 +| regular text annotation | table annotation |
+| :-------------------------------------------------: | :--------------------------------------------: |
+|
+| regular text annotation | table annotation |
+| :-------------------------------------------------: | :--------------------------------------------: |
+|  |
+| **irregular text annotation** | **key information annotation** |
+|
|
+| **irregular text annotation** | **key information annotation** |
+|  |
|  |
### Recent Update
diff --git a/PPOCRLabel/README_ch.md b/PPOCRLabel/README_ch.md
index 107f902a68bd68b30d286e8dd88b29752f0c6ad0..3ea684a3f09a6084403fa0b91e2511b7fd790f4b 100644
--- a/PPOCRLabel/README_ch.md
+++ b/PPOCRLabel/README_ch.md
@@ -1,10 +1,14 @@
[English](README.md) | 简体中文
-# PPOCRLabel
+# PPOCRLabelv2
PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注和四点标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
-
|
### Recent Update
diff --git a/PPOCRLabel/README_ch.md b/PPOCRLabel/README_ch.md
index 107f902a68bd68b30d286e8dd88b29752f0c6ad0..3ea684a3f09a6084403fa0b91e2511b7fd790f4b 100644
--- a/PPOCRLabel/README_ch.md
+++ b/PPOCRLabel/README_ch.md
@@ -1,10 +1,14 @@
[English](README.md) | 简体中文
-# PPOCRLabel
+# PPOCRLabelv2
PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注和四点标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
- +| 常规标注 | 表格标注 |
+| :-------------------------------------------------: | :--------------------------------------------: |
+|
+| 常规标注 | 表格标注 |
+| :-------------------------------------------------: | :--------------------------------------------: |
+|
+  +
+
> It is recommended to start with the “quick experience” in the document tutorial
@@ -113,18 +117,19 @@ PaddleOCR support a variety of cutting-edge algorithms related to OCR, and devel
- [Quick Start](./ppstructure/docs/quickstart_en.md)
- [Model Zoo](./ppstructure/docs/models_list_en.md)
- [Model training](./doc/doc_en/training_en.md)
- - [Layout Parser](./ppstructure/layout/README.md)
+ - [Layout Analysis](./ppstructure/layout/README.md)
- [Table Recognition](./ppstructure/table/README.md)
- - [DocVQA](./ppstructure/vqa/README.md)
- - [Key Information Extraction](./ppstructure/docs/kie_en.md)
+ - [Key Information Extraction](./ppstructure/kie/README.md)
- [Inference and Deployment](./deploy/README.md)
- [Python Inference](./ppstructure/docs/inference_en.md)
- - [C++ Inference]()
- - [Serving](./deploy/pdserving/README.md)
-- [Academic algorithms](./doc/doc_en/algorithms_en.md)
+ - [C++ Inference](./deploy/cpp_infer/readme.md)
+ - [Serving](./deploy/hubserving/readme_en.md)
+- [Academic Algorithms](./doc/doc_en/algorithm_overview_en.md)
- [Text detection](./doc/doc_en/algorithm_overview_en.md)
- [Text recognition](./doc/doc_en/algorithm_overview_en.md)
- - [End-to-end](./doc/doc_en/algorithm_overview_en.md)
+ - [End-to-end OCR](./doc/doc_en/algorithm_overview_en.md)
+ - [Table Recognition](./doc/doc_en/algorithm_overview_en.md)
+ - [Key Information Extraction](./doc/doc_en/algorithm_overview_en.md)
- [Add New Algorithms to PaddleOCR](./doc/doc_en/add_new_algorithm_en.md)
- Data Annotation and Synthesis
- [Semi-automatic Annotation Tool: PPOCRLabel](./PPOCRLabel/README.md)
@@ -135,9 +140,9 @@ PaddleOCR support a variety of cutting-edge algorithms related to OCR, and devel
- [General OCR Datasets(Chinese/English)](doc/doc_en/dataset/datasets_en.md)
- [HandWritten_OCR_Datasets(Chinese)](doc/doc_en/dataset/handwritten_datasets_en.md)
- [Various OCR Datasets(multilingual)](doc/doc_en/dataset/vertical_and_multilingual_datasets_en.md)
- - [layout analysis](doc/doc_en/dataset/layout_datasets_en.md)
- - [table recognition](doc/doc_en/dataset/table_datasets_en.md)
- - [DocVQA](doc/doc_en/dataset/docvqa_datasets_en.md)
+ - [Layout Analysis](doc/doc_en/dataset/layout_datasets_en.md)
+ - [Table Recognition](doc/doc_en/dataset/table_datasets_en.md)
+ - [Key Information Extraction](doc/doc_en/dataset/kie_datasets_en.md)
- [Code Structure](./doc/doc_en/tree_en.md)
- [Visualization](#Visualization)
- [Community](#Community)
@@ -176,7 +181,7 @@ PaddleOCR support a variety of cutting-edge algorithms related to OCR, and devel
+
-
PP-Structure
+PP-Structurev2
- layout analysis + table recognition
@@ -185,12 +190,28 @@ PaddleOCR support a variety of cutting-edge algorithms related to OCR, and devel
- SER (Semantic entity recognition)
可用于数据挖掘或对预测效率要求不高的场景。 | [模型下载](#2) | [中文](./高精度中文识别模型.md)/English | |
+| 手写体识别 | 新增字形支持 | [模型下载](#2) | [中文](./手写文字识别.md)/English |
|
+| 手写体识别 | 新增字形支持 | [模型下载](#2) | [中文](./手写文字识别.md)/English |  |
@@ -42,14 +42,14 @@ PaddleOCR场景应用覆盖通用,制造、金融、交通行业的主要OCR
### 金融
-| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
-| -------------- | ------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
-| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English |
|
@@ -42,14 +42,14 @@ PaddleOCR场景应用覆盖通用,制造、金融、交通行业的主要OCR
### 金融
-| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
-| -------------- | ------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
-| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English |  |
-| 增值税发票 | 尽请期待 | | | |
-| 印章检测与识别 | 端到端弯曲文本识别 | | | |
-| 通用卡证识别 | 通用结构化提取 | | | |
-| 身份证识别 | 结构化提取、图像阴影 | | | |
-| 合同比对 | 密集文本检测、NLP串联 | | | |
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| -------------- | ----------------------------- | -------------- | ------------------------------------- | ------------------------------------------------------------ |
+| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English | |
+| 增值税发票 | 关键信息抽取,SER、RE任务训练 | [模型下载](#2) | [中文](./发票关键信息抽取.md)/English |
|
-| 增值税发票 | 尽请期待 | | | |
-| 印章检测与识别 | 端到端弯曲文本识别 | | | |
-| 通用卡证识别 | 通用结构化提取 | | | |
-| 身份证识别 | 结构化提取、图像阴影 | | | |
-| 合同比对 | 密集文本检测、NLP串联 | | | |
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| -------------- | ----------------------------- | -------------- | ------------------------------------- | ------------------------------------------------------------ |
+| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English | |
+| 增值税发票 | 关键信息抽取,SER、RE任务训练 | [模型下载](#2) | [中文](./发票关键信息抽取.md)/English |  |
+| 印章检测与识别 | 端到端弯曲文本识别 | | | |
+| 通用卡证识别 | 通用结构化提取 | | | |
+| 身份证识别 | 结构化提取、图像阴影 | | | |
+| 合同比对 | 密集文本检测、NLP串联 | | | |
diff --git a/applications/README_en.md b/applications/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..95c56a1f740faa95e1fe3adeaeb90bfe902f8ed8
--- /dev/null
+++ b/applications/README_en.md
@@ -0,0 +1,79 @@
+English| [简体中文](README.md)
+
+# Application
+
+PaddleOCR scene application covers general, manufacturing, finance, transportation industry of the main OCR vertical applications, on the basis of the general capabilities of PP-OCR, PP-Structure, in the form of notebook to show the use of scene data fine-tuning, model optimization methods, data augmentation and other content, for developers to quickly land OCR applications to provide demonstration and inspiration.
+
+- [Tutorial](#1)
+ - [General](#11)
+ - [Manufacturing](#12)
+ - [Finance](#13)
+ - [Transportation](#14)
+
+- [Model Download](#2)
+
+
+
+## Tutorial
+
+
+
+### General
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ---------------------------------------------- | ---------------- | -------------------- | --------------------------------------- | ------------------------------------------------------------ |
+| High-precision Chineses recognition model SVTR | New model | [Model Download](#2) | [中文](./高精度中文识别模型.md)/English | |
+| Chinese handwriting recognition | New font support | [Model Download](#2) | [中文](./手写文字识别.md)/English | |
+
+
+
+### Manufacturing
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ------------------------------ | ------------------------------------------------------------ | -------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| Digital tube | Digital tube data sythesis, recognition model fine-tuning | [Model Download](#2) | [中文](./光功率计数码管字符识别/光功率计数码管字符识别.md)/English |
|
+| 印章检测与识别 | 端到端弯曲文本识别 | | | |
+| 通用卡证识别 | 通用结构化提取 | | | |
+| 身份证识别 | 结构化提取、图像阴影 | | | |
+| 合同比对 | 密集文本检测、NLP串联 | | | |
diff --git a/applications/README_en.md b/applications/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..95c56a1f740faa95e1fe3adeaeb90bfe902f8ed8
--- /dev/null
+++ b/applications/README_en.md
@@ -0,0 +1,79 @@
+English| [简体中文](README.md)
+
+# Application
+
+PaddleOCR scene application covers general, manufacturing, finance, transportation industry of the main OCR vertical applications, on the basis of the general capabilities of PP-OCR, PP-Structure, in the form of notebook to show the use of scene data fine-tuning, model optimization methods, data augmentation and other content, for developers to quickly land OCR applications to provide demonstration and inspiration.
+
+- [Tutorial](#1)
+ - [General](#11)
+ - [Manufacturing](#12)
+ - [Finance](#13)
+ - [Transportation](#14)
+
+- [Model Download](#2)
+
+
+
+## Tutorial
+
+
+
+### General
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ---------------------------------------------- | ---------------- | -------------------- | --------------------------------------- | ------------------------------------------------------------ |
+| High-precision Chineses recognition model SVTR | New model | [Model Download](#2) | [中文](./高精度中文识别模型.md)/English | |
+| Chinese handwriting recognition | New font support | [Model Download](#2) | [中文](./手写文字识别.md)/English | |
+
+
+
+### Manufacturing
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ------------------------------ | ------------------------------------------------------------ | -------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| Digital tube | Digital tube data sythesis, recognition model fine-tuning | [Model Download](#2) | [中文](./光功率计数码管字符识别/光功率计数码管字符识别.md)/English |  |
+| LCD screen | Detection model distillation, serving deployment | [Model Download](#2) | [中文](./液晶屏读数识别.md)/English |
|
+| LCD screen | Detection model distillation, serving deployment | [Model Download](#2) | [中文](./液晶屏读数识别.md)/English |  |
+| Packaging production data | Dot matrix character synthesis, overexposure and overdark text recognition | [Model Download](#2) | [中文](./包装生产日期识别.md)/English |
|
+| Packaging production data | Dot matrix character synthesis, overexposure and overdark text recognition | [Model Download](#2) | [中文](./包装生产日期识别.md)/English |  |
+| PCB text recognition | Small size text detection and recognition | [Model Download](#2) | [中文](./PCB字符识别/PCB字符识别.md)/English |
|
+| PCB text recognition | Small size text detection and recognition | [Model Download](#2) | [中文](./PCB字符识别/PCB字符识别.md)/English |  |
+| Meter text recognition | High-resolution image detection fine-tuning | [Model Download](#2) | | |
+| LCD character defect detection | Non-text character recognition | | | |
+
+
+
+### Finance
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ----------------------------------- | -------------------------------------------------- | -------------------- | ------------------------------------- | ------------------------------------------------------------ |
+| Form visual question and answer | Multimodal general form structured extraction | [Model Download](#2) | [中文](./多模态表单识别.md)/English | |
+| VAT invoice | Key information extraction, SER, RE task fine-tune | [Model Download](#2) | [中文](./发票关键信息抽取.md)/English | |
+| Seal detection and recognition | End-to-end curved text recognition | | | |
+| Universal card recognition | Universal structured extraction | | | |
+| ID card recognition | Structured extraction, image shading | | | |
+| Contract key information extraction | Dense text detection, NLP concatenation | | | |
+
+
+
+### Transportation
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ----------------------------------------------- | ------------------------------------------------------------ | -------------------- | ----------------------------------- | ------------------------------------------------------------ |
+| License plate recognition | Multi-angle images, lightweight models, edge-side deployment | [Model Download](#2) | [中文](./轻量级车牌识别.md)/English |
|
+| Meter text recognition | High-resolution image detection fine-tuning | [Model Download](#2) | | |
+| LCD character defect detection | Non-text character recognition | | | |
+
+
+
+### Finance
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ----------------------------------- | -------------------------------------------------- | -------------------- | ------------------------------------- | ------------------------------------------------------------ |
+| Form visual question and answer | Multimodal general form structured extraction | [Model Download](#2) | [中文](./多模态表单识别.md)/English | |
+| VAT invoice | Key information extraction, SER, RE task fine-tune | [Model Download](#2) | [中文](./发票关键信息抽取.md)/English | |
+| Seal detection and recognition | End-to-end curved text recognition | | | |
+| Universal card recognition | Universal structured extraction | | | |
+| ID card recognition | Structured extraction, image shading | | | |
+| Contract key information extraction | Dense text detection, NLP concatenation | | | |
+
+
+
+### Transportation
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ----------------------------------------------- | ------------------------------------------------------------ | -------------------- | ----------------------------------- | ------------------------------------------------------------ |
+| License plate recognition | Multi-angle images, lightweight models, edge-side deployment | [Model Download](#2) | [中文](./轻量级车牌识别.md)/English |  |
+| Driver's license/driving license identification | coming soon | | | |
+| Express text recognition | coming soon | | | |
+
+
+
+## Model Download
+
+- For international developers: We're building a way to download these trained models, and since the current tutorials are Chinese, if you are good at both Chinese and English, or willing to polish English documents, please let us know in [discussion](https://github.com/PaddlePaddle/PaddleOCR/discussions).
+- For Chinese developer: If you want to download the trained application model in the above scenarios, scan the QR code below with your WeChat, follow the PaddlePaddle official account to fill in the questionnaire, and join the PaddleOCR official group to get the 20G OCR learning materials (including "Dive into OCR" e-book, course video, application models and other materials)
+
+
|
+| Driver's license/driving license identification | coming soon | | | |
+| Express text recognition | coming soon | | | |
+
+
+
+## Model Download
+
+- For international developers: We're building a way to download these trained models, and since the current tutorials are Chinese, if you are good at both Chinese and English, or willing to polish English documents, please let us know in [discussion](https://github.com/PaddlePaddle/PaddleOCR/discussions).
+- For Chinese developer: If you want to download the trained application model in the above scenarios, scan the QR code below with your WeChat, follow the PaddlePaddle official account to fill in the questionnaire, and join the PaddleOCR official group to get the 20G OCR learning materials (including "Dive into OCR" e-book, course video, application models and other materials)
+
+  +
diff --git "a/applications/\345\217\221\347\245\250\345\205\263\351\224\256\344\277\241\346\201\257\346\212\275\345\217\226.md" "b/applications/\345\217\221\347\245\250\345\205\263\351\224\256\344\277\241\346\201\257\346\212\275\345\217\226.md"
new file mode 100644
index 0000000000000000000000000000000000000000..82f5b8d48600c6bebb4d3183ee801305d305d531
--- /dev/null
+++ "b/applications/\345\217\221\347\245\250\345\205\263\351\224\256\344\277\241\346\201\257\346\212\275\345\217\226.md"
@@ -0,0 +1,343 @@
+
+# 基于VI-LayoutXLM的发票关键信息抽取
+
+- [1. 项目背景及意义](#1-项目背景及意义)
+- [2. 项目内容](#2-项目内容)
+- [3. 安装环境](#3-安装环境)
+- [4. 关键信息抽取](#4-关键信息抽取)
+ - [4.1 文本检测](#41-文本检测)
+ - [4.2 文本识别](#42-文本识别)
+ - [4.3 语义实体识别](#43-语义实体识别)
+ - [4.4 关系抽取](#44-关系抽取)
+
+
+
+## 1. 项目背景及意义
+
+关键信息抽取在文档场景中被广泛使用,如身份证中的姓名、住址信息抽取,快递单中的姓名、联系方式等关键字段内容的抽取。传统基于模板匹配的方案需要针对不同的场景制定模板并进行适配,较为繁琐,不够鲁棒。基于该问题,我们借助飞桨提供的PaddleOCR套件中的关键信息抽取方案,实现对增值税发票场景的关键信息抽取。
+
+## 2. 项目内容
+
+本项目基于PaddleOCR开源套件,以VI-LayoutXLM多模态关键信息抽取模型为基础,针对增值税发票场景进行适配,提取该场景的关键信息。
+
+## 3. 安装环境
+
+```bash
+# 首先git官方的PaddleOCR项目,安装需要的依赖
+# 第一次运行打开该注释
+git clone https://gitee.com/PaddlePaddle/PaddleOCR.git
+cd PaddleOCR
+# 安装PaddleOCR的依赖
+pip install -r requirements.txt
+# 安装关键信息抽取任务的依赖
+pip install -r ./ppstructure/kie/requirements.txt
+```
+
+## 4. 关键信息抽取
+
+基于文档图像的关键信息抽取包含3个部分:(1)文本检测(2)文本识别(3)关键信息抽取方法,包括语义实体识别或者关系抽取,下面分别进行介绍。
+
+### 4.1 文本检测
+
+
+本文重点关注发票的关键信息抽取模型训练与预测过程,因此在关键信息抽取过程中,直接使用标注的文本检测与识别标注信息进行测试,如果你希望自定义该场景的文本检测模型,完成端到端的关键信息抽取部分,请参考[文本检测模型训练教程](../doc/doc_ch/detection.md),按照训练数据格式准备数据,并完成该场景下垂类文本检测模型的微调过程。
+
+
+### 4.2 文本识别
+
+本文重点关注发票的关键信息抽取模型训练与预测过程,因此在关键信息抽取过程中,直接使用提供的文本检测与识别标注信息进行测试,如果你希望自定义该场景的文本检测模型,完成端到端的关键信息抽取部分,请参考[文本识别模型训练教程](../doc/doc_ch/recognition.md),按照训练数据格式准备数据,并完成该场景下垂类文本识别模型的微调过程。
+
+### 4.3 语义实体识别 (Semantic Entity Recognition)
+
+语义实体识别指的是给定一段文本行,确定其类别(如`姓名`、`住址`等类别)。PaddleOCR中提供了基于VI-LayoutXLM的多模态语义实体识别方法,融合文本、位置与版面信息,相比LayoutXLM多模态模型,去除了其中的视觉骨干网络特征提取部分,引入符合阅读顺序的文本行排序方法,同时使用UDML联合互蒸馏方法进行训练,最终在精度与速度方面均超越LayoutXLM。更多关于VI-LayoutXLM的算法介绍与精度指标,请参考:[VI-LayoutXLM算法介绍](../doc/doc_ch/algorithm_kie_vi_layoutxlm.md)。
+
+#### 4.3.1 准备数据
+
+发票场景为例,我们首先需要标注出其中的关键字段,我们将其标注为`问题-答案`的key-value pair,如下,编号No为12270830,则`No`字段标注为question,`12270830`字段标注为answer。如下图所示。
+
+
+
diff --git "a/applications/\345\217\221\347\245\250\345\205\263\351\224\256\344\277\241\346\201\257\346\212\275\345\217\226.md" "b/applications/\345\217\221\347\245\250\345\205\263\351\224\256\344\277\241\346\201\257\346\212\275\345\217\226.md"
new file mode 100644
index 0000000000000000000000000000000000000000..82f5b8d48600c6bebb4d3183ee801305d305d531
--- /dev/null
+++ "b/applications/\345\217\221\347\245\250\345\205\263\351\224\256\344\277\241\346\201\257\346\212\275\345\217\226.md"
@@ -0,0 +1,343 @@
+
+# 基于VI-LayoutXLM的发票关键信息抽取
+
+- [1. 项目背景及意义](#1-项目背景及意义)
+- [2. 项目内容](#2-项目内容)
+- [3. 安装环境](#3-安装环境)
+- [4. 关键信息抽取](#4-关键信息抽取)
+ - [4.1 文本检测](#41-文本检测)
+ - [4.2 文本识别](#42-文本识别)
+ - [4.3 语义实体识别](#43-语义实体识别)
+ - [4.4 关系抽取](#44-关系抽取)
+
+
+
+## 1. 项目背景及意义
+
+关键信息抽取在文档场景中被广泛使用,如身份证中的姓名、住址信息抽取,快递单中的姓名、联系方式等关键字段内容的抽取。传统基于模板匹配的方案需要针对不同的场景制定模板并进行适配,较为繁琐,不够鲁棒。基于该问题,我们借助飞桨提供的PaddleOCR套件中的关键信息抽取方案,实现对增值税发票场景的关键信息抽取。
+
+## 2. 项目内容
+
+本项目基于PaddleOCR开源套件,以VI-LayoutXLM多模态关键信息抽取模型为基础,针对增值税发票场景进行适配,提取该场景的关键信息。
+
+## 3. 安装环境
+
+```bash
+# 首先git官方的PaddleOCR项目,安装需要的依赖
+# 第一次运行打开该注释
+git clone https://gitee.com/PaddlePaddle/PaddleOCR.git
+cd PaddleOCR
+# 安装PaddleOCR的依赖
+pip install -r requirements.txt
+# 安装关键信息抽取任务的依赖
+pip install -r ./ppstructure/kie/requirements.txt
+```
+
+## 4. 关键信息抽取
+
+基于文档图像的关键信息抽取包含3个部分:(1)文本检测(2)文本识别(3)关键信息抽取方法,包括语义实体识别或者关系抽取,下面分别进行介绍。
+
+### 4.1 文本检测
+
+
+本文重点关注发票的关键信息抽取模型训练与预测过程,因此在关键信息抽取过程中,直接使用标注的文本检测与识别标注信息进行测试,如果你希望自定义该场景的文本检测模型,完成端到端的关键信息抽取部分,请参考[文本检测模型训练教程](../doc/doc_ch/detection.md),按照训练数据格式准备数据,并完成该场景下垂类文本检测模型的微调过程。
+
+
+### 4.2 文本识别
+
+本文重点关注发票的关键信息抽取模型训练与预测过程,因此在关键信息抽取过程中,直接使用提供的文本检测与识别标注信息进行测试,如果你希望自定义该场景的文本检测模型,完成端到端的关键信息抽取部分,请参考[文本识别模型训练教程](../doc/doc_ch/recognition.md),按照训练数据格式准备数据,并完成该场景下垂类文本识别模型的微调过程。
+
+### 4.3 语义实体识别 (Semantic Entity Recognition)
+
+语义实体识别指的是给定一段文本行,确定其类别(如`姓名`、`住址`等类别)。PaddleOCR中提供了基于VI-LayoutXLM的多模态语义实体识别方法,融合文本、位置与版面信息,相比LayoutXLM多模态模型,去除了其中的视觉骨干网络特征提取部分,引入符合阅读顺序的文本行排序方法,同时使用UDML联合互蒸馏方法进行训练,最终在精度与速度方面均超越LayoutXLM。更多关于VI-LayoutXLM的算法介绍与精度指标,请参考:[VI-LayoutXLM算法介绍](../doc/doc_ch/algorithm_kie_vi_layoutxlm.md)。
+
+#### 4.3.1 准备数据
+
+发票场景为例,我们首先需要标注出其中的关键字段,我们将其标注为`问题-答案`的key-value pair,如下,编号No为12270830,则`No`字段标注为question,`12270830`字段标注为answer。如下图所示。
+
+ cv_all_img_names, bool det = true,
bool rec = true, bool cls = true);
-private:
- DBDetector *detector_ = nullptr;
- Classifier *classifier_ = nullptr;
- CRNNRecognizer *recognizer_ = nullptr;
-
+protected:
void det(cv::Mat img, std::vector &ocr_results,
std::vector ×);
void rec(std::vector img_list,
@@ -62,6 +58,11 @@ private:
std::vector ×);
void log(std::vector &det_times, std::vector &rec_times,
std::vector &cls_times, int img_num);
+
+private:
+ DBDetector *detector_ = nullptr;
+ Classifier *classifier_ = nullptr;
+ CRNNRecognizer *recognizer_ = nullptr;
};
} // namespace PaddleOCR
diff --git a/deploy/cpp_infer/include/paddlestructure.h b/deploy/cpp_infer/include/paddlestructure.h
new file mode 100644
index 0000000000000000000000000000000000000000..6d2c8b7d203a05f531b8d038d885061c42897373
--- /dev/null
+++ b/deploy/cpp_infer/include/paddlestructure.h
@@ -0,0 +1,76 @@
+// Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#pragma once
+
+#include "opencv2/core.hpp"
+#include "opencv2/imgcodecs.hpp"
+#include "opencv2/imgproc.hpp"
+#include "paddle_api.h"
+#include "paddle_inference_api.h"
+#include
+#include
+#include
+#include
+#include
+
+#include
+#include
+#include
+
+#include
+#include
+#include
+#include
+
+using namespace paddle_infer;
+
+namespace PaddleOCR {
+
+class PaddleStructure : public PPOCR {
+public:
+ explicit PaddleStructure();
+ ~PaddleStructure();
+ std::vector>
+ structure(std::vector cv_all_img_names, bool layout = false,
+ bool table = true);
+
+private:
+ StructureTableRecognizer *recognizer_ = nullptr;
+
+ void table(cv::Mat img, StructurePredictResult &structure_result,
+ std::vector &time_info_table,
+ std::vector &time_info_det,
+ std::vector &time_info_rec,
+ std::vector &time_info_cls);
+ std::string rebuild_table(std::vector rec_html_tags,
+ std::vector> rec_boxes,
+ std::vector &ocr_result);
+
+ float iou(std::vector &box1, std::vector &box2);
+ float dis(std::vector &box1, std::vector &box2);
+
+ static bool comparison_dis(const std::vector &dis1,
+ const std::vector &dis2) {
+ if (dis1[1] < dis2[1]) {
+ return true;
+ } else if (dis1[1] == dis2[1]) {
+ return dis1[0] < dis2[0];
+ } else {
+ return false;
+ }
+ }
+};
+
+} // namespace PaddleOCR
\ No newline at end of file
diff --git a/deploy/cpp_infer/include/postprocess_op.h b/deploy/cpp_infer/include/postprocess_op.h
index 4a98b151bdcc53e2ab3fbda1dca55dd9746bd86c..f5db52a6097f0fb916fc96fd8c76095f2ed1a9fa 100644
--- a/deploy/cpp_infer/include/postprocess_op.h
+++ b/deploy/cpp_infer/include/postprocess_op.h
@@ -34,7 +34,7 @@ using namespace std;
namespace PaddleOCR {
-class PostProcessor {
+class DBPostProcessor {
public:
void GetContourArea(const std::vector> &box,
float unclip_ratio, float &distance);
@@ -90,4 +90,20 @@ private:
}
};
+class TablePostProcessor {
+public:
+ void init(std::string label_path, bool merge_no_span_structure = true);
+ void Run(std::vector &loc_preds, std::vector &structure_probs,
+ std::vector &rec_scores, std::vector &loc_preds_shape,
+ std::vector &structure_probs_shape,
+ std::vector> &rec_html_tag_batch,
+ std::vector>> &rec_boxes_batch,
+ std::vector &width_list, std::vector &height_list);
+
+private:
+ std::vector label_list_;
+ std::string end = "eos";
+ std::string beg = "sos";
+};
+
} // namespace PaddleOCR
diff --git a/deploy/cpp_infer/include/preprocess_op.h b/deploy/cpp_infer/include/preprocess_op.h
index 31217de301573e078f8e11ef88657f369ede9b31..078f19d5b808c81e88d7aa464d6bfaca7fe1b14e 100644
--- a/deploy/cpp_infer/include/preprocess_op.h
+++ b/deploy/cpp_infer/include/preprocess_op.h
@@ -48,11 +48,12 @@ class PermuteBatch {
public:
virtual void Run(const std::vector imgs, float *data);
};
-
+
class ResizeImgType0 {
public:
- virtual void Run(const cv::Mat &img, cv::Mat &resize_img, int max_size_len,
- float &ratio_h, float &ratio_w, bool use_tensorrt);
+ virtual void Run(const cv::Mat &img, cv::Mat &resize_img, string limit_type,
+ int limit_side_len, float &ratio_h, float &ratio_w,
+ bool use_tensorrt);
};
class CrnnResizeImg {
@@ -69,4 +70,16 @@ public:
const std::vector &rec_image_shape = {3, 48, 192});
};
+class TableResizeImg {
+public:
+ virtual void Run(const cv::Mat &img, cv::Mat &resize_img,
+ const int max_len = 488);
+};
+
+class TablePadImg {
+public:
+ virtual void Run(const cv::Mat &img, cv::Mat &resize_img,
+ const int max_len = 488);
+};
+
} // namespace PaddleOCR
\ No newline at end of file
diff --git a/deploy/cpp_infer/include/structure_table.h b/deploy/cpp_infer/include/structure_table.h
new file mode 100644
index 0000000000000000000000000000000000000000..c09e65654a7c8a4deb6729ddfd876531020f306b
--- /dev/null
+++ b/deploy/cpp_infer/include/structure_table.h
@@ -0,0 +1,101 @@
+// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#pragma once
+
+#include "opencv2/core.hpp"
+#include "opencv2/imgcodecs.hpp"
+#include "opencv2/imgproc.hpp"
+#include "paddle_api.h"
+#include "paddle_inference_api.h"
+#include
+#include
+#include
+#include
+#include
+
+#include
+#include
+#include
+
+#include
+#include
+#include
+
+using namespace paddle_infer;
+
+namespace PaddleOCR {
+
+class StructureTableRecognizer {
+public:
+ explicit StructureTableRecognizer(
+ const std::string &model_dir, const bool &use_gpu, const int &gpu_id,
+ const int &gpu_mem, const int &cpu_math_library_num_threads,
+ const bool &use_mkldnn, const string &label_path,
+ const bool &use_tensorrt, const std::string &precision,
+ const int &table_batch_num, const int &table_max_len,
+ const bool &merge_no_span_structure) {
+ this->use_gpu_ = use_gpu;
+ this->gpu_id_ = gpu_id;
+ this->gpu_mem_ = gpu_mem;
+ this->cpu_math_library_num_threads_ = cpu_math_library_num_threads;
+ this->use_mkldnn_ = use_mkldnn;
+ this->use_tensorrt_ = use_tensorrt;
+ this->precision_ = precision;
+ this->table_batch_num_ = table_batch_num;
+ this->table_max_len_ = table_max_len;
+
+ this->post_processor_.init(label_path, merge_no_span_structure);
+ LoadModel(model_dir);
+ }
+
+ // Load Paddle inference model
+ void LoadModel(const std::string &model_dir);
+
+ void Run(std::vector img_list,
+ std::vector> &rec_html_tags,
+ std::vector &rec_scores,
+ std::vector>> &rec_boxes,
+ std::vector ×);
+
+private:
+ std::shared_ptr predictor_;
+
+ bool use_gpu_ = false;
+ int gpu_id_ = 0;
+ int gpu_mem_ = 4000;
+ int cpu_math_library_num_threads_ = 4;
+ bool use_mkldnn_ = false;
+ int table_max_len_ = 488;
+
+ std::vector mean_ = {0.485f, 0.456f, 0.406f};
+ std::vector scale_ = {1 / 0.229f, 1 / 0.224f, 1 / 0.225f};
+ bool is_scale_ = true;
+
+ bool use_tensorrt_ = false;
+ std::string precision_ = "fp32";
+ int table_batch_num_ = 1;
+
+ // pre-process
+ TableResizeImg resize_op_;
+ Normalize normalize_op_;
+ PermuteBatch permute_op_;
+ TablePadImg pad_op_;
+
+ // post-process
+ TablePostProcessor post_processor_;
+
+}; // class StructureTableRecognizer
+
+} // namespace PaddleOCR
\ No newline at end of file
diff --git a/deploy/cpp_infer/include/utility.h b/deploy/cpp_infer/include/utility.h
index eb18c0624492e9b47de156d60611d637d8dca6c3..85b280fe25a46be70dba529891c3470a729dfbf1 100644
--- a/deploy/cpp_infer/include/utility.h
+++ b/deploy/cpp_infer/include/utility.h
@@ -40,6 +40,15 @@ struct OCRPredictResult {
int cls_label = -1;
};
+struct StructurePredictResult {
+ std::vector box;
+ std::vector> cell_box;
+ std::string type;
+ std::vector text_res;
+ std::string html;
+ float html_score = -1;
+};
+
class Utility {
public:
static std::vector ReadDict(const std::string &path);
@@ -48,6 +57,10 @@ public:
const std::vector &ocr_result,
const std::string &save_path);
+ static void VisualizeBboxes(const cv::Mat &srcimg,
+ const StructurePredictResult &structure_result,
+ const std::string &save_path);
+
template
inline static size_t argmax(ForwardIterator first, ForwardIterator last) {
return std::distance(first, std::max_element(first, last));
@@ -68,6 +81,25 @@ public:
static void CreateDir(const std::string &path);
static void print_result(const std::vector &ocr_result);
+
+ static cv::Mat crop_image(cv::Mat &img, std::vector &area);
+
+ static void sorted_boxes(std::vector &ocr_result);
+
+ static std::vector xyxyxyxy2xyxy(std::vector> &box);
+ static std::vector xyxyxyxy2xyxy(std::vector &box);
+
+private:
+ static bool comparison_box(const OCRPredictResult &result1,
+ const OCRPredictResult &result2) {
+ if (result1.box[0][1] < result2.box[0][1]) {
+ return true;
+ } else if (result1.box[0][1] == result2.box[0][1]) {
+ return result1.box[0][0] < result2.box[0][0];
+ } else {
+ return false;
+ }
+ }
};
} // namespace PaddleOCR
\ No newline at end of file
diff --git a/deploy/cpp_infer/readme.md b/deploy/cpp_infer/readme.md
index a87db7e6596bc2528bfb4a93c3170ebf0482ccad..2974f3227aa6f9cdd967665addc905f7b902bac2 100644
--- a/deploy/cpp_infer/readme.md
+++ b/deploy/cpp_infer/readme.md
@@ -171,6 +171,9 @@ inference/
|-- cls
| |--inference.pdiparams
| |--inference.pdmodel
+|-- table
+| |--inference.pdiparams
+| |--inference.pdmodel
```
@@ -275,6 +278,17 @@ Specifically,
--cls=true \
```
+
+##### 7. table
+```shell
+./build/ppocr --det_model_dir=inference/det_db \
+ --rec_model_dir=inference/rec_rcnn \
+ --table_model_dir=inference/table \
+ --image_dir=../../ppstructure/docs/table/table.jpg \
+ --type=structure \
+ --table=true
+```
+
More parameters are as follows,
- Common parameters
@@ -293,9 +307,9 @@ More parameters are as follows,
|parameter|data type|default|meaning|
| :---: | :---: | :---: | :---: |
-|det|bool|true|前向是否执行文字检测|
-|rec|bool|true|前向是否执行文字识别|
-|cls|bool|false|前向是否执行文字方向分类|
+|det|bool|true|Whether to perform text detection in the forward direction|
+|rec|bool|true|Whether to perform text recognition in the forward direction|
+|cls|bool|false|Whether to perform text direction classification in the forward direction|
- Detection related parameters
@@ -329,6 +343,16 @@ More parameters are as follows,
|rec_img_h|int|48|image height of recognition|
|rec_img_w|int|320|image width of recognition|
+- Table recognition related parameters
+
+|parameter|data type|default|meaning|
+| :---: | :---: | :---: | :---: |
+|table_model_dir|string|-|Address of table recognition inference model|
+|table_char_dict_path|string|../../ppocr/utils/dict/table_structure_dict.txt|dictionary file|
+|table_max_len|int|488|The size of the long side of the input image of the table recognition model, the final input image size of the network is(table_max_len,table_max_len)|
+|merge_no_span_structure|bool|true|Whether to merge and to
-  +
+  +
+
+
+
+
+
+  +
+
+
+
+
+ 
- RE (Relation Extraction)
-  +
+  +
+
+
+
+
+
+
+
+
+
+
+ 
diff --git a/README_ch.md b/README_ch.md
index e801ce561cb41aafb376f81a3016f0a6b838320d..24a925f6c8092f28b58452e761ac74b0a5f3d2c3 100755
--- a/README_ch.md
+++ b/README_ch.md
@@ -27,28 +27,20 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
## 近期更新
-- **🔥2022.5.11~13 每晚8:30【超强OCR技术详解与产业应用实战】三日直播课**
- - 11日:开源最强OCR系统PP-OCRv3揭秘
- - 12日:云边端全覆盖的PP-OCRv3训练部署实战
- - 13日:OCR产业应用全流程拆解与实战
+- **🔥2022.8.24 发布 PaddleOCR [release/2.6](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.6)**
+ - 发布[PP-Structurev2](./ppstructure/),系统功能性能全面升级,适配中文场景,新增支持[版面复原](./ppstructure/recovery),支持**一行命令完成PDF转Word**;
+ - [版面分析](./ppstructure/layout)模型优化:模型存储减少95%,速度提升11倍,平均CPU耗时仅需41ms;
+ - [表格识别](./ppstructure/table)模型优化:设计3大优化策略,预测耗时不变情况下,模型精度提升6%;
+ - [关键信息抽取](./ppstructure/kie)模型优化:设计视觉无关模型结构,语义实体识别精度提升2.8%,关系抽取精度提升9.1%。
- 赶紧扫码报名吧!
-
- -
-
-
-- **🔥2022.5.9 发布PaddleOCR [release/2.5](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.5)**
+- **🔥2022.8 发布 [OCR场景应用集合](./applications)**
+ - 包含数码管、液晶屏、车牌、高精度SVTR模型、手写体识别等**9个垂类模型**,覆盖通用,制造、金融、交通行业的主要OCR垂类应用。
+
+- **2022.5.9 发布 PaddleOCR [release/2.5](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.5)**
- 发布[PP-OCRv3](./doc/doc_ch/ppocr_introduction.md#pp-ocrv3),速度可比情况下,中文场景效果相比于PP-OCRv2再提升5%,英文场景提升11%,80语种多语言模型平均识别准确率提升5%以上;
- 发布半自动标注工具[PPOCRLabelv2](./PPOCRLabel):新增表格文字图像、图像关键信息抽取任务和不规则文字图像的标注功能;
- 发布OCR产业落地工具集:打通22种训练部署软硬件环境与方式,覆盖企业90%的训练部署环境需求;
- 发布交互式OCR开源电子书[《动手学OCR》](./doc/doc_ch/ocr_book.md),覆盖OCR全栈技术的前沿理论与代码实践,并配套教学视频。
-- 2021.12.21 发布PaddleOCR [release/2.4](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.4)
- - OCR算法新增1种文本检测算法([PSENet](./doc/doc_ch/algorithm_det_psenet.md)),3种文本识别算法([NRTR](./doc/doc_ch/algorithm_rec_nrtr.md)、[SEED](./doc/doc_ch/algorithm_rec_seed.md)、[SAR](./doc/doc_ch/algorithm_rec_sar.md));
- - 文档结构化算法新增1种关键信息提取算法([SDMGR](./ppstructure/docs/kie.md)),3种[DocVQA](./ppstructure/vqa)算法(LayoutLM、LayoutLMv2,LayoutXLM)。
-- 2021.9.7 发布PaddleOCR [release/2.3](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.3)
- - 发布[PP-OCRv2](./doc/doc_ch/ppocr_introduction.md#pp-ocrv2),CPU推理速度相比于PP-OCR server提升220%;效果相比于PP-OCR mobile 提升7%。
-- 2021.8.3 发布PaddleOCR [release/2.2](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.2)
- - 发布文档结构分析[PP-Structure](./ppstructure/README_ch.md)工具包,支持版面分析与表格识别(含Excel导出)。
> [更多](./doc/doc_ch/update.md)
@@ -56,7 +48,9 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
支持多种OCR相关前沿算法,在此基础上打造产业级特色模型[PP-OCR](./doc/doc_ch/ppocr_introduction.md)和[PP-Structure](./ppstructure/README_ch.md),并打通数据生产、模型训练、压缩、预测部署全流程。
-
+
-
+  +
+
> 上述内容的使用方法建议从文档教程中的快速开始体验
@@ -71,24 +65,22 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
## 《动手学OCR》电子书
- [《动手学OCR》电子书📚](./doc/doc_ch/ocr_book.md)
-## 场景应用
-- PaddleOCR场景应用覆盖通用,制造、金融、交通行业的主要OCR垂类应用,在PP-OCR、PP-Structure的通用能力基础之上,以notebook的形式展示利用场景数据微调、模型优化方法、数据增广等内容,为开发者快速落地OCR应用提供示范与启发。详情可查看[README](./applications)。
## 开源社区
-
+- **项目合作📑:** 如果您是企业开发者且有明确的OCR垂类应用需求,填写[问卷](https://paddle.wjx.cn/vj/QwF7GKw.aspx)后可免费与官方团队展开不同层次的合作。
- **加入社区👬:** 微信扫描二维码并填写问卷之后,加入交流群领取福利
- - **获取5月11-13日每晚20:30《OCR超强技术详解与产业应用实战》的直播课链接**
+ - **获取PaddleOCR最新发版解说《OCR超强技术详解与产业应用实战》系列直播课回放链接**
- **10G重磅OCR学习大礼包:**《动手学OCR》电子书,配套讲解视频和notebook项目;66篇OCR相关顶会前沿论文打包放送,包括CVPR、AAAI、IJCAI、ICCV等;PaddleOCR历次发版直播课视频;OCR社区优秀开发者项目分享视频。
-
-- **社区贡献**🏅️:[社区贡献](./doc/doc_ch/thirdparty.md)文档中包含了社区用户**使用PaddleOCR开发的各种工具、应用**以及**为PaddleOCR贡献的功能、优化的文档与代码**等,是官方为社区开发者打造的荣誉墙,也是帮助优质项目宣传的广播站。
+- **社区项目**🏅️:[社区项目](./doc/doc_ch/thirdparty.md)文档中包含了社区用户**使用PaddleOCR开发的各种工具、应用**以及**为PaddleOCR贡献的功能、优化的文档与代码**等,是官方为社区开发者打造的荣誉墙,也是帮助优质项目宣传的广播站。
- **社区常规赛**🎁:社区常规赛是面向OCR开发者的积分赛事,覆盖文档、代码、模型和应用四大类型,以季度为单位评选并发放奖励,赛题详情与报名方法可参考[链接](https://github.com/PaddlePaddle/PaddleOCR/issues/4982)。
+
-
+
+
## PP-OCR系列模型列表(更新中)
@@ -96,14 +88,21 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
-| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
-| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
-| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
-更多模型下载(包括多语言),可以参考[PP-OCR 系列模型下载](./doc/doc_ch/models_list.md),文档分析相关模型参考[PP-Structure 系列模型下载](./ppstructure/docs/models_list.md)
+- 超轻量OCR系列更多模型下载(包括多语言),可以参考[PP-OCR系列模型下载](./doc/doc_ch/models_list.md),文档分析相关模型参考[PP-Structure系列模型下载](./ppstructure/docs/models_list.md)
+
+### PaddleOCR场景应用模型
+| 行业 | 类别 | 亮点 | 文档说明 | 模型下载 |
+| ---- | ------------ | ---------------------------------- | ------------------------------------------------------------ | --------------------------------------------- |
+| 制造 | 数码管识别 | 数码管数据合成、漏识别调优 | [光功率计数码管字符识别](./applications/光功率计数码管字符识别/光功率计数码管字符识别.md) | [下载链接](./applications/README.md#模型下载) |
+| 金融 | 通用表单识别 | 多模态通用表单结构化提取 | [多模态表单识别](./applications/多模态表单识别.md) | [下载链接](./applications/README.md#模型下载) |
+| 交通 | 车牌识别 | 多角度图像处理、轻量模型、端侧部署 | [轻量级车牌识别](./applications/轻量级车牌识别.md) | [下载链接](./applications/README.md#模型下载) |
+
+- 更多制造、金融、交通行业的主要OCR垂类应用模型(如电表、液晶屏、高精度SVTR模型等),可参考[场景应用模型下载](./applications)
+
## 文档教程
- [运行环境准备](./doc/doc_ch/environment.md)
@@ -120,7 +119,7 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
- [知识蒸馏](./doc/doc_ch/knowledge_distillation.md)
- [推理部署](./deploy/README_ch.md)
- [基于Python预测引擎推理](./doc/doc_ch/inference_ppocr.md)
- - [基于C++预测引擎推理](./deploy/cpp_infer/readme.md)
+ - [基于C++预测引擎推理](./deploy/cpp_infer/readme_ch.md)
- [服务化部署](./deploy/pdserving/README_CN.md)
- [端侧部署](./deploy/lite/readme.md)
- [Paddle2ONNX模型转化与预测](./deploy/paddle2onnx/readme.md)
@@ -132,16 +131,17 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
- [模型训练](./doc/doc_ch/training.md)
- [版面分析](./ppstructure/layout/README_ch.md)
- [表格识别](./ppstructure/table/README_ch.md)
- - [关键信息提取](./ppstructure/docs/kie.md)
- - [DocVQA](./ppstructure/vqa/README_ch.md)
+ - [关键信息提取](./ppstructure/kie/README_ch.md)
- [推理部署](./deploy/README_ch.md)
- [基于Python预测引擎推理](./ppstructure/docs/inference.md)
- - [基于C++预测引擎推理]()
- - [服务化部署](./deploy/pdserving/README_CN.md)
-- [前沿算法与模型🚀](./doc/doc_ch/algorithm.md)
- - [文本检测算法](./doc/doc_ch/algorithm_overview.md#11-%E6%96%87%E6%9C%AC%E6%A3%80%E6%B5%8B%E7%AE%97%E6%B3%95)
- - [文本识别算法](./doc/doc_ch/algorithm_overview.md#12-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95)
- - [端到端算法](./doc/doc_ch/algorithm_overview.md#2-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95)
+ - [基于C++预测引擎推理](./deploy/cpp_infer/readme_ch.md)
+ - [服务化部署](./deploy/hubserving/readme.md)
+- [前沿算法与模型🚀](./doc/doc_ch/algorithm_overview.md)
+ - [文本检测算法](./doc/doc_ch/algorithm_overview.md)
+ - [文本识别算法](./doc/doc_ch/algorithm_overview.md)
+ - [端到端OCR算法](./doc/doc_ch/algorithm_overview.md)
+ - [表格识别算法](./doc/doc_ch/algorithm_overview.md)
+ - [关键信息抽取算法](./doc/doc_ch/algorithm_overview.md)
- [使用PaddleOCR架构添加新算法](./doc/doc_ch/add_new_algorithm.md)
- [场景应用](./applications)
- 数据标注与合成
@@ -155,7 +155,7 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
- [垂类多语言OCR数据集](doc/doc_ch/dataset/vertical_and_multilingual_datasets.md)
- [版面分析数据集](doc/doc_ch/dataset/layout_datasets.md)
- [表格识别数据集](doc/doc_ch/dataset/table_datasets.md)
- - [DocVQA数据集](doc/doc_ch/dataset/docvqa_datasets.md)
+ - [关键信息提取数据集](doc/doc_ch/dataset/kie_datasets.md)
- [代码组织结构](./doc/doc_ch/tree.md)
- [效果展示](#效果展示)
- [《动手学OCR》电子书📚](./doc/doc_ch/ocr_book.md)
@@ -214,14 +214,30 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
- SER(语义实体识别)
+
-
+
+
+
+
+
+
+
+
+
+
+
- RE(关系提取)
+
-
+
+
+
+
+
+
+
+
+
+
+
diff --git a/__init__.py b/__init__.py
index 15a9aca4da19a981b9e678e7cc93e33cf40fc81c..a7c32e9629d2e5ff04dc2ca45c6317caac8fa631 100644
--- a/__init__.py
+++ b/__init__.py
@@ -16,5 +16,6 @@ from .paddleocr import *
__version__ = paddleocr.VERSION
__all__ = [
'PaddleOCR', 'PPStructure', 'draw_ocr', 'draw_structure_result',
- 'save_structure_res', 'download_with_progressbar'
+ 'save_structure_res', 'download_with_progressbar', 'sorted_layout_boxes',
+ 'convert_info_docx', 'to_excel'
]
diff --git a/applications/README.md b/applications/README.md
index 017c2a9f6f696904e9bf2f1180104e66c90ee712..2637cd6eaf0c3c59d56673c5e2d294ee7fca2b8b 100644
--- a/applications/README.md
+++ b/applications/README.md
@@ -20,10 +20,10 @@ PaddleOCR场景应用覆盖通用,制造、金融、交通行业的主要OCR
### 通用
-| 类别 | 亮点 | 模型下载 | 教程 |
-| ---------------------- | ------------ | -------------- | --------------------------------------- |
-| 高精度中文识别模型SVTR | 比PP-OCRv3识别模型精度高3%,可用于数据挖掘或对预测效率要求不高的场景。| [模型下载](#2) | [中文](./高精度中文识别模型.md)/English |
-| 手写体识别 | 新增字形支持 | | |
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| ---------------------- | ------------------------------------------------------------ | -------------- | --------------------------------------- | ------------------------------------------------------------ |
+| 高精度中文识别模型SVTR | 比PP-OCRv3识别模型精度高3%,
+可用于数据挖掘或对预测效率要求不高的场景。 | [模型下载](#2) | [中文](./高精度中文识别模型.md)/English |
|
+| 手写体识别 | 新增字形支持 | [模型下载](#2) | [中文](./手写文字识别.md)/English | |
@@ -42,14 +42,14 @@ PaddleOCR场景应用覆盖通用,制造、金融、交通行业的主要OCR
### 金融
-| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
-| -------------- | ------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
-| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English | |
-| 增值税发票 | 尽请期待 | | | |
-| 印章检测与识别 | 端到端弯曲文本识别 | | | |
-| 通用卡证识别 | 通用结构化提取 | | | |
-| 身份证识别 | 结构化提取、图像阴影 | | | |
-| 合同比对 | 密集文本检测、NLP串联 | | | |
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| -------------- | ----------------------------- | -------------- | ------------------------------------- | ------------------------------------------------------------ |
+| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English | |
+| 增值税发票 | 关键信息抽取,SER、RE任务训练 | [模型下载](#2) | [中文](./发票关键信息抽取.md)/English | |
+| 印章检测与识别 | 端到端弯曲文本识别 | | | |
+| 通用卡证识别 | 通用结构化提取 | | | |
+| 身份证识别 | 结构化提取、图像阴影 | | | |
+| 合同比对 | 密集文本检测、NLP串联 | | | |
diff --git a/applications/README_en.md b/applications/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..95c56a1f740faa95e1fe3adeaeb90bfe902f8ed8
--- /dev/null
+++ b/applications/README_en.md
@@ -0,0 +1,79 @@
+English| [简体中文](README.md)
+
+# Application
+
+PaddleOCR scene application covers general, manufacturing, finance, transportation industry of the main OCR vertical applications, on the basis of the general capabilities of PP-OCR, PP-Structure, in the form of notebook to show the use of scene data fine-tuning, model optimization methods, data augmentation and other content, for developers to quickly land OCR applications to provide demonstration and inspiration.
+
+- [Tutorial](#1)
+ - [General](#11)
+ - [Manufacturing](#12)
+ - [Finance](#13)
+ - [Transportation](#14)
+
+- [Model Download](#2)
+
+
+
+## Tutorial
+
+
+
+### General
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ---------------------------------------------- | ---------------- | -------------------- | --------------------------------------- | ------------------------------------------------------------ |
+| High-precision Chineses recognition model SVTR | New model | [Model Download](#2) | [中文](./高精度中文识别模型.md)/English | |
+| Chinese handwriting recognition | New font support | [Model Download](#2) | [中文](./手写文字识别.md)/English | |
+
+
+
+### Manufacturing
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ------------------------------ | ------------------------------------------------------------ | -------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| Digital tube | Digital tube data sythesis, recognition model fine-tuning | [Model Download](#2) | [中文](./光功率计数码管字符识别/光功率计数码管字符识别.md)/English | |
+| LCD screen | Detection model distillation, serving deployment | [Model Download](#2) | [中文](./液晶屏读数识别.md)/English | |
+| Packaging production data | Dot matrix character synthesis, overexposure and overdark text recognition | [Model Download](#2) | [中文](./包装生产日期识别.md)/English | |
+| PCB text recognition | Small size text detection and recognition | [Model Download](#2) | [中文](./PCB字符识别/PCB字符识别.md)/English | |
+| Meter text recognition | High-resolution image detection fine-tuning | [Model Download](#2) | | |
+| LCD character defect detection | Non-text character recognition | | | |
+
+
+
+### Finance
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ----------------------------------- | -------------------------------------------------- | -------------------- | ------------------------------------- | ------------------------------------------------------------ |
+| Form visual question and answer | Multimodal general form structured extraction | [Model Download](#2) | [中文](./多模态表单识别.md)/English | |
+| VAT invoice | Key information extraction, SER, RE task fine-tune | [Model Download](#2) | [中文](./发票关键信息抽取.md)/English | |
+| Seal detection and recognition | End-to-end curved text recognition | | | |
+| Universal card recognition | Universal structured extraction | | | |
+| ID card recognition | Structured extraction, image shading | | | |
+| Contract key information extraction | Dense text detection, NLP concatenation | | | |
+
+
+
+### Transportation
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ----------------------------------------------- | ------------------------------------------------------------ | -------------------- | ----------------------------------- | ------------------------------------------------------------ |
+| License plate recognition | Multi-angle images, lightweight models, edge-side deployment | [Model Download](#2) | [中文](./轻量级车牌识别.md)/English | |
+| Driver's license/driving license identification | coming soon | | | |
+| Express text recognition | coming soon | | | |
+
+
+
+## Model Download
+
+- For international developers: We're building a way to download these trained models, and since the current tutorials are Chinese, if you are good at both Chinese and English, or willing to polish English documents, please let us know in [discussion](https://github.com/PaddlePaddle/PaddleOCR/discussions).
+- For Chinese developer: If you want to download the trained application model in the above scenarios, scan the QR code below with your WeChat, follow the PaddlePaddle official account to fill in the questionnaire, and join the PaddleOCR official group to get the 20G OCR learning materials (including "Dive into OCR" e-book, course video, application models and other materials)
+
+
+  +
+
+
+ If you are an enterprise developer and have not found a suitable solution in the above scenarios, you can fill in the [OCR Application Cooperation Survey Questionnaire](https://paddle.wjx.cn/vj/QwF7GKw.aspx) to carry out different levels of cooperation with the official team **for free**, including but not limited to problem abstraction, technical solution determination, project Q&A, joint research and development, etc. If you have already used paddleOCR in your project, you can also fill out this questionnaire to jointly promote with the PaddlePaddle and enhance the technical publicity of enterprises. Looking forward to your submission!
+
+
+
+
+ 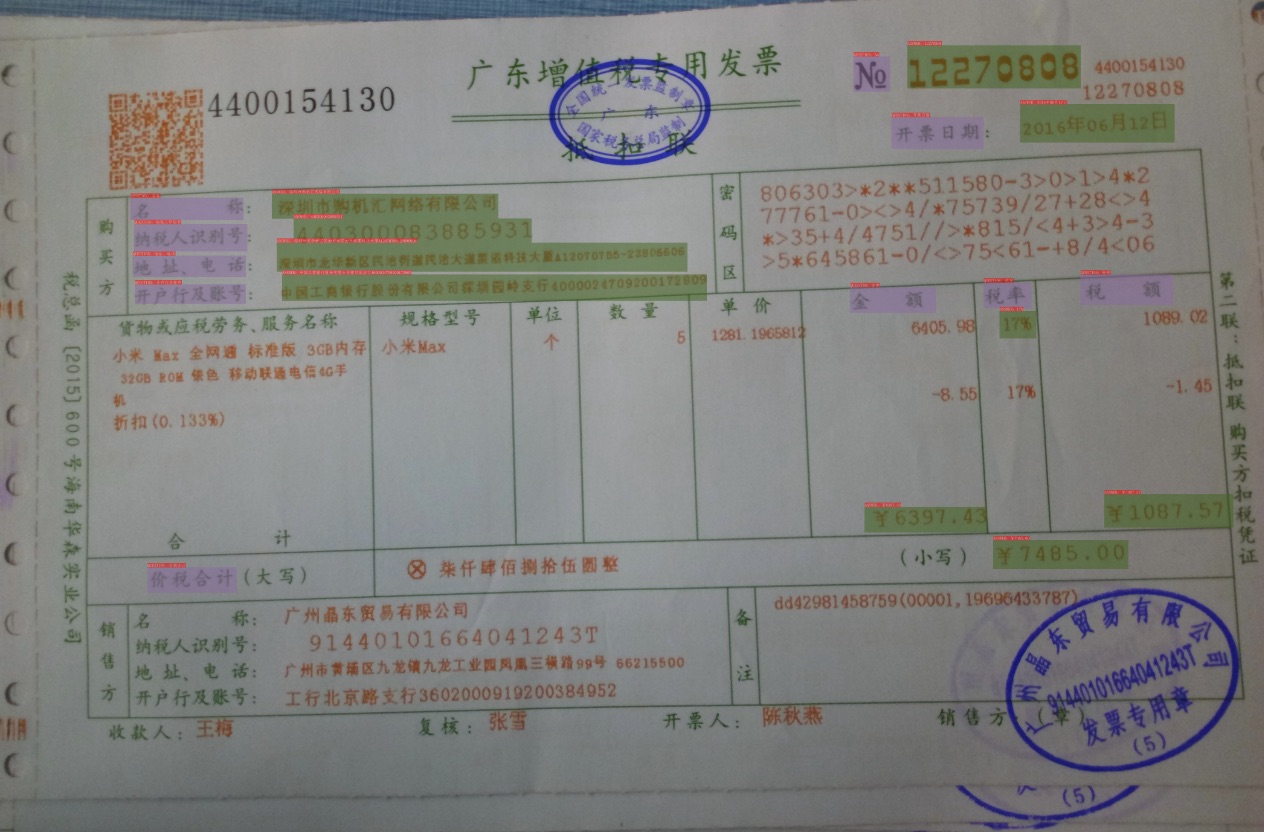 +
+
+
+**注意:**
+
+* 如果文本检测模型数据标注过程中,没有标注 **非关键信息内容** 的检测框,那么在标注关键信息抽取任务的时候,也不需要标注该部分,如上图所示;如果标注的过程,如果同时标注了**非关键信息内容** 的检测框,那么我们需要将该部分的label记为other。
+* 标注过程中,需要以文本行为单位进行标注,无需标注单个字符的位置信息。
+
+
+已经处理好的增值税发票数据集从这里下载:[增值税发票数据集下载链接](https://aistudio.baidu.com/aistudio/datasetdetail/165561)。
+
+下载好发票数据集,并解压在train_data目录下,目录结构如下所示。
+
+```
+train_data
+ |--zzsfp
+ |---class_list.txt
+ |---imgs/
+ |---train.json
+ |---val.json
+```
+
+其中`class_list.txt`是包含`other`, `question`, `answer`,3个种类的的类别列表(不区分大小写),`imgs`目录底下,`train.json`与`val.json`分别表示训练与评估集合的标注文件。训练集中包含30张图片,验证集中包含8张图片。部分标注如下所示。
+
+```py
+b33.jpg [{"transcription": "No", "label": "question", "points": [[2882, 472], [3026, 472], [3026, 588], [2882, 588]], }, {"transcription": "12269563", "label": "answer", "points": [[3066, 448], [3598, 448], [3598, 576], [3066, 576]], ]}]
+```
+
+相比于OCR检测的标注,仅多了`label`字段。
+
+
+#### 4.3.2 开始训练
+
+
+VI-LayoutXLM的配置为[ser_vi_layoutxlm_xfund_zh_udml.yml](../configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh_udml.yml),需要修改数据、类别数目以及配置文件。
+
+```yml
+Architecture:
+ model_type: &model_type "kie"
+ name: DistillationModel
+ algorithm: Distillation
+ Models:
+ Teacher:
+ pretrained:
+ freeze_params: false
+ return_all_feats: true
+ model_type: *model_type
+ algorithm: &algorithm "LayoutXLM"
+ Transform:
+ Backbone:
+ name: LayoutXLMForSer
+ pretrained: True
+ # one of base or vi
+ mode: vi
+ checkpoints:
+ # 定义类别数目
+ num_classes: &num_classes 5
+ ...
+
+PostProcess:
+ name: DistillationSerPostProcess
+ model_name: ["Student", "Teacher"]
+ key: backbone_out
+ # 定义类别文件
+ class_path: &class_path train_data/zzsfp/class_list.txt
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ # 定义训练数据目录与标注文件
+ data_dir: train_data/zzsfp/imgs
+ label_file_list:
+ - train_data/zzsfp/train.json
+ ...
+
+Eval:
+ dataset:
+ # 定义评估数据目录与标注文件
+ name: SimpleDataSet
+ data_dir: train_data/zzsfp/imgs
+ label_file_list:
+ - train_data/zzsfp/val.json
+ ...
+```
+
+LayoutXLM与VI-LayoutXLM针对该场景的训练结果如下所示。
+
+| 模型 | 迭代轮数 | Hmean |
+| :---: | :---: | :---: |
+| LayoutXLM | 50 | 100% |
+| VI-LayoutXLM | 50 | 100% |
+
+可以看出,由于当前数据量较少,场景比较简单,因此2个模型的Hmean均达到了100%。
+
+
+#### 4.3.3 模型评估
+
+模型训练过程中,使用的是知识蒸馏的策略,最终保留了学生模型的参数,在评估时,我们需要针对学生模型的配置文件进行修改: [ser_vi_layoutxlm_xfund_zh.yml](../configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml),修改内容与训练配置相同,包括**类别数、类别映射文件、数据目录**。
+
+修改完成后,执行下面的命令完成评估过程。
+
+```bash
+# 注意:需要根据你的配置文件地址与保存的模型地址,对评估命令进行修改
+python3 tools/eval.py -c ./fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy
+```
+
+输出结果如下所示。
+
+```
+[2022/08/18 08:49:58] ppocr INFO: metric eval ***************
+[2022/08/18 08:49:58] ppocr INFO: precision:1.0
+[2022/08/18 08:49:58] ppocr INFO: recall:1.0
+[2022/08/18 08:49:58] ppocr INFO: hmean:1.0
+[2022/08/18 08:49:58] ppocr INFO: fps:1.9740402401574881
+```
+
+#### 4.3.4 模型预测
+
+使用下面的命令进行预测。
+
+```bash
+python3 tools/infer_kie_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/XFUND/zh_val/val.json Global.infer_mode=False
+```
+
+预测结果会保存在配置文件中的`Global.save_res_path`目录中。
+
+部分预测结果如下所示。
+
+
+
+
+
+
+
+* 注意:在预测时,使用的文本检测与识别结果为标注的结果,直接从json文件里面进行读取。
+
+如果希望使用OCR引擎结果得到的结果进行推理,则可以使用下面的命令进行推理。
+
+
+```bash
+python3 tools/infer_kie_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/imgs/b25.jpg Global.infer_mode=True
+```
+
+结果如下所示。
+
+
+
+ 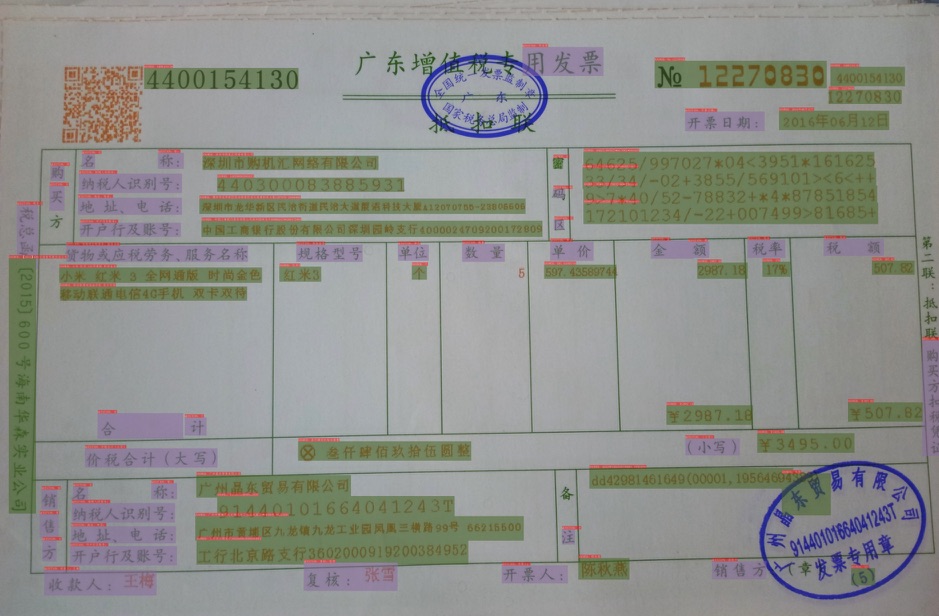 +
+
+
+它会使用PP-OCRv3的文本检测与识别模型进行获取文本位置与内容信息。
+
+可以看出,由于训练的过程中,没有标注额外的字段为other类别,所以大多数检测出来的字段被预测为question或者answer。
+
+如果希望构建基于你在垂类场景训练得到的OCR检测与识别模型,可以使用下面的方法传入检测与识别的inference 模型路径,即可完成OCR文本检测与识别以及SER的串联过程。
+
+```bash
+python3 tools/infer_kie_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/imgs/b25.jpg Global.infer_mode=True Global.kie_rec_model_dir="your_rec_model" Global.kie_det_model_dir="your_det_model"
+```
+
+### 4.4 关系抽取(Relation Extraction)
+
+使用SER模型,可以获取图像中所有的question与answer的字段,继续这些字段的类别,我们需要进一步获取question与answer之间的连接,因此需要进一步训练关系抽取模型,解决该问题。本文也基于VI-LayoutXLM多模态预训练模型,进行下游RE任务的模型训练。
+
+#### 4.4.1 准备数据
+
+以发票场景为例,相比于SER任务,RE中还需要标记每个文本行的id信息以及链接关系linking,如下所示。
+
+
+
+ 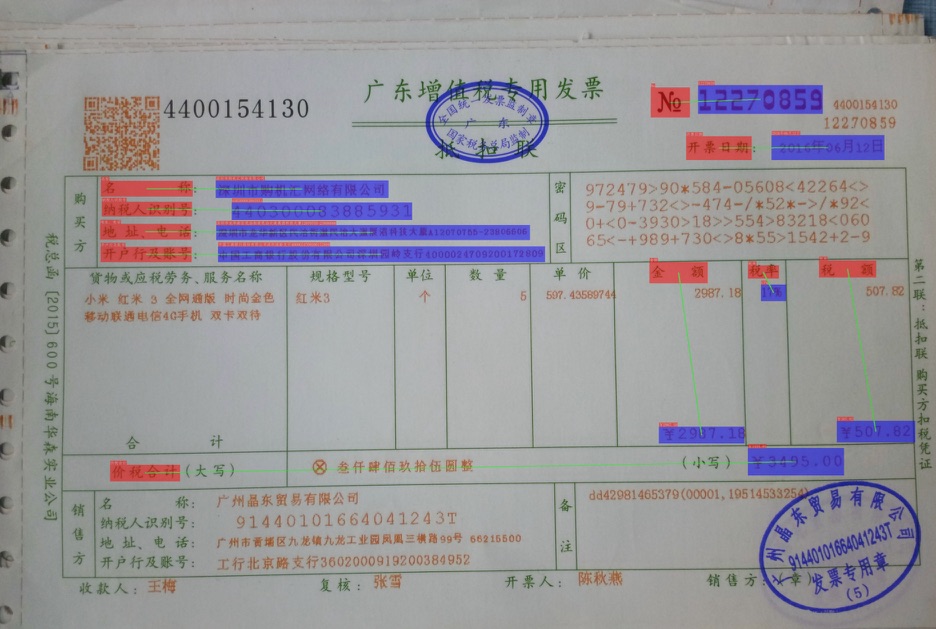 +
+
+
+
+标注文件的部分内容如下所示。
+
+```py
+b33.jpg [{"transcription": "No", "label": "question", "points": [[2882, 472], [3026, 472], [3026, 588], [2882, 588]], "id": 0, "linking": [[0, 1]]}, {"transcription": "12269563", "label": "answer", "points": [[3066, 448], [3598, 448], [3598, 576], [3066, 576]], "id": 1, "linking": [[0, 1]]}]
+```
+
+相比与SER的标注,多了`id`与`linking`的信息,分别表示唯一标识以及连接关系。
+
+已经处理好的增值税发票数据集从这里下载:[增值税发票数据集下载链接](https://aistudio.baidu.com/aistudio/datasetdetail/165561)。
+
+#### 4.4.2 开始训练
+
+基于VI-LayoutXLM的RE任务配置为[re_vi_layoutxlm_xfund_zh_udml.yml](../configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh_udml.yml),需要修改**数据路径、类别列表文件**。
+
+```yml
+Train:
+ dataset:
+ name: SimpleDataSet
+ # 定义训练数据目录与标注文件
+ data_dir: train_data/zzsfp/imgs
+ label_file_list:
+ - train_data/zzsfp/train.json
+ transforms:
+ - DecodeImage: # load image
+ img_mode: RGB
+ channel_first: False
+ - VQATokenLabelEncode: # Class handling label
+ contains_re: True
+ algorithm: *algorithm
+ class_path: &class_path train_data/zzsfp/class_list.txt
+ ...
+
+Eval:
+ dataset:
+ # 定义评估数据目录与标注文件
+ name: SimpleDataSet
+ data_dir: train_data/zzsfp/imgs
+ label_file_list:
+ - train_data/zzsfp/val.json
+ ...
+
+```
+
+LayoutXLM与VI-LayoutXLM针对该场景的训练结果如下所示。
+
+| 模型 | 迭代轮数 | Hmean |
+| :---: | :---: | :---: |
+| LayoutXLM | 50 | 98.0% |
+| VI-LayoutXLM | 50 | 99.3% |
+
+可以看出,对于VI-LayoutXLM相比LayoutXLM的Hmean高了1.3%。
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+
+
+
+
+
+#### 4.4.3 模型评估
+
+模型训练过程中,使用的是知识蒸馏的策略,最终保留了学生模型的参数,在评估时,我们需要针对学生模型的配置文件进行修改: [re_vi_layoutxlm_xfund_zh.yml](../configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml),修改内容与训练配置相同,包括**类别映射文件、数据目录**。
+
+修改完成后,执行下面的命令完成评估过程。
+
+```bash
+# 注意:需要根据你的配置文件地址与保存的模型地址,对评估命令进行修改
+python3 tools/eval.py -c ./fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/re_vi_layoutxlm_fapiao_udml/best_accuracy
+```
+
+输出结果如下所示。
+
+```py
+[2022/08/18 12:17:14] ppocr INFO: metric eval ***************
+[2022/08/18 12:17:14] ppocr INFO: precision:1.0
+[2022/08/18 12:17:14] ppocr INFO: recall:0.9873417721518988
+[2022/08/18 12:17:14] ppocr INFO: hmean:0.9936305732484078
+[2022/08/18 12:17:14] ppocr INFO: fps:2.765963539771157
+```
+
+#### 4.4.4 模型预测
+
+使用下面的命令进行预测。
+
+```bash
+# -c 后面的是RE任务的配置文件
+# -o 后面的字段是RE任务的配置
+# -c_ser 后面的是SER任务的配置文件
+# -c_ser 后面的字段是SER任务的配置
+python3 tools/infer_kie_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/re_vi_layoutxlm_fapiao_trained/best_accuracy Global.infer_img=./train_data/zzsfp/val.json Global.infer_mode=False -c_ser fapiao/ser_vi_layoutxlm.yml -o_ser Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_trained/best_accuracy
+```
+
+预测结果会保存在配置文件中的`Global.save_res_path`目录中。
+
+部分预测结果如下所示。
+
+
+
+
+
+
+
+* 注意:在预测时,使用的文本检测与识别结果为标注的结果,直接从json文件里面进行读取。
+
+如果希望使用OCR引擎结果得到的结果进行推理,则可以使用下面的命令进行推理。
+
+```bash
+python3 tools/infer_kie_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/re_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/val.json Global.infer_mode=True -c_ser fapiao/ser_vi_layoutxlm.yml -o_ser Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy
+```
+
+如果希望构建基于你在垂类场景训练得到的OCR检测与识别模型,可以使用下面的方法传入,即可完成SER + RE的串联过程。
+
+```bash
+python3 tools/infer_kie_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/re_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/val.json Global.infer_mode=True -c_ser fapiao/ser_vi_layoutxlm.yml -o_ser Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.kie_rec_model_dir="your_rec_model" Global.kie_det_model_dir="your_det_model"
+```
diff --git a/configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml b/configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml
index df429314cd0ec058aa6779a0ff55656f1b211bbf..0c6ab2a0d1d9733d647dc40a7b182fe201866a78 100644
--- a/configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml
+++ b/configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml
@@ -14,6 +14,9 @@ Global:
use_visualdl: False
infer_img: doc/imgs_en/img_10.jpg
save_res_path: ./output/det_db/predicts_db.txt
+ use_amp: False
+ amp_level: O2
+ amp_custom_black_list: ['exp']
Architecture:
name: DistillationModel
@@ -188,7 +191,6 @@ Eval:
channel_first: False
- DetLabelEncode: # Class handling label
- DetResizeForTest:
-# image_shape: [736, 1280]
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
diff --git a/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml b/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml
index ef58befd694e26704c734d7fd072ebc3370c8554..000d95e892cb8e6dcceeb7c22264c28934d1000c 100644
--- a/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml
+++ b/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml
@@ -24,6 +24,7 @@ Architecture:
model_type: det
Models:
Student:
+ pretrained:
model_type: det
algorithm: DB
Transform: null
@@ -40,6 +41,7 @@ Architecture:
name: DBHead
k: 50
Student2:
+ pretrained:
model_type: det
algorithm: DB
Transform: null
@@ -91,14 +93,11 @@ Loss:
- ["Student", "Student2"]
maps_name: "thrink_maps"
weight: 1.0
- # act: None
model_name_pairs: ["Student", "Student2"]
key: maps
- DistillationDBLoss:
weight: 1.0
model_name_list: ["Student", "Student2"]
- # key: maps
- # name: DBLoss
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
@@ -197,6 +196,7 @@ Train:
drop_last: false
batch_size_per_card: 8
num_workers: 4
+
Eval:
dataset:
name: SimpleDataSet
@@ -204,31 +204,21 @@ Eval:
label_file_list:
- ./train_data/icdar2015/text_localization/test_icdar2015_label.txt
transforms:
- - DecodeImage:
- img_mode: BGR
- channel_first: false
- - DetLabelEncode: null
- - DetResizeForTest: null
- - NormalizeImage:
- scale: 1./255.
- mean:
- - 0.485
- - 0.456
- - 0.406
- std:
- - 0.229
- - 0.224
- - 0.225
- order: hwc
- - ToCHWImage: null
- - KeepKeys:
- keep_keys:
- - image
- - shape
- - polys
- - ignore_tags
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - DetLabelEncode: # Class handling label
+ - DetResizeForTest:
+ - NormalizeImage:
+ scale: 1./255.
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: 'hwc'
+ - ToCHWImage:
+ - KeepKeys:
+ keep_keys: ['image', 'shape', 'polys', 'ignore_tags']
loader:
- shuffle: false
- drop_last: false
- batch_size_per_card: 1
- num_workers: 2
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 1 # must be 1
+ num_workers: 2
\ No newline at end of file
diff --git a/configs/det/det_r18_vd_ct.yml b/configs/det/det_r18_vd_ct.yml
new file mode 100644
index 0000000000000000000000000000000000000000..42922dfd22c0e49d20d50534c76fedae16b27a4a
--- /dev/null
+++ b/configs/det/det_r18_vd_ct.yml
@@ -0,0 +1,107 @@
+Global:
+ use_gpu: true
+ epoch_num: 600
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/det_ct/
+ save_epoch_step: 10
+ # evaluation is run every 2000 iterations
+ eval_batch_step: [0,1000]
+ cal_metric_during_train: False
+ pretrained_model: ./pretrain_models/ResNet18_vd_pretrained.pdparams
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: False
+ infer_img: doc/imgs_en/img623.jpg
+ save_res_path: ./output/det_ct/predicts_ct.txt
+
+Architecture:
+ model_type: det
+ algorithm: CT
+ Transform:
+ Backbone:
+ name: ResNet_vd
+ layers: 18
+ Neck:
+ name: CTFPN
+ Head:
+ name: CT_Head
+ in_channels: 512
+ hidden_dim: 128
+ num_classes: 3
+
+Loss:
+ name: CTLoss
+
+Optimizer:
+ name: Adam
+ lr: #PolynomialDecay
+ name: Linear
+ learning_rate: 0.001
+ end_lr: 0.
+ epochs: 600
+ step_each_epoch: 1254
+ power: 0.9
+
+PostProcess:
+ name: CTPostProcess
+ box_type: poly
+
+Metric:
+ name: CTMetric
+ main_indicator: f_score
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/total_text/train
+ label_file_list:
+ - ./train_data/total_text/train/train.txt
+ ratio_list: [1.0]
+ transforms:
+ - DecodeImage:
+ img_mode: RGB
+ channel_first: False
+ - CTLabelEncode: # Class handling label
+ - RandomScale:
+ - MakeShrink:
+ - GroupRandomHorizontalFlip:
+ - GroupRandomRotate:
+ - GroupRandomCropPadding:
+ - MakeCentripetalShift:
+ - ColorJitter:
+ brightness: 0.125
+ saturation: 0.5
+ - ToCHWImage:
+ - NormalizeImage:
+ - KeepKeys:
+ keep_keys: ['image', 'gt_kernel', 'training_mask', 'gt_instance', 'gt_kernel_instance', 'training_mask_distance', 'gt_distance'] # the order of the dataloader list
+ loader:
+ shuffle: True
+ drop_last: True
+ batch_size_per_card: 4
+ num_workers: 8
+
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/total_text/test
+ label_file_list:
+ - ./train_data/total_text/test/test.txt
+ ratio_list: [1.0]
+ transforms:
+ - DecodeImage:
+ img_mode: RGB
+ channel_first: False
+ - CTLabelEncode: # Class handling label
+ - ScaleAlignedShort:
+ - NormalizeImage:
+ order: 'hwc'
+ - ToCHWImage:
+ - KeepKeys:
+ keep_keys: ['image', 'shape', 'polys', 'texts'] # the order of the dataloader list
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 1
+ num_workers: 2
diff --git a/configs/e2e/e2e_r50_vd_pg.yml b/configs/e2e/e2e_r50_vd_pg.yml
index c4c5226e796a42db723ce78ef65473e357c25dc6..4642f544868f720d413f7f5242740705bc9fd0a5 100644
--- a/configs/e2e/e2e_r50_vd_pg.yml
+++ b/configs/e2e/e2e_r50_vd_pg.yml
@@ -13,6 +13,7 @@ Global:
save_inference_dir:
use_visualdl: False
infer_img:
+ infer_visual_type: EN # two mode: EN is for english datasets, CN is for chinese datasets
valid_set: totaltext # two mode: totaltext valid curved words, partvgg valid non-curved words
save_res_path: ./output/pgnet_r50_vd_totaltext/predicts_pgnet.txt
character_dict_path: ppocr/utils/ic15_dict.txt
@@ -32,6 +33,7 @@ Architecture:
name: PGFPN
Head:
name: PGHead
+ character_dict_path: ppocr/utils/ic15_dict.txt # the same as Global:character_dict_path
Loss:
name: PGLoss
@@ -45,16 +47,18 @@ Optimizer:
beta1: 0.9
beta2: 0.999
lr:
+ name: Cosine
learning_rate: 0.001
+ warmup_epoch: 50
regularizer:
name: 'L2'
- factor: 0
-
+ factor: 0.0001
PostProcess:
name: PGPostProcess
score_thresh: 0.5
mode: fast # fast or slow two ways
+ point_gather_mode: align # same as PGProcessTrain: point_gather_mode
Metric:
name: E2EMetric
@@ -76,9 +80,12 @@ Train:
- E2ELabelEncodeTrain:
- PGProcessTrain:
batch_size: 14 # same as loader: batch_size_per_card
+ use_resize: True
+ use_random_crop: False
min_crop_size: 24
min_text_size: 4
max_text_size: 512
+ point_gather_mode: align # two mode: align and none, align mode is better than none mode
- KeepKeys:
keep_keys: [ 'images', 'tcl_maps', 'tcl_label_maps', 'border_maps','direction_maps', 'training_masks', 'label_list', 'pos_list', 'pos_mask' ] # dataloader will return list in this order
loader:
diff --git a/configs/kie/layoutlm_series/re_layoutlmv2_xfund_zh.yml b/configs/kie/layoutlm_series/re_layoutlmv2_xfund_zh.yml
index 4b330d8d58bef2d549ec7e0fea5986746a23fbe4..3e3578d8cac1aadd484f583dbe0955f7c47fca73 100644
--- a/configs/kie/layoutlm_series/re_layoutlmv2_xfund_zh.yml
+++ b/configs/kie/layoutlm_series/re_layoutlmv2_xfund_zh.yml
@@ -11,11 +11,11 @@ Global:
save_inference_dir:
use_visualdl: False
seed: 2022
- infer_img: ppstructure/docs/vqa/input/zh_val_21.jpg
+ infer_img: ppstructure/docs/kie/input/zh_val_21.jpg
save_res_path: ./output/re_layoutlmv2_xfund_zh/res/
Architecture:
- model_type: vqa
+ model_type: kie
algorithm: &algorithm "LayoutLMv2"
Transform:
Backbone:
diff --git a/configs/kie/layoutlm_series/re_layoutxlm_xfund_zh.yml b/configs/kie/layoutlm_series/re_layoutxlm_xfund_zh.yml
index a092106eea10e0457419e5551dd75819adeddf1b..2401cf317987c5614a476065191e750587bc09b5 100644
--- a/configs/kie/layoutlm_series/re_layoutxlm_xfund_zh.yml
+++ b/configs/kie/layoutlm_series/re_layoutxlm_xfund_zh.yml
@@ -11,11 +11,11 @@ Global:
save_inference_dir:
use_visualdl: False
seed: 2022
- infer_img: ppstructure/docs/vqa/input/zh_val_21.jpg
+ infer_img: ppstructure/docs/kie/input/zh_val_21.jpg
save_res_path: ./output/re_layoutxlm_xfund_zh/res/
Architecture:
- model_type: vqa
+ model_type: kie
algorithm: &algorithm "LayoutXLM"
Transform:
Backbone:
diff --git a/configs/kie/layoutlm_series/ser_layoutlm_xfund_zh.yml b/configs/kie/layoutlm_series/ser_layoutlm_xfund_zh.yml
index 8c754dd8c542b12de4ee493052407bb0da687fd0..34c7d4114062e9227d48ad5684024e2776e68447 100644
--- a/configs/kie/layoutlm_series/ser_layoutlm_xfund_zh.yml
+++ b/configs/kie/layoutlm_series/ser_layoutlm_xfund_zh.yml
@@ -11,11 +11,11 @@ Global:
save_inference_dir:
use_visualdl: False
seed: 2022
- infer_img: ppstructure/docs/vqa/input/zh_val_42.jpg
+ infer_img: ppstructure/docs/kie/input/zh_val_42.jpg
save_res_path: ./output/re_layoutlm_xfund_zh/res
Architecture:
- model_type: vqa
+ model_type: kie
algorithm: &algorithm "LayoutLM"
Transform:
Backbone:
diff --git a/configs/kie/layoutlm_series/ser_layoutlmv2_xfund_zh.yml b/configs/kie/layoutlm_series/ser_layoutlmv2_xfund_zh.yml
index 3c0ffabe4465e36e5699a135a9ed0b6254cbf20b..c5e833524011b03110db3bd6f4bf845db8473922 100644
--- a/configs/kie/layoutlm_series/ser_layoutlmv2_xfund_zh.yml
+++ b/configs/kie/layoutlm_series/ser_layoutlmv2_xfund_zh.yml
@@ -11,11 +11,11 @@ Global:
save_inference_dir:
use_visualdl: False
seed: 2022
- infer_img: ppstructure/docs/vqa/input/zh_val_42.jpg
+ infer_img: ppstructure/docs/kie/input/zh_val_42.jpg
save_res_path: ./output/ser_layoutlmv2_xfund_zh/res/
Architecture:
- model_type: vqa
+ model_type: kie
algorithm: &algorithm "LayoutLMv2"
Transform:
Backbone:
diff --git a/configs/kie/layoutlm_series/ser_layoutxlm_xfund_zh.yml b/configs/kie/layoutlm_series/ser_layoutxlm_xfund_zh.yml
index 18f87bdebc249940ef3ec1897af3ad1a240f3705..abcfec2d16f13d4b4266633dbb509e0fba6d931f 100644
--- a/configs/kie/layoutlm_series/ser_layoutxlm_xfund_zh.yml
+++ b/configs/kie/layoutlm_series/ser_layoutxlm_xfund_zh.yml
@@ -11,11 +11,11 @@ Global:
save_inference_dir:
use_visualdl: False
seed: 2022
- infer_img: ppstructure/docs/vqa/input/zh_val_42.jpg
+ infer_img: ppstructure/docs/kie/input/zh_val_42.jpg
save_res_path: ./output/ser_layoutxlm_xfund_zh/res
Architecture:
- model_type: vqa
+ model_type: kie
algorithm: &algorithm "LayoutXLM"
Transform:
Backbone:
diff --git a/configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml b/configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml
index 89f7d5c3cb74854bb9fe7e28fdc8365ed37655be..ea9f50ef56ec8b169333263c1d5e96586f9472b3 100644
--- a/configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml
+++ b/configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml
@@ -11,11 +11,13 @@ Global:
save_inference_dir:
use_visualdl: False
seed: 2022
- infer_img: ppstructure/docs/vqa/input/zh_val_21.jpg
+ infer_img: ppstructure/docs/kie/input/zh_val_21.jpg
save_res_path: ./output/re/xfund_zh/with_gt
+ kie_rec_model_dir:
+ kie_det_model_dir:
Architecture:
- model_type: vqa
+ model_type: kie
algorithm: &algorithm "LayoutXLM"
Transform:
Backbone:
diff --git a/configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh_udml.yml b/configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh_udml.yml
index c1bfdb6c6cee1c9618602016fec6cc1ec0a7b3bf..b96528d2738e7cfb2575feca4146af1eed0c5d2f 100644
--- a/configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh_udml.yml
+++ b/configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh_udml.yml
@@ -11,11 +11,11 @@ Global:
save_inference_dir:
use_visualdl: False
seed: 2022
- infer_img: ppstructure/docs/vqa/input/zh_val_21.jpg
+ infer_img: ppstructure/docs/kie/input/zh_val_21.jpg
save_res_path: ./output/re/xfund_zh/with_gt
Architecture:
- model_type: &model_type "vqa"
+ model_type: &model_type "kie"
name: DistillationModel
algorithm: Distillation
Models:
diff --git a/configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml b/configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml
index d54125db64cef289457c4b855fe9bded3fa4149f..b8aa44dde8fd3fdc4ff14bbca20513b95178cdb0 100644
--- a/configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml
+++ b/configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml
@@ -11,16 +11,18 @@ Global:
save_inference_dir:
use_visualdl: False
seed: 2022
- infer_img: ppstructure/docs/vqa/input/zh_val_42.jpg
+ infer_img: ppstructure/docs/kie/input/zh_val_42.jpg
# if you want to predict using the groundtruth ocr info,
# you can use the following config
# infer_img: train_data/XFUND/zh_val/val.json
# infer_mode: False
save_res_path: ./output/ser/xfund_zh/res
+ kie_rec_model_dir:
+ kie_det_model_dir:
Architecture:
- model_type: vqa
+ model_type: kie
algorithm: &algorithm "LayoutXLM"
Transform:
Backbone:
diff --git a/configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh_udml.yml b/configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh_udml.yml
index 6f0961c8e80312ab26a8d1649bf2bb10f8792efb..238bbd2b2c7083b5534062afd3e6c11a87494a56 100644
--- a/configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh_udml.yml
+++ b/configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh_udml.yml
@@ -11,12 +11,12 @@ Global:
save_inference_dir:
use_visualdl: False
seed: 2022
- infer_img: ppstructure/docs/vqa/input/zh_val_42.jpg
+ infer_img: ppstructure/docs/kie/input/zh_val_42.jpg
save_res_path: ./output/ser_layoutxlm_xfund_zh/res
Architecture:
- model_type: &model_type "vqa"
+ model_type: &model_type "kie"
name: DistillationModel
algorithm: Distillation
Models:
diff --git a/configs/rec/PP-OCRv3/multi_language/arabic_PP-OCRv3_rec.yml b/configs/rec/PP-OCRv3/multi_language/arabic_PP-OCRv3_rec.yml
index 0ad1ab0adc189102ff07094fcda92d4f9ea9c662..8c650bd826d127f25c907f97d20d1a52f67f9203 100644
--- a/configs/rec/PP-OCRv3/multi_language/arabic_PP-OCRv3_rec.yml
+++ b/configs/rec/PP-OCRv3/multi_language/arabic_PP-OCRv3_rec.yml
@@ -12,7 +12,7 @@ Global:
checkpoints:
save_inference_dir:
use_visualdl: false
- infer_img: doc/imgs_words/ch/word_1.jpg
+ infer_img: ./doc/imgs_words/arabic/ar_2.jpg
character_dict_path: ppocr/utils/dict/arabic_dict.txt
max_text_length: &max_text_length 25
infer_mode: false
diff --git a/configs/rec/rec_r31_robustscanner.yml b/configs/rec/rec_r31_robustscanner.yml
new file mode 100644
index 0000000000000000000000000000000000000000..40d39aee3c42c18085ace035944dba057b923245
--- /dev/null
+++ b/configs/rec/rec_r31_robustscanner.yml
@@ -0,0 +1,109 @@
+Global:
+ use_gpu: true
+ epoch_num: 5
+ log_smooth_window: 20
+ print_batch_step: 20
+ save_model_dir: ./output/rec/rec_r31_robustscanner/
+ save_epoch_step: 1
+ # evaluation is run every 2000 iterations
+ eval_batch_step: [0, 2000]
+ cal_metric_during_train: True
+ pretrained_model:
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: False
+ infer_img: ./inference/rec_inference
+ # for data or label process
+ character_dict_path: ppocr/utils/dict90.txt
+ max_text_length: &max_text_length 40
+ infer_mode: False
+ use_space_char: False
+ rm_symbol: True
+ save_res_path: ./output/rec/predicts_robustscanner.txt
+
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ lr:
+ name: Piecewise
+ decay_epochs: [3, 4]
+ values: [0.001, 0.0001, 0.00001]
+ regularizer:
+ name: 'L2'
+ factor: 0
+
+Architecture:
+ model_type: rec
+ algorithm: RobustScanner
+ Transform:
+ Backbone:
+ name: ResNet31
+ init_type: KaimingNormal
+ Head:
+ name: RobustScannerHead
+ enc_outchannles: 128
+ hybrid_dec_rnn_layers: 2
+ hybrid_dec_dropout: 0
+ position_dec_rnn_layers: 2
+ start_idx: 91
+ mask: True
+ padding_idx: 92
+ encode_value: False
+ max_text_length: *max_text_length
+
+Loss:
+ name: SARLoss
+
+PostProcess:
+ name: SARLabelDecode
+
+Metric:
+ name: RecMetric
+ is_filter: True
+
+
+Train:
+ dataset:
+ name: LMDBDataSet
+ data_dir: ./train_data/data_lmdb_release/training/
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - SARLabelEncode: # Class handling label
+ - RobustScannerRecResizeImg:
+ image_shape: [3, 48, 48, 160] # h:48 w:[48,160]
+ width_downsample_ratio: 0.25
+ max_text_length: *max_text_length
+ - KeepKeys:
+ keep_keys: ['image', 'label', 'valid_ratio', 'word_positons'] # dataloader will return list in this order
+ loader:
+ shuffle: True
+ batch_size_per_card: 64
+ drop_last: True
+ num_workers: 8
+ use_shared_memory: False
+
+Eval:
+ dataset:
+ name: LMDBDataSet
+ data_dir: ./train_data/data_lmdb_release/evaluation/
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - SARLabelEncode: # Class handling label
+ - RobustScannerRecResizeImg:
+ image_shape: [3, 48, 48, 160]
+ max_text_length: *max_text_length
+ width_downsample_ratio: 0.25
+ - KeepKeys:
+ keep_keys: ['image', 'label', 'valid_ratio', 'word_positons'] # dataloader will return list in this order
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 64
+ num_workers: 4
+ use_shared_memory: False
+
diff --git a/configs/sr/sr_tsrn_transformer_strock.yml b/configs/sr/sr_tsrn_transformer_strock.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c8c308c4337ddbb2933714391762efbfda44bf32
--- /dev/null
+++ b/configs/sr/sr_tsrn_transformer_strock.yml
@@ -0,0 +1,85 @@
+Global:
+ use_gpu: true
+ epoch_num: 500
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/sr/sr_tsrn_transformer_strock/
+ save_epoch_step: 3
+ # evaluation is run every 2000 iterations
+ eval_batch_step: [0, 1000]
+ cal_metric_during_train: False
+ pretrained_model:
+ checkpoints:
+ save_inference_dir: sr_output
+ use_visualdl: False
+ infer_img: doc/imgs_words_en/word_52.png
+ # for data or label process
+ character_dict_path: ./train_data/srdata/english_decomposition.txt
+ max_text_length: 100
+ infer_mode: False
+ use_space_char: False
+ save_res_path: ./output/sr/predicts_gestalt.txt
+
+Optimizer:
+ name: Adam
+ beta1: 0.5
+ beta2: 0.999
+ clip_norm: 0.25
+ lr:
+ learning_rate: 0.0001
+
+Architecture:
+ model_type: sr
+ algorithm: Gestalt
+ Transform:
+ name: TSRN
+ STN: True
+ infer_mode: False
+
+Loss:
+ name: StrokeFocusLoss
+ character_dict_path: ./train_data/srdata/english_decomposition.txt
+
+PostProcess:
+ name: None
+
+Metric:
+ name: SRMetric
+ main_indicator: all
+
+Train:
+ dataset:
+ name: LMDBDataSetSR
+ data_dir: ./train_data/srdata/train
+ transforms:
+ - SRResize:
+ imgH: 32
+ imgW: 128
+ down_sample_scale: 2
+ - SRLabelEncode: # Class handling label
+ - KeepKeys:
+ keep_keys: ['img_lr', 'img_hr', 'length', 'input_tensor', 'label'] # dataloader will return list in this order
+ loader:
+ shuffle: False
+ batch_size_per_card: 16
+ drop_last: True
+ num_workers: 4
+
+Eval:
+ dataset:
+ name: LMDBDataSetSR
+ data_dir: ./train_data/srdata/test
+ transforms:
+ - SRResize:
+ imgH: 32
+ imgW: 128
+ down_sample_scale: 2
+ - SRLabelEncode: # Class handling label
+ - KeepKeys:
+ keep_keys: ['img_lr', 'img_hr','length', 'input_tensor', 'label'] # dataloader will return list in this order
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 16
+ num_workers: 4
+
diff --git a/configs/table/SLANet.yml b/configs/table/SLANet.yml
new file mode 100644
index 0000000000000000000000000000000000000000..a896614556e36f77bd784218b6c2f29914219dbe
--- /dev/null
+++ b/configs/table/SLANet.yml
@@ -0,0 +1,143 @@
+Global:
+ use_gpu: true
+ epoch_num: 100
+ log_smooth_window: 20
+ print_batch_step: 20
+ save_model_dir: ./output/SLANet
+ save_epoch_step: 400
+ # evaluation is run every 1000 iterations after the 0th iteration
+ eval_batch_step: [0, 1000]
+ cal_metric_during_train: True
+ pretrained_model:
+ checkpoints:
+ save_inference_dir: ./output/SLANet/infer
+ use_visualdl: False
+ infer_img: ppstructure/docs/table/table.jpg
+ # for data or label process
+ character_dict_path: ppocr/utils/dict/table_structure_dict.txt
+ character_type: en
+ max_text_length: &max_text_length 500
+ box_format: &box_format 'xyxy' # 'xywh', 'xyxy', 'xyxyxyxy'
+ infer_mode: False
+ use_sync_bn: True
+ save_res_path: 'output/infer'
+
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ clip_norm: 5.0
+ lr:
+ name: Piecewise
+ learning_rate: 0.001
+ decay_epochs : [40, 50]
+ values : [0.001, 0.0001, 0.00005]
+ regularizer:
+ name: 'L2'
+ factor: 0.00000
+
+Architecture:
+ model_type: table
+ algorithm: SLANet
+ Backbone:
+ name: PPLCNet
+ scale: 1.0
+ pretrained: true
+ use_ssld: true
+ Neck:
+ name: CSPPAN
+ out_channels: 96
+ Head:
+ name: SLAHead
+ hidden_size: 256
+ max_text_length: *max_text_length
+ loc_reg_num: &loc_reg_num 4
+
+Loss:
+ name: SLALoss
+ structure_weight: 1.0
+ loc_weight: 2.0
+ loc_loss: smooth_l1
+
+PostProcess:
+ name: TableLabelDecode
+ merge_no_span_structure: &merge_no_span_structure True
+
+Metric:
+ name: TableMetric
+ main_indicator: acc
+ compute_bbox_metric: False
+ loc_reg_num: *loc_reg_num
+ box_format: *box_format
+
+Train:
+ dataset:
+ name: PubTabDataSet
+ data_dir: train_data/table/pubtabnet/train/
+ label_file_list: [train_data/table/pubtabnet/PubTabNet_2.0.0_train.jsonl]
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - TableLabelEncode:
+ learn_empty_box: False
+ merge_no_span_structure: *merge_no_span_structure
+ replace_empty_cell_token: False
+ loc_reg_num: *loc_reg_num
+ max_text_length: *max_text_length
+ - TableBoxEncode:
+ in_box_format: *box_format
+ out_box_format: *box_format
+ - ResizeTableImage:
+ max_len: 488
+ - NormalizeImage:
+ scale: 1./255.
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: 'hwc'
+ - PaddingTableImage:
+ size: [488, 488]
+ - ToCHWImage:
+ - KeepKeys:
+ keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
+ loader:
+ shuffle: True
+ batch_size_per_card: 48
+ drop_last: True
+ num_workers: 1
+
+Eval:
+ dataset:
+ name: PubTabDataSet
+ data_dir: train_data/table/pubtabnet/val/
+ label_file_list: [train_data/table/pubtabnet/PubTabNet_2.0.0_val.jsonl]
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - TableLabelEncode:
+ learn_empty_box: False
+ merge_no_span_structure: *merge_no_span_structure
+ replace_empty_cell_token: False
+ loc_reg_num: *loc_reg_num
+ max_text_length: *max_text_length
+ - TableBoxEncode:
+ in_box_format: *box_format
+ out_box_format: *box_format
+ - ResizeTableImage:
+ max_len: 488
+ - NormalizeImage:
+ scale: 1./255.
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: 'hwc'
+ - PaddingTableImage:
+ size: [488, 488]
+ - ToCHWImage:
+ - KeepKeys:
+ keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 48
+ num_workers: 1
diff --git a/configs/table/SLANet_ch.yml b/configs/table/SLANet_ch.yml
new file mode 100644
index 0000000000000000000000000000000000000000..3b1e5c6bd9dd4cd2a084d557a1285983a56bdf2a
--- /dev/null
+++ b/configs/table/SLANet_ch.yml
@@ -0,0 +1,141 @@
+Global:
+ use_gpu: True
+ epoch_num: 400
+ log_smooth_window: 20
+ print_batch_step: 20
+ save_model_dir: ./output/SLANet_ch
+ save_epoch_step: 400
+ # evaluation is run every 331 iterations after the 0th iteration
+ eval_batch_step: [0, 331]
+ cal_metric_during_train: True
+ pretrained_model:
+ checkpoints:
+ save_inference_dir: ./output/SLANet_ch/infer
+ use_visualdl: False
+ infer_img: ppstructure/docs/table/table.jpg
+ # for data or label process
+ character_dict_path: ppocr/utils/dict/table_structure_dict_ch.txt
+ character_type: en
+ max_text_length: &max_text_length 500
+ box_format: &box_format xyxyxyxy # 'xywh', 'xyxy', 'xyxyxyxy'
+ infer_mode: False
+ use_sync_bn: True
+ save_res_path: output/infer
+
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ clip_norm: 5.0
+ lr:
+ learning_rate: 0.001
+ regularizer:
+ name: 'L2'
+ factor: 0.00000
+
+Architecture:
+ model_type: table
+ algorithm: SLANet
+ Backbone:
+ name: PPLCNet
+ scale: 1.0
+ pretrained: True
+ use_ssld: True
+ Neck:
+ name: CSPPAN
+ out_channels: 96
+ Head:
+ name: SLAHead
+ hidden_size: 256
+ max_text_length: *max_text_length
+ loc_reg_num: &loc_reg_num 8
+
+Loss:
+ name: SLALoss
+ structure_weight: 1.0
+ loc_weight: 2.0
+ loc_loss: smooth_l1
+
+PostProcess:
+ name: TableLabelDecode
+ merge_no_span_structure: &merge_no_span_structure True
+
+Metric:
+ name: TableMetric
+ main_indicator: acc
+ compute_bbox_metric: False
+ loc_reg_num: *loc_reg_num
+ box_format: *box_format
+ del_thead_tbody: True
+
+Train:
+ dataset:
+ name: PubTabDataSet
+ data_dir: train_data/table/train/
+ label_file_list: [train_data/table/train.txt]
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: False
+ - TableLabelEncode:
+ learn_empty_box: False
+ merge_no_span_structure: *merge_no_span_structure
+ replace_empty_cell_token: False
+ loc_reg_num: *loc_reg_num
+ max_text_length: *max_text_length
+ - TableBoxEncode:
+ in_box_format: *box_format
+ out_box_format: *box_format
+ - ResizeTableImage:
+ max_len: 488
+ - NormalizeImage:
+ scale: 1./255.
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: 'hwc'
+ - PaddingTableImage:
+ size: [488, 488]
+ - ToCHWImage:
+ - KeepKeys:
+ keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
+ loader:
+ shuffle: True
+ batch_size_per_card: 48
+ drop_last: True
+ num_workers: 1
+
+Eval:
+ dataset:
+ name: PubTabDataSet
+ data_dir: train_data/table/val/
+ label_file_list: [train_data/table/val.txt]
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: False
+ - TableLabelEncode:
+ learn_empty_box: False
+ merge_no_span_structure: *merge_no_span_structure
+ replace_empty_cell_token: False
+ loc_reg_num: *loc_reg_num
+ max_text_length: *max_text_length
+ - TableBoxEncode:
+ in_box_format: *box_format
+ out_box_format: *box_format
+ - ResizeTableImage:
+ max_len: 488
+ - NormalizeImage:
+ scale: 1./255.
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: 'hwc'
+ - PaddingTableImage:
+ size: [488, 488]
+ - ToCHWImage:
+ - KeepKeys:
+ keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 48
+ num_workers: 1
diff --git a/configs/table/table_master.yml b/configs/table/table_master.yml
index b8daf3630755e61322665b6fc5f830e4a45875b8..df437f7c95523c5fe12f7166d011b4ad8473628b 100755
--- a/configs/table/table_master.yml
+++ b/configs/table/table_master.yml
@@ -8,16 +8,15 @@ Global:
eval_batch_step: [0, 6259]
cal_metric_during_train: true
pretrained_model: null
- checkpoints:
+ checkpoints:
save_inference_dir: output/table_master/infer
use_visualdl: false
infer_img: ppstructure/docs/table/table.jpg
save_res_path: ./output/table_master
character_dict_path: ppocr/utils/dict/table_master_structure_dict.txt
infer_mode: false
- max_text_length: 500
- process_total_num: 0
- process_cut_num: 0
+ max_text_length: &max_text_length 500
+ box_format: &box_format 'xywh' # 'xywh', 'xyxy', 'xyxyxyxy'
Optimizer:
@@ -52,7 +51,8 @@ Architecture:
headers: 8
dropout: 0
d_ff: 2024
- max_text_length: 500
+ max_text_length: *max_text_length
+ loc_reg_num: &loc_reg_num 4
Loss:
name: TableMasterLoss
@@ -61,11 +61,13 @@ Loss:
PostProcess:
name: TableMasterLabelDecode
box_shape: pad
+ merge_no_span_structure: &merge_no_span_structure True
Metric:
name: TableMetric
main_indicator: acc
compute_bbox_metric: False
+ box_format: *box_format
Train:
dataset:
@@ -78,15 +80,18 @@ Train:
channel_first: False
- TableMasterLabelEncode:
learn_empty_box: False
- merge_no_span_structure: True
+ merge_no_span_structure: *merge_no_span_structure
replace_empty_cell_token: True
+ loc_reg_num: *loc_reg_num
+ max_text_length: *max_text_length
- ResizeTableImage:
max_len: 480
resize_bboxes: True
- PaddingTableImage:
size: [480, 480]
- TableBoxEncode:
- use_xywh: True
+ in_box_format: *box_format
+ out_box_format: *box_format
- NormalizeImage:
scale: 1./255.
mean: [0.5, 0.5, 0.5]
@@ -112,15 +117,18 @@ Eval:
channel_first: False
- TableMasterLabelEncode:
learn_empty_box: False
- merge_no_span_structure: True
+ merge_no_span_structure: *merge_no_span_structure
replace_empty_cell_token: True
+ loc_reg_num: *loc_reg_num
+ max_text_length: *max_text_length
- ResizeTableImage:
max_len: 480
resize_bboxes: True
- PaddingTableImage:
size: [480, 480]
- TableBoxEncode:
- use_xywh: True
+ in_box_format: *box_format
+ out_box_format: *box_format
- NormalizeImage:
scale: 1./255.
mean: [0.5, 0.5, 0.5]
diff --git a/configs/table/table_mv3.yml b/configs/table/table_mv3.yml
index 66c1c83e124d4e94e1f4036a494dfd80c840f229..9355a236e15b60db18e8715c2702701fd5d36c71 100755
--- a/configs/table/table_mv3.yml
+++ b/configs/table/table_mv3.yml
@@ -17,10 +17,9 @@ Global:
# for data or label process
character_dict_path: ppocr/utils/dict/table_structure_dict.txt
character_type: en
- max_text_length: 800
+ max_text_length: &max_text_length 500
+ box_format: &box_format 'xyxy' # 'xywh', 'xyxy', 'xyxyxyxy'
infer_mode: False
- process_total_num: 0
- process_cut_num: 0
Optimizer:
name: Adam
@@ -39,12 +38,14 @@ Architecture:
Backbone:
name: MobileNetV3
scale: 1.0
- model_name: large
+ model_name: small
+ disable_se: true
Head:
name: TableAttentionHead
hidden_size: 256
loc_type: 2
- max_text_length: 800
+ max_text_length: *max_text_length
+ loc_reg_num: &loc_reg_num 4
Loss:
name: TableAttentionLoss
@@ -72,6 +73,8 @@ Train:
learn_empty_box: False
merge_no_span_structure: False
replace_empty_cell_token: False
+ loc_reg_num: *loc_reg_num
+ max_text_length: *max_text_length
- TableBoxEncode:
- ResizeTableImage:
max_len: 488
@@ -87,15 +90,15 @@ Train:
keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
loader:
shuffle: True
- batch_size_per_card: 32
+ batch_size_per_card: 48
drop_last: True
num_workers: 1
Eval:
dataset:
name: PubTabDataSet
- data_dir: /home/zhoujun20/table/PubTabNe/pubtabnet/val/
- label_file_list: [/home/zhoujun20/table/PubTabNe/pubtabnet/val_500.jsonl]
+ data_dir: train_data/table/pubtabnet/val/
+ label_file_list: [train_data/table/pubtabnet/PubTabNet_2.0.0_val.jsonl]
transforms:
- DecodeImage: # load image
img_mode: BGR
@@ -104,6 +107,8 @@ Eval:
learn_empty_box: False
merge_no_span_structure: False
replace_empty_cell_token: False
+ loc_reg_num: *loc_reg_num
+ max_text_length: *max_text_length
- TableBoxEncode:
- ResizeTableImage:
max_len: 488
@@ -120,5 +125,5 @@ Eval:
loader:
shuffle: False
drop_last: False
- batch_size_per_card: 16
+ batch_size_per_card: 48
num_workers: 1
diff --git a/deploy/android_demo/app/src/main/cpp/native.cpp b/deploy/android_demo/app/src/main/cpp/native.cpp
index ced932556f09244d1e9e962e7b75461203a7cc3a..4961e5ecf141bb50701ecf9c3654a54f062937ce 100644
--- a/deploy/android_demo/app/src/main/cpp/native.cpp
+++ b/deploy/android_demo/app/src/main/cpp/native.cpp
@@ -47,7 +47,7 @@ str_to_cpu_mode(const std::string &cpu_mode) {
std::string upper_key;
std::transform(cpu_mode.cbegin(), cpu_mode.cend(), upper_key.begin(),
::toupper);
- auto index = cpu_mode_map.find(upper_key);
+ auto index = cpu_mode_map.find(upper_key.c_str());
if (index == cpu_mode_map.end()) {
LOGE("cpu_mode not found %s", upper_key.c_str());
return paddle::lite_api::LITE_POWER_HIGH;
@@ -116,4 +116,4 @@ Java_com_baidu_paddle_lite_demo_ocr_OCRPredictorNative_release(
ppredictor::OCR_PPredictor *ppredictor =
(ppredictor::OCR_PPredictor *)java_pointer;
delete ppredictor;
-}
\ No newline at end of file
+}
diff --git a/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/OCRPredictorNative.java b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/OCRPredictorNative.java
index 622da2a3f9a1233167e777e62b687c1f246df01f..41fa183dea1d968582dbedf4e831c55b043ae00f 100644
--- a/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/OCRPredictorNative.java
+++ b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/OCRPredictorNative.java
@@ -54,7 +54,7 @@ public class OCRPredictorNative {
}
public void destory() {
- if (nativePointer > 0) {
+ if (nativePointer != 0) {
release(nativePointer);
nativePointer = 0;
}
diff --git a/deploy/cpp_infer/docs/windows_vs2019_build.md b/deploy/cpp_infer/docs/windows_vs2019_build.md
index 4f391d925008b4bffcbd123e937eb608f502c646..bcaefa46f83a30a4c232add78dc2e9f521b9f84f 100644
--- a/deploy/cpp_infer/docs/windows_vs2019_build.md
+++ b/deploy/cpp_infer/docs/windows_vs2019_build.md
@@ -109,8 +109,10 @@ CUDA_LIB、CUDNN_LIB、TENSORRT_DIR、WITH_GPU、WITH_TENSORRT
运行之前,将下面文件拷贝到`build/Release/`文件夹下
1. `paddle_inference/paddle/lib/paddle_inference.dll`
-2. `opencv/build/x64/vc15/bin/opencv_world455.dll`
-3. 如果使用openblas版本的预测库还需要拷贝 `paddle_inference/third_party/install/openblas/lib/openblas.dll`
+2. `paddle_inference/third_party/install/onnxruntime/lib/onnxruntime.dll`
+3. `paddle_inference/third_party/install/paddle2onnx/lib/paddle2onnx.dll`
+4. `opencv/build/x64/vc15/bin/opencv_world455.dll`
+5. 如果使用openblas版本的预测库还需要拷贝 `paddle_inference/third_party/install/openblas/lib/openblas.dll`
### Step4: 预测
diff --git a/deploy/cpp_infer/include/args.h b/deploy/cpp_infer/include/args.h
index 473ff25d981f8409f60a43940aaaec376375adf5..f7fac9c92c421ca85818b2d04097ce8e55ea117e 100644
--- a/deploy/cpp_infer/include/args.h
+++ b/deploy/cpp_infer/include/args.h
@@ -30,7 +30,8 @@ DECLARE_string(image_dir);
DECLARE_string(type);
// detection related
DECLARE_string(det_model_dir);
-DECLARE_int32(max_side_len);
+DECLARE_string(limit_type);
+DECLARE_int32(limit_side_len);
DECLARE_double(det_db_thresh);
DECLARE_double(det_db_box_thresh);
DECLARE_double(det_db_unclip_ratio);
@@ -48,7 +49,14 @@ DECLARE_int32(rec_batch_num);
DECLARE_string(rec_char_dict_path);
DECLARE_int32(rec_img_h);
DECLARE_int32(rec_img_w);
+// structure model related
+DECLARE_string(table_model_dir);
+DECLARE_int32(table_max_len);
+DECLARE_int32(table_batch_num);
+DECLARE_string(table_char_dict_path);
+DECLARE_bool(merge_no_span_structure);
// forward related
DECLARE_bool(det);
DECLARE_bool(rec);
DECLARE_bool(cls);
+DECLARE_bool(table);
\ No newline at end of file
diff --git a/deploy/cpp_infer/include/ocr_det.h b/deploy/cpp_infer/include/ocr_det.h
index 7efd4d8f0f4ccb705fc34695bb9843e0b6af5a9b..d1421b103b28b44e15a7df53a63fd893ca60e529 100644
--- a/deploy/cpp_infer/include/ocr_det.h
+++ b/deploy/cpp_infer/include/ocr_det.h
@@ -41,8 +41,8 @@ public:
explicit DBDetector(const std::string &model_dir, const bool &use_gpu,
const int &gpu_id, const int &gpu_mem,
const int &cpu_math_library_num_threads,
- const bool &use_mkldnn, const int &max_side_len,
- const double &det_db_thresh,
+ const bool &use_mkldnn, const string &limit_type,
+ const int &limit_side_len, const double &det_db_thresh,
const double &det_db_box_thresh,
const double &det_db_unclip_ratio,
const std::string &det_db_score_mode,
@@ -54,7 +54,8 @@ public:
this->cpu_math_library_num_threads_ = cpu_math_library_num_threads;
this->use_mkldnn_ = use_mkldnn;
- this->max_side_len_ = max_side_len;
+ this->limit_type_ = limit_type;
+ this->limit_side_len_ = limit_side_len;
this->det_db_thresh_ = det_db_thresh;
this->det_db_box_thresh_ = det_db_box_thresh;
@@ -84,7 +85,8 @@ private:
int cpu_math_library_num_threads_ = 4;
bool use_mkldnn_ = false;
- int max_side_len_ = 960;
+ string limit_type_ = "max";
+ int limit_side_len_ = 960;
double det_db_thresh_ = 0.3;
double det_db_box_thresh_ = 0.5;
@@ -106,7 +108,7 @@ private:
Permute permute_op_;
// post-process
- PostProcessor post_processor_;
+ DBPostProcessor post_processor_;
};
} // namespace PaddleOCR
\ No newline at end of file
diff --git a/deploy/cpp_infer/include/paddleocr.h b/deploy/cpp_infer/include/paddleocr.h
index 6db9d86cb152bfcc708a87c6a98be59d88a5d8db..a2c60b14acceaa90a8d8e4a70ccc50f02f254eb6 100644
--- a/deploy/cpp_infer/include/paddleocr.h
+++ b/deploy/cpp_infer/include/paddleocr.h
@@ -47,11 +47,7 @@ public:
ocr(std::vector
+| Methods | R | P | F | FPS |
| SegLink [26] | 70.0 | 86.0 | 77.0 | 8.9 |
| PixelLink [4] | 73.2 | 83.0 | 77.8 | - |
| TextSnake [18] | 73.9 | 83.2 | 78.3 | 1.1 |
| TextField [37] | 75.9 | 87.4 | 81.3 | 5.2 |
| MSR[38] | 76.7 | 87.4 | 81.7 | - |
| FTSN [3] | 77.1 | 87.6 | 82.0 | - |
| LSE[30] | 81.7 | 84.2 | 82.9 | - |
| CRAFT [2] | 78.2 | 88.2 | 82.9 | 8.6 |
| MCN [16] | 79 | 88 | 83 | - |
| ATRR[35] | 82.1 | 85.2 | 83.6 | - |
| PAN [34] | 83.8 | 84.4 | 84.1 | 30.2 |
| DB[12] | 79.2 | 91.5 | 84.9 | 32.0 |
| DRRG [41] | 82.30 | 88.05 | 85.08 | - |
| Ours (SynText) | 80.68 | 85.40 | 82.97 | 12.68 |
| Ours (MLT-17) | 84.54 | 86.62 | 85.57 | 12.31 |