Merge branch 'release/v0.3.0' into develop
Showing
configs/hrnet_optic.yaml
0 → 100644
configs/hrnet_w18_pet.yaml
已删除
100644 → 0
configs/icnet_optic.yaml
0 → 100644
configs/icnet_pet.yaml
已删除
100644 → 0
configs/pspnet_optic.yaml
0 → 100644
configs/unet_optic.yaml
0 → 100644
configs/unet_pet.yaml
已删除
100644 → 0
contrib/ACE2P/download_ACE2P.py
0 → 100644

22.0 KB

2.1 KB
contrib/ACE2P/infer.py
0 → 100644
contrib/HumanSeg/utils/palette.py
0 → 100644
contrib/HumanSeg/utils/util.py
0 → 100644
文件已移动
文件已移动
contrib/RoadLine/infer.py
0 → 100644
contrib/RoadLine/utils/palette.py
0 → 100644
contrib/RoadLine/utils/util.py
0 → 100644
dataset/download_optic.py
0 → 100644
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已删除
文件已删除
文件已删除
文件已删除
文件已删除
文件已删除

106.8 KB
文件已移动

4.2 KB

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

| W: | H:

| W: | H:
docs/benchmark.md
已删除
100644 → 0
docs/imgs/annotation/image-11.png
0 → 100644
{kind=link}

435.0 KB
{kind=link}
{kind=link}
| W: | H:

| W: | H:
{kind=link}
{kind=link}
| W: | H:

| W: | H:
{kind=link}
{kind=link}
| W: | H:

| W: | H:
docs/imgs/dice.png
0 → 100644
{kind=link}

2.6 KB
docs/imgs/dice1.png
已删除
100644 → 0
{kind=link}

7.9 KB
docs/imgs/dice2.png
0 → 100644
{kind=link}

464 字节
docs/imgs/dice3.png
0 → 100644
{kind=link}
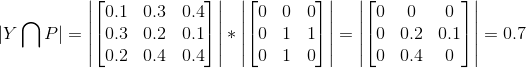
3.8 KB
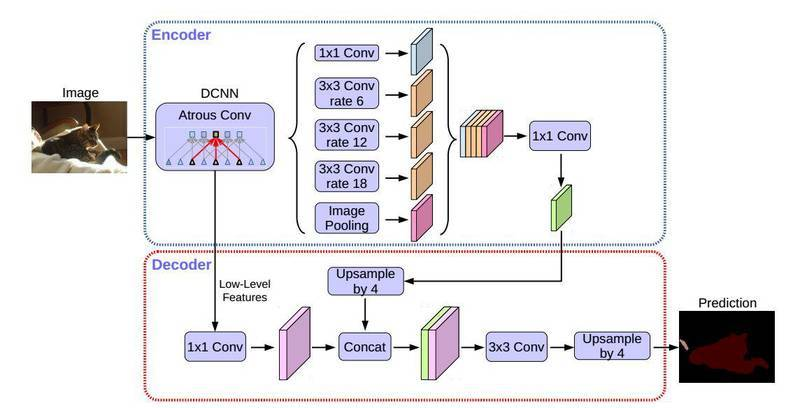
docs/imgs/hrnet.png
0 → 100644
{kind=link}

51.6 KB
{kind=link}
{kind=link}
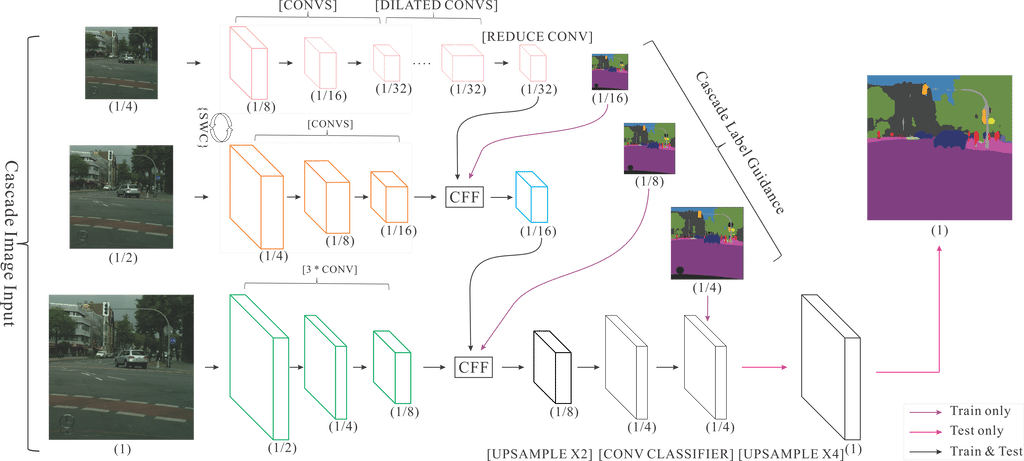
| W: | H:
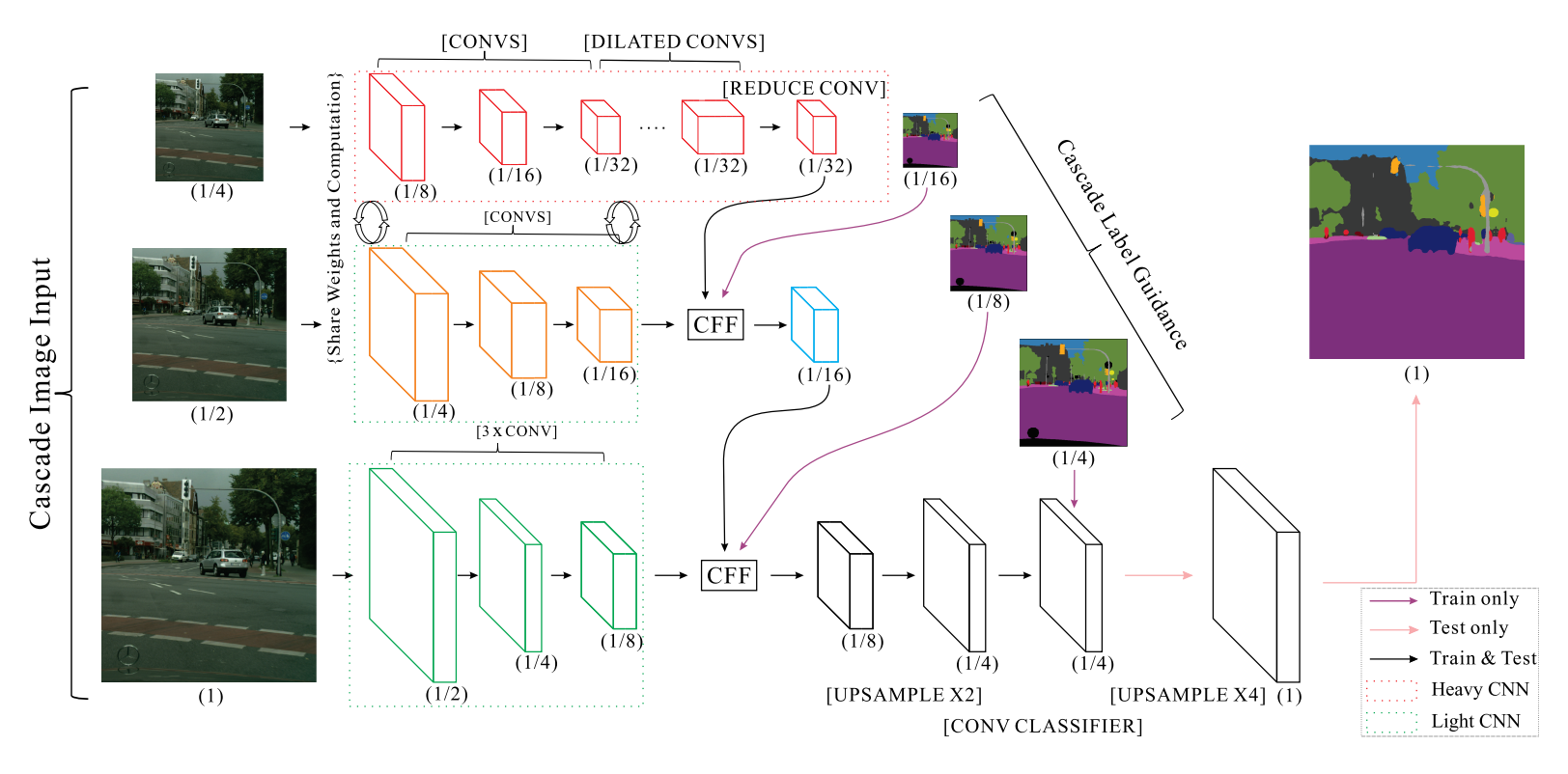
| W: | H:
docs/imgs/pspnet.png
0 → 100644
{kind=link}

450.9 KB
docs/imgs/pspnet2.png
0 → 100644
{kind=link}

995.7 KB
docs/imgs/softmax_loss.png
0 → 100644
{kind=link}

2.6 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:
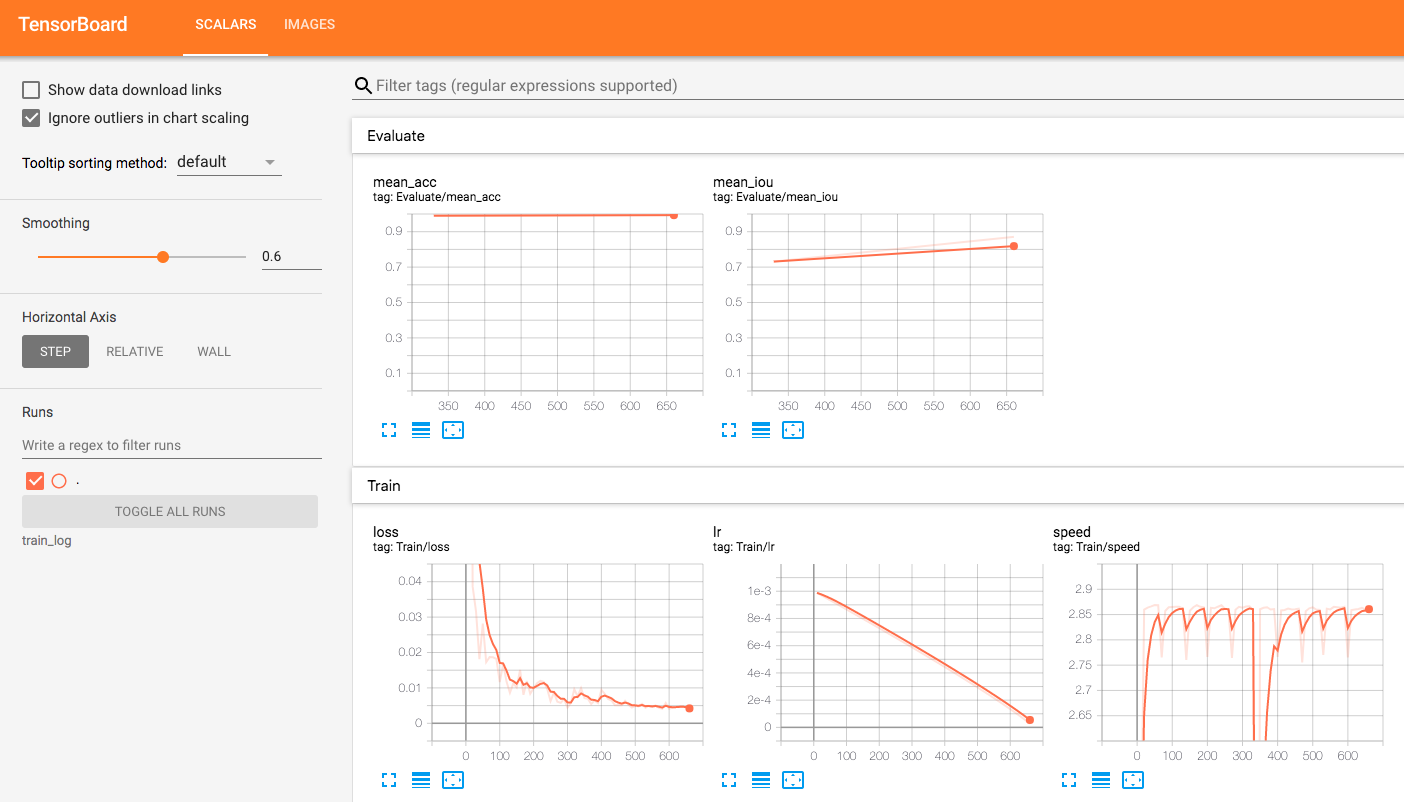
| W: | H:
{kind=link}
{kind=link}
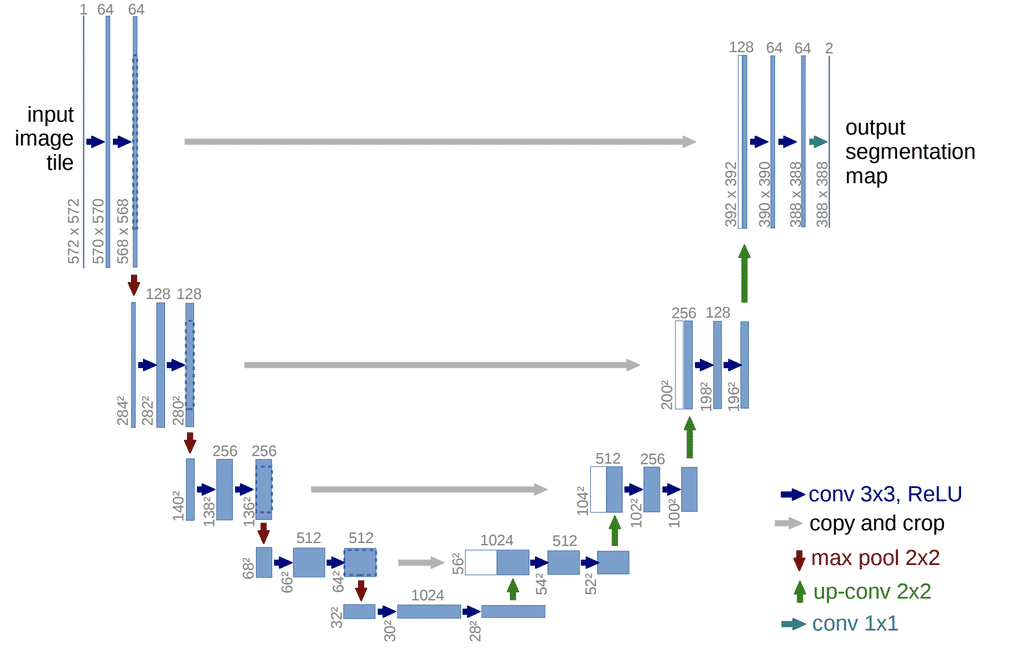
| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
docs/imgs/usage_vis_demo2.jpg
已删除
100644 → 0
{kind=link}

33.4 KB
docs/imgs/usage_vis_demo3.jpg
已删除
100644 → 0
{kind=link}

91.4 KB
docs/installation.md
已删除
100644 → 0
turtorial/imgs/optic.png
0 → 100644
{kind=link}

380.6 KB
turtorial/imgs/optic_deeplab.png
0 → 100644
{kind=link}

325.8 KB
turtorial/imgs/optic_hrnet.png
0 → 100644
{kind=link}

325.7 KB
turtorial/imgs/optic_icnet.png
0 → 100644
{kind=link}

326.0 KB
turtorial/imgs/optic_pspnet.png
0 → 100644
{kind=link}

325.6 KB
turtorial/imgs/optic_unet.png
0 → 100644
{kind=link}

325.8 KB