diff --git a/README.md b/README.md
index 31c0e8cf2fe234ff2bbdcc2b0683178a5ecba6ab..dcf69d92352704ecf4728e1154e90386b9465ee8 100644
--- a/README.md
+++ b/README.md
@@ -60,7 +60,9 @@ PaddleSeg支持多进程IO、多卡并行、跨卡Batch Norm同步等训练加
### 高级功能
* [PaddleSeg的数据增强](./docs/data_aug.md)
+* [PaddleSeg的loss选择](./docs/loss_select.md)
* [特色垂类模型使用](./contrib)
+* [多进程训练和混合精度训练](./docs/multiple_gpus_train_and_mixed_precision_train.md)
@@ -87,6 +89,10 @@ A: 降低Batch size,使用Group Norm策略;请注意训练过程中当`DEFAU
+#### Q: 出现错误 ModuleNotFoundError: No module named 'paddle.fluid.contrib.mixed_precision'
+
+A: 请将PaddlePaddle升级至1.5.2版本或以上。
+
## 在线体验
PaddleSeg在AI Studio平台上提供了在线体验的教程,欢迎体验:
@@ -100,15 +106,13 @@ PaddleSeg在AI Studio平台上提供了在线体验的教程,欢迎体验:
## 交流与反馈
-* 欢迎您通过Github Issues来提交问题、报告与建议
+* 欢迎您通过[Github Issues](https://github.com/PaddlePaddle/PaddleSeg/issues)来提交问题、报告与建议
* 微信公众号:飞桨PaddlePaddle
* QQ群: 796771754


微信公众号 官方技术交流QQ群
-* 论坛: 欢迎大家在[PaddlePaddle论坛](https://ai.baidu.com/forum/topic/list/168)分享在使用PaddlePaddle中遇到的问题和经验, 营造良好的论坛氛围
-
## 更新日志
* 2019.09.10
diff --git a/configs/deepglobe_road_extraction.yaml b/configs/deepglobe_road_extraction.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c06dd8c9a42ff67a85c5c2e1decdc085faa6a57e
--- /dev/null
+++ b/configs/deepglobe_road_extraction.yaml
@@ -0,0 +1,44 @@
+EVAL_CROP_SIZE: (1025, 1025) # (width, height), for unpadding rangescaling and stepscaling
+TRAIN_CROP_SIZE: (769, 769) # (width, height), for unpadding rangescaling and stepscaling
+AUG:
+ AUG_METHOD: u"stepscaling" # choice unpadding rangescaling and stepscaling
+ FIX_RESIZE_SIZE: (640, 640) # (width, height), for unpadding
+ INF_RESIZE_VALUE: 500 # for rangescaling
+ MAX_RESIZE_VALUE: 600 # for rangescaling
+ MIN_RESIZE_VALUE: 400 # for rangescaling
+ MAX_SCALE_FACTOR: 2.0 # for stepscaling
+ MIN_SCALE_FACTOR: 0.5 # for stepscaling
+ SCALE_STEP_SIZE: 0.25 # for stepscaling
+BATCH_SIZE: 8
+DATASET:
+ DATA_DIR: "./dataset/MiniDeepGlobeRoadExtraction/"
+ IMAGE_TYPE: "rgb" # choice rgb or rgba
+ NUM_CLASSES: 2
+ TEST_FILE_LIST: "dataset/MiniDeepGlobeRoadExtraction/val.txt"
+ TRAIN_FILE_LIST: "dataset/MiniDeepGlobeRoadExtraction/train.txt"
+ VAL_FILE_LIST: "dataset/MiniDeepGlobeRoadExtraction/val.txt"
+ IGNORE_INDEX: 255
+ SEPARATOR: '|'
+FREEZE:
+ MODEL_FILENAME: "model"
+ PARAMS_FILENAME: "params"
+ SAVE_DIR: "freeze_model"
+MODEL:
+ DEFAULT_NORM_TYPE: "bn"
+ MODEL_NAME: "deeplabv3p"
+ DEEPLAB:
+ BACKBONE: "mobilenet"
+ DEPTH_MULTIPLIER: 1.0
+ ENCODER_WITH_ASPP: False
+ ENABLE_DECODER: False
+TEST:
+ TEST_MODEL: "./saved_model/deeplabv3p_mobilenetv2-1-0_bn_deepglobe_road_extraction/final"
+TRAIN:
+ MODEL_SAVE_DIR: "./saved_model/deeplabv3p_mobilenetv2-1-0_bn_deepglobe_road_extraction/"
+ PRETRAINED_MODEL_DIR: "./pretrained_model/deeplabv3p_mobilenetv2-1-0_bn_coco/"
+ SNAPSHOT_EPOCH: 10
+SOLVER:
+ LR: 0.001
+ LR_POLICY: "poly"
+ OPTIMIZER: "adam"
+ NUM_EPOCHS: 300
diff --git a/configs/unet_pet.yaml b/configs/unet_pet.yaml
index 2f3cc50e7e99ea7b8ff749d57f8319aa6b212a6f..a1781c5e8c4963ac269c4850f1012cc3d9ad8d15 100644
--- a/configs/unet_pet.yaml
+++ b/configs/unet_pet.yaml
@@ -30,13 +30,13 @@ MODEL:
MODEL_NAME: "unet"
DEFAULT_NORM_TYPE: "bn"
TEST:
- TEST_MODEL: "./test/saved_model/unet_pet/final/"
+ TEST_MODEL: "./saved_model/unet_pet/final/"
TRAIN:
- MODEL_SAVE_DIR: "./test/saved_models/unet_pet/"
- PRETRAINED_MODEL_DIR: "./test/models/unet_coco/"
+ MODEL_SAVE_DIR: "./saved_model/unet_pet/"
+ PRETRAINED_MODEL_DIR: "./pretrained_model/unet_bn_coco/"
SNAPSHOT_EPOCH: 10
SOLVER:
- NUM_EPOCHS: 500
+ NUM_EPOCHS: 100
LR: 0.005
LR_POLICY: "poly"
OPTIMIZER: "adam"
diff --git a/dataset/README.md b/dataset/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..497934e29597f66be26a79022e32dc8006b52afe
--- /dev/null
+++ b/dataset/README.md
@@ -0,0 +1,31 @@
+# 数据下载
+## PASCAL VOC 2012数据集
+下载 PASCAL VOC 2012数据集并将分割部分的假彩色标注图(`SegmentationClass`文件夹)转换成灰度图并存储在`SegmentationClassAug`文件夹, 并在文件夹`ImageSets/Segmentation`下重新生成列表文件`train.list、val.list和trainval.list。
+
+```shell
+# 下载数据集并进行解压转换
+python download_and_convert_voc2012.py
+```
+
+如果已经下载好PASCAL VOC 2012数据集,将数据集移至dataset目录后使用下述命令直接进行转换即可。
+
+```shell
+# 数据集转换
+python convert_voc2012.py
+```
+
+## Oxford-IIIT Pet数据集
+我们使用了Oxford-IIIT中的猫和狗两个类别数据制作了一个小数据集mini_pet,更多关于数据集的介绍请参考[Oxford-IIIT Pet](https://www.robots.ox.ac.uk/~vgg/data/pets/)。
+
+```shell
+# 下载数据集并进行解压
+python dataset/download_pet.py
+```
+
+## Cityscapes数据集
+运行下述命令下载并解压Cityscapes数据集。
+
+```shell
+# 下载数据集并进行解压
+python dataset/download_cityscapes.py
+```
diff --git a/dataset/convert_voc2012.py b/dataset/convert_voc2012.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b7de80fb2131a6b6814870c2bc13fc4af1167ca
--- /dev/null
+++ b/dataset/convert_voc2012.py
@@ -0,0 +1,71 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+import numpy as np
+import os
+from PIL import Image
+import glob
+
+LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
+def remove_colormap(filename):
+ gray_anno = np.array(Image.open(filename))
+ return gray_anno
+
+
+def save_annotation(annotation, filename):
+ annotation = annotation.astype(dtype=np.uint8)
+ annotation = Image.fromarray(annotation)
+ annotation.save(filename)
+
+def convert_list(origin_file, seg_file, output_folder):
+ with open(seg_file, 'w') as fid_seg:
+ with open(origin_file) as fid_ori:
+ lines = fid_ori.readlines()
+ for line in lines:
+ line = line.strip()
+ line = '.'.join([line, 'jpg'])
+ img_name = os.path.join("JPEGImages", line)
+ line = line.replace('jpg', 'png')
+ anno_name = os.path.join(output_folder.split(os.sep)[-1], line)
+ new_line = ' '.join([img_name, anno_name])
+ fid_seg.write(new_line + "\n")
+
+if __name__ == "__main__":
+ pascal_root = "./VOCtrainval_11-May-2012/VOC2012"
+ pascal_root = os.path.join(LOCAL_PATH, pascal_root)
+ seg_folder = os.path.join(pascal_root, "SegmentationClass")
+ txt_folder = os.path.join(pascal_root, "ImageSets/Segmentation")
+ train_path = os.path.join(txt_folder, "train.txt")
+ val_path = os.path.join(txt_folder, "val.txt")
+ trainval_path = os.path.join(txt_folder, "trainval.txt")
+
+ # 标注图转换后存储目录
+ output_folder = os.path.join(pascal_root, "SegmentationClassAug")
+
+ print("annotation convert and file list convert")
+ if not os.path.exists(os.path.join(LOCAL_PATH, output_folder)):
+ os.mkdir(os.path.join(LOCAL_PATH, output_folder))
+ annotation_names = glob.glob(os.path.join(seg_folder, '*.png'))
+ for annotation_name in annotation_names:
+ annotation = remove_colormap(annotation_name)
+ filename = os.path.basename(annotation_name)
+ save_name = os.path.join(output_folder, filename)
+ save_annotation(annotation, save_name)
+
+ convert_list(train_path, train_path.replace('txt', 'list'), output_folder)
+ convert_list(val_path, val_path.replace('txt', 'list'), output_folder)
+ convert_list(trainval_path, trainval_path.replace('txt', 'list'), output_folder)
+
diff --git a/dataset/download_and_convert_voc2012.py b/dataset/download_and_convert_voc2012.py
new file mode 100644
index 0000000000000000000000000000000000000000..eef2e5de9eb68e131d03e7ec1dca4050281888fc
--- /dev/null
+++ b/dataset/download_and_convert_voc2012.py
@@ -0,0 +1,65 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+import numpy as np
+import os
+import glob
+
+LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
+TEST_PATH = os.path.join(LOCAL_PATH, "..", "test")
+sys.path.append(TEST_PATH)
+
+from test_utils import download_file_and_uncompress
+from convert_voc2012 import convert_list
+from convert_voc2012 import remove_colormap
+from convert_voc2012 import save_annotation
+
+
+
+def download_VOC_dataset(savepath, extrapath):
+ url = "https://paddleseg.bj.bcebos.com/dataset/VOCtrainval_11-May-2012.tar"
+ download_file_and_uncompress(
+ url=url, savepath=savepath, extrapath=extrapath)
+
+if __name__ == "__main__":
+ download_VOC_dataset(LOCAL_PATH, LOCAL_PATH)
+ print("Dataset download finish!")
+
+ pascal_root = "./VOCtrainval_11-May-2012/VOC2012"
+ pascal_root = os.path.join(LOCAL_PATH, pascal_root)
+ seg_folder = os.path.join(pascal_root, "SegmentationClass")
+ txt_folder = os.path.join(pascal_root, "ImageSets/Segmentation")
+ train_path = os.path.join(txt_folder, "train.txt")
+ val_path = os.path.join(txt_folder, "val.txt")
+ trainval_path = os.path.join(txt_folder, "trainval.txt")
+
+ # 标注图转换后存储目录
+ output_folder = os.path.join(pascal_root, "SegmentationClassAug")
+
+ print("annotation convert and file list convert")
+ if not os.path.exists(output_folder):
+ os.mkdir(output_folder)
+ annotation_names = glob.glob(os.path.join(seg_folder, '*.png'))
+ for annotation_name in annotation_names:
+ annotation = remove_colormap(annotation_name)
+ filename = os.path.basename(annotation_name)
+ save_name = os.path.join(output_folder, filename)
+ save_annotation(annotation, save_name)
+
+ convert_list(train_path, train_path.replace('txt', 'list'), output_folder)
+ convert_list(val_path, val_path.replace('txt', 'list'), output_folder)
+ convert_list(trainval_path, trainval_path.replace('txt', 'list'), output_folder)
+
diff --git a/dataset/download_mini_deepglobe_road_extraction.py b/dataset/download_mini_deepglobe_road_extraction.py
new file mode 100644
index 0000000000000000000000000000000000000000..13312407434b7186a782a99d38c9281c5c006c32
--- /dev/null
+++ b/dataset/download_mini_deepglobe_road_extraction.py
@@ -0,0 +1,33 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+
+LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
+TEST_PATH = os.path.join(LOCAL_PATH, "..", "test")
+sys.path.append(TEST_PATH)
+
+from test_utils import download_file_and_uncompress
+
+
+def download_deepglobe_road_dataset(savepath, extrapath):
+ url = "https://paddleseg.bj.bcebos.com/dataset/MiniDeepGlobeRoadExtraction.zip"
+ download_file_and_uncompress(
+ url=url, savepath=savepath, extrapath=extrapath)
+
+
+if __name__ == "__main__":
+ download_deepglobe_road_dataset(LOCAL_PATH, LOCAL_PATH)
+ print("Dataset download finish!")
diff --git a/docs/annotation/README.md b/docs/annotation/README.md
deleted file mode 100644
index 5be98ce7841af87c7a8f65e708c02aa9b08dc907..0000000000000000000000000000000000000000
--- a/docs/annotation/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
-# PaddleSeg 数据标注
-
-用户需预先采集好用于训练、评估和测试的图片,并使用数据标注工具完成数据标注。
-
-PaddleSeg支持2种标注工具:LabelMe、精灵数据标注工具。
-
-标注教程如下:
-- [LabelMe标注教程](labelme2seg.md)
-- [精灵数据标注工具教程](jingling2seg.md)
-
-最后用我们提供的数据转换脚本将上述标注工具产出的数据格式转换为模型训练时所需的数据格式。
-
diff --git a/docs/check.md b/docs/check.md
index c47618b67cbfb2de2bb90758cdd566aaea956310..fac9520f11ef46d3628ecab3fcc4127a468a3ca5 100644
--- a/docs/check.md
+++ b/docs/check.md
@@ -6,7 +6,7 @@
# YAML_FILE_PATH为yaml配置文件路径
python pdseg/check.py --cfg ${YAML_FILE_PATH}
```
-运行后,命令行将显示校验结果的概览信息,详细信息可到detail.log文件中查看。
+运行后,命令行将显示校验结果的概览信息,详细的错误信息可到detail.log文件中查看。
### 1 列表分割符校验
判断在`TRAIN_FILE_LIST`,`VAL_FILE_LIST`和`TEST_FILE_LIST`列表文件中的分隔符`DATASET.SEPARATOR`设置是否正确。
@@ -31,18 +31,24 @@ python pdseg/check.py --cfg ${YAML_FILE_PATH}
标注类别最好从0开始,否则可能影响精度。
### 6 标注像素统计
-统计每种类别像素数量,显示以供参考。
-
+统计每种类别的像素总数和所占比例,显示以供参考。统计结果如下:
+```
+Doing label pixel statistics:
+(label class, total pixel number, percentage) = [(0, 2048984, 0.5211), (1, 1682943, 0.428), (2, 197976, 0.0503), (3, 2257, 0.0006)]
+```
### 7 图像格式校验
检查图片类型`DATASET.IMAGE_TYPE`是否设置正确。
**NOTE:** 当数据集包含三通道图片时`DATASET.IMAGE_TYPE`设置为rgb;
当数据集全部为四通道图片时`DATASET.IMAGE_TYPE`设置为rgba;
-### 8 图像与标注图尺寸一致性校验
+### 8 图像最大尺寸统计
+统计数据集中图片的最大高和最大宽,显示以供参考。
+
+### 9 图像与标注图尺寸一致性校验
验证图像尺寸和对应标注图尺寸是否一致。
-### 9 模型验证参数`EVAL_CROP_SIZE`校验
+### 10 模型验证参数`EVAL_CROP_SIZE`校验
验证`EVAL_CROP_SIZE`是否设置正确,共有3种情形:
- 当`AUG.AUG_METHOD`为unpadding时,`EVAL_CROP_SIZE`的宽高应不小于`AUG.FIX_RESIZE_SIZE`的宽高。
@@ -51,5 +57,5 @@ python pdseg/check.py --cfg ${YAML_FILE_PATH}
- 当`AUG.AUG_METHOD`为rangscaling时,`EVAL_CROP_SIZE`的宽高应不小于缩放后图像中最大的宽高。
-### 10 数据增强参数`AUG.INF_RESIZE_VALUE`校验
+### 11 数据增强参数`AUG.INF_RESIZE_VALUE`校验
验证`AUG.INF_RESIZE_VALUE`是否在[`AUG.MIN_RESIZE_VALUE`~`AUG.MAX_RESIZE_VALUE`]范围内。若在范围内,则通过校验。
diff --git a/docs/configs/solver_group.md b/docs/configs/solver_group.md
index 8db49fce8268f6a7bde484ed5759f3601f849263..e068b9d36eedf2cb74e912f1705b66eac421cfdc 100644
--- a/docs/configs/solver_group.md
+++ b/docs/configs/solver_group.md
@@ -121,4 +121,20 @@ L2正则化系数
10(意味着每训练10个EPOCH保存一次模型)
-
\ No newline at end of file
+
+
+## `loss`
+
+训练时选择的损失函数, 支持`softmax_loss(sotfmax with cross entroy loss)`,
+`dice_loss(dice coefficient loss)`, `bce_loss(binary cross entroy loss)`三种损失函数。
+其中`dice_loss`和`bce_loss`仅在两类分割问题中适用,`softmax_loss`不能与`dice_loss`
+或`bce_loss`组合,`dice_loss`可以和`bce_loss`组合使用。使用示例如下:
+
+`['softmax_loss']`或`['dice_loss','bce_loss']`
+
+### 默认值
+
+['softmax_loss']
+
+
+
diff --git a/docs/data_prepare.md b/docs/data_prepare.md
index 13791dc5661e5e1393fda05469802e989d1e4d94..87d0ced32811c3772d1e7cafdee00fcb2e1a148d 100644
--- a/docs/data_prepare.md
+++ b/docs/data_prepare.md
@@ -2,10 +2,18 @@
## 数据标注
-数据标注推荐使用LabelMe工具,具体可参考文档[PaddleSeg 数据标注](./annotation/README.md)
+用户需预先采集好用于训练、评估和测试的图片,然后使用数据标注工具完成数据标注。
+PddleSeg已支持2种标注工具:LabelMe、精灵数据标注工具。标注教程如下:
-## 语义分割标注规范
+- [LabelMe标注教程](annotation/labelme2seg.md)
+- [精灵数据标注工具教程](annotation/jingling2seg.md)
+
+最后用我们提供的数据转换脚本将上述标注工具产出的数据格式转换为模型训练时所需的数据格式。
+
+## 文件列表
+
+### 文件列表规范
PaddleSeg采用通用的文件列表方式组织训练集、验证集和测试集。像素标注类别需要从0开始递增。
@@ -57,4 +65,94 @@ PaddleSeg采用通用的文件列表方式组织训练集、验证集和测试

+若数据集缺少标注图片,则文件列表不用包含分隔符和标注图片路径,如下图所示。
+
+
+**注意事项**
+
+此时的文件列表仅可在调用`pdseg/vis.py`进行可视化展示时使用,
+即仅可在`DATASET.TEST_FILE_LIST`和`DATASET.VIS_FILE_LIST`配置项中使用。
+不可在`DATASET.TRAIN_FILE_LIST`和`DATASET.VAL_FILE_LIST`配置项中使用。
+
+
完整的配置信息可以参考[`./dataset/cityscapes_demo`](../dataset/cityscapes_demo/)目录下的yaml和文件列表。
+
+### 文件列表生成
+PaddleSeg提供了生成文件列表的使用脚本,可适用于自定义数据集或cityscapes数据集,并支持通过不同的Flags来开启特定功能。
+```
+python pdseg/tools/create_dataset_list.py ${FLAGS}
+```
+运行后将在数据集根目录下生成训练/验证/测试集的文件列表(文件主名与`--second_folder`一致,扩展名为`.txt`)。
+
+**Note:** 若训练/验证/测试集缺少标注图片,仍可自动生成不含分隔符和标注图片路径的文件列表。
+
+#### 命令行FLAGS列表
+
+|FLAG|用途|默认值|参数数目|
+|-|-|-|-|
+|--type|指定数据集类型,`cityscapes`或`自定义`|`自定义`|1|
+|--separator|文件列表分隔符|'|'|1|
+|--folder|图片和标签集的文件夹名|'images' 'annotations'|2|
+|--second_folder|训练/验证/测试集的文件夹名|'train' 'val' 'test'|若干|
+|--format|图片和标签集的数据格式|'jpg' 'png'|2|
+|--postfix|按文件主名(无扩展名)是否包含指定后缀对图片和标签集进行筛选|'' ''(2个空字符)|2|
+
+#### 使用示例
+- **对于自定义数据集**
+
+如果用户想要生成自己数据集的文件列表,需要整理成如下的目录结构:
+```
+./dataset/ # 数据集根目录
+├── annotations # 标注目录
+│ ├── test
+│ │ ├── ...
+│ │ └── ...
+│ ├── train
+│ │ ├── ...
+│ │ └── ...
+│ └── val
+│ ├── ...
+│ └── ...
+└── images # 原图目录
+ ├── test
+ │ ├── ...
+ │ └── ...
+ ├── train
+ │ ├── ...
+ │ └── ...
+ └── val
+ ├── ...
+ └── ...
+Note:以上目录名可任意
+```
+必须指定自定义数据集目录,可以按需要设定FLAG。
+
+**Note:** 无需指定`--type`。
+```
+# 生成文件列表,其分隔符为空格,图片和标签集的数据格式都为png
+python pdseg/tools/create_dataset_list.py --separator " " --format png png
+```
+```
+# 生成文件列表,其图片和标签集的文件夹名为img和gt,训练和验证集的文件夹名为training和validation,不生成测试集列表
+python pdseg/tools/create_dataset_list.py \
+ --folder img gt --second_folder training validation
+```
+
+
+- **对于cityscapes数据集**
+
+必须指定cityscapes数据集目录,`--type`必须为`cityscapes`。
+
+在cityscapes类型下,部分FLAG将被重新设定,无需手动指定,具体如下:
+
+|FLAG|固定值|
+|-|-|
+|--folder|'leftImg8bit' 'gtFine'|
+|--format|'png' 'png'|
+|--postfix|'_leftImg8bit' '_gtFine_labelTrainIds'|
+
+其余FLAG可以按需要设定。
+```
+# 生成cityscapes文件列表,其分隔符为逗号
+python pdseg/tools/create_dataset_list.py --type cityscapes --separator ","
+```
diff --git a/docs/imgs/deepglobe.png b/docs/imgs/deepglobe.png
new file mode 100644
index 0000000000000000000000000000000000000000..cfd77f6b654dc16ad9687d16f8e836b278d26594
Binary files /dev/null and b/docs/imgs/deepglobe.png differ
diff --git a/docs/imgs/dice1.png b/docs/imgs/dice1.png
new file mode 100644
index 0000000000000000000000000000000000000000..f8520802296cc264849fae4a8442792cf56cb20a
Binary files /dev/null and b/docs/imgs/dice1.png differ
diff --git a/docs/imgs/file_list2.png b/docs/imgs/file_list2.png
new file mode 100644
index 0000000000000000000000000000000000000000..d90e057fde7870565994636f7392ba200a66a761
Binary files /dev/null and b/docs/imgs/file_list2.png differ
diff --git a/docs/imgs/loss_comparison.png b/docs/imgs/loss_comparison.png
new file mode 100644
index 0000000000000000000000000000000000000000..9a475570930f9c97e433ae9eb1f34ccae1b2444c
Binary files /dev/null and b/docs/imgs/loss_comparison.png differ
diff --git a/docs/imgs/usage_vis_demo.jpg b/docs/imgs/usage_vis_demo.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..50bedf2f547d11cb4aaefa0435022acc0392ba3c
Binary files /dev/null and b/docs/imgs/usage_vis_demo.jpg differ
diff --git a/docs/imgs/usage_vis_demo2.jpg b/docs/imgs/usage_vis_demo2.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..9665e9e2f4d90d6db75411d43d0dc5a34d8b28e7
Binary files /dev/null and b/docs/imgs/usage_vis_demo2.jpg differ
diff --git a/docs/imgs/usage_vis_demo3.jpg b/docs/imgs/usage_vis_demo3.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..318c06bcf7debf76b7bff504648df056802130df
Binary files /dev/null and b/docs/imgs/usage_vis_demo3.jpg differ
diff --git a/docs/installation.md b/docs/installation.md
index 751a0f77bb42d885c798dcd676764dda3bcb3bcd..9f2bbb54e2e2c9fd2184a996ca7ca0fb146e1185 100644
--- a/docs/installation.md
+++ b/docs/installation.md
@@ -1,15 +1,10 @@
# PaddleSeg 安装说明
-## 推荐开发环境
+## 1. 安装PaddlePaddle
-* Python 2.7 or 3.5+
-* CUDA 9.2
-* NVIDIA cuDNN v7.1
+版本要求
* PaddlePaddle >= 1.5.2
-* 如果有多卡训练需求,请安装 NVIDIA NCCL >= 2.4.7,并在Linux环境下运行
-
-
-## 1. 安装PaddlePaddle
+* Python 2.7 or 3.5+
### pip安装
@@ -27,6 +22,8 @@ PaddlePaddle最新版本1.5支持Conda安装,可以减少相关依赖安装成
conda install -c paddle paddlepaddle-gpu cudatoolkit=9.0
```
+ * 如果有多卡训练需求,请安装 NVIDIA NCCL >= 2.4.7,并在Linux环境下运行
+
更多安装方式详情可以查看 [PaddlePaddle安装说明](https://www.paddlepaddle.org.cn/documentation/docs/zh/beginners_guide/install/index_cn.html)
diff --git a/docs/loss_select.md b/docs/loss_select.md
new file mode 100644
index 0000000000000000000000000000000000000000..454085c9c22a5c3308c77c93c961628b53157042
--- /dev/null
+++ b/docs/loss_select.md
@@ -0,0 +1,77 @@
+# dice loss解决二分类中样本不均衡问题
+
+对于二类图像分割任务中,往往存在类别分布不均的情况,如:瑕疵检测,道路提取及病变区域提取等等。
+在DeepGlobe比赛的Road Extraction中,训练数据道路占比为:%4.5。如下为其图片样例:
+
+ 
+
+可以看出道路在整张图片中的比例很小。
+
+## 数据集下载
+我们从DeepGlobe比赛的Road Extraction的训练集中随机抽取了800张图片作为训练集,200张图片作为验证集,
+制作了一个小型的道路提取数据集[MiniDeepGlobeRoadExtraction](https://paddleseg.bj.bcebos.com/dataset/MiniDeepGlobeRoadExtraction.zip)
+
+## softmax loss与dice loss
+
+在图像分割中,softmax loss(sotfmax with cross entroy loss)同等的对待每一像素,因此当背景占据绝大部分的情况下,
+网络将偏向于背景的学习,使网络对目标的提取能力变差。`dice loss(dice coefficient loss)`通过计算预测与标注之间的重叠部分计算损失函数,避免了类别不均衡带来的影响,能够取得更好的效果。
+在实际应用中`dice loss`往往与`bce loss(binary cross entroy loss)`结合使用,提高模型训练的稳定性。
+
+dice loss的定义如下:
+
+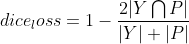
+
+其中  表示*Y*和*P*的共有元素数,
+实际计算通过求两者的乘积之和进行计算。如下所示:
+
+
+ 
+
+
+[dice系数详解](https://zh.wikipedia.org/wiki/Dice%E7%B3%BB%E6%95%B0)
+
+## PaddleSeg指定训练loss
+
+PaddleSeg通过`cfg.SOLVER.LOSS`参数可以选择训练时的损失函数,
+如`cfg.SOLVER.LOSS=['dice_loss','bce_loss']`将指定训练loss为`dice loss`与`bce loss`的组合
+
+## 实验比较
+
+在MiniDeepGlobeRoadExtraction数据集进行了实验比较。
+
+* 数据集下载
+```shell
+python dataset/download_mini_deepglobe_road_extraction.py
+```
+
+* 预训练模型下载
+```shell
+python pretrained_model/download_model.py deeplabv3p_mobilenetv2-1-0_bn_coco
+```
+* 配置/数据校验
+```shell
+python pdseg/check.py --cfg ./configs/deepglobe_road_extraction.yaml
+```
+
+* 训练
+```shell
+python pdseg/train.py --cfg ./configs/deepglobe_road_extraction.yaml --use_gpu SOLVER.LOSS "['dice_loss','bce_loss']"
+
+```
+
+* 评估
+```
+python pdseg/eval.py --cfg ./configs/deepglobe_road_extraction.yaml --use_gpu SOLVER.LOSS "['dice_loss','bce_loss']"
+
+```
+
+* 结果比较
+
+softmax loss和dice loss + bce loss实验结果如下图所示。
+图中橙色曲线为dice loss + bce loss,最高mIoU为76.02%,蓝色曲线为softmax loss, 最高mIoU为73.62%。
+
+ 
+
+
+
+
diff --git a/docs/multiple_gpus_train_and_mixed_precision_train.md b/docs/multiple_gpus_train_and_mixed_precision_train.md
new file mode 100644
index 0000000000000000000000000000000000000000..2ccc5cde23278c6b7041771bc2c15b83a832695e
--- /dev/null
+++ b/docs/multiple_gpus_train_and_mixed_precision_train.md
@@ -0,0 +1,62 @@
+# PaddleSeg 多进程训练和混合精度训练
+
+### 环境要求
+* PaddlePaddle >= 1.6.0
+* NVIDIA NCCL >= 2.4.7,并在Linux环境下运行
+
+环境配置,数据,预训练模型准备等工作请参考[安装说明](./installation.md),[PaddleSeg使用说明](./usage.md)
+
+### 多进程训练示例
+
+多进程训练,可以按如下方式启动
+```
+export CUDA_VISIBLE_DEVICES=0,1
+python -m paddle.distributed.launch pdseg/train.py --use_gpu \
+ --do_eval \
+ --cfg configs/unet_pet.yaml \
+ BATCH_SIZE 4 \
+ TRAIN.PRETRAINED_MODEL_DIR pretrained_model/unet_bn_coco \
+ SOLVER.LR 5e-5
+```
+
+### 混合精度训练示例
+
+启动混合精度训练,只需将```MODEL.FP16```设置为```True```,具体命令如下
+```
+export CUDA_VISIBLE_DEVICES=0,1
+python -m paddle.distributed.launch pdseg/train.py --use_gpu \
+ --do_eval \
+ --cfg configs/unet_pet.yaml \
+ BATCH_SIZE 4 \
+ TRAIN.PRETRAINED_MODEL_DIR pretrained_model/unet_bn_coco \
+ SOLVER.LR 5e-5 \
+ MODEL.FP16 True
+```
+这时候会采用动态scale的方式,若想使用静态scale的方式,可通过```MODEL.SCALE_LOSS```设置,具体命令如下
+
+```
+export CUDA_VISIBLE_DEVICES=0,1
+python -m paddle.distributed.launch pdseg/train.py --use_gpu \
+ --do_eval \
+ --cfg configs/unet_pet.yaml \
+ BATCH_SIZE 8 \
+ TRAIN.PRETRAINED_MODEL_DIR pretrained_model/unet_bn_coco \
+ SOLVER.LR 5e-5 \
+ MODEL.FP16 True \
+ MODEL.SCALE_LOSS 512.0
+```
+
+
+### benchmark
+
+| 模型 | 数据集合 | batch size | number gpu cards | 多进程训练 | 混合精度训练 | 显存占用 | 速度(image/s) | mIoU on val |
+|---|---|---|---|---|---|---|---|---|
+| DeepLabv3+/Xception65/bn | Cityscapes | 16 | 4 | False | False | 15988 MiB | 17.27 | 79.20 |
+| DeepLabv3+/Xception65/bn | Cityscapes | 16 | 4 | True | False | 15814 MiB | 19.80 | 78.90 |
+| DeepLabv3+/Xception65/bn | Cityscapes | 16 | 4 | True | True | 14922 MiB | 25.84 |79.06|
+
+
+### 参考
+
+- [Mixed Precision Training](https://arxiv.org/abs/1710.03740)
+
diff --git a/docs/usage.md b/docs/usage.md
index 03418eba8edff90e7350430fa97e83a0d4ec937c..f3c2bd297b768a070ee56ec330ea6e21d5405dcb 100644
--- a/docs/usage.md
+++ b/docs/usage.md
@@ -26,7 +26,7 @@ python pdseg/train.py BATCH_SIZE 1 --cfg configs/cityscapes.yaml
|-|-|-|-|-|
|--cfg|ALL|配置文件路径|None||
|--use_gpu|ALL|是否使用GPU进行训练|False||
-|--use_mpio|train/eval|是否使用多线程进行IO处理|False|打开该开关会占用一定量的CPU内存,但是可以提高训练速度。 **NOTE:** windows平台下不支持该功能, 建议使用自定义数据初次训练时不打开,打开会导致数据读取异常不可见。 |
+|--use_mpio|train/eval|是否使用多进程进行IO处理|False|打开该开关会占用一定量的CPU内存,但是可以提高训练速度。 **NOTE:** windows平台下不支持该功能, 建议使用自定义数据初次训练时不打开,打开会导致数据读取异常不可见。 |
|--use_tb|train|是否使用TensorBoard记录训练数据|False||
|--log_steps|train|训练日志的打印周期(单位为step)|10||
|--debug|train|是否打印debug信息|False|IOU等指标涉及到混淆矩阵的计算,会降低训练速度|
@@ -117,16 +117,24 @@ NOTE:
```shell
python pdseg/eval.py --use_gpu \
--cfg configs/unet_pet.yaml \
- TEST.TEST_MODEL test/saved_models/unet_pet/final
+ TEST.TEST_MODEL saved_model/unet_pet/final
```
+可以看到,在经过训练后,模型在验证集上的mIoU指标达到了0.70+(由于随机种子等因素的影响,效果会有小范围波动,属于正常情况)。
+
### 模型可视化
通过vis.py来评估模型效果,我们选择最后保存的模型进行效果的评估:
```shell
python pdseg/vis.py --use_gpu \
--cfg configs/unet_pet.yaml \
- TEST.TEST_MODEL test/saved_models/unet_pet/final
+ TEST.TEST_MODEL saved_model/unet_pet/final
```
+执行上述脚本后,会在主目录下产生一个visual/visual_results文件夹,里面存放着测试集图片的预测结果,我们选择其中几张图片进行查看,可以看到,在测试集中的图片上的预测效果已经很不错:
+
+
+
+
+
`NOTE`
1. 可视化的图片会默认保存在visual/visual_results目录下,可以通过`--vis_dir`来指定输出目录
2. 训练过程中会使用DATASET.VIS_FILE_LIST中的图片进行可视化显示,而vis.py则会使用DATASET.TEST_FILE_LIST
diff --git a/inference/CMakeLists.txt b/inference/CMakeLists.txt
index 994befc87be458ecab679c637d17cfd6239019fb..8c3808dabe86edb54e613a1b5a6b0a4a0617e79a 100644
--- a/inference/CMakeLists.txt
+++ b/inference/CMakeLists.txt
@@ -42,14 +42,23 @@ include_directories("${PADDLE_DIR}/third_party/install/protobuf/include")
include_directories("${PADDLE_DIR}/third_party/install/glog/include")
include_directories("${PADDLE_DIR}/third_party/install/gflags/include")
include_directories("${PADDLE_DIR}/third_party/install/xxhash/include")
-include_directories("${PADDLE_DIR}/third_party/install/snappy/include")
-include_directories("${PADDLE_DIR}/third_party/install/snappystream/include")
+if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/include")
+ include_directories("${PADDLE_DIR}/third_party/install/snappy/include")
+endif()
+if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/include")
+ include_directories("${PADDLE_DIR}/third_party/install/snappystream/include")
+endif()
include_directories("${PADDLE_DIR}/third_party/install/zlib/include")
include_directories("${PADDLE_DIR}/third_party/boost")
include_directories("${PADDLE_DIR}/third_party/eigen3")
-link_directories("${PADDLE_DIR}/third_party/install/snappy/lib")
-link_directories("${PADDLE_DIR}/third_party/install/snappystream/lib")
+if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
+ link_directories("${PADDLE_DIR}/third_party/install/snappy/lib")
+endif()
+if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
+ link_directories("${PADDLE_DIR}/third_party/install/snappystream/lib")
+endif()
+
link_directories("${PADDLE_DIR}/third_party/install/zlib/lib")
link_directories("${PADDLE_DIR}/third_party/install/protobuf/lib")
link_directories("${PADDLE_DIR}/third_party/install/glog/lib")
@@ -82,7 +91,7 @@ if (WIN32)
add_definitions(-DSTATIC_LIB)
endif()
else()
- set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -o2 -std=c++11")
+ set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -o2 -fopenmp -std=c++11")
set(CMAKE_STATIC_LIBRARY_PREFIX "")
endif()
@@ -160,13 +169,25 @@ if (NOT WIN32)
set(EXTERNAL_LIB "-lrt -ldl -lpthread")
set(DEPS ${DEPS}
${MATH_LIB} ${MKLDNN_LIB}
- glog gflags protobuf yaml-cpp snappystream snappy z xxhash
+ glog gflags protobuf yaml-cpp z xxhash
${EXTERNAL_LIB})
+ if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
+ set(DEPS ${DEPS} snappystream)
+ endif()
+ if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
+ set(DEPS ${DEPS} snappy)
+ endif()
else()
set(DEPS ${DEPS}
${MATH_LIB} ${MKLDNN_LIB}
- opencv_world346 glog libyaml-cppmt gflags_static libprotobuf snappy zlibstatic xxhash snappystream ${EXTERNAL_LIB})
+ opencv_world346 glog libyaml-cppmt gflags_static libprotobuf zlibstatic xxhash ${EXTERNAL_LIB})
set(DEPS ${DEPS} libcmt shlwapi)
+ if (EXISTS "${PADDLE_DIR}/third_party/install/snappy/lib")
+ set(DEPS ${DEPS} snappy)
+ endif()
+ if(EXISTS "${PADDLE_DIR}/third_party/install/snappystream/lib")
+ set(DEPS ${DEPS} snappystream)
+ endif()
endif(NOT WIN32)
if(WITH_GPU)
diff --git a/inference/README.md b/inference/README.md
index 15872fe20bde05e410300bbc7e2ae1586e349a92..5e65246dc1053b7f671a91ff11e7b00021edeb31 100644
--- a/inference/README.md
+++ b/inference/README.md
@@ -71,7 +71,7 @@ deeplabv3p_xception65_humanseg
### 2. 修改配置
-基于`PaddleSeg`训练的模型导出时,会自动生成对应的预测模型配置文件,请参考文档:[模型导出](../docs/export_model.md)。
+基于`PaddleSeg`训练的模型导出时,会自动生成对应的预测模型配置文件,请参考文档:[模型导出](../docs/model_export.md)。
`inference`源代码(即本目录)的`conf`目录下提供了示例人像分割模型的配置文件`humanseg.yaml`, 相关的字段含义和说明如下:
@@ -88,7 +88,7 @@ DEPLOY:
# 预测图片的的标准输入尺寸,输入尺寸不一致会做resize
EVAL_CROP_SIZE: (513, 513)
# 均值
- MEAN: [104.008, 116.669, 122.675]
+ MEAN: [0.40787450980392154, 0.4575254901960784, 0.481078431372549]
# 方差
STD: [1.0, 1.0, 1.0]
# 图片类型, rgb 或者 rgba
diff --git a/inference/conf/humanseg.yaml b/inference/conf/humanseg.yaml
index 78195d9e8b4fe2d9ed2758ab76d8e5f88fd104a9..4b09e18dc7ebdde9ef19c670234a4996e61b2f5f 100644
--- a/inference/conf/humanseg.yaml
+++ b/inference/conf/humanseg.yaml
@@ -1,15 +1,14 @@
DEPLOY:
USE_GPU: 1
MODEL_PATH: "/root/projects/models/deeplabv3p_xception65_humanseg"
- MODEL_NAME: "unet"
MODEL_FILENAME: "__model__"
PARAMS_FILENAME: "__params__"
EVAL_CROP_SIZE: (513, 513)
- MEAN: [0.5, 0.5, 0.5]
- STD: [1.0, 1.0, 1.0]
+ MEAN: [0.40787450980392154, 0.4575254901960784, 0.481078431372549]
+ STD: [0.00392156862745098, 0.00392156862745098, 0.00392156862745098]
IMAGE_TYPE: "rgb"
NUM_CLASSES: 2
CHANNELS : 3
PRE_PROCESSOR: "SegPreProcessor"
PREDICTOR_MODE: "NATIVE"
- BATCH_SIZE : 3
+ BATCH_SIZE : 1
diff --git a/inference/predictor/seg_predictor.cpp b/inference/predictor/seg_predictor.cpp
index ee32d75561e5d93fa11c7013d1a4a9f845dc9919..d70084f67f2f3c38624e15fc6a454aca22482572 100644
--- a/inference/predictor/seg_predictor.cpp
+++ b/inference/predictor/seg_predictor.cpp
@@ -1,4 +1,5 @@
#include "seg_predictor.h"
+#include
namespace PaddleSolution {
@@ -78,26 +79,8 @@ namespace PaddleSolution {
//post process
_mask.clear();
_scoremap.clear();
- int out_img_len = eval_height * eval_width;
- for (int i = 0; i < out_img_len; ++i) {
- float max_value = -1;
- int label = 0;
- for (int j = 0; j < eval_num_class; ++j) {
- int index = i + j * out_img_len;
- if (index >= blob_out_len) {
- break;
- }
- float value = p_out[index];
- if (value > max_value) {
- max_value = value;
- label = j;
- }
- }
- if (label == 0) max_value = 0;
- _mask[i] = uchar(label);
- _scoremap[i] = uchar(max_value * 255);
- }
-
+ std::vector out_shape{eval_num_class, eval_height, eval_width};
+ utils::argmax(p_out, out_shape, _mask, _scoremap);
cv::Mat mask_png = cv::Mat(eval_height, eval_width, CV_8UC1);
mask_png.data = _mask.data();
std::string nname(fname);
@@ -251,6 +234,7 @@ namespace PaddleSolution {
int idx = u * default_batch_size + i;
imgs_batch.push_back(imgs[idx]);
}
+
if (!_preprocessor->batch_process(imgs_batch, input_buffer.data(), org_height.data(), org_width.data())) {
return -1;
}
diff --git a/inference/preprocessor/preprocessor_seg.cpp b/inference/preprocessor/preprocessor_seg.cpp
index a3177da5cbb907c27a05d8c5e9290fc70ef9ab02..c2d056bfd2706ad441b96d76165804c0d81cdfaf 100644
--- a/inference/preprocessor/preprocessor_seg.cpp
+++ b/inference/preprocessor/preprocessor_seg.cpp
@@ -32,21 +32,7 @@ namespace PaddleSolution {
if (*ori_h != rh || *ori_w != rw) {
cv::resize(im, im, resize_size, 0, 0, cv::INTER_LINEAR);
}
-
- float* pmean = _config->_mean.data();
- float* pscale = _config->_std.data();
- for (int h = 0; h < rh; ++h) {
- const uchar* ptr = im.ptr(h);
- int im_index = 0;
- for (int w = 0; w < rw; ++w) {
- for (int c = 0; c < channels; ++c) {
- int top_index = (c * rh + h) * rw + w;
- float pixel = static_cast(ptr[im_index++]);
- pixel = (pixel / 255 - pmean[c]) / pscale[c];
- data[top_index] = pixel;
- }
- }
- }
+ utils::normalize(im, data, _config->_mean, _config->_std);
return true;
}
diff --git a/inference/preprocessor/preprocessor_seg.h b/inference/preprocessor/preprocessor_seg.h
index 8c280ab1d9a4e972de55e9afd2935a3a28e6bd90..eba904b8949b3c000799ee84541699989fea425a 100644
--- a/inference/preprocessor/preprocessor_seg.h
+++ b/inference/preprocessor/preprocessor_seg.h
@@ -1,6 +1,7 @@
#pragma once
#include "preprocessor.h"
+#include "utils/utils.h"
namespace PaddleSolution {
diff --git a/inference/utils/utils.h b/inference/utils/utils.h
index e349618a28282257b01ac44d661f292850cc19b9..894636499bb55b9018cd40072455ae5cedd8a63f 100644
--- a/inference/utils/utils.h
+++ b/inference/utils/utils.h
@@ -4,6 +4,10 @@
#include
#include
+#include
+#include
+#include
+
#ifdef _WIN32
#include
#else
@@ -59,5 +63,58 @@ namespace PaddleSolution {
return imgs;
}
#endif
+
+ // normalize and HWC_BGR -> CHW_RGB
+ inline void normalize(cv::Mat& im, float* data, std::vector& fmean, std::vector& fstd) {
+ int rh = im.rows;
+ int rw = im.cols;
+ int rc = im.channels();
+ double normf = (double)1.0 / 255.0;
+ #pragma omp parallel for
+ for (int h = 0; h < rh; ++h) {
+ const uchar* ptr = im.ptr(h);
+ int im_index = 0;
+ for (int w = 0; w < rw; ++w) {
+ for (int c = 0; c < rc; ++c) {
+ int top_index = (c * rh + h) * rw + w;
+ float pixel = static_cast(ptr[im_index++]);
+ pixel = (pixel * normf - fmean[c]) / fstd[c];
+ data[top_index] = pixel;
+ }
+ }
+ }
+ }
+
+ // argmax
+ inline void argmax(float* out, std::vector& shape, std::vector& mask, std::vector& scoremap) {
+ int out_img_len = shape[1] * shape[2];
+ int blob_out_len = out_img_len * shape[0];
+ /*
+ Eigen::TensorMap> out_3d(out, shape[0], shape[1], shape[2]);
+ Eigen::Tensor argmax = out_3d.argmax(0);
+ */
+ float max_value = -1;
+ int label = 0;
+ #pragma omp parallel private(label)
+ for (int i = 0; i < out_img_len; ++i) {
+ max_value = -1;
+ label = 0;
+ #pragma omp for reduction(max : max_value)
+ for (int j = 0; j < shape[0]; ++j) {
+ int index = i + j * out_img_len;
+ if (index >= blob_out_len) {
+ continue;
+ }
+ float value = out[index];
+ if (value > max_value) {
+ max_value = value;
+ label = j;
+ }
+ }
+ if (label == 0) max_value = 0;
+ mask[i] = uchar(label);
+ scoremap[i] = uchar(max_value * 255);
+ }
+ }
}
}
diff --git a/pdseg/check.py b/pdseg/check.py
index f1b70a6ae545d93990b860d4eb0f4c9ac1330866..5d11065a07d448cc18a62652f49529549a6fd0f4 100644
--- a/pdseg/check.py
+++ b/pdseg/check.py
@@ -16,6 +16,7 @@ import logging
from utils.config import cfg
+
def init_global_variable():
"""
初始化全局变量
@@ -31,8 +32,8 @@ def init_global_variable():
global min_aspectratio # 图片最小宽高比
global max_aspectratio # 图片最大宽高比
global img_dim # 图片的通道数
- global list_wrong #文件名格式错误列表
- global imread_failed #图片读取失败列表, 二元列表
+ global list_wrong # 文件名格式错误列表
+ global imread_failed # 图片读取失败列表, 二元列表
global label_wrong # 标注图片出错列表
global label_gray_wrong # 标注图非灰度图列表
@@ -52,29 +53,33 @@ def init_global_variable():
label_wrong = []
label_gray_wrong = []
+
def parse_args():
parser = argparse.ArgumentParser(description='PaddleSeg check')
parser.add_argument(
- '--cfg',
- dest='cfg_file',
- help='Config file for training (and optionally testing)',
- default=None,
- type=str
- )
+ '--cfg',
+ dest='cfg_file',
+ help='Config file for training (and optionally testing)',
+ default=None,
+ type=str)
return parser.parse_args()
+
def error_print(str):
return "".join(["\nNOT PASS ", str])
+
def correct_print(str):
return "".join(["\nPASS ", str])
+
def cv2_imread(file_path, flag=cv2.IMREAD_COLOR):
"""
解决 cv2.imread 在window平台打开中文路径的问题.
"""
return cv2.imdecode(np.fromfile(file_path, dtype=np.uint8), flag)
+
def get_image_max_height_width(img):
"""获取图片最大宽和高"""
global max_width, max_height
@@ -83,21 +88,24 @@ def get_image_max_height_width(img):
max_height = max(height, max_height)
max_width = max(width, max_width)
+
def get_image_min_max_aspectratio(img):
"""计算图片最大宽高比"""
global min_aspectratio, max_aspectratio
img_shape = img.shape
height, width = img_shape[0], img_shape[1]
- min_aspectratio = min(width/height, min_aspectratio)
- max_aspectratio = max(width/height, max_aspectratio)
+ min_aspectratio = min(width / height, min_aspectratio)
+ max_aspectratio = max(width / height, max_aspectratio)
return min_aspectratio, max_aspectratio
+
def get_image_dim(img):
"""获取图像的通道数"""
img_shape = img.shape
if img_shape[-1] not in img_dim:
img_dim.append(img_shape[-1])
+
def is_label_gray(grt):
"""判断标签是否为灰度图"""
grt_shape = grt.shape
@@ -106,6 +114,7 @@ def is_label_gray(grt):
else:
return False
+
def image_label_shape_check(img, grt):
"""
验证图像和标注的大小是否匹配
@@ -117,11 +126,11 @@ def image_label_shape_check(img, grt):
grt_height = grt.shape[0]
grt_width = grt.shape[1]
-
if img_height != grt_height or img_width != grt_width:
flag = False
return flag
+
def ground_truth_check(grt, grt_path):
"""
验证标注图像的格式
@@ -143,6 +152,7 @@ def ground_truth_check(grt, grt_path):
return png_format, unique, counts
+
def sum_gt_check(png_format, grt_classes, num_of_each_class):
"""
统计所有标注图上的格式、类别和每个类别的像素数
@@ -160,7 +170,8 @@ def sum_gt_check(png_format, grt_classes, num_of_each_class):
png_format_wrong_num += 1
if cfg.DATASET.IGNORE_INDEX in grt_classes:
- grt_classes2 = np.delete(grt_classes, np.where(grt_classes == cfg.DATASET.IGNORE_INDEX))
+ grt_classes2 = np.delete(
+ grt_classes, np.where(grt_classes == cfg.DATASET.IGNORE_INDEX))
else:
grt_classes2 = grt_classes
if min(grt_classes2) < 0 or max(grt_classes2) > cfg.DATASET.NUM_CLASSES - 1:
@@ -179,6 +190,7 @@ def sum_gt_check(png_format, grt_classes, num_of_each_class):
total_grt_classes += add_class
return is_label_correct
+
def gt_check():
"""
对标注图像进行校验,输出校验结果
@@ -192,16 +204,20 @@ def gt_check():
return
else:
logger.info(error_print("label format check"))
- logger.info("total {} label images are png format, {} label images are not png "
- "format".format(png_format_right_num, png_format_wrong_num))
+ logger.info(
+ "total {} label images are png format, {} label images are not png "
+ "format".format(png_format_right_num, png_format_wrong_num))
if len(png_format_wrong_image) > 0:
for i in png_format_wrong_image:
logger.debug(i)
-
- total_nc = sorted(zip(total_grt_classes, total_num_of_each_class))
- logger.info("\nDoing label pixel statistics...\nTotal label classes "
- "and their corresponding numbers:\n{} ".format(total_nc))
+ total_ratio = total_num_of_each_class / sum(total_num_of_each_class)
+ total_ratio = np.around(total_ratio, decimals=4)
+ total_nc = sorted(
+ zip(total_grt_classes, total_num_of_each_class, total_ratio))
+ logger.info(
+ "\nDoing label pixel statistics:\n"
+ "(label class, total pixel number, percentage) = {} ".format(total_nc))
if len(label_wrong) == 0 and not total_nc[0][0]:
logger.info(correct_print("label class check!"))
@@ -210,13 +226,15 @@ def gt_check():
if total_nc[0][0]:
logger.info("Warning: label classes should start from 0")
if len(label_wrong) > 0:
- logger.info("fatal error: label class is out of range [0, {}]".format(cfg.DATASET.NUM_CLASSES - 1))
+ logger.info(
+ "fatal error: label class is out of range [0, {}]".format(
+ cfg.DATASET.NUM_CLASSES - 1))
for i in label_wrong:
logger.debug(i)
-
-def eval_crop_size_check(max_height, max_width, min_aspectratio, max_aspectratio):
+def eval_crop_size_check(max_height, max_width, min_aspectratio,
+ max_aspectratio):
"""
判断eval_crop_siz与验证集及测试集的max_height, max_width的关系
param
@@ -225,69 +243,109 @@ def eval_crop_size_check(max_height, max_width, min_aspectratio, max_aspectratio
"""
if cfg.AUG.AUG_METHOD == "stepscaling":
- if max_width <= cfg.EVAL_CROP_SIZE[0] and max_height <= cfg.EVAL_CROP_SIZE[1]:
+ if max_width <= cfg.EVAL_CROP_SIZE[
+ 0] and max_height <= cfg.EVAL_CROP_SIZE[1]:
logger.info(correct_print("EVAL_CROP_SIZE check"))
+ logger.info(
+ "satisfy current EVAL_CROP_SIZE: ({},{}) >= max width and max height of images: ({},{})"
+ .format(cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1], max_width,
+ max_height))
else:
logger.info(error_print("EVAL_CROP_SIZE check"))
if max_width > cfg.EVAL_CROP_SIZE[0]:
- logger.info("The EVAL_CROP_SIZE[0]: {} should larger max width of images {}!".format(
- cfg.EVAL_CROP_SIZE[0], max_width))
+ logger.info(
+ "EVAL_CROP_SIZE[0]: {} should >= max width of images {}!".
+ format(cfg.EVAL_CROP_SIZE[0], max_width))
if max_height > cfg.EVAL_CROP_SIZE[1]:
- logger.info(error_print("The EVAL_CROP_SIZE[1]: {} should larger max height of images {}!".format(
- cfg.EVAL_CROP_SIZE[1], max_height)))
+ logger.info(
+ "EVAL_CROP_SIZE[1]: {} should >= max height of images {}!".
+ format(cfg.EVAL_CROP_SIZE[1], max_height))
elif cfg.AUG.AUG_METHOD == "rangescaling":
if min_aspectratio <= 1 and max_aspectratio >= 1:
- if cfg.EVAL_CROP_SIZE[0] >= cfg.AUG.INF_RESIZE_VALUE and cfg.EVAL_CROP_SIZE[1] >= cfg.AUG.INF_RESIZE_VALUE:
+ if cfg.EVAL_CROP_SIZE[0] >= cfg.AUG.INF_RESIZE_VALUE \
+ and cfg.EVAL_CROP_SIZE[1] >= cfg.AUG.INF_RESIZE_VALUE:
logger.info(correct_print("EVAL_CROP_SIZE check"))
+ logger.info(
+ "satisfy current EVAL_CROP_SIZE: ({},{}) >= ({},{}) ".
+ format(cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1],
+ cfg.AUG.INF_RESIZE_VALUE, cfg.AUG.INF_RESIZE_VALUE))
else:
logger.info(error_print("EVAL_CROP_SIZE check"))
- logger.info("EVAL_CROP_SIZE: ({},{}) must large than img size({},{})"
- .format(cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1],
- cfg.AUG.INF_RESIZE_VALUE, cfg.AUG.INF_RESIZE_VALUE))
+ logger.info(
+ "EVAL_CROP_SIZE must >= img size({},{}), current EVAL_CROP_SIZE is ({},{})"
+ .format(cfg.AUG.INF_RESIZE_VALUE, cfg.AUG.INF_RESIZE_VALUE,
+ cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1]))
elif min_aspectratio > 1:
max_height_rangscaling = cfg.AUG.INF_RESIZE_VALUE / min_aspectratio
max_height_rangscaling = round(max_height_rangscaling)
- if cfg.EVAL_CROP_SIZE[0] >= cfg.AUG.INF_RESIZE_VALUE and cfg.EVAL_CROP_SIZE[1] >= max_height_rangscaling:
+ if cfg.EVAL_CROP_SIZE[
+ 0] >= cfg.AUG.INF_RESIZE_VALUE and cfg.EVAL_CROP_SIZE[
+ 1] >= max_height_rangscaling:
logger.info(correct_print("EVAL_CROP_SIZE check"))
+ logger.info(
+ "satisfy current EVAL_CROP_SIZE: ({},{}) >= ({},{}) ".
+ format(cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1],
+ cfg.AUG.INF_RESIZE_VALUE, max_height_rangscaling))
else:
logger.info(error_print("EVAL_CROP_SIZE check"))
- logger.info("EVAL_CROP_SIZE: ({},{}) must large than img size({},{})"
- .format(cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1],
- cfg.AUG.INF_RESIZE_VALUE, max_height_rangscaling))
+ logger.info(
+ "EVAL_CROP_SIZE must >= img size({},{}), current EVAL_CROP_SIZE is ({},{})"
+ .format(cfg.AUG.INF_RESIZE_VALUE, max_height_rangscaling,
+ cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1]))
elif max_aspectratio < 1:
max_width_rangscaling = cfg.AUG.INF_RESIZE_VALUE * max_aspectratio
max_width_rangscaling = round(max_width_rangscaling)
- if cfg.EVAL_CROP_SIZE[0] >= max_width_rangscaling and cfg.EVAL_CROP_SIZE[1] >= cfg.AUG.INF_RESIZE_VALUE:
+ if cfg.EVAL_CROP_SIZE[
+ 0] >= max_width_rangscaling and cfg.EVAL_CROP_SIZE[
+ 1] >= cfg.AUG.INF_RESIZE_VALUE:
logger.info(correct_print("EVAL_CROP_SIZE check"))
+ logger.info(
+ "satisfy current EVAL_CROP_SIZE: ({},{}) >= ({},{}) ".
+ format(cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1],
+ max_height_rangscaling, cfg.AUG.INF_RESIZE_VALUE))
else:
logger.info(error_print("EVAL_CROP_SIZE check"))
- logger.info("EVAL_CROP_SIZE: ({},{}) must large than img size({},{})"
- .format(cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1],
- max_width_rangscaling, cfg.AUG.INF_RESIZE_VALUE))
+ logger.info(
+ "EVAL_CROP_SIZE must >= img size({},{}), current EVAL_CROP_SIZE is ({},{})"
+ .format(max_width_rangscaling, cfg.AUG.INF_RESIZE_VALUE,
+ cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1]))
elif cfg.AUG.AUG_METHOD == "unpadding":
if len(cfg.AUG.FIX_RESIZE_SIZE) != 2:
logger.info(error_print("EVAL_CROP_SIZE check"))
- logger.info("you set AUG.AUG_METHOD = 'unpadding', but AUG.FIX_RESIZE_SIZE is wrong. "
- "AUG.FIX_RESIZE_SIZE should be a tuple of length 2")
- elif cfg.EVAL_CROP_SIZE[0] >= cfg.AUG.FIX_RESIZE_SIZE[0] and cfg.EVAL_CROP_SIZE[1] >= cfg.AUG.FIX_RESIZE_SIZE[1]:
+ logger.info(
+ "you set AUG.AUG_METHOD = 'unpadding', but AUG.FIX_RESIZE_SIZE is wrong. "
+ "AUG.FIX_RESIZE_SIZE should be a tuple of length 2")
+ elif cfg.EVAL_CROP_SIZE[0] >= cfg.AUG.FIX_RESIZE_SIZE[0] \
+ and cfg.EVAL_CROP_SIZE[1] >= cfg.AUG.FIX_RESIZE_SIZE[1]:
logger.info(correct_print("EVAL_CROP_SIZE check"))
+ logger.info(
+ "satisfy current EVAL_CROP_SIZE: ({},{}) >= AUG.FIX_RESIZE_SIZE: ({},{}) "
+ .format(cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1],
+ cfg.AUG.FIX_RESIZE_SIZE[0], cfg.AUG.FIX_RESIZE_SIZE[1]))
else:
logger.info(error_print("EVAL_CROP_SIZE check"))
- logger.info("EVAL_CROP_SIZE: ({},{}) must large than img size({},{})"
- .format(cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1],
- cfg.AUG.FIX_RESIZE_SIZE[0], cfg.AUG.FIX_RESIZE_SIZE[1]))
+ logger.info(
+ "EVAL_CROP_SIZE: ({},{}) must >= AUG.FIX_RESIZE_SIZE: ({},{})".
+ format(cfg.EVAL_CROP_SIZE[0], cfg.EVAL_CROP_SIZE[1],
+ cfg.AUG.FIX_RESIZE_SIZE[0], cfg.AUG.FIX_RESIZE_SIZE[1]))
else:
- logger.info("\nERROR! cfg.AUG.AUG_METHOD setting wrong, it should be one of "
- "[unpadding, stepscaling, rangescaling]")
+ logger.info(
+ "\nERROR! cfg.AUG.AUG_METHOD setting wrong, it should be one of "
+ "[unpadding, stepscaling, rangescaling]")
+
def inf_resize_value_check():
if cfg.AUG.AUG_METHOD == "rangescaling":
if cfg.AUG.INF_RESIZE_VALUE < cfg.AUG.MIN_RESIZE_VALUE or \
cfg.AUG.INF_RESIZE_VALUE > cfg.AUG.MIN_RESIZE_VALUE:
- logger.info("\nWARNING! you set AUG.AUG_METHOD = 'rangescaling'"
- "AUG.INF_RESIZE_VALUE: {} not in [AUG.MIN_RESIZE_VALUE, AUG.MAX_RESIZE_VALUE]: "
- "[{}, {}].".format(cfg.AUG.INF_RESIZE_VALUE, cfg.AUG.MIN_RESIZE_VALUE, cfg.AUG.MAX_RESIZE_VALUE))
+ logger.info(
+ "\nWARNING! you set AUG.AUG_METHOD = 'rangescaling'"
+ "AUG.INF_RESIZE_VALUE: {} not in [AUG.MIN_RESIZE_VALUE, AUG.MAX_RESIZE_VALUE]: "
+ "[{}, {}].".format(cfg.AUG.INF_RESIZE_VALUE,
+ cfg.AUG.MIN_RESIZE_VALUE,
+ cfg.AUG.MAX_RESIZE_VALUE))
+
def image_type_check(img_dim):
"""
@@ -299,13 +357,17 @@ def image_type_check(img_dim):
if (1 in img_dim or 3 in img_dim) and cfg.DATASET.IMAGE_TYPE == 'rgba':
logger.info(error_print("DATASET.IMAGE_TYPE check"))
logger.info("DATASET.IMAGE_TYPE is {} but the type of image has "
- "gray or rgb\n".format(cfg.DATASET.IMAGE_TYPE))
- elif (1 not in img_dim and 3 not in img_dim and 4 in img_dim) and cfg.DATASET.IMAGE_TYPE == 'rgb':
+ "gray or rgb\n".format(cfg.DATASET.IMAGE_TYPE))
+ elif (1 not in img_dim and 3 not in img_dim
+ and 4 in img_dim) and cfg.DATASET.IMAGE_TYPE == 'rgb':
logger.info(correct_print("DATASET.IMAGE_TYPE check"))
- logger.info("\nWARNING: DATASET.IMAGE_TYPE is {} but the type of all image is rgba".format(cfg.DATASET.IMAGE_TYPE))
+ logger.info(
+ "\nWARNING: DATASET.IMAGE_TYPE is {} but the type of all image is rgba"
+ .format(cfg.DATASET.IMAGE_TYPE))
else:
logger.info(correct_print("DATASET.IMAGE_TYPE check"))
+
def shape_check():
"""输出shape校验结果"""
if len(shape_unequal_image) == 0:
@@ -313,7 +375,8 @@ def shape_check():
logger.info("All images are the same shape as the labels")
else:
logger.info(error_print("shape check"))
- logger.info("Some images are not the same shape as the labels as follow: ")
+ logger.info(
+ "Some images are not the same shape as the labels as follow: ")
for i in shape_unequal_image:
logger.debug(i)
@@ -321,13 +384,19 @@ def shape_check():
def file_list_check(list_name):
"""检查分割符是否复合要求"""
if len(list_wrong) == 0:
- logger.info(correct_print(list_name.split(os.sep)[-1] + " DATASET.SEPARATOR check"))
+ logger.info(
+ correct_print(
+ list_name.split(os.sep)[-1] + " DATASET.SEPARATOR check"))
else:
- logger.info(error_print(list_name.split(os.sep)[-1] + " DATASET.SEPARATOR check"))
- logger.info("The following list is not separated by {}".format(cfg.DATASET.SEPARATOR))
+ logger.info(
+ error_print(
+ list_name.split(os.sep)[-1] + " DATASET.SEPARATOR check"))
+ logger.info("The following list is not separated by {}".format(
+ cfg.DATASET.SEPARATOR))
for i in list_wrong:
logger.debug(i)
+
def imread_check():
if len(imread_failed) == 0:
logger.info(correct_print("dataset reading check"))
@@ -338,18 +407,34 @@ def imread_check():
for i in imread_failed:
logger.debug(i)
+
def label_gray_check():
if len(label_gray_wrong) == 0:
logger.info(correct_print("label gray check"))
logger.info("All label images are gray")
else:
logger.info(error_print("label gray check"))
- logger.info("{} label images are not gray\nLabel pixel statistics may "
- "be insignificant".format(len(label_gray_wrong)))
+ logger.info(
+ "{} label images are not gray\nLabel pixel statistics may be insignificant"
+ .format(len(label_gray_wrong)))
for i in label_gray_wrong:
logger.debug(i)
+def max_img_size_statistics():
+ logger.info("\nDoing max image size statistics:")
+ logger.info("max width and max height of images are ({},{})".format(
+ max_width, max_height))
+
+def num_classes_loss_matching_check():
+ loss_type = cfg.SOLVER.LOSS
+ num_classes = cfg.DATASET.NUM_CLASSES
+ if num_classes > 2 and (("dice_loss" in loss_type) or ("bce_loss" in loss_type)):
+ logger.info(error_print("loss check."
+ " Dice loss and bce loss is only applicable to binary classfication"))
+ else:
+ logger.info(correct_print("loss check"))
+
def check_train_dataset():
list_file = cfg.DATASET.TRAIN_FILE_LIST
@@ -376,15 +461,18 @@ def check_train_dataset():
if not is_gray:
label_gray_wrong.append(line)
grt = cv2.cvtColor(grt, cv2.COLOR_BGR2GRAY)
+ get_image_max_height_width(img)
get_image_dim(img)
is_equal_img_grt_shape = image_label_shape_check(img, grt)
if not is_equal_img_grt_shape:
shape_unequal_image.append(line)
- png_format, grt_classes, num_of_each_class = ground_truth_check(grt, grt_path)
+ png_format, grt_classes, num_of_each_class = ground_truth_check(
+ grt, grt_path)
if not png_format:
png_format_wrong_image.append(line)
- is_label_correct = sum_gt_check(png_format, grt_classes, num_of_each_class)
+ is_label_correct = sum_gt_check(png_format, grt_classes,
+ num_of_each_class)
if not is_label_correct:
label_wrong.append(line)
@@ -393,10 +481,9 @@ def check_train_dataset():
label_gray_check()
gt_check()
image_type_check(img_dim)
+ max_img_size_statistics()
shape_check()
-
-
-
+ num_classes_loss_matching_check()
def check_val_dataset():
@@ -417,7 +504,8 @@ def check_val_dataset():
img = cv2_imread(img_path, cv2.IMREAD_UNCHANGED)
grt = cv2_imread(grt_path, cv2.IMREAD_UNCHANGED)
except Exception as e:
- imread_failed.append((line, e.message))
+ imread_failed.append((line, str(e)))
+ continue
is_gray = is_label_gray(grt)
if not is_gray:
@@ -429,10 +517,12 @@ def check_val_dataset():
is_equal_img_grt_shape = image_label_shape_check(img, grt)
if not is_equal_img_grt_shape:
shape_unequal_image.append(line)
- png_format, grt_classes, num_of_each_class = ground_truth_check(grt, grt_path)
+ png_format, grt_classes, num_of_each_class = ground_truth_check(
+ grt, grt_path)
if not png_format:
png_format_wrong_image.append(line)
- is_label_correct = sum_gt_check(png_format, grt_classes, num_of_each_class)
+ is_label_correct = sum_gt_check(png_format, grt_classes,
+ num_of_each_class)
if not is_label_correct:
label_wrong.append(line)
@@ -441,8 +531,11 @@ def check_val_dataset():
label_gray_check()
gt_check()
image_type_check(img_dim)
+ max_img_size_statistics()
shape_check()
- eval_crop_size_check(max_height, max_width, min_aspectratio, max_aspectratio)
+ eval_crop_size_check(max_height, max_width, min_aspectratio,
+ max_aspectratio)
+
def check_test_dataset():
list_file = cfg.DATASET.TEST_FILE_LIST
@@ -470,7 +563,7 @@ def check_test_dataset():
img = cv2_imread(img_path, cv2.IMREAD_UNCHANGED)
grt = cv2_imread(grt_path, cv2.IMREAD_UNCHANGED)
except Exception as e:
- imread_failed.append((line, e.message))
+ imread_failed.append((line, str(e)))
continue
is_gray = is_label_gray(grt)
@@ -480,10 +573,12 @@ def check_test_dataset():
is_equal_img_grt_shape = image_label_shape_check(img, grt)
if not is_equal_img_grt_shape:
shape_unequal_image.append(line)
- png_format, grt_classes, num_of_each_class = ground_truth_check(grt, grt_path)
+ png_format, grt_classes, num_of_each_class = ground_truth_check(
+ grt, grt_path)
if not png_format:
png_format_wrong_image.append(line)
- is_label_correct = sum_gt_check(png_format, grt_classes, num_of_each_class)
+ is_label_correct = sum_gt_check(png_format, grt_classes,
+ num_of_each_class)
if not is_label_correct:
label_wrong.append(line)
else:
@@ -500,14 +595,17 @@ def check_test_dataset():
if has_label:
gt_check()
image_type_check(img_dim)
+ max_img_size_statistics()
if has_label:
shape_check()
- eval_crop_size_check(max_height, max_width, min_aspectratio, max_aspectratio)
+ eval_crop_size_check(max_height, max_width, min_aspectratio,
+ max_aspectratio)
+
def main(args):
if args.cfg_file is not None:
cfg.update_from_file(args.cfg_file)
- cfg.check_and_infer(reset_dataset=True)
+ cfg.check_and_infer()
logger.info(pprint.pformat(cfg))
init_global_variable()
@@ -521,6 +619,9 @@ def main(args):
inf_resize_value_check()
+ print("\nDetailed error information can be viewed in detail.log file.")
+
+
if __name__ == "__main__":
args = parse_args()
logger = logging.getLogger()
@@ -535,5 +636,3 @@ if __name__ == "__main__":
logger.addHandler(sh)
logger.addHandler(th)
main(args)
-
-
diff --git a/pdseg/data_aug.py b/pdseg/data_aug.py
index 474fba9a1236ee8db478a45dd5355f225c875afb..15186150a3734a3a0c026386a04206ac036c7858 100644
--- a/pdseg/data_aug.py
+++ b/pdseg/data_aug.py
@@ -361,7 +361,7 @@ def hsv_color_jitter(crop_img,
if brightness_jitter_ratio > 0 or \
saturation_jitter_ratio > 0 or \
contrast_jitter_ratio > 0:
- random_jitter(crop_img, saturation_jitter_ratio,
+ crop_img = random_jitter(crop_img, saturation_jitter_ratio,
brightness_jitter_ratio, contrast_jitter_ratio)
return crop_img
diff --git a/pdseg/loss.py b/pdseg/loss.py
index b2f7d4c924648b54f602095a68ddcd0609e229b0..36ba43b27fca957a31f9ba68160f66792686c619 100644
--- a/pdseg/loss.py
+++ b/pdseg/loss.py
@@ -29,6 +29,7 @@ def softmax_with_loss(logit, label, ignore_mask=None, num_classes=2):
label = fluid.layers.reshape(label, [-1, 1])
label = fluid.layers.cast(label, 'int64')
ignore_mask = fluid.layers.reshape(ignore_mask, [-1, 1])
+
loss, probs = fluid.layers.softmax_with_cross_entropy(
logit,
label,
@@ -36,18 +37,48 @@ def softmax_with_loss(logit, label, ignore_mask=None, num_classes=2):
return_softmax=True)
loss = loss * ignore_mask
- if cfg.MODEL.FP16:
- loss = fluid.layers.cast(loss, 'float32')
- avg_loss = fluid.layers.mean(loss) / fluid.layers.mean(ignore_mask)
- avg_loss = fluid.layers.cast(avg_loss, 'float16')
- else:
- avg_loss = fluid.layers.mean(loss) / fluid.layers.mean(ignore_mask)
- if cfg.MODEL.SCALE_LOSS > 1.0:
- avg_loss = avg_loss * cfg.MODEL.SCALE_LOSS
+ avg_loss = fluid.layers.mean(loss) / fluid.layers.mean(ignore_mask)
+
label.stop_gradient = True
ignore_mask.stop_gradient = True
return avg_loss
+# to change, how to appicate ignore index and ignore mask
+def dice_loss(logit, label, ignore_mask=None, epsilon=0.00001):
+ if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
+ raise Exception("dice loss is only applicable to one channel classfication")
+ ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
+ logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
+ label = fluid.layers.transpose(label, [0, 2, 3, 1])
+ label = fluid.layers.cast(label, 'int64')
+ ignore_mask = fluid.layers.transpose(ignore_mask, [0, 2, 3, 1])
+ logit = fluid.layers.sigmoid(logit)
+ logit = logit * ignore_mask
+ label = label * ignore_mask
+ reduce_dim = list(range(1, len(logit.shape)))
+ inse = fluid.layers.reduce_sum(logit * label, dim=reduce_dim)
+ dice_denominator = fluid.layers.reduce_sum(
+ logit, dim=reduce_dim) + fluid.layers.reduce_sum(
+ label, dim=reduce_dim)
+ dice_score = 1 - inse * 2 / (dice_denominator + epsilon)
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return fluid.layers.reduce_mean(dice_score)
+
+def bce_loss(logit, label, ignore_mask=None):
+ if logit.shape[1] != 1 or label.shape[1] != 1 or ignore_mask.shape[1] != 1:
+ raise Exception("bce loss is only applicable to binary classfication")
+ label = fluid.layers.cast(label, 'float32')
+ loss = fluid.layers.sigmoid_cross_entropy_with_logits(
+ x=logit,
+ label=label,
+ ignore_index=cfg.DATASET.IGNORE_INDEX,
+ normalize=True) # or False
+ loss = fluid.layers.reduce_sum(loss)
+ label.stop_gradient = True
+ ignore_mask.stop_gradient = True
+ return loss
+
def multi_softmax_with_loss(logits, label, ignore_mask=None, num_classes=2):
if isinstance(logits, tuple):
@@ -63,19 +94,28 @@ def multi_softmax_with_loss(logits, label, ignore_mask=None, num_classes=2):
avg_loss = softmax_with_loss(logits, label, ignore_mask, num_classes)
return avg_loss
+def multi_dice_loss(logits, label, ignore_mask=None):
+ if isinstance(logits, tuple):
+ avg_loss = 0
+ for i, logit in enumerate(logits):
+ logit_label = fluid.layers.resize_nearest(label, logit.shape[2:])
+ logit_mask = (logit_label.astype('int32') !=
+ cfg.DATASET.IGNORE_INDEX).astype('int32')
+ loss = dice_loss(logit, logit_label, logit_mask)
+ avg_loss += cfg.MODEL.MULTI_LOSS_WEIGHT[i] * loss
+ else:
+ avg_loss = dice_loss(logits, label, ignore_mask)
+ return avg_loss
-# to change, how to appicate ignore index and ignore mask
-def dice_loss(logit, label, ignore_mask=None, num_classes=2):
- if num_classes != 2:
- raise Exception("dice loss is only applicable to binary classfication")
- ignore_mask = fluid.layers.cast(ignore_mask, 'float32')
- label = fluid.layers.elementwise_min(
- label, fluid.layers.assign(np.array([num_classes - 1], dtype=np.int32)))
- logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
- logit = fluid.layers.reshape(logit, [-1, num_classes])
- logit = fluid.layers.softmax(logit)
- label = fluid.layers.reshape(label, [-1, 1])
- label = fluid.layers.cast(label, 'int64')
- ignore_mask = fluid.layers.reshape(ignore_mask, [-1, 1])
- loss = fluid.layers.dice_loss(logit, label)
- return loss
+def multi_bce_loss(logits, label, ignore_mask=None):
+ if isinstance(logits, tuple):
+ avg_loss = 0
+ for i, logit in enumerate(logits):
+ logit_label = fluid.layers.resize_nearest(label, logit.shape[2:])
+ logit_mask = (logit_label.astype('int32') !=
+ cfg.DATASET.IGNORE_INDEX).astype('int32')
+ loss = bce_loss(logit, logit_label, logit_mask)
+ avg_loss += cfg.MODEL.MULTI_LOSS_WEIGHT[i] * loss
+ else:
+ avg_loss = bce_loss(logits, label, ignore_mask)
+ return avg_loss
diff --git a/pdseg/models/backbone/mobilenet_v2.py b/pdseg/models/backbone/mobilenet_v2.py
index 5270a0b517c5257eb9b12645ba3b23a208d38ab4..ba9c2e7812cb2e19cc839e84b201e45c357cc692 100644
--- a/pdseg/models/backbone/mobilenet_v2.py
+++ b/pdseg/models/backbone/mobilenet_v2.py
@@ -228,7 +228,7 @@ class MobileNetV2():
num_groups=num_expfilter,
if_act=True,
name=name + '_dwise',
- use_cudnn=True if cfg.MODEL.FP16 else False)
+ use_cudnn=False)
depthwise_output = bottleneck_conv
diff --git a/pdseg/models/libs/model_libs.py b/pdseg/models/libs/model_libs.py
index 1292ed280217b637c4f4d554033bef220de16fc0..19afe54224f259cbd98c189d6bc7196138ed8863 100644
--- a/pdseg/models/libs/model_libs.py
+++ b/pdseg/models/libs/model_libs.py
@@ -149,7 +149,7 @@ def separate_conv(input, channel, stride, filter, dilation=1, act=None):
groups=input.shape[1],
padding=(filter // 2) * dilation,
dilation=dilation,
- use_cudnn=True if cfg.MODEL.FP16 else False,
+ use_cudnn=False,
param_attr=param_attr)
input = bn(input)
if act: input = act(input)
diff --git a/pdseg/models/model_builder.py b/pdseg/models/model_builder.py
index f2ba513a7b14b1b34c2f5dfba2080072cf965356..b52b87553c74d995fb346525737607134447f130 100644
--- a/pdseg/models/model_builder.py
+++ b/pdseg/models/model_builder.py
@@ -24,6 +24,8 @@ from paddle.fluid.proto.framework_pb2 import VarType
import solver
from utils.config import cfg
from loss import multi_softmax_with_loss
+from loss import multi_dice_loss
+from loss import multi_bce_loss
class ModelPhase(object):
@@ -109,6 +111,17 @@ def softmax(logit):
logit = fluid.layers.transpose(logit, [0, 3, 1, 2])
return logit
+def sigmoid_to_softmax(logit):
+ """
+ one channel to two channel
+ """
+ logit = fluid.layers.transpose(logit, [0, 2, 3, 1])
+ logit = fluid.layers.sigmoid(logit)
+ logit_back = 1 - logit
+ logit = fluid.layers.concat([logit_back, logit], axis=-1)
+ logit = fluid.layers.transpose(logit, [0, 3, 1, 2])
+ return logit
+
def build_model(main_prog, start_prog, phase=ModelPhase.TRAIN):
if not ModelPhase.is_valid_phase(phase):
@@ -140,15 +153,53 @@ def build_model(main_prog, start_prog, phase=ModelPhase.TRAIN):
capacity=cfg.DATALOADER.BUF_SIZE,
iterable=False,
use_double_buffer=True)
- if cfg.MODEL.FP16:
- image = fluid.layers.cast(image, "float16")
+
model_name = map_model_name(cfg.MODEL.MODEL_NAME)
model_func = get_func("modeling." + model_name)
+
+ loss_type = cfg.SOLVER.LOSS
+ if not isinstance(loss_type, list):
+ loss_type = list(loss_type)
+
+ if class_num > 2 and (("dice_loss" in loss_type) or ("bce_loss" in loss_type)):
+ raise Exception("dice loss and bce loss is only applicable to binary classfication")
+
+ if ("dice_loss" in loss_type) or ("bce_loss" in loss_type):
+ class_num = 1
+ if "softmax_loss" in loss_type:
+ raise Exception("softmax loss can not combine with dice loss or bce loss")
+
logits = model_func(image, class_num)
if ModelPhase.is_train(phase) or ModelPhase.is_eval(phase):
- avg_loss = multi_softmax_with_loss(logits, label, mask,
- class_num)
+ loss_valid = False
+ avg_loss_list = []
+ valid_loss = []
+ if "softmax_loss" in loss_type:
+ avg_loss_list.append(multi_softmax_with_loss(logits,
+ label, mask,class_num))
+ loss_valid = True
+ valid_loss.append("softmax_loss")
+ if "dice_loss" in loss_type:
+ avg_loss_list.append(multi_dice_loss(logits, label, mask))
+ loss_valid = True
+ valid_loss.append("dice_loss")
+ if "bce_loss" in loss_type:
+ avg_loss_list.append(multi_bce_loss(logits, label, mask))
+ loss_valid = True
+ valid_loss.append("bce_loss")
+ if not loss_valid:
+ raise Exception("SOLVER.LOSS: {} is set wrong. it should "
+ "include one of (softmax_loss, bce_loss, dice_loss) at least"
+ " example: ['softmax_loss'], ['dice_loss'], ['bce_loss', 'dice_loss']".format(cfg.SOLVER.LOSS))
+
+ invalid_loss = [x for x in loss_type if x not in valid_loss]
+ if len(invalid_loss) > 0:
+ print("Warning: the loss {} you set is invalid. it will not be included in loss computed.".format(invalid_loss))
+
+ avg_loss = 0
+ for i in range(0, len(avg_loss_list)):
+ avg_loss += avg_loss_list[i]
#get pred result in original size
if isinstance(logits, tuple):
@@ -161,17 +212,25 @@ def build_model(main_prog, start_prog, phase=ModelPhase.TRAIN):
# return image input and logit output for inference graph prune
if ModelPhase.is_predict(phase):
- logit = softmax(logit)
+ if class_num == 1:
+ logit = sigmoid_to_softmax(logit)
+ else:
+ logit = softmax(logit)
return image, logit
- out = fluid.layers.transpose(x=logit, perm=[0, 2, 3, 1])
- if cfg.MODEL.FP16:
- out = fluid.layers.cast(out, 'float32')
+ if class_num == 1:
+ out = sigmoid_to_softmax(logit)
+ out = fluid.layers.transpose(out, [0, 2, 3, 1])
+ else:
+ out = fluid.layers.transpose(logit, [0, 2, 3, 1])
+
pred = fluid.layers.argmax(out, axis=3)
pred = fluid.layers.unsqueeze(pred, axes=[3])
-
if ModelPhase.is_visual(phase):
- logit = softmax(logit)
+ if class_num == 1:
+ logit = sigmoid_to_softmax(logit)
+ else:
+ logit = softmax(logit)
return pred, logit
if ModelPhase.is_eval(phase):
diff --git a/pdseg/models/modeling/deeplab.py b/pdseg/models/modeling/deeplab.py
index bbf28eb3115342ac7f36d6b414a4a9cc0881510d..e7ed9604b2227bb498c2eb0b863804fbe0159333 100644
--- a/pdseg/models/modeling/deeplab.py
+++ b/pdseg/models/modeling/deeplab.py
@@ -27,7 +27,6 @@ from models.libs.model_libs import separate_conv
from models.backbone.mobilenet_v2 import MobileNetV2 as mobilenet_backbone
from models.backbone.xception import Xception as xception_backbone
-
def encoder(input):
# 编码器配置,采用ASPP架构,pooling + 1x1_conv + 三个不同尺度的空洞卷积并行, concat后1x1conv
# ASPP_WITH_SEP_CONV:默认为真,使用depthwise可分离卷积,否则使用普通卷积
@@ -48,13 +47,8 @@ def encoder(input):
with scope('encoder'):
channel = 256
with scope("image_pool"):
- if cfg.MODEL.FP16:
- image_avg = fluid.layers.reduce_mean(
- fluid.layers.cast(input, 'float32'), [2, 3], keep_dim=True)
- image_avg = fluid.layers.cast(image_avg, 'float16')
- else:
- image_avg = fluid.layers.reduce_mean(
- input, [2, 3], keep_dim=True)
+ image_avg = fluid.layers.reduce_mean(
+ input, [2, 3], keep_dim=True)
image_avg = bn_relu(
conv(
image_avg,
@@ -64,11 +58,8 @@ def encoder(input):
groups=1,
padding=0,
param_attr=param_attr))
- if cfg.MODEL.FP16:
- image_avg = fluid.layers.cast(image_avg, 'float32')
image_avg = fluid.layers.resize_bilinear(image_avg, input.shape[2:])
- if cfg.MODEL.FP16:
- image_avg = fluid.layers.cast(image_avg, 'float16')
+
with scope("aspp0"):
aspp0 = bn_relu(
conv(
@@ -157,12 +148,9 @@ def decoder(encode_data, decode_shortcut):
groups=1,
padding=0,
param_attr=param_attr))
- if cfg.MODEL.FP16:
- encode_data = fluid.layers.cast(encode_data, 'float32')
+
encode_data = fluid.layers.resize_bilinear(
encode_data, decode_shortcut.shape[2:])
- if cfg.MODEL.FP16:
- encode_data = fluid.layers.cast(encode_data, 'float16')
encode_data = fluid.layers.concat([encode_data, decode_shortcut],
axis=1)
if cfg.MODEL.DEEPLAB.DECODER_USE_SEP_CONV:
@@ -270,9 +258,6 @@ def deeplabv3p(img, num_classes):
padding=0,
bias_attr=True,
param_attr=param_attr)
- if cfg.MODEL.FP16:
- logit = fluid.layers.cast(logit, 'float32')
logit = fluid.layers.resize_bilinear(logit, img.shape[2:])
- if cfg.MODEL.FP16:
- logit = fluid.layers.cast(logit, 'float16')
+
return logit
diff --git a/pdseg/reader.py b/pdseg/reader.py
index e53b5912e07b1591d4014314f809e6997d925731..244b007f3c9e368a4fb2f31967691e5c46405f2e 100644
--- a/pdseg/reader.py
+++ b/pdseg/reader.py
@@ -32,7 +32,7 @@ import data_aug as aug
from utils.config import cfg
from data_utils import GeneratorEnqueuer
from models.model_builder import ModelPhase
-
+import copy
def cv2_imread(file_path, flag=cv2.IMREAD_COLOR):
# resolve cv2.imread open Chinese file path issues on Windows Platform.
@@ -49,15 +49,25 @@ class SegDataset(object):
self.shuffle = shuffle
self.data_dir = data_dir
+ self.shuffle_seed = 0
# NOTE: Please ensure file list was save in UTF-8 coding format
with codecs.open(file_list, 'r', 'utf-8') as flist:
self.lines = [line.strip() for line in flist]
- if shuffle:
+ self.all_lines = copy.deepcopy(self.lines)
+ if shuffle and cfg.NUM_TRAINERS > 1:
+ np.random.RandomState(self.shuffle_seed).shuffle(self.all_lines)
+ elif shuffle:
np.random.shuffle(self.lines)
def generator(self):
- if self.shuffle:
+ if self.shuffle and cfg.NUM_TRAINERS > 1:
+ np.random.RandomState(self.shuffle_seed).shuffle(self.all_lines)
+ num_lines = len(self.all_lines) // cfg.NUM_TRAINERS
+ self.lines = self.all_lines[num_lines * cfg.TRAINER_ID: num_lines * (cfg.TRAINER_ID + 1)]
+ self.shuffle_seed += 1
+ elif self.shuffle:
np.random.shuffle(self.lines)
+
for line in self.lines:
yield self.process_image(line, self.data_dir, self.mode)
@@ -78,8 +88,14 @@ class SegDataset(object):
def multiprocess_generator(self, max_queue_size=32, num_processes=8):
# Re-shuffle file list
- if self.shuffle:
+ if self.shuffle and cfg.NUM_TRAINERS > 1:
+ np.random.RandomState(self.shuffle_seed).shuffle(self.all_lines)
+ num_lines = len(self.all_lines) // self.num_trainers
+ self.lines = self.all_lines[num_lines * self.trainer_id: num_lines * (self.trainer_id + 1)]
+ self.shuffle_seed += 1
+ elif self.shuffle:
np.random.shuffle(self.lines)
+
# Create multiple sharding generators according to num_processes for multiple processes
generators = []
for pid in range(num_processes):
diff --git a/pdseg/solver.py b/pdseg/solver.py
index 8ed319417f9318b99f85c654cb28a3db19502205..8eea7400b5b3ad56777c6d00577a2725737f2089 100644
--- a/pdseg/solver.py
+++ b/pdseg/solver.py
@@ -18,7 +18,7 @@ import paddle.fluid as fluid
import numpy as np
import importlib
from utils.config import cfg
-from paddle.fluid.contrib.mixed_precision.fp16_utils import create_master_params_grads, master_param_to_train_param
+from paddle.fluid.contrib.mixed_precision.decorator import OptimizerWithMixedPrecison, decorate, AutoMixedPrecisionLists
class Solver(object):
@@ -74,15 +74,22 @@ class Solver(object):
regularization_coeff=self.weight_decay),
)
if cfg.MODEL.FP16:
- params_grads = optimizer.backward(loss, self.start_prog)
- master_params_grads = create_master_params_grads(
- params_grads, self.main_prog, self.start_prog,
- cfg.MODEL.SCALE_LOSS)
- optimizer.apply_gradients(master_params_grads)
- master_param_to_train_param(master_params_grads, params_grads,
- self.main_prog)
- else:
- optimizer.minimize(loss)
+ if cfg.MODEL.MODEL_NAME in ["pspnet"]:
+ custom_black_list = {"pool2d"}
+ else:
+ custom_black_list = {}
+ amp_lists = AutoMixedPrecisionLists(custom_black_list=custom_black_list)
+ assert isinstance(cfg.MODEL.SCALE_LOSS, float) or isinstance(cfg.MODEL.SCALE_LOSS, str), \
+ "data type of MODEL.SCALE_LOSS must be float or str"
+ if isinstance(cfg.MODEL.SCALE_LOSS, float):
+ optimizer = decorate(optimizer, amp_lists=amp_lists, init_loss_scaling=cfg.MODEL.SCALE_LOSS,
+ use_dynamic_loss_scaling=False)
+ else:
+ assert cfg.MODEL.SCALE_LOSS.lower() in ['dynamic'], "if MODEL.SCALE_LOSS is a string,\
+ must be set as 'DYNAMIC'!"
+ optimizer = decorate(optimizer, amp_lists=amp_lists, use_dynamic_loss_scaling=True)
+
+ optimizer.minimize(loss)
return decayed_lr
def adam_optimizer(self, lr_policy, loss):
diff --git a/pdseg/tools/__init__.py b/pdseg/tools/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5914a21f76a81bf8589b609b2dac8f0548aace4
--- /dev/null
+++ b/pdseg/tools/__init__.py
@@ -0,0 +1,14 @@
+# coding: utf8
+# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/pdseg/tools/create_dataset_list.py b/pdseg/tools/create_dataset_list.py
new file mode 100644
index 0000000000000000000000000000000000000000..aca6d95d20bc645c1843399c99f5e56d4560f7f8
--- /dev/null
+++ b/pdseg/tools/create_dataset_list.py
@@ -0,0 +1,155 @@
+# coding: utf8
+# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import glob
+import os.path
+import argparse
+import warnings
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='PaddleSeg generate file list on cityscapes or your customized dataset.')
+ parser.add_argument(
+ 'dataset_root',
+ help='dataset root directory',
+ type=str
+ )
+ parser.add_argument(
+ '--type',
+ help='dataset type: \n'
+ '- cityscapes \n'
+ '- custom(default)',
+ default="custom",
+ type=str
+ )
+ parser.add_argument(
+ '--separator',
+ dest='separator',
+ help='file list separator',
+ default="|",
+ type=str
+ )
+ parser.add_argument(
+ '--folder',
+ help='the folder names of images and labels',
+ type=str,
+ nargs=2,
+ default=['images', 'annotations']
+ )
+ parser.add_argument(
+ '--second_folder',
+ help='the second-level folder names of train set, validation set, test set',
+ type=str,
+ nargs='*',
+ default=['train', 'val', 'test']
+ )
+ parser.add_argument(
+ '--format',
+ help='data format of images and labels, e.g. jpg or png.',
+ type=str,
+ nargs=2,
+ default=['jpg', 'png']
+ )
+ parser.add_argument(
+ '--postfix',
+ help='postfix of images or labels',
+ type=str,
+ nargs=2,
+ default=['', '']
+ )
+
+ return parser.parse_args()
+
+
+def cityscape_cfg(args):
+ args.postfix = ['_leftImg8bit', '_gtFine_labelTrainIds']
+
+ args.folder = ['leftImg8bit', 'gtFine']
+
+ args.format = ['png', 'png']
+
+
+def get_files(image_or_label, dataset_split, args):
+ dataset_root = args.dataset_root
+ postfix = args.postfix
+ format = args.format
+ folder = args.folder
+
+ pattern = '*%s.%s' % (postfix[image_or_label], format[image_or_label])
+
+ search_files = os.path.join(dataset_root, folder[image_or_label],
+ dataset_split, pattern)
+ search_files2 = os.path.join(dataset_root, folder[image_or_label],
+ dataset_split, "*", pattern) # 包含子目录
+ search_files3 = os.path.join(dataset_root, folder[image_or_label],
+ dataset_split, "*", "*", pattern) # 包含三级目录
+
+ filenames = glob.glob(search_files)
+ filenames2 = glob.glob(search_files2)
+ filenames3 = glob.glob(search_files3)
+
+ filenames = filenames + filenames2 + filenames3
+
+ return sorted(filenames)
+
+
+def generate_list(args):
+ dataset_root = args.dataset_root
+ separator = args.separator
+
+ for dataset_split in args.second_folder:
+ print("Creating {}.txt...".format(dataset_split))
+ image_files = get_files(0, dataset_split, args)
+ label_files = get_files(1, dataset_split, args)
+ if not image_files:
+ img_dir = os.path.join(dataset_root, args.folder[0], dataset_split)
+ print("No files in {}".format(img_dir))
+ num_images = len(image_files)
+
+ if not label_files:
+ label_dir = os.path.join(dataset_root, args.folder[1], dataset_split)
+ print("No files in {}".format(label_dir))
+ num_label = len(label_files)
+
+ if num_images < num_label:
+ warnings.warn("number of images = {} < number of labels = {}."
+ .format(num_images, num_label))
+ continue
+
+ file_list = os.path.join(dataset_root, dataset_split + '.txt')
+ with open(file_list, "w") as f:
+ for item in range(num_images):
+ left = image_files[item].replace(dataset_root, '')
+ if left[0] == os.path.sep:
+ left = left.lstrip(os.path.sep)
+
+ try:
+ right = label_files[item].replace(dataset_root, '')
+ if right[0] == os.path.sep:
+ right = right.lstrip(os.path.sep)
+ line = left + separator + right + '\n'
+ except:
+ line = left + '\n'
+
+ f.write(line)
+ print(line)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ if args.type == 'cityscapes':
+ cityscape_cfg(args)
+ generate_list(args)
diff --git a/pdseg/train.py b/pdseg/train.py
index 22a430f7f1bd3ff4c5c1e5ee28a624badc3cac41..59349b33fadb980b2b1eab4b196b263ed1f2aba5 100644
--- a/pdseg/train.py
+++ b/pdseg/train.py
@@ -40,8 +40,7 @@ from models.model_builder import ModelPhase
from models.model_builder import parse_shape_from_file
from eval import evaluate
from vis import visualize
-from utils.fp16_utils import load_fp16_vars
-
+from utils import dist_utils
def parse_args():
parser = argparse.ArgumentParser(description='PaddleSeg training')
@@ -178,6 +177,9 @@ def load_checkpoint(exe, program):
return begin_epoch
+def print_info(*msg):
+ if cfg.TRAINER_ID == 0:
+ print(*msg)
def train(cfg):
startup_prog = fluid.Program()
@@ -201,7 +203,7 @@ def train(cfg):
batch_data = []
for b in data_gen:
batch_data.append(b)
- if len(batch_data) == cfg.BATCH_SIZE:
+ if len(batch_data) == (cfg.BATCH_SIZE // cfg.NUM_TRAINERS):
for item in batch_data:
yield item[0], item[1], item[2]
batch_data = []
@@ -212,11 +214,15 @@ def train(cfg):
yield item[0], item[1], item[2]
# Get device environment
+ # places = fluid.cuda_places() if args.use_gpu else fluid.cpu_places()
+ # place = places[0]
+ gpu_id = int(os.environ.get('FLAGS_selected_gpus', 0))
+ place = fluid.CUDAPlace(gpu_id) if args.use_gpu else fluid.CPUPlace()
places = fluid.cuda_places() if args.use_gpu else fluid.cpu_places()
- place = places[0]
+
# Get number of GPU
- dev_count = len(places)
- print("#Device count: {}".format(dev_count))
+ dev_count = cfg.NUM_TRAINERS if cfg.NUM_TRAINERS > 1 else len(places)
+ print_info("#Device count: {}".format(dev_count))
# Make sure BATCH_SIZE can divided by GPU cards
assert cfg.BATCH_SIZE % dev_count == 0, (
@@ -224,7 +230,7 @@ def train(cfg):
cfg.BATCH_SIZE, dev_count))
# If use multi-gpu training mode, batch data will allocated to each GPU evenly
batch_size_per_dev = cfg.BATCH_SIZE // dev_count
- print("batch_size_per_dev: {}".format(batch_size_per_dev))
+ print_info("batch_size_per_dev: {}".format(batch_size_per_dev))
py_reader, avg_loss, lr, pred, grts, masks = build_model(
train_prog, startup_prog, phase=ModelPhase.TRAIN)
@@ -240,13 +246,18 @@ def train(cfg):
exec_strategy.num_threads = fluid.core.get_cuda_device_count()
exec_strategy.num_iteration_per_drop_scope = 100
build_strategy = fluid.BuildStrategy()
+
+ if cfg.NUM_TRAINERS > 1 and args.use_gpu:
+ dist_utils.prepare_for_multi_process(exe, build_strategy, train_prog)
+ exec_strategy.num_threads = 1
+
if cfg.TRAIN.SYNC_BATCH_NORM and args.use_gpu:
if dev_count > 1:
# Apply sync batch norm strategy
- print("Sync BatchNorm strategy is effective.")
+ print_info("Sync BatchNorm strategy is effective.")
build_strategy.sync_batch_norm = True
else:
- print("Sync BatchNorm strategy will not be effective if GPU device"
+ print_info("Sync BatchNorm strategy will not be effective if GPU device"
" count <= 1")
compiled_train_prog = fluid.CompiledProgram(train_prog).with_data_parallel(
loss_name=avg_loss.name,
@@ -259,7 +270,7 @@ def train(cfg):
begin_epoch = load_checkpoint(exe, train_prog)
# Load pretrained model
elif os.path.exists(cfg.TRAIN.PRETRAINED_MODEL_DIR):
- print('Pretrained model dir:', cfg.TRAIN.PRETRAINED_MODEL_DIR)
+ print_info('Pretrained model dir: ', cfg.TRAIN.PRETRAINED_MODEL_DIR)
load_vars = []
load_fail_vars = []
@@ -283,22 +294,19 @@ def train(cfg):
load_vars.append(x)
else:
load_fail_vars.append(x)
- if cfg.MODEL.FP16:
- # If open FP16 training mode, load FP16 var separate
- load_fp16_vars(exe, cfg.TRAIN.PRETRAINED_MODEL_DIR, train_prog)
- else:
- fluid.io.load_vars(
- exe, dirname=cfg.TRAIN.PRETRAINED_MODEL_DIR, vars=load_vars)
+
+ fluid.io.load_vars(
+ exe, dirname=cfg.TRAIN.PRETRAINED_MODEL_DIR, vars=load_vars)
for var in load_vars:
- print("Parameter[{}] loaded sucessfully!".format(var.name))
+ print_info("Parameter[{}] loaded sucessfully!".format(var.name))
for var in load_fail_vars:
- print("Parameter[{}] don't exist or shape does not match current network, skip"
+ print_info("Parameter[{}] don't exist or shape does not match current network, skip"
" to load it.".format(var.name))
- print("{}/{} pretrained parameters loaded successfully!".format(
+ print_info("{}/{} pretrained parameters loaded successfully!".format(
len(load_vars),
len(load_vars) + len(load_fail_vars)))
else:
- print('Pretrained model dir {} not exists, training from scratch...'.
+ print_info('Pretrained model dir {} not exists, training from scratch...'.
format(cfg.TRAIN.PRETRAINED_MODEL_DIR))
fetch_list = [avg_loss.name, lr.name]
@@ -312,12 +320,14 @@ def train(cfg):
if args.use_tb:
if not args.tb_log_dir:
- print("Please specify the log directory by --tb_log_dir.")
+ print_info("Please specify the log directory by --tb_log_dir.")
exit(1)
from tb_paddle import SummaryWriter
log_writer = SummaryWriter(args.tb_log_dir)
+ # trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
+ # num_trainers = int(os.environ.get('PADDLE_TRAINERS_NUM', 1))
global_step = 0
all_step = cfg.DATASET.TRAIN_TOTAL_IMAGES // cfg.BATCH_SIZE
if cfg.DATASET.TRAIN_TOTAL_IMAGES % cfg.BATCH_SIZE and drop_last != True:
@@ -333,9 +343,9 @@ def train(cfg):
begin_epoch, cfg.SOLVER.NUM_EPOCHS))
if args.use_mpio:
- print("Use multiprocess reader")
+ print_info("Use multiprocess reader")
else:
- print("Use multi-thread reader")
+ print_info("Use multi-thread reader")
for epoch in range(begin_epoch, cfg.SOLVER.NUM_EPOCHS + 1):
py_reader.start()
@@ -348,7 +358,6 @@ def train(cfg):
program=compiled_train_prog,
fetch_list=fetch_list,
return_numpy=True)
-
cm.calculate(pred, grts, masks)
avg_loss += np.mean(np.array(loss))
global_step += 1
@@ -359,13 +368,13 @@ def train(cfg):
category_acc, mean_acc = cm.accuracy()
category_iou, mean_iou = cm.mean_iou()
- print((
+ print_info((
"epoch={} step={} lr={:.5f} loss={:.4f} acc={:.5f} mIoU={:.5f} step/sec={:.3f} | ETA {}"
).format(epoch, global_step, lr[0], avg_loss, mean_acc,
mean_iou, speed,
calculate_eta(all_step - global_step, speed)))
- print("Category IoU:", category_iou)
- print("Category Acc:", category_acc)
+ print_info("Category IoU: ", category_iou)
+ print_info("Category Acc: ", category_acc)
if args.use_tb:
log_writer.add_scalar('Train/mean_iou', mean_iou,
global_step)
@@ -390,7 +399,7 @@ def train(cfg):
avg_loss += np.mean(np.array(loss))
global_step += 1
- if global_step % args.log_steps == 0:
+ if global_step % args.log_steps == 0 and cfg.TRAINER_ID == 0:
avg_loss /= args.log_steps
speed = args.log_steps / timer.elapsed_time()
print((
@@ -414,7 +423,7 @@ def train(cfg):
except Exception as e:
print(e)
- if epoch % cfg.TRAIN.SNAPSHOT_EPOCH == 0:
+ if epoch % cfg.TRAIN.SNAPSHOT_EPOCH == 0 and cfg.TRAINER_ID == 0:
ckpt_dir = save_checkpoint(exe, train_prog, epoch)
if args.do_eval:
@@ -441,16 +450,20 @@ def train(cfg):
log_writer=log_writer)
# save final model
- save_checkpoint(exe, train_prog, 'final')
-
+ if cfg.TRAINER_ID == 0:
+ save_checkpoint(exe, train_prog, 'final')
def main(args):
if args.cfg_file is not None:
cfg.update_from_file(args.cfg_file)
if args.opts is not None:
cfg.update_from_list(args.opts)
- cfg.check_and_infer(reset_dataset=True)
- print(pprint.pformat(cfg))
+
+ cfg.TRAINER_ID = int(os.getenv("PADDLE_TRAINER_ID", 0))
+ cfg.NUM_TRAINERS = int(os.environ.get('PADDLE_TRAINERS_NUM', 1))
+
+ cfg.check_and_infer()
+ print_info(pprint.pformat(cfg))
train(cfg)
diff --git a/pdseg/utils/collect.py b/pdseg/utils/collect.py
index 6b8f2f4eb0b4c98ce3078812f41dacafc3097bc1..78baf63f2e9bc3b45aac6c9d9610878fa4a05a9c 100644
--- a/pdseg/utils/collect.py
+++ b/pdseg/utils/collect.py
@@ -88,7 +88,7 @@ class SegConfig(dict):
except KeyError:
raise KeyError('Non-existent config key: {}'.format(key))
- def check_and_infer(self, reset_dataset=False):
+ def check_and_infer(self):
if self.DATASET.IMAGE_TYPE in ['rgb', 'gray']:
self.DATASET.DATA_DIM = 3
elif self.DATASET.IMAGE_TYPE in ['rgba']:
@@ -110,17 +110,13 @@ class SegConfig(dict):
'EVAL_CROP_SIZE is empty! Please set a pair of values in format (width, height)'
)
- if reset_dataset:
- # Ensure file list is use UTF-8 encoding
- train_sets = codecs.open(self.DATASET.TRAIN_FILE_LIST, 'r',
- 'utf-8').readlines()
- val_sets = codecs.open(self.DATASET.VAL_FILE_LIST, 'r',
- 'utf-8').readlines()
- test_sets = codecs.open(self.DATASET.TEST_FILE_LIST, 'r',
- 'utf-8').readlines()
- self.DATASET.TRAIN_TOTAL_IMAGES = len(train_sets)
- self.DATASET.VAL_TOTAL_IMAGES = len(val_sets)
- self.DATASET.TEST_TOTAL_IMAGES = len(test_sets)
+ # Ensure file list is use UTF-8 encoding
+ train_sets = codecs.open(self.DATASET.TRAIN_FILE_LIST, 'r', 'utf-8').readlines()
+ val_sets = codecs.open(self.DATASET.VAL_FILE_LIST, 'r', 'utf-8').readlines()
+ test_sets = codecs.open(self.DATASET.TEST_FILE_LIST, 'r', 'utf-8').readlines()
+ self.DATASET.TRAIN_TOTAL_IMAGES = len(train_sets)
+ self.DATASET.VAL_TOTAL_IMAGES = len(val_sets)
+ self.DATASET.TEST_TOTAL_IMAGES = len(test_sets)
if self.MODEL.MODEL_NAME == 'icnet' and \
len(self.MODEL.MULTI_LOSS_WEIGHT) != 3:
@@ -139,7 +135,7 @@ class SegConfig(dict):
def update_from_file(self, config_file):
with codecs.open(config_file, 'r', 'utf-8') as file:
- dic = yaml.load(file)
+ dic = yaml.load(file, Loader=yaml.FullLoader)
self.update_from_segconfig(dic)
def set_immutable(self, immutable):
diff --git a/pdseg/utils/config.py b/pdseg/utils/config.py
index 12a3e1ba251ff8faa7a4fd7156d84894539c9317..f8bf79699e0129389b1f842cafccec366227bc5b 100644
--- a/pdseg/utils/config.py
+++ b/pdseg/utils/config.py
@@ -31,7 +31,10 @@ cfg.BATCH_SIZE = 1
cfg.EVAL_CROP_SIZE = tuple()
# 训练时图像裁剪尺寸(宽,高)
cfg.TRAIN_CROP_SIZE = tuple()
-
+# 多进程训练总进程数
+cfg.NUM_TRAINERS = 1
+# 多进程训练进程ID
+cfg.TRAINER_ID = 0
########################## 数据载入配置 #######################################
# 数据载入时的并发数, 建议值8
cfg.DATALOADER.NUM_WORKERS = 8
@@ -149,6 +152,8 @@ cfg.SOLVER.WEIGHT_DECAY = 0.00004
cfg.SOLVER.BEGIN_EPOCH = 1
# 训练epoch数,正整数
cfg.SOLVER.NUM_EPOCHS = 30
+# loss的选择,支持softmax_loss, bce_loss, dice_loss
+cfg.SOLVER.LOSS = ["softmax_loss"]
########################## 测试配置 ###########################################
# 测试模型路径
@@ -169,8 +174,8 @@ cfg.MODEL.DEFAULT_EPSILON = 1e-5
cfg.MODEL.BN_MOMENTUM = 0.99
# 是否使用FP16训练
cfg.MODEL.FP16 = False
-# FP16需对LOSS进行scale, 一般训练FP16设置为8.0
-cfg.MODEL.SCALE_LOSS = 1.0
+# 混合精度训练需对LOSS进行scale, 默认为动态scale,静态scale可以设置为512.0
+cfg.MODEL.SCALE_LOSS = "DYNAMIC"
########################## DeepLab模型配置 ####################################
# DeepLab backbone 配置, 可选项xception_65, mobilenetv2
diff --git a/pdseg/utils/dist_utils.py b/pdseg/utils/dist_utils.py
new file mode 100755
index 0000000000000000000000000000000000000000..64c8800fd2010d4e1e5def6cc4ea2e1ad673b4a3
--- /dev/null
+++ b/pdseg/utils/dist_utils.py
@@ -0,0 +1,92 @@
+#copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
+#
+#Licensed under the Apache License, Version 2.0 (the "License");
+#you may not use this file except in compliance with the License.
+#You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+#Unless required by applicable law or agreed to in writing, software
+#distributed under the License is distributed on an "AS IS" BASIS,
+#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+#See the License for the specific language governing permissions and
+#limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+import os
+import paddle.fluid as fluid
+
+
+def nccl2_prepare(args, startup_prog, main_prog):
+ config = fluid.DistributeTranspilerConfig()
+ config.mode = "nccl2"
+ t = fluid.DistributeTranspiler(config=config)
+
+ envs = args.dist_env
+
+ t.transpile(
+ envs["trainer_id"],
+ trainers=','.join(envs["trainer_endpoints"]),
+ current_endpoint=envs["current_endpoint"],
+ startup_program=startup_prog,
+ program=main_prog)
+
+
+def pserver_prepare(args, train_prog, startup_prog):
+ config = fluid.DistributeTranspilerConfig()
+ config.slice_var_up = args.split_var
+ t = fluid.DistributeTranspiler(config=config)
+ envs = args.dist_env
+ training_role = envs["training_role"]
+
+ t.transpile(
+ envs["trainer_id"],
+ program=train_prog,
+ pservers=envs["pserver_endpoints"],
+ trainers=envs["num_trainers"],
+ sync_mode=not args.async_mode,
+ startup_program=startup_prog)
+ if training_role == "PSERVER":
+ pserver_program = t.get_pserver_program(envs["current_endpoint"])
+ pserver_startup_program = t.get_startup_program(
+ envs["current_endpoint"],
+ pserver_program,
+ startup_program=startup_prog)
+ return pserver_program, pserver_startup_program
+ elif training_role == "TRAINER":
+ train_program = t.get_trainer_program()
+ return train_program, startup_prog
+ else:
+ raise ValueError(
+ 'PADDLE_TRAINING_ROLE environment variable must be either TRAINER or PSERVER'
+ )
+
+
+def nccl2_prepare_paddle(trainer_id, startup_prog, main_prog):
+ config = fluid.DistributeTranspilerConfig()
+ config.mode = "nccl2"
+ t = fluid.DistributeTranspiler(config=config)
+ t.transpile(
+ trainer_id,
+ trainers=os.environ.get('PADDLE_TRAINER_ENDPOINTS'),
+ current_endpoint=os.environ.get('PADDLE_CURRENT_ENDPOINT'),
+ startup_program=startup_prog,
+ program=main_prog)
+
+
+def prepare_for_multi_process(exe, build_strategy, train_prog):
+ # prepare for multi-process
+ trainer_id = int(os.environ.get('PADDLE_TRAINER_ID', 0))
+ num_trainers = int(os.environ.get('PADDLE_TRAINERS_NUM', 1))
+ if num_trainers < 2: return
+
+ build_strategy.num_trainers = num_trainers
+ build_strategy.trainer_id = trainer_id
+ # NOTE(zcd): use multi processes to train the model,
+ # and each process use one GPU card.
+ startup_prog = fluid.Program()
+ nccl2_prepare_paddle(trainer_id, startup_prog, train_prog)
+ # the startup_prog are run two times, but it doesn't matter.
+ exe.run(startup_prog)
diff --git a/test/configs/deeplabv3p_xception65_cityscapes.yaml b/test/configs/deeplabv3p_xception65_cityscapes.yaml
index 349646f743f10c7970b248b30c258574c8478c68..111452fb3e240409cfc18cc684a03f71746589c7 100644
--- a/test/configs/deeplabv3p_xception65_cityscapes.yaml
+++ b/test/configs/deeplabv3p_xception65_cityscapes.yaml
@@ -31,10 +31,10 @@ MODEL:
ASPP_WITH_SEP_CONV: True
DECODER_USE_SEP_CONV: True
TEST:
- TEST_MODEL: "snapshots/cityscape_v5/final/"
+ TEST_MODEL: "./saved_model/cityscape_v5/final/"
TRAIN:
- MODEL_SAVE_DIR: "snapshots/cityscape_v5/"
- PRETRAINED_MODEL_DIR: "pretrain/deeplabv3plus_gn_init"
+ MODEL_SAVE_DIR: "./saved_model/cityscape_v5/"
+ PRETRAINED_MODEL_DIR: "pretrained_model/deeplabv3plus_gn_init"
SNAPSHOT_EPOCH: 10
SOLVER:
LR: 0.001
diff --git a/test/configs/unet_pet.yaml b/test/configs/unet_pet.yaml
index 3a3cf65a09dfbff51e79ca65bd19c1c11fb75d64..b39b9386d55847f393a9826f147eb41066f42c4f 100644
--- a/test/configs/unet_pet.yaml
+++ b/test/configs/unet_pet.yaml
@@ -12,15 +12,15 @@ AUG:
MIN_SCALE_FACTOR: 0.75 # for stepscaling
SCALE_STEP_SIZE: 0.25 # for stepscaling
MIRROR: True
-BATCH_SIZE: 6
+BATCH_SIZE: 4
DATASET:
- DATA_DIR: "./dataset/pet/"
+ DATA_DIR: "./dataset/mini_pet/"
IMAGE_TYPE: "rgb" # choice rgb or rgba
- NUM_CLASSES: 4 # including ignore
- TEST_FILE_LIST: "./dataset/pet/test_list.txt"
- TRAIN_FILE_LIST: "./dataset/pet/train_list.txt"
- VAL_FILE_LIST: "./dataset/pet/val_list.txt"
- VIS_FILE_LIST: "./dataset/pet/val_list.txt"
+ NUM_CLASSES: 3
+ TEST_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
+ TRAIN_FILE_LIST: "./dataset/mini_pet/file_list/train_list.txt"
+ VAL_FILE_LIST: "./dataset/mini_pet/file_list/val_list.txt"
+ VIS_FILE_LIST: "./dataset/mini_pet/file_list/test_list.txt"
IGNORE_INDEX: 255
SEPARATOR: " "
FREEZE:
@@ -30,13 +30,13 @@ MODEL:
MODEL_NAME: "unet"
DEFAULT_NORM_TYPE: "bn"
TEST:
- TEST_MODEL: "./test/saved_model/unet_pet/final/"
+ TEST_MODEL: "./saved_model/unet_pet/final/"
TRAIN:
- MODEL_SAVE_DIR: "./test/saved_models/unet_pet/"
- PRETRAINED_MODEL_DIR: "./test/models/unet_coco/"
+ MODEL_SAVE_DIR: "./saved_model/unet_pet/"
+ PRETRAINED_MODEL_DIR: "./test/models/unet_coco_init/"
SNAPSHOT_EPOCH: 10
SOLVER:
- NUM_EPOCHS: 500
+ NUM_EPOCHS: 100
LR: 0.005
LR_POLICY: "poly"
OPTIMIZER: "adam"
diff --git a/test/local_test_cityscapes.py b/test/local_test_cityscapes.py
index 051faaa1b4e4c769a996b94b411b65815eb3a9e7..cff6a993cf34499567398f4107171e66845b18ce 100644
--- a/test/local_test_cityscapes.py
+++ b/test/local_test_cityscapes.py
@@ -50,7 +50,7 @@ if __name__ == "__main__":
dest="devices",
help="GPU id of running. if more than one, use spacing to separate.",
nargs="+",
- default=0,
+ default=[0],
type=int)
args = parser.parse_args()
diff --git a/test/local_test_pet.py b/test/local_test_pet.py
index f043d16a5c7a9d7d45db8ce91864a8c5325876b9..920aea654c6afc159e4ff1fab031b1c29ea69528 100644
--- a/test/local_test_pet.py
+++ b/test/local_test_pet.py
@@ -51,7 +51,7 @@ if __name__ == "__main__":
dest="devices",
help="GPU id of running. if more than one, use spacing to separate.",
nargs="+",
- default=0,
+ default=[0],
type=int)
args = parser.parse_args()
diff --git a/turtorial/finetune_deeplabv3plus.md b/turtorial/finetune_deeplabv3plus.md
index abc05f52f73b5d32538fdbd4aecc79c9b5a64da4..eee70fcea2c8b43f0fedcb7ab9da4755acbf274a 100644
--- a/turtorial/finetune_deeplabv3plus.md
+++ b/turtorial/finetune_deeplabv3plus.md
@@ -21,7 +21,7 @@ python dataset/download_pet.py
接着下载对应的预训练模型
```shell
-python pretrained_model/download_model.py deeplabv3p_xception65_bn_cityscapes
+python pretrained_model/download_model.py deeplabv3p_xception65_bn_coco
```
## 三. 准备配置
@@ -47,7 +47,7 @@ python pretrained_model/download_model.py deeplabv3p_xception65_bn_cityscapes
数据集的配置和数据路径有关,在本教程中,数据存放在`dataset/mini_pet`中
-其他配置则根据数据集和机器环境的情况进行调节,最终我们保存一个如下内容的yaml配置文件,存放路径为`configs/test_deeplabv3p_pet.yaml`
+其他配置则根据数据集和机器环境的情况进行调节,最终我们保存一个如下内容的yaml配置文件,存放路径为**configs/deeplabv3p_xception65_pet.yaml**
```yaml
# 数据集配置
@@ -91,7 +91,7 @@ SOLVER:
在开始训练和评估之前,我们还需要对配置和数据进行一次校验,确保数据和配置是正确的。使用下述命令启动校验流程
```shell
-python pdseg/check.py --cfg ./configs/test_deeplabv3p_pet.yaml
+python pdseg/check.py --cfg ./configs/deeplabv3p_xception65_pet.yaml
```
@@ -100,7 +100,7 @@ python pdseg/check.py --cfg ./configs/test_deeplabv3p_pet.yaml
校验通过后,使用下述命令启动训练
```shell
-python pdseg/train.py --use_gpu --cfg ./configs/test_deeplabv3p_pet.yaml
+python pdseg/train.py --use_gpu --cfg ./configs/deeplabv3p_xception65_pet.yaml
```
## 六. 进行评估
@@ -108,7 +108,7 @@ python pdseg/train.py --use_gpu --cfg ./configs/test_deeplabv3p_pet.yaml
模型训练完成,使用下述命令启动评估
```shell
-python pdseg/eval.py --use_gpu --cfg ./configs/test_deeplabv3p_pet.yaml
+python pdseg/eval.py --use_gpu --cfg ./configs/deeplabv3p_xception65_pet.yaml
```
## 模型组合
@@ -123,7 +123,7 @@ python pdseg/eval.py --use_gpu --cfg ./configs/test_deeplabv3p_pet.yaml
|xception41_imagenet|-|bn|ImageNet|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_41
MODEL.DEFAULT_NORM_TYPE: bn|
|xception65_imagenet|-|bn|ImageNet|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: bn|
|deeplabv3p_mobilenetv2-1-0_bn_coco|MobileNet V2|bn|COCO|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.0
MODEL.DEEPLAB.ENCODER_WITH_ASPP: False
MODEL.DEEPLAB.ENABLE_DECODER: False
MODEL.DEFAULT_NORM_TYPE: bn|
-|deeplabv3p_xception65_bn_coco|Xception|bn|COCO|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: bn |
+|**deeplabv3p_xception65_bn_coco**|Xception|bn|COCO|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: bn |
|deeplabv3p_mobilenetv2-1-0_bn_cityscapes|MobileNet V2|bn|Cityscapes|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: mobilenet
MODEL.DEEPLAB.DEPTH_MULTIPLIER: 1.0
MODEL.DEEPLAB.ENCODER_WITH_ASPP: False
MODEL.DEEPLAB.ENABLE_DECODER: False
MODEL.DEFAULT_NORM_TYPE: bn|
|deeplabv3p_xception65_gn_cityscapes|Xception|gn|Cityscapes|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: gn|
-|**deeplabv3p_xception65_bn_cityscapes**|Xception|bn|Cityscapes|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: bn|
+|deeplabv3p_xception65_bn_cityscapes|Xception|bn|Cityscapes|MODEL.MODEL_NAME: deeplabv3p
MODEL.DEEPLAB.BACKBONE: xception_65
MODEL.DEFAULT_NORM_TYPE: bn|
diff --git a/turtorial/finetune_icnet.md b/turtorial/finetune_icnet.md
index 54aa9d43c395abe32b76cfcdf74759fe58753cd7..f1a68e2c75821b5e90592ea82c07170fdc9805d2 100644
--- a/turtorial/finetune_icnet.md
+++ b/turtorial/finetune_icnet.md
@@ -47,7 +47,7 @@ python pretrained_model/download_model.py icnet_bn_cityscapes
数据集的配置和数据路径有关,在本教程中,数据存放在`dataset/mini_pet`中
-其他配置则根据数据集和机器环境的情况进行调节,最终我们保存一个如下内容的yaml配置文件,存放路径为`configs/test_pet.yaml`
+其他配置则根据数据集和机器环境的情况进行调节,最终我们保存一个如下内容的yaml配置文件,存放路径为**configs/icnet_pet.yaml**
```yaml
# 数据集配置
@@ -93,7 +93,7 @@ SOLVER:
在开始训练和评估之前,我们还需要对配置和数据进行一次校验,确保数据和配置是正确的。使用下述命令启动校验流程
```shell
-python pdseg/check.py --cfg ./configs/test_pet.yaml
+python pdseg/check.py --cfg ./configs/icnet_pet.yaml
```
@@ -102,7 +102,7 @@ python pdseg/check.py --cfg ./configs/test_pet.yaml
校验通过后,使用下述命令启动训练
```shell
-python pdseg/train.py --use_gpu --cfg ./configs/test_pet.yaml
+python pdseg/train.py --use_gpu --cfg ./configs/icnet_pet.yaml
```
## 六. 进行评估
@@ -110,11 +110,11 @@ python pdseg/train.py --use_gpu --cfg ./configs/test_pet.yaml
模型训练完成,使用下述命令启动评估
```shell
-python pdseg/eval.py --use_gpu --cfg ./configs/test_pet.yaml
+python pdseg/eval.py --use_gpu --cfg ./configs/icnet_pet.yaml
```
## 模型组合
|预训练模型名称|BackBone|Norm|数据集|配置|
|-|-|-|-|-|
-|icnet_bn_cityscapes|-|bn|Cityscapes|MODEL.MODEL_NAME: icnet
MODEL.DEFAULT_NORM_TYPE: bn
MULTI_LOSS_WEIGHT: [1.0, 0.4, 0.16]|
+|icnet_bn_cityscapes|-|bn|Cityscapes|MODEL.MODEL_NAME: icnet
MODEL.DEFAULT_NORM_TYPE: bn
MODEL.MULTI_LOSS_WEIGHT: [1.0, 0.4, 0.16]|
diff --git a/turtorial/finetune_unet.md b/turtorial/finetune_unet.md
index 656541d842c3e89ca0f41f50e23bb9a2b120988b..b1baff8b0d6a9438df0ae4ed6a5f0dfdae4d3414 100644
--- a/turtorial/finetune_unet.md
+++ b/turtorial/finetune_unet.md
@@ -47,7 +47,7 @@ python pretrained_model/download_model.py unet_bn_coco
数据集的配置和数据路径有关,在本教程中,数据存放在`dataset/mini_pet`中
-其他配置则根据数据集和机器环境的情况进行调节,最终我们保存一个如下内容的yaml配置文件,存放路径为`configs/test_unet_pet.yaml`
+其他配置则根据数据集和机器环境的情况进行调节,最终我们保存一个如下内容的yaml配置文件,存放路径为**configs/unet_pet.yaml**
```yaml
# 数据集配置
@@ -90,7 +90,7 @@ SOLVER:
在开始训练和评估之前,我们还需要对配置和数据进行一次校验,确保数据和配置是正确的。使用下述命令启动校验流程
```shell
-python pdseg/check.py --cfg ./configs/test_unet_pet.yaml
+python pdseg/check.py --cfg ./configs/unet_pet.yaml
```
@@ -99,7 +99,7 @@ python pdseg/check.py --cfg ./configs/test_unet_pet.yaml
校验通过后,使用下述命令启动训练
```shell
-python pdseg/train.py --use_gpu --cfg ./configs/test_unet_pet.yaml
+python pdseg/train.py --use_gpu --cfg ./configs/unet_pet.yaml
```
## 六. 进行评估
@@ -107,11 +107,11 @@ python pdseg/train.py --use_gpu --cfg ./configs/test_unet_pet.yaml
模型训练完成,使用下述命令启动评估
```shell
-python pdseg/eval.py --use_gpu --cfg ./configs/test_unet_pet.yaml
+python pdseg/eval.py --use_gpu --cfg ./configs/unet_pet.yaml
```
## 模型组合
|预训练模型名称|BackBone|Norm|数据集|配置|
|-|-|-|-|-|
-|unet_bn_coco|-|bn|Cityscapes|MODEL.MODEL_NAME: unet
MODEL.DEFAULT_NORM_TYPE: bn|
+|unet_bn_coco|-|bn|COCO|MODEL.MODEL_NAME: unet
MODEL.DEFAULT_NORM_TYPE: bn|