update doc
Showing
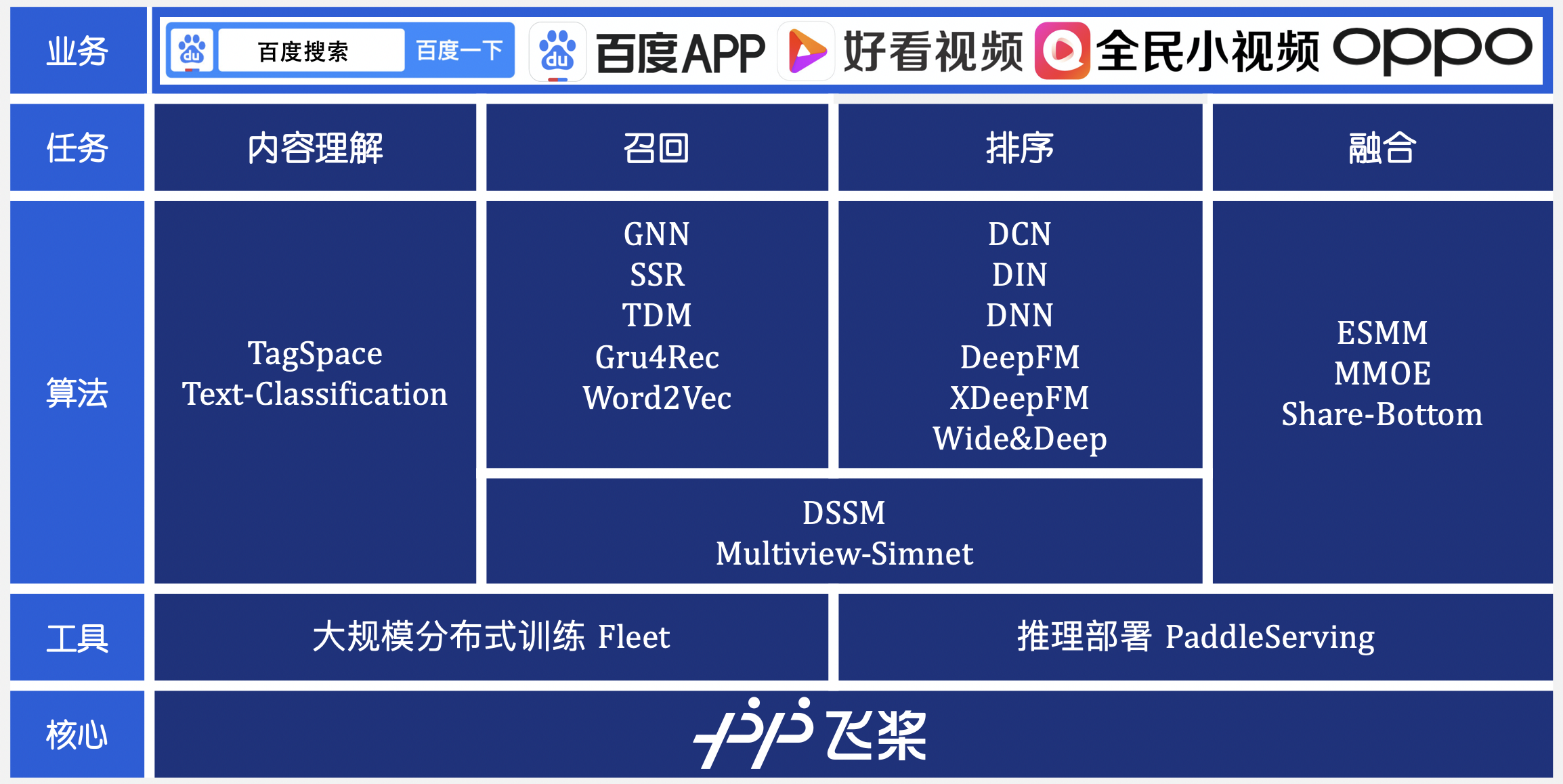
doc/imgs/overview.png
0 → 100644
{kind=link}
860.9 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
doc/model_list.md
0 → 100644
models/rank/dnn/README.md
0 → 100644
models/recall/tdm/README.md
0 → 100644