Merge remote-tracking branch 'origin/dygraph' into dygraph
Showing
doc/doc_en/logging_en.md
0 → 100644
doc/imgs_en/wandb_metrics.png
0 → 100644
{kind=link}
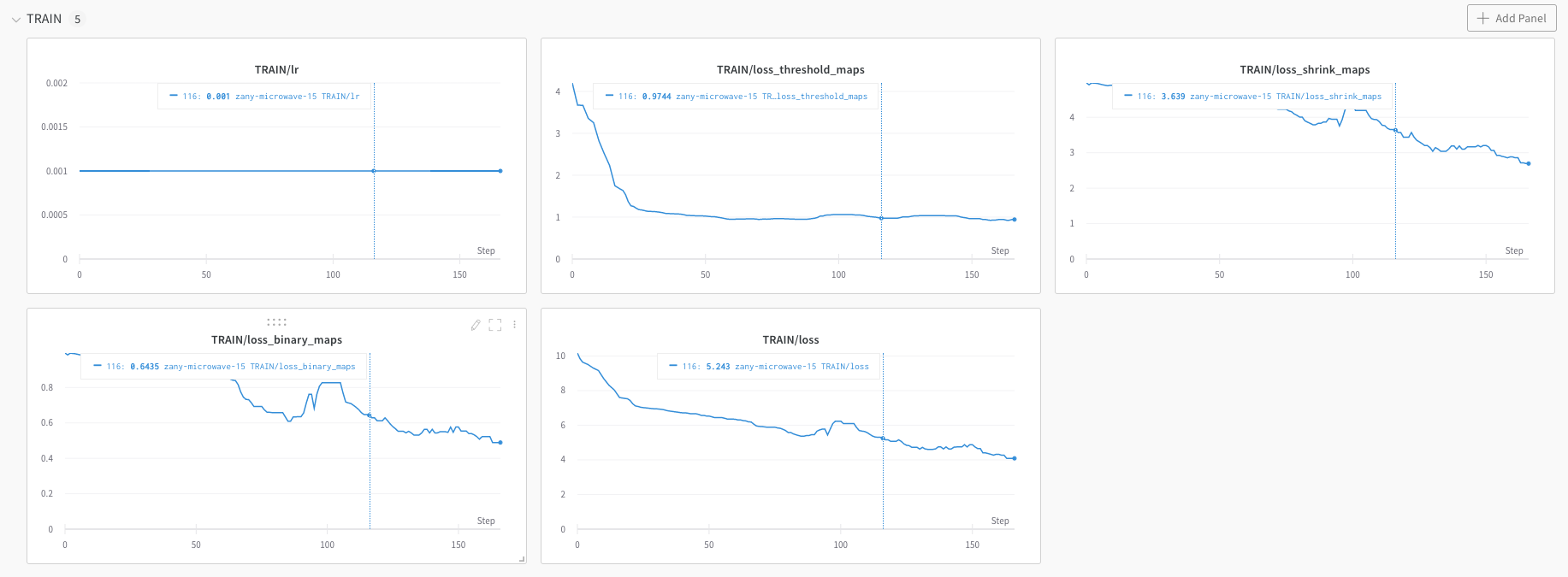
89.6 KB
doc/imgs_en/wandb_models.png
0 → 100644
{kind=link}
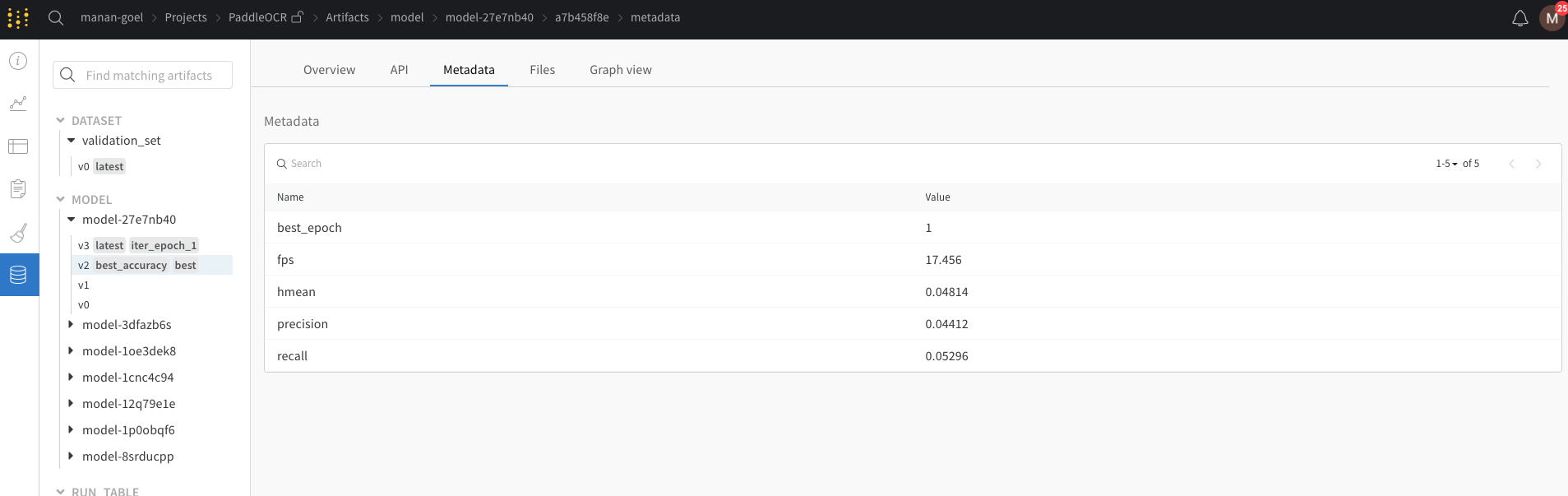
96.0 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
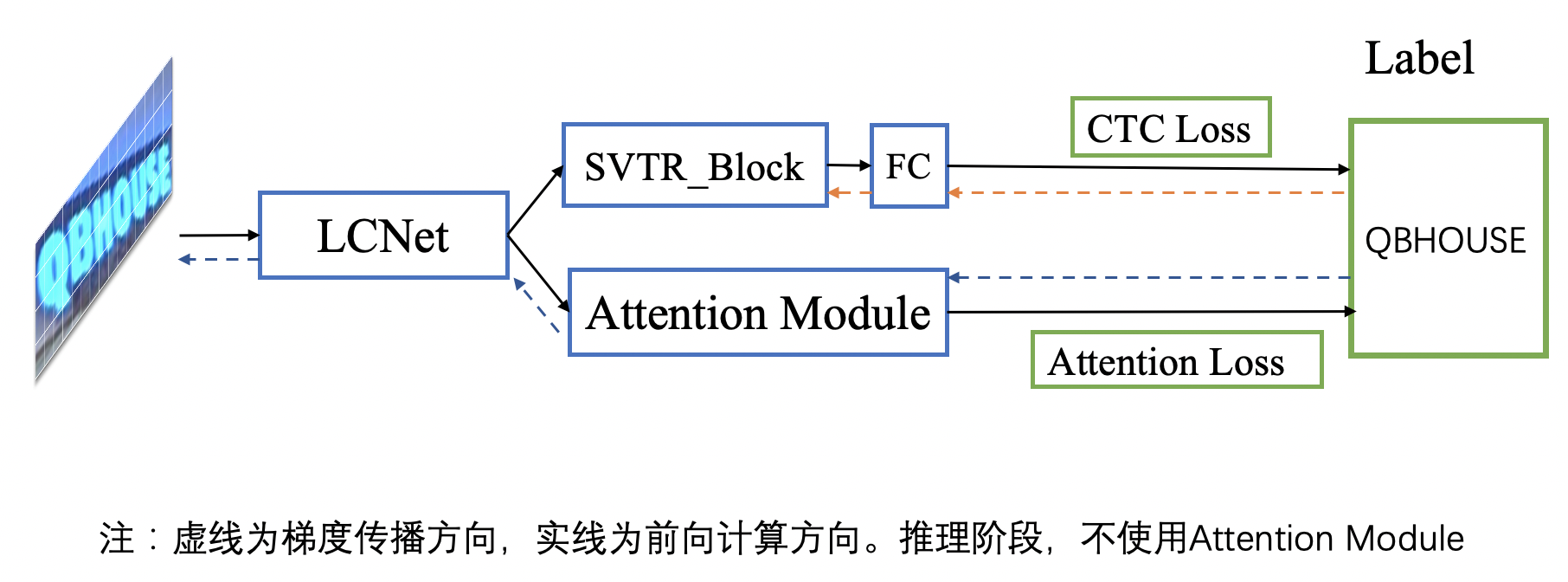
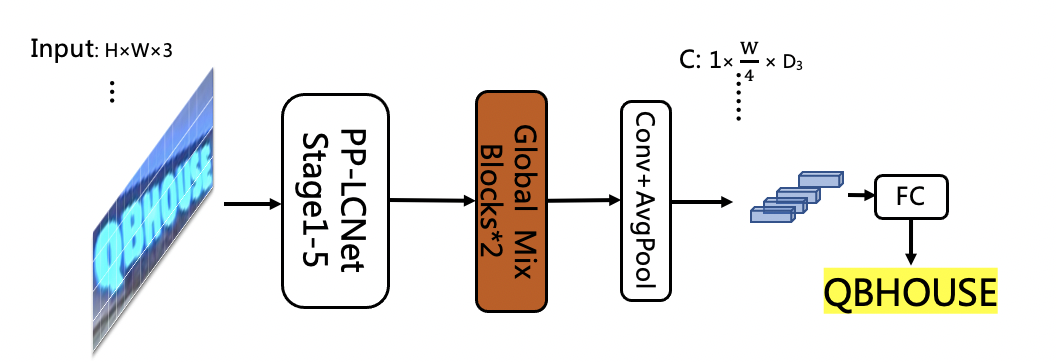
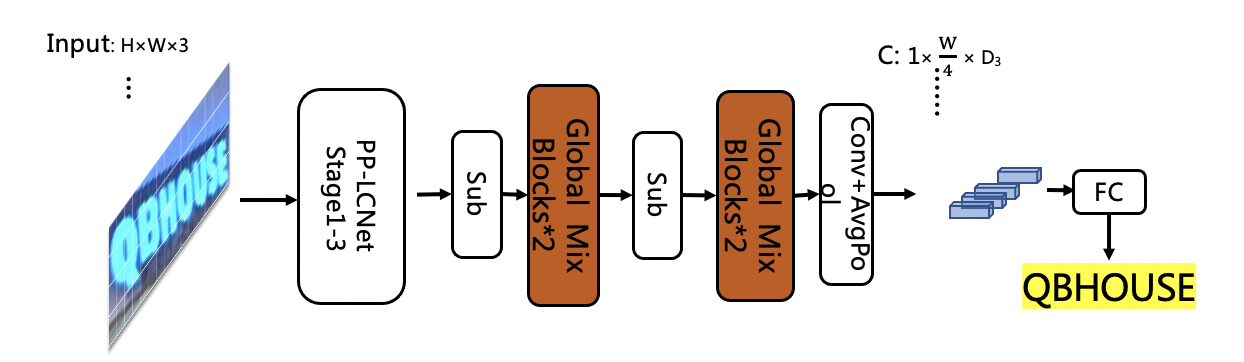
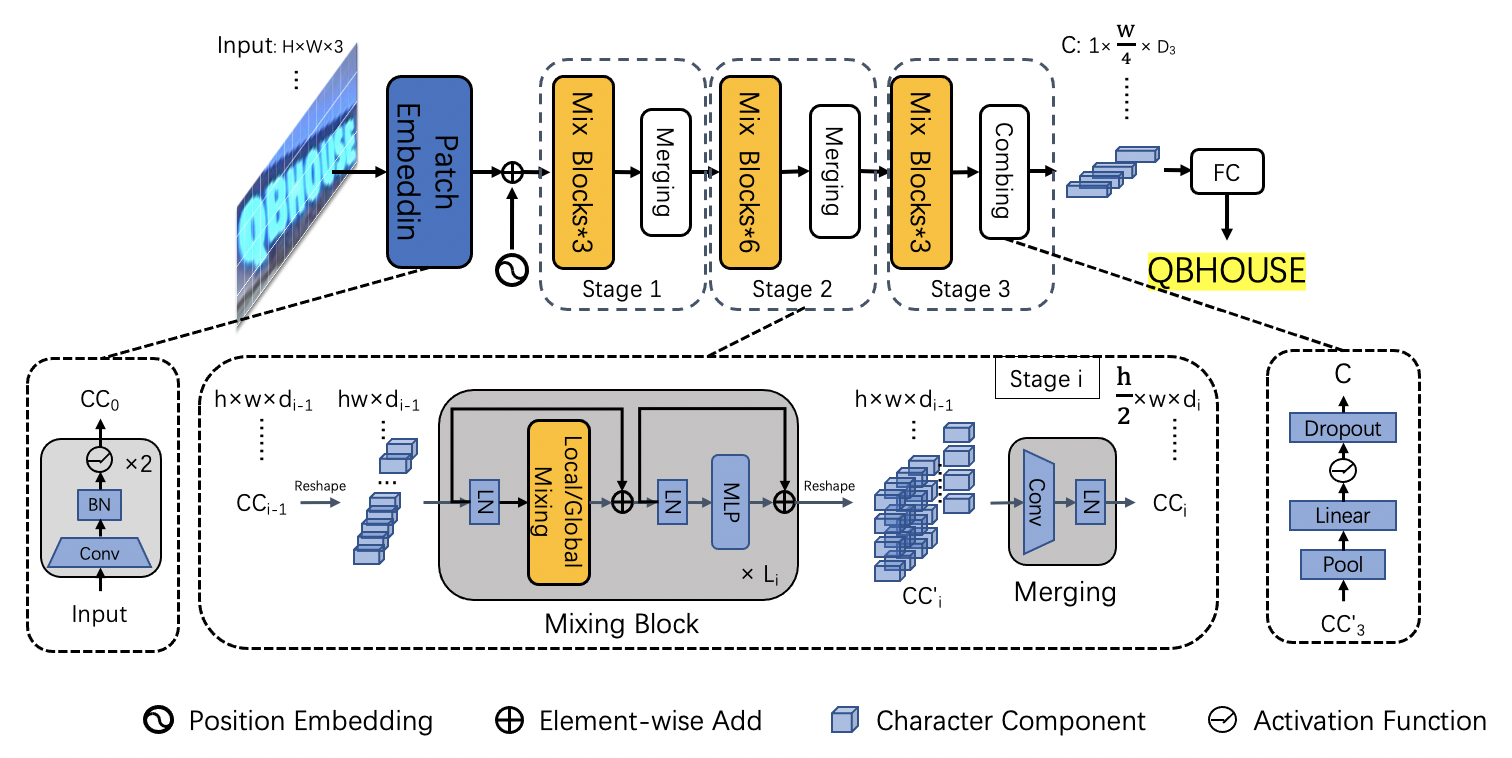
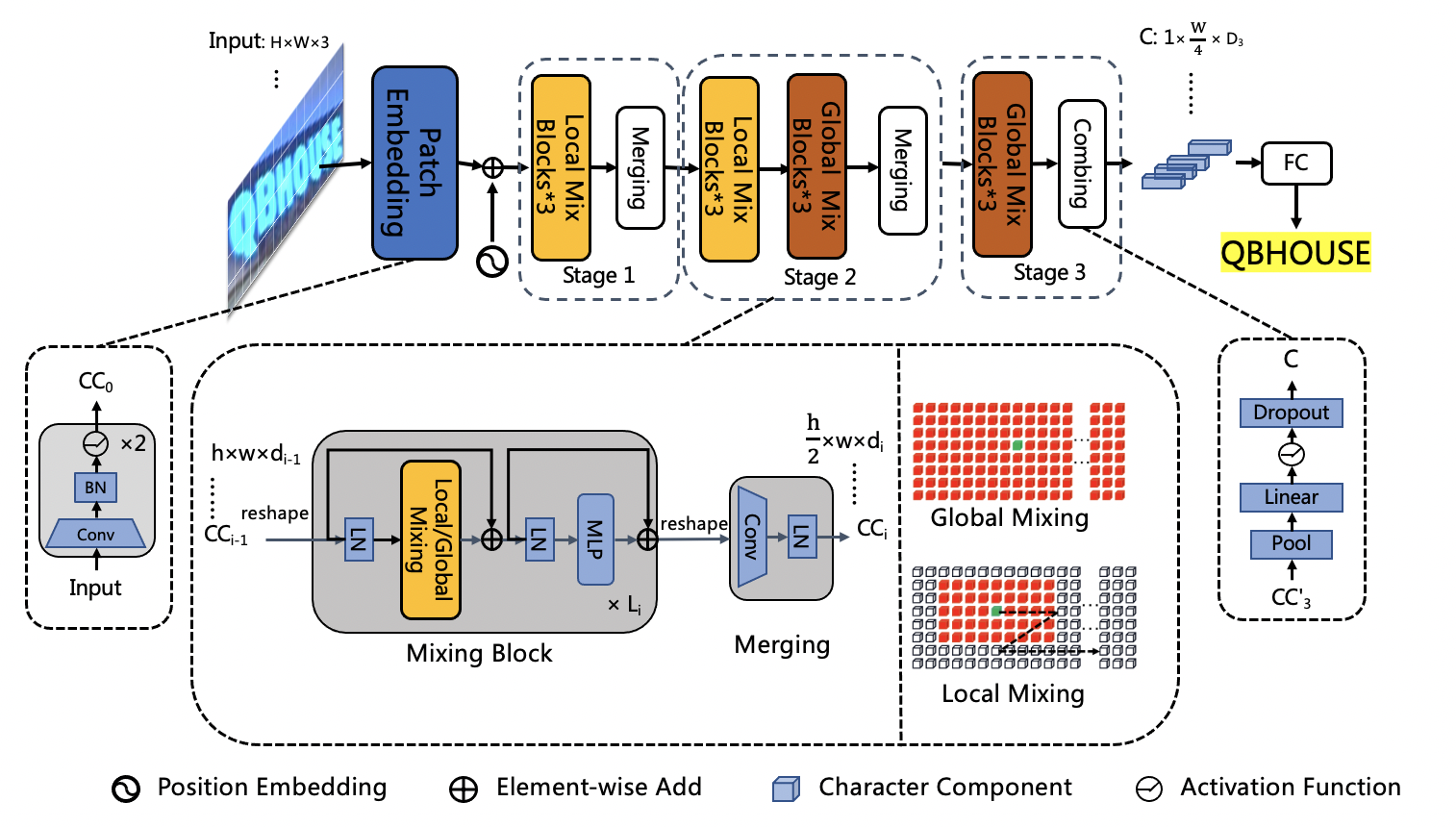
doc/ppocr_v3/LCNet_SVTR.png
0 → 100644
{kind=link}
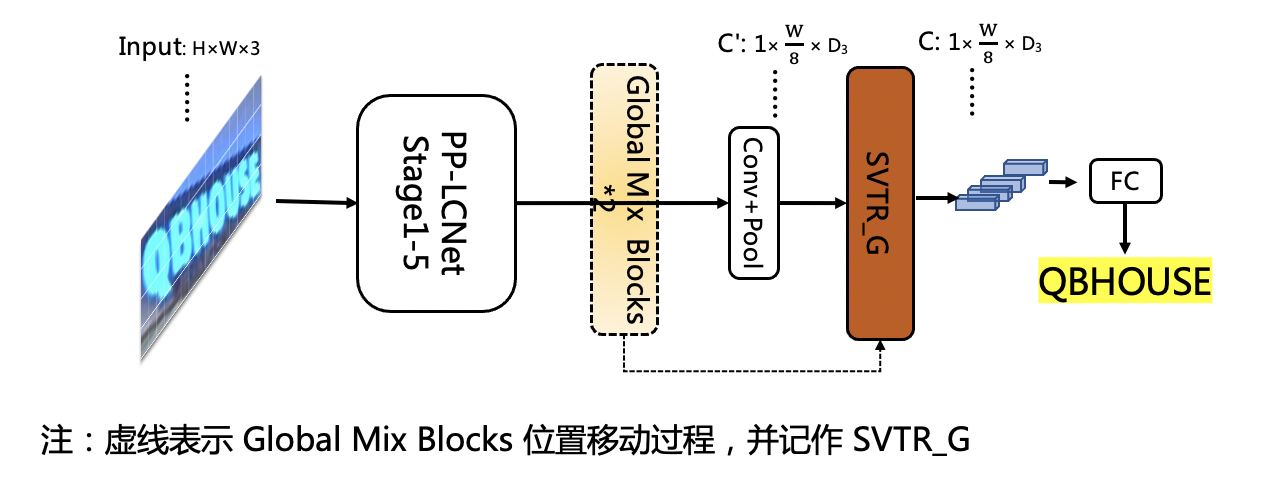
296.0 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
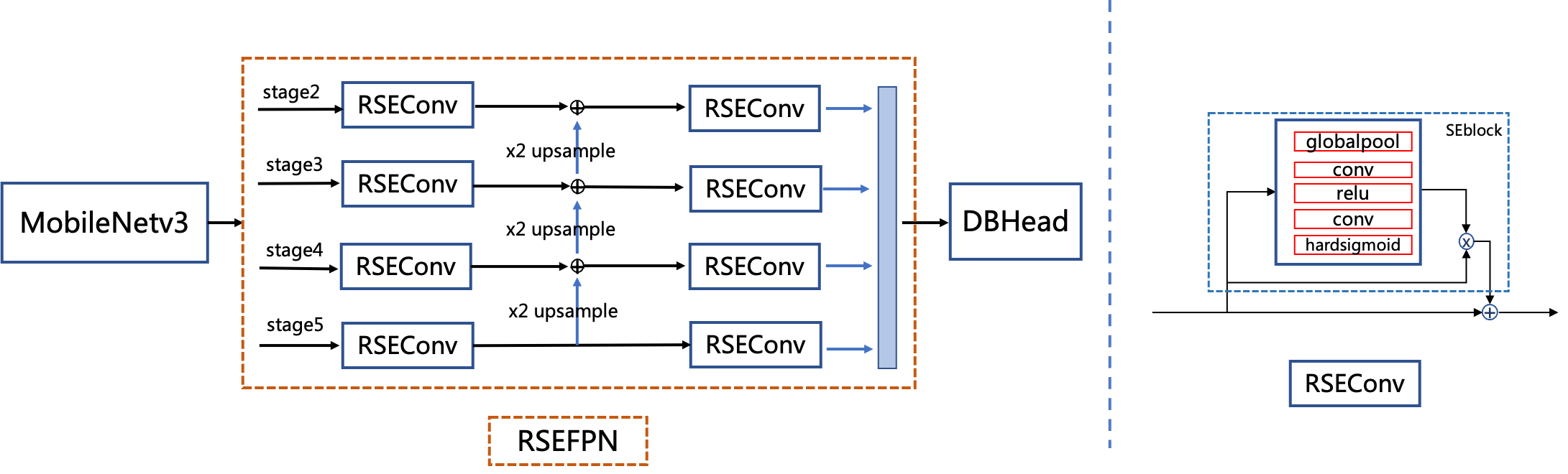
| W: | H:
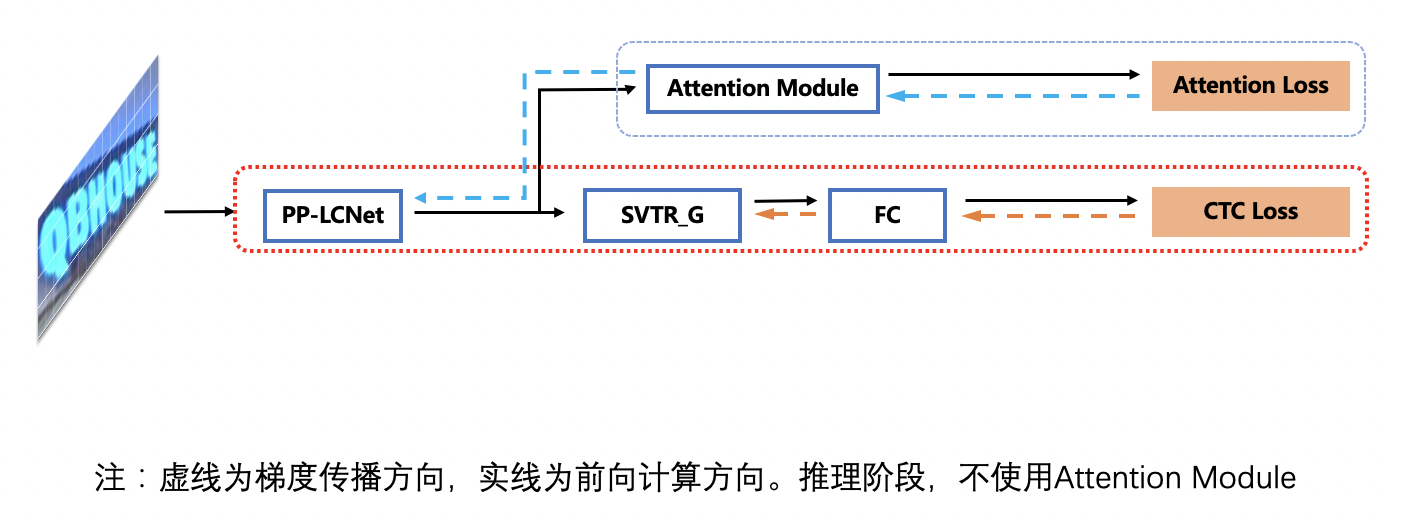
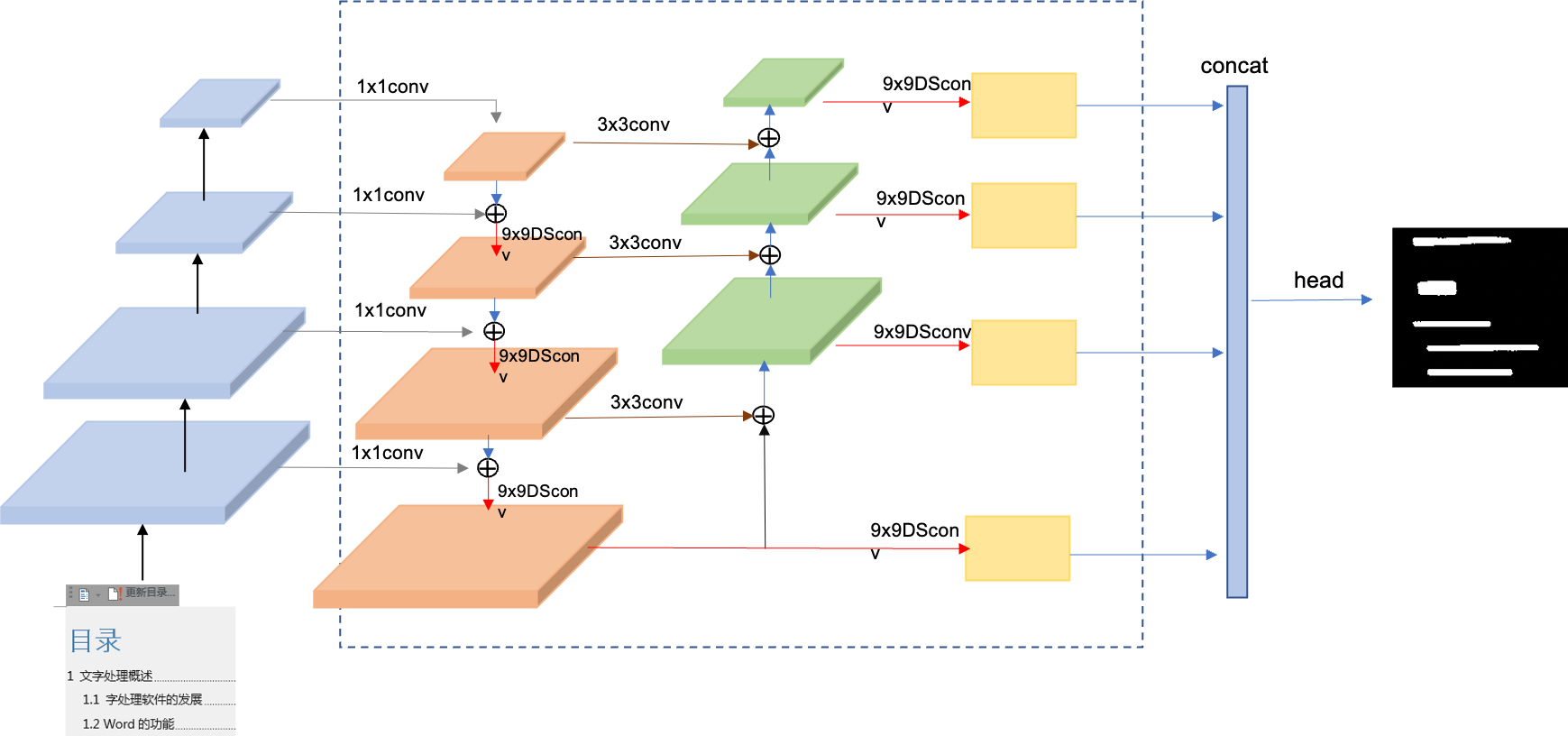
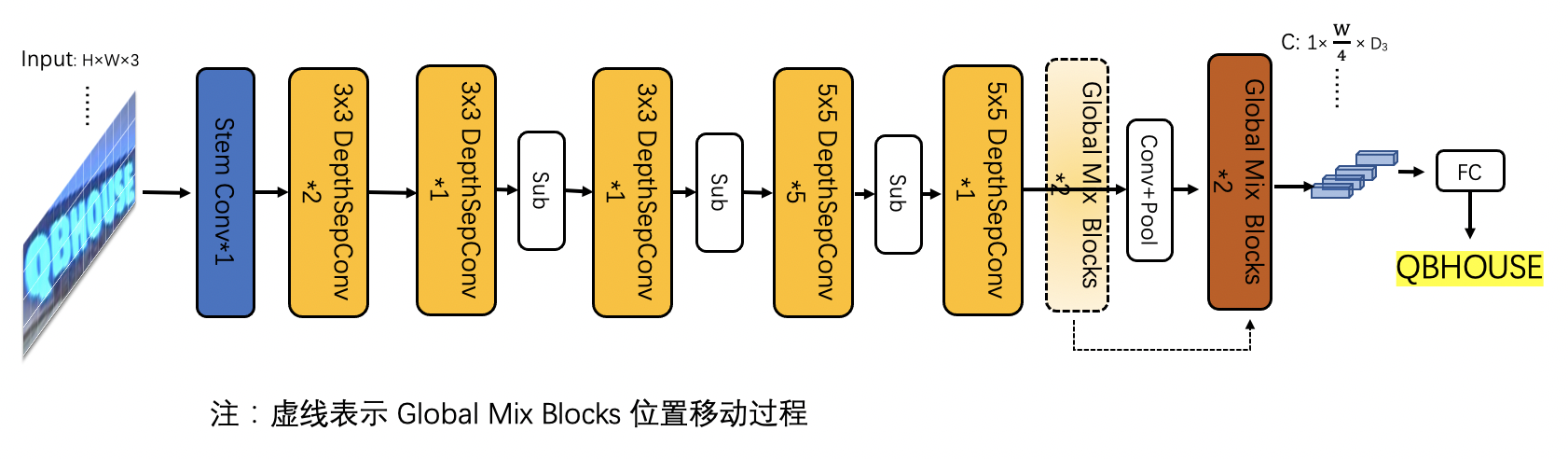
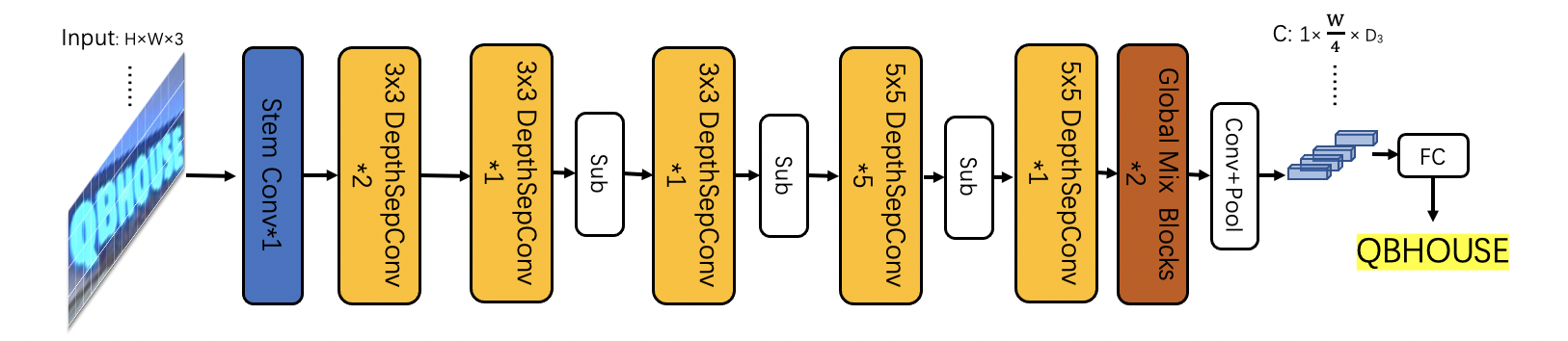
doc/ppocr_v3/UIM.png
0 → 100644
{kind=link}

82.6 KB
doc/ppocr_v3/ppocr_v3.png
已删除
100644 → 0
{kind=link}
426.2 KB
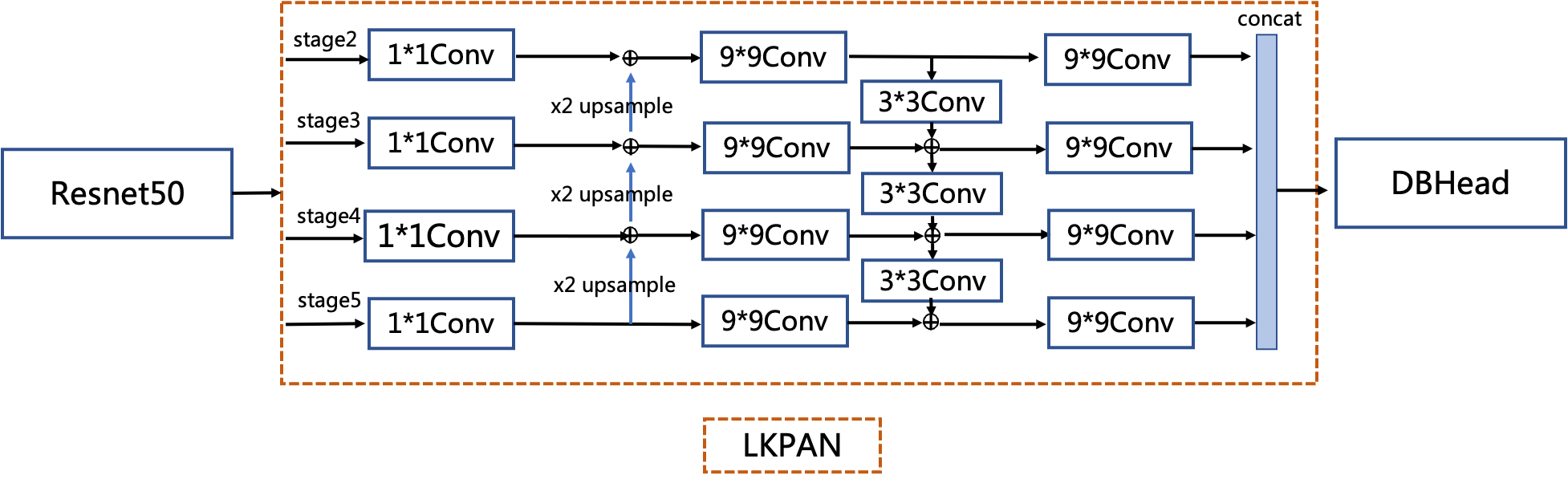
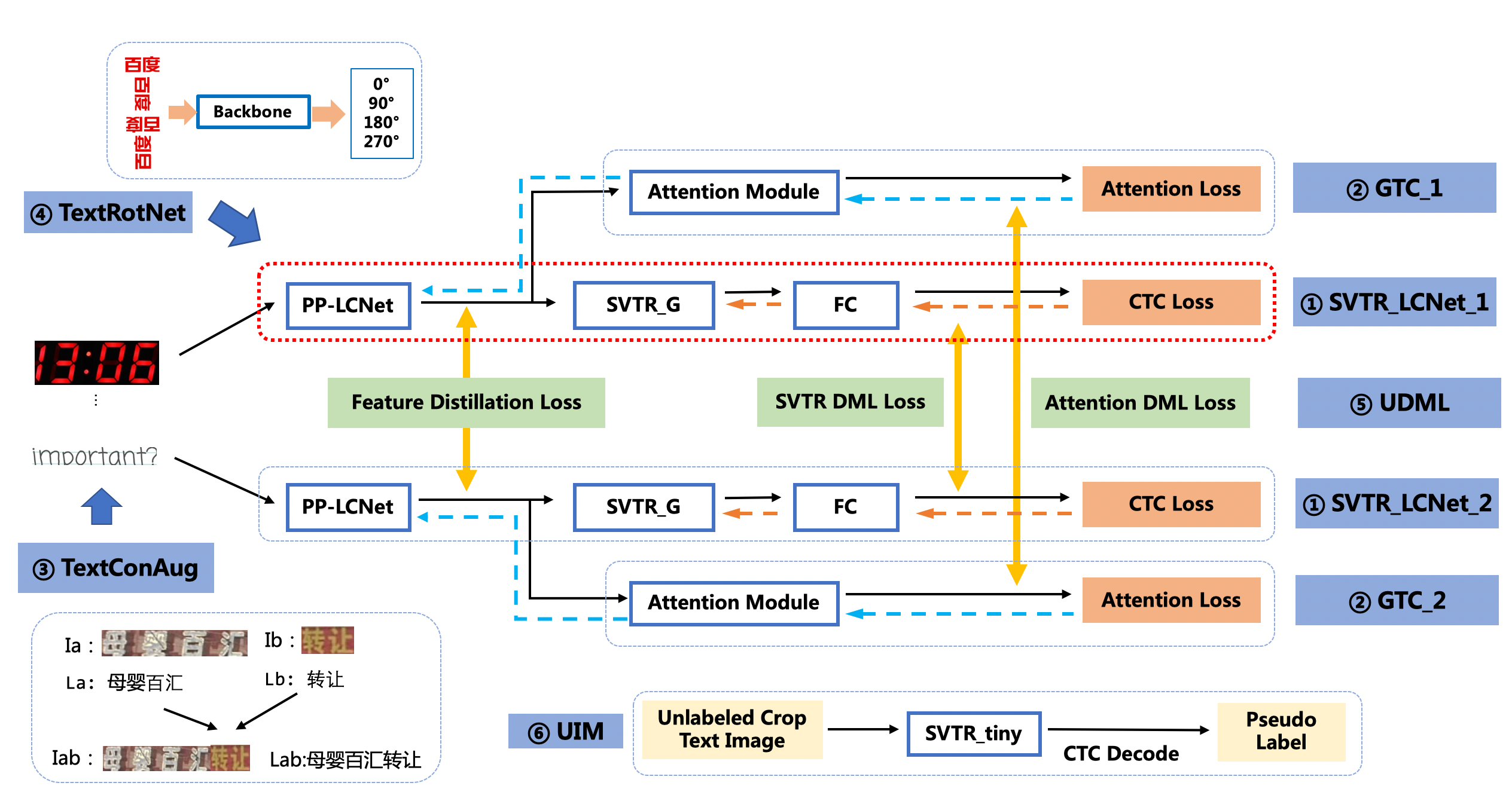
doc/ppocr_v3/ppocrv3_det_cml.png
0 → 100644
{kind=link}
261.9 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
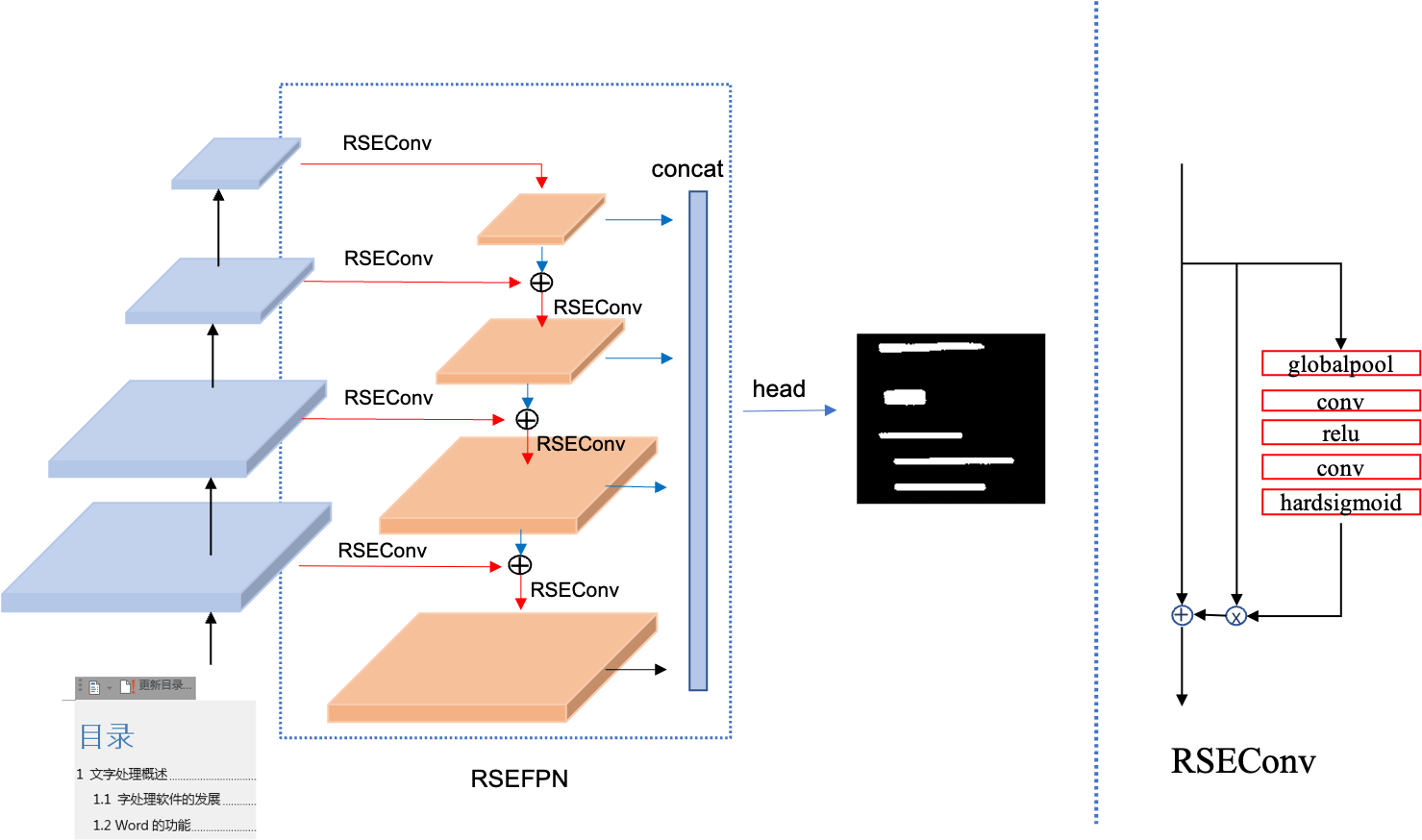
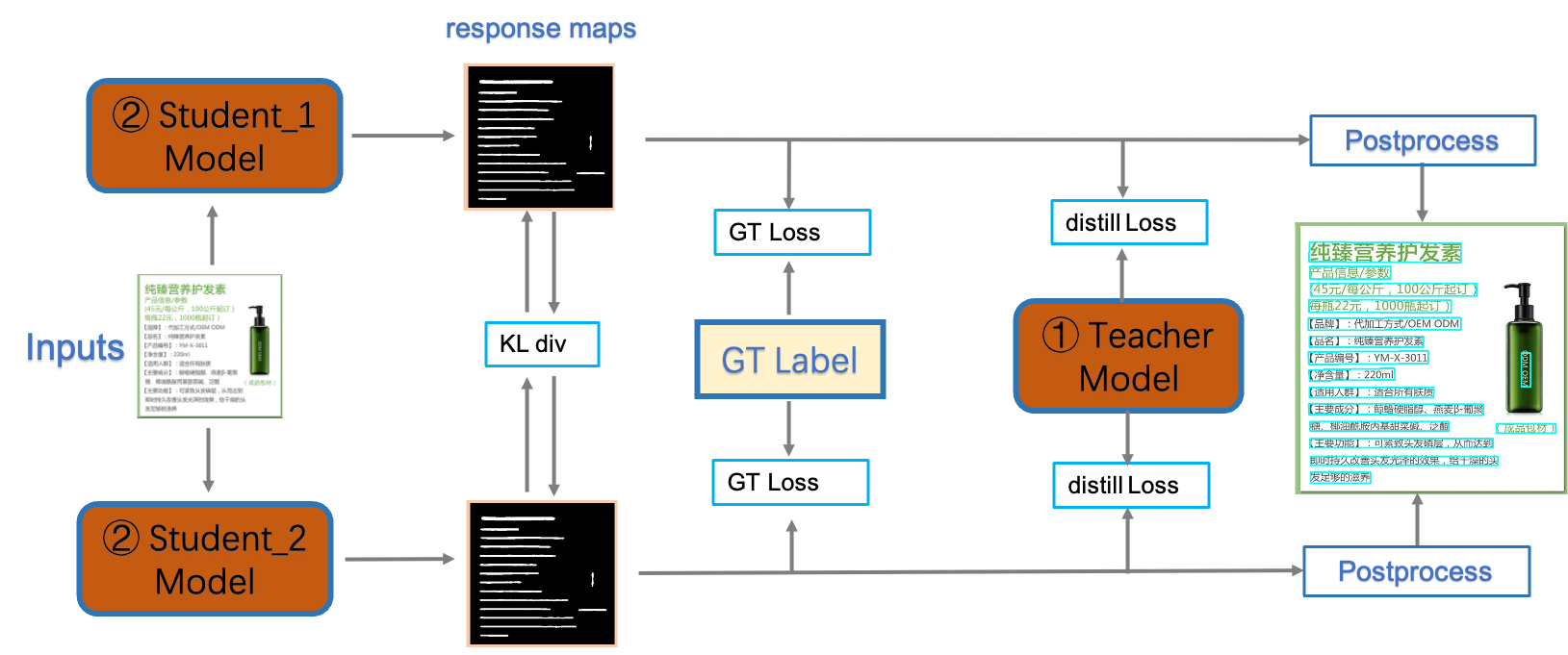
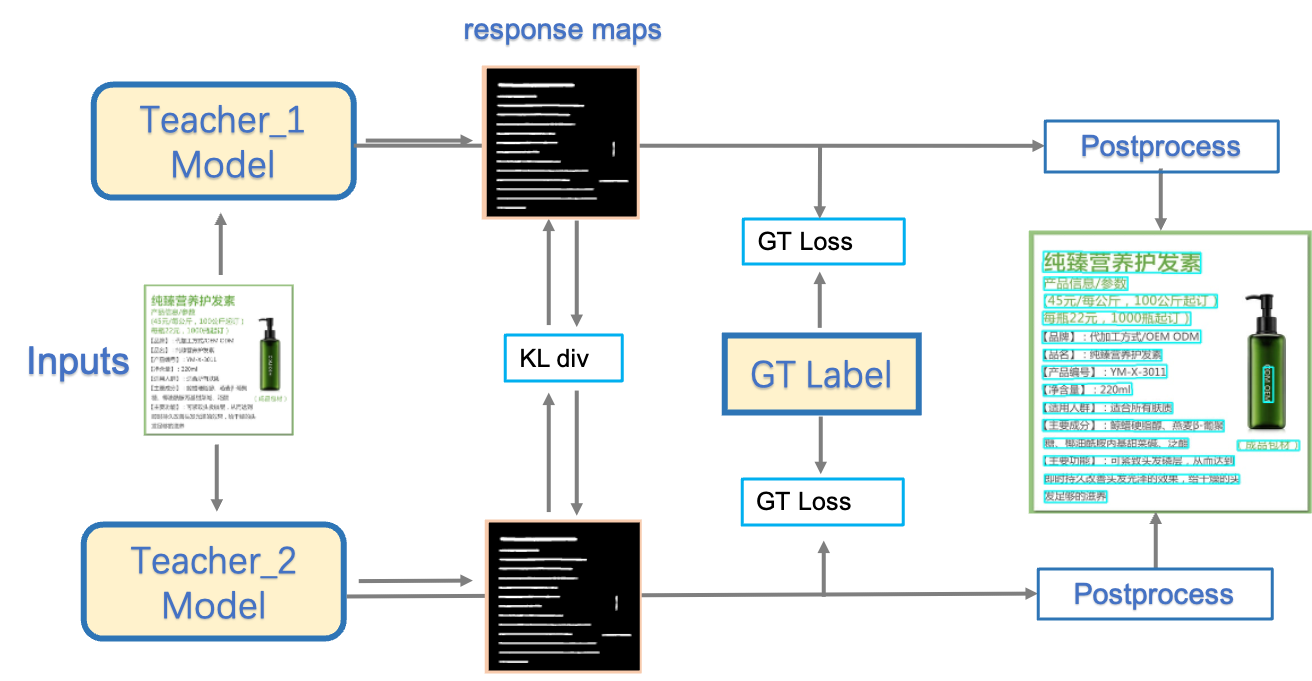
doc/ppocr_v3/teacher_dml.png
0 → 100644
{kind=link}
227.9 KB
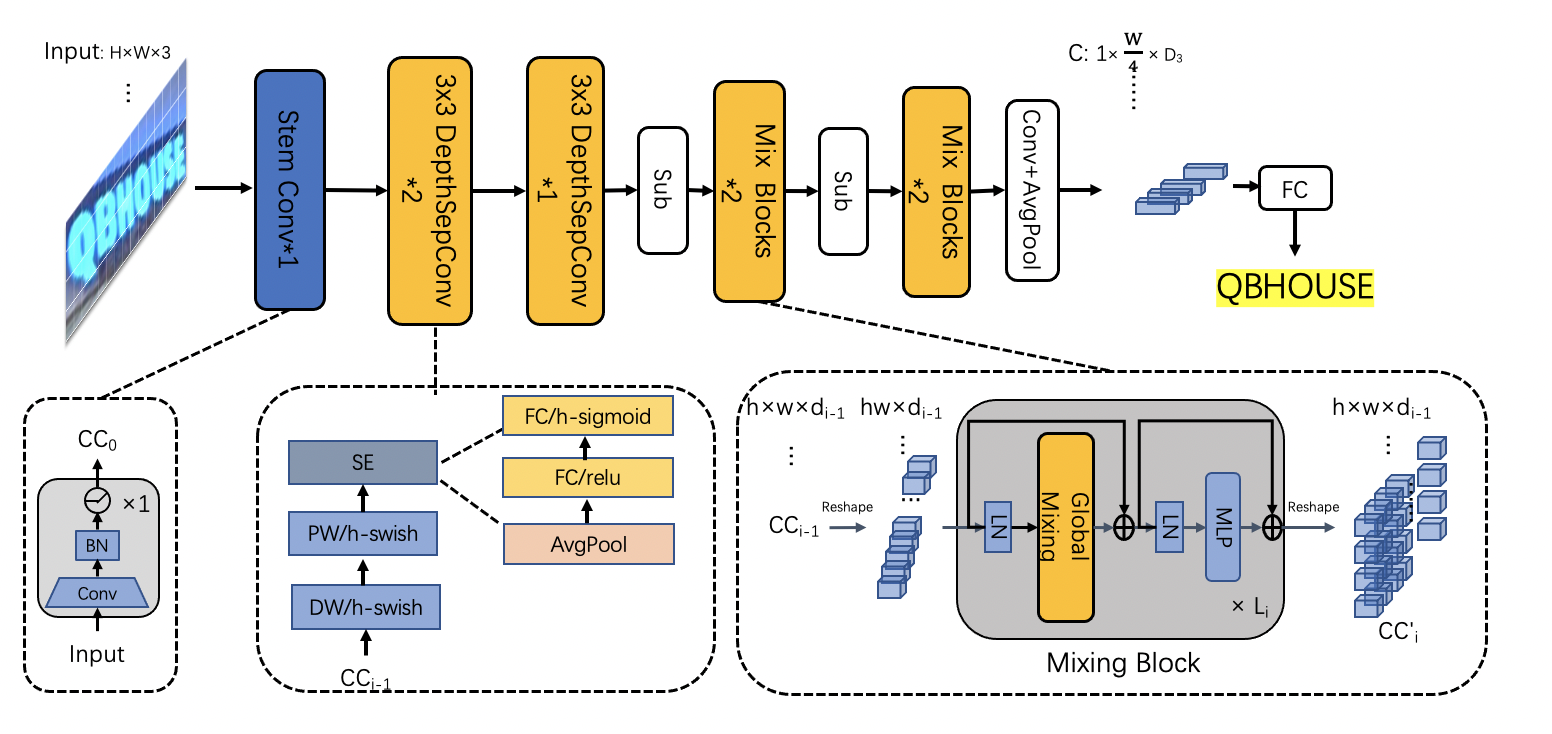
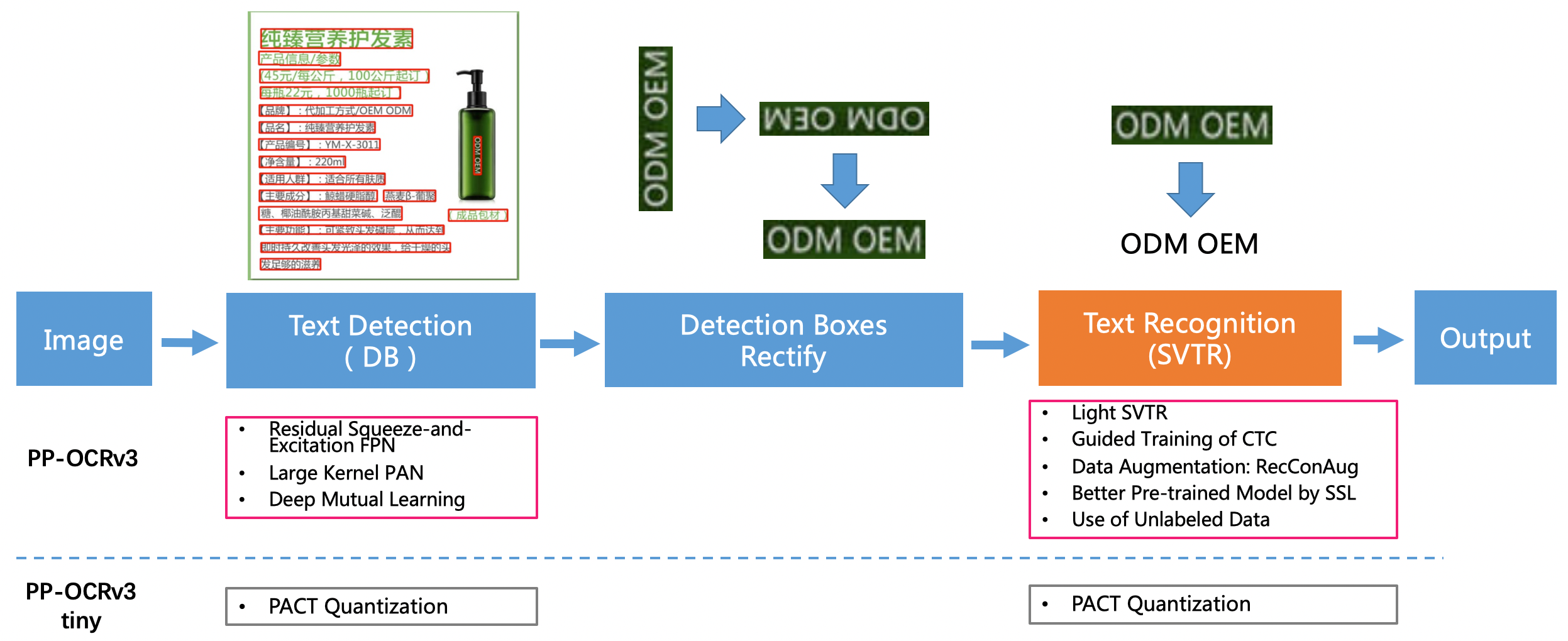
doc/ppocr_v3/v3_rec_pipeline.png
0 → 100644
{kind=link}
970.9 KB
{kind=link}
{kind=link}
| W: | H:
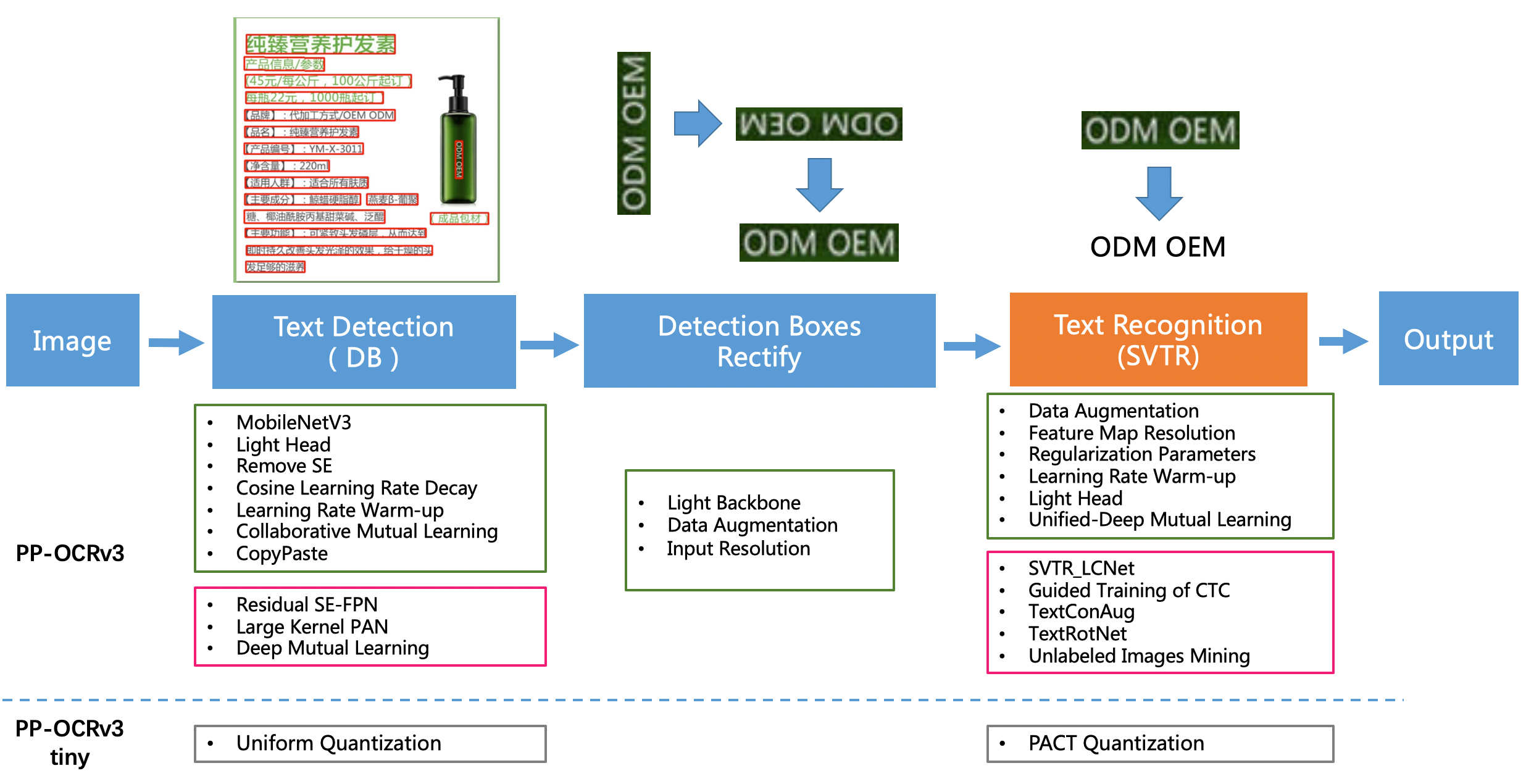
| W: | H:
ppocr/utils/loggers/__init__.py
0 → 100644
ppocr/utils/loggers/loggers.py
0 → 100644
ppocr/utils/loggers/vdl_logger.py
0 → 100644