You need to prepare a Jetson development hardware. If you need TensorRT, you need to prepare the TensorRT environment. It is recommended to use TensorRT version 7.1.3;
The PaddlePaddle download [link](https://www.paddlepaddle.org.cn/inference/user_guides/download_lib.html#python)
Please select the appropriate installation package for your Jetpack version, cuda version, and trt version. Here, we download paddlepaddle_gpu-2.3.0rc0-cp36-cp36m-linux_aarch64.whl.
*Note: Jetson hardware CPU is poor, dependency installation is slow, please wait patiently*
## 2. Perform prediction
## 2. 执行预测
Obtain the PPOCR model from the [document](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_en/ppocr_introduction_en.md#6-model-zoo) model library. The following takes the PP-OCRv3 model as an example to introduce the use of the PPOCR model on Jetson:
After executing the command, the predicted information will be printed out in the terminal, and the visualization results will be saved in the `./inference_results/` directory.
After executing the command, the predicted information will be printed out in the terminal, and the visualization results will be saved in the `./inference_results/` directory.

开启TRT预测只需要在以上命令基础上设置`--use_tensorrt=True`即可:
To enable TRT prediction, you only need to set `--use_tensorrt=True` on the basis of the above command:
This section introduces the deployment of PaddleOCR on Jetson NX, TX2, nano, AGX and other series of hardware.
本节介绍PaddleOCR在Jetson NX、TX2、nano、AGX等系列硬件的部署。
## 1. Prepare Environment
## 1. 环境准备
You need to prepare a Jetson development hardware. If you need TensorRT, you need to prepare the TensorRT environment. It is recommended to use TensorRT version 7.1.3;
The PaddlePaddle download [link](https://www.paddlepaddle.org.cn/inference/user_guides/download_lib.html#python)
Please select the appropriate installation package for your Jetpack version, cuda version, and trt version. Here, we download paddlepaddle_gpu-2.3.0rc0-cp36-cp36m-linux_aarch64.whl.
*Note: Jetson hardware CPU is poor, dependency installation is slow, please wait patiently*
*注:jetson硬件CPU较差,依赖安装较慢,请耐心等待*
## 2. Perform prediction
Obtain the PPOCR model from the [document](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_en/ppocr_introduction_en.md#6-model-zoo) model library. The following takes the PP-OCRv3 model as an example to introduce the use of the PPOCR model on Jetson:
After executing the command, the predicted information will be printed out in the terminal, and the visualization results will be saved in the `./inference_results/` directory.
After executing the command, the predicted information will be printed out in the terminal, and the visualization results will be saved in the `./inference_results/` directory.
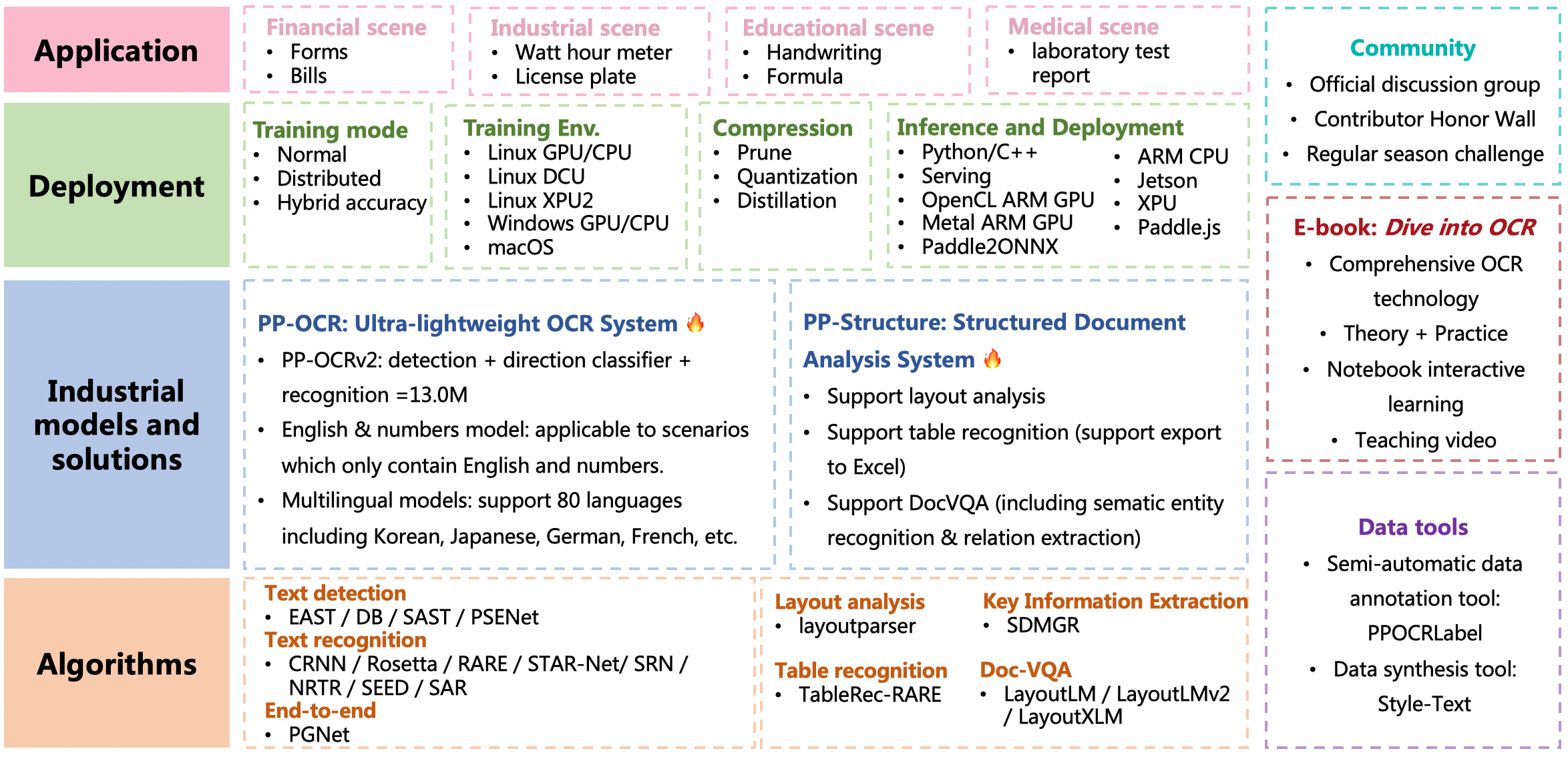
If you need the deployment tutorial of academic algorithm models other than PP-OCR, please directly enter the main page of corresponding algorithms, [entrance](../doc/doc_en/algorithm_overview_en.md)。
@@ -32,24 +32,18 @@ PP-OCR system is in continuous optimization. At present, PP-OCR and PP-OCRv2 hav
[2] On the basis of PP-OCR, PP-OCRv2 is further optimized in five aspects. The detection model adopts CML(Collaborative Mutual Learning) knowledge distillation strategy and CopyPaste data expansion strategy. The recognition model adopts LCNet lightweight backbone network, U-DML knowledge distillation strategy and enhanced CTC loss function improvement (as shown in the red box above), which further improves the inference speed and prediction effect. For more details, please refer to the technical report of PP-OCRv2 (https://arxiv.org/abs/2109.03144).
[3] PP-OCRv3 is further upgraded on the basis of PP-OCRv2.
PP-OCRv3 text detection has been further optimized from the two directions of network structure and distillation training strategy:
- Network structure improvement: Two improved FPN network structures, RSEFPN and LKPAN, are proposed to optimize the features in the FPN from the perspective of channel attention and a larger receptive field, and optimize the features extracted by the FPN.
- Distillation training strategy: First, use resnet50 as the backbone, the improved LKPAN network structure as the FPN, and use the DML self-distillation strategy to obtain a teacher model with higher accuracy; then, the FPN part of the student model adopts RSEFPN, and adopts the CML distillation method proposed by PPOCRV2, during the training process, dynamically adjust the proportion of CML distillation teacher loss.
[3] PP-OCRv3 is further upgraded on the basis of PP-OCRv2. The detection model is still based on DB algorithm, and the optimization strategies include a newly proposed FPN structure with residual attention mechanism named with RSEFPN, a PAN structure with enlarged receptive field named with LKPAN, and better teacher model based on DML training; The recognition model replaces the base model from CRNN with IJCAI 2022 paper [SVTR](https://arxiv.org/abs/2205.00159), and adopts lightweight SVTR, guided training of CTC, data augmentation strategy RecConAug, better pre-trained model by self-supervised training, and the use of unlabeled data to accelerate the model and improve the effect. For more details, please refer to PP-OCRv3 [technical report](./PP-OCRv3_introduction_en.md).
{kind=link}
{kind=link}


{kind=link}
{kind=link}

{kind=link}
