merge cpnflict 0815
Showing
{kind=link}

181.1 KB
{kind=link}

174.6 KB
doc/doc_ch/algorithm_kie_sdmgr.md
0 → 100644
doc/doc_ch/kie.md
0 → 100644
此差异已折叠。
ppocr/losses/stroke_focus_loss.py
0 → 100644
ppocr/metrics/sr_metric.py
0 → 100644
ppocr/modeling/transforms/tsrn.py
0 → 100644
{kind=link}
ppstructure/docs/kie.md
已删除
100644 → 0
{kind=link}

1.6 MB
{kind=link}

1.6 MB
{kind=link}
{kind=link}
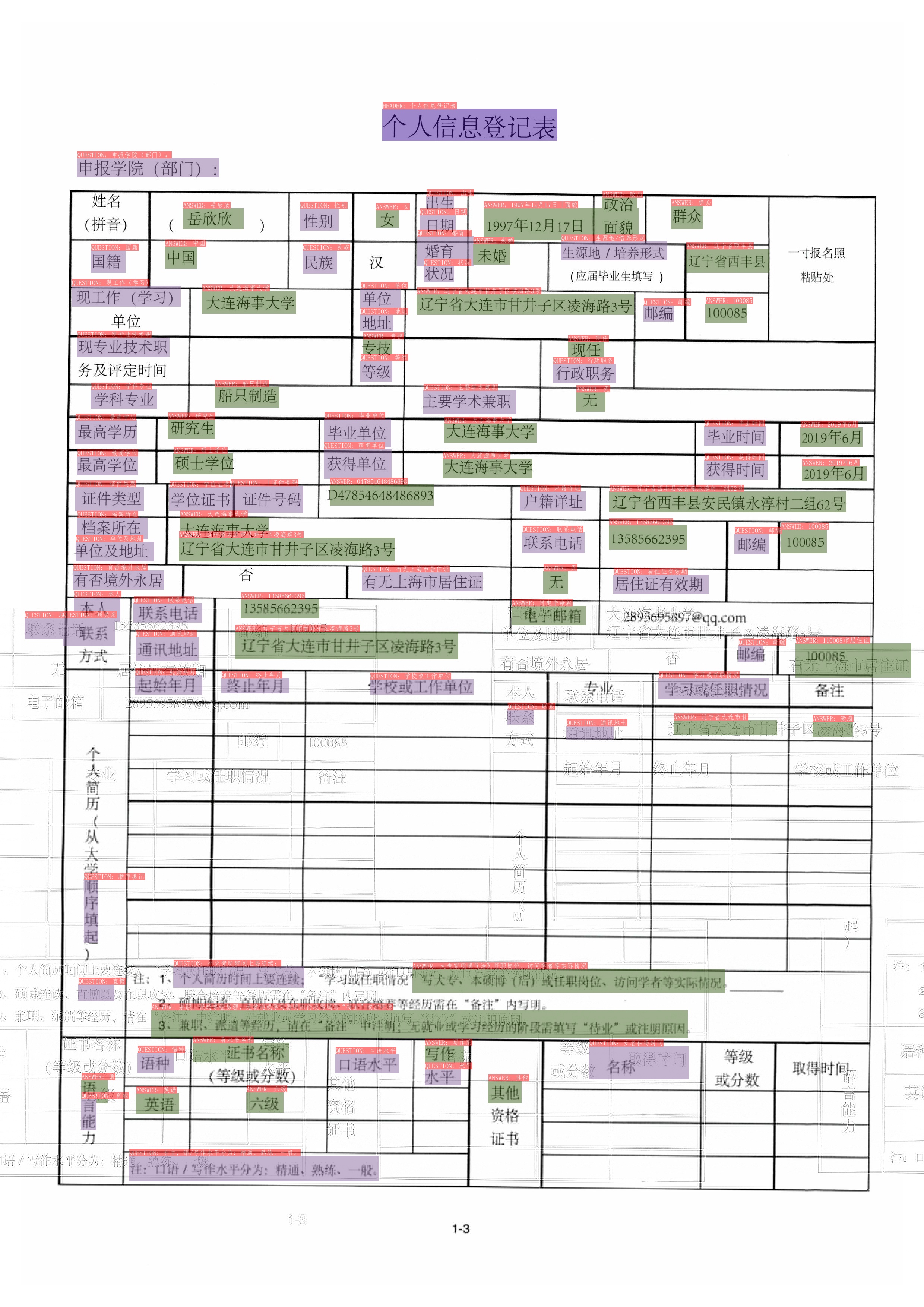
| W: | H:
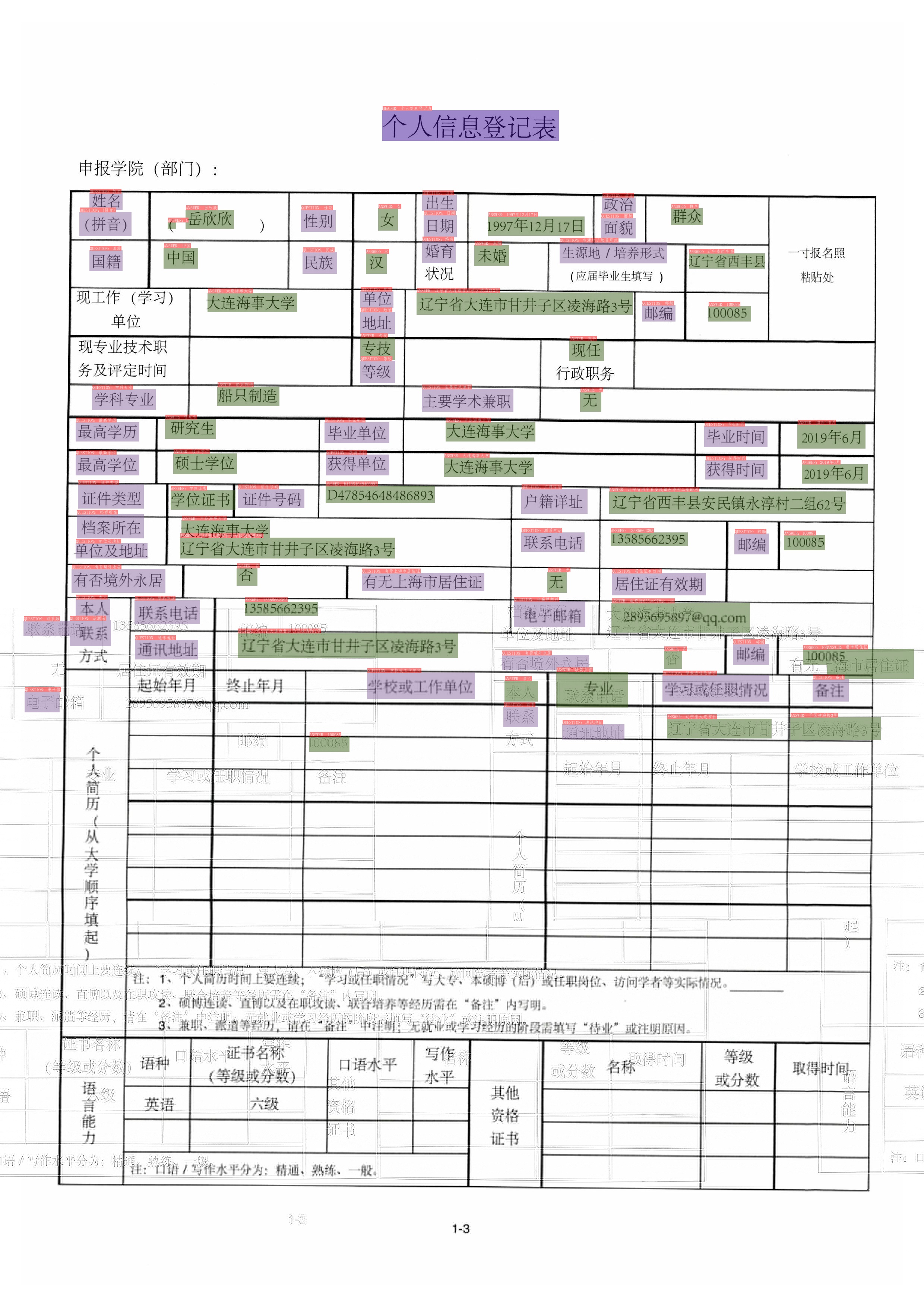
| W: | H:
{kind=link}

1.5 MB
ppstructure/vqa/how_to_do_kie.md
0 → 100644
tools/infer/predict_sr.py
0 → 100755
tools/infer_sr.py
0 → 100755