{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"*Note: The above pictures are from the Internet*\n",
"\n",
"# 1. OCR Technical Background\n",
"## 1.1 Application Scenarios of OCR Technology\n",
"\n",
"* **What is OCR**\n",
"\n",
"OCR (Optical Character Recognition) is one of the key directions in computer vision. The traditional definition of OCR is generally oriented to scanned document objects. Now we often say OCR generally refers to scene text recognition (Scene Text Recognition, STR), mainly for natural scenes, such as plaques and other visible texts in various natural scenes as shown in the figure below.\n",
"\n",
"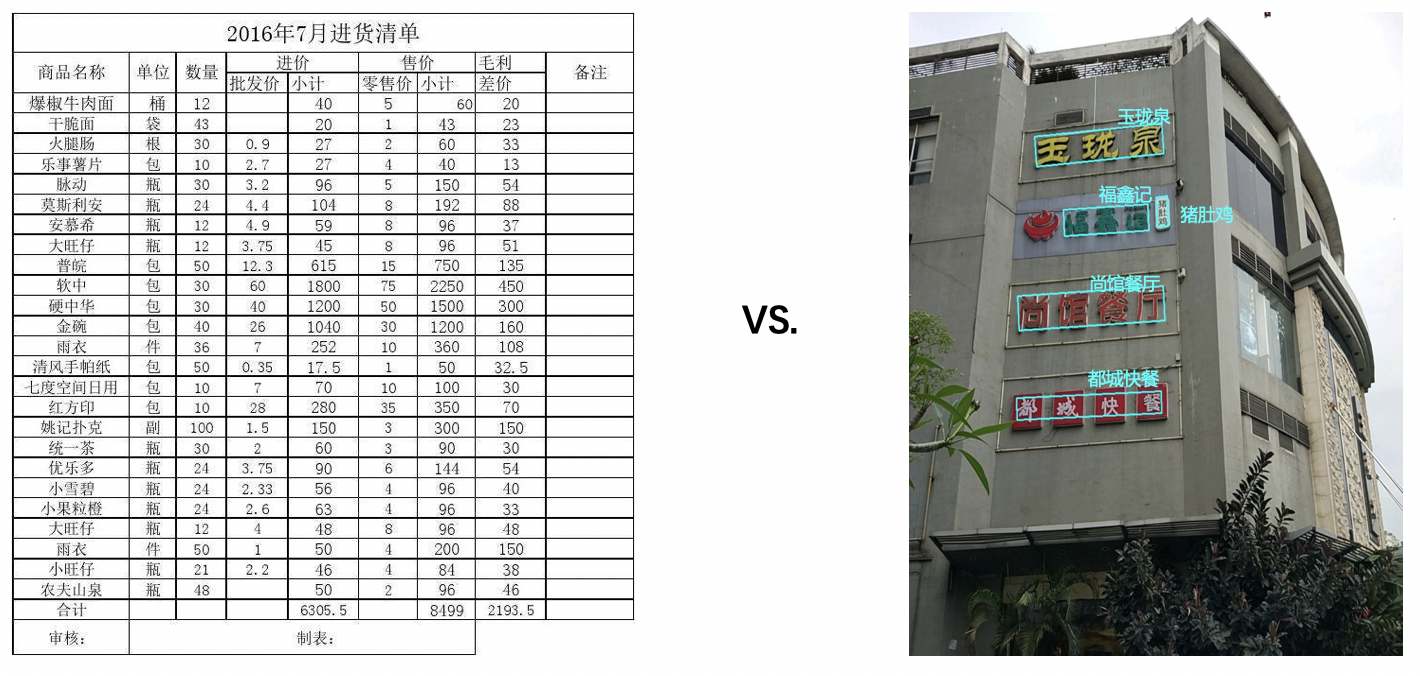\n",
"Figure 1: Document scene text recognition VS. Natural scene text recognition\n",
"\n",
"
\n",
"\n",
"* **What are the application scenarios of OCR? **\n",
"\n",
"OCR technology has a wealth of application scenarios. A typical scenario is vertically-oriented structured text recognition widely used in daily life, such as license plate recognition, bank card information recognition, ID card information recognition, train ticket information recognition, and so on. The common feature of these small verticals is that the format is fixed. Therefore, it is very suitable to use OCR technology for automation, greatly reducing labor costs and improving.\n",
"\n",
"This vertically-oriented structured text recognition is currently the most widely used and relatively mature technology scene in OCR.\n",
"\n",
"\n",
"Figure 2: Application scenarios of OCR technology\n",
"\n",
"In addition to vertically-oriented structured text recognition, general OCR technology also has a wide range of applications and is often combined with other technologies to complete multi-modal tasks. For example, in video scenes, OCR technology is often used for subtitle automatic translation, content security monitoring, etc., Or combined with visual features to complete tasks such as video understanding and video search.\n",
"\n",
"\n",
"Figure 3: General OCR in a multi-modal scene\n",
"\n",
"## 1.2 OCR Technical Challenge\n",
"The technical difficulties of OCR can be divided into two aspects: the algorithm layer and the application layer.\n",
"\n",
"* **Algorithm layer**\n",
"\n",
"The rich application scenarios of OCR determine that it will have many technical difficulties. Here are 8 common problems:\n",
"\n",
"\n",
"Figure 4: Technical difficulties of OCR algorithm layer\n",
"\n",
"These problems bring huge technical challenges to both text detection and text recognition. It can be seen that these challenges are mainly oriented to natural scenes. At present, research in academia mainly focuses on natural scenes, and the commonly used academic datasets in the OCR field are also natural scenes. There are many studies on these issues. Relatively speaking, identification is more challenging than detection.\n",
"\n",
"* **Application layer**\n",
"\n",
"In practical applications, especially in a wide range of general scenarios, in addition to the technical difficulties at the algorithm level such as affine transformation, scale problems, insufficient lighting, and shooting blur summarized in the previous section, OCR technology also faces two major difficulties:\n",
"1. **Massive data requires OCR to be able to process in real time.** OCR applications are often connected to massive data. Real-time processing of the data is required or hoped for. Real-time model speed is a big challenge.\n",
"2. **The end-side application requires that the OCR model is light enough and the recognition speed is fast enough.** OCR applications are often deployed on mobile terminals or embedded hardware. There are generally two modes for terminal-side OCR applications: upload to server vs. terminal-side direct recognition. Considering that the method of uploading to the server has requirements on the network, the real-time performance is low, and the server pressure is high when the request volume is too large, as well as the security of data transmission, we hope to complete the OCR identification directly on the terminal side. However, the storage space and computing power of the terminal side are limited, so there are high requirements for the size and prediction speed of the OCR model.\n",
"\n",
"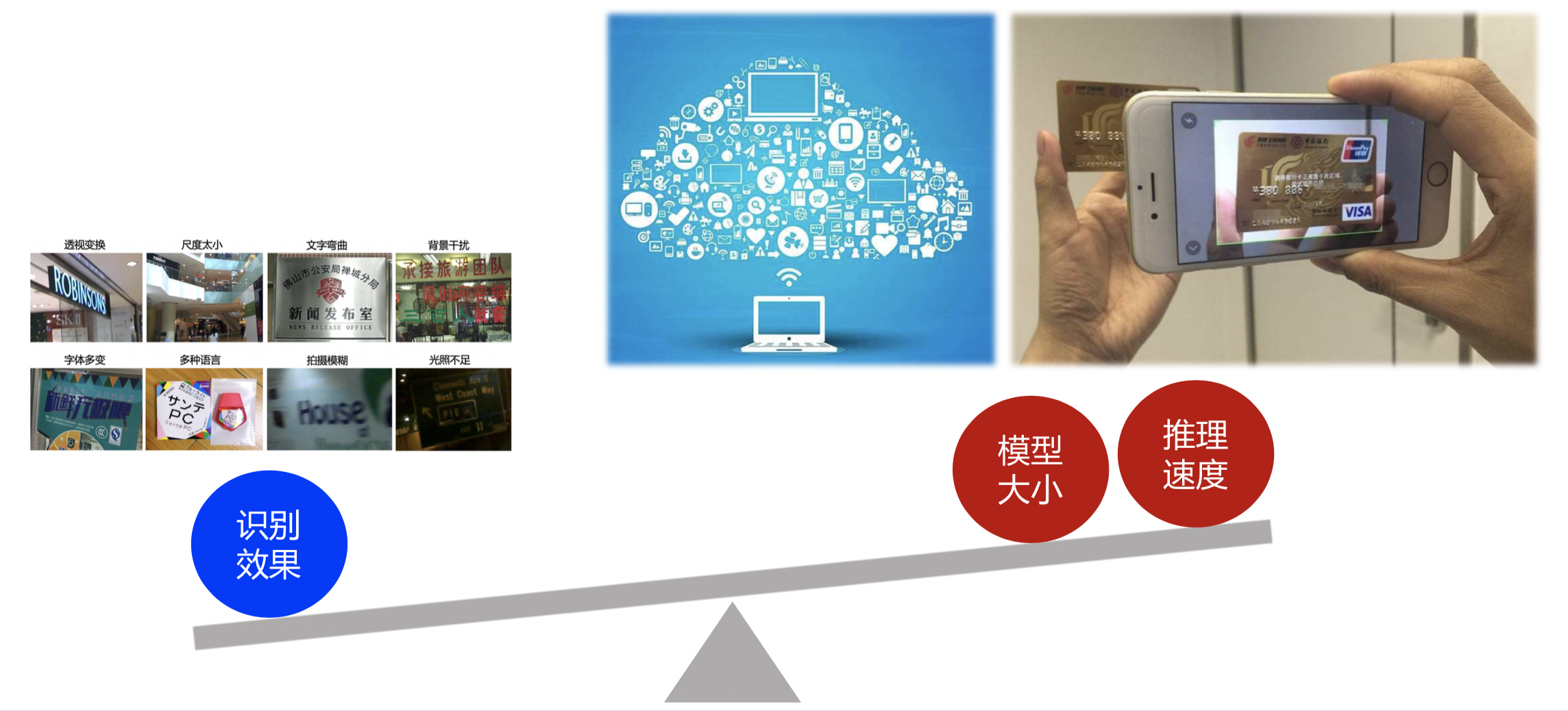\n",
"Figure 5: Technical difficulties of OCR application layer"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 2. OCR Cutting-edge Algorithm\n",
"\n",
"Although OCR is a relatively specific task, it involves many aspects of technology, including text detection, text recognition, end-to-end text recognition, document analysis, and so on. Academic research on various related technologies of OCR emerges endlessly. The following will briefly introduce the related work of several key technologies in the OCR task.\n",
"\n",
"## 2.1 Text Detection\n",
"\n",
"The task of text detection is to locate text regions in the input image. In recent years, research on text detection in academia has been very rich. A class of methods regard text detection as a specific scene in target detection, and improve and adapt based on general target detection algorithms. For example, TextBoxes[1] is based on one-stage target detector SSD. The algorithm [2] adjusts the target frame to fit text lines with extreme aspect ratios, while CTPN [3] is improved based on the Faster RCNN [4] architecture. However, there are still some differences between text detection and target detection in the target information and the task itself. For example, the text is generally larger in length and width, often in the shape of \"stripes\", and the text lines may be denser, curved text, etc. Therefore, many algorithms dedicated to text detection have been derived, such as EAST[5], PSENet[6], DBNet[7] and so on.\n",
"\n",
" \n",
"Figure 6: Example of text detection task\n",
"\n",
"
\n",
"Figure 6: Example of text detection task\n",
"\n",
"
\n",
"\n",
"At present, the more popular text detection algorithms can be roughly divided into two categories: **based on regression** and **based on segmentation**. There are also some algorithms that combine the two. Algorithms based on regression draw on general object detection algorithms, by setting the anchor regression detection frame, or directly doing pixel regression. This type of method has a better detection effect on regular-shaped text, but the detection effect on irregularly-shaped text will be relatively poor. For example, CTPN [3] has better detection effect on horizontal text, but poor detection effect on oblique and curved text. SegLink [8] is more effective for long text, but has limited effect on sparsely distributed text; algorithm based on segmentation Introduced Mask-RCNN [9], this type of algorithm can reach a higher level in various scenes and texts of various shapes, but the disadvantage is that the post-processing is generally more complicated, so there are often speed problems. And it cannot solve the problem of detecting overlapping text.\n",
"\n",
" \n",
"Figure 7: Overview of text detection algorithms\n",
"\n",
"
\n",
"Figure 7: Overview of text detection algorithms\n",
"\n",
"
\n",
"\n",
"||\n",
"|---|---|---|\n",
"Figure 8: (left) CTPN[3] algorithm optimization based on regression anchor (middle) DB[7] algorithm optimization post-processing based on segmentation (right) SAST[10] algorithm of regression + segmentation\n",
"\n",
"
\n",
"\n",
"The related technology of text detection will be interpreted and actual combat in detail in Chapter 2.\n",
"\n",
"## 2.2 Text Recognition\n",
"\n",
"The task of text recognition is to recognize the text content in the image, and the input generally comes from the text area of the image cut out by the text box obtained by text detection. Text recognition can generally be divided into two categories: **Regular Text Recognition** and **Irregular Text Recognition** according to the shape of the text to be recognized. Regular text mainly refers to printed fonts, scanned text, etc., and the text is roughly in the horizontal line position. Irregular text is often not in a horizontal position, and has problems such as bending, occlusion, and blurring. Irregular text scenes are very challenging, and it is also the main research direction in the field of text recognition.\n",
"\n",
"\n",
"Figure 9: (Left) Regular text VS. (Right) Irregular text\n",
"\n",
"
\n",
"\n",
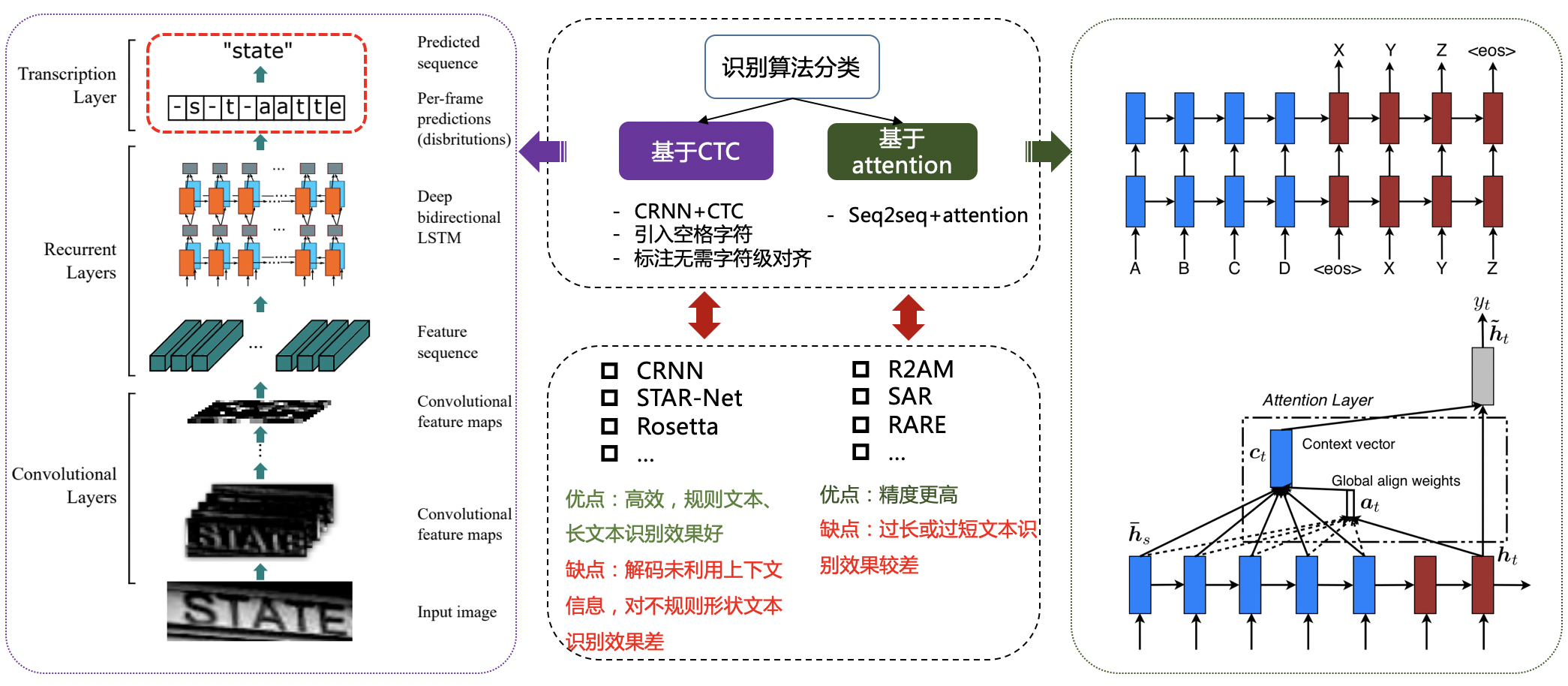
"The algorithm of regular text recognition can be roughly divided into two types based on CTC and Sequence2Sequence according to the different decoding methods. The processing methods of converting the sequence features learned by the network into the final recognition result are different. The algorithm based on CTC is represented by the classic CRNN [11].\n",
"\n",
"\n",
"Figure 10: CTC-based recognition algorithm VS. Attention-based recognition algorithm\n",
"\n",
"The recognition algorithms for irregular texts are more abundant. Methods such as STAR-Net [12] correct the irregular texts into regular rectangles by adding correction modules such as TPS before recognition. Attention-based methods such as RARE [13] enhance the attention to the correlation of parts between sequences. The segmentation-based method treats each character of a text line as an independent individual, and it is easier to recognize a single segmented character than to recognize the entire text line after correction. In addition, with the rapid development of Transformer [14] and its effectiveness in various tasks in recent years, a number of Transformer-based text recognition algorithms have also appeared. These methods use the transformer structure to solve the long-dependency modeling of CNN. The limitations of the problem, but also achieved good results.\n",
"\n",
"\n",
"Figure 11: Recognition algorithm based on character segmentation [15]\n",
"\n",
"
\n",
"\n",
"The related technologies of text recognition will be interpreted and actual combat in detail in Chapter 3.\n",
"\n",
"## 2.3 Document Structure Recognition\n",
"\n",
"OCR technology in the traditional sense can solve the detection and recognition needs of text. However, in practical application scenarios, structured information is often needed in the end, such as information formatting and extraction of ID cards and invoices, structured identification of tables, and so on. The application scenarios of OCR technology are mostly express document extraction, contract content comparison, financial factoring document information comparison, and logistics document identification. OCR result + post-processing is a commonly used structuring scheme, but the process is often complicated, and post-processing requires fine design and poor generalization. Under the background of the gradual maturity of OCR technology and the growing demand for structured information extraction, various technologies related to intelligent document analysis, such as layout analysis, table recognition, and key information extraction, have received more and more attention and research.\n",
"\n",
"* **Layout Analysis**\n",
"\n",
"Layout Analysis is mainly used to classify the content of document images. The categories can generally be divided into plain text, titles, tables, pictures, etc. Existing methods generally regard different plates in the document as different targets for detection or segmentation. For example, Soto Carlos [16], based on the target detection algorithm Faster R-CNN, combines context information and uses the inherent position information of the document content to improve the performance. Region detection performance. Sarkar Mausoom et al.[17] proposed a priori-based segmentation mechanism to train a document segmentation model on very high-resolution images, solving the problem that different structures in dense regions cannot be distinguished and merged due to excessive reduction of the original image.\n",
"\n",
"\n",
"Figure 12: Schematic diagram of layout analysis tasks\n",
"\n",
"
\n",
"\n",
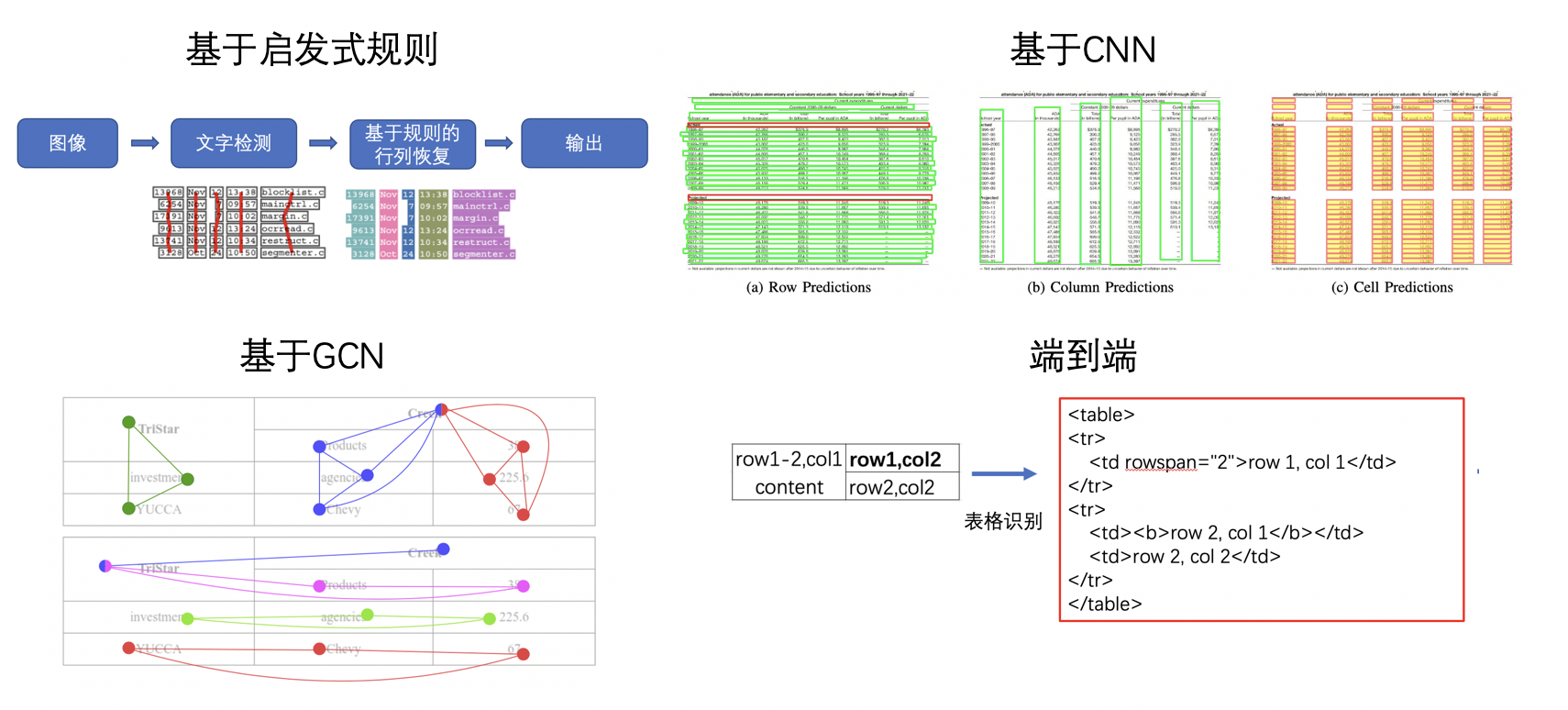
"* **Table Recognition**\n",
"\n",
"The task of table recognition is to identify and convert the table information in the document into an excel file. The types and styles of tables in text images are complex and diverse, such as different row and column combinations, different content text types, etc. In addition, the style of the document and the lighting environment during shooting have brought great challenges to table recognition. These challenges make table recognition always a research difficulty in the field of document understanding.\n",
"\n",
"\n",
"\n",
"Figure 13: Schematic diagram of form recognition task\n",
"\n",
"
\n",
"\n",
"There are many types of table recognition methods. The early traditional algorithms based on heuristic rules, such as the T-Rect algorithm proposed by Kieninger [18] and others, generally use manual design rules and connected domain detection and analysis. In recent years, with the development of deep learning, some CNN-based table structure recognition algorithms have emerged, such as DeepTabStR proposed by Siddiqui Shoaib Ahmed [19] and others, and TabStruct-Net proposed by Raja Sachin [20] and others. In addition, with the rise of *Graph Neural Network*, some researchers try to apply *Graph Neural Network* to the problem of table structure recognition. Based on the *Graph Neural Network*, table recognition is regarded as a graph reconstruction problem, such as Xue Wenyuan [21] TGRNet proposed by et al. The end-to-end method directly uses the network to complete the HTML representation output of the table structure. Most of the end-to-end methods use the Seq2Seq method to complete the prediction of the table structure, such as some methods based on Attention or Transformer, such as TableMaster [22].\n",
"\n",
"\n",
"Figure 14: Schematic diagram of form identification method\n",
"\n",
"
\n",
"\n",
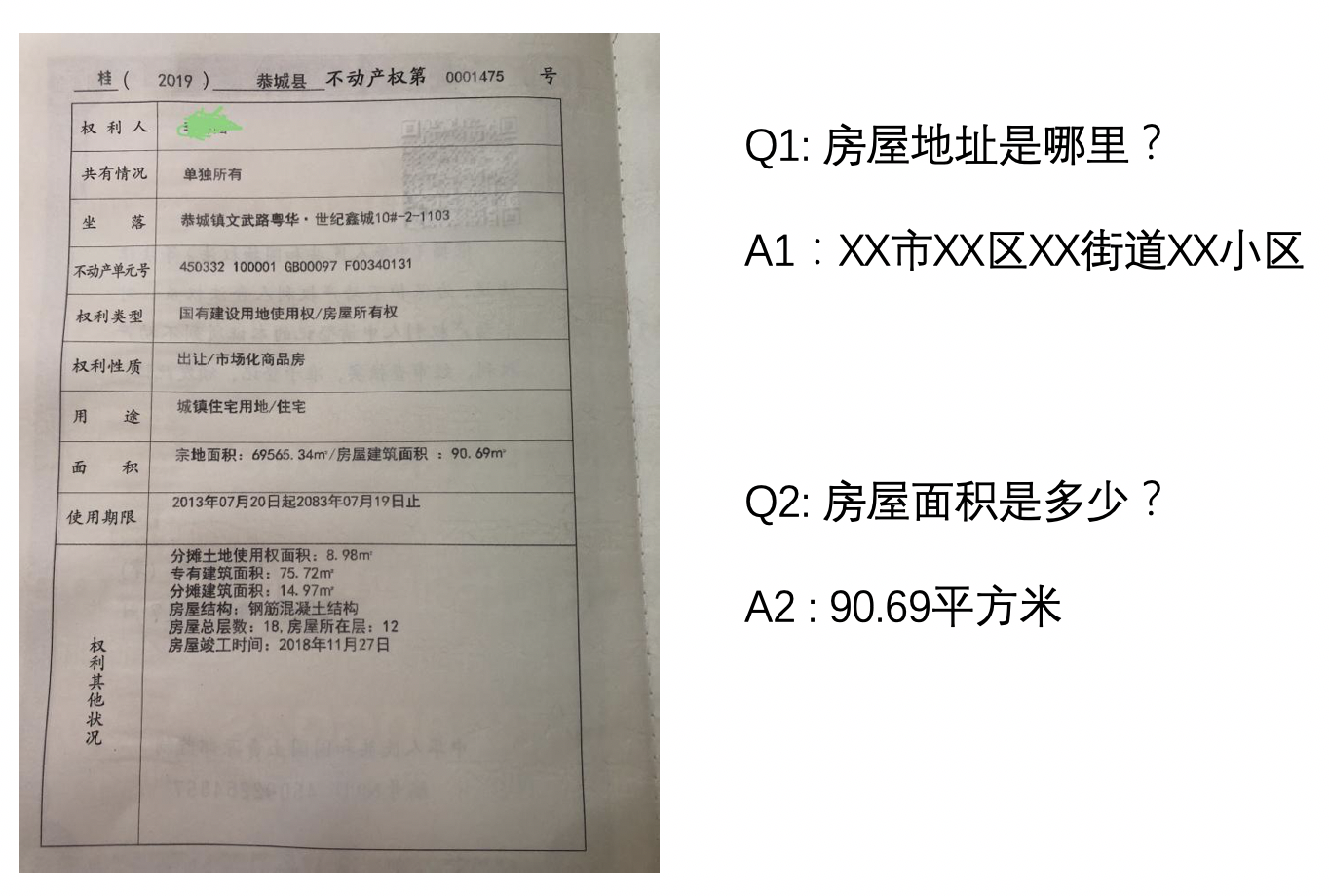
"* **Key Information Extraction**\n",
"\n",
"Key Information Extraction (KIE) is an important task in Document VQA. It mainly extracts the key information needed from images, such as extracting name and citizen ID number information from ID cards. The types of such information are often It is fixed under a specific task, but is different between different tasks.\n",
"\n",
"\n",
"Figure 15: Schematic diagram of DocVQA tasks\n",
"\n",
"
\n",
"\n",
"KIE is usually divided into two sub-tasks for research:\n",
"\n",
"- SER: Semantic Entity Recognition, to classify each detected text, such as dividing it into name and ID. As shown in the black box and red box in the figure below.\n",
"- RE: Relation Extraction, which classifies each detected text, such as dividing it into questions and answers. Then find the corresponding answer to each question. As shown in the figure below, the red and black boxes represent the question and the answer, respectively, and the yellow line represents the correspondence between the question and the answer.\n",
"\n",
"\n",
"Figure 16: ser and re tasks\n",
"\n",
"
\n",
"\n",
"The general KIE method is researched based on Named Entity Recognition (NER) [4], but this type of method only uses the text information in the image and lacks the use of visual and structural information, so the accuracy is not high. On this basis, the methods in recent years have begun to merge visual and structural information with text information. According to the principles used when fusing multi-modal information, these methods can be divided into the following four types:\n",
"\n",
"- Grid-based method\n",
"- Token-based method\n",
"- GCN-based method\n",
"- Based on End to End method\n",
"\n",
"
\n",
"\n",
"Document analysis related technologies will be explained and actual combat in detail in Chapter 6.\n",
"\n",
"## 2.4 Other Related Technologies\n",
"\n",
"The previous mainly introduced three key technologies in the OCR field: text detection, text recognition, document structured recognition, and more other cutting-edge technologies related to OCR, including end-to-end text recognition, image preprocessing technology in OCR, and OCR data synthesis Etc., please refer to Chapter 7 and Chapter 8 of the tutorial.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 3. Industrial Practice of OCR Technology\n",
"\n",
"\n",
"\n",
"> You are Xiao Wang, what should I do?\n",
"> 1. I won't, I can't, I won't do it 😭\n",
"> 2. It is recommended that the boss find an outsourcing company or commercialization plan, anyway, spend the boss's money 😊\n",
"> 3. Find similar projects online, programming for Github😏\n",
"\n",
"
\n",
"\n",
"OCR technology will eventually fall into industrial practice. Although there is a lot of academic research on OCR technology, and the commercial application of OCR technology is relatively mature compared with other AI technologies, there are still some difficulties and challenges in actual industrial applications. The following will analyze from two perspectives of technology and industrial practice.\n",
"\n",
"\n",
"## 3.1 Difficulties in Industrial Practice\n",
"\n",
"In actual industrial practice, developers often need to rely on open source community resources to start or promote projects, and developers using open source models often face three major problems:\n",
"\n",
"Figure 17: Three major problems in the practice of OCR technology industry\n",
"\n",
"**1. Can't find & can't choose**\n",
"\n",
"The open source community is rich in resources, but information asymmetry makes developers unable to solve pain points efficiently. On the one hand, the open source community resources are too rich. Faced with a requirement, developers cannot quickly find a project that matches the business requirement from the massive code repository, that is, there is a problem of \"can't find\". On the other hand, when selecting algorithms, the indicators on the English public dataset cannot provide a direct reference for the Chinese scenarios that developers often face. Algorithm-by-algorithm verification takes a lot of time and manpower, and there is no guarantee that the most suitable algorithm will be selected, that is, \"can't choose\".\n",
"\n",
"**2. Not applicable to industry scenarios**\n",
"\n",
"The work in the open source community tends to focus more on effect optimization, such as open source or reproduction of academic paper codes, and generally focus more on algorithm effects. Compared with the work that balances the size and speed of the model, it is much less, and the model size and prediction are time-consuming Two indicators that cannot be ignored in industrial practice are as important as the model effect. Whether it is on the mobile side or the server side, the number of images to be recognized is often very large, and it is hoped that the model will be smaller, more accurate, and faster in prediction. GPU is too expensive, it is better to use CPU to run more economically. On the premise of meeting business needs, the lighter the model, the less resources it takes.\n",
"\n",
"**3. Difficult optimization and many training deployment problems**\n",
"\n",
"The direct use of open source algorithms or models generally cannot directly meet business needs. In actual business scenarios, OCR faces a variety of problems. The personalization of business scenarios often requires retraining of custom data sets. On existing open source projects, various optimizations are experimented. The cost of the method is higher. In addition, OCR application scenarios are very rich. There are a wide range of application requirements on the server and various mobile devices. The diversification of the hardware environment needs to support rich deployment methods. The open source community’s projects focus more on algorithms and models, and predict deployment. This part is obviously under-supported. To apply OCR technology from the algorithm in the paper to the application of technology, it has high requirements for the algorithm and engineering ability of the developer.\n",
"\n",
"## 3.2 Industrial OCR Development Kit PaddleOCR\n",
"\n",
"OCR industry practice requires a complete set of full-process solutions to speed up the research and development progress and save valuable research and development time. In other words, the ultra-lightweight model and its full-process solutions, especially for mobile terminals and embedded devices with limited computing power and storage space, can be said to be a rigid demand.\n",
"\n",
"In this context, the industrial-grade OCR development kit [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR) came into being.\n",
"\n",
"The construction idea of PaddleOCR starts from user portraits and needs, and relies on the core framework of flying oars, selects and reproduces a wealth of cutting-edge algorithms, and develops PP characteristic models that are more suitable for industrial landing based on recurring algorithms, and integrates training and promotion to provide A variety of predictive deployment methods to meet different demand scenarios of actual applications.\n",
"\n",
"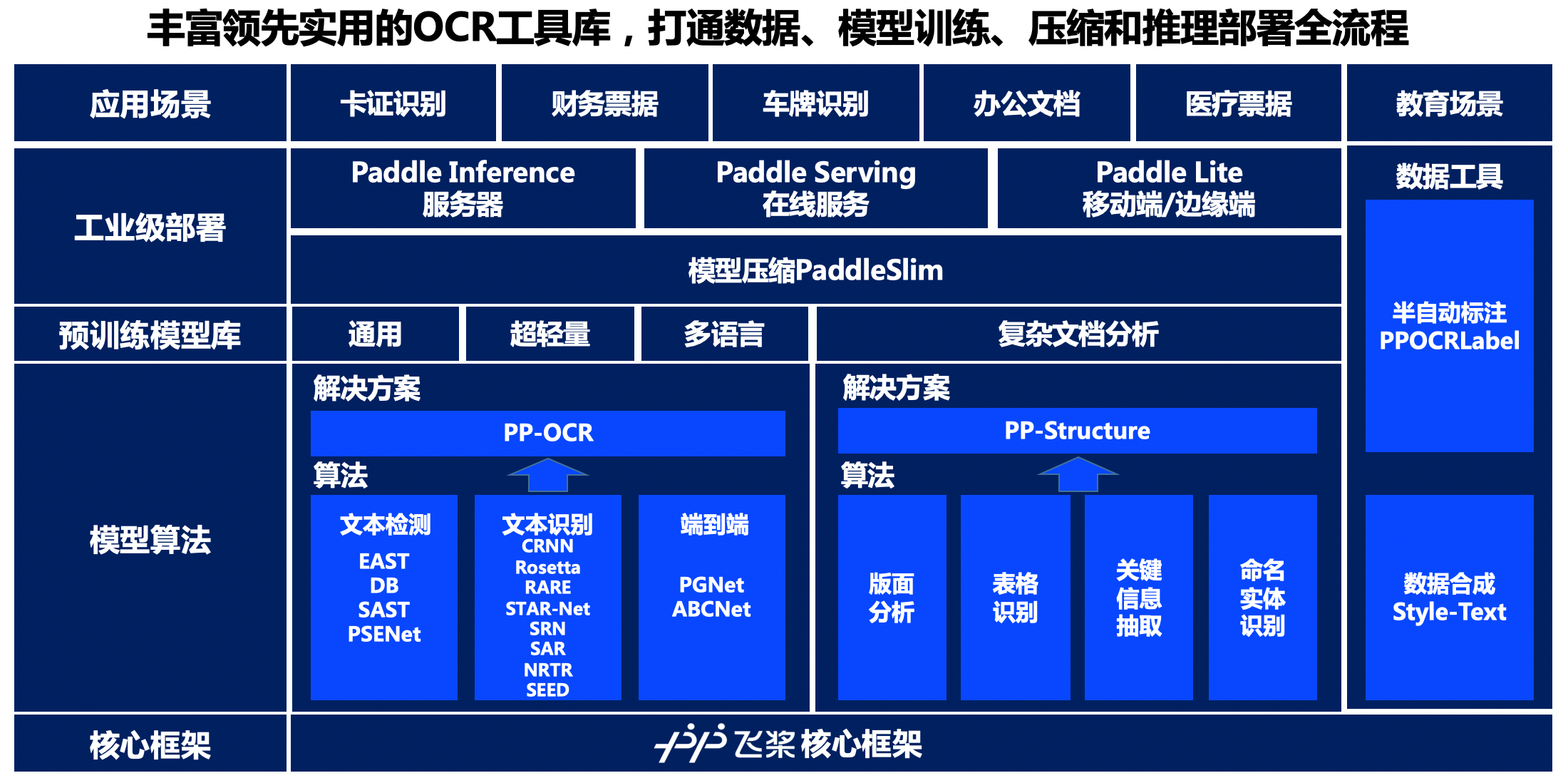\n",
"Figure 18: Panorama of PaddleOCR development kit\n",
"\n",
"
\n",
"\n",
"It can be seen from the panorama that PaddleOCR relies on the core framework of the flying paddle, and provides a wealth of solutions in the model algorithm, pre-training model library, industrial-grade deployment, etc., and provides data synthesis and semi-automatic data annotation tools to meet the needs of development Data production needs of the author.\n",
"\n",
"**At the model algorithm level**, PaddleOCR provides solutions for the two tasks of **text detection and recognition** and **document structure analysis** respectively. In terms of text detection and recognition, PaddleOCR has reproduced or open sourced 4 text detection algorithms, 8 text recognition algorithms, and 1 end-to-end text recognition algorithm. On this basis, a general text detection and recognition solution of the PP-OCR series is developed. In terms of document structure analysis, PaddleOCR provides algorithms such as layout analysis, table recognition, key information extraction, and named entity recognition, and based on this, it proposes a PP-Structure document analysis solution. A rich selection of algorithms can meet the needs of developers in different business scenarios. The unification of the code framework also facilitates the optimization and performance comparison of different algorithms for developers.\n",
"\n",
"**At the level of pre-training model library**, based on PP-OCR and PP-Structure solutions, PaddleOCR has developed and open-sourced PP series characteristic models suitable for industrial practice, including general-purpose, ultra-lightweight and multi-language text detection and recognition Models, and complex document analysis models. The PP series characteristic models are deeply optimized on the original algorithm, so that they can reach the practical level of the industry in terms of effect and performance. Developers can either directly apply to business scenarios or use business data for simple finetune. Easily develop a \"practical model\" suitable for your business needs.\n",
"\n",
"**At the industrial level of deployment**, PaddleOCR provides a server-side prediction solution based on Paddle Inference, a service-based deployment solution based on Paddle Serving, and an end-side deployment solution based on Paddle-Lite to meet the deployment needs of different hardware environments , At the same time, it provides a model compression scheme based on PaddleSlim, which can further compress the model size. The above deployment methods have completed the whole process of training and pushing to ensure that developers can deploy efficiently, stably and reliably.\n",
"\n",
"**At the data tool level**, PaddleOCR provides a semi-automatic data annotation tool PPOCRLabel and a data synthesis tool Style-Text to help developers more conveniently produce the data sets and annotation information required for model training. PPOCRLabel, as the industry's first open source semi-automatic OCR data annotation tool, is aimed at the tedious and tedious process of labeling, high mechanicality, manual labeling of a large amount of training data, and expensive time and money. The built-in PP-OCR model realizes pre-labeling + manual verification. The labeling mode can greatly improve labeling efficiency and save labor costs. The data synthesis tool Style-Text mainly solves the serious shortage of real data in actual scenes. Traditional synthesis algorithms cannot synthesize text styles (fonts, colors, spacing, background). Only a few target scene images are needed to synthesize a large number of target scene styles in batches. Similar text images.\n",
"\n",
"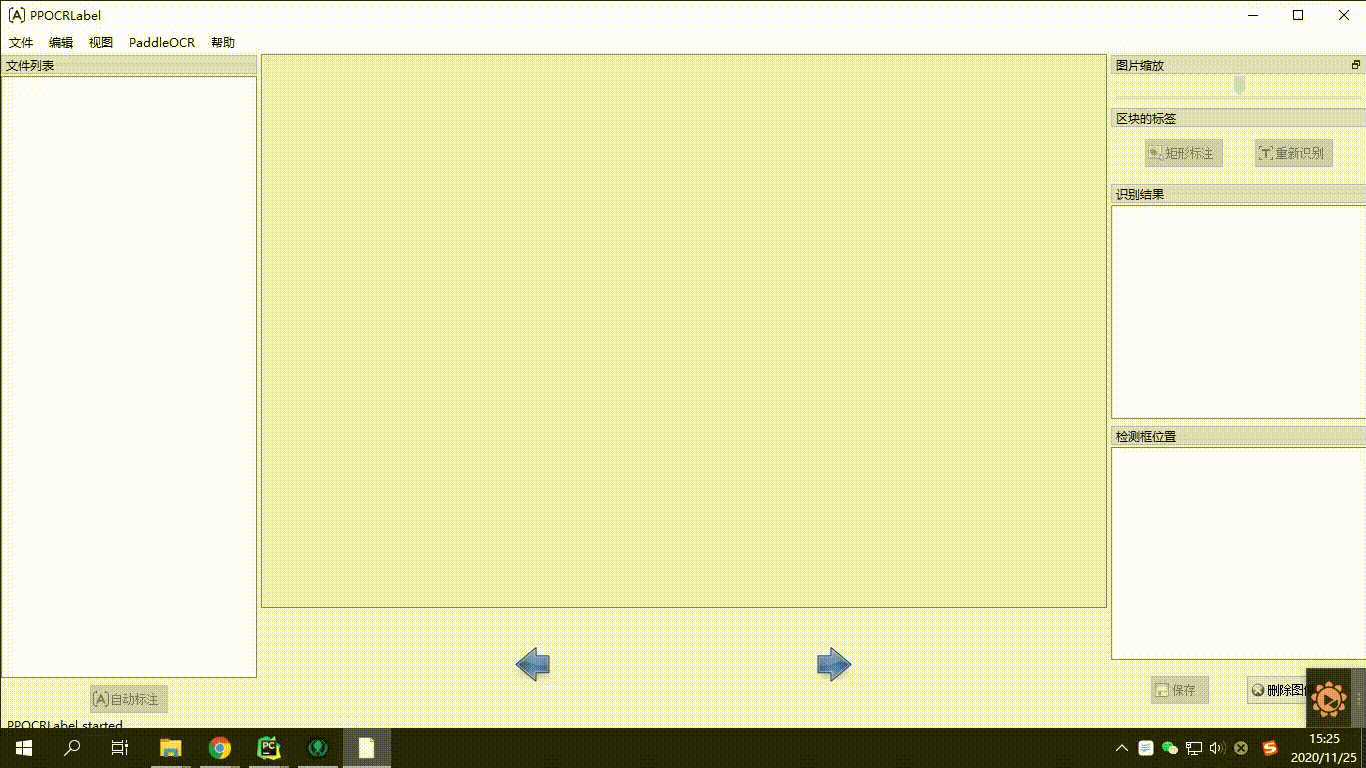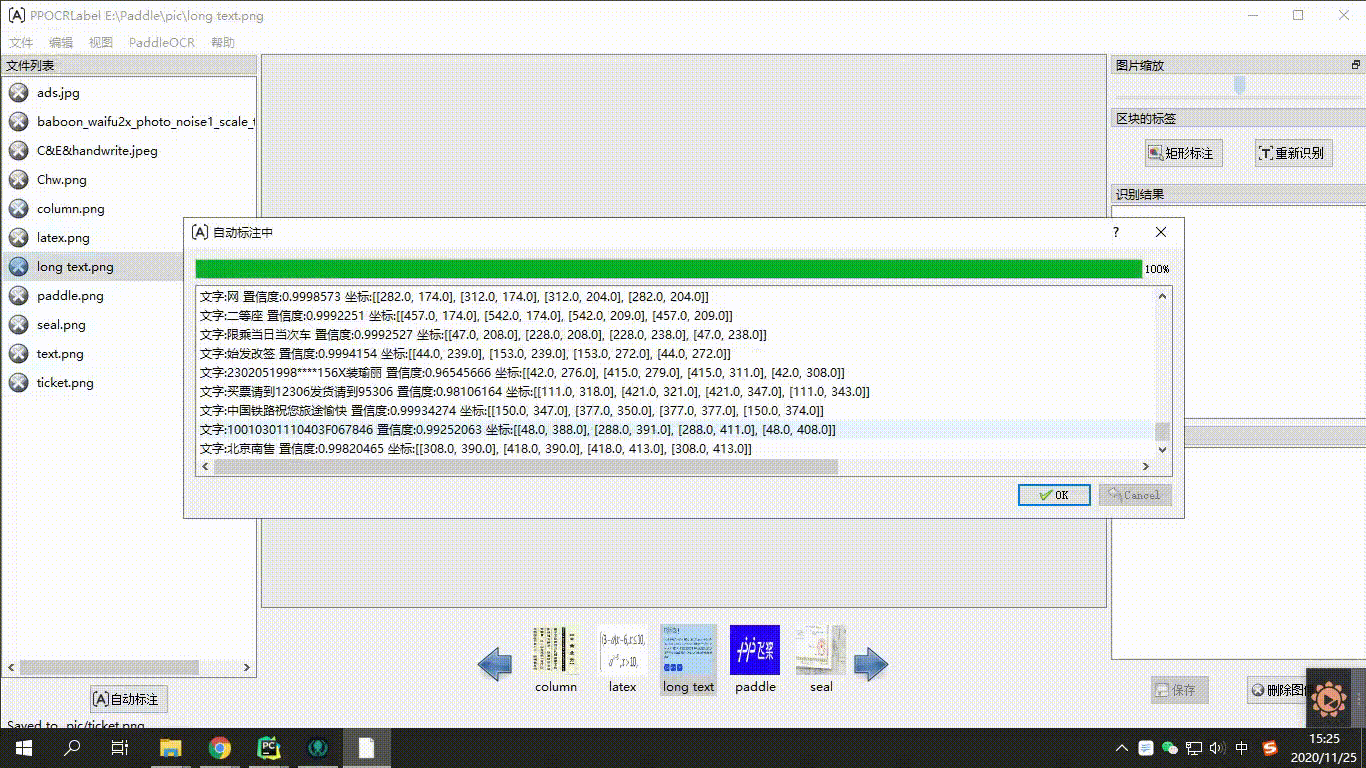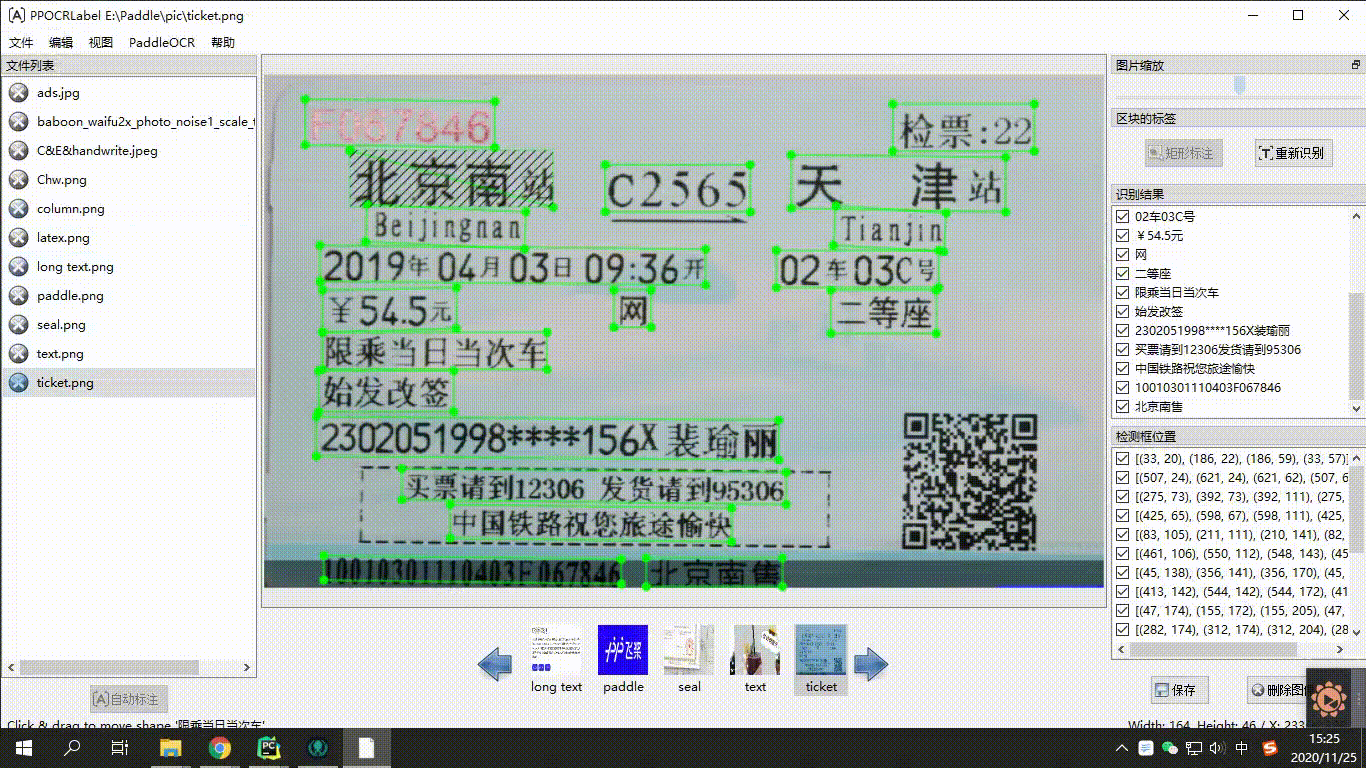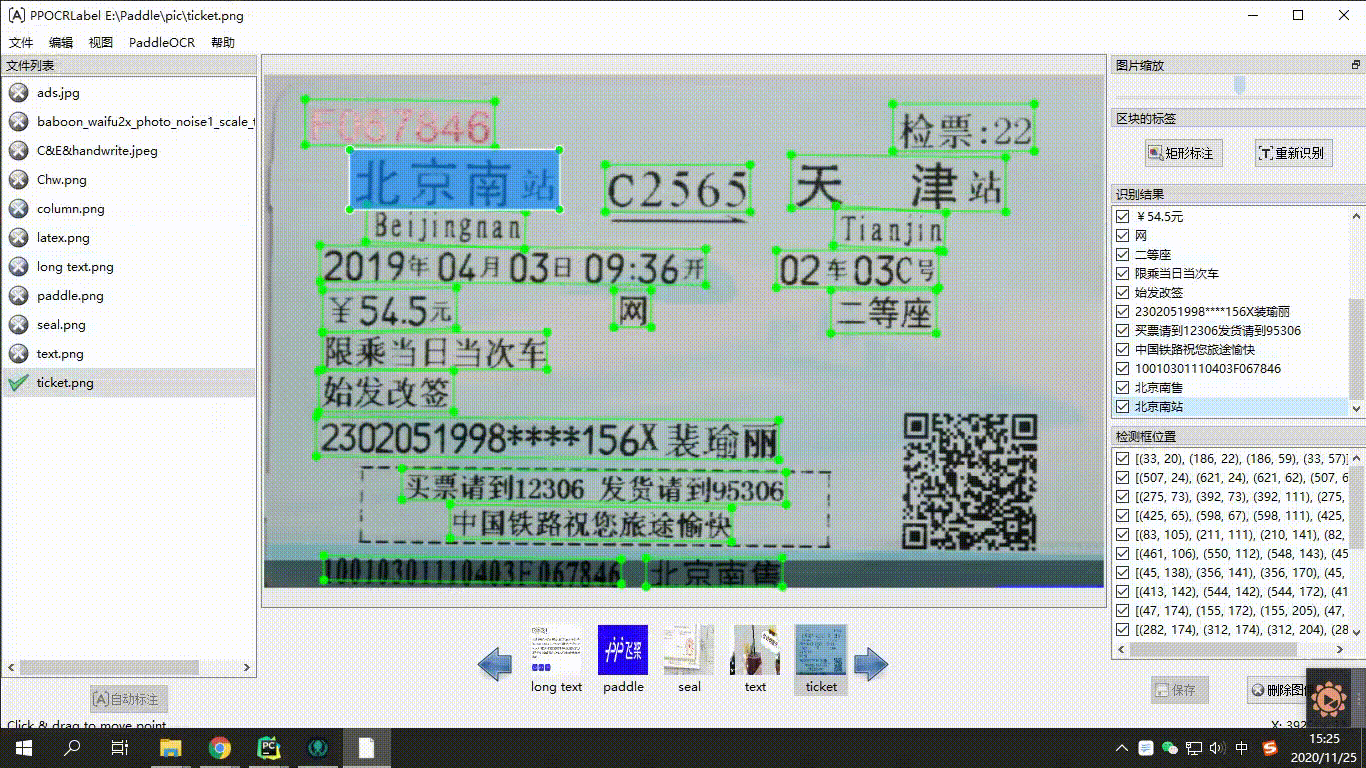\n",
"Figure 19: Schematic diagram of PPOCRLabel usage\n",
"
\n",
"\n",
"\n",
"Figure 20: Example of Style-Text synthesis effect\n",
"\n",
"
\n",
"\n",
"### 3.2.1 PP-OCR and PP-Structrue\n",
"\n",
"The PP series characteristic model is a model that is deeply optimized for the practical needs of the industry by various visual development kits of the flying propeller, striving for a balance between speed and accuracy. The PP series featured models in PaddleOCR include PP-OCR series models for text detection and recognition tasks and PP-Structure series models for document analysis.\n",
"\n",
"**(1) PP-OCR Chinese and English model**\n",
"\n",
"\n",
"\n",
"Figure 21: Example of PP-OCR model recognition results in Chinese and English\n",
"\n",
"
\n",
"\n",
"The typical two-stage OCR algorithm adopted by the Chinese and English models of PP-OCR, that is, the composition method of detection model + recognition model, the specific algorithm framework is as follows:\n",
"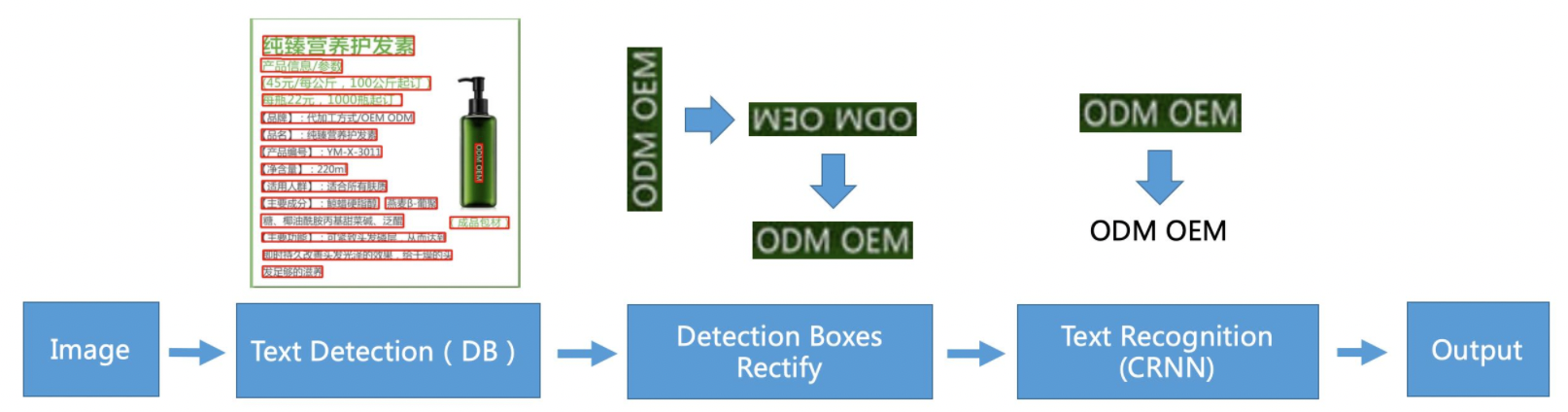\n",
"Figure 22: Schematic diagram of PP-OCR system pipeline\n",
"\n",
"
\n",
"\n",
"It can be seen that in addition to input and output, the core framework of PP-OCR contains 3 modules, namely: text detection module, detection frame correction module, and text recognition module.\n",
"- Text detection module: The core is a text detection model trained on the [DB](https://arxiv.org/abs/1911.08947) detection algorithm to detect the text area in the image;\n",
"- Detection frame correction module: Input the detected text box into the detection frame correction module. At this stage, the text box represented by the four points is corrected into a rectangular frame, which is convenient for subsequent text recognition. On the other hand, the text direction will be judged and corrected. For example, if the text line is judged to be upside down, it will be corrected. This function is realized by training a text direction classifier;\n",
"- Text recognition module: Finally, the text recognition module performs text recognition on the corrected detection box to obtain the text content in each text box. The classic text recognition algorithm used in PP-OCR [CRNN](https://arxiv.org/abs/1507.05717).\n",
"\n",
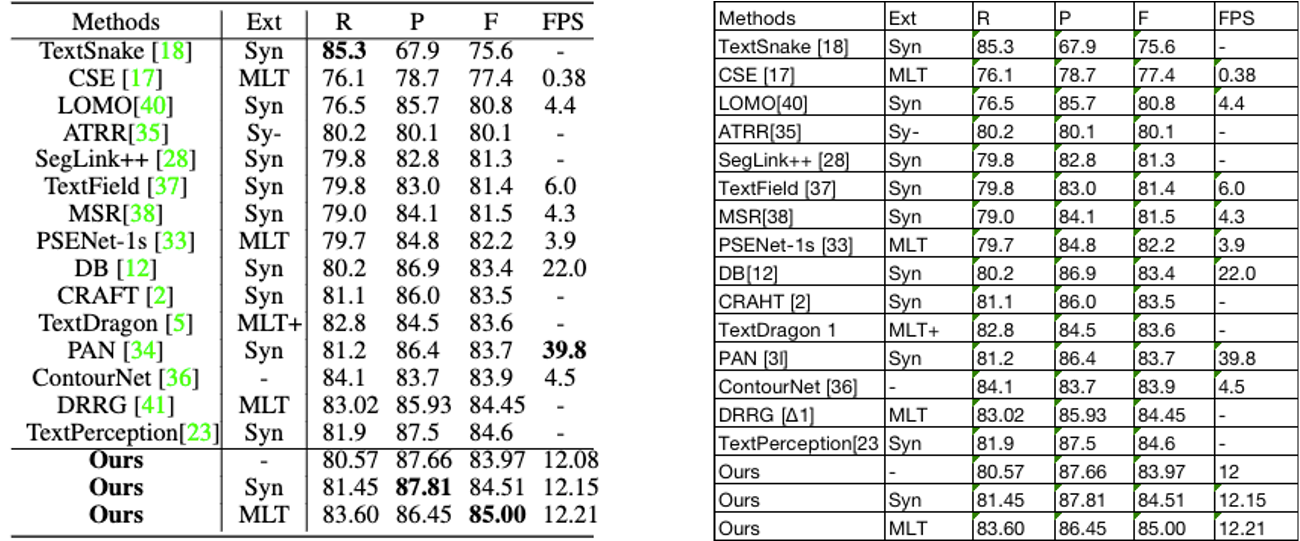
"PaddleOCR has successively introduced PP-OCR[23] and PP-OCRv2[24] models.\n",
"\n",
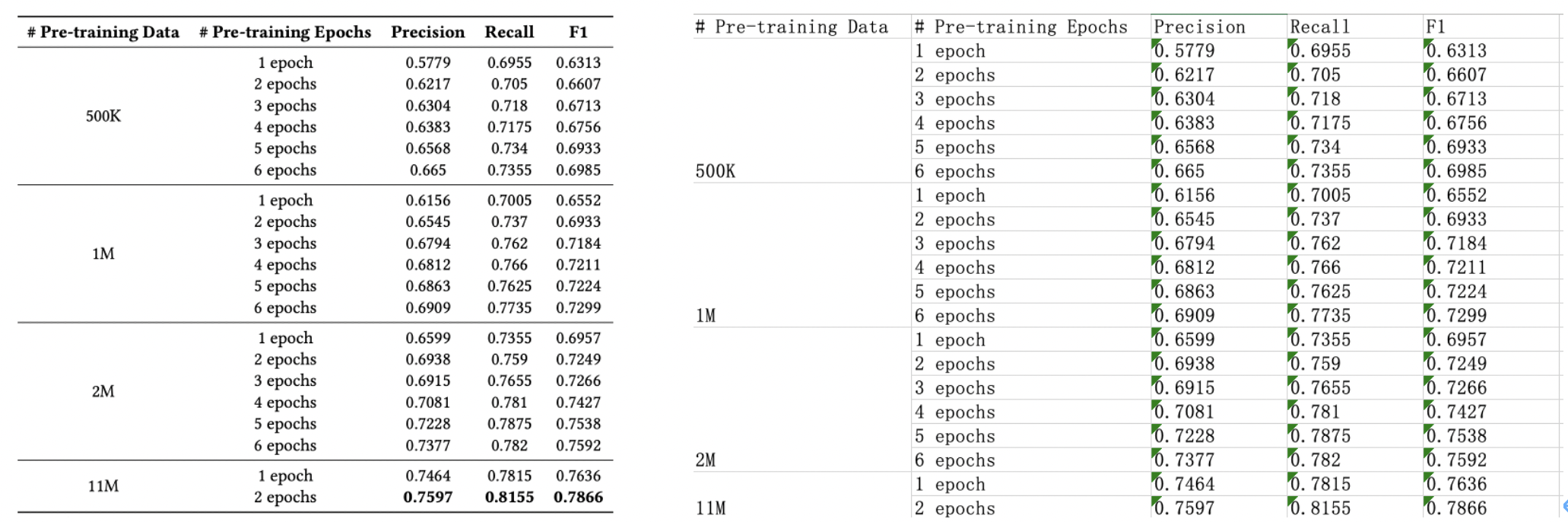
"PP-OCR model is divided into mobile version (lightweight version) and server version (universal version). The mobile version model is mainly optimized based on the lightweight backbone network MobileNetV3. The optimized model (detection model + text direction classification model + recognition model) ) The size is only 8.1M, the average single image prediction on the CPU takes 350ms, and the T4 GPU is about 110ms. After cropping and quantization, it can be further compressed to 3.5M without changing the accuracy, which is convenient for end-side deployment. The previous test predicts that it will only take 260ms. For more PP-OCR evaluation data, please refer to [benchmark](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/doc/doc_ch/benchmark.md).\n",
"\n",
"PP-OCRv2 maintains the overall framework of PP-OCR, mainly for further strategic optimization of effects. The improvement includes 3 aspects:\n",
"- Compared with the PP-OCR mobile version, the model effect is improved by over 7%;\n",
"- In terms of speed, compared to the PP-OCR server version, it has increased by more than 220%;\n",
"- In terms of model size, with a total size of 11.6M, both server and mobile terminals can be easily deployed.\n",
"\n",
"The specific optimization strategies of PP-OCR and PP-OCRv2 will be explained in detail in Chapter 4.\n",
"\n",
"In addition to the Chinese and English models, PaddleOCR also trained and open-sourced English digital models and multi-language recognition models based on different data sets. All of the above are ultra-lightweight models and are suitable for different language scenarios.\n",
"\n",
"\n",
"Figure 23: Schematic diagram of the recognition effect of the English digital model and multilingual model of PP-OCR\n",
"\n",
"
\n",
"\n",
"**(2) PP-Structure document analysis model**\n",
"\n",
"PP-Structure supports three subtasks: layout analysis, table recognition, and DocVQA.\n",
"\n",
"The core functions of PP-Structure are as follows:\n",
"- Support layout analysis of documents in the form of pictures, which can be divided into 5 types of areas: text, title, table, picture and list (used in conjunction with Layout-Parser)\n",
"- Support text, title, picture and list area to be extracted as text fields (used in conjunction with PP-OCR)\n",
"- Supports structured analysis in the table area, and the final result is output to an Excel file\n",
"- Support Python whl package and command line two ways, simple and easy to use\n",
"- Support custom training for two types of tasks: layout analysis and table structuring\n",
"- Support VQA tasks-SER and RE\n",
"\n",
"\n",
"Figure 24: Schematic diagram of PP-Structure system (this figure only contains layout analysis + table identification)\n",
"\n",
"
\n",
"\n",
"The specific plan of PP-Structure will be explained in detail in Chapter 6.\n",
"\n",
"### 3.2.2 Industrial-grade Deployment Plan\n",
"\n",
"The flying paddle supports full-process and full-scene inference deployment. There are three main sources of models. The first one uses PaddlePaddle API to build a network structure for training. The second is based on the flying paddle kit series. The flying paddle kit provides a wealth of models. Library, simple and easy-to-use API, with out-of-the-box use, including visual model library PaddleCV, intelligent speech library PaddleSpeech and natural language processing library PaddleNLP, etc. The third type uses X2Paddle tools from third-party frameworks (PyTorh, ONNX, TensorFlow, etc.) The output model.\n",
"\n",
"The paddle model can be compressed, quantified, and distilled using PaddleSlim tools. It supports five deployment schemes, namely, servicing Paddle Serving, server/cloud Paddle Inference, mobile/edge Paddle Lite, web front end Paddle.js, and for Paddle. Unsupported hardware, such as MCU, Horizon, Kunyun and other domestic chips, can be converted into a third-party framework that supports ONNX with the help of Paddle2ONNX.\n",
"\n",
"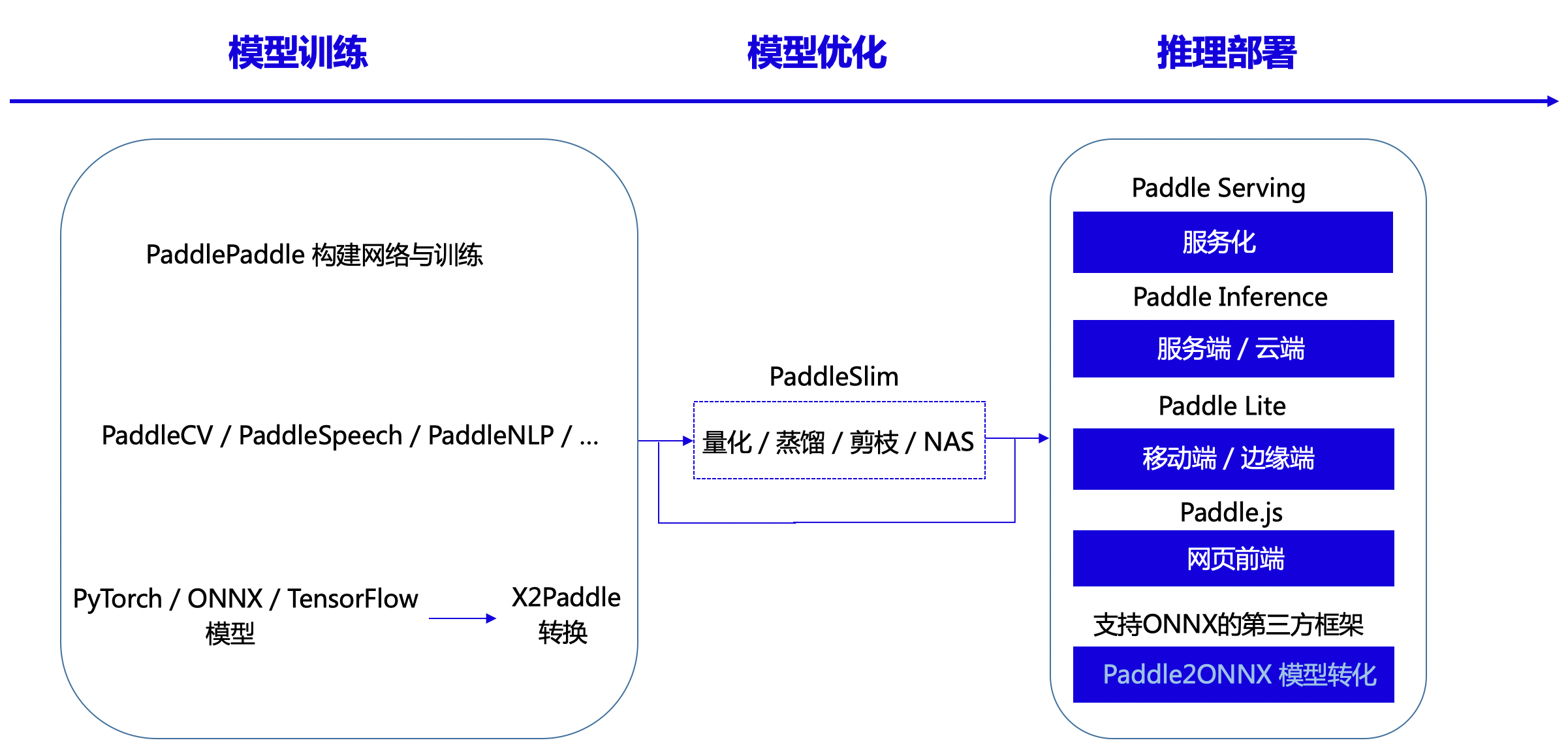\n",
"Figure 25: Flying propeller support deployment method\n",
"\n",
"
\n",
"\n",
"Paddle Inference supports server-side and cloud deployment, with high performance and versatility. It is deeply adapted and optimized for different platforms and different application scenarios. Paddle Inference is the native reasoning library for flying paddles, ensuring that the model can be trained on the server side. Use, rapid deployment, suitable for high-performance hardware using multiple application language environments to deploy models with complex algorithms. The hardware covers x86 CPUs, Nvidia GPUs, and AI accelerators such as Baidu Kunlun XPU and Huawei Shengteng.\n",
"\n",
"Paddle Lite is an end-side inference engine with lightweight and high-performance features. It has been configured and optimized in-depth for end-side devices and various application scenarios. Currently supports multiple platforms such as Android, IOS, embedded Linux devices, macOS, etc. The hardware covers ARM CPU and GPU, X86 CPU and new hardware such as Baidu Kunlun, Huawei Ascend and Kirin, Rockchip, etc.\n",
"\n",
"Paddle Serving is a high-performance service framework designed to help users quickly deploy models in cloud services in a few steps. At present, Paddle Serving supports functions such as custom pre-processing, model combination, model hot load update, multi-machine multi-card multi-model, distributed reasoning, K8S deployment, security gateway and model encryption deployment, and support for multi-language and multi-client access. Paddle Serving The official also provides deployment examples of more than 40 models, including PaddleOCR, to help users get started faster.\n",
"\n",
"\n",
"Figure 26: Support deployment mode of flying propeller\n",
"\n",
"
\n",
"\n",
"The above deployment plan will be explained in detail and actual combat based on the PP-OCRv2 model in Chapter 5."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 4. Summary\n",
"\n",
"This section first introduces the application scenarios and cutting-edge algorithms of OCR technology, and then analyzes the difficulties and three major challenges of OCR technology in industrial practice.\n",
"\n",
"The contents of the subsequent chapters of this tutorial are arranged as follows:\n",
"\n",
"* The second and third chapters introduce detection and identification technology and practice respectively;\n",
"* Chapter 4 introduces PP-OCR optimization strategy;\n",
"* Chapter 5 Predicting and deploying actual combat;\n",
"* Chapter 6 introduces document structuring;\n",
"* Chapter 7 introduces other OCR-related algorithms such as end-to-end, data preprocessing, and data synthesis;\n",
"* Chapter 8 introduces OCR related data sets and data synthesis tools.\n",
"\n",
"# Reference\n",
"\n",
"[1] Liao, Minghui, et al. \"Textboxes: A fast text detector with a single deep neural network.\" Thirty-first AAAI conference on artificial intelligence. 2017.\n",
"\n",
"[2] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.\n",
"\n",
"[3] Tian, Zhi, et al. \"Detecting text in natural image with connectionist text proposal network.\" European conference on computer vision. Springer, Cham, 2016.\n",
"\n",
"[4] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015, 28: 91-99.\n",
"\n",
"[5] Zhou, Xinyu, et al. \"East: an efficient and accurate scene text detector.\" Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017.\n",
"\n",
"[6] Wang, Wenhai, et al. \"Shape robust text detection with progressive scale expansion network.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\n",
"\n",
"[7] Liao, Minghui, et al. \"Real-time scene text detection with differentiable binarization.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 07. 2020.\n",
"\n",
"[8] Deng, Dan, et al. \"Pixellink: Detecting scene text via instance segmentation.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.\n",
"\n",
"[9] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.\n",
"\n",
"[10] Wang P, Zhang C, Qi F, et al. A single-shot arbitrarily-shaped text detector based on context attended multi-task \n",
"learning[C]//Proceedings of the 27th ACM international conference on multimedia. 2019: 1277-1285.\n",
"\n",
"[11] Shi, B., Bai, X., & Yao, C. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11), 2298-2304.\n",
"\n",
"[12] Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.\n",
"\n",
"[13] Shi, B., Wang, X., Lyu, P., Yao, C., & Bai, X. (2016). Robust scene text recognition with automatic rectification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4168-4176).\n",
"\n",
"[14] Sheng, F., Chen, Z., & Xu, B. (2019, September). NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 781-786). IEEE.\n",
"\n",
"[15] Lyu P, Liao M, Yao C, et al. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 67-83.\n",
"\n",
"[16] Soto C, Yoo S. Visual detection with context for document layout analysis[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 3464-3470.\n",
"\n",
"[17] Sarkar M, Aggarwal M, Jain A, et al. Document Structure Extraction using Prior based High Resolution Hierarchical Semantic Segmentation[C]//European Conference on Computer Vision. Springer, Cham, 2020: 649-666.\n",
"\n",
"[18] Kieninger T, Dengel A. A paper-to-HTML table converting system[C]//Proceedings of document analysis systems (DAS). 1998, 98: 356-365.\n",
"\n",
"[19] Siddiqui S A, Fateh I A, Rizvi S T R, et al. Deeptabstr: Deep learning based table structure recognition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1403-1409.\n",
"\n",
"[20] Raja S, Mondal A, Jawahar C V. Table structure recognition using top-down and bottom-up cues[C]//European Conference on Computer Vision. Springer, Cham, 2020: 70-86.\n",
"\n",
"[21] Xue W, Yu B, Wang W, et al. TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition[J]. arXiv preprint arXiv:2106.10598, 2021.\n",
"\n",
"[22] Ye J, Qi X, He Y, et al. PingAn-VCGroup's Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B: Table Recognition to HTML[J]. arXiv preprint arXiv:2105.01848, 2021.\n",
"\n",
"[23] Du Y, Li C, Guo R, et al. PP-OCR: A practical ultra lightweight OCR system[J]. arXiv preprint arXiv:2009.09941, 2020.\n",
"\n",
"[24] Du Y, Li C, Guo R, et al. PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System[J]. arXiv preprint arXiv:2109.03144, 2021.\n",
"\n"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "py35-paddle1.2.0"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.4"
}
},
"nbformat": 4,
"nbformat_minor": 4
}