Polish documents (#136)
* update all docs involving color label * modify usage.md * usage.md * Update data_prepare.md * Update jingling2seg.md * Update jingling2seg.md * Update labelme2seg.md * Update jingling2seg.md * a * Update config.md * Update config.md * Update config.py * Update config.py * Update config.py * Update config.md * Update basic_group.md * Update basic_group.md * Update data_aug.md * Update config.md * Update finetune_pspnet.md * Update finetune_pspnet.md * Update finetune_unet.md * Update finetune_unet.md * Update finetune_icnet.md * Update finetune_pspnet.md * Update finetune_hrnet.md * Update README.md * Update finetune_deeplabv3plus.md * Update finetune_deeplabv3plus.md * Update README.md * Update config.md * Update train_group.md * Update models.md * Update model_group.md * Update model_group.md * Update train_group.md * Update train_group.md * Update model_group.md * Update model_group.md * Update README.md * Update README.md * Update models.md * Add files via upload * Add files via upload * Update models.md * Update models.md * Add files via upload * Update README.md * Update models.md * Update models.md * Update models.md * Update models.md * Update models.md * Update models.md * Update models.md * Update models.md * Update models.md * Add files via upload * Update models.md * Update models.md * Update loss_select.md * Update README.md * Update loss_select.md * Add files via upload * Update loss_select.md * Add files via upload * Update loss_select.md * Update README.md
Showing
docs/imgs/hrnet.png
0 → 100644
{kind=link}

51.6 KB
docs/imgs/softmax_loss.png
0 → 100644
{kind=link}
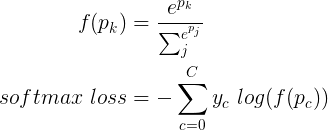
2.6 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H: