 -
-
-
- |
+| 液晶屏读数识别 | 检测模型蒸馏、Serving部署 | [模型下载](#2) | [中文](./液晶屏读数识别.md)/English |
|
+| 液晶屏读数识别 | 检测模型蒸馏、Serving部署 | [模型下载](#2) | [中文](./液晶屏读数识别.md)/English | 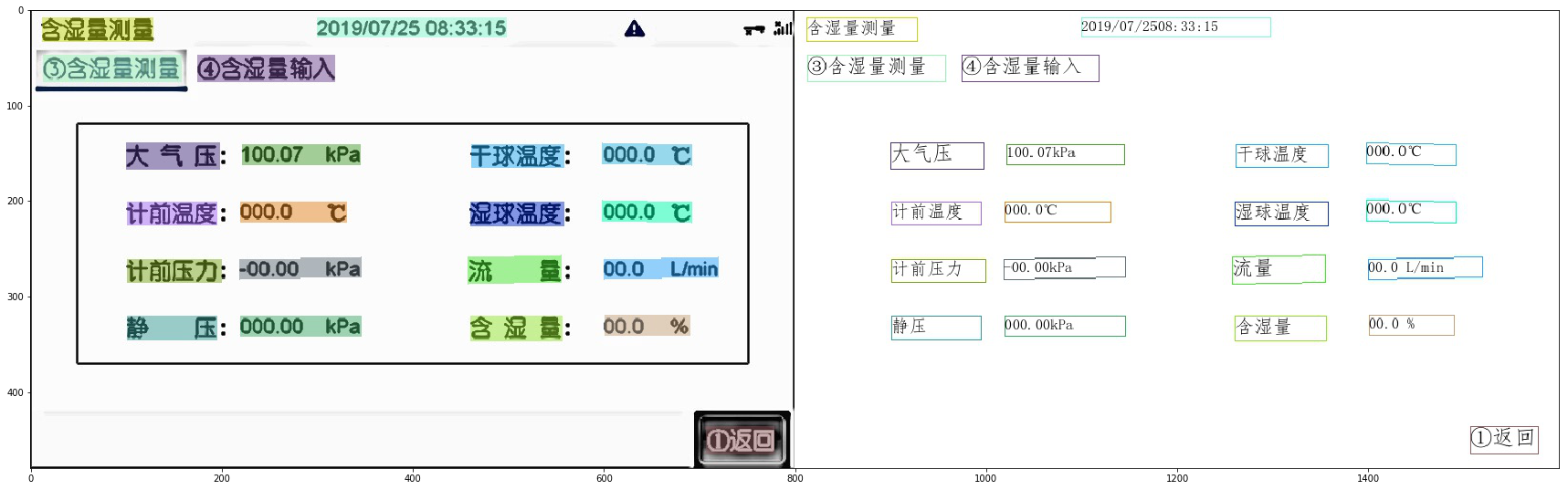 |
+| 包装生产日期 | 点阵字符合成、过曝过暗文字识别 | [模型下载](#2) | [中文](./包装生产日期识别.md)/English |
|
+| 包装生产日期 | 点阵字符合成、过曝过暗文字识别 | [模型下载](#2) | [中文](./包装生产日期识别.md)/English |  |
+| PCB文字识别 | 小尺寸文本检测与识别 | [模型下载](#2) | [中文](./PCB字符识别/PCB字符识别.md)/English |
|
+| PCB文字识别 | 小尺寸文本检测与识别 | [模型下载](#2) | [中文](./PCB字符识别/PCB字符识别.md)/English |  |
+| 电表识别 | 大分辨率图像检测调优 | [模型下载](#2) | | |
+| 液晶屏缺陷检测 | 非文字字符识别 | | | |
-| 类别 | 亮点 | 类别 | 亮点 |
-| ------------------------------------------------- | -------- | ---------- | ------------ |
-| [高精度中文识别模型SVTR](./高精度中文识别模型.md) | 新增模型 | 手写体识别 | 新增字形支持 |
+
-## 制造
+### 金融
-| 类别 | 亮点 | 类别 | 亮点 |
-| ------------------------------------------------------------ | ------------------------------ | ------------------------------------------- | -------------------- |
-| [数码管识别](./光功率计数码管字符识别/光功率计数码管字符识别.md) | 数码管数据合成、漏识别调优 | 电表识别 | 大分辨率图像检测调优 |
-| [液晶屏读数识别](./液晶屏读数识别.md) | 检测模型蒸馏、Serving部署 | [PCB文字识别](./PCB字符识别/PCB字符识别.md) | 小尺寸文本检测与识别 |
-| [包装生产日期](./包装生产日期识别.md) | 点阵字符合成、过曝过暗文字识别 | 液晶屏缺陷检测 | 非文字字符识别 |
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| -------------- | ------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
+| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English |
|
+| 电表识别 | 大分辨率图像检测调优 | [模型下载](#2) | | |
+| 液晶屏缺陷检测 | 非文字字符识别 | | | |
-| 类别 | 亮点 | 类别 | 亮点 |
-| ------------------------------------------------- | -------- | ---------- | ------------ |
-| [高精度中文识别模型SVTR](./高精度中文识别模型.md) | 新增模型 | 手写体识别 | 新增字形支持 |
+
-## 制造
+### 金融
-| 类别 | 亮点 | 类别 | 亮点 |
-| ------------------------------------------------------------ | ------------------------------ | ------------------------------------------- | -------------------- |
-| [数码管识别](./光功率计数码管字符识别/光功率计数码管字符识别.md) | 数码管数据合成、漏识别调优 | 电表识别 | 大分辨率图像检测调优 |
-| [液晶屏读数识别](./液晶屏读数识别.md) | 检测模型蒸馏、Serving部署 | [PCB文字识别](./PCB字符识别/PCB字符识别.md) | 小尺寸文本检测与识别 |
-| [包装生产日期](./包装生产日期识别.md) | 点阵字符合成、过曝过暗文字识别 | 液晶屏缺陷检测 | 非文字字符识别 |
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| -------------- | ------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
+| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English |  |
+| 增值税发票 | 尽请期待 | | | |
+| 印章检测与识别 | 端到端弯曲文本识别 | | | |
+| 通用卡证识别 | 通用结构化提取 | | | |
+| 身份证识别 | 结构化提取、图像阴影 | | | |
+| 合同比对 | 密集文本检测、NLP串联 | | | |
-## 金融
+
-| 类别 | 亮点 | 类别 | 亮点 |
-| ------------------------------ | ------------------------ | ------------ | --------------------- |
-| [表单VQA](./多模态表单识别.md) | 多模态通用表单结构化提取 | 通用卡证识别 | 通用结构化提取 |
-| 增值税发票 | 尽请期待 | 身份证识别 | 结构化提取、图像阴影 |
-| 印章检测与识别 | 端到端弯曲文本识别 | 合同比对 | 密集文本检测、NLP串联 |
+### 交通
+
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| ----------------- | ------------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
+| 车牌识别 | 多角度图像、轻量模型、端侧部署 | [模型下载](#2) | [中文](./轻量级车牌识别.md)/English |
|
+| 增值税发票 | 尽请期待 | | | |
+| 印章检测与识别 | 端到端弯曲文本识别 | | | |
+| 通用卡证识别 | 通用结构化提取 | | | |
+| 身份证识别 | 结构化提取、图像阴影 | | | |
+| 合同比对 | 密集文本检测、NLP串联 | | | |
-## 金融
+
-| 类别 | 亮点 | 类别 | 亮点 |
-| ------------------------------ | ------------------------ | ------------ | --------------------- |
-| [表单VQA](./多模态表单识别.md) | 多模态通用表单结构化提取 | 通用卡证识别 | 通用结构化提取 |
-| 增值税发票 | 尽请期待 | 身份证识别 | 结构化提取、图像阴影 |
-| 印章检测与识别 | 端到端弯曲文本识别 | 合同比对 | 密集文本检测、NLP串联 |
+### 交通
+
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| ----------------- | ------------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
+| 车牌识别 | 多角度图像、轻量模型、端侧部署 | [模型下载](#2) | [中文](./轻量级车牌识别.md)/English |  |
+| 驾驶证/行驶证识别 | 尽请期待 | | | |
+| 快递单识别 | 尽请期待 | | | |
+
+
+
+## 模型下载
+
+如需下载上述场景中已经训练好的垂类模型,可以扫描下方二维码,关注公众号填写问卷后,加入PaddleOCR官方交流群获取20G OCR学习大礼包(内含《动手学OCR》电子书、课程回放视频、前沿论文等重磅资料)
+
+
+
|
+| 驾驶证/行驶证识别 | 尽请期待 | | | |
+| 快递单识别 | 尽请期待 | | | |
+
+
+
+## 模型下载
+
+如需下载上述场景中已经训练好的垂类模型,可以扫描下方二维码,关注公众号填写问卷后,加入PaddleOCR官方交流群获取20G OCR学习大礼包(内含《动手学OCR》电子书、课程回放视频、前沿论文等重磅资料)
+
+
+ diff --git a/doc/doc_en/PP-OCRv3_introduction_en.md b/doc/doc_en/PP-OCRv3_introduction_en.md
index 481e0b8174b1e5ebce84eb1745c49dccd2c565f5..815ad9b0e5a7ff2dec36ceaef995212d122a9f89 100644
--- a/doc/doc_en/PP-OCRv3_introduction_en.md
+++ b/doc/doc_en/PP-OCRv3_introduction_en.md
@@ -55,10 +55,11 @@ The ablation experiments are as follows:
|ID|Strategy|Model Size|Hmean|The Inference Time(cpu + mkldnn)|
|-|-|-|-|-|
-|baseline teacher|DB-R50|99M|83.5%|260ms|
+|baseline teacher|PP-OCR server|49M|83.2%|171ms|
|teacher1|DB-R50-LK-PAN|124M|85.0%|396ms|
|teacher2|DB-R50-LK-PAN-DML|124M|86.0%|396ms|
|baseline student|PP-OCRv2|3M|83.2%|117ms|
+|student0|DB-MV3-RSE-FPN|3.6M|84.5%|124ms|
|student1|DB-MV3-CML(teacher2)|3M|84.3%|117ms|
|student2|DB-MV3-RSE-FPN-CML(teacher2)|3.6M|85.4%|124ms|
@@ -199,7 +200,7 @@ UDML (Unified-Deep Mutual Learning) is a strategy proposed in PP-OCRv2 which is
**(6)UIM:Unlabeled Images Mining**
-UIM (Unlabeled Images Mining) is a very simple unlabeled data mining strategy. The main idea is to use a high-precision text recognition model to predict unlabeled images to obtain pseudo-labels, and select samples with high prediction confidence as training data for training lightweight models. Using this strategy, the accuracy of the recognition model is further improved to 79.4% (+1%).
+UIM (Unlabeled Images Mining) is a very simple unlabeled data mining strategy. The main idea is to use a high-precision text recognition model to predict unlabeled images to obtain pseudo-labels, and select samples with high prediction confidence as training data for training lightweight models. Using this strategy, the accuracy of the recognition model is further improved to 79.4% (+1%). In practice, we use the full data set to train the high-precision SVTR_Tiny model (acc=82.5%) for data mining. [SVTR_Tiny model download and tutorial](../../applications/高精度中文识别模型.md).
diff --git a/doc/doc_en/PP-OCRv3_introduction_en.md b/doc/doc_en/PP-OCRv3_introduction_en.md
index 481e0b8174b1e5ebce84eb1745c49dccd2c565f5..815ad9b0e5a7ff2dec36ceaef995212d122a9f89 100644
--- a/doc/doc_en/PP-OCRv3_introduction_en.md
+++ b/doc/doc_en/PP-OCRv3_introduction_en.md
@@ -55,10 +55,11 @@ The ablation experiments are as follows:
|ID|Strategy|Model Size|Hmean|The Inference Time(cpu + mkldnn)|
|-|-|-|-|-|
-|baseline teacher|DB-R50|99M|83.5%|260ms|
+|baseline teacher|PP-OCR server|49M|83.2%|171ms|
|teacher1|DB-R50-LK-PAN|124M|85.0%|396ms|
|teacher2|DB-R50-LK-PAN-DML|124M|86.0%|396ms|
|baseline student|PP-OCRv2|3M|83.2%|117ms|
+|student0|DB-MV3-RSE-FPN|3.6M|84.5%|124ms|
|student1|DB-MV3-CML(teacher2)|3M|84.3%|117ms|
|student2|DB-MV3-RSE-FPN-CML(teacher2)|3.6M|85.4%|124ms|
@@ -199,7 +200,7 @@ UDML (Unified-Deep Mutual Learning) is a strategy proposed in PP-OCRv2 which is
**(6)UIM:Unlabeled Images Mining**
-UIM (Unlabeled Images Mining) is a very simple unlabeled data mining strategy. The main idea is to use a high-precision text recognition model to predict unlabeled images to obtain pseudo-labels, and select samples with high prediction confidence as training data for training lightweight models. Using this strategy, the accuracy of the recognition model is further improved to 79.4% (+1%).
+UIM (Unlabeled Images Mining) is a very simple unlabeled data mining strategy. The main idea is to use a high-precision text recognition model to predict unlabeled images to obtain pseudo-labels, and select samples with high prediction confidence as training data for training lightweight models. Using this strategy, the accuracy of the recognition model is further improved to 79.4% (+1%). In practice, we use the full data set to train the high-precision SVTR_Tiny model (acc=82.5%) for data mining. [SVTR_Tiny model download and tutorial](../../applications/高精度中文识别模型.md).