{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Document Analysis Technology\n",
"\n",
"This chapter mainly introduces the theoretical knowledge of document analysis technology, including background introduction, algorithm classification and corresponding ideas.\n",
"\n",
"Through the study of this chapter, you can master:\n",
"\n",
"1. Classification and typical ideas of layout analysis\n",
"2. Classification and typical ideas of table recognition\n",
"3. Classification and typical ideas of information extraction"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"Layout analysis is mainly used for document retrieval, key information extraction, content classification, etc. Its task is mainly to classify the content of document images. Content categories can generally be divided into plain text, titles, tables, pictures, and lists. However, the diversity and complexity of document layout, formats, poor document image quality, and the lack of large-scale annotated datasets make layout analysis still a challenging task. Document analysis often includes the following research directions:\n",
"\n",
"1. Layout analysis module: Divide each document page into different content areas. This module can be used not only to delimit relevant and irrelevant areas, but also to classify the types of content it recognizes.\n",
"2. Optical Character Recognition (OCR) module: Locate and recognize all text present in the document.\n",
"3. Form recognition module: Recognize and convert the form information in the document into an excel file.\n",
"4. Information extraction module: Use OCR results and image information to understand and identify the specific information expressed in the document or the relationship between the information.\n",
"\n",
"Since the OCR module has been introduced in detail in the previous chapters, the following three modules will be introduced separately for the above layout analysis, table recognition and information extraction. For each module, the classic or common methods and data sets of the module will be introduced."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 1. Layout Analysis\n",
"\n",
"### 1.1 Background Introduction\n",
"\n",
"Layout analysis is mainly used for document retrieval, key information extraction, content classification, etc. Its task is mainly to classify document images. Content categories can generally be divided into plain text, titles, tables, pictures, and lists. However, the diversity and complexity of document layouts, formats, poor document image quality, and the lack of large-scale annotated data sets make layout analysis still a challenging task.\n",
"The visualization of the layout analysis task is shown in the figure below:\n",
"\n",
" \n",
"Figure 1: Layout analysis effect diagram\n",
"\n",
"The existing solutions are generally based on target detection or semantic segmentation methods, which are based on detecting or segmenting different patterns in the document as different targets.\n",
"\n",
"Some representative papers are divided into the above two categories, as shown in the following table:\n",
"\n",
"| Category | Main paper |\n",
"| ---------------- | -------- |\n",
"| Method based on target detection | [Visual Detection with Context](https://aclanthology.org/D19-1348.pdf),[Object Detection](https://arxiv.org/pdf/2003.13197v1.pdf),[VSR](https://arxiv.org/pdf/2105.06220v1.pdf)\n",
"| Semantic segmentation method |[Semantic Segmentation](https://arxiv.org/pdf/1911.12170v2.pdf) |\n",
"\n",
"\n",
"### 1.2 Method Based on Target Detection \n",
"\n",
"Soto Carlos [1] is based on the target detection algorithm Faster R-CNN, combines context information and uses the inherent location information of the document content to improve the area detection performance. Li Kai [2] et al. also proposed a document analysis method based on object detection, which solved the cross-domain problem by introducing a feature pyramid alignment module, a region alignment module, and a rendering layer alignment module. These three modules complement each other. And adjust the domain from a general image perspective and a specific document image perspective, thus solving the problem of large labeled training datasets being different from the target domain. The following figure is a flow chart of layout analysis based on the target detection Faster R-CNN algorithm. \n",
"\n",
"\n",
"
\n",
"Figure 1: Layout analysis effect diagram\n",
"\n",
"The existing solutions are generally based on target detection or semantic segmentation methods, which are based on detecting or segmenting different patterns in the document as different targets.\n",
"\n",
"Some representative papers are divided into the above two categories, as shown in the following table:\n",
"\n",
"| Category | Main paper |\n",
"| ---------------- | -------- |\n",
"| Method based on target detection | [Visual Detection with Context](https://aclanthology.org/D19-1348.pdf),[Object Detection](https://arxiv.org/pdf/2003.13197v1.pdf),[VSR](https://arxiv.org/pdf/2105.06220v1.pdf)\n",
"| Semantic segmentation method |[Semantic Segmentation](https://arxiv.org/pdf/1911.12170v2.pdf) |\n",
"\n",
"\n",
"### 1.2 Method Based on Target Detection \n",
"\n",
"Soto Carlos [1] is based on the target detection algorithm Faster R-CNN, combines context information and uses the inherent location information of the document content to improve the area detection performance. Li Kai [2] et al. also proposed a document analysis method based on object detection, which solved the cross-domain problem by introducing a feature pyramid alignment module, a region alignment module, and a rendering layer alignment module. These three modules complement each other. And adjust the domain from a general image perspective and a specific document image perspective, thus solving the problem of large labeled training datasets being different from the target domain. The following figure is a flow chart of layout analysis based on the target detection Faster R-CNN algorithm. \n",
"\n",
"\n",
" \n",
"Figure 2: Flow chart of layout analysis based on Faster R-CNN\n",
"\n",
"### 1.3 Methods Based on Semantic Segmentation \n",
"\n",
"Sarkar Mausoom [3] et al. proposed a priori-based segmentation mechanism to train a document segmentation model on very high-resolution images, which solves the problem of indistinguishable and merging of dense regions caused by excessively shrinking the original image. Zhang Peng [4] et al. proposed a unified framework VSR (Vision, Semantics and Relations) for document layout analysis in combination with the vision, semantics and relations in the document. The framework uses a two-stream network to extract the visual and Semantic features, and adaptively fusion of these features through the adaptive aggregation module, solves the limitations of the existing CV-based methods of low efficiency of different modal fusion and lack of relationship modeling between layout components.\n",
"\n",
"### 1.4 Data Set\n",
"\n",
"Although the existing methods can solve the layout analysis task to a certain extent, these methods rely on a large amount of labeled training data. Recently, many data sets have been proposed for document analysis tasks.\n",
"\n",
"1. PubLayNet[5]: The data set contains 500,000 document images, of which 400,000 are used for training, 50,000 are used for verification, and 50,000 are used for testing. Five forms of table, text, image, title and list are marked.\n",
"2. HJDataset[6]: The data set contains 2271 document images. In addition to the bounding box and mask of the content area, it also includes the hierarchical structure and reading order of layout elements.\n",
"\n",
"A sample of the PubLayNet data set is shown in the figure below:\n",
"\n",
"
\n",
"Figure 2: Flow chart of layout analysis based on Faster R-CNN\n",
"\n",
"### 1.3 Methods Based on Semantic Segmentation \n",
"\n",
"Sarkar Mausoom [3] et al. proposed a priori-based segmentation mechanism to train a document segmentation model on very high-resolution images, which solves the problem of indistinguishable and merging of dense regions caused by excessively shrinking the original image. Zhang Peng [4] et al. proposed a unified framework VSR (Vision, Semantics and Relations) for document layout analysis in combination with the vision, semantics and relations in the document. The framework uses a two-stream network to extract the visual and Semantic features, and adaptively fusion of these features through the adaptive aggregation module, solves the limitations of the existing CV-based methods of low efficiency of different modal fusion and lack of relationship modeling between layout components.\n",
"\n",
"### 1.4 Data Set\n",
"\n",
"Although the existing methods can solve the layout analysis task to a certain extent, these methods rely on a large amount of labeled training data. Recently, many data sets have been proposed for document analysis tasks.\n",
"\n",
"1. PubLayNet[5]: The data set contains 500,000 document images, of which 400,000 are used for training, 50,000 are used for verification, and 50,000 are used for testing. Five forms of table, text, image, title and list are marked.\n",
"2. HJDataset[6]: The data set contains 2271 document images. In addition to the bounding box and mask of the content area, it also includes the hierarchical structure and reading order of layout elements.\n",
"\n",
"A sample of the PubLayNet data set is shown in the figure below:\n",
"\n",
"
 \n",
"\n",
"Figure 3: PubLayNet example\n",
"Reference:\n",
"\n",
"[1]:Soto C, Yoo S. Visual detection with context for document layout analysis[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 3464-3470.\n",
"\n",
"[2]:Li K, Wigington C, Tensmeyer C, et al. Cross-domain document object detection: Benchmark suite and method[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 12915-12924.\n",
"\n",
"[3]:Sarkar M, Aggarwal M, Jain A, et al. Document Structure Extraction using Prior based High Resolution Hierarchical Semantic Segmentation[C]//European Conference on Computer Vision. Springer, Cham, 2020: 649-666.\n",
"\n",
"[4]:Zhang P, Li C, Qiao L, et al. VSR: A Unified Framework for Document Layout Analysis combining Vision, Semantics and Relations[J]. arXiv preprint arXiv:2105.06220, 2021.\n",
"\n",
"[5]:Zhong X, Tang J, Yepes A J. Publaynet: largest dataset ever for document layout analysis[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1015-1022.\n",
"\n",
"[6]:Li M, Xu Y, Cui L, et al. DocBank: A benchmark dataset for document layout analysis[J]. arXiv preprint arXiv:2006.01038, 2020.\n",
"\n",
"[7]:Shen Z, Zhang K, Dell M. A large dataset of historical japanese documents with complex layouts[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020: 548-549."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
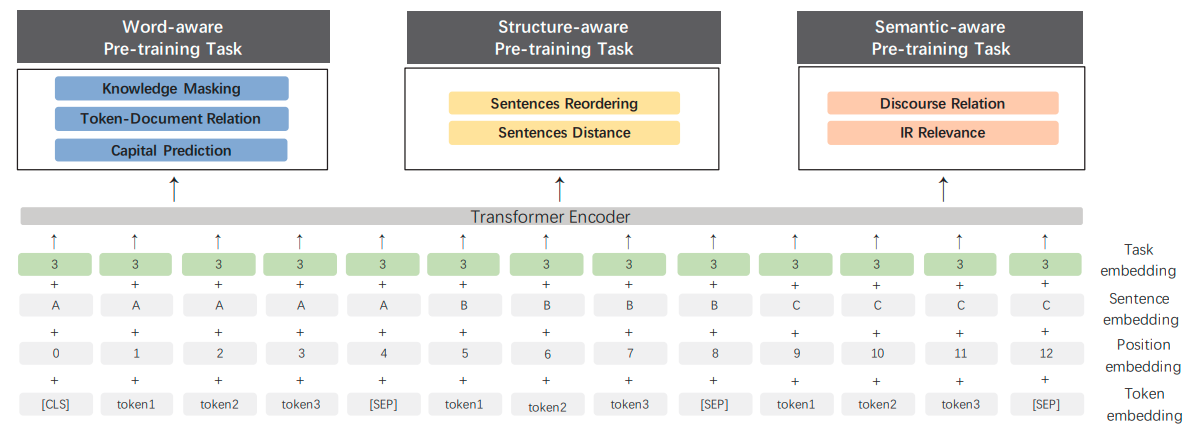
"## 2. Form Recognition\n",
"\n",
"### 2.1 Background Introduction\n",
"\n",
"Tables are common page elements in various types of documents. With the explosive growth of various types of documents, how to efficiently find tables from documents and obtain content and structure information, that is, table identification has become an urgent problem to be solved. The difficulties of form identification are summarized as follows:\n",
"\n",
"1. The types and styles of tables are complex and diverse, such as *different rows and columns combined, different content text types*, etc.\n",
"2. The style of the document itself has various styles.\n",
"3. The lighting environment during shooting, etc.\n",
"\n",
"The task of table recognition is to convert the table information in the document to an excel file. The task visualization is as follows:\n",
"\n",
"\n",
"
\n",
"\n",
"Figure 3: PubLayNet example\n",
"Reference:\n",
"\n",
"[1]:Soto C, Yoo S. Visual detection with context for document layout analysis[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 3464-3470.\n",
"\n",
"[2]:Li K, Wigington C, Tensmeyer C, et al. Cross-domain document object detection: Benchmark suite and method[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 12915-12924.\n",
"\n",
"[3]:Sarkar M, Aggarwal M, Jain A, et al. Document Structure Extraction using Prior based High Resolution Hierarchical Semantic Segmentation[C]//European Conference on Computer Vision. Springer, Cham, 2020: 649-666.\n",
"\n",
"[4]:Zhang P, Li C, Qiao L, et al. VSR: A Unified Framework for Document Layout Analysis combining Vision, Semantics and Relations[J]. arXiv preprint arXiv:2105.06220, 2021.\n",
"\n",
"[5]:Zhong X, Tang J, Yepes A J. Publaynet: largest dataset ever for document layout analysis[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1015-1022.\n",
"\n",
"[6]:Li M, Xu Y, Cui L, et al. DocBank: A benchmark dataset for document layout analysis[J]. arXiv preprint arXiv:2006.01038, 2020.\n",
"\n",
"[7]:Shen Z, Zhang K, Dell M. A large dataset of historical japanese documents with complex layouts[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020: 548-549."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 2. Form Recognition\n",
"\n",
"### 2.1 Background Introduction\n",
"\n",
"Tables are common page elements in various types of documents. With the explosive growth of various types of documents, how to efficiently find tables from documents and obtain content and structure information, that is, table identification has become an urgent problem to be solved. The difficulties of form identification are summarized as follows:\n",
"\n",
"1. The types and styles of tables are complex and diverse, such as *different rows and columns combined, different content text types*, etc.\n",
"2. The style of the document itself has various styles.\n",
"3. The lighting environment during shooting, etc.\n",
"\n",
"The task of table recognition is to convert the table information in the document to an excel file. The task visualization is as follows:\n",
"\n",
"\n",
" \n",
"\n",
"\n",
"Figure 4: Example image of table recognition, the left side is the original image, and the right side is the result image after table recognition, presented in Excel format\n",
"\n",
"Existing table recognition algorithms can be divided into the following four categories according to the principle of table structure reconstruction:\n",
"1. Method based on heuristic rules\n",
"2. CNN-based method\n",
"3. GCN-based method\n",
"4. Method based on End to End\n",
"\n",
"Some representative papers are divided into the above four categories, as shown in the following table:\n",
"\n",
"| Category | Idea | Main papers |\n",
"| ---------------- | ---- | -------- |\n",
"|Method based on heuristic rules|Manual design rules, connected domain detection analysis and processing|[T-Rect](https://www.researchgate.net/profile/Andreas-Dengel/publication/249657389_A_Paper-to-HTML_Table_Converting_System/links/0c9605322c9a67274d000000/A-Paper-to-HTML-Table-Converting-System.pdf),[pdf2table](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.724.7272&rep=rep1&type=pdf)|\n",
"| CNN-based method | target detection, semantic segmentation | [CascadeTabNet](https://arxiv.org/pdf/2004.12629v2.pdf), [Multi-Type-TD-TSR](https://arxiv.org/pdf/2105.11021v1.pdf), [LGPMA](https://arxiv.org/pdf/2105.06224v2.pdf), [tabstruct-net](https://arxiv.org/pdf/2010.04565v1.pdf), [CDeC-Net](https://arxiv.org/pdf/2008.10831v1.pdf), [TableNet](https://arxiv.org/pdf/2001.01469v1.pdf), [TableSense](https://arxiv.org/pdf/2106.13500v1.pdf), [Deepdesrt](https://www.dfki.de/fileadmin/user_upload/import/9672_PID4966073.pdf), [Deeptabstr](https://www.dfki.de/fileadmin/user_upload/import/10649_DeepTabStR.pdf), [GTE](https://arxiv.org/pdf/2005.00589v2.pdf), [Cycle-CenterNet](https://arxiv.org/pdf/2109.02199v1.pdf), [FCN](https://www.researchgate.net/publication/339027294_Rethinking_Semantic_Segmentation_for_Table_Structure_Recognition_in_Documents)|\n",
"| GCN-based method | Based on graph neural network, the table recognition is regarded as a graph reconstruction problem | [GNN](https://arxiv.org/pdf/1905.13391v2.pdf), [TGRNet](https://arxiv.org/pdf/2106.10598v3.pdf), [GraphTSR](https://arxiv.org/pdf/1908.04729v2.pdf)|\n",
"| Method based on End to End | Use attention mechanism | [Table-Master](https://arxiv.org/pdf/2105.01848v1.pdf)|\n",
"\n",
"### 2.2 Traditional Algorithm Based on Heuristic Rules\n",
"Early research on table recognition was mainly based on heuristic rules. For example, the T-Rect system proposed by Kieninger [1] et al. used a bottom-up method to analyze the connected domain of document images, and then merge them according to defined rules to obtain logical text blocks. Then, pdf2table proposed by Yildiz[2] et al. is the first method for table recognition on PDF documents, which utilizes some unique information of PDF files (such as text, drawing paths and other information that are difficult to obtain in image documents) to assist with table recognition. In recent work, Koci[3] et al. expressed the layout area in the page as a graph, and then used the Remove and Conquer (RAC) algorithm to identify the table as a subgraph.\n",
"\n",
"\n",
"
\n",
"\n",
"\n",
"Figure 4: Example image of table recognition, the left side is the original image, and the right side is the result image after table recognition, presented in Excel format\n",
"\n",
"Existing table recognition algorithms can be divided into the following four categories according to the principle of table structure reconstruction:\n",
"1. Method based on heuristic rules\n",
"2. CNN-based method\n",
"3. GCN-based method\n",
"4. Method based on End to End\n",
"\n",
"Some representative papers are divided into the above four categories, as shown in the following table:\n",
"\n",
"| Category | Idea | Main papers |\n",
"| ---------------- | ---- | -------- |\n",
"|Method based on heuristic rules|Manual design rules, connected domain detection analysis and processing|[T-Rect](https://www.researchgate.net/profile/Andreas-Dengel/publication/249657389_A_Paper-to-HTML_Table_Converting_System/links/0c9605322c9a67274d000000/A-Paper-to-HTML-Table-Converting-System.pdf),[pdf2table](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.724.7272&rep=rep1&type=pdf)|\n",
"| CNN-based method | target detection, semantic segmentation | [CascadeTabNet](https://arxiv.org/pdf/2004.12629v2.pdf), [Multi-Type-TD-TSR](https://arxiv.org/pdf/2105.11021v1.pdf), [LGPMA](https://arxiv.org/pdf/2105.06224v2.pdf), [tabstruct-net](https://arxiv.org/pdf/2010.04565v1.pdf), [CDeC-Net](https://arxiv.org/pdf/2008.10831v1.pdf), [TableNet](https://arxiv.org/pdf/2001.01469v1.pdf), [TableSense](https://arxiv.org/pdf/2106.13500v1.pdf), [Deepdesrt](https://www.dfki.de/fileadmin/user_upload/import/9672_PID4966073.pdf), [Deeptabstr](https://www.dfki.de/fileadmin/user_upload/import/10649_DeepTabStR.pdf), [GTE](https://arxiv.org/pdf/2005.00589v2.pdf), [Cycle-CenterNet](https://arxiv.org/pdf/2109.02199v1.pdf), [FCN](https://www.researchgate.net/publication/339027294_Rethinking_Semantic_Segmentation_for_Table_Structure_Recognition_in_Documents)|\n",
"| GCN-based method | Based on graph neural network, the table recognition is regarded as a graph reconstruction problem | [GNN](https://arxiv.org/pdf/1905.13391v2.pdf), [TGRNet](https://arxiv.org/pdf/2106.10598v3.pdf), [GraphTSR](https://arxiv.org/pdf/1908.04729v2.pdf)|\n",
"| Method based on End to End | Use attention mechanism | [Table-Master](https://arxiv.org/pdf/2105.01848v1.pdf)|\n",
"\n",
"### 2.2 Traditional Algorithm Based on Heuristic Rules\n",
"Early research on table recognition was mainly based on heuristic rules. For example, the T-Rect system proposed by Kieninger [1] et al. used a bottom-up method to analyze the connected domain of document images, and then merge them according to defined rules to obtain logical text blocks. Then, pdf2table proposed by Yildiz[2] et al. is the first method for table recognition on PDF documents, which utilizes some unique information of PDF files (such as text, drawing paths and other information that are difficult to obtain in image documents) to assist with table recognition. In recent work, Koci[3] et al. expressed the layout area in the page as a graph, and then used the Remove and Conquer (RAC) algorithm to identify the table as a subgraph.\n",
"\n",
"\n",
" \n",
"Figure 5: Schematic diagram of heuristic algorithm\n",
"\n",
"### 2.3 Method Based on Deep Learning CNN\n",
"With the rapid development of deep learning technology in computer vision, natural language processing, speech processing and other fields, researchers have applied deep learning technology to the field of table recognition and achieved good results.\n",
"\n",
"In the DeepTabStR algorithm, Siddiqui Shoaib Ahmed [12] et al. described the table structure recognition problem as an object detection problem, and used deformable convolution to better detect table cells. Raja Sachin[6] et al. proposed that TabStruct-Net combines cell detection and structure recognition visually to perform table structure recognition, which solves the problem of recognition errors due to large changes in the table layout. However, this method cannot Deal with the problem of more empty cells in rows and columns.\n",
"\n",
"\n",
"
\n",
"Figure 5: Schematic diagram of heuristic algorithm\n",
"\n",
"### 2.3 Method Based on Deep Learning CNN\n",
"With the rapid development of deep learning technology in computer vision, natural language processing, speech processing and other fields, researchers have applied deep learning technology to the field of table recognition and achieved good results.\n",
"\n",
"In the DeepTabStR algorithm, Siddiqui Shoaib Ahmed [12] et al. described the table structure recognition problem as an object detection problem, and used deformable convolution to better detect table cells. Raja Sachin[6] et al. proposed that TabStruct-Net combines cell detection and structure recognition visually to perform table structure recognition, which solves the problem of recognition errors due to large changes in the table layout. However, this method cannot Deal with the problem of more empty cells in rows and columns.\n",
"\n",
"\n",
" \n",
"Figure 6: Schematic diagram of algorithm based on deep learning CNN\n",
"\n",
"\n",
"
\n",
"Figure 6: Schematic diagram of algorithm based on deep learning CNN\n",
"\n",
"\n",
" \n",
"Figure 7: Example of algorithm error based on deep learning CNN\n",
"\n",
"The previous table structure recognition method generally starts from the elements of different granularities (row/column, text area), and it is easy to ignore the problem of merging empty cells. Qiao Liang [10] et al. proposed a new framework LGPMA, which makes full use of the information from local and global features through mask re-scoring strategy, and then can obtain more reliable alignment of the cell area, and finally introduces the inclusion of cell matching, empty The table structure restoration pipeline of cell search and empty cell merging handles the problem of table structure identification.\n",
"\n",
"In addition to the above separate table recognition algorithms, there are also some methods that complete table detection and table recognition in one model. Schreiber Sebastian [11] et al. proposed DeepDeSRT, which uses Faster RCNN for table detection and FCN semantic segmentation model for Table structure row and column detection, but this method uses two independent models to solve these two problems. Prasad Devashish [4] et al. proposed an end-to-end deep learning method CascadeTabNet, which uses the Cascade Mask R-CNN HRNet model to perform table detection and structure recognition at the same time, which solves the problem of using two independent methods to process table recognition in the past. The insufficiency of the problem. Paliwal Shubham [8] et al. proposed a novel end-to-end deep multi-task architecture TableNet, which is used for table detection and structure recognition. At the same time, additional spatial semantic features are added to TableNet during training to further improve the performance of the model. Zheng Xinyi [13] et al. proposed a system framework GTE for table recognition, using a cell detection network to guide the training of the table detection network, and proposed a hierarchical network and a new clustering-based cell structure recognition algorithm, the framework can be connected to the back of any target detection model to facilitate the training of different table recognition algorithms. Previous research mainly focused on parsing from scanned PDF documents with a simple layout and well-aligned table images. However, the tables in real scenes are generally complex and may have serious deformation, bending or occlusion. Therefore, Long Rujiao [14] et al. also constructed a table recognition data set WTW in a realistic complex scene, and proposed a Cycle-CenterNet method, which uses the cyclic pairing module optimization and the proposed new pairing loss to accurately group discrete units into structured In the table, the performance of table recognition is improved.\n",
"\n",
"\n",
"
\n",
"Figure 7: Example of algorithm error based on deep learning CNN\n",
"\n",
"The previous table structure recognition method generally starts from the elements of different granularities (row/column, text area), and it is easy to ignore the problem of merging empty cells. Qiao Liang [10] et al. proposed a new framework LGPMA, which makes full use of the information from local and global features through mask re-scoring strategy, and then can obtain more reliable alignment of the cell area, and finally introduces the inclusion of cell matching, empty The table structure restoration pipeline of cell search and empty cell merging handles the problem of table structure identification.\n",
"\n",
"In addition to the above separate table recognition algorithms, there are also some methods that complete table detection and table recognition in one model. Schreiber Sebastian [11] et al. proposed DeepDeSRT, which uses Faster RCNN for table detection and FCN semantic segmentation model for Table structure row and column detection, but this method uses two independent models to solve these two problems. Prasad Devashish [4] et al. proposed an end-to-end deep learning method CascadeTabNet, which uses the Cascade Mask R-CNN HRNet model to perform table detection and structure recognition at the same time, which solves the problem of using two independent methods to process table recognition in the past. The insufficiency of the problem. Paliwal Shubham [8] et al. proposed a novel end-to-end deep multi-task architecture TableNet, which is used for table detection and structure recognition. At the same time, additional spatial semantic features are added to TableNet during training to further improve the performance of the model. Zheng Xinyi [13] et al. proposed a system framework GTE for table recognition, using a cell detection network to guide the training of the table detection network, and proposed a hierarchical network and a new clustering-based cell structure recognition algorithm, the framework can be connected to the back of any target detection model to facilitate the training of different table recognition algorithms. Previous research mainly focused on parsing from scanned PDF documents with a simple layout and well-aligned table images. However, the tables in real scenes are generally complex and may have serious deformation, bending or occlusion. Therefore, Long Rujiao [14] et al. also constructed a table recognition data set WTW in a realistic complex scene, and proposed a Cycle-CenterNet method, which uses the cyclic pairing module optimization and the proposed new pairing loss to accurately group discrete units into structured In the table, the performance of table recognition is improved.\n",
"\n",
"\n",
" \n",
"Figure 8: Schematic diagram of end-to-end algorithm\n",
"\n",
"The CNN-based method cannot handle the cross-row and column tables well, so in the follow-up method, two research methods are divided to solve the cross-row and column problems in the table.\n",
"\n",
"### 2.4 Method Based on Deep Learning GCN\n",
"In recent years, with the rise of Graph Convolutional Networks (Graph Convolutional Network), some researchers have tried to apply graph neural networks to table structure recognition problems. Qasim Shah Rukh [20] et al. converted the table structure recognition problem into a graph problem compatible with graph neural networks, and designed a novel differentiable architecture that can not only take advantage of the advantages of convolutional neural networks to extract features, but also The advantages of the effective interaction between the vertices of the graph neural network can be used, but this method only uses the location features of the cells, and does not use the semantic features. Chi Zewen [19] et al. proposed a novel graph neural network, GraphTSR, for table structure recognition in PDF files. It takes cells in the table as input, and then uses the characteristics of the edges and nodes of the graph to be connected. Predicting the relationship between cells to identify the table structure solves the problem of cell identification across rows or columns to a certain extent. Xue Wenyuan [21] et al. reformulated the problem of table structure recognition as table map reconstruction, and proposed an end-to-end method for table structure recognition, TGRNet, which includes cell detection branch and cell logic location branch. , These two branches jointly predict the spatial and logical positions of different cells, which solves the problem that the previous method did not pay attention to the logical position of cells.\n",
"\n",
"Diagram of GraphTSR table recognition algorithm:\n",
"\n",
"\n",
"
\n",
"Figure 8: Schematic diagram of end-to-end algorithm\n",
"\n",
"The CNN-based method cannot handle the cross-row and column tables well, so in the follow-up method, two research methods are divided to solve the cross-row and column problems in the table.\n",
"\n",
"### 2.4 Method Based on Deep Learning GCN\n",
"In recent years, with the rise of Graph Convolutional Networks (Graph Convolutional Network), some researchers have tried to apply graph neural networks to table structure recognition problems. Qasim Shah Rukh [20] et al. converted the table structure recognition problem into a graph problem compatible with graph neural networks, and designed a novel differentiable architecture that can not only take advantage of the advantages of convolutional neural networks to extract features, but also The advantages of the effective interaction between the vertices of the graph neural network can be used, but this method only uses the location features of the cells, and does not use the semantic features. Chi Zewen [19] et al. proposed a novel graph neural network, GraphTSR, for table structure recognition in PDF files. It takes cells in the table as input, and then uses the characteristics of the edges and nodes of the graph to be connected. Predicting the relationship between cells to identify the table structure solves the problem of cell identification across rows or columns to a certain extent. Xue Wenyuan [21] et al. reformulated the problem of table structure recognition as table map reconstruction, and proposed an end-to-end method for table structure recognition, TGRNet, which includes cell detection branch and cell logic location branch. , These two branches jointly predict the spatial and logical positions of different cells, which solves the problem that the previous method did not pay attention to the logical position of cells.\n",
"\n",
"Diagram of GraphTSR table recognition algorithm:\n",
"\n",
"\n",
" \n",
"Figure 9: Diagram of GraphTSR table recognition algorithm\n",
"\n",
"### 2.5 Based on An End-to-End Approach\n",
"\n",
"Different from other post-processing to complete the reconstruction of the table structure, based on the end-to-end method, directly use the network to complete the HTML representation output of the table structure\n",
"\n",
"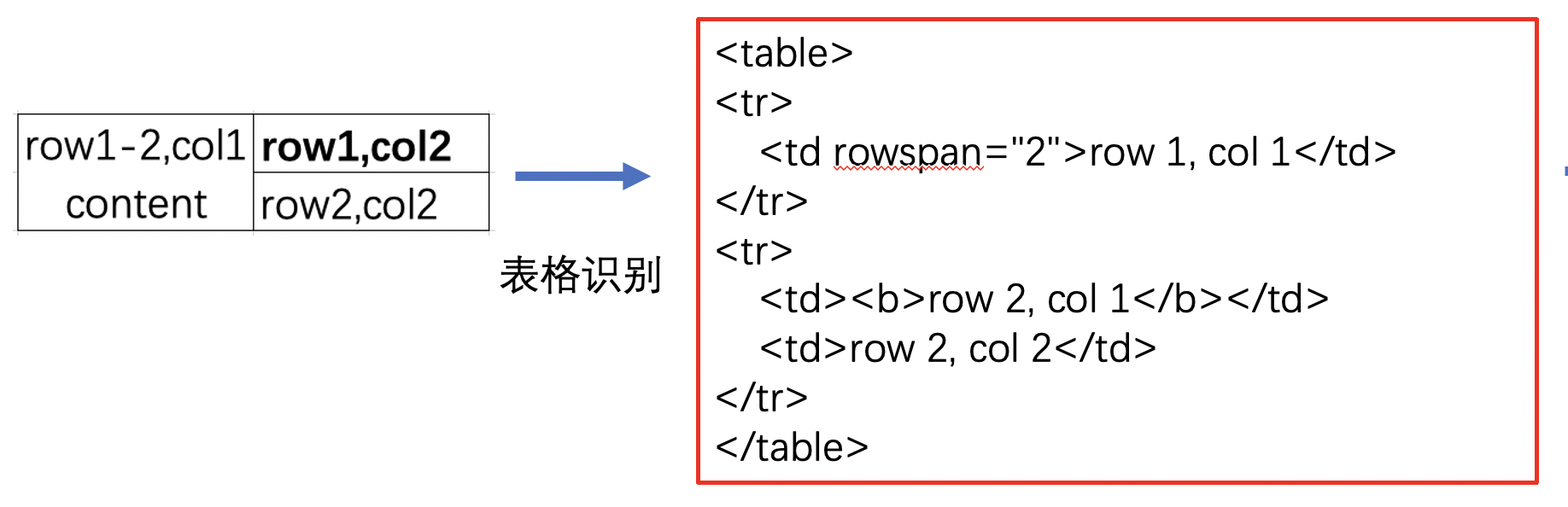 | )\n",
"---|---\n",
"Figure 10: Input and output of the end-to-end method | Figure 11: Image Caption example\n",
"\n",
"Most end-to-end methods use Image Caption's Seq2Seq method to complete the prediction of the table structure, such as some methods based on Attention or Transformer.\n",
"\n",
"\n",
"
\n",
"Figure 9: Diagram of GraphTSR table recognition algorithm\n",
"\n",
"### 2.5 Based on An End-to-End Approach\n",
"\n",
"Different from other post-processing to complete the reconstruction of the table structure, based on the end-to-end method, directly use the network to complete the HTML representation output of the table structure\n",
"\n",
" | )\n",
"---|---\n",
"Figure 10: Input and output of the end-to-end method | Figure 11: Image Caption example\n",
"\n",
"Most end-to-end methods use Image Caption's Seq2Seq method to complete the prediction of the table structure, such as some methods based on Attention or Transformer.\n",
"\n",
"\n",
" \n",
"Figure 12: Schematic diagram of Seq2Seq\n",
"\n",
"Ye Jiaquan [22] obtained the table structure output model in TableMaster by improving the Master text algorithm based on Transformer. In addition, a branch is added for the coordinate regression of the box. The author did not split the model into two branches in the last layer, but decoupled the sequence prediction and the box regression into two after the first Transformer decoding layer. Branches. The comparison between its network structure and the original Master network is shown in the figure below:\n",
"\n",
"\n",
"\n",
"
\n",
"Figure 12: Schematic diagram of Seq2Seq\n",
"\n",
"Ye Jiaquan [22] obtained the table structure output model in TableMaster by improving the Master text algorithm based on Transformer. In addition, a branch is added for the coordinate regression of the box. The author did not split the model into two branches in the last layer, but decoupled the sequence prediction and the box regression into two after the first Transformer decoding layer. Branches. The comparison between its network structure and the original Master network is shown in the figure below:\n",
"\n",
"\n",
"\n",
" \n",
"Figure 13: Left: master network diagram, right: TableMaster network diagram\n",
"\n",
"\n",
"### 2.6 Data Set\n",
"\n",
"Since the deep learning method is data-driven, a large amount of labeled data is required to train the model, and the small size of the existing data set is also an important constraint, so some data sets have also been proposed.\n",
"\n",
"1. PubTabNet[16]: Contains 568k table images and corresponding structured HTML representations.\n",
"2. PubMed Tables (PubTables-1M) [17]: Table structure recognition data set, containing highly detailed structural annotations, 460,589 pdf images used for table inspection tasks, and 947,642 table images used for table recognition tasks.\n",
"3. TableBank[18]: Table detection and recognition data set, using Word and Latex documents on the Internet to construct table data containing 417K high-quality annotations.\n",
"4. SciTSR[19]: Table structure recognition data set, most of the images are converted from the paper, which contains 15,000 tables from PDF files and their corresponding structure tags.\n",
"5. TabStructDB[12]: Includes 1081 table areas, which are marked with dense row and column information.\n",
"6. WTW[14]: Large-scale data set scene table detection and recognition data set, this data set contains table data in various deformation, bending and occlusion situations, and contains 14,581 images in total.\n",
"\n",
"Data set example\n",
"\n",
"\n",
"
\n",
"Figure 13: Left: master network diagram, right: TableMaster network diagram\n",
"\n",
"\n",
"### 2.6 Data Set\n",
"\n",
"Since the deep learning method is data-driven, a large amount of labeled data is required to train the model, and the small size of the existing data set is also an important constraint, so some data sets have also been proposed.\n",
"\n",
"1. PubTabNet[16]: Contains 568k table images and corresponding structured HTML representations.\n",
"2. PubMed Tables (PubTables-1M) [17]: Table structure recognition data set, containing highly detailed structural annotations, 460,589 pdf images used for table inspection tasks, and 947,642 table images used for table recognition tasks.\n",
"3. TableBank[18]: Table detection and recognition data set, using Word and Latex documents on the Internet to construct table data containing 417K high-quality annotations.\n",
"4. SciTSR[19]: Table structure recognition data set, most of the images are converted from the paper, which contains 15,000 tables from PDF files and their corresponding structure tags.\n",
"5. TabStructDB[12]: Includes 1081 table areas, which are marked with dense row and column information.\n",
"6. WTW[14]: Large-scale data set scene table detection and recognition data set, this data set contains table data in various deformation, bending and occlusion situations, and contains 14,581 images in total.\n",
"\n",
"Data set example\n",
"\n",
"\n",
" \n",
"Figure 14: Sample diagram of PubTables-1M data set\n",
"\n",
"\n",
"
\n",
"Figure 14: Sample diagram of PubTables-1M data set\n",
"\n",
"\n",
" \n",
"Figure 15: Sample diagram of WTW data set\n",
"\n",
"\n",
"\n",
"Reference\n",
"\n",
"[1]:Kieninger T, Dengel A. A paper-to-HTML table converting system[C]//Proceedings of document analysis systems (DAS). 1998, 98: 356-365.\n",
"\n",
"[2]:Yildiz B, Kaiser K, Miksch S. pdf2table: A method to extract table information from pdf files[C]//IICAI. 2005: 1773-1785.\n",
"\n",
"[3]:Koci E, Thiele M, Lehner W, et al. Table recognition in spreadsheets via a graph representation[C]//2018 13th IAPR International Workshop on Document Analysis Systems (DAS). IEEE, 2018: 139-144.\n",
"\n",
"[4]:Prasad D, Gadpal A, Kapadni K, et al. CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020: 572-573.\n",
"\n",
"[5]:Fischer P, Smajic A, Abrami G, et al. Multi-Type-TD-TSR–Extracting Tables from Document Images Using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: From OCR to Structured Table Representations[C]//German Conference on Artificial Intelligence (Künstliche Intelligenz). Springer, Cham, 2021: 95-108.\n",
"\n",
"[6]:Raja S, Mondal A, Jawahar C V. Table structure recognition using top-down and bottom-up cues[C]//European Conference on Computer Vision. Springer, Cham, 2020: 70-86.\n",
"\n",
"[7]:Agarwal M, Mondal A, Jawahar C V. Cdec-net: Composite deformable cascade network for table detection in document images[C]//2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021: 9491-9498.\n",
"\n",
"[8]:Paliwal S S, Vishwanath D, Rahul R, et al. Tablenet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 128-133.\n",
"\n",
"[9]:Dong H, Liu S, Han S, et al. Tablesense: Spreadsheet table detection with convolutional neural networks[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 69-76.\n",
"\n",
"[10]:Qiao L, Li Z, Cheng Z, et al. LGPMA: Complicated Table Structure Recognition with Local and Global Pyramid Mask Alignment[J]. arXiv preprint arXiv:2105.06224, 2021.\n",
"\n",
"[11]:Schreiber S, Agne S, Wolf I, et al. Deepdesrt: Deep learning for detection and structure recognition of tables in document images[C]//2017 14th IAPR international conference on document analysis and recognition (ICDAR). IEEE, 2017, 1: 1162-1167.\n",
"\n",
"[12]:Siddiqui S A, Fateh I A, Rizvi S T R, et al. Deeptabstr: Deep learning based table structure recognition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1403-1409.\n",
"\n",
"[13]:Zheng X, Burdick D, Popa L, et al. Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2021: 697-706.\n",
"\n",
"[14]:Long R, Wang W, Xue N, et al. Parsing Table Structures in the Wild[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 944-952.\n",
"\n",
"[15]:Siddiqui S A, Khan P I, Dengel A, et al. Rethinking semantic segmentation for table structure recognition in documents[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1397-1402.\n",
"\n",
"[16]:Zhong X, ShafieiBavani E, Jimeno Yepes A. Image-based table recognition: data, model, and evaluation[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16. Springer International Publishing, 2020: 564-580.\n",
"\n",
"[17]:Smock B, Pesala R, Abraham R. PubTables-1M: Towards a universal dataset and metrics for training and evaluating table extraction models[J]. arXiv preprint arXiv:2110.00061, 2021.\n",
"\n",
"[18]:Li M, Cui L, Huang S, et al. Tablebank: Table benchmark for image-based table detection and recognition[C]//Proceedings of the 12th Language Resources and Evaluation Conference. 2020: 1918-1925.\n",
"\n",
"[19]:Chi Z, Huang H, Xu H D, et al. Complicated table structure recognition[J]. arXiv preprint arXiv:1908.04729, 2019.\n",
"\n",
"[20]:Qasim S R, Mahmood H, Shafait F. Rethinking table recognition using graph neural networks[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 142-147.\n",
"\n",
"[21]:Xue W, Yu B, Wang W, et al. TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition[J]. arXiv preprint arXiv:2106.10598, 2021.\n",
"\n",
"[22]:Ye J, Qi X, He Y, et al. PingAn-VCGroup's Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B: Table Recognition to HTML[J]. arXiv preprint arXiv:2105.01848, 2021.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
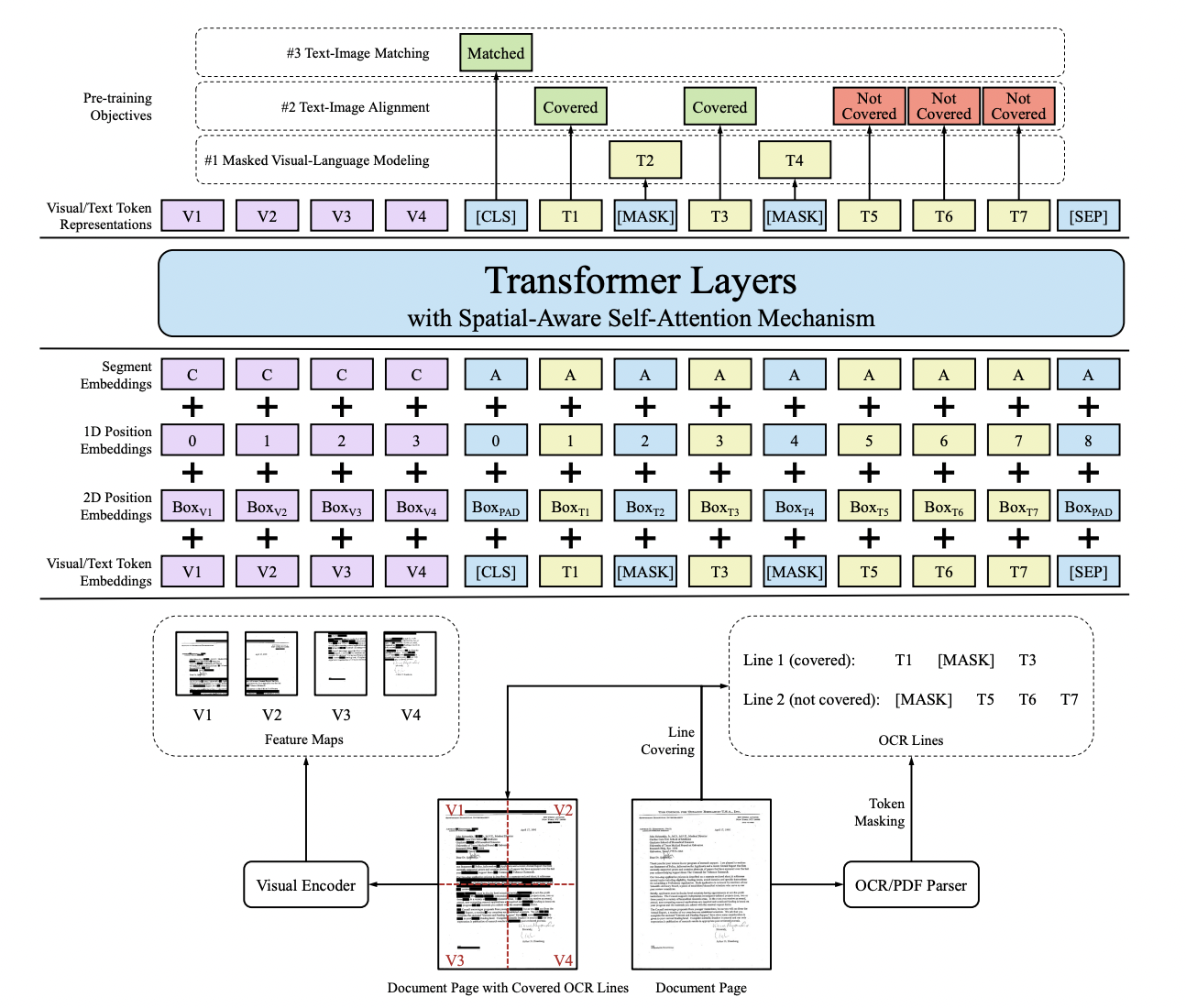
"## 3. Document VQA\n",
"\n",
"The boss sent a task: develop an ID card recognition system\n",
"\n",
"\n",
"
\n",
"Figure 15: Sample diagram of WTW data set\n",
"\n",
"\n",
"\n",
"Reference\n",
"\n",
"[1]:Kieninger T, Dengel A. A paper-to-HTML table converting system[C]//Proceedings of document analysis systems (DAS). 1998, 98: 356-365.\n",
"\n",
"[2]:Yildiz B, Kaiser K, Miksch S. pdf2table: A method to extract table information from pdf files[C]//IICAI. 2005: 1773-1785.\n",
"\n",
"[3]:Koci E, Thiele M, Lehner W, et al. Table recognition in spreadsheets via a graph representation[C]//2018 13th IAPR International Workshop on Document Analysis Systems (DAS). IEEE, 2018: 139-144.\n",
"\n",
"[4]:Prasad D, Gadpal A, Kapadni K, et al. CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020: 572-573.\n",
"\n",
"[5]:Fischer P, Smajic A, Abrami G, et al. Multi-Type-TD-TSR–Extracting Tables from Document Images Using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: From OCR to Structured Table Representations[C]//German Conference on Artificial Intelligence (Künstliche Intelligenz). Springer, Cham, 2021: 95-108.\n",
"\n",
"[6]:Raja S, Mondal A, Jawahar C V. Table structure recognition using top-down and bottom-up cues[C]//European Conference on Computer Vision. Springer, Cham, 2020: 70-86.\n",
"\n",
"[7]:Agarwal M, Mondal A, Jawahar C V. Cdec-net: Composite deformable cascade network for table detection in document images[C]//2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021: 9491-9498.\n",
"\n",
"[8]:Paliwal S S, Vishwanath D, Rahul R, et al. Tablenet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 128-133.\n",
"\n",
"[9]:Dong H, Liu S, Han S, et al. Tablesense: Spreadsheet table detection with convolutional neural networks[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 69-76.\n",
"\n",
"[10]:Qiao L, Li Z, Cheng Z, et al. LGPMA: Complicated Table Structure Recognition with Local and Global Pyramid Mask Alignment[J]. arXiv preprint arXiv:2105.06224, 2021.\n",
"\n",
"[11]:Schreiber S, Agne S, Wolf I, et al. Deepdesrt: Deep learning for detection and structure recognition of tables in document images[C]//2017 14th IAPR international conference on document analysis and recognition (ICDAR). IEEE, 2017, 1: 1162-1167.\n",
"\n",
"[12]:Siddiqui S A, Fateh I A, Rizvi S T R, et al. Deeptabstr: Deep learning based table structure recognition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1403-1409.\n",
"\n",
"[13]:Zheng X, Burdick D, Popa L, et al. Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2021: 697-706.\n",
"\n",
"[14]:Long R, Wang W, Xue N, et al. Parsing Table Structures in the Wild[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 944-952.\n",
"\n",
"[15]:Siddiqui S A, Khan P I, Dengel A, et al. Rethinking semantic segmentation for table structure recognition in documents[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1397-1402.\n",
"\n",
"[16]:Zhong X, ShafieiBavani E, Jimeno Yepes A. Image-based table recognition: data, model, and evaluation[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16. Springer International Publishing, 2020: 564-580.\n",
"\n",
"[17]:Smock B, Pesala R, Abraham R. PubTables-1M: Towards a universal dataset and metrics for training and evaluating table extraction models[J]. arXiv preprint arXiv:2110.00061, 2021.\n",
"\n",
"[18]:Li M, Cui L, Huang S, et al. Tablebank: Table benchmark for image-based table detection and recognition[C]//Proceedings of the 12th Language Resources and Evaluation Conference. 2020: 1918-1925.\n",
"\n",
"[19]:Chi Z, Huang H, Xu H D, et al. Complicated table structure recognition[J]. arXiv preprint arXiv:1908.04729, 2019.\n",
"\n",
"[20]:Qasim S R, Mahmood H, Shafait F. Rethinking table recognition using graph neural networks[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 142-147.\n",
"\n",
"[21]:Xue W, Yu B, Wang W, et al. TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition[J]. arXiv preprint arXiv:2106.10598, 2021.\n",
"\n",
"[22]:Ye J, Qi X, He Y, et al. PingAn-VCGroup's Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B: Table Recognition to HTML[J]. arXiv preprint arXiv:2105.01848, 2021.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3. Document VQA\n",
"\n",
"The boss sent a task: develop an ID card recognition system\n",
"\n",
"\n",
" \n",
"\n",
"> How to choose a plan\n",
"> 1. Use rules to extract information after text detection\n",
"> 2. Use scale type to extract information after text detection\n",
"> 3. Outsourcing\n",
"\n",
"\n",
"### 3.1 Background Introduction\n",
"In the VQA (Visual Question Answering) task, questions and answers are mainly aimed at the content of the image, but for text images, the content of interest is the text information in the image, so this type of method can be divided into Text-VQA and text-VQA in natural scenes. DocVQA of the scanned document scene, the relationship between the three is shown in the figure below.\n",
"\n",
"\n",
"
\n",
"\n",
"> How to choose a plan\n",
"> 1. Use rules to extract information after text detection\n",
"> 2. Use scale type to extract information after text detection\n",
"> 3. Outsourcing\n",
"\n",
"\n",
"### 3.1 Background Introduction\n",
"In the VQA (Visual Question Answering) task, questions and answers are mainly aimed at the content of the image, but for text images, the content of interest is the text information in the image, so this type of method can be divided into Text-VQA and text-VQA in natural scenes. DocVQA of the scanned document scene, the relationship between the three is shown in the figure below.\n",
"\n",
"\n",
" \n",
"Figure 16: VQA level\n",
"\n",
"The sample pictures of VQA, Text-VQA and DocVQA are shown in the figure below.\n",
"\n",
"|Task type|VQA | Text-VQA | DocVQA| \n",
"|---|---|---|---|\n",
"|Task description|Ask questions regarding **picture content**|Ask questions regarding **text content on pictures**|Ask questions regarding **text content of document images**|\n",
"|Sample picture||||\n",
"\n",
"Because DocVQA is closer to actual application scenarios, a large number of academic and industrial work has emerged. In common scenarios, the questions asked in DocVQA are fixed. For example, the questions in the ID card scenario are generally\n",
"1. What is the citizenship number?\n",
"2. What is your name?\n",
"3. What is a clan?\n",
"\n",
"\n",
"
\n",
"Figure 16: VQA level\n",
"\n",
"The sample pictures of VQA, Text-VQA and DocVQA are shown in the figure below.\n",
"\n",
"|Task type|VQA | Text-VQA | DocVQA| \n",
"|---|---|---|---|\n",
"|Task description|Ask questions regarding **picture content**|Ask questions regarding **text content on pictures**|Ask questions regarding **text content of document images**|\n",
"|Sample picture||||\n",
"\n",
"Because DocVQA is closer to actual application scenarios, a large number of academic and industrial work has emerged. In common scenarios, the questions asked in DocVQA are fixed. For example, the questions in the ID card scenario are generally\n",
"1. What is the citizenship number?\n",
"2. What is your name?\n",
"3. What is a clan?\n",
"\n",
"\n",
" \n",
"Figure 17: Example of an ID card\n",
"\n",
"\n",
"Based on this prior knowledge, DocVQA's research began to lean towards the Key Information Extraction (KIE) task. This time we also mainly discuss the KIE-related research. The KIE task mainly extracts the key information needed from the image, such as extracting from the ID card. Name and citizen identification number information.\n",
"\n",
"KIE is usually divided into two sub-tasks for research\n",
"1. SER: Semantic Entity Recognition, to classify each detected text, such as dividing it into name and ID. As shown in the black box and red box in the figure below.\n",
"2. RE: Relation Extraction, which classifies each detected text, such as dividing it into questions and answers. Then find the corresponding answer to each question. As shown in the figure below, the red and black boxes represent the question and the answer, respectively, and the yellow line represents the correspondence between the question and the answer.\n",
"\n",
"
\n",
"Figure 17: Example of an ID card\n",
"\n",
"\n",
"Based on this prior knowledge, DocVQA's research began to lean towards the Key Information Extraction (KIE) task. This time we also mainly discuss the KIE-related research. The KIE task mainly extracts the key information needed from the image, such as extracting from the ID card. Name and citizen identification number information.\n",
"\n",
"KIE is usually divided into two sub-tasks for research\n",
"1. SER: Semantic Entity Recognition, to classify each detected text, such as dividing it into name and ID. As shown in the black box and red box in the figure below.\n",
"2. RE: Relation Extraction, which classifies each detected text, such as dividing it into questions and answers. Then find the corresponding answer to each question. As shown in the figure below, the red and black boxes represent the question and the answer, respectively, and the yellow line represents the correspondence between the question and the answer.\n",
"\n",
" \n",
"Figure 18: Example of SER, RE task\n",
"\n",
"The general KIE method is researched based on Named Entity Recognition (NER) [4], but this type of method only uses the text information in the image and lacks the use of visual and structural information, so the accuracy is not high. On this basis, the methods in recent years have begun to integrate visual and structural information with text information. According to the principles used when fusing multimodal information, these methods can be divided into the following three types:\n",
"\n",
"1. Grid-based approach\n",
"1. Token-based approach\n",
"2. GCN-based method\n",
"3. Based on the End to End method\n",
"\n",
"Some representative papers are divided into the above three categories, as shown in the following table:\n",
"\n",
"| Category | Ideas | Main Papers |\n",
"| ---------------- | ---- | -------- |\n",
"| Grid-based method | Fusion of multi-modal information on images (text, layout, image) | [Chargrid](https://arxiv.org/pdf/1809.08799) |\n",
"| Token-based method|Using methods such as Bert for multi-modal information fusion|[LayoutLM](https://arxiv.org/pdf/1912.13318), [LayoutLMv2](https://arxiv.org/pdf/2012.14740), [StrucText](https://arxiv.org/pdf/2108.02923), |\n",
"| GCN-based method|Using graph network structure for multi-modal information fusion|[GCN](https://arxiv.org/pdf/1903.11279), [PICK](https://arxiv.org/pdf/2004.07464), [SDMG-R](https://arxiv.org/pdf/2103.14470), [SERA](https://arxiv.org/pdf/2110.09915) |\n",
"| Based on End to End method | Unify OCR and key information extraction into one network | [Trie](https://arxiv.org/pdf/2005.13118) |\n",
"\n",
"### 3.2 Grid-Based Method\n",
"\n",
"The Grid-based method performs multimodal information fusion at the image level. Chargrid[5] firstly performs character-level text detection and recognition on the image, and then completes the construction of the network input by filling the one-hot encoding of the category into the corresponding character area (the non-black part in the right image below) , the input is finally passed through the CNN network of the encoder-decoder structure to perform coordinate detection and category classification of key information.\n",
"\n",
"\n",
"
\n",
"Figure 18: Example of SER, RE task\n",
"\n",
"The general KIE method is researched based on Named Entity Recognition (NER) [4], but this type of method only uses the text information in the image and lacks the use of visual and structural information, so the accuracy is not high. On this basis, the methods in recent years have begun to integrate visual and structural information with text information. According to the principles used when fusing multimodal information, these methods can be divided into the following three types:\n",
"\n",
"1. Grid-based approach\n",
"1. Token-based approach\n",
"2. GCN-based method\n",
"3. Based on the End to End method\n",
"\n",
"Some representative papers are divided into the above three categories, as shown in the following table:\n",
"\n",
"| Category | Ideas | Main Papers |\n",
"| ---------------- | ---- | -------- |\n",
"| Grid-based method | Fusion of multi-modal information on images (text, layout, image) | [Chargrid](https://arxiv.org/pdf/1809.08799) |\n",
"| Token-based method|Using methods such as Bert for multi-modal information fusion|[LayoutLM](https://arxiv.org/pdf/1912.13318), [LayoutLMv2](https://arxiv.org/pdf/2012.14740), [StrucText](https://arxiv.org/pdf/2108.02923), |\n",
"| GCN-based method|Using graph network structure for multi-modal information fusion|[GCN](https://arxiv.org/pdf/1903.11279), [PICK](https://arxiv.org/pdf/2004.07464), [SDMG-R](https://arxiv.org/pdf/2103.14470), [SERA](https://arxiv.org/pdf/2110.09915) |\n",
"| Based on End to End method | Unify OCR and key information extraction into one network | [Trie](https://arxiv.org/pdf/2005.13118) |\n",
"\n",
"### 3.2 Grid-Based Method\n",
"\n",
"The Grid-based method performs multimodal information fusion at the image level. Chargrid[5] firstly performs character-level text detection and recognition on the image, and then completes the construction of the network input by filling the one-hot encoding of the category into the corresponding character area (the non-black part in the right image below) , the input is finally passed through the CNN network of the encoder-decoder structure to perform coordinate detection and category classification of key information.\n",
"\n",
"\n",
" \n",
"Figure 19: Chargrid data example\n",
"\n",
"\n",
"\n",
"
\n",
"Figure 19: Chargrid data example\n",
"\n",
"\n",
"\n",
" \n",
"Figure 20: Chargrid network\n",
"\n",
"\n",
"Compared with the traditional method based only on text, this method can use both text information and structural information, so it can achieve a certain accuracy improvement. It's good to combine the two.\n",
"\n",
"### 3.3 Token-Based Method\n",
"LayoutLM[6] encodes 2D position information and text information together into the BERT model, and draws on the pre-training ideas of Bert in NLP, pre-training on large-scale data sets, and in downstream tasks, LayoutLM also adds image information To further improve the performance of the model. Although LayoutLM combines text, location and image information, the image information is fused in the training of downstream tasks, so the multi-modal fusion of the three types of information is not sufficient. Based on LayoutLM, LayoutLMv2 [7] integrates image information with text and layout information in the pre-training stage through transformers, and also adds a spatial perception self-attention mechanism to the Transformer to assist the model to better integrate visual and text features. Although LayoutLMv2 fuses text, location and image information in the pre-training stage, the visual features learned by the model are not fine enough due to the limitation of the pre-training task. StrucTexT [8] based on the previous multi-modal methods, proposed two new tasks, Sentence Length Prediction (SLP) and Paired Boxes Direction (PBD) in the pre-training task to help the network learn fine visual features. Among them, the SLP task makes the model Learn the length of the text segment, the PDB task allows the model to learn the matching relationship between Box directions. Through these two new pre-training tasks, the deep cross-modal fusion between text, visual and layout information can be accelerated.\n",
"\n",
" | )\n",
"---|---\n",
"Figure 21: Transformer algorithm flow chart | Figure 22: LayoutLMv2 algorithm flow chart\n",
"\n",
"### 3.4 GCN-Based Method\n",
"\n",
"Although the existing GCN-based methods [10] use text and structure information, they do not make good use of image information. PICK [11] added image information to the GCN network and proposed a graph learning module to automatically learn edge types. SDMG-R [12] encodes the image as a bimodal graph. The nodes of the graph are the visual and textual information of the text area. The edges represent the direct spatial relationship between adjacent texts. By iteratively spreading information along the edges and inferring graph node categories, SDMG -R solves the problem that existing methods are incapable of unseen templates.\n",
"\n",
"\n",
"The PICK flow chart is shown in the figure below:\n",
"\n",
"\n",
"
\n",
"Figure 20: Chargrid network\n",
"\n",
"\n",
"Compared with the traditional method based only on text, this method can use both text information and structural information, so it can achieve a certain accuracy improvement. It's good to combine the two.\n",
"\n",
"### 3.3 Token-Based Method\n",
"LayoutLM[6] encodes 2D position information and text information together into the BERT model, and draws on the pre-training ideas of Bert in NLP, pre-training on large-scale data sets, and in downstream tasks, LayoutLM also adds image information To further improve the performance of the model. Although LayoutLM combines text, location and image information, the image information is fused in the training of downstream tasks, so the multi-modal fusion of the three types of information is not sufficient. Based on LayoutLM, LayoutLMv2 [7] integrates image information with text and layout information in the pre-training stage through transformers, and also adds a spatial perception self-attention mechanism to the Transformer to assist the model to better integrate visual and text features. Although LayoutLMv2 fuses text, location and image information in the pre-training stage, the visual features learned by the model are not fine enough due to the limitation of the pre-training task. StrucTexT [8] based on the previous multi-modal methods, proposed two new tasks, Sentence Length Prediction (SLP) and Paired Boxes Direction (PBD) in the pre-training task to help the network learn fine visual features. Among them, the SLP task makes the model Learn the length of the text segment, the PDB task allows the model to learn the matching relationship between Box directions. Through these two new pre-training tasks, the deep cross-modal fusion between text, visual and layout information can be accelerated.\n",
"\n",
" | )\n",
"---|---\n",
"Figure 21: Transformer algorithm flow chart | Figure 22: LayoutLMv2 algorithm flow chart\n",
"\n",
"### 3.4 GCN-Based Method\n",
"\n",
"Although the existing GCN-based methods [10] use text and structure information, they do not make good use of image information. PICK [11] added image information to the GCN network and proposed a graph learning module to automatically learn edge types. SDMG-R [12] encodes the image as a bimodal graph. The nodes of the graph are the visual and textual information of the text area. The edges represent the direct spatial relationship between adjacent texts. By iteratively spreading information along the edges and inferring graph node categories, SDMG -R solves the problem that existing methods are incapable of unseen templates.\n",
"\n",
"\n",
"The PICK flow chart is shown in the figure below:\n",
"\n",
"\n",
" \n",
"Figure 23: PICK algorithm flow chart\n",
"\n",
"SERA[10]The biaffine parser in dependency syntax analysis is introduced into document relation extraction, and GCN is used to fuse text and visual information.\n",
"\n",
"\n",
"
\n",
"Figure 23: PICK algorithm flow chart\n",
"\n",
"SERA[10]The biaffine parser in dependency syntax analysis is introduced into document relation extraction, and GCN is used to fuse text and visual information.\n",
"\n",
"\n",
" \n",
"Figure 24: SERA algorithm flow chart\n",
"\n",
"### 3.5 Method Based on End to End\n",
"\n",
"Existing methods divide KIE into two independent tasks: text reading and information extraction. However, they mainly focus on improving the task of information extraction, ignoring that text reading and information extraction are interrelated. Therefore, Trie [9] Proposed a unified end-to-end network that can learn these two tasks at the same time and reinforce each other in the learning process.\n",
"\n",
"\n",
"
\n",
"Figure 24: SERA algorithm flow chart\n",
"\n",
"### 3.5 Method Based on End to End\n",
"\n",
"Existing methods divide KIE into two independent tasks: text reading and information extraction. However, they mainly focus on improving the task of information extraction, ignoring that text reading and information extraction are interrelated. Therefore, Trie [9] Proposed a unified end-to-end network that can learn these two tasks at the same time and reinforce each other in the learning process.\n",
"\n",
"\n",
" \n",
"Figure 25: Trie algorithm flow chart\n",
"\n",
"\n",
"### 3.6 Data Set\n",
"The data sets used for KIE mainly include the following two:\n",
"1. SROIE: Task 3 of the SROIE data set [2] aims to extract four predefined information from the scanned receipt: company, date, address or total. There are 626 samples in the data set for training and 347 samples for testing.\n",
"2. FUNSD: FUNSD data set [3] is a data set used to extract form information from scanned documents. It contains 199 marked real scan forms. Of the 199 samples, 149 are used for training and 50 are used for testing. The FUNSD data set assigns a semantic entity tag to each word: question, answer, title or other.\n",
"3. XFUN: The XFUN data set is a multilingual data set proposed by Microsoft. It contains 7 languages. Each language contains 149 training sets and 50 test sets.\n",
"\n",
" | )\n",
"---|---\n",
"Figure 26: sroie example image | Figure 27: xfun example image\n",
"\n",
"Reference:\n",
"\n",
"[1]:Mathew M, Karatzas D, Jawahar C V. Docvqa: A dataset for vqa on document images[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2021: 2200-2209.\n",
"\n",
"[2]:Huang Z, Chen K, He J, et al. Icdar2019 competition on scanned receipt ocr and information extraction[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1516-1520.\n",
"\n",
"[3]:Jaume G, Ekenel H K, Thiran J P. Funsd: A dataset for form understanding in noisy scanned documents[C]//2019 International Conference on Document Analysis and Recognition Workshops (ICDARW). IEEE, 2019, 2: 1-6.\n",
"\n",
"[4]:Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[J]. arXiv preprint arXiv:1603.01360, 2016.\n",
"\n",
"[5]:Katti A R, Reisswig C, Guder C, et al. Chargrid: Towards understanding 2d documents[J]. arXiv preprint arXiv:1809.08799, 2018.\n",
"\n",
"[6]:Xu Y, Li M, Cui L, et al. Layoutlm: Pre-training of text and layout for document image understanding[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1192-1200.\n",
"\n",
"[7]:Xu Y, Xu Y, Lv T, et al. LayoutLMv2: Multi-modal pre-training for visually-rich document understanding[J]. arXiv preprint arXiv:2012.14740, 2020.\n",
"\n",
"[8]:Li Y, Qian Y, Yu Y, et al. StrucTexT: Structured Text Understanding with Multi-Modal Transformers[C]//Proceedings of the 29th ACM International Conference on Multimedia. 2021: 1912-1920.\n",
"\n",
"[9]:Zhang P, Xu Y, Cheng Z, et al. Trie: End-to-end text reading and information extraction for document understanding[C]//Proceedings of the 28th ACM International Conference on Multimedia. 2020: 1413-1422.\n",
"\n",
"[10]:Liu X, Gao F, Zhang Q, et al. Graph convolution for multimodal information extraction from visually rich documents[J]. arXiv preprint arXiv:1903.11279, 2019.\n",
"\n",
"[11]:Yu W, Lu N, Qi X, et al. Pick: Processing key information extraction from documents using improved graph learning-convolutional networks[C]//2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021: 4363-4370.\n",
"\n",
"[12]:Sun H, Kuang Z, Yue X, et al. Spatial Dual-Modality Graph Reasoning for Key Information Extraction[J]. arXiv preprint arXiv:2103.14470, 2021."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 4. Summary\n",
"In this section, we mainly introduce the theoretical knowledge of three sub-modules related to document analysis technology: layout analysis, table recognition and information extraction. Below we will explain this form recognition and DOC-VQA practical tutorial based on the PaddleOCR framework."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "py35-paddle1.2.0"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.4"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
\n",
"Figure 25: Trie algorithm flow chart\n",
"\n",
"\n",
"### 3.6 Data Set\n",
"The data sets used for KIE mainly include the following two:\n",
"1. SROIE: Task 3 of the SROIE data set [2] aims to extract four predefined information from the scanned receipt: company, date, address or total. There are 626 samples in the data set for training and 347 samples for testing.\n",
"2. FUNSD: FUNSD data set [3] is a data set used to extract form information from scanned documents. It contains 199 marked real scan forms. Of the 199 samples, 149 are used for training and 50 are used for testing. The FUNSD data set assigns a semantic entity tag to each word: question, answer, title or other.\n",
"3. XFUN: The XFUN data set is a multilingual data set proposed by Microsoft. It contains 7 languages. Each language contains 149 training sets and 50 test sets.\n",
"\n",
" | )\n",
"---|---\n",
"Figure 26: sroie example image | Figure 27: xfun example image\n",
"\n",
"Reference:\n",
"\n",
"[1]:Mathew M, Karatzas D, Jawahar C V. Docvqa: A dataset for vqa on document images[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2021: 2200-2209.\n",
"\n",
"[2]:Huang Z, Chen K, He J, et al. Icdar2019 competition on scanned receipt ocr and information extraction[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1516-1520.\n",
"\n",
"[3]:Jaume G, Ekenel H K, Thiran J P. Funsd: A dataset for form understanding in noisy scanned documents[C]//2019 International Conference on Document Analysis and Recognition Workshops (ICDARW). IEEE, 2019, 2: 1-6.\n",
"\n",
"[4]:Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[J]. arXiv preprint arXiv:1603.01360, 2016.\n",
"\n",
"[5]:Katti A R, Reisswig C, Guder C, et al. Chargrid: Towards understanding 2d documents[J]. arXiv preprint arXiv:1809.08799, 2018.\n",
"\n",
"[6]:Xu Y, Li M, Cui L, et al. Layoutlm: Pre-training of text and layout for document image understanding[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1192-1200.\n",
"\n",
"[7]:Xu Y, Xu Y, Lv T, et al. LayoutLMv2: Multi-modal pre-training for visually-rich document understanding[J]. arXiv preprint arXiv:2012.14740, 2020.\n",
"\n",
"[8]:Li Y, Qian Y, Yu Y, et al. StrucTexT: Structured Text Understanding with Multi-Modal Transformers[C]//Proceedings of the 29th ACM International Conference on Multimedia. 2021: 1912-1920.\n",
"\n",
"[9]:Zhang P, Xu Y, Cheng Z, et al. Trie: End-to-end text reading and information extraction for document understanding[C]//Proceedings of the 28th ACM International Conference on Multimedia. 2020: 1413-1422.\n",
"\n",
"[10]:Liu X, Gao F, Zhang Q, et al. Graph convolution for multimodal information extraction from visually rich documents[J]. arXiv preprint arXiv:1903.11279, 2019.\n",
"\n",
"[11]:Yu W, Lu N, Qi X, et al. Pick: Processing key information extraction from documents using improved graph learning-convolutional networks[C]//2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021: 4363-4370.\n",
"\n",
"[12]:Sun H, Kuang Z, Yue X, et al. Spatial Dual-Modality Graph Reasoning for Key Information Extraction[J]. arXiv preprint arXiv:2103.14470, 2021."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 4. Summary\n",
"In this section, we mainly introduce the theoretical knowledge of three sub-modules related to document analysis technology: layout analysis, table recognition and information extraction. Below we will explain this form recognition and DOC-VQA practical tutorial based on the PaddleOCR framework."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "py35-paddle1.2.0"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.4"
}
},
"nbformat": 4,
"nbformat_minor": 4
}