update
Showing
doc/doc_en/ocr_book_en.md
0 → 100644
doc/features_en.png
0 → 100644
{kind=link}
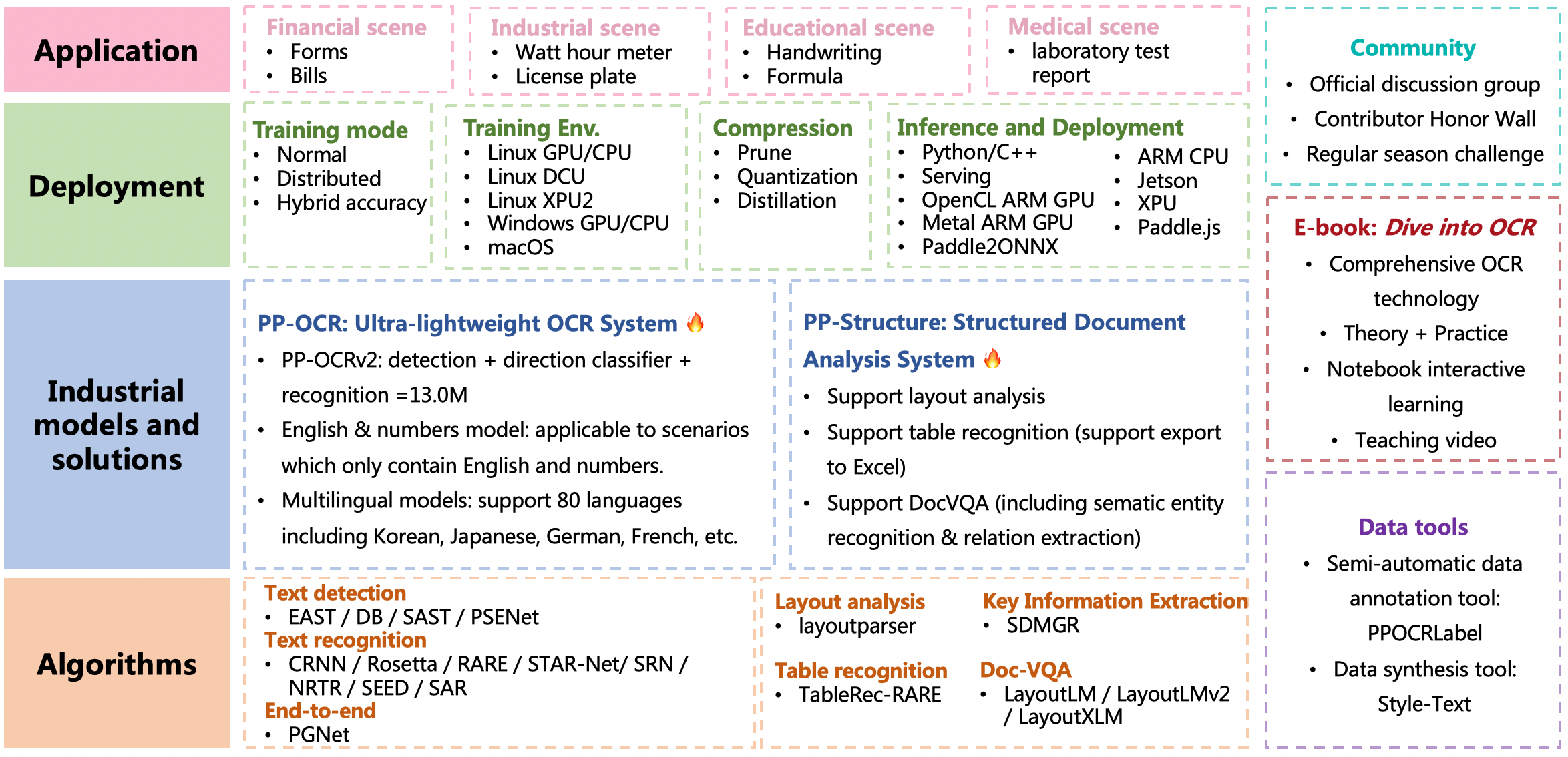
1.2 MB
ppstructure/docs/inference_en.md
0 → 100644
ppstructure/docs/quickstart_en.md
0 → 100644
1.2 MB