diff --git a/.travis.yml b/.travis.yml
new file mode 100644
index 0000000000000000000000000000000000000000..204c642f96995ec8012601443040ac016474be81
--- /dev/null
+++ b/.travis.yml
@@ -0,0 +1,14 @@
+language: python
+
+python:
+ - '2.7'
+ - '3.5'
+ - '3.6'
+
+script:
+ - /bin/bash ./test/ci/test_download_dataset.sh
+
+notifications:
+ email:
+ on_success: change
+ on_failure: always
diff --git a/README.md b/README.md
index 2b464d5db8484fcb2df8abbd3b8602c640e9ad53..19a600757c792c6db798511e687eb95bef48cc16 100644
--- a/README.md
+++ b/README.md
@@ -1,82 +1,106 @@
# PaddleSeg 语义分割库
+[](https://travis-ci.org/PaddlePaddle/PaddleSeg)
[](LICENSE)
## 简介
PaddleSeg是基于[PaddlePaddle](https://www.paddlepaddle.org.cn)开发的语义分割库,覆盖了DeepLabv3+, U-Net, ICNet三类主流的分割模型。通过统一的配置,帮助用户更便捷地完成从训练到部署的全流程图像分割应用。
-具备高性能、丰富的数据增强、工业级部署、全流程应用的特点。
+PaddleSeg具备高性能、丰富的数据增强、工业级部署、全流程应用的特点:
- **丰富的数据增强**
- - 基于百度视觉技术部的实际业务经验,内置10+种数据增强策略,可结合实际业务场景进行定制组合,提升模型泛化能力和鲁棒性。
-
+基于百度视觉技术部的实际业务经验,内置10+种数据增强策略,可结合实际业务场景进行定制组合,提升模型泛化能力和鲁棒性。
+
- **主流模型覆盖**
- - 支持U-Net, DeepLabv3+, ICNet三类主流分割网络,结合预训练模型和可调节的骨干网络,满足不同性能和精度的要求。
+支持U-Net, DeepLabv3+, ICNet三类主流分割网络,结合预训练模型和可调节的骨干网络,满足不同性能和精度的要求。
- **高性能**
- - PaddleSeg支持多进程IO、多卡并行、多卡Batch Norm同步等训练加速策略,通过飞桨核心框架的显存优化算法,可以大幅度节约分割模型的显存开销,更快完成分割模型训练。
-
-- **工业级部署**
+PaddleSeg支持多进程IO、多卡并行、跨卡Batch Norm同步等训练加速策略,结合飞桨核心框架的显存优化功能,可以大幅度减少分割模型的显存开销,更快完成分割模型训练。
- - 基于[Paddle Serving](https://github.com/PaddlePaddle/Serving)和PaddlePaddle高性能预测引擎,结合百度开放的AI能力,轻松搭建人像分割和车道线分割服务。
+- **工业级部署**
+基于[Paddle Serving](https://github.com/PaddlePaddle/Serving)和PaddlePaddle高性能预测引擎,结合百度开放的AI能力,轻松搭建人像分割和车道线分割服务。
-更多模型信息与技术细节请查看[模型介绍](./docs/models.md)和[预训练模型](./docs/model_zoo.md)
+
-## AI Studio教程
+## 使用教程
-### 快速开始
+我们提供了一系列的使用教程,来说明如何使用PaddleSeg完成一个语义分割模型的训练、评估、部署。
-通过 [PaddleSeg人像分割](https://aistudio.baidu.com/aistudio/projectDetail/100798) 教程可快速体验PaddleSeg人像分割模型的效果。
+这一系列的文档被分为`快速入门`、`基础功能`、`预测部署`、`高级功能`四个部分,四个教程由浅至深地介绍PaddleSeg的设计思路和使用方法。
-### 入门教程
+### 快速入门
-入门教程以经典的U-Net模型为例, 结合Oxford-IIIT宠物数据集,快速熟悉PaddleSeg使用流程, 详情请点击[U-Net宠物分割](https://aistudio.baidu.com/aistudio/projectDetail/102889)。
+* [安装说明](./docs/installation.md)
+* [训练/评估/可视化](./docs/usage.md)
-### 高级教程
+### 基础功能
-高级教程以DeepLabv3+模型为例,结合Cityscapes数据集,快速了解ASPP, Backbone网络切换,多卡Batch Norm同步等策略,详情请点击[DeepLabv3+图像分割](https://aistudio.baidu.com/aistudio/projectDetail/101696)。
+* [分割模型介绍](./docs/models.md)
+* [预训练模型列表](./docs/model_zoo.md)
+* [自定义数据的准备与标注](./docs/data_prepare.md)
+* [数据和配置校验](./docs/check.md)
+* [使用DeepLabv3+预训练模型](./turtorial/finetune_deeplabv3plus.md)
+* [使用UNet预训练模型](./turtorial/finetune_unet.md)
+* [使用ICNet预训练模型](./turtorial/finetune_icnet.md)
-### 垂类模型
+### 预测部署
-更多特色垂类分割模型如LIP人体部件分割、人像分割、车道线分割模型可以参考[contrib](./contrib)
+* [模型导出](./docs/model_export.md)
+* [C++预测库使用](./inference)
+* [PaddleSeg Serving服务化部署](./serving)
-## 使用文档
+### 高级功能
-* [安装说明](./docs/installation.md)
-* [数据准备](./docs/data_prepare.md)
-* [数据增强](./docs/data_aug.md)
-* [预训练模型](./docs/model_zoo.md)
-* [训练/评估/预测(可视化)](./docs/usage.md)
-* [预测库集成](./inference/README.md)
-* [服务端部署](./serving/README.md)
-* [垂类分割模型](./contrib/README.md)
+* [PaddleSeg的数据增强](./docs/data_aug.md)
+* [特色垂类模型使用](./contrib)
+
## FAQ
+#### Q: 安装requirements.txt指定的依赖包时,部分包提示找不到?
+
+A: 可能是pip源的问题,这种情况下建议切换为官方源
+
#### Q:图像分割的数据增强如何配置,unpadding, step-scaling, range-scaling的原理是什么?
-A: 数据增强的配置可以参考文档[数据增强](./docs/data_aug.md)
+A: 更详细数据增强文档可以参考[数据增强](./docs/data_aug.md)
#### Q: 预测时图片过大,导致显存不足如何处理?
A: 降低Batch size,使用Group Norm策略等。
+
+
+## 在线体验
+
+PaddleSeg提供了多种预训练模型,并且以NoteBook的方式提供了在线体验的教程,欢迎体验:
+
+|教程|链接|
+|-|-|
+|U-Net宠物分割|[点击体验](https://aistudio.baidu.com/aistudio/projectDetail/102889)|
+|PaddleSeg人像分割|[点击体验](https://aistudio.baidu.com/aistudio/projectDetail/100798)|
+|DeepLabv3+图像分割|[点击体验](https://aistudio.baidu.com/aistudio/projectDetail/101696)|
+|PaddleSeg特色垂类模型|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/115541)|
+
+
+
## 更新日志
-### 2019.08.26
+* 2019.08.26
-#### v0.1.0
+ **`v0.1.0`**
+ * PaddleSeg分割库初始版本发布,包含DeepLabv3+, U-Net, ICNet三类分割模型, 其中DeepLabv3+支持Xception, MobileNet两种可调节的骨干网络。
+ * CVPR19 LIP人体部件分割比赛冠军预测模型发布[ACE2P](./contrib/ACE2P)
+ * 预置基于DeepLabv3+网络的[人像分割](./contrib/HumanSeg/)和[车道线分割](./contrib/RoadLine)预测模型发布
-* PaddleSeg分割库初始版本发布,包含DeepLabv3+, U-Net, ICNet三类分割模型, 其中DeepLabv3+支持Xception, MobileNet两种可调节的骨干网络。
-* CVPR 19' LIP人体部件分割比赛冠军预测模型发布[ACE2P](./contrib/ACE2P)
-* 预置基于DeepLabv3+网络的[人像分割](./contrib/HumanSeg/)和[车道线分割](./contrib/RoadLine)预测模型发布
+
## 如何贡献代码
diff --git a/configs/cityscape.yaml b/configs/cityscape.yaml
index 0650d58a068e19c6cfe36f2d01c8e37dd5935045..f14234d77970e680cb39be46287f94ee5999c1a7 100644
--- a/configs/cityscape.yaml
+++ b/configs/cityscape.yaml
@@ -10,18 +10,6 @@ AUG:
MIN_SCALE_FACTOR: 0.5 # for stepscaling
SCALE_STEP_SIZE: 0.25 # for stepscaling
MIRROR: True
- RICH_CROP:
- ENABLE: False
- ASPECT_RATIO: 0.33
- BLUR: True
- BLUR_RATIO: 0.1
- FLIP: True
- FLIP_RATIO: 0.2
- MAX_ROTATION: 15
- MIN_AREA_RATIO: 0.5
- BRIGHTNESS_JITTER_RATIO: 0.5
- CONTRAST_JITTER_RATIO: 0.5
- SATURATION_JITTER_RATIO: 0.5
BATCH_SIZE: 4
DATASET:
DATA_DIR: "./dataset/cityscapes/"
@@ -44,8 +32,7 @@ TEST:
TEST_MODEL: "snapshots/cityscape_v5/final/"
TRAIN:
MODEL_SAVE_DIR: "snapshots/cityscape_v7/"
- PRETRAINED_MODEL: u"pretrain/deeplabv3plus_gn_init"
- RESUME: False
+ PRETRAINED_MODEL_DIR: "pretrain/deeplabv3plus_gn_init"
SNAPSHOT_EPOCH: 10
SOLVER:
LR: 0.001
diff --git a/configs/unet_pet.yaml b/configs/unet_pet.yaml
index 23bd68d5918fe89c3771cdc2e46871918b54e29c..2f3cc50e7e99ea7b8ff749d57f8319aa6b212a6f 100644
--- a/configs/unet_pet.yaml
+++ b/configs/unet_pet.yaml
@@ -12,18 +12,6 @@ AUG:
MIN_SCALE_FACTOR: 0.75 # for stepscaling
SCALE_STEP_SIZE: 0.25 # for stepscaling
MIRROR: True
- RICH_CROP:
- ENABLE: False
- ASPECT_RATIO: 0.33
- BLUR: True
- BLUR_RATIO: 0.1
- FLIP: True
- FLIP_RATIO: 0.2
- MAX_ROTATION: 15
- MIN_AREA_RATIO: 0.5
- BRIGHTNESS_JITTER_RATIO: 0.5
- CONTRAST_JITTER_RATIO: 0.5
- SATURATION_JITTER_RATIO: 0.5
BATCH_SIZE: 4
DATASET:
DATA_DIR: "./dataset/mini_pet/"
@@ -45,8 +33,7 @@ TEST:
TEST_MODEL: "./test/saved_model/unet_pet/final/"
TRAIN:
MODEL_SAVE_DIR: "./test/saved_models/unet_pet/"
- PRETRAINED_MODEL: "./test/models/unet_coco/"
- RESUME: False
+ PRETRAINED_MODEL_DIR: "./test/models/unet_coco/"
SNAPSHOT_EPOCH: 10
SOLVER:
NUM_EPOCHS: 500
diff --git a/contrib/ACE2P/README.md b/contrib/ACE2P/README.md
index 70bded0465794581bc8a84d04cf7012c2a94bb77..3b2a4400de02ba08eb9184163cc0f3593d2ec785 100644
--- a/contrib/ACE2P/README.md
+++ b/contrib/ACE2P/README.md
@@ -1,10 +1,5 @@
# Augmented Context Embedding with Edge Perceiving(ACE2P)
-
-- 类别: 图像-语义分割
-- 网络: ACE2P
-- 数据集: LIP
-
## 模型概述
人体解析(Human Parsing)是细粒度的语义分割任务,旨在识别像素级别的人类图像的组成部分(例如,身体部位和服装)。ACE2P通过融合底层特征、全局上下文信息和边缘细节,
端到端训练学习人体解析任务。以ACE2P单人人体解析网络为基础的解决方案在CVPR2019第三届LIP挑战赛中赢得了全部三个人体解析任务的第一名
diff --git a/dataset/download_cityscapes.py b/dataset/download_cityscapes.py
new file mode 100644
index 0000000000000000000000000000000000000000..ee25359e106ff634d28fe77f17f51f975168c228
--- /dev/null
+++ b/dataset/download_cityscapes.py
@@ -0,0 +1,33 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+
+LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
+TEST_PATH = os.path.join(LOCAL_PATH, "..", "test")
+sys.path.append(TEST_PATH)
+
+from test_utils import download_file_and_uncompress
+
+
+def download_cityscapes_dataset(savepath, extrapath):
+ url = "https://paddleseg.bj.bcebos.com/dataset/cityscapes.tar"
+ download_file_and_uncompress(
+ url=url, savepath=savepath, extrapath=extrapath)
+
+
+if __name__ == "__main__":
+ download_cityscapes_dataset(LOCAL_PATH, LOCAL_PATH)
+ print("Dataset download finish!")
diff --git a/dataset/download_pet.py b/dataset/download_pet.py
new file mode 100644
index 0000000000000000000000000000000000000000..e0473527e6de19c1841a0f5c1590ea576acbafaa
--- /dev/null
+++ b/dataset/download_pet.py
@@ -0,0 +1,33 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+
+LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
+TEST_PATH = os.path.join(LOCAL_PATH, "..", "test")
+sys.path.append(TEST_PATH)
+
+from test_utils import download_file_and_uncompress
+
+
+def download_pet_dataset(savepath, extrapath):
+ url = "https://paddleseg.bj.bcebos.com/dataset/mini_pet.zip"
+ download_file_and_uncompress(
+ url=url, savepath=savepath, extrapath=extrapath)
+
+
+if __name__ == "__main__":
+ download_pet_dataset(LOCAL_PATH, LOCAL_PATH)
+ print("Dataset download finish!")
diff --git a/docs/annotation/README.md b/docs/annotation/README.md
index 57c53b51da5d4474341b67cb57cf4a9c59067a5d..13a98e823eef195cef2acc457e7fa6df41bb9834 100644
--- a/docs/annotation/README.md
+++ b/docs/annotation/README.md
@@ -11,7 +11,7 @@
打开终端输入`labelme`会出现LableMe的交互界面,可以先预览`LabelMe`给出的已标注好的图片,再开始标注自定义数据集。
-

+

图1 LableMe交互界面的示意图
-

+

图2 已标注图片的示意图
-

+

图3 标注单个目标的示意图
-

+

图5 LableMe产出的真值文件的示意图
-

+

图6 训练所需的数据集目录的结构示意图
-

+

图7 训练所需的数据集各目录的内容示意图
@@ -19,7 +19,7 @@ BASIC Group存放所有通用配置
### 默认值
-[1.000, 1.000, 1.000]
+[0.5, 0.5, 0.5]
@@ -65,5 +65,7 @@ BASIC Group存放所有通用配置
* 增大BATCH_SIZE有利于模型训练时的收敛速度,但是会带来显存的开销。请根据实际情况评估后填写合适的值
+* 目前PaddleSeg提供的很多预训练模型都有BN层,如果BATCH SIZE设置为1,则此时训练可能不稳定导致nan
+
diff --git a/docs/configs/dataloader_group.md b/docs/configs/dataloader_group.md
index ff471833d2d014584cef7d72c4e708076b9820b5..8d324456b7c6880485491525590befbab9a2ae9c 100644
--- a/docs/configs/dataloader_group.md
+++ b/docs/configs/dataloader_group.md
@@ -13,7 +13,7 @@ DATALOADER Group存放所有与数据加载相关的配置
### 注意事项
* 该选项只在`pdseg/train.py`和`pdseg/eval.py`中使用到
-* 当使用多线程时,该字段表示线程数量,使用多进程时,该字段表示进程数量。一般该字段使用默认值即可
+* 该字段表示数据预处理时的进程数量,只有在`pdseg/train.py`或者`pdseg/eval.py`中打开了`--use_mpio`开关有效。一般该字段使用默认值即可
diff --git a/docs/configs/train_group.md b/docs/configs/train_group.md
index 3c7c0fbb6efc04d232bbe3ba54275cb91bac699b..6c8a0d79c79af665d8c7bf54a2b7555aa024bb8d 100644
--- a/docs/configs/train_group.md
+++ b/docs/configs/train_group.md
@@ -11,7 +11,7 @@ TRAIN Group存放所有和训练相关的配置
-## `PRETRAINED_MODEL`
+## `PRETRAINED_MODEL_DIR`
预训练模型路径
## 默认值
@@ -28,19 +28,15 @@ TRAIN Group存放所有和训练相关的配置
-## `RESUME`
-是否从预训练模型中恢复参数并继续训练
+## `RESUME_MODEL_DIR`
+从指定路径中恢复参数并继续训练
## 默认值
-False
+无
## 注意事项
-* 当该字段被置为True且`PRETRAINED_MODEL`不存在时,该选项不生效
-
-* 当该字段被置为True且`PRETRAINED_MODEL`存在时,PaddleSeg会恢复到上一次训练的最近一个epoch,并且恢复训练过程中的临时变量(如已经衰减过的学习率,Optimizer的动量数据等)
-
-* 当该字段被置为True且`PRETRAINED_MODEL`存在时,`PRETRAINED_MODEL`路径的最后一个目录必须为int数值或者字符串final,PaddleSeg会将int数值作为当前起始EPOCH继续训练,若目录为final,则不会继续训练。若目录不满足上述条件,PaddleSeg会抛出错误。
+* 当`RESUME_MODEL_DIR`存在时,PaddleSeg会恢复到上一次训练的最近一个epoch,并且恢复训练过程中的临时变量(如已经衰减过的学习率,Optimizer的动量数据等),`PRETRAINED_MODEL`路径的最后一个目录必须为int数值或者字符串final,PaddleSeg会将int数值作为当前起始EPOCH继续训练,若目录为final,则不会继续训练。若目录不满足上述条件,PaddleSeg会抛出错误。
@@ -57,4 +53,4 @@ False
* 仅在GPU多卡训练时该开关有效(Windows不支持多卡训练,因此无需打开该开关)
-* GPU多卡训练时,建议开启该开关,可以提升模型的训练效果
\ No newline at end of file
+* GPU多卡训练时,建议开启该开关,可以提升模型的训练效果
diff --git a/docs/data_aug.md b/docs/data_aug.md
index a8abdaab42ba145a9112961cb1c4b01bf4ab57ad..04a5ef3c6c3b37689fdace629f8973171904c389 100644
--- a/docs/data_aug.md
+++ b/docs/data_aug.md
@@ -55,7 +55,7 @@ rich crop是指对图像进行多种变换,保证在训练过程中数据的
- 输入图片格式
- 原图
- - 图片格式:rgb三通道图片和rgba四通道图片两种类型的图片进行训练,但是在一次训练过程只能存在一种格式。
+ - 图片格式:RGB三通道图片和RGBA四通道图片两种类型的图片进行训练,但是在一次训练过程只能存在一种格式。
- 图片转换:灰度图片经过预处理后之后会转变成三通道图片
- 图片参数设置:当图片为三通道图片时IMAGE_TYPE设置为rgb, 对应MEAN和STD也必须是一个长度为3的list,当图片为四通道图片时IMAGE_TYPE设置为rgba,对应的MEAN和STD必须是一个长度为4的list。
- 标注图
diff --git a/docs/data_prepare.md b/docs/data_prepare.md
index b1564124001a0598810cbb5b513852546919e583..13791dc5661e5e1393fda05469802e989d1e4d94 100644
--- a/docs/data_prepare.md
+++ b/docs/data_prepare.md
@@ -58,50 +58,3 @@ PaddleSeg采用通用的文件列表方式组织训练集、验证集和测试

完整的配置信息可以参考[`./dataset/cityscapes_demo`](../dataset/cityscapes_demo/)目录下的yaml和文件列表。
-
-## 数据校验
-从7方面对用户自定义的数据集和yaml配置进行校验,帮助用户排查基本的数据和配置问题。
-
-数据校验脚本如下,支持通过`YAML_FILE_PATH`来指定配置文件。
-```
-# YAML_FILE_PATH为yaml配置文件路径
-python pdseg/check.py --cfg ${YAML_FILE_PATH}
-```
-### 1 数据集基本校验
-* 数据集路径检查,包括`DATASET.TRAIN_FILE_LIST`,`DATASET.VAL_FILE_LIST`,`DATASET.TEST_FILE_LIST`设置是否正确。
-* 列表分割符检查,判断在`TRAIN_FILE_LIST`,`VAL_FILE_LIST`和`TEST_FILE_LIST`列表文件中的分隔符`DATASET.SEPARATOR`设置是否正确。
-
-### 2 标注类别校验
-检查实际标注类别是否和配置参数`DATASET.NUM_CLASSES`,`DATASET.IGNORE_INDEX`匹配。
-
-**NOTE:**
-标注图像类别数值必须在[0~(`DATASET.NUM_CLASSES`-1)]范围内或者为`DATASET.IGNORE_INDEX`。
-标注类别最好从0开始,否则可能影响精度。
-
-### 3 标注像素统计
-统计每种类别像素数量,显示以供参考。
-
-### 4 标注格式校验
-检查标注图像是否为PNG格式。
-
-**NOTE:** 标注图像请使用PNG无损压缩格式的图片,若使用其他格式则可能影响精度。
-
-### 5 图像格式校验
-检查图片类型`DATASET.IMAGE_TYPE`是否设置正确。
-
-**NOTE:** 当数据集包含三通道图片时`DATASET.IMAGE_TYPE`设置为rgb;
-当数据集全部为四通道图片时`DATASET.IMAGE_TYPE`设置为rgba;
-
-### 6 图像与标注图尺寸一致性校验
-验证图像尺寸和对应标注图尺寸是否一致。
-
-### 7 模型验证参数`EVAL_CROP_SIZE`校验
-验证`EVAL_CROP_SIZE`是否设置正确,共有3种情形:
-
-- 当`AUG.AUG_METHOD`为unpadding时,`EVAL_CROP_SIZE`的宽高应不小于`AUG.FIX_RESIZE_SIZE`的宽高。
-
-- 当`AUG.AUG_METHOD`为stepscaling时,`EVAL_CROP_SIZE`的宽高应不小于原图中最大的宽高。
-
-- 当`AUG.AUG_METHOD`为rangscaling时,`EVAL_CROP_SIZE`的宽高应不小于缩放后图像中最大的宽高。
-
-我们将计算并给出`EVAL_CROP_SIZE`的建议值。
diff --git a/docs/installation.md b/docs/installation.md
index cf544738326d7f1000f051a87db7108f22515de8..751a0f77bb42d885c798dcd676764dda3bcb3bcd 100644
--- a/docs/installation.md
+++ b/docs/installation.md
@@ -2,17 +2,18 @@
## 推荐开发环境
-* Python2.7 or 3.5+
+* Python 2.7 or 3.5+
* CUDA 9.2
-* cudnn v7.1
-
+* NVIDIA cuDNN v7.1
+* PaddlePaddle >= 1.5.2
+* 如果有多卡训练需求,请安装 NVIDIA NCCL >= 2.4.7,并在Linux环境下运行
## 1. 安装PaddlePaddle
### pip安装
-由于图像分割任务模型计算量大,强烈推荐在GPU版本的paddlepaddle下使用PaddleSeg.
+由于图像分割模型计算开销大,推荐在GPU版本的PaddlePaddle下使用PaddleSeg.
```
pip install paddlepaddle-gpu
@@ -26,7 +27,7 @@ PaddlePaddle最新版本1.5支持Conda安装,可以减少相关依赖安装成
conda install -c paddle paddlepaddle-gpu cudatoolkit=9.0
```
-更多安装方式详情可以查看 [PaddlePaddle快速开始](https://www.paddlepaddle.org.cn/start)
+更多安装方式详情可以查看 [PaddlePaddle安装说明](https://www.paddlepaddle.org.cn/documentation/docs/zh/beginners_guide/install/index_cn.html)
## 2. 下载PaddleSeg代码
@@ -39,14 +40,6 @@ git clone https://github.com/PaddlePaddle/PaddleSeg
## 3. 安装PaddleSeg依赖
```
+cd PaddleSeg
pip install -r requirements.txt
```
-
-
-## 4. 本地流程测试
-
-通过执行以下命令,会完整执行数据下载,训练,可视化,预测模型导出四个环节,用于验证PaddleSeg安装和依赖是否正常。
-
-```
-python test/local_test_cityscapes.py
-```
\ No newline at end of file
diff --git a/docs/model_export.md b/docs/model_export.md
new file mode 100644
index 0000000000000000000000000000000000000000..4389f2d07f445b861890f6ed0d3573e471bee72d
--- /dev/null
+++ b/docs/model_export.md
@@ -0,0 +1,21 @@
+# 模型导出
+
+通过训练得到一个满足要求的模型后,如果想要将该模型接入到C++预测库或者Serving服务,我们需要通过`pdseg/export_model.py`来导出该模型。
+
+该脚本的使用方法和`train.py/eval.py/vis.py`完全一样
+
+## FLAGS
+
+|FLAG|用途|默认值|备注|
+|-|-|-|-|
+|--cfg|配置文件路径|None||
+
+## 使用示例
+
+我们使用[训练/评估/可视化](./usage.md)一节中训练得到的模型进行试用,脚本如下
+
+```shell
+python pdseg/export_model.py --cfg configs/unet_pet.yaml TEST.TEST_MODEL test/saved_models/unet_pet/final
+```
+
+模型会导出到freeze_model目录
diff --git a/docs/model_zoo.md b/docs/model_zoo.md
index c3860ec1af61615423b2a7602575ad9d610f88ec..817acd5d55d55543f9a13c157d34f02b51fe4991 100644
--- a/docs/model_zoo.md
+++ b/docs/model_zoo.md
@@ -1,44 +1,44 @@
# PaddleSeg 预训练模型
-PaddleSeg对所有内置的分割模型都提供了公开数据集的下的预训练模型,通过加载预训练模型后训练可以在自定义数据集中得到更稳定地效果。
+PaddleSeg对所有内置的分割模型都提供了公开数据集下的预训练模型,通过加载预训练模型后训练可以在自定义数据集中得到更稳定地效果。
## ImageNet预训练模型
-所有Imagenet预训练模型来自于PaddlePaddle图像分类库,想获取更多细节请点击[这里](https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification))
+所有Imagenet预训练模型来自于PaddlePaddle图像分类库,想获取更多细节请点击[这里](https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification)
-| 模型 | 数据集合 | Depth multiplier | 模型加载config设置 | 下载地址 | Accuray Top1/5 Error|
-|---|---|---|---|---|---|
-| MobieNetV2_1.0x | ImageNet | 1.0x | MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.0
MODEL.DEFAULT_NORM_TYPE: bn| [MobileNetV2_1.0x](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_pretrained.tar) | 72.15%/90.65% |
-| MobieNetV2_0.25x | ImageNet | 0.25x | MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 0.25
MODEL.DEFAULT_NORM_TYPE: bn |[MobileNetV2_0.25x](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_x0_25_pretrained.tar) | 53.21%/76.52% |
-| MobieNetV2_0.5x | ImageNet | 0.5x | MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 0.5
MODEL.DEFAULT_NORM_TYPE: bn | [MobileNetV2_0.5x](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_x0_5_pretrained.tar) | 65.03%/85.72% |
-| MobieNetV2_1.5x | ImageNet | 1.5x | MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.5
MODEL.DEFAULT_NORM_TYPE: bn| [MobileNetV2_1.5x](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_x1_5_pretrained.tar) | 74.12%/91.67% |
-| MobieNetV2_2.0x | ImageNet | 2.0x | MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 2.0
MODEL.DEFAULT_NORM_TYPE: bn | [MobileNetV2_2.0x](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_x2_0_pretrained.tar) | 75.23%/92.58% |
+| 模型 | 数据集合 | Depth multiplier | 下载地址 | Accuray Top1/5 Error|
+|---|---|---|---|---|
+| MobieNetV2_1.0x | ImageNet | 1.0x | [MobileNetV2_1.0x](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_pretrained.tar) | 72.15%/90.65% |
+| MobieNetV2_0.25x | ImageNet | 0.25x |[MobileNetV2_0.25x](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_x0_25_pretrained.tar) | 53.21%/76.52% |
+| MobieNetV2_0.5x | ImageNet | 0.5x | [MobileNetV2_0.5x](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_x0_5_pretrained.tar) | 65.03%/85.72% |
+| MobieNetV2_1.5x | ImageNet | 1.5x | [MobileNetV2_1.5x](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_x1_5_pretrained.tar) | 74.12%/91.67% |
+| MobieNetV2_2.0x | ImageNet | 2.0x | [MobileNetV2_2.0x](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_x2_0_pretrained.tar) | 75.23%/92.58% |
用户可以结合实际场景的精度和预测性能要求,选取不同`Depth multiplier`参数的MobileNet模型。
-| 模型 | 数据集合 | 模型加载config设置 | 下载地址 | Accuray Top1/5 Error |
-|---|---|---|---|---|
-| Xception41 | ImageNet | MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_41
MODEL.DEFAULT_NORM_TYPE: bn| [Xception41_pretrained.tgz](https://paddleseg.bj.bcebos.com/models/Xception41_pretrained.tgz) | 79.5%/94.38% |
-| Xception65 | ImageNet | MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: bn| [Xception65_pretrained.tgz](https://paddleseg.bj.bcebos.com/models/Xception65_pretrained.tgz) | 80.32%/94.47% |
-| Xception71 | ImageNet | MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_71
MODEL.DEFAULT_NORM_TYPE: bn| coming soon | -- |
+| 模型 | 数据集合 | 下载地址 | Accuray Top1/5 Error |
+|---|---|---|---|
+| Xception41 | ImageNet | [Xception41_pretrained.tgz](https://paddleseg.bj.bcebos.com/models/Xception41_pretrained.tgz) | 79.5%/94.38% |
+| Xception65 | ImageNet | [Xception65_pretrained.tgz](https://paddleseg.bj.bcebos.com/models/Xception65_pretrained.tgz) | 80.32%/94.47% |
+| Xception71 | ImageNet | coming soon | -- |
## COCO预训练模型
-train数据集为coco instance分割数据集合转换成的语义分割数据集合
+数据集为COCO实例分割数据集合转换成的语义分割数据集合
-| 模型 | 数据集合 | 模型加载config设置 | 下载地址 |Output Strid|multi-scale test| mIoU |
-|---|---|---|---|---|---|---|
-| DeepLabv3+/MobileNetv2/bn | COCO | MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.0
MODEL.DEFAULT_NORM_TYPE: bn|[deeplabv3plus_coco_bn_init.tgz](https://bj.bcebos.com/v1/paddleseg/deeplabv3plus_coco_bn_init.tgz) | 16 | --| -- |
-| DeeplabV3+/Xception65/bn | COCO | MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: bn | [xception65_coco.tgz](https://paddleseg.bj.bcebos.com/models/xception65_coco.tgz)| 16 | -- | -- |
-| UNet/bn | COCO | MODEL.MODEL_NEME: unet
MODEL.DEFAULT_NORM_TYPE: bn | [unet](https://paddleseg.bj.bcebos.com/models/unet_coco_v3.tgz) | 16 | -- | -- |
+| 模型 | 数据集合 | 下载地址 |Output Strid|multi-scale test| mIoU |
+|---|---|---|---|---|---|
+| DeepLabv3+/MobileNetv2/bn | COCO |[deeplabv3plus_coco_bn_init.tgz](https://bj.bcebos.com/v1/paddleseg/deeplabv3plus_coco_bn_init.tgz) | 16 | --| -- |
+| DeeplabV3+/Xception65/bn | COCO | [xception65_coco.tgz](https://paddleseg.bj.bcebos.com/models/xception65_coco.tgz)| 16 | -- | -- |
+| U-Net/bn | COCO | [unet_coco.tgz](https://paddleseg.bj.bcebos.com/models/unet_coco_v3.tgz) | 16 | -- | -- |
## Cityscapes预训练模型
-train数据集合为Cityscapes 训练集合,测试为Cityscapes的验证集合
+train数据集合为Cityscapes训练集合,测试为Cityscapes的验证集合
-| 模型 | 数据集合 | 模型加载config设置 | 下载地址 |Output Stride| mutli-scale test| mIoU on val|
-|---|---|---|---|---|---|---|
-| DeepLabv3+/MobileNetv2/bn | Cityscapes |MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.0
MODEL.DEEPLAB.ENCODER_WITH_ASPP: False
MODEL.DEEPLAB.ENABLE_DECODER: False
MODEL.DEFAULT_NORM_TYPE: bn|[mobilenet_cityscapes.tgz](https://paddleseg.bj.bcebos.com/models/mobilenet_cityscapes.tgz) |16|false| 0.698|
-| DeepLabv3+/Xception65/gn | Cityscapes |MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: gn | [deeplabv3p_xception65_cityscapes.tgz](https://paddleseg.bj.bcebos.com/models/deeplabv3p_xception65_cityscapes.tgz) |16|false| 0.7804 |
-| DeepLabv3+/Xception65/bn | Cityscapes | MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: bn| [Xception65_deeplab_cityscapes.tgz](https://paddleseg.bj.bcebos.com/models/xception65_bn_cityscapes.tgz) | 16 | false | 0.7715 |
-| ICNet/bn | Cityscapes | MODEL.MODEL_NAME: icnet
MODEL.DEFAULT_NORM_TYPE: bn | [icnet_cityscapes.tgz](https://paddleseg.bj.bcebos.com/models/icnet_cityscapes.tgz) |16|false| 0.6854 |
+| 模型 | 数据集合 | 下载地址 |Output Stride| mutli-scale test| mIoU on val|
+|---|---|---|---|---|---|
+| DeepLabv3+/MobileNetv2/bn | Cityscapes |[mobilenet_cityscapes.tgz](https://paddleseg.bj.bcebos.com/models/mobilenet_cityscapes.tgz) |16|false| 0.698|
+| DeepLabv3+/Xception65/gn | Cityscapes |[deeplabv3p_xception65_cityscapes.tgz](https://paddleseg.bj.bcebos.com/models/deeplabv3p_xception65_cityscapes.tgz) |16|false| 0.7804 |
+| DeepLabv3+/Xception65/bn | Cityscapes |[Xception65_deeplab_cityscapes.tgz](https://paddleseg.bj.bcebos.com/models/xception65_bn_cityscapes.tgz) | 16 | false | 0.7715 |
+| ICNet/bn | Cityscapes |[icnet_cityscapes.tgz](https://paddleseg.bj.bcebos.com/models/icnet6831.tar.gz) |16|false| 0.6831 |
diff --git a/docs/models.md b/docs/models.md
index fb3c043747fa5dc2c3fa25c3b0715328bc7aaeea..680dfe87356db9dd6be181e003598d3eb8967ffe 100644
--- a/docs/models.md
+++ b/docs/models.md
@@ -1,4 +1,4 @@
-# PaddleSeg 模型列表
+# PaddleSeg 分割模型介绍
### U-Net
U-Net 起源于医疗图像分割,整个网络是标准的encoder-decoder网络,特点是参数少,计算快,应用性强,对于一般场景适应度很高。
diff --git a/docs/usage.md b/docs/usage.md
index 80c1c06556e45d53735b1c5b982678211f1fe276..7b06846c565281ede2dab7bc5d40eaa1eb607941 100644
--- a/docs/usage.md
+++ b/docs/usage.md
@@ -1,14 +1,14 @@
-PaddleSeg提供了 `训练`/`评估`/`预测(可视化)`/`模型导出` 等四个功能的使用脚本。四个脚本都支持通过不同的Flags来开启特定功能,也支持通过Options来修改默认的[训练配置](./config.md)。四者的使用方式非常接近,如下:
+# 训练/评估/可视化
+
+PaddleSeg提供了 `训练`/`评估`/`可视化` 等三个功能的使用脚本。三个脚本都支持通过不同的Flags来开启特定功能,也支持通过Options来修改默认的[训练配置](./config.md)。三者的使用方式非常接近,如下:
```shell
# 训练
python pdseg/train.py ${FLAGS} ${OPTIONS}
# 评估
python pdseg/eval.py ${FLAGS} ${OPTIONS}
-# 预测/可视化
+# 可视化
python pdseg/vis.py ${FLAGS} ${OPTIONS}
-# 模型导出
-python pdseg/export_model.py ${FLAGS} ${OPTIONS}
```
`Note`:
@@ -25,7 +25,7 @@ python pdseg/export_model.py ${FLAGS} ${OPTIONS}
|FLAG|支持脚本|用途|默认值|备注|
|-|-|-|-|-|
|--cfg|ALL|配置文件路径|None||
-|--use_gpu|train/eval/vis|是否使用GPU进行训练|False||
+|--use_gpu|ALL|是否使用GPU进行训练|False||
|--use_mpio|train/eval|是否使用多线程进行IO处理|False|打开该开关会占用一定量的CPU内存,但是可以提高训练速度。 NOTE:windows平台下不支持该功能, 建议使用自定义数据初次训练时不打开,打开会导致数据读取异常不可见。 |
|--use_tb|train|是否使用TensorBoard记录训练数据|False||
|--log_steps|train|训练日志的打印周期(单位为step)|10||
@@ -40,67 +40,57 @@ python pdseg/export_model.py ${FLAGS} ${OPTIONS}
详见[训练配置](./config.md)
## 使用示例
-下面通过一个简单的示例,说明如何使用PaddleSeg提供的预训练模型进行finetune。我们选择基于COCO数据集预训练的unet模型作为pretrained模型,在一个Oxford-IIIT Pet数据集上进行finetune。
+下面通过一个简单的示例,说明如何基于PaddleSeg提供的预训练模型启动训练。我们选择基于COCO数据集预训练的unet模型作为预训练模型,在一个Oxford-IIIT Pet数据集上进行训练。
**Note:** 为了快速体验,我们使用Oxford-IIIT Pet做了一个小型数据集,后续数据都使用该小型数据集。
### 准备工作
在开始教程前,请先确认准备工作已经完成:
-1. 下载合适版本的paddlepaddle
+1. 正确安装了PaddlePaddle
2. PaddleSeg相关依赖已经安装
如果有不确认的地方,请参考[安装说明](./installation.md)
### 下载预训练模型
```shell
-# 下载预训练模型
-wget https://bj.bcebos.com/v1/paddleseg/models/unet_coco_init.tgz
-# 解压缩到当前路径下
-tar xvzf unet_coco_init.tgz
+# 下载预训练模型并进行解压
+python pretrained_model/download_model.py unet_bn_coco
```
-### 下载Oxford-IIIT数据集
+### 下载mini_pet数据集
+我们使用了Oxford-IIIT中的猫和狗两个类别数据制作了一个小数据集mini_pet,用于快速体验
```shell
-# 下载Oxford-IIIT Pet数据集
-wget https://paddleseg.bj.bcebos.com/dataset/mini_pet.zip --no-check-certificate
-# 解压缩到当前路径下
-unzip mini_pet.zip
+# 下载预训练模型并进行解压
+python dataset/download_pet.py
```
-### Finetune
-接着开始Finetune,为了方便体验,我们在configs目录下放置了Oxford-IIIT Pet所对应的配置文件`unet_pet.yaml`,可以通过`--cfg`指向该文件来设置训练配置。
+### 模型训练
-我们选择两张GPU进行训练,这可以通过环境变量`CUDA_VISIBLE_DEVICES`来指定。
+为了方便体验,我们在configs目录下放置了mini_pet所对应的配置文件`unet_pet.yaml`,可以通过`--cfg`指向该文件来设置训练配置。
-除此之外,我们指定总BATCH_SIZE为4,PaddleSeg会根据可用的GPU数量,将数据平分到每张卡上,务必确保BATCH_SIZE为GPU数量的整数倍(在本例中,每张卡的BATCH_SIZE为2)。
+我们选择GPU 0号卡进行训练,这可以通过环境变量`CUDA_VISIBLE_DEVICES`来指定。
```
-export CUDA_VISIBLE_DEVICES=0,1
+export CUDA_VISIBLE_DEVICES=0
python pdseg/train.py --use_gpu \
--do_eval \
--use_tb \
--tb_log_dir train_log \
--cfg configs/unet_pet.yaml \
BATCH_SIZE 4 \
- TRAIN.PRETRAINED_MODEL unet_coco_init \
- DATASET.DATA_DIR mini_pet \
- DATASET.TEST_FILE_LIST mini_pet/file_list/test_list.txt \
- DATASET.TRAIN_FILE_LIST mini_pet/file_list/train_list.txt \
- DATASET.VAL_FILE_LIST mini_pet/file_list/val_list.txt \
- DATASET.VIS_FILE_LIST mini_pet/file_list/val_list.txt \
+ TRAIN.PRETRAINED_MODEL_DIR pretrained_model/unet_bn_coco \
TRAIN.SYNC_BATCH_NORM True \
SOLVER.LR 5e-5
```
`NOTE`:
-> * 上述示例中,一共存在三套配置方案: PaddleSeg默认配置/unet_pet.yaml/OPTIONS,三者的优先级顺序为 OPTIONS > yaml > 默认配置。这个原则对于train.py/eval.py/vis.py/export_model.py都适用
+> * 上述示例中,一共存在三套配置方案: PaddleSeg默认配置/unet_pet.yaml/OPTIONS,三者的优先级顺序为 OPTIONS > yaml > 默认配置。这个原则对于train.py/eval.py/vis.py都适用
>
> * 如果发现因为内存不足而Crash。请适当调低BATCH_SIZE。如果本机GPU内存充足,则可以调高BATCH_SIZE的大小以获得更快的训练速度
->
-> * windows并不支持多卡训练
### 训练过程可视化
当打开do_eval和use_tb两个开关后,我们可以通过TensorBoard查看训练的效果
+
```shell
tensorboard --logdir train_log --host {$HOST_IP} --port {$PORT}
```
@@ -121,30 +111,17 @@ NOTE:
```shell
python pdseg/eval.py --use_gpu \
--cfg configs/unet_pet.yaml \
- DATASET.DATA_DIR mini_pet \
- DATASET.VAL_FILE_LIST mini_pet/file_list/val_list.txt \
TEST.TEST_MODEL test/saved_models/unet_pet/final
```
-### 模型预测/可视化
+### 模型可视化
通过vis.py来评估模型效果,我们选择最后保存的模型进行效果的评估:
```shell
python pdseg/vis.py --use_gpu \
--cfg configs/unet_pet.yaml \
- DATASET.DATA_DIR mini_pet \
- DATASET.TEST_FILE_LIST mini_pet/file_list/test_list.txt \
TEST.TEST_MODEL test/saved_models/unet_pet/final
```
`NOTE`
1. 可视化的图片会默认保存在visual/visual_results目录下,可以通过`--vis_dir`来指定输出目录
2. 训练过程中会使用DATASET.VIS_FILE_LIST中的图片进行可视化显示,而vis.py则会使用DATASET.TEST_FILE_LIST
-
-### 模型导出
-当确定模型效果满足预期后,我们需要通过export_model.py来导出一个可用于部署到服务端预测的模型:
-```shell
-python pdseg/export_model.py --cfg configs/unet_pet.yaml \
- TEST.TEST_MODEL test/saved_models/unet_pet/final
-```
-
-模型会导出到freeze_model目录,接下来就是进行模型的部署,相关步骤,请查看[模型部署](../inference/README.md)
diff --git a/inference/CMakeLists.txt b/inference/CMakeLists.txt
index 4480161b4557c4ce507f93b41596b0e887c4f21d..994befc87be458ecab679c637d17cfd6239019fb 100644
--- a/inference/CMakeLists.txt
+++ b/inference/CMakeLists.txt
@@ -36,7 +36,7 @@ if (NOT DEFINED OPENCV_DIR OR ${OPENCV_DIR} STREQUAL "")
endif()
include_directories("${CMAKE_SOURCE_DIR}/")
-include_directories("${CMAKE_CURRENT_BINARY_DIR}/ext/yaml-cpp/src/yaml-cpp/include")
+include_directories("${CMAKE_CURRENT_BINARY_DIR}/ext/yaml-cpp/src/ext-yaml-cpp/include")
include_directories("${PADDLE_DIR}/")
include_directories("${PADDLE_DIR}/third_party/install/protobuf/include")
include_directories("${PADDLE_DIR}/third_party/install/glog/include")
@@ -82,7 +82,7 @@ if (WIN32)
add_definitions(-DSTATIC_LIB)
endif()
else()
- set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++14")
+ set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -o2 -std=c++11")
set(CMAKE_STATIC_LIBRARY_PREFIX "")
endif()
@@ -160,14 +160,13 @@ if (NOT WIN32)
set(EXTERNAL_LIB "-lrt -ldl -lpthread")
set(DEPS ${DEPS}
${MATH_LIB} ${MKLDNN_LIB}
- glog gflags protobuf snappystream snappy z xxhash
+ glog gflags protobuf yaml-cpp snappystream snappy z xxhash
${EXTERNAL_LIB})
else()
set(DEPS ${DEPS}
${MATH_LIB} ${MKLDNN_LIB}
opencv_world346 glog libyaml-cppmt gflags_static libprotobuf snappy zlibstatic xxhash snappystream ${EXTERNAL_LIB})
set(DEPS ${DEPS} libcmt shlwapi)
- set(DEPS ${DEPS} ${YAML_CPP_LIBRARY})
endif(NOT WIN32)
if(WITH_GPU)
@@ -206,13 +205,17 @@ ADD_LIBRARY(libpaddleseg_inference STATIC ${PADDLESEG_INFERENCE_SRCS})
target_link_libraries(libpaddleseg_inference ${DEPS})
add_executable(demo demo.cpp)
-ADD_DEPENDENCIES(libpaddleseg_inference yaml-cpp)
-ADD_DEPENDENCIES(demo yaml-cpp libpaddleseg_inference)
+ADD_DEPENDENCIES(libpaddleseg_inference ext-yaml-cpp)
+ADD_DEPENDENCIES(demo ext-yaml-cpp libpaddleseg_inference)
target_link_libraries(demo ${DEPS} libpaddleseg_inference)
-
-add_custom_command(TARGET demo POST_BUILD
+if (WIN32)
+ add_custom_command(TARGET demo POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.dll ./mklml.dll
COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.dll ./libiomp5md.dll
- COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mkldnn/bin/mkldnn.dll ./mkldnn.dll
- )
\ No newline at end of file
+ COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mkldnn/lib/mkldnn.dll ./mkldnn.dll
+ COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/mklml.dll ./release/mklml.dll
+ COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mklml/lib/libiomp5md.dll ./release/libiomp5md.dll
+ COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_DIR}/third_party/install/mkldnn/lib/mkldnn.dll ./mkldnn.dll
+ )
+endif()
diff --git a/inference/README.md b/inference/README.md
index e11ffb72e9d515c0302078d32dc4e7b09b4df9c3..a29a45b54de496399809081a3dd4bd0c8cbde929 100644
--- a/inference/README.md
+++ b/inference/README.md
@@ -4,132 +4,133 @@
本目录提供一个跨平台的图像分割模型的C++预测部署方案,用户通过一定的配置,加上少量的代码,即可把模型集成到自己的服务中,完成图像分割的任务。
-主要设计的目标包括以下三点:
-- 跨平台,支持在 windows和Linux完成编译、开发和部署
+主要设计的目标包括以下四点:
+- 跨平台,支持在 windows 和 Linux 完成编译、开发和部署
- 支持主流图像分割任务,用户通过少量配置即可加载模型完成常见预测任务,比如人像分割等
- 可扩展性,支持用户针对新模型开发自己特殊的数据预处理、后处理等逻辑
-
+- 高性能,除了`PaddlePaddle`自身带来的性能优势,我们还针对图像分割的特点对关键步骤进行了性能优化
## 主要目录和文件
-| 文件 | 作用 |
-|-------|----------|
-| CMakeList.txt | cmake 编译配置文件 |
-| external-cmake| 依赖的外部项目 cmake (目前仅有yaml-cpp)|
-| demo.cpp | 示例C++代码,演示加载模型完成预测任务 |
-| predictor | 加载模型并预测的类代码|
-| preprocess |数据预处理相关的类代码|
-| utils | 一些基础公共函数|
-| images/humanseg | 样例人像分割模型的测试图片目录|
-| conf/humanseg.yaml | 示例人像分割模型配置|
-| tools/visualize.py | 预测结果彩色可视化脚本 |
-
-## Windows平台编译
-
-### 前置条件
-* Visual Studio 2015+
-* CUDA 8.0 / CUDA 9.0 + CuDNN 7
-* CMake 3.0+
-
-我们分别在 `Visual Studio 2015` 和 `Visual Studio 2019 Community` 两个版本下做了测试.
-
-**下面所有示例,以根目录为 `D:\`演示**
-
-### Step1: 下载代码
-
-1. `git clone http://gitlab.baidu.com/Paddle/PaddleSeg.git`
-2. 拷贝 `D:\PaddleSeg\inference\` 目录到 `D:\PaddleDeploy`下
-
-目录`D:\PaddleDeploy\inference` 目录包含了`CMakelist.txt`以及代码等项目文件.
-
-
-
-### Step2: 下载PaddlePaddle预测库fluid_inference
-根据Windows环境,下载相应版本的PaddlePaddle预测库,并解压到`D:\PaddleDeploy\`目录
-
-| CUDA | GPU | 下载地址 |
-|------|------|--------|
-| 8.0 | Yes | [fluid_inference.zip](https://bj.bcebos.com/v1/paddleseg/fluid_inference_win.zip) |
-| 9.0 | Yes | [fluid_inference_cuda90.zip](https://paddleseg.bj.bcebos.com/fluid_inference_cuda9_cudnn7.zip) |
-
-`D:\PaddleDeploy\fluid_inference`目录包含内容为:
-```bash
-paddle # paddle核心目录
-third_party # paddle 第三方依赖
-version.txt # 编译的版本信息
```
+inference
+├── demo.cpp # 演示加载模型、读入数据、完成预测任务C++代码
+|
+├── conf
+│ └── humanseg.yaml # 示例人像分割模型配置
+├── images
+│ └── humanseg # 示例人像分割模型测试图片目录
+├── tools
+│ └── visualize.py # 示例人像分割模型结果可视化脚本
+├── docs
+| ├── linux_build.md # Linux 编译指南
+| ├── windows_vs2015_build.md # windows VS2015编译指南
+│ └── windows_vs2019_build.md # Windows VS2019编译指南
+|
+├── utils # 一些基础公共函数
+|
+├── preprocess # 数据预处理相关代码
+|
+├── predictor # 模型加载和预测相关代码
+|
+├── CMakeList.txt # cmake编译入口文件
+|
+└── external-cmake # 依赖的外部项目cmake(目前仅有yaml-cpp)
+```
-### Step3: 安装配置OpenCV
+## 编译
+支持在`Windows`和`Linux`平台编译和使用:
+- [Linux 编译指南](./docs/linux_build.md)
+- [Windows 使用 Visual Studio 2019 Community 编译指南](./docs/windows_vs2019_build.md)
+- [Windows 使用 Visual Studio 2015 编译指南](./docs/windows_vs2015_build.md)
-1. 在OpenCV官网下载适用于Windows平台的3.4.6版本, [下载地址](https://sourceforge.net/projects/opencvlibrary/files/3.4.6/opencv-3.4.6-vc14_vc15.exe/download)
-2. 运行下载的可执行文件,将OpenCV解压至指定目录,如`D:\PaddleDeploy\opencv`
-3. 配置环境变量,如下流程所示
- 1. 我的电脑->属性->高级系统设置->环境变量
- 2. 在系统变量中找到Path(如没有,自行创建),并双击编辑
- 3. 新建,将opencv路径填入并保存,如`D:\PaddleDeploy\opencv\build\x64\vc14\bin`
+`Windows`上推荐使用最新的`Visual Studio 2019 Community`直接编译`CMake`项目。
-### Step4: 以VS2015为例编译代码
+## 预测并可视化结果
-以下命令需根据自己系统中各相关依赖的路径进行修改
+完成编译后,便生成了需要的可执行文件和链接库,然后执行以下步骤:
-* 调用VS2015, 请根据实际VS安装路径进行调整,打开cmd命令行工具执行以下命令
-* 其他vs版本,请查找到对应版本的`vcvarsall.bat`路径,替换本命令即可
+### 1. 下载模型文件
+我们提供了一个人像分割模型示例用于测试,点击右侧地址下载:[示例模型下载地址](https://paddleseg.bj.bcebos.com/inference_model/deeplabv3p_xception65_humanseg.tgz)
+下载并解压,解压后目录结构如下:
```
-call "C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\vcvarsall.bat" amd64
+deeplabv3p_xception65_humanseg
+├── __model__ # 模型文件
+|
+└── __params__ # 参数文件
```
-
-* CMAKE编译工程
- * PADDLE_DIR: fluid_inference预测库目录
- * CUDA_LIB: CUDA动态库目录, 请根据实际安装情况调整
- * OPENCV_DIR: OpenCV解压目录
-
-```
-# 创建CMake的build目录
-D:
-cd PaddleDeploy\inference
-mkdir build
-cd build
-D:\PaddleDeploy\inference\build> cmake .. -G "Visual Studio 14 2015 Win64" -DWITH_GPU=ON -DPADDLE_DIR=D:\PaddleDeploy\fluid_inference -DCUDA_LIB=D:\PaddleDeploy\cudalib\v8.0\lib\x64 -DOPENCV_DIR=D:\PaddleDeploy\opencv -T host=x64
+解压后把上述目录拷贝到合适的路径:
+
+**假设**`Windows`系统上,我们模型和参数文件所在路径为`D:\projects\models\deeplabv3p_xception65_humanseg`。
+
+**假设**`Linux`上对应的路径则为`/root/projects/models/deeplabv3p_xception65_humanseg`。
+
+
+### 2. 修改配置
+源代码的`conf`目录下提供了示例人像分割模型的配置文件`humanseg.yaml`, 相关的字段含义和说明如下:
+```yaml
+DEPLOY:
+ # 是否使用GPU预测
+ USE_GPU: 1
+ # 模型和参数文件所在目录路径
+ MODEL_PATH: "/root/projects/models/deeplabv3p_xception65_humanseg"
+ # 模型文件名
+ MODEL_FILENAME: "__model__"
+ # 参数文件名
+ PARAMS_FILENAME: "__params__"
+ # 预测图片的的标准输入尺寸,输入尺寸不一致会做resize
+ EVAL_CROP_SIZE: (513, 513)
+ # 均值
+ MEAN: [104.008, 116.669, 122.675]
+ # 方差
+ STD: [1.0, 1.0, 1.0]
+ # 图片类型, rgb 或者 rgba
+ IMAGE_TYPE: "rgb"
+ # 分类类型数
+ NUM_CLASSES: 2
+ # 图片通道数
+ CHANNELS : 3
+ # 预处理方式,目前提供图像分割的通用处理类SegPreProcessor
+ PRE_PROCESSOR: "SegPreProcessor"
+ # 预测模式,支持 NATIVE 和 ANALYSIS
+ PREDICTOR_MODE: "ANALYSIS"
+ # 每次预测的 batch_size
+ BATCH_SIZE : 3
```
+修改字段`MODEL_PATH`的值为你在**上一步**下载并解压的模型文件所放置的目录即可。
-这里的`cmake`参数`-G`, 可以根据自己的`VS`版本调整,具体请参考[cmake文档](https://cmake.org/cmake/help/v3.15/manual/cmake-generators.7.html)
-* 生成可执行文件
+### 3. 执行预测
-```
-D:\PaddleDeploy\inference\build> msbuild /m /p:Configuration=Release cpp_inference_demo.sln
-```
-
-### Step5: 预测及可视化
-
-上步骤中编译生成的可执行文件和相关动态链接库并保存在build/Release目录下,可通过Windows命令行直接调用。
-可下载并解压示例模型进行测试,点击下载示例的人像分割模型[下载地址](https://paddleseg.bj.bcebos.com/inference_model/deeplabv3p_xception65_humanseg.tgz)
-
-假设解压至 `D:\PaddleDeploy\models\deeplabv3p_xception65_humanseg` ,执行以下命令:
+在终端中切换到生成的可执行文件所在目录为当前目录(Windows系统为`cmd`)。
+`Linux` 系统中执行以下命令:
+```shell
+./demo --conf=/root/projects/PaddleSeg/inference/conf/humanseg.yaml --input_dir=/root/projects/PaddleSeg/inference/images/humanseg/
```
-cd Release
-D:\PaddleDeploy\inference\build\Release> demo.exe --conf=D:\\PaddleDeploy\\inference\\conf\\humanseg.yaml --input_dir=D:\\PaddleDeploy\\inference\\images\humanseg\\
+`Windows` 中执行以下命令:
+```shell
+D:\projects\PaddleSeg\inference\build\Release>demo.exe --conf=D:\\projects\\PaddleSeg\\inference\\conf\\humanseg.yaml --input_dir=D:\\projects\\PaddleSeg\\inference\\images\humanseg\\
```
+
预测使用的两个命令参数说明如下:
| 参数 | 含义 |
|-------|----------|
-| conf | 模型配置的yaml文件路径 |
+| conf | 模型配置的Yaml文件路径 |
| input_dir | 需要预测的图片目录 |
-**配置文件**的样例以及字段注释说明请参考: [conf/humanseg.yaml](./conf/humanseg.yaml)
-样例程序会扫描input_dir目录下的所有图片,并生成对应的预测结果图片。
+配置文件说明请参考上一步,样例程序会扫描input_dir目录下的所有图片,并生成对应的预测结果图片:
文件`demo.jpg`预测的结果存储在`demo_jpg.png`中,可视化结果在`demo_jpg_scoremap.png`中, 原始尺寸的预测结果在`demo_jpg_recover.png`中。
输入原图
-
+
输出预测结果
-
+
diff --git a/inference/conf/humanseg.yaml b/inference/conf/humanseg.yaml
index cb5d2f165bfa3601cfec213e754d702b2e0c32ff..78195d9e8b4fe2d9ed2758ab76d8e5f88fd104a9 100644
--- a/inference/conf/humanseg.yaml
+++ b/inference/conf/humanseg.yaml
@@ -1,15 +1,15 @@
DEPLOY:
USE_GPU: 1
- MODEL_PATH: "C:\\PaddleDeploy\\models\\deeplabv3p_xception65_humanseg"
+ MODEL_PATH: "/root/projects/models/deeplabv3p_xception65_humanseg"
MODEL_NAME: "unet"
MODEL_FILENAME: "__model__"
PARAMS_FILENAME: "__params__"
EVAL_CROP_SIZE: (513, 513)
- MEAN: [104.008, 116.669, 122.675]
+ MEAN: [0.5, 0.5, 0.5]
STD: [1.0, 1.0, 1.0]
IMAGE_TYPE: "rgb"
NUM_CLASSES: 2
CHANNELS : 3
PRE_PROCESSOR: "SegPreProcessor"
- PREDICTOR_MODE: "ANALYSIS"
- BATCH_SIZE : 3
\ No newline at end of file
+ PREDICTOR_MODE: "NATIVE"
+ BATCH_SIZE : 3
diff --git a/inference/demo.cpp b/inference/demo.cpp
index 763e01b4ed163b7ac02800112a2faa114074bd12..657d4f4244069d0a59c4dee7827d047a375f2741 100644
--- a/inference/demo.cpp
+++ b/inference/demo.cpp
@@ -21,7 +21,6 @@ int main(int argc, char** argv) {
// 2. get all the images with extension '.jpeg' at input_dir
auto imgs = PaddleSolution::utils::get_directory_images(FLAGS_input_dir, ".jpeg|.jpg");
-
// 3. predict
predictor.predict(imgs);
return 0;
diff --git a/inference/docs/linux_build.md b/inference/docs/linux_build.md
new file mode 100644
index 0000000000000000000000000000000000000000..80dc2d0f24424ed7e2bdaa0a353cf86bd5b2c9ac
--- /dev/null
+++ b/inference/docs/linux_build.md
@@ -0,0 +1,85 @@
+# Linux平台 编译指南
+
+## 说明
+本文档在 `Linux`平台使用`GCC 4.8.5` 和 `GCC 4.9.4`测试过,如果需要使用更高G++版本编译使用,则需要重新编译Paddle预测库,请参考: [从源码编译Paddle预测库](https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/advanced_usage/deploy/inference/build_and_install_lib_cn.html#id15)。
+
+## 前置条件
+* G++ 4.8.2 ~ 4.9.4
+* CUDA 8.0/ CUDA 9.0
+* CMake 3.0+
+
+请确保系统已经安装好上述基本软件,**下面所有示例以工作目录为 `/root/projects/`演示**。
+
+### Step1: 下载代码
+
+1. `mkdir -p /root/projects/ && cd /root/projects`
+2. `git clone https://github.com/PaddlePaddle/PaddleSeg.git`
+
+`C++`预测代码在`/root/projects/PaddleSeg/inference` 目录,该目录不依赖任何`PaddleSeg`下其他目录。
+
+
+### Step2: 下载PaddlePaddle C++ 预测库 fluid_inference
+
+目前仅支持`CUDA 8` 和 `CUDA 9`,请点击 [PaddlePaddle预测库下载地址](https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/advanced_usage/deploy/inference/build_and_install_lib_cn.html)下载对应的版本。
+
+
+下载并解压后`/root/projects/fluid_inference`目录包含内容为:
+```
+fluid_inference
+├── paddle # paddle核心库和头文件
+|
+├── third_party # 第三方依赖库和头文件
+|
+└── version.txt # 版本和编译信息
+```
+
+### Step3: 安装配置OpenCV
+
+```shell
+# 0. 切换到/root/projects目录
+cd /root/projects
+# 1. 下载OpenCV3.4.6版本源代码
+wget -c https://paddleseg.bj.bcebos.com/inference/opencv-3.4.6.zip
+# 2. 解压
+unzip opencv-3.4.6.zip && cd opencv-3.4.6
+# 3. 创建build目录并编译, 这里安装到/usr/local/opencv3目录
+mkdir build && cd build
+cmake .. -DCMAKE_INSTALL_PREFIX=/root/projects/opencv3 -DCMAKE_BUILD_TYPE=Release -DBUILD_SHARED_LIBS=OFF -DWITH_ZLIB=ON -DBUILD_ZLIB=ON -DWITH_JPEG=ON -DBUILD_JPEG=ON -DWITH_PNG=ON -DBUILD_PNG=ON -DWITH_TIFF=ON -DBUILD_TIFF=ON
+make -j4
+make install
+```
+
+**注意:** 上述操作完成后,`opencv` 被安装在 `/root/projects/opencv3` 目录。
+
+### Step4: 编译
+
+`CMake`编译时,涉及到四个编译参数用于指定核心依赖库的路径, 他们的定义如下:
+
+| 参数名 | 含义 |
+| ---- | ---- |
+| CUDA_LIB | cuda的库路径 |
+| CUDNN_LIB | cuDnn的库路径|
+| OPENCV_DIR | OpenCV的安装路径, |
+| PADDLE_DIR | Paddle预测库的路径 |
+
+执行下列操作时,**注意**把对应的参数改为你的上述依赖库实际路径:
+
+```shell
+cd /root/projects/PaddleSeg/inference
+mkdir build && cd build
+cmake .. -DWITH_GPU=ON -DPADDLE_DIR=/root/projects/fluid_inference -DCUDA_LIB=/usr/local/cuda/lib64/ -DOPENCV_DIR=/root/projects/opencv3/ -DCUDNN_LIB=/usr/local/cuda/lib64/
+make
+```
+
+
+### Step5: 预测及可视化
+
+执行命令:
+
+```
+./demo --conf=/path/to/your/conf --input_dir=/path/to/your/input/data/directory
+```
+
+更详细说明请参考ReadMe文档: [预测和可视化部分](../README.md)
+
+
diff --git a/inference/docs/windows_vs2015_build.md b/inference/docs/windows_vs2015_build.md
new file mode 100644
index 0000000000000000000000000000000000000000..b57167aeb977be8b8003fb57bf5d12a4824c2059
--- /dev/null
+++ b/inference/docs/windows_vs2015_build.md
@@ -0,0 +1,98 @@
+# Windows平台使用 Visual Studio 2015 编译指南
+
+本文档步骤,我们同时在`Visual Studio 2015` 和 `Visual Studio 2019 Community` 两个版本进行了测试,我们推荐使用[`Visual Studio 2019`直接编译`CMake`项目](./windows_vs2019_build.md)。
+
+
+## 前置条件
+* Visual Studio 2015
+* CUDA 8.0/ CUDA 9.0
+* CMake 3.0+
+
+请确保系统已经安装好上述基本软件,**下面所有示例以工作目录为 `D:\projects`演示**。
+
+### Step1: 下载代码
+
+1. 打开`cmd`, 执行 `cd /d D:\projects`
+2. `git clone http://gitlab.baidu.com/Paddle/PaddleSeg.git`
+
+`C++`预测库代码在`D:\projects\PaddleSeg\inference` 目录,该目录不依赖任何`PaddleSeg`下其他目录。
+
+
+### Step2: 下载PaddlePaddle C++ 预测库 fluid_inference
+
+根据Windows环境,下载相应版本的PaddlePaddle预测库,并解压到`D:\projects\`目录
+
+| CUDA | GPU | 下载地址 |
+|------|------|--------|
+| 8.0 | Yes | [fluid_inference.zip](https://bj.bcebos.com/v1/paddleseg/fluid_inference_win.zip) |
+| 9.0 | Yes | [fluid_inference_cuda90.zip](https://paddleseg.bj.bcebos.com/fluid_inference_cuda9_cudnn7.zip) |
+
+解压后`D:\projects\fluid_inference`目录包含内容为:
+```
+fluid_inference
+├── paddle # paddle核心库和头文件
+|
+├── third_party # 第三方依赖库和头文件
+|
+└── version.txt # 版本和编译信息
+```
+
+### Step3: 安装配置OpenCV
+
+1. 在OpenCV官网下载适用于Windows平台的3.4.6版本, [下载地址](https://sourceforge.net/projects/opencvlibrary/files/3.4.6/opencv-3.4.6-vc14_vc15.exe/download)
+2. 运行下载的可执行文件,将OpenCV解压至指定目录,如`D:\PaddleDeploy\opencv`
+3. 配置环境变量,如下流程所示
+ - 我的电脑->属性->高级系统设置->环境变量
+ - 在系统变量中找到Path(如没有,自行创建),并双击编辑
+ - 新建,将opencv路径填入并保存,如`D:\PaddleDeploy\opencv\build\x64\vc14\bin`
+
+### Step4: 以VS2015为例编译代码
+
+以下命令需根据自己系统中各相关依赖的路径进行修改
+
+* 调用VS2015, 请根据实际VS安装路径进行调整,打开cmd命令行工具执行以下命令
+* 其他vs版本(比如vs2019),请查找到对应版本的`vcvarsall.bat`路径,替换本命令即可
+
+```
+call "C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\vcvarsall.bat" amd64
+```
+
+* CMAKE编译工程
+ * PADDLE_DIR: fluid_inference预测库路径
+ * CUDA_LIB: CUDA动态库目录, 请根据实际安装情况调整
+ * OPENCV_DIR: OpenCV解压目录
+
+```
+# 切换到预测库所在目录
+cd /d D:\projects\PaddleSeg\inference\
+# 创建构建目录, 重新构建只需要删除该目录即可
+mkdir build
+cd build
+# cmake构建VS项目
+D:\projects\PaddleSeg\inference\build> cmake .. -G "Visual Studio 14 2015 Win64" -DWITH_GPU=ON -DPADDLE_DIR=D:\projects\fluid_inference -DCUDA_LIB=D:\projects\cudalib\v8.0\lib\x64 -DOPENCV_DIR=D:\projects\opencv -T host=x64
+```
+
+这里的`cmake`参数`-G`, 表示生成对应的VS版本的工程,可以根据自己的`VS`版本调整,具体请参考[cmake文档](https://cmake.org/cmake/help/v3.15/manual/cmake-generators.7.html)
+
+* 生成可执行文件
+
+```
+D:\projects\PaddleSeg\inference\build> msbuild /m /p:Configuration=Release cpp_inference_demo.sln
+```
+
+### Step5: 预测及可视化
+
+上述`Visual Studio 2015`编译产出的可执行文件在`build\release`目录下,切换到该目录:
+```
+cd /d D:\projects\PaddleSeg\inference\build\release
+```
+
+之后执行命令:
+
+```
+demo.exe --conf=/path/to/your/conf --input_dir=/path/to/your/input/data/directory
+```
+
+更详细说明请参考ReadMe文档: [预测和可视化部分](../README.md)
+
+
diff --git a/inference/docs/windows_vs2019_build.md b/inference/docs/windows_vs2019_build.md
new file mode 100644
index 0000000000000000000000000000000000000000..b60201f7c7c16330fe50b4eb0f51019c4ec01f71
--- /dev/null
+++ b/inference/docs/windows_vs2019_build.md
@@ -0,0 +1,101 @@
+# Visual Studio 2019 Community CMake 编译指南
+
+Windows 平台下,我们使用`Visual Studio 2015` 和 `Visual Studio 2019 Community` 进行了测试。微软从`Visual Studio 2017`开始即支持直接管理`CMake`跨平台编译项目,但是直到`2019`才提供了稳定和完全的支持,所以如果你想使用CMake管理项目编译构建,我们推荐你使用`Visual Studio 2019`环境下构建。
+
+你也可以使用和`VS2015`一样,通过把`CMake`项目转化成`VS`项目来编译,其中**有差别的部分**在文档中我们有说明,请参考:[使用Visual Studio 2015 编译指南](./windows_vs2015_build.md)
+
+## 前置条件
+* Visual Studio 2019
+* CUDA 8.0/ CUDA 9.0
+* CMake 3.0+
+
+请确保系统已经安装好上述基本软件,我们使用的是`VS2019`的社区版。
+
+**下面所有示例以工作目录为 `D:\projects`演示**。
+
+### Step1: 下载代码
+
+1. 点击下载源代码:[下载地址](https://github.com/PaddlePaddle/PaddleSeg/archive/master.zip)
+2. 解压,解压后目录重命名为`PaddleSeg`
+
+以下代码目录路径为`D:\projects\PaddleSeg` 为例。
+
+
+### Step2: 下载PaddlePaddle C++ 预测库 fluid_inference
+
+根据Windows环境,下载相应版本的PaddlePaddle预测库,并解压到`D:\projects\`目录
+
+| CUDA | GPU | 下载地址 |
+|------|------|--------|
+| 8.0 | Yes | [fluid_inference.zip](https://bj.bcebos.com/v1/paddleseg/fluid_inference_win.zip) |
+| 9.0 | Yes | [fluid_inference_cuda90.zip](https://paddleseg.bj.bcebos.com/fluid_inference_cuda9_cudnn7.zip) |
+
+解压后`D:\projects\fluid_inference`目录包含内容为:
+```
+fluid_inference
+├── paddle # paddle核心库和头文件
+|
+├── third_party # 第三方依赖库和头文件
+|
+└── version.txt # 版本和编译信息
+```
+**注意:** `CUDA90`版本解压后目录名称为`fluid_inference_cuda90`。
+
+### Step3: 安装配置OpenCV
+
+1. 在OpenCV官网下载适用于Windows平台的3.4.6版本, [下载地址](https://sourceforge.net/projects/opencvlibrary/files/3.4.6/opencv-3.4.6-vc14_vc15.exe/download)
+2. 运行下载的可执行文件,将OpenCV解压至指定目录,如`D:\projects\opencv`
+3. 配置环境变量,如下流程所示
+ - 我的电脑->属性->高级系统设置->环境变量
+ - 在系统变量中找到Path(如没有,自行创建),并双击编辑
+ - 新建,将opencv路径填入并保存,如`D:\projects\opencv\build\x64\vc14\bin`
+
+### Step4: 使用Visual Studio 2019直接编译CMake
+
+1. 打开Visual Studio 2019 Community,点击`继续但无需代码`
+
+2. 点击: `文件`->`打开`->`CMake`
+
+
+选择项目代码所在路径,并打开`CMakeList.txt`:
+
+
+
+3. 点击:`项目`->`cpp_inference_demo的CMake设置`
+
+
+
+4. 点击`浏览`,分别设置编译选项指定`CUDA`、`OpenCV`、`Paddle预测库`的路径
+
+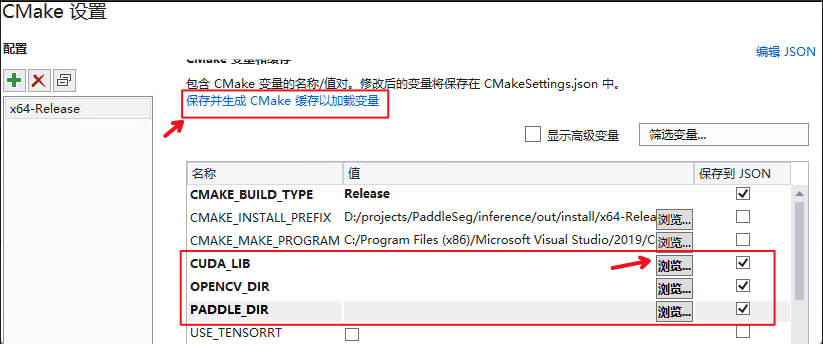
+
+三个编译参数的含义说明如下:
+
+| 参数名 | 含义 |
+| ---- | ---- |
+| CUDA_LIB | cuda的库路径 |
+| OPENCV_DIR | OpenCV的安装路径, |
+| PADDLE_DIR | Paddle预测库的路径 |
+
+**设置完成后**, 点击上图中`保存并生成CMake缓存以加载变量`。
+
+5. 点击`生成`->`全部生成`
+
+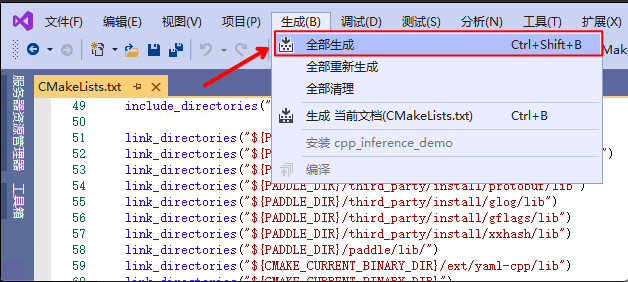
+
+
+### Step5: 预测及可视化
+
+上述`Visual Studio 2019`编译产出的可执行文件在`out\build\x64-Release`目录下,打开`cmd`,并切换到该目录:
+
+```
+cd /d D:\projects\PaddleSeg\inference\out\x64-Release
+```
+
+之后执行命令:
+
+```
+demo.exe --conf=/path/to/your/conf --input_dir=/path/to/your/input/data/directory
+```
+
+更详细说明请参考ReadMe文档: [预测和可视化部分](../ReadMe.md)
diff --git a/inference/external-cmake/yaml-cpp.cmake b/inference/external-cmake/yaml-cpp.cmake
index fefa1826876e5c25eef6367b6ca3bf49f72d7c10..15fa2674e00d85f1db7bbdfdceeebadaf0eabf5a 100644
--- a/inference/external-cmake/yaml-cpp.cmake
+++ b/inference/external-cmake/yaml-cpp.cmake
@@ -6,7 +6,7 @@ include(ExternalProject)
message("${CMAKE_BUILD_TYPE}")
ExternalProject_Add(
- yaml-cpp
+ ext-yaml-cpp
GIT_REPOSITORY https://github.com/jbeder/yaml-cpp.git
GIT_TAG e0e01d53c27ffee6c86153fa41e7f5e57d3e5c90
CMAKE_ARGS
@@ -26,4 +26,4 @@ ExternalProject_Add(
# Disable install step
INSTALL_COMMAND ""
LOG_DOWNLOAD ON
-)
\ No newline at end of file
+)
diff --git a/inference/images/humanseg/1.jpg b/inference/images/humanseg/1.jpg
deleted file mode 100644
index 33572fe5fcb36962e9b49cfcf7f9c888490226c1..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/1.jpg and /dev/null differ
diff --git a/inference/images/humanseg/10.jpg b/inference/images/humanseg/10.jpg
deleted file mode 100644
index 735d588935c618a4753f577b0411ca698de11030..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/10.jpg and /dev/null differ
diff --git a/inference/images/humanseg/11.jpg b/inference/images/humanseg/11.jpg
deleted file mode 100644
index 54ebeecf1c5374282cf1c5f927f655cdaafb03fe..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/11.jpg and /dev/null differ
diff --git a/inference/images/humanseg/12.jpg b/inference/images/humanseg/12.jpg
deleted file mode 100644
index 01c08457da7c8b077971b1801a4d209b2fbaee5a..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/12.jpg and /dev/null differ
diff --git a/inference/images/humanseg/13.jpg b/inference/images/humanseg/13.jpg
deleted file mode 100644
index bc989ebc693cb9b7cb2b8b78557e5d644b25712f..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/13.jpg and /dev/null differ
diff --git a/inference/images/humanseg/14.jpg b/inference/images/humanseg/14.jpg
deleted file mode 100644
index d5dbead2d253cca159028375f1a2c2dcae78a97f..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/14.jpg and /dev/null differ
diff --git a/inference/images/humanseg/2.jpg b/inference/images/humanseg/2.jpg
deleted file mode 100644
index b6e07945118facd5e40d4aa768394b3a3ef21201..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/2.jpg and /dev/null differ
diff --git a/inference/images/humanseg/3.jpg b/inference/images/humanseg/3.jpg
deleted file mode 100644
index 74a5e6e5841b3483dd5598a5390c13830fdc7b0e..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/3.jpg and /dev/null differ
diff --git a/inference/images/humanseg/4.jpg b/inference/images/humanseg/4.jpg
deleted file mode 100644
index 640fdf9167cd703b450dd4ad24d220ad4ea431a4..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/4.jpg and /dev/null differ
diff --git a/inference/images/humanseg/5.jpg b/inference/images/humanseg/5.jpg
deleted file mode 100644
index f6878129705b31f467729b06b176555cf6f956db..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/5.jpg and /dev/null differ
diff --git a/inference/images/humanseg/6.jpg b/inference/images/humanseg/6.jpg
deleted file mode 100644
index 3d10c0d1ea47987153f7c51e6b992d1dfe35d3ae..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/6.jpg and /dev/null differ
diff --git a/inference/images/humanseg/7.jpg b/inference/images/humanseg/7.jpg
deleted file mode 100644
index 41a99436a4d1cccdaf57e09646f1e40aca285a6b..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/7.jpg and /dev/null differ
diff --git a/inference/images/humanseg/8.jpg b/inference/images/humanseg/8.jpg
deleted file mode 100644
index 4f86baf95d9eb6b5849b84e58a7e2d47a18c8949..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/8.jpg and /dev/null differ
diff --git a/inference/images/humanseg/9.jpg b/inference/images/humanseg/9.jpg
deleted file mode 100644
index 9e4a6268ffc9377f729dcb391b1efef70139545c..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/9.jpg and /dev/null differ
diff --git a/inference/images/humanseg/demo.jpg b/inference/images/humanseg/demo.jpg
deleted file mode 100644
index 77b9a93e69db37e825c6e0c092636f9e4b3b5c33..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/demo.jpg and /dev/null differ
diff --git a/inference/images/humanseg/demo1.jpeg b/inference/images/humanseg/demo1.jpeg
new file mode 100644
index 0000000000000000000000000000000000000000..de231b52c7f0dc0848dea2bcf297cc8d908559ca
Binary files /dev/null and b/inference/images/humanseg/demo1.jpeg differ
diff --git a/inference/images/humanseg/demo2.jpeg b/inference/images/humanseg/demo2.jpeg
new file mode 100644
index 0000000000000000000000000000000000000000..c3919623107a4edc8210739d0f05930215f8cda6
Binary files /dev/null and b/inference/images/humanseg/demo2.jpeg differ
diff --git a/inference/images/humanseg/demo2_jpeg_recover.png b/inference/images/humanseg/demo2_jpeg_recover.png
new file mode 100644
index 0000000000000000000000000000000000000000..534bbd9443b1a93c65ce1ce7137a03a0ee0f864b
Binary files /dev/null and b/inference/images/humanseg/demo2_jpeg_recover.png differ
diff --git a/inference/images/humanseg/demo3.jpeg b/inference/images/humanseg/demo3.jpeg
new file mode 100644
index 0000000000000000000000000000000000000000..c02b837749065111d75a908d4f1182a593cdb143
Binary files /dev/null and b/inference/images/humanseg/demo3.jpeg differ
diff --git a/inference/images/humanseg/demo_jpg_recover.png b/inference/images/humanseg/demo_jpg_recover.png
deleted file mode 100644
index e28f06e30d5a6ea7373c5ff64c55b1d040f73a64..0000000000000000000000000000000000000000
Binary files a/inference/images/humanseg/demo_jpg_recover.png and /dev/null differ
diff --git a/inference/predictor/seg_predictor.cpp b/inference/predictor/seg_predictor.cpp
index 4b6e44e6f6662dbc67efe3db289e5a2f119b8f0c..ee32d75561e5d93fa11c7013d1a4a9f845dc9919 100644
--- a/inference/predictor/seg_predictor.cpp
+++ b/inference/predictor/seg_predictor.cpp
@@ -125,6 +125,10 @@ namespace PaddleSolution {
int Predictor::native_predict(const std::vector& imgs)
{
+ if (imgs.size() == 0) {
+ LOG(ERROR) << "No image found";
+ return -1;
+ }
int config_batch_size = _model_config._batch_size;
int channels = _model_config._channels;
@@ -205,6 +209,11 @@ namespace PaddleSolution {
int Predictor::analysis_predict(const std::vector& imgs) {
+ if (imgs.size() == 0) {
+ LOG(ERROR) << "No image found";
+ return -1;
+ }
+
int config_batch_size = _model_config._batch_size;
int channels = _model_config._channels;
int eval_width = _model_config._resize[0];
diff --git a/inference/preprocessor/preprocessor_seg.cpp b/inference/preprocessor/preprocessor_seg.cpp
index bb1622837cb7092fdf648aeec27d6a9ec071c963..a3177da5cbb907c27a05d8c5e9290fc70ef9ab02 100644
--- a/inference/preprocessor/preprocessor_seg.cpp
+++ b/inference/preprocessor/preprocessor_seg.cpp
@@ -42,7 +42,7 @@ namespace PaddleSolution {
for (int c = 0; c < channels; ++c) {
int top_index = (c * rh + h) * rw + w;
float pixel = static_cast(ptr[im_index++]);
- pixel = (pixel - pmean[c]) / pscale[c];
+ pixel = (pixel / 255 - pmean[c]) / pscale[c];
data[top_index] = pixel;
}
}
diff --git a/inference/utils/seg_conf_parser.h b/inference/utils/seg_conf_parser.h
index b2a2b4160217433b553540129e1075640822a9dc..078d04f3eb9dcd1763f69a8eb770c0853f9f1b24 100644
--- a/inference/utils/seg_conf_parser.h
+++ b/inference/utils/seg_conf_parser.h
@@ -28,7 +28,6 @@ namespace PaddleSolution {
_channels = 0;
_use_gpu = 0;
_batch_size = 1;
- _model_name.clear();
_model_file_name.clear();
_model_path.clear();
_param_file_name.clear();
@@ -57,7 +56,7 @@ namespace PaddleSolution {
}
bool load_config(const std::string& conf_file) {
-
+
reset();
YAML::Node config = YAML::LoadFile(conf_file);
@@ -79,8 +78,6 @@ namespace PaddleSolution {
_img_type = config["DEPLOY"]["IMAGE_TYPE"].as();
// 5. get class number
_class_num = config["DEPLOY"]["NUM_CLASSES"].as();
- // 6. get model_name
- _model_name = config["DEPLOY"]["MODEL_NAME"].as();
// 7. set model path
_model_path = config["DEPLOY"]["MODEL_PATH"].as();
// 8. get model file_name
@@ -101,7 +98,7 @@ namespace PaddleSolution {
}
void debug() const {
-
+
std::cout << "EVAL_CROP_SIZE: (" << _resize[0] << ", " << _resize[1] << ")" << std::endl;
std::cout << "MEAN: [";
@@ -129,7 +126,6 @@ namespace PaddleSolution {
std::cout << "DEPLOY.NUM_CLASSES: " << _class_num << std::endl;
std::cout << "DEPLOY.CHANNELS: " << _channels << std::endl;
std::cout << "DEPLOY.MODEL_PATH: " << _model_path << std::endl;
- std::cout << "DEPLOY.MODEL_NAME: " << _model_name << std::endl;
std::cout << "DEPLOY.MODEL_FILENAME: " << _model_file_name << std::endl;
std::cout << "DEPLOY.PARAMS_FILENAME: " << _param_file_name << std::endl;
std::cout << "DEPLOY.PRE_PROCESSOR: " << _pre_processor << std::endl;
@@ -152,8 +148,6 @@ namespace PaddleSolution {
int _channels;
// DEPLOY.MODEL_PATH
std::string _model_path;
- // DEPLOY.MODEL_NAME
- std::string _model_name;
// DEPLOY.MODEL_FILENAME
std::string _model_file_name;
// DEPLOY.PARAMS_FILENAME
diff --git a/inference/utils/utils.h b/inference/utils/utils.h
index e9c62b5778aa77e427ec5653d056035ee4028bd9..e349618a28282257b01ac44d661f292850cc19b9 100644
--- a/inference/utils/utils.h
+++ b/inference/utils/utils.h
@@ -3,7 +3,13 @@
#include
#include
#include
+
+#ifdef _WIN32
#include
+#else
+#include
+#include
+#endif
namespace PaddleSolution {
namespace utils {
@@ -14,7 +20,31 @@ namespace PaddleSolution {
#endif
return dir + seperator + path;
}
+ #ifndef _WIN32
+ // scan a directory and get all files with input extensions
+ inline std::vector get_directory_images(const std::string& path, const std::string& exts)
+ {
+ std::vector imgs;
+ struct dirent *entry;
+ DIR *dir = opendir(path.c_str());
+ if (dir == NULL) {
+ closedir(dir);
+ return imgs;
+ }
+ while ((entry = readdir(dir)) != NULL) {
+ std::string item = entry->d_name;
+ auto ext = strrchr(entry->d_name, '.');
+ if (!ext || std::string(ext) == "." || std::string(ext) == "..") {
+ continue;
+ }
+ if (exts.find(ext) != std::string::npos) {
+ imgs.push_back(path_join(path, entry->d_name));
+ }
+ }
+ return imgs;
+ }
+ #else
// scan a directory and get all files with input extensions
inline std::vector get_directory_images(const std::string& path, const std::string& exts)
{
@@ -28,5 +58,6 @@ namespace PaddleSolution {
}
return imgs;
}
+ #endif
}
}
diff --git a/pdseg/check.py b/pdseg/check.py
index 7937e046134548765a3b2a3c046798fd8997ee05..34372e2511c43a252304f8b22170fc4246ab6696 100644
--- a/pdseg/check.py
+++ b/pdseg/check.py
@@ -34,6 +34,7 @@ def init_global_variable():
global list_wrong #文件名格式错误列表
global imread_failed #图片读取失败列表, 二元列表
global label_wrong # 标注图片出错列表
+ global label_gray_wrong # 标注图非灰度图列表
png_format_right_num = 0
png_format_wrong_num = 0
@@ -49,6 +50,7 @@ def init_global_variable():
list_wrong = []
imread_failed = []
label_wrong = []
+ label_gray_wrong = []
def parse_args():
parser = argparse.ArgumentParser(description='PaddleSeg check')
@@ -68,10 +70,13 @@ def correct_print(str):
return "".join(["\nPASS ", str])
def cv2_imread(file_path, flag=cv2.IMREAD_COLOR):
- # resolve cv2.imread open Chinese file path issues on Windows Platform.
+ """
+ 解决 cv2.imread 在window平台打开中文路径的问题.
+ """
return cv2.imdecode(np.fromfile(file_path, dtype=np.uint8), flag)
def get_image_max_height_width(img):
+ """获取图片最大宽和高"""
global max_width, max_height
img_shape = img.shape
height, width = img_shape[0], img_shape[1]
@@ -79,6 +84,7 @@ def get_image_max_height_width(img):
max_width = max(width, max_width)
def get_image_min_max_aspectratio(img):
+ """计算图片最大宽高比"""
global min_aspectratio, max_aspectratio
img_shape = img.shape
height, width = img_shape[0], img_shape[1]
@@ -87,11 +93,19 @@ def get_image_min_max_aspectratio(img):
return min_aspectratio, max_aspectratio
def get_image_dim(img):
- """获取图像的维度"""
+ """获取图像的通道数"""
img_shape = img.shape
if img_shape[-1] not in img_dim:
img_dim.append(img_shape[-1])
+def is_label_gray(grt):
+ """判断标签是否为灰度图"""
+ grt_shape = grt.shape
+ if len(grt_shape) == 2:
+ return True
+ else:
+ return False
+
def image_label_shape_check(img, grt):
"""
验证图像和标注的大小是否匹配
@@ -110,17 +124,15 @@ def image_label_shape_check(img, grt):
def ground_truth_check(grt, grt_path):
"""
- 验证标注是否重零开始,标注值为0,1,...,num_classes-1, ingnore_idx
验证标注图像的格式
- 返回标注的像素数
- 检查图像是否都是ignore_index
+ 统计标注图类别和像素数
params:
grt: 标注图
grt_path: 标注图路径
return:
png_format: 返回是否是png格式图片
- label_correct: 返回标注是否是正确的
- label_pixel_num: 返回标注的像素数
+ unique: 返回标注类别
+ counts: 返回标注的像素数
"""
if imghdr.what(grt_path) == "png":
png_format = True
@@ -135,7 +147,7 @@ def sum_gt_check(png_format, grt_classes, num_of_each_class):
"""
统计所有标注图上的格式、类别和每个类别的像素数
params:
- png_format: 返回是否是png格式图片
+ png_format: 是否是png格式图片
grt_classes: 标注类别
num_of_each_class: 各个类别的像素数目
"""
@@ -188,7 +200,7 @@ def gt_check():
total_nc = sorted(zip(total_grt_classes, total_num_of_each_class))
- logger.info("\nDoing label pixel statistics...\nTotal label calsses "
+ logger.info("\nDoing label pixel statistics...\nTotal label classes "
"and their corresponding numbers:\n{} ".format(total_nc))
if len(label_wrong) == 0 and not total_nc[0][0]:
@@ -213,7 +225,7 @@ def eval_crop_size_check(max_height, max_width, min_aspectratio, max_aspectratio
"""
if cfg.AUG.AUG_METHOD == "stepscaling":
- if max_width <= cfg.EVAL_CROP_SIZE[0] or max_height <= cfg.EVAL_CROP_SIZE[1]:
+ if max_width <= cfg.EVAL_CROP_SIZE[0] and max_height <= cfg.EVAL_CROP_SIZE[1]:
logger.info(correct_print("EVAL_CROP_SIZE check"))
else:
logger.info(error_print("EVAL_CROP_SIZE check"))
@@ -322,6 +334,17 @@ def imread_check():
for i in imread_failed:
logger.debug(i)
+def label_gray_check():
+ if len(label_gray_wrong) == 0:
+ logger.info(correct_print("label gray check"))
+ logger.info("All label images are gray")
+ else:
+ logger.info(error_print("label gray check"))
+ logger.info("{} label images are not gray\nLabel pixel statistics may "
+ "be insignificant".format(len(label_gray_wrong)))
+ for i in label_gray_wrong:
+ logger.debug(i)
+
def check_train_dataset():
@@ -340,11 +363,15 @@ def check_train_dataset():
grt_path = os.path.join(cfg.DATASET.DATA_DIR, grt_name)
try:
img = cv2_imread(img_path, cv2.IMREAD_UNCHANGED)
- grt = cv2_imread(grt_path, cv2.IMREAD_GRAYSCALE)
+ grt = cv2_imread(grt_path, cv2.IMREAD_UNCHANGED)
except Exception as e:
imread_failed.append((line, str(e)))
continue
+ is_gray = is_label_gray(grt)
+ if not is_gray:
+ label_gray_wrong.append(line)
+ grt = cv2.cvtColor(grt, cv2.COLOR_BGR2GRAY)
get_image_dim(img)
is_equal_img_grt_shape = image_label_shape_check(img, grt)
if not is_equal_img_grt_shape:
@@ -359,6 +386,7 @@ def check_train_dataset():
file_list_check(list_file)
imread_check()
+ label_gray_check()
gt_check()
image_type_check(img_dim)
shape_check()
@@ -383,9 +411,14 @@ def check_val_dataset():
grt_path = os.path.join(cfg.DATASET.DATA_DIR, grt_name)
try:
img = cv2_imread(img_path, cv2.IMREAD_UNCHANGED)
- grt = cv2_imread(grt_path, cv2.IMREAD_GRAYSCALE)
+ grt = cv2_imread(grt_path, cv2.IMREAD_UNCHANGED)
except Exception as e:
imread_failed.append((line, e.message))
+
+ is_gray = is_label_gray(grt)
+ if not is_gray:
+ label_gray_wrong.append(line)
+ grt = cv2.cvtColor(grt, cv2.COLOR_BGR2GRAY)
get_image_max_height_width(img)
get_image_min_max_aspectratio(img)
get_image_dim(img)
@@ -401,6 +434,7 @@ def check_val_dataset():
file_list_check(list_file)
imread_check()
+ label_gray_check()
gt_check()
image_type_check(img_dim)
shape_check()
@@ -430,10 +464,15 @@ def check_test_dataset():
grt_path = os.path.join(cfg.DATASET.DATA_DIR, grt_name)
try:
img = cv2_imread(img_path, cv2.IMREAD_UNCHANGED)
- grt = cv2_imread(grt_path, cv2.IMREAD_GRAYSCALE)
+ grt = cv2_imread(grt_path, cv2.IMREAD_UNCHANGED)
except Exception as e:
imread_failed.append((line, e.message))
continue
+
+ is_gray = is_label_gray(grt)
+ if not is_gray:
+ label_gray_wrong.append(line)
+ grt = cv2.cvtColor(grt, cv2.COLOR_BGR2GRAY)
is_equal_img_grt_shape = image_label_shape_check(img, grt)
if not is_equal_img_grt_shape:
shape_unequal_image.append(line)
@@ -452,6 +491,8 @@ def check_test_dataset():
file_list_check(list_file)
imread_check()
+ if has_label:
+ label_gray_check()
if has_label:
gt_check()
image_type_check(img_dim)
diff --git a/pdseg/eval.py b/pdseg/eval.py
index c34a8b5e82aa7dc5a67d5b7386ca833917e334d8..815ebf56f09140a5911bdeb1aa4acd3dbf7950d1 100644
--- a/pdseg/eval.py
+++ b/pdseg/eval.py
@@ -102,7 +102,7 @@ def evaluate(cfg, ckpt_dir=None, use_gpu=False, use_mpio=False, **kwargs):
places = fluid.cuda_places() if use_gpu else fluid.cpu_places()
place = places[0]
dev_count = len(places)
- print("Device count = {}".format(dev_count))
+ print("#Device count: {}".format(dev_count))
exe = fluid.Executor(place)
exe.run(startup_prog)
diff --git a/pdseg/reader.py b/pdseg/reader.py
index 98a0eb0f4d5a1a51f6425bc049e46f6e741c765a..c839828cf99b89ceff62837cd6877a5659f80d06 100644
--- a/pdseg/reader.py
+++ b/pdseg/reader.py
@@ -106,19 +106,21 @@ class SegDataset(object):
def batch(self, reader, batch_size, is_test=False, drop_last=False):
def batch_reader(is_test=False, drop_last=drop_last):
if is_test:
- imgs, img_names, valid_shapes, org_shapes = [], [], [], []
- for img, img_name, valid_shape, org_shape in reader():
+ imgs, grts, img_names, valid_shapes, org_shapes = [], [], [], [], []
+ for img, grt, img_name, valid_shape, org_shape in reader():
imgs.append(img)
+ grts.append(grt)
img_names.append(img_name)
valid_shapes.append(valid_shape)
org_shapes.append(org_shape)
if len(imgs) == batch_size:
- yield np.array(imgs), img_names, np.array(
- valid_shapes), np.array(org_shapes)
- imgs, img_names, valid_shapes, org_shapes = [], [], [], []
+ yield np.array(imgs), np.array(
+ grts), img_names, np.array(valid_shapes), np.array(
+ org_shapes)
+ imgs, grts, img_names, valid_shapes, org_shapes = [], [], [], [], []
if not drop_last and len(imgs) > 0:
- yield np.array(imgs), img_names, np.array(
+ yield np.array(imgs), np.array(grts), img_names, np.array(
valid_shapes), np.array(org_shapes)
else:
imgs, labs, ignore = [], [], []
@@ -146,93 +148,64 @@ class SegDataset(object):
# reserver alpha channel
cv2_imread_flag = cv2.IMREAD_UNCHANGED
- if mode == ModelPhase.TRAIN or mode == ModelPhase.EVAL:
- parts = line.strip().split(cfg.DATASET.SEPARATOR)
- if len(parts) != 2:
+ parts = line.strip().split(cfg.DATASET.SEPARATOR)
+ if len(parts) != 2:
+ if mode == ModelPhase.TRAIN or mode == ModelPhase.EVAL:
raise Exception("File list format incorrect! It should be"
" image_name{}label_name\\n".format(
cfg.DATASET.SEPARATOR))
+ img_name, grt_name = parts[0], None
+ else:
img_name, grt_name = parts[0], parts[1]
- img_path = os.path.join(src_dir, img_name)
- grt_path = os.path.join(src_dir, grt_name)
- img = cv2_imread(img_path, cv2_imread_flag)
+ img_path = os.path.join(src_dir, img_name)
+ img = cv2_imread(img_path, cv2_imread_flag)
+
+ if grt_name is not None:
+ grt_path = os.path.join(src_dir, grt_name)
grt = cv2_imread(grt_path, cv2.IMREAD_GRAYSCALE)
+ else:
+ grt = None
- if img is None or grt is None:
- raise Exception(
- "Empty image, src_dir: {}, img: {} & lab: {}".format(
- src_dir, img_path, grt_path))
+ if img is None:
+ raise Exception(
+ "Empty image, src_dir: {}, img: {} & lab: {}".format(
+ src_dir, img_path, grt_path))
- img_height = img.shape[0]
- img_width = img.shape[1]
+ img_height = img.shape[0]
+ img_width = img.shape[1]
+
+ if grt is not None:
grt_height = grt.shape[0]
grt_width = grt.shape[1]
if img_height != grt_height or img_width != grt_width:
raise Exception(
"source img and label img must has the same size")
-
- if len(img.shape) < 3:
- img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
-
- img_channels = img.shape[2]
- if img_channels < 3:
- raise Exception(
- "PaddleSeg only supports gray, rgb or rgba image")
- if img_channels != cfg.DATASET.DATA_DIM:
- raise Exception(
- "Input image channel({}) is not match cfg.DATASET.DATA_DIM({}), img_name={}"
- .format(img_channels, cfg.DATASET.DATADIM, img_name))
- if img_channels != len(cfg.MEAN):
- raise Exception(
- "img name {}, img chns {} mean size {}, size unequal".
- format(img_name, img_channels, len(cfg.MEAN)))
- if img_channels != len(cfg.STD):
- raise Exception(
- "img name {}, img chns {} std size {}, size unequal".format(
- img_name, img_channels, len(cfg.STD)))
-
- # visualization mode
- elif mode == ModelPhase.VISUAL:
- if cfg.DATASET.SEPARATOR in line:
- parts = line.strip().split(cfg.DATASET.SEPARATOR)
- img_name = parts[0]
- else:
- img_name = line.strip()
-
- img_path = os.path.join(src_dir, img_name)
- img = cv2_imread(img_path, cv2_imread_flag)
-
- if img is None:
- raise Exception("empty image, src_dir:{}, img: {}".format(
- src_dir, img_name))
-
- # Convert grayscale image to BGR 3 channel image
- if len(img.shape) < 3:
- img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
-
- img_height = img.shape[0]
- img_width = img.shape[1]
- img_channels = img.shape[2]
-
- if img_channels < 3:
- raise Exception("this repo only recept gray, rgb or rgba image")
- if img_channels != cfg.DATASET.DATA_DIM:
- raise Exception("data dim must equal to image channels")
- if img_channels != len(cfg.MEAN):
- raise Exception(
- "img name {}, img chns {} mean size {}, size unequal".
- format(img_name, img_channels, len(cfg.MEAN)))
- if img_channels != len(cfg.STD):
+ else:
+ if mode == ModelPhase.TRAIN or mode == ModelPhase.EVAL:
raise Exception(
- "img name {}, img chns {} std size {}, size unequal".format(
- img_name, img_channels, len(cfg.STD)))
+ "Empty image, src_dir: {}, img: {} & lab: {}".format(
+ src_dir, img_path, grt_path))
- grt = None
- grt_name = None
- else:
- raise ValueError("mode error: {}".format(mode))
+ if len(img.shape) < 3:
+ img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
+
+ img_channels = img.shape[2]
+ if img_channels < 3:
+ raise Exception("PaddleSeg only supports gray, rgb or rgba image")
+ if img_channels != cfg.DATASET.DATA_DIM:
+ raise Exception(
+ "Input image channel({}) is not match cfg.DATASET.DATA_DIM({}), img_name={}"
+ .format(img_channels, cfg.DATASET.DATADIM, img_name))
+ if img_channels != len(cfg.MEAN):
+ raise Exception(
+ "img name {}, img chns {} mean size {}, size unequal".format(
+ img_name, img_channels, len(cfg.MEAN)))
+ if img_channels != len(cfg.STD):
+ raise Exception(
+ "img name {}, img chns {} std size {}, size unequal".format(
+ img_name, img_channels, len(cfg.STD)))
return img, grt, img_name, grt_name
@@ -288,17 +261,18 @@ class SegDataset(object):
SATURATION_JITTER_RATIO,
contrast_jitter_ratio=cfg.AUG.RICH_CROP.
CONTRAST_JITTER_RATIO)
- if cfg.AUG.RICH_CROP.FLIP:
- if cfg.AUG.RICH_CROP.FLIP_RATIO <= 0:
- n = 0
- elif cfg.AUG.RICH_CROP.FLIP_RATIO >= 1:
- n = 1
- else:
- n = int(1.0 / cfg.AUG.RICH_CROP.FLIP_RATIO)
- if n > 0:
- if np.random.randint(0, n) == 0:
- img = img[::-1, :, :]
- grt = grt[::-1, :]
+
+ if cfg.AUG.FLIP:
+ if cfg.AUG.FLIP_RATIO <= 0:
+ n = 0
+ elif cfg.AUG.FLIP_RATIO >= 1:
+ n = 1
+ else:
+ n = int(1.0 / cfg.AUG.FLIP_RATIO)
+ if n > 0:
+ if np.random.randint(0, n) == 0:
+ img = img[::-1, :, :]
+ grt = grt[::-1, :]
if cfg.AUG.MIRROR:
if np.random.randint(0, 2) == 1:
@@ -329,4 +303,4 @@ class SegDataset(object):
elif ModelPhase.is_eval(mode):
return (img, grt, ignore)
elif ModelPhase.is_visual(mode):
- return (img, img_name, valid_shape, org_shape)
+ return (img, grt, img_name, valid_shape, org_shape)
diff --git a/pdseg/train.py b/pdseg/train.py
index 05db0de833d76e43643a46a4b6da328b29f05f82..295468ef14b87d8f4886fe0203d362bef3611a42 100644
--- a/pdseg/train.py
+++ b/pdseg/train.py
@@ -152,15 +152,15 @@ def load_checkpoint(exe, program):
Load checkpoiont from pretrained model directory for resume training
"""
- print('Resume model training from:', cfg.TRAIN.PRETRAINED_MODEL)
- if not os.path.exists(cfg.TRAIN.PRETRAINED_MODEL):
+ print('Resume model training from:', cfg.TRAIN.RESUME_MODEL_DIR)
+ if not os.path.exists(cfg.TRAIN.RESUME_MODEL_DIR):
raise ValueError("TRAIN.PRETRAIN_MODEL {} not exist!".format(
- cfg.TRAIN.PRETRAINED_MODEL))
+ cfg.TRAIN.RESUME_MODEL_DIR))
fluid.io.load_persistables(
- exe, cfg.TRAIN.PRETRAINED_MODEL, main_program=program)
+ exe, cfg.TRAIN.RESUME_MODEL_DIR, main_program=program)
- model_path = cfg.TRAIN.PRETRAINED_MODEL
+ model_path = cfg.TRAIN.RESUME_MODEL_DIR
# Check is path ended by path spearator
if model_path[-1] == os.sep:
model_path = model_path[0:-1]
@@ -216,7 +216,7 @@ def train(cfg):
place = places[0]
# Get number of GPU
dev_count = len(places)
- print("#GPU-Devices: {}".format(dev_count))
+ print("#Device count: {}".format(dev_count))
# Make sure BATCH_SIZE can divided by GPU cards
assert cfg.BATCH_SIZE % dev_count == 0, (
@@ -255,29 +255,25 @@ def train(cfg):
# Resume training
begin_epoch = cfg.SOLVER.BEGIN_EPOCH
- if cfg.TRAIN.RESUME:
+ if cfg.TRAIN.RESUME_MODEL_DIR:
begin_epoch = load_checkpoint(exe, train_prog)
# Load pretrained model
- elif os.path.exists(cfg.TRAIN.PRETRAINED_MODEL):
- print('Pretrained model dir:', cfg.TRAIN.PRETRAINED_MODEL)
+ elif os.path.exists(cfg.TRAIN.PRETRAINED_MODEL_DIR):
+ print('Pretrained model dir:', cfg.TRAIN.PRETRAINED_MODEL_DIR)
load_vars = []
+ load_fail_vars = []
def var_shape_matched(var, shape):
"""
Check whehter persitable variable shape is match with current network
"""
var_exist = os.path.exists(
- os.path.join(cfg.TRAIN.PRETRAINED_MODEL, var.name))
+ os.path.join(cfg.TRAIN.PRETRAINED_MODEL_DIR, var.name))
if var_exist:
var_shape = parse_shape_from_file(
- os.path.join(cfg.TRAIN.PRETRAINED_MODEL, var.name))
- if var_shape == shape:
- return True
- else:
- print(
- "Variable[{}] shape does not match current network, skip"
- " to load it.".format(var.name))
- return False
+ os.path.join(cfg.TRAIN.PRETRAINED_MODEL_DIR, var.name))
+ return var_shape == shape
+ return False
for x in train_prog.list_vars():
if isinstance(x, fluid.framework.Parameter):
@@ -285,16 +281,25 @@ def train(cfg):
x.name).get_tensor().shape())
if var_shape_matched(x, shape):
load_vars.append(x)
+ else:
+ load_fail_vars.append(x)
if cfg.MODEL.FP16:
# If open FP16 training mode, load FP16 var separate
- load_fp16_vars(exe, cfg.TRAIN.PRETRAINED_MODEL, train_prog)
+ load_fp16_vars(exe, cfg.TRAIN.PRETRAINED_MODEL_DIR, train_prog)
else:
fluid.io.load_vars(
- exe, dirname=cfg.TRAIN.PRETRAINED_MODEL, vars=load_vars)
- print("Pretrained model loaded successfully!")
+ exe, dirname=cfg.TRAIN.PRETRAINED_MODEL_DIR, vars=load_vars)
+ for var in load_vars:
+ print("Parameter[{}] loaded sucessfully!".format(var.name))
+ for var in load_fail_vars:
+ print("Parameter[{}] shape does not match current network, skip"
+ " to load it.".format(var.name))
+ print("{}/{} pretrained parameters loaded successfully!".format(
+ len(load_vars),
+ len(load_vars) + len(load_fail_vars)))
else:
print('Pretrained model dir {} not exists, training from scratch...'.
- format(cfg.TRAIN.PRETRAINED_MODEL))
+ format(cfg.TRAIN.PRETRAINED_MODEL_DIR))
fetch_list = [avg_loss.name, lr.name]
if args.debug:
@@ -311,9 +316,6 @@ def train(cfg):
exit(1)
from tb_paddle import SummaryWriter
-
- if os.path.exists(args.tb_log_dir):
- shutil.rmtree(args.tb_log_dir)
log_writer = SummaryWriter(args.tb_log_dir)
global_step = 0
diff --git a/pdseg/utils/collect.py b/pdseg/utils/collect.py
index 0be64222044f665f430a5adadc90d21298181d62..010a5c4bcc7bc84b9bb21cdf4f845c4ad3de3dbc 100644
--- a/pdseg/utils/collect.py
+++ b/pdseg/utils/collect.py
@@ -98,6 +98,16 @@ class SegConfig(dict):
'DATASET.IMAGE_TYPE config error, only support `rgb`, `gray` and `rgba`'
)
+ if not self.TRAIN_CROP_SIZE:
+ raise ValueError(
+ 'TRAIN_CROP_SIZE is empty! Please set a pair of values in format (width, height)'
+ )
+
+ if not self.EVAL_CROP_SIZE:
+ raise ValueError(
+ 'EVAL_CROP_SIZE is empty! Please set a pair of values in format (width, height)'
+ )
+
if reset_dataset:
# Ensure file list is use UTF-8 encoding
train_sets = codecs.open(self.DATASET.TRAIN_FILE_LIST, 'r',
diff --git a/pdseg/utils/config.py b/pdseg/utils/config.py
index d386721f46b09f2d306ad753d3d5d4b71639fbc1..196dc1f090db521c2ef61d5a99631f371f346ef8 100644
--- a/pdseg/utils/config.py
+++ b/pdseg/utils/config.py
@@ -69,6 +69,10 @@ cfg.DATASET.IGNORE_INDEX = 255
########################### 数据增强配置 ######################################
# 图像镜像左右翻转
cfg.AUG.MIRROR = True
+# 图像上下翻转开关,True/False
+cfg.AUG.FLIP = False
+# 图像启动上下翻转的概率,0-1
+cfg.AUG.FLIP_RATIO = 0.5
# 图像resize的固定尺寸(宽,高),非负
cfg.AUG.FIX_RESIZE_SIZE = tuple()
# 图像resize的方式有三种:
@@ -116,9 +120,9 @@ cfg.AUG.RICH_CROP.FLIP_RATIO = 0.2
# 模型保存路径
cfg.TRAIN.MODEL_SAVE_DIR = ''
# 预训练模型路径
-cfg.TRAIN.PRETRAINED_MODEL = ''
+cfg.TRAIN.PRETRAINED_MODEL_DIR = ''
# 是否resume,继续训练
-cfg.TRAIN.RESUME = False
+cfg.TRAIN.RESUME_MODEL_DIR = ''
# 是否使用多卡间同步BatchNorm均值和方差
cfg.TRAIN.SYNC_BATCH_NORM = False
# 模型参数保存的epoch间隔数,可用来继续训练中断的模型
diff --git a/pdseg/vis.py b/pdseg/vis.py
index 0d7eb79893aaa263d0999f2a6ec3df3fbaf97c36..e798f2ed5c1b9adb3ad86721761a990ac2ba384f 100644
--- a/pdseg/vis.py
+++ b/pdseg/vis.py
@@ -171,7 +171,7 @@ def visualize(cfg,
fetch_list = [pred.name]
test_reader = dataset.batch(dataset.generator, batch_size=1, is_test=True)
img_cnt = 0
- for imgs, img_names, valid_shapes, org_shapes in test_reader:
+ for imgs, grts, img_names, valid_shapes, org_shapes in test_reader:
pred_shape = (imgs.shape[2], imgs.shape[3])
pred, = exe.run(
program=test_prog,
@@ -185,6 +185,7 @@ def visualize(cfg,
# Add more comments
res_map = np.squeeze(pred[i, :, :, :]).astype(np.uint8)
img_name = img_names[i]
+ grt = grts[i]
res_shape = (res_map.shape[0], res_map.shape[1])
if res_shape[0] != pred_shape[0] or res_shape[1] != pred_shape[1]:
res_map = cv2.resize(
@@ -196,6 +197,12 @@ def visualize(cfg,
res_map, (org_shape[1], org_shape[0]),
interpolation=cv2.INTER_NEAREST)
+ if grt is not None:
+ grt = grt[0:valid_shape[0], 0:valid_shape[1]]
+ grt = cv2.resize(
+ grt, (org_shape[1], org_shape[0]),
+ interpolation=cv2.INTER_NEAREST)
+
png_fn = to_png_fn(img_names[i])
if also_save_raw_results:
raw_fn = os.path.join(raw_save_dir, png_fn)
@@ -209,6 +216,8 @@ def visualize(cfg,
makedirs(dirname)
pred_mask = colorize(res_map, org_shapes[i], color_map)
+ if grt is not None:
+ grt = colorize(grt, org_shapes[i], color_map)
cv2.imwrite(vis_fn, pred_mask)
img_cnt += 1
@@ -233,7 +242,13 @@ def visualize(cfg,
img,
epoch,
dataformats='HWC')
- #TODO: add ground truth (label) images
+ #add ground truth (label) images
+ if grt is not None:
+ log_writer.add_image(
+ "Label/{}".format(img_names[i]),
+ grt[..., ::-1],
+ epoch,
+ dataformats='HWC')
# If in local_test mode, only visualize 5 images just for testing
# procedure
diff --git a/pretrained_model/download_model.py b/pretrained_model/download_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..b2bde566b210286452813c3ca4b2e424fb8af6b9
--- /dev/null
+++ b/pretrained_model/download_model.py
@@ -0,0 +1,78 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+
+LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
+TEST_PATH = os.path.join(LOCAL_PATH, "..", "test")
+sys.path.append(TEST_PATH)
+
+from test_utils import download_file_and_uncompress
+
+model_urls = {
+ # ImageNet Pretrained
+ "mobilnetv2-2-0_bn_imagenet":
+ "https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_x2_0_pretrained.tar",
+ "mobilnetv2-1-5_bn_imagenet":
+ "https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_x1_5_pretrained.tar",
+ "mobilnetv2-1-0_bn_imagenet":
+ "https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_pretrained.tar",
+ "mobilnetv2-0-5_bn_imagenet":
+ "https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_x0_5_pretrained.tar",
+ "mobilnetv2-0-25_bn_imagenet":
+ "https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_x0_25_pretrained.tar",
+ "xception41_imagenet":
+ "https://paddleseg.bj.bcebos.com/models/Xception41_pretrained.tgz",
+ "xception65_imagenet":
+ "https://paddleseg.bj.bcebos.com/models/Xception65_pretrained.tgz",
+
+ # COCO pretrained
+ "deeplabv3p_mobilnetv2-1-0_bn_coco":
+ "https://bj.bcebos.com/v1/paddleseg/deeplabv3plus_coco_bn_init.tgz",
+ "deeplabv3p_xception65_bn_coco":
+ "https://paddleseg.bj.bcebos.com/models/xception65_coco.tgz",
+ "unet_bn_coco": "https://paddleseg.bj.bcebos.com/models/unet_coco_v3.tgz",
+
+ # Cityscapes pretrained
+ "deeplabv3p_mobilenetv2-1-0_bn_cityscapes":
+ "https://paddleseg.bj.bcebos.com/models/mobilenet_cityscapes.tgz",
+ "deeplabv3p_xception65_gn_cityscapes":
+ "https://paddleseg.bj.bcebos.com/models/deeplabv3p_xception65_cityscapes.tgz",
+ "deeplabv3p_xception65_bn_cityscapes":
+ "https://paddleseg.bj.bcebos.com/models/xception65_bn_cityscapes.tgz",
+ "unet_bn_coco": "https://paddleseg.bj.bcebos.com/models/unet_coco_v3.tgz",
+ "icnet_bn_cityscapes":
+ "https://paddleseg.bj.bcebos.com/models/icnet6831.tar.gz"
+}
+
+if __name__ == "__main__":
+ if len(sys.argv) != 2:
+ print("usage:\n python download_model.py ${MODEL_NAME}")
+ exit(1)
+
+ model_name = sys.argv[1]
+ if not model_name in model_urls.keys():
+ print("Only support: \n {}".format("\n ".join(
+ list(model_urls.keys()))))
+ exit(1)
+
+ url = model_urls[model_name]
+ download_file_and_uncompress(
+ url=url,
+ savepath=LOCAL_PATH,
+ extrapath=LOCAL_PATH,
+ extraname=model_name)
+
+ print("Pretrained Model download success!")
diff --git a/requirements.txt b/requirements.txt
index 0d438f9949547df1a477b468382cc79d55866bb6..69bf08663d77f7b37df629ff577c1d06cfa70e9e 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -8,3 +8,5 @@ Pillow
numpy
six
opencv-python
+tqdm
+requests
diff --git a/serving/README.md b/serving/README.md
index 60a604d79327965fa8edaab25683c9d4aacc564a..71a1e6f442728cbb8791ca65b9406b070ecfe049 100644
--- a/serving/README.md
+++ b/serving/README.md
@@ -90,7 +90,7 @@ ln -s /usr/lib64/libcurl.so.4.3.0 /usr/lib64/libcurl.so
```bash
cd ~
-wget -c https://paddleseg.bj.bcebos.com/serving%2Fpaddle_seg_serving_centos7.6_gpu_cuda9.2.tar.gz
+wget -c --no-check-certificate https://paddleseg.bj.bcebos.com/serving/paddle_seg_serving_centos7.6_gpu_cuda9.2.tar.gz
tar xvfz PaddleSegServing.centos7.6_cuda9.2_gpu.tar.gz seg-serving
```
@@ -98,7 +98,7 @@ tar xvfz PaddleSegServing.centos7.6_cuda9.2_gpu.tar.gz seg-serving
```bash
cd ~
-wget -c https://paddleseg.bj.bcebos.com/serving%2Fpaddle_seg_serving_centos7.6_cpu.tar.gz
+wget -c --no-check-certificate https://paddleseg.bj.bcebos.com/serving/paddle_seg_serving_centos7.6_cpu.tar.gz
tar xvfz PaddleSegServing.centos7.6_cuda9.2_gpu.tar.gz seg-serving
```
diff --git a/serving/UBUNTU.md b/serving/UBUNTU.md
index ecbd846731ab3e6b7fcb4c95840d82b450c375b8..608a5ce9b53587595aed7c21f245cd36f09515a7 100644
--- a/serving/UBUNTU.md
+++ b/serving/UBUNTU.md
@@ -23,7 +23,7 @@ ln -s /usr/lib/x86_64-linux-gnu/libcurl.so.4.4.0 /usr/lib/x86_64-linux-gnu/libcu
```bash
# 下载nccl相关的deb包
-wget -c https://paddleseg.bj.bcebos.com/serving%2Fnccl-repo-ubuntu1604-2.4.8-ga-cuda9.2_1-1_amd64.deb
+wget -c --no-check-certificate https://paddleseg.bj.bcebos.com/serving/nccl-repo-ubuntu1604-2.4.8-ga-cuda9.2_1-1_amd64.deb
sudo apt-key add /var/nccl-repo-2.4.8-ga-cuda9.2/7fa2af80.pub
# 安装deb包
sudo dpkg -i nccl-repo-ubuntu1604-2.4.8-ga-cuda9.2_1-1_amd64.deb
@@ -47,7 +47,7 @@ sudo apt-get autoremove cmake
```bash
cd ~
-wget -c https://paddleseg.bj.bcebos.com/serving%2Fpaddle_seg_serving_ubuntu16.07_gpu_cuda9.2.tar.gz
+wget -c --no-check-certificate https://paddleseg.bj.bcebos.com/serving/paddle_seg_serving_ubuntu16.07_gpu_cuda9.2.tar.gz
tar xvfz PaddleSegServing.ubuntu16.07_cuda9.2_gpu.tar.gz seg-serving
```
@@ -55,7 +55,7 @@ tar xvfz PaddleSegServing.ubuntu16.07_cuda9.2_gpu.tar.gz seg-serving
```bash
cd ~
-wget -c https://paddleseg.bj.bcebos.com/serving%2Fpaddle_seg_serving_ubuntu16.07_cpu.tar.gz
+wget -c --no-check-certificate https://paddleseg.bj.bcebos.com/serving%2Fpaddle_seg_serving_ubuntu16.07_cpu.tar.gz
tar xvfz PaddleSegServing.ubuntu16.07_cuda9.2_gpu.tar.gz seg-serving
```
diff --git a/test/ci/check_code_style.sh b/test/ci/check_code_style.sh
new file mode 100644
index 0000000000000000000000000000000000000000..f88b8cb8aaaed416e4322aa9e83cbf5eeb0493a3
--- /dev/null
+++ b/test/ci/check_code_style.sh
@@ -0,0 +1,20 @@
+#!/bin/bash
+function abort(){
+ echo "Your change doesn't follow PaddleSeg's code style." 1>&2
+ echo "Please use pre-commit to check what is wrong." 1>&2
+ exit 1
+}
+
+trap 'abort' 0
+set -e
+
+cd $TRAVIS_BUILD_DIR
+export PATH=/usr/bin:$PATH
+pre-commit install
+
+if ! pre-commit run -a ; then
+ git diff
+ exit 1
+fi
+
+trap : 0
diff --git a/test/ci/test_download_dataset.sh b/test/ci/test_download_dataset.sh
new file mode 100644
index 0000000000000000000000000000000000000000..bd531fe9f9a915ec2fb15c73729264b02b83f179
--- /dev/null
+++ b/test/ci/test_download_dataset.sh
@@ -0,0 +1,7 @@
+#!/bin/bash
+set -o errexit
+
+base_path=$(cd `dirname $0`/../..; pwd)
+cd $base_path
+
+python dataset/download_pet.py
diff --git a/test/configs/deeplabv3p_xception65_cityscapes.yaml b/test/configs/deeplabv3p_xception65_cityscapes.yaml
index 612ac31bb304081a6c8900ff08d3ef61df62fbdf..349646f743f10c7970b248b30c258574c8478c68 100644
--- a/test/configs/deeplabv3p_xception65_cityscapes.yaml
+++ b/test/configs/deeplabv3p_xception65_cityscapes.yaml
@@ -10,18 +10,6 @@ AUG:
MIN_SCALE_FACTOR: 0.5 # for stepscaling
SCALE_STEP_SIZE: 0.25 # for stepscaling
MIRROR: True
- RICH_CROP:
- ENABLE: False
- ASPECT_RATIO: 0.33
- BLUR: True
- BLUR_RATIO: 0.1
- FLIP: True
- FLIP_RATIO: 0.2
- MAX_ROTATION: 15
- MIN_AREA_RATIO: 0.5
- BRIGHTNESS_JITTER_RATIO: 0.5
- CONTRAST_JITTER_RATIO: 0.5
- SATURATION_JITTER_RATIO: 0.5
BATCH_SIZE: 4
DATASET:
DATA_DIR: "./dataset/cityscapes/"
@@ -46,8 +34,7 @@ TEST:
TEST_MODEL: "snapshots/cityscape_v5/final/"
TRAIN:
MODEL_SAVE_DIR: "snapshots/cityscape_v5/"
- PRETRAINED_MODEL: "pretrain/deeplabv3plus_gn_init"
- RESUME: False
+ PRETRAINED_MODEL_DIR: "pretrain/deeplabv3plus_gn_init"
SNAPSHOT_EPOCH: 10
SOLVER:
LR: 0.001
diff --git a/test/configs/unet_pet.yaml b/test/configs/unet_pet.yaml
index e561e463bbdaddbe532d47a862c3e29095909f95..3a3cf65a09dfbff51e79ca65bd19c1c11fb75d64 100644
--- a/test/configs/unet_pet.yaml
+++ b/test/configs/unet_pet.yaml
@@ -12,18 +12,6 @@ AUG:
MIN_SCALE_FACTOR: 0.75 # for stepscaling
SCALE_STEP_SIZE: 0.25 # for stepscaling
MIRROR: True
- RICH_CROP:
- ENABLE: False
- ASPECT_RATIO: 0.33
- BLUR: True
- BLUR_RATIO: 0.1
- FLIP: True
- FLIP_RATIO: 0.2
- MAX_ROTATION: 15
- MIN_AREA_RATIO: 0.5
- BRIGHTNESS_JITTER_RATIO: 0.5
- CONTRAST_JITTER_RATIO: 0.5
- SATURATION_JITTER_RATIO: 0.5
BATCH_SIZE: 6
DATASET:
DATA_DIR: "./dataset/pet/"
@@ -45,8 +33,7 @@ TEST:
TEST_MODEL: "./test/saved_model/unet_pet/final/"
TRAIN:
MODEL_SAVE_DIR: "./test/saved_models/unet_pet/"
- PRETRAINED_MODEL: "./test/models/unet_coco/"
- RESUME: False
+ PRETRAINED_MODEL_DIR: "./test/models/unet_coco/"
SNAPSHOT_EPOCH: 10
SOLVER:
NUM_EPOCHS: 500
diff --git a/test/local_test_cityscapes.py b/test/local_test_cityscapes.py
index 0bf3c6aeb04e551da0cba454c6e9db7575efb1bb..051faaa1b4e4c769a996b94b411b65815eb3a9e7 100644
--- a/test/local_test_cityscapes.py
+++ b/test/local_test_cityscapes.py
@@ -14,6 +14,7 @@
from test_utils import download_file_and_uncompress, train, eval, vis, export_model
import os
+import argparse
LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
DATASET_PATH = os.path.join(LOCAL_PATH, "..", "dataset")
@@ -43,7 +44,17 @@ if __name__ == "__main__":
vis_dir = os.path.join(LOCAL_PATH, "visual", model_name)
saved_model = os.path.join(LOCAL_PATH, "saved_model", model_name)
- devices = ['0']
+ parser = argparse.ArgumentParser(description="PaddleSeg loacl test")
+ parser.add_argument(
+ "--devices",
+ dest="devices",
+ help="GPU id of running. if more than one, use spacing to separate.",
+ nargs="+",
+ default=0,
+ type=int)
+ args = parser.parse_args()
+
+ devices = [str(x) for x in args.devices]
export_model(
flags=["--cfg", cfg],
@@ -65,7 +76,7 @@ if __name__ == "__main__":
train(
flags=["--cfg", cfg, "--use_gpu", "--log_steps", "10"],
options=[
- "SOLVER.NUM_EPOCHS", "1", "TRAIN.PRETRAINED_MODEL", test_model,
+ "SOLVER.NUM_EPOCHS", "1", "TRAIN.PRETRAINED_MODEL_DIR", test_model,
"TRAIN.MODEL_SAVE_DIR", saved_model
],
devices=devices)
diff --git a/test/local_test_pet.py b/test/local_test_pet.py
index 1596f4b2b7be92c32dd8cad1d8be1d79e794d142..f043d16a5c7a9d7d45db8ce91864a8c5325876b9 100644
--- a/test/local_test_pet.py
+++ b/test/local_test_pet.py
@@ -14,6 +14,7 @@
from test_utils import download_file_and_uncompress, train, eval, vis, export_model
import os
+import argparse
LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
DATASET_PATH = os.path.join(LOCAL_PATH, "..", "dataset")
@@ -44,12 +45,22 @@ if __name__ == "__main__":
vis_dir = os.path.join(LOCAL_PATH, "visual", model_name)
saved_model = os.path.join(LOCAL_PATH, "saved_model", model_name)
- devices = ['0']
+ parser = argparse.ArgumentParser(description="PaddleSeg loacl test")
+ parser.add_argument(
+ "--devices",
+ dest="devices",
+ help="GPU id of running. if more than one, use spacing to separate.",
+ nargs="+",
+ default=0,
+ type=int)
+ args = parser.parse_args()
+
+ devices = [str(x) for x in args.devices]
train(
flags=["--cfg", cfg, "--use_gpu", "--log_steps", "10"],
options=[
- "SOLVER.NUM_EPOCHS", "1", "TRAIN.PRETRAINED_MODEL", test_model,
+ "SOLVER.NUM_EPOCHS", "1", "TRAIN.PRETRAINED_MODEL_DIR", test_model,
"TRAIN.MODEL_SAVE_DIR", saved_model, "DATASET.TRAIN_FILE_LIST",
os.path.join(DATASET_PATH, "mini_pet", "file_list",
"train_list.txt"), "DATASET.VAL_FILE_LIST",
diff --git a/test/test_utils.py b/test/test_utils.py
index e35c0326766ce395d66b5e6e9c726c4dbcf4f512..ed1f8ed89f9ad5204a3534c1c7e2531ce839add0 100644
--- a/test/test_utils.py
+++ b/test/test_utils.py
@@ -20,6 +20,7 @@ import sys
import tarfile
import zipfile
import platform
+import functools
lasttime = time.time()
FLUSH_INTERVAL = 0.1
@@ -67,7 +68,7 @@ def _download_file(url, savepath, print_progress):
if print_progress:
done = int(50 * dl / total_length)
progress("[%-50s] %.2f%%" %
- ('=' * done, float(dl / total_length * 100)))
+ ('=' * done, float(100 * dl) / total_length))
if print_progress:
progress("[%-50s] %.2f%%" % ('=' * 50, 100), end=True)
@@ -78,46 +79,53 @@ def _uncompress_file(filepath, extrapath, delete_file, print_progress):
if filepath.endswith("zip"):
handler = _uncompress_file_zip
- else:
+ elif filepath.endswith("tgz"):
handler = _uncompress_file_tar
+ else:
+ handler = functools.partial(_uncompress_file_tar, mode="r")
- for total_num, index in handler(filepath, extrapath):
+ for total_num, index, rootpath in handler(filepath, extrapath):
if print_progress:
done = int(50 * float(index) / total_num)
progress(
- "[%-50s] %.2f%%" % ('=' * done, float(index / total_num * 100)))
+ "[%-50s] %.2f%%" % ('=' * done, float(100 * index) / total_num))
if print_progress:
progress("[%-50s] %.2f%%" % ('=' * 50, 100), end=True)
if delete_file:
os.remove(filepath)
+ return rootpath
+
def _uncompress_file_zip(filepath, extrapath):
files = zipfile.ZipFile(filepath, 'r')
filelist = files.namelist()
+ rootpath = filelist[0]
total_num = len(filelist)
for index, file in enumerate(filelist):
files.extract(file, extrapath)
- yield total_num, index
+ yield total_num, index, rootpath
files.close()
- yield total_num, index
+ yield total_num, index, rootpath
-def _uncompress_file_tar(filepath, extrapath):
- files = tarfile.open(filepath, "r:gz")
+def _uncompress_file_tar(filepath, extrapath, mode="r:gz"):
+ files = tarfile.open(filepath, mode)
filelist = files.getnames()
total_num = len(filelist)
+ rootpath = filelist[0]
for index, file in enumerate(filelist):
files.extract(file, extrapath)
- yield total_num, index
+ yield total_num, index, rootpath
files.close()
- yield total_num, index
+ yield total_num, index, rootpath
def download_file_and_uncompress(url,
savepath=None,
extrapath=None,
+ extraname=None,
print_progress=True,
cover=False,
delete_file=True):
@@ -129,19 +137,27 @@ def download_file_and_uncompress(url,
savename = url.split("/")[-1]
savepath = os.path.join(savepath, savename)
- extraname = ".".join(savename.split(".")[:-1])
- extraname = os.path.join(extrapath, extraname)
+ savename = ".".join(savename.split(".")[:-1])
+ savename = os.path.join(extrapath, savename)
+ extraname = savename if extraname is None else os.path.join(
+ extrapath, extraname)
if cover:
if os.path.exists(savepath):
shutil.rmtree(savepath)
+ if os.path.exists(savename):
+ shutil.rmtree(savename)
if os.path.exists(extraname):
shutil.rmtree(extraname)
if not os.path.exists(extraname):
- if not os.path.exists(savepath):
- _download_file(url, savepath, print_progress)
- _uncompress_file(savepath, extrapath, delete_file, print_progress)
+ if not os.path.exists(savename):
+ if not os.path.exists(savepath):
+ _download_file(url, savepath, print_progress)
+ savename = _uncompress_file(savepath, extrapath, delete_file,
+ print_progress)
+ savename = os.path.join(extrapath, savename)
+ shutil.move(savename, extraname)
def _pdseg(command, flags, options, devices):
diff --git a/turtorial/finetune_deeplabv3plus.md b/turtorial/finetune_deeplabv3plus.md
new file mode 100644
index 0000000000000000000000000000000000000000..18e3e1428921e43dba92e39df53f362d5833206c
--- /dev/null
+++ b/turtorial/finetune_deeplabv3plus.md
@@ -0,0 +1,132 @@
+# 关于本教程
+
+* 本教程旨在介绍如何通过使用PaddleSeg提供的 ***`DeeplabV3+/Xception65/BatchNorm`*** 预训练模型在自定义数据集上进行训练。除了该配置之外,DeeplabV3+还支持以下不同[模型组合](#模型组合)的预训练模型,如果需要使用对应模型作为预训练模型,将下述内容中的Xception Backbone中的内容进行替换即可
+
+* 在阅读本教程前,请确保您已经了解过PaddleSeg的[快速入门](../README.md#快速入门)和[基础功能](../README.md#基础功能)等章节,以便对PaddleSeg有一定的了解
+
+* 本教程的所有命令都基于PaddleSeg主目录进行执行
+
+## 一. 准备待训练数据
+
+我们提前准备好了一份数据集,通过以下代码进行下载
+
+```shell
+python dataset/download_pet.py
+```
+
+## 二. 下载预训练模型
+
+关于PaddleSeg支持的所有预训练模型的列表,我们可以从[模型组合](#模型组合)中查看我们所需模型的名字和配置
+
+接着下载对应的预训练模型
+
+```shell
+python pretrained_model/download_model.py deeplabv3p_xception65_bn_cityscapes
+```
+
+## 三. 准备配置
+
+接着我们需要确定相关配置,从本教程的角度,配置分为三部分:
+
+* 数据集
+ * 训练集主目录
+ * 训练集文件列表
+ * 测试集文件列表
+ * 评估集文件列表
+* 预训练模型
+ * 预训练模型名称
+ * 预训练模型的backbone网络
+ * 预训练模型的Normalization类型
+ * 预训练模型路径
+* 其他
+ * 学习率
+ * Batch大小
+ * ...
+
+在三者中,预训练模型的配置尤为重要,如果模型或者BACKBONE配置错误,会导致预训练的参数没有加载,进而影响收敛速度。预训练模型相关的配置如第二步所展示。
+
+数据集的配置和数据路径有关,在本教程中,数据存放在`dataset/mini_pet`中
+
+其他配置则根据数据集和机器环境的情况进行调节,最终我们保存一个如下内容的yaml配置文件,存放路径为`configs/test_pet.yaml`
+
+```yaml
+# 数据集配置
+DATASET:
+ DATA_DIR: "./dataset/mini_pet/"
+ NUM_CLASSES: 3
+ TEST_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
+ TRAIN_FILE_LIST: "./dataset/mini_pet/file_list/train_list.txt"
+ VAL_FILE_LIST: "./dataset/mini_pet/file_list/val_list.txt"
+ VIS_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
+
+
+# 预训练模型配置
+MODEL:
+ MODEL_NAME: "deeplabv3p"
+ DEFAULT_NORM_TYPE: "bn"
+ DEEPLAB:
+ BACKBONE: "xception_65"
+TRAIN:
+ PRETRAINED_MODEL_DIR: "./pretrained_model/deeplabv3p_xception65_bn_pet/"
+
+
+# 其他配置
+TRAIN_CROP_SIZE: (512, 512)
+EVAL_CROP_SIZE: (512, 512)
+AUG:
+ AUG_METHOD: "unpadding"
+ FIX_RESIZE_SIZE: (512, 512)
+BATCH_SIZE: 4
+TRAIN:
+ MODEL_SAVE_DIR: "./finetune/deeplabv3p_xception65_bn_pet/"
+ SNAPSHOT_EPOCH: 10
+TEST:
+ TEST_MODEL: "./finetune/deeplabv3p_xception65_bn_pet/final"
+SOLVER:
+ NUM_EPOCHS: 500
+ LR: 0.005
+ LR_POLICY: "poly"
+ OPTIMIZER: "adam"
+```
+
+## 四. 配置/数据校验
+
+在开始训练和评估之前,我们还需要对配置和数据进行一次校验,确保数据和配置是正确的。使用下述命令启动校验流程
+
+```shell
+python pdseg/check.py --cfg ./configs/test_pet.yaml
+```
+
+
+## 五. 开始训练
+
+校验通过后,使用下述命令启动训练
+
+```shell
+python pdseg/train.py --use_gpu --cfg ./configs/test_pet.yaml
+```
+
+## 六. 进行评估
+
+模型训练完成,使用下述命令启动评估
+
+```shell
+python pdseg/eval.py --use_gpu --cfg ./configs/test_pet.yaml
+```
+
+## 模型组合
+
+|预训练模型名称|BackBone|Norm|数据集|配置|
+|-|-|-|-|-|
+|mobilenetv2-2-0_bn_imagenet|-|bn|ImageNet|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 2.0
MODEL.DEFAULT_NORM_TYPE: bn|
+|mobilenetv2-1-5_bn_imagenet|-|bn|ImageNet|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.5
MODEL.DEFAULT_NORM_TYPE: bn|
+|mobilenetv2-1-0_bn_imagenet|-|bn|ImageNet|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.0
MODEL.DEFAULT_NORM_TYPE: bn|
+|mobilenetv2-0-5_bn_imagenet|-|bn|ImageNet|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 0.5
MODEL.DEFAULT_NORM_TYPE: bn|
+|mobilenetv2-0-25_bn_imagenet|-|bn|ImageNet|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 0.25
MODEL.DEFAULT_NORM_TYPE: bn|
+|xception41_imagenet|-|bn|ImageNet|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_41
MODEL.DEFAULT_NORM_TYPE: bn|
+|xception65_imagenet|-|bn|ImageNet|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: bn|
+|deeplabv3p_mobilenetv2-1-0_bn_coco|MobileNet V2|bn|COCO|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.0
MODEL.DEEPLAB.ENCODER_WITH_ASPP: False
MODEL.DEEPLAB.ENABLE_DECODER: False
MODEL.DEFAULT_NORM_TYPE: bn|
+|deeplabv3p_xception65_bn_coco|Xception|bn|COCO|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: bn |
+|deeplabv3p_mobilenetv2-1-0_bn_cityscapes|MobileNet V2|bn|Cityscapes|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.0
MODEL.DEEPLAB.ENCODER_WITH_ASPP: False
MODEL.DEEPLAB.ENABLE_DECODER: False
MODEL.DEFAULT_NORM_TYPE: bn|
+|deeplabv3p_xception65_gn_cityscapes|Xception|gn|Cityscapes|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: gn|
+|**deeplabv3p_xception65_bn_cityscapes**|Xception|bn|Cityscapes|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: bn|
diff --git a/turtorial/finetune_icnet.md b/turtorial/finetune_icnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..231d163d53b25e870e2181ff4f9f500cb2e0a1b1
--- /dev/null
+++ b/turtorial/finetune_icnet.md
@@ -0,0 +1,120 @@
+# 关于本教程
+
+* 本教程旨在介绍如何通过使用PaddleSeg提供的 ***`ICNet`*** 预训练模型在自定义数据集上进行训练
+
+* 在阅读本教程前,请确保您已经了解过PaddleSeg的[快速入门](../README.md#快速入门)和[基础功能](../README.md#基础功能)等章节,以便对PaddleSeg有一定的了解
+
+* 本教程的所有命令都基于PaddleSeg主目录进行执行
+
+## 一. 准备待训练数据
+
+我们提前准备好了一份数据集,通过以下代码进行下载
+
+```shell
+python dataset/download_pet.py
+```
+
+## 二. 下载预训练模型
+
+关于PaddleSeg支持的所有预训练模型的列表,我们可以从[模型组合](#模型组合)中查看我们所需模型的名字和配置。
+
+接着下载对应的预训练模型
+
+```shell
+python pretrained_model/download_model.py icnet_bn_cityscapes
+```
+
+## 三. 准备配置
+
+接着我们需要确定相关配置,从本教程的角度,配置分为三部分:
+
+* 数据集
+ * 训练集主目录
+ * 训练集文件列表
+ * 测试集文件列表
+ * 评估集文件列表
+* 预训练模型
+ * 预训练模型名称
+ * 预训练模型的backbone网络
+ * 预训练模型的Normalization类型
+ * 预训练模型路径
+* 优化策略
+ * 学习率
+ * Batch Size
+ * ...
+
+在三者中,预训练模型的配置尤为重要,如果模型或者BACKBONE配置错误,会导致预训练的参数没有加载,进而影响收敛速度。预训练模型相关的配置如第二步所示。
+
+数据集的配置和数据路径有关,在本教程中,数据存放在`dataset/mini_pet`中
+
+其他配置则根据数据集和机器环境的情况进行调节,最终我们保存一个如下内容的yaml配置文件,存放路径为`configs/test_pet.yaml`
+
+```yaml
+# 数据集配置
+DATASET:
+ DATA_DIR: "./dataset/mini_pet/"
+ NUM_CLASSES: 3
+ TEST_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
+ TRAIN_FILE_LIST: "./dataset/mini_pet/file_list/train_list.txt"
+ VAL_FILE_LIST: "./dataset/mini_pet/file_list/val_list.txt"
+ VIS_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
+
+
+# 预训练模型配置
+MODEL:
+ MODEL_NAME: "icnet"
+ DEFAULT_NORM_TYPE: "bn"
+ MULTI_LOSS_WEIGHT: "[1.0, 0.4, 0.16]"
+TRAIN:
+ PRETRAINED_MODEL_DIR: "./pretrained_model/icnet_bn_cityscapes/"
+
+
+# 其他配置
+TRAIN_CROP_SIZE: (512, 512)
+EVAL_CROP_SIZE: (512, 512)
+AUG:
+ AUG_METHOD: "unpadding"
+ FIX_RESIZE_SIZE: (512, 512)
+BATCH_SIZE: 4
+TRAIN:
+ MODEL_SAVE_DIR: "./saved_model/icnet_pet/"
+ SNAPSHOT_EPOCH: 10
+TEST:
+ TEST_MODEL: "./saved_model/icnet_pet/final"
+SOLVER:
+ NUM_EPOCHS: 100
+ LR: 0.01
+ LR_POLICY: "poly"
+ OPTIMIZER: "sgd"
+```
+
+## 四. 配置/数据校验
+
+在开始训练和评估之前,我们还需要对配置和数据进行一次校验,确保数据和配置是正确的。使用下述命令启动校验流程
+
+```shell
+python pdseg/check.py --cfg ./configs/test_pet.yaml
+```
+
+
+## 五. 开始训练
+
+校验通过后,使用下述命令启动训练
+
+```shell
+python pdseg/train.py --use_gpu --cfg ./configs/test_pet.yaml
+```
+
+## 六. 进行评估
+
+模型训练完成,使用下述命令启动评估
+
+```shell
+python pdseg/eval.py --use_gpu --cfg ./configs/test_pet.yaml
+```
+
+## 模型组合
+
+|预训练模型名称|BackBone|Norm|数据集|配置|
+|-|-|-|-|-|
+|icnet_bn_cityscapes|-|bn|Cityscapes|MODEL.MODEL_NAME: icnet
MODEL.DEFAULT_NORM_TYPE: bn
MULTI_LOSS_WEIGHT: [1.0, 0.4, 0.16]|
diff --git a/turtorial/finetune_unet.md b/turtorial/finetune_unet.md
new file mode 100644
index 0000000000000000000000000000000000000000..77a407bac09a8ad0866c66f585c49390205aa6d8
--- /dev/null
+++ b/turtorial/finetune_unet.md
@@ -0,0 +1,119 @@
+# 关于本教程
+
+* 本教程旨在介绍如何通过使用PaddleSeg提供的 ***`UNet`*** 预训练模型在自定义数据集上进行训练
+
+* 在阅读本教程前,请确保您已经了解过PaddleSeg的[快速入门](../README.md#快速入门)和[基础功能](../README.md#基础功能)等章节,以便对PaddleSeg有一定的了解
+
+* 本教程的所有命令都基于PaddleSeg主目录进行执行
+
+## 一. 准备待训练数据
+
+我们提前准备好了一份数据集,通过以下代码进行下载
+
+```shell
+python dataset/download_pet.py
+```
+
+## 二. 下载预训练模型
+
+关于PaddleSeg支持的所有预训练模型的列表,我们可以从[模型组合](#模型组合)中查看我们所需模型的名字和配置。
+
+接着下载对应的预训练模型
+
+```shell
+python pretrained_model/download_model.py unet_bn_coco
+```
+
+## 三. 准备配置
+
+接着我们需要确定相关配置,从本教程的角度,配置分为三部分:
+
+* 数据集
+ * 训练集主目录
+ * 训练集文件列表
+ * 测试集文件列表
+ * 评估集文件列表
+* 预训练模型
+ * 预训练模型名称
+ * 预训练模型的backbone网络
+ * 预训练模型的Normalization类型
+ * 预训练模型路径
+* 其他
+ * 学习率
+ * Batch大小
+ * ...
+
+在三者中,预训练模型的配置尤为重要,如果模型或者BACKBONE配置错误,会导致预训练的参数没有加载,进而影响收敛速度。预训练模型相关的配置如第二步所展示。
+
+数据集的配置和数据路径有关,在本教程中,数据存放在`dataset/mini_pet`中
+
+其他配置则根据数据集和机器环境的情况进行调节,最终我们保存一个如下内容的yaml配置文件,存放路径为`configs/test_pet.yaml`
+
+```yaml
+# 数据集配置
+DATASET:
+ DATA_DIR: "./dataset/mini_pet/"
+ NUM_CLASSES: 3
+ TEST_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
+ TRAIN_FILE_LIST: "./dataset/mini_pet/file_list/train_list.txt"
+ VAL_FILE_LIST: "./dataset/mini_pet/file_list/val_list.txt"
+ VIS_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
+
+
+# 预训练模型配置
+MODEL:
+ MODEL_NAME: "unet"
+ DEFAULT_NORM_TYPE: "bn"
+TRAIN:
+ PRETRAINED_MODEL_DIR: "./pretrained_model/unet_bn_coco/"
+
+
+# 其他配置
+TRAIN_CROP_SIZE: (512, 512)
+EVAL_CROP_SIZE: (512, 512)
+AUG:
+ AUG_METHOD: "unpadding"
+ FIX_RESIZE_SIZE: (512, 512)
+BATCH_SIZE: 4
+TRAIN:
+ MODEL_SAVE_DIR: "./finetune/unet_pet/"
+ SNAPSHOT_EPOCH: 10
+TEST:
+ TEST_MODEL: "./finetune/unet_pet/final"
+SOLVER:
+ NUM_EPOCHS: 500
+ LR: 0.005
+ LR_POLICY: "poly"
+ OPTIMIZER: "adam"
+```
+
+## 四. 配置/数据校验
+
+在开始训练和评估之前,我们还需要对配置和数据进行一次校验,确保数据和配置是正确的。使用下述命令启动校验流程
+
+```shell
+python pdseg/check.py --cfg ./configs/test_pet.yaml
+```
+
+
+## 五. 开始训练
+
+校验通过后,使用下述命令启动训练
+
+```shell
+python pdseg/train.py --use_gpu --cfg ./configs/test_pet.yaml
+```
+
+## 六. 进行评估
+
+模型训练完成,使用下述命令启动评估
+
+```shell
+python pdseg/eval.py --use_gpu --cfg ./configs/test_pet.yaml
+```
+
+## 模型组合
+
+|预训练模型名称|BackBone|Norm|数据集|配置|
+|-|-|-|-|-|
+|unet_bn_coco|-|bn|Cityscapes|MODEL.MODEL_NAME: unet
MODEL.DEFAULT_NORM_TYPE: bn|
 -
-  +
+  +
+ 