Merge remote-tracking branch 'upstream/dygraph' into dy3
Showing
PPOCRLabel/README_ch.md
0 → 100644
PPOCRLabel/README_en.md
已删除
100644 → 0
README_en.md
已删除
100644 → 0
StyleText/README.md
0 → 100644
StyleText/README_ch.md
0 → 100644
StyleText/__init__.py
0 → 100644
StyleText/arch/__init__.py
0 → 100644
StyleText/arch/base_module.py
0 → 100644
StyleText/arch/decoder.py
0 → 100644
StyleText/arch/encoder.py
0 → 100644
StyleText/arch/spectral_norm.py
0 → 100644
StyleText/arch/style_text_rec.py
0 → 100644
StyleText/configs/config.yml
0 → 100644
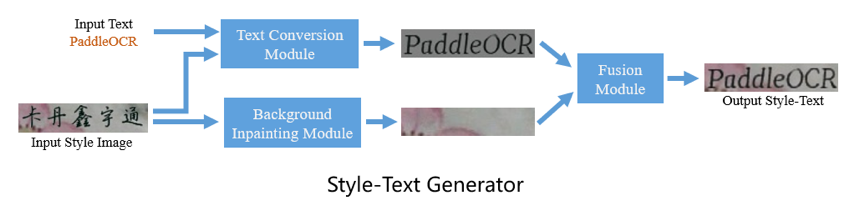
StyleText/doc/images/1.png
0 → 100644
{kind=link}

167.9 KB
StyleText/doc/images/10.png
0 → 100644
{kind=link}

191.5 KB
StyleText/doc/images/11.png
0 → 100644
{kind=link}

125.8 KB
StyleText/doc/images/2.png
0 → 100644
{kind=link}

200.7 KB
StyleText/doc/images/3.png
0 → 100644
{kind=link}
67.7 KB
StyleText/doc/images/4.jpg
0 → 100644
{kind=link}
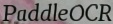
2.6 KB
StyleText/doc/images/5.png
0 → 100644
{kind=link}

118.0 KB
StyleText/doc/images/6.png
0 → 100644
{kind=link}

124.7 KB
StyleText/doc/images/7.jpg
0 → 100644
{kind=link}

1.5 KB
StyleText/doc/images/8.jpg
0 → 100644
{kind=link}
2.4 KB
StyleText/doc/images/9.png
0 → 100644
{kind=link}

154.4 KB
StyleText/engine/__init__.py
0 → 100644
StyleText/engine/predictors.py
0 → 100644
StyleText/engine/synthesisers.py
0 → 100644
StyleText/engine/text_drawers.py
0 → 100644
StyleText/engine/writers.py
0 → 100644
StyleText/examples/image_list.txt
0 → 100644
{kind=link}

2.5 KB
{kind=link}

3.3 KB
StyleText/fonts/ch_standard.ttf
0 → 100755
文件已添加
StyleText/fonts/en_standard.ttf
0 → 100755
文件已添加
StyleText/fonts/ko_standard.ttf
0 → 100755
文件已添加
StyleText/tools/__init__.py
0 → 100644
StyleText/tools/synth_image.py
0 → 100644
StyleText/utils/__init__.py
0 → 100644
StyleText/utils/config.py
0 → 100644
StyleText/utils/load_params.py
0 → 100644
StyleText/utils/logging.py
0 → 100644
StyleText/utils/math_functions.py
0 → 100644
StyleText/utils/sys_funcs.py
0 → 100644
configs/det/det_r50_vd_sast_icdar15.yml
100644 → 100755
configs/det/det_r50_vd_sast_totaltext.yml
100644 → 100755
deploy/hubserving/ocr_cls/params.py
100644 → 100755
deploy/hubserving/ocr_det/params.py
100644 → 100755
deploy/hubserving/ocr_system/params.py
100644 → 100755
deploy/hubserving/readme.md
100644 → 100755
deploy/hubserving/readme_en.md
100644 → 100755
deploy/pdserving/readme.md
已删除
100644 → 0
doc/doc_ch/algorithm_overview.md
100644 → 100755
doc/doc_ch/inference.md
100644 → 100755
doc/doc_en/algorithm_overview_en.md
100644 → 100755
doc/doc_en/benchmark_en.md
100644 → 100755
文件模式从 100644 更改为 100755
doc/doc_en/inference_en.md
100644 → 100755
此差异已折叠。
此差异已折叠。
{kind=link}
{kind=link}

| W: | H:

| W: | H:
doc/imgs_results/1.jpg
已删除
100644 → 0
{kind=link}

129.4 KB
doc/imgs_results/10.jpg
已删除
100644 → 0
{kind=link}

94.0 KB
doc/imgs_results/11.jpg
已删除
100644 → 0
{kind=link}

236.4 KB
doc/imgs_results/1101.jpg
已删除
100644 → 0
{kind=link}

81.7 KB
doc/imgs_results/1102.jpg
已删除
100644 → 0
{kind=link}

147.1 KB
doc/imgs_results/1103.jpg
已删除
100644 → 0
{kind=link}

124.2 KB
doc/imgs_results/1104.jpg
已删除
100644 → 0
{kind=link}
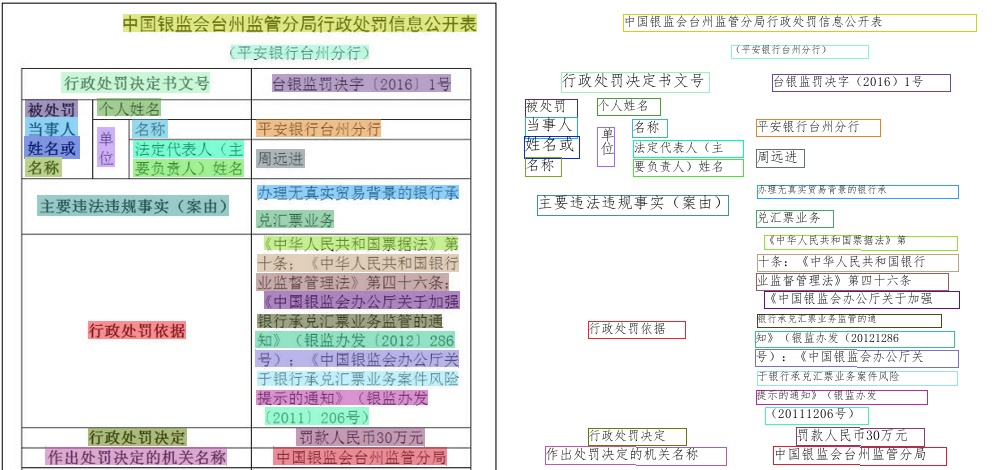
163.6 KB
doc/imgs_results/1105.jpg
已删除
100644 → 0
{kind=link}

136.8 KB
doc/imgs_results/1106.jpg
已删除
100644 → 0
{kind=link}

284.1 KB
doc/imgs_results/1110.jpg
已删除
100644 → 0
{kind=link}

243.6 KB
doc/imgs_results/12.jpg
已删除
100644 → 0
{kind=link}

180.4 KB
doc/imgs_results/13.png
已删除
100644 → 0
{kind=link}

305.0 KB
doc/imgs_results/15.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results/16.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results/17.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results/22.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results/3.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results/4.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results/5.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results/6.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results/7.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results/8.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results/9.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/imgs_results/det_res_22.jpg
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
{kind=link}
{kind=link}
doc/imgs_results/french_0.jpg
0 → 100644
{kind=link}
此差异已折叠。
doc/imgs_results/img_10.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results/img_11.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
doc/imgs_results_vis2/1.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/10.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/11.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/12.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/13.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/15.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/16.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/17.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/2.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/22.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/3.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/4.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/5.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/6.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/7.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/8.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_results_vis2/9.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/imgs_words_en/.DS_Store
已删除
100644 → 0
此差异已折叠。
ppocr/postprocess/east_postprocess.py
100644 → 100755
此差异已折叠。
ppocr/postprocess/sast_postprocess.py
100644 → 100755
此差异已折叠。
此差异已折叠。
tools/test_hubserving.py
100644 → 100755
此差异已折叠。
此差异已折叠。