diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
new file mode 100644
index 0000000000000000000000000000000000000000..a5052e2897ab9f09a6ed7b747f9fa1198af2a8ab
--- /dev/null
+++ "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
@@ -0,0 +1,648 @@
+# 基于PP-OCRv3的PCB字符识别
+
+- [1. 项目介绍](#1-项目介绍)
+- [2. 安装说明](#2-安装说明)
+- [3. 数据准备](#3-数据准备)
+- [4. 文本检测](#4-文本检测)
+ - [4.1 预训练模型直接评估](#41-预训练模型直接评估)
+ - [4.2 预训练模型+验证集padding直接评估](#42-预训练模型验证集padding直接评估)
+ - [4.3 预训练模型+fine-tune](#43-预训练模型fine-tune)
+- [5. 文本识别](#5-文本识别)
+ - [5.1 预训练模型直接评估](#51-预训练模型直接评估)
+ - [5.2 三种fine-tune方案](#52-三种fine-tune方案)
+- [6. 模型导出](#6-模型导出)
+- [7. 端对端评测](#7-端对端评测)
+- [8. Jetson部署](#8-Jetson部署)
+- [9. 总结](#9-总结)
+- [更多资源](#更多资源)
+
+# 1. 项目介绍
+
+印刷电路板(PCB)是电子产品中的核心器件,对于板件质量的测试与监控是生产中必不可少的环节。在一些场景中,通过PCB中信号灯颜色和文字组合可以定位PCB局部模块质量问题,PCB文字识别中存在如下难点:
+
+- 裁剪出的PCB图片宽高比例较小
+- 文字区域整体面积也较小
+- 包含垂直、水平多种方向文本
+
+针对本场景,PaddleOCR基于全新的PP-OCRv3通过合成数据、微调以及其他场景适配方法完成小字符文本识别任务,满足企业上线要求。PCB检测、识别效果如 **图1** 所示:
+
+
+图1 PCB检测识别效果
+
+注:欢迎在AIStudio领取免费算力体验线上实训,项目链接: [基于PP-OCRv3实现PCB字符识别](https://aistudio.baidu.com/aistudio/projectdetail/4008973)
+
+# 2. 安装说明
+
+
+下载PaddleOCR源码,安装依赖环境。
+
+
+```python
+# 如仍需安装or安装更新,可以执行以下步骤
+git clone https://github.com/PaddlePaddle/PaddleOCR.git
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR
+```
+
+
+```python
+# 安装依赖包
+pip install -r /home/aistudio/PaddleOCR/requirements.txt
+```
+
+# 3. 数据准备
+
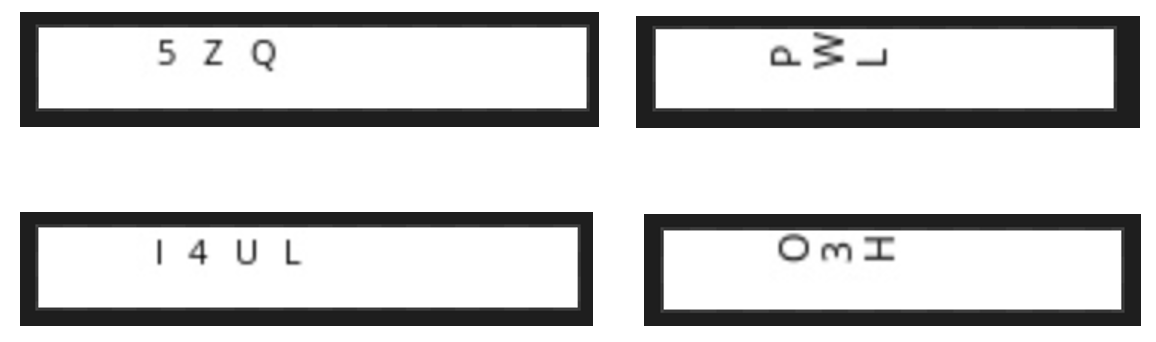
+我们通过图片合成工具生成 **图2** 所示的PCB图片,整图只有高25、宽150左右、文字区域高9、宽45左右,包含垂直和水平2种方向的文本:
+
+
+图2 数据集示例
+
+暂时不开源生成的PCB数据集,但是通过更换背景,通过如下代码生成数据即可:
+
+```
+cd gen_data
+python3 gen.py --num_img=10
+```
+
+生成图片参数解释:
+
+```
+num_img:生成图片数量
+font_min_size、font_max_size:字体最大、最小尺寸
+bg_path:文字区域背景存放路径
+det_bg_path:整图背景存放路径
+fonts_path:字体路径
+corpus_path:语料路径
+output_dir:生成图片存储路径
+```
+
+这里生成 **100张** 相同尺寸和文本的图片,如 **图3** 所示,方便大家跑通实验。通过如下代码解压数据集:
+
+
+图3 案例提供数据集示例
+
+
+```python
+tar xf ./data/data148165/dataset.tar -C ./
+```
+
+在生成数据集的时需要生成检测和识别训练需求的格式:
+
+
+- **文本检测**
+
+标注文件格式如下,中间用'\t'分隔:
+
+```
+" 图像文件名 json.dumps编码的图像标注信息"
+ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
+```
+
+json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 `points` 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。 `transcription` 表示当前文本框的文字,***当其内容为“###”时,表示该文本框无效,在训练时会跳过。***
+
+- **文本识别**
+
+标注文件的格式如下, txt文件中默认请将图片路径和图片标签用'\t'分割,如用其他方式分割将造成训练报错。
+
+```
+" 图像文件名 图像标注信息 "
+
+train_data/rec/train/word_001.jpg 简单可依赖
+train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
+...
+```
+
+
+# 4. 文本检测
+
+选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)中的PP-OCRv3模型进行文本检测和识别。针对检测模型和识别模型,进行了共计9个方面的升级:
+
+- PP-OCRv3检测模型对PP-OCRv2中的CML协同互学习文本检测蒸馏策略进行了升级,分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
+
+- PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。PP-OCRv3通过轻量级文本识别网络SVTR_LCNet、Attention损失指导CTC损失训练策略、挖掘文字上下文信息的数据增广策略TextConAug、TextRotNet自监督预训练模型、UDML联合互学习策略、UIM无标注数据挖掘方案,6个方面进行模型加速和效果提升。
+
+更多细节请参考PP-OCRv3[技术报告](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md)。
+
+
+我们使用 **3种方案** 进行检测模型的训练、评估:
+- **PP-OCRv3英文超轻量检测预训练模型直接评估**
+- PP-OCRv3英文超轻量检测预训练模型 + **验证集padding**直接评估
+- PP-OCRv3英文超轻量检测预训练模型 + **fine-tune**
+
+## **4.1 预训练模型直接评估**
+
+我们首先通过PaddleOCR提供的预训练模型在验证集上进行评估,如果评估指标能满足效果,可以直接使用预训练模型,不再需要训练。
+
+使用预训练模型直接评估步骤如下:
+
+**1)下载预训练模型**
+
+
+PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示:
+
+| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
+| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
+| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
+| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
+| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
+| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
+
+更多模型下载(包括多语言),可以参[考PP-OCR系列模型下载](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md)
+
+这里我们使用PP-OCRv3英文超轻量检测模型,下载并解压预训练模型:
+
+
+
+
+```python
+# 如果更换其他模型,更新下载链接和解压指令就可以
+cd /home/aistudio/PaddleOCR
+mkdir pretrain_models
+cd pretrain_models
+# 下载英文预训练模型
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar
+tar xf en_PP-OCRv3_det_distill_train.tar && rm -rf en_PP-OCRv3_det_distill_train.tar
+%cd ..
+```
+
+**模型评估**
+
+
+首先修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml`中的以下字段:
+```
+Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset'
+Eval.dataset.label_file_list:指向验证集标注文件,'/home/aistudio/dataset/det_gt_val.txt'
+Eval.dataset.transforms.DetResizeForTest: 尺寸
+ limit_side_len: 48
+ limit_type: 'min'
+```
+
+然后在验证集上进行评估,具体代码如下:
+
+
+
+```python
+cd /home/aistudio/PaddleOCR
+python tools/eval.py \
+ -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml \
+ -o Global.checkpoints="./pretrain_models/en_PP-OCRv3_det_distill_train/best_accuracy"
+```
+
+## **4.2 预训练模型+验证集padding直接评估**
+
+考虑到PCB图片比较小,宽度只有25左右、高度只有140-170左右,我们在原图的基础上进行padding,再进行检测评估,padding前后效果对比如 **图4** 所示:
+
+
+图4 padding前后对比图
+
+将图片都padding到300*300大小,因为坐标信息发生了变化,我们同时要修改标注文件,在`/home/aistudio/dataset`目录里也提供了padding之后的图片,大家也可以尝试训练和评估:
+
+同上,我们需要修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml`中的以下字段:
+```
+Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset'
+Eval.dataset.label_file_list:指向验证集标注文件,/home/aistudio/dataset/det_gt_padding_val.txt
+Eval.dataset.transforms.DetResizeForTest: 尺寸
+ limit_side_len: 1100
+ limit_type: 'min'
+```
+
+然后执行评估代码
+
+
+```python
+cd /home/aistudio/PaddleOCR
+python tools/eval.py \
+ -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml \
+ -o Global.checkpoints="./pretrain_models/en_PP-OCRv3_det_distill_train/best_accuracy"
+```
+
+## **4.3 预训练模型+fine-tune**
+
+
+基于预训练模型,在生成的1500图片上进行fine-tune训练和评估,其中train数据1200张,val数据300张,修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml`中的以下字段:
+```
+Global.epoch_num: 这里设置为1,方便快速跑通,实际中根据数据量调整该值
+Global.save_model_dir:模型保存路径
+Global.pretrained_model:指向预训练模型路径,'./pretrain_models/en_PP-OCRv3_det_distill_train/student.pdparams'
+Optimizer.lr.learning_rate:调整学习率,本实验设置为0.0005
+Train.dataset.data_dir:指向训练集图片存放目录,'/home/aistudio/dataset'
+Train.dataset.label_file_list:指向训练集标注文件,'/home/aistudio/dataset/det_gt_train.txt'
+Train.dataset.transforms.EastRandomCropData.size:训练尺寸改为[480,64]
+Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset/'
+Eval.dataset.label_file_list:指向验证集标注文件,'/home/aistudio/dataset/det_gt_val.txt'
+Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
+ limit_side_len: 64
+ limit_type:'min'
+```
+执行下面命令启动训练:
+
+
+```python
+cd /home/aistudio/PaddleOCR/
+python tools/train.py \
+ -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml
+```
+
+**模型评估**
+
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`:
+
+
+```python
+cd /home/aistudio/PaddleOCR/
+python3 tools/eval.py \
+ -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml \
+ -o Global.checkpoints="./output/ch_PP-OCR_V3_det/latest"
+```
+
+使用训练好的模型进行评估,指标如下所示:
+
+
+| 序号 | 方案 | hmean | 效果提升 | 实验分析 |
+| -------- | -------- | -------- | -------- | -------- |
+| 1 | PP-OCRv3英文超轻量检测预训练模型 | 64.64% | - | 提供的预训练模型具有泛化能力 |
+| 2 | PP-OCRv3英文超轻量检测预训练模型 + 验证集padding | 72.13% |+7.5% | padding可以提升尺寸较小图片的检测效果|
+| 3 | PP-OCRv3英文超轻量检测预训练模型 + fine-tune | 100% | +27.9% | fine-tune会提升垂类场景效果 |
+
+
+```
+注:上述实验结果均是在1500张图片(1200张训练集,300张测试集)上训练、评估的得到,AIstudio只提供了100张数据,所以指标有所差异属于正常,只要策略有效、规律相同即可。
+```
+
+# 5. 文本识别
+
+我们分别使用如下4种方案进行训练、评估:
+
+- **方案1**:**PP-OCRv3中英文超轻量识别预训练模型直接评估**
+- **方案2**:PP-OCRv3中英文超轻量检测预训练模型 + **fine-tune**
+- **方案3**:PP-OCRv3中英文超轻量检测预训练模型 + fine-tune + **公开通用识别数据集**
+- **方案4**:PP-OCRv3中英文超轻量检测预训练模型 + fine-tune + **增加PCB图像数量**
+
+
+## **5.1 预训练模型直接评估**
+
+同检测模型,我们首先使用PaddleOCR提供的识别预训练模型在PCB验证集上进行评估。
+
+使用预训练模型直接评估步骤如下:
+
+**1)下载预训练模型**
+
+
+我们使用PP-OCRv3中英文超轻量文本识别模型,下载并解压预训练模型:
+
+
+```python
+# 如果更换其他模型,更新下载链接和解压指令就可以
+cd /home/aistudio/PaddleOCR/pretrain_models/
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
+tar xf ch_PP-OCRv3_rec_train.tar && rm -rf ch_PP-OCRv3_rec_train.tar
+cd ..
+```
+
+**模型评估**
+
+
+首先修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv2_rec_distillation.yml`中的以下字段:
+
+```
+Metric.ignore_space: True:忽略空格
+Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset'
+Eval.dataset.label_file_list:指向验证集标注文件,'/home/aistudio/dataset/rec_gt_val.txt'
+```
+
+我们使用下载的预训练模型进行评估:
+
+
+```python
+cd /home/aistudio/PaddleOCR
+python3 tools/eval.py \
+ -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml \
+ -o Global.checkpoints=pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
+
+```
+
+## **5.2 三种fine-tune方案**
+
+方案2、3、4训练和评估方式是相同的,因此在我们了解每个技术方案之后,再具体看修改哪些参数是相同,哪些是不同的。
+
+**方案介绍:**
+
+1) **方案2**:预训练模型 + **fine-tune**
+
+- 在预训练模型的基础上进行fine-tune,使用1500张PCB进行训练和评估,其中训练集1200张,验证集300张。
+
+
+2) **方案3**:预训练模型 + fine-tune + **公开通用识别数据集**
+
+- 当识别数据比较少的情况,可以考虑添加公开通用识别数据集。在方案2的基础上,添加公开通用识别数据集,如lsvt、rctw等。
+
+3)**方案4**:预训练模型 + fine-tune + **增加PCB图像数量**
+
+- 如果能够获取足够多真实场景,我们可以通过增加数据量提升模型效果。在方案2的基础上,增加PCB的数量到2W张左右。
+
+
+**参数修改:**
+
+接着我们看需要修改的参数,以上方案均需要修改配置文件`configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml`的参数,**修改一次即可**:
+
+```
+Global.pretrained_model:指向预训练模型路径,'pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy'
+Optimizer.lr.values:学习率,本实验设置为0.0005
+Train.loader.batch_size_per_card: batch size,默认128,因为数据量小于128,因此我们设置为8,数据量大可以按默认的训练
+Eval.loader.batch_size_per_card: batch size,默认128,设置为4
+Metric.ignore_space: 忽略空格,本实验设置为True
+```
+
+**更换不同的方案**每次需要修改的参数:
+```
+Global.epoch_num: 这里设置为1,方便快速跑通,实际中根据数据量调整该值
+Global.save_model_dir:指向模型保存路径
+Train.dataset.data_dir:指向训练集图片存放目录
+Train.dataset.label_file_list:指向训练集标注文件
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+
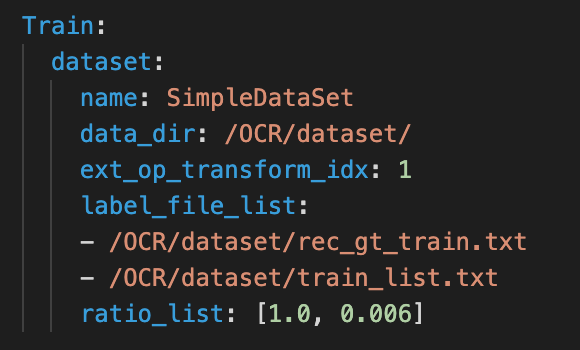
+同时**方案3**修改以下参数
+```
+Eval.dataset.label_file_list:添加公开通用识别数据标注文件
+Eval.dataset.ratio_list:数据和公开通用识别数据每次采样比例,按实际修改即可
+```
+如 **图5** 所示:
+
+图5 添加公开通用识别数据配置文件示例
+
+
+我们提取Student模型的参数,在PCB数据集上进行fine-tune,可以参考如下代码:
+
+
+```python
+import paddle
+# 加载预训练模型
+all_params = paddle.load("./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy.pdparams")
+# 查看权重参数的keys
+print(all_params.keys())
+# 学生模型的权重提取
+s_params = {key[len("student_model."):]: all_params[key] for key in all_params if "student_model." in key}
+# 查看学生模型权重参数的keys
+print(s_params.keys())
+# 保存
+paddle.save(s_params, "./pretrain_models/ch_PP-OCRv3_rec_train/student.pdparams")
+```
+
+修改参数后,**每个方案**都执行如下命令启动训练:
+
+
+
+```python
+cd /home/aistudio/PaddleOCR/
+python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
+```
+
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`:
+
+
+```python
+cd /home/aistudio/PaddleOCR/
+python3 tools/eval.py \
+ -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml \
+ -o Global.checkpoints=./output/rec_ppocr_v3/latest
+```
+
+所有方案评估指标如下:
+
+| 序号 | 方案 | acc | 效果提升 | 实验分析 |
+| -------- | -------- | -------- | -------- | -------- |
+| 1 | PP-OCRv3中英文超轻量识别预训练模型直接评估 | 46.67% | - | 提供的预训练模型具有泛化能力 |
+| 2 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune | 42.02% |-4.6% | 在数据量不足的情况,反而比预训练模型效果低(也可以通过调整超参数再试试)|
+| 3 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 公开通用识别数据集 | 77% | +30% | 在数据量不足的情况下,可以考虑补充公开数据训练 |
+| 4 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 99.99% | +23% | 如果能获取更多数据量的情况,可以通过增加数据量提升效果 |
+
+```
+注:上述实验结果均是在1500张图片(1200张训练集,300张测试集)、2W张图片、添加公开通用识别数据集上训练、评估的得到,AIstudio只提供了100张数据,所以指标有所差异属于正常,只要策略有效、规律相同即可。
+```
+
+# 6. 模型导出
+
+inference 模型(paddle.jit.save保存的模型) 一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。 训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
+
+
+```python
+# 导出检测模型
+python3 tools/export_model.py \
+ -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml \
+ -o Global.pretrained_model="./output/ch_PP-OCR_V3_det/latest" \
+ Global.save_inference_dir="./inference_model/ch_PP-OCR_V3_det/"
+```
+
+因为上述模型只训练了1个epoch,因此我们使用训练最优的模型进行预测,存储在`/home/aistudio/best_models/`目录下,解压即可
+
+
+```python
+cd /home/aistudio/best_models/
+wget https://paddleocr.bj.bcebos.com/fanliku/PCB/det_ppocr_v3_en_infer_PCB.tar
+tar xf /home/aistudio/best_models/det_ppocr_v3_en_infer_PCB.tar -C /home/aistudio/PaddleOCR/pretrain_models/
+```
+
+
+```python
+# 检测模型inference模型预测
+cd /home/aistudio/PaddleOCR/
+python3 tools/infer/predict_det.py \
+ --image_dir="/home/aistudio/dataset/imgs/0000.jpg" \
+ --det_algorithm="DB" \
+ --det_model_dir="./pretrain_models/det_ppocr_v3_en_infer_PCB/" \
+ --det_limit_side_len=48 \
+ --det_limit_type='min' \
+ --det_db_unclip_ratio=2.5 \
+ --use_gpu=True
+```
+
+结果存储在`inference_results`目录下,检测如下图所示:
+
+图6 检测结果
+
+
+同理,导出识别模型并进行推理。
+
+```python
+# 导出识别模型
+python3 tools/export_model.py \
+ -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml \
+ -o Global.pretrained_model="./output/rec_ppocr_v3/latest" \
+ Global.save_inference_dir="./inference_model/rec_ppocr_v3/"
+
+```
+
+同检测模型,识别模型也只训练了1个epoch,因此我们使用训练最优的模型进行预测,存储在`/home/aistudio/best_models/`目录下,解压即可
+
+
+```python
+cd /home/aistudio/best_models/
+wget https://paddleocr.bj.bcebos.com/fanliku/PCB/rec_ppocr_v3_ch_infer_PCB.tar
+tar xf /home/aistudio/best_models/rec_ppocr_v3_ch_infer_PCB.tar -C /home/aistudio/PaddleOCR/pretrain_models/
+```
+
+
+```python
+# 识别模型inference模型预测
+cd /home/aistudio/PaddleOCR/
+python3 tools/infer/predict_rec.py \
+ --image_dir="../test_imgs/0000_rec.jpg" \
+ --rec_model_dir="./pretrain_models/rec_ppocr_v3_ch_infer_PCB" \
+ --rec_image_shape="3, 48, 320" \
+ --use_space_char=False \
+ --use_gpu=True
+```
+
+```python
+# 检测+识别模型inference模型预测
+cd /home/aistudio/PaddleOCR/
+python3 tools/infer/predict_system.py \
+ --image_dir="../test_imgs/0000.jpg" \
+ --det_model_dir="./pretrain_models/det_ppocr_v3_en_infer_PCB" \
+ --det_limit_side_len=48 \
+ --det_limit_type='min' \
+ --det_db_unclip_ratio=2.5 \
+ --rec_model_dir="./pretrain_models/rec_ppocr_v3_ch_infer_PCB" \
+ --rec_image_shape="3, 48, 320" \
+ --draw_img_save_dir=./det_rec_infer/ \
+ --use_space_char=False \
+ --use_angle_cls=False \
+ --use_gpu=True
+
+```
+
+端到端预测结果存储在`det_res_infer`文件夹内,结果如下图所示:
+
+图7 检测+识别结果
+
+# 7. 端对端评测
+
+接下来介绍文本检测+文本识别的端对端指标评估方式。主要分为三步:
+
+1)首先运行`tools/infer/predict_system.py`,将`image_dir`改为需要评估的数据文件家,得到保存的结果:
+
+
+```python
+# 检测+识别模型inference模型预测
+python3 tools/infer/predict_system.py \
+ --image_dir="../dataset/imgs/" \
+ --det_model_dir="./pretrain_models/det_ppocr_v3_en_infer_PCB" \
+ --det_limit_side_len=48 \
+ --det_limit_type='min' \
+ --det_db_unclip_ratio=2.5 \
+ --rec_model_dir="./pretrain_models/rec_ppocr_v3_ch_infer_PCB" \
+ --rec_image_shape="3, 48, 320" \
+ --draw_img_save_dir=./det_rec_infer/ \
+ --use_space_char=False \
+ --use_angle_cls=False \
+ --use_gpu=True
+```
+
+得到保存结果,文本检测识别可视化图保存在`det_rec_infer/`目录下,预测结果保存在`det_rec_infer/system_results.txt`中,格式如下:`0018.jpg [{"transcription": "E295", "points": [[88, 33], [137, 33], [137, 40], [88, 40]]}]`
+
+2)然后将步骤一保存的数据转换为端对端评测需要的数据格式: 修改 `tools/end2end/convert_ppocr_label.py`中的代码,convert_label函数中设置输入标签路径,Mode,保存标签路径等,对预测数据的GTlabel和预测结果的label格式进行转换。
+```
+ppocr_label_gt = "/home/aistudio/dataset/det_gt_val.txt"
+convert_label(ppocr_label_gt, "gt", "./save_gt_label/")
+
+ppocr_label_gt = "/home/aistudio/PaddleOCR/PCB_result/det_rec_infer/system_results.txt"
+convert_label(ppocr_label_gt, "pred", "./save_PPOCRV2_infer/")
+```
+
+运行`convert_ppocr_label.py`:
+
+
+```python
+ python3 tools/end2end/convert_ppocr_label.py
+```
+
+得到如下结果:
+```
+├── ./save_gt_label/
+├── ./save_PPOCRV2_infer/
+```
+
+3) 最后,执行端对端评测,运行`tools/end2end/eval_end2end.py`计算端对端指标,运行方式如下:
+
+
+```python
+pip install editdistance
+python3 tools/end2end/eval_end2end.py ./save_gt_label/ ./save_PPOCRV2_infer/
+```
+
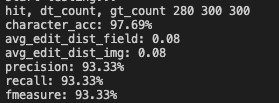
+使用`预训练模型+fine-tune'检测模型`、`预训练模型 + 2W张PCB图片funetune`识别模型,在300张PCB图片上评估得到如下结果,fmeasure为主要关注的指标:
+
+图8 端到端评估指标
+
+```
+注: 使用上述命令不能跑出该结果,因为数据集不相同,可以更换为自己训练好的模型,按上述流程运行
+```
+
+# 8. Jetson部署
+
+我们只需要以下步骤就可以完成Jetson nano部署模型,简单易操作:
+
+**1、在Jetson nano开发版上环境准备:**
+
+* 安装PaddlePaddle
+
+* 下载PaddleOCR并安装依赖
+
+**2、执行预测**
+
+* 将推理模型下载到jetson
+
+* 执行检测、识别、串联预测即可
+
+详细[参考流程](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/deploy/Jetson/readme_ch.md)。
+
+# 9. 总结
+
+检测实验分别使用PP-OCRv3预训练模型在PCB数据集上进行了直接评估、验证集padding、 fine-tune 3种方案,识别实验分别使用PP-OCRv3预训练模型在PCB数据集上进行了直接评估、 fine-tune、添加公开通用识别数据集、增加PCB图片数量4种方案,指标对比如下:
+
+* 检测
+
+
+| 序号 | 方案 | hmean | 效果提升 | 实验分析 |
+| ---- | -------------------------------------------------------- | ------ | -------- | ------------------------------------- |
+| 1 | PP-OCRv3英文超轻量检测预训练模型直接评估 | 64.64% | - | 提供的预训练模型具有泛化能力 |
+| 2 | PP-OCRv3英文超轻量检测预训练模型 + 验证集padding直接评估 | 72.13% | +7.5% | padding可以提升尺寸较小图片的检测效果 |
+| 3 | PP-OCRv3英文超轻量检测预训练模型 + fine-tune | 100% | +27.9% | fine-tune会提升垂类场景效果 |
+
+* 识别
+
+| 序号 | 方案 | acc | 效果提升 | 实验分析 |
+| ---- | ------------------------------------------------------------ | ------ | -------- | ------------------------------------------------------------ |
+| 1 | PP-OCRv3中英文超轻量识别预训练模型直接评估 | 46.67% | - | 提供的预训练模型具有泛化能力 |
+| 2 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune | 42.02% | -4.6% | 在数据量不足的情况,反而比预训练模型效果低(也可以通过调整超参数再试试) |
+| 3 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 公开通用识别数据集 | 77% | +30% | 在数据量不足的情况下,可以考虑补充公开数据训练 |
+| 4 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 99.99% | +23% | 如果能获取更多数据量的情况,可以通过增加数据量提升效果 |
+
+* 端到端
+
+| det | rec | fmeasure |
+| --------------------------------------------- | ------------------------------------------------------------ | -------- |
+| PP-OCRv3英文超轻量检测预训练模型 + fine-tune | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 93.3% |
+
+*结论*
+
+PP-OCRv3的检测模型在未经过fine-tune的情况下,在PCB数据集上也有64.64%的精度,说明具有泛化能力。验证集padding之后,精度提升7.5%,在图片尺寸较小的情况,我们可以通过padding的方式提升检测效果。经过 fine-tune 后能够极大的提升检测效果,精度达到100%。
+
+PP-OCRv3的识别模型方案1和方案2对比可以发现,当数据量不足的情况,预训练模型精度可能比fine-tune效果还要高,所以我们可以先尝试预训练模型直接评估。如果在数据量不足的情况下想进一步提升模型效果,可以通过添加公开通用识别数据集,识别效果提升30%,非常有效。最后如果我们能够采集足够多的真实场景数据集,可以通过增加数据量提升模型效果,精度达到99.99%。
+
+# 更多资源
+
+- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
+
+- 更多PaddleOCR使用教程,请参考:[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph)
+
+
+- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
+
+# 参考
+
+* 数据生成代码库:https://github.com/zcswdt/Color_OCR_image_generator
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/background/bg.jpg" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/background/bg.jpg"
new file mode 100644
index 0000000000000000000000000000000000000000..3cb6eab819c3b7d4f68590d2cdc9d36351590197
Binary files /dev/null and "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/background/bg.jpg" differ
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/corpus/text.txt" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/corpus/text.txt"
new file mode 100644
index 0000000000000000000000000000000000000000..8b8cb793ef6755bf00ed8c154e24638b07a519c2
--- /dev/null
+++ "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/corpus/text.txt"
@@ -0,0 +1,30 @@
+5ZQ
+I4UL
+PWL
+SNOG
+ZL02
+1C30
+O3H
+YHRS
+N03S
+1U5Y
+JTK
+EN4F
+YKJ
+DWNH
+R42W
+X0V
+4OF5
+08AM
+Y93S
+GWE2
+0KR
+9U2A
+DBQ
+Y6J
+ROZ
+K06
+KIEY
+NZQJ
+UN1B
+6X4
\ No newline at end of file
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/1.png" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/1.png"
new file mode 100644
index 0000000000000000000000000000000000000000..8a49eaa6862113044e05d17e32941a0a20911426
Binary files /dev/null and "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/1.png" differ
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/2.png" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/2.png"
new file mode 100644
index 0000000000000000000000000000000000000000..c3fcc0c92826b97b5f6abd970f1a0580eede0f5d
Binary files /dev/null and "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/2.png" differ
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/gen.py" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/gen.py"
new file mode 100644
index 0000000000000000000000000000000000000000..4c768067f998b6b4bbe0b2f5982f46a3f01fc872
--- /dev/null
+++ "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/gen.py"
@@ -0,0 +1,261 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This code is refer from:
+https://github.com/zcswdt/Color_OCR_image_generator
+"""
+import os
+import random
+from PIL import Image, ImageDraw, ImageFont
+import json
+import argparse
+
+
+def get_char_lines(txt_root_path):
+ """
+ desc:get corpus line
+ """
+ txt_files = os.listdir(txt_root_path)
+ char_lines = []
+ for txt in txt_files:
+ f = open(os.path.join(txt_root_path, txt), mode='r', encoding='utf-8')
+ lines = f.readlines()
+ f.close()
+ for line in lines:
+ char_lines.append(line.strip())
+ return char_lines
+
+
+def get_horizontal_text_picture(image_file, chars, fonts_list, cf):
+ """
+ desc:gen horizontal text picture
+ """
+ img = Image.open(image_file)
+ if img.mode != 'RGB':
+ img = img.convert('RGB')
+ img_w, img_h = img.size
+
+ # random choice font
+ font_path = random.choice(fonts_list)
+ # random choice font size
+ font_size = random.randint(cf.font_min_size, cf.font_max_size)
+ font = ImageFont.truetype(font_path, font_size)
+
+ ch_w = []
+ ch_h = []
+ for ch in chars:
+ wt, ht = font.getsize(ch)
+ ch_w.append(wt)
+ ch_h.append(ht)
+ f_w = sum(ch_w)
+ f_h = max(ch_h)
+
+ # add space
+ char_space_width = max(ch_w)
+ f_w += (char_space_width * (len(chars) - 1))
+
+ x1 = random.randint(0, img_w - f_w)
+ y1 = random.randint(0, img_h - f_h)
+ x2 = x1 + f_w
+ y2 = y1 + f_h
+
+ crop_y1 = y1
+ crop_x1 = x1
+ crop_y2 = y2
+ crop_x2 = x2
+
+ best_color = (0, 0, 0)
+ draw = ImageDraw.Draw(img)
+ for i, ch in enumerate(chars):
+ draw.text((x1, y1), ch, best_color, font=font)
+ x1 += (ch_w[i] + char_space_width)
+ crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
+ return crop_img, chars
+
+
+def get_vertical_text_picture(image_file, chars, fonts_list, cf):
+ """
+ desc:gen vertical text picture
+ """
+ img = Image.open(image_file)
+ if img.mode != 'RGB':
+ img = img.convert('RGB')
+ img_w, img_h = img.size
+ # random choice font
+ font_path = random.choice(fonts_list)
+ # random choice font size
+ font_size = random.randint(cf.font_min_size, cf.font_max_size)
+ font = ImageFont.truetype(font_path, font_size)
+
+ ch_w = []
+ ch_h = []
+ for ch in chars:
+ wt, ht = font.getsize(ch)
+ ch_w.append(wt)
+ ch_h.append(ht)
+ f_w = max(ch_w)
+ f_h = sum(ch_h)
+
+ x1 = random.randint(0, img_w - f_w)
+ y1 = random.randint(0, img_h - f_h)
+ x2 = x1 + f_w
+ y2 = y1 + f_h
+
+ crop_y1 = y1
+ crop_x1 = x1
+ crop_y2 = y2
+ crop_x2 = x2
+
+ best_color = (0, 0, 0)
+ draw = ImageDraw.Draw(img)
+ i = 0
+ for ch in chars:
+ draw.text((x1, y1), ch, best_color, font=font)
+ y1 = y1 + ch_h[i]
+ i = i + 1
+ crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
+ crop_img = crop_img.transpose(Image.ROTATE_90)
+ return crop_img, chars
+
+
+def get_fonts(fonts_path):
+ """
+ desc: get all fonts
+ """
+ font_files = os.listdir(fonts_path)
+ fonts_list=[]
+ for font_file in font_files:
+ font_path=os.path.join(fonts_path, font_file)
+ fonts_list.append(font_path)
+ return fonts_list
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--num_img', type=int, default=30, help="Number of images to generate")
+ parser.add_argument('--font_min_size', type=int, default=11)
+ parser.add_argument('--font_max_size', type=int, default=12,
+ help="Help adjust the size of the generated text and the size of the picture")
+ parser.add_argument('--bg_path', type=str, default='./background',
+ help='The generated text pictures will be pasted onto the pictures of this folder')
+ parser.add_argument('--det_bg_path', type=str, default='./det_background',
+ help='The generated text pictures will use the pictures of this folder as the background')
+ parser.add_argument('--fonts_path', type=str, default='../../StyleText/fonts',
+ help='The font used to generate the picture')
+ parser.add_argument('--corpus_path', type=str, default='./corpus',
+ help='The corpus used to generate the text picture')
+ parser.add_argument('--output_dir', type=str, default='./output/', help='Images save dir')
+
+
+ cf = parser.parse_args()
+ # save path
+ if not os.path.exists(cf.output_dir):
+ os.mkdir(cf.output_dir)
+
+ # get corpus
+ txt_root_path = cf.corpus_path
+ char_lines = get_char_lines(txt_root_path=txt_root_path)
+
+ # get all fonts
+ fonts_path = cf.fonts_path
+ fonts_list = get_fonts(fonts_path)
+
+ # rec bg
+ img_root_path = cf.bg_path
+ imnames=os.listdir(img_root_path)
+
+ # det bg
+ det_bg_path = cf.det_bg_path
+ bg_pics = os.listdir(det_bg_path)
+
+ # OCR det files
+ det_val_file = open(cf.output_dir + 'det_gt_val.txt', 'w', encoding='utf-8')
+ det_train_file = open(cf.output_dir + 'det_gt_train.txt', 'w', encoding='utf-8')
+ # det imgs
+ det_save_dir = 'imgs/'
+ if not os.path.exists(cf.output_dir + det_save_dir):
+ os.mkdir(cf.output_dir + det_save_dir)
+ det_val_save_dir = 'imgs_val/'
+ if not os.path.exists(cf.output_dir + det_val_save_dir):
+ os.mkdir(cf.output_dir + det_val_save_dir)
+
+ # OCR rec files
+ rec_val_file = open(cf.output_dir + 'rec_gt_val.txt', 'w', encoding='utf-8')
+ rec_train_file = open(cf.output_dir + 'rec_gt_train.txt', 'w', encoding='utf-8')
+ # rec imgs
+ rec_save_dir = 'rec_imgs/'
+ if not os.path.exists(cf.output_dir + rec_save_dir):
+ os.mkdir(cf.output_dir + rec_save_dir)
+ rec_val_save_dir = 'rec_imgs_val/'
+ if not os.path.exists(cf.output_dir + rec_val_save_dir):
+ os.mkdir(cf.output_dir + rec_val_save_dir)
+
+
+ val_ratio = cf.num_img * 0.2 # val dataset ratio
+
+ print('start generating...')
+ for i in range(0, cf.num_img):
+ imname = random.choice(imnames)
+ img_path = os.path.join(img_root_path, imname)
+
+ rnd = random.random()
+ # gen horizontal text picture
+ if rnd < 0.5:
+ gen_img, chars = get_horizontal_text_picture(img_path, char_lines[i], fonts_list, cf)
+ ori_w, ori_h = gen_img.size
+ gen_img = gen_img.crop((0, 3, ori_w, ori_h))
+ # gen vertical text picture
+ else:
+ gen_img, chars = get_vertical_text_picture(img_path, char_lines[i], fonts_list, cf)
+ ori_w, ori_h = gen_img.size
+ gen_img = gen_img.crop((3, 0, ori_w, ori_h))
+
+ ori_w, ori_h = gen_img.size
+
+ # rec imgs
+ save_img_name = str(i).zfill(4) + '.jpg'
+ if i < val_ratio:
+ save_dir = os.path.join(rec_val_save_dir, save_img_name)
+ line = save_dir + '\t' + char_lines[i] + '\n'
+ rec_val_file.write(line)
+ else:
+ save_dir = os.path.join(rec_save_dir, save_img_name)
+ line = save_dir + '\t' + char_lines[i] + '\n'
+ rec_train_file.write(line)
+ gen_img.save(cf.output_dir + save_dir, quality = 95, subsampling=0)
+
+ # det img
+ # random choice bg
+ bg_pic = random.sample(bg_pics, 1)[0]
+ det_img = Image.open(os.path.join(det_bg_path, bg_pic))
+ # the PCB position is fixed, modify it according to your own scenario
+ if bg_pic == '1.png':
+ x1 = 38
+ y1 = 3
+ else:
+ x1 = 34
+ y1 = 1
+
+ det_img.paste(gen_img, (x1, y1))
+ # text pos
+ chars_pos = [[x1, y1], [x1 + ori_w, y1], [x1 + ori_w, y1 + ori_h], [x1, y1 + ori_h]]
+ label = [{"transcription":char_lines[i], "points":chars_pos}]
+ if i < val_ratio:
+ save_dir = os.path.join(det_val_save_dir, save_img_name)
+ det_val_file.write(save_dir + '\t' + json.dumps(
+ label, ensure_ascii=False) + '\n')
+ else:
+ save_dir = os.path.join(det_save_dir, save_img_name)
+ det_train_file.write(save_dir + '\t' + json.dumps(
+ label, ensure_ascii=False) + '\n')
+ det_img.save(cf.output_dir + save_dir, quality = 95, subsampling=0)
diff --git "a/applications/\350\275\273\351\207\217\347\272\247\350\275\246\347\211\214\350\257\206\345\210\253.md" "b/applications/\350\275\273\351\207\217\347\272\247\350\275\246\347\211\214\350\257\206\345\210\253.md"
index 31b1b427db107dd191363838de7604bd099c10ac..7012c7f4bb022e58972c521452de0aade0fdb436 100644
--- "a/applications/\350\275\273\351\207\217\347\272\247\350\275\246\347\211\214\350\257\206\345\210\253.md"
+++ "b/applications/\350\275\273\351\207\217\347\272\247\350\275\246\347\211\214\350\257\206\345\210\253.md"
@@ -249,7 +249,7 @@ tar -xf ch_PP-OCRv3_det_distill_train.tar
cd /home/aistudio/PaddleOCR
```
-预训练模型下载完成后,我们使用[ch_PP-OCRv3_det_student.yml](../configs/chepai/ch_PP-OCRv3_det_student.yml) 配置文件进行后续实验,在开始评估之前需要对配置文件中部分字段进行设置,具体如下:
+预训练模型下载完成后,我们使用[ch_PP-OCRv3_det_student.yml](../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml) 配置文件进行后续实验,在开始评估之前需要对配置文件中部分字段进行设置,具体如下:
1. 模型存储和训练相关:
1. Global.pretrained_model: 指向PP-OCRv3文本检测预训练模型地址
@@ -787,12 +787,12 @@ python tools/infer/predict_system.py \
- 端侧部署
-端侧部署我们采用基于 PaddleLite 的 cpp 推理。Paddle Lite是飞桨轻量化推理引擎,为手机、IOT端提供高效推理能力,并广泛整合跨平台硬件,为端侧部署及应用落地问题提供轻量化的部署方案。具体可参考 [PaddleOCR lite教程](../dygraph/deploy/lite/readme_ch.md)
+端侧部署我们采用基于 PaddleLite 的 cpp 推理。Paddle Lite是飞桨轻量化推理引擎,为手机、IOT端提供高效推理能力,并广泛整合跨平台硬件,为端侧部署及应用落地问题提供轻量化的部署方案。具体可参考 [PaddleOCR lite教程](../deploy/lite/readme_ch.md)
### 4.5 实验总结
-我们分别使用PP-OCRv3中英文超轻量预训练模型在车牌数据集上进行了直接评估和 fine-tune 和 fine-tune +量化3种方案的实验,并基于[PaddleOCR lite教程](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/deploy/lite/readme_ch.md)进行了速度测试,指标对比如下:
+我们分别使用PP-OCRv3中英文超轻量预训练模型在车牌数据集上进行了直接评估和 fine-tune 和 fine-tune +量化3种方案的实验,并基于[PaddleOCR lite教程](../deploy/lite/readme_ch.md)进行了速度测试,指标对比如下:
- 检测
diff --git a/ppstructure/table/README.md b/ppstructure/table/README.md
index d21ef4aa3813b4ff49dc0580be35c5e2e0483c8f..b6804c6f09b4ee3d17cd2b81e6cc6642c1c1be9a 100644
--- a/ppstructure/table/README.md
+++ b/ppstructure/table/README.md
@@ -18,7 +18,7 @@ The table recognition mainly contains three models
The table recognition flow chart is as follows
-
+
1. The coordinates of single-line text is detected by DB model, and then sends it to the recognition model to get the recognition result.
2. The table structure and cell coordinates is predicted by RARE model.
diff --git a/test_tipc/configs/ch_PP-OCRv2/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
index fcac6e3984cf3fd45fec9f7b736f794289278b25..32b290a9ed0ca04032e7854d9739e1612a6a095f 100644
--- a/test_tipc/configs/ch_PP-OCRv2/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/ch_PP-OCRv2/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
@@ -6,10 +6,10 @@ infer_export:null
infer_quant:False
inference:tools/infer/predict_system.py
--use_gpu:False|True
---enable_mkldnn:False|True
---cpu_threads:1|6
+--enable_mkldnn:False
+--cpu_threads:6
--rec_batch_num:1
---use_tensorrt:False|True
+--use_tensorrt:False
--precision:fp32
--det_model_dir:
--image_dir:./inference/ch_det_data_50/all-sum-510/
diff --git a/test_tipc/configs/ch_PP-OCRv3/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv3/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
index a0448265010720a367249dad3e23c332583fee38..afacdc140515297c75f8674b245b34fce4c9fad9 100644
--- a/test_tipc/configs/ch_PP-OCRv3/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/ch_PP-OCRv3/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
@@ -6,10 +6,10 @@ infer_export:null
infer_quant:False
inference:tools/infer/predict_system.py --rec_image_shape="3,48,320"
--use_gpu:False|True
---enable_mkldnn:False|True
---cpu_threads:1|6
+--enable_mkldnn:False
+--cpu_threads:6
--rec_batch_num:1
---use_tensorrt:False|True
+--use_tensorrt:False
--precision:fp32
--det_model_dir:
--image_dir:./inference/ch_det_data_50/all-sum-510/
diff --git a/test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_distillation.yml b/test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_distillation.yml
index 4c8ba0a6fa4a355e9bad1665a8de82399f919740..f704a1dfb5dc2335c353a495dfbc0ce42cf35bf4 100644
--- a/test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_distillation.yml
+++ b/test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_distillation.yml
@@ -153,7 +153,7 @@ Train:
data_dir: ./train_data/ic15_data/
ext_op_transform_idx: 1
label_file_list:
- - ./train_data/ic15_data/rec_gt_train.txt
+ - ./train_data/ic15_data/rec_gt_train_lite.txt
transforms:
- DecodeImage:
img_mode: BGR
@@ -183,7 +183,7 @@ Eval:
name: SimpleDataSet
data_dir: ./train_data/ic15_data
label_file_list:
- - ./train_data/ic15_data/rec_gt_test.txt
+ - ./train_data/ic15_data/rec_gt_test_lite.txt
transforms:
- DecodeImage:
img_mode: BGR
diff --git a/test_tipc/configs/ch_PP-OCRv3_rec/train_fleet_infer_python.txt b/test_tipc/configs/ch_PP-OCRv3_rec/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt
similarity index 98%
rename from test_tipc/configs/ch_PP-OCRv3_rec/train_fleet_infer_python.txt
rename to test_tipc/configs/ch_PP-OCRv3_rec/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt
index 08e1fe9ba0aba4e3ab358be188aeed0212ad08ff..7fcc8b4418c65b0f98624d92bd3896518f2ed465 100644
--- a/test_tipc/configs/ch_PP-OCRv3_rec/train_fleet_infer_python.txt
+++ b/test_tipc/configs/ch_PP-OCRv3_rec/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt
@@ -38,7 +38,7 @@ infer_model:./inference/ch_PP-OCRv3_rec_infer
infer_export:null
infer_quant:False
inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
---use_gpu:True|False
+--use_gpu:False
--enable_mkldnn:False
--cpu_threads:6
--rec_batch_num:1|6
diff --git a/test_tipc/configs/ch_PP-OCRv3_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv3_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
index 68888082c36e77a0aeebcf7b4db80356efe2912b..99e3c4247716bdf139440e22ea80c8542b2d9830 100644
--- a/test_tipc/configs/ch_PP-OCRv3_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/ch_PP-OCRv3_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -4,7 +4,7 @@ python:python3.7
gpu_list:0|0,1
Global.use_gpu:True|True
Global.auto_cast:amp
-Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=50
Global.save_model_dir:./output/
Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
Global.pretrained_model:null
@@ -41,7 +41,7 @@ inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
--use_gpu:True|False
--enable_mkldnn:False
--cpu_threads:6
---rec_batch_num:1|6
+--rec_batch_num:6
--use_tensorrt:False
--precision:fp32
--rec_model_dir:
diff --git a/test_tipc/configs/ch_PP-OCRv3_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv3_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
index c00e6c4e4bb63055cfeb2b8dc6c62b547323ef72..c93b307debae630fccf41f29348c0b34761c1bf6 100644
--- a/test_tipc/configs/ch_PP-OCRv3_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/ch_PP-OCRv3_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -41,7 +41,7 @@ inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
--use_gpu:True|False
--enable_mkldnn:False
--cpu_threads:6
---rec_batch_num:1|6
+--rec_batch_num:6
--use_tensorrt:False
--precision:fp32
--rec_model_dir:
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
index 4a46f0cf09dcf2bb812910f0cf322dda0749b87c..becad991eab2535b2df7862d0d25707ef37f08f8 100644
--- a/test_tipc/configs/ch_ppocr_mobile_v2.0/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
@@ -6,10 +6,10 @@ infer_export:null
infer_quant:False
inference:tools/infer/predict_system.py
--use_gpu:False|True
---enable_mkldnn:False|True
---cpu_threads:1|6
+--enable_mkldnn:False
+--cpu_threads:6
--rec_batch_num:1
---use_tensorrt:False|True
+--use_tensorrt:False
--precision:fp32
--det_model_dir:
--image_dir:./inference/ch_det_data_50/all-sum-510/
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/model_linux_gpu_normal_normal_infer_python_jetson.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/model_linux_gpu_normal_normal_infer_python_jetson.txt
index 7d3f60bd42aad18c045aeee70fc60d2c17a2af13..24bb8746ab7793dbcb4af99102a007aca8b8e16b 100644
--- a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/model_linux_gpu_normal_normal_infer_python_jetson.txt
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/model_linux_gpu_normal_normal_infer_python_jetson.txt
@@ -1,5 +1,5 @@
===========================infer_params===========================
-model_name:ocr_det
+model_name:ch_ppocr_mobile_v2.0_det
python:python
infer_model:./inference/ch_ppocr_mobile_v2.0_det_infer
infer_export:null
@@ -7,10 +7,10 @@ infer_quant:False
inference:tools/infer/predict_det.py
--use_gpu:True|False
--enable_mkldnn:False
---cpu_threads:1|6
+--cpu_threads:6
--rec_batch_num:1
---use_tensorrt:False|True
---precision:fp16|fp32
+--use_tensorrt:False
+--precision:fp32
--det_model_dir:
--image_dir:./inference/ch_det_data_50/all-sum-510/
null:null
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_fleet_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_fleet_amp_infer_python_linux_gpu_cpu.txt
deleted file mode 100644
index bfb71b781039493b12875ed4e99c8cd004a2e295..0000000000000000000000000000000000000000
--- a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_fleet_amp_infer_python_linux_gpu_cpu.txt
+++ /dev/null
@@ -1,51 +0,0 @@
-===========================train_params===========================
-model_name:ocr_det
-python:python3.7
-gpu_list:xx.xx.xx.xx,yy.yy.yy.yy;0,1
-Global.use_gpu:True
-Global.auto_cast:fp32|amp
-Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=300
-Global.save_model_dir:./output/
-Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
-Global.pretrained_model:null
-train_model_name:latest
-train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
-null:null
-##
-trainer:norm_train|pact_train|fpgm_train
-norm_train:tools/train.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
-pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-fpgm_train:deploy/slim/prune/sensitivity_anal.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/det_mv3_db_v2.0_train/best_accuracy
-distill_train:null
-null:null
-null:null
-##
-===========================eval_params===========================
-eval:null
-null:null
-##
-===========================infer_params===========================
-Global.save_inference_dir:./output/
-Global.pretrained_model:
-norm_export:tools/export_model.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-fpgm_export:deploy/slim/prune/export_prune_model.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-distill_export:null
-export1:null
-export2:null
-inference_dir:null
-train_model:./inference/ch_ppocr_mobile_v2.0_det_train/best_accuracy
-infer_export:tools/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
-infer_quant:False
-inference:tools/infer/predict_det.py
---use_gpu:True|False
---enable_mkldnn:True|False
---cpu_threads:1|6
---rec_batch_num:1
---use_tensorrt:False|True
---precision:fp32|fp16|int8
---det_model_dir:
---image_dir:./inference/ch_det_data_50/all-sum-510/
-null:null
---benchmark:True
-null:null
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_mac_cpu_normal_normal_infer_python_mac_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_mac_cpu_normal_normal_infer_python_mac_cpu.txt
index 014dad5fc9d87c08a0725f57127f8bf2cb248be3..3f321a1903cdd1076e181c4bb901f1c9dc6d7f58 100644
--- a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_mac_cpu_normal_normal_infer_python_mac_cpu.txt
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_mac_cpu_normal_normal_infer_python_mac_cpu.txt
@@ -4,7 +4,7 @@ python:python
gpu_list:-1
Global.use_gpu:False
Global.auto_cast:null
-Global.epoch_num:lite_train_lite_infer=5|whole_train_whole_infer=300
+Global.epoch_num:lite_train_lite_infer=5|whole_train_whole_infer=50
Global.save_model_dir:./output/
Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
Global.pretrained_model:null
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_windows_gpu_normal_normal_infer_python_windows_cpu_gpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_windows_gpu_normal_normal_infer_python_windows_cpu_gpu.txt
index 6a63b39d976c0e9693deec097c37eb0ff212d8af..a3f6933a64bd64c8f39a90f72d139ad9fada55bb 100644
--- a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_windows_gpu_normal_normal_infer_python_windows_cpu_gpu.txt
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_windows_gpu_normal_normal_infer_python_windows_cpu_gpu.txt
@@ -4,7 +4,7 @@ python:python
gpu_list:0
Global.use_gpu:True
Global.auto_cast:fp32|amp
-Global.epoch_num:lite_train_lite_infer=5|whole_train_whole_infer=300
+Global.epoch_num:lite_train_lite_infer=5|whole_train_whole_infer=50
Global.save_model_dir:./output/
Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
Global.pretrained_model:null
@@ -39,10 +39,10 @@ infer_export:tools/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2
infer_quant:False
inference:tools/infer/predict_det.py
--use_gpu:True|False
---enable_mkldnn:True|False
+--enable_mkldnn:False
--cpu_threads:1|6
--rec_batch_num:1
---use_tensorrt:False|True
+--use_tensorrt:False
--precision:fp32|fp16|int8
--det_model_dir:
--image_dir:./inference/ch_det_data_50/all-sum-510/
diff --git a/test_tipc/configs/ch_ppocr_server_v2.0/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_server_v2.0/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
index 92d7031e884d10df3a5c98bf675d64d63b3cb335..b20596f7a1db6da04307a7e527ef596477d237d3 100644
--- a/test_tipc/configs/ch_ppocr_server_v2.0/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/ch_ppocr_server_v2.0/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
@@ -6,8 +6,8 @@ infer_export:null
infer_quant:True
inference:tools/infer/predict_system.py
--use_gpu:False|True
---enable_mkldnn:False|True
---cpu_threads:1|6
+--enable_mkldnn:False
+--cpu_threads:6
--rec_batch_num:1
--use_tensorrt:False
--precision:fp32
diff --git a/test_tipc/configs/det_r50_vd_sast_icdar15_v2.0/train_infer_python.txt b/test_tipc/configs/det_r50_vd_sast_icdar15_v2.0/train_infer_python.txt
index 11444a3ac1b99c54dae31d28b83ffe14269599d9..de9e336332ceb7bc79bf7814f6ed9296b4df7bda 100644
--- a/test_tipc/configs/det_r50_vd_sast_icdar15_v2.0/train_infer_python.txt
+++ b/test_tipc/configs/det_r50_vd_sast_icdar15_v2.0/train_infer_python.txt
@@ -4,7 +4,7 @@ python:python3.7
gpu_list:0|0,1
Global.use_gpu:True|True
Global.auto_cast:null
-Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=5000
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=500
Global.save_model_dir:./output/
Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
Global.pretrained_model:null
@@ -45,7 +45,7 @@ inference:tools/infer/predict_det.py
--use_tensorrt:False
--precision:fp32
--det_model_dir:
---image_dir:./inference/ch_det_data_50/all-sum-510/
+--image_dir:./inference/ch_det_data_50/all-sum-510/00008790.jpg
null:null
--benchmark:True
--det_algorithm:SAST
diff --git a/test_tipc/configs/en_table_structure/table_mv3.yml b/test_tipc/configs/en_table_structure/table_mv3.yml
new file mode 100755
index 0000000000000000000000000000000000000000..adf326bd02aeff4683c8f37a704125b4e426efa9
--- /dev/null
+++ b/test_tipc/configs/en_table_structure/table_mv3.yml
@@ -0,0 +1,117 @@
+Global:
+ use_gpu: true
+ epoch_num: 10
+ log_smooth_window: 20
+ print_batch_step: 5
+ save_model_dir: ./output/table_mv3/
+ save_epoch_step: 3
+ # evaluation is run every 400 iterations after the 0th iteration
+ eval_batch_step: [0, 400]
+ cal_metric_during_train: True
+ pretrained_model:
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: False
+ infer_img: doc/table/table.jpg
+ # for data or label process
+ character_dict_path: ppocr/utils/dict/table_structure_dict.txt
+ character_type: en
+ max_text_length: 100
+ max_elem_length: 800
+ max_cell_num: 500
+ infer_mode: False
+ process_total_num: 0
+ process_cut_num: 0
+
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ clip_norm: 5.0
+ lr:
+ learning_rate: 0.001
+ regularizer:
+ name: 'L2'
+ factor: 0.00000
+
+Architecture:
+ model_type: table
+ algorithm: TableAttn
+ Backbone:
+ name: MobileNetV3
+ scale: 1.0
+ model_name: large
+ Head:
+ name: TableAttentionHead
+ hidden_size: 256
+ l2_decay: 0.00001
+ loc_type: 2
+ max_text_length: 100
+ max_elem_length: 800
+ max_cell_num: 500
+
+Loss:
+ name: TableAttentionLoss
+ structure_weight: 100.0
+ loc_weight: 10000.0
+
+PostProcess:
+ name: TableLabelDecode
+
+Metric:
+ name: TableMetric
+ main_indicator: acc
+
+Train:
+ dataset:
+ name: PubTabDataSet
+ data_dir: ./train_data/pubtabnet/train
+ label_file_path: ./train_data/pubtabnet/train.jsonl
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - ResizeTableImage:
+ max_len: 488
+ - TableLabelEncode:
+ - NormalizeImage:
+ scale: 1./255.
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: 'hwc'
+ - PaddingTableImage:
+ - ToCHWImage:
+ - KeepKeys:
+ keep_keys: ['image', 'structure', 'bbox_list', 'sp_tokens', 'bbox_list_mask']
+ loader:
+ shuffle: True
+ batch_size_per_card: 32
+ drop_last: True
+ num_workers: 1
+
+Eval:
+ dataset:
+ name: PubTabDataSet
+ data_dir: ./train_data/pubtabnet/test/
+ label_file_path: ./train_data/pubtabnet/test.jsonl
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - ResizeTableImage:
+ max_len: 488
+ - TableLabelEncode:
+ - NormalizeImage:
+ scale: 1./255.
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: 'hwc'
+ - PaddingTableImage:
+ - ToCHWImage:
+ - KeepKeys:
+ keep_keys: ['image', 'structure', 'bbox_list', 'sp_tokens', 'bbox_list_mask']
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 16
+ num_workers: 1
diff --git a/test_tipc/configs/en_table_structure/train_infer_python.txt b/test_tipc/configs/en_table_structure/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..d9f3b30e16c75281a929130d877b947a23c16190
--- /dev/null
+++ b/test_tipc/configs/en_table_structure/train_infer_python.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:en_table_structure
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:./pretrain_models/en_ppocr_mobile_v2.0_table_structure_train/best_accuracy
+train_model_name:latest
+train_infer_img_dir:./ppstructure/docs/table/table.jpg
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/en_ppocr_mobile_v2.0_table_structure_infer
+infer_export:null
+infer_quant:False
+inference:ppstructure/table/predict_table.py --det_model_dir=./inference/en_ppocr_mobile_v2.0_table_det_infer --rec_model_dir=./inference/en_ppocr_mobile_v2.0_table_rec_infer --rec_char_dict_path=./ppocr/utils/dict/table_dict.txt --table_char_dict_path=./ppocr/utils/dict/table_structure_dict.txt --image_dir=./ppstructure/docs/table/table.jpg --det_limit_side_len=736 --det_limit_type=min --output ./output/table
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--table_model_dir:
+--image_dir:./ppstructure/docs/table/table.jpg
+null:null
+--benchmark:False
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,488,488]}]
diff --git a/test_tipc/configs/en_table_structure/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/en_table_structure/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
index c4bf14778b9c58da15760963524b849274705886..31ac1ed53f2adc9810bc4fd2cf4f874d89d49606 100644
--- a/test_tipc/configs/en_table_structure/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/en_table_structure/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -7,7 +7,7 @@ Global.auto_cast:amp
Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
Global.save_model_dir:./output/
Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
-Global.pretrained_model:./inference/en_ppocr_mobile_v2.0_table_structure_train/best_accuracy
+Global.pretrained_model:./pretrain_models/en_ppocr_mobile_v2.0_table_structure_train/best_accuracy
train_model_name:latest
train_infer_img_dir:./ppstructure/docs/table/table.jpg
null:null
diff --git a/test_tipc/configs/en_table_structure_KL/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/en_table_structure_KL/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e8f7bbaa50417b97f79596634677fff0a95cb47f
--- /dev/null
+++ b/test_tipc/configs/en_table_structure_KL/model_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,21 @@
+===========================train_params===========================
+model_name:en_table_structure_KL
+python:python3.7
+Global.pretrained_model:
+Global.save_inference_dir:null
+infer_model:./inference/en_ppocr_mobile_v2.0_table_structure_infer/
+infer_export:deploy/slim/quantization/quant_kl.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+infer_quant:True
+inference:ppstructure/table/predict_table.py --det_model_dir=./inference/en_ppocr_mobile_v2.0_table_det_infer --rec_model_dir=./inference/en_ppocr_mobile_v2.0_table_rec_infer --rec_char_dict_path=./ppocr/utils/dict/table_dict.txt --table_char_dict_path=./ppocr/utils/dict/table_structure_dict.txt --image_dir=./ppstructure/docs/table/table.jpg --det_limit_side_len=736 --det_limit_type=min --output ./output/table
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:int8
+--table_model_dir:
+--image_dir:./ppstructure/docs/table/table.jpg
+null:null
+--benchmark:False
+null:null
+null:null
diff --git a/test_tipc/configs/en_table_structure_PACT/train_infer_python.txt b/test_tipc/configs/en_table_structure_PACT/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f62e8b68bc6c1af06a65a8dfb438d5d63576e123
--- /dev/null
+++ b/test_tipc/configs/en_table_structure_PACT/train_infer_python.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:en_table_structure_PACT
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:./pretrain_models/en_ppocr_mobile_v2.0_table_structure_train/best_accuracy
+train_model_name:latest
+train_infer_img_dir:./ppstructure/docs/table/table.jpg
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/en_ppocr_mobile_v2.0_table_structure_infer
+infer_export:null
+infer_quant:True
+inference:ppstructure/table/predict_table.py --det_model_dir=./inference/en_ppocr_mobile_v2.0_table_det_infer --rec_model_dir=./inference/en_ppocr_mobile_v2.0_table_rec_infer --rec_char_dict_path=./ppocr/utils/dict/table_dict.txt --table_char_dict_path=./ppocr/utils/dict/table_structure_dict.txt --image_dir=./ppstructure/docs/table/table.jpg --det_limit_side_len=736 --det_limit_type=min --output ./output/table
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--table_model_dir:
+--image_dir:./ppstructure/docs/table/table.jpg
+null:null
+--benchmark:False
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,488,488]}]
diff --git a/test_tipc/configs/en_table_structure_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/en_table_structure_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..d7c847fcdc26834c96f033caa3ba97d323439445
--- /dev/null
+++ b/test_tipc/configs/en_table_structure_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:en_table_structure_PACT
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:./pretrain_models/en_ppocr_mobile_v2.0_table_structure_train/best_accuracy
+train_model_name:latest
+train_infer_img_dir:./ppstructure/docs/table/table.jpg
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/en_ppocr_mobile_v2.0_table_structure_infer
+infer_export:null
+infer_quant:True
+inference:ppstructure/table/predict_table.py --det_model_dir=./inference/en_ppocr_mobile_v2.0_table_det_infer --rec_model_dir=./inference/en_ppocr_mobile_v2.0_table_rec_infer --rec_char_dict_path=./ppocr/utils/dict/table_dict.txt --table_char_dict_path=./ppocr/utils/dict/table_structure_dict.txt --image_dir=./ppstructure/docs/table/table.jpg --det_limit_side_len=736 --det_limit_type=min --output ./output/table
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--table_model_dir:
+--image_dir:./ppstructure/docs/table/table.jpg
+null:null
+--benchmark:False
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,488,488]}]
diff --git a/test_tipc/docs/test_train_fleet_inference_python.md b/test_tipc/docs/test_train_fleet_inference_python.md
index 89cf5d5b6ddea29ae692e658d9a118851e474637..9fddb5d1634b452f1906a83bca4157dbaec47c81 100644
--- a/test_tipc/docs/test_train_fleet_inference_python.md
+++ b/test_tipc/docs/test_train_fleet_inference_python.md
@@ -15,7 +15,7 @@ Linux GPU/CPU 多机多卡训练推理测试的主程序为`test_train_inference
| 算法名称 | 模型名称 | device_CPU | device_GPU | batchsize |
| :----: | :----: | :----: | :----: | :----: |
-| PP-OCRv3 | ch_PP-OCRv3_rec | 支持 | 支持 | 1 |
+| PP-OCRv3 | ch_PP-OCRv3_rec | 支持 | - | 1/6 |
## 2. 测试流程
@@ -31,10 +31,10 @@ Linux GPU/CPU 多机多卡训练推理测试的主程序为`test_train_inference
#### 2.1.2 准备数据
-运行`prepare.sh`准备数据和模型,以配置文件`test_tipc/configs/ch_PP-OCRv3_rec/train_fleet_infer_python.txt`为例,数据准备命令如下所示。
+运行`prepare.sh`准备数据和模型,以配置文件`test_tipc/configs/ch_PP-OCRv3_rec/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt`为例,数据准备命令如下所示。
```shell
-bash test_tipc/prepare.sh test_tipc/configs/ch_PP-OCRv3_rec/train_fleet_infer_python.txt lite_train_lite_infer
+bash test_tipc/prepare.sh test_tipc/configs/ch_PP-OCRv3_rec/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt lite_train_lite_infer
```
**注意:** 由于是多机训练,这里需要在所有的节点上均运行启动上述命令,准备数据。
@@ -47,10 +47,10 @@ bash test_tipc/prepare.sh test_tipc/configs/ch_PP-OCRv3_rec/train_fleet_infer_py
export FLAGS_START_PORT=17000
```
-以配置文件`test_tipc/configs/ch_PP-OCRv3_rec/train_fleet_infer_python.txt`为例,测试方法如下所示。
+以配置文件`test_tipc/configs/ch_PP-OCRv3_rec/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt`为例,测试方法如下所示。
```shell
-bash test_tipc/test_train_inference_python.sh test_tipc/configs/ch_PP-OCRv3_rec/train_fleet_infer_python.txt lite_train_lite_infer
+bash test_tipc/test_train_inference_python.sh test_tipc/configs/ch_PP-OCRv3_rec/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt lite_train_lite_infer
```
**注意:** 由于是多机训练,这里需要在所有的节点上均运行启动上述命令进行测试。
diff --git a/test_tipc/prepare.sh b/test_tipc/prepare.sh
index daf6a329614b5cf8af66c1ef4fdf26cc68fe950f..8c9e12511dd4c9a1696fc7b4e4669a3749df7965 100644
--- a/test_tipc/prepare.sh
+++ b/test_tipc/prepare.sh
@@ -52,16 +52,27 @@ if [ ${MODE} = "lite_train_lite_infer" ];then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar --no-check-certificate
cd ./pretrain_models/ && tar xf ch_PP-OCRv3_det_distill_train.tar && cd ../
fi
+ if [ ${model_name} == "en_table_structure" ];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar --no-check-certificate
+ cd ./pretrain_models/ && tar xf en_ppocr_mobile_v2.0_table_structure_train.tar && cd ../
+ wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_det_infer.tar --no-check-certificate
+ wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_rec_infer.tar --no-check-certificate
+ cd ./inference/ && tar xf en_ppocr_mobile_v2.0_table_det_infer.tar && tar xf en_ppocr_mobile_v2.0_table_rec_infer.tar && cd ../
+ fi
cd ./pretrain_models/ && tar xf det_mv3_db_v2.0_train.tar && cd ../
rm -rf ./train_data/icdar2015
rm -rf ./train_data/ic15_data
+ rm -rf ./train_data/pubtabnet
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/icdar2015_lite.tar --no-check-certificate
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/ic15_data.tar --no-check-certificate
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/pubtabnet.tar --no-check-certificate
wget -nc -P ./inference https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/rec_inference.tar --no-check-certificate
wget -nc -P ./deploy/slim/prune https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/sen.pickle --no-check-certificate
- cd ./train_data/ && tar xf icdar2015_lite.tar && tar xf ic15_data.tar
+ cd ./train_data/ && tar xf icdar2015_lite.tar && tar xf ic15_data.tar && tar xf pubtabnet.tar
ln -s ./icdar2015_lite ./icdar2015
+ wget -nc -P ./ic15_data/ https://paddleocr.bj.bcebos.com/dataset/rec_gt_train_lite.txt --no-check-certificate
+ wget -nc -P ./ic15_data/ https://paddleocr.bj.bcebos.com/dataset/rec_gt_test_lite.txt --no-check-certificate
cd ../
cd ./inference && tar xf rec_inference.tar && cd ../
if [ ${model_name} == "ch_PP-OCRv2_det" ] || [ ${model_name} == "ch_PP-OCRv2_det_PACT" ]; then
@@ -112,9 +123,14 @@ elif [ ${MODE} = "whole_train_whole_infer" ];then
wget -nc -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/MobileNetV3_large_x0_5_pretrained.pdparams --no-check-certificate
rm -rf ./train_data/icdar2015
rm -rf ./train_data/ic15_data
+ rm -rf ./train_data/pubtabnet
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/icdar2015.tar --no-check-certificate
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/ic15_data.tar --no-check-certificate
- cd ./train_data/ && tar xf icdar2015.tar && tar xf ic15_data.tar && cd ../
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/pubtabnet.tar --no-check-certificate
+ cd ./train_data/ && tar xf icdar2015.tar && tar xf ic15_data.tar && tar xf pubtabnet.tar
+ wget -nc -P ./ic15_data/ https://paddleocr.bj.bcebos.com/dataset/rec_gt_train_lite.txt --no-check-certificate
+ wget -nc -P ./ic15_data/ https://paddleocr.bj.bcebos.com/dataset/rec_gt_test_lite.txt --no-check-certificate
+ cd ../
if [ ${model_name} == "ch_PP-OCRv2_det" ]; then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar --no-check-certificate
cd ./pretrain_models/ && tar xf ch_PP-OCRv2_det_distill_train.tar && cd ../
@@ -134,14 +150,25 @@ elif [ ${MODE} = "whole_train_whole_infer" ];then
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/total_text_lite.tar --no-check-certificate
cd ./train_data && tar xf total_text.tar && ln -s total_text_lite total_text && cd ../
fi
+ if [[ ${model_name} =~ "en_table_structure" ]];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar --no-check-certificate
+ cd ./pretrain_models/ && tar xf en_ppocr_mobile_v2.0_table_structure_train.tar && cd ../
+ wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_det_infer.tar --no-check-certificate
+ wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_rec_infer.tar --no-check-certificate
+ cd ./inference/ && tar xf en_ppocr_mobile_v2.0_table_det_infer.tar && tar xf en_ppocr_mobile_v2.0_table_rec_infer.tar && cd ../
+ fi
elif [ ${MODE} = "lite_train_whole_infer" ];then
wget -nc -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/MobileNetV3_large_x0_5_pretrained.pdparams --no-check-certificate
rm -rf ./train_data/icdar2015
rm -rf ./train_data/ic15_data
+ rm -rf ./train_data/pubtabnet
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/icdar2015_infer.tar --no-check-certificate
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/ic15_data.tar --no-check-certificate
- cd ./train_data/ && tar xf icdar2015_infer.tar && tar xf ic15_data.tar
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/pubtabnet.tar --no-check-certificate
+ cd ./train_data/ && tar xf icdar2015_infer.tar && tar xf ic15_data.tar && tar xf pubtabnet.tar
ln -s ./icdar2015_infer ./icdar2015
+ wget -nc -P ./ic15_data/ https://paddleocr.bj.bcebos.com/dataset/rec_gt_train_lite.txt --no-check-certificate
+ wget -nc -P ./ic15_data/ https://paddleocr.bj.bcebos.com/dataset/rec_gt_test_lite.txt --no-check-certificate
cd ../
if [ ${model_name} == "ch_PP-OCRv2_det" ]; then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar --no-check-certificate
@@ -151,6 +178,13 @@ elif [ ${MODE} = "lite_train_whole_infer" ];then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar --no-check-certificate
cd ./pretrain_models/ && tar xf ch_PP-OCRv3_det_distill_train.tar && cd ../
fi
+ if [[ ${model_name} =~ "en_table_structure" ]];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar --no-check-certificate
+ cd ./pretrain_models/ && tar xf en_ppocr_mobile_v2.0_table_structure_train.tar && cd ../
+ wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_det_infer.tar --no-check-certificate
+ wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_rec_infer.tar --no-check-certificate
+ cd ./inference/ && tar xf en_ppocr_mobile_v2.0_table_det_infer.tar && tar xf en_ppocr_mobile_v2.0_table_rec_infer.tar && cd ../
+ fi
elif [ ${MODE} = "whole_infer" ];then
wget -nc -P ./inference https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/ch_det_data_50.tar --no-check-certificate
wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/rec_inference.tar --no-check-certificate
@@ -310,6 +344,12 @@ elif [ ${MODE} = "whole_infer" ];then
wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_east_v2.0_train.tar --no-check-certificate
cd ./inference/ && tar xf det_r50_vd_east_v2.0_train.tar & cd ../
fi
+ if [[ ${model_name} =~ "en_table_structure" ]];then
+ wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar --no-check-certificate
+ wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_det_infer.tar --no-check-certificate
+ wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_rec_infer.tar --no-check-certificate
+ cd ./inference/ && tar xf en_ppocr_mobile_v2.0_table_structure_infer.tar && tar xf en_ppocr_mobile_v2.0_table_det_infer.tar && tar xf en_ppocr_mobile_v2.0_table_rec_infer.tar && cd ../
+ fi
fi
if [ ${MODE} = "klquant_whole_infer" ]; then
@@ -331,7 +371,10 @@ if [ ${MODE} = "klquant_whole_infer" ]; then
wget -nc -P ./inference https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar --no-check-certificate
wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/rec_inference.tar --no-check-certificate
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/ic15_data.tar --no-check-certificate
- cd ./train_data/ && tar xf ic15_data.tar && cd ../
+ cd ./train_data/ && tar xf ic15_data.tar
+ wget -nc -P ./ic15_data/ https://paddleocr.bj.bcebos.com/dataset/rec_gt_train_lite.txt --no-check-certificate
+ wget -nc -P ./ic15_data/ https://paddleocr.bj.bcebos.com/dataset/rec_gt_test_lite.txt --no-check-certificate
+ cd ../
cd ./inference && tar xf rec_inference.tar && tar xf ch_PP-OCRv3_rec_infer.tar && cd ../
fi
if [ ${model_name} = "ch_PP-OCRv2_det_KL" ]; then
@@ -350,7 +393,15 @@ if [ ${MODE} = "klquant_whole_infer" ]; then
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/ic15_data.tar --no-check-certificate
cd ./train_data/ && tar xf ic15_data.tar && cd ../
cd ./inference && tar xf ch_ppocr_mobile_v2.0_rec_infer.tar && tar xf rec_inference.tar && cd ../
- fi
+ fi
+ if [ ${model_name} = "en_table_structure_KL" ];then
+ wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar --no-check-certificate
+ wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_det_infer.tar --no-check-certificate
+ wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_rec_infer.tar --no-check-certificate
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/pubtabnet.tar --no-check-certificate
+ cd ./inference/ && tar xf en_ppocr_mobile_v2.0_table_structure_infer.tar && tar xf en_ppocr_mobile_v2.0_table_det_infer.tar && tar xf en_ppocr_mobile_v2.0_table_rec_infer.tar && cd ../
+ cd ./train_data/ && tar xf pubtabnet.tar && cd ../
+ fi
fi
if [ ${MODE} = "cpp_infer" ];then
diff --git a/test_tipc/test_inference_python.sh b/test_tipc/test_inference_python.sh
index a416d623d8565a04c5abfb823d97dd6c5bf6eb8f..2a31a468f0d54d1979e82c8f0da98cac6f4edcec 100644
--- a/test_tipc/test_inference_python.sh
+++ b/test_tipc/test_inference_python.sh
@@ -88,7 +88,7 @@ function func_inference(){
eval $command
last_status=${PIPESTATUS[0]}
eval "cat ${_save_log_path}"
- status_check $last_status "${command}" "${status_log}"
+ status_check $last_status "${command}" "${status_log}" "${model_name}"
done
done
done
@@ -119,7 +119,7 @@ function func_inference(){
eval $command
last_status=${PIPESTATUS[0]}
eval "cat ${_save_log_path}"
- status_check $last_status "${command}" "${status_log}"
+ status_check $last_status "${command}" "${status_log}" "${model_name}"
done
done
@@ -153,7 +153,7 @@ if [ ${MODE} = "whole_infer" ]; then
echo ${infer_run_exports[Count]}
eval $export_cmd
status_export=$?
- status_check $status_export "${export_cmd}" "${status_log}"
+ status_check $status_export "${export_cmd}" "${status_log}" "${model_name}"
else
save_infer_dir=${infer_model}
fi