{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"# Text Recognition Algorithm Theory\n",
"\n",
"This chapter mainly introduces the theoretical knowledge of text recognition algorithms, including background introduction, algorithm classification and some classic paper ideas.\n",
"\n",
"Through the study of this chapter, you can master:\n",
"\n",
"1. The goal of text recognition\n",
"\n",
"2. Classification of text recognition algorithms\n",
"\n",
"3. Typical ideas of various algorithms\n",
"\n",
"\n",
"## 1 Background Introduction\n",
"\n",
"Text recognition is a subtask of OCR (Optical Character Recognition), and its task is to recognize the text content of a fixed area. In the two-stage method of OCR, it is followed by text detection and converts image information into text information.\n",
"\n",
"Specifically, the model inputs a positioned text line, and the model predicts the text content and confidence level in the picture. The visualization results are shown in the following figure:\n",
"\n",
" \n",
"\n",
"
\n",
"\n",
" \n",
"
\n",
"
Figure 1: Visualization results of model predicttion\n",
"\n",
"There are many application scenarios for text recognition, including document recognition, road sign recognition, license plate recognition, industrial number recognition, etc. According to actual scenarios, text recognition tasks can be divided into two categories: **Regular text recognition** and **Irregular Text recognition**.\n",
"\n",
"* Regular text recognition: mainly refers to printed fonts, scanned text, etc., and the text is considered to be roughly in the horizontal position\n",
"\n",
"* Irregular text recognition: It often appears in natural scenes, and due to the huge differences in text curvature, direction, deformation, etc., the text is often not in the horizontal position, and there are problems such as bending, occlusion, and blurring.\n",
"\n",
"\n",
"The figure below shows the data patterns of IC15 and IC13, which represent irregular text and regular text respectively. It can be seen that irregular text often has problems such as distortion, blurring, and large font differences. It is closer to the real scene and is also more challenging.\n",
"\n",
"Therefore, the current major algorithms are trying to obtain higher indicators on irregular data sets.\n",
"\n",
" \n",
"
\n",
"
Figure 2: IC15 picture sample (irregular text)\n",
" \n",
"
\n",
"
Figure 3: IC13 picture sample (rule text)\n",
"\n",
"\n",
"When comparing the capabilities of different recognition algorithms, they are often compared on these two types of public data sets. Comparing the effects on multiple dimensions, currently the more common English benchmark data sets are classified as follows:\n",
"\n",
"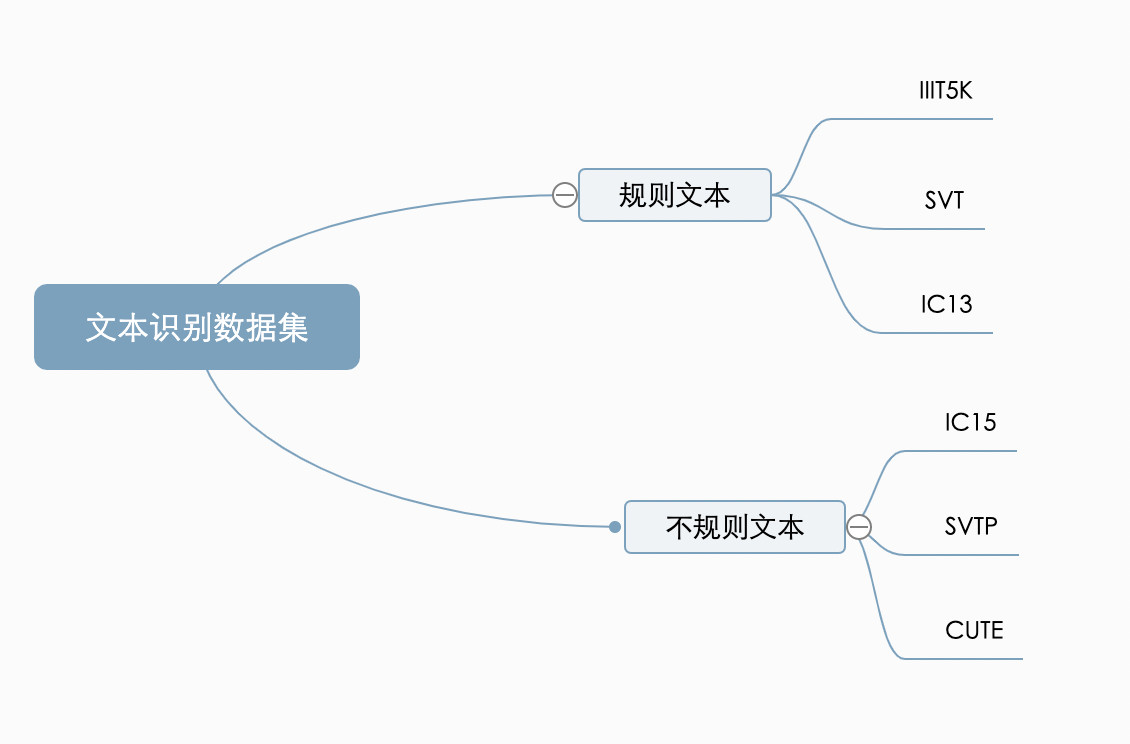 \n",
"
\n",
"
Figure 4: Common English benchmark data sets\n",
"\n",
"## 2 Text Recognition Algorithm Classification\n",
"\n",
"In the traditional text recognition method, the task is divided into 3 steps, namely image preprocessing, character segmentation and character recognition. It is necessary to model a specific scene, and it will become invalid once the scene changes. In the face of complex text backgrounds and scene changes, methods based on deep learning have better performance.\n",
"\n",
"Most existing recognition algorithms can be represented by the following unified framework, and the algorithm flow is divided into 4 stages:\n",
"\n",
"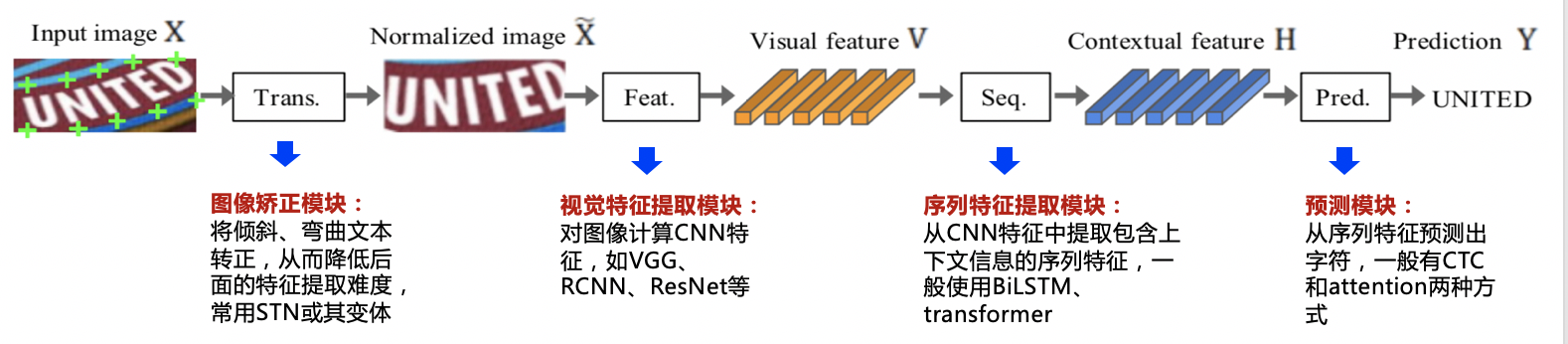\n",
"\n",
"\n",
"We have sorted out the mainstream algorithm categories and main papers, refer to the following table:\n",
"\n",
" \n",
"| Algorithm category | Main ideas | Main papers |\n",
"| -------- | --------------- | -------- |\n",
"| Traditional algorithm | Sliding window, character extraction, dynamic programming |-|\n",
"| ctc | Based on ctc method, sequence is not aligned, faster recognition | CRNN, Rosetta |\n",
"| Attention | Attention-based method, applied to unconventional text | RARE, DAN, PREN |\n",
"| Transformer | Transformer-based method | SRN, NRTR, Master, ABINet |\n",
"| Correction | The correction module learns the text boundary and corrects it to the horizontal direction | RARE, ASTER, SAR |\n",
"| Segmentation | Based on the method of segmentation, extract the character position and then do classification | Text Scanner, Mask TextSpotter |\n",
" \n",
"\n",
"\n",
"\n",
"### 2.1 Regular Text Recognition\n",
"\n",
"\n",
"There are two mainstream algorithms for text recognition, namely the CTC (Conectionist Temporal Classification)-based algorithm and the Sequence2Sequence algorithm. The difference is mainly in the decoding stage.\n",
"\n",
"The CTC-based algorithm connects the encoded sequence to the CTC for decoding; the Sequence2Sequence-based method connects the sequence to the Recurrent Neural Network (RNN) module for cyclic decoding. Both methods have been verified to be effective and mainstream. Two major practices.\n",
"\n",
"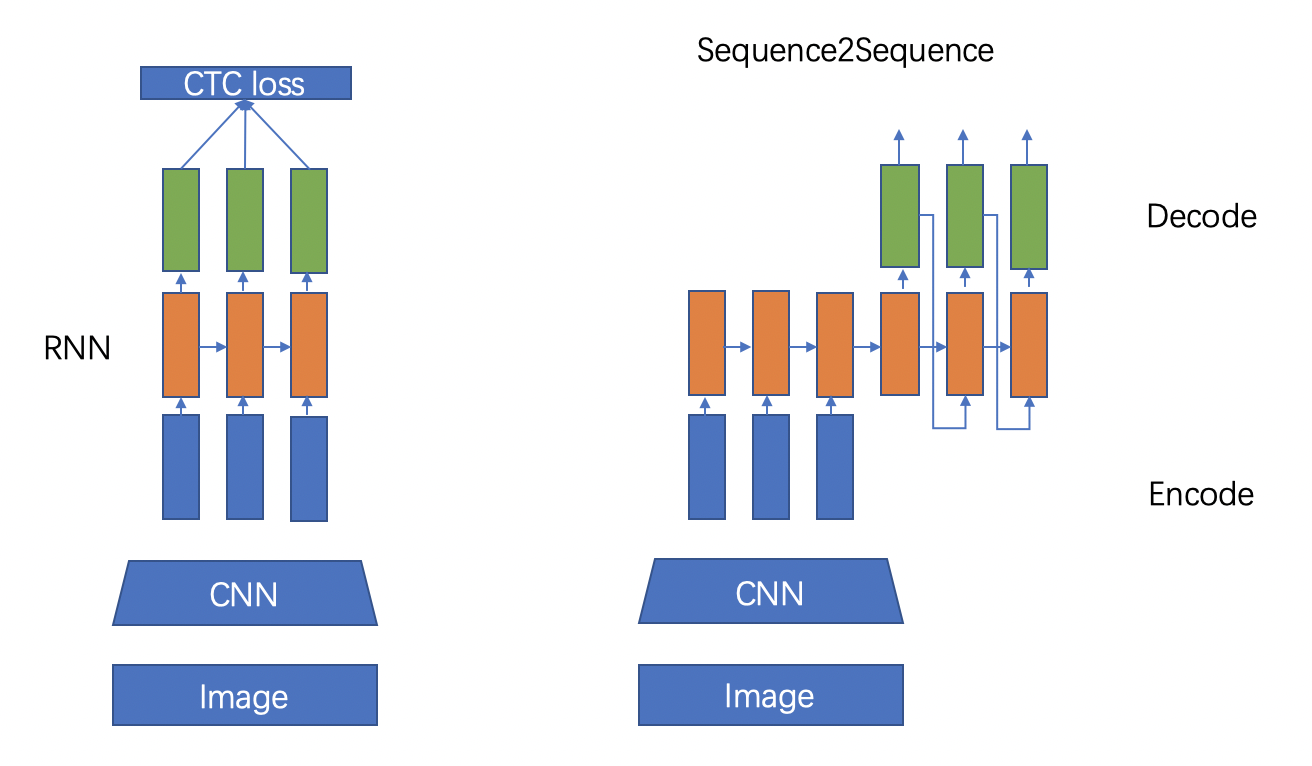 \n",
"
\n",
"
Figure 5: Left: CTC-based method, right: Sequece2Sequence-based method \n",
"\n",
"\n",
"#### 2.1.1 Algorithm Based on CTC\n",
"\n",
"The most typical algorithm based on CTC is CRNN (Convolutional Recurrent Neural Network) [1], and its feature extraction part uses mainstream convolutional structures, commonly used ResNet, MobileNet, VGG, etc. Due to the particularity of text recognition tasks, there is a large amount of contextual information in the input data. The convolution kernel characteristics of convolutional neural networks make it more focused on local information and lack long-dependent modeling capabilities, so it is difficult to use only convolutional networks. Dig into the contextual connections between texts. In order to solve this problem, the CRNN text recognition algorithm introduces the bidirectional LSTM (Long Short-Term Memory) to enhance the context modeling. Experiments prove that the bidirectional LSTM module can effectively extract the context information in the picture. Finally, the output feature sequence is input to the CTC module, and the sequence result is directly decoded. This structure has been verified to be effective and widely used in text recognition tasks. Rosetta [2] is a recognition network proposed by FaceBook, which consists of a fully convolutional model and CTC. Gao Y [3] et al. used CNN convolution instead of LSTM, with fewer parameters, and the performance improvement accuracy was the same.\n",
"\n",
"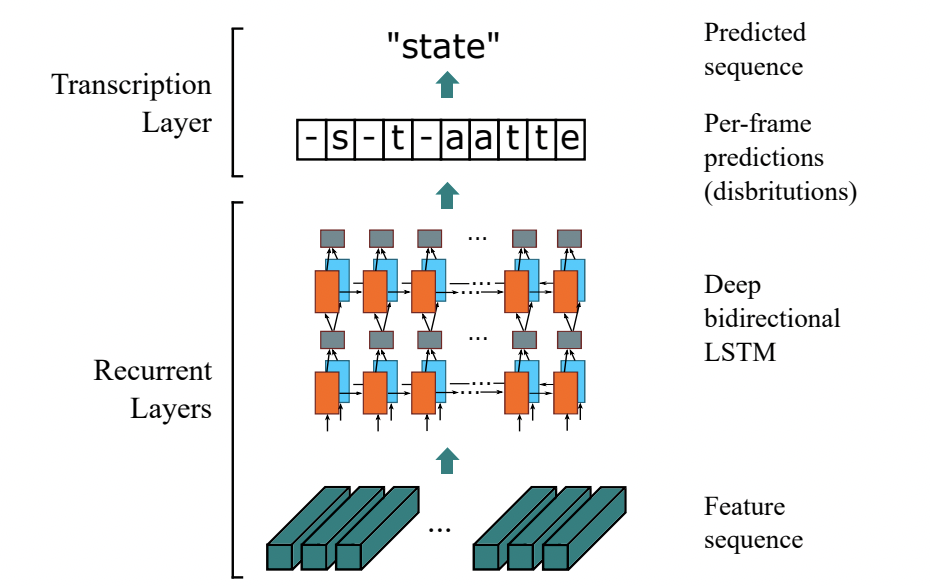 \n",
"Figure 6: CRNN structure diagram \n",
"\n",
"\n",
"#### 2.1.2 Sequence2Sequence algorithm\n",
"\n",
"In the Sequence2Sequence algorithm, the Encoder encodes all input sequences into a unified semantic vector, which is then decoded by the Decoder. In the decoding process of the decoder, the output of the previous moment is continuously used as the input of the next moment, and the decoding is performed in a loop until the stop character is output. The general encoder is an RNN. For each input word, the encoder outputs a vector and hidden state, and uses the hidden state for the next input word to get the semantic vector in a loop; the decoder is another RNN, which receives the encoder Output a vector and output a series of words to create a transformation. Inspired by Sequence2Sequence in the field of translation, Shi [4] proposed an attention-based codec framework to recognize text. In this way, rnn can learn character-level language models hidden in strings from training data.\n",
"\n",
"
\n",
"Figure 6: CRNN structure diagram \n",
"\n",
"\n",
"#### 2.1.2 Sequence2Sequence algorithm\n",
"\n",
"In the Sequence2Sequence algorithm, the Encoder encodes all input sequences into a unified semantic vector, which is then decoded by the Decoder. In the decoding process of the decoder, the output of the previous moment is continuously used as the input of the next moment, and the decoding is performed in a loop until the stop character is output. The general encoder is an RNN. For each input word, the encoder outputs a vector and hidden state, and uses the hidden state for the next input word to get the semantic vector in a loop; the decoder is another RNN, which receives the encoder Output a vector and output a series of words to create a transformation. Inspired by Sequence2Sequence in the field of translation, Shi [4] proposed an attention-based codec framework to recognize text. In this way, rnn can learn character-level language models hidden in strings from training data.\n",
"\n",
"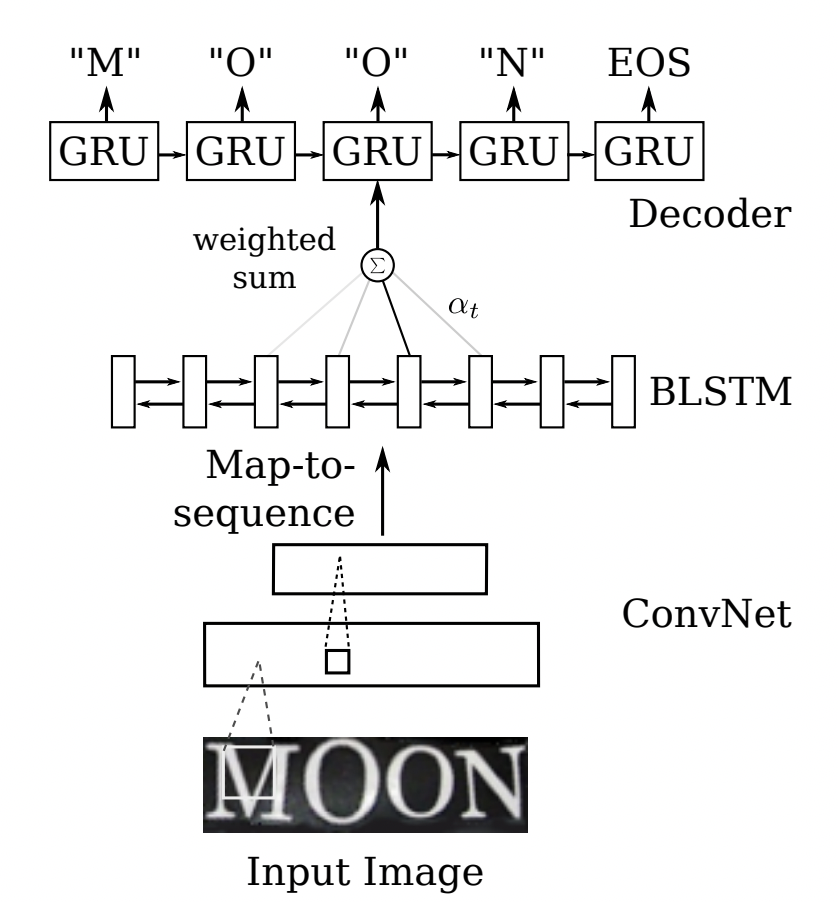 \n",
"Figure 7: Sequence2Sequence structure diagram \n",
"\n",
"The above two algorithms have very good effects on regular text, but due to the limitations of network design, this type of method is difficult to solve the task of irregular text recognition of bending and rotation. In order to solve such problems, some algorithm researchers have proposed a series of improved algorithms on the basis of the above two types of algorithms.\n",
"\n",
"### 2.2 Irregular Text Recognition\n",
"\n",
"* Irregular text recognition algorithms can be divided into 4 categories: correction-based methods; Attention-based methods; segmentation-based methods; and Transformer-based methods.\n",
"\n",
"#### 2.2.1 Correction-based Method\n",
"\n",
"The correction-based method uses some visual transformation modules to convert irregular text into regular text as much as possible, and then uses conventional methods for recognition.\n",
"\n",
"The RARE [4] model first proposed a correction scheme for irregular text. The entire network is divided into two main parts: a spatial transformation network STN (Spatial Transformer Network) and a recognition network based on Sequence2Squence. Among them, STN is the correction module. Irregular text images enter STN and are transformed into a horizontal image through TPS (Thin-Plate-Spline). This transformation can correct curved and transmissive text to a certain extent, and send it to sequence recognition after correction. Network for decoding.\n",
"\n",
"
\n",
"Figure 7: Sequence2Sequence structure diagram \n",
"\n",
"The above two algorithms have very good effects on regular text, but due to the limitations of network design, this type of method is difficult to solve the task of irregular text recognition of bending and rotation. In order to solve such problems, some algorithm researchers have proposed a series of improved algorithms on the basis of the above two types of algorithms.\n",
"\n",
"### 2.2 Irregular Text Recognition\n",
"\n",
"* Irregular text recognition algorithms can be divided into 4 categories: correction-based methods; Attention-based methods; segmentation-based methods; and Transformer-based methods.\n",
"\n",
"#### 2.2.1 Correction-based Method\n",
"\n",
"The correction-based method uses some visual transformation modules to convert irregular text into regular text as much as possible, and then uses conventional methods for recognition.\n",
"\n",
"The RARE [4] model first proposed a correction scheme for irregular text. The entire network is divided into two main parts: a spatial transformation network STN (Spatial Transformer Network) and a recognition network based on Sequence2Squence. Among them, STN is the correction module. Irregular text images enter STN and are transformed into a horizontal image through TPS (Thin-Plate-Spline). This transformation can correct curved and transmissive text to a certain extent, and send it to sequence recognition after correction. Network for decoding.\n",
"\n",
"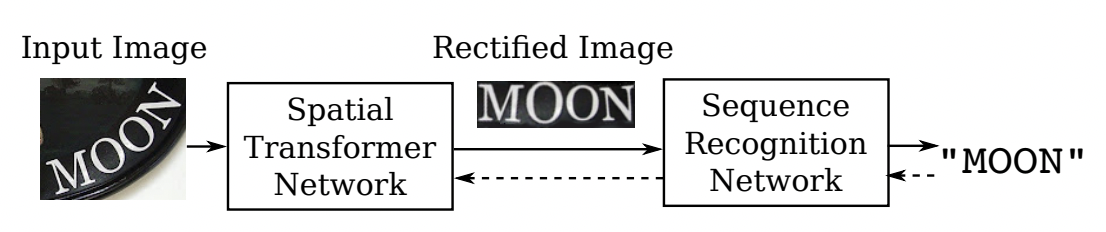 \n",
"Figure 8: RARE structure diagram \n",
"\n",
"The RARE paper pointed out that this method has greater advantages in irregular text data sets, especially comparing the two data sets CUTE80 and SVTP, which are more than 5 percentage points higher than CRNN, which proves the effectiveness of the correction module. Based on this [6] also combines a text recognition system with a spatial transformation network (STN) and an attention-based sequence recognition network.\n",
"\n",
"Correction-based methods have better migration. In addition to Attention-based methods such as RARE, STAR-Net [5] applies correction modules to CTC-based algorithms, which is also a good improvement compared to traditional CRNN.\n",
"\n",
"#### 2.2.2 Attention-based Method\n",
"\n",
"The Attention-based method mainly focuses on the correlation between the parts of the sequence. This method was first proposed in the field of machine translation. It is believed that the result of the current word in the process of text translation is mainly affected by certain words, so it needs to be The decisive word has greater weight. The same is true in the field of text recognition. When decoding the encoded sequence, each step selects the appropriate context to generate the next state, which is conducive to obtaining more accurate results.\n",
"\n",
"R^2AM [7] first introduced Attention into the field of text recognition. The model first extracts the encoded image features from the input image through a recursive convolutional layer, and then uses the implicitly learned character-level language statistics to decode the output through a recurrent neural network character. In the decoding process, the Attention mechanism is introduced to realize soft feature selection to make better use of image features. This selective processing method is more in line with human intuition.\n",
"\n",
"
\n",
"Figure 8: RARE structure diagram \n",
"\n",
"The RARE paper pointed out that this method has greater advantages in irregular text data sets, especially comparing the two data sets CUTE80 and SVTP, which are more than 5 percentage points higher than CRNN, which proves the effectiveness of the correction module. Based on this [6] also combines a text recognition system with a spatial transformation network (STN) and an attention-based sequence recognition network.\n",
"\n",
"Correction-based methods have better migration. In addition to Attention-based methods such as RARE, STAR-Net [5] applies correction modules to CTC-based algorithms, which is also a good improvement compared to traditional CRNN.\n",
"\n",
"#### 2.2.2 Attention-based Method\n",
"\n",
"The Attention-based method mainly focuses on the correlation between the parts of the sequence. This method was first proposed in the field of machine translation. It is believed that the result of the current word in the process of text translation is mainly affected by certain words, so it needs to be The decisive word has greater weight. The same is true in the field of text recognition. When decoding the encoded sequence, each step selects the appropriate context to generate the next state, which is conducive to obtaining more accurate results.\n",
"\n",
"R^2AM [7] first introduced Attention into the field of text recognition. The model first extracts the encoded image features from the input image through a recursive convolutional layer, and then uses the implicitly learned character-level language statistics to decode the output through a recurrent neural network character. In the decoding process, the Attention mechanism is introduced to realize soft feature selection to make better use of image features. This selective processing method is more in line with human intuition.\n",
"\n",
"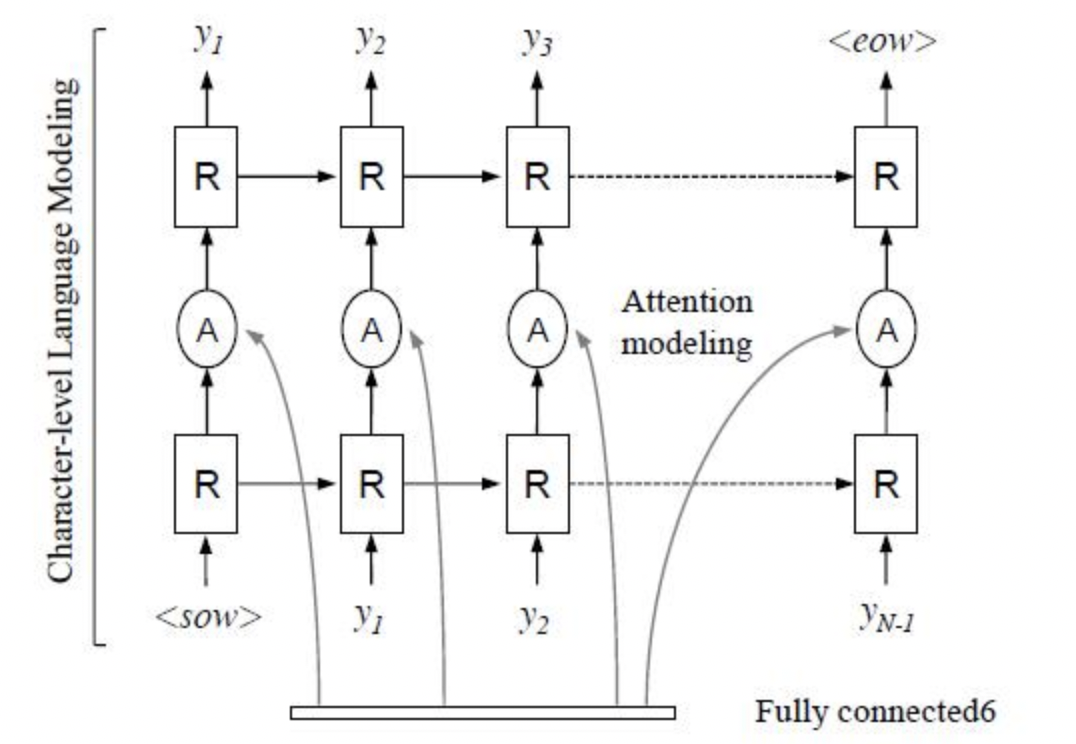 \n",
"Figure 9: R^2AM structure drawing \n",
"\n",
"A large number of algorithms will be explored and updated in the field of Attention in the future. For example, SAR[8] extends 1D attention to 2D attention. The RARE mentioned in the correction module is also a method based on Attention. Experiments prove that the Attention-based method has a good accuracy improvement compared with the CTC method.\n",
"\n",
"
\n",
"Figure 9: R^2AM structure drawing \n",
"\n",
"A large number of algorithms will be explored and updated in the field of Attention in the future. For example, SAR[8] extends 1D attention to 2D attention. The RARE mentioned in the correction module is also a method based on Attention. Experiments prove that the Attention-based method has a good accuracy improvement compared with the CTC method.\n",
"\n",
" \n",
"Figure 10: Attention diagram\n",
"\n",
"\n",
"#### 2.2.3 Method Based on Segmentation\n",
"\n",
"The method based on segmentation is to treat each character of the text line as an independent individual, and it is easier to recognize the segmented individual characters than to recognize the entire text line after correction. It attempts to locate the position of each character in the input text image, and applies a character classifier to obtain these recognition results, simplifying the complex global problem into a local problem solving, and it has a relatively good effect in the irregular text scene. However, this method requires character-level labeling, and there is a certain degree of difficulty in data acquisition. Lyu [9] et al. proposed an instance word segmentation model for word recognition, which uses a method based on FCN (Fully Convolutional Network) in its recognition part. [10] Considering the problem of text recognition from a two-dimensional perspective, a character attention FCN is designed to solve the problem of text recognition. When the text is bent or severely distorted, this method has better positioning results for both regular and irregular text.\n",
"\n",
"
\n",
"Figure 10: Attention diagram\n",
"\n",
"\n",
"#### 2.2.3 Method Based on Segmentation\n",
"\n",
"The method based on segmentation is to treat each character of the text line as an independent individual, and it is easier to recognize the segmented individual characters than to recognize the entire text line after correction. It attempts to locate the position of each character in the input text image, and applies a character classifier to obtain these recognition results, simplifying the complex global problem into a local problem solving, and it has a relatively good effect in the irregular text scene. However, this method requires character-level labeling, and there is a certain degree of difficulty in data acquisition. Lyu [9] et al. proposed an instance word segmentation model for word recognition, which uses a method based on FCN (Fully Convolutional Network) in its recognition part. [10] Considering the problem of text recognition from a two-dimensional perspective, a character attention FCN is designed to solve the problem of text recognition. When the text is bent or severely distorted, this method has better positioning results for both regular and irregular text.\n",
"\n",
" \n",
"Figure 11: Mask TextSpotter structure diagram \n",
"\n",
"\n",
"\n",
"#### 2.2.4 Transformer-based Method\n",
"\n",
"With the rapid development of Transformer, both classification and detection fields have verified the effectiveness of Transformer in visual tasks. As mentioned in the regular text recognition part, CNN has limitations in long-dependency modeling. The Transformer structure just solves this problem. It can focus on global information in the feature extractor and can replace additional context modeling modules (LSTM ).\n",
"\n",
"Part of the text recognition algorithm uses Transformer's Encoder structure and convolution to extract sequence features. The Encoder is composed of multiple blocks stacked by MultiHeadAttentionLayer and Positionwise Feedforward Layer. The self-attention in MulitHeadAttention uses matrix multiplication to simulate the timing calculation of RNN, breaking the barrier of long-term dependence on timing in RNN. There are also some algorithms that use Transformer's Decoder module to decode, which can obtain stronger semantic information than traditional RNNs, and parallel computing has higher efficiency.\n",
"\n",
"The SRN[11] algorithm connects the Encoder module of Transformer to ResNet50 to enhance the 2D visual features. A parallel attention module is proposed, which uses the reading order as a query, making the calculation independent of time, and finally outputs the aligned visual features of all time steps in parallel. In addition, SRN also uses Transformer's Eecoder as a semantic module to integrate the visual information and semantic information of the picture, which has greater benefits in irregular text such as occlusion and blur.\n",
"\n",
"NRTR [12] uses a complete Transformer structure to encode and decode the input picture, and only uses a few simple convolutional layers for high-level feature extraction, and verifies the effectiveness of the Transformer structure in text recognition.\n",
"\n",
"
\n",
"Figure 11: Mask TextSpotter structure diagram \n",
"\n",
"\n",
"\n",
"#### 2.2.4 Transformer-based Method\n",
"\n",
"With the rapid development of Transformer, both classification and detection fields have verified the effectiveness of Transformer in visual tasks. As mentioned in the regular text recognition part, CNN has limitations in long-dependency modeling. The Transformer structure just solves this problem. It can focus on global information in the feature extractor and can replace additional context modeling modules (LSTM ).\n",
"\n",
"Part of the text recognition algorithm uses Transformer's Encoder structure and convolution to extract sequence features. The Encoder is composed of multiple blocks stacked by MultiHeadAttentionLayer and Positionwise Feedforward Layer. The self-attention in MulitHeadAttention uses matrix multiplication to simulate the timing calculation of RNN, breaking the barrier of long-term dependence on timing in RNN. There are also some algorithms that use Transformer's Decoder module to decode, which can obtain stronger semantic information than traditional RNNs, and parallel computing has higher efficiency.\n",
"\n",
"The SRN[11] algorithm connects the Encoder module of Transformer to ResNet50 to enhance the 2D visual features. A parallel attention module is proposed, which uses the reading order as a query, making the calculation independent of time, and finally outputs the aligned visual features of all time steps in parallel. In addition, SRN also uses Transformer's Eecoder as a semantic module to integrate the visual information and semantic information of the picture, which has greater benefits in irregular text such as occlusion and blur.\n",
"\n",
"NRTR [12] uses a complete Transformer structure to encode and decode the input picture, and only uses a few simple convolutional layers for high-level feature extraction, and verifies the effectiveness of the Transformer structure in text recognition.\n",
"\n",
"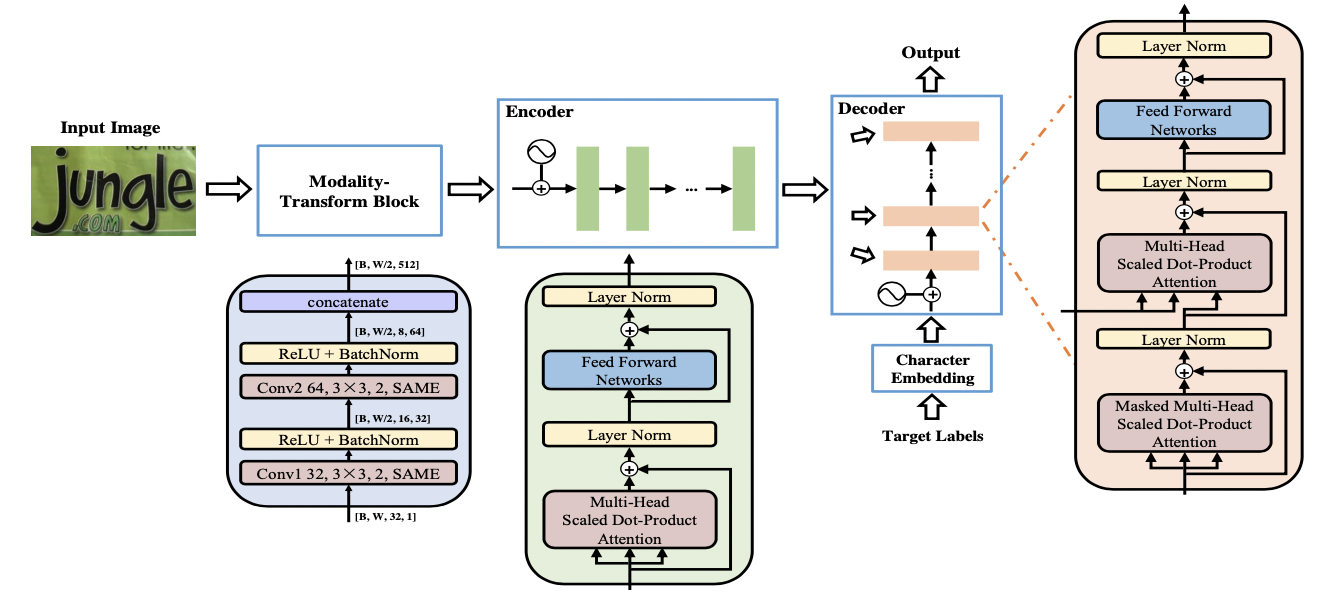 \n",
"Figure 12: NRTR structure drawing \n",
"\n",
"SRACN [13] uses Transformer's decoder to replace LSTM, once again verifying the efficiency and accuracy advantages of parallel training.\n",
"\n",
"## 3 Summary\n",
"\n",
"This section mainly introduces the theoretical knowledge and mainstream algorithms related to text recognition, including CTC-based methods, Sequence2Sequence-based methods, and segmentation-based methods. The ideas and contributions of classic papers are listed respectively. The next section will explain the practical course based on the CRNN algorithm, from networking to optimization to complete the entire training process,\n",
"\n",
"## 4 Reference\n",
"\n",
"\n",
"[1]Shi, B., Bai, X., & Yao, C. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11), 2298-2304.\n",
"\n",
"[2]Fedor Borisyuk, Albert Gordo, and Viswanath Sivakumar. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 71–79. ACM, 2018.\n",
"\n",
"[3]Gao, Y., Chen, Y., Wang, J., & Lu, H. (2017). Reading scene text with attention convolutional sequence modeling. arXiv preprint arXiv:1709.04303.\n",
"\n",
"[4]Shi, B., Wang, X., Lyu, P., Yao, C., & Bai, X. (2016). Robust scene text recognition with automatic rectification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4168-4176).\n",
"\n",
"[5] Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.\n",
"\n",
"[6]Baoguang Shi, Mingkun Yang, XingGang Wang, Pengyuan Lyu, Xiang Bai, and Cong Yao. Aster: An attentional scene text recognizer with flexible rectification. IEEE transactions on pattern analysis and machine intelligence, 31(11):855–868, 2018.\n",
"\n",
"[7] Lee C Y , Osindero S . Recursive Recurrent Nets with Attention Modeling for OCR in the Wild[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2016.\n",
"\n",
"[8]Li, H., Wang, P., Shen, C., & Zhang, G. (2019, July). Show, attend and read: A simple and strong baseline for irregular text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 8610-8617).\n",
"\n",
"[9]P. Lyu, C. Yao, W. Wu, S. Yan, and X. Bai. Multi-oriented scene text detection via corner localization and region segmentation. In Proc. CVPR, pages 7553–7563, 2018.\n",
"\n",
"[10] Liao, M., Zhang, J., Wan, Z., Xie, F., Liang, J., Lyu, P., ... & Bai, X. (2019, July). Scene text recognition from two-dimensional perspective. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 8714-8721).\n",
"\n",
"[11] Yu, D., Li, X., Zhang, C., Liu, T., Han, J., Liu, J., & Ding, E. (2020). Towards accurate scene text recognition with semantic reasoning networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12113-12122).\n",
"\n",
"[12] Sheng, F., Chen, Z., & Xu, B. (2019, September). NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 781-786). IEEE.\n",
"\n",
"[13]Yang, L., Wang, P., Li, H., Li, Z., & Zhang, Y. (2020). A holistic representation guided attention network for scene text recognition. Neurocomputing, 414, 67-75.\n",
"\n",
"[14]Wang, T., Zhu, Y., Jin, L., Luo, C., Chen, X., Wu, Y., ... & Cai, M. (2020, April). Decoupled attention network for text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 07, pp. 12216-12224).\n",
"\n",
"[15] Wang, Y., Xie, H., Fang, S., Wang, J., Zhu, S., & Zhang, Y. (2021). From two to one: A new scene text recognizer with visual language modeling network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 14194-14203).\n",
"\n",
"[16] Fang, S., Xie, H., Wang, Y., Mao, Z., & Zhang, Y. (2021). Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7098-7107).\n",
"\n",
"[17] Yan, R., Peng, L., Xiao, S., & Yao, G. (2021). Primitive Representation Learning for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 284-293)."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "py35-paddle1.2.0"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.4"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
\n",
"Figure 12: NRTR structure drawing \n",
"\n",
"SRACN [13] uses Transformer's decoder to replace LSTM, once again verifying the efficiency and accuracy advantages of parallel training.\n",
"\n",
"## 3 Summary\n",
"\n",
"This section mainly introduces the theoretical knowledge and mainstream algorithms related to text recognition, including CTC-based methods, Sequence2Sequence-based methods, and segmentation-based methods. The ideas and contributions of classic papers are listed respectively. The next section will explain the practical course based on the CRNN algorithm, from networking to optimization to complete the entire training process,\n",
"\n",
"## 4 Reference\n",
"\n",
"\n",
"[1]Shi, B., Bai, X., & Yao, C. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11), 2298-2304.\n",
"\n",
"[2]Fedor Borisyuk, Albert Gordo, and Viswanath Sivakumar. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 71–79. ACM, 2018.\n",
"\n",
"[3]Gao, Y., Chen, Y., Wang, J., & Lu, H. (2017). Reading scene text with attention convolutional sequence modeling. arXiv preprint arXiv:1709.04303.\n",
"\n",
"[4]Shi, B., Wang, X., Lyu, P., Yao, C., & Bai, X. (2016). Robust scene text recognition with automatic rectification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4168-4176).\n",
"\n",
"[5] Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.\n",
"\n",
"[6]Baoguang Shi, Mingkun Yang, XingGang Wang, Pengyuan Lyu, Xiang Bai, and Cong Yao. Aster: An attentional scene text recognizer with flexible rectification. IEEE transactions on pattern analysis and machine intelligence, 31(11):855–868, 2018.\n",
"\n",
"[7] Lee C Y , Osindero S . Recursive Recurrent Nets with Attention Modeling for OCR in the Wild[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2016.\n",
"\n",
"[8]Li, H., Wang, P., Shen, C., & Zhang, G. (2019, July). Show, attend and read: A simple and strong baseline for irregular text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 8610-8617).\n",
"\n",
"[9]P. Lyu, C. Yao, W. Wu, S. Yan, and X. Bai. Multi-oriented scene text detection via corner localization and region segmentation. In Proc. CVPR, pages 7553–7563, 2018.\n",
"\n",
"[10] Liao, M., Zhang, J., Wan, Z., Xie, F., Liang, J., Lyu, P., ... & Bai, X. (2019, July). Scene text recognition from two-dimensional perspective. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 8714-8721).\n",
"\n",
"[11] Yu, D., Li, X., Zhang, C., Liu, T., Han, J., Liu, J., & Ding, E. (2020). Towards accurate scene text recognition with semantic reasoning networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12113-12122).\n",
"\n",
"[12] Sheng, F., Chen, Z., & Xu, B. (2019, September). NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 781-786). IEEE.\n",
"\n",
"[13]Yang, L., Wang, P., Li, H., Li, Z., & Zhang, Y. (2020). A holistic representation guided attention network for scene text recognition. Neurocomputing, 414, 67-75.\n",
"\n",
"[14]Wang, T., Zhu, Y., Jin, L., Luo, C., Chen, X., Wu, Y., ... & Cai, M. (2020, April). Decoupled attention network for text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 07, pp. 12216-12224).\n",
"\n",
"[15] Wang, Y., Xie, H., Fang, S., Wang, J., Zhu, S., & Zhang, Y. (2021). From two to one: A new scene text recognizer with visual language modeling network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 14194-14203).\n",
"\n",
"[16] Fang, S., Xie, H., Wang, Y., Mao, Z., & Zhang, Y. (2021). Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7098-7107).\n",
"\n",
"[17] Yan, R., Peng, L., Xiao, S., & Yao, G. (2021). Primitive Representation Learning for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 284-293)."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "py35-paddle1.2.0"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.4"
}
},
"nbformat": 4,
"nbformat_minor": 4
}