diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
index a5052e2897ab9f09a6ed7b747f9fa1198af2a8ab..ee13bacffdb65e6300a034531a527fdca4ed29f9 100644
--- "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
+++ "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
@@ -206,7 +206,11 @@ Eval.dataset.transforms.DetResizeForTest: 尺寸
limit_type: 'min'
```
-然后执行评估代码
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+

+
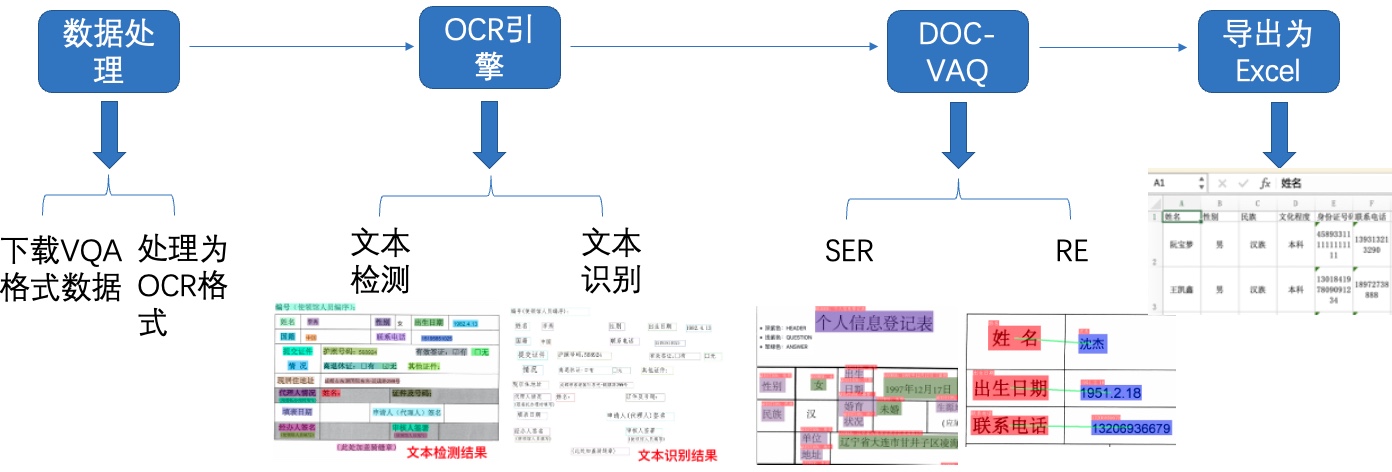 图1 多模态表单识别流程图
-注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375)(配备Tesla V100、A100等高级算力资源)
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375?contributionType=1)
-
-
-# 2 安装说明
+## 2 安装说明
下载PaddleOCR源码,上述AIStudio项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
```python
-! unzip -q PaddleOCR.zip
+unzip -q PaddleOCR.zip
```
```python
# 如仍需安装or安装更新,可以执行以下步骤
-# ! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
-# ! git clone https://gitee.com/PaddlePaddle/PaddleOCR
+# git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR
```
```python
# 安装依赖包
-! pip install -U pip
-! pip install -r /home/aistudio/PaddleOCR/requirements.txt
-! pip install paddleocr
+pip install -U pip
+pip install -r /home/aistudio/PaddleOCR/requirements.txt
+pip install paddleocr
-! pip install yacs gnureadline paddlenlp==2.2.1
-! pip install xlsxwriter
+pip install yacs gnureadline paddlenlp==2.2.1
+pip install xlsxwriter
```
-# 3 数据准备
+## 3 数据准备
这里使用[XFUN数据集](https://github.com/doc-analysis/XFUND)做为实验数据集。 XFUN数据集是微软提出的一个用于KIE任务的多语言数据集,共包含七个数据集,每个数据集包含149张训练集和50张验证集
@@ -59,7 +86,7 @@
图1 多模态表单识别流程图
-注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375)(配备Tesla V100、A100等高级算力资源)
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375?contributionType=1)
-
-
-# 2 安装说明
+## 2 安装说明
下载PaddleOCR源码,上述AIStudio项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
```python
-! unzip -q PaddleOCR.zip
+unzip -q PaddleOCR.zip
```
```python
# 如仍需安装or安装更新,可以执行以下步骤
-# ! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
-# ! git clone https://gitee.com/PaddlePaddle/PaddleOCR
+# git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR
```
```python
# 安装依赖包
-! pip install -U pip
-! pip install -r /home/aistudio/PaddleOCR/requirements.txt
-! pip install paddleocr
+pip install -U pip
+pip install -r /home/aistudio/PaddleOCR/requirements.txt
+pip install paddleocr
-! pip install yacs gnureadline paddlenlp==2.2.1
-! pip install xlsxwriter
+pip install yacs gnureadline paddlenlp==2.2.1
+pip install xlsxwriter
```
-# 3 数据准备
+## 3 数据准备
这里使用[XFUN数据集](https://github.com/doc-analysis/XFUND)做为实验数据集。 XFUN数据集是微软提出的一个用于KIE任务的多语言数据集,共包含七个数据集,每个数据集包含149张训练集和50张验证集
@@ -59,7 +86,7 @@
 图2 数据集样例,左中文,右法语
-## 3.1 下载处理好的数据集
+### 3.1 下载处理好的数据集
处理好的XFUND中文数据集下载地址:[https://paddleocr.bj.bcebos.com/dataset/XFUND.tar](https://paddleocr.bj.bcebos.com/dataset/XFUND.tar) ,可以运行如下指令完成中文数据集下载和解压。
@@ -69,13 +96,13 @@
```python
-! wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
-! tar -xf XFUND.tar
+wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
+tar -xf XFUND.tar
# XFUN其他数据集使用下面的代码进行转换
# 代码链接:https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.4/ppstructure/vqa/helper/trans_xfun_data.py
# %cd PaddleOCR
-# !python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
+# python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
# %cd ../
```
@@ -119,7 +146,7 @@
}
```
-## 3.2 转换为PaddleOCR检测和识别格式
+### 3.2 转换为PaddleOCR检测和识别格式
使用XFUND训练PaddleOCR检测和识别模型,需要将数据集格式改为训练需求的格式。
@@ -147,7 +174,7 @@ train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
```python
-! unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
+unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
```
已经提供转换脚本,执行如下代码即可转换成功:
@@ -155,21 +182,20 @@ train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
```python
%cd /home/aistudio/
-! python trans_xfund_data.py
+python trans_xfund_data.py
```
-# 4 OCR
+## 4 OCR
选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/README_ch.md)中的PP-OCRv2模型进行文本检测和识别。PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和[Enhanced CTC loss](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/enhanced_ctc_loss.md)损失函数改进,进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2[技术报告](https://arxiv.org/abs/2109.03144)。
-
-## 4.1 文本检测
+### 4.1 文本检测
我们使用2种方案进行训练、评估:
- **PP-OCRv2中英文超轻量检测预训练模型**
- **XFUND数据集+fine-tune**
-### **4.1.1 方案1:预训练模型**
+#### 4.1.1 方案1:预训练模型
**1)下载预训练模型**
@@ -195,8 +221,8 @@ PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示
```python
%cd /home/aistudio/PaddleOCR/pretrain/
-! wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
-! tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
+tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
% cd ..
```
@@ -226,7 +252,7 @@ Eval.dataset.label_file_list:指向验证集标注文件
```python
%cd /home/aistudio/PaddleOCR
-! python tools/eval.py \
+python tools/eval.py \
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml \
-o Global.checkpoints="./pretrain_models/ch_PP-OCRv2_det_distill_train/best_accuracy"
```
@@ -237,9 +263,9 @@ Eval.dataset.label_file_list:指向验证集标注文件
| -------- | -------- |
| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% |
-使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型有一定的泛化能力。
+使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型具有泛化能力。
-### **4.1.2 方案2:XFUND数据集+fine-tune**
+#### 4.1.2 方案2:XFUND数据集+fine-tune
PaddleOCR提供的蒸馏预训练模型包含了多个模型的参数,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
@@ -281,7 +307,7 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
```python
-! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+CUDA_VISIBLE_DEVICES=0 python tools/train.py \
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml
```
@@ -290,12 +316,18 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
图2 数据集样例,左中文,右法语
-## 3.1 下载处理好的数据集
+### 3.1 下载处理好的数据集
处理好的XFUND中文数据集下载地址:[https://paddleocr.bj.bcebos.com/dataset/XFUND.tar](https://paddleocr.bj.bcebos.com/dataset/XFUND.tar) ,可以运行如下指令完成中文数据集下载和解压。
@@ -69,13 +96,13 @@
```python
-! wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
-! tar -xf XFUND.tar
+wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
+tar -xf XFUND.tar
# XFUN其他数据集使用下面的代码进行转换
# 代码链接:https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.4/ppstructure/vqa/helper/trans_xfun_data.py
# %cd PaddleOCR
-# !python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
+# python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
# %cd ../
```
@@ -119,7 +146,7 @@
}
```
-## 3.2 转换为PaddleOCR检测和识别格式
+### 3.2 转换为PaddleOCR检测和识别格式
使用XFUND训练PaddleOCR检测和识别模型,需要将数据集格式改为训练需求的格式。
@@ -147,7 +174,7 @@ train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
```python
-! unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
+unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
```
已经提供转换脚本,执行如下代码即可转换成功:
@@ -155,21 +182,20 @@ train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
```python
%cd /home/aistudio/
-! python trans_xfund_data.py
+python trans_xfund_data.py
```
-# 4 OCR
+## 4 OCR
选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/README_ch.md)中的PP-OCRv2模型进行文本检测和识别。PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和[Enhanced CTC loss](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/enhanced_ctc_loss.md)损失函数改进,进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2[技术报告](https://arxiv.org/abs/2109.03144)。
-
-## 4.1 文本检测
+### 4.1 文本检测
我们使用2种方案进行训练、评估:
- **PP-OCRv2中英文超轻量检测预训练模型**
- **XFUND数据集+fine-tune**
-### **4.1.1 方案1:预训练模型**
+#### 4.1.1 方案1:预训练模型
**1)下载预训练模型**
@@ -195,8 +221,8 @@ PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示
```python
%cd /home/aistudio/PaddleOCR/pretrain/
-! wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
-! tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
+tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
% cd ..
```
@@ -226,7 +252,7 @@ Eval.dataset.label_file_list:指向验证集标注文件
```python
%cd /home/aistudio/PaddleOCR
-! python tools/eval.py \
+python tools/eval.py \
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml \
-o Global.checkpoints="./pretrain_models/ch_PP-OCRv2_det_distill_train/best_accuracy"
```
@@ -237,9 +263,9 @@ Eval.dataset.label_file_list:指向验证集标注文件
| -------- | -------- |
| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% |
-使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型有一定的泛化能力。
+使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型具有泛化能力。
-### **4.1.2 方案2:XFUND数据集+fine-tune**
+#### 4.1.2 方案2:XFUND数据集+fine-tune
PaddleOCR提供的蒸馏预训练模型包含了多个模型的参数,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
@@ -281,7 +307,7 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
```python
-! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+CUDA_VISIBLE_DEVICES=0 python tools/train.py \
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml
```
@@ -290,12 +316,18 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
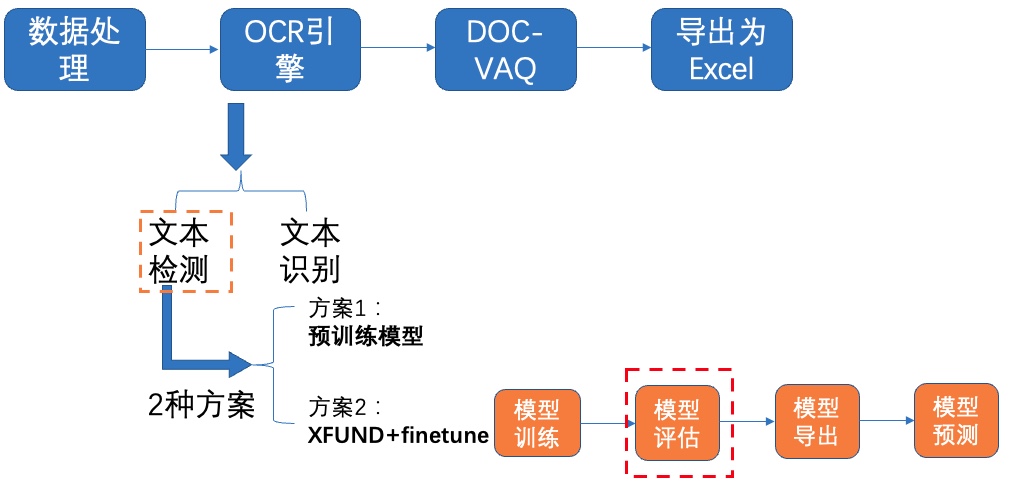 图8 文本检测方案2-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`,[模型下载地址](https://paddleocr.bj.bcebos.com/fanliku/sheet_recognition/ch_db_mv3-student1600-finetune.zip)
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
图8 文本检测方案2-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`,[模型下载地址](https://paddleocr.bj.bcebos.com/fanliku/sheet_recognition/ch_db_mv3-student1600-finetune.zip)
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+
+
 图27 导出Excel
@@ -859,7 +879,7 @@ with open('output/re/infer_results.txt', 'r', encoding='utf-8') as fin:
workbook.close()
```
-# 更多资源
+## 更多资源
- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
@@ -869,7 +889,7 @@ workbook.close()
- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
-# 参考链接
+## 参考链接
- LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding, https://arxiv.org/pdf/2104.08836.pdf
图27 导出Excel
@@ -859,7 +879,7 @@ with open('output/re/infer_results.txt', 'r', encoding='utf-8') as fin:
workbook.close()
```
-# 更多资源
+## 更多资源
- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
@@ -869,7 +889,7 @@ workbook.close()
- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
-# 参考链接
+## 参考链接
- LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding, https://arxiv.org/pdf/2104.08836.pdf