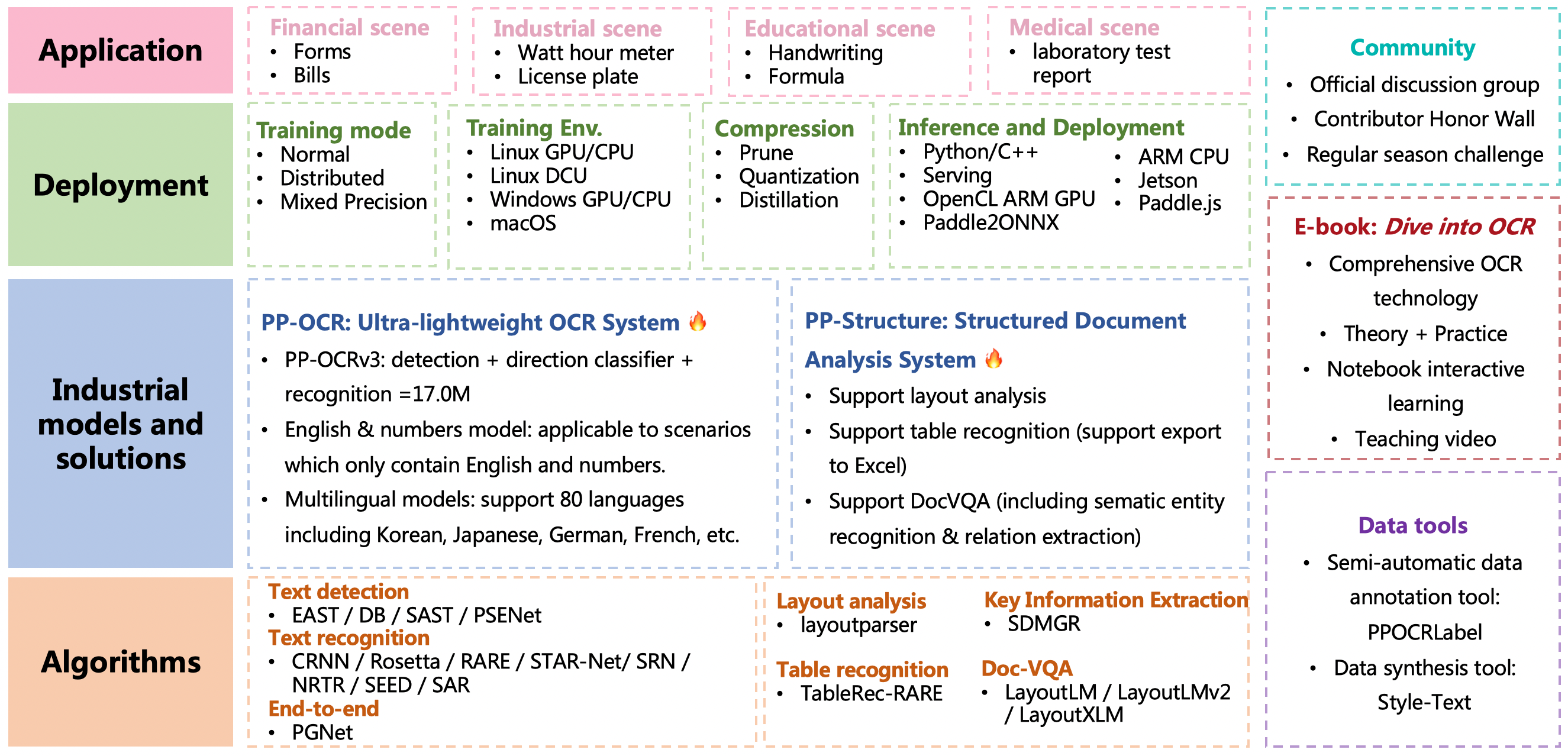
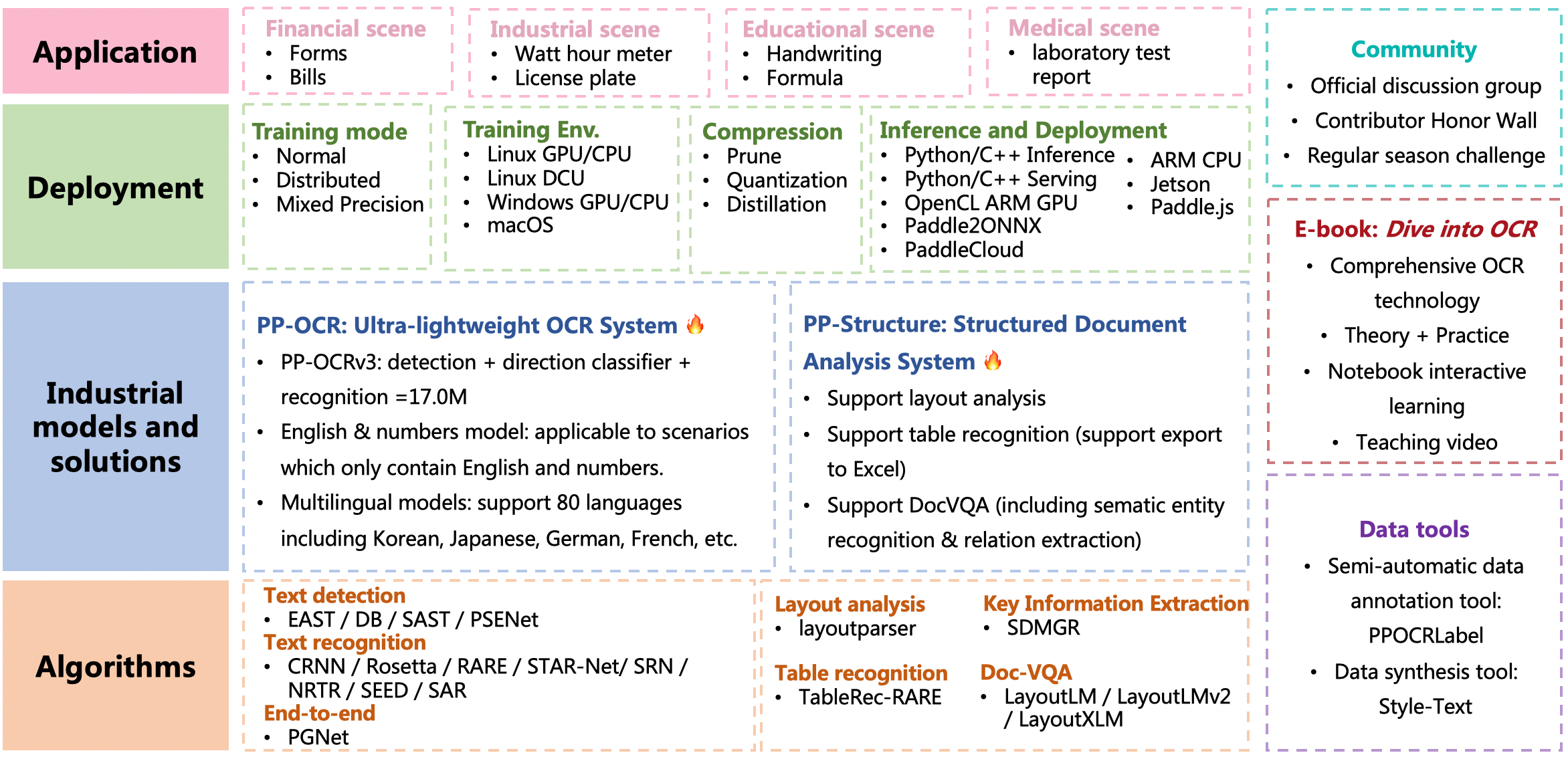
@@ -19,6 +19,10 @@ PaddleOCR aims to create multilingual, awesome, leading, and practical OCR tools
...
@@ -19,6 +19,10 @@ PaddleOCR aims to create multilingual, awesome, leading, and practical OCR tools
**Recent updates**
**Recent updates**
- 2022.5.9 release PaddleOCR v2.5, including:
-[PP-OCRv3](./doc/doc_en/ppocr_introduction_en.md#pp-ocrv3): With comparable speed, the effect of Chinese scene is further improved by 5% compared with PP-OCRv2, the effect of English scene is improved by 11%, and the average recognition accuracy of 80 language multilingual models is improved by more than 5%.
-[PPOCRLabelv2](./PPOCRLabel): Add the annotation function for table recognition task, key information extraction task and irregular text image.
- Interactive e-book [*"Dive into OCR"*](./doc/doc_en/ocr_book_en.md), covers the cutting-edge theory and code practice of OCR full stack technology.
- 2021.12.21 release PaddleOCR v2.4, release 1 text detection algorithm (PSENet), 3 text recognition algorithms (NRTR、SEED、SAR), 1 key information extraction algorithm (SDMGR, [tutorial](./ppstructure/docs/kie_en.md)) and 3 DocVQA algorithms (LayoutLM, LayoutLMv2, LayoutXLM, [tutorial](./ppstructure/vqa)).
- 2021.12.21 release PaddleOCR v2.4, release 1 text detection algorithm (PSENet), 3 text recognition algorithms (NRTR、SEED、SAR), 1 key information extraction algorithm (SDMGR, [tutorial](./ppstructure/docs/kie_en.md)) and 3 DocVQA algorithms (LayoutLM, LayoutLMv2, LayoutXLM, [tutorial](./ppstructure/vqa)).
- 2021.9.7 release PaddleOCR v2.3, [PP-OCRv2](./doc/doc_en/ppocr_introduction_en.md#pp-ocrv2) is proposed. The inference speed of PP-OCRv2 is 220% higher than that of PP-OCR server in CPU device. The F-score of PP-OCRv2 is 7% higher than that of PP-OCR mobile.
- 2021.9.7 release PaddleOCR v2.3, [PP-OCRv2](./doc/doc_en/ppocr_introduction_en.md#pp-ocrv2) is proposed. The inference speed of PP-OCRv2 is 220% higher than that of PP-OCR server in CPU device. The F-score of PP-OCRv2 is 7% higher than that of PP-OCR mobile.
- 2021.8.3 released PaddleOCR v2.2, add a new structured documents analysis toolkit, i.e., [PP-Structure](./ppstructure/README.md), support layout analysis and table recognition (One-key to export chart images to Excel files).
- 2021.8.3 released PaddleOCR v2.2, add a new structured documents analysis toolkit, i.e., [PP-Structure](./ppstructure/README.md), support layout analysis and table recognition (One-key to export chart images to Excel files).
...
@@ -122,6 +126,9 @@ PaddleOCR support a variety of cutting-edge algorithms related to OCR, and devel
...
@@ -122,6 +126,9 @@ PaddleOCR support a variety of cutting-edge algorithms related to OCR, and devel
[GTC](https://arxiv.org/pdf/2002.01276.pdf)(Guided Training of CTC),利用Attention模块以及损失,指导CTC损失训练,融合多种文本特征的表达,是一种有效的提升文本识别的策略。使用该策略,预测时完全去除 Attention 模块,在推理阶段不增加任何耗时,识别模型的准确率进一步提升到75.8%(+1.82%)。训练流程如下所示:
[GTC](https://arxiv.org/pdf/2002.01276.pdf)(Guided Training of CTC),利用Attention模块CTC训练,融合多种文本特征的表达,是一种有效的提升文本识别的策略。使用该策略,预测时完全去除 Attention 模块,在推理阶段不增加任何耗时,识别模型的准确率进一步提升到75.8%(+1.82%)。训练流程如下所示:
@@ -9,54 +9,49 @@ English | [简体中文](../doc_ch/PP-OCRv3_introduction.md)
...
@@ -9,54 +9,49 @@ English | [简体中文](../doc_ch/PP-OCRv3_introduction.md)
<aname="1"></a>
<aname="1"></a>
## 1. Introduction
## 1. Introduction
PP-OCRv3 is further upgraded on the basis of PP-OCRv2. The overall framework of PP-OCRv3 is same as that of PP-OCRv2. The text detection model and text recognition model are further optimized, respectively. Specifically, the detection network is still optimized based on DBNet, and base model of recognition network is replaced from CRNN to [SVTR](https://arxiv.org/abs/2205.00159), which is recorded in IJCAI 2022. The block diagram of the PP-OCRv3 system is as follows (strategies in the pink box are newly introduced in PP-OCRv3):
PP-OCRv3 is further upgraded on the basis of PP-OCRv2. The overall framework of PP-OCRv3 is same as that of PP-OCRv2. The text detection model and text recognition model are further optimized, respectively. Specifically, the detection network is still optimized based on DBNet, and base model of recognition network is replaced from CRNN to [SVTR](https://arxiv.org/abs/2205.00159, which is recorded in IJCAI 2022. The block diagram of the PP-OCRv3 system is as follows (the pink box is the new policies of PP-OCRv3):
<divalign="center">
<divalign="center">
<imgsrc="../ppocrv3_framework.png"width="800">
<imgsrc="../ppocrv3_framework.png"width="800">
</div>
</div>
There are 9 optimization tricks for text detection and recognition models in PP-OCRv3, which is as follows.
There are 9 optimization strategies for text detection and recognition models in PP-OCRv3, which are as follows.
- Text detection:
- Text detection:
- LK-PAN: PAN structure with large receptive field;
- LK-PAN: A PAN structure with large receptive field;
- DML: mutual learning strategy for teacher model;
- DML: Deep Mutual Learning strategy for teacher model;
- RSE-FPN: FPN structure of residual attention mechanism;
- RSE-FPN: A FPN structure with residual attention mechanism;
- Text recognition:
- Text recognition:
- SVTR_LCNet: Light-weight text recognition network;
- SVTR_LCNet: A Light-weight text recognition network;
- GTC: training strategy using Attention to guide CTC;
- GTC: Guided training of CTC by Attention;
- TextConAug: A data augmentation strategy for mining textual context information;
- TextConAug: A data augmentation strategy for mining textual context information;
- TextRotNet: self-supervised strategy to optimize the pretrained model;
- TextRotNet: Self-supervised strategy for a better pretrained model;
- UDML: unified deep mutual learning strategy;
- UDML: Unified deep mutual learning strategy;
- UIM: unlabeled data mining strategy.
- UIM: Unlabeled data mining strategy.
From the effect point of view, when the speed is comparable, the accuracy of various scenes has been greatly improved:
In terms of effect, when the speed is comparable, the accuracy of various scenes is greatly improved:
Finally, in the case of comparable inference speed, PP-OCRv3 significantly outperforms PP-OCRv2 in terms of accuracy in multiple scenarios.
- In Chinese scenarios, PP-OCRv3 outperforms PP-OCRv2 by more than 5%.
- In Chinese scenarios, PP-OCRv3 outperforms PP-OCRv2 by more than 5%.
- In English scenarios, PP-OCRv3 outperforms PP-OCRv2 by more than 11%.
- In English scenarios, PP-OCRv3 outperforms PP-OCRv2 by more than 11%.
- In multi-language scenarios, more than 80 languages and corresponding models are optimized, the average accuracy is increased by over 5%.
- In multi-language scenarios, models for more than 80 languages are optimized, the average accuracy is increased by more than 5%.
<aname="2"></a>
<aname="2"></a>
## 2. Optimization for Text Detection Model
## 2. Optimization for Text Detection Model
The PP-OCRv3 detection model is an upgrade of the [CML](https://arxiv.org/pdf/2109.03144.pdf)(Collaborative Mutual Learning) text detection distillation strategy in PP-OCRv2. As shown in the figure below, the core idea of CML combines ① the distillation of the traditional Teacher to guide Students and ② the DML mutual learning between the Students network, which allows the Students network to learn from each other. PP-OCRv3 further optimizes the effect of teacher model and student model respectively. For the Teacher model,
The PP-OCRv3 detection model upgrades the [CML](https://arxiv.org/pdf/2109.03144.pdf)(Collaborative Mutual Learning) distillation strategy proposed in PP-OCRv2. As shown in the figure below, the main idea of CML combines ① the traditional distillation strategy of Teacher guiding Student and ② the DML strategy, which allows the Students network to learn from each other. PP-OCRv3 further optimizes the effect of teacher model and student model respectively. For the Teacher model, a pan module with large receptive field named LK-PAN is proposed and the DML distillation strategy is adopted; for the student model, a FPN module with residual attention mechanism named RSE-FPN is proposed.
we propose a PAN structure LKPAN with a larger receptive field and use the DML (Deep Mutual Learning) distillation strategy to optimizing the Teacher model. For the student model,
we propose a lightweight FPN structure RSEFPN to improve the accuracy of the student model.
The environment: Intel Gold 6148 CPU, with MKLDNN acceleration enabled during inference.
Testing environment: Intel Gold 6148 CPU, with MKLDNN acceleration enabled during inference.
**(1) LK-PAN: A PAN structure with large receptive field**
**(1) LK-PAN: PAN structure with large receptive field**
LK-PAN (Large Kernel PAN) is a lightweight [PAN](https://arxiv.org/pdf/1803.01534.pdf) structure with larger receptive field. The main idea is to change the convolution kernel size in the path augmentation of the PAN structure from `3*3` to `9*9`. By increasing the convolution kernel size, the receptive field of each position of the feature map is improved, making it easier to detect text in large fonts and text with extreme aspect ratios. Using LK-PAN, the hmean of the teacher model can be improved from 83.2% to 85.0%.
LK-PAN (Large Kernel PAN) is a lightweight [PAN](https://arxiv.org/pdf/1803.01534.pdf) structure with a larger receptive field. The core is to change the convolution kernel in the path augmentation of the PAN structure from `3*3` to `9*9`. By increasing the convolution kernel, the receptive field covered by each position of the feature map is improved, and it is easier to detect text in large fonts and text with extreme aspect ratios. Using the LK-PAN, the hmean of the teacher model can be improved from 83.2% to 85.0%.
<divalign="center">
<divalign="center">
<imgsrc="../ppocr_v3/LKPAN.png"width="1000">
<imgsrc="../ppocr_v3/LKPAN.png"width="1000">
</div>
</div>
**(2) DML: Deep Mutual Learning Strategy for Teacher Model**
**(2) DML: The Mutual Learning Strategy for Teacher Model**
[DML](https://arxiv.org/abs/1706.00384)(Collaborative Mutual Learning), as shown in the figure below, can effectively improve the accuracy of the text detection model by learning from each other with two models with the same structure. The DML strategy is adopted in the teacher model training, and the hmean is increased from 85% to 86%. By updating the teacher model of CML in PP-OCRv2 to the above-mentioned higher-precision one, the hmean of the student model can be further improved from 83.2% to 84.3%.
The [DML](https://arxiv.org/abs/1706.00384) method, as shown in the figure below, can effectively improve the accuracy of the text detection model by learning from each other with two models with the same structure. The teacher model adopts the DML strategy, and the hmean is increased from 85% to 86%. By updating the teacher model of CML in PP-OCRv2 to the above-mentioned higher-precision teacher model, the hmean of the student model can be further improved from 83.2% to 84.3%.
<divalign="center">
<divalign="center">
...
@@ -92,11 +85,11 @@ The [DML](https://arxiv.org/abs/1706.00384) method, as shown in the figure below
...
@@ -92,11 +85,11 @@ The [DML](https://arxiv.org/abs/1706.00384) method, as shown in the figure below
</div>
</div>
**(3) RSE-FPN: FPN structure of residual attention mechanism**
**(3) RSE-FPN: A FPN structure with residual attention mechanism**
RSE-FPN (Residual Squeeze-and-Excitation FPN) is shown in the figure below. RSEFPN introduces the residual structure and the channel attention structure, and replaces the convolutional layer in the FPN with the RSEConv layer of the channel attention structure to improve the representation ability of the feature map.
RSE-FPN (Residual Squeeze-and-Excitation FPN) is shown in the figure below. RSE-FPN introduces residual attention mechanism by replacing the convolutional layer in the FPN with RSEConv, to improve the representation ability of the feature map.
Considering that the number of FPN channels in the detection model of PP-OCRv2 is very small, only 96, if SEblock is directly used to replace the convolution in FPN, the features of some channels will be suppressed, and the accuracy will be reduced. The introduction of residual structure in RSEConv will alleviate the above problems and improve the text detection effect. By further updating the FPN structure of the student model of CML in PP-OCRv2 to RSE-FPN, the hmean of the student model can be further improved from 84.3% to 85.4%.
Considering that the features of some channels will be suppressed if the convolution layer in FPN is directly replaced with SEblock, as the number of FPN channels in the detection model of PP-OCRv2 is 96, which is very small. The introduction of residual structure in RSEConv can alleviate the above problems and improve the text detection effect. By updating the FPN structure of the student model of CML to RSE-FPN, the hmean of the student model can be further improved from 84.3% to 85.4%.
<divalign="center">
<divalign="center">
<imgsrc=".././ppocr_v3/RSEFPN.png"width="1000">
<imgsrc=".././ppocr_v3/RSEFPN.png"width="1000">
...
@@ -104,16 +97,17 @@ Considering that the number of FPN channels in the detection model of PP-OCRv2 i
...
@@ -104,16 +97,17 @@ Considering that the number of FPN channels in the detection model of PP-OCRv2 i
<aname="3"></a>
<aname="3"></a>
## 3. Optimization for Text Recognition Model
## 3. Optimization for Text Recognition Model
The recognition module of PP-OCRv3 is optimized based on the text recognition algorithm [SVTR] (https://arxiv.org/abs/2205.00159). RNN is abandoned in SVTR, and the context information of the text line image is more effectively mined by introducing the Transformers structure, thereby improving the text recognition ability. The recognition model of PP-OCRv2 was directly replaced with SVTR_Tiny, and the recognition accuracy increased from 74.8% to 80.1% (+5.3%), but the prediction speed was nearly 11 times slower, and it took nearly 100ms to predict a text line on the CPU. Therefore, as shown in the figure below, PP-OCRv3 adopts the following six optimization strategies to accelerate the recognition model.
The recognition module of PP-OCRv3 is optimized based on the text recognition algorithm [SVTR](https://arxiv.org/abs/2205.00159). RNN is abandoned in SVTR, and the context information of the text line image is more effectively mined by introducing the Transformers structure, thereby improving the text recognition ability.
The recognition accuracy of SVTR_inty outperforms PP-OCRv2 recognition model by 5.3%, while the prediction speed nearly 11 times slower. It takes nearly 100ms to predict a text line on CPU. Therefore, as shown in the figure below, PP-OCRv3 adopts the following six optimization strategies to accelerate the recognition model.
Based on the above strategy, compared with PP-OCRv2, the PP-OCRv3 recognition model further improves the accuracy by 4.6% with comparable speed. The specific ablation experiments are as follows:
Based on the above strategy, compared with PP-OCRv2, the PP-OCRv3 recognition model further improves the accuracy by 4.6% with comparable speed. The ablation experiments are as follows:
| ID | strategy | Model size | accuracy | prediction speed(CPU + MKLDNN)|
| ID | strategy | Model size | accuracy | prediction speed(CPU + MKLDNN)|
|-----|-----|--------|----| --- |
|-----|-----|--------|----| --- |
...
@@ -127,11 +121,11 @@ Based on the above strategy, compared with PP-OCRv2, the PP-OCRv3 recognition mo
...
@@ -127,11 +121,11 @@ Based on the above strategy, compared with PP-OCRv2, the PP-OCRv3 recognition mo
| 08 | + UDML | 12M | 78.4% | 7.6ms |
| 08 | + UDML | 12M | 78.4% | 7.6ms |
| 09 | + UIM | 12M | 79.4% | 7.6ms |
| 09 | + UIM | 12M | 79.4% | 7.6ms |
Note: When testing the speed, the input image shape of Experiment 01-03 is (3, 32, 320), and the input image shape of 04-08 is (3, 48, 320). In the actual prediction, the image is a variable-length input, and the speed will vary. Test environment: Intel Gold 6148 CPU, with MKLDNN acceleration enabled during prediction.
Note: When testing the speed, the input image shape of Experiment 01-03 is (3, 32, 320), and the input image shape of 04-08 is (3, 48, 320). In the actual prediction, the image is a variable-length input, and the speed will vary. Testing environment: Intel Gold 6148 CPU, with MKLDNN acceleration enabled during prediction.
**(1)SVTR_LCNet:Lightweight Text Recognition Network**
**(1)SVTR_LCNet:Lightweight Text Recognition Network**
SVTR_LCNet is for text recognition tasks, which is a lightweight text recognition network fused by Transformer-based [SVTR](https://arxiv.org/abs/2205.00159) network and lightweight CNN network [PP-LCNet](https://arxiv.org/abs/ 2109.15099). Using this network, the prediction speed is 20% better than the recognition model of PP-OCRv2, but because the distillation strategy is not adopted, the effect of the recognition model is slightly worse. In addition, the height of the input image is further increased from 32 to 48, and the prediction speed is slightly slower, but the model effect is greatly improved, and the recognition accuracy reaches 73.98% (+2.08%), which is close to the recognition model effect of PP-OCRv2 using the distillation strategy.
SVTR_LCNet is a lightweight text recognition network fused by Transformer-based network [SVTR](https://arxiv.org/abs/2205.00159) and lightweight CNN-based network [PP-LCNet](https://arxiv.org/abs/2109.15099). The prediction speed of SVTR_LCNet is 20% faster than that of PP-OCRv2 recognizer while the effect is slightly worse because the distillation strategy is not adopted. In addition, the height of the input image is further increased from 32 to 48, which makes the prediction speed slightly slower, but the model effect greatly improved. The recognition accuracy reaches 73.98% (+2.08%), which is close to the accuracy of PP-OCRv2 recognizer trained with the distillation strategy.
SVTR_Tiny network structure is as follows:
SVTR_Tiny network structure is as follows:
...
@@ -160,7 +154,7 @@ Due to the limited model structure supported by the MKLDNN acceleration library,
...
@@ -160,7 +154,7 @@ Due to the limited model structure supported by the MKLDNN acceleration library,
<imgsrc="../ppocr_v3/LCNet_SVTR.png"width=800>
<imgsrc="../ppocr_v3/LCNet_SVTR.png"width=800>
</div>
</div>
The specific ablation experiments are as follows:
The ablation experiments are as follows:
| ID | strategy | Model size | accuracy | prediction speed(CPU + MKLDNN)|
| ID | strategy | Model size | accuracy | prediction speed(CPU + MKLDNN)|
|-----|-----|--------|----| --- |
|-----|-----|--------|----| --- |
...
@@ -175,7 +169,7 @@ Note: When testing the speed, the input image shape of 01-05 are all (3, 32, 320
...
@@ -175,7 +169,7 @@ Note: When testing the speed, the input image shape of 01-05 are all (3, 32, 320
**(2)GTC:Attention guides CTC training strategy**
**(2)GTC:Attention guides CTC training strategy**
[GTC](https://arxiv.org/pdf/2002.01276.pdf)(Guided Training of CTC),using the Attention module and loss to guide the CTC loss training and fuse the expression of multiple text features is an effective strategy to improve text recognition. Using this strategy, the Attention module is completely removed during prediction, and no time-consuming is added in the inference stage, and the accuracy of the recognition model is further improved to 75.8% (+1.82%). The training process is as follows:
[GTC](https://arxiv.org/pdf/2002.01276.pdf)(Guided Training of CTC), using the Attention module to guide the training of CTC to fuse multiple features is an effective strategy to improve text recognition accuracy. No more time-consuming is added in the inference process as the Attention module is completely removed during prediction. The accuracy of the recognition model is further improved to 75.8% (+1.82%). The training process is as follows:
<divalign="center">
<divalign="center">
<imgsrc="../ppocr_v3/GTC.png"width=800>
<imgsrc="../ppocr_v3/GTC.png"width=800>
...
@@ -183,16 +177,16 @@ Note: When testing the speed, the input image shape of 01-05 are all (3, 32, 320
...
@@ -183,16 +177,16 @@ Note: When testing the speed, the input image shape of 01-05 are all (3, 32, 320
**(3)TextConAug:Data Augmentation Strategy for Mining Text Context Information**
**(3)TextConAug:Data Augmentation Strategy for Mining Text Context Information**
TextConAug is a data augmentation strategy for mining textual context information. The main idea comes from the paper [ConCLR](https://www.cse.cuhk.edu.hk/~byu/papers/C139-AAAI2022-ConCLR.pdf) , the author proposes ConAug data augmentation to connect 2 different images in a batch to form new images and perform self-supervised comparative learning. PP-OCRv3 applies this method to supervised learning tasks, and designs the TextConAug data augmentation method, which can enrich the context information of training data and improve the diversity of training data. Using this strategy, the accuracy of the recognition model is further improved to 76.3% (+0.5%). The schematic diagram of TextConAug is as follows:
TextConAug is a data augmentation strategy for mining textual context information. The main idea comes from the paper [ConCLR](https://www.cse.cuhk.edu.hk/~byu/papers/C139-AAAI2022-ConCLR.pdf), in which the author proposes data augmentation strategy ConAug to concat 2 different images in a batch to form new images and perform self-supervised comparative learning. PP-OCRv3 applies this method to supervised learning tasks, and designs the TextConAug data augmentation method, which can enrich the context information of training data and improve the diversity of training data. Using this strategy, the accuracy of the recognition model is further improved to 76.3% (+0.5%). The schematic diagram of TextConAug is as follows:
TextRotNet is a pre-training model, which is trained by using a large amount of unlabeled text line data in a self-supervised manner. Refer to the paper [STR-Fewer-Labels](https://github.com/ku21fan/STR-Fewer-Labels). This model can initialize the initial weights of SVTR_LCNet, which helps the text recognition model to converge to a better position. Using this strategy, the accuracy of the recognition model is further improved to 76.9% (+0.6%). The TextRotNet training process is shown in the following figure:
TextRotNet is a pre-trained model trained with a large amount of unlabeled text line data in a self-supervised manner, refered to the paper [STR-Fewer-Labels](https://github.com/ku21fan/STR-Fewer-Labels). This model can initialize the weights of SVTR_LCNet, which helps the text recognition model to converge to a better position. Using this strategy, the accuracy of the recognition model is further improved to 76.9% (+0.6%). The TextRotNet training process is shown in the following figure:
<divalign="center">
<divalign="center">
<imgsrc="../ppocr_v3/SSL.png"width="500">
<imgsrc="../ppocr_v3/SSL.png"width="500">
...
@@ -201,12 +195,12 @@ TextRotNet is a pre-training model, which is trained by using a large amount of
...
@@ -201,12 +195,12 @@ TextRotNet is a pre-training model, which is trained by using a large amount of
**(5)UDML:Unified-Deep Mutual Learning**
**(5)UDML:Unified-Deep Mutual Learning**
UDML (Unified-Deep Mutual Learning) is a strategy adopted in PP-OCRv2 that is very effective for text recognition to improve the model effect. In PP-OCRv3, for two different SVTR_LCNet and Attention structures, the feature map of PP-LCNet, the output of the SVTR module and the output of the Attention module between them are simultaneously supervised and trained. Using this strategy, the accuracy of the recognition model is further improved to 78.4% (+1.5%).
UDML (Unified-Deep Mutual Learning) is a strategy proposed in PP-OCRv2 which is very effective to improve the model accuracy. In PP-OCRv3, for two different structures SVTR_LCNet and Attention, the feature map of PP-LCNet, the output of the SVTR module and the output of the Attention module between them are simultaneously supervised and trained. Using this strategy, the accuracy of the recognition model is further improved to 78.4% (+1.5%).
**(6)UIM:Unlabeled Images Mining**
**(6)UIM:Unlabeled Images Mining**
UIM (Unlabeled Images Mining) is a very simple unlabeled data mining scheme. The core idea is to use a high-precision text recognition model to predict unlabeled data, obtain pseudo-labels, and select samples with high prediction confidence as training data for training small models. Using this strategy, the accuracy of the recognition model is further improved to 79.4% (+1%).
UIM (Unlabeled Images Mining) is a very simple unlabeled data mining strategy. The main idea is to use a high-precision text recognition model to predict unlabeled images to obtain pseudo-labels, and select samples with high prediction confidence as training data for training lightweight models. Using this strategy, the accuracy of the recognition model is further improved to 79.4% (+1%).
<divalign="center">
<divalign="center">
<imgsrc="../ppocr_v3/UIM.png"width="500">
<imgsrc="../ppocr_v3/UIM.png"width="500">
...
@@ -216,7 +210,7 @@ UIM (Unlabeled Images Mining) is a very simple unlabeled data mining scheme. The
...
@@ -216,7 +210,7 @@ UIM (Unlabeled Images Mining) is a very simple unlabeled data mining scheme. The
## 4. End-to-end Evaluation
## 4. End-to-end Evaluation
After the optimization strategies mentioned above, under he condition of comparable speed, PP-OCRv3 outperforms PP-OCRv2 by 5% in terms of end-to-end Hmean for Chinese scenarios. The specific metrics are shown as follows.
With the optimization strategies mentioned above, PP-OCRv3 outperforms PP-OCRv2 by 5% in terms of end-to-end Hmean for Chinese scenarios with comparable speed. The specific metrics are shown as follows.
| Model | Hmean | Model Size (M) | Time Cost (CPU, ms) | Time Cost (T4 GPU, ms) |
| Model | Hmean | Model Size (M) | Time Cost (CPU, ms) | Time Cost (T4 GPU, ms) |
|-----|-----|--------|----| --- |
|-----|-----|--------|----| --- |
...
@@ -226,18 +220,18 @@ After the optimization strategies mentioned above, under he condition of compara
...
@@ -226,18 +220,18 @@ After the optimization strategies mentioned above, under he condition of compara
| PP-OCRv3 | 62.9% | 15.6 | 331 | 86.64 |
| PP-OCRv3 | 62.9% | 15.6 | 331 | 86.64 |
Test environment:
Testing environment:
- CPU: Intel Gold 6148, and MKLDNN acceleration is enabled during CPU inference.
- CPU: Intel Gold 6148, and MKLDNN acceleration is enabled during CPU inference.
In addition to updating the recognition model for Chinese, the recognition model for English is also optimized with an increasement of 11% for end-to-end Hmean, which is shown as follows.
In addition to Chinese scenarios, the recognition model for English is also optimized with an increasement of 11% for end-to-end Hmean, which is shown as follows.
| Model | Recall | Precision | Hmean |
| Model | Recall | Precision | Hmean |
|-----|-----|--------|----|
|-----|-----|--------|----|
| PP-OCR_en | 38.99% | 45.91% | 42.17% |
| PP-OCR_en | 38.99% | 45.91% | 42.17% |
| PP-OCRv3_en | 50.95% | 55.53% | 53.14% |
| PP-OCRv3_en | 50.95% | 55.53% | 53.14% |
At the same time, more than 80 language recognition models that have been supported have been upgraded this time, and the recognition accuracy of the four language families with evaluation sets has increased by more than 5% on average, which is shown as follows.
At the same time, recognition models for more than 80 language are also upgraded. The accuracy of the four language families with evaluation sets is increased by more than 5% on average, which is shown as follows.
-[PP-OCRv3](./doc/doc_en/ppocr_introduction_en.md#pp-ocrv3): With comparable speed, the effect of Chinese scene is further improved by 5% compared with PP-OCRv2, the effect of English scene is improved by 11%, and the average recognition accuracy of 80 language multilingual models is improved by more than 5%.
-[PPOCRLabelv2](./PPOCRLabel): Add the annotation function for table recognition task, key information extraction task and irregular text image.
- Interactive e-book [*"Dive into OCR"*](./doc/doc_en/ocr_book_en.md), covers the cutting-edge theory and code practice of OCR full stack technology.
- 2022.5.7 Add support for metric and model logging during training to [Weights & Biases](https://docs.wandb.ai/).
- 2022.5.7 Add support for metric and model logging during training to [Weights & Biases](https://docs.wandb.ai/).
- 2021.12.21 OCR open source online course starts. The lesson starts at 8:30 every night and lasts for ten days. Free registration: https://aistudio.baidu.com/aistudio/course/introduce/25207
- 2021.12.21 OCR open source online course starts. The lesson starts at 8:30 every night and lasts for ten days. Free registration: https://aistudio.baidu.com/aistudio/course/introduce/25207
- 2021.12.21 release PaddleOCR v2.4, release 1 text detection algorithm (PSENet), 3 text recognition algorithms (NRTR、SEED、SAR), 1 key information extraction algorithm (SDMGR) and 3 DocVQA algorithms (LayoutLM、LayoutLMv2,LayoutXLM).
- 2021.12.21 release PaddleOCR v2.4, release 1 text detection algorithm (PSENet), 3 text recognition algorithms (NRTR、SEED、SAR), 1 key information extraction algorithm (SDMGR) and 3 DocVQA algorithms (LayoutLM、LayoutLMv2,LayoutXLM).
{kind=link}
{kind=link}
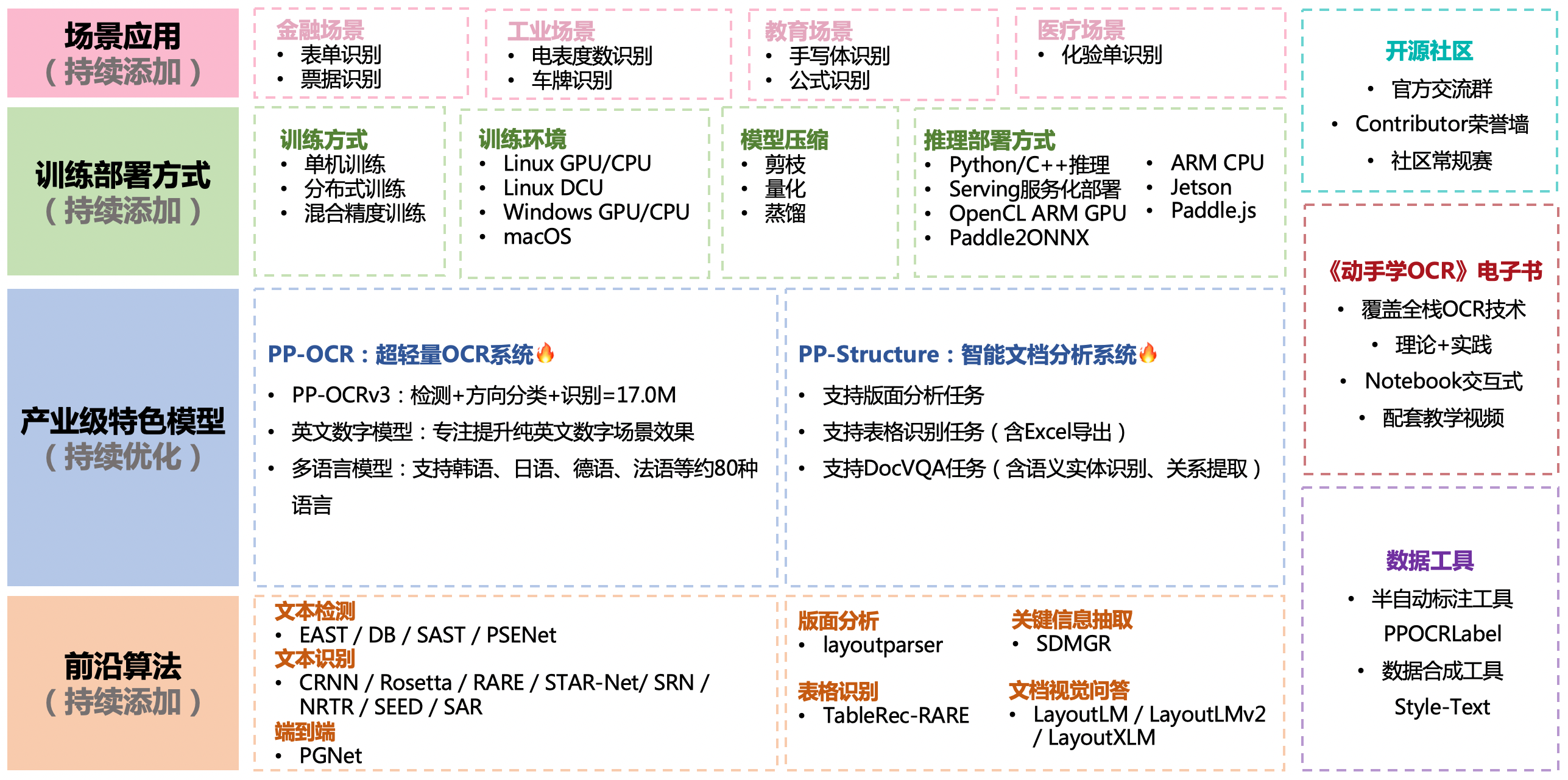
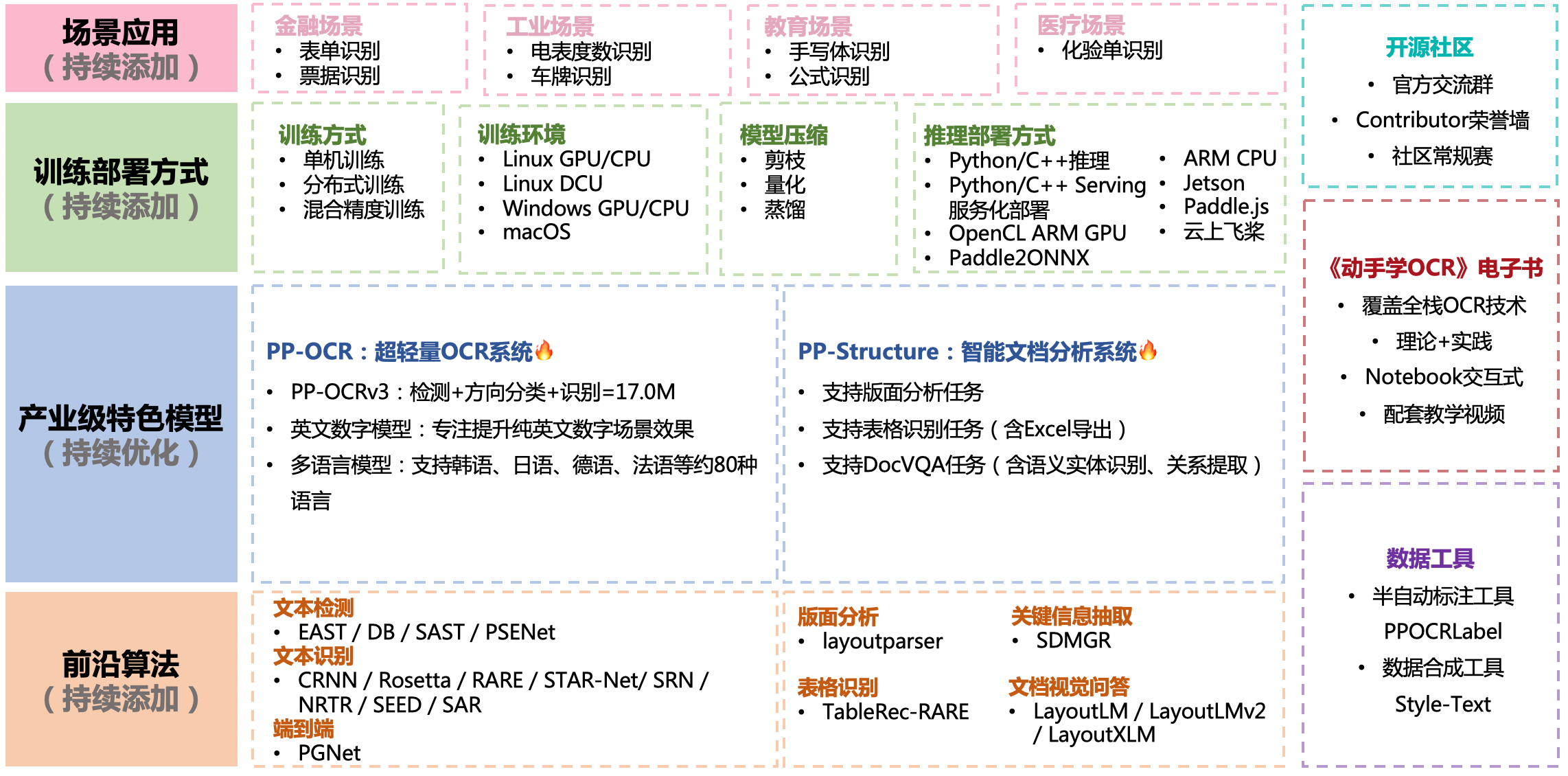
{kind=link}
{kind=link}