Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleOCR
提交
d17444f5
P
PaddleOCR
项目概览
PaddlePaddle
/
PaddleOCR
大约 1 年 前同步成功
通知
1528
Star
32962
Fork
6643
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
108
列表
看板
标记
里程碑
合并请求
7
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleOCR
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
108
Issue
108
列表
看板
标记
里程碑
合并请求
7
合并请求
7
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
d17444f5
编写于
5月 05, 2022
作者:
T
tink2123
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update pics
上级
e5eaeec8
变更
2
显示空白变更内容
内联
并排
Showing
2 changed file
with
3 addition
and
3 deletion
+3
-3
doc/doc_ch/ppocr_introduction.md
doc/doc_ch/ppocr_introduction.md
+3
-3
doc/ppocr_v3/ppocr_v3.png
doc/ppocr_v3/ppocr_v3.png
+0
-0
未找到文件。
doc/doc_ch/ppocr_introduction.md
浏览文件 @
d17444f5
...
...
@@ -60,7 +60,7 @@ PP-OCRv3文本检测从网络结构、蒸馏训练策略两个方向做了进一
由于 MKLDNN 加速库支持的模型结构有限,SVTR 在CPU+MKLDNN上相比PP-OCRv2慢了10倍。
PP-OCRv3 期望在提升模型精度的同时,不带来额外的推理耗时。通过分析发现,SVTR_Tiny结构的主要耗时模块为Mixing Block,因此我们对 SVTR_Tiny 的结构进行了一系列优化
,详细速度数据请参考下方消融实验表格
:
PP-OCRv3 期望在提升模型精度的同时,不带来额外的推理耗时。通过分析发现,SVTR_Tiny结构的主要耗时模块为Mixing Block,因此我们对 SVTR_Tiny 的结构进行了一系列优化
(详细速度数据请参考下方消融实验表格)
:
1.
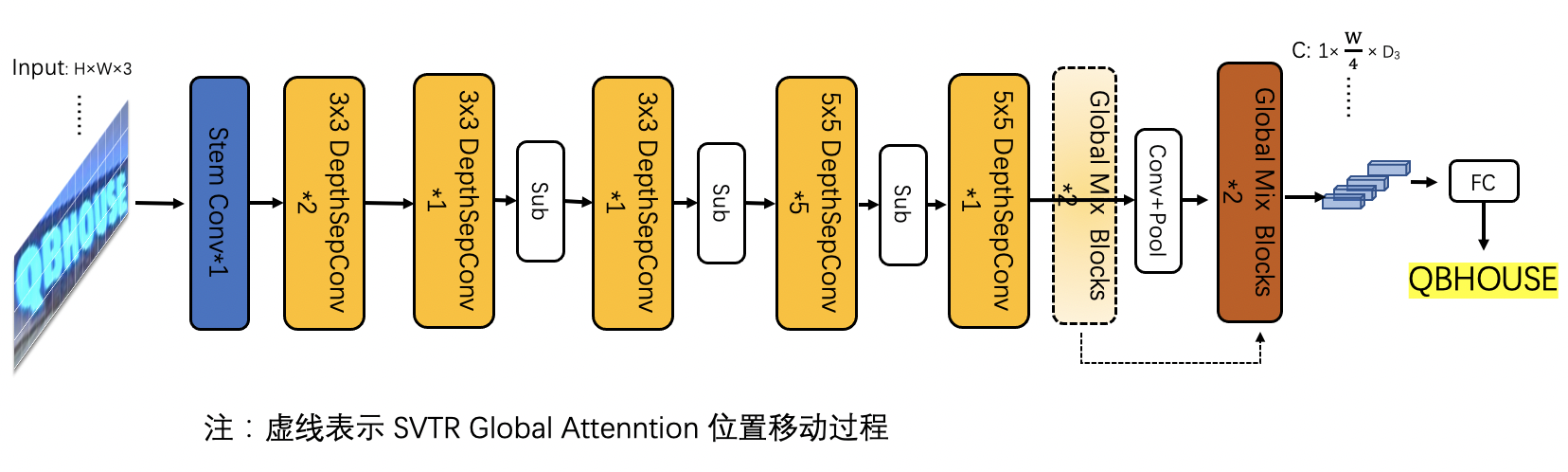
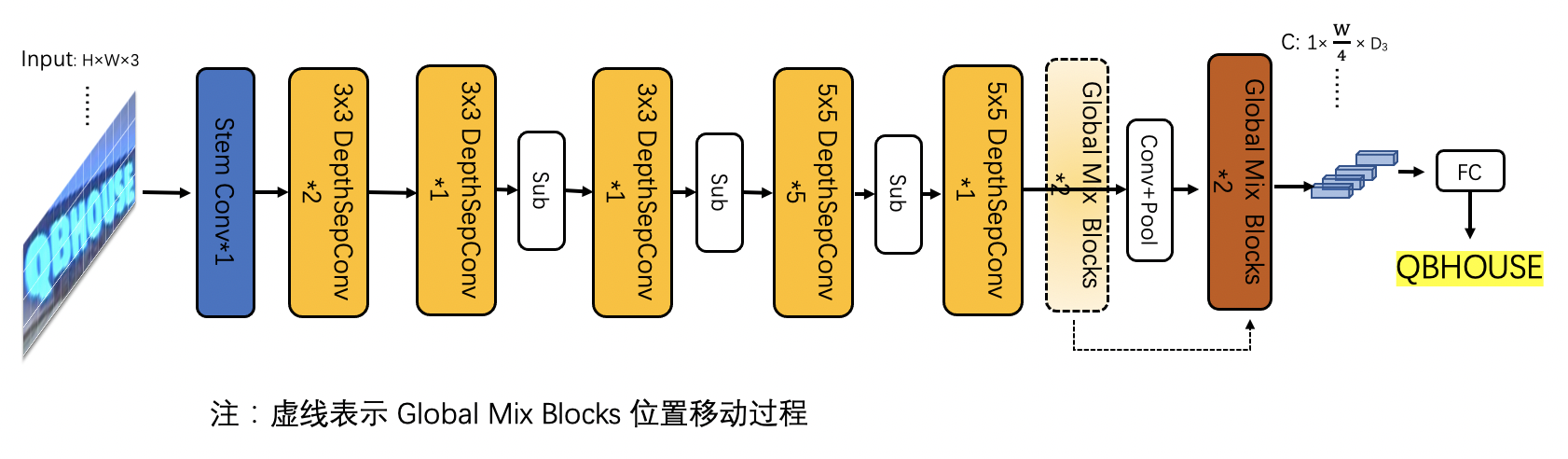
将SVTR网络前半部分替换为PP-LCNet的前三个stage,保留4个 Global Mixing Block ,精度为76%,加速69%,网络结构如下所示:
<img
src=
"../ppocr_v3/svtr_g4.png"
width=
800
>
...
...
@@ -90,7 +90,7 @@ PP-OCRv3 期望在提升模型精度的同时,不带来额外的推理耗时
-
训练策略上:参考
[
SSL
](
https://github.com/ku21fan/STR-Fewer-Labels
)
设计了方向分类前序任务,获取更优预训练模型,加速模型收敛过程,提升精度; 使用UDML蒸馏策略、监督attention、ctc两个分支得到更优模型。
-
数据增强上:基于
[
ConCLR
](
https://www.cse.cuhk.edu.hk/~byu/papers/C139-AAAI2022-ConCLR.pdf
)
中的ConAug方法,改进得到 RecConAug 数据增广方法,支持随机结合任意多张图片,提升训练数据的上下文信息丰富度,增强模型鲁棒性;使用 SVTR_large 预测无标签数据,向训练集中补充81w高质量真实数据。
基于上述策略,PP-OCRv3识别模型相比PP-OCRv2,在速度可比的情况下,精度进一步提升4.5%。 体消融实验如下所示:
基于上述策略,PP-OCRv3识别模型相比PP-OCRv2,在速度可比的情况下,精度进一步提升4.5%。
具
体消融实验如下所示:
实验细节:
...
...
@@ -108,7 +108,7 @@ PP-OCRv3 期望在提升模型精度的同时,不带来额外的推理耗时
| 09 | + UDML | 12M | 78.4% | 7.6ms |
| 10 | + unlabeled data | 12M | 79.4% | 7.6ms |
注: 测试速度时,
输入图片尺寸均为(3,32
,320)
注: 测试速度时,
实验01-05输入图片尺寸均为(3,32,320),06-10输入图片尺寸均为(3,48
,320)
<a
name=
"2"
></a>
## 2. 特性
...
...
doc/ppocr_v3/ppocr_v3.png
查看替换文件 @
e5eaeec8
浏览文件 @
d17444f5
426.0 KB
|
W:
|
H:
426.2 KB
|
W:
|
H:
2-up
Swipe
Onion skin
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}