English | [简体中文](README_ch.md)
# Layout Recovery
- [1. Introduction](#1)
- [2. Install](#2)
- [2.1 Install PaddlePaddle](#2.1)
- [2.2 Install PaddleOCR](#2.2)
- [3. Quick Start](#3)
- [3.1 Download models](#3.1)
- [3.2 Layout recovery](#3.2)
- [4. More](#4)
## 1. Introduction
Layout recovery means that after OCR recognition, the content is still arranged like the original document pictures, and the paragraphs are output to word document in the same order.
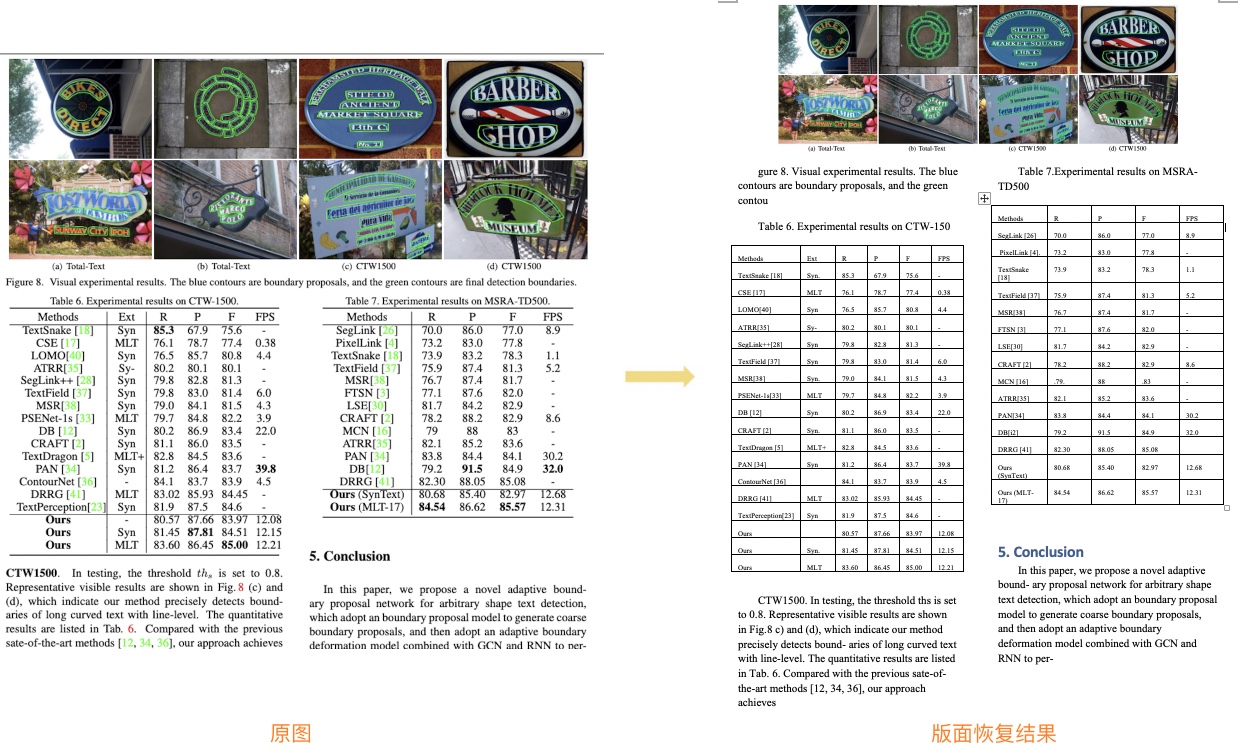
Layout recovery combines [layout analysis](../layout/README.md)、[table recognition](../table/README.md) to better recover images, tables, titles, etc. supports input files in PDF and document image formats in Chinese and English. The following figure shows the effect of restoring the layout of English and Chinese documents:
## 2. Install
### 2.1 Install PaddlePaddle
```bash
python3 -m pip install --upgrade pip
# If you have cuda9 or cuda10 installed on your machine, please run the following command to install
python3 -m pip install "paddlepaddle-gpu" -i https://mirror.baidu.com/pypi/simple
# CPU installation
python3 -m pip install "paddlepaddle" -i https://mirror.baidu.com/pypi/simple
````
For more requirements, please refer to the instructions in [Installation Documentation](https://www.paddlepaddle.org.cn/en/install/quick?docurl=/documentation/docs/en/install/pip/macos-pip_en.html).
### 2.2 Install PaddleOCR
- **(1) Download source code**
```bash
[Recommended] git clone https://github.com/PaddlePaddle/PaddleOCR
# If the pull cannot be successful due to network problems, you can also choose to use the hosting on the code cloud:
git clone https://gitee.com/paddlepaddle/PaddleOCR
# Note: Code cloud hosting code may not be able to synchronize the update of this github project in real time, there is a delay of 3 to 5 days, please use the recommended method first.
````
- **(2) Install recovery's `requirements`**
The layout restoration is exported as docx and PDF files, so python-docx and docx2pdf API need to be installed, and PyMuPDF api([requires Python >= 3.7](https://pypi.org/project/PyMuPDF/)) need to be installed to process the input files in pdf format.
```bash
python3 -m pip install -r ppstructure/recovery/requirements.txt
````
## 3. Quick Start
Through layout analysis, we divided the image/PDF documents into regions, located the key regions, such as text, table, picture, etc., and recorded the location, category, and regional pixel value information of each region. Different regions are processed separately, where:
- OCR detection and recognition is performed in the text area, and the coordinates of the OCR detection box and the text content information are added on the basis of the previous information
- The table area identifies tables and records html and text information of tables
- Save the image directly
We can restore the test picture through the layout information, OCR detection and recognition structure, table information, and saved pictures.
The whl package is also provided for quick use, follow the above code, for more infomation please refer to [quickstart](../docs/quickstart_en.md) for details.
```bash
paddleocr --image_dir=ppstructure/docs/table/1.png --type=structure --recovery=true --lang='en'
```
### 3.1 Download models
If input is English document, download English models:
```bash
cd PaddleOCR/ppstructure
# download model
mkdir inference && cd inference
# Download the detection model of the ultra-lightweight English PP-OCRv3 model and unzip it
https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar && tar xf en_PP-OCRv3_det_infer.tar
# Download the recognition model of the ultra-lightweight English PP-OCRv3 model and unzip it
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar && tar xf en_PP-OCRv3_rec_infer.tar
# Download the ultra-lightweight English table inch model and unzip it
wget https://paddleocr.bj.bcebos.com/ppstructure/models/slanet/en_ppstructure_mobile_v2.0_SLANet_infer.tar
tar xf en_ppstructure_mobile_v2.0_SLANet_infer.tar
# Download the layout model of publaynet dataset and unzip it
wget https://paddleocr.bj.bcebos.com/ppstructure/models/layout/picodet_lcnet_x1_0_fgd_layout_infer.tar
tar xf picodet_lcnet_x1_0_fgd_layout_infer.tar
cd ..
```
If input is Chinese document,download Chinese models:
[Chinese and English ultra-lightweight PP-OCRv3 model](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/README.md#pp-ocr-series-model-listupdate-on-september-8th)、[表格识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppstructure/docs/models_list.md#22-表格识别模型)、[版面分析模型](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppstructure/docs/models_list.md#1-版面分析模型)
### 3.2 Layout recovery
```bash
python3 predict_system.py \
--image_dir=./docs/table/1.png \
--det_model_dir=inference/en_PP-OCRv3_det_infer \
--rec_model_dir=inference/en_PP-OCRv3_rec_infer \
--rec_char_dict_path=../ppocr/utils/en_dict.txt \
--table_model_dir=inference/en_ppstructure_mobile_v2.0_SLANet_infer \
--table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
--layout_model_dir=inference/picodet_lcnet_x1_0_fgd_layout_infer \
--layout_dict_path=../ppocr/utils/dict/layout_dict/layout_publaynet_dict.txt \
--vis_font_path=../doc/fonts/simfang.ttf \
--recovery=True \
--save_pdf=False \
--output=../output/
```
After running, the docx of each picture will be saved in the directory specified by the output field
Field:
- image_dir:test file测试文件, can be picture, picture directory, pdf file, pdf file directory
- det_model_dir:OCR detection model path
- rec_model_dir:OCR recognition model path
- rec_char_dict_path:OCR recognition dict path. If the Chinese model is used, change to "../ppocr/utils/ppocr_keys_v1.txt". And if you trained the model on your own dataset, change to the trained dictionary
- table_model_dir:tabel recognition model path
- table_char_dict_path:tabel recognition dict path. If the Chinese model is used, no need to change
- layout_model_dir:layout analysis model path
- layout_dict_path:layout analysis dict path. If the Chinese model is used, change to "../ppocr/utils/dict/layout_dict/layout_cdla_dict.txt"
- recovery:whether to enable layout of recovery, default False
- save_pdf:when recovery file, whether to save pdf file, default False
- output:save the recovery result path
## 4. More
For training, evaluation and inference tutorial for text detection models, please refer to [text detection doc](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_en/detection_en.md).
For training, evaluation and inference tutorial for text recognition models, please refer to [text recognition doc](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_en/recognition_en.md).
For training, evaluation and inference tutorial for layout analysis models, please refer to [layout analysis doc](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppstructure/layout/README.md)
For training, evaluation and inference tutorial for table recognition models, please refer to [table recognition doc](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppstructure/table/README.md)