ${CUDA_LIB}/cublas${CMAKE_STATIC_LIBRARY_SUFFIX} )
- set(DEPS ${DEPS} ${CUDA_LIB}/cudnn${CMAKE_STATIC_LIBRARY_SUFFIX})
- endif()
-endif()
-
-if (NOT WIN32)
- set(EXTERNAL_LIB "-ldl -lrt -lgomp -lz -lm -lpthread")
- set(DEPS ${DEPS} ${EXTERNAL_LIB} ${OpenCV_LIBS})
-endif()
-
-add_executable(main main.cc humanseg.cc humanseg_postprocess.cc)
-target_link_libraries(main ${DEPS})
-
-if (WIN32)
- add_custom_command(TARGET main POST_BUILD
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.dll ./mklml.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.dll ./libiomp5md.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mkldnn/lib/mkldnn.dll ./mkldnn.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.dll ./release/mklml.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.dll ./release/libiomp5md.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mkldnn/lib/mkldnn.dll ./release/mkldnn.dll
- )
-endif()
diff --git a/contrib/RealTimeHumanSeg/cpp/CMakeSettings.json b/contrib/RealTimeHumanSeg/cpp/CMakeSettings.json
deleted file mode 100644
index 87cbe721..00000000
--- a/contrib/RealTimeHumanSeg/cpp/CMakeSettings.json
+++ /dev/null
@@ -1,42 +0,0 @@
-{
- "configurations": [
- {
- "name": "x64-Release",
- "generator": "Ninja",
- "configurationType": "RelWithDebInfo",
- "inheritEnvironments": [ "msvc_x64_x64" ],
- "buildRoot": "${projectDir}\\out\\build\\${name}",
- "installRoot": "${projectDir}\\out\\install\\${name}",
- "cmakeCommandArgs": "",
- "buildCommandArgs": "-v",
- "ctestCommandArgs": "",
- "variables": [
- {
- "name": "CUDA_LIB",
- "value": "D:/projects/packages/cuda10_0/lib64",
- "type": "PATH"
- },
- {
- "name": "CUDNN_LIB",
- "value": "D:/projects/packages/cuda10_0/lib64",
- "type": "PATH"
- },
- {
- "name": "OPENCV_DIR",
- "value": "D:/projects/packages/opencv3_4_6",
- "type": "PATH"
- },
- {
- "name": "PADDLE_DIR",
- "value": "D:/projects/packages/fluid_inference1_6_1",
- "type": "PATH"
- },
- {
- "name": "CMAKE_BUILD_TYPE",
- "value": "Release",
- "type": "STRING"
- }
- ]
- }
- ]
-}
\ No newline at end of file
diff --git a/contrib/RealTimeHumanSeg/cpp/README.md b/contrib/RealTimeHumanSeg/cpp/README.md
deleted file mode 100644
index 5f118413..00000000
--- a/contrib/RealTimeHumanSeg/cpp/README.md
+++ /dev/null
@@ -1,15 +0,0 @@
-# 视频实时图像分割模型C++预测部署
-
-本文档主要介绍实时图像分割模型如何在`Windows`和`Linux`上完成基于`C++`的预测部署。
-
-## C++预测部署编译
-
-### 1. 下载模型
-点击右边下载:[模型下载地址](https://paddleseg.bj.bcebos.com/deploy/models/humanseg_paddleseg_int8.zip)
-
-模型文件路径将做为预测时的输入参数,请解压到合适的目录位置。
-
-### 2. 编译
-本项目支持在Windows和Linux上编译并部署C++项目,不同平台的编译请参考:
-- [Linux 编译](./docs/linux_build.md)
-- [Windows 使用 Visual Studio 2019编译](./docs/windows_build.md)
diff --git a/contrib/RealTimeHumanSeg/cpp/docs/linux_build.md b/contrib/RealTimeHumanSeg/cpp/docs/linux_build.md
deleted file mode 100644
index 823ff3ae..00000000
--- a/contrib/RealTimeHumanSeg/cpp/docs/linux_build.md
+++ /dev/null
@@ -1,86 +0,0 @@
-# 视频实时人像分割模型Linux平台C++预测部署
-
-
-## 1. 系统和软件依赖
-
-### 1.1 操作系统及硬件要求
-
-- Ubuntu 14.04 或者 16.04 (其它平台未测试)
-- GCC版本4.8.5 ~ 4.9.2
-- 支持Intel MKL-DNN的CPU
-- NOTE: 如需在Nvidia GPU运行,请自行安装CUDA 9.0 / 10.0 + CUDNN 7.3+ (不支持9.1/10.1版本的CUDA)
-
-### 1.2 下载PaddlePaddle C++预测库
-
-PaddlePaddle C++ 预测库主要分为CPU版本和GPU版本。
-
-其中,GPU 版本支持`CUDA 10.0` 和 `CUDA 9.0`:
-
-以下为各版本C++预测库的下载链接:
-
-| 版本 | 链接 |
-| ---- | ---- |
-| CPU+MKL版 | [fluid_inference.tgz](https://paddle-inference-lib.bj.bcebos.com/1.6.3-cpu-avx-mkl/fluid_inference.tgz) |
-| CUDA9.0+MKL 版 | [fluid_inference.tgz](https://paddle-inference-lib.bj.bcebos.com/1.6.3-gpu-cuda9-cudnn7-avx-mkl/fluid_inference.tgz) |
-| CUDA10.0+MKL 版 | [fluid_inference.tgz](https://paddle-inference-lib.bj.bcebos.com/1.6.3-gpu-cuda10-cudnn7-avx-mkl/fluid_inference.tgz) |
-
-更多可用预测库版本,请点击以下链接下载:[C++预测库下载列表](https://paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/deploy/inference/build_and_install_lib_cn.html)
-
-
-下载并解压, 解压后的 `fluid_inference`目录包含的内容:
-```
-fluid_inference
-├── paddle # paddle核心库和头文件
-|
-├── third_party # 第三方依赖库和头文件
-|
-└── version.txt # 版本和编译信息
-```
-
-**注意:** 请把解压后的目录放到合适的路径,**该目录路径后续会作为编译依赖**使用。
-
-## 2. 编译与运行
-
-### 2.1 配置编译脚本
-
-打开文件`linux_build.sh`, 看到以下内容:
-```shell
-# 是否使用GPU
-WITH_GPU=OFF
-# Paddle 预测库路径
-PADDLE_DIR=/PATH/TO/fluid_inference/
-# CUDA库路径, 仅 WITH_GPU=ON 时设置
-CUDA_LIB=/PATH/TO/CUDA_LIB64/
-# CUDNN库路径,仅 WITH_GPU=ON 且 CUDA_LIB有效时设置
-CUDNN_LIB=/PATH/TO/CUDNN_LIB64/
-# OpenCV 库路径, 无须设置
-OPENCV_DIR=/PATH/TO/opencv3gcc4.8/
-
-cd build
-cmake .. \
- -DWITH_GPU=${WITH_GPU} \
- -DPADDLE_DIR=${PADDLE_DIR} \
- -DCUDA_LIB=${CUDA_LIB} \
- -DCUDNN_LIB=${CUDNN_LIB} \
- -DOPENCV_DIR=${OPENCV_DIR} \
- -DWITH_STATIC_LIB=OFF
-make -j4
-```
-
-把上述参数根据实际情况做修改后,运行脚本编译程序:
-```shell
-sh linux_build.sh
-```
-
-### 2.2. 运行和可视化
-
-可执行文件有 **2** 个参数,第一个是前面导出的`inference_model`路径,第二个是需要预测的视频路径。
-
-示例:
-```shell
-./build/main ./models /PATH/TO/TEST_VIDEO
-```
-
-点击下载[测试视频](https://paddleseg.bj.bcebos.com/deploy/data/test.avi)
-
-预测的结果保存在视频文件`result.avi`中。
diff --git a/contrib/RealTimeHumanSeg/cpp/docs/windows_build.md b/contrib/RealTimeHumanSeg/cpp/docs/windows_build.md
deleted file mode 100644
index 6937dbcf..00000000
--- a/contrib/RealTimeHumanSeg/cpp/docs/windows_build.md
+++ /dev/null
@@ -1,83 +0,0 @@
-# 视频实时人像分割模型Windows平台C++预测部署
-
-## 1. 系统和软件依赖
-
-### 1.1 基础依赖
-
-- Windows 10 / Windows Server 2016+ (其它平台未测试)
-- Visual Studio 2019 (社区版或专业版均可)
-- CUDA 9.0 / 10.0 + CUDNN 7.3+ (不支持9.1/10.1版本的CUDA)
-
-### 1.2 下载OpenCV并设置环境变量
-
-- 在OpenCV官网下载适用于Windows平台的3.4.6版本: [点击下载](https://sourceforge.net/projects/opencvlibrary/files/3.4.6/opencv-3.4.6-vc14_vc15.exe/download)
-- 运行下载的可执行文件,将OpenCV解压至合适目录,这里以解压到`D:\projects\opencv`为例
-- 把OpenCV动态库加入到系统环境变量
- - 此电脑(我的电脑)->属性->高级系统设置->环境变量
- - 在系统变量中找到Path(如没有,自行创建),并双击编辑
- - 新建,将opencv路径填入并保存,如D:\projects\opencv\build\x64\vc14\bin
-
-**注意:** `OpenCV`的解压目录后续将做为编译配置项使用,所以请放置合适的目录中。
-
-### 1.3 下载PaddlePaddle C++ 预测库
-
-`PaddlePaddle` **C++ 预测库** 主要分为`CPU`和`GPU`版本, 其中`GPU版本`提供`CUDA 9.0` 和 `CUDA 10.0` 支持。
-
-常用的版本如下:
-
-| 版本 | 链接 |
-| ---- | ---- |
-| CPU+MKL版 | [fluid_inference_install_dir.zip](https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/cpu/fluid_inference_install_dir.zip) |
-| CUDA9.0+MKL 版 | [fluid_inference_install_dir.zip](https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/post97/fluid_inference_install_dir.zip) |
-| CUDA10.0+MKL 版 | [fluid_inference_install_dir.zip](https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/post107/fluid_inference_install_dir.zip) |
-
-更多不同平台的可用预测库版本,请[点击查看](https://paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/deploy/inference/windows_cpp_inference.html) 选择适合你的版本。
-
-
-下载并解压, 解压后的 `fluid_inference`目录包含的内容:
-```
-fluid_inference_install_dir
-├── paddle # paddle核心库和头文件
-|
-├── third_party # 第三方依赖库和头文件
-|
-└── version.txt # 版本和编译信息
-```
-
-**注意:** 这里的`fluid_inference_install_dir` 目录所在路径,将用于后面的编译参数设置,请放置在合适的位置。
-
-## 2. Visual Studio 2019 编译
-
-- 2.1 打开Visual Studio 2019 Community,点击`继续但无需代码`, 如下图:
-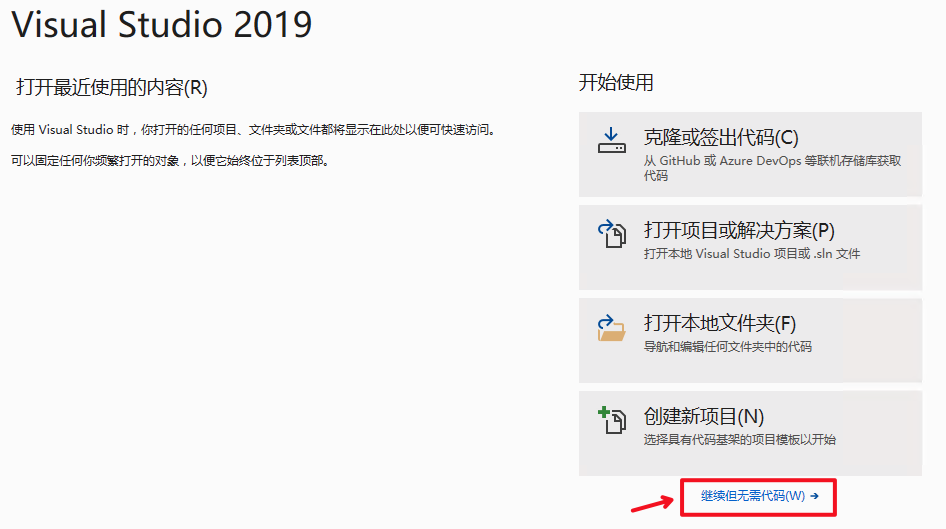
-
-- 2.2 点击 `文件`->`打开`->`CMake`, 如下图:
-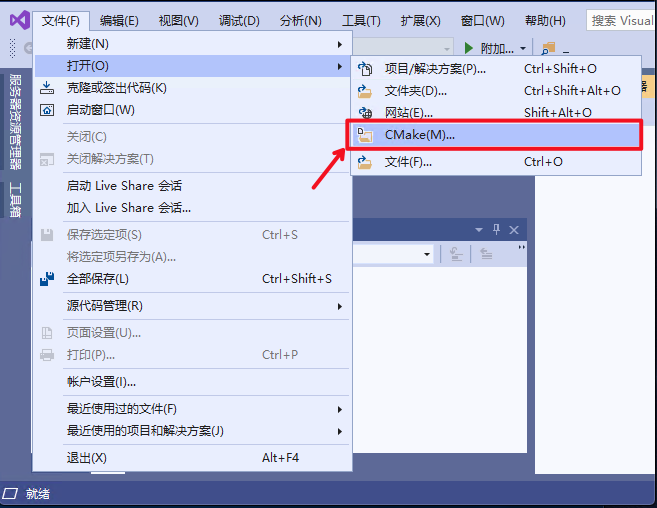
-
-- 2.3 选择本项目根目录`CMakeList.txt`文件打开, 如下图:
-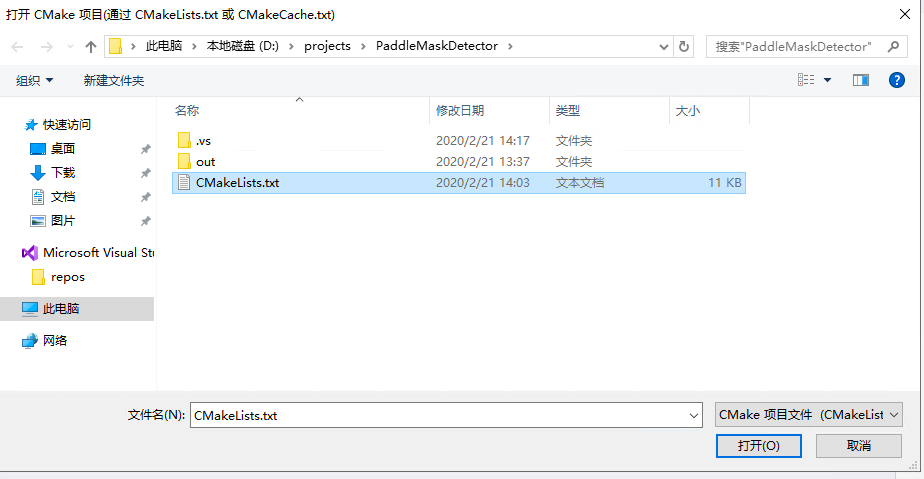
-
-- 2.4 点击:`项目`->`PaddleMaskDetector的CMake设置`
-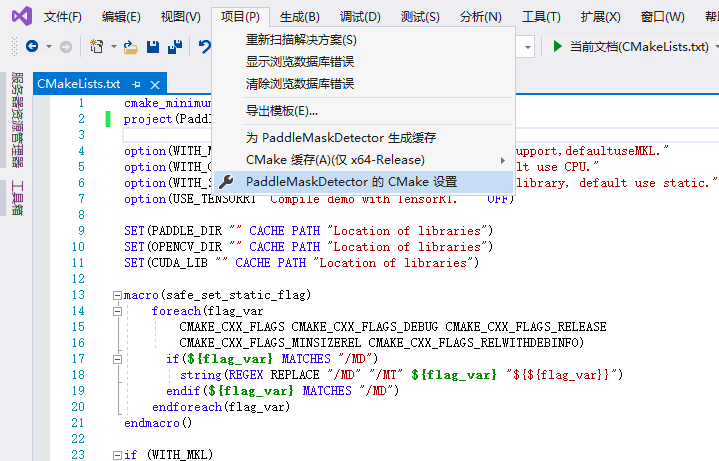
-
-- 2.5 点击浏览设置`OPENCV_DIR`, `CUDA_LIB` 和 `PADDLE_DIR` 3个编译依赖库的位置, 设置完成后点击`保存并生成CMake缓存并加载变量`
-
-
-- 2.6 点击`生成`->`全部生成` 编译项目
-
-
-## 3. 运行程序
-
-成功编译后, 产出的可执行文件在项目子目录`out\build\x64-Release`目录, 按以下步骤运行代码:
-
-- 打开`cmd`切换至该目录
-- 运行以下命令传入模型路径与测试视频
-
-```shell
-main.exe ./models/ ./data/test.avi
-```
-第一个参数即人像分割预测模型的路径,第二个参数即要预测的视频。
-
-点击下载[测试视频](https://paddleseg.bj.bcebos.com/deploy/data/test.avi)
-
-运行后,预测结果保存在文件`result.avi`中。
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg.cc b/contrib/RealTimeHumanSeg/cpp/humanseg.cc
deleted file mode 100644
index b81c8120..00000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg.cc
+++ /dev/null
@@ -1,132 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-# include "humanseg.h"
-# include "humanseg_postprocess.h"
-
-// Normalize the image by (pix - mean) * scale
-void NormalizeImage(
- const std::vector &mean,
- const std::vector &scale,
- cv::Mat& im, // NOLINT
- float* input_buffer) {
- int height = im.rows;
- int width = im.cols;
- int stride = width * height;
- for (int h = 0; h < height; h++) {
- for (int w = 0; w < width; w++) {
- int base = h * width + w;
- input_buffer[base + 0 * stride] =
- (im.at(h, w)[0] - mean[0]) * scale[0];
- input_buffer[base + 1 * stride] =
- (im.at(h, w)[1] - mean[1]) * scale[1];
- input_buffer[base + 2 * stride] =
- (im.at(h, w)[2] - mean[2]) * scale[2];
- }
- }
-}
-
-// Load Model and return model predictor
-void LoadModel(
- const std::string& model_dir,
- bool use_gpu,
- std::unique_ptr* predictor) {
- // Config the model info
- paddle::AnalysisConfig config;
- auto prog_file = model_dir + "/__model__";
- auto params_file = model_dir + "/__params__";
- config.SetModel(prog_file, params_file);
- if (use_gpu) {
- config.EnableUseGpu(100, 0);
- } else {
- config.DisableGpu();
- }
- config.SwitchUseFeedFetchOps(false);
- config.SwitchSpecifyInputNames(true);
- // Memory optimization
- config.EnableMemoryOptim();
- *predictor = std::move(CreatePaddlePredictor(config));
-}
-
-void HumanSeg::Preprocess(const cv::Mat& image_mat) {
- // Clone the image : keep the original mat for postprocess
- cv::Mat im = image_mat.clone();
- auto eval_wh = cv::Size(eval_size_[0], eval_size_[1]);
- cv::resize(im, im, eval_wh, 0.f, 0.f, cv::INTER_LINEAR);
-
- im.convertTo(im, CV_32FC3, 1.0);
- int rc = im.channels();
- int rh = im.rows;
- int rw = im.cols;
- input_shape_ = {1, rc, rh, rw};
- input_data_.resize(1 * rc * rh * rw);
- float* buffer = input_data_.data();
- NormalizeImage(mean_, scale_, im, input_data_.data());
-}
-
-cv::Mat HumanSeg::Postprocess(const cv::Mat& im) {
- int h = input_shape_[2];
- int w = input_shape_[3];
- scoremap_data_.resize(3 * h * w * sizeof(float));
- float* base = output_data_.data() + h * w;
- for (int i = 0; i < h * w; ++i) {
- scoremap_data_[i] = uchar(base[i] * 255);
- }
-
- cv::Mat im_scoremap = cv::Mat(h, w, CV_8UC1);
- im_scoremap.data = scoremap_data_.data();
- cv::resize(im_scoremap, im_scoremap, cv::Size(im.cols, im.rows));
- im_scoremap.convertTo(im_scoremap, CV_32FC1, 1 / 255.0);
-
- float* pblob = reinterpret_cast(im_scoremap.data);
- int out_buff_capacity = 10 * im.cols * im.rows * sizeof(float);
- segout_data_.resize(out_buff_capacity);
- unsigned char* seg_result = segout_data_.data();
- MergeProcess(im.data, pblob, im.rows, im.cols, seg_result);
- cv::Mat seg_mat(im.rows, im.cols, CV_8UC1, seg_result);
- cv::resize(seg_mat, seg_mat, cv::Size(im.cols, im.rows));
- cv::GaussianBlur(seg_mat, seg_mat, cv::Size(5, 5), 0, 0);
- float fg_threshold = 0.8;
- float bg_threshold = 0.4;
- cv::Mat show_seg_mat;
- seg_mat.convertTo(seg_mat, CV_32FC1, 1 / 255.0);
- ThresholdMask(seg_mat, fg_threshold, bg_threshold, show_seg_mat);
- auto out_im = MergeSegMat(show_seg_mat, im);
- return out_im;
-}
-
-cv::Mat HumanSeg::Predict(const cv::Mat& im) {
- // Preprocess image
- Preprocess(im);
- // Prepare input tensor
- auto input_names = predictor_->GetInputNames();
- auto in_tensor = predictor_->GetInputTensor(input_names[0]);
- in_tensor->Reshape(input_shape_);
- in_tensor->copy_from_cpu(input_data_.data());
- // Run predictor
- predictor_->ZeroCopyRun();
- // Get output tensor
- auto output_names = predictor_->GetOutputNames();
- auto out_tensor = predictor_->GetOutputTensor(output_names[0]);
- auto output_shape = out_tensor->shape();
- // Calculate output length
- int output_size = 1;
- for (int j = 0; j < output_shape.size(); ++j) {
- output_size *= output_shape[j];
- }
- output_data_.resize(output_size);
- out_tensor->copy_to_cpu(output_data_.data());
- // Postprocessing result
- return Postprocess(im);
-}
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg.h b/contrib/RealTimeHumanSeg/cpp/humanseg.h
deleted file mode 100644
index edaf825f..00000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg.h
+++ /dev/null
@@ -1,66 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#pragma once
-
-#include
-#include
-#include
-#include
-
-#include
-#include
-#include
-#include
-
-#include "paddle_inference_api.h" // NOLINT
-
-// Load Paddle Inference Model
-void LoadModel(
- const std::string& model_dir,
- bool use_gpu,
- std::unique_ptr* predictor);
-
-class HumanSeg {
- public:
- explicit HumanSeg(const std::string& model_dir,
- const std::vector& mean,
- const std::vector& scale,
- const std::vector& eval_size,
- bool use_gpu = false) :
- mean_(mean),
- scale_(scale),
- eval_size_(eval_size) {
- LoadModel(model_dir, use_gpu, &predictor_);
- }
-
- // Run predictor
- cv::Mat Predict(const cv::Mat& im);
-
- private:
- // Preprocess image and copy data to input buffer
- void Preprocess(const cv::Mat& im);
- // Postprocess result
- cv::Mat Postprocess(const cv::Mat& im);
-
- std::unique_ptr predictor_;
- std::vector input_data_;
- std::vector input_shape_;
- std::vector output_data_;
- std::vector scoremap_data_;
- std::vector segout_data_;
- std::vector mean_;
- std::vector scale_;
- std::vector eval_size_;
-};
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc b/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc
deleted file mode 100644
index a373df39..00000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc
+++ /dev/null
@@ -1,282 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-#include
-
-#include
-#include
-#include
-#include
-
-#include "humanseg_postprocess.h" // NOLINT
-
-int HumanSegTrackFuse(const cv::Mat &track_fg_cfd,
- const cv::Mat &dl_fg_cfd,
- const cv::Mat &dl_weights,
- const cv::Mat &is_track,
- const float cfd_diff_thres,
- const int patch_size,
- cv::Mat cur_fg_cfd) {
- float *cur_fg_cfd_ptr = reinterpret_cast(cur_fg_cfd.data);
- float *dl_fg_cfd_ptr = reinterpret_cast(dl_fg_cfd.data);
- float *track_fg_cfd_ptr = reinterpret_cast(track_fg_cfd.data);
- float *dl_weights_ptr = reinterpret_cast(dl_weights.data);
- uchar *is_track_ptr = reinterpret_cast(is_track.data);
- int y_offset = 0;
- int ptr_offset = 0;
- int h = track_fg_cfd.rows;
- int w = track_fg_cfd.cols;
- float dl_fg_score = 0.0;
- float track_fg_score = 0.0;
- for (int y = 0; y < h; ++y) {
- for (int x = 0; x < w; ++x) {
- dl_fg_score = dl_fg_cfd_ptr[ptr_offset];
- if (is_track_ptr[ptr_offset] > 0) {
- track_fg_score = track_fg_cfd_ptr[ptr_offset];
- if (dl_fg_score > 0.9 || dl_fg_score < 0.1) {
- if (dl_weights_ptr[ptr_offset] <= 0.10) {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score * 0.3
- + track_fg_score * 0.7;
- } else {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score * 0.4
- + track_fg_score * 0.6;
- }
- } else {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score * dl_weights_ptr[ptr_offset]
- + track_fg_score * (1 - dl_weights_ptr[ptr_offset]);
- }
- } else {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score;
- }
- ++ptr_offset;
- }
- y_offset += w;
- ptr_offset = y_offset;
- }
- return 0;
-}
-
-int HumanSegTracking(const cv::Mat &prev_gray,
- const cv::Mat &cur_gray,
- const cv::Mat &prev_fg_cfd,
- int patch_size,
- cv::Mat track_fg_cfd,
- cv::Mat is_track,
- cv::Mat dl_weights,
- cv::Ptr disflow) {
- cv::Mat flow_fw;
- disflow->calc(prev_gray, cur_gray, flow_fw);
-
- cv::Mat flow_bw;
- disflow->calc(cur_gray, prev_gray, flow_bw);
-
- float double_check_thres = 8;
-
- cv::Point2f fxy_fw;
- int dy_fw = 0;
- int dx_fw = 0;
- cv::Point2f fxy_bw;
- int dy_bw = 0;
- int dx_bw = 0;
-
- float *prev_fg_cfd_ptr = reinterpret_cast(prev_fg_cfd.data);
- float *track_fg_cfd_ptr = reinterpret_cast(track_fg_cfd.data);
- float *dl_weights_ptr = reinterpret_cast(dl_weights.data);
- uchar *is_track_ptr = reinterpret_cast(is_track.data);
-
- int prev_y_offset = 0;
- int prev_ptr_offset = 0;
- int cur_ptr_offset = 0;
- float *flow_fw_ptr = reinterpret_cast(flow_fw.data);
-
- float roundy_fw = 0.0;
- float roundx_fw = 0.0;
- float roundy_bw = 0.0;
- float roundx_bw = 0.0;
-
- int h = prev_fg_cfd.rows;
- int w = prev_fg_cfd.cols;
- for (int r = 0; r < h; ++r) {
- for (int c = 0; c < w; ++c) {
- ++prev_ptr_offset;
-
- fxy_fw = flow_fw.ptr(r)[c];
- roundy_fw = fxy_fw.y >= 0 ? 0.5 : -0.5;
- roundx_fw = fxy_fw.x >= 0 ? 0.5 : -0.5;
- dy_fw = static_cast(fxy_fw.y + roundy_fw);
- dx_fw = static_cast(fxy_fw.x + roundx_fw);
-
- int cur_x = c + dx_fw;
- int cur_y = r + dy_fw;
-
- if (cur_x < 0
- || cur_x >= h
- || cur_y < 0
- || cur_y >= w) {
- continue;
- }
- fxy_bw = flow_bw.ptr(cur_y)[cur_x];
- roundy_bw = fxy_bw.y >= 0 ? 0.5 : -0.5;
- roundx_bw = fxy_bw.x >= 0 ? 0.5 : -0.5;
- dy_bw = static_cast(fxy_bw.y + roundy_bw);
- dx_bw = static_cast(fxy_bw.x + roundx_bw);
-
- auto total = (dy_fw + dy_bw) * (dy_fw + dy_bw)
- + (dx_fw + dx_bw) * (dx_fw + dx_bw);
- if (total >= double_check_thres) {
- continue;
- }
-
- cur_ptr_offset = cur_y * w + cur_x;
- if (abs(dy_fw) <= 0
- && abs(dx_fw) <= 0
- && abs(dy_bw) <= 0
- && abs(dx_bw) <= 0) {
- dl_weights_ptr[cur_ptr_offset] = 0.05;
- }
- is_track_ptr[cur_ptr_offset] = 1;
- track_fg_cfd_ptr[cur_ptr_offset] = prev_fg_cfd_ptr[prev_ptr_offset];
- }
- prev_y_offset += w;
- prev_ptr_offset = prev_y_offset - 1;
- }
- return 0;
-}
-
-int MergeProcess(const uchar *im_buff,
- const float *scoremap_buff,
- const int height,
- const int width,
- uchar *result_buff) {
- cv::Mat prev_fg_cfd;
- cv::Mat cur_fg_cfd;
- cv::Mat cur_fg_mask;
- cv::Mat track_fg_cfd;
- cv::Mat prev_gray;
- cv::Mat cur_gray;
- cv::Mat bgr_temp;
- cv::Mat is_track;
- cv::Mat static_roi;
- cv::Mat weights;
- cv::Ptr disflow =
- cv::optflow::createOptFlow_DIS(
- cv::optflow::DISOpticalFlow::PRESET_ULTRAFAST);
-
- bool is_init = false;
- const float *cfd_ptr = scoremap_buff;
- if (!is_init) {
- is_init = true;
- cur_fg_cfd = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0));
- memcpy(cur_fg_cfd.data, cfd_ptr, height * width * sizeof(float));
- cur_fg_mask = cv::Mat(height, width, CV_8UC1, cv::Scalar::all(0));
-
- if (height <= 64 || width <= 64) {
- disflow->setFinestScale(1);
- } else if (height <= 160 || width <= 160) {
- disflow->setFinestScale(2);
- } else {
- disflow->setFinestScale(3);
- }
- is_track = cv::Mat(height, width, CV_8UC1, cv::Scalar::all(0));
- static_roi = cv::Mat(height, width, CV_8UC1, cv::Scalar::all(0));
- track_fg_cfd = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0));
-
- bgr_temp = cv::Mat(height, width, CV_8UC3);
- memcpy(bgr_temp.data, im_buff, height * width * 3 * sizeof(uchar));
- cv::cvtColor(bgr_temp, cur_gray, cv::COLOR_BGR2GRAY);
- weights = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0.30));
- } else {
- memcpy(cur_fg_cfd.data, cfd_ptr, height * width * sizeof(float));
- memcpy(bgr_temp.data, im_buff, height * width * 3 * sizeof(uchar));
- cv::cvtColor(bgr_temp, cur_gray, cv::COLOR_BGR2GRAY);
- memset(is_track.data, 0, height * width * sizeof(uchar));
- memset(static_roi.data, 0, height * width * sizeof(uchar));
- weights = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0.30));
- HumanSegTracking(prev_gray,
- cur_gray,
- prev_fg_cfd,
- 0,
- track_fg_cfd,
- is_track,
- weights,
- disflow);
- HumanSegTrackFuse(track_fg_cfd,
- cur_fg_cfd,
- weights,
- is_track,
- 1.1,
- 0,
- cur_fg_cfd);
- }
- int ksize = 3;
- cv::GaussianBlur(cur_fg_cfd, cur_fg_cfd, cv::Size(ksize, ksize), 0, 0);
- prev_fg_cfd = cur_fg_cfd.clone();
- prev_gray = cur_gray.clone();
- cur_fg_cfd.convertTo(cur_fg_mask, CV_8UC1, 255);
- memcpy(result_buff, cur_fg_mask.data, height * width);
- return 0;
-}
-
-cv::Mat MergeSegMat(const cv::Mat& seg_mat,
- const cv::Mat& ori_frame) {
- cv::Mat return_frame;
- cv::resize(ori_frame, return_frame, cv::Size(ori_frame.cols, ori_frame.rows));
- for (int i = 0; i < ori_frame.rows; i++) {
- for (int j = 0; j < ori_frame.cols; j++) {
- float score = seg_mat.at(i, j) / 255.0;
- if (score > 0.1) {
- return_frame.at(i, j)[2] = static_cast((1 - score) * 255
- + score*return_frame.at(i, j)[2]);
- return_frame.at(i, j)[1] = static_cast((1 - score) * 255
- + score*return_frame.at(i, j)[1]);
- return_frame.at(i, j)[0] = static_cast((1 - score) * 255
- + score*return_frame.at(i, j)[0]);
- } else {
- return_frame.at(i, j) = {255, 255, 255};
- }
- }
- }
- return return_frame;
-}
-
-int ThresholdMask(const cv::Mat &fg_cfd,
- const float fg_thres,
- const float bg_thres,
- cv::Mat& fg_mask) {
- if (fg_cfd.type() != CV_32FC1) {
- printf("ThresholdMask: type is not CV_32FC1.\n");
- return -1;
- }
- if (!(fg_mask.type() == CV_8UC1
- && fg_mask.rows == fg_cfd.rows
- && fg_mask.cols == fg_cfd.cols)) {
- fg_mask = cv::Mat(fg_cfd.rows, fg_cfd.cols, CV_8UC1, cv::Scalar::all(0));
- }
-
- for (int r = 0; r < fg_cfd.rows; ++r) {
- for (int c = 0; c < fg_cfd.cols; ++c) {
- float score = fg_cfd.at(r, c);
- if (score < bg_thres) {
- fg_mask.at(r, c) = 0;
- } else if (score > fg_thres) {
- fg_mask.at(r, c) = 255;
- } else {
- fg_mask.at(r, c) = static_cast(
- (score-bg_thres) / (fg_thres - bg_thres) * 255);
- }
- }
- }
- return 0;
-}
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h b/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h
deleted file mode 100644
index f5059857..00000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h
+++ /dev/null
@@ -1,34 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#pragma once
-
-#include
-#include
-#include
-#include
-
-int ThresholdMask(const cv::Mat &fg_cfd,
- const float fg_thres,
- const float bg_thres,
- cv::Mat& fg_mask);
-
-cv::Mat MergeSegMat(const cv::Mat& seg_mat,
- const cv::Mat& ori_frame);
-
-int MergeProcess(const uchar *im_buff,
- const float *im_scoremap_buff,
- const int height,
- const int width,
- uchar *result_buff);
diff --git a/contrib/RealTimeHumanSeg/cpp/linux_build.sh b/contrib/RealTimeHumanSeg/cpp/linux_build.sh
deleted file mode 100644
index da0f75ef..00000000
--- a/contrib/RealTimeHumanSeg/cpp/linux_build.sh
+++ /dev/null
@@ -1,31 +0,0 @@
-OPENCV_URL=https://bj.bcebos.com/paddleseg/deps/opencv346gcc4.8contrib.tar.bz2
-if [ ! -d "./deps/opencv346_with_contrib" ]; then
- mkdir -p deps
- cd deps
- wget -c ${OPENCV_URL}
- tar xvfj opencv346gcc4.8contrib.tar.bz2
- rm -rf opencv346gcc4.8contrib.tar.bz2
- cd ..
-fi
-
-WITH_GPU=OFF
-PADDLE_DIR=/root/project/fluid_inference/
-CUDA_LIB=/usr/local/cuda-10.0/lib64/
-CUDNN_LIB=/usr/local/cuda-10.0/lib64/
-OPENCV_DIR=$(pwd)/deps/opencv346_with_contrib/
-echo ${OPENCV_DIR}
-
-rm -rf build
-mkdir -p build
-cd build
-
-cmake .. \
- -DWITH_GPU=${WITH_GPU} \
- -DPADDLE_DIR=${PADDLE_DIR} \
- -DCUDA_LIB=${CUDA_LIB} \
- -DCUDNN_LIB=${CUDNN_LIB} \
- -DOPENCV_DIR=${OPENCV_DIR} \
- -DWITH_STATIC_LIB=OFF
-make clean
-make -j12
-
diff --git a/contrib/RealTimeHumanSeg/cpp/main.cc b/contrib/RealTimeHumanSeg/cpp/main.cc
deleted file mode 100644
index 303051f0..00000000
--- a/contrib/RealTimeHumanSeg/cpp/main.cc
+++ /dev/null
@@ -1,92 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-#include
-
-#include "humanseg.h" // NOLINT
-#include "humanseg_postprocess.h" // NOLINT
-
-// Do predicting on a video file
-int VideoPredict(const std::string& video_path, HumanSeg& seg)
-{
- cv::VideoCapture capture;
- capture.open(video_path.c_str());
- if (!capture.isOpened()) {
- printf("can not open video : %s\n", video_path.c_str());
- return -1;
- }
-
- int video_width = static_cast(capture.get(CV_CAP_PROP_FRAME_WIDTH));
- int video_height = static_cast(capture.get(CV_CAP_PROP_FRAME_HEIGHT));
- cv::VideoWriter video_out;
- std::string video_out_path = "result.avi";
- video_out.open(video_out_path.c_str(),
- CV_FOURCC('M', 'J', 'P', 'G'),
- 30.0,
- cv::Size(video_width, video_height),
- true);
- if (!video_out.isOpened()) {
- printf("create video writer failed!\n");
- return -1;
- }
- cv::Mat frame;
- while (capture.read(frame)) {
- if (frame.empty()) {
- break;
- }
- cv::Mat out_im = seg.Predict(frame);
- video_out.write(out_im);
- }
- capture.release();
- video_out.release();
- return 0;
-}
-
-// Do predicting on a image file
-int ImagePredict(const std::string& image_path, HumanSeg& seg)
-{
- cv::Mat img = imread(image_path, cv::IMREAD_COLOR);
- cv::Mat out_im = seg.Predict(img);
- imwrite("result.jpeg", out_im);
- return 0;
-}
-
-int main(int argc, char* argv[]) {
- if (argc < 3 || argc > 4) {
- std::cout << "Usage:"
- << "./humanseg ./models/ ./data/test.avi"
- << std::endl;
- return -1;
- }
-
- bool use_gpu = (argc == 4 ? std::stoi(argv[3]) : false);
- auto model_dir = std::string(argv[1]);
- auto input_path = std::string(argv[2]);
-
- // Init Model
- std::vector means = {104.008, 116.669, 122.675};
- std::vector scale = {1.000, 1.000, 1.000};
- std::vector eval_sz = {192, 192};
- HumanSeg seg(model_dir, means, scale, eval_sz, use_gpu);
-
- // Call ImagePredict while input_path is a image file path
- // The output will be saved as result.jpeg
- // ImagePredict(input_path, seg);
-
- // Call VideoPredict while input_path is a video file path
- // The output will be saved as result.avi
- VideoPredict(input_path, seg);
- return 0;
-}
diff --git a/contrib/RealTimeHumanSeg/python/README.md b/contrib/RealTimeHumanSeg/python/README.md
deleted file mode 100644
index 1e089c9f..00000000
--- a/contrib/RealTimeHumanSeg/python/README.md
+++ /dev/null
@@ -1,61 +0,0 @@
-# 实时人像分割Python预测部署方案
-
-本方案基于Python实现,最小化依赖并把所有模型加载、数据预处理、预测、光流处理等后处理都封装在文件`infer.py`中,用户可以直接使用或集成到自己项目中。
-
-
-## 前置依赖
-- Windows(7,8,10) / Linux (Ubuntu 16.04) or MacOS 10.1+
-- Paddle 1.6.1+
-- Python 3.0+
-
-注意:
-1. 仅测试过Paddle1.6 和 1.7, 其它版本不支持
-2. MacOS上不支持GPU预测
-3. Python2上未测试
-
-其它未涉及情形,能正常安装`Paddle` 和`OpenCV`通常都能正常使用。
-
-
-## 安装依赖
-### 1. 安装paddle
-
-PaddlePaddle的安装, 请按照[官网指引](https://paddlepaddle.org.cn/install/quick)安装合适自己的版本。
-
-### 2. 安装其它依赖
-
-执行如下命令
-
-```shell
-pip install -r requirements.txt
-```
-
-## 运行
-
-
-1. 输入图片进行分割
-```
-python infer.py --model_dir /PATH/TO/INFERENCE/MODEL --img_path /PATH/TO/INPUT/IMAGE
-```
-
-预测结果会保存为`result.jpeg`。
-2. 输入视频进行分割
-```shell
-python infer.py --model_dir /PATH/TO/INFERENCE/MODEL --video_path /PATH/TO/INPUT/VIDEO
-```
-
-预测结果会保存在`result.avi`。
-
-3. 使用摄像头视频流
-```shell
-python infer.py --model_dir /PATH/TO/INFERENCE/MODEL --use_camera 1
-```
-预测结果会通过可视化窗口实时显示。
-
-**注意:**
-
-
-`GPU`默认关闭, 如果要使用`GPU`进行加速,则先运行
-```
-export CUDA_VISIBLE_DEVICES=0
-```
-然后在前面的预测命令中增加参数`--use_gpu 1`即可。
diff --git a/contrib/RealTimeHumanSeg/python/infer.py b/contrib/RealTimeHumanSeg/python/infer.py
deleted file mode 100644
index 73df081e..00000000
--- a/contrib/RealTimeHumanSeg/python/infer.py
+++ /dev/null
@@ -1,345 +0,0 @@
-# coding: utf8
-# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""实时人像分割Python预测部署"""
-
-import os
-import argparse
-import numpy as np
-import cv2
-
-import paddle.fluid as fluid
-
-
-def human_seg_tracking(pre_gray, cur_gray, prev_cfd, dl_weights, disflow):
- """计算光流跟踪匹配点和光流图
- 输入参数:
- pre_gray: 上一帧灰度图
- cur_gray: 当前帧灰度图
- prev_cfd: 上一帧光流图
- dl_weights: 融合权重图
- disflow: 光流数据结构
- 返回值:
- is_track: 光流点跟踪二值图,即是否具有光流点匹配
- track_cfd: 光流跟踪图
- """
- check_thres = 8
- hgt, wdh = pre_gray.shape[:2]
- track_cfd = np.zeros_like(prev_cfd)
- is_track = np.zeros_like(pre_gray)
- # 计算前向光流
- flow_fw = disflow.calc(pre_gray, cur_gray, None)
- # 计算后向光流
- flow_bw = disflow.calc(cur_gray, pre_gray, None)
- get_round = lambda data: (int)(data + 0.5) if data >= 0 else (int)(data -0.5)
- for row in range(hgt):
- for col in range(wdh):
- # 计算光流处理后对应点坐标
- # (row, col) -> (cur_x, cur_y)
- fxy_fw = flow_fw[row, col]
- dx_fw = get_round(fxy_fw[0])
- cur_x = dx_fw + col
- dy_fw = get_round(fxy_fw[1])
- cur_y = dy_fw + row
- if cur_x < 0 or cur_x >= wdh or cur_y < 0 or cur_y >= hgt:
- continue
- fxy_bw = flow_bw[cur_y, cur_x]
- dx_bw = get_round(fxy_bw[0])
- dy_bw = get_round(fxy_bw[1])
- # 光流移动小于阈值
- lmt = ((dy_fw + dy_bw) * (dy_fw + dy_bw) + (dx_fw + dx_bw) * (dx_fw + dx_bw))
- if lmt >= check_thres:
- continue
- # 静止点降权
- if abs(dy_fw) <= 0 and abs(dx_fw) <= 0 and abs(dy_bw) <= 0 and abs(dx_bw) <= 0:
- dl_weights[cur_y, cur_x] = 0.05
- is_track[cur_y, cur_x] = 1
- track_cfd[cur_y, cur_x] = prev_cfd[row, col]
- return track_cfd, is_track, dl_weights
-
-
-def human_seg_track_fuse(track_cfd, dl_cfd, dl_weights, is_track):
- """光流追踪图和人像分割结构融合
- 输入参数:
- track_cfd: 光流追踪图
- dl_cfd: 当前帧分割结果
- dl_weights: 融合权重图
- is_track: 光流点匹配二值图
- 返回值:
- cur_cfd: 光流跟踪图和人像分割结果融合图
- """
- cur_cfd = dl_cfd.copy()
- idxs = np.where(is_track > 0)
- for i in range(len(idxs)):
- x, y = idxs[0][i], idxs[1][i]
- dl_score = dl_cfd[y, x]
- track_score = track_cfd[y, x]
- if dl_score > 0.9 or dl_score < 0.1:
- if dl_weights[x, y] < 0.1:
- cur_cfd[x, y] = 0.3 * dl_score + 0.7 * track_score
- else:
- cur_cfd[x, y] = 0.4 * dl_score + 0.6 * track_score
- else:
- cur_cfd[x, y] = dl_weights[x, y] * dl_score + (1 - dl_weights[x, y]) * track_score
- return cur_cfd
-
-
-def threshold_mask(img, thresh_bg, thresh_fg):
- """设置背景和前景阈值mask
- 输入参数:
- img : 原始图像, np.uint8 类型.
- thresh_bg : 背景阈值百分比,低于该值置为0.
- thresh_fg : 前景阈值百分比,超过该值置为1.
- 返回值:
- dst : 原始图像设置完前景背景阈值mask结果, np.float32 类型.
- """
- dst = (img / 255.0 - thresh_bg) / (thresh_fg - thresh_bg)
- dst[np.where(dst > 1)] = 1
- dst[np.where(dst < 0)] = 0
- return dst.astype(np.float32)
-
-
-def optflow_handle(cur_gray, scoremap, is_init):
- """光流优化
- Args:
- cur_gray : 当前帧灰度图
- scoremap : 当前帧分割结果
- is_init : 是否第一帧
- Returns:
- dst : 光流追踪图和预测结果融合图, 类型为 np.float32
- """
- width, height = scoremap.shape[0], scoremap.shape[1]
- disflow = cv2.DISOpticalFlow_create(
- cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
- prev_gray = np.zeros((height, width), np.uint8)
- prev_cfd = np.zeros((height, width), np.float32)
- cur_cfd = scoremap.copy()
- if is_init:
- is_init = False
- if height <= 64 or width <= 64:
- disflow.setFinestScale(1)
- elif height <= 160 or width <= 160:
- disflow.setFinestScale(2)
- else:
- disflow.setFinestScale(3)
- fusion_cfd = cur_cfd
- else:
- weights = np.ones((width, height), np.float32) * 0.3
- track_cfd, is_track, weights = human_seg_tracking(
- prev_gray, cur_gray, prev_cfd, weights, disflow)
- fusion_cfd = human_seg_track_fuse(track_cfd, cur_cfd, weights, is_track)
- fusion_cfd = cv2.GaussianBlur(fusion_cfd, (3, 3), 0)
- return fusion_cfd
-
-
-class HumanSeg:
- """人像分割类
- 封装了人像分割模型的加载,数据预处理,预测,后处理等
- """
- def __init__(self, model_dir, mean, scale, eval_size, use_gpu=False):
-
- self.mean = np.array(mean).reshape((3, 1, 1))
- self.scale = np.array(scale).reshape((3, 1, 1))
- self.eval_size = eval_size
- self.load_model(model_dir, use_gpu)
-
- def load_model(self, model_dir, use_gpu):
- """加载模型并创建predictor
- Args:
- model_dir: 预测模型路径, 包含 `__model__` 和 `__params__`
- use_gpu: 是否使用GPU加速
- """
- prog_file = os.path.join(model_dir, '__model__')
- params_file = os.path.join(model_dir, '__params__')
- config = fluid.core.AnalysisConfig(prog_file, params_file)
- if use_gpu:
- config.enable_use_gpu(100, 0)
- config.switch_ir_optim(True)
- else:
- config.disable_gpu()
- config.disable_glog_info()
- config.switch_specify_input_names(True)
- config.enable_memory_optim()
- self.predictor = fluid.core.create_paddle_predictor(config)
-
- def preprocess(self, image):
- """图像预处理
- hwc_rgb 转换为 chw_bgr,并进行归一化
- 输入参数:
- image: 原始图像
- 返回值:
- 经过预处理后的图片结果
- """
- img_mat = cv2.resize(
- image, self.eval_size, interpolation=cv2.INTER_LINEAR)
- # HWC -> CHW
- img_mat = img_mat.swapaxes(1, 2)
- img_mat = img_mat.swapaxes(0, 1)
- # Convert to float
- img_mat = img_mat[:, :, :].astype('float32')
- # img_mat = (img_mat - mean) * scale
- img_mat = img_mat - self.mean
- img_mat = img_mat * self.scale
- img_mat = img_mat[np.newaxis, :, :, :]
- return img_mat
-
- def postprocess(self, image, output_data):
- """对预测结果进行后处理
- Args:
- image: 原始图,opencv 图片对象
- output_data: Paddle预测结果原始数据
- Returns:
- 原图和预测结果融合并做了光流优化的结果图
- """
- scoremap = output_data[0, 1, :, :]
- scoremap = (scoremap * 255).astype(np.uint8)
- ori_h, ori_w = image.shape[0], image.shape[1]
- evl_h, evl_w = self.eval_size[0], self.eval_size[1]
- # 光流处理
- cur_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
- cur_gray = cv2.resize(cur_gray, (evl_w, evl_h))
- optflow_map = optflow_handle(cur_gray, scoremap, False)
- optflow_map = cv2.GaussianBlur(optflow_map, (3, 3), 0)
- optflow_map = threshold_mask(optflow_map, thresh_bg=0.2, thresh_fg=0.8)
- optflow_map = cv2.resize(optflow_map, (ori_w, ori_h))
- optflow_map = np.repeat(optflow_map[:, :, np.newaxis], 3, axis=2)
- bg_im = np.ones_like(optflow_map) * 255
- comb = (optflow_map * image + (1 - optflow_map) * bg_im).astype(np.uint8)
- return comb
-
- def run_predict(self, image):
- """运行预测并返回可视化结果图
- 输入参数:
- image: 需要预测的原始图, opencv图片对象
- 返回值:
- 可视化的预测结果图
- """
- im_mat = self.preprocess(image)
- im_tensor = fluid.core.PaddleTensor(im_mat.copy().astype('float32'))
- output_data = self.predictor.run([im_tensor])[0]
- output_data = output_data.as_ndarray()
- return self.postprocess(image, output_data)
-
-
-def predict_image(seg, image_path):
- """对图片文件进行分割
- 结果保存到`result.jpeg`文件中
- """
- img_mat = cv2.imread(image_path)
- img_mat = seg.run_predict(img_mat)
- cv2.imwrite('result.jpeg', img_mat)
-
-
-def predict_video(seg, video_path):
- """对视频文件进行分割
- 结果保存到`result.avi`文件中
- """
- cap = cv2.VideoCapture(video_path)
- if not cap.isOpened():
- print("Error opening video stream or file")
- return
- width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
- height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
- fps = cap.get(cv2.CAP_PROP_FPS)
- # 用于保存预测结果视频
- out = cv2.VideoWriter('result.avi',
- cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps,
- (width, height))
- # 开始获取视频帧
- while cap.isOpened():
- ret, frame = cap.read()
- if ret:
- img_mat = seg.run_predict(frame)
- out.write(img_mat)
- else:
- break
- cap.release()
- out.release()
-
-
-def predict_camera(seg):
- """从摄像头获取视频流进行预测
- 视频分割结果实时显示到可视化窗口中
- """
- cap = cv2.VideoCapture(0)
- if not cap.isOpened():
- print("Error opening video stream or file")
- return
- # Start capturing from video
- while cap.isOpened():
- ret, frame = cap.read()
- if ret:
- img_mat = seg.run_predict(frame)
- cv2.imshow('HumanSegmentation', img_mat)
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
- else:
- break
- cap.release()
-
-
-def main(args):
- """预测程序入口
- 完成模型加载, 对视频、摄像头、图片文件等预测过程
- """
- model_dir = args.model_dir
- use_gpu = args.use_gpu
-
- # 加载模型
- mean = [104.008, 116.669, 122.675]
- scale = [1.0, 1.0, 1.0]
- eval_size = (192, 192)
- seg = HumanSeg(model_dir, mean, scale, eval_size, use_gpu)
- if args.use_camera:
- # 开启摄像头
- predict_camera(seg)
- elif args.video_path:
- # 使用视频文件作为输入
- predict_video(seg, args.video_path)
- elif args.img_path:
- # 使用图片文件作为输入
- predict_image(seg, args.img_path)
-
-
-def parse_args():
- """解析命令行参数
- """
- parser = argparse.ArgumentParser('Realtime Human Segmentation')
- parser.add_argument('--model_dir',
- type=str,
- default='',
- help='path of human segmentation model')
- parser.add_argument('--img_path',
- type=str,
- default='',
- help='path of input image')
- parser.add_argument('--video_path',
- type=str,
- default='',
- help='path of input video')
- parser.add_argument('--use_camera',
- type=bool,
- default=False,
- help='input video stream from camera')
- parser.add_argument('--use_gpu',
- type=bool,
- default=False,
- help='enable gpu')
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- main(args)
diff --git a/contrib/RealTimeHumanSeg/python/requirements.txt b/contrib/RealTimeHumanSeg/python/requirements.txt
deleted file mode 100644
index 953dae0c..00000000
--- a/contrib/RealTimeHumanSeg/python/requirements.txt
+++ /dev/null
@@ -1,2 +0,0 @@
-opencv-python==4.1.2.30
-opencv-contrib-python==4.2.0.32
--
GitLab
-
-
diff --git a/contrib/RealTimeHumanSeg/cpp/CMakeLists.txt b/contrib/RealTimeHumanSeg/cpp/CMakeLists.txt
deleted file mode 100644
index 5a7b89ac..00000000
--- a/contrib/RealTimeHumanSeg/cpp/CMakeLists.txt
+++ /dev/null
@@ -1,221 +0,0 @@
-cmake_minimum_required(VERSION 3.0)
-project(PaddleMaskDetector CXX C)
-
-option(WITH_MKL "Compile demo with MKL/OpenBlas support,defaultuseMKL." ON)
-option(WITH_GPU "Compile demo with GPU/CPU, default use CPU." ON)
-option(WITH_STATIC_LIB "Compile demo with static/shared library, default use static." ON)
-option(USE_TENSORRT "Compile demo with TensorRT." OFF)
-
-SET(PADDLE_DIR "" CACHE PATH "Location of libraries")
-SET(OPENCV_DIR "" CACHE PATH "Location of libraries")
-SET(CUDA_LIB "" CACHE PATH "Location of libraries")
-
-macro(safe_set_static_flag)
- foreach(flag_var
- CMAKE_CXX_FLAGS CMAKE_CXX_FLAGS_DEBUG CMAKE_CXX_FLAGS_RELEASE
- CMAKE_CXX_FLAGS_MINSIZEREL CMAKE_CXX_FLAGS_RELWITHDEBINFO)
- if(${flag_var} MATCHES "/MD")
- string(REGEX REPLACE "/MD" "/MT" ${flag_var} "${${flag_var}}")
- endif(${flag_var} MATCHES "/MD")
- endforeach(flag_var)
-endmacro()
-
-if (WITH_MKL)
- ADD_DEFINITIONS(-DUSE_MKL)
-endif()
-
-if (NOT DEFINED PADDLE_DIR OR ${PADDLE_DIR} STREQUAL "")
- message(FATAL_ERROR "please set PADDLE_DIR with -DPADDLE_DIR=/path/paddle_influence_dir")
-endif()
-
-if (NOT DEFINED OPENCV_DIR OR ${OPENCV_DIR} STREQUAL "")
- message(FATAL_ERROR "please set OPENCV_DIR with -DOPENCV_DIR=/path/opencv")
-endif()
-
-include_directories("${CMAKE_SOURCE_DIR}/")
-include_directories("${PADDLE_DIR}/")
-include_directories("${PADDLE_DIR}/third_party/install/protobuf/include")
-include_directories("${PADDLE_DIR}/third_party/install/glog/include")
-include_directories("${PADDLE_DIR}/third_party/install/gflags/include")
-include_directories("${PADDLE_DIR}/third_party/install/xxhash/include")
-if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/include")
- include_directories("${PADDLE_DIR}/third_party/install/snappy/include")
-endif()
-if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/include")
- include_directories("${PADDLE_DIR}/third_party/install/snappystream/include")
-endif()
-include_directories("${PADDLE_DIR}/third_party/install/zlib/include")
-include_directories("${PADDLE_DIR}/third_party/boost")
-include_directories("${PADDLE_DIR}/third_party/eigen3")
-
-if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
- link_directories("${PADDLE_DIR}/third_party/install/snappy/lib")
-endif()
-if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
- link_directories("${PADDLE_DIR}/third_party/install/snappystream/lib")
-endif()
-
-link_directories("${PADDLE_DIR}/third_party/install/zlib/lib")
-link_directories("${PADDLE_DIR}/third_party/install/protobuf/lib")
-link_directories("${PADDLE_DIR}/third_party/install/glog/lib")
-link_directories("${PADDLE_DIR}/third_party/install/gflags/lib")
-link_directories("${PADDLE_DIR}/third_party/install/xxhash/lib")
-link_directories("${PADDLE_DIR}/paddle/lib/")
-link_directories("${CMAKE_CURRENT_BINARY_DIR}")
-if (WIN32)
- include_directories("${PADDLE_DIR}/paddle/fluid/inference")
- include_directories("${PADDLE_DIR}/paddle/include")
- link_directories("${PADDLE_DIR}/paddle/fluid/inference")
- include_directories("${OPENCV_DIR}/build/include")
- include_directories("${OPENCV_DIR}/opencv/build/include")
- link_directories("${OPENCV_DIR}/build/x64/vc14/lib")
-else ()
- find_package(OpenCV REQUIRED PATHS ${OPENCV_DIR}/share/OpenCV NO_DEFAULT_PATH)
- include_directories("${PADDLE_DIR}/paddle/include")
- link_directories("${PADDLE_DIR}/paddle/lib")
- include_directories(${OpenCV_INCLUDE_DIRS})
-endif ()
-
-if (WIN32)
- add_definitions("/DGOOGLE_GLOG_DLL_DECL=")
- set(CMAKE_C_FLAGS_DEBUG "${CMAKE_C_FLAGS_DEBUG} /bigobj /MTd")
- set(CMAKE_C_FLAGS_RELEASE "${CMAKE_C_FLAGS_RELEASE} /bigobj /MT")
- set(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} /bigobj /MTd")
- set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} /bigobj /MT")
- if (WITH_STATIC_LIB)
- safe_set_static_flag()
- add_definitions(-DSTATIC_LIB)
- endif()
-else()
- set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -g -o2 -fopenmp -std=c++11")
- set(CMAKE_STATIC_LIBRARY_PREFIX "")
-endif()
-
-# TODO let users define cuda lib path
-if (WITH_GPU)
- if (NOT DEFINED CUDA_LIB OR ${CUDA_LIB} STREQUAL "")
- message(FATAL_ERROR "please set CUDA_LIB with -DCUDA_LIB=/path/cuda-8.0/lib64")
- endif()
- if (NOT WIN32)
- if (NOT DEFINED CUDNN_LIB)
- message(FATAL_ERROR "please set CUDNN_LIB with -DCUDNN_LIB=/path/cudnn_v7.4/cuda/lib64")
- endif()
- endif(NOT WIN32)
-endif()
-
-
-if (NOT WIN32)
- if (USE_TENSORRT AND WITH_GPU)
- include_directories("${PADDLE_DIR}/third_party/install/tensorrt/include")
- link_directories("${PADDLE_DIR}/third_party/install/tensorrt/lib")
- endif()
-endif(NOT WIN32)
-
-if (NOT WIN32)
- set(NGRAPH_PATH "${PADDLE_DIR}/third_party/install/ngraph")
- if(EXISTS ${NGRAPH_PATH})
- include(GNUInstallDirs)
- include_directories("${NGRAPH_PATH}/include")
- link_directories("${NGRAPH_PATH}/${CMAKE_INSTALL_LIBDIR}")
- set(NGRAPH_LIB ${NGRAPH_PATH}/${CMAKE_INSTALL_LIBDIR}/libngraph${CMAKE_SHARED_LIBRARY_SUFFIX})
- endif()
-endif()
-
-if(WITH_MKL)
- include_directories("${PADDLE_DIR}/third_party/install/mklml/include")
- if (WIN32)
- set(MATH_LIB ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.lib
- ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.lib)
- else ()
- set(MATH_LIB ${PADDLE_DIR}/third_party/install/mklml/lib/libmklml_intel${CMAKE_SHARED_LIBRARY_SUFFIX}
- ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5${CMAKE_SHARED_LIBRARY_SUFFIX})
- execute_process(COMMAND cp -r ${PADDLE_DIR}/third_party/install/mklml/lib/libmklml_intel${CMAKE_SHARED_LIBRARY_SUFFIX} /usr/lib)
- endif ()
- set(MKLDNN_PATH "${PADDLE_DIR}/third_party/install/mkldnn")
- if(EXISTS ${MKLDNN_PATH})
- include_directories("${MKLDNN_PATH}/include")
- if (WIN32)
- set(MKLDNN_LIB ${MKLDNN_PATH}/lib/mkldnn.lib)
- else ()
- set(MKLDNN_LIB ${MKLDNN_PATH}/lib/libmkldnn.so.0)
- endif ()
- endif()
-else()
- set(MATH_LIB ${PADDLE_DIR}/third_party/install/openblas/lib/libopenblas${CMAKE_STATIC_LIBRARY_SUFFIX})
-endif()
-
-if (WIN32)
- if(EXISTS "${PADDLE_DIR}/paddle/fluid/inference/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX}")
- set(DEPS
- ${PADDLE_DIR}/paddle/fluid/inference/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX})
- else()
- set(DEPS
- ${PADDLE_DIR}/paddle/lib/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX})
- endif()
-endif()
-
-if(WITH_STATIC_LIB)
- set(DEPS
- ${PADDLE_DIR}/paddle/lib/libpaddle_fluid${CMAKE_STATIC_LIBRARY_SUFFIX})
-else()
- set(DEPS
- ${PADDLE_DIR}/paddle/lib/libpaddle_fluid${CMAKE_SHARED_LIBRARY_SUFFIX})
-endif()
-
-if (NOT WIN32)
- set(DEPS ${DEPS}
- ${MATH_LIB} ${MKLDNN_LIB}
- glog gflags protobuf z xxhash
- )
- if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
- set(DEPS ${DEPS} snappystream)
- endif()
- if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
- set(DEPS ${DEPS} snappy)
- endif()
-else()
- set(DEPS ${DEPS}
- ${MATH_LIB} ${MKLDNN_LIB}
- opencv_world346 glog gflags_static libprotobuf zlibstatic xxhash)
- set(DEPS ${DEPS} libcmt shlwapi)
- if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
- set(DEPS ${DEPS} snappy)
- endif()
- if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
- set(DEPS ${DEPS} snappystream)
- endif()
-endif(NOT WIN32)
-
-if(WITH_GPU)
- if(NOT WIN32)
- if (USE_TENSORRT)
- set(DEPS ${DEPS} ${PADDLE_DIR}/third_party/install/tensorrt/lib/libnvinfer${CMAKE_STATIC_LIBRARY_SUFFIX})
- set(DEPS ${DEPS} ${PADDLE_DIR}/third_party/install/tensorrt/lib/libnvinfer_plugin${CMAKE_STATIC_LIBRARY_SUFFIX})
- endif()
- set(DEPS ${DEPS} ${CUDA_LIB}/libcudart${CMAKE_SHARED_LIBRARY_SUFFIX})
- set(DEPS ${DEPS} ${CUDNN_LIB}/libcudnn${CMAKE_SHARED_LIBRARY_SUFFIX})
- else()
- set(DEPS ${DEPS} ${CUDA_LIB}/cudart${CMAKE_STATIC_LIBRARY_SUFFIX} )
- set(DEPS ${DEPS} ${CUDA_LIB}/cublas${CMAKE_STATIC_LIBRARY_SUFFIX} )
- set(DEPS ${DEPS} ${CUDA_LIB}/cudnn${CMAKE_STATIC_LIBRARY_SUFFIX})
- endif()
-endif()
-
-if (NOT WIN32)
- set(EXTERNAL_LIB "-ldl -lrt -lgomp -lz -lm -lpthread")
- set(DEPS ${DEPS} ${EXTERNAL_LIB} ${OpenCV_LIBS})
-endif()
-
-add_executable(main main.cc humanseg.cc humanseg_postprocess.cc)
-target_link_libraries(main ${DEPS})
-
-if (WIN32)
- add_custom_command(TARGET main POST_BUILD
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.dll ./mklml.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.dll ./libiomp5md.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mkldnn/lib/mkldnn.dll ./mkldnn.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.dll ./release/mklml.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.dll ./release/libiomp5md.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mkldnn/lib/mkldnn.dll ./release/mkldnn.dll
- )
-endif()
diff --git a/contrib/RealTimeHumanSeg/cpp/CMakeSettings.json b/contrib/RealTimeHumanSeg/cpp/CMakeSettings.json
deleted file mode 100644
index 87cbe721..00000000
--- a/contrib/RealTimeHumanSeg/cpp/CMakeSettings.json
+++ /dev/null
@@ -1,42 +0,0 @@
-{
- "configurations": [
- {
- "name": "x64-Release",
- "generator": "Ninja",
- "configurationType": "RelWithDebInfo",
- "inheritEnvironments": [ "msvc_x64_x64" ],
- "buildRoot": "${projectDir}\\out\\build\\${name}",
- "installRoot": "${projectDir}\\out\\install\\${name}",
- "cmakeCommandArgs": "",
- "buildCommandArgs": "-v",
- "ctestCommandArgs": "",
- "variables": [
- {
- "name": "CUDA_LIB",
- "value": "D:/projects/packages/cuda10_0/lib64",
- "type": "PATH"
- },
- {
- "name": "CUDNN_LIB",
- "value": "D:/projects/packages/cuda10_0/lib64",
- "type": "PATH"
- },
- {
- "name": "OPENCV_DIR",
- "value": "D:/projects/packages/opencv3_4_6",
- "type": "PATH"
- },
- {
- "name": "PADDLE_DIR",
- "value": "D:/projects/packages/fluid_inference1_6_1",
- "type": "PATH"
- },
- {
- "name": "CMAKE_BUILD_TYPE",
- "value": "Release",
- "type": "STRING"
- }
- ]
- }
- ]
-}
\ No newline at end of file
diff --git a/contrib/RealTimeHumanSeg/cpp/README.md b/contrib/RealTimeHumanSeg/cpp/README.md
deleted file mode 100644
index 5f118413..00000000
--- a/contrib/RealTimeHumanSeg/cpp/README.md
+++ /dev/null
@@ -1,15 +0,0 @@
-# 视频实时图像分割模型C++预测部署
-
-本文档主要介绍实时图像分割模型如何在`Windows`和`Linux`上完成基于`C++`的预测部署。
-
-## C++预测部署编译
-
-### 1. 下载模型
-点击右边下载:[模型下载地址](https://paddleseg.bj.bcebos.com/deploy/models/humanseg_paddleseg_int8.zip)
-
-模型文件路径将做为预测时的输入参数,请解压到合适的目录位置。
-
-### 2. 编译
-本项目支持在Windows和Linux上编译并部署C++项目,不同平台的编译请参考:
-- [Linux 编译](./docs/linux_build.md)
-- [Windows 使用 Visual Studio 2019编译](./docs/windows_build.md)
diff --git a/contrib/RealTimeHumanSeg/cpp/docs/linux_build.md b/contrib/RealTimeHumanSeg/cpp/docs/linux_build.md
deleted file mode 100644
index 823ff3ae..00000000
--- a/contrib/RealTimeHumanSeg/cpp/docs/linux_build.md
+++ /dev/null
@@ -1,86 +0,0 @@
-# 视频实时人像分割模型Linux平台C++预测部署
-
-
-## 1. 系统和软件依赖
-
-### 1.1 操作系统及硬件要求
-
-- Ubuntu 14.04 或者 16.04 (其它平台未测试)
-- GCC版本4.8.5 ~ 4.9.2
-- 支持Intel MKL-DNN的CPU
-- NOTE: 如需在Nvidia GPU运行,请自行安装CUDA 9.0 / 10.0 + CUDNN 7.3+ (不支持9.1/10.1版本的CUDA)
-
-### 1.2 下载PaddlePaddle C++预测库
-
-PaddlePaddle C++ 预测库主要分为CPU版本和GPU版本。
-
-其中,GPU 版本支持`CUDA 10.0` 和 `CUDA 9.0`:
-
-以下为各版本C++预测库的下载链接:
-
-| 版本 | 链接 |
-| ---- | ---- |
-| CPU+MKL版 | [fluid_inference.tgz](https://paddle-inference-lib.bj.bcebos.com/1.6.3-cpu-avx-mkl/fluid_inference.tgz) |
-| CUDA9.0+MKL 版 | [fluid_inference.tgz](https://paddle-inference-lib.bj.bcebos.com/1.6.3-gpu-cuda9-cudnn7-avx-mkl/fluid_inference.tgz) |
-| CUDA10.0+MKL 版 | [fluid_inference.tgz](https://paddle-inference-lib.bj.bcebos.com/1.6.3-gpu-cuda10-cudnn7-avx-mkl/fluid_inference.tgz) |
-
-更多可用预测库版本,请点击以下链接下载:[C++预测库下载列表](https://paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/deploy/inference/build_and_install_lib_cn.html)
-
-
-下载并解压, 解压后的 `fluid_inference`目录包含的内容:
-```
-fluid_inference
-├── paddle # paddle核心库和头文件
-|
-├── third_party # 第三方依赖库和头文件
-|
-└── version.txt # 版本和编译信息
-```
-
-**注意:** 请把解压后的目录放到合适的路径,**该目录路径后续会作为编译依赖**使用。
-
-## 2. 编译与运行
-
-### 2.1 配置编译脚本
-
-打开文件`linux_build.sh`, 看到以下内容:
-```shell
-# 是否使用GPU
-WITH_GPU=OFF
-# Paddle 预测库路径
-PADDLE_DIR=/PATH/TO/fluid_inference/
-# CUDA库路径, 仅 WITH_GPU=ON 时设置
-CUDA_LIB=/PATH/TO/CUDA_LIB64/
-# CUDNN库路径,仅 WITH_GPU=ON 且 CUDA_LIB有效时设置
-CUDNN_LIB=/PATH/TO/CUDNN_LIB64/
-# OpenCV 库路径, 无须设置
-OPENCV_DIR=/PATH/TO/opencv3gcc4.8/
-
-cd build
-cmake .. \
- -DWITH_GPU=${WITH_GPU} \
- -DPADDLE_DIR=${PADDLE_DIR} \
- -DCUDA_LIB=${CUDA_LIB} \
- -DCUDNN_LIB=${CUDNN_LIB} \
- -DOPENCV_DIR=${OPENCV_DIR} \
- -DWITH_STATIC_LIB=OFF
-make -j4
-```
-
-把上述参数根据实际情况做修改后,运行脚本编译程序:
-```shell
-sh linux_build.sh
-```
-
-### 2.2. 运行和可视化
-
-可执行文件有 **2** 个参数,第一个是前面导出的`inference_model`路径,第二个是需要预测的视频路径。
-
-示例:
-```shell
-./build/main ./models /PATH/TO/TEST_VIDEO
-```
-
-点击下载[测试视频](https://paddleseg.bj.bcebos.com/deploy/data/test.avi)
-
-预测的结果保存在视频文件`result.avi`中。
diff --git a/contrib/RealTimeHumanSeg/cpp/docs/windows_build.md b/contrib/RealTimeHumanSeg/cpp/docs/windows_build.md
deleted file mode 100644
index 6937dbcf..00000000
--- a/contrib/RealTimeHumanSeg/cpp/docs/windows_build.md
+++ /dev/null
@@ -1,83 +0,0 @@
-# 视频实时人像分割模型Windows平台C++预测部署
-
-## 1. 系统和软件依赖
-
-### 1.1 基础依赖
-
-- Windows 10 / Windows Server 2016+ (其它平台未测试)
-- Visual Studio 2019 (社区版或专业版均可)
-- CUDA 9.0 / 10.0 + CUDNN 7.3+ (不支持9.1/10.1版本的CUDA)
-
-### 1.2 下载OpenCV并设置环境变量
-
-- 在OpenCV官网下载适用于Windows平台的3.4.6版本: [点击下载](https://sourceforge.net/projects/opencvlibrary/files/3.4.6/opencv-3.4.6-vc14_vc15.exe/download)
-- 运行下载的可执行文件,将OpenCV解压至合适目录,这里以解压到`D:\projects\opencv`为例
-- 把OpenCV动态库加入到系统环境变量
- - 此电脑(我的电脑)->属性->高级系统设置->环境变量
- - 在系统变量中找到Path(如没有,自行创建),并双击编辑
- - 新建,将opencv路径填入并保存,如D:\projects\opencv\build\x64\vc14\bin
-
-**注意:** `OpenCV`的解压目录后续将做为编译配置项使用,所以请放置合适的目录中。
-
-### 1.3 下载PaddlePaddle C++ 预测库
-
-`PaddlePaddle` **C++ 预测库** 主要分为`CPU`和`GPU`版本, 其中`GPU版本`提供`CUDA 9.0` 和 `CUDA 10.0` 支持。
-
-常用的版本如下:
-
-| 版本 | 链接 |
-| ---- | ---- |
-| CPU+MKL版 | [fluid_inference_install_dir.zip](https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/cpu/fluid_inference_install_dir.zip) |
-| CUDA9.0+MKL 版 | [fluid_inference_install_dir.zip](https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/post97/fluid_inference_install_dir.zip) |
-| CUDA10.0+MKL 版 | [fluid_inference_install_dir.zip](https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/post107/fluid_inference_install_dir.zip) |
-
-更多不同平台的可用预测库版本,请[点击查看](https://paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/deploy/inference/windows_cpp_inference.html) 选择适合你的版本。
-
-
-下载并解压, 解压后的 `fluid_inference`目录包含的内容:
-```
-fluid_inference_install_dir
-├── paddle # paddle核心库和头文件
-|
-├── third_party # 第三方依赖库和头文件
-|
-└── version.txt # 版本和编译信息
-```
-
-**注意:** 这里的`fluid_inference_install_dir` 目录所在路径,将用于后面的编译参数设置,请放置在合适的位置。
-
-## 2. Visual Studio 2019 编译
-
-- 2.1 打开Visual Studio 2019 Community,点击`继续但无需代码`, 如下图:
-
-
-- 2.2 点击 `文件`->`打开`->`CMake`, 如下图:
-
-
-- 2.3 选择本项目根目录`CMakeList.txt`文件打开, 如下图:
-
-
-- 2.4 点击:`项目`->`PaddleMaskDetector的CMake设置`
-
-
-- 2.5 点击浏览设置`OPENCV_DIR`, `CUDA_LIB` 和 `PADDLE_DIR` 3个编译依赖库的位置, 设置完成后点击`保存并生成CMake缓存并加载变量`
-
-
-- 2.6 点击`生成`->`全部生成` 编译项目
-
-
-## 3. 运行程序
-
-成功编译后, 产出的可执行文件在项目子目录`out\build\x64-Release`目录, 按以下步骤运行代码:
-
-- 打开`cmd`切换至该目录
-- 运行以下命令传入模型路径与测试视频
-
-```shell
-main.exe ./models/ ./data/test.avi
-```
-第一个参数即人像分割预测模型的路径,第二个参数即要预测的视频。
-
-点击下载[测试视频](https://paddleseg.bj.bcebos.com/deploy/data/test.avi)
-
-运行后,预测结果保存在文件`result.avi`中。
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg.cc b/contrib/RealTimeHumanSeg/cpp/humanseg.cc
deleted file mode 100644
index b81c8120..00000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg.cc
+++ /dev/null
@@ -1,132 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-# include "humanseg.h"
-# include "humanseg_postprocess.h"
-
-// Normalize the image by (pix - mean) * scale
-void NormalizeImage(
- const std::vector &mean,
- const std::vector &scale,
- cv::Mat& im, // NOLINT
- float* input_buffer) {
- int height = im.rows;
- int width = im.cols;
- int stride = width * height;
- for (int h = 0; h < height; h++) {
- for (int w = 0; w < width; w++) {
- int base = h * width + w;
- input_buffer[base + 0 * stride] =
- (im.at(h, w)[0] - mean[0]) * scale[0];
- input_buffer[base + 1 * stride] =
- (im.at(h, w)[1] - mean[1]) * scale[1];
- input_buffer[base + 2 * stride] =
- (im.at(h, w)[2] - mean[2]) * scale[2];
- }
- }
-}
-
-// Load Model and return model predictor
-void LoadModel(
- const std::string& model_dir,
- bool use_gpu,
- std::unique_ptr* predictor) {
- // Config the model info
- paddle::AnalysisConfig config;
- auto prog_file = model_dir + "/__model__";
- auto params_file = model_dir + "/__params__";
- config.SetModel(prog_file, params_file);
- if (use_gpu) {
- config.EnableUseGpu(100, 0);
- } else {
- config.DisableGpu();
- }
- config.SwitchUseFeedFetchOps(false);
- config.SwitchSpecifyInputNames(true);
- // Memory optimization
- config.EnableMemoryOptim();
- *predictor = std::move(CreatePaddlePredictor(config));
-}
-
-void HumanSeg::Preprocess(const cv::Mat& image_mat) {
- // Clone the image : keep the original mat for postprocess
- cv::Mat im = image_mat.clone();
- auto eval_wh = cv::Size(eval_size_[0], eval_size_[1]);
- cv::resize(im, im, eval_wh, 0.f, 0.f, cv::INTER_LINEAR);
-
- im.convertTo(im, CV_32FC3, 1.0);
- int rc = im.channels();
- int rh = im.rows;
- int rw = im.cols;
- input_shape_ = {1, rc, rh, rw};
- input_data_.resize(1 * rc * rh * rw);
- float* buffer = input_data_.data();
- NormalizeImage(mean_, scale_, im, input_data_.data());
-}
-
-cv::Mat HumanSeg::Postprocess(const cv::Mat& im) {
- int h = input_shape_[2];
- int w = input_shape_[3];
- scoremap_data_.resize(3 * h * w * sizeof(float));
- float* base = output_data_.data() + h * w;
- for (int i = 0; i < h * w; ++i) {
- scoremap_data_[i] = uchar(base[i] * 255);
- }
-
- cv::Mat im_scoremap = cv::Mat(h, w, CV_8UC1);
- im_scoremap.data = scoremap_data_.data();
- cv::resize(im_scoremap, im_scoremap, cv::Size(im.cols, im.rows));
- im_scoremap.convertTo(im_scoremap, CV_32FC1, 1 / 255.0);
-
- float* pblob = reinterpret_cast(im_scoremap.data);
- int out_buff_capacity = 10 * im.cols * im.rows * sizeof(float);
- segout_data_.resize(out_buff_capacity);
- unsigned char* seg_result = segout_data_.data();
- MergeProcess(im.data, pblob, im.rows, im.cols, seg_result);
- cv::Mat seg_mat(im.rows, im.cols, CV_8UC1, seg_result);
- cv::resize(seg_mat, seg_mat, cv::Size(im.cols, im.rows));
- cv::GaussianBlur(seg_mat, seg_mat, cv::Size(5, 5), 0, 0);
- float fg_threshold = 0.8;
- float bg_threshold = 0.4;
- cv::Mat show_seg_mat;
- seg_mat.convertTo(seg_mat, CV_32FC1, 1 / 255.0);
- ThresholdMask(seg_mat, fg_threshold, bg_threshold, show_seg_mat);
- auto out_im = MergeSegMat(show_seg_mat, im);
- return out_im;
-}
-
-cv::Mat HumanSeg::Predict(const cv::Mat& im) {
- // Preprocess image
- Preprocess(im);
- // Prepare input tensor
- auto input_names = predictor_->GetInputNames();
- auto in_tensor = predictor_->GetInputTensor(input_names[0]);
- in_tensor->Reshape(input_shape_);
- in_tensor->copy_from_cpu(input_data_.data());
- // Run predictor
- predictor_->ZeroCopyRun();
- // Get output tensor
- auto output_names = predictor_->GetOutputNames();
- auto out_tensor = predictor_->GetOutputTensor(output_names[0]);
- auto output_shape = out_tensor->shape();
- // Calculate output length
- int output_size = 1;
- for (int j = 0; j < output_shape.size(); ++j) {
- output_size *= output_shape[j];
- }
- output_data_.resize(output_size);
- out_tensor->copy_to_cpu(output_data_.data());
- // Postprocessing result
- return Postprocess(im);
-}
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg.h b/contrib/RealTimeHumanSeg/cpp/humanseg.h
deleted file mode 100644
index edaf825f..00000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg.h
+++ /dev/null
@@ -1,66 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#pragma once
-
-#include
-#include
-#include
-#include
-
-#include
-#include
-#include
-#include
-
-#include "paddle_inference_api.h" // NOLINT
-
-// Load Paddle Inference Model
-void LoadModel(
- const std::string& model_dir,
- bool use_gpu,
- std::unique_ptr* predictor);
-
-class HumanSeg {
- public:
- explicit HumanSeg(const std::string& model_dir,
- const std::vector& mean,
- const std::vector& scale,
- const std::vector& eval_size,
- bool use_gpu = false) :
- mean_(mean),
- scale_(scale),
- eval_size_(eval_size) {
- LoadModel(model_dir, use_gpu, &predictor_);
- }
-
- // Run predictor
- cv::Mat Predict(const cv::Mat& im);
-
- private:
- // Preprocess image and copy data to input buffer
- void Preprocess(const cv::Mat& im);
- // Postprocess result
- cv::Mat Postprocess(const cv::Mat& im);
-
- std::unique_ptr predictor_;
- std::vector input_data_;
- std::vector input_shape_;
- std::vector output_data_;
- std::vector scoremap_data_;
- std::vector segout_data_;
- std::vector mean_;
- std::vector scale_;
- std::vector eval_size_;
-};
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc b/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc
deleted file mode 100644
index a373df39..00000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.cc
+++ /dev/null
@@ -1,282 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-#include
-
-#include
-#include
-#include
-#include
-
-#include "humanseg_postprocess.h" // NOLINT
-
-int HumanSegTrackFuse(const cv::Mat &track_fg_cfd,
- const cv::Mat &dl_fg_cfd,
- const cv::Mat &dl_weights,
- const cv::Mat &is_track,
- const float cfd_diff_thres,
- const int patch_size,
- cv::Mat cur_fg_cfd) {
- float *cur_fg_cfd_ptr = reinterpret_cast(cur_fg_cfd.data);
- float *dl_fg_cfd_ptr = reinterpret_cast(dl_fg_cfd.data);
- float *track_fg_cfd_ptr = reinterpret_cast(track_fg_cfd.data);
- float *dl_weights_ptr = reinterpret_cast(dl_weights.data);
- uchar *is_track_ptr = reinterpret_cast(is_track.data);
- int y_offset = 0;
- int ptr_offset = 0;
- int h = track_fg_cfd.rows;
- int w = track_fg_cfd.cols;
- float dl_fg_score = 0.0;
- float track_fg_score = 0.0;
- for (int y = 0; y < h; ++y) {
- for (int x = 0; x < w; ++x) {
- dl_fg_score = dl_fg_cfd_ptr[ptr_offset];
- if (is_track_ptr[ptr_offset] > 0) {
- track_fg_score = track_fg_cfd_ptr[ptr_offset];
- if (dl_fg_score > 0.9 || dl_fg_score < 0.1) {
- if (dl_weights_ptr[ptr_offset] <= 0.10) {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score * 0.3
- + track_fg_score * 0.7;
- } else {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score * 0.4
- + track_fg_score * 0.6;
- }
- } else {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score * dl_weights_ptr[ptr_offset]
- + track_fg_score * (1 - dl_weights_ptr[ptr_offset]);
- }
- } else {
- cur_fg_cfd_ptr[ptr_offset] = dl_fg_score;
- }
- ++ptr_offset;
- }
- y_offset += w;
- ptr_offset = y_offset;
- }
- return 0;
-}
-
-int HumanSegTracking(const cv::Mat &prev_gray,
- const cv::Mat &cur_gray,
- const cv::Mat &prev_fg_cfd,
- int patch_size,
- cv::Mat track_fg_cfd,
- cv::Mat is_track,
- cv::Mat dl_weights,
- cv::Ptr disflow) {
- cv::Mat flow_fw;
- disflow->calc(prev_gray, cur_gray, flow_fw);
-
- cv::Mat flow_bw;
- disflow->calc(cur_gray, prev_gray, flow_bw);
-
- float double_check_thres = 8;
-
- cv::Point2f fxy_fw;
- int dy_fw = 0;
- int dx_fw = 0;
- cv::Point2f fxy_bw;
- int dy_bw = 0;
- int dx_bw = 0;
-
- float *prev_fg_cfd_ptr = reinterpret_cast(prev_fg_cfd.data);
- float *track_fg_cfd_ptr = reinterpret_cast(track_fg_cfd.data);
- float *dl_weights_ptr = reinterpret_cast(dl_weights.data);
- uchar *is_track_ptr = reinterpret_cast(is_track.data);
-
- int prev_y_offset = 0;
- int prev_ptr_offset = 0;
- int cur_ptr_offset = 0;
- float *flow_fw_ptr = reinterpret_cast(flow_fw.data);
-
- float roundy_fw = 0.0;
- float roundx_fw = 0.0;
- float roundy_bw = 0.0;
- float roundx_bw = 0.0;
-
- int h = prev_fg_cfd.rows;
- int w = prev_fg_cfd.cols;
- for (int r = 0; r < h; ++r) {
- for (int c = 0; c < w; ++c) {
- ++prev_ptr_offset;
-
- fxy_fw = flow_fw.ptr(r)[c];
- roundy_fw = fxy_fw.y >= 0 ? 0.5 : -0.5;
- roundx_fw = fxy_fw.x >= 0 ? 0.5 : -0.5;
- dy_fw = static_cast(fxy_fw.y + roundy_fw);
- dx_fw = static_cast(fxy_fw.x + roundx_fw);
-
- int cur_x = c + dx_fw;
- int cur_y = r + dy_fw;
-
- if (cur_x < 0
- || cur_x >= h
- || cur_y < 0
- || cur_y >= w) {
- continue;
- }
- fxy_bw = flow_bw.ptr(cur_y)[cur_x];
- roundy_bw = fxy_bw.y >= 0 ? 0.5 : -0.5;
- roundx_bw = fxy_bw.x >= 0 ? 0.5 : -0.5;
- dy_bw = static_cast(fxy_bw.y + roundy_bw);
- dx_bw = static_cast(fxy_bw.x + roundx_bw);
-
- auto total = (dy_fw + dy_bw) * (dy_fw + dy_bw)
- + (dx_fw + dx_bw) * (dx_fw + dx_bw);
- if (total >= double_check_thres) {
- continue;
- }
-
- cur_ptr_offset = cur_y * w + cur_x;
- if (abs(dy_fw) <= 0
- && abs(dx_fw) <= 0
- && abs(dy_bw) <= 0
- && abs(dx_bw) <= 0) {
- dl_weights_ptr[cur_ptr_offset] = 0.05;
- }
- is_track_ptr[cur_ptr_offset] = 1;
- track_fg_cfd_ptr[cur_ptr_offset] = prev_fg_cfd_ptr[prev_ptr_offset];
- }
- prev_y_offset += w;
- prev_ptr_offset = prev_y_offset - 1;
- }
- return 0;
-}
-
-int MergeProcess(const uchar *im_buff,
- const float *scoremap_buff,
- const int height,
- const int width,
- uchar *result_buff) {
- cv::Mat prev_fg_cfd;
- cv::Mat cur_fg_cfd;
- cv::Mat cur_fg_mask;
- cv::Mat track_fg_cfd;
- cv::Mat prev_gray;
- cv::Mat cur_gray;
- cv::Mat bgr_temp;
- cv::Mat is_track;
- cv::Mat static_roi;
- cv::Mat weights;
- cv::Ptr disflow =
- cv::optflow::createOptFlow_DIS(
- cv::optflow::DISOpticalFlow::PRESET_ULTRAFAST);
-
- bool is_init = false;
- const float *cfd_ptr = scoremap_buff;
- if (!is_init) {
- is_init = true;
- cur_fg_cfd = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0));
- memcpy(cur_fg_cfd.data, cfd_ptr, height * width * sizeof(float));
- cur_fg_mask = cv::Mat(height, width, CV_8UC1, cv::Scalar::all(0));
-
- if (height <= 64 || width <= 64) {
- disflow->setFinestScale(1);
- } else if (height <= 160 || width <= 160) {
- disflow->setFinestScale(2);
- } else {
- disflow->setFinestScale(3);
- }
- is_track = cv::Mat(height, width, CV_8UC1, cv::Scalar::all(0));
- static_roi = cv::Mat(height, width, CV_8UC1, cv::Scalar::all(0));
- track_fg_cfd = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0));
-
- bgr_temp = cv::Mat(height, width, CV_8UC3);
- memcpy(bgr_temp.data, im_buff, height * width * 3 * sizeof(uchar));
- cv::cvtColor(bgr_temp, cur_gray, cv::COLOR_BGR2GRAY);
- weights = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0.30));
- } else {
- memcpy(cur_fg_cfd.data, cfd_ptr, height * width * sizeof(float));
- memcpy(bgr_temp.data, im_buff, height * width * 3 * sizeof(uchar));
- cv::cvtColor(bgr_temp, cur_gray, cv::COLOR_BGR2GRAY);
- memset(is_track.data, 0, height * width * sizeof(uchar));
- memset(static_roi.data, 0, height * width * sizeof(uchar));
- weights = cv::Mat(height, width, CV_32FC1, cv::Scalar::all(0.30));
- HumanSegTracking(prev_gray,
- cur_gray,
- prev_fg_cfd,
- 0,
- track_fg_cfd,
- is_track,
- weights,
- disflow);
- HumanSegTrackFuse(track_fg_cfd,
- cur_fg_cfd,
- weights,
- is_track,
- 1.1,
- 0,
- cur_fg_cfd);
- }
- int ksize = 3;
- cv::GaussianBlur(cur_fg_cfd, cur_fg_cfd, cv::Size(ksize, ksize), 0, 0);
- prev_fg_cfd = cur_fg_cfd.clone();
- prev_gray = cur_gray.clone();
- cur_fg_cfd.convertTo(cur_fg_mask, CV_8UC1, 255);
- memcpy(result_buff, cur_fg_mask.data, height * width);
- return 0;
-}
-
-cv::Mat MergeSegMat(const cv::Mat& seg_mat,
- const cv::Mat& ori_frame) {
- cv::Mat return_frame;
- cv::resize(ori_frame, return_frame, cv::Size(ori_frame.cols, ori_frame.rows));
- for (int i = 0; i < ori_frame.rows; i++) {
- for (int j = 0; j < ori_frame.cols; j++) {
- float score = seg_mat.at(i, j) / 255.0;
- if (score > 0.1) {
- return_frame.at(i, j)[2] = static_cast((1 - score) * 255
- + score*return_frame.at(i, j)[2]);
- return_frame.at(i, j)[1] = static_cast((1 - score) * 255
- + score*return_frame.at(i, j)[1]);
- return_frame.at(i, j)[0] = static_cast((1 - score) * 255
- + score*return_frame.at(i, j)[0]);
- } else {
- return_frame.at(i, j) = {255, 255, 255};
- }
- }
- }
- return return_frame;
-}
-
-int ThresholdMask(const cv::Mat &fg_cfd,
- const float fg_thres,
- const float bg_thres,
- cv::Mat& fg_mask) {
- if (fg_cfd.type() != CV_32FC1) {
- printf("ThresholdMask: type is not CV_32FC1.\n");
- return -1;
- }
- if (!(fg_mask.type() == CV_8UC1
- && fg_mask.rows == fg_cfd.rows
- && fg_mask.cols == fg_cfd.cols)) {
- fg_mask = cv::Mat(fg_cfd.rows, fg_cfd.cols, CV_8UC1, cv::Scalar::all(0));
- }
-
- for (int r = 0; r < fg_cfd.rows; ++r) {
- for (int c = 0; c < fg_cfd.cols; ++c) {
- float score = fg_cfd.at(r, c);
- if (score < bg_thres) {
- fg_mask.at(r, c) = 0;
- } else if (score > fg_thres) {
- fg_mask.at(r, c) = 255;
- } else {
- fg_mask.at(r, c) = static_cast(
- (score-bg_thres) / (fg_thres - bg_thres) * 255);
- }
- }
- }
- return 0;
-}
diff --git a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h b/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h
deleted file mode 100644
index f5059857..00000000
--- a/contrib/RealTimeHumanSeg/cpp/humanseg_postprocess.h
+++ /dev/null
@@ -1,34 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#pragma once
-
-#include
-#include
-#include
-#include
-
-int ThresholdMask(const cv::Mat &fg_cfd,
- const float fg_thres,
- const float bg_thres,
- cv::Mat& fg_mask);
-
-cv::Mat MergeSegMat(const cv::Mat& seg_mat,
- const cv::Mat& ori_frame);
-
-int MergeProcess(const uchar *im_buff,
- const float *im_scoremap_buff,
- const int height,
- const int width,
- uchar *result_buff);
diff --git a/contrib/RealTimeHumanSeg/cpp/linux_build.sh b/contrib/RealTimeHumanSeg/cpp/linux_build.sh
deleted file mode 100644
index da0f75ef..00000000
--- a/contrib/RealTimeHumanSeg/cpp/linux_build.sh
+++ /dev/null
@@ -1,31 +0,0 @@
-OPENCV_URL=https://bj.bcebos.com/paddleseg/deps/opencv346gcc4.8contrib.tar.bz2
-if [ ! -d "./deps/opencv346_with_contrib" ]; then
- mkdir -p deps
- cd deps
- wget -c ${OPENCV_URL}
- tar xvfj opencv346gcc4.8contrib.tar.bz2
- rm -rf opencv346gcc4.8contrib.tar.bz2
- cd ..
-fi
-
-WITH_GPU=OFF
-PADDLE_DIR=/root/project/fluid_inference/
-CUDA_LIB=/usr/local/cuda-10.0/lib64/
-CUDNN_LIB=/usr/local/cuda-10.0/lib64/
-OPENCV_DIR=$(pwd)/deps/opencv346_with_contrib/
-echo ${OPENCV_DIR}
-
-rm -rf build
-mkdir -p build
-cd build
-
-cmake .. \
- -DWITH_GPU=${WITH_GPU} \
- -DPADDLE_DIR=${PADDLE_DIR} \
- -DCUDA_LIB=${CUDA_LIB} \
- -DCUDNN_LIB=${CUDNN_LIB} \
- -DOPENCV_DIR=${OPENCV_DIR} \
- -DWITH_STATIC_LIB=OFF
-make clean
-make -j12
-
diff --git a/contrib/RealTimeHumanSeg/cpp/main.cc b/contrib/RealTimeHumanSeg/cpp/main.cc
deleted file mode 100644
index 303051f0..00000000
--- a/contrib/RealTimeHumanSeg/cpp/main.cc
+++ /dev/null
@@ -1,92 +0,0 @@
-// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-#include
-
-#include "humanseg.h" // NOLINT
-#include "humanseg_postprocess.h" // NOLINT
-
-// Do predicting on a video file
-int VideoPredict(const std::string& video_path, HumanSeg& seg)
-{
- cv::VideoCapture capture;
- capture.open(video_path.c_str());
- if (!capture.isOpened()) {
- printf("can not open video : %s\n", video_path.c_str());
- return -1;
- }
-
- int video_width = static_cast(capture.get(CV_CAP_PROP_FRAME_WIDTH));
- int video_height = static_cast(capture.get(CV_CAP_PROP_FRAME_HEIGHT));
- cv::VideoWriter video_out;
- std::string video_out_path = "result.avi";
- video_out.open(video_out_path.c_str(),
- CV_FOURCC('M', 'J', 'P', 'G'),
- 30.0,
- cv::Size(video_width, video_height),
- true);
- if (!video_out.isOpened()) {
- printf("create video writer failed!\n");
- return -1;
- }
- cv::Mat frame;
- while (capture.read(frame)) {
- if (frame.empty()) {
- break;
- }
- cv::Mat out_im = seg.Predict(frame);
- video_out.write(out_im);
- }
- capture.release();
- video_out.release();
- return 0;
-}
-
-// Do predicting on a image file
-int ImagePredict(const std::string& image_path, HumanSeg& seg)
-{
- cv::Mat img = imread(image_path, cv::IMREAD_COLOR);
- cv::Mat out_im = seg.Predict(img);
- imwrite("result.jpeg", out_im);
- return 0;
-}
-
-int main(int argc, char* argv[]) {
- if (argc < 3 || argc > 4) {
- std::cout << "Usage:"
- << "./humanseg ./models/ ./data/test.avi"
- << std::endl;
- return -1;
- }
-
- bool use_gpu = (argc == 4 ? std::stoi(argv[3]) : false);
- auto model_dir = std::string(argv[1]);
- auto input_path = std::string(argv[2]);
-
- // Init Model
- std::vector means = {104.008, 116.669, 122.675};
- std::vector scale = {1.000, 1.000, 1.000};
- std::vector eval_sz = {192, 192};
- HumanSeg seg(model_dir, means, scale, eval_sz, use_gpu);
-
- // Call ImagePredict while input_path is a image file path
- // The output will be saved as result.jpeg
- // ImagePredict(input_path, seg);
-
- // Call VideoPredict while input_path is a video file path
- // The output will be saved as result.avi
- VideoPredict(input_path, seg);
- return 0;
-}
diff --git a/contrib/RealTimeHumanSeg/python/README.md b/contrib/RealTimeHumanSeg/python/README.md
deleted file mode 100644
index 1e089c9f..00000000
--- a/contrib/RealTimeHumanSeg/python/README.md
+++ /dev/null
@@ -1,61 +0,0 @@
-# 实时人像分割Python预测部署方案
-
-本方案基于Python实现,最小化依赖并把所有模型加载、数据预处理、预测、光流处理等后处理都封装在文件`infer.py`中,用户可以直接使用或集成到自己项目中。
-
-
-## 前置依赖
-- Windows(7,8,10) / Linux (Ubuntu 16.04) or MacOS 10.1+
-- Paddle 1.6.1+
-- Python 3.0+
-
-注意:
-1. 仅测试过Paddle1.6 和 1.7, 其它版本不支持
-2. MacOS上不支持GPU预测
-3. Python2上未测试
-
-其它未涉及情形,能正常安装`Paddle` 和`OpenCV`通常都能正常使用。
-
-
-## 安装依赖
-### 1. 安装paddle
-
-PaddlePaddle的安装, 请按照[官网指引](https://paddlepaddle.org.cn/install/quick)安装合适自己的版本。
-
-### 2. 安装其它依赖
-
-执行如下命令
-
-```shell
-pip install -r requirements.txt
-```
-
-## 运行
-
-
-1. 输入图片进行分割
-```
-python infer.py --model_dir /PATH/TO/INFERENCE/MODEL --img_path /PATH/TO/INPUT/IMAGE
-```
-
-预测结果会保存为`result.jpeg`。
-2. 输入视频进行分割
-```shell
-python infer.py --model_dir /PATH/TO/INFERENCE/MODEL --video_path /PATH/TO/INPUT/VIDEO
-```
-
-预测结果会保存在`result.avi`。
-
-3. 使用摄像头视频流
-```shell
-python infer.py --model_dir /PATH/TO/INFERENCE/MODEL --use_camera 1
-```
-预测结果会通过可视化窗口实时显示。
-
-**注意:**
-
-
-`GPU`默认关闭, 如果要使用`GPU`进行加速,则先运行
-```
-export CUDA_VISIBLE_DEVICES=0
-```
-然后在前面的预测命令中增加参数`--use_gpu 1`即可。
diff --git a/contrib/RealTimeHumanSeg/python/infer.py b/contrib/RealTimeHumanSeg/python/infer.py
deleted file mode 100644
index 73df081e..00000000
--- a/contrib/RealTimeHumanSeg/python/infer.py
+++ /dev/null
@@ -1,345 +0,0 @@
-# coding: utf8
-# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""实时人像分割Python预测部署"""
-
-import os
-import argparse
-import numpy as np
-import cv2
-
-import paddle.fluid as fluid
-
-
-def human_seg_tracking(pre_gray, cur_gray, prev_cfd, dl_weights, disflow):
- """计算光流跟踪匹配点和光流图
- 输入参数:
- pre_gray: 上一帧灰度图
- cur_gray: 当前帧灰度图
- prev_cfd: 上一帧光流图
- dl_weights: 融合权重图
- disflow: 光流数据结构
- 返回值:
- is_track: 光流点跟踪二值图,即是否具有光流点匹配
- track_cfd: 光流跟踪图
- """
- check_thres = 8
- hgt, wdh = pre_gray.shape[:2]
- track_cfd = np.zeros_like(prev_cfd)
- is_track = np.zeros_like(pre_gray)
- # 计算前向光流
- flow_fw = disflow.calc(pre_gray, cur_gray, None)
- # 计算后向光流
- flow_bw = disflow.calc(cur_gray, pre_gray, None)
- get_round = lambda data: (int)(data + 0.5) if data >= 0 else (int)(data -0.5)
- for row in range(hgt):
- for col in range(wdh):
- # 计算光流处理后对应点坐标
- # (row, col) -> (cur_x, cur_y)
- fxy_fw = flow_fw[row, col]
- dx_fw = get_round(fxy_fw[0])
- cur_x = dx_fw + col
- dy_fw = get_round(fxy_fw[1])
- cur_y = dy_fw + row
- if cur_x < 0 or cur_x >= wdh or cur_y < 0 or cur_y >= hgt:
- continue
- fxy_bw = flow_bw[cur_y, cur_x]
- dx_bw = get_round(fxy_bw[0])
- dy_bw = get_round(fxy_bw[1])
- # 光流移动小于阈值
- lmt = ((dy_fw + dy_bw) * (dy_fw + dy_bw) + (dx_fw + dx_bw) * (dx_fw + dx_bw))
- if lmt >= check_thres:
- continue
- # 静止点降权
- if abs(dy_fw) <= 0 and abs(dx_fw) <= 0 and abs(dy_bw) <= 0 and abs(dx_bw) <= 0:
- dl_weights[cur_y, cur_x] = 0.05
- is_track[cur_y, cur_x] = 1
- track_cfd[cur_y, cur_x] = prev_cfd[row, col]
- return track_cfd, is_track, dl_weights
-
-
-def human_seg_track_fuse(track_cfd, dl_cfd, dl_weights, is_track):
- """光流追踪图和人像分割结构融合
- 输入参数:
- track_cfd: 光流追踪图
- dl_cfd: 当前帧分割结果
- dl_weights: 融合权重图
- is_track: 光流点匹配二值图
- 返回值:
- cur_cfd: 光流跟踪图和人像分割结果融合图
- """
- cur_cfd = dl_cfd.copy()
- idxs = np.where(is_track > 0)
- for i in range(len(idxs)):
- x, y = idxs[0][i], idxs[1][i]
- dl_score = dl_cfd[y, x]
- track_score = track_cfd[y, x]
- if dl_score > 0.9 or dl_score < 0.1:
- if dl_weights[x, y] < 0.1:
- cur_cfd[x, y] = 0.3 * dl_score + 0.7 * track_score
- else:
- cur_cfd[x, y] = 0.4 * dl_score + 0.6 * track_score
- else:
- cur_cfd[x, y] = dl_weights[x, y] * dl_score + (1 - dl_weights[x, y]) * track_score
- return cur_cfd
-
-
-def threshold_mask(img, thresh_bg, thresh_fg):
- """设置背景和前景阈值mask
- 输入参数:
- img : 原始图像, np.uint8 类型.
- thresh_bg : 背景阈值百分比,低于该值置为0.
- thresh_fg : 前景阈值百分比,超过该值置为1.
- 返回值:
- dst : 原始图像设置完前景背景阈值mask结果, np.float32 类型.
- """
- dst = (img / 255.0 - thresh_bg) / (thresh_fg - thresh_bg)
- dst[np.where(dst > 1)] = 1
- dst[np.where(dst < 0)] = 0
- return dst.astype(np.float32)
-
-
-def optflow_handle(cur_gray, scoremap, is_init):
- """光流优化
- Args:
- cur_gray : 当前帧灰度图
- scoremap : 当前帧分割结果
- is_init : 是否第一帧
- Returns:
- dst : 光流追踪图和预测结果融合图, 类型为 np.float32
- """
- width, height = scoremap.shape[0], scoremap.shape[1]
- disflow = cv2.DISOpticalFlow_create(
- cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
- prev_gray = np.zeros((height, width), np.uint8)
- prev_cfd = np.zeros((height, width), np.float32)
- cur_cfd = scoremap.copy()
- if is_init:
- is_init = False
- if height <= 64 or width <= 64:
- disflow.setFinestScale(1)
- elif height <= 160 or width <= 160:
- disflow.setFinestScale(2)
- else:
- disflow.setFinestScale(3)
- fusion_cfd = cur_cfd
- else:
- weights = np.ones((width, height), np.float32) * 0.3
- track_cfd, is_track, weights = human_seg_tracking(
- prev_gray, cur_gray, prev_cfd, weights, disflow)
- fusion_cfd = human_seg_track_fuse(track_cfd, cur_cfd, weights, is_track)
- fusion_cfd = cv2.GaussianBlur(fusion_cfd, (3, 3), 0)
- return fusion_cfd
-
-
-class HumanSeg:
- """人像分割类
- 封装了人像分割模型的加载,数据预处理,预测,后处理等
- """
- def __init__(self, model_dir, mean, scale, eval_size, use_gpu=False):
-
- self.mean = np.array(mean).reshape((3, 1, 1))
- self.scale = np.array(scale).reshape((3, 1, 1))
- self.eval_size = eval_size
- self.load_model(model_dir, use_gpu)
-
- def load_model(self, model_dir, use_gpu):
- """加载模型并创建predictor
- Args:
- model_dir: 预测模型路径, 包含 `__model__` 和 `__params__`
- use_gpu: 是否使用GPU加速
- """
- prog_file = os.path.join(model_dir, '__model__')
- params_file = os.path.join(model_dir, '__params__')
- config = fluid.core.AnalysisConfig(prog_file, params_file)
- if use_gpu:
- config.enable_use_gpu(100, 0)
- config.switch_ir_optim(True)
- else:
- config.disable_gpu()
- config.disable_glog_info()
- config.switch_specify_input_names(True)
- config.enable_memory_optim()
- self.predictor = fluid.core.create_paddle_predictor(config)
-
- def preprocess(self, image):
- """图像预处理
- hwc_rgb 转换为 chw_bgr,并进行归一化
- 输入参数:
- image: 原始图像
- 返回值:
- 经过预处理后的图片结果
- """
- img_mat = cv2.resize(
- image, self.eval_size, interpolation=cv2.INTER_LINEAR)
- # HWC -> CHW
- img_mat = img_mat.swapaxes(1, 2)
- img_mat = img_mat.swapaxes(0, 1)
- # Convert to float
- img_mat = img_mat[:, :, :].astype('float32')
- # img_mat = (img_mat - mean) * scale
- img_mat = img_mat - self.mean
- img_mat = img_mat * self.scale
- img_mat = img_mat[np.newaxis, :, :, :]
- return img_mat
-
- def postprocess(self, image, output_data):
- """对预测结果进行后处理
- Args:
- image: 原始图,opencv 图片对象
- output_data: Paddle预测结果原始数据
- Returns:
- 原图和预测结果融合并做了光流优化的结果图
- """
- scoremap = output_data[0, 1, :, :]
- scoremap = (scoremap * 255).astype(np.uint8)
- ori_h, ori_w = image.shape[0], image.shape[1]
- evl_h, evl_w = self.eval_size[0], self.eval_size[1]
- # 光流处理
- cur_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
- cur_gray = cv2.resize(cur_gray, (evl_w, evl_h))
- optflow_map = optflow_handle(cur_gray, scoremap, False)
- optflow_map = cv2.GaussianBlur(optflow_map, (3, 3), 0)
- optflow_map = threshold_mask(optflow_map, thresh_bg=0.2, thresh_fg=0.8)
- optflow_map = cv2.resize(optflow_map, (ori_w, ori_h))
- optflow_map = np.repeat(optflow_map[:, :, np.newaxis], 3, axis=2)
- bg_im = np.ones_like(optflow_map) * 255
- comb = (optflow_map * image + (1 - optflow_map) * bg_im).astype(np.uint8)
- return comb
-
- def run_predict(self, image):
- """运行预测并返回可视化结果图
- 输入参数:
- image: 需要预测的原始图, opencv图片对象
- 返回值:
- 可视化的预测结果图
- """
- im_mat = self.preprocess(image)
- im_tensor = fluid.core.PaddleTensor(im_mat.copy().astype('float32'))
- output_data = self.predictor.run([im_tensor])[0]
- output_data = output_data.as_ndarray()
- return self.postprocess(image, output_data)
-
-
-def predict_image(seg, image_path):
- """对图片文件进行分割
- 结果保存到`result.jpeg`文件中
- """
- img_mat = cv2.imread(image_path)
- img_mat = seg.run_predict(img_mat)
- cv2.imwrite('result.jpeg', img_mat)
-
-
-def predict_video(seg, video_path):
- """对视频文件进行分割
- 结果保存到`result.avi`文件中
- """
- cap = cv2.VideoCapture(video_path)
- if not cap.isOpened():
- print("Error opening video stream or file")
- return
- width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
- height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
- fps = cap.get(cv2.CAP_PROP_FPS)
- # 用于保存预测结果视频
- out = cv2.VideoWriter('result.avi',
- cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps,
- (width, height))
- # 开始获取视频帧
- while cap.isOpened():
- ret, frame = cap.read()
- if ret:
- img_mat = seg.run_predict(frame)
- out.write(img_mat)
- else:
- break
- cap.release()
- out.release()
-
-
-def predict_camera(seg):
- """从摄像头获取视频流进行预测
- 视频分割结果实时显示到可视化窗口中
- """
- cap = cv2.VideoCapture(0)
- if not cap.isOpened():
- print("Error opening video stream or file")
- return
- # Start capturing from video
- while cap.isOpened():
- ret, frame = cap.read()
- if ret:
- img_mat = seg.run_predict(frame)
- cv2.imshow('HumanSegmentation', img_mat)
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
- else:
- break
- cap.release()
-
-
-def main(args):
- """预测程序入口
- 完成模型加载, 对视频、摄像头、图片文件等预测过程
- """
- model_dir = args.model_dir
- use_gpu = args.use_gpu
-
- # 加载模型
- mean = [104.008, 116.669, 122.675]
- scale = [1.0, 1.0, 1.0]
- eval_size = (192, 192)
- seg = HumanSeg(model_dir, mean, scale, eval_size, use_gpu)
- if args.use_camera:
- # 开启摄像头
- predict_camera(seg)
- elif args.video_path:
- # 使用视频文件作为输入
- predict_video(seg, args.video_path)
- elif args.img_path:
- # 使用图片文件作为输入
- predict_image(seg, args.img_path)
-
-
-def parse_args():
- """解析命令行参数
- """
- parser = argparse.ArgumentParser('Realtime Human Segmentation')
- parser.add_argument('--model_dir',
- type=str,
- default='',
- help='path of human segmentation model')
- parser.add_argument('--img_path',
- type=str,
- default='',
- help='path of input image')
- parser.add_argument('--video_path',
- type=str,
- default='',
- help='path of input video')
- parser.add_argument('--use_camera',
- type=bool,
- default=False,
- help='input video stream from camera')
- parser.add_argument('--use_gpu',
- type=bool,
- default=False,
- help='enable gpu')
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- main(args)
diff --git a/contrib/RealTimeHumanSeg/python/requirements.txt b/contrib/RealTimeHumanSeg/python/requirements.txt
deleted file mode 100644
index 953dae0c..00000000
--- a/contrib/RealTimeHumanSeg/python/requirements.txt
+++ /dev/null
@@ -1,2 +0,0 @@
-opencv-python==4.1.2.30
-opencv-contrib-python==4.2.0.32
--
GitLab